MA-BERT: Learning Representation by Incorporating Multi-Attribute Knowledge in Transformers
MA-BERT: 在Transformer中融入多属性知识的学习表示方法
Abstract
摘要
Incorporating attribute information such as user and product features into deep neural networks has been shown to be useful in sentiment analysis. Previous works typically accomplished this in two ways: concatenating multiple attributes to word/text representation or treating them as a bias to adjust attention distribution. To leverage the advantages of both methods, this paper proposes a multi-attribute BERT (MA-BERT) to incorporate external attribute knowledge. The proposed method has two advantages. First, it applies multi-attribute transformer (MA-Transformer) encoders to incorporate multiple attributes into both input representation and attention distribution. Second, the MA-Transformer is implemented as a universal layer and stacked on a BERT-based model such that it can be initialized from a pre-trained checkpoint and fine-tuned for the downstream applications without extra pretraining costs. Experiments on three benchmark datasets show that the proposed method outperformed pre-trained BERT models and other methods incorporating external attribute knowledge.
将用户和产品特征等属性信息融入深度神经网络已被证明对情感分析有益。先前研究通常通过两种方式实现:将多个属性与词/文本表征拼接,或将其视为调整注意力分布的偏置项。为结合两种方法的优势,本文提出多属性BERT (MA-BERT) 来整合外部属性知识。该方法具有两大优势:首先,采用多属性Transformer (MA-Transformer) 编码器将多个属性同时融入输入表征和注意力分布;其次,MA-Transformer作为通用层实现,可堆叠在基于BERT的模型上,从而能够从预训练检查点初始化并针对下游应用微调,无需额外预训练成本。在三个基准数据集上的实验表明,该方法优于预训练BERT模型及其他整合外部属性知识的方法。
1 Introduction
1 引言
To learn a distributed text representation for sentiment classification (Pang and Lee, 2008; Liu, 2012), conventional deep neural networks, such as convolutional neural networks (CNN) (Kim, 2014) and long short-term memory (LSTM) (Hochreiter and Schmid huber, 1997), and common integration technics, such as self-attention mechanisms (Vaswani et al., 2017; Chaudhari et al., 2019) and dynamic routing algorithms (Gong et al., 2018; Sabour et al., 2017), are usually applied to compose the vectors of constituent words. To further enhance the performance, pre-trained models (PTMs), such as BERT (Devlin et al., 2019), ALBERT (Lan et al., 2019), RoBERTa (Liu et al., 2019), and XLM-
为学习情感分类的分布式文本表示(Pang and Lee, 2008; Liu, 2012),通常会应用传统深度神经网络,如卷积神经网络(CNN)(Kim, 2014)和长短期记忆网络(LSTM)(Hochreiter and Schmidhuber, 1997),以及常见的集成技术,如自注意力机制(Vaswani et al., 2017; Chaudhari et al., 2019)和动态路由算法(Gong et al., 2018; Sabour et al., 2017)来组合构成词的向量。为进一步提升性能,预训练模型(PTM),如BERT(Devlin et al., 2019)、ALBERT(Lan et al., 2019)、RoBERTa(Liu et al., 2019)和XLM-
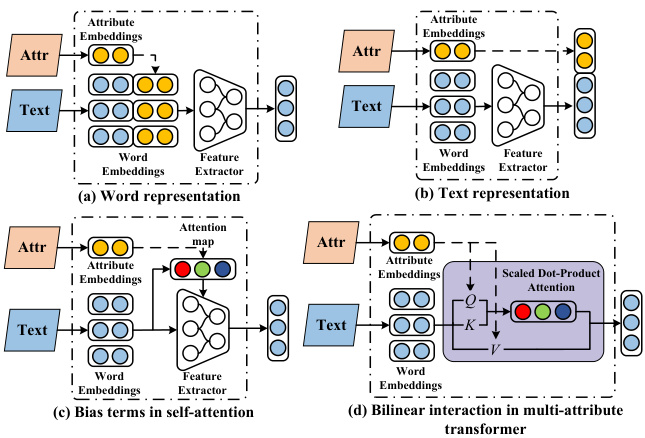
Figure 1: Different strategies to incorporate external attribute knowledge into deep neural networks.
图 1: 将外部属性知识融入深度神经网络的不同策略。
RoBERTa (Conneau et al., 2019) can be fine-tuned and transferred for sentiment analysis tasks. Practically, PTMs were first fed a large amount of unannotated data, and trained using a masked language model or next sentence prediction to learn the usage of various words and how the language is written in general. Then, the models are transferred to another task to be fed another smaller task-specific dataset.
RoBERTa (Conneau等人,2019) 可通过微调迁移用于情感分析任务。实际操作中,预训练模型(PTM)首先输入大量未标注数据,并通过掩码语言模型或下一句预测任务进行训练,以学习词汇用法和通用语言表达规律。随后,这些模型会被迁移到其他任务,并输入规模较小的任务专用数据集进行微调。
The above mentioned methods only use features from plain texts. Incorporating attribute information such as users and products can improve sentiment analysis task performance. Previous works typically incorporated such external knowledge by concatenating these attributes into word and text representations (Tang et al., 2015), as shown in Figs. 1(a) and (b). Such methods are often introduced in shallow models to attach attribute information to modify the representation of either words or texts. However, this may lack interaction between attributes and the text since it equally aligns words to attribute features, thus the model is unable to emphasize important tokens. Several works have used attribute features as a bias term in selfattention mechanisms to model meaningful relations between words and attributes (Wu et al., 2018; Chen et al., 2016b; Dong et al., 2017; Dou, 2017), as shown in Fig. 1(c). By using the sof tmax function for normalization to calculate the attention score, the incorporated attribute features only impact the allocation of the attention weights. As a result, the representation of input words has not been updated, and the information of these attributes will be lost. For example, depending on individual preferences for chili, readers may focus on reviews talking about spicy, but only those who like chili would consider such review recommendations useful. However, current self-attention models that learn text representations by adjusting the weights of spicy may still produce the same word representation of spicy for different persons, leading to confusion in distinguishing people who like chili or not.
上述方法仅利用了纯文本特征。融入用户和产品等属性信息可提升情感分析任务性能。先前研究通常通过将这些属性与词向量及文本表征拼接来引入外部知识 (Tang et al., 2015) ,如图 1(a) 和 (b) 所示。这类方法常见于浅层模型,通过附加属性信息来调整词或文本的表征。但由于其对所有token与属性特征进行平等对齐,可能缺乏属性与文本的交互,导致模型无法突出重要token。部分研究将属性特征作为自注意力机制中的偏置项,以建模词语与属性间的语义关联 (Wu et al., 2018; Chen et al., 2016b; Dong et al., 2017; Dou, 2017) ,如图 1(c) 所示。虽然通过softmax归一化计算注意力分数,但融入的属性特征仅影响注意力权重分配,输入词语的表征并未更新,导致属性信息丢失。例如:根据个人对辣椒的偏好,用户可能关注提及"辛辣"的评论,但只有喜好辣椒者会认为此类推荐有价值。然而现有自注意力模型通过调整"辛辣"的权重学习文本表征时,仍可能为不同用户生成相同的"辛辣"词向量,从而难以区分用户是否喜好辣椒。
To address the above problems, this study proposes a multi-attribute BERT (MA-BERT) model which applies multi-attribute transformer (MATransformer) encoders to incorporate external attribute knowledge. Different from being incorporated into the attention mechanism as bias terms, multiple attributes can be injected into both attention maps and input token representations using bilinear interaction, as shown in Fig. 1(d). In addition, the MA-Transformer is implemented as a universal layer and stacked on a BERT-based model such that it can be initialized from a pre-training checkpoint and fine-tuned for downstream tasks without extra pre-training costs. Experiments are conducted on three benchmark datasets (IMDB, Yelp-2013, and Yelp-2014) for sentiment polarity classification. The results show that the proposed MA-BERT model outperformed pre-trained BERT models and other methods incorporating external attribute knowledge.
为解决上述问题,本研究提出了一种多属性BERT模型(MA-BERT),该模型采用多属性Transformer编码器(MATransformer)来整合外部属性知识。与将多属性作为偏置项融入注意力机制不同,本研究通过双线性交互将多属性同时注入注意力图和输入Token表征中,如图1(d)所示。此外,MA-Transformer被实现为通用层,可堆叠在基于BERT的模型上,从而能够从预训练检查点初始化,并针对下游任务进行微调,无需额外预训练成本。我们在三个基准数据集(IMDB、Yelp-2013和Yelp-2014)上进行了情感极性分类实验。结果表明,所提出的MA-BERT模型优于预训练BERT模型及其他整合外部属性知识的方法。
The remainder of this paper is organized as follows. Section 2 provides a detailed description of the proposed methods. The empirical experiments are reported with analysis in Section 3. Conclusions are finally drawn in Section 4.
本文的其余部分组织如下。第2节详细描述了所提出的方法。第3节报告了实证实验并进行分析。最后,第4节给出结论。
2 Multi-Attribute BERT Model
2 多属性 BERT 模型
Fig. 2 shows an overview of the MA-BERT model. It mainly consists of two parts, including a BERTbased PTM model and several MA-Transformer encoders as extra layers stacked on BERT. Both components are described in detail below.
图 2: MA-BERT模型概览。该模型主要由两部分组成,包括基于BERT的PTM模型和多个作为额外层堆叠在BERT上的MA-Transformer编码器。下文将详细描述这两个组件。
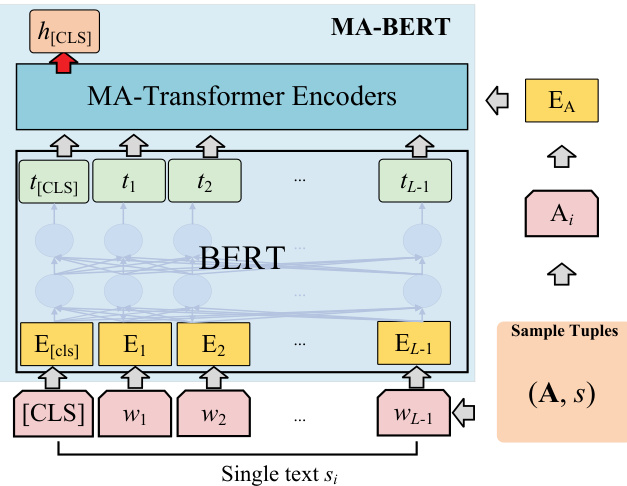
Figure 2: Overall architecture of the MA-BERT model.
图 2: MA-BERT模型的整体架构。
2.1 BERT Encoder
2.1 BERT编码器
By applying a word piece tokenizer (Wu et al., 2016), the input text can be denoted as a sequence of tokens, i.e., where L is the length of the text and w0 = [CLS] is a special classification token. Moreover, its corresponding attributes are denoted as , where $M$ is the number of attributes in the text. Thus, the $i$ -th input sample can be denoted as a tuple, i.e., $({\bf A}{i},s_{i})$ .
通过应用词片tokenizer (Wu et al., 2016),输入文本可表示为token序列 ,其中L为文本长度,w0 = [CLS]为特殊分类token。其对应属性表示为 $M$为文本属性数量。因此第$i$个输入样本可表示为元组$({\bf A}{i},s{i})$。
To learn the hidden representation, the pretrained language model BERT (Devlin et al., 2019) was used, achieving impressive performance for various natural language processing (NLP) tasks. We then fed the token sequence into the BERT model to obtain the representation, denoted as,
为了学习隐藏表示,我们使用了预训练语言模型BERT (Devlin et al., 2019),该模型在各种自然语言处理(NLP)任务中取得了令人印象深刻的性能。随后,我们将token序列输入BERT模型以获得表示,记为,
$$
T=[t_{0},...,t_{L-1}]=f_{\mathrm{BERT}}([w_{0},...,w_{L-1}];\theta_{\mathrm{BERT}})
$$
$$
T=[t_{0},...,t_{L-1}]=f_{\mathrm{BERT}}([w_{0},...,w_{L-1}];\theta_{\mathrm{BERT}})
$$
where $T\in\mathbb{R}^{L\times d_{t}}$ is the output representation of all tokens; $\theta_{\mathrm{BERT}}$ is the trainable parameters of BERT, which is initialized from a pretrained checkpoint and then fine-tuned during the model training; $d_{t}=768$ is the dimensionality of the output representation.
其中 $T\in\mathbb{R}^{L\times d_{t}}$ 表示所有 Token 的输出表征;$\theta_{\mathrm{BERT}}$ 是 BERT 的可训练参数,其初始值来自预训练检查点并在模型训练期间进行微调;$d_{t}=768$ 为输出表征的维度。
According to $\mathrm{Wu}$ et al. (2018) and Wang et al. (2017), all the attributes are mapped to attribute embeddings $E_{\mathrm{A}}=[E_{\mathrm{A},1},E_{\mathrm{A},2},...,E_{\mathrm{A},M}]\in$ RM×dE , which are randomly initialized and updated in the following training phase.
根据Wu等人 (2018) 和Wang等人 (2017) 的研究,所有属性都被映射到属性嵌入 $E_{\mathrm{A}}=[E_{\mathrm{A},1},E_{\mathrm{A},2},...,E_{\mathrm{A},M}]\in$ RM×dE,这些嵌入在训练阶段随机初始化并更新。
Multi-Attribute Attention. To incorporate multiple attributes into the MA-Transformer, we introduce multi-attribute attention (MAA), which is expressed as,
多属性注意力 (Multi-Attribute Attention)。为了将多个属性融入 MA-Transformer,我们引入了多属性注意力机制 (MAA),其表达式为:
$$
Y=\mathrm{MAA}(T,E_{\mathrm{A}}){=}[U_{1},\dots,U_{M}]W_{o}
$$
$$
Y=\mathrm{MAA}(T,E_{\mathrm{A}}){=}[U_{1},\dots,U_{M}]W_{o}
$$
$$
U_{m}=\mathrm{Att}(T,E_{\mathrm{A},m})=s o f t m a x\left(\frac{Q_{m}K_{m}^{\top}}{\sqrt{d}}\right)V_{m}
$$
$$
U_{m}=\mathrm{Att}(T,E_{\mathrm{A},m})=s o f t m a x\left(\frac{Q_{m}K_{m}^{\top}}{\sqrt{d}}\right)V_{m}
$$
where $U_{m}$ is the attention from $m$ -th attribute; $W_{o}\in R^{(M\cdot d)\times d_{t}}$ is the output linear projection and $d$ denotes the dimensionality of $Q,K$ and $V$ ; $Q,K$ and $V$ are matrices that package the queries, keys and values, which are defined as,
其中 $U_{m}$ 是第 $m$ 个属性的注意力; $W_{o}\in R^{(M\cdot d)\times d_{t}}$ 是输出线性投影, $d$ 表示 $Q,K$ 和 $V$ 的维度; $Q,K$ 和 $V$ 是打包查询(query)、键(key)和值(value)的矩阵,其定义为
$$
\begin{array}{r}{Q_{m}=T\cdot W_{q,m}\odot E_{\mathrm{A},m}}\ {~K_{m}=T\cdot W_{k,m}\odot E_{\mathrm{A},m}}\ {~V_{m}=T\cdot W_{v,m}\odot E_{\mathrm{A},m}}\end{array}
$$
$$
\begin{array}{r}{Q_{m}=T\cdot W_{q,m}\odot E_{\mathrm{A},m}}\ {~K_{m}=T\cdot W_{k,m}\odot E_{\mathrm{A},m}}\ {~V_{m}=T\cdot W_{v,m}\odot E_{\mathrm{A},m}}\end{array}
$$
where $Q_{m},K_{m}$ and $V_{m} \in~\mathbb{R}^{L\times d_{E}}$ are bilinear transformations (Huang et al., 2019) applied on the input representation $T$ and attribute representation $E_{\mathrm{A,m}}.W_{q,m},W_{k,m}$ and $W_{v,m}\in\mathbb{R}^{d_{t}\times d_{E}}$ are weight matrices for query, key and value projections, and $\cdot$ and $\odot$ respectively denote the inner and the Hadamard product.
其中 $Q_{m},K_{m}$ 和 $V_{m} \in~\mathbb{R}^{L\times d_{E}}$ 是对输入表示 $T$ 和属性表示 $E_{\mathrm{A,m}}$ 应用的双线性变换 (Huang et al., 2019)。$W_{q,m},W_{k,m}$ 和 $W_{v,m}\in\mathbb{R}^{d_{t}\times d_{E}}$ 分别是查询、键和值投影的权重矩阵,$\cdot$ 和 $\odot$ 分别表示内积和哈达玛积。
Similar to Vaswani et al. (2017), we also introduced multi-head mechanism for MA-Transformer, denoted as,
与 Vaswani 等人 (2017) 类似,我们同样为 MA-Transformer 引入了多头机制,表示为,
$$
U_{m}=\bigoplus_{k=1}^{K}\mathrm{Att}(T,E_{\mathrm{A},m}^{k})\in\mathbb{R}^{L\times(K\cdot d_{E})}
$$
$$
U_{m}=\bigoplus_{k=1}^{K}\mathrm{Att}(T,E_{\mathrm{A},m}^{k})\in\mathbb{R}^{L\times(K\cdot d_{E})}
$$
where $K$ is the number of heads for each attribute and $\bigoplus$ denotes the concatenation operator; $E_{\mathrm{A},m}^{k}\in\mathbb{R}^{d_{E}}$ is the $m$ -th attribute representation in the $k$ -th head, and its dimensionality should be ensured that $d_{E}=d_{t}/K$ . Given that different heads can capture different relation types along with text representations, different parameters are considered for different heads.
其中 $K$ 是每个属性的头数,$\bigoplus$ 表示拼接操作;$E_{\mathrm{A},m}^{k}\in\mathbb{R}^{d_{E}}$ 是第 $k$ 个头中的第 $m$ 个属性表示,其维度应确保 $d_{E}=d_{t}/K$。考虑到不同头可以捕获文本表示的不同关系类型,不同头采用不同参数。
2.2 MA-Transformer
2.2 MA-Transformer
Taking the representation of both text $T$ and attribute A as input, an MA-Transformer encoder then processes the same as a standard transformer encoder (Vaswani et al., 2017) to generate $Y\in$ $\mathbb{R}^{L\times d_{t}}$ . Then, $Y$ is connected by a normalization layer and a residual layer from the input representation $T$ . The intermediate output is then passed to a two-layered feed-forward network with a rectified linear unit (ReLU) activate function. Similarly, residual and normalization layers are connected to generate the final output which is taken as the input for the next encoder.
以文本 $T$ 和属性 A 的表示作为输入,MA-Transformer 编码器随后会像标准 Transformer 编码器 (Vaswani et al., 2017) 一样处理这些输入,生成 $Y\in$ $\mathbb{R}^{L\times d_{t}}$。接着,$Y$ 会通过一个归一化层和一个来自输入表示 $T$ 的残差层进行连接。中间输出随后被传递到一个带有修正线性单元 (ReLU) 激活函数的两层前馈网络。类似地,残差和归一化层被连接起来生成最终输出,该输出将作为下一个编码器的输入。
By stacking several MA-Transformer encoders on the BERT model, the MA-BERT model generates a review representation $h_{\mathrm{[CLS]}}$ consistent with the special token [CLS]. Then, a classifier comprised of a linear projection and a sof tmax activation (with the dimension identical to the number of classes) is used for classification.
通过在BERT模型上堆叠多个MA-Transformer编码器,MA-BERT模型生成与特殊token [CLS]一致的评论表示$h_{\mathrm{[CLS]}}$。随后,使用由线性投影和softmax激活函数(维度与类别数相同)构成的分类器进行分类。
3 Comparative Experiments
3 对比实验
Datasets. Following the experimental settings used in Tang et al. (2015), the proposed MABERT model is evaluated using three benchmark datasets 1 (IMDB, Yelp-2013, and Yelp-2014). The evaluation metrics include accuracy (Acc.) and root mean squared error $(R M S E)$ . Higher Acc. and lower $R M S E$ scores indicate higher performance.
数据集。根据 Tang 等人 (2015) 的实验设置,使用三个基准数据集 (IMDB、Yelp-2013 和 Yelp-2014) 评估提出的 MABERT 模型。评估指标包括准确率 (Acc.) 和均方根误差 $(R M S E)$。Acc. 值越高且 $R M S E$ 值越低,表示性能越好。
Implementation Details. The baseline methods can be divided into three groups. The first group includes the methods without user and product information such as CNN (Kim, 2014), BiLSTM (Hochreiter and Schmid huber, 1997), neural sentiment classification (NSC) (Chen et al., 2016a) and its variant with a local attention mechanism $(\mathbf{NSC+LA})$ . For the BERT-based methods, the uncased-base-BERT model consisting of 12 layers of transformer encoders was implemented for comparison. ToBERT (Pappagari et al., 2019) was trained non-end2end using a word-to-segment strategy in a two-stage way.
实现细节。基线方法可分为三组。第一组包含不使用用户和产品信息的方法,如CNN (Kim, 2014)、BiLSTM (Hochreiter和Schmidhuber, 1997)、神经情感分类(NSC) (Chen等, 2016a)及其采用局部注意力机制的变体$(\mathbf{NSC+LA})$。对于基于BERT的方法,我们实现了由12层Transformer编码器组成的uncased-base-BERT模型进行比较。ToBERT (Pappagari等, 2019)采用非端到端训练方式,通过词到片段的两阶段策略进行训练。
The second group includes existing methods incorporating user and product information such as NSC with user (U) and product (P) information incorporated into an attention (A) mecha- nism $(\mathbf{NSC}+\mathbf{UPA})$ ), user product neural network (UPNN) (Tang et al., 2015), hierarchical model with separate user attention and product attention (HUAPA) (Wu et al., 2018), and the chunk- wise importance matrix model (CHIM) (Amplayo, 2019).
第二组包括融合用户和产品信息的现有方法,例如将用户(U)和产品(P)信息融入注意力机制(A)的NSC方法$( \mathbf{NSC}+\mathbf{UPA} )$、用户产品神经网络(UPNN) (Tang et al., 2015)、具有独立用户注意力和产品注意力的分层模型(HUAPA) (Wu et al., 2018),以及分块重要性矩阵模型(CHIM) (Amplayo, 2019)。
The third group includes a set of BERT-based methods incorporating user and product information using different strategies, presented in Figs. 1(a)-(c). In detail, an uncased-base-BERT model first extracted fixed feature vectors from texts. Then, the BERT Concat (word) model incorporates attribute features into each word vector and stacks another 6 transformer encoders as the feature extractor. Similarly, the BERT Concat (text) incorporates attribute features into the representation of the special token [CLS] for the classification. Finally, the BERT Attention (bias) applied 6 more MA-Transformers which only inject attributes into $Q$ and $K$ to calculate attention score instead of $V$ in Eq. (6).
第三组包含一系列基于BERT的方法,这些方法采用不同策略整合用户和产品信息,如图1(a)-(c)所示。具体而言,一个uncased-base-BERT模型首先从文本中提取固定特征向量。随后,BERT Concat (word)模型将属性特征融入每个词向量,并堆叠另外6个Transformer编码器作为特征提取器。类似地,BERT Concat (text)将属性特征融入特殊Token [CLS]的表征以进行分类。最后,BERT Attention (bias)额外应用了6个MA-Transformer,这些模块仅将属性注入$Q$和$K$来计算注意力分数,而非式(6)中的$V$。
The proposed MA-BERT models applied 6 MATransformer encoders to incorporate user and product attributes, and stacking over the BERT model.
提出的MA-BERT模型采用6个MATransformer编码器来整合用户和产品属性,并堆叠在BERT模型之上。
Table 1: Comparative results of different methods for sentiment classification. The boldface figures indicate the best results among all methods and underscored figures represent the best performance for each group of methods. All results are averaged over five runs.
表 1: 情感分类不同方法的对比结果。加粗数字表示所有方法中的最佳结果,下划线数字代表每组方法中的最佳性能。所有结果为五次运行的平均值。
| 模型 | IMDB | Yelp-2013 | Yelp-2014 |
|---|---|---|---|
| 准确率 (%) | RMSE | 准确率 (%) | |
| 不使用用户和产品信息 | |||
| CNN (UPNN w/o UP) BiLSTM | 40.5 43.3 44.3 | 1.629 1.494 1.465 | 57.7 58.4 |
| NSC NSC+LA BERT | 48.7 51.8 | 1.381 1.191 | 62.7 63.1 67.7 |
| ToBERT 使用用户和产品信息 | 50.8 | 1.194 | 66.7 |
| 使用用户和产品信息 | |||
| UPNN | 43.5 | 1.602 | 59.6 |
| NSC+UPA | 53.3 | 1.281 | 65.0 |
| HUAPA | 55.0 | 1.185 | 68.3 |
| CHIMembedding | 56.4 | 1.161 | 67.8 |
| BERT Concat (word) | 56.8 | 1.106 | 69.9 |
| BERT Concat (text) | 54.6 | 1.168 | 68.5 |
| BERT Attention (bias) | 52.5 | 1.177 | 68.0 |
| 57.3 | - | - | |
| MA-BERT | - | 1.042 | 70.3 |
Each attribute is initialized in a uniform distribution $U\sim(-0.25,0.25)$ with the dimension of 768 $(d_{t})$ and head number of $12(K)$ . Thus, the dimension of each head $(d_{E})$ is set to 64. All other hyper-parameters in MA-Transformer encoders are identical with BERT-transformer encoders due to their isomorphic structure. For all models, the AdamW (Loshchilov and Hutter, 2017) optimizer was used with a base learning rate of 2e-5 in a warmup linear schedule. Early stopping (Prechelt, 1998) strategy with a patience of 3 epochs was also applied to avoid over fitting. The code for this paper is available at: https://github.com/yoyo-yun/ MA-Bert.
每个属性均采用均匀分布 $U\sim(-0.25,0.25)$ 初始化,维度为 768 $(d_{t})$ ,头数为 $12(K)$ ,因此每个头的维度 $(d_{E})$ 设为64。由于结构同构,MA-Transformer编码器中其余超参数均与BERT-Transformer编码器保持一致。所有模型均采用AdamW (Loshchilov and Hutter, 2017) 优化器,基础学习率为2e-5,并采用线性预热调度。为避免过拟合,同时应用了早停策略 (Prechelt, 1998) ,耐心值设为3个epoch。本文代码详见:https://github.com/yoyo-yun/MA-Bert。
Comparative Results and Discussion. Table 1 shows the comparative results of different methods for sentiment ordinal classification. For models without user and product attributes, BiLSTM outperforms CNN (UPNN w/o UP), due to its ability to encode text. Furthermore, both NSC and $\mathrm{NSC}{+\mathrm{LA}}$ outperformed BiLSTM mainly because of its hierarchical structure.
比较结果与讨论。表1展示了不同方法在情感序数分类上的比较结果。对于不含用户和产品属性的模型,BiLSTM由于具备文本编码能力,其表现优于CNN (UPNN w/o UP)。此外,NSC和$\mathrm{NSC}{+\mathrm{LA}}$凭借分层结构设计,整体性能均优于BiLSTM。
Incorporating the user and product attributes improved performance. For example, UPNN achieved a better result than its variant without user and product attributes, i.e., CNN (UPNN w/o UP). In addition, both $\mathrm{NSC+UPA}$ and HUAPA introduced the user and product information as a bias to guide the hierarchical attention, and thus outperformed NSC and $\mathrm{NSC}{+}\mathrm{LA}$ .
引入用户和产品属性提升了模型性能。例如,UPNN的表现优于其未引入用户和产品属性的变体CNN (UPNN w/o UP)。此外,$\mathrm{NSC+UPA}$和HUAPA都将用户与产品信息作为偏置项来引导层级注意力机制,因此性能超越了NSC和$\mathrm{NSC}{+}\mathrm{LA}$。
The proposed MA-BERT achieved the best performance on all datasets. Compared with baselines without user and product attributes, the MA-BERT can leverage implicit attribute features to boost performance. MA-BERT outperformed methods already incorporating user and product attributes (i.e., $\mathrm{NSC+UPA}$ , HUAPA and $\mathrm{CHIM}_{e m b e d d i n g})$ because the proposed model can incorporate attribute knowledge to both the attention map and input represent ation.
提出的MA-BERT在所有数据集上均取得最佳性能。与未使用用户和产品属性的基线方法相比,MA-BERT能利用隐含属性特征提升性能。MA-BERT还优于已融合用户和产品属性的方法(即 $\mathrm{NSC+UPA}$、HUAPA和 $\mathrm{CHIM}_{embedding}$),因为该模型能将属性知识同时整合到注意力图和输入表征中。
The BERT and ToBERT models achieved improvement on all datasets against the conventional models, due to the large knowledge migration from pre-training. Unfortunately, a lack of implicit extra features resulted in performance lower than that of the proposed MA-BERT model. MA-BERT also outperformed BERT Concat (word), BERT Concat (text) and BERT Attention (bias), indicating that the proposed MA-Transformer architecture can improve existing incorporation strategies. Furthermore, the proposed MA-BERT could be initialized from the pre-trained checkpoint of BERT, thus making full use of the parameter settings without bringing additional costs for pre-training.
BERT和ToBERT模型通过预训练阶段的大规模知识迁移,在所有数据集上均实现了对传统模型的性能提升。但由于缺乏隐式额外特征,其表现仍低于我们提出的MA-BERT模型。MA-BERT在性能上同时超越了BERT Concat (word)、BERT Concat (text) 和BERT Attention (bias),这表明所提出的MA-Transformer架构能够改进现有融合策略。此外,MA-BERT可直接加载BERT的预训练检查点进行初始化,从而充分利用既有参数配置而无需承担额外的预训练成本。
4 Conclusion
4 结论
This paper proposes a MA-BERT model capable of incorporating multiple attributes into BERT-based PTMs for learning attribute-specific text representation. Different from existing attention models, the MA-Transformer can inject external knowledge to both attention maps and the input representation.Additionally, the proposed model could be extended to other tasks by using the MA-Transformer encoder as a universal layer and stacking it on a BERT-based model. Future work will attempt to incorporate such or similar multiple attributes into PTMs in the pre-training phases.
本文提出了一种能够将多种属性融入基于BERT的预训练模型(PTM)以学习属性特定文本表示的MA-BERT模型。与现有注意力模型不同,MA-Transformer能够将外部知识同时注入注意力图和输入表示中。此外,通过将MA-Transformer编码器作为通用层堆叠在基于BERT的模型上,所提模型可扩展至其他任务。未来工作将尝试在预训练阶段将此类多重属性融入PTM中。