Self-training from Self-memory in Data-to-text Generation
数据到文本生成中的自记忆自训练
Hoang-Thang Taa
Hoang-Thang Taa
a Department of Information Technology, Dalat University, Da Lat, Vietnam
信息科技系,大叻大学,大叻,越南
Abstract
摘要
This paper introduces a novel training model, self-training from self-memory (STSM) in data-to-text generation (DTG), allowing the model to self-train on subsets, including self-memory as outputs inferred directly from the trained models and/or the new data. The quality of self-memory is validated by two models, data-to-text (D2T) and text-todata (T2D), by two pre-defined conditions: (1) the appearance of all source values in the outputs of the D2T model and (2) the ability to convert back to source data in the outputs in the T2D model. We utilize a greedy algorithm to generate shorter D2T outputs if they contain all source values. Subsequently, we use the T2D model to confirm that these outputs can capture input relationships by demonstrating their capacity to convert text back into data. With $30%$ of the dataset, we can train the D2T model with a competitive performance compared to full training in the same setup. We experiment with our model on two datasets, E2E NLG and DART. STSM offers the D2T model a generalization capability from its subset memory while reducing training data volume. Ultimately, we anticipate that this paper will contribute to continual learning solutions that adapt to new training data, incorporating it as a form of self-memory in DTG tasks. The curated dataset is publicly available at: https://github.com/ho ang than gta/STSM.
本文提出了一种新颖的训练模型——数据到文本生成(DTG)中的自记忆自训练(STSM),该模型能够在子集上进行自我训练,包括将训练模型直接推断的输出和/或新数据作为自记忆。自记忆的质量通过两个模型(数据到文本(D2T)和文本到数据(T2D))以及两个预定义条件进行验证:(1) D2T模型输出中包含所有源值,(2) T2D模型输出能够转换回源数据。我们采用贪心算法生成更短的D2T输出(前提是它们包含所有源值),随后使用T2D模型通过验证文本能否转换回数据来确认这些输出能捕捉输入关系。仅使用数据集的30%,我们就能训练出与全量训练配置下性能相当的D2T模型。我们在E2E NLG和DART两个数据集上进行了实验。STSM使D2T模型能够从子集记忆中获得泛化能力,同时减少训练数据量。最终,我们期待本文能为持续学习解决方案做出贡献,使其能够适应新的训练数据,并将其作为DTG任务中自记忆的一种形式。整理后的数据集已公开发布于:https://github.com/hoangthanhta/STSM。
Keywords: Natural Language Generation, Data-to-text Generation, Self-training, Self-memory
关键词:自然语言生成 (Natural Language Generation)、数据到文本生成 (Data-to-text Generation)、自训练 (Self-training)、自记忆 (Self-memory)
1. Introduction
1. 引言
Within the broad scope of natural language generation (NLG), DTG processes a problem involving con- verting structured data, typically presented as tables, meaning representations (MRs), knowledge graphs, or sets of triples, into natural language texts. The generated output can be either a summary of the input or a coherent text that adheres to specified criteria, including fluency, naturalness, and incorporating all source values.
在自然语言生成(NLG)的广泛范畴中,数据到文本生成(DTG)处理的是一项将结构化数据(通常以表格、意义表示(MRs)、知识图谱或三元组形式呈现)转换为自然语言文本的任务。生成结果既可以是输入数据的摘要,也可以是符合特定标准(包括流畅性、自然度以及涵盖所有源数据值)的连贯文本。
A prevalent approach to generating text from a set of triples involves employing a sequence-to-sequence architecture designed for handling sequential data. This often includes using encoder-decoder recurrent neural networks like Transformers. Specifically, it is transfer learning from pre-trained models such as BART and T5. Alternatively, recent methods leverage language instructions and large language models like Alpaca [1], ChatGPT [2], Flan-T5 [3], and Llama [4]. While these large models demonstrate relatively strong performance across various DTG tasks, it’s important to note that they demand massive memory and super computing resources, making them unsuitable for downstream tasks.
从一组三元组生成文本的常见方法是采用专为处理序列数据设计的序列到序列架构。这通常包括使用基于Transformer的编码器-解码器循环神经网络,具体而言是通过BART、T5等预训练模型进行迁移学习。另一种近期方案是利用语言指令和大语言模型,例如Alpaca [1]、ChatGPT [2]、Flan-T5 [3]和Llama [4]。虽然这些大模型在各类DTG任务中展现出较强的性能,但需注意它们需要消耗巨大的内存和超算资源,因此并不适合下游任务。
In this paper, we introduce a novel model as part of our exploration for an optimization strategy tailored for self-training in D2T, aiming to uphold model performance at a level comparable to full-data training. In each epoch, our model trains on a subset of the training set, incorporating a mix of self-memory derived from trained models and/or newly introduced data. This methodology enables us to reduce the volume of training data in each epoch while maintaining performance levels consistent with full training. Our model also provides helpfulness in continual learning studies, specifically when initiating training on new data from an existing dataset, as opposed to amalgamating new data with the old and training them collectively at the outset. In experiments, we train D2T and T2D models using $30%$ of the training set in each epoch, with the optional self-training in the T2D model. Ultimately, we compare the outputs of the D2T model with those of other widely adopted methods to clarify the effectiveness of our model over two datasets, DART and E2E NLG.
本文介绍了一种新颖模型,作为我们探索D2T(数据到文本)自训练优化策略的一部分,旨在将模型性能维持在接近全数据训练的水平。在每个训练周期中,我们的模型在训练集子集上进行训练,结合来自已训练模型的自我记忆和/或新引入的数据。这种方法使我们能在减少单周期训练数据量的同时,保持与完整训练相当的性能水平。该模型对持续学习研究也具实用价值,特别是在基于现有数据集启动新数据训练时,相较于一开就将新旧数据合并训练的传统方法。实验中,我们使用训练集的30%数据训练D2T和T2D(文本到数据)模型,并在T2D模型中采用可选的自训练策略。最终,我们将D2T模型的输出与其他广泛采用的方法进行对比,通过在DART和E2E NLG两个数据集上的实验验证模型的有效性。
The main contributions of our work are as follows:
我们工作的主要贡献如下:
• STSM (Self-training from Self-memory): The novel training model from the merge of self-memory and/or the new data to keep the output quality on par with the full data training.
• STSM (自训练自记忆):一种结合自记忆和/或新数据的新型训练模型,其输出质量可与全数据训练相媲美。
• Data self-training creation: Provide a step for selecting source-target pairs inferred from the D2T and T2D models by pre-defined criteria. Then, use different combinations of self-memory and/or the new data to create self-training subsets.
• 数据自训练创建:提供一个步骤,用于根据预定义标准从D2T和T2D模型推断出的源-目标对中进行选择。然后,使用自记忆和/或新数据的不同组合来创建自训练子集。
The rest of this document is structured as follows: Section 2 discusses previous NLG research, especially DTG problems. Section 3 and Section 4 supply datasets and methods involving our self-training model. Our experiments and discussions based on the results are performed in Section 5. Section 6 addresses the limitations of our work, and finally, we provide conclusions and outline future work in Section 7.
本文其余部分的结构安排如下:第2节讨论先前自然语言生成(NLG)研究,特别是数据到文本生成(DTG)问题。第3节和第4节提供涉及我们自训练模型的数据集和方法。第5节基于实验结果进行分析讨论。第6节阐述本研究的局限性,最后第7节给出结论并展望未来工作方向。
2. Related Works
2. 相关工作
Rather than handling diverse inputs like NLG, DTG converts structured or semi-structured data into highquality outputs as human texts. DTG is widely applicable due to its capacity to generate meaningful texts, making it valuable in various practical applications, such as weather reports [5], sport news [6], and financial comments [7]. It also encompasses a considerable number of datasets, including those containing tabular data(MLB [8], ToTTo [9], ROBOWIRE [10], WIKIBIO [11]), triples (DART [12], WebNLG), meaning representation (E2E NLG [13]). These data formats can be inter converted and are typically represented in a linearized text format for model training.
与处理多样化输入的NLG不同,DTG将结构化或半结构化数据转换为高质量的人类文本输出。DTG因其生成有意义文本的能力而具有广泛适用性,在天气预报[5]、体育新闻[6]和财经评论[7]等实际应用中极具价值。它还涵盖大量数据集,包括表格数据(MLB[8]、ToTTo[9]、ROBOWIRE[10]、WIKIBIO[11])、三元组(DART[12]、WebNLG)和语义表示(E2E NLG[13])。这些数据格式可相互转换,通常以线性化文本格式表示用于模型训练。
Traditional approaches utilized pipelines featuring multiple modules [14], rule-based generators [15], or statistical machine translation [15, 16]. However, they are inflexible when adapting to a wide range of datasets and domains compared to neural approaches. Recent DTG studies commonly employ neural networks, with a prevalent adoption of an encoder-decoder architecture [17, 18] and additional components. Ferreira et al. [19] applied Gated-Recurrent Units (GRU), Transformers [20] for comparing the model performance between neural pipelines and end-to-end approaches. They concluded that the models are better with explicit intermediate steps in the generation process. The process of linearizing inputs results in the loss of structure in the input data. To address this issue, Rebuffel et al. [21] introduced a hierarchical model incorporating a hierarchical encoder designed for structured data and utilizing hierarchical attention in the decoder. Puduppully et al. [8] also applied hierarchical attention and entity memory within an encoder-decoder neural network to enhance model performance compared to baseline methods.
