Synergistic Image and Feature Adaptation: Towards Cross-Modality Domain Adaptation for Medical Image Segmentation
图像与特征的协同适应:面向医学图像分割的跨模态领域自适应
Abstract
摘要
This paper presents a novel unsupervised domain adaptation framework, called Synergistic Image and Feature Adaptation (SIFA), to effectively tackle the problem of domain shift. Domain adaptation has become an important and hot topic in recent studies on deep learning, aiming to recover performance degradation when applying the neural networks to new testing domains. Our proposed SIFA is an elegant learning diagram which presents synergistic fusion of adaptations from both image and feature perspectives. In particular, we simultaneously transform the appearance of images across domains and enhance domain-invariance of the extracted features towards the segmentation task. The feature encoder layers are shared by both perspectives to grasp their mutual benefits during the end-to-end learning procedure. Without using any annotation from the target domain, the learning of our unified model is guided by adversarial losses, with multiple discriminators employed from various aspects. We have extensively validated our method with a challenging application of crossmodality medical image segmentation of cardiac structures. Experimental results demonstrate that our SIFA model recovers the degraded performance from $17.2%$ to $73.0%$ , and outperforms the state-of-the-art methods by a significant margin.
本文提出了一种名为协同图像与特征适配 (Synergistic Image and Feature Adaptation, SIFA) 的新型无监督领域自适应框架,以有效解决领域偏移问题。领域自适应已成为深度学习近期研究中的重要热点课题,旨在解决神经网络应用于新测试领域时的性能退化问题。我们提出的SIFA是一种优雅的学习框架,实现了图像层面与特征层面适配的协同融合。具体而言,我们同时实现了跨领域图像外观的转换和面向分割任务的提取特征的领域不变性增强。特征编码层在两种视角间共享,以便在端到端学习过程中获取相互增益。在不使用目标领域任何标注的情况下,我们通过对抗损失指导统一模型的学习,并采用了多判别器从不同角度进行约束。我们通过心脏结构跨模态医学图像分割这一挑战性应用对方法进行了广泛验证。实验结果表明,我们的SIFA模型将性能从17.2%提升至73.0%,并以显著优势超越了现有最优方法。
Introduction
引言
Deep convolutional neural networks (DCNNs) have made great breakthroughs in various challenging while crucial vision tasks (Long et al. 2015a; He et al. 2016). As investigations of DCNNs moving on, recent studies have frequently pointed out the problem of performance degradation when encountering domain shift, i.e., attempting to apply the learned models on testing data (target domain) that have different distributions from the training data (source domain). In medical image computing, which is an important area to apply AI for healthcare, the situation of heterogeneous domain shift is even more natural and severe, given the various imaging modalities with different physical principles.
深度卷积神经网络 (DCNN) 在各种具有挑战性但至关重要的视觉任务中取得了重大突破 (Long et al. 2015a; He et al. 2016)。随着对 DCNN 研究的深入,最近的研究经常指出在遇到领域偏移 (domain shift) 时的性能下降问题,即试图将学习到的模型应用于与训练数据 (源域) 分布不同的测试数据 (目标域)。在医疗图像计算这一应用人工智能 (AI) 于医疗保健的重要领域中,由于不同成像模态具有不同的物理原理,异构领域偏移的情况更加普遍且严重。
For example, as shown in Fig. 1, the cardiac areas present significantly different visual appearance when viewed from different modalities of medical images, such as the magnetic resonance (MR) imaging and computed tomography (CT). Un surprisingly, the DCNNs trained on MR data completely fail when being tested on CT images. To recover model performance, an easy way is to re-train or fine-tune models with additional labeled data from the target domain (Van Opbroek et al. 2015; Ghafoorian et al. 2017). However, annotating data for every new domain is obviously and prohibitively expensive, especially in medical area that requires expertise.
例如,如图 1 所示,心脏区域在磁共振 (MR) 成像和计算机断层扫描 (CT) 等不同模态的医学图像中呈现出显著不同的视觉外观。不出所料,在 MR 数据上训练的 DCNN 在 CT 图像测试时完全失效。为了恢复模型性能,一种简单的方法是使用目标域的额外标注数据重新训练或微调模型 (Van Opbroek et al. 2015; Ghafoorian et al. 2017)。然而,为每个新域标注数据显然成本高昂且难以实现,尤其是在需要专业知识的医学领域。
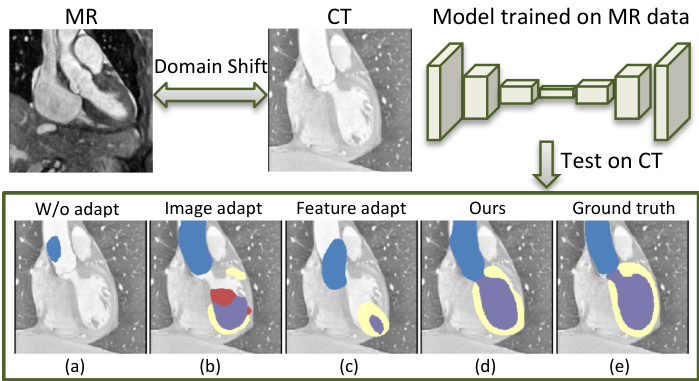
Figure 1: Illustration of addressing the severe cross-modality domain shift of medical images from different perspectives. The segmentation results of the CT images with the DCNN trained on MR data are shown in the bottom: a) without any adaptation; b) with pure image adaptation; c) with pure feature adaptation; d) our proposed synergistic image and feature adaptations; e) the ground truth.
图 1: 从不同角度解决医学图像严重跨模态域偏移的示意图。底部展示了使用在MR数据上训练的DCNN对CT图像的分割结果:a) 无任何适配;b) 纯图像适配;c) 纯特征适配;d) 我们提出的协同图像与特征适配;e) 真实标注。
To tackle this problem, unsupervised domain adaptation has been intensively studied to enable DCNNs to achieve competitive performance on unlabeled target data, only with annotations from the source domain. Prior works have treated domain shift mainly from two directions. One stream is the image adaptation, by aligning the image appearance between domains with the pixel-to-pixel transformation. In this way, the domain shift is addressed at input level to DCNNs. To preserve pixel-level contents in original images, the adaptation process is usually guided by a cycle-consistency constraint (Zhu et al. 2017; Hoffman et al. 2018). Typically, the transformed source-like images can be directly tested by pre-trained source models (Russo et al. 2017; Zhang et al. 2018b); alternatively, the generated target-like images can be used to train models in target domain (Bousmalis et al. 2017; Zhao et al. 2018). Although the synthesis images still cannot perfectly mimic the appearance of real images, the image adaptation process brings accurate pixelwise predictions on target images, as shown in Fig. 1.
为解决这一问题,无监督域适应 (unsupervised domain adaptation) 被深入研究,旨在仅利用源域的标注数据使深度卷积神经网络 (DCNNs) 在无标注目标数据上取得优异性能。先前工作主要从两个方向处理域偏移问题:
一是图像适应 (image adaptation),通过像素级变换实现跨域图像外观对齐。这种方法在DCNN的输入层面解决域偏移问题。为保留原始图像的像素级内容,适应过程通常采用循环一致性约束 (cycle-consistency constraint) 进行指导 (Zhu et al. 2017; Hoffman et al. 2018)。典型场景下,变换后的类源图像可直接用预训练源模型进行测试 (Russo et al. 2017; Zhang et al. 2018b);或者将生成的类目标图像用于目标域模型训练 (Bousmalis et al. 2017; Zhao et al. 2018)。虽然合成图像仍无法完美模拟真实图像外观,但如图1所示,图像适应过程能为目标图像提供精确的像素级预测。
图1:
The other stream for unsupervised domain adaptation follows the feature adaptation, which aims to extract domaininvariant features with DCNNs, regardless of the appearance difference between input domains. Most methods within this stream discriminate feature distributions of source/target domains in an adversarial learning scenario (Ganin et al. 2016; Tzeng et al. 2017; Dou et al. 2018). Furthermore, considering the high-dimensions of plain feature spaces, some recent works connected the disc rim in at or to more compact spaces. For examples, Tsai et al. inputs segmentation masks to the disc rim in at or, so that the supervision arises from a semantic prediction space (Tsai et al. 2018). Sankara narayan an et al. reconstructs the features into images and put a discriminator in the reconstructed image space (Sankara narayan an et al. 2018). Although the adversarial disc rim in at or s implicitly enhance domain invariance of features extracted by DCNNs, the adaptation process can output results with proper and smooth shape geometry.
