Relational Graph Learning on Visual and Kinematics Embeddings for Accurate Gesture Recognition in Robotic Surgery
基于视觉与运动学嵌入的关系图学习在机器人手术中的精准手势识别
Abstract— Automatic surgical gesture recognition is fundamentally important to enable intelligent cognitive assistance in robotic surgery. With recent advancement in robot-assisted minimally invasive surgery, rich information including surgical videos and robotic kinematics can be recorded, which provide complementary knowledge for understanding surgical gestures. However, existing methods either solely adopt uni-modal data or directly concatenate multi-modal representations, which can not sufficiently exploit the informative correlations inherent in visual and kinematics data to boost gesture recognition accuracies. In this regard, we propose a novel online approach of multi-modal relational graph network (i.e., MRGNet) to dynamically integrate visual and kinematics information through interactive message propagation in the latent feature space. In specific, we first extract embeddings from video and kinematics sequences with temporal convolutional networks and LSTM units. Next, we identify multi-relations in these multimodal embeddings and leverage them through a hierarchical relational graph learning module. The effectiveness of our method is demonstrated with state-of-the-art results on the public JIGSAWS dataset, outperforming current uni-modal and multi-modal methods on both suturing and knot typing tasks. Furthermore, we validated our method on in-house visual-kinematics datasets collected with da Vinci Research Kit (dVRK) platforms in two centers, with consistent promising performance achieved. Our code and data are released at: https://www.cse.cuhk.edu.hk/~yhlong/mrgnet.html.
摘要— 自动手术动作识别对于实现机器人手术中的智能认知辅助至关重要。随着机器人辅助微创手术的最新进展,包括手术视频和机器人运动学在内的丰富信息得以记录,这些信息为理解手术动作提供了互补性知识。然而,现有方法要么仅采用单模态数据,要么直接拼接多模态表征,无法充分利用视觉与运动学数据内在的信息关联来提升动作识别准确率。为此,我们提出一种新颖的多模态关系图网络在线方法(即MRGNet),通过在潜在特征空间中进行交互式消息传播,动态整合视觉与运动学信息。具体而言,我们首先使用时序卷积网络和LSTM单元从视频和运动学序列中提取嵌入特征,随后识别这些多模态嵌入中的多重关系,并通过分层关系图学习模块加以利用。本方法在公开JIGSAWS数据集上取得了最先进的性能表现,在缝合与打结两项任务中均优于当前单模态与多模态方法。此外,我们使用达芬奇研究套件(dVRK)平台在两个中心采集的内部视觉-运动学数据集验证了本方法,均取得了一致的优异性能。代码与数据发布于:https://www.cse.cuhk.edu.hk/~yhlong/mrgnet.html。
I. INTRODUCTION
I. 引言
Robot-assisted surgery, with a short but remarkable chronicle [1], has dramatically extended the dexterity and overall capability of surgeons, and plays an important role in modern minimally invasive surgery. Robotic systems enable precise control, efficient manipulation and vivid observation for the surgical procedures, yielding rich sources of information [2]. Intelligent understanding of such complex surgical procedure is highly desired for facilitating cognitive assistance. To this end, automatic gesture recognition is fundamentally required for supporting higher-level perception such as surgical decision making [3], surgical skill assessment [4] and surgical task automation [5] towards the next generation of operating
机器人辅助手术虽然历史短暂但成就显著[1],其显著拓展了外科医生的操作灵活性和综合能力,在现代微创手术中扮演着重要角色。机器人系统能为手术流程提供精准控制、高效操作和生动观察,从而产生丰富的信息源[2]。对这些复杂手术过程进行智能理解,对于实现认知辅助至关重要。为此,自动手势识别是支撑更高层次感知(如手术决策[3]、手术技能评估[4]以及面向新一代手术室的任务自动化[5])的基础需求。
This project was supported by CUHK Shun Hing Institute of Advanced Engineering (project MMT-p5-20), CUHK T Stone Robotics Institute, Hong Kong RGC TRS Project No.T42-409/18-R, and Multi-Scale Medical Robotics Center InnoHK under grant 8312051.
本项目由香港中文大学信兴高等工程研究所(项目编号MMT-p5-20)、香港中文大学天石机器人研究所、香港研究资助局主题研究计划(项目编号T42-409/18-R)及创新香港研发平台Multi-Scale Medical Robotics Center(资助编号8312051)支持。
Y. Long, Y. Jin, P. A. Heng and Q. Dou are with the Department of Computer Science and Engineering, The Chinese University of Hong Kong. P. A. Heng and Q. Dou are also with the T Stone Robotics Institute, CUHK. B. Lu and Y. H. Liu are with the T Stone Robotics Institute, the Department of Mechanical and Automation Engineering, The Chinese University of Hong Kong. J. Y. Wu and M. Unberath are with the Department of Computer Science, Johns Hopkins University.
Y. Long、Y. Jin、P. A. Heng 和 Q. Dou 任职于香港中文大学计算机科学与工程学系。P. A. Heng 和 Q. Dou 同时隶属于香港中文大学天石机器人研究所。B. Lu 和 Y. H. Liu 任职于香港中文大学天石机器人研究所及机械与自动化工程学系。J. Y. Wu 和 M. Unberath 任职于约翰霍普金斯大学计算机科学系。
theatres. However, accurately recognizing on-going surgical gesture is challenging, due to the complex multi-step actions, frequent state transitions, disturbance in sensor data, various manipulation habits and proficiency of different surgeons.
然而,由于复杂多步骤操作、频繁状态切换、传感器数据干扰、不同外科医生的操作习惯及熟练度差异,准确识别正在进行的手术手势具有挑战性。
To address above challenges in automatic surgical gesture recognition, a set of methods have been developed in the past decade. Some methods were based on processing sequential robotic kinematics data (e.g., the position and velocity of the tool tips), using traditional machine learning methods such as variants of hidden Markov models [6], [7], linear classifiers with hand-crafted metrics [8] and recent deep learning methods such as long short-term memory (LSTM) [9], multi-task recurrent neural network [10] and multi-scale recurrent network (offline) [11]. In the meanwhile, purely video based solutions have been intensively explored in the recent years, employing deep convolutional neural networks for extracting high-quality visual features. Promising gesture recognition results have been achieved relying on temporal convolutional network (TCN) [12], recurrent convolutional network [13], 3D convolutional network [14] and symmetric dilated convolution (offline) [15] to extract representative visual features. However, all these solutions only adopted a single source of information, without considering the multimodal joint knowledge inherent in kinematics and visual data synchronously recorded in robotic systems.
为解决自动手术动作识别中的上述挑战,过去十年间已发展出一系列方法。部分方法基于处理机器人运动学序列数据(如器械末端的位置和速度),采用传统机器学习技术,包括隐马尔可夫模型变体 [6][7]、基于人工设计指标的线性分类器 [8],以及近期深度学习方案如长短期记忆网络 (LSTM) [9]、多任务循环神经网络 [10] 和多尺度循环网络(离线)[11]。与此同时,近年来纯视频方案得到深入探索,通过深度卷积神经网络提取高质量视觉特征,利用时序卷积网络 (TCN) [12]、循环卷积网络 [13]、3D卷积网络 [14] 和对称扩张卷积(离线)[15] 提取代表性视觉特征已取得显著成果。然而,这些方案均仅采用单一信息源,未充分考虑机器人系统中同步记录的运动学与视觉数据所固有的多模态联合知识。
As we understand, the kinematics and video data can be regarded as the hands and eye of the surgical robot, with eye giving visual guidance information for two hands collaborative ly conducting specific actions, while hands drive changes in the visual scene. In this regard, there are complementary information and joint knowledge contained in the kinematics and video data which are crucial to help gesture recognition. Several recent works have attempted to develop multi-modal learning methods. For instance, some unsupervised multi-modal methods have been proposed to handle the problem of time-consuming annotation [16], [17]. Lea et al. [18] designed a latent convolutional skip-chain conditional random field model with variables of scenebased features and kinematics data. The work of FusionKV [19] learned individual networks for each modality, and combined their predictions through weighted voting at an output level. Qin et al. [20] further improved Fusion-KV with an attention-based LSTM decoder to predict the surgical state using concatenated multi-modal features. Despite gaining performance improvement, these multi-modal feature fusions seem straightforward. How to dynamically integrate the multiple sources of information in latent feature space, to reveal and leverage the underlying relationships inherent in kinematics sequences and video scenes, is important yet still remains under explored.
