FixCaps: An Improved Capsules Network for Diagnosis of Skin Cancer
FixCaps: 一种改进的胶囊网络用于皮肤癌诊断
This work was supported in part by the Chongqing Technology Innovation and Application Development Project.
本研究部分由重庆市技术创新与应用发展项目资助。
ABSTRACT The early detection of skin cancer substantially improves the five-year survival rate of patients. It is often difficult to distinguish early malignant tumors from skin images, even by expert dermatologists. Therefore, several classification methods of der matos co pic images have been proposed, but they have been found to be inadequate or defective for skin cancer detection, and often require a large amount of calculations. This study proposes an improved capsule network called FixCaps for der mos co pic image classification. FixCaps has a larger receptive field than CapsNets by applying a high-performance large-kernel at the bottom convolution layer whose kernel size is as large as $31\times31$ , in contrast to commonly used $9\times9$ . The convolutional block attention module was used to reduce the losses of spatial information caused by convolution and pooling. The group convolution was used to avoid model under fitting in the capsule layer. The network can improve the detection accuracy and reduce a great amount of calculations, compared with several existing methods. The experimental results showed that FixCaps is better than IRv2-SA for skin cancer diagnosis, which achieved an accuracy of $96.49%$ on the HAM10000 dataset.
摘要
皮肤癌的早期检测能显著提高患者的五年生存率。即使是专业的皮肤科医生,也往往难以从皮肤图像中区分早期恶性肿瘤。因此,已有多种皮肤镜图像分类方法被提出,但这些方法在皮肤癌检测中存在不足或缺陷,且通常需要大量计算。本研究提出了一种改进的胶囊网络FixCaps,用于皮肤镜图像分类。与CapsNets相比,FixCaps通过在最底层卷积层使用高性能大核(尺寸高达$31\times31$,而常用尺寸为$9\times9$)获得了更大的感受野。采用卷积块注意力模块来减少卷积和池化导致的空间信息损失,并通过组卷积避免胶囊层中的模型欠拟合。与现有多种方法相比,该网络既能提升检测精度,又能大幅减少计算量。实验结果表明,FixCaps在HAM10000数据集上达到了$96.49%$的准确率,优于IRv2-SA的皮肤癌诊断性能。
INDEX TERMS Capsule network, CBAM, image classification, large-kernel convolution, skin cancer.
索引术语 胶囊网络 (Capsule Network), CBAM, 图像分类, 大核卷积 (Large-Kernel Convolution), 皮肤癌。
I. INTRODUCTION
I. 引言
The American Association for Cancer Research’s Annual Cancer Report 2022 shows that cancer incidence and mortality in the United States continue to decline steadily [1]. The number of new cancer cases in China is approximately twice that in the United States, but nearly five times the number of deaths. It is helpful to reduce the cancer burden in China by comparing the latest cancer profiles, trends, and determinants between China and the United States, learning from the progress made in cancer prevention and care in the United State [2]. Skin cancer is one of the most common cancers diagnosed in the United States [3]. A report has shown that the five-year survival rate of localized malignant melanoma is $99%$ when diagnosed and treated early, whereas the survival rate of advanced melanoma is only $25%$ [4]. Hence, it is particularly important to detect and classify der matos co pic images so that skin cancer can be diagnosed early. The traditional method is to first go through a doctor’s visual inspection and then use der mos co pic imaging to aid in the diagnosis. However, a large number of skin cancer patients fail to receive early diagnosis and timely
美国癌症研究协会2022年度癌症报告显示,美国癌症发病率和死亡率持续稳步下降[1]。中国新增癌症病例数约为美国的两倍,但死亡人数却接近美国的五倍。通过对比中美两国最新癌症概况、趋势及决定因素,借鉴美国在癌症防治方面取得的进展,有助于减轻中国癌症负担[2]。皮肤癌是美国最常见的癌症之一[3]。有报告表明,局限性恶性黑色素瘤若早期诊断治疗,五年生存率可达$99%$,而晚期黑色素瘤生存率仅为$25%$[4]。因此,对皮肤镜图像进行检测分类以实现皮肤癌早期诊断尤为重要。传统诊断流程需先经医生肉眼观察,再借助皮肤镜成像辅助诊断。然而大量皮肤癌患者因医疗资源不足未能获得早期诊断和及时...
The associate editor coordinating the review of this manuscript and approving it for publication was Hossein Rahmani
协调审阅并批准发表本稿件的副编辑是Hossein Rahmani
treatment due to the lack of professional doctors in China, the uneven level of doctors, and the pressure of doctors on repetitive reading work. With the development of artificial intelligence (AI) in the medical field, deep learning (DL) has been widely used for the detection and classification of medical images over the past few years [5]. The application of artificial intelligence to medical image-assisted diagnosis is called AI image diagnosis. It plays a pivotal role in the field of medical artificial intelligence, especially in intelligent image recognition, human-computer interaction-assisted diagnosis, precision treatment-assisted decision making, and other aspects [6]. Capsule networks (CapsNets) [7] have been widely applied in the medical field as an important research topic for deep learning. Afshar et al. [8] reduced the number of convolution kernels in the convolution layer of the capsule network. It has been successfully applied to the classification of brain tumors using magnetic resonance imaging (MRI), and its accuracy is superior to that of traditional convolutional neural networks (CNNs) [9]. Lin et al. [10]proposed a classification recognition algorithm for skin lesions based on ‘‘Matrix Capsules with EM Routing’’ [11], which achieved a high recognition accuracy in ISIC2017 dataset [12]. Mensah et al. [13] proposed Gabor CapsNets for tomato and citrus disease image recognition, which could achieve $98.13%$ accuracy in the Plant-Village datasets [14], superior to AlexNet [15]and GoogLeNet [16] in terms of robustness and parameter amount. In addition, researchers have explored CapsNets from other aspects. Xiang et al. [17] proposed a multiscale capsule network and a capsule dropout. Robustness was achieved better than CapsNets on both Fashion MNIST dataset [18] and CIFAR10 dataset [19]. Raja sega ran et al. [20] constructed DeepCaps by using residual learning [21], which reduced the number of parameters by $68%$ compared with original CapsNets and was significantly superior to the existing capsule network architecture in benchmark datasets. This method provides a deep architecture for capsule networks. Other network models have been developed in the medical field. For example, Kawahara et al. proposed a fully convolutional network for skin-image classification. For the skin lesion datasets [22], the classification prediction accuracy was $81.8%$ [23]. Akram et al. [24] proposed a deep neural network based on integration and carried out a classification test in the ISIC2018 [25], [26].
