HAMLET: A Hierarchical Multimodal Attention-based Human Activity Recognition Algorithm
HAMLET:一种基于分层多模态注意力机制的人类活动识别算法
Abstract— To fluently collaborate with people, robots need the ability to recognize human activities accurately. Although modern robots are equipped with various sensors, robust human activity recognition (HAR) still remains a challenging task for robots due to difficulties related to multimodal data fusion. To address these challenges, in this work, we introduce a deep neural network-based multimodal HAR algorithm, HAMLET. HAMLET incorporates a hierarchical architecture, where the lower layer encodes spatio-temporal features from unimodal data by adopting a multi-head self-attention mechanism. We develop a novel multimodal attention mechanism for disentangling and fusing the salient unimodal features to compute the multimodal features in the upper layer. Finally, multimodal features are used in a fully connect neural-network to recognize human activities. We evaluated our algorithm by comparing its performance to several state-of-the-art activity recognition algorithms on three human activity datasets. The results suggest that HAMLET outperformed all other evaluated baselines across all datasets and metrics tested, with the highest top-1 accuracy of $95.12%$ and $97.45%$ on the UTD-MHAD [1] and the UT-Kinect [2] datasets respectively, and F1-score of $81.52%$ on the UCSD-MIT [3] dataset. We further visualize the unimodal and multimodal attention maps, which provide us with a tool to interpret the impact of attention mechanisms concerning HAR.
摘要— 为了与人类流畅协作,机器人需要具备准确识别人体活动的能力。尽管现代机器人配备了多种传感器,但由于多模态数据融合的困难,稳健的人体活动识别(HAR)对机器人而言仍是具有挑战性的任务。为解决这些难题,本研究提出了一种基于深度神经网络的多模态HAR算法HAMLET。HAMLET采用分层架构,其底层通过多头自注意力机制从单模态数据中编码时空特征。我们开发了一种新颖的多模态注意力机制,用于解耦并融合显著的单模态特征,从而在上层计算多模态特征。最终,多模态特征被输入全连接神经网络以识别人体活动。我们通过在三个人体活动数据集上与多种先进活动识别算法进行性能对比来评估本算法。结果表明,HAMLET在所有测试数据集和指标上均优于其他基线模型,在UTD-MHAD [1]和UT-Kinect [2]数据集上分别达到最高top-1准确率$95.12%$和$97.45%$,在UCSD-MIT [3]数据集上获得F1分数$81.52%$。我们还可视化单模态和多模态注意力图,这为解释注意力机制对HAR的影响提供了工具。
I. INTRODUCTION
I. 引言
Robots are sharing physical spaces with humans in various collaborative environments, from manufacturing to assisted living to healthcare [4]–[6], to improve productivity and to reduce human cognitive and physical workload [7]. To be effective in close proximity to people, collaborative robotic systems (CRS) need the ability to automatically and accurately recognize human activities [8]. This capability will enable CRS to operate safely and autonomously to work alongside human teammates [9].
机器人在从制造业到辅助生活再到医疗保健等各类协作环境中与人类共享物理空间[4]-[6],以提高生产力并减轻人类的认知和体力负担[7]。为在近距离接触人类时保持高效,协作机器人系统(CRS)需要具备自动准确识别人体活动的能力[8]。这一能力将使CRS能够安全自主地运行,与人类队友协同工作[9]。
To fluently and fluidly collaborate with people, CRS needs to recognize the activities performed by their human teammates robustly [3], [10], [11]. Although modern robots are equipped with various sensors, robust human activity recognition (HAR) remains a fundamental problem for CRS [5]. This is partly because fusing multimodal sensor data efficiently for HAR is challenging. Therefore, to date, many researchers have focused on recognizing human activities by leveraging on a single modality, such as visual, pose or wearable sensors [7], [12]–[15]. However, HAR models reliant on unimodal data often suffer a single point feature representation failure. For example, visual occlusion, poor lighting, shadows, or complex background can adversely affect only visual sensor-based HAR methods. Similarly, noisy data from acc el ero meter or gyroscope sensors can reduce the performance of HAR methods solely depending on these sensors [3], [16].
为了流畅自如地与人类协作,协作机器人系统(CRS)需要稳健地识别人类队友的活动[3]、[10]、[11]。尽管现代机器人配备了多种传感器,但稳健的人类活动识别(HAR)仍是CRS面临的基础性难题[5]。部分原因在于高效融合多模态传感器数据实现HAR具有挑战性。因此,迄今许多研究者专注于利用单一模态(如视觉、姿态或可穿戴传感器)来识别人类活动[7]、[12]-[15]。然而,依赖单模态数据的HAR模型常面临单点特征表征失效问题。例如视觉遮挡、光照不足、阴影或复杂背景会仅影响基于视觉传感器的HAR方法;同理,加速度计或陀螺仪传感器的噪声数据会降低仅依赖这些传感器的HAR方法性能[3]、[16]。

Fig. 1: Example of two activities (Sit-Down and Carry) from the UT-Kinect dataset (the first row). The second row presents the temporal-attention weights on the corresponding RGB frames using HAMLET. For these sequences, HAMLET pays more attention to the third RGB image segment for the Sit-Down activity (top) and on the fourth RGB image segment for the Carry activity (bottom). Here, a lighter color represents a lower attention.
图 1: UT-Kinect数据集中两个活动(坐下和搬运)的示例(第一行)。第二行展示了使用HAMLET模型在对应RGB帧上的时序注意力权重。对于这些序列,HAMLET对坐下活动(上方)的第三个RGB图像片段和搬运活动(下方)的第四个RGB图像片段给予了更多关注。此处,较浅的颜色表示较低的注意力权重。
Several approaches have been proposed to overcome the weaknesses of the unimodal methods by fusing multimodal sensor data that can provide complementary strengths to achieve a robust HAR [3], [16]–[20]. Although many of these approaches exhibit robust performances than unimodal HAR approaches, there remain several challenges that prevent these methods from efficiently working on CRSs [16]. For example, while fusing data from multiple modalities, these methods rely on a fixed-fusion approach, e.g., concatenate, average, or sum. Although one type of fusion approach works for a specific activity, these approaches can not provide any guaranty that the same performance can be achieved on a different activity class using the same merging method. Moreover, these proposed approaches provide uniform weightage on the data from all modalities. However, depending on the environment, one sensor modality may provide more enhanced information than the other sensor modality. For example, a visual sensor may provide valuable information about a gross human activity than a gyroscope sensor data, which a robot needs to learn from data automatically. Thus, these approaches can not provide robust HAR for CRSs.
为克服单模态方法的局限性,研究者提出了多种融合多模态传感器数据的方案,通过互补优势实现鲁棒的人体活动识别(HAR) [3], [16]–[20]。尽管这些方法大多展现出优于单模态HAR方案的性能,但在认知机器人系统(CRSs)中仍存在若干关键挑战[16]。例如,现有方法在融合多模态数据时普遍采用固定策略(如拼接、均值或求和),虽然特定融合方式对某类活动有效,但无法保证相同方法在其他活动类别上保持同等性能。此外,这些方案对所有模态数据赋予均等权重,而实际环境中不同传感器的信息贡献度存在差异(如视觉传感器对宏观人体活动的表征能力通常优于陀螺仪数据)。这种机制缺陷导致现有方法难以满足CRSs对鲁棒HAR的需求。
To address these challenges, in this work, we introduce a novel multimodal human activity recognition algorithm, called HAMLET: Hierarchical Multimodal Self-attention based HAR algorithm for CRS. HAMLET first extracts the spatio-temporal salient features from the unimodal data for each modality. HAMLET then employs a novel multimodal attention mechanism, called MAT: Multimodal Atention based Feature Fusion, for disentangling and fusing the unimodal features. These fused multimodal features enable
为了解决这些挑战,本工作提出了一种新颖的多模态人类活动识别算法,称为HAMLET:基于分层多模态自注意力机制的CRS活动识别算法。HAMLET首先从每种模态的单模态数据中提取时空显著特征。随后采用创新的多模态注意力机制MAT(基于多模态注意力的特征融合)来解耦和融合单模态特征。这些融合后的多模态特征能够...
