French Me dMC QA: A French Multiple-Choice Question Answering Dataset for Medical domain
French MedMC QA: 一个面向医学领域的法语多选题问答数据集
Abstract
摘要
This paper introduces French Me dMC QA, the first publicly available Multiple-Choice Question Answering (MCQA) dataset in French for medical domain. It is composed of 3,105 questions taken from real exams of the French medical specialization diploma in pharmacy, mixing single and multiple answers. Each instance of the dataset contains an identifier, a question, five possible answers and their manual correction(s). We also propose first baseline models to automatically process this MCQA task in order to report on the current performances and to highlight the difficulty of the task. A detailed analysis of the results showed that it is necessary to have representations adapted to the medical domain or to the MCQA task: in our case, English specialized models yielded better results than generic French ones, even though French Me dMC QA is in French. Corpus, models and tools are available online.
本文介绍了French Me dMC QA,这是首个公开的法语医学领域多项选择题问答(MCQA)数据集。该数据集包含3,105道取自法国药学专业医学文凭真实考试的题目,混合了单选和多选题型。每个数据实例包含一个标识符、问题、五个备选答案及其人工校正答案。我们还提出了首个基线模型来自动处理这项MCQA任务,以报告当前性能表现并突显该任务的难度。详细的结果分析表明,必须采用适配医学领域或MCQA任务的表征方法:在我们的案例中,即使French Me dMC QA是法语数据集,英语专业模型的表现仍优于通用法语模型。语料库、模型和工具均已在线发布。
1 Introduction
1 引言
Multiple-Choice Question Answering (MCQA) is a natural language processing (NLP) task that consists in correctly answering a set of questions by selecting one (or more) of the given $N$ candidates answers (also called options) while minimizing the number of errors. MCQA is one of the most difficult NLP tasks because it requires more advanced reading comprehension skills and external sources of knowledge to reach decent performance.
多项选择题回答 (Multiple-Choice Question Answering, MCQA) 是一种自然语言处理 (NLP) 任务,其目标是通过从给定的 $N$ 个候选答案 (也称为选项) 中选择一个 (或多个) 正确答案,同时最小化错误数量。MCQA 是最具挑战性的 NLP 任务之一,因为它需要更高级的阅读理解能力和外部知识来源才能达到理想性能。
In MCQA, we can distinguish two types of answers: (1) single and (2) multiple ones. Most datasets focus on single answer questions, such as MCTest (Richardson et al., 2013), ARCchallenge (Clark et al., 2018), OpenBookQA (Mihaylov et al., 2018), QASC (Khot et al., 2019), Social-IQA (Sap et al., 2019), or RACE (Lai et al., 2017). To our knowledge, few studies have been done to construct medical MCQA dataset. We can cite the MedMCQA (Pal et al., 2022) and HEADQA (Vilares and Gómez-Rodríguez, 2019) corpora which contain single answer questions in Spanish and English respectively. For the multiple answer questions, MLEC-QA (Li et al., 2021) provides 136k questions in Chinese covering various biomedical sub-fields, such as clinic, public health and traditional Chinese medicine.
在MCQA(多项选择题问答)中,我们可以区分两种类型的答案:(1) 单项选择 (2) 多项选择。大多数数据集专注于单项选择问题,例如MCTest (Richardson等人,2013)、ARC挑战赛(Clark等人,2018)、OpenBookQA (Mihaylov等人,2018)、QASC (Khot等人,2019)、Social-IQA (Sap等人,2019)或RACE (Lai等人,2017)。据我们所知,目前构建医学MCQA数据集的研究很少。我们可以引用MedMCQA (Pal等人,2022)和HEADQA (Vilares和Gómez-Rodríguez,2019)这两个语料库,它们分别包含西班牙语和英语的单项选择问题。对于多项选择问题,MLEC-QA (Li等人,2021)提供了13.6万个涵盖各种生物医学子领域(如临床、公共卫生和中医)的中文问题。
The French community has recently greatly increased its efforts to collect and distribute medical corpora. Even if no open language model is currently available, we can cite the named entity recognition (Névéol et al., 2014) and information extraction (Grabar et al., 2018) tasks. However, they remain relatively classic, current approaches already reaching a high level of performance.
法国学界近期显著加强了医学语料库的收集与共享工作。尽管目前尚无开源语言模型可用,但值得关注的有命名实体识别 (Névéol et al., 2014) 和信息抽取 (Grabar et al., 2018) 等任务。不过这些仍属于相对传统的研究方向,现有方法已能达到较高性能水平。
In this article, we introduce French Me dMC QA, the first publicly available MCQA corpus in French related to the medical field, and more particularly in the p harm a co logical domain. This dataset contains questions taken from real exams of the French diploma in pharmacy. Among the difficulties related to the task, the questions asked may require a single answer for some and multiple ones for others. We also propose to evaluate state-of-the-art MCQA approaches, including an original evaluation of several word representations across languages.
在本文中,我们介绍了French MedMC QA,这是首个公开的法语医学领域多项选择题问答(MCQA)语料库,尤其聚焦药理学领域。该数据集包含从法国药学文凭真实考试中提取的试题,其难点在于部分题目需要单一答案,而另一些则需要多个答案。我们还评估了最先进的MCQA方法,包括对跨语言词表征的原创性评估。
Main contributions of the paper concern (1) the distribution of an original MCQA dataset in French related to the medical field, (2) a state-of-the-art approach on this task and a first analysis of the results, and (3) an open corpus, including tools and models, all available online.
