Far3D: Expanding the Horizon for Surround-view 3D Object Detection
Far3D: 拓展环视3D物体检测的视野
Abstract
摘要
Recently 3D object detection from surround-view images has made notable advancements with its low deployment cost. However, most works have primarily focused on close perception range while leaving long-range detection less explored. Expanding existing methods directly to cover long distances poses challenges such as heavy computation costs and unstable convergence. To address these limitations, this paper proposes a novel sparse query-based framework, dubbed Far3D. By utilizing high-quality 2D object priors, we generate 3D adaptive queries that complement the 3D global queries. To efficiently capture disc rim i native features across different views and scales for long-range objects, we introduce a perspective-aware aggregation module. Additionally, we propose a range-modulated 3D denoising approach to address query error propagation and mitigate convergence issues in long-range tasks. Significantly, Far3D demonstrates SoTA performance on the challenging Argoverse 2 dataset, covering a wide range of 150 meters, surpassing several LiDAR-based approaches. The code is available at https://github.com/megvii-research/Far3D.
最近,基于环视图像的3D物体检测因部署成本低而取得显著进展。然而,大多数工作主要聚焦近距离感知范围,远距离检测研究相对不足。直接将现有方法扩展到远距场景会面临计算成本高昂和收敛不稳定等挑战。为解决这些局限,本文提出一种新型稀疏查询框架Far3D:通过高质量2D物体先验生成3D自适应查询,与3D全局查询形成互补;针对远距物体跨视角、跨尺度的特征提取问题,设计视角感知聚合模块;此外提出范围调制3D去噪方法,以解决查询误差传播并缓解远距任务中的收敛问题。Far3D在覆盖150米范围的Argoverse 2数据集上显著超越多个基于LiDAR的方案,达到当前最优性能。代码已开源:https://github.com/megvii-research/Far3D。
1 Introduction
1 引言
3D object detection plays an important role in understanding 3D scenes for autonomous driving, aiming to provide accurate object localization and category around the ego vehicle. Surround-view methods (Huang and Huang 2022; Li et al. 2023; Liu et al. 2022b; Li et al. $2022\mathrm{c}$ ; Yang et al. 2023; Park et al. 2022; Wang et al. 2023a), with their advantages of low cost and wide applicability, have achieved remarkable progress. However, most of them focus on close-range perception (e.g., ${\sim}50$ meters on nuScenes (Caesar et al. 2020)), leaving the long-range detection field less explored. Detecting distant objects is essential for real-world driving to maintain a safe distance, especially at high speeds or complex road conditions.
3D物体检测在自动驾驶的3D场景理解中扮演着重要角色,旨在为自车周围提供精准的物体定位与类别识别。环视方法 (Huang and Huang 2022; Li et al. 2023; Liu et al. 2022b; Li et al. $2022\mathrm{c}$; Yang et al. 2023; Park et al. 2022; Wang et al. 2023a) 凭借低成本、高适用性的优势取得了显著进展。但现有研究多集中于近距离感知 (例如 nuScenes (Caesar et al. 2020) 数据集约50米范围),对远距离检测领域的探索相对不足。在实际驾驶场景中,远距离物体检测对保持安全车距至关重要,尤其在高速行驶或复杂路况下。
Existing surround-view methods can be broadly categorized into two groups based on the intermediate representation, dense Bird’s-Eye-View (BEV) based methods and sparse query-based methods. BEV based methods (Huang et al. 2021; Huang and Huang 2022; Li et al. 2023, 2022c; Yang et al. 2023) usually convert perspective features to BEV features by employing a view transformer (Philion and Fidler 2020), then utilizing a 3D detector head to produce the 3D bounding boxes. However, dense BEV features come at the cost of high computation even for the close-range perception, making it more difficult to scale up to long-range perception. Instead, following DETR (Carion et al. 2020) style, sparse query-based methods (Wang et al. 2022; Liu et al. 2022a,b; Wang et al. 2023a) adopt learnable global queries to represent 3D objects, and interact with surroundview image features to update queries. Although sparse design can avoid the squared growth of query numbers, its global fixed queries cannot adapt to dynamic scenarios and usually miss targets in long-range detection. We adopt the sparse query design to maintain detection efficiency and introduce 3D adaptive queries to address the inflexibility
现有环视方法根据中间表示可大致分为两类:基于密集鸟瞰图(BEV)的方法和基于稀疏查询的方法。基于BEV的方法(Huang et al. 2021; Huang and Huang 2022; Li et al. 2023, 2022c; Yang et al. 2023)通常通过视图转换器(Philion and Fidler 2020)将透视图特征转换为BEV特征,再使用3D检测头生成3D边界框。然而密集BEV特征即使对近距离感知也会带来高计算成本,使其更难扩展至远距离感知。基于稀疏查询的方法(Wang et al. 2022; Liu et al. 2022a,b; Wang et al. 2023a)遵循DETR(Carion et al. 2020)范式,采用可学习的全局查询来表示3D物体,并通过与环视图像特征交互来更新查询。虽然稀疏设计能避免查询数量的平方增长,但其全局固定查询无法适应动态场景,通常在远距离检测中漏检目标。我们采用稀疏查询设计以保持检测效率,并引入3D自适应查询来解决灵活性不足的问题

Figure 1: Peformance comparisons on Argoverse 2 between 3D detection and 2D detection. (a) and (b) demonstrate predicted boxes of StreamPETR and YOLOX, respectively. (c) imply that 2D recall is notably better than 3D recall and can act as a bridge to achieve high-quality 3D detection. Note that 2D recall does not represent 3D upper bound due to different recall criteria. () Recall comparison
图 1: Argoverse 2 数据集上 3D 检测与 2D 检测的性能对比。(a) 和 (b) 分别展示了 StreamPETR 与 YOLOX 的预测框。(c) 表明 2D 召回率显著优于 3D 召回率,可作为实现高质量 3D 检测的桥梁。需注意由于召回标准不同,2D 召回率并不代表 3D 检测的上限。() 召回率对比
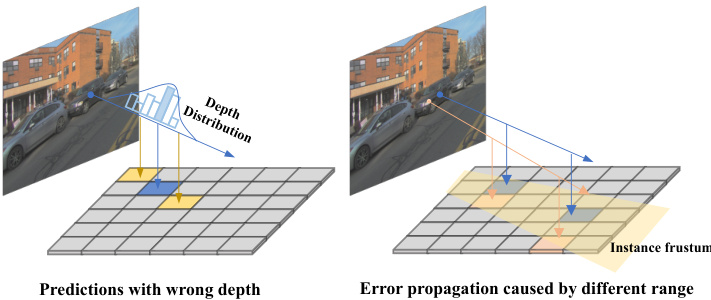
Figure 2: Different cases of transform img 2D points into 3D space. The blue dots indicate the centers of 3D objects in images. (a) shows the redundant prediction with the wrong depth, which is in yellow. (b) illustrates the error propagation problem dominated by different ranges.
图 2: 将二维图像点转换到三维空间的不同情况。蓝点表示图像中三维物体的中心。(a) 展示了深度错误导致的冗余预测(黄色部分)。(b) 呈现了由不同范围主导的误差传播问题。
weaknesses.
弱点。
To employ the sparse query-based paradigm for longrange detection, the primary challenge lies in poor recall performance. Due to the query sparsity in 3D space, assignments between predictions and ground-truth objects are affected, generating only a small amount of matched positive queries. As illustrated in Fig. 1, 3D detector recalls are pretty low, yet recalls from the existing 2D detector are much higher, showing a significant performance gap between them. Motivated by this, leveraging high-quality 2D object priors to improve 3D proposals is a promising approach, for enabling accurate localization and comprehensive coverage. Although previous methods like SimMOD (Zhang et al. 2023) and MV2D (Wang et al. 2023b) have explored using 2D predictions to initialize 3D object proposals, they primarily focus on close-range tasks and discard learnable object queries. Moreover, as depicted in Fig. 2, directly introducing 3D queries derived from 2D proposals for long-range tasks encounters two issues: 1) inferior redundant predictions due to uncertain depth distribution along the object rays, and 2) larger deviations in 3D space as the range increases due to frustum transformation. These noisy queries can impact the training stability, requiring effective denoising ways to optimize. Furthermore, within the training process, the model exhibits a tendency to overfit on densely populated close objects while disregarding sparsely distributed distant objects.
