DoubleU-Net: A Deep Convolutional Neural Network for Medical Image Segmentation
DoubleU-Net: 用于医学图像分割的深度卷积神经网络
Abstract—Semantic image segmentation is the process of labeling each pixel of an image with its corresponding class. An encoder-decoder based approach, like U-Net and its variants, is a popular strategy for solving medical image segmentation tasks. To improve the performance of U-Net on various segmentation tasks, we propose a novel architecture called DoubleU-Net, which is a combination of two U-Net architectures stacked on top of each other. The first U-Net uses a pre-trained VGG-19 as the encoder, which has already learned features from ImageNet and can be transferred to another task easily. To capture more semantic information efficiently, we added another U-Net at the bottom. We also adopt Atrous Spatial Pyramid Pooling (ASPP) to capture contextual information within the network. We have evaluated DoubleU-Net using four medical segmentation datasets, covering various imaging modalities such as colon os copy, dermoscopy, and microscopy. Experiments on the 2015 MICCAI sub-challenge on automatic polyp detection dataset, the CVC-ClinicDB, the 2018 Data Science Bowl challenge, and the Lesion boundary segmentation datasets demonstrate that the DoubleU-Net outperforms U-Net and the baseline models. Moreover, DoubleU-Net produces more accurate segmentation masks, especially in the case of the CVC-ClinicDB and 2015 MICCAI sub-challenge on automatic polyp detection dataset, which have challenging images such as smaller and flat polyps. These results show the improvement over the existing U-Net model. The encouraging results, produced on various medical image segmentation datasets, show that DoubleU-Net can be used as a strong baseline for both medical image segmentation and cross-dataset evaluation testing to measure the general iz ability of Deep Learning (DL) models.
摘要—语义图像分割是将图像每个像素标注对应类别的过程。基于编码器-解码器的U-Net及其变体是解决医学图像分割任务的常用策略。为提升U-Net在各类分割任务中的性能,我们提出名为DoubleU-Net的新型架构,该架构由两个级联的U-Net组成。首个U-Net采用预训练VGG-19作为编码器,该模型已从ImageNet学习特征并可轻松迁移至其他任务。为高效捕获更多语义信息,我们在底层追加了第二个U-Net,并采用空洞空间金字塔池化(ASPP)来捕获网络中的上下文信息。我们在涵盖结肠镜检、皮肤镜检和显微成像等多种模态的四个医学分割数据集上评估DoubleU-Net。在2015年MICCAI自动息肉检测子挑战数据集、CVC-ClinicDB、2018年Data Science Bowl挑战赛及病灶边界分割数据集上的实验表明,DoubleU-Net性能优于U-Net及基线模型。特别是在包含较小扁平息肉等挑战性图像的CVC-ClinicDB和2015年MICCAI自动息肉检测子挑战数据集上,DoubleU-Net能生成更精确的分割掩码。这些结果显示出对现有U-Net模型的改进。多个医学图像分割数据集上的优异表现表明,DoubleU-Net可作为医学图像分割和跨数据集评估测试的强基线,用于衡量深度学习(DL)模型的泛化能力。
Index Terms—semantic segmentation, convolutional neural network, U-Net, DoubleU-Net, CVC-ClinicDB, ETIS-Larib,ASPP, 2015 MICCAI sub-challenge on automatic polyp detection, 2018 Data Science Bowl, Lesion Boundary Segmentation challenge
索引术语—语义分割、卷积神经网络、U-Net、DoubleU-Net、CVC-ClinicDB、ETIS-Larib、ASPP、2015年MICCAI自动息肉检测子挑战赛、2018年数据科学碗、病灶边界分割挑战赛
I. INTRODUCTION
I. 引言
Medical image segmentation is the task of labeling each pixel of an object of interest in medical images. It is often a key task for clinical applications, varying from Computer Aided Diagnosis (CADx) for lesions detection to therapy planning and guidance [1]. Medical image segmentation helps clinicians focus on a particular area of the disease and extract detailed information for a more accurate diagnosis. The key challenges associated with medical image segmentation are the un availability of a large number of annotated, lack of highquality labeled images for training [2], low image quality, lack of a standard segmentation protocol, and a large variations of images among patients [3]. The quant if i cation of segmentation accuracy and uncertainty is essential to estimate the performance on other applications [1]. This indicates the requirement for an automatic, general iz able, and efficient semantic image segmentation approach.
医学图像分割的任务是对医学图像中感兴趣对象的每个像素进行标注。它通常是临床应用中的关键任务,涵盖从病变检测的计算机辅助诊断 (CADx) 到治疗规划和引导 [1]。医学图像分割帮助临床医生聚焦于疾病的特定区域,并提取详细信息以实现更精准的诊断。医学图像分割面临的主要挑战包括:缺乏大量标注数据、缺少高质量的训练标注图像 [2]、图像质量低、缺乏标准分割协议以及患者间图像存在较大差异 [3]。分割准确性和不确定性的量化对于评估其他应用的性能至关重要 [1],这表明需要一种自动化、可泛化且高效的语义图像分割方法。
Convolutional Neural Networks (CNNs) have shown stateof-the-art performance for automated medical image segmentation [4]. For semantic segmentation tasks, one of the earlier Deep Learning (DL) architecture trained end-to-end for pixel-wise prediction is a Fully Convolutional Network (FCN). U-Net [5] is another popular image segmentation architecture trained end-to-end for pixel-wise prediction. The U-Net architecture consists of two parts, namely, analysis path and synthesis path. In the analysis path, deep features are learned, and in the synthesis path, segmentation is performed based on the learned features. Additionally, U-Net uses skip connections operation. The skip connection allows propagating dense feature maps from the analysis path to the corresponding layers in the synthesis part. In this way, the spatial information is applied to the deeper layer, which significantly produces a more accurate output segmentation map. Thus, adding more layers to the U-Net will allow the network to learn more representative features leading to better output segmentation masks.