据我们理解,运动学数据和视频数据可视为手术机器人的双手与眼睛:眼睛为双手协作执行特定动作提供视觉引导信息,而双手则驱动视觉场景的变化。因此,运动学与视频数据中蕴含着互补信息与联合知识,这对实现手势识别至关重要。近期多项研究尝试开发多模态学习方法,例如针对标注耗时问题提出的无监督多模态方法 [16][17] 。Lea等人 [18] 设计了基于场景特征和运动学数据的隐式卷积跳链条件随机场模型。FusionKV [19] 通过为各模态训练独立网络,并在输出层采用加权投票整合预测结果。Qin等人 [20] 进一步改进Fusion-KV,采用基于注意力机制的LSTM解码器,利用串联的多模态特征预测手术状态。尽管这些多模态特征融合方法取得了性能提升,但其融合方式仍显简单。如何在潜在特征空间动态整合多源信息,揭示并利用运动学序列与视频场景间的内在关联,这一关键问题仍有待深入探索。
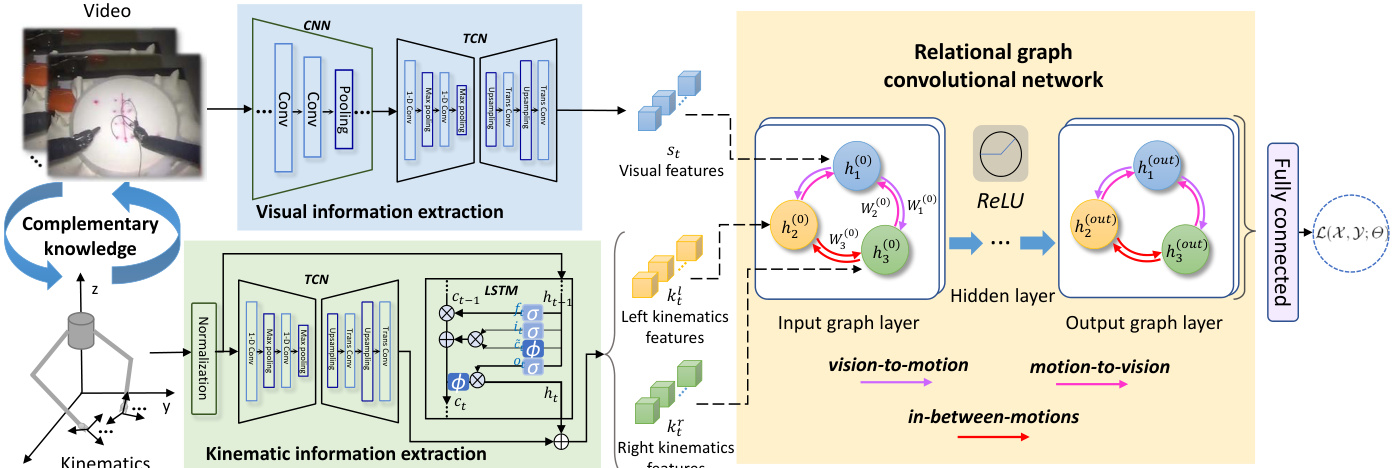
Fig. 1. The overview of our proposed multi-modal relational graph network for surgical gesture recognition in robot-assisted surgery.
图 1: 我们提出的用于机器人辅助手术中手术手势识别的多模态关系图网络概览。
Recently, graph neural networks have been increasingly receiving research interest, due to their capability to model non-Euclidean relationships among entities [21]–[23]. Graph convolutional networks (GCN) [24] have widely demonstrated promising performances on applications in various domains including image classification [25], neural machine translation [26], social relationship understanding [27], etc. Specifically for robotic surgery related scenarios, there have been pilot studies applying graph neural networks for tool detection in surgical videos [28], 3D point cloud classifica- tion [29], [30] and surgical activity recognition from robotic joint pose estimation [31]. These achievements inspired us to explore the potential of graph learning for modeling distinct multi-modal data recorded in robotic surgery.
近年来,图神经网络因其能够建模实体间的非欧几里得关系 [21]–[23] 而日益受到研究关注。图卷积网络 (GCN) [24] 在图像分类 [25]、神经机器翻译 [26]、社交关系理解 [27] 等多个领域的应用中展现出优异性能。在机器人手术相关场景中,已有先驱研究将图神经网络应用于手术视频中的器械检测 [28]、3D点云分类 [29][30] 以及基于机器人关节姿态估计的手术活动识别 [31]。这些成果启发我们探索图学习在机器人手术多模态数据建模中的潜力。
In this paper, we propose a novel multi-modal relational graph network (i.e., MRG-Net) to effectively exploit important yet complex relationships in robotics visual and kinematics data for accurate surgical gesture recognition. Specifically, we first extract the high-level embeddings from video scenes and kinematics sequences with temporal convolutional networks and LSTM units. Then, we leverage relational graph convolutional network to incorporate complementary sources of information and model the underlying multiple types of relations. Our main contributions are summarized as follows:
本文提出了一种新颖的多模态关系图网络(即MRG-Net),通过有效利用机器人视觉与运动学数据中重要而复杂的关系,实现精准的手术手势识别。具体而言,我们首先使用时序卷积网络和LSTM单元从视频场景与运动学序列中提取高层嵌入特征,随后利用关系图卷积网络整合互补信息源并建模潜在的多类型关系。主要贡献如下:
• We, for the first time, propose a novel online relational graph learning based framework to exploit the joint information with useful relationships in video and kinematics data for accurate surgical gesture recognition. • We evaluated our proposed method on the public robotic surgery dataset JIGSAWS, and set new state-of-the-art results on both suturing and knot typing tasks, showing the efficacy of combined usage of visual and kinematics information for robotic intelligence. We have extensively validated our method on in-house datasets collected from da Vinci Research Kit (dVRK) platforms in two centers (i.e., CUHK and JHU) with consistent promising results achieved, demonstrating the general effectiveness of our proposed method.
• 我们首次提出了一种新颖的在线关系图学习框架,通过挖掘视频与运动学数据中的联合信息及有效关联关系,实现精准的手术动作识别。
• 我们在公开机器人手术数据集JIGSAWS上评估了所提方法,在缝合与打结任务中均刷新了最优性能,证明了视觉与运动学信息结合对机器人智能的有效性。通过在两地(即香港中文大学和约翰霍普金斯大学)da Vinci Research Kit (dVRK)平台采集的内部数据集上进行广泛验证,该方法始终取得稳定优异的结果,展现了其普适性优势。
II. METHODS
II. 方法
In robot-assisted surgery, the robotic system can generate video frames from endoscopy and kinematics sequences from multiple robotic arms, which are later synchronized to the video timestamps. The overview of our proposed network is shown in Fig. 1. Our network consists of three components, i.e. visual and kinematic information extraction modules, as well as the relational graph convolutional network. We first extract the visual and kinematic embeddings with visual and kinematic information extraction modules, and then model the complementary information and integrate the informative joint knowledge of these multi-modal features with relational graph convolutional network. As a whole, MRG-Net forms a multi-input single-output design to predict the probability distributions of surgical gestures at each time step.