无监督域适应的另一流派遵循特征适应方法,其目标是通过深度卷积神经网络(DCNNs)提取域不变特征,而忽略输入域之间的外观差异。该方向的大多数方法在对抗学习框架下区分源域/目标域的特征分布 (Ganin et al. 2016; Tzeng et al. 2017; Dou et al. 2018)。考虑到原始特征空间的高维性,近期研究将判别器连接到更紧凑的空间。例如,Tsai等人将分割掩码输入判别器,使监督信号来自语义预测空间 (Tsai et al. 2018)。Sankaranarayanan等人将特征重构为图像,并在重构图像空间放置判别器 (Sankaranarayanan et al. 2018)。虽然对抗判别器隐式增强了DCNN提取特征的域不变性,但适配过程能够输出具有合理且平滑几何形状的结果。
Being aware that the image adaptation and feature adaptation address domain shift from complementary perspectives, we recognize that the two adaptation procedures can be performed together within one unified framework. With image transformation, the source images are transformed towards the appearance of target domain; afterwards, the remaining gap between the synthesis target-like images and real target images can be further addressed using the feature adaptation. Sharing this spirit, several very recent works have presented promising attempts using image and feature adaptations altogether (Hoffman et al. 2018; Zhang et al. 2018a). However, these existing methods conduct the two perspectives of adaptations sequentially, without leveraging mutual interactions and benefits. Surely, there still remains extensive space for synergistic merge of image and feature adaptations, to elegantly overcome hurdle of domain shift when generalizing DCNNs to new domains with zero extra annotation cost.
意识到图像适应和特征适应从互补的角度解决域偏移问题,我们认为这两种适应过程可以在一个统一框架内共同进行。通过图像变换,源图像会向目标域的外观转换;随后,合成类目标图像与真实目标图像之间的剩余差距可以通过特征适应进一步解决。基于这一理念,近期几项研究 (Hoffman et al. 2018; Zhang et al. 2018a) 已展示了同时使用图像和特征适应的有前景尝试。然而,这些现有方法仅以串行方式执行两种适应,未能利用相互间的交互与增益。显然,在零额外标注成本下将DCNN推广至新领域时,图像适应与特征适应的协同融合仍存在广阔空间来优雅克服域偏移障碍。
In this paper, we propose a novel unsupervised domain adaptation framework, called Synergistic Image and Feature Adaptation (SIFA), and successfully apply it to adaptation of cross-modality medical image segmentation under severe domain shift. Our designed SIFA presents an elegant learning diagram which enables synergistic fusion of adaptations from both image and feature perspectives. More specifically, we transform the labeled source images into the appearance of images drawn from the target domain, by using generative adversarial networks with cycle-consistency constraint. When using the synthesis target-like images to train a segmentation model, we further integrate feature adaptation to combat the remaining domain shift. Here, we use two discri minato rs, respectively connecting the semantic segmentation predictions and generated source-like images, to differentiate whether obtained from synthesis or real target images. Most importantly, in our designed SIFA framework, we share the feature encoder, such that it can simultaneously transform image appearance and extract domain-invariant representations for the segmentation task. The entire domain adaptation framework is unified and both image and feature adaptations are seamlessly integrated into an end-to-end learning diagram. The major contributions of this paper are as follows:
本文提出了一种名为协同图像与特征适配 (Synergistic Image and Feature Adaptation, SIFA) 的新型无监督域适应框架,并成功将其应用于严重域偏移下的跨模态医学图像分割任务。我们设计的SIFA框架采用优雅的学习架构,实现了图像层面与特征层面适配的协同融合。具体而言,通过采用带循环一致性约束的生成对抗网络,我们将带标注的源域图像转换为目标域风格的合成图像。当使用这些合成目标域图像训练分割模型时,我们进一步整合特征适配以应对残留的域偏移。在此过程中,我们使用两个判别器分别连接语义分割预测结果和生成的源域风格图像,以区分数据来自合成图像还是真实目标域图像。最关键的是,在SIFA框架中我们共享特征编码器,使其能同时完成图像风格转换和为分割任务提取域不变特征表示。整个域适应框架采用统一架构,图像适配与特征适配被无缝整合到端到端的学习流程中。本文的主要贡献如下:
• We present the SIFA, a novel unsupervised domain adaptation framework, that exploits synergistic image and feature adaptations to tackle domain shift via complementary perspectives. • We enhance feature adaptation by using disc rim in at or s in two aspects, i.e., semantic prediction space and generated image space. Both compact spaces help to further enhance domain-invariance of the extracted features. We validate the effectiveness of our SIFA on the challenging task of cross-modality cardiac structure segmentation. Our approach recovers the performance degradation from $17.2%$ to $73.0%$ , and outperforms the state-of- the-art methods by a significant margin. The code is available at https://github.com/cchen-cc/SIFA.
• 我们提出了SIFA,一种新颖的无监督域适应框架,通过协同图像和特征适配从互补视角解决域偏移问题。
• 我们在语义预测空间和生成图像空间两方面利用判别器增强特征适配,这两个紧凑空间有助于进一步提升提取特征的域不变性。
• 我们在跨模态心脏结构分割这一挑战性任务上验证了SIFA的有效性。该方法将性能衰减从$17.2%$恢复至$73.0%$,并以显著优势超越现有最优方法。代码已开源:https://github.com/cchen-cc/SIFA。
Related Work
相关工作
Addressing performance degradation of DCNNs under domain shift has been a highly active and fruitful research field in recent investigations of deep learning. A plentiful of adaptive methods have been proposed from different perspectives, including the image-level adaptation, feature-level adaptation and their mixtures. In this section, we overview the progress and state-of-the-art approaches along these streams, with a particular focus on unsupervised domain adaptation in image processing field. Studies on both natural and medical images are covered.
解决深度卷积神经网络 (DCNN) 在域偏移下的性能下降问题,已成为近年来深度学习研究中极其活跃且成果丰硕的领域。研究者们从图像级适配、特征级适配及其混合等不同角度提出了大量自适应方法。本节将综述这些方向的研究进展与前沿技术,特别聚焦图像处理领域的无监督域适应方法,涵盖自然图像与医学图像的相关研究。
With a gratitude to generative adversarial network (Goodfellow et al. 2014), image-level adaptation methods have been developed to tap domain shift at the input level to DCNNs. Some methods first trained a DCNN in source domain, and then transformed the target images into sourcelike ones, such that can be tested using the pre-trained source model (Russo et al. 2017; Zhang et al. 2018b; Chen et al. 2018). Inversely, other methods tried to transform the source images into the appearance of target images (Bousmalis et al. 2017; Shri vast ava et al. 2017; Hoffman et al. 2018). The transformed target-like images are then used to train a task model which could perform well in target domain. This has also been used in medical eye retinal fundus image analysis (Zhao et al. 2018). With the wide success of CycleGAN in unpaired image-to-image transformation, many previous image adaptation works were based on modified CycleGAN with applications in both natural datasets (Russo et al. 2017; Hoffman et al. 2018) and medical image segmentation (Huo et al. 2018; Zhang et al. 2018b; Chen et al. 2018).
得益于生成对抗网络 (Generative Adversarial Network, GAN) (Goodfellow et al. 2014) 的发展,研究者们开发了图像级适应方法来解决深度卷积神经网络 (DCNN) 输入层面的域偏移问题。部分方法先在源域训练DCNN,再将目标图像转换为类源域图像,从而直接使用预训练的源模型进行测试 (Russo et al. 2017; Zhang et al. 2018b; Chen et al. 2018)。相反地,另一些方法尝试将源图像转换为具有目标域外观特征的图像 (Bousmalis et al. 2017; Shrivastava et al. 2017; Hoffman et al. 2018),这些转换后的类目标域图像被用于训练能在目标域表现良好的任务模型。该技术已成功应用于医学眼底视网膜图像分析领域 (Zhao et al. 2018)。随着CycleGAN在非配对图像转换中的广泛应用,许多早期图像适应工作都基于改进版CycleGAN,既应用于自然数据集 (Russo et al. 2017; Hoffman et al. 2018),也用于医学图像分割任务 (Huo et al. 2018; Zhang et al. 2018b; Chen et al. 2018)。
Meanwhile, approaches for feature-level adaptation have also been investigated, aiming to reduce domain shift by extracting domain-invariant features in the DCNNs. Pioneer works tried to minimize the distance between domain statistics, such as the maximum mean distance (Long et al. 2015b) and the layer activation correlation (Sun and Saenko 2016). Later, representative methods of DANN (Ganin et al. 2016) and ADDA (Tzeng et al. 2017) advanced feature adaptation via adversarial learning, by using a discriminator to differentiate the feature space across domains.
