STATE SPACE MODEL MEETS TRANSFORMER: A NEW PARADIGM FOR 3D OBJECT DETECTION
状态空间模型遇上Transformer:3D物体检测新范式
ABSTRACT
摘要
DETR-based methods, which use multi-layer transformer decoders to refine object queries iterative ly, have shown promising performance in 3D indoor object detection. However, the scene point features in the transformer decoder remain fixed, leading to minimal contributions from later decoder layers, thereby limiting performance improvement. Recently, State Space Models (SSM) have shown efficient context modeling ability with linear complexity through iterative interactions between system states and inputs. Inspired by SSMs, we propose a new 3D object DEtection paradigm with an interactive STate space model (DEST). In the interactive SSM, we design a novel state-dependent SSM parameter iz ation method that enables system states to effectively serve as queries in 3D indoor detection tasks. In addition, we introduce four key designs tailored to the charact eris tics of point cloud and SSM: The serialization and bidirectional scanning strategies enable bidirectional feature interaction among scene points within the SSM. The inter-state attention mechanism models the relationships between state points, while the gated feed-forward network enhances inter-channel correlations. To the best of our knowledge, this is the first method to model queries as system states and scene points as system inputs, which can simultaneously update scene point features and query features with linear complexity. Extensive experiments on two challenging datasets demonstrate the effectiveness of our DESTbased method. Our method improves the GroupFree baseline in terms of $\mathrm{AP_{50}}$ on ScanNet V2 $(+5.3)$ and SUN RGB-D $(+3.2)$ datasets. Based on the VDETR baseline, Our method sets a new SOTA on the ScanNetV2 and SUN RGB-D datasets.
基于DETR的方法通过多层Transformer解码器迭代优化物体查询(query),在3D室内物体检测中展现出优异性能。但Transformer解码器中的场景点特征始终保持固定,导致后续解码层贡献有限,制约了性能提升。近期状态空间模型(SSM)通过系统状态与输入的迭代交互,展现出线性复杂度的高效上下文建模能力。受此启发,我们提出新型交互式状态空间3D检测范式DEST。该模型中,我们设计了状态依赖的SSM参数化方法,使系统状态能有效充当3D室内检测任务中的查询。此外,针对点云与SSM特性提出了四项核心设计:序列化与双向扫描策略实现SSM内场景点的双向特征交互;状态间注意力机制建模状态点关系;门控前馈网络增强通道间关联。据我们所知,这是首个将查询建模为系统状态、场景点作为系统输入的方法,能以线性复杂度同步更新场景点特征与查询特征。在两大挑战性数据集上的实验表明,DEST方法显著优于基线模型:在ScanNet V2和SUN RGB-D数据集上分别将GroupFree基线的$\mathrm{AP_{50}}$提升5.3和3.2个百分点。基于VDETR基线时,我们的方法在ScanNetV2和SUN RGB-D数据集上创造了新的SOTA性能。
1 INTRODUCTION
1 引言
With the widespread application of LiDAR and depth cameras, it is becoming easier to obtain 3D point clouds of real scenes. The large amounts of 3D scene data provide rich geometric information for 3D scene understanding in fields such as autonomous driving, robotics, and augmented reality. As a fundamental task in 3D scene understanding, 3D indoor object detection has garnered significant attention from both academia and industry. Unlike 3D object detection (Shi et al., 2019; Yin et al., 2021; Lang et al., 2019; Shi et al., 2020b;a) in autonomous driving scenarios, 3D indoor object detection involves objects with more diverse categories and shapes, posing more significant challenges for the model design and training.
随着激光雷达(LiDAR)和深度相机的广泛应用,获取真实场景的三维点云变得越来越容易。海量的三维场景数据为自动驾驶、机器人技术和增强现实等领域的场景理解提供了丰富的几何信息。作为三维场景理解的基础任务,室内三维物体检测受到了学术界和工业界的广泛关注。与自动驾驶场景中的三维物体检测(Shi et al., 2019; Yin et al., 2021; Lang et al., 2019; Shi et al., 2020b;a)不同,室内三维物体检测涉及更多样化的物体类别和形状,这对模型设计和训练提出了更大的挑战。
To address the above challenges, numerous 3D indoor object detection methods have been proposed, which can be roughly divided into three categories: vote-based methods (Qi et al., 2019; Xie et al., 2020; Zhang et al., 2020), expansion-based methods (Gwak et al., 2020; Rukhovich et al., 2022; Wang et al., 2022a), and DETR-based methods (Misra et al., 2021; Liu et al., 2021; Wang et al., 2023; Shen et al., 2024). Vote-based methods (Qi et al., 2019; Xie et al., 2020; Zhang et al., 2020) use a voting mechanism to shift surface points toward the object center and then generate candidate points by clustering the points that have shifted to the same regions. Although these methods have achieved great success in 3D object detection, The vote mechanism is performed in a categoryindependent manner, leading to the shifted points that are adjacent but belong to different categories being grouped, which limits the model detection capability. Expansion-based methods (Gwak et al., 2020; Rukhovich et al., 2022; Wang et al., 2022a) use generative sparse decoders to generate high-quality proposals based on object surface voxel features with the same semantic prediction. Compared with vote-based methods, expansion-based methods consider the semantic consistency of voxels within the same group and achieve better performance. However, expansion-based methods require a carefully designed proposal generation module and involve numerous manually set thresholds, which limits the model versatility. Recently, DETR-based methods (Misra et al., 2021; Liu et al., 2021; Wang et al., 2023; Shen et al., 2024) have shown promising performance in 3D object detection. Unlike the above methods, DETR-based methods select a small group of voxels or points as the initial object queries and use the scene point features to refine these queries. The query refinement module is simple in design and retains the original geometric structure of the input 3D point cloud. Based on the query refinement module, DETR-based methods have achieved the best performance in indoor object detection tasks. However, DETR-based methods still face a key issue that limits their performance. These methods employ multi-layer transformer decoders (Carion et al., 2020) to iterative ly refine the object queries. While the transformer decoder layers update the query point features, they do not simultaneously update the scene point features as shown in Figure 1 (a). As a result, each decoder layer uses the same scene point features to refine the queries, leading to only marginal improvements from the later layers. As shown in Figure 1 (b), we evaluate the detection accuracy improvements of different decoder layers in two DETR-based models (Liu et al., 2021; Shen et al., 2024) on the ScanNet V2 (Dai et al., 2017) dataset. GroupFree (Liu et al., 2021) achieves only a 2.12 performance improvement in the last six layers, while VDETR (Shen et al., 2024) shows a mere 0.64 improvement in the last four layers. Based on the above analysis, the fixed scene point features constrain the potential performance enhancement of the models.
为应对上述挑战,研究者们提出了众多3D室内物体检测方法,主要可分为三类:基于投票的方法(Qi等人,2019;Xie等人,2020;Zhang等人,2020)、基于扩展的方法(Gwak等人,2020;Rukhovich等人,2022;Wang等人,2022a)以及基于DETR的方法(Misra等人,2021;Liu等人,2021;Wang等人,2023;Shen等人,2024)。基于投票的方法(Qi等人,2019;Xie等人,2020;Zhang等人,2020)通过投票机制将表面点向物体中心偏移,再对偏移至相同区域的点进行聚类生成候选点。尽管这类方法在3D物体检测中取得了显著成功,但其投票过程与物体类别无关,导致相邻但属于不同类别的偏移点被归为一组,限制了模型检测能力。基于扩展的方法(Gwak等人,2020;Rukhovich等人,2022;Wang等人,2022a)利用生成式稀疏解码器,基于具有相同语义预测的物体体素特征生成高质量提案。相比基于投票的方法,这类方法考虑了同组体素的语义一致性,获得了更优性能。但基于扩展的方法需要精心设计的提案生成模块,并涉及大量人工设定阈值,制约了模型通用性。近年来,基于DETR的方法(Misra等人,2021;Liu等人,2021;Wang等人,2023;Shen等人,2024)在3D物体检测中展现出卓越性能。与前述方法不同,这类方法选取少量体素或点作为初始物体查询,并利用场景点特征优化这些查询。其查询优化模块设计简洁,保留了输入3D点云的原始几何结构。基于该模块,基于DETR的方法在室内物体检测任务中取得了最佳性能。然而,这类方法仍存在一个制约性能的关键问题:它们采用多层Transformer解码器(Carion等人,2020)迭代优化物体查询,但如图1(a)所示,解码器层在更新查询点特征时并未同步更新场景点特征。这导致每个解码层都使用相同的场景点特征优化查询,使得后续层仅能带来微小的性能提升。如图1(b)所示,我们在ScanNet V2(Dai等人,2017)数据集上评估了两个基于DETR的模型(Liu等人,2021;Shen等人,2024)不同解码层的检测精度提升。GroupFree(Liu等人,2021)在最后六层仅实现2.12的性能提升,而VDETR(Shen等人,2024)在最后四层仅显示0.64的改进。上述分析表明,固定的场景点特征限制了模型的潜在性能提升空间。
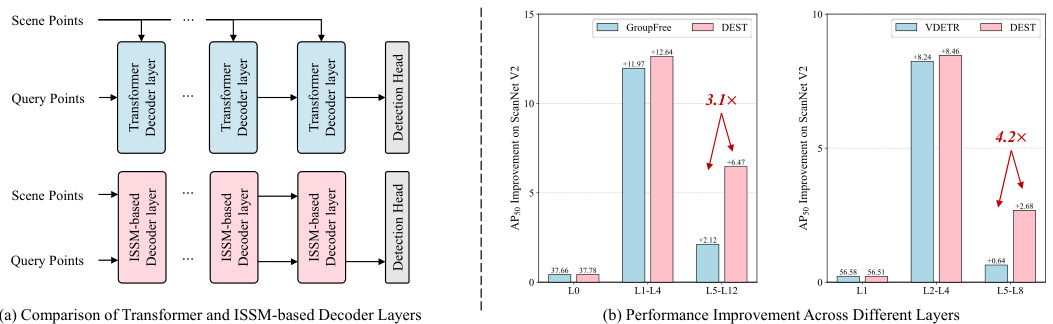
Figure 1: (a): Transformer decoder solely updates the features of the query points, while our ISSM-based decoder simultaneously updates the features of scene points and query points. (b): The DETR-based models show only slight accuracy enhancements in the later layers, whereas the DEST-based methods significantly boost the performance in the later layers.