在机器人辅助手术中,机器人系统可以从内窥镜生成视频帧,并从多个机械臂生成运动学序列,这些数据随后会与视频时间戳同步。我们提出的网络概述如图1所示。该网络包含三个组件:视觉信息提取模块、运动学信息提取模块以及关系图卷积网络。我们首先通过视觉和运动学信息提取模块获取对应的嵌入表示,然后利用关系图卷积网络建模互补信息并整合这些多模态特征的联合知识。整体上,MRG-Net采用多输入单输出设计,用于预测每个时间步手术手势的概率分布。
A. Visual and Kinematic Embeddings Extraction
A. 视觉与运动学嵌入提取
The first part of the network is the visual and kinematic information extraction modules which extract representative descriptors from each of the following streams respectively: the video frames and the kinematics sequences of robotic left and right arms. Regarding the visual information, for each time step $t$ , current video frames (RGB image) $I_{t}$ is forwarded to a standard CNN backbone (in this case we leverage a 18-layer deep residual network (ResNet-18) [32]), yielding a vector of spatial feature $u_{t}$ . For the entire video sample, the series of ${u_{t}}{t=1}^{T}$ are input to a temporal convolution module, which adopts an encoder-decoder operation to hierarchically capture relationships across frames at multitime-scales, yielding stronger spatio-temporal video features of ${s_{t}}_{t=1}^{T}$ .
网络的第一部分是视觉与运动学信息提取模块,它们分别从以下数据流中提取代表性特征描述符:视频帧和机器人左右臂的运动学序列。在视觉信息处理方面,对于每个时间步$t$,当前视频帧(RGB图像)$I_{t}$会被输入到标准CNN主干网络(本文采用18层深度残差网络(ResNet-18) [32]),生成空间特征向量$u_{t}$。对于整个视频样本,时序序列${u_{t}}{t=1}^{T}$会被输入到时序卷积模块,该模块通过编码器-解码器操作分层捕获多时间尺度的帧间关系,最终生成增强的时空视频特征${s_{t}}_{t=1}^{T}$。
For the kinematics data, our feature extractor incorporates TCN and LSTM in parallel for modeling the complex sequential information of physical elements and for better capturing the local and longer-term temporal dependencies. Specifically, the input to TCN stacks the kinematics variables from all time steps, followed by temporal convolutions, pooling, channel-wise normalization and upsampling to encode kinematics features as ttcn}tT=1. Meanwhile, LSTM obtains the feature $k_{t}^{l s t m}$ of the current step, by inputting a sequence of kinematics of all its previous steps, for capturing the long-term dependencies in motions. Then, the $k_{t}^{t c n}$ and $k_{t}^{l s t m}$ are averaged to represent the kinematics feature as $k_{t}$ . Note that we separately encode left and right kinematics as ${k_{t}^{l},k_{t}^{r}}_{t=1}^{T}$ , since the two robotic arms may conduct different actions and serve for specific purposes in surgery.
对于运动学数据,我们的特征提取器并行采用TCN和LSTM来建模物理元素的复杂序列信息,并更好地捕捉局部和长期时间依赖性。具体而言,TCN的输入堆叠所有时间步的运动学变量,随后通过时序卷积、池化、通道归一化和上采样将运动学特征编码为ttcn}tT=1。同时,LSTM通过输入所有先前步骤的运动学序列来获取当前步骤的特征$k_{t}^{lstm}$,以捕捉运动中的长期依赖关系。然后,将$k_{t}^{tcn}$和$k_{t}^{lstm}$取平均来表示运动学特征$k_{t}$。需要注意的是,我们分别对左右运动学进行编码为${k_{t}^{l},k_{t}^{r}}_{t=1}^{T}$,因为两只机械臂在手术中可能执行不同的动作并服务于特定目的。
B. Fusion of Multi-modal Embeddings with Graph Learning
B. 基于图学习的多模态嵌入融合
Next, a designed graph learning module is subsequently adopted to fuse the above extracted high-level embeddings ${s_{t},k_{t}^{l},k_{t}^{r}}$ of each time step. These features have already gained temporal information within each source of timeseries data. The following key issue is to effectively exploit their joint knowledge by imposing structured interactions between multi-modal features for accurate gesture recognition. Intuitively, the graph learning layer plays a role for differentiable message passing framework [33]. Specifically, we denote our graph as $G={\mathcal{V},\mathcal{E},\mathcal{R}}$ with nodes $v_{i}\in\mathcal{V}$ and edges $(v_{i},r,v_{j})\in\mathcal{E}$ where $r\in\mathcal R$ is a relation. As shown in Fig. 1, there are three node entities corresponding to video, left kinematics and right kinematics, whose associated feature descriptors of ${h_{1},h_{2},h_{3}}$ are initialized as ${s_{t},k_{t}^{l},k_{t}^{r}}$ . These descriptors are then updated by aggregating messages from neighboring nodes with a parameterized propagation rule, which can be generally written as:
接下来,采用设计的图学习模块融合上述每个时间步提取的高层嵌入 ${s_{t},k_{t}^{l},k_{t}^{r}}$ 。这些特征已蕴含各时序数据源中的时间信息,关键问题在于通过多模态特征间的结构化交互有效利用其联合知识以实现精准手势识别。直观上,图学习层充当了可微分消息传递框架 [33] 的角色。具体而言,我们将图表示为 $G={\mathcal{V},\mathcal{E},\mathcal{R}}$ ,其中节点 $v_{i}\in\mathcal{V}$ ,边 $(v_{i},r,v_{j})\in\mathcal{E}$ ,关系 $r\in\mathcal R$ 。如图 1 所示,存在对应视频、左运动学和右运动学的三个节点实体,其关联特征描述符 ${h_{1},h_{2},h_{3}}$ 初始化为 ${s_{t},k_{t}^{l},k_{t}^{r}}$ 。这些描述符通过聚合邻接节点的消息并应用参数化传播规则进行更新,该规则可统一表述为:
$$
h_{i}^{(l+1)}=\sigma\left(\sum_{j\in\mathcal{N}{i}}f_{m}(h_{i}^{(l)},h_{j}^{(l)})\right),
$$
$$
h_{i}^{(l+1)}=\sigma\left(\sum_{j\in\mathcal{N}{i}}f_{m}(h_{i}^{(l)},h_{j}^{(l)})\right),
$$
where $h_{i}^{(l)}$ is the hidden state of node $v_{i}$ in the $l$ -th graph network layer, $\mathcal{N}{i}$ is the set of indices of all nodes which are connected with node $i$ , the $f_{m}(\cdot,\cdot)$ denotes the function for accumulating incoming messages from a relational neighbor, and $\sigma(\cdot)$ is the element-wise non-linear activation, i.e., the ReLU in our model.
其中 $h_{i}^{(l)}$ 是第 $l$ 层图网络中节点 $v_{i}$ 的隐藏状态,$\mathcal{N}{i}$ 是与节点 $i$ 相连的所有节点的索引集合,$f_{m}(\cdot,\cdot)$ 表示从关系邻居累积传入消息的函数,$\sigma(\cdot)$ 是逐元素的非线性激活函数 (即本模型中的 ReLU)。
Intuitively, such interactive feature fusion is important to impose a learnable message passing process for the nodes which have some relations with each other. Given that the multiple data sources from robotic surgery contain plenty of complementary information, effectively digging the inherent useful relationships among them is difficult while critical to boost the performance of gesture recognition.