由于中国专业医生数量不足、医生水平参差不齐以及医生在重复性阅片工作上的压力,人工智能(AI)在医疗领域的发展使得深度学习(DL)近年来被广泛应用于医学影像的检测与分类[5]。将人工智能应用于医学影像辅助诊断被称为AI影像诊断,它在医疗人工智能领域发挥着关键作用,尤其在智能图像识别、人机交互辅助诊断、精准治疗辅助决策等方面[6]。胶囊网络(CapsNets)[7]作为深度学习的重要研究方向,已在医疗领域得到广泛应用。Afshar等人[8]减少了胶囊网络卷积层的卷积核数量,成功将其应用于脑肿瘤的磁共振成像(MRI)分类,其准确率优于传统卷积神经网络(CNN)[9]。Lin等人[10]提出基于"Matrix Capsules with EM Routing"[11]的皮肤病变分类识别算法,在ISIC2017数据集[12]中实现了较高的识别准确率。Mensah等人[13]提出用于番茄和柑橘病害图像识别的Gabor CapsNets,在Plant-Village数据集[14]中准确率可达98.13%,在鲁棒性和参数量方面优于AlexNet[15]和GoogLeNet[16]。此外,研究者们还从其他角度探索了胶囊网络。Xiang等人[17]提出多尺度胶囊网络和胶囊dropout方法,在Fashion MNIST数据集[18]和CIFAR10数据集[19]上均取得了优于原始CapsNets的鲁棒性。Raja sega ran等人[20]利用残差学习[21]构建了DeepCaps,相比原始CapsNets减少了68%的参数量,在基准数据集上显著优于现有胶囊网络架构,为胶囊网络提供了深度架构方案。其他网络模型也在医疗领域得到发展,例如Kawahara等人提出的全卷积网络用于皮肤图像分类,在皮肤病变数据集[22]上分类预测准确率达81.8%[23];Akram等人[24]提出基于集成的深度神经网络,并在ISIC2018[25][26]上进行了分类测试。
Although these studies have promoted the development of AI image diagnosis, they have been found to be either ineffective or defective to the prediction of skin lesions, and often need a great amount of calculations. Hence, we propose an improved capsule network called FixCaps for dermoscopic image classification in this study. It can obtain a larger receptive field than CapsNets by applying a largekernel convolution at the bottom layer whose kernel size is as large as $31\times31$ , in contrast to commonly used $9\times9$ . And the convolutional block attention module (CBAM) [27] is used to reduce the losses of spatial information caused by convolution and pooling. Meanwhile, the group convolution (GP) [15] is used to avoid model under fitting in the capsule layer. The network can improve the detection accuracy and reduce a large number of calculations, compared with the several existing methods. This research has verified the effectiveness of FixCaps for diagnosis (classification) of skin cancer. We address the problems of the limited amount of annotated data and the imbalance of class distributions. To ensure the validity of our perspectives, we make a large number of experiments on the HAM10000 dataset [26].
虽然这些研究推动了AI图像诊断的发展,但人们发现它们要么无效,要么在预测皮肤病变方面存在缺陷,且通常需要大量计算。因此,本研究提出了一种改进的胶囊网络FixCaps,用于皮肤镜图像分类。通过在最底层应用超大卷积核(尺寸达$31\times31$,而非常用的$9\times9$),该网络能获得比CapsNets更大的感受野。同时采用卷积块注意力模块(CBAM) [27]来减少卷积和池化导致的空间信息损失,并引入分组卷积(GP) [15]防止胶囊层出现模型欠拟合。与现有多种方法相比,该网络既能提升检测精度,又可大幅减少计算量。本研究验证了FixCaps在皮肤癌诊断(分类)中的有效性,解决了标注数据量有限和类别分布不平衡的问题。为确保观点可靠性,我们在HAM10000数据集[26]上进行了大量实验。
II. RELATED WORK
II. 相关工作
With the increasing incidence of skin cancers, a growing population, a lack of adequate clinical expertise and services, there is an immediate necessity for AI image diagnosis to assist clinicians in this field. Before 2016, most research adopted the traditional machine learning progress of preprocessing (augmentation), segmentation, feature extraction, and classification [28]. Nowadays, various types of skin lesion datasets are publicly accessible. Researchers have developed AI solutions, notably deep learning algorithms, to distinguish malignant skin lesions and benign lesions in different image modalities, such as der mos co pic, clinical and his to path ology images [29]. For instance, Datta et al. [30] combined soft-attention (SA) and Inception ResNet-V2 (IRv2) [31] to construct IRV2-SA for der mos co pic image classification, which reached an accuracy of $93.47%$ on the HAM10000 dataset.
