Understanding Dynamic Scenes using Graph Convolution Networks
基于图卷积网络的动态场景理解
Abstract— We present a novel Multi-Relational Graph Convolutional Network (MRGCN) based framework to model onroad vehicle behaviors from a sequence of temporally ordered frames as grabbed by a moving monocular camera. The input to MRGCN is a multi-relational graph where the graph’s nodes represent the active and passive agents/objects in the scene, and the bidirectional edges that connect every pair of nodes are encodings of their Spatio-temporal relations.
摘要—我们提出了一种基于多关系图卷积网络 (Multi-Relational Graph Convolutional Network,MRGCN) 的新框架,用于从移动单目摄像头抓取的时间有序帧序列中建模道路车辆行为。MRGCN的输入是一个多关系图,其中图的节点表示场景中的主动和被动智能体/对象,连接每对节点的双向边是它们的时空关系编码。
We show that this proposed explicit encoding and usage of an intermediate spatio-temporal interaction graph to be well suited for our tasks over learning end-end directly on a set of temporally ordered spatial relations. We also propose an attention mechanism for MRGCNs that conditioned on the scene dynamically scores the importance of information from different interaction types.
我们证明,这种显式编码和使用的中间时空交互图非常适合我们的任务,而不是直接在一组时间排序的空间关系上进行端到端学习。我们还为MRGCNs提出了一种注意力机制,该机制根据场景动态评分来自不同交互类型的信息重要性。
The proposed framework achieves significant performance gain over prior methods on vehicle-behavior classification tasks on four datasets. We also show a seamless transfer of learning to multiple datasets without resorting to fine-tuning. Such behavior prediction methods find immediate relevance in a variety of navigation tasks such as behavior planning, state estimation, and applications relating to the detection of traffic violations over videos.
所提框架在四个数据集上的车辆行为分类任务中,相比现有方法实现了显著的性能提升。我们还展示了无需微调即可将学习成果无缝迁移至多个数据集的能力。此类行为预测方法在多种导航任务中具有直接应用价值,例如行为规划、状态估计,以及基于视频的交通违章检测等应用场景。
I. INTRODUCTION
I. 引言
We consider dynamic traffic scenes consisting of potentially active participants/agents such as cars and other vehicles that constitute the traffic and passive objects such as lane markings and poles (see example in Fig. 1). In this work, we propose a framework to model the behavior of each such active agents by analyzing the Spatio-temporal evolution of their relations with other active and passive objects in the scene. By relation, we refer to the spatial relations an agent/object possesses and enjoys with other agents/objects, such as between the vehicle and lane markings, as shown in Fig. 1(c).
我们研究的动态交通场景包含两类对象:构成交通流的主动参与者/智能体(如汽车和其他车辆)和被动物体(如车道标线和立柱)(示例见图1)。本文提出一个框架,通过分析主动智能体与场景中其他主动/被动物体间时空关系演变来建模每个主动智能体的行为。所谓"关系",是指智能体/物体与其他智能体/物体之间的空间关系(例如图1(c)所示车辆与车道标线的关系)。
Here, we model both objects and agents, and thus for convenience, we commonly refer them as objects and specifically as agents when referring to active vehicles. The evolution of the spatial relationship between all pairs of objects in a scene is essential in understanding their behaviors. To this end, we propose an Interaction graph that models different agents and objects in the scene as nodes. This graph captures the Spatio-temporal evolution of relations between all-pair of objects in the scene with appropriate bi-directional asymmetric edges with annotations reflecting their evolution (see Fig. 1(c)).
在此,我们对物体和智能体进行建模,为方便起见,通常将它们统称为物体,特指主动车辆时则称为智能体。理解场景中所有物体对之间空间关系的演变对分析其行为至关重要。为此,我们提出了一种交互图 (Interaction graph),将场景中的不同智能体和物体建模为节点。该图通过带有关系演变标注的双向非对称边(见图1(c)),捕捉场景中所有物体对之间的时空关系演化。
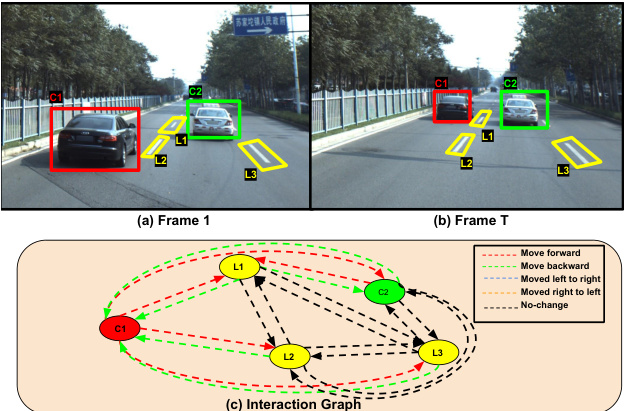
Fig. 1. The figures (a) and (b) show two cars and three lane-markings from two different time frames. The evolution of the whole scene is captured in the Interaction graph (c). Our proposed model infers over such Interaction graphs to classify objects’ behaviors. Here, the car on the left is moving ahead of lane markings and the car on the right. With the Interaction graph (c), our model can predict that the car on the left is overtaking the right-side car.
图 1: 图(a)和(b)展示了两个不同时间帧中的两辆汽车和三条车道标线。整个场景的演变过程被记录在交互图(c)中。我们提出的模型通过对此类交互图进行推理,从而对物体行为进行分类。在此场景中,左侧车辆正超越车道标线和右侧车辆。借助交互图(c),我们的模型可以预测左侧车辆正在超越右侧车辆。
The dynamic traffic scene modeled as an Interaction graph is then inputted to a Multi-Relational Graph Convolutional Network (MRGCN), which outputs the overall behavior exhibited by all the agents and objects in the scene. While the MRGCN maps the input graph to an output behavior for every graph node, we are only interested in active and not the passive objects. Hitherto by behavior, we denote the overall behavior of an active agent in the scene. For example, in Figure 1, the behavior of the car on the left is Overtaking, and the car on the right is moving ahead.
将动态交通场景建模为交互图后,输入到多关系图卷积网络(MRGCN)中,该网络输出场景中所有智能体和物体表现出的整体行为。虽然MRGCN将输入图映射为每个图节点的输出行为,但我们仅关注主动物体而非被动物体。至此,我们所说的行为是指场景中主动智能体的整体行为。例如,在图1中,左侧汽车的行为是超车(Overtaking),右侧汽车则是直行。
The choice of Graph Convolutional Networks (GCN) [1] and the use of its Multi-Relational Variant as a choice for this problem stems from the recent success of such models in learning over data that does not present itself in a regular grid like structure and yet can be modeled as a graph such as in social and biological networks. Since a road scene can also be represented as a graph with nodes sharing multiple relations with other nodes, a GCN based model is apt for inferring overall node (object) behavior from a graph of interconnected relationships.
选择图卷积网络 (Graph Convolutional Networks, GCN) [1] 及其多关系变体来解决该问题,源于此类模型近期在不呈现规则网格结构、却可建模为图结构的数据(如社交和生物网络)学习中的成功表现。由于道路场景同样可表示为节点间存在多重关系的图结构,基于GCN的模型能有效从互联关系图中推断整体节点(物体)行为。
The decomposition of a dynamic on-road scene into its associated Interaction graph and the classification of the agent behavior by the MRGCN supervised over labels that are human-understandable (Lane Change, Overtake, etc.) form the main thesis of this effort. Such behavior classification of agents in the scene finds immediate utility in downstream modules and applications. Recent research showcase results that understanding on-road vehicle behavior leads to better behavior planners for the ego vehicle [2]. In [2], belief states over driver intents of the other vehicles where the intents take the labels “Left Lane Change”, “Right Lane Change”, “Lane Keep” are used for a high-level POMDP based behavior planner for the ego vehicle. For example, the understanding that a car on the ego-vehicle’s right lane is executing a lane change behavior into the current lane of the ego-vehicle can activate its “Change to Right Lane” behavior operation option for path planning. Similarly, modeling an agent’s behavior such as a car in a parked state can make the ego vehicle use feature descriptors of the parked car to update its state accordingly, which would not be possible if the active object was engaged in any other behavior. Understanding on-road vehicle behaviors also lend itself to very pertinent applications such as detecting and classifying traffic scene violations such as “Overtaking Prohibited”, “Lane Change Prohibited.”