传统方法采用多模块流水线[14]、基于规则的生成器[15]或统计机器翻译[15,16]。但与神经方法相比,它们在适应多样化数据集和领域时缺乏灵活性。近期数据到文本生成(DTG)研究普遍采用神经网络,主要使用编码器-解码器架构[17,18]并添加额外组件。Ferreira等人[19]应用门控循环单元(GRU)和Transformer[20]比较神经流水线与端到端方法的模型性能,结论表明生成过程中包含显式中介步骤的模型表现更优。线性化输入会导致数据结构丢失,为此Rebuffel等人[21]提出分层模型,采用面向结构化数据的分层编码器,并在解码器中使用分层注意力机制。Puduppully等人[8]同样在编码器-解码器神经网络中应用分层注意力和实体记忆模块,相比基线方法提升了模型性能。
Instead of opting for single-stage generation, some works involve a two-stage generation strategy. The first stage usually prepares better input data or additional data that feeds into the text generation in the second stage. To address low-resource generation challenges, Ma et al. [22] utilized a two-stage model, first generating key facts and subsequently generating texts. Wang et al. [23] also implemented a two-stage method, employing an auto regressive pointer network for key token selection and a non-auto regressive model for text generation through iterative insertion and deletion operations. In another study, Puduppully and Lapata [24] also worked on a two-stage approach, wherein macro plans are derived from the training data and subsequently utilized in the text generation phase. Another type of two-stage generation involves initially producing outputs and subsequently evaluating and selecting the best one based on predetermined criteria. This type is similar to two-stage sum mari z ation [25, 26]. For example, Harkous et al. [27] integrated a semantic fidelity classifier to fine-tune language models to enhance semantic fidelity in a two-stage generation-reranking approach.
一些研究采用了两阶段生成策略,而非单阶段生成。第一阶段通常准备更优质的输入数据或额外数据,供第二阶段文本生成使用。针对低资源生成难题,Ma等[22]采用两阶段模型,首先生成关键事实,随后生成文本。Wang等[23]同样实施了两阶段方法,先使用自回归指针网络选择关键token,再通过非自回归模型进行迭代插入删除操作来生成文本。Puduppully和Lapata[24]在另一项研究中开发了两阶段方案:先从训练数据提取宏观规划,再将其用于文本生成阶段。另一类两阶段生成会先产生输出结果,再根据预设标准评估筛选最优结果,其原理类似于两阶段摘要生成[25, 26]。例如Harkous等[27]通过集成语义保真分类器,在生成-重排序的两阶段流程中微调语言模型以提升语义保真度。
Another line of DTG uses neural networks but applies self-training, usually with a few shot learners, to improve the model generalization and deal better with low-resource content. Mehta et al. [28] enhanced the model’s generalization ability by using a template-based input representation and a self-training method in a few shot settings on pseudo data. Ke et al. [29] also used self-training as a few-shot learning with pseudo-labeled data generated by the pre-trained model. Furthermore, they proposed Curriculum-Based Self-Training (CBST) to reduce the side effects of low-quality pseudo-labeled data. Deng et al. [30] proposed a unified framework for logical knowledge-conditioned text generation in the few-shot setting. Their approach leverages self-training and samples pseudo-logical forms based on content and structure consistency. Nie et al. [31] integrated a language understanding module with self-training iterations to achieve strong equivalence between input data and associated text. They then trained a vanilla sequence-to-sequence neural model on refined data to improve content accuracy and mitigate hallucination. On a different work, Kedzie and McKeown [32] introduced an architecture-agnostic self-training approach for sampling novel MR/text utterance pairs, effectively running on the expanded dataset, even simple encoderdecoder models with greedy decoding exhibited the capability to generate semantically correct utterances comparable to state-of-the-art outputs. In our study, we implement self-training on $30%$ of the training set in each epoch, encompassing both self-memory and the remaining data, instead of using smaller subsets.
另一类DTG方法采用神经网络并应用自训练(self-training)技术,通常结合少样本学习(few-shot learning)来提升模型泛化能力并更好地处理低资源内容。Mehta等人[28]通过在伪数据上采用基于模板的输入表示和少样本自训练方法增强了模型泛化能力。Ke等人[29]同样使用预训练模型生成的伪标注数据进行了少样本自训练,并提出基于课程的自训练(CBST)方法来降低低质量伪标注数据的负面影响。Deng等人[30]提出了少样本场景下逻辑知识条件文本生成的统一框架,其方法利用自训练技术并基于内容与结构一致性采样伪逻辑形式。Nie等人[31]将语言理解模块与自训练迭代相结合,确保输入数据与关联文本间的强等价性,随后在精炼数据上训练基础序列到序列神经网络模型以提高内容准确性并减少幻觉。Kedzie和McKeown[32]则提出了一种与架构无关的自训练方法,用于采样新型MR/文本话语对,实验表明即使在扩展数据集上运行,采用贪婪解码的简单编码器-解码器模型也能生成语义正确的语句,其质量可与最先进输出相媲美。本研究中,我们在每个训练周期对30%训练集(包含自记忆数据和剩余数据)实施自训练,而非使用较小数据子集。
Finally, some works employ cycle training to address both D2T and T2D problems simultaneously. Wang et al. [33] utilized cycle training with two inversely related models for D2T and T2D problems, demonstrating comparable performance to fully supervised approaches with limited labeled data. Polat et al. [34] applied cycle training by alternately generating text from an input graph and extracting a knowledge graph, emphasizing consistency between the two. They highlighted cycle training’s effectiveness in improving performance on evaluation metrics related to syntactic and semantic relations while reducing erroneous output. Guo et al. [35] introduced CycleGT, which utilizes fully nonparallel graph and text data to bootstrap and iterative ly back-translate between the two forms. Their unsupervised model, trained with the same amount of data, achieves performance on par with several fully supervised models, presenting an effective solution to address data scarcity. While using both D2T and T2D models, we exclusively use the T2D model to validate the output quality (self-memory) of the D2T model, then integrate this memory with new data for self-training the D2T model, with the possibility of optional self-training on the T2D model.
最后,一些研究采用循环训练来同时解决D2T和T2D问题。Wang等人[33]利用两个反向关联模型进行D2T和T2D问题的循环训练,证明了在有限标注数据下与全监督方法相当的性能。Polat等人[34]通过交替从输入图生成文本和提取知识图谱来应用循环训练,强调两者间的一致性。他们指出循环训练在提升句法和语义关系相关评估指标表现的同时,能有效减少错误输出。Guo等人[35]提出的CycleGT利用完全非并行的图和文本数据,在两种形式间进行自举迭代回译。他们的无监督模型在使用相同数据量训练时,达到了与多个全监督模型相当的性能,为解决数据稀缺问题提供了有效方案。虽然同时使用D2T和T2D模型,但我们仅用T2D模型验证D2T模型的输出质量(自记忆),然后将该记忆与新数据结合来自训练D2T模型,并可选择对T2D模型进行自训练。
3. Datasets
3. 数据集
In this section, we selected two datasets for our experiments, DART and E2E NLG. Both are medium-sized datasets wherein inputs consist of MRs or tables, sub- sequently transformed into concise texts. While DART exhibits diversity in its data, E2E NLG specifically centers around restaurant-related content.
在本节中,我们选择了两个数据集进行实验:DART和E2E NLG。这两个都是中等规模的数据集,其中输入由MR(语义表示)或表格组成,随后被转换为简洁的文本。DART的数据具有多样性,而E2E NLG则专门围绕餐厅相关内容展开。
3.1. DART
3.1. DART
DART (DAta-Record-to-Text) dataset comprises over 82,000 examples aimed at tackling the D2T generation problem, where triplesets serve as inputs and sentences as outputs [12]. Triplesets were extracted from tables, exploiting semantic dependencies among table headers and titles. The diverse domain dataset is a merge from WikiSQL, WikiTable Questions, WebNLG, and Cleaned E2E. It is categorized into training (62,659 examples), development (6,980 examples), and testing (12,552 examples). Due to its open-domain nature and ontologypreserving structure, DART poses challenges for stateof-the-art D2T models.
DART (DAta-Record-to-Text) 数据集包含超过 82,000 个样本,旨在解决 D2T 生成问题,其中三元组集合作为输入,句子作为输出 [12]。三元组集合从表格中提取,利用了表头和标题之间的语义依赖关系。该多样化领域数据集合并了 WikiSQL、WikiTable Questions、WebNLG 和 Cleaned E2E 的数据,分为训练集 (62,659 个样本)、开发集 (6,980 个样本) 和测试集 (12,552 个样本)。由于其开放领域特性和本体保留结构,DART 对当前最先进的 D2T 模型提出了挑战。
3.2. E2E NLG
3.2. 端到端自然语言生成 (E2E NLG)
E2E NLG is a dataset for producing short texts from restaurant-related meaning representations (MRs) [36]. Outputs are lexically rich and syntactically varied, requiring content selection during generation. Models trained on this dataset are expected to yield more natural, varied, and less template-like references. E2E NLG comprises $50\mathrm{,000+}$ dialogue-act-based MR combinations, averaging 8.1 references each. Data is split into training, validation, and testing sets (82:9:9 ratio) with similar distributions and distinct MRs. Picturebased data collection captures more natural and informative human references compared to textual MRs [37].
E2E NLG 是一个用于从餐厅相关语义表示 (MR) [36] 生成短文本的数据集。其输出词汇丰富且句法多样,需要在生成过程中进行内容选择。基于该数据集训练的模型预期能产生更自然、多样且模板化程度更低的参考文本。E2E NLG 包含 $50\mathrm{,000+}$ 条基于对话行为的 MR 组合,每条平均对应 8.1 个参考文本。数据按 82:9:9 的比例划分为训练集、验证集和测试集,各集合分布相似且 MR 互不重复。与文本式 MR 相比 [37],基于图片的数据采集方式能捕获更自然且信息量更大的人类参考文本。
3.3. Input Linear iz ation
3.3. 输入线性化
For sequence-to-sequence models, it’s necessary to have target-source pairs where both elements are in string format. This requires converting inputs into text, a process known as input linear iz ation. Table 1 displays two examples corresponding to two D2T datasets, DART and E2E NLG with our input linear iz ation.
