DATA EXTRAPOLATION FOR TEXT-TO-IMAGE GENER- ATION ON SMALL DATASETS
小数据集上的文本到图像生成数据外推
ABSTRACT
摘要
Text-to-image generation requires large amount of training data to synthesizing high-quality images. For augmenting training data, previous methods rely on data interpolations like cropping, flipping, and mixing up, which fail to introduce new information and yield only marginal improvements. In this paper, we propose a new data augmentation method for text-to-image generation using linear extrapolation. Specifically, we apply linear extrapolation only on text feature, and new image data are retrieved from the internet by search engines. For the reliability of new text-image pairs, we design two outlier detectors to purify retrieved images. Based on extrapolation, we construct training samples dozens of times larger than the original dataset, resulting in a significant improvement in text-to-image performance. Moreover, we propose a NULL-guidance to refine score estimation, and apply recurrent affine transformation to fuse text information. Our model achieves FID scores of 7.91, 9.52 and 5.00 on the CUB, Oxford and COCO datasets. The code and data will be available on GitHub.
文本到图像生成需要大量训练数据来合成高质量图像。为扩充训练数据,先前方法依赖于裁剪、翻转和混合等数据插值技术,这些方法无法引入新信息且仅带来边际改进。本文提出一种基于线性外推的文本到图像生成数据增强新方法。具体而言,我们仅对文本特征进行线性外推,并通过搜索引擎从互联网检索新图像数据。为确保新文本-图像对的可靠性,我们设计两个离群值检测器来净化检索图像。基于外推方法,我们构建了比原始数据集大数十倍的训练样本,使文本到图像生成性能显著提升。此外,我们提出NULL引导机制来优化分数估计,并应用循环仿射变换融合文本信息。我们的模型在CUB、Oxford和COCO数据集上分别取得7.91、9.52和5.00的FID分数。代码和数据将在GitHub开源。
1 INTRODUCTION
1 引言
Text-to-image generation aims to synthesize images according to textual descriptions. As the bridge between human language and generative models, textto-image generation (Reed et al., 2016b; Ye et al., 2023; Sauer et al., 2023; Rombach et al., 2022; Ramesh et al., 2022)is applied to more and more application domains, such as digital human (Yin & Li, 2023), image editing (Brack et al., 2024), and computer-aided design (Liu et al., 2023). The diversity of applications leads to a large number of small datasets, where existing data are not sufficient to train high-quality generative models, and generative large models cannot overcome the long-tail effect of diverse applications.
文本到图像生成旨在根据文本描述合成图像。作为人类语言与生成模型之间的桥梁,文本到图像生成 (Reed et al., 2016b; Ye et al., 2023; Sauer et al., 2023; Rombach et al., 2022; Ramesh et al., 2022) 被应用于越来越多的领域,例如数字人 (Yin & Li, 2023)、图像编辑 (Brack et al., 2024) 和计算机辅助设计 (Liu et al., 2023)。应用的多样性导致了大量小型数据集的出现,其中现有数据不足以训练高质量的生成模型,而生成式大模型也无法克服多样化应用的长尾效应。
To augment training data, existing methods typically rely on data interpolation techniques such as cropping, flipping, and mixing up images (Zhang et al., 2017). While these methods leverage human knowledge to create new perspectives on existing images or features, they do not introduce new information and yield only marginal improvements. Additionally, Retrieval-base models (Chen et al., 2022; Sheynin et al., 2022; Li et al., 2022) employs retrieval methods to gather relevant training data from external databases like WikiImages. However, these external databases often contain very few images for specific entries, and their description styles differ significantly from those in text-to-image datasets. Furthermore, VQ-diffusion (Gu et al., 2022) pre-trains its text-to-image model on the Conceptual Caption dataset with 15 million images, but the resulting improvements are not obvious.
为扩充训练数据,现有方法通常依赖于数据插值技术,例如裁剪、翻转和图像混合 (Zhang et al., 2017)。虽然这些方法利用人类知识从现有图像或特征中创造新视角,但并未引入新信息,仅带来边际提升。此外,基于检索的模型 (Chen et al., 2022; Sheynin et al., 2022; Li et al., 2022) 采用检索方法从WikiImages等外部数据库收集相关训练数据。然而这些外部数据库对特定条目的图像覆盖极少,且其描述风格与文生图数据集差异显著。VQ-diffusion (Gu et al., 2022) 虽在包含1500万图像的Conceptual Caption数据集上预训练文生图模型,但改进效果并不明显。
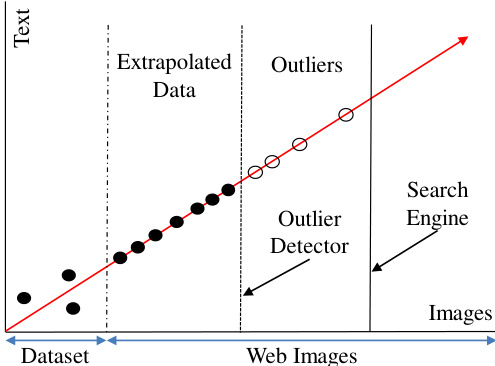
Figure 1: An illustration of data linear extrapolation. We use search engine and outlier detectors to ensure the image similarity. Extrapolation produces much more text-image pairs than the original dataset.
图 1: 数据线性外推示意图。我们使用搜索引擎和离群值检测器来确保图像相似性。外推生成的文本-图像对数量远超原始数据集。
In this paper, we explore data linear extrapolation to augment training data. Linear extrapolation can be risky, as similar text-image pairs may not be nearby in Euclidean space. For information reliability, as depicted in Figure 1, we explore linear extrapolation only on text data, and new image data are retrieved from the internet by search engines. And then outlier detectors are designed to purify retrieved web images. In this way, the reliability of new text-image pairs are guaranteed by search precision and outlier detection.
本文探讨了通过数据线性外推来增强训练数据的方法。由于相似的文本-图像对在欧氏空间中可能并不邻近,线性外推存在风险。为确保信息可靠性(如图 1 所示),我们仅对文本数据进行线性外推,新图像数据则通过搜索引擎从互联网检索获取。随后设计了离群值检测器来净化检索到的网络图像。通过这种方式,新文本-图像对的可靠性由搜索精度和离群值检测共同保证。
To detect outliers from web images, we divide outliers into irrelevant and similar ones. For detecting irrelevant outliers, K-means (Lloyd, 1982) algorithm is used to cluster noisy web images into similar images and outliers. In the image feature space generated by a CLIP encoder (Radford et al., 2021), similar images will be close to dataset images, while outliers will be far away. Based on this observation, we remove images that differ significantly from dataset images. For detecting similar outliers, each web image is assigned a label by a fine-grained classifier trained on the original dataset. If the label does not match the search keyword, the image is considered as an outlier and removed. For every purified web image, we extrapolate a new text descriptions according to the local manifold of dataset images. Based on extrapolation, we construct training samples dozens of times larger than the original dataset.
