Whisper-Flamingo: Integrating Visual Features into Whisper for Audio-Visual Speech Recognition and Translation
Abstract
摘要
Audio-Visual Speech Recognition (AVSR) uses lip-based video to improve performance in noise. Since videos are harder to obtain than audio, the video training data of AVSR models is usually limited to a few thousand hours. In contrast, speech models such as Whisper are trained with hundreds of thousands of hours of data, and thus learn a better speech-totext decoder. The huge training data difference motivates us to adapt Whisper to handle video inputs. Inspired by Flamingo which injects visual features into language models, we propose Whisper-Flamingo which integrates visual features into the Whisper speech recognition and translation model with gated cross attention. Our models achieve state-of-the-art ASR WER $(0.68%)$ and AVSR WER $(0.76%)$ on LRS3, and stateof-the-art ASR WER $(1.3%)$ and AVSR WER $(1.4%)$ on LRS2. Audio-visual Whisper-Flamingo outperforms audio-only Whisper on English speech recognition and En-X translation for 6 languages in noisy conditions. Moreover, Whisper-Flamingo is versatile and conducts all of these tasks using one set of parameters, while prior methods are trained separately on each language.
视听语音识别 (AVSR) 利用唇部视频提升噪声环境下的识别性能。由于视频数据比音频更难获取,AVSR 模型的视频训练数据通常仅限于数千小时。相比之下,Whisper 等语音模型使用数十万小时数据进行训练,因此能学习到更优质的语音到文本解码器。这种巨大的训练数据差异促使我们改造 Whisper 以处理视频输入。受 Flamingo 向语言模型注入视觉特征的启发,我们提出 Whisper-Flamingo,通过门控交叉注意力将视觉特征整合到 Whisper 语音识别与翻译模型中。我们的模型在 LRS3 上实现了最先进的 ASR 词错误率 $(0.68%)$ 和 AVSR 词错误率 $(0.76%)$,在 LRS2 上实现了最先进的 ASR 词错误率 $(1.3%)$ 和 AVSR 词错误率 $(1.4%)$。在噪声环境下,视听 Whisper-Flamingo 在英语语音识别和 6 种语言的英-X 翻译任务上均优于纯音频 Whisper。此外,Whisper-Flamingo 具有多功能性,仅用一组参数即可执行所有任务,而现有方法需针对每种语言单独训练。
Index Terms: audio-visual speech recognition, noise-robust
索引术语:视听语音识别,抗噪
1. Introduction
1. 引言
In recent years, major improvements in Automatic Speech Recognition (ASR) performance have been achieved by models trained on large-scale data [1, 2], but performance still declines in noise [3]. To enhance performance in noise, Audio-Visual Speech Recognition (AVSR) uses lip-based video in addition to audio inputs. Self-Supervised Learning (SSL) methods such as AV-HuBERT [4] pre-train on large-scale datasets of unlabeled videos and fine-tune on a few hundred hours of labeled videos to perform noise-robust AVSR. However, due to the difficulty in collecting publicly accessible videos, these models are usually trained on only a few thousand hours of data.
近年来,通过在大型数据集上训练的模型,自动语音识别 (ASR) 性能取得了显著提升 [1, 2],但在噪声环境下性能仍会下降 [3]。为提高噪声环境下的性能,视听语音识别 (AVSR) 除了音频输入外还加入了基于唇部的视频信息。自监督学习 (SSL) 方法(如 AV-HuBERT [4])先在未标注视频的大规模数据集上进行预训练,再用数百小时标注视频微调,从而实现抗噪声的 AVSR。然而,由于公开可获取视频的收集难度,这些模型通常仅用几千小时的数据进行训练。
To overcome the lack of video data, recent methods finetune audio-only models pre-trained on hundreds of thousands of hours of audio for audio-visual speech recognition [5–7]. The results show that such audio models combined with audiovisual fine-tuning on a few hundred hours of videos can approach the performance of video models pre-trained on thousands of hours of video [6]. However, these methods often train video models and text decoders from scratch on only a few hundred hours of data, which is suboptimal compared to training on large-scale data. Furthermore, only English data has been used.
为克服视频数据不足的问题,近期方法通过在数十万小时音频数据上预训练的纯音频模型进行微调,以实现视听语音识别 [5-7]。结果表明,这类音频模型结合数百小时视频数据的视听微调,其性能可接近基于数千小时视频数据预训练的视频模型 [6]。然而,这些方法通常仅用数百小时数据从头训练视频模型和文本解码器,相比大规模数据训练仍存在不足。此外,目前仅使用了英语数据。
In this work, we propose to integrate visual features from AV-HuBERT into Whisper [1], an audio-only model trained on 680k hours of speech with a strong multilingual decoder. Compared to the prior audio-visual adaptation methods, our video model and text decoder are pre-trained with large-scale data. This allows our method to perform well on audio-visual speech translation, a task not explored by prior methods [5–7].
在这项工作中,我们提出将AV-HuBERT的视觉特征集成到Whisper[1]中,这是一个仅在68万小时语音数据上训练的纯音频模型,具备强大的多语言解码器。与先前的视听适配方法相比,我们的视频模型和文本解码器都经过大规模数据预训练。这使得我们的方法在视听语音翻译任务上表现优异,这是先前方法[5-7]未曾探索的领域。
How to fuse modalities effectively in multi-modal models is an ongoing research question. One recent work, Flamingo [8], fuses visual features into text-only language models using gated cross attention and fine-tuning on a paired text-image dataset. The gated cross attention layers are initialized to the identity function and learn to attend to the visual features during finetuning. These layers have been shown to generalize to different modality pairs; Audio Flamingo [9] recently applied them for text-audio reasoning. Inspired by this method, we propose Whisper-Flamingo which inserts gated cross attention layers into Whisper’s decoder and enables Whisper to use lip-based features for speech recognition.
如何有效融合多模态模型中的不同模态是一个持续的研究课题。近期工作 Flamingo [8] 通过门控交叉注意力机制 (gated cross attention) 和在图文配对数据集上的微调,将视觉特征融入纯文本语言模型。这些门控交叉注意力层被初始化为恒等函数,并在微调过程中学习关注视觉特征。研究表明该结构能泛化至不同模态组合:Audio Flamingo [9] 近期将其应用于文本-音频推理任务。受此启发,我们提出 Whisper-Flamingo 模型,通过在 Whisper 解码器中插入门控交叉注意力层,使其能够利用唇部视觉特征进行语音识别。
On the English $\mathrm{(En)}$ LRS3 video dataset [10], our models achieve State-of-the-Art (SOTA) ASR WER $(0.68%)$ and AVSR WER $(0.76%)$ . On LRS2 [11], our models achieve SOTA ASR WER $(1.3%)$ and AVSR WER $(1.4%)$ . Our novel audiovisual Whisper-Flamingo significantly outperforms the audioonly Whisper baseline in noise. Moreover, Whisper-Flamingo achieves competitive noise-robust results compared to prior audio-visual models. Next, we demonstrate Whisper’s multilingual capabilities by extending Whisper-Flamingo for En-X translation on the MuAViC dataset [12]. Our model performs En transcription and En-X translation into 6 other languages, while the previous audio-visual SOTA requires fine-tuning on each language separately. Once again, Whisper-Flamingo significantly outperforms audio-only Whisper in noise for both En transcription and En-X translation. Code and models at https://github.com/roudimit/whisper-flamingo
在英语 (En) LRS3视频数据集[10]上,我们的模型实现了最先进的 (SOTA) 自动语音识别 (ASR) 词错误率 (WER) $(0.68%)$ 和视听语音识别 (AVSR) 词错误率 $(0.76%)$。在LRS2[11]上,我们的模型实现了SOTA ASR WER $(1.3%)$ 和AVSR WER $(1.4%)$。我们新颖的视听 Whisper-Flamingo 在噪声环境下显著优于纯音频 Whisper 基线。此外,Whisper-Flamingo 与之前的视听模型相比,实现了具有竞争力的噪声鲁棒性结果。接下来,我们通过在MuAViC数据集[12]上扩展Whisper-Flamingo进行En-X翻译,展示了Whisper的多语言能力。我们的模型能够进行英语转录和将英语翻译成其他6种语言,而之前的视听SOTA需要对每种语言分别进行微调。再次证明,Whisper-Flamingo在噪声环境下无论是英语转录还是En-X翻译,都显著优于纯音频Whisper。代码和模型详见 https://github.com/roudimit/whisper-flamingo
2. Method
2. 方法
In this section, we review audio-visual fusion methods for AVSR, and then explain our method. Two common fusion methods are early and late fusion. In early fusion, both modalities are first separately processed by light-weight encoders and then combined with feature addition or concatenation and used as input to an audio-visual Transformer [11, 13]. Both SSL models [4, 14, 15] and fully-supervised models [16–18] use this design. In late fusion, audio and video are processed separately by Transformer encoders, and afterwards features are fused with an MLP. The audio-visual features are then passed to a linearlayer or Transformer decoder. This approach is common for fully-supervised models [19–21]. Both early and late fusion need identical audio and visual feature rates so that they can be fused at each time step; a common design is to match the video’s frame rate by down sampling the audio features to $25\mathrm{Hz}$ .
在本节中,我们回顾了视听语音识别(AVSR)中的视听融合方法,并阐述我们的方法。两种常见融合方式是早期融合和晚期融合。早期融合中,两种模态先分别通过轻量编码器处理,再通过特征相加或拼接合并,作为视听Transformer的输入 [11, 13]。这种设计既见于自监督学习(SSL)模型 [4, 14, 15],也见于全监督模型 [16-18]。晚期融合中,音频和视频分别由Transformer编码器处理,之后通过MLP融合特征,最终传入线性层或Transformer解码器。这种方案常见于全监督模型 [19-21]。两种融合方式都要求音频和视觉特征速率一致以实现逐时间步融合,典型设计是将音频特征降采样至$25\mathrm{Hz}$以匹配视频帧率。
Most methods which adapt pre-trained audio-only models for AVSR through audio-visual fine-tuning use early fu- sion. FAVA [6] adapts BEST-RQ [22], an audio self-supervised model, through early fusion with a video model trained from scratch. Adaptive AV [7] prepends Whisper with an audiovisual Transformer to output a de-noised spec tr ogram, but does not use visual features directly in Whisper. However, we found gated cross attention with features from pre-trained AVHuBERT worked better than early fusion. Note that separate research focuses on using visual features from images or instruct ional videos for AVSR, where the visuals provide context and are only loosely synchronized with the audio [23, 24].
