HERMES: TEMPORAL-COHERENT LONG-FORMUNDERSTANDING WITH EPISODES AND SEMANTICS
HERMES: 基于情节与语义的时序连贯长文本理解
ABSTRACT
摘要
Existing research often treats long-form videos as extended short videos, leading to several limitations: inadequate capture of long-range dependencies, inefficient processing of redundant information, and failure to extract high-level semantic concepts. To address these issues, we propose a novel approach that more accurately reflects human cognition.1 This paper introduces HERMES: temporalcoHERent long-forM understanding with Episodes and Semantics, a model that simulates episodic memory accumulation to capture action sequences and reinforces them with semantic knowledge dispersed throughout the video. Our work makes two key contributions: First, we develop an Episodic COmpressor (ECO) module that efficiently aggregates crucial representations from micro to semimacro levels, overcoming the challenge of long-range dependencies. Second, we propose a Semantics reTRiever (SeTR) that enhances these aggregated representations with semantic information by focusing on the broader context, dramatically reducing feature dimensionality while preserving relevant macro-level information. This addresses the issues of redundancy and lack of high-level concept extraction. Extensive experiments demonstrate that HERMES achieves state-ofthe-art performance across multiple long-video understanding benchmarks in both zero-shot and fully-supervised settings. Our code will be made public.
现有研究通常将长视频视为加长版的短视频,导致存在三大局限:难以捕捉长程依赖关系、冗余信息处理效率低下、无法提取高层语义概念。为解决这些问题,我们提出了一种更贴近人类认知的新方法。本文介绍HERMES:基于情节记忆与语义知识的时序连贯长视频理解模型,该模型通过模拟情景记忆累积机制来捕捉动作序列,并利用视频中分散的语义知识进行强化。我们的工作有两大核心贡献:首先,开发了情节压缩器(Episodic COmpressor, ECO)模块,可高效聚合从微观到半宏观层面的关键表征,攻克长程依赖难题;其次,提出了语义检索器(Semantics reTRiever, SeTR),通过关注全局上下文为聚合表征注入语义信息,在保留相关宏观信息的同时显著降低特征维度,从而解决冗余信息和高层概念缺失问题。大量实验表明,HERMES在零样本和全监督设置下,于多个长视频理解基准测试中均达到最先进性能。代码将开源发布。
1 INTRODUCTION
1 引言
Video understanding reflects how humans perceive the world through one of our most essential senses, sight, and drives a wide range of visual and multimodal applications. Whether we want to create better video sum mari z ation tools, index and retrieve specifics from the vast and everexpanding array of video content, or improve content moderation and copyright enforcement, we need models that excel at video understanding. This requirement extends beyond short videos with few frames—a task that image models can already handle adequately—to encompass the analysis of extended video content spanning minutes and comprising thousands of interrelated frames.
视频理解反映了人类如何通过最重要的感官之一——视觉来感知世界,并推动了广泛的视觉和多模态应用。无论是开发更优秀的视频摘要工具、从海量且不断增长的视频内容中索引和检索特定片段,还是改进内容审核与版权保护,我们都需要擅长视频理解的模型。这一需求不仅限于图像模型已能胜任的少量帧的短视频任务,更延伸至对长达数分钟、包含数千帧关联画面的长视频内容进行分析。
Long-form video understanding is challenging for several reasons. First and foremost is the temporal complexity, as it requires handling a large number of frames throughout the video. Second, it requires a semantic understanding of high-level concepts as well as the narrative structure. The third challenge is the memory and computational constraints, making it non-trivial to solve the previous two challenges. Attempts to address these issues have been made by researchers who mainly borrow ideas from short videos (Wu & Krahenbuhl, 2021; Miech et al., 2020), which is a more mature area of research encompassing action recognition and video classification, among others, and for which datasets are more abundant. However, these approaches, which adopt techniques such as pooling (Faure et al., 2023), or 3D convolutions (Fei chten hofer et al., 2019), often do not fully account for the unique characteristics of long videos that distinguish them from a simple concatenation of short video segments. Some ideas about short-video modeling, especially for those at the spatial level, may also hold for longer ones, but when it comes to long-term modeling, macro-level representations should be extracted efficiently.
长视频理解面临多重挑战。首要挑战是时序复杂性,需要处理视频中大量帧序列。其次是语义理解需求,既要解析高层概念又要把握叙事结构。第三大挑战来自内存和计算限制,这使得前两个问题的解决更为困难。研究者们尝试借鉴短视频领域 (Wu & Krahenbuhl, 2021; Miech et al., 2020) 的成熟技术(包括动作识别和视频分类等方向,这些领域数据集更丰富),采用池化 (Faure et al., 2023) 或3D卷积 (Feichtenhöfer et al., 2019) 等方法,但这些方案往往未能充分考虑长视频区别于短视频简单拼接的独特性。虽然短视频建模(特别是空间层面)的部分思路可能适用,但在长期建模时,需要高效提取宏观层面的表征。
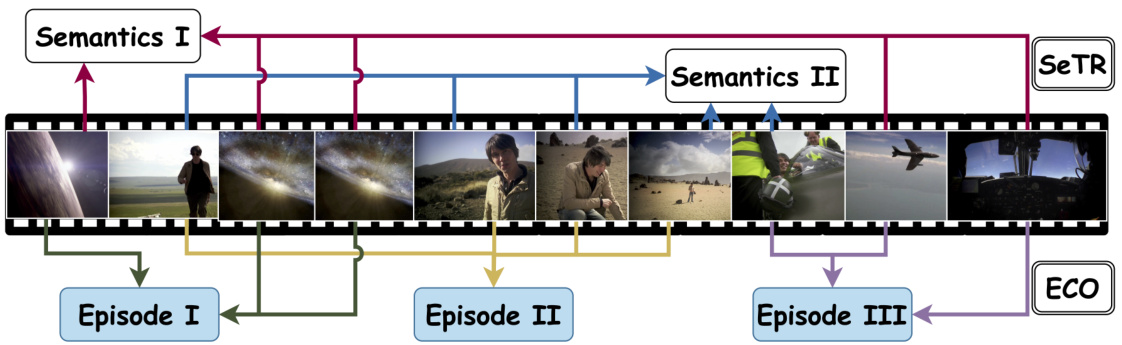
Figure 1: Semantic Knowledge and Episodic Memory Aggregation: Our Episodic COmpressor (ECO) processes input video frames and aggregates key episodes: (I) A cosmic setting with a planet and starfield, (II) A narrator explaining the scene, and (III) An aircraft viewed from inside and out. Concurrently, our Semantics reTRiever (SeTR) identifies high-level semantic cues throughout the video, including: (I) The theme of space exploration and (II) Human interaction with technology. This dual-level approach enables comprehensive video understanding by capturing both specific events and over arching concepts.
图 1: 语义知识与情景记忆聚合:我们的情景压缩器 (ECO) 处理输入视频帧并聚合关键情景:(I) 包含行星和星空的宇宙场景,(II) 解说场景的叙述者,(III) 从内外视角观察的飞行器。同时,我们的语义检索器 (SeTR) 识别贯穿视频的高层语义线索,包括:(I) 太空探索主题和 (II) 人类与技术的互动。这种双层级方法通过捕捉具体事件和 overarching 概念,实现全面的视频理解。
In video understanding, we can distinguish between two types of information: episodic and semantic. Episodic information refers to specific, sequential events that occur in a video, while semantic information encompasses over arching themes and concepts. To illustrate, imagine walking through a scene at a birthday party. Episodic information might include observing five people singing a birthday song, followed by one person cutting a cake. These are specific, timebound events. In contrast, semantic information might involve recognizing decorations scattered throughout the scene, instantly comprehending that you’re witnessing a birthday party. This highlevel understanding provides a concise overview of the scene and actions, transcending specific moments. Building on these concepts, we propose temporal-coHERent long-forM understanding with Episodes and Semantics (HERMES), a model designed to capture both episodic and semantic information in long-form videos. HERMES comprises two key components: ECO and SeTR. The Episodic COmpressor (ECO) aggregates key contiguous information as we process the video, shaping the model’s understanding of the scene sequentially without cluttering it. Complementing this, the SEmantic reTRiever (SeTR) identifies and extracts high-level cues that provide a concise overview of the scene and actions. HERMES achieves state-of-the-art performance on four longform video understanding benchmarks in both zero-shot and fully-supervised settings, notably outperforming the state-of-the-art by a significant $7.3%$ on LVU(Wu & Krahenbuhl, 2021) and $14.9%$ on MovieChat-1k (Song et al., 2024).
在视频理解领域,我们可以区分两种信息类型:情节性 (episodic) 和语义性 (semantic)。情节信息指视频中发生的具体时序事件,而语义信息则涵盖整体主题与概念。例如生日派对场景中,情节信息可能包括观察到五人唱生日歌、随后一人切蛋糕等具有时间界限的具体事件;语义信息则体现为识别场景中的装饰物,瞬间理解这是生日派对场景。这种高层认知能超越具体时刻,提供对场景与行为的概要理解。
基于这些概念,我们提出了时序连贯的长视频理解模型 HERMES (temporal-coHERent long-forM understanding with Episodes and Semantics),该模型专为捕捉长视频中的情节与语义信息而设计。HERMES 包含两个核心组件:ECO 和 SeTR。情节压缩器 (Episodic COmpressor, ECO) 在视频处理过程中聚合关键连续信息,使模型能够有序构建场景理解而不产生信息冗余;语义检索器 (SEmantic reTRiever, SeTR) 则负责识别并提取提供场景和行为概要的高层线索。
HERMES 在四个长视频理解基准测试的零样本和全监督设置下均达到最先进性能,其中在 LVU (Wu & Krahenbuhl, 2021) 上显著超越现有最佳结果 7.3%,在 MovieChat-1k (Song et al., 2024) 上提升幅度达 14.9%。
Our key contributions are as follows:
我们的主要贡献如下:
Through comprehensive evaluation across multiple benchmarks and detailed ablation studies, we validate the effectiveness of ECO and SeTR, and demonstrate their complementary roles in enhancing long-form video understanding
通过在多组基准测试中的全面评估和详细的消融研究,我们验证了ECO与SeTR的有效性,并证明了它们在增强长视频理解能力方面的互补作用
2 PROBLEM SETTING
2 问题设定
Given a long video $V={f_{1},f_{2},\dots,f_{N}}$ , where $f_{i}$ represents the $i$ -th frame and $N$ is the total number of frames, our objective is to develop a model M that can efficiently process $V$ and construct an internal understanding $U$ of its content. This understanding should enable the model to answer queries $Q$ or follow instructions $I$ related to the video content. Formally, we aim to optimize the function:
给定一个长视频 $V={f_{1},f_{2},\dots,f_{N}}$ ,其中 $f_{i}$ 表示第 $i$ 帧, $N$ 为总帧数。我们的目标是开发一个能高效处理 $V$ 并构建其内容内部理解 $U$ 的模型 M。该理解应使模型能够回答与视频内容相关的查询 $Q$ 或遵循指令 $I$ 。形式化表示为优化函数:
$$
\mathbf{M}:(V,I)\rightarrow U
$$
$$
\mathbf{M}:(V,I)\rightarrow U
$$
such that:
使得:
The key challenges in this formulation are:
这一表述中的关键挑战在于:
We aim to address these challenges, by proposing two key contributions:
我们旨在通过提出两个关键贡献来解决这些挑战:
1. Episodic COmpressor (ECO):
1. 情景压缩器 (ECO):
$E C O:f_{1},f_{2},\dots,f_{N}\rightarrow e_{1},e_{2},\dots,e_{K}$ where $K\ll N$ , and $e_{i}$ represents a compressed episodic memory.
