HuatuoGPT-II, One-stage Training for Medical Adaption of LLMs
HuatuoGPT-II,大语言模型医学适配的一站式训练方案
Abstract
摘要
Adapting a language model (LM) into a specific domain, a.k.a ‘domain adaption’, is a common practice when specialized knowledge, e.g. medicine, is not encapsulated in a general language model like Llama2. This typically involves a two-stage process including continued pre-training and supervised fine-tuning. Implementing a pipeline solution with these two stages not only introduces complexities (necessitating dual meticulous tuning) but also leads to two occurrences of data distribution shifts, exacerbating catastrophic forgetting. To mitigate these, we propose a one-stage domain adaption protocol where heterogeneous data from both the traditional pre-training and supervised stages are unified into a simple instructionoutput pair format to achieve efficient knowledge injection. Subsequently, a data priority sampling strategy is introduced to adaptively adjust data mixture during training. Following this protocol, we train HuatuoGPT-II, a specialized LLM for the medical domain in Chinese. HuatuoGPT-II achieve competitive performance with GPT4 across multiple benchmarks, which especially shows the state-of-the-art (SOTA) performance in multiple Chinese medical benchmarks and the newest pharmacist licensure examinations. Furthermore, we explore the phenomenon of onestage protocols, and the experiments reflect that the simplicity of the proposed protocol improves training stability and domain generalization. Our code, data, and models are available at https://github.com/Freedom Intelligence/HuatuoGPT-II.
将语言模型 (LM) 适配到特定领域(即"领域适应"),是当通用语言模型(如 Llama2)未涵盖专业知识(例如医学)时的常见做法。这通常涉及持续预训练和监督微调的两阶段流程。采用这种两阶段管道方案不仅会引入复杂性(需要双重精细调优),还会导致两次数据分布偏移,加剧灾难性遗忘。为缓解这些问题,我们提出一种单阶段领域适应协议:将传统预训练和监督阶段的异构数据统一为简单的指令-输出对格式,从而实现高效知识注入。随后引入数据优先级采样策略,在训练期间自适应调整数据混合比例。基于该协议,我们训练了中文医疗领域专用大语言模型 HuatuoGPT-II。该模型在多项基准测试中与 GPT4 表现相当,尤其在多个中文医疗基准和最新执业药师资格考试中展现出最先进 (SOTA) 性能。此外,我们探索了单阶段协议现象,实验表明该协议的简洁性提升了训练稳定性和领域泛化能力。代码、数据及模型详见 https://github.com/FreedomIntelligence/HuatuoGPT-II 。
1 Introduction
1 引言
Currently, general large language model (LLM), such as the Llama series (Touvron et al., 2023), are developing rapidly. Simultaneously, in some vertical domains1, some researchers (Cui et al., 2023; Yang et al., 2023c; Li et al., 2023a) attempt to develop specialized models. Specialized models have the potential to yield results comparable to those of larger models by utilizing a medium-sized model through the exclusion of certain general knowledge (Wang et al., 2024; Chen et al., 2023b; Yang et al., 2023c). For instance, financial knowledge may not be sufficiently usefully in the medical field and can be therefore omitted in moderately-sized medical LLMs, thereby freeing up more capacity for memorizing medical knowledge.
目前,通用大语言模型(如Llama系列 [Touvron等人,2023])正在快速发展。与此同时,在某些垂直领域,部分研究者 [Cui等人,2023; Yang等人,2023c; Li等人,2023a] 尝试开发专用模型。通过排除部分通用知识,专用模型有望利用中等规模模型获得与更大模型相当的结果 [Wang等人,2024; Chen等人,2023b; Yang等人,2023c]。例如,金融知识在医疗领域可能不够实用,因此可以在中等规模的医疗大语言模型中省略这部分内容,从而释放更多容量用于记忆医学知识。
The two-stage protocol Adaption of general large language models in vertical domains typically involves two stages: continued pre-training and supervised fine-tuning (SFT) (Wang et al., 2023a). For this adaption in medicine domain, continued pre-training aims to inject specialized knowledge, such as medical expertise, while supervised fine-tuning seeks to activate the ability to follow medical instruction, as stated in Zhou et al., 2023.
通用大语言模型在垂直领域的适配通常分为两个阶段:持续预训练和监督微调(SFT) (Wang et al., 2023a)。针对医学领域的适配,持续预训练旨在注入专业知识(如医学知识),而监督微调则致力于激活模型遵循医学指令的能力(Zhou et al., 2023)。
Issues of the two-stage protocol In the two-stage adaption, LLMs face two key challenge: 1) the difference in continual pre-training and supervised fine-tuning optimization objectives, and 2) the inherent difference in data distribution from general pre-training to continued pre-training. Therefore, the two-stage process suggests that the LLM experiences dual shifts in data distribution. As stated in Goodfellow et al., 2013, catastrophic forgetting occurs when neural networks learn multiple sequential tasks in a pipeline, resulting in the loss of knowledge from previously learned tasks. This problem worsens when the two-stage training involves significantly divergent data distributions and objectives (Bhat et al., 2022). Specifically, Cheng et al., 2023 argues continued pre-training on domain-specific corpora reduces the LLM’s prompting capabilities. Secondly, the two-stage training pipeline adds complexity due to the interdependence of its stages. This intricacy not only complicates the optimization process but also limits s cal ability and adaptability. Each stage possesses distinct hyper parameters such as batch size, learning rate, and warmup procedures. These parameters necessitate careful manual selection through rigorous experimentation.
两阶段协议的问题
在两阶段适应过程中,大语言模型面临两大关键挑战:1) 持续预训练与监督微调优化目标之间的差异,2) 从通用预训练到持续预训练的数据分布固有差异。因此,两阶段流程意味着大语言模型会经历数据分布的双重偏移。如Goodfellow等人在2013年所述,当神经网络以流水线方式学习多个连续任务时,会导致先前任务知识的丢失,即灾难性遗忘。当两阶段训练涉及显著不同的数据分布和目标时,这一问题会加剧 (Bhat等人, 2022)。具体而言,Cheng等人在2023年指出,针对特定领域语料库的持续预训练会削弱大语言模型的提示能力。其次,两阶段训练流程因其阶段的相互依赖性而增加了复杂性。这种复杂性不仅使优化过程更困难,还限制了扩展能力和适应性。每个阶段都具有独特的超参数,例如批量大小、学习率和预热过程,这些参数需要通过严格实验进行谨慎的手动选择。
The proposed one-stage protocol Following the philosophy of Parsimony, this work proposes a simpler protocol of domain adaption that unifies the two stages (continued pre-training and SFT) into a single stage. The core recipe is to transform domain-specific pre-training data into a unified format similar to fine-tuning data: a straightforward (instruction, output) pairs. This strategy diverges from the conventional dependence on unsupervised learning in continued pre-training, opting instead for a focused learning goal that emphasizes eliciting knowledge-driven responses to given instructions. The reformulated data is subsequently merged with fine-tuning data to facilitate one-stage domain adaption. In this process, we introduce a data priority sampling strategy aimed at initially learning domain knowledge from pre-training data and then progressively shifting focus to downstream fine-tuning data. This approach enhances the model’s capability to utilize domain knowledge effectively.
遵循简约原则,本文提出了一种更简单的领域适配协议,将两阶段(持续预训练和SFT)统一为单阶段。核心方法是将领域特定的预训练数据转换为类似微调数据的统一格式:简单的(指令,输出)对。该策略不同于持续预训练中对无监督学习的传统依赖,而是选择强调激发对给定指令的知识驱动响应的聚焦学习目标。重构后的数据随后与微调数据合并,以促进单阶段领域适配。在此过程中,我们引入了一种数据优先级采样策略,旨在首先从预训练数据中学习领域知识,然后逐步将重点转移到下游微调数据。这种方法增强了模型有效利用领域知识的能力。
Verification for the new protocol To verify the one-stage protocol, we experiment on Chinese healthcare 2 where ChatGPT and GPT-4 perform relatively poorly (Wang et al., 2023a). Leveraging the proposed protocol, we train a Chinese medical language model, HuatuoGPT-II. Inspired by back-translation (Li et al., 2023d), we employ the prowess of LLMs for data unification, where all diverse and multilingual pre-training data are converted to Chinese instructions with a consistent style. This stage bridges the gap between two-stage data, especially for training LLMs in unpopular languages, where English data is overwhelmingly more abundant and high-quality. Subsequently, a priority sampling strategy is used to integrate pre-training and SFT instructions for domain adaption. We believe this unified domain adaptation protocol can be similarly effective in other specialized areas such as finance and law, as well as in different languages.
验证新协议
为验证单阶段协议的有效性,我们在中文医疗领域展开实验(该领域ChatGPT和GPT-4表现较差 [Wang et al., 2023a])。基于该协议,我们训练了中文医疗大语言模型华佗GPT-II (HuatuoGPT-II)。受反向翻译技术 [Li et al., 2023d] 启发,我们利用大语言模型实现数据统一化——将所有多语言预训练数据转换为风格统一的中文指令。这一阶段弥合了双阶段数据间的鸿沟,尤其适用于训练小语种大语言模型(当前英语数据在数量和质量上占据绝对优势)。随后采用优先级采样策略整合预训练与监督微调(SFT)指令,实现领域适配。我们相信这种统一的领域适配协议同样适用于金融、法律等其他专业领域及不同语种场景。
Experimental Results Experimental results demonstrate that HuatuoGPT-II, a new Chinese medical language model, outperforms other open-source models and rivals proprietary ones like GPT-4 and ChatGPT in some Chinese medical Benchmarks. In expert manual evaluations, HuatuoGPT-II shows a remarkable win rate of $38%$ and tie in another $38%$ against GPT-4. Moreover, in a recent and untouched Chinese National Pharmacist Licensure Examination (2023), HuatuoGPTII’s superiority over other models, highlighting its specialized effectiveness in the medical field.
实验结果
实验结果表明,新型中文医疗大语言模型 HuatuoGPT-II 在部分中文医疗基准测试中表现优于其他开源模型,并与 GPT-4、ChatGPT 等专有模型不相上下。在专家人工评估中,HuatuoGPT-II 对 GPT-4 的胜率高达 $38%$,另有 $38%$ 结果为平局。此外,在最新的中国国家执业药师资格考试 (2023) 中,HuatuoGPT-II 的表现显著优于其他模型,突显了其在医疗领域的专业有效性。
Additionally, in a spectrum of evaluation methods, the one-stage protocol of HuatuoGPT-II prove more effective than the traditional two-stage training paradigm.
此外,在一系列评估方法中,HuatuoGPT-II的单阶段训练协议被证明比传统的两阶段训练范式更有效。
Contributions The key contributions are:
贡献 主要贡献包括:
2 Data Collection
2 数据收集
Domain data is typically divided into two parts: pre-training corpora and fine-tuning instructions.
领域数据通常分为两部分:预训练语料和微调指令。
Medical Pre-training Corpus Domain corpus is pivotal for augmenting domain-specific expertise. We collect 1.1TB of both Chinese and English corpus, sourced from encyclopedias, books, literature, and web corpus, blending general corpora like C4 and specialized corpora such as PubMed. All the corpora are publicly accessible, detailed in Appendix C. Then, a meticulous collection pipeline are established for curating high-quality domain data, detailed in the Appendix C. As a result, we obtained 5,252,894 premium medical documents for the pre-training corpus.
医学预训练语料库
领域语料库对于增强特定领域的专业知识至关重要。我们收集了1.1TB的中英文语料,来源包括百科全书、书籍、文献和网络语料,融合了C4等通用语料和PubMed等专业语料。所有语料均公开可获取,详见附录C。随后,我们建立了一套精细的收集流程以筛选高质量领域数据(附录C详述),最终获得5,252,894份优质医学文档用于预训练语料库。
Medical Fine-Tuning Instructions For the fine-tuning instruction, We acquire 142K real-world medical questions as instructions from Huatuo-26M (Li et al., 2023c), and had GPT-4 respond to them as outputs. The fine-tuning instruction is utilized to generalize the model’s capability to interact with users within the domain.
医学微调指令
对于微调指令,我们从Huatuo-26M (Li et al., 2023c) 中获取了142K个真实世界的医学问题作为指令,并由GPT-4生成对应的回答作为输出。该微调指令用于提升模型在医学领域与用户交互的泛化能力。

Figure 1: Schematic of One-stage Adaption of HuatuoGPT-II.
图 1: HuatuoGPT-II 单阶段适配示意图。
3 One-stage Adaption
3 单阶段适配
One-stage Adaption strategy aims to unify the conventional Two-stage Adaption process (continued pre-training and supervised fine-tuning) into a single stage, as shown in Figure 1. The adaption process can be executed in two succinct steps: 1) Data unification and 2) One-stage training.
一阶段适应策略旨在将传统的两阶段适应过程(持续预训练和监督微调)统一为单一阶段,如图 1 所示。适应过程可通过两个简洁步骤执行:1) 数据统一和 2) 一阶段训练。
Subsequently, we will detail our method for adapting to the Chinese healthcare sector and developing and the development of HuatuoGPT-II.
接下来,我们将详细介绍如何针对中国医疗行业进行适配,并开发HuatuoGPT-II。
3.1 Data Unification
3.1 数据统一
Domain pre-training corpus is pivotal for augmenting domain-specific expertise. However, it faces challenges such as diverse languages and genres, punctuation errors, and ethical concerns in its pre-training corpus. Particularly, there’s a noticeable discrepancy between its unsupervised training and the supervised instruction learning in Supervised Fine-Tuning (SFT). Data Unification aims to unify this data into a consistent format, aligning it with SFT data. Traditional methods like those in Cheng et al., 2023 fall short due to the variation in language and genre. Hence, we leverage Large Language Models to achieve effective data unification.
领域预训练语料对于增强特定领域的专业知识至关重要。然而,其预训练语料面临着语言和体裁多样、标点错误以及伦理问题等挑战。特别是在无监督训练与监督微调(SFT)中的监督指令学习之间存在明显差异。数据统一旨在将这些数据转换为统一格式,使其与SFT数据保持一致。传统方法如Cheng等人在2023年提出的方案因语言和体裁的多样性而效果有限。因此,我们利用大语言模型来实现有效的数据统一。
Our method of data unification is straightforward yet effective. We generate instructions based on the text of the corpus, and then we generate responses based on both the corpus and the instructions. The prompt for generating instructions is shown in Figure 2.
我们的数据统一方法简单而有效。我们基于语料库文本生成指令,然后根据语料库和指令生成响应。生成指令的提示如图 2 所示。

Figure 2: The prompt for question generation. [target language] is Chinese, and [domain-specific corpus] refers to a corpus in the domain-specific pre-training corpora.
图 2: 问题生成的提示语。[target language] 是中文,[domain-specific corpus] 指领域专用预训练语料库中的语料。
After obtaining questions from the corpus text, we use the prompt, shown in Figrue 3, to let a Large Language Model (LLM) generate responses based on the questions and the corpus. Therefore, all pre-training corpora are converted into a instruction-output format, identical to our single-turn SFT data. An example of our final SFT data is shown in Table 7.
从语料文本中获取问题后,我们使用图3所示的提示词(prompt)让大语言模型(LLM)基于问题和语料生成回答。因此,所有预训练语料都被转换为指令-输出格式,与我们的单轮监督微调(SFT)数据格式一致。最终监督微调数据的示例如表7所示。
Here, we use ChatGPT as the LLM for data unification, converting all the medical corpus into instructions of the same language and genre. As detailed in Appendix F, Data Unification can be achieved independently of external LLMs. In Appendix E, we verified that the selection of LLM for data unification is inconsequential. This strategy also mitigates potential ethical concerns inherent in the corpus. Additionally, we also use statistical and semantic recognition to keep the model-generated answers close to the data’s original content, as explained in Appendix H.
在此,我们采用ChatGPT作为大语言模型(LLM)进行数据统一,将所有医学语料转换为相同语言风格和类型的指令。如附录F所述,数据统一可不依赖外部大语言模型独立实现。附录E验证了数据统一环节选择不同大语言模型对结果无显著影响。该策略还能规避语料库中潜在的伦理问题。此外,如附录H所阐释,我们通过统计分析与语义识别技术确保模型生成答案贴近原始数据内容。
3.2 One-stage Training
3.2 单阶段训练
In the one-stage training process, we integrate data from the Medical Pre-training Instruction and Medical Fine-tuning Instruction datasets to form dataset $D$ . The traditional two-stage pipeline adopts a completely separate form, first learning knowledge and then learning instructions to
在一阶段训练过程中,我们将医学预训练指令(Medical Pre-training Instruction)和医学微调指令(Medical Fine-tuning Instruction)数据集整合形成数据集$D$。传统两阶段流程采用完全分离的形式,先学习知识再学习指令。

Figure 3: Prompt for answer generation. [model name] refers to HuatuoGPT-II, [domain] is medicine, and [question generated by LLM]] is the previously text-derived query.
图 3: 答案生成的提示语。[model name]指代华佗GPT-II,[domain]为医学领域,[question generated by LLM]]是此前基于文本生成的查询。
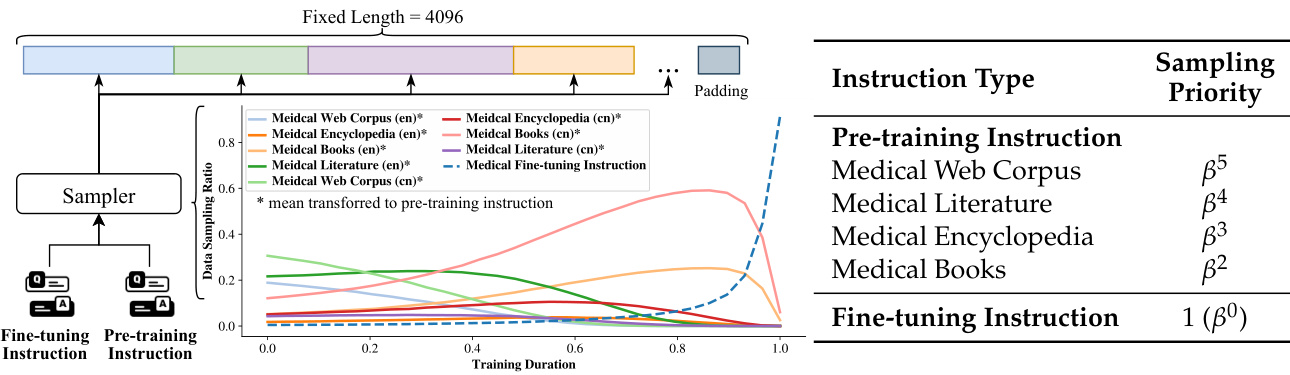
Figure 4: One-stage training process and sampling priority. The diagram (left) illustrates the onestage training methodology. The table (right) details the sampling priority for various instructional data types, with the $\beta$ (set as 2) dictating the relative priority. Higher $\beta$ values indicate a more sequential sampling approach, whereas lower values suggest a blended strategy.