大多数通过视听微调将纯音频预训练模型适配到视听语音识别(AVSR)的方法都采用早期融合策略。FAVA [6] 通过早期融合方式将自监督音频模型BEST-RQ [22] 与从头训练的视频模型结合。Adaptive AV [7] 在Whisper前端添加视听Transformer来输出降噪频谱图,但未直接在Whisper中使用视觉特征。然而,我们发现采用预训练AVHuBERT特征的门控交叉注意力机制比早期融合表现更优。需注意另有研究专注于利用图像或教学视频中的视觉特征进行AVSR,这类视觉信息主要提供上下文语境,与音频仅保持松散同步 [23, 24]。
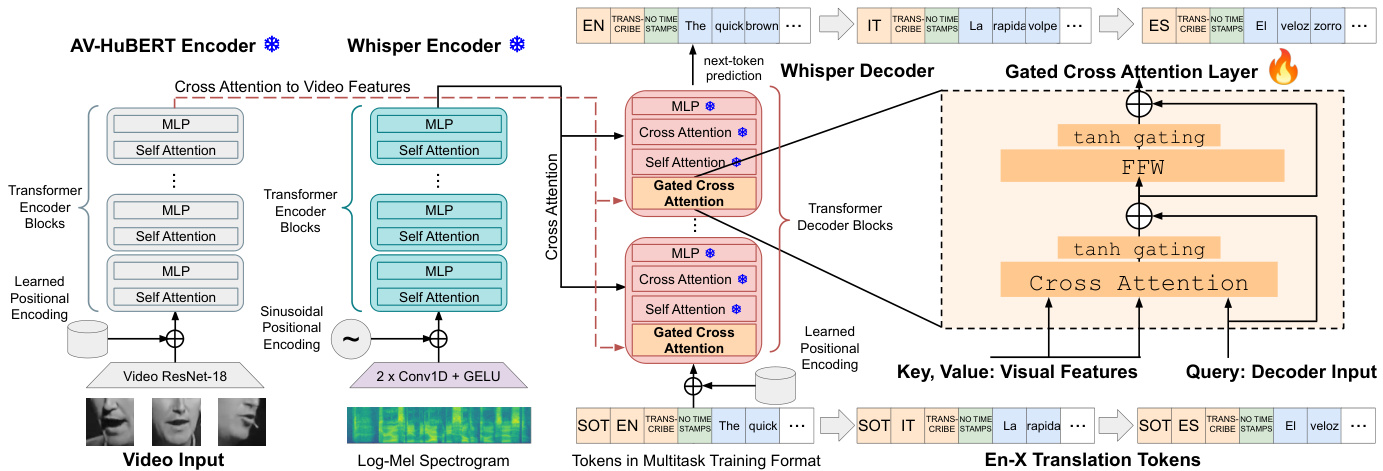
Figure 1: Diagram of Whisper-Flamingo based on Whisper [1] and Flamingo [8]. We first fine-tune all of Whisper’s parameters using English audio for English transcription and En-X translation. To train Whisper-Flamingo, we freeze the audio model, add gated cross attention layers into Whisper’s decoder attending to visual features from AV-HuBERT, and train the model on audio-visual inputs.
图 1: 基于Whisper [1]和Flamingo [8]的Whisper-Flamingo架构图。我们首先使用英语音频对Whisper的所有参数进行微调,用于英语转录和英-X翻译。训练Whisper-Flamingo时,冻结音频模型,在Whisper解码器中加入门控交叉注意力层以处理来自AV-HuBERT的视觉特征,并在音视觉输入上训练该模型。
Table 1: Hyper parameter summary. We first train WhisperLarge FT (Fine-tune) with audio-only, then use it to initialize Whisper-Flamingo. $A=$ audio, $A V{=}$ audio-visual. †=per sample.
表 1: 超参数汇总。我们首先仅用音频数据训练 WhisperLarge FT (微调版),随后将其用于初始化 Whisper-Flamingo。$A=$ 音频,$AV=$ 音视频。†=每样本。
| Whisper-Large FT | Whisper-Large FT | Whisper-Flamingo | Whisper-Flamingo | |
|---|---|---|---|---|
| TestModalities | A | A | AV | AV |
| En Recognition | ||||
| En-XTranslation | < | × | ||
| GPUs | 1 | 4 | 1 | 4 |
| TotalParams. | 1.55B | 1.55B | 2.5B | 2.5B |
| AV-HuBERTParams. | 325M | 325M | ||
| GatedX-AttnParams. | 630M | 630M | ||
| Trainable Params. | 1.55B | 1.55B | 631M | 631M |
| WarmupSteps | 1k | 1k | 5k | 5k |
| Total Steps | 90k | 225k | 20k | 40k |
| LearningRate | 5 × 10-6 | 5 × 10-6 | 1 × 10-4 | 1 × 10-4 |
| Batch per GPU (s) | 80 | 40 | 160 | 30 |
| Max Length (s) | 10 | 10 | 15 | 15 |
| Max Characters | 350 | 300 | 350 | 250 |
We propose to adapt Whisper’s decoder with visual features from AV-HuBERT using gated cross attention, as shown in Figure 1. Each of Whisper’s decoder blocks consists of a self-attention layer, cross attention layer attending to the audio features, and a Multi-Layer Perceptron (MLP). Based on Flamingo [8], the gated cross attention layer is defined as follows, where $\mathbf{x}$ is the input to the decoder block, $\mathbf{v}$ are the visual features, Attn is multi-head cross attention, LN is Layernorm [25], and FFW is an MLP:
我们提出使用门控交叉注意力机制将AV-HuBERT的视觉特征适配到Whisper的解码器中,如图1所示。Whisper的每个解码器块由自注意力层、针对音频特征的交叉注意力层以及多层感知机(MLP)组成。基于Flamingo [8],门控交叉注意力层定义如下:其中$\mathbf{x}$表示解码器块的输入,$\mathbf{v}$表示视觉特征,Attn表示多头交叉注意力,LN表示层归一化(Layernorm) [25],FFW表示MLP:
$$
\begin{array}{r l}&{\mathbf{x}^{\prime}=\mathbf{x}+\operatorname{tanh}(\alpha_{\mathrm{xattn}})\times\mathrm{Attn}(\mathrm{LN}(\mathbf{x}),\mathbf{v})}\ &{\mathbf{y}=\mathbf{x}^{\prime}+\operatorname{tanh}(\alpha_{\mathrm{mlp}})\times\mathrm{FFW}(\mathrm{LN}(\mathbf{x}^{\prime}))}\end{array}
$$
$$
\begin{array}{r l}&{\mathbf{x}^{\prime}=\mathbf{x}+\operatorname{tanh}(\alpha_{\mathrm{xattn}})\times\mathrm{Attn}(\mathrm{LN}(\mathbf{x}),\mathbf{v})}\ &{\mathbf{y}=\mathbf{x}^{\prime}+\operatorname{tanh}(\alpha_{\mathrm{mlp}})\times\mathrm{FFW}(\mathrm{LN}(\mathbf{x}^{\prime}))}\end{array}
$$
The learnable parameters $\alpha_{\mathrm{{xattn}}}$ and $\alpha_{\mathrm{mlp}}$ are initialized to 0 so that the layers initially function as the identity since $\operatorname{tanh}(0)=$ 0. Through audio-visual fine-tuning, the model adjusts the weights of $\alpha_{\mathrm{{xattn}}}$ and $\alpha_{\mathrm{{mlp}}}$ and learns to attend to the visual features. We insert the gated cross attention layers in Whisper’s decoder in the beginning of each block, before the self-attention layer. We tried to insert them in other orders within the decoder blocks, but the performance was slightly worse. The full analysis is shown in the Appendix, Section 8.4. Note that since the gated cross attention separately attends to the video features, the audio and video features can have different feature rates (for example, $50\mathrm{Hz}$ and $25\mathrm{Hz}$ ).
可学习参数 $\alpha_{\mathrm{{xattn}}}$ 和 $\alpha_{\mathrm{mlp}}$ 初始化为0,使得各层最初作为恒等函数运行,因为 $\operatorname{tanh}(0)=$ 0。通过视听微调,模型调整 $\alpha_{\mathrm{{xattn}}}$ 和 $\alpha_{\mathrm{{mlp}}}$ 的权重,并学会关注视觉特征。我们将门控交叉注意力层插入Whisper解码器每个模块的开头,位于自注意力层之前。我们尝试过在解码器模块内以其他顺序插入这些层,但性能稍差。完整分析见附录第8.4节。需要注意的是,由于门控交叉注意力分别处理视频特征,音频和视频特征可以有不同的特征速率(例如 $50\mathrm{Hz}$ 和 $25\mathrm{Hz}$)。
Table 2: Fusion ablation with Whisper-Medium on LRS3. We report results on the original test set (Clean) and with babble noise injected at 0-SNR (Noisy). $A=$ audio, $A V{=}$ audio-visual.
表 2: Whisper-Medium 在 LRS3 上的融合消融实验。我们报告了原始测试集 (Clean) 和注入 0-SNR 混叠噪声 (Noisy) 的结果。$A=$ 音频,$A V{=}$ 音视频。
| 模型 | 测试模态 | Clean WER√ | Noisy WER√ |
|---|---|---|---|
| Whisper, 零样本 | A | 2.3 | 22.2 |
| Whisper, 微调 | A | 1.9 | 12.6 |
| Whisper-Early-Fusion | AV | 1.7 | 10.0 |
| Whisper-Late-Fusion | AV | 2.1 | 16.5 |
| Whisper-Flamingo | AV | 1.5 | 7.0 |
Training pipeline. Before adding gated cross attention, we first fine-tune all layers of the audio-only Whisper model to adapt it to the domain of interest (denoted as Whisper Fine-tuned). We also add noise during fine-tuning to increase the noiserobustness. We use the standard cross-entropy loss between the model’s predicted transcript and the ground-truth tokens. To train Whisper-Flamingo, we freeze the fine-tuned Whisper, insert the gated cross attention layers, and fine-tune the model with audio-visual inputs. The gated cross attention layers and a linear layer on top of the visual features are trained from scratch, while all other parameters are frozen. The new layers can therefore be seen as a (large) set of adaptors [32]: removing them results in the audio-only Whisper weights.
