DFORMER: RETHINKING RGBD REPRESENTATION LEARNING FOR SEMANTIC SEGMENTATION
DFORMER: 重新思考RGBD语义分割的表征学习
ABSTRACT
摘要
We present DFormer, a novel RGB-D pre training framework to learn transferable representations for RGB-D segmentation tasks. DFormer has two new key innovations: 1) Unlike previous works that encode RGB-D information with RGB pretrained backbone, we pretrain the backbone using image-depth pairs from ImageNet-1K, and hence the DFormer is endowed with the capacity to encode RGB-D representations; 2) DFormer comprises a sequence of RGB-D blocks, which are tailored for encoding both RGB and depth information through a novel building block design. DFormer avoids the mismatched encoding of the 3D geometry relationships in depth maps by RGB pretrained backbones, which widely lies in existing methods but has not been resolved. We finetune the pretrained DFormer on two popular RGB-D tasks, i.e., RGB-D semantic segmentation and RGB-D salient object detection, with a lightweight decoder head. Experimental results show that our DFormer achieves new state-of-the-art performance on these two tasks with less than half of the computational cost of the current best methods on two RGB-D semantic segmentation datasets and five RGB-D salient object detection datasets. Our code is available at: https://github.com/VCIP-RGBD/DFormer.
我们提出DFormer,这是一种新颖的RGB-D预训练框架,旨在学习可迁移的RGB-D分割任务表征。DFormer具备两项关键创新:1) 不同于以往通过RGB预训练主干编码RGB-D信息的工作,我们使用ImageNet-1K中的图像-深度对进行主干预训练,从而使DFormer具备编码RGB-D表征的能力;2) DFormer由一系列RGB-D模块组成,这些模块通过新颖的结构设计专门用于编码RGB和深度信息。DFormer避免了现有方法中普遍存在但尚未解决的、由RGB预训练主干对深度图三维几何关系的不匹配编码问题。我们在两个主流RGB-D任务(RGB-D语义分割和RGB-D显著目标检测)上对预训练的DFormer进行轻量级解码头微调。实验结果表明,DFormer在两项任务上以不到当前最佳方法一半的计算成本,在两个RGB-D语义分割数据集和五个RGB-D显著目标检测数据集上实现了最先进的性能。代码已开源:https://github.com/VCIP-RGBD/DFormer。
1 INTRODUCTION
1 引言
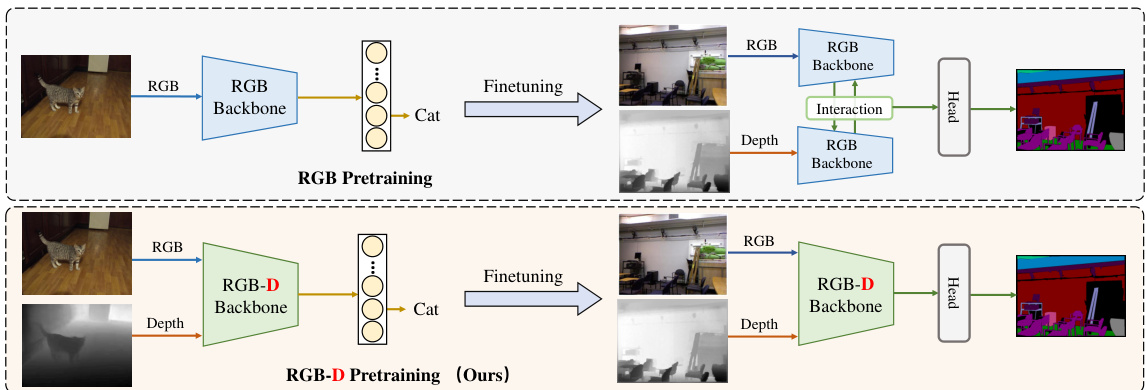
Figure 1: Comparisons between the existing popular training pipeline and ours for RGB-D segmentation. RGB pre training: Recent mainstream methods adopt two RGB pretrained backbones to separately encode RGB and depth information and fuse them at each stage. RGB-D pre training: The RGB-D backbone in DFormer learns transferable RGB-D representations during pre training and then is finetuned for segmentation.
图 1: 现有主流RGB-D分割训练流程与我们的方法对比。RGB预训练:当前主流方法采用两个RGB预训练主干网络分别编码RGB和深度信息,并在每个阶段进行特征融合。RGB-D预训练:DFormer中的RGB-D主干网络在预训练阶段学习可迁移的RGB-D表征,随后针对分割任务进行微调。
With the widespread use of 3D sensors, RGB-D data is becoming increasingly available to access. By incorporating 3D geometric information, it would be easier to distinguish instances and context, facilitating the RGB-D research for high-level scene understanding. Meanwhile, RGB-D data also presents considerable potential in a large number of applications, e.g., SLAM (Wang et al., 2023), automatic driving (Huang et al., 2022), and robotics (Marchal et al., 2020). Therefore, RGB-D research has attracted great attention over the past few years.
随着3D传感器的普及,RGB-D数据的获取日益便捷。通过融入3D几何信息,实例与场景的区分将更为容易,从而推动面向高级场景理解的RGB-D研究。同时,RGB-D数据在众多应用领域展现出巨大潜力,例如SLAM (Wang et al., 2023)、自动驾驶 (Huang et al., 2022) 和机器人技术 (Marchal et al., 2020)。因此,RGB-D研究在过去几年间备受关注。
Fig. 1 (top) shows the pipeline of current mainstream RGB-D methods. As can be observed, the features of the RGB images and depth maps are respectively extracted from two individual RGB pretrained backbones. The interactions between the information of these two modalities are performed during this process. Although the existing methods (Wang et al., 2022; Zhang et al., 2023b) have achieved excellent performance on several benchmark datasets, there are three issues that cannot be ignored: i) The backbones in the RGB-D tasks take an image-depth pair as input, which is inconsistent with the input of an image in RGB pre training, causing a huge representation distribution shift; ii) The interactions are densely performed between the RGB branch and depth branch during finetuning, which may destroy the representation distribution within the pretrained RGB backbones; iii) The dual backbones in RGB-D networks bring more computational cost compared to standard RGB methods, which is not efficient. We argue that an important reason leading to these issues is the pre training manner. The depth information is not considered during pre training.
图 1 (top) 展示了当前主流RGB-D方法的工作流程。如图所示,RGB图像和深度图的特征分别从两个独立的RGB预训练骨干网络中提取。在此过程中,这两种模态的信息会进行交互。尽管现有方法 (Wang et al., 2022; Zhang et al., 2023b) 在多个基准数据集上取得了优异性能,但仍存在三个不可忽视的问题:i) RGB-D任务中的骨干网络以图像-深度对作为输入,这与RGB预训练时的单图像输入不一致,导致表征分布发生显著偏移;ii) 微调阶段RGB分支与深度分支之间密集的交互可能会破坏预训练RGB骨干网络内部的表征分布;iii) 相比标准RGB方法,RGB-D网络采用双骨干结构会带来更高的计算成本,效率较低。我们认为导致这些问题的关键原因在于预训练方式——深度信息在预训练阶段未被纳入考量。
Taking the above issues into account, a straightforward question arises: Is it possible to specifically design an RGB-D pre training framework to eliminate this gap? This motivates us to present a novel RGB-D pre training framework, termed DFormer, as shown in Fig. 1 (bottom). During pre training, we consider taking imagedepth pairs 1, not just RGB images, as input and propose to build interactions between RGB and depth features within the building blocks of the encoder. Therefore, the inconsistency between the inputs of pre training and finetuning can be naturally avoided. In addition, during pretraining, the RGB and depth features can efficiently interact with each other in each building block, avoiding the heavy interaction modules outside the backbones, which is mostly adopted in current dominant methods. Furthermore, we also observe that the depth information only needs a small portion of channels to encode. There
考虑到上述问题,一个直接的问题随之产生:能否专门设计一个RGB-D预训练框架来消除这一差距?这促使我们提出了一种新颖的RGB-D预训练框架,称为DFormer,如图1(底部)所示。在预训练期间,我们考虑将图像-深度对1而不仅仅是RGB图像作为输入,并提议在编码器的构建块中建立RGB和深度特征之间的交互。因此,可以自然地避免预训练和微调输入之间的不一致性。此外,在预训练期间,RGB和深度特征可以在每个构建块中高效地相互交互,避免了当前主流方法中大多采用的骨干网络外部繁重的交互模块。此外,我们还观察到深度信息仅需要一小部分通道进行编码。
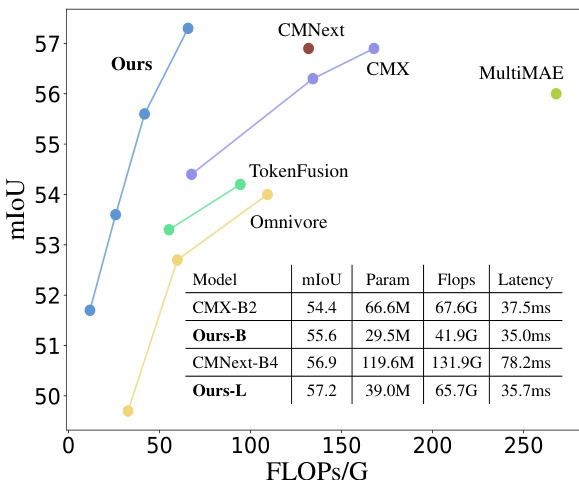
Figure 2: Performance vs. computational cost on the NYUDepthv2 dataset (Silberman et al., 2012). DFormer achieves the state-of-the-art $57.2%$ mIoU and the best trade-off compared to other methods.
图 2: NYUDepthv2数据集 (Silberman et al., 2012) 上的性能与计算成本对比。DFormer以57.2%的mIoU达到当前最优性能,并展现出最佳的性能-计算成本平衡。
is no need to use a whole RGB pretrained backbone to extract depth features as done in previous works. As the interaction starts from the pre training stage, the interaction efficiency can be largely improved compared to previous works as shown in Fig. 2.
无需像以往工作那样使用完整的RGB预训练主干网络来提取深度特征。由于交互从预训练阶段就开始进行,与之前的工作相比,交互效率可以得到大幅提升,如图2所示。
We demonstrate the effectiveness of DFormer on two popular RGB-D downstream tasks, i.e., semantic segmentation and salient object detection. By adding a lightweight decoder on top of our pretrained RGB-D backbone, DFormer sets new state-of-the-art records with less computation costs compared to previous methods. Remarkably, our largest model, DFormer-L, achieves a new stateof-the-art result, i.e., $57.2%$ mIoU on NYU Depthv2 with less than half of the computations of the second-best method CMNext (Zhang et al., 2023b). Meanwhile, our lightweight model DFormerT is able to achieve $51.8%$ mIoU on NYU Depthv2 with only $6.0\mathrm{M}$ parameters and 11.8G Flops. Compared to other recent models, our approach achieves the best trade-off between segmentation performance and computations.
我们在两个流行的RGB-D下游任务(即语义分割和显著目标检测)上验证了DFormer的有效性。通过在预训练的RGB-D骨干网络上添加轻量级解码器,DFormer以更低的计算成本创造了新的性能记录。值得注意的是,我们最大的模型DFormer-L在NYU Depthv2数据集上以不到第二名CMNext (Zhang et al., 2023b) 一半的计算量,取得了57.2% mIoU的最新最优结果。同时,轻量级模型DFormerT仅需6.0M参数和11.8G Flops,便在NYU Depthv2上实现了51.8% mIoU。与其他近期模型相比,我们的方法在分割性能与计算量之间实现了最佳平衡。
To sum up, our main contributions can be summarized as follows:
综上所述,我们的主要贡献可归纳如下:

Figure 3: Overall architecture of the proposed DFormer. First, we use the pretrained DFormer to encode the RGB-D data. Then, the features from the last three stages are concatenated and delivered to a lightweight decoder head for final prediction. Note that only the RGB features from the encoder are used in the decoder.
图 3: 提出的 DFormer 整体架构。首先,我们使用预训练的 DFormer 对 RGB-D 数据进行编码。然后,将最后三个阶段的特征拼接起来,并传递给轻量级解码器头部进行最终预测。请注意,解码器中仅使用编码器的 RGB 特征。
2 PROPOSED DFORMER
2 提出的 DFORMER
Fig. 3 illustrates the overall architecture of our DFormer, which follows the popular encoder-decoder framework. In particular, the hierarchical encoder is designed to generate high-resolution coarse features and low-resolution fine features, and a lightweight decoder is employed to transform these visual features into task-specific predictions.
图 3: 展示了我们DFormer的整体架构,它遵循了流行的编码器-解码器框架。具体而言,分层编码器被设计用于生成高分辨率的粗粒度特征和低分辨率的细粒度特征,并采用轻量级解码器将这些视觉特征转换为特定任务的预测。
Given an RGB image and the corresponding depth map with spatial size of $H\times W$ , they are first separately processed by two parallel stem layers consisting of two convolutions with kernel size $3\times3$ and stride 2. Then, the RGB features and depth features are fed into the hierarchical encoder to encode multi-scale features at ${1/4,1/8,1/16,1/32}$ of the original image resolution. Next, we pretrain this encoder using the image-depth pairs from ImageNet-1K using the classification objective to generate the transferable RGB-D representations. Finally, we send the visual features from the pretrained RGB-D encoder to the decoder to produce predictions, e.g., segmentation maps with a spatial size $H\times W$ . In the rest of this section, we will describe the encoder, RGB-D pre training framework, and task-specific decoder in detail.
