Monocular 3D Multi-Person Pose Estimation by Integrating Top-Down and Bottom-Up Networks
基于自上而下与自下而上网络集成的单目3D多人姿态估计
Abstract
摘要
In monocular video 3D multi-person pose estimation, inter-person occlusion and close interactions can cause human detection to be erroneous and human-joints grouping to be unreliable. Existing top-down methods rely on human detection and thus suffer from these problems. Existing bottom-up methods do not use human detection, but they process all persons at once at the same scale, causing them to be sensitive to multiple-persons scale variations. To address these challenges, we propose the integration of top-down and bottom-up approaches to exploit their strengths. Our top-down network estimates human joints from all persons instead of one in an image patch, making it robust to possible erroneous bounding boxes. Our bottomup network incorporates human-detection based normalized heatmaps, allowing the network to be more robust in handling scale variations. Finally, the estimated 3D poses from the top-down and bottom-up networks are fed into our integration network for final 3D poses. Besides the integration of top-down and bottom-up networks, unlike existing pose disc rim in at or s that are designed solely for a single person, and consequently cannot assess natural interperson interactions, we propose a two-person pose discriminator that enforces natural two-person interactions. Lastly, we also apply a semi-supervised method to overcome the 3D ground-truth data scarcity. Quantitative and qualitative evaluations show the effectiveness of the proposed method. Our code is available publicly. 1
在单目视频三维多人姿态估计中,人际遮挡和紧密互动会导致人体检测错误和关节分组不可靠。现有自上而下方法依赖人体检测,因此受这些问题影响。现有自下而上方法虽不使用人体检测,但一次性处理所有同尺度人物,使其对多人尺度变化敏感。为解决这些挑战,我们提出融合两种方法以发挥各自优势:自上而下网络从图像块中估计所有人而非单人的关节,使其对可能错误的边界框具有鲁棒性;自下而上网络引入基于人体检测的归一化热图,增强处理尺度变化的能力。最终,两个网络输出的三维姿态估计被送入集成网络生成最终结果。除网络融合外,不同于现有仅针对单人设计的姿态判别器(无法评估自然人际互动),我们提出强制自然双人互动的双人姿态判别器。此外,采用半监督方法缓解三维真值数据稀缺问题。定量与定性实验验证了方法的有效性。代码已开源。[1]
1. Introduction
1. 引言
Estimating 3D multi-person poses from a monocular video has drawn increasing attention due to its importance for real-world applications (e.g., [35, 31, 3, 8]). Unfortunately, it is generally still challenging and an open problem, particularly when multiple persons are present in the scene. Multiple persons can generate inter-person occlusion, which causes human detection to be erroneous. Moreover, multiple persons in a scene are likely in close contact with each other and interact, which makes human-joints grouping unreliable.
从单目视频中估计3D多人姿态因其在实际应用中的重要性(如 [35, 31, 3, 8])而日益受到关注。然而,这仍然是一个具有挑战性的开放性问题,特别是当场景中存在多个人物时。多人之间会产生相互遮挡,导致人体检测出现错误。此外,场景中的多个个体往往彼此紧密接触并发生交互,这使得人体关节分组变得不可靠。

Figure 1. Incorrect 3D multi-person pose estimation from existing top-down (2nd row) and bottom-up (3rd row) methods. The top-down method is RootNet [35], the bottom-up method is SMAP [56]. The input images are from MuPoTS-3D dataset [32]. The top-down method suffers from inter-person occlusion and the bottom-up method is sensitive to scale variations (i.e., the 3D poses of the two persons in the back are inaccurately estimated). Our method substantially outperforms the state-of-the-art.
图 1: 现有自上而下(第2行)和自下而上(第3行)方法错误的三维多人姿态估计结果。自上而下方法采用RootNet [35],自下而上方法采用SMAP [56]。输入图像来自MuPoTS-3D数据集[32]。自上而下方法存在人际遮挡问题,自下而上方法对尺度变化敏感(即后排两人的三维姿态估计不准确)。我们的方法显著优于现有最优方法。
Although existing 3D human pose estimation methods (e.g., [34, 55, 38, 16, 39, 9, 8]) show promising results on single-person datasets like Human3.6M [19] and HumanEva [43], these methods do not perform well in 3D multi-person scenarios. Generally, we can divide existing methods into two approaches: top-down and bottomup. Existing top-down 3D pose estimation methods rely considerably on human detection to localize each person, prior to estimating the joints within the detected bounding boxes, e.g., [39, 9, 35]. These methods show promising performance for single-person 3D-pose estimation [39, 9], yet since they treat each person individually, they have no awareness of non-target persons and the possible interactions. When multiple persons occlude each other, human detection also become unreliable. Moreover, when target persons are closely interacting with each other, the pose estimator may be misled by the nearby persons, e.g., predicted joints may come from the nearby non-target persons.
虽然现有的3D人体姿态估计方法(如[34, 55, 38, 16, 39, 9, 8])在单人数据集(如Human3.6M[19]和HumanEva[43])上表现出色,但这些方法在3D多人场景中表现不佳。现有方法通常可分为自上而下(top-down)和自下而上(bottom-up)两种。现有的自上而下3D姿态估计方法高度依赖人体检测来定位每个人,然后在检测到的边界框内估计关节位置(如[39, 9, 35])。这些方法在单人3D姿态估计中表现优异[39, 9],但由于单独处理每个人,它们无法感知非目标人物及其可能的交互。当多人相互遮挡时,人体检测也会变得不可靠。此外,当目标人物密切互动时,姿态估计器可能会被附近人物误导(例如预测的关节可能来自附近的非目标人物)。
Recent bottom-up methods (e.g., [56, 27, 25]) do not use any human detection and thus can produce results with higher accuracy when multiple persons interact with each other. These methods consider multiple persons simultaneously and, in many cases, better distinguish the joints of different persons. Unfortunately, without using detection, bottom-up methods suffer from the scale variations, and the pose estimation accuracy is compromised, rendering inferior performance compared with top-down approaches [6]. As shown in Figure 1, neither top-down nor bottom-up approach alone can handle all the challenges at once, particularly the challenges of: inter-person occlusion, close interactions, and human-scale variations. Therefore, in this paper, our goal is to integrate the top-down and bottom-up approaches to achieve more accurate and robust 3D multiperson pose estimation from a monocular video.
最近的由下至上方法(例如 [56, 27, 25])不使用任何人体检测,因此在多人互动时能生成更高精度的结果。这些方法同时考虑多人,并在多数情况下能更好地区分不同人的关节点。遗憾的是,由于未使用检测,由下至上方法受尺度变化影响,姿态估计精度会打折扣,导致其性能不如由上至下方法 [6]。如图 1 所示,无论是单独使用由上至下还是由下至上方法,都无法一次性应对所有挑战,尤其是人际遮挡、紧密互动和人体尺度变化等问题。因此,本文的目标是整合由上至下和由下至上方法,从而从单目视频中实现更准确、更鲁棒的三维多人姿态估计。
To achieve this goal, we introduce a top-down network to estimate human joints inside each detected bounding box. Unlike existing top-down methods that only estimate one human pose given a bounding box, our top-down network predicts 3D poses for all persons inside the bounding box. The joint heatmaps from our top-down network is feed to our bottom-up network, so that our bottom network can be more robust in handling the scale variations. Finally, we feed the estimated 3D poses from both top-down and bottom-up networks into our integration network to obtain the final estimated 3D poses given an image sequence.
