PANGU- $\alpha$ : LARGE-SCALE AUTO REGRESSIVE PRETRAINED CHINESE LANGUAGE MODELS WITH AUTO-PARALLEL COMPUTATION
PANGU-α: 基于自动并行计算的大规模自回归预训练中文语言模型
ABSTRACT
摘要
Large-scale Pretrained Language Models (PLMs) have become the new paradigm for Natural Language Processing (NLP). PLMs with hundreds of billions parameters such as GPT-3 [1] have demonstrated strong performances on natural language understanding and generation with few-shot in-context learning. In this work, we present our practice on training large-scale auto regressive language models named PanGu $\boldsymbol{\cdot}\alpha$ , with up to 200 billion parameters. PanGu $\boldsymbol{\cdot}\alpha$ is developed under the MindSpore2 and trained on a cluster of 2048 Ascend 910 AI processors 3. The training parallelism strategy is implemented based on MindSpore Auto-parallel, which composes five parallelism dimensions to scale the training task to 2048 processors efficiently, including data parallelism, op-level model parallelism, pipeline model parallelism, optimizer model parallelism and re materialization. To enhance the generalization ability of PanGu $\cdot\alpha$ , we collect 1.1TB high-quality Chinese data from a wide range of domains to pretrain the model. We empirically test the generation ability of PanGu $\alpha$ in various scenarios including text sum mari z ation, question answering, dialogue generation, etc. Moreover, we investigate the effect of model scales on the few-shot performances across a broad range of Chinese NLP tasks. The experimental results demonstrate the superior capabilities of PanGu $\alpha$ in performing various tasks under few-shot or zero-shot settings.
大规模预训练语言模型 (PLM) 已成为自然语言处理 (NLP) 的新范式。具有数千亿参数的 PLM(如 GPT-3 [1])通过少样本上下文学习在自然语言理解和生成方面展现出强大性能。本研究介绍了我们训练名为 PanGu $\boldsymbol{\cdot}\alpha$ 的大规模自回归语言模型的实践,其参数量高达 2000 亿。PanGu $\boldsymbol{\cdot}\alpha$ 基于 MindSpore 框架开发,并在 2048 块昇腾 910 AI 处理器集群上进行训练。训练并行策略通过 MindSpore 自动并行技术实现,该技术整合了五种并行维度(数据并行、算子级模型并行、流水线模型并行、优化器模型并行和重计算)来高效扩展至 2048 块处理器。为增强 PanGu $\cdot\alpha$ 的泛化能力,我们从多领域收集了 1.1TB 高质量中文数据进行预训练。我们在文本摘要、问答、对话生成等多个场景中实证检验了 PanGu $\alpha$ 的生成能力。此外,我们还探究了模型规模对中文 NLP 任务少样本性能的影响。实验结果表明 PanGu $\alpha$ 在零样本或少样本设置下执行各类任务时具有卓越能力。
Keywords Pre-trained Language Models $\cdot$ Large-scale Deep Models $\cdot$ Distributed Training $\cdot$ Chinese Language Understanding and Generation
关键词 预训练语言模型 $\cdot$ 大规模深度模型 $\cdot$ 分布式训练 $\cdot$ 中文理解与生成
1 Introduction
1 引言
Pre-trained Language Models (PLMs) [1, 2, 3, 4, 5, 6, 7, 8, 9, etc.] have gained great success in the Natural Language Processing (NLP). By learning contextual representation of text from large-scale corpora in a self-supervised manner, PLMs can achieve state-of-the-art performances on a wide range of Natural Language Understanding (NLU) and Natural Language Generation (NLG) tasks.
预训练语言模型 (PLMs) [1, 2, 3, 4, 5, 6, 7, 8, 9等] 在自然语言处理 (NLP) 领域取得了巨大成功。通过以自监督方式从大规模语料库中学习文本的上下文表征,PLMs 能在各类自然语言理解 (NLU) 和自然语言生成 (NLG) 任务上实现最先进的性能表现。
Radford et. al. [10] demonstrates a significant gains on a variety of NLP tasks via Generative Pre-trained Transformer (GPT), which is an auto regressive language model first pretrained on unsupervised text data and then finetuned for each supervised task. Devlin et.al. [2] proposes BERT, a bidirectional Transformer with the masked language model (MLM) pre training objective, which obtains new state-of-the-art performances on the GLUE benchmark of NLU tasks. After them, there have been an increasing number of research work on developing the pre training techniques and continuously improving the performance of downstream NLP tasks. Among all the techniques, researchers find that the performance of PLMs can be steadily improved simply by enlarging the amount of the training data as well as the capacity of the model. For instance, RoBERTa [5] shows that BERT can be substantially improved by training the model longer with more data. GPT-2 [11] as the successor of GPT, which shares the same architecture but contains 1.5 billion parameters and is trained with 40GB text, can perform reasonably well on multiple tasks in the zero-shot setting. The T5 model [6] with 11 billion parameters trained on the 745GB C4 data, keeps pushing the performance of both NLU and NLG tasks.
Radford等人[10]通过生成式预训练Transformer (GPT)模型在多种自然语言处理任务上实现了显著提升。该模型是一种自回归语言模型,先在无监督文本数据上进行预训练,再针对每个监督任务进行微调。Devlin等人[2]提出了BERT模型,这是一种采用掩码语言模型(MLM)预训练目标的双向Transformer,在GLUE自然语言理解基准测试中取得了当时最先进的性能。此后,关于预训练技术的研究工作不断涌现,持续推动下游NLP任务性能提升。研究人员发现,只需增加训练数据量和模型容量,预训练语言模型的性能就能稳步提高。例如,RoBERTa[5]表明通过延长训练时间和增加数据量可以显著改进BERT模型。作为GPT的继任者,GPT-2[11]采用相同架构但包含15亿参数,并使用40GB文本进行训练,在零样本设置下能在多项任务中表现优异。拥有110亿参数并在745GB C4数据上训练的T5模型[6],持续推动着自然语言理解和生成任务的性能边界。
Recently, the OpenAI team announced its lasted version of the GPT-series models: GPT-3 [1]. The largest GPT-3 model contains 175 billion parameters and is trained using 570GB of text data. Besides its strong capability in generating high-quality text, GPT-3 is especially effective in solving a wide range of tasks without task-specific finetuning in the few-shot, or even zero-shot settings. Moreover, on many of the tasks the performance improves steadily as the size of the GPT model grows, and sometimes even reaches the level of the prior state-of-the-art finetuning approaches. From applications perspective, GPT-3 is revolutionary, as it relieves the need for labelling many examples and retraining model for every new task, which hinders the applicability of NLP models in real-world applications.
近日,OpenAI团队发布了其GPT系列模型的最新版本:GPT-3 [1]。最大的GPT-3模型包含1750亿参数,并使用570GB文本数据进行训练。除了生成高质量文本的强大能力外,GPT-3在少样本甚至零样本设置下无需任务特定微调即可有效解决各类任务。此外,在许多任务中,随着GPT模型规模的增大,其性能稳步提升,有时甚至达到此前最先进微调方法的水平。从应用角度看,GPT-3具有革命性意义,它消除了为每个新任务标注大量样本和重新训练模型的需求,而这正是阻碍NLP模型在实际应用中落地的关键瓶颈。
However, GPT-3 is now only available for limited access via OpenAI API, and it is primarily trained with English data. To promote the public research of Chinese PLMs, we propose training a very large-scale Chinese PLM named PanGu $\cdot\alpha$ with number of parameters up to 200 billion. To the best of our knowledge, this is the largest Chinese PLM up to the publication of this technical report.
然而,GPT-3目前仅能通过OpenAI API进行有限访问,且主要基于英文数据训练。为促进中文预训练语言模型(PLM)的公共研究,我们提出训练一个超大规模的中文PLM——盘古$\cdot\alpha$,其参数量高达2000亿。据我们所知,这是截至本技术报告发布时最大的中文预训练语言模型。
he difficulty in training a PLM rises as the scale of the model grows beyond the level of 10 billion. The main challenges ie in three aspects:
训练大语言模型 (PLM) 的难度随着模型规模突破百亿级别而显著增加,主要挑战集中在三个方面:
We train three PanGu $\alpha$ models on a high-quality 1.1TB Chinese text corpus with increasing magnitude of parameter sizes, which are PanGu $\cdot\alpha$ 2.6B, PanGu $\cdot\alpha$ 13B, and PanGu $\cdot\alpha$ 200B, respectively. We first evaluate the models on language modeling tasks, showing that the perplexity can be decreased with the increase of model capacity and the amount of data and computation. Then we investigate the text generation ability of PanGu $\alpha$ in various scenarios such as dialogue generation, sum mari z ation, question answering, etc. We demonstrate a few generated samples for different applications in the experiment section. Furthermore, we evaluate the task-agnostic few-shot performances of PanGu $\boldsymbol{\cdot}\alpha:2.6\mathbf{B}$ and 13B on a wide range of NLP tasks, including cloze tasks, reading comprehension, closed-book QA, Winograd style tasks, commonsense reasoning, natural language inference, and text classification. The experimental results demonstrate that with the growing model capacity, the performance on various tasks can generally improve.
我们在一个高质量的中文文本语料库(1.1TB)上训练了三个不同参数规模的PanGu $\alpha$模型,分别为PanGu $\cdot\alpha$ 2.6B、PanGu $\cdot\alpha$ 13B和PanGu $\cdot\alpha$ 200B。首先在语言建模任务上评估这些模型,结果表明随着模型容量、数据量和计算量的增加,困惑度(perplexity)会降低。接着,我们研究了PanGu $\alpha$在对话生成、摘要、问答等多种场景下的文本生成能力,并在实验部分展示了不同应用的生成样例。此外,我们还评估了PanGu $\boldsymbol{\cdot}\alpha:2.6\mathbf{B}$和13B模型在零样本(zero-shot)和少样本(few-shot)设置下对各种NLP任务的通用性能,包括完形填空、阅读理解、闭卷问答、Winograd风格任务、常识推理、自然语言推理以及文本分类。实验结果显示,随着模型容量的增大,各项任务的性能普遍得到提升。
We are currently seeking a proper way to let both non-profit research institutes and commercial companies to get access to our pretrained PanGu $\alpha$ models, either by releasing the code and model or via APIs. We are also assessing the possibility of releasing all or part of our pre training data, within the constraints of the law and legality.
我们正在寻找合适的方式,让非营利研究机构和商业公司都能获取我们预训练的PanGu $\alpha$ 模型,无论是通过发布代码和模型还是通过API接口。同时,我们也在评估在法律和法规允许范围内,发布全部或部分预训练数据的可能性。
To facilitate the community to pretrain a large-scale language model by their own, the parallel computing functionalities are open-sourced in the Auto-parallel module of MindSpore5, a deep learning training/inference framework that could be used for mobile, edge and cloud scenarios. Besides the basic parallel functionalities, Auto-parallel is easy enough to use by freeing developers from parallel model training with minimal (or zero) code modifications from the standalone version, as $i f$ the model is trained on a single device.
为便于社区自行预训练大语言模型,深度学习训练/推理框架MindSpore5中的自动并行(Auto-parallel)模块开源了并行计算功能。该框架适用于移动、边缘和云端场景。除基础并行功能外,自动并行模块通过使开发者无需修改单机版代码(或仅需极少量改动)即可实现并行模型训练,其易用性让模型训练如同在单设备上运行般简单。
The reminder of this technical report is organized as follow. Section 2 describe the architecture of our PanGu $\alpha$ models. In section 3, we detail our methods to construct a 1.1TB high-quality training corpus from 80TB raw data collected from various sources. Section 4 addresses the parallel iz ation paradigm of model training and scheduling strategy on a cluster of Ascend processors. Section 5 presents the experimental results of PanGu $\cdot\alpha$ models on various tasks.