随着皮肤癌发病率上升、人口增长以及临床专业知识和服务不足,AI图像诊断技术亟需协助该领域的临床医生。2016年前,多数研究采用传统机器学习流程:预处理(增强)、分割、特征提取和分类 [28]。如今各类皮肤病变数据集已公开可用,研究者开发了基于深度学习算法的AI解决方案,用于区分不同成像模式(如皮肤镜图像、临床图像和组织病理图像)中的恶性与良性皮肤病变 [29]。例如,Datta等人 [30] 将软注意力机制(SA)与Inception ResNet-V2(IRv2)[31] 结合构建IRV2-SA模型,在HAM10000数据集上实现了$93.47%$的皮肤镜图像分类准确率。
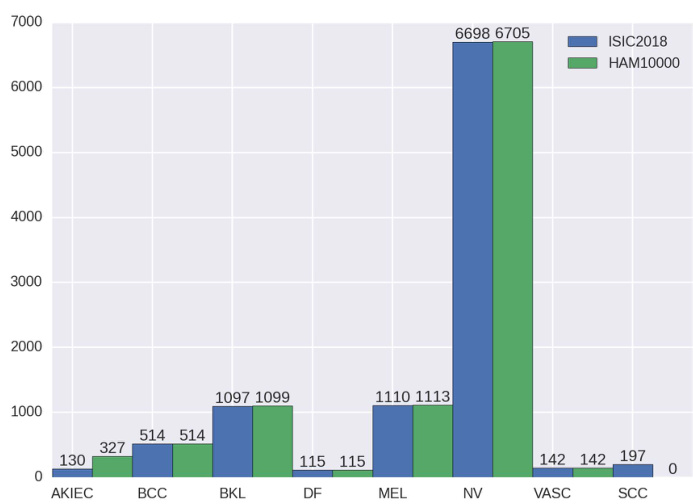
FIGURE 1. Sample distribution and comparison of different skin lesion images in ISIC2018 and HAM10000. The task3 of ISIC2018 included training data(HAM10000), validation data and test data. They are all organized into seven types of skin lesions. Zhao et al. added some images of squamous cell carcinoma(SCC) to ISIC2018 and deleted some samples, so that the distribution of ISIC2018 dataset is similar to that of ISIC2019 dataset. More details of the HAM10000 dataset are shown in the ‘‘DATASET’’ subsection.
图 1: ISIC2018和HAM10000中不同皮肤病变图像的样本分布及对比。ISIC2018的任务3包含训练数据(HAM10000)、验证数据和测试数据,均按七种皮肤病变类型分类。Zhao等人向ISIC2018添加了部分鳞状细胞癌(SCC)图像并删除了部分样本,使ISIC2018数据集的分布与ISIC2019数据集相似。HAM10000数据集的更多细节见"数据集"小节。
Zhao et al. [32] proposed a classification framework based on skin lesion augmentation style-based GAN (SLA-StyleGAN), which achieved an accuracy of $93.64%$ on ISIC2018 dataset and ISIC2019 dataset [33]. In their work, the distribution of the ISIC2018 dataset differs considerably from the HAM10000 dataset, as shown in Fig. 1. Hence, IRv2-SA is the state-of-the-art performance in the dermatoscopic image classification on HAM10000 dataset, to the best of our knowledge.
Zhao等人[32]提出了一种基于皮肤病变增强风格生成对抗网络(SLA-StyleGAN)的分类框架,在ISIC2018数据集和ISIC2019数据集[33]上达到了93.64%的准确率。在他们的工作中,ISIC2018数据集的分布与HAM10000数据集存在显著差异,如图1所示。因此据我们所知,IRv2-SA目前在HAM10000数据集皮肤镜图像分类任务中代表了最先进的性能水平。
III. FixCaps
III. FixCaps
As an important research direction in deep learning, the capsule network has the greatest advantage of being able to encode the pose and spatial relations of features, which significantly improves the shortcomings of deep learning in image classification. However, CapsNets [7] often exhibit poor performance in complex images, such as der matos co pic images. Studies have shown that multiple routing layers lead to higher training costs and reasoning time in large initial layers [34]. Therefore, an improved capsule network called FixCaps for der mos co pic image classification was proposed. The main components and architecture are described below.
作为深度学习的重要研究方向,胶囊网络 (Capsule Network) 的最大优势在于能够编码特征的姿态和空间关系,显著改善了深度学习在图像分类中的不足。然而,CapsNets [7] 在复杂图像 (如皮肤镜图像) 中往往表现不佳。研究表明,多层路由结构会导致初始大层中更高的训练成本和推理时间 [34]。因此,我们提出了一种改进的胶囊网络 FixCaps,用于皮肤镜图像分类。其主要组件和架构如下所述。
A. LARGE-KERNEL CONVOLUTION
A. 大核卷积
FixCaps, compared with paper [8], not only reduces the number of convolution kernels at the bottom convolution layer, but also increases fractional max-pooling (FMP) [35] to reduce the size of the initial layer and the cost of dynamic routing in the capsule layer. The commonly used convolution kernels are as follows: $3\times3,5\times5$ , or $7\times7$ in the convolutional layer of the neural network. In this study, the convolution layer with convolution kernels larger than $9\times9$ is called large-kernel convolution (LKC). The experimental result shows that the larger the convolution kernel is, the more picture information is ‘‘seen’’ and the better the features are learned [36]. In this study, the LKC has a larger receptive field compared to the small convolution kernel used in the literature compared with the small-kernel convolution used in the literature [7], [8], [17], [20]. The features available for CBAM screening are better, which improves the ability of the capsule layer to deal with the long-term relationship of feature vectors.