将动态道路场景分解为相应的交互图,并通过基于人类可理解标签(如变道、超车等)监督的MRGCN对交通参与者行为进行分类,是本研究的核心主题。这种场景中参与者行为的分类在下游模块和应用中具有直接效用。近期研究表明,理解道路上车辆行为能提升自车行为规划器的性能[2]。文献[2]中采用包含"左变道"、"右变道"、"保持车道"等标签的驾驶员意图信念状态,构建了基于高层POMDP的自车行为规划器。例如,当识别到自车右侧车道车辆正在执行变道行为进入自车当前车道时,可触发自车"向右变道"的行为选项进行路径规划。类似地,对停车状态车辆等参与者行为的建模,可使自车利用静止车辆的特征描述符更新自身状态——若该物体处于其他行为状态则无法实现此功能。理解道路车辆行为还能应用于检测和分类交通违规场景,如"禁止超车"、"禁止变道"等关键场景。
Our contributions are as follows:
我们的贡献如下:
- We propose a novel yet simple scheme for spatial behavior encoding from a sequence of single-camera observations using straight forward projective geometry techniques. This method of encoding spatial behaviors for agents is better than previous efforts that have used end-to-end learning of spatial behaviors [3].
- 我们提出了一种新颖而简单的方案,通过单摄像头观测序列结合直接投影几何技术来实现空间行为编码。这种为智能体编码空间行为的方法优于以往采用端到端学习空间行为的研究 [3]。
- We demonstrate the aptness of the proposed pipeline that directly encodes Spatio-temporal behaviors as an intermediate representation into the scene graph $G$ , followed by the MRGCN based behavioral classifier. We do this by comparing with two previous methods [3], [4] that are devoid of such intermediate Spatio-temporal representations but activate the behavior classifier on per frame spatial represent at ions sequenced temporally. Specifically we tabulate significant performance gain of at-least $25%$ on an average vis a vis [4] and $10%$ over [3] on a variety of datasets collected in various parts of the world [5], [6], [7] and our own native dataset (refer Table IV-B).
- 我们验证了所提出管道的适用性,该管道直接将时空行为编码为中间表示并融入场景图 $G$,随后通过基于MRGCN的行为分类器进行处理。通过与先前两种方法[3][4]的对比(这些方法缺乏此类中间时空表示,而是基于逐帧空间表征的时间序列激活行为分类器),我们在全球多地采集的数据集[5][6][7]及自建本地数据集上实现了显著性能提升(平均较[4]提升至少 $25%$,较[3]提升 $10%$,具体参见表IV-B)。
- We signify through a label deficient setup, the need for a neural-attention component that integrates with the MRGCN and further boosts its performance to nearly perfect predictions, as seen in Tables III and V. Critically incorporating the attention function leads to high performance even in a limited training set, which the MRGCN without attention function cannot replicate.
- 通过标签缺失实验表明,需要一种与MRGCN集成的神经注意力组件,从而将其性能提升至近乎完美的预测水平,如表III和表V所示。关键的是,即使在有限训练集中引入注意力函数也能实现高性能,这是不带注意力功能的MRGCN无法复现的。
- We also show seamless transfer of learning without further need to fine-tune across various combinations of datasets for the train and test split. Here again, we show better transfer capability of the current model vis a vis prior work, as shown in Table IV.
- 我们还展示了无需微调即可实现跨训练集和测试集多种组合的无缝迁移学习能力。如表 4 所示,当前模型相比先前工作展现出更优异的迁移性能。
II. RELATED WORK
II. 相关工作
- Vehicle Behavior and Scene Understanding: The problem of on-road vehicle scene understanding is an important problem within autonomous driving. Most earlier works relied on multiple sensor-based data to solve this task. Rulebased [8] and probabilistic modeling [9], [10], [11], [12], [13], [14], [15] where the goto approaches for classification of driver behavior with sensor data. Also, many of these works [11], [14] were concerned only with predicting future trajectories rather than classification. Herein, we chose a simpler and challenging set up to understand the scene and predict vehicle behaviors with observations from a singlecamera in this work. While there are few works based on a single-camera data feed, they only focus on ego-centered predictions [16]. Here we focus on classifying other vehicles’ behavior from an ego-vehicle perspective. Learning other vehicle behaviors can be helpful in behavior planning, state estimation, and applications relating to the detection of traffic violations over videos
- 车辆行为与场景理解:道路车辆场景理解问题是自动驾驶领域的重要课题。早期研究多依赖多传感器数据解决该任务,其中基于规则的方法 [8] 和概率建模方法 [9][10][11][12][13][14][15] 是使用传感器数据进行驾驶员行为分类的主流方案。值得注意的是,这些研究中有相当部分 [11][14] 仅关注未来轨迹预测而非行为分类。本文采用更简洁且具挑战性的方案,通过单摄像头观测数据实现场景理解与车辆行为预测。尽管存在少量基于单摄像头数据的研究,但它们仅聚焦于以自车为中心的预测 [16]。本研究则从自车视角出发对其他车辆行为进行分类,此类行为学习对行为规划、状态估计及视频交通违章检测等应用具有重要价值
- Graph based reasoning: Graphs are a popular choice of data structures to model numerous irregular domains. With the recent advent of Graph Convolutional Networks (GCNs) [1] that can obtain relevant node-level features for graphs, there is a widespread adaption of graph-based modeling of numerous computer vision problems such as in situationrecognition tasks [17]. [18] encodes object-centric relations in an image using a GCNS to learn object-centric policies for autonomous driving. [4] and [3] models objects in a video as Spatio-temporal graphs to make predictions of Spatiotemporal nature. It is common to model the temporal context of objects with recurrent neural nets and spatial context with a graph-based neural net.
- 基于图的推理:图是一种流行的数据结构,可用于建模众多不规则领域。随着图卷积网络 (GCNs) [1] 的最新出现(能够获取图的相关节点级特征),基于图的建模在众多计算机视觉问题中得到了广泛应用,例如情境识别任务 [17]。[18] 使用 GCNs 对图像中以物体为中心的关系进行编码,以学习用于自动驾驶的以物体为中心的策略。[4] 和 [3] 将视频中的物体建模为时空图,以预测时空特性。通常使用循环神经网络对物体的时间上下文进行建模,使用基于图的神经网络对空间上下文进行建模。
In this work, we focus on the task of on-road vehicle behavior and show that a proposed intermediate representation, called an Interaction graph, can yield better performance over working with a raw set of spatial graphs as done traditionally. This also portrays current models’ incapacity to learn endend and derive such useful features as with the Interaction graph from the raw spatial graphs. The closest works to ours are [16] and [19]. They generate an affinity graph that captures actor-objects relationships. A simple GCN is then used to reason over this graph to classify ego-car action and not other vehicles. In our work, we use a richer multirelational graph and a corresponding multi-relational GCN to work on the same. Further, we propose an attention based model that can leverage different relation types depending on the scene context.
在本研究中,我们专注于道路车辆行为分析任务,并提出了一种称为交互图(Interaction graph)的中间表示方法。相较于传统使用的原始空间图集,该方法能获得更优性能。这同时揭示了现有模型无法从原始空间图中端到端学习并提取类似交互图这类有效特征的局限性。与我们最接近的研究是[16]和[19],它们通过生成亲和力图(affinity graph)来捕捉智能体-对象关系,随后使用简单图卷积网络(GCN)对该图进行推理,但仅针对主车行为分类而非其他车辆。我们的研究采用了更丰富的多关系图及对应的多关系GCN进行处理,并进一步提出基于注意力机制的模型,该模型能根据场景上下文灵活利用不同关系类型。
III. PROPOSED METHODOLOGY
III. 研究方法
Dynamic scene understanding requires well modeling of the different Spatio-temporal relations that may exist between various active objects in a scene. Towards this goal, we propose a pipeline that first computes a time-based ordered set of spatial relations for each object in the video scene. Secondly, it generates a multi-relational interaction graph representing the temporal evolution of the spatial relations between entities obtained from the previous step. Finally, it leverages a graph-based behavior learning model to predict behaviors of vehicles in the scene. Fig 2 provides an overview of our proposed framework.
