Synth Ensemble: A Fusion of CNN, Vision Transformer, and Hybrid Models for Multi-Label Chest X-Ray Classification
Synth Ensemble: 融合CNN、Vision Transformer和混合模型的多标签胸部X光分类方法
Abstract—Chest X-rays are widely used to diagnose thoracic diseases, but the lack of detailed information about these abnormal i ties makes it challenging to develop accurate automated diagnosis systems, which is crucial for early detection and effective treatment. To address this challenge, we employed deep learning techniques to identify patterns in chest $\mathbf{X}$ -rays that correspond to different diseases. We conducted experiments on the ”ChestX-ray14” dataset using various pre-trained CNNs, transformers, hybrid $\mathbf{CNN+}$ Transformer) models, and classical models. The best individual model was the CoAtNet, which achieved an area under the receiver operating characteristic curve (AUROC) of $84.2%$ . By combining the predictions of all trained models using a weighted average ensemble where the weight of each model was determined using differential evolution, we further improved the AUROC to $85.4%$ , outperforming other state-of-the-art methods in this field. Our findings demonstrate the potential of deep learning techniques, particularly ensemble deep learning, for improving the accuracy of automatic diagnosis of thoracic diseases from chest $\mathbf{X}$ -rays. Code available at: https://github.com/syed nabi l ashraf/Synth Ensemble
摘要—胸部X光片被广泛用于诊断胸部疾病,但由于缺乏关于这些异常的详细信息,开发准确的自动诊断系统具有挑战性,这对早期发现和有效治疗至关重要。为解决这一挑战,我们采用深度学习技术来识别胸部$\mathbf{X}$光片中与不同疾病对应的模式。我们在"ChestX-ray14"数据集上使用各种预训练的CNN、Transformer、混合$\mathbf{CNN+}$Transformer模型以及经典模型进行了实验。表现最佳的单一模型是CoAtNet,其接收者操作特征曲线下面积(AUROC)达到$84.2%$。通过使用加权平均集成方法结合所有训练模型的预测(其中每个模型的权重通过差分进化确定),我们进一步将AUROC提升至$85.4%$,优于该领域的其他先进方法。我们的研究结果表明,深度学习技术,特别是集成深度学习,在提高胸部$\mathbf{X}$光片自动诊断准确性方面具有潜力。代码见: https://github.com/syed nabi l ashraf/Synth Ensemble
Index Terms—Chest X-ray, Medical Imaging, Ensemble Learning, Vision Transformer, CNN
索引术语—胸部X光、医学影像、集成学习、Vision Transformer、CNN
I. INTRODUCTION
I. 引言
The field of medical diagnostics has witnessed a growing interest and recognition because of deep learning as a promising and feasible approach. Specifically, using chest X-ray imaging as a screening and diagnostic modality in Artificial Intelligence tools holds significant importance for various thoracic diseases [1]. However, the lack of properly labeled hospitalscale datasets, as well as fine-grained features, are hindering the development of computer-aided diagnosis systems [2]. Despite this, the utilization of Convolutional Neural Networks (CNNs), pre-trained transformer models, and their subsequent fine-tuning for downstream tasks has demonstrated efficacy in situations where there is a scarcity of training data and quality features [3] [4]. Additionally, it is imperative to mitigate unexpected biases, as they are deemed undesirable within a medical scenario. In the context of low-resolution images and limited image data, it was seen that Swin Transformer V2 outperforms alternative vision transformer models [5].
由于深度学习作为一种前景广阔且可行的方法,医学诊断领域正受到越来越多的关注和认可。具体而言,在人工智能工具中使用胸部X光成像作为筛查和诊断手段,对多种胸部疾病具有重要意义[1]。然而,缺乏标注完善的医院级数据集以及细粒度特征,阻碍了计算机辅助诊断系统的发展[2]。尽管如此,在训练数据和质量特征稀缺的情况下,卷积神经网络(CNN)、预训练的Transformer模型及其在下游任务中的微调已展现出有效性[3][4]。此外,必须减少意外偏差,因为它们在医疗场景中被视为不利因素。在低分辨率图像和有限图像数据的情况下,Swin Transformer V2表现优于其他视觉Transformer模型[5]。
This study investigates various deep-learning approaches for the purpose of identifying features in chest radio graph y (CXR) pictures that are indicative of chest illnesses. In every instance of chest disease, we employ pre-trained convolutional neural network (CNN) models, vision transformer models, and a fusion of CNN and transformers, utilizing chest X-ray pictures as input. Furthermore, we optimize the hyper-parameters of the multi-label system, which encompasses 14 diagnostic labels concurrently.