与此同时,特征级适应方法也得到研究,旨在通过提取DCNN中的领域不变特征来减少领域偏移。先驱工作尝试最小化领域统计量之间的距离,例如最大均值差异 (Long et al. 2015b) 和层激活相关性 (Sun and Saenko 2016)。随后,DANN (Ganin et al. 2016) 和ADDA (Tzeng et al. 2017) 等代表性方法通过对抗学习推进了特征适应,即使用判别器来区分跨领域的特征空间。
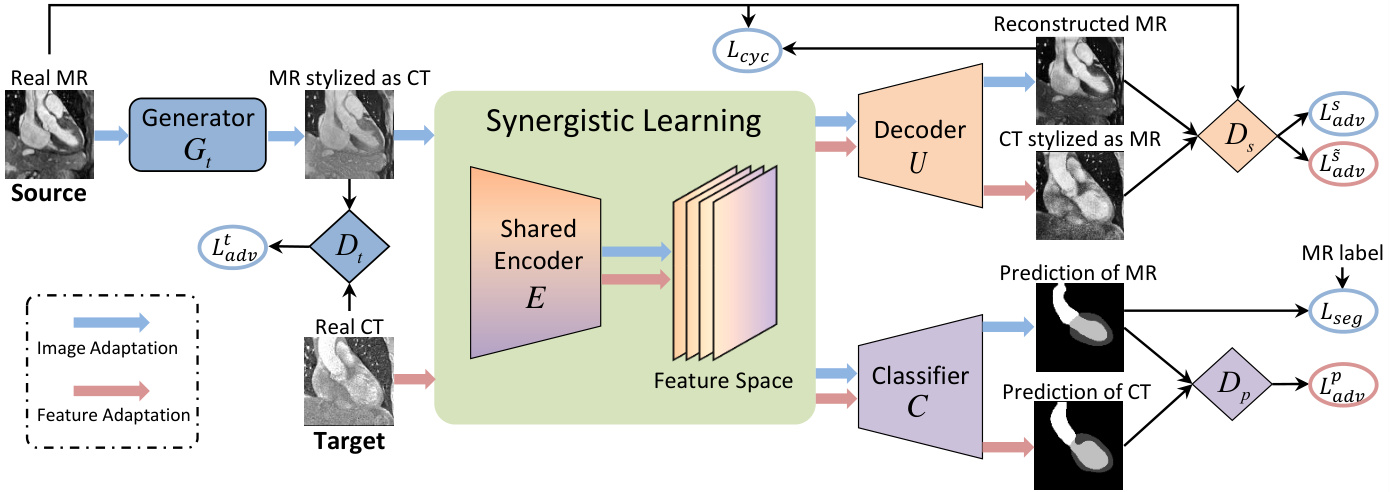
Figure 2: Overview of our unsupervised domain adaptation framework. The generator $G_{t}$ serves the source-to-target image transformation. The encoder $E$ and decoder $U$ form the reverse transformation, where the encoder $E$ is also connected with a classifier $C$ for image segmentation. The disc rim in at or s ${D_{t},D_{s},D_{p}}$ differentiate their inputs accordingly to derive adversarial losses. The blue and red arrows indicate the data flows for the image adaptation and feature adaptation respectively. The reverse cycle-consistency is omitted in this figure for ease of illustration.
图 2: 我们的无监督域适应框架概述。生成器 $G_{t}$ 负责源图像到目标图像的转换。编码器 $E$ 和解码器 $U$ 构成逆向转换,其中编码器 $E$ 还与用于图像分割的分类器 $C$ 相连。判别器 ${D_{t},D_{s},D_{p}}$ 根据输入进行区分以生成对抗损失。蓝色和红色箭头分别表示图像适应和特征适应的数据流。为简化示意图,本图中省略了反向循环一致性。
Effectiveness of this strategy has also been validated in medical applications of segmenting brain lesions (Kamnitsas et al. 2017) and cardiac structures (Dou et al. 2018; Joyce et al. 2018). Recent studies proposed to project the high-dimensional feature space to other compact spaces, such as the semantic prediction space (Tsai et al. 2018) or the image space (Sankara narayan an et al. 2018), and a discriminator operated in the compact spaces to derive adversarial losses for more effective feature alignment.
该策略的有效性已在脑部病变分割 (Kamnitsas et al. 2017) 和心脏结构分割 (Dou et al. 2018; Joyce et al. 2018) 的医学应用中得到验证。近期研究提出将高维特征空间投影到其他紧凑空间,例如语义预测空间 (Tsai et al. 2018) 或图像空间 (Sankara narayan an et al. 2018),通过在紧凑空间中运行的判别器来获取对抗损失,从而实现更有效的特征对齐。
The image and feature adaptations address domain shift from different perspectives to the DCNNs, which are in fact complementary to each other. Combining these two adaptive strategies to achieve a stronger domain adaption technique is under explorable progress. As the state-of-the-art methods for semantic segmentation adaptation methods, the CyCADA (Hoffman et al. 2018) and Zhang et al. (Zhang et al. 2018a) achieved leading performance in adaptation between synthetic to real world driving scene domains. However, their image and feature adaptations are sequentially connected and trained in stages without interactions.
图像和特征适配从不同角度解决了DCNN的领域偏移问题,实际上二者是互补的。目前正在探索将这两种适配策略结合起来以实现更强大的领域适配技术。作为语义分割适配方法的最先进技术,CyCADA (Hoffman et al. 2018) 和 Zhang等人 (Zhang et al. 2018a) 在合成场景到真实驾驶场景的领域适配中取得了领先性能。然而,它们的图像适配和特征适配是顺序连接、分阶段训练的,缺乏交互过程。
Considering the severe domain shift in cross-modality medical images, feature adaptation or image adaptation alone may not be sufficient in this challenging task while the simultaneous adaptations from the two perspectives have not been fully explored yet. To tackle the challenging crossmodality adaptation for segmentation task, we propose to synergistic ally merge the two adaptive processes in a unified network to fully exploit their mutual benefits towards unsupervised domain adaptation.
考虑到跨模态医学图像中严重的领域偏移,仅依赖特征适应或图像适应在这一挑战性任务中可能不足,而同时从这两个角度进行的适应尚未得到充分探索。为解决分割任务中跨模态适应的难题,我们提出在一个统一网络中协同融合这两个适应过程,以充分利用它们在无监督领域适应中的相互优势。
Methods
方法
An overview of our proposed method for unsupervised domain adaptation in medical image segmentation is shown in Fig. 2. We propose synergistic image and feature adaptations with a novel learning diagram to effectively narrow the performance gap due to domain shift. The two perspectives of adaptations are seamlessly integrated into a unified model, and hence, both aspects can mutually benefit each other during the end-to-end training procedure.
图 2 展示了我们提出的医学图像分割无监督域自适应方法概述。我们通过协同图像与特征自适应及新颖的学习框架,有效缩小由域偏移导致的性能差距。这两种自适应视角被无缝整合到统一模型中,从而在端到端训练过程中实现相互促进。
Image Adaptation for Appearance Alignment
图像自适应以实现外观对齐
First, with a set of labeled samples ${x_{i}^{s},y_{i}^{s}}{i=1}^{N}$ from the source domain $X^{s}$ , as well as unlabeled sa mples ${x_{j}^{t}}_{j=1}^{M}$ from the target domain $X^{t}$ , we aim to transform the source images $x^{s}$ towards the appearance of target ones $x^{t}$ , which hold different visual appearance due to domain shift. The obtained transformed image looks as if drawn from the target domain, while the original contents with structural semantics remain unaffected. Briefly speaking, this module narrows the domain shift between the source and target domains by aligning image appearance.
