Automated Concatenation of Embeddings for Structured Prediction
结构化预测中嵌入向量的自动拼接
Abstract
摘要
Pretrained contextual i zed embeddings are powerful word representations for structured prediction tasks. Recent work found that better word representations can be obtained by concatenating different types of embeddings. However, the selection of embeddings to form the best concatenated representation usually varies depending on the task and the collection of candidate embeddings, and the ever- increasing number of embedding types makes it a more difficult problem. In this paper, we propose Automated Concatenation of Embeddings (ACE) to automate the process of finding better concatenations of embeddings for structured prediction tasks, based on a formulation inspired by recent progress on neural architecture search. Specifically, a controller alternately samples a concatenation of embeddings, according to its current belief of the effec ti ve ness of individual embedding types in consideration for a task, and updates the belief based on a reward. We follow strategies in reinforcement learning to optimize the parameters of the controller and compute the reward based on the accuracy of a task model, which is fed with the sampled concatenation as input and trained on a task dataset. Empirical results on 6 tasks and 21 datasets show that our approach outperforms strong baselines and achieves state-of-the-art performance with fine-tuned embeddings in all the evaluations.1
预训练上下文嵌入(contextualized embeddings)是结构化预测任务中强大的词表征方式。近期研究发现,通过拼接不同类型的嵌入可以获得更优的词表征。然而,最优拼接组合的选择通常因任务和候选嵌入集而异,且嵌入类型的不断增加使得该问题更具挑战性。本文提出自动化嵌入拼接(Automated Concatenation of Embeddings,ACE)方法,基于神经架构搜索最新进展的启发式建模,自动寻找适用于结构化预测任务的更优嵌入组合。具体而言,控制器根据当前对各类嵌入在任务中有效性的评估,交替采样嵌入组合,并基于奖励信号更新评估。我们采用强化学习策略优化控制器参数,其奖励信号源自任务模型的准确率——该模型以采样组合作为输入,并在任务数据集上训练。在6个任务21个数据集上的实验表明,我们的方法优于强基线模型,且在所有评估中使用微调嵌入均达到了最先进性能[20]。
1 Introduction
1 引言
Recent developments on pretrained contextual i zed embeddings have significantly improved the performance of structured prediction tasks in natural language processing. Approaches based on contextualized embeddings, such as ELMo (Peters et al., 2018), Flair (Akbik et al., 2018), BERT (Devlin et al., 2019), and XLM-R (Conneau et al., 2020), have been consistently raising the state-of-the-art for various structured prediction tasks. Concurrently, research has also showed that word representations based on the concatenation of multiple pretrained contextual i zed embeddings and traditional non-contextual i zed embeddings (such as word2vec (Mikolov et al., 2013) and character embeddings (Santos and Zadrozny, 2014)) can further improve performance (Peters et al., 2018; Akbik et al., 2018; Straková et al., 2019; Wang et al., 2020b). Given the ever-increasing number of embedding learning methods that operate on different granular i ties (e.g., word, subword, or character level) and with different model architectures, choosing the best embeddings to concatenate for a specific task becomes non-trivial, and exploring all possible concatenations can be prohibitively demanding in computing resources.
预训练上下文嵌入的最新进展显著提升了自然语言处理中结构化预测任务的性能。基于上下文嵌入的方法,如ELMo (Peters et al., 2018)、Flair (Akbik et al., 2018)、BERT (Devlin et al., 2019)和XLM-R (Conneau et al., 2020),不断刷新各类结构化预测任务的技术水平。同时,研究表明将多种预训练上下文嵌入与传统非上下文嵌入(如word2vec (Mikolov et al., 2013)和字符嵌入 (Santos and Zadrozny, 2014))进行拼接的词表示方法能进一步提升性能 (Peters et al., 2018; Akbik et al., 2018; Straková et al., 2019; Wang et al., 2020b)。鉴于不同粒度(如词、子词或字符级别)和不同模型架构的嵌入学习方法数量持续增长,为特定任务选择最佳拼接组合变得尤为复杂,而穷尽所有可能的拼接方式在计算资源上往往难以承受。
Neural architecture search (NAS) is an active area of research in deep learning to automatically search for better model architectures, and has achieved state-of-the-art performance on various tasks in computer vision, such as image classification (Real et al., 2019), semantic segmentation (Liu et al., 2019a), and object detection (Ghiasi et al., 2019). In natural language processing, NAS has been successfully applied to find better RNN structures (Zoph and Le, 2017; Pham et al., 2018b) and recently better transformer structures (So et al., 2019; Zhu et al., 2020). In this paper, we propose Automated Concatenation of Embeddings (ACE) to automate the process of finding better concatenations of embeddings for structured prediction tasks. ACE is formulated as an NAS problem. In this approach, an iterative search process is guided by a controller based on its belief that models the effec ti ve ness of individual embedding candidates in consideration for a specific task. At each step, the controller samples a concatenation of embeddings according to the belief model and then feeds the concatenated word representations as inputs to a task model, which in turn is trained on the task dataset and returns the model accuracy as a reward signal to update the belief model. We use the policy gradient algorithm (Williams, 1992) in reinforcement learning (Sutton and Barto, 1992) to solve the optimization problem. In order to improve the efficiency of the search process, we also design a special reward function by accumulating all the rewards based on the transformation between the current concatenation and all previously sampled concatenations.
神经架构搜索 (NAS) 是深度学习领域的一个活跃研究方向,旨在自动搜索更优的模型架构,并在计算机视觉的多个任务中取得了最先进的性能,例如图像分类 (Real et al., 2019)、语义分割 (Liu et al., 2019a) 和物体检测 (Ghiasi et al., 2019)。在自然语言处理领域,NAS已成功应用于寻找更优的RNN结构 (Zoph and Le, 2017; Pham et al., 2018b),最近还被用于发现更优的Transformer结构 (So et al., 2019; Zhu et al., 2020)。本文提出自动化嵌入拼接 (Automated Concatenation of Embeddings, ACE) 方法,用于自动寻找结构化预测任务中更优的嵌入拼接方式。ACE被形式化为一个NAS问题。在该方法中,基于控制器对特定任务中各个嵌入候选有效性的建模信念,引导迭代搜索过程。每一步中,控制器根据信念模型采样一个嵌入拼接方案,然后将拼接后的词表征作为输入馈送给任务模型,该模型在任务数据集上进行训练并返回模型准确率作为奖励信号来更新信念模型。我们使用强化学习中的策略梯度算法 (Williams, 1992) (Sutton and Barto, 1992) 来解决这一优化问题。为了提高搜索效率,我们还设计了一个特殊的奖励函数,通过累积当前拼接方案与所有先前采样拼接方案之间的转换所产生的全部奖励。
Our approach is different from previous work on NAS in the following aspects:
我们的方法在以下方面与以往NAS研究不同:
Empirical results show that ACE outperforms strong baselines. Furthermore, when ACE is applied to concatenate pretrained contextual i zed embeddings fine-tuned on specific tasks, we can achieve state-of-the-art accuracy on 6 structured prediction tasks including Named Entity Recognition (Sundheim, 1995), Part-Of-Speech tagging (DeRose, 1988), chunking (Tjong Kim Sang and Buchholz, 2000), aspect extraction (Hu and Liu,
实证结果表明,ACE优于强基线方法。此外,当应用ACE串联针对特定任务微调的预训练上下文嵌入时,我们能在6项结构化预测任务中取得最先进的准确率,包括命名实体识别 (Sundheim, 1995) 、词性标注 (DeRose, 1988) 、组块分析 (Tjong Kim Sang and Buchholz, 2000) 、方面抽取 (Hu and Liu,
2004), syntactic dependency parsing (Tesnière, 1959) and semantic dependency parsing (Oepen et al., 2014) over 21 datasets. Besides, we also analyze the advantage of ACE and reward function design over the baselines and show the advantage of ACE over ensemble models.
