VERSATILE AUDIO-VISUAL LEARNING FOR EMOTION RECOGNITION
面向情感识别的通用视听学习
ABSTRACT
摘要
Most current audio-visual emotion recognition models lack the flexibility needed for deployment in practical applications. We envision a multimodal system that works even when only one modality is available and can be implemented interchangeably for either predicting emotional attributes or recognizing categorical emotions. Achieving such flexibility in a multimodal emotion recognition system is difficult due to the inherent challenges in accurately interpreting and integrating varied data sources. It is also a challenge to robustly handle missing or partial information while allowing direct switch between regression or classification tasks. This study proposes a versatile audiovisual learning (VAVL) framework for handling unimodal and multimodal systems for emotion regression or emotion classification tasks. We implement an audio-visual framework that can be trained even when audio and visual paired data is not available for part of the training set (i.e., audio only or only video is present). We achieve this effective representation learning with audio-visual shared layers, residual connections over shared layers, and a unimodal reconstruction task. Our experimental results reveal that our architecture significantly outperforms strong baselines on the CREMA-D, MSP-IMPROV, and CMU-MOSEI corpora. Notably, VAVL attains a new state-of-theart performance in the emotional attribute prediction task on the MSP-IMPROV corpus.
当前大多数视听情感识别模型缺乏实际应用部署所需的灵活性。我们设想了一种多模态系统,即使在仅有一种模态可用时仍能工作,并能灵活切换用于预测情感属性或识别分类情感。由于准确解释和整合多样化数据源存在固有挑战,实现这种多模态情感识别系统的灵活性十分困难。在允许回归或分类任务直接切换的同时,鲁棒地处理缺失或部分信息也是一项挑战。本研究提出了一种通用视听学习框架(VAVL),可处理单模态和多模态系统,适用于情感回归或情感分类任务。我们实现的视听框架即使在训练集中部分数据缺失配对模态时(即仅含音频或仅含视频)仍可训练。通过视听共享层、共享层残差连接和单模态重建任务,我们实现了有效的表征学习。实验结果表明,我们的架构在CREMA-D、MSP-IMPROV和CMU-MOSEI语料库上显著优于强基线模型。值得注意的是,VAVL在MSP-IMPROV语料库的情感属性预测任务中取得了新的最先进性能。
Keywords multimodal emotion recognition, audio-visual modeling, transformers, versatile learning, handling missing modalities
关键词 多模态情感识别、视听建模、Transformer、通用学习、处理缺失模态
1 Introduction
1 引言
Effective human interactions often include the expression and perceptions of emotional cues conveyed across multiple modalities to accurately comprehend and convey a message. During human interactions, there are two modalities that stand out as particularly significant: speech and facial expressions. These modalities play a crucial role in facilitating communication, making it essential for emotion recognition systems to incorporate speech-based cues [1] and facial expression-based cues [2, 3]. These modalities are intrinsically connected [4], proving complementary information [5]. Therefore, emotion recognition systems can be more accurate if they incorporate audio-visual solutions [6–9], mirroring the way humans interact in natural, real-world settings.
有效的人际互动通常涉及通过多种模态传递和感知情感线索,以准确理解和传达信息。在人类互动中,语音和面部表情这两种模态尤为重要。它们在促进沟通方面发挥着关键作用,因此情感识别系统必须整合基于语音的线索 [1] 和基于面部表情的线索 [2, 3]。这些模态本质上是相互关联的 [4],能提供互补信息 [5]。因此,若采用视听融合方案 [6–9],情感识别系统可以更准确地模拟人类在自然真实场景中的互动方式。
It is important to note that while humans primarily rely on these two modalities to recognize emotional states, there are scenarios in which only one modality may be utilized. In some cases, visual cues might be unavailable or occluded, leaving individuals to rely solely on acoustic information. Conversely, there might be situations where acoustic cues are insufficient or absent, requiring the exclusive use of visual cues for effective communication. As a result, it is vital for human computer interaction (HCI) systems to not only be capable of simultaneously handling both modalities, but also to adapt to unimodal situations. The straightforward approach is to have separate unimodal and multimodal solutions. However, it is more computationally effective to have versatile systems that can be adapted according to the available information. This flexibility ensures that HCI systems can accommodate a wide range of communication contexts and maintain their effectiveness in various real-world conditions.
需要注意的是,虽然人类主要依赖这两种模态来识别情绪状态,但在某些场景中可能仅使用单一模态。例如,视觉线索可能无法获取或被遮挡,此时人们只能依靠听觉信息。反之,也可能存在听觉线索不足或缺失的情况,需要仅凭视觉线索进行有效沟通。因此,人机交互 (HCI) 系统不仅需要具备同时处理多模态的能力,还必须适应单模态场景。最直接的方法是分别采用单模态和多模态解决方案,但从计算效率角度考虑,更理想的是构建能根据可用信息动态调整的通用系统。这种灵活性确保 HCI 系统能适应多样化的沟通场景,并在各种现实条件下保持有效性。
Artificial intelligent (AI) methods have been explored for audio-visual learning to achieve high performance in either multimodal or unimodal scenarios [10–12]. Most conventional models rely on building separate modality-specific branches [13–15] or employing ensemble-like techniques [16], which can lead to convoluted and complex architectures. With the introduction of transformer frameworks [17], many solutions have been developed to avoid training with modality-specific strategies. These models even implement formulations that unify the cross-modality relationships [18, 19] into a single, comprehensive model.
人工智能 (AI) 方法在视听学习领域已被广泛探索,旨在多模态或单模态场景中实现高性能 [10-12]。传统模型大多依赖构建独立的分支结构 [13-15] 或采用集成式技术 [16],这可能导致架构冗长复杂。随着 Transformer 框架 [17] 的引入,许多解决方案开始避免使用特定模态的训练策略。这些模型甚至通过统一跨模态关系 [18,19] 的数学表达,构建出单一而全面的架构。
Despite significant recent advancements in the construction of simpler multimodal models, there are still open research questions to be considered when constructing a unified multimodal model. One of these challenges is that current methods tend to solely focus on one type of machine learning (ML) task [20]. For example, they consider either classification or regression problems, without considering the potential need for versatility across different problem types. In emotion recognition, this problem is especially important, since emotions can be alternatively described with emotional attributes (e.g., arousal, valence, dominance) and categorical emotions (e.g., anger, happiness, sadness) [21].
尽管近期在构建更简单的多模态模型方面取得了显著进展,但在构建统一多模态模型时仍需考虑一些开放的研究问题。其中一个挑战是当前方法往往仅关注一种机器学习(ML)任务类型 [20]。例如,它们要么考虑分类问题,要么考虑回归问题,而没有考虑跨不同问题类型可能需要多功能性。在情感识别中,这个问题尤为重要,因为情感既可以用情感属性(如唤醒度、效价、支配度)也可以用分类情感(如愤怒、快乐、悲伤)来描述 [21]。
Depending on the setting, therefore, it is important to have a model that can be utilized for either regression (emotional attributes) or classification (categorical emotions) settings without making major changes in the architecture. Moreover, current methods often disregard the importance of maintaining distinct representations for each modality to capture modality-specific [22] features and characteristics within shared layers, which could affect performance in unimodal settings [13]. By failing to account for the unique characteristics of each modality, the models may not optimally leverage the strengths of each input type, ultimately limiting their effectiveness. Moreover, the complexity of many existing models can be a drawback, as it may lead to increased computational demands and reduced interpre t ability [23], making it more challenging for researchers and practitioners to analyze and adapt the models for various applications.
因此,根据具体场景需求,关键是要有一个能同时适用于回归(情感属性)和分类(分类情感)任务的模型,且无需对架构进行重大调整。此外,当前方法往往忽视了在共享层中保持各模态独立表征的重要性,这些表征用于捕捉模态特异性 [22] 的特征和特性,而忽略这点可能影响单模态场景下的性能 [13]。若未能考虑各模态的独特性,模型可能无法充分发挥每种输入类型的优势,最终限制其有效性。另外,许多现有模型的复杂性可能成为缺点,因为这会导致计算需求增加和可解释性降低 [23],使研究人员和实践者更难针对不同应用场景进行分析和模型适配。
Our main contribution in this study is the proposal of a versatile audio-visual learning (VAVL) model, which unifies multimodal and unimodal learning in a single framework that can be used for emotion regression and classification tasks. Our approach utilizes branches that separately process each modality. In addition, we introduce shared layers, residual connections over shared layers, and a unimodal reconstruction task. The shared layers encourage learning representations that reflect the connections between the two modalities. The addition of the auxiliary reconstruction task and unimodal residual connections over the shared layers helps the model learn representations that reflect the heterogeneity of the modalities. Collectively, these components are added to our framework to help with the multimodal feature representation, which is a core challenge in multimodal learning [24]. We implement this audio-visual framework so it can be trained even when audio and visual paired data is not available for part of the data. The proposed approach is attractive as it enables the training of multimodal systems using incomplete information from multimodal databases (e.g., audio-only or visual-only information is available for some data points), as well as unimodal databases. The proposed framework also has the versatility to be used for either regression or classification tasks without changing the architecture or training strategy.
本研究的主要贡献是提出了一种通用的视听学习(VAVL)模型,该模型将多模态和单模态学习统一在一个框架中,可用于情感回归和分类任务。我们的方法采用分支结构分别处理每种模态,并引入共享层、共享层上的残差连接以及单模态重建任务。共享层促进学习反映两种模态间关联的表征,而辅助重建任务和共享层上的单模态残差连接有助于模型学习反映模态异质性的表征。这些组件共同构成了我们框架的核心,以解决多模态学习中多模态特征表示这一关键挑战[24]。我们实现的这个视听框架即使在部分数据缺失配对音频或视觉信息时仍可训练。该方法的优势在于能够利用多模态数据库(如某些数据点仅含音频或仅含视觉信息)和单模态数据库中的不完整信息来训练多模态系统。所提框架还具有无需改变架构或训练策略即可灵活应用于回归或分类任务的通用性。
We quantitatively evaluate and compare the performance of our proposed model against strong baselines. The results demonstrate that our architecture achieves significantly better results on the CREMA-D [25], the CMU-MOSEI [22], and the MSP-IMPROV [26] corpora compared to the baselines. For example, VAVL achieves a new state-of-the-art result for the emotional attribute prediction task on the MSP-IMPROV corpus. Also, our architecture is able to sustain strong performance in audio-only and video-only settings, compared to strong unimodal baselines. Additionally, we conduct ablation studies into our model to understand the effects of each component on our model’s performance. These results show the benefits of our proposed framework for audio-visual emotion recognition.
我们定量评估并比较了所提模型与强基线的性能表现。实验结果表明,在CREMA-D [25]、CMU-MOSEI [22]和MSP-IMPROV [26]数据集上,我们的架构相比基线模型取得了显著更好的效果。例如,VAVL在MSP-IMPROV语料库的情感属性预测任务中创造了新的最优结果。同时,与强大的单模态基线相比,我们的架构在纯音频和纯视频场景下仍能保持强劲性能。此外,我们通过消融实验分析了各组件对模型性能的影响,这些结果验证了所提视听情感识别框架的优越性。
2 Background
2 背景
Emotion recognition has been widely explored using speech [1, 27, 28], facial expressions [29], and multimodal solutions [30–33]. However, most of these models have focused on solving either emotion classification tasks [33] or emotional attribute prediction tasks [27]. Furthermore, these studies are designed for either unimodal or multimodal solutions. Although some recent studies [15] have proposed approaches for audio-visual emotion recognition that can handle both tasks, they still rely on a single modality. There is a need for solutions that can handle multiple modality settings. Recent advancements in deep learning have resulted in the development of unified frameworks that aim to move away from unimodal implementations. This section focuses on relevant studies that address similar problems investigated in this paper.
情感识别已通过语音[1, 27, 28]、面部表情[29]和多模态解决方案[30–33]得到广泛研究。然而,这些模型大多专注于解决情感分类任务[33]或情感属性预测任务[27]。此外,这些研究要么针对单模态方案设计,要么针对多模态方案设计。尽管最近一些研究[15]提出了可同时处理这两类任务的视听情感识别方法,但它们仍依赖单一模态。当前亟需能处理多模态配置的解决方案。深度学习的最新进展催生了旨在摆脱单模态实现的统一框架,本节重点讨论与本文研究问题相关的同类工作。
2.1 Formulations for Emotion Recognition
2.1 情感识别公式
Although an individual’s cultural and ethnic background may impact her/his manner of expression, studies have indicated that certain basic emotions are very similar regardless of cultural differences [34]. These basic emotions are described as: happiness, sadness, surprise, fear, disgust, and anger. These basic emotional states are often the most widely explored task in emotion recognition, formulating the problem as a six-class classification problem [35, 36]. In fact, many of the affective corpora include all or a subset of these classes, including the CREMA-D [25], AffectNet [37], and AFEW [38] databases.