$E C O:f_{1},f_{2},\dots,f_{N}\rightarrow e_{1},e_{2},\dots,e_{K}$ 其中 $K\ll N$,且 $e_{i}$ 表示压缩后的情景记忆。
2. Semantics reTRiever (SeTR):
2. 语义检索器 (SeTR):
where $L\ll N$ , and $s_{i}$ represents extracted semantic knowledge.
其中 $L\ll N$ ,且 $s_{i}$ 表示提取的语义知识。
The final understanding $U$ is then generated by combining the outputs of ECO and SeTR:
最终理解 $U$ 通过结合 ECO 和 SeTR 的输出生成:
$$
U=G(E C O(V,I),S e T R(V))
$$
$$
U=G(E C O(V,I),S e T R(V))
$$
where $G$ is a function that integrates episodic and semantic information. This formulation allows us to approach long-form video understanding in a way that more closely mimics human cognition, addressing the identified challenges while maintaining computational efficiency.
其中 $G$ 是一个整合情景记忆和语义信息的函数。该公式化表达使我们能够以更接近人类认知的方式处理长视频理解任务,在保持计算效率的同时解决已识别的挑战。
3 PROPOSED FRAMEWORK: HERMES
3 提出的框架:HERMES
This paper is not about a new LLM or a new way to fine-tune existing LLMs or VLMs. It focuses on leveraging what we know about how humans understand visual scenes to guide the model through the same process. Although this work uses an LLM for auto regressive prediction, the core ideas of episodic memory compression (ECO) and semantic knowledge retrieval (SeTR) can be applied to other models where learning contiguous sequences and high-level representations is advantageous.
本文并非探讨新的大语言模型(LLM)或微调现有LLM/VLM的新方法,而是聚焦于利用人类理解视觉场景的认知机制来引导模型遵循相同处理流程。虽然本研究采用LLM进行自回归预测,但情景记忆压缩(ECO)和语义知识检索(SeTR)的核心思想可推广至其他需要学习连续序列与高层表征的模型。[20]
Given a video, short or long, and a set of instructions specifying what to do with the video, our method can return the specified output, such as video question answering (VQA) or video classification. It achieves this by leveraging two important properties of human understanding of scenes: episodic memory, which involves determining and stratifying a sequence of frames with similar properties, and semantic knowledge, which can help answer broad questions about the scene (e.g., does it occur at night or during the day?). We refer to the former as ECO, detailed in Section 3.2, and to the latter as SeTR, described in Section 3.4.
给定一段视频(无论长短)和一组指定如何处理该视频的指令,我们的方法能够返回指定的输出结果,例如视频问答(VQA)或视频分类。该方法通过利用人类理解场景的两个重要特性来实现:情景记忆(episodic memory)涉及确定并分层处理具有相似属性的帧序列;语义知识(semantic knowledge)则有助于回答关于场景的广泛问题(例如该场景发生在夜间还是白天?)。我们将前者称为ECO(详见第3.2节),后者称为SeTR(详见第3.4节)。
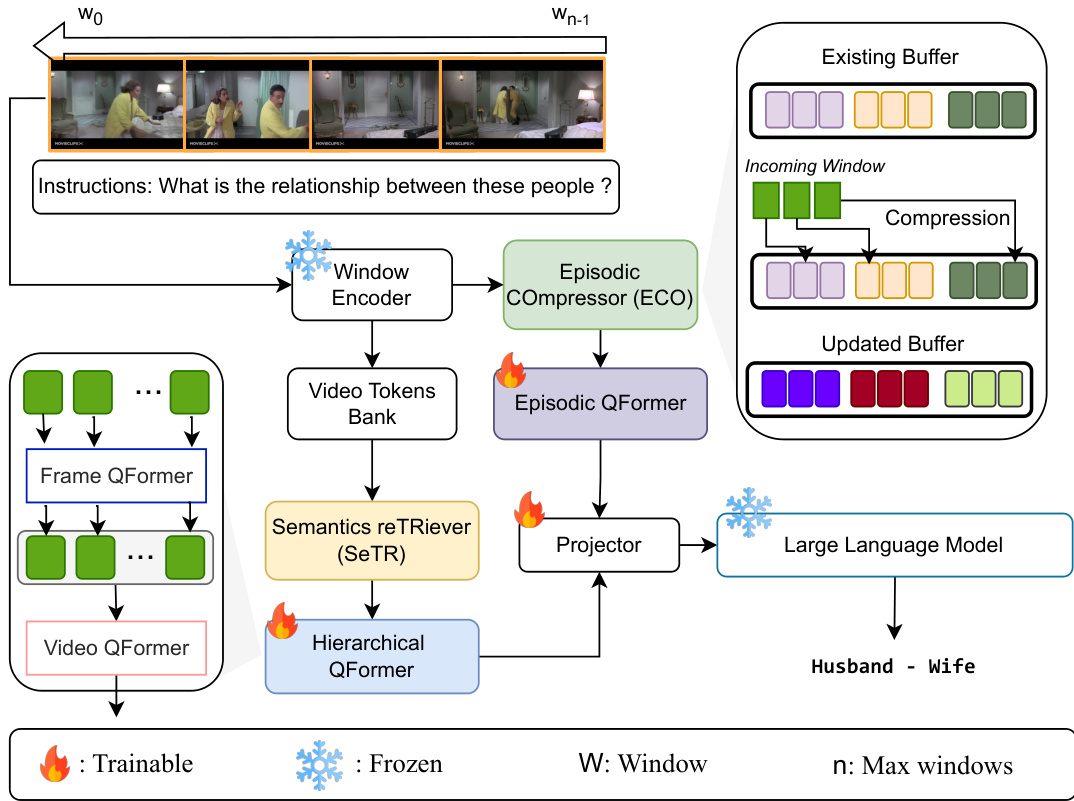
Figure 2: HERMES framework overview: We stream through a video window-by-window and extract features using a frozen ViT. Each window feature is processed by the Episodic COmpressor (ECO) in an online fashion, discarding redundancies along the way and retaining video episodes that are passed to an episodic Q-Former. The video token bank contains the concatenated features of every window, and SeTR selects only the high-level information to pass to a hierarchical frame-tosequence Q-Former. The episodic and high-level representations are then concatenated before being fed to the frozen LLM, which outputs a text following the instructions.
图 2: HERMES框架概览:我们逐窗口流式处理视频,并使用冻结的ViT提取特征。每个窗口特征通过Episodic COmpressor (ECO) 进行在线处理,沿途丢弃冗余信息并保留视频片段传递给episodic Q-Former。视频token库包含每个窗口的拼接特征,SeTR仅选择高层级信息传递给分层帧到序列Q-Former。随后将片段化表征与高层级表征拼接,输入冻结的大语言模型并生成遵循指令的文本输出。
3.1 WINDOW ENCODER
3.1 窗口编码器 (WINDOW ENCODER)
Our model takes as input a video of arbitrary length. To batch process the video, we first specify a number of frames $N$ to extract, leading to $\mathbf{v}={\mathbf{f}{1},\mathbf{f}{2},\dots,\mathbf{f}{N}}$ , where $\mathbf{f}{t}$ denotes the $t$ -th frame. The ViT-G/14 encoder (Fang et al., 2023) progressively encodes non-overlapping windows of the video data. The window size $w$ is a divisor of $N$ and determines how many frames to encode at once. The features of each window are denoted as $\mathbf{F}{w,i}\in\mathbb{R}^{B\times w\times T\times C}$ , where ${\bf F}{w,i}$ are the extracted features for the $i$ -th window, $B$ the batch size, $T$ the number of visual tokens, and $C$ the number of channels. ${\bf F}_{w}$ are then passed on to the Episodic COmpressor (ECO) described in Section 3.2.
我们的模型以任意长度的视频作为输入。为进行批量处理,首先需指定提取的帧数 $N$,得到 $\mathbf{v}={\mathbf{f}{1},\mathbf{f}{2},\dots,\mathbf{f}{N}}$,其中 $\mathbf{f}{t}$ 表示第 $t$ 帧。ViT-G/14编码器 (Fang et al., 2023) 逐步编码视频数据的非重叠窗口。窗口大小 $w$ 是 $N$ 的约数,决定了一次编码的帧数。每个窗口的特征表示为 $\mathbf{F}{w,i}\in\mathbb{R}^{B\times w\times T\times C}$,其中 ${\bf F}{w,i}$ 为第 $i$ 个窗口的提取特征,$B$ 为批次大小,$T$ 为视觉token数量,$C$ 为通道数。${\bf F}_{w}$ 随后传递至第3.2节所述的片段压缩器 (Episodic COmpressor, ECO)。
3.2 ECO: EPISODIC COMPRESSOR
3.2 ECO: 情节压缩器
The proposed Episodic COmpressor (ECO) aggregates the video frames into episodes. This module maintains a memory buffer with a maximum number of episodes $E$ . Upon receiving a window of $F_{w}$ frame features, we first check whether the buffer $\mathcal{M}$ has sufficient bandwidth to support the incoming features. If it does, we simply concatenate them to the buffer; otherwise, we proceed with the compression. At its core, ECO is a distribution process that determines the episode to which a certain frame
提出的情景压缩器 (ECO) 将视频帧聚合为情景片段。该模块维护一个最大情景数 $E$ 的记忆缓冲区。当接收到 $F_{w}$ 帧特征窗口时,首先检查缓冲区 $\mathcal{M}$ 是否具有足够的带宽来容纳新特征。若满足条件,则直接将其拼接至缓冲区;否则执行压缩操作。本质上,ECO 是一个分配过程,用于确定特定帧所属的情景片段。
Algorithm 1 ECO: Episodic COmpressor
算法 1 ECO: 情景压缩器
Where $\bigoplus$ is the concatenation operation, $|\mathcal{M}|$ and $|F_{w}|$ the sizes of the buffer and the incoming features, respectively.
其中 $\bigoplus$ 表示拼接操作,$|\mathcal{M}|$ 和 $|F_{w}|$ 分别为缓冲区和输入特征的大小。
ECO works as Algorithm 1. As long as concatenating the new window and the buffer results in a size greater than $E$ , we compute the cosine similarity between each pair of frame features in $\mathcal{M}\oplus\mathcal{F}{w}$ . We then iterative ly merge the most similar frames until the size constraint $E$ is satisfied. Specifically, where $\mathcal{M}$ is the existing buffer, $F_{w}$ represents the incoming window of $w$ frame features, $\mathcal{A}$ is the concatenated buffer and new window, and $|\mathcal A|$ is the size of $\mathcal{A}$ . To summarize Algorithm 1, $\frac{\mathcal{A}{i}\cdot\mathcal{A}{j}}{|\mathcal{A}{i}||\mathcal{A}{j}|}$ computes the cosine similarity between frame features $\mathcal{A}{i}$ and $\mathbf{\mathcal{A}}{j}$ , $\mathrm{arg}\mathrm{max}{i\neq j}$ finds the pair of frames with the highest cosine similarity, (Ai∗ +2Aj∗ ) combines the most similar frames, and ${\mathcal{A}}\setminus{\mathcal{A}}{j^{}}$ removes the frame $\boldsymbol{\mathcal{A}}_{j^{*}}$ from $\mathcal{A}$ after merging. The process repeats until the size of $\mathcal{A}$ is within the maximum allowed episodes $E$ .
