ReGen: Reinforcement Learning for Text and Knowledge Base Generation using Pretrained Language Models
ReGen: 基于预训练语言模型的文本与知识库生成强化学习
Abstract
摘要
Automatic construction of relevant Knowledge Bases (KBs) from text, and generation of semantically meaningful text from KBs are both long-standing goals in Machine Learning. In this paper, we present ReGen, a bidirectional generation of text and graph leveraging Reinforcement Learning (RL) to improve performance. Graph linear iz ation enables us to re-frame both tasks as a sequence to sequence generation problem regardless of the generative direction, which in turn allows the use of Reinforcement Learning for sequence training where the model itself is employed as its own critic leading to Self-Critical Sequence Training (SCST). We present an extensive inve stig ation demonstrating that the use of RL via SCST benefits graph and text generation on $\mathrm{WebNLG}+~2020$ and TEKGEN datasets. Our system provides state-of-the-art results on $\mathrm{WebNLG+\Sigma}.$ 2020 by significantly improving upon published results from the WebNLG $^{2020+}$ Challenge for both text-to-graph and graph-to-text generation tasks.
规则:
- 输出中文翻译部分时仅保留翻译标题,不含多余内容、重复或解释
- 不输出无关英文内容
- 保留原始段落格式及术语(如FLAC/JPEG)、公司缩写(如Microsoft/Amazon/OpenAI)
- 人名不译
- 保留文献引用标记如[20]
- 图表标题格式转换(Figure 1->图1,Table 1->表1)
- 全角括号转半角并添加间距
- 专业术语首现标注英文(如生成式AI(Generative AI))
策略:
- 特殊字符/公式原样保留
- HTML表格转Markdown格式
- 完整翻译确保信息无损
从文本自动构建相关知识库(KBs)以及从KBs生成语义化文本,始终是机器学习领域的长期目标。本文提出ReGen,通过强化学习(RL)实现文本与图结构的双向生成以提升性能。图线性化技术使我们能够将两个方向的生成任务统一重构为序列到序列问题,进而采用强化学习进行序列训练——该模型通过自我批判序列训练(SCST)机制充当自身的评估者。我们在$\mathrm{WebNLG}+~2020$和TEKGEN数据集上开展全面实验,证明基于SCST的强化学习方法能有效提升图结构与文本的生成质量。本系统在$\mathrm{WebNLG+\Sigma}$2020上取得最先进成果,显著超越WebNLG$^{2020+}$挑战赛已公布的文本到图/图到文本双任务基准成绩。
1 Introduction
1 引言
Graph representation of knowledge is a powerful tool to capture real-world information where complex relationships between node entities can be simply encoded. Automatic generation of Knowledge Bases (KBs) from free-form text and its counterpart of generating semantically relevant text from KBs are both active and challenging research topics.
知识图谱 (Graph representation of knowledge) 是一种强大的工具,能够以节点实体间的简洁关系编码来捕获现实世界信息。从自由文本自动生成知识库 (Knowledge Bases, KBs) 以及从知识库生成语义相关文本,都是活跃且具有挑战性的研究课题。
Recently, there has been an increased interest in leveraging Pretrained Language Models (PLMs) to improve performance for text generation from graph, or graph-to-text (G2T) task (Ribeiro et al., 2020). Indeed, large PLMs like T5 (Raffel et al., 2020) and BART (Lewis et al., 2020) that have been pretrained on vast amount of diverse and variedly structured data, are particularly good candidates for generating natural looking text from graph data.
近年来,利用预训练语言模型 (Pretrained Language Models, PLMs) 提升基于图结构的文本生成 (graph-to-text, G2T) 任务性能的研究日益受到关注 (Ribeiro et al., 2020)。事实上,像 T5 (Raffel et al., 2020) 和 BART (Lewis et al., 2020) 这类基于海量多样化结构化数据预训练的大规模 PLMs,尤其擅长从图数据生成自然流畅的文本。
BART- and T5-related models have been employed by top performers in public challenges such as the $\mathrm{WebNLG}+202(\$ Challenge (Castro Ferreira et al., 2020b) where both graph-to-text and textto-graph (T2G) tasks are offered, under the names RDF-to-Text and Text-to-RDF (semantic parsing) respectively (RDF stands for Resource Description Framework, a standard for describing web re- sources). One can notice that more teams entered the competition for the G2T task than for T2G as the latter is a much harder task. Best models generally use PLMs and fine-tune them for the target modality at hand (either graph or text). This is possible by re-framing the T2G and G2T generations as a sequence to sequence (Seq2Seq) generation problem, which suits fine-tuning PLMs well. One can therefore hope to leverage the large pre training of PLMs to improve the overall quality of generation.
BART和T5相关模型已被公开挑战赛中的顶尖选手采用,例如WebNLG+2020挑战赛 (Castro Ferreira et al., 2020b)。该赛事同时提供图到文本 (graph-to-text) 和文本到图 (text-to-graph, T2G) 任务,分别命名为RDF到文本 (RDF-to-Text) 和文本到RDF (Text-to-RDF)(语义解析任务)(RDF指资源描述框架,一种网络资源描述标准)。值得注意的是,参与G2T任务的团队数量远超T2G任务,因为后者难度显著更高。最佳模型通常采用预训练语言模型 (PLM),并针对当前目标模态(图或文本)进行微调。通过将T2G和G2T生成重构为序列到序列 (Seq2Seq) 生成问题,可以很好地适配PLM微调。因此有望利用PLM的大规模预训练来提升整体生成质量。
The Seq2Seq formulation requires a linearization of any input graph, which is not unique. This creates an opportunity for data augmentation where multiple linear iz at ions are provided to the model at training time so the model learns the content represented by the graph, not the order of its sequential representation.
Seq2Seq框架要求将任意输入图线性化,而这种线性化方式并不唯一。这为数据增强提供了机会:在训练时向模型提供多种线性化序列,使模型学习图所表示的内容,而非其序列化顺序。
In this work, we are interested in leveraging the power of PLMs for both G2T and T2G generation tasks, and will demonstrate the strength of our approach by improving upon the best results of the WebNLG $^+$ 2020 Challenge (rev 3.0) as reported by Castro Ferreira et al. (2020a) for both T2G (Semantic Parsing) and G2T (Data-to-Text) tasks. We will also present results for the TEKGEN Corpus (Agarwal et al., 2021) to show performance on a different, much larger dataset. To illustrate the task of generation, Fig. 1 provides examples of G2T and T2G outputs obtained using the proposed generation framework. The first two sentences of the abstract of this paper were used as input for T2G using our best model. The model generates a graph from the input text by simultaneously extracting relevant nodes and linking them coherently. For the G2T task, another model starts from the generated graph and generates semantically relevant text from it. As one can appreciate, the final text is quite readable and captures most facts from the original abstract sentences despite a strong domain mismatch between input data and training data, which both models were built on.
在本研究中,我们致力于利用预训练语言模型(PLM)的力量同时完成图到文(G2T)和文到图(T2G)生成任务。我们将通过改进WebNLG$^+$2020挑战赛(rev 3.0)中T2G(语义解析)和G2T(数据到文本)任务的最佳成绩(Castro Ferreira等人,2020a报告)来证明方法的优势。同时还将展示TEKGEN语料库(Agarwal等人,2021)上的实验结果,以证明模型在更大规模数据集上的性能表现。图1展示了采用本生成框架获得的G2T与T2G输出示例:使用本文摘要前两句作为输入,经最优T2G模型生成结构化图数据——该模型通过同步抽取相关节点并建立连贯连接来实现文本到图的转换;而G2T模型则以生成图为起点,输出语义连贯的文本。值得注意的是,尽管输入数据与训练数据存在显著领域差异,最终生成文本仍保持较高可读性,并准确捕捉了原文大部分事实信息。

Figure 1: Actual examples of generation for Text-to-Graph and Graph-to-Text tasks using our best RL models. The first two sentences of the abstract were processed through our best models. First, a graph was created capturing the facts from the input sentences. Then, this graph was used as input to generate text. Despite a strong domain mismatch between input data and models, the generated paragraph is capturing most of the original sentences content. Both models were trained using RL, specifically Self-Critical Sequence Training (SCST).
图 1: 使用我们最佳强化学习模型生成的文本到图 (Text-to-Graph) 和图到文本 (Graph-to-Text) 任务的实际示例。摘要的前两句话通过我们的最佳模型进行处理。首先,根据输入句子创建了一个捕捉事实的图。然后,将该图作为输入生成文本。尽管输入数据与模型之间存在强烈的领域不匹配,生成的段落仍捕捉了原始句子的大部分内容。这两个模型均使用强化学习 (RL) 进行训练,具体是自临界序列训练 (SCST)。
Since both T2G and G2T generative tasks can be formulated as a Seq2Seq problem, we propose to use Reinforcement Learning (RL) as part of the PLMs fine-tuning on the target domain data. For both G2T and T2G tasks, a differentiable function such as the cross-entropy (CE) loss function is often used, since minimizing it results in maximizing the probability of generating the correct token/word. However, when it comes to evaluating a model’s performance, benchmarks often use BLEU (Pa Pa Aung et al., 2020), METEOR (Lavie and Agarwal, 2007), $\mathrm{chrF++}$ (Popovic, 2017) for G2T, or simply F1, Precision, and Recall scores for T2G, none of which being differentiable. During training, one hopes that by minimizing the CE loss, the model will tend towards better prediction of the target tokens, hence improving on evaluation metrics as a beneficial by-product. Thankfully, RL provides a framework where we can update our model parameters so to improve evaluation met- rics directly. Mixed Incremental Cross-Entropy Reinforce (MIXER) from Ranzato et al. (2016) introduced using REINFORCE (Williams, 1992) for sequence training. We propose to use one of its variant known as Self-Critical Sequence Training (SCST) (Rennie et al., 2017) for both T2G and G2T training.
由于T2G和G2G生成任务均可表述为Seq2Seq问题,我们提出在目标领域数据上对PLMs进行微调时结合强化学习(RL)。对于G2T和T2G任务,通常会使用交叉熵(CE)损失函数等可微分函数,因为最小化该函数相当于最大化生成正确token/单词的概率。然而在模型评估阶段,基准测试往往采用BLEU (Pa Pa Aung等人, 2020)、METEOR (Lavie和Agarwal, 2007)、$\mathrm{chrF++}$ (Popovic, 2017) 来评估G2T任务,或直接使用F1值、精确率和召回率评估T2G任务——这些指标均不可微分。训练过程中,人们期望通过最小化CE损失使模型更准确地预测目标token,从而间接提升评估指标。值得庆幸的是,强化学习提供了直接优化评估指标的参数更新框架。Ranzato等人(2016)提出的混合增量交叉熵强化算法(MIXER)首次将REINFORCE (Williams, 1992)应用于序列训练。我们建议采用其变体——自关键序列训练(SCST) (Rennie等人, 2017) 来统一处理T2G和G2T训练任务。
To summarize, our main contributions are: • We propose to use RL-based sequence training, specifically SCST, for both G2T and T2G tasks.
总结来说,我们的主要贡献包括:
- 我们提出将基于强化学习 (RL) 的序列训练方法(特别是 SCST)同时应用于 G2T 和 T2G 任务。
approach over CE-trained baselines.
CE训练基线的优势方法。
2 Related work
2 相关工作
In the $ \mathrm{WebNLG}+202 $ 0 Challenge, most top performing models relied on fine-tuning of PLMs. Inte rest ingly, all four top teams in the Challenge proposed quite different approaches while leveraging PLMs. $1^{\mathrm{st}}$ place Amazon AI (Guo et al., 2020a) pipelined a relational graph convolutional network (R-GCN) and a T5 PLM with some canonical iz ation rules. $2^{\mathrm{nd}}$ place OSU Neural NLG (Li et al., 2020), the closest to our approach in spirit, used T5 and mBART PLMs to fine-tune after special data preprocessing. $3^{\mathrm{rd}}$ place FBConvAI (Yang et al., 2020) used BART PLM and multiple strategies to model input RDFs. $4^{\mathrm{th}}$ place bt5 employed a T5 PLM trained in a bi-lingual approach on English and Russian, even using WMT English/Russian parallel corpus.
在 $\mathrm{WebNLG}+202\$ 0$ 挑战赛中,表现最佳的模型大多依赖于预训练语言模型 (PLM) 的微调。有趣的是,尽管都利用了 PLM,挑战赛前四名的团队却提出了截然不同的方法。$1^{\mathrm{st}}$ 名 Amazon AI (Guo et al., 2020a) 采用了关系图卷积网络 (R-GCN) 和 T5 PLM 的流水线架构,并辅以一些规范化规则。$2^{\mathrm{nd}}$ 名 OSU Neural NLG (Li et al., 2020) 在理念上最接近我们的方法,他们在特殊数据预处理后使用 T5 和 mBART PLM 进行微调。$3^{\mathrm{rd}}$ 名 FBConvAI (Yang et al., 2020) 使用 BART PLM 和多种策略对输入 RDF 进行建模。$4^{\mathrm{th}}$ 名 bt5 采用双语训练方法,基于英语和俄语数据训练 T5 PLM,甚至动用了 WMT 英俄平行语料库。
Recently, Dognin et al. (2020); Guo et al. (2020b) proposed models trained to generate in both T2G and G2T directions, with consistency cycles created to enable the use of unsupervised datasets. In contrast, our approach of fine-tuning a T5 PLM is fully supervised but can produce either the specialized models for T2G and G2T tasks alone, or a hybrid model that can handle both T/G inputs simultaneously to generate the corresponding translated outputs G/T.
近期,Dognin等人 (2020) 和Guo等人 (2020b) 提出了可双向执行文本到图形(T2G)和图形到文本(G2T)生成的模型,通过构建一致性循环来利用无监督数据集。相比之下,我们采用微调T5预训练语言模型(PLM)的方法完全基于监督学习,但既能产出专精T2G或G2T任务的独立模型,也能构建同时处理文本/图形(T/G)输入并生成对应翻译输出(G/T)的混合模型。
Note that in contrast to many $\mathrm{WebNLG}+2020$ Challenge participants, e.g. (Li et al., 2020), no preprocessing of the data is performed for text, while for graph triples, we add tokens to mark subject, predicate, and object positions in their linearized sequence representation. Moreover, data augmentation is performed by allowing random shuffling of triples order in graph linear iz ation to avoid a model to learn the exact order of triples, especially for the T2G task.