图 1: (a) Transformer解码器仅更新查询点的特征,而基于ISSM的解码器同时更新场景点和查询点的特征。(b) 基于DETR的模型在后期层仅显示轻微精度提升,而基于DEST的方法在后期层显著提高了性能。
To address this issue, an intuitive idea is to introduce a self-attention mechanism (Vaswani, 2017) between different decoder layers to update the scene point features. However, the quadratic complexity of the self-attention mechanism significantly reduces the model efficiency, making this approach impractical. Recently, state space model-besed methods (Gu et al., 2021a; Gu & Dao, 2023; Dao & Gu, 2024) have shown efficient context modeling with linear complexity through interactions between system states and inputs. The pioneer works lead us to think: Is it possible to design a State Space Model (SSM) to replace the transformer decoder, enabling the simultaneous update of scene features and query point features? SSM is used to describe the evolution of system states and to predict future states and system outputs based on system inputs. Therefore, if we model the query point features as the system states and the scene point features as the system inputs at different time steps, we can simultaneously obtain the final system states (updated query point features) and the system outputs at each time step (updated scene point features). However, existing SSMs (Gu et al., 2021a; Gu & Dao, 2023; Dao & Gu, 2024) are not suitable for modeling queries as system states, for two main reasons: (1). Update the states solely based on the system inputs. Existing SSMs (Gu & Dao, 2023; Dao & Gu, 2024) adjust the SSM parameters $(\Delta,{\bf B},{\bf C})$ solely using system inputs without considering the system states. Therefore, the state points cannot adaptively select system inputs to update themselves, while different query points need to focus on distinct regions of the scene. (2). Cannot directly process 3D point cloud. Existing SSMs are inherently designed to process sequential data, and their unidirectional modeling and sensitivity to input order pose challenges for feature modeling of scene points and query points.
为了解决这一问题,一个直观的想法是在不同解码器层之间引入自注意力机制 (Vaswani, 2017) 来更新场景点特征。然而,自注意力机制的二次复杂度会显著降低模型效率,使得该方法不切实际。最近,基于状态空间模型的方法 (Gu et al., 2021a; Gu & Dao, 2023; Dao & Gu, 2024) 通过系统状态与输入之间的交互,展示了线性复杂度的高效上下文建模能力。这些开创性工作启发我们思考:能否设计一个状态空间模型 (State Space Model, SSM) 来替代 Transformer 解码器,实现场景特征与查询点特征的同步更新?SSM 用于描述系统状态的演化,并根据系统输入预测未来状态和系统输出。因此,若将查询点特征建模为系统状态,将场景点特征建模为不同时间步的系统输入,我们就能同时获得最终系统状态(更新后的查询点特征)和各时间步的系统输出(更新后的场景点特征)。然而,现有 SSM (Gu et al., 2021a; Gu & Dao, 2023; Dao & Gu, 2024) 并不适合将查询建模为系统状态,主要原因有二:(1) 仅基于系统输入更新状态。现有 SSM (Gu & Dao, 2023; Dao & Gu, 2024) 仅使用系统输入调整 SSM 参数 $(\Delta,{\bf B},{\bf C})$ ,而未考虑系统状态。因此,状态点无法自适应地选择系统输入来更新自身,而不同查询点需要关注场景的不同区域。(2) 无法直接处理 3D 点云。现有 SSM 本质上是为序列数据设计的,其单向建模特性及对输入顺序的敏感性给场景点和查询点的特征建模带来了挑战。
Based on the above discussion, we propose a new 3D object DEtection paradigm with a STate space model (DEST) to address the performance limitation caused by the fixed scene point features. The proposed DEST consists of two core components: a novel Interactive State Space Model (ISSM) and an ISSM-based decoder. In the ISSM, we model the query point features as the system states and the scene point features as the system inputs at different time steps. Unlike previous SSMs (Gu et al., 2021a; Gu & Dao, 2023; Dao & Gu, 2024), the proposed ISSM determines how to update the system states based on both the system states and system inputs. Specifically, we modify the SSM parameters $(\Delta,{\bf B},{\bf C})$ to be dependent on the system states and design a spatial correlation module to model the relationship between state points and scene points. Therefore, the system states in the ISSM can effectively fulfill the role of queries in complex 3D indoor detection tasks. In the ISSM-based decoder, four modules are designed for feature modeling of scene points and query points: Hilbert-based point cloud serialization strategy, ISSM-based Bidirectional Scan (IBS) module, Inter-state attention module, and Gated Feed-Forward Network (GFFN). The proposed seria liz ation strategy is designed to serialize the scene points based on the Hilbert curve (Hilbert & Hilbert, 1935), benefiting from its locality-preserving properties. The IBS module is designed to achieve bidirectional interaction among different scene points, while the inter-state attention module is designed to capture the relationships between state points. Lastly, the GFFN is designed to enhance inter-channel correlations through a gated linear unit. The ISSM-based decoder can replace the transformer decoder in DETR-based methods to address the performance limitations caused by fixed scene point features. As shown in Figure 1 (b), our DEST-based method significantly enhances the performance in the later layers.
基于上述讨论,我们提出了一种基于状态空间模型(STate space model)的新型3D目标检测范式DEST,以解决固定场景点特征导致的性能局限。该框架包含两个核心组件:创新的交互式状态空间模型(Interactive State Space Model,ISSM)和基于ISSM的解码器。在ISSM中,我们将查询点特征建模为系统状态,场景点特征作为不同时间步的系统输入。与先前SSMs (Gu et al., 2021a; Gu & Dao, 2023; Dao & Gu, 2024) 不同,ISSM根据系统状态和输入共同决定状态更新机制。具体而言,我们使SSM参数 $(\Delta,{\bf B},{\bf C})$ 具有状态依赖性,并设计空间关联模块建模状态点与场景点的关系,从而使系统状态能有效承担复杂3D室内检测任务中的查询功能。基于ISSM的解码器包含四个特征建模模块:基于Hilbert曲线的点云序列化策略、ISSM双向扫描(IBS)模块、状态间注意力模块和门控前馈网络(GFFN)。所提出的序列化策略利用Hilbert曲线 (Hilbert & Hilbert, 1935) 的局部保持特性组织场景点;IBS模块实现场景点间的双向交互,状态间注意力模块捕捉状态点关联,GFFN则通过门控线性单元增强通道相关性。该解码器可替代DETR类方法中的Transformer解码器,解决固定场景点特征导致的性能瓶颈。如图1(b)所示,基于DEST的方法在深层网络中表现出显著性能提升。
In summary, the core contributions of this paper are as follows: (1). We propose a novel SSM-based 3D object detection paradigm DEST to overcome the performance limitations caused by fixed scene point features during the query refinement process. To the best of our knowledge, this is the first method to model queries as system states within an SSM framework. (2). We design a novel ISSM whose system states can effectively function as queries in complex 3D indoor detection tasks. In addition, we develop an ISSM-based decoder tailored to the characteristics of 3D point clouds, fully harnessing the potential of the ISSM for 3D object detection. (3). Extensive experimental results demonstrate that the proposed SSM-based 3D object detection method consistently enhances the performance of baseline detectors on two challenging indoor datasets, i.e., ScanNet V2 (Dai et al., 2017) and SUN RGB-D (Song et al., 2015). Moreover, comprehensive ablation studies validate the effectiveness of each designed component.
综上所述,本文的核心贡献如下:(1) 我们提出了一种基于SSM的新型3D目标检测范式DEST,以克服查询优化过程中固定场景点特征导致的性能局限。据我们所知,这是首个在SSM框架中将查询建模为系统状态的方法。(2) 我们设计了一种新型ISSM,其系统状态能有效充当复杂3D室内检测任务中的查询。此外,我们开发了基于ISSM的解码器,该解码器针对3D点云特性定制,充分发挥了ISSM在3D目标检测中的潜力。(3) 大量实验结果表明,所提出的基于SSM的3D目标检测方法在两个具有挑战性的室内数据集ScanNet V2 (Dai et al., 2017)和SUN RGB-D (Song et al., 2015)上持续提升了基线检测器的性能。此外,全面的消融研究验证了每个设计组件的有效性。
2 RELATED WORK
2 相关工作
2.1 3D OBJECT DETECTION.
2.1 三维物体检测
The goal of 3D object detection is to estimate oriented 3D object bounding boxes with their category labels from a point cloud. According to the application scenario, 3D object detection is typically divided into outdoor and indoor detection tasks. Outdoor 3D object detection is commonly used in autonomous driving scenes, where objects are primarily distributed across a wide 2D plane. Therefore, outdoor 3D detection methods typically project the 3D point cloud into a bird’s-eye view (BEV) and utilize 2D convolutional networks to detect 3D objects. For instance, MV3D (Chen et al., 2017) directly projects the point cloud onto a 2D grid for feature processing and detection. VoxelNet (Zhou & Tuzel, 2018) first converts the point cloud into a 3D volumetric grid and uses a 3D CNN for feature extraction. Then, it projects the 3D voxels into a BEV for bounding box prediction. Point Pillars (Lang et al., 2019) employs PointNet (Qi et al., 2017a) to learn point cloud representations organized in vertical columns (pillars), then uses a 2D convolutional neural network to process flattened pillar features in the BEV.
