Escaping the Big Data Paradigm with Compact Transformers
用紧凑型Transformer (Compact Transformers) 逃离大数据范式
Abstract
摘要
With the rise of Transformers as the standard for language processing, and their advancements in computer vision, there has been a corresponding growth in parameter size and amounts of training data. Many have come to believe that because of this, transformers are not suitable for small sets of data. This trend leads to concerns such as: limited availability of data in certain scientific domains and the exclusion of those with limited resource from research in the field. In this paper, we aim to present an approach for small-scale learning by introducing Compact Transformers. We show for the first time that with the right size, convolutional token iz ation, transformers can avoid over fitting and outperform state-of-the-art CNNs on small datasets. Our models are flexible in terms of model size, and can have as little as 0.28M parameters while achieving competitive results. Our best model can reach $98%$ accuracy when training from scratch on CIFAR-10 with only 3.7M parameters, which is a significant improvement in data-efficiency over previous Transformer based models being over 10x smaller than other transformers and is $15%$ the size of ResNet50 while achieving similar performance. CCT also outperforms many modern CNN based approaches, and even some recent NAS-based approaches. Additionally, we obtain a new SOTA result on Flowers-102 with $99.76%$ top-1 accuracy, and improve upon the existing baseline on ImageNet $(82.71%$ accuracy with $29%$ as many parameters as ViT), as well as NLP tasks. Our simple and compact design for transformers makes them more feasible to study for those with limited computing resources and/or dealing with small datasets, while extending existing research efforts in data efficient transformers.
随着Transformer成为语言处理的标准模型,并在计算机视觉领域取得进展,其参数量与训练数据规模也相应增长。这使许多人认为Transformer不适用于小规模数据场景,由此引发诸多担忧:某些科学领域的数据可获得性受限,以及资源有限的研究者被排除在该领域研究之外。本文通过引入紧凑型Transformer (Compact Transformers) 提出小规模学习方法。我们首次证明:通过合理控制模型规模并采用卷积Token化 (convolutional tokenization) ,Transformer能够避免过拟合,并在小数据集上超越最先进的CNN模型。我们的模型具有参数量灵活性,最低仅需0.28M参数即可获得有竞争力的结果。在CIFAR-10数据集上,最优模型仅用3.7M参数从头训练即可达到98%准确率,其数据效率显著优于先前基于Transformer的模型——参数量比其他Transformer小10倍以上,且仅需ResNet50 15%的参数量即可达到相近性能。CCT还超越了许多基于CNN的现代方法,甚至部分最新的神经架构搜索 (NAS) 方法。此外,我们在Flowers-102数据集上取得99.76%的Top-1准确率(新SOTA结果),在ImageNet基准上提升现有基线(以ViT 29%的参数量达到82.71%准确率),并在NLP任务中表现优异。这种简洁紧凑的Transformer设计,为计算资源受限或处理小数据集的研究者提供了更可行的研究方案,同时拓展了数据高效Transformer的研究边界。
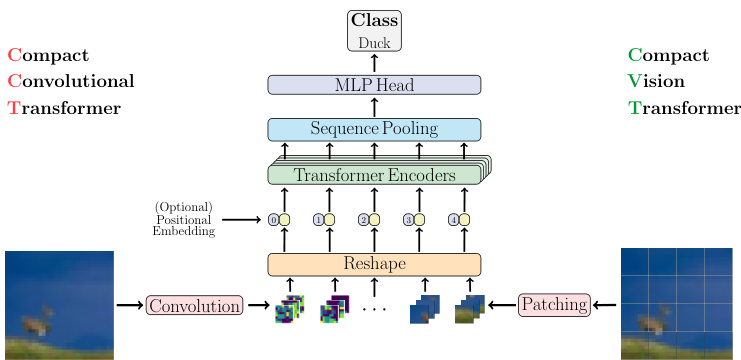
Figure 1: Overview of CVT (right), the basic compact transformer, and CCT (left), the convolutional variant of our compact transformer models. CCT can be quickly trained from scratch on small datasets, while achieving high accuracy (in under 30 minutes one can get $90%$ on an NVIDIA 2080Ti GPU or $80%$ on an AMD 5900X CPU on CIFAR-10 dataset).
图 1: CVT (右侧) 的基础紧凑型 Transformer 与 CCT (左侧) 的卷积变体模型概览。CCT 可在小型数据集上快速从头训练,同时实现高精度 (在 NVIDIA 2080Ti GPU 上 30 分钟内可达 CIFAR-10 数据集的 90%,AMD 5900X CPU 上可达 80%)。
1. Introduction
1. 引言
Convolutional neural networks (CNNs) [23] have been the standard for computer vision, since the success of AlexNet [22]. Krizhevsky et al. showed that convolutions are adept at vision based problems due to their invariance to spatial translations as well as having low relational inductive bias. He et al. [16] extended this work by introducing residual connections, allowing for significantly deeper models to perform efficiently. Convolutions leverage three im- portant concepts that lead to their efficiency: sparse interaction, weight sharing, and e qui variant representations [14]. Translational e qui variance and invariance are properties of the convolutions and pooling layers, respectively [14, 36]. They allow CNNs to leverage natural image statistics and subsequently allow models to have higher sampling efficiency [34, 34].
卷积神经网络 (CNNs) [23] 自 AlexNet [22] 取得成功后便成为计算机视觉领域的标准架构。Krizhevsky 等人证明了卷积运算凭借对空间平移的不变性及较低的关系归纳偏置,特别适合解决视觉相关问题。He 等人 [16] 通过引入残差连接扩展了这项工作,使得更深的模型能够高效运行。卷积运算利用三个关键概念实现高效性:稀疏交互 (sparse interaction)、权重共享 (weight sharing) 和等变表示 (equivariant representations) [14]。平移等变性和平移不变性分别是卷积层和池化层的特性 [14, 36],这些特性使 CNN 能够利用自然图像的统计规律,从而让模型具备更高的采样效率 [34, 34]。
On the other end of the spectrum, Transformers have become increasingly popular and a major focus of modern machine learning research. Since the advent of Attention is All You Need [41], the research community saw a spike in transformer-based and attention-based research. While this work originated in natural language processing, these models have been applied to other fields, such as computer vision. Vision Transformer (ViT) [12] was the first major demonstration of a pure transformer backbone being applied to computer vision tasks. ViT highlights not only the power of such models, but also that large-scale training can trump inductive biases. The authors argued that “Transformers lack some of the inductive biases inherent to CNNs, such as translation e qui variance and locality, and therefore do not generalize well when trained on insufficient amounts of data.” Over the past few years, an explosion in model sizes and datasets has also become noticeable which has led to a “data hungry” paradigm, making training transformers from scratch seem intractable for many types of pressing problems, where there are typically several orders of magnitude less data. It also limits major contributions in the research to those with vast computational resources.
另一方面,Transformer 已成为现代机器学习研究的热点与主流方向。自《Attention is All You Need》[41] 发表以来,基于 Transformer 和注意力机制的研究呈现爆发式增长。尽管这类模型最初源于自然语言处理领域,现已被成功应用于计算机视觉等其他领域。Vision Transformer (ViT) [12] 首次证明了纯 Transformer 架构在计算机视觉任务中的有效性,不仅展现了该模型的强大能力,更揭示了大规模训练可以超越归纳偏置的局限性。作者指出:"Transformer 缺乏 CNN 固有的归纳偏置(如平移等变性和局部性),因此在数据不足时泛化能力较差。"近年来,模型规模与数据集的爆炸式增长催生了"数据饥渴"范式,使得从头训练 Transformer 模型对于数据量通常低几个数量级的紧迫问题显得难以实现,同时也将重大研究突破的门槛抬高至需要庞大计算资源的机构。
As a result, CNNs are still the go-to models for smaller datasets because they are more efficient, both computationally and in terms of memory, when compared to transformers. Additionally, local inductive bias shows to be more important in smaller images. They require less time and data to train while also requiring a lower number of parameters to accurately fit data. However, they do not enjoy the long range interdependence that attention mechanisms in transformers provide. Reducing machine learning’s dependence on large sums of data is important, as many domains, such as science and medicine, would hardly have datasets the size of ImageNet [10]. This is because events are far more rare and it would be more difficult to properly assign labels, let alone create a set of data which has low bias and is appropriate for conventional neural networks. In medical research, for instance, it may be difficult to compile positive samples of images for a rare disease without other correlating factors, such as medical equipment being attached to patients who are actively being treated. Additionally, for a sufficiently rare disease there may only be a few thousand images for positive samples, which is typically not enough to train a network with good statistical prediction unless it can sufficiently be pre-trained on data with similar attributes. This inability to handle smaller datasets has impacted the scientific community where they are much more limited in the models and tools that they are able to explore. Frequently, problems in scientific domains have little in common with domains of pre-trained models and when domains are sufficiently distinct pre-training can have little to no effect on the performance within a new domain [54]. In addition, it has been shown that strong performance on
因此,CNN(卷积神经网络)仍是小数据集的首选模型,因为它们在计算和内存效率上优于Transformer。此外,局部归纳偏置在较小图像中显得更为重要。CNN需要更少的训练时间和数据,同时所需的参数量也更少,却能准确拟合数据。然而,它们无法像Transformer中的注意力机制那样捕捉长距离依赖关系。
降低机器学习对海量数据的依赖至关重要,因为在科学和医学等领域,几乎不可能获得ImageNet规模的数据集[10]。这些领域的事件极为罕见,正确标注标签已属不易,更遑论创建低偏差且适合传统神经网络的数据集。以医学研究为例,若要在不混杂其他相关因素(如患者治疗时连接的医疗设备)的情况下,收集某种罕见疾病的阳性样本图像可能极其困难。此外,对于极为罕见的疾病,阳性样本可能仅有数千张图像,这通常不足以训练出具有良好统计预测能力的网络,除非能在具有相似属性的数据上进行充分的预训练。
这种难以处理小数据集的局限性严重制约了科学界可探索的模型和工具。科学领域的问题往往与预训练模型的领域差异巨大,当领域差异足够显著时,预训练对新领域性能的影响微乎其微[54]。此外,研究表明......
ImageNet does not necessarily result in equally strong performance in other domains, such as medicine [20]. Furthermore, the requisite of large data results in a requisite of large computational resources and this prevents many researchers from being able to provide insight. This not only limits the ability to apply models in different domains, but also limits reproducibility. Verification of state of the art machine learning algorithms should not be limited to those with large infrastructures and computational resources.
ImageNet 在其他领域(如医学 [20])未必能带来同样强劲的性能表现。此外,大数据需求必然导致高计算资源消耗,这使得许多研究者难以开展深入分析。这不仅限制了模型跨领域应用的能力,也影响了结果的可复现性。前沿机器学习算法的验证不应仅局限于拥有庞大基础设施和计算资源的机构。
The above concerns motivated our efforts to build more efficient models that can be effective in less data intensive domains and allow for training on datasets that are orders of magnitude smaller than those conventionally seen in computer vision and natural language processing (NLP) problems. Both Transformers and CNNs have highly desirable qualities for statistical inference and prediction, but each comes with their own costs. In this work, we try to bridge the gap between these two architectures and develop an architecture that can both attend to important features within images, while also being spatially invariant, where we have sparse interactions and weight sharing. This allows for a Transformer based model to be trained from scratch on small datasets like CIFAR-10 and CIFAR-100, providing competitive results with fewer parameters and low computational requirements.
