Pediatric Wrist Fracture Detection Using Feature Context Excitation Modules in X-ray Images
基于特征上下文激励模块的X射线图像儿童腕部骨折检测
Abstract
摘要
Children often suffer wrist trauma in daily life, while they usually need radiologists to analyze and interpret X-ray images before surgical treatment by surgeons. The development of deep learning has enabled neural networks to serve as computer-assisted diagnosis (CAD) tools to help doctors and experts in medical image diagnostics. Since YOLOv8 model has obtained the satisfactory success in object detection tasks, it has been applied to various fracture detection. This work introduces four variants of Feature Contexts Excitation-YOLOv8 (FCE-YOLOv8) model, each incorporating a different FCE module (i.e., modules of Squeeze-and-Excitation (SE), Global Context (GC), Gather-Excite (GE), and Gaussian Context Transformer (GCT)) to enhance the model performance. Experimental results on GRAZPEDWRI-DX dataset demonstrate that our proposed YOLOv8+GC-M3 model improves the mAP $\ @50$ value from 65.78% to $66.32%$ , outperforming the state-of-the-art (SOTA) model while reducing inference time. Furthermore, our proposed YOLOv8 $^+$ SE-M3 model achieves the highest mAP $@50$ value of $67.07%$ , exceeding the SOTA performance. The implementation of this work is available at https://github.com/RuiyangJu/FCE-YOLOv8.
儿童在日常生活中常遭受手腕创伤,通常需要放射科医生分析解读X光影像后,再由外科医生进行手术治疗。随着深度学习的发展,神经网络可作为计算机辅助诊断(CAD)工具协助医生进行医学影像诊断。由于YOLOv8模型在目标检测任务中表现优异,该模型已被应用于多种骨折检测场景。本研究提出了四种特征上下文激励-YOLOv8(FCE-YOLOv8)模型变体,分别整合了不同的FCE模块(即Squeeze-and-Excitation(SE)、Global Context(GC)、Gather-Excite(GE)和Gaussian Context Transformer(GCT)模块)以提升模型性能。在GRAZPEDWRI-DX数据集上的实验表明,我们提出的YOLOv8+GC-M3模型将mAP$\ @50$值从65.78%提升至$66.32%$,在降低推理时间的同时超越了现有最优(SOTA)模型。此外,我们提出的YOLOv8$^+$SE-M3模型取得了$67.07%$的最高mAP$@50$值,超越了SOTA性能。本工作的实现代码已开源:https://github.com/RuiyangJu/FCE-YOLOv8。
Keywords: deep learning, computer vision, object detection, fracture detection, medical image processing, medical image diagnostics, you only look once (yolo), feature contexts excitation
关键词: 深度学习 (deep learning), 计算机视觉 (computer vision), 目标检测 (object detection), 骨折检测 (fracture detection), 医学图像处理 (medical image processing), 医学图像诊断 (medical image diagnostics), YOLO (you only look once), 特征上下文激励 (feature contexts excitation)
1 Into r duct ion
1 引言
Wrist trauma is common among children [18]. If they are not treated promptly and effectively, such trauma will result in wrist joint deformities, limited joint motion, and chronic pain [1]. In severe cases, an incorrect diagnosis would lead to lifelong complications and inconvenience [15].
手腕创伤在儿童中较为常见 [18]。若未得到及时有效的治疗,此类创伤会导致腕关节畸形、关节活动受限和慢性疼痛 [1]。严重情况下,误诊可能引发终身并发症与不便 [15]。
With the development of deep learning, neural networks are increasingly used as computerassisted diagnosis (CAD) tools to aid doctors and experts in analyzing medical images. Object detection networks can accurately predict fractures and reduce the probability of misdiagnosis. Although two-stage object detection networks obtain the excellent performance, one-stage object detection networks offer faster inference time. With the continued release of You Only Look Once (YOLO) series models, YOLOv8 [11] and YOLOv9 [21] models can perform object detection efficiently on low-computing platforms.
随着深度学习的发展,神经网络越来越多地被用作计算机辅助诊断 (CAD) 工具,帮助医生和专家分析医学图像。目标检测网络可以准确预测骨折并降低误诊概率。尽管两阶段目标检测网络性能优异,但一阶段目标检测网络具有更快的推理速度。随着 You Only Look Once (YOLO) 系列模型的持续发布,YOLOv8 [11] 和 YOLOv9 [21] 模型能够在低算力平台上高效执行目标检测任务。
Since the release of the GRAZPEDWRIDX [16] dataset by the Medical University of Graz, Ju et al. [12] have been the first to deploy YOLOv8 models to predict pediatric wrist fractures. This deployment helped surgeons to interpret fractures in X-ray images, reducing misdiagnosis and providing a better information base for the surgery. Chien et al. [5] developed YOLOv8-AM models by incorporating different attention modules into YOLOv8 [11], which improved the model performance. In addition, Chien et al. [4] applied YOLOv9 to this dataset, achieving the stateof-the-art (SOTA) model performance. However, there remains a great possibility for improving the performance of current SOTA models.
自格拉茨医科大学发布GRAZPEDWRIDX [16]数据集以来,Ju等人[12]率先部署YOLOv8模型预测儿童腕部骨折。该部署帮助外科医生解读X光图像中的骨折情况,减少误诊并为手术提供更好的信息基础。Chien等人[5]通过在YOLOv8 [11]中融入不同注意力模块,开发了YOLOv8-AM模型,从而提升了模型性能。此外,Chien等人[4]将YOLOv9应用于该数据集,实现了最先进(SOTA)的模型性能。然而,当前SOTA模型的性能仍有很大提升空间。
This work proposes FCE-YOLOv8 models, incorporating SE [9], GC [3], GE [8], and GCT [19] modules into YOLOv8, respectively, to enhance the model performance, and the results are shown in Fig. 1. This paper makes the following contributions: 1) Introduces four different FCE modules to YOLOv8 model architecture, demonstrating significant improvements in model performance for pediatric wrist fracture detection. 2) Evaluates the most efficient model architecture method for each variant of the FCE-YOLOv8 models. 3) Our proposed $\mathbf{YOLO}\mathbf{+GC}$ model achieves the second-best performance on mAP $\bf@50$ value on the GRAZPEDWRI-DX public dataset with only a slight increase in inference time.
本研究提出了FCE-YOLOv8模型,分别将SE [9]、GC [3]、GE [8]和GCT [19]模块集成到YOLOv8中以提高模型性能,结果如图1所示。本文的主要贡献包括:1) 在YOLOv8模型架构中引入四种不同的FCE模块,显著提升了儿童腕部骨折检测的模型性能;2) 评估了FCE-YOLOv8各变体模型中最有效的架构方法;3) 我们提出的$\mathbf{YOLO}\mathbf{+GC}$模型在GRAZPEDWRI-DX公开数据集上以仅轻微增加的推理时间,取得了mAP $\bf@50$值的第二优性能。
The rest of this paper is organized as follows: Section 2 reviews previous research on pediatric wrist fracture detection based on YOLO models. Section 3 introduces FCE-YOLOv8 model architectures on three different improved methods, and FCE modules used in this work. Section 4 presents the experiment conducted to evaluate the most efficient model architecture method for FCE-YOLOv8 models, and compares our proposed models with other SOTA models. Section 5 discusses the limitations of this work, particularly the class imbalance in the used dataset. Finally, Section 6 summaries the outcomes of this paper and suggests directions for future work.