首先,利用源域 $X^{s}$ 中的一组带标签样本 ${x_{i}^{s},y_{i}^{s}}{i=1}^{N}$ 和目标域 $X^{t}$ 中的无标签样本 ${x_{j}^{t}}_{j=1}^{M}$,我们的目标是将源图像 $x^{s}$ 转换为具有目标域 $x^{t}$ 外观的图像。由于域偏移 (domain shift) 的存在,两者视觉表现存在差异。转换后的图像看起来像是来自目标域,同时保持原始内容的结构语义不受影响。简而言之,该模块通过对齐图像外观来缩小源域与目标域之间的域偏移。
In practice, we use generative adversarial networks, which have made a wide success for pixel-to-pixel image transformation, by building a generator $G_{t}$ and a disc rim in at or $D_{t}$ . The generator aims to transform the source images to targetlike ones $G_{t}(x^{s})=x^{s\rightarrow t}$ . The disc rim in at or competes with the generator to correctly differentiate the fake transformed image $x^{s\rightarrow t}$ and the real target image $x^{t}$ . Therefore, in the target domain, the $G_{t}$ and $D_{t}$ form a minimax two-player game and are optimized via the adversarial learning:
在实践中,我们采用生成对抗网络 (Generative Adversarial Networks) 来实现像素到图像的转换,该方法已取得广泛成功。具体而言,我们构建生成器 $G_{t}$ 和判别器 $D_{t}$ 。生成器的目标是将源图像转换为目标域风格的图像 $G_{t}(x^{s})=x^{s\rightarrow t}$ ,而判别器则与生成器对抗,试图准确区分生成的转换图像 $x^{s\rightarrow t}$ 和真实目标图像 $x^{t}$ 。因此,在目标域中,$G_{t}$ 和 $D_{t}$ 形成了最小化最大化的二人博弈,并通过对抗学习进行优化:
$$
\begin{array}{r l}&{\mathcal{L}{a d\nu}^{t}(G_{t},D_{t})=\mathbb{E}{x^{t}\sim X^{t}}[\log D_{t}(x^{t})]+}\ &{\quad\quad\mathbb{E}{x^{s}\sim X^{s}}[\log(1-D_{t}(G_{t}(x^{s})))],}\end{array}
$$
$$
\begin{array}{r l}&{\mathcal{L}{a d\nu}^{t}(G_{t},D_{t})=\mathbb{E}{x^{t}\sim X^{t}}[\log D_{t}(x^{t})]+}\ &{\quad\quad\mathbb{E}{x^{s}\sim X^{s}}[\log(1-D_{t}(G_{t}(x^{s})))],}\end{array}
$$
where the disc rim in at or tries to maximize this objective to distinguish between $G_{t}(x^{s})=x^{s\rightarrow t}$ and $x^{t}$ , and meanwhile, the generator needs to minimize this objective to transform $x^{s}$ into realistic target-like images.
其中,判别器试图最大化这一目标以区分$G_{t}(x^{s})=x^{s\rightarrow t}$和$x^{t}$,同时生成器需要最小化该目标以将$x^{s}$转换为逼真的目标域图像。
To preserve original contents in the transformed images, a reverse generator is usually used to impose the cycle consistency (Zhu et al. 2017). As shown in Fig. 2, the encoder
为保留转换图像中的原始内容,通常会使用反向生成器来施加循环一致性 (Zhu et al. 2017) 。如图 2 所示,编码器
$E$ and upsampling decoder $U$ form the reverse target-tosource generator $G_{s}=E\circ U$ to reconstruct the $x^{s\rightarrow\overline{{t}}}$ back to the source domain, and a disc rim in at or $D_{s}$ operates in the source domain. This pair of source ${G_{s},D_{s}}$ are trained in the same manner as ${G_{t},D_{t}}$ with the adversarial loss $\mathcal{L}{a d\nu}^{s}$ . Then the pixel-wise cycle-consistency loss $\mathcal{L}{c\mathrm{v}c}$ is used to encourage $U(E(G_{t}(x^{\bar{s}})))\approx x^{s}$ and $G_{t}(U(E(x^{t})))\approx x^{t}$ for recovering the original image:
$E$ 和上采样解码器 $U$ 构成了逆向目标到源生成器 $G_{s}=E\circ U$,用于将 $x^{s\rightarrow\overline{{t}}}$ 重构回源域,同时判别器 $D_{s}$ 在源域中运作。这对源域组件 ${G_{s},D_{s}}$ 的训练方式与 ${G_{t},D_{t}}$ 相同,采用对抗损失 $\mathcal{L}{a d\nu}^{s}$。随后,像素级循环一致性损失 $\mathcal{L}{c\mathrm{v}c}$ 被用于促使 $U(E(G_{t}(x^{\bar{s}})))\approx x^{s}$ 和 $G_{t}(U(E(x^{t})))\approx x^{t}$,以实现原始图像的重建:
$$
\begin{array}{r}{\mathcal{L}{c y c}(G_{t},E,U)=\mathbb{E}{x^{s}\sim X^{s}}||U(E(G_{t}(x^{s})))-x^{s}||{1}+}\ {\mathbb{E}{x^{t}\sim X^{t}}||G_{t}(U(E(x^{t})))-x^{t}||_{1}.}\end{array}
$$
$$
\begin{array}{r}{\mathcal{L}{c y c}(G_{t},E,U)=\mathbb{E}{x^{s}\sim X^{s}}||U(E(G_{t}(x^{s})))-x^{s}||{1}+}\ {\mathbb{E}{x^{t}\sim X^{t}}||G_{t}(U(E(x^{t})))-x^{t}||_{1}.}\end{array}
$$
With the adversarial loss and cycle-consistency loss, the image adaptation transforms the source images $x^{s}$ into target-like images $x^{s\rightarrow t}$ with semantic contents preserved. Ideally, this pixel-to-pixel transformation could bring $x^{s\rightarrow t}$ into the data distribution of target domain, such that these synthesis images can be used to train a segmentation network for the target domain.
在对抗损失和循环一致性损失的作用下,图像自适应将源图像 $x^{s}$ 转换为具有保留语义内容的目标类图像 $x^{s\rightarrow t}$ 。理想情况下,这种像素到像素的转换能使 $x^{s\rightarrow t}$ 进入目标域的数据分布,从而使这些合成图像可用于训练目标域的分割网络。
Specifically, after extracting features from the adapted image $\bar{x}^{s\rightarrow t}$ , the feature maps $E(x^{s\rightarrow t})$ are forwarded to a classifier $C$ for predicting segmentation masks. In other words, the composition of $E\circ C$ serves as the segmentation network for the target domain. This part is trained using the sample pairs of ${x^{s\rightarrow t},y^{s}}$ by minimizing a hybrid loss $\mathcal{L}_{s e g}$ . Formally, denoting the segmentation prediction for $x^{s\rightarrow t}$ by $\hat{y}^{s\rightarrow t}{=}\bar{C}(E(x^{s\rightarrow\bar{t}}))$ , the segmentation loss is defined as:
具体来说,从适配图像$\bar{x}^{s\rightarrow t}$中提取特征后,特征图$E(x^{s\rightarrow t})$会被送入分类器$C$以预测分割掩码。换言之,$E\circ C$的组合充当目标域的分割网络。这部分训练使用样本对${x^{s\rightarrow t},y^{s}}$,通过最小化混合损失$\mathcal{L}_{s e g}$来实现。形式上,将$x^{s\rightarrow t}$的分割预测记为$\hat{y}^{s\rightarrow t}{=}\bar{C}(E(x^{s\rightarrow\bar{t}}))$,分割损失定义为:
$$
\mathcal{L}_{s e g}(E,C)=H(y^{s},\hat{y}^{s\rightarrow t})+\alpha\cdot D i c e(y^{s},\hat{y}^{s\rightarrow t}),
$$
$$
\mathcal{L}_{s e g}(E,C)=H(y^{s},\hat{y}^{s\rightarrow t})+\alpha\cdot D i c e(y^{s},\hat{y}^{s\rightarrow t}),
$$
where the first term represents cross-entropy loss, the second term is the Dice loss, and $\alpha$ is the trade-off hyper-parameter balancing them. The hybrid loss function is designed to meet the class imbalance in medical image segmentation.
其中第一项代表交叉熵损失,第二项是Dice损失,$\alpha$ 是平衡两者的超参数。该混合损失函数旨在解决医学图像分割中的类别不平衡问题。
Feature Adaptation for Domain Invariance
面向领域不变性的特征自适应
In above image adaptation, training a segmentation network with the transformed target-like images can already get appealing performance on target data. Unfortunately, when domain shift is severe, such as for cross-modality medical images, it is still insufficient to achieve desired domain adaptation results. To this end, we further impose additional discri minato rs to contribute from the perspective of feature adaptation, attempting to bridge the remaining domain gap between the synthesis target images and real target images.