尽管个人的文化和种族背景可能会影响其表达方式,但研究表明,某些基本情绪在不同文化间具有高度相似性 [34]。这些基本情绪被描述为:快乐、悲伤、惊讶、恐惧、厌恶和愤怒。这些基本情绪状态通常是情绪识别中最广泛研究的任务,将问题构建为一个六分类问题 [35, 36]。事实上,许多情感语料库都包含全部或部分这些类别,包括 CREMA-D [25]、AffectNet [37] 和 AFEW [38] 数据库。
An alternative way to describe emotions is to leverage the continuous space of emotional attributes or sentiment analysis. The emotional attributes approach identifies dimensions to describe expressive behaviors. The most common attributes are arousal (calm versus active), valence (negative versus positive), and dominance (weak versus strong) [39]. Several databases have explored the emotional attribute or sentiment analysis annotation of audio-visual stimuli, such as the IEMOCAP [40], MSP-IMPROV [26], and CMU-MOSEI [22] corpora. Studies have proposed algorithms to predict emotional attributes using audio-visual stimuli [41–43], facial expression [44], and speech [1, 45, 46].
描述情绪的另一种方法是利用情感属性或情感分析的连续空间。情感属性方法通过维度来描述表达行为,最常见的维度包括唤醒度(平静 vs 活跃)、效价(负面 vs 正面)和支配度(弱势 vs 强势)[39]。多个数据库已探索对视听刺激进行情感属性或情感分析标注,例如IEMOCAP [40]、MSP-IMPROV [26]和CMU-MOSEI [22]语料库。研究提出了通过视听刺激[41–43]、面部表情[44]和语音[1, 45, 46]来预测情感属性的算法。
2.2 Unified Multimodal Framework
2.2 统一多模态框架
Since the introduction of the transformer framework [17], many studies have explored multimodal frameworks that can still work even when only one modality is available [47]. Some proposed architectures employ training schemes that involve solely utilizing separate branches for different modalities, as seen in Baevski et al. [48]. These approaches construct branches containing unimodal information specific to each modality. In contrast, other studies explore the use of shared layers that encapsulate cross-modal information from multiple modalities [49, 50]. The aforementioned studies incorporate aspects that laid the foundation for modeling a more unified framework, but they still have some limitations. For example, common solutions require independent modality training, assume that all the modalities are available during inference, or fail to fully address the heterogeneity present in a multimodal setting. Recent studies have proposed audio-visual frameworks that can handle both unimodal and multimodal settings [51], but they still rely on having additional unimodal network branches. Gong et al. [19] proposed a unified audio-visual framework for classification, which incorporates some effective capabilities, such as independently processing audio and video, and including shared audio-visual layers into the model. However, the model focused only on a classification task.
自Transformer框架[17]提出以来,许多研究探索了在单一模态可用时仍能工作的多模态框架[47]。部分架构采用仅针对不同模态使用独立分支的训练方案,如Baevski等人[48]所示,这些方法构建了包含各模态专属单模态信息的分支。相比之下,另有研究探索使用共享层来封装来自多模态的跨模态信息[49,50]。上述研究为构建更统一的框架奠定了基础,但仍存在局限:常见解决方案需要独立模态训练、假设推理时所有模态可用,或未能完全解决多模态环境中的异构性问题。近期研究提出了能同时处理单模态和多模态设置的视听框架[51],但仍需依赖额外的单模态网络分支。Gong等人[19]提出了用于分类的统一视听框架,具备独立处理音频视频、在模型中集成共享视听层等能力,但该模型仅聚焦分类任务。
2.3 Versatile Task Modeling
2.3 多样化任务建模
For audio-visual unified models [19] and audio-visual models that have multiple modality branches and can handle unimodal scenarios [12], the final multimodal prediction is often obtained by averaging the outputs from different branches, receiving the contributions from all the modalities. In emotion classification tasks, the model output is a probability distribution over a set of discrete categories. Averaging predictions from multiple unimodal branches can help capture different aspects of the data, leading to improved classification accuracy. However, this approach may not be effective for emotion attribute regression tasks, as regression involves predicting a continuous numerical value rather than a discrete categorical emotion label. Therefore, the average of the predictions from different unimodal branches may not be appropriate. This is particularly true when considering the performance gap that often exists between speech and visual models for predicting arousal, valence, and dominance, as facial-only features are generally less effective than acoustic features [11]. Simply averaging these two results could lead to suboptimal outcomes. A potentially appealing alternative is to use a weighted combination of the predictions [52, 53]. However, this approach also has its limitations, as the prediction discrepancy may not be consistent across all data points. To address this issue, our study proposes training an audio-visual prediction layer, in addition to visual and acoustic prediction layers, used when only data from one modality is available. The audio-visual prediction layer is optimized only when both modalities are available. This layer can automatically learn appropriate weights to combine the modality representations and fuse them to generate a single audio-visual prediction. This approach works well for both emotion classification and regression settings.
对于视听统一模型[19]以及具有多模态分支并能处理单模态场景的视听模型[12],最终的多模态预测通常通过平均不同分支的输出获得,接收来自所有模态的贡献。在情感分类任务中,模型输出是一组离散类别上的概率分布。平均多个单模态分支的预测有助于捕捉数据的不同方面,从而提高分类准确性。然而,这种方法可能不适用于情感属性回归任务,因为回归涉及预测连续数值而非离散类别情感标签。因此,不同单模态分支预测的平均可能并不合适。考虑到语音和视觉模型在预测唤醒度、效价和支配力时通常存在的性能差距(仅面部特征通常不如声学特征有效[11]),简单平均这两个结果可能导致次优效果。一个潜在的替代方案是使用预测的加权组合[52,53],但这种方法也有其局限性,因为预测差异在所有数据点上可能并不一致。为解决这一问题,我们的研究提出在视觉和声学预测层之外,训练一个视听预测层,该层仅在单模态数据可用时使用。视听预测层仅在两种模态都可用时进行优化。该层可以自动学习适当的权重来组合模态表示,并将其融合以生成单一的视听预测。这种方法在情感分类和回归设置中均表现良好。
2.4 Relation to Prior Work
2.4 与先前工作的关联
While the implementation of our approach is with transformers, which have been used in the past in multimodal processing, our proposed VAVL model represents a significant contribution in comparison to previous works. The proposed architecture with shared layers, residual connections, reconstruction auxiliary tasks and separate audiovisual prediction layers is novel, where each of its components is carefully motivated to address a fundamental challenge in multimodal machine learning. We employ conformer layers [54] as our encoders, which are transformer-based encoders augmented with convolutions. The closest study to our framework is the work of Gong et al. [19], which proposed a unified audio-visual model for classification. Their framework involved the independent processing of audio and video features, with shared transformer and classification layers for both modalities. Prior to the shared transformer layers, they have modality-specific feature extractors and optional modality-specific transformers for each modality. In contrast, our framework employs conformer layers instead of vanilla transformers. Moreover, we introduce three important components to our framework. First, an audio-visual prediction layer is utilized solely when audio-visual modalities are available during inference, enhancing prediction accuracy and model versatility for both regression or classification tasks. Second, a unimodal reconstruction task is implemented during training to ensure that the shared layers capture the heterogeneity of the modalities. Third, residual connections are incorporated over the shared layers to ensure that the unimodal representations are not forgotten in the shared layers. This strategy maintains high performance even in unimodal settings. These novel additions represent significant contributions to the field of audio-visual emotion recognition. Additionally, our proposed model comprises approximately 86 million parameters. In comparison, TLSTM has 485,000 parameters, SFAV has 642,000 parameters, MulT has 749,000 parameters, and Auxformer has 1,226,000 parameters. While our model is more complex than these earlier models, it offers a significant reduction in complexity compared to the UAVM framework, which has 117 million parameters. This comparison indicates a reduction in complexity of approximately $26%$ relative to UAVM, highlighting the efficiency of our model in handling sophisticated multi-modal tasks.
虽然我们的方法实现采用了Transformer(过去已用于多模态处理),但相比先前工作,我们提出的VAVL模型具有显著创新。该架构包含共享层、残差连接、重构辅助任务和独立的视听预测层,其每个组件都针对多模态机器学习中的核心挑战进行了精心设计。我们采用基于Transformer并融合卷积的Conformer层[54]作为编码器。与我们框架最接近的是Gong等人[19]提出的统一视听分类模型,其框架包含独立处理的音频视频特征提取,以及两种模态共享的Transformer层和分类层。在共享Transformer层之前,他们为每种模态设置了专用特征提取器和可选的专用Transformer。相比之下,我们的框架采用Conformer层替代标准Transformer,并引入三个关键组件:首先,仅在推理阶段存在视听模态时启用的视听预测层,可提升回归或分类任务的预测精度与模型泛化能力;其次,训练阶段实施单模态重构任务以确保共享层捕获模态异质性;第三,共享层引入残差连接防止单模态表征丢失,使模型在单模态场景仍保持高性能。这些创新为视听情感识别领域作出重要贡献。此外,我们提出的模型包含约8600万参数,相比TLSTM(48.5万)、SFAV(64.2万)、MulT(74.9万)和Auxformer(122.6万)更为复杂,但较UAVM框架(1.17亿参数)显著降低了约26%的复杂度,体现了模型处理复杂多模态任务的高效性。
The proposed approach is significantly difference from our previous work on audio-visual emotion recognition [12]. Goncalves and Busso [12] proposed a method that incorporates two main components: the use of auxiliary unimodal networks and the use of modality dropout during training. The auxiliary networks ensure unimodal representations are separately embedded and not lost during the training of shared spaces within the cross-modal layers. The use of modality dropout enhances the ability of the model to retain performance when parts of the input data are missing. This model uses audiovisual paired data for training and performs averaging of prediction heads to obtain final predictions. In contrast, our approach utilizes distinct branches for processing each modality and introduces shared layers with residual connections, complemented by an unimodal reconstruction task. These shared layers are pivotal in facilitating the learning of representations that capture the interplay between audio and visual modalities. The shared layers take either visual or acoustic information, but not both, providing rich information to leverage cross-modality information. Furthermore, the incorporation of an auxiliary reconstruction task alongside unimodal residual connections enhances the model’s ability to understand the diverse characteristics inherent in each modality. A key innovation of our approach lies in its ability to effectively train with incomplete multimodal data, accommodating scenarios where only audio or visual information is available for certain data points. This flexibility addresses a significant challenge in multimodal learning and broadens the applicability of our model, making it a substantial contribution to the field. The approach allows us to use partial audio or visual information from multimodal and unimodal databases.
所提出的方法与我们之前关于视听情感识别的研究[12]有显著不同。Goncalves和Busso[12]提出的方法包含两个主要组件:使用辅助单模态网络以及在训练期间采用模态丢弃技术。辅助网络确保单模态表征在跨模态层共享空间训练过程中被单独嵌入且不丢失。模态丢弃技术增强了模型在输入数据部分缺失时保持性能的能力。该模型使用成对的视听数据进行训练,并通过预测头平均化获得最终预测结果。相比之下,我们的方法采用独立分支处理各模态,并引入带有残差连接的共享层,辅以单模态重建任务。这些共享层对于促进学习捕捉音频与视觉模态间相互作用的表征至关重要。共享层仅接收视觉或声学信息(而非两者),为利用跨模态信息提供了丰富的数据支撑。此外,通过结合辅助重建任务与单模态残差连接,模型理解各模态固有多样化特征的能力得到增强。本方法的核心创新在于能有效利用不完整多模态数据进行训练,适应某些数据点仅含音频或视觉信息的场景。这种灵活性解决了多模态学习中的关键挑战,拓宽了模型适用性,成为该领域的重要贡献。该方法使我们能够利用来自多模态和单模态数据库的部分音频或视觉信息。
In summary, in relation to previous works, the primary novelty of our framework lies within the unique organization and training methodology of its layers. Our approach strategically structures its layers in a manner that optimizes their functionality and efficacy for our specific application for audio-visual and unimodal (visual or acoustic) emotion recognition.