本文其余部分结构如下:第2节回顾了基于YOLO模型的儿童腕部骨折检测相关研究。第3节介绍了FCE-YOLOv8模型的三种改进方法架构,以及本工作中使用的FCE模块。第4节展示了为评估FCE-YOLOv8模型最高效架构方法而开展的实验,并将我们提出的模型与其他SOTA模型进行了对比。第5节讨论了本研究的局限性,特别是所用数据集的类别不平衡问题。最后,第6节总结了本文成果并提出了未来研究方向。
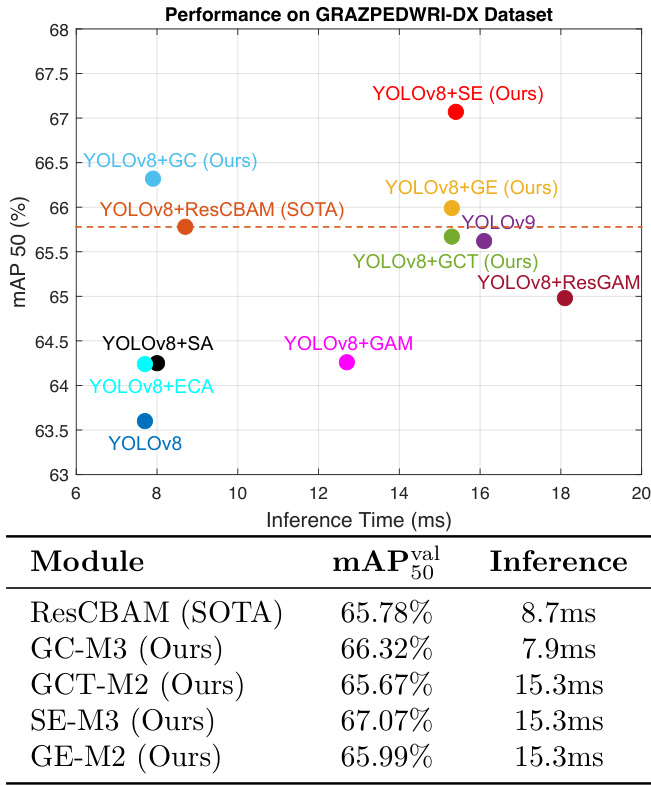
Fig. 1 GRAZPEDWRI-DX Dataset mAP@50 vs. Inference Time. The input image size is 1024; the sizes of YOLOv8 and its improved models are all large (L), and the size of YOLOv9 model is extended (E).
图 1: GRAZPEDWRI-DX数据集mAP@50与推理时间对比。输入图像尺寸为1024;YOLOv8及其改进模型的尺寸均为大(L),YOLOv9模型的尺寸为扩展(E)。
2 Related Work
2 相关工作
Pediatric wrist fracture detection is an important topic in medical image diagnostic tasks. Publicly available datasets [17] for wrist fracture detection in adults are limited, and even fewer datasets [6] for pediatrics. Nagy et al [16] published a pediatric related dataset named the GRAZPEDWRIDX dataset. Hrzic et al. [7] demonstrated that YOLOv4 [2] can enhance the accuracy of pediatric wrist trauma diagnoses in X-ray images. Ju et al. [12] developed an application employing YOLOv8 to assist doctors in interpreting pediatric wrist tramua X-ray images. Chien et al. [5] introduced four attention modules, including Convolutional Block Attention Module (CBAM) [24], Efficient Channel Attention (ECA) [22], Global Attention Mechanism (GAM) [14], and Shuffle Attention (SA) [25] to improve the model performance, where YOLOv8+ResCBAM achieving the SOTA performance on the mAP@50 value. In addition, Chien et al. [4] applied YOLOv9 [21] to this dataset, and achieved excellent performance.
儿童腕部骨折检测是医学影像诊断任务中的重要课题。目前公开的成人腕部骨折检测数据集[17]数量有限,而针对儿童的数据集[6]则更为稀少。Nagy等人[16]发布了一个名为GRAZPEDWRIDX的儿科相关数据集。Hrzic等人[7]证实YOLOv4[2]能提升X光图像中儿童腕部创伤诊断的准确性。Ju等人[12]开发了一款应用YOLOv8辅助医生解读儿童腕部创伤X光图像的应用程序。Chien等人[5]引入了四个注意力模块(包括卷积块注意力模块(CBAM)[24]、高效通道注意力(ECA)[22]、全局注意力机制(GAM)[14]和混洗注意力(SA)[25])以提升模型性能,其中YOLOv8+ResCBAM在mAP@50指标上达到了SOTA性能。此外,Chien等人[4]将YOLOv9[21]应用于该数据集,同样取得了优异表现。
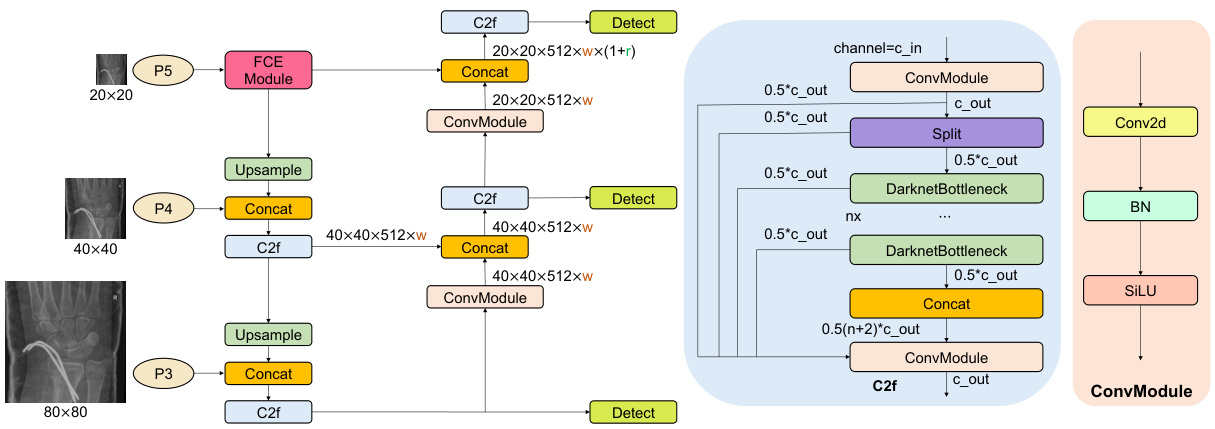
Fig. 2 Network architecture of improved method-1 (M1): adding one FCE module to the Backbone component of YOLOv8.
