Multimodal Prompt Retrieval for Generative Visual Question Answering
生成式视觉问答的多模态提示检索
Timothy Ossowski1, Junjie $\mathbf{H}\mathbf{u}^{1,2}$ 1 Department of Computer Science, 2 Department of Biostatistics and Medical Informatics University of Wisconsin, Madison, WI, USA ossowski@wisc.edu, junjie.hu@wisc.edu
Timothy Ossowski1, Junjie $\mathbf{H}\mathbf{u}^{1,2}$ 1 计算机科学系,2 生物统计学与医学信息学系 威斯康星大学麦迪逊分校,美国威斯康星州麦迪逊市 ossowski@wisc.edu, junjie.hu@wisc.edu
Abstract
摘要
Recent years have witnessed impressive results of pre-trained vision-language models on knowledge-intensive tasks such as visual question answering (VQA). Despite the recent ad- vances in VQA, existing methods mainly adopt a disc rim i native formulation that predicts answers within a pre-defined label set, leading to easy over fitting on low-resource domains with limited labeled data (e.g., medicine) and poor generalization under domain shift to another dataset. To tackle this limitation, we propose a novel generative model enhanced by multimodal prompt retrieval (MPR) that integrates retrieved prompts and multimodal features to generate answers in free text. Our generative model enables rapid zero-shot dataset adaptation to unseen data distributions and open-set answer labels across datasets. Our experiments on medical VQA tasks show that MPR outperforms its non-retrieval counterpart by up to $30%$ accuracy points in a few-shot domain adaptation setting.1
近年来,预训练视觉语言模型在知识密集型任务(如视觉问答 (VQA))上取得了显著成果。尽管VQA领域近期有所进展,现有方法主要采用判别式框架,即在预定义标签集内预测答案,这容易导致在标注数据有限的低资源领域(如医学)过拟合,并在跨数据集领域迁移时泛化能力较差。为解决这一局限,我们提出一种通过多模态提示检索 (MPR) 增强的生成式模型,该模型整合检索到的提示和多模态特征以生成自由文本答案。我们的生成式模型能够快速实现零样本数据集适配,适应未见过的数据分布和跨数据集的开放集答案标签。在医学VQA任务上的实验表明,在少样本领域适应场景下,MPR比非检索版本模型的准确率最高提升30%。[20]
1 Introduction
1 引言
Visual question answering (VQA) is a popular multimodal machine learning problem that challenges a model to answer a question posed about an image. As encouraged by recent advances in VQA, pioneering studies have investigated the application of VQA systems to low-resourced, knowledge- intensive domains such as medicine (Lin et al., 2021), where collecting domain-specific annotations is extremely costly and time-consuming. In particular, medical VQA has attracted increasing research interests (Hasan et al., 2018), with the target of supporting clinical decision-making such as acting as an auxiliary virtual “diagnostic radiologist” (Kovaleva et al., 2020).
视觉问答 (Visual Question Answering, VQA) 是一种流行的多模态机器学习任务,要求模型根据图像回答提出的问题。随着VQA领域的最新进展,先驱研究已开始探索将VQA系统应用于资源匮乏且知识密集的领域,例如医学领域 (Lin et al., 2021) —— 在这些领域收集特定领域的标注数据成本极高且耗时。特别是医学VQA正吸引越来越多的研究关注 (Hasan et al., 2018),其目标是为临床决策提供支持,例如充当辅助虚拟"诊断放射科医生" (Kovaleva et al., 2020)。
Despite recent progress in general VQA leveraging pre-training (Chen et al., 2022), retrieval (Wu et al., 2022), or knowledge bases (Narasimhan and Schwing, 2018; Shevchenko et al., 2021), several challenges still exist for medical VQA. First, medical VQA systems still suffer from a stark lack of high-quality labeled data. As a result, it is essential to leverage domain adaptation techniques (Zhou et al., 2019) that rapidly adapt models trained from a similar dataset to a target dataset. Second, as the medical domain covers a wide variety of complex diseases, there exists a large distribution shift across medical datasets, significantly increasing the complexity of learning medical images and texts by deep neural models. However, many existing medical VQA methods mainly focus on indomain evaluation, testing systems on a held-out test set under the same data distribution of the training data. Moreover, these methods often augment their model architecture with dataset-specific components such as an answer-type classifier (Zhan et al., 2020), separate models for each questiontype (Khare et al., 2021), or specific pre-trained medical encoders (Moon et al., 2022). These dataset-specific designs hinder the application of these medical VQA models across datasets in new domains. Furthermore, existing medical VQA approaches (Tanwani et al., 2022; Eslami et al., 2021) often adopt a disc rim i native model architecture that predicts a fixed set of answers, limiting model genera liz ation to different answer sets.
尽管通用视觉问答(VQA)领域在预训练(Chen et al., 2022)、检索(Wu et al., 2022)或知识库(Narasimhan and Schwing, 2018; Shevchenko et al., 2021)方面取得了进展,但医疗VQA仍面临诸多挑战。首先,医疗VQA系统仍严重缺乏高质量标注数据。因此,必须采用领域自适应技术(Zhou et al., 2019)来快速将类似数据集训练的模型适配到目标数据集。其次,由于医疗领域涵盖多种复杂疾病,不同医疗数据集间存在显著分布偏移,这极大增加了深度神经网络学习医学图像和文本的复杂性。然而,现有医疗VQA方法主要关注域内评估,即在训练数据相同分布下的保留测试集上测试系统性能。此外,这些方法常通过数据集特定组件来增强模型架构,例如答案类型分类器(Zhan et al., 2020)、针对每种问题类型的独立模型(Khare et al., 2021)或特定预训练医学编码器(Moon et al., 2022)。这些数据集特定设计阻碍了医疗VQA模型在新领域数据集上的应用。现有医疗VQA方法(Tanwani et al., 2022; Eslami et al., 2021)通常采用判别式模型架构预测固定答案集,限制了模型对不同答案集的泛化能力。
To tackle these challenges, we propose a domainagnostic generative VQA model with multimodal prompt retrieval (MPR) that retrieves relevant VQA examples to construct multimodal prompts and generates arbitrary free text as the answers, removing the restriction of predicting a fixed label set. To augment the retrieval data, we also investigate a data augmentation strategy to create a synthetic medical VQA dataset from medical image-captioning data. Our experiments on two medical VQA datasets demonstrate the effective adaptation of our proposed method to a new target medical dataset, while also showing similar in-domain performance of our models to existing disc rim i native baselines.
为解决这些挑战,我们提出了一种领域无关的生成式视觉问答(VQA)模型,该模型采用多模态提示检索(MPR)技术,通过检索相关VQA样本来构建多模态提示,并生成任意自由文本作为答案,从而摆脱了预测固定标签集的限制。为扩充检索数据,我们还研究了一种数据增强策略,利用医学图像描述数据生成合成医学VQA数据集。在两个医学VQA数据集上的实验表明,我们提出的方法能有效适应新的目标医学数据集,同时模型在领域内性能与现有判别式基线模型相当。
Our contributions are summarized below:
我们的贡献总结如下:
• We introduce a multimodal prompt retrieval module that improves VQA generalization across different data distributions even with noisy synthetic data and smaller retrieval datasets. • We investigate a zero-shot dataset adaptation setting for medical VQA systems across datasets, encouraging future research on in-context prediction of VQA systems for dataset adaptation. • We propose a novel prompt-based generative VQA model, which enables more flexible answer outputs and controllable generation guided by multimodal prompts.
• 我们提出了一种多模态提示检索模块,即使在噪声合成数据和小型检索数据集的情况下,也能提升VQA在不同数据分布间的泛化能力。
• 我们研究了医疗VQA系统跨数据集的零样本数据集适应设置,为未来VQA系统基于上下文预测实现数据集适应的研究提供方向。
• 我们提出了一种新型基于提示的生成式VQA模型,该模型支持更灵活的答案输出,并能通过多模态提示引导可控生成。
2 Preliminaries
2 预备知识
This section provides descriptions of the VQA task and the challenges faced in the medical domain.
本节介绍了视觉问答 (VQA) 任务及其在医疗领域面临的挑战。
Problem Setup Formally, given a VQA dataset of $n$ tuples ${\cal{D}}={(v_{i},x_{i},y_{i})}_ {i=1}^{n}$ , we aim to learn a model to predict an answer $y_{i}$ given a question $x_{i}$ and an image $v_{i}$ . Conventionally, a model consists of an image and text encoder that maps the inputs $v_{i}$ and $x_{i}$ to the latent space of $\nu$ and $\mathcal{X}$ respectively:
问题定义 给定一个由 $n$ 个元组 ${\cal{D}}={(v_{i},x_{i},y_{i})}_ {i=1}^{n}$ 组成的视觉问答(VQA)数据集,我们的目标是训练一个模型,使其能够根据问题 $x_{i}$ 和图像 $v_{i}$ 预测答案 $y_{i}$。传统方法中,模型由图像编码器和文本编码器组成,分别将输入 $v_{i}$ 和 $x_{i}$ 映射到潜在空间 $\nu$ 和 $\mathcal{X}$:
$$
\begin{array}{l}{\mathbf{v}_ {i}=\mathrm{ImgEncoder}(v_{i})\in\mathcal{V}}\ {\mathbf{x}_ {i}=\mathrm{TextEncoder}(x_{i})\in\mathcal{X}}\end{array}
$$
$$
\begin{array}{l}{\mathbf{v}_ {i}=\mathrm{ImgEncoder}(v_{i})\in\mathcal{V}}\ {\mathbf{x}_ {i}=\mathrm{TextEncoder}(x_{i})\in\mathcal{X}}\end{array}
$$
Most prior works learn a disc rim i native model $f_{\theta}$ that directly estimates a probability distribution over all possible answers in a pre-defined label set, i.e., $f_{\theta}:\mathcal{V},\mathcal{X}\rightarrow\mathcal{V}$ . In contrast, we adopt a generative model $g_{\phi}$ that predicts words in a vocabulary $\Sigma$ to generate a varying length text string $z\in\Sigma^{+}$ , and apply a deterministic function to map the answer string $z$ to the closest answer label $y\in\mathcal{V}$ .