卷积神经网络 (Convolutional Neural Networks, CNNs) 在自动化医学图像分割领域展现了最先进的性能 [4]。对于语义分割任务,最早实现端到端逐像素预测的深度学习 (Deep Learning, DL) 架构之一是全卷积网络 (Fully Convolutional Network, FCN)。U-Net [5] 是另一种流行的端到端逐像素预测图像分割架构。U-Net 架构包含两部分:分析路径和合成路径。在分析路径中学习深层特征,在合成路径中基于学习到的特征进行分割。此外,U-Net 采用了跳跃连接操作,这种连接能将密集特征图从分析路径传递到合成路径的对应层级。通过这种方式,空间信息被传递到更深的网络层,从而显著生成更精确的输出分割图。因此,为 U-Net 增加更多网络层可以让模型学习更具代表性的特征,进而获得更优的输出分割掩膜。
Generalization, i.e., the ability of the model to perform in an independent dataset, and robustness, i.e., the ability of the model to perform on challenging images, are keys for the development of Artificial Intelligence (AI) system to be used in clinical trials [6]. Therefore, it is essential to design a powerful architecture that is robust and general iz able across different biomedical applications. Pre-trained ImageNet [7] models have significantly improved the performance of the CNN architectures. One of the examples of such models trained on ImageNet is VGG19 [8]. Inspired by the success of U-Net and its variants for medical image segmentation, we propose an architecture that uses modified U-Net and VGG-19 in the encoder part of the network. Because we use two UNet architectures in the network, we term the architecture as DoubleU-Net. The main reasons for using the VGG network are: (1) VGG-19 is a lightweight model as compared to other pre-trained models, (2) the architecture of VGG-19 is similar to U-Net, making it easy to concatenate with U-Net, and (3) it will allow much deeper networks for producing better output segmentation mask. Thus, we aim to improve the overall segmentation performance of the network by enabling this architectural changes.
泛化性 (即模型在独立数据集上的表现能力) 和鲁棒性 (即模型在挑战性图像上的表现能力) 是开发用于临床试验的人工智能 (AI) 系统的关键 [6]。因此,设计一个强大且能跨不同生物医学应用保持稳健性和泛化能力的架构至关重要。预训练的 ImageNet [7] 模型显著提升了 CNN 架构的性能,VGG19 [8] 便是此类模型的代表之一。受 U-Net 及其变体在医学图像分割领域成功的启发,我们提出了一种在网络编码器部分使用改进版 U-Net 和 VGG-19 的架构。由于网络中使用了两个 U-Net 架构,我们将其命名为 DoubleU-Net。采用 VGG 网络的主要原因包括:(1) 与其他预训练模型相比,VGG-19 是轻量级模型;(2) VGG-19 的架构与 U-Net 相似,便于与之拼接;(3) 它能支持更深层的网络以生成更优的分割掩码输出。我们期望通过这些架构改进来全面提升网络的分割性能。
The main contributions of this work are:
这项工作的主要贡献包括:
The paper is organized into seven sections. Section II provides an overview of the related work in the field of medical image segmentation. In Section III, we describe the proposed architecture. Section IV describes the experiments. Section V presents the results obtained from the experimental evaluation on different datasets. A discussion of the work is provided in Section VI. Finally, we summarize the paper and discuss future work and limitations in Section VII.
本论文共分为七个部分。第II部分概述了医学图像分割领域的相关工作。第III部分描述了提出的架构。第IV部分介绍了实验设计。第V部分展示了在不同数据集上的实验结果评估。第VI部分对工作进行了讨论。最后,第VII部分总结了全文,并探讨了未来工作与局限性。
II. RELATED WORK
II. 相关工作
Among different CNN architectures, an encoder-decoder network like FCN [10] and its extension U-Net [5] have gained significant popularity among semantic segmentation approach for 2D images. Badri narayan et al. [11] proposed a deep fully CNN for semantic pixel-wise segmentation that has significantly fewer parameters and produces good segmentation maps. Yu et al. [12] proposed a new convolutional network module that particularly targeted dense prediction problems. The proposed module used dilated convolutions for systematically aggregating multi-scale contextual information, and the presented context module improved the accuracy for state-of-the-art semantic image segmentation systems.
在不同的CNN架构中,像FCN [10]及其扩展U-Net [5]这样的编码器-解码器网络在二维图像语义分割方法中获得了极大的流行。Badri Narayan等人 [11]提出了一种深度全卷积网络,用于语义像素级分割,该网络参数显著减少并能生成良好的分割图。Yu等人 [12]提出了一种新的卷积网络模块,专门针对密集预测问题。该模块使用扩张卷积系统地聚合多尺度上下文信息,所提出的上下文模块提高了最先进语义图像分割系统的准确性。
Chen et al. [13] proposed DeepLab to solve segmentation problem. Later, DeeplabV3 [9] significantly improved over their previous DeepLab versions without DenseCRF postprocessing. The DeepLabV3 architecture uses a synthesis path that contains the fewer number of convolutional layers that are different from the synthesis path of FCN and UNet. DeepLabV3 uses skip connection between analysis path and synthesis path similar to U-Net architecture. Zhao et al. [14] proposed effective scenes parsing network for complex scene understanding, where global pyramidal features provide an opportunity to capture additional contextual information. Zhang et al. [15] proposed Deep Residual U-Net, which uses residual connections better output segmentation map. Chen et al. [16] proposed Dense-Res-Inception Net (DRINET) for medical image segmentation and compared their results with FCN, U-Net, and ResUNet. Ibtehaz et al. [17] modified UNet and proposed an improved Multi Re sUN et architecture for medical image segmentation where they compared their results with U-Net on various medical image segmentation datasets and showed superior accuracy than U-Net.