本技术报告的剩余部分结构如下。第2节描述了我们PanGu $\alpha$ 模型的架构。第3节详细介绍了我们从80TB各类来源原始数据中构建1.1TB高质量训练语料库的方法。第4节阐述了在昇腾(Ascend)处理器集群上模型训练的并行化范式及调度策略。第5节展示了PanGu $\cdot\alpha$ 模型在多项任务上的实验结果。
2 Model
2 模型
2.1 Overview
2.1 概述
PanGu $\cdot\alpha$ is a large-scale auto regressive language model (ALM) pretrained on a large corpus of text, mostly in Chinese language. It models the generative process of all the tokens in the corpus, where the generation of a token depends on its previous tokens in a sequence. Assuming that a sequence $X={x_{1},x_{2},...,x_{N}}$ is composed of $N$ tokens, the training objective can be formulated as maximization of the log-likelihood:
PanGu $\cdot\alpha$ 是一个基于大规模中文文本语料预训练的自回归语言模型 (ALM) 。该模型对语料中所有token的生成过程进行建模,其中每个token的生成依赖于序列中先前的token。假设序列 $X={x_{1},x_{2},...,x_{N}}$ 由 $N$ 个token组成,其训练目标可表述为对数似然函数的最大化:
$$
\mathcal{L}=\sum_{n=1}^{N}\log p(x_{n}\vert x_{1},...,x_{n-1};\theta),
$$
$$
\mathcal{L}=\sum_{n=1}^{N}\log p(x_{n}\vert x_{1},...,x_{n-1};\theta),
$$
where $p(x_{n}|x_{1},...,x_{n-1};\theta)$ is the probability of observing the $n$ -th token $x_{n}$ given the previous context $x_{1:n-1}$ , and $\theta$ denotes the model parameters.
其中 $p(x_{n}|x_{1},...,x_{n-1};\theta)$ 表示在给定上文 $x_{1:n-1}$ 时观察到第 $n$ 个 token $x_{n}$ 的概率,$\theta$ 表示模型参数。
The architecture of PanGu $\alpha$ is based on Transformer [13], which has been extensively used as the backbone of a variety of pretrained language models such as BERT [2] and GPT [10, 11, 1]. Different from them, we develop an additional query layer on top of Transformer layers to predict the next token. The diagram of the model is shown in Figure 1. We elaborate each part as follow.
PanGu $\alpha$ 的架构基于 Transformer [13],该架构已被广泛用作多种预训练语言模型的主干,例如 BERT [2] 和 GPT [10, 11, 1]。与这些模型不同,我们在 Transformer 层之上额外开发了一个查询层来预测下一个 Token。模型结构如图 1 所示。各部分详细说明如下。
2.2 Model Structure
2.2 模型结构
2.2.1 Transformer Layers
2.2.1 Transformer层
A standard transformer layer includes two sub-layers: multi-head attention (MHA) and fully connected feed-forward network (FFN).
标准Transformer层包含两个子层:多头注意力机制 (MHA) 和全连接前馈网络 (FFN)。
Multi-head Attention: A self-attention network in the $l$ -th Transformer layer is parameterized by four projection matrices: $W_{h}^{k},W_{h}^{q},W_{h}^{v},W_{h}^{m}\in\mathbb{R}^{d\times d/N_{h}}$ , where $d$ is the hidden dimension, $h$ is the index of head, and $N_{h}$ is the number of heads. Given the output $H_{l-1}\in\mathbb{R}^{N\times d}$ from the precedent layer, three major components, i.e., query $Q_{h}=H_{l-1}W_{h}^{q}$ , key $K_{h}=H_{l-1}\dot{W}{h}^{k}$ , and value $V_{h}=H_{l-1}W_{h}^{v}$ are produced. The attention function is computed as:
多头注意力机制 (Multi-head Attention):第 $l$ 层 Transformer 中的自注意力网络由四个投影矩阵参数化:$W_{h}^{k},W_{h}^{q},W_{h}^{v},W_{h}^{m}\in\mathbb{R}^{d\times d/N_{h}}$,其中 $d$ 为隐藏层维度,$h$ 表示注意力头索引,$N_{h}$ 为注意力头数量。给定前一层输出 $H_{l-1}\in\mathbb{R}^{N\times d}$,可生成三个核心组件:查询向量 $Q_{h}=H_{l-1}W_{h}^{q}$、键向量 $K_{h}=H_{l-1}\dot{W}{h}^{k}$ 和值向量 $V_{h}=H_{l-1}W_{h}^{v}$。注意力函数计算公式为:
$$
\begin{array}{c}{{A_{h}=Q_{h}K_{h}^{\top}=H_{l-1}W_{h}^{q}W_{h}^{k^{\top}}H_{l-1}^{\top},}}\ {{\mathrm{Attention}{h}(H_{l-1})=\mathrm{Softmax}(\frac{A_{h}}{\sqrt{d}})V_{h}=\mathrm{Softmax}(\frac{A_{h}}{\sqrt{d}})H_{l-1}W_{h}^{v}.}}\end{array}
$$
$$
\begin{array}{c}{{A_{h}=Q_{h}K_{h}^{\top}=H_{l-1}W_{h}^{q}W_{h}^{k^{\top}}H_{l-1}^{\top},}}\ {{\mathrm{Attention}{h}(H_{l-1})=\mathrm{Softmax}(\frac{A_{h}}{\sqrt{d}})V_{h}=\mathrm{Softmax}(\frac{A_{h}}{\sqrt{d}})H_{l-1}W_{h}^{v}.}}\end{array}
$$
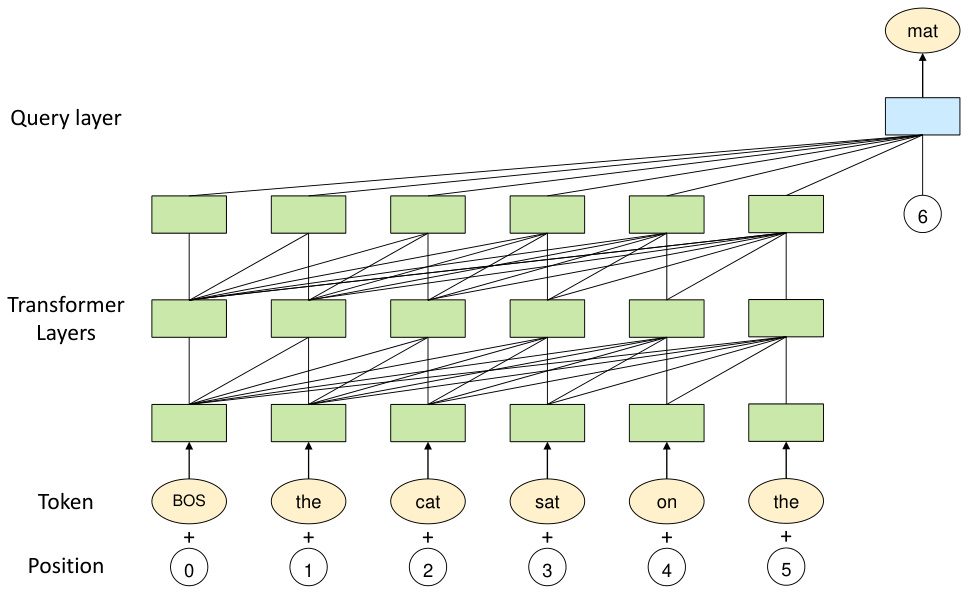
Figure 1: The architecture of PanGu $\alpha$ . The model is based on a uni-directional Transformer decoder. A query layer is stacked on top of Transformer layers with the position embedding as the query in the attention mechanism to generate the token at the next position.
图 1: PanGu $\alpha$ 架构。该模型基于单向Transformer解码器,在Transformer层之上叠加了一个查询层,其中位置嵌入作为注意力机制中的查询来生成下一个位置的Token。
With multiple attention heads, the output becomes:
通过多个注意力头 (attention head) ,输出变为:
$$
\begin{array}{r l}&{\mathrm{MHA}(H_{l-1})=\displaystyle\sum_{h=1}^{N_{h}}\mathrm{Attention}_{h}(H_{l-1})W_{h}^{m},}\ &{\quad\quad H_{l}^{\mathrm{MHA}}=H_{l-1}+\mathrm{MHA}(\mathrm{LayerNorm}(H_{l-1})).}\end{array}
$$
$$
\begin{array}{r l}&{\mathrm{MHA}(H_{l-1})=\displaystyle\sum_{h=1}^{N_{h}}\mathrm{Attention}_{h}(H_{l-1})W_{h}^{m},}\ &{\quad\quad H_{l}^{\mathrm{MHA}}=H_{l-1}+\mathrm{MHA}(\mathrm{LayerNorm}(H_{l-1})).}\end{array}
$$
Feed-forward Network: The FFN layer is composed of two linear layers, parameterized by $W^{1}\in\mathbb{R}^{d\times d_{f f}},b^{1}\in\mathbb{R}^{d_{f f}}$ , $W^{2}\in\mathbb{R}^{d_{f f}\times d}$ , $b^{2}\in\mathbb{R}^{d}$ , where $d_{f f}$ is the dimension of the inner-layer. Fed with the output of MHA layer as input, the output of FFN layer is then computed as:
前馈网络 (Feed-forward Network):FFN层由两个线性层组成,参数分别为 $W^{1}\in\mathbb{R}^{d\times d_{f f}},b^{1}\in\mathbb{R}^{d_{f f}}$ 、 $W^{2}\in\mathbb{R}^{d_{f f}\times d}$ 、 $b^{2}\in\mathbb{R}^{d}$ ,其中 $d_{f f}$ 表示内部层的维度。以MHA层的输出作为输入,FFN层的输出计算如下:
$$
\begin{array}{r}{\mathrm{FFN}(H_{l}^{\mathrm{MHA}})=\mathrm{GeLU}(H_{l}^{\mathrm{MHA}}W^{1}+b^{1})W^{2}+b^{2},\qquad}\ {H_{l}=H_{l}^{\mathrm{MHA}}+\mathrm{FFN}(\mathrm{LayerNorm}(H_{l}^{\mathrm{MHA}})).\qquad}\end{array}
$$
$$
\begin{array}{r}{\mathrm{FFN}(H_{l}^{\mathrm{MHA}})=\mathrm{GeLU}(H_{l}^{\mathrm{MHA}}W^{1}+b^{1})W^{2}+b^{2},\qquad}\ {H_{l}=H_{l}^{\mathrm{MHA}}+\mathrm{FFN}(\mathrm{LayerNorm}(H_{l}^{\mathrm{MHA}})).\qquad}\end{array}
$$
For both MHA and FFN, we take the pre-layer normalization scheme, which can make the training of Transformer model easier and faster [14].
对于MHA和FFN,我们采用预层归一化方案,这可以使Transformer模型的训练更简单、更快速[14]。
2.2.2 Query Layer
2.2.2 查询层
We design the query layer on top of the stacked Transformer layers, which aims to explicitly induce the expected output. In the pre training stage of the auto regressive model, it comes to the prediction of the next token. The structure of the query layer resembles the transformer layer, except that an additional embedding $p_{n}\in\mathbb{R}^{d}$ indicating the next position is used as the query vector in the attention mechanism. Specifically, assuming $H_{L}$ is the output of the uppermost transformer layer, the attention vector in the query layer is computed as:
我们在堆叠的Transformer层之上设计了查询层,旨在显式引导预期输出。在自回归模型的预训练阶段,其核心任务是预测下一个Token。查询层的结构与Transformer层类似,区别在于额外引入了一个表示下一位置的嵌入向量 $p_{n}\in\mathbb{R}^{d}$ 作为注意力机制中的查询向量。具体而言,假设 $H_{L}$ 是最上层Transformer的输出,查询层中的注意力向量计算方式为:
$$
a_{h}=p_{n}W_{h}^{q}W_{h}^{k^{\top}}H_{L}^{\top}.
$$
$$
a_{h}=p_{n}W_{h}^{q}W_{h}^{k^{\top}}H_{L}^{\top}.
$$
The subsequent computation of MHA and FFN remains the same as the original Transformer. We denote the final output as $o_{n}$ . The negative log-likelihood of next token becomes:
后续对多头注意力机制 (MHA) 和前馈网络 (FFN) 的计算保持与原版 Transformer 相同。我们将最终输出记为 $o_{n}$ ,下一个 token 的负对数似然为:
$$
\mathrm{CrossEntropy}(x_{n},\mathrm{Softmax}(o_{n}W^{o}+b^{o})),
$$
$$
\mathrm{CrossEntropy}(x_{n},\mathrm{Softmax}(o_{n}W^{o}+b^{o})),
$$
where $x_{n}$ denotes the true token and $W^{o},b^{o}$ is the additional task-dependent parameters.