给定一张空间尺寸为$H\times W$的RGB图像及其对应的深度图,首先通过两个并行的stem层(各包含两个核大小为$3\times3$、步长为2的卷积)分别处理。随后,RGB特征和深度特征被输入分层编码器,在原始图像分辨率的${1/4,1/8,1/16,1/32}$尺度下编码多尺度特征。接着,我们使用ImageNet-1K中的图像-深度对,以分类目标预训练该编码器,生成可迁移的RGB-D表征。最后,将预训练RGB-D编码器输出的视觉特征送入解码器生成预测结果(例如空间尺寸为$H\times W$的分割图)。本节剩余部分将详细阐述编码器、RGB-D预训练框架及任务专用解码器。
2.1 HIERARCHICAL ENCODER
2.1 分层编码器
As shown in Fig. 3, our hierarchical encoder is composed of four stages, which are utilized to generate multi-scale RGB-D features. Each stage contains a stack of RGB-D blocks. Two convolutions with kernel size $3\times3$ and stride 2 are used to down-sample RGB and depth features, respectively, between two consecutive stages.
如图 3 所示,我们的分层编码器由四个阶段组成,用于生成多尺度 RGB-D 特征。每个阶段包含一组 RGB-D 块。在两个连续阶段之间,分别使用核大小为 $3\times3$ 、步长为 2 的两次卷积对 RGB 和深度特征进行下采样。
Building Block. Our building block is mainly composed of the global awareness attention (GAA) module and the local enhancement attention (LEA) module and builds interaction between the RGB and depth modalities. GAA incorporates depth information and aims to enhance the capability of object localization from a global perspective, while LEA adopts a largekernel convolution to capture the local clues from the depth features, which can refine the details of the RGB representations. The details of the interaction modules are shown in Fig. 4.
构建模块。我们的构建模块主要由全局感知注意力 (GAA) 模块和局部增强注意力 (LEA) 模块组成,并在 RGB 和深度模态之间建立交互。GAA 整合深度信息,旨在从全局角度增强目标定位能力,而 LEA 采用大核卷积从深度特征中捕获局部线索,从而细化 RGB 表示的细节。交互模块的详细信息如图 4 所示。
Our GAA fuses depth and RGB features to build relationships across the whole scene, enhancing 3D awareness and further helping capture semantic objects. Different from the selfattention mechanism (Vaswani et al., 2017) that
我们的GAA通过融合深度和RGB特征来建立整个场景的关系,增强3D感知能力,并进一步帮助捕捉语义对象。与自注意力机制 (Vaswani et al., 2017) 不同
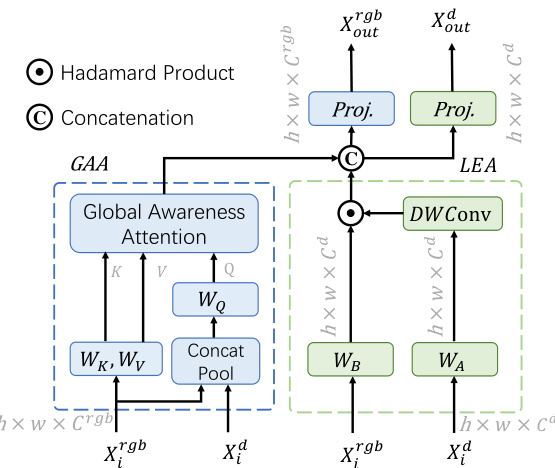
Figure 4: Diagrammatic details on how to conduct interactions between RGB and depth features.
图 4: RGB与深度特征交互机制的示意图
introduces quadratic computation growth as the pixels or tokens increase, the Query $(Q)$ in GAA is down-sampled to a fixed size and hence the computational complexity can be reduced. Tab. 7 illustrates that fusing depth features with $Q$ is adequate and there is no need to combine them with $K$ or $V$ , which brings computation increment but no performance improvement. So, $Q$ comes from the concatenation of the RGB features and depth features, while key $(K)$ and value $(V)$ are extracted from RGB features. Given the RGB features $X_{i}^{r g b}$ and depth features $X_{i}^{d}$ , the above process can be
随着像素或token数量增加导致计算量呈二次方增长,GAA中的查询向量$(Q)$会降采样至固定尺寸,从而降低计算复杂度。表7表明深度特征只需与$Q$融合即可,无需与键$(K)$或值$(V)$结合,后者会增加计算量但无法提升性能。因此$Q$由RGB特征与深度特征拼接而成,而键$(K)$和值$(V)$则从RGB特征中提取。给定RGB特征$X_{i}^{r g b}$和深度特征$X_{i}^{d}$,上述流程可表示为:
formulated as:
表述为:
$$
Q=\operatorname{Linear}(\mathrm{Pool}{k\times k}([X_{i}^{r g b},X_{i}^{d}])),K=\operatorname{Linear}(X_{i}^{r g b}),V=\operatorname{Linear}(X_{i}^{r g b}),
$$
$$
Q=\operatorname{Linear}(\mathrm{Pool}{k\times k}([X_{i}^{r g b},X_{i}^{d}])),K=\operatorname{Linear}(X_{i}^{r g b}),V=\operatorname{Linear}(X_{i}^{r g b}),
$$
where $[\cdot,\cdot]$ denotes the concatenation operation along the channel dimension, $\mathrm{Pool}_{k\times k}(\cdot)$ performs adaptively average pooling operation across the spatial dimensions to $k\times k$ size, and Linear is linear transformation. Based on the generated $Q\in\mathbb{R}^{k\times k\times C^{d}}$ , $\b{K}\in\mathbb{R}^{\b{h}\times\boldsymbol{w}\times\boldsymbol{C}^{d}}$ , and $V\in\mathbb{R}^{h\times w\times C^{d}}$ , where $h$ and $w$ are the height and width of features in the current stage, we formulate the GAA as follows:
其中 $[\cdot,\cdot]$ 表示沿通道维度的拼接操作,$\mathrm{Pool}_{k\times k}(\cdot)$ 在空间维度上执行自适应平均池化操作至 $k\times k$ 尺寸,Linear 表示线性变换。基于生成的 $Q\in\mathbb{R}^{k\times k\times C^{d}}$、$\b{K}\in\mathbb{R}^{\b{h}\times\boldsymbol{w}\times\boldsymbol{C}^{d}}$ 和 $V\in\mathbb{R}^{h\times w\times C^{d}}$(其中 $h$ 和 $w$ 分别表示当前阶段特征图的高度和宽度),我们将 GAA 表述如下:
$$
X_{G A A}=\mathrm{UP}(V\cdot\mathrm{Softmax}(\frac{Q^{\top}K}{\sqrt{C^{d}}})),
$$
$$
X_{G A A}=\mathrm{UP}(V\cdot\mathrm{Softmax}(\frac{Q^{\top}K}{\sqrt{C^{d}}})),
$$
where $\mathrm{UP}(\cdot)$ is a bilinear upsampling operation that converts the spatial size from $k\times k$ to $h\times w$ . In practical use, Eqn. 2 can also be extended to a multi-head version, as done in the original selfattention (Vaswani et al., 2017), to augment the feature representations.
其中 $\mathrm{UP}(\cdot)$ 是一个双线性上采样操作,将空间尺寸从 $k\times k$ 转换为 $h\times w$。实际应用中,公式2也可扩展为多头版本(如原始自注意力机制 [Vaswani et al., 2017] 所示)以增强特征表示。
We also design the LEA module to capture more local details, which can be regarded as a supplement to the GAA module. Unlike most previous works that use addition and concatenation to fuse the RGB features and depth features. We conduct a depth-wise convolution with a large kernel on the depth features and use the resulting features as attention weights to reweigh the RGB features via a simple Hadamard product inspired by (Hou et al., 2022). This is reasonable in that adjacent pixels with similar depth values often belong to the same object and the 3D geometry information thereby can be easily embedded into the RGB features. To be specific, the calculation process of LEA can be defined as follows:
我们还设计了LEA模块以捕捉更多局部细节,这可以视为对GAA模块的补充。不同于以往大多数工作通过加法或拼接来融合RGB特征和深度特征,我们受(Hou et al., 2022)启发,对深度特征执行大核深度卷积,并将结果特征作为注意力权重,通过简单的Hadamard乘积对RGB特征进行重加权。这种做法是合理的,因为具有相似深度值的相邻像素通常属于同一物体,从而能轻松将3D几何信息嵌入RGB特征。具体而言,LEA的计算过程可定义如下:
$$
X_{L E A}=\mathrm{DConv}{k\times k}(\mathrm{Linear}(X_{i}^{d}))\odot\mathrm{Linear}(X_{i}^{r g b}),
$$
$$
X_{L E A}=\mathrm{DConv}{k\times k}(\mathrm{Linear}(X_{i}^{d}))\odot\mathrm{Linear}(X_{i}^{r g b}),
$$
where $\ensuremath{\mathrm{DConv}}_{k\times k}$ is a depth-wise convolution with kernel size $k\times k$ and $\odot$ is the Hadamard product.
其中 $\ensuremath{\mathrm{DConv}}_{k\times k}$ 是核尺寸为 $k\times k$ 的深度卷积 (depth-wise convolution) ,$\odot$ 为哈达玛积 (Hadamard product) 。
To preserve the diverse appearance information, we also build a base module to transform the RGB features Xirgb to XBase, which has the same spatial size as XGAA and XLEA. The calculation process of $X_{B a s e}$ can be defined as follows:
为了保留多样化的外观信息,我们还构建了一个基础模块,用于将RGB特征Xirgb转换为XBase,其空间尺寸与XGAA和XLEA相同。$X_{B a s e}$的计算过程可定义如下:
$$
X_{B a s e}=\mathrm{DConv}{k\times k}(\mathrm{Linear}(X_{i}^{r g b}))\odot\mathrm{Linear}(X_{i}^{r g b}).
$$
$$
X_{B a s e}=\mathrm{DConv}{k\times k}(\mathrm{Linear}(X_{i}^{r g b}))\odot\mathrm{Linear}(X_{i}^{r g b}).
$$
fused together by concatenation and linear projection to update the RGB features Finally, the features, i.e., XGAA ∈ Rhi×wi×Cid , XLEA ∈ Rhi×wi×Cid , XBase ∈ Rhi×wi×Cirgb, $X_{o u t}^{r g b}$ and depth features Xodut.
通过拼接和线性投影融合,更新RGB特征。最终得到的特征包括:XGAA ∈ Rhi×wi×Cid、XLEA ∈ Rhi×wi×Cid、XBase ∈ Rhi×wi×Cirgb、$X_{o u t}^{r g b}$以及深度特征Xodut。
Overall Architecture. We empirically observe that encoding depth features requires fewer parameters compared to the RGB ones due to their less semantic information, which is verified in Fig. 6 and illustrated in detail in the experimental part. To reduce model complexity in our RGB-D block, we use a small portion of channels to encode the depth information. Based on the configurations of the RGB-D blocks in each stage, we design a series of DFormer encoder variants, termed DFormerT, DFormer-S, DFormer-B, and DFormer-L, respectively, with the same architecture but different model sizes. DFormer-T is a lightweight encoder for fast inference, while DFormer-L is the largest one for attaining better performance. For detailed configurations, readers can refer to Tab. 14.
整体架构。我们通过实验观察到,由于深度特征包含的语义信息较少,编码深度特征所需的参数比RGB特征更少,这一现象在图6中得到验证,并在实验部分详细说明。为降低RGB-D模块的模型复杂度,我们仅使用少量通道编码深度信息。基于各阶段RGB-D模块的配置,我们设计了DFormer编码器系列变体:DFormerT、DFormer-S、DFormer-B和DFormer-L,它们架构相同但模型规模不同。其中DFormer-T是轻量级编码器以实现快速推理,而DFormer-L是最大模型以获得更优性能。具体配置请参阅表14。
2.2 RGB-D PRE TRAINING
2.2 RGB-D 预训练
The purpose of RGB-D pre training is to endow the backbone with the ability to achieve the interaction between RGB and depth modalities and generate transferable representations with rich semantic and spatial information. To this end, we first apply a depth estimator, e.g., Adabin (Bhat et al., 2021), on the ImageNet-1K dataset (Russ a kov sky et al., 2015) to generate a large number of image-depth pairs. Then, we add a classifier head on the top of the RGB-D encoder to build the classification network for pre training. Particularly, the RGB features from the last stage are flattened along the spatial dimension and fed into the classifier head. The standard cross-entropy loss is employed as our optimization objective, and the network is pretrained on RGB-D data for 300 epochs, like ConvNext (Liu et al., 2022). Following previous works (Liu et al., 2022; Guo et al., 2022b), the AdamW (Loshchilov & Hutter, 2019) with learning rate 1e-3 and weight decay 5e-2 is employed as our optimizer, and the batch size is set to 1024. More specific settings for each variant of DFormer are described in the appendix.
RGB-D预训练的目的是让主干网络具备实现RGB与深度模态交互的能力,并生成具有丰富语义和空间信息的可迁移表征。为此,我们首先在ImageNet-1K数据集[20]上应用深度估计器(如Adabin[3])生成大量图像-深度对。接着,我们在RGB-D编码器顶部添加分类器头来构建用于预训练的分类网络。具体而言,将最后阶段提取的RGB特征沿空间维度展平后输入分类器头,采用标准交叉熵损失作为优化目标,并像ConvNext[15]那样在RGB-D数据上进行300轮预训练。沿用先前工作[15][7]的设置,我们采用学习率为1e-3、权重衰减为5e-2的AdamW优化器[14],批处理大小设为1024。DFormer各变体的具体配置详见附录。
Table 1: Results on NYU Depth V2 (Silberman et al., 2012) and SUN-RGBD (Song et al., 2015). Some methods do not report the results or settings on the SUN-RGBD datasets, so we reproduce them with the same training config. † indicates our implemented results. All the backbones are pre-trained on ImageNet-1K.
