FinTextQA: A Dataset for Long-form Financial Question Answering
FinTextQA: 长文本金融问答数据集
Jian Chen1 2 Peilin Zhou2 Yining Hua3 Yingxin Loh1 Kehui Chen1 Ziyuan Li1 Bing Zhu1* Junwei Liang2∗ 1HSBC Lab 2Hong Kong University of Science and Technology (Guangzhou) 3Harvard University {alex.j.chen, bing1.zhu}@hsbc.com, jchen524@connect.hkust-gz.edu.cn, jun wei liang@hkust-gz.edu.cn
Jian Chen1 2 Peilin Zhou2 Yining Hua3 Yingxin Loh1 Kehui Chen1 Ziyuan Li1 Bing Zhu1* Junwei Liang2∗ 1汇丰实验室 2香港科技大学(广州) 3哈佛大学 {alex.j.chen, bing1.zhu}@hsbc.com, jchen524@connect.hkust-gz.edu.cn, jun wei liang@hkust-gz.edu.cn
Abstract
摘要
Accurate evaluation of financial questionanswering (QA) systems necessitates a comprehensive dataset encompassing diverse question types and contexts. However, current financial QA datasets lack scope diversity and question complexity. This work introduces FinTextQA, a novel dataset for long-form question answering (LFQA) in finance. FinTextQA comprises 1,262 high-quality, source-attributed QA pairs extracted and selected from finance textbooks and government agency websites.Moreover, we developed a Retrieval-Augmented Generation (RAG)-based LFQA system, comprising an embedder, retriever, reranker, and generator. A multi-faceted evaluation approach, including human ranking, automatic metrics, and GPT-4 scoring, was employed to benchmark the performance of different LFQA system configurations under heightened noisy conditions. The results indicate that: (1) Among all compared generators, Baichuan2-7B competes closely with GPT-3.5-turbo in accuracy score; (2) The most effective system configuration on our dataset involved setting the embedder, retriever, reranker, and generator as Ada2, Automated Merged Retrieval, Bge-Reranker-Base, and Baichuan2-7B, respectively; (3) models are less susceptible to noise after the length of contexts reaching a specific threshold.
准确评估金融问答(QA)系统需要涵盖多样化问题类型和场景的综合性数据集。然而当前金融QA数据集存在范围单一和问题复杂度不足的缺陷。本文提出FinTextQA——一个面向金融领域长文本问答(LFQA)的新数据集,包含从金融教材和政府机构网站提取筛选的1,262个高质量、来源可溯的问答对。此外,我们开发了基于检索增强生成(RAG)的LFQA系统,由嵌入器、检索器、重排序器和生成器构成。通过人工排序、自动指标和GPT-4评分等多维度评估方法,测试了不同LFQA系统配置在强噪声环境下的性能表现。结果表明:(1) 在所有对比生成器中,Baichuan2-7B在准确度得分上与GPT-3.5-turbo表现相当;(2) 本数据集上最优系统配置为:嵌入器Ada2+检索器Automated Merged Retrieval+重排序器Bge-Reranker-Base+生成器Baichuan2-7B;(3) 当上下文长度达到特定阈值后,模型对噪声的敏感度显著降低。
1 Introduction
1 引言
The growing demand for financial data analysis and management has led to the expansion of artificial intelligence (AI)-driven question-answering (QA) systems. These systems not only enhance customer service but also assist in risk management and personalized stock recommendations (Wu et al., 2023). The intricate nature of financial data, with its domain-specific terminologies, concepts, and the inherent uncertainty of the market and decisionmaking processes, demands a deep understanding of the financial domain to generate accurate and informative responses (Conf a loni eri et al., 2021). In this context, long-form question answering (LFQA) scenarios become particularly relevant as they require models to demonstrate a broad spectrum of sophisticated skills, including information retrieval, sum mari z ation, data analysis, comprehension, and reasoning (Fan et al., 2019).
金融数据分析和管理的需求日益增长,推动了人工智能 (AI) 驱动的问答 (QA) 系统的发展。这些系统不仅能提升客户服务质量,还能辅助风险管理和个性化股票推荐 (Wu et al., 2023)。金融数据的复杂性体现在其领域专用术语、概念以及市场和决策过程中固有的不确定性,这要求系统对金融领域有深刻理解才能生成准确且信息丰富的回答 (Conf a loni eri et al., 2021)。在此背景下,长文本问答 (LFQA) 场景尤为重要,因为它要求模型展现包括信息检索、摘要、数据分析、理解和推理在内的多种复杂技能 (Fan et al., 2019)。

Figure 1: An LFQA sample in FinTextQA. Models are expected to generate paragraph-length answers when given questions and documents.
图 1: FinTextQA中的长格式问答样本。模型在给定问题和文档时需生成段落长度的回答。
In the general domain, there are several LFQA datasets available, including ELI5 (Fan et al., 2019), WikiHowQA (Bolotova-Baranova et al., 2023) and WebCPM (Qin et al., 2023). However, it is important to note that there is currently no LFQA dataset specifically tailored for the finance domain. Existing financial QA benchmarks often fall short in addressing question complexity and variety by primarily on sentiment analysis and numerical calculation, as comprehensive paragraph-length responses and relevant document retrievals are often required to answer intricate, open-domain questions (Han et al., 2023). To address these challenges, we intro- duce a new dataset, FinTextQA, which comprises LFQAs from finance-related textbooks and government agency websites to assess QA models on general finance and regulation or policy-related questions. FinTextQA consists of 1,262 high-quality, source-attributed question-answer pairs and associated document contexts. It contains six question types with an average text length of 19.7k words, curated from five rounds of human screening. This dataset is pioneering work in integrating financial regulations and policies into LFQA, challenging models with more demanding content.
在通用领域,已有多个长格式问答(LFQA)数据集,如ELI5 (Fan et al., 2019)、WikiHowQA (Bolotova-Baranova et al., 2023)和WebCPM (Qin et al., 2023)。但值得注意的是,目前尚无专门针对金融领域的长格式问答数据集。现有金融问答基准往往局限于情感分析和数值计算,难以应对复杂多样的开放式问题(Han et al., 2023),因为回答这类问题通常需要段落级详细解答和相关文档检索。为解决这些问题,我们推出了新数据集FinTextQA,该数据集收录来自金融教材和政府机构网站的长格式问答,用于评估模型在通用金融及监管政策类问题上的表现。FinTextQA包含1,262个高质量、来源可溯的问答对及相关文档上下文,涵盖六种问题类型,平均文本长度达1.97万词,经过五轮人工筛选。该数据集开创性地将金融法规政策融入长格式问答,为模型提供了更具挑战性的内容。

Figure 2: The workflow of our proposed RAG-based LFQA system. Embedder aims to encode documents and user’s question into semantic vectors. Retriever retrieves relevant document chunks based on the encoded question. Reranker removes less-similar chunks. With a prompt which combines question and chunks, the generator finally output desired answer.
图 2: 我们提出的基于RAG的LFQA系统工作流程。Embedder负责将文档和用户问题编码为语义向量。Retriever根据编码后的问题检索相关文档片段。Reranker剔除相似度较低的片段。通过将问题和片段组合成提示(prompt),生成器最终输出所需答案。
In addition to introducing the dataset, we conduct comprehensive benchmarking of state-of-theart (sota) models on FinTextQA to provide baselines for future research. Current LFQA systems frequently solely rely on fine-tuning pre-trained language models such as GPT-3.5-turbo, LLaMA2 (Touvron et al., 2023), Baichuan2 (Yang et al., 2023), etc., which often fail to provide detailed explanations or effectively handling complicated finance questions (Yuan et al., 2023). In response, we opt for the Retrieval-augmented generation (RAG) framework, as illustrated in Figure 2. By processing documents in multiple steps, RAG systems can pre-process and provide the most relevant information to LLMs, enhancing their performance and explanation capabilities (Guu et al., 2020).
除了介绍数据集外,我们对FinTextQA上的最先进(sota)模型进行了全面基准测试,为未来研究提供基线。当前的长格式问答(LFQA)系统往往仅依赖微调预训练语言模型,如GPT-3.5-turbo、LLaMA2 (Touvron等人,2023)、Baichuan2 (Yang等人,2023)等,这些模型通常无法提供详细解释或有效处理复杂金融问题(Yuan等人,2023)。为此,我们选择了检索增强生成(RAG)框架,如图2所示。通过多步骤处理文档,RAG系统能够预处理并向大语言模型提供最相关信息,从而提升其性能和解释能力(Guu等人,2020)。
We believe this work, by introducing the first LFQA financial dataset and conducting comprehensive benchmark experiments on the dataset, marks a milestone in advancing the comprehension of financial concepts and enhancing assistance in this field: FinTextQA offers a rich and rigorous framework for building and assessing the capabilities of general finance LFQA systems. Our experimental analysis not only highlights the efficacy of various model configurations but also underscores the critical need for enhancing current methodologies to improve both the precision and exp li c ability of financial question-answering systems.
我们相信,这项工作通过引入首个LFQA金融数据集并在该数据集上进行全面的基准实验,标志着在提升金融概念理解和加强该领域辅助方面的一个重要里程碑:FinTextQA为构建和评估通用金融LFQA系统的能力提供了一个丰富而严谨的框架。我们的实验分析不仅凸显了各种模型配置的有效性,还强调了提升当前方法以改进金融问答系统精确性和可解释性的迫切需求。
2 Related Work
2 相关工作
2.1 Long-Form Question Answering (LFQA)
2.1 长文本问答 (LFQA)
The goal of LFQA is to generate comprehensive, paragraph-length responses by retrieving and assimilating relevant information from various sources (Fan et al., 2019). This poses a significant test for current Natural Language Processing (NLP) and Artificial Intelligence (AI) models, given their limited understanding and learning capacities (Thompson et al., 2020).
长格式问答 (LFQA) 的目标是通过检索并整合来自不同来源的相关信息 (Fan et al., 2019) ,生成全面、段落长度的回答。这对当前自然语言处理 (NLP) 和人工智能 (AI) 模型提出了重大考验,因为它们的理解和学习能力有限 (Thompson et al., 2020)。
Several LFQA datasets are available in general domain, including ELI5 (Fan et al., 2019), WikiHowQA (Bolotova-Baranova et al., 2023), and WebCPM (Qin et al., 2023). In the financial domain, some QA datasets have been developed. However, none of them addresses LFQA. While these datasets like FinQA (Chen et al., 2021) and TATQA (Zhu et al., 2021) address specific scopes such as numerical reasoning, they do not touch upon general LFQA tasks. In addition, FIQA (Maia et al., 2018) only provides short-context documents, which may not adequately represent real-life scenarios and have limited industry applicability. Although Finance Bench (Islam et al., 2023) does cover a wider scope, it only offers 150 open-source question-answer pairs, while the question complexity and answer do not satisfy real-life LFQA scenarios.
通用领域已有多个长格式问答(LFQA)数据集,包括ELI5 (Fan等人, 2019)、WikiHowQA (Bolotova-Baranova等人, 2023)和WebCPM (Qin等人, 2023)。金融领域虽已开发部分问答数据集,但均未涉及LFQA任务。例如FinQA (Chen等人, 2021)和TATQA (Zhu等人, 2021)仅针对数值推理等特定范围,未涵盖通用LFQA任务。此外,FIQA (Maia等人, 2018)仅提供短上下文文档,难以充分反映现实场景且行业适用性有限。尽管Finance Bench (Islam等人, 2023)覆盖范围较广,但仅包含150个开源问答对,其问题复杂度和答案质量均无法满足现实LFQA场景需求。
2.2 Retrieval-Augmented Generation (RAG)
2.2 检索增强生成 (RAG)
RAG frameworks represent a significant advancement in LFQA, incorporating external knowledge sources and In-Context Learning (ICL) for efficient information retrieval and application. By combining diverse documents into comprehensive prompts, RAG enables language models to generate contextually informed responses without task-specific retraining (Lewis et al., 2020).
RAG框架代表了长格式问答(LFQA)领域的重大进步,它整合了外部知识源和上下文学习(ICL)机制,以实现高效的信息检索与应用。通过将多样化文档整合为综合性提示(prompt),RAG使语言模型无需针对特定任务进行重新训练就能生成具有上下文感知的响应 (Lewis et al., 2020)。
The evolution of RAG involves three principal stages: Naive RAG, Advanced RAG, and Modular RAG. Naive RAG offers improvements over traditional language models by providing costefficient indexing, retrieval, and generation, albeit with certain constraints. Advanced RAG ad- dresses these limitations by integrating refined indexing and retrieval techniques, optimizing data handling, and introducing strategic Retrieval and post-retrieval processes. Its capabilities include fine-tuning domain-specific embedders, employing dynamic ones for improved context comprehension, and applying reranker and prompt compression during post-retrieval processes (Ilin, 2023). Modular RAG represents a further advancement from traditional NLP frameworks by introducing specialized modules for similarity-based retrieval, fine-tuning, and problem-solving. It also incorporates innovative modules like Search and Memory (Cheng et al., 2023), Fusion (Rackauckas, 2024), and Routing to customize RAG for specific applications and improve search and retrieval operation (Gao et al., 2023). The ongoing evolution of RAG demonstrates its potential to revolutionize information retrieval and adaptability in language model systems within the fast-evolving field of computational linguistics. In this study, we choose to assess the effectiveness of Modular RAG with the rewrite, retrieve, re-rank, and read modules following previous work (Gao et al., 2023).
RAG的演进经历了三个阶段:朴素RAG (Naive RAG)、高级RAG (Advanced RAG) 和模块化RAG (Modular RAG)。朴素RAG通过经济高效的索引、检索和生成改进了传统语言模型,但仍存在一定局限。高级RAG通过整合精细化索引与检索技术、优化数据处理流程、引入战略性检索及检索后处理机制(如领域嵌入器微调、动态嵌入提升上下文理解、重排序与提示压缩技术)来突破这些限制 (Ilin, 2023)。模块化RAG则通过引入基于相似度的检索模块、微调模块、问题解决模块,以及搜索与记忆 (Cheng et al., 2023)、融合 (Rackauckas, 2024)、路由等创新模块,实现了对传统NLP框架的超越,可针对特定应用定制化优化搜索检索流程 (Gao et al., 2023)。RAG技术的持续演进展现了其在快速发展的计算语言学领域革新信息检索系统、增强语言模型适应性的潜力。本研究基于改写-检索-重排序-阅读框架 (Gao et al., 2023),重点评估模块化RAG的实际效能。
3 The FinTextQA Dataset
3 FinTextQA数据集
3.1 Data Sources
3.1 数据来源
The data in FinTextQA are sourced from wellestablished financial literature and government agencies, such as expert-authored question-answer pairs from recognized finance textbooks: Bank Management and Financial Services (BMFS), Fundamentals of Corporate Finance (FCF), and The Economics of Money, Banking, and Financial Markets (EMBFM). Additionally, crucial information regarding financial regulations and policies is incorporated from esteemed websites such as the Hong Kong Monetary Authority (HKMA) 1, European Union $(\mathrm{EU})^{2}$ , and the Federal Reserve $(\mathrm{FR})^{3}$ . Question types encompass various domains, spanning concept explanation and numerical calculation to comparative analysis and open-ended opinionbased queries.
FinTextQA中的数据来源于成熟的金融文献和政府机构,例如来自权威金融教材的专家编写问答对:《银行管理与金融服务》(BMFS)、《公司金融基础》(FCF)以及《货币、银行与金融市场经济学》(EMBFM)。此外,关于金融法规和政策的关键信息整合自香港金融管理局(HKMA) $^{1}$、欧盟(EU) $^{2}$ 和美联储(FR) $^{3}$ 等权威网站。问题类型涵盖多个领域,从概念解释、数值计算到比较分析和开放式观点类问题。
3.2 Selection of Policy and Regulation Data
3.2 政策法规数据的选择
In textbooks, questions are typically straight forward, and evidence (i.e., citations) can be easily found within each chapter. However, in policies and regulations, some of the questions draw from multiple sources and may not directly align with the documents in our dataset. This poses a challenge for the model to provide accurate answers. Additionally, policy and regulation data often require deeper analytical thinking and interpretation, demanding a robust reasoning ability from the QA system. Given the complexity and importance of financial regulations and policies, we have implemented a thorough two-step verification process to ensure the relevance and accuracy of the QA pairs and the associated regulation and policy documents:
在教材中,问题通常直截了当,且证据(即引用)能在各章节轻松找到。然而在政策法规领域,部分问题涉及多源信息,可能与数据集中的文件并不直接对应。这对模型提供准确答案构成了挑战。此外,政策法规数据往往需要更深层次的分析思考与解读,这对问答系统的推理能力提出了更高要求。鉴于金融法规政策的复杂性与重要性,我们实施了严格的两步验证流程,以确保问答对及相关政策法规文件的关联性与准确性:
- Evidence identification: Initially, annotators are tasked with locating relevant evidence (aka citations and references) for each questionanswer pair within the dataset. Any questions that cannot be feasibly linked to a valid citation or reference were promptly excluded from consideration;
- 证据识别:首先,标注员需要在数据集中为每个问答对定位相关证据(即引文和参考文献)。任何无法合理关联到有效引文或参考文献的问题都会被立即排除;
- Relevance evaluation: Another distinct group of annotators evaluates the coherence and connected ness between the question, context, and answer for each entry. Using a grading scale from 1 to 5, they ensure high standards of relevancy. Only entries with a score exceeding 2 across all three variables are included in the final dataset.
- 相关性评估:另一组独立的标注员评估每个条目中问题、上下文和答案之间的连贯性与关联性。他们采用1到5分的评分标准,确保相关性达到高标准。只有当所有三个变量的得分均超过2分时,条目才会被纳入最终数据集。
Table 1: Di sri but ion of numbers of documents and questions from different sources.
| Source | #of Document | #of Question |
| EU | 1 | 12 |
| FR | 8 | 190 |
| HKMA | 6 | 38 |
| BMFS | 19 | 319 |
| EMBFM | 26 | 472 |
| FCF | 20 | 231 |
表 1: 不同来源文档和问题数量分布
| Source | #of Document | #of Question |
|---|---|---|
| EU | 1 | 12 |
| FR | 8 | 190 |
| HKMA | 6 | 38 |
| BMFS | 19 | 319 |
| EMBFM | 26 | 472 |
| FCF | 20 | 231 |
Initially, we collected 300 regulation and policy question-answer pairs with related document contexts. After careful data quality control, 240 pairs were retained. The data selection process resulted in a dataset demonstrating strong relevance among answer-context (3.91), question-answer (4.88), and question-context (4.54), indicating its high quality and dependability. Further details of human evaluation can be found in Appendix A.1.
我们最初收集了300组法规政策相关的问答对及其对应文档上下文。经过严格的数据质量控制后,保留了240组数据。筛选后的数据集在答案-上下文(3.91)、问题-答案(4.88)和问题-上下文(4.54)三个维度均表现出高度相关性,证实了数据的优质性与可靠性。人工评估的详细结果参见附录A.1。
3.3 Dataset Statistics
3.3 数据集统计
FinTextQA contains 1,262 QA pairs, with 1,022 pairs from finance textbooks, accounting for $80.98%$ of the dataset, and 240 pairs from policies and regulations, accounting for $19.02%$ of the dataset. We randomly split the dataset into training, validation, and test sets following a 7:1:2 ratio for model fine-tuning and evaluation. Table 1 presents data distribution across different sources.
