ChatRadio-Valuer: A Chat Large Language Model for General iz able Radiology Report Generation Based on Multi-institution and Multi-system Data
ChatRadio-Valuer: 基于多机构多系统数据的通用放射学报告生成对话大语言模型
Tianyang Zhong ∗1, Wei Zhao ∗ $^{\mathrm{2,3,4}}$ , Yutong Zhang $^{5}$ , Yi Pan †6, Peixin Dong $^{\dagger1}$ , Zuowei Jiang $^{\dagger1}$ , Xiaoyan Kui $^{\dagger8}$ , Youlan Shang †2, Li Yang1, Yaonai Wei $^1$ , Longtao Yang2, Hao Chen1, Huan Zhao7, Yuxiao Liu $^{9,10}$ , Ning Zhu $^{1}$ , Yiwei Li $^{18}$ , Yisong Wang $^2$ , Jiaqi Yao $_ {11}$ , Jiaqi Wang12, Ying Zeng $^{2,13}$ , Lei He $^{14}$ , Chao Zheng $^{15}$ , Zhixue Zhang $16$ , Ming Li $^{17}$ , Zhengliang Liu $^{18}$ , Haixing Dai $^{18}$ , Zihao Wu $^{18}$ , Lu Zhang $^{19}$ , Shu Zhang $_ {12}$ , Xiaoyan Cai $^{1}$ , Xintao Hu $^{1}$ , Shijie Zhao $^{1}$ , Xi Jiang $7$ , Xin Zhang $^5$ , Xiang Li $^{20}$ , Dajiang Zhu $^{19}$ , Lei Guo $^1$ , Dinggang Shen $^{9,21,22}$ , Junwei Han $^{1}$ , Tianming Liu $^{18}$ , Jun Liu $^{\ddagger2,3}$ , and Tuo Zhang §1
钟天阳* 1, 赵伟* 2,3,4, 张雨桐†5, 潘毅†6, 董沛昕†1, 姜作伟†1, 隗晓燕†8, 尚幼兰†2, 杨莉1, 魏耀耐1, 杨龙涛2, 陈浩1, 赵欢7, 刘宇霄9,10, 朱宁1, 李一维18, 王轶松2, 姚佳琪11, 王佳琪12, 曾颖2,13, 何磊14, 郑超15, 张智学16, 李明17, 刘正亮18, 戴海星18, 吴子豪18, 张璐19, 张舒12, 蔡晓燕1, 胡新涛1, 赵世杰1, 蒋曦7, 张鑫5, 李想20, 朱大江19, 郭磊1, 沈定刚9,21,22, 韩俊伟1, 刘天明18, 刘军‡2,3, 张拓§1
Abstract
摘要
Radiology report generation, as a key step in medical image analysis, is critical to the quantitative analysis of clinically informed decision-making levels. However, complex and diverse radiology reports with cross-source heterogeneity pose a huge general iz ability challenge to the current methods under massive data volume, mainly because the style and norm at iv it y of radiology reports are obviously distinctive among institutions, body regions inspected and radiologists. Recently, the advent of large language models (LLM) offers great potential for recognizing signs of health conditions. To resolve the above problem, we collaborate with the Second Xiangya Hospital in China and propose ChatRadio-Valuer based on the LLM, a tailored model for automatic radiology report generation that learns general iz able representations and provides a basis pattern for model adaptation in sophisticated analysts’ cases. Specifically, ChatRadio-Valuer is trained based on the radiology reports from a single institution by means of supervised fine-tuning, and then adapted to disease diagnosis tasks for human multi-system evaluation (i.e., chest, abdomen, muscle-skeleton, head, and max ill o facial & neck) from six different institutions in clinical-level events. The clinical dataset utilized in this study encompasses a remarkable total of 332,673 observations. From the comprehensive results on engineering indicators, clinical efficacy and deployment cost metrics, it can be shown that ChatRadio-Valuer consistently outperforms state-of-the-art models, especially ChatGPT (GPT-3.5-Turbo) and GPT-4 et al., in terms of the diseases diagnosis from radiology reports. ChatRadio-Valuer provides an effective avenue to boost model generalization performance and alleviate the annotation workload of experts to enable the promotion of clinical AI applications in radiology reports.
放射学报告生成作为医学影像分析的关键步骤,对临床决策层面的定量分析至关重要。然而,在大数据量下,复杂多样且存在跨源异质性的放射学报告对现有方法提出了巨大的泛化能力挑战,这主要源于不同机构、检查部位和放射科医师之间报告风格与规范性的显著差异。近期,大语言模型(LLM)的出现为识别健康状况体征提供了巨大潜力。为解决上述问题,我们与中国中南大学湘雅二医院合作,提出了基于LLM的ChatRadio-Valuer——一种通过学习可泛化表征、为复杂分析案例提供模型适配基础范式的定制化放射学报告自动生成模型。具体而言,ChatRadio-Valuer首先通过监督微调基于单一机构的放射学报告进行训练,随后适配至临床级事件中来自六家不同机构的人类多系统(胸部、腹部、肌肉骨骼、头面部及颈部)疾病诊断任务。本研究使用的临床数据集包含总计332,673例观测记录。从工程指标、临床效能和部署成本等综合评估结果来看,ChatRadio-Valuer在放射学报告的疾病诊断方面持续优于最先进模型,特别是ChatGPT(GPT-3.5-Turbo)和GPT-4等。该模型为提升模型泛化性能、减轻专家标注工作量提供了有效途径,从而推动放射学报告中临床AI应用的发展。
1 Introduction
1 引言
Radiology exists as an essential department in hospitals or medical institutions, which substantially facilitates the progress of the detection, diagnosis, prediction, evaluation and follow-up for most of diseases. Radiology reports provide a comprehensive evaluation for different diseases, assisting clinicians in making decisions [1–5]. The natural process of generating a radiology report is that the radiologists conclude an impression after comprehensively describing the positive and negative image findings of a specific examination [6–9] (i.e., chest CT and abdominal CT). Considering the tremendous amounts of radiology examinations, especially in China, it places a heavy burden on radiologists to write radiology reports in daily work [10–12]. Besides, the style and norm at iv it y of radiology reports are variable among individuals and institutions, due to the different writing habits and education. This may confuse the patients if they receive different descriptions from many institutions and also limit the communication among different radiologists. Therefore, an efficient and standard way to generate the impression of radiology report is pursued by radiologists.
放射科是医院或医疗机构的重要科室,极大地促进了大多数疾病的检测、诊断、预测、评估和随访进程。放射报告为不同疾病提供全面评估,辅助临床医生决策[1-5]。生成放射报告的自然流程是放射科医师在综合描述特定检查(如胸部CT和腹部CT)的阳性和阴性影像表现后得出印象[6-9]。考虑到庞大的放射检查量(尤其在中国),撰写放射报告给放射科医师的日常工作带来了沉重负担[10-12]。此外,由于书写习惯和教育背景差异,放射报告的风格和规范性在个人与机构间存在较大差异。当患者从多家机构获得不同描述时可能产生困惑,同时也限制了不同放射科医师间的交流。因此,放射科医师亟需一种高效且标准化的放射报告印象生成方式。
Driven by the extensive clinical demands, automatic generating radiology reports becomes a new hotspot and promising direction [13–23]. In this context, natural language processing (NLP) strategies, which are widely used in non-medical areas, are recently adopted to tackle this issue [24]. With the aid of NLP techniques, the reporting time can be obviously reduced, resulting in the improvement of work efficiency. Another potential advantage of NLP in generating radiology reports is that the impression of radiology reports could be more structured and complete, further reducing error rates and facilitating the mutual communication from different institutions. In general, there are two main research directions: model-driven methods and data-driven methods.
在广泛临床需求的推动下,自动生成放射学报告成为新的热点和前景方向[13-23]。在此背景下,自然语言处理(NLP)策略这一在非医疗领域广泛应用的技术,近期被用于解决该问题[24]。借助NLP技术,报告时间可显著缩短,从而提升工作效率。NLP在生成放射学报告中的另一潜在优势是,可使报告结论部分更加结构化和完整,进一步降低错误率并促进不同机构间的相互交流。总体而言,该领域存在两个主要研究方向:模型驱动方法和数据驱动方法。
Many previous studies on radiology report generation have followed model-driven methods [7, 15–18]. Jing et al. [15] proposed a co-attention network to produce full paragraphs for automatically generating reports and demonstrated the effectiveness of their proposed methods on publicly available datasets. Chen et al. [7] proposed to generate radiology reports via a memory-driven transformer, which addressed what conventional image captioning methods are inefficient (and inaccurate) for generating long and detailed radiology reports. Chen et al. [16] proposed that incorporating memory into both the encoding process and decoding process can further enhance the generation ability of the transformer. Wang et al., [17] proposed a cross-modal network to facilitate cross-modal pattern learning, where the cross-modal prototype matrix is initialized with prior information and an improved multi-label contrastive loss is proposed to promote the cross-modal prototype learning. Wang et al., [18] proposed a self-boosting framework, where the main task of report generation helps learn highly text-correlated visual features, and an auxiliary task of image-text matching facilitates the alignment of visual features and textual features.
许多先前关于放射学报告生成的研究都遵循了模型驱动的方法 [7, 15–18]。Jing 等人 [15] 提出了一种协同注意力网络来生成完整段落,用于自动生成报告,并在公开数据集上证明了所提方法的有效性。Chen 等人 [7] 提出通过记忆驱动的 Transformer 生成放射学报告,解决了传统图像描述方法在生成长且详细的放射学报告时效率低下(且不准确)的问题。Chen 等人 [16] 提出在编码和解码过程中都引入记忆可以进一步增强 Transformer 的生成能力。Wang 等人 [17] 提出了一种跨模态网络以促进跨模态模式学习,其中跨模态原型矩阵用先验信息初始化,并提出了一种改进的多标签对比损失来促进跨模态原型学习。Wang 等人 [18] 提出了一种自我增强框架,其中报告生成的主要任务有助于学习高度文本相关的视觉特征,而图像-文本匹配的辅助任务促进了视觉特征和文本特征的对齐。
Other researchers deem that data is significant for deep learning based automatic report generation, and their research interests focus on data-driven methods [19–23]. Liu et al. [19] introduced three modules to utilize prior knowledge and posterior knowledge from radiology data for alleviating visual and textual data bias, and showed that their model outperforms previous methods on both language generation metrics and clinical evaluation. Inspired by curriculum learning, No oral a hz a deh et al. [20] extracted global concepts from the radiology data and utilized them as transition text from chest radio graphs to radiology reports (i.e., image-to-text-to-text). To alleviate the data bias and make the best use of available data, Liu et al. [21] proposed a competence-based multimodal curriculum learning framework, where each training instance was estimated and current models were evaluated and then the most suitable batch of training instances were selected considering current model competence. To make full use of limited data, Yan et al. [22] developed a weakly supervised approach to identify “hard” negative samples from radiology data and assign them with higher weights in training loss to enhance sample differences. Yuan et al. [23] introduced a sentence-level attention mechanism to fuse multi-view visual features and extracted medical concepts from radiology reports to fine-tune the encoder for extracting the most frequent medical concepts from the x-ray images.
其他研究者认为数据对基于深度学习的自动报告生成至关重要,他们的研究兴趣集中在数据驱动方法上[19–23]。Liu等人[19]引入了三个模块,利用放射学数据中的先验知识和后验知识来缓解视觉与文本数据偏差,并证明其模型在语言生成指标和临床评估上均优于先前方法。受课程学习启发,No oral a hz a deh等人[20]从放射学数据中提取全局概念,将其作为从胸部X光片到放射学报告的过渡文本(即图像-文本-文本)。为缓解数据偏差并充分利用现有数据,Liu等人[21]提出基于能力的多模态课程学习框架,通过评估每个训练实例和当前模型状态,选择最适合当前模型能力的训练批次。针对有限数据的最大化利用,Yan等人[22]开发弱监督方法从放射学数据中识别"困难"负样本,并在训练损失中赋予更高权重以增强样本差异性。Yuan等人[23]采用句子级注意力机制融合多视角视觉特征,并从放射学报告中提取医学概念来微调编码器,从而从X光图像中提取最高频的医学概念。
The above methods have made great progress in radiology report generation. However, there are still some limitations. Firstly, the current expansion of radiology data is largely contributed to the practice of sharing across multiple medical institutions, which leads to a complex data interaction, thus requiring insightful and controlled analysis. Secondly, the development of modern radiology imaging leads to data complexity increasing. Thirdly, in radiology report generation, NLP researchers have paid attention to image caption [25], which has demonstrated its effectiveness. Actually, the transfer properties of these models to radiology report generation encounter the model generalization problem. Model generalization requires a trained model to transfer its generation capacity to the target domain and produce accurate output for previously unseen instances. In radiology report generation, this requires generating clinically accurate reports for various medical subjects. While image caption has exhibited remarkable effectiveness in general text generation tasks, the complexities of medical terms and language introduce hindrances to model generalization.
上述方法在放射学报告生成方面取得了重大进展。然而仍存在一些局限性。首先,当前放射学数据的扩展主要得益于多家医疗机构间的共享实践,这导致了复杂的数据交互,因此需要深入且可控的分析。其次,现代放射成像技术的发展使得数据复杂性不断增加。第三,在放射学报告生成中,NLP研究者关注了图像描述[25]的有效性。实际上,这些模型向放射学报告生成的迁移特性会遇到模型泛化问题。模型泛化要求训练后的模型将其生成能力迁移到目标领域,并为未见过的实例生成准确输出。在放射学报告生成中,这需要为各种医学主题生成临床准确的报告。虽然图像描述在通用文本生成任务中表现出显著有效性,但医学术语和语言的复杂性给模型泛化带来了阻碍。
As one of the most influential artificial intelligence (AI) products today [26], LLMs, known as generative models, provide a user-friendly human-machine interaction platform that brings the powerful capabilities of large language models to the public and has been rapidly integrated into various fields of application [26–42]. Liu et al. [41] proposed Radiology-GPT, which uses instruction tuning approach to fine-tune Alpaca [43] for mining radiology domain knowledge, and prove its superior performance on reports sum mari z ation task. Based on Llama2, Liu et al. [42] further presented Radiology-Llama2 using instruction tuning to fine-tune Llama2 on radiology reports. However, they both ignore the fact that the style and norm at iv it y of radiology reports vary among individuals and institutions with writing habits and education. Therefore, they are difficult to achieve satisfactory results when training medical LLMs.
作为当今最具影响力的人工智能(AI)产品之一[26],大语言模型(LLM)作为生成式模型,提供了一个用户友好的人机交互平台,将大语言模型的强大能力带给公众,并已迅速融入各个应用领域[26-42]。Liu等人[41]提出了Radiology-GPT,采用指令微调方法对Alpaca[43]进行微调以挖掘放射学领域知识,并证明了其在报告摘要任务上的卓越性能。基于Llama2,Liu等人[42]进一步提出Radiology-Llama2,使用指令微调在放射学报告上对Llama2进行微调。然而,他们都忽略了放射学报告的风格和规范性因个人和机构的写作习惯及教育背景而异这一事实。因此,在训练医疗大语言模型时,他们难以取得令人满意的结果。
Inspired by large language models, we propose ChatRadio-Valuer by fine-tuning Llama2 on large-scale, high-quality instruction-following data in the radiology domain. ChatRadio-Valuer inherits robust language understanding ability across various domains and genres, coupled with complex reasoning and diverse generation abilities. Additionally, it learns high-level domain-specific knowledge during training in the radiology domain. This addresses the heterogeneity gaps among institutions and enables accurate radiology report generation. Extensive experiments are conducted with real radiology reports from a clinical pipeline in the Second Xiangya Hospital of China and the experimental results highlight the superiority of our method. The main contributions are summarized as follows:
受大语言模型 (Large Language Model) 启发,我们通过在放射学领域的大规模高质量指令跟随数据上微调 Llama2,提出了 ChatRadio-Valuer。该方法继承了跨领域跨体裁的强健语言理解能力,兼具复杂推理与多样化生成能力,同时在放射学领域训练过程中习得了高层次领域知识,有效解决了机构间的异质性差异,实现了精准的放射学报告生成。我们在中南大学湘雅二医院临床流程的真实放射学报告上进行了大量实验,结果凸显了本方法的优越性。主要贡献总结如下:
• To the best of our knowledge, a complete full-stack solution for clinical-level radiology report generation based on multi-institution and multi-system data is developed to obtain desirable performance results for the first time. The solution significantly outperforms the state-of-the-art counterparts, benefiting performance analysts of multiple data sources in radiology. • An effective ChatRadio-Valuer framework is proposed that can automatically utilize radiology domain knowledge for cross-institution adaptive radiology report generation based on singleinstitution samples, which can provide a fundamental scheme to boost model generalization performance from radiology reports. • We implement our framework and conduct substantial use cases on clinical utilities among six different institutions. Through the cases, we obtain valuable insights into radiology experts, which are beneficial to alleviate the annotation workload of experts. This opens the door to bridge LLMs’ domain adaptation application and radiology performance evaluation.
• 据我们所知,这是首次基于多机构、多系统数据开发的临床级放射学报告生成全栈解决方案,其性能表现达到理想水平。该方案显著优于现有最优方法,使放射学多数据源的性能分析人员受益。
• 提出了一种高效的ChatRadio-Valuer框架,能够基于单机构样本自动利用放射学领域知识进行跨机构自适应放射学报告生成,为提升放射学报告的模型泛化性能提供了基础方案。
• 我们在六个不同机构的临床应用中实施了该框架并开展大量用例研究。通过这些案例,我们获得了对放射学专家具有重要价值的洞见,有助于减轻专家的标注工作量。这为弥合大语言模型领域适应应用与放射学性能评估之间的鸿沟打开了大门。
2 Clinical Background and Data
2 临床背景与数据
2.1 Collaboration with the Second Xiangya Hospital of China
2.1 与中南大学湘雅二医院的合作
We have collaborated with the Second Xiangya Hospital of China. During the collaboration, we utilize the platform (the phase 1 in Figure 1) for data acquisition that enables physicians to gather and analyze medical data. The platform consists of three components: multi-center institutions inspection, multi-system analysis, and radiologists’ description. The ultimate goal is to propose a unified and general iz able framework, which can simulate radiology experts to execute disease diagnoses across multiple institutions and multiple systems, in order to improve clinical efficiency and reduce the workload of relevant staff in processing massive data.
我们与中南大学湘雅二医院开展了合作。在合作过程中,我们利用该平台(图1中的第一阶段)进行数据采集,使医生能够收集和分析医疗数据。该平台由三个部分组成:多中心机构检查、多系统分析和放射科医生描述。最终目标是提出一个统一且可泛化的框架,能够模拟放射学专家执行跨多个机构和多个系统的疾病诊断,以提高临床效率并减少相关人员处理海量数据的工作量。
Many factors have brought great challenges to this task. Specifically, in the first component of the platform, it describes that data acquisition comes from six different institutions, and the quality and quantity are different to varying degrees. The main reasons are the constraints of types of equipment and observable conditions among them. The specific materials will be introduced in Section 2.2. Next, the second component contains two message formats, such as CT and MRI modalities on the chest, abdomen, muscle-skeleton, head, and max ill o facial & neck systems. The prominent dissimilarity within this dataset arises primarily from significant variations in data source distributions between the two modalities, contingent upon the specific human body locations inspected. Specifically, Institution 1 contributes data for five complete systems, while institutions 2 through 6 provide data for individual human body systems, namely the chest, abdomen, mus cul o skeletal, head, and max ill o facial & neck systems. Then, during the third process, the information carrier from image to text conversion is performed by different levels of clinicians including junior, intermediate, and senior radiologists. Due to the different writing habits and education, the style and norm at iv it y of radiology reports are obviously distinctive among radiologists.
诸多因素给这项任务带来了巨大挑战。具体而言,平台的第一部分指出数据采集自六家不同机构,其质量和数量存在不同程度的差异,主要源于设备类型和观测条件的限制。具体材料将在2.2节详述。其次,第二部分包含两种信息载体格式(如胸部、腹部、肌肉骨骼、头颈颌面系统的CT和MRI模态),该数据集最显著的差异性源自两种模态间数据源分布的显著变化,这取决于具体检查的人体部位。具体表现为:机构1提供了五个完整系统的数据,而机构2至6仅分别提供胸部、腹部、肌肉骨骼、头颈颌面系统中单一系统的数据。最后在第三环节中,图像到文本转换的信息载体由不同层级的临床医生(包括初级、中级和高级放射科医师)完成。由于书写习惯和教育背景差异,放射科医师撰写的报告在风格和规范性方面存在明显区别。
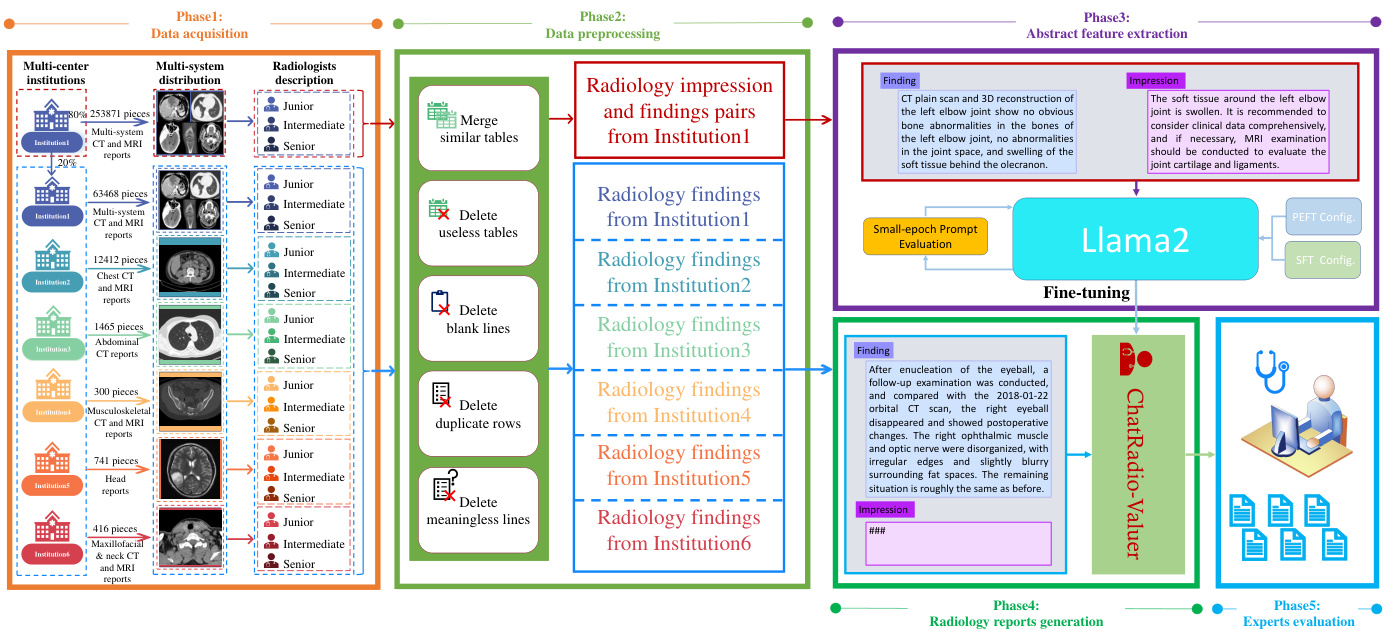
Figure 1: Overall framework of the proposed method for radiology report generation. Multiinstitution and multi-system clinical radiology reports are acquired in phase 1. Systematic data preprocessing is implemented and then synthesizes the samples into high-quality prompts in phase 2. The general iz able advanced features are extracted and applied for clinical utilities in phase $3&$ phase 4. The comprehensive evaluations on ChatRadio-Valuer’s efficacy are executed in phase 5.
图 1: 放射学报告生成方法的整体框架。第一阶段获取多机构、多系统的临床放射学报告。第二阶段实施系统性数据预处理,并将样本合成为高质量提示。第三和第四阶段提取可泛化的高级特征并应用于临床用途。第五阶段对ChatRadio-Valuer的效能进行全面评估。
In brief, multiple aspects, from institutions, multiple systems of human body, and radiologists, bring great dilemmas to the assignment, which may confuse the patients if they receive different descriptions from many institutions and also limit the free communication among different radiologists. The proposed framework named ChatRadio-Valuer is described in Section 3.
简言之,从医疗机构、人体多系统到放射科医师的多重因素,为诊断报告撰写带来了巨大困境。这不仅可能导致患者收到不同机构矛盾描述时的困惑,也限制了放射科医师间的自由交流。第3节将阐述所提出的ChatRadio-Valuer框架。
2.2 Data Description
2.2 数据描述
In this multi-institution modeling study, the radiology reports, including basic information, description and impression, were searched and downloaded in the report system from six institutions. In detail, the specific data attributes of a radiology report example are shown in Figure 2. And a comprehensive data distribution is illustrated in Table 1. In the Second Xiangya hospital dataset (Dataset SXY), 317339 radiology reports from five subgroups (94097 chest reports, 64550 abdominal reports, 46092 mus cul o skeletal reports, 69902 head reports, and 42698 max ill o facial & neck reports) were exported from 2012 year to 2023 year. These data were used for model development and internal testing. Other five datasets were collected for external testing, from the Huadong Hospital dataset (Dataset External 1, DE1, chest reports), Xiangtan Central Hospital (Dataset External 2, DE2, abdominal reports), The First Hospital of Hunan University of Chinese Medicine (Dataset External 3, DE3, mus cul o skeletal reports), The First People’s Hospital of Changde City (Dataset External 4, DE4, head reports), Yueyang Central Hospital City (Dataset External 5, DE5, max ill o facial & neck
在这项多机构建模研究中,我们从六家机构的报告系统中检索并下载了包含基本信息、描述和印象的放射学报告。具体而言,图2展示了一份放射学报告示例的具体数据属性,表1则呈现了全面的数据分布情况。
在湘雅二医院数据集(Dataset SXY)中,我们导出了2012年至2023年间五个亚组的317339份放射学报告(94097份胸部报告、64550份腹部报告、46092份肌肉骨骼报告、69902份头部报告以及42698份颌面颈部报告)。这些数据用于模型开发和内部测试。
外部测试数据来自另外五个数据集:华东医院数据集(Dataset External 1, DE1,胸部报告)、湘潭市中心医院(Dataset External 2, DE2,腹部报告)、湖南中医药大学第一附属医院(Dataset External 3, DE3,肌肉骨骼报告)、常德市第一人民医院(Dataset External 4, DE4,头部报告)以及岳阳市中心医院(Dataset External 5, DE5,颌面颈部报告)。
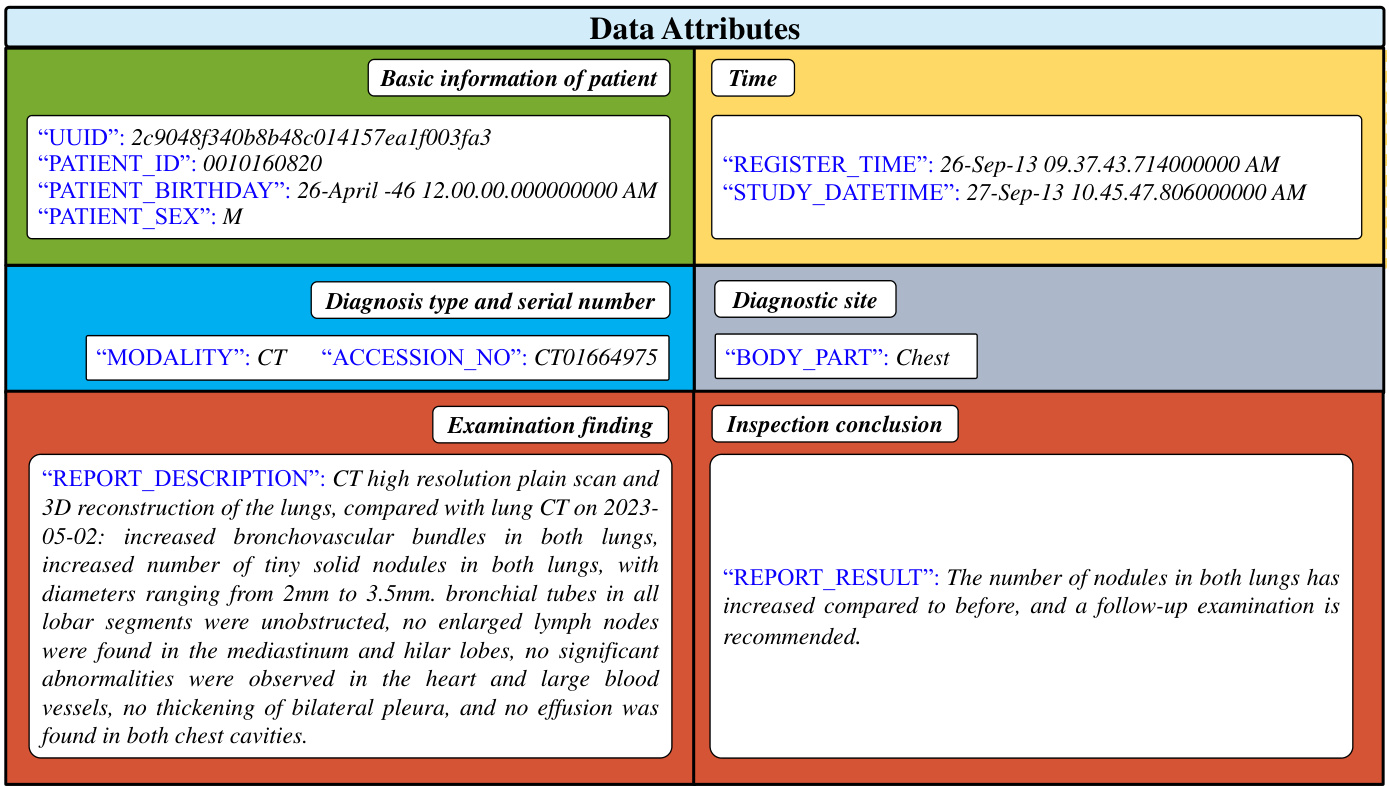
Figure 2: A radiology report example on its attributes. These attributes are manually diagnosed and described by radiologists at different levels, among which there are obvious variations in styles.
图 2: 放射学报告示例及其属性。这些属性由放射科医生在不同层级进行人工诊断和描述,其中存在明显的风格差异。
Table 1: The statistical analysis encompasses comprehensive information regarding the experimental dataset, including both the training and test sets, along with detailed statistical insights derived from data obtained from six distinct institutions.
表1: 统计分析涵盖了实验数据集的全面信息,包括训练集和测试集,以及从六个不同机构获得的数据中提取的详细统计结果。
| Variable | Training Set | Test Set | Total | |||||
| Institution 1 (80%) | Institution 1 (20%) | Institution 2 | Institution 3 | Institution 4 | Institution 5 | Institution 6 | All Set | |
| No.of pieces | 253871 | 63468 | 12412 | 1465 | 300 | 741 | 416 | 332673 |
| Age(y) | 0-103 | 0-101 | 0-96 | 9-95 | 1-92 | 0-100 | 0-91 | 0-103 |
| Sex | ||||||||
| Female | 119185 | 28993 | 7320 | 620 | 133 | 382 | 225 | 156858 |
| Male | 134686 | 34475 | 5092 | 845 | 167 | 359 | 191 | 175815 |
| Modality | ||||||||
| CT | 210487 | 49488 | 12397 | 1465 | 238 | 543 | 346 | 274964 |
| MRI | 43384 | 13980 | 15 | 0 | 62 | 198 | 70 | 57709 |
| System | ||||||||
| Chest | 75277 | 18820 | 12412 | 0 | 0 | 0 | 0 | 106509 |
| Abdomen | 51640 | 12910 | 0 | 1465 | 0 | 0 | 0 | 66015 |
| Muscle-skeletion | 36874 | 9218 | 0 | 0 | 300 | 0 | 0 | 46392 |
| Head | 55922 | 13980 | 0 | 0 | 0 | 741 | 0 | 70643 |
| Maxillofacial & neck | 34158 | 8540 | 0 | 0 | 0 | 0 | 416 | 43114 |
| 变量 | 训练集 | 测试集 | 总计 | |||||
|---|---|---|---|---|---|---|---|---|
| 机构1 (80%) | 机构1 (20%) | 机构2 | 机构3 | 机构4 | 机构5 | 机构6 | 全集 | |
| 数量(件) | 253871 | 63468 | 12412 | 1465 | 300 | 741 | 416 | 332673 |
| 年龄(岁) | 0-103 | 0-101 | 0-96 | 9-95 | 1-92 | 0-100 | 0-91 | 0-103 |
| 性别 | ||||||||
| 女性 | 119185 | 28993 | 7320 | 620 | 133 | 382 | 225 | 156858 |
| 男性 | 134686 | 34475 | 5092 | 845 | 167 | 359 | 191 | 175815 |
| 模态 | ||||||||
| CT | 210487 | 49488 | 12397 | 1465 | 238 | 543 | 346 | 274964 |
| MRI | 43384 | 13980 | 15 | 0 | 62 | 198 | 70 | 57709 |
| 系统 | ||||||||
| 胸部 | 75277 | 18820 | 12412 | 0 | 0 | 0 | 0 | 106509 |
| 腹部 | 51640 | 12910 | 0 | 1465 | 0 | 0 | 0 | 66015 |
| 肌肉骨骼 | 36874 | 9218 | 0 | 0 | 300 | 0 | 0 | 46392 |
| 头部 | 55922 | 13980 | 0 | 0 | 0 | 741 | 0 | 70643 |
| 颌面及颈部 | 34158 | 8540 | 0 | 0 | 0 | 0 | 416 | 43114 |
reports). They are denoted as from Institution 1 to Institution 6 respectively. This retrospective study was approved by The Second Xiangya Hospital, Institutional Review Board (Approval NO. LYF2023084), which waived the requirement for informed consent.
报告)。分别标记为机构1至机构6。这项回顾性研究经中南大学湘雅二医院伦理委员会批准(批准号LYF2023084),并豁免知情同意要求。
2.3 Data Preprocessing
2.3 数据预处理
In the overall framework of ChatRadio-Valuer, the quality of radiology reports plays a critical role in facilitating the method’s performance. Hence, the data preprocessing phase, encompassing the multi-system & multi-institution data refinement and prompt generation, assumes a pivotal role in ensuring the model’s efficacy and dependability when dealing with extensive domain-specific radiology reports originating from diverse institutions and systems. To achieve this objective, the operations proposed in this study are executed as indicated in Algorithm 1, aiming at a particular emphasis on mitigating improper interference caused by value and report title repetition, sheet inconsistencies and text irrelevance. The specific details are as follows:
在ChatRadio-Valuer的整体框架中,放射学报告的质量对方法性能起着关键作用。因此,数据预处理阶段(包括多系统多机构数据精炼与提示生成)对于确保模型在处理来自不同机构和系统的大规模领域特定放射学报告时的效能和可靠性具有决定性意义。为实现这一目标,本研究提出的操作如算法1所示,重点在于减轻由数值与报告标题重复、表格不一致及文本无关性造成的不当干扰。具体细节如下:
Algorithm 1 Training Preparation.
算法 1: 训练准备
- Data Synthesis: We aggregate data from multiple systems, group them by institution, and randomly process them according to their belonging centers, obtaining a comprehensive dataset $X_ {a l l}$ covering all the reports. Then we follow the sequence of these institutions, extracting the training set $X_ {t r a i n}$ and the test set $X_ {t e s t}$ according to the index of centers. In detail, the data from Institution 1 are randomly selected to fine-tune ChatRadio-Valuer, and the other institutions are utilized to test the performance of ChatRadio-Valuer. The entire training dataset are then split into an $80%$ training set and a $20%$ evaluation set. Data in $X_ {t e s t}$ are exclusively reserved for evaluation purposes for simplicity.
- 数据合成:我们从多个系统聚合数据,按机构分组,并根据所属中心随机处理,获得涵盖所有报告的综合数据集 $X_ {all}$。随后按照这些机构的顺序,根据中心索引提取训练集 $X_ {train}$ 和测试集 $X_ {test}$。具体而言,随机选择机构1的数据对ChatRadio-Valuer进行微调,其他机构则用于测试ChatRadio-Valuer的性能。整个训练数据集进一步划分为80%的训练集和20%的评估集。为简化流程,$X_ {test}$ 中的数据仅保留用于评估目的。
- Data Cleaning: For each dataset, a rigorous data cleaning process is conducted from three different perspectives: addressing repetition, rectifying inconsistencies, and filtering out text insignificance. To tackle repetition issues, manual searches are conducted to identify and eliminate extraneous elements related to values and report titles. This result in a curated dataset featuring unique values in a standardized format. In addressing inconsistencies arising from multiple sheets from different institutions, meticulous human scrutiny and manual consolidation are employed. Regarding text insignificance, a collaborative effort between experts from the Second Xiangya Hospital of China and our team led to the creation of a corpus containing non-essential terms, deemed too eclectic for LLMs to comprehend but crucial for clinical applications. Leveraging this corpus, a significant portion of irrelevant data is removed, yielding a refined dataset optimized for prompt generation. We combine this dataset and expert-curated templates $X_ {p t}$ to eventually construct high-quality prompts $X_ {p r o m p t}$ consisting of both training prompts Xtprrompt and evaluation prompts Xepvroalm pt, as described in the Section 3.
- 数据清洗:针对每个数据集,我们从三个维度进行严格的数据清洗:处理重复项、修正不一致性以及过滤无意义文本。为解决重复问题,通过人工检索剔除与数值和报告标题相关的冗余元素,最终生成具有标准化格式唯一值的精编数据集。对于不同机构多表格导致的不一致问题,采用人工核查与手动整合相结合的方式处理。在无意义文本过滤方面,由中南大学湘雅二医院专家团队与我们协作构建了非必要术语语料库,这些术语虽对大语言模型理解无关紧要但对临床应用至关重要。基于该语料库,我们移除了大量无关数据,生成适用于提示词生成的优化数据集。如第3节所述,我们将该数据集与专家编制的模板$X_ {pt}$结合,最终构建出包含训练提示词$X_ {tprrompt}$和评估提示词$X_ {epvroalmpt}$的高质量提示词集$X_ {prompt}$。
3 Framework
3 框架
In this section, we first define the problem of radiology report generation in this work and present an overview of ChatRadio-Valuer. Then, we introduce the implementation details of ChatRadio-Valuer.
在本节中,我们首先定义了本工作中放射学报告生成的问题,并概述了ChatRadio-Valuer。接着,我们介绍了ChatRadio-Valuer的实现细节。
3.1 Problem Formulation
3.1 问题表述
Due to factors of variations in physicians’ professional skills, differences in the operation of medical equipment across different hospitals, and variances in organ structures, radiology medical data often exhibit inconsistencies in both format and quality. These factors can be collectively referred to as heterogeneity in healthcare data.
由于医生专业技能差异、不同医院医疗设备操作方式不同以及器官结构差异等因素,放射医学数据在格式和质量上常存在不一致性。这些因素可统称为医疗数据异质性 (heterogeneity) 。
In the testing task, the input is defined as $\mathrm{Input}={f,X_ {\mathrm{test}}}$ , where $f$ represents the fine-tuned model, and $X_ {\mathrm{test}}$ belongs to the set ${X_ {1},X_ {2},X_ {3},X_ {4},X_ {5},X_ {6}}$ , which denotes the data from six different institutions. In a single sample, $x_ {m}$ represents "REPORT DESCRIPTION", while $y_ {m}$ denotes "REPORT RESULT".Each subset $X_ {i}$ can be further divided based on the system:
在测试任务中,输入定义为 $\mathrm{Input}={f,X_ {\mathrm{test}}}$ ,其中 $f$ 代表微调后的模型, $X_ {\mathrm{test}}$ 属于集合 ${X_ {1},X_ {2},X_ {3},X_ {4},X_ {5},X_ {6}}$ ,表示来自六个不同机构的数据。单个样本中, $x_ {m}$ 表示"报告描述", $y_ {m}$ 表示"报告结果"。每个子集 $X_ {i}$ 可按系统进一步划分:

Formally, the mathematical expression for the testing process can be represented as:
形式上,测试过程的数学表达式可表示为:
$$
\operatorname* {max}_ {f}\sum_ {X_ {i}^{j}\in X_ {\mathrm{test}}}\operatorname{Performance}(f,X_ {i}^{j})
$$
$$
\operatorname* {max}_ {f}\sum_ {X_ {i}^{j}\in X_ {\mathrm{test}}}\operatorname{Performance}(f,X_ {i}^{j})
$$
where $f$ represents the fine-tuned model, which needs to be evaluated in the testing task; $X_ {i}^{j}$ denotes a sample set from the $X_ {\mathrm{test}}$ collection, corresponding to different medical departments or system divisions; Performance $(f,X_ {i}^{j})$ is the metrics used to measure the performance of model $f$ on the sample set $X_ {i}^{j}$ . In Section 4, the similarity metrics R-1, R-2, and R-L are used as indicators.
其中 $f$ 代表经过微调的模型,需要在测试任务中进行评估;$X_ {i}^{j}$ 表示来自 $X_ {\mathrm{test}}$ 集合的样本子集,对应不同的医疗科室或系统部门;Performance $(f,X_ {i}^{j})$ 是用于衡量模型 $f$ 在样本集 $X_ {i}^{j}$ 上表现的指标。在第4节中,相似性指标R-1、R-2和R-L被用作评估指标。
Building upon this, we conduct experiments to assess the model’s performance from the following three aspects:
基于此,我们从以下三个方面开展实验以评估模型性能:
Our goal is to enable models to possess cross-institution and multi-system diagnostic capabilities. The fundamental challenge faced in mathematical analysis is how to leverage latent knowledge to constrain the model’s freedom within a vast space of heterogeneous data samples, thereby enabling the model to achieve an approximate global optimal solution in Eq.(1). In our experiments, the effective fine-tuning techniques are exploited to restrict the pre-trained model’s degrees of freedom, resulting in an improved generalization performance in the feature space.
我们的目标是让模型具备跨机构和多系统的诊断能力。数学分析面临的根本挑战在于如何利用潜在知识在异构数据样本的广阔空间中约束模型的自由度,从而使模型能够在方程(1)中实现近似全局最优解。在实验中,我们采用有效的微调技术来限制预训练模型的自由度,从而在特征空间中提升泛化性能。
3.2 Framework Overview
3.2 框架概述
This section provides a comprehensive introduction to the method presented in this article, with applicability to large-scale, multi-institution, and multi-system in the field of radiology, as illustrated in Figure 1. The method is based on a dataset comprising 332673 radiology records obtained from multi-institution and multi-system sources and designed to address the clinical challenge of radiology reports originating from multiple institutions. Here, we present an overall architecture of the proposed method by leveraging medical knowledge in the field of radiology, followed by a detailed description of each phase. The proposed method comprises five distinct phases: data acquisition, data preprocessing, abstract feature extraction, radiology report generation, and experts evaluation.
本节全面介绍了本文提出的方法,该方法适用于放射学领域的大规模、多机构、多系统场景,如图 1 所示。该方法基于一个包含 332673 份放射学记录的数据集,这些记录来自多机构和多系统,旨在解决来自多个机构的放射学报告的临床挑战。在此,我们通过利用放射学领域的医学知识,展示了所提方法的整体架构,随后详细描述了每个阶段。所提方法包括五个不同的阶段:数据采集、数据预处理、抽象特征提取、放射学报告生成和专家评估。
- Phase 1 (Data Acquisition): As an extremely important department in hospitals or medical institutions, the radiology department has different writing habits and styles of radiology reports, making it difficult to unify. Acknowledging this distinctive nature of report data within the radiology department, it is critical to address the inherent challenges in obtaining such data. This inherent challenge presents formidable obstacles when seeking to employ LLMs in the field of radiology. Therefore, in collaboration with Xiangya Second Hospital, we acquire radiology reports from six distinct institutions and five disparate systems. This meticulous data acquisition effort ensures the availability of high-quality data requisite for the training of our expected LLM, ChatRadio-Valuer. The description of the data acquisition can be found in Section 2.1 and 2.2.
- 第一阶段 (数据采集): 作为医院或医疗机构中极其重要的部门,放射科在撰写放射学报告时存在不同的书写习惯和风格,导致报告难以统一。认识到放射科报告数据的这一独特性,解决获取此类数据的内在挑战至关重要。这一固有挑战为在放射学领域应用大语言模型 (LLM) 带来了巨大障碍。因此,我们与湘雅二医院合作,从六家不同机构和五套独立系统中获取放射学报告。这一细致的数据采集工作确保了训练预期大语言模型 ChatRadio-Valuer 所需的高质量数据可用性。数据采集的具体描述详见第 2.1 和 2.2 节。
- Phase 2 (Data Preprocessing): LLMs necessitate the use of high-quality data for their pre-training, a critical property that distinguishes them from smaller-scale language models. The model capacity of LLMs is profoundly influenced by the pre-training corpus and its associated preprocessing methodologies, as expounded in [44]. The presence of a substantial number of bad samples within the corpus can significantly degrade the performance of the model. To alleviate the detrimental impact of such bad samples on model performance and enhance models’ adaptability and general iz ability, we collaborate closely with domain experts from hospitals to devise a method for the data preprocessing of these bad samples, which is discussed in Section 2.3.
- 阶段2 (数据预处理): 大语言模型(LLM)需要使用高质量数据进行预训练,这一关键特性使其区别于小规模语言模型。如[44]所述,大语言模型的容量深度受预训练语料库及其相关预处理方法的影响。语料库中存在大量劣质样本会显著降低模型性能。为减轻劣质样本对模型性能的负面影响并增强模型的适应性和泛化能力,我们与医院领域专家密切合作,设计了一套针对劣质样本的数据预处理方法,详见2.3节讨论。
- Phase 3 (Abstract Feature Extraction): LLMs invariably demand a heavy investment of human resources, computational resources, financial cost, and time consumption, presenting formidable challenges to researchers. Consequently, our method, following exhaustive investigations and rigorous experimental validation, leverages the Llama2 series of models. Additionally, we have employed proprietary datasets, acquired and pre processed in the previous two phases, for enhancing the performance of ChatRadio-Valuer. Comprehensive insights into this abstract feature extraction process are detailed in Section 3.3.
- 阶段3(抽象特征提取):大语言模型往往需要投入大量人力资源、计算资源、资金成本和时间消耗,这给研究人员带来了巨大挑战。因此,我们的方法在经过详尽调研和严格实验验证后,采用了Llama2系列模型。此外,我们还使用了在前两个阶段获取并预处理的专有数据集,以提升ChatRadio-Valuer的性能。关于这一抽象特征提取过程的全面阐述详见第3.3节。
- Phase 4 (Radiology Reports Generation): Leveraging the power of our proposed ChatRadioValuer, we can generate causal inferences with a specific set of configurations. The provided "Finding" is utilized as the input to the LLM, from which the "Impression", the output of the LLM, is derived. The explicit process to implement ChatRadio-Valuer for generating radiology reports refers to the Section 3.4.
- 阶段4 (放射学报告生成): 利用我们提出的ChatRadioValuer,可以通过特定配置生成因果推断。将提供的"发现(Findings)"作为大语言模型的输入,从中得到大语言模型的输出"印象(Impression)"。使用ChatRadioValuer生成放射学报告的具体实现流程详见第3.4节。
- Phase 5 (Experts Evaluation): Currently, there still exists controversy over the evaluation indicators for LLMs in the radiology field. Traditional similarity indicators fall short in accurately reflecting the specific performance of the model in this field, let alone measuring their practical applicability. In response to this challenge, our method, in collaboration with domain experts from medical institutions, introduces an evaluation framework tailored for medical LLMs. This framework not only excels in conventional similarity metrics as engineering ones but also offers a comprehensive assessment of the models’ practical clinical utility. Comparative analysis against the state-of-the-art (SOTA) methods reveals that the proposed ChatRadio-Valuer maintains a competitive advantage. A detailed exposition of this evaluation methodology can be found in Section 4.
- 阶段5(专家评估):目前针对放射学领域大语言模型(LLM)的评估指标仍存在争议。传统相似性指标难以准确反映模型在该领域的具体表现,更无法衡量其实际适用性。为解决这一挑战,我们联合医疗机构领域专家,提出了一套专为医疗大语言模型设计的评估框架。该框架不仅在工程性相似指标上表现优异,更能全面评估模型的临床实用价值。与前沿(SOTA)方法的对比分析表明,所提出的ChatRadio-Valuer保持竞争优势。该评估方法的具体阐述详见第4节。
3.3 How to Fine-tune ChatRadio-Valuer?
3.3 如何微调ChatRadio-Valuer?
3.3.1 Architecture of the Llama Model
3.3.1 Llama模型架构
In artificial intelligence, Llama has won the affection of a vast user base with its unique charm and unparalleled intelligence. However, this is not the end of the story. Llama2 not only inherits all the advantages of its predecessors but also brings significant innovations and improvements in many aspects. Taking into account the special problems of diagnosis of a variety of diseases based on radiology reports, the considerations for the foundation model are detailed as follows:
在人工智能领域,Llama以其独特的魅力和无与伦比的智能赢得了广大用户的喜爱。然而,这并非故事的终点。Llama2不仅继承了前代产品的全部优势,更在多方面带来了重大创新与提升。考虑到基于放射学报告诊断多种疾病的特殊问题,基础模型的考量细节如下:
matrix dimensions in the Feed forward Neural Network (FFN) module and introducing Grouped Query Attention (GQA) [46]. These improvements can enhance the model’s performance and efficiency, making it better suited to heterogeneous data. A schematic diagram of Llama2 is presented in Figure 3.
在前馈神经网络 (FFN) 模块中优化矩阵维度,并引入分组查询注意力 (Grouped Query Attention, GQA) [46]。这些改进能提升模型性能和效率,使其更适配异构数据。Llama2 的结构示意图见图 3:

Figure 3: The architecture diagram of Llama 2. The model structure of Llama 2 is basically consistent with the standard Transformer Decoder structure, mainly composed of 32 Transformer Blocks
图 3: Llama 2 架构图。Llama 2 的模型结构与标准 Transformer Decoder 结构基本一致,主要由 32 个 Transformer Blocks 组成
Some technical details are described as follows:
以下是一些技术细节:
• In the model’s Norm layer, RMSNorm is used without re-centering operations (the removal of the mean term), significantly improving model speed [47]. The RMSNorm formula is as follows:
• 在模型的 Norm 层中,使用 RMSNorm 时不进行重新居中操作(移除均值项),显著提升了模型速度 [47]。RMSNorm 公式如下:
$$
\mathrm{RMSNorm}(x)=\frac{x}{\sqrt{\mathrm{Mean}(x^{2})+\epsilon}}
$$
$$
\mathrm{RMSNorm}(x)=\frac{x}{\sqrt{\mathrm{Mean}(x^{2})+\epsilon}}
$$
where $x$ represents the input vector or tensor, typically the output of a neural network layer; $\epsilon$ is a small positive constant, usually used to prevent the denominator from being zero, ensuring numerical stability. It is typically a very small value, such as $1.0e^{-5}$ or $1.0e^{-6}$ .
其中 $x$ 代表输入向量或张量,通常是神经网络层的输出;$\epsilon$ 是一个小的正常数,通常用于防止分母为零,确保数值稳定性。它通常是一个非常小的值,例如 $1.0e^{-5}$ 或 $1.0e^{-6}$。
• SwiGLU activation function is employed in the Feed-Forward Network (FFN) to enhance performance. The implementation of the SwiGLU activation function is as follows:
• 在 Feed-Forward Network (FFN) 中采用 SwiGLU 激活函数以提升性能。SwiGLU 激活函数的实现方式如下:
$$
S w i G L U(x,W,V,b,c,\beta)=\mathrm{Swish}_ {\beta}(x W+b)\odot(x V+c)
$$
$$
S w i G L U(x,W,V,b,c,\beta)=\mathrm{Swish}_ {\beta}(x W+b)\odot(x V+c)
$$
where $S w i s h$ is defined as $S w i s h=x\cdot\sigma(\beta x)$ ; $\cal{G L U}$ is represented as $G L U(x)=\sigma(W x+b)\odot$ $(V x+c)$ ; $W$ and $V$ denote weight matrices; $b$ and $c$ represent biases; The symbol $\odot$ represents the element-wise Hadamard product, also known as element-wise multiplication.
其中 $Swish$ 定义为 $Swish=x\cdot\sigma(\beta x)$;$\cal{GLU}$ 表示为 $GLU(x)=\sigma(W x+b)\odot$ $(V x+c)$;$W$ 和 $V$ 表示权重矩阵;$b$ 和 $c$ 代表偏置;符号 $\odot$ 表示逐元素的哈达玛积 (Hadamard product),也称为逐元素乘法。
• RoPE (Rotary Position Embedding) is a technique used in neural networks to represent sequential position information, particularly in natural language processing tasks. The core idea behind RoPE is to introduce a rotational operation to represent position information, avoiding the fixed nature of traditional positional embeddings. Specifically, the formula for RoPE’s positional embedding is as follows:
• RoPE (Rotary Position Embedding) 是一种用于神经网络中表示序列位置信息的技术,尤其在自然语言处理任务中。RoPE 的核心思想是通过引入旋转操作来表示位置信息,避免传统位置嵌入的固定性。具体而言,RoPE 的位置嵌入公式如下:
$$
R o P E(\mathrm{position},d)=R_ {d}\cdot P_ {\mathrm{position}}
$$
$$
R o P E(\mathrm{position},d)=R_ {d}\cdot P_ {\mathrm{position}}
$$
where $R o P E(p o s i t i o n,d)$ represents the RoPE position embedding at a specific position; $d$ denotes the embedding dimension; $R_ {d}$ denotes a rotation matrix with dimensions of $d$ , utilized for rotating the position embedding; $P_ {p o s i t i o n}$ denotes an original position embedding vector, typically generated by sine and cosine functions. However, in RoPE, it is not static but can be rotated to adapt to different tasks.
其中 $R o P E(p o s i t i o n,d)$ 表示特定位置上的RoPE位置嵌入;$d$ 表示嵌入维度;$R_ {d}$ 表示维度为 $d$ 的旋转矩阵,用于旋转位置嵌入;$P_ {p o s i t i o n}$ 表示原始位置嵌入向量,通常由正弦和余弦函数生成。但在RoPE中,它不是静态的,而是可以旋转以适应不同任务。
• GQA is the abbreviation for grouped-query attention, which is a variant of the attention mechanism. In GQA, query heads are divided into multiple groups, each of which shares a single key and value matrix. This mechanism serves to reduce the size of the key-value cache during inference and significantly enhances inference throughput.
• GQA是分组查询注意力 (grouped-query attention) 的缩写,它是注意力机制的一种变体。在GQA中,查询头被分为多个组,每组共享一个键矩阵和值矩阵。该机制能减小推理过程中的键值缓存大小,并显著提升推理吞吐量。
Based on the selected Llama2 family (i.e., Llama2, Llama2-Chat, and Llama2-Chinese-Chat), the model fine-tuning process in this paper is described in Algorithm 2 and outlined as follows:
基于选定的Llama2系列(即Llama2、Llama2-Chat和Llama2-Chinese-Chat),本文中的模型微调过程如算法2所述并概述如下:
Algorithm 2 Train ChatRadio-Valuer.
算法 2: 训练 ChatRadio-Valuer
- Model Quantization: Leveraging the Transformers’ model quantization library, we employ the Bits And Bytes Config interface for model quantization. Essentially, this process involves converting model weights into int4 format through quantization layers and placing them on the GPU. Referring to Algorithm 2, we initialize the pre-train model $f_ {0}$ with the int4 quantization configuration $\pmb{\theta}_ {q u a n t i z a t i o n}$ to prepare for further model preparation. The core computation is carried out on the CUDA, reducing memory consumption and improving efficiency.
- 模型量化 (Model Quantization): 利用Transformers的模型量化库,我们采用Bits And Bytes Config接口进行模型量化。该过程本质上是通过量化层将模型权重转换为int4格式并置于GPU上。参考算法2,我们用int4量化配置$\pmb{\theta}_ {q u a n t i z a t i o n}$初始化预训练模型$f_ {0}$,为后续模型准备奠定基础。核心计算在CUDA上执行,从而降低内存消耗并提升效率。
- Model Fine-tuning: We incorporate LoRA (Low-Rank Adaptation) weights $\pmb{\theta}_ {p e f t-l o r a}$ and training parameters $\pmb{\theta}_ {t r}$ shown in Algorithm 2. In the first step, we fix the parameters of the model’s transformer component, focusing solely on training embeddings. This is done to adapt the newly added small-sample vectors without significantly interfering with the original model. Additionally, supervised Prompt data is utilized for fine-tuning, aiding in the selection of the most suitable prompts. In the second step, training continues on the remaining majority of samples while simultaneously updating LoRA parameters. The LoRA weights are then merged back into the initialized model $f_ {i n i t}$ , resulting in fine-tuned model $f$ with model parameters $\theta$
- 模型微调:我们引入LoRA (Low-Rank Adaptation)权重$\pmb{\theta}_ {p e f t-l o r a}$和训练参数$\pmb{\theta}_ {t r}$(如算法2所示)。第一步固定模型Transformer组件的参数,仅训练嵌入层,旨在适配新增的小样本向量而不显著干扰原始模型。同时利用监督式Prompt数据进行微调,辅助选择最合适的提示词。第二步继续训练剩余多数样本,并同步更新LoRA参数。最终将LoRA权重合并回初始化模型$f_ {i n i t}$,得到含参数$\theta$的微调模型$f$。
- Efficient Prompt Selection: During the stage of fine-tuning, to effectively activate the general iz ability and semantic capability of LLMs, prompt selection plays a significant role. However, fine-tuning any LLMs thoroughly is a time-consuming project, which requires sufficient computational resources and time capacity. Therefore, we employ small-epoch fine-tuning with our five expert-curated training prompts $X_ {prompt}^{tr}={sp_ {1}^{tr},sp_ {2}^{tr},...,sp_ {5}^{tr}}$ for time efficiency.
- 高效提示词选择:在微调阶段,为有效激活大语言模型(LLM)的泛化能力和语义理解能力,提示词选择至关重要。但由于完整微调任何大语言模型都是耗时工程,需要充足的计算资源和时间成本,因此我们采用小周期微调策略,使用五个专家精选的训练提示词$X_ {prompt}^{tr}={sp_ {1}^{tr},sp_ {2}^{tr},...,sp_ {5}^{tr}}$以提升时间效率。
We find the best prompt and its index $i d x$ through this small-epoch fine-tuning, and then inherit the model and parameters pair $(f_ {i d x},\theta_ {i d x})$ to continue the complete model fine-tuning mention above.
我们通过这个小周期的微调找到最佳提示及其索引$idx$,然后继承模型和参数对$(f_ {idx},\theta_ {idx})$,继续完成上述提到的完整模型微调。
3.3.2 Prompt Generation
3.3.2 提示生成
With the meticulously processed dataset proposed in Section 2.3, our objective is to generate complete prompts, subsequently employed by LLMs to yield effective causal inferences, contributing to either training or evaluation phases. Before introducing the proposed prompt, we first explicate the parts of the structure, which is accessible via a string and divided into three components: system description, instruction and input. The system description component is typically invoked at the outset to demarcate the task and constrain the instruction’s behavior, while the instruction component serves to provide direction for radiology report generation and the input component contains clinical radiology reports. The model output is generated by the response component, which serves as the basis for our dynamic prompt and iterative optimization framework.
利用第2.3节提出的精细处理数据集,我们的目标是生成完整提示词,随后由大语言模型(LLM)生成有效的因果推理结果,用于训练或评估阶段。在介绍所提出的提示结构前,首先解析其组成部分:该结构通过字符串实现,包含系统描述、指令和输入三个组件。系统描述组件通常在开始时调用,用于界定任务范围并约束指令行为;指令组件为放射学报告生成提供指导方向;输入组件则包含临床放射学报告。模型输出由响应组件生成,该组件是我们动态提示与迭代优化框架的基础。

Figure 4: Prompt generation overview. The overall framework contains three parts, system description, instruction, and input, which collaborative ly constitute a prompt. Within a prompt example (purple), expert instruction and input data on its right are inserted to the ${E x p e r t I n s t r u c t i o n}$ and ${I n p u t D a t a}$ , respectively. The derived impression is in the ${O u t p u t I m p r e s s i o n}$ .
图 4: 提示生成概览。整体框架包含系统描述、指令和输入三部分,协同构成一个提示。在提示示例(紫色)中,右侧的专家指令和输入数据分别插入到 ${E x p e r t I n s t r u c t i o n}$ 和 ${I n p u t D a t a}$ 中,生成的印象位于 ${O u t p u t I m p r e s s i o n}$。
Prior studies have used fixed-form prompts for straightforward tasks that could be easily generalized. However, these prompts lack the necessary prior knowledge for complex tasks and domain-specific datasets, resulting in low performance [29]. Thus, we propose a hypothesis that constructs dynamic prompts from relevant domain-specific corpora and can thus enhance the model’s comprehension and perception.
先前的研究使用固定形式的提示(prompt)来处理易于泛化的简单任务。然而,这些提示缺乏针对复杂任务和领域特定数据集所需的先验知识,导致性能低下[29]。因此,我们提出一个假设:从相关领域语料库构建动态提示,可以增强模型的理解和感知能力。
Specifically, in addition to the corpus containing pre processed multi-institution and multi-system data, domain experts contribute to the formulation of five prompt templates, instructions to LLMs, tailored to this study. Their professional advice helps provide refined instructions to LLMs to activate their ability to adapt to radiology domain and generate meaningful domain-specified results. Definitely referring to Algorithm 3, we combine the synthesized expert-curated instruction and system description set $X_ {p t}$ with the input data. As an illustrative example, one of these templates is shown in Figure 4, where Input Data is for data insertion and Expert Instruction is for instruction insertion. The complete prompt generation scheme is illustrated in Figure 4. Following this approach, five distinct prompt sets are generated, fully prepared for subsequent training and evaluation stages.
具体而言,除了包含预处理的多机构多系统数据的语料库外,领域专家还为本研究定制了五种提示模板和大语言模型指令。他们的专业建议有助于提供精细化指令,激活大语言模型适应放射学领域的能力,并生成有意义的领域特定结果。如算法3所示,我们将专家精心合成的指令和系统描述集$X_ {pt}$与输入数据相结合。其中一个模板示例如图4所示,其中输入数据用于数据插入,专家指令用于指令插入。完整的提示生成方案如图4所示。通过这种方法,我们生成了五个不同的提示集,为后续训练和评估阶段做好了充分准备。
Algorithm 3 Inference & Evaluate Reports.
算法 3: 推理与评估报告
3.4 How to Inference ChatRadio-Valuer?
3.4 如何推理ChatRadio-Valuer?
In the final phase, model reasoning testing and evaluation, clinging to the power of LLMs, including our proposed ChatRadio-Valuer especially, we exert them to generate casual inferences on the evaluation dataset $\pmb{I}$ for evaluating ChatRadio-Valuer’s performance over the other selected LLMs’.
在最终阶段,即模型推理测试与评估阶段,我们依托大语言模型(LLM)的强大能力(特别是我们提出的ChatRadio-Valuer),利用它们在评估数据集 $\pmb{I}$ 上生成因果推断,以评估ChatRadio-Valuer相较于其他选定大语言模型的性能表现。
In Algorithm 3, we have decided the best evaluation prompt template candidate $t_ {i d x}$ with its index $_ {i d x}$ . This template is also implemented in this module for saving computation resources and better exerting the capability of LLMs (i.e., no more prompt template selection is required due to its reliable credits in previous performance comparisons). Accordingly, this template indicates the expected evaluation prompts $s p_ {i d x}^{e v a l}$ . In terms of the test-institution prompt sets, following the same data preprocessing schematic in the second stage, we synthesize the cleaned test-institution data $X_ {t e s t}$ and the designated template candidate $t_ {i d x}$ into the final test-institution prompts $s p_ {c}$ .
在算法3中,我们确定了最佳评估提示模板候选$t_ {idx}$及其索引$_ {idx}$。该模板同样在本模块中实施,以节省计算资源并更好地发挥大语言模型的性能(即由于其在先前性能对比中的可靠表现,无需再进行提示模板选择)。因此,该模板指向预期的评估提示$sp_ {idx}^{eval}$。对于测试机构提示集,遵循第二阶段相同的数据预处理方案,我们将清洗后的测试机构数据$X_ {test}$与指定模板候选$t_ {idx}$合成为最终的测试机构提示$sp_ {c}$。
With the massive preparation work of multi-institution and multi-system prompts finished, we carefully construct our LLM pool for the final evaluation, containing total 15 LLMs, including our ChatRadio-Valuer. For each LLM, weights are accordingly initialized (i.e., ChatRadio-Valuer is initiated with SFT weights but others are with their official ones) and prepared for causal inference. With all inference configuration $\gamma$ , including top $k$ , top $p$ , temperature, etc., are specified, we leverage the power of these LLMs to inference casually, obtaining the reports $\pmb{I}_ {e v a l}$ and $I_ {c}$ . During the generation process, we pay great attention to the quality of the generated results. However, limited by the highly hardware-dependent properties of LLMs and randomness within their outputs, results sometimes encounter problems including the null output and repetitive words, leading to inaccurate representation of LLMs’ performances on generating casual inferences, specifically the quality of the reports without meaningless values. In order to solve these problems, we incorporate two modules to check whether the null output is generated and repetitive words are obtained during generation. These two modules maintain the quality of the final results in avoid of interference caused by meaningless values. In addition, more language-specifically, we leverage Chinese text segmentation to the results to improve the accuracy of ROUGE evaluation towards Chinese contexts. This segmentation provides a valuable vision for bilingual or multi-lingual tasks.
在多机构多系统提示词(prompt)的大规模准备工作完成后,我们精心构建了包含15个大语言模型(LLM)的评估池,其中包括我们的ChatRadio-Valuer。每个模型都进行了相应的权重初始化(ChatRadio-Valuer采用SFT权重,其余模型使用官方权重)并准备进行因果推理。当所有推理配置参数$\gamma$(包括top $k$、top $p$、温度值等)设定完毕后,我们驱动这些大语言模型进行自由推理,获得评估报告$\pmb{I}_ {eval}$和对比报告$I_ {c}$。
在生成过程中,我们高度重视输出结果的质量。但由于大语言模型高度依赖硬件设备的特性及其输出固有的随机性,结果有时会出现空输出和重复词汇等问题,导致无法准确反映模型在自由推理任务中的表现,特别是生成报告时出现无意义数值的情况。为解决这些问题,我们引入了两个检测模块:空输出检测和重复词汇检测。这两个模块通过过滤无意义数值的干扰,确保最终结果质量。
此外,针对中文语境特点,我们对结果进行中文分词处理以提高ROUGE评估的准确性。这种分词方法为双语或多语言任务提供了有价值的处理视角。
4 Performance Evaluation
4 性能评估
4.1 Performance Evaluation Indices
4.1 性能评估指标
To confirm the effectiveness, generalization, and transfer ability of our proposed ChatRadio-Valuer, we conduct a comprehensive analysis using engineering indexes and clinical evaluation from the aspects of feasibility, clinical performance, and application cost.
为验证所提出的ChatRadio-Valuer在有效性、泛化性和迁移能力上的表现,我们从可行性、临床性能和应用成本三个维度,结合工程指标与临床评估展开了全面分析。
For feasibility, we evaluate the performance of the models by the widely-used engineering index ROUGE [48] and report the $F_ {1}$ scores for ROUGE-N and ROUGE-L (denoted as R-1, R-2, and R-L), which measure the word-level N-gram-overlap and longest common sequence between the reference summaries and the candidate summaries respectively, as shown from Eq.(5)-Eq.(8). $P$ is denoted as the percentage of defects correctly assigned, while $R$ represents the ratio of accurately detected defects to total true defects. $F_ {1}$ measures the trade-off between Precision $\mathrm{\nabla}^{\cdot}P_ {\mathrm{\Phi}}^{\cdot}$ ) and $\operatorname{Recall}(R)$ .
为评估可行性,我们采用广泛使用的工程指标ROUGE[48]来衡量模型性能,并报告ROUGE-N和ROUGE-L的$F_ {1}$分数(记为R-1、R-2和R-L)。这些分数分别通过式(5)-式(8)计算参考摘要与候选摘要之间的词级N-gram重叠率和最长公共子序列。$P$表示正确分配的缺陷百分比,$R$代表准确检测到的缺陷占真实缺陷总数的比例。$F_ {1}$用于衡量精确率($P$)与召回率($R$)之间的平衡关系。
$$
R O U G E-N=\frac{\sum_ {S\in{R e f e r e n c e S u m m a r i e s}}\sum_ {g r a m_ {n}\in S}C o u n t_ {m a t c h}(g r a m_ {n})}{\sum_ {S\in{R e f e r e n c e S u m m a r i e s}}\sum_ {g r a m_ {n}\in S}C o u n t(g r a m_ {n})}
$$
$$
R O U G E-N=\frac{\sum_ {S\in{R e f e r e n c e S u m m a r i e s}}\sum_ {g r a m_ {n}\in S}C o u n t_ {m a t c h}(g r a m_ {n})}{\sum_ {S\in{R e f e r e n c e S u m m a r i e s}}\sum_ {g r a m_ {n}\in S}C o u n t(g r a m_ {n})}
$$
$$
R={\frac{L C S(R e f e r e n c e S u m m a r i e s,C a n d i d a t e S u m m a r i e s)}{m}}
$$
$$
R={\frac{L C S(R e f e r e n c e S u m m a r i e s,C a n d i d a t e S u m m a r i e s)}{m}}
$$
$$
P={\frac{L C S(R e f e r e n c e S u m m a r i e s,C a n d i d a t e S u m m a r i e s)}{n}}
$$
$$
P={\frac{L C S(R e f e r e n c e S u m m a r i e s,C a n d i d a t e S u m m a r i e s)}{n}}
$$
$$
F_ {1}={\frac{2R P}{R+P}}
$$
$$
F_ {1}={\frac{2R P}{R+P}}
$$
where $n$ stands for the length of the n-gram, $g r a n$ ; $C o u n t_ {m a t c h}(g r a m_ {n})$ is the maximum number of the n-grams co-occurring in a candidate summary and a set of reference summaries. $L C S$ is the length of the longest common sub sequence of Reference-Summaries and Candidate-Summaries. $m$ denotes the length of Reference-Summaries and $n$ is the length of Candidate-Summaries.
其中 $n$ 表示 n-gram 的长度 $gran$;$Count_ {match}(gram_ {n})$ 是候选摘要与参考摘要集中共现 n-gram 的最大数量。$LCS$ 是参考摘要与候选摘要的最长公共子序列长度。$m$ 表示参考摘要的长度,$n$ 表示候选摘要的长度。
For clinical performance, we assess ChatRadio-Valuer using an array of clinical indexes to test its performance, as illustrated in Figure 9. For each index, we utilize a 100-point scale and divide it into quintiles every 20 points. These clinical indexes include "Understand ability" which denotes the model’s capacity to be comprehended and interpreted by clinicians and relevant physicians.
在临床性能方面,我们通过一系列临床指标评估ChatRadio-Valuer的表现,如图9所示。每个指标采用百分制,并按每20分为一个五分位区间划分。这些临床指标包括"理解能力(Understand ability)",即模型被临床医生及相关医师理解和阐释的能力。
"Coherence" means the model’s ability to maintain logical consistency and unified structure in its outputs. Furthermore, "Relevance" means the model’s capacity to generate related information and insights for the current clinical context. "Conciseness" represents the importance of the model’s output being concise and reducing redundant information, ensuring that it effectively conveys essential clinical knowledge. "Clinical Utility" emphasizes the practical value of the model’s outputs, measuring its capacity to inform and enhance clinical decision-making processes. Moreover, the evaluation also examines the potential for "Missed Diagnosis" emphasizing the model’s ability to minimize instances where clinically significant conditions are overlooked or under emphasized. On the contrary, "Over diagnosis" assesses the condition where the model may lead to excessive diagnoses or over utilization of medical interventions. These clinical indexes inform the assessment of the model’s effectiveness, ensuring its effectiveness and appropriateness in the clinical domain. In addition to the basic interpretation of these metrics, the most essential factors for clinical utilities and significance are "Missed Diagnosis" and "Over diagnosis", explained more thoroughly as follows:
"连贯性"指模型在输出中保持逻辑一致性和结构统一的能力。"相关性"指模型为当前临床情境生成相关信息与见解的能力。"简洁性"强调模型输出需简明扼要,减少冗余信息,确保有效传递核心临床知识。"临床实用性"着重评估模型输出对临床决策的实际指导价值。此外,评估还关注"漏诊"风险,即模型能否最大限度避免遗漏临床重要病症;相反,"过度诊断"则评估模型可能导致过度医疗干预的情况。这些临床指标共同构成模型有效性的评估体系,确保其在医疗领域的适用性。除基础指标外,最具临床实用价值的关键因素是"漏诊"与"过度诊断",具体阐释如下:
Missed Diagnosis Missed diagnosis, or false negative in medical diagnostics, occurs when healthcare practitioners fail to detect a medical condition despite its actual presence. This diagnostic error stems from the inability of clinical assessments, tests, or screenings to accurately identify the condition, resulting in a lack of appropriate treatment. The consequences of missed diagnosis range from delayed therapy initiation to disease progression, with contributing factors including diagnostic modality limitations, inconspicuous symptoms, and cognitive biases. Timely and accurate diagnosis is fundamental to effective healthcare. Therefore, it is necessary to reduce the occurrence of missed diagnosis for improved patient outcomes and healthcare quality.
漏诊
漏诊,即医学诊断中的假阴性,指医疗从业者未能检测出实际存在的病症。这种诊断错误源于临床评估、检测或筛查无法准确识别病情,导致患者未得到适当治疗。漏诊的后果包括治疗延迟和疾病恶化,影响因素包括诊断方法局限性、症状不明显以及认知偏差。及时准确的诊断是有效医疗的基础,因此有必要减少漏诊发生率以改善患者预后和医疗质量。
Over diagnosis Over diagnosis is characterized by the erroneous or unnecessary identification of a medical condition upon closer examination. This diagnostic error arises when a condition is diagnosed but would not have caused harm or clinical symptoms during the patient’s lifetime. Over diagnosis often leads to unnecessary medical interventions, exposing patients to potential risks without significant benefits. It is particularly relevant in conditions with broad diagnostic criteria, where the boundaries between normal and pathological states are unclear. For example, early detection of certain malignancies can result in over diagnosis if the cancer has remained a symptomatic throughout the patient’s lifetime. Recognizing and addressing over diagnosis are critical aspects of modern healthcare, influencing resource allocation, patient well-being, and healthcare system sustainability.
过度诊断
过度诊断的特征是在进一步检查时错误或不必要地识别出某种疾病。这种诊断错误发生在确诊某种疾病,但该疾病在患者一生中不会造成伤害或临床症状的情况下。过度诊断常导致不必要的医疗干预,使患者暴露于潜在风险中却无明显获益。在诊断标准宽泛、正常与病理状态界限不明确的疾病中尤为突出。例如,某些恶性肿瘤若在患者一生中始终保持无症状状态,早期检测便可能导致过度诊断。识别并解决过度诊断是现代医疗的关键议题,影响着资源分配、患者福祉及医疗系统的可持续性。
As for application metrics, the assessment of practicality is critical for ChatRadio-Valuer. In this context, two critical indexes are "Time Cost" (i.e. "Fine-Tuning Time" and "Testing Time") and "Parameter Count". "Fine-tuning time" means the temporal duration during the iterative training process where the model acquires its knowledge and optimization. The duration of the training phase is of great importance, as it directly impacts the time-to-model readiness and the overall efficiency of the development workflow. "Testing Time" is an essential measure that gauges the computational expenses incurred during the model’s execution, including both the temporal and computational resources required for real-time deployment. This metric carries great significance, particularly in resource-limited settings where efficient use of computational resources is vital. "Parameter Count" is another vital evaluation metric, indicating the model’s demand for memory storage during execution. This aspect is of great importance, especially when dealing with data-intensive applications. An effective evaluation of memory size ensures that the model remains deployable on hardware configurations with adequate memory resources while avoiding performance degradation. In a word, these indexes serve as crucial benchmarks in the assessment of the model, allowing for a comprehensive evaluation of its computational efficiency and resource utilization in the specific operational setting.
就应用指标而言,ChatRadio-Valuer的实用性评估至关重要。在此背景下,两个关键指标是"时间成本"(即"微调时间"和"测试时间")与"参数量"。"微调时间"指模型在迭代训练过程中获取知识与优化的时间跨度。训练阶段的持续时间极为重要,因其直接影响模型就绪时间与整体开发流程效率。"测试时间"是衡量模型执行期间计算开销的关键指标,包括实时部署所需的时间与计算资源。该指标在资源受限环境中尤为重要,此时计算资源的高效利用至关重要。"参数量"是另一项重要评估指标,反映模型运行期间对内存存储的需求。这一特性在处理数据密集型应用时尤为关键。对内存占用的有效评估能确保模型在具有充足内存资源的硬件配置上保持可部署性,同时避免性能下降。简言之,这些指标作为模型评估的关键基准,可全面评估其在特定运行环境中的计算效率与资源利用率。
4.2 Experiment Setup
4.2 实验设置
We initially preprocess the multi-system data from multiple institutions (shown in Section 2.3) and established datasets for training and evaluation by combining these data with five prompt templates. After data preprocessing, we implement supervised fine-tuning (SFT) on ChatRadio-Valuer using these cleaned and standardized data. We also employ evaluation on the SFT ChatRadio-Valuer. To achieve reduced computational resource requirements, faster adaptation, and enhanced accessibility, we apply low-rank adaptation (LoRA), a technique for parameter-efficient fine-tuning (PEFT), and 4-bit quantization during the SFT stage. Technically, LoRA enhances the efficiency of adapting large, pre-trained language models to specific tasks by introducing trainable rank decomposition matrices. It significantly reduces the number of trainable parameters while maintaining high model quality when compared to traditional fine-tuning. In terms of quantization, it simplifies numerical representation by reducing data precision. In LLMs, it involves the conversion of high-precision floating-point values into lower-precision fixed-point representations, effectively diminishing memory and computational requirements. Quantized LLMs offer enhanced resource efficiency and compatibility with a wide array of hardware platforms. In the context of ChatRadio-Valuer, we implement 4-bit precision quantization.
我们首先对来自多个机构的多系统数据(如第2.3节所示)进行预处理,并通过将这些数据与五种提示模板结合,建立了用于训练和评估的数据集。数据预处理完成后,我们利用这些经过清洗和标准化的数据对ChatRadio-Valuer实施监督微调(SFT),并对SFT后的ChatRadio-Valuer进行评估。为降低计算资源需求、加快适应速度并提升可访问性,我们在SFT阶段采用了参数高效微调(PEFT)技术——低秩自适应(LoRA)以及4位量化技术。从技术角度看,LoRA通过引入可训练的秩分解矩阵,提升了将大型预训练语言模型适配到特定任务的效率。与传统微调相比,它在保持高质量模型表现的同时,显著减少了可训练参数数量。量化技术则通过降低数据精度来简化数值表示。在大语言模型中,该技术将高精度浮点值转换为低精度定点表示,从而有效降低内存和计算需求。量化后的大语言模型具有更高的资源效率,并能兼容更广泛的硬件平台。在ChatRadio-Valuer中,我们实现了4位精度的量化。
Before the training stage, we investigate the well-known LLMs from medical perspective and constructed LLM pool for model selection. We mainly focus on 6 aspects, indicated in Figure 5, domain adaptability, compatibility with medical standards, bilingual, open source, parameter efficiency, and cost and licensing. A brief introduction to these metrics is listed below:
在训练阶段之前,我们从医学角度调研了知名的大语言模型,并构建了用于模型选择的LLM池。主要关注6个方面(如图5所示): 领域适应性、医学标准兼容性、双语能力、开源性质、参数效率及成本与授权。这些指标的简要说明如下:
Eventually, we choose 12 SOTA LLMs and take 4 of them, Llama2-7B, Llama2-Chat-7B, Llama2- Chinese-Chat-7B and ChatGLM2-6B for fine-tuning. During the training stage, we conduct a total of three training epochs. The initial learning rate is set to $1.41e^{-5}$ , with a steady decrease as training steps progressed. The batch size is fixed at 64, and the maximum input/output sequence length are set to 512. To alleviate GPU memory load, we use gradient accumulation steps, which are set to 16. In terms of LoRA, we assign values of 64 and 16 to the parameters $r$ and $\alpha$ , respectively. During the evaluation stage, all inferences share the same configuration, with a maximum token generation length of 512. Temperature, top-k, and top-p values are set to 1.0, 50, and 1.0, respectively. The prevailing algorithms as the baseline to construct a LLM pool are shown in Figure 5 and explained as follows:
最终,我们选择了12个最先进的大语言模型(LLM),并对其中的4个模型(Llama2-7B、Llama2-Chat-7B、Llama2-Chinese-Chat-7B和ChatGLM2-6B)进行微调。训练阶段共进行三个训练周期,初始学习率设为$1.41e^{-5}$,随着训练步数增加逐步降低。批量大小固定为64,最大输入/输出序列长度设为512。为减轻GPU内存负载,我们采用梯度累积步数设置为16。在LoRA配置方面,参数$r$和$\alpha$分别设为64和16。评估阶段所有推理采用相同配置,最大token生成长度为512,温度值、top-k和top-p分别设置为1.0、50和1.0。图5展示了作为基线的主流算法构建的大语言模型池,具体说明如下:
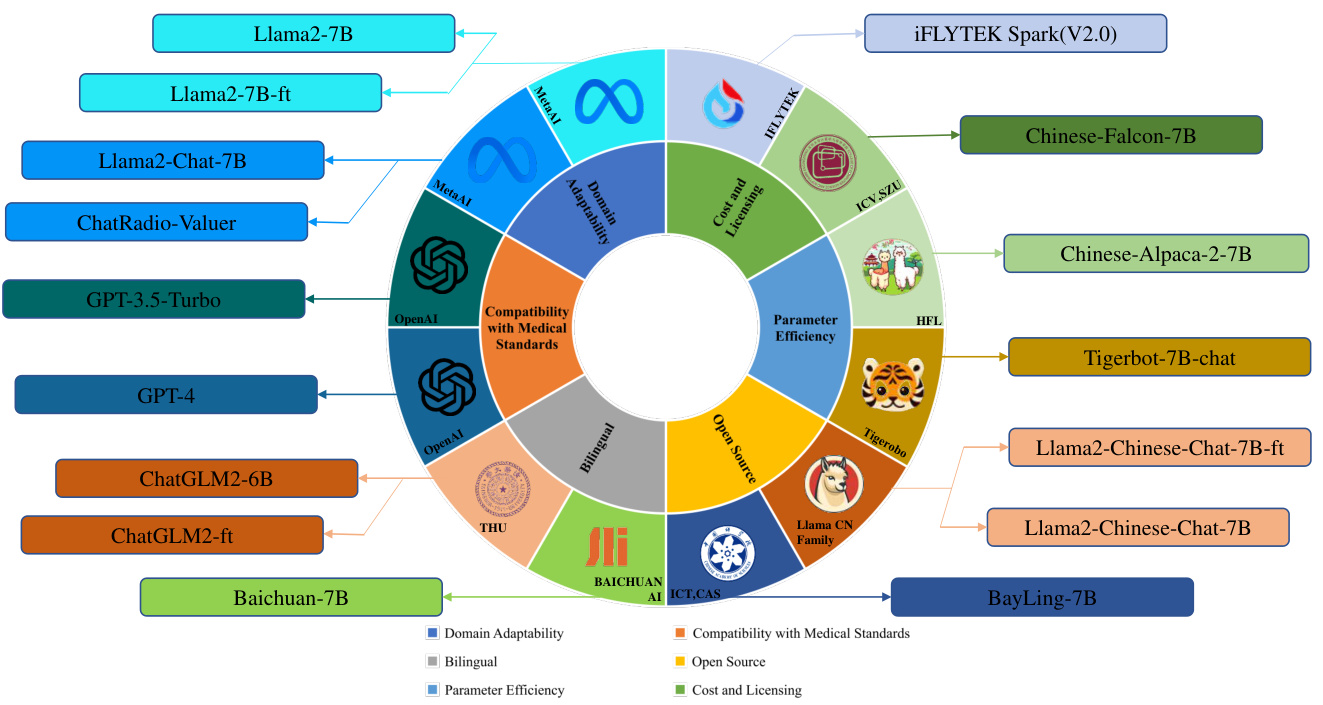
Figure 5: LLM pool for model selection. Considering the scene of medical application, six aspects are considered: domain adaptability, compatibility with medical standards, bilingual, open source, parameter efficiency, and cost and licensing. 15 SOTA LLMs (12 baseline models, 3 fine-tuning pairs, and 1 fine-tuned ChatGLM2-6B) from 10 organizations jointly are established by the LLM pool.
图 5: 大语言模型选型池。针对医疗应用场景,我们从六个维度进行评估:领域适应性、医疗标准兼容性、双语支持、开源属性、参数效率及成本许可。该模型池汇集了来自10家机构的15个前沿大语言模型 (包含12个基线模型、3组微调对比模型及1个微调版ChatGLM2-6B)。
Baseline Methods:
基线方法:
- Llama2: Llama2 [49] is a collection that comprises a meticulously curated set of pre-trained generative text models that have been expertly fine-tuned. These models operate as auto-regressive language models and are founded upon an optimized transformer architecture. The fine-tuned variants incorporate SFT and reinforcement learning with input from human feedback (RLHF) [50] to align with human preferences regarding both utility and safety. Our model selection includes Llama2-7B and Llama2-Chat-7B.
- Llama2: Llama2 [49] 是一个精心筛选的预训练生成文本模型集合,这些模型经过专家级微调。它们作为自回归大语言模型运行,基于优化后的Transformer架构。微调版本结合了监督微调(SFT) 和来自人类反馈的强化学习(RLHF) [50],以在实用性和安全性方面符合人类偏好。我们选用的模型包括Llama2-7B和Llama2-Chat-7B。
- Llama2-Chinese: Llama2-Chinese [51] is a collection containing LLMs pre-trained on a large-scale Chinese corpus, leveraging high-quality Chinese language datasets totaling 200 billion characters for fine-tuning. While this approach is costly, requiring significant resources in terms of both high-quality Chinese data and computational resources, its great advantage lies in enhancing Chinese language capabilities at the model’s core, achieving fundamental improvement and imparting strong Chinese language proficiency to the large model. In our study, we carefully select Llama2-Chinese-Chat-7B as the baseline method.
- Llama2-Chinese: Llama2-Chinese [51] 是一个包含基于大规模中文语料预训练的大语言模型合集,利用总计2000亿字符的高质量中文数据集进行微调。虽然这种方法成本高昂,需要大量高质量中文数据和计算资源,但其巨大优势在于从模型核心层面提升中文能力,实现根本性改进,并赋予大模型强大的中文处理能力。在我们的研究中,我们精心选择了Llama2-Chinese-Chat-7B作为基线方法。
- GPT-3.5-Turbo/GPT-4: ChatGPT and GPT4, both developed by OpenAI, are influential large language models. ChatGPT, also known as GPT-3.5-turbo, is an advancement based on GPT-2 and GPT-3, with its training process heavily influenced by instruct GP T [52]. A key distinction from GPT-3 [53] is the incorporation of RLHF [50], which refines model output through human feedback. This approach enhances the model’s ability to rank results effectively. ChatGPT excels in language comprehension, accommodating diverse expressions and queries. Its extensive knowledge base answers frequently asked questions and provides valuable information. GPT-4, being the successor of GPT-3, may possess enhanced capabilities. In our experiments, both ChatGPT and GPT4 are utilized.
- GPT-3.5-Turbo/GPT-4: 由OpenAI开发的ChatGPT和GPT4都是具有影响力的大语言模型。ChatGPT(即GPT-3.5-turbo)是在GPT-2和GPT-3基础上的改进版本,其训练过程深受instruct GPT [52]影响。与GPT-3 [53]的关键区别在于引入了RLHF [50]技术,通过人类反馈来优化模型输出。这种方法提升了模型对结果排序的能力。ChatGPT在语言理解方面表现优异,能够处理多样化的表达方式和查询需求。其庞大的知识库可以回答常见问题并提供有价值的信息。作为GPT-3的继任者,GPT-4可能具备更强的能力。本实验中同时使用了ChatGPT和GPT4。
- ChatGLM2-6B: ChatGLM2-6B [54, 55] is the second-generation bilingual chat model based on the open-source ChatGLM-6B framework. It has undergone pre-training with 1.4 trillion bilingual tokens, accompanied by human preference alignment training. This model successfully achieves several key objectives, including maintaining a smooth conversation flow, imposing minimal deployment requirements, and extending the context length to 32K tokens through the incorporation of Flash Attention.
- ChatGLM2-6B:ChatGLM2-6B [54, 55] 是基于开源框架 ChatGLM-6B 的第二代双语对话模型。该模型通过 1.4 万亿双语 token 的预训练及人类偏好对齐训练,成功实现了多项关键目标:保持流畅的对话体验、极低的部署需求,并通过引入 Flash Attention 技术将上下文长度扩展至 32K token。
- BayLing: BayLing [56] is a set of advanced language models that excel in English and Chinese text generation, adeptly follow instructions, and engage in multi-turn conversations. It seamlessly operates on a standard 16GB GPU, facilitating users with translation, writing, and creative suggestions, among other tasks. In our evaluation task, BayLing-7B was selected for evaluation.
- BayLing: BayLing [56] 是一套擅长中英文文本生成、精准遵循指令并支持多轮对话的先进语言模型。它可在标准16GB GPU上流畅运行,辅助用户完成翻译、写作及创意建议等任务。本次评估选用BayLing-7B模型进行测试。
- Baichuan-7B: Baichuan-7B [57], an open-source language model by Baichuan Intelligent Technology, utilizes the Transformer architecture with 7 billion parameters, trained on about 1.2 trillion tokens. It excels in both Chinese and English, featuring a 4096-token context window. It outperforms similar-sized models on standard Chinese and English benchmarks like C-Eval and MMLU.
- Baichuan-7B: Baichuan-7B [57] 是百川智能科技推出的开源大语言模型, 采用 Transformer 架构, 拥有 70 亿参数, 基于约 1.2 万亿 token 训练而成。该模型在中英文任务上均表现优异, 支持 4096 token 的上下文窗口, 在 C-Eval 和 MMLU 等中英文基准测试中超越了同规模模型。
- Tigerbot-7B-chat: Tigerbot-7B-chat [58], derived from TigerBot-7B-base, underwent fine-tuning with 20M data across various tasks for directives (SFT) and alignment using rejection sampling (RS-HIL). Across 13 key assessments in English and Chinese, it outperforms Llama2-Chat-7B by 29%, showcasing superior performance compared to similar open-source models worldwide.
- Tigerbot-7B-chat: Tigerbot-7B-chat [58] 基于 TigerBot-7B-base 开发,通过 20M 多任务指令数据进行了监督微调 (SFT),并采用拒绝采样对齐方法 (RS-HIL)。在涵盖中英文的 13 项核心评测中,其性能超越 Llama2-Chat-7B 达 29%,展现出全球同类开源模型中的卓越表现。
- Chinese-LLaMA-Alpaca-2: Chinese-LLaMA-Alpaca-2 [59], an evolution of Meta’s Llama2, marks the second iteration of the Chinese LLaMA & Alpaca LLM initiative. We’ve made the Chinese LLaMA-2 (the base model) and Alpaca-2 (the instruction-following model) open source. These models have been enhanced and refined with a broader Chinese vocabulary compared to the original Llama2. It conducted extensive pre-training with abundant Chinese data, significantly bolstering our grasp of Chinese language semantics, resulting in a substantial performance boost compared to the first-gen models. The standard version supports a 4K context, while the long-context version accommodates up to 16K context. Moreover, all models can expand their context size using the NTK method, going beyond 24K+.
- Chinese-LLaMA-Alpaca-2: Chinese-LLaMA-Alpaca-2 [59] 作为 Meta Llama2 的演进版本,标志着中文 LLaMA & Alpaca 大语言模型项目的第二次迭代。我们开源了中文 LLaMA-2 (基础模型) 和 Alpaca-2 (指令跟随模型)。相比原始 Llama2,这些模型通过扩充中文词表进行了增强优化,并基于海量中文数据开展了充分预训练,显著提升了对中文语义的理解能力,性能较第一代模型有大幅提升。标准版支持 4K 上下文长度,长上下文版本最高支持 16K。此外,所有模型均可通过 NTK 方法扩展上下文窗口至 24K+。
- Chinese-Falcon-7B: Chinese-Falcon-7B [60], developed by the Linly team, expands the Chinese vocabulary of the Falcon model and transfers its language capabilities to Chinese through Chinese and Chinese-English parallel incremental pre-training. Pre-training was conducted using 50GB of data, with 20GB of general Chinese corpora providing Chinese language proficiency and knowledge to the model, 10GB of Chinese-English parallel corpora aligning the model’s Chinese and English representations to transfer English language proficiency to Chinese, and 20GB of English corpora used for data replay to mitigate model forgetting.
- Chinese-Falcon-7B: Chinese-Falcon-7B [60] 由 Linly 团队开发,通过扩展 Falcon 模型的中文词汇表,并采用中英平行增量预训练方式将其语言能力迁移至中文领域。预训练使用 50GB 数据完成,其中 20GB 通用中文语料为模型提供中文语言能力与知识,10GB 中英平行语料对齐模型的中英文表征以实现英语能力向中文的迁移,另有 20GB 英文语料用于数据回放以防止模型遗忘。
- iFLYTEK Spark (V2.0): iFLYTEK Spark (V2.0) [61] is a next-generation cognitive intelligent model that possesses interdisciplinary knowledge and language comprehension capabilities. It can understand and execute tasks based on natural conversation. It offers functionalities such as multimodal interaction, coding abilities, text generation, mathematical capabilities, language comprehension, knowledge answering, and logical reasoning. Its API enables applications to quickly access interdisciplinary knowledge and powerful natural language understanding capabilities, effectively addressing pressing issues in specific contexts.
- 科大讯飞星火(V2.0): 科大讯飞星火(V2.0) [61] 是新一代认知智能模型,具备跨学科知识和语言理解能力。它能基于自然对话理解并执行任务,提供多模态交互、编程能力、文本生成、数学能力、语言理解、知识问答及逻辑推理等功能。其API可使应用快速接入跨学科知识和强大的自然语言理解能力,有效解决特定场景下的迫切问题。
For SFT, Llama2-7B, Llama2-7B-Chat, Llama2-Chinese-7B-Chat, and ChatGLM2-6B employed identical training and LoRA configuration settings. For inference, the anterior models with their SFT versions and the listed models above conformed to the same inference configuration. Experiments have been performed to validate the effectiveness of ChatRadio-Valuer on the multi-institution and multi-system radiology report generation.
对于监督微调(SFT),Llama2-7B、Llama2-7B-Chat、Llama2-Chinese-7B-Chat和ChatGLM2-6B均采用相同的训练和LoRA配置参数。在推理阶段,上述基础模型及其监督微调版本均遵循统一的推理配置。实验验证了ChatRadio-Valuer在多机构、多系统的放射学报告生成任务中的有效性。
4.3 Generalization Performance Evaluation Across Institutions
4.3 跨机构泛化性能评估
Firstly, to assess the ChatRadio-Valuer’s general iz able abilities to transfer its acquired knowledge and skills to diverse institutions or sources, we conduct extensive cross-institution performance comparisons involving 15 models. As shown in Table 2 and Table 3 for details, ChatRadio-Valuer’s evaluation encompasses treating data from Institutions 2 through 6 as external sources, revealing a noteworthy degree of general iz ability and similarity with the data originating from Institution 1. Our results underscore significant advantages of ChatRadio-Valuer over other models, particularly evident in its absolute superiority in R-1, R-2, and R-L scores on datasets from Institutions 2 and 5. Furthermore, ChatRadio-Valuer secures the highest R-2 score on the dataset from Institution 6. Although it does not attain the top score across all metrics for Institutions 3, 4, and 6, ChatRadioValuer consistently maintains a prominent position within the first tier. Taking into account influential external factors like hardware and environmental disparities, we can assert that ChatRadio-Valuer demonstrates exceptional cross-institution performance.
首先,为评估ChatRadio-Valuer将其所学知识和技能迁移至不同机构或数据源的泛化能力,我们开展了涵盖15个模型的跨机构性能对比实验。如表2和表3所示,当将机构2至6的数据视为外部源时,ChatRadio-Valuer展现出与机构1数据源显著相似的泛化性能。实验结果凸显了ChatRadio-Valuer相对于其他模型的显著优势:在机构2和5数据集上R-1、R-2及R-L分数绝对领先,同时斩获机构6数据集的最高R-2分数。尽管在机构3、4、6的部分指标上未达榜首,ChatRadio-Valuer始终稳居第一梯队。综合考虑硬件环境差异等外部影响因素,可以确认ChatRadio-Valuer具有卓越的跨机构表现。
This remarkable capacity for generalization across institutions significantly diminishes the model’s reliance on specific institutional data, thereby presenting promising advantages for data sharing and collaboration among institutions. The ability to seamlessly transfer and apply the model across institutions without necessitating retraining positions ChatRadio-Valuer as a preferred tool for numerous medical establishments. The potential value lies in its capability to enhance the quality of patient care, expedite disease diagnosis, and streamline clinical decision-making processes.
这种跨机构泛化的卓越能力显著降低了模型对特定机构数据的依赖,从而为机构间的数据共享与合作带来了显著优势。无需重新训练即可在不同机构间无缝迁移和应用模型的特点,使ChatRadio-Valuer成为众多医疗机构的优选工具。其潜在价值体现在提升患者护理质量、加速疾病诊断以及优化临床决策流程等方面。
Explore further, in order to evaluate the ChatRadio-Valuer’s general iz able ability to extend its knowledge and skills to multiple body systems within Institution 1, we conduct performance tests involving 15 models on the designated testing dataset from Institution 1. This testing dataset encompasses five distinct systems (chest, abdomen, skeletal muscle, head, and max ill o facial & neck parts). As listed in Table 4 and 5 for details, we calculate the similarity for each system among the model-generated diagnosis results (impression) and the professional diagnosis results (REPORT RESULT) provided by doctors, yielding R-1, R-2, and R-L values. The outcomes clearly showcase ChatRadio-Valuer’s remarkable advantages. Across three systems—abdomen, head, and max ill o facial & neck—ChatRadio-Valuer achieves the highest scores for R-1, R-2, and R-L values. In the chest system’s testing results, both R-1 and R-L values attain the highest scores as well. The remaining test results exhibit remarkable proximity to the maximum values, presenting significantly superior performance compared to the other two fine-tuned models. They firmly belong to the top tier.
为进一步评估ChatRadio-Valuer在机构1中将知识技能泛化至多人体系统的能力,我们在机构1指定测试集上对15个模型进行了性能测试。该测试集涵盖五大系统(胸部、腹部、骨骼肌、头部及颌面颈部)。如表4和表5所示,我们计算了各系统模型生成诊断结果(印象)与医生提供的专业诊断结果(报告结果)之间的R-1、R-2和R-L相似度值。结果清晰展现了ChatRadio-Valuer的显著优势:在腹部、头部和颌面颈部三个系统中,其R-1、R-2和R-L值均获最高分;胸部系统测试中R-1与R-L值同样登顶;其余测试结果与最大值差距微小,较另外两个微调模型展现出显著优越性,稳居第一梯队。
Table 2: Cross-institution comparison (Part 1). Results of data from Institution 1 - 3 are shown. For results within each institution, each model corresponds to three similarity scores, R-1, R-2, and R-L.
| Model | Institution 1 | Institution 2 | Institution 3 | ||||||
| R-1 | R-2 | R-L | R-1 | R-2 | R-L | R-1 | R-2 | R-L | |
| Llama2-7B | 0.0909 | 0.0402 | 0.0879 | 0.0825 | 0.0344 | 0.0784 | 0.0172 | 0.0062 | 0.0169 |
| Llama2-7B-ft | 0.4324 | 0.2680 | 0.4181 | 0.4657 | 0.2675 | 0.4489 | 0.0875 | 0.0250 | 0.0847 |
| Llama2-Chat-7B | 0.1983 | 0.0810 | 0.1885 | 0.1871 | 0.0478 | 0.1780 | 0.0178 | 0.0040 | 0.0168 |
| ChatRadio-Valuer | 0.4619 | 0.2872 | 0.4464 | 0.4807 | 0.2684 | 0.4608 | 0.0673 | 0.0191 | 0.0644 |
| Llama2-Chinese-Chat-7B | 0.1701 | 0.0751 | 0.1633 | 0.1411 | 0.0386 | 0.1352 | 0.0376 | 0.0127 | 0.0358 |
| Llama2-Chinese-Chat-7B-ft | 0.3221 | 0.1911 | 0.3106 | 0.4045 | 0.2250 | 0.3869 | 0.0675 | 0.0166 | 0.0647 |
| ChatGLM2-ft | 0.2639 | 0.1052 | 0.2556 | 0.2733 | 0.0818 | 0.2578 | 0.0458 | 0.0114 | 0.0441 |
| GPT-3.5-Turbo | 0.1411 | 0.0615 | 0.1341 | 0.0721 | 0.0221 | 0.0679 | 0.0644 | 0.0346 | 0.0623 |
| GPT-4 | 0.1080 | 0.0451 | 0.1029 | 0.0689 | 0.0215 | 0.0646 | 0.0752 | 0.0393 | 0.0729 |
| BayLing-7B | 0.2732 | 0.1128 | 0.2604 | 0.2643 | 0.0729 | 0.2519 | 0.0412 | 0.0112 | 0.0380 |
| Baichuan-7B | 0.1264 | 0.0578 | 0.1217 | 0.0846 | 0.0247 | 0.0816 | 0.0532 | 0.0234 | 0.0508 |
| Tigerbot-7B-chat-v3 | 0.1338 | 0.0587 | 0.1283 | 0.0783 | 0.0285 | 0.0750 | 0.0817 | 0.0260 | 0.0789 |
| Chinese-Alpaca-2-7B | 0.1884 | 0.0776 | 0.1800 | 0.1837 | 0.0476 | 0.1758 | 0.0546 | 0.0214 | 0.0522 |
| Chinese-Falcon-7B | 0.0770 | 0.0356 | 0.0742 | 0.0360 | 0.0127 | 0.0350 | 0.0391 | 0.0166 | 0.0382 |
| iFLYTEK Spark (V2.0) | 0.1186 | 0.0513 | 0.1142 | 0.0962 | 0.0254 | 0.0918 | 0.0642 | 0.0305 | 0.0622 |
表 2: 跨机构对比 (第一部分)。展示机构1-3的数据结果。各机构内部结果中,每个模型对应三个相似度分数:R-1、R-2和R-L。
| 模型 | 机构1-R-1 | 机构1-R-2 | 机构1-R-L | 机构2-R-1 | 机构2-R-2 | 机构2-R-L | 机构3-R-1 | 机构3-R-2 | 机构3-R-L |
|---|---|---|---|---|---|---|---|---|---|
| Llama2-7B | 0.0909 | 0.0402 | 0.0879 | 0.0825 | 0.0344 | 0.0784 | 0.0172 | 0.0062 | 0.0169 |
| Llama2-7B-ft | 0.4324 | 0.2680 | 0.4181 | 0.4657 | 0.2675 | 0.4489 | 0.0875 | 0.0250 | 0.0847 |
| Llama2-Chat-7B | 0.1983 | 0.0810 | 0.1885 | 0.1871 | 0.0478 | 0.1780 | 0.0178 | 0.0040 | 0.0168 |
| ChatRadio-Valuer | 0.4619 | 0.2872 | 0.4464 | 0.4807 | 0.2684 | 0.4608 | 0.0673 | 0.0191 | 0.0644 |
| Llama2-Chinese-Chat-7B | 0.1701 | 0.0751 | 0.1633 | 0.1411 | 0.0386 | 0.1352 | 0.0376 | 0.0127 | 0.0358 |
| Llama2-Chinese-Chat-7B-ft | 0.3221 | 0.1911 | 0.3106 | 0.4045 | 0.2250 | 0.3869 | 0.0675 | 0.0166 | 0.0647 |
| ChatGLM2-ft | 0.2639 | 0.1052 | 0.2556 | 0.2733 | 0.0818 | 0.2578 | 0.0458 | 0.0114 | 0.0441 |
| GPT-3.5-Turbo | 0.1411 | 0.0615 | 0.1341 | 0.0721 | 0.0221 | 0.0679 | 0.0644 | 0.0346 | 0.0623 |
| GPT-4 | 0.1080 | 0.0451 | 0.1029 | 0.0689 | 0.0215 | 0.0646 | 0.0752 | 0.0393 | 0.0729 |
| BayLing-7B | 0.2732 | 0.1128 | 0.2604 | 0.2643 | 0.0729 | 0.2519 | 0.0412 | 0.0112 | 0.0380 |
| Baichuan-7B | 0.1264 | 0.0578 | 0.1217 | 0.0846 | 0.0247 | 0.0816 | 0.0532 | 0.0234 | 0.0508 |
| Tigerbot-7B-chat-v3 | 0.1338 | 0.0587 | 0.1283 | 0.0783 | 0.0285 | 0.0750 | 0.0817 | 0.0260 | 0.0789 |
| Chinese-Alpaca-2-7B | 0.1884 | 0.0776 | 0.1800 | 0.1837 | 0.0476 | 0.1758 | 0.0546 | 0.0214 | 0.0522 |
| Chinese-Falcon-7B | 0.0770 | 0.0356 | 0.0742 | 0.0360 | 0.0127 | 0.0350 | 0.0391 | 0.0166 | 0.0382 |
| iFLYTEK Spark (V2.0) | 0.1186 | 0.0513 | 0.1142 | 0.0962 | 0.0254 | 0.0918 | 0.0642 | 0.0305 | 0.0622 |
Table 3: Cross-institution comparison (Part 2). Results of data from Institution 4 - 6 are shown. For results within each institution, each model corresponds to three similarity scores, R-1, R-2, and R-L.
| Model | Institution 4 | Institution 5 | Institution 6 | ||||||
| R-1 | R-2 | R-L | R-1 | R-2 | R-L | R-1 | R-2 | R-L | |
| Llama2-7B | 0.0028 | 0.0004 | 0.0028 | 0.0441 | 0.0138 | 0.0437 | 0.0122 | 0.0025 | 0.0120 |
| Llama2-7B-ft | 0.1368 | 0.0034 | 0.1368 | 0.1894 | 0.0715 | 0.1836 | 0.0745 | 0.0091 | 0.0715 |
| Llama2-Chat-7B | 0.0066 | 0.0011 | 0.0066 | 0.1184 | 0.0409 | 0.1153 | 0.0369 | 0.0036 | 0.0350 |
| ChatRadio-Valuer | 0.0827 | 0.0000 | 0.0827 | 0.2195 | 0.0835 | 0.2127 | 0.0824 | 0.0126 | 0.0779 |
| Llama2-Chinese-Chat-7B | 0.0124 | 0.0000 | 0.0124 | 0.1192 | 0.0419 | 0.1150 | 0.0356 | 0.0092 | 0.0345 |
| Llama2-Chinese-Chat-7B-ft | 0.0950 | 0.0000 | 0.0950 | 0.1787 | 0.0642 | 0.1741 | 0.0915 | 0.0093 | 0.0896 |
| ChatGLM2-ft | 0.0982 | 0.0007 | 0.0982 | 0.1380 | 0.0304 | 0.1336 | 0.0708 | 0.0044 | 0.0693 |
| GPT-3.5-Turbo | 0.0100 | 0.0000 | 0.0100 | 0.1043 | 0.0664 | 0.0994 | 0.0054 | 0.0000 | 0.0043 |
| GPT-4 | 0.0000 | 0.0000 | 0.0000 | 0.0755 | 0.0313 | 0.0697 | 0.0107 | 0.0000 | 0.0087 |
| BayLing-7B | 0.0108 | 0.0008 | 0.0108 | 0.1649 | 0.0598 | 0.1604 | 0.0677 | 0.0083 | 0.0642 |
| Baichuan-7B | 0.0061 | 0.0034 | 0.0061 | 0.1083 | 0.0377 | 0.1051 | 0.0329 | 0.0107 | 0.0312 |
| Tigerbot-7B-chat-v3 | 0.0121 | 0.0014 | 0.0121 | 0.1200 | 0.0328 | 0.1159 | 0.0784 | 0.0091 | 0.0782 |
| Chinese-Alpaca-2-7B | 0.0140 | 0.0011 | 0.0140 | 0.1274 | 0.0430 | 0.1230 | 0.0616 | 0.0082 | 0.0600 |
| Chinese-Falcon-7B | 0.0124 | 0.0000 | 0.0124 | 0.0447 | 0.0173 | 0.0432 | 0.0135 | 0.0005 | 0.0135 |
| iFLYTEK Spark (V2.0) | 0.0169 | 0.0034 | 0.0169 | 0.0756 | 0.0229 | 0.0721 | 0.0355 | 0.0062 | 0.0344 |
表 3: 跨机构对比 (第二部分)。展示机构 4-6 的数据结果。各机构内部结果中,每个模型对应三个相似度分数 R-1、R-2 和 R-L。
| 模型 | 机构 4 R-1 | 机构 4 R-2 | 机构 4 R-L | 机构 5 R-1 | 机构 5 R-2 | 机构 5 R-L | 机构 6 R-1 | 机构 6 R-2 | 机构 6 R-L |
|---|---|---|---|---|---|---|---|---|---|
| Llama2-7B | 0.0028 | 0.0004 | 0.0028 | 0.0441 | 0.0138 | 0.0437 | 0.0122 | 0.0025 | 0.0120 |
| Llama2-7B-ft | 0.1368 | 0.0034 | 0.1368 | 0.1894 | 0.0715 | 0.1836 | 0.0745 | 0.0091 | 0.0715 |
| Llama2-Chat-7B | 0.0066 | 0.0011 | 0.0066 | 0.1184 | 0.0409 | 0.1153 | 0.0369 | 0.0036 | 0.0350 |
| ChatRadio-Valuer | 0.0827 | 0.0000 | 0.0827 | 0.2195 | 0.0835 | 0.2127 | 0.0824 | 0.0126 | 0.0779 |
| Llama2-Chinese-Chat-7B | 0.0124 | 0.0000 | 0.0124 | 0.1192 | 0.0419 | 0.1150 | 0.0356 | 0.0092 | 0.0345 |
| Llama2-Chinese-Chat-7B-ft | 0.0950 | 0.0000 | 0.0950 | 0.1787 | 0.0642 | 0.1741 | 0.0915 | 0.0093 | 0.0896 |
| ChatGLM2-ft | 0.0982 | 0.0007 | 0.0982 | 0.1380 | 0.0304 | 0.1336 | 0.0708 | 0.0044 | 0.0693 |
| GPT-3.5-Turbo | 0.0100 | 0.0000 | 0.0100 | 0.1043 | 0.0664 | 0.0994 | 0.0054 | 0.0000 | 0.0043 |
| GPT-4 | 0.0000 | 0.0000 | 0.0000 | 0.0755 | 0.0313 | 0.0697 | 0.0107 | 0.0000 | 0.0087 |
| BayLing-7B | 0.0108 | 0.0008 | 0.0108 | 0.1649 | 0.0598 | 0.1604 | 0.0677 | 0.0083 | 0.0642 |
| Baichuan-7B | 0.0061 | 0.0034 | 0.0061 | 0.1083 | 0.0377 | 0.1051 | 0.0329 | 0.0107 | 0.0312 |
| Tigerbot-7B-chat-v3 | 0.0121 | 0.0014 | 0.0121 | 0.1200 | 0.0328 | 0.1159 | 0.0784 | 0.0091 | 0.0782 |
| Chinese-Alpaca-2-7B | 0.0140 | 0.0011 | 0.0140 | 0.1274 | 0.0430 | 0.1230 | 0.0616 | 0.0082 | 0.0600 |
| Chinese-Falcon-7B | 0.0124 | 0.0000 | 0.0124 | 0.0447 | 0.0173 | 0.0432 | 0.0135 | 0.0005 | 0.0135 |
| iFLYTEK Spark (V2.0) | 0.0169 | 0.0034 | 0.0169 | 0.0756 | 0.0229 | 0.0721 | 0.0355 | 0.0062 | 0.0344 |
On the other hand, to evaluate on ChatRadio-Valuer’s general iz able ability to extend its knowledge and skills to multiple body systems within external individual institutions, we conduct performance tests on chest, abdomen, skeletal muscle, head, and max ill o facial & neck parts respectively from Institution 2 to Institution 6. As shown in the columns from the corresponding institutions between Table 2 and Table 3, it can be found that in Institution 2 and Institution 5, ChatRadio-Valuer leads in all three metrics: R-1, R-2, and R-L, and ChatRadio-Valuer outperforms in R-2 far from other models in Institution 6 while only slightly inferior to others’ in R-1 and R-L, which is similar in Institution 3 and Institution 4. These concrete results are driven by ChatRadio-Valuer’s superior general iz ability derived from data in Institution 1. ChatRadio-Valuer successfully expand the knowledge acquired from Institution 1 to other idiosyncratic institutions. And as these institutions contain their corresponding disease system purely, in other words, ChatRadio-Valuer predominates in either broadening knowledge from single to multiple unseen datasets or applying this knowledge in addressing multi-system clinical problems.
另一方面,为评估ChatRadio-Valuer将知识与技能泛化至外部独立机构多人体系统的能力,我们分别对来自机构2至机构6的胸部、腹部、骨骼肌、头部及颌面颈部进行了性能测试。如从表2至表3对应机构列所示:在机构2和机构5中,ChatRadio-Valuer在R-1、R-2和R-L三项指标上全面领先;在机构6的R-2指标上显著优于其他模型,仅在R-1和R-L上略逊(机构3和机构4表现类似)。这些具体成果源于ChatRadio-Valuer通过机构1数据获得的卓越泛化能力,成功将机构1习得的知识迁移至其他特性迥异的机构。由于这些机构仅包含对应疾病系统的数据,这表明ChatRadio-Valuer无论在从单一数据集扩展到多未见数据集的知识泛化,还是在解决多系统临床问题的知识应用方面均占据优势。
Table 4: Multiple system similarity from Institution 1 (Part 1). The outcomes of data collected from systems 1 through 3 (i.e., Chest to Muscle-skeleton) within Institution 1 are presented herein. Each model is associated with three distinct similarity scores, denoted as R-1, R-2, and R-L.
| Model | Chest | Abdomen | Muscle-skeleton | ||||||
| R-1 | R-2 | R-L | R-1 | R-2 | R-L | R-1 | R-2 | R-L | |
| Llama2-7B | 0.0993 | 0.0390 | 0.0946 | 0.0934 | 0.0346 | 0.0917 | 0.1307 | 0.0744 | 0.1257 |
| Llama2-7B-ft | 0.5358 | 0.3369 | 0.5171 | 0.4851 | 0.3033 | 0.4709 | 0.4763 | 0.3077 | 0.4521 |
| Llama2-Chat-7B | 0.2133 | 0.0628 | 0.2024 | 0.2175 | 0.0949 | 0.2092 | 0.2727 | 0.1701 | 0.2507 |
| ChatRadio-Valuer | 0.5407 | 0.3155 | 0.5187 | 0.5283 | 0.3485 | 0.5139 | 0.4736 | 0.3035 | 0.4485 |
| Llama2-Chinese-Chat-7B | 0.1524 | 0.0445 | 0.1458 | 0.1662 | 0.0465 | 0.1612 | 0.3568 | 0.2636 | 0.3381 |
| Llama2-Chinese-Chat-7B-ft | 0.4661 | 0.2823 | 0.4476 | 0.3582 | 0.2020 | 0.3484 | 0.4067 | 0.2631 | 0.3885 |
| ChatGLM2-ft | 0.3060 | 0.1071 | 0.2940 | 0.3515 | 0.1472 | 0.3407 | 0.2240 | 0.1304 | 0.2174 |
| GPT-3.5-Turbo | 0.1082 | 0.0270 | 0.1041 | 0.1889 | 0.0659 | 0.1830 | 0.2620 | 0.1822 | 0.2378 |
| GPT-4 | 0.0514 | 0.0055 | 0.0507 | 0.1178 | 0.0220 | 0.1153 | 0.2747 | 0.2012 | 0.2525 |
| BayLing-7B | 0.2652 | 0.0829 | 0.2540 | 0.3414 | 0.1464 | 0.3256 | 0.3520 | 0.2065 | 0.3239 |
| Baichuan-7B | 0.0637 | 0.0172 | 0.0616 | 0.1391 | 0.0404 | 0.1328 | 0.2901 | 0.2038 | 0.2776 |
| Tigerbot-7B-chat-v3 | 0.0934 | 0.0276 | 0.0899 | 0.1394 | 0.0307 | 0.1341 | 0.3388 | 0.2300 | 0.3216 |
| Chinese-Alpaca-2-7B | 0.1645 | 0.0470 | 0.1582 | 0.2308 | 0.0770 | 0.2203 | 0.3396 | 0.2241 | 0.3198 |
| Chinese-Falcon-7B | 0.0383 | 0.0065 | 0.0376 | 0.0758 | 0.0120 | 0.0741 | 0.2420 | 0.1722 | 0.2289 |
| iFLYTEK Spark (V2.0) | 0.0514 | 0.0088 | 0.0503 | 0.1695 | 0.0410 | 0.1629 | 0.3136 | 0.2254 | 0.3001 |
表 4: 机构1多系统相似度(第一部分)。本文展示了机构1内系统1至系统3(即胸部至肌肉骨骼)收集数据的评估结果。每个模型对应三个不同的相似度分数,分别标记为R-1、R-2和R-L。
| 模型 | 胸部-R-1 | 胸部-R-2 | 胸部-R-L | 腹部-R-1 | 腹部-R-2 | 腹部-R-L | 肌肉骨骼-R-1 | 肌肉骨骼-R-2 | 肌肉骨骼-R-L |
|---|---|---|---|---|---|---|---|---|---|
| Llama2-7B | 0.0993 | 0.0390 | 0.0946 | 0.0934 | 0.0346 | 0.0917 | 0.1307 | 0.0744 | 0.1257 |
| Llama2-7B-ft | 0.5358 | 0.3369 | 0.5171 | 0.4851 | 0.3033 | 0.4709 | 0.4763 | 0.3077 | 0.4521 |
| Llama2-Chat-7B | 0.2133 | 0.0628 | 0.2024 | 0.2175 | 0.0949 | 0.2092 | 0.2727 | 0.1701 | 0.2507 |
| ChatRadio-Valuer | 0.5407 | 0.3155 | 0.5187 | 0.5283 | 0.3485 | 0.5139 | 0.4736 | 0.3035 | 0.4485 |
| Llama2-Chinese-Chat-7B | 0.1524 | 0.0445 | 0.1458 | 0.1662 | 0.0465 | 0.1612 | 0.3568 | 0.2636 | 0.3381 |
| Llama2-Chinese-Chat-7B-ft | 0.4661 | 0.2823 | 0.4476 | 0.3582 | 0.2020 | 0.3484 | 0.4067 | 0.2631 | 0.3885 |
| ChatGLM2-ft | 0.3060 | 0.1071 | 0.2940 | 0.3515 | 0.1472 | 0.3407 | 0.2240 | 0.1304 | 0.2174 |
| GPT-3.5-Turbo | 0.1082 | 0.0270 | 0.1041 | 0.1889 | 0.0659 | 0.1830 | 0.2620 | 0.1822 | 0.2378 |
| GPT-4 | 0.0514 | 0.0055 | 0.0507 | 0.1178 | 0.0220 | 0.1153 | 0.2747 | 0.2012 | 0.2525 |
| BayLing-7B | 0.2652 | 0.0829 | 0.2540 | 0.3414 | 0.1464 | 0.3256 | 0.3520 | 0.2065 | 0.3239 |
| Baichuan-7B | 0.0637 | 0.0172 | 0.0616 | 0.1391 | 0.0404 | 0.1328 | 0.2901 | 0.2038 | 0.2776 |
| Tigerbot-7B-chat-v3 | 0.0934 | 0.0276 | 0.0899 | 0.1394 | 0.0307 | 0.1341 | 0.3388 | 0.2300 | 0.3216 |
| Chinese-Alpaca-2-7B | 0.1645 | 0.0470 | 0.1582 | 0.2308 | 0.0770 | 0.2203 | 0.3396 | 0.2241 | 0.3198 |
| Chinese-Falcon-7B | 0.0383 | 0.0065 | 0.0376 | 0.0758 | 0.0120 | 0.0741 | 0.2420 | 0.1722 | 0.2289 |
| iFLYTEK Spark (V2.0) | 0.0514 | 0.0088 | 0.0503 | 0.1695 | 0.0410 | 0.1629 | 0.3136 | 0.2254 | 0.3001 |
Table 5: Multiple system similarity from Institution 1 (Part 2). Outcomes of data collected from systems 4 and 5 (i.e., "Head" and "Max ill o facial & neck") within Institution 1 are presented herein. Each model is associated with three distinct similarity scores, denoted as R-1, R-2, and R-L.
| Model | Head | Maxillofacial & neck | ||||
| R-1 | R-2 | R-L | R-1 | R-2 | R-L | |
| Llama2-7B | 0.0582 | 0.0293 | 0.0569 | 0.0516 | 0.0234 | 0.0510 |
| Llama2-7B-ft | 0.2276 | 0.1333 | 0.2246 | 0.2548 | 0.1222 | 0.2495 |
| Llama2-Chat-7B | 0.1236 | 0.0406 | 0.1210 | 0.1179 | 0.0478 | 0.1146 |
| ChatRadio-Valuer | 0.2853 | 0.1906 | 0.2825 | 0.3447 | 0.1902 | 0.3396 |
| Llama2-Chinese-Chat-7B | 0.0914 | 0.0325 | 0.0894 | 0.0947 | 0.0364 | 0.0920 |
| Llama2-Chinese-Chat-7B-ft | 0.0868 | 0.0442 | 0.0843 | 0.0762 | 0.0303 | 0.0742 |
| ChatGLM2-ft | 0.1342 | 0.0344 | 0.1319 | 0.2261 | 0.1045 | 0.2226 |
| GPT-3.5-Turbo | 0.0731 | 0.0287 | 0.0699 | 0.0750 | 0.0463 | 0.0750 |
| GPT-4 | 0.0737 | 0.0246 | 0.0695 | 0.0858 | 0.0346 | 0.0858 |
| BayLing-7B | 0.1628 | 0.0516 | 0.1593 | 0.2316 | 0.1187 | 0.2268 |
| Baichuan-7B | 0.0928 | 0.0353 | 0.0906 | 0.1304 | 0.0624 | 0.1279 |
| Tigerbot-7B-chat-v3 | 0.0650 | 0.0287 | 0.0632 | 0.0674 | 0.0217 | 0.0661 |
| Chinese-Alpaca-2-7B | 0.0959 | 0.0327 | 0.0933 | 0.1033 | 0.0420 | 0.1001 |
| Chinese-Falcon-7B | 0.0312 | 0.0154 | 0.0304 | 0.0449 | 0.0200 | 0.0440 |
| iFLYTEK Spark (V2.0) | 0.0514 | 0.0163 | 0.0496 | 0.0466 | 0.0176 | 0.0455 |
表 5: 机构1多系统相似性(第二部分)。本文展示了从机构1内系统4和系统5(即"头颈部"和"颌面颈部")收集数据的评估结果。每个模型对应三个不同的相似性分数,分别标记为R-1、R-2和R-L。
| 模型 | R-1 | R-2 | R-L | R-1 | R-2 | R-L |
|---|---|---|---|---|---|---|
| Llama2-7B | 0.0582 | 0.0293 | 0.0569 | 0.0516 | 0.0234 | 0.0510 |
| Llama2-7B-ft | 0.2276 | 0.1333 | 0.2246 | 0.2548 | 0.1222 | 0.2495 |
| Llama2-Chat-7B | 0.1236 | 0.0406 | 0.1210 | 0.1179 | 0.0478 | 0.1146 |
| ChatRadio-Valuer | 0.2853 | 0.1906 | 0.2825 | 0.3447 | 0.1902 | 0.3396 |
| Llama2-Chinese-Chat-7B | 0.0914 | 0.0325 | 0.0894 | 0.0947 | 0.0364 | 0.0920 |
| Llama2-Chinese-Chat-7B-ft | 0.0868 | 0.0442 | 0.0843 | 0.0762 | 0.0303 | 0.0742 |
| ChatGLM2-ft | 0.1342 | 0.0344 | 0.1319 | 0.2261 | 0.1045 | 0.2226 |
| GPT-3.5-Turbo | 0.0731 | 0.0287 | 0.0699 | 0.0750 | 0.0463 | 0.0750 |
| GPT-4 | 0.0737 | 0.0246 | 0.0695 | 0.0858 | 0.0346 | 0.0858 |
| BayLing-7B | 0.1628 | 0.0516 | 0.1593 | 0.2316 | 0.1187 | 0.2268 |
| Baichuan-7B | 0.0928 | 0.0353 | 0.0906 | 0.1304 | 0.0624 | 0.1279 |
| Tigerbot-7B-chat-v3 | 0.0650 | 0.0287 | 0.0632 | 0.0674 | 0.0217 | 0.0661 |
| Chinese-Alpaca-2-7B | 0.0959 | 0.0327 | 0.0933 | 0.1033 | 0.0420 | 0.1001 |
| Chinese-Falcon-7B | 0.0312 | 0.0154 | 0.0304 | 0.0449 | 0.0200 | 0.0440 |
| iFLYTEK Spark (V2.0) | 0.0514 | 0.0163 | 0.0496 | 0.0466 | 0.0176 | 0.0455 |
In summary, these successes unequivocally affirms the following conclusion:
总之,这些成功明确验证了以下结论:
• ChatRadio-Valuer showcases exceptional adaptability in handling the intricacies and nuances of radiology reports, enabling it to deliver precise and continuous diagnostic outcomes with
• ChatRadio-Valuer 在处理放射学报告的复杂性和细微差别方面展现出卓越的适应性,使其能够提供精确且连续的诊断结果。
superior performance.
卓越性能。
• ChatRadio-Valuer demonstrates a high degree of general iz ability in the diagnosis of multiple body systems, not limited to specific systems but capable of applying to diverse medical data and producing high-quality diagnostic results. • ChatRadio-Valuer exhibits robust generalization capabilities, efficiently handling a wide range of data from many institutions and adapting seamlessly to various medical scenarios.
• ChatRadio-Valuer 在多个身体系统的诊断中展现出高度泛化能力,不仅限于特定系统,还能适用于多样化的医疗数据并生成高质量诊断结果。
• ChatRadio-Valuer 具备强大的泛化性能,可高效处理来自多家机构的广泛数据,并能无缝适应各种医疗场景。
4.4 Generalization Performance for Multi-system Diseases
4.4 多系统疾病的泛化性能
To further explore the effectiveness and generalization of the ChatRadio-Valuer to broaden its knowledge and skills to multiple body systems from the whole institutions, we conduct experiments on data from all the five distinct systems (i.e. chest, abdomen, muscle-skeleton, head, max ill o facial & neck), with the experimental results reported in Table 6, and Table 7. This assessment involves 15 models and aims to gauge the model’s adaptability and effectiveness in handling diverse diseaserelated information. We can obtain several observations from the results. First, ChatRadio-Valuer outperforms its baselines on R-1, R-2, and R-L metrics across selected LLMs, regardless of the system considered (i.e., chest, abdomen, muscle-skeleton, head, max ill o facial & neck). The significant performance demonstrates the model’s generalization, particularly on disease data from the abdomen, head, and max ill o facial & neck. While ChatRadio-Valuer does not show the best performance across all metrics for Chest and muscle-skeleton data, it occupies a prominent position within the first tier of performance (refer to Table 6 for detailed metrics). This consistent performance highlights the model’s reliability in processing multi-disease data. Second, taking into account influential external factors like hardware and environmental disparities, we can confidently assert that ChatRadioValuer demonstrates exceptional cross-system performance. This great generalization performance across diseases significantly reduces the model’s reliance on disease-specific data, providing insights and suggestions for rare diseases and comprehensive diagnosis of disease. The potential value of
为进一步探究ChatRadio-Valuer在跨机构多系统场景中的有效性和泛化能力,我们在五大解剖系统(胸部、腹部、肌肉骨骼、头部、颌面颈部)数据上展开实验,结果如表6和表7所示。本次评估涵盖15个模型,旨在衡量模型处理多样化疾病信息的适应性和有效性。从结果中可得出以下发现:
首先,无论针对哪个解剖系统(胸部/腹部/肌肉骨骼/头部/颌面颈部),ChatRadio-Valuer在选定大语言模型的R-1、R-2和R-L指标上均超越基线模型。其在腹部、头部和颌面颈部疾病数据上的显著优势尤其体现了模型的泛化能力。尽管在胸部和肌肉骨骼数据上并非所有指标都最优,但ChatRadio-Valuer始终保持在性能第一梯队(具体指标见表6),这种稳定性凸显了其处理多病种数据的可靠性。
其次,综合考虑硬件和环境差异等外部因素后,可以确认ChatRadio-Valuer展现出卓越的跨系统性能。这种强大的疾病泛化能力显著降低模型对特定病种数据的依赖,为罕见病诊疗和疾病综合诊断提供了重要参考。
Table 6: Five-system comparison across institutions (Part 1). Results derived from the data acquired from systems 1 to 3, specifically labeled as "Chest" to "Muscle-skeleton," are herein disclosed. Each of these systems encompasses data stemming from two different institutions (comprising a blend), and for each model, three unique similarity scores are employed, namely, R-1, R-2, and R-L.
| Model | Chest | Abdomen | Muscle-skeleton | ||||||
| R-1 | R-2 | R-L | R-1 | R-2 | R-L | R-1 | R-2 | R-L | |
| Llama2-7B | 0.0921 | 0.0370 | 0.0877 | 0.0885 | 0.0328 | 0.0868 | 0.1258 | 0.0716 | 0.1209 |
| Llama2-7B-ft | 0.5058 | 0.3072 | 0.4880 | 0.4593 | 0.2892 | 0.4459 | 0.4633 | 0.2960 | 0.4399 |
| Llama2-Chat-7B | 0.2021 | 0.0564 | 0.1920 | 0.2045 | 0.0890 | 0.1967 | 0.2625 | 0.1636 | 0.2414 |
| ChatRadio-Valuer | 0.5151 | 0.2954 | 0.4939 | 0.4983 | 0.3271 | 0.4847 | 0.4586 | 0.2981 | 0.4345 |
| Llama2-Chinese-Chat-7B | 0.1476 | 0.0420 | 0.1413 | 0.1578 | 0.0443 | 0.1531 | 0.3436 | 0.2535 | 0.3256 |
| Llama2-Chinese-Chat-7B-ft | 0.4398 | 0.2578 | 0.4216 | 0.3393 | 0.1900 | 0.3300 | 0.3948 | 0.2531 | 0.3773 |
| ChatGLM2-ft | 0.2920 | 0.0963 | 0.2785 | 0.3317 | 0.1383 | 0.3214 | 0.2192 | 0.1254 | 0.2128 |
| GPT-3.5-Turbo | 0.0812 | 0.0233 | 0.0770 | 0.1192 | 0.0484 | 0.1154 | 0.1188 | 0.0787 | 0.1084 |
| GPT-4 | 0.0645 | 0.0174 | 0.0611 | 0.0940 | 0.0317 | 0.0916 | 0.0924 | 0.0676 | 0.0849 |
| BayLing-7B | 0.2648 | 0.0786 | 0.2531 | 0.3219 | 0.1376 | 0.3069 | 0.3389 | 0.1986 | 0.3119 |
| Baichuan-7B | 0.0726 | 0.0204 | 0.0702 | 0.1335 | 0.0393 | 0.1275 | 0.2792 | 0.1962 | 0.2672 |
| Tigerbot-7B-chat-v3 | 0.0870 | 0.0280 | 0.0835 | 0.1357 | 0.0304 | 0.1306 | 0.3262 | 0.2212 | 0.3098 |
| Chinese-Alpaca-2-7B | 0.1727 | 0.0472 | 0.1657 | 0.2194 | 0.0733 | 0.2094 | 0.3271 | 0.2155 | 0.3080 |
| Chinese-Falcon-7B | 0.0373 | 0.0091 | 0.0365 | 0.0734 | 0.0123 | 0.0718 | 0.2332 | 0.1656 | 0.2206 |
| iFLYTEK Spark (V2.0) | 0.0706 | 0.0159 | 0.0681 | 0.1626 | 0.0403 | 0.1564 | 0.3022 | 0.2169 | 0.2892 |
表 6: 跨机构五系统对比(第一部分)。本文披露了从系统1至系统3获取的数据结果,具体标注为"胸部"至"肌肉骨骼"。每个系统包含来自两个不同机构(混合组成)的数据,每个模型采用三个独特的相似度评分指标,即R-1、R-2和R-L。
| 模型 | R-1 | R-2 | R-L | R-1 | R-2 | R-L | R-1 | R-2 | R-L |
|---|---|---|---|---|---|---|---|---|---|
| 胸部 | 腹部 | 肌肉骨骼 | |||||||
| Llama2-7B | 0.0921 | 0.0370 | 0.0877 | 0.0885 | 0.0328 | 0.0868 | 0.1258 | 0.0716 | 0.1209 |
| Llama2-7B-ft | 0.5058 | 0.3072 | 0.4880 | 0.4593 | 0.2892 | 0.4459 | 0.4633 | 0.2960 | 0.4399 |
| Llama2-Chat-7B | 0.2021 | 0.0564 | 0.1920 | 0.2045 | 0.0890 | 0.1967 | 0.2625 | 0.1636 | 0.2414 |
| ChatRadio-Valuer | 0.5151 | 0.2954 | 0.4939 | 0.4983 | 0.3271 | 0.4847 | 0.4586 | 0.2981 | 0.4345 |
| Llama2-Chinese-Chat-7B | 0.1476 | 0.0420 | 0.1413 | 0.1578 | 0.0443 | 0.1531 | 0.3436 | 0.2535 | 0.3256 |
| Llama2-Chinese-Chat-7B-ft | 0.4398 | 0.2578 | 0.4216 | 0.3393 | 0.1900 | 0.3300 | 0.3948 | 0.2531 | 0.3773 |
| ChatGLM2-ft | 0.2920 | 0.0963 | 0.2785 | 0.3317 | 0.1383 | 0.3214 | 0.2192 | 0.1254 | 0.2128 |
| GPT-3.5-Turbo | 0.0812 | 0.0233 | 0.0770 | 0.1192 | 0.0484 | 0.1154 | 0.1188 | 0.0787 | 0.1084 |
| GPT-4 | 0.0645 | 0.0174 | 0.0611 | 0.0940 | 0.0317 | 0.0916 | 0.0924 | 0.0676 | 0.0849 |
| BayLing-7B | 0.2648 | 0.0786 | 0.2531 | 0.3219 | 0.1376 | 0.3069 | 0.3389 | 0.1986 | 0.3119 |
| Baichuan-7B | 0.0726 | 0.0204 | 0.0702 | 0.1335 | 0.0393 | 0.1275 | 0.2792 | 0.1962 | 0.2672 |
| Tigerbot-7B-chat-v3 | 0.0870 | 0.0280 | 0.0835 | 0.1357 | 0.0304 | 0.1306 | 0.3262 | 0.2212 | 0.3098 |
| Chinese-Alpaca-2-7B | 0.1727 | 0.0472 | 0.1657 | 0.2194 | 0.0733 | 0.2094 | 0.3271 | 0.2155 | 0.3080 |
| Chinese-Falcon-7B | 0.0373 | 0.0091 | 0.0365 | 0.0734 | 0.0123 | 0.0718 | 0.2332 | 0.1656 | 0.2206 |
| iFLYTEK Spark (V2.0) | 0.0706 | 0.0159 | 0.0681 | 0.1626 | 0.0403 | 0.1564 | 0.3022 | 0.2169 | 0.2892 |
Table 7: Five-system comparison across institutions (Part 2). Results derived from the data acquired from systems 4 and 5, specifically labeled as "Head" to "Max ill o facial & neck," are herein disclosed. Each of these systems encompasses data stemming from two different institutions (comprising a blend), and for each model, three unique similarity scores are employed, namely, R-1, R-2, and R-L.
| Model | Head | Maxillofacial & neck | ||||
| R-1 | R-2 | R-L | R-1 | R-2 | R-L | |
| Llama2-7B | 0.0573 | 0.0284 | 0.0561 | 0.0477 | 0.0213 | 0.0472 |
| Llama2-7B-ft | 0.2252 | 0.1295 | 0.2221 | 0.2370 | 0.1110 | 0.2319 |
| Llama2-Chat-7B | 0.1233 | 0.0406 | 0.1206 | 0.1099 | 0.0434 | 0.1067 |
| ChatRadio-Valuer | 0.2812 | 0.1840 | 0.2782 | 0.3188 | 0.1727 | 0.3138 |
| Llama2-Chinese-Chat-7B | 0.0931 | 0.0331 | 0.0910 | 0.0888 | 0.0337 | 0.0863 |
| Llama2-Chinese-Chat-7B-ft | 0.0925 | 0.0454 | 0.0899 | 0.0777 | 0.0282 | 0.0757 |
| ChatGLM2-ft | 0.1344 | 0.0341 | 0.1320 | 0.2108 | 0.0946 | 0.2075 |
| GPT-3.5-Turbo | 0.0917 | 0.0512 | 0.0875 | 0.0238 | 0.0123 | 0.0231 |
| GPT-4 | 0.0748 | 0.0286 | 0.0696 | 0.0305 | 0.0092 | 0.0291 |
| BayLing-7B | 0.1629 | 0.0521 | 0.1594 | 0.2154 | 0.1078 | 0.2108 |
| Baichuan-7B | 0.0938 | 0.0355 | 0.0915 | 0.1207 | 0.0573 | 0.1183 |
| Tigerbot-7B-chat-v3 | 0.0684 | 0.0289 | 0.0664 | 0.0684 | 0.0204 | 0.0673 |
| Chinese-Alpaca-2-7B | 0.0978 | 0.0333 | 0.0952 | 0.0992 | 0.0386 | 0.0961 |
| Chinese-Falcon-7B | 0.0320 | 0.0156 | 0.0312 | 0.0418 | 0.0181 | 0.0410 |
| iFLYTEK Spark (V2.0) | 0.0529 | 0.0167 | 0.0509 | 0.0455 | 0.0165 | 0.0444 |
表7: 跨机构五系统对比(第二部分)。本文披露了从系统4和系统5获取的数据结果,具体标注为"头颈部"至"颌面颈部"。每个系统包含来自两个不同机构(混合组成)的数据,每个模型采用三个独特的相似性评分指标,即R-1、R-2和R-L。
| 模型 | R-1 | R-2 | R-L | R-1 | R-2 | R-L |
|---|---|---|---|---|---|---|
| Llama2-7B | 0.0573 | 0.0284 | 0.0561 | 0.0477 | 0.0213 | 0.0472 |
| Llama2-7B-ft | 0.2252 | 0.1295 | 0.2221 | 0.2370 | 0.1110 | 0.2319 |
| Llama2-Chat-7B | 0.1233 | 0.0406 | 0.1206 | 0.1099 | 0.0434 | 0.1067 |
| ChatRadio-Valuer | 0.2812 | 0.1840 | 0.2782 | 0.3188 | 0.1727 | 0.3138 |
| Llama2-Chinese-Chat-7B | 0.0931 | 0.0331 | 0.0910 | 0.0888 | 0.0337 | 0.0863 |
| Llama2-Chinese-Chat-7B-ft | 0.0925 | 0.0454 | 0.0899 | 0.0777 | 0.0282 | 0.0757 |
| ChatGLM2-ft | 0.1344 | 0.0341 | 0.1320 | 0.2108 | 0.0946 | 0.2075 |
| GPT-3.5-Turbo | 0.0917 | 0.0512 | 0.0875 | 0.0238 | 0.0123 | 0.0231 |
| GPT-4 | 0.0748 | 0.0286 | 0.0696 | 0.0305 | 0.0092 | 0.0291 |
| BayLing-7B | 0.1629 | 0.0521 | 0.1594 | 0.2154 | 0.1078 | 0.2108 |
| Baichuan-7B | 0.0938 | 0.0355 | 0.0915 | 0.1207 | 0.0573 | 0.1183 |
| Tigerbot-7B-chat-v3 | 0.0684 | 0.0289 | 0.0664 | 0.0684 | 0.0204 | 0.0673 |
| Chinese-Alpaca-2-7B | 0.0978 | 0.0333 | 0.0952 | 0.0992 | 0.0386 | 0.0961 |
| Chinese-Falcon-7B | 0.0320 | 0.0156 | 0.0312 | 0.0418 | 0.0181 | 0.0410 |
| iFLYTEK Spark (V2.0) | 0.0529 | 0.0167 | 0.0509 | 0.0455 | 0.0165 | 0.0444 |
ChatRadio-Valuer is to improve comprehensive diagnostic quality, and streamline clinical decisionmaking processes. Finally, combining the results of Table 4, 5, 6, and 7, it can be found that the ChatRadio-Valuer can not only distinguish various diseases in a certain institution, but also distinguish multiple diseases in mixed institutions, which demonstrates the adaptability in learning distinct features of diseases information. Distinguishing and generating related information across different disease contexts, shows its significant promise in multi-system data analysis.
ChatRadio-Valuer旨在提升综合诊断质量,并优化临床决策流程。结合表4、表5、表6和表7的结果可以发现,该模型不仅能区分特定机构的各类疾病,还能识别混合机构中的多种病症,这体现了其学习疾病信息差异化特征的适应能力。在不同疾病场景中实现信息区分与生成,展现了其在多系统数据分析中的显著潜力。
4.5 Expert Evaluation
4.5 专家评估
The feasibility on ChatRadio-Valuer for radiology report generation has been fully verified in Table 2 - Table 7, which has proven its availability in smoothly presenting semantic information. However, further exploration of these results to determine their clinical value is necessarily required. Therefore, taking into account the practical clinical needs from both a holistic and specific data distribution perspective, we conduct a comprehensive analysis and study on the diagnostic effectiveness of different system diseases in different institutions. And the practical clinical evaluation metrics proposed by radiologists are shown in Figure 9.
ChatRadio-Valuer在放射学报告生成方面的可行性已在表2至表7中得到充分验证,证明其能够流畅呈现语义信息。然而仍需进一步探究这些结果的临床价值。为此,我们从整体数据分布和具体临床需求出发,对不同医疗机构中各类系统疾病的诊断效能进行了全面分析与研究。放射科医师提出的实际临床评估指标如图9所示。

Figure 6: Expert evaluation results on clinical metrics. The first row represents the overall clinical general iz ability (OG) across various systems with the whole institutions data. Results between the second row and the third row appraise models’ in-house general iz ability (IHG), and out-of-house general iz ability (OHG), respectively.
图 6: 临床指标专家评估结果。第一行展示了各系统在整个机构数据上的总体临床泛化能力(OG)。第二行与第三行分别评估了模型的院内泛化能力(IHG)和院外泛化能力(OHG)。
The evaluation results, including junior, intermediate, and senior radiologists, are performed to take the average operation, which are shown in Figure 6. All evaluations are based on the five systems: chest, abdomen, muscle-skeleton, head, and max ill o facial & neck. In each plot (e.g., "a. Chest", "b. Abdomen", "c. Mus cul o skeletal", etc.), the seven clinical metrics are uniformly distributed in the circle. The first row represents the evaluation on the scale of the whole testing dataset, including the dataset in the second row and third row. This result comprehensively evaluates the overall general iz ability (OG) across the whole institutions and systems. The second row refers to the evaluation on the specific dataset of Institution 1, which directly indicates the performance of our strategy of fine-tuning and the general iz ability within Institution 1, namely the in-house general iz ability (IHG). The final row, represents the evaluation of the testing dataset across institutions 2, 3, 4, 5 and 6, respectively. Since institutions 2, 3, 4, 5 and 6 are irrelevant to the training phase, the performance in this row more comprehensively evaluates our method’s adaptability and general iz ability across data from different institutions with different writing styles, defined by out-of-house general iz ability (OHG). To evaluate in detail, the expanding area of each plot indicates the clinical performance of models. In other words, the larger the covered area, the better the performance.
评估结果涵盖初级、中级和高级放射科医生,经取平均操作后如图6所示。所有评估基于胸部、腹部、肌肉骨骼、头部及颌面颈部五个系统。每个子图(如"a.胸部"、"b.腹部"、"c.肌肉骨骼"等)中,七项临床指标均匀分布在圆形区域内。首行代表整个测试数据集的评估结果,包含第二行和第三行的数据集,该结果综合评估了跨机构与跨系统的整体泛化能力(OG)。第二行展示机构1特定数据集的评估,直接反映我们微调策略的效能及该机构内部泛化能力(IHG)。末行分别呈现机构2、3、4、5、6的测试数据集评估,由于这些机构与训练阶段无关,该行结果更能全面评估我们方法对于不同机构、不同记录风格数据的适应性与跨机构泛化能力(OHG)。具体评估时,各子图的扩展面积代表模型临床性能,覆盖面积越大则性能越优。
Generally speaking, it can be demonstrated that ChatRadio-Valuer covers the most amounts of area in almost all subplots, across the three scales of the dataset. Within each row, ChatRadio-Valuer’s leading performance in the five systems—chest, abdomen, muscle-skeleton, head, and max ill o facial & neck-shows its versatility across different systems. In other words, for example, the OG, IHG, and OHG on the chest system (the first column "a. Chest" of the three rows) remain the same superior level. Expanding to the five systems, in the three rows, OG, IHG, and OHG respectively, ChatRadio-Valuer obtains excellent scores though the scores in "Head" are only slightly inferior to those in other systems (probably due to the written styles are hard to recognize for LLM). This reveals ChatRadio-Valuer’s great OHG. Notice that the best performance in "Head" is occupied by Llama2-Chinese-Chat-7B-ft which adopts our training strategy. These phenomena collaborative ly prove the success of the fine-tuning strategy and the advance of our proposed ChatRadio-Valuer. Its superior general iz ability sheds light on further real clinical radiology applications over even such complex and heterogeneous cases.
总体而言,可以证明ChatRadio-Valuer在数据集的三个尺度上几乎覆盖了所有子图中最大面积区域。在每一行中,ChatRadio-Valuer在五大系统(胸部、腹部、肌肉骨骼、头颈部及颌面颈部)的领先表现展示了其跨系统的通用性。例如,在胸部系统(三行中的首列"a.胸部")中,OG、IHG和OHG始终保持同等优越水平。扩展到五大系统后,ChatRadio-Valuer在三行(分别对应OG、IHG和OHG)中均获得优异分数,尽管"头颈部"得分仅略低于其他系统(可能由于大语言模型对书写风格的识别难度)。这揭示了ChatRadio-Valuer卓越的OHG能力。值得注意的是,"头颈部"最佳表现由采用我们训练策略的Llama2-Chinese-Chat-7B-ft取得。这些现象共同验证了微调策略的成功以及ChatRadio-Valuer的先进性。其卓越的泛化能力为未来在复杂异构病例中的真实临床放射学应用提供了重要启示。
4.6 Practical Utility Assessment
4.6 实用效用评估
In this section, we employ assessment on ChatRadio-Valuer’s practical utility shown in Table 8, involving three metrics: parameter count, fine-tuning time, and testing time. In the condition of the same amount of parameters, fine-tuning time evaluates how efficient for LLMs to achieve the desired level of model performance. Similarly, testing time indicates how long it takes to make a causal inference. Note that for doctors at the bottom of Table 8, the testing time refers to the time for them to derive a comprehensive impression from the corresponding report.
在本节中,我们对ChatRadio-Valuer的实际效用进行了评估,如表8所示,涉及三个指标:参数量、微调时间和测试时间。在参数量相同的条件下,微调时间评估了大语言模型达到预期性能水平的效率。同样,测试时间表明了进行因果推断所需的时间。需要注意的是,对于表8底部的医生而言,测试时间指的是他们从相应报告中得出全面印象所需的时间。
Table 8: Practical utility evaluation on the proposed ChatRadio-Valuer compared with SOTA LLMs.
| Model | Parameter Count | Fine-tuning Time (h) | Testing Time (s) |
| Llama2-7B Llama2-7B-ft | 7B 7B 7B | 54 54 54 54 | 17.9893 22.5722 8.9997 |
| Llama2-Chat-7B ChatRadio-Valuer Llama2-Chinese-Chat-7B | 7B 7B | 54 | 22.3577 7.8787 |
| Llama2-Chinese-Chat-7B-ft ChatGLM2-ft | 7B 6B | 54 | 16.2844 7.8340 |
| 28 | |||
| GPT-3.5-Turbo | 175B | NA | 1.2081 |
| GPT-4 | |||
| 1.8T | NA | 2.0228 | |
| BayLing-7B | 7B | NA | 12.8729 |
| Baichuan-7B | 7B | NA | 11.4543 |
| Chinese-Falcon-7B | 7B | NA | 5.8440 |
| Chinese-Alpaca-2-7B | 7B | NA | |
| Tigerbot-7B-chat-v3 | 7B | 4.9946 | |
| ≥ 170B | NA | 2.7295 | |
| iFLYTEK Spark (V2.0) | NA | 3.8263 | |
| Doctors | NA | NA |
表 8: 所提出的 ChatRadio-Valuer 与 SOTA 大语言模型的实用性能评估
| 模型 | 参数量 | 微调时间 (h) | 测试时间 (s) |
|---|---|---|---|
| Llama2-7B Llama2-7B-ft | 7B 7B 7B | 54 54 54 54 | 17.9893 22.5722 8.9997 |
| Llama2-Chat-7B ChatRadio-Valuer Llama2-Chinese-Chat-7B | 7B 7B | 54 | 22.3577 7.8787 |
| Llama2-Chinese-Chat-7B-ft ChatGLM2-ft | 7B 6B | 54 | 16.2844 7.8340 |
| 28 | |||
| GPT-3.5-Turbo | 175B | NA | 1.2081 |
| GPT-4 | |||
| 1.8T | NA | 2.0228 | |
| BayLing-7B | 7B | NA | 12.8729 |
| Baichuan-7B | 7B | NA | 11.4543 |
| Chinese-Falcon-7B | 7B | NA | 5.8440 |
| Chinese-Alpaca-2-7B | 7B | NA | |
| Tigerbot-7B-chat-v3 | 7B | 4.9946 | |
| ≥170B | NA | 2.7295 | |
| iFLYTEK Spark (V2.0) | NA | 3.8263 | |
| Doctors | NA | NA |
In the situation that most of the models, except the four, are 7B-version, the evaluation on them are only slightly affected by the model size, especially with the same fine-tuning and inferring configuration. We conduct fine-tuning on 4 models (i.e., Llama2-7B, Llama2-7B-Chat, Llama2- Chinese-Chat-7B, and ChatGLM2). The Llama2 family consumes approximately 54 hours for each while the ChatGLM2 only costs 28 hours. For the testing time, Llama2-7B-ft takes the longest time, 22.5722s, and our ChatRadio-Valuer uses 22.3577s for a single causal inference. The fastest models belong to the GPT family, 1.2081s for GPT-3.5-Turbo and 2.0228s for GPT-4 per inference. For doctors, from junior to senior, the diagnosing time ranges from 60s to 180s per sample inference. Supported by Table 2 - 7, the effectiveness of ChatRadio-Valuer is verified through high similarity scores among other prevailing methods. In comparison to different levels radiologists, ChatRadioValuer shows a significant advantage in terms of time efficiency indicated in Table 8. These results showcase ChatRadio-Valuer’s superior capability in both effectiveness and efficiency.
在除四个模型外大多数为7B版本的情况下,模型规模对评估结果的影响较小(尤其是采用相同的微调和推理配置时)。我们对4个模型(即Llama2-7B、Llama2-7B-Chat、Llama2-Chinese-Chat-7B和ChatGLM2)进行微调。Llama2系列每个模型耗时约54小时,而ChatGLM2仅需28小时。测试阶段中,Llama2-7B-ft耗时最长(22.5722秒),我们的ChatRadio-Valuer单次因果推理耗时22.3577秒。速度最快的属于GPT系列(GPT-3.5-Turbo单次推理1.2081秒,GPT-4为2.0228秒)。医生诊断时间从初级到高级医师的每样本推理耗时范围为60-180秒。如[表2-7]所示,ChatRadio-Valuer通过与其他主流方法的高相似度评分验证了有效性。与不同级别放射科医师相比,[表8]显示ChatRadio-Valuer在时间效率方面具有显著优势。这些结果证明了ChatRadio-Valuer在效果与效率上的卓越能力。
4.7 Result Analysis
4.7 结果分析
To assess the real-world performance of ChatRadio-Valuer and the SOTA LLMs (including three fine-tuning pairs, one fine-tuned ChatGLM2-6B, prestigious GPT family, etc. shown in Figure 5) in the domain of radiology report generation respectively across multiple institutions and diverse disease systems, we employ a random sampling approach to select representative data from each institution and across various disease systems for visualization in Figure 7 - 8, and 10 - 13. The illustration of the superiority of ChatRadio-Valuer and our fine-tuning strategy is shown in Figure 7 and Figure 8, respectively. Due the limitation of page size, we attach the rest four diagrams, Figure 10 - 13, in Appendix. Figure 7, 10, and 11 are results across institutions. The above blue box illustrates the process that findings from the six institutions are proceeded by doctors to generate the impressions. The green box below is the corresponding inference set constituting outputs from the selected models. Similarly, Figure 8, 12, and 13 represent the same but results across systems (i.e., findings are from the five systems rather than institutions).
为评估ChatRadio-Valuer与当前最优大语言模型(包括三组微调模型对、一个微调版ChatGLM2-6B、知名GPT系列等,如图5所示)在放射学报告生成领域的实际表现,我们采用随机抽样方法从多机构和不同疾病系统中选取代表性数据进行可视化展示(图7-8及10-13)。图7和图8分别展示了ChatRadio-Valuer及其微调策略的优越性。由于篇幅限制,其余四幅示意图(图10-13)附于附录。图7、10、11展示了跨机构的结果对比:上方蓝色框显示六家机构检查结果经医生处理生成印象的过程,下方绿色框则是对应模型输出的推理结果集。同理,图8、12、13展示了跨疾病系统(即检查结果来自五个系统而非机构)的对比结果。
For multi-institution comparison, referring to Figure 7, 10, and 11 (only take Figure 7 for example due to simplicity consideration), methods utilizing our fine-tuned strategy (i.e., with the suffix "-ft") have better performance in efficacy and meaning fulness. In terms of the finding and impression pair from Institution 1, the generated textual contents of our fine-tuned models are characterized by increased conciseness and precision, as they effectively reduce extraneous outputs while retaining essential clinical information. Upon a thorough examination of these findings, it is evident that ChatRadioValuer produces outcomes distinguished by a more intricate and refined linguistic granularity when compared to other fine-tuned models. Expanding on the aforementioned improvements, it demonstrates an elevated clinical utility. Similarly for multi-system comparison, indicated by Figure 8, 12, and 13, fine-tuned models perform better than other base models. Take the abdomen system in Figure 8 for example, fine-tuned models generate more succinct and relevant inferences. More significantly, again, ChatRadio-Valuer performs the best among other fine-tuned methods.