需要注意的是,与许多 $\mathrm{WebNLG}+2020$ 挑战赛参与者(如 (Li et al., 2020))不同,我们对文本数据未进行任何预处理,而对于图三元组,我们会在其线性化序列表示中添加 token 来标记主语、谓语和宾语的位置。此外,通过允许在图的线性化过程中随机打乱三元组顺序来进行数据增强,以避免模型学习三元组的精确顺序,这对于 T2G 任务尤为重要。
While the use of RL training in PLM has been explored in many works, the approach of (Chen et al., 2020) is closest to ours. However, their work focuses on the improved text generation in the context of natural question generation, while in our algorithm we use it for graph-to-text and text-tograph generations.
虽然强化学习 (RL) 训练在预训练语言模型 (PLM) 中的应用已有诸多研究,但 (Chen et al., 2020) 的方法与我们的最为接近。不过,他们的工作聚焦于自然问题生成场景下的文本生成改进,而我们的算法将其用于图到文本和图生成的场景。
3 Models
3 模型
Models are trained on a dataset $\mathcal{D}$ composed of a set of $(x_{\mathrm{T}},x_{\mathrm{G}})^{i}$ samples, where $x_{\mathrm{T}}$ is made of text (one or more sentences), and $x_{\mathrm{G}}$ is a graph represented as a list of triples $x_{\mathrm{{G}}}~=$ $[(s^{1},p^{1},o^{1}),\dots,(s^{K},p^{K},o^{K})]$ , where the $k$ -th triple is composed of a subject $s^{k}$ , predicate (relationship) $p^{k}$ , and object $o^{k}$ . The superscript $i$ denotes the $i$ -th sample in $\mathcal{D}$ . For G2T, the model is given $x_{\mathrm{G}}$ as input and must generate $\hat{x}_{\mathrm{T}}$ . A crossentropy loss is computed as an expectation:
模型在数据集 $\mathcal{D}$ 上进行训练,该数据集由一组 $(x_{\mathrm{T}},x_{\mathrm{G}})^{i}$ 样本组成,其中 $x_{\mathrm{T}}$ 由文本(一个或多个句子)构成,$x_{\mathrm{G}}$ 是以三元组列表表示的图 $x_{\mathrm{{G}}}~=$ $[(s^{1},p^{1},o^{1}),\dots,(s^{K},p^{K},o^{K})]$ ,其中第 $k$ 个三元组由主语 $s^{k}$ 、谓词(关系) $p^{k}$ 和宾语 $o^{k}$ 组成。上标 $i$ 表示 $\mathcal{D}$ 中的第 $i$ 个样本。对于 G2T 任务,模型接收 $x_{\mathrm{G}}$ 作为输入并需生成 $\hat{x}_{\mathrm{T}}$ 。交叉熵损失按期望计算:
$$
\mathcal{L}{\mathrm{CE}}^{\mathrm{T}}=\underset{x_{\mathrm{T}}\sim\mathcal{D}}{\mathbb{E}}\left[-\log p_{\theta}^{\mathrm{G2T}}(x_{\mathrm{T}})\right],
$$
$$
\mathcal{L}{\mathrm{CE}}^{\mathrm{T}}=\underset{x_{\mathrm{T}}\sim\mathcal{D}}{\mathbb{E}}\left[-\log p_{\theta}^{\mathrm{G2T}}(x_{\mathrm{T}})\right],
$$
where $p_{\theta}^{\mathrm{G2T}}(x_{\mathrm{T}})$ is the distribution of the generated sequence $\hat{x}{\mathrm{T}}=T_{\mathrm{G2T}}(x_{\mathrm{G}}),T_{\mathrm{G2T}}(x_{\mathrm{G}})$ being the transformation from graph to text, and where our model is parameterized by $\theta$ $\mathbf{\hat{\Pi}}\cdot\hat{x}{\mathrm{T}}=[\hat{w}{1},\hat{w}{2},\dots,\hat{w}_{T}]$ is a sequence of generated tokens/words. Similarly, for training a T2G model, the cross-entropy loss used in training is simply
其中 $p_{\theta}^{\mathrm{G2T}}(x_{\mathrm{T}})$ 表示生成序列 $\hat{x}{\mathrm{T}}=T_{\mathrm{G2T}}(x_{\mathrm{G}})$ 的分布,$T_{\mathrm{G2T}}(x_{\mathrm{G}})$ 为图到文本的转换过程,模型参数由 $\theta$ 决定。$\mathbf{\hat{\Pi}}\cdot\hat{x}{\mathrm{T}}=[\hat{w}{1},\hat{w}{2},\dots,\hat{w}_{T}]$ 是生成的token/词序列。同理,训练T2G模型时采用的交叉熵损失函数为
$$
\mathcal{L}{\mathrm{CE}}^{\mathrm{G}}=\underset{x_{\mathrm{G}}\sim\mathcal{D}}{\mathbb{E}}\left[-\log p_{\theta}^{\mathrm{T2G}}(x_{\mathrm{G}})\right],
$$
$$
\mathcal{L}{\mathrm{CE}}^{\mathrm{G}}=\underset{x_{\mathrm{G}}\sim\mathcal{D}}{\mathbb{E}}\left[-\log p_{\theta}^{\mathrm{T2G}}(x_{\mathrm{G}})\right],
$$
where $p_{\theta}^{\mathrm{T}2\mathrm{G}}(x_{\mathrm{G}})$ is the distribution of the generated graph $\hat{x}{\mathrm{G}}=T_{\mathrm{T2G}}(x_{\mathrm{T}})$ , $T_{\mathrm{T2G}}(x_{\mathrm{T}})$ being the transformation from text to graph.
其中 $p_{\theta}^{\mathrm{T}2\mathrm{G}}(x_{\mathrm{G}})$ 是生成图 $\hat{x}{\mathrm{G}}=T_{\mathrm{T2G}}(x_{\mathrm{T}})$ 的分布,$T_{\mathrm{T2G}}(x_{\mathrm{T}})$ 表示从文本到图的转换。
In both Eq. (1) and Eq. (2), $x_{\mathrm{G}}$ must be expressed as a sequence of tokens $t_{j}$ such that a list of triples $x_{\mathrm{G}}$ turns into a list of tokens $[t_{1},t_{2},\cdots,t_{M}]$ . This is simply done by adding tokens marking the subject, predicate, and object locations in the sequence such that each triple $(s^{k},p^{k},o^{k})$ is turned into a sequence such as $[<\mathrm{S}>,w_{1}^{s},<\mathrm{P}>,w_{1}^{p},w_{2}^{p},<\mathrm{O}>,w_{1}^{o},w_{2}^{o},w_{3}^{o}]$ , assuming our subject is made of 1 token, our predicate of 2 tokens, and our object of 3 tokens in this example. $<\mathrm{S}>,<\mathrm{P}>$ , and $<\mathrm{O}>$ are just special marker tokens to help the model know where subject, predicate and objects are located in the sequence.
在式(1)和式(2)中,$x_{\mathrm{G}}$必须表示为token序列$t_{j}$,使得三元组列表$x_{\mathrm{G}}$转换为token列表$[t_{1},t_{2},\cdots,t_{M}]$。具体实现方式是在序列中添加标记主语、谓语和宾语位置的token,例如将每个三元组$(s^{k},p^{k},o^{k})$转换为类似$[<\mathrm{S}>,w_{1}^{s},<\mathrm{P}>,w_{1}^{p},w_{2}^{p},<\mathrm{O}>,w_{1}^{o},w_{2}^{o},w_{3}^{o}]$的序列。在本示例中,假设主语由1个token组成,谓语由2个token组成,宾语由3个token组成。$<\mathrm{S}>$、$<\mathrm{P}>$和$<\mathrm{O}>$是特殊的标记token,用于帮助模型识别序列中主语、谓语和宾语的位置。
We start from a pretrained encoder-decoder $\mathcal{M}$ model that we fine-tune on either T2G to get $\mathcal{M}{\mathrm{T}}$ , or G2T task to get $\mathcal{M}{\mathrm{G}}$ . We also propose a third kind of model $\mathcal{M}{\mathrm{T+G}}$ to be fine-tuned on both T2G and G2T samples, i.e. the model will learn to generate in any direction, by supplying an input sample $x=[x_{\mathrm{T}};x_{\mathrm{G}}]^{\top}$ and corresponding target for it. Input from each modality is prefixed by a task specific string to distinguish samples ("Text to Graph:" for $x_{\mathrm{T}}$ and "Graph to Text:" for $x_{\mathrm{G}}$ ). For $\mathcal{M}{\mathrm{T+G}}$ models, the cross-entropy loss is similarly defined as for Eq. (1) and Eq. (2) such that $\mathcal{L}{\mathrm{CE}}^{\mathrm{T+G}}=\underset{x\sim\mathcal{D}}{\mathbb{E}}\left[-\log p_{\theta}(x)\right]$ . All models are shown in Fig. 2. By convention, we refer to models in this paper by their input modality T, G, or $\mathrm{T}{+}\mathrm{G}$ .
我们从预训练的编码器-解码器模型 $\mathcal{M}$ 出发,通过在T2G任务上微调得到 $\mathcal{M}{\mathrm{T}}$,或在G2T任务上微调得到 $\mathcal{M}{\mathrm{G}}$。此外,我们提出第三种模型 $\mathcal{M}{\mathrm{T+G}}$,通过在T2G和G2T样本上联合微调,使其能够学习双向生成。具体实现时,输入样本 $x=[x_{\mathrm{T}};x_{\mathrm{G}}]^{\top}$ 及其对应目标会被赋予模态特定的前缀字符串(文本到图任务用"Text to Graph:"标记 $x_{\mathrm{T}}$,图到文本任务用"Graph to Text:"标记 $x_{\mathrm{G}}$)。对于 $\mathcal{M}{\mathrm{T+G}}$ 模型,其交叉熵损失函数 $\mathcal{L}{\mathrm{CE}}^{\mathrm{T+G}}=\underset{x\sim\mathcal{D}}{\mathbb{E}}\left[-\log p_{\theta}(x)\right]$ 的定义与公式(1)和(2)保持形式一致。所有模型架构如图2所示。按照惯例,本文以输入模态类型T、G或 $\mathrm{T}{+}\mathrm{G}$ 来指代相应模型。
3.1 Reinforcement Learning
3.1 强化学习
A sequence generation task can be re-framed as a model picking the best word within a vocabulary to react to its environment and accounting for past predictions, we can then reformulate Seq2Seq generation into the Reinforcement Learning framework. A model is an agent that defines a policy resulting in the action of selecting each word during generation, as first introduced by Ranzato et al. (2016). REINFORCE, presented by Williams (1992), allows the optimization of a model’s parameters $\theta$ by maximizing the expected value of the reward $R(\hat{x}{\mathrm{T}})$ of generated sequence $\hat{x}{\mathrm{T}}=[\hat{w}{1},\dots,\hat{w}_{T}]$ . To match usual Deep Learning conventions, we can minimize a loss expressed as its negative value:
序列生成任务可以重新定义为模型在词汇表中选择最佳词语以响应其环境并考虑过去的预测,这样我们就可以将Seq2Seq生成重新表述为强化学习框架。模型是一个智能体,它定义了一种策略,在生成过程中选择每个词语作为动作,这一概念最初由Ranzato等人(2016)提出。Williams(1992)提出的REINFORCE方法允许通过最大化生成序列$\hat{x}{\mathrm{T}}=[\hat{w}{1},\dots,\hat{w}{T}]$的奖励$R(\hat{x}_{\mathrm{T}})$的期望值来优化模型参数$\theta$。为了符合通常的深度学习惯例,我们可以最小化表示为负值的损失函数:
$$
\begin{array}{r l r}{\mathcal{L}{\mathrm{RL}}=-\displaystyle\sum_{\hat{w}{1},\dots,\hat{w}{T}}p_{\theta}\big(\hat{w}{1},\dots,\hat{w}{T}\big)r\big(\hat{w}{1},\dots,\hat{w}{T}\big)}&{}&\ {=-\mathbb{E}{[\hat{w}{1},\dots,\hat{w}{T}]\sim p_{\theta}}R\big(\hat{w}{1},\dots,\hat{w}{T}\big),}&{}&\ {=-\mathbb{E}{\hat{x}{\Gamma}\sim p_{\theta}}R\big(\hat{x}_{\mathrm{T}}\big).}&{}&{(\mathfrak{L}}\end{array}
$$
$R(\hat{x}_{\mathrm{T}})$ is the reward for the generated text which is often associated with non-differentiable metrics
$R(\hat{x}_{\mathrm{T}})$ 是生成文本的奖励值,通常与不可微分指标相关联
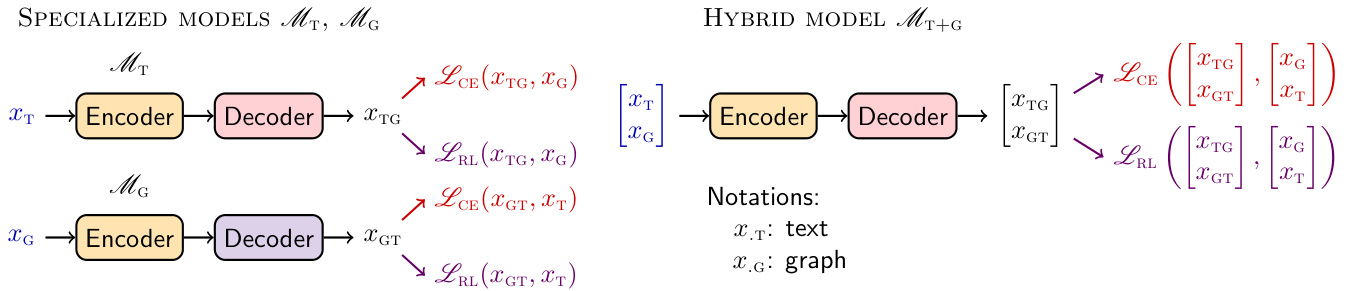
Figure 2: Specialized and hybrid models rely on the same losses for fine-tuning. However, specialized models are dedicated to a particular generation task while hybrid models can handle both generation directions.
