CFR-ICL: Cascade-Forward Refinement with Iterative Click Loss for Interactive Image Segmentation
CFR-ICL: 基于迭代点击损失级联前向优化的交互式图像分割
Abstract
摘要
The click-based interactive segmentation aims to extract the object of interest from an image with the guidance of user clicks. Recent work has achieved great overall performance by employing feedback from the output. However, in most state-of-theart approaches, 1) the inference stage involves inflexible heuristic rules and requires a separate refinement model, and 2) the number of user clicks and model performance cannot be balanced. To address the challenges, we propose a click-based and mask-guided interactive image segmentation framework containing three novel components: Cascade-Forward Refinement (CFR) Iterative Click Loss (ICL), and SUEM image augmentation. The CFR offers a unified inference framework to generate segmentation results in a coarse-to-fine manner. The proposed ICL allows model training to improve segmentation and reduce user interactions simultaneously. The proposed SUEM augmentation is a comprehensive way to create large and diverse training sets for interactive image segmentation. Extensive experiments demonstrate the state-of-the-art performance of the proposed approach on five public datasets. Remarkably, our model reduces by $33.2%$ , and $15.5%$ the number of clicks required to surpass an IoU of 0.95 in the previous state-of-the-art approach on the Berkeley and DAVIS sets, respectively.
基于点击的交互式分割旨在通过用户点击的引导从图像中提取感兴趣的对象。近期研究通过利用输出反馈取得了优异的整体性能。然而在现有最先进方法中仍存在两大问题:1) 推理阶段依赖僵化的启发式规则且需要独立优化模型;2) 用户点击次数与模型性能难以平衡。为此,我们提出包含三项创新组件的点击引导掩码交互式图像分割框架:级联前向优化(CFR)、迭代点击损失(ICL)和SUEM图像增强。CFR提供统一推理框架实现由粗到细的分割结果生成,ICL使模型训练能同步提升分割精度并减少用户交互,SUEM增强则为交互式图像分割创建大规模多样化训练集。大量实验证明该方法在五个公开数据集上达到最先进水平。值得注意的是,在Berkeley和DAVIS数据集上,我们的模型分别以33.2%和15.5%的点击量降幅超越了先前最佳方法达到0.95 IoU阈值所需的交互次数。
1 Introduction
1 引言
Interactive image segmentation extracts object(s) of interest from images with user input. It is essential for enabling the broader application of deep learning-based solutions in real-world scenarios. Deep neural networks (DNNs) often require extensive annotated data, which could be extremely expensive and timeconsuming to create due to high labor costs. Interactive segmentation offers a more cost-effective solution for generating largescale labeled datasets.
交互式图像分割通过用户输入从图像中提取感兴趣的目标。这对于在现实场景中更广泛地应用基于深度学习(deep learning)的解决方案至关重要。深度神经网络(DNN)通常需要大量标注数据,而由于高昂的人力成本,创建这些数据可能极其昂贵且耗时。交互式分割为生成大规模标注数据集提供了一种更具成本效益的解决方案。
Interactions in interactive segmentation include scribbles [26], boxes [12], and clicks [25]. This work focuses on the click-based approach, whereby the user provides positive and negative clicks on the image to identify foreground and background regions, respectively. Earlier click-based methods were developed using image processing techniques, such as the connected ness-based approach described in [25]. However, subsequent advancements in the field led to the development of deep learning-based methods, beginning with [28], which resulted in significant improvements in segmentation performance. Recently, more deep learningbased methods have been introduced, including [10, 23, 22, 1], which have further improved the efficiency of interactive segmentation.
交互式分割中的交互方式包括涂鸦[26]、框选[12]和点击[25]。本研究聚焦基于点击的方法,即用户通过在图像上提供正负点击来分别标识前景和背景区域。早期的点击式方法采用图像处理技术实现,例如[25]提出的基于连通性的方法。随着领域发展,基于深度学习的方法开始涌现,从[28]开始实现了分割性能的显著提升。近期又出现了更多深度学习方法[10, 23, 22, 1],进一步提高了交互分割的效率。
Many interactive segmentation methods [10, 23, 1, 22, 16] define the loss functions based on the difference between the predicted segmentation masks and ground truths, and have no explicit way to optimize the number of user clicks. Some studies [1] use a refinement of initial predictions to enhance the quality of outputs. These techniques necessitate additional trainable network modules to identify and fine-grind the local areas in the predicted masks, which increases the difficulty of training. In this paper, we put forward an Iterative Click Loss (ICL) that imposes penalties on instances with a large number of clicks. We present a novel strategy for refinement during inference time, named Cascade-Forward Refinement (CFR). The CFR is designed to improve segmentation details during the inference process, without the need for an additional network. Also, we disclose an effective image augmentation technique - SUEM Copy-Paste (C&P). This technique is an extension of the Simple Copy-Paste [6] metho specifically designed for interactive image segmentation tasks. The contributions of this work are summarized below.
许多交互式分割方法[10, 23, 1, 22, 16]基于预测分割掩码与真实标签的差异定义损失函数,但缺乏显式优化用户点击次数的机制。部分研究[1]通过细化初始预测来提升输出质量,这类技术需要额外可训练网络模块来识别和微调预测掩码中的局部区域,增加了训练难度。本文提出迭代点击损失(ICL),对高点击量实例施加惩罚。我们创新性地设计了推理阶段细化策略——级联前向细化(CFR),该策略无需额外网络即可在推理过程中优化分割细节。同时,我们公开了一种高效的图像增强技术SUEM复制粘贴(C&P),这是针对交互式图像分割任务特别设计的Simple Copy-Paste[6]方法扩展版本。本工作的贡献可归纳如下:
2 Related Work
2 相关工作
Interactive segmentation. Prior to the widespread adoption of deep learning techniques, interactive segmentation was primarily achieved through image processing-based methods, such as GrabCut [20], NC-Cut [26], and EISeg [25]. With the emergence of deep learning, deep learning-based interactive segmentation models have obtained increasing popularity. The DIOS model [28] encoded the background and foreground user clicks into two distance maps and concatenated the image with the two maps as input. The BRS [10] and f-BRS [23] formulated the task as an inference-time online optimization problem. BRS optimizes the image or distance maps during inference to improve the segmentation results for given user clicks, while f-BRS optimizes the intermediate layer weights to achieve the same goal and speed up the inference. FCA-Net [15] built a first-click attention module that enhances the importance of the first click as it usually plays a critical role to identify the location of the main body. UCP-Net [4] proposed a novel contour-based approach that asks the user to provide clicks on the contour of objects.