上述考虑促使我们致力于构建更高效的模型,这些模型能在数据密集度较低的领域有效工作,并允许在比计算机视觉和自然语言处理 (NLP) 问题传统数据集小几个数量级的数据集上进行训练。Transformer 和 CNN 在统计推断和预测方面都具有极佳的特性,但各自也存在相应的成本。在这项工作中,我们尝试弥合这两种架构之间的差距,开发一种既能关注图像中的重要特征,又能保持空间不变性的架构,其中包含稀疏交互和权重共享。这使得基于 Transformer 的模型能在 CIFAR-10 和 CIFAR-100 等小型数据集上从头开始训练,以更少的参数和较低的计算需求提供具有竞争力的结果。
In this paper we introduce ViT-Lite, a smaller and more compact version of ViT, which can obtain over $90%$ accuracy on CIFAR-10. We expand on ViT-Lite by introducing a sequence pooling and forming the Compact Vision Transformer (CVT). We further iterate by adding convolutional blocks to the token iz ation step and thus creating the Compact Convolutional Transformer (CCT). Both of these simple additions add to significant increases in performance, leading to a top $1%$ accuracy of $98%$ on CIFAR-10. This makes our work the only transformer based model in the top 25 best performing models on CIFAR-10, without pretraining, and significantly smaller than the vast majority. Our model also outperforms most comparable CNN-based models within this domain, with the exception of certain Neural Architectural Search techniques [5]. Additionally, we show that our model can be lightweight, only needing 0.28 million parameters and still reach close to $90%$ top $1%$ accuracy on CIFAR-10. On ImageNet, CCT achieves $80.67%$ accuracy while still maintaining a small number of parameters and reduced computation. CCT outperforms ViT, while containing less than a third of the number of parameters with about a third of the computational complexity (MACs). Additionally, CCT outperform similarly sized and more recent models, such as DeiT [19]. This demonstrates the s cal ability of our model while maintaining compactness and computational efficiency.
本文介绍了ViT的精简版本ViT-Lite,该模型在CIFAR-10上可获得超过$90%$的准确率。我们通过引入序列池化机制扩展ViT-Lite,构建出紧凑视觉Transformer(CVT)。进一步在Token化阶段加入卷积模块,由此创建出紧凑卷积Transformer(CCT)。这两项简单改进显著提升了性能,使CIFAR-10的Top $1%$准确率达到$98%$。这使得我们的工作成为CIFAR-10性能前25名模型中唯一无需预训练的Transformer架构,且参数量远小于绝大多数模型。除某些神经架构搜索技术[5]外,我们的模型也优于该领域大多数基于CNN的对比模型。实验表明,我们的模型仅需28万参数即可在CIFAR-10上实现接近$90%$的Top $1%$准确率。在ImageNet上,CCT以较小参数量和计算量取得$80.67%$的准确率。相比ViT,CCT以不足三分之一的参数量(约三分之一计算复杂度/MACs)实现更优性能,同时优于DeiT[19]等同类新模型。这证明了我们的模型在保持紧凑性和计算效率的同时具备优秀的可扩展性。
The main contributions of this paper are:
本文的主要贡献包括:
In addition, we demonstrate that our CCT model is fast, obtaining $90%$ accuracy on CIFAR-10 using a single NVIDIA 2080Ti GPU and $80%$ when trained on a CPU (AMD 5900X), both in under 30 minutes. Additionally, since our model has a relatively small number of parameters, it can be trained on the majority of GPUs, even if researchers do not have access to top of the line hardware. Through these efforts, we aim to help enable and extend research around Transformers to cases with limited data and/or researchers with limited resources.
此外,我们证明CCT模型训练速度快:在单张NVIDIA 2080Ti GPU上对CIFAR-10数据集达到90%准确率,使用CPU (AMD 5900X) 训练时达到80%准确率,两者耗时均低于30分钟。由于模型参数量较小,即使研究人员不具备顶级硬件设备,也能在大多数GPU上完成训练。通过这些努力,我们希望能推动Transformer在数据有限或资源受限场景下的研究拓展。
2. Related Works
2. 相关工作
In NLP research, attention mechanisms [15, 2, 28] gained popularity for their ability to weigh different features within sequential data. Transformers [41] were introduced as a fully attention-based model, primarily for machine translation and NLP in general. Following this, attentionbased models, specifically transformers have been applied to a wide variety of tasks beyond machine translation [11, 25, 46], including: visual question answering [27, 38], action recognition [4, 13], and the like. Many researchers also leveraged a combination of attention and convolutions in neural networks for visual tasks [42, 18, 3, 51]. Ramachandran et al. [33] introduced one of the first vision models that rely primarily on attention. Do sov it ski y et al. [12] introduced the first stand-alone transformer based model for image classification (ViT). In the following subsections, we briefly revisit ViT and several other related works.
在自然语言处理(NLP)研究中,注意力机制 [15, 2, 28] 因其能够权衡序列数据中不同特征的能力而广受欢迎。Transformer [41] 被提出作为一种完全基于注意力的模型,主要用于机器翻译和一般的自然语言处理任务。随后,基于注意力的模型,特别是Transformer,被广泛应用于机器翻译之外的多种任务 [11, 25, 46],包括:视觉问答 [27, 38]、动作识别 [4, 13] 等。许多研究者还结合了注意力机制和卷积神经网络来处理视觉任务 [42, 18, 3, 51]。Ramachandran等人 [33] 提出了首批主要依赖注意力的视觉模型之一。Dosovitskiy等人 [12] 提出了首个基于Transformer的独立图像分类模型(ViT)。在接下来的小节中,我们将简要回顾ViT及其他几项相关工作。
2.1. Vision Transformer
2.1. Vision Transformer
Do sov it ski y et al. [12] introduced ViT primarily to show that reliance on CNNs or their structure is unnecessary, as prior to it, most attention-based models for vision were used either with convolutions [42, 3, 51, 6], or kept some of their properties [33]. The motivation, beyond self-attention’s many desirable properties for a network, specifically its ability to make long range connections, was s cal ability. It was shown that ViT can successfully keep scaling, while CNNs start saturating in performance as the number of training samples grew. Through this, they concluded that large-scale training triumphs over the advantage of inductive bias that CNNs have, allowing their model to be competitive with CNN based architectures given sufficiently large amount of training data. ViT is composed of several parts: Image Token iz ation, Positional Embedding, Classification Token, the Transformer Encoder, and a Classification Head. These subjects are discussed in more detail below.
Do sov it ski y 等人 [12] 提出 ViT (Vision Transformer) 主要是为了证明无需依赖 CNN 或其结构。在此之前,大多数基于注意力的视觉模型要么与卷积结合使用 [42, 3, 51, 6],要么保留了部分 CNN 特性 [33]。其动机除了自注意力机制具备网络所需的诸多优良特性(特别是长距离关联能力)外,还在于可扩展性。研究表明,随着训练样本数量增加,ViT 能持续保持性能提升,而 CNN 会出现性能饱和。由此得出结论:在大规模训练数据下,训练规模的优势会超越 CNN 的归纳偏置优势,使其模型能够与基于 CNN 的架构竞争。ViT 由以下几个部分组成:图像 Token 化 (Image Tokenization)、位置嵌入 (Positional Embedding)、分类 Token (Classification Token)、Transformer 编码器 (Transformer Encoder) 和分类头 (Classification Head)。下文将对这些部分进行详细讨论。
Image Token iz ation: A standard transformer takes as input a sequence of vectors, called tokens. For traditional NLP based transformers, word ordering provides a natural order to sequence the data, but this is not so obvious for images. To tokenize an image, ViT subdivides an image into non-overlapping square patches in raster-scan order. The sequence of patches, $\mathbf{x_{p}}\in\mathbb{R}^{H\times(P^{2}C)}$ with patch size $P$ , are flattened into 1D vectors and transformed into latent vectors of dimension $d$ . This is equivalent to a convolutional layer with $d$ filters, and $P\times P$ kernel size and stride. This simple patching and embedding method has a few limitations, in particular: loss of information along the boundary regions.
图像 Token 化:标准 Transformer 的输入是一组称为 Token 的向量序列。对于基于传统自然语言处理的 Transformer 而言,词语顺序为数据提供了自然的序列化依据,但图像则不然。ViT 采用光栅扫描顺序将图像划分为不重叠的方形图块来实现图像 Token 化。这些图块序列 $\mathbf{x_{p}}\in\mathbb{R}^{H\times(P^{2}C)}$(图块尺寸为 $P$)会被展平为一维向量,并转换为维度为 $d$ 的潜在向量。该过程等效于使用 $d$ 个滤波器、$P\times P$ 卷积核尺寸及步长的卷积层操作。这种简单的图块划分与嵌入方法存在若干局限性,尤其是边界区域的信息丢失问题。
Positional Embedding: Positional embedding adds spatial information into the sequence. Since the model does not actually know anything about the spatial relationship between tokens, adding extra information to reflect that can be useful. Typically, this is either a learned embedding or tokens are given weights from two sine waves with high frequencies, which is sufficient for the model to learn that there exists a positional relationship between these tokens.
位置编码 (Positional Embedding): 位置编码为序列添加空间信息。由于模型实际上并不了解 token 之间的空间关系,添加额外信息来反映这种关系会很有帮助。通常,这要么是通过学习得到的嵌入向量,要么是给 token 赋予来自两个高频正弦波的权重,这足以让模型学习到这些 token 之间存在位置关系。
Transformer Encoder: A transformer encoder consists of a series of stacked encoding layers. Each encoder layer is comprised of two sub-layers: Multi-Headed Self-Attention (MHSA) and a Multi-Layer Perceptron (MLP) head. Each sub-layer is preceded by a layer normalization (LN), and followed by a residual connection to the next sub-layer.
Transformer编码器:Transformer编码器由一系列堆叠的编码层组成。每个编码层包含两个子层:多头自注意力机制(MHSA)和多层感知机(MLP)头部。每个子层前都进行层归一化(LN),并通过残差连接传递至下一子层。
Classification: Vision transformers typically add an extra learnable [class] token to the sequence of the embedded patches, representing the class parameter of an entire image and its state after transformer encoder can be used for classification. [class] token contains latent information, and through self-attention accumulates more information about the sequence, which is later used for classification. ViT [12] also explored averaging output tokens instead, but found no significant difference in performance. They did however find that the learning rates have to be adjusted between the two variants: [class] token vs. average pooling.
分类:视觉Transformer通常会在嵌入图像块的序列中添加一个额外的可学习[class] token,用于表示整个图像的类别参数,其经过Transformer编码器后的状态可用于分类。[class] token包含潜在信息,并通过自注意力机制积累更多关于序列的信息,最终用于分类。ViT [12]也尝试过使用平均输出token替代方案,但发现性能无明显差异。不过他们发现这两种变体([class] token与平均池化)需要调整不同的学习率。
2.2. Data-Efficient Transformers
2.2. 数据高效的 Transformer
In an effort to reduce dependence on data, Touvron et al. [40] proposed Data-Efficient Image Transformers (DeiT). Using more advanced training techniques, and a novel knowledge transfer method, DeiT improves the classification performance of ViT on ImageNet-1k without large-scale pre-training on datasets such as JFT-300M [39] or ImageNet-21k [10]. By relying only on more augmentations [8] and training techniques [50, 49], it is shown that much smaller ViT variants that were unexplored by Dosovitskiy et al. can outperform the larger ones on ImageNet1k without pre-training. Furthermore, DeiT variants were pushed even further through their novel knowledge transfer technique, specifically when using a convolutional model as the teacher. This work pushes forward accessibility of transformers in medium-sized datasets, and we aim to follow by extending the study to even smaller sets of data and smaller models. However, we base our work on the notion that $i f$ a small dataset happens to be sufficiently novel, pre-trained models will not help train on that domain and the model will not be appropriate for that dataset. While knowledge transfer is a strong technique, it requires a pre-trained model for any given dataset, adding to training time and complexity, with an additional forward pass, and as pointed out by Touvron et al. is usually only significant when there’s a convolutional teacher available to transfer the inductive biases. As a result, it can be argued that if a network utilized just the bare minimum of convolutions, while keeping the pure transformer structure, it may need to rely less on large-scale training and transfer of inductive biases through knowledge transfer.