图 2: 专用模型与混合模型采用相同的损失函数进行微调。但专用模型仅针对特定生成任务,而混合模型可同时处理两种生成方向。
such as BLEU, METEOR, chrF, etc. We circumvent this issue by using the REINFORCE policy gradient method:
例如 BLEU、METEOR、chrF 等。我们通过使用 REINFORCE 策略梯度方法规避了这个问题:
$$
\begin{array}{r}{\nabla_{\theta}\mathcal{L}{\mathrm{RL}}\propto-\left(R(\hat{x}{\mathrm{T}})-b\right)\nabla_{\theta}\log p_{\theta}(\hat{x}_{\mathrm{T}}),}\end{array}
$$
$$
\begin{array}{r}{\nabla_{\theta}\mathcal{L}{\mathrm{RL}}\propto-\left(R(\hat{x}{\mathrm{T}})-b\right)\nabla_{\theta}\log p_{\theta}(\hat{x}_{\mathrm{T}}),}\end{array}
$$
where $b$ is a baseline used to reduce the variance of our gradient estimate. $b$ can be any function, even a random variable, as long as it is independent of the actions taken to generate $\hat{x}{\mathrm{T}}$ , as described in Chapter 13.4 from Sutton and Barto (2018). In SelfCritical Sequence Training (SCST) (Rennie et al., 2017), $b$ is chosen to be the reward of $x_{\mathrm{{T}}}^{\ast}$ , the output generated by the model by greedy max generation, hence the model serving as its own critic:
其中 $b$ 是用于降低梯度估计方差的基线。根据 Sutton 和 Barto (2018) 第 13.4 章的描述,只要 $b$ 与生成 $\hat{x}{\mathrm{T}}$ 所采取的动作无关,它可以是任何函数,甚至是一个随机变量。在自关键序列训练 (SCST) (Rennie et al., 2017) 中,$b$ 被选为 $x_{\mathrm{{T}}}^{\ast}$ 的奖励值,即模型通过贪心最大化生成产生的输出,因此模型充当自身的评判者:
$$
\nabla_{\boldsymbol{\theta}}\mathcal{L}{\mathrm{scsr}}\propto-\left(R(\hat{x}{\mathrm{T}})-R(x_{\mathrm{T}}^{*})\right)\nabla_{\boldsymbol{\theta}}\log p_{\boldsymbol{\theta}}(\hat{x}_{\mathrm{T}}),
$$
$$
\nabla_{\boldsymbol{\theta}}\mathcal{L}{\mathrm{scsr}}\propto-\left(R(\hat{x}{\mathrm{T}})-R(x_{\mathrm{T}}^{*})\right)\nabla_{\boldsymbol{\theta}}\log p_{\boldsymbol{\theta}}(\hat{x}_{\mathrm{T}}),
$$
where $\hat{x}{\mathrm{T}}$ is sampled from our model and $x_{\mathrm{{T}}}^{\ast}$ is generated by greedy max. An interesting property of the baseline is that if $R(\hat{x}{\mathrm{T}})~>~R(x_{\mathrm{T}}^{})$ , sampled $\hat{x}{\mathrm{T}}$ has higher reward than $x_{\mathrm{T}}^{}$ , then the model is updated to reinforce the choices made by this generation. In the opposite case where $R(\hat{x}{\mathrm{T}})<R(x_{\mathrm{T}}^{})$ , the model update will take the negative gradient or the opposite model update to subdue such generation. When $R(\hat{x}{\mathrm{T}})=R(x_{\mathrm{T}}^{})$ , no update is performed on the model since the gradient is effectively zeroed out, regardless of the individual values $R(\hat{x}{\mathrm{T}})$ and $R(x_{\mathrm{T}}^{*})$ . This happens when $\hat{x}{\mathrm{T}}$ and $x_{\mathrm{{T}}}^{\ast}$ are identical (greedy-max and sampled sequences are identical). In that case the sample is lost for RL as no update to the model will result from this sample. Basically, REINFORCE is a Monte Carlo method of learning where a gradient update is applied in the direction decided by how $R(\hat{x}_{\mathrm{T}})$ compares to baseline $b$ , the role of $b$ being to reduce the variance of the gradient estimate. Variations around REINFORCE exist on how to apply the gradients, such as MIXER (Ranzato et al., 2016), or on how to evaluate the baseline (Luo, 2020) to minimize the gradient variance.
其中 $\hat{x}{\mathrm{T}}$ 是从我们的模型中采样的,而 $x_{\mathrm{{T}}}^{\ast}$ 是通过贪心最大化生成的。基线的一个有趣特性是,如果 $R(\hat{x}{\mathrm{T}})~>~R(x_{\mathrm{T}}^{})$,即采样的 $\hat{x}{\mathrm{T}}$ 比 $x_{\mathrm{T}}^{}$ 具有更高的奖励,那么模型会更新以强化这一生成所做的选择。在相反的情况下,即 $R(\hat{x}{\mathrm{T}})<R(x_{\mathrm{T}}^{})$,模型更新将采用负梯度或相反的模型更新来抑制这种生成。当 $R(\hat{x}{\mathrm{T}})=R(x_{\mathrm{T}}^{})$ 时,由于梯度实际上为零,无论 $R(\hat{x}{\mathrm{T}})$ 和 $R(x_{\mathrm{T}}^{*})$ 的具体值如何,模型都不会进行更新。这种情况发生在 $\hat{x}{\mathrm{T}}$ 和 $x_{\mathrm{{T}}}^{\ast}$ 完全相同(贪心最大化和采样序列相同)时。在这种情况下,样本对于强化学习来说是无效的,因为不会因该样本而对模型进行更新。
基本上,REINFORCE 是一种蒙特卡洛学习方法,其中梯度更新的方向由 $R(\hat{x}_{\mathrm{T}})$ 与基线 $b$ 的比较结果决定,$b$ 的作用是减少梯度估计的方差。围绕 REINFORCE 存在多种变体,例如在如何应用梯度方面(如 MIXER (Ranzato et al., 2016)),或在如何评估基线 (Luo, 2020) 以最小化梯度方差方面。
In our training, PLMs are first fine-tuned using $\mathcal{L}{\mathrm{CE}}$ loss. Once they reach a good generation quality, the training is switched to RL fine-tuning by minimizing ${\mathcal{L}}_{\mathrm{scsT}}$ .
在我们的训练中,预训练语言模型 (PLM) 首先使用 $\mathcal{L}{\mathrm{CE}}$ 损失进行微调。当生成质量达到较好水平后,训练转为通过最小化 ${\mathcal{L}}_{\mathrm{scsT}}$ 进行强化学习微调。
4 Experimental Setup
4 实验设置
In this Section, we present the experimental setup used for all the results reported in this paper.
在本节中,我们将介绍本文所有实验结果所使用的实验设置。
Models We used T5 PLMs (from Wolf et al. (2020)) for our experiments for two distinct models, t5-large [770M parameters] and $t5$ -base [220M parameters], with a special focus on t5-large as it is the best performing of the two on various NLP tasks. Models were fine-tuned to be either specialized on T2G $(\mathcal{M}{\mathrm{T}})$ or G2T $(\mathcal{M}{\mathrm{G}})$ task, or to accom- modate both directions of generation $(\mathcal{M}_{\mathrm{T+G}})$ .
模型
我们采用了 Wolf 等人 (2020) 提出的 T5 预训练语言模型 (PLM) 进行实验,包括 t5-large [7.7亿参数] 和 $t5$-base [2.2亿参数] 两个不同规模的模型,并重点关注 t5-large,因为它在各类 NLP 任务中表现更优。这些模型被微调为三种类型:专精于 T2G $(\mathcal{M}{\mathrm{T}})$ 任务、专精于 G2T $(\mathcal{M}{\mathrm{G}})$ 任务,或同时支持双向生成 $(\mathcal{M}_{\mathrm{T+G}})$。
Data processing Graphs are often represented as list of triples. However our model expects a sequence of input words/tokens to work on. The linear iz ation of graph triples is obviously ambiguous as there are many ways to traverse a graph (Breadth First Search, Depth First Search, random walk, etc.). In practice, we linearize the triples in the order of the list provided by the dataset, but use this inherent linear iz ation ambiguity as an opportunity to do data-augmentation. Indeed, models are first fine-tuned using cross-entropy loss that strongly penalizes generation if it is in any different order than the ground truth order. To avoid the model to overfit to our data and memorize observed triples order, we augment the data by including a few permutations of the graph triples.
数据处理
图通常以三元组列表的形式表示。然而,我们的模型需要处理输入词/token序列。图三元组的线性化显然存在歧义,因为图的遍历方式有多种(广度优先搜索、深度优先搜索、随机游走等)。实际应用中,我们按照数据集提供的列表顺序对三元组进行线性化,但利用这种固有的线性化歧义性进行数据增强。具体而言,模型首先通过交叉熵损失进行微调,若生成顺序与真实顺序存在差异则会受到严厉惩罚。为避免模型过拟合数据并记忆观察到的三元组顺序,我们通过包含少量图三元组排列来增强数据。
During graph linear iz ation, we encode the subject, predicate, and object positions by using $<\mathrm{S}>,<\mathrm{P}>,<\mathrm{O}>$ tokens. In practice, we expand the model vocabulary with these special indivisible tokens that are not split during token iz ation. No other preprocessing is done on the data for training. We explored masked and span-masked LM fine-tuning to match T5 pre training (Raffel et al., 2020) which did not lead to any noticeable improvements.
在图线性化过程中,我们使用$<\mathrm{S}>,<\mathrm{P}>,<\mathrm{O}>$ token对主语、谓语和宾语位置进行编码。实际应用中,我们在模型词汇表中新增了这些不可分割的特殊token,确保它们在token化过程中不会被拆分。训练数据未进行其他预处理。我们尝试了掩码语言模型和跨度掩码语言模型微调以匹配T5预训练(Raffel et al., 2020),但未观察到明显改进效果。
Table 1: G2T Best results on WebNLG 2020 Challenge (v3.0) dataset. The first four rows were the top performers of the Challenge. Results for CE and RL models are presented for our ReGen systems so to show gains from using SCST. Our G2T.RL is the best system overall, fine-tuning a t5-large model using METEOR reward. G2T.RL.ES and G2T.RL.best show the impact of using early stopping (ES) or best CE selection for starting SCST fine-tuning on a t5-base smaller model while using BLEU_NLTK reward.
表 1: WebNLG 2020挑战赛(v3.0)数据集上G2T的最佳结果。前四行是挑战赛的优胜者。我们的ReGen系统展示了CE和RL模型的结果,以显示使用SCST带来的提升。我们的G2T.RL是整体最佳系统,使用METEOR奖励对t5-large模型进行微调。G2T.RL.ES和G2T.RL.best展示了在使用BLEU_NLTK奖励时,对较小的t5-base模型采用早停(ES)或最佳CE选择启动SCST微调的影响。
| WebNLGG2T团队/模型 | BLEU↑ | BLEU↑ NLTK | METEOR↑ | chrF++↑ |
|---|---|---|---|---|
| Amazon AI (Shanghai) (Guo et al., 2020a) | 0.540 | 0.535 | 0.417 | 0.690 |
| OSU Neural NLG (Li et al., 2020) | 0.535 | 0.532 | 0.414 | 0.688 |
| FBConvAI (Yang et al., 2020) | 0.527 | 0.523 | 0.413 | 0.686 |
| bt5 (Agarwal et al., 2020) | 0.517 | 0.517 | 0.411 | 0.679 |
| ReGen (Ours) G2T.CE t5-large | 0.553 | 0.549 | 0.418 | 0.694 |
| ReGen (Ours) G2T.RL t5-large | 0.563 | 0.559 | 0.425 | 0.706 |
| ReGen (Ours) G2T.CE.ES t5-base (early CE) | 0.522 | 0.518 | 0.404 | 0.675 |
| ReGen (Ours) G2T.RL.ES t5-base (early CE) | 0.531 | 0.527 | 0.410 | 0.686 |
| ReGen (Ours) G2T.CE.best t5-base (best CE) | 0.524 | 0.520 | 0.404 | 0.677 |
| ReGen (Ours) G2T.RL.best t5-base (best CE) | 0.527 | 0.523 | 0.408 | 0.681 |
4.1 Datasets
4.1 数据集
WebNLG $^+$ 2020 We report results on WebNLG+ 2020 (v3.0) used in the WebNLG 2020 Challenge (Castro Ferreira et al., 2020b). The Challenge comprises of two tasks: RDF-to-text generation (G2T), and Text-to-RDF semantic parsing (T2G). The Resource Description Framework (RDF) language is used to encode DBpedia and is commonly used in linked data framework. ${\mathrm{WebNLG+}}$ uses RDF to encode graphs as sets of triples which are associated to one or more lexical iz at ions of one or more sentences each. Data for English and Russian are provided, but we only worked on the English subset made of 13,211 train, 1,667 dev, 2,155 testA (semantic parsing), and 1,779 testB (data-to-text) samples (triples sets w/ lexical iz at ions). The data is clustered semantically into 16 categories seen in train and dev sets (Airport, Astronaut, Building, etc.), while 3 categories (Film, Scientist, and Musical-Work) were introduced in test and are unseen, i.e. not present in training; see Castro Ferreira et al. (2020a) for more details. Results are aggregated for all, seen, and unseen categories during evaluation. Note that in the literature, prior work sometimes report ‘WebNLG’ results on previous dataset version, with completely different performance ranges. We compare all our results to $\mathrm{WebNLG}+2020$ (v3.0) numbers reported by Castro Ferreira et al. (2020a) in their Table 6 for G2T, and Table 10 for T2G tasks, using the provided official scoring scripts.