交互式分割。在深度学习技术广泛应用之前,交互式分割主要通过基于图像处理的方法实现,如 GrabCut [20]、NC-Cut [26] 和 EISeg [25]。随着深度学习的兴起,基于深度学习的交互式分割模型日益普及。DIOS 模型 [28] 将用户点击的前景和背景编码为两张距离图,并将图像与这两张图拼接作为输入。BRS [10] 和 f-BRS [23] 将该任务表述为推理时在线优化问题:BRS 通过优化推理过程中的图像或距离图来提升给定用户点击的分割效果,而 f-BRS 通过优化中间层权重实现相同目标并加速推理。FCA-Net [15] 构建了首点击注意力模块,强化首次点击的重要性(因其通常对主体定位起关键作用)。UCP-Net [4] 提出了一种基于轮廓的新方法,要求用户在物体轮廓上提供点击。

Figure 1: Examples of segmentation results that exceed an IoU of 0.95. The first column shows images with clicks (green for the foreground and red for the background) and segmentation masks from the proposed approach (blue). The second column shows the ground truth. The third column shows probability maps of the proposed approach. These raw images are from the Berkeley [18] and DAVIS [19] sets.
图 1: IoU超过0.95的分割结果示例。第一列显示带有点击标记的图像(绿色为前景,红色为背景)和所提方法的分割掩码(蓝色)。第二列显示真实标注。第三列展示所提方法的概率图。这些原始图像来自Berkeley [18]和DAVIS [19]数据集。
Iterative mask-guided interactive segmentation. An iterative sampling strategy has been proposed by [17] which samples a single point from the center of a mis classified area iterative ly. These iterative ly generated points are used in training to boost performance. RITM [22] adopted and modified the iterative sampling strategy during training and iterative ly uses the previous output as model input to achieve higher segmentation quality. The iterative mask-guided model only involves a simple feedforward process that is more computationally efficient than the inference-time optimization approaches such as BRS and f-BRS. More recently, FocalClick [1] proposed a coarse-to-fine pipeline with a SegFormer [27] backbone and achieved state-of-the-art results. It utilizes a heuristic strategy to determine local regions that possibly contain errors and uses a local refinement network to update these regions. Simple Click [16] greatly improved performance by adopting the Plain Vision Transformer (Plain ViT), which was pre-trained with MAE [9], as the backbone of the RITM approach. The advanced ViT network architecture has significantly benefited interactive segmentation. Our work builds upon the RITM and Simple Click approaches and further explores the nature of interactive segmentation.
迭代式掩码引导交互分割。[17]提出了一种迭代采样策略,该策略从误分类区域中心反复采样单个点。这些迭代生成的点被用于训练以提升性能。RITM [22]在训练中采用并改进了迭代采样策略,通过将前次输出作为模型输入进行迭代,实现了更高的分割质量。迭代掩码引导模型仅涉及简单的前馈过程,相比BRS和f-BRS等推理时优化方法具有更高计算效率。最新研究FocalClick [1]采用SegFormer [27]主干网络构建了由粗到精的流程,取得了最先进成果。该方法通过启发式策略定位可能包含错误的局部区域,并使用局部优化网络进行更新。Simple Click [16]采用MAE [9]预训练的Plain Vision Transformer (Plain ViT)作为RITM方法的主干网络,大幅提升了性能。先进的ViT网络架构为交互分割带来了显著增益。我们的工作基于RITM和Simple Click方法,进一步探索了交互分割的本质特性。
Segment Anything Model. The Segment Anything Model (SAM) [11] represents an advanced development in image segmentation. Building on the foundations of interactive segmentation, SAM facilitates varied user interactions. The concept of a ’promptable segmentation task’ underlies SAM’s design, en- abling the generation of valid segmentation masks in response to a variety of prompts including text, masks, clicks, and boxes. By integrating a heavyweight image encoder with a flexible prompt encoder and a fast mask decoder, SAM is capable of predicting multiple object masks, even in situations where the prompt may be ambiguous. SAM has the potential to function like a click-based interactive segmentation model when solely points and masks are utilized as input. To gauge its effectiveness on click-based interaction, we compare the SAM model with other leading click-based interactive segmentation models.
Segment Anything Model (SAM) [11] 代表了图像分割领域的前沿进展。该模型基于交互式分割技术基础,支持多样化的用户交互方式。其核心设计理念是"可提示分割任务",能够根据文本、掩码、点击和框选等多种提示生成有效的分割掩码。通过整合重型图像编码器、灵活提示编码器和快速掩码解码器,SAM即使在提示信息模糊的情况下也能预测多个物体掩码。当仅使用点击和掩码作为输入时,SAM可发挥类似基于点击的交互式分割模型功能。为评估其在点击交互方面的性能,我们将SAM模型与其他主流基于点击的交互式分割模型进行了对比。
Image augmentation. Deep learning applications typically require large amounts of data to achieve optimal model performance, and the diversity of the training samples is crucial. Therefore, it is essential to develop efficient data augmentation techniques to enhance data efficiency. The previous study [6] has shown that a simple copy-paste strategy can serve as a powerful data augmentation for instance-level segmentation tasks. We develop more specific image augmentation approaches for adapting interactive segmentation tasks.