为减少对数据的依赖,Touvron等人[40]提出了数据高效图像Transformer(DeiT)。通过采用更先进的训练技术和新颖的知识迁移方法,DeiT在无需JFT-300M[39]或ImageNet-21k[10]等数据集大规模预训练的情况下,提升了ViT在ImageNet-1k上的分类性能。研究表明,仅依靠更强的数据增强[8]和训练技术[50,49],Dosovitskiy等人未探索的更小ViT变体无需预训练即可在ImageNet1k上超越更大模型。此外,DeiT变体通过其新颖的知识迁移技术(特别是使用卷积模型作为教师网络时)实现了进一步突破。该研究推动了Transformer在中型数据集上的可及性,我们旨在将其研究延伸至更小规模的数据集和模型。但我们的工作基于以下假设:若小数据集本身具有足够新颖性,预训练模型将无法辅助该领域训练,且模型不适用于该数据集。虽然知识迁移是强大技术,但它要求针对每个数据集都需预训练模型,这会增加训练时间和复杂度(需额外前向传播),正如Touvron等人指出的,该方法通常仅在存在可迁移归纳偏置的卷积教师网络时效果显著。因此可以认为,若网络仅使用最基础的卷积操作并保持纯Transformer结构,或可减少对大规模训练和知识迁移中归纳偏置转移的依赖。
Yuan et al. [48] proposed Tokens-to-token ViT (T2TViT), which adopts a window- and attention-based tokenization strategy. Their tokenizer extracts patches of the input feature map, similar to a convolution, applies three sets of kernel weights, and produces three sets of feature maps, which are fed to self-attention as query and keyvalue pairs. This process is equivalent to convolutions producing the QKV projections in a self-attention module. Finally, this strategy is repeated twice, followed by a final patching and embedding. The entire process replaces patch and embedding in ViT. This strategy, along with their small-strided patch extraction, allows their network to model local structures, including along the boundaries between patches. This attention-based patch interaction leads to finer-grained tokens which allow T2T-ViT to outperform previous Transformer-based models on ImageNet. T2T-ViT differs from our work, in that it focuses on medium-sized datasets like ImageNet, which are not only far too large for many research problems in science and medicine but also resource demanding. T2T tokenizer also has more parameters and complexity compared to a convolutional one.
Yuan等人[48]提出了Tokens-to-token ViT (T2TViT),采用基于窗口和注意力的token化策略。该token提取器类似卷积操作提取输入特征图的局部块,应用三组卷积核权重生成三组特征图,作为查询和键值对输入自注意力模块。这一过程等价于在自注意力模块中用卷积生成QKV投影。最终重复两次该策略后执行最后一次分块嵌入,整体流程替代了ViT中的分块嵌入步骤。结合小步长分块提取策略,该网络能够建模局部结构(包括分块边界区域)。这种基于注意力的分块交互机制产生了更细粒度的token,使得T2T-ViT在ImageNet上超越了先前基于Transformer的模型。T2T-ViT与我们的工作差异在于:其聚焦ImageNet等中型数据集,这类数据集不仅远超科学和医学领域多数研究问题的规模需求,且计算资源消耗大;相比卷积式token化方案,T2T方案还具有更高的参数量与复杂度。
2.3. Convolution-inspired Transformers
2.3. 卷积启发的Transformer
Many works have been motivated to improve vision transformers and eliminate the need for large-scale pretraining. ConViT [9] introduces a gated positional selfattention (GPSA) that allows for a “soft” convolutional inductive bias within their model. GPSA allows their network to have more flexibility with respect to positional information. Since GPSA is able to be initialized as a convolutional layer, this allows their network to sometimes have the properties of convolutions or alternatively having the properties of attention. Its gating parameter can be adjusted by the network, allowing it to become more expressive and adapt to the needs of the dataset. Convolutionenhanced image Transformers (Ceit) [47] utilize convolutions throughout their model. They propose a convolutionbased Image-to-Token module for token iz ation. They also re-design the encoder with layers of multi-headed selfattention and their novel Locally Enhanced Feed forward Layer, which processes the spatial information form the extracted token. This allows creates a network that is competitive with other works such as DeiT on ImageNet. Convolutional vision Transformer (CvT) [45] introduces convolutional transformer encoder layers, which use convolutions instead of linear projections for the QKV in selfattention. They also introduce convolutions into their tokenization step, and report competitive results compared to other vision transformers on ImageNet-1k. All of these works report results when trained from scratch on ImageNet (or larger) datasets.
许多研究致力于改进视觉Transformer (Vision Transformer) 并消除对大规模预训练的依赖。ConViT [9] 提出了一种门控位置自注意力 (GPSA) 机制,在模型中实现了"软"卷积归纳偏置。GPSA 使网络对位置信息具有更高的灵活性。由于 GPSA 可初始化为卷积层,该网络既能保留卷积特性,也能展现注意力机制的特性。其门控参数可由网络动态调整,从而增强表达能力并适应数据集需求。卷积增强图像Transformer (Ceit) [47] 在模型中全程采用卷积操作,提出基于卷积的 Image-to-Token 模块进行 Token 化,并通过多头自注意力层与新颖的局部增强前馈层重构编码器,后者专门处理提取 Token 的空间信息。该网络在 ImageNet 上取得了与 DeiT 等模型相当的性能。卷积视觉Transformer (CvT) [45] 引入卷积Transformer编码层,用卷积替代自注意力中 QKV 的线性投影,并在 Token 化阶段融入卷积操作,在 ImageNet-1k 上报告了优于其他视觉Transformer的结果。这些工作均在 ImageNet(或更大规模)数据集上从头训练并验证效果。
2.4. Comparison
2.4. 对比
Our work differs from the aforementioned in several ways, in that it focuses on answering the following question: Can vision transformers be trained from scratch on small datasets? Focusing on a small datasets, we seek to create a model that can be trained, from scratch, on datasets that are orders of magnitude smaller than ImageNet. Having a model that is compact, small in size, and efficient allows greater accessibility, as training on ImageNet is still a difficult and data intensive task for many researchers. Thus our focus is on an accessible model, with few parameters, that can quickly and efficiently be trained on smaller platforms while still maintaining SOTA results.
我们的工作与上述研究在几个方面存在差异,重点在于回答以下问题:视觉Transformer (Vision Transformer) 能否在小规模数据集上从头训练?聚焦小规模数据,我们致力于构建一个可在比ImageNet小几个数量级的数据集上从头训练的模型。紧凑、轻量且高效的模型能显著提升可及性,因为对许多研究者而言,ImageNet训练仍是数据密集的高难度任务。因此我们专注于开发参数少、可访问的模型,使其能在小型平台上快速高效训练,同时保持SOTA (State-of-the-Art) 性能。
3. Method
3. 方法
In order to provide empirical evidence that vision transformers are trainable from scratch when dealing with small sets of data, we propose three different models: ViTLite, Compact Vision Transformers (CVT), and Compact Convolutional Transformers (CCT). ViT-Lite is nearly identical to the original ViT in terms of architecture, but with a more suitable size and patch size for small-scale learning. CVT builds on this by using our Sequence Pooling method (SeqPool), that pools the entire sequence of tokens produced by the transformer encoder. SeqPool replaces the conventional [class] token. CCT builds on CVT and utilizes a convolutional tokenizer, generating richer tokens and preserving local information. The convolutional tokenizer is better at encoding relationships between patches compared to the original ViT [12]. A detailed modular-level comparison of these models can be viewed in Figure 2.
为了提供视觉Transformer在小规模数据集上可从头训练的实证依据,我们提出了三种模型:ViTLite、紧凑视觉Transformer(CVT)和紧凑卷积Transformer(CCT)。ViT-Lite在架构上与原始ViT几乎相同,但针对小规模学习调整了更合适的模型尺寸和图像块尺寸。CVT在此基础上采用我们提出的序列池化方法(SeqPool),该方法对Transformer编码器输出的全部Token序列进行池化操作,替代了传统的[class] Token。CCT在CVT框架中引入卷积Tokenizer,通过生成更具表现力的Token来保留局部信息。与原始ViT [12] 相比,这种卷积Tokenizer能更有效地编码图像块间关系。各模型的模块级详细对比见图2:
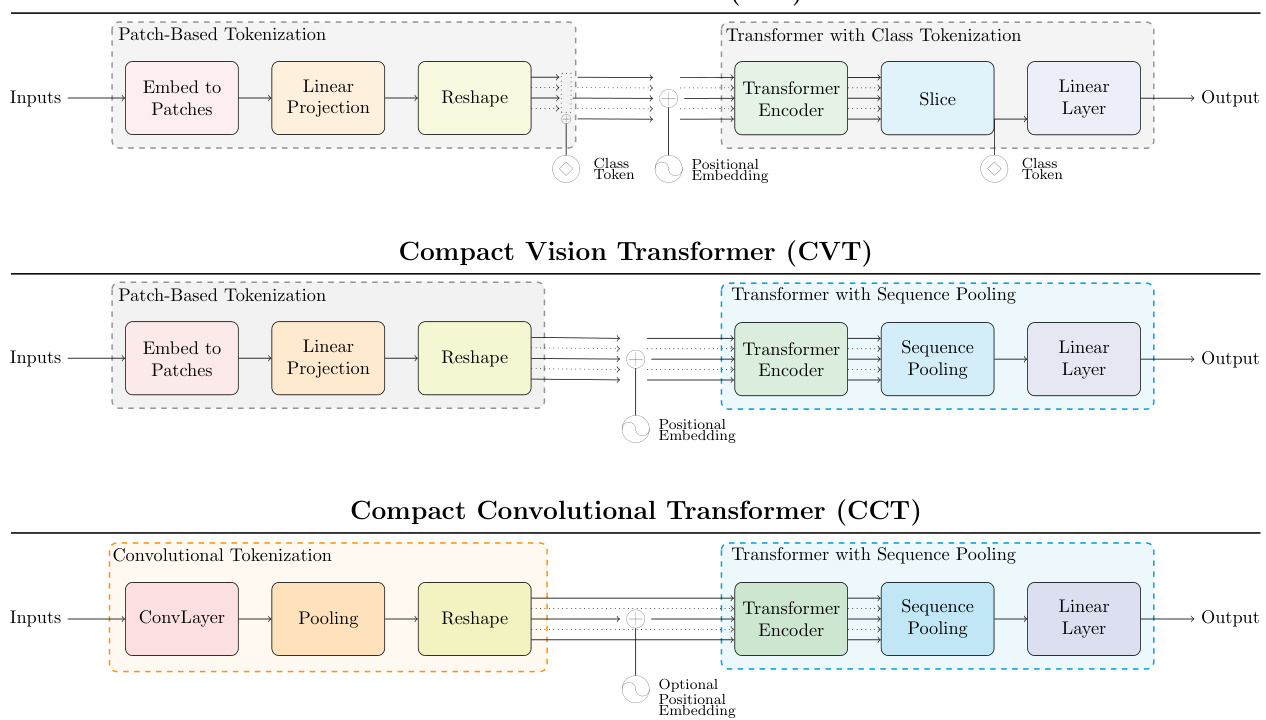
Figure 2: Comparing ViT (top) to CVT (middle) and CCT (bottom). CVT can be thought of as an ablated version of CCT, only utilizing sequence pooling and not a convolutional tokenizer. CVT may be preferable with more limited compute, as the patch-based token iz ation is faster.
图 2: ViT (上) 与 CVT (中) 和 CCT (下) 的对比。CVT 可视为 CCT 的简化版本,仅使用序列池化而不采用卷积分词器。在计算资源受限时,基于图像块的分词方式速度更快,因此 CVT 可能是更优选择。
The components of our compact transformers are further discussed in the following subsections: Transformer-based Backbone, Small and Compact Models, SeqPool, and Convolutional Tokenizer.
我们紧凑型 Transformer 的组件将在以下小节中进一步讨论:基于 Transformer 的主干网络、小型紧凑模型、SeqPool 和卷积 Tokenizer。
3.1. Transformer-based Backbone
3.1. 基于Transformer的主干网络
In terms of model design, we follow the original Vision Transformer [12], and original Transformer [41]. As mentioned in Section 2.1, the encoder consists of transformer blocks, each including an MHSA layer and an MLP block. The encoder also applies Layer Normalization, $G E L U$ activation, and dropout. Positional embeddings can be learnable or sinusoidal, both of which are effective.