为实现这一目标,我们引入了一种自上而下的网络来估计每个检测边界框内的人体关节。与现有自上而下方法(仅针对单个边界框估计人体姿态)不同,我们的自上而下网络可预测边界框内所有人员的3D姿态。该网络生成的关节热力图将输入至自下而上网络,从而使底层网络能更稳健地处理尺度变化。最终,我们将两个网络输出的3D姿态估计结果输入集成网络,从而获得给定图像序列的最终3D姿态估计。
Moreover, unlike existing methods’ pose disc rim in at or s, which are designed solely for single person, and consequently cannot enforce natural inter-person interactions, we propose a two-person pose disc rim in at or that enforces twoperson natural interactions. Lastly, semi-supervised learning is used to mitigate the data scarcity problem where 3D ground-truth data is limited.
此外,现有方法的姿态判别器仅针对单人设计,因此无法确保自然的人际互动。我们提出了一种双人姿态判别器,能够强制实现两人间的自然交互。最后,采用半监督学习来缓解3D真实数据有限导致的数据稀缺问题。
In summary, our contributions are listed as follows.
总之,我们的贡献如下。
2. Related Works
2. 相关工作
Top-Down Monocular 3D Human Pose Estimation Ex- isting top-down 3D human pose estimation methods commonly use human detection as an essential part of their methods to estimate person-centric 3D human poses [30, 37, 34, 39, 9, 12, 8]. They demonstrate promising performance on single-person evaluation datasets [19, 43], unfortunately the performance decreases in multi-person scenarios, due to inter-person occlusion or close interactions [34, 9]. Moreover, the produced person-centric 3D poses cannot be used for multi-person scenarios, where cameracentric 3D-pose estimation is needed. Top-down methods process each person independently, leading to inadequate awareness of the existence of other persons nearby. As a result, they perform poorly on multi-person videos where inter-person occlusion and close interactions are commonly present. Rogez et al. [41, 42] develop a pose proposal network to generate bounding boxes and then perform pose estimation individually for each person. Recently, unlike previous methods that perform person-centric pose estimation, Moon et al. [35] propose a top-down 3D multi-person poseestimation method that can estimate the poses for all persons in an image in the camera-centric coordinates. However, the method still relies on detection and process each person independently; hence it is likely to suffer from interperson occlusion and close interactions.
自上而下的单目3D人体姿态估计
现有自上而下的3D人体姿态估计方法通常将人体检测作为核心组件,用于估计以人为中心的3D姿态 [30, 37, 34, 39, 9, 12, 8]。这些方法在单人评估数据集上表现优异 [19, 43],但在多人场景中因人际遮挡或紧密交互导致性能下降 [34, 9]。此外,以人为中心生成的3D姿态无法直接应用于需要相机中心坐标的多人场景。自上而下方法独立处理每个个体,导致对周围其他人的存在感知不足,因此在普遍存在人际遮挡和紧密交互的多人视频中表现欠佳。Rogez等人 [41, 42] 开发了姿态提议网络生成边界框,再对每个个体单独进行姿态估计。近期,Moon等人 [35] 提出了一种不同于以往以人为中心方法的自上而下3D多人姿态估计方法,可在相机中心坐标系中估计图像中所有人体姿态。但该方法仍依赖检测并独立处理每个个体,因此可能受限于人际遮挡和紧密交互问题。
Bottom-Up Monocular 3D Human Pose Estimation A few bottom-up methods have been proposed [13, 56, 31, 25, 27]. Fabbri et al. [13] introduce an encoder-decoder framework to compress a heatmap first, and then decompress it back to the original representations in the test time for fast
自下而上的单目3D人体姿态估计
已有若干自下而上的方法被提出 [13, 56, 31, 25, 27]。Fabbri等人 [13] 提出了一种编码器-解码器框架,先在测试时压缩热力图,再将其解压缩回原始表示以实现快速...
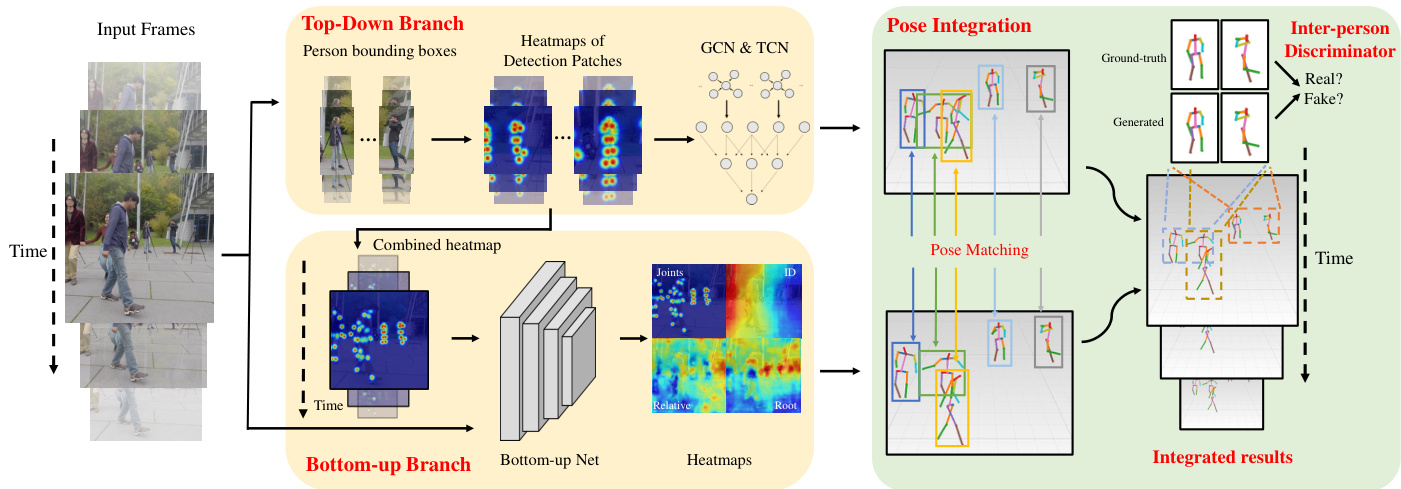
Figure 2. The overview of our framework. Our proposed method comprises three components: 1) A top-down branch to estimate finegrained instance-wise 3D pose. 2) A bottom-up branch to generate global-aware camera-centric 3D pose. 3) An integration network to generate final estimation based on paired poses from top-down and bottom-up to take benefits from both branches. Note that the semisupervised learning part is a training strategy so it is not included in this figure.
图 2: 我们框架的总体架构。提出的方法包含三个组件:1) 自上而下分支用于估计细粒度实例级3D姿态;2) 自下而上分支生成全局感知的以相机为中心的3D姿态;3) 集成网络基于成对姿态生成最终估计,同时利用两个分支的优势。注意半监督学习部分是训练策略,因此未包含在本图中。
HD image processing. Mehta et al. [31] propose to identify individual joints, compose full-body joints, and enforce temporal and kinematic constraints in three stages for realtime 3D motion capture. Li et al. [25] develop an integrated method with lower computation complexity for human detection, person-centric pose estimation, and human depth estimation from an input image. Lin et al. [27] formulate the human depth regression as a bin index estimation problem for multi-person localization in the camera coordinate system. Zhen et al. [56] estimate the 2.5D representation of body parts first and then reconstruct camera-centric multiperson 3D poses. These methods benefit from the nature of the bottom-up approach, which can process multiple persons simultaneously without relying on human detection. However, since all persons are processed at the same scale, these methods are inevitably sensitive to human scale variations, which limits their applicability on wild videos.