要在长距离检测中采用基于稀疏查询的范式,主要挑战在于召回性能较差。由于3D空间中的查询稀疏性,预测结果与真实物体之间的匹配关系受到影响,仅能生成少量匹配的正查询。如图1所示,3D检测器的召回率相当低,而现有2D检测器的召回率则高得多,两者之间存在显著性能差距。受此启发,利用高质量的2D物体先验信息来改进3D提案是一种有前景的方法,可实现精确定位和全面覆盖。尽管SimMOD (Zhang et al. 2023) 和MV2D (Wang et al. 2023b) 等先前方法已探索使用2D预测来初始化3D物体提案,但它们主要关注近距离任务,并丢弃了可学习的物体查询。此外,如图2所示,直接为长距离任务引入源自2D提案的3D查询会遇到两个问题:1) 由于沿物体射线的不确定深度分布导致冗余预测质量较差;2) 由于视锥变换,随着距离增加,3D空间中的偏差会更大。这些噪声查询会影响训练稳定性,需要有效的去噪方法进行优化。此外,在训练过程中,模型倾向于过度拟合密集分布的近距离物体,而忽略稀疏分布的远距离物体。
To address the aforementioned challenges, we design a novel 3D detection paradigm to expand the perception horizon. Despite the 3D global query that was learned from the dataset, our approach also incorporates auxiliary 2D proposals into 3D adaptive query generation. Specifically, we first produce reliable pairs of 2D object proposals and corresponding depths then project them to 3D proposals via spatial transformation. We compose 3D adaptive queries with the projected positional embedding and semantic context, which would be refined in the subsequent decoder. In the decoder layers, perspective-aware aggregation is employed across different image scales and views. It learns sampling offsets for each query and dynamically enables interactions with favorable features. For instance, distant object queries are beneficial to attend large-resolution features, while the opposite is better for close objects in order to capture highlevel context. Lastly, we design a range-modulated 3D denoising technique to mitigate query error propagation and slow convergence. Considering the different regression difficulties for various ranges, noisy queries are constructed based on ground-truth (GT) as well as referring to their distances and scales. Our method feeds multi-group noisy proposals around GT into the decoder and trains the model to a) recover 3D GT for positive ones and b) reject negative ones, respectively. The inclusion of query denoising also alleviates the problem of range-level unbalanced distribution.
为解决上述挑战,我们设计了一种新颖的3D检测范式以扩展感知范围。除了从数据集中学习到的3D全局查询(global query),我们的方法还将辅助2D提案(proposal)融入3D自适应查询生成。具体而言,我们首先生成可靠的2D目标提案及其对应深度,随后通过空间变换将其投影为3D提案。通过融合投影位置嵌入(positional embedding)与语义上下文,我们构建出3D自适应查询,这些查询将在后续解码器中被逐步优化。在解码器层中,采用跨图像尺度和视角的透视感知聚合(perspective-aware aggregation),该方法为每个查询学习采样偏移量,并动态建立与有利特征的交互。例如,远距离目标查询适合关注大分辨率特征,而近距离目标则更适合捕获高层级上下文。最后,我们设计了距离调制的3D去噪技术(range-modulated 3D denoising)以减少查询误差传播和收敛缓慢问题。针对不同距离的回归难度差异,噪声查询的构建既基于真实标注(GT),又参考其距离和尺度。我们的方法将多组围绕GT的噪声提案输入解码器,并训练模型分别实现:a)对正样本恢复3D GT;b)拒绝负样本。查询去噪机制的引入也缓解了距离层级分布不均衡的问题。
Our proposed method achieves remarkable performance advancements over state-of-the-art (SoTA) approaches in the challenging long-range Argoverse 2 dataset, as well as surpassing the prior arts of LiDAR-based methods. To evaluate the generalization capability, we further validate its results on nuScenes dataset and demonstrate SoTA metrics.
我们提出的方法在具有挑战性的长距离Argoverse 2数据集上实现了显著优于现有技术(SoTA)方法的性能提升,同时超越了基于LiDAR的现有方法。为评估泛化能力,我们进一步在nuScenes数据集上验证了结果,并展示了SoTA指标。
In summary, our contributions are:
总之,我们的贡献包括:
• We propose a novel sparse query-based framework to expand the perception range in 3D detection, by incorporating high-quality 2D object priors into 3D adaptive queries. • We develop perspective-aware aggregation that captures informative features from diverse scales and views, as well as a range-modulated 3D denoising technique to address query error propagation and convergence problems. • On the challenging long-range Argoverse 2 datasets, our method surpasses surround-view methods and outperforms several LiDAR-based methods. The generalization of our method is validated on the nuScenes dataset.
• 我们提出了一种新颖的基于稀疏查询的框架,通过将高质量2D物体先验融入3D自适应查询,扩展3D检测的感知范围。
• 我们开发了视角感知聚合机制以捕获多尺度和多视角的信息特征,并提出范围调制3D去噪技术来解决查询误差传播和收敛问题。
• 在具有挑战性的长距离Argoverse 2数据集上,我们的方法超越了环视方法,并优于多种基于LiDAR的方法。本方法在nuScenes数据集上验证了泛化能力。
2 Related Work
2 相关工作
2.1 Surround-view 3D Object Detection
2.1 环视3D目标检测
Recently 3D object detection from surround-view images has attracted much attention and achieved great progress, due to its advantages of low deployment cost and rich semantic information. Based on feature representation, existing methods (Wang et al. 2021, 2022; Liu et al. 2022a; Huang and Huang 2022; Li et al. 2023, 2022b; Jiang et al. 2023; Liu et al. 2022b; Li et al. 2022c; Yang et al. 2023; Park et al. 2022; Wang et al. 2023a; Zong et al. 2023; Liu et al. 2023) can be largely classified into BEV-based methods and sparse-query based methods.
近年来,基于环视图像的3D物体检测因其部署成本低和语义信息丰富的优势备受关注并取得显著进展。根据特征表示方式,现有方法 (Wang et al. 2021, 2022; Liu et al. 2022a; Huang and Huang 2022; Li et al. 2023, 2022b; Jiang et al. 2023; Liu et al. 2022b; Li et al. 2022c; Yang et al. 2023; Park et al. 2022; Wang et al. 2023a; Zong et al. 2023; Liu et al. 2023) 主要可分为基于鸟瞰图(BEV)的方法和基于稀疏查询的方法。
Extracting image features from surround views, BEVbased methods (Huang et al. 2021; Huang and Huang 2022; Li et al. 2023, 2022c) transform features into BEV space by leveraging estimated depths or attention layers, then a 3D detector head is employed to predict localization and other properties of 3D objects. For instance, BEVFormer (Li et al. 2022c) leverages both spatial and temporal features by interacting with spatial and temporal space through predefined grid-shaped BEV queries. BEVDepth (Li et al. 2023) propose a 3D detector with a trustworthy depth estimation, by introducing a camera-aware depth estimation module. On the other hand, sparse query-based paradigms (Wang et al. 2022; Liu et al. 2022a) learn global object queries from the representative data, then feed them into the decoder to predict 3D bounding boxes during inference. This line of work has the advantage of lightweight computing.