论文的主要贡献包括:(1) 发布了一个与医学领域相关的法语原创MCQA数据集,(2) 提出了该任务的先进方法并进行了初步结果分析,(3) 开放了一个包含工具和模型的语料库,所有资源均在线可用。
2 The French Me dMC QA Dataset
2 法语 Me dMC QA 数据集
In this section, we detail the French Me dMC QA dataset and discuss data collection and distribution.
在本节中,我们将详细介绍French MedMC QA数据集,并讨论数据收集与分布情况。
2.1 Dataset collection
2.1 数据集收集
The questions and their associated candidate answer(s) were collected from real French pharmacy exams on the remede1 website. This site was built around a community linked to the medical field (medicine, pharmacy, odontology...), offering multiple information (news, job offers, forums...) both for students and also professionals in these sectors of activity. Questions and answers were manually created by medical experts and used during examinations. The dataset is composed of 2,025 questions with multiple answers and 1,080 with a single one, for a total of 3,105 questions. Each instance of the dataset contains an identifier, a question, five options (labeled from A to E) and correct answer(s). The average question length is 14.17 tokens and the average answer length is 6.44 tokens. The vocabulary size is of $13\mathrm{k\Omega}$ words, of which $3.8\mathrm{k}$ are estimated medical domain-specific words (i.e. related to the medical field). We find an average of 2.5 medical domain-specific words in each question ( $17%$ of words in average of a question) and 2.0 in each answer ( $36%$ of words in average of an answer). On average, a targeted medical domainspecific word is present in 2 questions and in 8 answers.
问题和对应的备选答案收集自remede1网站上的真实法国药剂师考试题。该网站围绕医疗领域(医学、药学、牙科学等)的从业者社区建立,为相关行业的学生和专业人士提供多种信息(新闻、招聘启事、论坛等)。所有试题均由医学专家手工编写并用于正式考试。数据集包含2,025道多选题和1,080道单选题,共计3,105道试题。每条数据包含编号、问题、五个选项(标号为A至E)及正确答案。问题平均长度为14.17个token,答案平均长度为6.44个token。词汇表规模为$13\mathrm{k\Omega}$个单词,其中$3.8\mathrm{k}$个属于医学领域专有词汇(即与医疗领域相关)。平均每道问题包含2.5个医学专有词(占问题总词数的$17%$),每个答案含2.0个医学专有词(占答案总词数的$36%$)。平均每个目标医学专有词会出现在2道问题和8个答案中。
2.2 Dataset distribution
2.2 数据集分布
Table 1 presents the proposed French Me dMC QA dataset distribution for the train, development (dev) and test sets detailed per number of answers (i.e. number of correct responses per question). Globally, $70%$ of the questions are kept for the train, $10%$ for validation and last $20%$ for testing.
表 1: 展示了提出的 French Me dMC QA 数据集在训练集、开发集(dev)和测试集上的分布情况,按每个问题的答案数量(即每个问题的正确答案数量)详细划分。总体而言,$70%$的问题用于训练,$10%$用于验证,最后$20%$用于测试。
Table 1: French Me dMC QA dataset distribution.
表 1: 法语 Me dMC QA 数据集分布。
| #Answers | Training | Validation | Test | Total |
|---|---|---|---|---|
| 1 | 595 | 164 | 321 | 1,080 |
| 2 | 528 | 45 | 97 | 670 |
| 3 | 718 | 71 | 141 | 930 |
| 4 | 296 | 30 | 56 | 382 |
| 5 | 34 | 2 | 7 | 43 |
| Total | 2171 | 312 | 622 | 3,105 |
3 Methods
3 方法
The use alone of the question to automatically find the right answer(s) is not sufficient in the context of a MCQA task. State-of-the-art approaches then require external knowledge to improve system performances (Izacard and Grave, 2020; Khashabi et al., 2020). In our case, we decide to build a two-step retriever-reader architecture comparable to UnifiedQA (Khashabi et al., 2020), where the retriever job is to extract knowledge from an external corpus and using it by the reader to predict the correct answers for each question. Figure 1 presents the two-step general pipeline, first step being the retriever module, that extracts external context from the question (see Section 3.1), and second step being the reader, called here question-answering module (see Section 3.2), that automatically selects answer(s) to the targeted question.