WebNLG$^+$ 2020
我们报告了WebNLG+ 2020 (v3.0)的结果,该数据集用于WebNLG 2020挑战赛 (Castro Ferreira et al., 2020b)。挑战赛包含两项任务:RDF到文本生成 (G2T) 和文本到RDF语义解析 (T2G)。资源描述框架 (RDF) 语言用于编码DBpedia,并常用于关联数据框架。${\mathrm{WebNLG+}}$使用RDF将图编码为三元组集合,每个三元组关联一个或多个句子的一个或多个词汇化实例。数据集提供英语和俄语版本,但我们仅处理英语子集,包含13,211个训练样本、1,667个开发样本、2,155个测试A样本(语义解析)和1,779个测试B样本(数据到文本)(带词汇化的三元组集合)。数据按语义聚类为训练集和开发集中出现的16个类别(机场、宇航员、建筑等),而测试集中引入了3个未见类别(电影、科学家和音乐作品),即训练集中未出现;详见Castro Ferreira et al. (2020a)。评估时汇总所有类别、已见类别和未见类别的结果。需注意,在文献中,先前工作有时报告的是旧版数据集上的"WebNLG"结果,其性能范围完全不同。我们所有结果均与Castro Ferreira et al. (2020a) 在其表6(G2T)和表10(T2G)中报告的$\mathrm{WebNLG}+2020$ (v3.0) 数据进行比较,使用官方提供的评分脚本。
TEKGEN To further study the robustness of our system, we also provide experiments using TEKGEN dataset recently introduced in Agarwal et al. (2021). The graph-sentence alignments are curated using Wikipedia and Wikidata. This serves as a perfect large scale test-bed for both G2T and T2G tasks. Unfortunately, this dataset lacks in entity/relation/object boundaries, which makes it difficult to evaluate systems for T2G tasks. In order to address this issue, we further process the triple-text (with no triple boundaries) to create list of triples using Wikidata properties lookup, via Wikidata Query Service. Additionally, we limit the validation set and test set to 5K and 50K sentence-triples pairs respectively. Our training split after processing contains 6.3 million sentence-triples pairs. As a contribution to the work, we will open-source this further processed TEKGEN dataset with appropriate subject, object and relation boundaries, which enables conventional evaluation of research systems. An example of the processed TEKGEN is shown in Fig. 3 in Appendix.
TEKGEN
为进一步研究我们系统的鲁棒性,我们还使用了Agarwal等人 (2021) 最新提出的TEKGEN数据集进行实验。该数据集通过维基百科和维基数据构建了图-语句对齐关系,为G2T(图到文本)和T2G(文本到图)任务提供了理想的大规模测试平台。但该数据集存在实体/关系/对象边界缺失的问题,导致难以评估T2G任务的系统性能。为此,我们通过维基数据查询服务 (Wikidata Query Service) 对无边界的三元组文本进行进一步处理,利用维基数据属性查找生成三元组列表。同时,我们将验证集和测试集规模分别限制为5千和5万条语句-三元组对。经处理后,训练集包含630万条语句-三元组对。作为对本研究的贡献,我们将开源这个经过深化处理的TEKGEN数据集(包含明确的主语、宾语和关系边界),以便支持研究系统的常规评估。处理后的TEKGEN示例见附录中的图3。
Metrics $\mathrm{WebNLG}+2020$ provides automatic metrics to evaluate models. For G2T, we used BLEU, BLEU_NLTK, METEOR, and $\mathrm{chrF++}$ that are provided by the challenge. For T2G, F1, Precision, and Recall scores are utilized and computed for 4 levels of match: Exact, Ent_Type, Partial and Strict as described in Castro Ferreira et al. (2020a), which loosely correspond to different levels of relaxation of how close a match of an entity must be to the ground truth in content and position in a triple. Note that when generating graphs/RDFs, scoring metrics explore all possible permutations of a graph edges. For TEKGEN, we use the same metrics as for $\mathrm{WebNLG}+2020$ .
指标
$\mathrm{WebNLG}+2020$ 提供了评估模型的自动指标。对于G2T任务,我们使用了挑战赛提供的BLEU、BLEU_NLTK、METEOR和$\mathrm{chrF++}$指标。对于T2G任务,采用F1、精确率和召回率分数,并按照Castro Ferreira等人 (2020a) 描述的4种匹配级别进行计算:精确匹配 (Exact)、实体类型匹配 (Ent_Type)、部分匹配 (Partial) 和严格匹配 (Strict),这些级别大致对应三元组中实体内容与位置匹配真实值的不同宽松程度。需注意,在生成图/RDF时,评分指标会探索图边的所有可能排列组合。对于TEKGEN任务,我们使用与$\mathrm{WebNLG}+2020$相同的指标。
Table 2: T2G Best results on WebNLG $^+$ 2020 (v3.0) dataset. The top two teams were the first and second place winner of the Challeneg. Our T2G.CE model improves upon all metrics for all matching schemes, providing a new state-of-the-art results for this Challenge task. T2G.RL models, while still better than previous best results, does not improve upon its CE counterpart.
表 2: T2G 在 WebNLG$^+$ 2020 (v3.0) 数据集上的最佳结果。前两名团队是该挑战赛的冠亚军。我们的 T2G.CE 模型在所有匹配方案的所有指标上均有提升,为该挑战任务提供了新的最先进结果。T2G.RL 模型虽然仍优于之前的最佳结果,但未超越其 CE 版本。
| 团队/模型 | 指标 | 值1 | 值2 | 值3 |
|---|---|---|---|---|
| Amazon AI (Shanghai) (Guo et al., 2020a) | Exact | 0.689 | 0.689 | 0.690 |
| Ent_Type | 0.700 | 0.699 | 0.701 | |
| Partial | 0.696 | 0.696 | 0.698 | |
| Strict | 0.686 | 0.686 | 0.687 | |
| bt5 (Agarwal et al., 2020) | Exact | 0.682 | 0.670 | 0.701 |
| Ent_Type | 0.737 | 0.721 | 0.762 | |
| Partial | 0.713 | 0.700 | 0.736 | |
| Strict | 0.675 | 0.663 | 0.695 | |
| ReGen (Ours) T2G.CE | Exact | 0.723 | 0.714 | 0.738 |
| Ent_Type | 0.807 | 0.791 | 0.835 | |
| Partial | 0.767 | 0.755 | 0.788 | |
| Strict | 0.720 | 0.713 | 0.735 | |
| ReGen (Ours) T2G.RL | Exact | 0.720 | 0.712 | 0.734 |
| Ent_Type | 0.804 | 0.789 | 0.829 | |
| Partial | 0.764 | 0.752 | 0.784 | |
| Strict | 0.717 | 0.709 | 0.731 |
5 Results
5 结果
For all experiments, PLMs were first exposed to the target datasets $(\mathrm{WebNLG+}$ , TEKGEN) by finetuning using $\mathcal{L}{\mathrm{CE}}$ loss. They were then switched to RL training by optimizing the $\mathcal{L}_{\mathrm{scs{T}}}$ loss. Although no exact recipe has been established for Seq2Seq RL-training, starting from a good CE model helps RL training performance in practice (Ranzato et al., 2016; Rennie et al., 2017). There- fore, we followed the subsequent simple approach: During fine-tuning, the evaluations are conducted on the validation set. From the CE phase, the best performing model iteration is selected based on the METEOR and F1 score for the G2T and T2G tasks, respectively, to pursue RL fine-tuning. In case of G2T, potential ties in METEOR scores among candidate models, are resolved by using BLEU_NLTK, followed by the $\mathrm{chrF++}$ metric. Note that early stopping selection of CE models led to good performance for t5-base models as well. During the SCST phase, the best model iteration on the validation set is selected and its performance numbers on the test set are reported in our tables.
在所有实验中,预训练语言模型(PLM)首先通过微调使用$\mathcal{L}{\mathrm{CE}}$损失函数接触目标数据集$(\mathrm{WebNLG+}$和TEKGEN)。随后切换至强化学习训练,优化$\mathcal{L}_{\mathrm{scs{T}}}$损失函数。尽管序列到序列(Seq2Seq)的强化学习训练尚未确立精确方案,但实践中从优质交叉熵(CE)模型出发有助于提升强化学习训练性能(Ranzato等人,2016;Rennie等人,2017)。因此我们采用以下简单策略:微调阶段在验证集进行评估,分别根据G2T任务的METEOR分数和T2G任务的F1分数,从CE阶段选择最佳模型迭代进行RL微调。对于G2T任务,若候选模型METEOR分数出现平局,则依次使用BLEU_NLTK和$\mathrm{chrF++}$指标决断。值得注意的是,CE模型的早停策略对t5-base模型同样表现良好。在SCST阶段,我们选择验证集上表现最佳的模型迭代,并在表格中报告其测试集性能指标。
WebNLG $^+$ 2020 G2T For the ${\mathrm{WebNLG}}+2$ 020 Challenge, the results of the top four systems for RDF-to-text task can be found in Tab. 1 for all categories (results for seen and unseen categories are given in Tab. 5 in the Appendix), while descriptions the top teams’ systems were given in Section 2. We report our G2T results for both t5-large and t5- base models as well. For t5-large, ReGen G2T.CE is the best model from CE fine-tuning. ReGen G2T.RL is best model performance for SCST training while using METEOR as reward when starting from G2T.CE model. Tab. 1 shows that our CE model is better than models from all top teams, and the SCST results further improve significantly in all metrics achieving state-of-the-art results to our knowledge. The gain obtained by SCST alone is quite significant and demonstrates the benefits of RL fine-tuning for this task. While we report our best model results in Tab. 1, we also report mean and standard deviation results for multiple random number generator seeds in Tab. 10 in Appendix.
WebNLG$^+$ 2020 G2T
关于${\mathrm{WebNLG}}+2020$挑战赛,RDF到文本任务中前四名系统的结果可在表1中查看所有类别(已见和未见类别结果见附录表5),而顶尖团队系统的描述见第2节。我们还报告了t5-large和t5-base模型的G2T结果。对于t5-large,ReGen G2T.CE是通过CE微调得到的最佳模型。ReGen G2T.RL是从G2T.CE模型开始、使用METEOR作为奖励进行SCST训练时的最佳性能模型。表1显示,我们的CE模型优于所有顶尖团队的模型,且SCST结果在所有指标上均显著提升,达到了当前最先进水平。仅SCST带来的增益就非常显著,证明了RL微调对此任务的优势。尽管我们在表1中报告了最佳模型结果,但附录表10中还提供了多个随机数生成器种子的均值和标准差结果。
Table 3: G2T Results for TEKGEN dataset. ReGen-CE establishes a baseline on this dataset. ReGen-SCST consistently improve on the baseline on all metrics, for validation and test sets.
| TEKGEN G2T模型 | BLEU↑ | BLEU↑ NLTK | METEOR↑ | chrF++↑ |
|---|---|---|---|---|
| ReGen-CE | Val | 0.240 | 0.241 | 0.231 |
| Test | 0.241 | 0.242 | 0.233 | |
| ReGen-SCST | Val | 0.258 | 0.259 | 0.240 |
| Test | 0.262 | 0.262 | 0.242 |
表 3: TEKGEN数据集的G2T结果。ReGen-CE在该数据集上建立了基线指标。ReGen-SCST在验证集和测试集的所有指标上均持续超越基线表现。
Even in averaging results of various seeded models, we see a sustained gain from SCST for CE models in all metrics.
在不同种子模型的结果平均中,我们观察到SCST在所有指标上为CE模型带来的持续增益。
Multiple reward candidates were investigated (BLEU, BLEU_NLTK, METEOR, chrF) as well as some linear combinations of pairs of them, as can be seen in Tab. 7 in Appendix. In Tab. 7, for t5-large, METEOR is consistently the best SCST reward, and improves all the other metrics scores as well. However, for ‘smaller’ models such as t5-base, BLEU_NLTK is revealed to be the best reward for improving BLEU performance as expected. Again, SCST brings significant gains across all the metrics in that case. Note that for t5-base model, selecting a METEOR reward improves METEOR results significantly as reported in Tab. 9 in Appendix.
研究了多种奖励候选方案(BLEU、BLEU_NLTK、METEOR、chrF)以及它们的线性组合,详见附录表7。在表7中,对于t5-large模型,METEOR始终是最佳SCST奖励,同时也能提升其他所有指标得分。然而对于t5-base等"较小"模型,BLEU_NLTK如预期所示成为提升BLEU性能的最佳奖励。在此情况下,SCST同样为所有指标带来显著增益。需注意的是,如附录表9所示,对t5-base模型选择METEOR奖励可显著提升METEOR结果。
Another interesting fact is that early stopping of CE model G2T.CE.ES (at 5 epochs) leads to the best SCST model G2T.RL.ES for t5-base, while selecting the best CE model G2T.CE.best (at 11 epochs) still showed some gains from SCST model G2T.RL.best. SCST needs a good starting point, but a better CE model that has seen a lot more epochs of our dataset maybe harder for SCST to stir in a better solution in the parameter space. Moreover, the test split contains unseen categories not present in the validation dataset which render choices based on validation sub-optimal for the test dataset. The best models we report in this work are specialized models $\mathcal{M}_{\mathrm{G}}$ . Early in our investigation, hybrid models were the best performing model for G2T reaching 0.547 BLEU, 0.543 BLEU_NLTKand 0.417 METEOR, and first to beat the Challenge winning team. However, when batch size became larger (20-24 samples), the specialized models took the lead and retain it still.
另一个有趣的现象是,对于t5-base模型,提前停止CE模型G2T.CE.ES(在第5轮)会得到最佳的SCST模型G2T.RL.ES,而选择最佳CE模型G2T.CE.best(在第11轮)仍能从SCST模型G2T.RL.best中获得一些提升。SCST需要一个良好的起点,但对于已经在我们数据集上训练过多轮的更优CE模型,SCST可能更难在参数空间中找到一个更好的解决方案。此外,测试集包含验证集中未出现的类别,这使得基于验证集的选择对测试集来说并非最优。本工作中报告的最佳模型是专用模型$\mathcal{M}_{\mathrm{G}}$。在我们研究的早期阶段,混合模型在G2T任务中表现最佳,达到了0.547 BLEU、0.543 BLEU_NLTK和0.417 METEOR,并首次超越了挑战赛的获胜团队。然而,当批量增大(20-24个样本)时,专用模型开始领先并保持优势至今。
For training, we optimized all our models using AdamW (Loshchilov and Hutter, 2017), vari- ant of the Adam optimizer with default values of $\beta=[0.9,0.999]$ and weight decay of $10^{-2}$ . For learning rate, we used $5.10^{-6}$ for all our experiments as it was better than $10^{-5}$ and $10^{-6}$ as seen in Tab. 8 in Appendix. All our models were trained with 20-24 minibatch size on WebNLG. Further details on our experimental setup are provided in the Appendix in Section A.