3D物体检测的目标是从点云中估计带有类别标签的有向3D物体边界框。根据应用场景,3D物体检测通常分为室外和室内检测任务。室外3D物体检测常用于自动驾驶场景,其中物体主要分布在广阔的2D平面上。因此,室外3D检测方法通常将3D点云投影到鸟瞰图(BEV)中,并利用2D卷积网络来检测3D物体。例如,MV3D (Chen et al., 2017) 直接将点云投影到2D网格上进行特征处理和检测。VoxelNet (Zhou & Tuzel, 2018) 首先将点云转换为3D体素网格,并使用3D CNN进行特征提取,然后将3D体素投影到BEV中进行边界框预测。Point Pillars (Lang et al., 2019) 采用PointNet (Qi et al., 2017a) 学习以垂直柱(pillar)组织的点云表示,然后使用2D卷积神经网络处理BEV中展平的柱特征。
In contrast, indoor 3D object detection involves handling a more diverse set of object categories and shapes, as well as more complex spatial relationships between objects. Existing indoor 3D object detection methods can be broadly categorized into three groups: vote-based methods, expansionbased methods, and DETR-based methods. For vote-based methods, VoteNet (Qi et al., 2019), as the pioneering work, designs a novel 3D proposal mechanism based on deep Hough voting. MLCVNet (Xie et al., 2020) introduces three context modules into the voting and classifying stages of VoteNet to encode contextual information at different levels. BRNet (Cheng et al., 2021) backtraces the representative points from the vote centers to better capture the fine local structural features surrounding the potential objects from the raw point clouds. H3DNet (Zhang et al., 2020) predicts a hybrid set of geometric primitives and converts the predicted geometric primitives into object proposals. For expansion-based methods, GSDN (Gwak et al., 2020) proposes a generative sparse tensor decoder to generate virtual center features from surface features while discarding unlikely object centers. FCAF3D (Rukhovich et al., 2022) further introduces a fully convolutional anchorfree indoor 3D object detection method. CAGroup3D (Wang et al., 2022a) generates high-quality 3D proposals by leveraging a class-aware local grouping strategy on object surface voxels with consistent semantic predictions. The above methods require carefully designed proposal generation modules and involve several manually set thresholds. DETR (Carion et al., 2020) is a pioneering work that applies Transformers (Vaswani, 2017) to 2D object detection, eliminating many handcrafted components such as Non-Maximum Suppression (Neubeck & Van Gool, 2006) or anchor boxes (Girshick, 2015; Ren, 2015; Lin, 2017). Currently, DETR and its variants (Zhu et al., 2020; Dai et al., 2021; Liu et al., 2022) have achieved state-of-the-art results in various 2D object detection tasks. Inspired by these works, numerous DETR-based 3D object detection methods have been explored. 3DETR (Misra et al., 2021) is the first to introduce an end-to-end Transformer model for 3D object detection, achieving promising results. GroupFree (Liu et al., 2021) employs a key point sampling strategy to select candidate points and utilizes the attention mechanism to update query point features. LeadNet (Wang et al., 2023) further improves the transformer decoder by introducing a dynamic object query sampling module and a dynamic Gaussian weight map. Most recently, VDETR (Shen et al., 2024) proposes a novel 3D vertex relative position encoding method, which directs the model to focus on points near the object, achieving state-of-the-art performance. However, these DETR-based methods use fixed scene point features in different decoder layers, which limits the detection capabilities of later layers. Unlike the above methods, we propose an ISSM-based decoder that simultaneously updates both scene point and query point features.
相比之下,室内3D物体检测需要处理更多样化的物体类别和形状,以及更复杂的物体间空间关系。现有室内3D物体检测方法大致可分为三类:基于投票的方法、基于扩展的方法和基于DETR的方法。在基于投票的方法中,VoteNet (Qi et al., 2019) 作为开创性工作,设计了一种基于深度霍夫投票的新型3D提案机制。MLCVNet (Xie et al., 2020) 在VoteNet的投票和分类阶段引入了三个上下文模块,以编码不同层次的上下文信息。BRNet (Cheng et al., 2021) 从投票中心回溯代表性点,以更好地从原始点云中捕捉潜在物体周围的精细局部结构特征。H3DNet (Zhang et al., 2020) 预测一组混合几何基元,并将预测的几何基元转换为物体提案。
在基于扩展的方法中,GSDN (Gwak et al., 2020) 提出了一种生成式稀疏张量解码器,从表面特征生成虚拟中心特征,同时舍弃不太可能的物体中心。FCAF3D (Rukhovich et al., 2022) 进一步引入了一种全卷积无锚框的室内3D物体检测方法。CAGroup3D (Wang et al., 2022a) 通过对具有一致语义预测的物体表面体素采用类感知局部分组策略,生成高质量的3D提案。上述方法需要精心设计的提案生成模块,并涉及多个手动设置的阈值。
DETR (Carion et al., 2020) 是将Transformer (Vaswani, 2017) 应用于2D物体检测的开创性工作,消除了许多手工设计的组件,如非极大值抑制 (Neubeck & Van Gool, 2006) 或锚框 (Girshick, 2015; Ren, 2015; Lin, 2017)。目前,DETR及其变体 (Zhu et al., 2020; Dai et al., 2021; Liu et al., 2022) 已在各种2D物体检测任务中取得最先进的结果。受这些工作的启发,人们探索了许多基于DETR的3D物体检测方法。3DETR (Misra et al., 2021) 首次引入了用于3D物体检测的端到端Transformer模型,取得了令人瞩目的结果。GroupFree (Liu et al., 2021) 采用关键点采样策略选择候选点,并利用注意力机制更新查询点特征。LeadNet (Wang et al., 2023) 通过引入动态物体查询采样模块和动态高斯权重图,进一步改进了Transformer解码器。最近,VDETR (Shen et al., 2024) 提出了一种新颖的3D顶点相对位置编码方法,使模型专注于物体附近的点,实现了最先进的性能。然而,这些基于DETR的方法在不同解码器层中使用固定的场景点特征,限制了后续层的检测能力。与上述方法不同,我们提出了一种基于ISSM的解码器,可同时更新场景点和查询点特征。
2.2 STATE SPACE MODELS (SSMS).
2.2 状态空间模型 (SSMs)
Recently, SSMs (Kalman, 1960; Gu et al., 2021a;b) have become a prominent research focus. S4 (Gu et al., 2021a) demonstrates the capability of capturing long-range dependencies with linear complexity. Mamba (Gu & Dao, 2023) further enhances S4 by introducing a selection mechanism, specifically parameter i zing the SSM based on the system input. The selection mechanism allows Mamba to selectively retain information, facilitating the efficient processing of long sequence data. Inspired by Mamba, Vision Mamba (Zhu et al., 2024) introduces an SSM-based visual model. VMamba (Liu et al., 2024) furthermore incorporates a 2D selective scan module, enabling the model to perform selective scanning of two-dimensional images. In the field of point cloud understanding, numerous Mamba-based works have emerged. PointMamba (Liang et al., 2024) proposes a simple yet effective Mamba-based baseline, while PCM (Zhang et al., 2024) develops diverse point cloud serialization methods that significantly improve performance. These methods have achieved promising results by leveraging the efficient context modeling and linear complexity of Mamba. Unlike these methods that use SSMs to design feature encoders, we design an SSM-based decoder to address the performance limitations caused by fixed scene point features in the transformer decoder.
最近,SSM (Kalman, 1960; Gu et al., 2021a;b) 已成为研究热点。S4 (Gu et al., 2021a) 展示了以线性复杂度捕获长距离依赖的能力。Mamba (Gu & Dao, 2023) 通过引入选择机制进一步优化了 S4,该机制根据系统输入对 SSM 进行参数化。选择机制使 Mamba 能选择性保留信息,从而高效处理长序列数据。受 Mamba 启发,Vision Mamba (Zhu et al., 2024) 提出了基于 SSM 的视觉模型。VMamba (Liu et al., 2024) 进一步引入二维选择性扫描模块,使模型能对二维图像进行选择性扫描。在点云理解领域,涌现出许多基于 Mamba 的工作:PointMamba (Liang et al., 2024) 提出了简洁高效的 Mamba 基线,PCM (Zhang et al., 2024) 则开发了多种点云序列化方法显著提升性能。这些方法通过利用 Mamba 的高效上下文建模和线性复杂度取得了优异成果。与这些使用 SSM 设计特征编码器的方法不同,我们设计了基于 SSM 的解码器,以解决 Transformer 解码器中固定场景点特征导致的性能局限。
3 METHOD
3 方法
Below, we first briefly review the existing SSMs (Section 3.1), followed by an overview of the proposed DEST (Section 3.2). Subsequently, we offer detailed explanations of the two core components: the Interactive State Space Model (Section 3.3) and the ISSM-based decoder (Section 3.4). Lastly, we outline the model setups for the two baseline models (Section 3.5).
下面我们首先简要回顾现有的状态空间模型(SSMs)(第3.1节),然后概述提出的DEST(第3.2节)。接着详细解释两个核心组件:交互式状态空间模型(ISSM)(第3.3节)和基于ISSM的解码器(第3.4节)。最后概述两个基线模型的设置(第3.5节)。
3.1 PRELIMINARIES
3.1 基础知识
SSM is used to describe the evolution of system states $h(t)\in\mathbb{R}^{K}$ and predict future states $h^{\prime}(t)$ and system outputs $y(t)$ based on system inputs $x(t)$ . The system can be defined as follows:
SSM用于描述系统状态$h(t)\in\mathbb{R}^{K}$的演变,并根据系统输入$x(t)$预测未来状态$h^{\prime}(t)$和系统输出$y(t)$。该系统可定义如下:
$$
h^{\prime}(t)=\mathbf{A}h(t)+\mathbf{B}x(t),y(t)=\mathbf{C}h^{\prime}(t),
$$
$$
h^{\prime}(t)=\mathbf{A}h(t)+\mathbf{B}x(t),y(t)=\mathbf{C}h^{\prime}(t),
$$
where A RK×K r epresents the state transition matrix that describes how the system states evolve, $\mathbf{B}\in\mathbb{R}^{K\times1}$ denotes the control matrix that describes the influence of the system inputs on the system states, and $\mathbf{C_{\lambda}}\in\mathbb{R}^{1\times K}$ is the observation matrix characterizing the impact of the system states on
其中,A RK×K 表示描述系统状态演变的状态转移矩阵,$\mathbf{B}\in\mathbb{R}^{K\times1}$ 表示描述系统输入对系统状态影响的控制矩阵,$\mathbf{C_{\lambda}}\in\mathbb{R}^{1\times K}$ 是表征系统状态对观测影响的观测矩阵。
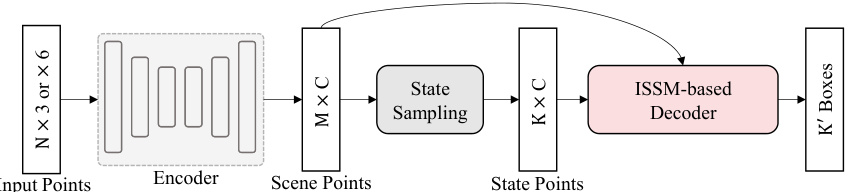
Figure 2: The overall framework of the DEST-based method for 3D object detection. We first utilize an encoder to extract 3D features, followed by a state sampling module to select state points, referred to as queries in DETR architecture. Subsequently, we input both the scene points and state points into the ISSM-based decoder for simultaneous updates. Finally, the updated state points are fed into a detection head to predict the 3D bounding boxes.
