Constrained Contrastive Distribution Learning for Unsupervised Anomaly Detection and Local is ation in Medical Images
医学图像无监督异常检测与定位的受限对比分布学习
Abstract. Unsupervised anomaly detection (UAD) learns one-class class if i ers exclusively with normal (i.e., healthy) images to detect any abnormal (i.e., unhealthy) samples that do not conform to the expected normal patterns. UAD has two main advantages over its fully supervised counterpart. Firstly, it is able to directly leverage large datasets available from health screening programs that contain mostly normal image samples, avoiding the costly manual labelling of abnormal samples and the subsequent issues involved in training with extremely classimbalanced data. Further, UAD approaches can potentially detect and localise any type of lesions that deviate from the normal patterns. One significant challenge faced by UAD methods is how to learn effective low-dimensional image representations to detect and localise subtle abnormalities, generally consisting of small lesions. To address this challenge, we propose a novel self-supervised representation learning method, called Constrained Contrastive Distribution learning for anomaly detection (CCD), which learns fine-grained feature representations by simultaneously predicting the distribution of augmented data and image contexts using contrastive learning with pretext constraints. The learned representations can be leveraged to train more anomaly-sensitive detection models. Extensive experiment results show that our method outperforms current state-of-the-art UAD approaches on three different colon os copy and fundus screening datasets. Our code is available at https://github.com/tianyu0207/CCD.
摘要。无监督异常检测 (UAD) 通过仅使用正常 (即健康) 图像训练单分类器,来检测不符合预期正常模式的任何异常 (即不健康) 样本。与全监督方法相比,UAD 具有两大优势:首先,它能直接利用健康筛查项目中包含大量正常图像样本的大规模数据集,避免了异常样本的高成本人工标注以及后续极端类别不平衡数据训练带来的问题;其次,UAD 方法有望检测并定位任何偏离正常模式的病变类型。UAD 方法面临的关键挑战在于如何学习有效的低维图像表示来检测和定位通常由微小病灶组成的细微异常。为此,我们提出了一种新型自监督表征学习方法——基于约束对比分布的异常检测学习 (CCD),该方法通过结合对比学习与前置约束,同时预测增强数据分布和图像上下文,从而学习细粒度特征表示。这些学习到的表征可用于训练对异常更敏感的检测模型。大量实验结果表明,在三种不同的结肠镜和眼底筛查数据集上,我们的方法优于当前最先进的 UAD 方案。代码已开源:https://github.com/tianyu0207/CCD。
Keywords: Anomaly detection $\cdot$ Unsupervised learning $\cdot$ Lesion detection and segmentation $\cdot$ Self-supervised pre-training $\cdot$ Colon os copy.
关键词: 异常检测 (Anomaly detection) $\cdot$ 无监督学习 (Unsupervised learning) $\cdot$ 病变检测与分割 (Lesion detection and segmentation) $\cdot$ 自监督预训练 (Self-supervised pre-training) $\cdot$ 结肠镜 (Colon os copy)
1 Introduction
1 引言
Classifying and localising malignant tissues have been vastly investigated in medical imaging [1, 11, 22–24, 26, 29, 42, 43]. Such systems are useful in health screening programs that require radiologists to analyse large quantities of images [35, 41], where the majority contain normal (or healthy) cases, and a small minority have abnormal (or unhealthy) cases that can be regarded as anomalies. Hence, to avoid the difficulty of learning from such class-imbalanced training sets and the prohibitive cost of collecting large sets of manually labelled abnormal cases, several papers investigate anomaly detection (AD) with a few or no labels as an alternative to traditional fully supervised imbalanced learning [1, 26, 28, 32, 33, 37, 38, 43–45]. UAD methods typically train a one-class classifier using data from the normal class only, and anomalies (or abnormal cases) are detected based on the extent the images deviate from the normal class.
在医学影像领域,对恶性组织的分类与定位已得到广泛研究 [1, 11, 22–24, 26, 29, 42, 43]。这类系统在需要放射科医师分析大量影像的健康筛查项目中尤为实用 [35, 41],其中多数为正常(或健康)案例,仅少数异常(或不健康)案例可视为异常值。为避免从类别不平衡训练集中学习的困难,以及人工标注大量异常案例的高昂成本,部分研究探索了少标签或无标签的异常检测 (anomaly detection, AD) 方法,作为传统全监督不平衡学习的替代方案 [1, 26, 28, 32, 33, 37, 38, 43–45]。无监督异常检测 (UAD) 方法通常仅使用正常类别数据训练单分类器,并通过图像偏离正常类别的程度来识别异常案例。
Current anomaly detection approaches [7, 8, 14, 27, 37, 43, 46] train deep generative models (e.g., auto-encoder [19], GAN [15]) to reconstruct normal images, and anomalies are detected from the reconstruction error [33]. These approaches rely on a low-dimensional image representation that must be effective at reconstructing normal images, where the main challenge is to detect anomalies that show subtle deviations from normal images, such as with small lesions [43]. Recently, self-supervised methods that learn auxiliary pretext tasks [2, 6, 13, 17, 18, 25] have been shown to learn effective representations for UAD in general computer vision tasks [2, 13, 18], so it is important to investigate if self-supervision can also improve UAD for medical images.
当前异常检测方法 [7, 8, 14, 27, 37, 43, 46] 通过训练深度生成模型 (如自编码器 [19]、GAN [15]) 来重建正常图像,并从重建误差中检测异常 [33]。这些方法依赖于低维图像表征,该表征必须能有效重建正常图像,其主要挑战在于检测与正常图像存在细微偏差的异常 (如微小病变 [43])。最近研究表明,通过自监督方法学习辅助代理任务 [2, 6, 13, 17, 18, 25] 可为通用计算机视觉任务中的无监督异常检测 (UAD) 学习有效表征 [2, 13, 18],因此探究自监督能否提升医学图像 UAD 性能具有重要意义。
The main challenge for the design of UAD methods for medical imaging resides in how to devise effective pretext tasks. Self-supervised pretext tasks consist of predicting geometric or brightness transformations [2, 13, 18], or contrastive learning [6, 17]. These pretext tasks have been designed to work for downstream classification problems that are not related to anomaly detection, so they may degrade the detection performance of UAD methods [47]. Sohn et al. [40] tackle this issue by using smaller batch sizes than in [6, 17] and a new data augmentation method. However, the use of selfsupervised learning in UAD for medical images has not been investigated, to the best of our knowledge. Further, although transformation prediction and contrastive learning show great success in self-supervised feature learning, there are no studies on how to properly combine these two approaches to learn more effective features for UAD.