图 2: 改进方法1 (M1) 的网络架构: 在YOLOv8的Backbone组件中增加一个FCE模块。
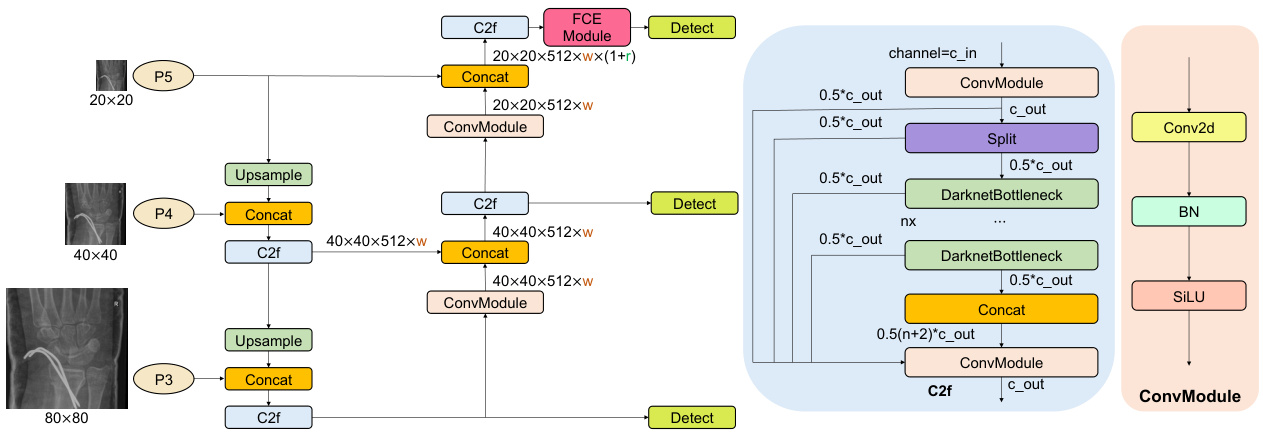
Fig. 3 Network architecture of improved method-2 (M2): adding one FCE module to the Head component of YOLOv8.
图 3: 改进方法-2 (M2) 的网络架构: 在YOLOv8的Head组件中添加一个FCE模块。
3 Proposed Method
3 提出的方法
3.1 Baseline Model
3.1 基线模型
The network architecture of YOLOv8 [11] comprises three components: Backbone, Neck, and Head. The Backbone component employs the Cross Stage Partial (CSP) [20] strategy, which divides the feature map into two parts. One part uses convolution operations, while the other is concatenated with the convolutional output of the first part. In the Neck component, YOLOv8 applies a combination of Feature Pyramid Network (FPN) and Path Aggregation Network (PAN) for multi-scale feature fusion. This component deletes convolution operations during the upsampling stage, allowing the top feature maps to retain more information by utilizing more layers, while minimizing the loss of location information in the bottom feature maps due to fewer convolutional layers.
YOLOv8 [11] 的网络架构由三部分组成:Backbone、Neck 和 Head。Backbone 部分采用跨阶段局部 (Cross Stage Partial, CSP) [20] 策略,将特征图分为两部分。一部分使用卷积运算,另一部分则与第一部分的卷积输出进行拼接。在 Neck 部分,YOLOv8 结合了特征金字塔网络 (Feature Pyramid Network, FPN) 和路径聚合网络 (Path Aggregation Network, PAN) 实现多尺度特征融合。该部分在上采样阶段删除了卷积操作,使得顶层特征图通过更多层保留更多信息,同时减少底层特征图因卷积层较少而导致的位置信息损失。
To enhance global feature extraction and capture comprehensive information from medical images, we have designed three improved methods by incorporating different FCE modules into different components of YOLOv8 network architecture, as illustrated in Figs. 2, 3, and 4, respectively. Specifically, in the improved method 1 (M1), FCE modules (i.e., SE, GC, GE, and GCT) are added after the Spatial Pyramid Pooling - Fast (SPPF) [11] layer in the Backbone component. In the improved method 2 (M2), different FCE modules are integrated into the final C2f [11] module of the Head component. While in the improved method 3 (M3), FCE modules are added after each of the four C2f modules in the Head component.
为增强全局特征提取能力并全面捕捉医学图像信息,我们在YOLOv8网络架构的不同组件中嵌入了多种FCE模块,分别设计了三种改进方法,如图2、图3和图4所示。具体而言,改进方法1 (M1) 在Backbone组件的空间金字塔池化快速层 (SPPF) [11] 后添加了FCE模块 (包括SE、GC、GE和GCT);改进方法2 (M2) 将不同FCE模块集成到Head组件的最后一个C2f [11] 模块中;而改进方法3 (M3) 则在Head组件的四个C2f模块后均添加了FCE模块。
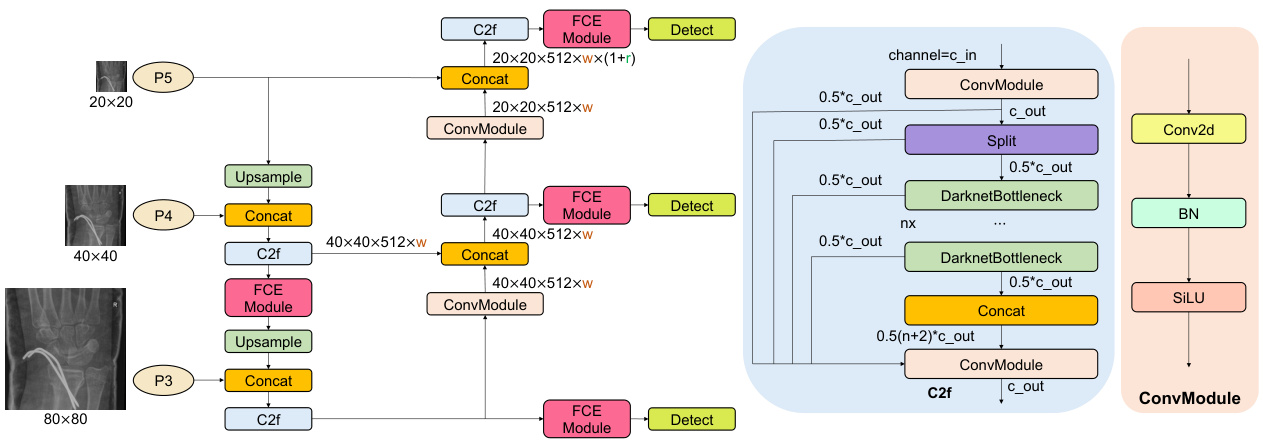
Fig. 4 Network architecture of improved method-3 (M3): adding four FCE modules to the Head component of YOLOv8.
图 4: 改进方法-3 (M3) 的网络架构: 在YOLOv8的Head组件中添加四个FCE模块。
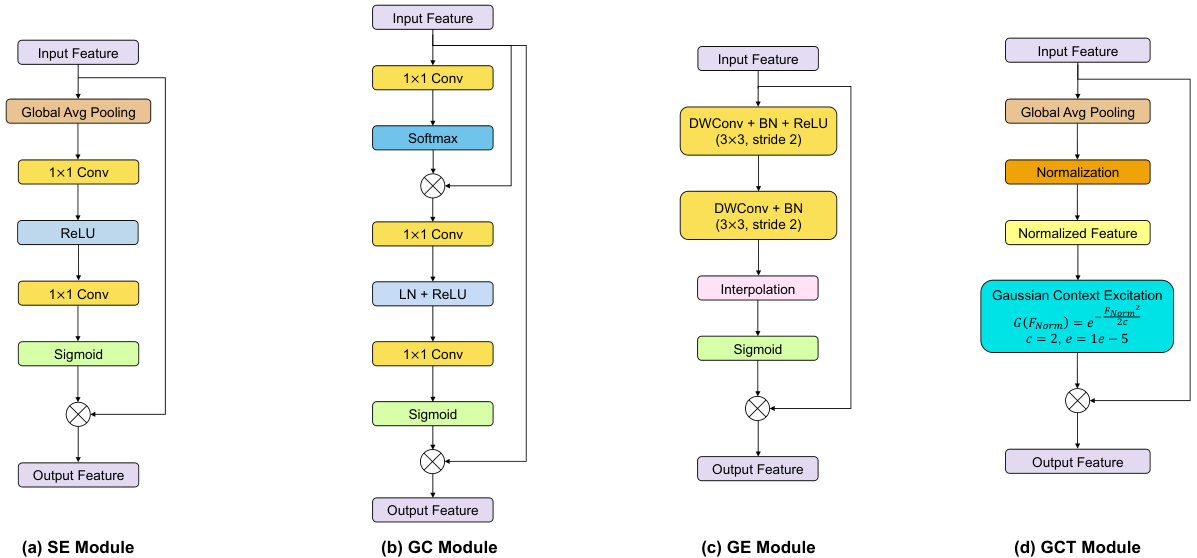
Fig. 5 Diagram of proposed FCE modules: (a) SE module, (b) GC module, (c) GE module, and (d) GCT module.