图像增强。深度学习应用通常需要大量数据才能达到最佳模型性能,而训练样本的多样性至关重要。因此,开发高效的数据增强技术以提高数据效率十分必要。先前研究[6]表明,简单的复制粘贴策略可作为实例级分割任务的强大数据增强方法。我们针对交互式分割任务开发了更具体的图像增强方法。
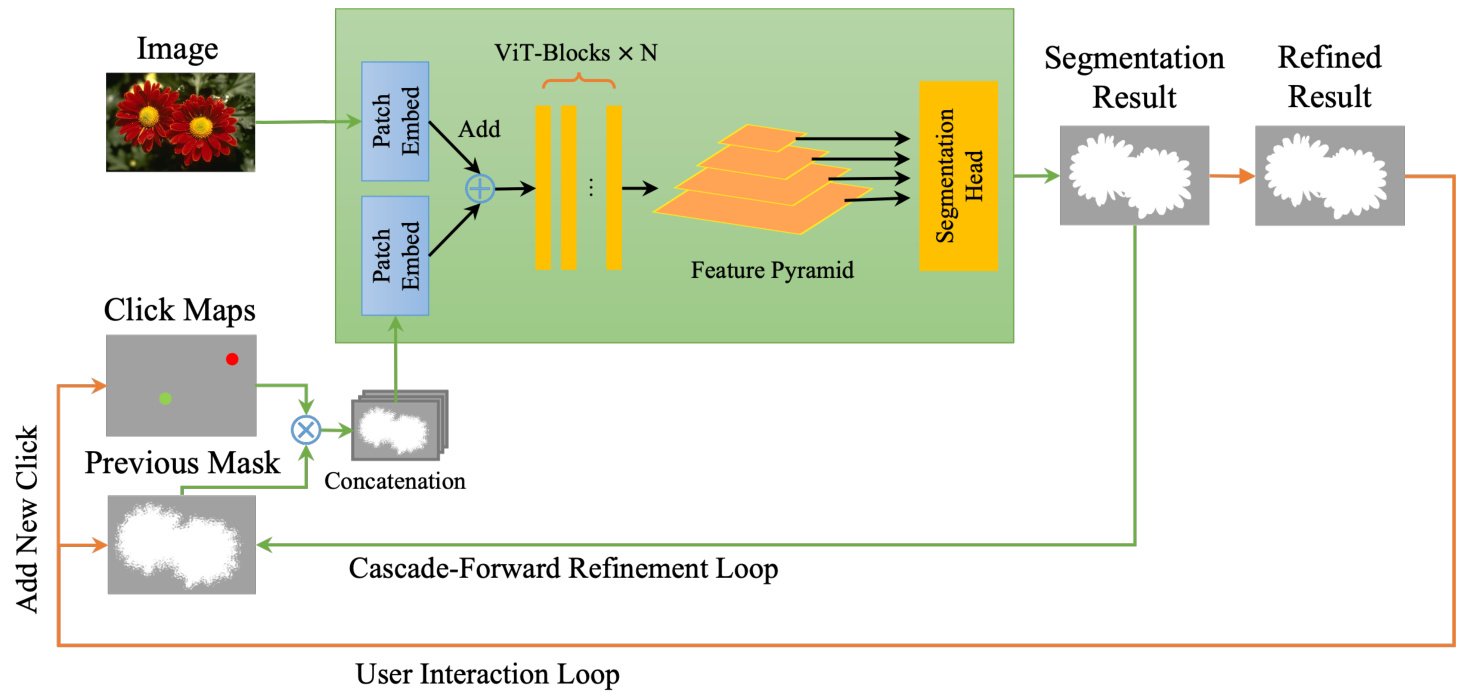
Figure 2: Overview of iterative mask-guided interactive segmentation integrated with Cascade-Forward Refinement. The orange colored lines represent the user interaction loop (outer loop). The green colored line represents the Refinement loop (inner loop). The black colored lines are shared processes for both loops. New clicks are added by the user in the user interaction loop. In the CFR loop, the previous mask is iterative ly optimized with clicks.
图 2: 集成级联前向优化(Cascade-Forward Refinement)的迭代掩码引导交互式分割流程概览。橙色线条表示用户交互循环(外循环),绿色线条表示优化循环(内循环),黑色线条为两个循环的共享流程。用户通过外循环添加新点击标注,在CFR循环中基于点击对前一掩码进行迭代优化。
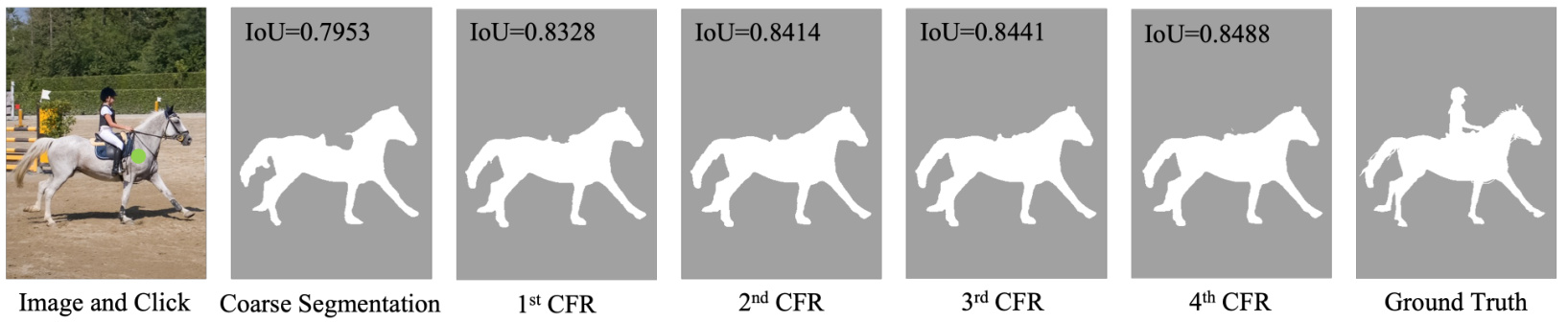
Figure 3: Sample results of Cascade-Forward Refinement.
图 3: 级联前向优化 (Cascade-Forward Refinement) 的示例结果。
3 Proposed Method
3 提出的方法
We build a new iterative mask-guided framework that includes 1) a novel training loss that encodes the number of clicks into the loss term and defines the model preference of fewer clicks; 2) an inference-time refinement scheme without the need for extra modules; 3) an effective image augmentation designed for the interactive segmentation scenario.
我们构建了一个新的迭代式掩码引导框架,包含:1) 一种新颖的训练损失函数,将点击次数编码到损失项中并定义模型对更少点击次数的偏好;2) 无需额外模块的推理时优化方案;3) 专为交互式分割场景设计的有效图像增强方法。
3.1 Iterative Click Loss
3.1 迭代点击损失
Sofiiuk et al. [23] encoded all generated user clicks for each image into two disk maps and inputted them into a segmentation network during training. The training process has no differences from conventional deep neural networks for image segmentation. In [17, 22], researchers adopted a hybrid strategy that combined randomly sampled clicks with iterative ly generated clicks to generate input maps. However, the trained models 1) may need more user interactions during inference, and 2) have no effective way to balance the number of inputted clicks and segmentation performance.