本研究探讨了多种深度学习方法,旨在识别胸部X光片(CXR)中与胸部疾病相关的特征。针对每种胸部疾病案例,我们采用预训练的卷积神经网络(CNN)模型、视觉Transformer模型以及CNN与Transformer的混合架构,以胸部X光图像作为输入。此外,我们还优化了包含14个并行诊断标签的多标签系统的超参数。
In our study, we present three noteworthy contributions:
在我们的研究中,我们提出了三个值得注意的贡献:
II. LITERATURE REVIEW
II. 文献综述
In recent years, significant progress has been made in the field of deep learning and the availability of extensive datasets in the task of medical imaging. These advancements have facilitated the development of methods that have demonstrated comparable performances against healthcare experts in various medical imaging tasks [6] [7] [8] [9] [10]. In particular, detection of diabetic ret in opa thy [6], classification of skin cancer [7], identifying arrhythmia [8], recognition of haemorrhage [9], and pulmonary tuberculosis detection in x-rays [10]
近年来,深度学习领域和医学影像任务中大规模数据集的可用性取得了显著进展。这些进步促进了多种方法的开发,这些方法在各种医学影像任务中展现出与医疗专家相当的性能 [6] [7] [8] [9] [10],具体包括:糖尿病视网膜病变检测 [6]、皮肤癌分类 [7]、心律失常识别 [8]、出血识别 [9] 以及X光片中的肺结核检测 [10]。
In continuation of expanding the realm of this medical imaging field, Wang et al. [2] introduced the ChestX-ray-14 dataset, which contains significantly larger data compared to prior datasets in the same domain. Additionally, Wang et al. conducted a comparative evaluation of various convolutional neural network architectures that had been pre-trained on ImageNet [11]. After that, researchers have come forward to improve the detection of different chest diseases by proposing and leveraging different methodologies, like Yao et al. [12], who tested the statistical dependencies among labels.
为进一步拓展医学影像领域的边界,Wang等人[2]提出了ChestX-ray-14数据集,其数据规模显著超越该领域先前的数据集。此外,Wang团队还对多种经ImageNet[11]预训练的卷积神经网络架构进行了对比评估。此后,研究者们陆续提出并采用不同方法来提升各类胸部疾病的检测效果,例如Yao等人[12]通过验证标签间的统计依赖性来优化模型。
A. Convolutional Neural Networks in medical image domain
A. 医学影像领域的卷积神经网络
In the field of medical image learning, it is not unexpected to leverage the Convolutional Neural Network (CNN) [13] as the foundation for the most successful models in the field of medical image learning. Among researchers, the CNN structure has been the prevailing choice for image recognition tasks. As a result, many have proposed efficient methodologies on top of the existing ones. Gao et al. [14] illustrated a solution to the vanishing-gradient problem in Convolutional Neural Networks (CNNs) by interconnecting each layer of the CNN with every subsequent layer. However, the complex architectures of CNNs give rise to concerns regarding interpret a bility and computational efficiency. Nevertheless, Pranav et al. successfully employed 121-layer CNNs to address medical imaging challenges in the realm of Cardiovascular diseases, demonstrating consistent performances [15].
在医学影像学习领域,利用卷积神经网络(CNN) [13]作为最成功模型的基础并不令人意外。研究人员普遍选择CNN结构来完成图像识别任务,因此许多人在现有方法基础上提出了更高效的方案。Gao等人[14]通过将CNN的每一层与后续所有层互联,解决了卷积神经网络中的梯度消失问题。然而,CNN的复杂架构引发了关于可解释性和计算效率的担忧。尽管如此,Pranav等人成功采用121层CNN解决心血管疾病领域的医学影像挑战,并展现出稳定性能[15]。
B. Transformer in the medical computer vision
B. 医疗计算机视觉中的Transformer
In recent times, in the context of the classification and detection task, self-supervised learning techniques such as masked auto encoders [16] are being used to improve the performance of pure CNNs. Post-2020, the adoption of the Transformer model in computer vision has become evident, attributed to its significant capability, as outlined in Vaswani et al.’s work [17]. Nevertheless, for effective utilization of transformers, self-attention, and self-supervision techniques in image processing, various researchers have suggested diverse enhancements. Zihang et al. [18] combined the strengths of transformers and convolutional networks, emphasizing the synergies between these two architectures. They also brought attention to the issue of limited s cal ability in the self-attention mechanism of transformers when dealing with larger image sizes. Addressing this concern, Li et al. [19], in their paper on Vision Outlooker (VOLO), pointed out its effectiveness in encoding fine-grain features and contextual information into tokens—an achievement not previously attainable through self-attention mechanisms. Additionally, this study led to the development of MaxVIT [20] to better accommodate larger image sizes.
近年来,在分类和检测任务中,诸如掩码自编码器 [16] 等自监督学习技术被用于提升纯卷积神经网络(CNN)的性能。2020年后,Transformer模型在计算机视觉领域的应用日益显著,这归功于Vaswani等人 [17] 所阐述的其强大能力。然而,为了在图像处理中有效利用Transformer、自注意力(self-attention)和自监督技术,多位研究者提出了不同的改进方案。Zihang等人 [18] 结合了Transformer与卷积网络的优点,强调这两种架构的协同效应。他们还指出,在处理较大尺寸图像时,Transformer的自注意力机制存在可扩展性受限的问题。针对这一问题,Li等人在其关于视觉展望器(VOLO)的论文 [19] 中指出,该模型能有效将细粒度特征和上下文信息编码为Token,这是自注意力机制此前无法实现的。此外,该研究还推动了MaxVIT [20] 的开发,以更好地适应更大尺寸的图像。
While both CNNs and Transformers contribute significant roles in medical computer vision, they exhibit distinct strengths and weaknesses. CNNs excel in s cal ability and have demonstrated high performance on large datasets. Conversely, transformers, such as ViTs, introduce innovative approaches with attention mechanisms. However, addressing the scalability limitations of transformers remains a considerable challenge, which this study tries to overcome. We have attempted to harness the capabilities of recent ViT models like Swin Transformer v2 [5], initially trained on low-quality images, to effectively handle downstream tasks involving higherresolution images and mitigate the s cal ability issues.