对于序列到序列模型来说,必须拥有目标-源对,且两者都以字符串格式呈现。这需要将输入转换为文本,该过程称为输入线性化。表1展示了两个对应不同D2T数据集(DART和E2E NLG)的示例,以及我们的输入线性化方法。
MRs/Triples are concatenated by each other by “ | ”, and elements of each are concatenated by “ : DART offers a group of triples that connect each triple subject to another triple object. Therefore, each triple takes the form of “s : p : o”. E2E NLG contains MRs with the common subject. Hence, we remove it in all triples. Each triple remains only two elements p and o in the form of “p : o”. We also insert the common subject in the first position of the input string. For example, “name : The Golden Curry” refers to the subject “The Golden Curry” of the E2ENLG example in E2E NLG. In this paper, “s”, “subject name”, “o”, and “qv” are called source values that any generated target must contain.
MR/Triple之间用“|”连接,各元素之间用“:”连接:DART提供了一组将每个三元组主语连接到另一个三元组宾语的三元组。因此,每个三元组采用“s : p : o”形式。E2E NLG包含具有共同主语的MR,因此我们在所有三元组中移除该主语。每个三元组仅保留“p : o”形式的两个元素p和o。我们还在输入字符串的首位插入共同主语。例如,“name : The Golden Curry”指的是E2E NLG示例中主语“The Golden Curry”。本文中,“s”、“subject name”、“o”和“qv”被称为源值,任何生成的目标都必须包含这些值。
4. Methodology
4. 方法论
4.1. Task Description
4.1. 任务描述
Let $\textbf{x}=(s_{0},p_{0},o_{0}),(s_{1},p_{1},o_{1}),...,(s_{N},p_{N},o_{N})$ rep- resent a set of triples with a size of $N$ . In each triple $(s,p,o)$ , $s$ denotes a subject, $o$ denotes an object, and $p$ signifies the relationship between $s$ and $o$ . If $\mathbf{X}$ is a set of MRs, we express it as $\mathbf{x}=(k_{0},\nu_{0}),(k_{1},\nu_{1}),...,(k_{N},\nu_{N})$ with a size of $N$ , where each element is a key-value pair. Then, let $\mathbf{y}={w_{0},w_{1},...,w_{M}}$ be a representation text for $\mathbf{X}$ with $M$ symbols.
设 $\textbf{x}=(s_{0},p_{0},o_{0}),(s_{1},p_{1},o_{1}),...,(s_{N},p_{N},o_{N})$ 表示一组大小为 $N$ 的三元组。在每个三元组 $(s,p,o)$ 中,$s$ 表示主语,$o$ 表示宾语,$p$ 表示 $s$ 和 $o$ 之间的关系。如果 $\mathbf{X}$ 是一组MR (Modality Representation),我们将其表示为 $\mathbf{x}=(k_{0},\nu_{0}),(k_{1},\nu_{1}),...,(k_{N},\nu_{N})$,大小为 $N$,其中每个元素都是一个键值对。然后,令 $\mathbf{y}={w_{0},w_{1},...,w_{M}}$ 为 $\mathbf{X}$ 的表示文本,包含 $M$ 个符号。
Next, $\mathbf{X}$ is transformed into a string in the linear iz ation process as in Section 3.3. There are two tasks: D2T and T2D. The first one involves converting an input $\mathbf{X}$ to $\mathbf{y}$ . Conversely, in the T2D task, when provided with an input $\mathbf{y}$ , the model is expected to convert it to $\mathbf{X}$ .
接下来,$\mathbf{X}$ 会按照第3.3节中的线性化过程转换为字符串。这里涉及两个任务:D2T和T2D。第一个任务是将输入 $\mathbf{X}$ 转换为 $\mathbf{y}$。相反,在T2D任务中,当给定输入 $\mathbf{y}$ 时,模型需要将其转换为 $\mathbf{X}$。
Table 1: Examples of two D2T datasets with our input linear iz ation.
表 1: 采用输入线性化的两个D2T数据集示例
| 数据集 | 示例 |
|---|---|
| DART | , ] , . , ] ] s "ENDED", “20 November"” ], [“Clapham", “LOAN_CLUB", “Wolverhamp- ton Wanderers"]] |
| source: Clapham : STARTED : 20 August | Clapham: ENDED : 20 November I Clapham : LOAN_CLUB : Wolverhampton Wanderers | |
| target:ClaphamwasloanedbytheWolverhamptonWanderersfrom20August to20November | |
| meaning representation: name[The Golden Curry], food[English], customer rating[5 out of 5], area[riverside], familyFriendly[yes], near[Café Rouge] | |
| source: name : The Golden Curry | food : English | customer rating : 5 out of | |
| 5 丨 area : riverside |familyFriendly : yes | near : Café Rouge | |
| target:TheGoldenCurry,a5-starfamilyfriendlybreakfast jointneartheCafé Rougeandneartheriver. |
4.2. Transformers
4.2. Transformers
We apply Transformers [20], a sequence-to-sequence architecture, to set up D2T and T2D models. A Transformer contains an encoder, a decoder, and an attention mechanism. Given a source $X={x_{1},x_{2},x_{3},...,x_{N}}$ with $N$ symbols and a target $Y~=~{y_{1},y_{2},y_{3},...,y_{M}}$ with $M$ symbols. The encoder yields a representation $Z={z_{1},z_{2},z_{3},...,z_{N}}$ from $X$ with the same number of symbols. Later, the decoder takes $Z$ to produce the target $Y$ . The chain rule probability $p(Y|Z)$ to generate $Y$ from $Z$ is:
我们采用Transformer [20]这一序列到序列架构来构建D2T和T2D模型。Transformer包含编码器、解码器和注意力机制。给定包含$N$个符号的源序列$X={x_{1},x_{2},x_{3},...,x_{N}}$和包含$M$个符号的目标序列$Y~=~{y_{1},y_{2},y_{3},...,y_{M}}$时,编码器会从$X$生成包含相同数量符号的表示$Z={z_{1},z_{2},z_{3},...,z_{N}}$。随后,解码器接收$Z$并生成目标$Y$。根据链式法则,从$Z$生成$Y$的条件概率$p(Y|Z)$为:
$$
p(Y|Z)=\prod_{i}^{M}p(y_{i}|Y_{<i},Z)
$$
$$
p(Y|Z)=\prod_{i}^{M}p(y_{i}|Y_{<i},Z)
$$
which $y_{0}$ is the “start” symbol $(<\mathtt{b o s}>)$ and $Y_{<i}$ is a sequence of previous symbols of $y_{i}$ . When meeting the “end” token $(<\mathtt{e o s}>)$ or the maximum length, the inference process ends. The cross-entropy loss $L_{e n t}$ minimizes the sum of negative log likelihoods of the symbols:
其中 $y_{0}$ 是"起始"符号 $(<\mathtt{b o s}>)$,$Y_{<i}$ 是 $y_{i}$ 之前的符号序列。当遇到"结束"标记 $(<\mathtt{e o s}>)$ 或达到最大长度时,推理过程终止。交叉熵损失 $L_{e n t}$ 最小化符号的负对数似然之和:
$$
L_{e n t}=-\sum_{j=1}^{M}\sum_{w}p_{t r u e}(w|Y_{<j},Z)l o g(p(w|Y_{<j},Z))
$$
$$
L_{e n t}=-\sum_{j=1}^{M}\sum_{w}p_{t r u e}(w|Y_{<j},Z)l o g(p(w|Y_{<j},Z))
$$
A Transformer has two attention functions: Scaled Dot-Product Attention and Multi-Head Attention. Let $Q,K,Q$ be the query matrix, the key matrix, and the value matrix correspondingly. Let $d_{k},d_{k}$ be the dimensions of queries and keys, and $d_{\nu}$ be the dimension of values. The attention function of Scaled Dot-Product Attention is [20]:
Transformer 有两种注意力函数:缩放点积注意力 (Scaled Dot-Product Attention) 和多头注意力 (Multi-Head Attention)。设 $Q,K,Q$ 分别为查询矩阵、键矩阵和值矩阵,$d_{k},d_{k}$ 为查询和键的维度,$d_{\nu}$ 为值的维度。缩放点积注意力的函数表达式为 [20]:
$$
A t t e n t i o n(Q,K,V)=s o f t m a x(\frac{Q K^{T}}{\sqrt{d_{k}}})V
$$
$$
A t t e n t i o n(Q,K,V)=s o f t m a x(\frac{Q K^{T}}{\sqrt{d_{k}}})V
$$
The purpose of using the scaling factor $\frac{1}{\sqrt{d_{k}}}$ is to avoid the softmax function from experiencing very small gradients when the value of $d_{k}$ becomes substantial. Additionally, the Multi-Head Attention mechanism operates with keys, values, and queries, each having a dimension of $d_{m o d e l}$ [20]. This setup enables the model to learn additional information from different positions’ subspace representations.
使用缩放因子 $\frac{1}{\sqrt{d_{k}}}$ 的目的是避免当 $d_{k}$ 的值较大时,softmax函数出现梯度极小的情况。此外,多头注意力 (Multi-Head Attention) 机制操作的键 (key)、值 (value) 和查询 (query) 的维度均为 $d_{m o d e l}$ [20]。这种设置使模型能够从不同位置的子空间表示中学习额外信息。
$$
\begin{array}{c}{{M u l t i H e a d(Q,K,V)=C o n c a t(h e a d_{1},h e a d_{2},...,h e a d_{h})W^{O}}}\ {{\mathrm{where~}h e a d_{i}=A t t e n t i o n(Q W_{i}^{Q},K W_{i}^{K},V W_{i}^{V})}}\end{array}
$$
$$
\begin{array}{c}{{M u l t i H e a d(Q,K,V)=C o n c a t(h e a d_{1},h e a d_{2},...,h e a d_{h})W^{O}}}\ {{\mathrm{where~}h e a d_{i}=A t t e n t i o n(Q W_{i}^{Q},K W_{i}^{K},V W_{i}^{V})}}\end{array}
$$
which $h$ refers to the number of heads. For each head $W_{i}^{Q} \in~\mathbb{R}^{d_{m o d e l}\times d_{k}}$ , $W_{i}^{K} \in~\mathbb{R}^{d_{m o d e l}\times d_{k}}$ , $W_{i}^{V} \in~\mathbb{R}^{d_{m o d e l}\times d_{\nu}}$ , $W^{O}\in\mathbb{R}^{d_{m o d e l}\times h d_{\nu}}$ are the parameter matrices.
