Multi-Stream Keypoint Attention Network for Sign Language Recognition and Translation
多流关键点注意力网络在手语识别与翻译中的应用
Abstract
摘要
Sign language serves as a non-vocal means of communication, transmitting information and significance through gestures, facial expressions, and bodily movements. The majority of current approaches for sign language recognition (SLR) and translation rely on RGB video inputs, which are vulnerable to fluctuations in the background. Employing a keypoint-based strategy not only mitigates the effects of background alterations but also substantially diminishes the computational demands of the model. Nevertheless, contemporary keypoint-based methodologies fail to fully harness the implicit knowledge embedded in keypoint sequences. To tackle this challenge, our inspiration is derived from the human cognition mechanism, which discerns sign language by analyzing the interplay between gesture configurations and supplementary elements. We propose a multi-stream keypoint attention network to depict a sequence of keypoints produced by a readily available keypoint estimator. In order to facilitate interaction across multiple streams, we investigate diverse methodologies such as keypoint fusion strategies, head fusion, and self-distillation. The resulting framework is denoted as MSKA-SLR, which is expanded into a sign language translation (SLT) model through the straightforward addition of an extra translation network. We carry out comprehensive experiments on well-known benchmarks like Phoenix-2014, Phoenix-2014T, and CSL-Daily to showcase the efficacy of our methodology. Notably, we have attained a novel state-of-the-art performance in the sign language translation task of Phoenix-2014T. The code and models can be accessed at: https://github.com/sutwangyan/MSKA.
手语作为一种非语音交流方式,通过手势、面部表情和身体动作传递信息与意义。当前大多数手语识别(SLR)和翻译方法依赖RGB视频输入,易受背景变化影响。采用基于关键点的策略不仅能降低背景变化的干扰,还可大幅减少模型计算需求。然而,现有基于关键点的方法未能充分利用关键点序列中隐含的知识。为解决这一问题,我们从人类认知机制获得启发——通过分析手势形态与辅助要素的相互作用来辨识手语。我们提出多流关键点注意力网络,用于描述由现有关键点估计器生成的关键点序列。为实现多流间交互,我们研究了关键点融合策略、头部融合及自蒸馏等多种方法。该框架被命名为MSKA-SLR,通过简单添加翻译网络即可扩展为手语翻译(SLT)模型。我们在Phoenix-2014、Phoenix-2014T和CSL-Daily等知名基准测试上进行了全面实验,验证了方法的有效性。特别值得注意的是,我们在Phoenix-2014T手语翻译任务中取得了最新的最先进性能。代码与模型已开源:https://github.com/sutwangyan/MSKA。
Keywords: Sign Language Recognition, Sign Language Translation, Self-Attention, Self-Distillation, Keypoint
关键词: 手语识别, 手语翻译, 自注意力机制, 自蒸馏, 关键点
1 Introduction
1 引言
Sign language, a form of communication utilizing gestures, expressions, and bodily movements, has been the subject of extensive study Bungeroth and Ney (2004); Starner et al (1998); Tamura and Kawasaki (1988). For the deaf and mute community, sign language serves as their primary mode of communication. It holds profound significance, offering an effective medium for this particular demographic to convey thoughts, emotions, and needs, thereby facilitating their active participation in social interactions. Sign language possesses a unique structure, incorporating elements such as the shape, direction, and placement of gestures, along with facial expressions. Its grammar diverges from that of spoken language, exhibiting differences in grammatical structure and sequence. To address such disparities, certain sign language translation (SLT) tasks integrate gloss sequences before text generation. The transition from visual input to gloss sequences constitutes the process of sign language recognition (SLR). Fig. 1(a) depicts both SLR and SLT tasks.
手语作为一种通过手势、表情和身体动作进行交流的方式,已被广泛研究 [Bungeroth and Ney (2004); Starner et al (1998); Tamura and Kawasaki (1988)]。对于聋哑群体而言,手语是他们主要的沟通媒介,具有深远意义——为这一特殊群体提供了表达思想、情感和需求的有效途径,从而促进其积极参与社会交往。手语具有独特的结构体系,包含手势的形状、方向、位置以及面部表情等要素,其语法规则与口语存在差异,在语法结构和语序上均有所不同。为解决这种差异,部分手语翻译 (SLT) 任务会在文本生成前融入手语标记序列。从视觉输入到手语标记序列的转换过程即构成手语识别 (SLR) 。图 1(a) 展示了 SLR 与 SLT 任务。
Gestures play a pivotal role in the recognition and translation of sign language. Indeed, gestures occupy a modest portion of the video, rendering them vulnerable to shifts in the background and swift hand movements during sign language communication. Consequently, this results in challenges in acquiring sign language attributes. Nevertheless, owing to robustness and computational efficiency of gestures, some methodologies advocate for the employment of keypoints to convey it. Ordinarily, sign language videos undergo keypoint extraction using off-the-shelf keypoint estimator. Following this, the keypoint sequences are regionally cropped to be utilized as input for the model, allowing a more precise focus on the character istics of hand shapes. The TwoStream method, as described in Chen et al (2022b), enhances feature extraction by converting keypoints into heatmaps and implementing 3D convolution. SignBERT $^+$ , detailed in the work by Hu et al (2023a), represents hand keypoints as a graphical framework and employs graph convolutional networks for extracting gesture features. Nevertheless, a key drawback of these approaches is the inadequate exploitation of correlation data among keypoints.
手势在手语的识别与翻译中扮演着关键角色。尽管手势仅占据视频的较小部分,但在手语交流过程中容易受到背景变化和快速手部动作的干扰,这导致获取手语特征面临挑战。然而,得益于手势的鲁棒性和计算效率,部分研究方法建议采用关键点来表征手势。通常,手语视频会先通过现有关键点提取器获取关键点序列,再经过区域裁剪作为模型输入,从而更精准地聚焦手形特征。如Chen等人(2022b)提出的TwoStream方法,通过将关键点转化为热力图并应用3D卷积来增强特征提取。Hu等人(2023a)开发的SignBERT$^+$则将手部关键点构建为图结构,利用图卷积网络提取手势特征。但这些方法存在一个主要缺陷:未能充分挖掘关键点间的关联数据。
To address this challenge, we introduce an innovative network framework that depends entirely on the interplay among keypoints to achieve proficiency in sign language recognition and translation endeavors. Our methodology is influenced by the innate human inclination to prioritize the configuration of gestures and the dynamic interconnection between the hands and other bodily elements in the process of sign language interpretation. The devised multi-stream keypoint attention (MSKA) mechanism is adept at facilitating sign language translation by integrating a supplementary translation network. As a result, the all-encompassing system is designated as MSKA-SLT, as illustrated in Fig. 1(b).
为应对这一挑战,我们提出了一种创新网络框架,该框架完全依赖关键点间的相互作用来实现手语识别与翻译任务的高效处理。我们的方法受到人类在解读手语时天然倾向于关注手势构型及手部与其他身体部位动态关联的启发。所设计的多流关键点注意力机制 (MSKA) 通过集成辅助翻译网络,能够有效促进手语翻译。最终,这个完整系统被命名为 MSKA-SLT,如图 1(b) 所示。
In summary, our contributions primarily consist of the following three aspects:
总之,我们的贡献主要包括以下三个方面:
- To the best of our knowledge, we are the first to propose a multi-stream keypoint attention, which is built with pure attention modules without manual designs of traversal rules or graph topologies.
据我们所知,我们是首个提出多流关键点注意力机制的团队,该机制完全由注意力模块构建,无需人工设计遍历规则或图拓扑结构。
- We propose to decouple the keypoint sequences into four streams, left hand stream, right hand stream, face stream and whole body stream, each focuses on a specific aspect of the skeleton sequence. By fusing different types of features, the model can have a more comprehensive understanding for sign language recognition and translation.
- 我们提出将关键点序列解耦为四个流:左手流、右手流、面部流和全身流,每个流专注于骨架序列的特定方面。通过融合不同类型的特征,模型能够对手语识别和翻译有更全面的理解。
- We conducted extensive experiments to validate the proposed method, demonstrating encouraging improvements in sign language recognition tasks on the three prevalent benchmarks, i.e., Phoenix-2014 Koller et al (2015), Phoenix-2014T Camgoz et al (2018) and CSL-Daily Zhou et al (2021a). Moreover, we achieved new state-of-the-art performance in the translation task of Phoenix-2014T.
- 我们进行了大量实验来验证所提出的方法,在三个主流手语识别基准测试中均取得了显著提升,即 Phoenix-2014 Koller et al (2015) 、Phoenix-2014T Camgoz et al (2018) 和 CSL-Daily Zhou et al (2021a) 。此外,我们在 Phoenix-2014T 的翻译任务中实现了新的最先进性能。
2 Related Work
2 相关工作
2.1 Sign Language Recognition and Translation
2.1 手语识别与翻译
Sign language recognition is a prominent research domain in the realm of computer vision, with the goal of deriving sign glosses through the analysis of video or image data. 2D CNNs are frequently utilized architectures in computer vision to analyze image data, and they have garnered extensive use in research pertaining to sign language recognition Cihan Camgoz et al (2017); Niu and Mak (2020); Cui et al (2019); Zhou et al (2021b); Hu et al (2023b,c); Guo et al (2023).
手语识别是计算机视觉领域的一个重要研究方向,其目标是通过分析视频或图像数据来推导出手语词汇。2D CNN (Convolutional Neural Network) 是计算机视觉中常用于分析图像数据的架构,在Cihan Camgoz等人 (2017)、Niu和Mak (2020)、Cui等人 (2019)、Zhou等人 (2021b)、Hu等人 (2023b,c) 以及Guo等人 (2023) 的手语识别相关研究中得到了广泛应用。
STMC Zhou et al (2021b) proposed a spatiotemporal multi-cue network to address the problem of visual sequence learning. CorrNet Hu et al (2023b) model captures crucial body movement trajectories by analyzing correlation maps between consecutive frames. It employs 2D CNNs to extract image features, followed by a set of 1D CNNs to acquire temporal characteristics. AdaBrowse Hu et al (2023c) introduced a novel adaptive model that dynamically selects the most informative sub sequence from the input video sequence by effectively utilizing redundancy modeled for sequential decision tasks. CTCA Guo et al (2023) build a dual-path network that contains two branches for perceptions of local temporal context and global temporal context. By extending 2D CNNs along the temporal dimension, 3D CNNs can directly process spatio-temporal information in video data. This approach enables a better understanding of the dynamic features of sign language movements, thus enhancing recognition accuracy Li et al (2020); Pu et al (2019); Chen et al (2022a). MMTLB Chen et al (2022a) utilize a pre-trained S3D Xie et al (2018) net- work to extract features from sign language videos for sign language recognition, followed by the use of a translation network for sign language translation tasks. Recent studies in gloss decoder design have predominantly employed either Hidden Markov Models (HMM) Koller et al (2017, 2018, 2020) or Connection is t Temporal Classification (CTC) Cheng et al (2020); Min et al (2021); Zhou et al (2021b), drawing from their success in automatic speech recognition. We opted for CTC due to its straightforward implementation. While CTC loss offers only modest sentence-level guidance, approaches such as those proposed by Cui et al (2019); Zhou et al (2019); Chen et al (2022b) suggest iterative ly deriving detailed pseudo labels from CTC outputs to enhance frame-level supervision. Additionally, Min et al (2021) achieves frame-level knowledge distillation by aligning the entire model with the visual encoder.