训练流程。在添加门控交叉注意力机制前,我们首先对纯音频Whisper模型的所有层进行微调(标记为Whisper Fine-tuned),使其适应目标领域。微调过程中还加入了噪声以增强抗噪性,使用模型预测文本与真实Token之间的标准交叉熵损失进行训练。针对Whisper-Flamingo的训练,我们冻结微调后的Whisper模型,插入门控交叉注意力层,并通过视听输入进行微调。其中门控交叉注意力层和视觉特征顶部的线性层从头开始训练,其余参数全部冻结。这些新增层可视为一组(大型)适配器[32]:移除它们即可恢复纯音频Whisper的原始权重。
From English to Multilingual. Whisper was trained for multilingual transcription and X-En translation (multilingual audio to En text). We tried Whisper-Flamingo on multilingual speech recognition and X-En translation using the videos in the MuAViC dataset [12] but found several issues. Most languages in the dataset have less than a third of the hours of English data available, which makes training new layers from scratch difficult. Also, the multilingual videos are longer on average than the English videos. This causes increased GPU memory pressure and requires a reduced batch size, which also makes training difficult. Therefore we focused on En-X translation (English audio to multilingual text) and propose to handle multilingual recognition and translation in future work [29, 33–36].
从英语到多语言。Whisper 是为多语言转录和 X-En 翻译(多语言音频到英文文本)而训练的。我们尝试使用 MuAViC 数据集 [12] 中的视频对 Whisper-Flamingo 进行多语言语音识别和 X-En 翻译测试,但发现了一些问题。该数据集中大多数语言的可用数据量不足英语数据的三分之一,这使得从头训练新层变得困难。此外,多语言视频的平均时长比英语视频更长。这导致 GPU 内存压力增加,需要减小批处理大小,同样使得训练变得困难。因此我们将重点放在 En-X 翻译(英语音频到多语言文本)上,并建议在未来工作中处理多语言识别和翻译问题 [29, 33-36]。
Table 3: Results for English transcription on LRS3. We report results on the original test set (Clean) and with babble noise added at 0-SNR (Noisy). Hours of unlabeled & labeled audio-visual data used to train each model are shown. $433h{=}L R S3$ , $1,759h{=}L R S3+V o x C e l e b2$ . Noise dataset $=$ dataset used to make babble noise for testing. Noisy WER from methods using different noise datasets are not directly comparable. Note† that u-HuBERT [14], AV-HuBERT [26], and CMA [27] use a different noise file than us. $^{*}=$ noisy results were not reported using 0-SNR.
表 3: LRS3 英语转录结果。我们报告了原始测试集 (Clean) 和添加 0-SNR 混响噪声 (Noisy) 的结果。显示了用于训练每个模型的未标记和标记视听数据小时数。$433h{=}LRS3$, $1,759h{=}LRS3+VoxCeleb2$。噪声数据集 $=$ 用于生成测试混响噪声的数据集。使用不同噪声数据集方法的噪声 WER 不可直接比较。注意† u-HuBERT [14]、AV-HuBERT [26] 和 CMA [27] 使用了与我们不同的噪声文件。$^{*}=$ 未报告使用 0-SNR 的噪声结果。
| 模型 | 噪声数据集 | 未标记视听训练小时数 | 标记视听训练小时数 | 语音识别 WER↓ (Clean) | 语音识别 WER↓ (Noisy) | 视听语音识别 WER↓ (Clean) | 视听语音识别 WER↓ (Noisy) |
|---|---|---|---|---|---|---|---|
| 仅使用带字幕视频训练的视听方法 | |||||||
| VIT 3D [17] | NoiseX | - | 90k | 1.6 | 6.1 | 1.6 | 2.9 |
| LP Conformer [28] | NoiseX | 100k | - | 0.9 | 1.9 | ||
| AutoAVSR [21] | NoiseX | 1,902 / 3,448 | 1.0/1.0 | 米 | 1.0/0.9 | * | |
| Fast Conformer [29] | NoiseX | 435 /3,116 | 1.6/0.7 | * | 1.7 /0.8 | * | |
| 视听自监督学习方法 | |||||||
| AV2vec [15] | MUSAN | 433 | 433 | 2.7 | 19.5 | 2.5 | 6.7 |
| AV-BEST-RQ [6] | NoiseX | 1,759 | 433 | 2.1 | 6.8 | ||
| BRAVEn [30] | NoiseX | 2,649 | 433 | 1.1 | |||
| AV-HuBERT [26] | LRS3↑ | 1,759 | 433 | 1.6 | 15.7 | 1.4 | 5.8 |
| u-HuBERT [14] | LRS3↑ | 1,759 | 433 | 1.4 | 19.3 | 1.3 | 4.6 |
| CMA [27] | LRS3↑ | 1,759 | 433 | 1.5 | 4.4 | ||
| 纯音频预训练+视听微调方法 | |||||||
| Adaptive AV [7] | MUSAN | 400 | 30 | 2.3 | 16.3 | ||
| FAVA-USM [6] | NoiseX | 433 | 1.3 | 6.2 | |||
| Llama-AVSR [31] | NoiseX | 1,759 | 433 /1,759 | 1.1/0.81 | 12.3 / - | 0.95/0.77 | 4.2 / - |
| 我们的纯音频 Whisper 零样本基线 | |||||||
| Whisper-Large, Zero-shot, Beam 1 | LRS3 | 2.3 | 23.3 | ||||
| →w/Beam search 15 | LRS3 | - | 2.1 | 20.8 | |||
| 我们未使用噪声训练的模型 | |||||||
| Whisper-Large, Fine-tuned w/o noise, Beam 1 | LRS3 | 433 / 1,759 | 1.0/0.68 | 21.6 / 23.6 | |||
| →w/Beam search 15 | LRS3 | 433 /1,759 | 1.3 / 1.5 | 23.1 /24.1 | |||
| Whisper-Flamingo, Fine-tuned w/o noise, Beam 1 | LRS3 | 1,759 | 433/1,759 | = | 1.1/0.76 | 13 / 14.9 | |
| →w/Beam search 15 | LRS3 | 1,759 | 433 /1,759 | 1 | 1.1/ 1.8 | 12.8 / 15.9 | |
| 我们使用噪声训练的模型 | |||||||
| Whisper-Large, Fine-tuned w/ noise, Beam 1 | LRS3 | 433 /1,759 | 1.1/0.85 | 12.4 / 11.9 | |||
| →w/Beam search15 | LRS3 | 433 /1,759 | 2.3/2.0 | 11.7/11.1 | |||
| Whisper-Flamingo,Fine-tuned w/ noise, Beam 1 | LRS3 | 1,759 | 433 /1,759 | 1.0/0.86 | 7.2/6.1 | ||
| →w/Beam search15 | LRS3 | 1,759 | 433 /1,759 | 1.5 / 2.0 | 5.6 / 5.6 |
Prior research shows that Whisper can be prompted for EnX translation, but it requires language-specific logit filtering and the performance can still be unsatisfactory [24]. Since finetuning Whisper has been shown to enable transcription of unseen languages [37], we propose to fine-tune Whisper for En-X translation. We fine-tune the audio model in a multi-task style to transcribe English audio and translate it to the other languages. To train Whisper-Flamingo, we freeze the fine-tuned audio model, add the gated cross attention layers and the linear layer on top of the visual features, and train the model on audio-visual inputs.
先前研究表明,Whisper可以通过提示实现英语到X语(EnX)翻译,但需要特定语言的logit过滤且性能仍不理想[24]。由于微调Whisper已被证明能实现未见过语言的转写[37],我们提出对Whisper进行英语到多语种(En-X)翻译的微调。我们以多任务方式微调音频模型,使其既能转写英语音频又能翻译成其他语言。为训练Whisper-Flamingo,我们冻结微调后的音频模型,在视觉特征顶部添加门控交叉注意力层和线性层,并在音视频输入上训练该模型。
3. Experiments on LRS3
3. LRS3 实验
3.1. Experimental Setup
3.1. 实验设置
To train our models, we use LRS3 [10] - the largest, publiclyavailable AVSR dataset in English (En), sourced from TED talks. We followed AV-HuBERT [4] to create a 433h training set, 1h validation set, and 1h test set. We also combined the LRS3 training videos with 1,326h of English videos from VoxCeleb2 [40] for training. Transcripts for the VoxCeleb2 videos were obtained from Whisper Large-v2 [41]. For En-X translation, we use the MuAViC [12] dataset which has translations of LRS3’s English text into 6 languages: Greek (El), Spanish (Es), French (Fr), Italian (It), Portuguese (Pt), and Russian $\mathrm{(Ru)}$ .
为训练我们的模型,我们使用LRS3 [10]——目前最大的公开英语视听语音识别(AVSR)数据集,数据源自TED演讲。参照AV-HuBERT [4]的方法,我们构建了433小时训练集、1小时验证集和1小时测试集。同时将LRS3训练视频与来自VoxCeleb2 [40]的1,326小时英语视频合并用于训练,VoxCeleb2视频的文本转录由Whisper Large-v2 [41]生成。针对英语到其他语言(En-X)的翻译任务,我们采用MuAViC [12]数据集,该数据集包含LRS3英语文本到6种语言的翻译:希腊语(El)、西班牙语(Es)、法语(Fr)、意大利语(It)、葡萄牙语(Pt)以及俄语$\mathrm{(Ru)}$。
We use Whisper Small, Medium, and Large-v2 with 244M, 769M, and 1.55B parameters [1]. We extract 80-bin log-Mel spec tro grams with a stride of 10ms and window size of $25\mathrm{ms}$ from audio sampled at 16kHz. We extract video features from the AV-HuBERT Large [4] encoder fine-tuned on LRS3 with 325M parameters. For Whisper Large, the gated cross attention layers add 630M parameters, bringing the total number of parameters to 2.5B (including AV-HuBERT). We freeze AVHuBERT but enable dropout and batch normalization updating during Whisper-Flamingo training. The videos have a frame rate of 25fps and are converted to grayscale. Dlib [42] is used to extract $96\mathrm{x}96$ crops centered on the lips which are aligned to a reference mean face [43]. During training, a random $88\mathrm{x}88$ crop is used and the video is flipped horizontally with probability 0.5. For testing, the center 88x88 crop is used.