其中 $x_{n}$ 表示真实 token,$W^{o},b^{o}$ 是额外的任务相关参数。
2.2.3 Model Configurations
2.2.3 模型配置
To evaluate the scaling ability of the PanGu $\alpha$ model, we train three models with increasing magnitude of parameter sizes, that is, PanGu $\boldsymbol{\cdot}\alpha:2.6\mathbf{B}$ , PanGu $\cdot\alpha$ 13B, and PanGu $\alpha$ 200B. Table 1 shows the detailed configurations of the three models, including the number of total parameters, the hidden dimension for the tokens, the inner dimension of the feed-forward layer, and the number of attention heads.
为了评估盘古$\alpha$模型的扩展能力,我们训练了三个参数规模依次增大的模型:盘古$\boldsymbol{\cdot}\alpha:2.6\mathbf{B}$、盘古$\cdot\alpha$ 13B和盘古$\alpha$ 200B。表1展示了这三个模型的详细配置,包括总参数量、Token的隐藏维度、前馈层内部维度以及注意力头数。
Table 1: Model sizes and hyper parameters of PanGu $\cdot\alpha$ models.
表 1: PanGu $\cdot\alpha$ 模型参数量级与超参数配置
| 模型 | 参数量(#Parameters) | 层数(#Layers) | 隐层维度(Hidden size) | 前馈网络维度(FFN size) | 注意力头数(#Heads) |
|---|---|---|---|---|---|
| PanGu-Q2.6B | 26亿 | 32 | 2560 | 10240 | 40 |
| PanGu-α 13B | 131亿 | 40 | 5120 | 20480 | 40 |
| PanGu-α 200B | 2070亿 | 64 | 16384 | 65536 | 128 |
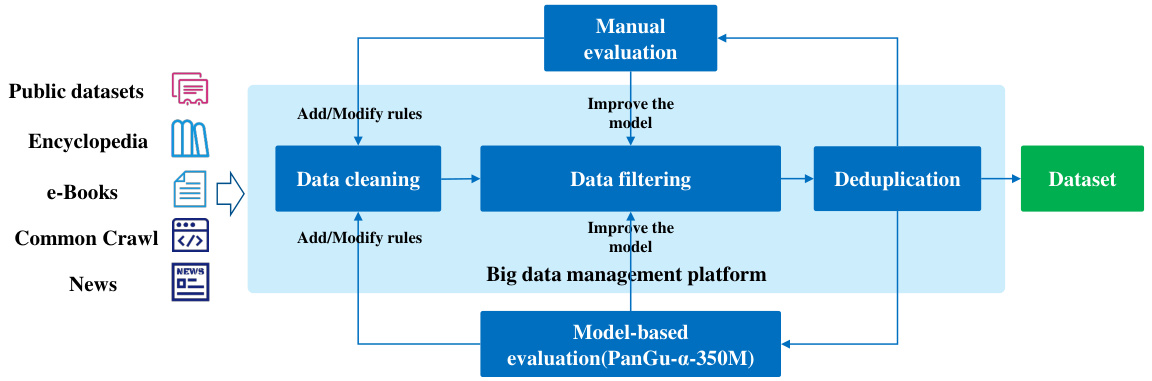
Figure 2: The data sources and the process of constructing pre training data for PanGu $\alpha$ .
图 2: PanGu $\alpha$ 预训练数据的数据来源及构建流程
3 Dataset
3 数据集
A large-scale Chinese text corpus of high quality is crucial for the pre training of our PanGu $\cdot\alpha$ models, especially the one with 200B parameters. Existing large-scale text corpora for pre training super large language models are mainly English. For example, the GPT-3 [1] is trained using a dataset which contains 570GB filtered texts from Common Crawl with $92.6%$ of the words are English. The Colossal Clean Crawled Corpus (C4) for training T5 consists of about 750GB clean English texts scraped from the web [6]. To the best of our knowledge, there are three Chinese text corpora that are above 100GB: (a) CLUE Corpus 2020 (100GB), which is retrieved from the Common Crawl dataset [15]; (b) the Chinese multi-modal pre training data, released by [16] which contains 300GB texts; and (c) Wu Dao Corpus 6, which opens about 300GB text data to only specific partners so far. However, all the above datasets are still not enough to train the super large-scale models up to 200B parameters compared to the data size used in existing English pretrained models.
高质量的大规模中文文本语料库对我们的盘古·α模型预训练至关重要,尤其是200B参数的版本。现有用于超大语言模型预训练的大规模文本语料库主要为英文,例如GPT-3[1]使用的数据集包含从Common Crawl中过滤出的570GB文本,其中92.6%为英文单词。用于训练T5的Colossal Clean Crawled Corpus(C4)包含约750GB从网络抓取的纯净英文文本[6]。据我们所知,目前仅有三个超过100GB的中文文本语料库:(a) CLUE Corpus 2020(100GB),源自Common Crawl数据集[15];(b) [16]发布的中文多模态预训练数据,包含300GB文本;(c) 悟道6号语料库,目前仅向特定合作伙伴开放约300GB文本数据。但与现有英文预训练模型使用的数据规模相比,上述数据集仍不足以训练参数高达200B的超大规模模型。
Even though the raw web datasets such as SogouT7 and Common Crawl8 contain massive amount of Chinese texts, the construction of our desired dataset is still challenging due to the highly varying quality of the raw web data, the huge amount of storage and computation to preprocess the data, and the lack of well-defined metrics to evaluate the quality of the data.
尽管搜狗T7和Common Crawl8等原始网络数据集包含海量中文文本,但由于原始网络数据质量参差不齐、预处理需消耗大量存储和计算资源,以及缺乏明确的数据质量评估指标,构建符合我们需求的数据集仍面临挑战。
To tackle the aforementioned issues, we construct a 1.1TB high-quality Chinese text corpus by cleaning and filtering enormous raw data from multiple sources. A big data management platform is built to accelerate the massive data analysis and processing. Both manual and model-based evaluation measures are used to guide the data preprocessing and training data selection, as detailed in the following sections.
为解决上述问题,我们通过清洗和过滤来自多源的海量原始数据,构建了一个1.1TB的高质量中文文本语料库。搭建了大数据管理平台以加速海量数据分析与处理,同时采用人工评估与模型评估相结合的方式指导数据预处理和训练数据筛选,具体方法将在后续章节详述。
3.1 Dataset Construction
3.1 数据集构建
To construct a large-scale high-quality Chinese corpus, we collect nearly 80TB raw data from the public datasets (e.g., BaiDuQA, CAIL2018, Sogou-CA, etc.), web pages data from Common Crawl, encyclopedia, news and e-books. As shown in Figure 2, our data construction process includes three steps: rule-based data cleaning, model-based data filtering and text de duplication. To improve the quality of the training dataset, the first two steps (i.e., cleaning and filtering) are iterative ly enhanced via manual and model-based data quality evaluations. The data construction process is done on a big data management platform built based on the open source Spark/Hadoop framework using
为构建大规模高质量中文语料库,我们从公共数据集(如BaiDuQA、CAIL2018、Sogou-CA等)、Common Crawl网页数据、百科全书、新闻和电子书中收集了近80TB原始数据。如图2所示,我们的数据构建流程包含三个步骤:基于规则的数据清洗、基于模型的数据过滤和文本去重。为提升训练数据集质量,前两个步骤(即清洗和过滤)通过人工与基于模型的数据质量评估进行迭代优化。整个数据构建流程基于开源Spark/Hadoop框架搭建的大数据管理平台完成。
Table 2: Processing time for each step in the dataset construction.
表 2: 数据集构建各步骤处理时间
| 数据量 | 我们的平台 | |
|---|---|---|
| 清洗 | 20TB | 70+小时 |
| 过滤 | 800GB | 10+小时 |
| 模糊去重 | 500GB | 3.5小时 |
8 high-performance computing nodes9. With the distributed processing capability and the tools of our platform, the efficiency of the data analysis and processing is significantly improved (see Table 3.1 for the processing time). Next, we introduce the details of each step in the dataset construction process.
8个高性能计算节点9。借助我们平台的分布式处理能力和工具,数据分析和处理效率显著提升(处理时间参见表3.1)。接下来,我们将详细介绍数据集构建过程中每个步骤的具体内容。
3.1.1 Cleaning and Filtering
3.1.1 清洗与过滤
Among the five data sources as shown in Fig 2, the Common Crawl data contributes the most amount to our corpus but unfortunately contains a significant amount of low-quality web pages. To improve the data quality, we first adopt the following rule-based text cleaning strategies over the raw web pages from Common Crawl:
在图 2 所示的五个数据源中,Common Crawl 数据对我们的语料库贡献最大,但不幸的是其中包含大量低质量网页。为提高数据质量,我们首先对来自 Common Crawl 的原始网页采用以下基于规则的文本清洗策略:
Then, three filters are applied to the pre processed documents to further remove the harmful, advertising and low-quality documents.
然后,对预处理后的文档应用三种过滤器,进一步去除有害、广告和低质量文档。
• Sensitive word filtering: The original documents of Common Crawl include a lot of harmful or sensitive website contents which would mislead our generative model. Thus, we manually collect 724 sensitive words and remove documents containing more than three of the sensitive words. • Model-based spam filtering: To further remove the advertisements and spams, we train a spam classification model using fastText10 on a manually labeled dataset. The negative training examples are 10K junk documents manually selected from the Common Crawl dataset, and the positive examples are sampled from the highquality Chinese text corpus. We remove the documents that are classified as spams. • Low-quality document filtering: Following the practice in GPT-3, we train a classifier to score the quality of each document and eliminate the documents with scores below a threshold (see Appendix A of [1] for details).
• 敏感词过滤:Common Crawl原始文档包含大量有害或敏感网站内容,可能误导生成式模型。为此,我们手动收集了724个敏感词,并移除包含超过三个敏感词的文档。
• 基于模型的垃圾信息过滤:为进一步去除广告和垃圾内容,我们使用fastText10在人工标注数据集上训练了一个垃圾信息分类模型。负样本是从Common Crawl数据集中手动选取的10K篇低质文档,正样本则来自高质量中文文本语料库。我们移除了被分类为垃圾信息的文档。
• 低质量文档过滤:遵循GPT-3的做法,我们训练了一个分类器对每篇文档进行质量评分,并剔除分数低于阈值的文档(详见[1]的附录A)。
3.1.2 Text De duplication
3.1.2 文本去重
Although we have removed duplicated paragraphs in each document in the previous step, there are still documents with highly overlapped content across different data sources. Therefore, we carry out fuzzy data de duplication over the documents across all our data sources.
尽管我们在上一步已对每份文档进行了去重处理,但不同数据源间仍存在大量内容高度重复的文档。因此我们对所有数据源的文档执行了模糊去重操作。
Due to the super large scale of the whole dataset, the conventional MinHashLSH algorithm in Spark incurs more than 8 hours to duplicate less than 200MB data, which is too slow to meet our efficiency requirement. To accelerate the de duplication process, we design a distributed large-scale text data duplication detection and de duplication algorithm by exploiting the computing framework of our big data management platform. The proposed algorithm takes only 3.5 hours to complete the de duplication process for 500GB documents.
由于整个数据集的超大规模,Spark中的常规MinHashLSH算法去重不到200MB数据需要耗费8小时以上,效率过低无法满足需求。为加速去重流程,我们基于大数据管理平台的计算框架,设计了一种分布式大规模文本数据重复检测与去重算法。该算法仅需3.5小时即可完成500GB文档的去重处理。
3.1.3 Data Quality Evaluation
3.1.3 数据质量评估
Give above preprocessing steps, one key question is how the cleaning rules and the filtering thresholds are decided. In this work, we evaluate the data quality after each round of preprocessing and update the cleaning rules and the filtering models according to the evaluation results. Both manual and model-based evaluations are considered. The manual evaluation is conducted over randomly sampled texts from the perspectives of sentence smoothness and the amount of low-quality contents (e.g., advertisements, repeated short sentences, spams, etc.). However, the manual evaluation can only cover a very small proportion of the whole dataset. To improve the accuracy of the data evaluation, we train the PanGu $\alpha$ 350M model using 30GB data sampled from the pre processed dataset and evaluate the data quality using the PPL on a high-quality development dataset. The pre processed dataset that achieves lower PPL is considered to have higher quality and its corresponding cleaning rules and filtering models are considered to be better.