动态场景理解需要充分建模场景中不同活动对象之间可能存在的时空关系。为此,我们提出了一种流程:首先为视频场景中的每个对象计算基于时间排序的空间关系集合;其次生成多关系交互图,表示上一步获取的实体间空间关系的时序演化;最后利用基于图的行为学习模型预测场景中车辆行为。图2展示了我们提出的框架概览。
Our proposed pipeline leverages and improves the data modeling pipeline introduced in [3] (MRGCN-LSTM). Our pipeline’s performance gains primarily stem from two of our contributions: (i) the interaction graph that provides useful and explicit temporal evolution information of spatial relations. (ii) Ttrahceke dp roposed Multi-Relational Graph Convolutional Network( a()MRGCN) with our novel multi-head relation attention function, which we name Relation-Attentive-GCN (Rel-Att-GCN).
我们提出的流程改进并利用了[3]中提出的数据建模流程(MRGCN-LSTM)。该流程的性能提升主要来自两项贡献:(i) 提供空间关系显式时序演化信息的交互图;(ii) 采用新型多头关系注意力函数的多关系图卷积网络(MRGCN),我们将其命名为关系注意力图卷积网络(Rel-Att-GCN)。
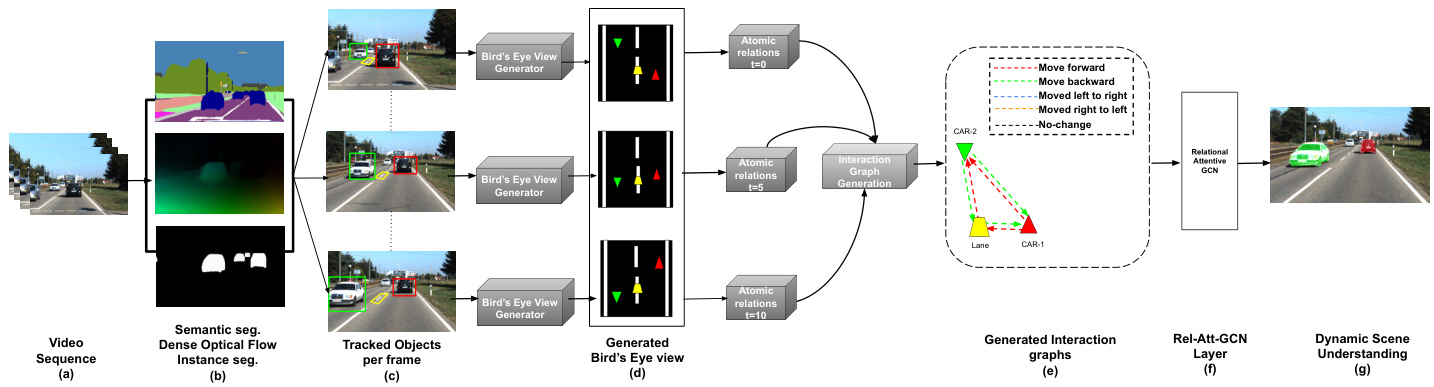
Fig. 2. Overall pipeline of our frBairGde’snm eeryaete iVo i new work: TScehne(-eeg)r apihsnput (a) to tPh Nr eot pe woos rekdp ipeline is moD n Sy c no e an me icc ular image frames. Various otiobnject tracking pipelines are used to detect and track objects as shown in (b). (c) denotes the tracked( d)objects. Tracklets for each (f)object are pro jU end cer(stgt)aendidng to 3D space, Bird’s eye-view at each time step, as shown in (d). Spatial relations from Bird’s eye view are used to generate Interaction graphs (e). This graph is passed through a Rel-Att-RGCN (f) to classify objects in the scene as shown in (g).
图 2: 我们工作的整体流程框架:(a) 原始视频输入通过(b)多种目标跟踪流程检测并追踪物体,如(b)所示。(c)表示被追踪的物体。(d)将每个物体的轨迹片段投射到3D空间,生成鸟瞰视图。(e)利用鸟瞰视角的空间关系构建交互图。(f)该图通过Rel-Att-RGCN网络处理,(g)最终实现场景中物体的分类。
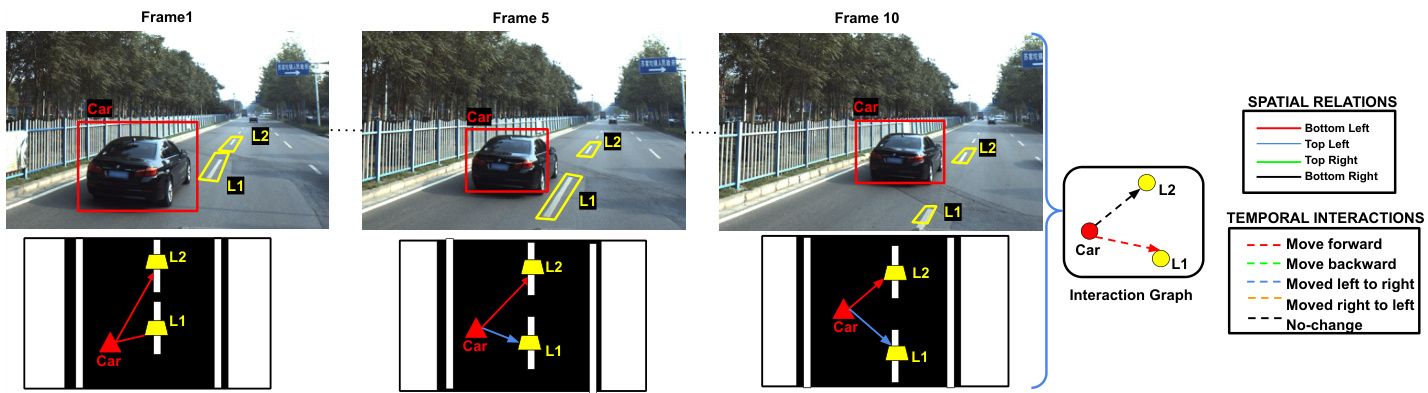
Fig. 3. Temporal Interaction Graph Generation: The top row contains image frames at $\scriptstyle{\mathrm{t=0}}$ , $\mathrm{t}{=}5$ , $_{\mathrm{t=10}}$ time step with tracked objects. The bottom row shows the corresponding bird’s eye view. In the scene, a car and two lane-markings are tracked at each time step. The thick red, blue edges between car, L1 in first, and the final frame denote their spatial relations. The car moves forward with respect to L1 and has no relational change with L2, as shown with thick edges in the Interaction graph. Temporal relations are represented with dotted lines, while spatial relations are represented with thick edges. Corresponding color coding is shown in legends.
图 3: 时序交互图生成:顶行展示的是在时间步 $\scriptstyle{\mathrm{t=0}}$、$\mathrm{t}{=}5$ 和 $_{\mathrm{t=10}}$ 时带有追踪目标的图像帧。底行则是对应的鸟瞰视图。场景中,每个时间步都追踪了一辆汽车和两条车道标线。首帧与末帧中汽车与L1之间的粗红、蓝边表示它们的空间关系。如图所示,汽车相对于L1向前移动,与L2无关系变化,这在交互图中以粗边表示。时序关系用虚线表示,空间关系用粗边表示。对应的颜色编码在图例中展示。
A. Spatial Graph Generation
A. 空间图生成
For dynamic scene understanding, we need to identify different objects in the scene and determine the atomic spatial relationships betweenL 2them at each time-step. This phase of the pipeline closely follows the spatial scene graph generation step of [3]. refer tLo1 the same for mode details.