ECO 的工作流程如算法1所示。只要将新窗口与缓冲区拼接后的尺寸大于 $E$ ,我们就计算 $\mathcal{M}\oplus\mathcal{F}{w}$ 中每对帧特征之间的余弦相似度。然后迭代合并最相似的帧,直到满足尺寸约束 $E$ 。具体来说,其中 $\mathcal{M}$ 是现有缓冲区, $F_{w}$ 表示传入的 $w$ 帧特征窗口, $\mathcal{A}$ 是拼接后的缓冲区与新窗口, $|\mathcal A|$ 表示 $\mathcal{A}$ 的尺寸。总结算法1, $\frac{\mathcal{A}{i}\cdot\mathcal{A}{j}}{|\mathcal{A}{i}||\mathcal{A}{j}|}$ 计算帧特征 $\mathcal{A}{i}$ 和 $\mathbf{\mathcal{A}}{j}$ 之间的余弦相似度, $\mathrm{arg}\mathrm{max}{i\neq j}$ 找到余弦相似度最高的帧对, (Ai∗ +2Aj∗ ) 合并最相似的帧, ${\mathcal{A}}\setminus{\mathcal{A}}{j^{}}$ 在合并后从 $\mathcal{A}$ 中移除帧 $\boldsymbol{\mathcal{A}}_{j^{*}}$ 。该过程重复执行,直到 $\mathcal{A}$ 的尺寸在允许的最大片段数 $E$ 以内。
Similarities can be drawn with He et al. (2024), where cosine similarity serves as the basis for frame reduction. However, their approach is notably inefficient and less intuitive. For a buffer of size $S$ , they iterate $S$ times until the buffer reaches capacity, after which each new incoming frame is compared against every other frame in the buffer.
与 He 等人 (2024) 的研究存在相似之处,他们都以余弦相似度作为帧缩减的基础。然而,他们的方法效率明显较低且不够直观。对于大小为 $S$ 的缓冲区,他们需要迭代 $S$ 次直至缓冲区达到容量上限,此后每个新输入的帧都需要与缓冲区中的所有其他帧进行比较。
3.3 EPISODIC Q-FORMER
3.3 情景式 Q-FORMER
The Episodic Q-Former uses the same architecture as the original Q-Former (Li et al., 2023a) and is loaded with weights pretrained by Dai et al. (2023). However, we insert ECO as a pruning module within the Q-Former to combine and branch queries into episodes over the long video. Given initial queries and instructions, we perform self-attention on these queries and then cross-attention between the queries and the visual representations $\mathcal{M}$ . The enhanced queries then undergo an ECO-like process, where we iterative ly merge similar queries across video windows, effectively forming video query episodes of high information density. The following equation summarizes the process,
情景化Q-Former采用与原始Q-Former (Li et al., 2023a)相同的架构,并加载了Dai等人(2023)预训练的权重。不过,我们在Q-Former中嵌入了ECO作为剪枝模块,将查询合并并分支为长视频中的情景片段。给定初始查询和指令后,我们先对这些查询执行自注意力机制,然后在查询与视觉表征$\mathcal{M}$之间进行交叉注意力计算。增强后的查询会经历类似ECO的处理流程:迭代合并跨视频窗口的相似查询,从而高效形成高信息密度的视频查询情景片段。该过程可总结为以下公式:
$$
Q={\mathrm{ECO}}{\mathfrak{q}}\left({\mathrm{CA}}\left({\mathrm{SA}}(Q_{0}),{\mathcal{M}}\right)\right)
$$
$$
Q={\mathrm{ECO}}{\mathfrak{q}}\left({\mathrm{CA}}\left({\mathrm{SA}}(Q_{0}),{\mathcal{M}}\right)\right)
$$
where $Q_{0}$ represents the initial queries, $\mathcal{M}$ denotes the visual representations from the visual ECO, $\operatorname{SA}(Q_{0})$ applies self-attention on the initial queries, and $\mathbf{CA}(\cdot,\mathcal{M})$ performs cross-attention between the self-attended queries and the visual representations. Finally, $\mathrm{ECO}_{\mathfrak{q}}(\cdot)$ – note the $\mathfrak{q}$ to differentiate it from the visual ECO – applies the iterative merging process similar to the visual compression detailed in Section 3.2 on the enhanced queries. The episodic Q-Former outputs with $B$ , $q$ and $C^{\prime}$ alluding to the batch size, the number of queries and the channel dimension, respectively.
其中 $Q_{0}$ 表示初始查询,$\mathcal{M}$ 表示来自视觉ECO的视觉表征,$\operatorname{SA}(Q_{0})$ 对初始查询应用自注意力机制,$\mathbf{CA}(\cdot,\mathcal{M})$ 在自注意力查询与视觉表征之间执行交叉注意力。最后,$\mathrm{ECO}_{\mathfrak{q}}(\cdot)$ ——注意这里的 $\mathfrak{q}$ 用于区分视觉ECO——对增强后的查询应用类似于第3.2节详述的视觉压缩过程的迭代合并操作。情景式Q-Former输出,其中 $B$、$q$ 和 $C^{\prime}$ 分别指代批次大小、查询数量和通道维度。
3.4 SETR: SEMANTICS RETRIEVER
3.4 SETR: 语义检索器
To complement ECO and capture higher-level semantic information from the video, we develop a Semantics reTRiever (SeTR). SeTR is designed to identify and consolidate important high-level information that may be scattered (contiguous ly or not) throughout the video. Given a video feature tensor $F\in\mathbb{R}^{B\times N\times T\times C}$ , where $B$ is the batch size, $N$ the number of frames, $T$ the number of tokens per frame and $C$ the channel dimension, SeTR operates as follows: we first normalize $F$ to ensure consistent scaling across features. Second, we apply a stride of $k$ to create two groups, group $X$ containing every $k$ -th frame, resulting in $\textstyle{\frac{N}{k}}$ frames and group $Y$ with the remaining $N^{-}-\frac{\dot{N}}{k}$ frames. Third, we calculate dot product similarity scores between frames in and . Finally, for each frame in $Y$ , we merge it with its most similar frame in $X$ , based on the computed scores by taking their mean.
为补充ECO并从视频中捕捉更高层次的语义信息,我们开发了语义检索器(SeTR)。SeTR旨在识别并整合视频中可能分散(连续或非连续)的重要高层信息。给定视频特征张量$F\in\mathbb{R}^{B\times N\times T\times C}$,其中$B$为批次大小,$N$为帧数,$T$为每帧token数,$C$为通道维度,SeTR按以下步骤运行:首先对$F$进行归一化以确保特征尺度一致;其次采用步长$k$创建两组数据,组$X$包含每隔$k$帧的$\textstyle{\frac{N}{k}}$帧,组$Y$包含剩余的$N^{-}-\frac{\dot{N}}{k}$帧;然后计算组$X$与组$Y$帧间的点积相似度得分;最后根据得分将$Y$中每帧与其在$X$中最相似的帧通过取均值方式进行合并。
This process effectively reduces the number of frames from $N$ to $\scriptstyle{\frac{N}{k}}$ , consolidating semantic information while maintaining the most relevant features across the video timeline. The resulting semantic representations are denoted as $\begin{array}{r}{F^{\prime}\in\mathbb{R}^{B\times\frac{N}{k}\times T\times C}}\end{array}$ . We evaluate the effectiveness of this approach in Section 4.3. While ToMe (Bolya et al., 2022) have explored token reduction in vision transformers, their approach and objectives differ significantly from ours. Their method focuses on minor token reductions within individual frames, specifically between different layers of a Vision Transformer. In contrast, SeTR retains the most salient frames while significantly reducing redundancies.
这一过程有效地将帧数从 $N$ 减少到 $\scriptstyle{\frac{N}{k}}$,在保留视频时间线上最相关特征的同时整合语义信息。最终得到的语义表征记为 $\begin{array}{r}{F^{\prime}\in\mathbb{R}^{B\times\frac{N}{k}\times T\times C}}\end{array}$。我们将在第4.3节评估该方法的有效性。虽然ToMe (Bolya et al., 2022) 探索过视觉Transformer中的Token缩减,但其方法和目标与我们有显著差异:他们的方法专注于单帧内不同Vision Transformer层间的少量Token缩减,而SeTR在显著减少冗余的同时保留了最突出的帧。
3.5 HIERARCHICAL QFORMER
3.5 分层QFORMER
Following our SeTR, is a hierarchical Q-Former composed of a frame Q-Former $(f Q F o r m e r)$ , a frame-to-sequence adapter and a video Q-Former $(v Q F o r m e r)$ . The frame Q-Former enhances each semantic piece of information, independently of the others, and the video Q-Former consolidates them. The resulting query $Q_{s e m}\in\mathbb{R}^{B\times q\times C^{\prime}}$ contains the semantic representations of the entire video.
在我们的SeTR之后,是一个由帧级Q-Former (f Q Former)、帧序列适配器和视频级Q-Former (v Q Former) 组成的层次化Q-Former。帧级Q-Former独立增强每一段语义信息,而视频级Q-Former则对它们进行整合。最终生成的查询 $Q_{s e m}\in\mathbb{R}^{B\times q\times C^{\prime}}$ 包含了整个视频的语义表征。
$$
Q_{s e m}=v Q F o r m e r(L i n e a r(f Q F o r m e r(F^{\prime})))
$$
$$
Q_{s e m}=v Q F o r m e r(L i n e a r(f Q F o r m e r(F^{\prime})))
$$
3.6 FROM REPRESENTATIONS TO NATURAL LANGUAGE
3.6 从表征到自然语言
After obtaining the episodic representations $Q$ and the semantic representations $Q_{s e m}$ , we prepare them for input into a Large Language Model (LLM). Specifically, we concatenate $Q$ and $Q_{s e m}$ to form a unified representation vector. This concatenated vector is then projected into the input embedding space of the LLM using a learned linear transformation. In our implementation, we utilize a Vicuna-7B model (Chiang et al., 2023) as LLM. The model, conditioned on this projected representation and guided by task-specific instructions, generates the requested natural language output. This approach allows us to leverage the LLM’s pretrained knowledge and language generation capabilities while incorporating our task-specific episodic and semantic information. The process is summarized by the following equation:
在获得情景表征 $Q$ 和语义表征 $Q_{sem}$ 后,我们将其准备为大语言模型 (LLM) 的输入。具体而言,我们将 $Q$ 和 $Q_{sem}$ 拼接形成统一的表征向量,然后通过学习的线性变换将该拼接向量投影到LLM的输入嵌入空间。本实验采用Vicuna-7B模型 (Chiang et al., 2023) 作为LLM。该模型基于投影后的表征,在任务特定指令的引导下生成所需的自然语言输出。这种方法既能利用LLM的预训练知识和语言生成能力,又能融入任务相关的情景与语义信息。该过程可概括为以下公式:
$$
\hat{Y}=\mathrm{LLM}(W[Q;Q_{s e m}]+b,I)
$$
$$
\hat{Y}=\mathrm{LLM}(W[Q;Q_{s e m}]+b,I)
$$
where $\hat{Y}$ is the generated output, $[Q;Q_{s e m}]$ denotes the concatenation of $Q$ and $Q_{s e m}$ , $W$ and $b$ are the learned projection matrix and bias respectively, and $I$ represents the task-specific instructions.
其中 $\hat{Y}$ 是生成的输出,$[Q;Q_{s e m}]$ 表示 $Q$ 和 $Q_{s e m}$ 的拼接,$W$ 和 $b$ 分别是学习到的投影矩阵和偏置,$I$ 代表任务特定的指令。
4 EXPERIMENTS
4 实验
4.1 DATASETS AND EVALUATION METRICS
4.1 数据集和评估指标
We evaluate our approach on two primary tasks: long-form video classification and long-form video question answering.