其中 $h$ 表示头数。对于每个头,$W_{i}^{Q} \in~\mathbb{R}^{d_{m o d e l}\times d_{k}}$ 、$W_{i}^{K} \in~\mathbb{R}^{d_{m o d e l}\times d_{k}}$ 、$W_{i}^{V} \in~\mathbb{R}^{d_{m o d e l}\times d_{\nu}}$ 和 $W^{O}\in\mathbb{R}^{d_{m o d e l}\times h d_{\nu}}$ 是参数矩阵。
4.3. Self-training Model
4.3. 自训练模型
The self-training framework, described in Figure 1, consists of two sequence-to-sequence models named T2D and D2T. These models engage in self-training using a freshly generated subset, identified based on predetermined criteria and data combinations. This subset encompasses both newly acquired data and specific selfmemory chosen during the optimization process.
图 1 所示的自训练框架包含两个序列到序列模型 T2D 和 D2T。这些模型通过基于预设标准和数据组合筛选出的新生成子集进行自训练。该子集包含新获取的数据以及在优化过程中选定的特定自记忆内容。
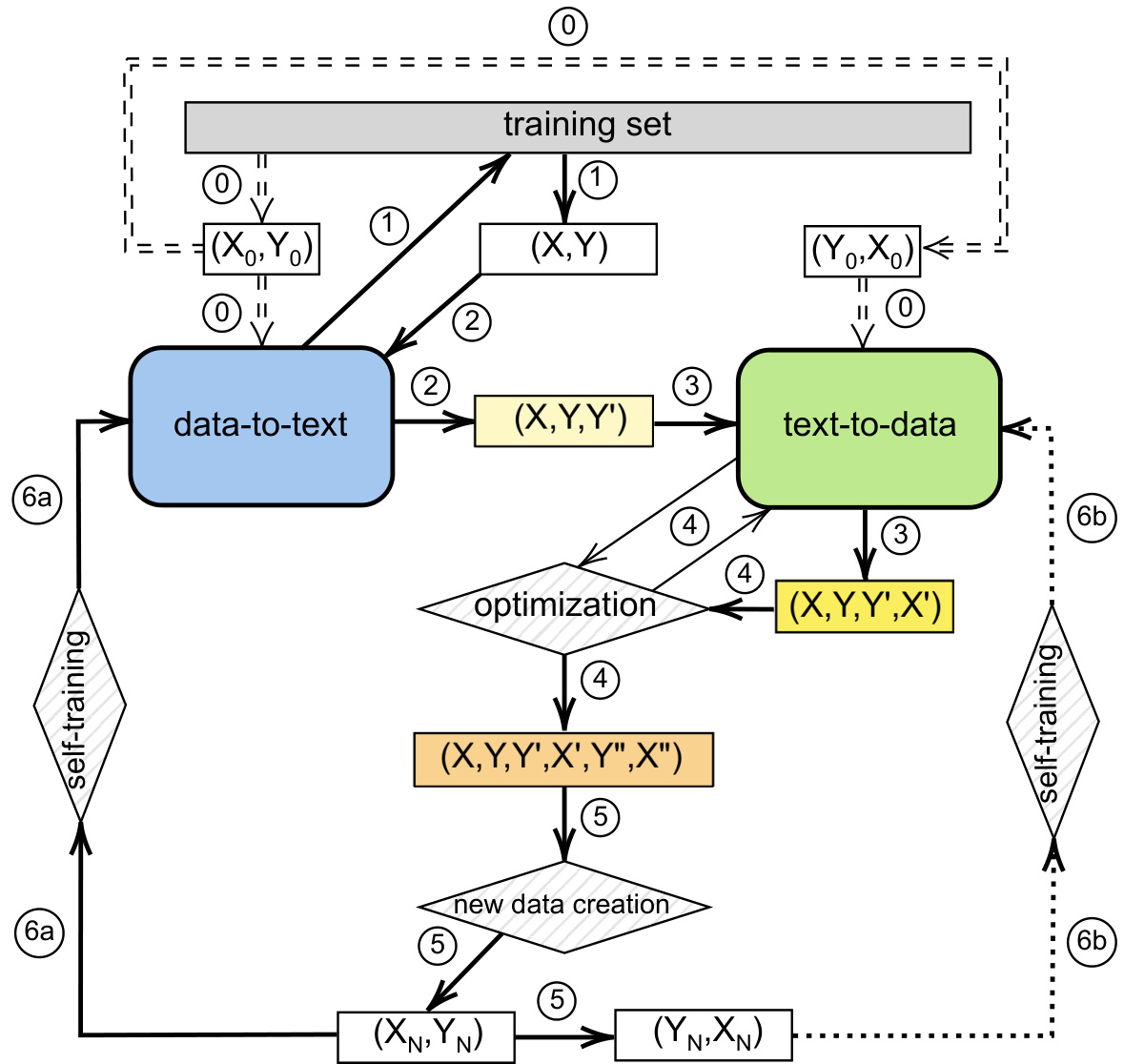
Figure 1: The self-training model. ${0}$ gets a fixed/random subset for first training D2T and T2D models; ${1}$ gets a fixed/random subset for starting to self-train D2T and T2D models; infer $Y^{\prime}$ and $X^{\prime};\stackrel{\widehat{(4)}}{\sim}$ optimizes $Y^{\prime}$ as $Y^{\prime\prime}$ and use it to infer $X^{\prime\prime};\stackrel{\widehat{\left(5\right)}}{\left(5\right)}$ creates new data, $(X_{N},Y_{N})$ and self-train D2T and T2D models on new data. The T2D self-training is optional.
图 1: 自训练模型。${0}$ 获取固定/随机子集用于首次训练 D2T 和 T2D 模型;${1}$ 获取固定/随机子集开始自训练 D2T 和 T2D 模型; 推断 $Y^{\prime}$ 和 $X^{\prime}$;$\stackrel{\widehat{(4)}}{\sim}$ 将 $Y^{\prime}$ 优化为 $Y^{\prime\prime}$ 并用其推断 $X^{\prime\prime}$;$\stackrel{\widehat{\left(5\right)}}{\left(5\right)}$ 生成新数据 $(X_{N},Y_{N})$ 和 $(Y_{N},X_{N})$;在新数据上自训练 D2T 和 T2D 模型。T2D 自训练为可选步骤。
Let define $D$ is the training set, and $(X,Y)$ is a subset of $D$ , including source-target pairs $(x_{i},y_{i})$ . Let’s define $(X^{\prime},Y^{\prime})$ as a set of target-source pairs $(x_{i}^{\prime},y_{i}^{\prime})$ inferred from the D2T and T2D models. Similarly, $(X^{\prime\prime},Y^{\prime\prime})$ is a set of source-target pairs $(x_{i}^{\prime\prime},y_{i}^{\prime\prime})$ after passing the optimization step. The self-training model contains these steps:
设 $D$ 为训练集,$(X,Y)$ 是 $D$ 的子集,包含源-目标对 $(x_{i},y_{i})$。定义 $(X^{\prime},Y^{\prime})$ 为由 D2T 和 T2D 模型推断出的目标-源对集合 $(x_{i}^{\prime},y_{i}^{\prime})$。类似地,$(X^{\prime\prime},Y^{\prime\prime})$ 是经过优化步骤后的源-目标对集合 $(x_{i}^{\prime\prime},y_{i}^{\prime\prime})$。自训练模型包含以下步骤:
T2D model or ${6}$ is not mandatory.
T2D 模型或 ${6}$ 不是必需的。
• Repeat from step ${1}$ to ${6}\mathrm{{a})\mathrm{{and}/\mathrm{{or}\left(\frac{6\mathrm{{b}}}{\mathrm{{b}}}\right)}}}$ by the given number of self-training epochs. Finally, we evaluate the output quality of the D2T model.
• 从步骤 ${1}$ 到 ${6}\mathrm{{a})\mathrm{{and}/\mathrm{{or}\left(\frac{6\mathrm{{b}}}{\mathrm{{b}}}\right)}}}$ 按给定的自训练轮数重复执行。最后,我们评估 D2T (Data-to-Text) 模型的输出质量。
The best D2T and T2D models are saved during each epoch based on metric values evaluated on the validation set. Specifically, the D2T model uses METEOR, while the T2D model uses OSF-precision (Overall Slot Filling) [38], as presented in detail in Section 5.1.
每个训练周期中,会根据验证集上的评估指标保存最优的D2T(数据到文本)和T2D(文本到数据)模型。具体而言,D2T模型采用METEOR指标,而T2D模型采用OSF-precision(整体槽位填充)[38],详见5.1节。
4.4. Target Optimization
4.4. 目标优化
In DTG, an ideal target must capture all information in the input, usually source values and relationships between subjects and objects (keys and values), and have no redundant information or hallucinations. With that sense, we believe that any generated target that satisfies these conditions and is shorter than the gold target should be chosen as the new gold target, or called the optimized target.
