Learning Semantics-enriched Representation via Self-discovery, Self-classification, and Self-restoration
通过自我发现、自我分类和自我恢复学习语义增强表示
Abstract. Medical images are naturally associated with rich semantics about the human anatomy, reflected in an abundance of recurring anatomical patterns, offering unique potential to foster deep semantic representation learning and yield semantically more powerful models for different medical applications. But how exactly such strong yet free semantics embedded in medical images can be harnessed for self-supervised learning remains largely unexplored. To this end, we train deep models to learn semantically enriched visual representation by self-discovery, selfclassification, and self-restoration of the anatomy underneath medical images, resulting in a semantics-enriched, general-purpose, pre-trained 3D model, named Semantic Genesis. We examine our Semantic Genesis with all the publicly-available pre-trained models, by either self-supervision or fully supervision, on the six distinct target tasks, covering both classification and segmentation in various medical modalities (i.e., CT, MRI, and X-ray). Our extensive experiments demonstrate that Semantic Genesis significantly exceeds all of its 3D counterparts as well as the de facto ImageNet-based transfer learning in 2D. This performance is attributed to our novel self-supervised learning framework, encouraging deep models to learn compelling semantic representation from abundant anatomical patterns resulting from consistent anatomies embedded in medical images. Code and pre-trained Semantic Genesis are available at https://github.com/JLiangLab/Semantic Genesis.
摘要。医学图像天然蕴含丰富的人体解剖语义信息,通过大量重复出现的解剖模式得以体现,这为促进深度语义表征学习及构建更强大的医学应用模型提供了独特潜力。然而,如何有效利用医学图像中这种强烈且自由的语义进行自监督学习仍亟待探索。为此,我们训练深度模型通过自发现、自分类和自恢复医学图像底层解剖结构来学习语义增强的视觉表征,最终构建出名为Semantic Genesis的通用预训练3D模型。我们在六项不同目标任务(涵盖CT、MRI和X射线等多种医学模态的分类与分割)上,对所有公开可用的自监督或全监督预训练模型进行了全面评测。大量实验表明,Semantic Genesis显著优于所有3D对比模型及基于ImageNet的2D迁移学习方法。这一优势源于我们新颖的自监督学习框架,该框架促使深度模型从医学图像中固有解剖结构所产生的大量解剖模式中学习具有说服力的语义表征。代码及预训练模型详见https://github.com/JLiangLab/Semantic_Genesis。
Keywords: Self-supervised learning · Transfer learning · 3D model pretraining.
关键词:自监督学习 · 迁移学习 · 3D模型预训练
1 Introduction
1 引言
Self-supervised learning methods aim to learn general image representation from unlabeled data; naturally, a crucial question in self-supervised learning is how to “extract” proper supervision signals from the unlabeled data directly. In large part, self-supervised learning approaches involve predicting some hidden properties of the data, such as color iz ation [16,17], jigsaw [15,18], and rotation [11,13].
自监督学习方法旨在从未标注数据中学习通用的图像表征;自然,自监督学习中的一个关键问题是如何直接从无标注数据中“提取”合适的监督信号。在很大程度上,自监督学习方法涉及预测数据的某些隐藏属性,例如着色 [16,17]、拼图 [15,18] 和旋转 [11,13]。
However, most of the prominent methods were derived in the context of natural images, without considering the unique properties of medical images.
然而,大多数知名方法都是在自然图像的背景下提出的,并未考虑医学图像的特殊属性。
In medical imaging, it is required to follow protocols for defined clinical purposes, therefore generating images of similar anatomies across patients and yielding recurrent anatomical patterns across images (see Fig. 1a). These recurring patterns are associated with rich semantic knowledge about the human body, thereby offering great potential to foster deep semantic representation learning and produce more powerful models for various medical applications. However, it remains an unanswered question: How to exploit the deep semantics associated with recurrent anatomical patterns embedded in medical images to enrich representation learning?
在医学影像领域,需要遵循针对特定临床目的制定的协议,因此能生成不同患者间的相似解剖结构图像,并在图像中呈现重复出现的解剖模式 (见图 1a)。这些重复模式与人体丰富的语义知识相关联,从而为促进深度语义表征学习提供了巨大潜力,并能构建更强大的模型以应用于各类医疗场景。然而,如何利用医学影像中重复解剖模式所蕴含的深层语义来丰富表征学习,仍是一个悬而未决的问题。
To answer this question, we present a novel self-supervised learning framework, which enables the capture of semantics-enriched representation from unlabeled medical image data, resulting in a set of powerful pre-trained models. We call our pre-trained models Semantic Genesis, because they represent a significant advancement from Models Genesis [25] by introducing two novel components: self-discovery and self-classification of the anatomy underneath medical images (detailed in Sec. 2). Specifically, our unique self-classification branch, with a small computational overhead, compels the model to learn semantics from consistent and recurring anatomical patterns discovered during the selfdiscovery phase, while Models Genesis learns representation from random subvolumes with no semantics as no semantics can be discovered from random sub-volumes. By explicitly employing the strong yet free semantic supervision signals, Semantic Genesis distinguishes itself from all other existing works, including color iz ation of colon os copy images [20], context restoration [9], Rubik’s cube recovery [26], and predicting anatomical positions within MR images [4].