图 4: 单阶段训练流程与采样优先级。示意图(左)展示了单阶段训练方法。表格(右)详细列出了不同指令数据类型的采样优先级,其中$\beta$(设为2)决定相对优先级。$\beta$值越高表示采用更顺序化的采样方式,而较低值则代表混合策略。
follow. It exacerbates the catastrophic forgetting of the knowledge acquired in the first stage (Bhat et al., 2022). Referring to Touvron et al., 2023, simply mixing all data could hinder the ability of Large Language Models (LLMs). To address this, we introduce a priority sampling strategy in this study. This strategy starts with domain knowledge, gradually transitioning to fine-tuning data while reducing the sampling ratio of previously learned data over time.
遵循这一做法会加剧第一阶段所学知识的灾难性遗忘 (Bhat et al., 2022) 。参考 Touvron 等人 2023 年的研究,简单地混合所有数据可能会阻碍大语言模型 (LLM) 的能力。为此,我们在本研究中引入了优先级采样策略。该策略从领域知识入手,逐步过渡到微调数据,同时随时间推移降低已学习数据的采样比例。
In the priority sampling strategy, the sampling probability of each data $x\in D$ changes over the course of training. The sampling probability of data $x$ at step $t$ during training is:
在优先级采样策略中,每个数据$x\in D$的采样概率会随着训练过程动态变化。训练第$t$步时数据$x$的采样概率为:
$$
P_ {t}(x)=\frac{\pi(x)}{\sum_ {y\in D-S_ {t}}\pi(y)}
$$
$$
P_ {t}(x)=\frac{\pi(x)}{\sum_ {y\in D-S_ {t}}\pi(y)}
$$
Here, $\pi(x)$ denotes the priority of element $x,$ , and $S_ {t}$ represents the sampled data before step t. The priority setting and data sampling distribution are delineated in Figure 4. Notably, the priority $\overset{\cdot}{\pi}(x)$ is static, whereas the sampling probabilities of each data source dynamically changes. More precisely, consider data sources $D_ {1}^{t},\bar{D}_ {2}^{t},\ldots,D_ {n}^{t}\subseteq D-S^{t}$ at time $t_ {.}$ , each with an assigned priority $\pi({\boldsymbol{x}}\in D_ {i}^{t})=\beta^{K_ {i}}$ . The probability of selecting an element from $D_ {i}^{t}$ is given by:
这里,$\pi(x)$ 表示元素 $x$ 的优先级,$S_ {t}$ 代表第 t 步前的采样数据。优先级设置与数据采样分布如图 4 所示。值得注意的是,优先级 $\overset{\cdot}{\pi}(x)$ 是静态的,而每个数据源的采样概率会动态变化。更准确地说,考虑时间 $t_ {.}$ 时的数据源 $D_ {1}^{t},\bar{D}_ {2}^{t},\ldots,D_ {n}^{t}\subseteq D-S^{t}$ ,每个数据源被赋予优先级 $\pi({\boldsymbol{x}}\in D_ {i}^{t})=\beta^{K_ {i}}$ 。从 $D_ {i}^{t}$ 中选择元素的概率由下式给出:
$$
P_ {t}(x\in D_ {i}^{t})=\frac{|D_ {i}^{t}|\beta^{K_ {i}}}{\sum_ {j=1}^{n}|D_ {j}^{t}|\beta^{K_ {j}}}
$$
After an element is selected from $D_ {i}^{t},$ the size of $D_ {i}^{t+1}$ becomes $|D_ {i}^{t+1}|=|D_ {i}^{t}|-1,$ , resulting in: $P_ {t+1}(x\in D_ {i.}^{t+1})<P_ {t}(x\in D_ {i}^{t})$ . Therefore, each selection from $D_ {i}$ slightly decreases its sampling probability, leading to a dynamic update. The parameter $\beta$ plays a crucial role in adjusting the sampling intensity among high-priority sources, with higher $\beta$ values favoring sequential sampling, while lower values encourage mixed sampling.
从 $D_ {i}^{t}$ 中选定一个元素后,$D_ {i}^{t+1}$ 的大小变为 $|D_ {i}^{t+1}|=|D_ {i}^{t}|-1$,从而得到:$P_ {t+1}(x\in D_ {i.}^{t+1})<P_ {t}(x\in D_ {i}^{t})$。因此,每次从 $D_ {i}$ 中进行选择都会略微降低其采样概率,实现动态更新。参数 $\beta$ 在调整高优先级数据源间的采样强度中起关键作用,$\beta$ 值越高越倾向于顺序采样,而较低值则促进混合采样。
To enable the model to first learn domain capabilities and then gradually shift to instruction interaction learning, we assign a higher priority to pre-training instruction data. Furthermore, to facilitate the model’s transition from low to high knowledge density learning, we assign different priorities to the four types of data sources. Appendix I shows details of how we determine sampling priority values for different types of data.
为了让模型先学习领域能力再逐步转向指令交互学习,我们为预训练指令数据分配了更高优先级。此外,为促进模型从低知识密度向高知识密度学习过渡,我们对四类数据源设定了不同优先级。附录I详细展示了如何确定不同类型数据的采样优先级值。
4 Experiments
4 实验
4.1 Experimental settings
4.1 实验设置
Base Model & Setup HuatuoGPT-II, tailored for Chinese healthcare, builds upon the foundations o f the Baichuan2-7B-Base and Baichuan2-13B-Base models. Since all data consists solely of singleround format instruction, we enrich the Medical Fine-tuning Instruction dataset by integrating ShareGPT data 3. This allows HuatuoGPT-II to support multi-round dialogues while maintaining its general domain capabilities. For training details, please see the Appendix J.
基础模型与配置
华佗GPT-II (HuatuoGPT-II) 专为中文医疗场景设计,基于百川2-7B基础版 (Baichuan2-7B-Base) 和百川2-13B基础版 (Baichuan2-13B-Base) 模型构建。由于原始数据仅包含单轮指令格式,我们通过整合ShareGPT数据[3]扩充了医疗微调指令数据集,使华佗GPT-II在保持通用领域能力的同时支持多轮对话。训练细节详见附录J。
Baselines We compare HuatuoGPT-II with several leading general large language models known for their excellent general chat capabilities in Chinese. These models are Baichuan2-7B/13BChat(Yang et al., 2023a), Qwen-7B/14B-Chat(Bai et al., 2023) and ChatGLM3-6B(Zeng et al., 2023). Additionally, for the Chinese medical context, we carefully select DISC-MedLLM(Bao et al., 2023) and HuatuoGPT(Zhang et al., 2023) based on an experimental experiment detailed in Appendix R. We also consider leading proprietary models, including ERNIE Bot ( 文心一言) (Sun et al., 2021), ChatGPT(OpenAI, 2022), and GPT $4^{4}$ (OpenAI, 2023), noted for their extensive parameters and superior performance. For the details of these models, please refer to Appendix M.
基线模型
我们将华佗GPT-II (HuatuoGPT-II) 与多款以优秀中文通用对话能力著称的主流大语言模型进行对比,包括百川2-7B/13B-Chat (Yang et al., 2023a)、通义千问-7B/14B-Chat (Bai et al., 2023) 和ChatGLM3-6B (Zeng et al., 2023)。针对中文医疗场景,基于附录R的实验筛选出DISC-MedLLM (Bao et al., 2023) 和华佗GPT (Zhang et al., 2023) 作为对照。同时纳入参数规模与性能领先的闭源模型:文心一言 (Sun et al., 2021)、ChatGPT (OpenAI, 2022) 以及GPT-4 (OpenAI, 2023)。各模型详情参见附录M。
4.2 Medical Benchmark
4.2 医疗基准测试
In this section, we evaluate the medical capabilities of HuatuoGPT-II on popular benchmarks. We focus on four medical benchmarks (MedQA, MedMCQA, CMB, CMExam) and two general benchmarks (C-Eval, CMMLU), focusing specifically on their medical components. See Appendix K for more details on these benchmarks. To ensure fairness, we use the most straightforward prompt for all the models, as shown in Appendix K.
在本节中,我们评估了HuatuoGPT-II在主流基准测试中的医疗能力。我们重点关注四个医疗基准(MedQA、MedMCQA、CMB、CMExam)和两个通用基准(C-Eval、CMMLU)的医疗相关部分。关于这些基准的详细信息请参阅附录K。为确保公平性,我们为所有模型使用最直接的提示方式,如附录K所示。
Medical Benchmark As shown in Table 1, the benchmark results highlight HuatuoGPT-II’s impressive proficiency in the medical domain. Its exceptional performance in Chinese medical benchmarks like CMB and CMExam reflects its deep understanding of medical concepts in a Chinese context. Moreover, HuatuoGPT-II maintains a high level on English benchmarks, demonstrating its medical capabilities. To further evaluate the medical expertise, we utilize a dataset with various Chinese national medical exams. The results, displayed in Table 4, reveal that HuatuoGPT-II surpass all open-source models and closely rivaled the proprietary model, ERNIE Bot. In Appendix B, we present the performance of HuatuoGPT-II on additional medical benchmarks.
医疗基准测试
如表 1 所示,基准测试结果突显了 HuatuoGPT-II 在医疗领域的卓越表现。其在 CMB 和 CMExam 等中文医疗基准测试中的优异表现,反映了其对中文语境下医疗概念的深刻理解。此外,HuatuoGPT-II 在英文基准测试中同样保持高水平,展现了其跨语言的医疗能力。
为进一步评估其专业医疗知识,我们采用了包含多种中国国家级医学考试的数据集。表 4 的结果显示,HuatuoGPT-II 超越了所有开源模型,并与专有模型 ERNIE Bot 表现接近。附录 B 中,我们展示了 HuatuoGPT-II 在其他医疗基准测试中的性能。
Table 1: Medical benchmark results. Med. signifies extraction of only medical-related questions. ’-’ indicate that the model cannot follow the question and make a choice. Due to the too large size of these benchmarks, we exclude the testing of GPT-4 and ERNIE Bot here.
| Model | English | Chinese | Average | ||||
| MedQA | MedMCQA | CMB | CMExam | CMMLUMed. | C_ EvalMed. | ||
| DISC-MedLLM | 28.67 | 32.47 | 36.62 | ||||
| HuatuoGPT | 25.77 | 31.20 | 28.81 | 31.07 | 33.23 | 36.53 | 31.92 |
| ChatGLM3-6B | 28.75 | 35.91 | 39.81 | 43.21 | 46.97 | 48.80 | 40.73 |
| Baichuan2-7B-Chat | 33.31 | 38.90 | 46.33 | 50.48 | 50.74 | 51.47 | 45.39 |
| Baichuan2-13B-Chat | 39.43 | 41.86 | 50.87 | 54.90 | 52.95 | 58.67 | 49.77 |
| Qwen-7B-Chat | 33.46 | 41.36 | 49.39 | 53.33 | 54.65 | 52.80 | 47.50 |
| Qwen-14B-Chat | 42.81 | 46.59 | 60.28 | 63.57 | 64.55 | 65.07 | 57.16 |
| ChatGPT (API) | 52.24 | 53.60 | 43.26 | 46.51 | 50.37 | 48.80 | 48.51 |
| HuatuoGPT-II (7B) | 41.13 | 41.87 | 60.39 | 65.81 | 59.08 | 62.40 | 55.13 |
| HuatuoGPT-II(13B) | 45.68 | 47.41 | 63.34 | 68.98 | 61.45 | 64.00 | 58.47 |
表 1: 医疗基准测试结果。Med. 表示仅提取与医疗相关的问题。"-" 表示模型无法理解问题并做出选择。由于这些基准测试规模过大,我们在此排除了 GPT-4 和 ERNIE Bot 的测试。
| 模型 | 英语 | 中文 | 平均 | ||||
|---|---|---|---|---|---|---|---|
| MedQA | MedMCQA | CMB | CMExam | CMMLUMed. | C_ EvalMed. | ||
| DISC-MedLLM | 28.67 | - | 32.47 | 36.62 | - | - | - |
| HuatuoGPT | 25.77 | 31.20 | 28.81 | 31.07 | 33.23 | 36.53 | 31.92 |
| ChatGLM3-6B | 28.75 | 35.91 | 39.81 | 43.21 | 46.97 | 48.80 | 40.73 |
| Baichuan2-7B-Chat | 33.31 | 38.90 | 46.33 | 50.48 | 50.74 | 51.47 | 45.39 |
| Baichuan2-13B-Chat | 39.43 | 41.86 | 50.87 | 54.90 | 52.95 | 58.67 | 49.77 |
| Qwen-7B-Chat | 33.46 | 41.36 | 49.39 | 53.33 | 54.65 | 52.80 | 47.50 |
| Qwen-14B-Chat | 42.81 | 46.59 | 60.28 | 63.57 | 64.55 | 65.07 | 57.16 |
| ChatGPT (API) | 52.24 | 53.60 | 43.26 | 46.51 | 50.37 | 48.80 | 48.51 |
| HuatuoGPT-II (7B) | 41.13 | 41.87 | 60.39 | 65.81 | 59.08 | 62.40 | 55.13 |
| HuatuoGPT-II (13B) | 45.68 | 47.41 | 63.34 | 68.98 | 61.45 | 64.00 | 58.47 |
Table 2: Results of the 2023 Chinese National Pharmacist Licensure Examination. It consists of two tracks of Pharmacy track and Traditional Chinese Medicine (TCM) Pharmacy track.
| Model | 2023PharmacistLicensureExamination (Pharmacy) | 2023PharmacistLicensureExamination (TCM) | Avg. | ||||||||
| Optimal Choice | Matched Selection | Integrated Analysis | Multiple Choice | Total Score | Optimal Choice | Matched Selection | Integrated Analysis | Multiple Choice | Total Score | ||
| DISC-MedLLM | 22.2 | 26.8 | 23.3 | 0.0 | 22.6 | 24.4 | 32.3 | 15.0 | 0.0 | 24.9 | 23.8 |
| HuatuoGPT | 25.6 | 25.5 | 23.3 | 2.6 | 23.4 | 24.1 | 26.8 | 31.6 | 7.5 | 24.9 | 24.2 |
| ChatGLM3-6B | 39.5 | 39.1 | 10.5 | 0.2 | 34.6 | 31.8 | 38.2 | 25.0 | 20.0 | 32.9 | 33.8 |
| Qwen-7B-chat | 43.8 | 46.8 | 33.3 | 18.4 | 41.9 | 40.0 | 43.2 | 33.3 | 17.5 | 38.8 | 40.4 |
| Qwen-14B-chat | 56.2 | 58.6 | 41.7 | 21.1 | 52.7 | 51.3 | 51.0 | 27.5 | 41.7 | 47.9 | 50.3 |
| Baichuan2-7B-Chat | 51.2 | 50.9 | 30.0 | 2.6 | 44.6 | 48.1 | 46.0 | 35.0 | 7.5 | 42.1 | 43.4 |
| Baichuan2-13B-Chat | 43.8 | 52.7 | 36.7 | 7.9 | 44.2 | 41.3 | 46.4 | 43.3 | 15.0 | 41.7 | 43.0 |
| ERNIE Bot (API) | 45.0 | 60.9 | 36.7 | 23.7 | 49.6 | 53.8 | 59.1 | 38.3 | 20.0 | 51.5 | 50.6 |
| ChatGPT (API) | 45.6 | 44.1 | 36.7 | 13.2 | 41.2 | 34.4 | 32.3 | 30.0 | 15.0 | 31.2 | 36.2 |
| GPT-4 (API) | 65.1 | 59.6 | 46.7 | 15.8 | 57.3 | 40.6 | 42.7 | 33.3 | 17.5 | 38.8 | 48.1 |
| HuatuoGPT-II(7B) | 41.9 | 61.0 | 35.0 | 15.7 | 47.7 | 52.5 | 51.4 | 41.7 | 15.0 | 47.5 | 47.6 |
| HuatuoGPT-II(13B) | 47.5 | 64.1 | 45.0 | 23.7 | 52.9 | 48.8 | 61.8 | 45.0 | 17.5 | 51.6 | 52.3 |
表 2: 2023年中国国家执业药师资格考试结果。包含药学和中药学两个方向。
| Model | 2023药师资格考试(药学) | 2023药师资格考试(中药学) | Avg. | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 最佳选择 | 匹配选择 | 综合分析 | 多选题 | 总分 | 最佳选择 | 匹配选择 | 综合分析 | 多选题 | 总分 | ||
| DISC-MedLLM | 22.2 | 26.8 | 23.3 | 0.0 | 22.6 | 24.4 | 32.3 | 15.0 | 0.0 | 24.9 | 23.8 |
| HuatuoGPT | 25.6 | 25.5 | 23.3 | 2.6 | 23.4 | 24.1 | 26.8 | 31.6 | 7.5 | 24.9 | 24.2 |
| ChatGLM3-6B | 39.5 | 39.1 | 10.5 | 0.2 | 34.6 | 31.8 | 38.2 | 25.0 | 20.0 | 32.9 | 33.8 |
| Qwen-7B-chat | 43.8 | 46.8 | 33.3 | 18.4 | 41.9 | 40.0 | 43.2 | 33.3 | 17.5 | 38.8 | 40.4 |
| Qwen-14B-chat | 56.2 | 58.6 | 41.7 | 21.1 | 52.7 | 51.3 | 51.0 | 27.5 | 41.7 | 47.9 | 50.3 |
| Baichuan2-7B-Chat | 51.2 | 50.9 | 30.0 | 2.6 | 44.6 | 48.1 | 46.0 | 35.0 | 7.5 | 42.1 | 43.4 |
| Baichuan2-13B-Chat | 43.8 | 52.7 | 36.7 | 7.9 | 44.2 | 41.3 | 46.4 | 43.3 | 15.0 | 41.7 | 43.0 |
| ERNIE Bot (API) | 45.0 | 60.9 | 36.7 | 23.7 | 49.6 | 53.8 | 59.1 | 38.3 | 20.0 | 51.5 | 50.6 |
| ChatGPT (API) | 45.6 | 44.1 | 36.7 | 13.2 | 41.2 | 34.4 | 32.3 | 30.0 | 15.0 | 31.2 | 36.2 |
| GPT-4 (API) | 65.1 | 59.6 | 46.7 | 15.8 | 57.3 | 40.6 | 42.7 | 33.3 | 17.5 | 38.8 | 48.1 |
| HuatuoGPT-II(7B) | 41.9 | 61.0 | 35.0 | 15.7 | 47.7 | 52.5 | 51.4 | 41.7 | 15.0 | 47.5 | 47.6 |
| HuatuoGPT-II(13B) | 47.5 | 64.1 | 45.0 | 23.7 | 52.9 | 48.8 | 61.8 | 45.0 | 17.5 | 51.6 | 52.3 |
The Fresh Medical Exams Tackling data contamination in LLM training is challenging (Huang et al., 2023), especially with extensive and intricate training data. To counter this, we selected the 2023 Chinese National Pharmacist Licensure Examination, held on October 21, 2023, as our benchmarks. This date is crucially before both our data collection cut-off (October 7, 2023) and the release of our assessment models. The annual uniqueness of the exam questions ensures a reliable safeguard against contamination risks. The results in Table 2 show that HuatuoGPT-II ranked second after GPT-4 in the Pharmacy track. However, in the Traditional Chinese Medicine track, HuatuoGPT-II led with 51.6 points. HuatuoGPT-II demonstrated superior performance in average scores across both tracks, highlighting its proficiency in the medical field.