在DTG中,理想的输出目标必须完整捕获输入信息(通常包括源值及主客体关系(键与值)),且不含冗余信息或幻觉内容。基于此,我们认为任何满足这些条件且比原始目标更短的生成结果,都应被选作新的黄金目标(或称优化目标)。
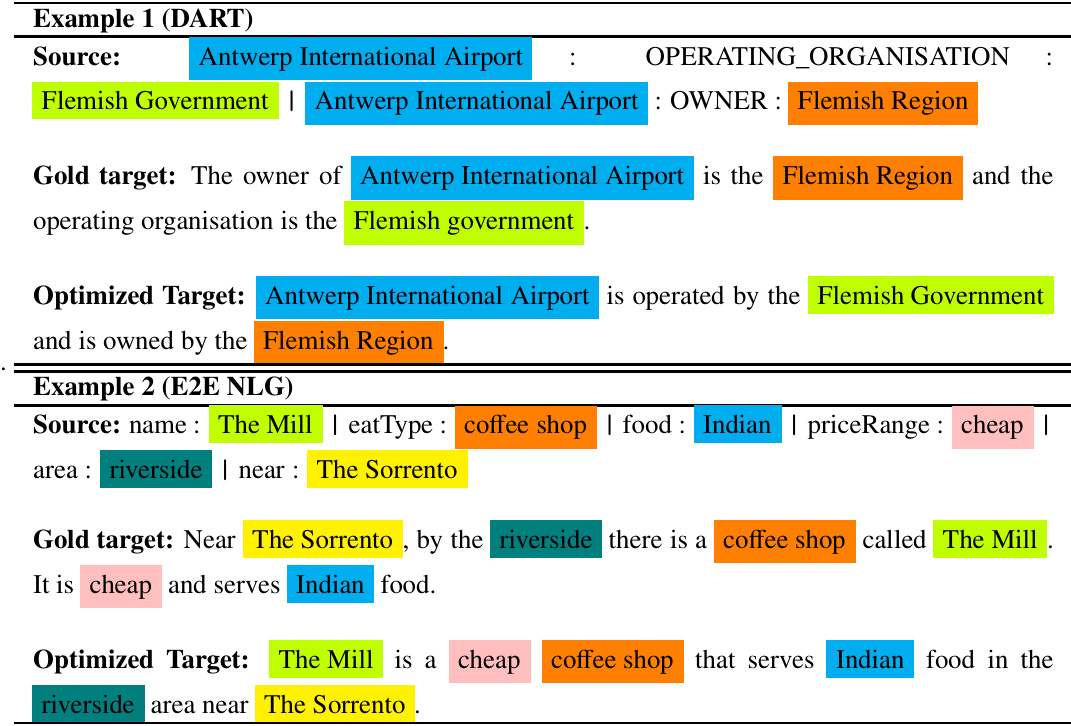
Table 2 displays two examples on DART and E2E NLG, each contains the optimized target and the gold target. The optimized target is more brief than the gold target and features a different word order. Consequently, we argue that BLUE may not be a suitable metric for evaluating the model’s performance. Therefore, we opt for METEOR. Note that the optimized target must validate its ability to capture the relationships in the source before being selected as self-memory for self-training, as shown in Section 4.6.
表 2: 展示了 DART 和 E2E NLG 的两个示例,每个示例包含优化目标和黄金目标。优化目标比黄金目标更简洁,且词序不同。因此,我们认为 BLUE 可能不适合评估模型性能,于是选择了 METEOR。需要注意的是,优化目标在被选为自训练的自我记忆 (self-memory) 前,必须验证其捕捉源数据关系的能力,如第 4.6 节所示。
Algorithm 1 Target optimization
算法 1: 目标优化
We apply Algorithm 1, a simple greedy algorithm, from a generated target to loop its sentence list to choose sentences containing source values. The input is a pair of source-target $(x^{\prime},y^{\prime})$ inferred from the D2T and T2D models, and the output is an optimized target $y^{\prime}$ . The optimized target is expected to capture all source values, each happening only once.
我们应用算法1(一种简单的贪心算法),从生成的目标开始循环其句子列表,选择包含源值的句子。输入是从D2T和T2D模型推断出的一对源-目标$(x^{\prime},y^{\prime})$,输出是一个优化的目标$y^{\prime}$。期望优化后的目标能捕获所有源值,且每个源值仅出现一次。
Here is the explanation of how Algorithm 1 works. From $(x^{\prime},y^{\prime})$ , the algorithm starts with creating two empty lists, the matched sentences $M S$ and the matched values $M V$ . It also extracts a list of sentences $S$ from $y^{\prime}$ and a list of source values $V$ from $x^{\prime}$ . Next, the algorithm uses two loops, one loop for each sentence $s$ in $S$ and one sub-loop for each value $\nu$ in $V$ . In each step, if $\nu$ appears in $s$ and does not exist in $M V$ , add it to $M V$ . If $s$ is not in $M S$ , add $s$ to $M S$ . The algorithm then compares the element numbers of $M V$ and $V$ . If they are equal, $M S$ is flattened into a string by concatenating each element with a blank, resulting in a new target $y^{\prime\prime}$ . Otherwise, we have no new target.
以下是算法1的工作原理说明。从$(x^{\prime},y^{\prime})$开始,该算法首先创建两个空列表:匹配句子$MS$和匹配值$MV$。同时从$y^{\prime}$中提取句子列表$S$,从$x^{\prime}$中提取源值列表$V$。接着,算法使用两个循环:外层循环遍历$S$中的每个句子$s$,内层循环遍历$V$中的每个值$\nu$。在每一步中,如果$\nu$出现在$s$中且不存在于$MV$,则将其加入$MV$。如果$s$不在$MS$中,则将$s$加入$MS$。然后算法比较$MV$和$V$的元素数量:若两者相等,则将$MS$中的元素用空格连接拼合成字符串,生成新目标$y^{\prime\prime}$;否则不生成新目标。
4.5. New Data Creation
4.5. 新数据创建
From tuple data $(X,Y,Y^{\prime},X^{\prime},Y^{\prime\prime},X^{\prime\prime})$ , we filter “elite” pairs of source-target from each tuple $(x,y,y^{\prime},x^{\prime},y^{\prime\prime},x^{\prime\prime})$ by two cases.
从元组数据 $(X,Y,Y^{\prime},X^{\prime},Y^{\prime\prime},X^{\prime\prime})$ 中,我们通过以下两种情况筛选出每个元组 $(x,y,y^{\prime},x^{\prime},y^{\prime\prime},x^{\prime\prime})$ 的“精英”源-目标对。
Case 1: If $y^{\prime\prime}$ is $y^{\prime}$ , there is no new optimized target. A pair $(x,y^{\prime})$ is chosen if it satisfies these conditions:
案例1:如果 $y^{\prime\prime}$ 等于 $y^{\prime}$ ,则不存在新的优化目标。当 $(x,y^{\prime})$ 满足以下条件时,该数据对将被选中:
• 1a. The length of $y^{\prime}$ is less than the length of $y$ . • $\mathbf{\delta}_{I b}$ . All source values of $x$ must appear in $y^{\prime}$ . • ${I c}$ . All MRs/triples of $x^{\prime}$ must be a subset of those of $x$ . In this case, we apply OSF-precision, as presented in Section 5.1.
• 1a. $y^{\prime}$ 的长度小于 $y$ 的长度。
• $\mathbf{\delta}_{I b}$。$x$ 的所有源值必须出现在 $y^{\prime}$ 中。
• ${I c}$。$x^{\prime}$ 的所有元组/MR 必须是 $x$ 的子集。此时,我们采用第 5.1 节提出的 OSF-precision 方法。
Case 2: If $y^{\prime\prime}$ is not $y^{\prime}$ , it means there has a new optimized target. In this case, we will select a pair $(x,y^{\prime\prime})$ if guarantee these conditions:
案例2:如果 $y^{\prime\prime}$ 不是 $y^{\prime}$ ,则意味着存在新的优化目标。在这种情况下,我们将选择一对 $(x,y^{\prime\prime})$ ,前提是满足以下条件:
• 2a. The length of $y^{\prime\prime}$ is less than the length of $y$ . • 2b. All source values of $x$ must appear in $y^{\prime\prime}$ . • $_{2c}$ . All MRs/triples of $x^{\prime}$ must be a subset of those of $x$ . In this case, we apply OSF-precision, as presented more Section 5.1.
- 2a. $y^{\prime\prime}$ 的长度小于 $y$ 的长度。
- 2b. $x$ 的所有源值必须出现在 $y^{\prime\prime}$ 中。
- 2c. $x^{\prime}$ 的所有MR/三元组必须是 $x$ 的子集。在这种情况下,我们应用 OSF-precision (原始语义框架精度),具体见第5.1节。
Let $(X,Y)$ be a set of distinctive pairs $(x,y)$ , which is used to feed to the D2T and T2D models to get a tuple $(Y^{\prime},X,^{\prime}Y^{\prime\prime},X^{\prime\prime})$ in Figure 1. Let $(X_{O},Y_{O})$ represent a set of distinctive pairs $(x_{o},y_{o})$ obtained by selecting either $y^{\prime}$ or $y^{\prime\prime}$ from pairs $(x,y^{\prime})$ and $(x,y^{\prime\prime})$ based on Case 1 or Case 2 decisions. Similarly, let $(X_{R},Y_{R})$ be the remaining new data with pairs $(x,y)$ where both $y^{\prime}$ and $y^{\prime\prime}$ cannot be inferred from $x$ . We combine $(X_{O},Y_{O})$ and $(X_{R},Y_{R})$ to form a new set $(X_{N},Y_{N})$ . If the number of pairs in $(X_{N},Y_{N})$ exceeds that of $(X,Y)$ , we randomly select pairs to match the number of pairs in $(X,Y)$ . This ensures an equivalent number of pairs in the subset for self-training. Finally, we have a new subset $(X_{N},Y_{N})$ with distinctive pairs and the same size as $(X,Y)$ .