在上述图像适配中,使用转换后的类目标图像训练分割网络已经能在目标数据上获得不错的效果。然而,当域偏移较为严重时(例如跨模态医学图像场景),这种方法仍不足以实现理想的域适配效果。为此,我们进一步引入判别器从特征适配角度进行优化,试图弥合合成目标图像与真实目标图像之间残留的域差异。
To make the extracted features domain-invariant, the most common way is using adversarial learning directly in feature space, such that a disc rim in at or fails to differentiate which features come from which domain. However, a feature space is with high-dimension, and hence difficult to be directly aligned. Instead, we choose to enhance the domaininvariance of feature distributions by using adversarial learning via two compact lower-dimensional spaces. Specifically, we inject adversarial losses via the semantic prediction space and the generated image space.
为了使提取的特征具有领域不变性,最常见的方法是直接在特征空间中使用对抗学习,使得判别器无法区分哪些特征来自哪个领域。然而,特征空间具有高维度,因此难以直接对齐。相反,我们选择通过两个紧凑的低维空间进行对抗学习,以增强特征分布的领域不变性。具体而言,我们通过语义预测空间和生成图像空间注入对抗损失。
As shown in Fig. 2, for prediction of segmentation masks from ${E,C}$ , we construct the disc rim in at or $D_{p}$ to classify the outputs corresponding to $x^{s\rightarrow t}$ or $x^{t}$ . The semantic prediction space represents the information of human-body anatomical structures, which should be consistent across different imaging modalities. If the features extracted from $x^{s\rightarrow t}$ are aligned with that from $x^{t}$ , the disc rim in at or $D_{p}$ would fail in differentiating their corresponding segmentation masks, as the anatomical shapes are consistent. Otherwise, the adversarial gradients are back-propagated to the feature extractor $E$ , so as to minimize the distance between the feature distributions from $x^{s\rightarrow t}$ and $x^{t}$ . The adversarial loss from semantic-level supervision for the feature adaptation is:
如图 2 所示,为了从 ${E,C}$ 预测分割掩码,我们在判别器 $D_{p}$ 中对 $x^{s\rightarrow t}$ 和 $x^{t}$ 的输出进行分类。语义预测空间表征了人体解剖结构信息,这种信息在不同成像模态间应保持一致。如果从 $x^{s\rightarrow t}$ 提取的特征与 $x^{t}$ 的特征对齐,判别器 $D_{p}$ 将无法区分它们对应的分割掩码,因为解剖形状是一致的。否则,对抗梯度会反向传播至特征提取器 $E$ ,从而最小化 $x^{s\rightarrow t}$ 和 $x^{t}$ 特征分布之间的距离。用于特征适配的语义级监督对抗损失为:
$$
\begin{array}{r l}&{\mathcal{L}{a d\nu}^{p}(E,C,D_{p})=\mathbb{E}{x^{s}\sim t\sim X^{s\rightarrow t}}[\log D_{p}(C(E(x^{s\rightarrow t})))]+}\ &{\qquad\mathbb{E}{x^{t}\sim X^{t}}[\log(1-D_{p}(C(E(x^{t}))))].}\end{array}
$$
$$
\begin{array}{r l}&{\mathcal{L}{a d\nu}^{p}(E,C,D_{p})=\mathbb{E}{x^{s}\sim t\sim X^{s\rightarrow t}}[\log D_{p}(C(E(x^{s\rightarrow t})))]+}\ &{\qquad\mathbb{E}{x^{t}\sim X^{t}}[\log(1-D_{p}(C(E(x^{t}))))].}\end{array}
$$
For generated source-like images from ${E,U}$ , we add an auxiliary task to the source disc rim in at or $D_{s}$ to differentiate whether the generated images are transformed from real target images $x^{t}$ or reconstructed from $x^{s\rightarrow t}$ . If the discriminator $D_{s}$ succeeded in classifying the domain of generated images, it means that the extracted features still contain domain characteristics. To make the features domain-invariant, the following adversarial loss is employed to supervise the feature extraction process:
对于从 ${E,U}$ 生成的类源图像,我们在源判别器 $D_{s}$ 上添加了一个辅助任务,用于区分生成的图像是由真实目标图像 $x^{t}$ 转换而来,还是从 $x^{s\rightarrow t}$ 重建而来。如果判别器 $D_{s}$ 成功分类生成图像的域,则表明提取的特征仍包含域特性。为了使特征具有域不变性,采用以下对抗损失来监督特征提取过程:
$$
\begin{array}{r l}&{\mathcal{L}{a d\nu}^{\tilde{s}}(E,D_{s})=\mathbb{E}{x^{s\rightarrow t}\sim X^{s\rightarrow t}}[\log D_{s}(U(E(x^{s\rightarrow t})))]+}\ &{\qquad\mathbb{E}{x^{t}\sim X^{t}}[\log(1-D_{s}(U(E(x^{t}))))].}\end{array}
$$
$$
\begin{array}{r l}&{\mathcal{L}{a d\nu}^{\tilde{s}}(E,D_{s})=\mathbb{E}{x^{s\rightarrow t}\sim X^{s\rightarrow t}}[\log D_{s}(U(E(x^{s\rightarrow t})))]+}\ &{\qquad\mathbb{E}{x^{t}\sim X^{t}}[\log(1-D_{s}(U(E(x^{t}))))].}\end{array}
$$
It is noted that the $E$ is encouraged to extract features with domain-invariance by connecting disc rim in at or from two aspects, i.e., segmentation predictions (high-level semantics) and generated source-like images (low-level appearance). By adversarial learning from these lower-dimensional compact spaces, the domain gap between synthesis target images xs→t a nd real target images $x^{t}$ can be effectively addressed.
值得注意的是,$E$ 被鼓励通过从两个方面(即分割预测(高层语义)和生成的类源图像(低层外观))连接判别器来提取具有域不变性的特征。通过对这些低维紧凑空间进行对抗学习,可以有效解决合成目标图像 $x^{s→t}$ 与真实目标图像 $x^{t}$ 之间的域差距。
Synergistic Learning Diagram
协同学习示意图
Importantly, a key characteristic in our proposed synergistic learning diagram is to share the feature encoder $E$ between both image and feature adaptations. More specifically, the $E$ is optimized with the adversarial loss $\mathcal{L}{a d\nu}^{s}$ and cycleconsistency loss $\mathcal{L}{c y c}$ via the image adaptation perspective. It also collects gradients back-propagated from the discriminators ${D_{p},D_{s}}$ towards feature adaptation. In these regards, the feature encoder is fitted inside a multi-task learning scenario, such that, it is able to present generic and robust represent at ions useful for multiple purposes. In turn, the different tasks bring complementary inductive bias to the encoder parameters, i.e., either emphasizing pixel-wise cyclic reconstruction or focusing on structural semantics. This can also contribute to alleviate the over-fitting problem with limited medical datasets when training such a complicated model.