STMC Zhou等(2021b)提出时空多线索网络来解决视觉序列学习问题。CorrNet Hu等(2023b)通过分析连续帧之间的相关性图来捕捉关键身体运动轨迹,采用2D CNN提取图像特征后,通过一组1D CNN获取时序特征。AdaBrowse Hu等(2023c)提出新型自适应模型,通过有效利用序列决策任务中的冗余建模,动态选择输入视频序列中最具信息量的子序列。CTCA Guo等(2023)构建了包含局部时序上下文和全局时序上下文感知双路径的网络。通过将2D CNN沿时间维度扩展,3D CNN可直接处理视频数据中的时空信息,这种方法能更好理解手语动作的动态特征,从而提高识别精度Li等(2020); Pu等(2019); Chen等(2022a)。MMTLB Chen等(2022a)使用预训练的S3D Xie等(2018)网络从手语视频中提取特征进行手语识别,再通过翻译网络完成手语翻译任务。
当前手语解码器设计主要采用隐马尔可夫模型(HMM) Koller等(2017,2018,2020)或连接时序分类(CTC) Cheng等(2020); Min等(2021); Zhou等(2021b),这些方法在自动语音识别领域已获成功。我们选择CTC因其实现简单。虽然CTC损失仅提供句子级监督,但Cui等(2019); Zhou等(2019); Chen等(2022b)提出的方法可通过CTC输出迭代生成详细伪标签来增强帧级监督。此外,Min等(2021)通过将整个模型与视觉编码器对齐,实现了帧级知识蒸馏。
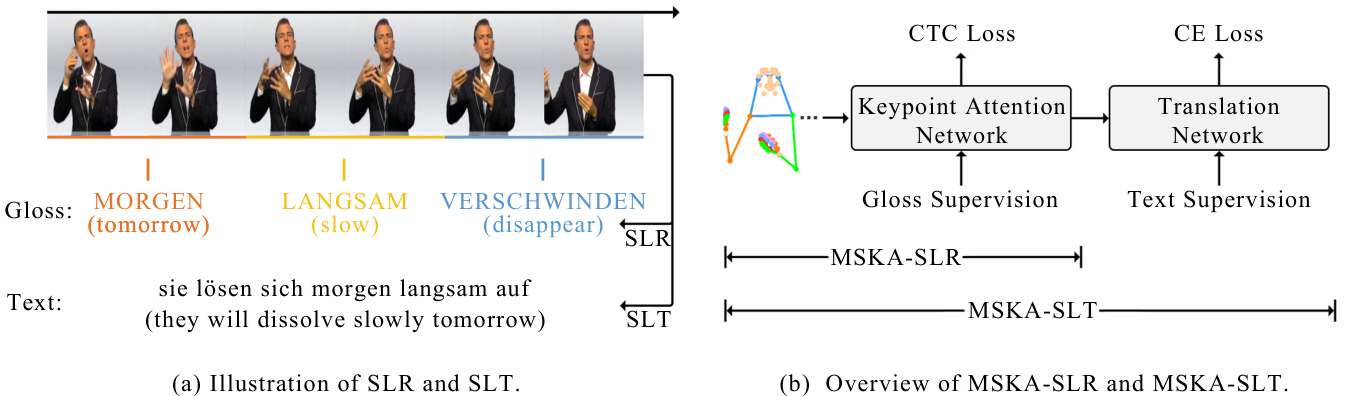
Fig. 1: (a)We choose a sign language video from the Phoenix-2014T dataset and display its gloss sequence alongside the corresponding text. The objective of sign language recognition (SLR) is to instruct models in producing matching gloss representations derived from sign language videos. Conversely, the task of sign language translation (SLT) entails creating textual representations that align with sign language videos. (b) MSKA-SLT is constructed on the foundation of MSKA-SLR to facilitate SLT. Keypoint sequences are depicted in coordinate form.
图 1: (a) 我们选取Phoenix-2014T数据集中的手语视频,展示其手语词序列与对应文本。手语识别(SLR)的任务是指导模型从手语视频中生成匹配的手语词表征,而手语翻译(SLT)则需要生成与手语视频对应的文本表征。(b) MSKA-SLT基于MSKA-SLR框架构建以实现手语翻译功能,关键点序列以坐标形式呈现。
In this study, our distillation process leverages the multi-stream architecture to incorporate ensemble knowledge into each individual stream, thereby improving interaction and coherence among the multiple streams. Sign language translation (SLT) involves directly generating textual outputs from sign language videos. Many existing methods frame this task as a neural machine translation (NMT) challenge, employing a visual encoder to extract visual features and feeding them into a translation network for text generation Camgoz et al (2018, 2020b); Chen et al (2022a); Li et al (2020); Zhou et al (2021a); Xie et al (2018); Chen et al (2022b). We adopt mBART Liu et al (2020) as our trans- lation network, given its impressive performance in SLT Chen et al (2022a,b). To attain satis- factory outcomes, gloss supervision is commonly employed in SLT. This involves pre-training the multi-stream attention network on SLR Camgoz et al (2020b); Zhou et al (2021b,a) and jointly training SLR and SLT Zhou et al (2021b,a).
本研究采用多流架构进行知识蒸馏,将集成知识融入每个独立流中,从而提升多流间的交互与连贯性。手语翻译(SLT)任务旨在从手语视频直接生成文本输出。现有方法多将其视为神经机器翻译(NMT)问题,通过视觉编码器提取视觉特征后输入翻译网络生成文本 Camgoz et al (2018, 2020b); Chen et al (2022a); Li et al (2020); Zhou et al (2021a); Xie et al (2018); Chen et al (2022b)。我们选用mBART Liu et al (2020)作为翻译网络,因其在手语翻译中表现优异 Chen et al (2022a,b)。为获得理想效果,手语翻译通常采用词目监督策略:先在手语识别(SLR)任务上预训练多流注意力网络 Camgoz et al (2020b); Zhou et al (2021b,a),再联合训练手语识别与手语翻译 Zhou et al (2021b,a)。
2.2 Introduce Keypoints into SLR and SLT
2.2 将关键点引入SLR和SLT
The optimization of keypoints to enhance the efficacy of SLR and SLT remains a challenging issue. Camgoz et al (2020a) introduce an innovative multichannel transformer design. The suggested structure enables the modeling of both inter and intra contextual connections among distinct sign art i cula tors within the transformer network, while preserving channel-specific details. Papa dimitri ou and Potamianos (2020) presenting an end-toend deep learning methodology that depends on the fusion of multiple spatio-temporal feature streams, as well as a fully convolutional encoderdecoder for prediction. TwoStream-SLR Chen et al (2022b) put forward a dual-stream network framework that integrates domain knowledge such as hand shapes and body movements by modeling the original video and keypoint sequences separately. It utilizes existing keypoint estimators to generate keypoint sequences and explores diverse techniques to facilitate interaction between the two streams. SignBERT $^+$ Hu et al (2023a) incorporates graph convolutional networks (GCN) into hand pose representations and amalgamating them with a self-supervised pre-trained model for hand pose, the aim is to enhance sign language understanding performance. This method utilizes a multi-level masking modeling approach (including joint, frame, and clip levels) to train on extensive sign language data, capturing multilevel contextual information in sign language data. $\mathrm{C^{2}}$ SLR Zuo and Mak (2024) aims to ensure coherence between the acquired attention masks and pose keypoint heatmaps to enable the visual module to concentrate on significant areas.
优化关键点以提升手语识别(SLR)和手语翻译(SLT)效能仍是一个具有挑战性的问题。Camgoz等人(2020a)提出了一种创新的多通道Transformer架构。该结构能够在Transformer网络中建模不同手语表达部位之间的跨通道和通道内上下文关联,同时保留通道特异性信息。Papadimitriou和Potamianos(2020)提出了一种端到端深度学习方法,该方法依赖于多时空特征流的融合,以及用于预测的全卷积编码器-解码器结构。TwoStream-SLR的Chen等人(2022b)提出了一个双流网络框架,通过分别建模原始视频和关键点序列,整合了手部形状和身体动作等领域知识。该方法利用现有关键点估计器生成关键点序列,并探索多种技术来促进双流间的交互作用。SignBERT$^+$的Hu等人(2023a)将图卷积网络(GCN)整合到手部姿态表示中,并将其与自监督预训练的手部姿态模型相结合,旨在提升手语理解性能。该方法采用多级掩码建模策略(包括关节级、帧级和片段级)在大量手语数据上进行训练,以捕捉手语数据中的多级上下文信息。$\mathrm{C^{2}}$SLR的Zuo和Mak(2024)致力于确保所获得的注意力掩码与姿态关键点热图之间的一致性,从而使视觉模块能够聚焦于重要区域。
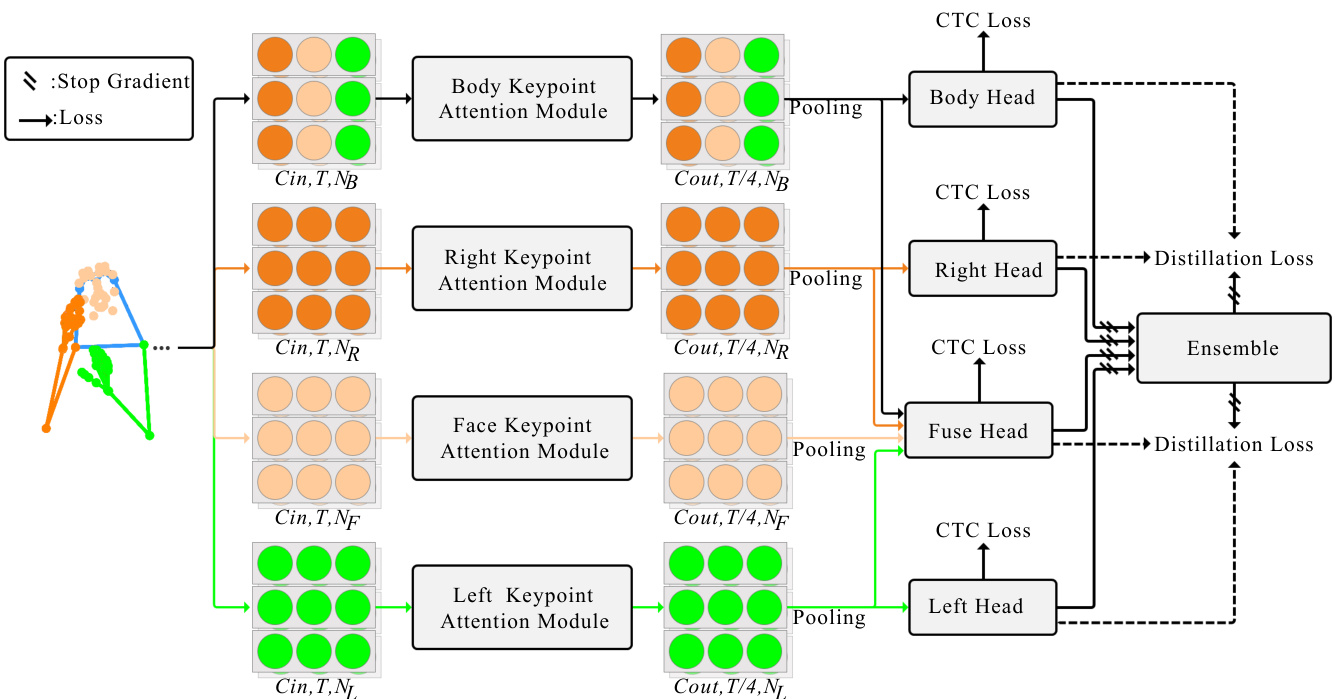
Fig. 2: The overview of our MSKA-SLR. The whole network is jointly supervised by the CTC losses and the self-distillation losses. Keypoints are represented in coordinate format.
