SPIdepth: Strengthened Pose Information for Self-supervised Monocular Depth Estimation
SPIdepth: 增强位姿信息的自监督单目深度估计
Abstract
摘要
Self-supervised monocular depth estimation has garnered considerable attention for its applications in autonomous driving and robotics. While recent methods have made strides in leveraging techniques like the Self Query Layer (SQL) to infer depth from motion, they often overlook the potential of strengthening pose information. In this paper, we introduce SPIdepth, a novel approach that prioritizes enhancing the pose network for improved depth estimation. Building upon the foundation laid by SQL, SPIdepth emphasizes the importance of pose information in capturing fine-grained scene structures. By enhancing the pose network’s capabilities, SPIdepth achieves remarkable advancements in scene understanding and depth estimation. Experimental results on benchmark datasets such as KITTI, Cityscapes, and Make3D showcase SPIdepth’s state-of-the-art performance, surpassing previous methods by significant margins. Specifically, SPIdepth tops the self-supervised KITTI benchmark. Additionally, SPIdepth achieves the lowest AbsRel (0.029), SqRel (0.069), and RMSE (1.394) on KITTI, establishing new state-of-theart results. On Cityscapes, SPIdepth shows improvements over SQLdepth of $2l.7%$ in AbsRel, $36.8%$ in SqRel, and $16.5%$ in RMSE, even without using motion masks. On Make3D, SPIdepth in zero-shot outperforms all other models. Remarkably, SPIdepth achieves these results using only a single image for inference, surpassing even methods that utilize video sequences for inference, thus demonstrating its efficacy and efficiency in real-world applications. Our approach represents a significant leap forward in self-supervised monocular depth estimation, underscoring the importance of strengthening pose information for advancing scene understanding in real-world applications. The code and pre-trained models are publicly available at https://github.com/Lavreniuk/SPIdepth.
自监督单目深度估计因其在自动驾驶和机器人领域的应用而备受关注。尽管现有方法通过自查询层(SQL)等技术从运动中推断深度取得了进展,但往往忽视了强化位姿信息的潜力。本文提出SPIdepth,这是一种通过优先增强位姿网络来改进深度估计的新方法。基于SQL框架,SPIdepth强调了位姿信息在捕捉细粒度场景结构中的重要性。实验结果表明,在KITTI、Cityscapes和Make3D等基准数据集上,SPIdepth以显著优势超越了现有方法。具体而言,SPIdepth在自监督KITTI基准测试中排名第一,并创下最低的AbsRel(0.029)、SqRel(0.069)和RMSE(1.394)记录。在Cityscapes数据集上,即使不使用运动掩码,SPIdepth相较SQLdepth在AbsRel指标提升2.7%,SqRel提升36.8%,RMSE提升16.5%。在Make3D的零样本测试中,SPIdepth超越了所有对比模型。值得注意的是,SPIdepth仅需单张图像即可实现这些成果,其性能甚至优于依赖视频序列进行推理的方法。代码和预训练模型已开源:https://github.com/Lavreniuk/SPIdepth。
1. Introduction
1. 引言
Monocular depth estimation is a critical component in the field of computer vision, with far-reaching applications in autonomous driving and robotics [14, 8, 1]. The evolution of this field has been marked by a transition towards self-supervised methods, which aim to predict depth from a single RGB image without extensive labeled data. These methods offer a promising alternative to traditional supervised approaches, which often require costly and timeconsuming data collection processes by sensors such as LiDAR [45, 57, 30, 48, 11].
单目深度估计是计算机视觉领域的关键组成部分,在自动驾驶和机器人技术中具有深远应用 [14, 8, 1]。该领域的发展呈现出向自监督方法的转变趋势,这类方法旨在无需大量标注数据的情况下从单张RGB图像预测深度。相较于传统监督方法(通常需要LiDAR等传感器进行昂贵耗时的数据采集 [45, 57, 30, 48, 11]),这些方法提供了极具前景的替代方案。
Recent advancements have seen the emergence of novel techniques that utilize motion cues and the Self Query Layer (SQL) to infer depth information [45]. Despite their contributions, these methods have not fully capitalized on the potential of pose estimation. Addressing this gap, we present SPIdepth, approach that prioritizes the refinement of the pose network to enhance depth estimation accuracy. By focusing on the pose network, SPIdepth captures the intricate details of scene structures more effectively, leading to significant improvements in depth prediction.
近期研究进展中,涌现出利用运动线索和自查询层(SQL)推断深度信息的新技术[45]。尽管这些方法有所贡献,但尚未充分挖掘姿态估计的潜力。为此,我们提出SPIdepth方法,通过优先优化姿态网络来提升深度估计精度。该方法聚焦姿态网络,能更有效地捕捉场景结构的复杂细节,从而显著改进深度预测效果。
SPIdepth extends the capabilities of SQL by strengthened robust pose information, which is crucial for interpreting complex spatial relationships within a scene. Our extensive evaluations on benchmark datasets such as KITTI, Cityscapes, Make3D and demonstrate SPIdepth’s superior performance, surpassing previous self-supervised methods in both accuracy and generalization capabilities. Remarkably, SPIdepth achieves these results using only a single image for inference, outperforming methods that rely on video sequences. Specifically, SPIdepth tops the self-supervised KITTI benchmark. Additionally, SPIdepth achieves the lowest AbsRel (0.029), SqRel (0.069), and RMSE (1.394) on KITTI, establishing new state-of-the-art results. On Cityscapes, SPIdepth shows improvements over SQLdepth of $21.7%$ in AbsRel, $36.8%$ in SqRel, and $16.5%$ in RMSE, even without using motion masks. On Make3D, SPIdepth in zero-shot outperforms all other models.
SPIdepth通过增强的鲁棒位姿信息扩展了SQL的功能,这对于解析场景内复杂的空间关系至关重要。我们在KITTI、Cityscapes、Make3D等基准数据集上的大量评估表明,SPIdepth在精度和泛化能力上均超越了以往的自监督方法,仅需单张图像进行推理即可超越依赖视频序列的方法。具体而言,SPIdepth在自监督KITTI基准测试中排名第一,并以AbsRel(0.029)、SqRel(0.069)和RMSE(1.394)创下KITTI最低误差记录,确立了新的技术标杆。在Cityscapes数据集上,即使不使用运动掩码,SPIdepth相较SQLdepth在AbsRel(提升21.7%)、SqRel(提升36.8%)和RMSE(提升16.5%)指标上均取得显著改进。在Make3D的零样本测试中,SPIdepth性能优于所有其他模型。
The contributions of SPIdepth are significant, establishing a new state-of-the-art in the domain of depth estimation. It underscores the importance of enhancing pose estimation within the self-supervised learning. Our findings suggest that incorporating strong pose information is essential for advancing autonomous technologies and improving scene
SPIdepth的贡献显著,在深度估计领域确立了新的技术标杆。该研究强调了在自监督学习中提升姿态估计的重要性。我们的研究结果表明,整合强姿态信息对于推动自主技术进步和优化场景理解至关重要。
understanding.