重要的是,我们提出的协同学习框架的一个关键特征是在图像适应和特征适应之间共享特征编码器 $E$。具体来说,$E$ 通过图像适应视角,利用对抗损失 $\mathcal{L}{a d\nu}^{s}$ 和循环一致性损失 $\mathcal{L}{c y c}$ 进行优化。同时,它还接收来自判别器 ${D_{p},D_{s}}$ 反向传播的梯度以进行特征适应。因此,特征编码器被置于多任务学习场景中,能够生成适用于多种用途的通用且鲁棒的表征。反过来,不同任务为编码器参数带来互补的归纳偏差,即要么强调像素级的循环重建,要么关注结构语义。这也有助于在训练如此复杂的模型时,缓解有限医学数据集带来的过拟合问题。
With the encoder enabling seamless integration of the image and feature adaptations, we can train the unified framework in an end-to-end manner. At each training iteration, all the modules are sequentially updated in the following order: $G_{t}\rightarrow D_{t}\rightarrow E\rightarrow C\rightarrow U\rightarrow D_{s}\rightarrow D_{p}$ . Specifically, The generator $G_{t}$ is updated first to obtain the transformed target-like images. Then the disc rim in at or $D_{t}$ is updated to differentiate the target-like images $x^{s\rightarrow t}$ and the real target images $x^{t}$ . Next, the encoder $E$ is updated for feature extraction from $x^{s\rightarrow t}$ and $x^{t}$ , followed by the updating of classifier $C$ and decoder $U$ to map the extracted features to the segmentation predictions and generated source-like images. Finally, the disc rim in at or $D_{s}$ and $D_{p}$ are updated to classify the domain of their inputs to enhance feature-invariance. The overall objective for our framework is as follows:
借助编码器实现图像与特征适配的无缝集成,我们能够以端到端方式训练统一框架。每个训练迭代中,所有模块按以下顺序依次更新: $G_{t}\rightarrow D_{t}\rightarrow E\rightarrow C\rightarrow U\rightarrow D_{s}\rightarrow D_{p}$ 。具体而言,生成器 $G_{t}$ 首先更新以获取目标域风格转换图像,随后判别器 $D_{t}$ 更新以区分转换图像 $x^{s\rightarrow t}$ 与真实目标图像 $x^{t}$ 。接着编码器 $E$ 更新以从两类图像中提取特征,分类器 $C$ 与解码器 $U$ 相继更新,将特征映射至分割预测结果并生成源域风格图像。最终判别器 $D_{s}$ 和 $D_{p}$ 通过域分类更新以增强特征不变性。框架整体目标函数如下:
$$
\begin{array}{r l}{\mathcal{L}=\mathcal{L}{a d\nu}^{t}(G_{t},D_{t})+\lambda_{a d\nu}^{s}\mathcal{L}{a d\nu}^{s}(E,U,D_{s})+}&{}\ {\lambda_{c y c}\mathcal{L}{c y c}(G_{t},E,U)+\lambda_{s e g}\mathcal{L}{s e g}(E,C)+}&{}\ {\lambda_{a d\nu}^{p}\mathcal{L}{a d\nu}^{p}(E,C,D_{p})+\lambda_{a d\nu}^{\tilde{s}}\mathcal{L}{a d\nu}^{\tilde{s}}(E,D_{s})}\end{array}
$$
$$
\begin{array}{r l}{\mathcal{L}=\mathcal{L}{a d\nu}^{t}(G_{t},D_{t})+\lambda_{a d\nu}^{s}\mathcal{L}{a d\nu}^{s}(E,U,D_{s})+}&{}\ {\lambda_{c y c}\mathcal{L}{c y c}(G_{t},E,U)+\lambda_{s e g}\mathcal{L}{s e g}(E,C)+}&{}\ {\lambda_{a d\nu}^{p}\mathcal{L}{a d\nu}^{p}(E,C,D_{p})+\lambda_{a d\nu}^{\tilde{s}}\mathcal{L}{a d\nu}^{\tilde{s}}(E,D_{s})}\end{array}
$$
where the ${\lambda_{a d\nu}^{s},\lambda_{c y c},\lambda_{s e g},\lambda_{a d\nu}^{p},\lambda_{a d\nu}^{\tilde{s}}}$ are trade-off parameters adjusting the importance of each component.
其中 ${\lambda_{a d\nu}^{s},\lambda_{c y c},\lambda_{s e g},\lambda_{a d\nu}^{p},\lambda_{a d\nu}^{\tilde{s}}}$ 是用于调整各组件重要性的权衡参数。
For training practice, when updating with the adversarial learning losses, we used the Adam optimizer with a learning rate of $\bar{2}\times10^{-4}$ . For segmentation task, the Adam optimizer was parameterized with an initial learning rate of $\mathrm{i\times10^{-3}}$ and a stepped decay rate of 0.9 every 2 epochs.
在训练实践中,使用对抗学习损失进行更新时,我们采用了学习率为 $\bar{2}\times10^{-4}$ 的Adam优化器。对于分割任务,Adam优化器的初始学习率设为 $\mathrm{i\times10^{-3}}$,并采用每2个周期衰减0.9的阶梯式学习率衰减策略。
During the testing procedure, when an image from the target domain arrives, this $x^{t}$ is forwarded into the encoder $E$ , followed by applying the classifier $C$ . In this way, the semantic segmentation result is obtained by $C(E(x^{i}))$ , using the domain adaptation framework which is learned without need of any target domain annotations.
在测试过程中,当目标域图像到达时,这个$x^{t}$会被送入编码器$E$,随后应用分类器$C$。通过这种方式,语义分割结果由$C(E(x^{i}))$获得,使用的域适应框架无需任何目标域标注即可学习。
Network Configurations of the Modules
模块的网络配置
In this section, we describe the detailed network configurations of every module in the proposed framework. Residual connections are widely used to ease the gradients flow inside our complicated model. We also actively borrow the previous successful experiences of training generative adversarial networks, as reported in the references.
在本节中,我们将详细描述所提出框架中每个模块的网络配置。残差连接被广泛用于简化复杂模型内部的梯度流动。我们还积极借鉴了先前训练生成对抗网络 (Generative Adversarial Networks) 的成功经验,具体可参考相关文献。
The layer configuration of the target generator $G_{t}$ follow the practice of CycleGAN (Zhu et al. 2017). It consists of 3 convolutional layers, 9 residual blocks, and 2 deconvolutional layers, finally using one convolutional layer to get the generated images. For the source decoder $U$ , we construct it with 1 convolutional layer, 4 residual blocks, and 3 deconvolutional layers, finally also followed by one convolutional output layer. For all the three disc rim in at or s ${D_{t},D_{s},D_{p}}$ , we follow the configuration of PatchGAN (Isola et al. 2017), by differentiating $70\times70$ patches. The networks consist of 5 convolutional layers with kernels as size of $4{\times}4$ and stride of 2, except for the last two layers, which use convolution stride of 1. The numbers of feature maps are ${64,128,256,512,1}$ for each layer, respectively. At the first four layers, each convolutional layer is followed by an instance normalization and a leaky ReLU parameterized with 0.2.
目标生成器 $G_{t}$ 的层配置遵循CycleGAN (Zhu et al. 2017) 的方案。它包含3个卷积层、9个残差块和2个反卷积层,最后使用一个卷积层生成图像。对于源解码器 $U$,我们采用1个卷积层、4个残差块和3个反卷积层构建,最终同样接一个卷积输出层。所有三个判别器 ${D_{t},D_{s},D_{p}}$ 均采用PatchGAN (Isola et al. 2017) 的配置,通过区分 $70\times70$ 的图像块实现。网络包含5个卷积层,除最后两层外均使用 $4{\times}4$ 核尺寸和步长2,最后两层采用步长1的卷积。各层特征图数量依次为 ${64,128,256,512,1}$。前四层每个卷积层后接实例归一化和斜率为0.2的Leaky ReLU激活函数。
The encoder $E$ uses residual connections and dilated convolutions (dilation rate $=2$ ) to enlarge the size of receptive field while preserving the spatial resolution for dense predictions (Yu et al. 2017). Let ${{\bf C}k,{\bf R}k,{\bf D}k}$ denote a convolutional layer, a residual block and a dilated residual block with $k$ channels, respectively. The $\mathbf{M}$ represents the maxpooling layer with a stride of 2. Our encoder module is deep by stacking layers of ${\mathbf{C1}6,\mathbf{R1}6,\mathbf{M},\mathbf{R3}2,\mathbf{M},2\times\mathbf{R}64,\mathbf{M},2\times$ R128, $4\times{\bf R}256$ , $2\times\mathbf{R}512$ , $2\times\mathrm{D}512$ , $2\times\mathbf{C}512}$ . Each convo- lution operation is connected to a batch normalization layer and ReLU activation. The classifier $C$ is a $1\times1$ convolutional layer followed by an upsampling layer to recover the resolution of segmentation predictions to original image size.
编码器 $E$ 采用残差连接和扩张卷积 (dilation rate $=2$) 来扩大感受野范围,同时保持空间分辨率以实现密集预测 (Yu et al. 2017)。设 ${{\bf C}k,{\bf R}k,{\bf D}k}$ 分别表示具有 $k$ 个通道的卷积层、残差块和扩张残差块。$\mathbf{M}$ 表示步长为2的最大池化层。我们的编码器模块通过堆叠 ${\mathbf{C1}6,\mathbf{R1}6,\mathbf{M},\mathbf{R3}2,\mathbf{M},2\times\mathbf{R}64,\mathbf{M},2\times$ R128, $4\times{\bf R}256$, $2\times\mathbf{R}512$, $2\times\mathrm{D}512$, $2\times\mathbf{C}512}$ 各层实现深度结构。每个卷积操作后都连接批量归一化层和ReLU激活函数。分类器 $C$ 是一个 $1\times1$ 卷积层,后接上采样层以将分割预测的分辨率恢复至原始图像尺寸。
Experimental Results Dataset and Evaluation Metrics
实验结果数据集与评估指标
We validated our proposed unsupervised domain adaptation method on the Multi-Modality Whole Heart Segmentation Challenge 2017 dataset for cardiac segmentation in MR and CT images (Zhuang and Shen 2016). The dataset consists of unpaired $20{\mathrm{MR}}$ and $20\mathrm{CT}$ volumes collected at different clinical sites. The ground truth masks of cardiac structures are provided, including the ascending aorta (AA), the left atrium blood cavity (LAC), the left ventricle blood cavity (LVC), and the myocardium of the left ventricle (MYO). We aim to adapt the segmentation network at the setting of cross-modality learning.