与论文[8]相比,FixCaps不仅减少了底部卷积层的卷积核数量,还增加了分数最大池化(FMP) [35]以缩小初始层尺寸并降低胶囊层动态路由的计算成本。神经网络卷积层常用的卷积核尺寸为$3\times3$、$5\times5$或$7\times7$。本研究将卷积核尺寸大于$9\times9$的卷积层称为大核卷积(LKC)。实验结果表明,卷积核越大,"看到"的图像信息越多,特征学习效果越好[36]。与文献[7]、[8]、[17]、[20]中使用的小核卷积相比,本研究的LKC具有更大的感受野,能为CBAM筛选提供更优质的特征,从而提升胶囊层处理特征向量长期关系的能力。
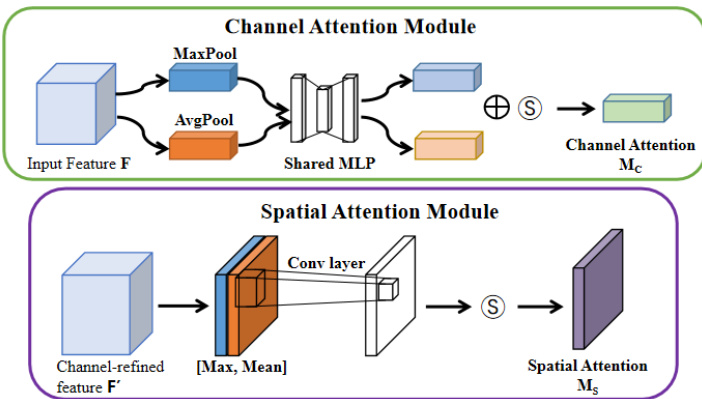
FIGURE 2. Diagram of each attention sub-module [27]: CBAM consists of two independent submodules the part in the green box is the channel attention module (CAM), the purple box is the spatial attention module (SAM), and $\textcircled{5}$ denotes the sigmoid function.
图 2: 各注意力子模块示意图 [27]: CBAM由两个独立子模块组成,绿色框部分为通道注意力模块 (CAM),紫色框为空间注意力模块 (SAM),$\textcircled{5}$表示sigmoid函数。
B. CONVOLUTIONAL BLOCK ATTENTION MODULE
B. 卷积块注意力模块
An CBAM (see Fig. 2) is added between the convolution layer at the bottom and the capsule layer to make FixCaps pay more attention to the object and reduce the losees of spatial information caused by convolution and pooling. The feature maps are output from the convolution layer through CAM and SAM to strengthen the connection of each feature in the channel and space. This enabled the network to effectively avoid over fitting without dropout [37].The overall attention process can be summarized as Formula (1).
在底部的卷积层和胶囊层之间添加了一个CBAM (见图2),使FixCaps更关注目标物体,并减少由卷积和池化导致的空间信息损失。特征图通过CAM和SAM从卷积层输出,以增强通道和空间中每个特征的连接。这使得网络能够有效避免过拟合,而无需使用dropout [37]。整体注意力过程可总结为公式(1)。
$$
F^{\prime}=M_{s}(M_{c}(F)\otimes F)\otimes F,
$$
$$
F^{\prime}=M_{s}(M_{c}(F)\otimes F)\otimes F,
$$
where $\otimes$ denotes the element-wise multiplication. During multiplication, the attention values are broadcasted (copied) accordingly: channel attention values are broadcasted along the spatial dimension and vice versa [27]. Here ${\bf M}{c}({\bf R}^{C\times1\times1})$ is the channel attention map, and $\mathbf{M}_{s}(\mathbf{R}^{1\times1\times H\times W})$ is the spatial attention map. $\mathrm{F}$ is the feature map output of the convolutional layer. $\mathrm{F}^{\prime}$ denotes the final refined output.
其中 $\otimes$ 表示逐元素相乘。在乘法运算过程中,注意力值会相应地进行广播(复制):通道注意力值沿空间维度广播,反之亦然 [27]。这里 ${\bf M}{c}({\bf R}^{C\times1\times1})$ 是通道注意力图,$\mathbf{M}_{s}(\mathbf{R}^{1\times1\times H\times W})$ 是空间注意力图。$\mathrm{F}$ 是卷积层的特征图输出,$\mathrm{F}^{\prime}$ 表示最终精炼后的输出。
C. CAPSULE LAYER
C. 胶囊层
The capsule layer is divided into two parts: the primary capsule and the digit capsule. FixCaps uses convolution with an inner size of nine and stride size of two in the primary capsule, which is consistent with CapsNets. In addition, the group convolution in the primary capsule was used to avoid underfitting of the model and reduce the amount of calculations while improving the accuracy of classification prediction. And the ‘‘Squashing’’ function is used to process the input vector, so that the modulus of the vector can represent the probability of this feature [7]. Its expression is shown in Equation (2).