医学影像无监督异常检测 (UAD) 方法设计的主要挑战在于如何设计有效的预训练任务。自监督预训练任务包括预测几何或亮度变换 [2, 13, 18] 或对比学习 [6, 17]。这些预训练任务专为与异常检测无关的下游分类问题设计,因此可能降低 UAD 方法的检测性能 [47]。Sohn 等人 [40] 通过采用比 [6, 17] 更小的批次大小和新的数据增强方法来解决此问题。然而据我们所知,自监督学习在医学影像 UAD 中的应用尚未得到研究。此外,尽管变换预测和对比学习在自监督特征学习中取得了巨大成功,但关于如何正确结合这两种方法来学习更有效的 UAD 特征尚未有研究。
In this paper, we propose Constrained Contrastive Distribution learning (CCD), a new self-supervised representation learning designed specifically to learn normality information from exclusively normal training images. The contributions of CCD are: a) contrastive distribution learning, and b)two pretext learning constraints, both of which are customised for anomaly detection (AD). Unlike modern self-supervised learning (SSL) [6, 17] that focuses on learning generic semantic representations for enabling diverse downstream tasks, CCD instead contrasts the distributions of strongly augmented images (e.g., random permutations). The strongly augmented images resemble some types of abnormal images, so CCD is enforced to learn disc rim i native normality representations by its contrastive distribution learning. The two pretext learning constraints on augmentation and location prediction are added to learn fine-grained normality represent at ions for the detection of subtle abnormalities. These two unique components result in significantly improved self-supervised AD-oriented representation learning, substantially outperforming previous general-purpose SOTA SSL approaches [2, 6, 13, 18]. Another important contribution of CCD is that it is agnostic to downstream anomaly class if i ers. We empirically show that our CCD improves the performance of three diverse anomaly detectors (f-anogan [37], IGD [8], MS-SSIM) [48]). Inspired by IGD [8], we adapt our proposed CCD pre training on global images and local patches, respectively. Extensive experimental results on three different health screening medical imaging benchmarks, namely, colon os copy images from two datasets [4, 27], and fundus images for glaucoma detection [21], show that our proposed self-supervised approach enables the production of SOTA anomaly detection and local is ation in medical images.
本文提出了一种专门从正常训练图像中学习正态信息的自监督表示学习方法——约束对比分布学习 (CCD)。CCD的核心贡献包括:a) 对比分布学习,b) 两个专为异常检测 (AD) 设计的预训练约束。不同于现代自监督学习 (SSL) [6,17] 致力于学习通用语义表示以支持多样下游任务,CCD通过对比强增强图像 (如随机排列) 的分布进行学习。由于强增强图像与某些异常图像相似,CCD的对比分布学习机制迫使模型学习具有判别力的正态表示。新增的增强预测和位置预测两个预训练约束,则用于学习细粒度正态表示以检测细微异常。这两个独特组件显著提升了面向异常检测的自监督表示学习效果,大幅超越先前通用型SOTA SSL方法 [2,6,13,18]。CCD的另一重要贡献是其与下游异常分类器的无关性。实验证明CCD能提升三种不同异常检测器 (f-anogan [37], IGD [8], MS-SSIM [48]) 的性能。受IGD [8] 启发,我们分别在全图与局部图像块上实施CCD预训练。在结肠镜图像 (来自两个数据集 [4,27]) 和青光眼检测眼底图像 [21] 这三个医疗筛查基准上的大量实验表明,该方法能在医学图像中实现SOTA级别的异常检测与定位。
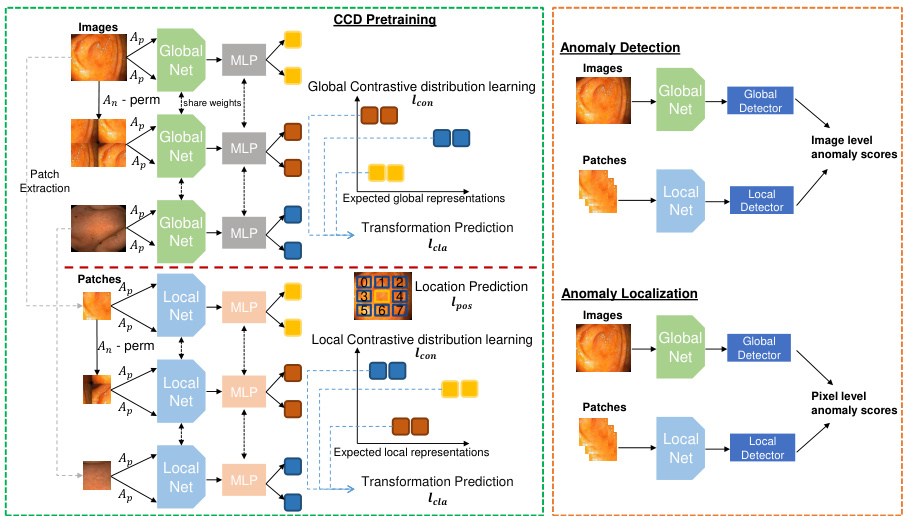
Fig. 1: Our proposed CCD framework. Left shows the proposed pre-training method that unifies a contrastive distribution learning and pretext learning on both global and local perspectives (Sec. 2.1), Right shows the inference for detection and local is ation (Sec. 2.2).
图 1: 我们提出的CCD框架。左侧展示了提出的预训练方法,该方法在全局和局部视角上统一了对比分布学习和借口学习 (第2.1节),右侧展示了用于检测和定位的推理过程 (第2.2节)。
2 Method
2 方法
2.1 Constrained Contrastive Distribution Learning
2.1 受限对比分布学习
Contrastive learning has been used by self-supervised learning methods to pre-train encoders with data augmentation [6, 17, 47] and contrastive learning loss [39]. The idea is to sample functions from a data augmentation distribution (e.g., geometric and brightness transformations), and assume that the same image, under separate augmentations, form one class to be distinguished against all other images in the batch [2, 13]. Another form of pre-training is based on a pretext task, such as solving jigsaw puzzle and predicting geometric and brightness transformations [6, 17]. These self-supervised learning approaches are useful to pre-train classification [6, 17] and segmentation models [31, 49]. Only recently, self-supervised learning using contrastive learning [40] and pretext learning [2,13] have been shown to be effective in anomaly detection. However, these two approaches are explored separately. In this paper, we aim at harnessing the power of both approaches to learn more expressive pre-trained features specifically for UAD. To this end, we propose the novel Constrained Contrastive Distribution learning method (CCD).