我们使用参数量分别为2.44亿、7.69亿和15.5亿的Whisper Small、Medium和Large-v2模型[1]。从16kHz采样的音频中提取80维对数梅尔频谱图,步长为10ms,窗宽为$25\mathrm{ms}$。视频特征通过参数量3.25亿、在LRS3数据集上微调的AV-HuBERT Large[4]编码器提取。Whisper Large模型的门控交叉注意力层新增6.3亿参数,使总参数量达到25亿(含AV-HuBERT)。训练过程中冻结AV-HuBERT参数,但在Whisper-Flamingo训练时启用dropout和批量归一化更新。视频帧率为25fps并转为灰度图,使用Dlib[42]提取以嘴唇为中心的$96\mathrm{x}96$区域,并基于参考平均人脸[43]进行对齐。训练时采用随机$88\mathrm{x}88$裁剪并以0.5概率水平翻转,测试时则使用中心88x88裁剪区域。
Table 1 summarizes the hyper parameters for the main experiments. We used A6000 GPUs with 48GB memory. Audio/video samples with similar lengths are batched together, and short samples are 0-padded. AdamW was used as the optimizer [44]. Following [1], we used Spec Augment [45] (Libri speechBasic) with Whisper-Large and did not use it with WhisperMedium. Training was done with PyTorch [46] and PyTorch Lightning [47]. We used the Spec Augment and batch sorter imple ment at ions from ESPnet [48].
表 1: 总结了主要实验的超参数。我们使用内存为48GB的A6000 GPU。将长度相近的音频/视频样本批量处理,短样本用0填充。优化器采用AdamW [44]。遵循[1]的做法,我们在Whisper-Large上使用了Spec Augment [45] (Libri speechBasic),但未在WhisperMedium上使用。训练基于PyTorch [46]和PyTorch Lightning [47]实现。Spec Augment和批次排序器实现来自ESPnet [48]。
We train our models in two conditions: without noise (clean) and with noise (noisy). For clean training, we do not add any noise to the audio. For noisy training, we randomly add noise to the audio with a signal-to-noise ratio (SNR) of 0. Following prior work [12, 26], the “natural”, “music” and “babble” noise are sampled from the MUSAN dataset [49], and overlapping “speech” noise is sampled from LRS3 [10]. To select the best checkpoints, we monitor the highest token prediction accuracy on the clean or noisy validation set every 1k steps. Following prior work [12], we use the Fairseq normalizer [50] to remove punctuation and lower-case text before calculating WER. For translation, we use SacreBLEU [51] with the default 13-a tokenizer to calculate BLEU [52].
我们在两种条件下训练模型:无噪声(干净)和有噪声(嘈杂)。对于干净训练,我们不对音频添加任何噪声。对于嘈杂训练,我们以0的信噪比(SNR)随机向音频添加噪声。遵循先前工作 [12, 26],"自然"、"音乐"和"嘈杂"噪声从MUSAN数据集 [49] 中采样,而重叠的"语音"噪声则从LRS3 [10] 中采样。为选择最佳检查点,我们每1k步监控干净或嘈杂验证集上的最高token预测准确率。遵循先前工作 [12],我们在计算WER前使用Fairseq标准化器 [50] 去除标点并将文本转为小写。对于翻译任务,我们使用默认13-a tokenizer的SacreBLEU [51] 计算BLEU [52]。
Table 4: Results for English transcription on LRS3 and En-X Translation on MuAViC. Babble noise is added at 0-SNR (Noisy). One Mode $!=$ the model translates to all languages with one set of parameters. Test Mod. $=$ inference modalities (Text: T, audio: A, video: V audio-visual: AV). Note† that Bilingual AV-HuBERT [12] use a different noise file than us that was not publicly available so the results in noisy conditions are not directly comparable.
表 4: LRS3英语转录和MuAViC英-X翻译结果。添加了0-SNR的混响噪声(Noisy)。One Mode $!=$ 表示模型使用一组参数翻译所有语言。Test Mod. $=$ 推理模态(文本: T, 音频: A, 视频: V, 视听: AV)。注意† 双语AV-HuBERT [12]使用了与我们不同的噪声文件(未公开),因此在噪声条件下的结果无法直接比较。
| 模型 | Test Mod. | One Model | 噪声数据集 | En WER↓ | El | Es | BLEU↑ | It | Pt | Ru | Avg w/oEn |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 文本到文本翻译 | |||||||||||
| Bilingual Transformer[12] | T | - | - | 25.8 | 29.5 | 27.0 | 22.6 | 23.9 | 17.2 | 24.3 | |
| M2M-100 [12,38] | - | 24.5 | 28.7 | 25.6 | 21.8 | 22.2 | 15.8 | 23.1 | |||
| 语音到文本翻译(纯净音频) | |||||||||||
| Bilingual AV-HuBERT [12] | A | - | - | 23.0 | 27.5 | 25.1 | 20.7 | 20.1 | 15.6 | 21.9 | |
| Whisper-Small, Fine-tuned | A | - | 2.0 | 22.4 | 27.1 | 24.9 | 20.7 | 21.6 | 15.6 | 22.1 | |
| Whisper-Medium, Fine-tuned | A | 2.1 | 22.9 | 27.5 | 26.1 | 20.9 | 21.4 | 15.1 | 22.5 | ||
| Whisper-Large, Fine-tuned | A | 1.5 | 23.7 | 27.9 | 26.0 | 21.8 | 21.4 | 15.7 | 22.7 | ||
| Bilingual AV-HuBERT [12] | AV | 23.4 | |||||||||
| (Ours) Whisper-Flamingo (Small) | AV | 2.0 | 22.6 | 26.6 | 25.3 | 20.7 | 20.5 | 14.6 | 21.9 | ||
| (Ours) Whisper-Flamingo (Medium) | AV | 1.6 | 23.8 | 28.0 | 26.1 | 22.5 | 21.3 | 16.0 | 23.0 | ||
| (Ours) Whisper-Flamingo (Large) | AV | 1.3 | 24.4 | 27.9 | 25.9 | 22.1 | 21.8 | 15.7 | 22.9 | ||
| 语音到文本翻译(MuAViC噪声音频) | |||||||||||
| Bilingual AV-HuBERT [12] | A | MuAViC | - | 15.9 | 19.2 | 17.1 | 12.9 | 14.4 | 10.3 | 15.0 | |
| Whisper-Small, Fine-tuned | A | MuAViC | 17.3 | 17.5 | 20.1 | 19.4 | 15.3 | 16.3 | 11.8 | 16.7 | |
| Whisper-Medium, Fine-tuned | A | MuAViC | 14.8 | 18.1 | 22.1 | 19.8 | 16.2 | 17.3 | 12.1 | 17.6 | |
| Whisper-Large, Fine-tuned | A | MuAViC | 13.8 | 19.7 | 23.4 | 20.4 | 17.4 | 17.7 | 13.3 | 18.6 | |
| Bilingual AV-HuBERT [12] | AV | MuAViCt | 22.7 | 24.8 | 23.8 | 20.0 | 20.0 | 13.7 | 20.8 | ||
| (Ours) Whisper-Flamingo (Small) | AV | MuAViC | 10.7 | 19.0 | 22.1 | 21.1 | 17.1 | 18.3 | 13.2 | 18.5 | |
| (Ours) Whisper-Flamingo (Medium) | AV | MuAViC | 8.3 | 20.7 | 24.5 | 21.6 | 18.8 | 18.6 | 13.7 | 19.6 | |
| (Ours) Whisper-Flamingo (Large) | AV | MuAViC | 7.2 | 21.1 | 25.4 | 22.4 | 19.3 | 19.9 | 14.7 | 20.5 | |
| 仅视频到文本翻译(无音频) | |||||||||||
| VSP-LLM[39] | V | 22.7 | 22.3 | 17.9 | 18.7 |
3.2. Modality Fusion Ablation with Whisper-Medium
3.2. Whisper-Medium 模态融合消融实验
We first compared gated cross attention to early and late fusion using Whisper Medium. For early fusion, we duplicate AVHuBERT’s $25\mathrm{Hz}$ video features to temporally align them with Whisper’s $50\mathrm{Hz}$ audio features (after the CNN layers) and use addition to fuse them before Whisper’s Transformer encoder. For late fusion, we use an MLP to fuse the video features with Whisper’s audio features after its Transformer encoder. In both cases, all of Whisper’s parameters are fine-tuned. For audioonly baselines, we use Whisper zero-shot (no fine-tuning) and fine-tuned on LRS3. We test models in both the clean and noisy conditions with babble-noise injected at 0-SNR. The results are shown in Table 2. Fine-tuning audio-only Whisper decreases the noisy WER of the zero-shot model from $22.2%$ to $12.6%$ . We then use the fine-tuned model as initialization to train the models with audio-visual fusion. Early-fusion obtained a small improvement in both the clean and noisy WERs. Late-fusion could not fuse the modalities well and performance became worse in both clean and noisy conditions. Finally, Whisper-Flamingo with gated cross attention obtained the best noisy WER, significantly improving the audio-only Whisper fine-tuned baseline from $12.6%$ to $7.0%$ , while the clean WER was slightly improved from $1.9%$ to $1.5%$ . Freezing Whisper helps retain its strong audio skills while new cross attention layers enable it to integrate the visual modality more effectively.