我们在2017年多模态全心脏分割挑战赛数据集上验证了提出的无监督域适应方法 (Zhuang and Shen 2016) ,该数据集用于MR和CT图像的心脏分割。该数据集包含在不同临床站点采集的20组MR和20组CT未配对体积数据,并提供了心脏结构的真实标注掩膜,包括升主动脉 (AA) 、左心房血腔 (LAC) 、左心室血腔 (LVC) 和左心室心肌 (MYO) 。我们的目标是在跨模态学习设置下适配分割网络。
We employed the MR images as the source domain, and the CT images as the target domain. Each modality was randomly split with $80%$ cases for training and $20%$ cases for testing. The ground truth of CT images were used for evaluation only, without being presented to the network during training phase. All the data were normalized as zero mean and unit variance. To train our model, we used the coronal view images slices, which were cropped into the size of $256\times256$ and augmented with rotation, scaling, and affine transformations to reduce over-fitting.
我们采用MR图像作为源域,CT图像作为目标域。每种模态数据按$80%$比例随机划分为训练集,剩余$20%$作为测试集。CT图像的真实标注仅用于评估,在训练阶段不会输入网络。所有数据均进行零均值单位方差归一化处理。训练时使用冠状面图像切片,裁剪为$256×256$尺寸,并通过旋转、缩放及仿射变换进行数据增强以防止过拟合。
For evaluation, we employed two commonly-used metrics to quantitatively evaluate the segmentation performance, which have also been used in previous cross-modality domain adaptation works (Dou et al. 2018; Joyce et al. 2018). One measurement is the Dice coefficient $([%])$ , which calculates the volume overlap between the prediction mask and the ground truth. The other is the average surface distance ASD ([voxel]) to assess the model performance at boundaries and a lower ASD indicates the better segmentation results.
为了评估,我们采用了两个常用指标来定量评估分割性能,这些指标在之前的跨模态域适应工作中也被使用过 (Dou et al. 2018; Joyce et al. 2018)。一个衡量指标是Dice系数 $([%])$,它计算预测掩码与真实标签之间的体积重叠度。另一个是平均表面距离ASD ([voxel]),用于评估模型在边界处的性能,较低的ASD表示更好的分割结果。
Comparison with the State-of-the-art Methods
与最先进方法的对比
We compare our framework with six recent popular unsupervised domain adaptation methods including DANN (Ganin et al. 2016), ADDA (Tzeng et al. 2017), CycleGAN (Zhu et al. 2017), CyCADA (Hoffman et al. 2018), Dou et al. (Dou et al. 2018), and Joyce et al. (Joyce et al. 2018). Among them, The first four are proposed for natural datasets, and we either used public available code or re-implemented them for our cardiac segmentation dataset. The DANN and ADDA employ only feature adaptation, the CycleGAN adapts image appearance, and the CyCADA conducts both image and feature adaptations. The last two methods are dedicated to adapt MR/CT cardiac segmentation networks in feature level using the same cross-modality dataset as ours, therefore, for which we directly reference the results from their papers. We also obtain the ”W/o adaptation” lower bound by directly applying the model learned in MR source domain to test target CT images without using any domain adaptation method.
我们将本框架与六种近期流行的无监督域适应方法进行比较,包括 DANN (Ganin et al. 2016)、ADDA (Tzeng et al. 2017)、CycleGAN (Zhu et al. 2017)、CyCADA (Hoffman et al. 2018)、Dou et al. (Dou et al. 2018) 和 Joyce et al. (Joyce et al. 2018)。其中前四种方法针对自然数据集提出,我们使用公开代码或针对心脏分割数据集重新实现了它们。DANN 和 ADDA 仅进行特征适应,CycleGAN 适应图像外观,CyCADA 同时进行图像和特征适应。后两种方法专门用于在特征级别适配 MR/CT 心脏分割网络,使用与我们相同的跨模态数据集,因此我们直接引用其论文中的结果。我们还通过直接将 MR 源域学习到的模型应用于测试目标 CT 图像(不使用任何域适应方法)获得了"无适应"下限。
Table 1 reports the comparison results, where we can see that our method significantly increased the segmentation performance over the ”W/o adaptation” lower bound and outperformed previous methods by a large margin in terms of both Dice and ASD. Without domain adaptation, the model only obtained the average Dice of $17.2%$ over the four cardiac structures, demonstrating the severe domain shift between MR and CT images. Remarkably, with our SIFA network, the average Dice was recovered to $73.0%$ and the average ASD was reduced to 8.1. We achieved over $80%$ Dice score for the AA structure and over $70%$ Dice score for the LAC and LVC. Notably, compared with CyCADA, which also conducts both image and feature adaptations, our method achieved superior performance especially for the LVC and MYO structures, which have limited contrast in CT images. This demonstrates the effectiveness of our synergistic learning diagram, which unleashes the benefits from mutual conduction of image and feature alignments.
表 1: 报告了对比结果,从中可以看出我们的方法显著提升了分割性能,远超"无自适应"的基线水平,并在Dice和ASD指标上大幅领先先前方法。未进行域适应时,模型在四个心脏结构上的平均Dice仅为$17.2%$,这表明MR与CT图像间存在严重的域偏移。值得注意的是,通过我们的SIFA网络,平均Dice恢复至$73.0%$,平均ASD降至8.1。我们在AA结构上获得了超过$80%$的Dice分数,在LAC和LVC结构上超过$70%$。特别地,与同样执行图像和特征双重适应的CyCADA相比,我们的方法在CT图像对比度有限的LVC和MYO结构上表现尤为突出。这证明了我们协同学习框架的有效性,该框架充分释放了图像对齐与特征对齐相互传导的优势。

Figure 3: Visual comparison of segmentation results produced by different methods. From left to right are the raw CT images (1st column), ”W/o Adaptation” lower bound (2nd column), results of other unsupervised domain adaptation methods (3rd-6th column), results of our SIFA network (7th column), and ground truth (last column). The cardiac structures of AA, LAC, LVC, and MYO are indicated in blue, red, purple, and yellow color respectively. Each row corresponds to one example.
图 3: 不同方法分割结果的视觉对比。从左至右依次为原始CT图像(第1列)、"无适应"下限(第2列)、其他无监督域适应方法的结果(第3-6列)、我们的SIFA网络结果(第7列)和真实标注(最后一列)。心脏结构AA、LAC、LVC和MYO分别用蓝色、红色、紫色和黄色标示。每行对应一个示例。
Table 1: Performance comparison between our method and other state-of-the-art unsupervised domain adaptation methods for the task of cardiac cross-modality segmentation. We report the Dice and ASD value for each cardiac structure and the average of the four structures. (Note: - means that the results are not reported by that methods and N/A means that the ASD value cannot be calculated due to no prediction for that cardiac structure.)
表 1: 我们的方法与其他最先进的无监督域适应方法在心脏跨模态分割任务上的性能对比。我们报告了每个心脏结构的Dice和ASD值以及四个结构的平均值。(注: -表示该方法未报告结果,N/A表示由于未预测该心脏结构而无法计算ASD值。)
| 方法 | 适应 | Dice | ASD | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 图像特征 | AA | LAC | LVC | MYO | 平均值 | AA | LAC | LVC | MYO | |
| 无适应 | 28.4 | 27.7 | 4.0 | 8.7 | 17.2 | 20.6 | 16.2 | N/A | 48.4 | |
| DANN (Ganin et al.2016) | 39.0 | 45.1 | 28.3 | 25.7 | 34.5 | 16.2 | 9.2 | 12.1 | 10.1 | |
| ADDA (Tzeng et al. 2017) | 47.6 | 60.9 | 11.2 | 29.2 | 37.2 | 13.8 | 10.2 | N/A | 13.4 | |
| CycleGAN(Zhu et al.2017) | 73.8 | 75.7 | 52.3 | 28.7 | 57.6 | 11.5 | 13.6 | 9.2 | 8.8 | |
| CyCADA (Hoffman et al. 2018) | √ | 72.9 | 77.0 | 62.4 | 45.3 | 64.4 | 9.6 | 8.0 | 9.6 | 10.5 |
| Dou et al. (Dou et al.2018) | 74.8 | 51.1 | 57.2 | 47.8 | 57.7 | 27.5 | 20.1 | 29.5 | 31.2 | |
| Joyce et al. (Joyce et al. 2018) | 二 | 66 | 44 | 二 | ||||||
| SIFA (Ours) | 81.1 | 76.4 | 75.7 | 58.7 | 73.0 | 10.6 | 7.4 | 6.7 | 7.8 |
Visual comparison results are further provided in Fig. 3. We can see that without adaptation, the network hardly outputs any correct prediction for the cardiac structures. By using feature adaptation (3rd and 4th columns) or image adaptation (5th column) alone, appreciable recovery in the segmentation prediction masks can be obtained, but the shape of predicted cardiac structures is quite cluttered and noisy. Only the two methods, CyCADA and our SIFA, which leverage both the feature and image adaptations, can generate semantically meaningful prediction for the four cardiac structures. Particularly, our SIFA network outperforms CyCADA especially for the segmentation of LVC and MYO. As can be seen in the last row in Fig. 3, the LVC and MYO structures have very limited intensity contrast with their surrounding tissues, but our method can make good predictions while all the other methods fail in this challenging case.