在训练过程中,我们使用AdamW优化器(Loshchilov和Hutter,2017)对所有模型进行优化,这是Adam优化器的一个变体,默认参数为$\beta=[0.9,0.999]$,权重衰减为$10^{-2}$。学习率统一设置为$5.10^{-6}$,如附录表8所示,该值优于$10^{-5}$和$10^{-6}$。所有模型在WebNLG数据集上训练时采用20-24的迷你批次大小。更多实验设置细节详见附录A节。
$\mathbf{WebNLG}+2\mathbf{0}2\mathbf{0}$ T2G Results for the Text-to-RDF task are reported in Tab. 2 for all categories. Results for our best model on seen and unseen categories are given in Tab. 6 in Appendix. AmazonAI and bt5 are the top performing teams. Again, the proposed ReGen T2G.CE model shows strong results that are better in term of all metrics, for all matching categories. In themselves, these numbers are a defacto new state-of-the-art for this dataset, as far as we know. SCST model T2G.RL fails to improve on this model though. The exact $F l$ metric was used as reward, but the model could never pull ahead of the CE model in our experiments. The exact F1 metric may not be a strong enough reward to really capture the dynamics of graph generation properly for ${\mathrm{WebNLG+}}$ as it is very rigid in its measure (one must have an exact match), although the same reward gave good results on our second dataset TEKGEN. A more sensitive metric could possibly help. We even tried to use n-gram based metrics (like BLEU) but to no avail. We further address this issue at the end on this Section.
$\mathbf{WebNLG}+2\mathbf{0}2\mathbf{0}$
文本到RDF任务的T2G结果如表2所示,涵盖所有类别。附录表6展示了我们最佳模型在已见和未见类别上的表现。AmazonAI和bt5是表现最优异的团队。同样,我们提出的ReGen T2G.CE模型在所有匹配类别上均展现出优于各项指标的强劲结果。据我们所知,这些数值本身已成为该数据集事实上的新最优水平。然而,SCST模型T2G.RL未能超越该模型。虽然采用了精确的$Fl$指标作为奖励,但在实验中该模型始终无法超越CE模型。对于${\mathrm{WebNLG+}}$而言,精确F1指标可能不足以有效捕捉图生成的动态特性(因其衡量标准极为严格,要求完全匹配),尽管同一奖励机制在第二个数据集TEKGEN上取得了良好效果。更灵敏的指标或许能改善此情况。我们甚至尝试了基于n-gram的指标(如BLEU),但未获成功。本节末尾我们将进一步探讨该问题。
TEKGEN G2T For the TEKGEN dataset, we present our results on Graph-to-Text generation in Tab. 3. Similar to the experiments in WebNLG+, we pick the best model during the CE fine-tuning based on the METEOR score and proceed with the RL fine-tuning. We observe that the RL fine-tuning step helps boost the test split scores on all metrics. It is worth noting that the scores are slightly underestimating the potential of our system because of the nature of the sentences in the TEKGEN dataset. Unlike WebNLG+, in a paired text-graph sample in TEKGEN, the linearized graph does not usually cover all the concepts described in the corresponding text. This leads to underestimating when the hypothesis is scored against the reference using n-gram metrics.
TEKGEN G2T
对于TEKGEN数据集,我们在表3中展示了图到文本生成( Graph-to-Text )的结果。与WebNLG+实验类似,我们根据METEOR分数在CE微调阶段选择最佳模型,然后进行RL微调。我们观察到RL微调步骤有助于提升所有指标在测试集上的分数。值得注意的是,由于TEKGEN数据集中句子的特性,这些分数略微低估了我们系统的潜力。与WebNLG+不同,在TEKGEN的配对文本-图样本中,线性化图通常不会覆盖对应文本描述的所有概念。这导致使用n-gram度量将假设文本与参考文本进行对比评分时会出现低估现象。
TEKGEN T2G Results for the Text-to-Graph for TEKGEN are reported in Tab. 4. Once the CE finetuning is done, we continue with the RL fine-tuning using exact F1 as reward. The performance is consistent with what we observe in G2T task for TEKGEN, where SCST step boosts the performance of the model. Since, we reformulate this dataset (refer Section 4.1) to offer as T2G and G2T tasks, our approach is the first attempt in understanding the nature of TEKGEN dataset and our methods provide a baseline for future research. Please note that for both T2G and G2T tasks in TEKGEN, we only start a t5-large PLM.
TEKGEN 文本到图(T2G)的结果如表 4 所示。完成交叉熵(CE)微调后,我们继续使用精确 F1 作为奖励进行强化学习(RL)微调。性能表现与我们在 TEKGEN 的图到文本(G2T)任务中观察到的结果一致,其中 SCST 步骤提升了模型性能。由于我们将该数据集重新构建(参见第 4.1 节)为 T2G 和 G2T 任务,我们的方法是首次尝试理解 TEKGEN 数据集的性质,并为未来研究提供了基线。请注意,对于 TEKGEN 中的 T2G 和 G2T 任务,我们仅启动了 t5-large 预训练语言模型(PLM)。
Table 4: T2G TEKGEN Results: ReGen-CE establishes a baseline of the dataset. ReGen-SCST improves results on the test set compared to ReGen-CE.
| T2G Model | F1↑ | P↑ | R↑ |
| Val ReGen-CE | 0.622 Test 0.619 | 0.608 0.605 | 0.647 0.643 |
| ReGen-SCST | Val Test | 0.615 0.600 0.623 0.610 | 0.640 0.647 |
表 4: T2G TEKGEN 结果: ReGen-CE 建立了数据集的基线。与 ReGen-CE 相比,ReGen-SCST 在测试集上提升了结果。
| T2G 模型 | F1↑ | P↑ | R↑ |
|---|---|---|---|
| Val ReGen-CE | 0.622 Test 0.619 | 0.608 0.605 | 0.647 0.643 |
| ReGen-SCST | Val Test | 0.615 0.600 0.623 0.610 | 0.640 0.647 |
Summary Results on $\mathrm{WebNLG}+2020$ and TEKGEN demonstrated that RL fine-tuning of models leads to significant improvements of results for T2G and G2T, establishing new state-of-the-art results for both tasks. For ${\mathrm{WebNLG+}}$ , T2G was a challenging task for RL fine-tuning. In further work, we plan to address this issue by investigating two points: First, look into a more sensible graphdependent sampling for graph structures, rather than the current multi no mi al sampling of the best tokens at each generation step. Second, try a different reward schemes where the reward is more attuned to the challenges of graph generation as well as graph structure, allowing for some curriculum learning, or increasing the harshness of rewards gradually during training. Results on TEKGEN showed that RL fine-tuning is a viable option even on large-scale datasets. To enrich this quantitative study of ReGen, we provide a few qualitative cherry picked results in Tab. 11 and Tab. 12 in Appendix.
在$\mathrm{WebNLG}+2020$和TEKGEN上的汇总结果表明,模型的强化学习(RL)微调显著提升了文本到图(T2G)和图到文本(G2T)任务的性能,为两项任务创造了新的最优结果。对于${\mathrm{WebNLG+}}$数据集,T2G任务对RL微调具有挑战性。后续工作中,我们计划通过以下两点解决该问题:首先,研究更合理的图结构依赖采样方法,替代当前每一步生成时对最佳token的多项式采样;其次,尝试改进奖励机制,使其更适配图生成与图结构的特性,支持课程学习或在训练中逐步提高奖励严格度。TEKGEN的实验证明,即使在大规模数据集上,RL微调仍是可行方案。为补充ReGen的定量分析,我们在附录表11和表12中提供了精选的定性结果案例。
6 Conclusions
6 结论
In this paper, we proposed to use RL for improving upon current generation for text-to-graph and graph-to-text tasks for the $\mathrm{WebNLG}+2020$ Challenge dataset using pre-trained LMs. We not only defined a novel Seq2Seq training of models in T2G and G2T generation tasks, but we established stateof-the-art results for ${\mathrm{WebNLG+}}$ for both tasks, significantly improving on the previously published results. We provided extensive analyses of our results and of the steps taken to reach these improvements. We then expanded our approach to large scale training by means of TEKGEN where we demonstrated that RL fine-tuning provides a robust way to improve upon regular model finetuning within a dataset that is orders of magnitude larger than the ${\mathrm{WebNLG+}}$ starting point. We established gains despite a weaker content overlap in text-graph data pairs for TEKGEN. Along the way, we constructed subject, and relation-object boundaries from TEKGEN sentence-triples pairs that we plan on releasing to benefit the research community.
本文提出使用强化学习(RL)改进预训练语言模型在$\mathrm{WebNLG}+2020$挑战数据集上的文本到图(T2G)和图到文本(G2T)任务生成效果。我们不仅定义了T2G和G2T生成任务中新颖的Seq2Seq模型训练方法,还在${\mathrm{WebNLG+}}$数据集上为两项任务建立了最先进的结果,显著超越了先前发表的研究成果。我们对实验结果及实现这些改进的具体步骤进行了全面分析。随后通过TEKGEN项目将方法扩展至大规模训练,证明在比${\mathrm{WebNLG+}}$初始数据集大数个数量级的场景下,RL微调能有效提升常规模型微调效果。尽管TEKGEN中文本-图数据对的内容重叠度较低,我们仍实现了性能提升。在此过程中,我们从TEKGEN的句子-三元组对中构建了主语和关系-宾语边界,计划公开这些资源以促进研究社区发展。
Future work will focus on developing a variant of SCST that leverages the unique structure of graph by either performing of more sensible graphdependent sampling, or by investigating different reward schemes more attuned to integrating the content and structure of graphs.
未来工作将重点开发SCST的一种变体,通过执行更合理的图依赖采样或研究更适合整合图内容与结构的奖励方案,来利用图的独特结构。
References
参考文献
Oshin Agarwal, Heming Ge, Siamak Shakeri, and Rami Al-Rfou. 2021. Knowledge graph based synthetic corpus generation for knowledge-enhanced language model pre-training.
Oshin Agarwal、Heming Ge、Siamak Shakeri 和 Rami Al-Rfou。2021. 基于知识图谱的合成语料生成技术用于知识增强型语言模型预训练。
Oshin Agarwal, Mihir Kale, Heming Ge, Siamak Shakeri, and Rami Al-Rfou. 2020. Machine translation aided bilingual data-to-text generation and se- mantic parsing. In Proceedings of the 3rd International Workshop on Natural Language Generation from the Semantic Web (WebNLG+), pages 125–130, Dublin, Ireland (Virtual). Association for Computational Linguistics.
Oshin Agarwal、Mihir Kale、Heming Ge、Siamak Shakeri和Rami Al-Rfou。2020。机器翻译辅助的双语数据到文本生成及语义解析。见《第三届语义网自然语言生成国际研讨会论文集》(WebNLG+),第125–130页,爱尔兰都柏林(线上)。计算语言学协会。
Thiago Castro Ferreira, Claire Gardent, Nikolai Ilinykh, Chris van der Lee, Simon Mille, Diego Moussallem, and Anastasia Shimorina. 2020a. The 2020 bilingual, bi-directional WebNLG $^+$ shared task: Overview and evaluation results (WebNLG $^+$ 2020). In Proceedings of the 3rd International Workshop on Natural Language Generation from the Semantic Web $(W e b N L G+,$ , pages 55–76, Dublin, Ireland (Virtual). Association for Computational Linguistics.
Thiago Castro Ferreira、Claire Gardent、Nikolai Ilinykh、Chris van der Lee、Simon Mille、Diego Moussallem和Anastasia Shimorina。2020a。2020年双语双向WebNLG$^+$共享任务:概述与评估结果(WebNLG$^+$2020)。载于第三届语义网自然语言生成国际研讨会论文集$(WebNLG+$,第55-76页,爱尔兰都柏林(线上)。计算语言学协会。
Thiago Castro Ferreira, Claire Gardent, Nikolai Ilinykh, Chris van der Lee, Simon Mille, Diego Moussallem, and Anastasia Shimorina, editors. 2020b. Proceedings of the 3rd International Workshop on Natural Language Generation from the Semantic Web $(W e b N L G+,$ ). Association for Computational Linguistics, Dublin, Ireland (Virtual).
Thiago Castro Ferreira、Claire Gardent、Nikolai Ilinykh、Chris van der Lee、Simon Mille、Diego Moussallem和Anastasia Shimorina编。2020b。《第三届语义网自然语言生成国际研讨会论文集》(WebNLG+)。计算语言学协会,爱尔兰都柏林(线上)。
Yu Chen, Lingfei Wu, and Mohammed J. Zaki. 2020. Reinforcement learning based graph-to-sequence model for natural question generation. In International Conference on Learning Representations.
Yu Chen、Lingfei Wu和Mohammed J. Zaki。2020。基于强化学习的图到序列模型用于自然问题生成。见于国际学习表征会议。
Pierre Dognin, Igor Melnyk, Inkit Padhi, Cicero Nogueira dos Santos, and Payel Das. 2020. Du- alTKB: A Dual Learning Bridge between Text and Knowledge Base. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 8605–8616, Online. Association for Computational Linguistics.
Pierre Dognin、Igor Melnyk、Inkit Padhi、Cicero Nogueira dos Santos 和 Payel Das。2020。DualTKB:文本与知识库间的双重学习桥梁。在《2020年自然语言处理实证方法会议论文集》(EMNLP)中,第8605–8616页,线上。计算语言学协会。
Qipeng Guo, Zhijing Jin, Ning Dai, Xipeng Qiu, Xiangyang Xue, David Wipf, and Zheng Zhang. 2020a. √2: A plan-and-pretrain approach for knowledge graph-to-text generation. In Proceedings of the 3rd International Workshop on Natural Language Generation from the Semantic Web (WebNLG+), pages 100–106, Dublin, Ireland (Virtual). Association for Computational Linguistics.
Qipeng Guo、Zhijing Jin、Ning Dai、Xipeng Qiu、Xiangyang Xue、David Wipf 和 Zheng Zhang。2020a。√2:一种用于知识图谱到文本生成的规划与预训练方法。见第三届语义网自然语言生成国际研讨会论文集 (WebNLG+),第100–106页,爱尔兰都柏林(线上)。计算语言学协会。
Qipeng Guo, Zhijing Jin, Xipeng Qiu, Weinan Zhang, David Wipf, and Zheng Zhang. 2020b. CycleGT: Unsupervised graph-to-text and text-to-graph generation via cycle training. In Proceedings of the 3rd Inter national Workshop on Natural Language Generation from the Semantic Web $(W e b N L G+,$ ), pages 77– 88, Dublin, Ireland (Virtual). Association for Computational Linguistics.