理解。
Our main contributions are as follows:
我们的主要贡献如下:
• Introducing SPIdepth, a novel self-supervised approach that significantly improves monocular depth estimation by focusing on the refinement of the pose network. This enhancement allows for more precise capture of scene structures, leading to substantial advancements in depth prediction accuracy.
• 介绍SPIdepth,这是一种新颖的自监督方法,通过专注于位姿网络(pose network)的优化,显著改进了单目深度估计。这一增强能够更精确地捕捉场景结构,从而大幅提升深度预测的准确性。
• Our self-supervised method sets a new benchmark in depth estimation, outperforming all existing methods on standard datasets like KITTI and Cityscapes using only a single image for inference, without the need for video sequences. Additionally, our approach achieves significant improvements in zero-shot performance on the Make3D dataset.
• 我们的自监督方法为深度估计设立了新标杆,仅需单张图像进行推理(无需视频序列),就在KITTI和Cityscapes等标准数据集上超越了所有现有方法。此外,该方法在Make3D数据集上实现了零样本性能的显著提升。
2. Related works
2. 相关工作
2.1. Supervised Depth Estimation
2.1. 监督式深度估计
The field of depth estimation has been significantly advanced by the introduction of learning-based methods, with Eigen et al. [10] that used a multiscale convolutional neural network as well as a scale-invariant loss function. Subsequent methods have typically fallen into two categories: regression-based approaches [10, 20, 58] that predict continuous depth values, and classification-based approaches [12, 7] that predict discrete depth levels.
深度估计领域因引入基于学习的方法而取得显著进展,其中Eigen等人[10]率先使用多尺度卷积神经网络和尺度不变损失函数。后续方法通常分为两类:预测连续深度值的回归方法[10, 20, 58],以及预测离散深度级别的分类方法[12, 7]。
To leverage the benefits of both methods, recent works [3, 21] have proposed a combined classification-regression approach. This method involves regressing a set of depth bins and then classifying each pixel to these bins, with the final depth being a weighted combination of the bin centers.
为了结合两种方法的优势,近期研究[3, 21]提出了一种分类-回归联合方法。该方法通过回归一组深度区间,然后将每个像素分类到这些区间中,最终深度为区间中心的加权组合。
2.2. Diffusion Models in Vision Tasks
2.2. 视觉任务中的扩散模型
Diffusion models, which are trained to reverse a forward noising process, have recently been applied to vision tasks, including depth estimation. These models generate realistic images from noise, guided by text prompts that are encoded into embeddings and influence the reverse diffusion process through cross-attention layers [36, 18, 29, 34, 37].
扩散模型 (Diffusion models) 通过训练逆转前向加噪过程,近期被应用于视觉任务(包括深度估计)。这类模型在文本提示的引导下从噪声生成逼真图像,其中文本提示被编码为嵌入向量,并通过交叉注意力层 [20] 影响逆向扩散过程 [36, 18, 29, 34, 37]。
The VPD approach [59] encodes images into latent represent at ions and processes them through the Stable Diffusion model [36]. Text prompts, through cross-attention, guide the reverse diffusion process, influencing the latent representations and feature maps. This method has shown that aligning text prompts with images significantly improves depth estimation performance. Different newer model further improve the accuracy of multi modal models based on Stable Diffusion [23, 22].
VPD方法 [59] 将图像编码为潜在表征(latent representations),并通过Stable Diffusion模型 [36] 进行处理。文本提示(prompt)通过交叉注意力机制引导逆向扩散过程,影响潜在表征和特征图。该方法表明,将文本提示与图像对齐能显著提升深度估计性能。基于Stable Diffusion的更新模型 [23, 22] 进一步提高了多模态模型的准确性。
2.3. Self-supervised Depth Estimation
2.3. 自监督深度估计
Ground truth data is not always available, prompting the development of self-supervised models that leverage either the temporal consistency found in sequences of monocular videos [61, 16], or the spatial correspondence in stereo vision [13, 15, 32].
真实标注数据并非总是可用,这促使了自监督模型的发展。这些模型要么利用单目视频序列中的时间一致性 [61, 16],要么利用立体视觉中的空间对应关系 [13, 15, 32]。
When only single-view inputs are available, models are trained to find coherence between the generated perspective of a reference point and the actual perspective of a related point. The initial framework SfMLearner [61], was developed to learn depth estimation in conjunction with pose prediction, driven by losses based on photometric alignment. This approach has been refined through various methods, such as enhancing the robustness of image reconstruction losses [17, 41], introducing feature-level loss functions [41, 56], and applying new constraints to the learning process [53, 54, 35, 63, 2].
当仅能获取单视图输入时,模型通过训练来寻找参考点生成视角与关联点真实视角之间的一致性。初始框架SfMLearner [61] 被开发用于结合位姿预测来学习深度估计,其驱动力来自基于光度对齐的损失函数。该方法通过多种途径得到改进,例如提升图像重建损失的鲁棒性 [17, 41]、引入特征级损失函数 [41, 56],以及对学习过程施加新约束 [53, 54, 35, 63, 2]。
In scenarios where stereo image pairs are available, the focus shifts to deducing the disparity map, which inversely correlates with depth [39]. This disparity estimation is crucial as it serves as a proxy for depth in the absence of direct measurements. The disparity maps are computed by exploiting the known geometry and alignment of stereo camera setups. With stereo pairs, the disparity calculation becomes a matter of finding correspondences between the two views. Early efforts in this domain, such as the work by Garg et al. [13], laid the groundwork for self-supervised learning paradigms that rely on the consistency of stereo images. These methods have been progressively enhanced with additional constraints like left-right consistency checks [15].
在可获得立体图像对的场景中,重点转向推断视差图(disparity map),其与深度呈反比关系 [39]。视差估计至关重要,因为在缺乏直接测量的情况下,它可作为深度的替代指标。通过利用立体相机设置的已知几何和对齐关系来计算视差图。对于立体图像对,视差计算转化为寻找两个视图间对应关系的问题。该领域的早期工作(如Garg等人 [13] 的研究)为依赖立体图像一致性的自监督学习范式奠定了基础。这些方法通过左右一致性检查 [15] 等附加约束逐步得到增强。
Parallel to the pursuit of depth estimation is the broader field of unsupervised learning from video. This area explores the development of pretext tasks designed to extract versatile visual features from video data. These features are foundational for a variety of vision tasks, including object detection and semantic segmentation. Notable tasks in this domain include ego-motion estimation, tracking, ensuring temporal coherence, verifying the sequence of events, and predicting motion masks for objects. [42] have also proposed a framework for the joint training of depth, camera motion, and scene motion from videos.
与深度估计研究并行的是更广泛的视频无监督学习领域。该领域探索如何设计预训练任务,以从视频数据中提取通用的视觉特征。这些特征是多种视觉任务的基础,包括目标检测和语义分割。该领域的代表性任务包括:自我运动估计、目标追踪、时序一致性保持、事件序列验证以及物体运动掩码预测。[42] 还提出了一个联合训练框架,可从视频中同步学习深度、相机运动和场景运动。
While self-supervised methods for depth estimation have advanced, they still fall short in effectively using pose data.