图 2: MSKA-SLR 整体架构。整个网络由 CTC (Connectionist Temporal Classification) 损失和自蒸馏损失联合监督。关键点以坐标格式表示。
2.3 Self-attention mechanism
2.3 自注意力机制 (Self-attention mechanism)
Serves as the foundational component within the transformer architecture Vaswani et al (2017); Dai et al (2019), representing a prevalent approach in the realm of natural language processing (NLP). Its operational framework encompasses a set of queries $Q$ , keys $K$ , and values $V$ , each with a dimensionality of $C$ , arranged in matrix format to facilitate efficient computation. Initially, the mechanism computes the dot product between the queries and all keys, subsequently normalizing each by $\sqrt{C}$ and applying a softmax function to derive the corresponding weights assigned to the values Vaswani et al (2017). Mathematically, this process can be formulated as follows:
作为Transformer架构中的基础组件 [Vaswani et al (2017); Dai et al (2019)] ,代表了自然语言处理 (NLP) 领域的流行方法。其操作框架包含一组查询 $Q$ 、键 $K$ 和值 $V$ ,每个矩阵的维度均为 $C$ ,通过矩阵排列实现高效计算。该机制首先计算查询与所有键的点积,随后通过 $\sqrt{C}$ 进行归一化,并应用softmax函数生成对应的值权重分配 [Vaswani et al (2017)] 。该过程的数学表达如下:
$$
A t t e n t i o n(Q,K,V)=s o f t m a x(\frac{Q K^{T}}{\sqrt{C}})V
$$
$$
A t t e n t i o n(Q,K,V)=s o f t m a x(\frac{Q K^{T}}{\sqrt{C}})V
$$
2.4 Multi-Stream Networks
2.4 多流网络
In this work, our approach directly models keypoint sequences through an attention module. Additionally, to mitigate the issue of data scarcity and better capture glosses across different body parts, we introduce multi-stream attention to drive meaningful feature extraction of local features. Modeling the interactions among distinct streams presents a challenging challenge. I3D Carreira and Zisserman (2017) adopts a late fusion strategy by simply averaging the predictions of the two streams. Another approach involves early fusion by lateral connections Fei chten hofer et al (2019), concatenation Zhou et al (2021b), or addition Cui et al (2019) to merge intermediary features of each stream. In this study, we utilize the concept of lateral connections to facilitate mutual supplement ation between multiple streams. Additionally, our self-distillation method integrates knowledge from multiple streams into the generated pseudo-targets, thereby achieving a more profound interaction.
在本研究中,我们的方法通过注意力模块直接建模关键点序列。此外,为缓解数据稀缺问题并更好地捕捉不同身体部位的手势特征,我们引入多流注意力机制以驱动局部特征的有意义提取。建模不同流之间的交互是一个具有挑战性的难题。I3D (Carreira和Zisserman,2017) 采用后期融合策略,通过简单平均两个流的预测结果。另一种方法则采用早期融合策略,通过横向连接 (Feichtenhofer等,2019)、串联 (Zhou等,2021b) 或相加 (Cui等,2019) 来合并每个流的中间特征。本研究利用横向连接的概念促进多流之间的相互补充。此外,我们的自蒸馏方法将多流知识整合到生成的伪目标中,从而实现更深入的交互。
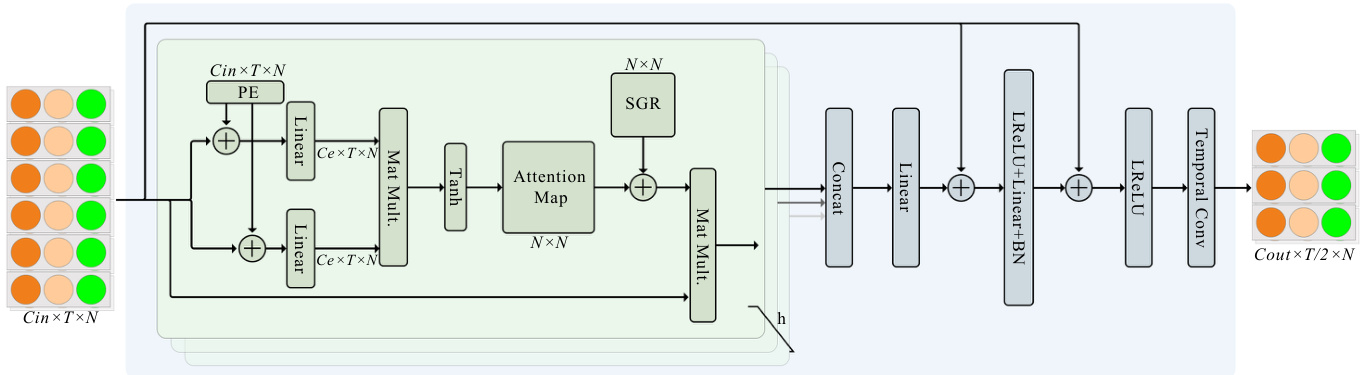
Fig. 3: Illustration of the attention module. We show the body attention module as an example. The others attention module is an analogy. The green rounded rectangle box represents a single-head selfattention module. There are totally $h$ self-attention heads, whose output are concatenated and fed into two linear layers to obtain the output. LReLU represents the leaky ReLU Maas et al (2013).
图 3: 注意力模块示意图。我们以身体注意力模块为例,其他注意力模块同理。绿色圆角矩形框代表单头自注意力模块。共有 $h$ 个自注意力头,其输出经拼接后输入两个线性层以获取最终输出。LReLU 表示带泄露修正线性单元 (leaky ReLU) Maas et al (2013)。
3 Proposed Method
3 提出的方法
In this section, we initially present the data augmentation techniques for keypoint sequences. Subsequently, we elaborate on the individual components of MSKA-SLR. Finally, we outline the composition of MSKA-SLT.
在本节中,我们首先介绍关键点序列的数据增强技术,随后详细阐述MSKA-SLR的各个组件,最后概述MSKA-SLT的构成。
3.1 Keypoint augment
3.1 关键点增强
Typically, sign language video datasets are constrained in size, underscoring the importance of data augmentation. In contrast to prior works such as Guo et al (2023); Hu et al (2023c,b); Chen et al (2022b), our input data comprises keypoint sequences. Analogous to the augmentation techniques employed in image-related tasks, we implement a step for keypoints: Utilizing HRNet Wang et al (2020) to extract keypoints from sign language videos, wherein the keypoint coordinates are denoted with respect to the topleft corner of the image, with the positive $X$ and $Y$ axes oriented towards the rightward and downward directions, respectively. To utilize data augmentation, we pull the origin back to the center of the image and normalize it by a function: $((x/W,(H-y)/H)-0.5)/0.5$ , with horizontal to the right and vertical upwards defining the positive directions of the $X$ and $Y$ axes, respectively. Within this context, the variables $x$ and $y$ denote the coordinates of a given point, whereas $H$ and $W$ symbolize the height and width of the image, respectively.
通常,手语视频数据集的规模有限,这凸显了数据增强的重要性。与Guo等人 (2023)、Hu等人 (2023c,b)、Chen等人 (2022b) 的先前工作不同,我们的输入数据由关键点序列组成。类似于图像相关任务中采用的增强技术,我们对关键点实施了以下处理步骤:使用HRNet (Wang等人, 2020) 从手语视频中提取关键点,其中关键点坐标以图像左上角为基准,正$X$轴和$Y$轴分别朝向右方和下方。为了实现数据增强,我们将原点移至图像中心,并通过函数$((x/W,(H-y)/H)-0.5)/0.5$进行归一化处理,此时水平向右和垂直向上分别定义为$X$轴和$Y$轴的正方向。在此背景下,变量$x$和$y$表示给定点的坐标,而$H$和$W$分别代表图像的高度和宽度。
- We adjust the temporal length of the keypoint sequences within the interval $[\times0.5\mathrm{-}\times1.5]$ , selecting valid frames randomly from this range. 2) The scaling process involves multiplying the coordinates of each point in the provided keypoint set by a scaling factor. 3) The transformation operation is implemented by applying the provided translation vector to the coordinates of each point in the provided set of keypoint coordinates. 4) During the process of rotation, we achieve this by creating a matrix representing the rotation angle. Given a point $P(x,y)$ in two dimensions, the formula for calculating for the resulting point $P^{\prime}(x^{\prime},y^{\prime})$ with the center at the origin, and a counterclockwise rotation by an angle of $\theta$ , is as
- 我们将关键点序列的时间长度调整在区间 $[\times0.5\mathrm{-}\times1.5]$ 内,并从这个范围内随机选择有效帧。
- 缩放过程涉及将所提供关键点集合中每个点的坐标乘以一个缩放因子。
- 变换操作是通过将提供的平移向量应用于所提供的关键点坐标集合中每个点的坐标来实现的。
- 在旋转过程中,我们通过创建一个表示旋转角度的矩阵来实现。给定二维空间中的一个点 $P(x,y)$,计算以原点为中心、逆时针旋转角度 $\theta$ 后的结果点 $P^{\prime}(x^{\prime},y^{\prime})$ 的公式如下:
Where $\cos(\theta)$ and $\displaystyle\sin(\theta)$ are respectively the cosine and sine values of the rotation angle $\theta$ . The matrix multiplication operation rotates a two-dimensional point at coordinates $(x,y)$ counter clockwise around the origin point by an angle of $\theta$ , yielding the rotated point $(x^{\prime},y^{\prime})$ .