图 2: 基于DEST的三维物体检测方法整体框架。我们首先使用编码器提取三维特征,随后通过状态采样模块选择状态点(即DETR架构中的queries)。接着将场景点和状态点同时输入基于ISSM的解码器进行同步更新。最终将更新后的状态点输入检测头以预测三维边界框。
the system outputs. To handle discrete-time sequence data inputs, the Zero-Order Hold is typically used to discretize the SSM. The disc ret i zed version of equation 1 is as follows:
系统输出。为处理离散时间序列数据输入,通常采用零阶保持器 (Zero-Order Hold) 对 SSM 进行离散化。方程 1 的离散化版本如下:
$$
h_{t}=\overline{{\mathbf{A}}}h_{t-1}+\overline{{\mathbf{B}}}x_{t},y_{t}=\overline{{\mathbf{C}}}h_{t},
$$
$$
h_{t}=\overline{{\mathbf{A}}}h_{t-1}+\overline{{\mathbf{B}}}x_{t},y_{t}=\overline{{\mathbf{C}}}h_{t},
$$
where $\Delta$ represents the timescale from system states $h_{t-1}$ to the next $h_{t}$ . The entire sequence transformation can also be represented in a convolutional form:
其中 $\Delta$ 表示从系统状态 $h_{t-1}$ 到下一个状态 $h_{t}$ 的时间尺度。整个序列变换也可以用卷积形式表示:
$$
\mathbf{\overline{{K}}}=(\mathbf{C}\mathbf{\overline{{B}}},\mathbf{C}\mathbf{\overline{{A}}}\mathbf{\overline{{B}}},\cdots,\mathbf{C}\mathbf{\overline{{A}}}^{N-1}\mathbf{\overline{{B}}}),y=x*\mathbf{\overline{{K}}},
$$
$$
\mathbf{\overline{{K}}}=(\mathbf{C}\mathbf{\overline{{B}}},\mathbf{C}\mathbf{\overline{{A}}}\mathbf{\overline{{B}}},\cdots,\mathbf{C}\mathbf{\overline{{A}}}^{N-1}\mathbf{\overline{{B}}}),y=x*\mathbf{\overline{{K}}},
$$
where $N$ is the length of the input sequence $x$ , and $\overline{{\mathbf{K}}}\in\mathbb{R}^{N}$ denotes a global convolution kernel, which can be efficiently pre-computed. However, due to the Linear Time-Invariant (LTI) nature of SSM, the parameters $(\pmb{\Delta},\pmb{\Lambda},\pmb{\mathrm{B}},\pmb{\mathrm{C}})$ remain fixed across all time steps, which limits their ability to handle varying input sequences.
其中 $N$ 是输入序列 $x$ 的长度,$\overline{{\mathbf{K}}}\in\mathbb{R}^{N}$ 表示全局卷积核,可以高效预计算。然而,由于 SSM 的线性时不变 (LTI) 特性,参数 $(\pmb{\Delta},\pmb{\Lambda},\pmb{\mathrm{B}},\pmb{\mathrm{C}})$ 在所有时间步上保持不变,这限制了其处理变化输入序列的能力。
Recently, Mamba (Gu & Dao, 2023) introduced a selection mechanism that treats the parameters $(\Delta,{\bf B},{\bf C})$ as functions of the input, effectively transforming the SSM into a time-varying model:
最近,Mamba (Gu & Dao, 2023) 提出了一种选择机制,将参数 $(\Delta,{\bf B},{\bf C})$ 作为输入的函数处理,从而有效地将 SSM 转变为时变模型:
$$
\begin{array}{r}{h_{t}=\phi_{\overline{{\mathbf{A}}}}(x_{t})h_{t-1}+\phi_{\overline{{\mathbf{B}}}}(x_{t})x_{t},y_{t}=\phi_{\overline{{\mathbf{C}}}}(x_{t})h_{t},}\end{array}
$$
$$
\begin{array}{r}{h_{t}=\phi_{\overline{{\mathbf{A}}}}(x_{t})h_{t-1}+\phi_{\overline{{\mathbf{B}}}}(x_{t})x_{t},y_{t}=\phi_{\overline{{\mathbf{C}}}}(x_{t})h_{t},}\end{array}
$$
where $\phi_{\overline{{\mathbf{A}}}}(x_{t}),\phi_{\overline{{\mathbf{B}}}}(x_{t})$ and $\phi_{\overline{{\mathbf{C}}}}(x_{t})$ denote the parameter matrices are dependent on the system inputs $x_{t}$ . While the selection mechanism addresses the limitations of the LTI model, it also does not allow for parallel computation using equation 4. To tackle this challenge, Mamba introduced hardware-aware selective scanning, achieving near-linear complexity. Mamba2 (Dao & Gu, 2024) propose a refinement version of the selective SSM by leveraging structured semi separable matrices and the state space dual framework, further enhancing performance and efficiency. In this paper, we model the relationship between the system states and system inputs based on Mamba and Mamba2, adapting it to more challenging point cloud tasks.
其中 $\phi_{\overline{{\mathbf{A}}}}(x_{t})$、$\phi_{\overline{{\mathbf{B}}}}(x_{t})$ 和 $\phi_{\overline{{\mathbf{C}}}}(x_{t})$ 表示参数矩阵依赖于系统输入 $x_{t}$。虽然选择机制解决了 LTI 模型的局限性,但它也无法使用公式 4 进行并行计算。为解决这一挑战,Mamba 引入了硬件感知选择性扫描 (hardware-aware selective scanning),实现了近线性复杂度。Mamba2 (Dao & Gu, 2024) 通过利用结构化半可分矩阵和状态空间对偶框架,提出了选择性 SSM 的改进版本,进一步提升了性能和效率。本文基于 Mamba 和 Mamba2 对系统状态与系统输入的关系进行建模,并将其适配到更具挑战性的点云任务中。
3.2 OVERVIEW
3.2 概述
Figure 2 presents the overall framework of the DEST-based method for 3D object detection. In 3D object detection on point clouds, given a set containing $N$ points, the objective is to generate a set of 3D oriented bounding boxes with classification scores to cover all ground-truth objects. The proposed DEST-based detector primarily consists of three components: an encoder for extracting point features, a sampling module for generating the initial system states, and an ISSM-based decoder to refine system states and predict the 3D oriented bounding boxes. In this paper, we focus primarily on the decoder design, leveraging the SSM to facilitate the simultaneous updating of query points and scene points, thereby mitigating the performance limitations.
图 2: 展示了基于 DEST 的三维物体检测方法整体框架。在点云三维物体检测任务中,给定包含 $N$ 个点的点集,其目标是生成一组带有分类分数的三维定向边界框以覆盖所有真实物体。提出的基于 DEST 的检测器主要由三部分组成:用于提取点特征的编码器、生成初始系统状态的采样模块,以及基于 ISSM 的解码器(用于优化系统状态并预测三维定向边界框)。本文主要聚焦解码器设计,通过利用 SSM 机制实现查询点与场景点的同步更新,从而突破性能瓶颈。
3.3 INTERACTIVE STATE SPACE MODEL
3.3 交互式状态空间模型
In the ISSM, we model the query points as the initial system states $h_{0}\in\mathbb{R}^{K\times C}$ and the scene points as the system inputs $\boldsymbol{x}^{*}\in\mathbf{\bar{R}}^{\dot{M}\times C}$ . As shown in Figure 3, we provide the overview of the ISSM. Compared to Mamba, we expand the dimension of $\Delta$ to make it state-dependent and design a spatial correlation module to generate the SSM parameters $(\Delta,\mathbf{B},\mathbf{C})$ .
在ISSM中,我们将查询点建模为初始系统状态 $h_{0}\in\mathbb{R}^{K\times C}$ ,场景点作为系统输入 $\boldsymbol{x}^{*}\in\mathbf{\bar{R}}^{\dot{M}\times C}$ 。如图 3 所示,我们提供了ISSM的概览。与Mamba相比,我们扩展了 $\Delta$ 的维度使其具有状态依赖性,并设计了一个空间关联模块来生成SSM参数 $(\Delta,\mathbf{B},\mathbf{C})$ 。
Extension of $\Delta$ . In Mamba, the important parameter $\pmb{\Delta}\in\mathbb{R}^{M\times C}$ controls the balance between how much to focus on or ignore the current input. Specifically, a larger $\Delta$ resets the states $h_{t-1}$ to focus on the current input $x_{t}$ , while a smaller $\Delta$ retains the states $h_{t-1}$ and disregards the current input $x_{t}$ . However, in both Mamba and Mamba2, $\Delta$ only considers the system inputs $x$ without accounting for differences in initial system states $h_{0}$ . In 3D object detection tasks, query points have different positions across varying scenes, and different query points focus on different system inputs. Updating the states $h$ by considering only the system inputs $x$ prevents the state points $h$ from adequately focusing on their respective regions. To address this issue, we modify $\Delta$ to have distinct values for each system input and state, expanding $\pmb{\Delta}\in\mathbb{R}^{M\times C}$ to $\pmb{\Delta}\in\mathbb{R}^{M\times K\times C}$ . Although the expansion of $\Delta$ affects the disc ret iz ation formula as equation 3, it does not impact the disc ret i zed state space model as equation 2. Therefore, the proposed ISSM can achieve efficient parallel computation by utilizing the hardware-aware selective scanning strategy (Gu & Dao, 2023) or the state space dual framework (Dao & Gu, 2024).