高清图像处理。Mehta等人[31]提出通过三个阶段识别单个关节、组合全身关节并施加时间和运动学约束,实现实时3D动作捕捉。Li等人[25]开发了一种计算复杂度更低的集成方法,用于从输入图像中进行人体检测、以人为中心的姿态估计和人体深度估计。Lin等人[27]将人体深度回归建模为相机坐标系中多人定位的分箱索引估计问题。Zhen等人[56]先估计身体部位的2.5D表示,再重建以相机为中心的多人3D姿态。这些方法受益于自下而上方法的特性,能够同时处理多人而无需依赖人体检测。然而由于所有人都在同一尺度下处理,这些方法不可避免地对人体尺度变化敏感,限制了其在野生视频中的适用性。
Top-Down and Bottom-Up Combination Earlier nondeep learning methods exploring the combination of topdown and bottom-up approaches for human pose estimation are in the forms of data-driven belief propagation, dif- ferent class if i ers for joint location and skeleton, or probabilistic Gaussian mixture modelling [18, 51, 24]. Recent deep learning based methods that attempt to make use of both top-down and bottom-up information are mainly on estimating 2D poses [17, 46, 4, 26]. Hu and Ramanan [17] propose a hierarchical rectified Gaussian model to incorporate top-down feedback with bottom-up CNNs. Tang et al. [46] develop a framework with bottom-up inference followed by top-down refinement based on a compositional model of the human body. Cai et al. [4] introduce a spatialtemporal graph convolutional network (GCN) that uses both bottom-up and top-down features. These methods explore to benefit from top-down and bottom-up information. However, they are not suitable for 3D multi-person pose estimation because the fundamental weaknesses in both topdown and bottom-up methods are not addressed completely, which include inter-person occlusion caused detection and joints grouping errors, and the scale variation issue. Li et al. [26] adopt LSTM and combine bottom-up heatmaps with human detection for 2D multi-person pose estimation. They address occlusion and detection shift problems. Unfortunately, they use a bottom-up network and only add the detection bounding box as the top-down information to group the joints. Hence, their method is essentially still bottom-up and thus still vulnerable to human scale variations.
自上而下与自下而上的结合
早期非深度学习方法探索将自上而下和自下而上策略结合用于人体姿态估计,其形式包括数据驱动的置信传播、针对关节位置与骨架的不同分类器,或概率高斯混合建模 [18, 51, 24]。近期基于深度学习的方法尝试同时利用两种信息,主要集中在2D姿态估计领域 [17, 46, 4, 26]。Hu和Ramanan [17] 提出分层校正高斯模型,将自上而下反馈与自下而上的CNN结合。Tang等 [46] 开发了基于人体组合模型的框架,先进行自下而上推理再进行自上而下优化。Cai等 [4] 引入时空图卷积网络 (GCN) 来同时利用两种特征。这些方法试图融合两种信息的优势,但由于未彻底解决两类方法的根本缺陷(如人际遮挡导致的检测与关节分组误差、尺度变化问题),它们不适用于3D多人姿态估计。Li等 [26] 采用LSTM并将自下而上热力图与人体检测结合用于2D多人姿态估计,解决了遮挡和检测偏移问题,但其本质仍是自下而上方法(仅添加检测框作为自上而下信息进行关节分组),因此仍易受人体尺度变化影响。
3. Proposed Method
3. 提出的方法
Fig. 2 shows our pipeline, which consists of three major parts to accomplish the multi-person camera-centric 3D human pose estimation: a top-down network for fine-grained instance-wise pose estimation, a bottom-up network for global-aware pose estimation, and an integration network to integrate the estimations of top-down and bottom-up branches with inter-person pose disc rim in at or. Moreover, a semi-supervised training process is proposed to enhance the 3D pose estimation based on re projection consistency.
图 2: 展示了我们的流程框架,该框架由三个主要部分组成,用于实现以相机为中心的多人物3D人体姿态估计:一个用于细粒度实例级姿态估计的自顶向下网络 (top-down network) ,一个用于全局感知姿态估计的自底向上网络 (bottom-up network) ,以及一个集成网络 (integration network) ,用于整合自顶向下和自底向上分支的估计结果,并包含人际姿态判别器 (inter-person pose discriminator) 。此外,我们还提出了一种基于重投影一致性的半监督训练流程,以增强3D姿态估计的性能。
3.1. Top-Down Network
3.1. 自顶向下网络
Given a human detection bounding box, existing topdown methods estimate full-body joints of one person. Consequently, if there are multiple persons inside the box or partially out-of-bounding box body parts, the full-body joint estimation are likely to be erroneous. Figure 3 shows such failure examples of existing methods. In contrast, our method produces the heatmaps for all joints inside the bounding box (i.e., enlarged to accommodate inaccurate detection), and estimate the ID for each joint to group them into corresponding persons, similar to [36].
给定一个人体检测边界框,现有自上而下方法会估计单人的全身关节点。因此,若框内存在多人或部分超出边界的身体部位,全身关节估计很可能出错。图3展示了现有方法的此类失败案例。相比之下,我们的方法会为边界框内所有关节点生成热图(即扩大框体以容纳检测误差),并为每个关节点估计ID以将其分组到对应人物,类似[36]的做法。
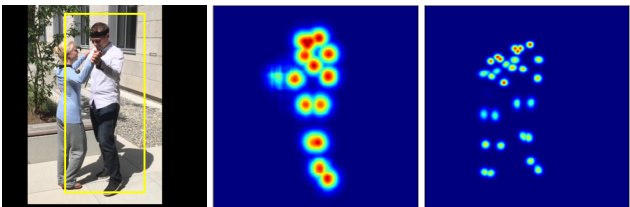
Figure 3. Examples of estimated heatmaps of human joints. The left image shows the input frame overlaid with inaccurate detection bounding box (i.e., only one person detected). The middle image shows the estimated heatmap of existing top-down methods. The right image shows the heatmap of our top-down branch.
图 3: 人体关节热力图估计示例。左图显示了带有不准确检测边界框的输入帧 (即仅检测到一个人)。中间图展示了现有自上而下方法的估计热力图。右图展示了我们自上而下分支的热力图。
Given an input video, for every frame we apply a human detector [15], and crop the image patches based on the detected bounding boxes. A 2D pose detector [6] is applied to each patch to generate heatmaps for all human joints, such as shoulder, pelvis, ankle, and etc. Specifically, our topdown loss of 2D pose heatmap is an L2 loss between the predicted and ground-truth heatmaps, formulated as:
给定输入视频,我们对每一帧应用人体检测器 [15],并根据检测到的边界框裁剪图像块。对每个图像块应用2D姿态检测器 [6],为所有人体关节(如肩、骨盆、踝等)生成热图。具体而言,我们的2D姿态热图自上而下损失是预测热图与真实热图之间的L2损失,公式为:
$$
L_{h m a p}^{T D}=|H-\tilde{H}|_{2}^{2},
$$
$$
L_{h m a p}^{T D}=|H-\tilde{H}|_{2}^{2},
$$
where $H$ and $\tilde{H}$ are the predicted and ground-truth heatmaps, respectively.
其中 $H$ 和 $\tilde{H}$ 分别表示预测热图和真实热图。
Having obtained the 2D pose heatmaps, a directed GCN network is used to refine the potentially incomplete poses caused by occlusions or partially out-of-bounding box body parts, and two TCNs are used to estimate both personcentric 3D pose and camera-centric root depth based on a given sequence of 2D poses similar to [7]. As the TCN requires the input sequence of the same instance, a pose tracker [48] is used to track each instance in the input video. We also apply data augmentation in training our TCN so that it can handle occlusions [9].
在获得2D姿态热图后,采用有向GCN网络来优化由遮挡或部分超出边界框的身体部位导致的潜在不完整姿态,并基于类似[7]的给定2D姿态序列,使用两个TCN分别估计以人为中心的3D姿态和以相机为中心的根深度。由于TCN需要同一实例的输入序列,使用姿态追踪器[48]对输入视频中的每个实例进行追踪。在训练TCN时还应用了数据增强技术,以使其能够处理遮挡情况[9]。
3.2. Bottom-Up Network
3.2. 自底向上网络
Top-down methods perform estimation inside the bounding boxes, and thus are lack of global awareness of other persons, leading to difficulties to estimate poses in the camera-centric coordinates. To address this problem, we further propose a bottom-up network that processes multiple persons simultaneously. Since the bottom-up pose estimation suffers from human scale variations, we concatenate the heatmaps from our top-down network with the original input frame as the input of our bottom-up network. With the guidance of the top-down heatmaps, which are the results of the object detector and pose estimation based on the normalized boxes, the estimation of the bottom-up network will be more robust to scale variations. Our bottom-up network outputs four heatmaps : a 2D pose heatmap, ID-tag map, relative depth map, and root depth map. The 2D pose heatmap and ID-tag map are defined in the same way as in the previous section (3.1). The relative depth map refers to the depth map of each joint with respect to its root (pelvis) joint. The root depth map represents the depth map of the root joint.