为回答这一问题,我们提出了一种新颖的自监督学习框架,能够从未标注的医学图像数据中捕获富含语义的表征,从而生成一组强大的预训练模型。我们将这些预训练模型命名为Semantic Genesis,因为它们通过引入两个创新组件(详见第2节)——医学图像底层解剖结构的自发现(self-discovery)与自分类(self-classification),实现了对Models Genesis [25] 的重大改进。具体而言,我们独特的自分类分支以极小的计算开销,迫使模型从自发现阶段识别出的、具有一致性和重复性的解剖模式中学习语义,而Models Genesis仅从无语义的随机子体积中学习表征(因为随机子体积无法发现任何语义)。通过显式利用这种强大且免费的语义监督信号,Semantic Genesis与所有现有工作形成鲜明区分,包括结肠镜图像着色 [20]、上下文恢复 [9]、魔方复原 [26] 以及MR图像内解剖位置预测 [4]。
As evident in Sec. 4, our extensive experiments demonstrate that (1) learning semantics through our two innovations significantly enriches existing selfsupervised learning approaches [9,19,25], boosting target tasks performance dramatically (see Fig. 2); (2) Semantic Genesis provides more generic and transferable feature representations in comparison to not only its self-supervised learning counterparts, but also (fully) supervised pre-trained 3D models (see Table 2); and Semantic Genesis significantly surpasses any 2D approaches (see Fig. 3).
如第4节所示,我们的大量实验证明:(1) 通过我们的两项创新学习语义显著丰富了现有的自监督学习方法 [9,19,25],大幅提升了目标任务性能 (见图2);(2) 与自监督学习方案及(完全)监督预训练的3D模型相比,Semantic Genesis能提供更通用、可迁移性更强的特征表示 (见表2);同时Semantic Genesis显著超越了所有2D方案 (见图3)。
This performance is ascribed to the semantics derived from the consistent and recurrent anatomical patterns, that not only can be automatically discovered from medical images but can also serve as strong yet free supervision signals for deep models to learn more semantically enriched representation automatically via self-supervision.
这一性能归功于从一致且反复出现的解剖模式中提取的语义信息,这些模式不仅能从医学图像中自动发现,还能作为强大而自由的监督信号,使深度学习模型通过自监督自动学习更具语义丰富性的表征。
2 Semantic Genesis
2 语义起源
Fig. 1 presents our self-supervised learning framework, which enables training Semantic Genesis from scratch on unlabeled medical images. Semantic Genesis is conceptually simple: an encoder-decoder structure with skip connections in between and a classification head at the end of the encoder. The objective for the model is to learn different sets of semantics-enriched representation from multiple perspectives. In doing so, our proposed framework consists of three important components: 1) self-discovery of anatomical patterns from similar patients; 2) self-classification of the patterns; and 3) self-restoration of the transformed patterns. Specifically, once the self-discovered anatomical pattern set is built, we jointly train the classification and restoration branches together in the model.
图 1 展示了我们的自监督学习框架,该框架能够在未标记的医学图像上从头开始训练 Semantic Genesis。Semantic Genesis 在概念上很简单:一个编码器-解码器结构,中间有跳跃连接,编码器末端有一个分类头。该模型的目标是从多个角度学习不同的语义丰富表示集。为此,我们提出的框架包含三个重要组成部分:1) 从相似患者中自我发现解剖模式;2) 对模式进行自分类;3) 对转换后的模式进行自我恢复。具体来说,一旦建立了自我发现的解剖模式集,我们就在模型中联合训练分类和恢复分支。
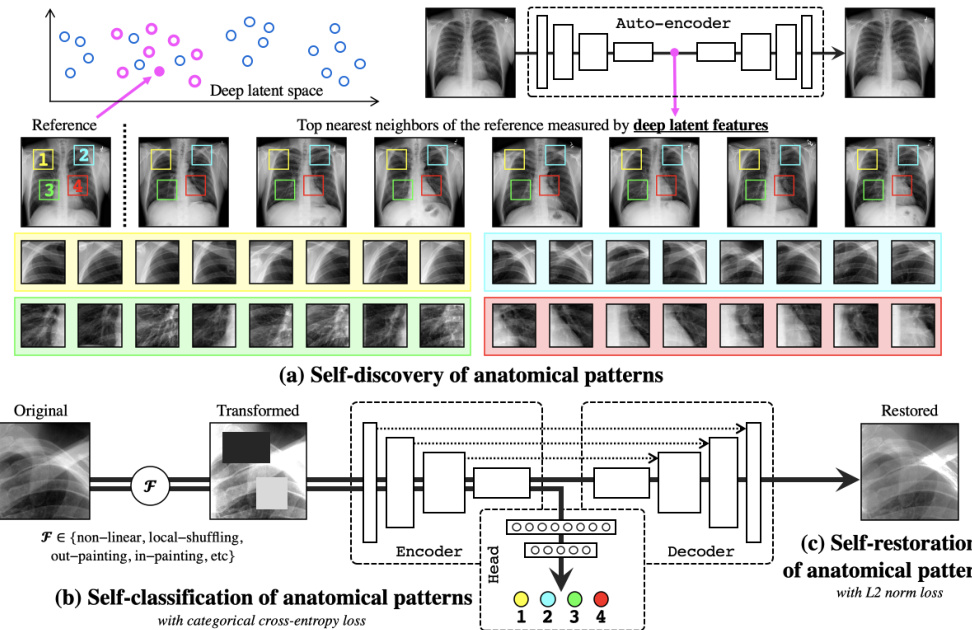
Fig. 1. Our self-supervised learning framework consists of (a) self-discovery, (b) selfclassification, and (c) self-restoration of anatomical patterns, resulting in semanticsenriched pre-trained models—Semantic Genesis—an encoder-decoder structure with skip connections in between and a classification head at the end of the encoder. Given a random reference patient, we find similar patients based on deep latent features, crop anatomical patterns from random yet fixed coordinates, and assign pseudo labels to the crops according to their coordinates. For simplicity and clarity, we illustrate our idea with four coordinates in X-ray images as an example. The input to the model is a transformed anatomical pattern crop, and the model is trained to classify the pseudo label and to recover the original crop. Thereby, the model aims to acquire semanticsenriched representation, producing more powerful application-specific target models.