HAMLET to achieve higher HAR accuracies (see Sec. III).
HAMLET 以实现更高的 HAR (Human Activity Recognition,人类活动识别) 准确率(见第 III 节)。
The modular approach to extract spatial-temporal salient features from unimodal data allows HAMLET to incorporate pre-trained feature encoders for some modalities, such as pre-trained ImageNet models for RGB and depth modalities. This flexibility enables HAMLET to incorporate deep neural network-based transfer learning approaches. Additionally, the proposed novel multimodal fusion approach (MAT) utilizes a multi-head self-attention mechanism, which allows HAMLET to be robust in learning weights of different modalities based on their relative importance in HAR from data.
采用从单模态数据中提取时空显著特征的模块化方法,使得HAMLET能够整合针对某些模态的预训练特征编码器(例如用于RGB和深度模态的预训练ImageNet模型)。这种灵活性使HAMLET能够结合基于深度神经网络的迁移学习方法。此外,所提出的新型多模态融合方法(MAT)采用了多头自注意力机制,使HAMLET能够根据数据中各模态在HAR中的相对重要性,稳健地学习不同模态的权重。
We evaluated HAMLET by assessing its performance on three human activity datasets (UCSD-MIT [3], UTD-MHAD [1] and UT-Kinect [2]) compared with several state-of-the-art activity recognition algorithms from prior literature ( [1], [3], [18], [21]–[27]) and two baseline methods (see Sec. IV). In our empirical evaluation, HAMLET outperformed all other evaluated baselines across all datasets and metrics tested, with the highest top-1 accuracy of $95.12%$ and $97.45%$ on the UTD-MHAD [1] and the UT-Kinect [2] datasets respectively, and F1-score of $81.52%$ on the UCSD-MIT [3] dataset (see Sec. V). We visualize an attention map representing how the unimodal and the multimodal attention mechanism impacts multimodal feature fusion for HAR (see Sec. V-D).
我们通过评估HAMLET在三个人体活动数据集(UCSD-MIT [3]、UTD-MHAD [1]和UT-Kinect [2])上的性能,与先前文献中的几种最先进活动识别算法([1]、[3]、[18]、[21]–[27])以及两种基线方法(见第IV节)进行了对比。在实证评估中,HAMLET在所有测试数据集和指标上均优于其他基线方法,在UTD-MHAD [1]和UT-Kinect [2]数据集上分别取得了最高top-1准确率$95.12%$和$97.45%$,在UCSD-MIT [3]数据集上取得了F1分数$81.52%$(见第V节)。我们可视化了一个注意力图,展示了单模态和多模态注意力机制如何影响HAR(人体活动识别)的多模态特征融合(见第V-D节)。
II. RELATED WORKS
II. 相关工作
Unimodal HAR: Human activity recognition has been extensively studied by analyzing and employing the unimodal sensor data, such as skeleton, wearable sensors, and visual (RGB or depth) modalities [28]. As generating hand- crafted features is found to be a difficult task, and these features are often highly domain-specific, many researchers are now utilizing the deep neural network-based approaches for human activity recognition.
单模态HAR:人类活动识别已通过分析和利用单模态传感器数据(如骨架、可穿戴传感器和视觉(RGB或深度)模态)得到广泛研究[28]。由于手工制作特征被认为是一项困难的任务,且这些特征通常具有高度领域特定性,许多研究者现在采用基于深度神经网络的方法进行人类活动识别。
Deep learning-based feature representation architectures, especially convolutional neural networks (CNNs) and longshort-term memory (LSTM), have been widely adopted to encode the spatio-temporal features from visual (i.e., RGB and depth) [12], [29]–[33] and non-visual (i.e., sEMG and IMUs) sensors data [3], [7], [34]. For example, Li et al. [29] developed a CNN-based learning method to capture the spatio-temporal co-occurrences of skeletal joints. To recognizing human activities from video data, Wang et al. proposed a 3D-CNN and LSTM-based hybrid model to detect compute salient features [35]. Recently, the graphical convolutional network has been adopted to find spatialtemporal patterns in unimodal data [13].
基于深度学习的特征表示架构,尤其是卷积神经网络 (CNN) 和长短期记忆网络 (LSTM),已被广泛用于从视觉(即RGB和深度)[12]、[29]–[33] 和非视觉(即sEMG和IMU)传感器数据 [3]、[7]、[34] 中编码时空特征。例如,Li等人 [29] 开发了一种基于CNN的学习方法,用于捕捉骨骼关节的时空共现特征。为了从视频数据中识别人体活动,Wang等人提出了一种基于3D-CNN和LSTM的混合模型来检测计算显著特征 [35]。最近,图卷积网络被用于在单模态数据中发现时空模式 [13]。
Although these deep-learning-based HAR methods have shown promising performances in many cases, these approaches rely significantly on modality-specific feature embeddings. If such an encoder fails to encode the feature properly because of noisy data (e.g., visual occlusion or missing or low-quality sensor data), then these activity recognition methods suffer to perform correctly.
尽管这些基于深度学习的HAR(人类活动识别)方法在许多情况下表现优异,但这些方法高度依赖于特定模态的特征嵌入。如果由于数据噪声(例如视觉遮挡、传感器数据缺失或质量低下)导致编码器无法正确编码特征,这些活动识别方法的性能就会受到影响。
Multimodal HAR: Many researchers have started working on designing multimodal learning methods by utilizing the complementary features from different modalities effectively to overcome the dependencies on a single modality data of modality-specific HAR models [17], [18], [36], [37]. One crucial challenge that remains in developing a multimodal learning model is to fuse the various unimodal features efficiently.
多模态HAR:许多研究者开始致力于设计多模态学习方法,通过有效利用不同模态间的互补特征来克服单模态HAR模型对单一模态数据的依赖性[17], [18], [36], [37]。开发多模态学习模型时仍面临一个关键挑战,即如何高效融合多种单模态特征。
Several approaches have been proposed to fuse data from similar modalities [38]–[42]. For example, Simonyan et al. proposed a two-stream CNN-based architecture, where they incorporated a spatial CNN network to capture the spatial features, and another CNN-based temporal network to learn the temporal features from visual data [38]. As CNN-based two-stream network architecture allows to appropriately combine the spatio-temporal features, it has been studied in several recent works, e.g., residual connection in streams [39], convolutional fusion [41] and slow-fast network [33].
已有多种方法被提出用于融合相似模态的数据 [38]–[42]。例如,Simonyan等人提出了一种基于双流CNN的架构,其中结合了空间CNN网络来捕捉空间特征,以及另一个基于CNN的时间网络来从视觉数据中学习时间特征 [38]。由于基于CNN的双流网络架构能够恰当结合时空特征,近期多项研究对其进行了探索,例如流中的残差连接 [39]、卷积融合 [41] 以及慢快网络 [33]。
Other works have focused on fusing features from various modalities, i.e., fusing features from visual (RGB), pose, and wearable sensor modalities simultaneously [16], [37], [43]. Minzner et al. [19] studied four types of feature fusion approaches: early fusion, sensor and channel-based late fusion, and shared filters hybrid fusion. They found that the late and hybrid fusion outperformed early fusion. Other approaches have focused on fusing modality-specific features at a different level of a neural network architecture [43]. For example, Joze et al. [37] designed an incremental feature fusion method, where the features are merged at different levels of the architecture. Although these approaches have been proposed in the literature, generating multimodal features by dynamically selecting the unimodal features is still an open challenge.
其他研究专注于融合来自不同模态的特征,即同时融合视觉(RGB)、姿态和可穿戴传感器模态的特征 [16], [37], [43]。Minzner 等人 [19] 研究了四种特征融合方法:早期融合、基于传感器和通道的晚期融合,以及共享滤波器混合融合。他们发现晚期和混合融合的表现优于早期融合。其他方法则侧重于在神经网络架构的不同层级融合特定模态的特征 [43]。例如,Joze 等人 [37] 设计了一种增量式特征融合方法,其中特征在架构的不同层级进行合并。尽管这些方法已在文献中提出,但通过动态选择单模态特征来生成多模态特征仍是一个开放的挑战。
Attention mechanism for HAR: Attention mechanism has been adopted in various learning architectures to improve the feature representation as it allows the feature encoder to focus on specific parts of the representation while extracting the salient features [18], [44]–[50]. Recently, several multihead self-attention based methods have been proposed, which permit to disentangle the feature embedding into multiple features (multi-head) and to fuse the salient features to produce a robust feature embedding [51].