在模型设计方面,我们遵循原始Vision Transformer [12]和原始Transformer [41]。如第2.1节所述,编码器由transformer块组成,每个块包含一个MHSA层和一个MLP块。编码器还应用了层归一化、$GELU$激活和dropout。位置嵌入可以是可学习的或正弦式的,这两种方式都有效。
3.2. Small and Compact Models
3.2. 小型紧凑模型
We propose smaller and more compact vision transformers. The smallest ViT variant, ViT-Base, includes a 12 layer transformer encoder with 12 attention heads, 64 dimensions per head, and 2048-dimensional hidden layers in the MLP blocks. This, along with the classifier and 16x16 patch and embedder results in over 85M parameters. We propose variants with as few as 2 layers, 2 heads, and 128-dimensional hidden layers. In Appendix A, we summarized the details of the variants we propose, the smallest of which can have as little as 0.22M parameters, while the largest (for small-scale learning) only have 3.8M parameters. We also adjust the tokenizer (patch size) according to the dataset we’re training on, based on its image resolution. These variants, which are mostly similar in architecture to ViT, but different in size, are referred to as ViT-Lite. In our notation, we use the number of layers to specify size, as well as token iz ation details: for instance, ViT-Lite-12/16 has 12 transformer encoder layers, and a $\mathbf{16}\mathbf{\times16}$ patch size.
我们提出更小更紧凑的视觉Transformer。最小的ViT变体ViT-Base包含12层Transformer编码器,每层12个注意力头,每个头64维,MLP模块中2048维的隐藏层。加上分类器、16x16图像块划分及嵌入层,参数量超过8500万。我们提出的变体最少仅需2层、2个注意力头和128维隐藏层。附录A总结了这些变体的细节,最小变体参数量可低至22万,最大变体(针对小规模学习)仅380万参数。我们还根据训练数据集的图像分辨率调整分词器(图像块大小)。这些架构与ViT基本相似但尺寸不同的变体称为ViT-Lite。在命名规则中,我们用层数表示模型规模并注明分词细节:例如ViT-Lite-12/16表示具有12层Transformer编码器,采用$\mathbf{16}\mathbf{\times16}$图像块划分。
3.3. SeqPool
3.3. SeqPool
In order to map the sequential outputs to a singular class index, ViT [12] and most other common transformer-based class if i ers follow BERT [11], in forwarding a learnable class or query token through the network and later feeding it to the classifier. Other common practices include global average pooling (averaging over tokens), which have been shown to be preferable in some scenarios. We introduce SeqPool, an attention-based method which pools over the output sequence of tokens. Our motivation is that the output sequence contains relevant information across different parts of the input image, therefore preserving this information can improve performance, and at no additional parameters compared to the learnable token. Additionally, this change slightly decreases computation, due one less token being forwarded. This operation consists of mapping the output sequence using the transformation T : Rb×n×d Rb×d. Given:
为了将序列输出映射到单一类别索引,ViT [12] 和大多数其他基于Transformer的分类器遵循BERT [11]的做法,通过网络传递一个可学习的类别或查询token,随后将其输入分类器。其他常见方法包括全局平均池化(对token取平均),在某些场景下已被证明更优。我们提出了SeqPool,这是一种基于注意力的方法,对输出token序列进行池化。我们的动机是输出序列包含了输入图像不同部分的相关信息,因此保留这些信息可以提升性能,且相比可学习token不会增加额外参数。此外,由于减少了一个token的前向传递,这一改动还略微降低了计算量。该操作通过变换T : ℝᵇ×ⁿ×ᵈ → ℝᵇ×ᵈ实现序列输出的映射。给定:
$$
\mathbf{x}{L}=\mathrm{f}(\mathbf{x}_{0})\in\mathbb{R}^{b\times n\times d}
$$
$$
\mathbf{x}{L}=\mathrm{f}(\mathbf{x}_{0})\in\mathbb{R}^{b\times n\times d}
$$
where $\mathbf{x}{L}$ is the output of an $L$ layer transformer encoder $f,b$ is batch size, $n$ is sequence length, and $d$ is the total embedding dimension. $\mathbf{x}{L}$ is fed to a linear layer $\mathrm{g}(\mathbf{x}_{L})\in$ $\mathbb{R}^{d\times1}$ , and softmax activation is applied to the output:
其中 $\mathbf{x}{L}$ 是 $L$ 层 Transformer 编码器 $f$ 的输出,$b$ 为批大小,$n$ 为序列长度,$d$ 为总嵌入维度。$\mathbf{x}{L}$ 被输入线性层 $\mathrm{g}(\mathbf{x}_{L})\in$ $\mathbb{R}^{d\times1}$,并对输出应用 softmax 激活函数:
$$
\mathbf{x}{L}^{\prime}=\mathrm{softmax}\left(\mathbf{g}(\mathbf{x}_{L})^{T}\right)\in\mathbb{R}^{b\times1\times n}
$$
$$
\mathbf{x}{L}^{\prime}=\mathrm{softmax}\left(\mathbf{g}(\mathbf{x}_{L})^{T}\right)\in\mathbb{R}^{b\times1\times n}
$$
This generates an importance weighting for each input token, which is applied as follows:
这为每个输入Token生成一个重要性权重,其应用方式如下:
$$
\mathbf{z}=\mathbf{x}{L}^{\prime}\mathbf{x}{L}=\mathrm{softmax}\left(\mathbf{g}(\mathbf{x}{L})^{T}\right)\times\mathbf{x}_{L}\in\mathbb{R}^{b\times1\times d}
$$
$$
\mathbf{z}=\mathbf{x}{L}^{\prime}\mathbf{x}{L}=\mathrm{softmax}\left(\mathbf{g}(\mathbf{x}{L})^{T}\right)\times\mathbf{x}_{L}\in\mathbb{R}^{b\times1\times d}
$$
By flattening, the output $\boldsymbol{z}\in\mathbb{R}^{b\times d}$ is produced. This output can then be sent through a classifier.
通过展平操作,生成输出 $\boldsymbol{z}\in\mathbb{R}^{b\times d}$。该输出随后可输入分类器。
SeqPool allows our network to weigh the sequential embeddings of the latent space produced by the transformer encoder and correlate data across the input data. This can be thought of this as attending to the sequential data, where we are assigning importance weights across the sequence of data, only after they have been processed by the encoder. We tested several variations of this pooling method, including learnable and static methods, and found that the learnable pooling performs the best. Static methods, such as global average pooling have already been explored by ViT as well, as pointed out in section 2.1. We believe that the learnable weighting is more efficient because each embedded patch does not contain the same amount of entropy. This allows the model to apply weights to tokens with respect to the relevance of their information. Additionally, sequence pooling allows our model to better utilize information across spatially sparse data. We will further study the effects of this pooling in the ablation study (Sec 4.4). By replacing the conventional class token in ViT-Lite with SeqPool, Compact Vision Transformer is created. We use the same notations for this model: for instance, CVT-7/4 has 7 transformer encoder layers, and a $4{\times}4$ patch size.
SeqPool 使我们的网络能够权衡由 Transformer 编码器生成的潜在空间中的序列嵌入,并在输入数据之间建立关联。这可以理解为对序列数据进行注意力加权,即在数据经过编码器处理后,为整个数据序列分配重要性权重。我们测试了该池化方法的多种变体(包括可学习和静态方法),发现可学习池化表现最佳。如第 2.1 节所述,ViT 也已探索过全局平均池化等静态方法。我们认为可学习加权更高效,因为每个嵌入块包含的熵值并不相同。这使得模型能根据 Token 信息的相关性分配权重。此外,序列池化使模型能更好地利用空间稀疏数据中的信息。我们将在消融研究中进一步分析该池化的影响(第 4.4 节)。通过用 SeqPool 替换 ViT-Lite 中的传统类别 Token,我们构建了紧凑视觉 Transformer (Compact Vision Transformer)。沿用相同命名规则:例如 CVT-7/4 表示具有 7 个 Transformer 编码器层和 $4{\times}4$ 分块尺寸。
3.4. Convolutional Tokenizer
3.4. 卷积分词器 (Convolutional Tokenizer)
In order to introduce an inductive bias into the model, we replace patch and embedding in ViT-Lite and CVT, with a simple convolutional block. This block follows conventional design, which consists of a single convolution, ReLU activation, and a max pool. Given an image or feature map x RH×W ×C:
为了在模型中引入归纳偏置,我们将ViT-Lite和CVT中的图像块(patch)与嵌入(embedding)替换为一个简单的卷积块。该模块采用常规设计,包含单层卷积、ReLU激活函数和最大池化操作。给定输入图像或特征图x∈R^(H×W×C):
$$
\mathbf{x}_{0}=\mathrm{MaxPool}(\mathrm{ReLU}(\mathrm{Conv2d}(\mathbf{x})))
$$
$$
\mathbf{x}_{0}=\mathrm{MaxPool}(\mathrm{ReLU}(\mathrm{Conv2d}(\mathbf{x})))
$$
where the Conv2d operation has $d$ filters, same number as the embedding dimension of the transformer backbone. Additionally, the convolution and max pool operations can be overlapping, which could increase performance by injecting inductive biases. This allows our model to maintain locally spatial information. Additionally, by using this convolutional block, the models enjoy an added flexibility over models like ViT, by no longer being tied to the input resolution strictly divisible by the pre-set patch size. We seek to use convolutions to embed the image into a latent represent ation, because we believe that it will be more efficient and produce richer tokens for the transformer. These blocks can be adjusted in terms of down sampling ratio (kernel size, stride and padding), and are repeatable for even further down sampling. Since self-attention has a quadratic time and space complexity with respect to the number of tokens, and number of tokens is equal to the resolution of the input feature map, more down sampling results in fewer tokens which noticeably decreases computation (at the expense of performance). We found that on top of the added performance gains, this choice in token iz ation also gives more flexibility toward removing the positional embedding in the model, as it manages to maintain a very good performance. This is further discussed in Appendix C.1.
其中 Conv2d 操作具有 $d$ 个滤波器,数量与 Transformer 主干的嵌入维度相同。此外,卷积和最大池化操作可以重叠,这能通过注入归纳偏置提升性能。该设计使模型能保留局部空间信息。同时,得益于该卷积块,模型相比 ViT 等架构获得了额外灵活性,不再严格受限于输入分辨率必须被预设分块大小整除的条件。我们采用卷积将图像嵌入潜在表征空间,因为该方式效率更高,能为 Transformer 生成更丰富的 Token。这些模块的下采样比例(核尺寸、步长和填充)可调,并可重复堆叠以实现更深层下采样。由于自注意力机制的时间空间复杂度与 Token 数量呈平方关系,而 Token 数量等于输入特征图分辨率,更多下采样会显著减少 Token 数量从而降低计算量(以性能为代价)。实验表明,这种 Token 化方案不仅能带来性能提升,还为去除模型中的位置嵌入提供了更大灵活性(因其仍能保持优异性能),详见附录 C.1。
This convolutional tokenizer, along with SeqPool and the transformer encoder create Compact Convolutional Transformers. We use a similar notation for CCT variants, with the exception of also denoting the number of convolutional layers: for instance, $\mathrm{CCT}\mathrm{-}7/3\mathrm{x}2$ has 7 transformer encoder layers, and a 2-layer convolutional tokenizer with $\hphantom{000}\hphantom{000}\hphantom{000}\hphantom{000}\hphantom{000}\hphantom{000}\hphantom{000}\hphantom{000}\hphantom{000}\hphantom{000}\hphantom{000}\hphantom{000}\hphantom{000}\hphantom{000}\hphantom{000}$ kernel size.