2004年)、句法依存分析(Tesnière, 1959)和语义依存分析(Oepen等, 2014)在内的21个数据集上的表现。此外,我们还分析了ACE和奖励函数设计相较于基线方法的优势,并展示了ACE相对于集成模型的优越性。
2 Related Work
2 相关工作
2.1 Embeddings
2.1 嵌入 (Embeddings)
Non-contextual i zed embeddings, such as word2vec (Mikolov et al., 2013), GloVe (Pennington et al., 2014), and fastText (Bojanowski et al., 2017), help lots of NLP tasks. Character embeddings (Santos and Zadrozny, 2014) are trained together with the task and applied in many structured prediction tasks (Ma and Hovy, 2016; Lample et al., 2016; Dozat and Manning, 2018). For pretrained contex- tualized embeddings, ELMo (Peters et al., 2018), a pretrained contextual i zed word embedding generated with multiple Bidirectional LSTM layers, significantly outperforms previous state-of-the-art approaches on several NLP tasks. Following this idea, Akbik et al. (2018) proposed Flair embeddings, which is a kind of contextual i zed character embeddings and achieved strong performance in sequence labeling tasks. Recently, Devlin et al. (2019) proposed BERT, which encodes contextualized sub-word information by Transformers (Vaswani et al., 2017) and significantly improves the performance on a lot of NLP tasks. Much research such as RoBERTa (Liu et al., 2019c) has focused on improving BERT model’s performance through stronger masking strategies. Moreover, multilingual contextual i zed embeddings become popular. Pires et al. (2019) and Wu and Dredze (2019) showed that Multilingual BERT (M-BERT) could learn a good multilingual representation effectively with strong cross-lingual zero-shot transfer performance in various tasks. Conneau et al. (2020) proposed XLM-R, which is trained on a larger multilingual corpus and significantly outperforms M-BERT on various multilingual tasks.
非上下文嵌入方法,如word2vec (Mikolov et al., 2013)、GloVe (Pennington et al., 2014)和fastText (Bojanowski et al., 2017),对众多自然语言处理任务大有裨益。字符嵌入(Santos and Zadrozny, 2014)与任务联合训练,被广泛应用于结构化预测任务(Ma and Hovy, 2016; Lample et al., 2016; Dozat and Manning, 2018)。在预训练上下文嵌入方面,ELMo (Peters et al., 2018)通过多层双向LSTM生成的预训练上下文词嵌入,在多项自然语言处理任务上显著超越先前最优方法。受此启发,Akbik et al. (2018)提出了Flair嵌入,这是一种上下文字符嵌入,在序列标注任务中表现优异。近期,Devlin et al. (2019)提出的BERT模型通过Transformer (Vaswani et al., 2017)架构编码上下文子词信息,大幅提升了众多自然语言处理任务的性能。许多研究如RoBERTa (Liu et al., 2019c)致力于通过更强大的掩码策略改进BERT模型表现。此外,多语言上下文嵌入逐渐流行,Pires et al. (2019)与Wu and Dredze (2019)研究表明多语言BERT (M-BERT)能有效学习优质多语言表征,在各种任务中展现出强大的跨语言零样本迁移能力。Conneau et al. (2020)提出的XLM-R基于更大规模多语言语料训练,在多语言任务上显著优于M-BERT。
2.2 Neural Architecture Search
2.2 神经架构搜索 (Neural Architecture Search)
Recent progress on deep learning has shown that network architecture design is crucial to the model performance. However, designing a strong neural architecture for each task requires enormous efforts, high level of knowledge, and experiences over the task domain. Therefore, automatic design of neural architecture is desired. A crucial part of
深度学习的最新进展表明,网络架构设计对模型性能至关重要。然而,为每项任务设计强大的神经网络架构需要大量精力、高水平专业知识以及对该任务领域的丰富经验。因此,自动化的神经架构设计成为迫切需求。其中关键环节在于
NAS is search space design, which defines the discoverable NAS space. Previous work (Baker et al., 2017; Zoph and Le, 2017; Xie and Yuille, 2017) designs a global search space (Elsken et al., 2019) which incorporates structures from hand-crafted architectures. For example, Zoph and Le (2017) designed a chained-structured search space with skip connections. The global search space usually has a considerable degree of freedom. For example, the approach of Zoph and Le (2017) takes 22,400 GPUhours to search on CIFAR-10 dataset. Based on the observation that existing hand-crafted architectures contain repeated structures (Szegedy et al., 2016; He et al., 2016; Huang et al., 2017), Zoph et al. (2018) explored cell-based search space which can reduce the search time to 2,000 GPU-hours.
NAS是搜索空间设计,它定义了可发现的NAS空间。先前的工作 (Baker et al., 2017; Zoph and Le, 2017; Xie and Yuille, 2017) 设计了一个全局搜索空间 (Elsken et al., 2019),其中包含了手工设计架构的结构。例如,Zoph和Le (2017) 设计了一个带有跳跃连接的链式结构搜索空间。全局搜索空间通常具有相当大的自由度。例如,Zoph和Le (2017) 的方法在CIFAR-10数据集上搜索需要22,400 GPU小时。基于现有手工设计架构包含重复结构 (Szegedy et al., 2016; He et al., 2016; Huang et al., 2017) 的观察,Zoph等人 (2018) 探索了基于单元的搜索空间,可将搜索时间减少到2,000 GPU小时。
In recent NAS research, reinforcement learning and evolutionary algorithms are the most usual approaches. In reinforcement learning, the agent’s actions are the generation of neural architectures and the action space is identical to the search space. Previous work usually applies an RNN layer (Zoph and Le, 2017; Zhong et al., 2018; Zoph et al., 2018) or use Markov Decision Process (Baker et al., 2017) to decide the hyper-parameter of each structure and decide the input order of each structure. Evolutionary algorithms have been applied to architecture search for many decades (Miller et al., 1989; Angeline et al., 1994; Stanley and Mi ikk ul a inen, 2002; Floreano et al., 2008; Jozefowicz et al., 2015). The algorithm repeatedly generates new populations through recombination and mutation operations and selects survivors through competing among the population. Recent work with evolutionary algorithms differ in the method on parent/survivor selection and population generation. For example, Real et al. (2017), Liu et al. (2018a), Wistuba (2018) and Real et al. (2019) applied tournament selection (Goldberg and Deb, 1991) for the parent selection while Xie and Yuille (2017) keeps all parents. Suganuma et al. (2017) and Elsken et al. (2018) chose the best model while Real et al. (2019) chose several latest models as survivors.
在近期的神经网络架构搜索(NAS)研究中,强化学习和进化算法是最常用的方法。在强化学习中,智能体的动作是生成神经架构,动作空间与搜索空间相同。先前的工作通常应用RNN层(Zoph和Le,2017;Zhong等,2018;Zoph等,2018)或使用马尔可夫决策过程(Baker等,2017)来决定每个结构的超参数和输入顺序。进化算法应用于架构搜索已有数十年历史(Miller等,1989;Angeline等,1994;Stanley和Miikkulainen,2002;Floreano等,2008;Jozefowicz等,2015)。该算法通过重组和变异操作反复生成新种群,并通过种群竞争选择幸存者。近期采用进化算法的工作在父代/幸存者选择和种群生成方法上有所不同。例如,Real等(2017)、Liu等(2018a)、Wistuba(2018)和Real等(2019)采用锦标赛选择(Goldberg和Deb,1991)进行父代选择,而Xie和Yuille(2017)保留所有父代。Suganuma等(2017)和Elsken等(2018)选择最佳模型,而Real等(2019)选择几个最新模型作为幸存者。
3 Automated Concatenation of Embeddings
3 嵌入向量的自动拼接
In ACE, a task model and a controller interact with each other repeatedly. The task model predicts the task output, while the controller searches for better embedding concatenation as the word representation for the task model to achieve higher accuracy.
在ACE中,任务模型和控制器反复交互。任务模型预测任务输出,而控制器搜索更好的嵌入拼接作为词表征,以使任务模型达到更高准确率。
Given an embedding concatenation generated from the controller, the task model is trained over the task data and returns a reward to the controller. The controller receives the reward to update its parameter and samples a new embedding concatenation for the task model. Figure 1 shows the general architecture of our approach.