$\Delta$ 的扩展。在 Mamba 中,关键参数 $\pmb{\Delta}\in\mathbb{R}^{M\times C}$ 控制着对当前输入关注或忽略的平衡。具体而言,较大的 $\Delta$ 会重置状态 $h_{t-1}$ 以聚焦当前输入 $x_{t}$,而较小的 $\Delta$ 会保留状态 $h_{t-1}$ 并忽略当前输入 $x_{t}$。然而,无论是 Mamba 还是 Mamba2,$\Delta$ 仅考虑系统输入 $x$,而未考虑初始系统状态 $h_{0}$ 的差异。在 3D 物体检测任务中,查询点在不同场景下具有不同位置,且不同查询点关注不同的系统输入。若仅通过系统输入 $x$ 来更新状态 $h$,会导致状态点 $h$ 无法充分聚焦于各自区域。为解决这一问题,我们修改 $\Delta$ 使其对每个系统输入和状态具有独立取值,将 $\pmb{\Delta}\in\mathbb{R}^{M\times C}$ 扩展为 $\pmb{\Delta}\in\mathbb{R}^{M\times K\times C}$。虽然 $\Delta$ 的扩展会影响如公式 3 所示的离散化公式,但不会影响如公式 2 的离散状态空间模型。因此,所提出的 ISSM 可通过硬件感知选择性扫描策略 (Gu & Dao, 2023) 或状态空间对偶框架 (Dao & Gu, 2024) 实现高效并行计算。
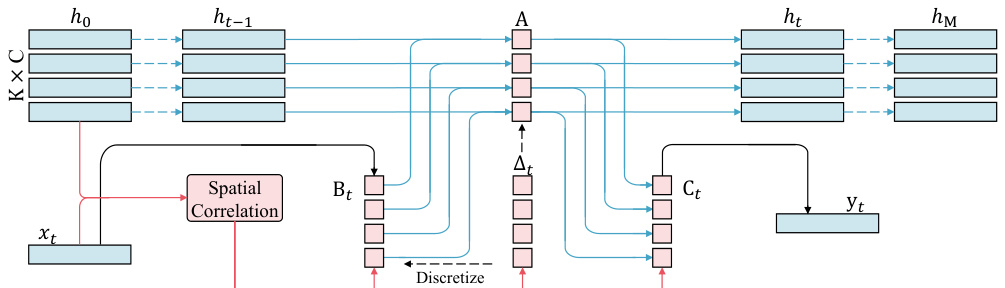
Figure 3: Overview of the Interactive State Space Model. In the ISSM, we model the query points as the system states and the scene points as the system inputs. We design a spatial correlation module to parameter ize the SSM based on the initial system states and inputs.
图 3: 交互式状态空间模型概览。在ISSM中,我们将查询点建模为系统状态,场景点建模为系统输入。我们设计了一个空间关联模块,基于初始系统状态和输入来参数化SSM。
Spatial Correlation. The success of Mamba demonstrates that the state selection mechanism is crucial for SSMs. For 3D object detection tasks, the proposed ISSM needs to address a more complex state updating problem. A key challenge lies in enabling state points to select the appropriate scene points for self-updating. DETR-based methods (Wang et al., 2023; Shen et al., 2024) have inspired us that query points should primarily focus on points surrounding the relevant 3D bounding boxes. Therefore, we design a spatial correlation module that encodes the spatial relationships between scene points $x$ and initial state points $h_{0}$ to derive the parameters $\left(\mathbf{\dot{\mathbf{A}}}\in\mathbb{R}^{M\times K\times C},\mathbf{\dot{B}}\in\mathbb{R}^{M\times K},\mathbf{C}\in\mathbb{R}^{M\times K}\right)$ in the ISSM. Specifically, for each state point $h_{0}^{i}$ , we first predict a rotated 3D bounding box. We then calculate the relative offsets $\triangle P^{i}\in\dot{\mathbb{R}}^{M\times K\times8\times3}$ between the scene points and the eight vertices of the bounding box. Finally, we use an MLP to map these positional relationships to the parameters in the ISSM:
空间相关性。Mamba的成功表明状态选择机制对SSMs至关重要。对于3D物体检测任务,提出的ISSM需要解决更复杂的状态更新问题。关键在于使状态点能选择适当的场景点进行自我更新。基于DETR的方法[20][21]启发我们:查询点应主要关注相关3D边界框周围的点。因此我们设计了空间关联模块,通过编码场景点$x$与初始状态点$h_{0}$的空间关系,推导出ISSM中的参数$\left(\mathbf{\dot{\mathbf{A}}}\in\mathbb{R}^{M\times K\times C},\mathbf{\dot{B}}\in\mathbb{R}^{M\times K},\mathbf{C}\in\mathbb{R}^{M\times K}\right)$。具体而言,对每个状态点$h_{0}^{i}$,首先生成旋转3D边界框,计算场景点与边界框8个顶点的相对偏移量$\triangle P^{i}\in\dot{\mathbb{R}}^{M\times K\times8\times3}$,最后通过MLP将这些位置关系映射到ISSM参数中:
$$
S^{i}=\sum_{j=1}^{8}\mathrm{MLP}(\triangle P_{j}^{i}),\Delta_{\bf s}^{\mathrm{i}}=\mathrm{Linear}{\mathrm{c}}(S^{i}),{\bf B_{s}^{\mathrm{i}}}=\mathrm{Linear}{1}(S^{i}),{\bf C_{s}^{\mathrm{i}}}=\mathrm{Linear}_{1}(S^{i}),
$$
$$
S^{i}=\sum_{j=1}^{8}\mathrm{MLP}(\triangle P_{j}^{i}),\Delta_{\bf s}^{\mathrm{i}}=\mathrm{Linear}{\mathrm{c}}(S^{i}),{\bf B_{s}^{\mathrm{i}}}=\mathrm{Linear}{1}(S^{i}),{\bf C_{s}^{\mathrm{i}}}=\mathrm{Linear}_{1}(S^{i}),
$$
where $\mathrm{Linear_{d}}$ is a parameterized projection to dimension d. Since there are numerous background points within the scene points, we need to prevent these from interfering with the system states. Therefore, we use the features of the scene points to modify the parameters of ISSM:
其中 $\mathrm{Linear_{d}}$ 是一个参数化投影到维度 d 的操作。由于场景点中存在大量背景点,我们需要防止这些点干扰系统状态。因此,我们利用场景点的特征来修改 ISSM 的参数:
$\Delta^{\textbf{i}}=\mathrm{BC}{\mathrm{k}}(\mathrm{Linear}{\mathrm{c}}(x))+\Delta_{\mathrm{s}}^{\textbf{i}},\mathbf{B}^{\textbf{i}}=\mathrm{BC}{\mathrm{k}}(\mathrm{Linear}{\mathrm{1}}(x))+\mathbf{B_{\mathrm{s}}^{\textbf{i}}},~\mathbf{C}^{\textbf{i}}=\mathrm{BC}{\mathrm{k}}(\mathrm{Linear}{\mathrm{1}}(x))+\mathbf{C_{\mathrm{s}}^{\textbf{i}}},$ (7) where $\mathrm{BC_{k}}$ denotes broadcasting the values to $K$ dimensions. Apart from modeling positional correlations and background information, we design an explicit delay kernel for $\Delta^{\mathrm{i}}$ :
$\Delta^{\textbf{i}}=\mathrm{BC}{\mathrm{k}}(\mathrm{Linear}{\mathrm{c}}(x))+\Delta_{\mathrm{s}}^{\textbf{i}},\mathbf{B}^{\textbf{i}}=\mathrm{BC}{\mathrm{k}}(\mathrm{Linear}{\mathrm{1}}(x))+\mathbf{B_{\mathrm{s}}^{\textbf{i}}},~\mathbf{C}^{\textbf{i}}=\mathrm{BC}{\mathrm{k}}(\mathrm{Linear}{\mathrm{1}}(x))+\mathbf{C_{\mathrm{s}}^{\textbf{i}}},$ (7) 其中 $\mathrm{BC_{k}}$ 表示将值广播到 $K$ 维。除了建模位置相关性和背景信息外,我们为 $\Delta^{\mathrm{i}}$ 设计了一个显式延迟核:
$$
\Delta_{\mathbf{g}}^{\mathbf{i}}=\Delta^{\mathbf{i}}\times\exp(\alpha\operatorname*{min}(R(h_{0}^{i})-P_{x},0)),
$$
$$
\Delta_{\mathbf{g}}^{\mathbf{i}}=\Delta^{\mathbf{i}}\times\exp(\alpha\operatorname*{min}(R(h_{0}^{i})-P_{x},0)),
$$
where $R(h_{0}^{i})$ is the circumscribed sphere radius of the bounding box predicted by the state point $h_{0}^{i},P_{x}$ denotes the position of the scene points and $\alpha$ is a learnable parameter. With the parameters $(\tilde{\bf\Delta}_{\bf g}^{i},{\bf B}^{i},{\bf C}^{i})$ , the state points $h$ can select the appropriate scene points $x$ for updating, while the scene points $x$ can simultaneously acquire surrounding structural information from the state points $h$ . In practice, we observe that the numerous combinations between state points $h$ and scene points $x$ result in significant memory overhead. Therefore, following VDETR (Shen et al., 2024), we utilize a smaller predefined 3D table $T\in\mathbb{R}^{10\times10\times10}$ to obtain $S^{i}$ of equation 6 through grid sampling. In Appendix, we further discuss the mathematical relationship between the system states in the state space model and the query points in the transformer decoder.