图 1: 我们的自监督学习框架包含 (a) 自发现、(b) 自分类和 (c) 解剖模式自恢复三个模块,最终形成语义增强的预训练模型——Semantic Genesis。该模型采用编码器-解码器结构,中间带有跳跃连接,编码器末端配有分类头。给定随机参考患者后,我们基于深度潜在特征寻找相似患者,从随机但固定的坐标位置裁剪解剖模式,并根据坐标位置为裁剪区域分配伪标签。为简明起见,我们以X光图像中的四个坐标为例进行说明。模型输入是经过变换的解剖模式裁剪区域,训练目标是分类伪标签并重建原始裁剪区域。通过这种方式,模型旨在获得语义增强的表征,从而生成更强大的应用专用目标模型。
- Self-discovery of anatomical patterns: We begin by building a set of anatomical patterns from medical images, as illustrated in Fig. 1a. To extract deep features of each (whole) patient scan, we first train an auto-encoder network with training data, which learns an identical mapping from scan to itself. Once trained, the latent representation vector from the auto-encoder can be used as an indicator of each patient. We randomly anchor one patient as a reference and search for its nearest neighbors through the entire dataset by computing the $L2$ distance of the latent representation vectors, resulting in a set of semantically similar patients. As shown in Fig. 1a, due to the consistent and recurring anatomies across these patients, that is, each coordinate contains a unique anatomical pattern, it is feasible to extract similar anatomical patterns according to the coordinates. Hence, we crop patches/cubes (for 2D/3D images) from $C$ number of random but fixed coordinates across this small set of discovered patients, which share similar semantics. Here we compute similarity in patient-level rather than pattern-level to ensure the balance between the diversity and consistency of anatomical patterns. Finally, we assign pseudo labels to these patches/cubes based on their coordinates, resulting in a new dataset, wherein each patch/cube is associated with one of the $C$ classes. Since the coordinates are randomly selected in the reference patient, some of the anatomical patterns may not be very meaningful for radiologists, yet these patterns are still associated with rich local semantics of the human body. For example, in Fig. 1a, four pseudo labels are defined randomly in the reference patient (top-left most), but as seen, they carry local information of (1) anterior ribs 2–4, (2) anterior ribs 1–3, (3) right pulmonary artery, and (4) LV. Most importantly, by repeating the above self-discovery process, enormous anatomical patterns associated with their pseudo labels can be automatically generated for representation learning in the following stages (refer to Appendix Sec. A).
- 解剖模式自发现:我们首先从医学图像中构建一组解剖模式,如图1a所示。为提取每例(完整)患者扫描的深层特征,我们先用训练数据训练一个自编码器网络,该网络学习从扫描到自身的恒等映射。训练完成后,自编码器的潜在表示向量可作为每位患者的表征指标。随机选取一位患者作为参考锚点,通过计算潜在表示向量的$L2$距离在整个数据集中搜索其最近邻,从而获得一组语义相似的患者。如图1a所示,由于这些患者具有一致且重复出现的解剖结构(即每个坐标点对应独特的解剖模式),按坐标提取相似解剖模式具有可行性。因此,我们从这组语义相似的已发现患者中,在$C$个随机但固定的坐标位置上裁剪图像块/立方体(分别对应2D/3D图像)。此处采用患者级而非模式级的相似度计算,以确保解剖模式多样性与一致性的平衡。最后根据坐标位置为这些图像块/立方体分配伪标签,形成新数据集,其中每个图像块/立方体归属于$C$个类别之一。由于坐标是在参考患者中随机选取的,部分解剖模式对放射科医生可能意义不大,但这些模式仍关联着丰富的人体局部语义。例如图1a中,参考患者(左上角)随机定义了四个伪标签,实际分别对应:(1) 第2-4前肋,(2) 第1-3前肋,(3) 右肺动脉,(4) 左心室的局部信息。最重要的是,通过重复上述自发现过程,可自动生成海量带伪标签的解剖模式用于后续阶段的表征学习(详见附录A节)。
- Self-classification of anatomical patterns: After self-discovery of a set of anatomical patterns, we formulate the representation learning as a $C$ -way multi-class classification task. The goal is to encourage models to learn from the recurrent anatomical patterns across patient images, fostering a deep semantically enriched representation. As illustrated in Fig. 1b, the classification branch encodes the input anatomical pattern into a latent space, followed by a sequence of fully-connected $(f c)$ layers, and predicts the pseudo label associated with the pattern. To classify the anatomical patterns, we adopt categorical cross-entropy loss function: $\begin{array}{r}{\mathcal{L}{c l s}=-\frac{1}{N}\sum_{b=1}^{N}\sum_{c=1}^{C}\mathcal{V}{b c}\log\mathcal{P}_{b c}}\end{array}$ , where $N$ denotes the batch size; $C$ denotes the number of classes; $\mathcal{V}$ and $\mathcal{P}$ represent the ground truth (one-hot pseudo label vector) and the prediction, respectively.