对比学习已被自监督学习方法用于通过数据增强 [6, 17, 47] 和对比学习损失 [39] 预训练编码器。其核心思想是从数据增强分布(如几何和亮度变换)中采样函数,并假设同一图像经过不同增强后形成的样本应归类为一类,与批次中其他图像区分开来 [2, 13]。另一种预训练形式基于代理任务,例如拼图游戏或预测几何与亮度变换 [6, 17]。这些自监督学习方法对分类 [6, 17] 和分割模型 [31, 49] 的预训练具有价值。直到最近,采用对比学习 [40] 和代理学习 [2,13] 的自监督学习才被证明在异常检测中有效。然而这两种方法此前未被联合探索。本文旨在结合两种方法的优势,学习专门针对无监督异常检测 (UAD) 更具表现力的预训练特征。为此,我们提出了新颖的约束对比分布学习方法 (CCD)。
Contrastive distribution learning is designed to enforce a non-uniform distribution of the representations in the space $\mathcal{Z}$ , which has been associated with more effective anomaly detection performance [40]. Our CCD method constrains the const r asti ve distribution learning with two pretext learning tasks, with the goal of enforcing further the non-uniform distribution of the representations. The CCD loss is defined as
对比分布学习旨在强制表示在空间$\mathcal{Z}$中呈现非均匀分布,这与更有效的异常检测性能相关[40]。我们的CCD方法通过两个前置学习任务约束对比分布学习,目的是进一步强化表示的非均匀分布。CCD损失定义为
$$
\ell_{C C D}(\mathcal{D};\theta,\beta,\gamma)=\ell_{c o n}(\mathcal{D};\theta)+\ell_{c l a}(\mathcal{D};\beta)+\ell_{p o s}(\mathcal{D};\gamma),
$$
$$
\ell_{C C D}(\mathcal{D};\theta,\beta,\gamma)=\ell_{c o n}(\mathcal{D};\theta)+\ell_{c l a}(\mathcal{D};\beta)+\ell_{p o s}(\mathcal{D};\gamma),
$$
where $\ell_{c o n}(\cdot)$ is the contrastive distribution loss, $\ell_{c l a}$ and $\ell_{p o s}$ are two pretext learning tasks added to constrain the optimisation; and $\theta$ , $\beta$ and $\gamma$ are trainable parameters. The contrastive distribution learning uses a dataset of weak data augmentations $\mathcal{A}{p}~=$ ${a_{l}:\mathcal{X}\to\mathcal{X}}{l=1}^{|\mathcal{A}{p}|}$ taicnudl asrt rdoantag aduagtam ea nut gat mio en n ta apt pi loin es d $\mathcal{A}{n}={a_{l}:\mathcal{X}\to\mathcal{X}}{l=1}^{|\mathcal{A}{n}|}$ ,d washere $a_{l}(\mathbf{x})$ $\mathbf{x}$
其中 $\ell_{con}(\cdot)$ 是对比分布损失函数,$\ell_{cla}$ 和 $\ell_{pos}$ 是用于约束优化的两个预训练任务;$\theta$、$\beta$ 和 $\gamma$ 是可训练参数。对比分布学习采用弱数据增强数据集 $\mathcal{A}{p}~=$ ${a_{l}:\mathcal{X}\to\mathcal{X}}{l=1}^{|\mathcal{A}{p}|}$ 以及强数据增强集 $\mathcal{A}{n}={a_{l}:\mathcal{X}\to\mathcal{X}}{l=1}^{|\mathcal{A}{n}|}$,其中 $a_{l}(\mathbf{x})$ 表示对样本 $\mathbf{x}$ 的增强操作。
$$
\begin{array}{r l}&{\ell_{c o n}(\mathcal{D};\theta)=}\ &{-\mathbb{E}\left[\log\frac{\exp\left[\frac{1}{\tau}f_{\theta}\left(a(\tilde{\mathbf{x}}^{j})\right)^{\top}f_{\theta}\left(a^{\prime}(\tilde{\mathbf{x}}^{j})\right)\right]}{\exp\left[\frac{1}{\tau}f_{\theta}\left(a(\tilde{\mathbf{x}}^{j})\right)^{\top}f_{\theta}\left(a^{\prime}(\tilde{\mathbf{x}}^{j})\right)\right]+\sum_{i=1}^{M}\exp\left[\frac{1}{\tau}f_{\theta}\left(a(\tilde{\mathbf{x}}^{j})\right)^{\top}f_{\theta}\left(a^{\prime}(\tilde{\mathbf{x}}_{i}^{j})\right)\right]}\right],}\end{array}
$$
$$
\begin{array}{r l}&{\ell_{c o n}(\mathcal{D};\theta)=}\ &{-\mathbb{E}\left[\log\frac{\exp\left[\frac{1}{\tau}f_{\theta}\left(a(\tilde{\mathbf{x}}^{j})\right)^{\top}f_{\theta}\left(a^{\prime}(\tilde{\mathbf{x}}^{j})\right)\right]}{\exp\left[\frac{1}{\tau}f_{\theta}\left(a(\tilde{\mathbf{x}}^{j})\right)^{\top}f_{\theta}\left(a^{\prime}(\tilde{\mathbf{x}}^{j})\right)\right]+\sum_{i=1}^{M}\exp\left[\frac{1}{\tau}f_{\theta}\left(a(\tilde{\mathbf{x}}^{j})\right)^{\top}f_{\theta}\left(a^{\prime}(\tilde{\mathbf{x}}_{i}^{j})\right)\right]}\right],}\end{array}
$$
where the expectation is over $\mathbf{x}\in\mathcal{D}$ , ${\mathbf{x}{i}}{i=1}^{M}\subset\mathcal{D}\setminus{\mathbf{x}},a(.),a^{\prime}(.)\in\mathcal{A}{p}$ , $\tilde{\mathbf{x}}^{j}\mathbf{\Phi}=$ $a_{j}(\mathbf{x})$ , $\tilde{\mathbf{x}}{i}^{j}=a_{j}(\mathbf{x}{i})$ , and $a_{j}(.)\in\mathcal A_{n}$ . The images augmented with the functions from the strong set $\mathcal{A}_{n}$ carry some ‘abnormality’ compared to the original images, which is helpful to learn a non-uniform distribution in the representation space $\mathcal{Z}$ .