HAR中的注意力机制:注意力机制已被应用于多种学习架构中以提升特征表示能力,它能让特征编码器在提取显著特征时聚焦于表示的特定部分 [18], [44]–[50]。近期提出的多头自注意力方法可将特征嵌入解耦为多重特征(多头),并通过融合显著特征生成鲁棒的特征嵌入 [51]。
Many researchers have started adopting the attention mechanism in human activity recognition [17], [18]. For example, Xiang et al. proposed a multimodal video classification network, where they utilized an attention-based spatio- temporal feature encoder to infer modality-specific feature representation [18]. The authors explored the different types of multimodal feature fusion approaches (feature concatenation, LSTM fusion, attention fusion, and probabilistic fusion), and found that the concatenated features showed the best performance among the other fusion methods. To date, most of the HAR approaches have utilized attention-based methods for encoding the unimodal features. However, the attention mechanism has not been used for extracting and fusing salient features from multiple modalities.
许多研究者已开始在人类活动识别(HAR)中采用注意力机制 [17][18]。例如Xiang等人提出了一种多模态视频分类网络,通过基于注意力的时空特征编码器来推断特定模态的特征表示 [18]。作者探索了多种多模态特征融合方法(特征拼接、LSTM融合、注意力融合和概率融合),发现拼接特征在其他融合方法中表现最佳。目前大多数HAR方法使用基于注意力的方法来编码单模态特征,但尚未将注意力机制用于从多模态中提取和融合显著特征。
To address these challenges, in our proposed multimodal HAR algorithm (HAMLET), we have designed a modular way to encode unimodal spatio-temporal features by adopting a multi-head self-attention approach. Additionally, we have developed a novel multimodal attention mechanism, MAT, for disentangling and fusing the salient unimodal features to compute the multimodal features.
为了解决这些挑战,我们在提出的多模态HAR算法(HAMLET)中设计了一种模块化方法,通过采用多头自注意力(self-attention)方法来编码单模态时空特征。此外,我们还开发了一种新颖的多模态注意力机制MAT,用于解耦和融合显著的单模态特征以计算多模态特征。

Fig. 2: HAMLET: Hierarchical Multimodal Self-Attention based HAR.
图 2: HAMLET: 基于分层多模态自注意力(Hierarchical Multimodal Self-Attention)的人体动作识别(HAR)框架。
III. PROPOSED MODULAR LEARNING METHOD
III. 提出的模块化学习方法
In this section, we present our proposed multimodal human-activity recognition method, called HAMLET: Hierarchical Multimodal Self-attention based HAR. We present the overall architecture in Fig. 2. In HAMLET, the multimodal features are encoded into two steps, and those features are then used for activity recognition as follows:
在本节中,我们提出了一种名为HAMLET的多模态人类活动识别方法:基于分层多模态自注意力的HAR。整体架构如图2所示。在HAMLET中,多模态特征分两步进行编码,这些特征随后用于活动识别,具体如下:
A. Unimodal Feature Encoder
A. 单模态特征编码器
The first step of HAMLET is to compute a feature representation for data from every modality. To achieve that, we have designed modality-specific feature encoders to encode data from different modalities. The main reasoning behind this type of modality-specific modular feature encoder architecture is threefold. First, each of the modalities has different feature distribution and thus needs to have a different feature encoder architecture. For example, the distribution and representation of visual data differ from the skeleton and inertial sensor data. Second, the modular architecture allows incorporating unimodal feature encoders without interrupting the performance of the encoders of other modalities. This capability enables the modality-specific transfer learning. Thus we can employ a pre-trained feature encoder to produce robust feature representation for each modality. Third, the unimodal feature encoders can be trained and executed in parallel, which reduces the computation time during the training and inference phases.
HAMLET的第一步是为每种模态的数据计算特征表示。为此,我们设计了针对特定模态的特征编码器来编码不同模态的数据。采用这种模块化模态专用特征编码器架构的主要原因有三点。首先,每种模态具有不同的特征分布,因此需要不同的特征编码器架构。例如,视觉数据的分布和表示与骨架及惯性传感器数据不同。其次,模块化架构可以在不影响其他模态编码器性能的情况下集成单模态特征编码器,这一特性支持模态特定的迁移学习,因此我们可以使用预训练的特征编码器为每种模态生成鲁棒的特征表示。第三,单模态特征编码器可以并行训练和执行,从而减少训练和推理阶段的计算时间。
Each of the unimodal feature encoders is divided into three separate sequential sub-modules: spatial feature encoder, temporal feature encoder, and unimodal attention module (UAT). Before applying a spatial feature encoder, at first the whole sequence of data $D^{m}=(d_{1}^{m},d_{2}^{m},...,d_{T}^{m})$ from modality $m$ is converted into segmented sequence $X^{m}=$ $\left(x_{1}^{m},x_{2}^{m},...,x_{S^{m}}^{m}\right)$ of size $B\times S^{m}\times E^{m}$ , where $B$ is the batch size, $S^{m}$ and $E^{m}$ are the number of segments and feature dimension for modality $m$ respectively. In this work, we represent the feature dimension $E^{m}$ for RGB and depth modality as $(c h a n n e l(C^{m})\times h e i g h t(H^{m})\times w i d t h(W^{m}))$ , where $C^{m}$ is the number of channels in an image.
每个单模态特征编码器分为三个独立的顺序子模块:空间特征编码器、时序特征编码器和单模态注意力模块 (UAT)。在应用空间特征编码器之前,首先将来自模态 $m$ 的整个数据序列 $D^{m}=(d_{1}^{m},d_{2}^{m},...,d_{T}^{m})$ 转换为大小为 $B\times S^{m}\times E^{m}$ 的分段序列 $X^{m}=$ $\left(x_{1}^{m},x_{2}^{m},...,x_{S^{m}}^{m}\right)$,其中 $B$ 是批处理大小,$S^{m}$ 和 $E^{m}$ 分别是模态 $m$ 的分段数量和特征维度。在这项工作中,我们将RGB和深度模态的特征维度 $E^{m}$ 表示为 $(通道数(C^{m})\times 高度(H^{m})\times 宽度(W^{m}))$,其中 $C^{m}$ 是图像中的通道数。
- Spatial Feature Encoder: We used a temporal pooling method to encode segment-level features instead of extracting the frame-level features, similar to [18]. We have implemented the temporal pooling for two reasons: first, as the successive frames represent similar features, it is redundant to apply spatial feature encoder on each frame, which increases the training and testing time. By Utilizing the temporal pooling, HAMLET reduces its computational time. Moreover, this polling approach is necessary to implement HAMLET on a real-time robotic system. Second, the application of recurrent neural networks for each frame is computationally expensive for a long sequence of data. We used adaptive temporal max-pool to pool the encoded segment level features.
- 空间特征编码器 (Spatial Feature Encoder): 我们采用类似 [18] 的时间池化方法对片段级特征进行编码,而非提取帧级特征。选择时间池化主要基于两点考量:首先,连续帧呈现相似特征,逐帧应用空间特征编码器会产生冗余计算,显著增加训练和测试时间。通过时间池化,HAMLET 有效降低了计算耗时,这种池化策略对于实时机器人系统的部署也至关重要。其次,对长序列数据逐帧应用循环神经网络会带来极高的计算开销。我们采用自适应时间最大池化来聚合编码后的片段级特征。
As our proposed modular architecture allows modalityspecific transfer learning, we have incorporated the available state-of-the-art pre-trained unimodal feature encoders. For example, we have incorporated ResNet50 to encode the RGB modality. We extend the convolutional co-occurrence feature learning method [29] to hierarchically encode segmented skeleton and inertial sensor data. In this work, we used two stacked 2D-CNNs architecture to encode co-occurrence features: first 2D-CNN encodes the intra-frame point-level information and second 2D-CNN extract the inter-frame features in a segment. Finally, spatial feature encoder for modality $m$ produces a spatial feature representation $F_{m}^{S}$ of size $(B\times S^{m}\times E^{S,m})$ from segmented $X^{m}$ , where $E^{S,m}$ is the spatial feature embedding dimension.