从环视图像中提取特征时,基于鸟瞰图(BEV)的方法(Huang et al. 2021; Huang and Huang 2022; Li et al. 2023, 2022c)通过估计深度或注意力层将特征转换到BEV空间,随后采用3D检测头预测三维物体的定位及其他属性。例如BEVFormer(Li et al. 2022c)通过预定义的网格状BEV查询,与时空特征进行交互来利用时空信息。BEVDepth(Li et al. 2023)则通过引入相机感知的深度估计模块,提出了具有可信深度估计的3D检测器。另一方面,基于稀疏查询的范式(Wang et al. 2022; Liu et al. 2022a)从代表性数据中学习全局物体查询,在推理阶段将其输入解码器来预测3D边界框。这类方法具有计算量轻的优势。
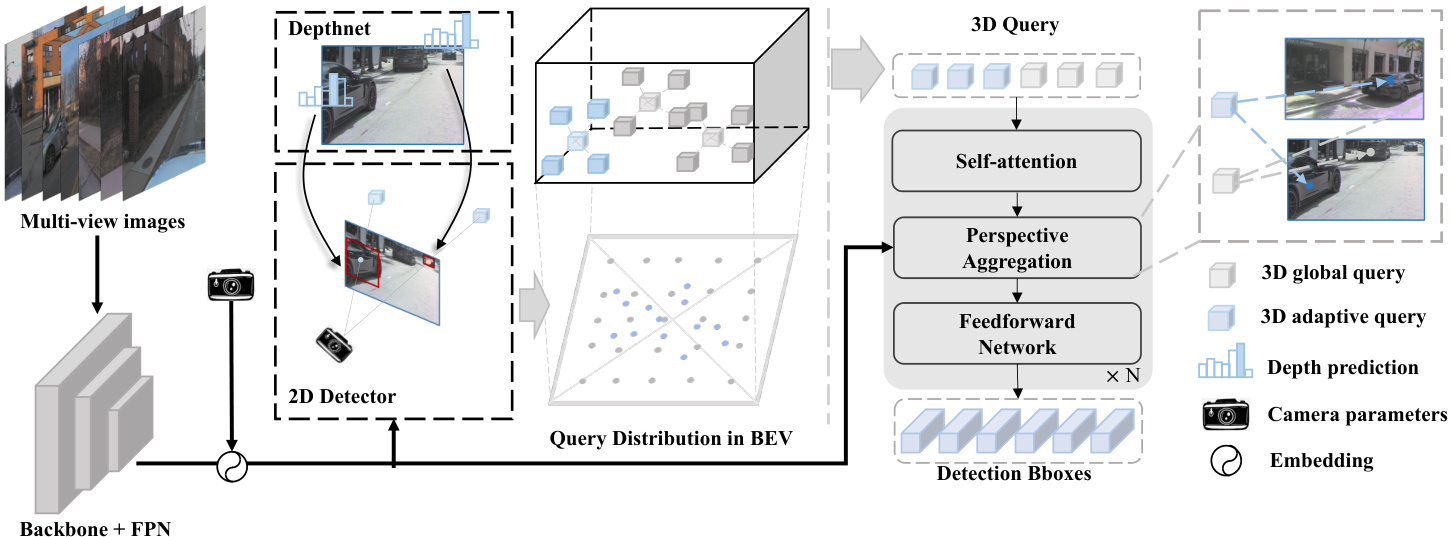
Figure 3: The overview of our proposed Far3D. Feeding surround-view images into the backbone and FPN neck, we obtain 2D image features and encode them with camera parameters for perspective-aware transformation. Utilizing a 2D detector and DepthNet, we generate reliable 2D box proposals and their corresponding depths, which are then concatenated and projected into 3D space. The generated 3D adaptive queries, combined with the initial 3D global queries, are iterative ly refined by the decoder layers to predict 3D bounding boxes. Furthermore, temporal modeling is equipped through long-term query propagation.
图 3: 我们提出的 Far3D 方法概览。将环视图像输入主干网络和 FPN 颈部结构后,我们获得 2D 图像特征并通过相机参数进行透视感知编码。利用 2D 检测器和 DepthNet 生成可靠的 2D 边界框提案及其对应深度信息,随后将这些数据拼接并投影至 3D 空间。生成的 3D 自适应查询与初始 3D 全局查询相结合,通过解码器层迭代优化以预测 3D 边界框。此外,通过长期查询传播实现时序建模。
Furthermore, temporal modeling for surround-view 3D detection can improve detection performance and decrease velocity errors significantly, and many works (Huang and Huang 2022; Liu et al. 2022b; Park et al. 2022; Wang et al. 2023a; Lin et al. 2022, 2023) aim to extend a single-frame framework to multi-frame design. BEVDet4D (Huang and Huang 2022) lifts the BEVDet paradigm from the spatialonly 3D space to the spatial-temporal 4D space, via fusing features with the previous frame. PETRv2 (Liu et al. 2022b) extends the 3D position embedding in PETR for temporal modeling through the temporal alignment of different frames. However, they use only limited history. To leverage both short-term and long-term history, SOLOFusion (Park et al. 2022) balances the impacts of spatial resolution and temporal difference on localization potential, then use it to design a powerful temporal 3D detector. StreamPETR (Wang et al. 2023a) develops an object-centric temporal mechanism in an online manner, where long-term historical information is propagated through object queries.
此外,环视3D检测中的时序建模能显著提升检测性能并降低速度误差。多项研究 (Huang and Huang 2022; Liu et al. 2022b; Park et al. 2022; Wang et al. 2023a; Lin et al. 2022, 2023) 致力于将单帧框架扩展为多帧设计。BEVDet4D (Huang and Huang 2022) 通过融合前一帧特征,将BEVDet范式从纯空间3D空间提升至时空4D空间。PETRv2 (Liu et al. 2022b) 通过不同帧的时序对齐,扩展了PETR中的3D位置嵌入以实现时序建模,但仅使用有限历史帧。为兼顾短期与长期历史信息,SOLOFusion (Park et al. 2022) 平衡了空间分辨率与时间差异对定位潜力的影响,进而设计出强大的时序3D检测器。StreamPETR (Wang et al. 2023a) 采用在线方式开发了以物体为中心的时序机制,通过物体查询传递长期历史信息。
2.2 2D Auxiliary Tasks for 3D Detection
2.2 用于3D检测的2D辅助任务
3D detection from surround-view images can be improved through 2D auxiliary tasks, and some works (Xie et al. 2022; Zhang et al. 2023; Wang, Jiang, and Li 2022; Yang et al. 2023; Wang et al. 2023b) aim to exploit its potential. There are several approaches including 2D pertaining, auxiliary supervision, and proposal generation. SimMOD (Zhang et al. 2023) exploits sample-wise object proposals and designs a two-stage training manner, where perspective object proposals are generated and followed by iterative refinement in DETR3D-style. Focal-PETR (Wang, Jiang, and Li 2022) performs 2D object supervision to adaptively focus the attention of 3D queries on disc rim i native foreground regions. BEV Former V 2 (Yang et al. 2023) presents a two-stage BEV detector where perspective proposals are fed into the BEV head for final predictions. MV2D (Wang et al. 2023b) designs a 3D detector head that is initialized by RoI regions of 2D predicted proposals.
通过2D辅助任务可以提升环视图像的3D检测性能,部分研究(Xie等人2022;Zhang等人2023;Wang、Jiang和Li 2022;Yang等人2023;Wang等人2023b)致力于挖掘其潜力。主要方法包括2D预训练、辅助监督和提案生成:SimMOD(Zhang等人2023)采用样本级物体提案并设计两阶段训练策略,首先生成透视物体提案,随后以DETR3D风格进行迭代优化;Focal-PETR(Wang、Jiang和Li 2022)实施2D物体监督,使3D查询的注意力自适应聚焦于判别性前景区域;BEV Former V2(Yang等人2023)提出两阶段BEV检测器,将透视提案输入BEV头部进行最终预测;MV2D(Wang等人2023b)设计了由2D预测提案的RoI区域初始化的3D检测头。
Compared to the above methods, our framework differs in the following aspects. Firstly, we aim to resolve the challenges of long-range detection with surrounding views, which are less explored in previous methods. Besides learning 3D global queries, we explicitly leverage 2D predicted boxes and depths to build 3D adaptive queries, utilizing positional prior and semantic context simultaneously. Furthermore, the designs of perspective-aware aggregation and 3D denoising are integrated to address task issues.