为检测网络图像中的异常值,我们将其划分为不相关异常与相似异常两类。针对不相关异常检测,采用K-means (Lloyd, 1982)算法对含噪网络图像进行聚类,分离出相似图像与异常值。在CLIP编码器 (Radford et al., 2021)生成的图像特征空间中,相似图像会接近数据集图像,而异常值则相距较远。基于此观察,我们移除与数据集图像差异显著的图像。对于相似异常检测,通过原始数据集训练的细粒度分类器为每张网络图像分配标签,若标签与搜索关键词不匹配则判定为异常值并移除。针对每张净化后的网络图像,我们根据数据集图像的局部流形结构外推生成新文本描述,基于此外推构建的训练样本规模可达原始数据集的数十倍。
Moreover, we propose NULL-condition guidance to refine score estimation for text-to-image generation. Classifier-free guidance (Ho & Salimans, 2022) uses a dummy label to refine labelconditioned image synthesis. Similarly, in text-to-image generation, such a dummy label can be replaced by a prompt with no new physical meaning. For example, “a picture of bird” provides no information for the CUB dataset “a picture of flower” provides no information for the Oxford dataset). In addition, we apply recurrent affine transformation (RAT) in the diffusion model for handling complex textual information.
此外,我们提出NULL-condition引导方法来优化文本到图像生成的分数估计。无分类器引导(Ho & Salimans, 2022)使用虚拟标签来优化标签条件图像合成。类似地,在文本到图像生成中,这种虚拟标签可以被替换为没有新物理意义的提示词(例如“一张鸟的图片”对CUB数据集不提供信息,“一张花的图片”对Oxford数据集不提供信息)。此外,我们在扩散模型中应用循环仿射变换(RAT)来处理复杂文本信息。
The contributions of this paper are summarized as follows:
本文的贡献总结如下:
2 RELATED WORK
2 相关工作
GAN-based text-to-image models. Text-to-image synthesis is a key task within conditional image synthesis (Feng et al., 2022; Tan et al., 2022; Peng et al., 2021; Hou et al., 2022). The pioneering work of (Reed et al., 2016b) first tackled this task using conditional GANs (Mirza & Osindero, 2014). To better integrate text information into the synthesis process, DF-GAN (Tao et al., 2022) introduced a deep fusion method featuring multiple affine layers within a single block. Unlike previous approaches, DF-GAN eliminated the normalization operation without sacrificing performance, thus reducing computational demands and alleviating limitations associated with large batch sizes. Building on DF-GAN, RAT-GAN employed a recurrent neural network to progressively incorporate text information into the synthesized images. GALIP (Tao et al., 2023) and StyleGAN-T (Sauer et al., 2023) explore the potential of combining GAN models with transformers for large-scale textto-image synthesis. However, the aforementioned GAN-based models often struggle to produce high-quality images.
基于GAN的文本到图像模型。文本到图像合成是条件图像合成中的关键任务 (Feng et al., 2022; Tan et al., 2022; Peng et al., 2021; Hou et al., 2022)。(Reed et al., 2016b) 的开创性工作首次使用条件GAN (Mirza & Osindero, 2014) 解决该任务。为更好地将文本信息融入合成过程,DF-GAN (Tao et al., 2022) 提出了一种深度融合方法,在单个模块中采用多重仿射层。与先前方法不同,DF-GAN在保持性能的同时移除了归一化操作,从而降低计算需求并缓解了大批量大小的限制。在DF-GAN基础上,RAT-GAN采用循环神经网络逐步将文本信息整合到合成图像中。GALIP (Tao et al., 2023) 和StyleGAN-T (Sauer et al., 2023) 探索了将GAN模型与Transformer结合用于大规模文本到图像合成的潜力。然而,上述基于GAN的模型往往难以生成高质量图像。
Diffusion-based text-to-image models. Recently, diffusion models (Ho et al., 2020; Song & Ermon, 2019; Song et al., 2021; Hyvarinen, 2005) have demonstrated impressive generation performance across various tasks. Building on this success, Imagen (Saharia et al., 2022) and DALL·E 2 (Ramesh et al., 2022) can synthesize images that are sufficiently realistic for real-world applications. To alleviate computational burdens, they first generate $64\times64$ images and then upsample them to high-resolution using another diffusion model. Additionally, the Latent Diffusion Model (Rombach et al., 2022) encodes high-resolution images into low-resolution latent codes, avoiding the exponential computation costs associated with increased resolution. DiT (Peebles & Xie, 2023)
基于扩散的文本到图像模型。近年来,扩散模型(Ho等人,2020;Song & Ermon,2019;Song等人,2021;Hyvarinen,2005)已在多项任务中展现出卓越的生成性能。基于这一成果,Imagen(Saharia等人,2022)和DALL·E 2(Ramesh等人,2022)能合成足以应用于现实场景的逼真图像。为减轻计算负担,它们首先生成$64\times64$尺寸的图像,再通过另一扩散模型上采样至高分辨率。此外,潜在扩散模型(Rombach等人,2022)将高分辨率图像编码为低分辨率潜在表征,避免了分辨率提升带来的指数级计算开销。DiT(Peebles & Xie,2023)
integrated latent diffusion models and transformers to enhance performance on large datasets. VQDiffusion (Gu et al., 2022) pre-train their text-to-image model on the Conceptual Caption dataset, which contains 15 million text-image pairs, and then fine-tune it on smaller datasets like CUB, Oxford, and COCO. Hence, VQ-Diffusion is the work most similar to ours but we use significantly less pre-training data while achieving better results.
集成潜在扩散模型和Transformer以提升在大规模数据集上的性能。VQDiffusion (Gu等人, 2022) 先在包含1500万文本-图像对的Conceptual Caption数据集上预训练其文生图模型,随后在CUB、Oxford和COCO等较小数据集上微调。因此VQ-Diffusion是与我们工作最接近的研究,但我们使用显著更少的预训练数据同时取得了更好的结果。
Data augmentation methods. Data augmentation increases training data to improve the performance of deep learning applications, from image classification (Krizhevsky et al., 2012) to speech recognition (Graves et al., 2013; Amodei et al., 2016). Common techniques include rotation, translation, cropping, resizing, flipping (LeCun et al., 2015; Vedaldi & Zisserman, 2016), and random erasing (Zhong et al., 2020) to promote visually plausible in variances. Similarly, label smoothing is widely used to boost the robustness and accuracy of trained models (Miller et al., 2019; Lukasik et al., 2020). Mixup (Zhang et al., 2017) involves training a neural network on convex combinations of examples and their labels. However, interpolated samples fail to introduce new information and effectively address data scarcity. Hence, Re-imagen (Chen et al., 2022; Sheynin et al., 2022; Li et al., 2022) retrieval relevant training data from external databases to augment training data.