Chen等人[13]提出了DeepLab来解决分割问题。随后,DeeplabV3[9]在无需DenseCRF后处理的情况下显著超越了之前的DeepLab版本。DeepLabV3架构采用了一条合成路径,其卷积层数量少于FCN和UNet的合成路径。与U-Net架构类似,DeepLabV3在分析路径和合成路径之间使用了跳跃连接。Zhao等人[14]提出了用于复杂场景理解的高效场景解析网络,其中全局金字塔特征为捕获额外上下文信息提供了可能。Zhang等人[15]提出了Deep Residual U-Net,通过残差连接获得更好的分割输出图。Chen等人[16]提出了用于医学图像分割的Dense-Res-Inception Net(DRINET),并将其结果与FCN、U-Net和ResUNet进行了对比。Ibtehaz等人[17]改进了UNet并提出增强版Multi ResUNet架构用于医学图像分割,他们在多个医学图像分割数据集上与U-Net进行对比,结果显示其精度优于U-Net。
Jha et al. [18] proposed ResUNet $^{++}$ , which is an enhanced version of standard ResUNet by integrating an additional layer such as squeeze-and-excite block, ASPP, and attention block to the network. The proposed architecture uses dice loss as the loss function and produces an improved output segmentation maps as compared to U-Net and ResUNet on the Kvasir-SEG [2] and CVC-ClinicDB [19] datasets. Zhou et al. [20] proposed ${\mathrm{UNet}}++$ , a neural network architectures for semantic and instance segmentation tasks. They improved the performance of ${\mathrm{UNet}}++$ by alleviating the unknown network depth, redesigning the skip connections, and devising a pruning scheme to the architecture.
Jha等人[18]提出了ResUNet$^{++}$,这是标准ResUNet的增强版本,通过在网络中集成额外的层(如压缩-激励块、ASPP和注意力块)。所提出的架构使用dice损失作为损失函数,在Kvasir-SEG[2]和CVC-ClinicDB[19]数据集上相比U-Net和ResUNet产生了改进的输出分割图。Zhou等人[20]提出了${\mathrm{UNet}}++$,这是一种用于语义和实例分割任务的神经网络架构。他们通过缓解未知网络深度、重新设计跳跃连接以及为该架构设计剪枝方案,提升了${\mathrm{UNet}}++$的性能。
From the above-related work, we can observe that there has been substantial efforts toward developing deep CNN architectures for the segmentation of both natural and medical images. Recently, more works are focused on developing general iz able models, which is why most of the researchers test their algorithms on different datasets [17], [18], [20]. The accuracy achieved is now is high for both natural imaging [13] and medical imaging [17], [18], [20]. However, AI in medicine is still an emerging field. One of the significant challenges in the medical domain is the lack of test datasets. Moreover, the obtained datasets are often imbalanced. To some extent, we can say that the performance is acceptable in the case of natural images. In the medical imaging, there are many challenging images (for example, flat polyps in colon os copy), which are usually missed out during colon os copy examination and can develop into cancer if early detection is not performed. Therefore, there is a need for a more accurate medical image segmentation approach to deal with the challenging images. Toward addressing this need, we have proposed DoubleU-Net architecture that produces efficient output segmentation masks with the challenging images.
从上述相关工作中可以看出,在开发用于自然图像和医学图像分割的深度CNN架构方面已经付出了大量努力。最近,更多工作集中在开发通用化模型上,这也是大多数研究者在不同数据集上测试其算法的原因 [17]、[18]、[20]。目前在自然图像 [13] 和医学图像 [17]、[18]、[20] 领域都取得了较高的准确率。然而,医学AI仍是一个新兴领域。医学领域面临的主要挑战之一是缺乏测试数据集,且获取的数据集往往存在不平衡问题。某种程度上可以说,在自然图像案例中的表现是可接受的。而在医学影像中,存在许多具有挑战性的图像(例如结肠镜检查中的扁平息肉),这些图像通常在结肠镜检查中被遗漏,若未进行早期检测可能发展为癌症。因此需要更精确的医学图像分割方法来处理这些挑战性图像。针对这一需求,我们提出了DoubleU-Net架构,该架构能在处理挑战性图像时生成高效的分割输出掩膜。
III. THE DOUBLEU-NET ARCHITECTURE
III. DOUBLEU-NET 架构
Figure 1 shows an overview of the proposed architecture. As seen from the figure, DoubleU-Net starts with a VGG-19 as encoder sub-network, which is followed by decoder subnetwork. What distinguishes DoubleU-Net from U-Net in the first network (NETWORK 1) is the use of VGG-19 marked in yellow, ASPP marked in blue, and decoder block marked in light green. The squeeze-and-excite block [21] is used in the encoder of NETWORK 1 and decoder blocks of NETWORK 1 and NETWORK 2. An element-wise multiplication is performed between the output of NETWORK 1 with the input of the same network. The difference between DoubleU-Net and
图 1: 展示了所提出架构的概览。如图所示,DoubleU-Net以VGG-19作为编码器子网络开始,随后是解码器子网络。DoubleU-Net与U-Net在第一个网络(NETWORK 1)中的区别在于使用了黄色标记的VGG-19、蓝色标记的ASPP以及浅绿色标记的解码器块。挤压激励模块[21]被用于NETWORK 1的编码器以及NETWORK 1和NETWORK 2的解码器块中。在NETWORK 1的输出与该网络的输入之间执行逐元素乘法。DoubleU-Net与
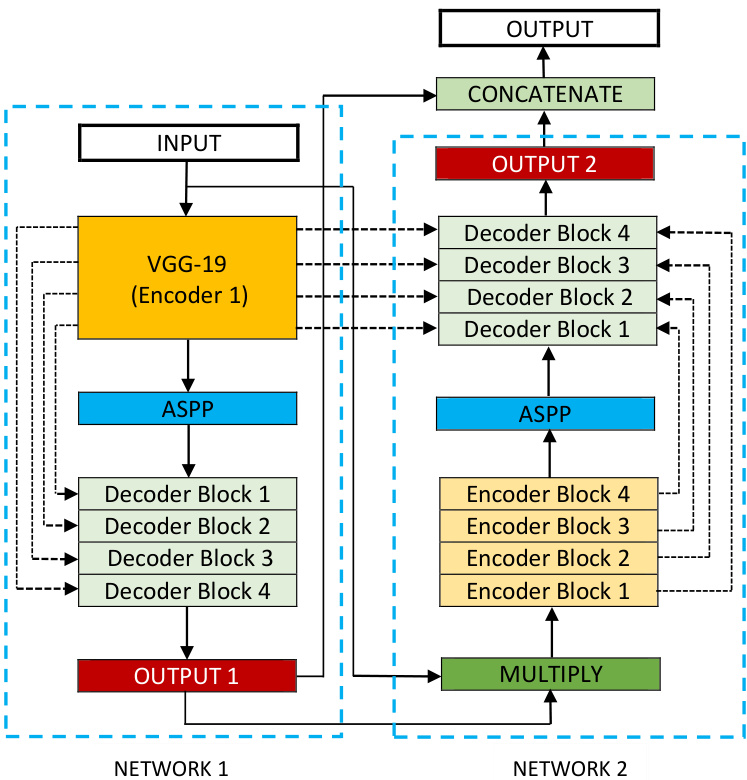
Fig. 1: Block diagram of the proposed DoubleU-Net architecture
图 1: 提出的 DoubleU-Net 架构框图
U-Net in the second network (NETWORK 2) is only the use of ASPP and squeeze-and-excite block. All other components remain the same.