- 解剖模式自分类: 在自主发现一组解剖模式后,我们将表征学习建模为一个$C$类多分类任务。该目标旨在促使模型从患者图像中反复出现的解剖模式中学习,从而形成深度语义增强的表征。如图1b所示,分类分支将输入解剖模式编码至潜在空间,随后通过全连接层$(fc)$序列,预测与该模式关联的伪标签。我们采用分类交叉熵损失函数进行解剖模式分类: $\begin{array}{r}{\mathcal{L}{c l s}=-\frac{1}{N}\sum_{b=1}^{N}\sum_{c=1}^{C}\mathcal{V}{b c}\log\mathcal{P}_{b c}}\end{array}$,其中$N$表示批次大小,$C$表示类别数量,$\mathcal{V}$和$\mathcal{P}$分别代表真实值(独热伪标签向量)和预测值。
- Self-restoration of anatomical patterns: The objective of self-restoration is for the model to learn different sets of visual representation by recovering original anatomical patterns from the transformed ones. We adopt the transformations proposed in Models Genesis [25], i.e., non-linear, local-shuffling, outpainting, and in-painting (refer to Appendix Sec. B). As shown in Fig. 1c, the restoration branch encodes the input transformed anatomical pattern into a latent space and decodes back to the original resolution, with an aim to recover the original anatomical pattern from the transformed one. To let Semantic Genesis restore the transformed anatomical patterns, we compute $L2$ distance between original pattern and reconstructed pattern as loss function: $\begin{array}{r}{\mathcal{L}{r e c}=\frac{1}{N}\sum_{i=1}^{N}|\mathcal{X}{i}-\mathcal{X}{i}^{\prime}|_{2}}\end{array}$ , where $N$ , $\mathcal{X}$ and $\mathcal{X}^{\prime}$ denote the batch size, ground truth (original anatomical pattern) and reconstructed prediction, respectively.
- 解剖模式自恢复:自恢复的目标是让模型通过从变换后的解剖模式中恢复原始解剖模式,学习不同的视觉表示集。我们采用Models Genesis [25]提出的变换方法,即非线性变换、局部打乱、外绘和内绘(详见附录B节)。如图1c所示,恢复分支将输入的变换解剖模式编码到潜在空间,并解码回原始分辨率,旨在从变换后的模式中恢复原始解剖模式。为使Semantic Genesis能恢复变换后的解剖模式,我们计算原始模式与重建模式之间的$L2$距离作为损失函数:$\begin{array}{r}{\mathcal{L}{r e c}=\frac{1}{N}\sum_{i=1}^{N}|\mathcal{X}{i}-\mathcal{X}{i}^{\prime}|_{2}}\end{array}$,其中$N$、$\mathcal{X}$和$\mathcal{X}^{\prime}$分别表示批次大小、真实值(原始解剖模式)和重建预测结果。
Formally, during training, we define a multi-task loss function on each transformed anatomical pattern as $\mathcal{L}=\lambda_{c l s}\mathcal{L}{c l s}+\lambda_{r e c}\mathcal{L}{r e c}$ , where $\lambda_{c l s}$ and $\lambda_{r e c}$ regulate the weights of classification and reconstruction losses, respectively. Our definition of $\mathcal{L}{c l s}$ allows the model to learn more semantically enriched representation. The definition of $\mathscr{L}{r e c}$ encourages the model to learn from multiple perspectives by restoring original images from varying image deformations. Once trained, the encoder alone can be fine-tuned for target classification tasks; while the encoder and decoder together can be fine-tuned for target segmentation tasks to fully utilize the advantages of the pre-trained models on the target tasks.
在训练过程中,我们为每个变换后的解剖模式定义了一个多任务损失函数 $\mathcal{L}=\lambda_{c l s}\mathcal{L}{c l s}+\lambda_{r e c}\mathcal{L}{r e c}$ ,其中 $\lambda_{c l s}$ 和 $\lambda_{r e c}$ 分别调节分类损失和重建损失的权重。$\mathcal{L}{c l s}$ 的定义使模型能够学习语义更丰富的表示,而 $\mathscr{L}_{r e c}$ 的定义则通过从不同图像变形中恢复原始图像,促使模型从多角度学习。训练完成后,可单独对编码器进行微调以适配目标分类任务;同时微调解码器与编码器则可应用于目标分割任务,从而充分利用预训练模型在目标任务中的优势。
Table 1. We evaluate the learned representation by fine-tuning it for six publiclyavailable medical imaging applications including 3D and 2D image classification and segmentation tasks, across diseases, organs, datasets, and modalities.
a The first letter denotes the object of interest (“N” for lung nodule, “L” for liver, etc); the second letter denotes the modality (“C” for CT, “X” for X-ray, “M” for MRI); the last letter denotes the task (“C” for classification, “S” for segmentation).
表 1: 我们通过微调学习到的表征,评估了其在六种公开可用的医学影像应用中的表现,涵盖3D和2D图像分类与分割任务,涉及不同疾病、器官、数据集和模态。
| 代码对象 | 目标部位 | 模态 | 数据集 | 应用 |
|---|---|---|---|---|
| NCC | 肺结节 | CT | LUNA-2016 [21] | 结节假阳性减少 |
| NCS | 肺结节 | CT | LIDC-IDRI [3] | 肺结节分割 |
| LCS | 肝脏 | CT | LiTS-2017 [6] | 肝脏分割 |
| BMS | 脑肿瘤 | MRI | BraTS2018 [5] | 脑肿瘤分割 |
| DXC | 胸部疾病 | X-ray | ChestX-Ray14 [23] | 十四种胸部疾病分类 |
| PXS | 气胸 | X-ray | SIIM-ACR-2019 [1] | 气胸分割 |
a 首字母表示目标部位 ("N"代表肺结节,"L"代表肝脏等);第二个字母表示模态 ("C"代表CT,"X"代表X射线,"M"代表MRI);最后一个字母表示任务 ("C"代表分类,"S"代表分割)。
3 Experiments
3 实验
Pre-training Semantic Genesis: Our Semantic Genesis 3D and 2D are selfsupervised pre-trained from 623 CT scans in LUNA-2016 [21] (same as the publicly released Models Genesis) and 75,708 X-ray images from ChestX-ray14 [22] datasets, respectively. Although Semantic Genesis is trained from only unlabeled images, we do not use all the images in those datasets to avoid test-image leaks between proxy and target tasks. In the self-discovery process, we select top $K$ most similar cases with the reference patient, according to the deep features computed from the pre-trained auto-encoder. To strike a balance between diversity and consistency of the anatomical patterns, we empirically set $K$ to 200/1000 for 3D/2D pre-training based on the dataset size. We set $C$ to 44/100 for 3D/2D images so that the anatomical patterns can largely cover the entire image while avoiding too much overlap with each other. For each random coordinate, we extract multi-resolution cubes/patches, then resize them all to 64 $\times$ 64 $\times$ 32 and 224 $\times$ 224 for 3D and 2D, respectively; finally, we assign $C$ pseudo labels to the cubes/patches based on their coordinates. For more details in implementation and meta-parameters, please refer to our publicly released code.