与上述方法相比,我们的框架在以下方面有所不同。首先,我们致力于解决多视角远距离检测的挑战,这一领域在先前方法中较少被探索。除了学习3D全局查询(global queries)外,我们显式利用2D预测框和深度信息构建3D自适应查询(adaptive queries),同时整合位置先验与语义上下文。此外,通过集成视角感知聚合(perspective-aware aggregation)和3D去噪(denoising)设计来解决任务相关问题。
3 Method
3 方法
3.1 Overview
3.1 概述
Fig. 3 shows the overall pipeline of our sparse query-based framework. Feeding surround-view images $\mathbf{I}={\mathbf{I^{1}},...,\mathbf{I^{n}}}$ , we extract multi-level images features $\mathbf{F}={\bar{\mathbf{F}}^{1},...,\bar{\mathbf{F}}^{\bar{\mathbf{n}}}}$ by using the backbone network (e.g. ResNet, ViT) and a FPN (Lin et al. 2017) neck. To generate 3D adaptive queries, we first obtain 2D proposals and depths using a 2D detector head and depth network, then filter reliable ones and transform them into 3D space to generate 3D object queries. In this way, informative object priors from 2D detections are encoded into the 3D adaptive queries.
图 3: 展示了我们基于稀疏查询框架的整体流程。输入环视图像 $\mathbf{I}={\mathbf{I^{1}},...,\mathbf{I^{n}}}$ 后,我们通过骨干网络 (如 ResNet、ViT) 和 FPN (Lin et al. 2017) 颈部结构提取多层级图像特征 $\mathbf{F}={\bar{\mathbf{F}}^{1},...,\bar{\mathbf{F}}^{\bar{\mathbf{n}}}}$ 。为生成 3D 自适应查询,首先使用 2D 检测头和深度网络获取 2D 提案及深度信息,随后筛选可靠提案并将其转换至 3D 空间以生成 3D 物体查询。通过这种方式,来自 2D 检测的信息化物体先验被编码到 3D 自适应查询中。
In the 3D detector head, we concatenate 3D adaptive queries and 3D global queries, then input them to transformer decoder layers including self-attention among queries and perspective-aware aggregation between queries and features. We propose perspective-aware aggregation to efficiently capture rich features in multiple views and scales by considering the projection of 3D objects. Besides, rangemodulated 3D denoising is introduced to alleviate query error propagation and stabilize the convergence, when training with long-range and imbalanced distributed objects. Sec 3.4 depicts the denoising technique in detail.
在3D检测头中,我们将3D自适应查询(adaptive queries)与3D全局查询(global queries)拼接后输入Transformer解码层,该层包含查询间自注意力机制(self-attention)以及查询与特征间的视角感知聚合(perspective-aware aggregation)。我们提出的视角感知聚合能通过考虑3D物体的投影,高效捕获多视角多尺度的丰富特征。此外,针对远距离及非均衡分布物体的训练场景,我们引入范围调制3D去噪(rangemodulated 3D denoising)技术来减轻查询误差传播并稳定收敛。第3.4节详细描述了该去噪技术。
3.2 Adaptive Query Generation
3.2 自适应查询生成
Directly extend existing 3D detectors from short range (e.g. ${\sim}50\mathrm{m})$ to long range (e.g. $\mathord{\sim}150\mathrm{m})$ suffers from several problems: heavy computation costs, inefficient convergence and declining localization ability. For instance, the query number is supposed to grow at least squarely to cover possible objects in a larger range, yet such a computing disaster is unacceptable in realistic scenarios. Besides that, small and sparse distant objects would hinder the convergence and even hurt the localization of close objects. Motivated by the high performance of 2D proposals, we propose to generate adaptive queries as objects prior to assist 3D localization. This paradigm compensates for the weakness of global fixed query design and allows the detector to generate adaptive queries near the ground-truth (GT) boxes for different images. In this way, the model is equipped with better generalization and practicality.
直接将现有3D检测器从短距离(如${\sim}50\mathrm{m}$)扩展到长距离(如$\mathord{\sim}150\mathrm{m}$)会面临几个问题:高昂的计算成本、低效的收敛性以及定位能力下降。例如,查询数量至少需要平方级增长才能覆盖更大范围内的潜在物体,但这种计算灾难在实际场景中是不可接受的。此外,小而稀疏的远距离物体会阻碍收敛,甚至影响近处物体的定位。受2D提案高性能的启发,我们提出在3D定位前生成自适应查询作为物体先验。这一范式弥补了全局固定查询设计的不足,使检测器能够针对不同图像在真实标注(GT)框附近生成自适应查询。通过这种方式,模型获得了更好的泛化能力和实用性。
Specifically, given image features after FPN neck, we feed them into the anchor-free detector head from YOLOX (Ge et al. 2021) and a light-weighted depth estimation net, outputting 2D box coordinates, scores and depth map. 2D detector head follows the original design, while the depth estimation is regarded as a classification task by disc ret i zing the depth into bins (Reading et al. 2021; Zhang et al. 2022). We then make pairs of 2D boxes and corresponding depths. To avoid the interference of low-quality proposals, we set a score threshold $\tau$ (e.g. 0.1) to leave only reliable ones. For each view $i$ , box centers $(\mathbf{c}{w},\mathbf{c}{h})$ from 2D predictions and depth ${\bf d}{w h}$ from depth map are combined and projected to 3D proposal centers ${\bf c}_{3d}$ .
具体而言,给定经过FPN颈部的图像特征后,我们将其输入来自YOLOX (Ge et al. 2021) 的无锚检测头和轻量化深度估计网络,输出2D框坐标、分数和深度图。2D检测头沿用原始设计,而深度估计通过将深度离散化为区间 (Reading et al. 2021; Zhang et al. 2022) 被视为分类任务。随后我们将2D框与对应深度配对。为避免低质量提案的干扰,设置分数阈值 $\tau$ (如0.1) 仅保留可靠提案。对于每个视角 $i$,将2D预测的框中心 $(\mathbf{c}{w},\mathbf{c}{h})$ 与深度图获取的深度 ${\bf d}{w h}$ 结合,投影为3D提案中心 ${\bf c}_{3d}$。
$$
\mathbf{c_{3d}}=K_{i}^{-1}I_{i}^{-1}[\mathbf{c}{w}\mathbf{d}{w h},\mathbf{c}{h}*\mathbf{d}{w h},\mathbf{d}_{w h},\mathbf{1}]^{T}
$$
$$
\mathbf{c_{3d}}=K_{i}^{-1}I_{i}^{-1}[\mathbf{c}{w}\mathbf{d}{w h},\mathbf{c}{h}*\mathbf{d}{w h},\mathbf{d}_{w h},\mathbf{1}]^{T}
$$
where $K_{i},I_{i}$ denote camera extrinsic and intrinsic matrices.
其中 $K_{i},I_{i}$ 表示相机外参矩阵和内参矩阵。
After obtaining projected 3D proposals, we encode them into 3D adaptive queries as follows,
在获取投影的3D提案后,我们按如下方式将其编码为3D自适应查询:
$$
{\bf Q}{p o s}=P o s E m b e d({\bf c}_{3d})
$$
$$
{\bf Q}{p o s}=P o s E m b e d({\bf c}_{3d})
$$
$$
\mathbf{Q}{s e m}=S e m E m b e d(\mathbf{z}{2d},\mathbf{s}_{2d})
$$
$$
\mathbf{Q}{s e m}=S e m E m b e d(\mathbf{z}{2d},\mathbf{s}_{2d})
$$
$$
\mathbf{Q}=\mathbf{Q}{p o s}+\mathbf{Q}_{s e m}
$$
$$
\mathbf{Q}=\mathbf{Q}{p o s}+\mathbf{Q}_{s e m}
$$
where $\mathbf{Q}{p o s},\mathbf{Q}{s e m}$ denote positional embedding and semantic embedding, respectively. ${\bf z}{2d}$ sampled from $\mathbf{F}$ corresponds to the semantic context of position $(\mathbf{c}{w},\mathbf{c}{h})$ , and ${\bf s}_{2d}$ is the confidence score of 2D boxes. $P o s E m b e d(\cdot)$ consists of a sinusoidal transformation (Vaswani et al. 2017) and a MLP, while $S e m E m b e d(\cdot)$ is another MLP.
其中 $\mathbf{Q}{pos}$ 和 $\mathbf{Q}{sem}$ 分别表示位置嵌入 (positional embedding) 和语义嵌入 (semantic embedding)。从 $\mathbf{F}$ 中采样的 ${\bf z}{2d}$ 对应位置 $(\mathbf{c}{w},\mathbf{c}{h})$ 的语义上下文,${\bf s}_{2d}$ 是 2D 边界框的置信度分数。$PosEmbed(\cdot)$ 由正弦变换 [20] 和多层感知机组成,而 $SemEmbed(\cdot)$ 是另一个多层感知机。
Lastly, the proposed 3D adaptive queries are concatenated with initialized global queries, and fed to subsequent transformer layers in the decoder.