我们提出的模块化架构支持模态特定的迁移学习,因此整合了当前最先进的预训练单模态特征编码器。例如,我们采用ResNet50对RGB模态进行编码,并扩展了卷积共现特征学习方法[29]来分层编码分割后的骨架和惯性传感器数据。本工作中,我们使用双层2D-CNN架构编码共现特征:第一层2D-CNN编码帧内点级信息,第二层2D-CNN提取片段中的帧间特征。最终,模态$m$的空间特征编码器从分割后的$X^{m}$生成尺寸为$(B\times S^{m}\times E^{S,m})$的空间特征表示$F_{m}^{S}$,其中$E^{S,m}$为空间特征嵌入维度。
- Temporal Feature Encoder: After encoding the segment level unimodal features, we employ recurrent neural networks, specifically unidirectional LSTM, to extract the temporal feature features $H^{m}=(h_{1}^{m},h_{2}^{m},...,h_{s}^{m})$ of size $(B\times S^{m}\times E^{H,m})$ from $F_{m}^{S}$ , where $E^{H,m}$ is the LSTM hidden feature dimension. Our choice of unidirectional LSTM over other recurrent neural network architectures (such as gated recurrent units) was based on the ability of LSTM units to capture long-term temporal relationships among the features. Besides, we need our model to detect human activities in real-time, which motivated our choice of unidirectional LSTMs over bi-directional LSTMs.
- 时序特征编码器: 在完成分段级单模态特征编码后,我们采用循环神经网络(具体为单向LSTM)从$F_{m}^{S}$中提取尺寸为$(B\times S^{m}\times E^{H,m})$的时序特征$H^{m}=(h_{1}^{m},h_{2}^{m},...,h_{s}^{m})$,其中$E^{H,m}$表示LSTM隐藏特征维度。选择单向LSTM而非其他循环神经网络架构(如门控循环单元)是基于LSTM单元捕获特征间长期时序关系的能力。此外,由于需要模型实时检测人类活动,这促使我们选择单向LSTM而非双向LSTM。
- Unimodal Self-Attention (UAT) Mechanism: The spatial and temporal feature encoder sequentially encodes the long-range features. However, it cannot extract salient features by employing sparse attention to the different parts of the spatial-temporal feature sequence. Self-attention allows the feature encoder to pay attention to the sequential features sparsely and thus produce a robust unimodal feature encoding. Taking inspiration from the Transformer-based multi-head self-attention methods [51], UAT combines the temporal sequential salient features for each modality. As each modality has its unique feature representation, the multi-head self-attention enables the UAT to disentangle and attend salient unimodal features.
- 单模态自注意力 (UAT) 机制:空间和时间特征编码器依次对长程特征进行编码。然而,它无法通过对时空特征序列的不同部分施加稀疏注意力来提取显著特征。自注意力机制使特征编码器能够稀疏地关注序列特征,从而生成鲁棒的单模态特征编码。受基于Transformer的多头自注意力方法 [51] 的启发,UAT为每种模态结合了时序显著特征。由于每种模态都有其独特的特征表示,多头自注意力使UAT能够解耦并关注显著的单模态特征。
To compute the attended modality-specific feature embedding $F_{m}^{a}$ for modality $m$ using unimodal multi-head selfattention method, at first we need to linearly project the spatial-temporal hidden feature embedding $H^{m}$ to create query $(Q_{i}^{m})$ , key $(K_{i}^{m})$ and value $(V_{i}^{m})$ for head $i$ in the following way,
为计算模态 $m$ 的注意力特征嵌入 $F_{m}^{a}$,我们首先采用单模态多头自注意力方法,将时空隐藏特征嵌入 $H^{m}$ 线性投影生成查询 $(Q_{i}^{m})$、键 $(K_{i}^{m})$ 和值 $(V_{i}^{m})$,具体方式如下:
$$
\begin{array}{c c c}{{Q_{i}^{m}}}&{{=}}&{{H^{m}W_{i}^{Q,m}}}\ {{K_{i}^{m}}}&{{=}}&{{H^{m}W_{i}^{K,m}}}\ {{V_{i}^{m}}}&{{=}}&{{H^{m}W_{i}^{V,m}}}\end{array}
$$
$$
\begin{array}{c c c}{{Q_{i}^{m}}}&{{=}}&{{H^{m}W_{i}^{Q,m}}}\ {{K_{i}^{m}}}&{{=}}&{{H^{m}W_{i}^{K,m}}}\ {{V_{i}^{m}}}&{{=}}&{{H^{m}W_{i}^{V,m}}}\end{array}
$$
Here, each modality $\begin{array}{r}{W_{i\ldots}^{Q,m}\in\mathbb{R}^{E^{H,m}\times\check{E}^{K}},W_{i}^{K,m}\in\mathbb{R}^{E^{H,m}\times E^{K}}}\end{array}$ $m$ has its own projection parameters, , and $W_{i}^{V,m}\in$ $\mathbb{R}^{\boldsymbol{E}^{H,m}\times\boldsymbol{E}^{V}}$ , where $E^{K}$ and $E^{V}$ are projection dimensions, $E^{K}=E^{V}=E^{H,m}/h^{m}$ , and $h$ is the total number of heads for modality $m$ . After that we used scaled dot-product softmax approach to compute the attention score for head $i$ as:
这里,每种模态 $m$ 都有其自身的投影参数 $\begin{array}{r}{W_{i\ldots}^{Q,m}\in\mathbb{R}^{E^{H,m}\times\check{E}^{K}},W_{i}^{K,m}\in\mathbb{R}^{E^{H,m}\times E^{K}}}\end{array}$ 和 $W_{i}^{V,m}\in$ $\mathbb{R}^{\boldsymbol{E}^{H,m}\times\boldsymbol{E}^{V}}$,其中 $E^{K}$ 和 $E^{V}$ 是投影维度,$E^{K}=E^{V}=E^{H,m}/h^{m}$,$h$ 是模态 $m$ 的总头数。之后,我们使用缩放点积 softmax 方法来计算头 $i$ 的注意力分数:
$$
\begin{array}{r c l}{{A t t n(Q_{i}^{m},K_{i}^{m},V_{i}^{m})}}&{{=}}&{{\sigma\left(\cfrac{Q_{i}^{m}K_{i}^{m^{T}}}{\sqrt{d_{k}^{m}}}\right)V_{i}^{m}}}\ {{h e a d_{i}^{m}}}&{{=}}&{{A t t n(Q_{i}^{m},K_{i}^{m},V_{i}^{m})}}\end{array}
$$
$$
\begin{array}{r c l}{{A t t n(Q_{i}^{m},K_{i}^{m},V_{i}^{m})}}&{{=}}&{{\sigma\left(\cfrac{Q_{i}^{m}K_{i}^{m^{T}}}{\sqrt{d_{k}^{m}}}\right)V_{i}^{m}}}\ {{h e a d_{i}^{m}}}&{{=}}&{{A t t n(Q_{i}^{m},K_{i}^{m},V_{i}^{m})}}\end{array}
$$
After that, all the head feature representation is concatenated and projected to produce the attended feature representation, $F_{m}^{a}$ in the following way,
之后,将所有头部特征表示拼接并投影,以生成注意力特征表示 $F_{m}^{a}$ ,具体方式如下:
$$
F_{m}^{a}=[h e a d_{1}^{m};...;h e a d_{h}^{m}]W^{O,m}
$$
$$
F_{m}^{a}=[h e a d_{1}^{m};...;h e a d_{h}^{m}]W^{O,m}
$$