虽然自监督深度估计方法已取得进展,但在有效利用位姿数据方面仍有不足。
3. Methodology
3. 方法论
We address the task of self-supervised monocular depth estimation, focusing on predicting depth maps from single RGB images without ground truth, akin to learning structure from motion (SfM). Our approach, SPIdepth fig. 1, introduces strengthen the pose network and enhances depth estimation accuracy. Unlike conventional methodologies that primarily focus on depth refinement, SPIdepth prioritizes improving the accuracy of the pose network to capture intricate scene structures more effectively, leading to significant advancements in depth prediction accuracy.
我们致力于自监督单目深度估计任务,重点研究从单张RGB图像预测深度图而无需真实值,类似于从运动恢复结构(SfM)的学习方式。我们的方法SPIdepth(图1)通过强化位姿网络来提升深度估计精度。与传统方法主要关注深度优化不同,SPIdepth优先提高位姿网络的准确性,从而更有效地捕捉复杂场景结构,实现深度预测精度的显著提升。
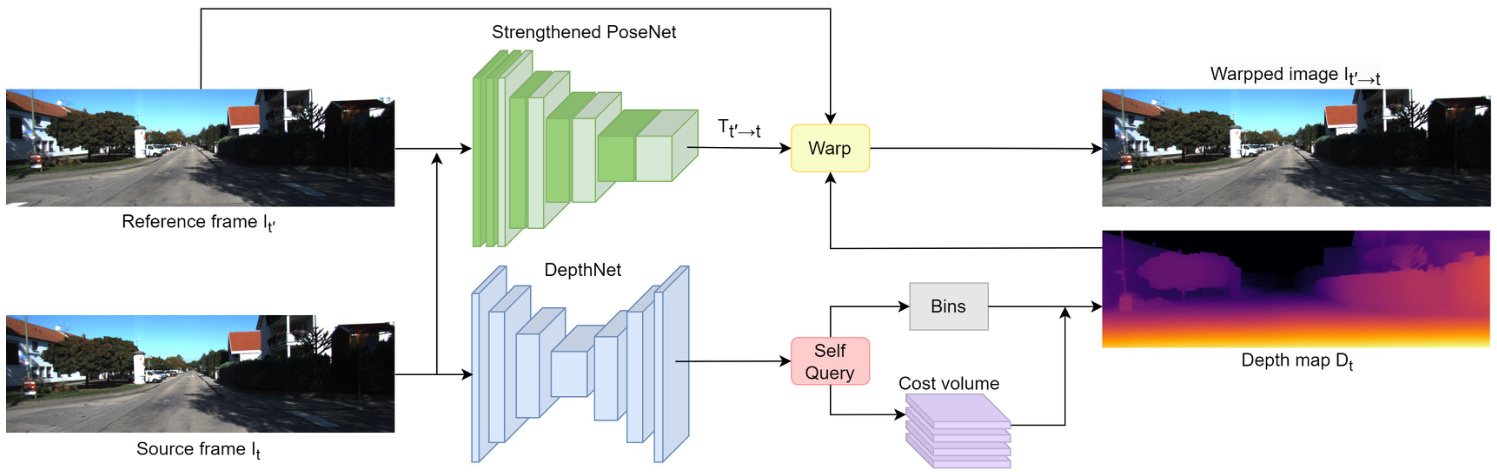
Figure 1: The SPIdepth architecture. An encoder-decoder extracts features from frame $I_{t}$ , which are then input into the Self Query Layer to obtain the depth map $D_{t}$ . Strengthened PoseNet predicts the relative pose between frame $I_{t}$ and reference frame $I_{t}^{\prime}$ using a powerful pose network, needed only during training. Pixels from frame $I_{t}^{\prime}$ are used to reconstruct frame $I_{t}$ with depth map $D_{t}$ and relative pose $T_{t^{\prime}\rightarrow t}$ . The loss function is based on the differences between the warped image $I_{t^{\prime}\rightarrow t}$ and the source image $I_{t}$ .
图 1: SPIdepth架构。编码器-解码器从帧$I_{t}$中提取特征,随后输入至自查询层(Self Query Layer)以获取深度图$D_{t}$。强化位姿网络(Strengthened PoseNet)通过高性能位姿网络预测帧$I_{t}$与参考帧$I_{t}^{\prime}$间的相对位姿,该网络仅在训练阶段需要。利用深度图$D_{t}$和相对位姿$T_{t^{\prime}\rightarrow t}$,通过帧$I_{t}^{\prime}$的像素重建帧$I_{t}$。损失函数基于变形图像$I_{t^{\prime}\rightarrow t}$与源图像$I_{t}$之间的差异构建。
Our method comprises two primary components: DepthNet for depth prediction and PoseNet for relative pose estimation.
我们的方法包含两个主要组件:用于深度预测的DepthNet和用于相对位姿估计的PoseNet。
DepthNet: Our method employs DepthNet, a cornerstone component responsible for inferring depth maps from single RGB images. To achieve this, DepthNet utilizes a sophisticated convolutional neural network architecture, designed to extract intricate visual features from the input images. These features are subsequently processed through an encoder-decoder framework, facilitating the extraction of detailed and high-resolution visual representations denoted as $\mathbf{S}$ with dimensions $\mathbb{R}^{C\times h\times w}$ . The integration of skip connections within the network architecture enhances the preservation of local fine-grained visual cues.
DepthNet: 我们的方法采用DepthNet作为核心组件,负责从单张RGB图像推断深度图。为此,DepthNet采用精心设计的卷积神经网络架构,能够从输入图像中提取复杂的视觉特征。这些特征随后通过编码器-解码器框架进行处理,从而提取出维度为$\mathbb{R}^{C\times h\times w}$的精细高分辨率视觉表示$\mathbf{S}$。网络架构中跳跃连接(skip connections)的集成增强了局部细粒度视觉线索的保留能力。
The depth estimation process could be written as:
深度估计过程可以表示为:
$$
D_{t}=\mathrm{DepthNet}(I_{t})
$$
$$
D_{t}=\mathrm{DepthNet}(I_{t})
$$
where $I_{t}$ denotes the input RGB image.
其中 $I_{t}$ 表示输入的 RGB 图像。
To ensure the efficacy and accuracy of DepthNet, we leverage a state-of-the-art ConvNext as the pretrained encoder. ConvNext’s ability to learn from large datasets helps DepthNet capture detailed scene structures, improving depth prediction accuracy.