虽然CNN和Transformer在医学计算机视觉领域都发挥着重要作用,但它们各自展现出独特的优缺点。CNN在可扩展性(s cal ability)方面表现优异,已证明能在大规模数据集上实现高性能。而Transformer架构(如ViT)通过注意力机制引入了创新方法。但解决Transformer的可扩展性限制仍是重大挑战,这也正是本研究试图攻克的课题。我们尝试利用Swin Transformer v2 [5]等最新ViT模型的能力(这些模型最初在低质量图像上训练),来有效处理涉及高分辨率图像的下游任务,从而缓解可扩展性问题。
III. METHODOLOGY
III. 方法论
A. Dataset Description
A. 数据集描述
Our research uses the ChestX-ray14 dataset [2], a robust compilation comprising 112,120 frontal-view X-ray images from 30,805 unique patients from 1992 to 2015. Expanding on the ChestX-ray8 dataset, this comprehensive collection incorporates six additional extra thoracic conditions, including Edema, Emphysema, Fibrosis, Pleural Thickening, and Hernia.
我们的研究使用了ChestX-ray14数据集 [2],这是一个包含1992年至2015年间30,805名患者的112,120张正面X光图像的强大合集。该数据集在ChestX-ray8基础上扩展,新增了六种胸外疾病,包括水肿(Edema)、肺气肿(Emphysema)、纤维化(Fibrosis)、胸膜增厚(Pleural Thickening)和疝气(Hernia)。
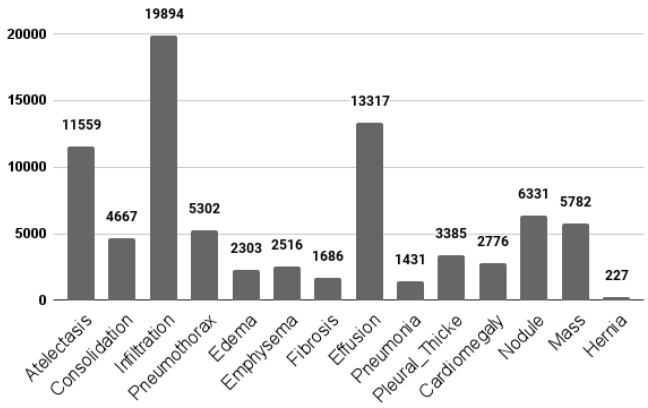
Fig. 1: Disease distribution in the dataset.
图 1: 数据集中的疾病分布。
Figure 1 illustrates the inherent class imbalance within our dataset, revealing that certain medical conditions are disproportionately represented. This imbalance could potentially lead to biased model performance. Moreover, a considerable portion of the dataset, amounting to more than 60,000 (out of 112,120 images), was categorized as ”No Findings,” indicating the absence of any of the 14 detectable diseases.
图 1: 展示了我们数据集中固有的类别不平衡问题,揭示某些医疗状况的样本比例明显失衡。这种不平衡可能导致模型性能出现偏差。此外,数据集中有相当一部分(112,120张图像中的60,000余张)被归类为"无异常",即未检测到14种可识别疾病中的任何一种。
B. Model Exploration
B. 模型探索
In this section, we briefly introduce different types of cutting-edge image classification models that we have selected for our experiment, including CNN, Vision Transformer (ViT), and Hybrid $(\mathrm{{CNN}+\mathrm{{ViT})}}$ models.
在本节中,我们简要介绍为实验选取的几种前沿图像分类模型,包括CNN、Vision Transformer (ViT) 以及混合 $(\mathrm{{CNN}+\mathrm{{ViT})}}$ 模型。
1) Hybrid architectures:
1) 混合架构:
• CoAtNet: CoAtNets [18] comprise a novel class of hybrid models that seamlessly merge depthwise convolution and self-attention through simple relative attention mechanisms. This approach leads to a coherent fusion of convolution and attention layers, effectively enhancing generalization, capacity, and efficiency. Furthermore, CoAtNets demonstrate improved performance by systematically stacking convolutional and attention layers in a meticulously designed manner. • MaxViT: MaxViT [20] is a pioneering model that leverages multi-axis attention to achieve powerful global-local spatial interactions on diverse input resolutions, all while maintaining linear complexity. By ingeniously incorporating blocked local and dilated global attention mechanisms, MaxViT empowers the integration of attention with convolutions. This ingenious synergy culminates in a hierarchical vision backbone, where the fundamental building block is seamlessly replicated across multiple stages.