设 $(X,Y)$ 为一组独特的数据对 $(x,y)$,用于输入 D2T 和 T2D 模型以获取图 1 中的元组 $(Y^{\prime},X,^{\prime}Y^{\prime\prime},X^{\prime\prime})$。设 $(X_{O},Y_{O})$ 表示通过根据案例 1 或案例 2 的决策从数据对 $(x,y^{\prime})$ 和 $(x,y^{\prime\prime})$ 中选择 $y^{\prime}$ 或 $y^{\prime\prime}$ 而得到的一组独特数据对 $(x_{o},y_{o})$。类似地,设 $(X_{R},Y_{R})$ 为剩余的新数据,其中包含数据对 $(x,y)$,且 $y^{\prime}$ 和 $y^{\prime\prime}$ 均无法从 $x$ 推断得出。我们将 $(X_{O},Y_{O})$ 和 $(X_{R},Y_{R})$ 组合成一个新的集合 $(X_{N},Y_{N})$。如果 $(X_{N},Y_{N})$ 中的数据对数量超过 $(X,Y)$,则随机选择数据对以匹配 $(X,Y)$ 的数量。这确保了自训练子集中数据对数量的等效性。最终,我们得到一个与 $(X,Y)$ 大小相同且包含独特数据对的新子集 $(X_{N},Y_{N})$。
4.6. Roles of the T2D model
4.6. T2D模型的作用
In DTG, popular methods usually apply a single D2T model to produce a target $y^{\prime}$ (greedy decoding) or a set of $y^{\prime}$ (beam search) from a given source $x$ . Later, these targets are validated by automatic metrics against the source, such as cosine similarity, ROUGE, and any metric combinations, or based on several pre-defined conditions to produce the quality scores. Though this method helps choose the best target, it remains unknown how a target can capture the relationships between MRs/triples in the source.
在DTG中,流行方法通常采用单一D2T模型从给定源数据$x$生成目标$y^{\prime}$(贪婪解码)或一组$y^{\prime}$(束搜索)。随后,这些目标会通过自动指标(如余弦相似度、ROUGE及任意指标组合)与源数据进行质量验证,或基于若干预定义条件生成质量分数。尽管该方法有助于选择最佳目标,但目标如何捕捉源数据中MR/三元组间的关系仍不明确。
A T2D model allows one to check the relationships the D2T target $y^{\prime}$ can capture by converting it back to $x^{\prime}$ . An ideal target $y^{\prime}$ is when its T2D output $x^{\prime}$ matches $x$ totally regarding MRs/triples. Applying this strict criterion to filter source-target pairs appears to result in a limited amount of new data available for self-training. This could be attributed to the varied and latent relationships the T2D model needs to handle when extracting text information. Instead, we use a looser condition (match a subset of MRs/triples), as presented ${l c}$ and $_{2c}$ in Section 4.5. The appearance of all source values of $x^{\prime}$ in $y$ can somewhat prove the capture of relationships of the target $y^{\prime}$ . In short, the T2D model can validate relationships of MRs/triples in a given D2T target.
T2D模型允许通过将D2T目标$y^{\prime}$转换回$x^{\prime}$来检查其能捕获的关系。当T2D输出$x^{\prime}$在MRs/三元组层面完全匹配$x$时,即为理想目标$y^{\prime}$。采用这一严格标准筛选源-目标对会导致可用于自训练的新数据量受限,这可能源于T2D模型提取文本信息时需要处理的多样潜在关系。为此,我们采用更宽松的条件(匹配MRs/三元组的子集),如第4.5节${l c}$和$_{2c}$所示。若$x^{\prime}$的所有源值均出现在$y$中,则能在一定程度上证明目标$y^{\prime}$捕获了相关关系。简言之,T2D模型可验证给定D2T目标中MRs/三元组的关系。
5. Experiments and Results
5. 实验与结果
5.1. Automatic Evaluation Metrics
5.1. 自动评估指标
We use widely used metrics to assess the quality of the produced texts, contrasting them with the references. These metrics can be classified into two essential categories: string-based and semantic-based. In this paper, we only use several string-based metrics such as BLEU, CIDEr, EPM, NIST, OSF, ROUGE, and TER.
我们采用广泛使用的指标来评估生成文本的质量,并将其与参考文本进行对比。这些指标可分为两大类:基于字符串 (string-based) 和基于语义 (semantic-based)。本文仅使用BLEU、CIDEr、EPM、NIST、OSF、ROUGE和TER等基于字符串的评估指标。
BLEU (Bilingual Evaluation Understudy): BLEU provides a resultant score for assessing the resemblance between a produced target and a reference target. It accomplishes this by tallying the shared n-grams while also considering a penalty for brevity based on text length. BLEU is commonly applied in tasks like machine translation, especially when the length of the target text is roughly equivalent to that of the source text [39].
BLEU (Bilingual Evaluation Understudy): BLEU通过统计共享n-gram并基于文本长度施加简短惩罚,为评估生成目标与参考目标之间的相似性提供综合评分。该指标常用于机器翻译等任务,尤其当目标文本长度与源文本大致相当时 [39]。
CIDEr (Consensus-based Image Description Evaluation): This metric evaluates the quality of captions created for images by contrasting them against reference captions supplied by human annotators. CIDEr examines the precision of the generated captions (how closely they align with the reference captions) and their distinctiveness (how dissimilar they are from one another). CIDEr delivers a more thorough evaluation than BLEU and ROUGE [40].
CIDEr (基于共识的图像描述评估): 该指标通过将图像描述与人工标注提供的参考描述进行对比,评估图像描述生成的质量。CIDEr考察生成描述的精确性(与参考描述的匹配程度)和独特性(描述之间的差异程度)。相比BLEU和ROUGE [40],CIDEr能提供更全面的评估。
EPM (Exact Phrase Matching): EMP is a simple metric to determine the quality of the generated target. It computes a score from the number of source values that appear precisely in the generated target over the number of source values extracted from the source. The phrase matching is not always correct when data types can be boolean or ordinal. However, the higher metric score generally reflects a more favorite quality.
EPM (精确短语匹配): EPM 是一种简单的衡量生成目标质量的指标。它通过计算生成目标中精确出现的源值数量与从源中提取的源值数量之比来得出分数。当数据类型为布尔值或有序类型时,短语匹配并不总是准确,但较高的指标分数通常反映出更优的质量。
METEOR (Metric for Evaluation of Translation with Explicit ORdering): It computes an F-score between the generated target and the gold target by the overlapped unigrams from three modules based on words: exact, stem, and synonymy [41]. METEOR is superior to BLEU when dealing with low-source texts and obtains a higher human judgment at sentence level [42].
METEOR (显式排序翻译评估指标): 该指标通过基于单词的精确匹配、词干和同义词三个模块的重叠单元组,计算生成目标与参考目标之间的F值 [41]。在处理低资源文本时,METEOR优于BLEU指标,并在句子级别获得更高的人类判断评分 [42]。
NIST (N-gram-based Integrated Evaluation Score): This metric is widespread in machine translation for evaluating the caliber of machine-produced translations. NIST calculates a similarity score by comparing the generated translation with the reference translation, relying on the overlap of n-grams. What sets NIST apart from specific alternative metrics is its integration of normalized weights assigned to varying n-gram lengths. This unique feature enables NIST to be flexible and adaptable across diverse languages and translation nuances [43].
NIST (基于N元语法的综合评估分数):该指标在机器翻译领域广泛用于评估机器生成翻译的质量。NIST通过比较生成翻译与参考翻译之间n元语法的重叠度来计算相似性分数。NIST区别于其他特定替代指标的关键在于其整合了针对不同长度n元语法的归一化权重。这一独特特性使NIST能够灵活适应不同语言和翻译细节[43]。
OSF (Overall Slot Filling): It evaluates precision (OSF-precision), recall (OSF-recall), and F-score (OSFF) by comparing two Knowledge Base (KB) representations. A slot is deemed correct if both the reconstructed KB and the input KB contain a matching pair of slot type and its corresponding slot value. [38]. Our work computes OSF-precision, OSF-recall, and OSF-F1 between D2T inputs and T2D outputs. An MR/triple of a D2T input must match totally that of a T2D output to be considered a match slot.
OSF (整体槽填充): 通过比较两个知识库(KB)表示来评估精确率(OSF-precision)、召回率(OSF-recall)和F值(OSF-F1)。当重构KB和输入KB同时包含匹配的槽类型及其对应槽值时,该槽被视为正确。[38]。我们的工作计算D2T输入与T2D输出之间的OSF-precision、OSF-recall和OSF-F1。只有当D2T输入的MR/三元组与T2D输出的MR/三元组完全匹配时,才被视为匹配槽。
ROUGE (Recall-Oriented Understudy for Gisting Evaluation): ROUGE is a traditional metric for summarization problems, computing the degree of similarity between a generated target and a gold target relying on the overlap rate of the number of semantic units (n-grams) appearing in both texts [44]. Several popular ROUGE types include ROUGE-1, ROUGE-2, and ROUGE-LCS (Longest Common Subsequent).
ROUGE (面向召回率的摘要评估替代指标): ROUGE是摘要任务中的传统评估指标,通过计算生成文本与参考文本之间语义单元(n-gram)重叠率来衡量两者的相似度[44]。常用ROUGE类型包括ROUGE-1、ROUGE-2和ROUGE-LCS(最长公共子序列)。
TER (Translation Edit Rate): It measures machine translation quality by quantifying edits needed to align the machine-generated translation with a human reference. Effective for assessing translations with substantial differences in word order, grammar, and structure, TER focuses on structural alignment. Lower TER scores indicate greater similarity between machinegenerated and reference translations. However, TER doesn’t account for nuances like meaning, word choice, or fluency, emphasizing structural alignment [45].
