ASR in German: A Detailed Error Analysis
德语ASR:详细错误分析
Abstract— The amount of freely available systems for automatic speech recognition (ASR) based on neural networks is growing steadily, with equally increasingly reliable predictions. However, the evaluation of trained models is typically exclusively based on statistical metrics such as WER or CER, which do not provide any insight into the nature or impact of the errors produced when predicting transcripts from speech input. This work presents a selection of ASR model architectures that are pretrained on the German language and evaluates them on a benchmark of diverse test datasets. It identifies cross-architectural prediction errors, classifies those into categories and traces the sources of errors per category back into training data as well as other sources. Finally, it discusses solutions in order to create qualitatively better training datasets and more robust ASR systems.
摘要—基于神经网络的自动语音识别(ASR)开源系统数量持续增长,其预测可靠性也在同步提升。然而,训练模型的评估通常仅基于WER或CER等统计指标,这些指标无法揭示语音输入转写预测过程中产生错误的本质或影响。本研究选取了多个针对德语预训练的ASR模型架构,在多样化测试数据集构成的基准上进行评估。通过识别跨架构的预测错误,将其分类并追溯每类错误的训练数据及其他来源,最终讨论了创建更优质训练数据集和构建更鲁棒ASR系统的解决方案。
Keywords—Automatic Speech Recognition, German
关键词—自动语音识别 (Automatic Speech Recognition)、德语
I. INTRODUCTION
I. 引言
“Benchmarks that are nearing or have reached saturation are problematic, since either they cannot be used for measuring and steering progress any longer, or – perhaps even more problematic – they see continued use but become misleading measures: actual progress of model capabilities is not properly reflected, statistical significance of differences in model performance is more difficult to achieve, and remaining progress becomes increasingly driven by over-optimization for specific benchmark characteristics that are not general iz able to other data distributions”[1]. Hence, novel benchmarks need to be created to complement or replace older benchmarks (ibid.). This description is also true for the English automatic speech recognition (ASR) benchmark Libri speech as seen in Figure 1. Therefore, several different benchmarks have been proposed, including Switchboard, TIMIT and WSJ. However, even on those, a couple of systems already achieve low single digit word error rates (WER) and small improvements are hard to interpret [2]. In the case of Switchboard, a considerable portion of the remaining errors involves filler words, hesitations and non-verbal back channel cues (ibid.).
接近或已达到饱和的基准测试存在诸多问题:它们要么无法继续用于衡量和引导技术进步,要么(可能更严重)虽被持续使用却沦为误导性指标——模型能力的真实进步无法准确体现,模型性能差异的统计显著性更难达成,剩余的进步日益依赖于对特定基准特性的过度优化,而这些特性无法泛化到其他数据分布[1]。因此需要创建新基准来补充或替代旧基准(同上)。这一描述同样适用于英语自动语音识别(ASR)基准LibriSpeech,如图1所示。为此学界提出了Switchboard、TIMIT和WSJ等多个替代基准,但即便在这些基准上,已有部分系统实现了个位数的词错率(WER),细微改进难以评估[2]。以Switchboard为例,剩余错误中相当部分涉及填充词、犹豫词和非言语反馈信号(同上)。
This paper investigates whether benchmarks for German ASR exhibit similar saturation, although there is far less available data for the German language compared to English with correspondingly fewer benchmark results being published. This includes detailed error analysis and error back tracing to determine specific improvements that are necessary to increase model performance in terms of training data quality and to more realistically represent model performance in evaluations.
本文研究了德语自动语音识别(ASR)的基准测试是否也表现出类似的饱和现象,尽管与英语相比,德语可用数据量要少得多,相应发布的基准测试结果也较少。研究包括详细的错误分析和错误回溯,以确定在训练数据质量方面提升模型性能所需的具体改进措施,并使评估结果能更真实地反映模型性能。
The rest of the paper is structured as follows. Related work is presented in section 2. Section 3 presents an overview of ASR models considered and which ones were chosen for further analysis. Section 4 describes the datasets that were used for analysis. Results in terms of WER are shown in section 5 before the detailed error analysis is presented in section 6. We briefly discuss possible resolutions for the different kinds of error in section 7 before the conclusion and outlook in section 8.
本文的其余部分结构如下。第2节介绍相关工作。第3节概述了所考虑的ASR (Automatic Speech Recognition) 模型以及选择用于进一步分析的模型。第4节描述了用于分析的数据集。第5节展示了以WER (Word Error Rate) 衡量的结果,随后第6节进行详细的错误分析。在第8节的结论与展望之前,我们在第7节简要讨论了针对不同类型错误的可能解决方案。
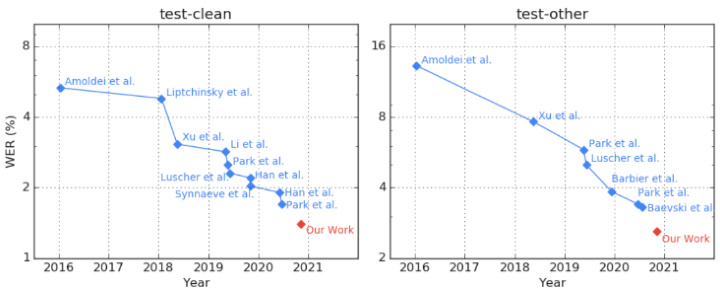
Figure 1: Libri speech benchmark reaching saturation [3]
图 1: Libri speech 基准测试达到饱和 [3]
II. RELATED WORK
II. 相关工作
Previous work was done on analyzing the robustness of ASR models in English language, by running them through a diverse set of test data [4], [5], see Table 1. Li k homan en ko et al. found that for models trained on a specific dataset there is a huge discrepancy between the WER when evaluating them on a test split of the same dataset and evaluating them on other datasets. In other words, ASR models are often not able to generalize well and the authors demand that models should always be evaluated on a diverse dataset consisting of at least Switchboard, Common Voice and TED-LIUM v3 for English language in the future. To reach that conclusion, they evaluated a single ASR model on five different public datasets.
先前已有研究通过多种测试数据集分析了英语自动语音识别(ASR)模型的鲁棒性[4][5],如表1所示。Li k homan en ko等人发现,针对特定数据集训练的模型,在相同数据集的测试集与其他数据集上评估时,其词错误率(WER)存在巨大差异。换言之,ASR模型通常难以实现良好泛化,作者主张未来评估英语模型时至少应包含Switchboard、Common Voice和TED-LIUM v3组成的多样化数据集。该结论基于他们在五个不同公共数据集上对单一ASR模型的评估得出。
TABLE I. BENCHMARKS USED FOR ASR EVALUATIONS
表 1: 用于 ASR 评估的基准数据集
| Source | Datasets for evaluation |
|---|---|
| [4] EN | WSJ, LibriSpeech, Tedlium, Switchboard, MCV |
| [5] EN | ST, LibriSpeech, Tedlium, Timit, Voxforge, RT, AMI, MCV |
| [5] DE | Voxforge, MCV, Tuda, SC10, VerbmobilII, Hempel |
| ours DE | Voxforge, MCV, Tuda, VoxPopuli, MLS, M-AILABS, SWC, HUI, GermanTEDTalks, ALC, SL10O, Thorsten, Bundestag |
Ulasik et al. collected a similar benchmark corpus of publicly available data for both English and German language, called CEASR. They evaluated it on four commercial and three open-source ASR systems. They found that the commercial systems outperform the open-source systems by a large percentage for some datasets. Additionally, the performance differences of single systems across different datasets were large. However, they use open-source systems that seem a bit outdated, even for the year of publication [6] and only conducted evaluations for the English language. For German, only anonymous commercial systems were evaluated. The best performing model achieves $11.8%$ WER on Mozilla Common Voice (MCV), which is less than Sc ribose r mo, an open source model based on Quartznet that delivers $7.7%$ WER on MCV [7]. For Tuda, (see section IV) Sc ribose r mo reports $11.7%$ WER whereas Ulasik et al. reports
Ulasik等人收集了一个类似的公开基准语料库CEASR,涵盖英语和德语。他们在4个商业和3个开源ASR系统上进行了评测,发现某些数据集中商业系统的性能显著优于开源系统。此外,单个系统在不同数据集上的表现差异较大。但值得注意的是,他们使用的开源系统即使在论文发表年份[6]也略显过时,且仅对英语进行了评测。德语部分仅评估了匿名商业系统。性能最佳的模型在Mozilla Common Voice(MCV)上达到11.8%词错误率(WER),低于基于Quartznet的开源模型Sc ribose r mo(该模型在MCV上取得7.7% WER)[7]。在Tuda数据集(见第IV节)上,Sc ribose r mo报告11.7% WER,而Ulasik等人报告的数值为...