为了理解动态场景,我们需要识别场景中的不同对象,并在每个时间步确定它们之间的原子空间关系。这一流程阶段紧密遵循[3]中的空间场景图生成步骤。更多细节请参考相同内容。
- Object Detection and Tracking: Different vehicles in the video frames are detected and tracked through instance segmentation [20] and per-pixel optical flow [21] respectively. The instance-level segmentation of an object obtained from MaskRCNN are projected to the next frame and are associated with the highest overlapping instance using optical flows. Apart from tracking vehicles in the scene, static objects such as lane markings are also tracked with semantic segmentation [22] to better understand changing relations among static and non-static objects. [3] has shown that performance improvement can be obtained by leveraging a higher number of static objects in the scene.
- 目标检测与跟踪:通过实例分割 [20] 和逐像素光流 [21] 分别检测并跟踪视频帧中的不同车辆。从 MaskRCNN 获得的目标实例级分割结果会投影至下一帧,并通过光流与重叠度最高的实例进行关联。除跟踪场景中的车辆外,车道标线等静态物体也会通过语义分割 [22] 进行跟踪,以更好地理解静态与非静态物体间的动态关系。[3] 表明,利用场景中更多静态物体可提升性能表现。
- Bird’s Eye View: The tracklets of objects obtained in the image space are re-oriented in the Bird’s eye view (Top View) by projecting the image coordinates into 3D coordinates as des(cb)ribed in [23]. This re orientation facilitates determining spatial relations between different entities. Each object is assigned a reference point to account for the difference in heights. The reference is at the center for lane markings, and for vehicles, it is the point adjacent to the road.
- 鸟瞰图: 通过将图像坐标投影到3D坐标(如[23]所述),将在图像空间中获取的物体轨迹重新定向到鸟瞰图(俯视图)。这种重新定向有助于确定不同实体之间的空间关系。为每个物体分配一个参考点以考虑高度差异,车道标记的参考点位于中心,而车辆的参考点是靠近道路的点。
- Spatial relations: At all $T$ frames of the video, the spatial relations between different entities are determined using their 3D positional information in the Bird’s eye view. Specifically, the spatial relations are the four quadrants, {top left, top right, bottom left, and bottom right}. For a subject entity, $i$ , its spatial relation with an object entity, $j$ at timestep, t is denoted as Sit,j.
- 空间关系:在视频的所有 $T$ 帧中,不同实体之间的空间关系通过它们在鸟瞰图中的3D位置信息确定。具体而言,空间关系分为四个象限:{左上、右上、左下、右下}。对于主体实体 $i$ 和客体实体 $j$ 在时间步 $t$ 的空间关系,记为 $S_{i}^{t,j}$。
B. Temporal Interaction Graph Generation
B. 时序交互图生成
Modeling object interactions as a time-based ordered set of spatial graphs is a popular approach in many Spatio-temporal problems. such as [24], [25], [26], [27] where spatial graphs are constructed over object interactions to classify actions in a video stream. [4], [3] use a similar approach for predicting on road object behaviors. We found that it is harder for models learned with such data to learn some of the simple temporal-evolution behaviors needed for the end task, specifically in our problem of interest. In our problem of focus, behavior prediction, it is important for the model to learn the nature of some simple temporal evolution of interaction between entities such as move-forward, move-backward, moved left to the right, moved right to the left, no-change. However, we found that explicitly modeling such information was highly beneficial. A simple rule-based model with such interaction information outperformed learned models on the primitive information at the level of spatial relations. Having motivated by this insight, we propose a way to define an Interaction graph with temporal evolution information and a new model that can benefit from such information.
将物体交互建模为基于时间排序的空间图集是解决许多时空问题的常用方法。例如[24]、[25]、[26]、[27]通过构建物体交互的空间图来分类视频流中的动作。[4]、[3]采用类似方法预测道路物体行为。我们发现,基于此类数据训练的模型更难学习目标任务所需的简单时序演化行为(特别是我们关注的问题)。在行为预测这一核心问题中,模型必须掌握实体间交互的简单时序演化特性,例如前进、后退、左移、右移、静止等。但实验表明,显式建模这类信息极具价值:基于此类交互信息的简单规则模型,在空间关系层面的基础信息处理上优于学习型模型。受此启发,我们提出了一种融合时序演化信息的交互图定义方法,以及能利用该信息的新模型。
For example, an object entity, $j$ that is initially in the bottom-left quadrant with respect to subject entity $i$ , changes it’s atomic spatial relation to top-left with respect to $i$ at some time $t$ , will have its temporal relation $E_{i,j}$ as move-forward. Similarly, an object entity, $j$ that is initially in bottom-left quadrant changes to bottom-right quadrant with respect to subject $i$ at some time $t$ , will have temporal relation $E_{i,j}$ as moved left-to-right. Since these temporal relation annotated edges have a proper direction semantics, we can’t treat the graph is undirected. Thus, we also introduce inverse edges for complementary relations suchs as moved forward and backward and moved left-to-right and moved right-to-left. An overview of the temporal interaction graph generation is presented in Fig. 3.
例如,一个物体实体 $j$ 最初相对于主体实体 $i$ 位于左下象限,在某个时间 $t$ 时,其相对于 $i$ 的原子空间关系变为左上,此时其时间关系 $E_{i,j}$ 为向前移动。类似地,一个物体实体 $j$ 最初位于左下象限,在某个时间 $t$ 时相对于主体 $i$ 变为右下象限,其时间关系 $E_{i,j}$ 为从左向右移动。由于这些带有时间关系标注的边具有明确的方向语义,我们不能将图视为无向图。因此,我们还引入了互补关系的反向边,例如向前移动与向后移动、从左向右移动与从右向左移动。时间交互图生成的概览如图 3 所示。
C. Behavior Prediction Model
C. 行为预测模型
We propose a Multi-relational Graph Convolution Network (MRGCN) with a relation-attention module that conditioned on the scene, automatically learns relevant information from different temporal relations necessary to predict vehicle behaviors.
我们提出了一种带有关联注意力模块的多关系图卷积网络(MRGCN),该模块基于场景条件,自动学习预测车辆行为所需的不同时间关系中的相关信息。
- Multi-Relational Graph Convolution Networks: Recently Graph convolution Networks [1] has become the popular choice to model graph-structured data. We model our task of maneuver prediction by using a variant of Graph Convolutional Networks, Multi-Relational Graph Convolutional Networks (MRGCN) [28] originally proposed for knowledge graphs with multiple relation types. MRGCN is composed of multiple graph convolutional layers, one for each relation between nodes. A Graph Convolution operation for a relation $r$ here is a simple neighborhood-based information aggregation function. In the MRGCN, information obtained from convolving over different relations is combined by summation.
- 多关系图卷积网络:近年来,图卷积网络 [1] 已成为建模图结构数据的流行选择。我们通过使用图卷积网络的变体——多关系图卷积网络 (MRGCN) [28] 来建模机动预测任务,该网络最初是为具有多种关系类型的知识图谱提出的。MRGCN 由多个图卷积层组成,每个层对应节点间的一种关系。这里针对关系 $r$ 的图卷积操作是一种简单的基于邻域的信息聚合函数。在 MRGCN 中,通过不同关系卷积获得的信息通过求和进行组合。
Let us formally define the temporal Interaction Graph as $G=(V,E)$ with vertex set $V$ and edge set, $E$ , where $E_{i,j}\in$ $R_{d}$ is an edge between node $i$ and $j$ . The $i^{t h}$ node feature obtained from a graph convolution over relation, $r$ in $l^{t h}$
让我们正式定义时序交互图 (temporal Interaction Graph) 为 $G=(V,E)$,其中顶点集为 $V$,边集为 $E$。$E_{i,j}\in$ $R_{d}$ 表示节点 $i$ 和 $j$ 之间的边。通过关系 $r$ 在图卷积操作中获得的第 $i^{t h}$ 个节点特征位于第 $l^{t h}$ 层。
layer is defined as follows:
该层定义如下:
$$
h_{r}^{l}[i]=\sum_{j\in\mathcal{N}{r}[i]}\frac{1}{c_{r}[i]}W_{r}^{l}h^{l-1}[j]
$$
$$
h_{r}^{l}[i]=\sum_{j\in\mathcal{N}{r}[i]}\frac{1}{c_{r}[i]}W_{r}^{l}h^{l-1}[j]
$$
where, $\mathcal{N}{r}[i]$ denotes set of neighbour nodes for $v_{i}$ under relation $r$ , $\mathcal{N}{r}[i]={j\in V|E_{j,i}=r}$ and $c_{r}[i]=\vert\mathcal{N}{r}[i]\vert$ is a normalization factor. Here, $W_{r}^{l}\in\dot{\mathcal{R}}^{d^{\prime}*d}$ is the weights associated with relation $r$ in the $l^{t h}$ layer of MR-GCN; $d^{\prime},d$ are dimensions of $(l-1)^{t h}$ and $l^{t h}$ layers of MRGCN.