第二网络(NETWORK 2)中的U-Net仅使用了ASPP和压缩激励模块(squeeze-and-excite block),其余所有组件保持不变。
In the NETWORK 1, the input image is fed to the modified U-Net, which generates a predicted mask (Output1). We then multiply the input image and the produced mask (Output1), which acts as an input for the second modified U-Net that produces another mask (Output2). Finally, we concatenate both the masks (Output1 and Output2) to see the qualitative difference between the intermediate mask (Output1) and final predicted mask (Output2).
在NETWORK 1中,输入图像被送入改进后的U-Net,生成预测掩码(Output1)。随后将输入图像与生成的掩码(Output1)相乘,作为第二个改进U-Net的输入以生成另一掩码(Output2)。最后拼接两个掩码(Output1和Output2),观察中间掩码(Output1)与最终预测掩码(Output2)的定性差异。
We assume that the produced output feature map from NETWORK 1 can still be improved by fetching the input image and its corresponding mask again, and concatenating with Output2 will produce a better segmentation mask than the previous one. This is the main motivation behind using two U-Net architectures in the proposed architecture. The squeezeand-excite block in the proposed networks reduces the redundant information and passes the most relevant information. ASPP has been a popular choice for modern segmentation architecture because it helps to extract high-resolution feature maps that lead to superior performance [18].
我们假设NETWORK 1生成的输出特征图仍可通过再次获取输入图像及其对应掩码来优化,与Output2拼接后将产生比先前更优的分割掩码。这是所提架构采用双重U-Net设计的主要动机。网络中引入的压缩激励模块(squeeze-and-excite block)能有效过滤冗余信息,仅传递最相关的特征。ASPP模块因其能提取高分辨率特征图从而提升性能[18],已成为现代分割架构的流行选择。
A. Encoder Explanation
A. 编码器解释
The first encoder in DoubleU-Net (encoder1) uses pretrained VGG-19, whereas the second encoder (encoder2), is built from scratch. Each encoder tries to encode the information contained in the input image. Each encoder block in the encoder2 performs two $3\times3$ convolution operation, each followed by a batch normalization. The batch normalization reduces the internal co-variant shift and also regularizes the model. A Rectified Linear Unit (ReLU) activation function is applied, which introduces non-linearity into the model. This is followed by a squeeze-and- excitation block, which enhances the quality of the feature maps. After that, max-pooling is performed with a $2\times2$ window and stride 2 to reduce the spatial dimension of the feature maps.
DoubleU-Net中的第一个编码器(encoder1)使用了预训练的VGG-19,而第二个编码器(encoder2)则是从头构建的。每个编码器都试图对输入图像中的信息进行编码。encoder2中的每个编码器块执行两次$3\times3$卷积操作,每次卷积后都进行批归一化(batch normalization)。批归一化减少了内部协变量偏移,同时也对模型进行了正则化。接着应用修正线性单元(ReLU)激活函数,为模型引入非线性。随后是一个压缩-激励块(squeeze-and-excitation block),用于提升特征图的质量。最后使用$2\times2$窗口和步长2进行最大池化(max-pooling),以降低特征图的空间维度。
B. Decoder Explanation
B. 解码器详解
As shown in Figure 1, we use two decoders in the entire network, with small modifications on the decoder as compared with that of the original U-Net. Each block in the decoder performs a $2\times2$ bi-linear up-sampling on the input feature, which doubles the dimension of the input feature maps. Now, we concatenate the appropriate skip connections feature maps from the encoder to the output feature maps. In the first decoder, we only use skip connection from the first encoder, but in the second decoder, we use skip connection from both the encoders, which maintains the spatial resolution and enhance the quality of the output feature maps. After concatenation, we again perform two $3\times3$ convolution operation, each of which is followed by batch normalization and then by a ReLU activation function. After that, we use a squeeze and excitation block. At last, we apply a convolution layer with a sigmoid activation function, which is used to generate the mask for the corresponding modified U-Net.
如图 1 所示,我们在整个网络中使用了两个解码器,相较于原始 U-Net 的解码器进行了小幅修改。解码器中的每个模块对输入特征执行 $2\times2$ 双线性上采样,使输入特征图的尺寸翻倍。随后,我们将编码器中相应的跳跃连接特征图与输出特征图进行拼接。在第一个解码器中,仅使用第一个编码器的跳跃连接;而在第二个解码器中,则同时采用两个编码器的跳跃连接,从而保持空间分辨率并提升输出特征图的质量。拼接操作后,我们再次执行两次 $3\times3$ 卷积运算,每次卷积后接批量归一化和 ReLU 激活函数。接着使用压缩激励模块 (squeeze and excitation block),最后通过带有 sigmoid 激活函数的卷积层生成对应改进版 U-Net 的掩码。
IV. EXPERIMENTS
IV. 实验
In this section, we present datasets, evaluation metrics, experiment setup and configuration, and data augmentation techniques used in all the experiments to validate the proposed framework.