最后,将提出的3D自适应查询与初始化的全局查询拼接,并输入解码器中后续的Transformer层。
3.3 Perspective-aware Aggregation
3.3 视角感知聚合
Existing sparse query-based approaches usually adopt one single-level feature map for computation effectiveness (e.g. StreamPETR). However, the single feature level is not optimal for all object queries of different ranges. For example, small distant objects require large-resolution features for precise localization, while high-level features are better suited for large close objects. To overcome the limitation, we propose perspective-aware aggregation, enabling efficient feature interactions on different scales and views.
现有基于稀疏查询的方法通常采用单层特征图以提高计算效率(例如StreamPETR)。然而,单一特征层级并不适用于所有不同距离的目标查询。例如,远处小物体需要大分辨率特征实现精确定位,而高层特征更适合处理近处大物体。为突破这一限制,我们提出视角感知聚合机制,实现跨尺度与多视角的高效特征交互。
Inspired by the deformable attention mechanism (Zhu et al. 2020), we apply a 3D spatial deformable attention consisting of 3D offsets sampling followed by view transformation. Formally, we first equip image features $\mathbf{F}$ with the camera information including intrinsic I and extrinsic parameters $\mathbf{K}$ . A squeeze-and-excitation block $\mathrm{Hu}$ , Shen, and Sun 2018) is used to explicitly enrich the features. Given enhanced feature $\mathbf{F}^{\prime}$ , we employ 3D deformable attention instead of global attention in PETR series (Liu et al. 2022a,b; Wang et al. 2023a). For each query reference point in 3D space, the model learns $M$ sampling offsets around and projects these references into different 2D scales and views.
受可变形注意力机制(Zhu et al. 2020)启发,我们采用了一种包含3D偏移采样与视角变换的3D空间可变形注意力。具体而言,我们首先为图像特征$\mathbf{F}$配备相机内参I和外参$\mathbf{K}$,并通过挤压激励模块(Hu et al. 2018)显式增强特征。基于增强后的特征$\mathbf{F}^{\prime}$,我们在PETR系列方法(Liu et al. 2022a,b; Wang et al. 2023a)中使用3D可变形注意力替代全局注意力。对于3D空间中的每个查询参考点,模型学习其周围$M$个采样偏移量,并将这些参考点投影至不同2D尺度与视角。
$$
\mathbf{P}{q}^{2d}=\mathbf{I}\cdot\mathbf{K}\cdot(\mathbf{P}{q}^{3d}+\Delta\mathbf{P}_{q}^{3d})
$$
$$
\mathbf{P}{q}^{2d}=\mathbf{I}\cdot\mathbf{K}\cdot(\mathbf{P}{q}^{3d}+\Delta\mathbf{P}_{q}^{3d})
$$
where $\mathbf{P}{q}^{3d},\Delta\mathbf{P}{q}^{3d}$ are 3D reference point and learned offsets for query $q$ , respectively. $\mathbf{P}_{q}^{2d}$ stands for the projected 2d reference point of different scales and views. For simplicity, we omit the subscripts of scales and views.
其中 $\mathbf{P}{q}^{3d},\Delta\mathbf{P}{q}^{3d}$ 分别是查询 $q$ 的3D参考点和学习到的偏移量。 $\mathbf{P}_{q}^{2d}$ 表示不同尺度和视角下的投影2D参考点。为简洁起见,我们省略了尺度和视角的下标。
Next, 3D object queries interact with multi-scale sampled features from $\bar{\mathbf{F}}^{\prime}$ , according to the above 2D reference points $\mathbf{P}_{q}^{2d}$ . In this way, diverse features from various vis and scales are aggregated into 3D queries by considering their relative importance.
接下来,3D物体查询根据上述2D参考点$\mathbf{P}_{q}^{2d}$,与来自$\bar{\mathbf{F}}^{\prime}$的多尺度采样特征进行交互。通过这种方式,来自不同视角和尺度的多样化特征被聚合到3D查询中,同时考虑了它们的相对重要性。
3.4 Range-modulated 3D Denoising
3.4 范围调制3D降噪
3D object queries at different distances have different regression difficulties, which is different from 2D queries that are usually treated equally for existing 2D denoising methods such as DN-DETR (Li et al. 2022a). The difficulty discrepancy comes from query density and error propagation. On the one hand, queries corresponding to distant objects are less matched compared to close ones. On the other hand, small errors of 2D proposals can be amplified when introducing 2D priors to 3D adaptive queries, illustrated in Fig. 2, not to mention which effect increases along with object distance. As a result, some query proposals near GT boxes can be regarded as noisy candidates, whereas others with notable deviation should be negative ones. Therefore we aim to recall those potential positive ones and directly reject solid negative ones, by developing a method called rangemodulated 3D denoising.
不同距离的3D物体查询具有不同的回归难度,这与现有2D去噪方法(如DN-DETR [20])通常平等对待2D查询的情况不同。这种难度差异源于查询密度和误差传播:一方面,远距离物体对应的查询匹配率低于近处物体;另一方面,如图2所示,当将2D先验引入3D自适应查询时,2D提案的小误差会被放大,且这种效应随物体距离增加而加剧。因此,靠近真实框的查询提案可视为噪声候选,而明显偏离的提案则应判定为负样本。为此,我们提出了一种称为"距离调制3D去噪"的方法,旨在召回潜在正样本并直接剔除明确负样本。
Concretely, we construct noisy queries based on GT objects by simultaneously adding positive and negative groups. For both types, random noises are applied according to object positions and sizes to facilitate denoising learning in long-range perception. Formally, we define the position of noisy queries as:
具体而言,我们通过在GT物体上同时添加正负样本组来构建带噪声的查询。对于这两种类型,根据物体位置和大小施加随机噪声,以促进远距离感知中的去噪学习。形式上,我们将带噪声查询的位置定义为:
$$
\tilde{\mathbf{P}}=\mathbf{P}{G T}+\alpha f_{p}(\mathbf{S}{G T})+(1-\alpha)f_{n}(\mathbf{P}_{G T})
$$
$$
\tilde{\mathbf{P}}=\mathbf{P}{G T}+\alpha f_{p}(\mathbf{S}{G T})+(1-\alpha)f_{n}(\mathbf{P}_{G T})
$$
where $\alpha\in{0,1}$ corresponds to the generation of negative and positive queries, respectively. $\mathbf{P}{G T}^{-},\mathbf{S}{G T}\in\mathbb{R}^{3}$ represents 3D center $(x,y,z)$ and box scale $(w,l,h)$ of GT, and $\tilde{\mathbf{P}}$ is noisy coordinates. We use functions $f_{p}$ and $f_{n}$ to encode position-aware noise for positive and negative samples.
其中 $\alpha\in{0,1}$ 分别对应生成负查询和正查询。$\mathbf{P}{G T}^{-},\mathbf{S}{G T}\in\mathbb{R}^{3}$ 表示真实标注 (GT) 的3D中心坐标 $(x,y,z)$ 和包围盒尺寸 $(w,l,h)$,$\tilde{\mathbf{P}}$ 为带噪声的坐标。我们使用函数 $f_{p}$ 和 $f_{n}$ 分别为正负样本编码位置感知噪声。
For positive noisy samples, we set $f_{p}(\mathbf{S}{G T})$ as a linear function of 3D box scale with a random variable. We incorporate the offset constraint within GT boxes to guide the model in accurately reconstructing the GT from positive queries, while ensuring clear distinction from surrounding adjacent boxes. For negative samples, the offsets are supposed to be relevant to their position range, thus we propose several implementations. For some examples, $f_{n}({\bf P}{G T})$ can be in forms of $l o g(\mathbf{P}{G T})$ , $\lambda_{2}\mathbf{P}{G T}$ or $\sqrt{\mathbf{P}_{G T}}$ . We show these attempts in Sec. 4.4. Moreover, multi-group samples are generated for each GT object to enhance query diversity. Each group comprises one positive sample and $K$ negative samples. This approach serves as an imitation of noisy positive candidates and false positive candidates during training.