$13.05%$ for the best commercial system. In contrast to that, our work evaluates six state-of-the-art (SOTA) open-source models in German language on thirteen datasets.
$13.05%$ 的最佳商用系统表现。相比之下,我们的工作评估了六种最先进 (SOTA) 的开源德语模型在十三个数据集上的表现。
Aksënova et al. analyzed the requirements for a new ASR benchmark, that fixes the shortcomings of existing ones [2]. They stated that a next-gen benchmark should cover the application areas dictation, voice search & control, audiobooks, voicemail, conversations and meetings as well as podcasts, movies and TV shows. Furthermore, it should cover technical challenges such as varying speed, acoustic environments, sample frequencies and terminology (ibid.). They identified coherent transcription conventions as a key element for building high quality datasets, as well as detecting and correcting errors in existing corpora. This paper applies exactly these approaches for the German language.
Aksënova等人分析了新一代自动语音识别(ASR)基准测试的需求[2],旨在解决现有基准的缺陷。他们指出,下一代基准应涵盖听写、语音搜索与控制、有声读物、语音邮件、会话会议以及播客电影电视节目等应用场景,同时需要应对语速变化、声学环境差异、采样频率多样化和专业术语等技术挑战。该研究特别强调连贯的转写规范是构建高质量数据集的关键要素,也是检测修正现有语料库错误的核心方法。本文正是将这些方法论应用于德语场景的实践探索。
Keung et al. [8] show that modern ASR architectures may even start emitting repetitive, nonsensical transcriptions when faced with audio from a domain that was not covered at training time. We found similar issues in our analysis.
Keung等人[8]指出,现代自动语音识别(ASR)架构在面对训练时未覆盖领域的音频时,甚至可能开始生成重复且无意义的转录文本。我们在分析中也发现了类似问题。
III. ASR MODELS
III. ASR 模型
There is a large variety of ASR models presented in literature [9]. Our selection considers speaker independent models with a very large vocabulary for continuous as well as spontaneous speech according to the classification in [9]. We are further looking for models with a publicly available implementation, either by the original authors of the model or a third party. Finally, we are using models that were already pretrained on German language. After first tests, we excluded models, that performed bad in our first tests without a language model, including Mozilla DeepSpeech [10] and Sc ribose r mo [7], which are both available as part of the Coqui project .
文献[9]中提出了多种ASR (Automatic Speech Recognition) 模型。根据[9]的分类标准,我们筛选了支持连续语音和自发语音的大词汇量、说话人无关模型,并优先选择具有公开实现(无论是原作者还是第三方提供)的模型。此外,我们仅使用已针对德语进行预训练的模型。初步测试后,我们排除了在不使用语言模型时表现不佳的模型,包括作为Coqui项目组成部分的Mozilla DeepSpeech [10]和Sc ribose r mo [7]。
The Kaldi project, which is one of the most popular opensource ASR projects, does not provide any publicly available pretrained models for German language2. The reported WERs for their model on MCV, Tuda, SWC and Voxforge are however worse than that of all models tested in this work, except Quartznet, although Tuda and SWC were included in the training data of Kaldi. Speech brain [11] can be seen as a potential successor of Kaldi with a more modern architecture and focus on neural models. It provides a CRDNN with CTC/Attention trained on MCV 7.0 German on hugging face 3 with a self-reported WER of $15.37%$ on MCV7. CRDNN stands for an architecture that combines convolutional, recurrent and fully connected layers.
Kaldi项目作为最受欢迎的开源ASR(自动语音识别)项目之一,并未提供公开可用的德语预训练模型。尽管其训练数据包含Tuda和SWC数据集,但该模型在MCV、Tuda、SWC和Voxforge数据集上报告的WER(词错误率)仍低于本研究中测试的所有模型(Quartznet除外)。SpeechBrain[11]可视为Kaldi的潜在继任者,采用更现代的架构并专注于神经模型。该项目在Hugging Face平台提供了基于MCV7.0德语数据集训练的CRDNN(卷积循环深度神经网络)模型,采用CTC/Attention机制,自报在MCV7数据集上的WER为$15.37%$。CRDNN指代结合卷积层、循环层和全连接层的混合架构。
Most of the tested models are provided by Nvidia as part of the NeMo toolkit [12]. Quartznet and Citrinet share a very similar architecture. While Quartznet targets small lightweight models with fast in ferenc ing [13], Citrinet is more targeted towards scaling to higher accuracy while keeping a moderate fast in ferenc ing speed [14]. ContextNet was originally developed by Google [15] and was adopted by Nvidia to be included in their NeMo toolbox. Finally, we have evaluated two Conformer models [16] that have been trained by Nvidia, one that is using CTC loss and the other one being a Conformer Transducer [17]. All Nvidia models can be found online 4 . We always use the “large” models if different versions are available. All models from Nvidia except
大多数测试模型由Nvidia作为NeMo工具包[12]的一部分提供。Quartznet和Citrinet采用非常相似的架构——Quartznet专注于轻量化快速推理的小型模型[13],而Citrinet更侧重在保持适中推理速度的同时提升准确率[14]。ContextNet最初由Google开发[15],后被Nvidia纳入其NeMo工具箱。我们还评估了Nvidia训练的两个Conformer模型[16]:一个使用CTC损失函数,另一个是Conformer Transducer[17]。所有Nvidia模型均可在线获取4。当存在不同版本时,我们始终采用"large"版本。除...
Quartznet are trained on the German parts of Mozilla Common Voice v7.0, Muli lingual Libri Speech and VoxPopuli. Quartznet has been pretrained on 3,000 hours of English data and then finetuned on Mozilla Common Voice v6.0 (see TABLE II. ).
Quartznet 在 Mozilla Common Voice v7.0、Multilingual LibriSpeech 和 VoxPopuli 的德语部分数据上进行训练。该模型已基于 3,000 小时英语数据完成预训练,并在 Mozilla Common Voice v6.0 上进行了微调 (见表 II)。
TABLE II. ASR MODELS WITH TRAINING DATA EVALUATED
表 II: 使用训练数据评估的 ASR (Automatic Speech Recognition) 模型
| 模型 | 训练数据集 |
|---|---|
| Citrinet | GermanMCV7, MLS, VoxPopuli |
| ContextNet | German MCV 7, MLS, VoxPopuli |
| ConformerCTC | GermanMCV7, MLS, VoxPopuli |
| ConformerTransducer | German MCV 7, MLS, VoxPopuli |
| Wav2Vec2.0 | 预训练 MLS EN, 微调 MCV6 |
| Quartznet | 预训练 3000h EN, 微调 MCV6 |
The last model evaluated in detail is Wav2Vec 2.0 [3] from Facebook AI research (FAIR). There are several pretrained models available on Hugging face. We picked the Wav2Vec2-Large-XLSR-53-German by Jonatas Grosman [18], since it had the lowest self-reported WER on Common Voice $(12.06%)$ compared to $18.5%$ reported for the original model provided by FAIR. Recently, there was an update on the model [19] with the new MCV v8 data, which was not included in the evaluation.
最后详细评估的模型是来自Facebook AI研究实验室(FAIR)的Wav2Vec 2.0 [3]。Hugging Face平台上提供了多个预训练模型。我们选择了Jonatas Grosman开发的Wav2Vec2-Large-XLSR-53-German [18],因为该模型在Common Voice数据集上自报的词错误率(WER)最低$(12.06%)$,而FAIR提供的原始模型报告结果为$18.5%$。最近该模型基于新版MCV v8数据进行了更新[19],但本次评估未包含该更新版本。
All models were evaluated without utilizing any language model in order not to introduce another source of error into the analysis. In this context, it is worth noting that two of the six models evaluated, ContextNet and Conformer Transducer, are auto regressive (based on RNN-T loss) while all others are based on CTC loss.