在MCQA(多项选择问答)任务中,仅依靠问题本身自动寻找正确答案是不够的。当前最先进的方法需要借助外部知识来提升系统性能 (Izacard和Grave, 2020; Khashabi等, 2020)。本研究采用与UnifiedQA (Khashabi等, 2020)类似的两阶段检索-阅读架构:检索器负责从外部语料库提取知识,阅读器则利用这些知识预测每个问题的正确答案。图1展示了这个两阶段通用流程:第一阶段是检索模块(详见3.1节),从问题中提取外部上下文;第二阶段是问答模块(详见3.2节),自动为目标问题选择答案。
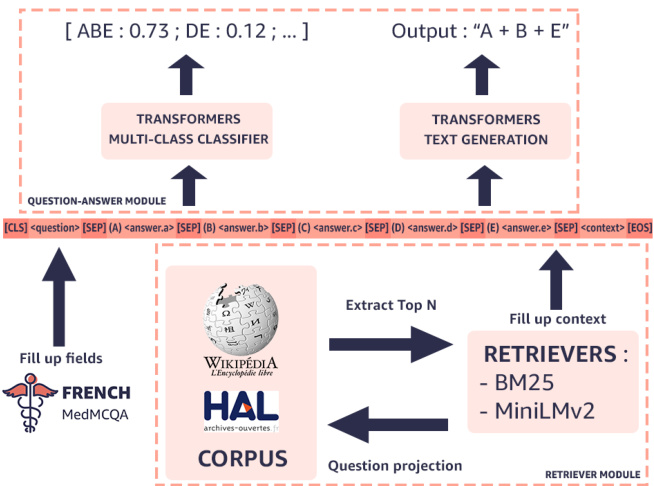
Figure 1: Steps of the pipeline.
图 1: 流程步骤。
3.1 Retriever module
3.1 检索模块
An external medical-related corpus fully composed of French has first been collected from two online sources: Wikipedia life science and HAL, the latter being an open archive run by the French National Centre for Scientific Research (CNRS) where authors can deposit scholarly documents from all academic fields. In our case, we focus on extracting papers and thesis from various specialization, such as Human health and pathology, Cancer ology, Public health and epidemiology, Immunology, Pharmaceutical sciences, Psychiatric disorders and Drugs. This results in 1 million of passages (i.e. a portion of text that contains at least 100 characters) in HAL and $286\mathrm{k}$ passages in Wikipedia.
首先从两个在线来源收集了一个完全由法语组成的外部医学相关语料库:维基百科生命科学和HAL,后者是由法国国家科学研究中心(CNRS)运营的开放存档库,作者可在其中提交来自所有学术领域的学术文献。在本研究中,我们专注于从多个专业领域提取论文和学位论文,例如人类健康与病理学、肿瘤学、公共卫生与流行病学、免疫学、药物科学、精神疾病和药物。最终在HAL中获得100万段文本(即包含至少100个字符的文本片段),在维基百科中获得$286\mathrm{k}$段文本。
This corpus is then used as a context extension for a question. We therefore used a retriever pipeline to automatically assign questions to the most likely passage in the external source. Two retrieval approaches are compared in this article:
随后,该语料库被用作问题的上下文扩展。为此,我们采用了一个检索器管道,自动将问题与外部资源中最相关的段落进行匹配。本文对比了两种检索方法:
• BM25 Okapi (Trotman et al., 2014) for the implementation of the base BM25 algorithm (Robertson and Sparck Jones, 1988). • Sentence Transformers framework (Reimers and Gurevych, 2019) is used to perform semantic search using state-of-the-art language representations taken from Hugging face’s Transformers library (Wolf et al., 2019).
• BM25 Okapi (Trotman et al., 2014) 用于实现基础 BM25 算法 (Robertson and Sparck Jones, 1988)。
• Sentence Transformers 框架 (Reimers and Gurevych, 2019) 用于通过 Hugging Face 的 Transformers 库 (Wolf et al., 2019) 提供的先进语言表征进行语义搜索。
For both approaches, the goal is to embed each passage of the external corpus into a vector space using one of the two representations. On its side, the question is concatenated with the five options (i.e. answers associated to the question) to form a new query embedded in the same vector space. Embeddings from question and passages are finally compared to return the closest passages of a query (here, the cosine similarity is the distance metric). For the Sentence Transformers approach, we used a fast and non domain specific model called MiniLMv2 (Wang et al., 2020). Note that the 1- best passage is only used in these experiments.
对于这两种方法,目标都是使用其中一种表征方式将外部语料库的每个段落嵌入向量空间。在问题端,问题会与五个选项(即与该问题关联的答案)拼接形成新查询,并嵌入同一向量空间。最终通过比较问题和段落的嵌入向量来返回与查询最接近的段落(此处采用余弦相似度作为距离度量指标)。在Sentence Transformers方案中,我们使用了名为MiniLMv2的非领域专用快速模型(Wang et al., 2020)。需要注意的是,本实验仅使用了1-best段落。
3.2 Question-answer module
3.2 问答模块
A goal of our experiments was to compare baseline approaches regarding two different paradigms. The first one is referred to a disc rim i native approach and consists in assigning one of $N$ classes to the input based on their projection in a multidimensional space. We also referred to it as a multi-class task. At the opposite, the second method is a generative one which consists of generating a sequence of tokens, also called free text, based on a sequence of input tokens identical to the one used for the discri mi native approach. The difference with the discri mi native approach lies in the fact that we are not outputting a single class, like ABE for the question $6234176387997480960$ , but a sequence of tokens following the rules of the natural language and referring to a combination of classes like $\mathrm{ \emph~{ A~} }+$ $\mathrm{ \textsf~{ B~} }+\mathrm{ \textsf~{ E~}~}$ in the case of our studied generative model (see Section 3.2.2).