TER (Translation Edit Rate): 该指标通过量化机器翻译结果与人工参考译文之间的编辑操作次数来衡量机器翻译质量。TER 擅长评估词序、语法和结构差异较大的翻译,其核心在于结构对齐。TER 分数越低,表明机器翻译与参考译文的相似度越高。但该指标不考虑语义、选词或流畅性等细微差异,仅关注结构对齐 [45]。
5.2. Experimental configurations
5.2. 实验配置
In all methods, the training process involves 3 epochs, with a maximum input/output length of 256, a minimum input/output length of 4, an adaptive learning rate, and greedy decoding in the inference time. Transfer learning is applied to train Transformer models on the full training data, leveraging pre-trained models like BARTbase, FLAN-T5-base, and T5-base. T5-base is utilized in all self-training methods to train on both random and fixed data.
在所有方法中,训练过程包含3个周期 (epoch),最大输入/输出长度为256,最小输入/输出长度为4,采用自适应学习率,并在推理时使用贪心解码 (greedy decoding)。迁移学习被应用于在完整训练数据上训练Transformer模型,利用了BARTbase、FLAN-T5-base和T5-base等预训练模型。在所有自训练方法中,使用T5-base在随机和固定数据上进行训练。
In this situation, it is evident that self-training methods utilize less data than full training with equivalent epochs. To be precise, a self-training method necessitates only $90%$ training data for 3 epochs, whereas a full-training method demands $300%$ training data for the same 3 epochs (with each utilizing $100%$ training data or the whole training set). Besides the type of training data, we also set up several different training methods:
在此情况下,显然自训练方法在相同训练周期内消耗的数据量少于全量训练。具体而言,自训练方法仅需 $90%$ 训练数据进行3个周期,而全量训练方法在相同3个周期内需要 $300%$ 训练数据(每次均使用 $100%$ 训练数据或完整训练集)。除训练数据类型外,我们还设置了多种不同的训练方法:
• self-mem $^+$ new data: Similar to self-mem, the training takes self-memory and new data for selftraining the D2T model but not the T2D model. • self-mem $^+$ new data $^+$ self $T2D$ : Similar to selfmem, the training takes self-memory and new data for self-training the D2T and T2D models.
• self-mem$^+$ new data:类似于self-mem,训练时采用自记忆(self-memory)和新数据对D2T模型进行自训练,但不训练T2D模型。
• self-mem$^+$ new data$^+$ self$T2D$:类似于self-mem,训练时采用自记忆和新数据对D2T及T2D模型进行自训练。
Figure 2 illustrates the data allocation across 3 epochs for various training methods. The full training method requires the largest dataset, encompassing the entire training set ( $100%$ data) for each epoch. Both no selfmem $I$ and self-mem with fixed data employ identical training data divided into three segments for each training epoch. Similarly, no self-mem 3 and self-mem with random data utilize random subset data for each training session. no self-mem 2 exclusively utilizes the first portion of the training set for training across 3 epochs, so this method has less data diversity than others.
图 2: 展示了不同训练方法在3个训练周期(epoch)中的数据分配情况。完整训练方法(full training)需要最大规模的数据集,每个周期都使用整个训练集(100%数据)。无记忆方法I(no selfmem I)和固定数据的自记忆方法(self-mem with fixed data)都采用相同的训练数据,并将数据划分为三个片段用于每个训练周期。同样地,无记忆方法3(no selfmem 3)和随机数据的自记忆方法(self-mem with random data)在每次训练时都使用随机子集数据。无记忆方法2(no selfmem 2)仅使用训练集的第一部分数据进行3个周期的训练,因此该方法的数据多样性低于其他方法。
5.3. DART’s results
5.3. DART 的结果
To ensure an equitable comparison, we employed the evaluation package from the challenge1, to assess BLEU, METEOR, and TER values on the test set. Our methods are compared to:
为确保公平比较,我们采用挑战赛提供的评估包1,在测试集上评估BLEU、METEOR和TER值。对比方法包括:
• LSTM with Attention: This model is a Bidirectional Long Short-Term Memory (Bi-LSTM) model featuring an attention mechanism [12]. The encoder comprises a 2-layer Bi-LSTM with 300- dimensional word embeddings and does not rely on pre-trained word vectors. For the decoder, the configuration includes 512 hidden units and a dropout rate of 0.3. • End-to-End Transformer: Nan et al. [12] utilized a Transformer architecture [20] for training their models, and we adopted their results. • BART-base: Our models underwent training on BART-base, a version of the BART model that incorporates a denoising auto encoder for the pretraining of sequence-to-sequence models [46]. Additionally, we utilized the results obtained from BART-base in the study by Nan et al. [12]. • T5-base: In a similar way, our models were trained on T5-base [47], and we took the results obtained by Nan et al. [12] for the purpose of comparison.
• 带注意力机制的LSTM (LSTM with Attention):该模型采用双向长短期记忆网络 (Bi-LSTM) 架构并集成注意力机制 [12]。编码器由300维词嵌入的双层Bi-LSTM构成,未使用预训练词向量。解码器设置包含512个隐藏单元及0.3的dropout率。
• 端到端Transformer (End-to-End Transformer):Nan等人 [12] 采用Transformer架构 [20] 训练模型,我们直接引用其实验结果。
• BART-base版本:我们的模型基于BART-base进行训练,该版本通过去噪自编码器实现序列到序列模型的预训练 [46]。同时引用了Nan等人 [12] 研究中BART-base的实验结果。
• T5-base版本:类似地,我们使用T5-base [47] 训练模型,并采用Nan等人 [12] 的对比实验结果。

Figure 2: The data allocation for different training methods. The figure is shown better with colors.
图 2: 不同训练方法的数据分配情况。该图在彩色显示时效果更佳。
le 3: Metric values between the generated targets and the gold targets on the test set of DART by different method
: higher is better, : lower is better 1A non-overlap data is allocated in each epoch, except no self-mem 2
表 3: 不同方法在DART测试集上生成目标与黄金目标之间的指标值
| 方法 | BLEU↑ | METEOR↑ | TER↓ |
|---|---|---|---|
| LSTM with Attention (Nan et al. [12]) End-to-End Transformer (Nan et al. [12]) BART-base (Nan et al. [12]) | 29.66 | 27 | 63 |
| 27.24 | 25 | 65 | |
| 47.11 | 38 | 46 | |
| T5-base (Nan et al. [12]) Our run | 49.21 | 40 | 44 |
| BART-base FLAN-T5-base | |||
| 46.15 | 38.13 | 48.20 | |
| 45.53 48.52 | 0.36 | 0.54 | |
| T5-base 30% fixed data per epoch' | 39.70 | 45.91 | |
| noself-mem1 | 44.86 | 50.83 | |
| noself-mem2 | 41.23 | 37.98 | |
| self-mem | 33.98 | 51.47 | |
| self-mem+selfT2D | 45.63 | 38.90 | 49.10 |
| self-mem+newdata | 46.14 | 38.86 | 49.08 |
| 47.76 | 39.51 | 48.28 | |
| self-mem+newdata+selfT2D | 47.60 | 39.39 | 48.23 |
| 30%random data per epoch | |||
| noself-mem3 | 46.90 | 38.92 | 46.61 |
| self-mem | 44.52 | 38.62 | 50.75 |
| self-mem+selfT2D | 45.62 | 38.81 | 48.95 |
| self-mem+newdata | 47.54 | 39.38 | 48.07 |
| self-mem+newdata+selfT2D | 47.32 | 39.19 | 47.34 |
: 数值越高越好, : 数值越低越好 1每轮分配非重叠数据,不含noself-mem 2
Table 3 shows the results of the test set using various methods evaluated through widely used string metrics such as BLEU, METEOR, and TER. T5-base, as reported by Nan et al. [12], demonstrated the highest performance, whereas our version exhibited a slightly lower performance but outperformed our FLAN-T5- base and BART-base models. In no self-memory training methods, no self-mem 3 trained on random data out- performed the other two methods (no self-mem 1 and no self-mem 2), which were trained on fixed data. Among the self-memory methods, training on fixed data generally yielded slightly better results than training on random data. Specifically, self-mem $^+$ new data on fixed data emerged as the optimized method, achieving highly competitive results compared to the best method over T5-base. Additionally, it was observed that self-training on the T2D model did not significantly contribute to performance improvement. Therefore, we recommend excluding this self-training to conserve time and computer resources.
表 3: 通过BLEU、METEOR和TER等广泛使用的字符串指标评估各种方法在测试集上的结果。如Nan等人[12]所述,T5-base表现出最高性能,而我们的版本性能略低,但优于FLAN-T5-base和BART-base模型。在无自记忆训练方法中,基于随机数据训练的no self-mem 3优于基于固定数据训练的另外两种方法(no self-mem 1和no self-mem 2)。在自记忆方法中,基于固定数据的训练通常比随机数据训练略优。具体而言,基于固定数据的self-mem$^+$new data成为优化方法,其效果与T5-base最佳方法相比具有高度竞争力。此外,观察到T2D模型的自训练对性能提升贡献不大,因此建议排除该自训练以节省时间和计算资源。
5.4. E2E NLG’s results
5.4. E2E NLG 的结果
Similar to the evaluation on DART, we use the original package from E2E NLG Challenge2 to have a fair comparison between our methods and others. This package measures the output quality by automatic metrics such as BLEU, NIST, METEOR, ROUGE-L, and CIDEr. We compare our self-memory methods to the training of full models and other benchmark methods, including:
与DART评估类似,我们使用E2E NLG Challenge2的原始包来公平比较我们的方法与其他方法。该包通过BLEU、NIST、METEOR、ROUGE-L和CIDEr等自动指标衡量输出质量。我们将自记忆方法与完整模型训练及其他基准方法进行对比,包括:
Similar to the training on DART, T5-base outperformed the other two, FLAN-T5-base and BART-base. Furthermore, the self-memory training shows worse when lacking both new data and self-training of T2D. Self-training on new data helps to improve the output quality, while self-training on the T2D model does not contribute significantly. The best METEOR score of 46.11 is achieved by self-mem $^+$ new data when incorporating newly added random data. On the other hand, its model trained on fixed data exhibits a competitive METEOR score of 46.07 and a competitive BLUE. The best model is Pragmatics [48] with a BLUE score of 68.60. Besides, the no self-memory models on subsets obtained a competitive performance compared to fulltraining and self-memory models.