该卷积分词器与SeqPool以及Transformer编码器共同构成了紧凑型卷积Transformer (Compact Convolutional Transformers)。我们采用类似的命名规则来区分CCT变体,但需额外标注卷积层数:例如$\mathrm{CCT}\mathrm{-}7/3\mathrm{x}2$表示包含7层Transformer编码器,以及采用$3\times3$卷积核的2层卷积分词器。
4. Experiments
4. 实验
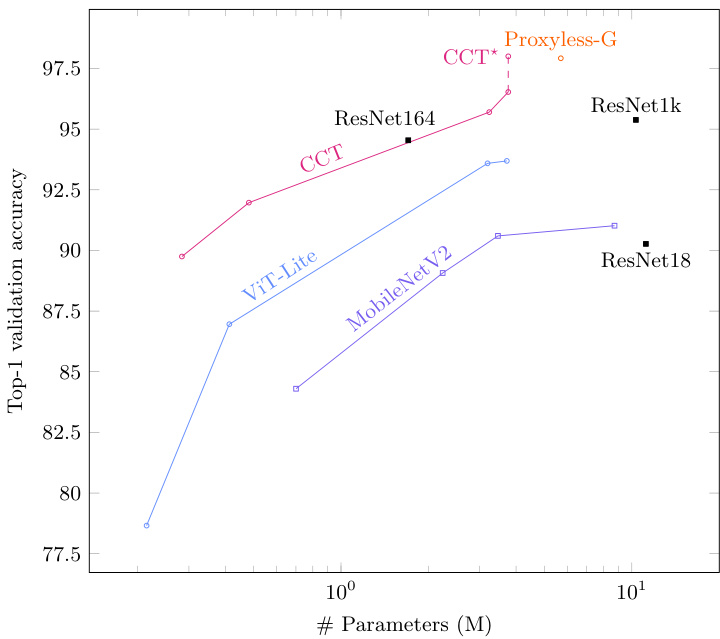
Figure 3: CIFAR-10 accuracy vs. model size (sizes $<12\mathbf{M})$ . $\mathrm{CCT^{\star}}$ was trained longer.
图 3: CIFAR-10 准确率与模型规模 (规模 $<12\mathbf{M})$ 的关系。$\mathrm{CCT^{\star}}$ 训练时间更长。
Table 1: Top-1 validation accuracy comparisons. $\star$ variants were trained longer (see Table 2 )
表 1: Top-1验证准确率对比。带$\star$的变体训练时间更长(见表2)
| 模型 | C-10 | C-100 | Fashion | MNIST | 参数量 | MACs |
|---|---|---|---|---|---|---|
| 卷积网络(专为ImageNet设计) | ||||||
| ResNet18 | 90.27% | 66.46% | 94.78% | 99.80% | 11.18 M | 0.04 G |
| ResNet34 | 90.51% | 66.84% | 94.78% | 99.77% | 21.29 M | 0.08 G |
| MobileNetV2/0.5MobileNetV2/2.0 | 84.78%91.02% | 56.32%67.44% | 93.93%95.26% | 99.70%99.75% | 0.70 M8.72 M | < 0.01 G0.02 G |
| 卷积网络(专为CIFAR设计) | ||||||
| ResNet56[16]ResNet110[16] | 94.63%95.08% | 74.81%76.63% | 95.25%95.32% | 99.27%99.28% | 0.85 M1.73 M | 0.13 G0.26 G |
| ResNet1k-v2*[17]Proxyless-G[5] | 95.38%97.92% | - | - | - | 10.33 M5.7 M | 1.55 G |
| Vision Transformers | ||||||
| ViT-12/16 | 83.04% | 57.97% | 93.61% | 99.63% | 85.63 M | 0.43 G |
| ViT-Lite-7/16 | 78.45% | 52.87% | 93.24% | 99.68% | 3.89 M | 0.02 G |
| ViT-Lite-7/8 | 89.10% | 67.27% | 94.49% | 99.69% | 3.74 M | 0.06 G |
| ViT-Lite-7/4 | 93.57% | 73.94% | 95.16% | 99.77% | 3.72 M | 0.26 G |
| CompactVisionTransformers | ||||||
| CVT-7/8 | 89.79% | 70.11% | 94.50% | 99.70% | 3.74 M | 0.06 G |
| CVT-7/4 | 94.01% | 76.49% | 95.32% | 99.76% | 3.72 M | 0.25 G |
| CompactConvolutionalTransformers | ||||||
| CCT-2/3x2CCT-7/3x2 | 89.75%95.04% | 66.93%77.72% | 94.08%95.16% | 99.70%99.76% | 0.28 M3.85 M | 0.04 G0.29 G |
| CCT-7/3x1 | 96.53% | 80.92% | - | - | 3.76 M | 1.19 G |
| CCT-7/3x1* | 98.00% | 82.72% | 95.56% | 99.82% | 3.76 M | 1.19 G |
Table 2: CCT $.7/3\times1$ top-1 accuracy on CIFAR-10/100 when trained longer
表 2: CCT $.7/3\times1$ 在 CIFAR-10/100 上长时间训练后的 top-1 准确率
| #Epochs | Pos. Emb. | CIFAR-10 | CIFAR-100 |
|---|---|---|---|
| 300 | Learnable | 96.53% | 80.92% |
| 1500 | Sinusoidal | 97.48% | 82.72% |
| 5000 | Sinusoidal | 98.00% | 82.87% |
MNIST and Fashion-MNIST only contain a single channel, greatly reducing the information density. Flowers-102 has a relatively small number of samples, while having relatively higher resolution images and 102 classes. We divided these datasets into three categories: small-scale small resolution datasets (CIFAR-10/100, MNIST, and FashionMNIST), small-scale larger resolution (Flowers-102), and medium-scale (ImageNet-1k) datasets. We also include a study on NLP classification, presented in appendix G.
MNIST和Fashion-MNIST仅包含单通道,显著降低了信息密度。Flowers-102样本数量较少,但图像分辨率较高且包含102个类别。我们将这些数据集分为三类:小规模低分辨率数据集(CIFAR-10/100、MNIST和FashionMNIST)、小规模高分辨率(Flowers-102)以及中规模(ImageNet-1k)数据集。我们还进行了NLP分类研究,详见附录G。
4.1. Datasets
4.1. 数据集
We conducted image classification experiments using our method on the following datasets: CIFAR-10, CIFAR100 (MIT License) [21], MNIST, Fashion-MNIST, Oxford Flowers-102 [30], and ImageNet-1k [10]. The first four datasets not only have a small number of training samples, but they are also small in resolution. Additionally,
我们使用以下数据集进行了图像分类实验:CIFAR-10、CIFAR-100 (MIT License) [21]、MNIST、Fashion-MNIST、Oxford Flowers-102 [30] 和 ImageNet-1k [10]。前四个数据集不仅训练样本数量少,而且分辨率也较低。此外,
4.2. Hyper parameters
4.2. 超参数
We used the timm package [43] to train the models (see Appendix E for details), except for cited works which are reported directly. For all experiments, we conducted a hyper parameter sweep for every different method and report the best results we were able to achieve. We will release all checkpoints corresponding to the reported numbers, and detailed training settings in the form of YAML files, with our code. We also provide a report on hyper param ter settings in Appendix E. Unless stated otherwise, all tests were run for 300 epochs, and the learning rate is reduced per epoch based on cosine annealing [26]. All transformer based models (ViT-Lite, CVT, and CCT) were trained using the AdamW optimizer.
我们使用 timm 包 [43] 训练模型(详见附录 E),直接引用的工作除外。所有实验均针对每种不同方法进行超参数扫描,并报告我们取得的最佳结果。我们将发布与报告数值对应的所有检查点,以及以 YAML 文件形式记录的详细训练设置(随代码一同发布)。附录 E 还提供了超参数设置报告。除非另有说明,所有测试均运行 300 个周期,学习率根据余弦退火 [26] 逐周期降低。所有基于 Transformer 的模型(ViT-Lite、CVT 和 CCT)均使用 AdamW 优化器进行训练。
Table 3: ImageNet Top-1 validation accuracy comparison (no extra data or pre training). This shows that larger variants of CCT could also be applicable to medium-sized datasets
表 3: ImageNet Top-1 验证准确率对比 (无额外数据或预训练)。这表明更大规模的 CCT 变体也可能适用于中等规模数据集
| 模型 | Top-1 | 参数量 | MACs | 训练周期 |
|---|---|---|---|---|
| ResNet50 [16] | 77.15% | 25.55M | 4.15 G | 120 |
| ResNet50 (2021) [44] | 79.80% | 25.55M | 4.15 G | 300 |
| ViT-S [19] | 79.85% | 22.05M | 4.61 G | 300 |
| CCT-14/7×2 | 80.67% | 22.36 M | 5.53 G | 300 |
| DeiT-S [19] | 81.16% | 22.44M | 4.63 G | 300 |
| CCT-14/7x2Distilled | 81.34% | 22.36M | 5.53G | 300 |
Table 4: Flowers-102 Top-1 validation accuracy comparison. CCT outperforms other competitive models, having significantly fewer parameters and GMACs. This demonstrates the compactness on small datasets even with large images
表 4: Flowers-102 Top-1验证准确率对比。CCT以显著更少的参数量和GMACs超越了其他竞争模型,这证明了即使在大图像的小型数据集上也具有紧凑性
| 模型 | 分辨率 | 预训练 | Top-1 | #Params | MACs |
|---|---|---|---|---|---|
| CCT-14/7×2 | 224 | 97.19% | 22.17 M | 18.63 G | |
| DeiT-B | 384 | ImageNet-1k | 98.80% | 86.25M | 55.68G |
| ViT-L/16 | 384 | JFT-300M | 99.74% | 304.71M | 191.30G |
| ViT-H/14 | 384 | JFT-300M | 99.68% | 661.00M | 504.00G |
| CCT-14/7×2 | 384 | ImageNet-1k | 99.76% | 22.17M | 18.63 G |
4.3. Performance Comparison
4.3. 性能对比
Small-scale small resolution training: In order to demonstrate that vision transformers can be as effective as convolutional neural networks, even in settings with small sets of data, we compare our compact transformers to ResNets [16], which are still very useful CNNs for small to medium amounts of data, as well as to Mobile Ne tV 2 [35], which are very compact and small-sized CNNs. We also compare with results from [17] where He et al. designed very deep (up to 1001 layers) CNNs specifically for CIFAR. The results are presented in Table 1, all of which are of models trained from scratch. We highlight the top performers. CCT-7/3x2 achieves on par results with the CNN models, while having significantly fewer parameters in some cases. We also compare our method to the original ViT [12] in order to express the effectiveness of smaller sized backbones, convolutional layers, as well our pooling technique. As these datasets were not trained from scratch in the original paper, we attempted to train the smallest variant: ViT-B/16 (ViT-12/16). We trained our best performing model, CCT-7/3x1, for longer than the 300 epochs to see how far it can go. Surprisingly, this model can get as high as $98%$ accuracy on CIFAR-10, and $82.87%$ accuracy on CIFAR-100 when trained for 5000 epochs, which is still fewer iterations an ImageNet pre-training would have. We present results from training on CIFAR-10/100 for 300, 1500 and 5000 epochs in Table 2. We observed that sinusoidal positional embedding had a small but noticeable edge over learnable when training longer. This represents the only transformer based model in the top 25 results on Papers With Code for CIFAR-10 where models have no extra data or pre-training . In addition to this, it is also one of the smallest models, being $15%$ the size of ResNet50 while maintaining similar performance. We present a plot of different models in Table 1 in Figure 3.