我们在两项主要任务上评估了我们的方法:长视频分类和长视频问答。
For long-form video classification, we utilize three diverse datasets. The first, LVU (Wu & Krahenbuhl, 2021), focuses on movie content, offering a rich source of narrative and thematic video data. The second, Breakfast (Tang et al., 2019), consists of instructional videos that emphasize procedural and step-by-step understanding. Lastly, COIN (Kuehne et al., 2014) is another instructional video dataset, but it covers a broader range of procedural activities compared to Breakfast. We report top-1 classification accuracy on these datasets.
针对长视频分类任务,我们采用了三个多样化数据集。首个数据集LVU (Wu & Krahenbuhl, 2021)聚焦电影内容,提供丰富的叙事性与主题性视频素材;第二个数据集Breakfast (Tang et al., 2019)由教学视频构成,侧重流程化与分步骤理解;最后的COIN (Kuehne et al., 2014)同样是教学视频数据集,但相比Breakfast覆盖了更广泛的操作性活动。我们在这些数据集上报告了top-1分类准确率。
For long-form video question answering, we employ the MovieChat $I k$ dataset (Song et al., 2024) and report both zero-shot and fully-supervised results. As evaluation metrics, we follow the evaluation protocol developed by Maaz et al. (2023), employing GPT-3.5-turbo (Brown et al., 2020) to assess both accuracy and answer quality score.
针对长视频问答任务,我们采用MovieChat $I k$数据集 (Song et al., 2024) ,同时报告零样本 (zero-shot) 和全监督条件下的实验结果。评估指标方面,我们遵循Maaz等人 (2023) 提出的评估方案,使用GPT-3.5-turbo (Brown et al., 2020) 来评估答案准确率和回答质量分数。
4.2 QUANTITATIVE RESULTS
4.2 定量结果
We present our long video action classification results in Table 1 for LVU (Wu & Krahenbuhl, 2021), Table 2 for Breakfast (Kuehne et al., 2014) and COIN (Tang et al., 2019), and compare HERMES ’s performance against transformer-based models, including Object Transformers (Wu & Krahenbuhl, 2021), Movies 2 Scenes (Chen et al., 2023), and FACT (Lu & Elhamifar, 2024); hybrid state-space and transformer-based models such as Vis4mer (Islam & Bertasius, 2022), TranS4mer (Islam et al., 2023), and S5 (Wang et al., 2023); as well as the LLM-based model MA-LMM (He et al., 2024). For the MovieChat-1k dataset (Song et al., 2024), our results are presented in Table 3, where we compare against recent LLM-based models including MovieChat (Song et al., 2024), Video-ChatGPT (Maaz et al., 2023), Video-LLaMA (Zhang et al., 2023), and VideoChat (Li et al., 2023b). Our method achieves state-of-the-art performance across all datasets, with notable accuracy improvements of $7.3%$ on LVU and $14.9%$ on MovieChat-1k, significantly surpassing previous methods.
我们在表1中展示了LVU (Wu & Krahenbuhl, 2021) 的长视频动作分类结果,在表2中展示了Breakfast (Kuehne et al., 2014) 和COIN (Tang et al., 2019) 的结果,并将HERMES的性能与基于Transformer的模型(包括Object Transformers (Wu & Krahenbuhl, 2021)、Movies 2 Scenes (Chen et al., 2023) 和FACT (Lu & Elhamifar, 2024))、混合状态空间与Transformer的模型(如Vis4mer (Islam & Bertasius, 2022)、TranS4mer (Islam et al., 2023) 和S5 (Wang et al., 2023))以及基于大语言模型的MA-LMM (He et al., 2024) 进行了比较。对于MovieChat-1k数据集 (Song et al., 2024),我们的结果展示在表3中,并与近期基于大语言模型的MovieChat (Song et al., 2024)、Video-ChatGPT (Maaz et al., 2023)、Video-LLaMA (Zhang et al., 2023) 和VideoChat (Li et al., 2023b) 进行了对比。我们的方法在所有数据集上均达到了最先进的性能,在LVU上显著提升了7.3%的准确率,在MovieChat-1k上提升了14.9%,大幅超越了先前的方法。
Table 1: SOTA Comparison on the LVU Dataset: The table presents Top-1 accuracy for various models. Unlike the minor incremental improvements observed among other methods, our model demonstrates a significant performance leap, outperforming its nearest competitor by $7.3%$ . The highest score is highlighted in bold, and the second highest is underlined.
表 1: LVU数据集上的SOTA对比:该表格展示了各模型的Top-1准确率。与其他方法观察到的微小渐进改进不同,我们的模型实现了显著的性能飞跃,以 $7.3%$ 的优势超越最接近的竞争对手。最高分以粗体标出,次高分以下划线标示。
| 模型 | 内容 | 元数据 | 平均 | |||||
|---|---|---|---|---|---|---|---|---|
| 关系 | 说话 | 场景 | 导演 | 类型 | 编剧 | 年份 | ||
| Object Transformer | 53.1 | 39.4 | 56.9 | 52.1 | 54.6 | 34.5 | 39.1 | 47.1 |
| VIS4mer | 57.1 | 40.8 | 67.4 | 62.6 | 54.7 | 48.8 | 44.8 | 53.7 |
| TranS4mer | 59.5 | 39.2 | 70.9 | 63.9 | 55.9 | 46.9 | 45.5 | 54.5 |
| S5 | 67.1 | 42.1 | 73.5 | 67.3 | 65.4 | 51.3 | 48.0 | 59.2 |
| Movies2Scenes | 71.2 | 42.2 | 68.2 | 70.9 | 57.8 | 55.9 | 53.7 | 60.0 |
| MA-LMM | 58.2 | 44.8 | 80.3 | 74.6 | 61.0 | 70.4 | 51.9 | 63.0 |
| HERMES (Ours) | 67.6 | 47.5 | 90.0 | 82.6 | 69.5 | 77.2 | 57.7 | 70.3 |
Table 2: Performance comparison on Breakfast and COIN datasets (Top1 accuracy). Our method outperforms state-of-the-art models on both datasets. Table 3: Zero-shot performance on MovieChat-1k. Our model significantly outperforms existing methods. The model marked with $^\ddagger$ is fully supervised.
表 2: Breakfast 和 COIN 数据集上的性能对比 (Top1准确率)。我们的方法在两个数据集上都优于现有最优模型。
表 3: MovieChat-1k 上的零样本性能。我们的模型显著优于现有方法。标有 $^\ddagger$ 的模型为全监督模型。
| Model | Breakfast | COIN | Model | Global | Breakpoint | ||
|---|---|---|---|---|---|---|---|
| Acc. | Score | Acc. | Score | ||||
| FACT | 86.1 | MovieChat | 63.7 | 3.15 | 48.1 | 2.46 | |
| VIS4mer | 88.2 | 88.4 | Video-ChatGPT | 58.7 | 2.89 | 47.8 | 2.43 |
| MA-LMM | 93.0 | 93.2 | Video-LLaMA | 56.3 | 2.72 | 45.8 | 2.11 |
| S5 | 90.7 | 90.8 | VideoChat | 60.2 | 3.08 | 46.3 | 2.32 |
| TranS4mer | 90.3 | 89.2 | HERMES (Ours) | 78.6 | 4.23 | 57.3 | 3.29 |
| HERMES (Ours) | 95.2 | 93.5 | HERMES (Ours)# | 84.9 | 4.40 | 65.8 | 3.65 |
4.3 ABLATION STUDIES
4.3 消融实验
Ablations are conducted on the MovieChat-1k test set (global mode) using the zero-shot setting with additional ablations on the Breakfast dataset using the fully-supervised setting. These experiments focus on our two primary contributions, ECO and SeTR. For an extended and more comprehensive ablations, please refer to Appendix A.4.
在MovieChat-1k测试集(全局模式)上采用零样本设置进行消融实验,并在Breakfast数据集上使用全监督设置进行补充消融。这些实验聚焦于我们的两大核心贡献:ECO与SeTR。如需更详尽的消融分析,请参阅附录A.4。
How important is ECO? In Table 4, we demonstrate the critical role of ECO through several experiments. The results clearly indicate that the absence of our ECO and the Episodic Q-Former leads to a significant degradation in model performance due to the model lacking micro-level continuous representations. We further explore alternative update strategies, including randomly selecting features to retain (Rand.) and employing a first-in-first-out (FIFO) streaming approach. Our proposed update strategy outperforms both the Rand. and FIFO methods, highlighting its efficacy in retaining more relevant episodes. It is worth noting that during these ablations, SeTR remains active.
ECO有多重要?在表4中,我们通过多项实验证明了ECO的关键作用。结果表明,由于模型缺乏微观层面的连续表征,缺少我们的ECO和Episodic Q-Former会导致模型性能显著下降。我们进一步探索了替代更新策略,包括随机选择保留特征(Rand.)和采用先进先出(FIFO)流式处理方法。我们提出的更新策略在保留更相关片段方面优于Rand.和FIFO方法,凸显了其有效性。值得注意的是,在这些消融实验中,SeTR始终保持激活状态。
How important is SeTR? SeTR is designed to complement the episodic knowledge of our model with semantic insights. In Table 5, we observe that removing SeTR results in a $5%$ drop in accuracy, which is substantial. Additionally, we show that naive methods such as max pooling and average pooling are not as effective.
SeTR有多重要?SeTR旨在通过语义洞察来补充我们模型的片段知识。在表 5 中,我们观察到移除SeTR会导致准确率下降 $5%$ ,这一影响相当显著。此外,我们还发现诸如最大池化和平均池化这类简单方法效果不佳。
Table 4: Ablations on the memory update design of our Episodic COmpressor (ECO).
表 4: 我们的情景压缩器 (ECO) 在记忆更新设计上的消融实验。
| Acc. | Score | |
|---|---|---|
| w/o | 55.1 | 3.55 |
| Rand. | 76.9 | 4.13 |
| FIFO | 77.1 | 4.15 |
| ECO | 78.6 | 4.23 |
Table 5: Ablations on different semantic compression methods.
表 5: 不同语义压缩方法的消融实验。
| Acc. | Score | |
|---|---|---|
| w/o | 73.3 | 4.09 |
| MaxPool | 70.4 | 3.99 |
| AvgPool | 73.3 | 4.04 |
| SeTR | 78.6 | 4.23 |
Table 6: Performance comparison between frame Q-Former, video Q-Former and our hierarchical $\mathsf{Q-}$ Former architecture.
表 6: 帧级 Q-Former、视频级 Q-Former 与我们提出的分层 $\mathsf{Q-}$ Former 架构的性能对比
| 准确率 | |
|---|---|
| FlatfQFormer | 93.2 |
| Flat vQFormer | 94.1 |
| Hierarchical QFormer | 95.2 |
Table 7: Zero-shot performance comparison of MA-LMM with and without ECO and SeTR integration on MovieChat-1k. Accuracy vs. Number of Episodes Accuracy vs. SeTR Compression Ratio
表 7: MA-LMM在MovieChat-1k数据集上集成/未集成ECO与SeTR的零样本性能对比
| 模型 | 准确率 | 得分 | 延迟 (秒) |
|---|---|---|---|
| MA-LMM | 73.3 | 4.05 | 467 |
| MA-LMM+ECO | 76.7 (+3.4) | 4.14 (+0.09) | 266 (-43%) |
| MA-LMM+SeTR | 77.1 (+3.8) | 4.16 (+0.11) | 474 (+1.5%) |
| HERMES (Ours) | 78.6 (+5.3) | 4.23 (+0.18) | 250 (-46%) |
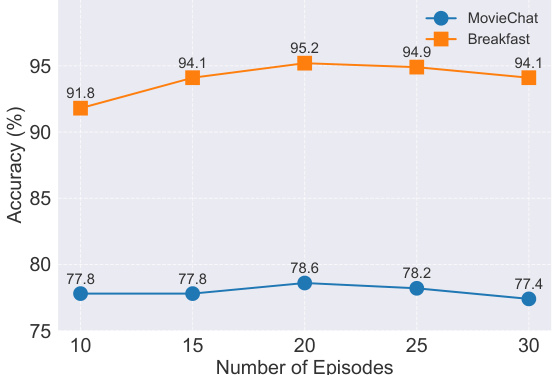
Figure 3: Effect of the number of ECO episodes on the model’s accuracy on the MovieChat-1k and Breakfast datasets.