给定控制器生成的嵌入拼接 (embedding concatenation),任务模型在任务数据上进行训练,并向控制器返回奖励值。控制器接收该奖励值以更新其参数,并为任务模型采样新的嵌入拼接。图 1: 展示了我们方法的整体架构。
3.1 Task Model
3.1 任务模型
For the task model, we emphasis on sequencestructured and graph-structured outputs. Given a structured prediction task with input sentence $_{x}$ and structured output $\pmb{y}$ , we can calculate the probability distribution $P(\pmb{y}|\pmb{x})$ by:
对于任务模型,我们重点关注序列结构和图结构输出。给定一个结构化预测任务,其输入句子为 $_{x}$,结构化输出为 $\pmb{y}$,我们可以通过以下方式计算概率分布 $P(\pmb{y}|\pmb{x})$:
$$
P(\pmb{y}|\pmb{x})=\frac{\exp\left(\operatorname{Score}(\pmb{x},\pmb{y})\right)}{\sum_{\pmb{y}^{\prime}\in\mathbb{X}(\pmb{x})}\exp\left(\operatorname{Score}(\pmb{x},\pmb{y}^{\prime})\right)}
$$
$$
P(\pmb{y}|\pmb{x})=\frac{\exp\left(\operatorname{Score}(\pmb{x},\pmb{y})\right)}{\sum_{\pmb{y}^{\prime}\in\mathbb{X}(\pmb{x})}\exp\left(\operatorname{Score}(\pmb{x},\pmb{y}^{\prime})\right)}
$$
where $\mathbb{Y}({\pmb x})$ represents all possible output structures given the input sentence $_{x}$ . Depending on different structured prediction tasks, the output structure $\pmb{y}$ can be label sequences, trees, graphs or other structures. In this paper, we use sequencestructured and graph-structured outputs as two exemplar structured prediction tasks. We use BiLSTM-CRF model (Ma and Hovy, 2016; Lample et al., 2016) for sequence-structured outputs and use BiLSTM-Biaffine model (Dozat and Manning, 2017) for graph-structured outputs:
其中 $\mathbb{Y}({\pmb x})$ 表示给定输入句子 $_{x}$ 的所有可能输出结构。根据不同的结构化预测任务,输出结构 $\pmb{y}$ 可以是标签序列、树结构、图结构或其他结构。本文采用序列结构和图结构输出作为两个典型的结构化预测任务:使用 BiLSTM-CRF 模型 (Ma and Hovy, 2016; Lample et al., 2016) 处理序列结构输出,使用 BiLSTM-Biaffine 模型 (Dozat and Manning, 2017) 处理图结构输出:
$$
\begin{array}{r l}&{\quad P^{\mathrm{seq}}({\pmb y}|{\pmb x})=\mathrm{BiLSTM-CRF}({\pmb V},{\pmb y})}\ &{\quad P^{\mathrm{graph}}({\pmb y}|{\pmb x})=\mathrm{BiLSTM-Biaffine}({\pmb V},{\pmb y})}\end{array}
$$
$$
\begin{array}{r l}&{\quad P^{\mathrm{seq}}({\pmb y}|{\pmb x})=\mathrm{BiLSTM-CRF}({\pmb V},{\pmb y})}\ &{\quad P^{\mathrm{graph}}({\pmb y}|{\pmb x})=\mathrm{BiLSTM-Biaffine}({\pmb V},{\pmb y})}\end{array}
$$
where $V=[\pmb{v}{1};\pmb{\cdot}\pmb{\cdot}\pmb{\cdot};\pmb{v}{n}]$ , $V\in\mathbb{R}^{d\times n}$ is a matrix of the word representations for the input sentence ${\pmb{x}}$ with $n$ words, $d$ is the hidden size of the concatenation of all embeddings. The word representation ${\boldsymbol{v}}_{i}$ of $i$ -th word is a concatenation of $L$ types of word embeddings:
其中 $V=[\pmb{v}{1};\pmb{\cdot}\pmb{\cdot}\pmb{\cdot};\pmb{v}{n}]$,$V\in\mathbb{R}^{d\times n}$ 是输入句子 ${\pmb{x}}$ 的词表示矩阵,包含 $n$ 个单词,$d$ 为所有嵌入拼接后的隐藏层大小。第 $i$ 个单词的词表示 ${\boldsymbol{v}}_{i}$ 由 $L$ 种词嵌入拼接而成:
$$
\pmb{v}{i}^{l}=\mathrm{embed}{i}^{l}(\pmb{x});~\pmb{v}{i}=[\pmb{v}{i}^{1};\pmb{v}{i}^{2};...;\pmb{v}_{i}^{L}]
$$
$$
\pmb{v}{i}^{l}=\mathrm{embed}{i}^{l}(\pmb{x});~\pmb{v}{i}=[\pmb{v}{i}^{1};\pmb{v}{i}^{2};...;\pmb{v}_{i}^{L}]
$$
where embedl is the model of $l$ -th embeddings, $\pmb{v}{i}\in\mathbb{R}^{d},\pmb{v}_{i}^{l}\in\mathbb{R}^{d^{l}}.\pmb{d}^{l}$ is the hidden size of embedl.
其中 embedl 是第 $l$ 个嵌入的模型,$\pmb{v}{i}\in\mathbb{R}^{d},\pmb{v}_{i}^{l}\in\mathbb{R}^{d^{l}}.\pmb{d}^{l}$ 是 embedl 的隐藏大小。
3.2 Search Space Design
3.2 搜索空间设计
The neural architecture search space can be represented as a set of neural networks (Elsken et al., 2019). A neural network can be represented as a directed acyclic graph with a set of nodes and directed edges. Each node represents an operation, while each edge represents the inputs and outputs between these nodes. In ACE, we represent each embedding candidate as a node. The input to the nodes is the input sentence $_{\pmb{x}}$ , and the outputs are the embeddings $v^{l}$ . Since we concatenate the embeddings as the word representation of the task model, there is no connection between nodes in our search space. Therefore, the search space can be significantly reduced. For each node, there are a lot of options to extract word features. Taking BERT embeddings as an example, Devlin et al. (2019) concatenated the last four layers as word features while Kondratyuk and Straka (2019) applied a weighted sum of all twelve layers. However, the empirical results (Devlin et al., 2019) do not show a significant difference in accuracy. We follow the typical usage for each embedding to further reduce the search space. As a result, each embedding only has a fixed operation and the resulting search space contains $2^{L}{-}1$ possible combinations of nodes.