其中 $\cos(\theta)$ 和 $\displaystyle\sin(\theta)$ 分别是旋转角度 $\theta$ 的余弦和正弦值。矩阵乘法运算将坐标 $(x,y)$ 处的二维点绕原点逆时针旋转角度 $\theta$,得到旋转后的点 $(x^{\prime},y^{\prime})$。
3.2 SLR
3.2 SLR
3.2.1 Keypoint decoupling
3.2.1 关键点解耦
We noted that the various components of the keypoint sequences within the same sign language sequence should convey the same semantic information. Thus, we divide the keypoint sequences into four sub-sequences: left hand, right hand, facial expressions and overall, and process them independently. Markers of different colors represent distinct keypoint sequences, as illustrated in Fig 2. This segmentation helps the model more accurately capture the relationships between different parts, facilitating the provision of richer diversity of information. By handling them separately, the model can more attentively capture their respective key features. This keypoint decoupling strategy result and enhances over SLR predictions as shown in our experiments.
我们注意到,同一手语序列中的关键点序列各组成部分应传达相同的语义信息。因此,我们将关键点序列划分为四个子序列:左手、右手、面部表情和整体,并分别进行处理。不同颜色的标记代表不同的关键点序列,如图2所示。这种分割有助于模型更准确地捕捉不同部位之间的关系,从而提供更丰富多样的信息。通过分别处理,模型能更专注地捕捉各自的关键特征。实验表明,这种关键点解耦策略有效提升了手语识别(SLR)的预测效果。
3.2.2 Keypoint attention module
3.2.2 关键点注意力模块
We employ HRNet Wang et al (2020), which has been trained on COCO-WholeBody Jin et al (2020) dataset, to generate 133 keypoints, including hand, mouth, eye, and body trunk keypoints. Consistent with Chen et al (2022b), we employ a subset of 79 keypoints, comprising 42 hand keypoints, 11 upper body keypoints covering shoulders, elbows, and wrists, and a subset of facial keypoints (10 mouth keypoints and 16 others). Concretely, denoting the keypoint sequence as a multidimensional array with dimensions $C\times T\times$ $N$ , where the elements of $C$ consist of $\left[x_{t}^{n},y_{t}^{n},c_{t}^{n}\right]$ , $(x_{t}^{n},y_{t}^{n})$ and $c_{t}^{n}$ denotes the coordinates and confidence of the $n$ -th keypoint in the $t$ -th frame, $T$ denotes the frame number, and $N$ is the total number of keypoints.
我们采用HRNet Wang等人 (2020) 生成133个关键点(包括手部、嘴部、眼部和躯干关键点),该模型已在COCO-WholeBody Jin等人 (2020) 数据集上训练。与Chen等人 (2022b) 一致,我们使用79个关键点的子集,包含42个手部关键点、11个覆盖肩部/肘部/腕部的上半身关键点,以及部分面部关键点(10个嘴部关键点和16个其他关键点)。具体而言,将关键点序列表示为维度为$C\times T\times$$N$的多维数组,其中$C$的元素由$\left[x_{t}^{n},y_{t}^{n},c_{t}^{n}\right]$构成,$(x_{t}^{n},y_{t}^{n})$和$c_{t}^{n}$分别表示第$t$帧中第$n$个关键点的坐标和置信度,$T$表示帧数,$N$为关键点总数。
As the attention modules for each stream are analogous, we choose the body keypoint attention module as an example for detailed elucidation. The complete attention module is depicted in the Fig. 3. The procedure within the green rounded rectangle outlines the process of single-head attention computation. The input $\textbf{\textit{X}}\in\mathbb{R}^{C\times T\times N}$ is first enriched with spatial positional encodings. It is then embedded into two linear mapping functions to obtain $\textbf{\textit{X}}\in\mathbb{R}^{C_{e}\times T\times N}$ , where $C_{e}$ is usually smaller than $C_{o u t}$ to alleviate feature redundancy and reduce computational complexity. The attention map is subjected to spatial global normalization. Note that when computing the attention map, we use the Tanh activation function instead of the softmax used in Vaswani et al (2017). This is because the output of Tanh is not restricted to positive values, thus allowing for negative correlations and providing more flexibility Shi et al (2020). Finally, the attention map is element-wise multiplied with the original input to obtain the output features.
由于各注意力模块结构类似,我们以身体关键点注意力模块为例进行详细说明。完整注意力模块如图3所示。绿色圆角矩形框内流程展示了单头注意力计算过程:输入 $\textbf{\textit{X}}\in\mathbb{R}^{C\times T\times N}$ 首先经过空间位置编码增强,随后嵌入两个线性映射函数得到 $\textbf{\textit{X}}\in\mathbb{R}^{C_{e}\times T\times N}$ ,其中 $C_{e}$ 通常小于 $C_{o u t}$ 以减轻特征冗余并降低计算复杂度。注意力图需进行空间全局归一化处理。需注意的是,在计算注意力图时,我们采用Tanh激活函数替代Vaswani等人(2017)使用的softmax,这是因为Tanh输出不限于正值,可保留负相关性从而提供更高灵活性(Shi等人, 2020)。最终,注意力图与原始输入进行逐元素相乘得到输出特征。
To facilitate the model to jointly attend to information from different representation subspaces, the module performs attention computation with $h$ heads. The outputs of all heads are concatenated and mapped to the output space. Similar to the Vaswani et al (2017), we add a feed forward layer at the end to generate the final output. We choose to use leaky ReLU Maas et al (2013) as the non-linear activation function. Additionally, the module includes two residual connections to stabilize network training and integrate different features, as illustrated in the Fig. 3. Finally, we employ 2D convolution to extract temporal features. All processes within the blue rounded rectangle constitute a complete keypoint attention module. It is worth noting that the weights of different keypoint attention modules are not shared.
为了使模型能够共同关注来自不同表示子空间的信息,该模块使用 $h$ 个头进行注意力计算。所有头的输出被拼接并映射到输出空间。与 Vaswani 等人 (2017) 类似,我们在最后添加了一个前馈层来生成最终输出。我们选择使用 leaky ReLU (Maas 等人,2013) 作为非线性激活函数。此外,该模块包含两个残差连接以稳定网络训练并整合不同特征,如图 3 所示。最后,我们采用 2D 卷积来提取时间特征。蓝色圆角矩形内的所有过程构成了一个完整的关键点注意力模块。值得注意的是,不同关键点注意力模块的权重不共享。
3.2.3 Position encoding
3.2.3 位置编码
The keypoint sequences are structured into a tensor and inputted to the neural network. Because there is no predetermined sequence or structure for each element of the tensor, we require a positional encoding mechanism to provide a unique label for every joint. Following Vaswani et al (2017); Shi et al (2020), we employ sinusoidal and cosine functions with different frequencies as
关键点序列被结构化为张量并输入到神经网络中。由于张量的每个元素没有预定的序列或结构,我们需要一种位置编码机制来为每个关节提供唯一标签。参照 Vaswani et al (2017) 和 Shi et al (2020) 的研究,我们采用不同频率的正弦和余弦函数作为...
encoding functions:
编码函数:
$$
\begin{array}{r}{P E(p,2i)=\sin(p/10000^{2i/C_{i n}})}\ {P E(p,2i+1)=\cos(p/10000^{2i/C_{i n}})}\end{array}
$$
$$
\begin{array}{r}{P E(p,2i)=\sin(p/10000^{2i/C_{i n}})}\ {P E(p,2i+1)=\cos(p/10000^{2i/C_{i n}})}\end{array}
$$
Where $p$ represents the position of the element and $i$ denotes the dimension of the positional encoding vector. Incorporating positional encoding allows the model to capture positional infor- mation of elements in the sequence. Their periodic nature provides different representations for distinct positions, enabling the model to better understand the relative positional relationships between elements in the sequence. Joints within a single frame are sequentially encoded, while identical joint across various frames shares a common encoding. It’s worth noting that in contrast to the approach proposed in Shi et al (2020), we only introduce positional encoding for the spatial dimension. We use 2D convolution to extract temporal features, eliminating the need for additional temporal encoding as the continuity of time is already considered in the convolution operation.
其中 $p$ 表示元素位置,$i$ 表示位置编码向量的维度。引入位置编码使模型能够捕捉序列中元素的位置信息,其周期性特征为不同位置提供了差异化表征,从而让模型更好地理解序列元素间的相对位置关系。同一帧内的关节采用顺序编码,而跨帧的相同关节则共享统一编码。值得注意的是,与 Shi et al (2020) 提出的方法不同,我们仅对空间维度引入位置编码。通过二维卷积提取时序特征,由于卷积运算已考虑时间连续性,因此无需额外的时间编码。
3.2.4 Spatial global regular iz ation
3.2.4 空间全局正则化
For action detection tasks on skeleton data, the fundamental concept is to utilize known information, namely that each joint of the human body have unique physical or semantic attributes that remain invariant and consistent across all time frames and instances of data. Utilizing this known information, the objective of spatial global regu lari z ation is to encourage the model to grasp broader attention patterns, thus better adapting to diverse data samples. This method is achieved by implementing a global attention matrix, presented in the form of $N\times N$ , showing the universal relationships among the body joints. This global attention matrix is shared across all data instances and optimized alongside other parameters during training of the network.
对于基于骨骼数据的动作检测任务,其核心理念在于利用已知信息——即人体每个关节都具有独特的物理或语义属性,这些属性在所有时间帧和数据实例中保持恒定不变。通过运用这种先验知识,空间全局正则化 (spatial global regularization) 的目标是促使模型掌握更广泛的注意力模式,从而更好地适应多样化的数据样本。该方法通过实现一个 $N\times N$ 形式的全局注意力矩阵来呈现,该矩阵展示了人体关节间的通用关联性。此全局注意力矩阵在所有数据实例间共享,并在网络训练过程中与其他参数同步优化。
3.2.5 Head Network
3.2.5 头部网络
The output feature from the final attention block undergoes spatial pooling to reduce its dimensions to $T/4\times256$ before being inputted into the head network in the Fig. 2. The primary objective of the head network is to further capture temporal context. It is comprised of a temporal linear layer, a batch normalization layer, a ReLU layer, along with a temporal convolutional block containing two temporal convolutional layers with a kernel size of 3 and a stride of 1, followed by a linear translation layer and another ReLU layer. The resulting feature, known as gloss representation, has dimensions of $T/4\times512$ . Subsequently, a linear classifier and a softmax function are utilized to extract gloss probabilities. We use connectionist temporal classification (CTC) loss $\mathcal{L}_{C T C}^{b o d y}$ to optimize the body attention module.