其中期望是对 $\mathbf{x}\in\mathcal{D}$ 、 ${\mathbf{x}{i}}{i=1}^{M}\subset\mathcal{D}\setminus{\mathbf{x}},a(.),a^{\prime}(.)\in\mathcal{A}{p}$ 、 $\tilde{\mathbf{x}}^{j}\mathbf{\Phi}=$ $a_{j}(\mathbf{x})$ 、 $\tilde{\mathbf{x}}{i}^{j}=a_{j}(\mathbf{x}{i})$ 以及 $a_{j}(.)\in\mathcal A_{n}$ 进行计算的。通过强增强集 $\mathcal{A}_{n}$ 中的函数增强后的图像相较于原始图像带有某种"异常性",这有助于在表示空间 $\mathcal{Z}$ 中学习非均匀分布。
We can then constrain further the training to learn more non-uniform representations with a self-supervised classification constraint $\ell_{c l a}(\cdot)$ that enforces the model to achieve accurate classification of the strong augmentation function:
然后,我们可以通过自监督分类约束 $\ell_{c l a}(\cdot)$ 进一步限制训练,以学习更多非均匀表示,该约束强制模型实现对强增强功能的准确分类:
$$
\ell_{c l a}(\mathcal{D};\beta)=-\mathbb{E}{{\mathbf{x}}\in\mathcal{D},a(.)\in\mathcal{A}{n}}\left[\log{\mathbf{a}^{\top}}f_{\beta}(f_{\theta}(a(\mathbf{x})))\right],
$$
$$
\ell_{c l a}(\mathcal{D};\beta)=-\mathbb{E}{{\mathbf{x}}\in\mathcal{D},a(.)\in\mathcal{A}{n}}\left[\log{\mathbf{a}^{\top}}f_{\beta}(f_{\theta}(a(\mathbf{x})))\right],
$$
where $f_{\beta}:\mathcal{Z}\rightarrow[0,1]^{\vert\mathcal{A}{n}\vert}$ is a fully-connected (FC) layer, and $\mathbf{a}\in{0,1}^{|A_{n}|}$ is a one-hot vector representing the strong augmentation $a(.)\in\mathcal A_{n}$ .
其中 $f_{\beta}:\mathcal{Z}\rightarrow[0,1]^{\vert\mathcal{A}{n}\vert}$ 是全连接层 (FC layer) , $\mathbf{a}\in{0,1}^{|A_{n}|}$ 是表示强增强 $a(.)\in\mathcal A_{n}$ 的独热向量。
The second constraint is based on the relative patch location from the centre of the training image – this positional information is important for segmentation tasks [20, 31]. This constraint is added to learn fine-grained features and achieve more accurate anomaly local is ation. Inspired by [10], the positional constraint predicts the relative position of the paired image patches, with its loss defined as
第二个约束基于训练图像中心相对补丁位置的位置信息——这种位置信息对于分割任务至关重要 [20, 31]。添加该约束是为了学习细粒度特征并实现更精确的异常定位。受 [10] 启发,位置约束通过预测配对图像补丁的相对位置来定义其损失函数
$$
\begin{array}{r}{\ell_{p o s}(\mathcal{D};\gamma)=-\mathbb{E}{{\mathbf{x}{\omega_{1}},\mathbf{x}{\omega_{2}}}\sim\mathbf{x}\in\mathcal{D}}\left[\log\mathbf{p}^{\top}f_{\gamma}(f_{\theta}(\mathbf{x}{\omega_{1}}),f_{\theta}(\mathbf{x}{\omega_{2}}))\right],}\end{array}
$$
$$
\begin{array}{r}{\ell_{p o s}(\mathcal{D};\gamma)=-\mathbb{E}{{\mathbf{x}{\omega_{1}},\mathbf{x}{\omega_{2}}}\sim\mathbf{x}\in\mathcal{D}}\left[\log\mathbf{p}^{\top}f_{\gamma}(f_{\theta}(\mathbf{x}{\omega_{1}}),f_{\theta}(\mathbf{x}{\omega_{2}}))\right],}\end{array}
$$
where $\mathbf{x}{\omega_{1}}$ is a randomly selected fixed-size image patch from x, $\mathbf{x}{\omega_{2}}$ is another image patch from one of its eight neighbouring patches (as shown in ‘patch location prediction’ in Fig. 1), $f_{\gamma}:\mathcal{Z}\times\mathcal{Z}\to[0,1]^{8}$ , and $\mathbf{p}={0,1}^{8}$ is a one-hot encoding of the synthetic class label.
其中 $\mathbf{x}{\omega_{1}}$ 是从 x 中随机选取的固定大小图像块,$\mathbf{x}{\omega_{2}}$ 是来自其八个相邻块之一的另一图像块 (如图 1 中的 "块位置预测" 所示),$f_{\gamma}:\mathcal{Z}\times\mathcal{Z}\to[0,1]^{8}$,而 $\mathbf{p}={0,1}^{8}$ 是合成类别标签的独热编码。
Overall, the constraints in (3) and (4) to the contrastive distribution loss in (2) are designed to increase the non-uniform representation distribution and to improve the representation disc rim inability between normal and abnormal samples, compared with [40].
总体而言,(3) 和 (4) 中对 (2) 对比分布损失的约束设计,旨在相较于 [40] 提升表征分布的非均匀性,并增强正常与异常样本间的表征区分能力。
2.2 Anomaly Detection and Local is ation
2.2 异常检测与定位
Building upon the pre-trained encoder $f_{\theta}(\cdot)$ using the loss in (1), we fine-tune two state-of-the-art UAD methods, IGD [8] and F-anoGAN [37], and a baseline method, multi-scale structural similarity index measure (MS-SSIM)-based auto-encoder [48]. All UAD methods use the same training set $\mathcal{D}$ that contains only normal image samples.