神经架构搜索空间可以表示为一组神经网络 (Elsken et al., 2019)。神经网络可以表示为具有一组节点和有向边的有向无环图。每个节点代表一个操作,而每条边代表这些节点之间的输入和输出。在ACE中,我们将每个嵌入候选表示为一个节点。节点的输入是句子 $_{\pmb{x}}$,输出是嵌入 $v^{l}$。由于我们将这些嵌入连接起来作为任务模型的词表示,因此搜索空间中的节点之间没有连接。因此,搜索空间可以显著缩小。对于每个节点,有许多提取词特征的选项。以BERT嵌入为例,Devlin et al. (2019) 将最后四层连接起来作为词特征,而Kondratyuk和Straka (2019) 则对所有十二层应用加权求和。然而,实证结果 (Devlin et al., 2019) 并未显示出准确率的显著差异。我们遵循每种嵌入的典型用法,以进一步缩小搜索空间。因此,每个嵌入只有一个固定的操作,最终的搜索空间包含 $2^{L}{-}1$ 种可能的节点组合。
In NAS, weight sharing (Pham et al., 2018a) shares the weight of structures in training different neural architectures to reduce the training cost. In comparison, we fixed the weight of pretrained embedding candidates in ACE except for the character embeddings. Instead of sharing the parameters of the embeddings, we share the parameters of the task models at each step of search. However, the hidden size of word representation varies over the concatenations, making the weight sharing of structured prediction models difficult. Instead of deciding whether each node exists in the graph, we keep all nodes in the search space and add an additional operation for each node to indicate whether the embedding is masked out. To represent the selected concatenation, we use a binary vector $\pmb{a}=[a_{1},\cdots,a_{l},\cdots,a_{L}]$ as an mask to mask out the embeddings which are not selected:
在神经架构搜索(NAS)中,权重共享(Pham等人,2018a)通过共享不同神经架构训练中的结构权重来降低训练成本。相比之下,我们在ACE中固定了预训练嵌入候选的权重(字符嵌入除外)。我们不是共享嵌入参数,而是在搜索的每一步共享任务模型的参数。然而,词表征的隐藏维度会随着拼接方式而变化,这使得结构化预测模型的权重共享变得困难。我们不是判断图中每个节点是否存在,而是保留搜索空间中的所有节点,并为每个节点添加额外操作来指示该嵌入是否被掩蔽。为了表示选定的拼接方式,我们使用二元向量$\pmb{a}=[a_{1},\cdots,a_{l},\cdots,a_{L}]$作为掩码来过滤未被选中的嵌入:
$$
\pmb{v}{i}=[\pmb{v}{i}^{1}a_{1};,...;\pmb{v}{i}^{l}a_{l};,...;\pmb{v}{i}^{L}a_{L}]
$$
$$
\pmb{v}{i}=[\pmb{v}{i}^{1}a_{1};,...;\pmb{v}{i}^{l}a_{l};,...;\pmb{v}{i}^{L}a_{L}]
$$
where $a_{l}$ is a binary variable. Since the input $V$ is applied to a linear layer in the BiLSTM layer, multiplying the mask with the embeddings is equivalent to directly concatenating the selected embeddings:
其中 $a_{l}$ 是二元变量。由于输入 $V$ 会作用于 BiLSTM 层的线性层,将掩码与嵌入向量相乘相当于直接拼接选中的嵌入向量:
$$
\boldsymbol{W}^{\top}\pmb{v}{i}=\sum_{l=1}^{L}\boldsymbol{W}{l}^{\top}\pmb{v}{i}^{l}\pmb{a}_{l}
$$
$$
\boldsymbol{W}^{\top}\pmb{v}{i}=\sum_{l=1}^{L}\boldsymbol{W}{l}^{\top}\pmb{v}{i}^{l}\pmb{a}_{l}
$$
where W =[W1; W2; . . . ; WL] and W ∈Rd×h and $\scriptstyle W_{l}\in\mathbb{R}^{d^{l}\times h}$ . Therefore, the model weights can be shared after applying the embedding mask to all embedding candidates’ concatenation. Another benefit of our search space design is that we can remove the unused embedding candidates and the corresponding weights in $W$ for a lighter task model after the best concatenation is found by ACE.
其中 W =[W1; W2; . . . ; WL] 且 W ∈Rd×h,同时 $\scriptstyle W_{l}\in\mathbb{R}^{d^{l}\times h}$。因此,在对所有嵌入候选进行拼接并应用嵌入掩码后,模型权重可以实现共享。我们设计的搜索空间还有另一个优势:当 ACE 找到最佳拼接方案后,可以移除未使用的嵌入候选及其在 $W$ 中对应的权重,从而获得更轻量的任务模型。
3.3 Searching in the Space
3.3 在空间中搜索
where $\sigma$ is the sigmoid function. Given the mask, the task model is trained until convergence and returns an accuracy $R$ on the development set. As the accuracy cannot be back-propagated to the controller, we use the reinforcement algorithm for optimization. The accuracy $R$ is used as the reward signal to train the controller. The controller’s target is to maximize the expected reward $J(\pmb\theta)=\mathbb{E}_{P^{\mathrm{ctrl}}(\pmb a;\pmb\theta)}[R]$ through the policy gradient method (Williams, 1992). In our approach, since calculating the exact expectation is intractable, the gradient of $J(\pmb\theta)$ is approximated by sampling only one selection following the distribution $P^{\mathrm{ctrl}}(\pmb{a};\pmb{\theta})$ at each step for training efficiency:
其中 $\sigma$ 是 sigmoid 函数。给定掩码后,任务模型训练至收敛并在开发集上返回准确率 $R$。由于准确率无法反向传播至控制器,我们采用强化学习算法进行优化。该准确率 $R$ 被用作奖励信号来训练控制器。控制器的目标是通过策略梯度法 (Williams, 1992) 最大化期望奖励 $J(\pmb\theta)=\mathbb{E}_{P^{\mathrm{ctrl}}(\pmb a;\pmb\theta)}[R]$。在我们的方法中,由于精确计算期望值不可行,为提升训练效率,每一步仅按分布 $P^{\mathrm{ctrl}}(\pmb{a};\pmb{\theta})$ 采样一个选择来近似计算 $J(\pmb\theta)$ 的梯度:
$$
\nabla_{\boldsymbol{\theta}}J(\boldsymbol{\theta})\approx\sum_{l=1}^{L}\nabla_{\boldsymbol{\theta}}\log P_{l}^{\mathrm{ctrl}}(a_{l};\theta_{l})(R-b)
$$
$$
\nabla_{\boldsymbol{\theta}}J(\boldsymbol{\theta})\approx\sum_{l=1}^{L}\nabla_{\boldsymbol{\theta}}\log P_{l}^{\mathrm{ctrl}}(a_{l};\theta_{l})(R-b)
$$
where $b$ is the baseline function to reduce the high variance of the update function. The baseline usually can be the highest accuracy during the search process. Instead of merely using the highest accuracy of development set over the search process as the baseline, we design a reward function on how each embedding candidate contributes to accuracy change by utilizing all searched concatenations’ development scores. We use a binary vector $\left|\pmb{a}^{t}-\pmb{a}^{i}\right|$ to represent the change between current embedding concatenation ${\pmb a}^{t}$ at current time step $t$ and ${\pmb a}^{i}$ at previous time step $i$ . We then define the reward function as:
其中 $b$ 是用于降低更新函数高方差的基线函数。基线通常可以设为搜索过程中的最高准确率。我们不仅将开发集在搜索过程中的最高准确率作为基线,还通过利用所有已搜索拼接组合的开发集得分,设计了一个衡量每个嵌入候选对准确率变化贡献度的奖励函数。我们使用二元向量 $\left|\pmb{a}^{t}-\pmb{a}^{i}\right|$ 来表示当前时间步 $t$ 的嵌入拼接组合 ${\pmb a}^{t}$ 与先前时间步 $i$ 的 ${\pmb a}^{i}$ 之间的变化,并将奖励函数定义为:
$$
\pmb{r}^{t}=\sum_{i=1}^{t-1}(R_{t}-R_{i})|\pmb{a}^{t}-\pmb{a}^{i}|
$$
$$
\pmb{r}^{t}=\sum_{i=1}^{t-1}(R_{t}-R_{i})|\pmb{a}^{t}-\pmb{a}^{i}|
$$
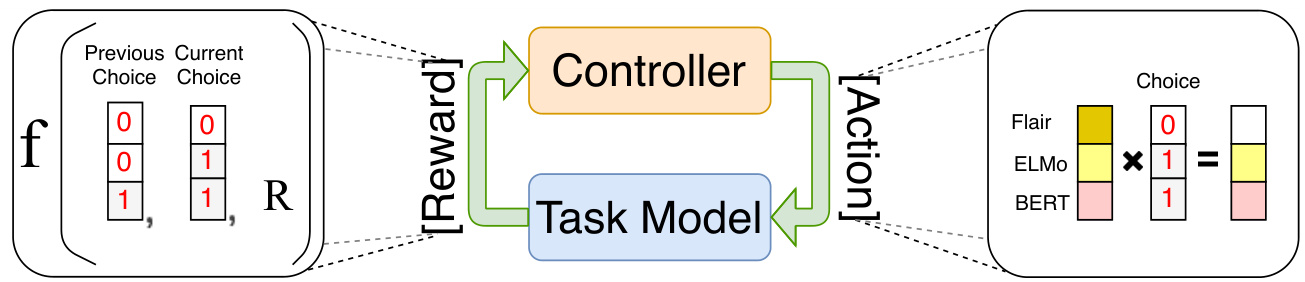
Figure 1: The main paradigm of our approach is shown in the middle, where an example of reward function is represented in the left and an example of a concatenation action is shown in the right.