在大语言模型(LLM)训练中解决数据污染问题具有挑战性(Huang et al., 2023),尤其是在处理海量复杂训练数据时。为此,我们选取2023年10月21日举行的中国国家执业药师资格考试作为基准测试,该日期早于我们的数据收集截止日(2023年10月7日)和评估模型发布时间。考卷每年的唯一性为防范数据污染风险提供了可靠保障。表2结果显示,在药学赛道华佗GPT-II仅次于GPT-4排名第二,而在中医药赛道则以51.6分领先。华佗GPT-II在两个赛道的平均得分均展现出卓越性能,凸显了其在医疗领域的专业优势。
4.3 Medical Response Quality
4.3 医疗响应质量
To evaluate the model’s performance in real-world medical scenarios, we utilize real-wrold questions in both single-round and multi-round formats, sourced respectively from KUAKE-QIC (Zhang et al., 2021) and Med-dialog (Zeng et al., 2020), following the approach of HuatuoGPT (Zhang et al., 2023). The assessment details are provided in the Appendix L.
为评估模型在真实医疗场景中的表现,我们采用单轮和多轮形式的真实世界问题,分别来自KUAKE-QIC (Zhang et al., 2021) 和 Med-dialog (Zeng et al., 2020),并遵循HuatuoGPT (Zhang et al., 2023) 的方法。具体评估细节见附录L。
Table 3: Results of the Automated Evaluation Using GPT-4 and Expert Evaluation.
| HuatuoGPT-II(7B)vsOtherModel | Single-roundQA | Multi-roundDialogue | Average Win/TieRate | ||||
| Win | Tie | Fail | Win | Tie | Fail | ||
| AutomatedEvaluationUsingGPT-4 | |||||||
| HuatuoGPT-II(7B)vs GPT-4 | 58 | 21 | 21 | 62 | 15 | 23 | 78.0% |
| HuatuoGPT-II(7B)vsChatGPT | 62 | 18 | 20 | 69 | 14 | 17 | 81.5% |
| HuatuoGPT-II(7B)vsBaichuan2-13B-Chat | 64 | 14 | 22 | 75 | 11 | 14 | 82.0% |
| HuatuoGPT-II(7B)vsHuatuoGPT | 87 | 7 | 6 | 67 | 15 | 18 | 88.0% |
| HumanExpertEvaluation | |||||||
| HuatuoGPT-II(7B)vs GPT-4 | 38 | 38 | 24 | 53 | 17 | 30 | 73% |
| HuatuoGPT-II(7B)vsChatGPT | 52 | 33 | 15 | 56 | 11 | 33 | 76% |
| HuatuoGPT-II(7B)vsBaichuan2-13B-Chat | 63 | 19 | 18 | 63 | 19 | 18 | 82% |
| HuatuoGPT-II(7B)vsHuatuoGPT | 81 | 11 | 8 | 68 | 6 | 26 | 83% |
表 3: 使用GPT-4自动评估与专家评估结果
| HuatuoGPT-II(7B)对比模型 | 单轮问答 | 多轮对话 | 平均胜率/平率 | ||||
|---|---|---|---|---|---|---|---|
| 胜 | 平 | 败 | 胜 | 平 | 败 | ||
| * * GPT-4自动评估* * | |||||||
| HuatuoGPT-II(7B) vs GPT-4 | 58 | 21 | 21 | 62 | 15 | 23 | 78.0% |
| HuatuoGPT-II(7B) vs ChatGPT | 62 | 18 | 20 | 69 | 14 | 17 | 81.5% |
| HuatuoGPT-II(7B) vs Baichuan2-13B-Chat | 64 | 14 | 22 | 75 | 11 | 14 | 82.0% |
| HuatuoGPT-II(7B) vs HuatuoGPT | 87 | 7 | 6 | 67 | 15 | 18 | 88.0% |
| * * 专家人工评估* * | |||||||
| HuatuoGPT-II(7B) vs GPT-4 | 38 | 38 | 24 | 53 | 17 | 30 | 73% |
| HuatuoGPT-II(7B) vs ChatGPT | 52 | 33 | 15 | 56 | 11 | 33 | 76% |
| HuatuoGPT-II(7B) vs Baichuan2-13B-Chat | 63 | 19 | 18 | 63 | 19 | 18 | 82% |
| HuatuoGPT-II(7B) vs HuatuoGPT | 81 | 11 | 8 | 68 | 6 | 26 | 83% |
Automatic Evaluation We utilize GPT-4 to evaluate which of the two models generated better outputs. The results, as indicated in Table 3 (for more compared baselines, see Table 13), show that HuatuoGPT-II has a higher win rate compared to other models. Notably, HuatuoGPT-II achieve a higher win rate in comparison with GPT-4. Although its fine-tuning data originated from GPT-4, its extensive medical corpus provided it with more medical knowledge, as shown in Table 2.
自动评估
我们利用 GPT-4 评估两个模型中哪个生成的输出更优。如表 3 所示(更多基线对比见表 13),华佗GPT-II 相比其他模型具有更高的胜率。值得注意的是,华佗GPT-II 在与 GPT-4 的对比中也取得了更高的胜率。尽管其微调数据源自 GPT-4,但其庞大的医学语料库为其提供了更丰富的医学知识,如表 2 所示。
Expert Evaluation For further evaluating the quality of the model outputs, we invite four licensed physicians to score them, with the detailed criteria available in the Appendix L.2. Due to the high cost of expert evaluation, we select four models for comparison with HuatuoGPT-II. Results, as outlined in Tables 3, indicate that HuatuoGPT-II consistently outperforms its peers, aligning with automatic evaluation. This consensus between expert opinions and GPT $\bar{4}^{\prime}\mathrm{s}$ evaluations underscores HuatuoGPT-II’s efficacy in medical response generation. The case study on the model’s response can be found in Appendix S.
专家评估
为进一步评估模型输出的质量,我们邀请四位执业医师进行评分,详细标准见附录 L.2。由于专家评估成本较高,我们选取了四个模型与HuatuoGPT-II进行对比。结果如表 3 所示,HuatuoGPT-II始终优于同类模型,与自动评估结果一致。专家意见与GPT $\bar{4}^{\prime}\mathrm{s}$ 评估之间的共识印证了HuatuoGPT-II在医疗应答生成方面的有效性。关于模型应答的案例分析见附录 S。
4.4 One-stage Vs. Two-stage Adaption
4.4 单阶段与双阶段适配
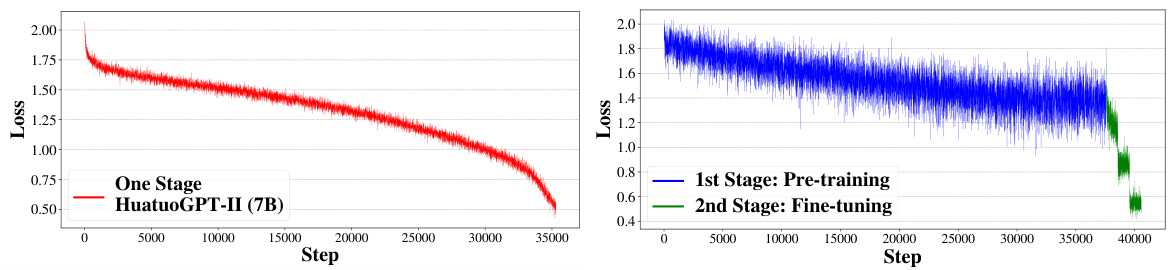
Figure 5: Comparison of the loss outcomes between proposed One-stage Adaption and conventional Two-stage Adaption using the same SFT data and medical corpus.
图 5: 使用相同监督微调(SFT)数据和医学语料库时,提出的单阶段适配方法与常规双阶段适配方法的损失结果对比。
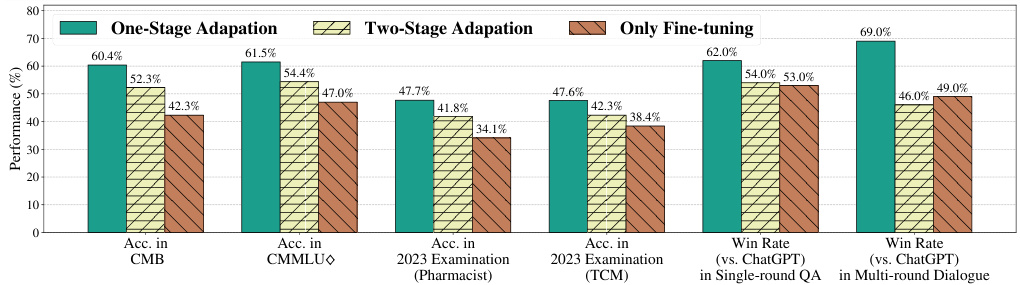
Figure 6: The comparison results of One-stage Adaption and Two-stage Adaption. "Only Finetuning" refers to the model that only fine-tunes the backbone directly. Win Rate is the result scored by automatic evaluation using GPT-4.
图 6: 单阶段适应与双阶段适应的对比结果。"Only Finetuning"指仅对主干网络直接微调的模型。胜率是通过GPT-4自动评估得出的结果。
To validate the superiority of One-stage Adaption, we conduct a traditional Two-stage Adaption to fine-tune the the Baichuan2-7B-Base on the same medical data.
为验证单阶段适配(One-stage Adaption)的优越性,我们在相同医疗数据上采用传统双阶段适配(Two-stage Adaption)对Baichuan2-7B-Base进行微调。
Figure 5 shows the training loss of these two training methods. The loss of Two-stage Adaption shows instability, marked by pronounced fluctuations and loss spikes. This instability arises from the varied content and styles within the medical pre-training corpus, which includes four distinct data types as detailed in Table 9. The variation is further amplified by the differences between Chinese and English datasets. Our one-stage Adaption unifies the diverse contents and styles of the pre-training corpus, improving training stability and reducing loss fluctuation. Moreover, due to data discrepancies between the two stages, there is a noticeable loss divergence between the pre-training and fine-tuning stages in Two-stage Adaption. In contrast, One-stage Adaption effectively resolves this issue by simplifying the pre-training corpus into a unified language and style, aligning with SFT data, making a more stable and smooth training process.
图 5 展示了两种训练方法的训练损失。两阶段适应 (Two-stage Adaption) 的损失表现出不稳定性,其特征是明显的波动和损失峰值。这种不稳定性源于医学预训练语料库中多样化的内容和风格,如表 9 所示,其中包含四种不同的数据类型。中英文数据集之间的差异进一步放大了这种变化。我们的一阶段适应 (One-stage Adaption) 统一了预训练语料库的多样化内容和风格,提高了训练稳定性并减少了损失波动。此外,由于两阶段之间的数据差异,两阶段适应在预训练和微调阶段之间存在明显的损失差异。相比之下,一阶段适应通过将预训练语料库简化为统一的语言和风格,与 SFT 数据保持一致,从而有效解决了这一问题,使训练过程更加稳定和平滑。
The results of the previously mentioned experiments also demonstrate that One-stage Adaption achieves better performance than other methods, as shown in Figure 6. It can be seen that on all six datasets, our One-stage Adaption performance is significantly better than the Two-stage Adaption performance (from $5.3%$ to $23%$ ), especially in single-round Q&A and multi-round conversation tasks. This superiority is likely due to two-stage unification and more effective knowledge generalization in One-stage Adaption.
前述实验结果也表明,One-stage Adaption方法性能优于其他方案,如图6所示。可以观察到在全部六个数据集上,我们的One-stage Adaption性能显著超越Two-stage Adaption方案(提升幅度从$5.3%$到$23%$),尤其在单轮问答和多轮对话任务中表现突出。这种优势可能源于One-stage Adaption实现了两阶段统一以及更高效的知识泛化能力。
4.5 The Relative Priority for Sampling
4.5 采样相对优先级
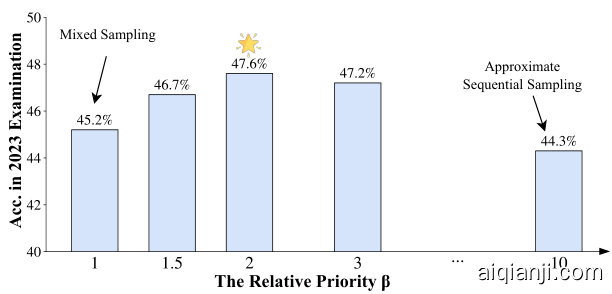
Figure 7: Comparison of model performance under different relative priority $\beta$ settings.
图 7: 不同相对优先级 $\beta$ 设置下的模型性能对比。
In evaluating the priority sampling strategy, we tested it across different $\beta$ settings using the same HuatuoGPT-II (7B) configuration. Our results show that model performance drastically drops when $\beta=0$ (mixed sampling) or when $\beta$ is excessively high (Sequential Sampling), highlighting the importance of priority sampling. The best performance is achieved when $\hat{\boldsymbol{\beta}}$ is around 2.
在评估优先级采样策略时,我们使用相同的华佗GPT-II (7B)配置测试了不同$\beta$设置下的效果。结果表明,当$\beta=0$(混合采样)或$\beta$过高(顺序采样)时,模型性能急剧下降,这凸显了优先级采样的重要性。最佳性能出现在$\hat{\boldsymbol{\beta}}$约为2时。
Moreover, we also conducted an ablation study on data unification in appendix G. The experiment indicates that data unification is crucial for the performance improvement of the one-stage training.
此外,我们还在附录G中对数据统一(Data Unification)进行了消融实验。结果表明,数据统一对单阶段训练的性能提升至关重要。
5 Conclusion
5 结论
In this work, we propose a one-stage domain adaption method, simplifying the conventional two-stage domain adaption process and mitigating its associated challenges. This approach is straightforward, involving the use of LLM capabilities to align domain corpus with SFT data and adopting a priority sampling strategy to enhance domain adaption. Based on this method, we develop a Chinese medical language model, HuatuoGPT-II. In the experiment, HuatuoGPT-II demonstrates state-of-the-art performance in the Chinese medicine domain across various benchmarks. It even surpasses proprietary models like ChatGPT and GPT-4 in some aspects, particularly in Traditional Chinese Medicine. The experimental results also confirm the reliability of the one-stage domain adaption method, which shows a significant improvement over the traditional two-stage performance. This One-stage Adaption promises to offer valuable insights and a methodological framework for future LLM domain adaption works.
在本工作中,我们提出了一种单阶段领域适配方法,简化了传统的两阶段领域适配流程并缓解了其相关挑战。该方法简单直接,包括利用大语言模型能力将领域语料与SFT数据对齐,并采用优先级采样策略以增强领域适配性。基于此方法,我们开发了中文医疗语言模型华佗GPT-II。实验中,华佗GPT-II在多个基准测试中展现出中医领域的最先进性能,在某些方面甚至超越了ChatGPT和GPT-4等专有模型,尤其在传统中医药领域表现突出。实验结果也证实了单阶段领域适配方法的可靠性,其性能较传统两阶段方法有显著提升。这种单阶段适配方法有望为未来大语言模型领域适配工作提供有价值的见解和方法论框架。
Ethic Statement
道德声明
The development of HuatuoGPT-II, a specialized language model for Chinese healthcare, raises several potential risks.
华佗GPT-II (HuatuoGPT-II)作为中文医疗领域专用大语言模型的开发存在若干潜在风险。
Accuracy of Medical Advice While HuatuoGPT-II has shown promising results in the domain of Chinese healthcare, it’s crucial to underscore that at this stage, it should not be used to provide any medical advice. This caution stems from the inherent limitations of large language models, including their capacity for generating plausible yet inaccurate or misleading information.
医疗建议的准确性
尽管华佗GPT-II (HuatuoGPT-II) 在中文医疗领域展现出积极成果,但必须强调现阶段不可将其用于提供任何医疗建议。这一警示源于大语言模型 (Large Language Model) 的固有局限性,包括其可能生成看似合理实则不准确或误导性信息的能力。
Data Privacy and Ethics The ethical handling of data is paramount, especially in the sensitive field of healthcare. The primary data sources for HuatuoGPT-II include medical texts, such as textbooks and literature, ensuring that patient-specific data is not utilized. This approach aligns with ethical guidelines and privacy regulations, ensuring that individual patient information is not compromised. Another significant aspect of our methodology is the ’data unification’ process, which aims to address potential ethical issues in the training data. By employing large language models to rewrite the medical corpora, we aim to eliminate any ethically questionable content, thereby ensuring that the training process and the model align with ethical standards.
数据隐私与伦理
在医疗等敏感领域,数据的伦理处理至关重要。HuatuoGPT-II的主要数据源包括医学教材和文献等文本,确保不使用患者特定数据。这一做法符合伦理准则和隐私法规,保障了患者个体信息的安全。我们方法的另一关键环节是"数据统一化"流程,旨在解决训练数据中潜在的伦理问题。通过使用大语言模型重写医学语料,我们力求消除任何存在伦理争议的内容,从而确保训练过程及模型本身符合伦理标准。
Acknowledgement
致谢
This work was supported by the Shenzhen Science and Technology Program (JCYJ20220818103001002), Shenzhen Doctoral Startup Funding (RCBS20221008093330065), Tianyuan Fund for Mathematics of National Natural Science Foundation of China (NSFC) (12326608), Shenzhen Key Laboratory of Cross-Modal Cognitive Computing (grant number
本研究由深圳市科技计划项目(JCYJ20220818103001002)、深圳市博士启动基金(RCBS20221008093330065)、国家自然科学基金数学天元基金(12326608)、深圳市跨模态认知计算重点实验室(资助编号
ZD S YS 20230626091302006), and Shenzhen Stability Science Program 2023, Shenzhen Key Lab of Multi-Modal Cognitive Computing.
ZD S YS 20230626091302006),以及深圳市稳定支持计划2023,深圳市多模态认知计算重点实验室。
References
参考文献
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report. arXiv preprint arXiv:2309.16609, 2023.
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, 等. Qwen技术报告. arXiv预印本 arXiv:2309.16609, 2023.
Zhijie Bao, Wei Chen, Shengze Xiao, Kuang Ren, Jiaao Wu, Cheng Zhong, Jiajie Peng, Xuanjing Huang, and Zhongyu Wei. Disc-medllm: Bridging general large language models and real-world medical consultation, 2023.
Zhijie Bao, Wei Chen, Shengze Xiao, Kuang Ren, Jiaao Wu, Cheng Zhong, Jiajie Peng, Xuanjing Huang, and Zhongyu Wei. Disc-MedLLM: 连接通用大语言模型与现实世界医疗咨询的桥梁, 2023.
Prashant Shivaram Bhat, Bahram Zonooz, and Elahe Arani. Consistency is the key to further mitigating catastrophic forgetting in continual learning. In Conference on Lifelong Learning Agents, pp. 1195–1212. PMLR, 2022.
Prashant Shivaram Bhat、Bahram Zonooz和Elahe Arani。一致性是持续学习中进一步缓解灾难性遗忘的关键。载于《终身学习智能体会议》,第1195-1212页。PMLR,2022。
Stella Biderman, Kieran Bicheno, and Leo Gao. Datasheet for the pile. arXiv preprint arXiv:2201.07311, 2022.
