FMix: Enhancing Mixed Sample Data Augmentation
FMix: 提升混合样本数据增强效果
Abstract—Mixed Sample Data Augmentation (MSDA) has received increasing attention in recent years, with many successful variants such as MixUp and CutMix. By studying the mutual information between the function learned by a VAE on the original data and on the augmented data we show that MixUp distorts learned functions in a way that CutMix does not. We further demonstrate this by showing that MixUp acts as a form of adversarial training, increasing robustness to attacks such as Deep Fool and Uniform Noise which produce examples similar to those generated by MixUp. We argue that this distortion prevents models from learning about sample specific features in the data, aiding generalisation performance. In contrast, we suggest that CutMix works more like a traditional augmentation, improving performance by preventing mem or is ation without distorting the data distribution. However, we argue that an MSDA which builds on CutMix to include masks of arbitrary shape, rather than just square, could further prevent mem or is ation whilst preserving the data distribution in the same way. To this end, we propose FMix, an MSDA that uses random binary masks obtained by applying a threshold to low frequency images sampled from Fourier space. These random masks can take on a wide range of shapes and can be generated for use with one, two, and three dimensional data. FMix improves performance over MixUp and CutMix, without an increase in training time, for a number of models across a range of data sets and problem settings, obtaining a new single model state-of-the-art result on CIFAR-10 without external data. We show that FMix can outperform MixUp in sentiment classification tasks with one dimensional data, and provides an improvement over the baseline in three dimensional point cloud classification. Finally, we show that a consequence of the difference between interpolating MSDA such as MixUp and masking MSDA such as FMix is that the two can be combined to improve performance even further. Code for all experiments is provided at https://github.com/ecs-vlc/FMix.
摘要—混合样本数据增强(MSDA)近年来受到越来越多的关注,已涌现出MixUp和CutMix等成功变体。通过研究VAE在原始数据和增强数据上学习到的函数之间的互信息,我们发现MixUp会扭曲学习到的函数,而CutMix则不会。进一步研究表明,MixUp起到了一种对抗训练的作用,能提升模型对Deep Fool和均匀噪声等攻击的鲁棒性——这些攻击生成的样本与MixUp生成的样本类似。我们认为这种扭曲效应能防止模型学习数据中的样本特异性特征,从而提升泛化性能。相比之下,CutMix更像传统的数据增强方法,通过防止过拟合来提升性能,且不会扭曲数据分布。但我们指出,基于CutMix开发能生成任意形状(而非仅限于方形)掩模的MSDA方法,可以在保持数据分布的同时更好地防止过拟合。为此,我们提出FMix:这种MSDA方法通过对傅里叶空间采样的低频图像进行阈值处理来获取随机二值掩模。这些随机掩模可呈现多种形状,并能生成适用于一维、二维和三维数据的版本。在多个模型、数据集和问题场景中,FMix在保持训练时间不变的前提下,性能优于MixUp和CutMix,并在不使用外部数据的情况下取得了CIFAR-10数据集上新的单模型最优结果。我们证明FMix在一维数据的情感分类任务中能超越MixUp,并在三维点云分类任务中优于基线方法。最后研究表明,插值型MSDA(如MixUp)与掩模型MSDA(如FMix)的本质差异使得二者结合能获得更优性能。所有实验代码详见https://github.com/ecs-vlc/FMix。
I. INTRODUCTION
I. 引言
R EDaCtEa NATuLgYm, ean tap tli eot nh o(raM SofD aAp) phraovaec hbeese tno pr Moi px oe s de dS awmhipclhe obtain state-of-the-art results, particularly in classification tasks [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]. MSDA involves combining data samples according to some policy to create an augmented data set on which to train the model. The policies so far proposed can be broadly categorised as either combining samples with interpolation (e.g. MixUp) or masking (e.g. CutMix). Traditionally, augmentation is viewed through the framework of statistical learning as Vicinal Risk Minim is ation (VRM) [12, 13]. Given some notion of the vicinity of a data point, VRM trains with vicinal samples in addition to the data points themselves. This is the motivation for MixUp [2]; to provide a new notion of vicinity based on mixing data samples. In the classical theory, validity of this technique relies on the strong assumption that the vicinal distribution precisely matches the true distribution of the data. As a result, the classical goal of augmentation is to maximally increase the data space, without changing the data distribution. Clearly, for all but the most simple augmentation strategies, the data distribution is in some way distorted. Furthermore, there may be practical implications to correcting this, as is demonstrated in Touvron et al. [14]. In light of this, three important questions arise regarding MSDA: What is good measure of the similarity between the augmented and the original data? Why is MixUp so effective when the augmented data looks so different? If the data is distorted, what impact does this have on trained models?
规则:
- 输出中文翻译部分时仅保留翻译标题,不含冗余内容、重复或解释
- 不输出无关内容
- 保留原始段落格式及术语(如FLAC/JPEG)、公司缩写(如Microsoft/Amazon/OpenAI)
- 人名不译
- 保留文献引用标记(如[20])
- 图表翻译保留原格式("图1:"/"表1:")
- 全角括号转半角并添加间距(示例:(xxx) )
- 专业术语首现标注英文(如"生成式AI (Generative AI)"),后续直接使用中文
- AI术语对照:
- Transformer -> Transformer
- Token -> Token
- LLM -> 大语言模型
- Zero-shot -> 零样本
- Few-shot -> 少样本
- AI Agent -> AI智能体
- AGI -> 通用人工智能
- Python -> Python语言
策略:
- 特殊字符/公式原样保留
- HTML表格转Markdown格式
- 确保完整翻译且符合中文表达
(以下为符合要求的Markdown格式翻译结果)
混合样本数据增强 (MSDA) 方法通过特定策略组合数据样本创建增强数据集,在分类任务中取得了最先进成果 [1-11]。现有策略主要分为样本插值混合(如MixUp)和掩码混合(如CutMix)两类。传统增强框架基于统计学习中的邻域风险最小化 (VRM) [12,13],通过数据点及其邻域样本进行训练。MixUp [2] 的动机正是建立在这种基于样本混合的新邻域概念上。经典理论要求邻域分布必须严格匹配真实数据分布,因此传统增强目标是在不改变数据分布的前提下最大化扩展数据空间。然而除简单策略外,大多数增强都会以某种方式扭曲数据分布——Touvron等人 [14] 已证明修正这种扭曲的实际影响。由此引发三个关键问题:如何有效衡量增强数据与原始数据的相似性?为何MixUp在增强数据明显失真时仍高效?数据扭曲对训练模型有何影响?
To construct a good measure of similarity, we note that the data only need be ‘perceived’ similar by the model. As such, we measure the mutual information between representations learned from the real and augmented data, thus character ising how well learning from the augmented data simulates learning from the real data. This measure shows the data-level distortion of MixUp by demonstrating that learned representations are compressed in comparison to those learned from the unaugmented data. To address the efficacy of MixUp, we look to the information bottleneck theory of deep learning [15]. By the data processing inequality, summarised as ‘post-processing cannot increase information’, deep networks can only discard information about the input with depth whilst preserving information about the targets. Tishby and Zaslavsky [15] assert that more efficient generalisation is achieved when each layer maximises the information it has about the target and minimises the information it has about the previous layer. Consequently, we posit that the distortion and subsequent compression induced by MixUp promotes generalisation. Another way to view this is that compression prevents the network from learning about highly sample-specific features in the data. Regarding the impact on trained models, and again armed with the knowledge that MixUp distorts learned functions, we show that MixUp acts as a kind of adversarial training [16], promoting robustness to additive noise. This accords with the theoretical result of Perrault-Ar chamba ul t et al. [17] and the robustness results of Zhang et al. [2]. However, we further show that MSDA does not generally improve adversarial robustness when measured as a worst case accuracy following multiple attacks as suggested by Carlini et al. [18]. Ultimately, our adversarial robustness experiments show that the distortion in the data observed by our mutual information analysis corresponds to practical differences in learned function.
为了构建一个良好的相似性度量,我们注意到数据只需被模型"感知"为相似即可。因此,我们测量从真实数据和增强数据中学到的表征之间的互信息,从而刻画通过增强数据学习能在多大程度上模拟从真实数据中学习。该度量通过展示学习到的表征相比未增强数据存在压缩现象,揭示了MixUp在数据层面造成的失真。针对MixUp的有效性,我们参考深度学习的信息瓶颈理论[15]。根据数据处理不等式(可概括为"后处理无法增加信息"),深度网络只能在保留目标信息的同时,随着深度增加逐步丢弃输入信息。Tishby和Zaslavsky[15]主张,当每一层最大化其拥有的目标信息并最小化其拥有的前一层信息时,能实现更高效的泛化。因此,我们认为MixUp引发的失真和后续压缩有助于提升泛化能力。另一种理解是,压缩能防止网络学习数据中高度样本特定的特征。关于对训练模型的影响,结合MixUp会扭曲学习函数这一认知,我们证明MixUp可视为一种对抗训练[16],能提升对加性噪声的鲁棒性。这与Perrault-Ar chamba ul t等人[17]的理论结果及Zhang等人[2]的鲁棒性结论一致。但我们进一步表明,当按照Carlini等人[18]建议采用多重攻击下的最坏情况准确率衡量时,MSDA通常不会提升对抗鲁棒性。最终,我们的对抗鲁棒性实验表明,通过互信息分析观察到的数据失真与学习函数的实际差异存在对应关系。
In contrast to our findings regarding MixUp, our mutual information analysis shows that CutMix causes learned models to retain a good knowledge of the real data, which we argue derives from the fact that individual features extracted by a convolutional model generally only derive from one of the mixed data points. This is further shown by our adversarial robustness results, where CutMix is not found to promote robustness in the same way. We therefore suggest that CutMix limits the ability of the model to over-fit by dramatically increasing the number of observable data points without distorting the data distribution, in keeping with the original intent of VRM. However, by restricting to only masking a square region, CutMix imposes some unnecessary limitations. First, the number of possible masks could be much greater if more mask shapes could be used. Second, it is likely that there is still some distortion since all of the images used during training will involve a square edge. It should be possible to construct an MSDA which uses masking similar to CutMix whilst increasing the data space much more dramatically. Motivated by this, we introduce FMix, a masking MSDA that uses binary masks obtained by applying a threshold to low frequency images sampled randomly from Fourier space. Using our mutual information measure, we show that learning with FMix simulates learning from the real data even better than CutMix. We subsequently demonstrate performance of FMix for a range of models and tasks against a series of augmented baselines and other MSDA approaches. FMix obtains a new single model state-of-the-art performance on CIFAR-10 [19] without external data and improves the performance of several state-ofthe-art models (ResNet, SE-ResNeXt, DenseNet, WideResNet, PyramidNet, LSTM, and Bert) on a range of problems and modalities.