在本节中,我们将介绍用于验证所提出框架的所有实验中使用的数据集、评估指标、实验设置与配置以及数据增强技术。
A. Datasets
A. 数据集
To evaluate the effectiveness of the DoubleU-Net, we have used four publicly available datasets from medical domain.
为了评估 DoubleU-Net 的有效性,我们使用了四个公开的医学领域数据集。
TABLE I: Summary of biomedical segmentation dataset used in our experiments
| Dataset | No.of Images | Input size | Application |
| 2015 MICCAI sub-challenge on automatic polyp detection dataset | 808 | 384×288 | Colonoscopy |
| CVC-ClinicDB | 612 | 384×288 | Colonoscopy |
| LesionBoundarySegmentation challenge | 2594 | Variable | Dermoscopy |
| 2018DataScienceBowl Challenge | 670 | 256×256 | Nuclei |
表 1: 实验中使用的生物医学分割数据集概览
| 数据集 | 图像数量 | 输入尺寸 | 应用领域 |
|---|---|---|---|
| 2015 MICCAI自动息肉检测子挑战数据集 | 808 | 384×288 | 结肠镜检查 |
| CVC-ClinicDB | 612 | 384×288 | 结肠镜检查 |
| LesionBoundarySegmentation挑战赛 | 2594 | 可变尺寸 | 皮肤镜检查 |
| 2018DataScienceBowl挑战赛 | 670 | 256×256 | 细胞核检测 |
More information about the datasets are presented in Table I. All of the datasets are clinically relevant during diagnosis, and therefore, their segmentation can be crucial for patient outcome.
有关数据集的更多信息见表1。所有数据集在诊断过程中都具有临床相关性,因此其分割结果对患者预后至关重要。
B. Evaluation metrics
B. 评估指标
DoubleU-Net is evaluated on the basis of S rensen dice coefficient (DSC), mean Intersection over Union (mIoU), Precision, and Recall. We evaluate all of these metrics for all four datasets. However, we compare and emphasize more on the official evaluation metrics that were used in the challenge. For example, the official evaluation metrics for the Lesion Boundary Segmentation challenge is mIoU.
DoubleU-Net基于Srensen骰子系数(DSC)、平均交并比(mIoU)、精确率(Precision)和召回率(Recall)进行评估。我们对所有四个数据集都评估了这些指标,但更侧重比较挑战赛官方采用的评估指标。例如,病灶边界分割挑战赛的官方评估指标是mIoU。
C. Experiment setup and configuration
C. 实验设置与配置
All models are implemented using Keras framework [26] with Tensorflow 2.1.0 [27] as backend. The implementation can be found at our GitHub repository 3. We ran our experiments on a Volta 100 GPU and an Nvidia DGX-2 AI system. In all of the datasets, we used $80%$ of dataset for training, $10%$ for validation, and $10%$ for testing. During training, we used the original image size for the smaller dataset, such as CVC-ClinicDB and Nuclei segmentation dataset, and resized the images to $384\times512$ for the Lesion Boundary segmentation challenge dataset to balance between training time and complexity. The size of ETIS-Larib was adjusted similarly to that of CVC-ClinicDB. We use binary crossentropy as the loss function for all the networks and the Nadam optimizer with its default parameters. For the lesion boundary segmentation dataset and the Nuclei segmentation dataset, where dice loss and Adam optimizer performed slightly higher, the batch size is set to 16 and the learning rate to 1e 5. All models are trained for 300 epochs. Early stopping and Reduce LR On Plateau is also used.
所有模型均使用Keras框架[26]实现,并以Tensorflow 2.1.0[27]作为后端。代码实现可在我们的GitHub仓库3中查看。实验在Volta 100 GPU和Nvidia DGX-2 AI系统上运行。所有数据集中,我们使用80%的数据进行训练,10%用于验证,10%用于测试。训练过程中,对于较小数据集(如CVC-ClinicDB和细胞核分割数据集)使用原始图像尺寸,而对病变边界分割挑战数据集将图像调整为384×512以平衡训练时间与复杂度。ETIS-Larib的尺寸调整方式与CVC-ClinicDB相同。所有网络均采用二元交叉熵作为损失函数,并默认使用Nadam优化器。在病变边界分割数据集和细胞核分割数据集中,当Dice损失和Adam优化器表现略优时,批次大小设为16,学习率为1e-5。所有模型均训练300个周期,并采用了早停法和学习率高原衰减策略。
D. Data augmentation techniques
D. 数据增强技术
Medical datasets are challenging to obtain and annotate [2]. Most existing datasets have only a few samples, which makes training DL models on these datasets challenging. One potential solution to the challenge of data insufficiency, is to use data augmentation techniques that increase the number of samples during training. For this, we first split the dataset into training, validation, and testing sets. We then apply different data augmentation methods to each set, including center crop, random rotation, transpose, elastic transform, etc. More details about the augmentation techniques we used can be found in our GitHub repository. A single image was converted into 25 different images; thus, in total, 26 images including the original image. The same augmentation techniques were applied to all four datasets.