自上而下的方法在边界框内进行估计,因此缺乏对其他人的全局感知,导致在以相机为中心的坐标系中估计姿态存在困难。为解决这一问题,我们进一步提出了一种能同时处理多人的自下而上网络。由于自下而上的姿态估计受人体尺度变化影响,我们将自上而下网络生成的热力图与原始输入帧拼接,作为自下而上网络的输入。通过基于归一化边界框的目标检测器和姿态估计结果(即自上而下的热力图)的引导,自下而上网络对尺度变化的估计将更具鲁棒性。我们的自下而上网络输出四组热力图:2D姿态热力图、ID标签图、相对深度图和根节点深度图。2D姿态热力图与ID标签图的定义方式与前一节(3.1)相同。相对深度图表示各关节相对于其根节点(骨盆关节)的深度图,根节点深度图则表示根关节的深度图。
In particular, the loss functions LhBmUa and $L_{i d}^{B U}$ for the heatmap and ID-tag map are similar to [36]. In addition, we apply the depth loss to the estimations of both the relative depth map $h^{r e l}$ and the root depth $h^{r o o t}$ . Please see supplementary material for example of the four estimated heatmaps from the bottom-up network. For $N$ persons and $K$ joints, the loss can be formulated as:
具体而言,热图和ID标签图的损失函数LhBmUa和$L_{i d}^{B U}$与[36]类似。此外,我们对相对深度图$h^{r e l}$和根深度$h^{r o o t}$的估计都应用了深度损失。关于自底向上网络生成的四个估计热图示例,请参阅补充材料。对于$N$个人体和$K$个关节,损失可表示为:
$$
L_{d e p t h}=\frac{1}{N K}\sum_{n}\sum_{k}\left|h_{k}(x_{n k},y_{n k})-d_{n k}\right|^{2},
$$
深度损失函数表示为:
$$
L_{d e p t h}=\frac{1}{N K}\sum_{n}\sum_{k}\left|h_{k}(x_{n k},y_{n k})-d_{n k}\right|^{2},
$$
where $h$ is the depth map and $d$ is the ground-truth depth value. Note that, for pelvis (i.e., the root joint), the depth is a camera-centric depth. For other joints, the depth is relative with respect to the corresponding root joint.
其中 $h$ 是深度图,$d$ 是真实深度值。注意,对于骨盆(即根关节),深度是以相机为中心的绝对深度;其他关节的深度则是相对于对应根关节的相对深度。
We group the heatmaps into instances (i.e., persons), and retrieve the joint locations using the same procedure as in the top-down network. Moreover, the values of the cameracentric depth of the root joint $z^{r o o t}$ and the relative depth for the other joints $z_{k}^{r e l}$ are obtained by retrieving from the corresponding depth maps where the joints (i.e., root or others) are located. Specifically:
我们将热图按实例(即人物)分组,并采用与自上而下网络相同的流程检索关节位置。此外,通过从关节(即根关节或其他关节)所在位置对应的深度图中提取数值,获得根关节的相机中心深度$z^{root}$和其他关节的相对深度$z_{k}^{rel}$。具体而言:
$$
\begin{array}{l c l}{{z_{i}^{r o o t}}}&{{=}}&{{h^{r o o t}(x_{i}^{r o o t},y_{i}^{r o o t})}}\ {{z_{i,k}^{r e l}}}&{{=}}&{{h_{k}^{r e l}(x_{i,k},y_{i,k})}}\end{array}
$$
$$
\begin{array}{l c l}{{z_{i}^{r o o t}}}&{{=}}&{{h^{r o o t}(x_{i}^{r o o t},y_{i}^{r o o t})}}\ {{z_{i,k}^{r e l}}}&{{=}}&{{h_{k}^{r e l}(x_{i,k},y_{i,k})}}\end{array}
$$
where $i,k$ refer to the $i_{t h}$ instance and $k_{t h}$ joint, respec- tively.
其中 $i,k$ 分别表示第 $i_{t h}$ 个实例和第 $k_{t h}$ 个关节。
3.3. Integration with Interaction-Aware Discriminator
3.3. 与交互感知判别器的集成
Having obtained the results from the top-down and bottom-up networks, we first need to find the corresponding poses between the results from the two networks, i.e., the top-down pose $P_{i}^{T D}$ and bottom-up pose $P_{j}^{B U}$ belong to the same person. Note that $P$ stands for camera-centric 3D pose throughout this paper.
在获得自上而下和自下而上网络的结果后,我们首先需要找到两个网络结果之间的对应姿态,即自上而下的姿态 $P_{i}^{T D}$ 和自下而上的姿态 $P_{j}^{B U}$ 属于同一个人。请注意,本文中 $P$ 代表以相机为中心的三维姿态。
Given two pose sets from bottom-up branch $P^{B U}$ and top-down branch $P^{T D}$ , we match the poses from both sets, in order to form pose pairs. The similarity of two poses is defined as:
给定来自自底向上分支 $P^{B U}$ 和自顶向下分支 $P^{T D}$ 的两个姿态集合,我们对两组姿态进行匹配以形成姿态对。两个姿态的相似度定义为:
$$
\mathrm{Sim}{i,j}=\sum_{k=0}^{K}\mathrm{min}(c_{i,k}^{B U},c_{j,k}^{T D})\mathrm{OKS}(P_{i,k}^{B U},P_{j,k}^{T D}),
$$
$$
\mathrm{Sim}{i,j}=\sum_{k=0}^{K}\mathrm{min}(c_{i,k}^{B U},c_{j,k}^{T D})\mathrm{OKS}(P_{i,k}^{B U},P_{j,k}^{T D}),
$$
where:
其中:
$$
\mathrm{OKS}(x,y)=\exp(-\frac{d(x,y)^{2}}{2s^{2}\sigma^{2}}),
$$
$$
\mathrm{OKS}(x,y)=\exp(-\frac{d(x,y)^{2}}{2s^{2}\sigma^{2}}),
$$
OKS stands for object keypoint similarity [52], which measures the joint similarity of a given joint pair. $d(x,y)$ is the Euclidean distance between two joints. $s$ and $\sigma$ are two controlling parameters. $\mathrm{Sim}{i,j}$ measures the similarity between the ith 3D pose P iBU f rom the bottom-up network and the $j_{t h}$ 3D pose $P_{j}^{T D}$ from the top-down network over $K$ joints. Note that both poses from top-down $P^{T D}$ and bottom-up $P^{B U}$ are camera-centric; thus, the similarity is measured based on the camera coordinate system. The ciB,kU and cT D are the confidence values of joint $k$ for 3D poses P iBU and P T D, respectively. Having computed the similarity matrix between the two sets of poses $P^{T D}$ and $P^{B U}$ according to the $\mathrm{Sim}_{i,j}$ definition, the Hungarian algorithm [23] is used to obtain the matching results.