预训练语义起源:我们的Semantic Genesis 3D和2D模型分别通过自监督方式预训练,数据来源为LUNA-2016 [21] 数据集中的623例CT扫描(与公开发布的Models Genesis相同)和ChestX-ray14 [22] 数据集中的75,708张X光片。尽管语义起源仅使用未标注图像进行训练,但为避免代理任务与目标任务间的测试图像泄露,我们并未使用这些数据集中的所有图像。在自发现过程中,我们根据预训练自编码器提取的深度特征,筛选出与参考患者最相似的$K$个病例。为平衡解剖模式的多样性与一致性,基于数据集规模,我们经验性地将3D/2D预训练的$K$值设为200/1000。将$C$设置为44/100(3D/2D图像),确保解剖模式能覆盖大部分图像区域,同时避免过多重叠。针对每个随机坐标,我们提取多分辨率立方体/图像块,并将其统一调整为64$\times$64$\times$32(3D)和224$\times$224(2D),最后根据坐标位置为立方体/图像块分配$C$个伪标签。具体实现细节与元参数请参阅我们公开的代码。
Baselines and implementation: Table 1 summarizes the target tasks and datasets. Since most self-supervised learning methods are initially proposed in 2D, we have extended two most representative ones [9,19] into their 3D version for a fair comparison. Also, we compare Semantic Genesis with Rubik’s cube [26], the most recent multi-task self-supervised learning method for 3D medical imaging. In addition, we have examined publicly available pre-trained models for 3D transfer learning in medical imaging, including NiftyNet [12], MedicalNet [10], Models Genesis [25], and Inflated 3D (I3D) [8] that has been successfully transferred to 3D lung nodule detection [2], as well as ImageNet models, the most influential weights initialization in 2D target tasks. 3D U-Net $^{3}$ /U-Net $^4$ architectures used in 3D/2D applications, have been modified by appending fullyconnected layers to end of the encoders. In proxy tasks, we set $\lambda_{r e c}=1$ and $\lambda_{c l s}~=~0.01$ . Adam with a learning rate of 0.001 is used for optimization. We first train classification branch for 20 epochs, then jointly train the entire model for both classification and restoration tasks. For CT target tasks, we investigate the capability of both 3D volume-based solutions and 2D slice-based solutions, where the 2D representation is obtained by extracting axial slices from volumetric datasets. For all applications, we run each method 10 times on the target task and report the average, standard deviation, and further present statistical analyses based on independent two-sample $t$ -test.
基准方法与实现:表1总结了目标任务和数据集。由于大多数自监督学习方法最初是针对2D提出的,我们扩展了两种最具代表性的方法[9,19]到3D版本以确保公平比较。同时,我们将Semantic Genesis与最新的3D医学影像多任务自监督学习方法Rubik's cube[26]进行对比。此外,我们还评估了医学影像3D迁移学习的公开预训练模型,包括NiftyNet[12]、MedicalNet[10]、Models Genesis[25]以及已成功迁移至3D肺结节检测的Inflated 3D (I3D)[8],还有在2D目标任务中最具影响力的ImageNet模型权重初始化方案。针对3D/2D应用场景的3D U-Net$^{3}$/U-Net$^4$架构,我们通过在编码器末端添加全连接层进行了修改。在代理任务中,设置$\lambda_{r e c}=1$和$\lambda_{c l s}~=~0.01$,采用学习率为0.001的Adam优化器。先单独训练分类分支20个周期,再联合训练整个模型完成分类和重建任务。对于CT目标任务,我们同时研究了基于3D体素和2D切片的解决方案,其中2D表示通过从体数据集中提取轴向切片获得。所有实验均在目标任务上重复运行10次,报告平均值、标准差,并基于独立双样本$t$检验进行统计分析。
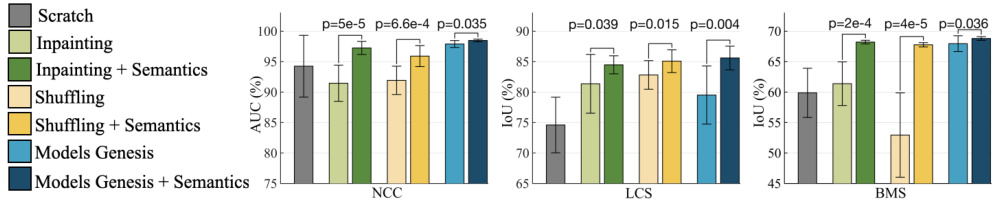
Fig. 2. With and without semantics-enriched representation in the self-supervised learning approaches contrast a substantial ( $\textit{p}<0.05)$ performance difference on target classification and segmentation tasks. By introducing self-discovery and selfclassification, we enhance semantics in three most recent self-supervised learning advances (i.e., image in-painting [19], patch-shuffling [9], and Models Genesis [25]).