与我们在 MixUp 上的发现相反,互信息分析表明 CutMix 能使学习模型保留对真实数据的良好认知。我们认为这源于卷积模型提取的单个特征通常仅来自混合数据点之一。对抗鲁棒性结果进一步证明了这一点——CutMix 并未以相同方式提升鲁棒性。因此我们提出,CutMix 通过大幅增加可观测数据点数量(同时保持数据分布不变)来限制模型过拟合能力,这符合 VRM 的原始意图。
但仅限定方形掩码区域使 CutMix 存在不必要的限制:其一,若采用更多掩码形状,可能掩码数量会显著增加;其二,由于训练中所有图像都涉及方形边缘,仍可能存在某些失真。理论上可以构建一种类似 CutMix 掩码机制的 MSDA (混合样本数据增强) 方法,同时更大幅度扩展数据空间。
基于此,我们提出 FMix——通过傅里叶空间随机采样低频图像并阈值化获得二值掩码的 MSDA 方法。互信息测量显示,FMix 比 CutMix 更能模拟真实数据的学习过程。后续实验证明,在一系列模型、任务及增强基线对比中,FMix 均优于其他 MSDA 方法。FMix 在 CIFAR-10 [19] 上无需外部数据即达到新的单模型最优性能,并在多种任务和模态中提升了当前最优模型(ResNet、SE-ResNeXt、DenseNet、WideResNet、PyramidNet、LSTM 和 Bert)的表现。
In light of our experimental results, we go on to suggest that the compressing qualities of MixUp are most desirable when data is limited and learning from individual examples is easier. In contrast, masking MSDAs such as FMix are most valuable when data is abundant. We suggest that there is no reason to see the desirable properties of masking and interpolation as mutually exclusive. In light of these observations, we plot the performance of MixUp, FMix, a baseline, and a hybrid policy where we alternate between batches of MixUp and FMix, as the number of CIFAR-10 training examples is reduced. This experiment confirms our above suggestions and shows that the hybrid policy can outperform both MixUp and FMix.
根据实验结果,我们进一步提出:当数据有限且更容易从单个样本中学习时,MixUp的压缩特性最为理想;而当数据充足时,FMix等掩码型混合样本数据增强(MSDA)方法最具价值。我们认为,没有必要将掩码和插值的优势特性视为互斥关系。基于这些观察,我们绘制了MixUp、FMix、基线方法以及混合策略(在MixUp和FMix批次间交替使用)在CIFAR-10训练样本数量递减时的性能曲线。该实验验证了上述观点,并表明混合策略可以同时超越MixUp和FMix的表现。
II. RELATED WORK
II. 相关工作
In this section, we review the fundamentals of MSDA. Let $p_{X}(x)$ denote the input data distribution. In general, we can define MSDA for a given mixing function, $\operatorname*{mix}(X_{1},X_{2},\Lambda)$ , where $X_{1}$ and $X_{2}$ are independent random variables on the data domain and $\Lambda$ is the mixing coefficient. Synthetic minority over-sampling [1], a predecessor to modern MSDA approaches, can be seen as a special case of the above where $X_{1}$ and $X_{2}$ are dependent, jointly sampled as nearest neighbours in feature space. These synthetic samples are drawn only from the minority class to be used in conjunction with the original data, addressing the problem of imbalanced data. The mixing function is linear interpolation, $\operatorname*{mix}(x_{1},x_{2},\lambda)=$ $\lambda x_{1}+(1-\lambda)x_{2}$ , and $p_{\Lambda}=\mathcal{U}(0,1)$ . More recently, Zhang et al. [2], Tokozume et al. [3], and Inoue [5] concurrently proposed using this formulation (as MixUp, Between-Class (BC) learning, and sample pairing respectively) on the whole data set, although the choice of distribution for the mixing coefficients varies for each approach. Tokozume et al. [4] subsequently proposed $\mathrm{BC+}$ , which uses a normalised variant of the mixing function. We refer to these approaches as interpol at ive MSDA, where, following Zhang et al. [2], we use the symmetric Beta distribution, that is $p_{\Lambda}=\mathrm{Beta}(\alpha,\alpha)$ .
在本节中,我们回顾MSDA的基础知识。设$p_{X}(x)$表示输入数据分布。通常,我们可以为给定的混合函数$\operatorname*{mix}(X_{1},X_{2},\Lambda)$定义MSDA,其中$X_{1}$和$X_{2}$是数据域上的独立随机变量,$\Lambda$是混合系数。现代MSDA方法的前身——合成少数类过采样[1],可视为上述情况的一个特例,其中$X_{1}$和$X_{2}$是依赖的,在特征空间中作为最近邻联合采样。这些合成样本仅从少数类中抽取,与原始数据结合使用,以解决数据不平衡问题。混合函数为线性插值$\operatorname*{mix}(x_{1},x_{2},\lambda)=\lambda x_{1}+(1-\lambda)x_{2}$,且$p_{\Lambda}=\mathcal{U}(0,1)$。最近,Zhang等人[2]、Tokozume等人[3]和Inoue[5]分别提出了在整个数据集上使用该公式(分别称为MixUp、类间(BC)学习和样本配对),尽管每种方法对混合系数分布的选择各不相同。Tokozume等人[4]随后提出了$\mathrm{BC+}$,它使用了混合函数的归一化变体。我们将这些方法称为插值MSDA,其中遵循Zhang等人[2]的做法,使用对称Beta分布,即$p_{\Lambda}=\mathrm{Beta}(\alpha,\alpha)$。
Recent variants adopt a binary masking approach [6, 7, 8]. Let $M=\mathrm{mask}(\Lambda)$ be a random variable with $\mathrm{mask}(\lambda)\in$ ${0,1}^{n}$ and $\mu(\mathrm{mask}(\lambda))=\lambda$ , that is, generated masks are binary with average value equal to the mixing coefficient. The mask mixing function is $\operatorname*{mix}(\mathbf{x}{1},\mathbf{x}{2},\mathbf{m})=\mathbf{m}\odot\mathbf{x}{1}+$ $(1-\mathbf{m})\odot\mathbf{x}{2}$ , where $\odot$ denotes point-wise multiplication. A notable masking MSDA which motivates our approach is CutMix [6]. CutMix is designed for two dimensional data, with $\mathrm{mask}(\lambda)\in{0,1}^{w\times h}$ , and uses $\mathrm{mask}(\lambda){\it\Delta\phi}=$ ra $\mathrm{nd_rect}(w\sqrt{1-\lambda},h\sqrt{1-\lambda})$ , where rand rec $\mathrm{{;t}}(r_{w},r_{h})\in$ ${0,1}^{w\times h}$ yields a binary mask with a shaded rectangular region of size $r_{w}\times r_{h}$ at a uniform random coordinate. CutMix improves upon the performance of MixUp on a range of experiments.
最近的变体采用了二元掩码方法 [6, 7, 8]。设 $M=\mathrm{mask}(\Lambda)$ 为一个随机变量,其中 $\mathrm{mask}(\lambda)\in$ ${0,1}^{n}$ 且 $\mu(\mathrm{mask}(\lambda))=\lambda$,即生成的掩码是二元的,其平均值等于混合系数。掩码混合函数为 $\operatorname*{mix}(\mathbf{x}{1},\mathbf{x}{2},\mathbf{m})=\mathbf{m}\odot\mathbf{x}{1}+$ $(1-\mathbf{m})\odot\mathbf{x}{2}$,其中 $\odot$ 表示逐点乘法。CutMix [6] 是一个值得注意的掩码 MSDA,它启发了我们的方法。CutMix 专为二维数据设计,其中 $\mathrm{mask}(\lambda)\in{0,1}^{w\times h}$,并使用 $\mathrm{mask}(\lambda){\it\Delta\phi}=$ ra $\mathrm{nd_rect}(w\sqrt{1-\lambda},h\sqrt{1-\lambda})$,其中 rand rec $\mathrm{{;t}}(r_{w},r_{h})\in$ ${0,1}^{w\times h}$ 生成一个二元掩码,其阴影矩形区域大小为 $r_{w}\times r_{h}$,位于均匀随机坐标处。CutMix 在一系列实验中提升了 MixUp 的性能。
In all MSDA approaches the targets are mixed in some fashion, typically to reflect the mixing of the inputs. For the typical case of classification with a cross entropy loss (and for all of the experiments in this work), the objective function is simply the interpolation between the cross entropy against each of the ground truth targets. It could be suggested that by mixing the targets differently, one might obtain better results. However, there are key observations from prior art which give us cause to doubt this supposition; in particular, Liang et al. [20] performed a number of experiments on the importance of the mixing ratio of the labels in MixUp. They concluded that when the targets are not mixed in the same proportion as the inputs the model can be regular is ed to the point of under fitting. However, despite this conclusion their results show only a mild performance change even in the extreme event that targets are mixed randomly, independent of the inputs. For these reasons, we focus only on the development of a better input mixing function for the remainder of the paper.