Sofiiuk等人[23]将每张图像生成的所有用户点击编码为两个磁盘映射图,并在训练时将其输入分割网络。该训练过程与常规的深度神经网络图像分割方法无异。在[17, 22]中,研究者采用混合策略,将随机采样的点击与迭代生成的点击结合来生成输入映射图。然而,训练出的模型存在两个问题:1) 在推理阶段可能需要更多用户交互;2) 缺乏有效方法来平衡输入点击数量与分割性能。
To overcome the challenges, we propose the Iterative Click Loss (ICL) approach which embeds the number of clicks during training. An initial set of randomly sampled clicks, denoted as $P^{0}$ , is generated from the ground truth to forward the model and obtain an initial output $Y^{0}$ . Clicks are generated iterative ly (one click at a time) by sampling from the mis classified regions in $Y^{0}$ , and the newly produced click is combined with $P^{0}$ to form a new sequence $P^{1}$ . This process is repeated to generate the whole click sequence $P^{t}$ . The click-sampling strategy can be formulated as
为了克服这些挑战,我们提出了迭代点击损失 (ICL) 方法,该方法在训练过程中嵌入了点击次数。首先从真实标注中随机采样一组初始点击 $P^{0}$,用于前向传播模型并得到初始输出 $Y^{0}$。然后通过从 $Y^{0}$ 中的错误分类区域采样,迭代生成点击(每次一个点击),新生成的点击与 $P^{0}$ 结合形成新序列 $P^{1}$。重复这一过程以生成完整的点击序列 $P^{t}$。点击采样策略可表述为
$$
\begin{array}{r l}&{P^{0}=\mathrm{Random sample from~\mathbb{Y}}}\ &{Y^{0}=f(X,P^{0},0)}\ &{P^{1}=P^{0}\cup S(\mathbb{Y},Y^{0})}\ &{Y^{1}=f(X,P^{1},Y^{0})}\ &{\dots}\ &{P^{t}=P^{t-1}\cup S(\mathbb{Y},Y^{t-1})}\ &{Y^{t}=f(X,P^{t},Y^{t-1}),}\end{array}
$$
$$
\begin{array}{r l}&{P^{0}=\mathrm{Random sample from~\mathbb{Y}}}\ &{Y^{0}=f(X,P^{0},0)}\ &{P^{1}=P^{0}\cup S(\mathbb{Y},Y^{0})}\ &{Y^{1}=f(X,P^{1},Y^{0})}\ &{\dots}\ &{P^{t}=P^{t-1}\cup S(\mathbb{Y},Y^{t-1})}\ &{Y^{t}=f(X,P^{t},Y^{t-1}),}\end{array}
$$
where 0 is the zero-initialized mask, $\mathbb{Y}$ is the ground truth, and
其中 0 为零初始化的掩码,$\mathbb{Y}$ 是真实标签,

Figure 4: Illustration of copy-paste modes.
图 4: 复制粘贴模式示意图。
$S$ is a sampling function [22] that proposes a single click among the mis classified areas in the output mask. A conventional total loss function [22] is defined by
$S$ 是一个采样函数 [22],用于在输出掩码的错误分类区域中提出单个点击。传统的总损失函数 [22] 定义为
$$
L=\mathbb{L}(Y^{t},\mathbb{Y}).
$$
$$
L=\mathbb{L}(Y^{t},\mathbb{Y}).
$$
where $\mathbb{L}$ is the Normalized Focal Loss [21]. Note that in Eq. 2, a sequence of click sets $[P^{0},P^{1},...,P^{t}]$ and a sequence of outputs $[Y^{0},Y^{1},...,Y^{t-1}]$ are used to generate segmentation mask $Y^{t}$ ; however, only the final output is applied to calculate the Normalized Focal Loss and update the model parameters. In the proposed ICL approach, a new loss function is built to accumulate the weighted losses of the generated mask sequence.
其中 $\mathbb{L}$ 是归一化焦点损失 (Normalized Focal Loss) [21]。需要注意的是,在公式2中,使用点击序列 $[P^{0},P^{1},...,P^{t}]$ 和输出序列 $[Y^{0},Y^{1},...,Y^{t-1}]$ 来生成分割掩码 $Y^{t}$;但只有最终输出会用于计算归一化焦点损失并更新模型参数。在所提出的交互式持续学习 (ICL) 方法中,构建了新的损失函数来累积生成掩码序列的加权损失。
$$
L_{I C L}=\sum_{i=1}^{t}\beta_{i}\mathbb{L}(Y^{i},\mathbb{Y}),
$$
$$
L_{I C L}=\sum_{i=1}^{t}\beta_{i}\mathbb{L}(Y^{i},\mathbb{Y}),
$$
where $\beta_{i}$ is used to control the weight of each term. Each click produces one loss term in the above equation, and minimizing the loss improves the segmentation performance and reduces the number of clicks simultaneously. By increasing the weights of the loss term for more clicks (larger $i\dot{\phantom{}}$ ), the model is in centi viz ed to use fewer clicks to achieve accurate segmentation. ICL offers a novel approach to define preference on interactive segmentation models with fewer user clicks.
其中 $\beta_{i}$ 用于控制各项的权重。每次点击会在上述方程中产生一个损失项,最小化损失可同时提升分割性能并减少点击次数。通过增加更多点击次数(更大的 $i\dot{\phantom{}}$ )对应损失项的权重,模型被激励使用更少的点击实现精准分割。ICL 提供了一种新方法来定义对交互式分割模型的偏好,即用更少的用户点击。
3.2 Cascade-Forward Refinement
3.2 级联前向优化
Similar coarse-to-fine pipelines [1] were proposed to incorporate a local refinement module to improve the details of local regions after the initial coarse segmentation of the entire image. These coarse-to-fine strategies demonstrate impressive overall performance; however, the approaches 1) depend on heuristic rules to select image regions for further refinement and 2) have to train two individual deep learning models independently.
类似由粗到精的流程 [1] 被提出,通过在初始整图粗分割后加入局部优化模块来提升细节区域的精度。这种由粗到精的策略展现了优异的整体性能,但存在两个局限:1) 依赖启发式规则选择待优化区域;2) 需要独立训练两个深度学习模型。
We introduce the Cascade-Forward Refinement (CFR)-based inference strategy, which enables iterative refinement of the segmentation results without needing two models. The proposed CFR has two inference loops, i.e., the outer loop generates coarse segmentation masks using incremental user interactions, and the inner loop refines the masks by forwarding the segmentation model multiple times with the same input image and user clicks.