我们首先比较了使用Whisper Medium的门控交叉注意力与早期及晚期融合的效果。对于早期融合,我们将AVHuBERT的$25\mathrm{Hz}$视频特征复制以与Whisper CNN层后的$50\mathrm{Hz}$音频特征时间对齐,并通过加法在Whisper的Transformer编码器前融合它们。对于晚期融合,我们使用MLP在Whisper的Transformer编码器后将视频特征与音频特征融合。两种情况下,Whisper的所有参数均进行了微调。纯音频基线采用零样本Whisper(未微调)和在LRS3上微调的版本。我们在纯净和含0-SNR混叠噪声的条件下测试模型,结果如表2所示。微调纯音频Whisper将零样本模型的噪声WER从$22.2%$降至$12.6%$。随后以该微调模型为初始化,训练视听融合模型。早期融合在纯净和噪声WER上均获得小幅提升,而晚期融合未能有效融合模态,两种条件下性能均下降。最终,采用门控交叉注意力的Whisper-Flamingo取得最佳噪声WER,将纯音频微调基线的$12.6%$显著提升至$7.0%$,同时纯净WER从$1.9%$微升至$1.5%$。冻结Whisper参数可保留其强大音频能力,而新增的交叉注意力层能更高效整合视觉模态。
3.3. Whisper-Flamingo English Speech Recognition
3.3. Whisper-Flamingo 英语语音识别
For our main experiments in Table 3, we use Whisper-Large. We report results using beam search with beam size 1 and 15. In noisy conditions, we use babble noise at 0-SNR constructed following AV-HuBERT [26] by adding audio from 30 speakers from LRS3. Results for additional noise types and SNR levels
在我们的主要实验中(表3),我们使用Whisper-Large模型。报告结果采用束搜索(beam search)方法,束宽度分别为1和15。在噪声条件下,我们采用0-SNR的混杂噪声(babble noise),该噪声通过遵循AV-HuBERT[26]的方法构建,即在LRS3数据集中30位说话者的音频基础上叠加生成。其他噪声类型和信噪比水平的结果
are shown in the Appendix, Section 8.2.
附录第8.2节中展示了相关图表。
Training on clean audio (without noise). Compared to zeroshot audio-only Whisper-Large, fine-tuning without noise improves the clean ASR WER from $2.1%$ to $1.0%$ (using LRS3 433h) and $0.68%$ (using LRS3+VoxCeleb2 1,759h). Our finetuned Whisper-Large achieves SOTA ASR on LRS3 $(\mathbf{0.68}%)$ and matches the previous SOTA of $0.7%$ from Fast Conformer [29]. We then use our fine-tuned Whisper models to initialize audio-visual Whisper-Flamingo and achieve $1.1%$ $/0.76%$ AVSR WER using LRS3 433h / LRS3+VoxCeleb2 1,759h respectively. Our audio-visual Whisper-Flamingo achieves SOTA AVSR on LRS3 $(0.76%)$ and matches the current SOTA from Llama-AVSR $(0.77%)$ using LRS3 $^{\ast+}$ VoxCeleb2 and Fast Conformer $(0.8%)$ using additional data. Notably, our method only uses 2.5B parameters, while Llama-AVSR uses over 8B parameters. Also, our method achieves better AVSR performance than LP Conformer $(0.9%)$ which was trained on 100k videos. Fine-tuning Whisper on clean audio does not improve the noisy WER, while training Whisper-Flamingo on clean audio improves the noisy WER.
在纯净音频(无噪声)上的训练。与零样本纯音频版Whisper-Large相比,无噪声微调将纯净音频的ASR词错误率从$2.1%$降至$1.0%$(使用LRS3 433小时数据)和$0.68%$(使用LRS3+VoxCeleb2 1,759小时数据)。我们微调后的Whisper-Large在LRS3上实现了SOTA ASR性能 $(\mathbf{0.68}%)$ ,并与Fast Conformer [29]先前$0.7%$的SOTA结果持平。随后,我们使用微调后的Whisper模型初始化视听版Whisper-Flamingo,分别在LRS3 433小时/LRS3+VoxCeleb2 1,759小时数据上实现$1.1%$/$0.76%$的AVSR词错误率。我们的视听版Whisper-Flamingo在LRS3上取得SOTA AVSR成绩 $(0.76%)$ ,与采用LRS3$^{\ast+}$VoxCeleb2数据的Llama-AVSR $(0.77%)$ 及使用额外数据的Fast Conformer $(0.8%)$ 当前SOTA结果相当。值得注意的是,我们的方法仅使用25亿参数,而Llama-AVSR参数超过80亿。此外,我们的方法AVSR性能优于在10万视频上训练的LP Conformer $(0.9%)$ 。在纯净音频上微调Whisper不会改善带噪音频的词错误率,而在纯净音频上训练Whisper-Flamingo则可提升带噪音频的词错误率。
Training on noisy audio. Compared to zero-shot audio-only Whisper-Large, fine-tuning with noise improves the noisy ASR WER from $20.8%$ to $11.7%$ (using LRS3 433h) and $11.1%$ (using LRS3+VoxCeleb2 1,759h). The clean ASR WER is slightly worse compared to Whisper fine-tuned without noise, however, the results are close $0.85%$ vs $0.68%$ ). We then use our fine-tuned Whisper models to initialize audio-visual WhisperFlamingo and significantly improve the noisy WER to $5.6%$ / $5.6%$ AVSR WER using LRS3 433h / LRS3 $^+$ VoxCeleb2 1,759h respectively $(49.5%$ relative noisy WER improvement compared to fine-tuned audio-only Whisper). The clean AVSR WER is slightly worse compared to Whisper-Flamingo trained without noise, however, the results are close $0.86%$ vs $0.76%$ ). Comparing noisy results to SOTA. Table 3 also shows a comparison with prior audio-visual SSL methods and audio-visual fine-tuning methods on LRS3. Direct comparison in noisy conditions is challenging since different noise datasets were used to generate the babble noise. SSL methods AV-HuBERT [26], $\mathbf{u}$ -HuBERT [14], and CMA [27] used LRS3 to generate babble noise, but the noise file they generated was not publicly available. We followed their procedure to generate the noise, so our noisy conditions are similar but not identical. Compared with AV-HuBERT, Whisper-Flamingo achieves better clean performance $0.86%$ vs $1.4%$ ) and slightly better noisy results $(5.6%$ vs $5.8%$ ), which shows that Whisper-Flamingo is effective at adapting Whisper to the visual features from AVHuBERT. Moreover, a major advantage of Whisper-Flamingo over AV-HuBERT is improved translation performance (Section 3.4). The best noisy performances are reported by uHuBERT and CMA; we would like to try them as visual encoders for Whisper-Flamingo, but the weights are not publicly available. Finally, Whisper-Flamingo outperforms other methods in noise which adapt audio-only models through audiovisual fine-tuning [6, 7], including FAVA-USM [6] which was pre-trained on 12M hours of unlabeled audio [2]. However, the babble noise was generated from different datasets making results not strictly comparable.
在含噪音频上的训练。与零样本纯音频Whisper-Large相比,加入噪声微调将含噪ASR词错误率(WER)从$20.8%$降至$11.7%$(使用LRS3 433小时数据)和$11.1%$(使用LRS3+VoxCeleb2 1,759小时数据)。与未加噪声微调的Whisper相比,纯净音频的ASR WER略有下降,但差距微小($0.85%$ vs $0.68%$)。随后我们使用微调后的Whisper模型初始化视听版WhisperFlamingo,将含噪WER显著改善至$5.6%$/ $5.6%$ AVSR WER(分别使用LRS3 433小时/LRS3$^+$VoxCeleb2 1,759小时数据)(相较纯音频微调Whisper相对提升49.5%)。与未加噪声训练的Whisper-Flamingo相比,纯净AVSR WER略高但接近($0.86%$ vs $0.76%$)。
含噪环境与SOTA对比。表3还展示了与现有视听自监督学习(SSL)方法及LRS3微调方法的比较。由于不同研究使用不同噪声数据集生成混杂噪声,直接对比具有挑战性。SSL方法AV-HuBERT[26]、$\mathbf{u}$-HuBERT[14]和CMA[27]使用LRS3生成噪声,但其噪声文件未公开。我们遵循其流程生成噪声,因此噪声环境相似但不完全相同。相比AV-HuBERT,Whisper-Flamingo在纯净环境下表现更优($0.86%$ vs $1.4%$),含噪环境略胜($5.6%$ vs $5.8%$),表明该方法能有效使Whisper适配AVHuBERT的视觉特征。此外,Whisper-Flamingo相较AV-HuBERT的主要优势在于提升的翻译性能(见3.4节)。当前最佳含噪性能由uHuBERT和CMA保持,我们拟尝试将其作为视觉编码器,但其权重未公开。最终,Whisper-Flamingo在噪声环境中优于其他通过视听微调适配纯音频模型的方法[6,7],包括基于1.2万小时无标注音频预训练的FAVA-USM[6]。但由于噪声数据集不同,结果无法严格对比。
3.4. Whisper-Flamingo En-X Speech Translation
3.4. Whisper-Flamingo 英语-X 语音翻译
For these experiments, we fine-tune Whisper and train WhisperFlamingo with noise. We report results with a beam size of 15.
在这些实验中,我们对Whisper进行微调,并用含噪数据训练WhisperFlamingo。报告结果时采用的束搜索(beam search)大小为15。
Audio Results. In Table 4, we show the result of fine-tuning audio-only Whisper-Large for En-X translation using the 6 languages in the MuAViC dataset (“Whisper-Large, Fine-tuned”). Although Whisper was not originally trained for En-X translation, it adapts well to the new task. Testing with clean audio, we achieve an average BLEU score of 22.7, which outperforms the previous SOTA of 21.9 from Bilingual AV-HuBERT. Moreover, our model transcribes En audio (WER of $1.5%$ ) and translates to 6 languages with a single set of parameters, while Bilingual AV-HuBERT fine-tunes separately for each language pair and trains language-specific decoders from scratch. Our model nearly reaches the text-to-text performance from machine translation models using the ground-truth English text; those models achieve average BLEU scores of 23.1 from a multilingual model and 24.3 from bilingual models.
音频结果。在表4中,我们展示了使用MuAViC数据集中的6种语言对仅音频的Whisper-Large进行英译X微调的结果("Whisper-Large, Fine-tuned")。虽然Whisper最初并非为英译X任务训练,但其对新任务适应良好。在纯净音频测试中,我们取得了22.7的平均BLEU分数,优于此前Bilingual AV-HuBERT创下的21.9的SOTA成绩。此外,我们的模型通过单一参数集即可实现英文音频转录(WER为$1.5%$)和6种语言翻译,而Bilingual AV-HuBERT需为每个语言对单独微调并从头训练语言专用解码器。我们的模型几乎达到了基于真实英文文本的机器翻译模型的文本到文本性能;这些模型取得的平均BLEU分数分别为多语言模型23.1和双语模型24.3。
Audio-Visual Results. Once we fine-tune audio-only Whisper for En-X translation, we use it to train Whisper-Flamingo by freezing the weights and adding gated cross attention layers. Testing with clean audio, Whisper-Flamingo slightly outperforms the audio-only model with an average BLEU score of 22.9 and En WER of $1.3%$ . In noisy conditions, we use multilingual babble noise constructed following MuAViC [12] by adding audio in 9 different languages from 30 speakers. Note that their noise file was not publicly available, so our noisy conditions are similar but not identical. With multilingual babble noise, Whisper-Flamingo significantly outperforms the audioonly Whisper model in average BLEU score (20.5 vs 18.6) and En WER $7.2%$ vs $13.8%$ ). Compared with the previous SOTA bilingual AV-HuBERT, our audio-only average BLEU is much better (18.6 vs 15.0), but our audio-visual performance is slightly worse (20.5 vs 20.8). However, our models perform both $\mathbf{En}{\bf-}\mathbf{X}$ translation and En transcription with a single model, while their models fine-tune separately for each language pair. Finally, we show the results using Whisper-Medium and Whisper-Small: Whisper-Flamingo always does better in noise compared to the audio-only baselines, and performance tends to improve as the model size increases.