总之,相较于先前工作,我们框架的主要创新点在于其各层的独特组织结构和训练方法。我们的方法通过战略性层级构建,针对视听及单模态(视觉或听觉)情感识别这一特定应用优化了功能与效能。
3 Proposed Approach
3 研究方法
Figure 1 illustrates the architecture of the proposed approach, which consists of four major components. Each of these components is represented in the figure by the set of weights $\theta_{v}$ , $\theta_{a}$ , $\theta_{s}$ , and $\theta_{a v}$ . The orange branches represent parts of the model where only visual information flows. This region is parameterized by the weights $\theta_{v}$ , and includes the visual conformer encoder layers that encode the visual input representations, the visual prediction layer for visual-only predictions, and the MLP reconstruction layers for the averaged visual input features. The green branches represent parts of the model where only acoustic information flows. This region is parameterized by the weights $\theta_{a}$ , and consists of the acoustic conformer encoder layers that encode the acoustic input representations, the acoustic prediction layer for acoustic-only predictions, and the MLP reconstruction layers for the averaged acoustic input features. The shared layers, depicted in purple in Figure 1, are parameterized by the weights $\theta_{s}$ . This block processes both acoustic and visual inputs to learn intermediate audio-visual representations from both modalities. It also contains residual connections from the unimodal branches to the shared layers to preserve information from the unimodal representations. Lastly, the audio-visual prediction layer is parameterized by the weights $\theta_{a v}$ , which focuses on processing audio-visual representations from the shared layers when the model receives paired audio-visual data for training or inference. The following sections describe these components in detail.
图 1: 展示了所提出方法的架构,该架构由四个主要组件组成。图中通过权重集合 $\theta_{v}$、$\theta_{a}$、$\theta_{s}$ 和 $\theta_{a v}$ 分别表示这些组件。橙色分支代表模型中仅处理视觉信息的部分,该区域由权重 $\theta_{v}$ 参数化,包括编码视觉输入表示的视觉conformer编码器层、纯视觉预测的视觉预测层,以及用于平均视觉输入特征的多层感知机(MLP)重建层。绿色分支表示模型中仅处理声学信息的部分,该区域由权重 $\theta_{a}$ 参数化,包含编码声学输入表示的声学conformer编码器层、纯声学预测的声学预测层,以及用于平均声学输入特征的MLP重建层。共享层在图1中以紫色显示,由权重 $\theta_{s}$ 参数化。该模块同时处理声学和视觉输入,以从两种模态中学习中间视听表示。它还包含从单模态分支到共享层的残差连接,以保留单模态表示的信息。最后,视听预测层由权重 $\theta_{a v}$ 参数化,当模型接收配对的视听数据进行训练或推理时,该层专注于处理来自共享层的视听表示。以下各节将详细描述这些组件。
3.1 Acoustic and Visual Layers
3.1 声学与视觉层
As shown in Figure 1, the acoustic and visual layers mirror each other. Both layers share the same basic structure and training mechanism. The main components of these layers are conformer encoders [54], which process all the sequential video or acoustic frames in parallel, depending on the modality available during either training or inference. To obtain inputs for our model, we utilize pre-trained feature extractors that produce a 1,408D feature vector for each visual frame and a 1,024D feature vector for each acoustic frame. Section 4.2 describes these feature extractor modules in detail. We apply a 1D temporal convolutional layer at the frame level before entering the feature vectors to their corresponding conformer encoder layers. This step ensures that each element in the input sequences is aware of its neighboring elements. This approach also allows us to project both feature vectors into a 50D feature representation, matching their dimensions. The dimensionality of the projection was determined based on preliminary experiments. These experiments indicated that a 50D representation strikes an effective balance: it retains essential information from the original feature vectors while keeping the model’s complexity manageable.
如图 1 所示,声学层与视觉层相互镜像。两层共享相同的基础结构和训练机制。这些层的主要组件是 conformer 编码器 [54],它们根据训练或推理期间可用的模态,并行处理所有连续的视频或声学帧。为了获取模型输入,我们使用预训练的特征提取器,为每个视觉帧生成 1,408 维特征向量,为每个声学帧生成 1,024 维特征向量。4.2 节将详细描述这些特征提取模块。在将特征向量输入对应的 conformer 编码器层之前,我们在帧级别应用一维时序卷积层。这一步骤确保输入序列中的每个元素都能感知其相邻元素。该方法还能将两个特征向量投影为 50 维特征表示,实现维度匹配。投影维度是通过初步实验确定的,结果表明 50 维表示能实现有效平衡:既保留了原始特征向量的关键信息,又使模型复杂度保持在可控范围内。
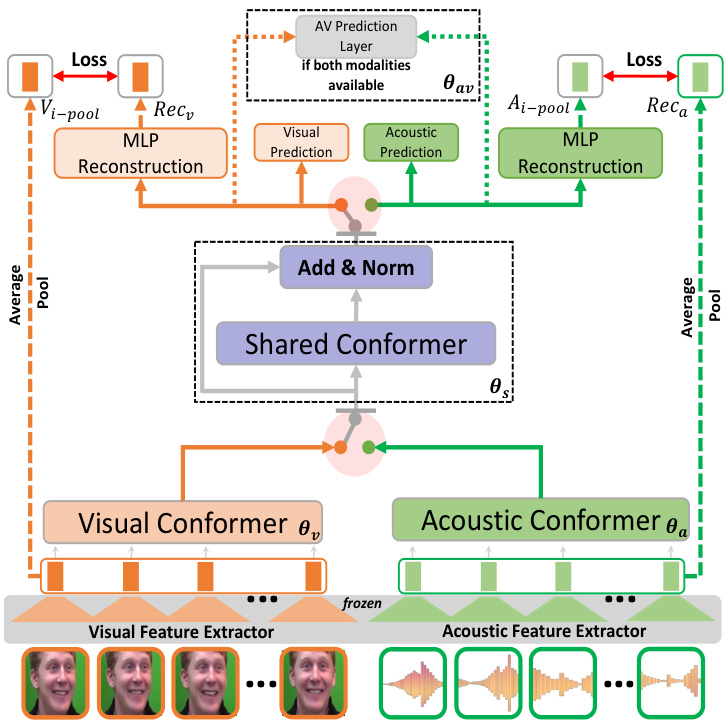
Figure 1: Overview of our proposed versatile audio-visual learning (VAVL) framework. The orange branches represent the visual information and are parameterized by the weights $\theta_{v}$ . The green branches represent the acoustic information and are parameterized by the weights $\theta_{a}$ . The purple modules are the shared layers where both modalities flow through, which are parameterized by the weights $\theta_{s}$ . Finally, the gray module is the audio-visual prediction layer, which is parameterized by the weights $\theta_{a v}$ .
图 1: 我们提出的多功能视听学习 (VAVL) 框架概述。橙色分支代表视觉信息,由权重 $\theta_{v}$ 参数化。绿色分支代表声学信息,由权重 $\theta_{a}$ 参数化。紫色模块是两种模态共同流经的共享层,由权重 $\theta_{s}$ 参数化。最后,灰色模块是视听预测层,由权重 $\theta_{a v}$ 参数化。
As seen in the top region of Figure 1, there are two additional components separately implemented for each modality (acoustic and visual) that are implemented to (1) predict the emotional attributes, and (2) reconstruct the unimodal feature representations. For the prediction of the emotional attributes, the acoustic and visual layers contain a set of prediction layers, referred to as visual prediction and acoustic prediction in Figure 1. They are responsible for generating unimodal predictions, which are utilized when our model operates in a unimodal setting. For the reconstruction of the unimodal feature representation, the model has a multilayer perceptron (MLP) head that serves as an auxiliary reconstruction task. The reconstruction task is used to have the model reconstruct the average-pooled input representations for the modality being used during training at that moment. The input of the reconstruction is the average-pooled representations obtained at the output of the shared layers (Sec. 3.2). Equation 1 shows the total loss function of the model,
如图 1 顶部区域所示,针对每种模态(听觉和视觉)分别实现了两个附加组件,用于:(1) 预测情感属性,(2) 重建单模态特征表示。在情感属性预测方面,听觉层和视觉层包含一组预测层(图 1 中标注为视觉预测和听觉预测),负责生成单模态预测结果,这些预测将在模型单模态运行时使用。对于单模态特征表示的重建任务,模型采用多层感知机 (MLP) 头作为辅助重建模块,其功能是让模型重建当前训练阶段所用模态的平均池化输入表示。重建任务的输入数据来自共享层输出端获取的平均池化表示(见第 3.2 节)。公式 1 展示了模型的总损失函数,
$$
\mathcal{L}=\mathcal{L}{p r e d}(y,p r e d)+\alpha\mathcal{L}{M S E}(x_{p o o l},R e c_{M})
$$
$$
\mathcal{L}=\mathcal{L}{p r e d}(y,p r e d)+\alpha\mathcal{L}{M S E}(x_{p o o l},R e c_{M})
$$
where $\mathcal{L}{p r e d}$ is the emotion task-specific loss (i.e., cross-entropy – Eq. 2, or concordance correlation coefficient (CCC) – Eq. 3), $y$ is the input label, pred is the emotional prediction of the model, $\alpha$ is the scaling weight for the reconstruction loss, $\mathcal{L}{M S E}$ is mean squared error (MSE) loss between the average-pooled input value $x_{p o o l}$ and the reconstructed input $R e c_{M}$ for modality $M$ . The terms $x_{p o o l}$ and $R e c_{M}$ are specific to each modality; $x_{p o o l}$ represents the pooled features of the input (audio or video), while $R e c_{M}$ represents the reconstructed features for the corresponding modality. This differentiation ensures that the reconstruction loss appropriately guides the model to retain and reconstruct modality-specific information.
其中 $\mathcal{L}{p r e d}$ 是情感任务特定的损失函数(即交叉熵——公式2,或一致性相关系数 (CCC)——公式3),$y$ 是输入标签,pred 是模型的情感预测结果,$\alpha$ 是重建损失的缩放权重,$\mathcal{L}{M S E}$ 是平均池化输入值 $x_{p o o l}$ 与模态 $M$ 的重建输入 $R e c_{M}$ 之间的均方误差 (MSE) 损失。$x_{p o o l}$ 和 $R e c_{M}$ 针对每种模态具有特定含义:$x_{p o o l}$ 表示输入(音频或视频)的池化特征,而 $R e c_{M}$ 表示对应模态的重建特征。这种区分确保重建损失能有效引导模型保留并重建模态特定的信息。
The reconstruction task is included in our model to promote the learning of more general features that can be applied to both modalities while preserving separate information for each modality, as the reconstruction from the shared layers requires the model to retain information from both modalities.
重建任务被纳入我们的模型,以促进学习适用于两种模态的更通用特征,同时保留各模态的独立信息。因为从共享层进行重建需要模型保留来自两种模态的信息。
3.2 Shared Layers
3.2 共享层
The shared layers, depicted in purple in Figure 1, mainly comprise a conformer encoder, following a similar structure to the acoustic and visual layers. These shared layers are modality-agnostic, meaning that during training and inference, the features from both modalities will pass through these layers whenever each modality is available. The purpose of this block is to ensure that the shared layers maintain information from both modalities incorporated in our model.
共享层(如图 1 中的紫色部分)主要由一个 Conformer 编码器组成,其结构与声学和视觉层类似。这些共享层是模态无关的,意味着在训练和推理过程中,只要每种模态可用,来自两种模态的特征都会通过这些层。该模块的目的是确保共享层保留模型中两种模态的信息。
We also introduce a residual connection over the shared layers (gray arrow in model $\theta_{s}$ shown in Fig. 1). This residual connection from the unimodal branches over the shared layers ensures that the model retains unimodal separable information. This mechanism complements the reconstruction tasks mentioned in Section 3.1 to increase the robustness of the system when only one modality is available. The approach allows the gradients to flow directly from the shared layers to the unimodal branches, preserving modality-specific information in our model.
我们还引入了共享层上的残差连接(模型$\theta_{s}$中的灰色箭头,如图1所示)。这种来自单模态分支跨越共享层的残差连接确保了模型保留单模态可分离信息。该机制与第3.1节提到的重构任务相辅相成,增强了系统在单一模态可用时的鲁棒性。该方法使梯度能够直接从共享层流向单模态分支,从而在我们的模型中保留特定模态信息。
3.3 Audio-Visual Prediction Layer
3.3 视听预测层
When only one modality is available, the system will use the visual or acoustic prediction blocks. When both modalities are available for training or inference, we use the audio-visual prediction layer, highlighted in gray in Figure 1. This layer plays a crucial role in making our approach versatile. Unlike other methods that rely on averaging predictions from different branches in their models, the audio-visual layers effectively utilize the contributions of acoustic and visual inputs in the audio-visual space. The audio-visual prediction layer consists of two fully connected layers that feed into a final audio-visual prediction head. We added this simple structure to ensure that representations from both modalities, obtained from the average-pooled output of each modality from the shared layers, are properly combined to obtain a final audio-visual prediction. During training, when audio-visual data is available, all other layers of the model are frozen after updating with acoustic and visual data. Only this layer is separately optimized to learn the required weights for audio-visual predictions. This layer ensures proper combination of audio-visual representations for robust predictions in both classification or regression settings.