医疗数据集难以获取和标注 [2]。大多数现有数据集仅包含少量样本,这使得在这些数据集上训练深度学习 (Deep Learning, DL) 模型具有挑战性。针对数据不足的挑战,一种潜在的解决方案是使用数据增强技术,在训练过程中增加样本数量。为此,我们首先将数据集划分为训练集、验证集和测试集。随后对每个子集应用不同的数据增强方法,包括中心裁剪、随机旋转、转置、弹性变换等。所使用的增强技术细节可在我们的GitHub仓库中查阅。单张图像被转换为25张不同的图像,因此连同原始图像共计26张。所有四个数据集均采用相同的数据增强技术。
TABLE II: Experimental results using the 2015 MICCAI subchallenge on automatic polyp detection dataset
| Method | DSC | mloU | Recall | Precision |
| FCN-VGG[28] | 0.7023 | 0.5420 | 1 | |
| Mask R-CNN with Resnet101 [29] | 0.7042 | 0.6124 | ||
| U-Net | 0.2920 | 0.1759 | 0.5930 | 0.2021 |
| DoubleU-Net | 0.7649 | 0.6255 | 0.7156 | 0.8007 |
表 II: 使用2015年MICCAI自动息肉检测子挑战数据集的实验结果
| 方法 | DSC | mloU | Recall | Precision |
|---|---|---|---|---|
| FCN-VGG[28] | 0.7023 | 0.5420 | 1 | |
| Mask R-CNN with Resnet101[29] | 0.7042 | 0.6124 | ||
| U-Net | 0.2920 | 0.1759 | 0.5930 | 0.2021 |
| DoubleU-Net | 0.7649 | 0.6255 | 0.7156 | 0.8007 |

Fig. 2: Qualitative result of DoubleU-Net on large, medium, and flat polyps from 2015 MICCAI sub-challenge on automatic polyp detection dataset
图 2: DoubleU-Net在2015年MICCAI自动息肉检测子挑战数据集上对大、中、平坦息肉的分割定性结果
V. RESULTS
V. 结果
In this section, we present the results and compare them with the baselines on the respective datasets. U-Net is still considered as the baseline for various medical image segmentation tasks. Therefore, we compare the proposed model with U-Net by using the same data augmentation techniques as described above to demonstrate its effectiveness. We also report the results on four datasets and show the qualitative results to prove the usefulness of DoubleU-Net. In all of the figures demonstrating the qualitative results, the sequence of input, ground truth, Output1, and Output2 are followed, where Output1 and Output2 are the intermediate and final output respectively.
在本节中,我们展示了结果,并将其与各数据集上的基线方法进行比较。U-Net仍被视为多种医学图像分割任务的基线模型。因此,我们采用上述相同的数据增强技术,将所提模型与U-Net进行对比以验证其有效性。我们在四个数据集上报告了结果,并通过定性分析证明了DoubleU-Net的实用性。所有展示定性结果的图中,均按输入图像、真实标注、Output1(中间输出)和Output2(最终输出)的顺序排列。
A. Comparison on 2015 MICCAI sub-challenge on automatic polyp detection dataset
A. 2015年MICCAI自动息肉检测子挑战数据集对比
Our quantitative results on the 2015 MICCAI sub-challenge on automatic polyp detection dataset are summarized in Table II. The experimental results shows that DoubleU-Net achieved a DSC of 0.7649 and a mIoU of 0.6255. From
我们在2015年MICCAI自动息肉检测子挑战数据集上的量化结果总结如表II所示。实验结果表明,DoubleU-Net取得了0.7649的DSC值和0.6255的mIoU值。
TABLE III: Result comparison on CVC-ClinicDB
表 III: CVC-ClinicDB 上的结果对比

Fig. 3: Qualitative result of DoubleU-Net on challenging images from CVC-ClinicDB
图 3: DoubleU-Net在CVC-ClinicDB挑战性图像上的定性结果
Table II, we can see that DoubleU-Net outperforms the baseline [29] by $6.07%$ in terms of DSC and $1.31%$ in mIoU. From the above table, we can also observe that the model that uses a pre-trained ImageNet network (for instance, Resnet101 or VGG-16) as a backbone achieves a higher score on crossdataset evaluation as compared to that of training a network from scratch (see Table II). The visual results of the proposed model can be seen in Figure 2. From the visual analysis, we can observe that the segmentation mask produced by Output2 is better than that of Output1. This also justifies the significance of the proposed model over U-Net.
表 II 中可以看出,DoubleU-Net 在 DSC (Dice相似系数) 指标上比基线方法 [29] 高出 6.07%,在 mIoU (平均交并比) 指标上高出 1.31%。从上表还可以观察到,使用预训练 ImageNet 网络(如 Resnet101 或 VGG-16)作为骨干的模型,在跨数据集评估中比从头训练的网络获得更高分数(见表 II)。所提模型的视觉结果如图 2 所示,通过视觉分析可以看出 Output2 生成的分割掩模优于 Output1,这也印证了该模型相对于 U-Net 的改进意义。
B. Comparison on CVC-ClinicDB
B. CVC-ClinicDB 对比实验
DoubleU-Net is compared with U-Net and the recent works that used the same dataset for evaluation. Table III shows the results on CVC-ClinicDB dataset. The evaluation results shows that DoubleU-Net achieve a DSC of 0.9239 which is $3.91%$ higher than [34] and mIoU of 0.8611, which is $1.14%$ higher than [17]. A careful visual analysis of the result shows that DoubleU-Net produces better segmentation masks as compared to the intermediate network. The model performs reasonably well on the challenging images such as flat and small polyps, which are usually missed-out during colon os copy examinations (see Figure 3).