图 1: 我们的方法主要范式如中间部分所示,左侧展示了奖励函数示例,右侧展示了拼接操作示例。
where $\pmb{r}^{t}$ is a vector with length $L$ representing the reward of each embedding candidate. $R_{t}$ and $R_{i}$ are the reward at time step $t$ and $i$ When the Hamming distance of two concatenations $H a m m(\pmb{a}^{t},\pmb{a}^{i})$ gets larger, the changed candidates’ contribution to the accuracy becomes less noticeable. The controller may be misled to reward a candidate that is not actually helpful. We apply a discount factor to reduce the reward for two concatenations with a large Hamming distance to alleviate this issue. Our final reward function is:
其中 $\pmb{r}^{t}$ 是一个长度为 $L$ 的向量,表示每个嵌入候选的奖励。$R_{t}$ 和 $R_{i}$ 分别是时间步 $t$ 和 $i$ 的奖励。当两个拼接的汉明距离 $Hamm(\pmb{a}^{t},\pmb{a}^{i})$ 增大时,被修改候选对准确率的贡献会变得不明显。控制器可能会误判并奖励实际上无益的候选。我们引入折扣因子来降低具有较大汉明距离的拼接奖励,以缓解该问题。最终的奖励函数为:
$$
r^{t}{=}\sum_{i=1}^{t-1}(R_{t}{-}R_{i})\gamma^{H a m m(a^{t},a^{i})-1}|a^{t}{-}a^{i}|
$$
$$
r^{t}{=}\sum_{i=1}^{t-1}(R_{t}{-}R_{i})\gamma^{H a m m(a^{t},a^{i})-1}|a^{t}{-}a^{i}|
$$
where $\gamma\in(0,1)$ . Eq. 4 is then reformulated as:
其中 $\gamma\in(0,1)$。式4可改写为:
$$
\nabla_{\boldsymbol{\theta}}J_{t}(\boldsymbol{\theta})\approx\sum_{l=1}^{L}\nabla_{\boldsymbol{\theta}}\log P_{l}^{\mathrm{ctrl}}(a_{l}^{t};\theta_{l})r_{l}^{t}
$$
$$
\nabla_{\boldsymbol{\theta}}J_{t}(\boldsymbol{\theta})\approx\sum_{l=1}^{L}\nabla_{\boldsymbol{\theta}}\log P_{l}^{\mathrm{ctrl}}(a_{l}^{t};\theta_{l})r_{l}^{t}
$$
3.4 Training
3.4 训练
To train the controller, we use a dictionary $\mathbb{D}$ to store the concatenations and the corresponding validation scores. At $t=1$ , we train the task model with all embedding candidates concatenated. From $t=2$ , we repeat the following steps until a maximum iteration $T$ :
为了训练控制器,我们使用字典 $\mathbb{D}$ 来存储拼接组合及其对应的验证分数。在 $t=1$ 时,我们用所有候选嵌入的拼接来训练任务模型。从 $t=2$ 开始,我们重复以下步骤直到达到最大迭代次数 $T$:
When sampling ${\mathbf{}}a^{t}$ , we avoid selecting the previous concatenation ${\pmb a}^{t-1}$ and the all-zero vector (i.e., selecting no embedding). If ${\mathbf{}}a^{t}$ is in the dictionary $\mathbb{D}$ , we compare the $R_{t}$ with the value in the dictionary and keep the higher one.
在采样 ${\mathbf{}}a^{t}$ 时,我们避免选择先前的拼接 ${\pmb a}^{t-1}$ 和全零向量(即不选择任何嵌入)。如果 ${\mathbf{}}a^{t}$ 在字典 $\mathbb{D}$ 中,我们会将 $R_{t}$ 与字典中的值进行比较,并保留较高的那个。
4 Experiments
4 实验
We use ISO 639-1 language codes to represent languages in the table2.
我们使用ISO 639-1语言代码来表示表2中的语言。
4.1 Datasets and Configurations
4.1 数据集与配置
To show ACE’s effectiveness, we conduct extensive experiments on a variety of structured prediction tasks varying from syntactic tasks to semantic tasks. The tasks are named entity recognition (NER), PartOf-Speech (POS) tagging, Chunking, Aspect Extraction (AE), Syntactic Dependency Parsing (DP) and Semantic Dependency Parsing (SDP). The details of the 6 structured prediction tasks in our experiments are shown in below:
为了验证ACE的有效性,我们在多种结构化预测任务上进行了广泛实验,涵盖句法任务到语义任务。具体任务包括命名实体识别(NER)、词性标注(POS)、组块分析(Chunking)、方面抽取(AE)、句法依存分析(DP)和语义依存分析(SDP)。实验中涉及的6项结构化预测任务详情如下:
• NER: We use the corpora of 4 languages from the CoNLL 2002 and 2003 shared task (Tjong Kim Sang, 2002; Tjong Kim Sang and De Meulder, 2003) with standard split.
• NER (命名实体识别): 我们使用来自 CoNLL 2002 和 2003 共享任务的 4 种语言语料库 (Tjong Kim Sang, 2002; Tjong Kim Sang and De Meulder, 2003) 并采用标准划分。
• POS Tagging: We use three datasets, Ritter11-TPOS (Ritter et al., 2011), ARK-Twitter (Gimpel et al., 2011; Owoputi et al., 2013) and Tweebank- v2 (Liu et al., 2018b) datasets (Ritter, ARK and TB-v2 in simplification). We follow the dataset split of Nguyen et al. (2020).
• 词性标注 (POS Tagging): 我们使用了三个数据集: Ritter11-TPOS (Ritter et al., 2011)、ARK-Twitter (Gimpel et al., 2011; Owoputi et al., 2013) 和 Tweebank-v2 (Liu et al., 2018b) 数据集 (简称为 Ritter、ARK 和 TB-v2)。我们遵循 Nguyen et al. (2020) 的数据集划分方式。
• Chunking: We use CoNLL 2000 (Tjong Kim Sang and Buchholz, 2000) for chunking. Since there is no standard development set for CoNLL 2000 dataset, we split $10%$ of the training data as the development set.
• 分块 (Chunking): 我们使用 CoNLL 2000 (Tjong Kim Sang 和 Buchholz, 2000) 进行分块。由于 CoNLL 2000 数据集没有标准开发集,我们将训练数据的 $10%$ 划分为开发集。
• Aspect Extraction: Aspect extraction is a subtask of aspect-based sentiment analysis (Pontiki et al., 2014, 2015, 2016). The datasets are from the laptop and restaurant domain of SemEval
• 方面提取 (Aspect Extraction): 方面提取是基于方面的情感分析 (Pontiki et al., 2014, 2015, 2016) 的子任务。数据集来自 SemEval 的笔记本电脑和餐厅领域。
Table 1: Comparison with concatenating all embeddings and random search baselines on 6 tasks.
表 1: 在6项任务上与全嵌入拼接及随机搜索基线的对比结果
14, restaurant domain of SemEval 15 and restaurant domain of SemEval 16 shared task (14Lap, 14Res, 15Res and 16Res in short). Additionally, we use another 4 languages in the restaurant domain of SemEval 16 to test our approach in multiple languages. We randomly split $10%$ of the training data as the development set following Li et al. (2019).
14、SemEval 15的餐厅领域和SemEval 16共享任务的餐厅领域(简称14Lap、14Res、15Res和16Res)。此外,我们使用SemEval 16餐厅领域的另外4种语言来测试我们的多语言方法。按照Li等人(2019)的方法,我们随机划分了$10%$的训练数据作为开发集。
• Syntactic Dependency Parsing: We use Penn Tree Bank (PTB) 3.0 with the same dataset preprocessing as (Ma et al., 2018).
• 句法依存分析:我们使用宾州树库(PTB)3.0版本,数据集预处理方式与(Ma et al., 2018)保持一致。
• Semantic Dependency Parsing: We use DM, PAS and PSD datasets for semantic dependency parsing (Oepen et al., 2014) for the SemEval 2015 shared task (Oepen et al., 2015). The three datasets have the same sentences but with different formalisms. We use the standard split for SDP. In the split, there are in-domain test sets and out-of-domain test sets for each dataset.
• 语义依存解析:我们使用DM、PAS和PSD数据集进行语义依存解析 (Oepen et al., 2014) ,用于SemEval 2015共享任务 (Oepen et al., 2015) 。这三个数据集包含相同句子但采用不同形式化表示。我们采用SDP标准划分方案,其中每个数据集均包含域内测试集和域外测试集。
Among these tasks, NER, POS tagging, chunking and aspect extraction are sequence-structured outputs while dependency parsing and semantic dependency parsing are the graph-structured outputs. POS Tagging, chunking and DP are syntactic structured prediction tasks while NER, AE, SDP are semantic structured prediction tasks.