当仅有一种模态可用时,系统将使用视觉或声学预测模块。当训练或推理时两种模态都可用时,我们会使用图1中灰色高亮的视听预测层。该层对实现方法的通用性起着关键作用。与其他依赖模型不同分支预测平均值的方法不同,视听层能有效利用声学和视觉输入在视听空间中的贡献。视听预测层由两个全连接层组成,最终接入视听预测头。我们添加这一简单结构是为了确保来自共享层各模态平均池化输出的双模态表征能被正确组合,从而获得最终的视听预测结果。训练过程中,当存在视听数据时,模型其他所有层在完成声学和视觉数据更新后都会被冻结,仅优化该层以学习视听预测所需的权重。该层能确保视听表征的正确组合,从而在分类或回归场景中实现稳健预测。
3.4 Versatile Model Training
3.4 通用模型训练
We train our proposed VAVL model using Algorithm 1. The training process can involve either a single modality or both modalities at any given iteration. If both modalities are available, the model first back propagates the errors using the acoustic predictions to optimize the acoustic and shared weights $(\theta_{a},\theta_{s})$ . Then, it back propagates the errors using the visual predictions to optimize the visual and shared weights $(\theta_{v},\theta_{s})$ . Next, it freezes all the parameters of the models other than the audio-visual prediction block (i.e., $\theta_{v}$ , $\theta_{a}$ , and $\theta_{s}$ are frozen). Then, it back propagates the errors using the audio-visual predictions to optimize the audio-visual prediction weights $(\theta_{a v})$ . This method facilitates the use of unpaired and paired audio-visual data for training. If only one modality is available, we only update either the visual and shared weights $(\theta_{v},\theta_{s})$ or acoustic and shared weights $(\theta_{a},\theta_{s})$ . Essentially, most of the blocks in the proposed architecture are trained with either acoustic features or visual features. The only block that requires paired data is the audio-visual prediction layer. The shared conformer layer processes each modality separately when full audiovisual information is available, so the dimension of the input to this block has always consistent dimension. The outputs are then combined in the audio-visual prediction layer.
我们使用算法1训练提出的VAVL模型。训练过程在每次迭代中可涉及单一模态或双模态。若双模态数据可用,模型首先通过声学预测反向传播误差以优化声学及共享权重$(\theta_{a},\theta_{s})$,随后通过视觉预测反向传播误差优化视觉及共享权重$(\theta_{v},\theta_{s})$。接着冻结除视听预测块外的所有模型参数(即冻结$\theta_{v}$、$\theta_{a}$和$\theta_{s}$),再通过视听预测反向传播误差优化视听预测权重$(\theta_{a v})$。该方法支持使用非配对和配对视听数据进行训练。若仅单模态可用,则仅更新视觉与共享权重$(\theta_{v},\theta_{s})$或声学与共享权重$(\theta_{a},\theta_{s})$。本质上,该架构大部分模块仅需声学或视觉特征训练,唯一需要配对数据的模块是视听预测层。共享Conformer层在完整视听信息可用时分别处理各模态,因此该模块输入维度始终保持一致,最终输出在视听预测层进行融合。
At inference time, the model utilizes the available information to make predictions, and in cases where both modalities are present, the model outputs the predictions from the audio-visual prediction layer. When only one modality is available during inference, the model outputs the prediction from the corresponding visual or acoustic prediction blocks.
在推理时,模型利用可用信息进行预测。当两种模态同时存在时,模型会输出视听预测层的预测结果。若推理期间仅存在单一模态,则模型会输出对应视觉或声学预测模块的预测值。
3.5 Complexity Analysis
3.5 复杂度分析
An analysis of the complexity of the VAVL method reveals a framework with 86M trainable parameters, underscoring its capacity for handling complex multi-modal tasks. Central to the framework, we have the acoustic and visual conformers, each equipped with 34M parameters, adeptly processing audio and visual inputs. The shared conformer, integral to the model’s functionality, contains 15M parameters, facilitating seamless integration of different modalities. A crucial aspect of our model is the 1D temporal convolutional layers, containing 650k parameters. These blocks are important in projecting both visual and acoustic features into a representation with the same dimension. Additionally, the model features three specialized prediction heads for acoustic, audio-visual, and visual processing, each with 390K parameters, further enhancing its processing capabilities. Lastly, the reconstruction MLP layers contain a combined total of 1.4 million parameters. To evaluate the practical efficiency, we measured the inference latency and realtime factor (RTF) on a 3090 RTX GPU. The results are as follows: audio-only mode had an average latency of 0.003499 seconds (RTF: 0.000005), video-only mode had an average latency of 0.001759 seconds (RTF: 0.000003), and audiovisual mode had an average latency of 0.003770 seconds (RTF: 0.000006).
对VAVL方法复杂度的分析显示,该框架包含8600万个可训练参数,凸显其处理复杂多模态任务的能力。框架的核心是声学和视觉Conformer模块,各配备3400万参数,能高效处理音频和视觉输入。模型中起关键作用的共享Conformer包含1500万参数,可实现不同模态的无缝集成。模型的重要组件是包含65万个参数的1D时序卷积层,这些模块对将视觉和声学特征投影至相同维度至关重要。此外,模型还配置了三个专用预测头(声学、视听、视觉处理),各含39万参数,进一步强化处理能力。最后,重建MLP层总计包含140万个参数。为评估实际效率,我们在3090 RTX GPU上测量了推理延迟和实时系数(RTF):纯音频模式平均延迟0.003499秒(RTF: 0.000005),纯视频模式0.001759秒(RTF: 0.000003),视听模式0.003770秒(RTF: 0.000006)。
算法 1 - VAVL (训练与推理)
确保: D = {A, V, Label}, M = {0a, θu, 0s, θav }
训练(D, M, α)
1: while i < 最大训练迭代次数 do
2: 采样一批 {Ai, V, Labeli}
3: if A 不为空 then
4: Preda, Ai-pool, ReCa = M{ 0a,0s}(Ai)
5: C = Lpred(Labeli, Preda) + αLMsE(Ai-pool, Reca)
6: 反向传播并更新 {0a, 0s}
7: if V 不为空 then
8: Predv, Vi-pool, ReCu = M{ 0u,0s}(Vi)
9: C = Lpred(Labeli, Predu) + αLMsE(Vi-pool, Recu)
10: 反向传播并更新 {0u, 0s}
11: if A 不为空 and V ≠ 空 then
12: 冻结 {0a, 0v,0s}
13: Predau = Mr0a,00,0s,0au}(Ai, Vi)
14: L = Lpred(Labeli, Predau)
15: 反向传播并更新 {0av}
16: 返回 M
推理({A, V}, M)
17: if A ≠ 空 and V ≠ 空 then
18: Pred = M{0a,0u,0s,0au}(A, V)
19: else if 某模态不可用 then
20: Pred = M{0a,0s}(A) when V == 空
21: Pred = Mr{0u,0s}(V) when A == 空
4 Experimental Settings
4 实验设置
4.1 Emotional Corpora
4.1 情感语料库
In this study, we use the CREMA-D [25], the MSP-IMPROV [26], and the CMU-MOSEI [22] corpora. The CREMAD corpus is an audio-visual corpus with high-quality recordings from 91 ethically and racially diverse actors (48 male, 43 female). Actors were asked to convey specific emotions while reciting sentences. Videos were recorded against a green screen background, with two directors overseeing the data collection. One director worked with 51 actors, while the other worked with 40 actors. Emotional labels were assigned by at least seven annotators. In total, 7,442 clips were collected and rated by 2,443 raters. We use the perceived emotions from the audio-visual modality in the CREMA-D corpus for our classification task. We consider six emotional classes: anger, disgust, fear, happiness, sadness, and neutral state.
在本研究中,我们使用了CREMA-D [25]、MSP-IMPROV [26]和CMU-MOSEI [22]语料库。CREMA-D语料库是一个包含91位不同种族演员(48名男性,43名女性)高质量录音的视听语料库。演员被要求在朗读句子时传达特定情绪。视频以绿幕为背景录制,由两名导演监督数据采集过程,其中一位导演负责51名演员,另一位负责40名演员。情绪标签由至少七名标注者共同判定,共收集了7,442个片段并由2,443名评分者进行评分。我们采用CREMA-D语料库中视听模态的情感感知数据作为分类任务基础,共包含六类情绪:愤怒、厌恶、恐惧、快乐、悲伤及中性状态。
The MSP-IMPROV corpus [26] is the second audio-visual database used in this study. The corpus was collected to study emotion perception. The corpus required sentences with identical lexical content but conveying different emotions. Instead of actors reading sentences, a sophisticated protocol elicited spontaneous target sentence renditions. The corpus includes 20 target sentences with four emotional states, resulting in 80 scenarios and 652 speaking turns. It also contains the interactions that prompted the target sentence (4,381 spontaneous speaking turns), natural interactions during breaks between the recording of dyadic scenarios (2,785 natural speaking turns), and read recordings expressing the target emotional classes (620 read speaking turns). In total, the MSP-IMPROV corpus contains 7,818 non-read speaking turns and 620 read sentences. The corpus was annotated using a crowd sourcing protocol, monitoring the quality of the workers in real-time. Each sentence was annotated for arousal (calm versus active), valence (negative versus positive), and dominance (weak versus strong) by five or more raters using a five-point Likert scale. We employ these three emotional attributes for our regression task.
MSP-IMPROV语料库[26]是本研究使用的第二个视听数据库。该语料库旨在研究情感感知,要求包含词汇内容相同但情感表达不同的句子。与演员朗读句子不同,该语料库通过精密实验协议诱发自发性的目标语句表达,包含20个目标句在四种情感状态下的80种场景和652个话轮。此外还收录了诱发目标语句的互动内容(4,381个自发性话轮)、双人场景录制间歇的自然互动(2,785个自然话轮)以及朗读目标情感类别的录音(620个朗读话轮),总计包含7,818个非朗读话轮和620个朗读语句。该语料库采用众包协议进行标注,实时监控标注者质量,每个句子由至少五位标注者使用五点李克特量表对唤醒度(平静vs活跃)、效价(消极vs积极)和支配度(弱势vs强势)进行标注。我们将这三个情感属性用于回归任务。
The CMU-MOSEI [22] comprises review video clips of movies sourced from YouTube. Each clip is annotated by human experts with a sentiment score ranging from -3 to 3. We retrieved the data from the author’s SDK and obtained a total of 22,859 files of which, based on their standard splits, 16,326 are used for training, 1,871 are used for development, and 4,659 are used for testing. This database consists of in-the-wild audio-visual recordings.
CMU-MOSEI [22] 包含从YouTube采集的电影评论视频片段。每个片段由人类专家标注了-3到3的情感评分。我们通过作者提供的SDK获取数据,共获得22,859个文件,根据其标准划分,其中16,326个用于训练,1,871个用于开发,4,659个用于测试。该数据库由真实场景的视听记录组成。
4.2 Acoustic and Visual Features
4.2 声学与视觉特征
For the CREMA-D and MSP-IMPROV corpora, we have access to the raw videos and audio recordings, so we can extract audio and visual features. Our acoustic feature extractor is based on the “wav2vec2-large-robust” architecture [55], which has shown superior emotion recognition performance compared to other variants of the Wav2vec2.0 model [56], as demonstrated in the study by Wagner et al. [45]. The downstream head of our model consists of two fully connected layers with 1,024 nodes, layer normalization, and rectified linear unit (ReLU) activation function, followed by a linear output layer with three nodes for predicting emotional attribute scores (arousal, dominance, and valence). We import the pre-trained “wav2vec2-large-robust” model from the Hugging Face library [57]. We use this wav2vec2 model specifically pre-trained for emotion recognition tasks before its integration to ensure the representations used are optimal for emotion recognition. We aggregate the output of the transformer encoder using average pooling and feed them to the downstream head. To regularize the model and prevent over fitting, we utilize dropout with a rate of $p=0.5$ applied to all hidden layers. To fine-tune the model, we use the training set of the MSP-Podcast corpus (release of v1.10) [58]. The ADAM optimizer [59] is employed with a learning rate set to 0.0001. We update the model with mini-batches of 32 utterances for 10 epochs. With the fine-tuned “wav2vec2-large-robust” model, we extract acoustic representations with a $25\mathrm{ms}$ window size and a $20~\mathrm{ms}$ stride from the given audio, which are then used as the acoustic features. This strategy creates 50 frames per second.