为确保DepthNet的效能和准确性,我们采用了最先进的ConvNext作为预训练编码器。ConvNext从大型数据集学习的能力有助于DepthNet捕捉细致的场景结构,从而提升深度预测的准确度。
PoseNet: PoseNet plays a crucial role in our methodology, estimating the relative pose between input and reference images for view synthesis. This estimation is essential for accurately aligning the predicted depth map with the reference image during view synthesis. To achieve robust and accurate pose estimation, PoseNet utilizes a powerful pretrained model, such as a ConvNet or Transformer. Leveraging the representations learned by the pretrained model enhances the model’s ability to capture complex scene structures and geometric relationships, ultimately improving depth estimation accuracy. Given a source image $I_{t}$ and a reference image $I_{t^{\prime}}$ , PoseNet predicts the relative pose $T_{t\rightarrow t^{\prime}}$ . The predicted depth map $D_{t}$ and relative pose $T_{t\rightarrow t^{\prime}}$ are then used to perform view synthesis:
PoseNet: PoseNet 在我们的方法中起着关键作用,用于估计输入图像与参考图像之间的相对位姿,以进行视图合成。这一估计对于在视图合成过程中将预测的深度图与参考图像准确对齐至关重要。为了实现稳健且精确的位姿估计,PoseNet 采用了强大的预训练模型,例如 ConvNet 或 Transformer。利用预训练模型学习到的表征,增强了模型捕捉复杂场景结构和几何关系的能力,最终提升了深度估计的准确性。给定源图像 $I_{t}$ 和参考图像 $I_{t^{\prime}}$,PoseNet 预测相对位姿 $T_{t\rightarrow t^{\prime}}$。随后,预测的深度图 $D_{t}$ 和相对位姿 $T_{t\rightarrow t^{\prime}}$ 被用于执行视图合成:
$$
I_{t^{\prime}\rightarrow t}=I_{t^{\prime}}\left\langle\mathrm{proj}\left(D_{t},T_{t\rightarrow t^{\prime}},K\right)\right\rangle
$$
$$
I_{t^{\prime}\rightarrow t}=I_{t^{\prime}}\left\langle\mathrm{proj}\left(D_{t},T_{t\rightarrow t^{\prime}},K\right)\right\rangle
$$
where $\langle\rangle$ denotes the sampling operator and proj returns the 2D coordinates of the depths in $D_{t}$ when re projected into the camera view of $I_{t^{\prime}}$ .
其中 $\langle\rangle$ 表示采样运算符,proj 返回深度图 $D_{t}$ 中的深度值重投影到 $I_{t^{\prime}}$ 相机视图时的二维坐标。
To capture intra-geometric clues for depth estimation, we employ a Self Query Layer (SQL) [45]. The SQL builds a self-cost volume to store relative distance representations, approximating relative distances between pixels and patches. Let S denote the immediate visual representations extracted by the encoder-decoder. The self-cost volume $\mathbf{V}$ is calculated as follows:
为了捕捉深度估计中的内部几何线索,我们采用了自查询层(SQL) [45]。该层通过构建自代价体积来存储相对距离表征,从而近似像素与图像块之间的相对距离。设S表示编码器-解码器提取的即时视觉表征,自代价体积$\mathbf{V}$的计算方式如下:
$$
V_{i,j,k}=Q_{i}^{T}\cdot S_{j,k}
$$
$$
V_{i,j,k}=Q_{i}^{T}\cdot S_{j,k}
$$
where $Q_{i}$ represents the coarse-grained queries, and $S_{j,k}$ denotes the per-pixel immediate visual representations.
其中 $Q_{i}$ 表示粗粒度查询,$S_{j,k}$ 表示逐像素的即时视觉表征。
We calculate depth bins by tallying latent depths within the self-cost volume $\mathbf{V}$ . These bins portray the distribution of depth values and are determined through regression using a multi-layer perceptron (MLP) to estimate depth. The process for computing the depth bins is as follows:
我们通过统计自代价体积 $\mathbf{V}$ 中的潜在深度来计算深度区间。这些区间描述了深度值的分布,并通过使用多层感知机 (MLP) 进行回归来估计深度。计算深度区间的过程如下:
$$
\mathbf{b}=\mathbf{MLP}\left(\bigoplus_{i=1}^{Q}\sum_{(j,k)=(1,1)}^{(h,w)}\operatorname{softmax}(V_{i})_{j,k}\cdot S_{j,k}\right)
$$
$$
\mathbf{b}=\mathbf{MLP}\left(\bigoplus_{i=1}^{Q}\sum_{(j,k)=(1,1)}^{(h,w)}\operatorname{softmax}(V_{i})_{j,k}\cdot S_{j,k}\right)
$$
Here, $\oplus$ denotes concatenation, $Q$ represents the number of coa rse-grained queries, and $h$ and $w$ are the height and width of the immediate visual representations.
这里,$\oplus$ 表示连接操作,$Q$ 代表粗粒度查询的数量,$h$ 和 $w$ 则是即时视觉表征的高度和宽度。
To generate the final depth map, we combine depth estimations from coarse-grained queries using a probabilistic linear combination approach. This involves applying a plane-wise softmax operation to convert the self-cost volume V into plane-wise probabilistic maps, which facilitates depth calculation for each pixel.
为生成最终深度图,我们采用概率线性组合方法整合来自粗粒度查询的深度估计。具体而言,通过应用平面级softmax运算将自代价体积(self-cost volume) V转换为平面级概率图,从而计算每个像素的深度。
During training, both DepthNet and PoseNet are simultaneously optimized by minimizing the photometric reprojection error. We adopt established methodologies [13, 61, 62], optimizing the loss for each pixel by selecting the per-pixel minimum over the reconstruction loss $p e$ defined in Equation 1, where $t^{\prime}$ ranges within $(t-1,t+1)$ .
在训练过程中,DepthNet和PoseNet通过最小化光度重投影误差同时进行优化。我们采用已有方法 [13, 61, 62],通过选择公式1中定义的重构损失$pe$的逐像素最小值来优化每个像素的损失,其中$t^{\prime}$的取值范围为$(t-1,t+1)$。
$$
L_{p}=\operatorname*{min}{t^{\prime}}p e\left(I_{t},I_{t^{\prime}\rightarrow t}\right)
$$
$$
L_{p}=\operatorname*{min}{t^{\prime}}p e\left(I_{t},I_{t^{\prime}\rightarrow t}\right)
$$
In real-world scenarios, stationary cameras and dynamic objects can influence depth prediction. We utilize an automasking strategy [16] to filter stationary pixels and lowtexture regions, ensuring s cal ability and adaptability.
在实际场景中,静态摄像头和动态物体会影响深度预测。我们采用自动掩码策略 [16] 来过滤静止像素和低纹理区域,确保可扩展性和适应性。
We employ the standard photometric loss combined with L1 and SSIM [46] as shown in Equation 2.
我们采用结合了L1和SSIM [46]的标准光度损失,如公式2所示。
$$
p e\left(I_{a},I_{b}\right)=\frac{\alpha}{2}\left(1-\mathrm{SSIM}\left(I_{a},I_{b}\right)\right)+\left(1-\alpha\right)\left\Vert I_{a}-I_{b}\right\Vert_{1}
$$
$$
p e\left(I_{a},I_{b}\right)=\frac{\alpha}{2}\left(1-\mathrm{SSIM}\left(I_{a},I_{b}\right)\right)+\left(1-\alpha\right)\left\Vert I_{a}-I_{b}\right\Vert_{1}
$$
To regularize depth in texture less regions, edge-aware smooth loss is utilized.