视听结果。在我们针对En-X翻译对纯音频Whisper进行微调后,通过冻结权重并添加门控交叉注意力层来训练Whisper-Flamingo。在清晰音频测试中,Whisper-Flamingo以平均BLEU分数22.9和En WER $1.3%$ 略优于纯音频模型。在噪声条件下,我们采用MuAViC [12]方法构建的多语言混杂噪声(添加来自30位说话者的9种不同语言音频)。需注意其噪声文件未公开,因此我们的噪声条件类似但不完全相同。在多语言混杂噪声下,Whisper-Flamingo在平均BLEU分数(20.5 vs 18.6)和En WER($7.2%$ vs $13.8%$)上显著优于纯音频Whisper模型。与之前SOTA的双语AV-HuBERT相比,我们的纯音频平均BLEU更优(18.6 vs 15.0),但视听性能稍逊(20.5 vs 20.8)。不过我们的模型使用单一模型同时执行$\mathbf{En}{\bf-}\mathbf{X}$翻译和En转录,而他们的模型需为每个语言对单独微调。最后我们展示了使用Whisper-Medium和Whisper-Small的结果:与纯音频基线相比,Whisper-Flamingo在噪声环境下始终表现更好,且性能随模型规模增大而提升。
Comparison with VSP-LLM. Finally, we compare with VSPLLM [39], a recent LLM-based approach which uses features from AV-HuBERT as input to an LLM to perform lip-reading and translation using video inputs only (no audio). Even with noise in the audio, our Whisper-Flamingo (Large) outperforms VSP-LLM on all 4 languages evaluated, which shows the advantage of using both audio and video as inputs instead of just video. Also, our model only has 2.5B parameters compared with VSP-LLM’s 7B parameters.
与 VSP-LLM 的对比。最后,我们与 VSPLLM [39] 进行了比较,这是一种基于大语言模型的最新方法,它使用 AV-HuBERT 的特征作为大语言模型的输入,仅通过视频输入(无音频)进行唇读和翻译。即使在音频存在噪声的情况下,我们的 Whisper-Flamingo (Large) 在所有评估的 4 种语言上都优于 VSP-LLM,这表明同时使用音频和视频作为输入而非仅使用视频的优势。此外,我们的模型仅有 25 亿参数,而 VSP-LLM 有 70 亿参数。
Table 5: Results for English transcription on LRS2. We report results on the original test set (Clean). Hours of unlabeled & labeled audio-visual data used to train each model are shown. Note† that we used AV-HuBERT fine-tuned on LRS3 433h.
表 5: LRS2英语转录结果。我们报告了原始测试集(Clean)的结果。显示了用于训练每个模型的未标记和标记视听数据的小时数。注意†我们使用了在LRS3 433h上微调的AV-HuBERT。
| 模型 | AV训练小时数 未标记 标记 | Clean WER↓ ASR | AVSR | |
|---|---|---|---|---|
| 仅使用转录视频训练的视听方法 | ||||
| TM-seq2seq [11] | 223 | 9.7 | 8.5 | |
| CTC/Attention[53] | 380 | 8.3 | 7.0 | |
| TDNN [54] | 223 | 6.7 | 5.9 | |
| CM-seq2seq[20] | 380 | 3.9 | 3.7 | |
| EfficientConformer[55] | 818 | 2.4 | 2.3 | |
| AutoAVSR[21] | 3,448 | 1.5 | 1.5 | |
| 视听自监督学习方法 | ||||
| UniAVSR [5] | 380 | 2.7 | 2.6 | |
| RAVEn [56] | 1,759 | 223 | 2.5 | |
| USR [57] | 1,759 | 223 | 1.9 | 1.9 |
| 我们的纯音频Whisper零样本基线 | ||||
| Whisper-Medium, Beam1 | - | 5.2 5.5 | ||
| Whisper-Large, Beam 1 我们的带噪声训练模型 | ||||
| Whisper-Medium FT, Beam1 | 223 | 1.3 | ||
| Whisper-Flamingo, Beam1 | 1,759 | 223 | 1.4 |
4. Experiments on LRS2
4. LRS2 实验
We use our framework to conduct experiments on the LRS2 dataset [11]. We followed AutoAVSR [21] to create a 223h training set, 0.6h validation set, and 0.5h test set. We add noise to the audio while training our models. We report the ASR and AVSR WER on the LRS2 test set (clean) in Table 5. Comparing zero-shot Whisper Medium and Whisper Large V2, the medium model performs slightly better $(5.2%$ vs $5.5%$ ), therefore we use Whisper medium for our experiments. Our fine-tuned Whisper and Whisper-Flamingo models have 769M and 1.39B parameters respectively. Compared to zero-shot Whisper, fine-tuned Whisper improves the ASR WER from $5.2%$ to $1.3%$ , achieving a new SOTA ASR WER on LRS2. Finally, Whisper- Flamingo achieves SOTA AVSR WER of $1.4%$ . WhisperFlamingo outperforms recent SSL method USR [57] $(1.9%)$ trained with the same hours of video and outperforms AutoAVSR [21] $(1.5%)$ trained with more hours of video. Finally, Whisper-Flamingo outperforms Whisper in noisy conditions (shown in the Appendix, Section 8.3).
我们使用自己的框架在LRS2数据集[11]上进行实验。按照AutoAVSR[21]的方法,我们创建了223小时的训练集、0.6小时的验证集和0.5小时的测试集。在训练模型时,我们向音频添加了噪声。表5展示了LRS2测试集(干净)上的ASR和AVSR WER结果。比较零样本Whisper Medium和Whisper Large V2,中等规模模型表现略优$(5.2%$ vs $5.5%)$,因此我们选用Whisper medium进行实验。我们微调后的Whisper和Whisper-Flamingo模型分别具有7.69亿和13.9亿参数。与零样本Whisper相比,微调后的Whisper将ASR WER从$5.2%$提升至$1.3%$,创下了LRS2上新的SOTA ASR WER记录。最终,Whisper-Flamingo以$1.4%$的WER实现了SOTA AVSR性能。Whisper-Flamingo超越了近期使用相同时长视频训练的SSL方法USR[57]$(1.9%)$,也优于使用更长时间视频训练的AutoAVSR[21]$(1.5%)$。此外,Whisper-Flamingo在噪声环境下的表现优于Whisper(详见附录第8.3节)。
5. Conclusion
5. 结论
We introduced Whisper-Flamingo, a novel audio-visual model that combines the strengths of AV-HuBERT and Whisper using gated cross attention. Our audio-visual Whisper-Flamingo significantly outperforms audio-only Whisper in noise. We showed that Whisper can be fine-tuned for the new task of XEn translation. Our model performs both En speech recognition and En-X speech translation using one set of parameters while previous methods fine-tune separately on each language. Our method is a generic way of fusing a visual encoder into the decoder of an ASR model to enable AVSR, and it could work with other models trained on more data in the future.
我们提出了Whisper-Flamingo这一新型视听模型,它通过门控交叉注意力机制融合了AV-HuBERT和Whisper的优势。实验表明,在噪声环境下,我们的视听版Whisper-Flamingo显著优于纯音频版Whisper。我们证明了Whisper可通过微调适应XEn翻译这一新任务。该模型仅用一组参数即可同时执行英语(En)语音识别和En-X语音翻译,而现有方法需针对每种语言单独微调。本方法是将视觉编码器融合至ASR模型解码器的通用方案,未来可适配更多数据训练的其他模型来实现视听语音识别(AVSR)。
6. Acknowledgments
6. 致谢
We thank Alex H. Liu, Mohamed Anwar, and the reviewers for helpful discussion. We thank Videet Mehta for help with the experiments in Table A2. This research was supported by the MIT-IBM Watson AI Lab and an NDSEG Fellowship to A.R.
我们感谢 Alex H. Liu、Mohamed Anwar 以及审稿人提供的宝贵讨论。感谢 Videet Mehta 对表 A2 中实验的帮助。本研究得到了 MIT-IBM Watson AI Lab 的支持,以及 A.R. 获得的 NDSEG Fellowship 资助。
7. References
7. 参考文献
8. Appendix
8. 附录
8.1. Original Results Table
8.1. 原始结果表
Table A1 shows the results reported in the original paper (V1 on ArXiv). For these results, beam search with a beam size of 15 was used. Note that the current results for Whisper-Flamingo in Table 3 are a superset of those reported in Table A1 (the original results remained the same and we added more results in the current main table).
表 A1 显示了原始论文 (V1 on ArXiv) 中报告的结果。这些结果使用了束搜索 (beam search) ,束宽为 15。请注意,表 3 中 Whisper-Flamingo 的当前结果是表 A1 报告结果的超集 (原始结果保持不变,我们在当前主表中添加了更多结果)。
8.2. LRS3: Testing Different Noise Types and Noise Levels
8.2. LRS3: 测试不同噪声类型和噪声水平
Table A2 shows the results on LRS3 433h with different noise types and SNR levels ${-10,-5,0,5,10,\infty}$ . The noise setups follow AV-HuBERT [26] and CMA [27], and we also test on multilingual babble noise that we made using audio from
表 A2 展示了 LRS3 433h 数据集在不同噪声类型和信噪比水平 ${-10,-5,0,5,10,\infty}$ 下的结果。噪声设置遵循 AV-HuBERT [26] 和 CMA [27],我们还测试了使用多语言混杂噪声(通过音频自建)。
MuAViC. However, some of the differences in the results across methods might be due to different random seeds since the noise files are sampled from a list of candidates (except for babble noise from LRS3 and babble noise from MuAViC which only use 1 noise file for testing). We first compare models testing with audio only and then compare models testing with both audio and visual modalities. We use the Large versions of our English models fine-tuned with noise and report decoding results with beam size 1 and 15. We make the following observations:
MuAViC。然而,不同方法之间的结果差异可能源于随机种子的不同,因为噪声文件是从候选列表中采样的(除了LRS3的混叠噪声和MuAViC的混叠噪声,这两者仅使用1个噪声文件进行测试)。我们首先比较仅使用音频测试的模型,然后比较同时使用音频和视觉模态测试的模型。我们使用了经过噪声微调的英文大模型版本,并报告了束搜索大小为1和15的解码结果。我们得出以下观察结论:
Overall, the results confirm Whisper-Flamingo’s noise robustness using audio and visual modalities. Future work can focus on enhancing the performance in low SNR conditions and comparing more comprehensively with prior work [11, 58–62].