最终注意力块的输出特征经过空间池化,维度降至 $T/4\times256$ 后输入图 2 中的头部网络。头部网络的主要目标是进一步捕捉时序上下文,其结构包含:时序线性层、批归一化层、ReLU层,以及由两个核大小为3、步长为1的时序卷积层构成的时序卷积块,后接线性变换层和另一个ReLU层。所得特征(称为手语词表征)维度为 $T/4\times512$,随后通过线性分类器和softmax函数提取手语词概率。我们使用连接时序分类 (CTC) 损失 $\mathcal{L}_{C T C}^{b o d y}$ 来优化主体注意力模块。
3.2.6 Fuse Head and Ensemble
3.2.6 融合头与集成
Every keypoint attention module possesses a distinct array of network heads. To thoroughly harness the capabilities of our multi-stream architecture, we integrate an auxiliary fuse head, designed to assimilate outputs from various streams. This fusion head’s configuration mirrors that of its counterparts, like the body head, and is likewise governed by CTC loss, represented as $\mathcal{L}_{C T C}^{f u s e}$ . The forecasted frame gloss probabilities are averaged and subsequently furnished to an ensemble to fabricate the gloss sequence. This ensemble approach amalgamates outcomes from multiple streams, thereby enhancing predictions, as demonstrated in the experiments.
每个关键点注意力模块都拥有独特的网络头阵列。为充分发挥多流架构的潜力,我们引入了一个辅助融合头,用于整合不同流的输出。该融合头的配置与身体头等其他头类似,同样受CTC损失($\mathcal{L}_{C T C}^{f u s e}$)约束。预测帧手语词概率经平均处理后输入集成器以生成手语词序列,这种集成方法通过融合多流结果提升预测性能(如实验所示)。
3.2.7 Self-Distillation
3.2.7 自蒸馏
Frame-Level Self-Distillation Chen et al (2022b) is employed, where the predicted frame gloss probabilities are used as pseudo-targets. In addition to coarse-grained CTC loss, extra fine-grained supervision is provided. Pursuant to our multi-stream design, we use the average gloss probability from the four head networks as pseudo-targets to guide the learning process of each stream. In a formal capacity, we endeavor to diminish the KL divergence between the pseudo-targets and the predictions of the four head networks. This process is designated as frame-level self-distillation loss, for it provides not merely frame-specific oversight but also filters insights from the concluding ensemble into each distinct stream.
采用帧级自蒸馏 (Chen et al, 2022b) 方法,将预测的帧手语词概率作为伪目标。除了粗粒度的 CTC (Connectionist Temporal Classification) 损失外,还提供了细粒度的额外监督。根据多流设计,我们使用四个头网络的平均手语词概率作为伪目标来指导每个流的学习过程。正式而言,我们致力于减小伪目标与四个头网络预测之间的 KL (Kullback-Leibler) 散度。这一过程被称为帧级自蒸馏损失,它不仅提供帧级监督,还将最终集成模型的洞察力过滤到每个独立流中。
3.2.8 Loss Function
3.2.8 损失函数
The overall loss of MSKA-SLR is composed of two parts:1) the CTC losses applied on the outputs of the left stream( $|\mathcal{L}{C T C}^{l e f t})$ , right stream $(\mathcal{L}_{\mathit{C T C}}^{\mathit{r i g h t}})$ , body
MSKA-SLR的整体损失由两部分组成:1) 应用于左流输出 $(|\mathcal{L}{C T C}^{l e f t})$、右流 $(\mathcal{L}_{\mathit{C T C}}^{\mathit{r i g h t}})$ 和身体部分的CTC损失
stream $(\mathcal{L}{C T C}^{b o d y})$ , fuse $\mathrm{stream}({\mathcal{L}}{C T C}^{f u s e});$ 2) the distillation loss $(\mathcal{L}_{D i s t})$ . We formulate the recognition loss as follows:
流式 $(\mathcal{L}{C T C}^{b o d y})$ ,融合 $\mathrm{stream}({\mathcal{L}}{C T C}^{f u s e})$;2) 蒸馏损失 $(\mathcal{L}_{D i s t})$。我们将识别损失公式化如下:
$$
{\cal L}{S L R}={\cal L}{C T C}^{l e f t}+{\cal L}{C T C}^{r i g h t}+{\cal L}{C T C}^{b o d y}+{\cal L}{C T C}^{f u s e}+{\cal L}_{D i s t}
$$
$$
{\cal L}{S L R}={\cal L}{C T C}^{l e f t}+{\cal L}{C T C}^{r i g h t}+{\cal L}{C T C}^{b o d y}+{\cal L}{C T C}^{f u s e}+{\cal L}_{D i s t}
$$
Up to now, we have introduced all components of MSKA-SLR. Once the training is finished, MSKASLR is capable of predicting a gloss sequence by fuse head network.
截至目前,我们已经介绍了MSKA-SLR的所有组件。训练完成后,MSKA-SLR能够通过融合头网络预测手语词序列。
3.3 SLT
3.3 SLT
The traditional methodologies from previous times frequently described sign language translation (SLT) tasks as challenges in neural machine translation (NMT), where the input to the translation network is visual information. This research followed to this approach and implemented a multi-layer perceptron (MLP) with two hidden layers into the MSKA-SLR framework proposed, followed by the translation process, thereby accomplishing SLT. The network constructed in this manner is named MSKA-SLT, with its architecture illustrated in Fig. 1(b). We chose to utilize employ mBART Liu et al (2020) as the translation network due to its outstanding performance in cross-lingual translation tasks. To fully exploit the multi-stream architecture we designed, we appended an MLP and a translation network to the fuse head. The input to the MLP consists of encoded features by the fuse head network, namely the gloss representations. The translation loss is a standard sequence-to-sequence crossentropy loss Vaswani et al (2017). MSKA-SLT includes the recognition loss Eq. 4 and the translation loss represented by $L_{T}$ , as specified in the formula:
传统方法常将手语翻译(SLT)任务描述为神经机器翻译(NMT)的挑战,其翻译网络的输入是视觉信息。本研究沿用这一思路,在提出的MSKA-SLR框架中嵌入了具有两个隐藏层的多层感知机(MLP),随后进行翻译处理,从而完成SLT。按此方式构建的网络命名为MSKA-SLT,其架构如图1(b)所示。我们选择采用mBART [20] 作为翻译网络,因其在跨语言翻译任务中表现优异。为充分发挥我们设计的多流架构,我们在融合头后添加了MLP和翻译网络。MLP的输入由融合头网络编码的特征(即手势表征)构成。翻译损失采用标准的序列到序列交叉熵损失 [20]。MSKA-SLT包含公式4所示的识别损失和由 $L_{T}$ 表示的翻译损失,具体如公式所示:
$$
L_{S L T}=L_{S L R}+L_{T}
$$
$$
L_{S L T}=L_{S L R}+L_{T}
$$
4 Experiments
4 实验
Implementation Details
实现细节
To demonstrate the generalization of our methods, unless otherwise specified, we maintain the same configuration for all experiments. The network employs four streams, with each stream consisting 8 attention blocks, and each block containing 6 attention heads. The output channels are set as follows: 64, 64, 128, 128, 256, 256, 256 and 256 respectively. For SLR tasks, we utilize a cosine annealing schedule over 100 epochs and an Adam optimizer with weight decay set to $1e-3$ , and an initial learning rate of $1e-3$ . The batch size is set to 8. Following Chen et al (2022a,b), we initialize our translation network with mBART-large-cc251 pretrained on CC252. We use a beam width of 5 for both the CTC decoder and the SLT decoder during inference. We train for 40 epochs with an initial learning rate of $1e\mathrm{-~}3$ for the MLP and $1e-5$ for MSKA-SLR and the translation network in MSKA-SLT. Other hyper-parameters remain consistent with MSKA-SLR. We train our models on one Nvidia 3090 GPU.
为验证方法的泛化性,除非另有说明,所有实验均保持相同配置。网络采用四流架构,每流包含8个注意力块,每块配置6个注意力头。输出通道数依次设置为:64、64、128、128、256、256、256和256。针对手语识别(SLR)任务,我们采用100个周期的余弦退火调度,使用权重衰减为$1e-3$的Adam优化器,初始学习率为$1e-3$,批大小设为8。参照Chen等人(2022a,b)的方案,翻译网络采用CC252预训练的mBART-large-cc25进行初始化。推理阶段CTC解码器与手语翻译(SLT)解码器的束宽均设为5。多层感知器(MLP)初始学习率为$1e\mathrm{-~}3$,MSKA-SLR及MSKA-SLT中翻译网络的初始学习率为$1e-5$,共训练40个周期。其余超参数与MSKA-SLR保持一致。所有实验在Nvidia 3090 GPU上完成训练。
4.1 Datasets and Evaluation Metrics 4.1.1 Phoenix-2014
4.1 数据集和评估指标 4.1.1 Phoenix-2014
Phoenix-2014 Koller et al (2015) is from weather forecast broadcasts aired on the German public TV station PHOENIX over a span of three years. This is a German SLR dataset with a vocabulary size of 1081 for glosses. The dataset comprises 5672, 540, and 629 instances in the training, development and testing set.
Phoenix-2014 Koller et al (2015) 是一个来自德国公共电视台 PHOENIX 三年间天气预报节目的数据集。该数据集为德语手语识别 (SLR) 数据集,词汇表包含 1081 个手势词。训练集、开发集和测试集分别包含 5672、540 和 629 个样本。
4.1.2 Phoenix-2014T
4.1.2 Phoenix-2014T
Phoenix-2014T Camgoz et al (2018)is an exten- sion of Phoenix-2014, has ascended as the foremost benchmark for SLR and SLT research in recent years Camgoz et al (2018); Simonyan and Zisserman (2014); Tang et al (2021); Tran et al (2015). It encompasses an array of RGB sign language videos performed by a cadre of nine adept signers using German Sign Language (DGS). These videos are meticulously annotated with sentence-level glosses and accompanied by precise German translations transcribed from spoken news content. The dataset is methodically divided into training, development, and testing subsets, the dataset comprises 7096, 519, and 642 video segments, respectively. With a vocabulary size of 1066 for sign glosses and 2887 for German text, Phoenix-2014T provides a rich resource for SLT research. With all ablation studies conducted using this comprehensive dataset.