其中,$\mathcal{N}{r}[i]$ 表示节点 $v_{i}$ 在关系 $r$ 下的邻居节点集合,$\mathcal{N}{r}[i]={j\in V|E_{j,i}=r}$,且 $c_{r}[i]=\vert\mathcal{N}{r}[i]\vert$ 为归一化因子。此处,$W_{r}^{l}\in\dot{\mathcal{R}}^{d^{\prime}*d}$ 是 MR-GCN 第 $l^{t h}$ 层中与关系 $r$ 关联的权重;$d^{\prime},d$ 分别表示 MRGCN 第 $(l-1)^{t h}$ 层和第 $l^{t h}$ 层的维度。
Neighborhood information aggregated from all the relations are then combined by a simple summation to obtain the node representation as follows:
随后通过简单求和将所有关系聚合的邻域信息结合起来,得到节点表示如下:
$$
h^{l}[i]=R e L U(W_{s}^{l}h^{l-1}[i]+\sum_{r\in R_{d}}h_{r}^{l}[i])
$$
$$
h^{l}[i]=R e L U(W_{s}^{l}h^{l-1}[i]+\sum_{r\in R_{d}}h_{r}^{l}[i])
$$
where, the first terms correspond to the node information (self-loop) and $W_{s}\in\mathcal{R}^{d^{\prime}*d}$ is the weight associated with self-loop. To account for the nature of the entity (active or passive), we learn entity embeddings, $\mathcal{E}{i}\in\mathbb{R}^{|O|*d}$ for node $v_{i}$ , where $\textit{O}={V e h i c l e s$ , Lane Markings}. The input to the first layer of the MRGCN, $h^{0}[i]$ , is the embedding $\mathcal{E}_{i}$ based on type of node $i$ .
其中,第一项对应节点信息(自循环),$W_{s}\in\mathcal{R}^{d^{\prime}*d}$ 是与自循环相关的权重。为了考虑实体(主动或被动)的性质,我们学习实体嵌入 $\mathcal{E}{i}\in\mathbb{R}^{|O|*d}$ 用于节点 $v_{i}$,其中 $\textit{O}={Vehicles, Lane Markings}$。MRGCN 第一层的输入 $h^{0}[i]$ 是基于节点 $i$ 类型的嵌入 $\mathcal{E}_{i}$。
- Relation-Attention MRGCN (Rel-Att-GCN): The MRGCN defined in Eqn: 2 treats information from all the relations equally, which might be a sub-optimal choice to learn disc rim i native features for certain classes. Motivated by this, we propose a simple attention mechanism that scores the node information’s importance along with individual neighborhood information from each relation.
- 关系注意力多关系图卷积网络 (Rel-Att-GCN): 公式2中定义的MRGCN对所有关系的信息进行同等处理,这对于学习某些类别的判别特征可能是次优选择。受此启发,我们提出了一种简单的注意力机制,该机制通过评分节点信息的重要性以及来自每个关系的单独邻域信息来优化特征学习。
The attention scores, $\alpha$ are computed by concatenating the information from the node $(h^{l-1})$ and its relational neighbors $(h_{r}^{l})$ and transforming it with a linear layer to predict scores for each component. The predicted scores are softmax normalized. The attention scores are computed as defined below.
注意力分数 $\alpha$ 的计算方式为:将节点 $(h^{l-1})$ 与其关系邻居 $(h_{r}^{l})$ 的信息拼接后,通过线性层变换来预测各成分的得分。预测得分经过softmax归一化处理。具体计算公式如下:
$$
\alpha^{l}[i]=s o f t m a x([h^{l-1}[i]\parallel h_{1}^{l}[i]\parallel h_{2}^{l}[i]...\parallel h_{|R_{d}|}^{l}]W_{u}^{l})
$$
$$
\alpha^{l}[i]=s o f t m a x([h^{l-1}[i]\parallel h_{1}^{l}[i]\parallel h_{2}^{l}[i]...\parallel h_{|R_{d}|}^{l}]W_{u}^{l})
$$
where, $\parallel$ represents concatenation and $\alpha^{l}[i]\in~{\mathcal{R}}^{|R_{d}+1|}$ with $\boldsymbol{W}_{u}^{l}$ being the linear attention layer weights. These probabilities depict the importance of a specific relation conditioned on that node and its neighborhood.
其中,$\parallel$ 表示拼接操作,$\alpha^{l}[i]\in~{\mathcal{R}}^{|R_{d}+1|}$ 且 $\boldsymbol{W}_{u}^{l}$ 为线性注意力层的权重。这些概率表示在给定节点及其邻域条件下特定关系的重要性。
The attention scores are used to scale the node and neighbor information accordingly to obtain the node representation as follows.
注意力分数用于相应地缩放节点和邻居信息,从而获得如下所示的节点表示。
$$
h^{l}[i]=R e L U(\alpha_{n o d e}^{l}[i]h^{l-1}[i]+\sum_{r\in R_{d}}\alpha_{r}^{l}[i]h_{r}^{l}[i])
$$
$$
h^{l}[i]=R e L U(\alpha_{n o d e}^{l}[i]h^{l-1}[i]+\sum_{r\in R_{d}}\alpha_{r}^{l}[i]h_{r}^{l}[i])
$$
where, $\alpha_{n o d e}^{l}$ is the attention score for self-loop. The node representation obtained at the last layer is used to predict labels, and the model is trained by minimizing the crossentropy loss.
其中,$\alpha_{n o d e}^{l}$ 是自循环的注意力分数。最后一层获得的节点表示用于预测标签,并通过最小化交叉熵损失来训练模型。
IV. EXPERIMENT AND ANALYSIS
IV. 实验与分析
A. Dataset
A. 数据集
Numerous datasets have been released in the interest of solving problems related to autonomous driving. We choose four datasets for evaluating our framework, of which three are publicly available: ApolloS capes [6], KITTI [29], Honda Driving dataset [7] and one is a proprietary Indian dataset. These datasets provide hours of driving data with monocular image feed in various driving conditions. We use the same dataset Train/Test/Val splits from [3] for Apollo Scape, KITTI, and Indian dataset and extend the setup to Honda dataset and manually annotated accordingly for our task.
为推进自动驾驶相关问题的研究,已发布众多数据集。我们选取四个数据集评估框架性能,其中三个为公开数据集:ApolloScapes [6]、KITTI [29]、本田驾驶数据集 [7],另有一个印度专有数据集。这些数据集提供不同驾驶环境下数小时的单目图像数据流。对于ApolloScape、KITTI和印度数据集,我们沿用文献[3]的Train/Test/Val划分方案,并将该设置扩展至本田数据集,根据任务需求进行人工标注。
- Apollo Dataset: We choose Apollo-scapes as our primary dataset as it contains a large number of driving scenarios that are of interest. It includes vehicles depicting overtake and lane-change behaviors. The dataset consists of image feed collected from urban areas and contains various objects such as Cars, Buses, etc. The final dataset used here contains a total of 4K frames with multiple behaviors. 2) KITTI Dataset: It consists of images collected majorly from highways and wide open-roads, unlike Apollo-scapes. We select 700 frames from Tracking Sequences 4, 5, and 10 for our purpose. These chosen sequences contained a variety of driving behaviors compared to the rest. 3) Honda Driving Dataset: This dataset consists of multiple datasets in itself. From among them, we choose the H3D dataset for our task as it contained lane change behaviors. H3D comprises driving in urban city conditions where lane changes are prominent. We excluded overtaking behavior here due to its fewer occurrences in the dataset. It consists of a total of 1.5K frames. 4) Indian Dataset Although the datasets mentioned above are widely used and include wide vehicle behaviors, they mostly contain standard vehicle frames only. To showcase models’ transfer learning capabilities on less standard vehicles, we also use an Indian driving dataset that includes vehicles such as auto-rickshaw, trucks, tankers, etc. This dataset contains 600 frames.