图 5: 提出的FCE模块示意图: (a) SE模块, (b) GC模块, (c) GE模块, 以及 (d) GCT模块。
3.2 FCE Modules
3.2 FCE模块
SE enhances the representational capacity of neural networks, including YOLOv8, by dynamically adjusting the weights of feature channels based on their importance. This enables YOLOv8 to focus more on relevant channel features while disregarding less significant ones. Specifically, SE employs the “Squeeze” and ”Excitation” operations to enhance the representation of meaningful features, improving both classification and detection performance. In object detection tasks (e.g., fracture detection), integrating SE into YOLOv8 can significantly improve the model performance
SE通过根据特征通道的重要性动态调整其权重,增强了包括YOLOv8在内的神经网络的表征能力。这使得YOLOv8能够更专注于相关通道特征,同时忽略不太重要的特征。具体而言,SE采用“压缩(Squeeze)”和“激励(Excitation)”操作来增强有意义特征的表征,从而提升分类和检测性能。在目标检测任务(如骨折检测)中,将SE集成到YOLOv8中可以显著提高模型性能
GC is highly suitable for fracture detection tasks due to its flexible properties and ease of integration into different neural network architectures, including the YOLOv8 model. This module combines the advantages of the Simplified Non-Local (SNL) [3] block, which effectively models longrange dependencies, and the SE module, known for its computational efficiency. In addition, GC follows the NL [23] block and aggregates the global context across all locations, enabling the capture of long-range dependencies. Furthermore, GC is lightweight and can be applied to multiple layers, enhancing the model ability to capture long-range dependencies with only a slight increase in computational cost.
GC因其灵活的特性以及易于集成到不同神经网络架构(包括YOLOv8模型)的特点,非常适合用于裂缝检测任务。该模块结合了简化非局部 (SNL) [3] 块(能有效建模长程依赖关系)和SE模块(以计算效率著称)的优势。此外,GC遵循NL [23] 块的设计,聚合所有位置的全局上下文,从而能够捕获长程依赖关系。更重要的是,GC是轻量级的,可应用于多个层级,仅以轻微的计算成本增加为代价,就显著提升了模型捕获长程依赖关系的能力。
GE can efficiently aggregate the global context information while maintaining spatial resolution, without significantly increasing the model computational demands. This makes it possible for use in CAD tools on the low-computing-power platform for fracture prediction. By gathering the global context information from the entire feature map, GE captures broader context effectively. In addition, different from other methods [10] that aggregate global context information, GE preserves spatial resolution, which is useful for tasks requiring precise localization, such as fracture detection. Overall, GE can enhance the feature representation capabilities of the network, improving YOLOv8 model performance.
GE能高效聚合全局上下文信息,同时保持空间分辨率,且不会显著增加模型计算需求。这使得它可在低算力平台的CAD工具中用于骨折预测。通过从整个特征图收集全局上下文信息,GE能有效捕捉更广泛的上下文。此外,与其他聚合全局上下文信息的方法[10]不同,GE保留了空间分辨率,这对需要精确定位的任务(如骨折检测)非常有用。总体而言,GE能增强网络的特征表示能力,提升YOLOv8模型性能。
GCT can enhance the ability of YOLOv8 to capture context information by incorporating the Gaussian filter. This integration improves the capacity of the model for data modeling and allows for more effective utilization of training data by weighting both local and global context information. In addition, this module increases the effi- ciency of data utilization, reducing the demands for extensive datasets. Furthermore, by replacing the traditional self-attention mechanism with the Gaussian filter, GCT decreases computational complexity and enhances efficiency, particularly with large-scale data. In general, the Gaussian filter contributes to the model stability during training, mitigating issues such as gradient explosion or vanishing gradients, which results in improved convergence model speed and performance.
GCT通过融入高斯滤波器(Gaussian filter),增强了YOLOv8捕捉上下文信息的能力。这种整合提升了模型的数据建模能力,并通过加权局部和全局上下文信息,更有效地利用训练数据。此外,该模块提高了数据利用效率,降低了对大规模数据集的需求。更重要的是,GCT用高斯滤波器取代传统的自注意力机制(self-attention mechanism),降低了计算复杂度,尤其在大规模数据场景下显著提升了效率。总体而言,高斯滤波器有助于提升模型训练稳定性,缓解梯度爆炸或消失等问题,从而加快模型收敛速度并提升性能。
4 Experiments
4 实验
4.1 Datasets
4.1 数据集
GRAZPEDWRI-DX dataset, introduced by Nagy et al. [16], is a publicly available collection of pediatric wrist trauma X-ray images provided by the Medical University of Graz. This dataset was collected by radiologists at the University Hospital Graz between 2008 and 2018, and includes 20,327 X-ray images. In addition, it covers 6,091 pediatric patients and contains 10,643 studies, with a total of 74,459 image labels and 67,771 annotated objects. Nagy et al. [16] emphasize that prior to the release of their dataset, there are few publicly available relevant pediatric datasets. Therefore, we only used this dataset for our experiments.
GRAZPEDWRI-DX数据集由Nagy等人[16]提出,是由格拉茨医科大学提供的公开儿科腕部创伤X光图像集合。该数据集由格拉茨大学医院的放射科医师在2008年至2018年间收集,包含20,327张X光图像。此外,它涵盖了6,091名儿科患者和10,643项研究,共有74,459个图像标签和67,771个标注对象。Nagy等人[16]强调,在他们的数据集发布之前,公开的相关儿科数据集很少。因此,我们仅使用该数据集进行实验。
4.2 Evaluation Metrics
4.2 评估指标
Fracture detection on pediatric wrist X-ray images belongs to object detection tasks, and six evaluation metrics in object detection tasks are applicable, including the model parameters (Params), floating-point operations (FLOPs), F1- Score, mean average precision at $50%$ intersection over union (mAP@50), mean average pre- cision from $50%$ to $95%$ intersection over union (mAP@50-95), and the inference time per image.