Phoenix-2014T Camgoz等人(2018)是Phoenix-2014的扩展版本,近年来已成为手语识别(SLR)和手语翻译(SLT)研究最重要的基准数据集Camgoz等人(2018); Simonyan和Zisserman(2014); Tang等人(2021); Tran等人(2015)。该数据集包含由9名熟练手语者使用德国手语(DGS)演示的RGB手语视频序列,每个视频都配有句子级的手语标注(gloss)以及从新闻播音内容转写的精确德语翻译文本。数据集被系统划分为训练集、开发集和测试集,分别包含7096、519和642个视频片段。其手语标注词汇量为1066个,德语文本词汇量达2887个,为手语翻译研究提供了丰富资源。所有消融实验均基于这一完整数据集开展。
Table 1: Comparison with previous works on Sign Language Recognition (SLR). WER is adopted as the evaluation metric. Pre: pre-trained.
表 1: 手语识别 (SLR) 与先前工作的对比。采用 WER 作为评估指标。Pre: 预训练。
| 方法 | Pre | Phoenix-2014 Dev | Phoenix-2014 Test | Phoenix-2014T Dev | Phoenix-2014T Test | CSL-Daily Dev | CSL-Daily Test |
|---|---|---|---|---|---|---|---|
| 基于RGB的方法 | |||||||
| SubUNets Cihan Camgoz et al (2017) | 40.8 | 40.7 | 41.4 | 41.0 | |||
| LS-HAN Huang et al (2018) | 39.0 | 39.4 | |||||
| Hybrid CNN-HMM Koller et al (2018) | 31.6 | 32.5 | |||||
| DNF Cui et al (2019) | √ | 23.8 | 24.4 | 32.8 | 32.4 | ||
| CNN-LSTM-HMM Koller et al (2020) | × | 26.0 | 26.0 | 22.1 | 24.1 | ||
| FCN Cheng et al (2020) | 23.7 | 23.9 | 23.3 | 25.1 | 33.2 | 33.5 | |
| Joint-SLRT Camgoz et al (2020b) | × | 24.6 | 24.5 | 33.1 | 32.0 | ||
| PiSLTRc-R Xie et al (2021) | √ | 23.4 | 23.2 | ||||
| SignBT Zhou et al (2021a) | √ | 22.7 | 23.9 | 33.2 | 33.2 | ||
| VAC Min et al (2021) | 21.2 | 22.3 | |||||
| STMC Zhou et al (2021b) | 21.7 | 20.7 | 19.6 | 21.0 | |||
| MMTLB Chen et al (2022a) | = | 21.9 | 22.5 | ||||
| C2SLR Zuo and Mak (2022) | √ | 20.5 | 20.4 | 20.2 | 20.4 | ||
| CorrNet Hu et al (2023b) | √ | 18.8 | 19.4 | 18.9 | 20.5 | 30.6 | 30.1 |
| TwoStream-SLR Chen et al (2022b) | 18.4 | 18.8 | 17.7 | 19.3 | 25.4 | 25.3 | |
| SignBERT+(+ R)Hu et al (2023a) | √ | 19.9 | 20.0 | 18.8 | 19.9 | ||
| CTCA Guo et al (2023) | 19.5 | 20.1 | 19.3 | 20.3 | 31.3 | 29.4 | |
| AdaBrowse+ Hu et al (2023c) | 19.6 | 20.7 | 19.5 | 20.6 | 31.2 | 30.7 | |
| 基于关键点的方法 | |||||||
| TwoStream-SLR Chen et al (2022b) | 28.6 | 28.0 | 27.1 | 27.2 | 34.6 | 34.1 | |
| 33.6 | |||||||
| SignBERT+ Hu et al (2023a) Ours | × | 34.0 21.7 | 34.1 22.1 | 32.9 20.1 | 20.5 | 28.2 | 27.8 |
4.1.3 CSL-Daily
4.1.3 CSL-Daily
CSL-Daily Zhou et al (2021a) is a recently released dataset for the translation of Chinese Sign Language (CSL), recorded in a studio environment. It encompasses 20654 triplets of (video, gloss, text) enacted by ten unique signers. The dataset delves into diverse subjects such as familial existence, healthcare, and academic milieu. CSL-Daily is composed of 18401, 1077, and 1176 partitions in the training, development and testing sections, correspondingly. The vocabulary size is 2000 for sign glosses and 2343 for Chinese text.
CSL-Daily Zhou等人 (2021a) 是近期发布的中国手语(CSL)翻译数据集,录制于影棚环境。该数据集包含10位不同手语表演者演绎的20654组(视频、手势符号、文本)三元组,涵盖家庭生活、医疗健康、校园环境等多元主题。CSL-Daily按18401、1077和1176的规模划分为训练集、验证集和测试集,其手势符号词汇量为2000,中文文本词汇量为2343。
4.1.4 Evaluation Metrics
4.1.4 评估指标
Following previous works Chen et al (2022a); Zhou et al (2021b); Camgoz et al (2020b, 2018); Chen et al (2022b); Hu et al (2023a), we adopt word error rate (WER) for SLR evaluation, and BLEU Papineni et al (2002) and ROUGE-L Lin (2004) to evaluate SLT. Lower WER indicates better recognition performance. For BLEU and ROUGE-L, the higher, the better.
遵循先前的研究 Chen et al (2022a); Zhou et al (2021b); Camgoz et al (2020b, 2018); Chen et al (2022b); Hu et al (2023a), 我们采用词错误率 (WER) 进行手语识别 (SLR) 评估, 并使用 BLEU Papineni et al (2002) 和 ROUGE-L Lin (2004) 评估手语翻译 (SLT)。WER 越低表示识别性能越好, 而 BLEU 和 ROUGE-L 则是越高越好。
4.2 Comparison with State-of-the-art Methods
4.2 与最先进方法的对比
In this section, we compare our method with previous state-of-the-art methods on two main downstream tasks, including SLR and SLT. For comparison, we group them into RGB-based and Keypoint-based methods.
在本节中,我们将我们的方法与之前最先进的方法在两个主要下游任务上进行比较,包括手语识别(SLR)和手语翻译(SLT)。为了进行比较,我们将它们分为基于RGB和基于关键点的方法。
For SLR, we compare our recognition network with state-of-the-art methods on Phoenix2014, Phoenix-2014T and CSL-Daily, as shown in Table 1. The MSKA-SLR achieves $22.1%$ , $20.5%$ and 27.8% WER on the test sets of these three datasets, respectively. Typically, keypointbased approaches are significantly falling short of RGB-based methods; however, our MSKASLR has substantially reduced this disparity.
在连续手语识别(SLR)方面,我们将识别网络与Phoenix2014、Phoenix-2014T和CSL-Daily数据集上的先进方法进行了对比,如表1所示。MSKA-SLR在这三个数据集测试集上的词错误率(WER)分别达到22.1%、20.5%和27.8%。通常基于关键点的方法性能显著低于基于RGB的方法,但我们的MSKA-SLR大幅缩小了这一差距。
Table 2: Performance comparison of MSKA-SLT with methods for SLT on Phoenix-2014T and CSLDaily.
表 2: MSKA-SLT 在 Phoenix-2014T 和 CSLDaily 数据集上与 SLT 方法的性能对比
| 方法 | Phoenix-2014T | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ROUGE | Dev BLEU-2 | BLEU-3 | Test | |||||||
| BLEU-1 | BLEU-4 | ROUGE | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | ||||
| RGB-based | ||||||||||
| Sign2Text Cihan Camgoz et al (2018) | 31.80 | 31.87 | 19.11 | 13.16 | 9.94 | 31.80 | 32.24 | 19.03 | 12.83 | 9.58 |
| TSPNet Li et al (2020) | 34.96 | 36.10 | 23.12 | 16.88 | 13.41 | |||||
| MCT Camgoz et al (2020a) | 45.90 | = | 19.51 | 43.57 | = | 18.51 | ||||
| SL-Trans Camgoz et al (2020b) | 47.26 | 34.40 | 27.05 | 22.38 | = | 46.61 | 33.73 | 26.19 | 21.32 | |
| BN-TIN-Trans Zhou et al (2021a) | 46.87 | 46.90 | 33.98 | 26.49 | 21.78 | 46.98 | 47.57 | 34.64 | 26.78 | 21.68 |
| Joint-SLRT Camgoz et al (2020b) | 47.73 | 34.82 | 27.11 | 22.11 | 48.47 | 35.35 | 27.57 | 22.45 | ||
| SimulSLT Yin et al (2021) | 36.04 | 36.01 | 22.60 | 16.05 | 12.39 | 35.13 | 35.92 | 22.70 | 16.03 | 12.27 |
| PiSLTRc-T Xie et al (2021) | 47.89 | 46.51 | 33.78 | 26.78 | 21.48 | 48.13 | 46.22 | 33.56 | 26.04 | 21.29 |
| STMC Zhou et al (2021b) | 48.24 | 47.60 | 36.43 | 29.18 | 24.08 | 46.65 | 46.98 | 36.09 | 28.70 | 23.65 |
| SignBT Zhou et al (2021a) | 50.29 | 51.11 | 37.90 | 29.80 | 24.45 | 49.54 | 50.80 | 37.75 | 29.72 | 24.32 |
| MMTLB Chen et al (2022a) | 53.10 | 53.95 | 41.12 | 33.14 | 27.61 | 52.65 | 53.97 | 41.75 | 33.84 | 28.39 |
| TwoStream-SLT Chen et al (2022b) | 54.08 | 54.32 | 41.99 | 34.15 | 28.66 | 53.48 | 54.90 | 42.43 | 34.46 | 28.95 |
| ConSLT Fu et al (2023) | 47.52 | 24.27 | 47.65 | 51.57 | 38.81 | 30.91 | 25.48 | |||
| SignBERT+(+ R) Hu et al(2023a) | 51.12 | 51.46 | 38.28 | 30.30 | 24.95 | 50.63 | 52.01 | 39.19 | 31.06 | 25.70 |
| XmDA Ye et al (2023) | 52.42 | 25.86 | 49.87 | 25.36 | ||||||
| IP-SLT Yao et al (2023) | 54.43 | 54.10 | 41.56 | 33.66 | 28.22 | 53.72 | 54.25 | 41.51 | 33.45 | 27.97 |
| Keypoint-based | ||||||||||
| Skeletor Jiang et al (2021) | 32.66 | 31.97 | 19.53 | 14.01 | 10.91 | 31.80 | 31.86 | 19.11 | 13.49 | 10.35 |
| TwoStream-SLT Chen et al (2022b) | 53.32 | 53.66 | 41.31 | 33.55 | 28.10 | 53.19 | 54.22 | 41.72 | 33.82 | 28.42 |
| SignBERT+ Hu et al (2023a) | 45.53 | 44.45 | 31.88 | 24.59 | 19.86 | 44.89 | 44.35 | 32.09 | 24.92 | 20.41 |
| Ours | 52.67 | 54.09 | 41.29 | 33.24 | 27.63 | 53.54 | 54.79 | 42.42 | 34.49 | 29.03 |
| 方法 | ROUGE | BLEU-1 | Dev BLEU-2 | BLEU-3 | CSL-Daily | Test | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| RGB-based | BLEU-4 | ROUGE | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | ||||
| SL-Trans Camgoz et al (2020b) | 37.06 | 37.47 | 24.67 | 16.86 | 11.88 | 36.74 | 37.38 | 24.36 | 16.55 | 11.79 |
| Joint-SLRT Camgoz et al (2020b) | 44.18 | 46.82 | 32.22 | 22.49 | 15.94 | 44.81 | 47.09 | 32.49 | 22.61 | 16.24 |
| SignBT Zhou et al (2021a) | 49.49 | 51.46 | 37.23 | 27.51 | 49.31 | 51.42 | 37.26 | 27.76 | 21.34 | |
| MMTLB Chen et al (2022a) | 53.38 | 53.81 | 40.84 | 31.29 | 20.80 | 53.25 | 53.31 | 40.41 | 30.87 | 23.92 |
| TwoStream-SLT Chen et al (2022b) | 55.10 | 55.21 | 42.31 | 32.71 | 24.42 25.76 | 55.72 | 55.44 | 42.59 | 32.87 | 25.79 |
| ConSLT Fu et al (2023) | 41.46 | 40.98 | ||||||||
| XmDA Ye et al (2023) | 49.36 | 14.8 | = | 14.53 | ||||||
| IP-SLT Yao et al (2023) | 44.33 | 21.69 | 49.34 | 21.58 | ||||||
| 45.26 | 31.77 | 22.87 | 16.74 | 44.09 | 44.85 | 31.50 | 22.66 | 16.72 | ||
| Keypoint-based | ||||||||||
| TwoStream-SLT Chen et al (2022b) Ours | 54.03 53.53 | 54.43 55.95 | 41.60 42.38 | 31.95 32.37 | 25.01 25.16 | 55.07 54.04 | 55.34 56.37 | 42.36 42.80 | 32.58 32.78 | 25.42 25.52 |
Among keypoint-based methods, our method significantly surpasses the most challenging competitor TwoStream-SLR Chen et al (2022b) with $5.9%$ , $6.7%$ and $6.3%$ WER improvement on the testing sets of these three datasets, respectively. Note TwoStream-SLR Chen et al (2022b) and SignBERT $^+$ Hu et al (2023a) utilize pre-trained model that leverage more model parameters and additional resources than MSKA-SLR.