与在DART上的训练类似,T5-base的表现优于FLAN-T5-base和BART-base。此外,当缺乏新数据且未对T2D进行自训练时,自记忆训练的效果更差。对新数据的自训练有助于提高输出质量,而对T2D模型的自训练贡献不明显。结合新增随机数据时,自记忆 $^+$ 新数据的训练取得了最佳METEOR分数46.11。另一方面,其基于固定数据训练的模型表现出具有竞争力的METEOR分数46.07和BLUE分数。最佳模型是Pragmatics [48],其BLUE分数为68.60。此外,在子集上未使用自记忆的模型与全训练和自记忆模型相比,表现也具有竞争力。
5.5. General results
5.5. 总体结果
With results over DART and E2E NLG, we realize that $s e l f{\cdot}m e m+n e w$ data is the optimized self-memory method which has a competitive performance compared to the full data training. It combines self-memory and new data, with self-training the D2T model and without self-training the T2D model. Moreover, self-training on the T2D model is unnecessary, and we only need to train the T2D model once to check the quality of texts inferred from the D2T model. The superiority between self-training on fixed data and random data remains uncertain. Nonetheless, opting for fixed data in training is more advantageous, particularly in scenarios involving continual learning with the introduction of new data.
在DART和E2E NLG上的实验结果表明,$s e l f{\cdot}m e m+n e w$数据是优化的自记忆方法,其性能与全量数据训练相当。该方法结合了自记忆数据和新数据,对D2T模型进行自训练,但不对T2D模型进行自训练。此外,对T2D模型进行自训练并无必要,我们只需训练一次T2D模型来检验D2T模型生成文本的质量。固定数据与随机数据在自训练中的优劣尚不明确,但在涉及持续学习并引入新数据的场景中,选择固定数据进行训练更具优势。
6. Limitation
6. 局限性
The first limitation pertains to our model’s evaluation, which was confined to small-scale pre-trained models such as BART-base and T5-base. Another limitation stems from the exclusive focus of experiments on E2E NLG and DART. To overcome these limitations and enhance the robustness of our model, it is crucial to broaden our evaluation scope. This involves extending assessments to larger models like BART-large and exploring the performance across a spectrum of large language models, including Alpaca [1], ChatGPT [2], Flan-T5 [3], and Llama [4]. Furthermore, testing our model with various NLG datasets, such as WebNLG and Totto, is imperative for a more comprehensive under standing of its capabilities and limitations in various domains.
第一个限制涉及我们模型的评估,该评估仅限于小规模预训练模型(如 BART-base 和 T5-base)。另一个限制源于实验仅专注于端到端自然语言生成 (E2E NLG) 和 DART。为了克服这些限制并增强模型的鲁棒性,关键在于扩大评估范围。这包括将评估扩展到更大的模型(如 BART-large),并探索其在一系列大语言模型中的性能,包括 Alpaca [1]、ChatGPT [2]、Flan-T5 [3] 和 Llama [4]。此外,使用各种自然语言生成数据集(如 WebNLG 和 Totto)测试我们的模型,对于更全面理解其在不同领域的能力和限制至关重要。
Although our self-training model diminishes the volume of training data required, we are curious about the training time of self-training methods versus full training methods. It remains uncertain whether the inference time of self-memory contributes to an extended training duration. This limitation is solved simply by measuring the training time of those methods.
尽管我们的自训练模型减少了所需的训练数据量,但我们仍对自训练方法与完整训练方法的训练时间感到好奇。目前尚不确定自记忆的推理时间是否会导致训练时长增加。这一限制只需通过测量这些方法的训练时间即可解决。
Lastly, we currently lack a mechanism to regulate the ratio between self-mem and new data in self-training T2D and D2T models. Our current approach involves maintaining a consistent data distribution $(30%)$ in each training iteration. If self-memory data are deficient, we compensate by incorporating additional input data during inference to augment the dataset. However, this adjustment may result in prolonged training times.
最后,我们目前缺乏一种机制来调节自训练T2D和D2T模型中自记忆数据与新数据的比例。当前的做法是在每次训练迭代中保持固定的数据分布$(30%)$。若自记忆数据不足,我们会在推理阶段通过引入额外输入数据来扩充数据集。但这种调整可能导致训练时间延长。
7. Conclusion
7. 结论
We introduced a novel training model, STSM, designed for DTG problems. This model incorporates self-memory and newly acquired data to self-train D2T and T2D models. Through experiments conducted on two datasets, DART and E2E NLG, our findings indicate that our model performs competitively compared to full data training when using less training data. We identified that the optimal method involves training on a mixture of self-memory and new data, incorporating self-training on the D2T model without needing selftraining on the T2D model. It also shows that selftraining on the T2D model is unimportant. Moreover, the question of whether training on fixed data is superior to training on random data remains uncertain.
我们提出了一种名为STSM的新型训练模型,专为DTG问题设计。该模型结合了自记忆模块和新获取的数据,用于对D2T和T2D模型进行自训练。通过在DART和E2E NLG两个数据集上的实验,我们发现当使用较少训练数据时,该模型的表现与全量数据训练相当。研究结果表明:最佳训练方式是混合使用自记忆数据与新数据,且仅需对D2T模型进行自训练(无需对T2D模型进行自训练),同时证实T2D模型的自训练并不重要。此外,固定数据训练是否优于随机数据训练仍无定论。
Table 4: Metric values between the generated and targets on the test set of E2E NLG by different methods.
: higher is better 1A non-overlap data is allocated in each epoch, except for no self-mem 2
表 4: 不同方法在E2E NLG测试集上生成结果与目标之间的指标值
| 方法 | BLEU↑ | ME↑ | NIST↑ | ROUGE-L↑ | CIDEr↑ |
|---|---|---|---|---|---|
| Pragmatics (Shen et al. [48]) | 68.60 | 45.25 | 8.73 | 70.82 | 2.37 |
| EDA_CS (Roberti et al. [49]) | 67.05 | 44.49 | 8.51 | 68.94 | 2.23 |
| SLUG (Juraska et al. [50]) | 66.19 | 44.54 | 8.61 | 67.72 | - |
| TGEN (Dusek et al. [13]) | 65.93 | 44.83 | 8.60 | 68.50 | 2.23 |
| Our run | |||||
| BART-base | 65.74 | 45.60 | 8.46 | 68.76 | 2.20 |
| FLAN-T5-base | 65.65 | 45.54 | 8.49 | 67.85 | 2.12 |
| T5-base | 66.95 | 45.70 | 8.59 | 68.97 | 2.27 |
| 30% fixed data per epoch1 | |||||
| no self-mem 1 | 65.47 | 45.84 | 8.32 | 68.33 | 2.17 |
| no self-mem 2 | 64.94 | 45.13 | 8.33 | 67.76 | 2.21 |
| self-mem | 61.28 | 44.84 | 8.05 | 66.58 | 2.05 |
| self-mem + self T2D | 60.69 | 44.48 | 8.03 | 66.45 | 2.03 |
| self-mem + new data | 65.55 | 46.07 | 8.35 | 68.16 | 2.10 |
| self-mem + new data + self T2D | 65.47 | 46.10 | 8.38 | 68.11 | 2.07 |
| 30% random data per epoch | |||||
| no self-mem 3 | 65.50 | 45.30 | 8.40 | 68.24 | 2.20 |
| self-mem | 61.98 | 44.48 | 8.05 | 66.44 | 2.14 |
| self-mem + self T2D | 61.74 | 44.89 | 8.07 | 66.54 | 2.11 |
| self-mem + new data | 65.11 | 46.11 | 8.35 | 68.41 | 2.08 |
| self-mem + new data + self T2D | 65.55 | 45.69 | 8.41 | 68.45 | 2.16 |
: 数值越高越好 1除no self-mem 2外,每个epoch分配非重叠数据
Moving forward, we plan to conduct more in-depth investigations into the optimal rate combination of selfmemory and new data for self-training. Additionally, we aim to test our model on other NLG datasets and large language models to assess self-memory effectiveness in the self-training process. Moreover, we are keen on exploring the intriguing approach of integrating selfmemory with external data generated by ChatGPT.
下一步,我们计划对自训练中自记忆 (self-memory) 与新数据的最佳比例组合进行更深入研究。此外,我们将在其他自然语言生成 (NLG) 数据集和大语言模型上测试我们的模型,以评估自训练过程中自记忆的有效性。同时,我们期待探索将自记忆与 ChatGPT 生成的外部数据相结合这一有趣方向。
Compliance with Ethical Standards
符合伦理标准
• This article does not contain any studies with human participants or animals performed by any of the authors.
• 本文不包含任何由作者进行的人体或动物研究。
• All authors certify that they have no affiliations with or involvement in any organization or entity with any financial interest or non-financial interest in the subject matter or materials discussed in this manuscript.
• 所有作者均确认,他们与本文所讨论主题或材料相关的任何组织或实体不存在任何财务利益或非财务利益的关联或参与。
Data Availability Statement
数据可用性声明
The curated dataset is publicly available at:
精选数据集公开获取地址:
• https://github.com/ho ang than gta/STSM
• https://github.com/ho ang than gta/STSM