在这些任务中,命名实体识别(NER)、词性标注(POS tagging)、组块分析和方面抽取是序列结构输出,而依存句法分析和语义依存分析是图结构输出。词性标注、组块分析和依存句法分析属于句法结构化预测任务,而命名实体识别、方面抽取和语义依存分析属于语义结构化预测任务。
We train the controller for 30 steps and save the task model with the highest accuracy on the development set as the final model for testing. Please refer to Appendix A for more details of other settings.
我们对控制器进行了30步训练,并将在开发集上准确率最高的任务模型保存为最终测试模型。其他设置的详细信息请参阅附录A。
4.2 Embeddings
4.2 嵌入 (Embeddings)
Basic Settings: For the candidates of embeddings on English datasets, we use the languagespecific model for ELMo, Flair, base BERT, GloVe word embeddings, fastText word embeddings, noncontextual character embeddings (Lample et al., 2016), multilingual Flair (M-Flair), M-BERT and
基础设置:对于英文数据集的嵌入候选,我们采用以下语言专用模型:ELMo、Flair、基础BERT、GloVe词嵌入、fastText词嵌入、非上下文字符嵌入 (Lample et al., 2016)、多语言Flair (M-Flair)、M-BERT
XLM-R embeddings. The size of the search space in our experiments is $2^{11}-1=2047^{3}$ . For languagespecific models of other languages, please refer to Appendix A for more details. In AE, there is no available Russian-specific BERT, Flair and ELMo embeddings and there is no available Turkishspecific Flair and ELMo embeddings. We use the corresponding English embeddings instead so that the search spaces of these datasets are almost identical to those of the other datasets. All embeddings are fixed during training except that the character embeddings are trained over the task. The empirical results are reported in Section 4.3.1.
XLM-R嵌入。我们实验中的搜索空间大小为$2^{11}-1=2047^{3}$。其他语言的特定模型详情请参阅附录A。在AE中,没有可用的俄语专用BERT、Flair和ELMo嵌入,也没有土耳其语专用的Flair和ELMo嵌入。我们使用相应的英语嵌入替代,因此这些数据集的搜索空间几乎与其他数据集相同。除字符嵌入在任务训练过程中更新外,所有嵌入在训练期间均保持固定。实证结果见第4.3.1节。
Embedding Fine-tuning: A usual approach to get better accuracy is fine-tuning transformer-based embeddings. In sequence labeling, most of the work follows the fine-tuning pipeline of BERT that connects the BERT model with a linear layer for word-level classification. However, when multiple embeddings are concatenated, fine-tuning a specific group of embeddings becomes difficult because of complicated hyper-parameter settings and massive GPU memory consumption. To alleviate this problem, we first fine-tune the transformer-based embeddings over the task and then concatenate these embeddings together with other embeddings in the basic setting to apply ACE. The empirical results are reported in Section 4.3.2.
嵌入微调:提升准确率的常用方法是对基于Transformer的嵌入进行微调。在序列标注任务中,多数工作遵循BERT的微调流程,即将BERT模型与用于词级分类的线性层相连。然而,当需要拼接多个嵌入时,由于复杂的超参数设置和巨大的GPU内存消耗,对特定嵌入组进行微调变得困难。为解决这一问题,我们首先针对任务微调基于Transformer的嵌入,随后将这些嵌入与基础配置中的其他嵌入拼接,再应用ACE(自适应上下文嵌入)。实证结果详见第4.3.2节。
4.3 Results
4.3 结果
We use the following abbreviations in our experiments: UAS: Unlabeled Attachment Score; LAS: Labeled Attachment Score; ID: In-domain test set; OOD: Out-of-domain test set. We use language codes for languages in NER and AE.
我们在实验中使用以下缩写:UAS:无标记依存准确率;LAS:有标记依存准确率;ID:域内测试集;OOD:域外测试集。对于NER和AE任务中的语言,我们使用语言代码。
4.3.1 Comparison With Baselines
4.3.1 与基线方法对比
To show the effectiveness of our approach, we compare our approach with two strong baselines. For the first one, we let the task model learn by itself the contribution of each embedding candidate that is helpful to the task. We set $^{a}$ to all-ones (i.e., the concatenation of all the embeddings) and train the task model (All). The linear layer weight $W$ in Eq. 2 reflects the contribution of each candidate. For the second one, we use the random search (Random), a strong baseline in NAS (Li and Talwalkar, 2020). For Random, we run the same maximum iteration as in ACE. For the experiments, we report the averaged accuracy of 3 runs. Table 1 shows that ACE outperforms both baselines in 6 tasks over 23 test sets with only two exceptions. Comparing Random with All, Random outperforms All by 0.4 on average and surpasses the accuracy of All on 14 out of 23 test sets, which shows that concatenating all embeddings may not be the best solution to most structured prediction tasks. In general, searching for the concatenation for the word representation is essential in most cases, and our search design can usually lead to better results compared to both of the baselines.
为了验证我们方法的有效性,我们将其与两个强基线进行比较。第一种基线让任务模型自行学习对任务有帮助的每个嵌入候选的贡献,我们将$a$设为全1向量(即所有嵌入的拼接)并训练任务模型(All)。公式2中的线性层权重$W$反映了各候选嵌入的贡献。第二种基线采用随机搜索(Random),这是NAS领域公认的强基线(Li和Talwalkar,2020)。对于Random,我们设置与ACE相同的最大迭代次数。实验报告了3次运行的平均准确率。表1显示,在23个测试集的6项任务中,ACE有21项超越了两个基线。比较Random与All,Random平均领先All 0.4个百分点,在23个测试集中有14个准确率超过All,这表明全嵌入拼接并非多数结构化预测任务的最佳方案。总体而言,在多数情况下搜索词表征的最优拼接组合是必要的,而我们的搜索设计通常能获得优于两个基线的结果。
4.3.2 Comparison With State-of-the-Art approaches
4.3.2 与最先进方法的对比
As we have shown, ACE has an advantage in searching for better embedding concatenations. We further show that ACE is competitive or even stronger than state-of-the-art approaches. We additionally use XLNet (Yang et al., 2019) and RoBERTa as the candidates of ACE. In some tasks, we have several additional settings to better compare with previous work. In NER, we also conduct a comparison on the revised version of German datasets in the CoNLL 2006 shared task (Buchholz and Marsi, 2006). Recent work such as $\mathrm{Yu}$ et al. (2020) and Yamada et al. (2020) utilizes document contexts in the datasets. We follow their work and extract document embeddings for the transformer-based embeddings. Specifically, we follow the fine-tune process of Yamada et al. (2020) to fine-tune the transformer-based embeddings over the document except for BERT and M-BERT embeddings. For BERT and M-BERT, we follow the document extraction process of Yu et al. (2020) because we find that the model with such document embeddings is significantly stronger than the model trained with the fine-tuning process of Yamada et al. (2020). In SDP, the state-of-the-art approaches used POS tags and lemmas as additional word features to the network. We add these two features to the embedding candidates and train the embeddings together with the task. We use the fine-tuned transformer-based embeddings on each task instead of the pretrained version of these embeddings as the candidates.4
如我们所示,ACE在搜索更好的嵌入(embedding)拼接方式上具有优势。我们进一步证明,ACE与最先进方法相比具有竞争力甚至更优。我们还使用XLNet (Yang et al., 2019)和RoBERTa作为ACE的候选模型。在某些任务中,我们设置了若干附加条件以更好地与先前工作进行比较。在命名实体识别(NER)任务中,我们还对CoNLL 2006共享任务中修订版德语数据集(Buchholz and Marsi, 2006)进行了对比。近期工作如$\mathrm{Yu}$等(2020)和Yamada等(2020)利用了数据集中的文档上下文。我们遵循他们的方法,为基于Transformer的嵌入提取文档嵌入。具体而言,除BERT和M-BERT嵌入外,我们按照Yamada等(2020)的微调流程对所有基于Transformer的嵌入进行文档级微调。对于BERT和M-BERT,我们采用Yu等(2020)的文档提取流程,因为发现采用此类文档嵌入的模型性能显著优于使用Yamada等(2020)微调流程训练的模型。在语义依存分析(SDP)任务中,现有最佳方法使用词性标注(POS tags)和词元(lemmas)作为网络的附加词特征。我们将这两个特征加入嵌入候选集,并与任务共同训练嵌入。我们采用各任务上微调后的基于Transformer的嵌入(而非预训练版本)作为候选嵌入。4
We additionally compare with fine-tuned XLMR model for NER, POS tagging, chunking and AE, and compare with fine-tuned XLNet model for DP and SDP, which are strong fine-tuned models in most of the experiments. Results are shown in Table 2, 3, 4. Results show that ACE with fine-tuned embeddings achieves state-of-the-art performance in all test sets, which shows that finding a good embedding concatenation helps structured prediction tasks. We also find that ACE is stronger than the fine-tuned models, which shows the effectiveness of concatenating the fine-tuned embedding s 5.