对于正样本噪声,我们将 $f_{p}(\mathbf{S}{G T})$ 设为3D框尺度的线性函数并引入随机变量。通过在GT框内加入偏移约束,引导模型从正查询中准确重建GT,同时确保与周围相邻框的清晰区分。对于负样本,偏移量应与其位置范围相关,因此我们提出了几种实现方式:例如 $f_{n}({\bf P}{G T})$ 可表现为 $l o g(\mathbf{P}{G T})$ 、$\lambda_{2}\mathbf{P}{G T}$ 或 $\sqrt{\mathbf{P}_{G T}}$ 等形式(详见第4.4节)。此外,每个GT对象会生成多组样本来增强查询多样性,每组包含1个正样本和 $K$ 个负样本,该方法模拟了训练过程中带噪声的正候选样本和假正例候选样本。
Table 1: Comparisons on the Argoverse $2\phantom{+}\nabla\bar{\alpha}\perp\phantom{+}$ set. We evaluate 26 object categories with a range of 150 meters. Far3D outperform previous surround-view methods with a large margin, and surpass several SoTA LiDAR-based methods. Surround-view methods except for PETR are with temporal modeling. ‡ are reproduced by ourselves.
表 1: Argoverse $2\phantom{+}\nabla\bar{\alpha}\perp\phantom{+}$ 数据集上的对比结果。我们在150米范围内评估了26个物体类别。Far3D大幅超越之前的环视方法,并超过多个基于LiDAR的先进方法。除PETR外,其他环视方法均采用时序建模。‡表示我们自行复现的结果。
| 方法 | 骨干网络 | 模态 | 图像/体素尺寸 | mAP | CDS↑ | mATE↓ | mASE↓ | mAOE↓ |
|---|---|---|---|---|---|---|---|---|
| BEVStereo+ | VoV-99 | 相机 | 960 × 640 | 0.146 | 0.104 | 0.847 | 0.397 | 0.901 |
| SOLOFusion+ | VoV-99 | 相机 | 960 × 640 | 0.149 | 0.106 | 0.934 | 0.425 | 0.779 |
| PETR | VoV-99 | 相机 | 960 × 640 | 0.176 | 0.122 | 0.911 | 0.339 | 0.819 |
| Sparse4Dv2 | VoV-99 | 相机 | 960 × 640 | 0.189 | 0.134 | 0.832 | 0.343 | 0.723 |
| StreamPETR | VoV-99 | 相机 | 960 × 640 | 0.203 | 0.146 | 0.843 | 0.321 | 0.650 |
| Far3D (Ours) | VoV-99 | 相机 | 960 × 640 | 0.244 | 0.181 | 0.796 | 0.304 | 0.538 |
| CenterPoint | - | LiDAR | (0.2,0.2,0.2) | 0.274 | 0.210 | 0.548 | 0.362 | 0.781 |
| FSD | - | LiDAR | (0.2,0.2,0.2) | 0.291 | 0.233 | 0.468 | 0.299 | 0.740 |
| VoxelNeXt | - | LiDAR | (0.1, 0.1, 0.2) | 0.307 | 0.225 | 0.431 | 0.291 | 1.157 |
| Far3D (Ours) | ViT-L | 相机 | 1536 × 1536 | 0.316 | 0.239 | 0.732 | 0.303 | 0.459 |
Table 2: Comparison on the nuScenes val and test splits. Far3D achieves the highest performance compared to prior-arts, validating its generalization ability. ∗Benefited from the perspective-view pre-training. We employ the resolution $512\times1408$ for $\mathtt{v a l}$ and $1536\times1536$ for test split.
表 2: nuScenes验证集和测试集对比结果。Far3D相比现有技术取得最高性能,验证了其泛化能力。*受益于视角预训练。验证集采用 $512\times1408$ 分辨率,测试集采用 $1536\times1536$ 分辨率。
| 方法 | 骨干网络 | 数据集 | mAP↑ | NDS↑ | mATE↓ | mASE↓ | mAOE↓ | mAVE↓ | mAAE↓ |
|---|---|---|---|---|---|---|---|---|---|
| PETR | ResNet101 | val | 0.366 | 0.441 | 0.717 | 0.261 | 0.412 | 0.834 | 0.190 |
| SOLOFusion | ResNet101 | val | 0.483 | 0.582 | 0.503 | 0.264 | 0.381 | 0.246 | 0.207 |
| StreamPETR | ResNet101 | val | 0.504 | 0.592 | 0.569 | 0.262 | 0.315 | 0.257 | 0.199 |
| Sparse4Dv2* | ResNet101 | val | 0.505 | 0.594 | 0.548 | 0.268 | 0.348 | 0.239 | 0.184 |
| Far3D (Ours)* | ResNet101 | val | 0.510 | 0.594 | 0.551 | 0.258 | 0.372 | 0.238 | 0.195 |
| SOLOFusion | ConvNeXt-B | test | 0.540 | 0.619 | 0.453 | 0.257 | 0.376 | 0.267 | 0.148 |
| Sparse4Dv2 | VoV-99 | test | 0.556 | 0.638 | 0.462 | 0.238 | 0.328 | 0.264 | 0.115 |
| StreamPETR | ViT-L | test | 0.620 | 0.676 | 0.470 | 0.241 | 0.258 | 0.236 | 0.134 |
| Far3D (Ours) | ViT-L | test | 0.635 | 0.687 | 0.432 | 0.237 | 0.278 | 0.227 | 0.130 |
4 Experiment
4 实验
4.1 Datasets and Metrics
4.1 数据集与评估指标
We use the large-scale Argoverse 2 dataset (Wilson et al. 2023) and nuScenes dataset (Caesar et al. 2020) to explore and evaluate the effectiveness of our approach.
我们使用大规模Argoverse 2数据集 (Wilson et al. 2023) 和nuScenes数据集 (Caesar et al. 2020) 来探索和评估我们方法的有效性。
Argoverse 2 is a dataset for perception and prediction studies in the autonomous driving domain. It contains 1000 scenes with 15 seconds duration and $10\mathrm{Hz}$ annotation frequency for each scene. And these total scenes are divided into 700 for training, 150 for validation, and 150 for testing. Seven high-resolution ring cameras are provided with a combined $360^{\circ}$ field of view. We evaluate it with 26 categories and a 150-meter range, satisfying the need for long-range tasks. In addition to the mean Average Precision (mAP), we evaluate the methods with the metrics that Argoverse 2 dataset proposed: the Composite Detection Score (CDS), which is the main metric combining all factors in Argoverse 2 dataset, and three true positive metrics, including ATE, ASE, and AOE.
Argoverse 2 是一个面向自动驾驶领域感知与预测研究的数据集。它包含 1000 段场景数据,每段时长 15 秒且标注频率为 $10\mathrm{Hz}$。这些场景被划分为 700 段训练集、150 段验证集和 150 段测试集。数据集提供 7 个高分辨率环视摄像头,总视场角达 $360^{\circ}$。我们在 26 个类别和 150 米检测范围内进行评估,满足远距离任务需求。除平均精度均值 (mAP) 外,我们还采用 Argoverse 2 数据集提出的指标进行评估:综合检测分数 (CDS) ——该数据集整合所有因素的主要指标,以及三个真阳性指标(包括 ATE、ASE 和 AOE)。
nuScenes is one of the most trustworthy datasets for multi-camera 3D object detection containing 1000 driving scenes in total. Each scene, approximately 20 seconds long, is annotated in 10 categories with 3D bounding boxes for sampled keyframes. We further conduct experiments on the dataset and compare the results with other methods using the following metrics, including mAP and the nuScenes Detection Score (NDS).
nuScenes 是多摄像头3D物体检测领域最值得信赖的数据集之一,共包含1000个驾驶场景。每个场景时长约20秒,对采样关键帧标注了10个类别的3D边界框。我们在该数据集上进一步开展实验,并采用以下指标与其他方法进行对比,包括mAP和nuScenes检测分数(NDS)。
4.2 Implementation Details
4.2 实现细节
With StreamPETR (Wang et al. 2023a) as our baseline, Far3D is composed of a backbone, an FPN neck, a 2D proposal head, and a 3D detection head. We adopt VoVNet99 (Lee et al. 2019) pre-trained with FCOS3D (Wang et al. 2021) on nuScenes as the backbone to conduct main experiments. ViT-Large (Do sov it ski y et al. 2020) pre-trained by Objects365 (Shao et al. 2019) and COCO (Lin et al. 2014) dataset is used to scale up our model. By default, the FPN gives 4-level feature maps with sizes of 1/8, 1/16, 1/32, and 1/64. The perception range is set as $152.4\mathrm{m}\times152.4\mathrm{m}$ .