在基于关键点的方法中,我们的方法显著超越了最具挑战性的竞争对手 TwoStream-SLR (Chen et al, 2022b) ,在这三个数据集的测试集上分别实现了 $5.9%$ 、 $6.7%$ 和 $6.3%$ 的词错误率 (WER) 提升。需要注意的是,TwoStream-SLR (Chen et al, 2022b) 和 SignBERT $^+$ (Hu et al, 2023a) 使用了预训练模型,相比 MSKA-SLR 利用了更多的模型参数和额外资源。
For SLT, we compare our MSKA-SLT with state-of-the-art methods on Phoenix-2014T and CSL-Daily as shown in Tab. 2. We achieved BLEU-4 scores of 29.03 and 25.43 on the test sets of these two datasets, respectively, marking an improvement of 0.61 and 0.1 BLEU-4 scores compared to the keypoint-based methods. Furthermore, our approach on the Phoenix-2014T dataset demonstrated a 0.08 improvement in BLEU-4 score compared to the previous state-of-the-art (SOTA) method.
对于手语翻译(SLT),我们在Phoenix-2014T和CSL-Daily数据集上将MSKA-SLT方法与最先进方法进行对比,如表2所示。在这两个数据集的测试集上,我们分别取得了29.03和25.43的BLEU-4分数,相比基于关键点的方法提升了0.61和0.1个BLEU-4分数。此外,在Phoenix-2014T数据集上,我们的方法相比之前的最先进(SOTA)方法实现了0.08的BLEU-4分数提升。
The results indicate that our MSKA demonstrates significant performance enhancements on SLR and SLT. This highlights the benefit of initially decoupling keypoint sequences for multistream attention, followed by aggregating distinct stream feature representations, thereby distinguishing our MSKA from previous SLR and SLT systems.
结果表明,我们的MSKA在SLR和SLT上展现出显著的性能提升。这凸显了先解耦关键点序列进行多流注意力处理,再聚合不同流特征表示的优势,从而使MSKA与以往的SLR和SLT系统区分开来。
4.3 Ablation Studies
4.3 消融研究
4.3.1 Impact of Keypoint Augment
4.3.1 关键点增强的影响
To explore the significance of different data augmentation techniques in SLR endeavors, we methodically implemented each augmentation approach in the training of our models and assessed their efficacy in the context of the
为了探究不同数据增强技术在SLR(Sign Language Recognition,手语识别)研究中的重要性,我们在模型训练过程中系统地实施了每种增强方法,并评估了它们在...
Table 3: Study the effects of each component of MSKA-SLR on the Phoenix-2014T SLR task.
表 3: 研究 MSKA-SLR 各组件在 Phoenix-2014T SLR 任务中的效果。
| Body | Left | Face | Right | Fuse Head | Distillation | Dev | Test |
|---|---|---|---|---|---|---|---|
| √ | 25.30 | 25.50 | |||||
| √ | 57.37 | 57.60 | |||||
| √ | 34.90 | 36.26 | |||||
| 35.28 | 35.58 | ||||||
| √ | √ | 25.86 | 26.05 | ||||
| √ | 25.27 | 25.69 | |||||
| √ | 23.08 | 23.67 | |||||
| √ | 22.69 | 22.70 | |||||
| √ | √ | √ | 20.09 | 20.54 |
Phoenix-2014T SLR challenge. The outcomes are detailed in Table 4a. It is discernible that the efficacy of model began to diminish upon integrating of translation and scaling data augmentation methods. We posit that these particular augmentation strategies introduced discrepancies in the data alignment with the validation set, consequently resulting in over fitting. Hence, we made the decision to exclusively employ temporal and rotational augmentations.
Phoenix-2014T SLR挑战赛。具体结果详见表4a。可以观察到,当引入平移和缩放数据增强方法时,模型性能开始下降。我们认为这些特定的增强策略会导致数据与验证集的对齐出现偏差,从而引发过拟合。因此,我们最终决定仅采用时序和旋转增强方法。
4.3.2 Impact of Each Component
4.3.2 各组件的影响
We initially demonstrate the impacts of each stream of MSKA-SLR in Table. 3. In the absence of the multi-stream architecture, the solitary body stream (where one keypoint attention module manages all keypoints) achieves $25.30%$ and 25.50% WER on the Phoenix-2014T. Within Table. 3, we present the results separately for the left, face and right streams, as well as the fused outcome. This signifies that the precision of segregated streams is substandard compared to that of the solitary body stream, attributable to the loss of certain information. Nonetheless, owing to the distinct focuses and mutual enhancement among these three streams, their fusion culminates in a WER performance of $23.67%$ , marking a $1.83%$ enhancement over the solitary body stream. To optimize the attributes that our model attends to, we integrate the body stream into the fusion head, resulting in a WER performance of $22.70%$ . Ultimately, by incorporating the self-distillation, our framework achieves the optimal outcome, yielding a WER of $20.54%$ .
我们首先在表3中展示了MSKA-SLR各分支的影响。未采用多分支架构时,单一身体分支(即一个关键点注意力模块处理所有关键点)在Phoenix-2014T上达到25.30%和25.50%的词错误率(WER)。表3中我们分别展示了左分支、面部分支、右分支的结果以及融合效果。这表明独立分支的精度低于单一身体分支,这是由于部分信息丢失所致。然而得益于三个分支的差异化关注点和相互增强作用,其融合结果将WER提升至23.67%,较单一身体分支有1.83%的改进。为优化模型关注特征,我们将身体分支融入融合头,使WER达到22.70%。最终通过引入自蒸馏机制,我们的框架取得20.54%的最佳WER表现。
Moreover, in our experiments, we also found that in sign language, the right hand exhibits a more prevailing role compared to the left hand. In our study, the results from only using the left hand and the right hand differ by approximately $22%$ . This discrepancy may be attributed to the fact that in the majority of individuals, the right hand is the dominant hand, while the left hand is the non-dominant hand. Consequently, the right hand is more suitable for performing the detailed and sophisticated gestures essential for sign language. This results in the right hand typically bearing more responsibility and encompassing more information in sign language.
此外,在我们的实验中还发现,在手语中右手相比左手具有更主导的作用。研究中仅使用左手与仅使用右手的结果相差约 $22%$ 。这种差异可能源于大多数人以右手为惯用手,而左手为非惯用手。因此,右手更适合执行手语所需的精细复杂手势,这使得右手在手语中通常承担更多责任并包含更多信息。
4.3.3 Impact of Attention Modules
4.3.3 注意力模块的影响
The influence of network depth on model efficacy stands as a pivotal concern within the realm of deep learning. Broadly speaking, increasing the number of network layers may enhance model performance, but it can also lead to over fitting. Consequently, we have deliberated upon the impact of the number of attention modules on model efficacy. We have designated the number of modules as 6, 8, 10 and 12, as delineated in Table 4b. We ascertain that the pinnacle of performance is attained with 8 modules, yielding the superlative outcome of $20.54%$ WER. Additionally, we have delved into the ramifications of attention heads within the attention module on the network. This facilitates the model to simultaneously assimilate information across diverse representation subspaces. Each head possesses the capabil- ity to concentrate on distinct segments of the input sequence, thereby significantly amplifying the model’s eloquent capacity and its adeptness in capturing intricate relationships. To scrutinize (a) The combined effects of various data augmentation techniques.
网络深度对模型效能的影响是深度学习领域的一个关键问题。一般而言,增加网络层数可能提升模型性能,但也可能导致过拟合。因此,我们探讨了注意力模块数量对模型效能的影响。如表4b所示,我们将模块数量设定为6、8、10和12。我们发现,当模块数量为8时,模型性能达到最佳,获得了20.54%的词错误率(WER)。此外,我们还研究了注意力模块中注意力头对网络的影响。这使得模型能够同时从不同的表示子空间中吸收信息。每个头都能够聚焦于输入序列的不同部分,从而显著增强模型的表达能力及其捕捉复杂关系的能力。为了研究 (a) 各种数据增强技术的综合效果。
Table 4: Ablation studies of: (a) methods for augmenting keypoint data; (b) the impact of varying the number of keypoint attention modules; (c) the effects of varying the number of attention heads in an attention module; (d) the weight of the distillation loss; (e) impact of Spatial Global Regular iz ation; (f) effectiveness of the spatial-temporal attention.