其中 $R(h_{0}^{i})$ 是状态点 $h_{0}^{i}$ 预测边界框的外接球半径,$P_{x}$ 表示场景点的位置,$\alpha$ 是可学习参数。通过参数 $(\tilde{\bf\Delta}_{\bf g}^{i},{\bf B}^{i},{\bf C}^{i})$,状态点 $h$ 能筛选合适的场景点 $x$ 进行更新,同时场景点 $x$ 也能从状态点 $h$ 获取周围结构信息。实际应用中,我们观察到状态点 $h$ 与场景点 $x$ 的大量组合会导致显著内存开销。因此,参照 VDETR (Shen et al., 2024),我们采用较小的预定义三维表格 $T\in\mathbb{R}^{10\times10\times10}$ 通过网格采样获取公式6中的 $S^{i}$。附录中我们进一步讨论了状态空间模型中系统状态与Transformer解码器查询点的数学关系。
3.4 ISSM-BASED DECODER
3.4 基于 ISSM 的解码器
Based on the above ISSM, we further design an ISSM-based decoder suitable for 3D point cloud detection as shown in Figure 4 (a). The ISSM-based decoder consists of four core components:
基于上述ISSM,我们进一步设计了一种适用于3D点云检测的ISSM解码器,如图4(a)所示。该ISSM解码器包含四个核心组件:

Figure 4: (a): Illustration of ISSM-based decoder architecture. (b): Detailed Structure of the ISSMbased Bidirectional Scan. (c): Detailed Structure of the Gated Feed-Forward Network (GFFN).
图 4: (a): 基于ISSM的解码器架构示意图。(b): ISSM双向扫描的详细结构。(c): 门控前馈网络(GFFN)的详细结构。
a Hilbert-based point cloud serialization strategy, an inter-state attention module, an ISSM-based Bidirectional Scan (IBS) module, and a Gated Feed-Forward Network (GFFN).
基于Hilbert的点云序列化策略、状态间注意力模块、基于ISSM的双向扫描(IBS)模块,以及门控前馈网络(GFFN)。
Hilbert-based point cloud serialization strategy. SSMs are designed for ordered 1D sequences, which are not suitable for unordered point clouds. To model the scene points as the system inputs of the ISSM, we need to serialize the scene points. Following PTv3 (Wu et al., 2024), we leverage space-filling curves to serialize point clouds. Among these space-filling curves, the Hilbert curve (Hilbert & Hilbert, 1935) is renowned for its efficient locality preservation. Thus, we generate six different serialized results for the point cloud by reordering the x, y, and z axes of the Hilbert curve, aiming for comprehensive observation of the point cloud. The detailed serialization process is shown in Appendix A.3. Additionally, unlike serialized attention in PTv3, the sequential feature modeling in ISSM is more sensitive to changes in the serialization method. Therefore, we apply different serialization methods for each decoder layer without the shuffle order strategy used in PTv3, ensuring that the ISSM-based decoder can comprehensively capture scene point features.
基于Hilbert的点云序列化策略。SSM(State Space Model)专为有序的一维序列设计,不适用于无序点云。为了将场景点建模为ISSM(Implicit State Space Model)的系统输入,我们需要对场景点进行序列化处理。借鉴PTv3(Wu等人,2024)的方法,我们利用空间填充曲线对点云进行序列化。在众多空间填充曲线中,Hilbert曲线(Hilbert & Hilbert,1935)以其高效的局部性保持特性著称。因此,我们通过调整Hilbert曲线的x、y、z轴顺序,为点云生成六种不同的序列化结果,以实现对点云的全面观测。具体序列化流程详见附录A.3。此外,与PTv3中的序列化注意力机制不同,ISSM中的序列特征建模对序列化方法的变化更为敏感。为此,我们在每个解码器层应用不同的序列化方法,且不采用PTv3中的随机打乱策略,从而确保基于ISSM的解码器能够全面捕捉场景点特征。
Inter-state attention module. In 3D object detection, objects in a scene often exhibit strong correlations. For example, tables and chairs commonly appear together, while beds and toilets rarely coexist in the same room. In DETR-based decoder layers (Carion et al., 2020; Misra et al., 2021; Liu et al., 2021; Shen et al., 2024), the self-attention mechanism for queries is employed to model the correlations between different objects. However, in the ISSM, there is no design specifically for interactions between state points. To capture such relationships, we employ a standard self-attention mechanism for state points. The inter-state attention module allows states to capture richer features, particularly enhancing the detection performance for objects with ambiguous boundaries or those that are challenging to distinguish from the background.
状态间注意力模块。在3D物体检测中,场景中的物体往往存在强相关性。例如桌椅常同时出现,而床和马桶很少共存于同一房间。基于DETR的解码器层(Carion等人, 2020; Misra等人, 2021; Liu等人, 2021; Shen等人, 2024)采用查询的自注意力机制来建模不同物体间的关联。但在ISSM中,并未专门设计状态点间的交互机制。为捕捉此类关系,我们对状态点采用标准自注意力机制。该模块使状态能捕获更丰富的特征,尤其提升边界模糊或易与背景混淆物体的检测性能。
IBS module. To facilitate bidirectional interaction among different scene points in a single pass, we follow Vision Mamba (Zhu et al., 2024) and introduce a bidirectional scanning mechanism into our ISSM. Figure 4 (b) illustrates the detailed structure of the IBS module. Firstly, we input the forwardordered and backward-ordered scene points into their respective forward and backward ISSMs. Both the forward and backward ISSMs use state points as system states, with each ISSM generating the updated features of the scene points and state points as outputs. We then fuse the outputs using a linear layer to obtain the final features of the scene points and state points. Additionally, we incorporate a depthwise convolution (Chollet, 2017) for local feature extraction of the scene points. In Appendix A.2, we provide detailed algorithmic procedures of the IBS module.
IBS模块。为了实现单次前向传播中不同场景点的双向交互,我们借鉴Vision Mamba (Zhu et al., 2024) 的思路,在ISSM中引入了双向扫描机制。图4(b) 展示了IBS模块的详细结构:首先将正向排序和反向排序的场景点分别输入前向ISSM和后向ISSM,两个ISSM均以状态点作为系统状态,各自输出更新后的场景点特征和状态点特征;随后通过线性层融合两组输出,得到最终的场景点特征和状态点特征。此外,我们还采用深度可分离卷积 (depthwise convolution) [20] 来提取场景点的局部特征。附录A.2给出了IBS模块的详细算法流程。
GFFN. The gating mechanism (Dauphin et al., 2017) introduces gated linear units, allowing the model to dynamically select activation paths based on the input. This selectivity enhances the model flexibility, enabling the model to better capture complex patterns. Thus, we design the GFFN to replace the standard FFN, as shown in Figure 4 (c). For the ordered scene points, we also incorporate a depthwise convolution to fully leverage the spatial structural information of the point cloud.
GFFN。门控机制 (Dauphin et al., 2017) 引入了门控线性单元,使模型能够根据输入动态选择激活路径。这种选择性增强了模型灵活性,使其能更好地捕捉复杂模式。因此,我们设计GFFN来替代标准FFN,如图4 (c) 所示。针对有序场景点,我们还加入了深度卷积以充分利用点云的空间结构信息。
3.5 MODEL SETUPS
3.5 模型配置
For a fair comparison, we build our DEST-based 3D detector based on two baseline DETR-based models: GroupFree (Liu et al., 2021) and VDETR (Shen et al., 2024), respectively. For GroupFree baseline, the input points $P_{i n}\in\mathbb{R}^{N\times3}$ contain only position information. We replace all transformer decoder layers with our proposed ISSM-based decoder layers while retaining the original spatial encodings and the original detection heads. For the training loss, we employ the same detection loss with GroupFree and introduce an additional objectness loss for the scene points. Specifically, we use a MLP head to determine whether a scene point is a foreground point and apply a binary focal loss to supervise the prediction results. For VDETR baseline, the input points $\dot{P_{i n}}\in\mathbb{R}^{N\times\check{6}}$ include both position and RGB information. In the decoder, we also replace all transformer decoder layers with our ISSM-based decoder layers while retaining the original detection heads. Regarding the spatial encodings, we generate them for the corresponding state points using the predicted 3D bounding boxes and for the scene points using their point positions. For the training loss, we employ the same detection loss with VDETR and introduce the same objectness loss as above for the scene points. Due to space limitations, more details can be found in the Appendix.
为了公平比较,我们基于两种DETR基准模型分别构建了DEST三维检测器:GroupFree (Liu et al., 2021) 和 VDETR (Shen et al., 2024)。对于GroupFree基准模型,输入点云 $P_{i n}\in\mathbb{R}^{N\times3}$ 仅包含位置信息。我们保留了原始空间编码和检测头,将所有Transformer解码器层替换为提出的基于ISSM的解码器层。训练损失方面,除沿用GroupFree的检测损失外,还为场景点引入了前景点判断损失——通过MLP头预测场景点是否属于前景点,并使用二元焦点损失监督预测结果。对于VDETR基准模型,输入点云 $\dot{P_{i n}}\in\mathbb{R}^{N\times\check{6}}$ 包含位置和RGB信息。解码器中同样替换所有Transformer层为ISSM解码器层,同时保留原始检测头。空间编码则分别基于预测的3D边界框生成状态点编码,基于点坐标生成场景点编码。训练损失沿用VDETR的检测损失,并添加与上述相同的场景点前景判断损失。更多细节详见附录。
4 EXPERIMENTAL RESULTS
4 实验结果
4.1 DATASETS AND METRICS
4.1 数据集与评估指标
Dataset. We evaluate our DEST-based detector on two challenging 3D indoor object detection datasets, including ScanNet V2 (Dai et al., 2017) and SUN RGB-D (Song et al., 2015). ScanNet V2 dataset contains 1201 training samples and 312 validation samples, each annotated with per-point instance and semantic labels, as well as axis-aligned 3D bounding boxes across 18 categories. SUN RGB-D dataset is a monocular dataset, containing over 10000 indoor RGB-D images annotated with per-point semantic labels and oriented 3D bounding boxes across 37 categories. We follow previous methods (Qi et al., 2019; Liu et al., 2021) to evaluate our approach on the 10 most common classes of objects. The training and validation splits contain 5285 and 5050 point clouds, respectively.