所有模型在评估时均未使用任何语言模型,以避免在分析中引入额外的误差源。值得注意的是,在评估的六个模型中,ContextNet和Conformer Transducer是自回归模型(基于RNN-T损失函数),其余模型则基于CTC损失函数。
IV. DATASETS
IV. 数据集
The evaluation was intended to include as many and diverse publicly available datasets as possible. They should include spontaneous as well as continuous speech, shorter and longer sentences as well as a diverse set of vocabulary in order to find systematic errors that models have learned and to identify how well the selected models can generalize on unseen data.
评估旨在涵盖尽可能多且多样化的公开数据集。这些数据集应包含自发和连续语音、长短不一的句子以及多样化的词汇,以便发现模型学习到的系统性错误,并确定所选模型在未见数据上的泛化能力。
Mozilla Common Voice [20] is a multi-lingual speech corpus with regular releases and a steadily growing amount of data. It is crowd sourced and contains 1,062 hours of German speech data in its 8.0 release from January 2022 ( $965~\mathrm{h}$ for v7.0). Tuda is a dataset for German ASR that was collected by TU Darmstadt in 2015 [21]. In contrast to those, some of the datasets collected from the Bavarian Speech Archive (BAS) were not intended for ASR but “were originally intended either for research into the (dialectal) variation of German or for studies in conversation analysis and related fields” [22]. Tuda contains 127 hours of training data from 147 speakers with very little noise.
Mozilla Common Voice [20] 是一个多语言语音语料库,定期发布且数据量稳步增长。它采用众包方式收集,在2022年1月发布的8.0版本中包含1,062小时的德语语音数据 (v7.0版本为 $965~\mathrm{h}$)。Tuda是由达姆施塔特工业大学于2015年收集的德语自动语音识别(ASR)数据集[21]。与这些数据集不同,从巴伐利亚语音档案馆(BAS)收集的部分数据集并非为ASR设计,而是"最初旨在研究德语(方言)变体,或用于会话分析及相关领域研究"[22]。Tuda包含来自147位说话者的127小时训练数据,且噪声极少。
Several datasets are based on the Librivox project [23], where volunteers read and record public domain books. Among them is the M-AILabs dataset [24] which contains 237 hours of German speech from 29 speakers. It also includes Angela Merkel, a speaker from a political context and thus quite different from the other speakers. We therefore excluded this part from the M-AILabs dataset and listed it separately. Voxforge is another dataset derived from Librivox [10]. It contains only 35 hours of speech from 180 speakers. MLS is the Multilingual Libri Speech corpus [25] compiled by Facebook that contains over 3,000 hours of German speech and is also based on Librivox. Finally, the HUI speech corpus was originally designed to be used for text-to-speech (TTS) systems [26], but can also be used for ASR with its 326 hours of German speech recorded by 122 different speakers of the Librivox project. We expect the datasets based on Librivox to have a large overlap; however, no further analyses were conducted to determine exact values.
多个数据集基于Librivox项目[23],该项目由志愿者朗读并录制公有领域书籍。其中包括M-AILabs数据集[24],该数据集包含29位说话者的237小时德语语音。其中还包含政治背景的说话者Angela Merkel,与其他说话者差异显著,因此我们将这部分从M-AILabs数据集中剔除并单独列出。Voxforge是另一个源自Librivox的数据集[10],仅包含180位说话者的35小时语音。MLS(Multilingual Libri Speech)语料库由Facebook整理[25],包含超过3,000小时的德语语音,同样基于Librivox。最后,HUI语音语料库最初设计用于文本转语音(TTS)系统[26],但由于其包含122位不同说话者录制的326小时Librivox德语语音,也可用于自动语音识别(ASR)。我们预计基于Librivox的数据集存在大量重叠,但未进行进一步分析以确定具体数值。
Similar to the HUI dataset is Thorsten Voice [27]. It also was created for training TTS systems with 23 hours of German speech. It was, however, recorded by a single speaker. It contains mostly short sentences, primarily related to voice assistant prompts. All spoken words and utterances are pronounced in an unambiguous and very clear manner.
与HUI数据集类似的是Thorsten Voice [27]。该数据集同样用于训练TTS(文本转语音)系统,包含23小时的德语语音。不过,它仅由一位说话者录制而成,主要收录与语音助手提示相关的短句。所有发音和语句都以清晰明确的方式呈现。
Another major source of audio data in German originates from political speeches. VoxPopuli is a multilingual dataset based on speeches held at the European parliament [28]. It contains both unlabeled and labeled data, which results in 268 hours of German speech data suitable for training and evaluation. At Hof University, an ASR dataset based on speeches at the German Bundestag5 was prepared using 211 hours of commission sessions and 393 hours of plenary sessions. The test split of the dataset is already released6.
德国音频数据的另一主要来源是政治演讲。VoxPopuli是基于欧洲议会演讲构建的多语言数据集[28],包含未标注和已标注数据,可提供268小时适用于训练和评估的德语语音数据。霍夫大学利用211小时委员会会议和393小时全体会议录音,构建了基于德国联邦议院(Bundestag)演讲的自动语音识别(ASR)数据集,其测试集已公开发布6。
The Spoken Wikipedia Corpus (SWC) is a multilingual dataset comprising 285 hours of read articles from Wikipedia [29]. “Being recorded by volunteers reading complete articles, the data represents the way a user naturally speaks very well, arguably better than a controlled recording in a lab. The vocabulary is quite large due to the encyclopedic nature of the articles” [30].
口语维基百科语料库(SWC)是一个多语言数据集,包含285小时的维基百科文章朗读录音[29]。"由于录音是由志愿者朗读完整文章完成的,这些数据很好地反映了用户自然说话的方式,可以说比实验室受控录音更具代表性。由于文章具有百科全书性质,其词汇量相当庞大"[30]。
TABLE III. DATASETS USED IN EVALUATION
表 III. 评估使用的数据集
| 数据集 | 小时数(全部|测试) | 说话人数 | 类型 | 时长(最小/平均/最大) |
|---|---|---|---|---|
| MCV 7.0 | 965|26.8 | 15,620 | 朗读 | 1.3/6.1/11.2s |
| Tuda | 127|11.9 | 147 | 朗读 | 2.5/8.4/33.1s |
| SWC | 285|9.1 | 363 | 朗读 | 5.0/7.9/24.9s |
| M-AILabs | 237|10.8 | 29 | 朗读 | 0.4/7.2/24.2s |
| MLS | 3287|14.3 | 244 | 朗读 | 10/15.2/22s |
| VoxForge | 35|2.7 | 180 | 朗读 | 1.2/5.1/17.0s |
| HUI | 326|16.3 | 122 | 5.0/9.0/34.3s | |
| Thorsten | 23|1.1 | 1 | 朗读 | 0.2/3.4/11.5s |
| VoxPopuli | 268|4.9 | 530 | 口语 | 0.6/9.0/36.4s |
| Bundestag | 604|5.1 | 口语 | 5.0/7.2/35.6s | |
| Merkel | 1.0 | 1 | 口语 | 0.7/6.9/17.1s |
| TED Talks | 16|1.6 | 71 | 口语 | 0.2/5.1/118s |
| ALC | 95|2.6 | 朗读 | 2.0/12.5/62s | |
| BAS SI100 | 31|1.8 | 101 | 朗读 | 2.1/12.7/54.1s |
One of the few datasets with spontaneous speech besides the political speeches is the TED Talks corpus [31]. It is similar to the English TED-lium corpus [32] and contains data from German, Swiss and Austrian speakers. It contains only 16 hours of speech but is a valuable addition due to its unique features.
除了政治演讲外,少数包含自发演讲的数据集之一是TED Talks语料库[31]。它与英文TED-lium语料库[32]类似,包含来自德国、瑞士和奥地利演讲者的数据。虽然仅包含16小时的语音,但由于其独特特征,仍是一个有价值的补充。
Additionally, we also included a few corpora that were collected for linguistic research, namely ALC, a corpus for the use of language under the influence of alcohol [33] and BAS SI100, a corpus created by the LMU Munich with 101 speakers (50 female, 50 male, 1 unknown). Each speaker has read $\mathord{\sim}100$ sentences from either the SZ subcorpus or the CeBit subcorpus [34]. The subcorpus SZ contains 544 sentences from newspaper articles (“Sued deutsche Zeitung”). The subcorpus CeBit contains 483 sentences from newspaper articles about the CeBit 1995.