基于使用(1)中损失预训练的编码器$f_{\theta}(\cdot)$,我们对两种最先进的异常检测方法IGD [8]和F-anoGAN [37]以及基线方法——基于多尺度结构相似性指数(MS-SSIM)的自编码器[48]进行微调。所有异常检测方法均使用仅包含正常图像样本的相同训练集$\mathcal{D}$。
IGD [8] combines three loss functions: 1) two reconstruction losses based on local and global multi-scale structural similarity index measure (MS-SSIM) [48] and mean absolute error (MAE) to train the encoder $f_{\theta}(\cdot)$ and decoder $g_{\phi}(\cdot),2)$ a regular is ation loss to train adversarial interpolations from the encoder [3], and 3) an anomaly classification loss to train $h_{\psi}(\cdot)$ . The anomaly detection score of image $\mathbf{x}$ is
IGD [8] 结合了三种损失函数:1) 基于局部和全局多尺度结构相似性指数 (MS-SSIM) [48] 和平均绝对误差 (MAE) 的两个重建损失,用于训练编码器 $f_{\theta}(\cdot)$ 和解码器 $g_{\phi}(\cdot)$;2) 一个正则化损失,用于训练来自编码器的对抗插值 [3];3) 一个异常分类损失,用于训练 $h_{\psi}(\cdot)$。图像 $\mathbf{x}$ 的异常检测分数为
$$
s_{I G D}(\mathbf{x})=\xi\ell_{r e c}(\mathbf{x},\tilde{\mathbf{x}})+(1-\xi)(1-h_{\psi}(f_{\theta}(\mathbf{x}))),
$$
$$
s_{I G D}(\mathbf{x})=\xi\ell_{r e c}(\mathbf{x},\tilde{\mathbf{x}})+(1-\xi)(1-h_{\psi}(f_{\theta}(\mathbf{x}))),
$$
where $\tilde{\mathbf{x}}=g_{\phi}(f_{\theta}(\mathbf{x}))$ , $h_{\psi}(f_{\theta}(\mathbf{x}))\in[0,1]$ returns the likelihood that $\mathbf{x}$ belongs to the normal class, $\xi\in[0,1]$ is a hyper-parameter, and
其中 $\tilde{\mathbf{x}}=g_{\phi}(f_{\theta}(\mathbf{x}))$,$h_{\psi}(f_{\theta}(\mathbf{x}))\in[0,1]$ 返回 $\mathbf{x}$ 属于正常类的概率,$\xi\in[0,1]$ 是一个超参数,且
$$
\ell_{r e c}(\mathbf{x},\tilde{\mathbf{x}})=\rho|\mathbf{x}-\tilde{\mathbf{x}}|{1}+\left(1-\rho\right)\left(1-\left(\nu m_{G}(\mathbf{x},\tilde{\mathbf{x}})+(1-\nu)m_{L}(\mathbf{x},\tilde{\mathbf{x}})\right)\right),
$$
$$
\ell_{r e c}(\mathbf{x},\tilde{\mathbf{x}})=\rho|\mathbf{x}-\tilde{\mathbf{x}}|{1}+\left(1-\rho\right)\left(1-\left(\nu m_{G}(\mathbf{x},\tilde{\mathbf{x}})+(1-\nu)m_{L}(\mathbf{x},\tilde{\mathbf{x}})\right)\right),
$$
with $\rho,\nu\in[0,1],m_{G}(\cdot)$ and $m_{L}(\cdot)$ denoting the global and local MS-SSIM scores [8]. Anomaly local is ation uses (5) to compute $s_{I G D}(\mathbf{x}{\omega})$ , $\forall\omega\in\mathcal{\varOmega}$ , where $\mathbf{x}_{\omega}\in\mathbb{R}^{\hat{H}\times\hat{W}\times C}$ is an image region–this forms a heatmap, where large values denote anomalous regions.
其中 $\rho,\nu\in[0,1]$,$m_{G}(\cdot)$ 和 $m_{L}(\cdot)$ 分别表示全局和局部 MS-SSIM 分数 [8]。异常定位使用 (5) 式计算 $s_{I G D}(\mathbf{x}{\omega})$,$\forall\omega\in\mathcal{\varOmega}$,其中 $\mathbf{x}_{\omega}\in\mathbb{R}^{\hat{H}\times\hat{W}\times C}$ 是一个图像区域——这将形成一个热力图,其中较大的值表示异常区域。
F-anoGAN [37] combines generative adversarial networks (GAN) and auto-encoder models to detect anomalies. Training involves the minim is ation of reconstruction losses in both the original image and representation spaces to model $f_{\theta}(\cdot)$ and $g_{\phi}(\cdot)$ . It also uses a GAN loss [15] to model $g_{\phi}(\cdot)$ and $h_{\psi}(\cdot)$ . Anomaly detection for image $\mathbf{x}$ is
F-anoGAN [37] 结合了生成对抗网络 (GAN) 和自编码器模型来检测异常。训练过程包括最小化原始图像和表示空间中的重建损失,以建模 $f_{\theta}(\cdot)$ 和 $g_{\phi}(\cdot)$。它还使用 GAN 损失 [15] 来建模 $g_{\phi}(\cdot)$ 和 $h_{\psi}(\cdot)$。对于图像 $\mathbf{x}$ 的异常检测是
$$
s_{F A N}(\mathbf{x})=|\mathbf{x}-g_{\phi}(f_{\theta}(\mathbf{x}))|+\kappa|f_{\theta}(\mathbf{x})-f_{\theta}(g_{\phi}(f_{\theta}(\mathbf{x})))|.
$$
$$
s_{F A N}(\mathbf{x})=|\mathbf{x}-g_{\phi}(f_{\theta}(\mathbf{x}))|+\kappa|f_{\theta}(\mathbf{x})-f_{\theta}(g_{\phi}(f_{\theta}(\mathbf{x})))|.
$$
Anomaly local is ation at $\mathbf{x}{\omega}\in\mathbb{R}^{\hat{H}\times\hat{W}\times C}$ is achieved by $|{\bf x}{\omega}-g_{\phi}(f_{\theta}({\bf x}_{\omega}))|$ , $\forall\omega\in\mathcal{\varOmega}$
异常定位在 $\mathbf{x}{\omega}\in\mathbb{R}^{\hat{H}\times\hat{W}\times C}$ 处通过 $|{\bf x}{\omega}-g_{\phi}(f_{\theta}({\bf x}_{\omega}))|$ 实现,其中 $\forall\omega\in\mathcal{\varOmega}$
For the MS-SSIM auto-encoder [48], we train it with the MS-SSIM loss for reconstructing the training images. Anomaly detection for $\mathbf{x}$ is based on $s_{M S I}({\bf x}){\bf\Psi}={\bf\Psi}$ $1-\left(\nu m_{G}(\mathbf{x},\tilde{\mathbf{x}})+(1-\nu)m_{L}(\mathbf{x},\tilde{\mathbf{x}})\right)$ , with $\tilde{\bf x}$ as defined in (5). Anomaly local is ation is performed with $s_{M S I}(\mathbf{x}{\omega})$ at image regions $\mathbf{x}_{\omega}\in\mathbb{R}^{\hat{H}\times\hat{W}\times C}$ , $\forall\omega\in\mathcal{Q}$ . Inspired by IGD [8], we also pretrain a local model using our CCD pre training approach based on the local patches for $\mathrm{F}$ -anogan [37] and MS-SSIM auto encoder [48], respectively.