图 3: ECO训练轮数对模型在MovieChat-1k和Breakfast数据集上准确率的影响
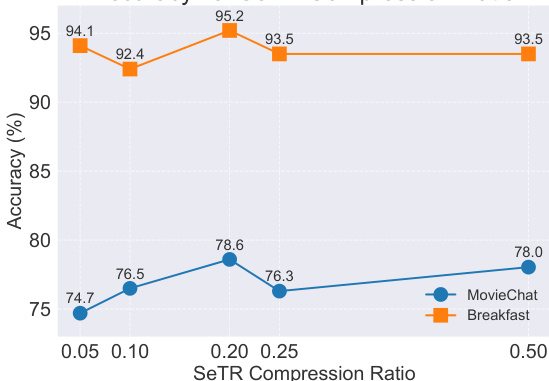
Figure 4: Effect of the SeTR ’s keep ratio on the model’s accuracy on the MovieChat-1k and Breakfast datasets.
图 4: SeTR保留比例对模型在MovieChat-1k和Breakfast数据集上准确率的影响。
Do we need a hier a chic al Q-Former? Yes. We conducted an ablation study on the Breakfast dataset (Kuehne et al., 2014), to evaluate the efficacy of our proposed hierarchical Q-Former architecture. As shown in Table 6, our hierarchical Q-Former achieves superior performance with an accuracy of $95.2%$ , outperforming both flat frame-level $(f Q F o r m e r,93.2%)$ and video-level (vQF ormer, $94.1%$ ) architectures. This improvement can be attributed to the hierarchical structure’s ability to capture multi-scale features, effectively aggregating information from frame to video level. By first processing frame-level details and then aggregating them at the video level, our approach mitigates information loss that may occur in direct video-level processing while avoiding the computational intensity of processing every frame individually.
我们需要分层级Q-Former吗?是的。我们在Breakfast数据集 (Kuehne et al., 2014) 上进行了消融实验,以评估所提出的分层级Q-Former架构的有效性。如表6所示,我们的分层级Q-Former以 $95.2%$ 的准确率实现了更优性能,优于平面帧级 $(fQFomer,93.2%)$ 和视频级 (vQFomer, $94.1%$) 架构。这一改进可归因于分层结构捕获多尺度特征的能力,能有效聚合从帧到视频层级的信息。通过先处理帧级细节再在视频层级进行聚合,我们的方法缓解了直接视频级处理可能出现的信息丢失问题,同时避免了逐帧处理的计算负担。
ECO as off-the-shelf memory manager. We evaluate the impact of our Episodic COmpressor (ECO) as plug-ins to the existing MA-LMM model (He et al., 2024) by replacing the memory bank of MA-LMM. ECO is designed to efficiently process long video sequences while preserving temporal coherence and narrative structure. The results in Table 7 demonstrate substantial improvements with ECO integration with an accuracy increase by $3.4%$ . Moreover, ECO demonstrates superior efficiency compared to MA-LMM’s memory bank, almost halving the overall inference latency.
将ECO作为现成的内存管理器进行评估。我们通过替换MA-LMM模型 (He et al., 2024) 的记忆库,评估了情景压缩器 (Episodic COmpressor, ECO) 作为插件的影响。ECO旨在高效处理长视频序列,同时保持时间连贯性和叙事结构。表7的结果显示,集成ECO带来了显著改进,准确率提高了 $3.4%$ 。此外,与MA-LMM的记忆库相比,ECO展现出更高的效率,几乎将整体推理延迟减少了一半。
SeTR as off-the-shelf semantics retriever. We also integrate our Semantics reTRiever (SeTR) into MA-LMM. SeTR is designed to enhance long video understanding by distilling high-level semantic cues, providing a cohesive framework for comprehending context and themes in long-form videos. As shown in Table 7, the integration of SeTR results in significant performance improvements. Accuracy increases by $3.8%$ , while the score improved by 0.11 points. Remarkably, these substantial performance gains were achieved with only a marginal $1.5%$ increase in inference time, highlighting the computational efficiency of SeTR and its potential for seamless integration into models requiring enhanced semantic representations.
SeTR作为现成的语义检索器。我们还将语义检索器(SeTR)集成到MA-LMM中。SeTR旨在通过提炼高级语义线索来增强长视频理解,为理解长视频中的上下文和主题提供连贯框架。如表7所示,集成SeTR带来了显著的性能提升:准确率提高$3.8%$,分数提升0.11分。值得注意的是,这些显著性能提升仅伴随$1.5%$的推理时间边际增长,凸显了SeTR的计算效率及其在需要增强语义表征的模型中无缝集成的潜力。
Both SeTR and ECO yield significant performance enhancements when integrated with MA-LMM. SeTR showed a marginally higher performance boost in accuracy, which is expected given its role as a semantic add-on to MA-LMM’s existing memory management system.
SeTR和ECO与MA-LMM集成时均带来显著的性能提升。SeTR在准确率上表现出略高的性能增幅,这符合预期,因为它是MA-LMM现有内存管理系统的语义增强组件。
How effective and efficient is ECO compared to other memory compressors? To demonstrate the effectiveness and efficiency of our proposed ECO, we conduct a comparative analysis against two strong existing compression techniques: ToMe (Bolya et al., 2022) and MALMM (He et al., 2024) in Figure 5. We calculate the inference time for each model on the MovieChat-1k dataset. Powered by ECO our model achieves the highest accuracy $(78.6%)$ among all models, outperforming MA-LMM by $5.3%$ and ToMe by a substantial $13.8%$ . HERMES achieves the highest inference speed among the compared models, while also maintaining superior accuracy. It is slightly faster than ToMe and significantly outperforms MALMM, reducing inference time by $46%$ com
与其他内存压缩器相比,ECO的效能和效率如何?为了展示我们提出的ECO方法的有效性和效率,我们在图5中与两种现有强力压缩技术进行了对比分析:ToMe (Bolya等人, 2022) 和MALMM (He等人, 2024)。我们在MovieChat-1k数据集上计算了每个模型的推理时间。在ECO的支持下,我们的模型以$(78.6%)$的准确率在所有模型中位列第一,分别以$5.3%$和$13.8%$的优势超过MA-LMM和ToMe。HERMES在对比模型中实现了最高的推理速度,同时保持了卓越的准确率。它比ToMe略快,并显著优于MALMM,将推理时间降低了$46%$。
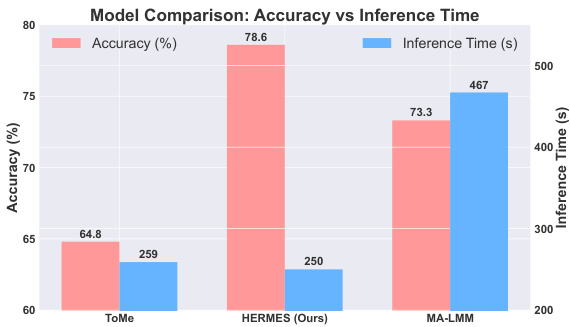
Figure 5: Our method is $46%$ faster than MALMM while being $5.3%$ more accurate, and registers an absolute gain of $13.8%$ accuracy compared to ToMe.
图 5: 我们的方法比 MALMM 快 46%,同时准确率高出 5.3%,与 ToMe 相比实现了 13.8% 的绝对准确率提升。
pared to the latter. These results demonstrate our model’s ability to deliver state-of-the-art accuracy without compromising on efficiency.
与后者相比。这些结果表明我们的模型能够在保持效率的同时提供最先进的准确性。
Hyper parameters for ECO and SeTR. Our experiments on the MovieChat-1k (zero-shot) and Breakfast (fully-supervised) datasets reveal compelling insights into the optimal configuration of ECO (Figure 3) and SeTR (Figure 4). For ECO, we discover that an episodic memory size of 20 consistently yields peak performance across both datasets, achieving a $78.6%$ accuracy on MovieChat1k and a $95.2%$ on Breakfast. This sweet spot balances comprehensive video representation with computational efficiency, as larger memory sizes show diminishing returns. SeTR’s performance proved equally intriguing, with a keep ratio of $20%$ (reducing representations by $80%$ ) emerging as the optimal choice. Remarkably, even at extreme keep ratios as low as $5%$ , our model exhibits robust performance, with a very slight decrease in accuracy. Such results demonstrate the resilience of HERMES to hyper parameter variations suggesting that it is suitable for deployment across diverse video understanding datasets with minimal hyper parameter tuning.
ECO 和 SeTR 的超参数 (hyper parameters)。我们在 MovieChat-1k (零样本) 和 Breakfast (全监督) 数据集上的实验揭示了关于 ECO (图 3) 和 SeTR (图 4) 最优配置的重要发现。对于 ECO,我们发现当情景记忆 (episodic memory) 大小设为 20 时,两个数据集均达到峰值性能:在 MovieChat1k 上获得 78.6% 准确率,在 Breakfast 上获得 95.2% 准确率。这个最佳值在视频表征全面性和计算效率之间取得了平衡,因为更大的记忆容量只会带来边际收益。SeTR 的表现同样引人注目,保持比率 (keep ratio) 为 20% (即减少 80% 的表征量) 时达到最优效果。值得注意的是,即使在极端低至 5% 的保持比率下,我们的模型仍表现出稳健性能,准确率仅有微小下降。这些结果表明 HERMES 对超参数变化具有强健性,意味着它只需极少的超参数调整即可适用于各类视频理解数据集。
4.4 QUALITATIVE RESULTS
4.4 定性结果
We present qualitative results on a challenging movie scene from the MovieChat-1k dataset to evaluate our model’s capability in answering both fine-grained and general questions about an extended video (14,000 frames). To rigorously assess the models, we bypass the original, basic Q&A from the dataset (e.g., Q: What’s the time in the video? A: Day; Q: Are there any shooting scenes? A: Yes) and pose questions that require a deeper understanding of the scene and actions, such as those concerning the expressions on the faces of the spectators. Our model demonstrates an ability to accurately respond to these questions while exhibiting a candid acknowledgment of its limitations (e.g., Q3). In contrast, MovieChat (Song et al., 2024) frequently generates hallucinated and incorrect answers. For instance, in response to Q2, MovieChat avoids answering the question directly and
我们在MovieChat-1k数据集中选取了一个具有挑战性的电影场景进行定性分析,以评估模型在回答关于长视频(14,000帧)的细粒度和通用问题上的能力。为了严格评估模型性能,我们跳过了数据集中原始的基础问答(例如:Q:视频中是什么时间?A:白天;Q:有枪战场景吗?A:有),转而提出需要深入理解场景和动作的问题,例如关于观众面部表情的提问。我们的模型展现出准确回答这些问题的能力,同时坦率承认自身局限(如Q3所示)。相比之下,MovieChat (Song et al., 2024) 经常产生虚假错误的回答。例如在回答Q2时,MovieChat回避直接回答问题...

Figure 6: Qualitative Results: We select a challenging video from the MovieChat-1k dataset and pose various difficult questions to both MovieChat (Song et al., 2024) and HERMES. The results demonstrate our model’s superior ability to answer both fine-grained questions (Q1 and Q3) and general questions (Q2). Answers highlighted in blue denote tentative answers, red denote wrong answers, purple denote hallucinations, and green denote correct answers.