小规模低分辨率训练:为证明视觉Transformer (Vision Transformer) 在小数据场景下仍能媲美卷积神经网络,我们将紧凑型Transformer与适用于中小规模数据的经典CNN模型ResNet [16]、超轻量级CNN模型MobileNetV2 [35] 进行对比,同时参照He等人在[17]中为CIFAR数据集设计的超深CNN(最高1001层)。所有模型均从头开始训练,结果如表1所示(加粗显示最优性能)。CCT-7/3x2在参数量显著更少的情况下达到与CNN相当的效果。为验证小尺寸主干网络、卷积层和池化技术的有效性,我们还与原始ViT [12] 进行对比(由于原文未从头训练,我们选择最小变体ViT-B/16即ViT-12/16进行训练)。将最佳模型CCT-7/3x1延长训练至5000轮后,其在CIFAR-10和CIFAR-100上分别达到 $98%$ 和 $82.87%$ 准确率——这仍比ImageNet预训练所需迭代次数更少。表2展示了300/1500/5000轮训练结果,其中正弦位置编码在长时训练中相比可学习编码具有微小但稳定的优势。该模型是Papers With Code公布的CIFAR-10无额外数据/预训练条件下Top25中唯一的Transformer架构,同时尺寸仅为ResNet50的 $15%$ 且性能相当。不同模型对比见图3。
Medium-scale training: ImageNet training results are presented in Table 3, and compared to ResNet50 [16], ViT, and DeiT. We report ResNet50 from the original paper [16], as well as from Wightman et al. [44] which uses a similar training schedule to ours, and is therefore a fairer comparison. We also report a smaller ViT variant as proposed by Touvron et al. [40]. We also report CCT’s performance with knowledge distillation, in order to compare it to DeiT [40]. Similar to DeiT, we trained our CCT-14/7x2 with a convolutional teacher and hard distillation loss. We used a RegNetY-16GF [32] (84M parameters), the same model
中等规模训练:ImageNet训练结果如表3所示,并与ResNet50 [16]、ViT和DeiT进行对比。我们引用了原始论文[16]中的ResNet50结果,以及Wightman等人[44]采用与我们相似训练方案的结果(后者更具可比性)。同时列出了Touvron等人[40]提出的较小ViT变体性能。为与DeiT [40]公平对比,我们还报告了采用知识蒸馏的CCT性能:类似DeiT方案,使用卷积教师模型和硬蒸馏损失训练了CCT-14/7x2模型,教师模型采用RegNetY-16GF [32](8400万参数)。
DeiT selected as the teacher. It is noticeable that distillation does not have as significant of an effect on CCT it does on DeiT. This can be attributed to the already existing inductive biases from the convolutional tokenizer. DeiT authors argued that a convolutional teacher would be able to transfer inductive biases to the student model.
DeiT 被选作教师模型。值得注意的是,蒸馏对 CCT 的影响不如对 DeiT 那样显著。这可以归因于卷积分词器 (convolutional tokenizer) 已有的归纳偏置。DeiT 作者认为,卷积教师模型能够将归纳偏置传递给学生模型。
Small-scale higher-resolution training: We also present our results on Flowers-102, in which we successfully reach reasonable performance without any pretraining, and with the same model size as our ImageNet model. We also claim state of the art with $99.76%$ topaccuracy with ImageNet pre training, which exceeds even far larger models pre-trained on JFT-300M. In addition to this we note that our model is at least a quarter the size of the next best model and almost $30\times$ smaller than ViT-H/14. It can also be seen that CCT is $3-27\times$ more computationally efficient.
小规模高分辨率训练:我们还在Flowers-102数据集上展示了实验结果,该实验中我们在未使用任何预训练、且模型尺寸与ImageNet模型相同的情况下,成功达到了合理性能。同时我们以99.76%的top-1准确率(基于ImageNet预训练)刷新了当前最佳水平,这一表现甚至超过了在JFT-300M上预训练的更大规模模型。此外需要指出,我们的模型体积仅为次优模型的四分之一,比ViT-H/14缩小近30倍。数据还显示CCT模型的计算效率提升了3-27倍。
4.4. Ablation Study
4.4. 消融实验
We extend our previous comparisons by doing an ablation study on our methods. In this study, we progressively transform the original ViT into ViT-Lite, CVT, and CCT, and compare their top-1 accuracy scores. In this particular study, we report the results on CIFAR-10 and CIFAR-100 in Table 8 in Appendix F.
我们通过对方法进行消融研究来扩展之前的比较。在此研究中,我们逐步将原始ViT转换为ViT-Lite、CVT和CCT,并比较它们的top-1准确率分数。本研究中,我们在附录F的表8中报告了CIFAR-10和CIFAR-100上的结果。
5. Conclusion
5. 结论
Transformers have commonly been perceived to be only applicable to larger-scale or medium-scale training. While their s cal ability is undeniable, we have shown within this paper that with proper configuration, a transformer can be successfully used in small data regimes as well, and outperform convolutional models of equivalent, and even larger, sizes. Our method is simple, flexible in size, and the smallest of our variants can be easily loaded on even a minimal GPU, or even a CPU. While part of research has been focused on large-scale models and datasets, we focus on smaller scales in which there is still much research to be done in data efficiency. We show that CCT can outperform other transformer based models on small datasets while also having a significant reduction in computational costs and memory constraints. This work demonstrates that transformers do not require vast computational resources and can allow for their applications in even the most modest of settings. This type of research is important to many scientific domains where data is far more limited that the conventional machine learning datasets which are used in general research. Continuing research in this direction will help open research up to more people and domains, extending machine learning research.
Transformers 通常被认为仅适用于大规模或中等规模的训练。虽然其扩展能力毋庸置疑,但我们在本文中表明,通过适当配置,transformer 也能成功应用于小数据场景,并超越同等甚至更大规模的卷积模型。我们的方法简单、尺寸灵活,最小变体甚至可以在低配 GPU 或 CPU 上轻松运行。尽管部分研究聚焦于大规模模型和数据集,我们关注仍存在大量数据效率研究空间的小规模场景。实验证明 CCT 在小数据集上能超越其他基于 transformer 的模型,同时显著降低计算成本和内存限制。这项工作表明 transformer 并不需要庞大计算资源,可在最简易的环境中实现应用。此类研究对数据量远少于常规机器学习研究数据集的科学领域尤为重要。持续开展该方向研究将有助于向更多人群和领域开放研究,拓展机器学习研究的边界。
A. Variants
A. 变体
Within this appendix, we present architectural details of our variants in Tables 5 and 6.
在本附录中,我们通过表5和表6展示了各变体的架构细节。
Table 5: Transformer backbones in each variant.
表 5: 各变体中的Transformer主干结构。
| 模型 | 层数 | 头数 | 比率 | 维度 |
|---|---|---|---|---|
| ViT-Lite-6 | 6 | 4 | 2 | 256 |
| ViT-Lite-7 | 7 | 4 | 2 | 256 |
| CVT-6 | 6 | 4 | 2 | 256 |
| CVT-7 | 7 | 4 | 2 | 256 |
| CCT-2 | 2 | 2 | 1 | 128 |
| CCT-4 | 4 | 2 | 1 | 128 |
| CCT-6 | 6 | 4 | 2 | 256 |
| CCT-7 | 7 | 4 | 2 | 256 |
| CCT-14 | 14 | 6 | 3 | 384 |
Table 6: Tokenizers in each variant.
表 6: 各变体中的 Tokenizer。
| Model | #Layers | s#Convs | Kernel | Stride |
|---|---|---|---|---|
| ViT-Lite-7/8 | 7 | 1 | 8x8 | 8x8 |
| ViT-Lite-7/4 | 7 | 1 | 4x4 | 4x4 |
| CVT-7/8 | 7 | 1 | 8x8 | 8x8 |
| CVT-7/4 | 7 | 1 | 4x4 | 4x4 |
| CCT-2/3x2 | 2 | 2 | 3x3 | 1x1 |
| CCT-7/3x1 | 7 | 1 | 3x3 | 1x1 |
| CCT-7/7x2 | 7 | 2 | 7×7 | 2x2 |
B. Computational Resources
B. 计算资源
For most experiments, we used a machine with an Intel(R) Core(TM) i9-9960X CPU $_{(a)}3.10\mathrm{GHz}$ and 4 NVIDIA(R) RTX(TM) 2080Tis (11GB). The exception was the CPU test which was performed with an AMD Ryzen 9 5900X. Each ImageNet experiment was performed on a single machine either with 2 AMD EPYC(TM) 7662s and 8 NVIDIA(R) RTX(TM) A6000s (48GB), or 2 AMD EPYC(TM) 7713s and 8 NVIDIA(R) A100s (80GB).
在大多数实验中,我们使用的机器配置为 Intel(R) Core(TM) i9-9960X CPU $_{(a)}3.10\mathrm{GHz}$ 和 4 块 NVIDIA(R) RTX(TM) 2080Ti (11GB)。例外情况是 CPU 测试采用了 AMD Ryzen 9 5900X。每个 ImageNet 实验均在单台机器上完成,机器配置为 2 颗 AMD EPYC(TM) 7662 处理器和 8 块 NVIDIA(R) RTX(TM) A6000 (48GB),或 2 颗 AMD EPYC(TM) 7713 处理器和 8 块 NVIDIA(R) A100 (80GB)。
C. Additional analyses
C. 附加分析
Within this appendix we present some additional performance analyses which were conducted.
在本附录中,我们展示了一些额外进行的性能分析。
C.1. Positional Embedding
C.1. 位置嵌入 (Positional Embedding)
To determine the effects of our small & compact design, sequence pooling, and convolutional tokenizer, we perform an ablation study focused on positional embedding, seen in Table 7. In this study, we experiment with ViT (original sizing), ViT-Lite, CVT, and CCT, and investigate the effects of: a learnable positional embedding, a standard sinusoidal embedding, as well as no positional embedding. We finish the table with our best model, which also has augmented training and an optimal tuning (refer to Appendix E). In these experiments, we find that positional encoding matters in all variants, but to varying degrees. In particular, CCT relies less on positional encoding, and it can be safely removed much impact in accuracy. We also tested our CCT model without SeqPool, using the standard [class] token instead, and found that there was little to no effect from having a positional encoder or not, depending on model size. This suggests that convolutions are what helps provide spatially sparse information to the transformer, while also helping the model overcome some of the previous limitations, allowing for more efficient use of data. We do find that SeqPool helps slightly in this respect, but overall has a larger effect on increasing total accuracy. Lastly, we find that with proper data augmentation and tuning, the overall performance can be increased, and a low dependence on positional information can be maintained.
为了评估我们小型紧凑设计、序列池化(SeqPool)和卷积分词器的影响,我们针对位置嵌入进行了消融实验,结果如表7所示。实验中我们测试了ViT(原始尺寸)、ViT-Lite、CVT和CCT模型,并对比分析了可学习位置嵌入、标准正弦位置嵌入以及无位置嵌入的效果。表格最后展示了我们经过数据增强和最优调参的最佳模型(详见附录E)。实验表明:位置编码对所有变体都有影响但程度各异,其中CCT对位置编码依赖度最低,移除后精度损失较小。我们还测试了不使用SeqPool而采用标准[class] token的CCT模型,发现位置编码的影响与模型规模相关。这表明卷积操作能为Transformer提供空间稀疏信息,帮助模型突破原有局限并提升数据利用率。虽然SeqPool对此略有助益,但其主要作用体现在整体精度提升上。最后实验证明,恰当的数据增强和参数调优既能提高整体性能,又能保持对位置信息的低依赖性。
C.2. Performance vs Dataset Size
C.2. 性能与数据集规模的关系
In this experiment, we evaluated model performance on smaller subsets of CIFAR-10 to determine the relationship between performance and the number of samples within a dataset. Samples were removed uniformly from each class in CIFAR-10. For this experiment, we compared ViTLite and CCT. In Figure 4, we see the comparison of each model’s accuracy vs the number of samples per class. We show how each model performs when given only 500, 1000, 2000, 3000, 4000, or 5000 (original) samples per class, meaning the total training set ranges from one tenth the size to full. It can be ovserved that CCT is more robust since it is able to obtain higher accuracy with a lower number of samples per class, especially in the low sample regime.