对于CREMA-D和MSP-IMPROV数据集,我们能够获取原始视频和音频记录,因此可以提取音频和视觉特征。我们的声学特征提取器基于"wav2vec2-large-robust"架构[55],该架构在Wagner等人的研究[45]中显示出优于其他Wav2vec2.0模型变体[56]的情感识别性能。模型的下游头部由两个全连接层组成(每层1,024个节点),包含层归一化和修正线性单元(ReLU)激活函数,最后接一个三节点的线性输出层用于预测情感属性得分(唤醒度、支配度和效价)。我们从Hugging Face库[57]导入预训练的"wav2vec2-large-robust"模型,并专门使用针对情感识别任务预训练的该模型,以确保所用表征对情感识别是最优的。我们通过平均池化聚合transformer编码器的输出,并将其馈送到下游头部。为规范模型并防止过拟合,我们对所有隐藏层采用丢弃率为$p=0.5$的dropout。使用MSP-Podcast语料库(v1.10版本)[58]的训练集对模型进行微调,采用学习率为0.0001的ADAM优化器[59],以32个话语为小批量更新模型,共训练10个周期。通过微调后的"wav2vec2-large-robust"模型,我们从给定音频中以$25\mathrm{ms}$窗口大小和$20~\mathrm{ms}$步长提取声学表征,作为声学特征使用,该策略每秒生成50帧。
To obtain visual features, we used the multi-task cascaded convolutional neural network (MTCNN) face detection algorithm [60] to extract faces from each image frame in the corpora using bounding boxes. Following the extraction of bounding boxes, we resize the images to a predetermined dimension of $224\times224\times3$ . After face extraction, we utilize the pre-trained Efficient Net-B2 model [29] to extract emotional feature representations. At the time of our study, this model was among the top performers on the AffectNet corpus [37]. Similarly to the acoustic feature extractor, the Efficient Net-B2 model is pre-trained for emotion recognition tasks before its integration. This approach helps ensure the representations obtained from videos are optimal for emotion recognition. The representation obtained from the Efficient Net-B2 model is retrieved from the last fully connected layer before classification, with an array dimension of 1,408. This representation is then concatenated row-wise with all other frames within each clip from the datasets, serving as the input for the visual branch of our framework.
为获取视觉特征,我们采用多任务级联卷积神经网络 (MTCNN) 人脸检测算法 [60] 从语料库的每帧图像中通过边界框提取人脸。完成边界框提取后,将图像尺寸统一调整为 $224\times224\times3$ 的预设维度。人脸提取完成后,使用预训练的 Efficient Net-B2 模型 [29] 提取情感特征表示。该模型在研究期间是 AffectNet 语料库 [37] 上性能最佳的模型之一。与声学特征提取器类似,Efficient Net-B2 模型在集成前已针对情感识别任务进行预训练,这有助于确保从视频中获取的表征最适合情感识别。从 Efficient Net-B2 模型获取的表征采自分类前的最后一个全连接层,其数组维度为 1,408。随后将该表征与数据集中每个片段内所有其他帧进行行级拼接,作为我们框架视觉分支的输入。
The CMU-MOSEI dataset offers pre-extracted features instead of raw data. Specifically, for the visual modality, it provides 35 facial action units, while the audio data includes features such as Mel-frequency cepstral coefficients (MFCCs), pitch tracking, glottal source, and peak slope parameters, totaling 74 features. Consequently, we could not use the same set of features used to conduct experiments on the CREMA-D and MSP-IMPROV corpora (i.e., wav2vec2 and Efficient Net-B2 based features). Instead, we use the features provided with the release, which also facilitates the comparison with other methods using this corpus.
CMU-MOSEI数据集提供预提取特征而非原始数据。具体而言,视觉模态包含35个面部动作单元,音频数据则包含梅尔频率倒谱系数(MFCCs)、基频追踪、声源参数和峰值斜率参数等74种特征。因此,我们无法使用在CREMA-D和MSP-IMPROV语料库实验中相同的特征集(即基于wav2vec2和Efficient Net-B2的特征),转而采用该数据集发布时提供的特征,这也便于与其他使用该语料库的方法进行比较。
4.3 Implementation Details
4.3 实现细节
We implemented the conformer blocks with an encoder hidden layer set to 512D, with 8 attention heads. We set a dropout rate to $p=0.1$ . The number of layers in the acoustic, visual, and shared conformer layers were set to three, three, and two, respectively. The acoustic/visual prediction layers and the reconstruction layers are implemented using a fully-connected structure with three layers. The first two layers are implemented with 512 nodes and 256 nodes, respectively. For the acoustic and visual prediction modules, the third layer is the output layer, where the size depends on the emotion recognition task (i.e., classification or regression). For the reconstruction task, the third layer is the target representation to be reconstructed, so it has 1,024 nodes for the acoustic features and 1,408 nodes for the visual features. The fully connected layers are implemented with dropout, with the rate set to $p=0.2$ . Similarly, the audiovisual prediction layers have a mostly identical fully-connected hidden layer structure to the unimodal prediction layers. The only difference is that the input layers are now 1,024D, as they need to take both unimodal representations from the shared layers as inputs. We trained the models for 20 epochs using the ADAM optimizer, with the ReLU as the activation function. The learning rate is set to 5e-5. We used a batch size of 32 for the CREMA-D and CMU-MOSEI dataset experiments, and a batch size of 16 for the MSP-IMPROV dataset experiments, since the MSP-IMPROV has longer sentences. The model was implemented in PyTorch and trained using an Nvidia Tesla V100.
我们实现的Conformer块编码器隐藏层设置为512维,配备8个注意力头。Dropout率设为$p=0.1$。声学、视觉及共享Conformer层的层数分别设置为3层、3层和2层。声学/视觉预测层和重构层采用三层全连接结构实现,前两层分别设置为512节点和256节点。对于声学和视觉预测模块,第三层为输出层,其尺寸取决于情感识别任务类型(分类或回归)。重构任务的第三层是待重构的目标表示,因此声学特征设置为1,024节点,视觉特征设置为1,408节点。全连接层均采用$p=0.2$的dropout率。视听预测层与单模态预测层的全连接隐藏层结构基本一致,唯一区别是输入层需同时接收共享层的双模态表示,因此维度提升至1,024维。模型使用ADAM优化器训练20个epoch,激活函数采用ReLU,学习率设为5e-5。CREMA-D和CMU-MOSEI数据集实验采用32的批量大小,而MSP-IMPROV数据集因语句较长采用16的批量大小。模型基于PyTorch框架实现,并在Nvidia Tesla V100显卡上完成训练。
The recordings in each database are divided into train, development, and test sets, with approximately $70%$ , $15%$ , and $15%$ of the data in each set, respectively. The splits were carried out in a speaker-independent manner, ensuring that no speaker appeared in more than one set. We trained each model five times, with different splits each time. All models were trained using the train set, and the best-performing model on the development set was selected and used to make predictions on the test set.
每个数据库中的录音被划分为训练集、开发集和测试集,各占数据量的约$70%$、$15%$和$15%$。划分过程采用说话人无关的方式,确保同一说话人不会出现在多个集合中。每个模型均训练五次,每次采用不同的数据划分。所有模型均使用训练集进行训练,并选择在开发集上表现最佳的模型用于测试集预测。
4.4 Cost Functions and Evaluation Metrics
4.4 成本函数与评估指标
Three of the most prominent tasks in affective computing are classification tasks for categorical emotions, regression models for emotional attributes, and sentiment analysis which can be approached as either a classification or a regression task, depending on the specifics of the problem and the nature of the sentiment scores. Our model is designed to be utilized and evaluated in both formulations (i.e., classification or regression tasks).
情感计算中最突出的三个任务是分类情感的分类任务、情感属性的回归模型,以及可以作为分类或回归任务处理的情感分析(具体取决于问题的细节和情感评分的性质)。我们的模型设计用于这两种形式(即分类或回归任务)的利用和评估。
For emotion classification, our training objective is based on the multiclass cross-entropy loss, as seen in equation 2,
对于情感分类,我们的训练目标基于多类交叉熵损失,如公式2所示,
$$
\mathcal{L}{C E}=-\sum_{c=1}^{M}y_{o,c}\log(p_{o,c})
$$
$$
\mathcal{L}{C E}=-\sum_{c=1}^{M}y_{o,c}\log(p_{o,c})
$$
where $M$ is number of classes, log is the natural log, $c$ is the correct label for observation $o$ , and $p$ is the predicted probability that observation $o$ belong to class $c$ . We predict the emotional state/value for each input sequence in our test set and report the ‘micro’ and ‘macro’ F1-scores. The ‘micro’ F1-score is computed by considering the total number of true positives, false negatives, and false positives, making it sensitive to class imbalance. The ‘macro’ F1-score calculates the F1-score for each class separately and aggregated the scores with equal weight, so the performance on the minority class is as important as the performance in the majority class.
其中 $M$ 是类别数量,log 表示自然对数,$c$ 是观测值 $o$ 的正确标签,$p$ 是观测值 $o$ 属于类别 $c$ 的预测概率。我们对测试集中每个输入序列预测情绪状态/值,并报告"微平均"和"宏平均"F1分数。"微平均"F1分数通过计算真正例、假反例和假正例的总数得出,因此对类别不平衡敏感。"宏平均"F1分数则分别计算每个类别的F1分数后等权聚合,使得少数类的性能与多数类同等重要。
For emotional attributes regression models, we use the concordance correlation coefficient (CCC), which measures the agreement between the true and predicted emotional attribute scores. Equation 3 illustrates the CCC measurements,
对于情感属性回归模型,我们使用一致性相关系数 (concordance correlation coefficient, CCC) 来衡量真实情感属性分数与预测分数之间的一致性。公式3展示了CCC的测量方法,
$$
\mathcal{L}{C C C}=\frac{2\rho\sigma_{x}\sigma_{y}}{\sigma_{x}^{2}+\sigma_{y}^{2}+(\mu_{x}-\mu_{y})^{2}}
$$
$$
\mathcal{L}{C C C}=\frac{2\rho\sigma_{x}\sigma_{y}}{\sigma_{x}^{2}+\sigma_{y}^{2}+(\mu_{x}-\mu_{y})^{2}}
$$
where $\mu_{x}$ and $\mu_{y}$ are the means of the true and predicted scores, $\sigma_{x}$ and $\sigma_{y}$ are the standard deviation of the true and predicted scores, and $\rho$ is their Pearson’s correlation coefficient. We train our model to maximize CCC so that the predicted scores have a high correlation with the true scores, while reducing their errors in the prediction. We use the CCC metric for model evaluation of the predictions of arousal, valence, and dominance.
其中 $\mu_{x}$ 和 $\mu_{y}$ 分别表示真实分数和预测分数的均值,$\sigma_{x}$ 和 $\sigma_{y}$ 是真实分数和预测分数的标准差,$\rho$ 是它们的皮尔逊相关系数。我们训练模型以最大化CCC (Concordance Correlation Coefficient),使得预测分数与真实分数保持高相关性,同时减少预测误差。我们使用CCC指标来评估模型对唤醒度 (arousal)、效价 (valence) 和支配度 (dominance) 的预测效果。
We formulate the prediction of sentiment analysis as the prediction of a continuous number between -3 to 3. We employ the mean absolute error (MAE) as the primary training objective. This $L I$ loss function is defined as the average of the absolute differences between the predicted sentiment scores and the true sentiment scores. The L1 loss is formulated as shown in Equation 4:
我们将情感分析预测建模为对-3到3之间连续数值的预测。采用平均绝对误差(MAE)作为主要训练目标,该L1损失函数定义为预测情感分数与真实情感分数之间绝对差值的平均值。如公式4所示:
$$
\mathcal{L}{L1}=\frac{1}{N}\sum_{i=1}^{N}\left|y_{i}-\hat{y}_{i}\right|
$$
$$
\mathcal{L}{L1}=\frac{1}{N}\sum_{i=1}^{N}\left|y_{i}-\hat{y}_{i}\right|
$$
where $N$ is the number of samples, $y_{i}$ is the true sentiment score, and $\hat{y}_{i}$ is the predicted sentiment score for the $i$ -th sample. The L1 loss is particularly suitable for sentiment analysis as it robustly handles outliers and ensures a linear error pen aliz ation. Our model aims to minimize this loss during training, thereby reducing the average magnitude of errors in sentiment score predictions. This loss function is instrumental in achieving high accuracy in predicting the nuanced sentiment scores across the specified range.