我们实验的一个目标是比较两种不同范式下的基线方法。第一种被称为判别式方法 (discriminative approach) ,其核心是将输入基于其在多维空间中的投影分配到 $N$ 个类别之一。我们也将其称为多分类任务。与之相反,第二种方法是生成式方法 (generative approach) ,它根据与判别式方法相同的输入 token 序列生成一个 token 序列(也称为自由文本)。与判别式方法的区别在于,我们并非输出单一类别(例如问题 $6234176387997480960$ 的答案 ABE),而是输出遵循自然语言规则且指向类别组合的 token 序列,例如在我们研究的生成式模型中会出现 $\mathrm{ \emph~{ A~} }+$ $\mathrm{ \textsf~{ B~} }+\mathrm{ \textsf~{ E~}~}$ 这样的形式(参见第3.2.2节)。
3.2.1 Disc rim i native representations
3.2.1 判别式表征
Four disc rim i native representations are studied in this paper. We firstly propose to use CamemBERT (Martin et al., 2020), a generic French pretrained language model based on RoBERTa (Liu et al., 2019). Since no language representation adapted to the medical domain are publicly available for French, we propose to evaluate the two pre-trained representations BioBERT (Lee et al., 2019) and PubMedBERT (Gu et al., 2022), both trained on English medical data and reaching SOTA results on biomedical NLP tasks, including QA (Pal et al., 2022). Finally, we consider a multilingual generic pre-trained model, XLM-RoBERTa (Conneau et al., 2020) based on RoBERTa, to evaluate the gap in terms of performance with CamemBERT.
本文研究了四种磁盘边缘的本地表示方法。我们首先提出使用CamemBERT (Martin et al., 2020),这是一个基于RoBERTa (Liu et al., 2019)的通用法语预训练语言模型。由于目前没有公开适用于法语医学领域的语言表示模型,我们建议评估两种预训练表示方法:BioBERT (Lee et al., 2019)和PubMedBERT (Gu et al., 2022),这两种模型均在英语医学数据上训练,并在生物医学NLP任务(包括问答系统(QA) (Pal et al., 2022))中达到了最先进(SOTA)水平。最后,我们考虑使用基于RoBERTa的多语言通用预训练模型XLM-RoBERTa (Conneau et al., 2020),以评估其与CamemBERT在性能上的差距。
3.2.2 Generative representation
3.2.2 生成式表征 (Generative representation)
Recently, generative models have demonstrated their interest on several NLP tasks, in particular for text generation and comprehension tasks. Among these approaches, BART (Lewis et al., 2019) is a denoising auto encoder built with a sequence-tosequence model. Due to its bidirectional encoder and left-to-right decoder, it can be considered as generalizing BERT and GPT (Radford et al., 2019), respectively. BART training has two stages: (1) a noising function used to corrupt the input text, and (2) a sequence-to-sequence model learned to reconstruct the original input text. We then propose to evaluate this representation in this paper.
近来,生成式模型在多项自然语言处理任务中展现出独特价值,尤其在文本生成与理解任务中表现突出。其中,BART (Lewis等人,2019) 是一种基于序列到序列模型的去噪自编码器。凭借其双向编码器和自左向右的解码器结构,该模型可视为分别对BERT与GPT (Radford等人,2019) 的泛化延伸。BART的训练包含两个阶段:(1) 使用噪声函数破坏输入文本;(2) 训练序列到序列模型重建原始文本。本文拟对该表征方法进行评估。
4 Experimental protocol
4 实验方案
Each studied disc rim i native and generative model is fine-tuned on the MCQA task with FrenchMedMCQA training data using an input sequence composed of a question, its associated options (i.e. possible answers) and its additional context, all separated with a "[SEP]" token, e.g. [CLS] $<$ question> [SEP] (A) <answer.a> [SEP] (B) <answer.b> [SEP] (C) <answer.c> [SEP] (D) <answer.d> [SEP] (E) <answer.e> [SEP]
每种研究的判别式和生成式模型都在MCQA任务上使用FrenchMedMCQA训练数据进行微调,输入序列由问题、其关联选项(即可能的答案)及其附加上下文组成,各部分用"[SEP]" token分隔,例如:[CLS]
For each question, the context is the text passage with highest confidence rate and can either be obtained using the BM25 algorithm or semantic search as described in Section 3.1.
对于每个问题,上下文是置信度最高的文本段落,可以通过BM25算法或第3.1节所述的语义搜索获取。
Concerning the outputs of the systems, we have for the BART generative model a plain text containing the letter of the answers from $A$ to $E$ separated with plus signs in case of the questions with multiple answers, e.g. $\mathrm{A}+\mathrm{D}+\mathrm{E}$ . For the other architectures (i.e. disc rim i native approaches), we simplify the multi-label problem into a multi-class one by classifying the inputs into one of the 31 existing combinations in the corpus. Here, a class may be a combination of multiple labels, e.g. if the correct answers are the $A$ and $B$ ones, then we consider the correct class being $A B$ , which explains the number of 31 classes.