Qipeng Guo、Zhijing Jin、Xipeng Qiu、Weinan Zhang、David Wipf 和 Zheng Zhang。2020b。CycleGT:通过循环训练实现无监督的图到文本和文本到图生成。载于第三届语义网自然语言生成国际研讨会论文集$(WebNLG+$,),第77–88页,爱尔兰都柏林(线上)。计算语言学协会。
Alon Lavie and Abhaya Agarwal. 2007. METEOR: An automatic metric for MT evaluation with high levels of correlation with human judgments. In Proceedings of the Second Workshop on Statistical Machine Translation, pages 228–231, Prague, Czech Republic. Association for Computational Linguistics.
Alon Lavie和Abhaya Agarwal。2007。METEOR:一种与人工评估高度相关的机器翻译自动评估指标。在《第二届统计机器翻译研讨会论文集》中,第228–231页,捷克共和国布拉格。计算语言学协会。
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghaz vi nine j ad, Abdel rahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Z ett le moyer. 2020. BART: Denoising sequence-to-sequence pretraining for natural language generation, translation, and comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7871–7880, Online. Association for Computational Linguistics.
Mike Lewis、Yinhan Liu、Naman Goyal、Marjan Ghazvininejad、Abdelrahman Mohamed、Omer Levy、Veselin Stoyanov 和 Luke Zettlemoyer。2020。BART:用于自然语言生成、翻译和理解的去噪序列到序列预训练。载于《第58届计算语言学协会年会论文集》,第7871–7880页,线上会议。计算语言学协会。
Xintong Li, Aleksandre Mask hara sh vili, Symon Jory Stevens-Guille, and Michael White. 2020. Leveraging large pretrained models for WebNLG 2020. In Proceedings of the 3rd International Workshop on Natural Language Generation from the Semantic Web $(W e b N L G+,$ , pages 117–124, Dublin, Ireland (Virtual). Association for Computational Linguistics.
Xintong Li、Aleksandre Mask hara sh vili、Symon Jory Stevens-Guille 和 Michael White。2020。利用大型预训练模型实现 WebNLG 2020。载于《第三届语义网自然语言生成国际研讨会论文集》$(WebNLG+$),第117–124页,爱尔兰都柏林(线上)。计算语言学协会。
Ilya Loshchilov and Frank Hutter. 2017. Fixing weight decay regular iz ation in adam. CoRR, abs/1711.05101.
Ilya Loshchilov and Frank Hutter. 2017. 修复Adam中的权重衰减正则化。CoRR, abs/1711.05101.
Ruotian Luo. 2020. A better variant of self-critical sequence training.
罗若天. 2020. 自关键序列训练的改进变体.
San Pa Pa Aung, Win Pa Pa, and Tin Lay Nwe. 2020. Automatic Myanmar image captioning using CNN and LSTM-based language model. In Proceedings of the 1st Joint Workshop on Spoken Language Technologies for Under-resourced languages (SLTU) and Collaboration and Computing for Under-Resourced Languages (CCURL), pages 139–143, Marseille, France. European Language Resources association.
San Pa Pa Aung、Win Pa Pa和Tin Lay Nwe。2020。基于CNN与LSTM语言模型的缅甸语图像自动描述生成。见《第一届资源稀缺语言语音技术联合研讨会(SLTU)暨资源稀缺语言协作计算会议(CCURL)论文集》,第139-143页,法国马赛。欧洲语言资源协会。
Maja Popovic. 2017. chrF $^{++}$ : words helping character n-grams. In Proceedings of the Second Conference on Machine Translation, pages 612–618, Copenhagen, Denmark. Association for Computational Linguistics.
Maja Popovic. 2017. chrF$^{++}$: 字符n元词组的辅助词语。载于第二届机器翻译会议论文集,第612-618页,丹麦哥本哈根。计算语言学协会。
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer.
Colin Raffel、Noam Shazeer、Adam Roberts、Katherine Lee、Sharan Narang、Michael Matena、Yanqi Zhou、Wei Li 和 Peter J. Liu。2020。探索迁移学习的极限:基于统一文本到文本Transformer的研究。
Marc’Aurelio Ranzato, Sumit Chopra, Michael Auli, and Wojciech Zaremba. 2016. Sequence level training with recurrent neural networks.
Marc’Aurelio Ranzato、Sumit Chopra、Michael Auli 和 Wojciech Zaremba。2016。基于循环神经网络的序列级训练。
Steven J Rennie, Etienne Marcheret, Youssef Mroueh, Jerret Ross, and Vaibhava Goel. 2017. Self-critical sequence training for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7008–7024.
Steven J Rennie、Etienne Marcheret、Youssef Mroueh、Jerret Ross 和 Vaibhava Goel。2017. 图像描述生成的自关键序列训练。见《IEEE计算机视觉与模式识别会议论文集》,第7008-7024页。
Leonardo F. R. Ribeiro, Martin Schmitt, Hinrich Schütze, and Iryna Gurevych. 2020. Investigating pretrained language models for graph-to-text generation.
Leonardo F. R. Ribeiro、Martin Schmitt、Hinrich Schütze 和 Iryna Gurevych。2020。探究预训练语言模型在图到文本生成中的应用。
Richard S. Sutton and Andrew G. Barto. 2018. Reinforcement Learning: An Introduction. A Bradford Book, Cambridge, MA, USA.
Richard S. Sutton 和 Andrew G. Barto. 2018. 强化学习: 导论. A Bradford Book, 剑桥, 马萨诸塞州, 美国.
Ronald J Williams. 1992. Simple statistical gradientfollowing algorithms for connection is t reinforcement learning. Machine learning, 8(3-4):229–256.
Ronald J Williams. 1992. 用于连接主义强化学习的简单统计梯度跟随算法. Machine learning, 8(3-4):229–256.
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pier- ric Cistac, Tim Rault, Remi Louf, Morgan Funtow- icz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander Rush. 2020. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 38–45, Online. Association for Computational Linguistics.
Thomas Wolf、Lysandre Debut、Victor Sanh、Julien Chaumond、Clement Delangue、Anthony Moi、Pier-ric Cistac、Tim Rault、Remi Louf、Morgan Funtowicz、Joe Davison、Sam Shleifer、Patrick von Platen、Clara Ma、Yacine Jernite、Julien Plu、Canwen Xu、Teven Le Scao、Sylvain Gugger、Mariama Drame、Quentin Lhoest 和 Alexander Rush。2020。Transformer:最先进的自然语言处理技术。载于《2020年自然语言处理实证方法会议:系统演示论文集》,第38-45页,线上。计算语言学协会。
Zixiaofan Yang, Arash E in ol gh oz at i, Hakan Inan, Keith Diedrick, Angela Fan, Pinar Donmez, and Sonal Gupta. 2020. Improving text-to-text pretrained models for the graph-to-text task. In Proceedings of the 3rd International Workshop on Natural Language Generation from the Semantic Web $(W e b N L G+,$ , pages 107–116, Dublin, Ireland (Virtual). Association for Computational Linguistics.
Zixiaofan Yang、Arash Einolghozati、Hakan Inan、Keith Diedrick、Angela Fan、Pinar Donmez 和 Sonal Gupta。2020。改进图到文本任务的文本到文本预训练模型。在第三届语义网自然语言生成国际研讨会论文集 $(WebNLG+$,第107–116页,爱尔兰都柏林(线上)。计算语言学协会。
A Training Setup
训练设置
All our experiments were run using NVIDIA V100 GPUs for training and validation, some trainings were done on A100. We distributed our training to 2-4 GPUs depending on availability. Each training epoch for CE ranged from 30 minutes to 1 hour depending on number of GPUs utilized.
我们所有的实验均使用NVIDIA V100 GPU进行训练和验证,部分训练在A100上完成。根据资源可用性,我们将训练任务分配到2-4块GPU上。每次CE训练的周期时长在30分钟至1小时之间,具体取决于所使用的GPU数量。
Validation and testing (1,779 and 2,155 samples for testA and testB of $\mathrm{WebNLG}+2020),$ lasted from 40 minutes to 1 hour depending on machines. Computation was dominated by beam search generation as we used beam search with beam size of 5 and a max sequence length of 192 (since linearized graph sequence can be quite long). We used the official scoring scripts released by WebNLG+ 2020 Challenge to score all our experiments. The evaluation of graph being the most computationally expensive as all possible matching combinations are tested in what looks like a factorial complexity, taking scoring of set of triples larger than 8 from impractical to not feasible.
验证与测试 (WebNLG+2020的testA和testB分别包含1,779和2,155个样本) 耗时40分钟至1小时不等,具体取决于机器性能。计算时间主要消耗在束搜索(beam search)生成阶段,我们使用了束宽为5、最大序列长度为192的束搜索(因线性化图序列可能较长)。所有实验均采用WebNLG+ 2020挑战赛官方发布的评分脚本进行评估。其中图结构的评估计算成本最高,由于需要测试所有可能的匹配组合(呈现阶乘级复杂度),当三元组数量超过8时,评分从难以实现变为完全不可行。
All our models were built using PyTorch. Total effective batch sizes were set to either 20 or 24 samples for our distributed training. We adjusted the batch size on each worker to ensure consistent global batch size of 20 or 24.
我们的所有模型均采用PyTorch语言构建。分布式训练的总有效批次大小设置为20或24个样本。我们调整了每个工作节点上的批次大小,以确保全局批次大小始终保持在20或24。
We did some search on learning rates for t5- large training and SCST rewards, see discussion and results in Section C.
我们对 T5-large 训练和 SCST 奖励的学习率进行了一些搜索,具体讨论和结果见附录 C。
All our trainings have a seeded random number generator for reproducibility. We also report results on $\mathrm{WebNLG}+2020\mathrm{G}2\mathrm{T}$ tasks for each training setup by showing results for 3 models from different seeds, and provide means and standard deviations of these results in Tab. 10.
我们的所有训练都使用固定种子的随机数生成器以确保可复现性。我们还通过展示不同种子训练的3个模型结果,报告了每个训练设置在$\mathrm{WebNLG}+2020\mathrm{G}2\mathrm{T}$任务上的表现,并在表10中提供了这些结果的均值和标准差。
B WebNLG $^+$ 2020 Results per Categories for Best G2T and T2G Models
B WebNLG$^+$ 2020 年最佳 G2T 和 T2G 模型按类别结果
In Tab. 5, we are reporting results for all ${\mathrm{WebNLG+}}$ 2020 categories for our best CE and RL models. While results for unseen categories are much worse than for seen categories, RL fine-tuning manages to improve on both seen and unseen categories.
在表5中,我们展示了最佳CE和RL模型在${\mathrm{WebNLG+}}$ 2020所有类别上的结果。虽然未见类别的结果远逊于已见类别,但RL微调在已见和未见类别上均实现了性能提升。
Tab. 6 provides results for seen, unseen and all categories for our best CE model ReGen T2G.CE which established state-of-the-art results on T2G task of ${\mathrm{WebNLG+}}$ 2020 Challenge dataset.
表 6 展示了我们最佳 CE 模型 ReGen T2G.CE 在已见类别、未见类别及所有类别上的结果,该模型在 ${\mathrm{WebNLG+}}$ 2020 挑战赛数据集的 T2G 任务中取得了最先进的成果。
C Ablation Studies
C 消融实验
In Tables 7 and 8 we present ablation studies of different optimized metrics and learning rates for SCST training. As can be seen from Table 7, when METEOR is used as a reward, we get the best performance across all the metrics. We also tried using a combination of multiple rewards with different scaling but did not get any gain over the single metric rewards. In Table 8. we also show the effect of learning rate on SCST performance. Using $l r=5\cdot10^{-6}$ gave us the best performance, while higher rates, such as $10^{-4}$ , led to unstable training and collapse of SCST.
在表7和表8中,我们展示了SCST训练中不同优化指标和学习率的消融研究。从表7可以看出,当使用METEOR作为奖励时,我们在所有指标上获得了最佳性能。我们还尝试了结合多种不同缩放的奖励,但未获得比单一指标奖励更好的效果。在表8中,我们还展示了学习率对SCST性能的影响。使用$lr=5\cdot10^{-6}$时获得了最佳性能,而较高的学习率(如$10^{-4}$)会导致训练不稳定和SCST崩溃。
D G2T Results t5-base models for SCST with METEOR Reward
D G2T SCST 采用 METEOR 奖励的 t5-base 模型结果
Results for SCST fine-tuning of t5-base models using a METEOR reward are compiled in Tab. 9. Clearly, these models achieve better METEOR results as expected since they are RL optimzed on this metric.
表 9 汇总了使用 METEOR 奖励对 t5-base 模型进行 SCST 微调的结果。显然,这些模型如预期那样取得了更好的 METEOR 分数,因为它们是针对该指标进行强化学习优化的。
E G2T Results for Models from Multiple Random Seeds
多随机种子模型的 E G2T 结果
All our training have a seeded random number generator for reproducibility. We also report the mean and standard deviations for all our G2T models. Each model setup was run 3 times using three independent and distinct seeds, following the same exact process. This is to ensure that our results are not just the product of a lucky system configuration or otherwise advantageous random shuffling of our training dataset. The gain reported between CE and RL for our t5-large models are clearly still showing after average of all 3 models from distinct random seeds. For t5-base, gains between CE and RL are still present, albeit smaller than for our best systems.
我们的所有训练都使用带种子的随机数生成器以确保可复现性。同时报告了所有G2T模型的平均值和标准差。每个模型配置均使用三个独立不同的种子重复运行三次,遵循完全相同的流程。这种做法旨在确保实验结果并非源于幸运的系统配置或训练数据集的有利随机排序。在不同随机种子的三个模型取平均后,t5-large模型在交叉熵(CE)与强化学习(RL)间的性能增益仍然显著。对于t5-base模型,CE与RL间的增益虽然小于最优系统,但依然存在。
F Processed TEKGEN Dataset
F 处理后的TEKGEN数据集
In Fig. 3 we show an example of our processing of TEKGEN dataset in establishing subject, relation, object boundaries. This enables both training and evaluating systems for T2G and G2T tasks.