此外,我们还纳入了部分为语言学研究收集的语料库,包括ALC(一种记录酒精影响下语言使用的语料库)[33] 以及由慕尼黑大学创建的BAS SI100语料库(包含101位说话人:50名女性、50名男性、1名未知性别)。每位说话人朗读了约100个句子,这些句子选自SZ子语料库或CeBit子语料库[34]。其中SZ子语料库包含544条来自《南德意志报》的新闻句子,CeBit子语料库则包含483条关于1995年CeBit展会的新闻报道句子。
TABLE III. summarizes the key metrics of the datasets. The numbers reported for M-AILabs are for the whole dataset regarding number of speakers and total hours, but for test hours and durations we are referring to the test dataset without Merkel. The statistics of this subset are reported separately. We used the official test splits where applicable. For the other datasets, a random split with $10%$ of the overall data per set was created. Inclusion of more datasets proved to be unnecessarily tedious due to diverse formats of transcriptions with no tool to automatically convert between different styles.
表 III: 总结了数据集的关键指标。M-AILabs报告的说话人数量和总时长数据针对整个数据集,但测试时长和持续时间数据则指代不含Merkel的测试子集,该子集统计数据单独列出。我们尽可能采用官方测试划分方案,其余数据集则按每组数据总量的$10%$进行随机划分。由于转录格式差异且缺乏自动转换工具,纳入更多数据集被证明会带来不必要的繁琐工作。
V. EVALUATION RESULTS
V. 评估结果
First, a conventional evaluation of the models based on WER was performed using the WER collected on every dataset in order to put their accuracy into perspective and to collect prediction errors for further processing.
首先,基于WER对模型进行常规评估,通过收集每个数据集上的WER值来量化其准确性,并收集预测误差以供进一步处理。
TABLE IV. WORD ERROR RATES FOR ALL MODELS AND ALL DATASETS
表 IV: 所有模型和数据集下的词错误率
| Citrinet | Conf.CTC | Conf.T | Contextnet | Wav2Vec2.0 | Quartznet | |
|---|---|---|---|---|---|---|
| MCV 7.0 | 8.78% | 8.00% | 6.28% | 7.33% | 10.97% | 13.90% |
| Bundestag | 13.25% | 13.65% | 11.16% | 14.44% | 21.78% | 28.61% |
| VoxPopuli | 10.35% | 10.82% | 8.98% | 10.13% | 21.96% | 28.34% |
| Merkel | 13.63% | 17.17% | 13.49% | 15.92% | 21.81% | 27.57% |
| MLS | 5.56% | 5.16% | 4.11% | 4.62% | 13.04% | 20.34% |
| MAI-LABS | 5.52% | 5.56% | 4.28% | 4.32% | 9.94% | 18.47% |
| Voxforge | 4.15% | 3.95% | 3.36% | 4.16% | 5.64% | 7.58% |
| HUI | 2.31% | 2.45% | 1.89% | 2.02% | 8.52% | 14.66% |
| Thorsten | 6.74% | 8.49% | 6.20% | 9.21% | 7.57% | 5.95% |
| Tuda | 9.16% | 7.81% | 5.82% | 7.91% | 12.69% | 20.31% |
| SWC | 10.15% | 9.36% | 8.04% | 9.29% | 15.01% | 16.49% |
| GermanTED | 34.53% | 35.77% | 31.98% | 35.58% | 41.90% | 47.75% |
| ALC | 31.42% | 31.30% | 25.90% | 26.85% | 40.94% | 45.53% |
| BAS SL100 | 23.13% | 24.81% | 22.82% | 22.74% | 28.84% | 28.94% |
| Average | 12.76% | 13.16% | 11.02% | 12.47% | 18.62% | 23.17% |
| Median | 9.65% | 8.93% | 7.16% | 9.25% | 14.02% | 20.33% |
The numbers reported in TABLE IV. show that Conformer Transducer outperforms all other models regarding WER. Quartznet scored worst on all but a single test set. Citrinet, Conformer CTC and ContextNet perform very similar with less than $0.5%$ absolute difference in WER. However, the median of Conformer CTC is the best of those three models although the average is the worst, which means that its output predictions show higher variation than those of the two other models, which we count as an indicator for lower robustness. Citrinet and Quartznet have the lowest difference between average and median, which we count as an indicator for robustness. Wav2Vec 2.0 is the second worst model and does exceptionally bad for German TED and ALC. This is similar to Quartznet. We hypothesize that this stems from filling words like “äh” and “hm” occurring in their output transcript predictions, which, in contrast, are omitted in the predictions of all other models. These fillers are also missing in all ground truth transcripts. The WERs for the three political datasets are nearly identical for Wav2Vec. For the Conformer models and Contextnet, VoxPopuli WERs are much better than for Bundestag and Merkel, which is expected with respect to the training data. However, it is not clear why Bundestag has lower WERs than Merkel for those models. It could be due to less errors in the transcript. The HUI dataset has the lowest WERs of all datasets. This is due to the alignment process, where ASR was already used and sentences, that could not be aligned with ASR were discarded. The significant differences in WERs between Merkel and the rest of MAI-Labs on the one hand and the similarities to Bundestag on the other hand, confirm our decision to treat Merkel separately.
表 IV 中的数据表明,Conformer Transducer 在词错误率 (WER) 方面优于所有其他模型。Quartznet 在除一个测试集外的所有测试集上表现最差。Citrinet、Conformer CTC 和 ContextNet 的表现非常相似,WER 绝对差异小于 $0.5%$。然而,Conformer CTC 的中位数是这三个模型中最好的,尽管平均值最差,这意味着其输出预测显示出比其他两个模型更高的变异性,我们认为这是鲁棒性较低的指标。Citrinet 和 Quartznet 的平均值和中位数差异最小,我们认为这是鲁棒性的指标。Wav2Vec 2.0 是第二差的模型,在 German TED 和 ALC 上表现特别差,这与 Quartznet 类似。我们假设这是因为其输出转录预测中填充了“äh”和“hm”等词语,而其他所有模型的预测中都省略了这些填充词。这些填充词在所有真实转录中也都没有出现。Wav2Vec 在三个政治数据集上的 WER 几乎相同。对于 Conformer 模型和 Contextnet,VoxPopuli 的 WER 远好于 Bundestag 和 Merkel,这与训练数据的预期一致。然而,尚不清楚为什么这些模型在 Bundestag 上的 WER 低于 Merkel。可能是由于转录中的错误较少。HUI 数据集在所有数据集中的 WER 最低。这是由于对齐过程中已经使用了 ASR,并且无法与 ASR 对齐的句子被丢弃。Merkel 与 MAI-Labs 其他数据集在 WER 上的显著差异,以及与 Bundestag 的相似性,证实了我们决定将 Merkel 单独处理的合理性。
In general, the datasets with spontaneous speech show a higher WER than the ones with continuous speech, which is in line with findings for the English language [4].
通常情况下,包含自发语音的数据集比包含连续语音的数据集显示出更高的词错误率 (WER) ,这与英语语言的研究结果一致 [4]。
TABLE V. PERFORMANCE COMPARISON OF ASR MODELS
表 V: ASR模型性能对比
| 参数量 | 磁盘占用 | 自回归 | RTF | 速度 | |
|---|---|---|---|---|---|
| Citrinet | 142.0 M | 532 MB | 否 | 0.007 | 158% |
| ConformerCTC | 118.8 M | 452 MB | 否 | 0.006 | 124% |
| ConformerT | 118.0 M | 446 MB | 是 | 0.015 | 323% |
| Contextnet | 112.7 M | 476 MB | 是 | 0.013 | 291% |
| Wav2Vec2.0 | 317.0 M | 1204 MB | 否 | 0.021 | 464% |
| Quartznet | 18.9 M | 71 MB | 否 | 0.005 | 100% |
When evaluating the speed of the models in a batch operation with ${\sim}1\mathrm{h}$ of audio in 600 files on a AMD Ryzen 3700X with 16 GB RAM and Nvidia GTX 1080 GPU, they all perform reasonably well (see Fehler! Ver we is quelle konnte nicht gefunden werden.). Quartznet is the fastest, with Conformer CTC and Citrinet being close. ContextNet and Conformer Transducer are about three times slower due to their auto regressive nature. Wav2Vec 2.0 performs worst due to its large model size and needs 4.6 times as long as Quartznet.