关于系统的输出,对于BART生成模型,我们得到的是纯文本,包含从$A$到$E$的答案字母,对于多选题则用加号分隔,例如$\mathrm{A}+\mathrm{D}+\mathrm{E}$。对于其他架构(即判别式方法),我们将多标签问题简化为多分类问题,将输入分类为语料库中31种现有组合之一。这里的类别可能是多个标签的组合,例如,如果正确答案是$A$和$B$,则我们认为正确类别是$A B$,这也解释了为何有31个类别。
4.1 Evaluation metrics
4.1 评估指标
The majority of tasks concentrate either on multiclass or binary classification since they have a single class at a time. However, occasionally, we will have a task where each observation has many labels. In this case, we would have different metrics to evaluate the system itself because multi-label prediction has an additional notion of being partially correct. Here, we focused on two metrics called the Hamming score (commonly also multilabel accuracy) and Exact Match Ratio (EMR).
大多数任务集中于多分类或二分类问题,因为它们每次只涉及单一类别。然而,有时我们会遇到每个观测样本带有多个标签的任务。这种情况下,我们需要采用不同的指标来评估系统性能,因为多标签预测存在部分正确的额外概念。本文重点讨论两个指标:汉明分数(通常也称为多标签准确率)和精确匹配率(EMR)。
Table 2: Performance (in $%$ ) on the test set using the Hamming score and EMR metrics.
表 2: 使用汉明分数 (Hamming score) 和 EMR 指标在测试集上的性能 (单位: $%$ )
| 架构 | 汉明 (无上下文) | EMR (无上下文) | 汉明 (Wiki/BM25) | EMR (Wiki/BM25) | 汉明 (HAL/BM25) | EMR (HAL/BM25) | 汉明 (Wiki/MiniLMv2) | EMR (Wiki/MiniLMv2) | 汉明 (HAL/MiniLMv2) | EMR (HAL/MiniLMv2) |
|---|---|---|---|---|---|---|---|---|---|---|
| BioBERTV1.1 | 36.19 | 15.43 | 38.72 | 16.72 | 33.33 | 14.14 | 35.13 | 16.23 | 34.27 | 13.98 |
| PubMedBERT | 33.98 | 14.14 | 34.00 | 13.98 | 35.66 | 15.59 | 33.87 | 14.79 | 35.44 | 14.79 |
| CamemBERT-base | 36.24 | 16.55 | 34.19 | 14.46 | 34.78 | 15.43 | 34.66 | 14.79 | 34.61 | 14.95 |
| XLM-RoBERTa-base | 37.92 | 17.20 | 31.26 | 11.89 | 35.84 | 16.07 | 32.47 | 14.63 | 33.00 | 14.95 |
| BART-base | 31.93 | 15.91 | 34.98 | 18.64 | 33.80 | 17.68 | 29.65 | 12.86 | 34.65 | 18.32 |
4.1.1 Hamming score
4.1.1 汉明分数 (Hamming score)
The accuracy for each instance is defined as the proportion of the predicted correct labels to the total number (predicted and actual) of labels for that instance. Overall accuracy is the average across all instances. It is less ambiguously referred to as the Hamming score rather than Multi-label Accuracy.
每个实例的准确率定义为预测正确标签数与该实例标签总数(预测和实际)的比例。总体准确率是所有实例的平均值。为避免歧义,它更常被称为汉明得分(Hamming score)而非多标签准确率。
4.1.2 Exact Match Ratio (EMR)
4.1.2 精确匹配率 (EMR)
The Exact Match Ratio (EMR) is the percentage of predictions matching exactly the ground truth answers. To be computed, we sum the number of fully correct questions divided by the total number of questions available in the set. A question is considered fully correct when the predictions are exactly equal to the ground truth answers for the question (e.g. all multiple answers should be correct to count as a correct question).
准确匹配率 (EMR) 是指预测结果与标准答案完全一致的百分比。计算方法是将完全正确的问题数量除以问题集中的总问题数。当某个问题的所有预测答案均与标准答案完全一致时 (例如多选题必须全对) ,该问题才被视为完全正确。
5 Results
5 结果
Table 2 compiled the performance (in terms of Hamming score and EMR) of all the studied archi tec ture s and retrievers pipelines. For sake of comparison, the column Without Context has been added, considering that no retriever is used (i.e. no external passage is present in the QA system).
表 2: 汇总了所有研究的架构和检索器管道的性能(以汉明分数和EMR衡量)。为了便于比较,添加了Without Context列,表示未使用任何检索器(即QA系统中不存在外部段落)的情况。
As we can see, the best performing model is different according to the used metric. BioBERT V1.1 reaches best performance using the Hamming score and BART-base in the case of the EMR. These first observations are quite surprising since both models are trained on English data. While we could expect higher performance with French models (CamemBERT for example), the fact that these models are trained on specialized data for one (BioBERT) and on a model designed for the targeted task (SOTA on question-answering for BART) finally shows that language models trained on generic data are inefficient for the MCQA task on medical domain.
我们可以看到,根据所使用的指标,表现最佳的模型各不相同。BioBERT V1.1 在使用汉明分数时表现最佳,而 BART-base 在 EMR 指标下表现最优。这些初步观察结果相当令人意外,因为这两个模型都是在英语数据上训练的。尽管我们可能预期法语模型(例如 CamemBERT)会有更高的性能,但事实表明,一个模型是在专业数据上训练的(BioBERT),另一个则是针对目标任务设计的模型(BART 在问答任务上达到 SOTA),最终证明在通用数据上训练的语言模型对于医疗领域的 MCQA 任务是低效的。
In all considered architectures, context seems to have a small impact on systems performance, with a limited increase or drop depending on the config u rations. Clearly, the RoBERTa performance is much higher without context (i.e. without the use of the retriever part), while models based on BERT generally (8 times on 12) outperform their own baseline performances with external context. The fact that we consider the 1-best passage only may explain this impact.