对于MS-SSIM自编码器[48],我们使用MS-SSIM损失函数训练其重建训练图像。异常检测基于公式 $s_{M S I}({\bf x}){\bf\Psi}={\bf\Psi}$ $1-\left(\nu m_{G}(\mathbf{x},\tilde{\mathbf{x}})+(1-\nu)m_{L}(\mathbf{x},\tilde{\mathbf{x}})\right)$ ,其中 $\tilde{\bf x}$ 如(5)式定义。异常定位通过图像区域 $\mathbf{x}{\omega}\in\mathbb{R}^{\hat{H}\times\hat{W}\times C}$ 的 $s_{M S I}(\mathbf{x}_{\omega})$ 实现, $\forall\omega\in\mathcal{Q}$ 。受IGD[8]启发,我们还分别针对F-AnoGAN[37]和MS-SSIM自编码器[48],基于局部图像块使用CCD预训练方法预训练了局部模型。
3 Experiments
3 实验
3.1 Dataset
3.1 数据集
We test our framework on three health screening datasets. We test both anomaly detection and local is ation on the colon os copy images of Hyper-Kvasir dataset [4]. On the glaucoma datasets using fundus images [21] and colon os copy dataset [27] that do not have lesion masks, we test anomaly detection only. Detection is assessed with area under the ROC curve (AUC). Local is ation is measured with intersection over union (ioU).
我们在三个健康筛查数据集上测试了我们的框架。在Hyper-Kvasir数据集[4]的结肠镜图像上,我们同时测试了异常检测和定位任务。对于使用眼底图像的青光眼数据集[21]以及没有病灶掩模的结肠镜数据集[27],我们仅测试了异常检测。检测性能通过ROC曲线下面积(AUC)评估,定位性能通过交并比(IoU)衡量。
Hyper-Kvasir is a large multi-class public gastrointestinal dataset. The data was collected from the g astros copy and colon os copy procedures from Baerum Hospital in Norway. All labels were produced by experienced radiologists. The dataset contains 110,079 images from abnormal (i.e., unhealthy) and normal (i.e., healthy) patients, with 10,662 labelled. We use part of the clean images from the dataset to train our UAD methods. Specifically, 2,100 images from ‘cecum’, ‘ileum’ and ‘bbps-2-3’ are selected as normal, from which we use 1,600 for training and 500 for testing. We also take 1,000 abnormal images and their segmentation masks and stored them in the testing set.
Hyper-Kvasir是一个大型多分类公共胃肠道数据集。该数据采集自挪威Baerum医院的胃镜和结肠镜检查过程,所有标注均由经验丰富的放射科医生完成。数据集包含110,079张来自异常(即不健康)和正常(即健康)患者的图像,其中10,662张带有标注。我们使用该数据集中的部分清洁图像训练UAD方法,具体选取了"cecum"、"ileum"和"bbps-2-3"类别的2,100张正常图像(其中1,600张用于训练,500张用于测试),同时选取了1,000张异常图像及其分割掩码存入测试集。
LAG is a large scale fundus image dataset for glaucoma detection [21], containing 4,854 fundus images with 1,711 positive glaucoma scans and 3,143 negative glaucoma scans. We reorganised this dataset for training the UAD methods, with 2,343 normal (negative glaucoma) images for training, and 800 normal images and 1,711 abnormal images with positive glaucoma for testing.
LAG是一个用于青光眼检测的大规模眼底图像数据集 [21],包含4,854张眼底图像,其中1,711张为青光眼阳性扫描,3,143张为青光眼阴性扫描。我们重新组织该数据集以训练UAD方法,使用2,343张正常(青光眼阴性)图像进行训练,800张正常图像和1,711张异常(青光眼阳性)图像用于测试。
Liu et al.’s colon os copy dataset is a colon os copy image dataset for UAD using 18 colonocopy videos from 15 patients [27]. The training set contains 13,250 normal (healthy) images without any polyps, and the testing set contains 967 images, having 290 abnormal images with polyps and 677 normal (healthy) images without polyps.
Liu等人的结肠镜拷贝数据集是一个用于UAD的结肠镜拷贝图像数据集,包含来自15名患者的18段结肠镜视频[27]。训练集包含13,250张正常(健康)的无息肉图像,测试集包含967张图像,其中290张为带息肉的异常图像,677张为无息肉的正常(健康)图像。
3.2 Implementation Details
3.2 实现细节
For pre-training, we use Resnet18 [16] as the backbone architecture for the encoder $f_{\boldsymbol{\theta}}(\mathbf{x})$ , and similarly to previous works [6, 40], we add an MLP to this backbone as the projection head for the contrastive learning. All images from the Hyper-Kvasir [4] and LAG [21] datasets are resized to $256\times256$ pixels. For the Liu et al.’s colon os copy dataset, images are resized to $64\times64$ pixels. The batch size is set to 32 and learning rate to 0.01 for the self-supervised pre-training. We investigate the impact of different strong augmentations in $\mathcal{A}{n}$ such as rotation, permutation, cutout and Gaussian noise. All weak augmentations in $\mathcal{A}{p}$ are the same as SimCLR [6] (i.e., colour jittering, random grey scale, crop, resize, and Gaussian blur). The model is trained using SGD optimiser with temperature 0.2. The encoder $f_{\theta}(\cdot)$ outputs a 128 dimensional feature in $\mathcal{Z}$ . All datasets are pre-trained for 2,000 epochs.