Here, $W^{O,m}$ is the projection parameters of size $E^{H,m}\times E^{H}$ , and the shape of $F_{m}^{a}$ is $(B\times S^{m}\times E^{H})$ , where $E^{H}$ is the attended feature embedding size. We used the same feature embedding size $E^{H}$ for all modalities to simplify the application of multimodal attention MAT for fusing all the modality- specific feature representation, which is presented in the next section III-B. However, our proposed multimodal attention based feature fusion method can handle different unimodal feature dimensions. Finally, we fused the attended segmented sequential feature representation $F_{m}^{a}$ to produce the local unimodal feature representation $F_{m}$ of size $(B\times E^{H})$ . We can use different types of fusion to combine the spatiotemporal segmented feature encodings, such as sum, max, or concatenation. However, the concatenation fusion method is not a suitable approach to fuse large sequences, whereas max fusion may lose the temporal feature embedding information. As the sequential feature representations produced from the same modality, we have used the sum fusion approach to fuse attended unimodal spatial-temporal feature embedding $F_{m}^{a}$ m
此处,$W^{O,m}$ 是尺寸为 $E^{H,m}\times E^{H}$ 的投影参数,$F_{m}^{a}$ 的形状为 $(B\times S^{m}\times E^{H})$,其中 $E^{H}$ 是注意力特征嵌入维度。我们为所有模态使用相同的特征嵌入维度 $E^{H}$,以简化多模态注意力 MAT 的应用,用于融合所有模态特定的特征表示,这将在下一节 III-B 中介绍。然而,我们提出的基于多模态注意力的特征融合方法可以处理不同的单模态特征维度。最后,我们融合了注意力分割的序列特征表示 $F_{m}^{a}$,生成尺寸为 $(B\times E^{H})$ 的局部单模态特征表示 $F_{m}$。我们可以使用不同类型的融合方法来组合时空分割特征编码,例如求和、最大值或拼接。然而,拼接融合方法不适合融合长序列,而最大值融合可能会丢失时序特征嵌入信息。由于同一模态产生的序列特征表示,我们使用求和融合方法来融合注意力单模态时空特征嵌入 $F_{m}^{a}$。
$$
F_{m}=\sum_{s\in S^{m}}F_{m,s}^{a}
$$
$$
F_{m}=\sum_{s\in S^{m}}F_{m,s}^{a}
$$
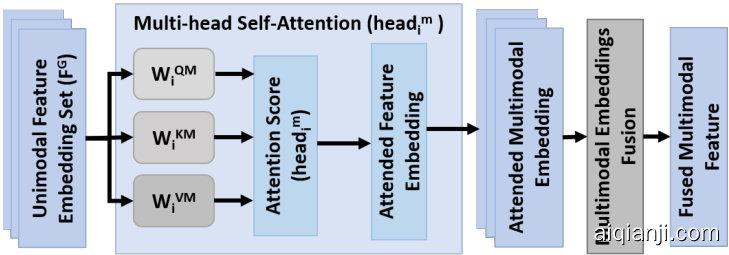
Fig. 3: MAT: Multimodal Attention-based Feature Fusion Architecture.
图 3: MAT: 基于多模态注意力(Multimodal Attention)的特征融合架构。
B. Multimodal Feature Fusion
B. 多模态特征融合
In this work, we developed a novel multimodal feature fusion architecture based on our proposed multi-head selfattention model, MAT: Multimodal Atention based Feature Fusion, which is depicted in Fig. 3. After encoding the unimodal features using the modular feature encoders, we combine these feature embeddings $F_{m}$ in an unordered multimodal feature embedding set $F^{G^{u}}=(F_{1},F_{2},...,F_{M})$ of size $(B\times M\times D^{H})$ , where $M$ is the total number of modalities. After that, we fed the set of unimodal feature representations $F^{G^{u}}$ into MAT, which produces the attended fused multimodal feature representation $F^{G^{a}}$ .
在本工作中,我们基于提出的多头自注意力模型MAT(Multimodal Attention based Feature Fusion)开发了一种新颖的多模态特征融合架构,如图3所示。通过模块化特征编码器对单模态特征进行编码后,我们将这些特征嵌入$F_{m}$组合成一个无序的多模态特征嵌入集$F^{G^{u}}=(F_{1},F_{2},...,F_{M})$,其尺寸为$(B\times M\times D^{H})$,其中$M$表示模态总数。随后,我们将单模态特征表示集$F^{G^{u}}$输入MAT模型,生成经过注意力加权的融合多模态特征表示$F^{G^{a}}$。
The multimodal multi-head self-attention computation is almost similar to the self-attention method described in Section III-A.3. However, there are two key differences. First, unlike encoding the positional information using LSTM to produce the sequential spatial-temporal feature embedding before applying the multi-head self-attention, in MAT, we combine all the modalities feature embeddings without encoding any positional information. Also, MAT and UAT modules have separate multi-head self-attention parameters. Second, after applying the multimodal attention method on the extracted unimodal features, we used two fusion approaches to fused the multimodal features:
多模态多头自注意力计算与第III-A.3节所述的自注意力方法基本相似,但存在两个关键差异。首先,在应用多头自注意力之前,MAT (Multimodal Attention Transformer) 未像传统方法那样使用LSTM编码位置信息来生成序列时空特征嵌入,而是直接合并所有模态的特征嵌入而不编码任何位置信息。此外,MAT和UAT (Unimodal Attention Transformer) 模块拥有独立的多头自注意力参数。其次,在提取的单模态特征上应用多模态注意力方法后,我们采用两种融合策略来整合多模态特征:
MAT-SUM: extracted unimodal features are summed after applying the multimodal attention
MAT-SUM:应用多模态注意力后对提取的单模态特征进行求和
$$
F^{G}=\sum_{m=1}^{M}{F_{m}^{G^{a}}}
$$
$$
F^{G}=\sum_{m=1}^{M}{F_{m}^{G^{a}}}
$$
• MAT-CONCAT: in this approach the attended multimodal features are concatenated
• MAT-CONCAT:该方法将经过注意力处理的多模态特征进行拼接
$$
\begin{array}{r c l}{{{\cal F}^{G}}}&{{=}}&{{[F_{1}^{G^{a}};F_{2}^{G^{a}};...;F_{M}^{G^{a}}]}}\end{array}
$$
$$
\begin{array}{r c l}{{{\cal F}^{G}}}&{{=}}&{{[F_{1}^{G^{a}};F_{2}^{G^{a}};...;F_{M}^{G^{a}}]}}\end{array}
$$
C. Activity Recognition
C. 活动识别
Finally, the fused multimodal feature representation $F^{G}$ is passed through a couple of fully-connected layers to compute the probability for each activity class. For aiding the learning process, we applied activation, dropout, batch normalization in different parts of the learning architecture (see the section IV-B for the implementation details). As all the tasks of human-activity recognition, which we addressed in this work, are multiclass classification, we trained the model using cross-entropy loss function, mini-batch stochastic gradient optimization with weight decay regular iz ation [52].
最后,融合的多模态特征表示 $F^{G}$ 会经过几个全连接层来计算每个活动类别的概率。为了辅助学习过程,我们在学习架构的不同部分应用了激活函数、Dropout和批量归一化(具体实现细节参见第4.2节)。由于本研究中涉及的所有人类活动识别任务都是多类别分类问题,我们采用交叉熵损失函数进行模型训练,并使用带权重衰减正则化[52]的小批量随机梯度优化方法。
$$
l o s s(y,\hat{y})=\frac{1}{B}\sum_{i=1}^{B}y_{i}\log\hat{y_{i}}
$$
$$
l o s s(y,\hat{y})=\frac{1}{B}\sum_{i=1}^{B}y_{i}\log\hat{y_{i}}
$$
TABLE I: Performance comparison (mean top-1 accuracy) of multimodal fusion methods in HAMLET on UT-Kinect dataset [2]
表 1: HAMLET 中多模态融合方法在 UT-Kinect 数据集 [2] 上的性能对比 (平均 top-1 准确率)
| NumberofHeads | FusionMethod |
|---|---|
| UAT | MAT-SUM |
| 1 | |
| 1 | |
| 2 | |
| 2 |
A. Datasets
A. 数据集
We evaluated the performance of our proposed multimodal HAR method, HAMLET, using three human-activity datasets: UTD-MHAD [1], UT-Kinect [2], UCSD-MIT [3].