数据集。我们在两个具有挑战性的3D室内物体检测数据集上评估基于DEST的检测器,包括ScanNet V2 (Dai et al., 2017) 和 SUN RGB-D (Song et al., 2015)。ScanNet V2数据集包含1201个训练样本和312个验证样本,每个样本均标注了点级实例和语义标签,以及18个类别的轴对齐3D边界框。SUN RGB-D数据集是一个单目数据集,包含超过10000张室内RGB-D图像,标注了点级语义标签和37个类别的定向3D边界框。我们遵循先前方法 (Qi et al., 2019; Liu et al., 2021) 在最常见的10个物体类别上评估我们的方法。训练集和验证集分别包含5285和5050个点云。
Evaluation Metrics. Following the standard evaluation protocol (Qi et al., 2019), we evaluate our ISSM-based detector performance with the mean Average Precision $\mathrm{(AP_{25}}$ and $\mathrm{AP_{50}}$ ) under two different Intersections over Union (IoU) thresholds of 0.25 and 0.5. Since the input point clouds are obtained through random sampling, both the training and testing processes are stochastic. To ensure the reliability of the test results, we run the training 5 times and independently test each trained model 5 times. We report both the highest performance and the average results under $5\times5$ trials.
评估指标。遵循标准评估协议 (Qi et al., 2019),我们使用不同交并比 (IoU) 阈值 (0.25 和 0.5) 下的平均精度 $\mathrm{(AP_{25}}$ 和 $\mathrm{AP_{50}}$) 来评估基于 ISSM 的检测器性能。由于输入点云是通过随机采样获得的,训练和测试过程都具有随机性。为确保测试结果的可靠性,我们进行了 5 次训练,并对每个训练好的模型独立测试 5 次。我们报告了 $5\times5$ 次试验中的最高性能和平均结果。
4.2 COMPARISON WITH STATE-OF-THE-ART METHODS
4.2 与现有最优方法的对比
Different 3D detection models employ various techniques in terms of encoder architecture and bounding box parameter iz ation, with some methods using point clouds with color information as model inputs. Therefore, it is unfair to compare the performance of different methods directly. Among these 3D detection methods, GroupFree (Liu et al., 2021) is a pioneer in designing the DETR-based method for point clouds, demonstrating strong performance across multiple datasets. VDETR (Shen et al., 2024) builds upon 3DETR (Misra et al., 2021) by introducing the positional encoding in the decoder, achieving state-of-the-art performance. To demonstrate the effectiveness of our method, we implement the DEST-based detector on top of the two DETR-based methods.
不同的3D检测模型在编码器架构和边界框参数化方面采用了多种技术,部分方法使用带有颜色信息的点云作为模型输入。因此直接比较不同方法的性能并不公平。在这些3D检测方法中,GroupFree (Liu等人,2021) 是首个基于DETR的点云检测方法,在多个数据集上展现出优异性能。VDETR (Shen等人,2024) 在3DETR (Misra等人,2021) 基础上通过解码器引入位置编码,实现了最先进的性能。为验证本方法的有效性,我们在两种基于DETR的方法上实现了基于DEST的检测器。
As shown in Table 1, we compare our DEST-based detector with the previous 3D object detection methods on the ScanNet V2 and SUN RGB-D datasets. The results indicate that our method significantly outperforms the baseline methods on both datasets, whether measured by the highest performance or the average results over multiple trials. For the GroupFree baseline, our DEST-based detector demonstrates substantial performance improvements across different decoder scales. For example, on the ScanNetV2 dataset, our method achieves a 4.3 increase in $\mathrm{AP_{50}}$ based on GroupFree (S) and a 5.3 increase based on GroupFree (L). For the VDETR baseline, our DEST-based detector achieves new state-of-the-art performance on both datasets. Specifically, our approach reaches 78.8 in $\mathrm{AP_{25}}$ and 67.9 in $\mathrm{AP_{50}}$ on the ScanNet V2 dataset, which is 1.0 and 1.9 better than the baseline model. Additionally, our method achieves 69.2 in $\mathrm{AP_{25}}$ and 52.2 in $\mathrm{AP_{50}}$ on the SUN RGB-D dataset with the gains of 1.2 and 1.1. In Appendix, we further present a visual comparison of the prediction results with different baseline methods. The experimental results clearly demonstrate the effectiveness of our method. Our DEST-based decoder addresses the performance limitations caused by fixed scene point features during the query refinement process, resulting in a significant performance boost.
如表 1 所示,我们在 ScanNet V2 和 SUN RGB-D 数据集上将基于 DEST 的检测器与先前的 3D 物体检测方法进行了对比。结果表明,无论是最高性能指标还是多次试验的平均结果,我们的方法在两个数据集上都显著优于基线方法。对于 GroupFree 基线模型,基于 DEST 的检测器在不同解码器规模下均展现出显著的性能提升。例如在 ScanNetV2 数据集上,我们的方法在 GroupFree (S) 基础上实现了 $\mathrm{AP_{50}}$ 指标 4.3 的提升,在 GroupFree (L) 基础上实现了 5.3 的提升。对于 VDETR 基线模型,基于 DEST 的检测器在两个数据集上都达到了新的最先进性能:在 ScanNet V2 数据集上 $\mathrm{AP_{25}}$ 达到 78.8,$\mathrm{AP_{50}}$ 达到 67.9,分别比基线模型提升 1.0 和 1.9;在 SUN RGB-D 数据集上 $\mathrm{AP_{25}}$ 达到 69.2,$\mathrm{AP_{50}}$ 达到 52.2,分别提升 1.2 和 1.1。附录部分我们进一步展示了与不同基线方法的预测结果可视化对比。实验结果充分证明了方法的有效性:基于 DEST 的解码器解决了查询优化过程中固定场景点特征导致的性能瓶颈,从而实现了显著的性能突破。
Table 1: Comparison on the ScanNet V2 and SUN RGB-D datasets. We report both the highest performance (H) and the average results (A) under multiple trials. ‘RGB’ indicates that the input point clouds of the methods include color information. GroupFree(S) denotes a model with a 6-layer decoder and 256 object candidates. GroupFree(L) denotes a model with a 12-layer decoder and 512 object candidates. TTA is the test-time augmentation used in VDETR.
表 1: ScanNet V2 和 SUN RGB-D 数据集上的对比。我们报告了多次试验中的最高性能 (H) 和平均结果 (A)。"RGB"表示方法的输入点云包含颜色信息。GroupFree(S) 表示具有 6 层解码器和 256 个候选对象的模型。GroupFree(L) 表示具有 12 层解码器和 512 个候选对象的模型。TTA 是 VDETR 中使用的测试时增强。
| 方法 | RGB | ScanNet V2(H) AP25 | ScanNet V2(H) AP50 | ScanNet V2(A) AP25 | ScanNet V2(A) AP50 | SUN RGB-D(H) AP25 | SUN RGB-D(H) AP50 | SUN RGB-D(A) AP25 | SUN RGB-D(A) AP50 |
|---|---|---|---|---|---|---|---|---|---|
| VoteNet (Qi et al., 2019) | × | 62.9 | 39.9 | 57.7 | |||||
| HGNet (Chen et al., 2020) | × | 61.3 | 34.4 | 61.6 | |||||
| 3D-MPA (Engelmann et al., 2020) | × | 64.2 | 49.2 | ||||||
| MLCVNet (Xie et al., 2020) | × | 64.5 | 41.4 | 59.8 | |||||
| GSDN (Gwak et al., 2020) | × | 62.8 | 34.8 | ||||||
| H3DNet (Zhang et al., 2020) | × | 64.4 | 43.4 | 60.1 | 39.0 | ||||
| BRNet (Cheng et al., 2021) | 66.1 | 50.9 | 61.1 | 43.7 | |||||
| 3DETR (Misra et al., 2021) | × | 65.0 | 47.0 | 59.1 | 32.7 | ||||
| VENet (Xie et al., 2021) | × | 67.7 | 62.5 | 39.2 | |||||
| GroupFree(S)(Liu et al., 2021) | × | 67.3 | 48.9 | 66.3 | 48.5 | 63.0 | 45.2 | 62.6 | 44.4 |
| GroupFree(L)(Liu et al., 2021) | × | 69.1 | 52.8 | 68.6 | 51.8 | ||||
| RBGNet (Wang et al., 2022b) | × | 70.6 | 55.2 | 69.9 | 54.7 | 64.1 | 47.2 | 63.6 | 46.3 |
| HyperDet3D (Zheng et al., 2022) | × | 70.9 | 57.2 | - | 63.5 | 47.3 | - | ||
| LeadNet (Wang et al., 2023) | × | 68.0 | 51.3 | = | = | 63.4 | 45.8 | ||
| FCAF3D (Rukhovich et al., 2022) | 71.5 | 57.3 | 70.7 | 56.0 | 64.2 | 48.9 | 63.8 | 48.2 | |
| TR3D (Rukhovich et al., 2023) | √ | 72.9 | 59.3 | 72.0 | 57.4 | 67.1 | 50.4 | 66.3 | 49.6 |
| CAGroup3D (Wang et al., 2022a) | √ | 75.1 | 61.3 | 74.5 | 60.3 | 66.8 | 50.2 | 66.4 | 49.5 |
| VDETR (Shen et al.,2024) | 77.4 | 65.0 | 76.8 | 64.5 | 67.5 | 50.4 | 66.8 | 49.7 | |
| VDETR(TTA) (Shen et al., 2024) | 77.8 | 66.0 | 77.0 | 65.3 | 68.0 | 51.1 | 67.5 | 50.0 | |
| GroupFree(S)(Liu et al., 2021) + DEST(ours) | × | 67.3 | 48.9 | 66.3 | 48.5 | 63.0 | 45.2 | 62.6 | 44.4 |
| GroupFree(L)(Liu et al., 2021) | × | 69.1 | 52.8 | 68.6 | 51.8 | ||||
| + DEST(ours) | × | 71.3(+2.2) | 58.1(+5.3) | 70.5(+1.9) | 56.8(+5.0) | ||||
| VDETR (Shen et al., 2024) | 77.4 | 65.0 | 76.8 | 64.5 | 67.5 | 50.4 | 66.8 | 49.7 | |
| + DEST(ours) | 78.5(+1.1) | 66.6(+1.6) | 77.8(+1.0) | 66.2(+1.7) | 68.4(+0.9) | 51.8(+1.4) | 67.4(+0.8) | 50.9(+1.2) | |
| VDETR(TTA) (Shen et al., 2024) | 77.8 | 66.0 | 77.0 | 65.3 | 68.0 | 51.1 | 67.5 | 50.0 | |
| + DEST(ours) | 78.8(+1.0) | 67.9(+1.9) | 78.3(+1.3) | 66.9(+1.6) | 69.2(+1.2) | 52.2(+1.1) | 68.8(+1.3) | 51.6(+1.6) |
4.3 ABLATION EXPERIMENTS
4.3 消融实验
In this section, we verify the key design moduels of our DEST-based detector. All ablation experiments are conducted on the ScanNet V2 dataset with the GroupFree(S) baseline. Following GroupFree (Liu et al., 2021), we report the average performance of 25 trials by default.