将DoubleU-Net与U-Net以及近期使用相同数据集进行评估的工作进行了对比。表III展示了在CVC-ClinicDB数据集上的结果。评估结果显示,DoubleU-Net达到了0.9239的DSC (dice similarity coefficient) ,比[34]高出3.91%,mIoU (mean intersection over union) 为0.8611,比[17]高出1.14%。对结果进行细致的视觉分析表明,与中间网络相比,DoubleU-Net产生了更好的分割掩码。该模型在具有挑战性的图像(如平坦和小息肉)上表现相当好,这些图像通常在结肠镜检查中被遗漏(见图3)。
TABLE IV: Result on Lesion boundary segmentation dataset from ISIC-2018
| Method | DSC | mIoU | Recall | Precision |
| U-Net [17] | 0.7642±0.4518 | |||
| Multi-ResUNet [17] | 0.8029 ± 0.3717 | 一 | ||
| DoubleU-Net | 0.8962 | 0.8212 | 0.8780 | 0.9459 |
表 IV: ISIC-2018病灶边界分割数据集结果
| 方法 | DSC | mIoU | Recall | Precision |
|---|---|---|---|---|
| U-Net [17] | 0.7642±0.4518 | |||
| Multi-ResUNet [17] | 0.8029 ± 0.3717 | — | ||
| DoubleU-Net | 0.8962 | 0.8212 | 0.8780 | 0.9459 |

Fig. 4: Qualitative result of DoubleU-Net on small, medium and large size skin lesions from Lesion Boundary segmentation challenge
图 4: DoubleU-Net在皮肤病变边界分割挑战赛中对小、中、大尺寸皮肤病变的定性结果
C. Comparison on Lesion Boundary segmentation challenge dataset
C. 病灶边界分割挑战数据集对比
The official evaluation metric for the challenge was mIoU. DoubleU-Net achieve a DSC of 0.8962 and mIoU of 0.8212 on this challenge dataset. From the quantitative results comparison (see Table IV), we can see that the DoubleU-Net outperforms U-Net [17] by an approximate margin of $5.7%$ , and Multi-ResUNet [17] by an approximate margin of $1.83%$ in terms of mIoU on Lesion boundary segmentation challenge dataset from ISIC-2018. Figure 4 shows the qualitative results. From the figure, we can see that both intermediate output and the final output produced by the network perform well on all types of lesions ranging from small to medium to large lesions. However, a careful analysis shows that the final output produced by the network is better than the intermediate one.
本次挑战赛的官方评估指标为mIoU。DoubleU-Net在该挑战数据集上取得了0.8962的DSC分数和0.8212的mIoU分数。从定量结果对比(见表IV)可以看出,在ISIC-2018病灶边界分割挑战数据集上,DoubleU-Net的mIoU指标比U-Net[17]高出约$5.7%$,比Multi-ResUNet[17]高出约$1.83%$。图4展示了定性结果。从图中可以看出,该网络生成的中间输出和最终输出在从小型到中型再到大型的各种病灶上都表现良好。但仔细分析表明,网络生成的最终输出优于中间输出。
D. Comparison on 2018 Data Science Bowl challenge dataset
D. 2018 Data Science Bowl挑战赛数据集对比
Table $\mathrm{v}$ and Figure 5 presents the quantitative and qualitative results on 2018 Data Science Bowl challenge dataset. We have compared our work with $\mathrm{U-Net++}$ [20]. Our method produced a DSC of 0.9133, which is $1.59%$ higher than the method proposed by Zhou et. al [20], and comparable mIoU with U-Net and $\mathrm{UNet}++$ that uses Resnet101 as the backbone model. UNet++ has been used as a strong baseline for result comparison over various image segmentation tasks.
表 $\mathrm{v}$ 和图 5 展示了 2018 Data Science Bowl 挑战赛数据集的定量与定性结果。我们将工作与 $\mathrm{U-Net++}$ [20] 进行了对比。我们的方法取得了 0.9133 的 DSC (Dice Similarity Coefficient) 值,比 Zhou 等人 [20] 提出的方法高出 $1.59%$,同时与基于 Resnet101 骨干网络的 U-Net 及 $\mathrm{UNet}++$ 具有相当的 mIoU (Mean Intersection over Union) 性能。UNet++ 已被广泛用作各类图像分割任务结果对比的强基线模型。
TABLE V: Result on Nuclei segmentation from 2018 Data Science Bowl challenge
| Method | Pre-trained network | DSC | mloU | Recall | Precision |
| U-Net [20] | Resnet101 | 0.7573 | 0.9103 | ||
| UNet++ [20] | Resnetl01 | 0.8974 | 0.9255 | - | - |
| DoubleU-Net | VGG-19 | 0.9133 | 0.8407 | 0.6407 | 0.9496 |
表 V: 2018 Data Science Bowl挑战赛的细胞核分割结果
| 方法 | 预训练网络 | DSC | mloU | 召回率 | 精确率 |
|---|---|---|---|---|---|
| U-Net [20] | Resnet101 | 0.7573 | 0.9103 | ||
| UNet++ [20] | Resnetl01 | 0.8974 | 0.9255 | - | - |
| DoubleU-Net | VGG-19 | 0.9133 | 0.8407 | 0.6407 | 0.9496 |

Fig. 5: Qualitative result of DoubleU-Net on Nuclei images from 2018 Data Science Bowl challenge dataset
图 5: DoubleU-Net在2018年数据科学碗挑战赛数据集上的细胞核图像定性结果
Therefore, the DoubleU-Net set a new baseline for semantic image segmentation task.
因此,DoubleU-Net为语义图像分割任务设立了新的基准。
VI. DISCUSSION
VI. 讨论
Table VI shows the DSC comparison of U-Net and DoubleU-Net. From the above table, we can see that DoubleUNet performs reasonably well as compared to U-Net for all the presented datasets. For the CVC-ClinicDB dataset, the performance of U-Net is competitive. However, for 2015 MICCAI sub-challenge on automatic polyp detection dataset and the 2018 Data Science Bowl, DoubleU-Net has a significant DSC improvement of $0.4729%$ and $15.60%$ respectively. Additionally, the 2015 MICCAI sub-challenge on automatic polyp detection dataset provides us the opportunity to study the cross-data general iz ability, which is critical in the medical domain [35]. The generalization test showed that DoubleU-Net outperforms its competitors (see Table II). From the Table, we observe that the model trained on pre-trained ImageNet [7] performs much better on the cross-dataset test than that of the model trained from scratch. We have trained U-Net on the CVC-ClinicDB dataset, which is competitive with DoubleUNet when tested on the same dataset (see Table III). The same model was used to test against the ETIS-Larib dataset. However, the performance of the U-Net was poor as compared to that of DoubleU-Net (see Table II). This fact suggests that DoubleU-Net is more general iz able and can be used for the cross-dataset test across the different domains.