表 1: NYU Depth V2 (Silberman et al., 2012) 和 SUN-RGBD (Song et al., 2015) 数据集上的结果。部分方法未报告 SUN-RGBD 数据集的结果或设置,因此我们使用相同的训练配置复现了这些结果。† 表示我们实现的结果。所有骨干网络均在 ImageNet-1K 上进行了预训练。
| 模型 | 骨干网络 | 参数量 | NYUDepthv2 | SUN-RGBD | 代码 | ||||
|---|---|---|---|---|---|---|---|---|---|
| 输入尺寸 | 计算量 (Flops) | mIoU | 输入尺寸 | 计算量 (Flops) | mIoU | ||||
| ACNet19 (Hu et al.) | ResNet-50 | 116.6M | 480×640 | 126.7G | 48.3 | 530×730 | 163.9G | 48.1 | Link |
| SGNet2o (Chen et al.) | ResNet-101 | 64.7M | 480×640 | 108.5G | 51.1 | 530×730 | 151.5G | 48.6 | Link |
| SA-Gate2o (Chen et al.) | ResNet-101 | 110.9M | 480×640 | 193.7G | 52.4 | 530×730 | 250.1G | 49.4 | Link |
| CEN2o (Wang et al.) | ResNet-101 | 118.2M | 480×640 | 618.7G | 51.7 | 530×730 | 790.3G | 50.2 | Link |
| CEN2o (Wang et al.) | ResNet-152 | 133.9M | 480×640 | 664.4G | 52.5 | 530×730 | 849.7G | 51.1 | Link |
| ShapeConv21 (Cao et al.) | ResNext-101 | 86.8M | 480×640 | 124.6G | 51.3 | 530×730 | 161.8G | 48.6 | Link |
| ESANet21 (Seichter et al.) | ResNet-34 | 31.2M | 480×640 | 34.9G | 50.3 | 480×640 | 34.9G | 48.2 | Link |
| FRNet22 (Zhou et al.) | ResNet-34 | 85.5M | 480×640 | 115.6G | 53.6 | 530×730 | 150.0G | 51.8 | Link |
| PGDENet22 (Zhou et al.) | ResNet-34 | 100.7M | 480×640 | 178.8G | 53.7 | 530×730 | 229.1G | 51.0 | Link |
| EMSANet22 (Seichter et al.) | ResNet-34 | 46.9M | 480×640 | 45.4G | 51.0 | 530×730 | 58.6G | 48.4 | Link |
| TokenFusion22 (Wang et al.) | MiT-B2 | 26.0M | 480×640 | 55.2G | 53.3 | 530×730 | 71.1G | 50.3 | Link |
| TokenFusion22 (Wang et al.) | MiT-B3 | 45.9M | 480×640 | 94.4G | 54.2 | 530×730 | 122.1G | 51.0t | Link |
| MultiMAE22 (Bachmann et al.) | ViT-B | 95.2M | 640×640 | 267.9G | 56.0 | 640×640 | 267.9G | 51.1 | Link |
| Omnivore22 (Girdhar et al.) | Swin-T | 29.1M | 480×640 | 32.7G | 49.7 | 530×730 | Link | ||
| Omnivore22 (Girdhar et al.) | Swin-S | 51.3M | 480×640 | 59.8G | 52.7 | 530×730 | Link | ||
| Omnivore22 (Girdhar et al.) | Swin-B | 95.7M | 480×640 | 109.3G | 54.0 | 530×730 | Link | ||
| CMX22 (Zhang et al.) | MiT-B2 | 66.6M | 480×640 | 67.6G | 54.4 | 530×730 | 86.3G | 49.7 | Link |
| CMX22 (Zhang et al.) | MiT-B4 | 139.9M | 480×640 | 134.3G | 56.3 | 530×730 | 173.8G | 52.1 | Link |
| CMX22 (Zhang et al.) | MiT-B5 | 181.1M | 480×640 | 167.8G | 56.9 | 530×730 | 217.6G | 52.4 | Link |
| CMNext23 (Zhang et al.) | MiT-B4 | 119.6M | 480×640 | 131.9G | 56.9 | 530×730 | 170.3G | 51.9t | Link |
| DFormer-T | Ours-T | 6.0M | 480×640 | 11.8G | 51.8 | 530×730 | 15.1G | 48.8 | Link |
| DFormer-S | Ours-S | 18.7M | 480×640 | 25.6G | 53.6 | 530×730 | 33.0G | 50.0 | Link |
| DFormer-B | Ours-B | 29.5M | 480×640 | 41.9G | 55.6 | 530×730 | 54.1G | 51.2 | Link |
| DFormer-L | Ours-L | 39.0M | 480×640 | 65.7G | 57.2 | 530×730 | 83.3G | 52.5 | Link |
2.3 TASK-SPECIFIC DECODER.
2.3 任务专用解码器
For the applications of our DFormer to downstream tasks, we just add a lightweight decoder on top of the pretrained RGBD backbone to build the task-specific network. After being finetuned on corresponding benchmark datasets, the task-specific network is able to generate great predictions, without using extra designs like fusion modules (Chen et al., 2020a; Zhang et al., 2023a).
为了将我们的DFormer应用于下游任务,我们只需在预训练的RGBD主干网络上添加一个轻量级解码器来构建任务专用网络。在相应的基准数据集上进行微调后,该任务专用网络无需使用融合模块等额外设计 (Chen et al., 2020a; Zhang et al., 2023a) 就能生成出色的预测结果。
Take RGB-D semantic segmentation as an example. Following SegNext (Guo et al., 2022a), we adopt a lightweight Hamburger head (Geng et al., 2021) to aggregate the multi-scale RGB features from the last three stages of our pretrained encoder. Note that, our decoder only uses the $X^{r g b}$ features, while other methods (Zhang et al., 2023a; Wang et al., 2022; Zhang et al., 2023b) mostly design modules that fuse both modalities features $X^{r g b}$ and $X^{d}$ for final predictions. We will show in our experiments that our $X^{r g b}$ features can efficiently extract the 3D geometry clues from the depth modality thanks to our powerful RGB-D pretrained encoder. Delivering the depth features $X^{\dot{d}}$ to the decoder is not necessary.
以RGB-D语义分割为例。遵循SegNext (Guo等人, 2022a)的方法,我们采用轻量级Hamburger头模块(Geng等人, 2021)来聚合预训练编码器最后三个阶段的多尺度RGB特征。值得注意的是,我们的解码器仅使用$X^{r g b}$特征,而其他方法(Zhang等人, 2023a; Wang等人, 2022; Zhang等人, 2023b)大多设计融合双模态特征$X^{r g b}$和$X^{d}$的模块进行最终预测。实验将表明,得益于强大的RGB-D预训练编码器,我们的$X^{r g b}$特征能有效从深度模态中提取3D几何线索,因此无需向解码器传递深度特征$X^{\dot{d}}$。
3 EXPERIMENTS
3 实验
3.1 RGB-D SEMANTIC SEGMENTATION
3.1 RGB-D 语义分割
Datasets& implementation details. Following the common experiment settings of RGB-D semantic segmentation methods (Xie et al., 2021; Guo et al., 2022a), we finetune and evaluate the DFormer on two widely used datasets, i.e., NYUDepthv2 (Silberman et al., 2012) and SUN-RGBD (Song et al., 2015). Following SegNext Guo et al. (2022a), we employ Hamburger (Geng et al., 2021), a lightweight head, as the decoder to build our RGB-D semantic segmentation network. During finetuning, we only adopt two common data augmentation strategies, i.e., random horizontal flipping and random scaling (from 0.5 to 1.75). The training images are cropped and resized to $480\times640$ and $480\times480$ respectively for NYU Depthv2 and SUN-RGBD benchmarks. Cross-entropy loss is utilized as the optimization objective. We use AdamW (Kingma & Ba, 2015) as our optimizer with an initial learning rate of 6e-5 and the poly decay schedule. Weight decay is set to 1e-2. During testing, we employ mean Intersection over Union (mIoU), which is averaged across semantic categories, as the primary evaluation metric to measure the segmentation performance. Following recent works (Zhang et al., 2023a; Wang et al., 2022; Zhang et al., 2023b), we adopt multi-scale (MS) flip inference strategies with scales ${0.5,0.75,1,1.25,1.5}$ .
数据集与实现细节。遵循RGB-D语义分割方法的通用实验设置 (Xie et al., 2021; Guo et al., 2022a),我们在两个广泛使用的数据集NYUDepthv2 (Silberman et al., 2012) 和SUN-RGBD (Song et al., 2015) 上对DFormer进行微调和评估。参照SegNext Guo et al. (2022a) 的做法,我们采用轻量级头部Hamburger (Geng et al., 2021) 作为解码器来构建RGB-D语义分割网络。微调过程中仅采用两种常见数据增强策略:随机水平翻转和随机缩放(0.5至1.75倍)。训练图像分别裁剪调整为$480\times640$(NYU Depthv2)和$480\times480$(SUN-RGBD)尺寸。优化目标采用交叉熵损失,使用AdamW (Kingma & Ba, 2015) 优化器,初始学习率6e-5并采用多项式衰减策略,权重衰减设为1e-2。测试阶段采用语义类别平均的mIoU (mean Intersection over Union) 作为主要分割性能指标。根据近期研究 (Zhang et al., 2023a; Wang et al., 2022; Zhang et al., 2023b),我们采用多尺度(MS)翻转推理策略,尺度参数为${0.5,0.75,1,1.25,1.5}$。
Table 2: Quantitative comparisons on RGB-D SOD benchmarks. The best results are highlighted.
表 2: RGB-D SOD基准测试的定量比较。最佳结果已高亮显示。
| 数据集指标 | 参数量 (M) | 计算量 (G) | DES(135) | NLPR(300) | NJU2K(500) | STERE(1,000) | SIP(929) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| M | F | S | E | M | F | S | E | M | F | S | E | M | F | S | E | M | |||
| BBSNet21 (Zhai et al.) | 49.8 | 31.3 | .021 | .942 | .934 | .955 | .023 | .927 | .930 | .953 | .035 | .931 | .920 | .941 | .041 | .919 | .908 | .931 | .055 |
| DCF21 (Ji et al.) | 108.5 | 54.3 | .024 | .910 | .905 | .941 | .022 | .918 | .924 | .958 | .036 | .922 | .912 | .946 | .039 | .911 | .902 | .940 | .052 |
| DSA2F21 (Sun et al.) | 36.5 | 172.7 | .021 | .896 | .920 | .962 | .024 | .897 | .918 | .950 | .039 | .901 | .903 | .923 | .036 | .898 | .904 | .933 | |
| CMINet21 (Zhang et al.) | = | = | .016 | .944 | .940 | .975 | .020 | .931 | .932 | .959 | .028 | .940 | .929 | .954 | .032 | .925 | .918 | .946 | .040 |
| DSNet21 (Wen et al.) | 172.4 | 141.2 | .021 | .939 | .928 | .956 | .024 | .925 | .926 | .951 | .034 | .929 | .921 | .946 | .036 | .922 | .914 | .941 | .052 |
| UTANet21 (Zhao et al.) | 48.6 | 27.4 | .026 | .921 | .900 | .932 | .020 | .928 | .932 | .964 | .037 | .915 | .902 | .945 | .033 | .921 | .910 | .948 | .048 |
| BIANet21 (Zhang et al.) | 49.6 | 59.9 | .017 | .948 | .942 | .972 | .022 | .926 | .928 | .957 | .034 | .932 | .923 | .945 | .038 | .916 | .908 | .935 | .046 |
| SPNet21 (Zhou et al.) | 150.3 | 68.1 | .014 | .950 | .945 | .980 | .021 | .925 | .927 | .959 | .028 | .935 | .925 | .954 | .037 | .915 | .907 | .944 | .043 |
| VST21 (Liu et al.) | 83.3 | 31.0 | .017 | .940 | .943 | .978 | .024 | .920 | .932 | .962 | .035 | .920 | .922 | .951 | .038 | .907 | .913 | .951 | .040 |
| RD3D+22 (Chen et al.) | 28.9 | 43.3 | .017 | .946 | .950 | .982 | .022 | .921 | .933 | .964 | .033 | .928 | .928 | .955 | .037 | .905 | .914 | .946 | .046 |
| BPGNet22 (Yang et al.) | 84.3 | 138.6 | .020 | .932 | .937 | .973 | .024 | .914 | .927 | .959 | .034 | .926 | .923 | .953 | .040 | .904 | .907 | .944 | |
| C2DFNet22 (Zhang et al.) | 47.5 | 21.0 | .020 | .937 | .922 | .948 | .021 | .926 | .928 | .956 | .038 | .911 | .902 | .938 | .053 | .894 | |||
| MVSalNet22 (Zhou et al.) | = | = | .019 | .942 | .937 | .973 | .022 | .931 | .930 | .960 | .036 | .923 | .912 | .944 | .036 | .921 | .913 | .944 | |
| SPSN22 (Lee et al.) | 37.0 | 100.3 | .017 | .942 | .937 | .973 | .023 | .917 | .923 | .956 | .032 | .927 | .918 | .949 | .035 | .909 | .906 | .941 | .043 |
| HiDANet23 (Wu et al.) | 130.6 | 71.5 | .013 | .952 | .946 | .980 | .021 | .929 | .930 | .961 | .029 | .939 | .926 | .954 | .035 | .921 | .911 | .946 | .043 |
| DFormer-T | 5.9 | 4.5 | .016 | .947 | .941 | .975 | .021 | .931 | .932 | .960 | .028 | .937 | .927 | .953 | .033 | .921 | .915 | .945 | .039 |
| DFormer-S | 18.5 | 10.1 | .016 | .950 | .939 | .970 | .020 | .937 | .936 | .965 | .026 | .941 | .931 | .960 | .031 | .928 | .920 | .951 | .041 |
| DFormer-B | 29.3 | 16.7 | .013 | .957 | .948 | .982 | .019 | .933 | .936 | .965 | .025 | .941 | .933 | .960 | .029 | .931 | .925 | .951 | .035 |
| DFormer-L | 38.8 | 26.2 | .013 | .956 | .948 | .980 | .016 | .939 | .942 | .971 | .023 | .946 | .937 | .964 | .030 | .929 | .923 | .952 | .032 |
Table 3: RGB-D pre training. $\mathbf{\sigma}\cdot\mathbf{RGB}{+}\mathbf{RGB}$ ’ pretraining replaces depth maps with RGB images during pre training. Input channel of the stem layer is modified from 1 to 3. The depth map is duplicated three times during finetuning.