胶囊层分为两部分:初级胶囊和数字胶囊。FixCaps在初级胶囊中采用内尺寸为9、步幅为2的卷积操作,这与CapsNets保持一致。此外,初级胶囊中采用分组卷积来避免模型欠拟合,并在提升分类预测精度的同时减少计算量。通过"Squashing"函数处理输入向量,使向量模长能够表示该特征的概率[7]。其表达式如公式(2)所示。
$$
V_{j}={\frac{\left|S_{j}\right|^{2}}{1+\left|S_{j}\right|^{2}}}\cdot{\frac{S_{j}}{\left|S_{j}\right|}},
$$
$$
V_{j}={\frac{\left|S_{j}\right|^{2}}{1+\left|S_{j}\right|^{2}}}\cdot{\frac{S_{j}}{\left|S_{j}\right|}},
$$
where $\mathrm{V}{j}$ is the vector output of capsule $\mathrm{j}$ and $\mathrm{S}_{j}$ is the total input. FixCaps uses the marginal loss as a loss function to enhance the class probability of the correct class [7]. Its expression is as Equation (3):
其中 $\mathrm{V}{j}$ 是胶囊 $\mathrm{j}$ 的向量输出,$\mathrm{S}_{j}$ 是总输入。FixCaps 采用边际损失 (marginal loss) 作为损失函数来增强正确类别的分类概率 [7],其表达式如式 (3) 所示:
$$
\begin{array}{r l}{L_{k}=T_{k}\cdot m a x(0,m^{+}-|V_{k}|)^{2}}&{{}}\ {\qquad}&{{}+\lambda(1-T_{k})\cdot m a x(0,|V_{k}|-m^{-})^{2},}\end{array}
$$
$$
\begin{array}{r l}{L_{k}=T_{k}\cdot m a x(0,m^{+}-|V_{k}|)^{2}}&{{}}\ {\qquad}&{{}+\lambda(1-T_{k})\cdot m a x(0,|V_{k}|-m^{-})^{2},}\end{array}
$$
where $\mathrm{T}_{k}\mathbf{=}1,\lambda\mathbf{=}0.5,\mathbf{m}^{+}\mathbf{=}0.9$ and $\mathrm{m}^{-}{=}0.1$ . The total loss is simply the sum of the losses of all the digit capsules. It was found in the experiment that the reconstruction cost of CapsNets was too high for large-size and high-resolution images such as der mos co pic imaging. Run FixCaps with and without the re constitution module on server A. The results showed that reconstruction is not helpful in the classification of der matos co pic images. Hence, the aim was to reduce the run time of FixCaps by deleting the re constitution module. In the eval stage, the L2 norm of the output vector of the digit capsule layer is calculated, and the index number of the longest layer is taken as the predicted classification label. The calculation formula is given by Equation (4).
其中 $\mathrm{T}_{k}\mathbf{=}1,\lambda\mathbf{=}0.5,\mathbf{m}^{+}\mathbf{=}0.9$ 且 $\mathrm{m}^{-}{=}0.1$。总损失仅是所有数字胶囊损失的简单求和。实验发现,对于大尺寸高分辨率图像(如皮肤镜图像),CapsNets的重构成本过高。在服务器A上运行带/不带重构模块的FixCaps,结果表明重构对皮肤镜图像的分类并无帮助。因此,目标是通过删除重构模块来缩短FixCaps的运行时间。在评估阶段,计算数字胶囊层输出向量的L2范数,并将最长层的索引号作为预测分类标签,计算公式如式(4)所示。
$$
\left|{\cal V}{j}\right|{2}=\sqrt{a_{1}^{2}+a_{2}^{2}+\cdot\cdot\cdot+a_{i}^{2}},
$$
where $\mathrm{V}{j}$ is the output vector of the digit capsule and $\in[1,7]$ . The $\mathrm{a}{i}$ is the value of the $\mathrm{V}{j}$ , and $_{\mathrm{i}\in\left[1,16\right]}$ . Here i and j are the positive integers.
其中 $\mathrm{V}{j}$ 是数字胶囊的输出向量,且 $\in[1,7]$。$\mathrm{a}{i}$ 是 $\mathrm{V}{j}$ 的值,且 $_{\mathrm{i}\in\left[1,16\right]}$。这里的 i 和 j 为正整数。
D. FixCaps-DS
D. FixCaps-DS
Increasing the depth of the model is an important research direction for deep learning, but the deeper the model is, the faster the gradient vanishes, so that back propagation is difficult to train the shallow network, and the network performance deteriorates instead. Residual learning makes it easier for gradients to shallow networks, and skip connections improve the performance of deep models [21]. However, the consequent problem is a rapid increase in the number of model parameters. In recent years, models such as GoogLeNet, Inception, and ResNet have used convolution with an inner size of 1 [38] to lightweight the model, but they still fail to solve the problem in which the weight parameters are too large to be applied in mobile terminals. CapsNets and their improved models strive for a balance between network depth and performance, as do FixCaps, the architecture of which is shown in Fig. 3. In this study, FixCaps-DS is a deep-wise separable convolution (DS) [39] combined with FixCaps. It only has approximately $35%$ parameter and $50%$ computation amount combined with FixCaps and is more suitable for mobile terminal deployment. The experimental results showed that FixCaps-DS was also better than IRv2-SA in classification prediction of der matos co pic images, which is achieved an accuracy of $96.13%$ on the HAM10000 dataset.
增加模型深度是深度学习的重要研究方向,但模型越深梯度消失越快,导致反向传播难以训练浅层网络,反而使网络性能下降。残差学习使梯度更容易传递到浅层网络,跳跃连接提升了深层模型的性能 [21]。但随之而来的问题是模型参数量急剧增加。近年来,GoogLeNet、Inception和ResNet等模型采用1×1卷积 [38] 实现模型轻量化,但仍未解决权重参数过大难以部署移动端的问题。CapsNets及其改进模型力求在网络深度与性能间取得平衡,FixCaps亦是如此,其架构如图3所示。本研究中,FixCaps-DS是将深度可分离卷积 (DS) [39] 与FixCaps结合的方案,参数量仅为FixCaps的约35%,计算量减少50%,更适用于移动端部署。实验结果表明,FixCaps-DS在皮肤镜图像分类预测上也优于IRv2-SA,在HAM10000数据集上达到了96.13%的准确率。

FIGURE 3. Diagram of FixCaps: The main components include convolution layer with large-kernel, CBAM, and capsule layer.