其中 $N$ 是样本数量,$y_{i}$ 是真实情感分数,$\hat{y}_{i}$ 是第 $i$ 个样本的预测情感分数。L1损失函数特别适合情感分析任务,因为它能稳健处理异常值并确保线性误差惩罚。我们的模型在训练过程中以最小化该损失为目标,从而降低情感分数预测的平均误差幅度。该损失函数对于在指定范围内精准预测细微情感分数具有关键作用。
We conducted each experiment in this work five times with different partitions or seeds and reported the average metrics. Additionally, we performed statistical analyses to evaluate our model’s performance against the baseline models. We used a two-tailed t-test, asserting a significance level at $p$ -value $<0.05$ .
我们在本工作中对每个实验进行了五次不同划分或种子的重复,并报告了平均指标。此外,我们通过统计分析评估了模型相对于基线模型的性能,采用双尾t检验,显著性水平设为$p$值$<0.05$。
Table 1: Comparison between the VAVL model and the audio-visual and unimodal baselines. The table reports the average performance metrics across five trials. The symbol $^*$ indicates that the VAVL model is significantly better than the other baselines on the CREMA-D and CMU-MOSEI datasets.
表 1: VAVL模型与视听及单模态基线的对比。表格报告了五次试验的平均性能指标。符号$^*$表示VAVL模型在CREMA-D和CMU-MOSEI数据集上显著优于其他基线。
| CREMA-D | CMU-MOSEI | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 视听 | 声学 | 视觉 | 视听 | 声学 | 视觉 | ||||
| 模型 | F1宏 | F1微 | F1宏 | F1微 | F1宏 | F1微 | MAE | MAE | MAE |
| VAVL | 0.779±.025 | 0.826*±.015 | 0.628±.013 | 0.701*±.015 | 0.738*±.033 | 0.787*±.020 | 0.792±.029 | 0.829±.034 | 0.795*±.028 |
| UAVM | 0.737±.018 | 0.804±.008 | 0.552±.034 | 0.607±.033 | 0.691±.017 | 0.748±.013 | 0.802±.029 | 0.862±.031 | 0.803±.026 |
| AuxFormer | 0.743±.019 | 0.791±.017 | 0.504±.084 | 0.578±.046 | 0.692±.033 | 0.739±.032 | 0.808±.030 | 0.830±.032 | 0.806±.028 |
| SFAV | 0.771±.020 | 0.810±.010 | 0.658±.015 | 0.699±.014 | 0.656±.019 | 0.709±.015 | 0.804±.024 | 0.821±.032 | 0.813±.032 |
| TLSTM | 0.667±.012 | 0.746±.012 | 0.503±.046 | 0.543±.042 | 0.574±.020 | 0.651±.025 | 0.811±.022 | 0.821±.032 | 0.815±.028 |
| MulT | 0.714±.015 | 0.762±.015 | 0.810±.028 | ||||||
| Uni. (A) | 0.625±.024 | 0.690±.015 | 0.821±.028 | ||||||
| Uni. (V) | 0.725±.039 | 0.783±.028 | 0.859±.032 |
Table 2: Comparison between the VAVL model and the audio-visual and unimodal baselines. The table reports the average performance metrics across five trials. The symbol $^*$ indicates that the VAVL model is significantly better than the other baselines on the MSP-IMPROV dataset.
表 2: VAVL模型与视听模态及单模态基线的对比。表格报告了五次试验的平均性能指标。符号$^*$表示VAVL模型在MSP-IMPROV数据集上显著优于其他基线。
| 模型 | 视听模态 Aro. | Val. | Dom. | 声学模态 Aro. | Val. | Dom. | 视觉模态 Aro. | Val. | Dom. |
|---|---|---|---|---|---|---|---|---|---|
| VAVL | 0.856*±.110 | 0.876*±.095 | 0.814*±.151 | 0.853*±.104 | 0.858±.111 | 0.783±.155 | 0.422*±.133 | 0.631*±.032 | 0.375±.112 |
| UAVM | 0.471±.257 | 0.687±.329 | 0.544±.309 | 0.578±.316 | 0.705±.339 | 0.637±.384 | 0.274±.145 | 0.522±.260 | 0.296±.163 |
| AuxFormer | 0.672±.134 | 0.820±.071 | 0.652±.149 | 0.722±.218 | 0.789±.142 | 0.730±.162 | 0.363±.153 | 0.581±.071 | 0.293±.141 |
| SFAV | 0.786±.103 | 0.761±.119 | 0.721±.147 | 0.745±.081 | 0.699±.073 | 0.628±.140 | 0.345±.192 | 0.572±.175 | 0.473±.148 |
| TLSTM | 0.832±.095 | 0.843±.103 | 0.767±.155 | 0.835±.117 | 0.765±.188 | 0.841±.125 | 0.172±.140 | 0.574±.094 | 0.201±.066 |
| MulT | 0.775±.088 | 0.761±.056 | 0.778±.136 | - | - | - | - | - | - |
| Uni. (A) | - | - | - | 0.841±.095 | 0.878±.108 | 0.820±.158 | - | - | - |
| Uni. (V) | - | - | - | - | - | - | 0.383±.065 | 0.598±.093 | 0.321±.070 |
4.5 Baselines
4.5 基线方法
To evaluate the performance of our proposed model, we conducted experiments with three strong audio-visual frameworks and one unimodal framework. Baseline models 1, 2, 3, and 4 were implemented utilizing the code available in their respective repositories. For Baseline 5, the implementation was carried out in accordance with the specifications outlined in its associated paper. Baseline 6 represents a unimodal variant of our model, specifically crafted for comparisons in a unimodal setting.
为了评估我们提出的模型性能,我们与三个强大的视听框架和一个单模态框架进行了对比实验。基线模型1、2、3和4均采用各自代码库中的公开实现。基线5则严格依照其关联论文的描述进行复现。基线6是我们模型的单模态变体,专为单模态场景下的对比而设计。
4.5.1 Baseline 1: UAVM
4.5.1 基线1: UAVM
Gong et al. [19] proposed a unified audio-visual framework for classification, which independently processes audio and video features. The framework includes a shared transformer component and a classification layer, whose weights are shared between the modalities.
Gong等人[19]提出了一种用于分类的统一视听框架,该框架独立处理音频和视频特征。该框架包含一个共享的Transformer组件和一个分类层,其权重在模态间共享。
4.5.2 Baseline 2: AuxFormer
4.5.2 基线模型 2: AuxFormer
Goncalves and Busso [51] proposed an audio-visual transformer-based framework that creates cross-modal representations through transformer layers, sharing representations from query inputs from one modality to the keys and values of another modality. Additionally, their architecture includes unimodal auxiliary networks and modality dropout during training to enhance the robustness to missing modalities, allowing the model to be used in both audio-visual and unimodal settings.
Goncalves和Busso [51]提出了一种基于Transformer的视听框架,该框架通过Transformer层创建跨模态表征,将来自一种模态的查询输入表征共享到另一种模态的键和值中。此外,他们的架构在训练过程中包含单模态辅助网络和模态丢弃,以增强对缺失模态的鲁棒性,使模型能够在视听和单模态场景中使用。
4.5.3 Baseline 3: MulT
4.5.3 基线3: MulT
Tsai et al. [61] proposed a multimodal transformer architecture for human language time-series data. Their model uses a cross-modal transformer framework that generates pairs of bimodal representations, where the keys and values of one modality interact with the queries of a target modality. Vectors with similar target modalities are concatenated and passed to another transformer layer that generates representations used for prediction. The original model considered textual, visual, and acoustic features. We adapt the model from the original study by removing the dependencies on the textual branch, focusing only on visual and acoustic features.
Tsai等人[61]提出了一种针对人类语言时间序列数据的多模态Transformer架构。该模型采用跨模态Transformer框架,生成双模态表征对,其中一个模态的键和值与目标模态的查询进行交互。具有相似目标模态的向量被拼接后传递至另一层Transformer,生成用于预测的表征。原模型考虑了文本、视觉和声学特征。我们通过移除对文本分支的依赖,仅保留视觉和声学特征来调整该模型。
4.5.4 Baseline 4: SFAV
4.5.4 基线4: SFAV
Chuma chen ko et al. [62] present an architecture for audiovisual emotion recognition, particularly addressing the challenge of incomplete data from either modality during inference. Their model is designed to learn from both audio and visual data and incorporates robust fusion mechanisms that perform well even when one modality is absent. The authors explore fusion techniques, such as late transformer fusion and intermediate transformer fusion to more effectively integrate features from the audio and visual branches. In this paper, we refer to this baseline as SFAV in agreement with their methodology approach which uses self-attention fusion for audio-visual emotion recognition.
Chuma chen ko等人[62]提出了一种视听情感识别架构,特别针对推理过程中任一模态数据不完整的挑战。该模型设计用于从音频和视觉数据中学习,并采用鲁棒的融合机制,即使在缺失一种模态时仍能保持良好性能。作者探索了多种融合技术,例如后期Transformer融合和中间Transformer融合,以更有效地整合音频与视觉分支的特征。本文将该基线称为SFAV,因其采用自注意力融合方法进行视听情感识别。
4.5.5 Baseline 5: TSLTM
4.5.5 基线5: TSLTM
Huang et al. [63] propose a multimodal transformer architecture for continuous emotion recognition, leveraging the Transformer’s ability to model long-term temporal dependencies with self-attention mechanisms. Their model combines audio and visual modalities through model-level fusion without an encoder-decoder structure. It employs multihead attention to learn emotional temporal dynamics and fuses audio-visual modalities into a shared semantic space, outperforming traditional fusion methods. Additionally, the architecture integrates long short-term memory (LSTM) networks to further improve performance. In our study, we refer to the model as TLSTM consistent with their method of combining the transformer model and LSTM for emotion recognition.
Huang等[63]提出了一种用于连续情绪识别的多模态Transformer架构,利用Transformer通过自注意力机制建模长期时间依赖的能力。该模型通过模型级融合结合音频和视觉模态,无需编码器-解码器结构,采用多头注意力学习情绪时间动态特征,并将视听模态融合到共享语义空间,性能优于传统融合方法。此外,该架构整合了长短期记忆(LSTM)网络以进一步提升性能。在本研究中,我们沿用其将Transformer模型与LSTM结合进行情绪识别的方法,将该模型称为TLSTM。
4.5.6 Baseline 6: Unimodal Acoustic and Visual Model
4.5.6 基线6:单模态声学与视觉模型
The unimodal baseline model has a similar structure to the model proposed in this study. Like the acoustic and visual layers of our model, it uses conformer encoder layers [54] to process all sequential video or acoustic frames in parallel. The output of the conformer layers is then average-pooled and fed into a network that contains two fully connected layers to generate the prediction. We build the unimodal network with five conformer layers to match the structure of the full VAVL network.
单模态基线模型的结构与本研究中提出的模型类似。与我们模型的声学和视觉层一样,它使用conformer编码器层[54]并行处理所有时序视频或声学帧。conformer层的输出经过平均池化后,输入到一个包含两个全连接层的网络中以生成预测。我们构建了包含五个conformer层的单模态网络,以匹配完整VAVL网络的结构。
5 Experimental Results
5 实验结果
5.1 Comparison with Baselines
5.1 与基线方法的对比
This section compares our proposed model with the audiovisual and unimodal baselines explored in this study. All models were trained using the details discussed in Section 4.3. Tables 1 and 2 presents the average results for all the models across the five trials on each corpus. The models’ performances are evaluated based on three modalities: audiovisual, acoustic, and visual. For the MSP-IMPROV dataset, the performance is assessed using the CCC predictions for arousal (Aro.), valence (Val.), and dominance (Dom.). For the CREMA-D dataset, we report the $F I$ -Macro (F1-Ma) and $F l$ -Micro (F1-Mi) scores. For the CMU-MOSEI dataset, we report Mean Absolute Error (MAE). Upon examining the performance metrics presented in the tables, the VAVL model demonstrates notable superiority across various tasks when compared to the baseline models on CREMA-D, MSP-IMPROV, and CMU-MOSEI datasets. This superiority is quantified by the asterisks indicating statistical significance.
本节将我们提出的模型与本研究探讨的视听和单模态基线进行比较。所有模型均按照第4.3节讨论的细节进行训练。表1和表2展示了各模型在五个试验中的平均结果。模型性能基于三种模态进行评估:视听、声学和视觉。对于MSP-IMPROV数据集,使用唤醒度(Aro.)、效价(Val.)和支配度(Dom.)的CCC预测进行评估。对于CREMA-D数据集,我们报告了$F I$-Macro(F1-Ma)和$F l$-Micro(F1-Mi)分数。对于CMU-MOSEI数据集,我们报告了平均绝对误差(MAE)。通过分析表格中的性能指标,VAVL模型在CREMA-D、MSP-IMPROV和CMU-MOSEI数据集上相比基线模型展现出显著优势,该优势通过星号标注的统计显著性进行量化。
In the audio-visual modality on the CREMA-D dataset, the VAVL model achieves an F1-Macro score of $0.779{\scriptstyle\pm0.025}$ , which is significantly higher than that of the strongest baseline, the TSLTM model, at $0.667{\scriptstyle\pm0.012}$ . This pattern is consistent in the F1-Micro score, where VAVL scores $0.826{\scriptstyle\pm0.015}$ , outperforming the second-best SFAV model’s score of $0.810{\scriptstyle\pm0.010}$ .