表 3: RGB-D 预训练。$\mathbf{\sigma}\cdot\mathbf{RGB}{+}\mathbf{RGB}$ 预训练在预训练阶段用 RGB 图像替换深度图。主干层的输入通道从 1 修改为 3。在微调阶段,深度图会被复制三次。
| pretrain | Finetune | mIoU (%) |
|---|---|---|
| RGB+RGB | RGB+D | 53.3 |
| RGB+D (Ours) | RGB+D | 55.6 |
Table 4: Different inputs of the decoder head for DFormer-B. means simultaneously uses RGB and depth features. Specifically, both features from the last three stages are used as the input of the decoder head.
表 4: DFormer-B解码器头的不同输入。表示同时使用RGB和深度特征。具体来说,最后三个阶段的特征都用作解码器头的输入。
| 解码器输入 | #Params | FLOPs | mIoU(%) |
|---|---|---|---|
| Xrgb (Ours) | 29.5 | 41.9 | 55.6 |
| Xrgb + Xd | 30.8 | 44.8 | 55.5 |
Comparison with state-of-the-art methods. We compare our DFormer with 13 recent RGB-D semantic segmentation methods on the NYUDepthv2 (Silberman et al., 2012) and SUN-RGBD (Song et al., 2015) datasets. These methods are chosen according to three criteria: a) recently published, b) representative, and c) with open-source code. As shown in Tab. 1, our DFormer achieves new state-of-the-art performance across these two benchmark datasets. We also plot the performanceefficiency curves of different methods on the validation set of the NYUDepthv2 (Silberman et al., 2012) dataset in Fig. 2. It is clear that DFormer achieves much better performance and computation trade-off compared to other methods. Particularly, DFormer-L yields $57.2%$ mIoU with 39.0M parameters and 65.7G Flops, while the recent best RGB-D semantic segmentation method, i.e., CMX (MiT-B2), only achieves $54.4%$ mIoU using $66.6\mathbf{M}$ parameters and 67.6G Flops. It is noteworthy that our DFormer-B can outperform CMX (MIT-B2) by $1.2%$ mIoU with half of the parameters (29.5M, 41.9G vs 66.6M, 67.6G). Moreover, the qualitative comparisons between the semantic segmentation results of our DFormer and CMNext (Zhang et al., 2023b) in Fig. 14 of the appendix further demonstrate the advantage of our method. In addition, the experiments on SUN-RGBD (Song et al., 2015) also present similar advantages of our DFormer over other methods. These consistent improvements indicate that our RGB-D backbone can more efficiently build interaction between RGB and depth features, and hence yields better performance with even lower computational cost.
与先进方法的比较。我们在NYUDepthv2 (Silberman et al., 2012) 和 SUN-RGBD (Song et al., 2015) 数据集上将DFormer与13种最新的RGB-D语义分割方法进行对比。这些方法根据三个标准选取:a) 近期发表,b) 具有代表性,c) 提供开源代码。如表 1 所示,我们的DFormer在这两个基准数据集上均实现了最先进的性能。图 2 展示了不同方法在NYUDepthv2验证集上的性能-效率曲线,明显可见DFormer在性能与计算量权衡方面显著优于其他方法。具体而言,DFormer-L以39.0M参数量和65.7G Flops实现了57.2% mIoU,而当前最优的RGB-D语义分割方法CMX (MiT-B2) 使用66.6M参数和67.6G Flops仅达到54.4% mIoU。值得注意的是,我们的DFormer-B仅用一半参数量 (29.5M, 41.9G vs 66.6M, 67.6G) 即可超越CMX (MIT-B2) 1.2% mIoU。此外,附录图 14 中DFormer与CMNext (Zhang et al., 2023b) 的语义分割结果定性对比进一步验证了本方法的优势。在SUN-RGBD (Song et al., 2015) 数据集上的实验同样表明DFormer的优越性。这些一致性改进证明我们的RGB-D主干网络能更高效地建立RGB与深度特征间的交互,从而以更低计算成本获得更优性能。
3.2 RGB-D SALIENT OBJECT DETCTION
3.2 RGB-D 显著目标检测
Dataset & implementation details. We finetune and test DFormer on five popular RGB-D salient object detection datasets. The finetuning dataset consists of 2,195 samples, where 1,485 are from NJU2K-train (Ju et al., 2014) and the other 700 samples are from NLPR-train (Peng et al., 2014). The model is evaluated on five datasets, i.e., DES (Cheng et al., 2014) (135), NLPR-test (Peng et al., 2014) (300), NJU2K-test (Ju et al., 2014) (500), STERE (Niu et al., 2012) (1,000), and SIP (Fan et al., 2020) (929). For performance evaluation, we adopt four golden metrics of this task, i.e., Structure-measure (S) (Fan et al., 2017), mean absolute error (M) (Perazzi et al., 2012), max F-measure (F) (Margolin et al., 2014), and max E-measure (E) (Fan et al., 2018).
数据集与实现细节。我们在五个流行的RGB-D显著目标检测数据集上对DFormer进行微调和测试。微调数据集包含2,195个样本,其中1,485个来自NJU2K-train (Ju et al., 2014),其余700个样本来自NLPR-train (Peng et al., 2014)。模型在五个数据集上进行评估,即DES (Cheng et al., 2014) (135)、NLPR-test (Peng et al., 2014) (300)、NJU2K-test (Ju et al., 2014) (500)、STERE (Niu et al., 2012) (1,000)和SIP (Fan et al., 2020) (929)。为评估性能,我们采用该任务的四个黄金指标:结构度量(S) (Fan et al., 2017)、平均绝对误差(M) (Perazzi et al., 2012)、最大F值(F) (Margolin et al., 2014)和最大E值(E) (Fan et al., 2018)。
Comparisons with state-of-the-art methods. We compare our DFormer with 11 recent RGB-D salient object detection methods on the five popular test datasets. As shown in Tab. 2, our DFormer is able to surpass all competitors with the least computational cost. More importantly, our DFormer
与现有最优方法的对比。我们将DFormer与11种最新的RGB-D显著目标检测方法在五个常用测试数据集上进行比较。如表2所示,DFormer能以最低计算成本超越所有竞争对手。更重要的是,我们的DFormer

Figure 5: Visualization s of the feature maps around the last RGB-D block of the first stage.
图 5: 第一阶段最后一个RGB-D块周围特征图的可视化。
Table 5: Ablation results on the components of the RGB-D block in DFormer-S.
| Model | #Params | FLOPs | mIoU (%) |
| DFormer-S | 18.7M | 25.6G | 53.6 |
| w/oBase | 14.6M | 19.6G | 52.1 |
| w/oGAA | 16.5M | 21.7G | 52.3 |
| w/oLEA | 16.3M | 23.3G | 52.6 |
表 5: DFormer-S 中 RGB-D 模块组件的消融实验结果
| 模型 | 参数量 (#Params) | 计算量 (FLOPs) | mIoU (%) |
|---|---|---|---|
| DFormer-S | 18.7M | 25.6G | 53.6 |
| w/oBase | 14.6M | 19.6G | 52.1 |
| w/oGAA | 16.5M | 21.7G | 52.3 |
| w/oLEA | 16.3M | 23.3G | 52.6 |
Table 7: Different fusion methods for $Q$ , $K$ , and $V$ . We can see that there is no need to fuse RGB and depth features for $K$ and $V$ .
表 7: 针对 $Q$、$K$ 和 $V$ 的不同融合方法。可以看出,无需为 $K$ 和 $V$ 融合 RGB 和深度特征。
| 融合变量 | 参数量 | 计算量 (FLOPs) | mIoU (%) |
|---|---|---|---|
| 无 | 18.5M | 25.4G | 53.2 |
| (sno) Xquo | 18.7M | 25.6G | 53.6 |
| Q, K, V | 19.3M | 28.5G | 53.6 |
Table 6: Ablation on GAA in the DFormer-S. $\mathbf{\nabla}\times\mathbf{\nabla}\times\mathbf{\nabla}$ means the adaptive pooling size of $Q$ .
表 6: DFormer-S 中 GAA 的消融实验。$\mathbf{\nabla}\times\mathbf{\nabla}\times\mathbf{\nabla}$ 表示 $Q$ 的自适应池化大小。
| 核尺寸 | 参数量 | FLOPs | mIoU (%) |
|---|---|---|---|
| 3×3 | 18.7M | 22.0G | 52.7 |
| 5×5 | 18.7M | 23.3G | 53.1 |
| 7×7 | 18.7M | 25.6G | 53.6 |
| 9×9 | 18.7M | 28.8G | 53.6 |
Table 8: Different fusion manners in LEA module. Fusion manner refers to the operation to fuse the RGB and depth information in LEA (Eqn. 3).
表 8: LEA模块中的不同融合方式。融合方式指的是在LEA (Eqn. 3)中融合RGB和深度信息的操作。
| 融合方式 | #Params | FLOPs | mIoU(%) |
|---|---|---|---|
| Addition | 18.6M | 25.1G | 53.1 |
| Concatenation | 19.0M | 26.4G | 53.3 |
| Hadamard | 18.7M | 25.6G | 53.6 |
T yields comparable performance to the recent state-of-the-art method SPNet (Zhou et al., 2021a) with less than $10%$ computational cost (5.9M, 4.5G vs 150.3M, 68.1G). The significant improvement further illustrates the strong performance of DFormer.
T 的性能与近期最先进的方法 SPNet (Zhou et al., 2021a) 相当,但计算成本不到其 10% (5.9M, 4.5G vs 150.3M, 68.1G)。这一显著改进进一步证明了 DFormer 的强大性能。
3.3 ABLATION STUDY AND ANALYSIS
3.3 消融研究与分析
We perform ablation studies to investigate the effectiveness of each component. All experiments here are conducted under RGB-D segmentation setting on NYU DepthV2 (Silberman et al., 2012).
我们通过消融实验来验证各模块的有效性。所有实验均在NYU DepthV2数据集 (Silberman et al., 2012) 的RGB-D分割设置下进行。
RGB-D vs. RGB pre training. To explain the necessity of the RGB-D pre training, we attempt to replace the depth maps with RGB images during pre training, dubbed as RGB pre training. To be specific, RGB pre training modifies the input channel of the depth stem layer from 1 to 3 and duplicates the depth map three times during finetuning. Note that for the finetuning setting, the modalities of the input data and the model structure are the same. As shown in Tab. 3, our RGB-D pre training brings $2.3%$ improvement for DFormer-B compared to the RGB pre training in terms of mIoU on NYU DepthV2. We argue that this is because our RGB-D pre training avoids the mismatch encoding of the 3D geometry features of depth maps caused by the use of pretrained RGB backbones and enhances the interaction efficiency between the two modalities. Tab. 12 and Fig. 7 in the appendix also demonstrate this. These experiment results indicate that the RGB-D representation capacity learned during the RGB-D pre training is crucial for segmentation accuracy.
RGB-D与RGB预训练对比。为说明RGB-D预训练的必要性,我们尝试在预训练阶段用RGB图像替代深度图(称为RGB预训练)。具体而言,RGB预训练将深度分支层的输入通道从1改为3,并在微调阶段对深度图进行三次复制。需注意的是,微调设置中输入数据的模态与模型结构保持不变。如表3所示,在NYU DepthV2数据集上,我们的RGB-D预训练相比RGB预训练为DFormer-B带来了2.3%的mIoU提升。我们认为这是由于RGB-D预训练避免了使用预训练RGB主干网络导致的深度图3D几何特征编码失配,并增强了双模态间的交互效率。附录中的表12和图7也验证了这一点。实验结果表明,RGB-D预训练期间学习到的表征能力对分割精度至关重要。
Input features of the decoder. Benefiting from the powerful RGB-D pre training, the features of the RGB branch can efficiently fuse the information of two modalities. Thus, our decoder only uses the RGB features $X^{r g b}$ , which contains expressive clues, instead of using both $X^{r g b}$ and $X^{d}$ . As shown in Tab. 4, using only $X^{r g b}$ can save computational cost without performance drop, while other methods usually need to use both $X^{r g b}$ and $X^{d}$ . This difference also demonstrates that our proposed RGB-D pre training pipeline and block are more suitable for RGB-D segmentation.