在本实验中,我们评估了模型在CIFAR-10较小子集上的性能,以确定性能与数据集样本数量之间的关系。从CIFAR-10的每个类别中均匀移除样本。本实验比较了ViTLite和CCT两种模型。图4展示了各模型准确率与每类样本数量的对比情况。我们展示了当每类仅提供500、1000、2000、3000、4000或5000(原始)个样本时各模型的表现,这意味着训练集规模从十分之一到完整不等。可以观察到CCT更具鲁棒性,因为它能够在每类样本较少时获得更高准确率,尤其在低样本情况下表现突出。
C.3. Performance vs Dimensionality
C.3. 性能与维度
In order to determine whether transformers are dependant on high dimensional data, as opposed to the number of samples (explored in Appendix C.2), we experimented with down sampled and upsampled versions of CIFAR-10. In Figure 5, we present the image dimensionality vs the performance of CCT vs. ViT-Lite. Both models were trained with images of sizes ranging from $16\times16$ to $64\times64$ . It can be observed that CCT performs better on all image sizes, with a widening difference as the number of pixels increases. From this, it can be inferred that CCT is able to better utilize the information density of an image, while ViT does not see continued performance increases after the standard 32x32 size.
为了验证Transformer是否依赖高维数据(而非样本数量,详见附录C.2),我们对CIFAR-10进行了下采样和上采样实验。图5展示了CCT与ViT-Lite在不同图像维度下的性能对比。两种模型均在$16\times16$至$64\times64$尺寸的图像上进行训练。实验表明:CCT在所有尺寸上表现更优,且随着像素量增加优势扩大。由此可推断,CCT能更高效利用图像信息密度,而ViT在标准32x32尺寸后性能不再持续提升。

Figure 4: Reduced # samples / class (CIFAR-10)
图 4: 减少每类样本数 (CIFAR-10)
D. Dimensionality Experiments
D. 维度实验
Within this appendix, we extend the analysis from Appendix C.3, showing the difference in performance when using different types of positional embedding. Figure 6 shows the difference of the accuracy when models are being trained from scratch. On the other hand, Figure 7 shows the performance difference when models are only used in inference and pre-trained on the $32\times32$ sized images. We note that in Figure 7(a) that we do not provide inference for image sizes greater than the pre-trained image because the learnable positional embeddings do not allow us to extend in this direction. We draw the reader’s attention to Figure 6(c) and Figure 7(c) to denote the large difference between the models when positional embedding is not used. We can see that in training CCT has very little difference when positional embeddings are used. Additionally, it should be noted that when performing inference our non-positional embedding CCT model has much higher general iz ability than its ViT-Lite counterpart.
在本附录中,我们延续附录C.3的分析,展示使用不同位置嵌入(positional embedding)类型时的性能差异。图6展示了模型从头训练时的准确率差异,而图7则展示了模型仅在推理阶段使用且预训练图像尺寸为$32\times32$时的性能差异。需注意在图7(a)中,我们未提供大于预训练图像尺寸的推理结果,因为可学习的位置嵌入无法向该方向扩展。请读者重点关注图6(c)和图7(c),这些图表表明当不使用位置嵌入时模型之间存在显著差异。可以看出在训练过程中,CCT模型在使用位置嵌入时差异极小。此外值得注意的是,在推理时我们的无位置嵌入CCT模型比ViT-Lite对应模型具有更强的泛化(generalization)能力。
E. Hyper parameter tuning
E. 超参数调优
We used the timm package [43] for our experiments (excluding NLP experiments). We also sued CutMix [49], Mixup [50], Rand augment [8], and Random Erasing [53]. For our small-scale small-resolution experiments, we conducted a hyper parameter sweep for each model on each dataset separately. However, all experiments that trained models from scratch, were trained for 300 epochs, unless mentioned otherwise. ViT, CVT and CCT all used the weighted Adam optimizer $\textstyle(\beta_{1}=0.9$ and $\beta_{2}~=~0.999)$ . For CNNs, we observed that some models and datasets achieved their best results using AdamW, while most others performed best with SGD with momentum (0.9). We will release model checkpoints (PyTorch pickle files), as well as a full list of hyper parameters and training settings (in the form of YAML files readable by timm) along with our code for reproduction.
我们使用timm包[43]进行实验(不包括NLP实验),同时采用了CutMix[49]、Mixup[50]、Rand augment[8]和Random Erasing[53]技术。在小规模低分辨率实验中,我们为每个模型在各自数据集上分别进行了超参数搜索。除非特别说明,所有从头开始训练的模型均进行了300轮训练。ViT、CVT和CCT均采用加权Adam优化器$\textstyle(\beta_{1}=0.9$和$\beta_{2}~=~0.999)$。对于CNN模型,我们发现部分模型和数据集使用AdamW优化器效果最佳,而多数其他情况采用带动量(0.9)的SGD表现更好。我们将发布模型检查点(PyTorch pickle文件)、完整的超参数列表与训练配置(以timm可读的YAML文件形式),以及用于复现的代码。

Figure 5: Image Size vs Accuracy (CIFAR-10)
图 5: 图像尺寸 vs 准确率 (CIFAR-10)
F. Ablation Study
F. 消融实验
Here in Table 8 we present the results from section 4.4. We provide a full list of ablated terms showing which factors give the largest boost in performances. “Model” column refers to variant (see Table 5 for details), “Conv” specifies the number of convolutional blocks (if an), and “Conv Size” specifies the kernel size. “Aug” denotes the use of Auto Augment [7]. “Tuning” specifies a minor change in dropout, attention dropout, and/or stochastic depth (see Table 9). The first row in Table 8 is essentially ViT. The next three rows are modified variants of ViT, which are not proposed in the original paper. These variants are more compact and use smaller patch sizes. It should be noted that the numbers reported in this table are best out of 4.
表8中我们展示了4.4节的结果。我们提供了完整的消融项列表,显示哪些因素对性能提升最大。"Model"列指变体(详见表5),"Conv"指定卷积块数量(如有),"Conv Size"指定卷积核大小。"Aug"表示使用了Auto Augment [7]。"Tuning"指定了dropout、attention dropout和/或随机深度的微小调整(见表9)。表8第一行本质上是ViT。接下来三行是ViT的修改变体,这些变体未在原论文中提出。这些变体更紧凑且使用更小的patch尺寸。需注意本表数据是4次实验中最佳结果。
G. NLP experiments
G. NLP实验
To demonstrate the general purpose nature of our model we extended it to the domain of Natural Language Processing, focusing on classification tasks. This shows that our model is a general purpose classifier and is not restricted to the domain of image classification. Within this section, we present our text classification results on 5 datasets: AGNews [52], TREC [24], SST [37], IMDb [29], DBpedia [1]. The results are summarized in Table 10. As can be seen, our model outperforms the vanilla transformer, demonstrating that the techniques we use here also help with NLP tasks.
为验证模型的通用性,我们将其扩展至自然语言处理领域,重点研究分类任务。这表明我们的模型是通用分类器,不局限于图像分类领域。本节展示了在AGNews [52]、TREC [24]、SST [37]、IMDb [29]、DBpedia [1]五个数据集上的文本分类结果(如表10所示)。实验证明,我们的模型性能优于标准Transformer,说明本文采用的技术对NLP任务同样有效。
Table 7: Top-1 validation accuracy comparison when changing the positional embedding method. Augmentations and training techniques such as Mixup and CutMix were turned off for these experiments to highlight differences better. The numbers reported are best out of 4 runs with random initialization s. $\dagger$ denotes model trained with extra augmentation and hyperparameter tuning.
表 7: 不同位置嵌入方法下的Top-1验证准确率对比。本实验关闭了Mixup和CutMix等数据增强及训练技术以更突出差异。报告数值为4次随机初始化实验中的最佳结果。$\dagger$表示使用额外数据增强和超参数调优训练的模型。
| 模型 | PE | CIFAR-10 | CIFAR-100 |
|---|---|---|---|
| 传统视觉Transformer更依赖位置嵌入 | |||
| ViT-12/16 | Learnable | 69.82% (+3.11%) | 40.57% (+1.01%) |
| Sinusoidal | 69.03% (+2.32%) | 39.48% (-0.08%) | |
| None | 66.71% (baseline) | 39.56% (baseline) | |
| ViT-Lite-7/8 | Learnable | 83.38% (+7.25%) | 55.69% (+7.15%) |
| Sinusoidal | 80.86% (+4.73%) | 53.50% (+4.96%) | |
| None | 76.13% (baseline) | 48.54% (baseline) | |
| CVT-7/8 | Learnable | 84.24% (+6.52%) | 55.49% (+7.23%) |
| Sinusoidal | 80.84% (+3.12%) | 50.82% (+2.56%) | |
| None | 77.72% (baseline) | 48.26% (baseline) | |
| 紧凑卷积Transformer对位置嵌入依赖较低 | |||
| CCT-7/7 | Learnable | 82.03% (+0.21%) | 63.01% (+3.24%) |
| Sinusoidal | 81.15% (-0.67%) | 60.40% (+0.63%) | |
| None | 81.82% (baseline) | 59.77% (baseline) | |
| CCT-7/3x2 | Learnable | 90.69% (+1.67%) | 65.88% (+2.82%) |
| Sinusoidal | 89.93% (+0.91%) | 64.12% (+1.06%) | |
| None | 89.02% (baseline) | 63.06% (baseline) | |
| CCT-7/3x2t | Learnable | 95.04% (+0.64%) | 77.72% (+0.20%) |
| Sinusoidal | 94.80% (+0.40%) | 77.82% (+0.30%) | |
| None | 94.40% (baseline) | 77.52% (baseline) | |
| CCT-7/3x1t | Learnable | 96.53% (+0.29%) | 80.92% (+0.65%) |
| Sinusoidal | 96.27% (+0.03%) | 80.12% (-0.15%) | |
| None | 96.24% (baseline) | 80.27% (baseline) | |
| CCT-7/7x1-noSeqPool | Learnable | 82.41% (+0.12%) | 62.61% (+3.31%) |
| Sinusoidal | 81.94% (-0.35%) | 61.04% (+1.74%) | |
| None | 82.29% (baseline) | 59.30% (baseline) | |
| CCT-7/3x2-noSeqPool | Learnable | 90.41% (+1.49%) | 66.57% (+1.40%) |
| Sinusoidal | 89.84% (+0.92%) | 64.71% (-0.46%) | |
| None | 88.92% (baseline) | 65.17% (baseline) |
The network is slightly modified from the vision CCT. We use GloVe (Apache License 2.0) [31] to provide the word embedding for the model, and do not train these parameters. Note that model sizes do not reflect the number of parameters for GloVe, which is around 20M. We treat text as single channel data and the embedding dimension as size 300. Additionally, the convolution kernels have size 1. Finally, we include masking in the typical manner. By doing so, CCT can get upwards of a $3%$ improvement on some datasets while using less parameters than vanilla transformers. Similar to our vision results, we find that CCT performs well on small NLP datasets. We note that the CCT models that perform best all have less than 1M parameters, which are significantly smaller than there vanilla counterparts, while out performing them.
该网络对视觉CCT进行了轻微修改。我们使用GloVe (Apache License 2.0) [31]为模型提供词嵌入(word embedding),且不训练这些参数。需注意模型大小未包含GloVe约20M的参数量。我们将文本视为单通道数据,嵌入维度设为300。此外,卷积核尺寸为1。最后,我们以典型方式加入掩码机制。通过这种方式,CCT在某些数据集上能获得超过$3%$的性能提升,同时使用的参数量少于标准Transformer。与视觉实验结果类似,我们发现CCT在小型NLP数据集上表现优异。值得注意的是,性能最佳的CCT模型参数量均低于1M,远小于对应的标准模型,同时性能更优。
Table 8: CIFAR Top-1 validation accuracy when transforming ViT into CCT step by step. We disabled advanced training techniques and augmentations for these runs.