我们使用三个人类活动数据集评估了所提出的多模态HAR方法HAMLET的性能:UTD-MHAD [1]、UT-Kinect [2]、UCSD-MIT [3]。
UTD-MHAD [1] human activity dataset consists of a total of 27 human actions covering from sports, to hand gestures, to training exercises and daily activities. Eight people repeated each action for four times. After removing the corrupted sequences, this dataset contains a total of 861 data samples.
UTD-MHAD [1] 人类活动数据集共包含27种动作,涵盖体育运动、手势动作、训练动作及日常活动。8名受试者每人重复执行每个动作4次。剔除损坏序列后,该数据集共包含861个有效数据样本。
UT-Kinect [2] dataset contains a total of ten indoor daily life activities (e.g., walking, standing up, etc.) with three modalities: RGB, depth, and 3D skeleton. Each activity was performed two times by each person. Thus there were a total of 200 activity samples in this dataset.
UT-Kinect [2] 数据集包含十种室内日常活动(例如行走、站立等),提供三种模态数据:RGB、深度信息和3D骨架。每种活动由每位参与者执行两次,因此该数据集共包含200个活动样本。
UCSD-MIT [3] human activity dataset consists of eleven sequential activities in an automotive assembly task. Each assembly task was performed five people, and each person performed the task for five times. This dataset contains there modalities: 3D skeleton data from a motion capture system, and sEMG and IMUs data from a wearable sensor.
UCSD-MIT [3] 人类活动数据集包含汽车装配任务中的11个连续活动。每项装配任务由5人执行,每人重复操作5次。该数据集包含三种模态数据:来自运动捕捉系统的3D骨骼数据,以及来自可穿戴传感器的表面肌电信号(sEMG)和惯性测量单元(IMU)数据。
B. Implementation Details
B. 实现细节
Spatial-temporal feature encoder: We incorporated pretrained ResNet50 for encoding the RGB and depth data [53]. We applied max pooling with a kernel size of five and stride of three for pooling segment level features. We extended the co-occurrence [29] feature extraction network to encode segmented skeleton and inertial sensor features. Finally, for capturing the temporal features, we used a twolayer unidirectional LSTM. We used embedding size 128 and 256 for UCSD-MIT [3] and UT-Kinect [2] spatial-temporal features embedding respectively.
时空特征编码器:我们采用预训练的ResNet50来编码RGB和深度数据[53]。对于片段级特征池化,使用了核大小为5、步长为3的最大池化操作。通过扩展共现(co-occurrence)特征提取网络[29]来编码分割后的骨架和惯性传感器特征。最后采用双层单向LSTM捕捉时序特征,分别为UCSD-MIT[3]和UT-Kinect[2]数据集配置了128维和256维的时空特征嵌入。
Hyper-parameters and optimizer: We utilized the pre- trained ResNet architecture for encoding RGB and depth modality. However, in the case of a co-occurrence feature encoder (skeleton and inertial sensor), we applied BatchNorm2D, ReLu activation, and Dropout layers sequentially. After encoding each unimodal features, we applied ReLu activation and Dropout. Finally, in MAT, after fusing the multimodal features, we used BatchNorm-1D, ReLu activation, and Dropout sequentially. We varied the dropout probability between in different layers. In multi-head selfattention for both unimodal and multimodal feature encoders, we varied the number of heads from one to eight. We train the learning model using Adam optimizer with weight decay regular iz ation option [52] and cosine annealing warm restarts [54] with an initial learning rate set to $3e^{-4}$ .
超参数与优化器:我们采用预训练的ResNet架构对RGB和深度模态进行编码。对于共现特征编码器(骨骼与惯性传感器),则依次应用BatchNorm2D、ReLu激活函数和Dropout层。完成各单模态特征编码后,均使用ReLu激活和Dropout处理。在MAT(多模态注意力Transformer)中融合多模态特征后,依次采用BatchNorm-1D、ReLu激活及Dropout。不同层的Dropout概率在范围内调整。单模态与多模态特征编码器的多头自注意力机制中,头数设置为1至8个不等。训练采用带权重衰减正则化[52]的Adam优化器,配合初始学习率为$3e^{-4}$的余弦退火热重启策略[54]。
IV. EXPERIMENTAL SETUP TABLE II: Performance comparison (mean top-1 accuracy) of multimodal HAR methods on UT-Kinect dataset [2]
IV. 实验设置
表 2: 多模态HAR方法在UT-Kinect数据集[2]上的性能对比(平均top-1准确率)
| 方法 | 融合类型 | Top-1准确率(%) |
|---|---|---|
| NSA | SUM | 54.34 |
| CONCAT | 52.31 | |
| USA | SUM | 55.82 |
| CONCAT | 54.34 | |
| KEYLESS18 | CONCAT | 94.50 |
| HAMLET | MAT-SUM | 95.56 |
| MAT-CONCAT | 97.45 |
Training environment: We implemented all the parts of the learning model using Pytorch-1.4 deep learning framework [55]. We trained our model in different types of GPUbased computing environments (GPUs: P100, V100, K80, and RTX6000).
训练环境:我们使用Pytorch-1.4深度学习框架[55]实现了学习模型的所有部分。我们在不同类型的基于GPU的计算环境(GPU:P100、V100、K80和RTX6000)中训练了模型。
C. State-of-the-art Methods and Baselines
C. 先进方法与基线
We designed two baseline HAR methods and reproduce a state-of-art HAR method to evaluate the impact of attention method in encoding and fusing multimodal features:
我们设计了两种基线HAR方法,并复现了一种最先进的HAR方法,以评估注意力机制在编码和融合多模态特征中的影响:
Baseline-1 (NSA) does not use the attention mechanism for encoding unimodal or fusing multimodal features. • Baseline-2 (USA) only applies multi-head self-attention to encode unimodal features but fuses the multimodal embedding without applying attention. This baseline method is similar to the self-attention based multimodal HAR proposed in [17]. • Keyless Attention [18] employed an attention mechanism to encode the modality-specific features. However, it did not utilize attention methods to fuse the multimodal features, instead those were concatenated.
基线1 (NSA) 未使用注意力机制来编码单模态或融合多模态特征。
• 基线2 (USA) 仅应用多头自注意力来编码单模态特征,但在融合多模态嵌入时未使用注意力。该基线方法与[17]中提出的基于自注意力的多模态HAR类似。
• 无键注意力 [18] 采用注意力机制编码模态特定特征,但未利用注意力方法融合多模态特征,而是直接拼接。
D. Evaluation metrics
D. 评估指标
To evaluate the accuracy of HAMLET, the Keyless Attention model [18], the NSA, and the USA algorithms, we performed leave-one-actor-out cross-validation across all the trials for each person on each dataset. Similar to the original evaluation schemes, we reported activity recognition accuracy for the UT-Kinect [2] and the UTD-MHAD datasets [1], and F1-score (in $%$ ) for the UCSD-MIT dataset [3].
为了评估HAMLET、Keyless Attention模型[18]、NSA和USA算法的准确性,我们对每个数据集中的每位受试者进行了留一法交叉验证。与原始评估方案一致,我们在UT-Kinect[2]和UTD-MHAD数据集[1]上报告了活动识别准确率,在UCSD-MIT数据集[3]上报告了F1分数(以$%$计)。
To evaluate HAMLET, the Keyless attention method, and baseline methods on UT-Kinect and UTD-MHAD datasets, we used RGB and skeleton data. We leveraged skeleton, IMUs, and sEMG modalities on the UCSD-MIT dataset.