解码器的输入特征。得益于强大的RGB-D预训练,RGB分支的特征能高效融合两种模态的信息。因此我们的解码器仅使用包含丰富线索的RGB特征$X^{r g b}$,而非同时使用$X^{r g b}$和$X^{d}$。如表4所示,仅使用$X^{r g b}$可在不损失性能的情况下节省计算成本,而其他方法通常需要同时使用$X^{r g b}$和$X^{d}$。这一差异也证明我们提出的RGB-D预训练流程和模块更适合RGB-D分割任务。
Components in our RGB-D block. Our RGB-D block is composed of a base module, GAA module, and LEA module. We take out these three components from DFormer respectively, where the results are shown in Tab. 5. It is clear that all of them are essential for our DFormer. Moreover, we visualize the features around the RGB-D block in Fig. 5. It can be seen the output features can capture more comprehensive details. As shown in Tab. 7, in the GAA module, we find that only fusing the depth features into $Q$ is adequate and further fusing depth features to $K$ and $V$ brings negligible improvement but extra computational burdens. Moreover, we find that the performance of DFormer initially rises as the fixed pooling size of the GAA increases, and it achieves the best when the fixed pooling size is set to $7\times7$ in Tab. 6. We also use two other fusion manners to replace that in LEA, i.e., concatenation, addition. As shown in Tab. 8, using the depth features that processed by a large kernel depth-wise convolution as attention weights to reweigh the RGB features via a simple Hadamard product achieves the best performance.
我们RGB-D模块中的组件。我们的RGB-D模块由基础模块、GAA模块和LEA模块组成。我们分别从DFormer中取出这三个组件进行测试,结果如 表5 所示。显然,它们对DFormer都至关重要。此外,我们在 图5 中可视化了RGB-D模块周围的特征,可以看到输出特征能捕捉更全面的细节。
如 表7 所示,在GAA模块中,我们发现仅将深度特征融合到 $Q$ 就已足够,进一步将深度特征融合到 $K$ 和 $V$ 带来的提升微乎其微,却会增加计算负担。此外,我们发现DFormer的性能最初随着GAA固定池化尺寸的增大而提升,当固定池化尺寸设为 $7\times7$ 时达到最佳(见 表6)。我们还尝试用两种其他融合方式(拼接和相加)替代LEA中的融合方式。如 表8 所示,使用经过大核深度卷积处理的深度特征作为注意力权重,通过简单的Hadamard乘积对RGB特征进行重新加权,能获得最佳性能。
Table 9: Comparison under the RGB-only pretraining. ‘NYU’ and ‘SUN’ means the performance on the NYU DepthV2 and SUNRGBD.
表 9: 仅使用RGB预训练时的对比结果。"NYU"和"SUN"分别表示在NYU DepthV2和SUNRGBD数据集上的性能。
| Model | Params | FLOPs | NYU | SUN |
|---|---|---|---|---|
| CMX (MiT-B2) | 66.6M | 67.6G | 54.4 | 49.7 |
| DFormer-B | 29.5M | 41.9G | 53.3 | 49.5 |
| DFormer-L | 39.0M | 65.7G | 55.4 | 50.6 |
Table 10: Comparison under the RGB-D pretraining. ‘NYU’ and ‘SUN’ means the performance on the NYU DepthV2 and SUNRGBD.
表 10: RGB-D预训练下的对比。"NYU"和"SUN"分别表示在NYU DepthV2和SUNRGBD数据集上的性能。
| 模型 | 参数量 | 计算量(FLOPs) | NYU | SUN |
|---|---|---|---|---|
| CMX (MiT-B2) | 66.6M | 67.6G | 55.8 | 51.1 |
| DFormer-B | 29.5M | 41.9G | 55.6 | 51.2 |
| DFormer-L | 39.0M | 65.7G | 57.2 | 52.5 |
Channel ratio between RGB and depth. RGB images contain information pertaining to object color, texture, shape, and its surroundings. In contrast, depth images typically convey the distance information from each pixel to the camera. Here, we in- vestigate the channel ratio that is used to encode the depth information. In Fig. 6, we present the performance of DFormer-S with different channel ratios, i.e., $C^{d}/C^{r g b}$ . We can see that when the channel ratio excceds $\ '1/2'$ , the improvement is trivial while the computational burden is significantly increased. Therefore, we set the ratio to 1/2 by default.
RGB与深度通道比例。RGB图像包含物体颜色、纹理、形状及其周围环境的信息,而深度图像通常传递每个像素到相机的距离信息。本文研究了用于编码深度信息的通道比例。如图6所示,我们展示了DFormer-S在不同通道比例(即$C^{d}/C^{r g b}$)下的性能表现。可以看出,当通道比例超过$\ '1/2'$时,性能提升微乎其微,而计算负担却显著增加。因此,我们默认将该比例设为1/2。
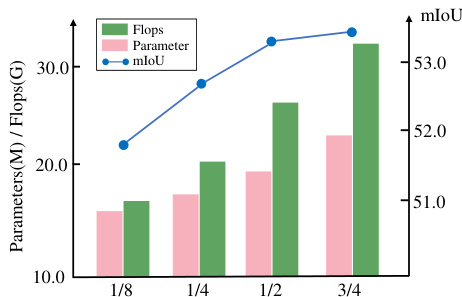
Figure 6: Performance on different channel ratios $C^{d}/C^{r g b}$ based on DFormer-S. $C^{r g b}$ is fixed and we adjust $C^{d}$ to get different ratios.
图 6: 基于 DFormer-S 的不同通道比例 $C^{d}/C^{rgb}$ 性能表现。固定 $C^{rgb}$ 并调整 $C^{d}$ 以获得不同比例。
Apply the RGB-D pre training manner to CMX. To verify the effect of the RGB-D pre training on other methods and make the comparison more fair, we pretrain the CMX (MiT-B2) on RGB-D data of ImageNet and it obtains about $1.4%$ mIoU improvement, as shown in Tab. 10. Under the RGB-D pre training, DFormer-L still outperforms CMX (MiT-B2) by a large margin, which should be attributed to that the pretrained fusion weight within DFormer can achieve better and efficient fusion between RGB-D data. Besides, we provide the RGB pretrained DFormers to provide more insights in Tab. 9. The similar situation appears under the RGB-only pre training.
对CMX采用RGB-D预训练方式。为验证RGB-D预训练对其他方法的效果并确保对比更公平,我们在ImageNet的RGB-D数据上预训练CMX (MiT-B2),其mIoU提升约$1.4%$,如 表 10 所示。在RGB-D预训练下,DFormer-L仍大幅领先CMX (MiT-B2),这应归因于DFormer内预训练的融合权重能实现RGB-D数据间更优且高效的融合。此外,我们在 表 9 中提供了RGB预训练的DFormers以提供更多洞察。仅使用RGB预训练时也出现类似情况。
Dicussion on the generalization to other modalities. Through RGB-D pre training, the DFormer is endowed with the capacity to interact the RGB and depth during pre training. To verify whether the interaction is still work when replace the depth with another modality, we apply our DFormer to some benchmarks with other modalities, i.e., RGB-T on MFNet (Ha et al., 2017) and RGB-L on KITTI-360 (Liao et al., 2021). As shown in the Tab. 11 (comparison to more methods are in the Tab. 15 and Tab. 16), RGB-D pre training still improves the performance on the RGB and other modalities, nevertheless, the improvement is limited com
关于多模态泛化能力的探讨。通过RGB-D预训练,DFormer获得了在预训练期间交互RGB和深度信息的能力。为验证这种交互机制在替换深度模态后是否依然有效,我们将DFormer应用于其他模态的基准测试:MFNet数据集(Ha等人,2017)的RGB-T模态和KITTI-360数据集(Liao等人,2021)的RGB-L模态。如表11所示(更多方法对比见表15和表16),RGB-D预训练仍能提升RGB与其他模态的性能表现,但提升幅度有限。
Table 11: Results on the RGB-T semantic segmentation benchmark MFNet (Ha et al., 2017) and RGB-L semantic segmentation benchmark KITTI-360 (Liao et al., 2021). ‘(RGB)’ and ‘(RGBD)’ mean the RGB-only and RGB-D pretraining, respectively.
表 11: RGB-T语义分割基准MFNet (Ha et al., 2017)和RGB-L语义分割基准KITTI-360 (Liao et al., 2021)上的结果。'(RGB)'和'(RGBD)'分别表示仅使用RGB和RGB-D的预训练。
| 模型 | 参数量 | 计算量 (FLOPs) | MFNet | KITTI |
|---|---|---|---|---|
| CMX-B2 | 66.6M | 67.6G | 58.2 | 64.3 |
| CMX-B4 | 139.9M | 134.3G | 59.7 | 65.5* |
| CMNeXt-B2 | 65.1M | 65.5G | 58.4* | 65.3 |
| CMNeXt-B4 | 135.6M | 132.6G | 59.9 | 65.6* |
| Ours-L(RGB) | 39.0M | 65.7G | 59.5 | 65.2 |
| Ours-L(RGBD) | 39.0M | 65.7G | 60.3 | 66.1 |
pared to that on RGB-D scenes. To address this issue, a foreseeable solution is to further scale the pre training of DFormer to other modalities. There are two ways to solve the missing of large-scale modal dataset worth trying, i.e., synthesizing the pseudo modal data, and seperately pre training on single modality dataset. As far as the former, there are some generation methods to generate other pseudo modal data. For example, Pseudo-lidar (Wang et al., 2019) propose a method to generate the pesudo lidar data from the depth map, and N-ImageNet (Kim et al., 2021) obtain the event data on the ImageNet. Besides, collecting data and training the modal generator for more modalities, is also worth exploring. For the latter one, we can separately pretrain the model for processing the supplementary modality and then combine it with the RGB model. We will attempt these methods to bring more significant improvements for DFormer on more multimodal scenes.
与RGB-D场景相比。为解决这一问题,一个可行的方案是进一步扩展DFormer在其他模态上的预训练。针对大规模多模态数据缺失问题,有两种值得尝试的解决途径:合成伪模态数据,以及在单模态数据集上分别进行预训练。就前者而言,现有多种生成方法可用于产生其他伪模态数据。例如,Pseudo-lidar (Wang等人,2019) 提出了一种从深度图生成伪激光雷达数据的方法,N-ImageNet (Kim等人,2021) 则在ImageNet上获取事件数据。此外,收集数据并训练更多模态的生成器也值得探索。对于后者,我们可以分别预训练处理补充模态的模型,再将其与RGB模型结合。我们将尝试这些方法,以期为DFormer在更多多模态场景中带来更显著的性能提升。
4 RELATED WORK
4 相关工作
RGB-D Scene Parsing In recent years, with the rise of deep learning technologies, e.g., CNNs (He et al., 2016), and Transformers (Vaswani et al., 2017; Li et al., 2023a), significant progress has been made in scene parsing (Xie et al., 2021; Yin et al., 2022; Chen et al., 2023; Zhang et al., 2023d), one of the core pursuits of computer vision. However, most methods still struggle to cope with some challenging scenes in the real world (Li et al., 2023b; Sun et al., 2020), as they only focus on RGB images that provide them with distinct colors and textures but not 3D geometric information. To overcome these challenges, researchers combine images with depth maps for a comprehensive understanding of scenes.
RGB-D场景解析
近年来,随着深度学习技术的兴起,例如CNN (He et al., 2016) 和Transformer (Vaswani et al., 2017; Li et al., 2023a),场景解析 (Xie et al., 2021; Yin et al., 2022; Chen et al., 2023; Zhang et al., 2023d) 作为计算机视觉的核心研究方向之一取得了显著进展。然而,大多数方法仍难以应对现实世界中的一些复杂场景 (Li et al., 2023b; Sun et al., 2020),因为它们仅关注提供颜色和纹理信息的RGB图像,而缺乏3D几何信息。为了克服这些挑战,研究者将图像与深度图结合以实现对场景的全面理解。
Semantic segmentation and salient object detection are two active areas in RGB-D scene parsing. Particularly, the former aims to produce per-pixel category prediction across a given scene, and the latter attempts to capture the most attention-grabbing objects. To achieve the interaction and alignment between RGB-D modalities, the dominant methods investigate a lot of effort in building fusion modules to bridge the RGB and depth features extracted by two parallel pretrained backbones. For example, methods like CMX (Zhang et al., 2023a), Token Fusion (Wang et al., 2022), and HiDANet (Wu et al., 2023) dynamically fuse the RGB-D representations from RGB and depth encoders and aggregate them in the decoder. Indeed, the evolution of fusion manners has dramatically pushed the performance boundary in these applications of RGB-D scene parsing. Nevertheless, the three common issues, as discussed in Sec. 1, are still left unresolved. Another line of work focuses on the design of operators (Wang & Neumann, 2018; Wu et al., 2020; Cao et al., 2021; Chen et al., 2021a) to extract complementary information from RGB-D modalities. For instance, methods like ShapeConv (Cao et al., 2021), SGNet (Chen et al., 2021a), and Z-ACN (Wu et al., 2020) propose depth-aware convolutions, which enable efficient RGB features and 3D spatial information integration to largely enhance the capability of perceiving geometry. Although these methods are efficient, the improvements brought by them are usually limited due to the insufficient extraction and utilization of the 3D geometry information involved in the depth modal.