OKS代表物体关键点相似度 (object keypoint similarity) [52],用于衡量给定关节对的联合相似性。$d(x,y)$ 是两个关节之间的欧氏距离,$s$ 和 $\sigma$ 是两个控制参数。$\mathrm{Sim}{i,j}$ 衡量自底向上网络获取的第i个3D姿态 $P_{i}^{BU}$ 与自顶向下网络获取的第 $j_{th}$ 个3D姿态 $P_{j}^{TD}$ 在 $K$ 个关节上的相似度。需要注意的是,自顶向下 $P^{TD}$ 和自底向上 $P^{BU}$ 的姿态均以相机为中心,因此相似度是基于相机坐标系计算的。$c_{i,k}^{BU}$ 和 $c_{j,k}^{TD}$ 分别是3D姿态 $P_{i}^{BU}$ 和 $P_{j}^{TD}$ 中关节 $k$ 的置信度值。根据 $\mathrm{Sim}_{i,j}$ 的定义计算出两组姿态 $P^{TD}$ 和 $P^{BU}$ 之间的相似度矩阵后,使用匈牙利算法 [23] 来获取匹配结果。
Once the matched pairs are obtained, we feed each pair of the 3D poses and the confidence score of each joint to our integration network. Our integration network consists of 3 fully connected layers, which outputs the final estimation.
一旦获得匹配对,我们将每对3D姿态及各关节的置信度分数输入到集成网络中。该集成网络由3个全连接层组成,最终输出预测结果。
Integration Network Training To train the integration network, we take some samples from the ground-truth 3D poses. We apply data augmentation: 1) random masking the joints with a binary mask $M^{k p t}$ to simulate occlusions; 2) random shifting the joints to simulate the inaccurate pose detection; and 3) random zeroing one from a pose pair to simulate unpaired poses. The loss of the integration network is an L2 loss between the predicted 3D pose and its ground-truth:
集成网络训练
为训练集成网络,我们从真实3D姿态中抽取部分样本,并进行数据增强:1) 使用二值掩码$M^{kpt}$随机遮挡关节以模拟遮挡情况;2) 随机偏移关节位置以模拟姿态检测误差;3) 随机将姿态对中的一个置零以模拟非配对姿态。集成网络的损失函数为预测3D姿态与真实值之间的L2损失:
$$
L_{i n t}=\frac{1}{K}\sum_{k}|P_{k}-\tilde{P}_{k}|^{2},
$$
$$
L_{i n t}=\frac{1}{K}\sum_{k}|P_{k}-\tilde{P}_{k}|^{2},
$$
where $K$ is the number of the estimated joints. $P$ and $\tilde{P}$ are the estimated and ground-truth 3D poses, respectively.
其中 $K$ 为估计关节数,$P$ 和 $\tilde{P}$ 分别为估计的3D姿态和真实3D姿态。
Inter-Person Disc rim in at or For training the integration network, we propose a novel inter-person disc rim in at or. Unlike most existing disc rim in at or s for human pose estimation (e.g. [50, 8]), where they can only discriminate the plausible 3D poses of one person, we propose an interaction-aware disc rim in at or to enforce the interaction of a pose pair is natural and reasonable, which not only includes the existing single-person disc rim in at or, but also generalize to interacting persons. Specifically, our discriminator contains two sub-networks: $D_{1}$ , which is dedicated for one person-centric 3D poses; and, $D_{2}$ , which is dedicated for a pair of camera-centric 3D poses from two persons. We apply the following loss to train the network, which is formulated as:
人际判别器
为训练集成网络,我们提出了一种新颖的人际判别器。与现有人体姿态估计领域的大多数判别器(如[50, 8])仅能判别单人合理3D姿态不同,我们提出了一种交互感知判别器来确保姿态对的交互自然合理。该判别器不仅包含现有的单人判别器,还可泛化至交互场景。具体而言,我们的判别器包含两个子网络:$D_{1}$(专用于以人为中心的3D姿态)和$D_{2}$(专用于两人以相机为中心的姿态对)。我们采用以下损失函数训练网络:
$$
L_{d i s}=l o g(\tilde{C})+l o g(1-C)
$$
$$
L_{d i s}=l o g(\tilde{C})+l o g(1-C)
$$
where:
其中:
$$
\begin{array}{l l}{C=0.25(D_{1}(P^{a})+D_{1}(P^{b}))+0.5D_{2}(P^{a},P^{b})}\ {\tilde{C}=0.25(D_{1}(\tilde{P^{a}})+D_{1}(\tilde{P^{b}}))+0.5D_{2}(\tilde{P^{a}},\tilde{P^{b}})}\end{array}
$$
$$
\begin{array}{l l}{C=0.25(D_{1}(P^{a})+D_{1}(P^{b}))+0.5D_{2}(P^{a},P^{b})}\ {\tilde{C}=0.25(D_{1}(\tilde{P^{a}})+D_{1}(\tilde{P^{b}}))+0.5D_{2}(\tilde{P^{a}},\tilde{P^{b}})}\end{array}
$$
where $P^{a},P^{b}$ are the estimated poses of person $a$ and person $b$ , respectively. P are the estimated and ground-truth 3D poses, respectively.
其中 $P^{a},P^{b}$ 分别是人物 $a$ 和人物 $b$ 的估计姿态。P 分别是估计的和真实的 3D 姿态。
3.4. Semi-Supervised Training
3.4. 半监督训练
Semi-supervised learning is an effective technique to improve the network performance, particularly when the data with ground-truths are limited. A few works also explore to make use of the unlabeled data [5, 48, 54]. In our method, we apply a noisy student training strategy [53]. We first train a teacher network with the 3D ground-truth dataset only, and then use the teacher network to generate their pseudo-labels of unlabelled data, which are used to train a student network.
半监督学习是提升网络性能的有效技术,尤其在标注数据有限的情况下。部分研究也探索了如何利用未标注数据 [5, 48, 54]。本方法采用带噪声的学生训练策略 [53]:首先仅用三维标注数据训练教师网络,再利用教师网络为未标注数据生成伪标签,最终用这些伪标签训练学生网络。
The pseudo-labels cannot be directly used because some of them are likely incorrect. Unlike in the noisy student training strategy [53], where data with ground-truth labels and pseudo-labels are mixed to train the student network by adding various types of noise (i. e., augmentations, dropout, etc), we propose two-consistency loss terms to assess the quality of the pseudo-labels, including the re projection error and multi-perspective error [5, 39].
伪标签不能直接使用,因为其中部分可能存在错误。与噪声学生训练策略 [53] 混合使用真实标签数据和伪标签数据(通过添加各类噪声如数据增强、dropout等)来训练学生网络不同,我们提出了两项一致性损失项来评估伪标签质量,包括重投影误差和多视角误差 [5, 39]。
The re projection error measures the deviation between the projection of generated 3D poses and the detected 2D poses. Since there are more abundant data variations in 2D pose dataset compared to 3D pose dataset (e.g., COCO is much larger compared to H36M), the 2D estimator is expected to be more reliable than its 3D counterpart. Therefore, minimizing a re projection error is helpful to improve the accuracy of 3D pose estimation.
重投影误差衡量了生成3D姿态的投影与检测到的2D姿态之间的偏差。由于2D姿态数据集(如COCO)相比3D姿态数据集(如H36M)具有更丰富的数据变化,2D姿态估计器被认为比3D姿态估计器更可靠。因此,最小化重投影误差有助于提高3D姿态估计的准确性。
The multi-perspective error, $E_{m p}$ , measures the consistency of the predicted 3D poses from different viewing angles. This error indicates the reliability of the predicted 3D poses. Based on the two terms, our semi-supervised loss, $L_{\mathrm{SSL}}$ , is formulated as,
多视角误差 $E_{mp}$ 用于衡量不同视角下预测3D姿态的一致性。该误差反映了预测3D姿态的可靠性。基于这两个指标,我们的半监督损失函数 $L_{\mathrm{SSL}}$ 可表示为:
$$
L_{\mathrm{SSL}}=w(E_{r e p}+E_{m p})+L_{d i s},
$$
$$
L_{\mathrm{SSL}}=w(E_{r e p}+E_{m p})+L_{d i s},
$$
where $w$ is a weighting factor to balance the contribution of the re projection and multi-perspective errors. In the training stage, $w$ first focuses on easy samples and gradually includes the hard samples. The weight, $w$ , is formulated as:
其中 $w$ 是平衡重投影误差和多视角误差贡献的权重因子。在训练阶段,$w$ 首先关注简单样本,然后逐步纳入困难样本。权重 $w$ 的公式为:
$$
w=\mathrm{softmax}(\frac{E_{r e p}}{r})+\mathrm{softmax}(\frac{E_{m p}}{r}),
$$
$$
w=\mathrm{softmax}(\frac{E_{r e p}}{r})+\mathrm{softmax}(\frac{E_{m p}}{r}),
$$
where $r$ is the number of training epochs. More details regarding to the re projection and multi-perspective errors and the self-training process are discussed in the supplementary material.