图 3: FixCaps结构图: 主要组件包括大核卷积层、CBAM和胶囊层。
IV. EXPERIMENTS AND RESULTS
IV. 实验与结果
In this study, all the experiments were implemented using PyTorch 1.8, except augmentation of the training set. Run FixCaps and FixCaps-DS on two servers. The difference is that DS is used in convolution, and everything else is the same. Run FixCaps on server A, which was configured with an Intel I9 CPU and an RTX 3090 GPU. FixCaps-DS was run on server B, which was configured with an Intel I5 CPU and an RTX 3070 GPU.
在本研究中,除训练集扩增外,所有实验均使用PyTorch 1.8实现。FixCaps与FixCaps-DS分别运行于两台服务器:FixCaps在配备Intel I9 CPU和RTX 3090 GPU的服务器A上运行,FixCaps-DS则在配备Intel I5 CPU和RTX 3070 GPU的服务器B上运行。两者唯一区别在于卷积层是否采用DS结构。
A. DATASET
A. 数据集
The dataset used in this study was HAM10000 [26], which consisted of 10015 der matos co pic images with a size of $450\times600$ . There are seven types of skin lesions: actinic keratosis/intra epithelial carcinoma (AKIEC), basal cell carcinoma (BCC), benign keratosis (BKL), der mato fib roma (DF), melanoma (MEL), mel a no cy tic nevi (NV), and vascular lesions (VASC), as shown in Fig. 4. To make a fair comparison with IRV2-SA, 828 images were extracted from the dataset as the test set in the same manner as IRV2-SA in the dataset division and data augmentation of the training set [30]. Subsequently, translation and other methods were used to increase the number of samples in the training set, and the processed data were saved as $299\times299$ JPG images.
本研究使用的数据集是HAM10000 [26],包含10015张尺寸为$450\times600$的皮肤镜图像。皮肤病变分为七类:光化性角化病/上皮内癌(AKIEC)、基底细胞癌(BCC)、良性角化病(BKL)、皮肤纤维瘤(DF)、黑色素瘤(MEL)、黑素细胞痣(NV)和血管性病变(VASC),如图4所示。为与IRV2-SA进行公平对比,我们按照该研究在数据集划分和训练集数据增强[30]中的相同方法,从数据集中提取828张图像作为测试集。随后采用平移等方法增加训练集样本数量,处理后的数据保存为$299\times299$的JPG图像。
It was found that the pixels in the center of the image had a high correlation with the prediction, whereas the pixels in the edge had a low correlation with the prediction in the experiment. So the original image of the dataset is decomposed into R, G, and B channels before training; subsequently, they are considered as input matrix A. Three matrices U, $\Sigma$ , and $\mathrm{v}$ are obtained after singular value decomposition (SVD) according to Formula (5). In the experiment, $\mathrm{K}=90$ was used to obtain $\scriptstyle\mathrm{\mathbf{R}}^{},\mathrm{\mathbf{G}}^{}$ , and $\mathbf{B}^{*}$ , which were subsequently fused and stored the
研究发现,实验中图像中心区域的像素与预测结果高度相关,而边缘区域的像素相关性较低。因此,在训练前将数据集的原始图像分解为R、G、B三个通道,并将其作为输入矩阵A。根据公式(5)进行奇异值分解(SVD)后,得到三个矩阵U、$\Sigma$和$\mathrm{v}$。实验中设定$\mathrm{K}=90$,从而获得$\scriptstyle\mathrm{\mathbf{R}}^{},\mathrm{\mathbf{G}}^{}$和$\mathbf{B}^{*}$,随后进行融合存储。

FIGURE 4. Example of Skin lesions in HAM10000 dataset. Among them, BKL, DF, NV, and VASC are benign tumors, whereas AKIEC, BCC, and MEL are malignant tumors.
图 4: HAM10000数据集中皮肤病变示例。其中BKL、DF、NV和VASC为良性肿瘤,而AKIEC、BCC和MEL为恶性肿瘤。
images in the PNG format.
PNG格式的图像。
$$
A_{(m,n)}=U_{(m,k)}\cdot\Sigma_{k}\cdot V_{(k,n)}\quad,
$$
$$
A_{(m,n)}=U_{(m,k)}\cdot\Sigma_{k}\cdot V_{(k,n)}\quad,
$$
where $\mathrm{U}$ and $\mathrm{v}$ are orthogonal matrices called the left and right singular values, respectively, and $\Sigma$ is the singular value. In sigma, the singular values are arranged from the largest to the smallest, with the latter values closer to zero and retaining less image information.
其中 $\mathrm{U}$ 和 $\mathrm{v}$ 是正交矩阵,分别称为左奇异值和右奇异值,而 $\Sigma$ 是奇异值。在 sigma 中,奇异值按从大到小排列,后面的值更接近零,保留的图像信息更少。
B. EVALUATION METRICS
B. 评估指标
In this study, the model was evaluated using Recall, Accuracy and $\mathrm{F}_{1}$ -score. The calculation formula is given by Equation (6). In the confusion matrix, TP samples were distributed on the diagonals (in this study, the diagonals refer to the diagonals from the upper left to the lower right). Accuracy was defined as the ratio of the number of correctly classified samples (on the diagonal) to the total number of samples.