直观来看,这种交互式特征融合对于存在关联关系的节点施加可学习的消息传递过程至关重要。鉴于机器人手术中的多源数据包含大量互补信息,有效挖掘其内在有用关联虽具挑战性,但对提升手势识别性能具有关键作用。
C. Multi-relation Modelling in Graph Latent Space
C. 图潜在空间中的多关系建模
In our scenario of robot-assisted surgery, there are at least three important types of relations in the video and kinematics data. Specifically, the first is the vision-to-motion relation which can be understood as the human’s perception with the “eyes” to provide guidance information for the “hands” to move. Inversely, the second relation is motion-to-vision which reflects the mechanism of “hands” giving feedback to “eyes” and also resembles hand-eye coordinates projection of robotic vision [34]. The last relation is in-between-motions of left and right arms, which can be considered as two “hand” assisting each other to complete a task. The widely-used conventional graph convolutional network [24] is inadequate to handle various different types of relations, given that its undirected graph with $|{\mathcal{R}}|=1$ is insufficient to model multirelations of nodes. Instead, we leverage the more powerful relational graph learning scheme, so that our $G$ is a directed graph endowing a higher capacity for modeling multiple types of directed edges between nodes. In this way, the para meter i zed propagation function $f_{m}(\cdot,\cdot)$ in Eq.(1) becomes relation-specific, where the forwarding message update to node $i$ from a relational node $j$ is elaborated as $\overset{\vartriangle}{c_{i,r}}\dot{h_{j}^{(l)}}W_{r}^{(l)}$ The W r(l) represents a trainable transformation matrix that is uniquely associated to one certain type of relation $r\in\mathcal R$ . In other words, different relation types use individual matrices, and only directed edges of the same relation type share their weights. The parameter $c_{i,r}$ is a normalization constant that correlates to the structure of the graph. In this way, the layerwise propagation is achieved by accumulating the message updates through a normalized sum of all neighbor nodes under all relation types.
在我们的机器人辅助手术场景中,视频与运动学数据中至少存在三种重要关系。具体而言,首先是视觉-运动关系,可理解为人类通过"眼睛"感知来为"手部"运动提供引导信息;反之,第二种是运动-视觉关系,反映了"手部"向"眼睛"提供反馈的机制,也类似于机器人视觉中的手眼坐标投影[34]。最后一种是左右臂间的运动协调关系,可视为两个"手部"相互协作完成任务。传统广泛使用的图卷积网络[24]由于采用无向图且$|\mathcal{R}|=1$,难以建模节点的多重关系。为此,我们采用更强大的关系图学习方案,使$G$成为有向图,从而具备建模节点间多种有向边类型的能力。此时,式(1)中的参数化传播函数$f_{m}(\cdot,\cdot)$变为关系特定的,从关系节点$j$到节点$i$的前向消息更新可表示为$\overset{\vartriangle}{c_{i,r}}\dot{h_{j}^{(l)}}W_{r}^{(l)}$。其中$W_{r}^{(l)}$是与特定关系类型$r\in\mathcal{R}$唯一关联的可训练变换矩阵,不同关系类型使用独立矩阵,仅相同关系类型的有向边共享权重。参数$c_{i,r}$是与图结构相关的归一化常数。通过这种方式,分层传播通过所有关系类型下邻域节点的归一化求和来实现消息更新。
Hierarchically, we stack two such relational graph learning layers, with each single layer having its separate set of projection weights ${\breve{W_{r}}^{(l)}}_{l=0}^{1}$ . No deeper layers are added to alleviate the over-smooth problem [35] of GCN, and our preliminary experiments also evidenced that additional layers yielded worse performance yet with heavier computations. After feature interactions, the final output representation associated with each node is computed by:
在层次结构上,我们堆叠了两个这样的关系图学习层,每个单层都有其独立的投影权重集 ${\breve{W_{r}}^{(l)}}_{l=0}^{1}$。为避免图卷积网络(GCN)的过平滑问题[35],我们没有添加更深的层,初步实验也证明额外层会导致性能下降且计算量更大。经过特征交互后,与每个节点相关的最终输出表示通过以下方式计算:
$$
h_{i}^{\mathrm{(out)}}=\sigma\left(\sum_{r\in{\mathcal{R}}}\sum_{j\in N_{i}^{r}}c_{i,r}\sigma\left(\sum_{r\in{\mathcal{R}}}\sum_{j\in N_{i}^{r}}c_{i,r}h_{j}^{\left(0\right)}W_{r}^{\left(0\right)}\right)W_{r}^{\left(1\right)}\right),
$$
$$
h_{i}^{\mathrm{(out)}}=\sigma\left(\sum_{r\in{\mathcal{R}}}\sum_{j\in N_{i}^{r}}c_{i,r}\sigma\left(\sum_{r\in{\mathcal{R}}}\sum_{j\in N_{i}^{r}}c_{i,r}h_{j}^{\left(0\right)}W_{r}^{\left(0\right)}\right)W_{r}^{\left(1\right)}\right),
$$
where the $\mathcal{N}{i}^{r}$ denotes the set of neighbor indices of node $i$ under a relation type $r\in\mathcal R$ . Specifically in our model, we identify three different types of relations with $|\mathcal{R}|=3$ . For instance, as shown in Fig. 1, the video node $h_{1}$ receives messages from kinematics nodes ${h_{2},h_{3}}$ , both under the relation type of motion-to-vision (cf. $W_{2}^{(0)}$ in brown arrow). The left kinematics node $h_{2}$ receives messages from video node $h_{1}$ under relation type of vision-to-motion (cf. $W_{1}^{(0)}$ in purple arrow), and from right kinematics $h_{3}$ under relation type of in-between-motions (cf. W 3(0) in red arrow). The weight $c_{i,r}$ is heuristic ally set as $1/|\mathcal{N}{i}^{r}|$ . We exclude the self-loop aggregation for each node, with the consideration that, for our graph classification task, the self-loop information tends to result in feature redundancy during the update process, weakening the messages propagated from neighbor nodes (i.e., other modalities). Note that such a practice does not cause knowledge leakage since the hierarchical propagation can compensate those self-contained information through iterative interactions among nodes. In addition, the regular iz ation strategy of basis decomposition [36] is applied for ${W_{r}^{(l)}}_{l=0}^{1}$ to prevent rapid growth of the number of parameters with multi-relational data.