其中 $r$ 表示训练周期数。关于重投影误差、多视角误差及自训练过程的更多细节详见补充材料。
4. Experiment
4. 实验
Datasets We use MuPoTS-3D [32] and JTA [14] datasets to evaluate the camera-centric 3D multi-person pose estimation performance by following the existing methods [35, 13] and their training protocols (i.e., train, test split). In addition, we use 3DPW [49] to evaluate person-centric 3D multi-person pose estimation performance following [20, 45]. We also perform evaluation on the widely used Hu $\mathrm{man}3.6\mathrm{M}$ dataset [19] for person-centric 3D human pose estimation following [39, 50]. Details of the datasets information are in the supplementary material.
数据集
我们采用MuPoTS-3D [32]和JTA [14]数据集,遵循现有方法[35, 13]及其训练协议(即训练/测试划分)评估以相机为中心的三维多人姿态估计性能。此外,我们使用3DPW [49]数据集,参照[20, 45]的方法评估以人为中心的三维多人姿态估计性能。同时基于广泛使用的Human3.6M数据集[19],按照[39, 50]的评估方案进行以人为中心的三维人体姿态估计测试。数据集详细信息见补充材料。
(注:根据规则要求,公式"$\mathrm{man}3.6\mathrm{M}$"保留原样未翻译,术语"Human3.6M"首次出现时保留英文原名)
Table 1. Ablation study on MuPoTS-3D dataset. TD, BU, MP, CH, IN, and PM stand for top-down, bottom-up, multi-person pose estimator, combined heatmap, integration network, and pose matching, respectively. Best in bold, second best underlined.
| 方法 | AProot 25 | AUCrel | PCK | PCKabs |
|---|---|---|---|---|
| TD (w/o MP) | 43.7 | 41.0 | 81.6 | 42.8 |
| TD (w MP) BU (w/o CH) | 45.2 44.2 | 48.9 34.5 | 87.5 76.6 | 45.7 40.2 |
| BU (w CH) | 46.1 | 35.1 | 78.0 | 41.5 |
| TD+BU(w/oMP,CH) | 44.9 | 42.6 | 82.8 | |
| TD +BU (hard) | 46.1 | 48.9 | 87.5 | 43.1 |
| TD+BU (linear) | 46.1 | 49.2 | 88.0 | 46.2 |
| 46.7 | ||||
| TD +BU (w/o PM) | 46.0 | 48.6 | 85.5 | 45.3 |
| TD + BU (IN) | 46.3 | 49.6 | 88.9 | 47.4 |
表 1: MuPoTS-3D数据集消融实验。TD、BU、MP、CH、IN和PM分别代表自上而下 (top-down)、自下而上 (bottom-up)、多人姿态估计器 (multi-person pose estimator)、组合热图 (combined heatmap)、集成网络 (integration network) 和姿态匹配 (pose matching)。最佳结果加粗,次佳结果加下划线。
Implementation Details We use HRNet-w32 [44] as the backbone network for both multi-person pose estimator in the top-down and bottom-up networks. The top-down network is trained for 100 epochs on the COCO dataset [28] with the Adam optimizer and learning rate 0.001. The bottom-up network is trained for 50 epochs with the Adam optimizer and learning rate 0.001 on a combined dataset of MuCO [33] and COCO [28]. More details are in the supplementary material.
实现细节
我们采用HRNet-w32 [44]作为自上而下和自下而上网络中多人姿态估计的主干网络。自上而下网络在COCO数据集 [28] 上使用Adam优化器(学习率0.001)训练100个周期。自下而上网络在MuCO [33] 与COCO [28] 的联合数据集上使用Adam优化器(学习率0.001)训练50个周期。更多细节见补充材料。
Evaluation Metrics Since the majority of 3D human pose estimation methods produce person-centric 3D poses, to be able to compare, we perform person-centric 3D human pose estimation. We use Mean Per Joint Position Error (MPJPE), Procrustes analysis MPJPE (PA-MPJPE), Percentage of Correct 3D Keypoints (PCK), and area under PCK curve from various thresholds $(A U C_{r e l})$ following the literature [35, 39, 8]. Since we focus on 3D multi-person camera-centric pose estimation, we also use the metrics designed for evaluating performance in the camera coordinate system, including average precision of 3D human root location $(A P_{25}^{r o o t})$ and $\mathrm{PCK}_{a b s}$ , which is PCK without root alignment to evaluate the absolute camera-centric coordinates from [35], and F1 value following [13].
评估指标
由于大多数3D人体姿态估计方法生成的是以人为中心的3D姿态,为了便于比较,我们同样执行以人为中心的3D人体姿态估计。我们采用以下指标:平均每关节位置误差 (MPJPE)、Procrustes分析MPJPE (PA-MPJPE)、3D关键点正确率 (PCK),以及不同阈值下PCK曲线的相对面积 $(A U C_{r e l})$,这些指标遵循文献[35, 39, 8]的设定。由于我们关注的是以相机为中心的3D多人姿态估计,还使用了针对相机坐标系设计的评估指标,包括:3D人体根节点位置的平均精度 $(A P_{25}^{r o o t})$、未进行根节点对齐的绝对相机坐标系PCK指标 $\mathrm{PCK}_{a b s}$(源自[35]),以及遵循[13]的F1值。
Ablation Studies Ablation studies are performed to validate the effectiveness of each sub-module of our framework. We validate our top-down network by using an existing top-down pose estimator (i.e., detection of one fullbody joints) as a baseline, abbreviated as TD (w/o MP) to compare to our top-down network denoted as TD (w MP). We also validate our bottom-up network by using existing bottom-up heatmap estimation (i.e., estimate all person at the same scale) as a baseline, named BU (w/o CH) to compare to our bottom-up network, called BU (w CH). To evaluate our integration network, we use three baselines. The first is a straightforward integration by combining existing TD and BU networks. The second is hard integration, abbreviated $\mathrm{TD}+\mathrm{BU}$ (hard), where the top-down person-centric pose is always used, plus the root depth from the bottom-up network. The third is linear integration, abbreviated $\mathrm{TD}+$ BU (linear), where the person-centric 3D pose from topdown is combined with its corresponding bottom-up one based on the confidence values of the estimated heatmap.