在完成上述预处理步骤后,一个关键问题是如何确定清洗规则和过滤阈值。本工作中,我们在每轮预处理后评估数据质量,并根据评估结果更新清洗规则和过滤模型。评估同时考虑了人工和基于模型的方法:人工评估通过随机采样文本,从语句流畅度和低质量内容(如广告、重复短句、垃圾信息等)占比两个维度进行。但人工评估仅能覆盖数据集的极小部分。为提高数据评估的准确性,我们使用预处理数据集中采样的30GB数据训练PanGu $\alpha$ 350M模型,并在高质量开发集上通过PPL (Perplexity) 指标评估数据质量。获得更低PPL的预处理数据集被认为质量更高,其对应的清洗规则和过滤模型也被视为更优方案。
Table 3: Data composition of the 1.1TB Chinese text corpus.
表 3: 1.1TB 中文文本语料库的数据构成。
| 大小 (GB) | 数据来源 | 处理步骤 | |
|---|---|---|---|
| 公共数据集 | 27.9 | 15个公共数据集,包括DuReader、BaiDuQA、CAIL2018、Sog0u-CA等 | 格式转换和文本去重 |
| 百科全书 | 22 | 百度百科、搜狗百科等 | 文本去重 |
| 电子书籍 | 299 | 各类主题的电子书籍(如小说、历史、诗歌、古文等) | 敏感词过滤和基于模型的垃圾内容过滤 |
| Common Crawl | 714.9 | 来自Common Crawl的2018年1月至2020年12月的网络数据 | 全部处理步骤 |
| 新闻数据 | 35.5 | 1992年至2011年的新闻数据 | 文本去重 |
Table 4: Sampling strategy of the corpora in training PanGu $\alpha$ models.
表 4: 训练盘古 $\alpha$ 模型时的语料库采样策略
| PanGu-α200B | PanGu-Q 2.6B&13B | ||||
|---|---|---|---|---|---|
| Quantity (tokens) | Weight in training mix | Epochs elapsed when training | Quantity (tokens) | Weight in training mix | |
| Public datasets | 25.8B | 10.23% | 3.65 | 7B | 27.99% |
| e-Books | 30.9B | 12.23% | 0.41 | 5.6B | 18% |
| CommonCrawl | 176.2B | 62.81% | 0.85 | 2.5B | 10% |
| News | 19.8B | 7.83% | 2.2 | 5.6B | 22% |
| Encyclopedia data | 5.8B | 6.9% | 3 | 5.8B | 23% |
3.2 Training Data Selection
3.2 训练数据选择
Using the construction process in Figure 2, a Chinese text corpus with 1.1TB data is built from the five types of data sources. The composition of our corpus and the processing steps adopted to each data source is shown in Table 3.2. Based on the new corpus, we construct two training datasets with 100GB and 1TB text data for our medium (2.6B and 13B) and large (200B) models, respectively. As shown in Table 3.2, each data source is sampled during training with different proportions according to the quality of the processed dataset evaluated using the method in Section 3.1.3. The distribution of the number of token in each training dataset is shown in Figure 3. The averaged document lengths of the 100GB and 1TB dataset are 239 and 405 tokens, respectively. The 1TB dataset has a larger averaged document length due to the large proportion of Common Crawl dataset. Note that the length of the text will affect the generation performance of the model. When the averaged number of token for the training samples is small, the model will be biased to generate short texts and be good at processing downstream tasks requiring short texts, and vice versa.
利用图2中的构建流程,我们从五类数据源中构建了一个1.1TB的中文文本语料库。表3.2展示了该语料库的构成及针对各数据源采用的处理步骤。基于新语料库,我们分别为中型(2.6B和13B参数)和大型(200B参数)模型构建了100GB和1TB文本的训练数据集。如表3.2所示,训练时根据3.1.3节方法评估的处理后数据集质量,按不同比例对各数据源进行采样。各训练数据集的token数量分布如图3所示。100GB和1TB数据集的平均文档长度分别为239和405个token。由于Common Crawl数据集占比较高,1TB数据集具有更大的平均文档长度。需注意文本长度会影响模型的生成性能:当训练样本的平均token数较少时,模型会偏向生成短文本并擅长处理需要短文本的下游任务,反之亦然。
4 System
4 系统
Training PanGu $\alpha$ 200B and using it for inference are difficult. The memory requirement for just storing PanGu $\cdot\alpha$ 200B is around 750 GB. Training such a huge model consumes several times more memory than just storing the parameters, since the gradients and optimizer states are also essential for updating the parameters. As a contrast, the memory of modern AI processors (e.g., GPU, Ascend 910 AI processor [12]) is still around 30-40 GB. Thus, it is inevitable to partition the model to a collection of devices (processors). The problem is challenging in two perspectives. First, multiple basic parallel functionalities should be combined to acquire the end-to-end high performance. Finding the best combination strategy is challenging due to the huge strategy space. Second, parallel training should be easy to use, and the underlying parallel-related code should be removed from the model definition code. We use Auto-parallel in MindSpore to address the problem by maximizing the ratio of the computation over the communication. Auto-parallel supports five-dimensional parallel functionalities, and employs topology-aware scheduling to map partitioned model slices to the cluster for the end-to-end high performance. Furthermore, Auto-parallel enables the least code modifications from the standalone version for parallel training.
训练 PanGu $\alpha$ 200B 并用于推理具有较高难度。仅存储 PanGu $\alpha$ 200B 就需要约 750 GB 内存。训练如此庞大的模型所需内存远超参数存储量,因为梯度和优化器状态对参数更新同样至关重要。相比之下,现代 AI 处理器(如 GPU、Ascend 910 AI 处理器 [12])的内存仍维持在 30-40 GB 左右。因此,必须将模型分割到多个设备(处理器)上运行。这一挑战体现在两个方面:首先,需要组合多种基础并行功能以实现端到端高性能,但由于策略空间庞大,寻找最优组合方案极具挑战性;其次,并行训练应保持易用性,且需将底层并行相关代码从模型定义中剥离。我们采用 MindSpore 的自动并行(Auto-parallel)技术,通过最大化计算与通信的比值来解决该问题。自动并行支持五维并行功能,并采用拓扑感知调度将分片模型映射至集群,从而实现端到端高性能。此外,该技术仅需对单机版代码进行最小改动即可实现并行训练。
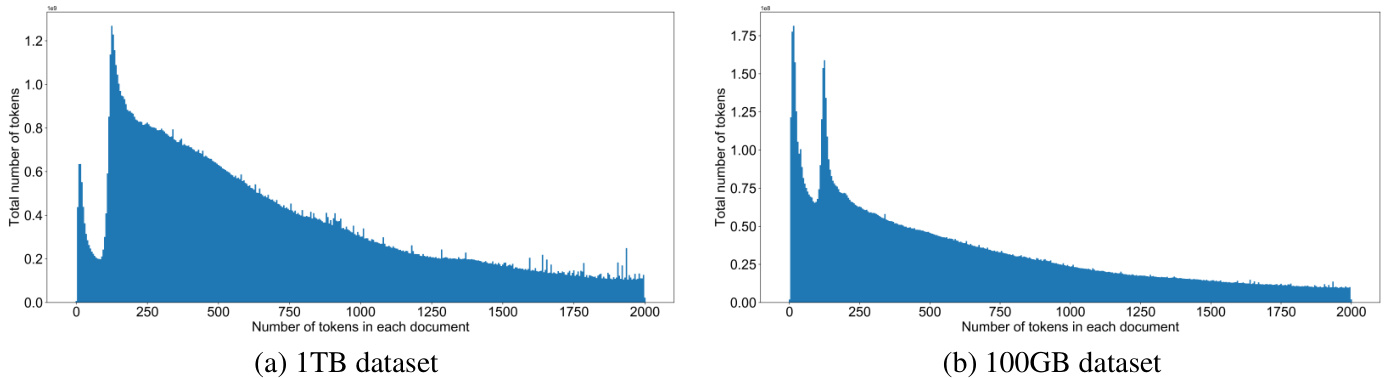
Figure 3: The distribution of tokens in (a) 1TB dataset and (b) 100GB dataset. The total number of tokens represents the (number of tokens in each document) $\times$ (number of documents with this token number).
图 3: (a) 1TB数据集和(b) 100GB数据集中的token分布情况。总token数表示(每份文档的token数量) $\times$ (具有该token数量的文档数)。
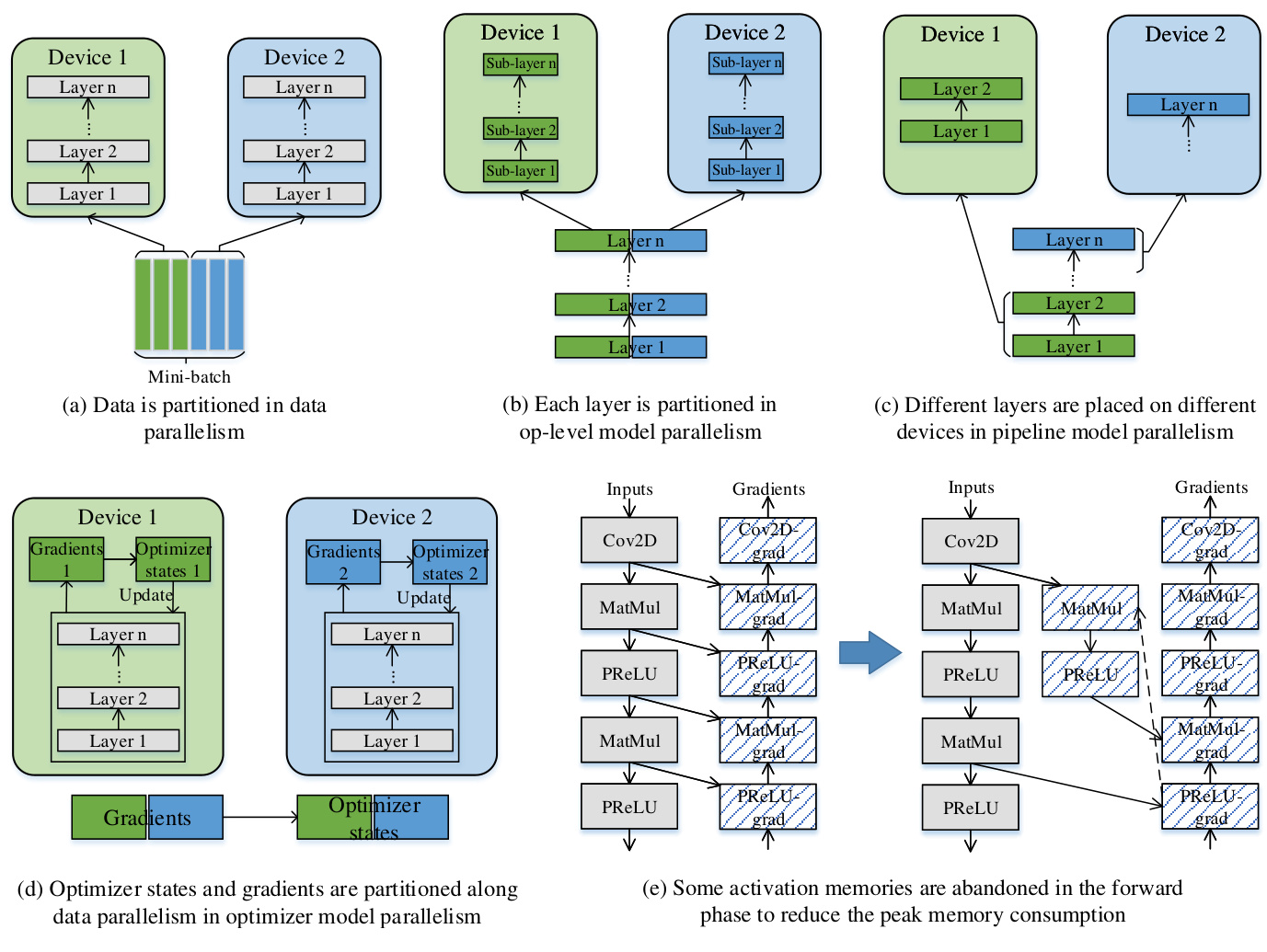
Figure 4: Five parallel functionalities, and how each works to optimize memory and throughput.