图 2: 在自监督学习方法中,使用和未使用语义增强表示对目标分类和分割任务性能存在显著差异 (p<0.05)。通过引入自发现和自分类机制,我们在三种前沿自监督学习方法 (即图像修复 [19]、块重排 [9] 和 Models Genesis [25]) 中增强了语义表征能力。
4 Results
4 结果
Learning semantics enriches existing self-supervised learning approaches:
学习语义丰富现有自监督学习方法:
Our proposed self-supervised learning scheme should be considered as an addon, which can be added to and boost existing self-supervised learning methods. Our results in Fig. 2 indicate that by simply incorporating the anatomical patterns with representation learning, the semantics-enriched models consistently outperform each and every existing self-supervised learning method [19,9,25]. Specifically, the semantics-enriched representation learning achieves performance gains by $5%$ , 3%, and $1%$ in NCC, compared with the original in-painting, patchshuffling, and Models Genesis, respectively; and the performance improved by
我们提出的自监督学习方案应被视为一种附加组件,可增强现有自监督学习方法的效果。图 2 中的结果表明,仅通过将解剖模式与表征学习相结合,语义增强模型就能持续超越所有现有自监督学习方法 [19,9,25]。具体而言,与原始修复、块重排和 Models Genesis 相比,语义增强表征学习在 NCC 指标上分别实现了 5%、3% 和 1% 的性能提升;性能进一步提高了
Table 2. Semantic Genesis outperforms learning 3D models from scratch, three competing publicly available (fully) supervised pre-trained 3D models, and four selfsupervised learning approaches in four target tasks. For every target task, we report the mean and standard deviation (mean $\pm$ s.d.) across ten trials and further perform independent two sample $t$ -test between the best (bolded) vs. others and highlighted boxes in blue when they are not statistically significantly different at $p=0.05$ level.
‡ Models Genesis used only synthetic images of BraTS-2013, however we examine real and only MR Flair images for segmenting brain tumors, so the results are not submitted to BraTS-2018.
表 2: Semantic Genesis在四项目标任务中优于从零开始学习3D模型、三种公开可用的(完全)监督预训练3D模型以及四种自监督学习方法。对于每项目标任务,我们报告了十次试验的平均值和标准差(mean $\pm$ s.d.),并在最佳结果(加粗)与其他方法之间进行了独立双样本$t$检验,当$p=0.05$水平无显著统计学差异时用蓝色高亮标出。
| 预训练方式 | 初始化方法 | NCC(AUC%) | LCS(IoU%) | NCS(IoU%) | BMS+(IoU%) |
|---|---|---|---|---|---|
| Random | 94.25±5.07 | 74.60±4.57 | 74.05±1.97 | 59.87±4.04 | |
| 监督学习 | NiftyNet 12 | 94.14±4.57 | 83.23±1.05 | 52.98±2.05 | 60.78±1.60 |
| MedicalNet [10] | 95.80±0.51 | 83.32±0.85 | 75.68±0.32 | 66.09±1.35 | |
| Inflated3D (I3D) 8 | 98.26±0.27 | 70.65±4.26 | 71.31±0.37 | 67.83±0.75 | |
| Autoencoder | 88.43±10.25 | 78.16±2.07 | 75.10±0.91 | 56.36±5.32 | |
| In-painting [19] | 91.46±2.97 | 81.36±4.83 | 75.86±0.26 | 61.38±3.84 | |
| Patch-shuffling [9] | 91.93±2.32 | 82.82±2.35 | 75.74±0.51 | 52.95±6.92 | |
| Self-supervised Rubik's Cube[26] | 95.56±1.57 | 76.07±0.20 | 70.37±1.13 | 62.75±1.93 | |
| Self-restoration [25] | 98.07±0.59 | 78.78±3.11 | 77.41±0.40 | 67.96±1.29 | |
| Self-classification | 97.41±0.32 | 83.61±2.19 | 76.23±0.42 | 66.02±0.83 | |
| SemanticGenesis3D | 98.47±0.22 | 85.60±1.94 | 77.24±0.68 | 68.80±0.30 |
‡ Models Genesis仅使用了BraTS-2013的合成图像,但我们使用真实且仅含MR Flair图像进行脑肿瘤分割,因此结果未提交至BraTS-2018。
$3%$ , 2%, and 6% in LCS and 6%, 14%, and 1% in BMS. We conclude that our proposed self-supervised learning scheme, by autonomously discovering and classifying anatomical patterns, learns a unique and complementary visual representation in comparison with that of an image restoration task. Thereby, due to this combination, the models are enforced to learn from multiple perspectives, especially from the consistent and recurring anatomical structure, resulting in more powerful image representation.