数据增强方法。数据增强通过增加训练数据来提升深度学习应用性能,涵盖从图像分类 (Krizhevsky et al., 2012) 到语音识别 (Graves et al., 2013; Amodei et al., 2016) 等多个领域。常用技术包括旋转、平移、裁剪、缩放、翻转 (LeCun et al., 2015; Vedaldi & Zisserman, 2016) 以及随机擦除 (Zhong et al., 2020) 以增强视觉合理性。类似地,标签平滑被广泛用于提升训练模型的鲁棒性和准确率 (Miller et al., 2019; Lukasik et al., 2020)。Mixup (Zhang et al., 2017) 通过在样本及其标签的凸组合上训练神经网络实现增强,但插值样本无法引入新信息以有效解决数据稀缺问题。因此,Re-imagen (Chen et al., 2022; Sheynin et al., 2022; Li et al., 2022) 通过从外部数据库检索相关训练数据来实现数据增强。
3 LINEAR EXTRAPOLATION FOR TEXT-TO-IMAGE GENERATION
3 文本到图像生成的线性外推
In this section, we begin by collecting similar images from the internet. Next, we explain how to extrapolate text descriptions. Following that, we use the extrapolated text-image pairs to train a diffusion model with RAT blocks. Finally, we sample images using NULL-condition guidance.
在本节中,我们首先从互联网收集相似图像,接着说明如何外推文本描述。随后,利用外推的文本-图像对训练带有RAT模块的扩散模型。最后,采用NULL-condition引导进行图像采样。
3.1 COLLECTING SIMILAR AND CLEAN IMAGES
3.1 收集相似且干净的图像
Linear extrapolation requires the images to be sufficiently close in semantic space. Hence, we auto mati call y retrieve similar images by searching for their classification labels. However, search engines return both similar images and outliers. To eliminate unwanted outliers, we employ a cluster detector for irrelevant outliers and a classification detector for similar outliers. For the cluster detector, each image is encoded into a vector using the CLIP image encoder. Images retrieved with the same keyword are then clustered using K-means. If the distance from the cluster center to dataset images exceeds a threshold, this cluster is excluded. For the classification detector, we train a finegrained classification model on the original dataset, which assigns a label to each web image. If the label does not match with the search keyword, corresponding image is then excluded.
线性外推要求图像在语义空间中足够接近。因此,我们通过搜索分类标签自动检索相似图像。然而,搜索引擎会同时返回相似图像和离群值。为消除无关离群值,我们采用聚类检测器处理不相关离群值,并使用分类检测器筛选相似离群值。对于聚类检测器,每张图像通过CLIP图像编码器转换为向量,相同关键词检索到的图像通过K-means聚类。若某聚类中心与数据集图像的距离超过阈值,则排除该聚类。对于分类检测器,我们在原始数据集上训练细粒度分类模型,为每张网络图像分配标签。若标签与搜索关键词不匹配,则排除对应图像。
3.2 LINEAR EXTRAPOLATION ON TEXT FEATURE SPACE
3.2 文本特征空间上的线性外推
Here we introduce how to extrapolates text descriptions for web images. Assuming that web images are sufficiently close to dataset images in semantic space, each web image can be represented by nearest $\mathrm{k\Omega}$ images:
这里我们介绍如何推断网络图像的文本描述。假设网络图像在语义空间与数据集图像足够接近,每张网络图像可以用最近的 $\mathrm{k\Omega}$ 张图像表示:
$$
\underset{W}{\arg\operatorname*{min}}|\mathbf{f}-\mathbf{F}\times\mathbf{w}|^{2},
$$
$$
\underset{W}{\arg\operatorname*{min}}|\mathbf{f}-\mathbf{F}\times\mathbf{w}|^{2},
$$
where $\mathbf{w}=[w_{1},w_{2},...,w_{k}]\mathrm{are}$ the reconstruction weights and $\mathbf{F}~=~[\mathbf{f}_{1},\mathbf{f}_{2},...,\mathbf{f}_{k}]$ are the image features of dataset images produced by CLIP image encoder. Since the above equation is a superdetermined problem, we solve this coefficient using least squares:
其中 $\mathbf{w}=[w_{1},w_{2},...,w_{k}]\mathrm{是}$ 重建权重,$\mathbf{F}~=~[\mathbf{f}_{1},\mathbf{f}_{2},...,\mathbf{f}_{k}]$ 是由 CLIP 图像编码器生成的数据集图像特征。由于上述方程是一个超定问题,我们使用最小二乘法求解该系数:
$$
\mathbf{w}=(\mathbf{F}^{T}\mathbf{F})^{-1}\mathbf{F}^{T}\mathbf{f}.
$$
$$
\mathbf{w}=(\mathbf{F}^{T}\mathbf{F})^{-1}\mathbf{F}^{T}\mathbf{f}.
$$
We assume that the image feature space and text feature space share the same local manifold. Hence, the image reconstruction efficient w can be used to compute the text feature of web images:
我们假设图像特征空间和文本特征空间共享相同的局部流形。因此,图像重建效率w可用于计算网络图像的文本特征:
$$
\begin{array}{r}{\mathbf{s}=\mathbf{S}\times\mathbf{w},}\end{array}
$$
$$
\begin{array}{r}{\mathbf{s}=\mathbf{S}\times\mathbf{w},}\end{array}
$$
where $\mathbf{S}=[\pmb{s}{1},\pmb{s}{2},...,\pmb{s}_{k}]$ is the fake sentence features for nearest $\mathbf{k}$ dataset images, and $\mathbf{s}$ is the sentence feature for a web image.
其中 $\mathbf{S}=[\pmb{s}{1},\pmb{s}{2},...,\pmb{s}_{k}]$ 是最近 $\mathbf{k}$ 个数据集图像的伪句子特征,$\mathbf{s}$ 是网络图像的句子特征。
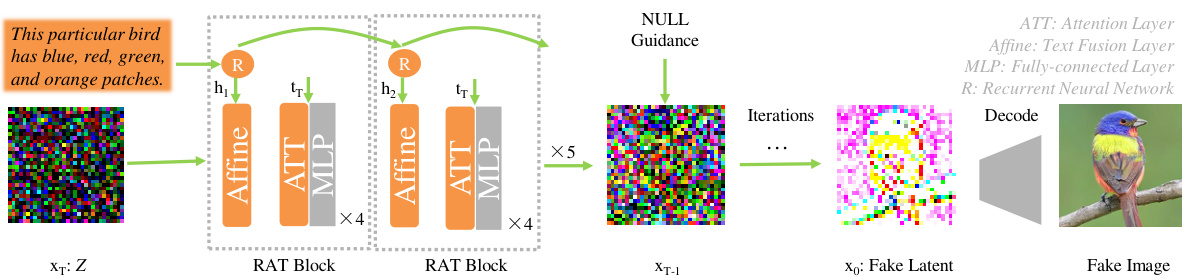
Figure 2: Latent diffusion model with recurrent affine transformation and NULL-guidance for textto-image synthesis. The RAT blocks are connected by a recurrent neural network to ensure the global assignment of text information.