图 3 进一步提供了视觉对比结果。可以看到,未经自适应调整时,网络几乎无法对心脏结构输出任何正确预测。单独使用特征自适应 (第3-4列) 或图像自适应 (第5列) 时,分割预测掩模能得到明显改善,但预测的心脏结构形状仍存在大量杂乱噪声。只有同时利用特征和图像自适应的 CyCADA 和我们的 SIFA 方法,才能对四个心脏结构生成具有语义意义的预测。特别是我们的 SIFA 网络在 LVC 和 MYO 分割任务上显著优于 CyCADA。如图 3 最后一行所示,LVC 和 MYO 结构与周围组织的灰度对比度极低,但我们的方法仍能做出准确预测,而其他所有方法在这一挑战性案例中均告失败。

Figure 4: Examples of image transformation between MR and CT images.
图 4: MR与CT图像间转换示例。
Table 2: Effectiveness of each key component in SIFA. ”IA” denotes image adaptation; ”FA-P” and ”FA-I” respectively denote the feature adaptation in the semantic prediction space and the generated image space.
表 2: SIFA中各组件的有效性。"IA"表示图像适应;"FA-P"和"FA-I"分别表示语义预测空间和生成图像空间中的特征适应。
| 方法 | IA | Cadu | Cadu | 平均Dice值 |
|---|---|---|---|---|
| 无适应 | 17.2 | |||
| + 图像适应 | √ | 58.0 | ||
| + FA-P | √ | √ | 65.7 | |
| + FA-I | √ | √ | 73.0 |
Effectiveness of Key Components
关键组件的有效性
We conduct ablation experiments to evaluate the effectiveness of each key component in our proposed synergistic learning framework of image and feature adaptations. The results are presented in Table 2. Our baseline network uses image adaptation only, which is constructed by removing the feature adaptation adversarial loss $\mathcal{L}{a d\nu}^{p}$ and $\mathcal{L}_{a d\nu}^{\tilde{s}}$ when training the network, i.e., removing the data flow of red arrows in Fig. 2. Compared with the ”W/o adaptation” lower bound, our baseline network with pure image adaptation already achieved inspiring increase in segmentation accuracy with average Dice increased to $58.0%$ . This reflects that with image transformation, the source images have been successfully brought closer to the target domain. Fig. 4 shows four examples of image transformation from source to target domain and vice versa. As illustrated in the figure, the appearance of images is successfully adapted across domains while the semantic contents in original images are well-preserved.
我们通过消融实验评估所提出的图像与特征自适应协同学习框架中各关键组件的有效性,结果如表2所示。基准网络仅采用图像自适应,即在训练时移除特征自适应对抗损失$\mathcal{L}{a d\nu}^{p}$和$\mathcal{L}_{a d\nu}^{\tilde{s}}$(对应图2中红色箭头数据流)。相比"无自适应"下限,纯图像自适应的基准网络已实现分割精度显著提升,平均Dice系数增至$58.0%$,表明图像变换成功将源图像拉近至目标域。图4展示了四组源域与目标域双向图像变换的实例,可见图像外观成功跨域适配的同时,原始语义内容得到完整保留。
Next, we combine baseline image adaptation with one aspect of feature adaptation, i.e., adding the adversarial learning in the semantic prediction space, which corresponds to adding the disc rim in at or guided by $\mathcal{L}_{a d\nu}^{p}$ . The increased performance over the image adaptation baseline, from $58.0%$ to $65.7%$ , demonstrates that the image and feature adaptations are complementary to each other and can be jointly conducted to achieve better domain adaptation. Finally, further adding the feature adaptation by aligning generated sourcelike images with Cad, completes our full SIFA network. This leads to further obvious improvement in the average Dice accuracy of segmentation results, indicating that the feature adaptation in these two compact spaces would inject effects from integral aspects to encourage feature invariance.
接下来,我们将基线图像适应与特征适应的一个方面相结合,即在语义预测空间中加入对抗学习,这相当于在 $\mathcal{L}_{a d\nu}^{p}$ 的引导下添加判别器。性能从 $58.0%$ 提升至 $65.7%$,表明图像适应与特征适应互为补充,可联合执行以实现更好的域适应。最后,通过将生成的类源图像与 Cad 对齐,进一步加入特征适应,从而完成完整的 SIFA 网络。这使得分割结果的平均 Dice 准确率得到更显著的提升,表明这两个紧凑空间中的特征适应能从整体层面注入效果以促进特征不变性。

Figure 5: Illustration of effectiveness of each key component in our method: ”IA” denotes our network with image adaptation only; ”IA with FA-P” denotes the combination of image adaptation and the feature adaptation in semantic prediction space; ”SIFA” is our overall framework.
图 5: 本方法各关键组件的有效性示意图: "IA"表示仅采用图像自适应(Image Adaptation)的网络; "IA with FA-P"表示在语义预测空间结合了图像自适应和特征自适应(Feature Adaptation)的方案; "SIFA"是我们的完整框架。
Fig. 5 shows the visual comparison results of our network with different components. We can see that the segmentation results become increasingly accurate as more adaptation components being included. Our baseline network with image adaptation alone can correctly identify the cardiac structures, but the predicted shape is irregular and noisy. Adding the feature adaptation in the two lower-dimensional spaces further encourages the network to capture the proper shape of cardiac structures and produce clear predictions. Overall, our SIFA network synergistic ally merges different adaptation strategies to exploit their complementary contributions to unsupervised domain adaptation.
图 5: 展示了我们网络在不同组件下的视觉对比结果。可以看出,随着更多适应组件的加入,分割结果逐渐变得更加精确。仅使用图像适应的基线网络能够正确识别心脏结构,但预测形状不规则且存在噪声。在较低维度的两个空间中加入特征适应后,网络能更好地捕捉心脏结构的正确形状并生成清晰的预测结果。总体而言,我们的SIFA网络通过协同整合不同适应策略,充分发挥了它们在无监督域适应中的互补优势。
Conclusion
结论
This paper proposes a novel approach SIFA for unsupervised domain adaptation of cross-modality medical image segmentation. Our SIFA network synergistic ally combines the image and feature adaptations to conduct image appearance transformation and domain-invariant feature learning simultaneously. The two adaptive perspectives are guided by the adversarial learning with partial parameter sharing to exploit their mutual benefits for reducing domain shift during the end-to-end training. We validate our method on unpaired MR to CT adaptation for cardiac segmentation by comparing it with various state-of-the-art methods. Experimental results demonstrate the superiority of our network over the others in terms of both the Dice and ASD value. Our method is general and can be easily extended to other segmentation applications of unsupervised domain adaptation.
本文提出了一种名为SIFA的新方法,用于跨模态医学图像分割的无监督域适应。我们的SIFA网络协同结合了图像和特征适应,以同时进行图像外观转换和域不变特征学习。这两个适应视角通过部分参数共享的对抗学习来指导,以利用它们的相互优势,在端到端训练过程中减少域偏移。我们通过将其与各种最先进的方法进行比较,验证了我们的方法在心脏分割的未配对MR到CT适应上的有效性。实验结果表明,我们的网络在Dice和ASD值方面均优于其他方法。我们的方法具有通用性,可以轻松扩展到无监督域适应的其他分割应用中。