图 4: 五个并行功能模块及其各自优化内存与吞吐量的工作原理。
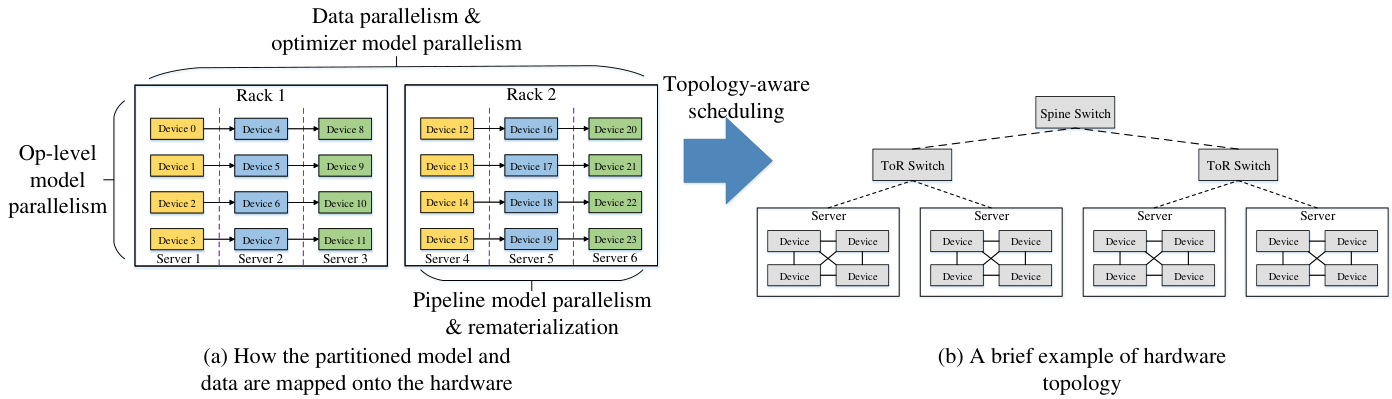
Figure 5: A combined parallel iz ation of the model, and how it is scheduled to the cluster.
图 5: 模型并行化组合方案及其在集群中的调度方式
4.1 Five-dimensional Parallelisms and Topology-aware Scheduling
4.1 五维并行性与拓扑感知调度
The most applied parallelism way is data parallelism, which partitions the training batches across devices, and synchronizes the gradients from different devices before taking an optimizer step, as shown in Figure 4(a). There are three regimes in model parallelism. One regime is op-level model parallelism [17, 18, 19, 20, 21, 22, 23], which partitions its involved tensors of each operator (layer), as shown in Figure 4(b). Op-level model parallelism reduces the memory consumption by slicing the parameters and the activation memory, however, it introduces communications to keep the distributed tensor layouts consistent between successive operators. The second regime is pipeline model parallelism [24, 25, 26, 27, 28], which partitions the total layers to stages, and then places stages to different devices, as shown in Figure 4(c). The memory benefit comes from that each device holds a subset of total layers of the model, and the communications only happen at the boundaries of stages. The third regime is optimizer model parallelism [29] (Figure 4(d)), which aims to reduce the redundant optimizer memory and computation consumption resulted from data parallelism. Some outputs of operators in forward phase reside in memory for a fairly long time, because they are used in the backward phase for gradient calculations. Re materialization (Figure 4(e)) abandons these memories to reduce the peak memory consumption in the whole training time, by re computing the corresponding forward operators.
最常用的并行方式是数据并行 (data parallelism) ,它将训练批次划分到不同设备上,并在执行优化器步骤前同步来自不同设备的梯度,如图 4(a) 所示。模型并行有三种模式。第一种是算子级模型并行 (op-level model parallelism) [17, 18, 19, 20, 21, 22, 23],它对每个算子(层)涉及的张量进行划分,如图 4(b) 所示。算子级模型并行通过切分参数和激活内存来减少内存消耗,但需要引入通信以保持连续算子间分布式张量布局的一致性。第二种是流水线模型并行 (pipeline model parallelism) [24, 25, 26, 27, 28],它将总层数划分为多个阶段,然后将不同阶段放置到不同设备上,如图 4(c) 所示。其内存优势在于每个设备仅持有模型总层数的子集,且通信仅发生在阶段边界。第三种是优化器模型并行 (optimizer model parallelism) [29](图 4(d)),旨在减少数据并行导致的冗余优化器内存和计算消耗。前向阶段中部分算子的输出会长时间驻留内存,因为它们被用于反向传播阶段的梯度计算。重计算 (re materialization)(图 4(e))通过重新执行对应的前向算子来释放这些内存,从而降低整个训练过程的峰值内存消耗。
Each parallelism dimension trades computation (or communication) overheads for memory (or throughput) benefits. To acquire maximum end-to-end throughput, a balanced composition point should be found along these dimensions. The problem becomes more challenging when considering the heterogeneous bandwidths in a cluster of devices.
每个并行维度都在计算(或通信)开销与内存(或吞吐量)收益之间进行权衡。要获得最大的端到端吞吐量,需要在这些维度上找到一个平衡点。当考虑到设备集群中的异构带宽时,问题变得更加复杂。
Figure 5(b) demonstrates a typical organization of a cluster. Each server includes multiple devices, and the servers in a rack are connected by a ToR (top of rack) switch. Racks are then connected by the Spine switch. The bandwidth between devices in a server is greater than that across servers in a rack, and the latter one is greater than that across racks. Therefore, the model is partitioned across servers in a rack using the pipeline parallelism regime, resulting in that each server holds a stage of the model layers. Then, the stage is split using the op-level parallelism across the devices in each server, in order to utilize the high bandwidths. Each rack owns the whole model, and different racks are data parallel. Deploying data parallelism and optimizer parallelism across racks is due to that the induced communication operators are not on the critical path of the training iteration, which could be fused and overlapped with backward propagation to improve the performance.
图 5(b) 展示了一个典型的集群组织架构。每台服务器包含多个设备,机架内的服务器通过ToR (top of rack)交换机相连,机架之间则通过Spine交换机连接。服务器内设备间的带宽高于同机架跨服务器带宽,后者又高于跨机架带宽。因此,模型采用流水线并行(pipeline parallelism)策略在机架内跨服务器划分,使得每台服务器承载模型的一个阶段(stage)。随后,为利用高带宽优势,每个阶段通过算子级并行(op-level parallelism)在服务器内的设备间进一步切分。每个机架拥有完整模型副本,不同机架间采用数据并行。将数据并行和优化器并行部署在跨机架层级,是因为其引发的通信算子不在训练迭代的关键路径上,可通过与反向传播过程融合重叠来提升性能。
Figure 6 shows how a combined parallel iz ation is applied to the PanGu $\cdot\alpha$ 200B model. First, 64 layers of the model are partitioned into 16 stages, each stage containing 4 layers. For each layer, involved parameters and tensors are partitioned for each operator. Specifically, the parameters involved in query $(Q)$ , key $(K)$ and value $(V)$ operators are partitioned into 8 slices. The input tensor of these three operators is partitioned into 16 slices, and the number of optimizer model parallelism is determined accordingly.12 Parallel iz ation strategies for other operators in the layer are configured likewise. Re materialization is configured to perform within each layer, which limits the extra computation overheads. Totally, 2048 Ascend 910 AI processors are used to train the full PanGu $\alpha$ 200B model.
图 6: 展示了组合并行化方法在PanGu $\cdot\alpha$ 200B模型中的应用。首先,模型的64层被划分为16个阶段,每个阶段包含4层。针对每一层,相关参数和张量会按算子进行划分:查询 $(Q)$ 、键 $(K)$ 和值 $(V)$ 算子涉及的参数被切分为8片,这三个算子的输入张量则划分为16片,并据此确定优化器模型并行数。12 该层其他算子的并行化策略采用相同配置。重计算被限定在每层内部执行以控制额外计算开销。整个PanGu $\alpha$ 200B模型的训练共使用了2048块昇腾910 AI处理器。
4.2 Implementation
4.2 实现
The parallel-related functionalities are implemented in the Auto-parallel module of MindSpore. The Auto-parallel decouples machine learning models from complicated underlying parallel implementations, and let researchers focus on the development of new models. Auto-parallel enables parallel training by just adding annotations on the standalone model script. Here, we briefly go through two model parallelism regimes.
并行相关功能在MindSpore的自动并行(Auto-parallel)模块中实现。该模块将机器学习模型与复杂的底层并行实现解耦,让研究人员专注于新模型的开发。只需在单机模型脚本上添加注解即可启用并行训练。下面简要介绍两种模型并行方案:
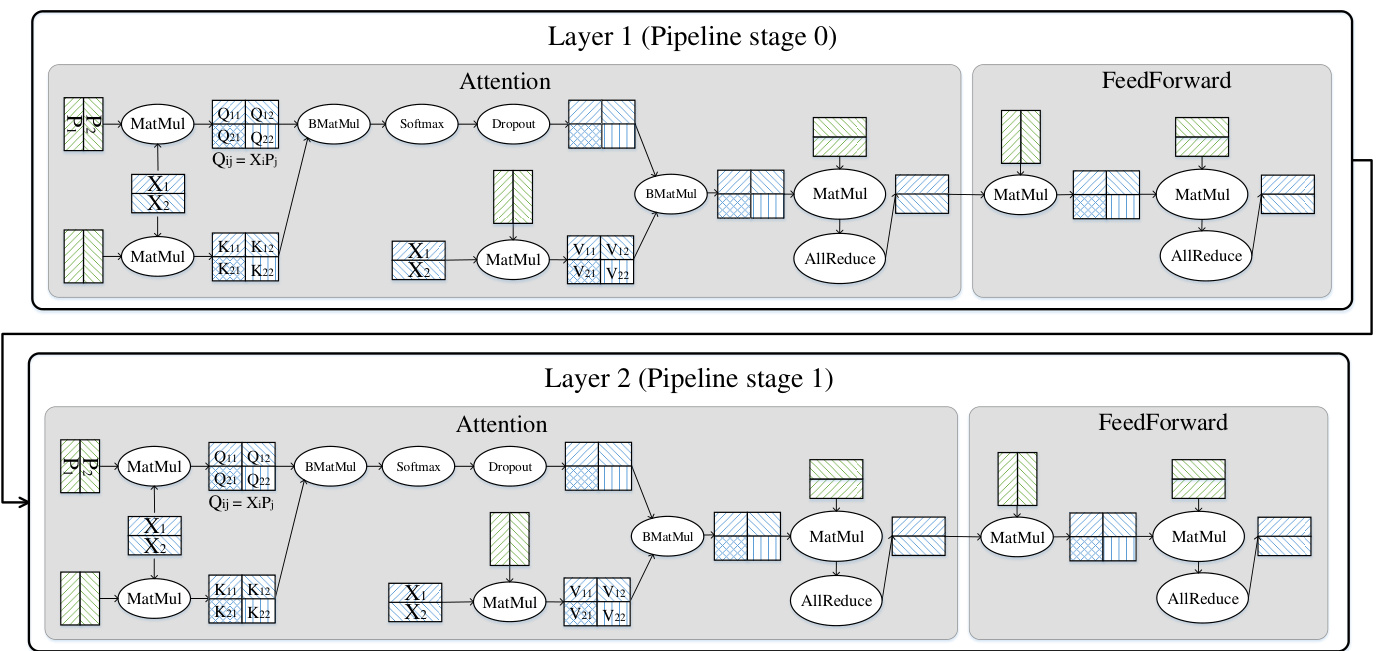
Figure 6: A simplified PanGu $\alpha$ ’s parallel iz ation strategy. The ellipsoids stand for the operators, blue rectangles represent tensors, and green rectangles represent trainable parameters. Parameters are partitioned along the row and column dimension respectively, and the input tensor is partitioned along the row dimension. And, two layers are assigned to different pipeline stages.
图 6: 简化的 PanGu $\alpha$ 并行策略示意图。椭圆代表算子,蓝色矩形表示张量,绿色矩形表示可训练参数。参数分别沿行和列维度进行划分,输入张量沿行维度划分。此外,两个层被分配到不同的流水线阶段。
Figure 7 shows how to specify the combined parallel iz ation strategy to PanGu $\boldsymbol{\cdot}\alpha$ . Figure 7(a) and Figure 7(b) shows the pseudocode of configuring Attention and Feed Forward to conduct op-level parallelism, respectively. qkv_mm’s sharding strategy is ((2, 1), (1, 2)), indicating that $\mathtt{x}$ is partitioned along the row (batch or data) dimension into 2 slices, while $\mathtt{q}{-}\mathtt{w}$ , k_w and $\boldsymbol{\nabla}{-}\boldsymbol{\mathbf{\nabla}}\mathbf{\cdot}$ are partitioned along the column dimension. Since the device number is 4 here, each device holds a distinct pair of a x’s slice and a $\mathtt{q}_{-}\mathtt{w}$ ’s (k_w’s and v_w’s) slice. matmul’s sharding strategy is ((2, 2), (2, 1)), where the contracting dimension is partitioned, thus an AllReduce is needed here to perform the operation. Likewise, another AllReduce is needed in Figure 7(b)’s matmul2. Auto-parallel can find such needed operators. Furthermore, the tensor redistribution is designed to automatically find the transformation (a list of operators) between any two inconsistent distributed tensor layouts with minimum communication cost, and then the operators are inserted into the data flow graph. The sharding strategy of batch_mm in Figure 7(a) corresponds to splitting the batch and head dimension.