语义分割和显著目标检测是RGB-D场景解析中的两个活跃领域。前者旨在对给定场景进行逐像素类别预测,后者则试图捕捉最引人注目的物体。为实现RGB-D模态间的交互与对齐,主流方法致力于构建融合模块来桥接两个并行预训练主干网络提取的RGB与深度特征。例如CMX (Zhang et al., 2023a)、Token Fusion (Wang et al., 2022)和HiDANet (Wu et al., 2023)等方法动态融合RGB-D编码器提取的表征,并在解码器中聚合。融合方式的演进确实显著推动了RGB-D场景解析应用的性能边界,但如第1节所述,三个常见问题仍未解决。另一研究方向聚焦于设计算子 (Wang & Neumann, 2018; Wu et al., 2020; Cao et al., 2021; Chen et al., 2021a) 以从RGB-D模态中提取互补信息。例如ShapeConv (Cao et al., 2021)、SGNet (Chen et al., 2021a)和Z-ACN (Wu et al., 2020)提出的深度感知卷积,通过高效整合RGB特征与3D空间信息来增强几何感知能力。尽管这些方法效率较高,但由于对深度模态中3D几何信息的提取和利用不足,其带来的性能提升通常有限。
Multi-modal Learning The great success of the pretrain-and-finetune paradigm in natural language processing and computer vision has been expanded to the multi-modal domain, and the learned transferable representations have exhibited remarkable performance on a wide variety of downstream tasks. Existing multi-modal learning methods cover a large number of modalities, e.g., image and text (Castrejon et al., 2016; Chen et al., 2020b; Radford et al., 2021; Zhang et al., 2021c; Wu et al., 2022), text and video (Akbari et al., 2021), text and 3D mesh (Zhang et al., 2023c), image, depth, and video (Girdhar et al., 2022). These methods can be categorized into two groups, i.e., multi- and joint-encoder ones. Specifically, the multi-encoder methods exploit multiple encoders to independently project the inputs in different modalities into a common space and minimize the distance or perform representation fusion between them. For example, methods like CLIP (Radford et al., 2021) and VATT (Akbari et al., 2021) employ several individual encoders to embed the representations in different modalities and align them via a contrastive learning strategy. In contrast, the joint-encoder methods simultaneously input the different modalities and use a multi-modal encoder based on the attention mechanism to model joint representations. For instance, MultiMAE (Bachmann et al., 2022) adopts a unified transformer to encode the tokens with a fixed dimension that are linearly projected from a small subset of randomly sampled multi-modal patches and multiple task-specific decoders to reconstruct their corresponding masked patches by the attention mechanism separately.
多模态学习
预训练-微调范式在自然语言处理和计算机视觉领域的巨大成功已扩展到多模态领域,学习到的可迁移表征在各种下游任务中展现出卓越性能。现有多模态学习方法涵盖大量模态组合,例如图像与文本 (Castrejon et al., 2016; Chen et al., 2020b; Radford et al., 2021; Zhang et al., 2021c; Wu et al., 2022)、文本与视频 (Akbari et al., 2021)、文本与3D网格 (Zhang et al., 2023c)、图像/深度/视频 (Girdhar et al., 2022)。这些方法可分为两类:多编码器与联合编码器。具体而言,多编码器方法采用多个编码器将不同模态输入独立映射到共享空间,并最小化其间距或执行表征融合。例如CLIP (Radford et al., 2021) 和VATT (Akbari et al., 2021) 通过对比学习策略对齐不同模态的表征。而联合编码器方法通过基于注意力机制的多模态编码器同步处理不同模态输入以建模联合表征。例如MultiMAE (Bachmann et al., 2022) 采用统一Transformer编码从随机采样的多模态图像块线性投影得到的固定维度token,并通过多个任务特定解码器分别重建掩码图像块。
In this paper, we propose DFormer, a novel framework that achieves RGB-D representation learning in a pre training manner. To the best of our knowledge, this is the first attempt to encourage the semantic cues from RGB and depth modalities to align together by the explicit supervision signals of classification, yielding transferable representations for RGB-D downstream tasks.
本文提出DFormer, 一种通过预训练方式实现RGB-D表征学习的新框架。据我们所知, 这是首次尝试通过分类任务的显式监督信号, 促使RGB和深度模态的语义线索对齐, 从而为RGB-D下游任务生成可迁移表征。
5 CONCLUSIONS
5 结论
In this paper, we propose a novel RGB-D pre training framework to learn transferable representations for RGB-D downstream tasks. Thanks to the tailored RGB-D block, our method is able to achieve better interactions between the RGB and depth modalities during pre training. Our experiments suggest that DFormer can achieve new state-of-the-art performance in RGB-D downstream tasks, e.g., semantic segmentation and salient object detection, with far less computational cost compared to existing methods.
本文提出了一种新颖的RGB-D预训练框架,用于学习可迁移的RGB-D下游任务表征。得益于定制的RGB-D模块,我们的方法能够在预训练过程中实现RGB与深度模态间更优的交互。实验表明,DFormer能以远低于现有方法的计算成本,在语义分割和显著目标检测等RGB-D下游任务中达到新的最先进性能。
ACKNOWLEDGMENTS
致谢
This research was supported by National Key Research and Development Program of China (No. 2021YFB3100800), NSFC (NO. 62225604, No. 62276145, and No. 62376283), the Fundamental Research Funds for the Central Universities (Nankai University, 070-63223049), CAST through Young Elite Scientist Sponsorship Program (No. YES S 20210377). Computations were supported by the Super computing Center of Nankai University (NKSC).
本研究得到国家重点研发计划(No. 2021YFB3100800)、国家自然科学基金(No. 62225604、No. 62276145和No. 62376283)、中央高校基本科研业务费专项资金(南开大学, 070-63223049)、中国科协青年人才托举工程(No. YES S 20210377)的资助。计算资源由南开大学超级计算中心(NKSC)提供支持。
REPRODUCIBILITY STATEMENT
可复现性声明
Ensuring the reproducibility of our research is important to us. In this reproducibility statement, we outline the measures taken to facilitate the replication of our work and provide references to the relevant sections in the main paper, appendix, and the code.
确保研究的可复现性对我们至关重要。在本可复现性声明中,我们概述了为便于复现工作所采取的措施,并提供了主要论文、附录及代码中相关章节的参考文献。
Source code. We have made our source code anonymously available in Link, allowing researchers to access and utilize our code for reproducing our experiments and results. Detailed installation instructions are in ‘README.md.’ The source code and model weights will be made public available.
源代码。我们已将源代码匿名发布在Link中,方便研究人员访问和使用我们的代码以复现实验和结果。详细安装说明请参阅"README.md"。源代码和模型权重将公开发布。
Experimental setup. In the main paper, we provided basic parameter settings and implementation settings in Sec. 2.2 (pre training), Sec. 3.1 (RGB-D semantic segmentation), and Sec. 3.2 (RGB-D salient object detection). In the Tab. 14 of the appendix, we provide the detailed configuration for different variants of our DFormer. We provide the training details in Tab. 17 and Tab. 18. Moreover, the experimental setups can be seen in the source code in the supplementary materials.
实验设置。在正文中,我们在第2.2节(预训练)、第3.1节(RGB-D语义分割)和第3.2节(RGB-D显著目标检测)提供了基本参数设置和实现配置。在附录的表14中,我们提供了DFormer不同变体的详细配置。训练细节见表17和表18。此外,实验设置可在补充材料中的源代码中查看。
By providing these resources and references, we aim to enhance the reproducibility of our work and enable fellow researchers to verify and build upon our findings. We welcome any inquiries or requests for further clarification on our methods to ensure the transparency and reliability of our research.
通过提供这些资源和参考文献,我们旨在提升本研究的可复现性,使同行研究者能够验证并拓展我们的发现。我们欢迎任何关于研究方法的问询或进一步说明的请求,以确保研究的透明度和可靠性。
REFERENCES
参考文献
- 4, 17
2015年4月17日
Wujie Zhou, Enquan Yang, Jingsheng Lei, and Lu Yu. Frnet: Feature reconstruction network for rgb-d indoor scene parsing. JSTSP, 16(4):677–687, 2022d. 5
Wujie Zhou、Enquan Yang、Jingsheng Lei和Lu Yu。Frnet:面向RGB-D室内场景解析的特征重建网络。JSTSP,16(4):677–687,2022d。5
Zhuangwei Zhuang, Rong Li, Kui Jia, Qicheng Wang, Yuanqing Li, and Mingkui Tan. Perceptionaware multi-sensor fusion for 3d lidar semantic segmentation. In ICCV, 2021. 20
庄伟庄、李荣、贾奎、王启程、李元庆和谭明奎。面向3D激光雷达语义分割的多传感器感知融合。收录于ICCV,2021。[20]
APPENDIX
附录
In Sec. A, we first provide further analysis of our DFormer: 1) the efficiency in encoding the depth maps; 2) the effect of depth maps in different quality during pre training. Then we present more detailed descriptions of DFormer in Sec. B and the experimental settings in Sec. C. Finally, we provide more visualization results of DFormer in Sec. D and future exploring directions in Sec. E.
在附录A中,我们首先对DFormer进行进一步分析:1) 深度图编码效率;2) 预训练中不同质量深度图的影响。随后在附录B中详细描述DFormer架构,附录C说明实验设置。最后在附录D展示更多DFormer可视化结果,附录E探讨未来研究方向。
A MORE ANALYSIS OF DFORMER
关于DFORMER的进一步分析

Figure 7: Encoding depth maps with backbones pretrained on different types of training data. (a) Pre training with RGB data. (b) Pre training with depth maps. During finetuning, we only take the depth maps as input to see which backbone works better. We visualize some features from the two backbones as shown in the bottom part. Obviously, the backbone pretrained on depth maps can generate more expressive feature maps.
图 7: 使用在不同类型训练数据上预训练的骨干网络编码深度图。(a) 使用RGB数据预训练。(b) 使用深度图预训练。在微调阶段,我们仅以深度图作为输入来观察哪种骨干网络表现更优。底部展示了两种骨干网络的部分特征可视化结果。显然,基于深度图预训练的骨干网络能生成更具表现力的特征图。
Table 12: Performance of the RGB pretrained and depth pretrained backbone processing depth maps for segmentation. The two backbones adopt the same pre training setting and architecture but are pretrained on the ImageNet images and their depth maps respectively.
表 12: 基于RGB预训练和深度预训练主干网络处理深度图进行分割的性能对比。两种主干网络采用相同的预训练设置和架构,但分别基于ImageNet图像及其深度图进行预训练。
| Backbone | #Params | FLOPs | mIoU(%) |
|---|---|---|---|
| RGB | 11.2M | 13.7G | 27.6 |
| Depth | 11.2M | 13.7G | 42.8 |
Why involving depth information in pre training? The existing state-of-the-art RGB-D methods (Zhang et al., 2023a; Wang et al., 2022) tend to use models pretrained on RGB images to encode 3D geometry information for depth maps. We argue that the huge representation distribution shift caused by using RGB backbone to encode the depth maps may influence the extraction of the 3D geometry. To demonstrate this, we respectively use RGB and depth data to pretrain the RGB and depth backbone and then take only the depth maps as input for segmentation, as shown in Fig. 7. From Tab. 12, we can see under the same network architecture, the model pretrained on depth images performs much better than the one pretrained on RGB images, i.e., yielding an improvement of $15%$ mIoU. To delve into the reasons, we visualize the feature maps as shown in the bottom part of Fig. 7. Before fing, the backbone pretrained on RGB data is not able to extract expressive features from the depth maps. After fing, the model using RGB backbones still struggles to extract diverse features from the depth maps. On the contrary, the features from the backbone pretrained on depth data are better. These experiments indicate that there exists significant difference RGB and depth maps and it is difficult to process depth data with RGB pretrained weights. This also motivates us to involve depth data during ImageNet pre training.
为什么要在预训练中加入深度信息?现有的最先进RGB-D方法 (Zhang et al., 2023a; Wang et al., 2022) 通常使用在RGB图像上预训练的模型来编码深度图的3D几何信息。我们认为,使用RGB主干网络编码深度图导致的巨大表征分布偏移可能会影响3D几何特征的提取。为验证这一点,我们分别用RGB和深度数据预训练RGB与深度主干网络,然后仅以深度图作为分割输入,如图7所示。从表12可以看出,在相同网络架构下,深度图像预训练的模型性能显著优于RGB图像预训练的模型,即mIoU指标提升了$15%$。为探究原因,我们对特征图进行了可视化(图7底部)。在微调前,基于RGB数据预训练的主干网络无法从深度图中提取有表现力的特征。微调后,使用RGB主干网络的模型仍难以从深度图中提取多样化特征。相比之下,深度数据预训练的主干网络提取的特征更优。这些实验表明,RGB与深度图存在显著差异,使用RGB预训练权重处理深度数据具有挑战性。这也促使我们在ImageNet预训练阶段引入深度数据。

Figure 8: Comparison of esitimated depth maps that generated by Adabins (Bhat et al., 2021) and more advanced Omnidata (Eftekhar et al., 2021). We visualize the depth maps in color for better comparison.
图 8: Adabins (Bhat et al., 2021) 与更先进的 Omnidata (Eftekhar et al., 2021) 生成的估计深度图对比。我们采用彩色可视化深度图以便更好比较。
Impact of the quality of depth maps. In the main paper, we use a depth estimation method Adabins (Bhat et al., 2021) to predict depth maps for the ImageNet-1K (Russ a kov sky et al., 2015) dataset. Both the ImageNet images and the generated depth maps are used to pretrain our DFormer. Here, we explore the effect of depth maps in different quality on the performance of DFormer. To this end, we also choose a more advanced depth estimation method, i.e., Omnidata (Eftekhar et al., 2021), to generate the depth maps. In Fig. 8, we visualize the generated depth maps that are generated by these two methods. We use the Omnidata-predicted depth maps to replace the Adabins-predicted ones during RGB-D pre training. Then, we use this to pretrain the DFormer-Base and it achieves nearly the same performance, i.e., 55.6 mIoU on NYUDepth v2. This indicates the quality of depth maps has little effect on the performance of DFormer.
深度图质量的影响。在正文中,我们使用深度估计方法Adabins (Bhat et al., 2021) 为ImageNet-1K (Russakovsky et al., 2015) 数据集预测深度图。ImageNet图像和生成的深度图均用于预训练我们的DFormer。此处,我们探究不同质量的深度图对DFormer性能的影响。为此,我们还选择了更先进的深度估计方法Omnidata (Eftekhar et al., 2021) 来生成深度图。图8展示了这两种方法生成的深度图可视化效果。在RGB-D预训练阶段,我们用Omnidata预测的深度图替换Adabins预测的结果。随后使用该数据预训练DFormer-Base模型,其性能基本持平(在NYUDepth v2上达到55.6 mIoU)。这表明深度图质量对DFormer性能影响甚微。

Figure 9: The statistics of distribution shift on the finetuning of DFormer-S that uses different pre training manners. The BN layer at the first block of stage 2 is chosen for this visualization.