我们还比较了针对NER(命名实体识别)、POS(词性标注)、组块分析和AE(自动编码)任务微调后的XLMR模型,以及针对DP(依存解析)和SDP(语义依存解析)任务微调后的XLNet模型,这些模型在大多数实验中表现强劲。结果如表2、3、4所示。结果表明,采用微调嵌入的ACE(自适应上下文嵌入)在所有测试集上都达到了最先进的性能,这说明找到良好的嵌入拼接方式有助于结构化预测任务。我们还发现ACE优于微调模型,这证明了拼接微调嵌入的有效性[5]。
5 Analysis
5 分析
5.1 Efficiency of Search Methods
5.1 搜索方法的效率
To show how efficient our approach is compared with the random search algorithm, we compare the algorithm in two aspects on CoNLL English NER dataset. The first aspect is the best development accuracy during training. The left part of Figure 2 shows that ACE is consistently stronger than the random search algorithm in this task. The second aspect is the searched concatenation at each time step. The right part of Figure 2 shows that the accuracy of ACE gradually increases and gets stable when more concatenations are sampled.
为展示我们的方法相比随机搜索算法的高效性,我们在CoNLL英文NER数据集上从两方面进行对比。第一方面是训练期间的最佳开发集准确率,图2左侧显示ACE在该任务中始终优于随机搜索算法;第二方面是每个时间步的拼接搜索情况,图2右侧表明随着采样拼接次数的增加,ACE的准确率逐步提升并趋于稳定。
5.2 Ablation Study on Reward Function Design
5.2 奖励函数设计的消融研究
To show the effectiveness of the designed reward function, we compare our reward function (Eq. 6) with the reward function without discount factor (Eq. 5) and the traditional reward function (reward term in Eq. 4). We sample 2000 training sentences on CoNLL English NER dataset for faster training and train the controller for 50 steps. Table 5 shows that both the discount factor and the binary vector $\left|\boldsymbol{a}^{t}-\boldsymbol{a}^{i}\right|$ for the task are helpful in both development and test datasets.
为了验证所设计奖励函数的有效性,我们将本文奖励函数(式6)与无折扣因子的奖励函数(式5)以及传统奖励函数(式4中的奖励项)进行对比。我们在CoNLL英文NER数据集上采样2000条训练语句以加速训练,并对控制器进行50步训练。表5显示,折扣因子和任务二元向量$\left|\boldsymbol{a}^{t}-\boldsymbol{a}^{i}\right|$在开发集和测试集上均具有提升效果。
Table 2: Comparison with state-of-the-art approaches in NER and POS tagging. †: Models are trained on both train and development set.
表 2: 命名实体识别(NER)和词性标注(POS)任务中与最先进方法的对比。†: 模型在训练集和开发集上均进行了训练。
| NER | POS | |||||||
|---|---|---|---|---|---|---|---|---|
| de | de06 | nl | Ritter | ARK | TB-v2 | |||
| Baevski et al.(2019) | 93.5 | Owoputi et al.(2013) | 90.4 | 93.2 | 94.6 | |||
| Strakova et al.(2019) | 85.1 | 93.4 | 88.8 92.7 | Gui et al.(2017) | 90.9 | 92.8 | ||
| Yu et al.(2020) | 86.4 | 90.3 | 93.5 | 90.3 93.7 | Gui et al.(2018) | 91.2 | 92.4 | |
| Yamada et al.(2020) | - | 94.3 | Nguyen et al.(2020) | 90.1 | 94.1 | 95.2 | ||
| XLM-R+Fine-tune | 87.7 | 91.4 | 94.1 | - 89.3 95.3 | XLM-R+Fine-tune | 92.3 | 93.7 | 95.4 |
| ACE+Fine-tune | 88.3 | 91.7 | 94.6 | 95.9 95.7 | ACE+Fine-tune | 93.4 | 94.4 | 95.8 |
Table 3: Comparison with state-of-the-art approaches in chunking and aspect extraction. †: We report the results reproduced by Wei et al. (2020).
表 3: 分块和方面提取任务中与最先进方法的对比。†: 我们报告了Wei等人(2020)复现的结果。
| CHUNK CoNLL2000 | AE | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 14Lap | 14Res | 15Res | 16Res | es | nl | ru | tr | |||
| Akbik等人(2018) | 96.7 | Xu等人(2018) | 84.2 | 84.6 | 72.0 | 75.4 | ||||
| Clark等人(2018) | 97.0 | Xu等人(2019) | 84.3 | 78.0 | ||||||
| Liu等人(2019b) | 97.3 | Wang等人(2020a) | 72.8 | 74.3 | 72.9 | 71.8 | 59.3 | |||
| Chen等人(2020) | 95.5 | Wei等人(2020) | 82.7 | 87.1 | 72.7 | 77.7 | ||||
| XLM-R+Fine-tune | 97.0 | XLM-R+Fine-tune | 85.9 | 90.5 | 76.4 | 78.9 | 77.0 | 77.6 | 77.7 | 74.1 |
| ACE+Fine-tune | 97.3 | ACE+Fine-tune | 87.4 | 92.0 | 80.3 | 81.3 | 79.9 | 80.5 | 79.4 | 81.9 |

Figure 2: Comparing the efficiency of random search (Random) and ACE. The $\mathbf{X}$ -axis is the number of time steps. The left y-axis is the averaged best validation accuracy on CoNLL English NER dataset. The right y-axis is the averaged validation accuracy of the current selection.
图 2: 随机搜索 (Random) 与 ACE 的效率对比。X 轴为时间步数,左侧 y 轴为 CoNLL 英语 NER 数据集上的平均最佳验证准确率,右侧 y 轴为当前选择的平均验证准确率。
5.3 Comparison with Embedding Weighting & Ensemble Approaches
5.3 与嵌入加权及集成方法的对比
We compare ACE with two more approaches to further show the effectiveness of ACE. One is a variant of All, which uses a weighting parameter $\pmb{b}=[b_{1},\cdots,b_{l},\cdots,b_{L}]$ passing through a sigmoid function to weight each embedding candidate. Such an approach can explicitly learn the weight of each embedding in training instead of a binary mask. We call this approach All+Weight. Another one is model ensemble, which trains the task model with each embedding candidate individually and uses the trained models to make joint prediction on the test set. We use voting for ensemble as it is simple and fast. For sequence labeling tasks, the models vote for the predicted label at each position. For DP, the models vote for the tree of each sentence. For SDP, the models vote for each potential labeled arc. We use the confidence of model predictions to break ties if there are more than one agreement with the same counts. We call this approach Ensemble. One of the benefits of voting is that it combines the predictions of the task models efficiently without any training process. We can search all possible $2^{L}{-}1$ model ensembles in a short period of time through caching the outputs of the models. Therefore, we search for the best ensemble of models on the development set and then evaluate the best ensemble on the test set $(\mathtt{E n s e m b1e}{\mathtt{d e v}})$ ). Moreover, we additionally search for the best ensemble on the test set for reference $(\mathtt{E n s e m b1e}_{\mathtt{t e s t}})$ , which is the upper bound of the approach. We use the same setting as in Section 4.3.1 and select one of the datasets from each task. For NER, POS tagging, AE, and SDP, we use CoNLL 2003 English, Ritter, 16Res, and DM datasets, respectively. The results are shown in Table 6. Empirical results show that ACE outperforms all the settings of these approaches and even Ensemble test, which shows the effectiveness of ACE and the limitation of ensemble models. All, All+Weight and Ensemb $\exists\in\operatorname{dev}$ are competitive in most of the cases and there is no clear winner of these approaches on all the datasets. These results show the strength of embedding concatenation. Concatenating the embeddings incorporates information from all the embeddings and forms stronger word representations for the task model, while in model ensemble, it is difficult for the individual task models to affect each other.