为评估HAMLET、Keyless注意力方法及基线方法在UT-Kinect和UTD-MHAD数据集上的表现,我们采用了RGB视频与骨骼数据。针对UCSD-MIT数据集,我们则使用了骨骼数据、IMU传感器和sEMG肌电信号三种模态。
V. RESULTS AND DISCUSSION
五、结果与讨论
A. Multimodal Attention-based Fusion Approaches
A. 基于多模态注意力机制的融合方法
We first evaluated the accuracy of two multimodal attention-based feature fusion approaches of HAMLET: MAT-SUM and MAT-CONCAT. We also varied the number of heads used in UAT and MAT steps to determine the optimal configuration of these values.
我们首先评估了HAMLET中两种基于多模态注意力的特征融合方法MAT-SUM和MAT-CONCAT的准确性。同时,我们调整了UAT和MAT步骤中使用的头数,以确定这些值的最佳配置。
Results: We evaluated UAT and MAT attention methods as well as the fusion approaches (MAT-SUM and MATCONCAT) on the UT-Kinect dataset [2], presented in Table I. We used the RGB and skeleton modalities and reported top-1 accuracy by following the original evaluation scheme. The results suggest that the MAT-CONCAT fusion method showed the highest top-1 accuracy $(97.45%)$ , with one and two heads in UAT and MAT methods, respectively.
结果:我们在UT-Kinect数据集[2]上评估了UAT和MAT注意力方法以及融合方法(MAT-SUM和MATCONCAT),如表1所示。我们采用RGB和骨骼模态,并遵循原始评估方案报告了top-1准确率。结果表明,当UAT和MAT方法分别使用1个头和2个头时,MAT-CONCAT融合方法取得了最高的top-1准确率$(97.45%)$。
TABLE III: Performance comparison (mean top-1 accuracy) of multimodal fusion methods on UTD-MHAD dataset [1]
表 III: 多模态融合方法在UTD-MHAD数据集[1]上的性能对比(平均top-1准确率)
| 方法 | 年份 | Top-1准确率(%) |
|---|---|---|
| Kinect&Inertial[1] | 2015 | 79.10 |
| DMM-MFF[27] | 2015 | 88.40 |
| DCNN[26] | 2016 | 91.2 |
| JDM-CNN[25] | 2017 | 88.10 |
| S2DDI[22] | 2017 | 89.04 |
| SOS[24] | 2018 | 86.97 |
| MCRL[23] | 2018 | 93.02 |
| PoseMap[21] | 2018 | 94.51 |
| HAMLET(MAT-CONCAT) | 95.12 |
Discussion: The results suggest the concatenation-based fusion approach (MAT-CONCAT) performed better than the summation-based fusion approach (MAT-SUM). Because the MAT-CONCAT allows MAT to disentangle and apply attention mechanisms on the unimodal features to generate robust multimodal features for activity classification. On the other hand, the sum-based fusion method merged the unimodal features into a single representation, which makes it difficult for MAT to disentangle and apply appropriate attention to unimodal features.
讨论:结果表明,基于拼接的融合方法(MAT-CONCAT)优于基于求和的融合方法(MAT-SUM)。因为MAT-CONCAT允许MAT对单模态特征进行解耦并应用注意力机制,从而为活动分类生成鲁棒的多模态特征。另一方面,基于求和的融合方法将单模态特征合并为单一表示,这使得MAT难以解耦并对单模态特征施加适当的注意力。
The results from Table I also indicate an improvement in activity recognition accuracy with the increment of the number of heads in the MAT when keeping the number of heads fixed in the UAT. However, this relationship does not hold when the number of heads was changed in the UAT. As a large number of heads reduce the size of feature embedding, increasing the number of heads in the UAT may result in an inadequate feature representation. Thus, based on the size of the features used in this work, the results suggest that one head in the UAT and two heads in the MAT methods display the best accuracy. Thus, we utilized these values for further evaluations.
表 I 的结果还表明,在保持 UAT 头数不变的情况下,随着 MAT 头数的增加,活动识别准确率有所提升。但当 UAT 的头数发生变化时,这种关系不再成立。由于多头机制会缩减特征嵌入 (feature embedding) 的尺寸,增加 UAT 的头数可能导致特征表征不充分。因此,基于本研究所用特征尺寸,结果表明采用 UAT 单头与 MAT 双头方案时准确率最优。后续评估均采用此参数配置。
B. Comparison with Multimodal HAR Methods
B. 与多模态HAR方法的对比
As HAMLET takes a multimodal approach, it is reasonable to evaluate the accuracy against the state-of-the-art multimodal approaches. Thus, we compare the performance of HAMLET with two baseline methods (the USA and the NSA, see Sec. IV-C) and several state-of-the-art multimodal approaches. We presented the results in Tables II (UTKinect), III (UTD-MHAD) & IV (UCSD-MIT).
由于HAMLET采用多模态方法,将其准确性与最先进的多模态方法进行对比评估是合理的。因此,我们将HAMLET的性能与两种基线方法(USA和NSA,见第IV-C节)及若干前沿多模态方法进行比较。实验结果分别展示在表II (UTKinect)、表III (UTD-MHAD) 和表IV (UCSD-MIT) 中。
Results: In the UT-Kinect dataset, RGB and skeleton modalities have been used to train the learning models. Following the original evaluation scheme, we report the top1 accuracy in Table II. The results indicate that HAMLET achieved the highest $97.45%$ top-1 accuracy across all other methods.
结果:在UT-Kinect数据集中,我们使用RGB和骨骼模态来训练学习模型。按照原始评估方案,我们在表II中报告了top1准确率。结果表明,HAMLET以$97.45%$的top-1准确率在所有方法中表现最佳。
We also evaluate the performance of HAMLET on the UTD-MHAD [1] dataset. We train and test HAMLET on RGB and Skeleton data and report the top-1 accuracy while using MAT-CONCAT in Table III. The results suggest that HAMLET outperformed all the evaluated state-of-the-art baselines and achieved the highest accuracy of $95.12%$ .
我们还在UTD-MHAD [1]数据集上评估了HAMLET的性能。我们使用RGB和骨骼数据对HAMLET进行训练和测试,并在表III中报告了使用MAT-CONCAT时的top-1准确率。结果表明,HAMLET优于所有评估的先进基线方法,并达到了最高准确率$95.12%$。
For the UCSD-MIT dataset, all the learning methods are trained on the skeleton, inertial, and sEMG data. All the training models have been used late or intermediate fusion except for the results presented from [3], which used an early feature fusion approach. In Table IV, the results suggest that HAMLET with MAT-SUM fusion method outperformed the baselines and state-of-the-art works by achieving the highest $81.52%$ F1-score (in $%$ ).
对于UCSD-MIT数据集,所有学习方法均在骨骼、惯性和sEMG数据上进行训练。除[3]采用早期特征融合方法外,其余训练模型均使用晚期或中期融合策略。表IV显示,采用MAT-SUM融合方法的HAMLET以81.52%的最高F1分数(单位:%)超越了基线方法和当前最优研究成果。
TABLE IV: Performance comparison (mean F1-scores in $%$ ) of multimodal HAR methods on UCSD-MIT dataset [3]
表 IV: 多模态HAR方法在UCSD-MIT数据集[3]上的性能对比(平均F1分数,单位为$%$)
| 方法 | 融合类型 | F1分数(%) |
|---|---|---|
| NSA | SUM | 59.61 |
| CONCAT | 45.10 | |
| USA | SUM | 60.78 |
| CONCAT | 69.85 | |
| KEYLESS[18] (2018) | CONCAT | 74.40 |
| Best of UCSD-MIT 3 | EarlyFusion | 59.0 |
| HAMLET | MAT-SUM | 81.52 |
| MAT-CONCAT | 76.86 |
Discussion: HAMLET outperformed all other evaluated baselines across all datasets and metrics tested. The results on the UTD-MHAD dataset suggest that HAMLET outperformed all the state-of-the-art multimodal HAR methods. These methods didn’t leverage the attention-based approaches to dynamically weighting the unimodal features to generate multimodal features. The results also suggest that, the other attention-based approaches, such as USA and Keyless [18], also showed better performance compared to the non-attention based approaches on UT-Kinect (Table II) and UCSD-MIT (Table II) datasets. The overall results support that our proposed approach is robust in finding appropriate multimodal features, hence it has achieved the highest HAR accuracies.