以StreamPETR (Wang et al. 2023a)为基线,Far3D由主干网络、FPN颈部、2D提议头和3D检测头组成。我们采用在nuScenes数据集上通过FCOS3D (Wang et al. 2021)预训练的VoVNet99 (Lee et al. 2019)作为主干网络进行主要实验。通过Objects365 (Shao et al. 2019)和COCO (Lin et al. 2014)数据集预训练的ViT-Large (Dosovitskiy et al. 2020)用于扩展模型规模。默认情况下,FPN生成4级特征图,尺寸分别为1/8、1/16、1/32和1/64。感知范围设置为$152.4\mathrm{m}\times152.4\mathrm{m}$。

Figure 4: 3D Recall and AP of each method with different distance thresholds. Metrics of different ranges show that our approach consistently achieves a better result.
图 4: 各方法在不同距离阈值下的 3D 召回率 (Recall) 和平均精度 (AP) 。不同范围指标显示我们的方法始终能取得更好结果。
Table 3: Ablation of our components on Argoverse $2\lor\exists\perp$ set. StreamPETR is employed as the baseline, and we add the adaptive query, perspective-aware aggregation (PA) and range-modulated 3D denoising in order.
表 3: Argoverse $2\lor\exists\perp$ 数据集上的组件消融实验。以StreamPETR作为基线,依次添加自适应查询 (adaptive query)、视角感知聚合 (PA) 和范围调制3D去噪 (range-modulated 3D denoising) 模块。
| # | Adaptive Query | PA | 3DDenoising | mAP[%]↑ | CDS[%]↑ |
|---|---|---|---|---|---|
| 1 | 20.3 | 14.6 | |||
| 2 | ? | 22.4 | 16.1 | ||
| 3 | √ | 23.4 | 17.3 | ||
| 4 | 24.4 (+4.1) | 18.1 (+3.5) |
We use AdamW (Loshchilov and Hutter 2017) optimizer with a weight decay of 0.01. The total batch size is 8 and the learning rate is set to 2e-4. The models are totally trained for 6 epochs, following the previous method (Chen et al. 2023). Since the resolution of the front-view image is different from other views in Argoverse 2 dataset, we first resize the front image to a consistent resolution, then do the same image data augmentation as other images do. We do not use any BEV data augmentation on Argoverse 2 dataset. On the nuScenes dataset, we set the batch size as 32 and use the ResNet101 (He et al. 2016) backbone to train our method for 60 epochs. Other settings keep in line with StreamPETR.
我们使用 AdamW (Loshchilov and Hutter 2017) 优化器,权重衰减设为 0.01。总批次大小为 8,学习率设置为 2e-4。模型共训练 6 个周期,遵循先前方法 (Chen et al. 2023)。由于 Argoverse 2 数据集中前视图图像分辨率与其他视图不同,我们首先将前视图调整为统一分辨率,随后执行与其他图像相同的数据增强操作。在 Argoverse 2 数据集上未使用任何 BEV 数据增强。对于 nuScenes 数据集,我们将批次大小设为 32,采用 ResNet101 (He et al. 2016) 骨干网络训练 60 个周期,其余设置与 StreamPETR 保持一致。
4.3 Main Results
4.3 主要结果
Argoverse 2 Dataset. We compare the proposed framework with the existing state-of-the-arts on Argoverse $2\phantom{+}\nabla\bar{\alpha}]$ set. As shown in Tab. 1, when adopting VoV-99 backbone and $960\times640$ input size, our method demonstrates a substantial superiority over other methods, achieving an impressive margin of $4.1%$ mAP and $3.5%$ CDS. Besides the listed sparse query-based methods, we also conduct experiments on dense BEV-based methods, BEVStereo (Li et al. 2022b) and SOLOFusion (Park et al. 2022). The results are barely satisfactory and we suppose that is because of the greater difficulty of depth estimation. We also reproduce MV2D (Wang et al. 2023b) but it can hardly converge here. The reason is mainly the generated anchors lack accurate depth estimation, leading to large localization deviations over long distances. To sum up, the convergence problem in long-range detection is severe for the above methods, and we believe that our depth estimation and 3D denoising play key roles to solve it. More explanations are in the supplementary.
Argoverse 2数据集。我们在Argoverse $2\phantom{+}\nabla\bar{\alpha}]$ 数据集上将所提框架与现有最优方法进行对比。如表1所示,当采用VoV-99主干网络和$960\times640$输入尺寸时,我们的方法展现出显著优势,以4.1% mAP和3.5% CDS的显著差距领先其他方法。除列出的基于稀疏查询的方法外,我们还对基于密集BEV的方法BEVStereo (Li et al. 2022b)和SOLOFusion (Park et al. 2022)进行了实验。结果不尽如人意,我们认为这是由于深度估计难度更大所致。我们还复现了MV2D (Wang et al. 2023b),但其在此难以收敛,主要原因在于生成的锚框缺乏精确深度估计,导致远距离定位偏差较大。综上所述,上述方法在远距离检测中的收敛问题较为严重,而我们的深度估计和3D去噪技术对解决该问题起到了关键作用。更多说明详见补充材料。
Table 4: Ablation study with different score threshold $\tau$ for 2D proposals.
表 4: 不同得分阈值 $\tau$ 对2D提案的消融研究
| T | mAP[%]↑ | CDS[%]↑ | mATE↓ | mASE↓ | mAOE↓ |
|---|---|---|---|---|---|
| 0.01 | 23.1 | 17.2 | 0.807 | 0.307 | 0.531 |
| 0.05 | 23.4 | 17.3 | 0.806 | 0.312 | 0.531 |
| 0.1 | 24.4 | 18.1 | 0.796 | 0.304 | 0.538 |
| 0.2 | 23.7 | 17.6 | 0.802 | 0.307 | 0.530 |
| 0.3 | 23.5 | 17.4 | 0.799 | 0.307 | 0.577 |
We further compare it with LiDAR-based SoTAs, CenterPoint (Yin, Zhou, and Krahenbuhl 2021), FSD (Fan et al. 2022), and VoxelNeXt (Chen et al. 2023). With a ViT-L backbone and $1536\times1536$ resolution, our method outperforms them, showcasing the great potential of surround-view methods. In detail, LiDAR-based methods have a lower localization error (i.e. ATE) due to accurate depth information, while surround-view ones identify orientation properties (i.e. AOE) better.
我们进一步将其与基于激光雷达 (LiDAR) 的先进技术进行比较,包括 CenterPoint (Yin, Zhou, and Krahenbuhl 2021)、FSD (Fan et al. 2022) 和 VoxelNeXt (Chen et al. 2023)。采用 ViT-L 主干网络和 $1536\times1536$ 分辨率时,我们的方法表现更优,展现了环视方法的巨大潜力。具体而言,基于激光雷达的方法因精确深度信息具有更低的定位误差 (即 ATE),而环视方法在方向属性识别 (即 AOE) 方面表现更好。
As shown in Fig. 4, we present the 3D recall and mAP results with different distances of $0{\cdot}150\mathrm{m}$ and $50{\cdot}150\mathrm{m}$ . Far3D consistently outperforms other methods. For distant objects, Far3D has a greater improvement when comparing recall and mAP with thresholds of $2\mathrm{m}$ and $4\mathrm{m}$ .