在 AMD Ryzen 3700X (16 GB RAM) 和 Nvidia GTX 1080 GPU 上对 600 个音频文件 (总计约 1 小时时长) 进行批量处理的速度评估中,所有模型表现均较为理想 (参见 Fehler! Ver we is quelle konnte nicht gefunden werden.)。Quartznet 速度最快,Conformer CTC 和 Citrinet 紧随其后。由于自回归特性,ContextNet 和 Conformer Transducer 的处理速度约为前者的三分之一。Wav2Vec 2.0 因模型体积庞大表现最差,耗时达到 Quartznet 的 4.6 倍。
VI. ERROR IDENTIFICATION
VI. 错误识别
As shown in TABLE IV. , WER can be used to determine how well models perform generally and in relation to each other. However, a single metric does not suffice for the identification of cases, in which ASR systems perform particularly poorly and for what reasons. The following sections describe the methods performed to accumulate crossmodel and model-exclusive prediction errors, to classify those further, and how their root causes can be traced back to training and test data.
如表 IV 所示,WER (Word Error Rate) 可用于衡量模型的整体性能及相互比较。但单一指标不足以识别语音识别 (ASR) 系统表现特别差的案例及其原因。以下部分将阐述跨模型和模型专属预测错误的积累方法、进一步分类方案,以及如何将这些错误的根本原因追溯至训练和测试数据。
A. Method
A. 方法
For deeper error analysis, subsets of the total error set (all predictions with $\mathrm{WER}\neq0$ , excluding pure spacing errors) of all models were created. On one hand, difference sets were formed to identify model- and architecture-specific error sources. On the other hand, the intersection of the incorrectly predicted transcripts of all models was created to identify model-independent error causes, which this work focuses on. It was expected that consistent cross-model errors could be traced back to shared training data or ambiguous and lowquality test data.
为进行更深入的错误分析,我们创建了所有模型总错误集(所有预测中$\mathrm{WER}\neq0$的部分,不含纯空格错误)的子集。一方面,通过构建差异集来识别模型和架构特有的错误来源;另一方面,通过建立所有模型错误预测转录结果的交集,以识别与模型无关的错误成因(本研究重点关注这部分)。预期跨模型一致的错误可追溯至共享训练数据或存在歧义/低质量的测试数据。
In addition, the vocabulary of the training datasets of the models was accumulated and compared to that of the test datasets in order to determine how well models can generalize to unseen words, as well as how many words were regularly predicted incorrectly although they were contained within the training datasets.
此外,模型训练数据集的词汇被累积并与测试数据集的词汇进行比较,以确定模型对未见词汇的泛化能力,以及有多少词汇虽然包含在训练数据集中但仍被频繁预测错误。
B. Error Classification
B. 错误分类
From the intersection of the previously described crossmodel prediction errors, 2,000 samples were extracted and manually assigned error categories. This partitioning was intended to more distinctively specify the degree of impact and the cause of several groups of errors in false transcript predictions. All mis predicted transcripts across all models could be assigned at least one of the following categories.
从上述跨模型预测错误的交叉分析中,我们提取了2000个样本并手动标注了错误类别。这一划分旨在更清晰地界定错误转录预测中若干组错误的影响程度和成因。所有模型中的错误预测转录至少可归入以下类别之一:
1) Negligible Errors
1) 可忽略误差
This category includes different forms of otherwise correct transcript predictions, i.e., most models in use were trained on non normalized and commonly abbreviated phrases like “et cetera” or “etc.”, which increases the word error rate due to normalized ground truth transcripts but does not represent an actual error. All models except Quartznet and Wav2Vec 2.0 were trained using non normalized abbreviations, which appear in the training datasets of MLS and VoxPopuli. This category also includes words which can be correctly written in multiple possible ways (including obsolete orthography).
此类情况包括其他形式正确的转录预测,即大多数使用中的模型是在非标准化且常见缩写短语(如"et cetera"或"etc.")上训练的。由于标准化真实转录本的存在,这会增加词错误率,但并不代表实际错误。除Quartznet和Wav2Vec 2.0外,所有模型都使用非标准化缩写进行训练,这些缩写出现在MLS和VoxPopuli的训练数据集中。该类别还包括可以用多种正确方式书写的单词(包括过时的拼写)。
2) Minor Errors (noncontext-breaking)
2) 次要错误 (不影响上下文)
Primarily Quartznet and Wav2Vec 2.0, which were trained on less German data than all other models, often produce transcript predictions with redundant letters, omit single letters or predict hard instead of soft vowels and vice versa (e.g., confusion between d and t) without distorting the meaning. These errors are quickly recognized by humans as spelling errors and can usually be corrected when utilizing a language model, thus having little impact on potential context misinterpretations of model outputs. While increasing character error rate only slightly, WER quickly rises to unrealistic values if these minor errors are included.
主要基于Quartznet和Wav2Vec 2.0的模型(其德语训练数据量少于其他所有模型)常出现字母冗余、漏字母或硬/软元音误判(如d与t混淆)等不影响语义的转写错误。这类错误易被人类识别为拼写错误,通过语言模型通常可修正,因此对模型输出的上下文误读影响较小。虽然这些细微错误仅轻微提升字符错误率(CER),但若计入此类错误,词错误率(WER)会迅速攀升至不合理的数值。
3) Major Errors (context-breaking)
3) 重大错误 (破坏上下文)
Fully incorrectly transcribed or omitted words and omitted or inserted letters that change the meaning of a transcript or exclude necessary information and sentence components represent the most critical category for which the causes were to be identified. Those are further discussed in the following section. A specifically humorous example is:
完全错误转录或遗漏的词语,以及改变转录含义或排除必要信息和句子成分的遗漏或插入字母,是需要识别原因的最关键类别。这些将在下一节进一步讨论。一个特别幽默的例子是:
Ground truth: “an einem stand werden waffeln verkauft um die verein sk asse auf zu besser n” (EN: waffles sold) Prediction: “an einem strand werden waffen verkauft um die verein sk asse auf zu besser n” (EN: weapons sold)
真实情况: "an einem stand werden waffeln verkauft um die verein sk asse auf zu besser n" (英文: 华夫饼出售)
预测结果: "an einem strand werden waffen verkauft um die verein sk asse auf zu besser n" (英文: 武器出售)
4) Names, Loan Words and Anglicisms
4) 名称、外来词和英语借词
A commonly occurring type of error in ASR systems, since names can often be spelled in several ways and only a small fraction of common names is usually found in training datasets, foreign words are strongly domain dependent, and some anglicisms have homophonic pronunciations to German phonemes and therefore can often only be correctly interpreted in a strongly context-dependent manner. Anglicisms are closely related to code-switching ASR.
ASR系统中常见的一类错误,由于人名通常存在多种拼写方式且训练数据集中通常只包含少量常见姓名,外来词高度依赖具体领域,部分英语借词与德语发音存在同音异义现象,因此往往需要极强的上下文依赖才能正确识别。英语借词与语码转换( code-switching ) ASR密切相关。
Although errors in this subcategory often have similar effects to contextual understanding as major errors, they have been separated due to being generally underrepresented in publicly available datasets for a single language.
尽管该子类别中的错误通常与主要错误对上下文理解产生相似影响,但由于其在公开单语数据集中的普遍低代表性,故单独划分。
5) Homophones
5) 同音词
Another highly contextual source of error, which is often obviously recognized as wrong by humans, but can change the entire context of transcripts in some cases (e.g., “Graph” and “Graf”; in English: “Graph” and “Count”, a noble title). In those instances, contextual information is lost, but the underlying phonemes were in general correctly interpreted by the system. Occurrences of homophones might also indicate that a network was merely trained on a single representation and context of phonemes, thus always predicting the previously seen representation.
另一个高度依赖上下文的错误来源,虽然人类通常能明显识别其错误,但在某些情况下会彻底改变文本的语境(例如英语中"Graph"和"Graf"分别对应"图表"和"伯爵"这种贵族头衔)。这类情况会导致上下文信息丢失,但系统对基础音素的识别通常是正确的。同音异义词的出现也可能表明,网络仅针对音素的单一表征和上下文进行过训练,因此总是预测之前见过的表征形式。
6) Flawed Ground Truth Transcripts
6) 存在缺陷的真实文本转录
While it is assumed that almost all transcripts correspond to the actual statements of the respective audio recordings in training and test data sets, there are frequent inconsistencies. This is caused by various factors such as incorrect normalization of numbers and symbols, transcripts that are correct in terms of their meaning but not in terms of their wording, and strong deviations and tolerances in the alignment process during the (automated) creation of data sets.