在所有MSDA方法中,目标会以某种方式混合,通常是为了反映输入的混合情况。对于使用交叉熵损失进行分类的典型情况(以及本文中的所有实验),目标函数只是针对每个真实目标交叉熵的插值。有人可能会建议通过不同的方式混合目标来获得更好的结果。然而,先前研究的关键观察让我们对这一假设产生了怀疑;特别是,Liang等人[20]对MixUp中标签混合比例的重要性进行了大量实验。他们得出结论,当目标不以与输入相同的比例混合时,模型可能会被正则化到欠拟合的程度。然而,尽管得出了这一结论,他们的结果显示即使在目标与输入无关、随机混合的极端情况下,性能变化也很小。基于这些原因,在本文的剩余部分,我们仅专注于开发更好的输入混合函数。
Attempts to explain the success of MSDAs were not only made when they were introduced, but also through subsequent empirical and theoretical studies. In addition to their experimentation with the targets, Liang et al. [20] argue that linear interpolation of inputs limits the mem or is ation ability of the network. Gontijo-Lopes et al. [21] propose two measures to explain the impact of augmentation on generalisation when jointly optimised: affinity and diversity. While the former captures the shift in the data distribution as perceived by the baseline model, the latter measures the training loss when learning with augmented data. A more mathematical view on MSDA was adopted by Guo et al. [22], who argue that MixUp regular is es the model by constraining it outside the data manifold. They point out that this could lead to reducing the space of possible hypotheses, but could also lead to generated examples contradicting original ones, degrading quality. Upon Taylor-expanding the objective, Carratino et al.
试图解释多源数据增强(MSDA)成功的原因不仅在其被提出时就已开始,还贯穿于后续的实证与理论研究。除对目标数据的实验外,Liang等人[20]指出输入数据的线性插值会限制网络的记忆能力。Gontijo-Lopes等人[21]提出亲和度(affinity)与多样性(diversity)两项指标,用于解释联合优化时数据增强对泛化能力的影响:前者反映基线模型感知的数据分布偏移,后者衡量使用增强数据训练时的损失值。Guo等人[22]则从数学视角分析MSDA,认为MixUp通过将模型约束在数据流形之外实现正则化。他们指出这虽可能缩小假设空间,但也可能导致生成样本与原始数据矛盾而降低质量。Carratino等人通过对目标函数进行泰勒展开...
TABLE I: Mutual information between VAE latent spaces $(Z_{A})$ and the CIFAR-10 test set $(I(Z_{A};X))$ , and the CIFAR10 test set as reconstructed by a baseline VAE $(I(Z_{A};\hat{X}))$ for VAEs trained with a range of MSDAs. MixUp prevents the model from learning about specific features in the data. Uncertainty estimates are the standard deviation following 5 trials.
表 1: VAE潜在空间 $(Z_{A})$ 与CIFAR-10测试集 $(I(Z_{A};X))$ 之间的互信息,以及基线VAE重建的CIFAR10测试集 $(I(Z_{A};\hat{X}))$(使用多种MSDA方法训练的VAE)。MixUp会阻止模型学习数据中的特定特征。不确定性估计为5次试验后的标准差。
| I(ZA; X) | I(ZA;X) | MSE | |
|---|---|---|---|
| Baseline | 78.05±0.53 | 74.40±0.45 | 0.256±0.002 |
| MixUp | 70.38±0.90 | 68.58±1.12 | 0.288±0.003 |
| CutMix | 83.17±0.72 | 79.46±0.75 | 0.254±0.003 |
[23] motivate the success of MixUp by the co-action of four different regular is ation factors. A similar analysis is carried out in parallel by Zhang et al. [24].
[23] 将 MixUp 的成功归因于四种不同正则化因素的协同作用。Zhang 等人 [24] 也进行了类似的分析。
Following Zhang et al. [2], He et al. [25] take a statistical learning view of MSDA, basing their study on the observation that MSDA distorts the data distribution and thus does not perform VRM in the traditional sense. They subsequently propose separating features into ‘minor’ and ‘major’, where a feature is referred to as ‘minor’ if it is highly sample-specific. Augmentations that significantly affect the distribution are said to make the model predominantly learn from ‘major’ features. From an information theoretic perspective, ignoring these ‘minor’ features corresponds to increased compression of the input by the model. Although He et al. [25] noted the importance of character ising the effect of data augmentation from an information perspective, they did not explore any measures that do so. Instead, He et al. [25] analysed the variance in the learned representations. This is analogous to the entropy of the representation since entropy can be estimated via the pairwise distances between samples, with higher distances corresponding to both greater entropy and variance [26]. In proposing Manifold MixUp, Verma et al. [27] additionally suggest that MixUp works by increasing compression. The authors compute the singular values of the representations in early layers of trained networks, with smaller singular values again corresponding to lower entropy. A potential issue with these approaches is that the entropy of the representation is only an upper bound on the information that the representation has about the input.
遵循张等人[2]的研究思路,何等人[25]从统计学习视角分析多源域自适应(MSDA),基于MSDA会扭曲数据分布因而无法执行传统变分风险最小化(VRM)的观察。他们提出将特征划分为"次要"和"主要"两类——当某特征具有高度样本特异性时即被归为"次要特征"。那些显著影响数据分布的增强操作会使模型主要从"主要特征"中学习。从信息论角度看,忽略这些"次要特征"相当于模型对输入信息进行了更高程度的压缩。虽然何等人[25]指出从信息角度表征数据增强效果的重要性,但未深入探索相关度量方法,转而分析学习表征的方差。这与表征熵具有相似性,因为熵可以通过样本间成对距离来估算,距离越大对应熵和方差越高[26]。Verma等人在提出流形混合(Manifold MixUp)时[27]也指出MixUp通过增强压缩发挥作用,作者计算训练网络浅层表征的奇异值,较小奇异值同样对应较低熵。这些方法的潜在问题在于:表征熵仅是表征所含输入信息量的上限。
III. ANALYSIS
III. 分析
We now analyse both interpol at ive and masking MSDAs with a view to distinguishing their impact on learned representations and finding answers to the questions established in our introduction. We first desire a measure which captures the extent to which learning about the augmented data simulates learning about the original data. We propose training unsupervised models on real data and augmented data and then measuring the mutual information, the reduction in uncertainty about one variable given knowledge of another, between the representations they learn. To achieve this, we use Variation al Auto-Encoders (VAEs) [29], which provide a rich depiction of the salient or compressible information in the data [30]. Note that we do not expect these representations to directly relate to those of trained class if i ers. Our requirement is a probabilistic model of the data, for which a VAE is well suited.
我们现在分析插值和掩码两种多模态数据增强方法(MSDA),旨在区分它们对学习表示的影响,并回答引言中提出的问题。首先需要一种衡量标准,用于量化增强数据的学习能在多大程度上模拟原始数据的学习。我们提出在真实数据和增强数据上训练无监督模型,然后测量它们学习到的表示之间的互信息(即已知一个变量后对另一个变量不确定性的减少量)。为此,我们使用变分自编码器(VAE)[29],它能充分表征数据中的显著或可压缩信息[30]。需要注意的是,这些表示与训练分类器的表示不一定直接相关。我们需要的是一种数据概率模型,而VAE非常适合这一需求。
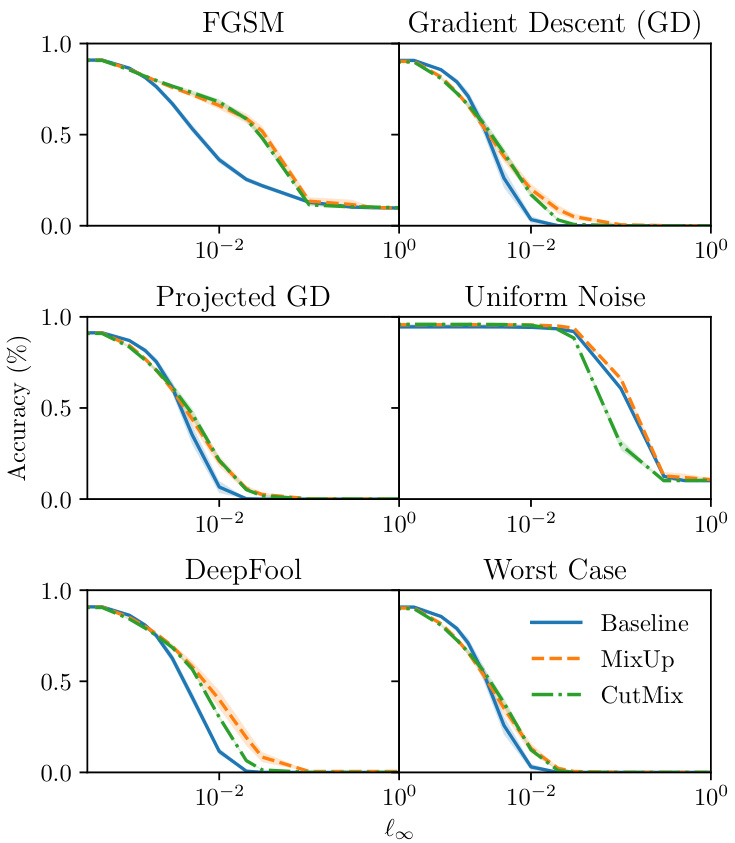
Fig. 1: Robustness of PreAct-ResNet18 models trained on CIFAR-10 with standard augmentations (Baseline) and the addition of MixUp and CutMix to the Fast Gradient Sign Method (FGSM), simple gradient descent, projected gradient descent, uniform noise, DeepFool [28], and the worst case performance after all attacks. MixUp improves robustness to adversarial examples with similar properties to images generated with MixUp (acting as adversarial training), but MSDA does not improve robustness in general. Shaded region indicates the standard deviation following 5 repeats.