在本研究中,模型采用召回率 (Recall)、准确率 (Accuracy) 和 $\mathrm{F}_{1}$ 值进行评估。计算公式如式 (6) 所示。在混淆矩阵中,TP样本分布于对角线上 (本研究中对角线指从左上到右下的对角线)。准确率定义为正确分类样本数 (对角线上) 与总样本数的比值。
For multi-classification problems, the accuracy measures the prediction of global samples, whereas $\mathrm{F}{1}$ -score and recall represent the prediction of a certain category. Therefore, the $\mathrm{F}_{1}$ -score and recall of each skin lesion must be calculated separately, but the accuracy does not. The confusion matrix in multi-classification has a special case: micro-precision, micro-recall, and the accuracy is always the same. Because the FP is in one class of samples, to the others must be FN.
对于多分类问题,准确率衡量的是全局样本的预测效果,而 $\mathrm{F}{1}$ -score和召回率则代表某一特定类别的预测表现。因此,必须分别计算每种皮肤病变的 $\mathrm{F}_{1}$ -score和召回率,但准确率无需单独计算。多分类混淆矩阵存在一个特殊情况:微观精确率(micro-precision)、微观召回率(micro-recall)与准确率始终相等。因为某类样本的假阳性(FP)对其他类而言必然是假阴性(FN)。
$$
\begin{array}{r}{P r e c i s i o n=\frac{T P}{T P+F P}}\ {R e c a l l=\frac{T P}{T P+F N}}\end{array}
$$
$$
\begin{array}{r}{P r e c i s i o n=\frac{T P}{T P+F P}}\ {R e c a l l=\frac{T P}{T P+F N}}\end{array}
$$
TABLE 1. Classification accuracy $(%)$ on the HAM10000 test set. FixCaps-DS has 0.08 billion FLOPs, which is only $66%$ of MobileNet V3 (0.12 billion FLOPs).
表 1: HAM10000测试集上的分类准确率 $(%)$。FixCaps-DS的FLOPs为0.08亿,仅为MobileNet V3 (0.12亿FLOPs) 的 $66%$。
| 方法 | 准确率[%] | 参数量(M) | FLOPs(G) |
|---|---|---|---|
| GoogLeNet | 83.94 | 5.98 | 1.58 |
| InceptionV3 | 86.82 | 22.8 | 5.73 |
| MobileNetV3 | 89.97 | 1.53 | 0.12 |
| IRv2-SA | 93.47 | 47.5 | 25.46 |
| FixCaps-DS | 96.13 | 0.14 | 0.08 |
| FixCaps | 96.49 | 0.50 | 6.74 |
$$
\begin{array}{l}{\displaystyle A c c u r a c y=\frac{T P+T N}{T}}\ {\displaystyle F_{1}-s c o r e=\frac{2\cdot P r e c i s i o n\cdot R e c a l l}{P r e c i s i o n+R e c a l l},}\end{array}
$$
$$
\begin{array}{l}{\displaystyle 准确率=\frac{TP+TN}{T}}\ {\displaystyle F_{1}值=\frac{2\cdot 精确率\cdot 召回率}{精确率+召回率},}\end{array}
$$
where TP, FP, FN, and $\mathrm{T}$ are the true negative, true positive, false positive, false negative, and the total number of samples, respectively.
其中TP、FP、FN和$\mathrm{T}$分别表示真负例、真正例、假正例、假负例以及样本总数。
C. RESULTS
C. 结果
We compare the performance of FixCaps, IRv2-SA and other methods while classifying skin lesions, as shown in Table 1. FixCaps outperforms GoogleNet, IRv2, and other methods in terms of accuracy on the HAM10000 dataset. It is worth noting that FixCaps has fewer parameters and lower complexity than IRv2-SA. And FixCaps has 6.74 billion FLOPs, which is only $26%$ of IRv2-SA (25.46 billion FLOPs). Moreover, FixCaps-DS has 0.14 million parameters, which is approximately 10 percent of MobileNet V3 [40] (1.53 million parameters).
我们在皮肤病变分类任务中对比了FixCaps、IRv2-SA等方法的表现,如表1所示。FixCaps在HAM10000数据集上的准确率优于GoogleNet、IRv2等方法。值得注意的是,FixCaps相比IRv2-SA具有更少的参数量和更低的复杂度。FixCaps的运算量为67.4亿FLOPs,仅为IRv2-SA (254.6亿FLOPs) 的26%。此外,FixCaps-DS的参数量为14万,约为MobileNet V3 [40] (153万参数) 的10%。
V. DISCUSSION
V. 讨论
In the clinical, the first task needs a correct specific diagnosis out of multiple classes on skin lesion classification. $\mathrm{F}{1}$ -score and AUC (area under ROC curve) both hope that the actual true samples can be detected. The difference between the two is that AUC aims for a model with as few false positives as possible, while $\mathrm{F}_{1}$ -score aims for a model that does not miss any possibilities. We hope to diagnose as many suspected cases as possible, so we prefer F1-score as the evaluation index of the model. In fact, FixCaps has a good performance of ‘‘Recall’’ on skin cancer classification. The details of the performance of different methods on the test set are listed in Table 2. The last column shows the number of samples of each skin lesion type in the test set. Clearly, FixCaps outperformed IRv2-SA on diagnosis (classification) of skin cancer, except for the VASC type. There are two main reasons for this consequence. One is that capsule networks not only learn excellent weights for feature extraction and image classification, but also learn how to encode the pose and spatial relations of features [7]. The other is FixCaps can obtain a larger receptive field than IRV2-SA by applying a highperformance LKC whose kernel size is as large as $31\times31$ , in contrast to IRV2-SA used $3\times3$ .