在预训练阶段,我们采用Resnet18 [16]作为编码器$f_{\boldsymbol{\theta}}(\mathbf{x})$的骨干架构,并参照先前工作[6,40]的做法,在该骨干网络上添加了一个MLP作为对比学习的投影头。Hyper-Kvasir [4]和LAG [21]数据集的所有图像均被调整为$256\times256$像素。对于Liu等人的结肠镜拷贝数据集,图像被调整为$64\times64$像素。自监督预训练的批次大小设为32,学习率为0.01。我们研究了$\mathcal{A}{n}$中不同强增强方法(如旋转、排列、截除和高斯噪声)的影响。$\mathcal{A}{p}$中的所有弱增强均与SimCLR [6]保持一致(即色彩抖动、随机灰度化、裁剪、尺寸调整和高斯模糊)。模型训练使用SGD优化器,温度参数设为0.2。编码器$f_{\theta}(\cdot)$在$\mathcal{Z}$空间输出128维特征。所有数据集均进行了2000轮预训练。
For the training of IGD [8], F-anoGAN [37] and MS-SSIM auto-encoder [8], we use the hyper-parameters suggested by the respective papers. For local is ation, we compute the heatmap based on the localised anomaly scores from IGD, where the final map is obtained by summing the global and local maps. In our experiments, the local map is obtained by considering each $32\times32$ image patch as a instance and apply our proposed self-supervised learning to it. The global map is computed based on the whole image sized as $256\times256$ . For F-anoGAN and MS-SSIM auto-encoder, we use the same setup as the IGD, where models based the $256\times256$ whole image and the $32\times32$ patches are trained, respectively. Code will be made publicly available upon paper acceptance.
在训练IGD [8]、F-anoGAN [37]和MS-SSIM自编码器 [8]时,我们采用了各自论文推荐的超参数。对于局部定位任务,我们基于IGD的局部异常分数计算热力图,最终通过叠加全局图与局部图获得结果图。实验中,局部图通过将每个$32\times32$图像块视为独立实例并应用我们提出的自监督学习方法生成。全局图则基于$256\times256$尺寸的完整图像计算。F-anoGAN和MS-SSIM自编码器采用与IGD相同的配置,分别训练基于$256\times256$完整图像和$32\times32$图像块的模型。代码将在论文录用后公开。
3.3 Ablation Study
3.3 消融实验
In Fig. 2 (right), we explore the influence of strong augmentation strategies, represented by rotation, permutation, cutout and Gaussian noise, on the AUC results on HyperKvasir dataset, based on our self-supervised pre-training with IGD as anomaly detector.
在图 2 (右) 中, 我们基于以 IGD 作为异常检测器的自监督预训练方法, 探讨了旋转、置换、剪切和高斯噪声等强数据增强策略对 HyperKvasir 数据集 AUC 结果的影响。

Fig. 2: Left: Anomaly detection performance results based on different batch sizes of self-supervised pre-training. Right: Anomaly detection performance in terms of different types of strong augmentations. Both results are on Hyper-Kvasir test set using IGD as anomaly detector.
图 2: 左: 基于不同批次大小的自监督预训练异常检测性能结果。右: 不同类型强增强下的异常检测性能。两项结果均在Hyper-Kvasir测试集上使用IGD作为异常检测器得出。
Table 1: Ablation study of the loss terms in (1) on Hyper-Kvasir, using IGD as anomaly detector.
表 1: 在Hyper-Kvasir数据集上使用IGD作为异常检测器时,(1)式中损失项的消融研究。
| Ccon [6,17] lcon lpre (pat | AUC-Hyper-Kvasir |
|---|---|
| √ | 0.913 |
| √ 人 | 0.937 |
| √ √ √ | 0.964 0.972 |
Table 2: Anomaly local is ation: Mean IoU results on Hyper-Kvasir on 5 different groups of 100 images with ground truth masks. * indicates that we pretrained the geometric transformation-based anomaly detection [13] using IGD [8] as the UAD method.
| 监督方式 | 方法 | 定位交并比 (Localisation-IoU) |
|---|---|---|
| 有监督 | U-Net [36] | 0.746 |
| U-Net++ [50] | 0.743 | |
| ResUNet [9] | 0.793 | |
| SFA [12] | 0.611 | |
| RotNet[13]+IGD[8]* | 0.276 | |
| 无监督 | CAVGA-Ru[46] | 0.349 |
| Ours-IGD | - | |
| 0.372 |
表 2: 异常定位: Hyper-Kvasir数据集上5组100张带真实掩码图像的均值交并比结果。*表示我们使用IGD [8]作为无监督异常检测(UAD)方法对基于几何变换的异常检测[13]进行了预训练。
The experiment indicates that the use of random permutations as strong augmentations yields the best AUC results. We also explore the relation between batch size and AUC results in Fig. 2 (left). The results suggest that small batch size (equal to 16) leads to a relatively low AUC, which increases for batch size 32, and then decreases for larger batch sizes. Given these results, we use permutation as the strong augmentation for colon os copy images and training batch size is set to 32. For the LAG dataset, we omit the results, but we use rotation as the strong augmentation because it produced the largest AUC. We also used batch size of 32 for the LAG dataset.
实验表明,使用随机排列作为强增强方法能获得最佳AUC结果。我们在图2(左)中还探究了批量大小与AUC结果的关系。结果显示较小批量(16)会导致相对较低的AUC,批量增至32时AUC上升,而更大批量时AUC反而下降。基于这些结果,我们对结肠OS拷贝图像采用排列作为强增强方法,并将训练批量设为32。对于LAG数据集,我们未展示具体结果,但选用旋转作为强增强方法(因其产生最大AUC),同样采用32的批量大小。
We also present an ablation study that shows the influence of each loss term in (1) in Tab. 1, again on Hyper-Kvasir dataset, based on our self-supervised pre-training with IGD. The vanilla contrastive learning in [6, 17] only achieves $91.3%$ of AUC. After replacing it with our distribution contrastive loss from (2), the performance increases by $2.4%$ AUC. Adding distribution classification and patch position prediction losses boosts the performance by another $2.7%$ and $0.8%$ AUC, respectively.