图 6: 定性分析结果: 我们从MovieChat-1k数据集中选取了一段具有挑战性的视频,并向MovieChat (Song等人, 2024) 和HERMES模型提出了多个高难度问题。结果显示我们的模型在回答细粒度问题 (Q1和Q3) 和通用问题 (Q2) 方面都展现出更优异的能力。蓝色高亮的回答表示试探性答案,红色表示错误答案,紫色表示幻觉生成内容,绿色表示正确答案。
instead describes the scene. Notably, our model achieves this performance by processing only 100 out of the 14,000 frames (approximately $0.7%$ ), whereas MovieChat processes 2,048 frames, which is more than 20 times the data utilized by our model. For additional qualitative results, including failure cases of our model, please refer to Appendix A.5.
相反,它描述的是场景。值得注意的是,我们的模型仅处理了14,000帧中的100帧(约$0.7%$)就实现了这一性能,而MovieChat处理了2,048帧,是我们模型所用数据的20多倍。更多定性结果(包括我们模型的失败案例)请参阅附录A.5。
5 RELATED WORK
5 相关工作
Action recognition is an essential task in video understanding, primarily focusing on identifying specific actions within short video clips. Various approaches have been developed, with convolutional neural networks (CNNs) forming the core of many of them. Early work by Ji et al. (2012) utilize 3D convolutions, while Varol et al. (2017) employed temporal convolutions. More recently, transformer-based models have gained prominence, as demonstrated in works such as Faure et al. (2023), Xu et al. (2021), and Zhang et al. (2022).
动作识别是视频理解中的一项核心任务,主要关注短视频片段中特定动作的识别。目前已发展出多种方法,其中卷积神经网络 (CNN) 构成许多方法的核心。Ji等人 (2012) 的早期研究采用3D卷积,而Varol等人 (2017) 则运用了时序卷积。近年来,基于Transformer的模型日益突出,如Faure等人 (2023) 、Xu等人 (2021) 和张等人 (2022) 的研究所示。
Video question answering (VideoQA) aims to answer questions related to video content, requiring a deep understanding of both visual and textual information. Datasets such as Activity Net-QA (Yu et al., 2019) for short videos, and MovieChat-1k for long videos (Song et al., 2024) provide benchmarks for evaluating models in this field, allowing for several research endeavors on this subject (Zhang et al., 2020; Zhuang et al., 2020; Pan et al., 2023).
视频问答 (VideoQA) 旨在回答与视频内容相关的问题,需要对视觉和文本信息有深入理解。针对短视频的 Activity Net-QA (Yu et al., 2019) 和针对长视频的 MovieChat-1k (Song et al., 2024) 等数据集为该领域模型评估提供了基准,推动了多项相关研究 (Zhang et al., 2020; Zhuang et al., 2020; Pan et al., 2023)。
Long-form video understanding presents unique challenges due to the extended duration and complex narrative structures involved. Datasets with these properties include LVU (Wu & Krahenbuhl, 2021), COIN (Tang et al., 2019), Breakfast (Kuehne et al., 2014), and MovieChat-1k (Song et al., 2024). Traditional approaches to tackling such a task often extend methods designed for short videos to handle longer sequences namely pooling over the temporal dimension (Tang et al., 2020; Faure et al., 2023). Other methods such as Wu & Krahenbuhl (2021); He et al. (2024); Wu et al. (2022) and Song et al. (2024) explore memory techniques, emphasizing the need for more sophisticated models capable of managing large temporal spans. Wang et al. (2023) introduce selective structured state-spaces for long-form videos, followed by others Islam & Bertasius (2022); Islam et al. (2023) exploiting the ability of state-space models to retain long-term context.
长视频理解因其较长的持续时间和复杂的叙事结构而面临独特挑战。具有这些特性的数据集包括 LVU (Wu & Krahenbuhl, 2021)、COIN (Tang et al., 2019)、Breakfast (Kuehne et al., 2014) 和 MovieChat-1k (Song et al., 2024)。传统处理此类任务的方法通常将针对短视频设计的技术扩展至长视频序列,例如沿时间维度进行池化 (Tang et al., 2020; Faure et al., 2023)。其他方法如 Wu & Krahenbuhl (2021)、He et al. (2024)、Wu et al. (2022) 和 Song et al. (2024) 探索了记忆技术,强调需要能够处理大时间跨度的更复杂模型。Wang et al. (2023) 提出了针对长视频的选择性结构化状态空间方法,随后 Islam & Bertasius (2022) 和 Islam et al. (2023) 进一步挖掘了状态空间模型保持长期上下文的能力。
LLM-based Long-Form Video Understanding: Recent advancements in large language models (LLMs) (Touvron et al., 2023; Chiang et al., 2023) have piqued researchers’ curiosity regarding their use for video understanding (Maaz et al., 2023). It turns out to be a good match, as understanding videos often involves transforming their content into words, whether it’s video captioning, video question answering, or even action classification. Song et al. (2024) and He et al. (2024) propose
基于大语言模型的长视频理解:大语言模型 (LLMs) (Touvron et al., 2023; Chiang et al., 2023) 的最新进展引发了研究者对其在视频理解领域应用的兴趣 (Maaz et al., 2023)。事实证明这是一个很好的匹配,因为视频理解通常涉及将其内容转化为文字,无论是视频描述、视频问答还是动作分类。Song et al. (2024) 和 He et al. (2024) 提出了
6 CONCLUSION
6 结论
We propose HERMES, a novel framework designed to enhance long-form video understanding through two key components inspired by cognitive processes. The first, Episodic COmpressor (ECO), captures representations as sequences of continuous actions, reflecting episodic memory. The second, Semantics reTRiever (SeTR), serves as a high-level summarizer, distilling essential semantic information. Our model achieves state-of-the-art results on several long-video datasets, significantly outperforming existing methods. Through experiments on LVU, Breakfast, COIN and MovieChat, we have demonstrated the effectiveness and efficiency of ECO and SeTR.
我们提出HERMES框架,该创新设计通过两个受认知过程启发的核心组件来增强长视频理解能力。首先,情景压缩器 (Episodic COmpressor, ECO) 将视频表征捕获为连续动作序列,模拟情景记忆机制;其次,语义检索器 (Semantics reTRiever, SeTR) 作为高层摘要生成器,提炼关键语义信息。我们的模型在多个长视频数据集上取得最先进成果,显著超越现有方法。通过在LVU、Breakfast、COIN和MovieChat上的实验,我们验证了ECO与SeTR模块的有效性和高效性。
REFERENCES
参考文献
Md Mohaiminul Islam and Gedas Bertasius. Long movie clip classification with state-space video models. In European Conference on Computer Vision, pp. 87–104. Springer, 2022.
Md Mohaiminul Islam 和 Gedas Bertasius。基于状态空间视频模型的长电影片段分类。载于欧洲计算机视觉会议,第87-104页。Springer出版社,2022年。
Md Mohaiminul Islam, Mahmudul Hasan, Kishan Shamsundar Athrey, Tony Braskich, and Gedas Bertasius. Efficient movie scene detection using state-space transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 18749–18758, 2023.
Md Mohaiminul Islam、Mahmudul Hasan、Kishan Shamsundar Athrey、Tony Braskich 和 Gedas Bertasius。基于状态空间 Transformer (State-Space Transformer) 的高效电影场景检测。见《IEEE/CVF 计算机视觉与模式识别会议论文集》,第 18749–18758 页,2023 年。
A APPENDIX
A 附录
The Appendix is organized as follows:
附录结构如下:
A.1 REPRODUCIBILITY STATEMENT
A.1 可复现性声明
To facilitate the reproducibility of our work, we will make our code, pretrained models, default hyper parameters, and pre processed annotations publicly available. Detailed hyper parameters for each dataset are also provided in Table 8. Our model demonstrates efficient performance, completing inference on the MovieChat-1k test set in 13 minutes (22 FPS) using a single V100 GPU (32 GB), and training on the MovieChat-1k dataset in less than 12 minutes with 8x 32 GB GPUs. In contrast to recent LLM-based approaches that necessitate extensive and costly multi-stage pre training on increasingly large datasets, our model is designed for accessibility, thereby lowering the barrier for researchers without access to high-end computing resources. We achieve high performance while maintaining accessibility by leveraging existing pretrained weights and implementing our trainingfree ECO and SeTR, resulting in a model where finetuning is optional.
为便于复现我们的工作,我们将公开代码、预训练模型、默认超参数和预处理标注。各数据集的详细超参数见表8。我们的模型展现出高效性能:在单块V100 GPU (32GB)上仅用13分钟(22 FPS)完成MovieChat-1k测试集推理,使用8块32GB GPU时在12分钟内完成MovieChat-1k数据集训练。与当前需要昂贵多阶段预训练的大语言模型方案不同,我们的模型注重易用性,降低了研究者使用高端计算资源的门槛。通过复用现有预训练权重并采用免训练的ECO与SeTR模块,我们在保持高性能的同时实现了可选项微调的设计。
A.2 IMPLEMENTATION DETAILS
A.2 实现细节
To ensure the reproducibility of our results, we provide the training details, which are also the defaults in our soon-to-be-released code. These settings are mostly consistent across different datasets.
为确保结果的可复现性,我们提供了训练细节,这些也是即将发布代码中的默认设置。这些参数在不同数据集间基本保持一致。
Table 8: Hyper parameters used for different datasets.
表 8: 不同数据集使用的超参数。
| Dataset | Max Epochs | LR | Batch | Frames (N) | Episodes | Keep Ratio |
|---|---|---|---|---|---|---|
| MovieChat-1k (G) | 1 | 1e-4 | 32 | 100 | 20 | 0.2 |
| MovieChat-1k (B) | 1 | 1e-4 | 32 | 40 | 10 | 0.5 |
| LVU | 20 | 1e-4 | 32 | 100 | 20 | 0.2 |
| COIN | 20 | 1e-4 | 32 | 100 | 20 | 0.2 |
| Breakfast | 20 | 1e-4 | 32 | 100 | 20 | 0.2 |
LR is the learning rate, and Keep Ratio is the SeTR keep ratio. Episodes refer to the number of episodes to which we compress the input frames (i.e., the capacity of ECO). The number of frames (N) represents the quantity of frames retained from the original video to serve as input to the model. These frames are selected by applying a regular stride over the original video’s frame sequence, where the stride length is determined by the ratio of original frame count to N. Max Epoch $=20$ means we run the program for 20 epochs, performing evaluation after each epoch, and then pick the model with the highest validation accuracy. MovieChat-1k (G) and MovieChat-1k (B) denote global and breakpoint modes, respectively. All models were trained on 8 V100 GPUs (32GB VRAM each).
LR 是学习率 (learning rate),Keep Ratio 是 SeTR 保留比例。Episodes 指我们将输入帧压缩到的片段数 (即 ECO 的容量)。帧数 (N) 表示从原始视频中保留作为模型输入的帧数量,这些帧通过对原始视频帧序列应用固定步长进行选择,步长由原始帧数与 N 的比值决定。Max Epoch $=20$ 表示我们运行程序 20 个周期,每个周期后进行验证,然后选择验证准确率最高的模型。MovieChat-1k (G) 和 MovieChat-1k (B) 分别表示全局模式和断点模式。所有模型均在 8 块 V100 GPU (每块 32GB 显存) 上训练。
A.3 MODEL DETAILS
A.3 模型细节
A.3.1 DETAILS OF OUR EPISODIC QFORMER
A.3.1 我们的情景式 QFORMER 细节
The Episodic Q-Former, as visualized in Figure 7, extends the original QFormer architecture by inserting the Episodic COmpressor (ECO) described in Section 3.2. It begins with a set of initial queries that undergo a self-attention process, enhancing internal query representations. These queries then interact with episodic visual features through cross-attention, allowing the incorporation of contextual visual information. The resulting enhanced queries are fed into our ECO module alongside existing query episodes, which represent previously processed queries grouped into episodes. ECO iterative ly updates the query episodes, adding the new queries to the existing episodes. This Episodic QFormer allows the model to better handle long sequences or repeated queries by maintaining richer contextual knowledge across iterations.