表 8: 将ViT逐步转换为CCT时的CIFAR Top-1验证准确率。这些实验运行中禁用了高级训练技术和数据增强。
| 模型 | CLS | # Conv | Conv Size | Aug | Tuning | C-10 | C-100 | # Params | MACs |
|---|---|---|---|---|---|---|---|---|---|
| ViT-12/16 | CT | 69.82% | 40.57% | 85.63 M | 0.43 G | ||||
| ViT-Lite-7/16 | CT | × | × | × | × | 71.78% | 41.59% | 3.89 M | 0.02 G |
| ViT-Lite-7/8 | CT | × | × | × | 83.38% | 55.69% | 3.74 M | 0.06 G | |
| ViT-Lite-7/4 | CT | × | × | × | × | 83.59% | 58.43% | 3.72 M | 0.26 G |
| CVT-7/16 | SP | × | × | × | × | 72.26% | 42.37% | 3.89 M | 0.02 G |
| CVT-7/8 | SP | × | × | × | × | 84.24% | 55.49% | 3.74 M | 0.06 G |
| CVT-7/8 | SP | × | × | 87.15% | 63.14% | 3.74 M | 0.06 G | ||
| CVT-7/4 | SP | × | × | × | 88.06% | 62.06% | 3.72 M | 0.25 G | |
| CVT-7/4 | SP | × | × | × | 91.72% | 69.59% | 3.72 M | 0.25 G | |
| CVT-7/4 | SP | × | × | 92.43% | 73.01% | 3.72 M | 0.25 G | ||
| CVT-7/2 | SP | × | 84.80% | 57.98% | 3.76 M | 1.18 G | |||
| CCT-7/7x1 | SP | 1 | 7×7 | × | 87.81% | 62.83% | 3.74 M | 0.26 G | |
| CCT-7/7x1 | SP | 1 | 7×7 | 91.85% | 69.43% | 3.74 M | 0.26 G | ||
| CCT-7/7x1 | SP | 1 | 7×7 | 92.29% | 72.46% | 3.74 M | 0.26 G | ||
| CCT-7/3x2 | SP | 2 | 3×3 | √ | 93.65% | 74.77% | 3.85 M | 0.29 G | |
| CCT-7/3x1 | SP | 1 | 3×3 | √ | 94.47% | 75.59% | 3.76 M | 1.19 G |
Table 9: Difference between tuned and not tuned runs in Table 8.
表 9: 表 8 中调参与未调参运行的差异。
| Hyper Param | Not Tuned | Tuned |
|---|---|---|
| MLP Dropout | 0.1 | 0 |
| MSA Dropout | 0 | 0.1 |
| StochasticDepth | 0 | 0.1 |
H. Additional experiments
H. 补充实验
H.1. Extended small-scale experiments
H.1. 扩展小规模实验
We present the extended version of Table 1 here with additional models in Table 11.
我们在表 11 中展示了表 1 的扩展版本,其中包含更多模型。
Table 10: Top-1 validation accuracy on text classification datasets. The number of parameters does not include the word embedding layer, because we use pretrained word-embeddings and freeze those layers while training.
表 10: 文本分类数据集的 Top-1 验证准确率。参数量不包括词嵌入层,因为我们使用预训练的词嵌入并在训练期间冻结这些层。
| 模型 | AGNews | TREC | SST | IMDb | DBpedia | #Params |
|---|---|---|---|---|---|---|
| VanillaTransformerEncoders | ||||||
| Transformer-2 | 93.28% | 90.40% | 67.15% | 86.01% | 98.63% | 1.086 M |
| Transformer-4 | 93.25% | 92.54% | 65.20% | 85.98% | 96.91% | 2.171 M |
| Transformer-6 | 93.55% | 92.78% | 65.03% | 85.87% | 98.24% | 4.337 M |
| VisionTransformers | ||||||
| ViT-Lite-2/1 | 93.02% | 90.32% | 67.66% | 87.69% | 98.99% | 0.238 M |
| ViT-Lite-2/2 | 92.20% | 90.12% | 64.44% | 87.39% | 98.88% | 0.276 M |
| ViT-Lite-2/4 | 90.53% | 90.00% | 62.37% | 86.17% | 98.72% | 0.353 M |
| ViT-Lite-4/1 | 93.48% | 91.50% | 66.81% | 87.38% | 99.04% | 0.436 M |
| ViT-Lite-4/2 | 92.06% | 90.42% | 63.75% | 87.00% | 98.92% | 0.474 M |
| ViT-Lite-4/4 | 90.93% | 89.30% | 60.83% | 86.71% | 98.81% | 0.551 M |
| ViT-Lite-6/1 | 93.07% | 91.92% | 64.95% | 87.58% | 99.02% | 3.237 M |
| ViT-Lite-6/2 | 92.56% | 89.38% | 62.78% | 86.96% | 98.89% | 3.313 M |
| ViT-Lite-6/4 | 91.12% | 90.36% | 60.97% | 86.42% | 98.72% | 3.467 M |
| CompactVisionTransformers | ||||||
| CVT-2/1 | 93.24% | 90.44% | 67.88% | 87.68% | 98.98% | 0.238 M |
| CVT-2/2 | 92.29% | 89.96% | 64.26% | 86.99% | 98.93% | 0.276 M |
| CVT-2/4 | 91.10% | 89.84% | 62.22% | 86.39% | 98.75% | 0.353 M |
| CVT-4/1 | 93.53% | 92.58% | 66.64% | 87.27% | 99.04% | 0.436 M |
| CVT-4/2 CVT-4/4 | 92.35% | 90.36% | 63.90% | 86.96% | 98.93% 98.80% | 0.474 M 0.551 M |
| CVT-6/1 | 90.71% | 90.14% | 61.98% 65.94% | 86.77% 86.78% | 99.02% | 3.237 M |
| CVT-6/2 | 93.38% 92.57% | 92.06% 91.14% | 64.57% | 86.61% | 98.86% | 3.313 M |
| CVT-6/4 | 61.63% | 86.13% | ||||
| 91.35% | 91.66% | 98.76% | 3.467 M | |||
| Compact Convolutional Transformers | ||||||
| CCT-2/1x1 | 93.40% | 90.86% | 68.76% | 88.95% | 99.01% | 0.238 M 0.276 M |
| CCT-2/2x1 | 93.38% | 91.86% | 67.19% | 89.13% | 99.04% 99.04% | 0.353 M |
| CCT-2/4x1 | 93.80% | 91.42% | 64.47% | 88.92% | ||
| CCT-4/1x1 | 93.49% | 91.84% | 68.21% | 88.71% | 99.03% | 0.436 M |
| CCT-4/2x1 | 93.30% | 93.54% | 66.42% | 88.94% | 99.05% | 0.474 M |
| CCT-4/4x1 | 93.09% | 93.20% | 66.57% | 88.86% | 99.02% | 0.551 M |
| CCT-6/1x1 | 93.73% | 91.22% | 66.59% | 88.81% | 98.99% | 3.237 M |
| CCT-6/2x1 | 93.29% | 92.10% | 65.02% | 88.74% | 99.02% | 3.313 M |
| CCT-6/4x1 | 92.86% | 92.96% | 65.84% | 88.68% | 99.02% | 3.467 M |
Table 11: Top-1 comparisons. $\star$ were trained longer (see Tab 2).
表 11: Top-1 对比。$\star$ 表示训练时间更长 (参见表 2)。
| 模型 | C-10 | C-100 | Fashion | MNIST | #Params | MACs |
|---|---|---|---|---|---|---|
| 卷积网络 (专为 ImageNet 设计) | ||||||
| ResNet18 | 90.27% | 66.46% | 94.78% | 99.80% | 11.18 M | 0.04 G |
| ResNet34 | 90.51% | 66.84% | 94.78% | 99.77% | 21.29 M | 0.08 G |
| ResNet50 | 91.63% | 68.27% | 94.99% | 99.79% | 23.53 M | 0.08 G |
| MobileNetV2/0.5 | 84.78% | 56.32% | 93.93% | 99.70% | 0.70 M | < 0.01 G |
| MobileNetV2/1.0 | 89.07% | 63.69% | 94.85% | 99.75% | 2.24 M | 0.01 G |
| MobileNetV2/1.25 | 90.60% | 65.24% | 95.05% | 99.77% | 3.47 M | 0.01 G |
| MobileNetV2/2.0 | 91.02% | 67.44% | 95.26% | 99.75% | 8.72 M | 0.02 G |
| 卷积网络 (专为 CIFAR 设计) | ||||||
| ResNet56[16] | 94.63% | 74.81% | 95.25% | 99.27% | 0.85 M | 0.13 G |
| ResNet110[16] | 95.08% | 76.63% | 95.32% | 99.28% | 1.73 M | 0.26 G |
| ResNet164-v1[17] | 94.07% | 74.84% | - | - | 1.70 M | 0.26 G |
| ResNet164-v2[17] | 94.54% | 75.67% | - | - | 1.70 M | 0.26 G |
| ResNet1k-v1[17] | 92.39% | 72.18% | - | - | 10.33 M | 1.55 G |
| ResNet1k-v2[17] | 95.08% | 77.29% | - | - | 10.33 M | 1.55 G |
| ResNet1k-v2*[17] | 95.38% | - | - | - | 10.33 M | 1.55 G |
| Proxyless-G[5] | 97.92% | - | - | - | 5.7 M | - |
| 视觉 Transformer | ||||||
| ViT-12/16 | 83.04% | 57.97% | 93.61% | 99.63% | 85.63 M | 0.43 G |
| ViT-Lite-7/16 | 78.45% | 52.87% | 93.24% | 99.68% | 3.89 M | 0.02 G |
| ViT-Lite-6/16 | 78.12% | 52.68% | 93.09% | 99.66% | 3.36 M | 0.02 G |
| ViT-Lite-7/8 | 89.10% | 67.27% | 94.49% | 99.69% | 3.74 M | 0.06 G |
| ViT-Lite-6/8 | 88.29% | 66.40% | 94.36% | 99.73% | 3.22 M | 0.06 G |
| ViT-Lite-7/4 | 93.57% | 73.94% | 95.16% | 99.77% | 3.72 M | 0.26 G |
| ViT-Lite-6/4 | 93.08% | 73.33% | 95.14% | 99.74% | 3.19 M | 0.22 G |
| 紧凑视觉 Transformer | ||||||
| CVT-7/8 | 89.79% | 70.11% | 94.50% | 99.70% | 3.74 M | 0.06 G |
| CVT-6/8 | 89.50% | 68.80% | 94.53% | 99.74% | 3.21 M | 0.05 G |
| CVT-7/4 | 94.01% | 76.49% | 95.32% | 99.76% | 3.72 M | 0.25 G |
| CVT-6/4 | 93.60% | 74.23% | 95.00% | 99.75% | 3.19 M | 0.22 G |
| 紧凑卷积 Transformer | ||||||
| CCT-2/3x2 | 89.75% | 66.93% | 94.08% | 99.70% | 0.28 M | 0.04 G |
| CCT-4/3x2 | 91.97% | 71.51% | 94.74% | 99.73% | 0.48 M | 0.05 G |
| CCT-6/3x2 | 94.43% | 77.14% | 95.34% | 99.75% | 3.33 M | 0.25 G |
| CCT-7/3x2 | 95.04% | 77.72% | 95.16% | 99.76% | 3.85 M | 0.29 G |
| CCT-6/3x1 | 95.70% | 79.40% | 95.41% | 99.79% | 3.23 M | 1.02 G |
| CCT-7/3x1 | 96.53% | 80.92% | 95.56% | 99.82% | 3.76 M | 1.19 G |
| CCT-7/3x1* | 98.00% | 82.72% | - | - | 3.76 M | 1.19 G |

Figure 6: CIFAR-10 resolution vs top $1%$ validation accuracy (training from scratch). Images are square.
图 6: CIFAR-10 分辨率与 top $1%$ 验证准确率关系 (从头开始训练) 。图像为正方形。


Figure 7: CIFAR-10 resolution vs top $1%$ validation accuracy (inference only). Images are square.
图 7: CIFAR-10 分辨率与前 $1%$ 验证准确率关系(仅推理)。图像为正方形。