图 1: 在CIFAR-10上训练的PreAct-ResNet18模型使用标准数据增强(基线)及加入MixUp和CutMix后,对快速梯度符号法(FGSM)、简单梯度下降、投影梯度下降、均匀噪声、DeepFool [28]以及所有攻击后最坏情况表现的鲁棒性。MixUp提升了对抗样本的鲁棒性(这些样本具有与MixUp生成图像相似的特性,起到对抗训练的作用),但混合样本数据增强(MSDA)总体上并未提高鲁棒性。阴影区域表示5次重复实验的标准差。
We wish to estimate the mutual information between the representation learned by a VAE from the original data set, $Z_{X}$ , and the representation learned from some augmented data set, $Z_{A}$ , written ${\cal I}\left(Z_{X};Z_{A}\right)=\mathbb{E}{Z_{X}}\left[D\left(p_{\left(Z_{A}\mid Z_{X}\right)}\mid\mid p_{Z_{A}}\right)\right]$ . This quantity acts as a good measure of the similarity between the augmented and the original data since it captures only the similarity between learnable or salient features. VAEs comprise an encoder, $p_{\left(Z\mid X\right)}$ , and a decoder, $p_{(X\mid Z)}$ . We impose a Normal prior on $Z$ , and train the model to maximise the Evidence Lower BOund (ELBO) objective
我们希望估计变分自编码器(VAE)从原始数据集学习到的表示 $Z_{X}$ 与从增强数据集学习到的表示 $Z_{A}$ 之间的互信息,记为 ${\cal I}\left(Z_{X};Z_{A}\right)=\mathbb{E}{Z_{X}}\left[D\left(p_{\left(Z_{A}\mid Z_{X}\right)}\mid\mid p_{Z_{A}}\right)\right]$。该量能有效衡量增强数据与原始数据之间的相似性,因为它仅捕捉可学习或显著特征之间的相似性。VAE包含编码器 $p_{\left(Z\mid X\right)}$ 和解码器 $p_{(X\mid Z)}$。我们对 $Z$ 施加正态先验,并通过最大化证据下界(ELBO)目标来训练模型。
$$
\begin{array}{r l}&{\mathcal{L}=\mathbb{E}{X}\left[\mathbb{E}{Z|X}\left[\mathrm{log}\big(p_{\left(X\mid Z\right)}\big)\right]\right.}\ &{\qquad\left.-D\big(p_{\left(Z|X\right)}\big|\big|\mathcal{N}\big(\mathbf{0},I\big)\big)\right].}\end{array}
$$
$$
\begin{array}{r l}&{\mathcal{L}=\mathbb{E}{X}\left[\mathbb{E}{Z|X}\left[\mathrm{log}\big(p_{\left(X\mid Z\right)}\big)\right]\right.}\ &{\qquad\left.-D\big(p_{\left(Z|X\right)}\big|\big|\mathcal{N}\big(\mathbf{0},I\big)\big)\right].}\end{array}
$$
Denoting the outputs of the decoder of the VAE trained on the augmentation as ${\bf\hat{X}}=d e c o d e(Z_{X})$ , and by the data processing inequality, we have $I(Z_{A};\hat{X})\leq I(Z_{A};Z_{X})$ with equality when the decoder retains all of the information in $Z$ . Now, we need only observe that we already have a model of $p_{(Z_{A}\mid X)}$ , the encoder trained on the augmented data. Estimating the marginal $p_{Z_{A}}$ presents a challenge as it is a Gaussian mixture. However, we can measure an alternative form of the mutual information that is equivalent up to an additive constant, and for which the divergence has a closed form solution, with
将经过增强训练的VAE解码器输出表示为 ${\bf\hat{X}}=d e c o d e(Z_{X})$ ,根据数据处理不等式可得 $I(Z_{A};\hat{X})\leq I(Z_{A};Z_{X})$ ,当解码器保留 $Z$ 中全部信息时取等号。此时只需注意到我们已拥有增强数据训练的编码器 $p_{(Z_{A}\mid X)}$ 模型。估计边缘分布 $p_{Z_{A}}$ 存在挑战,因其为高斯混合分布。不过我们可以测量另一种形式的互信息(该形式与原始互信息仅相差加性常数),其散度具有闭式解:
$$
\begin{array}{r l}{\mathbb{E}{\hat{X}}\big[D\big(p_{(Z_{A}|\hat{X})}\left\Vert p_{Z_{A}}\right)\big]=}&{}\ {\mathbb{E}{\hat{X}}\big[D\big(p_{(Z_{A}|\hat{X})}\left\Vert\mathcal{N}(\mathbf{0},I)\right)\big]}&{}\ {-D\big(p_{Z_{A}}\left\Vert\mathcal{N}(\mathbf{0},I)\right).}\end{array}
$$
$$
\begin{array}{r l}{\mathbb{E}{\hat{X}}\big[D\big(p_{(Z_{A}|\hat{X})}\left\Vert p_{Z_{A}}\right)\big]=}&{}\ {\mathbb{E}{\hat{X}}\big[D\big(p_{(Z_{A}|\hat{X})}\left\Vert\mathcal{N}(\mathbf{0},I)\right)\big]}&{}\ {-D\big(p_{Z_{A}}\left\Vert\mathcal{N}(\mathbf{0},I)\right).}\end{array}
$$
The above holds for any choice of distribution that does not depend on X. Conceptually, this states that we will always lose more information on average if we approximate $p_{\left(Z_{A}\mid\hat{X}\right)}$ with any constant distribution other than the marginal $p_{Z_{A}}$ . Additionally note that we implicitly minimise during training of the VAE [31]. In light of this fact, we can write $I(\bar{Z_{A}};\hat{X})\approx\mathbb{E}{\hat{X}}[D\big(p_{(Z_{A}|\hat{X})}\bar{|}\mathcal{N}(\mathbf{0},I)\big)]$ . We can now easily obtain a helpful upper bound of $I(Z_{A};Z_{X})$ such that it is bounded on both sides. Since $Z_{A}$ is just a function of $X$ , again by the data processing inequality, we have $I(Z_{A};X)\ge I(Z_{A};Z_{X})$ . This is easy to compute since it is just the relative entropy term from the ELBO objective.
上述结论适用于任何不依赖于X的分布选择。从概念上讲,这表明如果我们用任何非边缘分布$p_{Z_{A}}$的恒定分布来近似$p_{\left(Z_{A}\mid\hat{X}\right)}$,平均而言总会损失更多信息。此外需注意,在训练VAE时我们隐式地最小化了[31]。基于这一事实,可以表示为$I(\bar{Z_{A}};\hat{X})\approx\mathbb{E}{\hat{X}}[D\big(p_{(Z_{A}|\hat{X})}\bar{|}\mathcal{N}(\mathbf{0},I)\big)]$。现在我们可以轻松得到$I(Z_{A};Z_{X})$的一个有用上界,使其在两侧都有界。由于$Z_{A}$仅是$X$的函数,根据数据处理不等式可得$I(Z_{A};X)\ge I(Z_{A};Z_{X})$。这个值很容易计算,因为它就是ELBO目标函数中的相对熵项。
To summarise, we can compute our measure by first training two VAEs, one on the original data and one on the augmented data. We then generate reconstructions of data points in the original data with one VAE and encode them in the other. We now compute the expected value of the relative entropy between the encoded distribution and an estimate of the marginal to obtain an estimate of a lower bound of the mutual information between the representations. We then recompute this using real data points instead of reconstructions to obtain an upper bound. Table I gives these quantities for MixUp, CutMix, and a baseline. The results show that MixUp consistently reduces the amount of information that is learned about the original data. In contrast, CutMix manages to induce greater mutual information with the data than is obtained from just training on the un-augmented data. Crucially, the results present concrete evidence that interpol at ive MSDA differs fundamentally from masking MSDA in how it impacts learned representations.
总结来说,我们可以通过以下步骤计算该指标:首先训练两个VAE(变分自编码器),一个在原始数据上训练,另一个在增强数据上训练。接着用其中一个VAE生成原始数据点的重构样本,并用另一个VAE对其进行编码。此时,我们通过计算编码分布与边缘分布估计之间的相对熵期望值,来获得表示间互信息下界的估计。随后改用真实数据点(而非重构样本)重新计算该值,从而得到上界。表1展示了MixUp、CutMix和基线的这些量化结果。结果表明,MixUp持续降低了模型从原始数据中学习到的信息量;而CutMix则能诱导出比未增强数据训练更高的互信息。关键的是,这些结果为插值型多源数据增强(MSDA)与掩码型MSDA对学习表示的影响机制存在本质差异提供了具体证据。
Having shown this is true for VAEs, we now wish to understand whether the finding also holds for trained class if i ers. To this end, we analysed the decisions made by a classifier using Gradient-weighted Class Activation Maps (Grad-CAMs) [32]. Grad-CAM finds the regions in an image that contribute the most to the network’s prediction by taking the derivative of the model’s output with respect to the activation maps and weighting them according to their contribution. If MixUp prevents the network from learning about highly specific features in the data we would expect more of the early features to contribute to the network output. It would be difficult to ascertain qualitatively whether this is the case. Instead, we compute the average sum of Grad-CAM heatmaps over the CIFAR-10 test set for 5 repeats (independently trained PreActResNet18 models). We obtain the following scores: baseline - $146{\scriptstyle\pm5}$ , MixUp - $162{\scriptstyle\pm3}$ , CutMix - $131{\scriptstyle\pm6}$ . The result suggeststhat more of the early features contribute to the decisions made by MixUp trained models and that this result is consistent across independent runs.