在CREMA-D数据集的多模态实验中,VAVL模型的F1-Macro得分为$0.779{\scriptstyle\pm0.025}$,显著优于最强基线TSLTM模型的$0.667{\scriptstyle\pm0.012}$。这一优势同样体现在F1-Micro指标上:VAVL以$0.826{\scriptstyle\pm0.015}$的成绩超越第二名SFAV模型的$0.810{\scriptstyle\pm0.010}$。
The VAVL model’s performance in acoustic modality is also strong, with a MAE of $0.829{\scriptstyle\pm0.034}$ on the CMU-MOSEI dataset, which is lower than the best-performing baseline model (AuxFormer) with an MAE of $0.830{\scriptstyle\pm0.032}$ . Lower MAE indicates better performance, and these numbers underscore the predictive accuracy of the VAVL model in capturing sentiment changes. On the visual modality of the CMU-MOSEI dataset, The MAE of the VAVL model is $0.795{\scriptstyle\pm0.028}$ , which again is the lowest error rate compared to the baselines. The closest competitor is the MulT model with an MAE of $0.815{\scriptstyle\pm0.028}$ , indicating that VAVL is more precise in interpreting visual data for sentiment analysis.
VAVL模型在声学模态上的表现同样出色,在CMU-MOSEI数据集上的MAE为$0.829{\scriptstyle\pm0.034}$,低于表现最佳的基线模型(AuxFormer)的MAE值$0.830{\scriptstyle\pm0.032}$。更低的MAE意味着更好的性能,这些数据凸显了VAVL模型在捕捉情绪变化方面的预测准确性。在CMU-MOSEI数据集的视觉模态上,VAVL模型的MAE为$0.795{\scriptstyle\pm0.028}$,与基线模型相比再次达到最低错误率。最接近的竞争对手是MulT模型(MAE为$0.815{\scriptstyle\pm0.028}$),这表明VAVL在解读视觉数据以进行情感分析时更为精准。
The MSP-IMPROV dataset further showcases the VAVL’s robustness, particularly in the audio-visual category for arousal (Aro.), with a score of $0.856{\scriptstyle\pm0.110}$ , significantly surpassing the UAVM model which has a score of $0.471{\scriptstyle\pm0.257}$ . Similarly, in dominance (Dom.), VAVL scores $0.814{\scriptstyle\pm0.095}$ , while the next best is the TSLTM model at $0.782{\scriptstyle\pm0.145}$ . The results for the audio-visual setting on the MSP-IMPROV corpus reinforce our hypothesis that the use of averaging unimodal predictions, as employed by some baselines, might not work well for regression tasks. These metrics highlight the strong capability of the VAVL framework in detecting the intensity and control aspects of emotions conveyed through both audio and visual cues.
MSP-IMPROV数据集进一步验证了VAVL的鲁棒性,尤其在视听维度的唤醒度(Aro.)指标上取得$0.856{\scriptstyle\pm0.110}$分,显著优于UAVM模型的$0.471{\scriptstyle\pm0.257}$分。在支配度(Dom.)维度,VAVL以$0.814{\scriptstyle\pm0.095}$分领先,次优模型TSLTM得分为$0.782{\scriptstyle\pm0.145}$。这些在MSP-IMPROV语料库上的视听实验结果支持了我们的假设:部分基线模型采用单模态预测平均值的策略可能不适用于回归任务。这些指标凸显了VAVL框架在通过视听线索检测情感强度与控制维度方面的强大能力。

Figure 2: Performance of the proposed model under audio-visual settings on the CREMA-D corpus with partial visual or acous1tic0 information 2. 0The figure p3lo0ts the micro 4F01-scores as a5 f0unction of th6e 0 percentage o7f t0he frames in8cl0uded for the masked modality (the other modality is assumed to be complete).
图 2: 所提模型在CREMA-D语料库上视听设置下的性能表现(部分视觉或听觉信息缺失) 该图绘制了微平均F1分数随被遮蔽模态(另一模态假定完整)包含帧百分比的变化曲线。

Figure 3: Performance of the proposed model under audio-visual settings on the MSP-IMPROV corpus with partial visual or acoustic information. The figure plots the CCC scores as a function of the percentage of the frames included for the masked modality (the other modality is assumed to be complete).
图 3: 所提模型在MSP-IMPROV语料库中视听设置下的性能表现(部分视觉或听觉信息缺失)。该图展示了CCC分数随掩蔽模态(另一模态假设完整)包含帧百分比的变化曲线。
In summary, the VAVL model not only consistently outperforms the baseline models in terms of CCC and macro and micro F1 scores, it also maintains lower MAE across datasets, showcasing its superior ability to accurately recognize and predict emotions. The numerical superiority of the VAVL model across various datasets which have been collected under diverse scenarios emphasizes its potential for practical applications in emotion recognition systems.
总之,VAVL模型不仅在CCC、宏观F1值和微观F1值上持续优于基线模型,还在各数据集中保持较低的MAE值,展现了其精准识别和预测情绪的卓越能力。该模型在多种场景采集的多样化数据集上均表现出数值优势,凸显了其在情绪识别系统中实际应用的潜力。
5.2 Random Masking of Features
5.2 特征随机掩码
This section evaluates the system’s performance in scenarios with absent features, simulating missing data by randomly zeroing out either visual or acoustic data at the frame level. To analyze the system’s resilience to incomplete information, we increment ally mask available frames from $0%$ to $90%$ in $10%$ increments. For instance, in the $30%$ condition, $30%$ of the frames from the modality being masked are replaced with zeros. This evaluation helps us understand the model’s performance variations when audio-visual data is available but partially incomplete. The rationale behind our approach of simulating missing modalities by randomly dropping frames at varying percentages is to closely mimic conditions where input data might be incomplete or degraded due to practical issues. In realworld scenarios, data loss can occur randomly due to face occlusions, hardware intermittent malfunctions, or other environmental factors. Randomly dropping frames aims to replicate these unpredictable disruptions. We focus on the MSP-IMPROV and CREMA-D corpora, which allow us to use our entire framework—from processing raw inputs to predicting emotions - a process not possible with the CMU-MOSEI corpus due to the absence of raw data. The MSP-IMPROV and CREMA-D corpora provide consistency in frame-wise facial feature extraction and synchronize acoustic feature extraction timing, employing a $25~\mathrm{ms}$ window size and a $20\mathrm{ms}$ stride for both corpora.
本节评估系统在特征缺失场景下的性能,通过在帧级别随机将视觉或声学数据置零来模拟数据缺失。为分析系统对不完整信息的鲁棒性,我们以10%为增量逐步将可用帧从$0%$掩蔽至$90%$。例如在$30%$条件下,被掩蔽模态中30%的帧会被替换为零值。该评估有助于理解当视听数据可用但部分不完整时模型的性能变化。
我们采用随机按比例丢弃帧来模拟模态缺失的方法,其核心理念是紧密模拟实际场景中可能因硬件间歇故障、面部遮挡或其他环境因素导致输入数据随机不完整的状况。MSP-IMPROV和CREMA-D语料库支持从原始输入处理到情感预测的完整流程(CMU-MOSEI因缺乏原始数据无法实现),这两个语料库均采用$25~\mathrm{ms}$窗口大小和$20\mathrm{ms}$步长,确保帧级面部特征提取与声学特征提取时序同步。
Figures 2(a) and 2(b) show the average results on the CREMA-D corpus for masking audio and visual inputs, respectively, obtained from the model’s audio-visual prediction heads. The results indicate that removing either modality impacts the model. With random audio masking, performance remains stable when we mask up to $30%$ of the frames.
图 2(a) 和 2(b) 分别展示了在 CREMA-D 语料库上对音频和视觉输入进行掩码的平均结果,这些结果来自模型的视听预测头。结果表明,移除任一模态都会影响模型性能。在随机音频掩码情况下,当掩码帧数达到 $30%$ 时,模型性能仍保持稳定。
Table 3: Ablation analysis of the proposed VAVL model using the MSP-IMPROV and CREMA-D corpora. Ablation 1 removes the residual connections over the shared layers. Ablation 2 removes reconstruction step from the framework. Ablation 3 removes audio-visual prediction layer, estimating the output by averaging the unimodal predictions.
表 3: 使用 MSP-IMPROV 和 CREMA-D 语料库对提出的 VAVL 模型进行消融分析。消融实验1移除了共享层的残差连接。消融实验2移除了框架中的重构步骤。消融实验3移除了视听预测层,通过平均单模态预测来估计输出。
| MSP-IMPROV | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Audio-Visual | Acoustic | Visual | Audio-Visual | Acoustic | Visual | ||||||||||
| Model | Aro. | Val. | Dom. | Aro. | Val. | Dom. | Aro. | Val. | Dom. | F1-Ma | F1-Mi | F1-Ma | F1-Mi | F1-Ma | F1-Mi |
| VAVL | 0.856 | 0.876 | 0.814 | 0.853 | 0.858 | 0.783 | 0.422 | 0.631 | 0.375 | 0.779 | 0.826 | 0.628 | 0.701 | 0.738 | 0.787 |
| Ablt.1 | 0.716 | 0.779 | 0.705 | 0.682 | 0.753 | 0.712 | 0.176 | 0.341 | 0.133 | 0.751 | 0.807 | 0.397 | 0.528 | 0.727 | 0.783 |
| Ablt.2 | 0.810 | 0.873 | 0.788 | 0.791 | 0.864 | 0.780 | 0.172 | 0.577 | 0.227 | 0.761 | 0.816 | 0.604 | 0.684 | 0.718 | 0.775 |
| Ablt.3 | 0.711 | 0.843 | 0.659 | 0.784 | 0.870 | 0.776 | 0.374 | 0.617 | 0.265 | 0.762 | 0.814 | 0.629 | 0.691 | 0.713 | 0.764 |
The model reaches an F1 Macro score of approximately 0.72 when only $10%$ of the audio frames are present. In contrast, visual masking results in a sharper drop in performance when we mask $30%$ of the frames. The approach has a low F1 Macro score of about 0.51 when only $10%$ of the video frames are present. This score is significantly lower than those in Table 1 using only the acoustic head, implying that the audio-visual head may get confused with zero-masked frames. When the percentage of missing visual frames is higher than $60{-}70%$ , it is better to rely solely on the acoustic modality.
该模型在仅保留 $10%$ 音频帧时达到约0.72的F1宏平均分数。相比之下,当遮蔽 $30%$ 视频帧时,视觉遮蔽会导致性能急剧下降。该方法在仅保留 $10%$ 视频帧时F1宏平均分数低至约0.51,显著低于表1中仅使用音频头的结果,表明视听头可能被全零遮蔽帧干扰。当缺失视觉帧比例高于 $60{-}70%$ 时,完全依赖音频模态效果更佳。
Figures 3(a) and 3(b) depict average results on the MSP-IMPROV corpus for masking audio and visual inputs. The results from the audio-visual prediction heads show that the performance with random audio masking is steady up to $30%$ , then drops sharply, reaching scores of about $\mathrm{0.4}\mathrm{CCC}$ for valence, and $:0.2\mathrm{CCC}:\$ for arousal and dominance. This result suggests that the emotional attribute models rely more on the acoustic modality to achieve high performance. Masking the audio frames can lead to lower performances than using only the visual head for prediction. When we miss more than $60%$ of the acoustic features, it is better to focus solely on visual features, using the results from the visual head. Conversely, masking visual features results in a smaller performance drop. Even when we mask $90%$ of the visual features, we still achieve scores of $\mathrm{0.85~CCC}$ for valence, $\ensuremath{0.82}\mathrm{CCC}$ for arousal, and $\begin{array}{r}{0.75\mathrm{CCC}}\end{array}$ for dominance. These findings confirm that the model is more dependent on acoustic features than visual features to predict emotional attributes.