在所有考虑的架构中,上下文对系统性能的影响似乎较小,具体表现为有限度的提升或下降,这取决于配置情况。显然,RoBERTa在没有上下文(即不使用检索器部分)时表现更好,而基于BERT的模型在12次中有8次借助外部上下文超越了其基线性能。我们仅考虑1-best段落的事实可能解释了这一影响。
Concerning XLM-RoBERTa-base (cross lingual representation), we obtain in the case of the context extracted using BM25 from Wikipedia, the worst Hamming score and EMR out of all the discri mi native approaches. This confirms our first observation that a non-specialized model does not allow to achieve the best performance on this task.
关于XLM-RoBERTa-base(跨语言表示),在使用BM25从维基百科提取上下文的情况下,我们获得了所有判别式方法中最差的汉明分数(Hamming score)和EMR。这证实了我们的第一个观察结果:非专用模型无法在此任务上实现最佳性能。
Using BM25 promotes better context than semantic search using MiniLMv2 on both Wikipedia and HAL for most of the runs. Finally, the source depends of the retriever and model used. A majority of the experiments demonstrate that HAL outperforms Wikipedia on BM25 despite the fact that the best model was obtained using Wikipedia.
在大多数实验中,使用BM25在Wikipedia和HAL上都比使用MiniLMv2进行语义搜索能提供更好的上下文。最终,数据源的选择取决于所使用的检索器和模型。多数实验表明,尽管最佳模型是通过Wikipedia获得的,但HAL在BM25上的表现优于Wikipedia。
The scripts to replicate the experiments as well as the pre-trained models3 are available online.
用于复现实验的脚本以及预训练模型3已在线发布。
6 Conclusion
6 结论
We proposed in this paper French Me dMC QA, an original, open and publicly available MultipleChoice Question Answering (MCQA) dataset in the medical field. This is the first French corpus in this domain, including single and multiple answers to questions. Several state-the art systems have been evaluated to show current performance on the dataset. The analysis of these first results notably highlighted the fact that language models specialized to the medical domain allow us to reach better performance than generic models, even if these have been trained in a different language (here, English biomedical models applied to French).
我们在本文中提出了French MedMC QA,这是一个原创、开放且公开可用的医学领域多选题问答(MCQA)数据集。这是该领域首个法语语料库,包含单答案和多答案问题。我们评估了多种前沿系统以展示当前在该数据集上的性能表现。对这些初步结果的分析特别指出:即使通用模型是在不同语言(此处为应用于法语环境的英语生物医学模型)上训练的,专注于医学领域的语言模型仍能实现更优性能。
In future works, we will focus on improving the existing methods for the task of MCQA, considering other strategies for the retriever module (multiple passages, combining contexts...). Likewise, we will also consider the construction of data representation models for French specialized for medical domain.
在未来的工作中,我们将专注于改进现有方法以应对多项选择问答(MCQA)任务,探索检索模块的其他策略(多段落检索、上下文组合等)。同时,我们也将考虑构建法语医疗领域专用的数据表征模型。
7 Acknowledgments
7 致谢
This work was financially supported by Zenidoc, the DIETS project financed by the Agence Nationale de la Recherche (ANR) under contract ANR-20-CE23-0005 and the ANR AIBy4 (ANR20-THIA-0011). This work was performed using HPC resources from GENCI-IDRIS (Grant 2022- AD011013061R1 and 2022-AD011013715).
本研究由Zenidoc、法国国家研究署 (ANR) 资助的DIETS项目 (合同号ANR-20-CE23-0005) 以及ANR AIBy4项目 (ANR20-THIA-0011) 提供资金支持。计算资源由GENCI-IDRIS高性能计算平台提供 (授权号2022-AD011013061R1和2022-AD011013715)。
References
参考文献
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. 2018. Think you have solved question answering? try arc, the ai2 reasoning challenge. $A r X i\nu$ , abs/1803.05457.
Peter Clark、Isaac Cowhey、Oren Etzioni、Tushar Khot、Ashish Sabharwal、Carissa Schoenick 和 Oyvind Tafjord。2018。自认为已解决问答问题?试试ARC——AI2推理挑战赛。$A r X i\nu$,abs/1803.05457。
Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer, and Veselin Stoyanov. 2020. Unsupervised cross-lingual representation learning at scale. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 8440– 8451, Online. Association for Computational Linguistics.
Alexis Conneau、Kartikay Khandelwal、Naman Goyal、Vishrav Chaudhary、Guillaume Wenzek、Francisco Guzmán、Edouard Grave、Myle Ott、Luke Zettlemoyer 和 Veselin Stoyanov。2020。大规模无监督跨语言表征学习。载于《第58届计算语言学协会年会论文集》,第8440-8451页,线上会议。计算语言学协会。
Natalia Grabar, Vincent Claveau, and Clément Dalloux. 2018. CAS: French corpus with clinical cases. In Proceedings of the Ninth International Workshop on Health Text Mining and Information Analysis, pages 122–128, Brussels, Belgium. Association for Computational Linguistics.