在证明了VAE确实如此后,我们现在希望了解这一发现是否也适用于训练过的分类器。为此,我们使用梯度加权类激活图(Grad-CAMs)[32]分析了分类器的决策过程。Grad-CAM通过计算模型输出相对于激活图的导数,并根据其贡献进行加权,从而找出图像中对网络预测贡献最大的区域。如果MixUp阻止网络学习数据中高度特定的特征,我们预计会有更多早期特征对网络输出产生贡献。定性判断这种情况是否属实较为困难。因此,我们针对CIFAR-10测试集计算了5次独立训练的PreActResNet18模型的Grad-CAM热图平均总和,得到以下分数:基线 - $146{\scriptstyle\pm5}$,MixUp - $162{\scriptstyle\pm3}$,CutMix - $131{\scriptstyle\pm6}$。结果表明,MixUp训练的模型决策过程中有更多早期特征参与贡献,且该结果在不同独立运行中保持一致。
Having established that MixUp distorts learned functions, we now seek to answer the third question from our introduction by determining the impact of data distortion on trained class if i ers. Since it is our assessment that models trained with MixUp have an altered ‘perception’ of the data distribution, we suggest an analysis based on adversarial attacks, which involve perturbing images outside of the perceived data distribution to alter the given classification. We perform fast gradient sign method, standard gradient descent, projected gradient descent, additive uniform noise, and DeepFool [28] attacks over the whole CIFAR-10 test set on PreAct-ResNet18 models subject to $\ell_{\infty}$ constraints using the Foolbox library [33, 34]. The plots for the additive uniform noise and DeepFool attacks, given in Figure 1, show that MixUp provides an improvement over CutMix and the augmented baseline in this setting. This is because MixUp acts as a form of adversarial training [16], equipping the models with valid classifications for images of a similar nature to those generated by the additive noise and DeepFool attacks. In Figure 1, we additionally plot the worst case robustness following all attacks as suggested by Carlini et al. [18]. These results show that the adversarial training effect of MixUp is limited and does not correspond to a general increase in robustness. The key observation regarding these results is that there may be practical consequences to training with MixUp that are present but to a lesser degree when training with CutMix. There may be value to creating a new MSDA that goes even further than CutMix to minimise these practical consequences.
在确认MixUp会扭曲学习到的函数后,我们试图通过研究数据扭曲对训练分类器的影响来回答引言中的第三个问题。由于我们评估认为使用MixUp训练的模型对数据分布产生了"感知"上的改变,因此建议基于对抗攻击进行分析——这类攻击通过扰动感知分布之外的图像来改变既定分类。我们使用Foolbox库[33,34]对PreAct-ResNet18模型在整个CIFAR-10测试集上实施了快速梯度符号法、标准梯度下降、投影梯度下降、加性均匀噪声以及DeepFool[28]攻击,并施加$\ell_{\infty}$约束。图1所示的加性均匀噪声和DeepFool攻击曲线表明,在此设定下MixUp较CutMix和数据增强基线有所改进。这是因为MixUp作为一种对抗训练形式[16],使模型能对加性噪声和DeepFool攻击生成的同类图像进行有效分类。图1中我们还按照Carlini等人[18]的建议绘制了所有攻击后的最差鲁棒性曲线。这些结果表明MixUp的对抗训练效果有限,并未带来鲁棒性的普遍提升。关键发现在于:使用MixUp训练可能产生实际影响,而CutMix训练时这些影响程度较轻。开发比CutMix更进一步的新型混合样本数据增强(MSDA)方法来最小化这些实际影响可能具有价值。
IV. FMIX: IMPROVED MASKING
IV. FMIX: 改进的掩码策略
Our principle finding is that the masking MSDA approach works because it effectively preserves the data distribution in a way that interpol at ive MSDAs do not, particularly in the perceptual space of a Convolutional Neural Network (CNN). This derives from the fact that each convolutional neuron at a particular spatial position generally encodes information from only one of the inputs at a time. This could also be viewed as local consistency in the sense that elements that are close to each other in space typically derive from the same data point. To the detriment of CutMix, the number of possible examples is limited by only using square masks. In this section we propose FMix, a masking MSDA which maximises the number of possible masks whilst preserving local consistency. For local consistency, we require masks that are predominantly made up of a single shape or contiguous region. We might think of this as trying to minimise the number of times the binary mask transitions from $\mathbf{\nabla}^{\leftarrow}0^{\bullet}$ to $\mathbf{\hat{\Pi}}^{\epsilon}\mathbf{1}^{\epsilon}$ or vice-versa. For our approach, we begin by sampling a low frequency greyscale mask from Fourier space which can then be converted to binary with a threshold. We will first detail our approach for obtaining the low frequency image before discussing our approach for choosing the threshold. Let $Z$ denote a complex random variable with values on the domain $\mathcal{Z}=\mathbb{C}^{\bar{w}\times h}$ , with density $p_{\Re(Z)}=\mathcal{N}(\mathbf{0},I_{w\times h})$ and $p_{\Im(Z)}=\mathcal{N}(\mathbf{0},I_{w\times h})$ , where $\Re$ and $\mathfrak{I}$ return the real and imaginary parts of their input respectively. Let $\operatorname{freq}(w,h)[i,j]$ denote the magnitude of the sample frequency corresponding to the $i,j^{\prime}$ ’th bin of the $w\times h$ discrete Fourier transform. We can apply a low pass filter to $Z$ by decaying its high frequency components. Specifically, for a given decay power $\delta$ , we use
我们的核心发现是:掩码式混合样本数据增强(MSDA)方法之所以有效,是因为它能以插值式MSDA无法实现的方式保持数据分布特性,尤其在卷积神经网络(CNN)的感知空间中。这源于卷积神经元在特定空间位置通常每次仅编码单个输入信息的特性,也可理解为空间相邻元素往往源自同一数据点的局部一致性。CutMix的缺陷在于仅使用方形掩码限制了样本多样性。本节提出FMix——一种在保持局部一致性的同时最大化掩码可能性的掩码式MSDA方法。对于局部一致性,我们要求掩码主要由单一形状或连续区域构成,可视为最小化二值掩码在$\mathbf{\nabla}^{\leftarrow}0^{\bullet}$与$\mathbf{\hat{\Pi}}^{\epsilon}\mathbf{1}^{\epsilon}$间切换的次数。具体实现分为三步:首先从傅里叶空间采样低频灰度掩码,再通过阈值二值化。设$Z$为定义在$\mathcal{Z}=\mathbb{C}^{\bar{w}\times h}$上的复随机变量,其实部密度$p_{\Re(Z)}=\mathcal{N}(\mathbf{0},I_{w\times h})$,虚部密度$p_{\Im(Z)}=\mathcal{N}(\mathbf{0},I_{w\times h})$,其中$\Re$与$\mathfrak{I}$分别返回输入的实部和虚部。令$\operatorname{freq}(w,h)[i,j]$表示$w\times h$离散傅里叶变换第$i,j'$个频段对应的采样频率幅值。通过衰减高频分量可实现低通滤波:给定衰减功率$\delta$时,采用...

Fig. 2: Example masks and mixed images from CIFAR-10 for FMix with $\delta=3$ and $\lambda=0.5$ .
图 2: 使用 $\delta=3$ 和 $\lambda=0.5$ 参数时,CIFAR-10数据集上FMix生成的掩膜示例与混合图像。
$$
\mathrm{filter}({\bf z},\delta)[i,j]=\frac{{\bf z}[i,j]}{\mathrm{freq}(w,h)\left[i,j\right]^{\delta}}.
$$
$$
\mathrm{filter}({\bf z},\delta)[i,j]=\frac{{\bf z}[i,j]}{\mathrm{freq}(w,h)\left[i,j\right]^{\delta}}.
$$
Defining ${\mathcal{F}}^{-1}$ as the inverse discrete Fourier transform, we can obtain a grey-scale image with
定义 ${\mathcal{F}}^{-1}$ 为离散傅里叶逆变换,我们可以得到一个灰度图像
$$
G=\Re\big(\mathcal{F}^{-1}\big(\operatorname{filter}\big(Z,\delta\big)\big)\big)~.
$$
$$
G=\Re\big(\mathcal{F}^{-1}\big(\operatorname{filter}\big(Z,\delta\big)\big)\big)~.
$$
All that now remains is to convert the grey-scale image to a binary mask such that the mean value is some given $\lambda$ . Let $\mathrm{top}(n,{\bf x})$ return a set containing the top $n$ elements of the input $\mathbf{x}$ . Setting the top $\lambda w h$ elements of some grey-scale image $\mathbf{g}$ to have value $\mathbf{\hat{\Pi}}^{\epsilon}\mathbf{1}^{\epsilon}$ and all others to have value $\mathbf{\nabla}^{\leftarrow}0^{\cdot}$ we obtain a binary mask with mean $\lambda$ .
现在剩下的就是将灰度图像转换为二值掩码,使得平均值为某个给定的 $\lambda$。设 $\mathrm{top}(n,{\bf x})$ 返回一个包含输入 $\mathbf{x}$ 中前 $n$ 个元素的集合。将某个灰度图像 $\mathbf{g}$ 中前 $\lambda w h$ 个元素的值设为 $\mathbf{\hat{\Pi}}^{\epsilon}\mathbf{1}^{\epsilon}$,其余设为 $\mathbf{\nabla}^{\leftarrow}0^{\cdot}$,即可得到平均值为 $\lambda$ 的二值掩码。
To recap, we first sample a random complex tensor for which both the real and imaginary part are independent and Gaussian. We then scale each component according to its frequency via the parameter $\delta$ such that higher values of $\delta$ correspond to increased decay of high frequency information. Next, we perform an inverse Fourier transform on the complex tensor and take the real part to obtain a grey-scale image. Finally, we set the top proportion of the image to have value ‘1’ and the rest to have value $\mathrm{{}^{\cdot}0^{\cdot}}$ to obtain our binary mask. Although we have only considered two dimensional data here it is generally possible to create masks with any number of dimensions. We provide some example two dimensional masks and mixed images (with $\delta:=:3$ and $\lambda~=~0.5)$ in Figure 2. We can see that the space of artefacts is significantly increased, furthermore, FMix achieves $I(Z_{A};X)=83.67_{\pm0.89}.$ , $I(Z_{A};\hat{X})=80.28{\scriptstyle\pm0.75}$ , and $\mathrm{MSE}=0.255{\scriptstyle\pm0.003}$ , showing that learning from FMix simulates learning from the un-augmented data to an even greater extent than CutMix.