儿童手腕X光图像的骨折检测属于目标检测任务,适用于目标检测任务的六项评估指标,包括模型参数(Params)、浮点运算量(FLOPs)、F1分数、交并比50%时的平均精度(mAP@50)、交并比50%至95%的平均精度(mAP@50-95)以及单张图像推理时间。
Params in the model are determined by the architecture layer count, the number of neurons per layer, and the overall complexity of the model. In general, an increase in Params corresponds to a larger model size. While larger models generally offer better model performance, they also require more computational resources. Therefore, it is important to balance the model size with computational cost in practical applications.
模型中的参数(Params)由架构层数、每层神经元数量及模型整体复杂度决定。通常参数增加意味着更大的模型体积。虽然大模型通常能提供更好的性能,但也需要更多计算资源。因此在实际应用中需权衡模型体积与计算成本。
FLOPs representing floating-point operations, are commonly used to evaluate the computational complexity of the model. This metric serves as an indicator of the computational performance and speed of the models. In general, the models with lower FLOPs are more suitable for resource-limited environments, while the models with higher FLOPs require more powerful hardware support.
FLOPs (floating-point operations) 通常用于评估模型的计算复杂度。这一指标反映了模型的计算性能和速度。一般来说,FLOPs较低的模型更适合资源有限的环境,而FLOPs较高的模型需要更强大的硬件支持。
F1-Score is the harmonic mean of the Precision and Recall of the model, ranging from 0 to 1. The value closer to 1 indicates that the model has achieved a better balance between Precision and Recall. Conversely, if either Precision or Recall is close to 0, F1-Score will also approach 0, signaling poor model performance.
F1分数是模型精确率(Precision)和召回率(Recall)的调和平均数,取值范围为0到1。该值越接近1,表明模型在精确率和召回率之间取得了更好的平衡。反之,如果精确率或召回率接近0,F1分数也会趋近于0,这意味着模型性能较差。
mAP is a widely used metric for evaluating the performance of object detection models. In object detection tasks, the model aims to recognize objects within an image and determines their locations. For each class, the model calculates the area under the Precision-Recall curve, known as average precision (AP), which measures the model detection performance for that specific class. The mAP score is calculated by averaging the AP values across all classes, providing an overall measure of the model detection accuracy.
mAP是评估目标检测模型性能的广泛使用指标。在目标检测任务中,模型旨在识别图像中的物体并确定其位置。对于每个类别,模型会计算精确率-召回率曲线下的面积,称为平均精度(AP),用于衡量模型对该特定类别的检测性能。mAP分数通过对所有类别的AP值取平均计算得出,提供了模型检测准确率的整体衡量标准。
Inference time denotes the time taken by the network model from the input of an X-ray image to the generation of the prediction output, encompassing preprocessing, inference, and post-processing steps. In this work, inference time per image was measured using a single NVIDIA GeForce RTX 3090 GPU.
推理时间指网络模型从输入X射线图像到生成预测输出所需的时间,包括预处理、推理和后处理步骤。本研究中,每张图像的推理时间使用单块NVIDIA GeForce RTX 3090 GPU进行测量。
Table 1 Experimental results of the SE module based on YOLOv8 on the GRAZPEDWRI-DX dataset. 1The input image size is 640. 2The input image size is 1024.
表 1: 基于 YOLOv8 的 SE (Squeeze-and-Excitation) 模块在 GRAZPEDWRI-DX 数据集上的实验结果。1输入图像尺寸为 640。2输入图像尺寸为 1024。
| 模块 | 参数量 | FLOPs | mAP@50 | 推理时间 |
|---|---|---|---|---|
| SE-M1-S | 11.30M | 29.1G | 62.18% | 2.6ms |
| SE-M1-M | 26.12M | 79.8G | 62.35% | 5.1ms |
| SE-M1-L | 43.93M | 166.3G | 62.93% | 7.6ms |
| SE-M2-S | 11.17M | 28.7G | 61.45% | 2.5ms |
| SE-M2-M | 25.90M | 79.1G | 61.75% | 5.0ms |
| SE-M2-L | 43.67M | 165.5G | 64.08% | 8.0ms |
| SE-M3-S | 11.19M | 28.7G | 61.72% | 2.6ms |
| SE-M3-M | 25.95M | 79.2G | 62.63% | 5.0ms |
| SE-M3-L | 43.85M | 165.6G | 62.79% | 7.6ms |
| SE-M1-S | 11.30M | 29.1G | 63.24% | 4.9ms |
| SE-M1-M | 26.12M | 79.8G | 63.70% | 10.1ms |
| SE-M1-L | 43.93M | 166.3G | 64.55% | 15.4ms |
| SE-M2-S | 11.17M | 28.7G | 62.90% | 5.0ms |
| SE-M2-M | 25.90M | 79.1G | 63.68% | 10.0ms |
| SE-M2-L | 43.67M | 165.5G | 64.40% | 14.7ms |
| SE-M3-S | 11.19M | 28.7G | 62.77% | 5.1ms |
| SE-M3-M | 25.95M | 79.2G | 64.10% | 10.0ms |
| SE-M3-L | 43.85M | 165.6G | 67.07% | 15.3ms |
4.3 Data Preparation
4.3 数据准备
To ensure fairness in model performance comparison, the same data is used for all model training. We randomly divide the GRAZPEDWRI-DX [16] dataset into training, validation, and test sets in the ratio of $70%$ , $20%$ , and $10%$ , respectively. Specifically, the training set contains 14,204 images (69.88%); the validation set contains 4,094 images $(20.14%$ ), and the test set contains 2,029 images (9.98%). Furthermore, data augmentation is performed on the training set before all models training. Specifically, this work adjusts the contrast and brightness of the X-ray images using the add Weighted function in the Open Source Computer Vision Library (OpenCV), and expanding the original training dataset from 14,204 images to 28,408 images.
为确保模型性能对比的公平性,所有模型训练均采用相同数据。我们将GRAZPEDWRI-DX [16]数据集按$70%$、$20%$和$10%$的比例随机划分为训练集、验证集和测试集。具体而言,训练集包含14,204张图像(69.88%);验证集包含4,094张图像$(20.14%)$,测试集包含2,029张图像(9.98%)。此外,在所有模型训练前对训练集进行了数据增强。具体而言,本研究使用开源计算机视觉库(OpenCV)中的addWeighted函数调整X光图像的对比度和亮度,将原始训练数据集从14,204张图像扩充至28,408张图像。
4.4 Training
4.4 训练
To ensure a fair comparison of the performance of different models on the GRAZPEDWRI-DX [16] dataset for pediatric wrist fracture detection, the same training environment and hardware (NVIDIA GeForce RTX 3090 GPUs) are used for all models training and evaluation. This work employs Python 3.9 and the PyTorch framework for training all of the models. For the hyperparameters of the model training, we set the batch size to 16 and the number of epochs of 100. In addition, all models are trained using the SGD optimizer, with the weight decay of 0.0005, momentum of 0.937, and the initial learning rate of 0.01.
为确保在GRAZPEDWRI-DX [16] 数据集上公平比较不同模型对儿童手腕骨折检测的性能,所有模型的训练和评估均采用相同的训练环境与硬件 (NVIDIA GeForce RTX 3090 GPU) 。本研究使用Python语言 3.9版本和PyTorch框架训练所有模型。模型训练超参数设置为:批次大小16、训练轮次100。所有模型均采用SGD优化器,权重衰减0.0005,动量0.937,初始学习率0.01。
Table 2 Experimental results of the GC module based on YOLOv8 on the GRAZPEDWRI-DX dataset. 1The input image size is 640. 2The input image size is 1024.