总体而言,实验结果证实了Whisper-Flamingo模型通过音频和视觉模态实现的噪声鲁棒性。未来工作可着重提升低信噪比(SNR)环境下的性能表现,并与前人研究[11, 58–62]进行更全面的对比。
8.3. LRS2: Testing Different Noise Types and Noise Levels
8.3. LRS2: 测试不同噪声类型和噪声水平
Table A3 shows the results on LRS2 223h with different noise types and SNR levels ${-10,-5,0,5,10,\infty}$ . The noise setups follow AV-HuBERT [26], and we also test on multilingual babble noise that we made using audio from MuAViC. We compare Whisper Medium zero-shot, Whisper Medium finetuned, and Whisper-Flamingo. We report decoding results with beam size 1 and 15. In general, the observations follow those in Section 8.2. Most importantly, fine-tuned Whisper outperforms zero-shot Whisper, and Whisper-Flamingo outperforms fine-tuned Whisper in most noise types and levels. However, Whisper-Flamingo’s improvements over fine-tuned Whisper are not as substantial compared to the improvements achieved on the LRS3 dataset (Table A2). A potential reason could be that we use AV-HuBERT trained on LRS3 and VoxCeleb2, and we do not update its weights while training Whisper-Flamingo. Future work should direct more attention to improving the noise robustness of Whisper-Flamingo on LRS2.
表 A3 展示了 LRS2 223h 数据集在不同噪声类型和信噪比水平 ${-10,-5,0,5,10,\infty}$ 下的结果。噪声设置遵循 AV-HuBERT [26],我们还测试了使用 MuAViC 音频制作的多语言混杂噪声。我们比较了 Whisper Medium 零样本、Whisper Medium 微调版本以及 Whisper-Flamingo,并报告了束搜索大小为 1 和 15 的解码结果。总体而言,观察结果与第 8.2 节的结论一致。最重要的是,微调后的 Whisper 优于零样本 Whisper,而 Whisper-Flamingo 在大多数噪声类型和水平下都优于微调后的 Whisper。不过,与 LRS3 数据集上的改进幅度(表 A2)相比,Whisper-Flamingo 相对于微调 Whisper 的提升并不显著。潜在原因可能是我们使用了在 LRS3 和 VoxCeleb2 上训练的 AV-HuBERT,且在训练 Whisper-Flamingo 时未更新其权重。未来工作应更关注提升 Whisper-Flamingo 在 LRS2 上的噪声鲁棒性。
8.4. Analysis of Gated Cross Attention Position
8.4. 门控交叉注意力位置分析
Table A4 shows the analysis of the position to insert the gated cross attention layers into Whisper. Refer to Figure 1 for the ordering of layers in the transformer decoder and encoder blocks. We first tried all possible positions in Whisper’s decoder blocks and found the beginning of each block to work the best $(5.6%$ noisy AVSR WER), although after the MLP in each block also worked well ( $5.7%$ noisy AVSR WER). We then tried to insert the layers in both Whisper’s decoder and encoder blocks, but this did not provide any additional gains.
表 A4 展示了在 Whisper 中插入门控交叉注意力层的位置分析。关于 Transformer 解码器和编码器块的层顺序,请参考图 1。我们首先尝试了 Whisper 解码器块中的所有可能位置,发现每个块的开头效果最佳(噪声 AVSR WER 为 5.6%),尽管每个块中 MLP 之后的效果也不错(噪声 AVSR WER 为 5.7%)。随后我们尝试同时在 Whisper 的解码器和编码器块中插入这些层,但并未带来额外收益。
Table A1: This table appeared in the original version of the paper. Results for English transcription on LRS3. We report results on the original test set (Clean) and with babble noise added at 0-SNR (Noisy). $A=$ Audio, $A V{=}$ Audio-Visual. Noise datase $t=$ dataset used to make babble noise. Hours of unlabeled / labeled data used to train each model are shown. Note† that $u$ -HuBERT [14] and AV-HuBERT [26] use a different noise file than us.
表 A1: 该表格出现在论文原版中。LRS3 英语转录结果。我们报告了原始测试集 (Clean) 和添加 0-SNR 混响噪声 (Noisy) 的结果。$A=$ 音频,$AV=$ 视听。噪声数据集 $t=$ 用于生成混响噪声的数据集。显示了训练每个模型时使用的未标注/标注数据小时数。注意† $u$-HuBERT [14] 和 AV-HuBERT [26] 使用了与我们不同的噪声文件。
| 模型 | 测试模态 | 噪声数据集 | 未标注小时数 (A) | 未标注小时数 (AV) | 标注小时数 (A) | 标注小时数 (AV) | Clean WER | Noisy WER |
|---|---|---|---|---|---|---|---|---|
| 视听自监督学习方法 | ||||||||
| AV-BEST-RQ[6] | AV | NoiseX | 1759 | 433 | 2.1 | 6.8 | ||
| AV2vec[15] | AV | MUSAN | 433 | 433 | 2.5 | 6.7 | ||
| AV-HuBERT[26] | AV | LRS3+ | 1759 | 433 | 1.4 | 5.8 | ||
| u-HuBERT[14] | AV | LRS3+ | 1759 | 433 | 1.3 | 4.6 | ||
| 仅音频预训练+视听微调方法 | ||||||||
| AdaptiveAV[7] | AV | MUSAN | 400 | 680k | 30 | 2.3 | 16.3 | |
| FAVA [6] | AV | NoiseX | 1759 | 433 | 1.7 | 6.6 | ||
| FAVA-USM [6] | AV | NoiseX | 12M | 5000 | 433 | 1.3 | 6.2 | |
| 我们的仅音频 Whisper 基线 | ||||||||
| Whisper-Large, 零样本 (无微调) | A | LRS3 | 680k | 2.1 | 20.8 | |||
| Whisper-Large, 在 LRS3 上微调 | A | LRS3 | 680k | 2.3 | 11.7 | |||
| 提出的视听微调方法 | ||||||||
| Whisper-Flamingo (Ours) | AV | LRS3 | 1759 | 680k | 433 | 1.5 | 5.6 |
Table A2: Results for English transcription on LRS3 433h with different noise types and SNR levels. We use the large versions of our English models fine-tuned with noise and by default report results for beam search decoding with beam size 1. The results for Music and Natural noise from MUSAN are averaged.
表 A2: 不同噪声类型和信噪比(SNR)水平下LRS3 433h英语转录结果。我们使用经过噪声微调的英语大模型,默认报告beam size为1的束搜索解码结果。MUSAN中的音乐和自然噪声结果取平均值。
| 方法 | 纯净 | Babble (LRS3),SNR= | Babble (MUSAN),SNR= | Babble(MuAViC),SNR= | Speech(LRS3),SNR= | Music+Natural,SNR= | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8 | -10 | -5 | 0 | 5 | 10 | -10 -5 | 0 | 5 10 | -10 | -5 | 0 | 5 | 10 | -10 | -5 | |
| 仅音频测试 | ||||||||||||||||
| AV-HuBERT[26] | 1.6 | 97.5 | 62.3 | 15.7 | 5.1 | 81.7 | 56.2 | 37.3 | ||||||||
| Whisper,零样本 | 2.3 | 101 | 90.2 | 23.3 | 5.5 | 2.9 | 79.7 | 20.9 | 5.4 2.8 | 101 | 89.2 | 28.1 | 6.8 | 101 | 77.4 | 35.6 |
| →w/Beam search15 | 2.1 | 99.3 | 86.4 | 20.8 | 4.9 | 2.5 | 98.6 73.6 | 19.1 | 5 2.6 | 99.5 | 85.1 | 25.1 | 5.9 | 99.3 | 71.9 | 27.3 |
| Whisper,微调 | 1.0 | 111 | 71.1 | 12.3 | 2.8 | 1.4 | 106 57.6 | 10.6 | 2.4 1.3 | 107 | 79.1 | 15.1 | 3.5 | 46.1 | 25.9 | 14.9 |
| →w/Beam search15 | 2.7 | 109 | 68.1 | 11.8 | 3.2 2.4 | 106 | 55.4 10.3 | 3.1 | 2.1 | 110 | 74.8 | 14.3 | 3.9 2.3 | 45.8 | 25.2 | 16.0 |
| AV-HuBERT[26] | 音视频测试 | |||||||||||||||
| CMA [27] | 1.4 1.5 | 28.4 25.8 | 13.4 11.9 | 5.0 4.4 | 2.6 | 1.9 1.8 | 11.4 | 4.6 | 2.9 2.5 | |||||||
| Whisper-Flamingo | 1.0 | 42.6 | 28.0 | 6.3 | 2.4 2.0 | 22.7 1.4 44.2 | 9.9 22.6 | 4.0 5.8 | 2.2 2.1 | 49.3 | 28.4 | 7.2 | 2.5 | 5.4 23.8 | 3.2 13.4 | 8.1 |
| →w/Beam search15 | 1.5 | 37.7 | 23.5 | 5.6 | 2.1 | 1.6 37.5 | 19.8 | 5.0 | 2.1 | 40.2 | 25.2 | 6.6 | 2.5 | 21.2 | 13.0 | 6.9 |
Table A3: Results for English transcription on LRS2 223h with different noise types and SNR levels. We use the medium versions of our English models fine-tuned with noise and by default report results for beam search decoding with beam size 1. The results for Music and Natural noise from MUSAN are averaged.