我们提出了基于级联前向优化 (Cascade-Forward Refinement, CFR) 的推理策略,该策略无需两个模型即可实现分割结果的迭代优化。所提出的 CFR 包含两个推理循环:外循环通过增量式用户交互生成粗分割掩码,内循环则通过将分割模型在同一输入图像和用户点击下多次前向传播来优化掩码。
Let $f$ denote a deep neural network for segmentation, $Y^{t}$ be the output of the $t$ -th step, and the $X$ be the input image. The sequence of user clicks at the $t$ -th step is denoted as $P^{t}=$ ${(u_{k},v_{k},l_{k})}{k=1}^{t}$ , where $(u_{k},v_{k})$ represents the coordinates of a user click and $l_{k}\in{0,1}$ denotes its label (0 for background and 1 for foreground). The model’s inputs are raw images, maps generated by clicks, and previous segmentation masks. We define the CFR as
设 $f$ 表示用于分割的深度神经网络,$Y^{t}$ 为第 $t$ 步的输出,$X$ 为输入图像。第 $t$ 步的用户点击序列记为 $P^{t}=$ ${(u_{k},v_{k},l_{k})}{k=1}^{t}$,其中 $(u_{k},v_{k})$ 表示用户点击的坐标,$l_{k}\in{0,1}$ 表示其标签 (0 为背景,1 为前景)。模型的输入包括原始图像、点击生成的映射图和先前的分割掩码。我们将 CFR 定义为
$$
Y_{0}^{t}=f(X,P^{t},Y_{n}^{t-1}),\mathrm{and}
$$
$$
Y_{0}^{t}=f(X,P^{t},Y_{n}^{t-1}),\mathrm{and}
$$
$$
Y_{i}^{t}=f(X,P^{t},Y_{i-1}^{t}),i\in{1,2,3,...,n},
$$
$$
Y_{i}^{t}=f(X,P^{t},Y_{i-1}^{t}),i\in{1,2,3,...,n},
$$
where $Y_{0}^{t}$ denotes the output of the $t$ -th coarse segmentation step (outer loop), and $Y_{n}^{t-1}$ is the last refined mask at step $t-1$ . Eq. 5 defines the refinement results at the $i$ -th step in the inner loop, and $n$ defines the number of refinement steps which could be defined as a fixed number or determined adaptively. The CascadeForward Refinement approach iterative ly updates the coarse segmentation masks and refinement masks using Eqs. 4 and 5. No additional user clicks are required during the refinement process (inner loop), and the segmentation mask is continuously refined to provide higher-quality input. Figure 2 illustrates the overview pipeline of the CFR and Figure 3 shows a series of CFR refined results.
其中 $Y_{0}^{t}$ 表示第 $t$ 次粗分割步骤(外循环)的输出,$Y_{n}^{t-1}$ 是第 $t-1$ 步的最后一次精修掩码。公式5定义了内循环中第 $i$ 步的精修结果,$n$ 定义了精修步骤的数量,该数量可以设定为固定值或自适应确定。级联前向精修(CascadeForward Refinement)方法通过公式4和5迭代更新粗分割掩码和精修掩码。在精修过程(内循环)中不需要额外的用户点击,分割掩码会持续优化以提供更高质量的输入。图2展示了CFR的整体流程,图3显示了一系列CFR精修结果。
Fixed-step CFR and Adaptive CFR Inference. A fixedstep CFR applies $n$ times refinement for each user click. This refinement is employed during inference to enhance the quality of the output and can be integrated into any iterative mask-based model without the need for model modification. In addition to the fixed-step approach, we propose and validate an adaptive CFR (A-CFR) scheme. It counts the number of altered pixels between $Y_{i}^{t}$ and $Y_{i-1}^{t}$ and terminates the inner loop when the number of changed pixels falls below a specified threshold, or the maximum step is reached. We use CFR $n$ and A-CFR $n$ to denote fixed $n$ step CFR and adaptive CFR with maximum $n$ step, respectively.
固定步长CFR与自适应CFR推理。固定步长CFR对每次用户点击执行$n$次细化操作,该过程在推理阶段用于提升输出质量,且无需修改模型即可集成到任何基于迭代掩模的模型中。除固定步长方法外,我们提出并验证了自适应CFR(A-CFR)方案:通过统计$Y_{i}^{t}$与$Y_{i-1}^{t}$之间的像素变化数量,当变化像素数低于设定阈值或达到最大步长时终止内循环。CFR $n$和A-CFR $n$分别表示最大步长为$n$的固定步长CFR与自适应CFR。
3.3 SUEM Copy-paste
3.3 SUEM 复制粘贴
To generate large and diverse datasets for interactive segmentation scenarios, we proposed a comprehensive image augmenta- tion method, namely SUEM Copy-paste (C&P), that consists of four C&P modes, Simple C&P [6], Union C&P, Exclusion C&P, and the image Mixing.
为生成适用于交互式分割场景的大规模多样化数据集,我们提出了一种全面的图像增强方法——SUEM复制粘贴(C&P),包含四种复制粘贴模式:简单复制粘贴(Simple C&P) [6]、联合复制粘贴(Union C&P)、排除复制粘贴(Exclusion C&P)以及图像混合(image Mixing)。
The underlying principle of the C&P method involves inserting randomly selected objects from one image into another. In the context of interactive segmentation, we refer to the object of interest and its corresponding image as the source object and source image, respectively. Conversely, the object and its corresponding image selected randomly from the training set are denoted as the extra object and extra image.
C&P方法的基本原理是将一张图像中随机选取的对象插入到另一张图像中。在交互式分割的背景下,我们将感兴趣的对象及其对应图像分别称为源对象和源图像。相反,从训练集中随机选取的对象及其对应图像则被称为额外对象和额外图像。
Table 1: The Effectiveness of ICL and SUEM C&P.
| GrabCut | Berkeley | DAVIS | PascalVOC | SBD | |
|---|---|---|---|---|---|
| NoC@ | 90 | 95 | 90 | 95 | 90 |
| 模型 | |||||
| SimpleClick | 1.54 | 2.16 | 2.46 | 6.71 | 5.48 |
| ICL | 1.50 | 2.00 | 2.34 | 6.48 | 5.44 |
| SUEMC&P | 1.44 | 1.74 | 1.97 | 5.08 | 5.28 |
表 1: ICL 和 SUEM C&P 的有效性
Simple C&P Mode. The simple copy-paste mode involves inserting a source object into a randomly selected extra image, with the mask of the source object serving as the ground truth. Figure 4 (b) provides a visual representation of this mode.
简单复制粘贴模式。该模式将源对象插入随机选择的额外图像中,并以源对象的掩码作为真实值。图4(b)直观展示了这种模式。
Union C&P Mode. Interactive segmentation typically involves identifying a target object that comprises multiple objects, such as a man embracing a child. To simulate such a scenario, we employ the union copy-paste mode, where an extra object is pasted into the source image, and the ground truth is determined as the union of their respective masks. Figure 4 (c) depicts the resulting image in this mode.
联合复制粘贴模式。交互式分割通常涉及识别包含多个对象的目标物体,例如一个抱着孩子的男人。为了模拟这种情况,我们采用联合复制粘贴模式,即在源图像中粘贴一个额外对象,并将真实标注确定为其各自掩码的联合。图4(c)展示了该模式下的结果图像。
Exclusion C&P Mode. Another scenario that frequently arises is that the object of interest is obstructed by another object, such as a person standing behind a pole. To address this issue, we introduce the exclusion copy-paste mode, where an extra object is copied into the source image, and the mask of the source object is utilized as the ground truth, excluding the mask of the extra object. Figure 4 (d) provides a visual representation of this mode.