- Apollo数据集:我们选择Apollo-scapes作为主要数据集,因其包含大量具有研究价值的驾驶场景,涵盖超车和变道等行为。该数据集采集自城市区域的图像流,包含汽车、巴士等多种物体。最终使用的数据集共包含4000帧具有多类行为的画面。
- KITTI数据集:与Apollo-scapes不同,该数据集主要采集自高速公路和开阔道路。我们从Tracking Sequences 4/5/10中选取700帧,这些序列相比其他序列包含更丰富的驾驶行为。
- 本田驾驶数据集:该数据集包含多个子集,我们选用其中记录变道行为的H3D子集。H3D聚焦城市道路场景中显著的变道行为,由于超车行为样本较少故未采用,共包含1500帧画面。
- 印度数据集:尽管上述数据集被广泛使用且覆盖多种车辆行为,但仅包含标准车型。为测试模型在非标准车辆(如机动三轮车、卡车、油罐车等)上的迁移学习能力,我们额外采用包含600帧画面的印度驾驶数据集。
Class labels: The vehicle behaviors predicted in these datasets are: (i) Moving Away from Us (MAU), (ii) Moving Towards Us (MTU), (iii) Parked (PRK), (iv) Lane Change from Left-right (LCL), (v) Lane Change from left-Right (LCR) and (vi) Overtake (OVT).
类别标签:这些数据集中预测的车辆行为包括:(i) 远离我们 (MAU)、(ii) 接近我们 (MTU)、(iii) 停放 (PRK)、(iv) 从左向右变道 (LCL)、(v) 从右向左变道 (LCR) 以及 (vi) 超车 (OVT)。
B. Experimentation details
B. 实验细节
All the models, both learning and rule-based, use the same pre-processing steps to identify and track objects in the scene, as explained in section: III-A.1 for $T=10$ timesteps (frames). The Spatial graphs at each time frame are constructed by considering a maximum of 10 vehicles in the scene nearest to the ego-vehicle for classifying them. Then, an Interaction graph is independently generated from the set of $T$ temporally ordered spatial graphs. The MRGCN used is identical in both models MRGCN and Rel-Att-GCN. Note that the input and output dimensions of attention are equal. We empirically found that using 3 layers of MRGCN with dimensions 64, 32, and 6 (number of classes) respectively works best for our task. In the case of Rel-Att-GCN, simple attention is applied over the output of MRGCN for each node individually with 2 heads. Outputs of the heads are concatenated across relations and projected back to the MRGCN layer’s output dimension with a linear transformation. We found adding skip connection from every layer $l$ to $(l+2)^{t h}$ layer to be beneficial.
所有模型(包括基于学习和基于规则的)都采用相同的预处理步骤来识别和跟踪场景中的物体,如第III-A.1节所述,处理时长为 $T=10$ 个时间步(帧)。每帧的空间图通过选取场景中距离自车最近的10辆车辆进行分类构建。随后,从这组按时间顺序排列的 $T$ 个空间图中独立生成交互图。MRGCN模型在MRGCN和Rel-Att-GCN中结构相同,需注意注意力机制的输入输出维度相等。实验表明,采用3层MRGCN(维度分别为64、32和6[类别数])最适合本任务。对于Rel-Att-GCN,会在MRGCN每个节点的输出上单独应用2头简单注意力机制,多头输出按关系拼接后通过线性变换投影回MRGCN层的输出维度。我们发现,从每层 $l$ 到 $(l+2)^{t h}$ 层添加跳跃连接能提升性能。
TABLE I VEHICLE BEHAVIOR PREDICTION ON APOLLO SCAPE DATASET.
表 1: APOLLO SCAPE 数据集上的车辆行为预测
| 使用的图类型 | 方法 | 远离 (MAU) | 接近 (MTU) | 停车 | 左变道 (LCL) | 右变道 (LCR) | 超车 |
|---|---|---|---|---|---|---|---|
| 时序空间图集 | St-RNN [4] | 76 | 51 | 83 | 52 | 57 | 63 |
| MRGCN-LSTM [3] | 85 | 89 | t6 | 84 | 86 | 72 | |
| 时空交互图 | 基于规则 | 90 | 99 | 98 | 81 | 87 | 06 |
| MRGCN [28], [3] | 94 | 95 | t6 | 97 | 93 | 86 | |
| Rel-Att-GCN | 95 | 99 | 98 | 97 | 97 | 89 |
The inference time for the models: MRGCN-LSTM, MRGCN, and Rel-Att-GCN averaged over 1K graphs are 0.02, 0.03, and 0.04 seconds respectively. Note that the latter two models inference time also includes the creation of the Interaction graph. All the training and testing was done on a single Nvidia Geforce Gtx 1080 GPU. More details regarding the implementation can be found on our project website, 1.
模型在1K张图上的平均推理时间分别为:MRGCN-LSTM 0.02秒、MRGCN 0.03秒、Rel-Att-GCN 0.04秒。需注意后两种模型的推理时间包含交互图(Interaction graph)的构建过程。所有训练和测试均在单块Nvidia Geforce GTX 1080 GPU上完成。更多实现细节详见我们的项目网站[1]。
C. Baseline Comparisons
C. 基线对比
In Table: IV-B, we compare our models with Spatiotemporal approaches as well as a rule-based method on the Interaction graph. Table IV-B reports class-wise Recall scores of these methods. The results reported here in all the tables are averaged over 5 runs.
在表 IV-B 中,我们将我们的模型与时空方法以及基于规则的方法在交互图(Interaction graph)上进行了比较。表 IV-B 报告了这些方法的类别召回率(Recall)分数。这里报告的所有表格结果均为 5 次运行的平均值。
- Spatio-Temporal approaches: To depict the importance of encoding Spatio-temporal information as an Interaction graph, we compare our model with Structural-RNN [4] and MRCGN-LSTM [3] that processes a time based ordered set of spatial graphs. Structural-RNN (St-RNN) encodes the spatial representation for each frame in a graph and then reasons over the temporal evolution of these graphs by feeding it to a Recurrent Neural Network. We adapt St-RNN’s pipeline to our problem by replacing humans and objects in their model with vehicles and stationary landmarks, respectively. A similar methodology is employed for MRGCN-LSTM [3].
- 时空方法:为了说明将时空信息编码为交互图的重要性,我们将模型与处理基于时间排序的空间图集的 Structural-RNN [4] 和 MRCGN-LSTM [3] 进行对比。Structural-RNN (St-RNN) 将每帧的空间表征编码为图结构,再通过循环神经网络 (RNN) 推演这些图的时序演化。我们将 St-RNN 的流程适配到本任务:用车辆替换原模型中的人类,用静态地标替换物体。对 MRGCN-LSTM [3] 采用了相同的方法论。
We show a quantitative comparison with our pipeline/model variations in Table IV-B. St-RNN that doesn’t have any GCN components fare the worst. In Table IV-B, we observe that our method outperforms the traditional temporal based approach, St-RNN, by a significant margin. The gap is even more prominent when comparing the harder classes such as lane changing and overtaking, where we observe an average difference of $40%$ and $26%$ , respectively. A comparison between MRGCNLSTM that uses a set of spatial graphs vs. MRGCN that uses the proposed interaction graph clearly shows the benefit of the proposed interaction graph. MRGCN outperforms its counter that learns in an end-end manner. This shows how such simple inherent behaviors are still hard for GCNs to learn. Further, with the addition of the attention mechanism, the Rel-Att-GCN model achieves an additional absolute $3-4%$ improvement on a few hard classes.