• CoAtNet: CoAtNets [18] 提出了一类创新的混合模型,通过简单的相对注意力机制将深度卷积与自注意力无缝融合。这种方法实现了卷积层与注意力层的连贯结合,有效提升了泛化能力、模型容量和效率。此外,CoAtNets通过精心设计的层次化堆叠方式,系统整合卷积与注意力层,从而展现出更优的性能表现。
• MaxViT: MaxViT [20] 是一种开创性模型,利用多轴注意力机制在不同输入分辨率上实现强大的全局-局部空间交互,同时保持线性计算复杂度。该模型创新性地结合了分块局部注意力和扩张全局注意力机制,使注意力与卷积的融合成为可能。这种精妙的协同作用最终形成了层次化的视觉主干网络,其基础模块可在多阶段中无缝复用。
2) Vision Transformer (ViT):
2) Vision Transformer (ViT):
• Swin V2: Swin Transformer V2 [5] introduces an array of strategies, including residual-post-norm with cosine attention, log-spaced position bias, and SimMIM selfsupervised pre-training. These techniques collectively foster training stability, resolution transfer, and reduction in labeled data dependency. The outcome is a model that achieves remarkable performance across diverse vision tasks, surpassing state-of-the-art benchmarks.
• Swin V2: Swin Transformer V2 [5] 提出了一系列创新策略,包括采用余弦注意力机制的残差后归一化 (residual-post-norm) 、对数间隔位置偏置 (log-spaced position bias) 以及 SimMIM 自监督预训练技术。这些方法协同提升了训练稳定性、分辨率迁移能力,并降低了对标注数据的依赖。最终该模型在多种视觉任务中实现了突破性性能,超越了现有最优基准。
• VOLO: Addressing the limitations of self-attention, Vision Outlooker (VOLO) [19] introduces outlook attention, an innovative technique that efficiently captures finegrained features and contexts at a more granular level. This novel approach, embodied in the VOLO architecture, stands in contrast to conventional self-attention, which predominantly focuses on coarser global dependency modeling.
• VOLO: 针对自注意力(self-attention)的局限性,Vision Outlooker (VOLO) [19]提出了outlook attention这一创新技术,能够在更细粒度层面高效捕获精细特征和上下文信息。这种体现在VOLO架构中的新方法,与主要关注粗粒度全局依赖建模的传统自注意力形成鲜明对比。
3) Convolutional Neural Network (CNN):
3) 卷积神经网络 (CNN):
• DenseNet: Dense Convolutional Networks (DenseNets) [14] present a departure from conventional architectures by establishing dense connections that link each layer to all other layers in a feed-forward manner. This unique connectivity pattern results in an exponential increase in direct connections, mitigating challenges associated with vanishing gradients and facilitating robust feature propagation. DenseNets also engender feature reuse and parameter reduction, showcasing their efficacy in optimizing image classification tasks.
• DenseNet: 密集卷积网络 (DenseNets) [14] 通过建立密集连接 (每个层以前馈方式连接到所有其他层) 突破了传统架构。这种独特的连接模式导致直接连接呈指数级增长,缓解了梯度消失问题并促进了鲁棒的特征传播。DenseNets 还实现了特征复用和参数减少,展现了其在优化图像分类任务中的高效性。
• ConvNeXt V2: Building upon the ConvNeXt framework, ConvNeXt V2 [4] introduces an upgraded model with a fully convolutional masked auto encoder structure and a Global Response Normalization (GRN) layer. This integration of self-supervised learning techniques and architectural refinements contributes to substantial performance enhancements across various recognition benchmarks, underscoring the potency of combined approaches in image classification.
• ConvNeXt V2: 基于ConvNeXt框架,ConvNeXt V2 [4] 引入了升级版模型,采用全卷积掩码自编码器结构和全局响应归一化 (GRN) 层。这种自监督学习技术与架构优化的结合,显著提升了多种识别基准测试的性能,彰显了组合方法在图像分类中的强大潜力。
C. Data pre-processing and splitting
C. 数据预处理与分割
This section outlines the fundamental steps taken to preprocess the data, ensuring its suitability for subsequent analysis and model training.
本节概述了预处理数据的基本步骤,以确保其适用于后续分析和模型训练。
- Image Resizing and Normalization: Initially, the images were sized 1024x1024 pixels, and we resized them to more manageable dimensions of $224\mathrm{x}224$ pixels to enhance computational efficiency within resource constraints. We normalized the images using a mean and standard deviation of images from the Imagenet dataset.
- 图像调整大小与归一化:初始图像尺寸为1024x1024像素,我们将其调整为更易处理的$224\mathrm{x}224$像素尺寸,以在资源限制下提升计算效率。使用Imagenet数据集的均值和标准差对图像进行归一化处理。
- Horizontal Flips and Rotation: We incorporated random horizontal flips and rotations to enhance orientation robustness and promote feature learning. These augmentations were applied with a $50%$ probability each, and rotations were confined to a maximum of 10 degrees.