Natalia Grabar、Vincent Claveau和Clément Dalloux。2018. CAS: 法国临床病例语料库。载于《第九届健康文本挖掘与信息分析国际研讨会论文集》,第122-128页,比利时布鲁塞尔。计算语言学协会。
Yu Gu, Robert Tinn, Hao Cheng, Michael Lucas, Naoto Usuyama, Xiaodong Liu, Tristan Naumann, Jianfeng Gao, and Hoifung Poon. 2022. Domainspecific language model pre training for biomedical natural language processing. ACM Transactions on Computing for Healthcare, 3(1):1–23.
Yu Gu、Robert Tinn、Hao Cheng、Michael Lucas、Naoto Usuyama、Xiaodong Liu、Tristan Naumann、Jianfeng Gao 和 Hoifung Poon。2022。面向生物医学自然语言处理的领域专用语言模型预训练。《ACM医疗计算汇刊》3(1):1-23。
Gautier Izacard and Edouard Grave. 2020. Leveraging passage retrieval with generative models for open domain question answering. arXiv preprint arXiv:2007.01282.
Gautier Izacard 和 Edouard Grave. 2020. 利用生成式模型结合段落检索实现开放域问答. arXiv 预印本 arXiv:2007.01282.
Daniel Khashabi, Sewon Min, Tushar Khot, Ashish Sabharwal, Oyvind Tafjord, Peter Clark, and Hannaneh Hajishirzi. 2020. Unifiedqa: Crossing format boundaries with a single qa system.
Daniel Khashabi、Sewon Min、Tushar Khot、Ashish Sabharwal、Oyvind Tafjord、Peter Clark 和 Hannaneh Hajishirzi。2020。UnifiedQA: 跨越格式界限的单一问答系统。
Tushar Khot, Peter Clark, Michal Guerquin, Peter Jansen, and Ashish Sabharwal. 2019. Qasc: A dataset for question answering via sentence composition.
Tushar Khot、Peter Clark、Michal Guerquin、Peter Jansen 和 Ashish Sabharwal。2019. QASC: 一个通过句子组合进行问答的数据集。
Guokun Lai, Qizhe Xie, Hanxiao Liu, Yiming Yang, and Eduard Hovy. 2017. RACE: Large-scale ReAding comprehension dataset from examinations. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 785–794, Copenhagen, Denmark. Association for Computational Linguistics.
Guokun Lai、Qizhe Xie、Hanxiao Liu、Yiming Yang和Eduard Hovy。2017. RACE: 来自考试的大规模阅读理解数据集。载于《2017年自然语言处理实证方法会议论文集》,第785–794页,丹麦哥本哈根。计算语言学协会。
Jinhyuk Lee, Wonjin Yoon, Sungdong Kim, Donghyeon Kim, Sunkyu Kim, Chan Ho So, and Jaewoo Kang. 2019. BioBERT: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics.
Jinhyuk Lee、Wonjin Yoon、Sungdong Kim、Donghyeon Kim、Sunkyu Kim、Chan Ho So 和 Jaewoo Kang。2019. BioBERT: 一种用于生物医学文本挖掘的预训练生物医学语言表示模型。Bioinformatics。
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghaz vi nine j ad, Abdel rahman Mohamed, Omer Levy, Ves Stoyanov, and Luke Z ett le moyer. 2019. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension.
Mike Lewis、Yinhan Liu、Naman Goyal、Marjan Ghazvininejad、Abdelrahman Mohamed、Omer Levy、Ves Stoyanov 和 Luke Zettlemoyer。2019. BART: 用于自然语言生成、翻译和理解的去噪序列到序列预训练。
Jing Li, Shangping Zhong, and Kaizhi Chen. 2021. MLEC-QA: A Chinese Multi-Choice Biomedical Question Answering Dataset. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 8862–8874, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
Jing Li、Shangping Zhong和Kaizhi Chen。2021。MLEC-QA:一个中文生物医学多选题问答数据集。载于《2021年自然语言处理实证方法会议论文集》,第8862–8874页,线上及多米尼加共和国蓬塔卡纳。计算语言学协会。
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Z ett le moyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pre training approach.
Yinhan Liu、Myle Ott、Naman Goyal、Jingfei Du、Mandar Joshi、Danqi Chen、Omer Levy、Mike Lewis、Luke Zettlemoyer 和 Veselin Stoyanov。2019。RoBERTa: 一种稳健优化的BERT预训练方法。
Louis Martin, Benjamin Muller, Pedro Javier Ortiz Suárez, Yoann Dupont, Laurent Romary, Éric de la Clergerie, Djamé Seddah, and Benoît Sagot. 2020. CamemBERT: a tasty French language model. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7203–7219, Online. Association for Computational Linguistics.
Louis Martin、Benjamin Muller、Pedro Javier Ortiz Suárez、Yoann Dupont、Laurent Romary、Éric de la Clergerie、Djamé Seddah和Benoît Sagot。2020。CamemBERT: 一款美味的法语语言模型。在《第58届计算语言学协会年会论文集》中,第7203–7219页,线上会议。计算语言学协会。
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. 2018. Can a suit of armor conduct electricity? a new dataset for open book question answering. In EMNLP.