我们在表 IV-B 中展示了与不同管道/模型变体的定量对比。不含任何 GCN (Graph Convolutional Network) 组件的 St-RNN 表现最差。从表 IV-B 可见,我们的方法显著优于传统基于时序的 St-RNN 方法。在变道和超车等难度更高的类别上,优势更为明显,平均差异分别达到 $40%$ 和 $26%$。通过对比使用固定空间图集的 MRGCNLSTM 与采用交互图的 MRGCN,清晰证明了所提交互图的优势。MRGCN 的表现超过了端到端学习的对比模型,这说明此类简单固有行为对 GCN 而言仍具挑战性。此外,引入注意力机制后,Rel-Att-GCN 模型在部分困难类别上实现了 $3-4%$ 的绝对提升。
- Rule Based Baseline: To showcase the effectiveness of an information-rich Interaction graph over traditional Spatiotemporal modeling with a set of spatial graphs, we propose a rule-based approach to infer over the Interaction graph as one of our baselines. We use the Interaction Graphs generated by our pipeline (ref section:III-B) and employ an expert set of rules carefully framed to classify between behaviors. The deterministic classification is a simple max function over different relations a vehicle is associated with.
- 基于规则的基线 (Rule Based Baseline): 为了展示信息丰富的交互图 (Interaction Graph) 相对于传统使用一组空间图进行时空建模的有效性,我们提出了一种基于规则的方法来推断交互图作为我们的基线之一。我们使用由我们的流程生成的交互图 (参考章节: III-B) ,并采用一组精心设计的专家规则来对行为进行分类。确定性分类是一个简单的最大值函数,作用于车辆所关联的不同关系上。
TABLE II REL-ATT-GCN VS RULE-BASED MODEL ON APOLLOS CAPE DATASET. BOTH THE MODELS USE THE PROPOSED INTERACTION GRAPH.
表 II REL-ATT-GCN 与基于规则的模型在 APOLLOS CAPE 数据集上的对比。两个模型均使用提出的交互图。
| 模型 | Rel-Att-GCN | 基于规则的模型 | ||||
|---|---|---|---|---|---|---|
| 性能指标 | 精确率 | 召回率 | F1 | 精确率 | 召回率 | F1 |
| MAU MTU PRK LCL LCR OVT | 97 95 100 94 97 71 | 95 99 98 97 97 89 | 96 97 99 95 97 79 | 97 100 100 96 97 36 | 91 99 99 81 88 90 | 94 99 99 88 92 |
| 微观平均 宏观平均 | 97 92 | 97 96 | 97 94 | 95 88 | 95 91 | 52 95 87 |
Relational behavior with majority count decides to which class the object belongs to from the following, {moving away, moving towards us, and lane changes}. For example, a node having the highest count for behavioral relation moved left to right would have its class as Lane change (Left to right). To obtain classification for overtake behavior, we iterate over all pair of vehicles, $i$ and $j$ , that are not classified as parked or moving towards us in the first iteration and then we observe if there exists $e_{i,j}=$ move-forward, in which
根据多数统计的关系行为决定对象所属类别,包括{远离、靠近、车道变换}。例如,若某节点在"从左向右移动"行为关系中计数最高,则其类别为"车道变换(从左向右)"。为判断超车行为,我们遍历所有车辆对$i$和$j$(首轮筛选中未被归类为停放或靠近的车辆),并检测是否存在$e_{i,j}=$前进关系。
The quantitative comparison in Table IV-B, clearly depicts the advantage of a rich temporal Interaction graph over models that directly utilize a set of spatial graphs, especially in the complex behavior class overtaking where it shows an $18%$ and $27%$ over MRGCN and St-RNN respectively. Though the rule-based model performs well compared to the Spatio-temporal approaches, it falls short against the learning-based models trained on the Interaction graph. The rule-based model is not powerful enough, especially on lane-change classes. This clearly explains the need for a learnable model to learn complicated patterns. On a closer look in Table II, it is clear that the rule-based method is not consistently better, especially on precision and recall metrics of Overtake and lane-change classes, respectively. The proposed Rel-Att-GCN clear outperforms the rule-based model on aggregate Micro and Macro average scores.
表 IV-B 中的定量对比清晰展示了富时序交互图 (Interaction graph) 模型相对于直接使用空间图集的优势,尤其在超车这类复杂行为分类上,其性能分别比 MRGCN 和 St-RNN 高出 $18%$ 和 $27%$。尽管基于规则的方法在时空方法中表现尚可,但相比基于交互图的机器学习模型仍有差距。该规则模型能力不足的问题在换道类别中尤为明显,这充分说明需要可学习模型来捕获复杂模式。细察表 II 可见,规则方法并非持续占优——尤其在超车类的精确率和换道类的召回率指标上。我们提出的 Rel-Att-GCN 在微观和宏观平均分数上全面超越了规则模型。
TABLE III RECALL ON APOLLOS CAPE DATASET FOR DIFFERENT AMOUNT OF TRAINING DATA
表 III 不同训练数据量在APOLLOS CAPE数据集上的召回率
| TrainRatio | 0.05 | 0.1 | 0.2 |
|---|---|---|---|
| Method | MRGCN | Rel-Att GCN | MRGCN |
| MAU | 61 | 6 | 91 |
| MTU | 47 | 99 | 75 |
| PRK | 90 | 98 | 86 |
| LCL | 36 | 98 | 69 |
| LCR | 54 | 6 | 73 |
| OVT | 50 | 60 | 58 |
D. Analysis of Relation-Attention MRGCN (Rel-Att-GCN)
D. 关系注意力 MRGCN (Rel-Att-GCN) 分析
The Rel-Att-GCN model is the MRGCN model with an additional attention component. The proposed Attention function factors into account that different types of relations in the interaction graph may have different relevancy to predict different classes. The varying importance of the relations in classifying vehicle behaviors can be visualized by analyzing normalized attention scores across relations for each class. One such visualization for the Apollo Scape dataset is depicted in Fig. 4. Higher values in each class (row) denote higher importance given by the attention function to that particular relation (column) to predict that class. The attention map clearly shows how classes such as overtake and lane changes depend on moving forward and moved left to right or right to left respectively. Despite how both MVA and OVT classes have high probability mass on moveforward relation, they can distinguish themselves based on the attention score spread over other relations.
Rel-Att-GCN模型是在MRGCN模型基础上增加了注意力组件的改进模型。该注意力函数的设计考虑了交互图中不同类型的关系对于预测不同类别可能具有不同的相关性。通过分析每个类别在不同关系上的归一化注意力分数,可以可视化各类关系在车辆行为分类中的动态重要性。图4展示了Apollo Scape数据集的一个可视化示例,其中每个类别(行)的较高数值表示注意力函数在预测该类别时赋予特定关系(列)更高的重要性。注意力图谱清晰显示出超车和变道等类别分别依赖于前进、左右移动等关系。尽管MVA和OVT两类在前进关系上都表现出高概率密度,但它们可以通过在其他关系上的注意力分数分布实现自我区分。

Fig. 4. Figure shows attention scores between class labels (rows) and types of spatio-temporal interactions (columns). Higher scores for a particular relation indicates a higher dependence of the class on that particular relation.
图 4: 该图展示了类别标签(行)与时空交互类型(列)之间的注意力分数。特定关系得分越高,表示该类别对该关系的依赖性越强。
Such reasoning helps the network to learn effectively under label scarcity, as given in Table III. Herein, we report results for models trained with $5%$ , $10%$ and $20%$ of training data. Rel-Att-GCN is able to show fidelity even when only $5%$ percent of data is present in contrast to a normal MRGCN trained on the same interaction graph, which finds it difficult to learn from the smaller dataset. A similar trend is observed as we increase the size of training data to $10%$ and $20%$ of the actual dataset. In Table V, where the model is learned with $70%$ data, we observe that Rel-AttGCN achieves superior performance across all datasets when compared with plain MR-GCN as well as temporal based methods.