- 水平翻转和旋转:我们加入了随机水平翻转和旋转以增强方向鲁棒性并促进特征学习。这些增强操作每次应用的概率为 $50%$,且旋转角度限制在最大10度以内。
- Splitting: The dataset was divided into distinct groups, with $70%$ allocated for training, $20%$ for testing, and $10%$ for validation. Notably, patient overlaps were meticulously avoided across these divisions, as evident in Table I. As indicated by Yao et al. [12], variations in random splitting negligibly impact performance, thus guaranteeing an equitable basis for comparison.
- 划分: 数据集被划分为不同组别,其中70%用于训练,20%用于测试,10%用于验证。值得注意的是,如表1所示,这些划分中严格避免了患者重叠。如Yao等人[12]所指出的,随机划分的差异对性能影响微乎其微,从而确保了比较的公平基础。
TABLE I: SPLITTING OF THE DATASET
表 1: 数据集划分
| 总计 | 训练集 | 验证集 | 测试集 | |
|---|---|---|---|---|
| 图像 | 112120 | 78544 | 11220 | 22356 |
| 独立患者数 | 30805 | 21563 | 3081 | 6161 |
D. Training and Optimization
D. 训练与优化
• Finding initial learning rate: To identify the initial learning rate (LR), we leverage the Learning Rate Range Test, a technique discussed by Smith [21]. The crux of this approach is centered around the concept of cyclical learning rate (CLR), which alternately increases and decreases during the training process. Our choice of the optimizer is AdamW [22], which we adopt with CLR during training. We ran a small training session for 100 iterations in which the learning rate was increased between two boundaries, min lr and max lr, which were 1e-7 and 1e-1, respectively. We then plot the LR vs. Loss curve and pick the midpoint of the steepest descending portion of the curve as the maximum bound for training with CLR.
• 寻找初始学习率:为了确定初始学习率 (LR),我们采用了Smith [21] 提出的学习率范围测试 (Learning Rate Range Test) 技术。该方法的核心思想基于循环学习率 (CLR) 的概念,即在训练过程中交替增减学习率。我们选择AdamW [22] 作为优化器,并在训练时采用CLR。我们进行了100次迭代的小规模训练,学习率在1e-7(最小学习率)和1e-1(最大学习率)之间递增。随后绘制LR与损失函数的关系曲线,并选择曲线最陡下降段的中点作为CLR训练的最大边界值。
• Training DNN: Figure 2a illustrates the architecture used for training every DNN. We employed pre-trained weights sourced from ImageNet for initializing each neural network. The model’s head was trained for three epochs, as it was randomly initialized. Then, the full network was fine-tuned for ten epochs with disc rim i native LR, where the model’s initial layers were trained with a lower LR compared to the final layers. Training was halted when the model failed to improve for three consecutive epochs. The best model with the lowest validation loss during training was saved. To optimize the initial learning rate for the fine-tuned model, the weights of the saved model were loaded, and the LR Range Test was re-run. The entire model was then trained for a second time using the optimal initial learning rate for five epochs, saving only the model with the best validation loss. While training in the second phase only slightly improved the validation loss for some models like CoAtNet, all six models were trained using the same approach with two phases.
• 训练深度神经网络 (DNN):图 2a 展示了用于训练每个 DNN 的架构。我们采用 ImageNet 的预训练权重来初始化每个神经网络。由于模型头部是随机初始化的,因此对其进行了三个周期的训练。随后,以判别性学习率 (LR) 对整个网络进行了十个周期的微调,其中模型初始层的学习率低于最终层。当模型连续三个周期未出现改进时,训练即停止。训练过程中验证损失最低的最佳模型会被保存。为了优化微调模型的初始学习率,我们加载了保存模型的权重并重新运行了 LR 范围测试。接着使用最优初始学习率对整个模型进行了五个周期的二次训练,仅保留验证损失最佳的模型。虽然第二阶段的训练仅对 CoAtNet 等部分模型的验证损失有轻微改善,但所有六个模型均采用相同的两阶段训练方法。
• Training Classical Models as Meta-Learner: To enhance outcomes, we explored utilizing feature vectors generated by the top-performing DNN as input for classical models like XGBoost and Random Forest. We pursued two strategies: firstly, training classical models with the output vectors from the second-to-last layer of our DNN models (varied per model) as depicted in Figure 2c; secondly, training them with the last layer of our custom head, producing 512 features for each DNN as shown in Figure 2b. Integrating the top-performing DNN with classical models aimed to synergize model strengths and enhance overall performance.
• 将经典模型作为元学习器进行训练:为提升效果,我们探索了使用性能最佳的深度神经网络(DNN)生成的特征向量作为XGBoost和随机森林等经典模型的输入。我们采用两种策略:首先如图2c所示,使用DNN模型倒数第二层(不同模型层数不同)的输出向量训练经典模型;其次如图2b所示,使用自定义头部最后一层输出的512维特征进行训练。通过将最优DNN与经典模型结合,旨在实现模型优势互补并提升整体性能。

Fig. 2: Architecture for DNN and classical model. CH: Custom Head. XGB: XGBoost. RF: Random Forest
图 2: DNN与传统模型的架构。CH: 自定义头部。XGB: XGBoost。RF: 随机森林

Fig. 3: Average weighted ensemble with differential evolution.