图 2: 采用循环仿射变换和NULL引导的潜在扩散模型用于文本到图像合成。RAT模块通过循环神经网络连接以确保文本信息的全局分配。
3.3 RECURRENT DIFFUSION TRANSFORMER ON LATENT SPACE
3.3 潜在空间中的循环扩散Transformer
The training objective of the diffusion model is the squared error loss proposed by DDPM (Ho et al., 2020):
扩散模型的训练目标是 DDPM (Ho et al., 2020) 提出的平方误差损失:
$$
L(\theta)=\left|\epsilon-\epsilon_{\theta}\left(\sqrt{\bar{\alpha}{t}}\mathrm{x}{0}+\sqrt{1-\bar{\alpha}_{t}}\epsilon\right)\right|^{2},
$$
$$
L(\theta)=\left|\epsilon-\epsilon_{\theta}\left(\sqrt{\bar{\alpha}{t}}\mathrm{x}{0}+\sqrt{1-\bar{\alpha}_{t}}\epsilon\right)\right|^{2},
$$
where $\epsilon\in N(0,1)$ is the score noise injected at every diffusion step, and $\epsilon_{\theta}$ is the predicted noise by a diffusion network consisted of 12 transformer layers. $\overline{{\bar{\alpha}}}{t}$ and ${\bar{\alpha}_{t}}$ are hyper-parameters controlling the speed of diffusion. The work of score mismatching (Ye & Liu, 2024) shows that predicting the score noise leads to an unbiased estimation.
其中 $\epsilon\in N(0,1)$ 是每个扩散步骤注入的分数噪声,$\epsilon_{\theta}$ 是由12层Transformer组成的扩散网络预测的噪声。$\overline{{\bar{\alpha}}}{t}$ 和 ${\bar{\alpha}_{t}}$ 是控制扩散速度的超参数。分数失配研究 (Ye & Liu, 2024) 表明,预测分数噪声可实现无偏估计。
Network architecture. As depicted in Fig 8, the diffusion network consists of transformer blocks. Recurrent affine transformation is used to enhance the consistency between transformer blocks. To avoid directly mixing text embedding and time embedding, we stack four transformer blocks as a RAT block and text embedding is fed into the top of each RAT block. Each RAT block applies a channel-wise shifting operation on a image feature map:
网络架构。如图 8 所示,扩散网络由 Transformer 块组成。采用循环仿射变换 (recurrent affine transformation) 增强 Transformer 块间的一致性。为避免文本嵌入 (text embedding) 与时间嵌入 (time embedding) 直接混合,我们将四个 Transformer 块堆叠为 RAT 块,并将文本嵌入输入每个 RAT 块顶部。每个 RAT 块会对图像特征图执行通道平移操作:
$$
c^{\prime}=c+\beta,
$$
$$
c^{\prime}=c+\beta,
$$
where $c$ is the image feature vector and $\beta$ is shifting parameters predicted by a one-hidden-layer multi-layer perception (MLP) conditioned on recurrent neural network hidden state $h_{t}$ .
其中 $c$ 是图像特征向量,$\beta$ 是由基于循环神经网络隐藏状态 $h_{t}$ 的单隐藏层多层感知机 (MLP) 预测的平移参数。
In each transformer block, we inject time embedding by a channel-wise scaling operation and a channel-wise shifting operation on $c$ . At last, the image feature $c$ is multiplied by a scaling parameter $\alpha$ . This process can be formally expressed as:
在每个Transformer块中,我们通过对$c$进行通道级缩放操作和通道级平移操作来注入时间嵌入。最后,图像特征$c$会乘以一个缩放参数$\alpha$。这一过程可以形式化表示为:
$$
c^{\prime}=T r a n s f o r m e r((1+\gamma)\cdot c+\beta)\cdot\alpha,
$$
$$
c^{\prime}=T r a n s f o r m e r((1+\gamma)\cdot c+\beta)\cdot\alpha,
$$
where $\alpha,\gamma,\beta$ are parameters predicted by two one-hidden-layer MLPs conditioned on time embedding.
其中 $\alpha,\gamma,\beta$ 是由两个以时间嵌入为条件的单隐藏层 MLP 预测的参数。
When applied to an image feature map composed of $w\times h$ feature vectors, the same affine transformation is repeated for every feature vector.
当应用于由 $w\times h$ 个特征向量组成的图像特征图时,会对每个特征向量重复相同的仿射变换。
Early stop of fine-tuning. Extrapolation may produces training data very close to the original dataset, which makes fine-tuning saturate very quickly. Excessive fine-tuning epochs would forget knowledge gained from the extrapolated data and overfit small datasets. As a result, the training loss of the diffusion model becomes unreliable. Therefore, fine-tuning should be stopped when the FID score begins to increase.
早停微调。外推生成的数据可能与原始数据集高度相似,导致微调迅速饱和。过多的微调轮次会遗忘从外推数据中获得的知识,并对小数据集过拟合。因此,扩散模型的训练损失将变得不可靠。当FID分数开始上升时,应停止微调。
3.4 SYNTHESIZING FAKE IMAGES
3.4 合成虚假图像
Finally, we introduces how to synthesizing images from scratch. As depicted in Figure 8, the synthesis begins with sampling a random vector $z$ from standard Gaussian distribution. And then, this
最后,我们介绍如何从零开始合成图像。如图 8 所示,合成过程从标准高斯分布中采样一个随机向量 $z$ 开始,然后...
noise is gradually denoised into an image latent code by the diffusion model. The reverse diffusion iterations are formulated as:
噪声通过扩散模型逐步去噪为图像潜在代码。反向扩散迭代过程可表示为:
$$
\mathbf{x}{t-1}=\frac{1}{\sqrt{\alpha_{t}}}\left(\mathbf{x}{t}-\frac{1-\alpha_{t}}{\sqrt{1-\bar{\alpha}{t}}}\epsilon_{\theta}\left(\mathbf{x}{t},t\right)\right)+\sigma_{t}\mathbf{z},
$$
$$
\mathbf{x}{t-1}=\frac{1}{\sqrt{\alpha_{t}}}\left(\mathbf{x}{t}-\frac{1-\alpha_{t}}{\sqrt{1-\bar{\alpha}{t}}}\epsilon_{\theta}\left(\mathbf{x}{t},t\right)\right)+\sigma_{t}\mathbf{z},
$$
where, $\alpha_{t},\bar{\alpha}{t}$ and $\sigma_{t}$ are diffusion hyper-parameters, and $z$ is a random vector sampled from standard Gaussian distribution. At last, we decode image latent codes into images with the pre-trained decoder from Stable Diffusion (Rombach et al., 2022).
其中,$\alpha_{t},\bar{\alpha}{t}$ 和 $\sigma_{t}$ 是扩散超参数,$z$ 是从标准高斯分布采样的随机向量。最后,我们使用 Stable Diffusion (Rombach et al., 2022) 的预训练解码器将图像潜在编码解码为图像。
NULL guidance. A sentence with no new information is able to boost text-to-image performance obviously. This guidance is inspired by Classifier-free diffusion guidance (Ho & Salimans, 2022) which uses a dummy class label to boost label-to-image performance. Similarly, we design CLIP prompt without obvious visual meaning and embed them into the diffusion model. Specifically, we denote the original score estimation based on text description as $\epsilon_{t e x t}$ and score estimation based on null description as $\epsilon_{n u l l}$ . Then we mix these two estimations for a more accurate estimation $\epsilon^{\prime}$ :
NULL引导。一个不含新信息的句子能显著提升文本到图像的生成效果。该方法的灵感来自Classifier-free扩散引导(Ho & Salimans, 2022)通过使用虚拟类别标签来提升标签到图像的生成性能。类似地,我们设计了无明显视觉含义的CLIP提示词,并将其嵌入扩散模型。具体而言,我们将基于文本描述的原始分数估计记为$\epsilon_{text}$,基于空描述的分数估计记为$\epsilon_{null}$。随后混合这两个估计值以获得更精确的估计$\epsilon^{\prime}$:
$$
\epsilon^{\prime}=\left(\epsilon_{t e x t}-\epsilon_{n u l l}\right)\times\eta+\epsilon_{n u l l},
$$
$$
\epsilon^{\prime}=\left(\epsilon_{t e x t}-\epsilon_{n u l l}\right)\times\eta+\epsilon_{n u l l},
$$
where, $\eta$ is the guidance ration controlling the balance of two estimations. When $\eta=1$ , NULL Guidance falls back to an ordinary score estimation. Usually, a NULL prompt with the average meaning of the dataset achieve the best performance.