其中 $\mathcal{N}{i}^{r}$ 表示节点 $i$ 在关系类型 $r\in\mathcal R$ 下的邻居索引集合。具体到我们的模型中,我们定义了三种不同类型的关系,对应 $|\mathcal{R}|=3$。例如,如图 1 所示,视频节点 $h_{1}$ 接收来自运动学节点 ${h_{2},h_{3}}$ 的消息,二者均属于运动到视觉的关系类型 (参见棕色箭头所示的 $W_{2}^{(0)}$)。左侧运动学节点 $h_{2}$ 接收来自视频节点 $h_{1}$ 的消息 (属于视觉到运动的关系类型,参见紫色箭头所示的 $W_{1}^{(0)}$),以及来自右侧运动学节点 $h_{3}$ 的消息 (属于运动间关系类型,参见红色箭头所示的 $W_{3}^{(0)}$)。权重 $c_{i,r}$ 启发式地设置为 $1/|\mathcal{N}_{i}^{r}|$。
我们排除了每个节点的自循环聚合,因为考虑到对于图分类任务,自循环信息容易在更新过程中导致特征冗余,从而削弱来自邻居节点 (即其他模态) 传播的消息。需要注意的是,这种做法不会导致知识泄露,因为通过节点间的迭代交互,层级传播可以补偿那些自包含的信息。此外,我们对 ${W_{r}^{(l)}}_{l=0}^{1}$ 采用了基分解 [36] 的正则化策略,以防止多关系数据下参数数量的快速增长。
D. Overall Loss Function
D. 总体损失函数
After interacting the multi-modal information in latent space for capturing joint knowledge, the relational graph learning layers produce updated representations for the nodes. Recall that the hidden state for each node represents the descriptors for each modality at time step $t$ , so we rphsf video, left and right kinematics after graph learning. They are concatenated to convey the joint knowledge, and forwarded to a fully-connected layer for obtaining the classification prediction $\hat{p}_{t}$ for each frame:
在潜在空间中交互多模态信息以捕捉联合知识后,关系图学习层会为节点生成更新后的表征。需注意,每个节点的隐藏状态表示时间步 $t$ 下各模态的描述符,因此我们通过图学习重构视频、左右运动学数据。这些表征经拼接传递联合知识后,输入全连接层以获得每帧的分类预测 $\hat{p}_{t}$:
$$
\hat{p}{t}=S o f t m a x({\mathbf{concat}}[\tilde{s}{t},\tilde{k}{t}^{l},\tilde{k}{t}^{r}]W_{\mathrm{fc}}+b).
$$
$$
\hat{p}{t}=S o f t m a x({\mathbf{concat}}[\tilde{s}{t},\tilde{k}{t}^{l},\tilde{k}{t}^{r}]W_{\mathrm{fc}}+b).
$$
With the situation in the robotic surgery that the duration of each conducted gesture varies widely (e.g., the gesture of “loosening more suture” occupies only about $1%$ time on average of the whole suturing task, while “pushing needle through tissue” takes up almost $30%$ task duration), we use the weighted cross-entropy loss to combat such inter-class imbalance for training samples. Denoting $\alpha$ as the class balancing weight, $\Theta$ as MRG-Net parameters of all trainable layers, we optimize the overall loss function:
在机器人手术中,由于每个执行手势的持续时间差异很大(例如"松开更多缝合线"手势仅占整个缝合任务平均时长的约$1%$,而"将针推过组织"则占据近$30%$的任务时长),我们采用加权交叉熵损失(weighted cross-entropy loss)来解决训练样本中的类间不平衡问题。设$\alpha$为类别平衡权重,$\Theta$为MRG-Net所有可训练层的参数,我们优化以下整体损失函数:
$$
\mathcal{L}(\boldsymbol{\chi},\boldsymbol{\mathcal{y}};\boldsymbol{\Theta})=\frac{1}{T}\sum_{t}-\alpha\cdot\log\hat{p}_{t},
$$
$$
\mathcal{L}(\boldsymbol{\chi},\boldsymbol{\mathcal{y}};\boldsymbol{\Theta})=\frac{1}{T}\sum_{t}-\alpha\cdot\log\hat{p}_{t},
$$
where $\mathcal{X}$ is the multi-modal input space, $\mathcal{V}$ denotes the gesture categories.
其中 $\mathcal{X}$ 是多模态输入空间,$\mathcal{V}$ 表示手势类别。
$E$ . Implementation Details
$E$ . 实现细节
Overall, the entire framework composing of the relational graph layers and the separate video and kinematics feature extractors is trained end-to-end. The encoder and decoder of TCN backbone consists of 3 temporal convolutional layers with $\lbrace64,96,128\rbrace$ filters for encoder and ${96,64,64}$ filters for decoder, with the kernel size of 51. For the visual information, we first train the CNN backbone (ResNet-18) using video sequences, then we generate the spatial-CNN features $u_{t}\in\mathbb{R}^{128}$ from the pretrained backbone to train the whole model more efficiently. For kinematic data, we first convert the rotation matrix into Euler angles, then normalize all the data to zero mean and unit variance. The relational graph layers have 64-dimensional hidden states and output states, with dropout (rate $=0.2$ ) applied.
总体而言,整个框架由关系图层和独立的视频与运动学特征提取器组成,采用端到端训练方式。TCN主干网络的编码器和解码器各包含3个时间卷积层:编码器使用 $\lbrace64,96,128\rbrace$ 个滤波器,解码器使用 ${96,64,64}$ 个滤波器,卷积核尺寸为51。对于视觉信息,我们首先使用视频序列训练CNN主干网络(ResNet-18),然后从预训练主干网络中提取空间CNN特征 $u_{t}\in\mathbb{R}^{128}$ 以提升整体模型训练效率。运动学数据方面,我们先将旋转矩阵转换为欧拉角,再将所有数据归一化为零均值和单位方差。关系图层采用64维隐藏状态和输出状态,并应用了丢弃率为 $=0.2$ 的dropout机制。
Our graph learning framework is implemented with the Deep Graph Library (DGL) [37] in PyTorch with an NVIDIA Titan Xp GPU. The video frames are resized to resolution $320^{}256$ with random crop $224^{*}224$ to reduce the training parameters and prevent over-fitting. We used the Adam [38] optimiser with learning rate of $5e^{-3}$ and weight decay of $5e^{-4}$ to train the proposed network. The training process took around 3 hours for a hundred epochs. To avoid the case of coincidence, we trained the same model for three times and reported their average results.
我们的图学习框架采用PyTorch中的Deep Graph Library (DGL) [37]实现,并使用NVIDIA Titan Xp GPU进行加速。视频帧被调整为$320^{}256$分辨率,并随机裁剪为$224^{*}224$以降低训练参数量并防止过拟合。我们使用Adam [38]优化器进行训练,学习率为$5e^{-3}$,权重衰减为$5e^{-4}$。训练过程耗时约3小时完成100个周期。为避免偶然性,我们对同一模型进行了三次训练并报告其平均结果。
III. EXPERIMENTS
III. 实验
A. Public Dataset and Evaluation Metrics
A. 公共数据集和评估指标
We first extensively validate our proposed MRG-Net on the public dataset of JIGSAWS [39] (JHU-ISI Gesture and Skill Assessment Working Set) on two tasks (i.e., suturing and knot typing), which consist of 39 videos and 36 videos respectively alongside with kinematics data of left and right robotic arms from the da Vinci surgical system. The kinematics sequences include position, rotation matrix, linear velocity, rotational velocity of tool tip and angles of gripper. A total of ten categories of surgical gestures are annotated for each single frame in suturing task and six in knot typing task (cf. [39] for detailed gesture definitions). Our experimental setting adopts leave-one-user-out cross validation, following the practice of previous works on this benchmark [40]. The employed evaluation metrics on JIGSAWS dataset include: i) Accuracy $(%)$ in the framewise level, which is to calculate the percentage of correctly recognized frames, ii) Edit Score [41] (in range $[0,100]$ , the higher score the better), which is designed to measure the performance in video segmentation level for emphasizing temporal smoothness.
我们首先在JIGSAWS [39] (JHU-ISI Gesture and Skill Assessment Working Set) 公开数据集上对提出的MRG-Net进行了全面验证,针对缝合和打结两项任务(分别包含39段和36段视频)以及da Vinci手术系统左右机械臂的运动学数据。运动学序列包含工具末端的位置、旋转矩阵、线速度、角速度以及夹持器角度。缝合任务中每帧标注了十类手术手势,打结任务标注了六类(具体手势定义参见[39])。实验采用留一用户交叉验证法,遵循该基准测试的先前研究惯例[40]。JIGSAWS数据集采用的评估指标包括:i) 帧级准确率 (%) ,计算正确识别帧的百分比;ii) 编辑分数 [41](范围 [0,100] ,分值越高越好),该指标用于视频分割层面的性能评估,强调时序平滑性。
TABLE I RESULTS OF DIFFERENT METHODS ON JIGSAWS SUTURING DATASET FOR GESTURE RECOGNITION.