图 3: 采用差分进化的平均加权集成方法。
• Ensembling DNN: To make our predictions more robust with reduced variance, we used two different ensemble techniques on the validation split before evaluating on test data. (1) Stacking: we concatenated the six probability vectors outputted by all 6 DNNs to form 84 features (6 DNN models $^{*14}$ probabilities each $=84$ features) for each image and trained XGBoost as a meta classifier to make the final predictions. (2) Weighted average: we averaged the six probability vectors using different weights for each DNN to produce one probability vector for each image. The optimal weight for each model, which determined its contribution to the weighted final prediction, was found using a stochastic global search algorithm known as differential evolution [23]. The weights were bounded 0 and 1 (inclusive) and summed to 1. This was the superior ensemble technique and has been shown in Figure 3.
• 集成DNN:为了使我们的预测更加稳健并减少方差,我们在评估测试数据前对验证集使用了两种不同的集成技术。(1) 堆叠:我们将所有6个DNN输出的六个概率向量拼接起来,为每张图像形成84个特征 (6个DNN模型 * 14个概率 = 84个特征),并训练XGBoost作为元分类器进行最终预测。(2) 加权平均:我们使用每个DNN的不同权重对六个概率向量进行平均,为每张图像生成一个概率向量。每个模型的最优权重(决定其对加权最终预测的贡献)通过一种称为差分进化 [23] 的随机全局搜索算法确定。权重范围在0到1之间(含端点)且总和为1。这是更优的集成技术,如图3所示。
IV. EXPERIMENTS
IV. 实验
A. Experimental Setup
A. 实验设置
We chose PyTorch as our implementation platform. Our experiments were run on two Nvidia T4 GPUs with 16GB of memory each. We selected Binary cross-entropy loss as our loss function for multi-label classification. We employed AdamW as our optimizer with a true weight decay of 1e-2 for every DNN and a momentum of 0.9. We set the batch size to 32, which used the full capacity of our GPUs. Our training process incorporates an early stopping mechanism, stopping training if the validation loss does not improve by a margin of 1e-3 within five epochs. Additionally, to safeguard model progress, we implement a checkpoint system, preserving the model’s state each time the validation loss experiences a reduction of at least 1e-4.
我们选择 PyTorch 作为实现平台。实验在两块内存均为 16GB 的 Nvidia T4 GPU 上运行,选用二元交叉熵损失 (Binary cross-entropy loss) 作为多标签分类的损失函数。采用 AdamW 作为优化器,每个 DNN 的真实权重衰减 (weight decay) 设为 1e-2,动量 (momentum) 设为 0.9。批量大小 (batch size) 设置为 32 以充分利用 GPU 算力。训练过程包含早停机制 (early stopping),若验证损失在五个周期内未提升超过 1e-3 则终止训练。此外,通过检查点系统 (checkpoint system) 保障模型进度,每当验证损失降低至少 1e-4 时保存模型状态。
B. Models Performance
B. 模型性能
Among all of our DNN models, CoAtNet performed the best among all models with a mean AUROC of $84.2%$ , followed by ConvNeXtV2 with $84.1%$ (shown in Table II).
在我们所有的DNN模型中,CoAtNet表现最佳,平均AUROC为$84.2%$,其次是ConvNeXtV2,达到$84.1%$ (如表II所示)。
TABLE II: AUROC of DNN models
表 II: DNN模型的AUROC值
| 模型 | 类型 | 模型参数量 (M) | AUROC |
|---|---|---|---|
| CoAtNet | Hybrid | 73.9 | 0.84239 |
| MaxViT | Hybrid | 116 | 0.84013 |
| DenseNet121 | CNN | 8 | 0.82440 |
| ConvNeXtV2 | CNN | 198 | 0.84091 |
| VOLO | Transformer | 58.7 | 0.83205 |
| SwinV2 | Transformer | 49.7 | 0.83573 |
Next, we used the feature vectors from these models to train classical models (XGBoost and Random Forest), as detailed in Table III. Notably, CoAtNet features surpassed ConvNeXtV2 in both cases (last and second-to-last layers), with clear performance improvement using 512 features compared to the larger alternative.
接下来,我们利用这些模型的特征向量训练经典模型 (XGBoost 和随机森林),具体如 表 III 所示。值得注意的是,CoAtNet 的特征在两种情况下 (最后一层和倒数第二层) 均优于 ConvNeXtV2,且使用 512 个特征时相比更大规模的替代方案展现出明显的性能提升。
TABLE III: AUROC OF CLASSICAL MODELS
表 III: 经典模型的AUROC
| 特征提取模型 (FeatureExtractionModel) | 分类器模型 (ClassifierModel) | 特征数 (Features) | AUROC |
|---|---|---|---|
| CoAtNet | XGB | 512 | 0.83814 |
| CoAtNet | XGB | 2048 | 0.82354 |
| ConvNeXtV2 | XGB | 512 | 0.82536 |
| ConvNeXtV2 | XGB | 3072 | 0.81160 |
| CoAtNet | RF | 512 | 0.81441 |
| CoAtNet | RF | 2048 | 0.80607 |
| ConvNeXtV2 | RF | 512 | 0.80150 |
| ConvNeXtV2 | RF | 3072 | 0.79458 |
Lastly, we ensembled all 6 DNNs with two distinct techniques. (1) Stacking: the probability vectors outputted by each DNN to train XGBoost as a meta-classifier. (2) Unweighted and weighted average ensemble where the weights were determined using differential evolution. We assessed each technique on validation split before evaluating on test data, as shown in Table IV. The weighted average ensemble demonstrated superior performance overall, outperforming individual DNN models as well as other ensemble methods.