表 2: 基于YOLOv8的GC模块在GRAZPEDWRI-DX数据集上的实验结果。1输入图像尺寸为640。2输入图像尺寸为1024。
| 模块 | 参数量 | 计算量(FLOPs) | mAP@50 | 推理时间 |
|---|---|---|---|---|
| GC-M1-S | 11.34M | 29.1G | 60.68% | 1.7ms |
| GC-M1-M | 26.17M | 79.9G | 63.07% | 2.5ms |
| GC-M1-L | 43.97M | 166.3G | 64.55% | 3.5ms |
| GC-M2-S | 11.21M | 28.7G | 61.30% | 1.9ms |
| GC-M2-M | 25.95M | 79.2G | 62.71% | 2.7ms |
| GC-M2-L | 43.70M | 165.5G | 64.54% | 3.5ms |
| GC-M3-S | 11.24M | 28.7G | 62.19% | 1.9ms |
| GC-M3-M | 26.03M | 79.2G | 62.77% | 2.7ms |
| GC-M3-L | 43.85M | 165.6G | 63.97% | 3.6ms |
| GC-M1-S | 11.34M | 29.1G | 63.24% | 2.9ms |
| GC-M1-M | 26.17M | 79.9G | 63.87% | 5.1ms |
| GC-M1-L | 43.97M | 166.3G | 64.85% | 7.8ms |
| GC-M2-S | 11.21M | 28.7G | 63.51% | 2.8ms |
| GC-M2-M | 25.95M | 79.2G | 65.25% | 5.1ms |
| GC-M2-L | 43.70M | 165.5G | 65.70% | 7.8ms |
| GC-M3-S | 11.24M | 28.7G | 64.16% | 2.8ms |
| GC-M3-M | 26.03M | 79.2G | 64.33% | 5.2ms |
| GC-M3-L | 43.85M | 165.6G | 66.32% | 7.9ms |
4.5 Selection of Improved Methods
4.5 改进方法的选择
This work presents three different methods for improving model architecture, resulting in FCEYOLOv8 models. Given four proposed FCE modules (i.e., SE, GC, GE, and GCT), we conduct the experiment to determine the most suitable improved method for each module. The experimental results are shown in Tables 1, 2, 3, and 4. As described in Section 3.1, we apply three methods (i.e., M1, M2, and M3) to train FCE-YOLOv8with SE, GC, GE, and GCT modules, respectively. Apart from the parameters of module, model size, and input image size, all other settings remain the same for all models.
本研究提出了三种改进模型架构的方法,最终形成FCEYOLOv8模型系列。针对四种提出的FCE模块(即SE、GC、GE和GCT),我们通过实验确定各模块最适合的改进方法。实验结果如表1、表2、表3和表4所示。如第3.1节所述,我们采用三种方法(即M1、M2和M3)分别训练搭载SE、GC、GE和GCT模块的FCE-YOLOv8模型。除模块参数、模型规模和输入图像尺寸外,所有模型的其余设置均保持一致。
Table 1 presents the experimental results for YOLOv8 $^+$ SE. It can be seen that for the SE module, when the input image size is 640, choosing M2 to construct the YOLOv8+SE model can get the highest mAP $@$ 50 value of $64.08%$ ; while the input image size is 1024, choosing M3 to construct the YOLOv8+SE model can get the highest mAP@50 value of $67.07%$ . In addition, with the input size of 640, Tables 2, 3, and 4 show that the most suitable method for GC, GE, and GCT modules is all M1. YOLOv8+GC, YOLOv8+GE, and YOLOv8 $^+$ GCT with M1 achieve the highest mAP@50 values of $64.55%$ , $64.15%$ , and $63.70%$ , respectively. However, when the input size is set to 1024, the most effective method for YOLOv8 $^+$ GC is M3, resulting in the mAP@50 value of $66.32%$ . For both YOLOv8+GE and YOLOv8+GCT, M2 is the most effective, obtaining the mAP@50 values of $65.99%$ and 65.67%, respectively. Since the input image size is set to 1024 for comparisons with the SOTA models, as shown in Section 4.6, we select M3, M3, M2, and M2 for SE, GC, GE, and GCT, respectively.
表1展示了YOLOv8 $^+$ SE的实验结果。可以看出,对于SE模块,当输入图像尺寸为640时,选择M2构建YOLOv8+SE模型可获得最高mAP $@$ 50值 $64.08%$;而输入图像尺寸为1024时,选择M3构建YOLOv8+SE模型可获得最高mAP@50值 $67.07%$。此外,在输入尺寸为640的情况下,表2、表3和表4显示GC、GE和GCT模块最适合的方法均为M1。采用M1的YOLOv8+GC、YOLOv8+GE和YOLOv8 $^+$ GCT分别实现了 $64.55%$、$64.15%$ 和 $63.70%$ 的最高mAP@50值。然而,当输入尺寸设为1024时,YOLOv8 $^+$ GC最有效的方法是M3,其mAP@50值为 $66.32%$;对于YOLOv8+GE和YOLOv8+GCT,最有效的方法均为M2,分别获得 $65.99%$ 和65.67%的mAP@50值。由于在4.6节与SOTA模型对比时设定输入图像尺寸为1024,我们最终分别为SE、GC、GE和GCT模块选择了M3、M3、M2和M2方案。
Table 3 Experimental results of the GE module based on YOLOv8 on the GRAZPEDWRI-DX dataset. 1The input image size is 640. 2The input image size is 1024.
表 3: 基于YOLOv8的GE模块在GRAZPEDWRI-DX数据集上的实验结果。1输入图像尺寸为640。2输入图像尺寸为1024。
| 模块 | 参数量 | 计算量 | mAPyal 50 | 推理时间 |
|---|---|---|---|---|
| GE-M1-S | 11.28M | 29.1G | 62.44% | 2.6ms |
| GE-M1-M | 26.10M | 79.8G | 63.00% | 5.1ms |
| GE-M1-L | 43.91M | 166.3G | 64.15% | 7.6ms |
| GE-M2-S | 11.15M | 28.7G | 62.07% | 2.6ms |
| GE-M2-M | 25.87M | 79.1G | 63.20% | 5.1ms |
| GE-M2-L | 43.65M | 165.4G | 64.02% | 7.6ms |
| GE-M3-S | 11.16M | 28.7G | 61.89% | 2.7ms |
| GE-M3-M | 25.90M | 79.1G | 62.22% | 5.2ms |
| GE-M3-L | 43.68M | 165.5G | 62.42% | 7.7ms |
| GE-M1-S | 11.28M | 29.1G | 63.72% | 5.2ms |
| GE-M1-M | 26.10M | 79.8G | 63.81% | 10.0ms |
| GE-M1-L | 43.91M | 166.3G | 64.34% | 15.4ms |
| GE-M2-S | 11.15M | 28.7G | 62.51% | 5.1ms |
| GE-M2-M | 25.87M | 79.1G | 64.28% | 10.0ms |
| GE-M2-L | 43.65M | 165.4G | 65.99% | 15.3ms |
| GE-M3-S | 11.16M | 28.7G | 62.42% | 4.8ms |
| GE-M3-M | 25.90M | 79.1G | 62.63% | 10.3ms |
| GE-M3-L | 43.68M | 165.5G | 64.35% | 15.7ms |
Table 4 Experimental results of GCT module based on YOLOv8 on the GRAZPEDWRI-DX dataset. 1The input image size is 640. 2The input image size is 1024.