FinTextQA包含1,262个问答对,其中1,022对来自金融教科书,占数据集的80.98%,240对来自政策法规,占数据集的19.02%。我们按7:1:2的比例随机将数据集划分为训练集、验证集和测试集,用于模型微调和评估。表1展示了不同来源的数据分布情况。
Table 1 illustrates the distribution of these questions, representing various aspects of financial regulations and policies. The European Commission subset comprises 12 questions focused on transaction regulation and its interpretations. The Federal Reserve subset, containing over 190 questions, addresses topics such as banking regulations, monetary policy strategies, and international banking operations. The Hong Kong Monetary Authority subset contains 38 questions covering anti-money laundering, counter-terrorist financing ordinance, and credit card business regulations, etc.
表 1: 展示了这些问题的分布情况,涉及金融监管与政策的多个方面。欧洲委员会 (European Commission) 子集包含12个重点关注交易监管及其解释的问题。美联储 (Federal Reserve) 子集包含190多个问题,涉及银行监管、货币政策策略和国际银行业务等主题。香港金融管理局 (Hong Kong Monetary Authority) 子集包含38个问题,涵盖反洗钱、打击恐怖主义融资条例和信用卡业务监管等内容。
FinTextQA consists mainly of compound questions, where each primary question includes 2-3 related sub-questions. This hierarchical format introduces more complexity for question understanding and reasoning. These sub-questions come in different forms, leading to a variety of interrogative words as illustrated in Figure 3. Our analysis shows that $36.98%$ of the questions start with "what", making it the most common starting word, followed by "how" at $19.63%$ , "why" at $12.59%$ , and "can" at $6.81%$ . The diversity in the types of interrogative words enriches the dataset, providing a more thorough test of large language models’ ability to read and understand text.
FinTextQA主要由复合问题构成,每个主问题包含2-3个相关子问题。这种层级结构增加了问题理解和推理的复杂性。这些子问题形式多样,如图3所示,产生了多种疑问词。我们的分析显示,$36.98%$的问题以"what"开头,成为最常见的起始词,其次是"how"占$19.63%$,"why"占$12.59%$,"can"占$6.81%$。疑问词类型的多样性丰富了数据集,更全面地测试大语言模型的文本阅读理解能力。
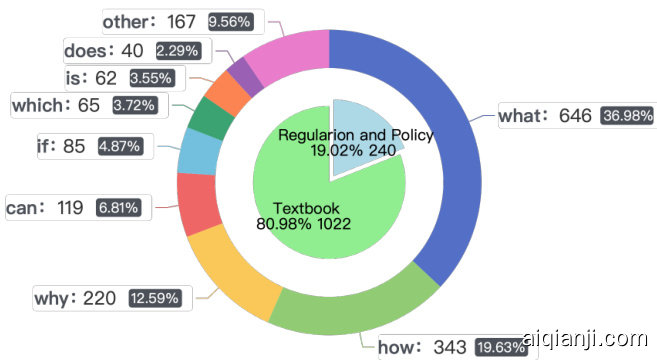
Figure 3: Distribution of data sources and interrogative words in FinTextQA.
图 3: FinTextQA 中数据源和疑问词的分布。
3.4 Comparison to Existing Datasets
3.4 与现有数据集的对比
Table 2 shows a comparison of LFQA datasets, not limited to finance. FinTextQA stands out with an average question length of 28.5 words, answers of 75 words, and notably extended document contexts, averaging 19,779.5 words. These extensive contexts, segmented into chapters or sessions, are designed to enhance retrieval tasks. Furthermore, FinTextQA covers a broad scope, including multiturn, numerical, finance domain, and open-ended questions. It contains the most complex questions and longest answers alongside the widest scope, as compared with other finance QA datasets. Further details of question types can be found in Appendix A.4.
表 2 展示了 LFQA 数据集的对比情况(不限于金融领域)。FinTextQA 以平均 28.5 个单词的问题长度、75 个单词的答案长度以及显著延长的文档上下文(平均 19,779.5 个单词)脱颖而出。这些被分割为章节或会话的扩展上下文旨在提升检索任务效果。此外,FinTextQA 涵盖范围广泛,包含多轮对话、数值型、金融领域和开放式问题。与其他金融问答数据集相比,它包含了最复杂的问题、最长的答案以及最广的覆盖范围。更多问题类型细节详见附录 A.4。
4 Benchmarks on FinTextQA
4 FinTextQA 基准测试
4.1 RAG-based LFQA system
4.1 基于RAG的长格式问答系统
We employ the modular RAG as discussed in (Gao et al., 2023) and follow the guidelines outlined in Llama Index 4 to construct the RAG-based LFQA system. As shown in Figure 2, this LFQA system consists of four modules: embedder, retriever, reranker, and generator. The first three modules together serve to find relevant information (aka evidence or citations) from contexts. The last module synthesizes responses using the retrieved information. Each module can be implemented by different models, and the combinations of models for all modules constitutes the system’s configurations.
我们采用 (Gao et al., 2023) 中讨论的模块化 RAG 方法,并遵循 Llama Index 4 的指导原则构建基于 RAG 的 LFQA 系统。如图 2 所示,该 LFQA 系统包含四个模块:嵌入器 (embedder)、检索器 (retriever)、重排序器 (reranker) 和生成器 (generator)。前三个模块共同作用是从上下文中查找相关信息(即证据或引用),最后一个模块则利用检索到的信息合成回答。每个模块可由不同模型实现,所有模块的模型组合构成了系统的配置。
Table 2: Comparison of various financial QA datasets. FinTextQA offers substantially longer questions and answers. Meanwhile, has a wider scope compared with other finance QA datasets.
| Dataset | Average#ofWords | Scope | |||||||
| Question | Document | Answer | Multi-turn | Comparative | Numerical | Domain | Open-minded | CauseandEffect | |
| FIQA (Maia et al.,2018) | 12.8 | 136.4 | √ | ||||||
| TAT-QA (Zhu et al.,2021) | 12.4 | 42.6 | 4.3 | √ | |||||
| FinQA (Chen et al., 2021) | 16.6 | 628.1 | 1.1 | 人 | |||||
| FinanceBench(Islametal.,2023) | 27.0 | 65,615.6 | 12.66 | √ | |||||
| FinTextQA(ours) | 28.5 | 19,779.5 | 75 | √ | √ | √ | √ | √ | |
表 2: 各类金融问答数据集对比。FinTextQA提供了显著更长的问题和答案,同时相比其他金融问答数据集具有更广泛的范围。
| 数据集 | 平均词数 | 范围 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 问题 | 文档 | 答案 | 多轮 | 对比 | 数值 | 领域 | 开放思维 | 因果 | |
| FIQA (Maia et al., 2018) | 12.8 | 136.4 | √ | ||||||
| TAT-QA (Zhu et al., 2021) | 12.4 | 42.6 | 4.3 | √ | |||||
| FinQA (Chen et al., 2021) | 16.6 | 628.1 | 1.1 | 人 | |||||
| FinanceBench (Islam et al., 2023) | 27.0 | 65,615.6 | 12.66 | √ | |||||
| FinTextQA (ours) | 28.5 | 19,779.5 | 75 | √ | √ | √ | √ | √ |
| Generator | Retriever | Embedder | Reranker | Answer Accuracy | ROUGE-1 | ROUGE-2 | ROUGE-L | BLEU |
| GPT-3.5-turbo | AMR | Ada2 | LLMRerank | 4.411 | 0.346 | 0.134 | 0.224 | 0.062 |
| AMR | Ember-v1 | LLMRerank | 4.365 | 0.341 | 0.130 | 0.221 | 0.060 | |
| AMR | Ember-v1 | Bge-Reranker-Base | 4.439 | 0.339 | 0.131 | 0.221 | 0.062 | |
| Baichuan2-7B | AMR | Ada2 | LLMRerank | 4.578 | 0.340 | 0.124 | 0.219 | 0.057 |
| AMR | Ada2 | Bge-Reranker-Base | 4.612 | 0.338 | 0.123 | 0.217 | 0.054 | |
| AMR | Ember-v1 | Bge-Reranker-Base | 4.513 | 0.333 | 0.120 | 0.215 | 0.053 | |
| Solar-10.7B | AMR | Ember-v1 | Bge-Reranker-Base | 4.348 | 0.329 | 0.119 | 0.205 | 0.052 |
| AMR | Bge-Small-en-v1.5 | Bge-Reranker-Base | 4.310 | 0.329 | 0.118 | 0.205 | 0.051 | |
| AMR | Ada2 | Bge-Reranker-Base | 4.378 | 0.327 | 0.119 | 0.204 | 0.051 | |
| Qwen-7B | AMR | Bge-Small-en-v1.5 | LLMRerank | 4.414 | 0.341 | 0.125 | 0.217 | 0.059 |
| AMR | Ada2 | Bge-Reranker-Base | 4.405 | 0.337 | 0.120 | 0.216 | 0.056 | |
| AMR | Ember-v1 | LLMRerank | 4.432 | 0.339 | 0.121 | 0.215 | 0.056 | |
| LLaMA2-7B | SWR | Ada2 | All-Mpnet-Base-v2 | 4.184 | 0.233 | 0.078 | 0.152 | 0.030 |
| AMR | Bge-Small-en-v1.5 | Bge-Reranker-Base | 4.268 | 0.239 | 0.078 | 0.151 | 0.031 | |
| AMR | Bge-Small-en-v1.5 | LLMRerank | 4.287 | 0.233 | 0.076 | 0.149 | 0.031 | |
| Gemini-Pro | AMR | Ember-v1 | Bge-Reranker-Base | 3.970 | 0.304 | 0.118 | 0.211 | 0.048 |
| AMR | Ember-v1 | LLMRerank | 3.990 | 0.306 | 0.119 | 0.211 | 0.052 | |
| AMR | Bge-Small-en-v1.5 | LLMRerank | 3.989 | 0.303 | 0.119 | 0.210 | 0.051 |
Table 3: Systematic performance comparison of RAG-based LFQA system with different configurations.
| 生成器 (Generator) | 检索器 (Retriever) | 嵌入器 (Embedder) | 重排序器 (Reranker) | 答案准确率 (Answer Accuracy) | ROUGE-1 | ROUGE-2 | ROUGE-L | BLEU |
|---|---|---|---|---|---|---|---|---|
| GPT-3.5-turbo | AMR | Ada2 | LLMRerank | 4.411 | 0.346 | 0.134 | 0.224 | 0.062 |
| GPT-3.5-turbo | AMR | Ember-v1 | LLMRerank | 4.365 | 0.341 | 0.130 | 0.221 | 0.060 |
| GPT-3.5-turbo | AMR | Ember-v1 | Bge-Reranker-Base | 4.439 | 0.339 | 0.131 | 0.221 | 0.062 |
| Baichuan2-7B | AMR | Ada2 | LLMRerank | 4.578 | 0.340 | 0.124 | 0.219 | 0.057 |
| Baichuan2-7B | AMR | Ada2 | Bge-Reranker-Base | 4.612 | 0.338 | 0.123 | 0.217 | 0.054 |
| Baichuan2-7B | AMR | Ember-v1 | Bge-Reranker-Base | 4.513 | 0.333 | 0.120 | 0.215 | 0.053 |
| Solar-10.7B | AMR | Ember-v1 | Bge-Reranker-Base | 4.348 | 0.329 | 0.119 | 0.205 | 0.052 |
| Solar-10.7B | AMR | Bge-Small-en-v1.5 | Bge-Reranker-Base | 4.310 | 0.329 | 0.118 | 0.205 | 0.051 |
| Solar-10.7B | AMR | Ada2 | Bge-Reranker-Base | 4.378 | 0.327 | 0.119 | 0.204 | 0.051 |
| Qwen-7B | AMR | Bge-Small-en-v1.5 | LLMRerank | 4.414 | 0.341 | 0.125 | 0.217 | 0.059 |
| Qwen-7B | AMR | Ada2 | Bge-Reranker-Base | 4.405 | 0.337 | 0.120 | 0.216 | 0.056 |
| Qwen-7B | AMR | Ember-v1 | LLMRerank | 4.432 | 0.339 | 0.121 | 0.215 | 0.056 |
| LLaMA2-7B | SWR | Ada2 | All-Mpnet-Base-v2 | 4.184 | 0.233 | 0.078 | 0.152 | 0.030 |
| LLaMA2-7B | AMR | Bge-Small-en-v1.5 | Bge-Reranker-Base | 4.268 | 0.239 | 0.078 | 0.151 | 0.031 |
| LLaMA2-7B | AMR | Bge-Small-en-v1.5 | LLMRerank | 4.287 | 0.233 | 0.076 | 0.149 | 0.031 |
| Gemini-Pro | AMR | Ember-v1 | Bge-Reranker-Base | 3.970 | 0.304 | 0.118 | 0.211 | 0.048 |
| Gemini-Pro | AMR | Ember-v1 | LLMRerank | 3.990 | 0.306 | 0.119 | 0.211 | 0.052 |
| Gemini-Pro | AMR | Bge-Small-en-v1.5 | LLMRerank | 3.989 | 0.303 | 0.119 | 0.210 | 0.051 |
表 3: 基于RAG的LFQA系统在不同配置下的系统性性能对比
Table 4: Performance comparison of embedders, retrievers, rerankers, and best-performing configuration. GPT-4 scores are generated regarding question-evidence relevance.
| Module | Model | Average |
| Score | ||
| Embedder | Ada2 | 4.586 |
| Ember-v1 | 4.486 | |
| Bge-Small-en-v1.5 | 4.455 | |
| Gte-Large | 4.261 | |
| Retriever | AMR | 4.492 |
| SWR | 4.466 | |
| VectorRetrieval | 4.358 | |
| Reranker | Bge-Reranker-Base | 4.489 |
| LLMRerank | 4.469 | |
| All-Mpnet-Base-v2 | 4.383 | |
| Best-perfoming Configurations | AMR+Ada2+LLMRerank | 4.622 |
| SWR+Ada2+Bge-Reranker-Base | 4.620 | |
| SWR+Ada2+All-Mpnet-Base-v2 | 4.620 |
表 4: 嵌入器、检索器、重排序器及最佳性能配置的性能对比。GPT-4 分数基于问题-证据相关性生成。
| 模块 | 模型 | 平均分数 |
|---|---|---|
| Embedder | Ada2 | 4.586 |
| Ember-v1 | 4.486 | |
| Bge-Small-en-v1.5 | 4.455 | |
| Gte-Large | 4.261 | |
| Retriever | AMR | 4.492 |
| SWR | 4.466 | |
| VectorRetrieval | 4.358 | |
| Reranker | Bge-Reranker-Base | 4.489 |
| LLMRerank | 4.469 | |
| All-Mpnet-Base-v2 | 4.383 | |
| Best-perfoming Configurations | AMR+Ada2+LLMRerank | 4.622 |
| SWR+Ada2+Bge-Reranker-Base | 4.620 | |
| SWR+Ada2+All-Mpnet-Base-v2 | 4.620 |
The selection of the models for each module is summarzied as follows:
各模块的模型选择总结如下:
The Embedder Module The role of the embedder module is to convert human language into a vector representation that can be understood and processed by computers. In our experiments, we adopt four popular embedding models that have achieved high rankings on the Hugging Face leaderboard, including (1) BAAI’s Bge-small-en-v1.5 (Xiao and Liu, 2023), (2) NLPer’s Gte-large (Li et al., 2023), (3) LLMRails’ Ember-v15, and (4) OpenAI’s Ada26.
嵌入模块
嵌入模块的作用是将人类语言转换为计算机能够理解和处理的向量表示。在我们的实验中,我们采用了四种在Hugging Face排行榜上排名靠前的流行嵌入模型,包括:(1) BAAI的Bge-small-en-v1.5 (Xiao和Liu, 2023)、(2) NLPer的Gte-large (Li等, 2023)、(3) LLMRails的Ember-v15,以及(4) OpenAI的Ada26。
The Retriever Module The retriever module forms the backbone of our experiment by searching and retrieving relevant context related to a given question. We explore three retriever methods, including Auto Merging Retriever (AMR) (Liu, 2023), (2) Sentence Window Retriever (SWR) (llamaindex, 2023), and a simple vector-based retriever approach. AMR organizes documents into a hierarchical tree system with parent nodes’ contents distributed among child nodes. This enables users to determine the relevance of the parent node based on its child nodes’ relevance to the query. SWR fetches context from a custom knowledge base by considering a broader context and retrieving sentences around the most relevant sentence. This leads to the generation of higher-quality context. Finally, the vector-based retriever approach simply searches for related context through a vector index. The Reranker Module The primary objective of rerankers is to refine the retrieved information by re positioning the most pertinent content towards the prompt edges. To accomplish this, we examine the influence of three rerankers on the overall system performance: (1) LLMRerank (Fajardo, 2023), (2) Bge-Ranker-Base7, and (3) All-Mpnet-Basev2(Song et al., 2020).
检索器模块
检索器模块通过搜索和检索与给定问题相关的上下文,构成我们实验的核心部分。我们探索了三种检索方法:(1) 自动合并检索器 (AMR) (Liu, 2023),(2) 句子窗口检索器 (SWR) (llamaindex, 2023),以及 (3) 简单的基于向量的检索方法。AMR 将文档组织成具有父子节点关系的层级树系统,父节点内容分布在子节点中。这使得用户可以根据子节点与查询的相关性来判断父节点的相关性。SWR 通过考虑更广泛的上下文并检索最相关句子周围的句子,从自定义知识库中获取上下文,从而生成更高质量的上下文。最后,基于向量的检索方法仅通过向量索引搜索相关上下文。
重排序模块
重排序器的主要目标是通过将最相关内容重新定位到提示边缘来优化检索到的信息。为此,我们研究了三种重排序器对整体系统性能的影响:(1) LLMRerank (Fajardo, 2023),(2) Bge-Ranker-Base7,以及 (3) All-Mpnet-Basev2 (Song et al., 2020)。
Table 5: Performance comparison of generators. # of Unanswered Questions is the number of "can not provide answer based on the content" generated by different generators. We use the same embedder, retriever, and reranker in this experiment. An example of unanswered questions is shown in Appendix Table 23.
| Model | #ofUnanswered Questions | Accuracy(%) | Answer&Evidence Relevance | ROUGE-L | BLEU | |||||
| Base | Fine-tuned | Base | Fine-tuned | Base | Fine-tuned | Base | Fine-tuned | Base | Fine-tuned | |
| GPT-3.5-turbo | 21 | 0 | 4.30 | 4.08 | 4.34 | 4.39 | 0.21 | 0.19 | 0.05 | 0.03 |
| Baichuan2-7B | 0 | 0 | 4.50 | 4.51 | 4.73 | 4.73 | 0.20 | 0.20 | 0.05 | 0.04 |
| Qwen-7B | 13 | 10 | 4.43 | 4.43 | 4.59 | 4.35 | 0.19 | 0.19 | 0.04 | 0.04 |
| Solar-10.7B | 13 | 12 | 4.38 | 4.38 | 4.50 | 4.50 | 0.19 | 0.18 | 0.04 | 0.04 |
| LLaMA2-7B | 0 | 0 | 4.14 | 4.27 | 4.22 | 4.28 | 0.10 | 0.10 | 0.02 | 0.02 |
| Gemini-Pro | 61 | 2.46 | 1.85 | 0.15 | 0.02 | |||||
表 5: 生成器性能对比。未回答问题数量是指不同生成器产生的"无法根据内容提供答案"的数量。本实验使用相同的嵌入器、检索器和重排序器。未回答问题的示例见附录表23。
| 模型 | 未回答问题数量 | 准确率(%) | 答案与证据相关性 | ROUGE-L | BLEU |
|---|---|---|---|---|---|
| 基础 | 微调 | 基础 | 微调 | 基础 | |
| GPT-3.5-turbo | 21 | 0 | 4.30 | 4.08 | 4.34 |
| Baichuan2-7B | 0 | 0 | 4.50 | 4.51 | 4.73 |
| Qwen-7B | 13 | 10 | 4.43 | 4.43 | 4.59 |
| Solar-10.7B | 13 | 12 | 4.38 | 4.38 | 4.50 |
| LLaMA2-7B | 0 | 0 | 4.14 | 4.27 | 4.22 |
| Gemini-Pro | 61 | - | 2.46 | - | 1.85 |
The Generator Module The generator module first consolidates the query and relevant document context prepared by the former modules into a wellstructured and coherent prompt. These prompts are then fed to a LLM to generate final responses. To evaluate the performance of various LLMs, we include six sota models, including (1) Qwen-7B (Bai et al., 2023), (2) Baichuan2-7B (Yang et al., 2023), (3)LLaMA2-7B (Touvron et al., 2023), (4) GPT-3.5-turbo, (5) Solar-10.7B (Kim et al., 2023), and (6) Gemini-Pro (Team et al., 2023).