表 VI 展示了 U-Net 和 DoubleU-Net 的 DSC (Dice Similarity Coefficient) 对比结果。从上表可以看出,DoubleU-Net 在所有数据集上的表现均优于 U-Net。在 CVC-ClinicDB 数据集上,U-Net 的表现具有竞争力。然而,在 2015 MICCAI 自动息肉检测子挑战赛数据集和 2018 Data Science Bowl 数据集上,DoubleU-Net 的 DSC 分别显著提升了 $0.4729%$ 和 $15.60%$。此外,2015 MICCAI 自动息肉检测子挑战赛数据集为我们提供了研究跨数据泛化能力的机会,这在医学领域至关重要 [35]。泛化测试表明 DoubleU-Net 优于其他模型 (见表 II)。从表中可以观察到,基于预训练 ImageNet [7] 的模型在跨数据集测试中表现显著优于从头训练的模型。我们在 CVC-ClinicDB 数据集上训练了 U-Net,当在同一数据集上测试时,其表现与 DoubleU-Net 相当 (见表 III)。但使用相同模型测试 ETIS-Larib 数据集时,U-Net 的表现远逊于 DoubleU-Net (见表 II)。这一事实表明 DoubleU-Net 具有更强的泛化能力,可应用于跨领域的跨数据集测试。
TABLE VI: Relative improvement of DoubleU-Net on U-Net
| Modality | U-Net (DSC) | DoubleU-Net (DSC) | Overall Improvement |
| Colonoscopy (MICCAI 2015) | 0.2920 | 0.7649 | 0.4729 |
| Colonoscopy (CVC-ClinicDB) | 0.8781 | 0.9239 | 0.0458 |
| Dermoscopy (ISIC-2018) | 一 | 0.8962 | 一 |
| Microscopy(2018 Data Science Bowl) | 0.7573 | 0.9133 | 0.1560 |
表 VI: DoubleU-Net相对于U-Net的相对改进
| 模态 | U-Net (DSC) | DoubleU-Net (DSC) | 整体改进 |
|---|---|---|---|
| 结肠镜检查 (MICCAI 2015) | 0.2920 | 0.7649 | 0.4729 |
| 结肠镜检查 (CVC-ClinicDB) | 0.8781 | 0.9239 | 0.0458 |
| 皮肤镜检查 (ISIC-2018) | — | 0.8962 | — |
| 显微镜检查 (2018 Data Science Bowl) | 0.7573 | 0.9133 | 0.1560 |
From the qualitative results, we can see that DoubleU-Net is capable of producing better segmentation mask even for the challenging images. This can be observed from Figure 2 and Figure 3. Moreover, Figure 4 and Figure 5 show that the model produces high-quality segmentation masks for Lesion Boundary Segmentation challenge dataset and 2018 Data Science Bowl challenge dataset. The overall qualitative result shows that the model performs well for different multi-organ and multi-centered medical image segmentation datasets. Thus, the above results suggest that the robustness of the proposed model.
从定性结果可以看出,DoubleU-Net即使在具有挑战性的图像上也能生成更好的分割掩码。这一点可以从图2和图3中观察到。此外,图4和图5表明,该模型在Lesion Boundary Segmentation挑战数据集和2018 Data Science Bowl挑战数据集上生成了高质量的分割掩码。整体定性结果表明,该模型在不同多器官、多中心的医学图像分割数据集上表现良好。因此,上述结果证明了所提出模型的鲁棒性。
From the above experiments, we observed that the transfer learning from a pre-trained ImageNet network significantly improves the results on every dataset, which tries to compensate for the lack of enough training data. The qualitative and quantitative results suggest using DoubleU-Net as a baseline for result comparisons over four medical image segmentation datasets.
从上述实验中我们观察到,基于预训练ImageNet网络的迁移学习显著提升了各数据集上的结果,这有效弥补了训练数据不足的问题。定性和定量结果表明,DoubleU-Net可作为四个医学图像分割数据集结果比较的基准模型。
VII. CONCLUSION
VII. 结论
In this paper, we have proposed a novel CNN architecture called DoubleU-Net. The DoubleU-Net has five main components, namely two U-Net networks, VGG-19, a squeeze-andexcite block and ASPP. The performance of DoubleU-Net is significantly better when compared with the baselines and UNet on all four datasets.
本文提出了一种名为DoubleU-Net的新型CNN架构。DoubleU-Net包含五个主要组件:两个U-Net网络、VGG-19、压缩激励模块 (squeeze-and-excite block) 和ASPP。在所有四个数据集上,DoubleU-Net的性能均显著优于基线模型和U-Net。
Moreover, the proposed architecture is flexible, and that makes it possible to integrate other CNN blocks into DoubleUNet. We believe that the segmentation results can be improved by further integrating different CNN blocks and by the use of post-processing techniques such as conditional random field and Otsu threshold.
此外,所提出的架构具有灵活性,这使得将其他CNN模块整合到DoubleUNet中成为可能。我们相信,通过进一步整合不同的CNN模块以及使用条件随机场和Otsu阈值等后处理技术,可以提升分割效果。
In the future, we plan to research building one model for different medical image segmentation tasks and focus on simplifying the architecture while retaining its ability to produce high segmentation masks. A limitation of the DoubleU-Net is that it uses more parameters as compared to U-Net, which leads to an increase in the training time. In the future, the research should focus more on designing simplified architectures with fewer parameters while maintaining its ability.
未来,我们计划研究构建一个适用于不同医学图像分割任务的单一模型,并着重在简化架构的同时保留其生成高质量分割掩膜的能力。DoubleU-Net的一个局限性在于其参数量比U-Net更多,这会导致训练时间增加。未来的研究应更关注设计参数量更少但性能相当的简化架构。