图 7 展示了如何为 PanGu $\boldsymbol{\cdot}\alpha$ 指定组合并行策略。图 7(a) 和图 7(b) 分别展示了配置 Attention 和 Feed Forward 实现算子级并行的伪代码。qkv_mm 的分片策略为 ((2, 1), (1, 2)) ,表示 $\mathtt{x}$ 沿行(批次或数据)维度被划分为 2 片,而 $\mathtt{q}{-}\mathtt{w}$ 、k_w 和 $\boldsymbol{\nabla}{-}\boldsymbol{\mathbf{\nabla}}\mathbf{\cdot}$ 沿列维度划分。由于此处设备数为 4,每个设备持有不同的 $\mathtt{x}$ 切片与 $\mathtt{q}_{-}\mathtt{w}$ (k_w 和 v_w)切片组合。matmul 的分片策略为 ((2, 2), (2, 1)) ,其中收缩维度被划分,因此需要在此处执行 AllReduce 操作。同理,图 7(b) 的 matmul2 也需要另一个 AllReduce。自动并行机制能够识别此类必需算子。此外,张量重分布功能被设计为自动寻找任意两个不一致分布式张量布局间通信代价最小的转换(一组算子序列),随后将这些算子插入数据流图。图 7(a) 中 batch_mm 的分片策略对应批次和头维度的切分。
Figure 7(d) shows the pseudocode of conducting pipeline parallelism in MindSpore. The number of stages is configured as 2, and the number of devices is 8. Thus, 4 devices together perform each stage. The layer1 is configured to be the stage 0, thus replicated on 4 devices. Likewise, layer2 is replicated on the other 4 devices. If combined with Figure 7(a) and Figure 7(b), the desired parallel iz ation strategy is obtained to PanGu $\alpha$ .13 Send and Receive are inferred to communicate the activation output from stage 0 to stage 1, and then are automatically inserted into the data flow graphs on two stages, respectively.
图 7(d) 展示了在MindSpore中实现流水线并行(pipeline parallelism)的伪代码。阶段(stage)数设置为2,设备数为8,因此每个阶段由4台设备共同执行。layer1被配置为stage 0,因而在4台设备上复制。同理,layer2在另外4台设备上复制。若结合图7(a)与图7(b),即可获得适用于PanGu $\alpha$ 的理想并行化策略。Send和Receive操作被推断用于将激活输出从stage 0传递至stage 1,随后被分别自动插入两个阶段的数据流图中。
In the future, we will: a) develop a cost model and a parallel iz ation strategy searching algorithm for all parallelism dimensions in order to completely liberate developers from the underlying parallel-related works; b) support the heterogeneous-parallelism to offload a part of tensors and the corresponding computations to the host CPU to accelerate the training; c) use Sparse Attention to speedup the computation.
未来我们将:a) 为所有并行维度开发成本模型和并行策略搜索算法,使开发者彻底摆脱底层并行相关工作;b) 支持异构并行,将部分张量及对应计算卸载到主机CPU以加速训练;c) 采用稀疏注意力 (Sparse Attention) 技术提升计算速度。
All training and inference jobs are run on the Model Arts 14 platform, which manages the end-to-end workflows and provides the functionality of cluster scheduling for a job to acquire a hierarchical cluster.
所有训练和推理任务均在Model Arts 14平台上运行,该平台管理端到端工作流,并为任务提供获取分层集群的集群调度功能。

Figure 7: The pseudocode of configuring op-level and pipeline parallelism in MindSpore. The red bold fonts are keywords to specify parallel iz ation strategies.
图 7: MindSpore中配置算子级( op-level )和流水线并行( pipeline parallelism )的伪代码。红色加粗字体为指定并行化( parallel iz ation )策略的关键字。
Table 5: The detailed settings for training PanGu $\alpha$ models.
表 5: PanGu $\alpha$ 模型的详细训练设置
| 模型 | 训练步数 | Ascend处理器数量 | AdamBetas | 学习率 | 权重衰减 |
|---|---|---|---|---|---|
| PanGu-α2.6B | 0~70,000 | 512 | β1=0.9, β2=0.999 | 1e-4 | 0.01 |
| PanGu-α13B | 0~84,000 | 1024 | β1=0.9, β2=0.98 | 5e-5 | 0.01 |
| PanGu-α200B | 0 |
2048 1024 | β1=0.9, β2=0.95 | 2e-5 | 0.1 |
5 Experiments
5 实验
5.1 Training Details
5.1 训练细节
Our PanGu $\cdot\alpha$ models are developed under the Mindspore framework and are trained on a cluster of 2048 Ascend 910 AI processors. The detailed settings are shown in Table 5. For the training of the 200B model, we use 2048 Ascend processors at the first phase and then switch to 1024 Ascends processors in the middle, in order to conduct other experiments using the rest of resources. The Byte Pair Encoding (BPE) is used as the tokenizer, and the vocabulary size are 40,000. The sequence length for the training data is set to 1024 for all the models.
我们的盘古·α模型基于MindSpore框架开发,并在2048块昇腾910 AI处理器集群上进行训练。具体配置如表5所示。针对200B模型的训练,我们初期使用2048块昇腾处理器,中期切换至1024块以腾出资源进行其他实验。采用字节对编码(BPE)作为分词器(Tokenizer),词表规模为40,000。所有模型的训练数据序列长度均设置为1024。
The curves of training loss for the PanGu $\alpha$ models are shown in Figure 8. We adopt the number of training tokens as the $\mathbf{X}$ -axis since the batch size for the 200B model is not comparable to that of the 13B and 2.6B models. The loss of 200B model converges to around 2.49, while the losses of 13B and 2.6B models converge to 2.58 and 2.64 respectively. From the training curves, we can observed that the losses are still decreasing by the end of training, which indicates that our PanGu $\alpha$ model are still under-trained, and may have great potential to improve. We also evaluate the perplexity of our PanGu $\cdot\alpha$ models on the validation set, which is randomly sampled from the Common Crawl dataset. The results in Table 6 show that PanGu $\alpha$ models with larger parameters sizes achieve smaller perplexity values, indicating that larger PanGu $\cdot\alpha$ models are better language models.
PanGu $\alpha$ 模型的训练损失曲线如图 8 所示。由于 200B 模型的批量大小与 13B 和 2.6B 模型不可比,我们采用训练 token 数量作为 $\mathbf{X}$ 轴。200B 模型的损失收敛至约 2.49,而 13B 和 2.6B 模型的损失分别收敛至 2.58 和 2.64。从训练曲线可以看出,训练结束时损失仍在下降,这表明我们的 PanGu $\alpha$ 模型仍处于欠训练状态,可能具有很大的改进潜力。我们还在验证集上评估了 PanGu $\alpha$ 模型的困惑度,该验证集是从 Common Crawl 数据集中随机采样的。表 6 的结果显示,参数规模更大的 PanGu $\alpha$ 模型获得了更小的困惑度值,表明更大的 PanGu $\alpha$ 模型是更优的语言模型。

Table 6: The validation perplexity of the PanGu $\alpha$ models.
表 6: PanGu $\alpha$ 模型的验证困惑度。
| Models | ValidationPPL |
|---|---|
| PanGu-α 2.6B | 19.33 |
| PanGu-α 13B | 17.69 |
| PanGu-α 200B | 15.59 |
5.2 Task Description
5.2 任务描述
In this section, we evaluate our models on a broad spectrum of natural language processing tasks. Similar to the GPT-3 [1], the experiments are conducted under three learning settings, i.e., zero-shot, one-shot, and few-shot, without any finetuning. For each task, we evaluate the models with the test sets when publicly available. Otherwise, we use the development sets instead. For some tasks with a very large test set or development set, we randomly sample a subset from the dataset in the experiments to reduce the computational cost. The evaluation datasets are classified into 7 categories by the task similarities, and we describe each category as follows.
在本节中,我们在广泛的自然语言处理任务上评估模型性能。与GPT-3 [1]类似,实验在零样本(zero-shot)、单样本(one-shot)和少样本(few-shot)三种学习设置下进行,且不进行任何微调。针对每项任务,若测试集公开可用则采用测试集评估,否则改用开发集。对于测试集或开发集规模过大的任务,我们会随机采样数据子集以降低计算成本。根据任务相似性,评估数据集被划分为7个类别,具体如下:
Cloze and completion tasks, including WPLC, CHID [30], PD&CFT [31], CMRC2017 [32], and CMRC2019 [33]. Chinese WPLC (Word Prediciton with Long Context) is a dataset created to test the ability to model long-range dependencies, similar to the LAMBADA dataset [34] for English. The CHID (Chinese IDiom dataset) requires the model to identify the ground-truth idiom from 10 candidate idioms. The PD&CFT task requires the model to predict the mask words in sentences derived from People’s Daily (PD) news dataset and Children’s Fairy Tale (CFT) dataset. The CMRC2017 (Chinese Machine Reading Comprehension) task contains two different sub-task: cloze-style task and user query reading comprehension task, among which we only evaluate our models on the cloze-style task. While the aforementioned tasks are word-level tasks, the CMRC2019 is a sentence cloze-style dataset that involves filling the right sentence from several candidate sentences into the passage. For the CMRC2019 and the CHID, a list of candidate choices are provided, making them classification tasks, while for WPLC, CMRC2017 and PD&CFT, the models need to generate the answer as no candidate choices are given. Accuracy metric is employed for evaluating the cloze-style tasks.
填空和补全任务,包括 WPLC、CHID [30]、PD&CFT [31]、CMRC2017 [32] 和 CMRC2019 [33]。中文 WPLC (Word Prediction with Long Context) 是一个为测试长距离依赖建模能力而创建的数据集,类似于英语的 LAMBADA 数据集 [34]。CHID (Chinese IDiom dataset) 要求模型从 10 个候选成语中识别出真实成语。PD&CFT 任务要求模型预测来自《人民日报》(PD) 新闻数据集和儿童童话 (CFT) 数据集句子中的掩码词。CMRC2017 (Chinese Machine Reading Comprehension) 任务包含两个不同的子任务:填空式任务和用户查询阅读理解任务,其中我们仅评估模型在填空式任务上的表现。虽然上述任务是词级任务,但 CMRC2019 是一个句子填空式数据集,涉及从几个候选句子中选择正确的句子填入段落。对于 CMRC2019 和 CHID,提供了候选选项列表,使其成为分类任务,而对于 WPLC、CMRC2017 和 PD&CFT,由于未给出候选选项,模型需要生成答案。填空式任务采用准确率作为评估指标。
Reading comprehension tasks, including CMRC2018 [35], DRCD [36], and DuReader [37]. These are all spanextraction tasks originally. That is, given a passage as context and a question, the models need to extract a text span from the passage which contains the correct answer to the question. The evaluation metrics, including F1 and exact match (EM), measure the similarity between the predicted span and the ground-truth text span. Instead of span-extraction, we formulate these task as generation tasks where the models generate the texts directly. The similarity between the generated text span and the ground-truth text span is evaluated. Note that for the DuReader task, we select the Zhidao subset for evaluation in our experiment.
阅读理解任务,包括CMRC2018 [35]、DRCD [36]和DuReader [37]。这些原本都是跨度提取任务。即给定一段文本作为上下文和一个问题,模型需要从文本中提取包含问题正确答案的文本片段。评估指标包括F1和精确匹配(EM),用于衡量预测片段与真实文本片段之间的相似度。我们不再采用跨度提取方式,而是将这些任务重新定义为生成任务,由模型直接生成文本内容,并评估生成文本片段与真实文本片段之间的相似度。需要注意的是,在实验中我们对DuReader任务选择了"知道"子集进行评估。
Closed-book question answering (QA) tasks, including WebQA [38]. We follow the same closed-book setting in GPT-3 [1], where the models are not allowed to access any external knowledge when answering open-domain factoid questions about broad factual knowledge.