总结来说,我们首先对一个随机复数张量进行采样,其实部和虚部均为独立高斯分布。随后通过参数 $\delta$ 按频率缩放各分量,使得 $\delta$ 值越大对应高频信息的衰减越显著。接着对该复数张量执行逆傅里叶变换并取实部得到灰度图像。最后将图像顶部比例设为"1",其余部分设为 $\mathrm{{}^{\cdot}0^{\cdot}}$ 以生成二值掩码。虽然本文仅讨论二维数据,但该方法可推广至任意维度。图2展示了部分二维掩码与混合图像示例(参数 $\delta:=:3$ 和 $\lambda~=~0.5)$ 。可见该方法显著扩大了伪影空间,同时FMix实现了 $I(Z_{A};X)=83.67_{\pm0.89}$ 、 $I(Z_{A};\hat{X})=80.28{\scriptstyle\pm0.75}$ 和 $\mathrm{MSE}=0.255{\scriptstyle\pm0.003}$ ,表明相比CutMix,FMix能更有效地模拟未增强数据的学习过程。
V. EXPERIMENTS
V. 实验
We now perform a series of experiments to compare the performance of FMix with that of MixUp, CutMix, and augmented baselines. For each problem setting and data set, we provide exposition on the results and any relevant caveats.
我们现在进行一系列实验来比较FMix与MixUp、CutMix以及增强基线的性能。针对每个问题设置和数据集,我们将详细说明结果及相关注意事项。

Fig. 3: Ablation study showing the performance of a PreActResNet18 trained on CIFAR-10 with FMix. Performance increases with decay power up to a point (around $\delta=3$ ). Choice of $\alpha$ does not significantly impact performance.
图 3: 在CIFAR-10数据集上使用FMix训练的PreActResNet18消融研究。性能随衰减功率(decay power)提升至某临界点(约$\delta=3$)后趋于稳定。参数$\alpha$的选择对性能影响不显著。
Throughout, we use the hyper-parameters and light augmentations (flipping, normalisation, cropping, etc.) which yield the best results in the literature for each setting.
我们始终采用文献中针对每种设置效果最佳的超参数和轻度数据增强(翻转、归一化、裁剪等)。
In Figure 3, we perform an ablation study in order to identify sensible default values for the FMix hyper parameters $\alpha$ and $\delta$ . We see that all $\alpha$ values perform similarly, with a slight peak at $\alpha=1$ , which is equivalent to sampling the mixing coefficients from a uniform distribution. Consequently, we choose this value for the majority of our experiments. For decay powers $\delta<2$ , we see decreased accuracy and $\delta\geq2$ offering relatively consistent accuracy. We choose $\delta=3$ for this reason and since it was found to produce large artefacts with sufficient diversity as seen Figure 2.
在图3中,我们进行了消融实验以确定FMix超参数$\alpha$和$\delta$的合理默认值。结果显示所有$\alpha$值表现相近,其中$\alpha=1$时(相当于从均匀分布中采样混合系数)出现小幅峰值,因此我们在多数实验中选用该值。当衰减幂次$\delta<2$时准确率下降,而$\delta\geq2$能保持相对稳定的准确率。基于此我们选择$\delta=3$,同时该值如图2所示能生成具有足够多样性的显著伪影。
For all experiments, we perform repeats where possible and report the average performance and standard deviation after the last epoch of training. A complete discussion of the experimental set-up can be found in Appendix A along with the standard augmentations used for all models on each data set. In all tables, we give the best result and results that are within its margin of error in bold. We discuss any cases where the results obtained by us do not match the results obtained by the authors in the accompanying text, and give the authors results in parentheses. Uncertainty estimates are the standard deviation over 5 repeats. Code for all experiments is provided at https://github.com/ecs-vlc/FMix.
在所有实验中,我们尽可能进行重复实验,并报告训练最后一个周期后的平均性能和标准差。实验设置的完整讨论见附录A,同时列出了每个数据集上所有模型使用的标准数据增强方法。所有表格中,我们将最佳结果及其误差范围内的结果加粗显示。若我们获得的结果与原作者结果不一致,将在正文中讨论相关情况,并将原作者结果标注在括号内。不确定性估计为5次重复实验的标准差。所有实验代码详见 https://github.com/ecs-vlc/FMix。
A. Image Classification
A. 图像分类
We first discuss image classification results on the CIFAR10/100 [19], Fashion MNIST [35], and Tiny-ImageNet [36] data sets. Our experiments use the original version of the Fashion MNIST data set (the same data used with Random Erase [37]), which had some overlap between the train and test sets. As such, on the most recent version of the data set we would expect slightly (around $0.3%$ ) lower test performance. We train: PreAct-ResNet18 [38], WideResNet-28-10 [39], DenseNet-BC-190 [40] and PyramidNet-272-200 [41]. For PyramidNet, we additionally apply Fast Auto Augment [42], a successor to Auto Augment [43], and ShakeDrop [44] following Lim et al. [42]. The results in Table II show that FMix offers a significant improvement (greater than one standard deviation) over the other methods on test, with the exception of the WideResNet on CIFAR-10/100 and the PreAct-ResNet on Tiny-ImageNet. In combination with PyramidNet, FMix achieves, to the best of our knowledge, a new state-of-theart single model classification accuracy on CIFAR-10 without use of external data. By the addition of Fast Auto Augment, this setting bares some similarity to the recently proposed AugMix [45] which performs MixUp on heavily augmented variants of the same image. Note that Zhang et al. [2] also performed experiments with the PreAct-ResNet18, WideResNet28-10, and DenseNet-BC-190 on CIFAR-10 and CIFAR-100. There are some discrepancies between the authors results and the results obtained by our implementation. Whether any differences are significant is difficult to ascertain as no measure of deviation is provided in Zhang et al. [2]. However, since our implementation is based on the implementation from Zhang et al. [2], and most of the differences are small, we have no reason to doubt it. We speculate that these discrepancies are simply a result of random initial is ation, but could also be due to differences in reporting or training configuration (we report the average terminal accuracy, some works report the best accuracy achieved at any point during training).
我们首先讨论在CIFAR10/100 [19]、Fashion MNIST [35]和Tiny-ImageNet [36]数据集上的图像分类结果。实验采用Fashion MNIST数据集的原始版本(与Random Erase [37]所用数据相同),其训练集与测试集存在部分重叠。因此在最新版本数据集上,测试性能预计会略微下降(约$0.3%$)。我们训练了以下模型:PreAct-ResNet18 [38]、WideResNet-28-10 [39]、DenseNet-BC-190 [40]和PyramidNet-272-200 [41]。对于PyramidNet,我们额外应用了Auto Augment [43]的改进版Fast Auto Augment [42]以及ShakeDrop [44],具体实现参照Lim等人[42]的方法。表II结果显示,除CIFAR-10/100上的WideResNet和Tiny-ImageNet上的PreAct-ResNet外,FMix在测试集上的性能提升显著(超过一个标准差)。结合PyramidNet时,据我们所知,FMix在不使用外部数据的情况下实现了CIFAR-10单模型分类精度的新最优水平。通过引入Fast Auto Augment,该设置与近期提出的AugMix [45]存在相似性——后者对同一图像的多重增强变体进行MixUp操作。需注意Zhang等人[2]同样使用PreAct-ResNet18、WideResNet28-10和DenseNet-BC-190在CIFAR-10/100上进行了实验,其实验结果与我们的实现存在差异。由于Zhang等人[2]未提供偏差度量,这些差异是否显著难以判定。但鉴于我们的实现基于Zhang等人[2]的代码且多数差异较小,我们认为这些差异可能源于随机初始化,也可能由报告方式或训练配置差异导致(我们报告最终平均精度,部分研究则报告训练过程中的最佳精度)。
TABLE II: Image classification accuracy for our approach, FMix, against baselines for: PreAct-ResNet18 (ResNet), WideResNet-28-10 (WRN), DenseNet-BC-190 (Dense), PyramidNet-272-200 $^+$ ShakeDrop $^+$ Fast Auto Augment (Pyramid). Parentheses indicate author quoted result.
表 II: 我们的方法 FMix 与基线模型在图像分类准确率上的对比,包括:PreAct-ResNet18 (ResNet)、WideResNet-28-10 (WRN)、DenseNet-BC-190 (Dense)、PyramidNet-272-200 $^+$ ShakeDrop $^+$ Fast Auto Augment (Pyramid)。括号内为作者引用的结果。
| 数据集 | 模型 | 基线 | FMix | MixUp | CutMix |
|---|---|---|---|---|---|
| CIFAR-10 | ResNet | 94.63±0.21 | 96.14±0.10 | 95.66±0.11 | 96.00±0.07 |
| WRN | 95.25±0.10 | 96.38±0.06 | (97.3) 96.60±0.09 | 96.53±0.10 | |
| Dense | 96.26±0.08 | 97.30±0.05 | (97.3) 97.05±0.05 | 96.96±0.01 | |
| Pyramid | 98.31 | 98.64 | 97.92 | 98.24 | |
| CIFAR-100 | ResNet | 75.22±0.20 | 79.85±0.27 | (78.9) 77.44±0.50 | 79.51±0.38 |
| WRN | 78.26±0.25 | 82.03±0.27 | (82.5) 81.09±0.33 | 81.96±0.40 | |
| Dense | 81.73±0.30 | 83.95±0.24 | 83.23±0.30 | 82.79±0.46 | |
| Fashion MNIST | ResNet | 95.70±0.09 | 96.36±0.03 | 96.28±0.08 | 96.03±0.10 |
| WRN | 95.29±0.17 | 96.00±0.11 | 95.75±0.09 | 95.64±0.20 | |
| Dense | 95.84±0.10 | 96.26±0.10 | 96.30±0.04 | 96.12±0.13 | |
| Tiny-ImageNet | ResNet | 55.94±0.28 | 61.43±0.37 | 55.96±0.41 | 64.08±0.32 |
| Google commands | ResNet (α=1.0) | 97.69±0.04 | 98.59±0.03 | 98.46±0.08 | 98.46±0.08 |
| ResNet (α=0.2) | 98.44±0.06 | 98.31±0.08 | 98.48±0.06 | ||
| ModelNet10 | PointNet | 89.10±0.32 | 89.57±0.44 |
TABLE III: Classification performance for a ResNet101 trained on ImageNet for 90 epochs with a batch size of 256, and evaluated on ImageNet and ImageNet-a, adversarial examples to ImageNet. Note that Zhang et al. [2] (MixUp) use a batch size of 1024 and Yun et al. [6] (CutMix) train for 300 epochs, so these results should not be directly compared.