Stella Biderman、Kieran Bicheno 和 Leo Gao。《The Pile数据集说明书》。arXiv预印本 arXiv:2201.07311,2022年。
Yirong Chen, Zhenyu Wang, Xiaofen Xing, huimin zheng, Zhipei Xu, Kai Fang, Junhong Wang, Sihang Li, Jieling Wu, Qi Liu, and Xiangmin Xu. Bianque: Balancing the questioning and suggestion ability of health llms with multi-turn health conversations polished by chatgpt, 2023a.
Yirong Chen, Zhenyu Wang, Xiaofen Xing, huimin zheng, Zhipei Xu, Kai Fang, Junhong Wang, Sihang Li, Jieling Wu, Qi Liu, and Xiangmin Xu. Bianque: 通过ChatGPT优化的多轮健康对话平衡健康大语言模型的提问与建议能力, 2023a.
Zeming Chen, Alejandro Hernández Cano, Angelika Romanou, Antoine Bonnet, Kyle Matoba, Francesco Salvi, Matteo Pag liard in i, Simin Fan, Andreas Köpf, Amirkeivan Mohtashami, et al. Meditron-70b: Scaling medical pre training for large language models. arXiv preprint arXiv:2311.16079, 2023b.
Zeming Chen, Alejandro Hernández Cano, Angelika Romanou, Antoine Bonnet, Kyle Matoba, Francesco Salvi, Matteo Pagliardini, Simin Fan, Andreas Köpf, Amirkeivan Mohtashami等。Meditron-70b: 大语言模型的医疗预训练扩展。arXiv预印本arXiv:2311.16079, 2023b。
Zhihong Chen, Feng Jiang, Junying Chen, Tiannan Wang, Fei Yu, Guiming Chen, Hongbo Zhang, Juhao Liang, Chen Zhang, Zhiyi Zhang, et al. Phoenix: Democratizing chatgpt across languages. arXiv preprint arXiv:2304.10453, 2023c.
Zhihong Chen、Feng Jiang、Junying Chen、Tiannan Wang、Fei Yu、Guiming Chen、Hongbo Zhang、Juhao Liang、Chen Zhang、Zhiyi Zhang等。Phoenix: 跨语言普及ChatGPT。arXiv预印本arXiv:2304.10453,2023c。
Daixuan Cheng, Shaohan Huang, and Furu Wei. Adapting large language models via reading comprehension. arXiv preprint arXiv:2309.09530, 2023.
戴轩程、黄少晗、魏福如。基于阅读理解的大语言模型适配方法。arXiv预印本 arXiv:2309.09530,2023。
Jiaxi Cui, Zongjian Li, Yang Yan, Bohua Chen, and Li Yuan. Chatlaw: Open-source legal large language model with integrated external knowledge bases. arXiv preprint arXiv:2306.16092, 2023.
贾曦崔, 宗建李, 阳颜, 博华陈, 和莉袁. Chatlaw: 集成外部知识库的开源法律大语言模型. arXiv预印本 arXiv:2306.16092, 2023.
Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, et al. The pile: An 800gb dataset of diverse text for language modeling. arXiv preprint arXiv:2101.00027, 2020.
Leo Gao、Stella Biderman、Sid Black、Laurence Golding、Travis Hoppe、Charles Foster、Jason Phang、Horace He、Anish Thite、Noa Nabeshima等。The Pile:一个用于语言建模的800GB多样化文本数据集。arXiv预印本arXiv:2101.00027,2020。
Ian J Goodfellow, Mehdi Mirza, Da Xiao, Aaron Courville, and Yoshua Bengio. An empirical investigation of catastrophic forgetting in gradient-based neural networks. arXiv preprint arXiv:1312.6211, 2013.
Ian J Goodfellow、Mehdi Mirza、Da Xiao、Aaron Courville 和 Yoshua Bengio。基于梯度的神经网络中灾难性遗忘的实证研究。arXiv预印本 arXiv:1312.6211,2013。
Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, et al. Textbooks are all you need. arXiv preprint arXiv:2306.11644, 2023.
Suriya Gunasekar、Yi Zhang、Jyoti Aneja、Caio César Teodoro Mendes、Allie Del Giorno、Sivakanth Gopi、Mojan Javaheripi、Piero Kauffmann、Gustavo de Rosa、Olli Saarikivi等。《教科书即所需》。arXiv预印本arXiv:2306.11644,2023。
Yuzhen Huang, Yuzhuo Bai, Zhihao Zhu, Junlei Zhang, Jinghan Zhang, Tangjun Su, Junteng Liu, Chuancheng Lv, Yikai Zhang, Jiayi Lei, et al. C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models. arXiv preprint arXiv:2305.08322, 2023.
黄雨真, 白雨卓, 朱志豪, 张俊磊, 张靖涵, 苏堂峻, 刘俊腾, 吕传成, 张艺凯, 雷佳艺等. C-Eval: 面向基础模型的多层次多学科中文评估套件. arXiv预印本 arXiv:2305.08322, 2023.
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. What disease does this patient have? a large-scale open domain question answering dataset from medical exams. Applied Sciences, 11(14):6421, 2021.
Di Jin、Eileen Pan、Nassim Oufattole、Wei-Hung Weng、Hanyi Fang 和 Peter Szolovits。《这位患者患有何种疾病?基于医学考试构建的大规模开放域问答数据集》。Applied Sciences,11(14):6421,2021年。
Chuyi Kong, Yaxin Fan, Xiang Wan, Feng Jiang, and Benyou Wang. Large language model as a user simulator. arXiv preprint arXiv:2308.11534, 2023.
孔楚一, 范雅欣, 万翔, 蒋峰, 王本友. 大语言模型作为用户模拟器. arXiv预印本 arXiv:2308.11534, 2023.
Cheng Li, Ziang Leng, Chenxi Yan, Junyi Shen, Hao Wang, Weishi Mi, Yaying Fei, Xiaoyang Feng, Song Yan, HaoSheng Wang, et al. Chatharuhi: Reviving anime character in reality via large language model. arXiv preprint arXiv:2308.09597, 2023a.
Cheng Li, Ziang Leng, Chenxi Yan, Junyi Shen, Hao Wang, Weishi Mi, Yaying Fei, Xiaoyang Feng, Song Yan, HaoSheng Wang, 等. Chatharuhi: 基于大语言模型的动漫角色现实复现. arXiv预印本 arXiv:2308.09597, 2023a.
Haonan Li, Yixuan Zhang, Fajri Koto, Yifei Yang, Hai Zhao, Yeyun Gong, Nan Duan, and Timothy Baldwin. Cmmlu: Measuring massive multitask language understanding in chinese. arXiv preprint arXiv:2306.09212, 2023b.
Haonan Li、Yixuan Zhang、Fajri Koto、Yifei Yang、Hai Zhao、Yeyun Gong、Nan Duan 和 Timothy Baldwin。CMMLU: 中文大规模多任务语言理解评估。arXiv预印本 arXiv:2306.09212,2023b。
Jianquan Li, Xidong Wang, Xiangbo Wu, Zhiyi Zhang, Xiaolong Xu, Jie Fu, Prayag Tiwari, Xiang Wan, and Benyou Wang. Huatuo-26m, a large-scale chinese medical qa dataset. arXiv preprint arXiv:2305.01526, 2023c.
Jianquan Li、Xidong Wang、Xiangbo Wu、Zhiyi Zhang、Xiaolong Xu、Jie Fu、Prayag Tiwari、Xiang Wan和Benyou Wang。Huatuo-26m:一个大规模中文医疗问答数据集。arXiv预印本arXiv:2305.01526,2023c。
Xian Li, Ping Yu, Chunting Zhou, Timo Schick, Luke Z ett le moyer, Omer Levy, Jason Weston, and Mike Lewis. Self-alignment with instruction back translation. arXiv preprint arXiv:2308.06259, 2023d.
Xian Li、Ping Yu、Chunting Zhou、Timo Schick、Luke Zettlemoyer、Omer Levy、Jason Weston 和 Mike Lewis。基于指令回译的自对齐方法。arXiv预印本 arXiv:2308.06259,2023年。
Yuanzhi Li, Sébastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar, and Yin Tat Lee. Textbooks are all you need ii: phi-1.5 technical report. arXiv preprint arXiv:2309.05463, 2023e.
Yuanzhi Li、Sébastien Bubeck、Ronen Eldan、Allie Del Giorno、Suriya Gunasekar和Yin Tat Lee。《教科书即所需 II:phi-1.5技术报告》。arXiv预印本arXiv:2309.05463,2023年。
Junling Liu, Peilin Zhou, Yining Hua, Dading Chong, Zhongyu Tian, Andrew Liu, Helin Wang, Chenyu You, Zhenhua Guo, Lei Zhu, et al. Benchmarking large language models on cmexam–a comprehensive chinese medical exam dataset. arXiv preprint arXiv:2306.03030, 2023.
Junling Liu、Peilin Zhou、Yining Hua、Dading Chong、Zhongyu Tian、Andrew Liu、Helin Wang、Chenyu You、Zhenhua Guo、Lei Zhu 等。大语言模型在CMExam上的基准测试——一个全面的中文医学考试数据集。arXiv预印本 arXiv:2306.03030,2023。
OpenAI. Introducing chatgpt. https://openai.com/blog/chatgpt, 2022.
OpenAI. 发布 ChatGPT. https://openai.com/blog/chatgpt, 2022.
OpenAI. Gpt-4 technical report, 2023.
OpenAI. GPT-4技术报告, 2023.
Ankit Pal, Logesh Kumar Umapathi, and Malai kann an Sankara sub bu. Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering. In Conference on Health, Inference, and Learning, pp. 248–260. PMLR, 2022.
Ankit Pal、Logesh Kumar Umapathi 和 Malai kann an Sankara sub bu。Medmcqa: 面向医疗领域问答的大规模多学科多选题数据集。In Conference on Health, Inference, and Learning, pp. 248–260. PMLR, 2022。
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. The Journal of Machine Learning Research, 21(1):5485–5551, 2020.
Colin Raffel、Noam Shazeer、Adam Roberts、Katherine Lee、Sharan Narang、Michael Matena、Yanqi Zhou、Wei Li 和 Peter J Liu。探索文本到文本Transformer (text-to-text transformer) 迁移学习的极限。《机器学习研究期刊》,21(1):5485–5551, 2020。
Yu Sun, Shuohuan Wang, Shikun Feng, Siyu Ding, Chao Pang, Junyuan Shang, Jiaxiang Liu, Xuyi Chen, Yanbin Zhao, Yuxiang Lu, et al. Ernie 3.0: Large-scale knowledge enhanced pre-training for language understanding and generation. arXiv preprint arXiv:2107.02137, 2021.
Yu Sun, Shuohuan Wang, Shikun Feng, Siyu Ding, Chao Pang, Junyuan Shang, Jiaxiang Liu, Xuyi Chen, Yanbin Zhao, Yuxiang Lu, 等. ERNIE 3.0: 面向语言理解与生成的大规模知识增强预训练. arXiv预印本 arXiv:2107.02137, 2021.
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
Hugo Touvron、Louis Martin、Kevin Stone、Peter Albert、Amjad Almahairi、Yasmine Babaei、Nikolay Bashlykov、Soumya Batra、Prajjwal Bhargava、Shruti Bhosale等。Llama 2:开放基础与微调对话模型。arXiv预印本arXiv:2307.09288,2023。
Benyou Wang, Qianqian Xie, Jiahuan Pei, Zhihong Chen, Prayag Tiwari, Zhao Li, and Jie Fu. Pretrained language models in biomedical domain: A systematic survey. ACM Computing Surveys, 56(3):1–52, 2023a.
Benyou Wang、Qianqian Xie、Jiahuan Pei、Zhihong Chen、Prayag Tiwari、Zhao Li和Jie Fu。生物医学领域的预训练语言模型:系统性综述。ACM Computing Surveys,56(3):1–52,2023a。
A Related Work
相关工作
A.1 Domain adaption
A.1 领域自适应
Recent research has also indicated that such domain adaption using further training Cheng et al., 2023 leads to a drastic drop despite still benefiting fine-tuning evaluation and knowledge probing tests. This inspires us to design a different protocol for domain adaption. Also, Gunasekar et al. (2023); Li et al. (2023e); Chen et al. (2023c); Kong et al. (2023) show a possibility that the 10B well-selected dataset could achieve comparable performance to a much larger model.
近期研究还表明,尽管这种通过额外训练实现的领域适应(Cheng等人,2023)仍有助于微调评估和知识探测测试,但会导致性能急剧下降。这启发我们设计了一种不同的领域适应方案。此外,Gunasekar等人(2023)、Li等人(2023e)、Chen等人(2023c)和Kong等人(2023)的研究表明,经过精心筛选的100亿规模数据集有可能达到与更大模型相媲美的性能。
A.2 Medical LLMs
A.2 医疗大语言模型
The rapid advancement of large language models (LLMs) in Chinese medical field is driven by the release of open-source Chinese LLMs, notably trained via instruction fine-tuning. DoctorGLM (Xiong et al., 2023) and MedicalGPT (Xu, 2023) are fine-tuned on various Chinese and English medical dialogue datasets. Another Chinese medical LLM, BenTsao (Wang et al., 2023b) is finetuned on distilled data derived from knowledge graphs. Bianque-2 (Chen et al., 2023a) includes multiple rounds of medical expansions, encompassing drug instructions and encyclopedia knowledge instructions. ChatMed-Consult (Zhu & Wang, 2023) is fine-tuned on both Chinese online consultation data and ChatGPT responses. DISC-MedLLM (Bao et al., 2023) is fine-tuned on more than 470,000 medical data including doctor-patient dialogues and knowledge QA pairs.
开源中文大语言模型的发布,尤其是基于指令微调训练的模型,推动了中文医疗领域大语言模型的快速发展。DoctorGLM (Xiong et al., 2023) 和 MedicalGPT (Xu, 2023) 在多种中英文医疗对话数据集上进行了微调。另一款中文医疗大语言模型 BenTsao (Wang et al., 2023b) 则基于知识图谱蒸馏数据进行了优化。Bianque-2 (Chen et al., 2023a) 包含多轮医学扩展,涵盖药品说明书和百科知识指令。ChatMed-Consult (Zhu & Wang, 2023) 同时微调了中文在线问诊数据和 ChatGPT 生成内容。DISC-MedLLM (Bao et al., 2023) 在超过 47 万条医患对话和知识问答对组成的医疗数据上进行了训练。
By integrating the reinforcement learning, HuatuoGPT (Zhang et al., 2023) is fine-tuned on a 220,000 medical dataset consisting of ChatGPT-distilled instructions and dialogues alongside real doctorpatient single-turn Q&As and multi-turn dialogues. ZhongJing (Yang et al., 2023b) undergoes a comprehensive three-stage training process: continuous pre-training on various medical data, instruction fine-tuning on single-turn and multi-turn dialogue data as well as medical NLP tasks data, and reinforcement learning adjudicated by experts to ensure reliability and safety.
通过整合强化学习技术,华佗GPT (Zhang et al., 2023) 在22万条医疗数据集上进行了微调,该数据集包含ChatGPT蒸馏的指令对话、真实医患单轮问答及多轮对话。仲景 (Yang et al., 2023b) 采用三阶段训练流程:基于多样化医疗数据的持续预训练、针对单轮/多轮对话数据及医疗NLP任务数据的指令微调、以及由专家监督的强化学习以确保可靠性与安全性。
B Supplementary Experiment
B 补充实验
Table 4: The results of Chinese National Medical Licensing Examinations. The year represents the actual examination year. Note that the exam here may not be complete, and the blue fonts indicates the number of questions.
| Model | TraditionalChineseMedicine | Clinical | Avg. | |||||||||||||
| Assistant | Physician | Pharmacist | Assistant | Physician | ||||||||||||
| 2015 (300) | 2016 (220) | 2017 (116) | 2012 (600) | 2013 (600) | 2016 (430) | 2017 2018 (168) (167) | 2019 (223) | 2018 | 2019 (234) (244) | 2020 (244) | 2018 | 2019 (449) (476) | 2020 (436) | |||
| HuatuoGPT | 26.0 | 30.9 | 32.8 | 31.3 | 26.8 | 30.2 | 18.4 | 27.5 | 25.1 | 32.5 | 33.6 | 27.5 | 32.7 | 28.6 | 30.1 | 28.9 |
| DISC-MedLLM | 38.3 | 41.8 | 26.7 | 36.2 | 38.7 | 35.1 | 25.0 | 22.2 | 22.0 | 49.2 | 36.1 | 41.8 | 41.4 | 36.6 | 35.8 | 35.1 |
| ChatGLM3-6B | 45.7 | 45.0 | 50.0 | 46.3 | 45.8 | 46.5 | 42.3 | 28.1 | 35.4 | 50.9 | 48.8 | 43.9 | 41.7 | 43.9 | 43.6 | 43.9 |
| Baichuan2-7B-Chat | 57.3 | 57.3 | 58.6 | 55.7 | 58.5 | 57.9 | 41.7 | 41.9 | 45.7 | 61.1 | 55.7 | 55.3 | 51.0 | 53.6 | 50.0 | 53.4 |
| Baichuan2-13B-Chat | 64.7 | 58.2 | 62.9 | 61.7 | 61.5 | 63.3 | 54.2 | 38.9 | 48.4 | 66.2 | 64.8 | 63.1 | 65.9 | 58.8 | 61.5 | 59.6 |
| Qwen-7B-Chat | 54.7 | 55.9 | 56.0 | 52.7 | 53.5 | 54.4 | 44.0 | 33.5 | 43.0 | 68.8 | 63.9 | 57.8 | 60.6 | 57.6 | 54.1 | 54.0 |
| Qwen-14B-Chat | 65.3 | 63.2 | 67.2 | 64.8 | 63.3 | 67.9 | 54.8 | 49.1 | 52.5 | 74.8 | 75.0 | 69.3 | 73.7 | 69.7 | 68.8 | 65.3 |
| ERNIE Bot (API) | 73.3 | 66.3 | 73.3 | 70.0 | 71.8 | 66.7 | 55.9 | 50.3 | 60.0 | 78.2 | 77.0 | 77.5 | 66.6 | 70.8 | 74.1 | 68.8 |
| ChatGPT (API) | 46.0 | 36.4 | 41.4 | 36.7 | 38.5 | 40.5 | 32.1 | 28.1 | 30.0 | 63.3 | 57.8 | 53.7 | 53.7 | 52.5 | 51.8 | 44.2 |
| GPT-4 (API) | 47.3 | 48.2 | 53.5 | 50.3 | 53.7 | 54.2 | 41.1 | 43.7 | 48.0 | 79.9 | 72.5 | 70.9 | 74.8 | 73.1 | 68.4 | 58.6 |
| HuatuoGPT-II(7B) | 67.1 | 65.2 | 67.5 | 67.9 | 67.4 | 64.9 | 53.0 | 46.7 | 51.0 | 70.9 | 73.2 | 69.4 | 68.8 | 66.5 | 67.7 | 64.5 |
| HuatuoGPT-II(13B) | 70.3 | 70.0 | 71.6 | 71.0 | 69.2 | 70.2 | 56.5 | 52.1 | 54.7 | 73.1 | 76.6 | 70.1 | 72.8 | 68.9 | 72.2 | 68.0 |
表 4: 中国国家医学资格考试结果。年份代表实际考试年份。请注意,此处列出的考试可能不完整,蓝色字体表示题目数量。
| 模型 | 中医 | 临床 | 平均 | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 助理 | 医师 | 药师 | 助理 | 医师 | ||||||||||||
| 2015 (300) | 2016 (220) | 2017 (116) | 2012 (600) | 2013 (600) | 2016 (430) | 2017 2018 (168) (167) | 2019 (223) | 2018 | 2019 (234) (244) | 2020 (244) | 2018 | 2019 (449) (476) | 2020 (436) | |||
| HuatuoGPT | 26.0 | 30.9 | 32.8 | 31.3 | 26.8 | 30.2 | 18.4 | 27.5 | 25.1 | 32.5 | 33.6 | 27.5 | 32.7 | 28.6 | 30.1 | 28.9 |
| DISC-MedLLM | 38.3 | 41.8 | 26.7 | 36.2 | 38.7 | 35.1 | 25.0 | 22.2 | 22.0 | 49.2 | 36.1 | 41.8 | 41.4 | 36.6 | 35.8 | 35.1 |
| ChatGLM3-6B | 45.7 | 45.0 | 50.0 | 46.3 | 45.8 | 46.5 | 42.3 | 28.1 | 35.4 | 50.9 | 48.8 | 43.9 | 41.7 | 43.9 | 43.6 | 43.9 |
| Baichuan2-7B-Chat | 57.3 | 57.3 | 58.6 | 55.7 | 58.5 | 57.9 | 41.7 | 41.9 | 45.7 | 61.1 | 55.7 | 55.3 | 51.0 | 53.6 | 50.0 | 53.4 |
| Baichuan2-13B-Chat | 64.7 | 58.2 | 62.9 | 61.7 | 61.5 | 63.3 | 54.2 | 38.9 | 48.4 | 66.2 | 64.8 | 63.1 | 65.9 | 58.8 | 61.5 | 59.6 |
| Qwen-7B-Chat | 54.7 | 55.9 | 56.0 | 52.7 | 53.5 | 54.4 | 44.0 | 33.5 | 43.0 | 68.8 | 63.9 | 57.8 | 60.6 | 57.6 | 54.1 | 54.0 |
| Qwen-14B-Chat | 65.3 | 63.2 | 67.2 | 64.8 | 63.3 | 67.9 | 54.8 | 49.1 | 52.5 | 74.8 | 75.0 | 69.3 | 73.7 | 69.7 | 68.8 | 65.3 |
| ERNIE Bot (API) | 73.3 | 66.3 | 73.3 | 70.0 | 71.8 | 66.7 | 55.9 | 50.3 | 60.0 | 78.2 | 77.0 | 77.5 | 66.6 | 70.8 | 74.1 | 68.8 |
| ChatGPT (API) | 46.0 | 36.4 | 41.4 | 36.7 | 38.5 | 40.5 | 32.1 | 28.1 | 30.0 | 63.3 | 57.8 | 53.7 | 53.7 | 52.5 | 51.8 | 44.2 |
| GPT-4 (API) | 47.3 | 48.2 | 53.5 | 50.3 | 53.7 | 54.2 | 41.1 | 43.7 | 48.0 | 79.9 | 72.5 | 70.9 | 74.8 | 73.1 | 68.4 | 58.6 |
| HuatuoGPT-II(7B) | 67.1 | 65.2 | 67.5 | 67.9 | 67.4 | 64.9 | 53.0 | 46.7 | 51.0 | 70.9 | 73.2 | 69.4 | 68.8 | 66.5 | 67.7 | 64.5 |
| HuatuoGPT-II(13B) | 70.3 | 70.0 | 71.6 | 71.0 | 69.2 | 70.2 | 56.5 | 52.1 | 54.7 | 73.1 | 76.6 | 70.1 | 72.8 | 68.9 | 72.2 | 68.0 |
Chinese Medical Licensing Examination To evaluate HuatuoGPT-II’s medical competence, we utilize a dataset comprising medical examination questions from China and the United States. This approach aims to measure the model’s adaptability and proficiency across varied medical knowledge frameworks and terminologies. The results of the Chinese National Medical Licensing Examination are outlined in Table 4. In the results, HuatuoGPT-II (13B) not only surpassed all open-source models but also closely approached the performance of the leading proprietary model, ERNIE Bot. This notable outcome reflects the model’s advanced understanding of Chinese medical principles and its adeptness in applying this knowledge in complex examination contexts. The 13B variant’s elevated scores signify enhanced analytical capabilities and deeper comprehension of the nuances inherent in Chinese medical practice.
中国执业医师资格考试
为评估华佗GPT-II的医学能力,我们采用了包含中美两国医学考试题目的数据集。该方法旨在衡量模型在不同医学知识框架和术语体系中的适应性与熟练度。中国国家医学资格考试结果如 表 4 所示。结果显示,华佗GPT-II (13B)不仅超越了所有开源模型,还显著逼近了领先的专有模型ERNIE Bot的表现。这一突出成果反映了该模型对中文医学原理的深刻理解,以及在复杂考试场景中灵活应用知识的能力。13B版本更高的分数标志着其分析能力的提升,以及对中文医疗实践细节更深入的理解。
CMB-Clin CMB-Clin is a dataset designed to evaluate the Clinical Diagnostic capabilities of LLMs, based on 74 classical complex and real-world cases derived from textbooks. Distinct from the response quality evaluations, CMB-Clin provides standard answers for reference and scores each model individually. We follow the same evaluation strategy from the original paper which utilizes GPT-4 as the evaluator. Results, as delineated in Table 5, indicate that HuatuoGPT-II outperforms its counterparts, excluding GPT-4. Intriguingly, the 7B version of HuatuoGPT-II demonstrates superior efficacy over its 13B variant, a phenomenon potentially attributable to foundational capacity variances, as evidenced by Baichuan2-7B-Chat’s superior performance compared to Baichuan2-13BChat.
CMB-Clin
CMB-Clin是一个用于评估大语言模型(LLM)临床诊断能力的数据集,包含74个源自教科书的经典复杂真实病例。与回答质量评估不同,CMB-Clin提供标准参考答案并对每个模型单独评分。我们沿用原论文的评估策略,使用GPT-4作为评估器。如表5所示,除GPT-4外,华佗GPT-II表现优于其他模型。值得注意的是,华佗GPT-II的7B版本展现出优于13B版本的效能,这一现象可能与基础能力差异有关——百川2-7B-Chat的表现同样优于百川2-13B-Chat[20]佐证了该推测。
Table 5: Results of CMB-Clin on Automatic Evaluation using GPT-4.
| Model | Fluency | Relevance | Completeness | Proficiency | Avg.↑ |
| GPT-4 | 4.95 | 4.71 | 4.35 | 4.66 | 4.67 |
| HuatuoGPT-II (7B) | 4.94 | 4.56 | 4.24 | 4.46 | 4.55 |
| ERNIEBot | 4.92 | 4.53 | 4.16 | 4.55 | 4.54 |
| ChatGPT | 4.97 | 4.49 | 4.12 | 4.53 | 4.53 |
| HuatuoGPT-II(13B) | 4.92 | 4.38 | 4.00 | 4.40 | 4.43 |
| Baichuan2-7B-Chat | 4.93 | 4.41 | 4.03 | 4.36 | 4.43 |
| Qwen-14B-Chat | 4.90 | 4.35 | 3.93 | 4.48 | 4.41 |
| Qwen-7B-Chat | 4.94 | 4.17 | 3.67 | 4.33 | 4.28 |
| Baichuan2-13B-Chat | 4.88 | 4.18 | 3.78 | 4.27 | 4.28 |
| ChatGLM3-6B | 4.92 | 4.11 | 3.74 | 4.23 | 4.25 |
| HuatuoGPT | 4.89 | 3.76 | 3.38 | 3.86 | 3.97 |
| DISC-MedLLM | 4.82 | 3.24 | 2.75 | 3.51 | 3.58 |
表 5: CMB-Clin 使用 GPT-4 进行自动评估的结果
| 模型 | 流畅性 | 相关性 | 完整性 | 专业性 | 平均↑ |
|---|---|---|---|---|---|
| GPT-4 | 4.95 | 4.71 | 4.35 | 4.66 | 4.67 |
| HuatuoGPT-II (7B) | 4.94 | 4.56 | 4.24 | 4.46 | 4.55 |
| ERNIEBot | 4.92 | 4.53 | 4.16 | 4.55 | 4.54 |
| ChatGPT | 4.97 | 4.49 | 4.12 | 4.53 | 4.53 |
| HuatuoGPT-II(13B) | 4.92 | 4.38 | 4.00 | 4.40 | 4.43 |
| Baichuan2-7B-Chat | 4.93 | 4.41 | 4.03 | 4.36 | 4.43 |
| Qwen-14B-Chat | 4.90 | 4.35 | 3.93 | 4.48 | 4.41 |
| Qwen-7B-Chat | 4.94 | 4.17 | 3.67 | 4.33 | 4.28 |
| Baichuan2-13B-Chat | 4.88 | 4.18 | 3.78 | 4.27 | 4.28 |
| ChatGLM3-6B | 4.92 | 4.11 | 3.74 | 4.23 | 4.25 |
| HuatuoGPT | 4.89 | 3.76 | 3.38 | 3.86 | 3.97 |
| DISC-MedLLM | 4.82 | 3.24 | 2.75 | 3.51 | 3.58 |
USMLE The United States Medical Licensing Examination (USMLE) outcomes, as delineated in Table 6, reveal that HuatuoGPT-II (13B) outperforms comparative open-source models. Despite a discernible disparity with ChatGPT, it is important to note that the USMLE’s English-centric nature imposes constraints on HuatuoGPT-II, primarily designed for Chinese medical contexts. However, its commendable performance in the USMLE underscores its proficiency in employing medical knowledge across diverse scenarios, effectively addressing the range of challenges posed by the USMLE.
美国医师执照考试 (USMLE) 结果如表 6 所示,华佗GPT-II (13B) 的表现优于其他开源模型。尽管与 ChatGPT 存在明显差距,但需注意 USMLE 以英语为主的特性对主要面向中文医疗场景设计的华佗GPT-II 形成了限制。然而,其在 USMLE 中的出色表现印证了该模型跨场景运用医学知识的能力,能有效应对 USMLE 提出的各类挑战。
C Domain Corpus Collection
C 领域语料库收集
Domain corpus is pivotal for augmenting domain-specific expertise. Domain data necessitates a comprehensive collection of high-quality and domain-specific content, surpassing the scope of the
领域语料库对于增强领域专业知识至关重要。领域数据需要全面收集高质量且具有领域针对性的内容,其范围远超...
| Models | Stagel (6308) | Stage2&3 (5148) | Avg. (11456) |
| HuatuoGPT | 28.68 | 28.38 | 28.54 |
| ChatGLM3-6B | 33.39 | 32.49 | 32.98 |
| Baichuan2-7B-Chat | 38.11 | 37.32 | 37.76 |
| Baichuan2-13B-Chat | 44.99 | 45.57 | 45.25 |
| Qwen-7B-Chat | 40.90 | 36.09 | 38.73 |
| Qwen-14B-Chat | 48.73 | 42.45 | 45.90 |
| ChatGPT (API) | 57.04 | 56.27 | 56.69 |
| HuatuoGPT-II(7B) | 45.72 | 44.45 | 45.15 |
| HuatuoGPT-II(13B) | 47.34 | 49.37 | 48.25 |
| 模型 | 阶段1 (6308) | 阶段2&3 (5148) | 平均值 (11456) |
|---|---|---|---|
| HuatuoGPT | 28.68 | 28.38 | 28.54 |
| ChatGLM3-6B | 33.39 | 32.49 | 32.98 |
| Baichuan2-7B-Chat | 38.11 | 37.32 | 37.76 |
| Baichuan2-13B-Chat | 44.99 | 45.57 | 45.25 |
| Qwen-7B-Chat | 40.90 | 36.09 | 38.73 |
| Qwen-14B-Chat | 48.73 | 42.45 | 45.90 |
| ChatGPT (API) | 57.04 | 56.27 | 56.69 |
| HuatuoGPT-II(7B) | 45.72 | 44.45 | 45.15 |
| HuatuoGPT-II(13B) | 47.34 | 49.37 | 48.25 |

Figure 8: Domain Data collection. Figure 9: Summary of the Medical Pre-training Corpus.
图 8: 领域数据收集。图 9: 医学预训练语料库概述。
| Type of Data | #Doc | Source |
| Chinese | ||
| WebCorpus | 640,621 | Wudao |
| Books Encyclopedia | 1,802,517 411,183 | Textbook Online Encyclopedia |
| Literature | 177,261 | ChineseLiterature |
| English | ||
| Web Corpus | 394,490 | C4 |
| Books | 801,522 | Textbook, |
| Encyclopedia | 147,059 | the_ pile_ books3 Wikipida |
| Literature | 878,241 | PubMed |
| Total | 5,252,894 |
| 数据类型 | 文档数量 | 来源 |
|---|---|---|
| 中文 | ||
| 网络语料 | 640,621 | Wudao |
| 书籍百科 | 1,802,517 | Textbook Online Encyclopedia |
| 411,183 | ||
| 文学作品 | 177,261 | ChineseLiterature |
| 英文 | ||
| 网络语料 | 394,490 | C4 |
| 书籍 | 801,522 | Textbook |
| 百科全书 | 147,059 | the_ pile_ books3 Wikipida |
| 文学作品 | 878,241 | PubMed |
| 总计 | 5,252,894 |
foundational corpus. We identified four primary data types for extensive collection: encyclopedias, books, academic literature, and web content. Focusing on these categories, we amassed 1.1TB of Chinese and English data, as shown in Table 9.
基础语料库。我们确定了四种主要数据类型进行大规模收集:百科全书、书籍、学术文献和网络内容。聚焦这些类别,我们积累了1.1TB的中英文数据,如表9所示。
The domain data collection pipeline is an essential part of ensuring the quality of domain language corpora, designed to extract high-quality and diverse domain corpora from large-scale corpora. The methodology encompasses four primary steps:
领域数据收集流程是确保领域语言语料质量的关键环节,旨在从大规模语料中提取高质量、多样化的领域语料。该方法包含四个主要步骤:
- Extract Medical Corpus: This process aims to remove irrelevant domain corpora, serving as the first step in filtering massive corpora. We employ a dictionary-based approach, obtaining dictionaries containing medical vocabulary from THUOCL5 and The SPECIALIST Lexicon6 from the Unified Medical Language System. We strive to exclude non-medical terms to form a domain-specific dictionary. For each text segment, we evaluate whether it’s domain-specific by assessing the density of matched domain words from the dictionary. This dictionary method is an effective and efficient way to extract domain text.
- 提取医学语料库:该流程旨在去除无关领域的语料,作为海量语料筛选的第一步。我们采用基于词典的方法,从THUOCL5和统一医学语言系统中的SPECIALIST Lexicon6获取包含医学术语的词典。通过排除非医学术语,力求构建专业领域词典。针对每个文本片段,我们通过评估词典中匹配领域词汇的密度来判断其领域相关性。这种词典方法是提取领域文本高效且有效的方式。
Our data sources consist of four categories: (1) Web Corpus, which includes C4 (Raffel et al., 2020) and Wudao (Yuan et al., 2021); (2) Books, primarily comprising Textbook and the pile books 3(Gao et al., 2020); (3) Encyclopedia, encompassing Chinese Medical Encyclopedia and Wikipedia; (4) Medical Literature, which consists of PubMed and Chinese literature. Following the aforementioned steps, the corpus is converted into 5,252K of instruction data.
我们的数据源包含四类:(1) 网络语料库,包括C4 (Raffel et al., 2020) 和悟道 (Yuan et al., 2021);(2) 书籍,主要涵盖教科书和The Pile书籍 (Gao et al., 2020);(3) 百科全书,包含中国医学百科全书和维基百科;(4) 医学文献,由PubMed和中文文献组成。通过上述步骤,语料库被转化为5252K条指令数据。
D Example of Data Unification
D 数据统一示例
Table 7 illustrates the process of generating instruction and response based on documents in Data Unification.
表 7: 展示了基于数据统一(Data Unification)中文档生成指令和响应的过程。
Table 7: An example of our final SFT data.
| Description | content |
| RawData(fromEn- glishTextbook) | It is one of themost frequent mentalillnesses,making up alarge proportion of persons in assisted living and skilled nursingfacilities.AlthoughAlzheimer diseasehasbeendescribed ateveryperiod of adult life,the majority ofpatients arein theirsixtiesor older; arelatively small numberhavebeenin theirlatefifties or younger.... |
| QueryofDataUnifica- tion | 什么是阿尔茨海默病的主要临床和病理特征?(Translation:Whatarethemainclinicalandpathologicalfeatures ofAlzheimer'sdisease?) |
| AnswerofDataUnifi- cation | 阿尔茨海默病是一种最常见的精神疾病,占据了较大比例的辅助生活和专业护理设施的人群。虽然阿尔茨 海默病在成年期的各个阶段都可能出现,但大多数患者在六十岁或以上;只有一小部分在五十多岁甚至更年 轻...(Translation:Alzheimer's disease is one of themost common mentalillnesses,occupying a larger percentage ofthepopulationinassistedlivingandskillednursingfacilities.AlthoughAlzheimer'sdiseasecanoccur at all stages of adulthood,most patients arein their sixties or older; only a small percentage arein their fifties or even younger...) |
表 7: 最终SFT数据示例
| 描述 | 内容 |
|---|---|
| 原始数据 (来自英语教材) | It is one of themost frequent mentalillnesses,making up alarge proportion of persons in assisted living and skilled nursingfacilities.AlthoughAlzheimer diseasehasbeendescribed ateveryperiod of adult life,the majority ofpatients arein theirsixtiesor older; arelatively small numberhavebeenin theirlatefifties or younger.... |
| 数据统一查询 | 什么是阿尔茨海默病的主要临床和病理特征?(Translation:Whatarethemainclinicalandpathologicalfeatures ofAlzheimer'sdisease?) |
| 数据统一回答 | 阿尔茨海默病是一种最常见的精神疾病,占据了较大比例的辅助生活和专业护理设施的人群。虽然阿尔茨海默病在成年期的各个阶段都可能出现,但大多数患者在六十岁或以上;只有一小部分在五十多岁甚至更年轻...(Translation:Alzheimer's disease is one of themost common mentalillnesses,occupying a larger percentage ofthepopulationinassistedlivingandskillednursingfacilities.AlthoughAlzheimer'sdiseasecanoccur at all stages of adulthood,most patients arein their sixties or older; only a small percentage arein their fifties or even younger...) |
E Pre-training Instruction: Knowledge Provision
E 预训练指令:知识提供
As shown in Section 3.1, we use external LLMs (like ChatGPT) for data unification for two main purposes:
如第3.1节所示,我们使用外部大语言模型(如ChatGPT)进行数据统一主要出于两个目的:
- Data Unification using ChatGPT: The primary data source at this stage is raw medical corpora, not ChatGPT. ChatGPT is merely utilized for data refinement and back translation. Its function is similar to rule-based data polishing software or a fine-tuned T5 model, where medical expertise is not essential. We will subsequently present a case study using ’Baichuan2-Chat ${\dot{7}}\mathrm{B^{\prime}}$ as an alternative for data unification.
- 使用ChatGPT进行数据统一:现阶段的主要数据源是原始医学语料库,而非ChatGPT。ChatGPT仅用于数据精炼和回译,其功能类似于基于规则的数据抛光软件或微调后的T5模型,无需具备医学专业知识。后续我们将以"百川2-Chat ${\dot{7}}\mathrm{B^{\prime}}$"为例展示替代性数据统一方案。
- Fine-tuning Datasets using GPT-4 and ChatGPT: Our fine-tuning data and ShareGPT are used to train our model to follow instructions and engage in conversation. However, they don’t significantly contribute to the medical knowledge of our model. This aligns with the ’Superficial Alignment Hypothesis’, suggesting that a model’s knowledge and capabilities are primarily derived during its pre-training phase. Instruction fine-tuning mainly guides the model to apply specific formats and styles during user interaction, rather than substantially enhancing its knowledge base.
- 使用GPT-4和ChatGPT进行微调数据集:我们的微调数据和ShareGPT用于训练模型遵循指令并进行对话。但它们对模型的医学知识贡献有限。这与"表层对齐假说"一致,即模型的知识和能力主要来自预训练阶段。指令微调主要引导模型在用户交互时采用特定格式和风格,而非显著扩充其知识库。
To illustrate, we conduct experiments to deeply analyze how using external large models affects HautuoGPT-II’s medical knowledge. We sample 1/40 of our pre-training and fine-tuning data to assess their impact on the model’s medical capability:
为了说明这一点,我们通过实验深入分析了使用外部大模型对HautuoGPT-II医学知识的影响。我们采样了预训练和微调数据的1/40,以评估它们对模型医学能力的影响:
Table 8: Experiment on data scale.
| Exper. No. | # Fine-Tuning Data | # Pre-Training Data | 2023 Exam (Pharmacist) | 2023 Exam (TCM) |
| #1 | 3.6K | 131.3K | 38.9 | 37.7 |
| #2 | 3.6K + 60K | 131.3K | 37.7 | 38.1 |
| #3 | 3.6K | 131.3K+60K | 37.9 | 40.0 |
| #4 | 3.6K + 120K | 131.3K | 37.3 | 35.7 |
| #5 | 3.6K | 131.3K + 120K | 39.6 | 40.2 |
表 8: 数据规模实验
| 实验编号 | 微调数据量 | 预训练数据量 | 2023年考试(药师) | 2023年考试(中医) |
|---|---|---|---|---|
| #1 | 3.6K | 131.3K | 38.9 | 37.7 |
| #2 | 3.6K + 60K | 131.3K | 37.7 | 38.1 |
| #3 | 3.6K | 131.3K+60K | 37.9 | 40.0 |
| #4 | 3.6K + 120K | 131.3K | 37.3 | 35.7 |
| #5 | 3.6K | 131.3K + 120K | 39.6 | 40.2 |
The comparison between Experiments #4 and #5 shows that augmenting pre-training data is more effective than adding an equivalent amount of instruction tuning data. This suggests that the enhancement in medical knowledge benchmarks is primarily due to the raw data itself. ChatGPT play a role in transforming this raw data into formats that are more digestible for the trained LLMs, leading to our model outperforming ChatGPT and GPT-4 in medical benchmarks.
实验 #4 和 #5 的对比表明,增加预训练数据比添加等量的指令微调数据更有效。这说明医学知识基准的提升主要源于原始数据本身。ChatGPT 的作用是将这些原始数据转化为更易于训练的大语言模型消化的格式,从而使我们的模型在医学基准测试中优于 ChatGPT 和 GPT-4。
Furthermore, as outlined in Appendix M, leading Chinese medical models like DISC-MedLLM also employ ChatGPT and GPT-4 for their training data construction, yet our model surpasses them in domain benchmarks.
此外,如附录 M 所述,DISC-MedLLM 等领先的中国医疗模型也使用 ChatGPT 和 GPT-4 构建训练数据,但我们的模型在领域基准测试中表现更优。
F Data Unification without External LLMs
F 不依赖外部大语言模型的数据统一
To eliminate the performance improvement of our method caused by relying on external large language models, we experiment e with adapting Baichuan2-7B-Chat in the medical domain using our method, without the assistance of other LLMs. We randomly select $5%$ of the pre-training corpus and medical queries, using Baichuan2-7B-Chat itself for data unification and direct response to the SFT-data’s queries as fine-tuning data, a process we term as self-data-unification. The experiment is carried out as shown in Table F.
为消除我们方法因依赖外部大语言模型带来的性能提升,我们尝试在医疗领域使用Baichuan2-7B-Chat进行适配实验,全程未借助其他大语言模型。我们随机选取预训练语料库和医疗查询中$5%$的数据,利用Baichuan2-7B-Chat自身完成数据统一化处理,并直接响应SFT-data的查询作为微调数据,这一过程称为自数据统一(self-data-unification)。实验结果如 表 F 所示。
The results show that when using self-data-unification to perform self-data-unification, our method named One-stage Adaptation still exceeds Two-stage Adaptation by an average of 6.6 points. This
结果表明,在使用自数据统一(self-data-unification)执行自数据统一时,我们的One-stage Adaptation方法仍比Two-stage Adaptation平均高出6.6分。
demonstrates our method’s ability to function independently of other LLMs, effectively enhancing the model’s domain adaptation capabilities and outperforming traditional continuous pre-training.
| CMExam | 2023Exam (Pharmacist) | 2023 Exam (TCM) | |
| Two-stage Adaptation on Baichuan2-Chat-7B (Without Data-Unification) | 40.5 | 33.5 | 34.8 |
| Our One-stage Adaptation on Baichuan2-Chat-7B (WithData- Unification) | 48.3 | 40.0 | 40.3 |
展示了我们的方法能够独立于其他大语言模型运行,有效提升模型的领域适应能力,并优于传统的持续预训练。
| CMExam | 2023Exam (Pharmacist) | 2023 Exam (TCM) | |
|---|---|---|---|
| 两阶段适应 Baichuan2-Chat-7B (无数据统一) | 40.5 | 33.5 | 34.8 |
| 我们的一阶段适应 Baichuan2-Chat-7B (带数据统一) | 48.3 | 40.0 | 40.3 |
Moreover, we find even Baichuan2-7B-Chat demonstrates a good ability to perform data-unification, as shown in the Table 10:
此外,我们发现即使Baichuan2-7B-Chat也展现出良好的数据统一能力,如表10所示:
Table 9: Adaptation gaps between Two-stage and On-stage adaptation.
| Description | content |
| Raw Data(from PubMed) | Thefunctional andstructuralalterationsofthestriatuminchronicspontaneousurticaria.Thebrainhaslongbeen known to be the regulation center of itch, but the neuropathology of chronic itch, su ch as chronic spontaneous urticaria(CSU).. |
| QueryofDataUnifi- cation( (Generatedby Baichuan2-7B-Chat) | ationsin the activity and structure of brainregions associated with clinical symptomsin chronic spontaneousurticaria (CSU)?) |
| AnswerofDataUni- fication(Generatedby Baichuan2-7B-Chat) | 在慢性自发性荨麻疹(CSU)中,确实存在与临床症状相关的脑区活性和结构改变。研究表明,大脑特别是纹状 体(striatum)在调节癌痒方面起着关键作用。对于慢性癌痒,如慢性自发性荨麻疹(CSU)..(Translation:In chronic spontaneousurticaria(CSU),alterationsinthe activity andstructure ofbrainregions associatedwithclinical symptoms do exist.Studies have shown that the brain, especially the striatum (striatum), plays a key role in the regulation of itch.For chronicitch,such as chronic spontaneousurticaria(CSU).) |
表 9: 两阶段与单阶段适应的差距对比
| 描述 | 内容 |
|---|---|
| 原始数据(来自PubMed) | Thefunctional andstructuralalterationsofthestriatuminchronicspontaneousurticaria.Thebrainhaslongbeen known to be the regulation center of itch, but the neuropathology of chronic itch, su ch as chronic spontaneous urticaria(CSU).. |
| 数据统一查询(由Baichuan2-7B-Chat生成) | ationsin the activity and structure of brainregions associated with clinical symptomsin chronic spontaneousurticaria (CSU)?) |
| 数据统一回答(由Baichuan2-7B-Chat生成) | 在慢性自发性荨麻疹(CSU)中,确实存在与临床症状相关的脑区活性和结构改变。研究表明,大脑特别是纹状体(striatum)在调节癌痒方面起着关键作用。对于慢性癌痒,如慢性自发性荨麻疹(CSU)..(Translation:In chronic spontaneousurticaria(CSU),alterationsinthe activity andstructure ofbrainregions associatedwithclinical symptoms do exist.Studies have shown that the brain, especially the striatum (striatum), plays a key role in the regulation of itch.For chronicitch,such as chronic spontaneousurticaria(CSU).) |
G Ablation Study of Data Unification
G 数据统一化的消融研究
Table 10: An example of QA data generated by Baichuan2-7B-Chat.
| Setting | CMExam | 2023Exam (Pharmacist) | 2023Exam (TCM) |
| Two-stage, Without Data Unification | 50.5 | 38.8 | 38.3 |
| One-stage, Without Data Unification | 49.3 | 37.2 | 35.6 |
| One-stage, With Data Unification | 53.4 | 39.7 | 40.2 |
表 10: Baichuan2-7B-Chat 生成的问答数据示例。
| Setting | CMExam | 2023Exam (Pharmacist) | 2023Exam (TCM) |
|---|---|---|---|
| Two-stage, Without Data Unification | 50.5 | 38.8 | 38.3 |
| One-stage, Without Data Unification | 49.3 | 37.2 | 35.6 |
| One-stage, With Data Unification | 53.4 | 39.7 | 40.2 |
Table 11: Performance comparison: with vs. without Data Unification.
表 11: 性能对比: 使用数据统一化与未使用数据统一化
To validate the importance of Data Unification, we conducted an ablation study on Data Unification using a reduced dataset $'5%$ due to time constraints) as shown in figure G.
为验证数据统一化(Data Unification)的重要性,我们使用缩减后的数据集(由于时间限制仅保留5%)进行了消融实验,如图G所示。
The results emphasize the importance of Data Unification. Without it, the single-stage method falls short of the two-stage one. This could be due to the considerable discrepancies between the two data stages. Simply merging them doesn’t yield effective results.
结果强调了数据统一的重要性。若缺乏这一步骤,单阶段方法的表现将逊于两阶段方法。这可能是由于两个数据阶段之间存在显著差异,简单合并无法产生有效结果。
H Deviate Detection
H偏离检测
In the data unification phase, we instruct LLM to refer to the text content to provide a detailed response. The responses are expected to mainly contain information from the text. However, the ability of the language models to follow instructions can’t be fully guaranteed, and there might be instances where the model answers a question without referring to the text. To ensure that the response contains text knowledge, we adopt the following two methods to detect deviations from the original text:
在数据统一阶段,我们指示大语言模型(LLM)参考文本内容提供详细回答。预期回答应主要包含文本中的信息。但由于语言模型遵循指令的能力无法完全保证,可能会出现模型未参考文本直接回答问题的情况。为确保回答包含文本知识,我们采用以下两种方法来检测与原文的偏差:
Based on these detection methods, if a generated response fails the tests, we instruct the Large Language Model (LLM) to regenerate it.
基于这些检测方法,如果生成的响应未通过测试,我们会指示大语言模型 (LLM) 重新生成。
I Priority Sampling Strategy
I 优先级采样策略
In this section, we first explain how we handle ordering between pre-training and SFT data, and then give details of ordering within pre-training data
在本节中,我们首先说明如何处理预训练数据和监督微调(SFT)数据间的顺序关系,随后详述预训练数据内部的排序方法
Order between pre-training and SFT data We adopt a sequential training approach, prioritizing Pre-training Data followed by Fine-tuning Data (Pre-training Data $\rightarrow$ Fine-tuning Data). This method mirrors human learning processes: akin to initially learning from textbooks before attempting exercises. The rationale is straightforward comprehensive foundational knowledge, gained from pre-training data, should precede the more specific applications found in fine-tuning data. This sequence prevents a scenario akin to attempting exercises without sufficient textbook study, which could lead to random guesses and, in the context of our model, the propensity to generate inaccurate or ’hallucinated’ information. Additionally, the fine-tuning data, often structured in a question-andanswer format, closely aligns with real-world user interactions. By introducing this type of data later in the training process, we ensure that the model is better attuned to actual user scenarios, enhancing its practical applicability and effectiveness.
预训练与SFT数据间的顺序
我们采用顺序训练方法,优先处理预训练数据(Pre-training Data),随后进行微调数据(Fine-tuning Data)训练 (预训练数据 $\rightarrow$ 微调数据)。这种方式模拟人类学习过程:类似于先通过教材学习基础知识,再尝试习题练习。其原理很明确——从预训练数据获得的全面基础认知,应当先于微调数据中的具体应用场景。这种顺序避免了类似未充分学习教材就做题的情况,否则可能导致随机猜测行为,反映在模型中则会产生不准确或"幻觉"信息。此外,微调数据通常以问答形式组织,与现实用户交互场景高度契合。通过在训练后期引入此类数据,可确保模型更适配真实使用场景,从而提升实际应用性与有效性。
Order within pre-training data Data quality is gauged using the data sampling epochs from the LLaMA (Touvron et al., 2023) study, as is shown in Table 12.
预训练数据中的顺序
数据质量通过LLaMA (Touvron et al., 2023) 研究中的数据采样周期来衡量,如表 12 所示。
Initially, the significance of different data sources, as determined by sampling epochs in LLaMA, was ranked as "Web Corpus $\rightarrow$ Literature $\rightarrow$ Books $\rightarrow$ Encyclopedia". Nevertheless, after consulting with medical experts, it became clear that Books should be accorded greater importance. Consequently, we have adjusted our training sequence to: Web Corpus→Literature $\rightarrow$ Encyclopedia $\rightarrow$ Books. Lastly, we set the relative priority, a hyper-parameter in priority sampling.
最初,LLaMA 中通过采样周期确定的不同数据源重要性排序为"网络语料 (Web Corpus) → 文献 (Literature) → 书籍 (Books) → 百科全书 (Encyclopedia)"。但在咨询医学专家后,我们明确认识到应提高书籍的优先级。因此,我们将训练顺序调整为:网络语料→文献→百科全书→书籍。最后,我们设定了优先级采样的超参数——相对优先级。
Table 12: Sampling Epochs in LLaMA (Touvron et al., 2023).
| Dataset | Data Type | LLaMA Sampling Epochs |
| C4 | WebCorpus | 1.06 |
| ArXiv | Literature | 1.06 |
| Books | Book | 2.23 |
| Wikipedia | Encyclopedia | 2.45 |
表 12: LLaMA 采样周期 (Touvron et al., 2023).
| 数据集 | 数据类型 | LLaMA 采样周期 |
|---|---|---|
| C4 | 网络语料 | 1.06 |
| ArXiv | 文献 | 1.06 |
| Books | 书籍 | 2.23 |
| Wikipedia | 百科全书 | 2.45 |
J Training Detail
J 训练细节
For HuatuoGPT-II, $\beta$ was set to 2. In other settings, we set the sampling epoch for Medical Finetuning Instruction to 1 and for Medical Pre-training Instruction to 3. Additionally, we unified the data encoding. Sampled instructions were concatenated as much as possible to form a fixed-length token sequence of 4096 for training. The training was conducted with a batch size of 128 and a learning rate of 1e-4. As all the data are instructional, we only optimize the output loss and do not learn from the input loss. Our model is implemented in PyTorch using the Accelerate and leverage ZeRO algorithm to distribute the model. Training was conducted using 8 Nvidia A100 cards, and the HuatuoGPT-II (7B) training time was about 4 days.
对于HuatuoGPT-II,$\beta$设为2。其他设置中,我们将医学微调指令(Medical Finetuning Instruction)的采样周期设为1,医学预训练指令(Medical Pre-training Instruction)设为3。同时统一了数据编码方式,尽可能将采样的指令拼接成固定长度4096的token序列用于训练。训练采用128的批次大小和1e-4的学习率。由于所有数据均为指令数据,我们仅优化输出损失而不学习输入损失。模型基于PyTorch实现,使用Accelerate框架并借助ZeRO算法进行分布式训练。训练使用8张Nvidia A100显卡,HuatuoGPT-II(7B)耗时约4天。
K Benchmark Details
K Benchmark 详情
We evaluate the medical capabilities of HuatuoGPT-II on popular benchmarks. Here, we select four medical benchmarks and three general benchmarks, noting that we only evaluate the medical part of the general benchmarks. The medical benchmarks include: MedQA (Jin et al., 2021), which is collected from professional medical board exams in various languages. We used its English test set for evaluation. MedMCQA (Pal et al., 2022), amassed from Indian medical entrance exams, and we evaluate it using the development set. CMB (Wang et al., 2023d), a comprehensive medical benchmark in Chinese, where we specifically used the CMB-Exam for evaluation. CMExam (Liu et al., 2023), a comprehensive Chinese medical exam dataset. The general benchmarks include: C-Eval (Huang et al., 2023), an all-encompassing Chinese evaluation framework. CMMLU (Li et al., 2023b), designed to critically appraise the knowledge and reasoning prowess of large language models in Chinese.
我们在多个流行基准上评估了HuatuoGPT-II的医疗能力。本次选取了四个医疗专项基准和三个通用基准(仅评估其中的医疗部分)。医疗基准包括:MedQA (Jin et al., 2021) ,该数据集收集自多国医学执业资格考试,我们使用其英文测试集进行评估;MedMCQA (Pal et al., 2022) ,源自印度医学入学考试,我们采用开发集进行评估;CMB (Wang et al., 2023d) ,这是一个中文综合医疗基准,我们专门使用其中的CMB-Exam进行评估;CMExam (Liu et al., 2023) ,一个综合性中文医学考试数据集。通用基准包括:C-Eval (Huang et al., 2023) ,一个全面的中文评估框架;CMMLU (Li et al., 2023b) ,专为评估大语言模型的中文知识与推理能力而设计。
For the general benchmarks, we only use their medically related evaluation content. For CMMLU, the evaluation sections used are ’clinical knowledge’, ’agronomy’, ’college medicine’, ’genetics’, ’nutrition’, ’Traditional Chinese Medicine’, and ’virology’. For C-Eval, we use the ’clinical medicine’ and ’basic medicine’ parts.
在通用基准测试中,我们仅采用其医学相关评估内容。对于CMMLU,使用的评估板块包括"临床知识"、"农学"、"大学医学"、"遗传学"、"营养学"、"中医学"和"病毒学"。对于C-Eval,我们采用"临床医学"和"基础医学"部分。
Since all evaluations in our experiments are for Chat models, we uniformly adopted a Zero-shot setting, using a consistent form, shown as below:
由于我们实验中的所有评估都是针对聊天模型进行的,因此统一采用零样本 (Zero-shot) 设置,使用如下一致形式:
Translation:
翻译:
Please answer the following multiple choice questions. Of little significance in assessing the prognosis of a patient with cirrhosis is
请回答以下选择题。对评估肝硬化患者预后意义不大的是
L Details of HuatuoEval
L HuatuoEval 详细说明
We utilize the single-round and multi-round evaluation data from HuatuoGPT (Wang et al., 2023b) to evaluate the model’s medical response capability. Sources from these datasets include KUAKEQIC (Zhang et al., 2021) for single-round questions and Med-dialog (Zeng et al., 2020) for multiround cases. We slightly modify these evaluations for fairer assessment, focusing on the information in the answers rather than the tone of a doctor’s response.
我们利用HuatuoGPT (Wang et al., 2023b)的单轮和多轮评估数据来评估模型的医疗应答能力。这些数据集中的单轮问题来自KUAKEQIC (Zhang et al., 2021),多轮案例则来自Med-dialog (Zeng et al., 2020)。我们对这些评估稍作修改以实现更公平的评判,重点关注答案中的信息而非医生回答的语气。
This evaluation is designed to evaluate the response capabilities of large-scale language models in medical scenarios. It includes two types of evaluations. The first type assesses the singleround answer capability, primarily comprising real patient questions sourced from KUAKE-QIC. The second type is a multi-round diagnostic evaluation, with data containing real patient case information, sourced from Med-dialog. In the single-round evaluation, we have the models directly answer medical questions. In the multi-round evaluation, we simulate a patient asking questions to a doctor using ChatGPT, based on the patient’s medical record information. The simulated patient’s prompt is shown as below( [Patient Case Information] is patient case in multi-round data of HuatuoEval.). The models then engage in dialogue with the simulated patient to generate conversations. For a fair comparison, we have the ChatGPT-simulated patient continuously asking questions, and each model must respond twice.
本次评估旨在评测大语言模型在医疗场景下的应答能力,包含两类评估。第一类评估单轮问答能力,主要包含来自KUAKE-QIC的真实患者提问;第二类是多轮诊断评估,数据含有真实患者病例信息,源自Med-dialog。在单轮评估中,我们让模型直接回答医疗问题。在多轮评估中,我们基于患者病历信息,使用ChatGPT模拟患者向医生提问的过程([Patient Case Information]即HuatuoEval多轮数据中的患者病例)。模型随后与模拟患者进行对话生成会话。为确保公平比较,我们让ChatGPT模拟的患者持续提问,每个模型需应答两次。
| HuatuoGPT-II(7B)vsOtherModel | Single-roundQA | Multi-roundDialogue | Average Win/TieRate | ||||
| Win | Tie | Fail | Win | Tie | Fail | ||
| HuatuoGPT-II(7B)vsHuatuoGPT-II(13B) | 39 | 22 | 39 | 41 | 13 | 46 | 57.5% |
| HuatuoGPT-II(7B)vsERNIEBot | 62 | 13 | 26 | 64 | 12 | 24 | 75.0% |
| HuatuoGPT-II(7B) )vsChatGLM3-6B | 75 | 11 | 14 | 76 | 10 | 14 | 86.0% |
| HuatuoGPT-II(7B)vsBaichuan2-7B-Chat | 75 | 7 | 18 | 84 | 7 | 9 | 86.5% |
| HuatuoGPT-II(7B)vsDISC-MedLLM | 80 | 8 | 12 | 73 | 15 | 12 | 88.0% |
| HuatuoGPT-II(7B)vsQwen-14B-Chat | 82 | 7 | 6 | 79 | 9 | 12 | 91.0% |
| HuatuoGPT-II(7B)vsQwen-7B-Chat | 89 | 6 | 5 | 75 | 12 | 13 | 91.0% |
Table 13: Results of the Automated Evaluation Using GPT-4 in Chinese medical scenarios.
表 13: 中文医疗场景下使用 GPT-4 自动评估结果
| HuatuoGPT-II(7B) vs 其他模型 | 单轮问答 | 多轮对话 | 平均胜率/平率 | ||||
|---|---|---|---|---|---|---|---|
| 胜 | 平 | 败 | 胜 | 平 | 败 | ||
| HuatuoGPT-II(7B) vs HuatuoGPT-II(13B) | 39 | 22 | 39 | 41 | 13 | 46 | 57.5% |
| HuatuoGPT-II(7B) vs ERNIEBot | 62 | 13 | 26 | 64 | 12 | 24 | 75.0% |
| HuatuoGPT-II(7B) vs ChatGLM3-6B | 75 | 11 | 14 | 76 | 10 | 14 | 86.0% |
| HuatuoGPT-II(7B) vs Baichuan2-7B-Chat | 75 | 7 | 18 | 84 | 7 | 9 | 86.5% |
| HuatuoGPT-II(7B) vs DISC-MedLLM | 80 | 8 | 12 | 73 | 15 | 12 | 88.0% |
| HuatuoGPT-II(7B) vs Qwen-14B-Chat | 82 | 7 | 6 | 79 | 9 | 12 | 91.0% |
| HuatuoGPT-II(7B) vs Qwen-7B-Chat | 89 | 6 | 5 | 75 | 12 | 13 | 91.0% |
你是一名患者,下面是你的病情,你正在向医生咨询病情相关的问题,注意这是一个多轮问诊过程,切记不要让对话结束,要继续追问医生病情有关的问题。
我是一名患者,以下是我的病情描述,正在向医生咨询相关问题。请注意这是多轮问诊过程,请持续追问与病情相关的问题。
[Patient Case Information]
[患者病例信息]
Translation:
翻译:
You are a patient, here is your condition and you are asking the doctor questions related to your condition, note that this is a multi-round questioning process, remember not to let the dialogue end, but continue to ask the doctor questions related to your condition.
你是一名患者,以下是你的病情描述,你正在向医生咨询与病情相关的问题。请注意这是一个多轮问答过程,记住不要让对话结束,而要持续向医生提出与病情相关的问题。
[Patient Case Information]
[患者病例信息]
L.1 Automatic Evaluation
L.1 自动评估
During automatic evaluation, we compare model responses in pairs. We present the dialogue or Q&A content of two models to GPT-4, which then judges which model’s response is better. The prompts for single-round and multi-round automatic evaluations are shown in Table 14. To mitigate potential position bias in GPT-4 as a judge, each data point is evaluated for interaction position twice.
在自动评估过程中,我们会对模型响应进行两两比较。将两个模型的对话或问答内容呈现给GPT-4,由其判断哪个模型的响应更优。单轮与多轮自动评估的提示词如表14所示。为缓解GPT-4作为评判者可能存在的位置偏差,每个数据点会进行两次交互位置评估。
| ThePromptforSingle-RoundAutomaticEvaluation: | |
| [Question] | |
| [Question] | |
| [EndofQuestion] | |
| [Assistant 1] | |
| [TheResponseofModel1] | |
| [EndofAssistant1] | |
| [Assistant 2] | |
| [TheResponseofModel 2] | |
| [EndofAssistant2] |
| 单轮自动评估提示词: | |
| [问题] | |
| [问题] | |
| [问题结束] | |
| [助手1] | |
| [模型1的响应] | |
| [助手1结束] | |
| [助手2] | |
| [模型2的响应] | |
| [助手2结束] | |
[System]
[系统]
We would like to request your feedback on the two AI assistants in response to the user question displayed above.
我们希望您能就上述用户问题对两位AI助手的回答提供反馈。
Requirements: The response should be to the point and adress the problem of user. The description of symptoms should be comprehensive and accurate, and the provided diagnosis should be the most reasonable inference based on all relevant factors and possibilities. The treatment recommendations should be effective and reliable, taking into account the severity or stages of the illness. The prescriptions should be effective and reliable, considering indications, contra indications, and dosages. Please compare the performance of their responses. You should tell me whether Assistant 1 is ‘better than‘, ‘worse than‘, or ‘equal to‘ Assistant 2.
要求:
- 回复应直击要点,解决用户问题。
- 症状描述需全面准确,提供的诊断应基于所有相关因素和可能性做出最合理推断。
- 治疗建议需考虑病情严重程度或阶段,确保有效可靠。
- 处方需兼顾适应症、禁忌症及剂量,保证有效性和可靠性。
请比较两者的回复表现,并告知Assistant 1是“优于”“逊于”还是“等同于”Assistant 2。
ase first compare their responses and analyze which one is more in line with the given requirements.
首先比较它们的响应,分析哪一个更符合给定的要求。
In the last line, please output a single line containing only a single label selecting from ‘Assistant 1 is better than Assistant $2^{\prime}$ , ‘Assistant 1 is worse than Assistant 2‘, and ‘Assistant 1 is equal to Assistant 2‘.
在最后一行,请输出单独一行,仅包含从以下选项中选择的一个标签:'Assistant 1 is better than Assistant 2'、'Assistant 1 is worse than Assistant 2' 或 'Assistant 1 is equal to Assistant 2'。
The Prompt for Multi-Round Automatic Evaluation:
多轮自动评估提示词:
Table 14: The prompt for automatic evaluation on single-round and multi-round setting. Note that [.] is what needs to be filled in. ’Model 1’ and ’Model $2^{\prime}$ Indicates two models to be compared.
表 14: 单轮和多轮设置下的自动评估提示。注意 [.] 是需要填充的内容。'Model 1' 和 'Model $2^{\prime}$' 表示待比较的两个模型。
L.2 Expert Evaluation
L.2 专家评估
For manual evaluation, we provide licensed medical doctors with evaluation criteria shown as below. We then offer a platform for experts to conduct evaluations. Experts choose which response (from a pair of model responses) is better. The selection interface is shown in Figure 10. All model information is anonymized and interaction positions are randomized to ensure fairness.
对于人工评估,我们为持有执照的医生提供如下所示的评估标准。随后,专家们通过我们提供的平台进行评估,从一对模型回答中选择更优的答案。选择界面如图 10 所示。所有模型信息均经过匿名处理,交互位置随机排序以确保公平性。
Translation:
翻译:
M Baselines
M 基线方法
Open-Source Baselines We compare to the most representative general large language models, which possess excellent chat capabilities and are adaptable to various scenarios, including healthcare. They are as follows:
开源基线
我们对比了最具代表性的通用大语言模型,这些模型具备出色的对话能力,并能适应包括医疗健康在内的多种场景。具体如下:
Huatuo Human Evaluation qa_ 3
Huatuo Human Evaluation qa_ 3
标注提示:我们将给您呈现一些患者的问题和来自两个模型的回答,请您评价两个模型哪个的回答更优秀。请注意以下几点:
标注提示:我们将给您呈现一些患者的问题和来自两个模型的回答,请您评价两个模型哪个的回答更优秀。请注意以下几点:

Figure 10: The interface of the expert evaluation.
图 10: 专家评估界面。
• Baichuan2-7B/13B-Chat(Yang et al., 2023a) The Baichuan2-7B and Baichuan2-13B models are trained on 2.6 trillion tokens. Sharing the same backbone as ours, their chat-version models are well adapted to the base, fully leveraging its capabilities. • Qwen-7B/14B-Chat(Bai et al., 2023) The Qwen series are trained on 3 trillion tokens of diverse texts and codes. The chat models are fine-tuned carefully on a dataset related to different tasks. RLHF is also applied to generate human-preferred responses. • ChatGLM3-6B(Zeng et al., 2023) ChatGLM2-6B is a model trained with 1.4 trillion bilingual tokens. Based on ChatGLM2, the ChatGLM3 model has a more diverse training dataset, increased training steps, and a more reasonable training strategy. • Llama2-7B/13B-Chat (Touvron et al., 2023) Llama2 series are successors models of Llama trained on 2 trillion tokens with diverse datasets. Their chat model has robust performance. Unlike the first three Chinese-supported models, Llama2 series are English models.
• Baichuan2-7B/13B-Chat (Yang et al., 2023a) Baichuan2-7B和Baichuan2-13B模型基于2.6万亿token训练而成。其对话版本与我们的模型共享相同主干架构,能充分发挥基础模型能力。
• Qwen-7B/14B-Chat (Bai et al., 2023) Qwen系列模型基于3万亿包含文本与代码的token训练。对话模型通过多任务相关数据集精细微调,并采用RLHF技术生成符合人类偏好的响应。
• ChatGLM3-6B (Zeng et al., 2023) ChatGLM2-6B是基于1.4万亿双语token训练的模型。ChatGLM3在ChatGLM2基础上扩展了训练数据多样性,增加训练步数并优化训练策略。
• Llama2-7B/13B-Chat (Touvron et al., 2023) Llama2系列是基于2万亿token多领域数据集训练的Llama迭代模型,其对话版本表现稳健。与前三个支持中文的模型不同,Llama2是纯英文模型。
Additionally, we select two representative and strong large language models for Chinese medical scenario. (we conducted an experimental experiment to select these two models, see Appendix R for details). These models are:
此外,我们针对中文医疗场景选用了两个具有代表性且性能强劲的大语言模型(通过实验筛选得出,详见附录R)。这两个模型分别是:
Proprietary Baselines Furthermore, we compare three representative proprietary models, which have larger parameters and stronger performance:
专有基线模型
此外,我们还比较了三款具有更大参数量和更强性能的代表性专有模型:
N Distribution of Synthesized Questions
N 合成问题的分布
We sampled 100 questions from the pre-training instructions and manually categorized their type as follows:
我们从预训练指令中抽取了100个问题,并手动将其类型分类如下:
Table 15: Distribution of synthesized questions.
| Yes/No Question | Open-ended Question | Comparison Question | Causal Question | |
| #Question | 12 | 47 | 9 | 32 |
表 15: 合成问题的分布。
| 是非题 (Yes/No Question) | 开放性问题 (Open-ended Question) | 对比题 (Comparison Question) | 因果题 (Causal Question) | |
|---|---|---|---|---|
| 问题数量 | 12 | 47 | 9 | 32 |
O Performance on Different Sizes of Models
不同规模模型的性能表现
The effect differences of HuatuoGPT2 with different model parameters:
不同参数规模的华佗GPT2效果差异:
Table 16: Performance on different sizes of models.
| Model Size | Backbone | CMExam | 2023Pharmacist | 2023 TCM |
| 7B | Baichuan2-7B | 65.8 | 47.7 | 47.5 |
| 13B | Baichuan2-13B | 69.0 | 52.9 | 51.6 |
| 34B | Yi-34B | 77.2 | 65.5 | 62.4 |
表 16: 不同规模模型的性能表现。
| 模型规模 | 主干网络 | CMExam | 2023Pharmacist | 2023 TCM |
|---|---|---|---|---|
| 7B | Baichuan2-7B | 65.8 | 47.7 | 47.5 |
| 13B | Baichuan2-13B | 69.0 | 52.9 | 51.6 |
| 34B | Yi-34B | 77.2 | 65.5 | 62.4 |
P Other SFT Data
P 其他SFT数据
We conducted experiments with different LLMs to generate SFT data, using $5%$ of the data, to verify the importance of SFT data. The results are shown in the table.
我们使用不同的大语言模型生成监督微调(SFT)数据,并采用5%的数据量来验证SFT数据的重要性,结果如下表所示。
It shows minimal impact with the other LLM, which indicates that SFT data does not provide primary knowledge.
这表明对其他大语言模型的影响微乎其微,说明监督微调(SFT)数据并未提供核心知识。
Table 17: Results on different SFT data
| CMExam | 2023Pharmacist | 2023TCM | |
| One Stage, with SFT data g generated by GPT-4 | 53.4 | 39.7 | 40.2 |
| One Stage, with SFT data generated by ChatGPT | 52.6 | 40.0 | 39.8 |
表 17: 不同SFT数据上的结果
| CMExam | 2023Pharmacist | 2023TCM | |
|---|---|---|---|
| One Stage, with SFT data g generated by GPT-4 | 53.4 | 39.7 | 40.2 |
| One Stage, with SFT data generated by ChatGPT | 52.6 | 40.0 | 39.8 |
Q One Stage Training for Other Domains
Q 其他领域的单阶段训练
The proposed one-stage training protocol is applicable beyond the Chinese medical domain.
所提出的一阶段训练方案不仅适用于中医领域。
To address the reviewer’s question, we tested it on the MedQA-English (Jin et al., 2021) and CaseHOLD (Zheng et al., 2021) datasets, which represent the English medical and law domains, respectively. For MedQA-English, we used MedQA’s English textbooks as the pre-training corpus and its training set for Supervised Fine-Tuning (SFT). For CaseHOLD, we sampled $4%$ of the corpora from FreeLaw Opinions (Biderman et al., 2022) as the pre-training corpus and used its training set for SFT. The data characteristics are as follows:
为回应审稿人的问题,我们在MedQA-English (Jin等人,2021) 和CaseHOLD (Zheng等人,2021) 数据集上进行了测试,这两个数据集分别代表英语医学和法律领域。对于MedQA-English,我们使用MedQA的英文教材作为预训练语料库,并使用其训练集进行监督微调 (SFT)。对于CaseHOLD,我们从FreeLaw Opinions (Biderman等人,2022) 中抽样了$4%$的语料作为预训练语料库,并使用其训练集进行SFT。数据特征如下:
| Dataset | # Pre-training documents | #SFTdata | #Testdata | Domain |
| MedQA-en | 156,960 | 10,178 | 1,273 | English Medical Domain |
| CaseHOLD | 141,342 | 45,000 | 3,900 | LawDomain |
| 数据集 | 预训练文档数量 | SFT数据量 | 测试数据量 | 领域 |
|---|---|---|---|---|
| MedQA-en | 156,960 | 10,178 | 1,273 | 英文医疗领域 |
| CaseHOLD | 141,342 | 45,000 | 3,900 | 法律领域 |
Table 18: Dataset characteristics in other domains.
表 18: 其他领域的数据集特征。
We trained on Baichuan2-7B-Base and compared one-stage training with traditional two-stage training: Table 19: Performance comparison of training methods across domains
| Method | MedQA-en (English Medical Domain) | CaseHOLD (LawDomain) |
| Two-stage training | 46.2 | 41.8 |
| One-stage training | 48.6 | 43.6 |
我们在Baichuan2-7B-Base上训练,并比较了单阶段训练与传统两阶段训练的效果:
表 19: 跨领域训练方法性能对比
| 方法 | MedQA-en (英文医学领域) | CaseHOLD (法律领域) |
|---|---|---|
| 两阶段训练 | 46.2 | 41.8 |
| 单阶段训练 | 48.6 | 43.6 |
The results indicate that one-stage training can enhance performance across domains.
结果表明,单阶段训练可以提升跨领域性能。
R Other Medical Models
R 其他医疗模型
When selecting baselines for Chinese medical applications, we also tested the performance of other Chinese medical large models in the Chinese National Medical Licensing Examination. The results, as shown in Table 20, indicate that based on their superior performance, HuatuoGPT and DISC-MedLLM were chosen as the baselines for comparison.
在选择中文医疗应用的基线模型时,我们还测试了其他中文医疗大语言模型在国家医师资格考试中的表现。结果如表20所示,基于其优异表现,我们选择华佗GPT (HuatuoGPT) 和 DISC-MedLLM 作为对比基线。
S Case Study
S 案例研究
In our study, we observed that many models, including GPT-4, experience significant hallucinations in Chinese medical contexts. These hallucinations arise from two factors: 1) The model itself lacks specific medical knowledge; 2) Misconceptions arise in Chinese. Tables 21 and 22 present two examples of simple Chinese medical questions about pharmaceuticals.
在我们的研究中发现,包括GPT-4在内的许多模型在中文医疗场景下会出现明显的幻觉现象。这些幻觉源于两个因素:1) 模型本身缺乏特定医学知识;2) 中文表述引发误解。表21和表22展示了两个关于药品的简单中文医疗问题示例。
| Model | Traditional ChineseMedicine (中医) | Clinical (临床) | ||||||||||||||
| Assistant (执业助理医师) | Physician (执业医师) | Pharmacist (药师) | Assistant (执业助理医师) | Physician (执业医师) | Avg. | |||||||||||
| 2015 | 2016 | 2017 | 2012 | 2013 | 2016 | 2017 2018 | 2019 2018 | 2019 | 2020 | 2018 | 2019 | 2020 | ||||
| DoctorGLMXiongetal.(2023) | 3.0 | 1.4 | 3.5 | 1.8 | 1.8 | 2.1 | 1.8 | 2.4 | 2.2 | 2.6 | 3.3 | 1.6 | 1.6 | 2.7 | 1.8 | 2.2 |
| BianQue-2(Chen et al.,2023a) | 3.7 | 2.3 | 3.5 | 4.2 | 4.5 | 4.0 | 7.1 | 4.2 | 9.0 | 4.7 | 5.3 | 1.6 | 3.8 | 5.9 | 3.7 | 4.5 |
| ChatMed-Consult(Wang et al.,2023c) | 20.0 | 17.3 | 14.7 | 21.3 | 18.2 | 20.0 | 16.7 | 15.0 | 17.5 | 27.8 | 21.3 | 19.3 | 23.8 | 21.4 | 19.5 | 20.0 |
| BenTsao (Wang et al.,2023b) | 23.3 | 26.8 | 17.2 | 19.0 | 19.5 | 22.1 | 20.2 | 20.4 | 18.8 | 18.4 | 24.6 | 27.5 | 21.6 | 18.9 | 18.1 | 21.1 |
| ChatGLM-Med(Wangetal.,2023c) | 20.7 | 23.2 | 20.7 | 21.8 | 21.8 | 22.6 | 16.7 | 21.0 | 15.3 | 30.3 | 23.0 | 29.9 | 18.5 | 20.4 | 24.8 | 22.0 |
| MedicalGPT (Xu,2023) | 25.0 | 24.1 | 21.6 | 26.3 | 27.0 | 27.0 | 22.6 | 21.0 | 20.6 | 38.9 | 29.1 | 28.3 | 33.4 | 32.1 | 26.2 | 26.9 |
| HuatuoGPT (Selected) | 26.0 | 30.9 | 32.8 | 31.3 | 26.8 | 30.2 | 18.4 | 27.5 | 25.1 | 32.5 | 33.6 | 27.5 | 32.7 | 28.6 | 30.1 | 28.9 |
| DISC-MedLLM (Selected) | 38.3 | 41.8 | 26.7 | 36.2 | 38.7 | 35.1 | 25.0 | 22.2 | 22.0 | 49.2 | 36.1 | 41.8 | 41.4 | 36.6 | 35.8 | 35.1 |
| HuatuoGPT-II (7B) | 67.1 | 65.2 | 67.5 | 67.9 | 67.4 | 64.9 | 53.0 | 46.7 | 51.0 | 70.9 | 73.2 | 69.4 | 68.8 | 66.5 | 67.7 | 64.5 |
Table 20: The results of the Chinese National Medical Licensing Examination.
| 模型 | 中医 | 临床 | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 执业助理医师 | 执业医师 | 药师 | 执业助理医师 | 执业医师 | 平均 | |||||||||||
| 2015 | 2016 | 2017 | 2012 | 2013 | 2016 | 2017 | 2018 | 2019 | 2018 | 2019 | 2020 | 2018 | 2019 | 2020 | ||
| DoctorGLMXiongetal.(2023) | 3.0 | 1.4 | 3.5 | 1.8 | 1.8 | 2.1 | 1.8 | 2.4 | 2.2 | 2.6 | 3.3 | 1.6 | 1.6 | 2.7 | 1.8 | 2.2 |
| BianQue-2(Chen et al.,2023a) | 3.7 | 2.3 | 3.5 | 4.2 | 4.5 | 4.0 | 7.1 | 4.2 | 9.0 | 4.7 | 5.3 | 1.6 | 3.8 | 5.9 | 3.7 | 4.5 |
| ChatMed-Consult(Wang et al.,2023c) | 20.0 | 17.3 | 14.7 | 21.3 | 18.2 | 20.0 | 16.7 | 15.0 | 17.5 | 27.8 | 21.3 | 19.3 | 23.8 | 21.4 | 19.5 | 20.0 |
| BenTsao (Wang et al.,2023b) | 23.3 | 26.8 | 17.2 | 19.0 | 19.5 | 22.1 | 20.2 | 20.4 | 18.8 | 18.4 | 24.6 | 27.5 | 21.6 | 18.9 | 18.1 | 21.1 |
| ChatGLM-Med(Wangetal.,2023c) | 20.7 | 23.2 | 20.7 | 21.8 | 21.8 | 22.6 | 16.7 | 21.0 | 15.3 | 30.3 | 23.0 | 29.9 | 18.5 | 20.4 | 24.8 | 22.0 |
| MedicalGPT (Xu,2023) | 25.0 | 24.1 | 21.6 | 26.3 | 27.0 | 27.0 | 22.6 | 21.0 | 20.6 | 38.9 | 29.1 | 28.3 | 33.4 | 32.1 | 26.2 | 26.9 |
| HuatuoGPT (Selected) | 26.0 | 30.9 | 32.8 | 31.3 | 26.8 | 30.2 | 18.4 | 27.5 | 25.1 | 32.5 | 33.6 | 27.5 | 32.7 | 28.6 | 30.1 | 28.9 |
| DISC-MedLLM (Selected) | 38.3 | 41.8 | 26.7 | 36.2 | 38.7 | 35.1 | 25.0 | 22.2 | 22.0 | 49.2 | 36.1 | 41.8 | 41.4 | 36.6 | 35.8 | 35.1 |
| HuatuoGPT-II (7B) | 67.1 | 65.2 | 67.5 | 67.9 | 67.4 | 64.9 | 53.0 | 46.7 | 51.0 | 70.9 | 73.2 | 69.4 | 68.8 | 66.5 | 67.7 | 64.5 |
表 20: 中国国家医师资格考试结果。
As shown in Table 21, GPT-4 seems to misunderstand the drug compound ’Meth oxy ph enamine’, essentially providing irrelevant responses. Baichuan2-7B-Chat appears to comprehend this drug but only answers correctly in part, also exhibiting significant hallucinations. In contrast, HuatuoGPT-II accurately and comprehensively addresses the drug’s details.
如表 21 所示,GPT-4 似乎误解了药物化合物 "Meth oxy ph enamine",基本上提供了无关的回应。Baichuan2-7B-Chat 似乎理解了这种药物,但仅部分回答正确,同时也表现出明显的幻觉。相比之下,HuatuoGPT-II 准确而全面地解答了该药物的详细信息。
| Query: |
| 介绍下复方甲氧那明 |
| ( Translation: Introduce compound methoxyphenamine) |
查询:
介绍下复方甲氧那明 (Translation: Introduce compound methoxyphenamine)
GPT-4:
GPT-4:
复方甲氧那明是一种用于缓解流感和感冒症状的药物。它通常包含以下几种成分:
复方甲氧那明是一种用于缓解流感和感冒症状的药物。它通常包含以下几种成分:
- 甲氧那明:这是一种抗组胺药,用于减轻过敏症状,如打喷嚏、流涕和眼睛发痒。在复方甲氧那明中,它有助于缓解由感冒或流感引起的鼻塞和其他相关症状。
- 甲氧那明:这是一种抗组胺药,用于减轻过敏症状,如打喷嚏、流涕和眼睛发痒。在复方甲氧那明中,它有助于缓解由感冒或流感引起的鼻塞和其他相关症状。
- 对乙酰氨基酚(扑热息痛):这是一种常见的镇痛剂和退热药,用于缓解疼痛和降低由感冒或流感引起的发热...
- 对乙酰氨基酚(扑热息痛):这是一种常见的镇痛剂和退热药,用于缓解疼痛和降低由感冒或流感引起的发热...
( Translation: Compound Meth oxy ph enamine is a medicine used to relieve flu and cold symptoms. It usually contains the following ingredients:
复方甲氧那明是一种用于缓解流感及感冒症状的药物,通常含有以下成分:
- Meth oxy ph enamine: This is an antihistamine used to relieve allergy symptoms such as sneezing, runny nose and itchy eyes. In compounded meth enamine, it helps to relieve nasal congestion and other related symptoms caused by a cold or flu.
- 甲氧非那明 (Meth oxy ph enamine): 这是一种抗组胺药,用于缓解打喷嚏、流鼻涕和眼睛发痒等过敏症状。在复方甲氧非那明制剂中,它有助于缓解由感冒或流感引起的鼻塞及其他相关症状。
- Acetaminophen (Paracetamol): This is a common analgesic and anti pyre tic used to relieve pain and reduce fever caused by colds or flu... )
- 对乙酰氨基酚 (Paracetamol): 这是一种常见的镇痛解热药,用于缓解感冒或流感引起的疼痛和发热... )
Baichuan2-7B-Chat:
Baichuan2-7B-Chat:
复方甲氧那明是一种处方药,主要用于治疗各种炎症性疾病,如支气管炎、哮喘、过敏性鼻炎等。它是由四种成分组成的复方制剂:甲氧那明(一种支气管扩张剂)、氯苯那敏(一种抗组胺药)、氢氧化铝(一种胃酸抑制剂)和甲基硫酸吡啶酸(一种非处方解热镇痛药)...
复方甲氧那明是一种处方药,主要用于治疗各种炎症性疾病,如支气管炎、哮喘、过敏性鼻炎等。它是由四种成分组成的复方制剂:甲氧那明(一种支气管扩张剂)、氯苯那敏(一种抗组胺药)、氢氧化铝(一种胃酸抑制剂)和甲基硫酸吡啶酸(一种非处方解热镇痛药)...
( Translation: Compound Meth oxy ph enamine is a prescription medication used to treat a variety of inflammatory diseases, such as bronchitis, asthma, and allergic rhinitis. It is a combination of four ingredients: Meth oxy ph enamine (a broncho dil at or), chlo rp he nira mine (an antihistamine), aluminum hydroxide (a gastric acid inhibitor), and pyridinium methyl sulfate (an over-the-counter anti pyre tic and analgesic)...)
规则:
- 输出时仅保留翻译后的标题,不包含任何冗余内容、重复或解释。
- 不输出与原文无关的内容。
- 保持原始段落格式及术语(如FLAC、JPEG)、公司缩写(如Microsoft、Amazon、OpenAI)不变。
- 人名不翻译。
- 保留文献引用标记(如[20])。
- 图表标题翻译格式为"图1: "、"表1: "。
- 全角括号转为半角括号,并确保括号前后有半角空格。
- 专业术语首次出现时标注英文(如"生成式AI (Generative AI)"),后续直接使用中文。
- 标准AI术语对照:
- Transformer -> Transformer
- Token -> Token
- LLM -> 大语言模型
- Zero-shot -> 零样本
- Few-shot -> 少样本
- AI Agent -> AI智能体
- AGI -> 通用人工智能
- Python -> Python语言
策略:
- 特殊字符/公式原样保留
- HTML表格转为Markdown格式
- 确保翻译准确完整,符合中文表达习惯
最终仅返回Markdown格式的翻译结果。
HuatuoGPT-II(7B):
华佗GPT-II(7B):
Table 21: Chinese medical hallucinations case. The green font indicates correct information, and the brown font indicates incorrect information.
表 21: 中医药幻觉案例。绿色字体表示正确信息,棕色字体表示错误信息。
Another example, as illustrated in Table 22, involves a direct question in Chinese about ’OxyContin’. GPT-4 erroneously associates it with ’Os cill o cocci num’, providing misleading information. Meanwhile, Baichuan2-7B-Chat experienced more severe hallucinations, referring to a non-existent drug named ’Os cill oc las m’. HuatuoGPT-II, however, correctly understood this as ’Oxycodone’ and provided accurate information.
另一个例子如表 22 所示,涉及一个关于"OxyContin"的中文直接提问。GPT-4 错误地将其与"Os cill o cocci num"关联,提供了误导性信息。而 Baichuan2-7B-Chat 出现了更严重的幻觉,引用了一种名为"Os cill oc las m"的不存在药物。但 HuatuoGPT-II 正确理解了这是"Oxycodone"并提供了准确信息。
| Query: 奥斯康定是什么药物 ( Translation: What is the medication OxyContin?) |
| GPT-4: 奥斯康定(Oscillococcinum)是一种用于流感症状治疗的顺势疗法药物。它通常用于轻微或初期 的流感症状,如发烧、寒战、疲倦和头痛。奥斯康定的主要成分是从鸭肝和鸭心提取的物质,这种 提取物被高度稀释,以符合顺势疗法的原则。 ( Translation: OxyContin (Oscillococcinum) is a homeopathic medicine used for the treatment of flu symptoms. It is usually used for mild or initial flu symptoms such as fever, chills, fatigue and headache. The main ingredient in Oscillococcinum is a substance extracted from the liver and heart of ducks, and this extract is highly diluted to comply with homeopathic principles... ) |
| Baichuan2-7B-Chat: 奥斯康定(Oscilloclasm)是一种抗癫痫药物,主要用于治疗各种类型的癫痫发作。它的化学名为 ‘2-[(3,4-二甲氧基苯甲酰)氨基]-2-氧代丙酸”,其结构式为C16H17NO4,分子量为285.35。 |
| (Translation: OxyContin (Oscilloclasm) is an antiepileptic drug that is primarily used to treat various types of seizures. Its chemical name is "2-[(3,4-dimethoxybenzoyl)amino]-2-oxopropionic acid",its structural formula is C16H17NO4,and its molecular weightis 285.35.) |
| 查询: 奥斯康定是什么药物 (Translation: What is the medication OxyContin?) |
|---|
| GPT-4: 奥斯康定 (Oscillococcinum) 是一种用于流感症状治疗的顺势疗法药物。它通常用于轻微或初期的流感症状,如发烧、寒战、疲倦和头痛。奥斯康定的主要成分是从鸭肝和鸭心提取的物质,这种提取物被高度稀释,以符合顺势疗法的原则。 (Translation: OxyContin (Oscillococcinum) is a homeopathic medicine used for the treatment of flu symptoms. It is usually used for mild or initial flu symptoms such as fever, chills, fatigue and headache. The main ingredient in Oscillococcinum is a substance extracted from the liver and heart of ducks, and this extract is highly diluted to comply with homeopathic principles...) |
| Baichuan2-7B-Chat: 奥斯康定 (Oscilloclasm) 是一种抗癫痫药物,主要用于治疗各种类型的癫痫发作。它的化学名为 "2-[(3,4-二甲氧基苯甲酰)氨基]-2-氧代丙酸",其结构式为C16H17NO4,分子量为285.35。 (Translation: OxyContin (Oscilloclasm) is an antiepileptic drug that is primarily used to treat various types of seizures. Its chemical name is "2-[(3,4-dimethoxybenzoyl)amino]-2-oxopropionic acid", its structural formula is C16H17NO4, and its molecular weight is 285.35.) |
HuatuoGPT-II(7B):
华佗GPT-II(7B):
奥斯康定(Oxycodone)是一种强效的阿片类镇痛药,主要用于治疗中度到重度的疼痛。阿片类药物主要通过影响大脑中的阿片受体来减轻疼痛,这些受体主要存在于大脑和脊髓中。奥斯康定在医疗领域有广泛的应用,包括用于术后疼痛、癌症疼痛、慢性疼痛等。然而,由于其强效的镇痛效果,奥斯康定也有可能被滥用,导致成瘾问题...
奥斯康定 (Oxycodone) 是一种强效的阿片类镇痛药,主要用于治疗中度到重度的疼痛。阿片类药物主要通过影响大脑中的阿片受体来减轻疼痛,这些受体主要存在于大脑和脊髓中。奥斯康定在医疗领域有广泛的应用,包括用于术后疼痛、癌症疼痛、慢性疼痛等。然而,由于其强效的镇痛效果,奥斯康定也有可能被滥用,导致成瘾问题...
(Translation: OxyContin (Oxycodone) is a potent opioid analgesic used primarily to treat moderate to severe pain. Opioids reduce pain primarily by affecting opioid receptors in the brain, which are found mainly in the brain and spinal cord.
规则:
- 输出中文翻译部分时仅保留翻译标题,不包含任何冗余内容,不重复,不解释。
- 不输出与英文内容无关的信息。
- 保留原始段落格式及专业术语(如FLAC、JPEG等)。公司缩写保留原样(如Microsoft、Amazon、OpenAI等)。
- 人名不翻译。
- 保留文献引用标记(如[20])。
- 图表标题翻译格式:"Figure 1: "译作"图1: ","Table 1: "译作"表1: "。
- 全角括号转换为半角括号,并在左括号前、右括号后添加半角空格。
- 专业术语首次出现时标注英文原文(如"生成式AI (Generative AI)"),后续直接使用中文。
- 常见AI术语对照:
- Transformer -> Transformer
- Token -> Token
- LLM/Large Language Model -> 大语言模型
- Zero-shot -> 零样本
- Few-shot -> 少样本
- AI Agent -> AI智能体
- AGI -> 通用人工智能
- Python -> Python语言
策略:
- 特殊字符及公式不作翻译,原样保留
- HTML表格转换为Markdown格式
- 确保翻译内容符合中文表达习惯且信息完整
最终输出仅包含Markdown格式的翻译结果。
OxyContin has a wide range of applications in the medical field, including for post-operative pain, cancer pain, and chronic pain. However, due to its potent analgesic effects, OxyContin also has the potential to be abused, leading to addiction issues...)
奥施康定 (OxyContin) 在医疗领域有广泛应用,包括术后疼痛、癌痛和慢性疼痛治疗。然而由于其强效镇痛作用,该药物也存在滥用风险,可能导致成瘾问题...)
Table 22: Chinese medical hallucinations case. The green font indicates correct information, and the brown font indicates incorrect information.
表 22: 中医幻觉案例。绿色字体表示正确信息,棕色字体表示错误信息。
These instances highlight GPT-4’s limitations in the Chinese medical domain. We believe there is a critical need to enhance domain-specific capabilities, especially for sensitive topics like healthcare, and HuatuoGPT-II appears to be more adept at this during its current developmental phase.
这些实例凸显了GPT-4在中文医疗领域的局限性。我们认为亟需增强领域特定能力,尤其是医疗等敏感主题,而当前开发阶段的华佗GPT-II似乎更擅长于此。