表 1: 不同方法在 JIGSAWS 缝合数据集上的手势识别结果
| 方法 | 输入数据 | 准确率 | 编辑得分 | |
|---|---|---|---|---|
| Kin | Vid | |||
| TCN [42] Forward LSTM[9] TricorNet[43] Bidir.LSTM [9] | √ | 79.6 80.5 ± 6.2 82.9 83.3 ± 5.7 84.7 ± 6.0 | 85.8 75.3 86.8 81.1 88.5 | |
| APc [10] TCN [42] Policy+Value[45] 3D CNN(K)+window[14] | √ | √ | 85.5 81.4 81.7 84.3 | 85.3 83.1 88.5 80.0 |
| LC-SC-CRF[18] Fusion-KV [19] MRG-Net(我们的方法) | √ | √ | 83.5 86.3 87.9 ± 4.2 | 76.8 87.2 |

Fig. 2. Color-coded ribbon illustration of surgical gesture recognition on Suturing task (a) and Knot Typing task (b) with ground truth (top) and our results (bottom).
图 2: 缝合任务 (a) 和打结任务 (b) 的手术手势识别彩色带状图示,包含真实标注 (顶部) 和我们的结果 (底部)。
B. Comparison with Other State-of-the-art Methods
B. 与其他最先进方法的对比
We compare our proposed MRG-Net with previous stateof-the-art methods on the benchmark dataset and we report the mean accuracy and mean Edit Score with standard deviation (std.) (those results without std. mean the original paper didn’t report them). These methods are grouped into purely kinematics based (i.e., SC-CRF [40], TCN [42], Forward and Bidirectional LSTM [9], Bidirectional GRU [44], TricorNet [43] of hybrid TCN and LSTM, APc [10] using multi-task RNN), purely video based (i.e., TCN [42], Policy+Value [45] of offline reinforcement learning, 3D CNN with post-processing [14]), and multi-modal based methods (i.e., LC-SC-CRF [18] and MsM-CRF [40] with traditional machine learning, BoF [40] with manual extracted features and Fusion-KV [19] with deep learning).
我们在基准数据集上将提出的MRG-Net与先前最先进方法进行对比,并报告了平均准确率和平均编辑分数(Edit Score)及其标准差(std.)(未标注std.的结果表示原论文未报告)。这些方法分为三类:纯基于运动学的方法(如SC-CRF [40]、TCN [42]、前向与双向LSTM [9]、双向GRU [44]、混合TCN与LSTM的TricorNet [43]、采用多任务RNN的APc [10])、纯基于视频的方法(如TCN [42]、离线强化学习的Policy+Value [45]、带后处理的3D CNN [14]),以及多模态方法(如传统机器学习的LC-SC-CRF [18]和MsM-CRF [40]、手工特征提取的BoF [40]、深度学习的Fusion-KV [19])。
For the suturing task, which is the most popular task with more samples and gestures in JIGSAWS, we compare our results with eleven state-of-the-art methods listed in Table I. We first see that our MRG-Net significantly outperforms the state-of-the-art uni-modal methods, with the accuracy exceeding the previous best kinematics based method [10] by $2.4%$ and best video method [14] by $3.6%$ . With multimodal learning to capture the complementary information of visual and motion data, improved results are obtained, with the LC-SC-CRF [18] outperforming six of the uni-modal methods on accuracy and the Fusion-KV [19] outperforming all of them. Importantly, our MRG-Net achieves the highest accuracy of $87.9%$ (with lowest std. $4.2%$ ) and Edit Score of 89.3 (with lowest std. 5.2) compared among the multimodal methods, demonstrating the superiority of our method enabling dynamic interactions for modeling the inherent relations of multiple input sources with graph learning.
在缝合任务(JIGSAWS数据集中样本量和手势最丰富的任务)中,我们将结果与表I列出的11种前沿方法进行对比。首先观察到,MRG-Net显著优于当前最优单模态方法:准确率超越此前基于运动学的最佳方法[10]达2.4%,超越最佳视频方法[14]达3.6%。通过多模态学习融合视觉与运动数据的互补信息,LC-SC-CRF[18]在准确率上超越六种单模态方法,Fusion-KV[19]则全面超越所有单模态方法。值得注意的是,在多模态方法对比中,我们的MRG-Net以87.9%的最高准确率(最低标准差4.2%)和89.3的编辑分数(最低标准差5.2)保持领先,这验证了通过图学习动态交互建模多输入源内在关系的优越性。
TABLE II RESULTS OF DIFFERENT METHODS ON JIGSAWS KNOT TYPING DATASET FOR GESTURE RECOGNITION.
表 II 不同方法在 JIGSAWS 结扎打字数据集上的手势识别结果
| 方法 | 输入数据 | 准确率 | 编辑得分 | |
|---|---|---|---|---|
| Kin | Vid | |||
| SC-CRF [40] | √ | 78.9 | N/A | |
| BoF [40] | 86.5 | N/A | ||
| MsM-CRF [40] | 人 | √ | 77.3 | N/A |
| MRG-Net (Ours) | 人 | 88.1 ± 3.8 | 87.0 ± 6.8 |

Fig. 3. Bar chart of gesture-wise recognition accuracy.
图 3: 手势识别准确率的柱状图。
For the knot typing task, which is more complex than suturing while less validated in previous works, we list the results in Table II. The performance of current state-of-the-art uni-modal and multi-modal methods are referenced from the benchmark in [40]. It can be observed that traditional multimodal method (MsM-CRF), if without sufficient integration of the visual and kinematics information in the complex task, even obtained worse performance compared with pure video based method and pure kinematics based method. Leveraging our proposed relational graph learning method to interact the visual and kinematics embeddings in the latent space, a high recognition accuracy of $88.1%$ can be achieved on this task.
在打结类型识别任务中(该任务比缝合更复杂,但在先前工作中验证较少),我们将结果列于表 II。当前最先进的单模态和多模态方法性能参考自[40]的基准测试。可以观察到,传统多模态方法(MsM-CRF)若未充分整合复杂任务中的视觉与运动学信息,其表现甚至逊于纯视频方法和纯运动学方法。通过运用我们提出的关系图学习方法在潜在空间交互视觉与运动学嵌入,该任务识别准确率可达$88.1%$。
For qualitative results, Fig. 2 illustrates the visualization results on both suturing and knot typing tasks in the form of color-coded ribbon, demonstrating the temporal consistency and smoothness of the surgical gesture predictions leveraging the high-quality multi-modal representations.
图 2: 以彩色编码带状图形式展示了缝合和打结任务的可视化结果,证明了利用高质量多模态表征进行手术动作预测的时间一致性和流畅性。
C. Ablation Analysis on Our Method
C. 方法消融分析
To validate the contribution of each key component in our proposed MRG-Net, Table III lists the results of five ablation studies implemented with our own backbone on suturing task for direct comparison: 1) Pure-Vis: uni-modal using visual data, 2) Pure-Kin: uni-modal using kinematics, 3) TCN-KV (w/o split): merging video and kinematics (without splitting left and right arms) with TCN, 4) TCN-KV: merging video and kinematics (splitting left/right arms) with TCN, 5) GCNKV: multi-modal learning with plain GCN without multirelation, and finally our proposed multi-relational MRG-Net.