如图 4 所示,我们展示了在 $0{\cdot}150\mathrm{m}$ 和 $50{\cdot}150\mathrm{m}$ 不同距离下的 3D 召回率与 mAP 结果。Far3D 始终优于其他方法。对于远距离物体,当召回率和 mAP 的阈值分别为 $2\mathrm{m}$ 和 $4\mathrm{m}$ 时,Far3D 的提升更为显著。
nuScenes Dataset. To evaluate the generalization ability of our approach, we conducted additional comparisons on nuScenes dataset, as shown in Tab. 2. Notably, our method outperforms previous SoTA methods with impressive results, achieving $51.0%$ mAP and $59.4%$ NDS on the val set and $63.5%$ mAP and $68.7%$ NDS on the test set. These superior metrics specifically highlight its effectiveness.
nuScenes数据集。为评估我们方法的泛化能力,我们在nuScenes数据集上进行了额外对比实验,如表2所示。值得注意的是,我们的方法以显著优势超越此前所有SoTA方法,在验证集上达到51.0% mAP和59.4% NDS,在测试集上达到63.5% mAP和68.7% NDS。这些优异指标充分证明了其有效性。
4.4 Ablation Study & Analysis
4.4 消融研究与分析
In this section, we present a comprehensive analysis of the essential components of our model. As shown in Tab. 3, we start from StreamPETR as the baseline in #1 and add each
在本节中,我们对模型的核心组件进行全面分析。如表 3 所示,我们以 StreamPETR 作为 #1 的基线,并逐步添加各

Figure 5: Visualization results on Argoverse 2 dataset. We show 3D bounding boxes predicted both in multi-camera images and bird’s eye view. As illustrated, the view of the front center is distinguished from the other six views. The detection boxes predicted from 3D adaptive queries and 3D global queries are drawn in blue and green respectively. The GTs in orange are presented in BEV only.
图 5: Argoverse 2 数据集上的可视化结果。我们展示了多摄像头图像和鸟瞰图中预测的 3D 边界框。如图所示,前中心视角与其他六个视角有所区分。由 3D 自适应查询 (3D adaptive queries) 和 3D 全局查询 (3D global queries) 预测的检测框分别用蓝色和绿色绘制。橙色的真实标注 (GTs) 仅显示在鸟瞰图中。
Table 5: Performance Comparison of negative denoising samples with different designs and numbers.
表 5: 不同设计和数量的负样本去噪性能对比
| # 负样本 | 方法 | mAP[%]↑ | CDS[%]↑ |
|---|---|---|---|
| 0 | 23.4 | 17.3 | |
| 1 | ()601 | 24.0 | 17.7 |
| 2 | log(.) | 24.4 | 18.1 |
| 3 | log(.) | 24.3 | 18.0 |
| 2 | linear | 24.1 | 17.9 |
| 2 | sqrt | 24.0 | 17.7 |
| 2 | ficed | 23.7 | 17.6 |
module to verify its effect.
模块以验证其效果。
Adaptive Query. Comparing #1 and $#2$ in Tab. 3, we can observe that adaptive query brings an improvement of $2.1%$ mAP and $1.5%$ CDS. Adaptive queries are insensitive to object range due to the robustness of 2D detectors in images, thus it is more suitable for general detection scenarios. To choose the optimal score threshold of 2D proposals, we conduct experiments shown in Tab. 4. Besides, we visualize the detection results in Fig. 5 and distinguish the boxes predicted from 3D adaptive queries and 3D global queries. The predictions from 3D adaptive queries cover a larger range, showing their indispensable significance.
自适应查询 (Adaptive Query)。对比表 3 中的 #1 和 $#2$,我们可以观察到自适应查询带来了 2.1% mAP 和 1.5% CDS 的提升。由于图像中 2D 检测器的鲁棒性,自适应查询对物体范围不敏感,因此更适合通用检测场景。为了选择 2D 提议 (proposals) 的最佳分数阈值,我们进行了如表 4 所示的实验。此外,我们在图 5 中可视化了检测结果,并区分了来自 3D 自适应查询和 3D 全局查询的预测框。来自 3D 自适应查询的预测覆盖了更大范围,显示出其不可或缺的重要性。
Perspective-aware Aggregation. Adding the perspectiveaware aggregation contributes a gain of $1.0%$ mAP and $1.2%$ CDS. Distant objects only occupy a few pixels on the image, therefore employing multi-level scales and views brings rich features according to different object locations.
视角感知聚合。引入视角感知聚合使mAP提升1.0%,CDS提升1.2%。远处物体在图像中仅占据少量像素,因此采用多尺度多视角策略能根据物体位置差异提供丰富特征。
Range-modulated 3D Denoising. 3D denoising brings an improvement of $1.0%$ mAP and $0.8%$ CDS. Penalizing negative samples flexibly alleviates the challenge of false proposals and helps localize 3D objects, by taking the object range into consideration. We present experiments on different noising designs and numbers of negative samples, shown in Tab. 5. The results imply that the logarithm function and two negative samples are optimal settings.
范围调制3D去噪。3D去噪带来1.0% mAP和0.8% CDS的提升。通过考虑物体范围,灵活惩罚负样本缓解了错误提议的挑战,有助于定位3D物体。我们在表5中展示了不同噪声设计和负样本数量的实验结果。结果表明对数函数和两个负样本是最优设置。
Effect of the Global Query. We also design the experiment to investigate the effect of global query in Tab. 6. 3D global queries and adaptive queries coexist in our framework and compensate for each other. As a baseline, StreamPETR suffers from the convergence problem when using a small number of global queries (e.g. 100), and only works for a sufficient amount. In contrast, our method showcases distinctive robustness. As the number of global queries decreases, our performance shows a slight decline.
全局查询的影响。我们还设计了实验来探究全局查询在表6中的作用。在我们的框架中,3D全局查询与自适应查询共存并相互补充。作为基线,StreamPETR在使用少量全局查询(如100个)时会出现收敛问题,仅当数量充足时才有效。相比之下,我们的方法展现出显著的鲁棒性。随着全局查询数量的减少,我们的性能仅出现轻微下降。
Table 6: The impact of global query number. StreamPETR suffers from the convergence problem, where NaN denotes the failed training. In contrast, our framework shows robust performance even with only adaptive queries.
表 6: 全局查询数量的影响。StreamPETR存在收敛问题,其中NaN表示训练失败。相比之下,我们的框架即使仅使用自适应查询也表现出稳健性能。
| # Global query | StreamPETR | Far3D (Ours) | ||||
|---|---|---|---|---|---|---|
| 100 | 300 | 644 | 100 | 300 | 644 | |
| mAP[%]↑ | 1.5 | 16.9 | 20.5 | 23.5 | 23.6 | 24.4 |
| CDS[%]↑ | 0.9 | 11.8 | 14.8 | 17.4 | 17.5 | 18.1 |
5 Conclusion
5 结论
In this paper, we present a sparse query-based method for 3D long-range detection. Our approach incorporates 3D adaptive queries derived from 2D object priors, yielding highquality proposals for the decoder. To improve training efficacy, we introduce a perspective-aware aggregation and range-modulated 3D denoising technique. Experimental results demonstrate the promising performance of our method, indicating its great potential for practical applications.
本文提出了一种基于稀疏查询的3D远距离检测方法。该方法通过从2D物体先验中提取3D自适应查询,为解码器生成高质量提案。为提高训练效率,我们引入了视角感知聚合和范围调制的3D去噪技术。实验结果表明该方法性能优异,展现出良好的实际应用潜力。
Limitations and Future Work. Despite our development for long-range detection, several limitations require future solutions. On the one hand, existing approaches exhibit poor performance on long-tail classes, ultimately lowering the average precision on Argoverse 2 dataset. On the other hand, evaluating long-range and close-range objects using unified metrics may not be suitable, emphasizing the need for practical and dynamic evaluation criteria that cater to diverse realworld scenarios.
局限性与未来工作。尽管我们针对远距离检测进行了开发,但仍存在若干需在未来解决的局限性。一方面,现有方法在长尾类别上表现不佳,最终降低了Argoverse 2数据集的平均精度。另一方面,使用统一指标评估远距离和近距离物体可能并不合适,这凸显了需要针对多样化现实场景制定实用且动态的评估标准。