闭卷问答(Closed-book QA)任务,包括WebQA [38]。我们遵循GPT-3 [1]中的相同闭卷设置,即模型在回答关于广泛事实知识的开放领域事实性问题时不允许访问任何外部知识。
Winograd-Style tasks, including CLUE WSC 2020 [39]. CLUE WSC 2020 is a Chinese Winograd Schema Challenge dataset, which is an anaphora/co reference resolution task. In practice, we convert the task into a multiple-choice classification problem.
Winograd风格任务,包括CLUE WSC 2020 [39]。CLUE WSC 2020是一个中文Winograd模式挑战数据集,属于指代消解任务。实际应用中,我们将该任务转换为多项选择分类问题。
Common sense reasoning tasks, including $\mathrm{{C^{3}}}$ [39]. $C^{3}$ is a free-form multiple-choice reading comprehension dataset which can benefit from common sense reasoning. Different from the extraction-based reading comprehension tasks, the answers to of $C^{3}$ questions cannot be directly found in the given context. Therefore, we use it to evaluate the common sense reasoning ability of the models.
常识推理任务,包括 $\mathrm{{C^{3}}}$ [39]。$C^{3}$ 是一个自由形式的多项选择阅读理解数据集,可以从常识推理中受益。与基于抽取的阅读理解任务不同,$C^{3}$ 问题的答案无法直接从给定上下文中找到。因此,我们用它来评估模型的常识推理能力。
Natural language inference (NLI) tasks, including Chinese Multi-Genre NLI (CMNLI) and Original Chinese Natural Language Inference (OCNLI) [39]. The NLI tasks require the model to identify the relation between two sentences, either entailment, neutral or contradiction. We formulate these tasks as three-class classification problems.
自然语言推理 (NLI) 任务,包括中文多类型自然语言推理 (CMNLI) 和原生中文自然语言推理 (OCNLI) [39]。NLI任务要求模型识别两个句子之间的关系,可能是蕴含、中立或矛盾。我们将这些任务建模为三分类问题。
Text classification tasks, including TouTiao Text Classification for News Titles (TNEWS), IFLYTEK app description classification (IFLYTEK), Ant Financial Question Matching Corpus (AFQMC), and Chinese Scientific Literature (CSL) [39]. These text classification tasks covers broad domains of text, including news, applications, financial text, scientific text. For the TNEWS and IFLYTEK tasks, there are 15 and 119 categories originally. However, we randomly sample three candidates as negative labels for each instance and perform 4-class classification. The reason is that the computational cost of our perplexity-based classification method increases linearly to the total number of candidate categories, which will be described in the next section.
文本分类任务,包括今日头条新闻标题分类 (TNEWS)、科大讯飞应用描述分类 (IFLYTEK)、蚂蚁金融问题匹配语料库 (AFQMC) 和中文科学文献 (CSL) [39]。这些文本分类任务涵盖了广泛的文本领域,包括新闻、应用程序、金融文本和科学文本。对于 TNEWS 和 IFLYTEK 任务,原始类别分别为 15 个和 119 个。但我们为每个实例随机采样三个候选作为负标签,并进行 4 分类任务。这是因为我们基于困惑度的分类方法的计算成本会随候选类别总数线性增加,具体将在下一节说明。
5.3 Evaluation Details
5.3 评估细节
The tasks can be generally classified into two-categories: classification tasks and generation tasks. For the classification tasks, we resolve the task as perplexity comparison tasks. For some tasks, the samples needs to be filled into a tailor-designed template as the input to the models. The templates for each task are described in Table 7, where $"/"$ means the task does not involve a template. The decoding strategies for these text generation tasks are described in Table 8.
任务通常可分为两类:分类任务和生成任务。对于分类任务,我们将其处理为困惑度比较任务。部分任务需要将样本填入定制设计的模板作为模型输入。各任务模板详见表7,其中 $"/"$ 表示该任务不涉及模板。文本生成任务的解码策略如表8所示。
Table 8: The decoding strategies for text generation tasks.
表 8: 文本生成任务的解码策略。
| 任务 | 数据集 | 解码策略 |
|---|---|---|
| 完形填空与补全 | WPLC | top-k, k=1 |
| PD&CFT | top-k, k=1, temperature=0.9 | |
| CMRC2017 | top-p, p=0.9, temperature=1 | |
| 阅读理解 | CMRC2018 | top-p, p=0.8, temperature=0.8 |
| DRCD | top-p, p=0.8, temperature=0.8 | |
| DuReader | top-p, p=0.9, temperature=0.7 | |
| 闭卷问答 | WebQA | top-k, k=5 |
5.3.1 Generation method
5.3.1 生成方法
The generation tasks include word-level generation tasks and sentence-level generation tasks. Since our PanGu $\cdot\alpha$ models are auto regressive language models capable of text generation, the generation tasks can be solved naturally by simply generating the answers. For the cloze tasks such as WPLC, PD&CFT, and CMRC2017, the prompts are the context before the positions to be predicted. For the reading comprehension tasks and closed book QA tasks, templates are designed if necessary. For example, in the reading comprehension tasks, the sample is filled into a template Reading document : Question Answer:, which serves as the prompt for the model to generate the answer.
生成任务包括词级生成任务和句级生成任务。由于我们的PanGu $\cdot\alpha$ 模型是能够进行文本生成的自回归语言模型,因此这些生成任务可以通过直接生成答案来自然解决。对于WPLC、PD&CFT和CMRC2017等完形填空任务,提示词(prompt)是需要预测位置之前的上下文。对于阅读理解任务和闭卷问答任务,必要时会设计模板。例如在阅读理解任务中,样本会被填入模板"阅读文档:问题 答案:",作为模型生成答案的提示词。
As in GPT-3, the few-shot task is designed as in-context learning, where $K$ prompts are concatenated one by one. The first $K-1$ prompts contain the ground truth answer while the last prompt is the sample we want to predict. An example for CMRC2018 task is shown in Figure 9
与GPT-3类似,少样本任务被设计为上下文学习形式,其中$K$个提示被逐一串联。前$K-1$个提示包含真实答案,而最后一个提示是我们要预测的样本。图9展示了CMRC2018任务的一个示例

Figure 9: A prompt for generation task of CMRC2018
图 9: CMRC2018生成任务的提示词
5.3.2 Perplexity-based method
5.3.2 基于困惑度的方法
The perplexity-based method solves the classifications tasks. For each pair of <text, label>, an input will be generated automatically according to a pre-designed criteria, as shown in Table 7. The sequence generated by the template will be fed into the model and a perplexity value will be computed. The label associated with the smallest perplexity value will be considered as the predicted label for this passage.
基于困惑度的方法解决了分类任务。对于每对<文本, 标签>,系统会根据预设标准自动生成输入内容,如表7所示。通过模板生成的序列将被输入模型并计算困惑度值,与该段落最小困惑度值相关联的标签将被视为预测标签。
We also employ the in-context learning strategy for solving few-shot tasks. An example for few-shot OCNLI task is shown in Figure 10.
我们还采用上下文学习策略来解决少样本任务。图 10 展示了一个少样本 OCNLI 任务的示例。
5.4 Results
5.4 结果
Table 9 compares PanGu $\alpha2.6\mathrm{B}$ with CPM [3] 15, a recently released generative Chinese PLM with 2.6B parameters, on 16 downstream tasks in Chinese. PanGu $\cdot\alpha$ 2.6B achieves higher performance compared to CPM 2.6B on more than 11 tasks in zero-shot setting, 12 tasks on the one-shot setting, and 14 tasks on the few-shot setting. In general, the experimental results indicate that PanGu $\cdot\alpha$ 2.6B achieves higher in-context learning ability over CPM 2.6B, especially for few-shot learning and generation-tasks. Regarding generation-tasks, PanGu $\alpha2.6\mathrm{B}$ outperforms CPM 2.6B with an improvement of 6 points on average. To be more specific, PanGu $\cdot\alpha$ 2.6B surpasses CPM 2.6B with 5 points in scores for both reading comprehension and closed-book QA tasks, 7 points in scores for cloze (without choices) tasks respectively. Regarding perplexity-tasks, PanGu-αis comparable to CPM 2.6B on natural language inference with CMNLI and OCNLI datasets, while it is slightly worse than CPM on classification tasks with TNEWS and IFLYTEK datasets. We suppose that the main factor that contributes to the different performance of CPM 2.6B and PanGu $\alpha$ 2.6B is the training data. We collect massive and diverse data from a wide range of sources, which allows our PanGu $\alpha$ model to handle more diverse tasks.
表 9 将 PanGu $\alpha2.6\mathrm{B}$ 与近期发布的 26 亿参数中文生成式预训练模型 CPM [3] 15 在 16 项中文下游任务上进行了对比。在零样本设置下,PanGu $\cdot\alpha$ 2.6B 在超过 11 项任务中表现优于 CPM 2.6B;在单样本设置下领先 12 项任务;在少样本设置下优势扩大到 14 项任务。实验结果表明,PanGu $\cdot\alpha$ 2.6B 展现出比 CPM 2.6B 更强的上下文学习能力,尤其在少样本学习和生成类任务中表现突出。在生成类任务上,PanGu $\alpha2.6\mathrm{B}$ 平均领先 CPM 2.6B 6 个百分点:阅读理解与闭卷问答任务得分高出 5 分,无选项完形填空任务领先 7 分。在困惑度类任务中,PanGu-α 在 CMNLI 和 OCNLI 数据集的自然语言推理任务上与 CPM 2.6B 持平,但在 TNEWS 和 IFLYTEK 数据集的分类任务上略逊一筹。我们认为训练数据差异是导致两者性能分化的主因——PanGu $\alpha$ 模型通过整合多源异构数据,获得了更广泛的任务适应能力。

Figure 10: Prompt for perplexity-based tasks of OCNLI
图 10: OCNLI基于困惑度任务的提示
Table 9: Performance comparison of CPM 2.6B v.s. PanGu $\alpha$ 2.6B on few-shot NLP tasks.
表 9: CPM 2.6B 与 PanGu-α 2.6B 在少样本 NLP 任务上的性能对比
| 数据集 | 方法指标 | 任务类型 | 零样本 | 单样本 | 少样本 |
|---|---|---|---|---|---|
| CPM 2.6B | PanGu-α 2.6B | CPM 2.6B | |||
| CMRC2018 | 生成 | Em/F1 | 阅读理解 | 0.59/10.12 | 1.21/16.647 |
| DRCD | 生成 | Em/F1 | 阅读理解 | 0/4.62 | 0.8/9.99 |
| DuReader | 生成 | Rouge-1 | 阅读理解 | 16.63 | 21.07 |
| WebQA | 生成 | Em/f1 | 闭卷问答 | 6/12.59 | 6/16.32 |
| PD-CFT | 生成 | Acc | 完形填空(无选项) | 35.73/38.99 | 38.47/42.39 |
| CMRC2017 | 生成 | Acc | 完形填空(无选项) | 24.60 | 37.83 |
| CHID | PPL | Acc | 完形填空(多选) | 68.62 | 68.73 |
| CMRC2019 | PPL | Acc | 完形填空(多选) | 47.69 | 61.93 |
| CMNLI | PPL | Acc | 自然语言推理 | 49.10 | 50.20 |
| OCNLI | PPL | Acc | 自然语言推理 | 44.20 | 42.61 |
| TNEWS | PPL | Acc | 文本分类 | 65.44 | 60.95 |
| IFLYTEK | PPL | Acc | 文本分类 | 68.91 | 74.26 |
| AFQMC | PPL | Acc | 句子对相似度 | 66.34 | 59.29 |
| CSL | PPL | Acc | 关键词识别 | 52.30 | 50.50 |
| CLUEWSC2020 | PPL | Acc | WSC | 73.684 | 73.36 |
| C3 | PPL | Acc | 常识推理 | 49.81 | 53.42 |
Table 10: Performance comparison of PanGu $\alpha$ 2.6B v.s. PanGu $\alpha$ 13B on few-shot NLP tasks.