为了在无纹理区域规范化深度,采用了边缘感知平滑损失。
$$
L_{s}=|\partial_{x}d_{t}^{}|e^{-|\partial_{x}I_{t}|}+|\partial_{y}d_{t}^{*}|e^{-|\partial_{y}I_{t}|}
$$
$$
L_{s}=|\partial_{x}d_{t}^{}|e^{-|\partial_{x}I_{t}|}+|\partial_{y}d_{t}^{*}|e^{-|\partial_{y}I_{t}|}
$$
We apply an auto-masking strategy to filter out stationary pixels and low-texture regions consistently observed across frames.
我们采用自动掩码策略来过滤掉在连续帧中观察到的静止像素和低纹理区域。
The final training loss integrates per-pixel smooth loss and masked photometric losses, enhancing resilience and accuracy in diverse scenarios, as depicted in Equation 4.
最终训练损失整合了逐像素平滑损失和掩膜光度损失,增强了不同场景下的鲁棒性和准确性,如公式4所示。
$$
{\cal L}=\mu L_{p}+\lambda L_{s}
$$
$$
{\cal L}=\mu L_{p}+\lambda L_{s}
$$
4. Results
4. 结果
Our assessment of SPIDepth encompasses three widelyused datasets: KITTI, Cityscapes and Make3D, employing established evaluation metrics.
我们对SPIDepth的评估涵盖了三个广泛使用的数据集:KITTI、Cityscapes和Make3D,并采用了既定的评估指标。
4.1. Datasets
4.1. 数据集
4.1.1 KITTI Dataset
4.1.1 KITTI数据集
KITTI [14] provides stereo image sequences, a staple in self-supervised monocular depth estimation. We adopt the Eigen split [9], using approximately $26\mathrm{k\Omega}$ images for training and 697 for testing. Notably, our training procedure for SQLdepth on KITTI starts from scratch, without utilizing motion masks [16], additional stereo pairs, or auxiliary data. During testing, we maintain a stringent regime, employing only a single frame as input, diverging from methods that exploit multiple frames for enhanced accuracy.
KITTI [14] 提供了立体图像序列,这是自监督单目深度估计的基础数据集。我们采用 Eigen 划分 [9],使用约 $26\mathrm{k\Omega}$ 张图像进行训练,697 张用于测试。值得注意的是,我们在 KITTI 上训练 SQLdepth 时从零开始,未使用运动掩码 [16]、额外立体图像对或辅助数据。测试阶段保持严格设定,仅输入单帧图像,与依赖多帧提升精度的方法形成对比。
4.1.2 Cityscapes Dataset
4.1.2 Cityscapes数据集
Cityscapes [6] poses a unique challenge with its plethora of dynamic objects. To gauge SPIDepth’s adaptability, we fine-tune on Cityscapes using pre-trained models from KITTI. Notably, we abstain from leveraging motion masks, a feature common among other methods, even in the presence of dynamic objects. Our performance improvements hinge solely on SPIDepth’s design and generalization capacity. This approach allows us to scrutinize SPIDepth’s robustness in dynamic environments. We adhere to data preprocessing practices from [61], ensuring consistency by preprocessing image sequences into triples.
Cityscapes [6] 因其大量动态物体带来了独特挑战。为评估 SPIDepth 的适应性,我们使用 KITTI 预训练模型在 Cityscapes 上进行微调。值得注意的是,即便存在动态物体,我们也不采用其他方法常用的运动掩模技术。性能提升完全依赖于 SPIDepth 的设计和泛化能力。该方法使我们能严格检验 SPIDepth 在动态环境中的鲁棒性。我们遵循 [61] 的数据预处理规范,通过将图像序列预处理为三元组来确保一致性。
4.1.3 Make3D Dataset
4.1.3 Make3D 数据集
Make3D [38] is a monocular depth estimation dataset containing 400 high-resolution RGB and low-resolution depth map pairs for training, and 134 test samples. To evaluate SPIDepth’s generalization ability on unseen data, zero-shot evaluation on the Make3D test set has been performed using the SPIDepth model pre-trained on KITTI.
Make3D [38] 是一个单目深度估计数据集,包含400对高分辨率RGB图像和低分辨率深度图用于训练,以及134个测试样本。为评估SPIDepth在未见数据上的泛化能力,我们使用在KITTI上预训练的SPIDepth模型对Make3D测试集进行了零样本评估。
4.2. KITTI Results
4.2. KITTI 结果
We present the performance comparison of SPIDepth with several state-of-the-art self-supervised depth estimation models on the KITTI dataset, as summarized in Table 1. SPIDepth achieves superior performance compared to all other models across various evaluation metrics. Notably, it achieves the lowest values of AbsRel (0.071), SqRel (0.531), RMSE (3.662), and RMSElog (0.153), indicating its exceptional accuracy in predicting depth values.
我们在KITTI数据集上将SPIDepth与几种最先进的自我监督深度估计模型进行了性能对比,如表 1 所示。SPIDepth在所有评估指标上均优于其他模型,尤其以AbsRel (0.071)、SqRel (0.531)、RMSE (3.662) 和 RMSElog (0.153) 的最低值展现了卓越的深度预测精度。
Moving on to Table 2, we compare the performance of SPIDepth with several supervised depth estimation models on the KITTI eigen benchmark. Despite being self- supervised and metric fine-tuned, SPIDepth outperforms supervised methods across all these metrics, indicating its superior accuracy in predicting metric depth values.
转到表 2: 我们在KITTI eigen基准上比较了SPIDepth与几种有监督深度估计模型的性能。尽管SPIDepth是自监督且经过度量微调的模型,但它在所有指标上都优于有监督方法,这表明其在预测度量深度值方面具有更高的准确性。
Furthermore, SPIDepth surpasses Lighted Depth, a model that operates on video sequences (more than one frame) and outperforms a good pre-trained models like EVP based on stable diffusion [36]. Despite Lighted Depth’s advantage of using multiple frames, SPIDepth shows improvements of 0.012 $(29.3%)$ in AbsRel, 0.038 $(34.3%)$ in SqRel, 0.354 $(20.3%)$ in RMSE, and 0.011 $(18.6%)$ in RM-SElog, highlighting SPIDepth’s robustness and effectiveness even in challenging scenarios.
此外,SPIDepth超越了基于视频序列(多帧)运行的Lighted Depth模型,并优于基于稳定扩散(stable diffusion)预训练的EVP等优秀模型[36]。尽管Lighted Depth具有使用多帧的优势,SPIDepth在各项指标上仍展现出显著提升:AbsRel提升0.012 $(29.3%)$,SqRel提升0.038 $(34.3%)$,RMSE提升0.354 $(20.3%)$,RM-SElog提升0.011 $(18.6%)$。这一结果凸显了SPIDepth即使在复杂场景下仍具备的鲁棒性和有效性。
Table 1: Performance comparison on KITTI [14] eigen benchmark. In the Train column, S: trained with synchronized stereo pairs, M: trained with monocular videos, MS: trained with monocular videos and stereo pairs, Distill: self-distillation training, Aux: using auxiliary information. In the Test column, 1: one single frame as input, 2(-1, 0): two frames (the previous and current) as input. The best results are in bold, and second best are underlined. All self-supervised methods use median-scaling in [9] to estimate the absolute depth scale.