在图3中,我们展示了处理TEKGEN数据集时确立主语、关系、宾语边界的示例。这为T2G和G2T任务的系统训练与评估提供了支持。
Table 5: G2T: Results for seen, unseen, and all categories subsets in $\mathrm{WebNLG}+2020$ Challenge Test dataset. As expected, unseen categories much worse results than for seen categories. RL fine-tuning manages to improve on both seen and unseen categories.
| WebNLGG2TBestModels | Category | BLEU↑ | BLEU↑ NLTK | METEOR↑ | chrF++↑ |
| Ours t5-large ReGen-CE | unseen | 48.76 | 0.489 | 0.397 | 0.653 |
| seen | 59.73 | 0.592 | 0.433 | 0.722 | |
| all | 55.26 | 0.549 | 0.418 | 0.694 | |
| Ours t5-large ReGen-SCST | unseen | 49.06 | 0.493 | 0.404 | 0.665 |
| seen | 61.22 | 0.605 | 0.440 | 0.734 | |
| all | 56.25 | 0.559 | 0.425 | 0.706 |
表 5: G2T: $\mathrm{WebNLG}+2020$ 挑战测试数据集中已见类别、未见类别及全部类别子集的结果。与预期一致,未见类别的结果远逊于已见类别。RL (强化学习) 微调成功提升了已见和未见类别的表现。
| WebNLGG2TBestModels | Category | BLEU↑ | BLEU↑ NLTK | METEOR↑ | chrF++↑ |
|---|---|---|---|---|---|
| Ours t5-large ReGen-CE | unseen | 48.76 | 0.489 | 0.397 | 0.653 |
| seen | 59.73 | 0.592 | 0.433 | 0.722 | |
| all | 55.26 | 0.549 | 0.418 | 0.694 | |
| Ours t5-large ReGen-SCST | unseen | 49.06 | 0.493 | 0.404 | 0.665 |
| seen | 61.22 | 0.605 | 0.440 | 0.734 | |
| all | 56.25 | 0.559 | 0.425 | 0.706 |
Table 6: T2G: Results for seen, unseen, and all categories subsets in $\mathrm{WebNLG}+2020$ Challenge Test dataset. As expected the performance drops significantly for unseen categories and are the best for seen categories.
| WebNLGT2G ReGen T2G.CE | Match | F1↑ | Precision↑ | Recall↑ |
| unseen | Exact Ent_Type Partial Strict | 0.5809 0.7014 0.6453 0.5754 | 0.5662 0.6741 0.6241 0.5608 | 0.6069 0.7497 0.6826 0.6012 |
| seen | Exact Ent_Type Partial Strict | 0.8322 0.8878 0.8604 0.8317 | 0.8286 0.8811 0.8553 0.8282 | 0.8384 0.8998 0.8696 0.8379 |
| all | Exact Ent_Type Partial Strict | 0.7229 0.8067 0.7668 0.7202 | 0.7144 0.7910 0.7547 0.7118 | 0.7376 0.8345 0.7882 0.7349 |
表 6: T2G: WebNLG+2020 挑战赛测试数据集中可见、不可见及全部类别的子集结果。与预期一致,不可见类别的性能显著下降,而可见类别的表现最佳。
| WebNLGT2G ReGen T2G.CE | Match | F1↑ | Precision↑ | Recall↑ |
|---|---|---|---|---|
| unseen | Exact Ent_Type Partial Strict | 0.5809 0.7014 0.6453 0.5754 | 0.5662 0.6741 0.6241 0.5608 | 0.6069 0.7497 0.6826 0.6012 |
| seen | Exact Ent_Type Partial Strict | 0.8322 0.8878 0.8604 0.8317 | 0.8286 0.8811 0.8553 0.8282 | 0.8384 0.8998 0.8696 0.8379 |
| all | Exact Ent_Type Partial Strict | 0.7229 0.8067 0.7668 0.7202 | 0.7144 0.7910 0.7547 0.7118 | 0.7376 0.8345 0.7882 0.7349 |
Table 7: Ablation study of metrics used as rewards in SCST for t5-large models. The results shown are on the test split.
| SCST Reward | BLEU↑ | BLEU↑ NLTK | METEOR↑ | chrF++↑ |
| BLEU | 0.556 | 0.552 | 0.420 | 0.698 |
| BLEUNLTK | 0.558 | 0.554 | 0.422 | 0.700 |
| METEOR | 0.563 | 0.559 | 0.425 | 0.706 |
| chrF++ | 0.554 | 0.551 | 0.423 | 0.701 |
| 1/2.METEOR+1/2·BLEU NLTK | 0.555 | 0.551 | 0.421 | 0.699 |
| 2/3·METEOR+1/3·BLEU NLTK | 0.547 | 0.543 | 0.419 | 0.697 |
表 7: T5-large模型在SCST中作为奖励指标的消融研究。结果显示为测试集上的结果。
| SCST Reward | BLEU↑ | BLEU↑ NLTK | METEOR↑ | chrF++↑ |
|---|---|---|---|---|
| BLEU | 0.556 | 0.552 | 0.420 | 0.698 |
| BLEUNLTK | 0.558 | 0.554 | 0.422 | 0.700 |
| METEOR | 0.563 | 0.559 | 0.425 | 0.706 |
| chrF++ | 0.554 | 0.551 | 0.423 | 0.701 |
| 1/2.METEOR+1/2·BLEU NLTK | 0.555 | 0.551 | 0.421 | 0.699 |
| 2/3·METEOR+1/3·BLEU NLTK | 0.547 | 0.543 | 0.419 | 0.697 |
| Learning Rate | BLEU↑ | BLEU↑ NLTK | METEOR↑ | chrF++↑ |
| 10-6 | 0.553 | 0.549 | 0.420 | 0.698 |
| 5·10-6 | 0.558 | 0.554 | 0.422 | 0.700 |
| 10-5 | 0.544 | 0.542 | 0.419 | 0.696 |
Table 8: Ablation study on learning rates in SCST (using BLEU NLTK as the optimized metric)
| 学习率 | BLEU↑ | BLEU↑ NLTK | METEOR↑ | chrF++↑ |
|---|---|---|---|---|
| 10^-6 | 0.553 | 0.549 | 0.420 | 0.698 |
| 5·10^-6 | 0.558 | 0.554 | 0.422 | 0.700 |
| 10^-5 | 0.544 | 0.542 | 0.419 | 0.696 |
表 8: SCST中学习率的消融研究 (使用BLEU NLTK作为优化指标)
Table 9: G2T: Best results for t5-base fine-tuned with SCST using METEOR as reward.
| WebNLGG2T Team/model | BLEU↑ | BLEU↑ NLTK | METEOR↑ | chrF++↑ |
| ReGen G2T.RL.ES.meteor t5-base e (early CE) | 0.527 | 0.523 | 0.413 | 0.689 |
| ReGen G2T.RL.best.meteor t5-base e (bestCE) | 0.528 | 0.526 | 0.412 | 0.681 |
表 9: G2T: 使用METEOR作为奖励的SCST微调t5-base最佳结果
| WebNLGG2T Team/model | BLEU↑ | BLEU↑ NLTK | METEOR↑ | chrF++↑ |
|---|---|---|---|---|
| ReGen G2T.RL.ES.meteor t5-base e (early CE) | 0.527 | 0.523 | 0.413 | 0.689 |
| ReGen G2T.RL.best.meteor t5-base e (bestCE) | 0.528 | 0.526 | 0.412 | 0.681 |
| Team Name | BLEU↑ | BLEU↑ NLTK | METEOR↑ | chrF++↑ |
| ReGen G2T.CE t5-large | 0.543±0.007 | 0.540±0.007 | 0.416±0.002 | 0.691±0.002 |
| ReGen G2T.RL t5-large | 0.553±0.007 | 0.550±0.007 | 0.422±0.002 | 0.702±0.003 |
| ReGen G2T.CE.ES t5-base (early CE) | 0.521±0.004 | 0.517±0.004 | 0.404±0.001 | 0.675±0.002 |
| ReGen G2T.RL.ES t5-base (early CE) | 0.528±0.007 | 0.523±0.007 | 0.408±0.002 | 0.682±0.003 |
| ReGen G2T.CE.best t5-base (best CE) | 0.524±0.000 | 0.520±0.001 | 0.404±0.000 | 0.670±0.000 |
| ReGen G2T.RL.best t5-base (best CE) | 0.525±0.007 | 0.522±0.007 | 0.407±0.002 | 0.681±0.003 |
| ReGen G2T.RL.ES.meteor t5-base (early CE) | 0.525±0.007 | 0.521±0.007 | 0.412±0.002 | 0.687±0.003 |
| ReGen G2T.RL.best.meteor t5-base (best CE) | 0.527±0.007 | 0.524±0.007 | 0.410±0.002 | 0.686±0.003 |
Table 10: Results means and standard deviations (SD), shown as mean $\pm\mathrm{SD}$ , for CE and SCST trained models (including our best results model) for a total of 3 different random number generator seeds used in training.
| 团队名称 | BLEU↑ | BLEU↑ NLTK | METEOR↑ | chrF++↑ |
|---|---|---|---|---|
| ReGen G2T.CE t5-large | 0.543±0.007 | 0.540±0.007 | 0.416±0.002 | 0.691±0.002 |
| ReGen G2T.RL t5-large | 0.553±0.007 | 0.550±0.007 | 0.422±0.002 | 0.702±0.003 |
| ReGen G2T.CE.ES t5-base (early CE) | 0.521±0.004 | 0.517±0.004 | 0.404±0.001 | 0.675±0.002 |
| ReGen G2T.RL.ES t5-base (early CE) | 0.528±0.007 | 0.523±0.007 | 0.408±0.002 | 0.682±0.003 |
| ReGen G2T.CE.best t5-base (best CE) | 0.524±0.000 | 0.520±0.001 | 0.404±0.000 | 0.670±0.000 |
| ReGen G2T.RL.best t5-base (best CE) | 0.525±0.007 | 0.522±0.007 | 0.407±0.002 | 0.681±0.003 |
| ReGen G2T.RL.ES.meteor t5-base (early CE) | 0.525±0.007 | 0.521±0.007 | 0.412±0.002 | 0.687±0.003 |
| ReGen G2T.RL.best.meteor t5-base (best CE) | 0.527±0.007 | 0.524±0.007 | 0.410±0.002 | 0.686±0.003 |
表 10: CE和SCST训练模型(包括我们的最佳结果模型)的结果均值和标准差(SD), 以均值$\pm\mathrm{SD}$形式显示, 训练中使用了3个不同的随机数生成器种子。

Figure 3: An example from the processed TEKGEN dataset. The original dataset lacks KG boundaries, which makes it difficult to evaluate T2G systems efficiently.