表 III: 在ImageNet上训练90个周期、批大小为256的ResNet101分类性能评估结果,测试集包括ImageNet和ImageNet-a(ImageNet对抗样本)。注意:Zhang等人[2](MixUp)使用批大小1024,Yun等人[6](CutMix)训练300个周期,这些结果不应直接比较。
| 数据集 | 0 | Baseline | FMix | MixUp | CutMix | ||||
|---|---|---|---|---|---|---|---|---|---|
| Top-1 | Top-5 | Top-1 | Top-5 | Top-1 | Top-5 | Top-1 | Top-5 | ||
| ImageNet | 1.0 | 77.28 | 93.63 | 77.42 | 93.92 | 75.89 | 93.06 | 76.92 | 93.55 |
| 0.2 | 77.70 | 93.97 | 77.23 | 93.81 | 76.72 | 93.46 | |||
| ImageNet-a | 1.0 | 4.08 | 28.87 | 7.19 | 33.65 | 8.69 | 34.89 | 6.92 | 34.03 |
| 0.2 | 5.32 | 31.21 | 5.81 | 31.43 | 6.08 | 31.56 |
Next, we obtain classification results on the ImageNet Large Scale Visual Recognition Challenge (ILSVRC2012) data set [46]. We train a ResNet-101 on the full data set (ImageNet), additionally evaluating on ImageNet-a [47], a set of natural adversarial examples to ImageNet models, to further assess adversarial robustness. We train for 90 epochs with a batch size of 256. We perform experiments with both $\alpha~= 1.0$ and $\alpha=0.2$ (as this was used by Zhang et al. [2]). The results, given in Table III, show that FMix was the only MSDA to provide an improvement over the baseline with these hyper-parameters. Note that MixUp obtains an accuracy of 78.5 in Zhang et al. [2] when using a batch size of 1024. Additionally note that MixUp obtains an accuracy of 79.48 and CutMix obtains an accuracy of 79.83 in Yun et al. [6] when training for 300 epochs. Due to hardware constraints we cannot replicate these settings and so it is not known how FMix would compare. On ImageNet-a, the general finding is that MSDA gives a good improvement in robustness to adversarial examples. Interestingly, MixUp with $\alpha~=~1.0$ yields a lower accuracy on ImageNet but a much higher accuracy on ImageNet-a. Since the ImageNet-a examples are chosen specifically to fool an ImageNet trained ResNet, good performance on ImageNet-a does not necessarily imply greater adversarial robustness. Instead, ImageNet-a performance can be viewed as a measure of how much the learned function differs from the baseline. These results support our argument since models which were less distorted (worse ImageNet-a performance) tended to perform better on ImageNet.
接下来,我们在ImageNet大规模视觉识别挑战赛(ILSVRC2012)数据集[46]上获得分类结果。我们在完整数据集(ImageNet)上训练ResNet-101,并额外在ImageNet-a[47](一组针对ImageNet模型的自然对抗样本)上进行评估,以进一步评估对抗鲁棒性。我们以256的批次大小训练90个周期,分别采用$\alpha~= 1.0$和$\alpha=0.2$(如Zhang等人[2]所用)进行实验。表III所示结果表明,在这些超参数下,FMix是唯一优于基线的MSDA方法。需注意,Zhang等人[2]在使用1024批次大小时,MixUp获得了78.5的准确率;而Yun等人[6]在训练300个周期时,MixUp和CutMix分别达到79.48和79.83的准确率。由于硬件限制,我们无法复现这些设置,因此无法比较FMix的表现。在ImageNet-a上,总体发现是MSDA显著提升了对抗样本的鲁棒性。有趣的是,使用$\alpha~=~1.0$的MixUp在ImageNet上准确率较低,但在ImageNet-a上却高得多。由于ImageNet-a样本是专门为欺骗ImageNet训练的ResNet而选,其良好表现未必意味着更强的对抗鲁棒性,而可视为学习函数与基线差异程度的度量。这些结果支持了我们的论点:扭曲程度较低的模型(ImageNet-a表现较差)往往在ImageNet上表现更好。
For a final experiment with image data, we use the Bengali.AI handwritten grapheme classification data set [48], from a recent Kaggle competition. Classifying graphemes is a multiclass problem, they consist of a root graphical form (a vowel or consonant, 168 classes) which is modified by the addition of other vowel (11 classes) or consonant (7 classes) diacritics. To correctly classify the grapheme requires classifying each of these individually, where only the root is necessarily always present. We train separate models for each sub-class, and report the individual classification accuracies and the combined accuracy (where the output is considered correct only if all three predictions are correct). We report results for 5 folds where $80%$ of the data is used for training and the rest for testing. We extract the region of the image which contains the grapheme and resize to $64\times64$ , performing no additional augmentation. The results for these experiments, with an SE-ResNeXt-50 [49, 50], are given in Table IV. FMix and CutMix both clearly offer strong improvement over the baseline and MixUp, with FMix performing significantly better than CutMix on the root and vowel classification tasks. As a result, FMix obtains a significant improvement when classifying the whole grapheme. In addition, note that FMix was used in the competition by Singer and Gordeev [51] in their second place prize-winning solution. This was the best result obtained with MSDA.
在最终的图像数据实验中,我们使用了来自近期Kaggle竞赛的Bengali.AI手写字素分类数据集[48]。字素分类是一个多类别问题,它们由基础图形形式(元音或辅音,168类)加上其他元音(11类)或辅音(7类)变音符号组成。要正确分类字素,需要分别对这三部分进行分类,其中只有基础图形必然始终存在。我们为每个子类训练了单独的模型,并分别报告了分类准确率及综合准确率(仅当三个预测全部正确时才视为正确输出)。实验采用5折交叉验证,其中80%数据用于训练,其余用于测试。我们提取包含字素的图像区域并缩放到64×64分辨率,未进行额外数据增强。使用SE-ResNeXt-50[49,50]的实验结果如表IV所示。FMix和CutMix均明显优于基线方法和MixUp,其中FMix在基础图形和元音分类任务上显著优于CutMix。因此,FMix在整个字素分类中获得了显著提升。此外需注意,FMix曾被Singer和Gordeev[51]用于该竞赛并获得第二名的获奖方案,这是采用MSDA方法取得的最佳成绩。
TABLE IV: Classification performance for FMix against baselines on Bengali grapheme classification [48] with an SEResNeXt-50 [49, 50].
表 IV: 在孟加拉语字形分类任务[48]中,FMix与基线方法(SEResNeXt-50[49,50])的性能对比
| 类别 | 基线方法 | FMix | MixUp | CutMix |
|---|---|---|---|---|
| 词根 | 92.86±0.20 | 96.13±0.14 | 94.80±0.10 | 95.74±0.20 |
| 辅音变音符号 | 96.23±0.35 | 97.05±0.23 | 96.42±0.42 | 96.96±0.21 |
| 元音变音符号 | 96.91±0.19 | 97.77±0.30 | 96.74±0.95 | 97.37±0.60 |
| 字形 | 87.60±0.45 | 91.87±0.30 | 89.23±1.04 | 91.08±0.49 |
B. Audio Classification
B. 音频分类
We now perform experiments on the Google Commands data set, which was created to promote deep learning research on speech recognition problems. It is comprised of 65,000 one second utterances of one of 30 words, with 10 of those words being the target classes and the rest considered unrelated or background noise. We perform MSDA on a Mel-frequency spec tr ogram of each utterance. The results for a PreAct ResNet-18 are given in Table II. We evaluate FMix, MixUp, and CutMix for the standard $\alpha=1$ used for the majority of our experiments and $\alpha=0.2$ recommended by Zhang et al. [2] for MixUp. We see in both cases that FMix and CutMix improve performance over MixUp outside the margin of error, with the best result achieved by FMix with $\alpha=1$ .
我们现在在Google Commands数据集上进行实验,该数据集旨在促进语音识别问题的深度学习研究。它包含65,000个1秒的语音片段,涵盖30个单词中的某一个,其中10个单词是目标类别,其余被视为无关或背景噪声。我们对每个语音片段的梅尔频谱图进行MSDA(多风格数据增强)。PreAct ResNet-18的结果如表II所示。我们评估了FMix、MixUp和CutMix在标准$\alpha=1$(我们大多数实验采用的参数)和$\alpha=0.2$(Zhang等人[2]为MixUp推荐的参数)下的表现。在这两种情况下,FMix和CutMix的性能提升均超出误差范围,其中最佳结果由$\alpha=1$的FMix取得。
C. Point Cloud Classification
C. 点云分类
We now demonstrate the extension of FMix to 3D through point cloud classification on ModelNet10 [52]. We transform the point clouds to a voxel representation before applying a 3D FMix mask. Table II reports the average median accuracy from the last 5 epochs, due to large variability in the results. Although mild, FMix does improve performance in this setting where neither MixUp nor CutMix can be used.
我们现在通过在ModelNet10 [52]上进行点云分类来展示FMix向3D的扩展。在应用3D FMix掩码之前,我们将点云转换为体素表示。由于结果存在较大波动性,表II报告了最后5个周期的平均中值准确率。尽管提升幅度不大,但在无法使用MixUp或CutMix的场景下,FMix确实能提高性能。
D. Sentiment Analysis
D. 情感分析
We can further extend the MSDA formulation for classification of one dimensional data. In Table V, we perform a series of experiments with MSDAs for the purpose of sentiment analysis. In order for MSDA to be effective, we group elements into batches of similar sequence length as is already a standard practice. This ensures that the mixing does not introduce multiple end tokens or other strange artefacts (as would be the case if batches were padded to a fixed length). The models used are: pre-trained FastText-300d [53] embedding followed by a simple three layer CNN [54], the FastText embedding followed by a two layer bi-directional LSTM [55], and pretrained Bert [56] provided by the Hugging Face transformers library [57]. For the LSTM and CNN models we compare MixUp and FMix with a baseline. For the Bert fine-tuning we do not compare to MixUp as the model input is a series of tokens, interpolations between which are meaningless. We first report results on the Toxic Comments [58] data set, a Kaggle competition to classify text into one of 6 classes. For this data set we report the ROC-AUC metric, as this was used in the competition. Note that these results are computed over the whole test set and are therefore not comparable to the competition scores, which were computed over a subset of the test data. In this setting, both MixUp and FMix provide an improvement over the baseline, with FMix consistently providing a further improvement over MixUp. The improvement when fine-tuning Bert with FMix is outside the margin of error of the baseline, but mild in comparison to the improvement obtained in the other settings. We additionally report results on the IMDb [59], Yelp binary, and Yelp fine-grained [60] data sets. For the IMDb data set, which has one tenth of the number of examples, we found $\alpha=0.2$ to give the best results for both MSDAs. Here, MixUp provides a clear improvement over both FMix and the baseline for both models. This suggests that MixUp may perform better when there are fewer examples.