在临床中,首个任务需要从皮肤病变分类的多个类别中得出正确的具体诊断。$\mathrm{F}{1}$分数和AUC(ROC曲线下面积)都希望检测出实际真实样本。两者的区别在于,AUC追求尽可能减少假阳性的模型,而$\mathrm{F}_{1}$分数则追求不遗漏任何可能性的模型。我们希望能诊断出尽可能多的疑似病例,因此更倾向于将F1分数作为模型的评估指标。实际上,FixCaps在皮肤癌分类上具有出色的"召回率"表现。不同方法在测试集上的性能细节列于表2。最后一列显示了测试集中每种皮肤病变类型的样本数量。显然,除VASC类型外,FixCaps在皮肤癌诊断(分类)上优于IRv2-SA。这一结果主要有两个原因:一是胶囊网络不仅学习了出色的特征提取和图像分类权重,还学会了如何编码特征的姿态和空间关系[7];二是FixCaps通过采用高性能的$31\times31$大核卷积(LKC),相比IRv2-SA使用的$3\times3$卷积,能获得更大的感受野。
As shown in Table 3 and Fig. 5, FixCaps’ performance on the test was evaluated by using different LKC. Finally, it was found that the convolution with kernel size of $31\times31$ showed the best performance. In conclusion, this work has proven the effectiveness of FixCaps in the classification prediction of der matos co pic images, and demonstrated that using the large convolutional kernels instead of a stack of small kernels could be a more powerful paradigm.
如表 3 和图 5 所示,FixCaps 在测试中的性能通过使用不同的 LKC 进行了评估。最终发现,使用 $31\times31$ 核大小的卷积表现出最佳性能。综上所述,这项工作证明了 FixCaps 在 der matos co pic 图像分类预测中的有效性,并表明使用大卷积核而非堆叠小核可能是一种更强大的范式。
TABLE 2. Evaluation metrics of FixCaps and IRV2-SA for each skin lesion type on the test set.
表 2: 测试集上FixCaps和IRV2-SA针对每种皮肤病变类型的评估指标。
| Dis. | Recall | F1-score | # |
|---|---|---|---|
| Fix Caps-DS | Fix Caps | IRv2-SA [30] | |
| AKIEC | 0.913 | 0.957 | 0.520 |
| BCC | 0.769 | 0.846 | 0.880 |
| BKL | 0.803 | 0.864 | 0.830 |
| DF | 0.833 | 0.667 | 0.170 |
| MEL | 0.853 | 0.912 | 0.650 |
| NV | 0.992 | 0.986 | 0.980 |
| VASC | 1 | 0.700 | 1 |

FIGURE 5. The accuracy is evaluated on the test set by using different LKC. The ‘‘kernel ${\bf N}^{\prime\prime}$ denotes a convolution kernel of $\mathsf{N}\times\mathsf{N}$ in the FixCaps.
图 5: 使用不同 LKC 在测试集上评估的准确率。其中 "kernel ${\bf N}^{\prime\prime}$ 表示 FixCaps 中 $\mathsf{N}\times\mathsf{N}$ 的卷积核。
TABLE 3. The $\mathsf{F}_{1}$ -score is evaluated on the test set by using different LKC.
表 3: 使用不同 LKC 在测试集上评估的 $\mathsf{F}_{1}$ 分数
| Dis. | F1-score |
|---|---|
| 9 | |
| AKIEC | 0.323 |
| BCC | 0.410 |
| BKL | 0.4260.516 |
| DF | 0 |
| MEL | 0.261 |
| NV | 0.923 |
| VASC |
VI. CONCLUSION
VI. 结论
In this work, we introduced an improved capsule network called FixCaps for der mos co pic image classification. FixCaps can obtain a larger receptive field than CapsNets by applying a high-performance large-kernel at the bottom convolution layer whose kernel size is as large as $31\times31$ , in contrast to commonly used $9\times9$ . Moreover, the CBAM was used to reduce the losses of spatial information and the GP was used to avoid model under fitting in the capsule layer. We evaluate FixCaps on HAM10000 dataset, and the experiment results show that FixCaps achieves an accuracy of $96.49%$ , while achieving a $92%$ reduction in the number of parameters. FixCap can improve the detection accuracy with less calculations, compared with several existing methods. Hence, FixCaps will be helpful to doctors (especially those with little experience) by providing valid auxiliary diagnosis. Moreover, it will promote the perfection and popularization of skin cancer screening technologies. In this work, however, the generalization performance of FixCaps has not been adequately studied, which we will study in the future.
在本研究中,我们提出了一种改进的胶囊网络FixCaps,用于皮肤镜图像分类。与常用的$9\times9$卷积核相比,FixCaps通过在底层卷积层应用高性能的大尺寸卷积核(核尺寸高达$31\times31$),能够获得比CapsNets更大的感受野。此外,我们采用CBAM模块减少空间信息损失,并引入GP机制防止胶囊层出现欠拟合现象。在HAM10000数据集上的实验表明,FixCaps实现了$96.49%$的准确率,同时参数数量减少$92%$。与现有多种方法相比,FixCaps能以更少的计算量提升检测精度。因此,FixCaps能为医生(特别是经验不足者)提供有效的辅助诊断,并推动皮肤癌筛查技术的完善与普及。但本研究尚未充分验证FixCaps的泛化性能,这将是未来的研究方向。