虽然假定几乎所有转录文本在训练和测试数据集中都与相应录音的实际陈述相符,但仍存在频繁的不一致现象。这由多种因素导致,例如数字和符号的错误标准化、语义正确但措辞不符的转录文本,以及在(自动化)数据集创建过程中对齐流程出现的显著偏差和容错。
TABLE VI. EXEMPLARY COMPARISON BETWEEN GROUND TRUTH, ACTUAL TRANSCRIPT AND TRANSCRIPT PREDICTIONS
表 VI: 真实标注、人工转写与预测转写的示例对比
| Groundtruth | aufderbrueckewartetenderkoenigu undderkronprinz |
| Manual transcript | auf der bruecke warten der koenig und der kronprinz |
| Allmodels | auf der bruecke warten der koenig und der kronprinz |
TABLE VI. shows a typical example of erroneous ground truth transcripts. While all ASR systems predicted the word "warten", which was verified by a manual transcription, the actual ground truth transcript contains the word "warteten". These incorrect data consequently lead to worse benchmark results of the models than deserved.
表 VI: 展示了错误真实转录文本的典型示例。虽然所有自动语音识别(ASR)系统都预测了单词"warten"(经人工转录验证),但实际真实转录文本包含的是单词"warteten"。这些错误数据导致模型的基准测试结果比应得的表现更差。
7) Ambiguous Audio Input
7) 模糊音频输入
Especially in spontaneously spoken utterances, dialogues, and uncontrolled recording conditions, but also through stuttering, certain words may be pronounced or perceived indistinctly. This can result in transcript predictions of homophones, but also complete word substitutions or omitted words.
尤其在自发口语表达、对话以及非受控录音环境下,或因口吃现象,某些词语的发音或感知可能含糊不清。这会导致转录预测出现同音词误判,甚至出现完整词语替换或遗漏的情况。
8) Flawed Audio Input
8) 有缺陷的音频输入
Especially in automatically generated datasets (e.g. by utilization of CTC segmentation [35]) long audio recordings are often split very precisely at the end of a word, which can lead to cutoffs of spoken words at the beginning or end of audio snippets. In addition, datasets such as MCV and Voxforge are not fully quality-assured and contain recordings with extremely poor recording quality, which are difficult to understand, even for human listeners. These aspects form a category of their own, as it cannot be expected that correct transcript predictions can be generated from incomplete or corrupted input data.
尤其在自动生成的数据集(如利用CTC分割[35])中,长音频通常会在单词结尾处被精确切割,这可能导致音频片段开头或结尾的词语被截断。此外,MCV和Voxforge等数据集未经过全面质量验证,包含录音质量极差的片段,即使对人类听众而言也难以理解。这些情况自成类别,因为无法期望从不完整或损坏的输入数据中生成正确的转录预测。
C. Results and Error Origins
C. 结果与误差来源
After manually transcribing and classifying 2,000 audio samples with incorrect transcript prediction across all used models, the numbers of occurring errors were put in relation as displayed in TABLE VII.
在对所有使用模型中转录预测错误的2000个音频样本进行人工转录和分类后,各类错误的发生比例如表 VII 所示。
TABLE VII. ERROR CLASSIFICATION AND PROPORTIONS
表 VII: 错误分类及占比
| 序号 | 错误类别 | 错误占比 |
|---|---|---|
| 1 | 可忽略错误 | 9.40% |
| 2 | 非语境破坏性错误 | 11.95% |
| 3 | 语境破坏性错误 | 19.01% |
| 4 | 专名/英语借词/外来词 | 19.82% |
| 5 | 同音异义词 | 2.92% |
| 6 | 有缺陷的真实文本 | 17.85% |
| 7 | 模糊音频输入 | 11.13% |
| 8 | 缺陷音频输入 | 7.91% |
Within the classified samples, about $27%$ of prediction errors (category $1{+}6)$ can be attributed to incorrect ground truth transcripts, outdated spellings and mostly negligible word separation errors, from which can be concluded, that the realistic WER across models would be even lower than previously determined by automated WER calculations. This proportion would rise even further if flawed audio inputs were also considered.
在分类样本中,约$27%$的预测错误(类别$1{+}6$)可归因于错误的真实文本转录、过时拼写以及大多可忽略的分词错误。由此可得出结论:各模型的实际WER (Word Error Rate) 比自动化WER计算得出的数值更低。若将存在缺陷的音频输入也纳入考量,这一比例还将进一步上升。
With just under one fifth of the classified errors, names, foreign words and anglicisms make up a large part of all crossmodel mis predictions. This type of mis prediction ranges from alternative spellings for names (with little effect) to completely incomprehensible transcript predictions, which have a similar effect on human comprehension as errors from the context-breaking category. However, this category is generally known to cause problems for ASR systems. Humans also have problems correctly spelling names, they are not familiar with. A common way to obtain more reliable predictions is finetuning on domain-specific datasets and utilizing a language model.
分类错误中近五分之一的名称、外来词和英语借词构成了跨模型误预测的主要部分。这类误预测范围从名称的替代拼写(影响较小)到完全无法理解的转录预测,对人类理解的影响与上下文断裂类别的错误相似。然而,这类问题通常被认为是自动语音识别 (ASR) 系统的通病。人类同样难以正确拼写不熟悉的名称。提升预测可靠性的常见方法包括对领域特定数据集进行微调以及利用语言模型。
In more than $11%$ of the samples (category 7), even human listeners were unable to produce clear and correct transcripts from audio recordings, because the pronunciation was too unclear. This could be traced back to speakers having learned German as a second language (L2 speakers), multiple German dialects, simple pronunciation errors and slips of the tongue. Increasing the robustness of ASR systems for non-native speakers and dialects is an ongoing research topic (e.g., [36]) and is especially challenging due to lack of standard orthography [37] for dialect speech.
在超过 $11%$ 的样本(类别7)中,甚至人类听写者也无法从录音中生成清晰准确的文字记录,因为发音过于模糊。这可以追溯到说话者将德语作为第二语言学习(L2使用者)、多种德语方言、简单的发音错误和口误。提高自动语音识别(ASR)系统对非母语使用者和方言的鲁棒性是一个持续的研究课题(例如[36]),由于缺乏方言语音的标准拼写[37],这一任务尤其具有挑战性。
Nevertheless, almost another fifth of the total errors contained in the sample derive from words consistently predicted incorrectly or mapped to entirely different words, some with similar meaning, some completely incorrect. Because this category has the strongest impact on reading comprehension, these errors were further divided into subgroups and their causes traced back to systematic errors within the training data. All the following observed errors occur exclusively in predictions from models trained on MLS and VoxPopuli (both datasets were prepared by FAIR):
然而,样本中近五分之一的错误源于被持续预测错误或映射到完全不同单词的情况,其中部分词义相近,部分则完全错误。由于这类错误对阅读理解影响最大,我们将其进一步细分子类,并将成因追溯至训练数据中的系统性错误。以下观察到的所有错误仅出现在基于MLS和VoxPopuli(这两个数据集均由FAIR制备)训练的模型预测中:
1) Naive Normalization
1) 朴素归一化 (Naive Normalization)
The most obvious instance of incorrect normalization can be seen in the transcription of pronounced years from the past millennium. In this case, the training data sets do not contain years written out but interpreted as integers. Consider the following example:
过去千年中发音年份的转录是最明显的归一化错误实例。这种情况下,训练数据集不包含拼写出的年份,而是将其解释为整数。请看以下示例:
Ground truth: Neu nz eh nh under t drei und s ech zig (Nineteen Sixty-Three) Prediction: E in tau send ne unh under t drei und s ech zig (One Thousand Nine Hundred Sixty-Three).
真实值:Neu nz eh nh under t drei und s ech zig (1963)
预测值:E in tau send ne unh under t drei und s ech zig (1963).
All models except for Quartznet and Wav2vec 2.0 produced this mis prediction.
除 Quartznet 和 Wav2vec 2.0 外,所有模型均产生了这一错误预测。
Consistently incorrect normalization of numbers in training data does not only affect years, also larger integer values like “sie b zig tau send” (seventy thousand) are predicted as “siebzig null” (seventy zero).
训练数据中数字归一化不一致的问题不仅影响年份预测,较大整数值如"sie b zig tau send"(七万)也会被错误预测为"siebzig null"(七十零)。
In addition, pronounced punctuation marks such as "punkt" (full stop) or "komma" (comma) were not converted to verbatim expressions in training data but completely removed and thus ignored in predictions. Lack of normalization was particularly evident in the ALC and SI100 test datasets, which intentionally contain many numbers (including chains of single digits) and literally pronounced punctuation marks. Therefore, one important distinction is whether corpora adopt ‘spoken-domain’ transcriptions (orthographic), where numbers are spelled out in words (e.g. ‘three thirty’), or ‘written-domain’ transcriptions, where they are rendered in the typical written form $(^{\leftarrow}3{:}30^{\bullet}$ , non orthographic) [2]. Models trained on one type of dataset will generate errors when evaluated with the other type of dataset.
此外,诸如"punkt"(句号)或"komma"(逗号)等明显标点符号在训练数据中并未转换为逐字表达,而是被完全移除,因此在预测时被忽略。这种缺乏规范化的现象在ALC和SI100测试数据集中尤为明显,这些数据集特意包含大量数字(包括连续单数字串)和逐字发音的标点符号。因此,一个关键区别在于语料库是采用'口语领域'转写(正字法,如将数字拼写为'three thirty')还是'书面领域'转写(以典型书面形式呈现,如$(^{\leftarrow}3{:}30^{\bullet}$,非正字法)[2]。使用某类数据集训练的模型在评估另一类数据集时会产生错误。
2) Indirect Transcription
2) 间接转录
A significant number of ground truth transcripts contain statements of the same meaning, but not the verbatim expression of the corresponding audio snippet. For instance, the word "weil" (because) was interpreted regularly as "denn" (since), which did not change the meaning in any of the observed cases. Alteration of context cannot be ruled out for further samples.
大量真实文本记录包含意义相同但并非对应音频片段逐字表述的陈述。例如,"weil" (因为) 经常被解释为 "denn" (由于),这在所有观察案例中均未改变原意。对于更多样本,不能排除语境改变的可能性。
3) Consistently Wrong Transcriptions
3) 持续错误的转录
Certain terms such as "paragraph" (article) were transcribed as "ziffer" (sub paragraph) within the ground truth transcripts. As a result, models trained on this wrong data consistently predicted these spoken words (as well as a number of others) incorrectly.
在真实转录文本中,某些术语如"paragraph"(条款)被误录为"ziffer"(子条款)。因此,基于这些错误数据训练的模型会持续错误预测这些口语词汇(以及其他一些词汇)。
4) Constant Sentence Structures
4) 恒定句式结构
The VoxPopuli dataset occasionally contains the statement “Herr Präsident” (Mister President) at the beginning of a sentence, but in several cases, this was not actually said; it is a systematic transcript error. Trained models have adopted this phrase and regularly predict it at sentence beginnings. This was primarily observed in predictions of test datasets with similar recording environments to VoxPopuli (e.g., TED talks). Additionally, for poorly edited audio inputs (starting in the middle of a sentence or word), models predicted sentence beginnings that were not present in the audio, and in most cases turned out to be incorrect. This type of error fits into the category " hallucinations" as described in [2].
VoxPopuli数据集中偶尔会在句首出现"Herr Präsident"(主席先生)的陈述,但在多个案例中这并非真实发言内容,而是一种系统性转录错误。训练后的模型习得了这一短语,并频繁在句首位置进行预测。这种现象主要出现在与VoxPopuli录音环境相似的测试数据集(例如TED演讲)预测结果中。此外,对于编辑粗糙的音频输入(从句子或单词中间开始),模型会预测出音频中根本不存在的句首内容,且大多数情况下这些预测都是错误的。这类错误符合文献[2]中描述的"幻觉(hallucinations)"范畴。
The previously listed categories reveal systematic errors in the datasets MLS and VoxPopuli primarily caused by flawed data preprocessing steps, which become particularly obvious in contrast to transcript predictions by models trained without these datasets.
之前列出的类别揭示了 MLS 和 VoxPopuli 数据集中的系统性错误,这些错误主要由有缺陷的数据预处理步骤引起,与未使用这些数据集训练的模型生成的转录预测相比尤为明显。
D. Further Sources of Error
D. 其他误差来源
While the error classification and analysis identified systematic dataset errors, it was also examined how well models could perform predictions for words outside the vocabulary of their training data.
虽然错误分类和分析发现了系统性数据集错误,但也研究了模型对其训练数据词汇表之外的单词预测能力。
TABLE VIII. TRAINING VOCABULARY, ABSOLUTE NUMBER OF UNSEEN WORDS AND CORRECTLY PREDICTED UNSEEN WORDS IN PERCENT
表 VIII: 训练词汇量、未见过单词的绝对数量及正确预测未见过单词的百分比
| 模型 | 训练词汇量 | 未见过单词 | 正确预测率 |
|---|---|---|---|
| Citrinet | 467,740 | 15,836 | 47% |
| ConformerCTC | 467,740 | 15,836 | 50% |
| ConformerT | 467,740 | 15,836 | 53% |
| Contextnet | 467,740 | 15,836 | 50% |
| Wav2Vec2.0 | 210,407 | 32,972 | 52% |
| Quartznet | 210,407 | 32,972 | 45% |
TABLE VIII. shows that about half of all words that were unseen during the training process could be transcribed correctly. It should be noted that Quartznet and Wav2Vec 2.0 were trained using a significantly smaller German vocabulary. Despite that, Wav2Vec 2.0 was able to correctly predict an above-average number of words.
表 VIII: 数据显示约半数训练过程中未见的词汇能被正确转写。值得注意的是 Quartznet 和 Wav2Vec 2.0 是使用规模小得多的德语词汇库训练的。尽管如此,Wav2Vec 2.0 仍能正确预测超出平均水平的词汇量。
TABLE IX. WER ON THORSTEN WITH AND WITHOUT SILENCE
表 IX: THORSTEN 数据集在静音处理前后的词错误率 (WER)
| 原始值 | 静音处理后 | 差值 | |
|---|---|---|---|
| Citrinet | 6.74% | 4.09% | -2.65% |
| Conformer CTC | 8.49% | 3.96% | -4.53% |
| Conformer Trans | 6.20% | 3.61% | -2.59% |
| Contextnet | 9.21% | 3.35% | -5.86% |
| Wav2Vec2.0 | 7.57% | 5.11% | -2.46% |
| Quartznet | 5.95% | 5.00% | -0.95% |
A final error that affects multiple datasets is especially severe for Thorsten (see TABLE IX. ). All models perform significantly worse on audio files that have too few leading and trailing silence included. This was already recognized in previous work [38]. After finding many missing characters or words at the beginning and end of the transcripts, we added 0.3s silence at the beginning and end of every audio file for Thorsten. Rerunning the ASR inferences showed a significant decrease in WERs so that Thorsten became the best recognized dataset after HUI, although it was not included in the training data like Voxforge. ContextNet benefits most of this additional silence with a WER reduction of $5.9%$ absolute, whereas Quartznet seems to be affected the least by missing silence. It took the lead regarding WER for the original Thorsten data and had only a minor reduction in WER with additional silence.
影响多个数据集的最后一个错误对Thorsten尤为严重(见表IX)。所有模型在包含过少首尾静音的音频文件上表现明显更差,这一点在先前的研究中已被发现[38]。在发现转录文本首尾存在大量缺失字符或单词后,我们为Thorsten的每个音频文件首尾添加了0.3秒静音。重新运行ASR推断显示WER显著下降,使得Thorsten成为继HUI之后识别效果最佳的数据集,尽管它和Voxforge一样未被包含在训练数据中。ContextNet从额外静音中获益最多,WER绝对值降低5.9%,而Quartznet似乎受静音缺失的影响最小。该模型在原始Thorsten数据上的WER保持领先,且额外静音仅带来微小的WER下降。
VII. PROPOSED RESOLUTIONS
VII. 提议的决议
For the cross-model errors identified and evaluated in the previous chapter, a selection of methods was determined to minimize or eliminate the impact of these errors in future trained models.