我们可以进一步扩展MSDA(Manifold Spectral Data Augmentation)在一维数据分类上的应用。表V展示了一系列针对情感分析任务的MSDA对比实验。为确保增强有效性,我们按序列长度进行批处理(此为常规操作),避免混合操作引入多余终止符或异常伪影(固定长度填充会导致此类问题)。实验模型包括:基于预训练FastText-300d [53]词嵌入的三层CNN [54]、同词嵌入的双向双层LSTM [55],以及Hugging Face transformers库 [57]提供的预训练Bert [56]。LSTM和CNN模型对比了MixUp、FMix与基线的性能,而Bert微调实验未比较MixUp(因其Token序列插值无意义)。
首组实验在Toxic Comments [58]数据集(Kaggle六分类文本竞赛)上进行,采用竞赛指标ROC-AUC。需注意本文测试集为全集,与竞赛子集结果不可比。实验显示MixUp和FMix均优于基线,且FMix持续超越MixUp。虽然FMix微调Bert的提升超出误差范围,但幅度小于其他场景。
另在IMDb [59]、Yelp二分类及Yelp细粒度 [60]数据集上测试。样本量仅十分之一的IMDb数据集中,$\alpha=0.2$对两种MSDA效果最佳。此时两种模型下MixUp均显著优于FMix和基线,暗示少样本场景中MixUp可能更具优势。
TABLE V: Classification performance of FMix and baselines on sentiment analysis tasks. All models use $\alpha=1$ barring: Toxic Bert with $\alpha=0.1$ and IMDb CNN/BiLSTM with $\alpha=$ 0.2.
表 5: FMix与基线方法在情感分析任务上的分类性能。所有模型均使用$\alpha=1$,除了:Toxic Bert使用$\alpha=0.1$,IMDb CNN/BiLSTM使用$\alpha=0.2$。
| 数据集 | 模型 | 基线 | FMix | MixUp |
|---|---|---|---|---|
| Toxic (ROC-AUC) | CNN | 96.04±0.16 | 96.80±0.06 | 96.62±0.10 97.15±0.06 |
| BiLSTM | 96.72±0.04 | 97.35±0.05 | ||
| IMDb | Bert | 98.22±0.03 | 98.26±0.03 | |
| CNN BiLSTM | 86.68±0.50 88.29±0.17 | 87.31±0.34 88.47±0.24 | 88.94±0.13 88.72±0.17 | |
| YelpBinary | CNN | |||
| BiLSTM | 95.47±0.08 96.41±0.05 | 95.80±0.14 96.68±0.06 | 95.91±0.10 96.71±0.07 | |
| Yelp Fine-grained | CNN | |||
| BiLSTM | 63.78±0.18 62.96±0.18 | 64.46±0.07 66.46±0.13 | 64.56±0.12 66.11±0.13 |
$E.$ . Combining MSDAs
E. 结合MSDAs
We have established through our analysis that models trained with interpol at ive MSDA perform a different function to models trained with masking. We now wish to understand whether the benefits of interpolation and masking are mutually exclusive. We therefore perform experiments with simultaneous action of multiple MSDAs, alternating their application per batch with a PreAct-ResNet18 on CIFAR-10. A combination of interpolation and masking, particularly FMix+MixUp $(96.30_{\pm0.08})$ , gives the best results, with CutMix+MixUp performing slightly worse $(96.26_{\pm0.04})$ . In contrast, combining FMix and CutMix gives worse results $(95.85{\scriptstyle\pm0.1})$ than using either method on its own. For a final experiment, we note that our results suggest that interpolation performs better when there is less data available (e.g. the IMDb data set) and that masking performs better when there is more data available (e.g. ImageNet and the Bengali.AI data set). This finding is supported by our analysis since it is always easier for the model to learn specific features, and so we would naturally expect that preventing this is of greater utility, when there is less data. We confirm this empirically by varying the size of the CIFAR-10 training set and training with different MSDAs in Figure 4. Notably, the FMix $^{+}$ MixUp policy obtains superior performance irrespective of the amount of available data.
通过分析我们发现,采用插值法(interpolative) MSDA训练的模型与掩码(masking)训练的模型具有不同功能。现在我们希望探究插值与掩码的优势是否互斥。为此,我们在CIFAR-10数据集上使用PreAct-ResNet18,通过每批次交替应用多种MSDA方法进行组合实验。其中插值与掩码的组合(特别是FMix+MixUp $(96.30_{\pm0.08})$)效果最佳,CutMix+MixUp组合 $(96.26_{\pm0.04})$ 略逊一筹。而FMix与CutMix的组合 $(95.85{\scriptstyle\pm0.1})$ 则比单独使用任一方法效果更差。最后实验表明:插值法在数据量较少时(如IMDb数据集)表现更优,而掩码法在数据充足时(如ImageNet和Bengali.AI数据集)效果更好。这一发现与我们的分析一致——模型总是更容易学习具体特征,因此在数据不足时限制这种特性会更有价值。我们通过调整CIFAR-10训练集规模并搭配不同MSDA方法进行实证验证(见图4)。值得注意的是,FMix$^{+}$MixUp策略在不同数据量下均能保持优异性能。

Fig. 4: CIFAR-10 performance for a PreAct-ResNet18 as we change the amount of training data.
图 4: 展示 PreAct-ResNet18 在 CIFAR-10 数据集上随训练数据量变化的性能表现。
VI. CONCLUSIONS AND FUTURE WORK
VI. 结论与未来工作
In this paper we have introduced FMix, a masking MSDA that improves classification performance for a series of models, modalities, and dimensional i ties. We believe the strength of masking methods resides in preserving local features and we improve upon existing approaches by increasing the number of possible mask shapes. We have verified this intuition through a novel analysis. Our analysis shows that interpolation causes models to encode more general features, whereas masking causes models to encode the same information as when trained with the original data whilst eliminating mem or is ation. Our preliminary experiments suggest that combining interpolative and masking MSDA could improve performance further, although further work is needed to fully understand this phenomenon. Future work should also look to expand on the finding that masking MSDA works well in combination with Fast Auto Augment [42], perhaps by experimenting with similar methods like Auto Augment [43] or Rand Augment [61].
本文介绍了FMix,一种掩码式多模态数据增强(MSDA)方法,能提升多种模型、模态和维度下的分类性能。我们认为掩码方法的优势在于保留局部特征,并通过增加掩码形状的多样性改进了现有方法。通过创新性分析验证了这一观点:插值法会促使模型编码更通用的特征,而掩码法则使模型编码与原始数据训练时相同的信息,同时避免记忆效应。初步实验表明,结合插值与掩码的MSDA可能进一步提升性能,但需进一步研究该现象。未来工作可拓展掩码MSDA与快速自动增强[42]的协同效应,尝试与自动增强[43]、随机增强[61]等方法结合实验。
APPENDIX A EXPERIMENTAL DETAILS
附录 A 实验细节
In this section we provide the experimental details for all experiments presented in the main paper. Unless otherwise stated, the following parameters are chosen: $\alpha=1$ , $\delta=3$ , weight decay of $1\times10^{4}$ and optimised using SGD with momentum of 0.9. For cross validation experiments, 3 or 5 folds of $10%$ of the training data are generated and used for a single run each. Test set experiments use the entire training set and give evaluations on the test sets provided. If no test set is provided then a constant validation set of $10%$ of the available data is used. Table VI provides general training details that were present in all experiments.
在本节中,我们提供了主论文中所有实验的详细说明。除非另有说明,以下参数均采用默认设置:$\alpha=1$、$\delta=3$、权重衰减为$1\times10^{4}$,并使用动量0.9的SGD优化器进行优化。对于交叉验证实验,每次运行会生成并采用训练数据中3折或5折的$10%$作为验证集。测试集实验则使用完整训练集,并在提供的测试集上进行评估。若未提供测试集,则固定使用可用数据中$10%$作为验证集。表VI列出了所有实验共有的通用训练参数。
All experiments were run on a single GTX1080ti or V100, with the exceptions of ImageNet experiments $(4\times$ GTX1080ti) and DenseNet/PyramidNet experiments $(2\times$ V100). ResNet18 and LSTM experiments ran within 2 hours in all instances, PointNet experiments ran within 10 hours, WideResNet/DenseNet experiments ran within 2.5 days and auto-augment experiments ran within 10 days. For all image experiments we use standard augmentations to normalise the image to [0, 1] and perform random crops and random horizontal flips. For the google commands experiment we used the transforms and augmentations implemented here https://github. com/tugstugi/pytorch-speech-commands for their solution to the tensorflow speech recognition challenge.
所有实验均在单块GTX1080ti或V100上运行,ImageNet实验 $(4\times$ GTX1080ti) 和DenseNet/PyramidNet实验 $(2\times$ V100) 除外。ResNet18和LSTM实验在所有情况下均在2小时内完成,PointNet实验在10小时内完成,WideResNet/DenseNet实验在2.5天内完成,自动增强实验在10天内完成。对于所有图像实验,我们使用标准增强方法将图像归一化至[0, 1]范围,并进行随机裁剪和水平翻转。在Google语音命令实验中,我们采用了该解决方案中实现的变换和增强方法 (https://github.com/tugstugi/pytorch-speech-commands) ,该方案曾用于TensorFlow语音识别挑战赛。