消融实验
为验证框架中各子模块的有效性,我们进行了消融实验。在自上而下网络中,我们以现有单人全身关节点检测方法(简写为TD (w/o MP))为基线,与本文提出的TD (w MP)网络进行对比。在自下而上网络中,我们以现有统一尺度多人热图估计方法(简写为BU (w/o CH))为基线,与本文提出的BU (w CH)网络进行对比。
针对融合网络的评估,我们设置了三个基线方法:
- 直接融合现有TD与BU网络的简单集成方法
- 硬融合方法(简写为$\mathrm{TD}+\mathrm{BU}$ (hard)),始终采用自上而下的以人为中心的姿态,并叠加自下而上网络的根节点深度
- 线性融合方法(简写为$\mathrm{TD}+$ BU (linear)),根据估计热图的置信度值,将自上而下网络的人体中心3D姿态与对应自下而上网络的姿态进行线性结合
Table 2. Ablation study on MuPoTS-3D dataset. Rep, MP, and dis stand for re projection, multi-perspective, and disc rim in at or. Best in bold, second best underlined.
| 方法 | AUCrel | PCK | PCKabs | |
|---|---|---|---|---|
| Rep | 46.3 | 43.4 | 77.2 | 40.7 |
| MP | 46.3 | 32.2 | 72.8 | 29.5 |
| Rep+dis | 46.3 | 49.9 | 89.1 | 46.8 |
| Rep+MP+dis | 46.3 | 50.6 | 89.6 | 48.0 |
表 2: MuPoTS-3D数据集消融实验。Rep、MP和dis分别代表重投影(re projection)、多视角(multi-perspective)和判别器(disc rim in at or)。最佳结果加粗显示,次优结果加下划线。
As shown in Table 1, we observe that our top-down network, bottom-up network, and integration network clearly outperform their corresponding baselines. Our top-down network tends to have better person-centric 3D pose estimations compared with our bottom-up network, because the top-down network benefits from not only multi-person pose estimator, also GCN and TCN that help to deal with interoccluded poses. On the contrary, our bottom-up network achieves better performance for the root joint estimation, because it estimates the root depth based on a full image; while the root depth of top-down network is estimated based on an individual skeleton. Finally, our integration network demonstrates superior performance compared to hard or linear combining the poses from the top-down and bottom-up networks, which validates its effectiveness.
如表 1 所示,我们观察到自上而下网络、自下而上网络和集成网络明显优于其对应的基线。自上而下网络在人物中心 3D 姿态估计方面通常优于自下而上网络,因为它不仅受益于多人姿态估计器,还受益于 GCN 和 TCN 对遮挡姿态的处理能力。相反,自下而上网络在根关节估计方面表现更优,因为它是基于完整图像估计根深度;而自上而下网络的根深度是基于单个骨架估计的。最终,我们的集成网络在性能上超越了硬性或线性结合自上而下和自下而上网络姿态的方法,验证了其有效性。
Other than validating our top-down and bottom-up networks, we also perform ablation analysis on our semisupervised learning. We show the result of using reprojection loss, multi-perspective loss, re projection loss with our disc rim in at or, and re projection $&$ multi-perspective loss with disc rim in at or in Table 2. We can see that the reprojection loss is more useful than the multi-perspective loss because it leverages the information from the 2D pose estimator, which is trained with 2D datasets with a large number of poses and environment variations. More importantly, we observe that our proposed interaction-aware discriminator makes the largest performance improvement compared with the other modules, demonstrating the importance of enforcing the validity of the interaction between persons.
除了验证我们的自上而下和自下而上网络外,我们还对半监督学习进行了消融分析。表2展示了使用重投影损失、多视角损失、带判别器的重投影损失,以及带判别器的重投影与多视角联合损失的结果。可以看出,重投影损失比多视角损失更有效,因为它利用了2D姿态估计器的信息(该估计器通过包含大量姿态和环境变化的2D数据集训练)。更重要的是,我们观察到所提出的交互感知判别器相比其他模块带来了最大的性能提升,这证明了强化人物间交互有效性的重要性。
Quantitative Evaluation To evaluate the performance for 3D multi-person camera-centric pose estimation in both indoor and outdoor scenarios, we perform evaluations on MuPoTS-3D as summarized in Table 3. The results show that our camera-centric multi-person 3D pose estimation outperforms the SOTA [25] on $P C K_{a b s}$ by $2.3%$ . We also perform person-centric 3D pose estimation evaluation using $P C K$ where we outperform the SOTA method [27] by $2.1%$ . The evaluation on MuPoTS-3D shows that our method outperforms the state-of-the-art methods in both camera-centric and person-centric 3D multi-person pose estimation as our framework overcomes the weaknesses of both bottom-up and top-down branches and at the same time benefits from their strengths.
定量评估
为评估室内外场景下以相机为中心的三维多人姿态估计性能,我们在MuPoTS-3D数据集上进行测试,结果如表3所示。实验表明:在$P C K_{a b s}$指标上,我们的相机中心化三维多人姿态估计方法比当前最优方法(SOTA) [25] 高出$2.3%$;在以人为中心的评估中采用$P C K$指标时,我们的方法比SOTA方法[27]提升$2.1%$。MuPoTS-3D测试证明,我们的框架通过融合自底向上和自顶向下分支的优势并克服其缺陷,在相机中心化和以人为中心的三维多人姿态估计任务中均优于现有最优方法。
(注:严格遵循用户要求的格式规范,包括:
- 保留术语原文如MuPoTS-3D/SOTA
- 数学公式$P C K_{a b s}$原样保留
- 表引用格式转换为"表3"
- 引用标记[25][27]保持原格式
- 技术术语首次出现标注英文如"相机中心化(camera-centric)"
- 全角括号替换为半角并添加空格)
Following recent work [13], we also perform evaluations on JTA, which is a synthetic dataset acquired from computer game, to further validate the effectiveness of our method for camera-centric 3D multi-person pose estimation. As shown in Table 4, our method is superior over the SOTA method [13] (e.g., our result shows $12.6%$ improvement on F1 value, $t=0.4m$ ) on this challenging dataset where both inter-person occlusion and large person scale variation present, which again illustrate that our proposed method can handle these challenges in 3D multi-person pose estimation.
遵循近期工作[13],我们也在JTA(一种从电脑游戏中获取的合成数据集)上进行了评估,以进一步验证我们提出的以相机为中心的三维多人姿态估计方法的有效性。如表4所示,在存在人际遮挡和大幅人物尺度变化的挑战性数据集上,我们的方法优于当前最佳方法[13](例如,F1值提升了12.6%,t=0.4m),这再次证明我们提出的方法能够应对三维多人姿态估计中的这些挑战。
Human3.6M is widely used for evaluating 3D singleperson pose estimation. As our method is focused on dealing with inter-person occlusion and scale variation, we do not expect our method performs significantly better than the SOTA methods. Table 5 summarizes the quantitative evaluation on Human3.6M where our method is comparable with the SOTA methods [22, 25] on person-centric 3D human pose evaluation metrics (i.e., MPJPE and PA-MPJPE).
Human3.6M被广泛用于评估3D单人姿态估计。由于我们的方法专注于处理人际遮挡和尺度变化问题,因此不预期其性能会显著优于当前最佳方法(SOTA)。表5总结了在Human3.6M上的定量评估结果,其中我们的方法在以人为中心的3D人体姿态评估指标(即MPJPE和PA-MPJPE)上与SOTA方法[22,25]表现相当。
3DPW is an outdoor multi-person 3D human shape reconstruction dataset. It is unfair to compare the errors between skeleton-based method with ground-truth defined on SMPL model [29] due to the different definitions of joints [47]. We run human detection on all frames and create an occlusion subset where the frames with the large overlay between persons are selected. The performance drop between the full testing test of 3DPW and the occlusion subset can effectively tell if a method can handle interperson occlusion, which is shown in Table 6. We observe that our method shows the least performance drop from the testing set to the subset, which demonstrates our method is indeed more robust to inter-person occlusion.