讨论:HAMLET在所有测试数据集和指标上均优于其他评估基线。UTD-MHAD数据集的结果表明,HAMLET超越了所有最先进的多模态HAR方法。这些方法未采用基于注意力的方法来动态加权单模态特征以生成多模态特征。结果还显示,其他基于注意力的方法(如USA和Keyless [18])在UT-Kinect(表II)和UCSD-MIT(表II)数据集上也比非基于注意力的方法表现更优。总体结果证明,我们提出的方法在寻找合适多模态特征方面具有鲁棒性,因此实现了最高的HAR准确率。
The results indicate that the MAT-CONCAT approach achieved higher accuracy on the UT-Kinect dataset; however, the MAT-SUM approach delivered higher accuracy on the UCSD-MIT dataset. One explanation behind this variation is that the modalities (skeleton, sEMG, and IMUs) in the UCSD-MIT dataset represent similar physical body features, thus summing up the feature vectors work well. However, as the UT-Kinect dataset modalities have different characteristics, the visual (RGB) and the physical body (skeleton) features, MAT-CONCAT works better than MAT-SUM.
结果表明,MAT-CONCAT方法在UT-Kinect数据集上取得了更高的准确率,而MAT-SUM方法在UCSD-MIT数据集上表现更优。这种差异的一个解释是:UCSD-MIT数据集中的模态(骨骼、sEMG和IMU)表征相似的身体特征,因此特征向量求和效果良好。然而,由于UT-Kinect数据集的模态(视觉RGB特征与物理骨骼特征)具有不同特性,MAT-CONCAT方法比MAT-SUM表现更佳。
Finally, the overall results suggest that HAMLET achieved the mean F-1 score of $81.52%$ on the UCSD-MIT dataset, which is lower compared to the highest accuracy on other datasets (please note that the top-1 accuracies were presented for other datasets). The main reason behind this performance degradation in UCSD-MIT is that this dataset contains missing data, especially sEMG, and IMUs data are missing in many instances. However, in the presence of the missing information, HAMLET showed the best performance compared to all other approaches.
最终,总体结果表明,HAMLET在UCSD-MIT数据集上的平均F-1得分为$81.52%$,与其他数据集的最高准确率相比略低(请注意其他数据集展示的是top-1准确率)。UCSD-MIT数据集性能下降的主要原因是该数据集存在缺失数据,特别是sEMG和IMU数据在许多样本中缺失。然而,在信息缺失的情况下,HAMLET相比其他所有方法仍表现出最佳性能。
C. Combined Impact of Unimodal and Multimodal Attention
C. 单模态与多模态注意力的综合影响
We evaluated the comparative importance of unimodal and multimodal attention mechanism (presented in Fig. 4). We can observe that the incorporation of unimodal attention (Fig. 4-b) can help to reduce the miss-classification error in comparison to the non-attention based feature learning method (Fig. 4-a). This is because unimodal attention can able to extract the sparse salient spatio-temporal features. We also can observe an improved accuracy in activity classification when the multimodal attention based unimodal feature fusion approach was incorporated (Fig. 4-c vs. a, b). The results indicate that HAMLET can reduce the number of miss-classification, especially in the cases of similar activities, such as sitDown and pickUp, which is depicted in the confusion matrix in Fig. 4-c.
我们评估了单模态和多模态注意力机制(如图4所示)的相对重要性。可以观察到,与基于非注意力的特征学习方法(图4-a)相比,引入单模态注意力(图4-b)有助于减少错误分类。这是因为单模态注意力能够提取稀疏的显著时空特征。我们还发现,当采用基于多模态注意力的单模态特征融合方法时(图4-c对比a、b),活动分类的准确率有所提升。结果表明,HAMLET能够减少错误分类的数量,尤其是在相似活动(如sitDown和pickUp)的情况下,这一点在图4-c的混淆矩阵中得到了体现。

Fig. 4: Comparative impact of multimodal and unimodal attention in HAMLET for different activities on UT-Kinect dataset.
图 4: HAMLET 模型中多模态与单模态注意力在 UT-Kinect 数据集上对不同活动的对比影响。

Fig. 5: Multimodal and unimodal attention visualization for different activities on UT-Kinect Dataset.
图 5: UT-Kinect数据集中不同活动的多模态与单模态注意力可视化。
D. Visualizing Impact of Multimodal Attention: MAT
D. 可视化多模态注意力影响:MAT
We visualize the attention map of the unimodal and multimodal feature encoders to gauge the impact of attention in local (unimodal) and global (multimodal) feature representation in Fig 5. We used the data of the eighth performer from the UT-Kinect dataset [2] as a sample data to produce the attention map for different activities, as shown in Fig. 5, where we observe that the unimodal attention is able to detect salient segments of RGB (Fig 5-a) and skeleton (Fig 5- b) modalities. For example, the unimodal attention method focuses on the beginning parts of the sitDown and the pull activities, as these activities have distinguishable actions in the beginning parts of the activity. On the other hand, the unimodal attention method needs to pay attention to the full sequence to differentiate the carry and the push activities, as a specific part of these activities are not more informative than the other parts.
我们在图5中可视化了单模态和多模态特征编码器的注意力图,以评估注意力在局部(单模态)和全局(多模态)特征表示中的影响。我们使用UT-Kinect数据集[2]中第八位表演者的数据作为样本,生成了不同活动的注意力图,如图5所示。观察发现,单模态注意力能够检测RGB(图5-a)和骨架(图5-b)模态的显著片段。例如,单模态注意力方法集中在sitDown和pull活动的起始部分,因为这些活动在开始阶段具有可区分的动作。另一方面,单模态注意力方法需要关注完整序列来区分carry和push活动,因为这些活动的特定部分并不比其他部分更具信息量。
Moreover, we evaluate the impact of MAT by observing the multimodal attention map in Fig. 5-c, which represents the relative attention given to unimodal features. For example, the pickUp and sitDown may involve similar skeleton joints movements, and thus if we concentrate only on the skeleton data, it may be challenging to differentiate between these two activities. However, if we incorporate the complementary modalities, such as RGB and skeleton, it may be easier to differentiate between similar activities. Thus, MAT pays equal attention to the RGB and skeleton data while recognizing the sitDown activity, whereas solely pay attention to the skeleton data while identifying the pickUp activity (Fig. 5-c).
此外,我们通过观察图5-c中的多模态注意力图来评估MAT的影响,该图表示对单模态特征的相对关注度。例如,pickUp和sitDown可能涉及相似的骨骼关节运动,因此如果我们仅关注骨骼数据,可能难以区分这两种活动。然而,如果我们结合互补模态(如RGB和骨骼数据),则更容易区分相似活动。因此,MAT在识别sitDown活动时对RGB和骨骼数据给予同等关注,而在识别pickUp活动时仅关注骨骼数据(图5-c)。
VI. CONCLUSION
VI. 结论
In this paper, we presented HAMLET, a novel multimodal human activity recognition algorithm, for collaborative robotic systems. HAMLET first extracts the spatiotemporal salient features from the unimodal data and then employs a novel multimodal attention mechanism for disentangling and fusing the unimodal features for activity recognition. The experimental results suggest that HAMLET outperformed all other evaluated baselines across all datasets and metrics tested for human activity recognition.
本文提出了一种新型多模态人类活动识别算法HAMLET,用于协作机器人系统。HAMLET首先从单模态数据中提取时空显著特征,然后采用创新的多模态注意力机制来解耦和融合单模态特征以实现活动识别。实验结果表明,在所有测试数据集和指标上,HAMLET在人类活动识别任务中的表现均优于其他基线方法。
In the future, we plan to implement HAMLET on a robotic system to enable it to perform collaborative activities in close proximity with people in an industrial environment. We also plan to extend HAMLET so that it can appropriately learn the relationship among the data from the modalities to address the missing data problem.
未来,我们计划在机器人系统上实现HAMLET,使其能够在工业环境中与人类近距离协作。我们还计划扩展HAMLET功能,使其能正确学习多模态数据间的关系,以解决数据缺失问题。