图 3: 经过处理的 TEKGEN 数据集示例。原始数据集缺少知识图谱 (KG) 边界标注,这导致难以高效评估 T2G 系统。
Table 11: Few cherry-picked generation for T2G task for $\mathrm{WebNLG}+2020$ (top three) and TEKGEN (bottom three). For each source (Text), we show the ground truth (Gold) and system generated hypothesis from the best CE $\left(\mathrm{Hyp-CE}\right)$ and SCST models $({\mathrm{Hyp-SCST}})$ . Note that the set of triples in ${\mathrm{WebNLG+}}$ takes the form $x_{\mathrm{G}}=$ $[(s^{1}\diamondsuit p^{1}\diamondsuit o^{1}),\dots,(s^{K}\diamondsuit p^{K}\diamondsuit o^{K})]$ , whereas the same for TEKGEN is of form $\boldsymbol{x}_{\mathrm{G}}=[s\diamond(p^{1}\diamondsuit o^{1}),\ldots,(p^{K}\diamondsuit o^{K})]$
| Type | Sentence / Graph |
| Source | Michigan. |
| Gold | Pontiac_Rageous productionStartYear 1997Pontiac_RageousassemblyMichigan Pontiac_Rageous assembly Detroit Pontiac_Rageous productionEndYear 1997 Detroit |
| Hyp-CE | type City_(Michigan) Pontiac_Rageous assembly Detroit Pontiac_Rageous modelYears 1997 Pontiac_Rageous |
| Hyp-SCST | modelYears 1997 Detroit isPartOf Michigan Pontiac_Rageous assembly Detroit Pontiac_Rageous modelYears 1997 Pontiac_Rageous assembly Michigan |
| Source | In the United States, where Abraham A, Ribicoff was born, African Americans are one of the ethnic |
| Gold | groups. Abraham A. Ribicoff was married to Ruth Ribicoff. Abraham_A._Ribicoff spouse"Ruth Ribicoff"Abraham_A._Ribicoff birthPlace United_States United_States ethnicGroup African_Americans Abraham_A._Ribicoff |
| Hyp-CE | nationalityUnited_States Abraham_A._Ribicoff birthPlace United_States Abraham_A._Ribicoff spouse "Ruth |
| Hyp-SCST | Ribicoff" United_States ethnicGroup African_Americans Abraham_A._Ribicoff birthPlace United_States Abraham_A._Ribicoff spouse "Ruth Ribicoff" Abraham_A._Ribicoff nationality American United_States ethnicGroup |
| Source Gold | Super Capers, edited by Stacy Katzman, is a 98 minute film starring Michael Rooker and Tom Sizemore. Super_Capers editing Stacy_Katzman Super_Capers starringMichael_Rooker Su- |
| Hyp-CE | per_Capers starringTom_Sizemore Super_Capers runtime I98.0 Super_Capers starring Tom_Sizemore Super_Capers timeOut "980.0"(minutes) Su- |
| Hyp-SCST | per_Capers starring Michael_Rooker Super_Capers editor Stacy_Katzman Super_Capers starring Tom_Sizemore < Super_Capers length < 98.0 (minutes) Super_Capers |
| Source | Doctor George Cary (1611-1680), Professor of Sacred Theology, lord of the manor of Clovelly, Devon, |
| Gold | decoration of Exeter Cathedral). |
| Hyp-CE | birth001611dateofdeath001680 George Cary (priest) date of birth 01 January 1611 date of death 01 January 1680 |
| Hyp-SCST | George Cary (priest) position held Dean of Exeter date of birth 01 January 1611 date of |
| Source | death01January1680 Early general elections were held in the Bahamas on 10 April 1968. |
| Gold | to jurisdictionThe Bahamas |
| Hyp-CE | 1968 Bahamian general election point in time 10 April 1968 |
| Hyp-SCST | 1968 Bahamian general election point in time 10 April 1968 country The Bahamas |
| The school was established on 6 January 1930, by former education minister, Cww Kannangara, who | |
| Source | |
| additionally founded two other colleges located in central Ceylon. | |
| Gold | |
| Kattankudy Central Collegeinstance of School | |
| Hyp-CE | Government Polytechnic ,Colombo inception 00 1930 Government Polytechnic ,Colomboinception 00 1930instance ofSchool |
表 11: T2G任务中精选的少样本生成示例,包含WebNLG+2020数据集(前三条)和TEKGEN数据集(后三条)。每个输入文本(Text)对应展示了标准答案(Gold)、最佳交叉熵模型生成结果(Hyp-CE)和SCST模型生成结果(Hyp-SCST)。需注意WebNLG+数据集的三元组形式为$x_{\mathrm{G}}=[(s^{1}\diamondsuit p^{1}\diamondsuit o^{1}),\dots,(s^{K}\diamondsuit p^{K}\diamondsuit o^{K})]$,而TEKGEN数据集的形式为$\boldsymbol{x}_{\mathrm{G}}=[s\diamond(p^{1}\diamondsuit o^{1}),\ldots,(p^{K}\diamondsuit o^{K})]$。
| 类型 | 句子/图结构 |
|---|---|
| 输入文本 | Michigan. |
| 标准答案 | Pontiac_Rageous productionStartYear 1997Pontiac_RageousassemblyMichigan Pontiac_Rageous assembly Detroit Pontiac_Rageous productionEndYear 1997 Detroit |
| Hyp-CE | type City_(Michigan) Pontiac_Rageous assembly Detroit Pontiac_Rageous modelYears 1997 Pontiac_Rageous |
| Hyp-SCST | modelYears 1997 Detroit isPartOf Michigan Pontiac_Rageous assembly Detroit Pontiac_Rageous modelYears 1997 Pontiac_Rageous assembly Michigan |
| 输入文本 | In the United States, where Abraham A, Ribicoff was born, African Americans are one of the ethnic |
| 标准答案 | groups. Abraham A. Ribicoff was married to Ruth Ribicoff. Abraham_A._Ribicoff spouse"Ruth Ribicoff"Abraham_A._Ribicoff birthPlace United_States United_States ethnicGroup African_Americans Abraham_A._Ribicoff |
| Hyp-CE | nationalityUnited_States Abraham_A._Ribicoff birthPlace United_States Abraham_A._Ribicoff spouse "Ruth |
| Hyp-SCST | Ribicoff" United_States ethnicGroup African_Americans Abraham_A._Ribicoff birthPlace United_States Abraham_A._Ribicoff spouse "Ruth Ribicoff" Abraham_A._Ribicoff nationality American United_States ethnicGroup |
| 输入文本 | Super Capers, edited by Stacy Katzman, is a 98 minute film starring Michael Rooker and Tom Sizemore. |
| 标准答案 | Super_Capers editing Stacy_Katzman Super_Capers starringMichael_Rooker Super_Capers starringTom_Sizemore Super_Capers runtime I98.0 |
| Hyp-CE | per_Capers starring Tom_Sizemore Super_Capers timeOut "980.0"(minutes) Su- |
| Hyp-SCST | per_Capers starring Michael_Rooker Super_Capers editor Stacy_Katzman Super_Capers starring Tom_Sizemore < Super_Capers length < 98.0 (minutes) Super_Capers |
| 输入文本 | Doctor George Cary (1611-1680), Professor of Sacred Theology, lord of the manor of Clovelly, Devon, |
| 标准答案 | decoration of Exeter Cathedral). |
| Hyp-CE | birth001611dateofdeath001680 George Cary (priest) date of birth 01 January 1611 date of death 01 January 1680 |
| Hyp-SCST | George Cary (priest) position held Dean of Exeter date of birth 01 January 1611 date of |
| 输入文本 | death01January1680 Early general elections were held in the Bahamas on 10 April 1968. |
| 标准答案 | to jurisdictionThe Bahamas |
| Hyp-CE | 1968 Bahamian general election point in time 10 April 1968 |
| Hyp-SCST | 1968 Bahamian general election point in time 10 April 1968 country The Bahamas |
| 输入文本 | The school was established on 6 January 1930, by former education minister, Cww Kannangara, who additionally founded two other colleges located in central Ceylon. |
| 标准答案 | Kattankudy Central Collegeinstance of School |
| Hyp-CE | Government Polytechnic ,Colombo inception 00 1930 Government Polytechnic ,Colomboinception 00 1930instance ofSchool |
Table 12: Few cherry-picked generation for G2T task for $\mathrm{WebNLG}+2020$ (top three) and TEKGEN (bottom three). For each source (Graph), we show the ground truth (Gold) and system generated hypothesis from the best CE $\left(\mathrm{Hyp-CE}\right)$ and SCST models $({\mathrm{Hyp-SCST}})$ . Note that the set of triples in $\mathrm{WebNLG+\Sigma}$ 2020 takes the form $x_{\mathrm{G}}=$ $[(s^{1}\diamondsuit p^{1}\diamondsuit o^{1}),\dots,(s^{K}\diamondsuit p^{K}\diamondsuit o^{K})]$ , whereas the same for TEKGEN is of form $\boldsymbol{x}_{\mathrm{G}}=[s\diamond(p^{1}\diamondsuit o^{1}),\ldots,(p^{K}\diamondsuit o^{K})]$
| Type | Graph/Sentence |
| Source | McVeagh_of_the_South_Seas starring gHarry_Carey_(actor_born_1878) McVeagh_of_the_South_Seas writer Harry_Carey_(actor_born_1878) |
| Gold | Born in 1878, Harry Carey later grew up to write and star in the movie McVeagh of the South Seas. Harry Carey, born in 1878, wrote and appeared in the movie McVeagh of the South Seas. Harry Carey, who was born in 1878, wrote and starred the film of Mc Veagh of the South Seas. |
| Hyp-CE Hyp-SCST | McVeagh of the South Seas was written by Harry Carey, who was born in 1878. Mc Veagh of the South Seas was written by Harry Carey and starred the actor Harry Carey who was born in 1878. |
| Source | Aleksandr_Prudnikov height185.0(centimetres)Aleksandr_Prudnikov youthclub FC_Spartak_Moscow FC_Spartak_Moscow ground Otkrytiye_Arena |
| Gold | Aleksandr Prudnikov, 185cm tall played for FC Spartak Moscow's youth team. FC Spartak Moscow is based in the Otkrytiye Arena. Aleksandr Prudnikov who is 185 cm tall is a member of the youth side of FC Spartak Moscow. The home ground of FC Spartak Moscow is Otkrytiye Arena.Aleksandr Prudnikov |
| Hyp-CE | is 185.0 cm tall and played for the FC Spartak Moscow at the Otkrytiye Arena. Aleksandr Prudnikov is 185 cm tall and played for FC Spartak Moscow's youth team at the Otkrytiye |
| Hyp-SCST | Arena. Aleksandr Prudnikov is 185 cm tall and played for the youth team of FC Spartak Moscow whose home |
| Source | ground is the Otkrytiye Arena. Baku_Turkish_Martyrs'_Memorial I Baku_Turkish_Martyrs'_Memorial locationAzerbaijan |
| Gold | The Native name of the Baku Turkish Martyrs'Memorial is "Turk \$ehitleri Aniti"which is located in Azerbaijan. The native name of the Baku Turkish Martyrs' Memorial is Turk Sehitleri Aniti located in |
| Hyp-CE Hyp-SCST | Azerbaijan. The native name for the Baku Turkish Martyrs’ Memorial is Turk Sehitleri Aniti, which is located in Baku, Azerbaijan. The native name of the Baku Turkish Martyrs'Memorial in Azerbaijan is Turk Sehitleri Anit1. The Baku Turkish Martyrs’ Memorial is located in Azerbaijan and is known locally as Turk Sehitleri |
| Source | Aniti. John Banister (anatomist) occupation Surgeon date of birth 01 January 1533 date of death |
| Gold | 01 January1610 John Banister (1533-1610) was an English anatomist, surgeon and teacher. |
| Hyp-CE | John Banister (1533-1610) was an English surgeon. |
| Hyp-SCST | John Banister (1533-1610) was an English surgeon and anatomist. |
| Source Gold | WNPT (TV) country United States instance of Television station WNPT, virtual channel 8 (VHF digital channel 7), is a PBS member television station licensed to Nashville, Tennessee, United States. |
| Hyp-CE | WNPT, virtual channel 3 (UHF digital channel 15), is a Fox-affiliated television station licensed to Portland, Oregon, United States. |
| Hyp-SCST | WNPT,virtual channel 4 (UHF digital channel 16),is a Public Broadcasting Service (PBS) member |
| television station licensed to Portland, Oregon, United States. | |
| Source Gold | OurLady of thePresentationCathedral,Natalinception21 November1988 Our Lady of the Presentation Cathedral, Natal was inaugurated on November 21, 1988, and is located in |
| the district of Cidade Alta in Natal, capital of the Brazilian state of Rio Grande do Norte. | |
| Hyp-CE | Our Lady of the Presentation Cathedral, Natal was built in 1988. |
| Hyp-SCST | |
| Our Lady of the Presentation Cathedral, Natal was consecrated on 21 November 1988. | |
表 12: G2T任务中精选的生成示例,包括 $\mathrm{WebNLG}+2020$ (前三) 和 TEKGEN (后三)。对于每个来源 (Graph),我们展示了真实值 (Gold) 以及最佳 CE $\left(\mathrm{Hyp-CE}\right)$ 和 SCST 模型 $({\mathrm{Hyp-SCST}})$ 生成的假设。请注意,$\mathrm{WebNLG+\Sigma}$ 2020 中的三元组集合形式为 $x_{\mathrm{G}}=$ $[(s^{1}\diamondsuit p^{1}\diamondsuit o^{1}),\dots,(s^{K}\diamondsuit p^{K}\diamondsuit o^{K})]$,而 TEKGEN 的形式为 $\boldsymbol{x}_{\mathrm{G}}=[s\diamond(p^{1}\diamondsuit o^{1}),\ldots,(p^{K}\diamondsuit o^{K})]$。
| 类型 | 图/句子 |
|---|---|
| 来源 | McVeagh_of_the_South_Seas 主演 gHarry_Carey_(actor_born_1878) McVeagh_of_the_South_Seas 编剧 Harry_Carey_(actor_born_1878) |
| 真实值 | 出生于1878年的Harry Carey后来成长为《南海的McVeagh》的编剧和主演。Harry Carey,出生于1878年,编写并出演了电影《南海的McVeagh》。Harry Carey,出生于1878年,编写并主演了电影《南海的McVeagh》。 |
| Hyp-CE Hyp-SCST | 《南海的McVeagh》由出生于1878年的Harry Carey编写。《南海的McVeagh》由Harry Carey编写,并由出生于1878年的演员Harry Carey主演。 |
| 来源 | Aleksandr_Prudnikov 身高185.0(厘米) Aleksandr_Prudnikov 青年俱乐部 FC_Spartak_Moscow FC_Spartak_Moscow 主场 Otkrytiye_Arena |
| 真实值 | 身高185厘米的Aleksandr Prudnikov曾效力于FC Spartak Moscow的青年队。FC Spartak Moscow的主场是Otkrytiye Arena。身高185厘米的Aleksandr Prudnikov是FC Spartak Moscow青年队的一员。FC Spartak Moscow的主场是Otkrytiye Arena。Aleksandr Prudnikov |
| Hyp-CE | 身高185.0厘米,曾在Otkrytiye Arena为FC Spartak Moscow效力。Aleksandr Prudnikov身高185厘米,曾在Otkrytiye为FC Spartak Moscow青年队效力。 |
| Hyp-SCST | Arena。Aleksandr Prudnikov身高185厘米,曾效力于FC Spartak Moscow青年队,其主场是Otkrytiye Arena。 |
| 来源 | Baku_Turkish_Martyrs'_Memorial I Baku_Turkish_Martyrs'_Memorial 所在地 Azerbaijan |
| 真实值 | Baku Turkish Martyrs' Memorial的本地名称是"Turk $ehitleri Aniti",位于阿塞拜疆。Baku Turkish Martyrs' Memorial的本地名称是Turk Sehitleri Aniti,位于阿塞拜疆。 |
| Hyp-CE Hyp-SCST | Baku Turkish Martyrs' Memorial的本地名称是Turk Sehitleri Aniti,位于阿塞拜疆巴库。Baku Turkish Martyrs' Memorial在阿塞拜疆的本地名称是Turk Sehitleri Anit1。Baku Turkish Martyrs' Memorial位于阿塞拜疆,当地称为Turk Sehitleri Aniti。 |
| 来源 | John Banister (anatomist) 职业 外科医生 出生日期 01 January 1533 死亡日期 01 January1610 |
| 真实值 | John Banister (1533-1610) 是一位英国解剖学家、外科医生和教师。 |
| Hyp-CE | John Banister (1533-1610) 是一位英国外科医生。 |
| Hyp-SCST | John Banister (1533-1610) 是一位英国外科医生和解剖学家。 |
| 来源 真实值 | WNPT (TV) 国家 美国 实例 电视台 WNPT,虚拟频道8 (VHF数字频道7),是一家获得美国田纳西州纳什维尔许可的PBS成员电视台。 |
| Hyp-CE | WNPT,虚拟频道3 (UHF数字频道15),是一家获得美国俄勒冈州波特兰许可的Fox附属电视台。 |
| Hyp-SCST | WNPT,虚拟频道4 (UHF数字频道16),是一家获得美国俄勒冈州波特兰许可的公共广播服务 (PBS) 成员电视台。 |
| 来源 真实值 | OurLady of thePresentationCathedral,Natal 成立日期 21 November1988 Our Lady of the Presentation Cathedral, Natal 于1988年11月21日启用,位于巴西里奥格兰德北州首府纳塔尔市的Cidade Alta区。 |
| Hyp-CE | Our Lady of the Presentation Cathedral, Natal 建于1988年。 |
| Hyp-SCST | Our Lady of the Presentation Cathedral, Natal 于1988年11月21日祝圣。 |