表 1: KITTI [14] eigen 基准测试性能对比。Train 列中,S: 使用同步立体图像对训练,M: 使用单目视频训练,MS: 使用单目视频和立体图像对训练,Distill: 自蒸馏训练,Aux: 使用辅助信息。Test 列中,1: 单帧输入,2(-1, 0): 两帧 (前一帧和当前帧) 输入。最佳结果加粗显示,次佳结果加下划线。所有自监督方法均采用 [9] 中的中值缩放法估计绝对深度尺度。
| Method | Train | Test | HxW | AbsRel↓ | SqRel↓ | RMSE↓ | RMESlog | δ<1.25↑ | δ<1.25²↑ | δ<1.25³↑ |
|---|---|---|---|---|---|---|---|---|---|---|
| Monodepth2 [16] | MS | 1 | 1024×320 | 0.106 | 0.806 | 4.630 | 0.193 | 0.876 | 0.958 | 0.980 |
| Wang et al.[44] | M | 2(-1, 0) | 1024×320 | 0.106 | 0.773 | 4.491 | 0.185 | 0.890 | 0.962 | 0.982 |
| XDistill[30] | S+Distill | 1 | 1024×320 | 0.102 | 0.698 | 4.439 | 0.180 | 0.895 | 0.965 | 0.983 |
| HR-Depth [28] | MS | 1 | 1024×320 | 0.101 | 0.716 | 4.395 | 0.179 | 0.899 | 0.966 | 0.983 |
| FeatDepth-MS [41] | MS | 1 | 1024×320 | 0.099 | 0.697 | 4.427 | 0.184 | 0.889 | 0.963 | 0.982 |
| DIFFNet [60] | M | 1 | 1024×320 | 0.097 | 0.722 | 4.345 | 0.174 | 0.907 | 0.967 | 0.984 |
| Depth Hints [47] | S+Aux | 1 | 1024×320 | 0.096 | 0.710 | 4.393 | 0.185 | 0.890 | 0.962 | 0.981 |
| CADepth-Net[51] | MS | 1 | 1024×320 | 0.096 | 0.694 | 4.264 | 0.173 | 0.908 | 0.968 | 0.984 |
| EPCDepth [30] | S+Distill | 1 | 1024×320 | 0.091 | 0.646 | 4.207 | 0.176 | 0.901 | 0.966 | 0.983 |
| ManyDepth[48] | M | 2(-1,0)+TTR | 1024×320 | 0.087 | 0.685 | 4.142 | 0.167 | 0.920 | 0.968 | 0.983 |
| SQLdepth [45] | MS | 1 | 1024×320 | 0.075 | 0.539 | 3.722 | 0.156 | 0.937 | 0.973 | 0.985 |
| SPIDepth | MS | 1 | 1024×320 | 0.071 | 0.531 | 3.662 | 0.153 | 0.940 | 0.973 | 0.985 |
Table 2: Comparison with supervised methods on KITTI [14] eigen benchmark using self-supervised pretrained and metric fine-tuned model. The best results are in bold, and second best are underlined.
| 方法 | AbsRel | SqRel ↓ | RMSE↓ | RMESlog | < 1.25 ↑ | <1.252 ↑ | 8 < 1.253 |
|---|---|---|---|---|---|---|---|
| BTS [24] | 0.061 | 0.261 | 2.834 | 0.099 | 0.954 | 0.992 | 0.998 |
| AdaBins [3] | 0.058 | 0.190 | 2.360 | 0.088 | 0.964 | 0.995 | 0.999 |
| ZoeDepth [4] | 0.057 | 0.194 | 2.290 | 0.091 | 0.967 | 0.995 | 0.999 |
| NeWCRFs [55] | 0.052 | 0.155 | 2.129 | 0.079 | 0.974 | 0.997 | 0.999 |
| iDisc [31] | 0.050 | 0.148 | 2.072 | 0.076 | 0.975 | 0.997 | 0.999 |
| NDDepth [40] | 0.050 | 0.141 | 2.025 | 0.075 | 0.978 | 0.998 | 0.999 |
| SwinV2-L1K-MIM[50] | 0.050 | 0.139 | 1.966 | 0.075 | 0.977 | 0.998 | 1.000 |
| GEDepth [52] | 0.048 | 0.142 | 2.044 | 0.076 | 0.976 | 0.997 | 0.999 |
| EVP [23] | 0.048 | 0.136 | 2.015 | 0.073 | 0.980 | 0.998 | 1.000 |
| SQLdepth [45] | 0.043 | 0.105 | 1.698 | 0.064 | 0.983 | 0.998 | 0.999 |
| LightedDepth [64] | 0.041 | 0.107 | 1.748 | 0.059 | 0.989 | 0.998 | 0.999 |
| SPIDepth | 0.029 | 0.069 | 1.394 | 0.048 | 0.990 | 0.999 | 1.000 |
表 2: 在 KITTI [14] eigen 基准测试中使用自监督预训练和度量微调模型的监督方法对比。最佳结果以粗体显示,次佳结果带下划线。
Additionally, SPIDepth demonstrates significant performance improvements over SQLdepth, a model that serves as the foundation for its development. In the self-supervised setting, SPIDepth shows improvements of $5.3%$ in AbsRel, $1.5%$ in SqRel, $1.6%$ in RMSE, and $1.9%$ in RMSElog. In the supervised setting, SPIDepth shows improvements of $32.6%$ in AbsRel, $35.6%$ in SqRel, $17.9%$ in RMSE, and $25%$ in RMSElog. These substantial improvements underscore the impact of strengthening the pose net and its information in SPIDepth.
此外,SPIDepth 相比其开发基础模型 SQLdepth 展现出显著性能提升。在自监督设定下,SPIDepth 在 AbsRel 指标提升 $5.3%$,SqRel 提升 $1.5%$,RMSE 提升 $1.6%$,RMSElog 提升 $1.9%$。在全监督设定中,SPIDepth 在 AbsRel 指标提升 $32.6%$,SqRel 提升 $35.6%$,RMSE 提升 $17.9%$,RMSElog 提升 $25%$。这些显著改进印证了强化姿态网络及其信息传递对 SPIDepth 的关键影响。
Overall, these results underscore the effectiveness of SPIDepth in self-supervised monocular depth estimation, positioning it as a leading model in the field. Qualitative results further illustrate the superior performance of SPIDepth, as shown in Figure 2.
总体而言,这些结果凸显了SPIDepth在自监督单目深度估计中的有效性,使其成为该领域的领先模型。定性结果进一步展示了SPIDepth的卓越性能,如图2所示。
4.3. Cityscapes Results
4.3. Cityscapes 实验结果
To evaluate the generalization of SPIDepth, we conducted fine-tuning experiments in a self-supervised manner without using a motion mask on the Cityscapes dataset. Starting from a KITTI pre-trained model, we fine-tuned it on Cityscapes. The results, summarized in Table 3, demonstrate that SPIDepth outperforms all other methods, including those that use motion masks.