图 3(a) 和 3(b) 展示了在 MSP-IMPROV 语料库上对音频和视觉输入进行掩码的平均结果。视听预测头的结果表明,随机音频掩码的性能在 $30%$ 以内保持稳定,之后急剧下降,效价得分降至约 $\mathrm{0.4}\mathrm{CCC}$,而唤醒度和支配度得分降至 $:0.2\mathrm{CCC}:\$。这一结果表明,情感属性模型更依赖声学模态来实现高性能。对音频帧进行掩码会导致性能低于仅使用视觉头进行预测的情况。当声学特征缺失超过 $60%$ 时,仅关注视觉特征并使用视觉头的结果更为可取。相反,掩码视觉特征导致的性能下降较小。即使掩码 $90%$ 的视觉特征,我们仍能获得效价 $\mathrm{0.85~CCC}$、唤醒度 $\ensuremath{0.82}\mathrm{CCC}$ 和支配度 $\begin{array}{r}{0.75\mathrm{CCC}}\end{array}$ 的得分。这些发现证实,模型在预测情感属性时更依赖声学特征而非视觉特征。
5.3 Ablation Analysis of the VAVL Framework
5.3 VAVL框架的消融分析
Table 3 presents the results of an ablation analysis of the VAVL model on the MSP-IMPROV and CREMA-D corpora, comparing the performance of the full model with its ablated versions. In these experiments, we focus on the on the MSP-IMPROV and CREMA-D corpora, since with these corpora we were able to use our entire framework from raw inputs to emotion predictions, which was not possible with CMU-MOSEI since raw datapoints are not provided. Three ablated models are considered: Ablation 1 (Ablt. 1) removes the residual connections over the shared layers, Ablation 2 (Ablt. 2) removes the reconstruction step from the framework, and Ablation 3 (Ablt. 3) removes the audio-visual prediction layer, using the average of the unimodal predictions as the audio-visual prediction.
表 3 展示了 VAVL 模型在 MSP-IMPROV 和 CREMA-D 语料库上的消融分析结果,对比了完整模型与其消融版本的性能。在这些实验中,我们重点关注 MSP-IMPROV 和 CREMA-D 语料库,因为使用这些语料库时,我们能够从原始输入到情感预测完整应用框架,而 CMU-MOSEI 由于未提供原始数据点无法实现这一点。实验中考虑了三种消融模型:消融 1 (Ablt. 1) 移除了共享层的残差连接,消融 2 (Ablt. 2) 移除了框架中的重构步骤,消融 3 (Ablt. 3) 移除了视听预测层,采用单模态预测的平均值作为视听预测结果。
In the MSP-IMPROV dataset, the full VAVL model outperforms all the ablated versions in terms of arousal, valence, and dominance for the audio-visual and visual modalities. In the acoustic modality, VAVL shows the best performance for arousal and valence. However, Ablation 2 and 3 slightly surpass the VAVL results for dominance. These results indicate that the residual connections, reconstruction step, and audio-visual prediction layer all contribute to the strong performance of the VAVL model.
在MSP-IMPROV数据集中,完整VAVL模型在视听模态和视觉模态的唤醒度(arousal)、效价(valence)和支配度(dominance)指标上均优于所有消融版本。在听觉模态中,VAVL在唤醒度和效价指标上表现最佳,但Ablation 2和Ablation 3在支配度指标上略优于VAVL。这些结果表明:残差连接、重构步骤和视听预测层共同促成了VAVL模型的优异性能。
On the CREMA-D dataset, VAVL consistently achieves the highest F1-Macro and F1-Micro scores across multimodal and unimodal settings, indicating that the full model is superior to its ablated versions. Ablation 1 has the lowest performance in the acoustic modality, while Ablations 2 and 3 show competitive results in some cases, albeit not surpassing the results of the full VAVL model. These results are consistent with the MSP-IMPROV ablation results and suggest that the combination of all components in the VAVL model leads to the best performance, with each component playing a significant role in the overall success of the model.
在CREMA-D数据集上,VAVL在多模态和单模态设置中始终获得最高的F1-Macro和F1-Micro分数,表明完整模型优于其消融版本。消融实验1在声学模态中表现最差,而消融实验2和3在某些情况下显示出竞争力,但均未超越完整VAVL模型的结果。这些结果与MSP-IMPROV消融实验结果一致,表明VAVL模型中所有组件的组合能带来最佳性能,每个组件都对模型整体成功起到重要作用。
5.4 Shared Embedding Analysis
5.4 共享嵌入分析
In this section, we perform analysis on the output embedding representations for each modality at the output of the shared layers from our VAVL model and the baselines. This experiment is conducted to investigate whether the shared layers of a multimodal model are capable of producing different representations for each modality. Using shared layers in a multimodal model allows the architecture to learn a common representation across different modalities, which can help in tasks that require integrating information from multiple sources. However, maintaining distinct representations for each modality in a multimodal model is crucial for several reasons. First, it allows the model to capture modalityspecific information, which is essential for optimal performance. Second, it enhances interpret ability by making it easier to analyze each modality’s contribution to the final output or decision. Lastly, distinct representations ensure the model’s adaptability, enabling it to perform well even when some modalities are missing or incomplete. To verify our proposed model’s capability of generating distinct separable representations for each modality from the shared layers, we obtain separate output embeddings from the shared layers of the trained model using either acoustic or visual information. Then, we calculate the cosine distance between their respective embeddings. On the one hand, a high cosine distance indicates that the embeddings are more dissimilar, and thus capturing modality-specific information. On the other hand, a low cosine distance implies that the embeddings are more similar, potentially indicating that the model is not effectively capturing the unique features of each modality, and thus not effectively utilizing the multimodal input.
在本节中,我们对VAVL模型及基线模型共享层输出的各模态嵌入表征进行分析。该实验旨在探究多模态模型的共享层是否能生成不同模态的差异化表征。多模态模型中采用共享层可使架构学习跨模态的通用表征,这对需要整合多源信息的任务有所助益。然而,保持多模态模型中各模态表征的独立性至关重要,原因有三:首先,这使模型能捕获模态特异性信息,这对最优性能至关重要;其次,通过便于分析各模态对最终输出或决策的贡献,可增强模型可解释性;最后,差异化表征能确保模型适应性,使其在部分模态缺失或不完整时仍保持良好性能。为验证所提模型能否从共享层生成可分离的差异化模态表征,我们分别使用声学或视觉信息从训练好的模型共享层获取输出嵌入,并计算其对应嵌入间的余弦距离。一方面,高余弦距离表明嵌入表征差异较大,因而能捕获模态特异性信息;另一方面,低余弦距离意味着嵌入表征相似度高,可能表明模型未能有效捕获各模态独有特征,因而未能充分利用多模态输入。

Figure 4: Comparison of average cosine distances between acoustic and visual representations generated by shared layers of the VAVL, AuxFormer, and UAVM models.
图 4: VAVL、AuxFormer 和 UAVM 模型共享层生成的声学与视觉表征之间平均余弦距离对比。
Figure 4 presents a comparison of the average cosine distances between acoustic and visual representations generated by the shared layers of our proposed framework (VAVL). For comparison, we use the shared models from the AuxFormer architecture [51], which are implemented with cross-modal layers (the same type of layers used in the MulT model [61]), and from the UAVM model [19]. Based on the average cosine distance values obtained, the VAVL shared layers is the most effective model in generating distinct representations for the acoustic and visual modalities. The cross-modal layers show moderate effectiveness, while the UAVM shared layers seem to struggle in separating the modalities. These results correlate with our model’s superior overall performance in unimodal settings compared to the baselines.
图 4: 展示了我们提出的框架(VAVL)共享层生成的声学与视觉表征之间的平均余弦距离对比。作为对比基线,我们采用了AuxFormer架构[51]的共享模型(该模型使用跨模态层实现,与MulT模型[61]采用的层类型相同)以及UAVM模型[19]的共享层。根据获得的平均余弦距离值,VAVL共享层在生成声学和视觉模态的差异化表征方面效果最佳,跨模态层表现中等,而UAVM共享层似乎难以有效区分不同模态。这些结果与我们模型在单模态设置中优于基线的整体性能表现相吻合。
6 Conclusions
6 结论
This study introduced the VAVL model, a novel versatile framework for audio-visual, audio-only, and video-only emotion recognition. The proposed approach is built with shared layers, residual connections over shared layers, and a unimodal reconstruction task. It attains high emotion recognition performance and can be trained even when paired audio and visual data is unavailable for part of the recordings. Furthermore, the model allows for direct application across both emotion regression and classification tasks. In the MSP-IMPROV corpus, the VAVL model consistently outperforms the CCC predictions of all multimodal baselines across all emotional attributes, achieving 0.856, 0.876, and 0.814 for arousal, valence, and dominance in audio-visual settings. Our results demonstrate that our method is able to better leverage visual representations to improve both unimodal and audio-visual performance, particularly in the visual-only setting. In the CREMA-D corpus, VAVL consistently surpasses baselines across all settings, achieving the highest F1-Macro (0.779) and F1-Micro (0.826) scores in the audio-visual modality. Under more naturalistic environment with the CMU-MOSEI corpus, we achieve better audio-visual and visual MAE scores than the strong baselines explored for sentiment score prediction. In addition to high performance on emotion recognition tasks, we show through the experimental evaluation our models’ capabilities on handling missing modalities at the audio-visual setting and we also ran experiments to show that the shared layers of the proposed architecture are able to better capture the distinct features contained in acoustic and visual inputs, when compared to the shared layers of the baseline models.
本研究介绍了VAVL模型,这是一种用于音视频、纯音频和纯视频情感识别的新型通用框架。该方案采用共享层、共享层残差连接和单模态重建任务构建,不仅能实现高水平的情感识别性能,还能在部分录音缺少配对音视频数据时完成训练。此外,该模型可直接应用于情感回归和分类任务。在MSP-IMPROV语料库中,VAVL模型在所有情感属性的CCC预测值上持续超越多模态基线模型,音视频场景下的唤醒度、效价和支配力分别达到0.856、0.876和0.814。实验结果表明,我们的方法能更有效地利用视觉表征提升单模态和音视频性能,尤其在纯视觉场景表现突出。在CREMA-D语料库中,VAVL在所有设置下均超越基线模型,音视频模态的F1宏平均(0.779)和F1微平均(0.826)达到最高值。在CMU-MOSEI语料库的更自然场景中,我们获得的音视频和视觉MAE分数均优于情感分数预测的强基线模型。除情感识别任务的高性能外,实验评估还验证了模型处理音视频场景缺失模态的能力。对比实验表明,与基线模型的共享层相比,该架构的共享层能更有效捕捉声学和视觉输入中的独特特征。
While our training pipeline offers flexibility by accommodating both single and dual modalities, we acknowledge potential limitations. Specifically, training can become unstable when dealing with extremely highly imbalanced data from the two modalities. To mitigate this problem, we employ careful batch management and learning rate adjustments to ensure stability. Additionally, the iterative freezing and unfreezing of weights introduces some complexity to the training process, but these steps are crucial for effective learning from both unpaired and paired data.
虽然我们的训练流程通过支持单模态和双模态提供了灵活性,但我们承认存在潜在限制。具体而言,当处理两种模态间极度不平衡的数据时,训练可能会变得不稳定。为了缓解这个问题,我们采用精细的批次管理和学习率调整来确保稳定性。此外,权重迭代冻结与解冻操作会增加训练过程的复杂度,但这些步骤对于从非配对和配对数据中有效学习至关重要。
Future work for this study is to utilize this framework on other audio-visual tasks such as sound recognition [64], scene classification [65], event localization [66], and audio-visual speech recognition [67]. Furthermore, extension to this work can include considering additional modalities, such as electroencephalogram (EEG) [68]. Integrating EEG data with facial expressions could provide complementary information, enriching multi-modal emotion analysis and opening new research avenues. This approach is significantly less complex compared to other methods, such as cross-modal learning [51, 61]. In cross-modal learning, bimodal context representation vectors are developed, and the introduction of each additional modality requires the addition of $M*(M^{-}1)$ context layers to the model, where $M$ represents the number of modalities. We expect that our approach will be easier to computationally scale to incorporate new modalities.
本研究未来的工作是将该框架应用于其他视听任务,如声音识别 [64]、场景分类 [65]、事件定位 [66] 和视听语音识别 [67]。此外,这项工作的扩展可以包括考虑其他模态,例如脑电图 (EEG) [68]。将 EEG 数据与面部表情相结合可以提供互补信息,丰富多模态情绪分析并开辟新的研究途径。与其他方法(如跨模态学习 [51, 61])相比,这种方法复杂度显著降低。在跨模态学习中,需要开发双模态上下文表示向量,并且每增加一个模态都需要向模型添加 $M*(M^{-}1)$ 个上下文层,其中 $M$ 表示模态数量。我们预计,我们的方法在计算上更容易扩展以纳入新模态。