图 9: 采用不同预训练方式的 DFormer-S 微调过程中分布偏移的统计结果。该可视化选取了阶段 2 第一个块的 BN (Batch Normalization) 层进行展示。
Observations towards the distribution shift. Interacting the RGB and depth features within the RGB-pretrained encoders would bring in drastic changing of the feature distribution, which makes the previous statistic of batch normalization incompatible with the input features. Folowing the (Chen et al., 2021b), we visualize the statistics of the BN layers during the finetuning to reflect the distribution shift. Specifically, we visualize the statistics of batch normalization for a random layer in the DFormer in Fig. 9 of the new revision to observe the statistic of the fused features to the RGB backbone. For the RGBD-pretrained DFormer, the running mean and variance of the BN layer only have slight changes after finetuning, illustrating the learned RGBD representation is transferable for the RGBD segmentation tasks. In contract, for the RGB-pretrained one, the statistics of the BN layer are indeed drastically changed after finetuning, which indicates the encoding is mismatched. The situation forces RGB-pretrained weights to adapt the input features fused by two modalities. We also visualize some features of the DFormer that uses the RGB and RGBD pre training, as shown in Fig. 10.
关于分布偏移的观察。在RGB预训练编码器内交互RGB和深度特征会导致特征分布剧烈变化,这使得批量归一化之前的统计量与输入特征不兼容。遵循 (Chen et al., 2021b) 的方法,我们通过可视化微调过程中BN层的统计量来反映分布偏移。具体而言,在新修订版的图9中,我们可视化了DFormer随机层的批量归一化统计量,以观察融合特征对RGB主干的统计影响。对于RGBD预训练的DFormer,BN层的滑动均值和方差在微调后仅有轻微变化,表明学习到的RGBD表征可迁移至RGBD分割任务。相比之下,RGB预训练模型的BN层统计量在微调后发生剧烈变化,说明编码存在失配。这种情况迫使RGB预训练权重必须适应两种模态融合的输入特征。我们还分别可视化采用RGB与RGBD预训练的DFormer特征,如图10所示。

Figure 10: Visualization of the features within the finetuned models that load RGB-pretrained and RGBDpretrained weights. The features are randomly picked from the first stage output in the DFormer-S.
图 10: 微调模型中加载 RGB 预训练和 RGBD 预训练权重的特征可视化。这些特征随机选自 DFormer-S 第一阶段输出。
B DETAILS OF DFORMER
B DFORMER 的详细说明
Structure. In the main paper, we only present the structure map of the interaction modules due to the limited space, and the base modules is omitted. The detailed structure of our RGB-D block is presented in Fig. 11. The GAA, LEA and base modules jointly construct the block, and each of them is essential and contribute to the performance improvement. GAA and LEA aims to conduct interactions between different modalities globally and locally, while the base module is only responsible for encoding RGB features. As the first stage focuses on encoding low-level feature, we do not use GAA in the first stage for the sake of efficiency. Moreover, the MLP layers for the RGB and depth features are indivisual.
结构。由于篇幅限制,主论文中仅展示了交互模块的结构图,基础模块部分未予呈现。图 11 展示了我们 RGB-D (Red Green Blue-Depth) 模块的详细结构。全局注意力适配器 (GAA)、局部嵌入适配器 (LEA) 和基础模块共同构建该模块,三者缺一不可且均对性能提升有所贡献。GAA 和 LEA 旨在全局与局部层面实现不同模态间的交互,而基础模块仅负责编码 RGB 特征。由于第一阶段专注于低级特征编码,出于效率考虑我们未在第一阶段使用 GAA。此外,RGB 与深度特征所用的多层感知机 (MLP) 层是独立设计的。
Inference time analysis. Real-time inference of an RGB-D model plays a key role in a wide spectrum of downstream applications, as stated by (Chen et al., 2020a). To this end, we conduct experiments to explore the real-time potential of our DFormer and other methods. To ensure fairness, all comparisons are performed on the same device, i.e., a single 3090 RTX GPU, and the same image resolution, i.e., $480\times640$ . As illustrated in Fig. 12, our DFormer-L achieves $57.2%$ mIoU with $35.7\mathrm{ms}$ latency, while the latency of current state-of-the-art CMNext is $78.2\mathrm{ms}$ . Remarkably, our DFormer-S can process an image in $20\mathrm{ms}$ and achieve about 50 frames per second (FPS) with competitive performance on NYU Depthv2, i.e., $53.6%$ mIoU.
推理时间分析。如 (Chen et al., 2020a) 所述,RGB-D 模型的实时推理在广泛的下游应用中起着关键作用。为此,我们通过实验探索 DFormer 及其他方法的实时潜力。为确保公平性,所有比较均在相同设备(即单块 3090 RTX GPU)和相同图像分辨率($480\times640$)下进行。如图 12 所示,我们的 DFormer-L 以 $35.7\mathrm{ms}$ 延迟实现 $57.2%$ mIoU,而当前最优方法 CMNext 的延迟为 $78.2\mathrm{ms}$。值得注意的是,DFormer-S 仅需 $20\mathrm{ms}$ 即可处理单张图像,在 NYU Depthv2 数据集上达到约 50 帧/秒 (FPS) 的速率,同时保持 $53.6%$ mIoU 的竞争力性能。

Figure 12: Performance vs. Latency when processing $480\times640$ images.
图 12: 处理 $480\times640$ 图像时的性能与延迟对比。
More detailed ablation towards the block. In the main paper, we have provided the ablation experiments about the components of our RGB-D block, the pooling size of our GAA, as well as the fusion manners in GAA and LEA. Here we provide more results for the modules that encode RGB features, as shown in Tab. 13. Due to limited time and computation resources, we use a short pre training duration of 100 epochs on the DFormer-S. Note that the results in the below table only ablates the stucture within the modules (gray part in Fig. 11) that only process the RGB features.
关于模块的更详细消融实验。在正文中,我们已经提供了关于RGB-D模块组件的消融实验、GAA的池化大小以及GAA和LEA中融合方式的消融结果。这里我们提供了更多关于RGB特征编码模块的结果,如 表13 所示。由于时间和计算资源有限,我们在DFormer-S上仅进行了100个epoch的短期预训练。请注意,下表中的结果仅针对仅处理RGB特征的模块内部结构(图11 中的灰色部分)进行消融。

Figure 11: Detailed structure of our RGB-D block in DFormer.
图 11: DFormer中RGB-D模块的详细结构。
Table 13: Ablation towards the base modules within the building block of DFormer-S.
表 13: DFormer-S 构建模块中基础组件的消融实验
| DWConvSetting | AttentionOperation | Param | Flops | NYUDepthV2 |
|---|---|---|---|---|
| DWConv7×7 | HadamardProduct | 18.7M | 25.6G | 51.9 |
| DWConv5×5 | HadamardProduct | 18.7M | 23.9G | 51.6 |
| DWConv9×9 | HadamardProduct | 18.7M | 27.1G | 51.9 |
| DwConv7×7 | Addition | 18.7M | 25.0G | 51.3 |
| DWConv7×7 | Concatanation | 19.3M | 26.9G | 51.7 |
B.1 COMPARISON ON THE MFNET AND KITTI-360
B.1 MFNET 与 KITTI-360 的对比
For a more comprehensive comparison, we compare our DFormer and more other state-of-theart methods on the MFNet (Ha et al., 2017) and KITTI-360 (Liao et al., 2021) in Tab. 16 and Tab. 15, as a supplement to the main paper.
为了进行更全面的比较,我们在表 15 和表 16 中将我们的 DFormer 与更多其他先进方法在 MFNet (Ha et al., 2017) 和 KITTI-360 (Liao et al., 2021) 上进行了对比,作为主论文的补充。
C EXPERIMENTAL DETAILS
C 实验细节
C.1 IMAGENET PRE TRAINING
C.1 IMAGENET 预训练
We provide DFormers’ ImageNet-1K pre training settings in Tab. 17. All DFormer variants use the same settings, except the stochastic depth rate. Besides, the data augmentation strategies related to color, e.g., auto contrast, are only used for RGB images, while other common strategies are simultaneously performed on RGB images and depth maps, e.g., random rotation.
我们在表17中提供了DFormers在ImageNet-1K上的预训练设置。所有DFormer变体使用相同的设置,除了随机深度率。此外,与颜色相关的数据增强策略(如自动对比度)仅用于RGB图像,而其他常见策略(如随机旋转)则同时在RGB图像和深度图上执行。
C.2 RGB-D SEMANTIC SEGMENTATION FINETUNING
C.2 RGB-D 语义分割微调
The finetuning settings for NYUDepth v2 and SUNRGBD datasets are listed in Tab. 18. The batch sizes, input sizes, base learning rate, epochs and stochastic depth are different for the two datasets.
NYUDepth v2和SUNRGBD数据集的微调设置如 表 18 所示。两个数据集的批量大小、输入尺寸、基础学习率、训练轮次和随机深度均不相同。
Datasets. Following the common experiment settings of RGB-D semantic segmentation methods (Xie et al., 2021; Guo et al., 2022a), we finetune and evaluate the DFormer on two widely used datasets, i.e., NYUDepthv2 (Silberman et al., 2012) and SUN-RGBD (Song et al., 2015). To be specific, NYUDepthv2 (Silberman et al., 2012) contains 1,449 RGB-D samples covering 40 categories, where the resolution of all RGB images and depth maps is unified as $480\times640$ . Particularly, 795 image-depth pairs are used to train the RGB-D model, and the remaining 654 are utilized for testing. SUN-RGBD (Song et al., 2015) includes 10,335 RGB-D images with $530\times730$ resolution, where the objects are in 37 categories. All samples of this dataset are divided into 5,285 and 5,050 splits for training and testing, respectively.
数据集。遵循RGB-D语义分割方法的常见实验设置 (Xie et al., 2021; Guo et al., 2022a),我们在两个广泛使用的数据集上对DFormer进行微调和评估,即NYUDepthv2 (Silberman et al., 2012) 和 SUN-RGBD (Song et al., 2015)。具体而言,NYUDepthv2 (Silberman et al., 2012) 包含1,449个RGB-D样本,涵盖40个类别,其中所有RGB图像和深度图的分辨率统一为$480\times640$。特别地,795对图像-深度数据用于训练RGB-D模型,其余654对用于测试。SUN-RGBD (Song et al., 2015) 包含10,335张分辨率为$530\times730$的RGB-D图像,其中物体分为37个类别。该数据集的所有样本被划分为5,285和5,050份,分别用于训练和测试。
Table 14: Detailed configurations of the proposed DFormer. $\dot{\boldsymbol{C}}^{}\boldsymbol{C}^{}=(^{}\boldsymbol{C}{r g b},^{}\boldsymbol{C}{d}^{}){:}$ , which respectively represent the channel number of the RGB part and the depth part in different stages. $N_{i}^{,}$ is the number of building blocks in $i$ -th stage. ‘Expansion’ is the expand ratio for the number of channels in MLPs. ‘Decoder dimension’ denotes the channel dimension in the decoder.
表 14: 提出的 DFormer 的详细配置。$\dot{\boldsymbol{C}}^{}\boldsymbol{C}^{}=(^{}\boldsymbol{C}{r g b},^{}\boldsymbol{C}{d}^{*}){:}$,分别表示不同阶段 RGB 部分和深度部分的通道数。$N_{i}^{,}$ 是第 $i$ 阶段构建块的数量。"Expansion" 是 MLP 中通道数的扩展比率。"Decoder dimension" 表示解码器中的通道维度。
| Stage | Output size | Expansion | DFormer-T | DFormer-S | DFormer-B | DFormer-L | |
|---|---|---|---|---|---|---|---|
| Stem | × | M 4 | C = (16,8) | (32,16) | (32,16) | (48, 24) | |
| C= (32,16),N1 = 3 | (64,32), 2 | (64,32),3 | (96, 48),3 | ||||
| 1 2 | 8HHH | 4 M | 8 8 | (128,64),2 | (128,64),3 | (192,96),3 | |
| X H | C= (64,32),N2 = 3 | ||||||
| 3 4 | 16 H | M × 16 | 4 4 | C = (128,64), N3 = 5 | (256,128),4 | (256,128),12 | (288,144),12 |
| W × 32 | C=(256,128),N4 = 2 | (512,256),2 | (512,256),2 | (576,288),3 | |||
| Decoderdimension | 512 | 512 | 512 | ||||
| Parameters (M) | 18.7 | 29.5 | 39.0 |
Table 15: MFNet (RGB-T) (Ha et al., 2017).