在本节中,我们验证基于DEST的检测器关键设计模块。所有消融实验均在ScanNet V2数据集上采用GroupFree(S)基线进行。遵循GroupFree (Liu et al., 2021) 的设定,默认报告25次试验的平均性能。
Effect of the designed modules. As shown in Table 2, we increment ally add each designed module in an SSM-based baseline. The SSM-based baseline is also built on GroupFree(S), using the standard Mamba2 block and FFN as the decoder components. The SSM-based baseline lacks the adaptability to the state points and cannot handle unordered point cloud inputs, resulting in a significant performance drop. Introducing the serialization and bidirectional scan strategies improves the model performance, but still lags behind GroupFree(S). A substantial performance boost is observed when the proposed ISSM replaces the Mamba2 block. This boost is attributed to the adaptive ability of the ISSM, allowing state points to select appropriate scene points for feature updating. Further incorporating an inter-state mechanism and a gated linear unit achieves the best performance.
所设计模块的效果。如表 2 所示,我们在基于 SSM 的基线模型上逐步添加每个设计模块。该基线模型同样基于 GroupFree(S) 构建,使用标准 Mamba2 模块和 FFN 作为解码组件。基于 SSM 的基线模型缺乏对状态点的适应能力,无法处理无序点云输入,导致性能显著下降。引入序列化和双向扫描策略后模型性能有所提升,但仍落后于 GroupFree(S)。当采用提出的 ISSM 替代 Mamba2 模块时,性能得到显著提升,这归功于 ISSM 的自适应能力使状态点能选择合适的场景点进行特征更新。进一步引入状态间机制和门控线性单元后,模型达到了最佳性能。
Effect of the ISSM. ISSM is the core of the proposed DEST and is responsible for the information exchange and updating between scene and state points. Compared with the selective SSM, ISSM extends the dimension of $\Delta$ and introduces a spatial correlation module and a delay kernel to assist scene points in generating the SSM parameters. To analyze the impact of parameter generation, we evaluate different combinations of parameter generation methods. As shown in the second and third rows of Table 3, using the spatial correlation module and delay kernel to generate SSM parameters leads to a significant performance improvement. The results indicate that allowing state points to focus on their relevant regions is crucial for designing SSMs for 3D object detection. Moreover, comparing the fourth and fifth rows, we find that considering only spatial relationships also results in a drop in performance. When the above modules are combined to generate SSM parameters, the DEST-based detector achieves the best performance.
ISSM的影响。ISSM是所提出的DEST的核心,负责场景点与状态点之间的信息交换与更新。相较于选择性SSM,ISSM扩展了$\Delta$的维度,并引入空间相关性模块和延迟核来辅助场景点生成SSM参数。为分析参数生成方式的影响,我们评估了不同参数生成方法的组合效果。如表3第2-3行所示,采用空间相关性模块和延迟核生成SSM参数会带来显著的性能提升。结果表明,让状态点聚焦其相关区域对设计3D目标检测的SSM至关重要。此外,对比第4-5行可发现,仅考虑空间关系也会导致性能下降。当结合上述模块生成SSM参数时,基于DEST的检测器取得了最佳性能。
Table 2: Effect of the designed modules. We progressively add the proposed modules to the SSM-based baseline to verify the contribution of each module.
表 2: 各模块设计效果。我们在基于SSM的基线模型上逐步添加提出的模块,以验证每个模块的贡献。
| Method | AP25 | AP50 |
|---|---|---|
| GroupFree(S) | 66.3 | 48.5 |
| Baseline | 60.2 | 41.6 |
| w/serialization | 62.8 | 43.5 |
| w/bidirectionalscan | 63.7 | 44.8 |
| w/ISSM | 67.1 | 50.6 |
| w/inter-stateattention | 67.6 | 51.9 |
| W/GFFN | 67.9 | 52.7 |
Table 4: Effect of the simultaneous updating. “Fixed” denotes that the scene point features used in each decoder layer remain as those outputted by the encoder. “GroupFree∗” indicates that we introduced a GFFN in each decoder layer to update the scene point features.
表 4: 同步更新的效果。"Fixed"表示每个解码器层中使用的场景点特征保持编码器输出的状态。"GroupFree∗"表示我们在每个解码器层引入了GFFN来更新场景点特征。
| Method | Fixed | AP25 | AP50 |
|---|---|---|---|
| GroupFree(S) | 66.3 | 48.5 | |
| GroupFree * | 66.8 | 49.0 | |
| DEST(ours) | √ | 66.6 | 49.3 |
| DEST(ours) | x | 67.9 | 52.7 |
Table 3: Effect of the ISSM. Here, $\phi(x)$ represents generating the SSM parameters using the scene points $x$ . $\phi(S)$ indicates the incorporation of spatial correlation $S$ to generate the parameters. $R(h)$ denotes the addition of a delay kernel for $\Delta$ .
表 3: ISSM 的效果。这里,$\phi(x)$ 表示使用场景点 $x$ 生成 SSM 参数。$\phi(S)$ 表示引入空间相关性 $S$ 来生成参数。$R(h)$ 表示为 $\Delta$ 添加延迟核。
| Φ(x) | p(S) | R(h) | AP25 | AP50 |
|---|---|---|---|---|
| 64.3 | 46.1 | |||
| 67.2 | 51.3 | |||
| √ | 67.4 | 50.8 | ||
| √ | √ | 66.7 | 49.4 | |
| 67.9 | 52.7 |
Table 5: Comparison of the model parameters and inference speed on ScanNet V2. “Param.” denotes the total parameters.
表 5: ScanNet V2 上的模型参数量和推理速度对比。"Param." 表示总参数量。
| Method | Param. | Latency | AP25 AP50 |
|---|---|---|---|
| GroupFree(S) +DEST(ours) | 13.8M | 21 ms | 67.3 48.9 |
| GroupFree(L) | 19.6M | 34 ms | 68.8 53.2 |
| 28.2M | 68 ms | 69.1 52.8 | |
| + DEST(ours) FCAF3D | 39.8M | 98 ms | 71.3 58.1 |
| CAGroup3D VDETR + DEST(ours) | 67.2M | 138ms | 71.5 57.3 |
| 120.7M | 472ms | 75.1 61.3 | |
| 75.6M | 238ms | 77.8 66.0 |
Effect of the scene point updating. To evaluate the impact of scene point feature updating, we conduct ablation experiments as shown in Table 4. In the second row, we add the proposed GFFN to GroupFree(S) to update the scene point features. However, due to its limited receptive field, it only achieves a slight performance improvement. In the third row, we fix the scene point features in the proposed DEST-based detector, which results in a significant performance decline. These results demonstrate the effectiveness of the simultaneous updating in DEST-based methods. In the DEST-based methods, scene points can capture global contextual information through state points for self-updating, thereby providing more effective information for subsequent decoder layers.
场景点更新的效果。为评估场景点特征更新的影响,我们进行了如表4所示的消融实验。第二行中,我们在GroupFree(S)中加入提出的GFFN来更新场景点特征,但由于其感受野有限,仅带来轻微性能提升。第三行固定了基于DEST的检测器中场景点特征,导致性能显著下降。这些结果证明了基于DEST方法中同步更新的有效性:场景点可通过状态点捕获全局上下文信息进行自我更新,从而为后续解码层提供更有效信息。
4.4 COMPARISON OF PARAMETERS AND INFERENCE SPEED
4.4 参数与推理速度对比
The model complexity of both DETR-based and DEST-based methods is determined by the number of scene points and query points. To ensure a fair comparison, we compare the model parameters and inference speed with different DETR-based baseline methods. All experiments are conducted on a Tesla V100 GPU. As shown in Table 5, our method demonstrates comparable model parameter efficiency and inference speed while enabling simultaneous updates of scene points and state points. Although there is a slight increase in parameter count and computational cost compared to the baseline methods, this overhead is acceptable given the substantial performance gains.
基于DETR和DEST的方法的模型复杂度均由场景点数量与查询点数量决定。为公平对比,我们将模型参数量与推理速度同不同DETR基线方法进行比较,所有实验均在Tesla V100 GPU上完成。如表5所示,本方法在实现场景点与状态点同步更新的同时,仍保持相当的参数量效率与推理速度。尽管相比基线方法参数量与计算成本略有增加,但考虑到显著的性能提升,这部分开销是可接受的。
5 CONCLUSION
5 结论
In this paper, we identify a crucial issue in DETR-based decoders: the fixed scene point features lead to suboptimal refinement of query points in the later layers. To address this issue, we introduce a novel DEST-based method that simultaneously updates scene and query point features. The key contribution lies in designing the ISSM, which models query points as system states and scene points as system inputs, allowing simultaneous updates with linear complexity. Our DEST-based method demonstrates significant advantages through comparison experiments with two DETR-based methods, and comprehensive ablation studies validate the effectiveness of each designed module.
本文揭示了基于DETR的解码器存在一个关键问题:固定场景点特征导致后续层中查询点的优化效果欠佳。为解决该问题,我们提出了一种基于DEST的新方法,可同步更新场景和查询点特征。核心创新在于设计了ISSM模块,将查询点建模为系统状态、场景点作为系统输入,以线性复杂度实现同步更新。通过与两种DETR方法的对比实验,我们的DEST方法展现出显著优势,全面的消融实验也验证了各模块设计的有效性。