表 4: 消融研究内容: (a) 关键点数据增强方法; (b) 关键点注意力模块数量的影响; (c) 注意力模块中注意力头数量的影响; (d) 蒸馏损失权重; (e) 空间全局正则化的影响; (f) 时空注意力的有效性。
| temporal | rotate | translate | scale | Dev | Test |
|---|---|---|---|---|---|
| 24.98 | 25.75 | ||||
| √ | 20.25 | 21.58 | |||
| 人 | 20.09 | 20.54 | |||
| √ | 20.37 | 21.01 | |||
| 人 | 人 | √ | √ | 21.21 | 22.21 |
| 模块数 | 开发集 | 测试集 |
|---|---|---|
| 6 | 20.79 | 21.28 |
| 8 | 20.09 | 20.54 |
| 10 | 20.87 | 21.53 |
| 12 | 22.45 | 22.71 |
| 头数 (Heads) | 开发集 (Dev) | 测试集 (Test) |
|---|---|---|
| 2 | 20.97 | 21.42 |
| 4 | 20.47 | 21.39 |
| 6 | 20.09 | 20.54 |
| 8 | 20.20 | 21.53 |
(b) The number of attention modules.
(b) 注意力模块数量。
(c) The number of attention heads.
(c) 注意力头数量。
(d) The weight of the distil- lation loss.
| L | Dev | Test |
|---|---|---|
| 0.1 | 20.60 | 20.96 |
| 0.5 | 20.12 | 21.08 |
| 1 | 20.09 | 20.54 |
| 2 | 20.77 | 21.79 |
(d) 蒸馏损失 (distillation loss) 的权重。
(e) SGR: Spatial Global Regular iz ation.
| SGR | Dev | Test |
|---|---|---|
| 21.24 | 21.15 | |
| 人 | 20.09 | |
| 20.54 |
(e) SGR: 空间全局正则化 (Spatial Global Regularization)。
(f) Spatial-attnention and temporalattention.
| Spatial-attn | Temporal-attn | Dev | Test |
|---|---|---|---|
| √ | 20.09 | 20.54 | |
| √ | 25.45 | 25.73 |
(f) 空间注意力 (Spatial-attention) 和时间注意力 (Temporal-attention)。
the significance of the number of heads in keypoint attention, we employ assorted quantities of heads and evaluate their performance in the SLR task, as delineated in Table 4c.
为探究关键点注意力机制中头数的重要性,我们采用不同数量的注意力头并评估其在手语识别(SLR)任务中的表现,如表 4c 所示。
4.3.4 Impact of Self-Distillation weight
4.3.4 自蒸馏权重的影响
As different streams embody the same meaning, we integrate self-distillation loss at the end of the model to integrate the features learned by each component. It is a hyper-parameter that is designed to balance the effect of CTC loss and the self-distillation loss. We conduct experiments by varying the weight. Table 4d shows that our MSKA-SLR attains the best performance when the weight is set to 1.0.
由于不同流体现相同的含义,我们在模型末端整合自蒸馏损失以融合各组件学习到的特征。这是一个用于平衡CTC损失和自蒸馏损失影响的超参数。我们通过调整权重进行实验。表4d显示,当权重设为1.0时,我们的MSKA-SLR达到最佳性能。
4.3.5 Impact of Spatial Global Regular iz ation
4.3.5 空间全局正则化 (Spatial Global Regularization) 的影响
SGR operates on the attention maps within the attention module to mitigate over fitting. In our experiments, delineated in Table 4e, we initially attained a performance of $21.15%$ WER on the SLR task without incorporating SGR. Subsequently, through the inclusion of SGR, we achieved the optimal performance of
SGR通过操作注意力模块中的注意力图来缓解过拟合问题。在我们的实验中(如表4e所示),未引入SGR时在SLR任务上初始性能为$21.15%$ WER,随后通过加入SGR实现了最优性能
$20.54%$ WER. Moreover, we explored methodologies for managing temporal information in keypoint sequences: 1) reorganizing temporal data via temporal attention post spatial attention, and 2) exclusively employing 2D convolutions devoid of temporal attention. The outcomes are delineated in Table 4f. It is evident that model achieves WER of $25.73%$ with the inclusion of temporal attention, whereas utilizing only 2D convolutions results in $20.54%$ WER. This could be ascribed to the augmentation in parameter quantity, the comparatively diminutive dataset extent, and the heightened vulnerability of model to over fitting.
$20.54%$ 的词错误率 (WER)。此外,我们探索了两种关键点序列时序信息处理方法:1) 在空间注意力后通过时序注意力重组时序数据;2) 仅使用不含时序注意力的二维卷积。结果如表 4f 所示。可见引入时序注意力时模型 WER 达 $25.73%$,而仅使用二维卷积可获得 $20.54%$ 的 WER。这可能归因于参数量增加、数据集规模较小以及模型更容易过拟合。
5 Conclusion
5 结论
In this paper, we concentrate on how to introduce domain knowledge into sign language understanding. To achieve the goal, we present a innovative framework named MSKA-SLR which adopts four streams to keypoint sequences for sign language recognition. A variety of methodologies to make the four streams interact with each other. We further extend MSKA-SLR to a sign language translation model by attaching an MLP and a translation network, resulting in the translation frame- work named MSKA-SLT. Our MSKA-SLR and
本文重点研究如何将领域知识引入手语理解。为实现这一目标,我们提出了创新框架MSKA-SLR,该框架采用四流处理关键点序列进行手语识别,并运用多种方法实现四流间的交互。我们进一步通过添加MLP和翻译网络将MSKA-SLR扩展为手语翻译模型,最终形成名为MSKA-SLT的翻译框架。
MSKA-SLT achieve encouraging improved performance on SLR and SLT tasks across a series of datasets including Phoenix-2014, Phoenix-2014T, and CSL-Daily. We achieved state-of-the-art performance in the Phoenix-2014T sign language translation task. We hope that our approach can serve as a baseline to facilitate future research.
MSKA-SLT 在一系列数据集(包括 Phoenix-2014、Phoenix-2014T 和 CSL-Daily)上的手语识别 (SLR) 和手语翻译 (SLT) 任务中实现了令人鼓舞的性能提升。我们在 Phoenix-2014T 手语翻译任务中取得了最先进的性能。希望我们的方法能作为基线促进未来研究。
Data Availability. The Phoenix-2014 and Phoenix-2014T datasets are publicly available at https://www-i6.informatik. rwth-aachen.de/ $\sim$ koller/RWTH-PHOENIX/ and https://www-i6.informatik.rwth-aachen. de/ $\sim$ koller/RWTH-PHOENIX-2014-T/, respec- tively. The CSL-Daily datasets will be made available on reasonable request at http://home. ustc.edu.cn/ $\sim$ zhouh156/dataset/csl-daily/.
数据可用性。Phoenix-2014和Phoenix-2014T数据集已公开发布于https://www-i6.informatik.rwth-aachen.de/$\sim$koller/RWTH-PHOENIX/和https://www-i6.informatik.rwth-aachen.de/$\sim$koller/RWTH-PHOENIX-2014-T/。CSL-Daily数据集将根据合理请求在http://home.ustc.edu.cn/$\sim$zhouh156/dataset/csl-daily/提供。
References
参考文献
Li D, Xu C, Yu X, et al (2020) Tspnet: Hier- archical feature learning via temporal semantic pyramid for sign language translation. Advances in Neural Information Processing Systems 33:12034–12045
Li D, Xu C, Yu X 等 (2020) Tspnet: 基于时序语义金字塔的手语翻译分层特征学习. Advances in Neural Information Processing Systems 33:12034–12045
Lin CY (2004) Rouge: A package for automatic evaluation of summaries. In: Text summariza- tion branches out, pp 74–81
Lin CY (2004) Rouge: 自动摘要评估工具包。见: 文本摘要分支, 第74–81页
Liu Y, Gu J, Goyal N, et al (2020) Multilin- gual denoising pre-training for neural machine translation. Transactions of the Association for Computational Linguistics 8:726–742
Liu Y, Gu J, Goyal N 等 (2020) 面向神经机器翻译的多语言去噪预训练. Transactions of the Association for Computational Linguistics 8:726–742
Maas AL, Hannun AY, Ng AY, et al (2013) Rectifier nonlinear i ties improve neural network acoustic models. In: Proc. icml, Atlanta, GA, p 3
Maas AL, Hannun AY, Ng AY 等 (2013) 整流器非线性特性提升神经网络声学模型性能. 见: Proc. icml, 亚特兰大, 佐治亚州, 第3页
Min Y, Hao A, Chai X, et al (2021) Visual align- ment constraint for continuous sign language recognition. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pp 11542–11551
Min Y, Hao A, Chai X 等 (2021) 连续手语识别的视觉对齐约束. 见: IEEE/CVF国际计算机视觉大会 (ICCV) 论文集, 第11542–11551页
Niu Z, Mak B (2020) Stochastic fine-grained labeling of multi-state sign glosses for continuous sign language recognition. In: Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XVI 16, Springer, pp 172–186
牛Z, Mak B (2020) 多状态手语词素的随机细粒度标注用于连续手语识别。见: 《计算机视觉-ECCV 2020: 第16届欧洲计算机视觉会议论文集》(第16部分), Springer出版社, 第172-186页
Papa dimitri ou K, Potamianos G (2020) Multimodal sign language recognition via temporal deformable convolutional sequence learning. In: Inter speech, pp 2752–2756
Papa dimitri ou K, Potamianos G (2020) 基于时序可变形卷积序列学习的多模态手语识别. In: Inter speech, pp 2752–2756
Papineni K, Roukos S, Ward T, et al (2002) Bleu: a method for automatic evaluation of machine translation. In: Proceedings of the 40th annual meeting of the Association for Computational Linguistics, pp 311–318
Papineni K, Roukos S, Ward T 等 (2002) Bleu: 一种机器翻译自动评估方法。见: 第40届计算语言学协会年会论文集, 第311–318页
Pu J, Zhou W, Li H (2019) Iterative alignment network for continuous sign language recognition. In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition, pp 4165–4174
Pu J, Zhou W, Li H (2019) 用于连续手语识别的迭代对齐网络。见: IEEE/CVF计算机视觉与模式识别会议论文集, pp 4165–4174
accuracy trade-offs in video classification. In: Proceedings of the European conference on computer vision (ECCV), pp 305–321
视频分类中的准确率权衡。见:欧洲计算机视觉会议 (ECCV) 论文集,第305–321页