如图 7 所示,情景式 Q-Former (Episodic Q-Former) 通过嵌入 3.2 节所述的情景压缩器 (ECO) 扩展了原始 Q-Former 架构。它从一组初始查询 (query) 开始,经过自注意力 (self-attention) 处理以增强内部查询表征。随后这些查询通过交叉注意力 (cross-attention) 与情景视觉特征交互,从而融入上下文视觉信息。增强后的查询会与代表历史处理查询分组的情景化查询片段 (query episodes) 一起输入 ECO 模块。ECO 会迭代更新查询片段,将新查询整合到现有片段中。该架构使模型能够通过维护跨迭代的丰富上下文知识,更好地处理长序列或重复查询。

Figure 7: Illustration of our Episodic QFormer: We insert our ECO in the original QFormer to effectively and efficiently compute and aggregate queries across long video sequences. It returns query episodes representing the whole video.
图 7: Episodic QFormer 示意图: 我们在原始 QFormer 中插入 ECO (Episodic Context Operator) 模块, 高效计算并聚合长视频序列中的查询, 最终输出代表整段视频的查询片段。

Figure 8: Illustration of SeTR: Our Semantics reTRiever uses a stride of $k$ split the videos into groups $X$ of $N/k$ frames and $Y$ of $\begin{array}{r}{N-\frac{\Bar{N}}{k}}\end{array}$ frames, then merge each frame from $Y$ to its most semantically similar in $X$ .
图 8: SeTR示意图:我们的语义检索器 (Semantics reTRiever) 采用步长 $k$ 将视频分割为 $N/k$ 帧的组 $X$ 和 $\begin{array}{r}{N-\frac{\Bar{N}}{k}}\end{array}$ 帧的组 $Y$,然后将 $Y$ 中的每帧合并到其语义最相似的 $X$ 帧中。
A.3.2 DETAILS OF SETR
A.3.2 SETR 详细信息
We design SeTR as an efficient tool to retrieve semantic information from a long video. Given tokens extracted from a long video sequence, we use a stride of size $k$ , to form a group of $\textstyle{\frac{N}{k}}$ frames representing the number of semantics we want to extract. We then compress the remaining $\begin{array}{r}{N-\frac{N}{k}}\end{array}$ frames into extracted $\textstyle{\frac{N}{k}}$ frames to obtain the semantic representations. SeTR is illustrated in Figure 8.
我们将SeTR设计为一种从长视频中高效检索语义信息的工具。给定从长视频序列中提取的token,我们采用大小为$k$的步长,形成包含$\textstyle{\frac{N}{k}}$帧的分组来表示需要提取的语义数量。随后将剩余的$\begin{array}{r}{N-\frac{N}{k}}\end{array}$帧压缩至提取的$\textstyle{\frac{N}{k}}$帧中,以获取语义表征。SeTR的工作原理如图8所示。
A.4 EXTENDED ABLATIONS
A.4 扩展消融实验
A.4.1 HOW DOES THE NUMBER OF FRAMES AFFECT THE MODEL’S ACCURACY AND LATENCY?
A.4.1 帧数如何影响模型的准确性和延迟?
MovieChat (Song et al., 2024) processes 2048 frames for each video, while we use only 100 frames, as previous studies have demonstrated how redundant video data is (Simonyan & Zisserman, 2014; Wang et al., 2016). Given that the MovieChat-1k dataset contains very long videos (some exceeding 14,000 frames), we conducted experiments to extend the number of frames our model processes. Specifically, we experiment with 40, 80, 100, 300, 500, and 1000 frames while keeping the number of episodes constant. As for the SeTR keep ratio, we decrease it in function of the number frames so that the number of semantic features we keep equals 20.
MovieChat (Song等人,2024) 为每个视频处理2048帧,而我们仅使用100帧,因为先前研究已证明视频数据存在冗余性 (Simonyan & Zisserman, 2014; Wang等人,2016)。鉴于MovieChat-1k数据集包含超长视频(部分超过14,000帧),我们通过实验扩展了模型处理的帧数。具体而言,在保持片段数量不变的情况下,我们测试了40、80、100、300、500和1000帧的配置。对于SeTR保留比率,我们根据帧数进行动态下调,使保留的语义特征数量恒定为20。
We observe a complex relationship between model accuracy, processing latency, and the number of frames analyzed. Figure 9 illustrates these relationships, providing insights into the performance trade-offs of our model. As evident from Figure 9, the relationship between accuracy and the number of frames is non-monotonic. Accuracy initially increases as the number of frames grows, reaching a peak of $79.4%$ at 80 frames with a modest latency (note that we use 100 frames as the default parameter in other experiments for consistency with other datasets). This suggests that up to this point, additional frames provide valuable context that enhances the model’s understanding. However, beyond 80 frames, we observe a decline in accuracy, possibly due to the introduction of noise or irrelevant information from temporally distant parts of the video.
我们观察到模型准确率、处理延迟和所分析帧数之间存在复杂关系。图9展示了这些关系,为我们理解模型性能权衡提供了洞见。从图9可以明显看出,准确率与帧数的关系是非单调的。随着帧数增加,准确率最初呈现上升趋势,在80帧时达到峰值79.4%,此时延迟处于适中水平(注意我们在其他实验中默认使用100帧以保持与其他数据集的一致性)。这表明在此阈值之前,额外帧数能为模型理解提供有价值的上下文信息。然而超过80帧后,我们观察到准确率开始下降,这可能是由于视频时间跨度较远部分引入噪声或无关信息所致。

Figure 9: Accuracy and latency as functions of the number of frames pro- cessed: This figure demonstrates the non-monotonic relationship between accuracy and frame count, with peak performance at 80 frames. Latency increases super-linearly with frame count while accuracy stalls, highlighting the redundancy of video data.
图 9: 准确率与延迟随处理帧数的变化关系:该图展示了准确率与帧数之间的非单调关系,在80帧时达到峰值性能。延迟随帧数超线性增长而准确率停滞,凸显了视频数据的冗余性。

Figure 10: Accuracy and latency as functions of input window size: The graph illustrates the interplay between model accuracy, processing latency, and the window size. Notably, accuracy peaks at a window size of 10, while latency stabilizes for window sizes of 10 and above. In all cases the accuracy only slightly fluctuates.
图 10: 准确率与延迟随输入窗口大小的变化关系:该图表展示了模型准确率、处理延迟和窗口大小之间的相互作用。值得注意的是,准确率在窗口大小为10时达到峰值,而延迟在窗口大小为10及以上时趋于稳定。在所有情况下,准确率仅出现轻微波动。
Latency, on the other hand, exhibits a near-linear increase with the number of frames up to 300 frames, after which it grows super-linearly. This rapid increase in latency for higher frame counts underscores the computational challenges of processing large numbers of frames, particularly in real-time or near-real-time applications.
另一方面,延迟在帧数达到300帧之前呈现近乎线性的增长,之后则呈超线性增长。高帧数下延迟的快速上升凸显了处理大量帧数的计算挑战,尤其是在实时或近实时应用中。
Interestingly, the model’s performance at 1000 frames $76.7%$ accuracy) is lower than its performance at 40 frames $77.6%$ accuracy), but with a significantly higher latency (2676s vs. 143s). This observation highlights the diminishing returns and potential drawbacks of simply increasing the number of processed frames. It also underscores the importance of thoughtful frame selection in video understanding tasks. Future work could explore adaptive frame selection techniques that dynamically adjust the number of frames based on video content, potentially optimizing both accuracy and efficiency.
有趣的是,该模型在1000帧时的性能(76.7%准确率)低于其在40帧时的表现(77.6%准确率),但延迟却显著更高(2676秒 vs. 143秒)。这一观察结果凸显了单纯增加处理帧数带来的收益递减和潜在缺陷,同时也强调了视频理解任务中帧选择策略的重要性。未来工作可以探索自适应帧选择技术,根据视频内容动态调整帧数,从而可能同时优化准确率和效率。
A.4.2 HOW DOES THE WINDOW SIZE AFFECT THE MODEL’S ACCURACY AND LATENCY?
A.4.2 窗口大小如何影响模型的准确性和延迟?
Our analysis of our model’s zero-shot performance on the MovieChat-1k test set reveals intriguing relationships between accuracy, latency, and input window size. Figure 10 illustrates these trade-offs. As evident from Figure 10, the relationship between accuracy and window size is nonmonotonic. Accuracy initially increases with window size, reaching a peak of $78.6%$ at a window size of 10. This suggests that providing more context to the model improves its performance up to a certain point. However, beyond this optimal window size, accuracy begins to decline, possibly due to the introduction of irrelevant context.
我们对模型在MovieChat-1k测试集上零样本性能的分析揭示了准确率、延迟和输入窗口大小之间的有趣关系。图10展示了这些权衡关系。从图10可以明显看出,准确率与窗口大小的关系并非单调递增。准确率最初随窗口大小增加而上升,在窗口大小为10时达到峰值78.6%。这表明在一定范围内,为模型提供更多上下文能提升其性能。然而超过这个最佳窗口大小后,准确率开始下降,可能是由于引入了无关上下文所致。
Latency exhibits a sharp decrease from window size 1 to 5, after which it remains relatively stable. This indicates that while smaller window sizes may seem computationally advantageous, they incur higher latency, possibly due to the need for more frequent ECO call. The optimal trade-off occurs at a window size of 10, where we observe peak accuracy and stabilized latency suggesting that carefully tuned context windows can enhance long-form video understanding without incurring additional computational costs.
延迟从窗口大小1到5急剧下降,之后保持相对稳定。这表明虽然较小的窗口大小在计算上看似有利,但它们会导致更高的延迟,可能是由于需要更频繁的ECO调用。最佳权衡出现在窗口大小为10时,此时我们观察到峰值准确性和稳定的延迟,这表明经过精心调整的上下文窗口可以在不增加计算成本的情况下增强长视频理解能力。
A.4.3 A NOTE ON LATENCY
A.4.3 关于延迟的说明
The MovieChat-1k test set comprises 170 videos, from each of which our model samples 100 frames. This results in a total of 17,000 frames to be processed. Our empirical measurements show that the model requires 774 seconds to complete end-to-end inference on this dataset using a single V100 GPUs (32GB VRAM). This translates to a processing speed of approximately 22 frames per second (FPS), which is very close to real-time performance. Such a result suggests that our approach is not only effective in terms of accuracy but also efficient enough for practical applications in video understanding tasks.
MovieChat-1k测试集包含170个视频,我们的模型从每个视频中采样100帧。这总共需要处理17,000帧。我们的实验测量表明,使用单个V100 GPU(32GB显存)在该数据集上完成端到端推理需要774秒。这意味着处理速度约为每秒22帧(FPS),非常接近实时性能。这一结果表明,我们的方法不仅在准确性方面有效,而且在视频理解任务的实际应用中也足够高效。

MovieChat: A cheetah appears several times in the video.They can be seer walking in grass fields,standing in grass fields,and running in grass fields. Ours: Leopard
图 1:
MovieChat: 视频中多次出现一只猎豹。可以看到它们在草丛中行走、站立和奔跑。
我们的结果: 豹
(a) Animal Identification: MovieChat mistakenly identifies a Leopard as a Cheetah, even though no Cheetah appears in the video.