排除复制粘贴模式。另一种常见情况是目标物体被其他物体遮挡,例如人站在柱子后面。为解决这一问题,我们引入了排除复制粘贴模式:将额外物体复制到源图像中,并以源物体掩膜作为真实标注,同时排除额外物体的掩膜。图4(d)直观展示了该模式的运作方式。
Image Mixing Mode. The approach of image-mixing involves blending a source image with an extra image and utilizing the mask of the source object as the ground truth. The imagemixing mode is depicted in Figure 4 (e)
图像混合模式。图像混合方法涉及将源图像与额外图像进行融合,并使用源对象的掩码作为真实标注。该模式如图4(e)所示。
The above strategies are combined to generate training images in our experiments.
上述策略被结合用于在我们的实验中生成训练图像。
Table 2: $\operatorname{NoC@95}$ of RITM, EMC-Click [3] and proposed approach. HRNet32 backbone and training set $\mathrm{C+L}$ are used.
表 2: RITM、EMC-Click [3] 和所提方法的 $\operatorname{NoC@95}$ 指标对比。采用 HRNet32 主干网络和 $\mathrm{C+L}$ 训练集。
| RITM | EMC-Click | Ours | |
|---|---|---|---|
| GrabCut | 2.48 | 1.94 | 1.96 |
| Berkeley | 5.41 | 6.92 | 5.05 |
| DAVIS | 11.52 | 11.26 | 10.85 |
| Pascal VOC | 3.44 | 3.57 | |
| SBD | 12.00 | 11.68 | 12.02 |
4 Experiments
4 实验
4.1 Datasets and Experiment Setup
4.1 数据集与实验设置
Datasets. The following image sets are used to evaluate the performance of our approaches.
数据集。以下图像集用于评估我们方法的性能。
• DAVIS [19]: This dataset has 345 images extracted by [10] from 50 videos with high-quality segmentation masks.
• DAVIS [19]: 该数据集包含345张图像,由[10]从50个带有高质量分割掩码的视频中提取。
• Pascal VOC [5]: Only the validation set is utilized, featuring 1449 images and 3427 instances.
• Pascal VOC [5]: 仅使用验证集,包含1449张图像和3427个实例。
• SBD [8]: The training set comprises of 8497 images with 20172 instances. The validation set holds 2857 images with 6671 instances.
- SBD [8]: 训练集包含8497张图像,共20172个实例。验证集包含2857张图像,共6671个实例。
• COCO $[\mathbf{14}]{+}\mathbf{LVIS}$ [7] $\left(\mathbf{C}{+}\mathbf{L}\right)$ : The COCO dataset involves 99k images with 1.2M instances in its training subset. The LVIS dataset includes $100\mathrm{k}$ images with 1.2M total instances. A combined $\mathrm{C+L}$ [22] dataset was synthesized from COCO and LVIS encompassing 104k images and 1.6M instances, intended solely for training.
• COCO [14]+LVIS [7] (C+L): COCO数据集包含99k张训练图像和120万个实例。LVIS数据集包含100k张图像和120万个实例。通过合并COCO和LVIS形成的C+L数据集[22]包含104k张图像和160万个实例,该数据集仅用于训练用途。
Evaluation Metric. We evaluate model performance using the Number of Clicks (NoC) metric. This standard measure quantifies the user inputs needed to achieve satisfactory segmentation results that surpass a pre-defined Intersection over Union (IoU) threshold. In this study, we report $\mathrm{NoC@90}$ and $\operatorname{Noc@95}$ . Although earlier studies frequently reported $\operatorname{NoC@85}$ and $\mathrm{NoC@90}$ thresholds, the increasing demand for high-quality segmentation necessitates stricter criteria for model appraisal. We employ the method delineated in [13] to generate clicks during evaluation. The maximum number of clicks is limited to 20.
评估指标。我们采用点击次数(NoC)指标评估模型性能。该标准度量量化了用户为获得超过预设交并比(IoU)阈值的满意分割结果所需的输入次数。本研究中我们报告$\mathrm{NoC@90}$和$\operatorname{Noc@95}$。虽然早期研究常采用$\operatorname{NoC@85}$和$\mathrm{NoC@90}$阈值,但对高质量分割日益增长的需求要求采用更严格的模型评估标准。我们采用[13]所述方法在评估过程中生成点击,最大点击次数限制为20次。
Backbone models. In line with the methodology suggested by Simple Click [16], we adopted the Simple Click ViT-Base and ViT-Huge (ViT-B and ViT-H) models for our experiments. These models employ the Plain Vision Transformer [2] as the backbone. Afterward, we fine-tuned these pre-trained models by leveraging our proposed methods. To further explore the adaptability of our methodological approaches, we also expanded our experiment to incorporate the HRNet [24] backbone.
骨干模型 (Backbone models)。按照Simple Click [16]建议的方法论,我们在实验中采用了Simple Click ViT-Base和ViT-Huge (ViT-B和ViT-H)模型。这些模型使用Plain Vision Transformer [2]作为骨干网络。随后,我们通过提出的方法对这些预训练模型进行了微调。为了进一步探索我们方法论的适应性,还将实验扩展到HRNet [24]骨干网络。
Implementation details. Our Iterative Click Learning (ICL) utilizes three iterative ly generated clicks for model training, setting $\beta_{i}\in[1,2,3]$ . We employ the Adam optimizer, with parameters $\beta_{1}=0.9,\beta_{2}=0.999$ , coupled with a learning rate of $5\times10^{-6}$ . All models, fine-tuned over one epoch, are initially derived from the trained Simple Click models. The batch sizes are set at 140 for Vit-B and 32 for Vit-H. We employ the Normalized Focal Loss (NFL) [21] for training, with the parameters set at $\alpha=0.5$ , $\gamma=2$ . Beyond the proposed SUEM C&P augmentation, we deploy image augmentations including resizing, flipping, rotation, brightness contrast adjustment, and cropping. The input images are unified to $448\times448$ . The clicks are encoded into disk maps with a radius of 5. All models are trained on the NVIDIA Quadro RTX 8000 GPU.