为验证所提出的MRG-Net中每个关键组件的贡献,表III列出了在缝合任务上使用自主骨干网络实施的五项消融研究结果以供直接对比:1) Pure-Vis:仅使用视觉数据的单模态方法;2) Pure-Kin:仅使用运动学数据的单模态方法;3) TCN-KV (w/o split):采用TCN融合视频与运动学数据(未区分左右手臂);4) TCN-KV:采用TCN融合视频与运动学数据(区分左右手臂);5) GCNKV:未采用多关系机制的普通GCN多模态学习方法;最后是我们提出的多关系MRG-Net。
We see that fusing visual and kinematics features in latent space can provide richer knowledge for achieving higher performance, even using simple concatenation of representations in temporal convolutional networks. Note that splitting left and right kinematics data yields better results than treating both kinematics as a whole (comparing 3rd/4th rows with TCN), which also reveals the different information contained in the left and right “hands” of robotic systems. Moreover, our graph learning for interactive multi-modal message passing can bring improvement over TCN. Further modelling multi-relations as designed based on domain knowledge, the gesture recognition performance gets higher, which confirms the significance of considering the “edges” between “nodes” diversely, as they incorporate distinct types of relations among various information sources.
我们发现,在潜在空间中融合视觉和运动学特征能为实现更高性能提供更丰富的知识,即便只是使用时序卷积网络(TCN)中简单的表征拼接。值得注意的是,将左右运动学数据分开处理比整体处理能获得更好效果(对比TCN的第3/4行结果),这也揭示了机器人系统左右"手"所包含的不同信息。此外,我们提出的交互式多模态消息传递图学习方法相比TCN能带来性能提升。进一步基于领域知识设计的多关系建模使手势识别性能更优,这验证了多样化考虑"节点"间"边"的重要性——因为它们融合了不同信息源之间的多种关系类型。
TABLE III ABLATION STUDY ON KEY COMPONENTS OF OUR METHOD USING THE SAME BACKBONE ON JIGSAWS SUTURING DATASET.
表 3: 在 JIGSAWS 缝合数据集上使用相同骨干网络对我们的方法关键组件进行的消融研究
| 方法 | 输入数据 | 准确率 | EditScore | |
|---|---|---|---|---|
| Kin | Vid | |||
| Pure-Vis | √ | 81.7 ± 6.7 | 86.5 ±6.9 | |
| Pure-Kin | √ | 82.6 ±6.5 | 86.6 ±7.5 | |
| TCN-KV (w/o split) | √ | √ | 86.1 ±5.6 | 85.3 ±7.1 |
| TCN-KV | √ | √ | 86.2 ±5.4 | 86.1 ±6.4 |
| GCN-KV | √ | √ | 86.8 ±4.9 | 87.4 ±6.5 |
| MRG-Net | √ | √ | 87.9 ±4.2 | - |

Fig. 4. Embeddings of pre- (left) and post- (right) relational graph message propagation multi-modal features (blue: vision, red: left kinematics, pink: right kinematics). Best viewed in color.
图 4: 关系图消息传播前后的多模态特征嵌入 (左: 传播前, 右: 传播后) (蓝色: 视觉, 红色: 左运动学, 粉色: 右运动学)。建议彩色查看。
In addition, we analyze the detailed accuracy across gesture category, as shown in Fig. 3. We notice a large variance in the results with the highest accuracy achieving $93%$ (G1 “reaching for needle with right hand”), while the lowest being less than $10%$ (G10 “loosening more suture”). The performance imbalance may be still due to the large variance in gesture frequency and sample numbers, which reflects the challenges in this recognition task which remains to be further conquered in future research. Besides, we see that our relational graph multi-modal learning consistently outperforms Pure-Vis and Pure-Kin by a large margin (especially for G9 “using right hand to help tighten suture” with strong visual/motion relationships), demonstrating the stable effectiveness of our method. Last but not least, Fig. 4 visualizes the node features from MRG-Net learning process with t-SNE [46], where the left and right embed the sets of ${s_{t},k_{t}^{l},k_{t}^{r}}$ and ${\tilde{s}{t},\tilde{k}{t}^{l},\tilde{k}_{t}^{r}}$ , respectively, for observing feature clusters before and after multi-relational graph updates. It clearly shows that multi-modal features are harmoniously fused from interactive message propagation and aggregation.
此外,我们分析了不同手势类别的详细准确率,如图 3 所示。注意到结果存在较大波动:最高准确率达 93% (G1 "右手取针动作"),而最低不足 10% (G10 "松解缝线动作")。这种性能不均衡可能仍源于手势频率与样本数量的显著差异,反映了该识别任务的挑战性,有待未来研究进一步攻克。值得注意的是,我们的关系图多模态学习方法始终大幅领先 Pure-Vis 和 Pure-Kin 方法 (尤其在具有强视觉/运动关联的 G9 "右手辅助拉紧缝线"动作中),证明了本方法的稳定有效性。最后,图 4 通过 t-SNE [46] 可视化 MRG-Net 学习过程中的节点特征,左右两侧分别呈现多关系图更新前后的特征集合 ${s_{t},k_{t}^{l},k_{t}^{r}}$ 与 ${\tilde{s}{t},\tilde{k}{t}^{l},\tilde{k}_{t}^{r}}$ 的嵌入结果。清晰可见,通过交互式消息传递与聚合,多模态特征实现了和谐融合。
D. Experiment on In-house dVRK Dataset from Two Centers
D. 基于两家中心内部dVRK数据集的实验
To further validate our method, we have collected robotic multi-modal datasets on dVRK platforms in two centers from CUHK and JHU. The data collection conditions of the two datasets had variations in settings of hand-eye calibrations, illuminations, operating locations, which reflected complications in real-world practice. Both kinematics sequences and camera videos have been recorded and synchronized.
为了进一步验证我们的方法,我们在香港中文大学(CUHK)和约翰霍普金斯大学(JHU)的两个中心收集了基于dVRK平台的机器人多模态数据集。这两个数据集在采集条件上存在手眼校准设置、光照条件和操作位置等差异,反映了实际应用中的复杂性。所有运动学序列和摄像头视频均经过同步记录。

Fig. 5. (a) Gestures of peg transfer, (b) Color-coded ribbon illustration of surgical gesture recognition on peg transfer task with ground truth (top) and our results (bottom).
图 5: (a) 钉转移手势, (b) 钉转移任务中手术手势识别的彩色带状图示, 上方为真实值 (ground truth), 下方为我们的结果。
To build the in-house dVRK datasets, we experimented on the peg transfer task (see Fig. 5 (a)), which is one of the most popular tasks present in Fundamentals of La paros co pic Surgery [47] and widely adopted for surgical skill training [48]. Specifically, we defined and manually annotated five different gestures for peg transfer: A1: Idle (No action performed); A2: Reach for peg (with left hand); A3: Lift peg (with left hand); A4: Exchange (transfer the peg to right hand); A5: Place peg (with right hand). The dataset consists of 24 sequences with 12 sequences from CUHK and JHU each. The duration of sequences is within the range of 20-60 seconds due to different length settings to transfer the peg. Within each site, all the operation records were performed by the same user who is familiar with using dVRK platform. The kinematics data includes the position/orientation of endeffector and opening angle of the gripper, at the meanwhile, videos are synchronously recorded and there are all downsampled to $10\mathrm{Hz}$ in pre-processing.
为构建内部dVRK数据集,我们在 peg transfer 任务(见图 5(a))上进行了实验,该任务是腹腔镜手术基础训练[47]中最常见的任务之一,并广泛用于手术技能培训[48]。具体而言,我们定义并手动标注了五种不同的peg transfer动作:A1: 空闲(无动作);A2: 伸手取peg(左手);A3: 抬起peg(左手);A4: 交换(将peg转移到右手);A5: 放置peg(右手)。该数据集包含24个序列,其中12个序列分别来自CUHK和JHU。由于转移peg的长度设置不同,序列时长在20-60秒范围内。在每个实验点,所有操作记录均由熟悉dVRK平台的同一用户完成。运动学数据包括末端执行器的位置/姿态和夹爪开合角度,同时同步录制视频,并在预处理阶段将所有数据降采样至$10\mathrm{Hz}$。
Considering different conditions in data acquisition such as hand-eye settings of dVRK systems, appearances of peg transfer boards, we individually trained and tested models for each dataset, in which we split each dataset to perform 3-fold cross-validation (8 sequences for training and 4 for testing). We adopted the same evaluation metrics as JIGSAWS (i.e., accuracy and Edit Score). The results are listed in the Table IV and Table V, in which Baseline means the standard 2D CNN backbone used in MRG-Net (ResNet-18), while Pure-Vis and Pure-Kin represent the same configurations as Table III, which adopted TCN and LSTM.
考虑到dVRK系统的手眼设置、钉板转移台外观等数据采集条件的不同,我们为每个数据集单独训练和测试模型,并将数据集划分为3折交叉验证(8个序列用于训练,4个用于测试)。我们采用与JIGSAWS相同的评估指标(即准确率和编辑得分)。结果如 表 IV 和 表 V 所示,其中Baseline代表MRG-Net中使用的标准2D CNN骨干网络(ResNet-18),而Pure-Vis和Pure-Kin的配置与 表 III 相同,均采用TCN和LSTM。
It can be observed that, on both datasets, compared to 2D based Baseline, the methods of Pure-Vis and Pure-Kin can obtain higher accuracies and Edit Scores, leveraging their consideration of temporal information in the sequential data. On both the datasets, our proposed MRG-Net achieves the highest accuracy and Edit Score, consistently outperforming the Baseline, Pure-Vis and Pure-Kin methods with a notable margin. The Edit Scores reaches as high as $98.7%$ on CUHK dataset and $96.4%$ on JHU dataset, which reflects the good smoothness and stability of the prediction on dVRK data. In addition, we notice that the model performances for CUHK dataset are overall slightly higher than that for JHU dataset.
可以观察到,在这两个数据集上,与基于2D的Baseline相比,Pure-Vis和Pure-Kin方法通过利用序列数据中的时序信息,能够获得更高的准确率和Edit Score。在两个数据集上,我们提出的MRG-Net均取得了最高的准确率和Edit Score,始终以显著优势超越Baseline、Pure-Vis和Pure-Kin方法。Edit Score在CUHK数据集上高达$98.7%$,在JHU数据集上达到$96.4%$,这反映出对dVRK数据的预测具有良好的平滑性和稳定性。此外,我们注意到模型在CUHK数据集上的表现总体上略高于JHU数据集。
TABLE IV RESULTS OF DIFFERENT METHODS ON PEG TRANSFER DATASET IN SITE CUHK FOR GESTURE RECOGNITION.
表 IV: 香港中文大学站点 PEG TRANSFER 数据集上不同手势识别方法的结果
| 方法 | 输入数据 | 准确率 | EditScore | |
|---|---|---|---|---|
| Kin | Vid | |||
| Baseline(ResNet-18) | 80.7 ± 7.4 | 35.1 ± 8.6 | ||
| Pure-Vis | √ | 88.9 ± 2.8 | 96.7 ± 3.9 | |
| Pure-Kin | √ | 89.2 ± 2.5 | 95.6 ± 3.7 | |
| MRG-Net (Ours) | √ | 91.0 ± 2.1 | 98.7 ± 3.4 |
TABLE V RESULTS OF DIFFERENT METHODS ON PEG TRANSFER DATASET IN SITE JHU FOR GESTURE RECOGNITION.
表 5: JHU站点PEG TRANSFER数据集中不同方法在手势识别上的结果
| 方法 | 输入数据 | 准确率 | EditScore | |
|---|---|---|---|---|
| Kin | Vid | |||
| Baseline(ResNet-18) | 78.5 ±8.2 | 21.3 ± 9.8 | ||
| Pure-Vis | 83.0± 3.6 | 95.1 ± 4.2 | ||
| Pure-Kin | √ | 85.1± 3.4 | 95.5 ± 3.9 | |
| MRG-Net(ours) | √ | 87.3±2.9 | 96.4±3.6 |
We analyze that this is related to the variation of task duration between these two sites. The data recorded from JHU present larger diversity regarding task completion speed compared to CUHK data, thus may be more challenging for recognition. It will be interesting and valuable to further investigate model behavior differences between two datasets in our future work.
我们分析这与两个站点之间任务时长的差异有关。JHU记录的数据在任务完成速度上比CUHK数据呈现出更大的多样性,因此可能对识别更具挑战性。未来工作中进一步探究两个数据集间模型行为的差异将具有重要价值。
IV. CONCLUSION AND FUTURE WORK
IV. 结论与未来工作
This paper presents a novel online multi-modal graph learning method to dynamically integrate complementary information in video and kinematics data from robotic systems, to achieve accurate surgical gesture recognition. Multirelational representation aggregation is achieved through a designed directed graph to capture the underlying joint knowledge between the visual scenes and kinematics motions. The effectiveness of our method is validated with stateof-the-art performance on the public dataset of JIGSAWS on two tasks of suturing and knot typing. Meanwhile, we investigate the significance of each component in our network by conducting ablation studies on JIGSAWS suturing dataset. Furthermore, the proposed method is validated on our collected in-house dVRK datasets, shedding light on the general efficacy of our approach.
本文提出了一种新颖的在线多模态图学习方法,通过动态整合机器人系统中视频与运动学数据的互补信息,实现精准的手术手势识别。我们通过设计有向图实现多关系表征聚合,以捕捉视觉场景与运动学动作间的潜在关联知识。该方法在公开数据集JIGSAWS的缝合与打结两项任务中取得了最先进的性能表现。同时,我们通过在JIGSAWS缝合数据集上进行消融实验,验证了网络中各组件的显著性。此外,所提方法在我们收集的dVRK内部数据集上得到验证,进一步证明了该方案的通用有效性。
In our future work, we shall explore how to resolve the data variance and domain gap due to different acquisition environments and hardware platforms of our two in-house datasets. Potentially, we will design a 6-DOF transformer (a trainable homogeneous mapping) to uniformly align kinematics data from different platforms to a common feature space, and rely on optical flow to tackle the visual gap among different environment. With the help of these methods, we can improve the generalization ability of our method, so as to make full use of more robotic surgery datasets and achieve a cross-platform training and testing scheme. Moreover, we will investigate how to extract the multi-modal embeddings with unsupervised learning schemes in order to reduce the annotation cost. We will also apply the developed visualkinematics based surgical gesture recognition to downstream scenarios such as sub-task automation for robotic surgery.
在我们未来的工作中,将探索如何解决因两个内部数据集采集环境和硬件平台不同导致的数据差异与领域鸿沟。我们计划设计一个6自由度Transformer (可训练齐次映射) ,将不同平台的运动学数据统一对齐到公共特征空间,并借助光流技术处理不同环境间的视觉差异。通过这些方法提升模型的泛化能力,从而充分利用更多机器人手术数据集,实现跨平台训练与测试方案。此外,我们将研究如何通过无监督学习方案提取多模态嵌入表征以降低标注成本。同时会将开发的视觉-运动学手术动作识别技术应用于机器人手术子任务自动化等下游场景。