为评估 SPIDepth 的泛化能力,我们在 Cityscapes 数据集上以自监督方式(不使用运动掩码)进行了微调实验。从 KITTI 预训练模型出发,在 Cityscapes 上进行微调。表 3 结果显示,SPIDepth 优于所有其他方法(包括使用运动掩码的方法)。
Despite not using a motion mask—a technique commonly employed to handle the high proportion of moving objects in the Cityscapes dataset—SPIDepth achieves remarkable improvements over other models. Compared to SQLdepth, SPIDepth shows significant advancements: improvements of 0.023 $(21.7%)$ in AbsRel, 0.432 $(36.8%)$ in SqRel, and 1.032 $(16.5%)$ in RMSE.
尽管未使用运动掩码(一种常用于处理Cityscapes数据集中高比例运动物体的技术),SPIDepth相比其他模型仍取得了显著提升。与SQLdepth相比,SPIDepth展现出重大进步:AbsRel提升0.023 $(21.7%)$,SqRel提升0.432 $(36.8%)$,RMSE提升1.032 $(16.5%)$。

Figure 2: Qualitative results on the KITTI dataset. From left to right: Input RGB image, Ground Truth, SQLdepth prediction, and SPIdepth prediction. Table 3: Performance comparison on the Cityscapes [6] dataset. The table presents results of models trained in a selfsupervised manner on Cityscapes. K denotes training on KITTI, C denotes training on Cityscapes, and $\mathbf K{\to}\mathbf C$ denotes models pretrained on KITTI and then fine-tuned on Cityscapes. MMask indicates the use of a motion mask to handle moving objects, which is crucial for training on Cityscapes, while – indicates no use of a motion mask. The best results are in bold, and second best are underlined.
图 2: KITTI 数据集的定性结果。从左到右依次为:输入 RGB 图像、真实值 (Ground Truth)、SQLdepth 预测结果和 SPIdepth 预测结果。
表 3: Cityscapes [6] 数据集的性能对比。该表展示了在 Cityscapes 上以自监督方式训练的模型结果。K 表示在 KITTI 上训练,C 表示在 Cityscapes 上训练,$\mathbf K{\to}\mathbf C$ 表示先在 KITTI 上预训练再在 Cityscapes 上微调的模型。MMask 表示使用运动掩码处理运动物体(这对 Cityscapes 训练至关重要),而 – 表示未使用运动掩码。最佳结果以粗体显示,次佳结果带下划线。
| 方法 | 训练 | AbsRel↓ | SqRel ↓ | RMSE↓ | RMESlog | δ<1.25↑ | δ<1.25²↑ | δ<1.25³↑ |
|---|---|---|---|---|---|---|---|---|
| Pilzer et al.[33] Struct2Depth 2 [5] | GAN,C | 0.240 | 4.264 | 8.049 7.280 | 0.334 0.205 | 0.710 | 0.871 | 0.937 |
| MMask, C -,C | 0.145 0.129 | 1.737 1.569 | 6.876 | 0.187 | 0.813 0.849 | 0.942 0.957 | 0.976 0.983 | |
| Monodepth2[16] Videos in theWild[17] | MMask, C | 1.330 | ||||||
| Li et al. [27] | 0.127 | 6.960 | 0.195 | 0.830 | 0.947 | 0.981 | ||
| Lee et al. [26] | MMask, C | 0.119 | 1.290 | 6.980 | 0.190 | 0.846 | 0.952 | 0.982 |
| MMask, C MMask, C | 0.116 | 1.213 | 6.695 | 0.186 | 0.852 | 0.951 | 0.982 | |
| ManyDepth [48] | MMask, C | 0.114 | 1.193 | 6.223 | 0.170 | 0.875 | 0.967 | 0.989 |
| InstaDM [25] | -,K→C | 0.111 | 1.158 | 6.437 | 0.182 | 0.868 | 0.961 | 0.983 |
| SQLdepth [45] | MMask, C | 0.106 | 1.173 | 6.237 | 0.163 | 0.888 | 0.972 | 0.990 |
| ProDepth [49] | MMask, C | 0.095 | 0.876 | 5.531 | 0.146 | 0.908 | 0.978 | 0.993 |
| RM-Depth [19] | -, K→→C | 0.090 | 0.825 | 5.503 | 0.143 | 0.913 | 0.980 | 0.993 |
| SPIDepth | 0.083 | 0.741 | 5.205 | 0.130 | 0.931 | 0.986 | 0.995 |
Moreover, compared to the previous state-of-the-art model RM-Depth, which also uses motion masks, SPIDepth achieves improvements of 0.007 $(7.8%)$ in AbsRel, 0.084 $(10.2%)$ in SqRel, and 0.298 $(5.4%)$ in RMSE.
此外,与同样采用运动掩模的前沿模型 RM-Depth 相比,SPIDepth 在 AbsRel 指标上提升了 0.007 $(7.8%)$,SqRel 指标提升 0.084 $(10.2%)$,RMSE 指标提升 0.298 $(5.4%)$。
These results underscore SPIDepth’s exceptional generalization and accuracy, achieved without the use of motion masks. This makes SPIDepth a highly robust and efficient option for depth estimation tasks. Its performance demonstrates its capability for quick deployment in new datasets, effectively addressing the challenges posed by moving objects.
这些结果凸显了SPIDepth在不使用运动掩模的情况下所实现的卓越泛化能力和准确性。这使SPIDepth成为深度估计任务中高度稳健且高效的选择。其性能证明了它在新数据集上快速部署的能力,有效解决了移动物体带来的挑战。
4.4. Make3D results
4.4. Make3D 结果
To assess the generalization capacity of SPIDepth, a zero-shot evaluation was performed on the Make3D dataset [38] using pretrained weights from KITTI. Adhering to the evaluation settings of [15, 45], SPIDepth achieved superior results compared to other methods, including SQLdepth. Table 4 highlights these findings, showcasing the remarkable zero-shot generalization ability of the SPIDepth model.
为评估SPIDepth的泛化能力,我们使用KITTI预训练权重在Make3D数据集[38]上进行了零样本测试。遵循[15, 45]的评估设置,SPIDepth取得了优于SQLdepth等方法的性能。表4展示了这些结果,凸显了该模型卓越的零样本泛化能力。
As summarized in Table 4, SPIDepth achieves the lowest values in all evaluation metrics, with AbsRel (0.299), SqRel (1.931), RMSE (6.672), and $l o g_{10}$ (0.144). These results highlight the remarkable zero-shot generalization ability of the SPIDepth model, significantly outperforming the previous best model, SQLdepth. The improvements of SPIDepth over SQLdepth are 0.007 $(2.3%)$ in AbsRel, 0.471 $(19.6%)$ in SqRel, 0.184 $(2.7%)$ in RMSE, and 0.007 $(4.6%)$ in $l o g_{10}$ , underscoring its superior performance in challenging zero-shot scenarios.