其中,$\eta$ 是控制两种估计平衡的引导比率。当 $\eta=1$ 时,NULL 引导退化为普通分数估计。通常,具有数据集平均意义的 NULL 提示能实现最佳性能。
4 EXPERIMENTS
4 实验
A small bird This bird is This bird is A bird with This flower has This flower has This flower has A pale purple with blue-grey white from mainly grey, it blue head, a lot of dark red petals that are large smooth five petaled wings, rust crown to belly, has brown on white belly and petals and no purple and white petals flower with colored sides with gray the feathers and breast, and the visible outer bunched that turn yellow yellow stamen and white wingbars and back of the tail. bill is pointed. stigma or together. toward the and green collar. retrices. stamen. center. stigma.
一只小鸟
这只鸟是
这只鸟是
一只拥有
这朵花有
这朵花有
这朵花有
浅紫色带蓝灰色
白色为主,略带灰色
蓝色头部,
许多深红色花瓣
花瓣大而光滑,五瓣
翅膀呈锈色
从冠部到腹部,
腹部和胸部为白色
羽毛和尾羽背面为灰色
喙尖锐。
无明显柱头或雄蕊。
花瓣聚拢。
逐渐向中心变黄
黄色雄蕊和绿色领状结构。
尾羽。
雄蕊。
中心。
柱头。

Figure 3: Qualitative comparison on the CUB and Oxford dataset. The input text descriptions are given in the first row and the corresponding generated images from different methods are shown in the same column. Best view in color and zoom in.
图 3: CUB 和 Oxford 数据集上的定性对比。首行展示输入文本描述,同列显示不同方法生成的对应图像。建议彩色查看并放大观察。
Datasets. We report results on the popular CUB, Oxford-102, and MS COCO datasets. The CUB dataset includes 200 categories with a total of 11,788 bird images, while the Oxford-102 dataset contains 102 categories with 8,189 flower images. Unlike the approaches taken in Reed et al. (2016a;b), we utilize the entire dataset for both training and testing. Each image is paired with 10 captions. To expand the original datasets, we collect 300,000 bird images and 130,000 flower images. The MS COCO dataset comprises 123,287 images, each with 5 sentence annotations. We use the official training split of COCO for training and the official validation split for testing. During mini-batch selection, a random image view (e.g., crop or flip) is chosen for one of the captions.
数据集。我们在常用的CUB、Oxford-102和MS COCO数据集上报告结果。CUB数据集包含200个类别共计11,788张鸟类图像,Oxford-102数据集包含102个类别共计8,189张花卉图像。与Reed等人(2016a;b)采用的方法不同,我们将完整数据集同时用于训练和测试。每张图像配有10条描述文本。为扩展原始数据集,我们额外收集了300,000张鸟类图像和130,000张花卉图像。MS COCO数据集包含123,287张图像,每张图像配有5条语句标注。我们使用COCO官方训练集划分进行训练,并采用官方验证集划分进行测试。在迷你批次选择过程中,会随机选取某条描述文本对应的图像视图(如裁剪或翻转)。
Web images. For the CUB and Oxford datasets, we collected 603,484 bird images and 331,602 flower images using search engines, utilizing fine-grained classification labels as search keywords. After removing detected outliers, we retained 399,246 bird images and 132,648 flower images. In the case of the COCO dataset, we gathered 770,059 daily images without applying any outlier detection, as the precise descriptions in COCO allow search engines to retrieve clean images effectively.
网络图像。对于CUB和Oxford数据集,我们使用搜索引擎收集了603,484张鸟类图像和331,602张花卉图像,利用细粒度分类标签作为搜索关键词。在剔除检测到的异常值后,保留了399,246张鸟类图像和132,648张花卉图像。针对COCO数据集,我们收集了770,059张日常图像且未进行异常值检测,因为COCO的精确描述能使搜索引擎有效检索到干净图像。
Training details. The text encoder is a pre-trained CLIP text encoder with an output of size 512. The latent encoder and decoder is pre-trained by Stable Diffusion (Rombach et al., 2022). We have tried to pre-train new latent encoders on extrapolated data but the results are not satisfying. Adam optimizer is used to optimize the network with base learning rates of 0.0001 and weight decay of 0. The same as RAT-GAN, we used a mini-batch size of 24 to train the model. Most training and testing of our model are conducted on 2 RTX 3090 Ti and the detailed training consumption is listed in Table 3.
训练细节。文本编码器采用预训练的CLIP文本编码器,输出维度为512。潜在空间编码器与解码器由Stable Diffusion (Rombach等人,2022) 预训练。我们尝试在扩展数据上预训练新的潜在编码器,但效果不佳。使用Adam优化器进行网络训练,基础学习率为0.0001,权重衰减为0。与RAT-GAN相同,我们采用24的小批量规模进行模型训练。大部分训练和测试在2块RTX 3090 Ti显卡上完成,具体训练耗时如 表3 所示。
Evaluation metrics. We adopt the widely used Inception Score (IS) (Salimans et al., 2016) and Fréchet Inception Distance (FID) (Heusel et al., 2017) to quantify the performance. On the MS COCO dataset, an Inception-v3 network pre-trained on the ImageNet dataset is used to compute the KL-divergence between the conditional class distribution (generated images) and the marginal class distribution (real images). The presence of a large IS indicates that the generated images are of high quality. The FID computes the Fréchet Distance between the image feature distributions of the generated and real-world images. The image features are extracted by the same pre-trained Inception v3 network. A lower FID implies the generated images are closer to the real images. We only compare the FID on the COCO dataset. On the CUB and Oxford-102 dataset, pre-trained Inception models are fine-tuned on two fine-grained classification tasks (Zhang et al., 2019).