表 A3: 在 LRS2 223h 数据集上针对不同噪声类型和信噪比 (SNR) 水平的英语转录结果。我们使用经过噪声微调的中等规模英文模型,默认报告束宽为 1 的束搜索解码结果。MUSAN 数据集中的音乐和自然噪声结果取平均值。
| 方法 | 纯净音频 | Babble (LRS3), SNR= | Babble (MUSAN), SNR= | Babble (MuAViC), SNR= | Speech (LRS3), SNR= | Music+Natural, SNR= | ||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| -5 | 0 | 5 | 10 | -10 | -5 | 0 | 5 | 10 | -10 | -5 | 0 | 5 | 10 | -10 | -5 | 0 | 5 | 10 | -10 | -5 | 0 | 5 | 10 | |||
| 仅音频测试 | ||||||||||||||||||||||||||
| Whisper, 零样本 | 5.2 | 103 | 98.9 | 31.7 | 10.1 | 5.5 | 117 | 103.5 | 11.3 6.2 | 111 | 88.3 | 34.8 | 9.9 | 5.9 | 96.1 | 72.2 | 30.9 | 9.9 | 5.1 | 56.1 | 27.6 | 10.9 | 6.4 | |||
| →w/束搜索15 | 3.9 | 98.7 | 83.4 | 29.2 | 8.2 | 4.7 | 99.8 | 91.5 | 37.7 | 10.1 4.8 | 100 | 80.7 | 29.2 | 8.7 | 4.8 | 98 | 73.6 | 27.4 | 7.7 | 4.7 | 45.9 | 23.3 | 9.4 | 5.2 | ||
| Whisper, 微调 | 1.3 | 136 | 73.5 | 15.5 | 4.5 | 2.2 | 144 | 94.1 | 20.6 | 4.4 2.0 | 134 | 68.2 | 13.8 | 4.1 | 2.2 | 34 | 15.5 | 6.3 | 2.9 | 2.0 | 36.3 | 14.1 | 4.9 | 2.1 | ||
| →w/束搜索15 | 1.7 | 114 | 70.4 | 14.5 | 4.4 | 2.3 | 125 | 89.2 | 18.8 | 4.5 2.3 | 115 | 62.1 | 12.5 | 4.1 | 2.5 | 31.7 | 13.7 | 6.1 | 3.2 | 2.3 | 35.8 | 13.9 | 5.1 | 2.8 | ||
| 音视频联合测试 | ||||||||||||||||||||||||||
| Whisper-Flamingo →w/束搜索15 | 1.4 | 65.5 59.9 | 12.9 12.2 | 4.1 2.0 4.3 2.4 | 123 118 | 83.1 78.2 | 15.1 | 16.4 | 3.9 2.1 4.1 2.5 | 103 106 | 55.8 51.8 | 11.9 12.0 | 3.5 3.6 | 1.9 2.3 | 29.5 27.8 | 13.1 12.6 | 5.5 6.1 | 2.8 3.8 | 2.0 31.1 2.6 30.1 | 11.5 10.9 | 4.1 4.2 | 2.1 2.7 |
Table A4: Analysis of position to insert gated cross attention layers into Whisper. All models are trained on LRS3 433h and evaluated with babble noise added at 0-SNR.
表 A4: 在 Whisper 中插入门控交叉注意力层的插入位置分析。所有模型均在 LRS3 433h 数据集上训练,并在 0-SNR 的嘈杂环境下进行评估。
| 位置 | 含噪 WER |
|---|---|
| Whisper 解码器模块 | |
| 起始位置 | 5.6 |
| 自注意力后 | 6.1 |
| 交叉注意力后 | 6.3 |
| MLP 后 | 5.7 |
| Whisper 编码器模块 | |
| 起始位置 | 6.1 |
| 自注意力后 | 6.1 |
8.5. Analysis of Training With and Without Noise
8.5. 带噪声与无噪声训练分析
Table A5 shows the full analysis of fine-tuning Whisper-Large and training Whisper-Flamingo with and without noise on
表 A5 展示了在有无噪声情况下对 Whisper-Large 进行微调及训练 Whisper-Flamingo 的完整分析
LRS3 433h. The results are the same as in Table 3 with additional results for audio-visual Whisper-Flamingo. We first present the audio-only Whisper baselines: zero-shot (no finetuning), fine-tuned without noise, and fine-tuned with noise. We report results using beam search with a beam size of 1 (greedy) and 15. For Whisper-Flamingo audio-visual training, we initialize the model using each of our three Whisper models and add the new gated cross attention layers. We then train WhisperFlamingo with noise or without noise. The takeaways are as follows. First, initializing Whisper-Flamingo from Whisper zeroshot does not work well. The performance is poor even testing on clean audio. We believe that Whisper-Flamingo must solve three problems to work effectively: 1. it needs to handle noisy audio, 2. it needs to adapt to the specific domain of interest (Ted talks), 3. it needs to integrate a new modality (visual features). Solving all three of these tasks might be too difficult for Whisper-Flamingo without fine-tuning Whisper. Fine-tuning Whisper solves the first two problems and enables Whisper-Flamingo to focus on adapting to visual features. Next, for Whisper-Flamingo trained on clean audio (without noise), initializing from either Whisper fine-tuned without noise or Whisper fine-tuned with noise both achieve good clean AVSR WER $1.1%$ and $1.0%$ WER respectively). Interestingly, Whisper-Flamingo always achieves better noisy WER than the corresponding fine-tuned audio-only Whisper, which shows the advantage of using both audio and video modalities. Finally, for Whisper-Flamingo trained on noisy audio, initializing from Whisper fine-tuned with noise performs better than initializing from Whisper fine-tuned without noise. The former achieves $5.6%$ AVSR WER while the latter achieves $8.5%$ AVSR WER. Overall, Whisper-Flamingo trained with noise achieves the best noisy WER $(5.6%)$ and matches the clean WER of our best finetuned Whisper model $1.0%$ WER).
LRS3 433h。结果与表3相同,并增加了音频-视觉 Whisper-Flamingo 的额外结果。我们首先展示纯音频 Whisper 基线:零样本(未微调)、无噪声微调以及带噪声微调。我们报告了使用束搜索(beam size为1(贪婪)和15的结果。对于 Whisper-Flamingo 音频-视觉训练,我们使用三种 Whisper 模型中的每一种初始化模型,并添加新的门控交叉注意力层。然后,我们使用噪声或无噪声训练 Whisper-Flamingo。主要结论如下:首先,从 Whisper 零样本初始化 Whisper-Flamingo 效果不佳,即使在干净音频上测试性能也很差。我们认为,Whisper-Flamingo 必须解决三个问题才能有效工作:1. 需要处理带噪声的音频;2. 需要适应特定领域(Ted演讲);3. 需要整合新模态(视觉特征)。对于未经微调的 Whisper-Flamingo 来说,同时解决这三个任务可能过于困难。微调 Whisper 解决了前两个问题,使 Whisper-Flamingo 能够专注于适应视觉特征。其次,对于在干净音频(无噪声)上训练的 Whisper-Flamingo,无论是从未经噪声微调的 Whisper 还是带噪声微调的 Whisper 初始化,都能取得良好的干净 AVSR WER(分别为 $1.1%$ 和 $1.0%$ WER)。有趣的是,Whisper-Flamingo 在带噪声 WER 上始终优于相应的纯音频微调 Whisper,这展示了同时使用音频和视频模态的优势。最后,对于在带噪声音频上训练的 Whisper-Flamingo,从带噪声微调的 Whisper 初始化比从未经噪声微调的 Whisper 初始化表现更好。前者达到 $5.6%$ AVSR WER,而后者为 $8.5%$ AVSR WER。总体而言,带噪声训练的 Whisper-Flamingo 取得了最佳带噪声 WER $(5.6%)$,并与我们最佳微调 Whisper 模型的干净 WER $1.0%$ WER 相当。
Table A5: Full analysis of clean vs noisy training for Whisper-Large and Whisper-Flamingo. All models are trained on LRS3 433h. We report results on the original test set (Clean) and with babble noise added at 0-SNR (Noisy). Init. $=$ Initialized.
表 A5: Whisper-Large 与 Whisper-Flamingo 在干净与含噪训练下的完整分析。所有模型均在 LRS3 433h 上训练。我们在原始测试集 (Clean) 和添加 0-SNR 混响噪声的测试集 (Noisy) 上报告结果。Init. $=$ 初始化。
| 模型 | ASR WER↓ (Clean) | ASR WER↓ (Noisy) | AVSR WER↓ (Clean) | AVSR WER↓ (Noisy) |
|---|---|---|---|---|
| 我们的纯音频 Whisper 基线 | ||||
| Whisper, 零样本, Beam 1 | 2.3 | 23.3 | - | - |
| → w/Beam search 15 | 2.1 | 20.8 | - | - |
| Whisper, 无噪声微调, Beam 1 | 1.0 | 21.6 | - | - |
| → w/Beam search 15 | 1.3 | 23.1 | - | - |
| Whisper, 含噪声微调, Beam 1 | 1.1 | 12.4 | - | - |
| → w/Beam search 15 | 2.3 | 11.7 | - | - |
| 无噪声训练的 Whisper-Flamingo | ||||
| 从 "Whisper, 零样本" 初始化, Beam 1 | - | - | 13.5 | 48.6 |
| → w/Beam search 15 | - | - | 15.3 | 31.9 |
| 从 "Whisper, 无噪声微调" 初始化, Beam 1 | - | - | 1.1 | 13.0 |
| → w/Beam search 15 | - | - | 1.1 | 12.8 |
| 从 "Whisper, 含噪声微调" 初始化, Beam 1 | - | - | 1.0 | 8.1 |
| → w/Beam search 15 | - | - | 1.2 | 7.3 |
| 含噪声训练的 Whisper-Flamingo | ||||
| 从 "Whisper, 零样本" 初始化, Beam 1 | - | - | 12.9 | 32.8 |
| → w/Beam search 15 | - | - | 13.8 | 29.0 |
| 从 "Whisper, 无噪声微调" 初始化, Beam 1 | - | - | 1.1 | 9.6 |
| → w/Beam search 15 | - | - | 1.3 | 8.5 |
| 从 "Whisper, 含噪声微调" 初始化, Beam 1 | - | - | 1.0 | 7.2 |
| → w/Beam search 15 | - | - | 1.5 | 5.6 |