最后,我们采用两种不同技术集成了全部6个DNN模型:(1) 堆叠法:使用每个DNN输出的概率向量训练XGBoost作为元分类器;(2) 未加权与加权平均集成,其中权重通过差分进化算法确定。如表4所示,我们在验证集上评估了每种技术后再进行测试数据评估。加权平均集成整体表现最优,超越了单个DNN模型及其他集成方法。
TABLE IV: AUROC WITH DIFFERENT ENSEMBLE TECHNIQUES
表 IV: 不同集成技术下的AUROC
| 技术 | AUROC |
|---|---|
| 基于元分类器 (XGB) 的堆叠 | 0.84518 |
| 未加权平均集成 | 0.85327 |
| 加权平均集成 | 0.85433 |
C. Comparison of DNN, ML and Ensemble model
C. DNN、ML 和集成模型的对比
Our experimental investigation was structured around three distinct categories: Deep Learning Models, Classical Models with deep learning model features, and an ensemble approach that combines all models. Within the Deep Learning Models category, we further categorized models into CNN, Transformer, and Hybrid (CNN $^+$ Transformer) architectures, as shown in Table V. Our selection process involved identifying the most promising model from each category within Deep Neural Network (DNN), classical Machine Learning (ML), and Ensemble models.
我们的实验研究围绕三个不同类别展开:深度学习模型、具有深度学习模型特征的经典模型,以及结合所有模型的集成方法。在深度学习模型类别中,我们进一步将模型分为CNN、Transformer和混合(CNN $^+$ Transformer)架构,如表V所示。我们的筛选流程包括从深度神经网络(DNN)、经典机器学习(ML)和集成模型中的每个类别中选出最有前景的模型。
Among six evaluated DNN models (CoAtNet, MaxViT, Dense Net 121, ConvNeXtV2, VOLO, and SwinV2), CoAtNet performed the best. We used CoAtNet and ConvNeXtV2’s feature vectors for training classical ML models (XGBoost, Random Forest), but they fell short of deep learning models’ performance. Instead, an ensemble model combining all models consistently outperformed others, emphasizing its predictive accuracy and robustness. In summary, CoAtNet excelled in DNNs, classical models couldn’t match deep learning models’ performance, and the ensemble model dominated predictive accuracy across all labels.
在评估的六个DNN模型(CoAtNet、MaxViT、DenseNet 121、ConvNeXtV2、VOLO和SwinV2)中,CoAtNet表现最佳。我们使用CoAtNet和ConvNeXtV2的特征向量训练传统机器学习模型(XGBoost、随机森林),但其性能仍不及深度学习模型。相反,整合所有模型的集成模型始终优于其他方法,突显了其预测准确性和鲁棒性。综上所述,CoAtNet在DNN中表现优异,传统模型无法匹敌深度学习模型性能,而集成模型在所有标签的预测准确性上均占据主导地位。
TABLE V: AUROC OF BEST DNN, CLASSICAL AND ENSEMBLE MODEL FOR ALL DISEASES
表 V: 所有疾病的最佳DNN、经典模型和集成模型的AUROC
| 疾病 | CoAtNet | CoAtNet+XGB | WeightedEnsemble |
|---|---|---|---|
| 肺不张 | 0.82313 | 0.82364 | 0.83390 |
| 实变 | 0.80980 | 0.81151 | 0.81575 |
| 浸润 | 0.73105 | 0.73199 | 0.74102 |
| 气胸 | 0.89660 | 0.89068 | 0.90164 |
| 水肿 | 0.90185 | 0.90214 | 0.91034 |
| 肺气肿 | 0.92067 | 0.91891 | 0.92946 |
| 纤维化 | 0.81574 | 0.80103 | 0.83347 |
| 积液 | 0.88203 | 0.88147 | 0.88977 |
| 肺炎 | 0.76093 | 0.75798 | 0.77648 |
| 胸膜增厚 | 0.80053 | 0.80448 | 0.81270 |
| 心脏扩大 | 0.90788 | 0.90909 | 0.91954 |
| 结节 | 0.79828 | 0.79695 | 0.80611 |
| 肿块 | 0.86191 | 0.86310 | 0.87315 |
| 疝 | 0.88305 | 0.84093 | 0.91723 |
| 平均 | 0.84239 | 0.83814 | 0.85433 |

Fig. 4: ROC curve for all 14 diseases displaying the True Positive against False Positive rate, which illustrates the model’s capacity to differentiate effectively.