实现细节。我们的迭代点击学习 (ICL) 采用三次迭代生成的点击进行模型训练,设置 $\beta_{i}\in[1,2,3]$。我们使用 Adam 优化器,参数为 $\beta_{1}=0.9,\beta_{2}=0.999$,学习率设为 $5\times10^{-6}$。所有模型均基于训练好的 Simple Click 模型进行单轮微调,批量大小设置为 Vit-B 140 和 Vit-H 32。训练采用归一化焦点损失 (NFL) [21],参数设为 $\alpha=0.5$, $\gamma=2$。除提出的 SUEM C&P 增强外,我们还应用了包括调整大小、翻转、旋转、亮度对比度调整和裁剪等图像增强方法。输入图像统一调整为 $448\times448$,点击编码为半径 5 的圆盘图。所有模型均在 NVIDIA Quadro RTX 8000 GPU 上训练。
Table 3: Results of CFR Schemes. The ’StdInfer’ denotes the standard inference [22]; CFR $^{\cdot n}$ is CFR with fixed step $n$ ; and A-CFR $n$ is the adaptive CFR with maximum steps $n$ .
表 3: CFR 方案的结果。'StdInfer' 表示标准推理 [22];CFR $^{\cdot n}$ 是固定步长为 $n$ 的 CFR;A-CFR $n$ 是最大步长为 $n$ 的自适应 CFR。
| GrabCut | Berkeley | DAVIS | Pascal VOC | SBD | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| NoC@ | 90 | 95 | 90 | 95 | 90 | 95 | 90 | 95 | 90 | 95 |
| Inference | ||||||||||
| StdInfer | 1.54 | 2.16 | 2.46 | 6.71 | 5.48 | 12.23 | 2.81 | 3.75 | 5.24 | 11.23 |
| CFR-1 | 1.44 | 2.04 | 2.35 | 6.43 | 5.33 | 11.99 | 2.70 | 3.58 | 5.11 | 11.14 |
| CFR-4 | 1.50 | 2.18 | 2.38 | 6.46 | 5.31 | 11.94 | 2.72 | 3.59 | 5.16 | 11.16 |
| A-CFR-4 | 1.50 | 2.06 | 2.39 | 6.43 | 5.28 | 11.90 | 2.73 | 3.60 | 5.17 | 11.14 |
Table 4: Comparison with state-of-the-art approaches. ’!’ indicates a model trained on the Pascal VOC [5] dataset. ’#’ denotes a model trained on the SBD [8] dataset. ’-’ denotes a model trained on the SA-1B [11] dataset and, ’*’ denotes a model trained on the $\mathrm{C+L}$ [22] dataset. ’-’ represents unavailable value. Percentages that appear as superscripts indicate a reduction of number of clicks from the corresponding baseline model.
表 4: 与最先进方法的对比。'!' 表示在 Pascal VOC [5] 数据集上训练的模型,'#' 表示在 SBD [8] 数据集上训练的模型,'-' 表示在 SA-1B [11] 数据集上训练的模型,'*' 表示在 $\mathrm{C+L}$ [22] 数据集上训练的模型。'-' 表示不可用值。上标百分比表示相对于基线模型的点击次数减少比例。
4.2 The Effectiveness of ICL and SUEM C&P
4.2 ICL与SUEM C&P的有效性
We fine-tuned the Simple Click Vit-Base model, initially trained on the SBD dataset, using the proposed ICL and SUEM C&P methods on the SBD dataset. Table 1 compares the performance of the original Simple Click model with the models fine-tuned via ICL and SUEM C&P. As Table 1 reveals, ICL enhances the Simple Click model across all five datasets. In contrast, SUEM C&P significantly advances the model’s efficacy on the GrabCut, Berkeley, and DAVIS datasets, thus highlighting the benefits of ICL and SUEM C&P.
我们在SBD数据集上使用提出的ICL和SUEM C&P方法对最初在SBD数据集上训练的Simple Click Vit-Base模型进行了微调。表1比较了原始Simple Click模型与通过ICL和SUEM C&P微调后的模型性能。如表1所示,ICL在所有五个数据集上都提升了Simple Click模型的表现。相比之下,SUEM C&P显著提高了模型在GrabCut、Berkeley和DAVIS数据集上的效果,从而凸显了ICL和SUEM C&P的优势。
To probe further into the applicability of the proposed training methods, we also applied ICL $^{+}$ SUEM C&P on HRNet32 and compared it against the RITM and EMC-Click. Table 2 illustrates the results generated using ICL $^{+}$ SUEM C&P with the HRNet32 backbone. These outcomes highlight a significant reduction of $\operatorname{NoC@95}$ compared with the RITM model in the Grab-
为了进一步探究所提训练方法的适用性,我们还在HRNet32上应用了ICL$^{+}$ SUEM C&P,并与RITM和EMC-Click进行了对比。表2展示了使用HRNet32骨干网的ICL$^{+}$ SUEM C&P生成的结果。这些结果表明,与Grab数据集上的RITM模型相比,$\operatorname{NoC@95}$显著降低。
Cut, Berkeley, and DAVIS datasets by $-20.97%$ , $-6.65%$ , and - $5.82%$ respectively, when deploying the proposed method. The proposed method achieves competitive results on GrabCut, Pascal VOC, and SBD, and significantly outperforms EMC-Click on Berkeley and DAVIS datasets. This suggests the robust compatibility of ICL and SUEM C&P with varying backbones.
在部署所提出的方法时,Cut、Berkeley和DAVIS数据集的性能分别提升了$-20.97%$、$-6.65%$和$-5.82%$。该方法在GrabCut、Pascal VOC和SBD上取得了具有竞争力的结果,并在Berkeley和DAVIS数据集上显著优于EMC-Click。这表明ICL和SUEM C&P与不同骨干网络具有强大的兼容性。
4.3 Inference Using the CFR Scheme
4.3 使用 CFR 方案进行推理
Table 3 validates the efficacy of the CFR inference process. We used both the fixed-step CFR and the adaptive CFR (A-CFR) for the inference phase of the SBD-trained Simple Click ViT-B model, testing on the SBD test set. As shown in Table 3, all three CFR inference procedures (CFR-1, CFR-4, and A-CFR-4) outperform the standard inference method (’StdInfer’) [22], thus demonstrating CFR’s capability to improve interactive segmentation performance.
表 3 验证了 CFR (Click Feedback Refinement) 推理过程的有效性。我们在 SBD 测试集上测试了采用固定步长 CFR 和自适应 CFR (A-CFR) 进行推理的 SBD 训练版 Simple Click ViT-B 模型。如表 3 所示,三种 CFR 推理流程 (CFR-1、CFR-4 和 A-CFR-4) 均优于标准推理方法 (’StdInfer’) [22],这证明了 CFR 能够提升交互式分割性能。
Even though CFR-4 consumes more computational resource, its advancement over CFR-1 is not marginal, suggesting that increasing steps do not guarantee better outcomes. A-CFR-4 surpasses CFR-4 by adaptively halting refinement when changes fall below a set threshold, 20 pixels in this case. CFR-1 and A-CFR-4 show comparable performances but differ in aspects of efficiency and adaptability. For instance, CFR-1 performs only a single step, whereas A-CFR-4 can be fine-tuned with optimal thresholds to cater to specific situations. Following the assessment of computational efficiency, we selected CFR-1 for following experiments.
尽管CFR-4消耗更多计算资源,但其相对CFR-1的提升并不显著,这表明增加步骤并不能保证更好的结果。A-CFR-4通过自适应地在变化低于设定阈值(本案例中为20像素)时停止优化,从而超越了CFR-4。CFR-1与A-CFR-4表现出相近的性能,但在效率和适应性方面存在差异。例如,CFR-1仅执行单步优化,而A-CFR-4可通过调整最佳阈值来适应特定场景。基于计算效率评估,我们选择CFR-1进行后续实验。
4.4 Comparison With State-of-the-art
4.4 与最先进技术的对比
Table 4 details our proposed models’ performances and twelve advanced deep learning-based interactive segmentation methods. Our approach (’Ours’) incorporates ICL and SUEM C&P to finetune the ViT-H model. In Table 4, separated by double solid lines and identified by symbols ’!’, ’#’, ’-’, and ’*’, represent models trained on Pascal VOC, SBD, SA-1B [11], and $\mathrm{C+L}$ datasets, respectively. As Pascal VOC is small, its use in training is seldom reported.
表 4 详细展示了我们提出的模型性能与十二种先进的基于深度学习的交互式分割方法对比。我们的方法 (Ours) 结合了 ICL 和 SUEM C&P 来微调 ViT-H 模型。在表 4 中,通过双实线分隔并用符号 !、#、- 和 * 标识的模型,分别代表在 Pascal VOC、SBD、SA-1B [11] 和 $\mathrm{C+L}$ 数据集上训练的模型。由于 Pascal VOC 规模较小,其用于训练的情况鲜有报道。
Table 4 demonstrates that Simple Click ViT-H models trained on SBD and $\mathrm{C+L}$ exceed prior methods across five test datasets in $\mathrm{NoC@90}$ and $\operatorname{NoC@95}$ . Consequently, we select these models as the baselines, denoted ’Baseline’.
表 4 表明,在 SBD 和 $\mathrm{C+L}$ 上训练的 Simple Click ViT-H 模型在 $\mathrm{NoC@90}$ 和 $\operatorname{NoC@95}$ 指标上超越了先前方法在五个测试数据集上的表现。因此,我们选择这些模型作为基线,记为 "Baseline"。
For SBD trained models, applying our CFR-1 inference to the Simple Click baseline model significantly decreases all metrics except $\mathrm{NoC@90}$ on Berkeley. Specifically, CFR-1 decreases $\mathrm{NoC@90}$ and $\operatorname{NoC@95}$ on GrabCut by $8.3%$ , and $15.2%$ respec- tively. The proposed model, ’Ours CFR-1’, built with ICL and SUEM C&P, decreases clicks required for reaching an IoU of 0.9 $\left(\mathrm{NoC@90}\right)$ by $16.7%$ . Importantly, it decreases $\operatorname{NoC@95}$ by $30.0%$ compared to the baseline, indicating effectiveness in high-precision image segmentation. Nevertheless, there is no remarkable improvement on the GrabCut, PascalVOC, and SBD testing sets. This can be attributed to the less complicated visual content in Grabcut and PascalVOC, and inaccurately annotated ground truths in SBD, rendering significant user click reduction with high IoU thresholds difficult.
对于经过SBD训练的模型,在Simple Click基线模型上应用我们的CFR-1推理方法,除Berkeley数据集上的$\mathrm{NoC@90}$外,所有指标均显著下降。具体而言,CFR-1使GrabCut数据集的$\mathrm{NoC@90}$和$\operatorname{NoC@95}$分别降低$8.3%$和$15.2%$。我们提出的模型"Ours CFR-1"结合了ICL和SUEM C&P技术,将达到IoU 0.9所需的点击次数$\left(\mathrm{NoC@90}\right)$减少了$16.7%$。值得注意的是,与基线相比,该模型将$\operatorname{NoC@95}$降低了$30.0%$,表明其在高精度图像分割中的有效性。然而,在GrabCut、PascalVOC和SBD测试集上未见显著提升,这可能源于GrabCut和PascalVOC的视觉内容相对简单,以及SBD数据集中存在标注不准确的问题,使得在高IoU阈值下大幅减少用户点击变得困难。
Similar outcomes are observed for $\mathrm{C+L}$ dataset-trained models. The Simple Click CFR-1 model improves $\mathrm{NoC@90}$ and $\operatorname{NoC@95}$ on all excluding GrabCut. Noteworthy improvements of the ’Ours CFR-1’ model are visible on the Berkeley and DAVIS sets.
在 $\mathrm{C+L}$ 数据集训练的模型中也观察到了类似结果。Simple Click CFR-1 模型在除 GrabCut 外的所有数据集上提升了 $\mathrm{NoC@90}$ 和 $\operatorname{NoC@95}$ 指标。值得注意的是,'Ours CFR-1' 模型在 Berkeley 和 DAVIS 数据集上表现出显著改进。
5 Conclusion
5 结论
In this study, we present an interactive image segmentation framework based on deep neural networks (DNN), comprising three innovative components. These include: 1) iterative click loss (ICL)-based training, 2) cascade-forward refinement (CFR)-based inference, and 3) SUEM Copy-Paste image augmentation. The proposed framework is applicable to other iterative mask-guided interactive segmentation approaches. The proposed ICL introduces an innovative approach for minimizing the number of clicks. The CFR inference employs a unified framework that iterative ly refines segmentation results using two loops. The proposed SUEM C&P is a comprehensive image augmentation approach that generates more diverse training sets. Comprehensive experiments have been conducted to validate the effectiveness of all components, demonstrating that the proposed approach achieves stateof-the-art performance.
本研究提出了一种基于深度神经网络 (DNN) 的交互式图像分割框架,包含三项创新组件:1) 基于迭代点击损失 (ICL) 的训练方法,2) 基于级联前向优化 (CFR) 的推理机制,以及 3) SUEM复制粘贴图像增强技术。该框架可适配其他基于迭代掩模引导的交互式分割方法。提出的ICL通过创新性方法实现了点击次数最小化,CFR推理采用双循环迭代优化分割结果的统一框架,SUEM C&P则是能生成更丰富训练集的综合性图像增强方案。通过大量实验验证了各模块的有效性,结果表明所提方法达到了当前最优性能水平。