表 III 展示了这种推理方法能帮助网络在标签稀缺情况下有效学习。我们报告了使用 $5%$、$10%$ 和 $20%$ 训练数据时的模型结果。与在相同交互图上训练的标准 MRGCN 相比,Rel-Att-GCN 即使在仅 $5%$ 数据量时仍能保持性能,而普通 MRGCN 难以从小数据集中学习。当训练数据增至实际数据集的 $10%$ 和 $20%$ 时,我们观察到相似趋势。在表 V 中,当模型使用 $70%$ 数据训练时,Rel-AttGCN 相比普通 MR-GCN 和时序方法在所有数据集上都展现出更优性能。
E. Transfer Learning
E. 迁移学习
To showcase our proposed pipeline’s generality, we trained the model only on the Apollo dataset and tested it on validation sets of Honda, KITTI, and Indian datasets. At the testing phase, we removed the classes which were not present in corresponding datasets. As the proposed pipeline does not rely upon any visually learned features, we can achieve fidelity across all datasets, as seen in Table IV. Evaluation results for the model trained and tested on validation sets of the same dataset can be found in Table V. From a comparison between Table IV and Table V, the transfer learning model though not better than models that are trained and tested on the same dataset, is on par with them. Notably, in the Honda dataset, the Rel-Att-MRGCN performs better in transfer for all classes than the model trained and tested on Honda. We attribute this behavior to high variation present in the Apollo dataset, which the other datasets lack.
为验证所提流程的泛化性,我们仅在Apollo数据集上训练模型,并在Honda、KITTI和Indian数据集的验证集上进行测试。测试阶段移除了各数据集中不存在的类别。由于该流程不依赖任何视觉学习特征,如表IV所示,我们在所有数据集上均实现了高保真度。同一数据集训练测试的模型评估结果见表V。对比表IV与表V可知,迁移学习模型虽不及同数据集训练的模型,但性能与之相当。值得注意的是,在Honda数据集中,Rel-Att-MRGCN模型在所有类别的迁移表现均优于该数据集原生训练模型。我们认为这是由于Apollo数据集具有其他数据集缺乏的高变异性特征。
TABLE IV TRANSFER LEARNING RESULTS: WE TRAIN THE MODELS ON APOLLO SCAPES DATASET AND TEST ON HONDA, KITTI AND INDIAN DATASETS.
表 IV 迁移学习结果:我们在 Apollo Scapes 数据集上训练模型,并在 Honda、KITTI 和 Indian 数据集上进行测试。
| 训练数据 | Apollo |
|---|---|
| 测试数据 | Honda |
| 方法 | MRGCN LSTM |
| 远离我们 | 55 |
| 靠近我们 | 79 |
| 停放 | 91 |
| 左变道 | 65 |
| 右变道 | 87 |
TABLE V PERFORMANCE OF METHODS ON DIFFERENT DATASETS. THE MODELS HERE ARE TRAINED AND TESTED ON THE SAME DATASET.
表 V 不同数据集上的方法性能对比。此处模型均在相同数据集上训练和测试。
| 训练及测试数据集 | Apollo | Honda | KITTI | Indian |
|---|---|---|---|---|
| 方法 | MRGCN LSTM | MRGCN | Rel-Att GCN | MRGCN LSTM |
| 远离我们 | 85 | 94 | 95 | 83 |
| 接近我们 | 89 | 95 | 99 | 79 |
| 静止 | 94 | 94 | 86 | 85 |
| 左变道 | 84 | 97 | 97 | 75 |
| 右变道 | 86 | 93 | 97 | 60 |
| 超车 | 72 | 86 | 89 |
F. Qualitative
F. 定性分析
A video demonstration of the qualitative performance of our model on different datasets can be found here2. In Fig. 5 and 6 we showcase few qualitative results from different video snapshots. We follow a consistent convention for colorcoding to depict behaviors. Red depicts vehicles Moving Away From Us, Green for Moving towards Us and Blue for Parked vehicles and Yellow and Orange depict Lane Change Left to right and Lane Change Right to left respectively while Magenta corresponds to overtaking vehicles.
我们模型在不同数据集上的定性性能视频演示可在此处查看2。图5和图6展示了不同视频快照中的部分定性结果。我们采用统一的颜色编码规则来呈现行为:红色表示远离我们的车辆,绿色表示靠近我们的车辆,蓝色表示停放的车辆,黄色和橙色分别表示从左向右变道和从右向左变道,而洋红色对应超车车辆。
In Fig. 5, sub-figures (a) and (b) show instances of vehicles Moving Away From Us and Moving towards on the KITTI dataset. On the same Fig. 5, sub-figures (c) and (d), showcase results from the Indian Dataset, wherein image (c), we see a bus and truck parked and in (d) we see Lane change behavior depicted by the car on the right.
在图 5 中,子图 (a) 和 (b) 展示了 KITTI 数据集中车辆远离我们和靠近的实例。同一图 5 的子图 (c) 和 (d) 展示了印度数据集的结果,其中图像 (c) 显示了一辆停放的公交车和卡车,(d) 展示了右侧车辆的车道变换行为。
In Fig. 6 (a) we see a car changing lane and in Fig. 6 (b) we observe a car classified as overtaking. Fig. 6 (c) and (d) show fidelity of our pipeline in traffic scenarios. In Fig.6 (c) we observe a car changing lane and merging into the road on the right and two cars coming towards us, in (d) we see a car changing a lane (on the right), a car parked on the left and two pickup trucks moving away from us. The qualitative results validates the proposed model’s near-perfect classification and general iz ability across datasets even in the presence of less (or not) observed test vehicles.
在图 6 (a) 中我们看到一辆车正在变道,而在图 6 (b) 中我们观察到一辆被归类为超车的车辆。图 6 (c) 和 (d) 展示了我们的流程在交通场景中的保真度。在图 6 (c) 中,我们看到一辆车正在变道并汇入右侧道路,同时有两辆车朝我们驶来;在 (d) 中,我们看到一辆车正在变道(右侧),一辆车停在左侧,还有两辆皮卡车正远离我们驶去。定性结果验证了所提模型即使在测试车辆较少(或未被观测到)的情况下,仍能实现近乎完美的分类能力,并展现出跨数据集的泛化能力。
V. CONCLUSIONS
V. 结论
This paper proposed a novel pipeline for on-road vehicle behavior understanding and classification. It decomposed an evolving dynamic scene into a multi-relational Interaction graph whose nodes are the agents/actors in the scene, and edges are Spatio-temporal encodings that signify the agents’ spatial behaviors. The interaction graph was further acted upon by a Multi-Relational Graph Convolution Network (MRGCN) to learn and classify the vehicle’s overall behavior. The key takeaway is this two-stage classification that showed much-improved performance over end-end learning frameworks. The improved performance is attributed to edge encodings of the interaction graph being an accurate intermediate representation of spatial behaviors between agents that are difficult to characterize in an end-end learning framework. The MRGCN is integrated with an attention layer that further improved the performance, often nearperfect performance. Significant performance gain on various datasets that are consistent across several metrics confirms the efficacy of the proposed framework. Seamless data transfer across datasets further showcases its reliability. Future directions include integrating the proposed framework with a behavior planner.
本文提出了一种用于道路车辆行为理解与分类的新流程。该方法将动态演变的场景分解为多关系交互图 (Interaction graph),其中节点代表场景中的智能体/参与者,边表示智能体空间行为的时空编码 (Spatio-temporal encodings)。通过多关系图卷积网络 (Multi-Relational Graph Convolution Network, MRGCN) 对该交互图进行处理,以学习并分类车辆的整体行为。关键创新在于这种两阶段分类方法,其性能显著优于端到端学习框架。性能提升归因于交互图的边编码能准确表征智能体间难以用端到端框架描述的空间行为中间表示。MRGCN 集成注意力层后进一步提升了性能,常达到近乎完美的表现。在多个数据集上各项指标一致的显著性能提升验证了该框架的有效性,跨数据集的无缝数据传输更展现了其可靠性。未来研究方向包括将该框架与行为规划器进行集成。