表 10: PanGu $\alpha$ 2.6B 与 PanGu $\alpha$ 13B 在少样本 NLP 任务上的性能对比
| 指标 | 零样本 | 单样本 | 少样本 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 数据集 | 方法 | 生成 | Em/F1 | 阅读理解 | 1.21/16.65 | 1.46/19.28 | 2.49/18.57 | 3.76/21.46 | 动态 | 5.68/23.22 |
| CMRC2018 | 生成 | Em/F1 | 阅读理解 | 0.8/9.99 | 0.66/10.55 | 2.47/12.48 | 4.22/15.01 | 动态 | 5.31/18.29 | 9.09/23.46 |
| DRCD DuReader | 生成 | Rouge-1 | 阅读理解 | 21.07 | 24.46 | 20.18 | 25.99 | 6,6 | 21.43 | 27.67 |
| WebQA | 生成 | Em/f1 | 闭卷问答 | 4.43/13.71 | 5.13/14.47 | 10.22/20.56 | 13.43/24.52 | 8,8 | 23.71/33.81 | 31.18/41.21 |
| PD-CFT | 生成 | Acc | 完形填空(无选项) | 38.47/42.39 | 43.86/46.60 | 38.8/41.61 | 40.97/45.42 | 3,3 | 39.07/42.05 | 41.13/45.86 |
| CMRC2017 | 生成 | Acc | 完形填空(无选项) | 37.83 | 38.90 | 38.00 | 38.40 | 3,3 | 37.86 | |
| CHID | PPL | Acc | 完形填空(多选) | 68.73 | 70.64 | 68.16 | 70.05 | 3,3 | 36.33 | 70.91 |
| CMRC2019 | PPL | Acc | 完形填空(多选) | 68.22 | 70.54 | 68.05 | 70.02 | 2,2 | 66.56 | |
| CMNLI | PPL | Acc | 自然语言推理 | 50.20 | 48.44 | 49.54 | 66.26 | 71.28 | ||
| OCNLI | PPL | Acc | 自然语言推理 | 42.61 | 41.53 | 44.00 | 46.81 | 6,12 | 51.17 | 46.18 |
| TNEWS | PPL | Acc | 文本分类 | 60.95 | 60.26 | 57.95 | 44.10 | 3,6 6,6 | 46.78 | 46.44 |
| IFLYTEK | PPL | Acc | 文本分类 | 79.03 | 63.83 | 63.62 | 65.17 | |||
| AFQMC | PPL | Acc | 74.26 59.29 | 73.80 65.76 | 64.62 | 78.95 | 3,3 | 80.15 | 80.34 | |
| CSL | PPL | Acc | 句子对相似度 | 50.50 | 49.30 | 50.90 | 63.55 | 4,4 10,10 | 69.00 | 68.91 |
| CLUEWSC2020 | PPL | Acc | 关键词识别 WSC | 73.36 | 75.00 | 75.33 | 50.20 75.00 | 14,14 | 52.00 | 55.70 |
| C3 | PPL | Acc | 54.47 | 52.82 | 3,3 | 72.70 | 78.62 | |||
| WPLC | PPL | ppl | 常识推理中文 WPLC | 53.42 16.70 | 19.18 | 53.92 二 | , | 53.64 | 54.58 |
Table 11: An example of the reading comprehension by PanGu $\alpha$ model.
表 11: PanGu $\alpha$ 模型阅读理解示例
| 阅读理解 |
|---|
| 提示 |
| 生成结果 |
Table 12: An example of open domain QA by PanGu $\alpha$ model. The second example implies that PanGu $\cdot\alpha$ model does not simply act like a retrieval model to answer open domain questions, but can understand and decompose the questions and generated answers accordingly.
表 12: PanGu $\alpha$ 模型在开放域问答中的示例。第二个例子表明,PanGu $\alpha$ 模型并非简单地像检索模型那样回答开放域问题,而是能够理解并分解问题,从而生成相应的答案。
| 开放域问答示例 |
|---|
| 提示生成 中国的首都是哪里? 中国的首都是北京。 |
| 提示生成 中国、美国、日本和澳大利亚的首都分别是哪里? 中国的首都是北京,美国的首都是华盛顿,日本的首都是东京,澳大利亚的首都是堪培拉。 |
| 提示生成 五一川西行程规划 五一川西旅游活动主要集中在绵阳、成都、雅安、甘孜4市(州),主要景区有大九 |
Table 10 compares PanGu $\cdot\alpha$ 13B with PanGu $\cdot\alpha$ 2.6B. PanGu $\alpha$ 13B outperforms PanGu $\alpha2.6\mathrm{B}$ on all generation-tasks and most of the perplexity-tasks. Regarding CMRC2018, DRCD and WebQA tasks of PanGu $\alpha$ 13B, the few-shot performance surpasses zero-shot by more than 10 points, demonstrating that PanGu $\cdot\alpha$ 13B has superior in-context learning ability. PanGu $\boldsymbol{\cdot}\alpha$ 13B outperforms PanGu $\alpha2.6\mathrm{B}$ with an improvement of 3 points on average. To be more specific, PanGu $\alpha$ 13B surpasses PanGu $\boldsymbol{\cdot}\alpha2.6\mathbf{B}$ with 4 points for both reading comprehension and closed-book QA tasks, 2 points for cloze (without choices) tasks respectively. Regarding the NLI tasks, the 13B model performs worse than the 2.6B model, which is consistent with the observations in GPT-3. Overall, the comparison results between PanGu $\alpha$ 13B with PanGu $\boldsymbol{\cdot}\alpha\boldsymbol{2.6}\mathbf{B}$ demostrate that a larger scale of pretrained model generally improves the performance on few-shot learning tasks.
表 10 对比了 PanGu $\cdot\alpha$ 13B 与 PanGu $\cdot\alpha$ 2.6B。PanGu $\alpha$ 13B 在所有生成任务和大部分困惑度任务上均优于 PanGu $\alpha2.6\mathrm{B}$。在 PanGu $\alpha$ 13B 的 CMRC2018、DRCD 和 WebQA 任务中,少样本性能比零样本高出 10 分以上,表明 PanGu $\cdot\alpha$ 13B 具有更强的上下文学习能力。PanGu $\boldsymbol{\cdot}\alpha$ 13B 平均比 PanGu $\alpha2.6\mathrm{B}$ 高出 3 分。具体而言,PanGu $\alpha$ 13B 在阅读理解任务和闭卷问答任务上均比 PanGu $\boldsymbol{\cdot}\alpha2.6\mathbf{B}$ 高出 4 分,在完形填空(无选项)任务上高出 2 分。在自然语言推理(NLI)任务中,13B 模型表现略逊于 2.6B 模型,这与 GPT-3 的观察结果一致。总体而言,PanGu $\alpha$ 13B 与 PanGu $\boldsymbol{\cdot}\alpha\boldsymbol{2.6}\mathbf{B}$ 的对比结果表明,更大规模的预训练模型通常能提升少样本学习任务的性能。
5.5 Natural Language Generation Examples
5.5 自然语言生成示例
We evaluate the generation capabilities of PanGu $\cdot\alpha$ 200B on various text generation scenarios. We show some of the examples in this section. We do not conduct any post-editing to the generated text, except that we truncate the generated text when the model does not stop generation at a reasonable point. Among the scenarios we have tested, we find that our PanGu $\alpha$ model is particularly good at poetry&duilian generation, text sum mari z ation, dialog generation, and fiction generation, where roughly $90%$ of the generated examples are acceptable to human. We believe there are certainly more applications for PanGu $\alpha$ models to explore in the future.
我们评估了盘古$\cdot\alpha$ 200B模型在多种文本生成场景下的能力。本节展示部分生成示例,除模型未在合理位置停止生成时进行截断外,所有生成文本均未经过人工润色。测试表明,盘古$\alpha$模型在诗词对联生成、文本摘要、对话生成和小说创作场景表现尤为突出,约$90%$的生成结果可被人类接受。我们相信盘古$\alpha$模型未来还有更多应用场景值得探索。
Table 13: PanGu $\cdot\alpha$ model can generate Gushi and Duilian without finetuning on the domain-specific data.
表 13: PanGu $\cdot\alpha$ 模型无需在领域特定数据上微调即可生成古诗和对联。
| 古诗&对联生成 | |
|---|---|
| 提示词 | 以枯藤、老树、夕阳作一首诗: |
| 生成结果 | 藤影参差绕蓝桥,野花压枝低袅风,山风习习观残雪,村舍依依麦已深。 |
| 提示词 | 上联:欢天喜地度佳节 下联:喜气洋洋迎新年 |
Table 14: Our PanGu $\cdot\alpha$ model is especially good at text sum mari z ation. We tried several latest news articles which are not in our training data. For more than $90%$ of the input article, our PanGu $\alpha$ model can generate satisfactory results. Source of the prompt: https://new.qq.com/omn/20210421/20210421 A 079 J 800.html
表 14: 我们的 PanGu $\cdot\alpha$ 模型尤其擅长文本摘要任务。我们测试了多篇未包含在训练数据中的最新新闻稿件。对于超过 $90%$ 的输入文章,PanGu $\alpha$ 模型都能生成令人满意的摘要结果。提示词来源:https://new.qq.com/omn/20210421/20210421A079J800.html
| 文本摘要 |
|---|
| 提示词 |
| 生成结果 |
| 提示词 |
| 生成结果 |
Table 15: Examples of QA with long answers by PanGu $\alpha$ . These questions are from Zhihu.com. Overall, the answers seems plausible, but still contain irrelevant or repetitive or illogical sentences.
表 15: PanGu $\alpha$ 生成长回答的问答示例。这些问题来自知乎网。总体而言,答案看似合理,但仍包含无关、重复或不合逻辑的句子。
| 提示 | 生成内容 |
|---|---|
| 有哪些办法可以教育猫?我觉得猫并不是不懂事的孩子,而是不懂事的孩子才会乱咬东西,所以,最好的办法 | 就是给猫咪找个好的主人。楼主给它找家宠物店的话,在宠物店里买猫砂,不过,家里应该再放一个猫盆或者专用的宠物用盆。还有要提醒楼主一点的是,猫咪的牙齿问题也很容易使它们咬东西,所以,一定要给猫咪好好刷牙,定期的给猫咪洗澡,因为猫咪喜欢闻自己的身体的味道,所以,洗澡也是一种很好的办法。在给猫咪买吃的东西的时候,一定要注意,那些味道重的,可能就是猫咪误食的了,那就赶紧停止吃东西,或者把饭菜都吐出来,不然的话,就很可能误食一些它没有办法去辨识的东西,所以,为了防止这些东西误食,最好还是给猫咪买猫咪专用的,防止猫咪误食的。在给猫咪换洗干净的衣服或者是被子的时候,一定要用干净的猫砂盆,不要用热水,也不要用很烫的水,因为猫咪的身体素质很好,耐热能力也很强,所以,很容易伤到它 |
| 们的身体。猫可以聪明到什么程度?流浪猫可以聪明到什么程度?我想够聪明的猫应该算是了。那么我们来看看,到底有多聪明。美国科学家研究发现,猫学会了同人类社会和动物社会的语言和相处的 | 能力,这也是它能从孤僻的猫种中脱颖而出的原因。其中包括做过面部美容手术以及爱好钓鱼的猫。曾有这样一个实验,在野外的一个植物园,喂养了一批神秘猫。在吃了这些猫饲料后,发现这些猫学习能力、注意力以及对野外生存能力的提高幅度都于察言观色,通过观察在野外工作的猫,能逐渐熟悉它的身体构造。观察者指出,猫能通过眼睛和嘴来收集情报,在它们与我们人共同生活的初期,就能把眼神、表情、姿势和其他习性反映给我们,而且它们能学会在距离不远的地方伏击猎物。而生活在现代社会的我们,早已学会了隐藏和保密。久而久之,我们培养起了对“猫“的感情依赖,“猫"也自然而然成了我们生活中不可缺少的一部分。正所谓:猫能够聪明到什么程度? |
6 Conclusion
6 结论
We have pretrained large-scale Chinese auto regressive language models named PanGu $\alpha$ , with up to 200 billion parameters. PanGu $\alpha$ has been developed under the MindSpore framework and trained on a cluster of 2048 Ascend AI processors. We believe there are many open problems in the field of large-scale PLMs:
我们预训练了名为PanGu $\alpha$的大规模中文自回归语言模型,参数量高达2000亿。PanGu $\alpha$基于MindSpore框架开发,并在2048颗昇腾AI处理器集群上完成训练。我们认为大规模预训练语言模型(PLM)领域仍存在诸多开放性问题: