RE-IMAGEN: RETRIEVAL-AUGMENTED TEXT-TO-IMAGE GENERATOR
RE-IMAGEN: 检索增强的文本到图像生成器
Wenhu Chen, Hexiang Hu, Chitwan Saharia, William W. Cohen Google Research {wenhuchen,sahariac,hexiang,wcohen}@google.com
温虎陈、胡鹤翔、Chitwan Saharia、William W. Cohen
谷歌研究院
{wenhuchen,sahariac,hexiang,wcohen}@google.com
ABSTRACT
摘要
Research on text-to-image generation has witnessed significant progress in generating diverse and photo-realistic images, driven by diffusion and auto-regressive models trained on large-scale image-text data. Though state-of-the-art models can generate high-quality images of common entities, they often have difficulty generating images of uncommon entities, such as ‘Chortai (dog)’ or ‘Picarones (food)’. To tackle this issue, we present the Retrieval-Augmented Text-to-Image Generator (Re-Imagen), a generative model that uses retrieved information to produce high-fidelity and faithful images, even for rare or unseen entities. Given a text prompt, Re-Imagen accesses an external multi-modal knowledge base to retrieve relevant (image, text) pairs and uses them as references to generate the image. With this retrieval step, Re-Imagen is augmented with the knowledge of highlevel semantics and low-level visual details of the mentioned entities, and thus improves its accuracy in generating the entities’ visual appearances. We train ReImagen on a constructed dataset containing (image, text, retrieval) triples to teach the model to ground on both text prompt and retrieval. Furthermore, we develop a new sampling strategy to interleave the classifier-free guidance for text and retrieval conditions to balance the text and retrieval alignment. Re-Imagen achieves significant gain on FID score over COCO and WikiImage. To further evaluate the capabilities of the model, we introduce Entity Draw Bench, a new benchmark that evaluates image generation for diverse entities, from frequent to rare, across multiple object categories including dogs, foods, landmarks, birds, and characters. Human evaluation on Entity Draw Bench shows that Re-Imagen can significantly improve the fidelity of generated images, especially on less frequent entities.
文本到图像生成研究在扩散模型和自回归模型的推动下取得了显著进展,这些模型通过大规模图文数据训练能够生成多样化且逼真的图像。尽管当前最先进的模型可以生成常见实体的高质量图像,但在生成罕见实体(如"Chortai(犬种)"或"Picarones(食物)")时往往表现不佳。为解决这一问题,我们提出了检索增强文本到图像生成器(Re-Imagen),该生成模型利用检索信息生成高保真图像,即使对于罕见或未见过的实体也能保持准确性。给定文本提示时,Re-Imagen会访问外部多模态知识库检索相关(图像,文本)对,并将其作为参考生成图像。通过这种检索机制,模型能够获取所述实体的高层语义和底层视觉细节知识,从而提升生成实体视觉外观的准确性。我们在构建的(图像,文本,检索)三元组数据集上训练Re-Imagen,使模型能够同时基于文本提示和检索信息进行生成。此外,我们开发了新的采样策略,通过交错文本条件和检索条件的无分类器引导,平衡文本与检索的对齐效果。Re-Imagen在COCO和WikiImage数据集上的FID分数显著提升。为进一步评估模型能力,我们提出了实体绘制基准(Entity Draw Bench),该基准评估从高频到低频实体(涵盖犬类、食物、地标、鸟类和角色等多个类别)的图像生成能力。在实体绘制基准上的人工评估表明,Re-Imagen能显著提升生成图像的保真度,尤其在低频实体上表现突出。
1 INTRODUCTION
1 引言
Recent research efforts on conditional generative modeling, such as Imagen (Saharia et al., 2022), DALL·E 2 (Ramesh et al., 2022), and Parti (Yu et al., 2022), have advanced text-to-image generation to an unprecedented level, producing accurate, diverse, and even create images from text prompts. These models leverage paired image-text data at Web scale (with hundreds of millions of training examples), and powerful backbone generative models, i.e., auto regressive models (Van Den Oord et al., 2017; Ramesh et al., 2021; Yu et al., 2022), diffusion models (Ho et al., 2020; Dhariwal & Nichol, 2021), etc, and generate highly realistic images. Studying these models’ generation results, we discovered their outputs are surprisingly sensitive to the frequency of the entities (or objects) in the text prompts. In particular, when generating text prompts about frequent entities, these models often generate realistic images, with faithful grounding to the entities’ visual appearance. However, when generating from text prompts with less frequent entities, those models either hallucinate nonexistent entities, or output related frequent entities (see Figure 1), failing to establish a connection between the generated image and the visual appearance of the mentioned entity. This key limitation can greatly harm the trustworthiness of text-to-image models in real-world applications and even raise ethical concerns. In our studies, we found these models suffer from significant quality degradation in generating visual objects associated with under-represented groups.
近期关于条件生成建模的研究,如Imagen (Saharia等人, 2022)、DALL·E 2 (Ramesh等人, 2022)和Parti (Yu等人, 2022),已将文本到图像生成推至前所未有的水平,能够根据文本提示生成准确、多样甚至富有创意的图像。这些模型利用了网络规模的图文配对数据(训练样本数达数亿),以及强大的骨干生成模型,如自回归模型 (Van Den Oord等人, 2017; Ramesh等人, 2021; Yu等人, 2022)、扩散模型 (Ho等人, 2020; Dhariwal & Nichol, 2021)等,从而生成高度逼真的图像。通过研究这些模型的生成结果,我们发现其输出对文本提示中实体(或物体)的出现频率异常敏感。具体而言,当生成涉及高频实体的文本提示时,这些模型通常能生成逼真图像,且与实体的视觉外观高度吻合。然而,当处理包含低频实体的文本提示时,这些模型要么幻觉出不存在实体,要么输出相关的高频实体(见图1),无法在生成图像与提及实体的视觉外观间建立联系。这一关键缺陷会严重损害文本到图像模型在实际应用中的可信度,甚至引发伦理问题。我们的研究表明,这些模型在生成与少数群体相关的视觉对象时存在显著的质量下降。
In this paper, we propose a Retrieval-augmented Text-to-Image Generator (Re-Imagen), which alleviates such limitations by searching for entity information in a multi-modal knowledge base, rather than attempting to memorize the appearance of rare entities. Specifically, we define our multi-modal knowledge base encodes the visual appearances and descriptions of entities with a collection of reference <image, text> pairs’. To use this resource, Re-Imagen first uses the input text prompt to retrieve the most relevant <image, text> pairs from the external multi-modal knowledge base, then uses the retrieved knowledge as model additional inputs to synthesize the target images. Consequently, the retrieved references provide knowledge regarding the semantic attributes and the concrete visual appearance of mentioned entities to guide Re-Imagen to paint the entities in the target images.
本文提出了一种检索增强型文本到图像生成器(Re-Imagen),通过在多模态知识库中搜索实体信息来缓解上述限制,而非试图记忆罕见实体的外观。具体而言,我们定义的多模态知识库通过一组参考<图像,文本>对来编码实体的视觉外观和描述。在使用该资源时,Re-Imagen首先利用输入文本提示从外部多模态知识库中检索最相关的<图像,文本>对,然后将检索到的知识作为模型额外输入来合成目标图像。因此,检索到的参考信息提供了关于所述实体的语义属性和具体视觉外观的知识,以指导Re-Imagen在目标图像中绘制这些实体。

Figure 1: Comparison of images generated by Imagen and Re-Imagen on less frequent entities. We observe that Imagen hallucinates the entities while Re-Imagen maintains better faithfulness.
图 1: Imagen 与 Re-Imagen 在低频实体上的生成图像对比。我们观察到 Imagen 会产生实体幻觉,而 Re-Imagen 保持了更高的忠实度。
The backbone of Re-Imagen is a cascaded diffusion model (Ho et al., 2022), which contains three independent generation stages (implemented as U-Nets (Ronne berger et al., 2015)) to gradually produce high-resolution (i.e., $1024\times1024)$ images. In particular, we train Re-Imagen on a dataset constructed from the image-text dataset used by Imagen (Saharia et al., 2022), where each data instance is associated with the top-k nearest neighbors within the dataset, based on text-only BM25 score. The retrieved top-k <image, text> pairs will be used as a reference for the model attend to. During inference, we design an interleaved guidance schedule that switches between text guidance and retrieval guidance, which ensures both text alignment and entity alignment. We show some examples generated by Re-Imagen, and compare them against Imagen in Figure 1. We can qualitatively observe that our images are more faithful to the appearance of the reference entity.
Re-Imagen的核心是一个级联扩散模型 (Ho et al., 2022) ,包含三个独立的生成阶段 (基于U-Net实现 (Ronneberger et al., 2015) ) ,用于逐步生成高分辨率 (即 $1024\times1024$) 图像。具体而言,我们在Imagen (Saharia et al., 2022) 使用的图文数据集基础上构建训练集,每个数据实例通过纯文本BM25分数关联数据集内的top-k最近邻。检索到的top-k<图像,文本>对将作为模型的参考依据。在推理阶段,我们设计了文本引导与检索引导交替进行的混合引导策略,确保文本对齐和实体对齐的双重效果。图1展示了Re-Imagen的生成样例及其与Imagen的对比结果,可直观观察到我们的生成结果更忠实于参考实体的外观特征。
To further quantitatively evaluate Re-Imagen, we present zero-shot text-to-image generation results on two challenging datasets: COCO (Lin et al., 2014) and WikiImages (Chang et al., 2022)1. ReImagen uses an external non-overlapping image-text database as the knowledge base for retrieval and then grounds on the retrieval to synthesize the target image. We show that Re-Imagen achieves the state-of-the-art performance for text-to-image generation on COCO and WikiImages, measured in FID score (Heusel et al., 2017), among non-fine-tuned models. For the non-entity-centric dataset COCO, the performance gain is coming from biasing the model to generate images with similar styles as the retrieved in-domain images. For the entity-centric dataset WikiImages, the performance gain comes from grounding the generation on retrieved images containing similar entities. We further evaluate Re-Imagen on a more challenging benchmark — Entity Draw Bench, to test the model’s ability to generate a variety of infrequent entities (dogs, landmarks, foods, birds, animated characters) in different scenes. We compare Re-Imagen with Imagen (Saharia et al., 2022), DALLE 2 (Ramesh et al., 2022) and Stable Diffusion (Rombach et al., 2022) in terms of faithfulness and photo realism with human raters. We demonstrate that Re-Imagen can generate faithful and realistic images on $80%$ over input prompts, beating the existing best models by at least $30%$ on EntityDrawBench. Analysis shows that the improvements are mostly coming from low-frequency visual entities.
为了进一步定量评估Re-Imagen,我们在两个具有挑战性的数据集上展示了零样本文本到图像生成结果:COCO (Lin et al., 2014) 和WikiImages (Chang et al., 2022)。Re-Imagen使用外部非重叠的图文数据库作为检索知识库,并基于检索结果合成目标图像。实验表明,在未微调的模型中,Re-Imagen以FID分数 (Heusel et al., 2017) 衡量,在COCO和WikiImages上实现了最先进的文本到图像生成性能。对于非实体中心数据集COCO,性能提升源于引导模型生成与检索到的域内图像风格相似的图像;对于实体中心数据集WikiImages,性能提升则来自基于包含相似实体的检索图像进行生成。我们进一步在更具挑战性的基准测试Entity Draw Bench上评估Re-Imagen,测试模型在不同场景中生成各类低频实体(狗、地标、食物、鸟类、动画角色)的能力。通过与Imagen (Saharia et al., 2022)、DALL·E 2 (Ramesh et al., 2022) 和Stable Diffusion (Rombach et al., 2022) 在忠实度和照片真实感方面的人工评分对比,证明Re-Imagen能在80%的输入提示上生成忠实且逼真的图像,在EntityDrawBench上至少领先现有最佳模型30%。分析表明,改进主要来自低频视觉实体。
To summarize, our key contributions are: (1) a novel retrieval-augmented text-to-image model ReImagen, which improves FID scores on two datasets; (2) interleaved classifier-free guidance during sampling to ensure both text alignment and entity fidelity; and (3) We introduce Entity Draw Bench and show that Re-Imagen can significantly improve faithfulness on less-frequent entities.
总结来说,我们的主要贡献包括:(1) 提出了一种新颖的检索增强型文本到图像模型 ReImagen,该模型在两个数据集上提升了 FID (Frechet Inception Distance) 分数;(2) 在采样过程中采用交错式无分类器引导,确保文本对齐和实体保真度;(3) 我们引入了 Entity Draw Bench 基准测试,并证明 Re-Imagen 能显著提升低频实体的还原准确性。
2 RELATED WORK
2 相关工作
Text-to-Image Diffusion Models There has been a wide-spread success (Ashual et al., 2022; Ramesh et al., 2022; Saharia et al., 2022; Nichol et al., 2021) in modeling text-to-image generation with diffusion models, which has outperformed GANs (Goodfellow et al., 2014) and auto-regressive Transformers (Ramesh et al., 2021) in photo realism and diversity (under similar model size), without training instability and mode collapsing issues. Among them, some recent large text-to-image models such as Imagen (Saharia et al., 2022), GLIDE (Nichol et al., 2021), and DALL-E2 (Ramesh et al., 2022) have demonstrated excellent generation from complex prompt inputs. These models achieve highly fine-grained control over the generated images with text inputs. However, they do not perform explicit grounding over external visual knowledge and are restricted to memorizing the visual appearance of every possible visual entity in their parameters. This makes it difficult for them to generalize to rare or even unseen entities. In contrast, Re-Imagen is designed to free the diffusion model from memorizing, as models are encouraged to retrieve semantic neighbors from the knowledge base and use retrievals as context to paint the image. Re-Imagen improves the grounding of the diffusion models to real-world knowledge and is therefore capable of faithful image synthesis.
文生图扩散模型
扩散模型在文生图任务中取得了广泛成功 (Ashual et al., 2022; Ramesh et al., 2022; Saharia et al., 2022; Nichol et al., 2021),在照片真实感和多样性方面(相同模型规模下)超越了生成对抗网络 (GANs) (Goodfellow et al., 2014) 和自回归 Transformer (Ramesh et al., 2021),且不存在训练不稳定和模式坍塌问题。其中,Imagen (Saharia et al., 2022)、GLIDE (Nichol et al., 2021) 和 DALL-E2 (Ramesh et al., 2022) 等近期大型文生图模型已展现出对复杂提示词的出色生成能力。这些模型通过文本输入实现了对生成图像的高度精细化控制,但未对外部视觉知识进行显式关联,仅依赖参数记忆所有可能视觉实体的外观特征,导致难以泛化至罕见或未见过的实体。相比之下,Re-Imagen 通过鼓励模型从知识库检索语义邻居并将检索结果作为绘制图像的上下文,使扩散模型摆脱了强记负担。该设计增强了扩散模型与现实知识的关联性,从而实现了更精准的图像合成。
Concurrent Work There are several concurrent works (Li et al., 2022; Blattmann et al., 2022; Ashual et al., 2022), that also leverage retrieval to improve diffusion models. RDM (Blattmann et al., 2022) is trained similarly to Re-Imagen, using examples and near neighbors, but the neighbors in RDM are selected using image features, and at inference time retrievals are replaced with user-chosen exemplars. RDM was shown to effectively transfer artistic style from exemplars to generated images. In contrast, our proposed Re-Imagen conditions on both text and multi-modal neighbors to generate the image includes retrieval at inference time and is demonstrated to improve performance on rare images (as well as more generally). KNN-Diffusion (Ashual et al., 2022) is more closely related work to us, as it also uses retrieval to the quality of generated images. However, KNN-Diffusion uses discrete image representations, while Re-Imagen uses the raw pixels, and Re-Imagen’s retrieved neighbors can be <image, text> pairs, while KNN-Diffusion’s are only images. Quantitatively, Re-Imagen outperforms KNN-Diffusion on the COCO dataset significantly.
同期工作
存在多项同期研究 (Li et al., 2022; Blattmann et al., 2022; Ashual et al., 2022) 也利用检索技术改进扩散模型。RDM (Blattmann et al., 2022) 的训练方式与Re-Imagen类似,均使用样本及其近邻数据,但RDM通过图像特征选择近邻,且在推理阶段将检索结果替换为用户指定的示例。实验表明RDM能有效将艺术风格从示例迁移至生成图像。相比之下,我们提出的Re-Imagen同时以文本和多模态近邻作为生成条件,在推理阶段保持检索机制,并被证实能提升罕见图像(及更广泛场景)的生成性能。KNN-Diffusion (Ashual et al., 2022) 与我们的工作关联更紧密,同样通过检索提升生成图像质量。但KNN-Diffusion使用离散图像表征,而Re-Imagen直接处理原始像素,且Re-Imagen的检索近邻可为<图像,文本>对,而KNN-Diffusion仅支持图像检索。量化实验显示,Re-Imagen在COCO数据集上显著优于KNN-Diffusion。
Others Due to the space limit, we provide an additional literature review in Appendix A.
其他
由于篇幅限制,我们在附录A中提供了额外的文献综述。
3 MODEL
3 模型
In this section, we start with background knowledge, in the form of a brief overview of the cascaded diffusion models used by Imagen. Next, we describe the concrete technical details of how we incorporate retrieval for Re-Imagen. Finally, we discuss interleaved guidance sampling.
在本节中,我们首先以Imagen采用的级联扩散模型 (cascaded diffusion models) 简要概述为背景知识开端。接着阐述Re-Imagen实现检索机制的具体技术细节。最后讨论交错引导采样 (interleaved guidance sampling) 方法。
3.1 PRELIMINARIES
3.1 预备知识
Diffusion Models Diffusion models (Sohl-Dickstein et al., 2015) are latent variable models, parameterized by $\theta$ , in the form of $\begin{array}{r}{p_{\theta}(\pmb{x}_ {0}):=\int p_{\theta}(\pmb{x}_ {0:T})d\pmb{x}_ {1:T}}\end{array}$ , where $\pmb{x}_ {1},\cdots,\pmb{x}_ {T}$ are “noised” latent versions of the input image ${\pmb x}_ {0}\sim q({\pmb x}_ {0})$ . Note that the dimensionality of both latents and the image is the same throughout the entire process, with $\pmb{x}_ {0:T}\in\mathbb{R}^{d}$ and $d$ equals the product of <height, width, # of channels $>$ . The process that computes the posterior distribution $q(\pmb{x}_ {1:T}|\pmb{x}_ {0})$ is also called the forward (or diffusion) process, and is implemented as a predefined Markov chain that gradually adds Gaussian noise to the data according to a schedule $\beta_{t}$ :
扩散模型 (Diffusion Models)
扩散模型 (Sohl-Dickstein et al., 2015) 是一种潜在变量模型,其参数化为 $\theta$,形式为 $\begin{array}{r}{p_{\theta}(\pmb{x}_ {0}):=\int p_{\theta}(\pmb{x}_ {0:T})d\pmb{x}_ {1:T}}\end{array}$,其中 $\pmb{x}_ {1},\cdots,\pmb{x}_ {T}$ 是输入图像 ${\pmb x}_ {0}\sim q({\pmb x}_ {0})$ 的“加噪”潜在版本。需要注意的是,潜在变量和图像的维度在整个过程中保持一致,即 $\pmb{x}_ {0:T}\in\mathbb{R}^{d}$,且 $d$ 等于 <高度, 宽度, 通道数> 的乘积。计算后验分布 $q(\pmb{x}_ {1:T}|\pmb{x}_ {0})$ 的过程也称为前向 (或扩散) 过程,它被实现为一个预定义的马尔可夫链,根据调度 $\beta_{t}$ 逐步向数据添加高斯噪声:
$$
q(\pmb{x}_ {1:T}|\pmb{x}_ {0})=\prod_{t=1}^{T}q(\pmb{x}_ {t}|\pmb{x}_ {t-1}) \quad q(\pmb{x}_ {t}|\pmb{x}_ {t-1}):=\mathcal{N}(\pmb{x}_ {t};\sqrt{1-\beta_{t}}\pmb{x}_ {t-1},\beta_{t}\pmb{I})
$$
$$
q(\pmb{x}_ {1:T}|\pmb{x}_ {0})=\prod_{t=1}^{T}q(\pmb{x}_ {t}|\pmb{x}_ {t-1}) \quad q(\pmb{x}_ {t}|\pmb{x}_ {t-1}):=\mathcal{N}(\pmb{x}_ {t};\sqrt{1-\beta_{t}}\pmb{x}_ {t-1},\beta_{t}\pmb{I})
$$
Diffusion models are trained to learn the image distribution by reversing the diffusion Markov chain. Theoretically, this reduces to learning to denoise ${\pmb x}_ {t}\sim q({\pmb x}_ {t}|{\pmb x}_ {0})$ into $\mathbf{\boldsymbol{{x}}}_{0}$ , with a time re-weighted square error loss—see Ho et al. (2020) for the complete proof:
扩散模型通过逆转扩散马尔可夫链来学习图像分布。理论上,这简化为学习将${\pmb x}_ {t}\sim q({\pmb x}_ {t}|{\pmb x}_ {0})$去噪为$\mathbf{\boldsymbol{{x}}}_{0}$,并采用时间加权的平方误差损失——完整证明参见Ho等人 (2020)的研究:
$$
\mathbb{E}_ {\pmb{x}_ {0},\pmb{\epsilon},\pmb{t}}[\pmb{w}_ {t}\cdot||\hat{\pmb{x}}_ {\theta}(\pmb{x}_ {t},\pmb{c})-\pmb{x}_ {0}||_{2}^{2}]
$$
$$
\mathbb{E}_ {\pmb{x}_ {0},\pmb{\epsilon},\pmb{t}}[\pmb{w}_ {t}\cdot||\hat{\pmb{x}}_ {\theta}(\pmb{x}_ {t},\pmb{c})-\pmb{x}_ {0}||_{2}^{2}]
$$
Here, the noised image is denoted as $\begin{array}{r}{\mathbf{\boldsymbol{x}}_ {t}:=\sqrt{\bar{\alpha}_ {t}}\mathbf{\boldsymbol{x}}_ {0}+\sqrt{1-\bar{\alpha}_ {t}}\mathbf{\boldsymbol{\epsilon}},}\end{array}$ , $\mathbf{\boldsymbol{x}}_ {0}$ is the ground-truth image, $_ c$ is the condition, $\mathbf{\boldsymbol{\epsilon}}\sim\mathcal{N}(\mathbf{0},\mathbf{I})$ is the noise term, $\alpha_{t}:=1-\beta_{t}$ and $\textstyle{\bar{\alpha}}_ {t}:=\prod_{s=1}^{t}\alpha_{s}$ . To simplify notation, we will allow the condition $_ c$ to include multiple conditioning signals, such as text prompts $c_{p}$ , a low-resolution image input $\scriptstyle{c_{x}}$ (which is used in super-resolution), or retrieved neighboring images $c_{n}$ (which are used in Re-Imagen). Imagen (Saharia et al., 2022) uses a U-Net (Ronne berger et al., 2015) to implement $\epsilon_{\theta}(\mathbf{x}_{t},\mathbf{c},\bar{t})$ . The U-Net represents the reversed noise generator as follows:
这里,带噪图像表示为 $\begin{array}{r}{\mathbf{\boldsymbol{x}}_ {t}:=\sqrt{\bar{\alpha}_ {t}}\mathbf{\boldsymbol{x}}_ {0}+\sqrt{1-\bar{\alpha}_ {t}}\mathbf{\boldsymbol{\epsilon}},}\end{array}$,$\mathbf{\boldsymbol{x}}_ {0}$ 是真实图像,$_ c$ 是条件,$\mathbf{\boldsymbol{\epsilon}}\sim\mathcal{N}(\mathbf{0},\mathbf{I})$ 是噪声项,$\alpha_{t}:=1-\beta_{t}$ 且 $\textstyle{\bar{\alpha}}_ {t}:=\prod_{s=1}^{t}\alpha_{s}$。为简化表示,我们将允许条件 $_ c$ 包含多个条件信号,例如文本提示 $c_{p}$、低分辨率图像输入 $\scriptstyle{c_{x}}$(用于超分辨率)或检索到的相邻图像 $c_{n}$(用于 Re-Imagen)。Imagen (Saharia et al., 2022) 使用 U-Net (Ronneberger et al., 2015) 来实现 $\epsilon_{\theta}(\mathbf{x}_{t},\mathbf{c},\bar{t})$。U-Net 将反向噪声生成器表示如下:
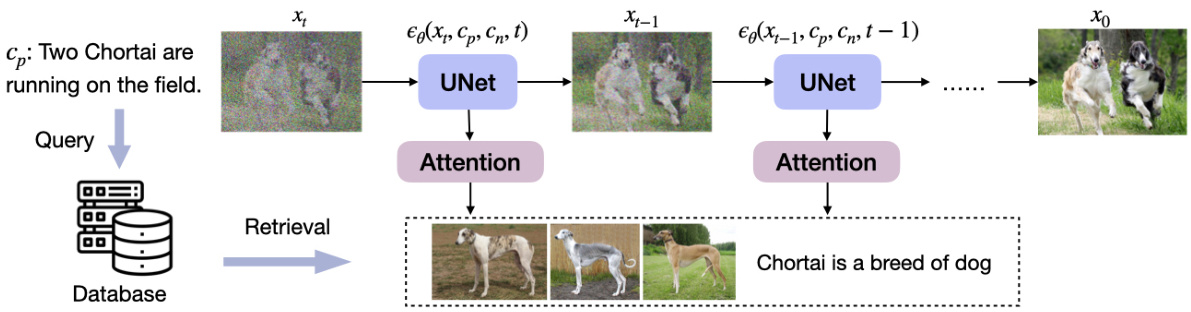
Figure 2: An illustration of the text-to-image generation pipeline in the $64\times$ diffusion model. Specifically, Re-Imagen learns a UNet to iterative ly predict $\epsilon(x_{t},c_{n},c_{p},t)$ that denoises the image. $(\boldsymbol{c}_ {n}$ : a set of retrieved image-text pairs from the database; $c_{p}$ : input text prompt; $t$ : current time-step)
图 2: 展示 $64\times$ 扩散模型中文本到图像生成的流程示意图。具体而言,Re-Imagen 通过学习一个 UNet 来迭代预测 $\epsilon(x_{t},c_{n},c_{p},t)$ 以实现图像去噪。 $(\boldsymbol{c}_ {n}$ : 从数据库中检索到的一组图像-文本对; $c_{p}$ : 输入的文本提示; $t$ : 当前时间步)
$$
\hat{\pmb{x}}_ {\theta}(\pmb{x}_ {t},\pmb{c}):=(\pmb{x}_ {t}-\sqrt{1-\bar{\alpha}_ {t}}\pmb{\epsilon}_ {\theta}(\pmb{x}_ {t},\pmb{c},t))/\sqrt{\bar{\alpha}_{t}}
$$
$$
\hat{\pmb{x}}_ {\theta}(\pmb{x}_ {t},\pmb{c}):=(\pmb{x}_ {t}-\sqrt{1-\bar{\alpha}_ {t}}\pmb{\epsilon}_ {\theta}(\pmb{x}_ {t},\pmb{c},t))/\sqrt{\bar{\alpha}_{t}}
$$
During the training, we randomly sample $t~\sim~\mathcal{U}([0,1])$ and image $\mathbf{\boldsymbol{x}}_ {0}$ from the dataset $\mathcal{D}$ , and minimize the difference between $\hat{\boldsymbol{x}}_ {\boldsymbol{\theta}}(\boldsymbol{x}_ {t},\boldsymbol{c})$ and $\mathbf{\boldsymbol{x}}_{0}$ according to Equation 2. At the inference time, the diffusion model uses DDPM (Ho et al., 2020) to sample recursively as follows:
在训练过程中,我们从数据集 $\mathcal{D}$ 中随机采样 $t~\sim~\mathcal{U}([0,1])$ 和图像 $\mathbf{\boldsymbol{x}}_ {0}$,并根据公式2最小化 $\hat{\boldsymbol{x}}_ {\boldsymbol{\theta}}(\boldsymbol{x}_ {t},\boldsymbol{c})$ 与 $\mathbf{\boldsymbol{x}}_{0}$ 之间的差异。在推理阶段,扩散模型使用DDPM (Ho et al., 2020) 进行如下递归采样:
$$
\mathbf{x}_ {t-1}=\frac{\sqrt{\bar{\alpha}_ {t-1}}\beta_{t}}{1-\bar{\alpha}_ {t}}\hat{x}_ {\theta}(\mathbf{x}_ {t},c)+\frac{\sqrt{\alpha_{t}}(1-\bar{\alpha}_ {t-1})}{1-\bar{\alpha}_ {t}}\mathbf{x}_ {t}+\frac{\sqrt{(1-\bar{\alpha}_ {t-1})\beta_{t}}}{\sqrt{1-\bar{\alpha}_{t}}}\boldsymbol{\epsilon}
$$
$$
\mathbf{x}_ {t-1}=\frac{\sqrt{\bar{\alpha}_ {t-1}}\beta_{t}}{1-\bar{\alpha}_ {t}}\hat{x}_ {\theta}(\mathbf{x}_ {t},c)+\frac{\sqrt{\alpha_{t}}(1-\bar{\alpha}_ {t-1})}{1-\bar{\alpha}_ {t}}\mathbf{x}_ {t}+\frac{\sqrt{(1-\bar{\alpha}_ {t-1})\beta_{t}}}{\sqrt{1-\bar{\alpha}_{t}}}\boldsymbol{\epsilon}
$$
The model sets ${\pmb x}_ {T}$ as a Gaussian noise with $T$ denoting the total number of diffusion steps, and then keeps sampling in reverse until step $T=0$ , i.e. $\pmb{x}_ {T}\rightarrow\pmb{x}_ {T-1}\rightarrow\dots$ , to reach the final image $\hat{\mathbf{\mathit{x}}}_{0}$ .
该模型将 ${\pmb x}_ {T}$ 设为高斯噪声,其中 $T$ 表示扩散步骤的总数,然后持续反向采样直至步骤 $T=0$,即 $\pmb{x}_ {T}\rightarrow\pmb{x}_ {T-1}\rightarrow\dots$,最终得到生成图像 $\hat{\mathbf{\mathit{x}}}_{0}$。
For better generation efficiency, cascaded diffusion models (Ho et al., 2022; Ramesh et al., 2022; Saharia et al., 2022) use three separate diffusion models to generate high-resolution images gradually, going from low resolution to high resolution. The three models $64\times$ model, $256\times$ super-resolution model, and $1024\times$ super-resolution model gradually increase the model resolution to $1024\times1024$ .
为了提高生成效率,级联扩散模型 (Ho et al., 2022; Ramesh et al., 2022; Saharia et al., 2022) 采用三个独立的扩散模型逐步生成高分辨率图像,从低分辨率过渡到高分辨率。这三个模型分别是 $64\times$ 基础模型、 $256\times$ 超分辨率模型和 $1024\times$ 超分辨率模型,逐步将分辨率提升至 $1024\times1024$。
Classifier-free Guidance Ho & Salimans (2021) first proposed classifier-free guidance to trade off diversity and sample quality. This sampling strategy has been widely used due to its simplicity. In particular, Imagen (Saharia et al., 2022) adopts an adjusted $\epsilon$ -prediction as follows:
无分类器引导
Ho & Salimans (2021) 首次提出无分类器引导方法,以权衡多样性与样本质量。该采样策略因其简洁性而被广泛采用。具体而言,Imagen (Saharia et al., 2022) 采用如下调整后的 $\epsilon$ 预测方式:
$$
\hat{\epsilon}=w\cdot\epsilon_{\theta}(\pmb{x}_ {t},\pmb{c},t)-(w-1)\cdot\epsilon_{\theta}(\pmb{x}_{t},t)
$$
$$
\hat{\epsilon}=w\cdot\epsilon_{\theta}(\pmb{x}_ {t},\pmb{c},t)-(w-1)\cdot\epsilon_{\theta}(\pmb{x}_{t},t)
$$
where $w$ is the guidance weight. The unconditional $\epsilon$ -prediction $\epsilon_{\boldsymbol{\theta}}(\boldsymbol{x}_{t},t)$ is calculated by dropping the condition, i.e. the text prompt.
其中 $w$ 为引导权重。无条件 $\epsilon$ 预测 $\epsilon_{\boldsymbol{\theta}}(\boldsymbol{x}_{t},t)$ 通过丢弃条件(即文本提示)计算得出。
3.2 GENERATING IMAGE WITH MULTI-MODAL KNOWLEDGE
3.2 基于多模态知识的图像生成
Similar to Imagen (Saharia et al., 2022), Re-Imagen is a cascaded diffusion model, consisting of $64\times$ , $256\times$ , and $1024\times$ diffusion models. However, Re-Imagen augments the diffusion model with the new capability of leveraging multimodal ‘knowledge’ from the external database, thus freeing the model from memorizing the appearance of rare entities. For brevity (and concrete ness) we present below a high-level overview of the $64\times$ model: the others are similar.
与Imagen (Saharia等人,2022)类似,Re-Imagen是一个级联扩散模型,包含$64\times$、$256\times$和$1024\times$扩散模型。但Re-Imagen通过新增利用外部数据库多模态"知识"的能力增强了扩散模型,从而无需让模型记忆罕见实体的外观。为简洁(且具体)起见,下文概述$64\times$模型的核心架构:其他模型结构类似。
Main Idea As shown in Figure 2, during the denoising process, Re-Imagen conditions its generation result not only on the text prompt $c_{p}$ (and also with $\scriptstyle{c_{x}}$ for super-resolution), but on the neighbors $c_{n}$ that were retrieved from the external knowledge base. Here, the text prompt $\pmb{c}_ {p}\in\mathbb{R}^{n\times d}$ is represented using a T5 embedding (Raffel et al., 2020), with $n$ being the text length and $d$ being the embedding dimension. Meanwhile, the top-k neighbors $c_{n}:=[{\mathrm{<image,text>}}_ {1},\cdot\cdot\cdot,{\mathrm{<image,text>}}_{k}]$ are retrieved from external knowledge base $\boldsymbol{\mathcal{B}}$ , using the input prompt $p$ as the query and a retrieval similarity function $\gamma(p,B)$ . We experimented with two different choices for the similarity function: maximum inner product scores for BM25 (Robertson et al., 2009) and CLIP (Radford et al., 2021).
核心思想
如图 2 所示,在去噪过程中,Re-Imagen 的生成结果不仅以文本提示 $c_{p}$ (以及超分辨率中的 $\scriptstyle{c_{x}}$) 为条件,还以从外部知识库检索到的邻近项 $c_{n}$ 为条件。其中,文本提示 $\pmb{c}_ {p}\in\mathbb{R}^{n\times d}$ 使用 T5 嵌入 (Raffel et al., 2020) 表示,$n$ 为文本长度,$d$ 为嵌入维度。同时,使用输入提示 $p$ 作为查询和检索相似度函数 $\gamma(p,B)$,从外部知识库 $\boldsymbol{\mathcal{B}}$ 中检索出前k个邻近项 $c_{n}:=[{\mathrm{<image,text>}}_ {1},\cdot\cdot\cdot,{\mathrm{<image,text>}}_{k}]$。我们实验了两种不同的相似度函数选择:BM25 (Robertson et al., 2009) 的最大内积分数和 CLIP (Radford et al., 2021)。
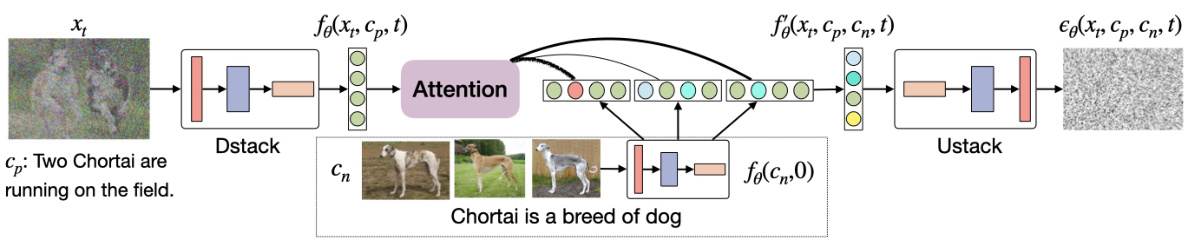
Figure 3: The detailed architecture of our model. The retrieved neighbors are first encoded using the DStack encoder and then used to augment the intermediate representation of the denoising image (via cross-attention). The augmented representation is fed to the UStack to predict the noise.
图 3: 我们模型的详细架构。检索到的相邻样本首先通过 DStack 编码器进行编码,然后用于增强去噪图像的中间表示 (通过交叉注意力机制)。增强后的表示被输入到 UStack 以预测噪声。
Model Architecture We show the architecture of our model in Figure 3, where we decompose the UNet into the down sampling encoder (DStack) and the upsampling decoder (UStack). Specifically, the DStack takes an image, a text, and a time step as the input, and generates a feature map, which is denoted as $f_{\theta}(\pmb{x}_ {t},\pmb{c}_ {p},\dot{t})\in\mathbb{R}^{F\times F\times d}$ , with $F$ denoting the feature map width and $d$ denoting the hidden dimension. We share the same DStack encoder when we encode the retrieved <image, text> pairs (with $t$ set to zero) which produce a set of feature maps $f_{\theta}(\pmb{c}_ {n},0)\in\mathbb{R}^{K\times F\times F\times d}$ . We then use a multi-head attention module (Vaswani et al., 2017) to extract the most relevant information to produce a new feature map $f_{\theta}^{\prime}(\pmb{x}_ {t},\pmb{c}_ {p},\pmb{c}_ {n},t)=A t t n(f_{\theta}(\pmb{x}_ {t},\pmb{c}_ {p},t),f_{\theta}(\pmb{c}_ {n},0))$ . The upsampling stack decoder then predicts the noise term $\epsilon_{\theta}(\pmb{x}_ {t},\pmb{c}_ {p},\pmb{c}_ {n},t)$ and uses it to compute ${\hat{\mathbf{\mathit{x}}}}_{\theta}$ with Equation 3, which is either used for regression during training or DDPM sampling.
模型架构
我们在图 3 中展示了模型的架构,将 UNet 分解为下采样编码器 (DStack) 和上采样解码器 (UStack)。具体而言,DStack 以图像、文本和时间步作为输入,生成特征图,表示为 $f_{\theta}(\pmb{x}_ {t},\pmb{c}_ {p},\dot{t})\in\mathbb{R}^{F\times F\times d}$,其中 $F$ 表示特征图宽度,$d$ 表示隐藏维度。在编码检索到的 <图像, 文本> 对时(设 $t$ 为零),我们共享相同的 DStack 编码器,生成一组特征图 $f_{\theta}(\pmb{c}_ {n},0)\in\mathbb{R}^{K\times F\times F\times d}$。随后,我们使用多头注意力模块 (Vaswani et al., 2017) 提取最相关信息,生成新特征图 $f_{\theta}^{\prime}(\pmb{x}_ {t},\pmb{c}_ {p},\pmb{c}_ {n},t)=A t t n(f_{\theta}(\pmb{x}_ {t},\pmb{c}_ {p},t),f_{\theta}(\pmb{c}_ {n},0))$。上采样堆栈解码器则预测噪声项 $\epsilon_{\theta}(\pmb{x}_ {t},\pmb{c}_ {p},\pmb{c}_ {n},t)$,并通过公式 3 计算 ${\hat{\mathbf{\mathit{x}}}}_{\theta}$,该结果既用于训练时的回归,也用于 DDPM 采样。
Model Training In order to train Re-Imagen, we construct a new dataset KNN-ImageText based on the 50M ImageText-dataset used in Imagen. There are two motivations for selecting this dataset. (1) the dataset contains many similar photos regarding specific entities, which is extremely helpful for obtaining similar neighbors, and (2) the dataset is highly sanitized with fewer unethical or harmful images. For each instance in the 50M ImageText-dataset, we search over the same dataset with text-to-text BM25 similarity to find the top-2 neighbors as $c_{n}$ (excluding the query instance). We experimented with both CLIP and BM25 similarity scores, and retrieval was implemented with ScaNN (Guo et al., 2020). We train Re-Imagen on the KNN-ImageText by minimizing the loss function of Equation 2. During training, we also randomly drop the text and neighbor conditions independently with $10%$ chance. Such random dropping will help the model learn the marginalized noise term $\epsilon_{\theta}(\pmb{x}_ {t},\pmb{c}_ {p},t)$ and $\epsilon_{\theta}(\pmb{x}_ {t},\pmb{c}_{n},t)$ , which will be used for the classifier-free guidance.
模型训练
为了训练Re-Imagen,我们在Imagen使用的50M ImageText-dataset基础上构建了新数据集KNN-ImageText。选择该数据集有两个动机:(1) 该数据集包含大量特定实体的相似照片,这对获取相似邻居极为有利;(2) 该数据集经过严格净化,不道德或有害图像较少。对于50M ImageText-dataset中的每个实例,我们通过文本到文本BM25相似度在同一数据集中搜索,找出前2个邻居作为$c_{n}$(排除查询实例本身)。我们同时测试了CLIP和BM25相似度分数,检索通过ScaNN实现[20]。我们通过最小化公式2的损失函数在KNN-ImageText上训练Re-Imagen。训练过程中还会以$10%$概率随机独立丢弃文本和邻居条件。这种随机丢弃有助于模型学习边缘化噪声项$\epsilon_{\theta}(\pmb{x}_ {t},\pmb{c}_ {p},t)$和$\epsilon_{\theta}(\pmb{x}_ {t},\pmb{c}_{n},t)$,这些项将用于无分类器引导。
Interleaved Classifier-free Guidance Different from existing diffusion models, our model needs to deal with more than one condition, i.e., text prompts $\mathbf{}c_{t}$ and retrieved neighbors $\scriptstyle{c_{n}}$ , which allows new options for incorporating guidance. In particular, Re-Imagen could use classifier-free guidance by subtracting the un conditioned $\epsilon$ -predictions, or either of the two partially conditioned $\epsilon$ -predictions. Empirically, we observed that subtracting un conditioned $\epsilon$ -predictions (the standard classifier-free guidance of Figure 3.1) often leads to an undesired imbalance, where the outputs are either dominated by the text condition or the neighbor condition. Hence, we designed an interleaved guidance schedule that balances the two conditions. Formally, we define the two adjusted $\epsilon$ -predictions as:
交错式无分类器引导
与现有扩散模型不同,我们的模型需要处理多个条件,即文本提示 $\mathbf{}c_{t}$ 和检索邻居 $\scriptstyle{c_{n}}$,这为引入引导提供了新的选择。具体而言,Re-Imagen 可以通过减去无条件 $\epsilon$ 预测,或两个部分条件 $\epsilon$ 预测中的任意一个,来使用无分类器引导。根据经验,我们发现减去无条件 $\epsilon$ 预测(图 3.1 的标准无分类器引导)通常会导致不理想的失衡,即输出要么被文本条件主导,要么被邻居条件主导。因此,我们设计了一种交错式引导调度来平衡这两个条件。形式上,我们将两个调整后的 $\epsilon$ 预测定义为:
$$
\begin{array}{r}{\hat{\epsilon}_ {p}=w_{p}\cdot\epsilon_{\theta}(x_{t},c_{p},c_{n},t)-(w_{p}-1)\cdot\epsilon_{\theta}(x_{t},c_{n},t)}\ {\hat{\epsilon}_ {n}=w_{n}\cdot\epsilon_{\theta}(x_{t},c_{p},c_{n},t)-(w_{n}-1)\cdot\epsilon_{\theta}(x_{t},c_{p},t)}\end{array}
$$
$$
\begin{array}{r}{\hat{\epsilon}_ {p}=w_{p}\cdot\epsilon_{\theta}(x_{t},c_{p},c_{n},t)-(w_{p}-1)\cdot\epsilon_{\theta}(x_{t},c_{n},t)}\ {\hat{\epsilon}_ {n}=w_{n}\cdot\epsilon_{\theta}(x_{t},c_{p},c_{n},t)-(w_{n}-1)\cdot\epsilon_{\theta}(x_{t},c_{p},t)}\end{array}
$$
where $\hat{\epsilon}_ {p}$ and $\hat{\epsilon}_ {n}$ are the text-enhanced and neighbor-enhanced $\epsilon$ -predictions, respectfully. Here, $w_{p}$ is the text guidance weight and $w_{n}$ is the neighbor guidance weight. We then interleave the two guidance predictions by a certain predefined ratio $\eta$ . Specifically, at each guidance step, we sample a [0, 1]-uniform random number $R$ , and $R<\eta$ , we use $\hat{\epsilon}_ {p}$ , and otherwise $\hat{\epsilon}_{n}$ . We can adjust $\eta$ to balance the faithfulness w.r.t text description or the retrieved image-text pairs.
其中 $\hat{\epsilon}_ {p}$ 和 $\hat{\epsilon}_ {n}$ 分别是文本增强和邻域增强的 $\epsilon$ 预测值。这里 $w_{p}$ 是文本引导权重,$w_{n}$ 是邻域引导权重。然后我们按预设比例 $\eta$ 交替使用这两种引导预测。具体而言,在每个引导步骤中,我们采样一个[0,1]均匀随机数 $R$,若 $R<\eta$ 则使用 $\hat{\epsilon}_ {p}$,否则使用 $\hat{\epsilon}_{n}$。通过调整 $\eta$ 可以平衡生成结果对文本描述或检索到的图文对的忠实度。
4 EXPERIMENTS
4 实验
Re-Imagen consists of three submodels: a 2.5B $64\times64$ text-to-image model, a 750M $256\times256$ super-resolution model and a $400\mathbf{M}1024\times1024$ super-resolution model. We also have a Re-Imagensmall with 1.4B $64\times64$ text-to-image model to understand the impact of model size.
Re-Imagen包含三个子模型:一个25亿参数的$64\times64$文生图模型、一个7.5亿参数的$256\times256$超分辨率模型,以及一个4亿参数的$1024\times1024$超分辨率模型。我们还开发了轻量版Re-Imagensmall,采用14亿参数的$64\times64$文生图模型以研究模型规模的影响。
Table 1: MS-COCO results for text-to-image generation. We use a guidance weight of 1.25 for the $64\times$ diffusion model and 5 for our $256\times$ super-resolution model. ( is fine-tuned)
| Model | Params | COCO FID ZSFID | Wikilmages FID ZS FID | ||
| GLIDE (Nichol et al.,2021) | 5B | 12.24 | |||
| DALL-E 2 (Ramesh et al.,2022) | ~5B | 10.39 | |||
| Stable-Diffusion (Rombachet al.,2022) | 1B | 12.63 | 7.50 | ||
| Imagen (Saharia et al., 2022) | 3B | 7.27 | 6.44 | ||
| Make-A-Scene (Gafni et al., 2022) | 4B | 7.55t | 11.84 | ||
| Parti (Yu et al.,2022) | 20B | 3.22t | 7.23 | ||
| Retrieval-Augmented Model | |||||
| KNN-Diffusion (Ashual et al., 2022) | 16.66 | ||||
| Memory-Driven Text-to-Image (Li et al., 2022) | 19.47 | ||||
| Re-Imagen (=BM25; B=IND; k=2) | 3.6B | 5.25 | 5.88 | ||
| Re-Imagen (=BM25; B=OOD; k=2) | 3.6B | 6.88 | 5.80 | ||
| Re-Imagen-small (=BM25; B=IND; k=2) | 2.4B | 5.73 | 6.32 | ||
| Re-Imagen-small (=BM25; B=OOD; k=2) | 2.4B | 7.32 | 6.04 | ||
表 1: 文本到图像生成的 MS-COCO 结果。我们对 $64\times$ 扩散模型使用 1.25 的引导权重,对 $256\times$ 超分辨率模型使用 5 的引导权重。(已微调)
| 模型 | 参数量 | COCO FID ZSFID | Wikilmages FID ZS FID | ||
|---|---|---|---|---|---|
| GLIDE (Nichol et al.,2021) | 5B | 12.24 | |||
| DALL-E 2 (Ramesh et al.,2022) | ~5B | 10.39 | |||
| Stable-Diffusion (Rombachet al.,2022) | 1B | 12.63 | 7.50 | ||
| Imagen (Saharia et al., 2022) | 3B | 7.27 | 6.44 | ||
| Make-A-Scene (Gafni et al., 2022) | 4B | 7.55t | 11.84 | ||
| Parti (Yu et al.,2022) | 20B | 3.22t | 7.23 | ||
| Retrieval-Augmented Model | |||||
| KNN-Diffusion (Ashual et al., 2022) | 16.66 | ||||
| Memory-Driven Text-to-Image (Li et al., 2022) | 19.47 | ||||
| Re-Imagen (=BM25; B=IND; k=2) | 3.6B | 5.25 | 5.88 | ||
| Re-Imagen (=BM25; B=OOD; k=2) | 3.6B | 6.88 | 5.80 | ||
| Re-Imagen-small (=BM25; B=IND; k=2) | 2.4B | 5.73 | 6.32 | ||
| Re-Imagen-small (=BM25; B=OOD; k=2) | 2.4B | 7.32 | 6.04 |
We finetune these models on the constructed KNN-ImageText dataset. We evaluate the model under two settings: (1) automatic evaluation on COCO and WikiImages dataset, to measure the model’s general performance to generate photo realistic images, and (2) human evaluation on the newly introduced Entity Draw Bench, to measure the model’s capability to generate long-tail entities.
我们在构建的KNN-ImageText数据集上对这些模型进行微调。评估分为两种设置:(1) 在COCO和WikiImages数据集上进行自动评估,以衡量模型生成逼真图像的通用性能;(2) 在新引入的Entity Draw Bench上进行人工评估,以测试模型生成长尾实体的能力。
Training and Evaluation details The fine-tuning was run for 200K steps on 64 TPU-v4 chips and completed within two days. We use Adafactor for the $64\times$ model and Adam for the $256\times$ superresolution model with a learning rate of 1e-4. We set the number of neighbors $k{=}2$ and set $\gamma{=}\mathrm{BM}25$ during training. For the image-text database $\boldsymbol{\mathcal{B}}$ , we consider three different variants: (1) the indomain training set, which contains non-overlapping small-scale in-domain image-text pairs from COCO or WikiImages, (2) the out-of-domain LAION dataset (Schuhmann et al., 2021) containing 400M <image, text> crawled pairs. Since indexing ImageText and LAION with CLIP encodings is expensive, we only considered the BM25 retriever for these databases.
训练与评估细节
微调过程在64块TPU-v4芯片上运行了20万步,两天内完成。对于$64\times$模型使用Adafactor优化器,$256\times$超分辨率模型采用Adam优化器(学习率1e-4)。训练中设置近邻数$k{=}2$,$\gamma{=}\mathrm{BM}25$。针对图文数据库$\boldsymbol{\mathcal{B}}$,我们评估了三种变体:(1) 域内训练集(包含来自COCO或WikiImages的非重叠小规模域内图文对),(2) 域外LAION数据集(Schuhmann等人,2021)含4亿条爬取的<图像,文本>对。由于用CLIP编码器索引ImageText和LAION成本过高,这些数据库仅采用BM25检索器。
4.1 EVALUATION ON COCO AND WIKIIMAGES
4.1 在COCO和WIKIIMAGES上的评估
In these two experiments, we used the standard non-interleaved classifier-free guidance (Figure 3.1) with $T{=}1000$ steps for both the $64\times$ diffusion model and $256\times$ super-resolution model. The guidance weight $w$ for the $64\times$ model is swept over [1.0, 1.25, 1.5, 1.75, 2.0], while the $256\times256$ superresolution models’ guidance weight $w$ is swept over [1.0, 5.0, 8.0, 10.0]. We select the guidance $w$ with the best FID score, which is reported in Table 1. We also demonstrate examples in Figure 4.
在这两个实验中,我们使用标准的非交错分类器自由引导 (图 3.1),对 $64\times$ 扩散模型和 $256\times$ 超分辨率模型均采用 $T{=}1000$ 步。$64\times$ 模型的引导权重 $w$ 在 [1.0, 1.25, 1.5, 1.75, 2.0] 范围内扫描,而 $256\times256$ 超分辨率模型的引导权重 $w$ 在 [1.0, 5.0, 8.0, 10.0] 范围内扫描。我们选择具有最佳 FID 分数的引导权重 $w$,结果如 表 1 所示。同时,我们在 图 4 中展示了示例。
COCO Results COCO is the most widely-used benchmark for text-to-image generation models. Although COCO does not contain many rare entities, it does contain unusual combinations of common entities, so it is plausible that retrieval augmentation could also help with some challenging text prompts. We adopt FID (Heusel et al., 2017) score to measure image quality. Following the previous literature, we randomly sample 30K prompts from the validation set as input to the model. The generated images are compared with the reference images from the full validation set (42K). We list the results in two columns: FID-30K denotes that the model with access to the in-domain COCO train set, while Zero-shot FID-30K does not have access to any COCO data.
COCO 评测结果
COCO 是文本到图像生成模型使用最广泛的基准测试。虽然 COCO 不包含许多罕见实体,但它确实包含常见实体的不寻常组合,因此检索增强可能也有助于处理一些具有挑战性的文本提示。我们采用 FID (Heusel et al., 2017) 分数来衡量图像质量。遵循先前文献,我们从验证集中随机抽取 30K 个提示作为模型输入。生成的图像与完整验证集 (42K) 中的参考图像进行比较。我们将结果分为两列列出:FID-30K 表示模型可以访问域内 COCO 训练集,而零样本 FID-30K 则无法访问任何 COCO 数据。
Re-Imagen can achieve a significant gain on FID by retrieving from external databases: roughly a 2.0 absolute FID improvement over Imagen. Its performance is even better than fine-tuned MakeA-Scene (Gafni et al., 2022). We found that Re-Imagen retrieving from OOD database achieves less gain than IND database, but still obtains a 0.4 FID improvement over Imagen. When comparing with other retrieval-augmented models, Re-Imagen is shown to outperform KNN-Diffusion and MemoryDriven T2I models by a significant margin of 11 FID score. We also note that Re-Imagen-small is also competent in the FID, which outperforms normal-sized Imagen with fewer parameters.
Re-Imagen通过从外部数据库检索可以在FID上实现显著提升:相比Imagen绝对FID值提升约2.0。其表现甚至优于微调后的Make-A-Scene (Gafni et al., 2022)。我们发现从OOD数据库检索的Re-Imagen增益小于IND数据库,但仍比Imagen获得0.4的FID提升。与其他检索增强模型相比,Re-Imagen以11分的FID显著优于KNN-Diffusion和MemoryDriven T2I模型。我们还注意到轻量版Re-Imagen-small在FID指标上同样出色,能以更少参数超越标准尺寸的Imagen。
As COCO does not contain infrequent entities, retrievals from the in-domain database mainly provide useful ‘style knowledge’ for the model to ground on. Re-Imagen can better adapt to COCO distribution, thus achieving a better FID score. As can be seen in the upper part of from Figure 4, Re-Imagen with retrieval generates images of the same style as COCO, while without retrieval, the output is still high quality, but the style is less similar to COCO.
由于COCO不包含低频实体,从领域内数据库检索主要为模型提供了有用的"风格知识"作为基础。Re-Imagen能更好地适应COCO分布,从而获得更优的FID分数。如图4上半部分所示,带检索的Re-Imagen生成图像与COCO风格一致,而未使用检索时输出质量虽高,但风格与COCO相似度较低。
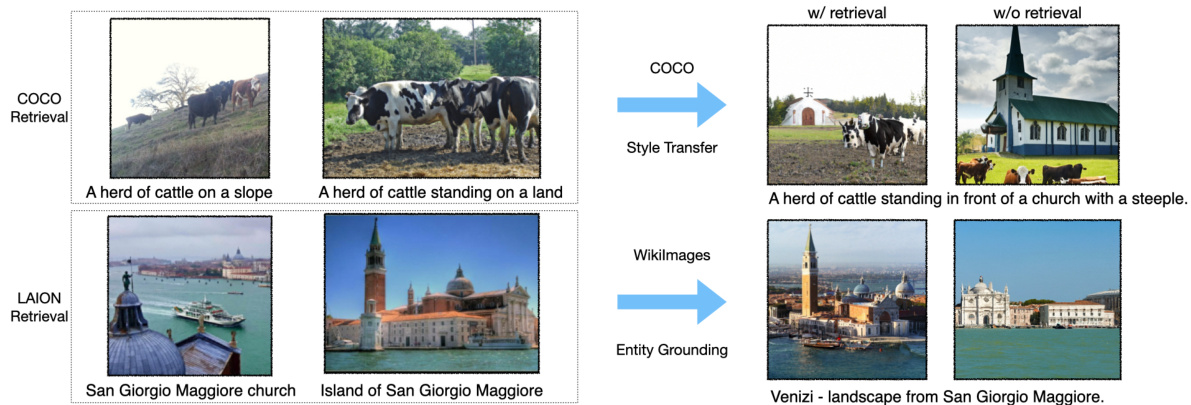
Figure 4: The retrieved top-2 neighbors of COCO and WikiImages and model generation.
图 4: COCO和WikiImages检索到的top-2邻近样本及模型生成结果。
WikiImages Results WikiImages is constructed based on the multimodal corpus provided in WebQA (Chang et al., 2022), which consists of <image, text> pairs crawled from Wikimedia Commons2. We filtered the original corpus to remove noisy data (see AppendixB), which leads to a total of 320K examples. We randomly sample 22K as our validation set to perform zero-shot evaluation, we further sample 20K prompts from the dataset as the input. Similar to the previous experiment, we also adopt the guidance weight schedule as before and evaluate $256\times256$ images.
WikiImages 结果
WikiImages 基于 WebQA (Chang et al., 2022) 提供的多模态语料库构建,该语料库包含从 Wikimedia Commons2 爬取的<图像,文本>对。我们对原始语料库进行过滤以去除噪声数据(详见附录B),最终得到 32 万组样本。我们随机抽取 2.2 万组作为验证集进行零样本评估,并进一步从数据集中采样 2 万条提示词作为输入。与先前实验类似,我们采用相同的引导权重调度策略,并评估 $256\times256$ 分辨率图像。
From Table 1, we found that using the OOD database (LAION) actually achieves better performance than using the IND database. Unlike COCO, WikiImages contains mostly entity-focused images, thus the importance of finding relevant entities in the database is more important than distilling the styles from the training set—and since the scale of LAION-400M is $100\mathrm{x}$ larger than an in-domain database, the chance of retrieving related entities is much higher, which leads to better performance. One example is depicted in the lower part of Figure 4, where the LAION retrieval finds ‘Island of San Giorgio Maggiore’, which helps the model generate the classical Renaissance-style church.
从表1中我们发现,使用OOD数据库(LAION)的实际表现优于IND数据库。与COCO不同,WikiImages主要收录以实体为中心的图像,因此从数据库中检索相关实体的重要性远高于从训练集中提取风格特征。由于LAION-400M的规模比领域内数据库大100倍,检索到相关实体的概率显著提升,从而获得更优性能。如图4下半部分所示案例,通过LAION检索到的"圣乔治马焦雷岛"有效辅助模型生成具有文艺复兴风格的教堂建筑。
4.2 ENTITY FOCUSED EVALUATION ON ENTITY DRAW BENCH
4.2 基于ENTITY DRAW BENCH的实体聚焦评估
Dataset Construction We introduce Entity Draw Bench to evaluate the model’s capability to generate diverse sets of entities in different visual scenes. Specifically, we pick various types of visual entities (dog breeds, landmarks, foods, birds, and animated characters) from Wikipedia Commons, Google Landmarks and Fandom to construct our prompts. In total, we collect 250 entity-centric prompts for evaluation. These prompts are mostly very unique and we cannot find them on the Internet, let alone the model training data. The dataset construction details are in Appendix C. To evaluate the model’s capability to ground on broader types of entities, we also randomly select 20 objects like ‘sunglasses, backpack, vase, teapot, etc’ and write creative prompts for them. We compare our generation results with the results from DreamBooth (Ruiz et al., 2022) in Appendix H.
数据集构建
我们引入Entity Draw Bench来评估模型在不同视觉场景中生成多样化实体集合的能力。具体而言,我们从Wikipedia Commons、Google Landmarks和Fandom中选取了多种类型的视觉实体(犬种、地标、食物、鸟类和动画角色)来构建提示词。总共收集了250个以实体为中心的提示词用于评估。这些提示词大多非常独特,在互联网上难以找到,更不用说模型训练数据中了。数据集构建细节详见附录C。
为了评估模型对更广泛类型实体的理解能力,我们还随机选取了20个物体(如"太阳镜、背包、花瓶、茶壶等")并为其编写创意提示词。在附录H中,我们将生成结果与DreamBooth (Ruiz et al., 2022) 的结果进行了对比。
We use the constructed prompt as the input and its corresponding image-text pairs as the ‘retrieval’ for Re-Imagen, to generate four $1024\times1024$ images. For the other models, we feed the prompts directly also to generate four images. We pick the best image of 4 random samples to rate its Photorealism and Faithfulness by human raters. For photo realism, we rate 1 if the image is moderately realistic without noticeable artifacts. For the faithfulness measure, we rate 1 if the image is faithful to both the entity appearance and the text description.
我们使用构建的提示词作为输入,并将其对应的图文对作为Re-Imagen的"检索"依据,生成四张$1024\times1024$尺寸的图像。对于其他模型,我们同样直接输入提示词生成四张图像。从四次随机采样中选取最佳图像,由人工评估者对其照片真实感(Photorealism)和忠实度(Faithfulness)进行评分。照片真实感方面,若图像具有适度真实感且无明显伪影则评1分;忠实度方面,若图像同时忠实于实体外观和文本描述则评1分。
Entity Draw Bench Results We use the proposed interleaved classifier-free guidance (subsection 3.2) for the $64\times$ diffusion model, which runs for 256 diffusion steps under a strong guidance weight of $w{=}30$ for both text and neighbor conditions. For the $256\times$ and $1024\times$ resolution models, we use a constant guidance weight of 5.0 and 3.0, respectively, with 128 and 32 diffusion steps.
实体绘制基准测试结果
我们对 $64\times$ 扩散模型采用了提出的交错式无分类器引导(第3.2小节),在文本和邻近条件的强引导权重 $w{=}30$ 下运行256次扩散步骤。对于 $256\times$ 和 $1024\times$ 分辨率模型,分别采用固定引导权重5.0和3.0,对应128次和32次扩散步骤。
Table 2: Human evaluation results for different models on different types of entities.
| Model | Faithfulness | Photorealism All | |||||
| Dogs | Foods | Landmarks | Birds | Characters | Broader | ||
| Imagen | 0.28 | 0.26 | 0.27 | 0.84 | 0.10 | 0.54 | 0.98 |
| DALL-E2 | 0.60 | 0.47 | 0.36 | 0.82 | 0.08 | 0.58 | 0.98 |
| Stable-Diffusion | 0.16 | 0.24 | 0.24 | 0.68 | 0.08 | 0.46 | 0.92 |
| Re-Imagen (K=2) | 0.80 | 0.80 | 0.82 | 0.92 | 0.54 | 0.80 | 0.98 |
表 2: 不同模型在各类实体上的人类评估结果
| Model | Dogs | Foods | Landmarks | Birds | Characters | Broader | Photorealism All |
|---|---|---|---|---|---|---|---|
| Imagen | 0.28 | 0.26 | 0.27 | 0.84 | 0.10 | 0.54 | 0.98 |
| DALL-E2 | 0.60 | 0.47 | 0.36 | 0.82 | 0.08 | 0.58 | 0.98 |
| Stable-Diffusion | 0.16 | 0.24 | 0.24 | 0.68 | 0.08 | 0.46 | 0.92 |
| Re-Imagen (K=2) | 0.80 | 0.80 | 0.82 | 0.92 | 0.54 | 0.80 | 0.98 |
The inference speed is 30-40 secs for 4 images on 4 TPU-v4 chips. We demonstrate our human evaluation results for faithfulness and photo realism in Table 2.
在4个TPU-v4芯片上处理4张图像的推理速度为30-40秒。我们在表2中展示了人类评估结果,包括忠实度和照片真实感。
We can observe that Re-Imagen can in general achieve much higher faithfulness than the existing models while maintaining similar photo realism scores. When comparing with our backbone Imagen, we see the faithfulness score improves by around $40%$ , which indicates that our model is paying attention to the retrieved knowledge and assimilating it into the generation process.
我们可以观察到,Re-Imagen 在保持相近照片真实感分数的同时,普遍比现有模型实现了更高的忠实度。与我们的基础模型 Imagen 相比,忠实度分数提升了约 $40%$ ,这表明我们的模型正在关注检索到的知识并将其融入生成过程。

Figure 5: The human evaluation scores for both frequent and infrequent entities.
图 5: 高频实体与低频实体的人工评估得分。
We further partition the entities into ‘frequent’ and ‘infrequent’ categories based on their frequency (top $50%$ as ‘frequent’). We plot the faithfulness score for ‘frequent’ and ‘infrequent’ separately in Figure 5. We can see that Re-Imagen is less sensitive to the frequency of the input entities than the other models with only minor performance drops. This study reflects the effectiveness of text-toimage generation models on long-tail entities. More generation examples are shown in Appendix F.
我们进一步根据实体出现频率将其划分为"高频"和"低频"两类(前50%为"高频")。图5分别展示了"高频"和"低频"实体的忠实度评分。可以看出,与其他模型相比,Re-Imagen对输入实体频率的敏感性较低,仅出现轻微性能下降。该研究反映了文生图(Text-to-Image)模型在长尾实体上的有效性。更多生成示例见附录F。
4.3 ANALYSIS
4.3 分析
Comparison to Other Models We demonstrate some examples from different models in Figure 6. As can be seen, the images generated from Re-Imagen strike a good balance between text alignment and entity fidelity. Unlike image editing to perform in-place modification, Re-Imagen can transform the neighbor entities both geometrically and semantically according to the text guidance. As a concrete example, Re-Imagen generates the Braque Saint-Germain (2nd row in Figure 6) on the grass, in a different viewpoint from to the reference image.
与其他模型的对比
我们在图6中展示了不同模型的一些示例。可以看出,Re-Imagen生成的图像在文本对齐和实体保真度之间取得了良好的平衡。与执行原位修改的图像编辑不同,Re-Imagen能够根据文本引导在几何和语义上转换相邻实体。具体而言,Re-Imagen生成的Braque Saint-Germain(图6第2行)位于草地上,其视角与参考图像不同。
Impact of Number of Retrievals The number of retrievals $K$ is an important factor for Re-Imagen. We vary the number of $K$ for all three datasets to understand their impact on the model performance. From Figure 7, we found that on COCO and WikiImages, increasing K from 1 to 4 does not lead to many changes in the FID score. However, on Entity Draw Bench, increasing K will dramatically improve the faithfulness of generated image. It indicates the importance of having multiple images to help Re-Imagen ground on the visual entity. We provide visual examples in Appendix D.
检索次数的影响
检索次数 $K$ 是 Re-Imagen 的重要参数。我们通过调整三个数据集的 $K$ 值来探究其对模型性能的影响。从图 7 可以看出,在 COCO 和 WikiImages 数据集上,将 K 从 1 增加到 4 时 FID 分数变化不大;但在 Entity Draw Bench 数据集上,增加 K 值会显著提升生成图像的忠实度。这表明多张参考图像对 Re-Imagen 视觉实体定位的重要性。附录 D 提供了可视化案例。
Text and Entity Faithfulness Trade-offs In our experiments, we found that there is a trade-off between fai the fulness to the text prompt and faithfulness to the retrieved entity images. Based on Equation 6, by adjusting $\eta$ , i.e.the proportion of $\hat{\epsilon}_ {p}$ and $\hat{\epsilon}_{n}$ in the sampling schedule, we can control Re-Imagen so as to generate images that explore this tradeoff: decreasing $\eta$ will increase the entity’s entity faithfulness but decrease the text alignment. We found that having $\eta$ around 0.5 is usually a ‘sweet spot’ that balances both conditions.
文本与实体忠实度的权衡
在我们的实验中,我们发现文本提示的忠实度与检索实体图像的忠实度之间存在权衡。根据公式6,通过调整 $\eta$ (即采样计划中 $\hat{\epsilon}_ {p}$ 和 $\hat{\epsilon}_{n}$ 的比例),我们可以控制Re-Imagen以生成探索这种权衡的图像:降低 $\eta$ 会增加实体的忠实度但会降低文本对齐度。我们发现将 $\eta$ 设置在0.5左右通常是平衡两种条件的"最佳点"。


Figure 6: None-cherry picked examples from Entity Draw Bench for different models. Figure 7: Ablation Study of retrieval number K on different datasets.
图 6: Entity Draw Bench中不同模型的非精选示例。
图 7: 不同数据集上检索数量K的消融研究。

A flock of birds fly around Visoki Decani church. Figure 8: Ablation study of interleaved guidance ratio $\eta$ to show the trade-off.
一群鸟儿在Visoki Decani教堂周围飞翔。图8: 交错引导比率$\eta$的消融研究,展示权衡关系。
5 CONCLUSIONS
5 结论
We present Re-Imagen, a retrieval-augmented diffusion model, and demonstrate its effectiveness in generating realistic and faithful images. We exhibit such advantages not only through automatic FID measures on standard benchmarks (i.e., COCO and WikiImage) but also through human evaluation of the newly introduced Entity Draw Bench. We further demonstrate that our model is particularly effective in generating an image from text that mentions rare entities.
我们提出了Re-Imagen,一种检索增强的扩散模型,并展示了其在生成逼真且忠实图像方面的有效性。我们不仅通过标准基准测试(即COCO和WikiImage)上的自动FID指标,还通过新引入的Entity Draw Bench的人工评估来展示这些优势。我们进一步证明,我们的模型在根据提及稀有实体的文本生成图像方面特别有效。
Re-Imagen still suffers from well-known issues in text-to-image generation, which we review below in section 5. In addition, Re-Imagen also has some unique limitations due to the retrieval-augmented modeling. First, because Re-Imagen is sensitive to retrieved image-text pairs it is conditioned on when the retrieved image is of low quality, there will be a negative influence on the generated image. Second, Re-Imagen sometimes still fails to generate high-quality images with highly compositional prompts, where multiple entities are involved. Thirdly, the super-resolution model is still not competent at capturing low-level details of retrieved entities leading to visual distortion. In future work, we plan to further investigate the above limitations and address them.
Re-Imagen 仍然存在文本到图像生成领域的已知问题,我们将在第5节进行回顾。此外,由于检索增强建模的特性,Re-Imagen 还存在一些独特限制:首先,当检索到的图像质量较低时,模型对条件图像-文本对的敏感性会导致生成图像质量下降;其次,面对涉及多实体的高度组合型提示词时,Re-Imagen 仍可能无法生成高质量图像;第三,超分辨率模型在捕捉检索实体的底层细节时仍存在不足,会导致视觉失真。我们计划在未来工作中深入研究并解决上述局限性。
ETHICS STATEMENT
伦理声明
Strong text-to-image generation models, i.e., Imagen (Saharia et al., 2022) and Parti (Yu et al., 2022), raise ethical challenges along dimensions such as the social bias. Re-Imagen is exposed to the same challenges, as we employed Web-scale datasets that are similar to the prior models.
强大的文本到图像生成模型,如Imagen (Saharia等人,2022)和Parti (Yu等人,2022),在社会偏见等维度上提出了伦理挑战。Re-Imagen也面临着同样的挑战,因为我们采用了与先前模型类似的网络规模数据集。
The retrieval-augmented modeling techniques of Re-Imagen have substantially improved the controll ability and attribution of the generated image. Like many basic research topics, this additional control could be used for beneficial or harmful purposes. One obvious danger is that Re-Imagen (or similar models) could be used for malicious purposes like spreading misinformation, e.g., by producing realistic images of specific people in misleading visual contexts. On the other side, additional control has many potential benefits. One general benefit is that Re-Imagen can reduce hallucination and increase the faithfulness of the generated image to the user’s intent. Another benefit is that the ability to work with tail entities makes the model more useful for minorities and other users in smaller communities: for example, Re-Imagen is more effective at generating images of landmarks famous in smaller communities or cultures and generating images of indigenous foods and cultural artifacts. We argue that this model can help decrease the frequency-caused bias in current neural network-based AI systems.
Re-Imagen的检索增强建模技术显著提升了生成图像的可控性和归属性。与许多基础研究课题类似,这种额外控制既可能用于有益目的,也可能被滥用。一个明显的风险是Re-Imagen(或类似模型)可能被恶意利用来传播虚假信息,例如通过生成特定人物在误导性视觉场景中的逼真图像。另一方面,额外控制也带来诸多潜在益处:其一是能减少幻觉现象,使生成图像更忠实于用户意图;其二是处理长尾实体的能力使模型对少数群体和小型社区用户更具价值——例如更擅长生成小型社区/文化中的著名地标图像,或原住民食物与文化工艺品图像。我们认为该模型有助于缓解当前基于神经网络的AI系统中由频率偏差引发的问题。
Considering such potential threats to the public, we will be cautious about code and API release. In future work, we will explore a framework for responsible use that balances the value of external auditing of research with the risks of unrestricted open access, allowing this work to be used in a safe and beneficial way.
考虑到这些对公众的潜在威胁,我们将谨慎对待代码和API的发布。在未来的工作中,我们将探索一个负责任使用的框架,在平衡研究外部审计的价值与无限制开放访问的风险的同时,确保这项工作能以安全且有益的方式被利用。
REFERENCES
参考文献
Ruiqi Guo, Philip Sun, Erik Lindgren, Quan Geng, David Simcha, Felix Chern, and Sanjiv Kumar. Accelerating large-scale inference with anisotropic vector quantization. In International Conference on Machine Learning, pp. 3887–3896. PMLR, 2020.
Ruiqi Guo、Philip Sun、Erik Lindgren、Quan Geng、David Simcha、Felix Chern和Sanjiv Kumar。利用各向异性向量量化加速大规模推理。见《国际机器学习会议》第3887-3896页。PMLR,2020年。
Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-shot text-to-image generation. In International Conference on Machine Learning, pp. 8821–8831. PMLR, 2021.
Aditya Ramesh、Mikhail Pavlov、Gabriel Goh、Scott Gray、Chelsea Voss、Alec Radford、Mark Chen 和 Ilya Sutskever。零样本文本到图像生成。见《国际机器学习会议》,第8821-8831页。PMLR,2021年。
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical textconditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 2022.
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. 基于CLIP潜在空间的层级文本条件图像生成. arXiv preprint arXiv:2204.06125, 2022.
A EXTENDED LITERATURE REVIEW
扩展文献综述
As aforementioned in the main text, in this section, we provide an additional review of related works, on (1) Retrieval-augmented Generative Models; and (2) Text-guided Image Editing.
如前文所述,本节我们将对以下两个方向的相关工作做进一步综述:(1) 检索增强生成模型 (Retrieval-augmented Generative Models);(2) 文本引导图像编辑 (Text-guided Image Editing)。
Retrieval-Augmented Generative Models Knowledge grounding has also drawn significant attention in the natural language processing (NLP) community. Different semi-parametric models like KNN-LM (Khandelwal et al., 2019), RAG (Lewis et al., 2020), REALM (Guu et al., 2020), RETRO (Borgeaud et al., 2021) have been proposed to leverage external textual knowledge into the transformer language models. These models have demonstrated great advantages in increasing the language model’s faithfulness and reducing the computation/memory cost. Such attempts have also been made in visual tasks like image recognition (Long et al., 2022), 2-D scene reconstruction (Siddiqui et al., 2021), and image inpainting (Xu et al., 2021). Our proposed method follows the same theme to incorporate visual knowledge into a pre-trained text-to-image generation model to help the model generalize to long-tail entities or even unseen entities without scaling up the parameters.
检索增强生成模型
知识基础在自然语言处理(NLP)领域也引起了广泛关注。诸如KNN-LM (Khandelwal等人,2019)、RAG (Lewis等人,2020)、REALM (Guu等人,2020)、RETRO (Borgeaud等人,2021)等不同的半参数化模型被提出,用于将外部文本知识融入Transformer语言模型。这些模型在提升语言模型忠实度和降低计算/内存成本方面展现出显著优势。类似尝试也出现在图像识别(Long等人,2022)、二维场景重建(Siddiqui等人,2021)和图像修复(Xu等人,2021)等视觉任务中。我们提出的方法遵循相同理念,将视觉知识整合到预训练的文本到图像生成模型中,帮助模型泛化至长尾实体甚至未见实体,而无需增加参数量。
Text-Guided Image Editing The work of text-guided image editing aims at preserving the object’s appearance while changing certain contexts in the image. Previously, GANs (Goodfellow et al., 2014) have been used to achieve significant performance on image editing (Zhu et al., 2016; Abdal et al., 2019; Zhu et al., 2020; Roich et al., 2021; Tov et al., 2021; Wang et al., 2022; Alaluf et al., 2022). The problem is also known as inversion as it normally requires finding the initial noise vector added in the generation process. More recently, Prompt-to-Prompt (Hertz et al., 2022) propose to use pre-trained text-image models for image editing. Image editing is focused on performing in-place modifications to the input image, either changing the global styles or editing a local region specifically without modifying the object’s appearance. However, we treat the retrieved image as ‘knowledge’ and ground on it to synthesize new images. Thus, we are not restricted to in-place modifications and are able to perform more sophisticated transformations over the objects.
文本引导图像编辑
文本引导图像编辑工作旨在保留物体外观的同时改变图像中的某些内容。此前,GAN (Goodfellow等人,2014) 在图像编辑领域已展现出显著性能 (Zhu等人,2016; Abdal等人,2019; Zhu等人,2020; Roich等人,2021; Tov等人,2021; Wang等人,2022; Alaluf等人,2022)。该问题也被称为反演,因其通常需要找到生成过程中添加的初始噪声向量。最近,Prompt-to-Prompt (Hertz等人,2022) 提出使用预训练的文本-图像模型进行图像编辑。图像编辑侧重于对输入图像进行原位修改,无论是改变全局风格还是专门编辑局部区域而不改变物体外观。然而,我们将检索到的图像视为"知识"并以其为基础合成新图像。因此,我们不受限于原位修改,能够对物体进行更复杂的变换。
B WIKIIMAGES DATASET
B WIKIIMAGES 数据集
The WikiImages dataset is taken from WebQA (Chang et al., 2022). Images were crawled from Wikimedia Commons via the Bing Visual Search API. Since lots of Wikimedia’s topics are not visually interesting, the authors seeded with natural scenes and gradually refine the search pool to obtain more interesting images. The images are mostly containing entities from Wikipedia or WikiData. However, the original dataset still contains heavy noises. Therefore, we apply further filtering to obtain the more plausible ones for image generation. Specifically, we remove all the image-text pairs with text lengths larger than 15 tokens and all the text with a date or wiki-id information.
WikiImages数据集取自WebQA (Chang et al., 2022)。图像通过Bing Visual Search API从Wikimedia Commons抓取。由于Wikimedia的许多主题在视觉上并不吸引人,作者以自然场景为种子,逐步优化搜索池以获得更有趣的图像。这些图像主要包含来自Wikipedia或WikiData的实体。然而,原始数据集仍包含大量噪声。因此,我们应用进一步过滤以获得更适合图像生成的样本。具体而言,我们移除了所有文本长度超过15个token的图文对,以及所有包含日期或wiki-id信息的文本。
C ENTITY DRAW BENCH
C ENTITY DRAW BENCH
For dog breeds and birds, we sample 50 from Wikipedia Commons as our candidates. For landmarks, we sample 50 from Google Landmarks (Weyand et al., 2020) as our candidate. For foods, we sample 50 from Wikipedia4 as our candidates. For film characters, we collected 50 images from Starwars from Fandom5. We use appropriately paired source images as the retrieved ‘knowledge’. For each entity category, we write 5 prompt templates with an entity name placeholder, which describes the entity in different scenes. Each entity will sample a template and replace the placeholder with the entity’s name to generate a prompt, which is used as input to the text-to-image generation model.
对于狗品种和鸟类,我们从维基共享资源中抽取50个样本作为候选。对于地标建筑,我们从Google Landmarks (Weyand et al., 2020) 中抽取50个样本作为候选。对于食物类别,我们从维基百科抽取50个样本作为候选。对于电影角色,我们从Fandom的《星球大战》资料库收集了50张图像。我们使用恰当配对的源图像作为检索到的"知识"。每个实体类别编写5个带有实体名称占位符的提示模板,这些模板以不同场景描述实体。每个实体会随机选取一个模板,并将占位符替换为实体名称来生成提示词,作为文生图模型的输入。

Figure 9: The construction process of Entity Draw Bench. We first list entity names and then find their source images from Wikimedia, and finally generate prompts related to these entities.
图 9: Entity Draw Bench构建流程。我们首先列出实体名称,然后从维基媒体(Wikimedia)查找对应的源图像,最后生成与这些实体相关的提示词。
We list all the prompt templates as Figure 10.
我们将所有提示模板列于图10。
Figure 10: The Entity Draw Bench prompt templates for all the different entity categories.
| Type | Template1 | Template2 | Template3 | Template4 | Template5 |
| Dog | [DoG]issleepingontheground. | [DoG]isrunningbytheriver. | [DOG]iscatching a frisbee. | [DOG] is taking a shower. | [DOG] is fighting with another 6op |
| Food | [FooD]isplacedonthegrass. | [FOOD] is served with wine. | [FooD]withpopcornonthe side. | A dog is beside [FOOD] (food). | [FOOD] is decorated with flowers. |
| Landmark | A dog is sitting in front of [LANDMARK] | Abigcrowdoftouristsinfrontof [LANDMARK]. | A rainy day in [LANDMARK]. | [LANDMARK] is lit up during the night. | cars parking in front of [LANDMARK]. |
| Bird | A [BIRD] is docking on a pier. | A [BIRD] is drinking water. | A [BIRD] is flapping its wings. | A [BIRD] is diving from the sky. | A [BIRD] is swimming in the river. |
| Character | flying in the sky. | TheStarWarscharacter[ENTITY]isTheStarWarscharacter[ENTITY]isTheStarWarscharacter[ENTITY]The character[ENTITY] is standing in the water. | is standing in the garden. | in a shopping mall. | TheStarWars character [ENTITY] is in the kitchen. |
图 10: 实体绘制基准测试中所有不同实体类别的提示模板。
| 类型 | 模板1 | 模板2 | 模板3 | 模板4 | 模板5 |
|---|---|---|---|---|---|
| 狗 | [DoG]正在地上睡觉。 | [DoG]正在河边奔跑。 | [DOG]正在接飞盘。 | [DOG]正在洗澡。 | [DOG]正在和另一只狗打架。 |
| 食物 | [FooD]被放在草地上。 | [FOOD]与葡萄酒一起供应。 | [FooD]旁边有爆米花。 | 一只狗在[FOOD]旁边。 | [FOOD]用鲜花装饰。 |
| 地标 | 一只狗坐在[LANDMARK]前面。 | 一大群游客在[LANDMARK]前面。 | [LANDMARK]的一个雨天。 | [LANDMARK]在夜晚被点亮。 | 汽车停在[LANDMARK]前面。 |
| 鸟 | 一只[BIRD]停靠在码头上。 | 一只[BIRD]正在喝水。 | 一只[BIRD]正在拍打翅膀。 | 一只[BIRD]从天空俯冲下来。 | 一只[BIRD]在河里游泳。 |
| 角色 | 在空中飞翔。 | 星球大战角色[ENTITY]是 | 角色[ENTITY]站在水中。 | 站在花园里。 | 在购物中心。 |
D IMPACT OF RETRIEVAL NUMBER K
D 检索数量K的影响
We change the retrieval number K from 1 to 2 to see its impact on the model output. We show some examples in Figure 11 to demonstrate the advantage of having multiple retrievals to help the model better capture the visual appearance of the given entities.
我们将检索数量K从1调整到2,以观察其对模型输出的影响。图11展示了一些示例,说明多次检索有助于模型更好地捕捉给定实体的视觉外观优势。

Figure 11: Generation Examples for setting K to 1 and 2.
图 11: K值设为1和2时的生成示例。
We demonstrate different types of sampling strategy to leverage two conditions: standard joint condition guidance sampling, weighted guidance sampling, and our proposed interleaved guidance sampling.
我们展示了利用两种条件的不同采样策略类型:标准联合条件引导采样、加权引导采样以及我们提出的交错引导采样。
The standard joint condition guidance only considers the joint diffusion score $\epsilon(x_{t},c_{n},c_{p})$ to meet both conditions. In contrast, weighted guidance sampling uses the weighted sum of text-enhanced epsilon $\hat{\epsilon}_ {p}$ and neighbor-enhanced epsilon $\hat{\epsilon}_ {n}$ . Our interleaved classifier guidance switches between $\hat{\epsilon}_ {p}$ and $\hat{\epsilon}_ {n}$ , with a ratio of $\eta:1-\eta$ . We plot their conceptual difference in Figure 12. Essentially, $\epsilon_{n}$ and $\epsilon_{p}$ do not have dependency in weighted sampling, however, they are dependent in interleaved sampling. In an extreme case where $\epsilon_{n}$ and $\epsilon_{p}$ are contradictory to each other, the model will get stuck in a local region. In contrast, Interleaved sampling can alleviate this issue.
标准的联合条件引导仅考虑联合扩散分数 $\epsilon(x_{t},c_{n},c_{p})$ 来满足两个条件。相比之下,加权引导采样使用文本增强epsilon $\hat{\epsilon}_ {p}$ 和邻域增强epsilon $\hat{\epsilon}_ {n}$ 的加权和。我们的交错分类器引导在 $\hat{\epsilon}_ {p}$ 和 $\hat{\epsilon}_ {n}$ 之间切换,比例为 $\eta:1-\eta$。我们在图12中绘制了它们的概念差异。本质上,$\epsilon_{n}$ 和 $\epsilon_{p}$ 在加权采样中没有依赖关系,但在交错采样中是相互依赖的。在 $\epsilon_{n}$ 和 $\epsilon_{p}$ 相互矛盾的极端情况下,模型会陷入局部区域。相比之下,交错采样可以缓解这一问题。

Figure 12: Weighted Guidance Sampling vs. Interleaved Guidance Sampling.
图 12: 加权引导采样 (Weighted Guidance Sampling) 与交错引导采样 (Interleaved Guidance Sampling) 对比。
We compare $20\mathrm{dog}$ images generated from these three sampling strategies in Entity Draw Bench. We vary the number of diffusion step to observe their human evaluation score curve and show case some generated outputs in Figure 13. As can be seen, the joint decoding is either dominated by the retrieval image or by the text prompt. Weighted and Interleave can help balance the two conditions to generate better images. We also found that with less sampling steps $\mathrm{K}{=}200$ , “weighted” sampling actually achieves better results than “interleaved” sampling. However, as the sampling steps increase, our proposed “interleaved” sampling achieves better human evaluation score.
我们在Entity Draw Bench中比较了这三种采样策略生成的20张狗图像。通过调整扩散步数观察其人工评估得分曲线,并在图13中展示部分生成结果。可以看出,联合解码要么被检索图像主导,要么被文本提示主导。加权(weighted)和交错(interleave)采样能帮助平衡这两种条件以生成更好的图像。我们还发现,在较少采样步数(K=200)时,"加权"采样实际效果优于"交错"采样;但随着采样步数增加,我们提出的"交错"采样获得了更高的人工评估得分。

Figure 13: Different classifier-free guidance sampling strategy (Interleave is ours).
图 13: 不同无分类器引导采样策略对比 (交错采样为本文方法)。
F GENERATION EXAMPLES
F 生成示例
We provide more generation examples in Figure 14 and Figure 15.
我们在图14和图15中提供了更多生成示例。

Figure 14: Extra None-cherry picked examples from Entity Draw Bench for different models.
图 14: Entity Draw Bench中不同模型的额外非精选示例。

Figure 15: Extra None-cherry picked examples from Entity Draw Bench for different models.
图 15: 来自Entity Draw Bench的不同模型的额外非精选示例。
G IMAGINARY EXAMPLES
G 假想示例
We provide generation results for imaginary scene in Figure 16.
我们在图 16 中提供了虚构场景的生成结果。

Figure 16: Imaginary Scenes generated by Re-Imagen.
图 16: 由 Re-Imagen 生成的虚构场景。
H COMPARISON WITH DREAMBOOTH
H 与DREAMBOOTH的对比
We also add comparison to DreamBooth (Ruiz et al., 2022). We adopt almost the same input images from DreamBooth and display our generation results in Figure 17, Figure 18 and Figure 19.
我们还与DreamBooth (Ruiz et al., 2022) 进行了对比。我们采用了与DreamBooth几乎相同的输入图像,并在图17、图18和图19中展示了我们的生成结果。
Re-lmagen
Re-lmagen
DreamBooth
DreamBooth

Figure 17: Imaginary Scenes generated by Re-Imagen.
图 17: 由 Re-Imagen 生成的虚构场景。
DreamBooth
DreamBooth

Figure 18: Imaginary Scenes generated by Re-Imagen.
图 18: Re-Imagen 生成的虚构场景。

Re-Imagen Figure 19: Imaginary Scenes generated by Re-Imagen.
图 19: Re-Imagen 生成的虚构场景
DreamBooth
DreamBooth
I FAILURE EXAMPLES
故障案例
We found that Re-Imagen can also fail in a lot of cases. We demonstrate a few examples in Figure 20. As can be seen, the model sometimes has a few failure modes: (1) the text input prior is too strong like ‘Zoom’ will be interpreted as a ‘Zoom-in’ picture by the model. (2) the model cannot ground the retrieval text on the retrieval image, for example, the model believes that only the ‘beef tenderloin inside the bowl’ is ‘Escudella’ rather than the whole stew, therefore generating ‘beef tenderloin on the grass’. (3) the model can sometimes mess up two conditions, for example, the reference ‘Australian Pinscher’ and the ‘rabbit’ in the prompt gets mixed into a single object.
我们发现Re-Imagen在许多情况下也会失败。图20展示了一些示例。可以看出,该模型有时存在几种失败模式:(1) 文本输入的先验性过强,例如"Zoom"会被模型理解为"Zoom-in"图片;(2) 模型无法将检索文本与检索图像对应起来,例如模型认为只有"碗里的牛里脊"是"Escudella"而不是整个炖菜,因此生成了"草地上的牛里脊";(3) 模型有时会混淆两个条件,例如将参考图像中的"Australian Pinscher"和提示词中的"rabbit"混合成单个对象。

Figure 20: Failure examples from Entity Draw Bench for dogs, landmarks, and foods.
图 20: Entity Draw Bench中关于狗、地标和食物的失败案例。