针对上一章节识别并评估的跨模型错误,我们确定了一系列方法来最小化或消除这些错误对未来训练模型的影响。
A. Verification of (correct) Normalization
A. (正确)归一化的验证
Since all models trained using MLS and VoxPopuli produce inconsistent output for spoken years, single letters, symbols, and abbreviations due to incorrect normalization of the training data, further verification of the correctness of these datasets must be conducted. The primary requirements are cross-dataset consistency of normalization and avoidance of information loss (e.g., no general removal of punctuation marks).
由于使用 MLS 和 VoxPopuli 训练的所有模型在口语年份、单个字母、符号和缩写方面因训练数据归一化错误而产生不一致的输出,必须进一步验证这些数据集的正确性。主要要求是归一化的跨数据集一致性,并避免信息丢失(例如,不普遍移除标点符号)。
Performing a mostly automated verification of training datasets and manually correcting or discarding poorly normalized data rows can significantly increase the degree of alignment between audio recordings and transcripts, not only preventing incorrectly trained alignments from occurring within predictions, but potentially improving overall model performance through more consistent overall training of audio-transcript-alignment.
对训练数据集进行大部分自动化验证,并手动修正或删除归一化较差的数据行,可以显著提高录音与文本之间的对齐程度。这不仅能防止预测中出现错误训练的对齐,还可能通过更一致的音频-文本对齐整体训练,从而提升模型的整体性能。
B. Extension of Vocabulary through Text To Speech
B. 通过文本转语音扩展词汇量
By using a text-to-speech system, models could be finetuned on domain-specific terms for which no audio recordings exist. Furthermore, training data could be generated which does not correspond to any sentence structure of written texts and more to that of spontaneously spoken utterances. This could increase the performance of models in dialogues and natural speech as well as prevent architectures from over fitting on frequent beginnings of sentences.
通过使用文本转语音系统,可以在没有音频记录的领域特定术语上对模型进行微调。此外,生成的训练数据可以不局限于书面文本的句子结构,而更贴近自发口语表达。这种方法既能提升模型在对话和自然语音中的表现,也能防止架构对常见句子开头产生过拟合。
However, it must be ensured that the TTS system itself generates sufficiently good predictions for the given words. Especially with terms and names of several different languages, insufficiently trained neural networks for speech synthesis may lead to unusable audio outputs and even worsen the performance of models for speech recognition.
然而,必须确保TTS (Text-to-Speech) 系统本身能为给定词汇生成足够优质的预测。特别是在处理多语言术语及名称时,未经充分训练的语音合成神经网络可能导致无法使用的音频输出,甚至降低语音识别模型的性能。
C. Training on Phoneme Vocabulary
C. 音素词汇训练
Although the use of phoneme-based ASR systems adds another non-trivial step, the mapping of phonemes to character sequences, further measures can be applied to determine con textually correct homophones or to separately interpret and process the speech input of L2 speakers or speakers with dialect. This can be implemented using other specialized systems on, e.g., dialect classification [39], thus detaching more specialized and advanced tasks from speech recognition systems.
尽管基于音素的ASR系统增加了另一个重要步骤——将音素映射到字符序列,但可以进一步采取措施来确定上下文正确的同音字,或单独解释和处理第二语言(L2)使用者或方言使用者的语音输入。这可以通过其他专门系统实现,例如方言分类[39],从而将更专业和高级的任务从语音识别系统中分离出来。
D. Audio Preprocessing
D. 音频预处理
Particularly for dialogues, podium speeches and recordings with poor recording quality, it may be worthwhile to apply various methods of audio preprocessing, such as speaker separation, audio normalization and audio enhancement. The utilization of these methods of course depends on whether the desired system should consist of a single, more robust ASR model, or a composition of preprocessing steps and a downstream ASR model. Undoubtedly, such measures degrade the real time factor of an ASR system but could significantly increase the quality of transcript predictions or assist in the identification of flawed audio inputs.
特别是对于对话、讲台演讲和录音质量较差的录音,可能值得应用各种音频预处理方法,例如说话人分离、音频归一化和音频增强。当然,这些方法的使用取决于所需系统是由一个更稳健的自动语音识别 (ASR) 模型组成,还是由预处理步骤和下游 ASR 模型组合而成。毫无疑问,这些措施会降低 ASR 系统的实时性,但可以显著提高转录预测的质量,或帮助识别有缺陷的音频输入。
VIII. CONCLUSION
VIII. 结论
The presented work has demonstrated that sources of error of speech recognition systems based on neural networks can be identified by the generation of sets of prediction errors as well as by dataset and vocabulary analysis, and that those can be traced back to consistently erroneous training and test data. By utilizing the mentioned methods, it was not only shown that models perform on average better than represented by metrics such as automatically calculated WER on test benchmarks, but also how erroneous data preparation and other task-specific aspects have a lasting negative impact on the performance of trained models.
研究表明,基于神经网络的语音识别系统误差源可通过预测误差集生成、数据集及词汇分析进行定位,这些误差可追溯至训练与测试数据中持续存在的错误。运用上述方法不仅证明模型实际表现优于测试基准中自动计算的WER等指标反映的水平,更揭示了错误数据预处理及其他任务特定因素对训练模型性能造成的长期负面影响。
Implementation of the countermeasures proposed for this purpose could lead to more realistic evaluations in future models, as well as more robust models overall. However, some aspects of automatic speech recognition are still weak.
针对此目的提出的对策实施后,可使未来模型的评估更加贴近实际,同时提升模型的整体鲁棒性。然而,自动语音识别 (Automatic Speech Recognition) 的某些方面仍存在不足。
It turns out, that there is no single ASR model, that works best in all scenarios. Although Conformer Transducer has the lowest WER overall, it produces a number of errors that are prohibitive in some scenarios. Especially the described hallucinations, omitting and changing of words impact transcript predictions very negatively, if one is interested in the details a person said. Wav2Vec 2.0 on the other hand has a comparably high WER overall but stays very close to the phones that were really said.
事实证明,并不存在一个适用于所有场景的最佳ASR模型。尽管Conformer Transducer的整体词错误率(WER)最低,但其在某些场景中产生的错误会严重影响使用效果。特别是前文所述的幻觉现象、词语遗漏和篡改问题,会极大程度地损害转录文本的准确性——当用户需要精确还原说话内容时尤为明显。相比之下,Wav2Vec 2.0虽然整体WER较高,但能更准确地保留实际发音的音素特征。
Since there are no large scale ASR datasets in German language like SPGISpeech [40] with 5,000 hours or Gigaspeech [41] with even 10,000 hours of transcribed audio, future research should aim at carefully correcting errors in existing corpora and complement them with additional data that fills the gaps, like the underrepresented spontaneous speech. It would also be desirable to have several alternative versions of the transcripts so that users can choose the style that is suitable for their application area. There should further be a GDPR-compliant large-scale dataset for German ASR, at least with unsupervised data like LibriLight. Additionally, the available amounts of speech in regional dialects should be made available for ASR, by providing phonetic transcripts instead of analogous translations in standard German. Finally, datasets for L2 speakers as well as those containing technical terms, e.g., in the medical or legal domain would be desirable.
由于德语缺乏像SPGISpeech [40](5000小时)或Gigaspeech [41](甚至10000小时)这样的大规模自动语音识别(ASR)数据集,未来的研究应着重于仔细修正现有语料库中的错误,并通过补充数据(如代表性不足的自发语音)填补空白。此外,提供多种转录版本供用户根据应用场景选择合适风格也很有必要。德国ASR领域亟需一个符合《通用数据保护条例》(GDPR)的大规模数据集,至少包含LibriLight这样的无监督数据。同时,应通过提供方言音标转录(而非标准德语的类比翻译)来扩充方言语音数据。最后,针对第二语言(L2)使用者及包含医学术语、法律术语等专业领域的数据集也值得期待。
By applying a high-quality (neural) language model, we expect a further decrease in WER of $1-2%$ absolute. We will investigate the training of an own language model since we did not find any high-quality model to be freely available.
通过应用高质量(神经)语言模型,我们预计词错误率(WER)将绝对降低1-2%。由于未找到可自由使用的高质量模型,我们将研究自主训练语言模型。
Another aspect for future research is to evaluate the models’ in ferenc ing speed on different hardware to meet the demand of Aksënova et al. for paying attention to real-time factor and resource usage.
未来研究的另一个方向是评估模型在不同硬件上的推理速度,以满足Aksënova等人提出的关注实时因子和资源使用率的需求。