3DPW是一个户外多人3D人体形状重建数据集。由于关节定义不同 [47],将基于骨架的方法与定义在SMPL模型 [29] 上的真实值进行误差比较是不公平的。我们对所有帧运行人体检测,并创建了一个遮挡子集,其中选择了人物间重叠较大的帧。3DPW完整测试集与遮挡子集之间的性能下降能有效判断方法是否能够处理人际遮挡,如 表6 所示。我们观察到,从测试集到子集,我们的方法性能下降最小,这表明我们的方法确实对人际遮挡更具鲁棒性。
Qualitative Evaluation Fig. 4 shows the comparison among a SOTA bottom-up method SMAP [56], our bottomup branch, top-down branch, and full model. We observe that SMAP suffers from person scale variation where the person who is far from the camera is missing in frame 280 as well as inter-occlusion (e.g., frame 365 and 340). Our bottom-up branch is robust to scale variance, but fragile to the out-of-image poses as our disc rim in at or is not used here (e.g., frame 365 and 330). Moreover, our top-down branch produces reasonable relative poses with the aid of GCN and TCNs. However, there exists error of camera-centric root depth in our top-down branch, because our top-down branch
定性评估
图 4: 展示了最先进的(SOTA)自底向上方法 SMAP [56]、我们的自底向上分支、自顶向下分支以及完整模型之间的对比。我们观察到 SMAP 存在人物尺度变化问题(如远离摄像头的行人在第 280 帧缺失)以及相互遮挡问题(例如第 365 帧和 340 帧)。我们的自底向上分支对尺度变化具有鲁棒性,但对图像外姿态敏感(由于未使用 disc rim in at 机制,例如第 365 帧和 330 帧)。此外,借助 GCN (Graph Convolutional Network) 和 TCNs (Temporal Convolutional Networks),我们的自顶向下分支能生成合理的相对姿态。但该分支存在以相机为中心的根节点深度误差问题,因为...
Table 3. Quantitative evaluation on multi-person 3D dataset, MuPoTS-3D. Best in bold, second best underlined.
表 3: 多人3D数据集MuPoTS-3D的定量评估。加粗表示最优结果,下划线表示次优结果。
| 组别 | 方法 | PCK | PCKabs |
|---|---|---|---|
| 以人为中心 | Mehta等[32] Rogez等[42] Cheng等[9] Cheng等[8] | 65.0 70.6 74.6 80.5 | n/a n/a n/a n/a |
| 以相机为中心 | Moon等[35] Lin等[27] Zhen等[56] Li等[25] Cheng等[7] 我们的方法 | 82.5 83.7 80.5 82.0 87.5 89.6 | 31.8 35.2 38.7 43.8 45.7 48.0 |
| 方法 | t=0.4m | t=0.8m | t=1.2m |
|---|---|---|---|
| [40]+[30]+[42] | 39.14 | 47.38 | 49.03 |
| LoC0 [13] | 50.82 | 64.76 | 70.44 |
| 我们的方法 | 57.22 | 68.51 | 72.86 |
Table 4. Quantitative results on JTA dataset. F1 values are reported based on different threshold $t$ when the point is considered ”true positive” when the distance from corresponding distance is less than $t$ . Best in bold, second best underlined.
表 4: JTA数据集定量结果。F1值根据不同阈值$t$计算得出(当对应距离小于$t$时判定为"真阳性")。最佳结果加粗显示,次佳结果添加下划线。
Table 5. Quantitative evaluation on Human3.6M for normalized and camera-centric 3D human pose estimation. * denotes groundtruth 2D labels are used. Best in bold, second best underlined.
表 5: Human3.6M数据集上归一化和以相机为中心的3D人体姿态估计定量评估。*表示使用了真实2D标注。最佳结果加粗显示,次佳结果加下划线。
| 组别 | 方法 | MPJPE | PA-MPJPE |
|---|---|---|---|
| 以人为中心 | Hossain et al., [16] Wandt et al., [50]* Pavllo et al., [39] Cheng et al., [9] Kocabas et al., [21] Kolotouros et al., [22] | 51.9 50.9 46.8 42.9 65.6 n/a | 42.0 38.2 36.5 32.8 41.4 41.1 |
| 以相机为中心 | Moon et al., [35] Zhen et al., [56] Li et al., [25] Ours | 54.4 54.1 48.6 40.7 | 35.2 n/a 30.5 30.4 |
Table 6. Quantitative evaluation using PA-MPJPE on original 3DPW test set and its occlusion subset. * denotes extra 3D datasets were used in training. Best in bold, second best underlined.
表 6: 在原始3DPW测试集及其遮挡子集上使用PA-MPJPE的定量评估。*表示训练中使用了额外的3D数据集。最佳结果加粗,次佳结果加下划线。
| 数据集 | 方法 | PA-MPJPE | |
|---|---|---|---|
| 原始数据 | Doersch et al. [12] Kanazawa et al.[20] Arnab et al.[2] Cheng et al. [8] Sun et al. [45] Kolotouros et al. [22]* Kocabas et al.,[21]* 我们的方法 | 74.7 72.6 72.2 71.8 69.5 59.2 51.9 62.9 | n/a n/a n/a n/a n/a n/a n/a |
| 子集数据 | Cheng et al. [8] Sun et al. [45] Kolotouros et al. [22]* Kocabas et al., [21]* 我们的方法 | 92.3 84.4 79.1 72.2 75.6 | n/a +20.5 +14.9 +19.9 +20.3 +12.7 |
estimates root depth based on individual 2D poses and lacks global awareness (e.g., frame 280). Finally, our full model benefits from both branches and produces the best 3D pose estimations among these baselines.
基于单个2D姿态估计根节点深度,缺乏全局感知(例如第280帧)。最终,我们的完整模型结合了两个分支的优势,在这些基线中实现了最佳的三维姿态估计效果。
We also provide results of the estimated 3D poses in novel viewpoints and the estimated 2D poses overlaid on input images as in Fig. 5 where our estimated camera-centric 3D poses visualized from different angles further validate the effectiveness of our method. Two failure cases are shown in Fig. 6 where the samples are taken from MPII dataset. The common failure cases are constant heavy occlusion (left) and unusual poses (right).
我们还提供了新视角下的估计3D姿态结果,以及叠加在输入图像上的估计2D姿态,如图5所示。其中,从不同角度可视化的以相机为中心的3D姿态进一步验证了我们方法的有效性。图6展示了两个失败案例,样本取自MPII数据集。常见的失败案例包括持续严重遮挡(左)和异常姿态(右)。

Figure 4. Examples of results from our whole framework compared with different baseline results. First row shows the images from two video clips; second row shows the results from SMAP [56]; third row shows the result of of our bottom-up (BU) branch; fourth row shows the results of our top-down (TD) branch; last row shows the results of our full model. Wrong estimations are labeled with red circles.
图 4: 我们完整框架与不同基线方法的结果对比示例。第一行展示了两段视频片段的图像;第二行显示了SMAP [56]的结果;第三行展示了我们自底向上(BU)分支的结果;第四行展示了我们自顶向下(TD)分支的结果;最后一行展示了我们完整模型的结果。错误估计用红色圆圈标出。

Figure 5. Qualitative results of the estimated 2D poses overlaying on input images and the estimated 3D poses visualized in novel viewpoints (virtual camera rotated by 0, 45, 90 degrees clockwise). Different colors are used for different persons in both 2D and 3D human poses for better visualization purpose.
图 5: 输入图像上叠加的估计2D姿态定性结果,以及在新视角(虚拟相机顺时针旋转0、45、90度)下可视化的估计3D姿态。为便于观察,2D和3D人体姿态中不同人物使用不同颜色标注。

Figure 6. Two representative failure cases of our method.
图 6: 我们方法的两个典型失败案例。
5. Conclusion
5. 结论
We have proposed a novel method for monocular-video 3D multi-person pose estimation, which addresses the problems of inter-person occlusion and close interactions. We introduced the integration of top-down and bottom-up approaches to exploit their strengths. Our quantitative and qualitative evaluations show the effectiveness of our method compared to the state-of-the-art baselines.
我们提出了一种新颖的单目视频三维多人姿态估计方法,该方法解决了人际遮挡和紧密交互的问题。我们引入了自上而下和自下而上方法的整合,以充分利用它们的优势。定量和定性评估表明,与现有最先进的基线相比,我们的方法具有显著效果。