表 4 基于YOLOv8的GCT模块在GRAZPEDWRI-DX数据集上的实验结果。1输入图像尺寸为640。2输入图像尺寸为1024。
| 模块 | 参数量 | 计算量 | mAPyal 50 | 推理时间 |
|---|---|---|---|---|
| GCT-M1-S1 | 11.27M | 29.1G | 61.91% | 2.7ms |
| GCT-M1-M1 | 26.08M | 79.8G | 62.64% | 5.1ms |
| GCT-M1-L1 | 43.90M | 166.3G | 63.70% | 7.6ms |
| GCT-M2-S1 | 11.14M | 28.7G | 61.36% | 2.6ms |
| GCT-M2-M1 | 25.86M | 79.1G | 62.19% | 5.1ms |
| GCT-M2-L1 | 43.64M | 165.4G | 63.42% | 7.6ms |
| GCT-M3-S1 | 11.14M | 28.7G | 52.07% | 2.7ms |
| GCT-M3-M1 | 25.86M | 79.1G | 53.60% | 5.2ms |
| GCT-M3-L1 | 43.64M | 165.4G | 57.88% | 7.6ms |
| GCT-M1-S2 | 11.27M | 29.1G | 62.49% | 5.1ms |
| GCT-M1-M2 | 26.08M | 79.8G | 63.47% | 10.1ms |
| GCT-M1-L2 | 43.90M | 166.3G | 63.87% | 15.3ms |
| GCT-M2-S2 | 11.14M | 28.7G | 63.51% | 5.0ms |
| GCT-M2-M2 | 25.86M | 79.1G | 64.46% | 10.1ms |
| GCT-M2-L2 | 43.64M | 165.4G | 65.67% | 15.3ms |
| GCT-M3-S2 | 11.14M | 28.7G | 52.53% | 5.1ms |
| GCT-M3-M2 | 25.86M | 79.1G | 53.70% | 10.1ms |
| GCT-M3-L2 | 43.64M | 165.4G | 58.15% | 15.7ms |
satisfactory performance. Specifically, our proposed YOLOv8+GC-M3 and YOLOv8+SE-M3 models achieve the same F1-Score as YOLOv9, which is 0.66, reaching the SOTA level. In addition, the mAP@50 value of our proposed YOLOv8+SE-M3 model obtains the highest value of $67.07%$ , surpassing $65.78%$ of the previous SOTA model, YOLOv8+ResCBAM. Furthermore, our YOLOv8+GC-M3 model achieves the second-highest mAP@50 value of $66.32%$ . Based on this, the inference time of our YOLOv8+GCM3 model is significantly shorter at 7.9 ms, compared to 8.7 ms of YOLOv8 $^+$ ResCBAM and 16.1 ms of YOLOv9. For the model parameters and FLOPs, our proposed FCE-YOLOv8 models are also more efficient than the previous SOTA model. These experimental results demonstrate the positive effect of adding FCE modules to YOLOv8 on the model performance.
性能表现良好。具体而言,我们提出的YOLOv8+GC-M3和YOLOv8+SE-M3模型取得了与YOLOv9相同的F1分数(0.66),达到SOTA水平。此外,YOLOv8+SE-M3模型的mAP@50值达到最高值$67.07%$,超越了此前SOTA模型YOLOv8+ResCBAM的$65.78%$。而YOLOv8+GC-M3模型则以$66.32%$的mAP@50值位居第二。值得注意的是,YOLOv8+GC-M3模型的推理时间显著缩短至7.9毫秒,优于YOLOv8$^+$ResCBAM的8.7毫秒和YOLOv9的16.1毫秒。在参数量和FLOPs方面,我们提出的FCE-YOLOv8模型也比之前的SOTA模型更高效。这些实验结果证明了在YOLOv8中添加FCE模块对模型性能的积极影响。
4.6 Comparison with SOTA Models
4.6 与SOTA模型的对比
For a comparative analysis with other SOTA models, this work sets the input image size to 1024 and configures all YOLOv8 models to large (L) and YOLOv9 to extended (E). The experimental results in Table 5 demonstrate that the proposed FCE-YOLOv8 models achieve
为了与其他SOTA模型进行对比分析,本研究将输入图像尺寸设置为1024,并将所有YOLOv8模型配置为大型(L),YOLOv9配置为扩展型(E)。表5的实验结果表明,所提出的FCE-YOLOv8模型实现了
Fig. 6 presents the Precision-Recall Curve of our proposed FCE-YOLOv8 and other SOTA models for each class. According to Fig. 6, all models have good abilities to correctly detect the “fracture”, “metal”, and “text” classes, with the accuracy all above 90%. However, the poor ability of these models to detect the “bone anomaly” class seriously affects the mAP@50 values of the models. The proposed FCE-YOLOv8 models detect the “bone anomaly” class with the highest accuracy of $16.1%$ , compared to $15.0%$ of YOLOv8 $^+$ ResCBAM, and $11.3%$ of $\mathrm{YOLOv9}$ . Details of this issue and its solution will be presented in Section 5.
图 6 展示了我们提出的 FCE-YOLOv8 与其他 SOTA (state-of-the-art) 模型在各类别上的精确率-召回率曲线。根据图 6,所有模型在检测"骨折"、"金属"和"文本"类别时均表现良好,准确率均超过 90%。然而,这些模型在检测"骨骼异常"类别时的较差表现严重影响了模型的 mAP@50 值。提出的 FCE-YOLOv8 模型检测"骨骼异常"类别的最高准确率为 $16.1%$,而 YOLOv8$^+$ ResCBAM 为 $15.0%$,$\mathrm{YOLOv9}$ 为 $11.3%$。该问题的详细分析及解决方案将在第 5 节中阐述。
Table 5 Quantitative comparison with other models for pediatric wrist fracture detection on the GRAZPEDWRI-DX dataset. The sizes of YOLOv8 and its improved models are all large (L), and the size of YOLOv9 model is extended (E). The best performance and the 2nd best performance are in red and blue colors, respectively.
表 5: 在GRAZPEDWRI-DX数据集上与其他模型进行儿科腕部骨折检测的定量比较。YOLOv8及其改进模型的尺寸均为大(L),YOLOv9模型的尺寸为扩展(E)。最佳性能和次佳性能分别用红色和蓝色标注。
| 模型 | 输入尺寸 | 参数量 | 计算量(FLOPs) | F1分数 | 推理时间 | |
|---|---|---|---|---|---|---|
| YOLOv8 | 1024 | 43.61M | 164.9G | 0.62 | 63.58% | 7.7ms |
| YOLOv8+SA | 1024 | 43.64M | 165.4G | 0.63 | 64.25% | 8.0ms |
| YOLOv8+ECA | 1024 | 43.64M | 165.5G | 0.65 | 64.24% | 7.7ms |
| YOLOv8+GAM | 1024 | 49.29M | 183.5G | 0.65 | 64.26% | 12.7ms |
| YOLOv8+ResGAM | 1024 | 49.29M | 183.5G | 0.64 | 64.98% | 18.1ms |
| YOLOv8+ResCBAM | 1024 | 53.87M | 196.2G | 0.64 | 65.78% | 8.7ms |
| YOLOv9 | 1024 | 69.42M | 244.9G | 0.66 | 65.62% | 16.1ms |
| YOLOv8+GC-M3 | 1024 | 43.85M | 165.6G | 0.66 | 66.32% | 7.9ms |
| YOLOv8+GCT-M2 | 1024 | 43.64M | 165.4G | 0.64 | 65.67% | 15.3ms |
| YOLOv8+SE-M3 | 1024 | 43.85M | 165.6G | 0.66 | 67.07% | 15.3ms |
| YOLOv8+GE-M2 | 1024 | 43.65M | 165.4G | 0.64 | 65.99% | 15.3ms |

Fig. 6 Visualization of the accuracy of predicting each class using our proposed FCE-YOLOv8 models and other SOTA models on the GRAZPEDWRI-DX dataset with the input image size of 1024.
图 6: 在输入图像尺寸为1024的GRAZPEDWRI-DX数据集上,使用我们提出的FCE-YOLOv8模型与其他SOTA模型预测各类别准确率的可视化对比
In a real-world diagnostic scenario, to evalu- ate the accuracy improvement of YOLOv8 models enhanced with FCE modules for pediatric wrist fracture detection, four X-ray images are randomly selected from the used dataset. Fig. 7 presents the predictions of our proposed models and YOLOv8+ResCBAM, as well as the Ground-Truth images. Compared to the previous SOTA model (i.e., YOLOv8 $^+$ ResCBAM), our proposed YOLOv8+GC and YOLOv8+SE models demonstrated greater accuracy in detecting “bone anomalies”, particularly in the first X-ray image on the left side of Fig. 7. This highlights the suitability of our proposed models as CAD tools to assist doctors and experts.
在实际诊断场景中,为评估采用FCE模块增强的YOLOv8模型在儿童腕部骨折检测中的准确率提升效果,我们从数据集中随机选取了四张X光片。图7展示了我们提出的模型与YOLOv8+ResCBAM的预测结果及真实标注图像对比。相较于之前的SOTA模型(即YOLOv8 $^+$ ResCBAM),我们提出的YOLOv8+GC和YOLOv8+SE模型在检测"骨骼异常"方面表现出更高准确度,尤其体现在图7左侧首张X光片的检测结果中。这证明我们提出的模型适合作为辅助医生和专家的CAD工具。

Fig. 7 Examples of prediction results by our proposed models and other SOTA models, and Ground-Truth images of pediatric wrist fracture detection on X-ray Images.
图 7: 我们提出的模型与其他SOTA模型的预测结果示例,以及X光图像上儿童手腕骨折检测的真实图像。
5 Discussion
5 讨论
Although the highest mAP $\mathrm{@50}$ value of the proposed FCE-YOLOv8 models achieve $67.07%$ (surpassing the SOTA level), it falls short of the $70%$ . This limitation is primarily due to the poor performance of the model in predicting the “bone anomaly” and “soft tissue” classes. The GRAZPEDWRI-DX [16] dataset suffers from the class imbalance, for example, compared to 23,722 and 18,090 labels of the “text” and “fracture” classes, there are only 276 and 464 labels of the “bone anomaly” and “soft tissue” classes. The performance of YOLO models mainly depends on the quality and diversity of the training data. The limited training samples for these underrepresented classes result in the poor prediction ability of the model. Therefore, to further improve the model performance, obtaining more data for the “bone anomaly” and “soft tissue” classes is important. Our research team continues to search for additional data, and given the scarcity of pediatricrelated X-ray images, we will immediately apply any newly available datasets to our FCE-YOLOv8 model training.
尽管提出的FCE-YOLOv8模型在mAP $\mathrm{@50}$ 指标上达到了最高值 $67.07%$ (超越SOTA水平) ,但仍未突破 $70%$ 大关。这一局限主要源于模型在"骨骼异常(bone anomaly)"和"软组织(soft tissue)"类别上的预测表现欠佳。GRAZPEDWRI-DX [16] 数据集存在类别不平衡问题,例如相较于"文字(text)"类别的23,722个标注和"骨折(fracture)"类别的18,090个标注,"骨骼异常"和"软组织"类别分别仅有276和464个标注。YOLO模型的性能主要取决于训练数据的质量和多样性,这些少数类别的有限训练样本导致模型预测能力不足。因此,为进一步提升模型表现,获取更多"骨骼异常"和"软组织"类别的数据至关重要。我们的研究团队持续搜寻补充数据,鉴于儿科相关X光影像的稀缺性,我们将第一时间将任何新获取的数据集应用于FCE-YOLOv8模型训练。
6 Conclusion
6 结论
Applying YOLOv8 [12], YOLOv8-AM [5, 13], and YOLOv9 [4] to pediatric wrist fracture detection has led to significant performance improvements on the publicly available GRAZPEDWRIDX dataset [16]. On this dataset, the current SOTA model, YOLOv8 $^+$ ResCBAM-L, obtains the mAP@50 values of 65.78%. However, this model is significantly larger than the original YOLOv8 model in terms of parameters and FLOPs. For example, the original YOLOv8- L model has only 43.61M parameters, while YOLOv8+ResCBAM-L has 53.87M, which is not satisfactory. Therefore, this paper proposes FCEYOLOv8-L to improve the model performance effectively in a lightweight way. The parameters of all the proposed models are only from 43.64M to 43.85M, while the highest mAP $@$ 50 value reaches $67.07%$ , which exceeds the SOTA level.
将YOLOv8 [12]、YOLOv8-AM [5, 13]和YOLOv9 [4]应用于儿童腕部骨折检测后,在公开数据集GRAZPEDWRIDX [16]上取得了显著性能提升。当前最优模型YOLOv8$^+$ResCBAM-L在该数据集上的mAP@50值为65.78%,但其参数量和FLOPs显著大于原始YOLOv8模型(例如原始YOLOv8-L仅43.61M参数,而YOLOv8+ResCBAM-L达53.87M)。为此,本文提出FCEYOLOv8-L模型,通过轻量化方式有效提升性能。所有新模型的参数量仅43.64M至43.85M,最高mAP$@$50值达$67.07%$,超越了现有SOTA水平。
To make this work available as CAD tools for medical image diagnostics, we plan to deploy our proposed FCE-YOLOv8 models as both web application and mobile phone application (e.g., Android and iOS) in the future, ensuring easy accessibility for doctors and experts.
为了使这项成果能作为医疗影像诊断的CAD工具使用,我们计划在未来将提出的FCE-YOLOv8模型部署为网页应用和手机应用 (如Android和iOS) ,确保医生和专家能够便捷访问。
7 Declarations
7 声明
This paper is an expanded paper from International Symposium on Intelligent Signal Processing and Communication Systems (ISPACS) held on December 10-13, 2024 in Kaohsiung, Taiwan.
本文是2024年12月10日至13日在中国台湾高雄举行的智能信号处理与通信系统国际研讨会(ISPACS)的扩展论文。
This work is supported by National Science and Technology Council of Taiwan, under Grant Number: NSTC 112-2221-E-032-037-MY2.
本工作由台湾国家科学及技术委员会资助,资助编号:NSTC 112-2221-E-032-037-MY2。