LCS中为3%、2%和6%,BMS中为6%、14%和1%。我们得出结论,与图像修复任务相比,我们提出的自监督学习方案通过自主发现和分类解剖模式,学习到了独特且互补的视觉表示。因此,由于这种组合,模型被迫从多个角度学习,特别是从一致且重复出现的解剖结构中学习,从而获得了更强大的图像表示能力。
Semantic Genesis 3D provides more generic and transferable representations in comparison to publicly available pre-trained 3D models: We have compared our Semantic Genesis 3D with the competitive publicly available pre-trained models, applied to four distinct 3D target medical applications. Our statistical analysis in Table 2 suggests three major results. Firstly, compared to learning 3D models from scratch, fine-tuning from Semantic Genesis offers performance gains by at least 3%, while also yielding more stable performances in all four applications. Secondly, fine-tuning models from Semantic Genesis achieves significantly higher performances than those fine-tuned from other selfsupervised approaches, in all four distinct 3D medical applications, i.e., NCC, LCS, NCS, and BMS. In particular, Semantic Genesis surpasses Models Genesis, the state-of-the-art 3D pre-trained models created by image restoration based self-supervised learning, in three applications (i.e., NCC, LCS, and BMS), and offers equivalent performance in NCS. Finally, even though our Semantic Genesis learns representation without using any human annotation, we still have examined it with 3D models pre-trained from full supervision, i.e., MedicalNet, NiftyNet, and I3D. Without any bells and whistles, Semantic Genesis outperforms supervised pre-trained models in all four target tasks. Our results evidence that in contrast to other baselines, which show fluctuation in different applications,
与公开可用的预训练3D模型相比,Semantic Genesis 3D提供了更通用且可迁移的表征:我们将Semantic Genesis 3D与具有竞争力的公开预训练模型进行了比较,并应用于四个不同的3D目标医疗应用。表2中的统计分析显示了三个主要结果。首先,与从头开始学习3D模型相比,基于Semantic Genesis进行微调在所有四个应用中至少带来3%的性能提升,同时表现也更稳定。其次,在四个不同的3D医疗应用(即NCC、LCS、NCS和BMS)中,基于Semantic Genesis微调的模型性能显著高于其他自监督方法的微调结果。特别是,Semantic Genesis在三个应用(NCC、LCS和BMS)中超越了当前最先进的基于图像复原自监督学习的3D预训练模型Models Genesis,并在NCS中表现相当。最后,尽管Semantic Genesis学习表征时未使用任何人工标注,我们仍将其与全监督预训练的3D模型(如MedicalNet、NiftyNet和I3D)进行了对比。在没有任何额外修饰的情况下,Semantic Genesis在所有四个目标任务中均优于监督预训练模型。我们的结果表明,与其他基线方法在不同应用中表现波动的情况形成鲜明对比,

Fig. 3. To solve target tasks in 3D medical modality (NCC and NCS), 3D approaches empowered by Semantic Genesis 3D, significantly outperforms any 2D slice-based approaches, including the state-of-the-art ImageNet models. For target tasks in 2D modality (PXS and DXC), Semantic Genesis 2D outperforms Models Genesis 2D and, noticeably, yields higher performance than ImageNet in PXS.
图 3: 在解决3D医学模态(NCC和NCS)目标任务时,采用Semantic Genesis 3D增强的3D方法显著优于任何基于2D切片的方法(包括最先进的ImageNet模型)。对于2D模态(PXS和DXC)目标任务,Semantic Genesis 2D优于Models Genesis 2D,值得注意的是在PXS任务中表现超越了ImageNet。
Semantic Genesis is consistently capable of generalizing well in all tasks even when the domain distance between source and target datasets is large (i.e., LCS and BMS tasks). Conversely, Semantic Genesis benefits explicitly from the deep semantic features enriched by self-discovering and self-classifying anatomical patterns embedded in medical images, and thus contrasts with any other existing 3D models pre-trained by either self-supervision or full supervision.
语义生成(Semantic Genesis)在所有任务中始终表现出良好的泛化能力,即使源数据集与目标数据集之间存在较大领域差异(如LCS和BMS任务)。与通过自监督或全监督预训练的其他现有3D模型不同,该模型通过自主发现和分类医学图像中嵌入的解剖模式,显式利用了深度语义特征的增强优势。
Semantic Genesis 3D significantly surpasses any 2D approaches: To address the problem of limited annotation in volumetric medical imaging, one can reformulate and solve 3D imaging tasks in 2D [25]. However, this approach may lose rich 3D anatomical information and inevitably compromise the performance. Evidenced by Fig. 3 (NCC and NCS), Semantic Genesis 3D outperforms all 2D solutions, including ImageNet models as well as downgraded Semantic Genesis 2D and Models Genesis 2D, demonstrating that 3D problems in medical imaging demand 3D solutions. Moreover, as an ablation study, we examine our Semantic Genesis 2D with Models Genesis 2D (self-supervised) and ImageNet models (fully supervised) in four target tasks, covering classification and segmentation in CT and X-ray. Referring to Fig. 3, Semantic Genesis 2D: 1) significantly surpasses training from scratch and Models Genesis 2D in all four and three applications, respectively; 2) outperforms ImageNet model in PXS and achieves the performance equivalent to ImageNet in NCC and NCS, which is a significant achievement because to date, all self-supervised approaches lag behind fully supervised training [14,7,24].
语义Genesis 3D显著超越所有2D方法:为解决容积医学影像标注数据有限的问题,可将3D成像任务转化为2D形式处理[25]。但这种方法会丢失丰富的3D解剖学信息,不可避免地影响模型性能。如图3(NCC和NCS)所示,语义Genesis 3D在所有2D解决方案(包括ImageNet模型及降级的语义Genesis 2D和Models Genesis 2D)中表现最优,证明医学影像中的3D问题需要3D解决方案。此外,作为消融实验,我们在四个目标任务(涵盖CT和X射线的分类与分割)中对比了语义Genesis 2D与Models Genesis 2D(自监督)及ImageNet模型(全监督)的表现。参考图3可知,语义Genesis 2D:1)在所有四项应用中显著优于从头训练,在三项应用中超越Models Genesis 2D;2)在PXS任务中优于ImageNet模型,在NCC和NCS任务中达到与ImageNet相当的水平——这是重大突破,因为迄今为止所有自监督方法都落后于全监督训练[14,7,24]。
Self-classification and self-restoration lead to complementary representation: In theory, our Semantic Genesis benefits from two sources: pattern classification and pattern restoration, so we further conduct an ablation study to investigate the effect of each isolated training scheme. Referring to Table 2, the combined training scheme (Semantic Genesis 3D) consistently offers significantly higher and more stable performance compared to each of the isolated training schemes (self-restoration and self-classification) in NCS, LCS, and BMS. Moreover, self-restoration and self-classification reveal better performances in four target applications, alternating ly. We attribute their complementary results to the different visual representations that they have captured from each isolated pre-training scheme, leading to different behaviors in different target applications. These complementary representations, in turn, confirm the importance of the unification of self-classification and self-restoration in our Semantic Genesis and its significance for medical imaging.
自分类与自修复形成互补表征:理论上,我们的语义生成框架 (Semantic Genesis) 受益于模式分类和模式修复两个来源。如表 2 所示,在NCS、LCS和BMS评估中,联合训练方案 (Semantic Genesis 3D) 始终显著优于孤立训练方案 (自修复和自分类) ,且表现更稳定。值得注意的是,自修复和自分类在四项目标应用中交替展现出优势。我们认为这种互补性源于两种预训练方案捕获了不同的视觉表征,从而导致在不同目标应用中的差异化表现。这些互补表征反过来印证了自分类与自修复统一在医学影像领域的重要性。
5 Conclusion
5 结论
A key contribution of ours is designing a self-supervised learning framework that not only allows deep models to learn common visual representation from image data directly, but also leverages semantics-enriched representation from the consistent and recurrent anatomical patterns, one of a broad set of unique properties that medical imaging has to offer. Our extensive results demonstrate that Semantic Genesis is superior to publicly available 3D models pre-trained by either self-supervision or even full supervision, as well as ImageNet-based transfer learning in 2D. We attribute this outstanding results to the compelling deep semantics learned from abundant anatomical patterns resulted form consistent anatomies naturally embedded in medical images.
我们的一个关键贡献是设计了一个自监督学习框架,该框架不仅能让深度模型直接从图像数据中学习通用视觉表征,还能利用来自一致且重复出现的解剖模式的语义增强表征(这是医学影像所具备的众多独特属性之一)。大量实验结果表明,Semantic Genesis在性能上超越了通过自监督甚至全监督预训练的公开3D模型,以及基于ImageNet的2D迁移学习方法。我们将这一卓越成果归因于从医学图像天然蕴含的一致解剖结构中,学习到了由丰富解剖模式产生的强大深度语义。
Acknowledgments: This research has been supported partially by ASU and Mayo Clinic through a Seed Grant and an Innovation Grant, and partially by the NIH under Award Number R 01 HL 128785. The content is solely the responsibility of the authors and does not necessarily represent the official views of the NIH. We thank Zuwei Guo for implementing Rubik’s cube, and Jiaxuan Pang for evaluating I3D. The content of this paper is covered by patents pending.
致谢:本研究部分由亚利桑那州立大学(ASU)和梅奥诊所(Mayo Clinic)通过种子基金和创新基金资助,部分由美国国立卫生研究院(NIH)资助,项目编号R01 HL 128785。内容完全由作者负责,并不一定代表NIH的官方观点。感谢郭祖伟实现了魔方(Rubik's cube)算法,感谢庞家轩对I3D的评估。本文内容涉及多项待审专利。
References
参考文献
Appendix
附录
A Visualizing the self-discovery process in Semantic Genesis
语义起源中的自我发现过程可视化

Fig. 4. Our self-discovery process aims to automatically discover similar anatomical patterns across patients, as illustrated in the yellow boxes within the patients framed in pink. Patches extracted at the same coordinate across patients may be very different (the yellow boxes within the patients framed in blue). We overcome this issue by first computing similarity at the patient level using the deep latent features from an autoencoder and then selecting the top nearest neighbors (framed in pink) of the reference patient. Extracting anatomical patterns from these similar patients strikes a balance between consistency and diversity in pattern appearance for each anatomical pattern.
图 4: 我们的自发现流程旨在自动识别跨患者间的相似解剖模式 (如粉色框患者内的黄色方框所示) 。从不同患者相同坐标提取的图像块可能存在显著差异 (蓝色框患者内的黄色方框) 。我们通过以下方法解决该问题: 首先利用自编码器的深度潜在特征计算患者级相似度, 然后选择参考患者的Top最近邻 (粉色框) 。从这些相似患者中提取解剖模式, 可在每种解剖模式的外观一致性与多样性之间取得平衡。
B Visualizing transformed anatomical patterns
B 可视化转换后的解剖模式

Fig. 5. In the self-restoration process, Semantic Genesis aims to learn general-purpose visual representation by recovering original anatomical patterns from their transformed ones. We have adopted four image transformations as suggested in [25]. To be selfcontained, we provide three examples of anatomical patterns from CT slices and three from X-ray images. The original and transformed anatomical patterns are presented in Column 1 and Columns 2—7, respectively. Note that the original Models Genesis [25] involve no anatomical patterns but just random patches, while our Semantic Genesis benefits from the rich semantics associated with recurrent anatomical patterns embedded in medical images.
图 5: 在自恢复过程中,Semantic Genesis 旨在通过从变换后的解剖模式中恢复原始解剖模式来学习通用视觉表示。我们采用了文献 [25] 建议的四种图像变换方式。为保持完整性,我们展示了 CT 切片的三组解剖模式示例和 X 光图像的三组示例。原始解剖模式与变换后的解剖模式分别呈现在第 1 列和第 2-7 列。需注意的是,原始 Models Genesis [25] 仅涉及随机图像块而非解剖模式,而我们的 Semantic Genesis 得益于医学图像中反复出现的解剖模式所蕴含的丰富语义信息。