评估指标。我们采用广泛使用的 Inception Score (IS) (Salimans et al., 2016) 和 Fréchet Inception Distance (FID) (Heusel et al., 2017) 来量化性能。在 MS COCO 数据集上,使用 ImageNet 数据集预训练的 Inception-v3 网络计算条件类别分布(生成图像)与边缘类别分布(真实图像)之间的 KL 散度。较高的 IS 值表明生成图像质量较好。FID 计算生成图像与真实图像特征分布之间的 Fréchet 距离,图像特征由相同的预训练 Inception v3 网络提取。较低的 FID 值意味着生成图像更接近真实图像。我们仅在 COCO 数据集上比较 FID。在 CUB 和 Oxford-102 数据集上,预训练的 Inception 模型会在两个细粒度分类任务上进行微调 (Zhang et al., 2019)。
There are two conflicts in evaluation methods in previous works. First, some studies report Inception Score (IS) using the ImageNet Inception model, while others use a fine-tuned version. Second, some works evaluate using the entire training data, whereas others use only the test split. To address these inconsistencies, we report IS and FID using both Inception models and employ the same Inception model as DM-GAN for consistency. Additionally, to resolve conflicts related to data splits, we report the FID scores of our model and other re-implemented models using the entire dataset for both training and testing. According to results from RAT-GAN (Ye et al., 2023), training and testing on the full dataset typically yields the best FID scores. We will also release all evaluation codes on GitHub.
先前工作中的评估方法存在两个冲突。首先,部分研究使用ImageNet Inception模型报告Inception Score (IS),而其他研究则使用微调版本。其次,有些工作使用全部训练数据进行评估,而另一些仅使用测试集划分。为解决这些不一致性,我们同时采用两种Inception模型报告IS和FID,并保持与DM-GAN相同的Inception模型以确保一致性。此外,针对数据划分的冲突,我们使用完整数据集进行训练和测试,报告本模型及其他重新实现模型的FID分数。根据RAT-GAN (Ye et al., 2023) 的研究结果,在全数据集上训练和测试通常能获得最佳FID分数。我们也将所有评估代码发布在GitHub上。
Compared models. We compare our model with recent state-of-the-art methods: Stack $\mathrm{GAN{++}}$ (Zhang et al., 2019), DM-GAN (Zhu et al., 2019), DF-GAN (Tao et al., 2022), DAE- GAN (Ruan et al., 2021), VQ-diffusion (Gu et al., 2022), AttnGAN (Xu et al., 2018), GALIP (Zhang & Schomaker, 2021),U-ViT (Bao et al., 2023), and RAT-GAN (Ye et al., 2023).
对比模型。我们将我们的模型与以下最新先进方法进行比较:Stack $\mathrm{GAN{++}}$ (Zhang et al., 2019)、DM-GAN (Zhu et al., 2019)、DF-GAN (Tao et al., 2022)、DAE-GAN (Ruan et al., 2021)、VQ-diffusion (Gu et al., 2022)、AttnGAN (Xu et al., 2018)、GALIP (Zhang & Schomaker, 2021)、U-ViT (Bao et al., 2023) 以及 RAT-GAN (Ye et al., 2023)。
4.1 COMPARISONS WITH OTHERS
4.1 与其他方法的对比
Quantitative results. We present results for the CUB dataset of bird images, the Oxford-102 dataset of flower images, and the MS COCO dataset of common objects, as shown in Table 1. On the CUB dataset, our model achieve an IS score of 6.56 and an FID score of 6.36, outperforming all the previous models. For the Oxford dataset, we achieve an IS score of 4.35 and an FID score of 6.36, outperforming all the previous models. On the COCO dataset, our model achieves an FID score of 5.00 that is competitive with previous best result.Compared with VQ-Diffusion, our model uses less training data and achieve much better performance. This comparison reveals that pre-training on large datasets can be inefficient and lead to suboptimal results. Moreover, results in Table 1 reveal that Inception model pre-trained on ImageNet is less sensitive than fine-tuned on small datasets. Additionally, the Inception score on the Oxford dataset exceeds that of real images (4.10). Extensive results demonstrate the effectiveness and generalization ability of the proposed data extrapolation method.
定量结果。我们在鸟类图像的CUB数据集、花卉图像的Oxford-102数据集和常见物体的MS COCO数据集上的结果如表1所示。在CUB数据集上,我们的模型取得了6.56的IS分数和6.36的FID分数,优于所有先前模型。对于Oxford数据集,我们取得了4.35的IS分数和6.36的FID分数,同样优于所有先前模型。在COCO数据集上,我们的模型取得了5.00的FID分数,与之前的最佳结果相当。与VQ-Diffusion相比,我们的模型使用更少的训练数据却实现了更好的性能。这一比较表明,在大数据集上进行预训练可能效率低下并导致次优结果。此外,表1中的结果显示,在ImageNet上预训练的Inception模型比在小数据集上微调的模型更不敏感。值得注意的是,Oxford数据集的Inception分数甚至超过了真实图像的分数(4.10)。大量实验结果证明了所提数据外推方法的有效性和泛化能力。
Qualitative results. We present qualitative results for the CUB dataset of bird images and the Oxford-102 dataset of flower images. In Figure 3 , we compare the visualization results of DFGAN, RAT-GAN, and our model. DF-GAN and RAT-GAN are previous state-of-the-art methods for text-to-image synthesis. On the CUB dataset, with more clear details such as feathers, eyes, and feet, our model clearly outperforms DF-GAN and RAT-GAN. Additionally, the background in our model’s results is more coherent compared to RAT-GAN. On the Oxford dataset, our model exhibits better texture and more relevant colors than the others. With the proposed text extrapolation, RAT block, and null-guidance, our model demonstrates fewer distorted shapes and more relevant content compared to the other two models.
定性结果。我们展示了鸟类图像CUB数据集和花卉图像Oxford-102数据集的定性分析结果。在图3中,我们对比了DFGAN、RAT-GAN与本模型的可视化效果。DF-GAN和RAT-GAN是文本到图像合成领域先前最先进的两种方法。在CUB数据集上,由于羽毛、眼睛和脚部等细节更清晰,我们的模型明显优于DF-GAN和RAT-GAN。此外,与RAT-GAN相比,本模型生成结果的背景更具连贯性。在Oxford数据集上,我们的模型展现出比其他方法更好的纹理和更协调的色彩。通过提出的文本外推法、RAT模块和空值引导机制,本模型相比另外两个模型呈现出更少的形状畸变和更高相关性的内容。
Table 1: Performance of IS and FID of $\mathrm{StackGAN{+}{+}}$ , AttnGAN, SSGAN, DM-GAN, DTGAN, DF-GAN and our method on the CUB, Oxford and MS COCO datasets. The results are taken from the authors’ own papers. The best results are in bold.