我们进一步比较ACE与另外两种方法以验证其有效性。第一种是All的变体,通过sigmoid函数对权重参数$\pmb{b}=[b_{1},\cdots,b_{l},\cdots,b_{L}]$进行处理来加权每个嵌入候选,该方法能在训练中显式学习各嵌入权重而非二元掩码,称为All+Weight。第二种是模型集成,即用每个嵌入候选单独训练任务模型,并通过联合预测进行测试集评估。采用简单高效的投票集成:序列标注任务对每个位置标签投票,依存句法分析(DP)对整句树结构投票,语义依存分析(SDP)对带标签弧投票。当最高票数相同时,用模型预测置信度决断。该方法称为Ensemble。投票优势在于无需训练即可高效整合模型预测,通过缓存模型输出可快速搜索开发集上$2^{L}{-}1$种可能集成组合$(\mathtt{Ensemble}{\mathtt{dev}})$,并在测试集评估最优组合。另搜索测试集最优集成$(\mathtt{Ensemble}{\mathtt{test}})$作为理论上限。实验设置与4.3.1节相同,各任务选用CoNLL 2003 English(NER)、Ritter(词性标注)、16Res(AE)和DM(SDP)数据集。表6显示ACE在所有设置下均优于对比方法(包括Ensemble test),证明集成模型的局限性。All、All+Weight和Ensemble$_{\mathtt{dev}}$在多数情况下表现相近,无绝对优势方法。结果表明嵌入拼接能整合所有嵌入信息形成更强词表征,而模型集成中各任务模型难以相互影响。
Table 4: Comparison with state-of-the-art approaches in DP and SDP. †: For reference, they additionally used constituency dependencies in training. We also find that the PTB dataset used by Mrini et al. (2020) is not identical to the dataset in previous work such as Zhang et al. (2020) and Wang and Tu (2020). : For reference, we confirmed with the authors of He and Choi (2020) that they used a different data pre-processing script with previous work.
表 4: 与当前最先进的 DP 和 SDP 方法对比。†: 作为参考,他们在训练中还额外使用了成分依存关系。我们还发现 Mrini 等人 (2020) 使用的 PTB 数据集与 Zhang 等人 (2020) 和 Wang 与 Tu (2020) 之前工作中使用的数据集并不相同。: 作为参考,我们与 He 和 Choi (2020) 的作者确认过,他们使用了与之前工作不同的数据预处理脚本。
| DP | SDP | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| PTB UAS | DM | PAS | PSD | ||||||
| LAS | ID | OOD | ID | OOD | ID | OOD | |||
| Zhou and Zhao (2019) | 97.2 | 95.7 | He and Choi (2020) | 94.6 | 90.8 | 96.1 | 94.4 | 86.8 | 79.5 |
| Mrini et al. (2020) | 97.4 | 96.3 | D&M(2018) | 93.7 | 88.9 | 93.9 | 90.6 | 81.0 | 79.4 |
| Liet al.(2020) | 96.6 | 94.8 | Wang et al. (2019) | 94.0 | 89.7 | 94.1 | 91.3 | 81.4 | 79.6 |
| Zhang et al. (2020) | 96.1 | 94.5 | Jia et al.(2020) | 93.6 | 89.1 | - | - | ||
| Wang and Tu (2020) | 96.9 | 95.3 | F&G(2020) | 94.4 | 91.0 | 95.1 | 93.4 | 82.6 | 82.0 |
| XLNET+Fine-tune | 97.0 | 95.6 | XLNet+Fine-tune | 94.2 | 90.6 | 94.8 | 93.4 | 82.7 | 81.8 |
| ACE+Fine-tune | 97.2 | 95.8 | ACE+Fine-tune | 95.6 | 92.6 | 95.8 | 94.6 | 83.8 | 83.4 |
Table 5: Comparison of reward functions.
表 5: 奖励函数对比
| DEV | TEST | |
|---|---|---|
| ACE Nodiscount (Eq. 5) | 93.18 92.98 | 90.00 89.90 |
| Simple (Eq. 4) | 92.89 | 89.82 |
Table 6: A comparison among All, Random, ACE, All+Weight and Ensemble. CHK: chunking.
表 6: All、Random、ACE、All+Weight 和 Ensemble 的对比。CHK: 分块。
| DP | SDP | NER | POS | AE | CHK | UAS | LAS | ID | OOD | |
|---|---|---|---|---|---|---|---|---|---|---|
| All | 92.4 | 90.6 | 73.2 | 96.7 | 96.7 | 95.1 | 94.3 | 90.8 | ||
| Random | 92.6 | 91.3 | 74.7 | 96.7 | 96.8 | 95.2 | 94.4 | 90.8 | ||
| ACE | 93.0 | 91.7 | 75.6 | 96.8 | 96.9 | 95.3 | 94.5 | 90.9 | ||
| All+Weight | 92.7 | 90.4 | 73.7 | 96.7 | 96.7 | 95.1 | 94.3 | |||
| Ensemble | 92.2 | 90.6 | 68.1 | 96.5 | 96.1 | 94.3 | 94.1 | |||
| Ensembledev | 92.2 | 90.8 | 70.2 | 96.7 | 96.8 | 95.2 | 94.3 | |||
| Ensembletest | 92.7 | 91.4 | 73.9 | 96.7 | 96.8 | 95.2 | 94.4 | 90.8 |
6 Discussion: Practical Usability of ACE
6 讨论:ACE的实际可用性
Concatenating multiple embeddings is a commonly used approach to improve accuracy of structured prediction. However, such approaches can be comput ation ally costly as multiple language models are used as input. ACE is more practical than concatenating all embeddings as it can remove those embeddings that are not very useful in the concatenation. Moreover, ACE models can be used to guide the training of weaker models through techniques such as knowledge distillation in structured prediction (Kim and Rush, 2016; Kuncoro et al., 2016; Wang et al., 2020a, 2021b), leading to models that are both stronger and faster.
连接多个嵌入向量是提升结构化预测准确性的常用方法。然而,这种方法可能因使用多个语言模型作为输入而导致计算成本高昂。ACE (Adaptive Concatenated Embeddings) 比直接拼接所有嵌入更实用,因为它能剔除拼接过程中效用较低的嵌入。此外,ACE模型可通过知识蒸馏等技术 (Kim and Rush, 2016; Kuncoro et al., 2016; Wang et al., 2020a, 2021b) 指导较弱模型的训练,从而获得性能更强、速度更快的模型。
7 Conclusion
7 结论
In this paper, we propose Automated Concatenation of Embeddings, which automatically searches for better embedding concatenation for structured prediction tasks. We design a simple search space and use the reinforcement learning with a novel reward function to efficiently guide the controller to search for better embedding concatenations. We take the change of embedding concatenations into the reward function design and show that our new reward function is stronger than the simpler ones. Results show that ACE outperforms strong baselines. Together with fine-tuned embeddings, ACE achieves state-of-the-art performance in 6 tasks over 21 datasets.
本文提出自动嵌入拼接技术(ACE, Automated Concatenation of Embeddings),通过自动搜索为结构化预测任务寻找更优的嵌入拼接方案。我们设计了一个简洁的搜索空间,采用强化学习方法配合新型奖励函数,高效引导控制器探索更优的嵌入组合。通过将嵌入拼接变化纳入奖励函数设计,我们证明了新奖励函数优于简单方案。实验结果表明,ACE在21个数据集的6项任务中超越强基线方法,结合微调嵌入后取得了最先进性能。