如表 4 所示,SPIDepth 在所有评估指标中均取得最低值,包括 AbsRel (0.299)、SqRel (1.931)、RMSE (6.672) 和 $l o g_{10}$ (0.144)。这些结果凸显了 SPIDepth 模型卓越的零样本泛化能力,显著超越了此前最佳模型 SQLdepth。SPIDepth 相较 SQLdepth 的改进幅度为:AbsRel 提升 0.007 $(2.3%)$,SqRel 提升 0.471 $(19.6%)$,RMSE 提升 0.184 $(2.7%)$,$l o g_{10}$ 提升 0.007 $(4.6%)$,充分证明了其在挑战性零样本场景中的卓越性能。
Table 4: Performance comparison on Make3D dataset [38]. The best results are in bold, and second best are underlined.
表 4: Make3D数据集[38]上的性能对比。最佳结果以粗体显示,次优结果加下划线。
| 方法 | 类型 | AbsRel↓ | SqRel↓ | RMSE√ | log10 |
|---|---|---|---|---|---|
| Monodepth[15] Zhou[62] | S M | 0.544 0.383 | 10.94 5.321 | 11.760 10.470 | 0.193 0.478 |
| DDVO[43] Monodepth2[16] | M M | 0.387 | 4.720 | 8.090 | 0.204 |
| CADepthNet[51] | M | 0.322 | 3.589 | 7.417 | 0.163 |
| 0.312 | 3.086 | 7.066 | 0.159 | ||
| SQLdepth[45] | M | 0.306 | 2.402 | 6.856 | 0.151 |
| SPIDepth | M | 0.299 | 1.931 | 6.672 | 0.144 |
5. Ablation Study
5. 消融研究
To assess the impact of Strengthened Pose Information (SPI) on depth estimation performance, we conducted an ablation study using various backbone networks, evaluated on the KITTI dataset in both self-supervised and supervised fine-tuning settings. This study compared ConvNeXt Large, ConvNeXt X-Large, and ConvNeXtV2 Huge with and without SPI, as summarized in Table 5.
为了评估强化姿态信息(SPI)对深度估计性能的影响,我们在KITTI数据集上分别采用自监督和监督微调设置,使用不同骨干网络进行了消融实验。如表5所示,该研究对比了ConvNeXt Large、ConvNeXt X-Large和ConvNeXtV2 Huge在启用与禁用SPI时的表现。
Initially, we evaluated ConvNeXt Large using the standard pose net configuration, as employed in previous stateof-the-art approach - SQLdepth [45]. Without SPI, it achieved an AbsRel of 0.075 and RMSE of 3.722 in selfsupervised settings. Introducing SPI improved these metrics to AbsRel 0.072 and RMSE 3.677. In supervised fine-tuning, the SPI-enhanced model showed a reduction of 0.006 $(14%)$ in AbsRel, and a reduction of 0.101 $(5.9%)$ in RMSE. ConvNeXt X-Large and ConvNeXtV2 Huge with SPI further improved performance, reaching AbsRel 0.071 and RMSE 3.662 in self-supervised settings, and AbsRel 0.029 and RMSE 1.394 in supervised fine-tuning.
我们首先采用最先进方法SQLdepth[45]的标准姿态网络配置评估了ConvNeXt Large。未引入SPI时,该模型在自监督设置下的AbsRel为0.075,RMSE为3.722。引入SPI后,指标提升至AbsRel 0.072和RMSE 3.677。在监督微调中,SPI增强模型的AbsRel降低了0.006 $(14%)$,RMSE降低了0.101 $(5.9%)$。采用SPI的ConvNeXt X-Large和ConvNeXtV2 Huge进一步提升了性能,在自监督设置下达到AbsRel 0.071和RMSE 3.662,在监督微调下达到AbsRel 0.029和RMSE 1.394。
While changing the backbone size provides only slight improvements in the self-supervised setting compared to the impact of SPI, it does result in more significant gains in supervised settings. These results highlight that SPI significantly enhances performance. The benefits of SPI outweigh the incremental improvements offered by larger backbones, demonstrating that SPI’s impact on accuracy is more substantial than merely increasing the backbone size.
虽然改变主干网络规模在自监督设置下相比SPI的影响仅带来轻微改进,但在监督设置中确实能产生更显著的提升。这些结果表明SPI能显著增强性能。SPI带来的优势超过了增大主干网络规模所获得的渐进式改进,证明SPI对准确率的提升效果远比单纯扩大主干网络规模更为显著。
Table 5: Ablation Study Results on KITTI Dataset. The table compares the performance of different backbone networks with and without Strengthened Pose Information (SPI) in both self-supervised and supervised settings.
表 5: KITTI数据集消融研究结果。该表比较了不同骨干网络在自监督和监督设置下是否使用强化位姿信息(SPI)的性能表现。
| Backbone | SPI | Self-Supervised | Supervised | ||
|---|---|---|---|---|---|
| AbsRel | RMSE | AbsRel | RMSE | ||
| ConvNeXtLarge | 0.075 | 3.722 | 0.043 | 1.698 | |
| ConvNeXtLarge | √ | 0.072 | 3.677 | 0.037 | 1.597 |
| ConvNeXtX-Large | √ | 0.071 | 3.670 | 0.034 | 1.529 |
| ConvNeXtV2Huge | √ | 0.071 | 3.662 | 0.029 | 1.394 |
6. Conclusion
6. 结论
In summary, SPIdepth achieves significant advancements in self-supervised monocular depth estimation by enhancing the pose network during training, with no changes needed for inference. Despite adding only a minimal number of parameters compared to the depth model, SPIdepth delivers exceptional accuracy.
总之,SPIdepth通过训练期间增强位姿网络,在自监督单目深度估计领域取得显著进展,且无需改变推理过程。尽管相比深度模型仅增加了极少参数量,SPIdepth仍能实现卓越精度。
On the KITTI, Cityscapes, and Make3D datasets, SPIdepth sets new benchmarks in both self-supervised and fine-tuning settings, outperforming models that use multiple frames for inference. Its effectiveness in scenarios with dynamic objects and zero-shot settings demonstrates its robustness and versatility.
在KITTI、Cityscapes和Make3D数据集上,SPIdepth在自监督和微调场景下均创下新基准,性能超越使用多帧推理的模型。其在动态物体场景和零样本设置中的有效性,证明了该模型的鲁棒性与多功能性。
These results highlight SPIdepth’s potential for realworld applications, offering precise depth estimation and superior performance across diverse challenges. Its lightweight design and adaptability make it an ideal candidate for integration into various systems, enabling rapid deployment and scalable solutions in environments where accurate depth perception is crucial.
这些结果凸显了SPIdepth在实际应用中的潜力,它能够提供精确的深度估计,并在各种挑战中展现出卓越性能。其轻量级设计和高度适应性使其成为集成到各类系统的理想选择,可在需要精准深度感知的环境中实现快速部署和可扩展解决方案。