我们还通过基于IGD的自监督预训练方法,在Hyper-Kvasir数据集上进行了消融实验,以展示(1)式中各损失项的影响,结果如 表1 所示。文献[6, 17]中的原始对比学习仅获得91.3%的AUC值。当使用我们(2)式中的分布对比损失进行替换后,性能提升了2.4% AUC。进一步添加分布分类和图像块位置预测损失后,AUC值分别再提升2.7%和0.8%。
3.4 Comparison to SOTA Models
3.4 与SOTA模型的对比
In Tab. 3, we show the results of anomaly detection on Hyper-Kvasir, Liu et al.’s colon os copy dataset and LAG datasets. The IGD, F-anoGAN and MS-SSIM methods improve their baselines (without our self-supervision method) from $3.3%$ to $5.1%$ of AUC on Hyper-Kvasir, from $-0.3%$ to $12.2%$ on Liu et al.’s dataset, and from $0.9%$ to $7.8%$ on LAG. The IGD with our pre-trained features achieves SOTA anomaly detection AUC on all three datasets. Such results suggest that our self-supervised pre-training can effectively produce good representations for various types of anomaly detectors and datasets. OCGAN [34] constrained the latent space based on two disc rim in at or s to force the latent representations of normal data to fall at a bounded area. CAVGA $\mathcal{R}_{u}$ [46] is a recently proposed approach for anomaly detection and local is ation that uses an attention expansion loss to encourage the model to focus on normal object regions in the images. These two methods achieve $81.3%$ and $92.8%$ AUC on Hyper-Kvasir, respectively, which are well behind our self-supervised pre-training with IGD of $97.2%$ AUC.
在表3中,我们展示了在Hyper-Kvasir、Liu等人的结肠镜数据集和LAG数据集上的异常检测结果。IGD、F-anoGAN和MS-SSIM方法在使用我们的自监督方法后,相比基线(未使用自监督方法)在Hyper-Kvasir上的AUC提升了3.3%到5.1%,在Liu等人数据集上从-0.3%提升至12.2%,在LAG数据集上从0.9%提升至7.8%。采用我们预训练特征的IGD在所有三个数据集上都达到了最先进的异常检测AUC。这些结果表明,我们的自监督预训练能有效为各类异常检测器和数据集生成优质表征。OCGAN [34] 通过两个判别器约束潜在空间,迫使正常数据的潜在表征落入有界区域。CAVGA $\mathcal{R}_{u}$ [46] 是近期提出的异常检测与定位方法,它使用注意力扩展损失促使模型聚焦图像中的正常物体区域。这两种方法在Hyper-Kvasir上分别达到81.3%和92.8%的AUC,远低于我们采用自监督预训练的IGD所取得的97.2% AUC。
Table 3: Anomaly detection: AUC results on Hyper-Kvasir, Liu et al.’s colonocopy and LAG, respectively. * indicates that the model does not use Imagenet pre-training.
| 方法 | Hyper-AUC | CLiuetal.-AUC | LAG-AUC |
|---|---|---|---|
| DAE [30] | 0.705 | 0.629 * | |
| OCGAN[34] | 0.813 | 0.592 | |
| F-anoGAN[37] | 0.907 | 0.691 * | 0.778 |
| ADGAN[26] | 0.913 | 0.730 米 | |
| CAVGA-Ru[46] | 0.928 | ||
| MS-SSIM[8] | 0.917 | 0.799 | 0.823 |
| IGD [8] | 0.939 | 0.787 | 0.796 |
| RotNet[13]+IGD[8] | 0.905 | ||
| Ours-MS-SSIM | 0.945 | 0.796 | 0.839 |
| Ours-F-anoGAN | 0.958 | 0.813 | 0.787 |
| Ours-IGD | 0.972 | 0.837 | 0.874 |
表 3: 异常检测: 分别在 Hyper-Kvasir、Liu等人的结肠镜数据和 LAG 上的 AUC 结果。* 表示模型未使用 Imagenet 预训练。
We also investigate the anomaly local is ation performance on Hyper-Kvasir in Tab. 2. Compared to the SOTA UAD local is ation method, CAVGA $R_{u}$ [46], our approach with IGD is more than $3%$ better in terms of IoU. We also compare our results to fully supervised methods [9,12,36,50] to assess how much performance is lost by suppressing supervision from abnormal data. The fully supervised baselines [9, 12, 36, 50] use $80%$ of the annotated 1,000 colon os copy images containing polyps during training, and $10%$ for validation and $10%$ for testing. We validate our approach using the same number of testing samples, but without using abnormal samples for training. The local is ation results are post processed by the Connected Component Analysis (CCA) [5]. Notice on Tab. 2 that we lose between 0.3 and $0.4~\mathrm{IoU}$ for not using abnormal samples for training.
我们还在表2中研究了Hyper-Kvasir上的异常定位性能。与当前最优的异常检测定位方法CAVGA $R_{u}$ [46]相比,采用IGD的我们的方法在IoU指标上高出3%以上。我们还与全监督方法[9,12,36,50]进行了对比,以评估因抑制异常数据监督而损失的性能。全监督基线[9,12,36,50]在训练时使用了80%标注的1000张含息肉结肠镜图像,10%用于验证,10%用于测试。我们使用相同数量的测试样本验证了我们的方法,但未使用异常样本进行训练。定位结果通过连通域分析(CCA) [5]进行后处理。注意表2中显示,由于未使用异常样本训练,我们的IoU指标下降了0.3至$0.4~\mathrm{IoU}$。
We present visual anomaly local is ation results of our IGD with self-supervised pretraining on the abnormal images from Hyper Kvasir [4] test set in Fig. 3. Notice how our model can accurately localise polyps with various size and textures.
我们在图3中展示了使用自监督预训练的IGD模型在Hyper Kvasir [4]测试集异常图像上的视觉异常定位结果。值得注意的是,我们的模型能够准确定位不同大小和纹理的息肉。
4 Conclusion
4 结论
To conclude, we proposed a self-supervised pre-training for UAD named as constrained contrastive distribution learning for anomaly detection. Our approach enforces nonuniform representation distribution by constraining contrastive distribution learning with two pretext tasks. We validate our approach on three medical imaging benchmarks and achieve SOTA anomaly detection and local is ation results using three UAD methods. In future work, we will investigate more choices of pretext tasks for UAD.
总结来说,我们提出了一种名为约束对比分布学习的自监督预训练方法用于异常检测 (UAD)。该方法通过两个预训练任务约束对比分布学习,强制形成非均匀表征分布。我们在三个医学影像基准上验证了该方法的有效性,并采用三种UAD方法实现了当前最优 (SOTA) 的异常检测与定位效果。未来工作中,我们将探索更多适用于UAD的预训练任务选择。

Fig. 3: Qualitative results of our local is ation network based on IGD with self-supervised pre-training on the abnormal images from Hyper Kvasir [4] test set.
图 3: 基于IGD的自监督预训练定位网络在Hyper Kvasir [4] 测试集异常图像上的定性结果。