Todor Mihaylov、Peter Clark、Tushar Khot和Ashish Sabharwal。2018。一套盔甲能导电吗?开放书籍问答的新数据集。载于EMNLP。
Aurélie Névéol, Cyril Grouin, Jeremy Leixa, So- phie Rosset, and Pierre Zweigen baum. 2014. The QUAERO French medical corpus: A ressource for medical entity recognition and normalization. In Proc of Bio Text Mining Work, pages 24–30.
Aurélie Névéol、Cyril Grouin、Jeremy Leixa、Sophie Rosset和Pierre Zweigenbaum。2014. QUAERO法语医学语料库:用于医学实体识别与标准化的资源。见《生物文本挖掘研讨会论文集》(Proc of Bio Text Mining Work),第24-30页。
Ankit Pal, Logesh Kumar Umapathi, and Malaikannan Sankara sub bu. 2022. Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering. In Proceedings of the Conference on Health, Inference, and Learning, volume 174 of Proceedings of Machine Learning Research, pages 248–260. PMLR.
Ankit Pal、Logesh Kumar Umapathi 和 Malaikannan Sankara sub bu. 2022. Medmcqa: 一个面向医疗领域问答的大规模多学科多选题数据集. 见《健康、推理与学习会议论文集》, 第174卷《机器学习研究论文集》, 第248–260页. PMLR.
Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language models are unsupervised multitask learners.
Alec Radford、Jeff Wu、Rewon Child、David Luan、Dario Amodei 和 Ilya Sutskever。2019。语言模型是无监督多任务学习器。
Nils Reimers and Iryna Gurevych. 2019. Sentencebert: Sentence embeddings using siamese bertnetworks.
Nils Reimers 和 Iryna Gurevych. 2019. SentenceBERT: 使用孪生BERT网络生成句子嵌入。
Matthew Richardson, Christopher J.C. Burges, and Erin Renshaw. 2013. MCTest: A challenge dataset for the open-domain machine comprehension of text. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, pages 193–203, Seattle, Washington, USA. Association for Computational Linguistics.
Matthew Richardson、Christopher J.C. Burges 和 Erin Renshaw。2013. MCTest: 一个面向开放域文本机器理解 (machine comprehension) 的挑战数据集。载于《2013年自然语言处理实证方法会议论文集》,第193-203页,美国华盛顿州西雅图。计算语言学协会。
Stephen E. Robertson and Karen Sparck Jones. 1988. Relevance Weighting of Search Terms, page 143–160. Taylor Graham Publishing, GBR.
Stephen E. Robertson 和 Karen Sparck Jones. 1988. 检索词相关性加权 (Relevance Weighting of Search Terms), 第 143–160 页. Taylor Graham Publishing, 英国.
Maarten Sap, Hannah Rashkin, Derek Chen, Ronan LeBras, and Yejin Choi. 2019. Socialiqa: Commonsense reasoning about social interactions.
Maarten Sap、Hannah Rashkin、Derek Chen、Ronan LeBras和Yejin Choi。2019。SocialiQA:关于社交互动的常识推理。
Andrew Trotman, Antti Puurula, and Blake Burgess. 2014. Improvements to bm25 and language models examined. In Proceedings of the 2014 Australasian Document Computing Symposium, ADCS ’14, page 58–65, New York, NY, USA. Association for Computing Machinery.
Andrew Trotman、Antti Puurula 和 Blake Burgess。2014. BM25与语言模型的改进研究。载于《2014年澳大利亚文档计算研讨会论文集》(ADCS '14),第58-65页,美国纽约州纽约市。计算机协会。
David Vilares and Carlos Gómez-Rodríguez. 2019. HEAD-QA: A healthcare dataset for complex rea- soning. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguis- tics, pages 960–966, Florence, Italy. Association for Computational Linguistics.
David Vilares 和 Carlos Gómez-Rodríguez. 2019. HEAD-QA: 面向复杂推理的医疗数据集. 在《第57届计算语言学协会年会论文集》中, 第960-966页, 意大利佛罗伦萨. 计算语言学协会.
Wenhui Wang, Hangbo Bao, Shaohan Huang, Li Dong, and Furu Wei. 2020. Minilmv2: Multi-head selfattention relation distillation for compressing pretrained transformers.
王雯慧、鲍航波、黄少晗、董力和韦福如。2020. Minilmv2: 多头部自注意力关系蒸馏用于压缩预训练Transformer。
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pier- ric Cistac, Tim Rault, Rémi Louf, Morgan Funtow- icz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush. 2019. Hugging face’s transformers: State-of-the-art natural language processing.
Thomas Wolf、Lysandre Debut、Victor Sanh、Julien Chaumond、Clement Delangue、Anthony Moi、Pier-ric Cistac、Tim Rault、Rémi Louf、Morgan Funtowicz、Joe Davison、Sam Shleifer、Patrick von Platen、Clara Ma、Yacine Jernite、Julien Plu、Canwen Xu、Teven Le Scao、Sylvain Gugger、Mariama Drame、Quentin Lhoest 和 Alexander M. Rush。2019。Hugging Face的Transformers:最先进的自然语言处理技术。