表 1: StackGAN++、AttnGAN、SSGAN、DM-GAN、DTGAN、DF-GAN 以及我们的方法在 CUB、Oxford 和 MS COCO 数据集上的 IS 和 FID 性能对比。结果取自作者原文,最优结果以粗体标出。
| Methods | IS(Fine-tune) ↑ CUB | IS(Fine-tune) ↑ Oxford | IS(ImageNet) ↑ CUB | IS(ImageNet) ↑ Oxford | FID(Fine-tune)↓ CUB | FID(Fine-tune)↓ Oxford | FID(ImageNet) ↓ CUB | FID(ImageNet) ↓ Oxford | FID(ImageNet) ↓ COCO |
|---|---|---|---|---|---|---|---|---|---|
| StackGAN++ | 4.04 | 3.26 | 4.04 | 3.26 | 23.96 | 48.68 | 15.30 | 32.33 | 81.59 |
| AttnGAN | 4.36 | 4.36 | 23.98 | 、 | 35.49 | ||||
| DAE-GAN | 4.42 | 15.19 | 28.12 | ||||||
| DM-GAN | 4.75 | 16.09 | 32.64 | ||||||
| DF-GAN | 5.10 | 3.80 | 4.96 | 3.92 | 17.23 | 18.90 | 14.81 | 22.56 | 21.42 |
| RAT-GAN | 5.36 | 4.09 | 5.00 | 3.95 | 13.91 | 16.04 | 10.21 | 18.68 | 14.60 |
| GALIP | 10.05 | 5.85 | |||||||
| VQ-Diffusion | 10.32 | 14.10 | 13.86 | ||||||
| U-ViT | 5.45 | ||||||||
| Ours | 6.56 | 4.35 | 6.37 | 4.11 | 7.91 | 8.58 | 6.36 | 9.52 | 5.00 |
A police man on a A man riding a wave on Some red and Assorted electronic An elephant raising its motorcycle is idle in top of a surfboard. green flower in a room. devices sitting together truck with a tree in front of a bush. in a photo. background.
一名警察骑着摩托车闲坐在灌木丛前。
一名男子在冲浪板上乘风破浪。
房间里有一朵红绿相间的花。
各种电子设备堆放在一起的照片。
一头大象站在卡车旁,背景中有棵树。

Figure 4: Qualitative comparison of our model with RAT-GAN on the COCO dataset.
图 4: 我们的模型与 RAT-GAN 在 COCO 数据集上的定性对比。
The qualitative results for the COCO dataset are shown in Figure 4. The COCO dataset includes a wide variety of common objects, which makes it particularly susceptible to the long-tail problem (Chen et al., 2022). With additional training data obtained through extrapolation, our model generates more realistic objects compared to RAT-GAN. However, the collected 770,059 images are still insufficient to cover the entire distribution of images in COCO. As a result, the outputs from COCO are not as realistic as those from the CUB and Oxford datasets.
COCO数据集的定性结果如图4所示。该数据集包含种类繁多的常见物体,因此特别容易受到长尾问题的影响 (Chen et al., 2022)。通过外推法获得额外训练数据后,我们的模型相比RAT-GAN能生成更逼真的物体。但收集的770,059张图像仍不足以覆盖COCO的全部图像分布,因此其生成效果不如CUB和Oxford数据集逼真。
4.2 ABLATION STUDIES
4.2 消融实验
Analysis of outlier detectors. In Table 2, we present text-to-image results without cluster detector or classification detector. According to $\mathrm{ID}0{,}1$ and 2, the FID score without outlier detectors degrade severely because noisy images force the diffusion model to generate irrelevant objects. Although fine-tuning on small datasets could alleviate noise pollution but parameters also forget general knowledge at the same time. According to ID 2 and 3, classification detector performs better than cluster detector because it has utilized fine-grained classification labels.
异常检测器分析。表 2 展示了未使用聚类检测器或分类检测器的文生图结果。根据 $\mathrm{ID}0{,}1$ 和 2 的数据,未使用异常检测器的 FID 分数显著下降,因为噪声图像会迫使扩散模型生成无关对象。虽然在小数据集上进行微调可以缓解噪声污染,但模型参数也会同时遗忘通用知识。根据 ID 2 和 3 的数据,分类检测器性能优于聚类检测器,因其利用了细粒度分类标签。
Table 2: Ablation studies on the CUB dataset. We utilize a NULL-guidance ratio of 1.5 during sampling. The FID score was employed to evaluate generation performance.
表 2: CUB数据集消融实验。采样时采用1.5的NULL引导比率,使用FID分数评估生成性能。
| ID | 组件 | 外推数量(k) | 400 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 聚类 | 分类 | RAT | NULL | 0 | 50 | 100 | 200 | 300 | |||
| 0 | 16.74 | 30.78 | |||||||||
| 1 | - | - | 20.67 | ||||||||
| 2 | - | √ | - | - | - | 12.45 | |||||
| 3 | - | - | - | 9.87 | |||||||
| 4 | √ | √ | - | - | - | - | 8.76 | ||||
| 5 | 人 | 人 | 二 | - | - | 7.65 | |||||
| 6 | √ | √ | √ | 9.56 | 7.34 | 6.87 | 6.54 | 6.36 |
Table 3: Training consumption on the CUB, Oxford and COCO datasets. Fine-tuning is performed on the original dataset until the FID scores increase.
表 3: CUB、Oxford 和 COCO 数据集上的训练消耗。微调在原始数据集上进行,直到 FID 分数上升。
| 数据集 | 设备 | 原始数据集 | 外推数据 | 微调 |
|---|---|---|---|---|
| CUB | 2RTX3090Ti | 5天/1500轮 | 10天/100轮 | 6小时/50轮 |
| 2RTX3090Ti | 5天/1500轮 | 8天/200轮 | 6小时/50轮 | |
| COCO | 2RTX4090 | 10天/125轮 | 20天/95轮 | 7天/70轮 |
Analysis of extrapolation quantity. More images generally lead to improved text-to-image results. however, this trend saturates around 100,000 images, after which the improvement in FID becomes less significant with more training samples. This phenomenon aligns with that diffusion models perform much better than GANs on the COCO dataset (84K images) but exhibit similar performance to GANs on the CUB and Oxford datasets( 10K images). Furthermore, with transformers as core building blocks, GALIP performs similarly to previous models on the CUB dataset. This suggests that transformer architectures exacerbate the need for larger training datasets.
外推数量分析。通常情况下,增加图像数量能提升文生图效果,但该趋势在约10万张图像时趋于饱和——超过该数量后,FID指标随训练样本增加的提升幅度显著减弱。这一现象与扩散模型在COCO数据集(8.4万张图像)上表现远优于GAN,但在CUB和Oxford数据集(1万张图像)上与GAN性能相近的规律一致。此外,采用Transformer核心架构的GALIP在CUB数据集表现与先前模型相当,这表明Transformer架构会放大对大规模训练数据的需求。
Analysis of NULL guidance. The performance of NULL guidance is influenced by both the NULL prompt and the guidance ratio. The results in Table 4 indicate that a NULL prompt reflecting the average meaning of the dataset achieves the best performance. Additionally, a suitable guidance ratio is crucial for optimal results, and we find that a ratio around 1.5 yields the best performance on the CUB and COCO datasets. However, on the Oxford dataset, NULL guidance improves the Inception Score from 4.10 to 4.35 but degrades the FID score from 9.52 to 11.07.
NULL引导分析。NULL引导的性能受NULL提示词和引导比例共同影响。表4结果显示,反映数据集平均含义的NULL提示词能实现最佳性能。此外,合适的引导比例对优化结果至关重要,我们发现1.5左右的引导比例在CUB和COCO数据集上表现最优。但在Oxford数据集上,NULL引导虽将Inception Score从4.10提升至4.35,却导致FID分数从9.52恶化至11.07。
Table 4: The impact of various NULL prompts on FID scores in the CUB dataset.