(a) 动物识别: MovieChat 错误地将一只豹子 (Leopard) 识别为猎豹 (Cheetah), 尽管视频中并未出现猎豹。

(b) Animal Counting: This question is particularly challenging because the bears appear infrequently in the video, and the question specifically asks about “baby bears.” Despite MovieChat analyzing 2048 frames and our model only analyzing 100 frames, our model was able to locate and count the baby bears accurately.
(b) 动物计数: 这个问题尤其具有挑战性, 因为熊在视频中出现频率很低, 且问题明确询问的是"幼熊"。尽管 MovieChat 分析了 2048 帧画面, 而我们的模型仅分析了 100 帧, 但我们的模型仍能准确定位并统计出幼熊数量。

(c) Determining People’s Relationships: We compare our results with those of MA-LMM, with both models trained on the LVU dataset. Thanks to our episodic memory compression, our model excels at determining people’s relationships across thousands of frames of interactions.
(c) 人物关系判定:我们将结果与MA-LMM进行对比,两个模型均在LVU数据集上训练。得益于情景记忆压缩技术,我们的模型在跨越数千帧交互的人物关系判定任务中表现优异。
Figure 11: Qualitative results demonstrating the capabilities of our model compared to MovieChat and MA-LMM across different tasks. (a) Animal identification shows MovieChat’s confusion between Leopard and Cheetah. (b) Animal counting highlights the challenge of locating baby bears with limited appearances in the video, where our model outperforms despite fewer frames. (c) Relationship determination benefits from our episodic memory compression, enabling better identification of relationships over extended interactions.
图 11: 展示我们模型与MovieChat和MA-LMM在不同任务上能力的定性对比结果。(a) 动物识别任务显示MovieChat混淆了豹(Leopard)和猎豹(Cheetah)。(b) 动物计数任务突显了视频中出镜有限的幼熊定位难题,我们的模型在帧数更少的情况下表现更优。(c) 关系判定任务得益于我们的情景记忆压缩机制,能在持续互动中更准确地识别关系。
A.5 MORE QUALITATIVE RESULTS
A.5 更多定性结果
To further illustrate the capabilities of our model, we present a series of qualitative examples that highlight its strengths in various long-form video understanding tasks.
为了进一步展示我们模型的能力,我们提供了一系列定性示例,突显其在各种长视频理解任务中的优势。
Animal Identification. Figure 11a demonstrates our model’s superior performance in animal identification compared to MovieChat. In this example, MovieChat incorrectly identifies a leopard as a cheetah, despite no cheetah being present in the video. This misidentification underscores the importance of accurate visual feature extraction and semantic understanding in long-form video analysis.
动物识别。图 11a 展示了我们的模型在动物识别方面优于 MovieChat 的表现。在此示例中,MovieChat 错误地将一只豹子识别为猎豹,尽管视频中并未出现猎豹。这一误判凸显了在长视频分析中准确提取视觉特征和理解语义的重要性。
Animal Counting. Figure 11b showcases our model’s ability to perform complex counting tasks, even with limited information. The task involves counting baby bears, which appear infrequently in the video. Despite analyzing only 100 frames compared to MovieChat’s 2048 frames, our model accurately locates and counts the baby bears. This demonstrates the efficiency of our ECO and SeTR modules in capturing and retaining crucial information from sparse appearances.
动物计数。图 11b 展示了我们的模型执行复杂计数任务的能力,即使在信息有限的情况下。该任务涉及统计视频中不常出现的幼熊数量。尽管仅分析 100 帧(而 MovieChat 分析 2048 帧),我们的模型仍能准确定位并统计幼熊数量。这证明了我们的 ECO 和 SeTR 模块在从稀疏出现中捕获并保留关键信息方面的效率。
Determining People’s Relationships. In Figure 11c, we compare our model’s performance against MA-LMM in determining relationships between people over extended video sequences. Both models were trained on the LVU dataset. Our model’s superior performance in this task can be attributed to the episodic memory compression technique, which allows for better retention and analysis of interactions across thousands of frames.
判定人物关系。在图 11c 中,我们比较了模型与 MA-LMM 在长视频序列中判定人物关系的性能。两个模型均在 LVU 数据集上训练。我们模型在此任务中的优势可归因于情景记忆压缩 (episodic memory compression) 技术,该技术能更好地保留和分析跨越数千帧的交互行为。

Figure 12: Where and when HERMES fail: The top row shows a marine life video where the model fails to recognize underwater scenes. The bottom row depicts a wildlife documentary where the model struggles with quantitative reasoning and event inference across multiple frames. These cases highlight limitations in contextual understanding and temporal information integration.
图 12: HERMES的失效场景及原因:首行展示了一段海洋生物视频,模型未能识别水下场景。底行呈现野生动物纪录片案例,模型在跨帧定量推理和事件推断方面存在困难。这些案例凸显了模型在上下文理解与时序信息整合方面的局限性。
A.6 ERROR ANALYSIS: WHEN DOES HERMES FAIL AND WHY?
A.6 错误分析:HERMES 在何时失败及原因?
Our model, while generally effective, demonstrates several notable failure cases that warrant further investigation and improvement. Figure 12 illustrates examples where the model’s predictions deviate from ground truth answers, revealing key limitations in contextual reasoning and temporal information integration. Figure 12 presents two sets of video frame sequences that highlight shortcomings in our model’s performance. In the top row, we observe a documentary on marine life. Despite clear visual cues of underwater scenes and diving equipment, the model incorrectly predicts that no one got underwater. The bottom row showcases a more complex scenario from a wildlife documentary. Here, the model exhibits multiple errors: It underestimates the number of cheetahs involved in the hunt, predicting only one when at least three are present. This indicates a weakness in quantitative reasoning across temporally distributed information. The model incorrectly predicts that the cheetah’s hunt was unsuccessful, contradicting the visual evidence. This error points to difficulties in inferring outcomes from sequences of events. Lastly, the model fails to recognize the fate of a dead baby giraffe, predicting “nothing” when the correct answer is “eaten by hyenas”.
我们的模型虽然总体有效,但仍存在若干值得深入研究和改进的显著失败案例。图12展示了模型预测与真实答案存在偏差的示例,揭示了其在上下文推理和时间信息整合方面的关键局限。图12呈现了两组突出模型性能缺陷的视频帧序列:顶部序列显示海洋生物纪录片场景,尽管存在清晰的水下画面和潜水装备视觉线索,模型仍错误预测"无人下水";底部野生动物纪录片场景中,模型表现出多重错误:(1) 低估猎豹数量(预测1只而实际至少3只),暴露了跨时间分布信息量化推理的弱点;(2) 错误预测猎豹狩猎失败,与视觉证据相矛盾,表明事件序列结果推断存在困难;(3) 未能识别死亡幼年长颈鹿的命运(正确答案"被鬣狗吃掉"时预测"无事件")。
These examples emphasize the need for improved mechanisms to aggregate and reason over longrange temporal dependencies, as well as enhanced capabilities in scene understanding and event inference.
这些例子强调了需要改进机制来聚合和推理长程时间依赖关系,以及增强场景理解和事件推断的能力。
A.7 HOW IS OUR APPROACH RELATED TO COGNITIVE PROCESSES?
A.7 我们的方法与认知过程有何关联?
Our approach to long-form video understanding is inspired by cognitive processes involving memory and comprehension. According to the literature on neuroscience (Tulving et al., 1972; Schacter & Tulving, 1982; Tulving, 1983), human cognition involves two primary types of memory: episodic and semantic. Episodic memory is the ability to recall specific events or episodes, while semantic memory refers to the storage of general knowledge and concepts. These forms of memory are crucial for understanding long-form narratives, where a coherent understanding arises from the integration of specific events and over arching themes.
我们对长视频理解的方法受到涉及记忆与理解的认知过程启发。根据神经科学文献 (Tulving et al., 1972; Schacter & Tulving, 1982; Tulving, 1983),人类认知包含两种主要记忆类型:情景记忆 (episodic memory) 和语义记忆 (semantic memory)。情景记忆指回忆特定事件或情节的能力,而语义记忆则存储通用知识与概念。这些记忆形式对理解长篇叙事至关重要,其连贯性源自具体事件与核心主题的整合。
The proposed HERMES model incorporates these cognitive processes through its two main components, ECO and SeTR. ECO, akin to the function of episodic memory, selectively retains and compresses key events from the video, allowing the model to form a structured representation of the narrative as it unfolds. This approach is an oversimplified abstraction of findings in cognitive neuroscience, which highlight the role of the hippocampus in the consolidation of episodic memories (Eichenbaum, 2004; Schacter & Tulving, 1982), and the concept of subjective time (Arstila et al., 2014) that sees a scene (or a video) not as a series of frames but as a series of experiences. The hippocampus enables the organization of temporally distinct experiences into a coherent memory trace, something that we aim to capture with ECO. Moreover, the sequential processing and aggregation of information in our model align with the concept of event segmentation in cognitive psychology (Zacks et al., 2007). Humans naturally segment continuous experiences into discrete events, which aids in memory formation and recall.
提出的HERMES模型通过其两个主要组件ECO和SeTR整合了这些认知过程。ECO类似于情景记忆的功能,选择性地保留并压缩视频中的关键事件,使模型能够随着叙事的展开形成结构化表征。这种方法是对认知神经科学发现的过度简化抽象,强调了海马体在情景记忆巩固中的作用 (Eichenbaum, 2004; Schacter & Tulving, 1982),以及将场景(或视频)视为一系列体验而非连续帧的主观时间概念 (Arstila et al., 2014)。海马体能够将时间上分散的体验组织成连贯的记忆痕迹,这正是我们试图通过ECO捕捉的特性。此外,模型中信息的顺序处理与聚合符合认知心理学中的事件分割概念 (Zacks et al., 2007)。人类会自然地将连续体验分割为离散事件,这有助于记忆的形成与提取。
Meanwhile, SeTR functions similarly to semantic memory, extracting and reinforcing high-level semantic cues. This process mirrors how the brain integrates detailed episodic memories with broader semantic knowledge stored in the neocortex (McClelland et al., 1995; Binder & Desai, 2011). Also related is the concept of gist extraction which involves rapidly comprehending the essence or overall meaning of a scene or situation (Oliva, 2005). This ability allows humans to quickly understand the context of a complex scene without processing every detail. Our SeTR operates similarly by identifying and extracting high-level semantic cues that provide a concise overview of the scene and actions.
与此同时,SeTR的功能类似于语义记忆,能够提取并强化高层级的语义线索。这一过程反映了大脑如何将详细的情景记忆与存储在新皮层中的广泛语义知识相整合 (McClelland et al., 1995; Binder & Desai, 2011)。与之相关的还有要点提取 (gist extraction) 概念,即快速理解场景或情境的核心要义 (Oliva, 2005)。这种能力使人类无需处理每个细节就能迅速理解复杂场景的上下文。我们的SeTR通过识别和提取高层级语义线索来提供场景与行为的简明概览,其运作机制与此类似。
The integration of these cognitive processes not only aligns with human-like comprehension but also offers a framework for efficiently handling the vast and diverse information present in long-form videos. Significant improvements over existing state-of-the-art models, underscore the effectiveness of this cognition-inspired approach. While our model is a oversimplified abstraction of human cognition, it provides a foundation for exploring more complex cognitive mechanisms in future work.
这些认知过程的整合不仅符合类人理解能力,还为高效处理长视频中庞大多样的信息提供了框架。相较于现有最先进模型的显著提升,凸显了这种认知启发方法的有效性。虽然我们的模型是对人类认知的过度简化抽象,但它为未来探索更复杂的认知机制奠定了基础。