图 4: 14种疾病的ROC曲线,显示真阳性率与假阳性率的关系,展示了模型有效区分的能力。
D. Comparison with existing approaches
D. 与现有方法的对比
A comparative analysis was conducted between our proposed model and previous competing models, as shown in Table VI. The results demonstrated that our novel ensemble model produced superior outcomes. Notably, two exceptions occurred: ImageGCN performed slightly better in the context of Hernia while $A^{3}$ Net [24] took the lead in relation to Emphysema and Fibrosis detection. As depicted by the ROC curve in Figure 4, the ensemble model does well for all 14 diseases, excelling particularly in the case of Emphysema, yet showing comparatively less effectiveness for Infiltration.
对我们的提出的模型与之前的竞争模型进行了比较分析,如表 VI 所示。结果表明,我们的新型集成模型产生了更优的结果。值得注意的是,出现了两个例外情况:ImageGCN 在疝气 (Hernia) 的检测中表现略好,而 $A^{3}$ Net [24] 在肺气肿 (Emphysema) 和纤维化 (Fibrosis) 检测方面领先。如图 4 中的 ROC 曲线所示,集成模型在所有 14 种疾病上都表现良好,尤其在肺气肿方面表现突出,但在浸润 (Infiltration) 方面的效果相对较弱。
V. CONCLUSION
V. 结论
In this paper, we proposed an ensemble model for multilabel classification of chest $\boldsymbol{\mathrm X}$ -rays (CXRs) using deep learning techniques. Firstly, we trained and evaluated several pure transformers, CNN, and hybrid models on the ChestX-ray14 dataset and found that the hybrid model CoAtNet performed the best individually, achieving an AUROC of $84.2%$ . We also explored the performance of classical models like XGBoost and Random Forest when trained with feature vectors from our best-performing individual DNNs. Finally, we implemented a weighted average ensemble on the predictions of our DNNs using differential evolution to determine the optimal weight for each model. Our experiments show that our proposed ensemble model achieves better results than other state-ofthe-art methods in this field, with a mean AUROC of $85.4%$ . This demonstrates the potential of ensemble deep learning for improving the accuracy of automatic diagnosis of thoracic diseases from CXRs.
本文提出了一种基于深度学习技术的胸部X光片 (CXRs) 多标签分类集成模型。首先,我们在ChestX-ray14数据集上训练并评估了多种纯Transformer、CNN和混合模型,发现混合模型CoAtNet个体表现最佳,AUROC达到84.2%。我们还探究了XGBoost和随机森林等经典模型在使用最佳个体DNN生成的特征向量进行训练时的表现。最后,我们采用差分进化算法对DNN预测结果进行加权平均集成,以确定各模型最优权重。实验表明,我们提出的集成模型平均AUROC达到85.4%,优于该领域其他最先进方法。这证明了集成深度学习在提升胸部X光片疾病自动诊断准确性方面的潜力。
TABLE VI: COMPARISON OF AUROC WITH PREVIOUS WORK ON CHESTX-RAY14 DATASET
表 VI: CHESTX-RAY14数据集上AUROC与先前工作的对比
| 疾病 | Ensemble (Ours) | CoAtNet(Ours) | A3Net[24] | ImageGCN[25] | Wang et al. [2] | Li et al. [26] |
|---|---|---|---|---|---|---|
| 肺不张 | 0.83390 | 0.82313 | 0.779 | 0.802 | 0.716 | 0.800 |
| 实变 | 0.81575 | 0.80980 | 0.759 | 0.796 | 0.708 | 0.800 |
| 浸润 | 0.74102 | 0.73105 | 0.710 | 0.702 | 0.609 | 0.700 |
| 气胸 | 0.90164 | 0.89660 | 0.878 | 0.900 | 0.806 | 0.870 |
| 水肿 | 0.91034 | 0.90185 | 0.855 | 0.883 | 0.835 | 0.880 |
| 肺气肿 | 0.92946 | 0.92067 | 0.933 | 0.915 | 0.815 | 0.910 |
| 纤维化 | 0.83347 | 0.81574 | 0.838 | 0.825 | 0.769 | 0.780 |
| 积液 | 0.88977 | 0.88203 | 0.836 | 0.874 | 0.784 | 0.870 |
| 肺炎 | 0.77648 | 0.76093 | 0.737 | 0.715 | 0.633 | 0.670 |
| 胸膜增厚 | 0.81270 | 0.80053 | 0.791 | 0.791 | 0.708 | 0.760 |
| 心脏扩大 | 0.91954 | 0.90788 | 0.895 | 0.894 | 0.807 | 0.870 |
| 结节 | 0.80611 | 0.79828 | 0.777 | 0.768 | 0.671 | 0.750 |
| 肿块 | 0.87315 | 0.86191 | 0.834 | 0.843 | 0.706 | 0.830 |
| 疝 | 0.91723 | 0.88305 | 0.938 | 0.943 | 0.767 | 0.770 |
| 平均值 | 0.85433 | 0.84239 | 0.826 | 0.832 | 0.738 | 0.804 |