表 15: MFNet (RGB-T) (Ha et al., 2017).
| 方法 | 主干网络 | mIoU (%) |
|---|---|---|
| ACNet (Hu et al.) FuseSeg (Sun et al.) ABMDRNet (Zhang et al.) LASNet (Li et al.) FEANet (Deng et al.) MFTNet (Zhou et al.) GMNet (Zhou et al.) DooDLeNet (Frigo et al.) | ResNet-50 DenseNet-161 ResNet-18 ResNet-152 ResNet-152 ResNet-152 ResNet-50 ResNet-101 | 46.3 54.5 54.8 54.9 55.3 57.3 57.3 57.3 |
| CMX (Zhang et al.) CMX (Zhang et al.) CMNeXt (Zhang et al.) | MiT-B2 MiT-B4 | 58.2 59.7 59.9 |
| (RGB) DFormer | MiT-B4 Ours-B | 59.5 |
| (RGBD) DFormer | Ours-L | 60.3 |
表 16: KITTI-360 (RGB-L) (Lia0 et al.).
| 方法 | 主干网络 | mIoU (%) |
|---|---|---|
| HRFuser (Broedermann et al.) | HRFormer-T | |
| PMF (Zhuang et al.) | SalsaNext | 48.7 |
| 54.5 54.6 | ||
| TokenFusion (Wang et al.) TransFuser (Prakash et al.) CMX (Zhang et al.) CMNeXt (Zhang et al.) | MiT-B2 RegNetY MiT-B2 | 56.6 64.3 |
Implementation Details. Following SegNext Guo et al. (2022a), we employ Hamburger (Geng et al., 2021), a lightweight head, as the decoder to build our RGB-D semantic segmentation network. During finetuning, we only adopt two common data augmentation strategies, i.e., random horizontal flipping and random scaling (from 0.5 to 1.75). The training images are cropped and resized to $480\times640$ and $480\times480$ respectively for NYU Depthv2 and SUN-RGBD benchmarks. Crossentropy loss is utilized as the optimization objective. We use AdamW (Kingma & Ba, 2015) as our optimizer with an initial learning rate of 6e-5 and the poly decay schedule. Weight decay is set to 1e-2. During testing, we employ mean Intersection over Union (mIoU), which is averaged across semantic categories, as the primary evaluation metric to measure the segmentation performance. Following recent works (Zhang et al., $2023\mathrm{a}$ ; Wang et al., 2022; Zhang et al., 2023b), we adopt multi-scale (MS) flip inference strategies with scales ${0.5,0.75,1,1.25,1.5}$ .
实现细节。我们遵循SegNext (Guo et al., 2022a)的方法,采用轻量级头部Hamburger (Geng et al., 2021)作为解码器来构建RGB-D语义分割网络。在微调阶段,仅使用两种常见的数据增强策略:随机水平翻转和随机缩放(缩放系数0.5至1.75)。训练图像在NYU Depthv2和SUN-RGBD基准测试中分别被裁剪并调整至$480\times640$和$480\times480$分辨率。采用交叉熵损失作为优化目标,使用AdamW (Kingma & Ba, 2015)优化器,初始学习率为6e-5并采用多项式衰减策略,权重衰减设为1e-2。测试阶段以语义类别平均的交并比(mIoU)作为主要评估指标。参照近期研究(Zhang et al., $2023\mathrm{a}$; Wang et al., 2022; Zhang et al., 2023b),我们采用多尺度(MS)翻转推理策略,尺度参数为${0.5,0.75,1,1.25,1.5}$。
Table 17: DFormer ImageNet-1K pre training settings. All the pre training experiments are conducted on 8 NVIDIA 3090 GPUs.
表 17: DFormer ImageNet-1K 预训练设置。所有预训练实验均在 8 块 NVIDIA 3090 GPU 上完成。
| 预训练配置 | DFormer-T | DFormer-S | DFormer-B | DFormer-L |
|---|---|---|---|---|
| 输入尺寸 | 2242 | 2242 | 2242 | 2242 |
| 权重初始化 | 截断正态 (0.2) | 截断正态 (0.2) | 截断正态 (0.2) | 截断正态 (0.2) |
| 优化器 | AdamW | AdamW | AdamW | AdamW |
| 基础学习率 | 1e-3 | 1e-3 | 1e-3 | 1e-3 |
| 权重衰减 | 0.05 | 0.05 | 0.05 | 0.05 |
| 优化器动量 | β1, β2=0.9,0.999 | β1, β2=0.9,0.999 | β1, β2=0.9,0.999 | β1,β2=0.9,0.999 |
| 批次大小 | 1024 | 1024 | 1024 | 1024 |
| 训练周期 | 300 | 300 | 300 | 300 |
| 学习率调度 | 余弦衰减 | 余弦衰减 | 余弦衰减 | 余弦衰减 |
| 预热周期 | 5 | 5 | 5 | 5 |
| 预热调度 | 线性 | 线性 | 线性 | 线性 |
| 分层学习率衰减 | 无 | 无 | 无 | 无 |
| 随机增强 | (9,0.5) | (9,0.5) | (9,0.5) | (9,0.5) |
| 混合增强 | 0.8 | 0.8 | 0.8 | 0.8 |
| 剪切混合 | 1.0 | 1.0 | 1.0 | 1.0 |
| 随机擦除 | 0.25 | 0.25 | 0.25 | 0.25 |
| 标签平滑 | 0.1 | 0.1 | 0.1 | 0.1 |
| 随机深度 | 0.1 | 0.1 | 0.15 | 0.2 |
| 头部初始化缩放 | 无 | 无 | 无 | 无 |
| 梯度裁剪 | 无 | 无 | 无 | 无 |
| 指数移动平均 (EMA) | 无 | 无 | 无 | 无 |
Table 18: DFormer finetuning settings on NYUDepthv2/SUNRGBD. Multiple stochastic depth rates, input sizes and batch sizes are for NYUDepthv2 and SUNRGBD datasets respectively. All the finetuning experiments for RGB-D semantic seg me nations are conducted on 2 NVIDIA 3090 GPUs.
表 18: DFormer在NYUDepthv2/SUNRGBD上的微调设置。多重随机深度率、输入尺寸和批次大小分别对应NYUDepthv2和SUNRGBD数据集。所有RGB-D语义分割的微调实验均在2块NVIDIA 3090 GPU上进行。
| 预训练配置 | DFormer-T | DFormer-S | DFormer-B | DFormer-L |
|---|---|---|---|---|
| 输入尺寸 | 480×640/480² | 480×640/480² | 480×640/480² | 480×640/480² |
| 优化器 | AdamW | AdamW | AdamW | AdamW |
| 基础学习率 | 6e-5/8e-5 | 6e-5/8e-5 | 6e-5/8e-5 | 6e-5/8e-5 |
| 权重衰减 | 0.01 | 0.01 | 0.01 | 0.01 |
| 批次大小 | 8/16 | 8/16 | 8/16 | 8/16 |
| 训练轮次 | 500/300 | 500/300 | 500/300 | 500/300 |
| 优化器动量 | β1,β2=0.9,0.999 | β1,β2=0.9,0.999 | β1,β2=0.9,0.999 | β1,β2=0.9,0.999 |
| 实际训练轮次 | 300 | 300 | 300 | 300 |
| 学习率调度 | 线性衰减 | 线性衰减 | 线性衰减 | 线性衰减 |
| 预热轮次 | 10 | 10 | 10 | 10 |
| 预热策略 | 线性 | 线性 | 线性 | 线性 |
| 分层学习率衰减 | 无 | 无 | 无 | 无 |
| 辅助头 | 无 | 无 | 无 | 无 |
| 随机深度 | 0.1/0.1 | 0.1/0.1 | 0.1/0.1 | 0.15/0.2 |
C.3 RGB-D SALIENT OBJECT DETECTION
C.3 RGB-D 显著目标检测
Dataset. We finetune and test DFormer on five popular RGB-D salient object detection datasets. The finetuning dataset consists of 2,195 samples, where 1,485 are from NJU2K-train (Ju et al., 2014) and the other 700 samples are from NLPR-train (Peng et al., 2014). The model is evaluated on eight datasets, i.e., DES (Cheng et al., 2014) (135 samples), NLPR-test (Peng et al., 2014) (300), NJU2K-test (Ju et al., 2014) (500), STERE (Niu et al., 2012) (1,000), SIP (Fan et al., 2020) (929). The comparison of our method and other state-of-the-art methods is shown in the Tab. 2.
数据集。我们在五个流行的RGB-D显著目标检测数据集上对DFormer进行微调和测试。微调数据集包含2,195个样本,其中1,485个来自NJU2K-train (Ju et al., 2014),其余700个样本来自NLPR-train (Peng et al., 2014)。模型在八个数据集上进行评估,包括DES (Cheng et al., 2014) (135个样本)、NLPR-test (Peng et al., 2014) (300)、NJU2K-test (Ju et al., 2014) (500)、STERE (Niu et al., 2012) (1,000)、SIP (Fan et al., 2020) (929)。我们的方法与其他最先进方法的对比结果如 表2 所示。
Implementation Details. We set the output channel of Hamburger (Geng et al., 2021) head to 1, which is further added on the top of our RGB-D backbone to build the RGB-D salient object detection network. For model finetuning, we adopt the same data augmentation strategies and model optimizer as in SPNet (Zhou et al., 2021a). For performance evaluation, we adopt four golden metrics of this task, i.e., Structure-measure (S) (Fan et al., 2017), mean absolute error (M) (Perazzi et al., 2012), max F-measure (F) (Margolin et al., 2014), and max E-measure $(\mathrm{E})$ (Fan et al., 2018).
实现细节。我们将Hamburger (Geng等人,2021)头的输出通道设为1,并进一步添加在RGB-D主干网络顶部以构建RGB-D显著目标检测网络。对于模型微调,我们采用与SPNet (Zhou等人,2021a)相同的数据增强策略和模型优化器。性能评估方面,我们采用该任务的四个黄金指标:结构度量(S) (Fan等人,2017)、平均绝对误差(M) (Perazzi等人,2012)、最大F值(F) (Margolin等人,2014)以及最大E值$(\mathrm{E})$ (Fan等人,2018)。

Figure 13: Detailed illustration for the input features of the decoder head. Top: Only the features in the RGB branch are sent to the decoder. Bottom: The features of both RGB and depth branches are sent to the decoder.
图 13: 解码器头部输入特征的详细说明。上:仅RGB分支的特征被送入解码器。下:RGB和深度分支的特征均被送入解码器。
C.4 MORE DETAILS ABOUT THE DECODER INPUT FEATURES
C.4 解码器输入特征的更多细节
Benefiting from the powerful RGB-D pre training, the features of the RGB branch can better fuse the information of the two modalities compared to the ones with RGB pre training. Thus, our decoder only takes the RGB features $X_{i}^{r g b}$ instead of both $X_{i}^{r g b}$ and $X_{i}^{d}$ as input. The detailed structures of the two forms are shown in Fig. 13, as a supplement for Tab. 4 in the main paper.
得益于强大的RGB-D预训练,与仅进行RGB预训练的特征相比,RGB分支的特征能更好地融合两种模态的信息。因此,我们的解码器仅以RGB特征$X_{i}^{r g b}$作为输入,而非同时输入$X_{i}^{r g b}$和$X_{i}^{d}$。两种结构的详细形式如图13所示,作为主论文中表4的补充说明。
D MORE VISUALIZATION RESULTS
D 更多可视化结果
In this section, we provide more visualization results in Fig. 14. Our DFormer produces higher segmentation accuracy than the current state-of-the-art CMNext (MiT-B4). Moreover, the visualization comparison on RGB-D salient object detection are shown in Fig. 15.
在本节中,我们通过图 14 展示了更多可视化结果。我们的 DFormer 比当前最先进的 CMNext (MiT-B4) 实现了更高的分割精度。此外,图 15 展示了 RGB-D 显著目标检测的可视化对比结果。
E FUTURE WORK
E 未来工作
We argue that there are a number of foreseeable directions for future research: 1) Applications on a wider range of RGB-D downstream tasks. Considering that our pretrained DFormer backbones own better RGB-D representation capabilities, it is promising to apply them to more RGB-D tasks, e.g., RGB-D face anti-spoofing (George & Marcel, 2021), 3D visual grounding (Liu et al., 2021a), RGB-D tracking (Yan et al., 2021), and human volumetric capture (Yu et al., 2021). 2) Extension to other modalities. Based on the well-designed framework, it is interesting to produce multi-modal representations by substituting depth with other sensor data in other modalities, such as thermal and lidar data. The incorporation of additional modalities can facilitate the development of specialized and powerful encoders to meet the needs of various tasks. 3) More lightweight models. Current RGB-D methods are usually too heavy to deploy to mobile devices. Although DFormer is efficient, there is still a gap and development space in practical applications. We hope this paper could inspire researchers to develop better RGB-D encoding method, pushing the boundaries of what’s feasible in real-world scenarios.
我们认为未来研究有以下几大可预见方向:
- 更广泛的RGB-D下游任务应用。鉴于我们预训练的DFormer骨干网络具备更优的RGB-D表征能力,将其应用于更多RGB-D任务前景广阔,例如RGB-D人脸防伪 (George & Marcel, 2021)、3D视觉定位 (Liu et al., 2021a)、RGB-D追踪 (Yan et al., 2021) 以及人体体积捕捉 (Yu et al., 2021)。
- 多模态扩展。基于精心设计的框架,可通过将深度数据替换为其他模态传感器数据(如热成像和激光雷达数据)来生成多模态表征。引入更多模态有助于开发专业化强编码器,满足多样化任务需求。
- 更轻量化模型。现有RGB-D方法通常体积庞大,难以部署至移动设备。尽管DFormer效率出众,实际应用中仍存在差距与发展空间。我们希望本文能启发研究者开发更优的RGB-D编码方法,突破现实场景应用的可行性边界。

Figure 14: Qualitative comparison of DFormer-L (Ours) and CMNext (MiT-B4) (Zhang et al., 2023b) on the NYU Depthv2 (Silberman et al., 2012) dataset.
图 14: DFormer-L (Ours) 与 CMNext (MiT-B4) (Zhang et al., 2023b) 在 NYU Depthv2 (Silberman et al., 2012) 数据集上的定性对比。

Figure 15: Qualitative comparison of DFormer-L (Ours), HiDANet (Wu et al., 2023), and SPNet Zhou et al. (2021a) on the NJU2K dataset.
图 15: DFormer-L (Ours)、HiDANet (Wu et al., 2023) 和 SPNet Zhou et al. (2021a) 在 NJU2K 数据集上的定性对比。