生成器模块
生成器模块首先将前序模块准备的查询和相关文档上下文整合为一个结构良好、连贯的提示(prompt)。这些提示随后被输入大语言模型以生成最终响应。为评估不同大语言模型的性能,我们纳入了六种前沿模型,包括:(1) Qwen-7B (Bai et al., 2023)、(2) Baichuan2-7B (Yang et al., 2023)、(3) LLaMA2-7B (Touvron et al., 2023)、(4) GPT-3.5-turbo、(5) Solar-10.7B (Kim et al., 2023) 以及 (6) Gemini-Pro (Team et al., 2023)。
4.2 Experimental Settings
4.2 实验设置
To ensure a thorough understanding of each model within every module in a controlled manner, we systematically tested all configurations of models in each module in the RAG-based LFQA system to determine the optimal one. All configurations are evaluated on two sets of experiments - one where the generators were fine-tuned using the training set of FinTextQA, and another without such finetuning. Note that Gemini-Pro remains a private model and is thus excluded from the fine-tuning process.
为确保以可控方式深入理解每个模块中的模型,我们系统测试了基于RAG的LFQA系统中各模块模型的所有配置以确定最优方案。所有配置均通过两组实验进行评估:一组使用FinTextQA训练集对生成器进行微调,另一组则不进行微调。需注意Gemini-Pro仍为私有模型,因此未参与微调过程。
To understand the robustness of the best systems, we select the three highest-ranking configurations based on their performance with generators in their base form. This criterion ensures a fair comparison with Gemini-Pro. We then evaluate the performance of these systems under conditions of increased noise by increment ally adding numbers of documents from one to three.
为了评估最佳系统的鲁棒性,我们根据基础形态生成器的性能选取了排名前三的配置方案。这一标准确保了与Gemini-Pro的公平对比。随后,我们通过逐步添加1至3份含噪文档来测试这些系统在噪声增强条件下的表现。
Hyper parameter settings involved in the experiments are set as follows:
实验涉及的超参数设置如下:
Retrievers For AMR, we define three levels of chunk sizes: 2048 for the first level, 512 for the second, and 128 for the third. For the SWR method, we set the window size to 3. For all retrievers, the similarity top $k$ value was set to 6.
对于AMR,我们定义了三个层级的块大小:第一级为2048,第二级为512,第三级为128。对于SWR方法,我们将窗口大小设置为3。所有检索器的相似度top $k$ 值均设为6。
Rerankers We set the LLMRerank batch size to 5, and the top $n$ values of LLMRerank, BgeReranker-Base, and All-Mpnet-Base-v2 to 4.
重排序器
我们将LLMRerank的批次大小设为5,并将LLMRerank、BgeReranker-Base和All-Mpnet-Base-v2的top $n$值设为4。
Generator We use Azure Open a i’s API 8 to access GPT-3.5-turbo and GPT-4-0314 for GPT series models. Google VertexAI $\mathrm{API}^{9}$ is used to access Gemini-Pro. The LLaMA2, Baichuan2, and Qwen models are all used in their 7B versions, while the Solar model is accessed in the 10.7B version. Finetuning of open-source models is carried out on the training set of FinTextQA. For GPT-3.5-turbo, we adopt the fine-tuning methods in Azure AI Studio10, setting the batch size to 2, learning rate multiplier to 1, and epochs to 5.
生成器
我们使用 Azure OpenAI 的 API 8 访问 GPT 系列模型中的 GPT-3.5-turbo 和 GPT-4-0314。Google VertexAI 的 $\mathrm{API}^{9}$ 用于访问 Gemini-Pro。LLaMA2、Baichuan2 和 Qwen 模型均采用 7B 版本,而 Solar 模型则使用 10.7B 版本。开源模型的微调在 FinTextQA 的训练集上进行。对于 GPT-3.5-turbo,我们采用 Azure AI Studio10 中的微调方法,设置批大小为 2,学习率乘数为 1,训练轮数为 5。
GPTQConfig (Frantar et al., 2022) is used to load the Qwen-7B model in 4-bit, the Generation Config (Joao Gante, 2022) for Baichuan2-7B in 4-bit, and the Bits And Bytes Config (Belkada, 2023) for LLaMA2-7B and Solar-10.7B in 4-bit. We employ LoRA for LLaMA2-7B, Baichuan2-7B, Qwen-7B, and Solar-10.7B, with the rank set to 1, alpha set to 32, and dropout at 0.1. Prefix token lengths are set to 2048, learning rate to 1.0e-3, batch size to 2, and maximum input and target length to 2048. All fine-tuning efforts are performed using 12 NVIDIA RTX3090 GPUs for 10 epochs.
GPTQConfig (Frantar et al., 2022) 用于加载 4 比特的 Qwen-7B 模型,Generation Config (Joao Gante, 2022) 用于 4 比特的 Baichuan2-7B,而 Bits And Bytes Config (Belkada, 2023) 则用于 4 比特的 LLaMA2-7B 和 Solar-10.7B。我们对 LLaMA2-7B、Baichuan2-7B、Qwen-7B 和 Solar-10.7B 采用 LoRA,秩设为 1,alpha 设为 32,dropout 为 0.1。前缀 token 长度设为 2048,学习率为 1.0e-3,批量大小为 2,最大输入和目标长度均为 2048。所有微调工作均使用 12 块 NVIDIA RTX3090 GPU 进行 10 个轮次。
4.3 Evaluation Methods
4.3 评估方法
4.3.1 Evaluation of Individual Modules
4.3.1 单个模块评估
Embedders, Retrievers, and Rerankers. To evaluate the performance of these modules and their combined performance in evidence generation, we use GPT-4 to analyze the relevance between questions and retrieved citations (aka. evidence). In detail, GPT-4 is asked to grade the question-evidence relevance on a five-point Likert scale. The average score, referred to as the ‘GPT-4 score’, is calculated for overall performance evaluation. The prompt used for GPT-4-aided evaluation is shown in Appendix A.2.
嵌入器 (Embedders)、检索器 (Retrievers) 和重排序器 (Rerankers)。为了评估这些模块的性能及其在证据生成中的综合表现,我们使用 GPT-4 来分析问题与检索到的引用(即证据)之间的相关性。具体而言,GPT-4 被要求按照五点李克特量表 (Likert scale) 对问题-证据相关性进行评分。计算平均得分(称为 "GPT-4 分数")以进行整体性能评估。用于 GPT-4 辅助评估的提示词见附录 A.2。
Generators. To evaluate the performance of generators, we employ automatic metrics comprising matching-based measures such as ROUGE-1, ROUGE-2, and ROUGE-L (Lin, 2004), as well as the BLEU score (Papineni et al., 2002). However, since prior research (Zheng et al., 2023) shows that matching-based metrics may overestimate performance in long sequences, we also use the GPT4 evaluation method mentioned above to assess evidence-answer relevance. In addition, we report the ratio of unanswered questions in the responses (e.g., cases when models return "can not provide answer based on the content).
生成器。为评估生成器的性能,我们采用自动指标,包括基于匹配的度量方法如ROUGE-1、ROUGE-2和ROUGE-L (Lin, 2004),以及BLEU分数 (Papineni et al., 2002)。然而,由于先前研究 (Zheng et al., 2023) 表明基于匹配的指标可能高估长序列中的性能,我们还使用上述GPT4评估方法来衡量证据-答案相关性。此外,我们统计了响应中未回答问题(例如模型返回"无法根据内容提供答案"的情况)的比例。
4.3.2 Overall Evaluation of the RAG-based LFQA System
4.3.2 基于RAG的LFQA系统整体评估
ROUGE (Lin, 2004) and BLEU (Papineni et al., 2002)) are used to automatically measure the overall system performance. The GPT-4 scoring method is used to evaluate the answers from helpfulness, relevance, accuracy, depth, and creativity. Additionally, we invite three annotators to rank top-performing answers from all tested models and compare them with the ground truth answers, capturing human perception and assessing subjective response quality. Further details of human evaluation can be found in Appendix A.1.
ROUGE (Lin, 2004) 和 BLEU (Papineni et al., 2002) 用于自动衡量系统整体性能。采用 GPT-4 评分方法从帮助性、相关性、准确性、深度和创造性五个维度评估答案质量。此外,我们邀请三位标注员对所有测试模型中表现最佳的答案进行排序,并与标准答案对比,以捕捉人类感知并评估主观响应质量。人工评估的更多细节详见附录 A.1。
4.4 Results
4.4 结果
Embedders, Retrievers, and Rerankers Table 4 shows the GPT-4 score of different embedders, retrievers, and rerankers, which constitute the evidence generation pipeline. It also shows at the end the best-performing evidence-generation module combinations. We observe that the highestperforming embedding model is Ada2, achieving a score of 4.586, followed by Ember-v1 (4.486) and Bge-Small-en-v1.5 (4.455) with similar scores.
嵌入器、检索器和重排序器
表 4 展示了不同嵌入器、检索器和重排序器的 GPT-4 评分,这些组件构成了证据生成流程。表格末尾还列出了性能最优的证据生成模块组合。我们观察到表现最佳的嵌入模型是 Ada2,得分为 4.586,其次是得分相近的 Ember-v1 (4.486) 和 Bge-Small-en-v1.5 (4.455)。
Table 6: Comparison of the average rankings of four answers generated by top RAG systems.
| Answer One | Answer Two | Answer Three | Answer Four | |
| Average Ranking | 2.19 | 2.11 | 3.10 | 2.60 |
表 6: 顶级RAG系统生成的四种答案的平均排名对比
| 答案一 | 答案二 | 答案三 | 答案四 | |
|---|---|---|---|---|
| 平均排名 | 2.19 | 2.11 | 3.10 | 2.60 |
Gte-Large lagged with a noticeable gap with a score of 4.261. Among the retrievers we assess, AMR outperforms the rest with an impressive score of 4.492. SWR ranks second at 4.466, while the simple vector-based approach has the lowest performance with a score of 4.358.
Gte-Large 以 4.261 分的成绩明显落后。在我们评估的检索器中,AMR 以 4.492 分的出色表现领先,SWR 以 4.466 分位居第二,而简单的基于向量的方法表现最差,得分为 4.358。
Among the rerankers, Bge-Reranker-Base performs the best, achieving a competitive score of 4.489. LLMRerank ranks second with a score of 4.469, followed by All-Mpnet-Base-v2 with a score of 4.383.
在重排序模型中,Bge-Reranker-Base表现最佳,获得了4.489的竞争性得分。LLMRerank以4.469分位列第二,All-Mpnet-Base-v2则以4.383分紧随其后。
The evidence generation modules together, we observe that the combination of AMR, Ada2, and Bge-Reranker-Base yields the highest score of 4.622, followed by the combination of SWR, Ada2, and Bge-Reranker-Base/All-Mpnet-Base-v2, with a score of 4.620. The marginal differences in performance among these leading combinations indicate that a variety of configurations are capable of yielding satisfactory outcomes for evidence generation.
通过整合证据生成模块,我们发现AMR、Ada2和Bge-Reranker-Base的组合得分最高(4.622分),其次是SWR、Ada2与Bge-Reranker-Base/All-Mpnet-Base-v2的组合(4.620分)。这些领先组合之间微小的性能差异表明,多种配置都能为证据生成提供令人满意的结果。
Generators Table 5 shows the comparison of different generators, contrasted by their base form and fine-tuned form. Although the fine-tuned models have a decreasing loss (from 2.5 to 0.1), they do not have significant improvement. They demonstrate slightly lower performance in terms of GPT-4 score, ROUGE-L, and BLEU scores. However, fine-tuned models have less unanswered questions, showing better understanding capabilities than their base forms.
生成器对比
表 5 展示了不同生成器的对比结果,分别对比了基础形态和微调形态。尽管微调模型的损失值有所下降(从 2.5 降至 0.1),但并未带来显著提升。在 GPT-4 评分、ROUGE-L 和 BLEU 分数方面,微调模型的表现略逊一筹。然而,微调模型的未回答问题更少,显示出比基础形态更强的理解能力。
We also observe that while Gemini-Pro shows high numeric scores, it struggles the most in generating con textually relevant responses. Conversely, Baichuan2-7B demonstrates the best prompt comprehension ability. GPT-3.5-turbo experiences more difficulty with contextual understanding, affecting its overall performance, while LLaMA2 has minimal context-related problems. However, LLaMA2 generates instances of simply rephrasing prompts, resulting in reduced accuracy scores.
我们还观察到,尽管Gemini-Pro在数值评分上表现优异,但其在生成上下文相关响应时最为吃力。相反,Baichuan2-7B展现出最佳的提示理解能力。GPT-3.5-turbo在上下文理解方面遇到更多困难,影响了整体表现,而LLaMA2几乎没有上下文相关问题。但LLaMA2存在直接复述提示的情况,导致准确率得分降低。
RAG-based LFQA System Table 3 shows the performance comparison of RAG-based LFQA system with generators in their base forms. We observe that system with the top-3 performing configurations incorporate GPT-3.5-turbo and Baichuan2- 7B as generators. In contrast, system configurations using the Gemini-Pro generator yield suboptimal performance in terms of accuracy. Meanwhile, we observe that system employing LLaMA2-7B as generators show the lowest ROUGE and BLEU scores among all the configurations tested. More results on the performances of different generators in the RAG systems are provided in Appendix A.3.
基于RAG的LFQA系统
表3展示了基于RAG的LFQA系统与基础形态生成器的性能对比。我们发现,性能排名前三的系统配置均采用了GPT-3.5-turbo和Baichuan2-7B作为生成器。相比之下,使用Gemini-Pro生成器的系统配置在准确率方面表现欠佳。同时,采用LLaMA2-7B作为生成器的系统在所有测试配置中显示出最低的ROUGE和BLEU分数。更多关于RAG系统中不同生成器性能的结果详见附录A.3。
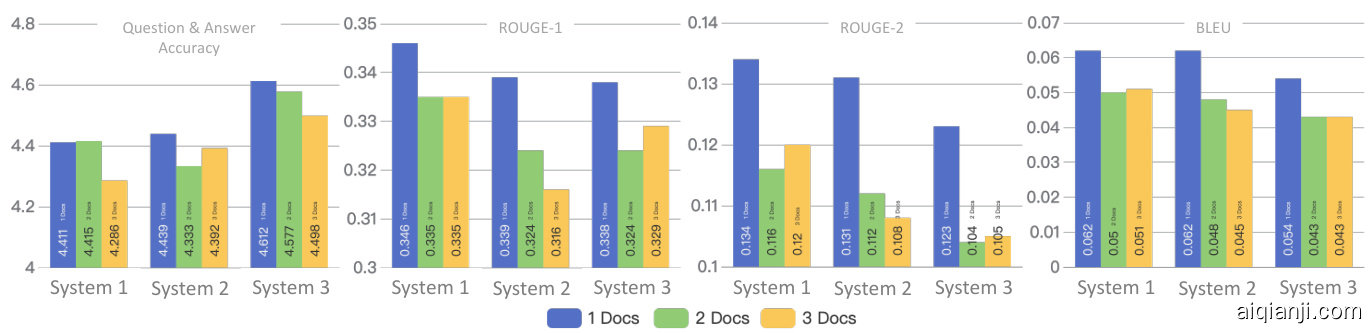
Figure 4: Evaluation of Three Best-performing system configurations with Different Numbers of Input Documents
图 4: 不同输入文档数量下三种最佳系统配置的评估
The top-scoring system configurations comprise (1) GPT-3.5-turbo, AMR, Ada2, and LLMRERanker (noted as system 1); GPT-3.5-turbo, AMR, Ember-v1, and Bge-Reranker-Base (system 2); (3) Baichuan2-7B, AMR, Ada2, and Bge- Reranker-Base (system 3).
得分最高的系统配置包括:(1) GPT-3.5-turbo、AMR、Ada2 和 LLMRERanker (记为系统 1); (2) GPT-3.5-turbo、AMR、Ember-v1 和 Bge-Reranker-Base (系统 2); (3) Baichuan2-7B、AMR、Ada2 和 Bge-Reranker-Base (系统 3)。
Table 6 shows the annotator-ranked preference of these top system configurations. We notice that some model-generated answers obtain higher average rankings than corresponding ground truths. For instance, Answer 2, produced by system 3, attains an average ranking of 2.11, outperforming the ground truth (2.19). Further investigation into annotator feedback reveals that annotators favor Answer 2 because it gives accurate responses while providing additional details. Answer 3, generated by system 1 performs the worst with the highest average ranking (3.10). Answer 4, generated by system 2, achieves an average ranking of 2.60.
表6展示了标注者对顶级系统配置的偏好排名。我们注意到某些模型生成的答案获得了比对应真实答案更高的平均排名。例如系统3生成的答案2平均排名2.11,优于真实答案(2.19)。进一步分析标注者反馈发现,他们偏爱答案2是因为它在提供准确回应的同时补充了额外细节。系统1生成的答案3表现最差,平均排名最高(3.10)。系统2生成的答案4平均排名为2.60。
Best system configuration in Multi-Document Settings Figure 4 shows the performance of the three best-performing system configurations when given different numbers $\mathbf{\check{n}}=1$ to 3) of documents. We observe a consistent pattern from the results: as the number of input documents increases, all system performance tend to decline. However, exceptions are also noted. For instance, the scores for certain instances with three documents marginally surpasses those with two documents in system 2 when compared to the accuracy score. Further inve stig ation shows that the performance is dependent on the total context words of the input. When the number of context words reaches about $34\mathrm{k\Omega}$ words, adding more input documents exerts a less marginal effect on system performance.
多文档设置中的最佳系统配置
图 4 展示了三种性能最佳的系统配置在输入不同数量文档 ($\mathbf{\check{n}}=1$ 至 3) 时的表现。我们从结果中观察到一个一致的模式:随着输入文档数量的增加,所有系统性能都呈现下降趋势。但也存在例外情况,例如系统2在准确率指标上,某些三文档实例的得分略高于双文档实例。进一步研究表明,性能取决于输入文本的总上下文词数。当上下文词数达到约 $34\mathrm{k\Omega}$ 词时,增加更多输入文档对系统性能的边际影响会减弱。
5 Conclusion
5 结论
This study presents FinTextQA, an LFQA dataset specifically designed for the financial domain. The dataset is comprehensive, covering complex financial question systems and including queries on financial regulations and policies. This makes it a valuable resource for further research and evaluation of RAG modules and large language models. We also introduce a robust evaluation system that leverages human ranking, automatic metrics, and GPT-4 scoring to assess various facets of model performance. Our results suggest that the most effective combination of models and modules for finance-related LFQA tasks includes Ada2, AMR, Bge-Reranker-Base, and Baichuan2-7B.
本研究提出了FinTextQA,一个专为金融领域设计的LFQA数据集。该数据集全面覆盖复杂金融问题体系,包含金融法规政策类查询,为RAG模块和大语言模型的进一步研究与评估提供了宝贵资源。我们还引入了一套包含人工排序、自动指标和GPT-4评分的评估体系,用于多维度评估模型性能。实验结果表明,Ada2、AMR、Bge-Reranker-Base与Baichuan2-7B的组合在金融类LFQA任务中表现最优。
Limitations
局限性
Despite its expert curation and high quality, FinTextQA contains a relatively smaller number of QA pairs compared to larger AI-generated datasets. This limitation could potentially affect the generaliz ability of models trained on it when applied to broader real-world applications. High-quality data are challenging to acquire, and copyright restrictions often prevent sharing. Therefore, future research should concentrate on data augmentation and the development of innovative methods to address data scarcity. Expanding the dataset by incorpora ting more diverse sources and exploring advanced RAG capabilities and retrieval frameworks could also be beneficial.
尽管经过专家精心整理且质量较高,但相比AI生成的大规模数据集,FinTextQA包含的问答对数量相对较少。这一局限性可能会影响基于该数据集训练的模型在更广泛实际应用中的泛化能力。高质量数据获取难度大,且版权限制常阻碍共享。因此,未来研究应聚焦数据增强和开发创新方法以应对数据稀缺问题。通过整合更多样化的数据源来扩展数据集,并探索先进的RAG(检索增强生成)能力和检索框架也将大有裨益。
Ethical Statement
伦理声明
In this study, we uphold rigorous ethical standards and endeavor to mitigate any potential risks.
在本研究中,我们秉持严格的伦理标准,并努力降低任何潜在风险。
• While constructing our dataset, we meticulously ensure that all data are acquired through lawful and ethical means. Adhering to the Fair Use principle, the dataset is exclusively utilized for academic research purposes and is strictly prohibited from commercial exploitation.
• 在构建数据集的过程中,我们严格确保所有数据均通过合法合规的途径获取。遵循合理使用 (Fair Use) 原则,该数据集仅用于学术研究目的,严禁商业用途。
• We bear the responsibility of openly sharing the interface, dataset, codes, and trained models with the public. Nonetheless, there exists a possibility of malicious misuse of these resources. For instance, our models could be employed to generate responses without approp riat ely crediting the information source. We are committed to ensuring their ethical use and guarding against any malicious or harmful intent.
• 我们承担向公众公开分享接口、数据集、代码及训练模型的责任。然而,这些资源存在被恶意滥用的可能性。例如,我们的模型可能被用于生成回应却未适当标注信息来源。我们致力于确保其合乎道德的使用,并防范任何恶意或有害意图。
• We are dedicated to mitigating bias, discrimination, or stereotypes during annotation by systematically excluding any questionable examples. To achieve this, we provide thorough training to annotators using 20 samples until they achieve an average accuracy score of 3.8 out of 5. We continually assess their performance throughout the annotation process. Additionally, we provide compensation of $\$114$ per day to annotators until the completion of the annotation task.
• 我们致力于通过系统性排除任何可疑样本,在标注过程中减少偏见、歧视或刻板印象。为此,我们为标注员提供20个样本的全面培训,直至其平均准确率达到5分制中的3.8分,并在整个标注流程中持续评估其表现。此外,在标注任务完成前,我们为标注员提供每日114美元的报酬。
Roberto Conf a loni eri, Ludovik Coba, Benedikt Wagner, and Tarek R Besold. 2021. A historical perspective of explain able artificial intelligence. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 11(1):e1391.
Roberto Confalonieri, Ludovik Coba, Benedikt Wagner, and Tarek R Besold. 2021. 可解释人工智能的历史视角. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 11(1):e1391.
Andrei Fajardo. 2023. Llm reranker demonstration (great gatsby).
Andrei Fajardo. 2023. Llm reranker demonstration (great gatsby).
Angela Fan, Yacine Jernite, Ethan Perez, David Grangier, Jason Weston, and Michael Auli. 2019. Eli5: Long form question answering. arXiv preprint arXiv:1907.09190.
Angela Fan、Yacine Jernite、Ethan Perez、David Grangier、Jason Weston 和 Michael Auli。2019。Eli5: 长形式问答。arXiv预印本 arXiv:1907.09190。
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. 2022. Gptq: Accurate post-training quantization for generative pre-trained transformers. arXiv preprint arXiv:2210.17323.
Elias Frantar、Saleh Ashkboos、Torsten Hoefler 和 Dan Alistarh。2022。GPTQ: 生成式预训练Transformer的高精度训练后量化。arXiv预印本 arXiv:2210.17323。
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, and Haofen Wang. 2023. Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997.
Yunfan Gao、Yun Xiong、Xinyu Gao、Kangxiang Jia、Jinliu Pan、Yuxi Bi、Yi Dai、Jiawei Sun 和 Haofen Wang。2023。大语言模型的检索增强生成技术综述。arXiv预印本 arXiv:2312.10997。
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Mingwei Chang. 2020. Retrieval augmented language model pre-training. In International conference on machine learning, pages 3929–3938. PMLR.
Kelvin Guu、Kenton Lee、Zora Tung、Panupong Pasupat和Mingwei Chang。2020。检索增强的语言模型预训练。见:国际机器学习会议,第3929-3938页。PMLR。
Wookje Han, Jinsol Park, and Kyungjae Lee. 2023. Prewome: Exploiting presuppositions as working memory for long form question answering. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 8312–8322.
Wookje Han、Jinsol Park和Kyungjae Lee。2023。Prewome:利用预设作为工作记忆的长篇问答研究。载于《2023年自然语言处理实证方法会议论文集》,第8312–8322页。
Ivan Ilin. 2023. Advanced rag techniques: an illustrated overview.
Ivan Ilin. 2023. 高级RAG技术图解综述。
References
参考文献
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. 2023. Qwen technical report. arXiv preprint arXiv:2309.16609.
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, 等. 2023. Qwen技术报告. arXiv预印本 arXiv:2309.16609.
Younes Belkada. 2023. Bits and bytes.
Younes Belkada. 2023. 位与字节。
Valeriia Bolotova-Baranova, Vladislav Blinov, Sofya Filippova, Falk Scholer, and Mark Sanderson. 2023. Wikihowqa: A comprehensive benchmark for multidocument non-factoid question answering. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5291–5314.
Valeriia Bolotova-Baranova、Vladislav Blinov、Sofya Filippova、Falk Scholer 和 Mark Sanderson。2023。Wikihowqa:一个全面的多文档非事实类问答基准测试。载于《第61届计算语言学协会年会论文集(第一卷:长论文)》,第5291–5314页。
Zhiyu Chen, Wenhu Chen, Charese Smiley, Sameena Shah, Iana Borova, Dylan Langdon, Reema Moussa, Matt Beane, Ting-Hao Huang, Bryan Routledge, et al. 2021. Finqa: A dataset of numerical reasoning over financial data. arXiv preprint arXiv:2109.00122.
陈志宇、陈文虎、Charese Smiley、Sameena Shah、Iana Borova、Dylan Langdon、Reema Moussa、Matt Beane、黄廷浩、Bryan Routledge等。2021。FinQA:基于财务数据的数值推理数据集。arXiv预印本 arXiv:2109.00122。
Xin Cheng, Di Luo, Xiuying Chen, Lemao Liu, Dongyan Zhao, and Rui Yan. 2023. Lift yourself up: Retrieval-augmented text generation with self memory. arXiv preprint arXiv:2305.02437.
程鑫、罗迪、陈秀英、刘乐茂、赵东岩、严锐。2023。自我提升:基于自记忆的检索增强文本生成。arXiv预印本arXiv:2305.02437。
Pranab Islam, Anand Kannappan, Douwe Kiela, Re- becca Qian, Nino Scherrer, and Bertie Vidgen. 2023. Finance bench: A new benchmark for financial question answering. arXiv preprint arXiv:2311.11944.
Pranab Islam、Anand Kannappan、Douwe Kiela、Rebecca Qian、Nino Scherrer 和 Bertie Vidgen。2023。Finance Bench:金融问答新基准。arXiv预印本 arXiv:2311.11944。
Sylvain Gugger Joao Gante. 2022. [link].
Sylvain Gugger Joao Gante. 2022. [链接].
Dahyun Kim, Chanjun Park, Sanghoon Kim, Wonsung Lee, Wonho Song, Yunsu Kim, Hyeonwoo Kim, Yungi Kim, Hyeonju Lee, Jihoo Kim, et al. 2023. Solar 10.7 b: Scaling large language models with simple yet effective depth up-scaling. arXiv preprint arXiv:2312.15166.
Dahyun Kim, Chanjun Park, Sanghoon Kim, Wonsung Lee, Wonho Song, Yunsu Kim, Hyeonwoo Kim, Yungi Kim, Hyeonju Lee, Jihoo Kim, 等. 2023. Solar 10.7 b: 通过简单高效的深度扩展实现大语言模型规模化. arXiv预印本 arXiv:2312.15166.
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rock- täschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33:9459–9474.
Patrick Lewis、Ethan Perez、Aleksandra Piktus、Fabio Petroni、Vladimir Karpukhin、Naman Goyal、Heinrich Küttler、Mike Lewis、Wen-tau Yih、Tim Rocktäschel 等. 2020. 面向知识密集型 NLP 任务的检索增强生成. Advances in Neural Information Processing Systems, 33:9459–9474.
Zehan Li, Xin Zhang, Yanzhao Zhang, Dingkun Long, Pengjun Xie, and Meishan Zhang. 2023. Towards general text embeddings with multi-stage contrastive learning. arXiv preprint arXiv:2308.03281.
Zehan Li、Xin Zhang、Yanzhao Zhang、Dingkun Long、Pengjun Xie 和 Meishan Zhang。2023。基于多阶段对比学习的通用文本嵌入研究。arXiv预印本 arXiv:2308.03281。
Chin-Yew Lin. 2004. Rouge: A package for automatic evaluation of summaries. In Text sum mari z ation branches out, pages 74–81.
Chin-Yew Lin. 2004. ROUGE: 自动摘要评估工具包。In Text summarization branches out, pages 74-81.
Jerry Liu. 2023. Auto merging retriever.
Jerry Liu. 2023. 自动合并检索器
llamaindex. 2023. Sentence window retriever.
llamaindex. 2023. 句子窗口检索器 (Sentence window retriever).
Macedo Maia, Siegfried Handschuh, André Freitas, Brian Davis, Ross McDermott, Manel Zarrouk, and Alexandra Balahur. 2018. Www’18 open challenge: financial opinion mining and question answering. In Companion proceedings of the the web conference 2018, pages 1941–1942.
Macedo Maia、Siegfried Handschuh、André Freitas、Brian Davis、Ross McDermott、Manel Zarrouk和Alexandra Balahur。2018。WWW'18开放挑战赛:金融观点挖掘与问答系统。见《2018年万维网大会配套论文集》,第1941-1942页。
Kishore Papineni, Salim Roukos, Todd Ward, and WeiJing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318.
Kishore Papineni、Salim Roukos、Todd Ward和WeiJing Zhu。2002。BLEU:一种机器翻译自动评估方法。载于《第40届计算语言学协会年会论文集》,第311-318页。
Yujia Qin, Zihan Cai, Dian Jin, Lan Yan, Shihao Liang, Kunlun Zhu, Yankai Lin, Xu Han, Ning Ding, Huadong Wang, et al. 2023. Webcpm: Interactive web search for chinese long-form question answering. arXiv preprint arXiv:2305.06849.
Yujia Qin, Zihan Cai, Dian Jin, Lan Yan, Shihao Liang, Kunlun Zhu, Yankai Lin, Xu Han, Ning Ding, Huadong Wang, 等. 2023. WebCPM: 面向中文长问答的交互式网络搜索. arXiv预印本 arXiv:2305.06849.
Zackary Rackauckas. 2024. Rag-fusion: a new take on retrieval-augmented generation. arXiv preprint arXiv:2402.03367.
Zackary Rackauckas. 2024. Rag-fusion: 检索增强生成的新方法. arXiv预印本 arXiv:2402.03367.
Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, and TieYan Liu. 2020. Mpnet: Masked and permuted pretraining for language understanding. Advances in Neural Information Processing Systems, 33:16857– 16867.
宋凯涛、谭旭、秦涛、卢剑锋和刘铁岩。2020。MPNet:面向语言理解的掩码与置换预训练。神经信息处理系统进展,33:16857–16867。
Gemini Team, Rohan Anil, Sebastian Borgeaud, Yonghui Wu, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, et al. 2023. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805.
Gemini团队、Rohan Anil、Sebastian Borgeaud、Yonghui Wu、Jean-Baptiste Alayrac、Jiahui Yu、Radu Soricut、Johan Schalkwyk、Andrew M Dai、Anja Hauth等。2023。Gemini:一个能力强大的多模态模型家族。arXiv预印本arXiv:2312.11805。
Neil C Thompson, Kristjan Greenewald, Keeheon Lee, and Gabriel F Manso. 2020. The computational limits of deep learning. arXiv preprint arXiv:2007.05558.
Neil C Thompson、Kristjan Greenewald、Keeheon Lee和Gabriel F Manso。2020。深度学习的计算极限。arXiv预印本arXiv:2007.05558。
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
Hugo Touvron、Louis Martin、Kevin Stone、Peter Albert、Amjad Almahairi、Yasmine Babaei、Nikolay Bashlykov、Soumya Batra、Prajjwal Bhargava、Shruti Bhosale等。2023。Llama 2:开放基础与微调对话模型。arXiv预印本arXiv:2307.09288。
Jiayang Wu, Wensheng Gan, Zefeng Chen, Shicheng Wan, and Hong Lin. 2023. Ai-generated content (aigc): A survey. arXiv preprint arXiv:2304.06632.
Jiayang Wu、Wensheng Gan、Zefeng Chen、Shicheng Wan 和 Hong Lin。2023。AI生成内容 (AIGC) 综述。arXiv预印本 arXiv:2304.06632。
Shitao Xiao and Zheng Liu. 2023. [link].
Shitao Xiao 和 Zheng Liu。2023。[链接]。
Aiyuan Yang, Bin Xiao, Bingning Wang, Borong Zhang, Ce Bian, Chao Yin, Chenxu Lv, Da Pan, Dian Wang, Dong Yan, et al. 2023. Baichuan 2: Open large-scale language models. arXiv preprint arXiv:2309.10305.
Aiyuan Yang, Bin Xiao, Bingning Wang, Borong Zhang, Ce Bian, Chao Yin, Chenxu Lv, Da Pan, Dian Wang, Dong Yan, 等. 2023. 百川 2: 开放大规模语言模型. arXiv预印本 arXiv:2309.10305.
Zhiqiang Yuan, Junwei Liu, Qiancheng Zi, Mingwei Liu, Xin Peng, and Yiling Lou. 2023. Evaluating instruction-tuned large language models on code comprehension and generation. arXiv preprint arXiv:2308.01240.
Zhiqiang Yuan、Junwei Liu、Qiancheng Zi、Mingwei Liu、Xin Peng和Yiling Lou。2023。评估指令调优大语言模型在代码理解与生成上的表现。arXiv预印本arXiv:2308.01240。
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena. arXiv preprint arXiv:2306.05685.
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing等. 2023. 用MT-Bench和Chatbot Arena评估大语言模型作为裁判的能力. arXiv预印本arXiv:2306.05685.
Fengbin Zhu, Wenqiang Lei, Youcheng Huang, Chao Wang, Shuo Zhang, Jiancheng Lv, Fuli Feng, and Tat-Seng Chua. 2021. Tat-qa: A question answering benchmark on a hybrid of tabular and textual content in finance. arXiv preprint arXiv:2105.07624.
冯斌朱、文强雷、有成黄、超王、硕张、建成吕、富力冯和 Tat-Seng Chua。2021。Tat-qa: 一个关于金融领域表格与文本混合内容问答的基准测试。arXiv预印本 arXiv:2105.07624。
A Appendix
A 附录
A.1 Evaluate Human Performance
A.1 评估人类表现
In our study, we’ve made it a priority to closely consider the human aspect of performance, covering everything from how we gather data to how we evaluate the answers produced. Our team of annotators, all of whom hold master’s degrees with their education conducted in English, play a crucial role in this process.
在我们的研究中,我们优先考虑绩效的人性化因素,涵盖从数据收集到答案评估的各个环节。我们的标注团队均持有英语授课的硕士学位,在此过程中发挥着关键作用。
To accurately identify citations and references, we’ve laid out a detailed five-step annotation process. At the outset, we provide our team of three annotators with a benchmark example of what a correct citation looks like (shown in Table 9). This serves to clarify several critical criteria: how well the answer fits with the context (Grounded ness), how relevant the answer is to the question asked (Answer Relevance), and how the question relates to the context provided (Context Relevance).
为了准确识别引用和参考文献,我们制定了一个详细的五步标注流程。首先,我们向由三位标注员组成的团队提供了一个正确引用的基准示例(如表 9 所示)。这有助于明确几个关键标准:答案与上下文的契合度(Grounded ness)、答案与所提问题的相关性(Answer Relevance),以及问题与所提供上下文的相关性(Context Relevance)。
After this initial step, the annotators first conduct a practice round involving 20 data samples. Here, they compare their citation identification s against gold standard annotations. We then score their findings and give them feedback to help refine their skills. Once they’ve shown they’ve got a good handle on the process, they move on to four more rounds, each with an increasing number of data samples to work through. By the end of this process, after completing 300 tasks, our annotators are well-versed in our annotation standards, ensuring a high level of accuracy in our data collection and analysis.
在完成初始步骤后,标注人员首先进行包含20个数据样本的练习轮次。在此阶段,他们将自身的引文识别结果与黄金标准标注进行比对。随后我们对他们的发现进行评分并提供反馈,以帮助提升其标注技能。当标注人员展现出对流程的良好掌握后,他们将进入后续四轮标注,每轮需处理的数据样本数量逐步增加。通过完成总计300项标注任务,我们的标注人员最终能熟练掌握标注标准,从而确保数据收集与分析的高准确性。
In each round, we randomly select $10%$ of the samples for evaluating annotator performance (Table 8). To minimize potential biases, we engage another three annotators to rate relevance and accuracy using a 5-point Likert Scale. Table 7 presents the performance of annotators, revealing that the average scores are above 4 after the first round’s training. Context Relevance and Answer Relevance scores are above 3.
每一轮中,我们随机选取 $10%$ 的样本用于评估标注员表现 (表 8)。为减少潜在偏差,我们另聘三名标注员采用5级李克特量表对相关性和准确性进行评分。表 7 展示了标注员的表现,可见首轮训练后平均分均高于4分,上下文相关性和答案相关性分数均超过3分。
The relevance scores in the 5th round are comparatively lower due to the difficulty in finding citations in many pairs. Ultimately, we remove 60 pairs with relevance scores lower than 2 or those lacking citations in the document, retaining 240 pairs for further analysis. This rigorous evaluation and annotation process ensures the quality of FinTextQA.
第五轮的相关性分数相对较低,因为许多配对难以找到引用。最终,我们移除了60个相关性分数低于2或在文档中缺乏引用的配对,保留了240个配对用于进一步分析。这一严格的评估和标注过程确保了FinTextQA的质量。
During the answer evaluation phase, annotator competence is measured through their performance in three TOEFL reading tests, ensuring strong reading comprehension skills. Proceeding to the ranking of generated answers, several responses — including ground truth answers — are presented without revealing their origin. If ground truth answers rank too low, the evaluation is considered unsuitable; if ranked within the top two among four responses, the evaluation is considered appropriate.
在答案评估阶段,通过标注员在三项托福阅读测试中的表现来衡量其能力,确保具备较强的阅读理解技能。进入生成答案的排序环节时,会展示多个回答(包括真实答案)但不透露来源。若真实答案排名过低,则视为评估不适用;若在四个回答中位列前两名,则视为评估有效。
Table 7: Performance of human annotation
| Round | Average Score | Context Relevance | Answer Relevance |
| 1st-20 pairs | 3.83 | 4.05 | 3.44 |
| 2nd-40pairs | 4.08 | 4.32 | 3.75 |
| 3rd-60pairs | 4.17 | 4.13 | 3.65 |
| 4th-80pairs | 4.04 | 4.08 | 3.50 |
| 5th-100pairs | 4.13 | 3.51 | 3.13 |
表 7: 人工标注性能
| 轮次 | 平均分 | 上下文相关性 | 答案相关性 |
|---|---|---|---|
| 第1-20对 | 3.83 | 4.05 | 3.44 |
| 第21-40对 | 4.08 | 4.32 | 3.75 |
| 第41-60对 | 4.17 | 4.13 | 3.65 |
| 第61-80对 | 4.04 | 4.08 | 3.50 |
| 第81-100对 | 4.13 | 3.51 | 3.13 |
Table 8: An example of scoring evidence found by annotators
| GroundTruthCitation1.Belowthenotificationthresh- olds,theCommissionshouldbe abletorequirethenotifi- cationofpotentiallysubsidisedconcentrationsthatwere notyetimplemented orthenotificationofpotentiallysub- sidised bids prior to the award of a contract,if it considers thattheconcentrationorthebidwouldmeritexantereview given its impact in the Union. 2. The Commission may request the prior notification of any concentration which is not a notifiable concentration within the meaning of Ar- Commission suspects that foreign subsidies may have been granted to the undertakings concerned in the three years prior to the concentration. Such concentration shall be deemed to be a notifiable concentration for the purposes of this Regulation. 3. By way of derogation from paragraph 2 of this Article, Articles 21 and 29 shall apply from 12 |
| October2023. Annotator Citation "1. This Regulation shall enter into force on the twentieth day following that of its publication in the Official Journal of the European Union. 2. It shall apply from 12 July 2023.3.By way of derogation from paragraph 2 of this Article, Articles 47 and 48 shall apply from 11 January 2023and Article 14(5), (6) and (7) shall apply from 12 January 2024.4. By way of derogation from paragraph 2 of this Article, Articles 21 and 29 shall apply |
| from12October2023." Score:3/5 Feedback:Only select part of the citations, which can |
| notfully answer the question. |
表 8: 标注员发现的证据评分示例
| 真实引用 | 1. 在通知阈值以下,委员会应能够要求对尚未实施的潜在补贴集中行为进行通知,或在合同授予前对潜在补贴投标进行通知,前提是委员会认为该集中行为或投标基于其对欧盟的影响值得进行审查。2. 对于不属于本条例所指可通知集中行为的任何集中,若委员会怀疑相关企业在集中前三年内可能获得外国补贴,可要求其事先通知。此类集中应被视为本条例所指的可通知集中。3. 作为对本条第2款的减损,第21条和第29条应自2023年10月12日起适用。 |
|---|---|
| 标注员引用 | "1. 本条例应自其在欧盟官方公报公布后的第二十日起生效。2. 本条例自2023年7月12日起适用。3. 作为对本条第2款的减损,第47条和第48条应自2023年1月11日起适用,第14条第(5)、(6)和(7)款应自2024年1月12日起适用。4. 作为对本条第2款的减损,第21条和第29条应自2023年10月12日起适用。" |
| 评分 | 3/5 |
| 反馈 | 仅选取了部分引用内容,无法完整回答问题。 |
A.2 Prompt of GPT-4-aided Evaluation
A.2 GPT-4辅助评估的提示词
Figure 5 shows the prompt we use to ask GPT-4 to evaluate the relevance and accuracy of modelgenerated answers in our experiments.
图 5: 展示了我们在实验中用于要求 GPT-4 评估模型生成答案相关性和准确性的提示。
A.3 Experiment Results of Different Generators in RAG Systems
A.3 RAG系统中不同生成器的实验结果
Table 10 - 15 shows a systematic performance comparison of RAG systems with different models in each module.
表 10 - 15 展示了不同模块中 RAG 系统与各模型的系统性性能对比。
A.4 Example of Question Types
A.4 问题类型示例
Table 16 - 21 shows the samples of QA pairs in each question type.
表 16 - 21 展示了每种问题类型的问答对样本。
YSTEM: "You are a helpful AI assistant who is good at analyze the text content”
系统:"你是一位善于分析文本内容的AI助手"
USER: f'''
用户: f'''
the user instruction {question prompt} includes the question and content. the response {generated answer} is generated by GPT model.
用户指令 {question prompt} 包含问题和内容。响应 {generated answer} 由GPT模型生成。
Please act as an impartial judge and evaluate the quality of the response provided by AI assistant to the content and question displayed upper!
请作为公正的评判员,评估AI助手对上述内容和问题所提供回答的质量!
You should give three scores to the response. the highest score is 5 and the lowest score is 1. the scores include:
应为回答给出三个评分,最高5分,最低1分。评分包括:
Avoid any position biases and ensure that the order in which the responses were presented does not influence your decision. Do not allow the length of the responses to influence your evaluation,
避免任何位置偏见,确保回答的呈现顺序不会影响你的决策。不要让回答的长度影响你的评估。
Do not favor certain names of the assistants.
不要偏爱某些AI助手的名称。
Be as objective as possible.
尽可能保持客观。
Directly output the score and strictly follow the format: ### Score 1: number ### Score 2: number ### Score 3: number
分数 1: 数字
分数 2: 数字
分数 3: 数字
| Institute | European Union |
| Document | REGULATION(EU)2022/2560OF THE EUROPEAN PARLIAMENTANDOF THECOUNCIL |
| Question | Are transactions signed between 12 July 2023 and 12 Oc- tober 2023 (and implemented on 12 October 2023 or later) subject to mandatory notification under Regulation EU 2022/2560? Notifiable concentrations under Article 20 of Regulation EU |
| Answer | 2022/2560 for which the agreement was concluded on 12 July 2023 or later but which have not yet been implemented on 12 October 2023, will need to be notified pursuant to the standstill obligation under Article 24 of Regulation EU 2022/2560. By contrast, the notification obligation does not apply to concentrations for which the agreement was con- cluded on 12 July 2023 or later but which are implemented before 12 October 2023. Notifying Parties are encouraged to engage in pre-notification contacts, in principle as of September 2023, in advance to facilitate the submission of notifications as from 12 October 2023. |
| Citation | Notifiable concentrations under Article 20 of Regulation EU 2022/2560 for which the agreement was concluded on 12 July 2023 or later but which have not yet been implemented on 12 October 2023, will need to be notified pursuant to Article 21 of Regulation EU 2022/2560 and are subject to the standstill obligation under Article 24 of Regulation EU 2022/2560. By contrast, the notification obligation does not apply to concentrations for which the agreement was con- cluded on 12 July 2023 or later but which are implemented before 12 October 2023. Notifying Parties are encouraged to engage in pre-notification contacts, in principle as of September 2023, in advance to facilitate the submission of |
| Groundedness Answer Relevance5 | notifications as from 12 October 2023. 5 |
| Groundedness 5 |
| Answer Relevance 5 |
| Context Relevance 5 |
| 机构 | 欧盟 |
| 文件 | 欧洲议会和欧盟理事会第(EU)2022/2560号条例 |
| 问题 | 2023年7月12日至2023年10月12日期间签署(并于2023年10月12日或之后实施)的交易是否需要根据欧盟第2022/2560号条例进行强制申报?欧盟条例第20条规定的应申报集中情形 |
| 答复 | 根据欧盟第2022/2560号条例第24条暂停义务规定,对于2023年7月12日或之后达成协议但截至2023年10月12日尚未实施的集中情形需进行申报。相反,对于2023年7月12日或之后达成协议但在2023年10月12日前已实施的集中情形则不适用申报义务。建议申报方原则上自2023年9月起开展预申报接触,以便利2023年10月12日起的申报提交工作。 |
| 引述 | 根据欧盟第2022/2560号条例第21条规定,对于2023年7月12日或之后达成协议但截至2023年10月12日尚未实施的应申报集中情形需进行申报,并受该条例第24条暂停义务约束。相反,对于2023年7月12日或之后达成协议但在2023年10月12日前已实施的集中情形则不适用申报义务。建议申报方原则上自2023年9月起开展预申报接触,以便利2023年10月12日起的申报提交工作。 |
| 事实依据性5 | 自2023年10月12日起的申报工作。5 |
| 事实依据性5 |
| 答复相关性5 |
| 上下文相关性5 |
Table 9: A Sample of Ground Truth Annotations
表 9: 真实标注样本
Table 10: Detailed Experiment Results of GPT-3.5-turbo in RAG Systems.
| Retriever | Embedder | Reranker | Question&Answer Accuracy | ROUGE-1 | ROUGE-2 | ROUGE-L | BLEU |
| AMR | Bge-Small-en-v1.5 | Bge-Reranker-Base | 4.420 | 0.340 | 0.130 | 0.218 | 0.062 |
| LLMRerank | 4.399 | 0.335 | 0.126 | 0.214 | 0.058 | ||
| All-Mpnet-Base-v2 | 4.261 | 0.320 | 0.116 | 0.205 | 0.048 | ||
| Ada2 | Bge-Reranker-Base | 4.359 | 0.338 | 0.129 | 0.218 | 0.060 | |
| LLMRerank | 4.411 | 0.346 | 0.134 | 0.224 | 0.062 | ||
| All-Mpnet-Base-v2 | 4.291 | 0.327 | 0.121 | 0.209 | 0.053 | ||
| Ember-v1 | Bge-Reranker-Base | 4.439 | 0.339 | 0.131 | 0.221 | 0.062 | |
| LLMRerank | 4.365 | 0.341 | 0.130 | 0.221 | 0.060 | ||
| All-Mpnet-Base-v2 | 4.278 | 0.328 | 0.120 | 0.211 | 0.052 | ||
| Gte-Large | Bge-Reranker-Base | 4.319 | 0.332 | 0.125 | 0.213 | 0.056 | |
| LLMRerank | 4.312 | 0.325 | 0.121 | 0.207 | 0.052 | ||
| All-Mpnet-Base-v2 | 4.252 | 0.312 | 0.108 | 0.197 | 0.045 | ||
| SWR | Bge-Small-en-v1.5 | Bge-Reranker-Base | 4.426 | 0.322 | 0.114 | 0.208 | 0.050 |
| LLMRerank | 4.378 | 0.325 | 0.114 | 0.209 | 0.050 | ||
| All-Mpnet-Base-v2 | 4.367 | 0.327 | 0.116 | 0.211 | 0.051 | ||
| Ada2 | Bge-Reranker-Base | 4.464 | 0.320 | 0.113 | 0.208 | 0.048 | |
| LLMRerank | 4.462 | 0.321 | 0.116 | 0.209 | 0.052 | ||
| All-Mpnet-Base-v2 | 4.361 | 0.320 | 0.116 | 0.206 | 0.052 | ||
| Ember-v1 | Bge-Reranker-Base | 4.405 | 0.331 | 0.120 | 0.216 | 0.053 | |
| LLMRerank | 4.384 | 0.328 | 0.118 | 0.214 | 0.053 | ||
| All-Mpnet-Base-v2 | 4.394 | 0.323 | 0.113 | 0.210 | 0.049 | ||
| Gte-Large | Bge-Reranker-Base LLMRerank | 4.183 4.268 | 0.312 0.309 | 0.108 | 0.200 | 0.046 | |
| All-Mpnet-Base-v2 | 4.255 | 0.311 | 0.109 0.108 | 0.201 0.201 | 0.047 | ||
| Bge-Reranker-Base | 0.046 | ||||||
| VectorRetriever | Bge-Small-en-v1.5 | 4.255 | 0.325 | 0.121 | 0.209 | 0.053 | |
| LLMRerank | 4.255 | 0.330 | 0.126 | 0.212 | 0.057 | ||
| All-Mpnet-Base-v2 | 4.215 | 0.339 | 0.125 | 0.216 | 0.058 | ||
| Ada2 | Bge-Reranker-Base | 4.218 | 0.331 | 0.125 | 0.213 | 0.057 | |
| LLMRerank | 4.289 | 0.326 | 0.124 | 0.210 | 0.057 | ||
| All-Mpnet-Base-v2 | 4.249 | 0.332 | 0.124 | 0.213 | 0.058 | ||
| Ember-v1 | Bge-Reranker-Base | 4.243 | 0.330 | 0.124 | 0.212 | 0.056 | |
| LLMRerank | 4.253 | 0.327 | 0.119 | 0.208 | 0.053 | ||
| All-Mpnet-Base-v2 | 4.278 | 0.327 | 0.124 | 0.210 | 0.057 | ||
| Gte-Large | Bge-Reranker-Base | 4.065 | 0.316 | 0.110 | 0.200 | 0.048 | |
| LLMRerank | 4.034 | 0.320 | 0.115 | 0.204 | 0.051 | ||
| All-Mpnet-Base-v2 | 4.099 | 0.314 | 0.112 | 0.199 | 0.049 |
表 10: GPT-3.5-turbo 在 RAG 系统中的详细实验结果
| 检索器 (Retriever) | 嵌入器 (Embedder) | 重排序器 (Reranker) | 问答准确率 (Question&Answer Accuracy) | ROUGE-1 | ROUGE-2 | ROUGE-L | BLEU |
|---|---|---|---|---|---|---|---|
| AMR | Bge-Small-en-v1.5 | Bge-Reranker-Base | 4.420 | 0.340 | 0.130 | 0.218 | 0.062 |
| LLMRerank | 4.399 | 0.335 | 0.126 | 0.214 | 0.058 | ||
| All-Mpnet-Base-v2 | 4.261 | 0.320 | 0.116 | 0.205 | 0.048 | ||
| Ada2 | Bge-Reranker-Base | 4.359 | 0.338 | 0.129 | 0.218 | 0.060 | |
| LLMRerank | 4.411 | 0.346 | 0.134 | 0.224 | 0.062 | ||
| All-Mpnet-Base-v2 | 4.291 | 0.327 | 0.121 | 0.209 | 0.053 | ||
| Ember-v1 | Bge-Reranker-Base | 4.439 | 0.339 | 0.131 | 0.221 | 0.062 | |
| LLMRerank | 4.365 | 0.341 | 0.130 | 0.221 | 0.060 | ||
| All-Mpnet-Base-v2 | 4.278 | 0.328 | 0.120 | 0.211 | 0.052 | ||
| Gte-Large | Bge-Reranker-Base | 4.319 | 0.332 | 0.125 | 0.213 | 0.056 | |
| LLMRerank | 4.312 | 0.325 | 0.121 | 0.207 | 0.052 | ||
| All-Mpnet-Base-v2 | 4.252 | 0.312 | 0.108 | 0.197 | 0.045 | ||
| SWR | Bge-Small-en-v1.5 | Bge-Reranker-Base | 4.426 | 0.322 | 0.114 | 0.208 | 0.050 |
| LLMRerank | 4.378 | 0.325 | 0.114 | 0.209 | 0.050 | ||
| All-Mpnet-Base-v2 | 4.367 | 0.327 | 0.116 | 0.211 | 0.051 | ||
| Ada2 | Bge-Reranker-Base | 4.464 | 0.320 | 0.113 | 0.208 | 0.048 | |
| LLMRerank | 4.462 | 0.321 | 0.116 | 0.209 | 0.052 | ||
| All-Mpnet-Base-v2 | 4.361 | 0.320 | 0.116 | 0.206 | 0.052 | ||
| Ember-v1 | Bge-Reranker-Base | 4.405 | 0.331 | 0.120 | 0.216 | 0.053 | |
| LLMRerank | 4.384 | 0.328 | 0.118 | 0.214 | 0.053 | ||
| All-Mpnet-Base-v2 | 4.394 | 0.323 | 0.113 | 0.210 | 0.049 | ||
| Gte-Large | Bge-Reranker-Base | 4.183 | 0.312 | 0.108 | 0.200 | 0.046 | |
| LLMRerank | 4.268 | 0.309 | 0.108 | 0.201 | 0.046 | ||
| All-Mpnet-Base-v2 | 4.255 | 0.311 | 0.109 | 0.201 | 0.047 | ||
| VectorRetriever | Bge-Small-en-v1.5 | Bge-Reranker-Base | 4.255 | 0.325 | 0.121 | 0.209 | 0.053 |
| LLMRerank | 4.255 | 0.330 | 0.126 | 0.212 | 0.057 | ||
| All-Mpnet-Base-v2 | 4.215 | 0.339 | 0.125 | 0.216 | 0.058 | ||
| Ada2 | Bge-Reranker-Base | 4.218 | 0.331 | 0.125 | 0.213 | 0.057 | |
| LLMRerank | 4.289 | 0.326 | 0.124 | 0.210 | 0.057 | ||
| All-Mpnet-Base-v2 | 4.249 | 0.332 | 0.124 | 0.213 | 0.058 | ||
| Ember-v1 | Bge-Reranker-Base | 4.243 | 0.330 | 0.124 | 0.212 | 0.056 | |
| LLMRerank | 4.253 | 0.327 | 0.119 | 0.208 | 0.053 | ||
| All-Mpnet-Base-v2 | 4.278 | 0.327 | 0.124 | 0.210 | 0.057 | ||
| Gte-Large | Bge-Reranker-Base | 4.065 | 0.316 | 0.110 | 0.200 | 0.048 | |
| LLMRerank | 4.034 | 0.320 | 0.115 | 0.204 | 0.051 | ||
| All-Mpnet-Base-v2 | 4.099 | 0.314 | 0.112 | 0.199 | 0.049 |
Table 11: Detailed Experiment Results of Baichuan2-7B in RAG Systems.
| Retriever | Embedder | Reranker | Question&Answer Accuracy | ROUGE-1 | ROUGE-2 | ROUGE-L | BLEU |
| AMR | Bge-Small-en-v1.5 | Bge-Reranker-Base | 4.536 | 0.331 | 0.119 | 0.213 | 0.052 |
| LLMRerank | 4.544 | 0.336 | 0.120 | 0.213 | 0.052 | ||
| All-Mpnet-Base-v2 | 4.527 | 0.320 | 0.110 | 0.201 | 0.047 | ||
| Ada2 | Bge-Reranker-Base | 4.612 | 0.338 | 0.123 | 0.217 | 0.054 | |
| LLMRerank | 4.578 | 0.340 | 0.124 | 0.219 | 0.057 | ||
| All-Mpnet-Base-v2 | 4.521 | 0.320 | 0.112 | 0.201 | 0.049 | ||
| Ember-v1 | Bge-Reranker-Base | 4.513 | 0.333 | 0.120 | 0.215 | 0.053 | |
| LLMRerank | 4.618 | 0.334 | 0.124 | 0.215 | 0.058 | ||
| All-Mpnet-Base-v2 | 4.549 | 0.331 | 0.116 | 0.209 | 0.050 | ||
| Gte-Large | Bge-Reranker-Base | 4.540 | 0.323 | 0.112 | 0.208 | 0.050 | |
| LLMRerank | 4.532 | 0.328 | 0.119 | 0.210 | 0.053 | ||
| All-Mpnet-Base-v2 | 4.536 | 0.314 | 0.102 | 0.198 | 0.044 | ||
| SWR | Bge-Small-en-v1.5 | Bge-Reranker-Base | 4.605 | 0.294 | 0.090 | 0.183 | 0.034 |
| LLMRerank | 4.593 | 0.304 | 0.097 | 0.192 | 0.038 | ||
| All-Mpnet-Base-v2 | 4.616 | 0.302 | 0.097 | 0.189 | 0.038 | ||
| Ada2 | Bge-Reranker-Base | 4.606 | 0.305 | 0.101 | 0.195 | 0.041 | |
| LLMRerank | 4.586 | 0.309 | 0.099 | 0.191 | 0.039 | ||
| All-Mpnet-Base-v2 | 4.540 | 0.307 | 0.100 | 0.193 | 0.039 | ||
| Ember-v1 | Bge-Reranker-Base | 4.584 | 0.311 | 0.105 | 0.197 | 0.043 | |
| LLMRerank | 4.568 | 0.311 | 0.104 | 0.194 | 0.044 | ||
| All-Mpnet-Base-v2 Bge-Reranker-Base | 4.571 | 0.308 | 0.104 | 0.195 | 0.042 | ||
| Gte-Large | LLMRerank | 4.589 4.553 | 0.307 | 0.101 | 0.193 | 0.041 | |
| All-Mpnet-Base-v2 | 4.576 | 0.305 0.300 | 0.101 0.098 | 0.193 0.188 | 0.042 | ||
| 0.039 | |||||||
| Vector Retriever | Bge-Small-en-v1.5 | Bge-Reranker-Base | 4.458 | 0.316 | 0.109 | 0.203 | 0.045 |
| LLMRerank | 4.481 | 0.314 | 0.106 | 0.201 | 0.045 | ||
| All-Mpnet-Base-v2 | 4.422 | 0.317 | 0.108 | 0.202 | 0.044 | ||
| Ada2 | Bge-Reranker-Base | 4.477 | 0.319 | 0.113 | 0.206 | 0.050 | |
| LLMRerank | 4.481 | 0.318 | 0.113 | 0.204 | 0.050 | ||
| All-Mpnet-Base-v2 | 4.470 | 0.317 | 0.112 | 0.202 | 0.049 | ||
| Ember-v1 | Bge-Reranker-Base | 4.513 | 0.324 | 0.113 | 0.207 | 0.049 | |
| LLMRerank | 4.464 | 0.329 | 0.115 | 0.210 | 0.051 | ||
| All-Mpnet-Base-v2 | 4.501 | 0.319 | 0.109 | 0.204 | 0.047 | ||
| Gte-Large | Bge-Reranker-Base | 4.416 | 0.317 | 0.106 | 0.201 | 0.048 | |
| LLMRerank | 4.454 | 0.321 | 0.110 | 0.205 | 0.050 | ||
| All-Mpnet-Base-v2 | 4.409 | 0.312 | 0.108 | 0.202 | 0.045 |
表 11: Baichuan2-7B 在 RAG 系统中的详细实验结果
| 检索器 | 嵌入器 | 重排序器 | 问答准确率 | ROUGE-1 | ROUGE-2 | ROUGE-L | BLEU |
|---|---|---|---|---|---|---|---|
| AMR | Bge-Small-en-v1.5 | Bge-Reranker-Base | 4.536 | 0.331 | 0.119 | 0.213 | 0.052 |
| AMR | Bge-Small-en-v1.5 | LLMRerank | 4.544 | 0.336 | 0.120 | 0.213 | 0.052 |
| AMR | Bge-Small-en-v1.5 | All-Mpnet-Base-v2 | 4.527 | 0.320 | 0.110 | 0.201 | 0.047 |
| AMR | Ada2 | Bge-Reranker-Base | 4.612 | 0.338 | 0.123 | 0.217 | 0.054 |
| AMR | Ada2 | LLMRerank | 4.578 | 0.340 | 0.124 | 0.219 | 0.057 |
| AMR | Ada2 | All-Mpnet-Base-v2 | 4.521 | 0.320 | 0.112 | 0.201 | 0.049 |
| AMR | Ember-v1 | Bge-Reranker-Base | 4.513 | 0.333 | 0.120 | 0.215 | 0.053 |
| AMR | Ember-v1 | LLMRerank | 4.618 | 0.334 | 0.124 | 0.215 | 0.058 |
| AMR | Ember-v1 | All-Mpnet-Base-v2 | 4.549 | 0.331 | 0.116 | 0.209 | 0.050 |
| AMR | Gte-Large | Bge-Reranker-Base | 4.540 | 0.323 | 0.112 | 0.208 | 0.050 |
| AMR | Gte-Large | LLMRerank | 4.532 | 0.328 | 0.119 | 0.210 | 0.053 |
| AMR | Gte-Large | All-Mpnet-Base-v2 | 4.536 | 0.314 | 0.102 | 0.198 | 0.044 |
| SWR | Bge-Small-en-v1.5 | Bge-Reranker-Base | 4.605 | 0.294 | 0.090 | 0.183 | 0.034 |
| SWR | Bge-Small-en-v1.5 | LLMRerank | 4.593 | 0.304 | 0.097 | 0.192 | 0.038 |
| SWR | Bge-Small-en-v1.5 | All-Mpnet-Base-v2 | 4.616 | 0.302 | 0.097 | 0.189 | 0.038 |
| SWR | Ada2 | Bge-Reranker-Base | 4.606 | 0.305 | 0.101 | 0.195 | 0.041 |
| SWR | Ada2 | LLMRerank | 4.586 | 0.309 | 0.099 | 0.191 | 0.039 |
| SWR | Ada2 | All-Mpnet-Base-v2 | 4.540 | 0.307 | 0.100 | 0.193 | 0.039 |
| SWR | Ember-v1 | Bge-Reranker-Base | 4.584 | 0.311 | 0.105 | 0.197 | 0.043 |
| SWR | Ember-v1 | LLMRerank | 4.568 | 0.311 | 0.104 | 0.194 | 0.044 |
| SWR | Ember-v1 | All-Mpnet-Base-v2 Bge-Reranker-Base | 4.571 | 0.308 | 0.104 | 0.195 | 0.042 |
| SWR | Gte-Large | LLMRerank | 4.589 4.553 | 0.307 | 0.101 | 0.193 | 0.041 |
| SWR | Gte-Large | All-Mpnet-Base-v2 | 4.576 | 0.305 0.300 | 0.101 0.098 | 0.193 0.188 | 0.042 |
| SWR | Gte-Large | 0.039 | |||||
| Vector Retriever | Bge-Small-en-v1.5 | Bge-Reranker-Base | 4.458 | 0.316 | 0.109 | 0.203 | 0.045 |
| Vector Retriever | Bge-Small-en-v1.5 | LLMRerank | 4.481 | 0.314 | 0.106 | 0.201 | 0.045 |
| Vector Retriever | Bge-Small-en-v1.5 | All-Mpnet-Base-v2 | 4.422 | 0.317 | 0.108 | 0.202 | 0.044 |
| Vector Retriever | Ada2 | Bge-Reranker-Base | 4.477 | 0.319 | 0.113 | 0.206 | 0.050 |
| Vector Retriever | Ada2 | LLMRerank | 4.481 | 0.318 | 0.113 | 0.204 | 0.050 |
| Vector Retriever | Ada2 | All-Mpnet-Base-v2 | 4.470 | 0.317 | 0.112 | 0.202 | 0.049 |
| Vector Retriever | Ember-v1 | Bge-Reranker-Base | 4.513 | 0.324 | 0.113 | 0.207 | 0.049 |
| Vector Retriever | Ember-v1 | LLMRerank | 4.464 | 0.329 | 0.115 | 0.210 | 0.051 |
| Vector Retriever | Ember-v1 | All-Mpnet-Base-v2 | 4.501 | 0.319 | 0.109 | 0.204 | 0.047 |
| Vector Retriever | Gte-Large | Bge-Reranker-Base | 4.416 | 0.317 | 0.106 | 0.201 | 0.048 |
| Vector Retriever | Gte-Large | LLMRerank | 4.454 | 0.321 | 0.110 | 0.205 | 0.050 |
| Vector Retriever | Gte-Large | All-Mpnet-Base-v2 | 4.409 | 0.312 | 0.108 | 0.202 | 0.045 |
Table 12: Detailed Experiment Results of Solar-10.7B in RAG Systems.
| Retriever | Embedder | Reranker | Question&Answer Accuracy | ROUGE-1 | ROUGE-2 | ROUGE-L | BLEU |
| AMR | Bge-Small-en-v1.5 | Bge-Reranker-Base | 4.310 | 0.329 | 0.118 | 0.205 | 0.051 |
| LLMRerank | 4.418 | 0.323 | 0.115 | 0.200 | 0.050 | ||
| All-Mpnet-Base-v2 | 4.331 | 0.312 | 0.106 | 0.193 | 0.045 | ||
| Ada2 | Bge-Reranker-Base | 4.378 | 0.327 | 0.119 | 0.204 | 0.051 | |
| LLMRerank | 4.350 | 0.322 | 0.116 | 0.200 | 0.050 | ||
| All-Mpnet-Base-v2 | 4.357 | 0.323 | 0.111 | 0.197 | 0.045 | ||
| Ember-v1 | Bge-Reranker-Base | 4.348 | 0.329 | 6110 | 0.205 | 0.052 | |
| LLMRerank | 4.388 | 0.330 | 0.117 | 0.204 | 0.052 | ||
| All-Mpnet-Base-v2 | 4.317 | 0.319 | 0.110 | 0.196 | 0.046 | ||
| Gte-Large | Bge-Reranker-Base | 4.328 | 0.318 | 0.113 | 0.198 | 0.048 | |
| LLMRerank | 4.338 | 0.318 | 0.110 | 0.197 | 0.045 | ||
| All-Mpnet-Base-v2 | 4.262 | 0.302 | 0.098 | 0.185 | 0.039 | ||
| SWR | Bge-Small-en-v1.5 | Bge-Reranker-Base | 4.431 | 0.296 | 0.094 | 0.184 | 0.037 |
| LLMRerank | 4.462 | 0.298 | 0.095 | 0.184 | 0.037 | ||
| All-Mpnet-Base-v2 | 4.458 | 0.300 | 0.094 | 0.185 | 0.037 | ||
| Ada2 | Bge-Reranker-Base | 4.424 | 0.296 | 0.095 | 0.183 | 0.037 | |
| LLMRerank | 4.460 | 0.297 | 0.096 | 0.182 | 0.037 | ||
| All-Mpnet-Base-v2 | 4.431 | 0.293 | 0.093 | 0.180 | 0.037 | ||
| Ember-v1 | Bge-Reranker-Base | 4.456 | 0.305 | 0.097 | 0.190 | 0.039 | |
| LLMRerank | 4.376 | 0.305 | 0.099 | 0.190 | 0.039 | ||
| All-Mpnet-Base-v2 | 4.394 | 0.307 | 0.100 | 0.190 | 0.041 | ||
| Gte-Large | Bge-Reranker-Base LLMRerank | 4.344 4.354 | 0.297 | 600 | 0.184 | 0.037 | |
| All-Mpnet-Base-v2 | 4.361 | 0.296 0.297 | 0.094 | 0.184 | 0.037 | ||
| 0.095 | 0.184 | 0.038 | |||||
| VectorRetriever | Bge-Small-en-v1.5 | Bge-Reranker-Base | 4.375 | 0.300 | 0.105 | 0.183 | 0.043 |
| LLMRerank | 4.384 | 0.300 | 0.105 | 0.184 | 0.042 | ||
| All-Mpnet-Base-v2 | 4.414 | 0.301 | 0.106 | 0.184 | 0.043 | ||
| Ada2 | Bge-Reranker-Base | 4.422 | 0.298 | 0.106 | 0.183 | 0.044 | |
| LLMRerank | 4.409 | 0.297 | 0.105 | 0.183 | 0.044 | ||
| All-Mpnet-Base-v2 | 4.359 | 0.299 | 0.107 | 0.184 | 0.045 | ||
| Ember-v1 | Bge-Reranker-Base | 4.441 | 0.299 | 0.106 | 0.185 | 0.045 | |
| LLMRerank | 4.384 | 0.301 | 0.106 | 0.186 | 0.045 | ||
| All-Mpnet-Base-v2 | 4.420 | 0.297 | 0.106 | 0.184 | 0.045 | ||
| Gte-Large | Bge-Reranker-Base | 4.253 | 0.285 | 0.096 | 0.172 | 0.040 | |
| LLMRerank | 4.298 | 0.287 | 0.097 | 0.174 | 0.040 | ||
| All-Mpnet-Base-v2 | 4.304 | 0.290 | 0.096 | 0.174 | 0.040 |
表 12: Solar-10.7B 在 RAG 系统中的详细实验结果
| 检索器 | 嵌入器 | 重排序器 | 问答准确率 | ROUGE-1 | ROUGE-2 | ROUGE-L | BLEU |
|---|---|---|---|---|---|---|---|
| AMR | Bge-Small-en-v1.5 | Bge-Reranker-Base | 4.310 | 0.329 | 0.118 | 0.205 | 0.051 |
| AMR | Bge-Small-en-v1.5 | LLMRerank | 4.418 | 0.323 | 0.115 | 0.200 | 0.050 |
| AMR | Bge-Small-en-v1.5 | All-Mpnet-Base-v2 | 4.331 | 0.312 | 0.106 | 0.193 | 0.045 |
| AMR | Ada2 | Bge-Reranker-Base | 4.378 | 0.327 | 0.119 | 0.204 | 0.051 |
| AMR | Ada2 | LLMRerank | 4.350 | 0.322 | 0.116 | 0.200 | 0.050 |
| AMR | Ada2 | All-Mpnet-Base-v2 | 4.357 | 0.323 | 0.111 | 0.197 | 0.045 |
| AMR | Ember-v1 | Bge-Reranker-Base | 4.348 | 0.329 | 6110 | 0.205 | 0.052 |
| AMR | Ember-v1 | LLMRerank | 4.388 | 0.330 | 0.117 | 0.204 | 0.052 |
| AMR | Ember-v1 | All-Mpnet-Base-v2 | 4.317 | 0.319 | 0.110 | 0.196 | 0.046 |
| AMR | Gte-Large | Bge-Reranker-Base | 4.328 | 0.318 | 0.113 | 0.198 | 0.048 |
| AMR | Gte-Large | LLMRerank | 4.338 | 0.318 | 0.110 | 0.197 | 0.045 |
| AMR | Gte-Large | All-Mpnet-Base-v2 | 4.262 | 0.302 | 0.098 | 0.185 | 0.039 |
| SWR | Bge-Small-en-v1.5 | Bge-Reranker-Base | 4.431 | 0.296 | 0.094 | 0.184 | 0.037 |
| SWR | Bge-Small-en-v1.5 | LLMRerank | 4.462 | 0.298 | 0.095 | 0.184 | 0.037 |
| SWR | Bge-Small-en-v1.5 | All-Mpnet-Base-v2 | 4.458 | 0.300 | 0.094 | 0.185 | 0.037 |
| SWR | Ada2 | Bge-Reranker-Base | 4.424 | 0.296 | 0.095 | 0.183 | 0.037 |
| SWR | Ada2 | LLMRerank | 4.460 | 0.297 | 0.096 | 0.182 | 0.037 |
| SWR | Ada2 | All-Mpnet-Base-v2 | 4.431 | 0.293 | 0.093 | 0.180 | 0.037 |
| SWR | Ember-v1 | Bge-Reranker-Base | 4.456 | 0.305 | 0.097 | 0.190 | 0.039 |
| SWR | Ember-v1 | LLMRerank | 4.376 | 0.305 | 0.099 | 0.190 | 0.039 |
| SWR | Ember-v1 | All-Mpnet-Base-v2 | 4.394 | 0.307 | 0.100 | 0.190 | 0.041 |
| SWR | Gte-Large | Bge-Reranker-Base LLMRerank | 4.344 4.354 | 0.297 | 600 | 0.184 | 0.037 |
| SWR | Gte-Large | All-Mpnet-Base-v2 | 4.361 | 0.296 0.297 | 0.094 | 0.184 | 0.037 |
| SWR | Gte-Large | 0.095 | 0.184 | 0.038 | |||
| VectorRetriever | Bge-Small-en-v1.5 | Bge-Reranker-Base | 4.375 | 0.300 | 0.105 | 0.183 | 0.043 |
| VectorRetriever | Bge-Small-en-v1.5 | LLMRerank | 4.384 | 0.300 | 0.105 | 0.184 | 0.042 |
| VectorRetriever | Bge-Small-en-v1.5 | All-Mpnet-Base-v2 | 4.414 | 0.301 | 0.106 | 0.184 | 0.043 |
| VectorRetriever | Ada2 | Bge-Reranker-Base | 4.422 | 0.298 | 0.106 | 0.183 | 0.044 |
| VectorRetriever | Ada2 | LLMRerank | 4.409 | 0.297 | 0.105 | 0.183 | 0.044 |
| VectorRetriever | Ada2 | All-Mpnet-Base-v2 | 4.359 | 0.299 | 0.107 | 0.184 | 0.045 |
| VectorRetriever | Ember-v1 | Bge-Reranker-Base | 4.441 | 0.299 | 0.106 | 0.185 | 0.045 |
| VectorRetriever | Ember-v1 | LLMRerank | 4.384 | 0.301 | 0.106 | 0.186 | 0.045 |
| VectorRetriever | Ember-v1 | All-Mpnet-Base-v2 | 4.420 | 0.297 | 0.106 | 0.184 | 0.045 |
| VectorRetriever | Gte-Large | Bge-Reranker-Base | 4.253 | 0.285 | 0.096 | 0.172 | 0.040 |
| VectorRetriever | Gte-Large | LLMRerank | 4.298 | 0.287 | 0.097 | 0.174 | 0.040 |
| VectorRetriever | Gte-Large | All-Mpnet-Base-v2 | 4.304 | 0.290 | 0.096 | 0.174 | 0.040 |
Table 13: Detailed Experiment Results of Qwen-7B in RAG Systems.
| Retriever | Embedder | Reranker | Question&Answer Accuracy | ROUGE-1 | ROUGE-2 | ROUGE-L | BLEU |
| AMR | Bge-Small-en-v1.5 | Bge-Reranker-Base | 4.445 | 0.331 | 0.118 | 0.211 | 0.055 |
| LLMRerank | 4.414 | 0.341 | 0.125 | 0.217 | 0.059 | ||
| All-Mpnet-Base-v2 | 4.414 | 0.320 | 0.107 | 0.198 | 0.047 | ||
| Ada2 | Bge-Reranker-Base | 4.405 | 0.337 | 0.120 | 0.216 | 0.056 | |
| LLMRerank | 4.538 | 0.335 | 0.119 | 0.211 | 0.055 | ||
| All-Mpnet-Base-v2 | 4.420 | 0.333 | 0.115 | 0.209 | 0.052 | ||
| Ember-v1 | Bge-Reranker-Base | 4.456 | 0.341 | 0.120 | 0.215 | 0.056 | |
| LLMRerank | 4.432 | 0.339 | 0.121 | 0.215 | 0.056 | ||
| All-Mpnet-Base-v2 | 4.361 | 0.328 | 0.110 | 0.204 | 0.050 | ||
| Gte-Large | Bge-Reranker-Base | 4.399 | 0.336 | 0.118 | 0.210 | 0.051 | |
| LLMRerank | 4.424 | 0.331 | 0.117 | 0.210 | 0.052 | ||
| All-Mpnet-Base-v2 | 4.368 | 0.315 | 0.103 | 0.195 | 0.044 | ||
| SWR | Bge-Small-en-v1.5 | Bge-Reranker-Base | 4.529 | 0.314 | 0.101 | 0.194 | 0.044 |
| LLMRerank | 4.517 | 0.320 | 0.104 | 0.198 | 0.043 | ||
| All-Mpnet-Base-v2 | 4.490 | 0.322 | 0.105 | 0.198 | 0.047 | ||
| Ada2 | Bge-Reranker-Base | 4.540 | 0.326 | 0.110 | 0.206 | 0.050 | |
| LLMRerank | 4.548 | 0.322 | 0.104 | 0.199 | 0.049 | ||
| All-Mpnet-Base-v2 | 4.525 | 0.323 | 0.110 | 0.204 | 0.051 | ||
| Ember-v1 | Bge-Reranker-Base | 4.473 | 0.324 | 0.106 | 0.202 | 0.046 | |
| LLMRerank | 4.511 | 0.326 | 0.109 | 0.203 | 0.048 | ||
| All-Mpnet-Base-v2 Bge-Reranker-Base | 4.508 | 0.321 | 0.106 | 0.198 | 0.045 | ||
| Gte-Large | LLMRerank | 4.483 4.424 | 0.314 | 0.102 | 0.193 | 0.045 | |
| All-Mpnet-Base-v2 | 4.430 | 0.316 0.310 | 0.104 0.099 | 0.196 0.190 | 0.046 | ||
| 0.042 | |||||||
| Vector Retriever | Bge-Small-en-v1.5 | Bge-Reranker-Base | 4.424 | 0.310 | 0.101 | 0.194 | 0.046 |
| LLMRerank | 4.416 | 0.302 | 0.098 | 0.190 | 0.040 | ||
| All-Mpnet-Base-v2 | 4.388 | 0.290 | 0.093 | 0.180 | 0.038 | ||
| Ada2 | Bge-Reranker-Base | 4.430 | 0.299 | 0.102 | 0.190 | 0.044 | |
| LLMRerank | 4.382 | 0.298 | 0.100 | 0.190 | 0.042 | ||
| All-Mpnet-Base-v2 | 4.378 | 0.298 | 0.096 | 0.184 | 0.042 | ||
| Ember-v1 | Bge-Reranker-Base | 4.405 | 0.311 | 0.102 | 0.194 | 0.045 | |
| LLMRerank | 4.468 | 0.312 | 0.099 | 0.194 | 0.041 | ||
| All-Mpnet-Base-v2 | 4.489 | 0.294 | 0.095 | 0.182 | 0.039 | ||
| Gte-Large | Bge-Reranker-Base | 4.302 | 0.288 | 0.086 | 0.175 | 0.037 | |
| LLMRerank | 4.357 | 0.289 | 0.088 | 0.179 | 0.037 | ||
| All-Mpnet-Base-v2 | 4.369 | 0.294 | 0.094 | 0.183 | 0.039 |
表 13: Qwen-7B 在 RAG 系统中的详细实验结果
| 检索器 (Retriever) | 嵌入器 (Embedder) | 重排序器 (Reranker) | 问答准确率 (Question&Answer Accuracy) | ROUGE-1 | ROUGE-2 | ROUGE-L | BLEU |
|---|---|---|---|---|---|---|---|
| AMR | Bge-Small-en-v1.5 | Bge-Reranker-Base | 4.445 | 0.331 | 0.118 | 0.211 | 0.055 |
| LLMRerank | 4.414 | 0.341 | 0.125 | 0.217 | 0.059 | ||
| All-Mpnet-Base-v2 | 4.414 | 0.320 | 0.107 | 0.198 | 0.047 | ||
| Ada2 | Bge-Reranker-Base | 4.405 | 0.337 | 0.120 | 0.216 | 0.056 | |
| LLMRerank | 4.538 | 0.335 | 0.119 | 0.211 | 0.055 | ||
| All-Mpnet-Base-v2 | 4.420 | 0.333 | 0.115 | 0.209 | 0.052 | ||
| Ember-v1 | Bge-Reranker-Base | 4.456 | 0.341 | 0.120 | 0.215 | 0.056 | |
| LLMRerank | 4.432 | 0.339 | 0.121 | 0.215 | 0.056 | ||
| All-Mpnet-Base-v2 | 4.361 | 0.328 | 0.110 | 0.204 | 0.050 | ||
| Gte-Large | Bge-Reranker-Base | 4.399 | 0.336 | 0.118 | 0.210 | 0.051 | |
| LLMRerank | 4.424 | 0.331 | 0.117 | 0.210 | 0.052 | ||
| All-Mpnet-Base-v2 | 4.368 | 0.315 | 0.103 | 0.195 | 0.044 | ||
| SWR | Bge-Small-en-v1.5 | Bge-Reranker-Base | 4.529 | 0.314 | 0.101 | 0.194 | 0.044 |
| LLMRerank | 4.517 | 0.320 | 0.104 | 0.198 | 0.043 | ||
| All-Mpnet-Base-v2 | 4.490 | 0.322 | 0.105 | 0.198 | 0.047 | ||
| Ada2 | Bge-Reranker-Base | 4.540 | 0.326 | 0.110 | 0.206 | 0.050 | |
| LLMRerank | 4.548 | 0.322 | 0.104 | 0.199 | 0.049 | ||
| All-Mpnet-Base-v2 | 4.525 | 0.323 | 0.110 | 0.204 | 0.051 | ||
| Ember-v1 | Bge-Reranker-Base | 4.473 | 0.324 | 0.106 | 0.202 | 0.046 | |
| LLMRerank | 4.511 | 0.326 | 0.109 | 0.203 | 0.048 | ||
| All-Mpnet-Base-v2 Bge-Reranker-Base | 4.508 | 0.321 | 0.106 | 0.198 | 0.045 | ||
| Gte-Large | LLMRerank | 4.483 4.424 | 0.314 | 0.102 | 0.193 | 0.045 | |
| All-Mpnet-Base-v2 | 4.430 | 0.316 0.310 | 0.104 0.099 | 0.196 0.190 | 0.046 | ||
| 0.042 | |||||||
| Vector Retriever | Bge-Small-en-v1.5 | Bge-Reranker-Base | 4.424 | 0.310 | 0.101 | 0.194 | 0.046 |
| LLMRerank | 4.416 | 0.302 | 0.098 | 0.190 | 0.040 | ||
| All-Mpnet-Base-v2 | 4.388 | 0.290 | 0.093 | 0.180 | 0.038 | ||
| Ada2 | Bge-Reranker-Base | 4.430 | 0.299 | 0.102 | 0.190 | 0.044 | |
| LLMRerank | 4.382 | 0.298 | 0.100 | 0.190 | 0.042 | ||
| All-Mpnet-Base-v2 | 4.378 | 0.298 | 0.096 | 0.184 | 0.042 | ||
| Ember-v1 | Bge-Reranker-Base | 4.405 | 0.311 | 0.102 | 0.194 | 0.045 | |
| LLMRerank | 4.468 | 0.312 | 0.099 | 0.194 | 0.041 | ||
| All-Mpnet-Base-v2 | 4.489 | 0.294 | 0.095 | 0.182 | 0.039 | ||
| Gte-Large | Bge-Reranker-Base | 4.302 | 0.288 | 0.086 | 0.175 | 0.037 | |
| LLMRerank | 4.357 | 0.289 | 0.088 | 0.179 | 0.037 | ||
| All-Mpnet-Base-v2 | 4.369 | 0.294 | 0.094 | 0.183 | 0.039 |
Table 14: Detailed Experiment Results of LLaMA2-7B in RAG Systems.
| Retriever | Embedder | Reranker | Question&Answer Accuracy | ROUGE-1 | ROUGE-2 | ROUGE-L | BLEU |
| AMR | Bge-Small-en-v1.5 | Bge-Reranker-Base | 4.268 | 0.239 | 0.078 | 0.151 | 0.031 |
| LLMRerank | 4.287 | 0.233 | 0.076 | 0.149 | 0.031 | ||
| All-Mpnet-Base-v2 | 4.240 | 0.199 | 0.058 | 0.127 | 0.021 | ||
| Ada2 | Bge-Reranker-Base | 4.220 | 0.218 | 0.073 | 0.138 | 0.029 | |
| LLMRerank | 4.250 | 0.219 | 0.074 | 0.141 | 0.030 | ||
| All-Mpnet-Base-v2 | 4.203 | 0.206 | 0.062 | 0.131 | 0.022 | ||
| Ember-v1 | Bge-Reranker-Base | 4.215 | 0.230 | 0.076 | 0.146 | 0.031 | |
| LLMRerank | 4.287 | 0.223 | 0.075 | 0.142 | 0.029 | ||
| All-Mpnet-Base-v2 | 4.272 | 0.215 | 0.063 | 0.134 | 0.021 | ||
| Gte-Large | Bge-Reranker-Base | 4.279 | 0.221 | 0.074 | 0.142 | 0.029 | |
| LLMRerank | 4.272 | 0.212 | 0.068 | 0.135 | 0.025 | ||
| All-Mpnet-Base-v2 | 4.181 | 0.213 | 0.059 | 0.133 | 0.019 | ||
| SWR | Bge-Small-en-v1.5 | Bge-Reranker-Base | 4.141 | 0.214 | 0.067 | 0.137 | 0.025 |
| LLMRerank | 4.202 | 0.225 | 0.072 | 0.145 | 0.027 | ||
| All-Mpnet-Base-v2 | 4.216 | 0.215 | 0.066 | 0.136 | 0.025 | ||
| Ada2 | Bge-Reranker-Base | 4.222 | 0.220 | 0.070 | 0.141 | 0.026 | |
| LLMRerank | 4.230 | 0.224 | 0.071 | 0.144 | 0.028 | ||
| All-Mpnet-Base-v2 | 4.184 | 0.233 | 0.078 | 0.152 | 0.030 | ||
| Ember-v1 | Bge-Reranker-Base | 4.215 | 0.218 | 0.070 | 0.139 | 0.025 | |
| LLMRerank | 4.196 | 0.203 | 0.065 | 0.131 | 0.023 | ||
| All-Mpnet-Base-v2 | 4.295 | 0.214 | 0.067 | 0.138 | 0.026 | ||
| Gte-Large | Bge-Reranker-Base LLMRerank | 4.181 4.181 | 0.206 0.198 | 0.064 0.058 | 0.135 | 0.022 | |
| All-Mpnet-Base-v2 | 4.259 | 0.206 | 0.062 | 0.127 0.131 | 0.021 | ||
| 0.022 | |||||||
| VectorRetriever | Bge-Small-en-v1.5 | Bge-Reranker-Base | 4.193 | 0.175 | 0.049 | 0.110 | 0.016 |
| LLMRerank | 4.243 | 0.168 | 0.049 | 0.108 | 0.016 | ||
| All-Mpnet-Base-v2 | 4.193 | 0.162 | 0.043 | 0.102 | 0.013 | ||
| Ada2 | Bge-Reranker-Base | 4.246 | 0.178 | 0.054 | 0.111 | 0.019 | |
| LLMRerank | 4.179 | 0.176 | 0.055 | 0.110 | 0.022 | ||
| All-Mpnet-Base-v2 | 4.247 | 0.164 | 0.047 | 0.104 | 0.014 | ||
| Ember-v1 | Bge-Reranker-Base | 4.151 | 0.180 | 0.054 | 0.113 | 0.016 | |
| LLMRerank | 4.256 | 0.177 | 0.052 | 0.111 | 0.017 | ||
| All-Mpnet-Base-v2 | 4.193 | 0.176 | 0.048 | 0.109 | 0.015 | ||
| Gte-Large | Bge-Reranker-Base | 4.229 | 0.155 | 0.042 | 0.098 | 0.013 | |
| LLMRerank | 4.215 | 0.172 | 0.049 | 0.106 | 0.019 | ||
| All-Mpnet-Base-v2 | 4.245 | 0.166 | 0.046 | 0.106 | 0.016 |
表 14: LLaMA2-7B 在 RAG (Retrieval-Augmented Generation) 系统中的详细实验结果
| Retriever | Embedder | Reranker | Question&Answer Accuracy | ROUGE-1 | ROUGE-2 | ROUGE-L | BLEU |
|---|---|---|---|---|---|---|---|
| AMR | Bge-Small-en-v1.5 | Bge-Reranker-Base | 4.268 | 0.239 | 0.078 | 0.151 | 0.031 |
| LLMRerank | 4.287 | 0.233 | 0.076 | 0.149 | 0.031 | ||
| All-Mpnet-Base-v2 | 4.240 | 0.199 | 0.058 | 0.127 | 0.021 | ||
| Ada2 | Bge-Reranker-Base | 4.220 | 0.218 | 0.073 | 0.138 | 0.029 | |
| LLMRerank | 4.250 | 0.219 | 0.074 | 0.141 | 0.030 | ||
| All-Mpnet-Base-v2 | 4.203 | 0.206 | 0.062 | 0.131 | 0.022 | ||
| Ember-v1 | Bge-Reranker-Base | 4.215 | 0.230 | 0.076 | 0.146 | 0.031 | |
| LLMRerank | 4.287 | 0.223 | 0.075 | 0.142 | 0.029 | ||
| All-Mpnet-Base-v2 | 4.272 | 0.215 | 0.063 | 0.134 | 0.021 | ||
| Gte-Large | Bge-Reranker-Base | 4.279 | 0.221 | 0.074 | 0.142 | 0.029 | |
| LLMRerank | 4.272 | 0.212 | 0.068 | 0.135 | 0.025 | ||
| All-Mpnet-Base-v2 | 4.181 | 0.213 | 0.059 | 0.133 | 0.019 | ||
| SWR | Bge-Small-en-v1.5 | Bge-Reranker-Base | 4.141 | 0.214 | 0.067 | 0.137 | 0.025 |
| LLMRerank | 4.202 | 0.225 | 0.072 | 0.145 | 0.027 | ||
| All-Mpnet-Base-v2 | 4.216 | 0.215 | 0.066 | 0.136 | 0.025 | ||
| Ada2 | Bge-Reranker-Base | 4.222 | 0.220 | 0.070 | 0.141 | 0.026 | |
| LLMRerank | 4.230 | 0.224 | 0.071 | 0.144 | 0.028 | ||
| All-Mpnet-Base-v2 | 4.184 | 0.233 | 0.078 | 0.152 | 0.030 | ||
| Ember-v1 | Bge-Reranker-Base | 4.215 | 0.218 | 0.070 | 0.139 | 0.025 | |
| LLMRerank | 4.196 | 0.203 | 0.065 | 0.131 | 0.023 | ||
| All-Mpnet-Base-v2 | 4.295 | 0.214 | 0.067 | 0.138 | 0.026 | ||
| Gte-Large | Bge-Reranker-Base | 4.181 | 0.206 | 0.064 | 0.135 | 0.022 | |
| LLMRerank | 4.181 | 0.198 | 0.058 | 0.131 | 0.022 | ||
| All-Mpnet-Base-v2 | 4.259 | 0.206 | 0.062 | 0.127 | 0.021 | ||
| VectorRetriever | Bge-Small-en-v1.5 | Bge-Reranker-Base | 4.193 | 0.175 | 0.049 | 0.110 | 0.016 |
| LLMRerank | 4.243 | 0.168 | 0.049 | 0.108 | 0.016 | ||
| All-Mpnet-Base-v2 | 4.193 | 0.162 | 0.043 | 0.102 | 0.013 | ||
| Ada2 | Bge-Reranker-Base | 4.246 | 0.178 | 0.054 | 0.111 | 0.019 | |
| LLMRerank | 4.179 | 0.176 | 0.055 | 0.110 | 0.022 | ||
| All-Mpnet-Base-v2 | 4.247 | 0.164 | 0.047 | 0.104 | 0.014 | ||
| Ember-v1 | Bge-Reranker-Base | 4.151 | 0.180 | 0.054 | 0.113 | 0.016 | |
| LLMRerank | 4.256 | 0.177 | 0.052 | 0.111 | 0.017 | ||
| All-Mpnet-Base-v2 | 4.193 | 0.176 | 0.048 | 0.109 | 0.015 | ||
| Gte-Large | Bge-Reranker-Base | 4.229 | 0.155 | 0.042 | 0.098 | 0.013 | |
| LLMRerank | 4.215 | 0.172 | 0.049 | 0.106 | 0.019 | ||
| All-Mpnet-Base-v2 | 4.245 | 0.166 | 0.046 | 0.106 | 0.016 |
Table 15: Detailed Experiment Results of Gemini-Pro in RAG Systems.
| Retriever | Embedder | Reranker | Question&Answer Accuracy | ROUGE-1 | ROUGE-2 | ROUGE-L | BLEU |
| AMR | Bge-Small-en-v1.5 | Bge-Reranker-Base | 3.887 | 0.298 | 0.115 | 0.206 | 0.045 |
| LLMRerank | 3.989 | 0.303 | 0.119 | 0.210 | 0.051 | ||
| All-Mpnet-Base-v2 2 | 3.567 | 0.272 | 0.099 | 0.187 | 0.036 | ||
| Ada2 | Bge-Reranker-Base | 4.063 | 0.302 | 0.118 | 0.208 | 0.049 | |
| LLMRerank | 3.983 | 0.300 | 0.119 | 0.208 | 0.048 | ||
| All-Mpnet-Base-v2 | 3.698 | 0.278 | 0.102 | 0.190 | 0.037 | ||
| Ember-v1 | Bge-Reranker-Base | 3.970 | 0.304 | 0.118 | 0.211 | 0.048 | |
| LLMRerank | 3.990 | 0.306 | 0.119 | 0.211 | 0.052 | ||
| All-Mpnet-Base-v2 | 3.667 | 0.279 | 0.102 | 0.191 | 0.039 | ||
| Gte-Large | Bge-Reranker-Base | 3.840 | 0.294 | 0.111 | 0.199 | 0.042 | |
| LLMRerank | 3.793 | 0.284 | 0.104 | 0.195 | 0.042 | ||
| All-Mpnet-Base-v2 | 3.344 | 0.255 | 0.093 | 0.178 | 0.030 | ||
| SWR | Bge-Small-en-v1.5 | Bge-Reranker-Base | 3.894 | 0.257 | 0.091 | 0.178 | 0.028 |
| LLMRerank | 3.922 | 0.257 | 0.094 | 0.177 | 0.030 | ||
| All-Mpnet-Base-v2 | 3.894 | 0.259 | 0.092 | 0.179 | 0.033 | ||
| Ada2 | Bge-Reranker-Base | 3.996 | 0.254 | 0.088 | 0.177 | 0.028 | |
| LLMRerank | 3.975 | 0.253 | 0.089 | 0.176 | 0.030 | ||
| All-Mpnet-Base-v2 | 4.023 | 0.261 | 0.095 | 0.183 | 0.032 | ||
| Ember-v1 | Bge-Reranker-Base | 3.938 | 0.272 | 0.102 | 0.189 | 0.036 | |
| LLMRerank | 4.037 | 0.268 | 0.101 | 0.188 | 0.036 | ||
| All-Mpnet-Base-v2 | 4.035 | 0.269 | 0.094 | 0.184 | 0.030 | ||
| Gte-Large Bge-Small-en-v1.5 | Bge-Reranker-Base LLMRerank | 3.743 | 0.246 | 0.086 | 0.174 | 0.026 | |
| All-Mpnet-Base-v2 2 | 3.731 3.772 | 0.249 0.246 | 0.093 0.091 | 0.176 0.174 | 0.033 | ||
| 0.030 | |||||||
| VectorRetriever | Bge-Reranker-Base | 3.914 | 0.262 | 0.091 | 0.177 | 0.032 | |
| LLMRerank | 3.948 | 0.256 | 0.091 | 0.177 | 0.036 | ||
| All-Mpnet-Base-v2 | 3.819 | 0.257 | 0.094 | 0.177 | 0.034 | ||
| Ada2 | Bge-Reranker-Base | 3.930 | 0.262 | 0.097 | 0.180 | 0.040 | |
| LLMRerank | 3.863 | 0.266 | 0.100 | 0.183 | 0.041 | ||
| All-Mpnet-Base-v2 | 3.981 | 0.254 | 0.089 | 0.173 | 0.033 | ||
| Ember-v1 | Bge-Reranker-Base | 3.946 | 0.265 | 0.094 | 0.184 | 0.038 | |
| LLMRerank | 3.873 | 0.258 | 0.090 | 0.176 | 0.033 | ||
| All-Mpnet-Base-v2 | 4.044 | 0.262 | 0.091 | 0.179 | 0.036 | ||
| Gte-Large | Bge-Reranker-Base | 3.521 | 0.227 | 0.076 | 0.157 | 0.027 | |
| LLMRerank | 3.544 | 0.237 | 0.078 | 0.163 | 0.027 | ||
| All-Mpnet-Base-v2 | 3.542 | 0.229 | 0.078 | 0.158 | 0.027 |
表 15: Gemini-Pro 在 RAG (Retrieval-Augmented Generation) 系统中的详细实验结果
| 检索器 (Retriever) | 嵌入器 (Embedder) | 重排序器 (Reranker) | 问答准确率 (Question&Answer Accuracy) | ROUGE-1 | ROUGE-2 | ROUGE-L | BLEU |
|---|---|---|---|---|---|---|---|
| AMR | Bge-Small-en-v1.5 | Bge-Reranker-Base | 3.887 | 0.298 | 0.115 | 0.206 | 0.045 |
| LLMRerank | 3.989 | 0.303 | 0.119 | 0.210 | 0.051 | ||
| All-Mpnet-Base-v2 2 | 3.567 | 0.272 | 0.099 | 0.187 | 0.036 | ||
| Ada2 | Bge-Reranker-Base | 4.063 | 0.302 | 0.118 | 0.208 | 0.049 | |
| LLMRerank | 3.983 | 0.300 | 0.119 | 0.208 | 0.048 | ||
| All-Mpnet-Base-v2 | 3.698 | 0.278 | 0.102 | 0.190 | 0.037 | ||
| Ember-v1 | Bge-Reranker-Base | 3.970 | 0.304 | 0.118 | 0.211 | 0.048 | |
| LLMRerank | 3.990 | 0.306 | 0.119 | 0.211 | 0.052 | ||
| All-Mpnet-Base-v2 | 3.667 | 0.279 | 0.102 | 0.191 | 0.039 | ||
| Gte-Large | Bge-Reranker-Base | 3.840 | 0.294 | 0.111 | 0.199 | 0.042 | |
| LLMRerank | 3.793 | 0.284 | 0.104 | 0.195 | 0.042 | ||
| All-Mpnet-Base-v2 | 3.344 | 0.255 | 0.093 | 0.178 | 0.030 | ||
| SWR | Bge-Small-en-v1.5 | Bge-Reranker-Base | 3.894 | 0.257 | 0.091 | 0.178 | 0.028 |
| LLMRerank | 3.922 | 0.257 | 0.094 | 0.177 | 0.030 | ||
| All-Mpnet-Base-v2 | 3.894 | 0.259 | 0.092 | 0.179 | 0.033 | ||
| Ada2 | Bge-Reranker-Base | 3.996 | 0.254 | 0.088 | 0.177 | 0.028 | |
| LLMRerank | 3.975 | 0.253 | 0.089 | 0.176 | 0.030 | ||
| All-Mpnet-Base-v2 | 4.023 | 0.261 | 0.095 | 0.183 | 0.032 | ||
| Ember-v1 | Bge-Reranker-Base | 3.938 | 0.272 | 0.102 | 0.189 | 0.036 | |
| LLMRerank | 4.037 | 0.268 | 0.101 | 0.188 | 0.036 | ||
| All-Mpnet-Base-v2 | 4.035 | 0.269 | 0.094 | 0.184 | 0.030 | ||
| Gte-Large Bge-Small-en-v1.5 | Bge-Reranker-Base LLMRerank | 3.743 | 0.246 | 0.086 | 0.174 | 0.026 | |
| All-Mpnet-Base-v2 2 | 3.731 3.772 | 0.249 0.246 | 0.093 0.091 | 0.176 0.174 | 0.033 | ||
| 0.030 | |||||||
| VectorRetriever | Bge-Reranker-Base | 3.914 | 0.262 | 0.091 | 0.177 | 0.032 | |
| LLMRerank | 3.948 | 0.256 | 0.091 | 0.177 | 0.036 | ||
| All-Mpnet-Base-v2 | 3.819 | 0.257 | 0.094 | 0.177 | 0.034 | ||
| Ada2 | Bge-Reranker-Base | 3.930 | 0.262 | 0.097 | 0.180 | 0.040 | |
| LLMRerank | 3.863 | 0.266 | 0.100 | 0.183 | 0.041 | ||
| All-Mpnet-Base-v2 | 3.981 | 0.254 | 0.089 | 0.173 | 0.033 | ||
| Ember-v1 | Bge-Reranker-Base | 3.946 | 0.265 | 0.094 | 0.184 | 0.038 | |
| LLMRerank | 3.873 | 0.258 | 0.090 | 0.176 | 0.033 | ||
| All-Mpnet-Base-v2 | 4.044 | 0.262 | 0.091 | 0.179 | 0.036 | ||
| Gte-Large | Bge-Reranker-Base | 3.521 | 0.227 | 0.076 | 0.157 | 0.027 | |
| LLMRerank | 3.544 | 0.237 | 0.078 | 0.163 | 0.027 | ||
| All-Mpnet-Base-v2 | 3.542 | 0.229 | 0.078 | 0.158 | 0.027 |
Table 16: An Example of Numerical Reasoning QA Pairs
| Question Type Numerical Reasoning | |
| Amount | 336 |
| Question | Critics have charged that compensation to top managers in the United States is simply too high and should be cut back. For example, focusing on large corporations, Mark Parker, CEO of Nike, earned about $47.6 million in 2016. Are such amounts excessive? In answering, it might be help- ful to recognize that superstar athletes such as LeBron James, top entertainers such as Taylor Swift and Dwayne Johnson, and many others at the top of their respective fields earn at least as much, if not a great deal more. |
| Answer | "How much is too much? Who is worth more, Mark Parker or LeBron James? The simplest answer is that there is a market for executives just as there is for all types of labor. Executive com- pensation is the price that clears the market. The same is true for athletes and performers. Having said that, one aspect of executive compensation has grown so dramatically is that companies have increasingly moved to stock-based compensation. Such movement is obviously consistent with the attempt to better align stockholder and management interests. In recent years, stock prices have soared, so management has cleaned up. It is sometimes argued that much of this reward is due to rising stock prices in general, not managerial performance. Perhaps in the future, executive compen- sation will be designed to reward only differential performance, that is, stock price increases in excess of general market increases. |
表 16: 数值推理问答对示例
| 问题类型 | 数值推理 |
|---|---|
| 数量 | 336 |
| 问题 | 批评者指责美国高管的薪酬过高,应予以削减。例如,以大型企业为例,耐克CEO马克·帕克2016年的收入约为4760万美元。这样的金额是否过高?在回答时,可能需要认识到像勒布朗·詹姆斯这样的超级明星运动员、泰勒·斯威夫特和道恩·强森这样的顶级艺人,以及其他各领域顶尖人物的收入至少与之相当,甚至更高。 |
| 答案 | "多少才算过多?马克·帕克和勒布朗·詹姆斯谁的价值更高?最简单的答案是,高管市场和其他劳动力市场一样存在。高管薪酬是市场出清的价格。运动员和表演者也是如此。话虽如此,高管薪酬的一个方面增长如此显著的原因是公司越来越多地转向基于股票的薪酬。这种做法显然符合更好地协调股东和管理层利益的尝试。近年来,股价飙升,管理层因此获益。有时人们认为,这种奖励很大程度上是由于整体股价上涨,而非管理绩效。也许在未来,高管薪酬将设计为仅奖励差异化绩效,即超过整体市场涨幅的股价上涨。" |
Table 17: An Example of Multi-turn QA Pairs
| Question TypeMulti-turn | |
| Amount | 985 |
| Question | Who owns a corporation? Describe the process whereby the own- ers control the firm's management. What is the main reason that an In this context, what kinds of problems can arise? |
| Answer | In the corporate form of ownership, the shareholders are the own- ers of the firm. The shareholders elect the directors of the corpora tion, who in turn appoint the firm's management. This separation of ownership from control in the corporate form of organization is what causes agency problems to exist. Management may act in its own or someone else's. best interests, rather than those of the shareholders. If such events occur, they may contradict the goal of maximizing the share price of the equity of the firm. |
表 17: 多轮问答对示例
| 问题类型 | 多轮 |
|---|---|
| 数量 | 985 |
| 问题 | 谁拥有公司?描述所有者控制公司管理的过程。在这种情况下,主要问题是什么?可能会出现哪些问题? |
| 回答 | 在公司所有权形式中,股东是公司的所有者。股东选举公司董事,董事再任命公司的管理层。这种公司组织形式中所有权与控制权的分离是导致代理问题存在的原因。管理层可能出于自身或他人的最佳利益行事,而非股东利益。如果发生此类事件,可能会与公司股权价值最大化的目标相矛盾。 |
Table 18: An Example of Finance Domain Knowledge QA Pairs
| Question Type | Finance Domain Knowledge |
| Amount | 1205 |
| Question | What is a pro forma statement of cash flows and what is its pur- pose? |
| Answer | A pro forma statement of cash flows estimates the borrower's future cash flows. It is supposed to provide insight into the future cash flows of the borrower and its ability to repay the loan. |
表 18: 金融领域知识问答示例
| 问题类型 | 金融领域知识 |
|---|---|
| 数量 | 1205 |
| 问题 | 什么是模拟现金流量表(pro forma statement of cash flows)?它的用途是什么? |
| 答案 | 模拟现金流量表用于预估借款方未来现金流。该报表旨在帮助了解借款方未来现金流状况及其偿还贷款的能力。 |
Table 19: Example of Comparative Analysis QA Pair
| QuestionType | Comparative Analysis |
| Amount | 71 |
| Question | Suppose a company has a preferred stock issue and a common stock issue. Both have just paid a $2 dividend. Which do you think will have a higher price, a share of the preferred or a share ofthecommon? |
| Answer | The common stock probably has a higher price because the div- idend can grow, whereas it is fixed on the preferred. However, the preferred is less risky because of the dividend and liquidation preference, so it is possible the preferred could be worth more, depending on the circumstances. |
表 19: 比较分析问答对示例
| 问题类型 | 比较分析 |
|---|---|
| 数量 | 71 |
| 问题 | 假设一家公司同时发行了优先股和普通股,两者刚支付了2美元股息。你认为哪种股票的单股价格会更高:优先股还是普通股? |
| 答案 | 普通股价格可能更高,因为其股息可以增长,而优先股的股息是固定的。不过优先股由于享有股息和清算优先权,风险较低,因此在某些情况下优先股可能价值更高。 |
Table 20: Example of Open-minded QA Pair
| Question TypeOpen-minded | |
| Amount | 436 |
| Question | Suppose you were the financial manager of a not-for-profit busi- ness (a not-for-profit hospital, perhaps). What kinds of goals do you think would be appropriate? |
| Answer | Such organizations frequently pursue social or political missions, so many different goals are conceivable. One goal that is often cited is revenue minimization; that is, provide whatever goods and services are offered at the lowest possible cost to society. A better approach might be to observe that even a not-for-profit business has equity. Thus, one answer is that the appropriate goal is to maximize the value of the equity. |
表 20: 开放式问答对示例
| 问题类型 | 开放式 |
|---|---|
| 数量 | 436 |
| 问题 | 假设你是一家非营利企业(比如非营利医院)的财务经理,你认为什么样的目标是合适的? |
| 答案 | 这类组织通常追求社会或政治使命,因此可以设想许多不同的目标。一个经常被提及的目标是收入最小化,即以尽可能低的社会成本提供所供应的商品和服务。更好的方法可能是注意到即使是非营利企业也拥有权益。因此,一个答案是合适的目标是实现权益价值的最大化。 |
Table 21: Example of Cause and Effect Analysis QA Pair
| Question TypeCause and Effect Analysis | |
| Amount | 37 |
| Question | Last month, Central Virginia Power Company, which had been having trouble with cost overruns on a nuclear power plant that it had been building, announced that it was temporarily suspending payments due to the cash flow crunch associated with its invest- ment program. The company stock price dropped from $28.50 to 25 when this announcement was made. How would you interpret this change in the stock price (that is, what would you say caused it)? |
| Answer | The stock price dropped because of an expected drop in future dividends. Since the stock price is the present value of all future dividend payments, if the expected future dividend payments de- crease, then the stock price will decline. |
表 21: 因果关系分析问答对示例
| 问题类型 | 因果关系分析 |
|---|---|
| 数量 | 37 |
| 问题 | 上个月,因核电站建设项目成本超支而陷入困境的中弗吉尼亚电力公司宣布,由于投资计划导致的现金流紧张,将暂时暂停付款。此公告发布后,公司股价从28.50美元跌至25美元。你如何解读股价的这一变化(即你认为是什么原因导致的)? |
| 答案 | 股价下跌是由于预期未来股息下降。由于股票价格是所有未来股息支付的现值,如果预期的未来股息支付减少,那么股票价格就会下跌。 |
Table 22: Example of Open-minded QA Pair
| Question Type Open-minded | |
| Amount | 436 |
| Question | Suppose you were the financial manager of a not-for-profit busi- ness (a not-for-profit hospital, perhaps). What kinds of goals do you think would be appropriate? |
| Answer | Such organizations frequently pursue social or political missions, so many different goals are conceivable. One goal that is often cited is revenue minimization; that is, provide whatever goods and services are offered at the lowest possible cost to society. A better approach might be to observe that even a not-for-profit business has equity. Thus, one answer is that the appropriate goal is to maximize the value of the equity. |
表 22: 开放式问答对示例
| 问题类型 | 开放式 |
|---|---|
| 数量 | 436 |
| 问题 | 假设你是一家非营利企业(比如非营利医院)的财务经理,你认为什么样的目标是合适的? |
| 答案 | 这类组织通常追求社会或政治使命,因此可以设想许多不同的目标。一个经常被提及的目标是收入最小化,即以尽可能低的社会成本提供所供应的商品和服务。更好的方法可能是注意到即使是非营利企业也有权益。因此,一个答案是合适的目标是最大化权益的价值。 |
| Question | Refer to the previous exercise. Which type of foreign market intervention must the central bank of Colombia conduct to keep the exchange rate at a level where the currency is not under- or overvaluedintermsofPPP? |
| Baichuan2-7B | To answer the above question, we need to know the current ex- change rate of the Colombian peso relative to the U.S. dollar. Assuming the current exchange rate is not under- or overvalued in terms of PPP, the central bank of Colombia should conduct sterilized intervention to maintain this exchange rate. Sterilized intervention involves selling foreign assets (e.g., dollars) and pur- chasing domestic assets (e.g., pesos) to offset the effect of the intervention on the money supply. If the central bank sells dollars and buys pesos, the money supply in pesos will increase while the money supply in dollars will decrease. This will cause the value of the peso to appreciate relative to the dollar, maintaining the |
| GPT-3.5-turbo | current exchange rate. Based on the content provided, the information necessary to an- swer the question is not present. The content does not mention the central bank of Colombia or provide any information about the exchange rate of the Colombian currency. Therefore, we cannot determine which type of foreign market intervention the central bank of Colombia must conduct to keep the exchange rate at a level where the currency is not under- or overvalued in terms of PPP. |
| Ground Truth | To eliminate the overvaluation in terms of PPP, the exchange rate for the Columbian peso needs to decline. The central bank of Colombia should undertake an unsterilized foreign market inter- vention in which it will sell the domestic currency (COP) and buy foreign reserves, in order to increase reserves of its banking system, decrease the domestic interest rate, and shift the expected return on domestic currency denominated assets curve to the left. |
Table 23: An Example of Unanswered Questions. We compare answers generated by GPT-3.5-turbo and Baichuan2- 7B with the same embedder, retriever, and Reranker.
表 23: 未回答问题示例。我们比较了 GPT-3.5-turbo 和 Baichuan2-7B 使用相同嵌入器、检索器和重排器生成的答案。