表 4: 不同 NULL prompts 对 CUB 数据集中 FID 分数的影响
| NULLPrompts | GuidanceRatio 1.25 | 1.5 | 2.0 |
|---|---|---|---|
| "Null" | 7.23 | 7.16 | 7.68 |
| "a picture" | 6.89 | 6.54 | 7.14 |
| "no description" | 6.97 | 6.47 | 7.25 |
| "a picture of bird" | 6.46 | 6.36 | 6.86 |
| "a picture of flower" | 9.04 | 10.6 | 11.4 |
| "we don't know what it is" | 8.98 | 9.35 | 9.94 |
Analysis of text injection. Text injection is crucial for text-to-image genera- tion. As shown in $\textrm{I D4}$ and 5 of Ta- ble 2, RAT significantly improves the FID score. Further experiments indicate that directly mixing text feature with time embedding results in an FID score of 25.41, which is much worse than 16.74 achieved by RAT. This suggests that time embedding provides information very different to text embedding. Additionally, incorporat
文本注入分析。文本注入对于文生图生成至关重要。如表 2 中 $\textrm{I D4}$ 和 5 所示,RAT 显著提升了 FID 分数。进一步实验表明,直接将文本特征与时间嵌入混合会导致 FID 分数降至 25.41,远差于 RAT 实现的 16.74。这表明时间嵌入提供的信息与文本嵌入存在显著差异。此外,incorporat
Table 5: Ablation studies on the MS COCO dataset. We adopt “A picture” as the NULL prompt.
表 5: 在 MS COCO 数据集上的消融研究。我们采用 "A picture" 作为 NULL 提示。
| 训练数据 | FIDS score =2.0 |
|---|---|
| COCO | n = 1.0 = 1.5 11.89 |
| 7.99 8.43 9.24 | |
| Extrapolation 12.33 COCO-ft 8.45 | 8.41 5.00 5.56 |
ing a scaling operator into RAT can lead to model collapse, as information becomes highly compressed in latent space. Consequently, the mean value of the latent code becomes sensitive, and the scaling operation disrupts the information structure.
在RAT中引入缩放算子可能导致模型崩溃,因为信息在潜在空间中被高度压缩。因此,潜在代码的均值变得敏感,而缩放操作会破坏信息结构。

This flower is purple and white, and has petals that are bulb shaped and drooping downward.
这朵花呈紫白双色,花瓣呈球状且向下低垂。
Figure 5: Randomly generated images from the Oxford dataset. Best view in color and zoom in.
图 5: 牛津数据集中随机生成的图像。建议彩色查看并放大。
| 模型 | FID | 类型 | 预训练图像 | 参数量 |
|---|---|---|---|---|
| Parti (Yu et al., 2022) | 3.22 | 自回归 | 4.8B | 20B |
| Make-A-Scene (Gafni et al., 2022) | 7.55 | 自回归 | 35M | 4B |
| Re-Imagen (Chen et al., 2022) | 5.25 | 扩散 | 50M | 2.5B |
| VQ-Diffusion (Gu et al., 2022) | 19.75 | 扩散 | 15M | 370M |
| 我们的模型 | 5.00 | 扩散 | 7M | 464M |
Table 6: Comparison of pre-training dataset and parameter quantity of different models on the MS COCO dataset. Parameters for text encoder, latent encoder and super resolution are not counted.
表 6: 不同模型在 MS COCO 数据集上的预训练数据和参数量对比。文本编码器、潜在编码器和超分辨率部分的参数未计入。
Ablation studies on the MS COCO dataset. We conduct ablation studies on the MS COCO dataset, as presented in Table 5. The MS COCO dataset differs significantly from the CUB and Oxford datasets in terms of variety and image quantity. Experimental results demonstrate that linear extrapolation and fine-tuning (5.00) outperform the original COCO dataset (7.99). However, unlike CUB and Oxford, fine-tuning on COCO requires much more time, as shown in Table 3. Additionally, we observe that early stopping is unnecessary for fine-tuning on the COCO dataset due to its larger image volume compared to CUB and Oxford.
在 MS COCO 数据集上的消融研究。我们在 MS COCO 数据集上进行了消融研究,如表 5 所示。MS COCO 数据集在多样性和图像数量方面与 CUB 和 Oxford 数据集存在显著差异。实验结果表明,线性外推和微调 (5.00) 优于原始 COCO 数据集 (7.99)。但与 CUB 和 Oxford 不同,COCO 上的微调需要更多时间,如表 3 所示。此外,我们发现由于 COCO 的图像量大于 CUB 和 Oxford,因此在该数据集上微调时无需早停机制。
In Table 6, we compare the pre-training dataset and model parameters with previous models on the MS COCO dataset. The compared models are all pre-trained on external datasets and fine-tuned on MS COCO dataset. Our result outperforms all previous models except for Parti but we use much less pre-training images and parameters than Parti. Moreover, our diffusion model is designed for small datasets and requires very few GPUs for training.
在表6中,我们将预训练数据集和模型参数与MS COCO数据集上的先前模型进行了比较。对比模型均在外部数据集上预训练并在MS COCO数据集上微调。除Parti外,我们的结果优于所有先前模型,但使用的预训练图像和参数远少于Parti。此外,我们的扩散模型专为小数据集设计,训练所需GPU数量极少。
Diversity. To qualitatively evaluate the diversity of our proposed model, we generate random images conditioned on the same text description and different random noises. In Figure 5, we present 10 images generated from the same text. These images exhibit similar foreground elements while showcasing high diversity in spatial structure, demonstrating that our model effectively controls the image content.
多样性。为定性评估所提出模型的多样性,我们在相同文本描述和不同随机噪声条件下生成随机图像。图 5 展示了基于同一文本生成的 10 幅图像,这些图像在保持前景元素相似性的同时,呈现出空间结构的高度多样性,表明我们的模型能有效控制图像内容。
5 CONCLUSION AND FUTURE WORK
5 结论与未来工作
In this paper, we propose a new data augmentation method for text-to-image generation using linear extrapolation. Specifically, we apply linear extrapolation only on text data, and new image data are retrieved from the internet by search engines. For the reliability of new text-image pairs, we design two outlier detectors to purify retrieved images. Based on extrapolation, we construct training samples dozens of times larger than the original dataset, resulting in a significant improvement in text-to-image performance. Moreover, we propose a NULL-condition guidance to refine the score estimation for text-to-image generation. This guidance is also applicable to existing text-to-image models without further training. In the future, linear extrapolation and NULL-condition guidance could be applied to tasks beyond text-to-image generation.
本文提出了一种基于线性外推的文本到图像生成数据增强新方法。具体而言,我们仅对文本数据进行线性外推,并通过搜索引擎从互联网检索新图像数据。为确保新文本-图像对的可靠性,我们设计了两类离群值检测器来净化检索到的图像。基于外推方法,我们构建了比原始数据集大数十倍的训练样本,显著提升了文本到图像生成性能。此外,我们提出NULL-condition引导机制来优化文本到图像生成的分数估计。该机制无需额外训练即可应用于现有文本到图像模型。未来,线性外推和NULL-condition引导可扩展至文本到图像生成之外的其他任务。