在多机构对比中,参考图7、10和11(为简化说明仅以图7为例),采用我们微调策略的方法(即带有"-ft"后缀的模型)在效果和意义性上表现更优。以机构1的检查发现与影像诊断配对为例,经微调的模型生成文本内容具有更高的简洁性和精确性,能有效减少冗余输出同时保留关键临床信息。通过全面分析这些结果可发现,与其他微调模型相比,ChatRadioValuer产生的输出在语言粒度上展现出更精细复杂的特征。基于上述改进,该模型进一步体现出更高的临床实用性。
在多系统对比方面(见图8、12和13),微调模型同样优于其他基线模型。以图8中的腹部系统为例,微调模型能生成更简洁且相关的推断。更重要的是,ChatRadioValuer再次在所有微调方法中表现最佳。
Supported by Figure 6, experts’ evaluation on the seven clinical metrics, proposed in Section 4.1 and Figure 9, have acknowledged the power of our fine-tuning strategy (i.e., all fine-tuned methods cover larger areas in each plot than others do, even beating the prevailing GPT family). Of greater significance, among all the fine-tuned models, our ChatRadio-Valuer consistently achieves the highest scores on these seven metrics in most cases (either in multi-institution evaluation or in multi-system evaluation), thereby demonstrating its substantial potential and value in clinical practice.
如图 6 所示,专家们对第 4.1 节和图 9 中提出的七项临床指标的评估结果印证了我们微调策略的优越性 (即所有经过微调的方法在各指标图中覆盖的面积均大于其他方法,甚至超越了当前主流的 GPT 系列模型)。更重要的是,在所有微调模型中,我们的 ChatRadio-Valuer 在多数情况下 (无论是多机构评估还是多系统评估) 都能在这七项指标上取得最高分,充分展现了其在临床实践中的巨大潜力与价值。
5 Discussion
5 讨论
Significance: This work demonstrates the potential of using large language models for automatic radiology report generation. By training a model on a large multi-institution, multi-system dataset, this method shows the feasibility of generating accurate and coherent impressions from radiology findings. The model’s strong performance even when evaluated on external test sets indicates its ability to generalize across institutions and body systems. This has significant implications for improving radiologist workflow efficiency and standardizing impression styles across healthcare systems. More broadly, it highlights the promise of large language models for clinical NLP tasks given sufficient domain-specific training data.
意义:这项工作展示了大语言模型在自动生成放射学报告方面的潜力。通过在大型多机构、多系统数据集上训练模型,该方法证明了从放射学检查结果生成准确连贯印象的可行性。该模型在外部测试集上仍表现优异,表明其具备跨机构和人体系统的泛化能力。这对提升放射科医生工作效率、统一医疗系统印象风格具有重大意义。更广泛而言,该研究凸显了在充足领域专用训练数据支持下,大语言模型在临床自然语言处理任务中的应用前景。

Figure 7: Diagram of the response results among fine-tuned models and state-of-the-art LLMs across institutions (Part 1). Within each institution (containing the institutions from 1 to 6), every model generates corresponding clinical inference based on the same finding.
图 7: 各机构微调模型与前沿大语言模型间的响应结果对比图(第一部分)。每个机构(包含1至6号机构)中,所有模型基于相同检查结果生成对应的临床推断。

Figure 8: Diagram of the response results among fine-tuned models and state-of-the-art LLMs across systems (Part 1). Within each system (i.e., chest, abdomen, muscle-skeleton, head, and max ill o facial & neck), each model generates corresponding clinical inference based on the same finding.
图 8: 各系统微调模型与前沿大语言模型响应结果对比图(第一部分)。在每个系统(即胸部、腹部、肌肉骨骼、头颈部及颌面颈部)中,各模型基于相同检查结果生成相应的临床推断。
Insights: While our proposed model outperforms the previous models and obtains a state-of-the-art performance, the subgroup analysis presents different performances in specific system radiology reports. In the current study, the performance of our proposed model in generating head and max ill o facial & neck CT reports is inferior to that of chest, abdominal, and mus cul o skeletal reports. This maybe due to the more comprehensive description of anatomical structure and multi-sequence of MRI reports, making it more difficult for the model to conclude and summarize the impression. Including more training data would be a strategy to improve the performance in these subgroups. Another reason may be that different radiologists have respective styles in drawing a conclusion for the same abn or mi ties in head radiology reports. For example, the presenting spotted lesions with hypo intensity in T1-weighted imaging, hyper intensity in T2-weighted imaging, and FLAIR imaging may be concluded as “ischemia lesions”, “cerebral white matter lesions” or “infraction lesions” by different radiologists. This also may confuse the model and limit its performance.
洞察:尽管我们提出的模型优于先前模型并实现了最先进的性能,但亚组分析显示其在特定系统放射学报告中的表现存在差异。当前研究中,我们提出的模型在生成头颈部及颌面部CT报告方面的表现逊色于胸部、腹部和肌肉骨骼报告。这可能源于MRI报告对解剖结构和多序列描述更为全面,导致模型更难归纳总结影像学印象。增加训练数据量将是提升这些亚组表现的可行策略。另一个潜在原因是不同放射科医师对头部影像报告中相同异常表现存在个性化结论风格。例如,对于T1加权像低信号、T2加权像高信号、FLAIR成像高信号的斑点状病灶,不同医师可能分别诊断为"缺血灶"、"脑白质病变"或"梗死灶",这种诊断差异性可能干扰模型判断并限制其表现。
Limitations: Although this work systematically evaluates ChatRadio-Valuer for radiology report generation in detecting diverse diseases, there are several limitations and challenges requiring further exploration in future work. First, we only included Chinese radiology reports and the performance of our proposed model in other languages or styles of radiology reports should be further investigated with more diverse and balanced data distribution to verify the model generalization. Second, considering only CT and MRI reports were collected and analyzed in the current study, other image modality reports (e.g., X-ray, PETCT, and ultrasound) will be our future direction. Third, reports generation based on causal explanatory reasoning is very necessary, which will guarantee and promote the reliability of the impressions from LLMs. These aspects will be paid more attention in our future work.
局限性:尽管本研究系统评估了ChatRadio-Valuer在放射学报告生成中对多种疾病的检测能力,但仍存在若干局限性和挑战需在未来工作中进一步探索。首先,我们仅纳入了中文放射学报告,所提模型在其他语言或报告风格中的性能表现需通过更多样化、均衡分布的数据进行验证以确认模型泛化性。其次,当前研究仅收集分析了CT和MRI报告,其他影像模态报告(如X光、PETCT和超声)将成为我们未来的研究方向。第三,基于因果解释推理的报告生成十分必要,这将保障并提升大语言模型诊断印象的可信度。这些方面将在我们后续工作中得到更多关注。
General iz ability: While tested on CT reports from Chinese hospitals, this approach could potentially generalize to other report types given sufficient training data. However, there are several factors affecting general iz ability to other languages and healthcare systems. Radiology reporting conventions differ across countries, which could impact impression styles. Out-of-vocabulary medical terms may also emerge. Extensive testing and adaptation to localized datasets would be necessary before deployment in other global contexts. Furthermore, the model may need retraining if deployed in specialized settings like pediatric hospitals where disease patterns differ. Overall, the model shows promising generalization capacity within the Chinese clinical context, but global applicability would require additional investigation.
泛化能力:虽然该方法在中国医院的CT报告上进行了测试,但只要有足够的训练数据,它也有可能推广到其他类型的报告。然而,影响其跨语言和跨医疗系统泛化能力的因素包括:各国放射学报告规范差异可能影响印象描述风格,且可能出现词汇表外的医学术语。在其他地区部署前,需针对本地数据集进行大量测试与适配。若应用于儿科医院等疾病谱系不同的专科场景,模型可能还需重新训练。总体而言,该模型在中国临床环境中展现出良好的泛化潜力,但全球适用性仍需进一步验证。
6 Conclusion and Future Work
6 结论与未来工作
In our work, we delve into the exploration current obstacles in clinical AI applications of radiology—notably, the complicated heterogeneity of multi-institution and multi-system data distribution, limited performance and general iz ability. This avenue of research is of critical importance in the contemporary digital medical landscape, where radiology report generation plays a vital role yet are often complex and time-consuming to diagnose and annotate by the massive skilled experts.
在我们的工作中,我们深入探讨了当前放射学临床AI应用中的障碍——特别是多机构、多系统数据分布的复杂异质性,以及有限的性能和泛化能力。这一研究方向在当代数字医疗领域至关重要,放射学报告生成在其中扮演着关键角色,但通常需要大量专业人员进行复杂耗时的诊断和标注。
To our knowledge, this investigation is groundbreaking in its focus as it offers fresh perspectives into the potential of employing large language models for the purpose of radiology report generation. Moreover, an innovative scheme is proposed in this paper, aiming for faster and more data-efficient diagnostics. This could revolutionize the diagnosis process for patients with systemic diseases.
据我们所知,这项研究具有开创性意义,它为利用大语言模型(Large Language Model)生成放射学报告提供了全新视角。此外,本文提出了一种创新方案,旨在实现更快速、更高效的数据诊断,这或将彻底改变全身性疾病患者的诊断流程。
We have verified the efficacy and efficiency of ChatRadio-Valuer in clinical-level domain adaptation scenarios, indicating high performance and general iz ability for detecting diverse diseases based on radiology reports. Specifically, the experimental results reveal that the impressions generated by ChatRadio-Valuer are more prevailing than those of the state-of-the-art LLMs (such as ChatGPT and GPT-4 et al.), based on massive and complex radiology reports from multiple institutions and systems. The superiority is evident in terms of rigorous engineering indicators, clinical efficacy, and deployment cost metrics when evaluated by radiologists with varying levels of experience. It’s also worth noting that many referring physicians favor the impressions generated by ChatRadio-Valuer, attributing this perceived superior preference to its better coherence and a lower tendency to omit vital information. This is particularly significant concerning metrics like missed diagnoses and over diagnosis, which heavily impact on clinical utility.
我们已验证ChatRadio-Valuer在临床级领域适应场景中的有效性和效率,表明其基于放射学报告检测多种疾病具有高性能和泛化能力。具体而言,实验结果表明,基于来自多个机构和系统的大量复杂放射学报告,ChatRadio-Valuer生成的印象比最先进的大语言模型(如ChatGPT和GPT-4等)更具优势。这种优势体现在严格的工程指标、临床效果和部署成本指标上,且经不同经验水平的放射科医师评估得到验证。值得注意的是,许多转诊医师更青睐ChatRadio-Valuer生成的印象,认为其具有更好的连贯性和更低的关键信息遗漏倾向。这在漏诊和过度诊断等对临床效用影响重大的指标上尤为重要。
Looking ahead to the future, the potential for integrating the text-handling capabilities of LLMs with other analysis methods appears substantial. Such synergistic combinations could unlock new approaches to radiology reports generation analysis, leading to broader medical general iz ability across more languages styles and more modalities carriers.
展望未来,将大语言模型(LLM)的文本处理能力与其他分析方法相结合的潜力巨大。这种协同组合可能为放射学报告生成分析开辟新途径,从而在更多语言风格和模态载体上实现更广泛的医疗通用性。
Acknowledgments
致谢
The study is supported by National Natural Science Foundation of China (31971288, U1801265); National Natural Science Foundation of China (82102157, U22A2034); Hunan Provincial Natural Science Foundation for Excellent Young Scholars (2022 JJ 20089); Research Project of Postgraduate Education and Teaching Reform of Central South University (2022JGB117); Clinical Research Center For Medical Imaging In Hunan Province (2020SK4001); Science and Technology Innovation Program of Hunan Province (2021RC4016); Central South University Research Programme of Advanced Interdisciplinary Studies (No. 2023 Q YJ C 020)
本研究由国家自然科学基金(31971288, U1801265)、国家自然科学基金(82102157, U22A2034)、湖南省优秀青年自然科学基金(2022JJ20089)、中南大学研究生教育教学改革研究项目(2022JGB117)、湖南省医学影像临床医学研究中心(2020SK4001)、湖南省科技创新计划项目(2021RC4016)、中南大学学科交叉研究计划项目(2023QYJC020)资助。
References
参考文献
Appendix
附录
Evaluation
评估
Understand ability. The impression should be easy to understand, expressed in concise language, and avoid using overly technical or complex terms, so that users can easily comprehend the meaning and significance.
可理解性。印象应易于理解,用简洁的语言表达,避免使用过于技术性或复杂的术语,以便用户轻松理解其含义和重要性。
Q1: Is the impression easy to understand and explain to ordinary people or clinical physician?
Q1: 印象是否容易让普通人群或临床医生理解和解释?
Very Easy(80-100) Fairly Easy(60-80) Moderate(40-60) Somewhat Difficult(20-40) Very Difficult(0-20)
非常简单 (80-100)
较为简单 (60-80)
中等难度 (40-60)
稍有难度 (20-40)
非常困难 (0-20)
Q2: If the text is not clinically relevant or has no relationship, please choose 0 or NA and explain why summary:[copy paste In comprehensibility part]; Briefly explain (one on each line).
Q2: 如果文本与临床无关或没有关联,请选择0或NA并解释原因摘要: [复制粘贴不可理解部分];简要说明 (每条一行)。
Coherence. A coherent impression should have a good structure and organization, rather than just being a collection of related information. Each sentence should be con textually connected, and collectively establish a coherent body of information on a specific topic.
连贯性。一个连贯的印象应具备良好的结构和组织,而非仅是相关信息的堆砌。每句话都应在语境上相互关联,共同构建关于特定主题的连贯信息整体。
Q1: Is the impression logically clear, with a coherent structure between different parts?
Q1: 印象是否逻辑清晰,各部分之间结构连贯?
$\bigcirc$ Highly Coherent(80-100) Fairly Coherent(60-80) Moderately Coherent(40-60) $\bigcirc$ Somewhat Incoherent(20-40) Highly Incoherent(0-20)
$\bigcirc$ 高度连贯(80-100)
$\bigcirc$ 较为连贯(60-80)
$\bigcirc$ 中等连贯(40-60)
$\bigcirc$ 稍不连贯(20-40)
$\bigcirc$ 高度不连贯(0-20)
Q2: If the text is not clinically relevant or has no relationship, please choose 0 or NA and explain why :
Q2: 若文本与临床无关或无关联,请选择0或NA并说明原因:
summary:[copy paste incoherent part]; Briefly explain (one on each line).
摘要:[复制粘贴不连贯部分];简要说明(每行一条)。
Relevance. The impression should be closely related to the question or need, addressing the posed question or focusing on the main topic, and providing useful information that is relevant to it, ensuring the relevance of the response.
相关性。印象应与问题或需求密切相关,针对提出的问题或聚焦主题,提供与之相关的有用信息,确保回答的相关性。
Q1: Is the impression relevant to the given topic or content?
Q1: 该印象是否与给定主题或内容相关?
$\bigcirc$ Highly Relevant(80-100) Fairly Relevant(60-80) Moderately Relevant(40-60) $\bigcirc$ Somewhat Irrelevant(20-40) Completely Irrelevant(0-20)
○ 高度相关 (80-100)
○ 相当相关 (60-80)
○ 中度相关 (40-60)
○ 略微不相关 (20-40)
○ 完全不相关 (0-20)
: If the text is not clinically relevant or has no relationship, please choose 0 or NA and explain why summary:[copy paste Irrelevant part]; Briefly explain (one on each line).
如果文本与临床无关或没有关联,请选择0或NA并解释原因摘要:[复制粘贴无关部分];简要说明(每行一条)。
Conciseness. The impression should be as concise and clear as possible, avoiding lengthy descriptions and unnecessary repetitions, in order to save readers' time and effort. However, it should also ensure that important details and information are not lost.
简洁性。印象应尽可能简洁明了,避免冗长的描述和不必要的重复,以节省读者的时间和精力。但同时也要确保重要的细节和信息不丢失。
Q1: Is the impression concise and free of redundant or unnecessary information?
Q1: 印象是否简洁且没有冗余或不必要的信息?
$\bigcirc$ Very Concise(80-100) Fairly Concise(60-80) Moderately Concise(40-60) $\bigcirc$ Somewhat Verbose(20-40) Excessively Wordy(0-20)
○ 非常简洁(80-100) ○ 较为简洁(60-80) ○ 中等简洁(40-60) ○ 稍显冗长(20-40) ○ 过度冗长(0-20)
Q2: If the text is not clinically relevant or has no relationship, please choose 0 or NA and explain why summary:[copy paste verbose part]; Briefly explain (one on each line).
Q2: 若文本与临床无关或无关联,请选择0或NA并说明原因 摘要: [复制粘贴详细内容]; 简要说明 (每条一行)。
Clinical Utility. The impression should have a certain degree of clinical utility, providing medical professionals with information about the patient's condition, diagnosis, treatment recommendations, or other practical medical information, helping them make accurate judgments and decisions.
临床实用性。印象部分应具备一定的临床实用性,为医疗专业人员提供关于患者病情、诊断、治疗建议或其他实用医疗信息,帮助他们做出准确判断和决策。
Q1: Does the impression have practical value in medical clinical practice?
Q1: 印象在医疗临床实践中是否具有实用价值?
Highly Useful(80-100) Fairly Useful(60-80) Moderately Useful(40-60) Somewhat Unhelpful(20-40) Completely Useless(0-20)
非常有用 (80-100)
比较有用 (60-80)
中等有用 (40-60)
稍显无用 (20-40)
完全无用 (0-20)
Q2: If the text is not clinically relevant or has no relationship, please choose 0 or NA and explain why :
Q2: 若文本与临床无关或无关联,请选择0或NA并说明原因:
summary:[copy paste useless part]; Briefly explain (one on each line).
摘要:[复制粘贴无用部分];简要说明(每行一个)。
Missed Diagnosis. Missed diagnosis refers to failure to correctly diagnose a patient's actual diseases or symptoms. This may result in delayed treatment or failure to provide appropriate care, posing risks to the patient's health and potentially leading to disease progression or deterioration. In clinical practice, reducing missed diagnoses is crucial for effectively identifying and treating patients.
漏诊。漏诊指未能正确诊断患者实际存在的疾病或症状。这可能导致延误治疗或无法提供适当护理,对患者健康构成风险,甚至引发病情进展或恶化。在临床实践中,降低漏诊率对于有效识别和治疗患者至关重要。
Q1: Does the impression contain any missed diagnosis, where it failed to correctly identify or confirm a disease?
Q1: 印象中是否包含任何漏诊,即未能正确识别或确认某种疾病?
Very Few(80-100) Relatively Few(60-80) Moderate Number(40-60) Relative Serious(20-40) Extremely Serious(0-20)
极少(80-100) 较少(60-80) 中等数量(40-60) 较严重(20-40) 极其严重(0-20)
Q2:If the text is not clinically relevant or has no relationship, please select 0 or NA and explain why :
Q2:如果文本与临床无关或没有关联,请选择0或NA并说明原因:
summary:[copy paste incorrect diagnosis section.]; Briefly explain (one on each line).
总结:[复制粘贴错误诊断部分];简要说明(每条一行)。
Over diagnosis. Over diagnosis refers to unnecessary diagnosis of a person, even if they do not actually have the disease. This may lead to unnecessary treatment and intervention measures, increase healthcare costs, and potentially have negative impacts on an individual's health.
过度诊断。过度诊断指对个体进行不必要的诊断,即使其实际并未患病。这可能导致不必要的治疗和干预措施,增加医疗成本,并可能对个人健康产生负面影响。
Q1: Does the impression include any cases of over diagnosis, where normal conditions are incorrectly diagnosed as diseases or mild conditions are over treated?
Q1: 印象中是否存在过度诊断的情况,例如将正常状况误诊为疾病或对轻微病症进行过度治疗?

Q2:If the text is not clinically relevant or has no relationship, please choose 0 or NA and explain why :
Q2:如果文本与临床无关或没有关联,请选择0或NA并解释原因:
summary:[copy paste over diagnosis part]; Briefly explain (one on each line).
总结:[复制粘贴诊断部分];简要说明(每行一条)。
Figure 9: Questionnaire for experts evaluation. Seven metrics (i.e., understand ability, coherence, relevance, conciseness, clinical utility, missed Diagnosis, over diagnosis), are provided for radiologists to comprehensively evaluate the results in clinical usage.
图 9: 专家评估问卷。为放射科医师提供七项指标 (即理解能力、连贯性、相关性、简洁性、临床实用性、漏诊率、过度诊断率) 以全面评估临床使用效果。

Figure 10: Diagram of the response results among fine-tuned models and state-of-the-art LLMs across institutions (Part 2). Within each institution (containing the institutions from 1 to 6), every model generates corresponding clinical inference based on the same finding.
图 10: 各机构微调模型与前沿大语言模型响应结果对比图(第二部分)。每个机构(包含机构1至6)内,所有模型基于相同检查结果生成相应临床推断。

Figure 11: Diagram of the response results among fine-tuned models and state-of-the-art LLMs across institutions (Part 3). Within each institution (containing the institutions from 1 to 6), every model generates corresponding clinical inference based on the same finding.
图 11: 各机构微调模型与先进大语言模型间的响应结果对比图(第三部分)。每个机构(包含机构1至6)中,所有模型基于相同检查结果生成相应的临床推断。

Figure 12: Diagram of the response results among fine-tuned models and state-of-the-art LLMs across systems (Part 2). Within each system (i.e., chest, abdomen, muscle-skeleton, head, and max ill o facial & neck), each model generates corresponding clinical inference based on the same finding.
图 12: 各系统(胸部、腹部、肌肉骨骼、头部及颌面颈部)中微调模型与顶尖大语言模型的响应结果对比图(第二部分)。在每个系统内部,所有模型基于相同检查结果生成对应的临床推断。

Figure 13: Diagram of the response results among fine-tuned models and state-of-the-art LLMs across systems (Part 3). Within each system (i.e., chest, abdomen, muscle-skeleton, head, and max ill o facial & neck), each model generates corresponding clinical inference based on the same finding.
图 13: 各系统(胸部、腹部、肌肉骨骼、头部及颌面颈部)中微调模型与前沿大语言模型(LLM)的响应结果对比图(第3部分)。每个模型基于相同检查结果在对应系统中生成临床推断。