大多数先前的工作都学习一个判别模型 $f_{\theta}$,它直接估计预定义标签集中所有可能答案的概率分布,即 $f_{\theta}:\mathcal{V},\mathcal{X}\rightarrow\mathcal{V}$。相比之下,我们采用生成模型 $g_{\phi}$ 来预测词汇表 $\Sigma$ 中的单词,生成可变长度的文本字符串 $z\in\Sigma^{+}$,并应用确定性函数将答案字符串 $z$ 映射到最接近的答案标签 $y\in\mathcal{V}$。
Dataset Adaptation: We also focus on a dataset adaptation setting where a model is trained on a source labeled dataset $\mathcal{D}_ {\mathrm{src}}$ and further adapted to a target dataset $\mathcal{D}_ {\mathrm{tgt}}$ with a different label set, i.e., $\mathcal{V}_ {\mathrm{src}}\neq\mathcal{V}_ {\mathrm{tgt}}$ . Thus, it is nontrivial for a discriminative model $f_{\theta}$ to perform adaptation over different label sets. For adaptation with generative models, we consider two strategies of using target labeled data for (a) in-context prediction without updating the source-trained models $g_{\phi}$ and (b) continued fine-tuning $g_{\phi}$ . While our method focuses on incontext prediction (§3), we also compare these two strategies in our experiments (§5).
数据集适应:我们还关注一种数据集适应场景,其中模型在源标注数据集 $\mathcal{D}_ {\mathrm{src}}$ 上训练,并进一步适应具有不同标签集的目标数据集 $\mathcal{D}_ {\mathrm{tgt}}$ ,即 $\mathcal{V}_ {\mathrm{src}}\neq\mathcal{V}_ {\mathrm{tgt}}$ 。因此,对于判别模型 $f_{\theta}$ 而言,在不同标签集上进行适应并非易事。对于生成式模型的适应,我们考虑两种利用目标标注数据的策略:(a) 不更新源训练模型 $g_{\phi}$ 的上下文预测,以及 (b) 继续微调 $g_{\phi}$ 。虽然我们的方法主要关注上下文预测(第3节),但在实验中(第5节)我们也对这两种策略进行了比较。
Types of Medical VQA: According to the annotations of popular medical VQA tasks (e.g., SLAKE (Liu et al., 2021) and VQA-RAD (Lau et al., 2018)), there are two answer types Atype: closed answers where the set of possible answers are disclosed in a question (e.g., yes-no questions); and open answers that can be free-form texts. Besides, there are multiple different question types $\mathcal{Q}_{\mathrm{type}}$ such as organ, abnormality, or modality, indicating the medicinal category for which the question is intended. Prior medical VQA models (Zhan et al., 2020; Eslami et al., 2021) use a binary clas- sifier to distinguish the two answer types based on questions and apply two disc rim i native models to predict answers, while we propose to predict both types of answers by a single generative model in this work.
医疗VQA的类型:根据主流医疗VQA任务(如SLAKE (Liu et al., 2021)和VQA-RAD (Lau et al., 2018))的标注标准,答案可分为两种类型Atype:封闭式答案(即问题中明确给出可选答案集,如是非题)和开放式答案(即自由文本形式)。此外,还存在多种不同的问题类型$\mathcal{Q}_{\mathrm{type}}$(如器官、异常或模态),用于标识问题的医学类别。现有医疗VQA模型(Zhan et al., 2020; Eslami et al., 2021)通过二元分类器区分问题对应的答案类型,并采用两个判别式模型预测答案,而本研究提出用单一生成式模型同时预测两种答案类型。
3 Methods
3 方法
In this section, we start by introducing the text and image encoding for retrieval (§3.1), then describe the prompt construction from retrieval (§3.3), and prompt integration in our generative model (§3.4).
在本节中,我们首先介绍用于检索的文本和图像编码 (§3.1),然后描述从检索结果构建提示的过程 (§3.3),以及生成模型中提示集成的方法 (§3.4)。
Overview: For each $(v,x,y)\in\mathcal{D}_ {\mathrm{src}}$ during training, we propose to retrieve similar tuples from the training dataset $\mathcal{D}_ {\mathrm{src}}$ , integrate the retrieved tuples for prediction, and update the model. We also assume to have access to a target labeled dataset $\mathcal{D}_ {\mathrm{tgt}}$ for dataset adaptation. Note that we mainly describe the in-context prediction using $\mathcal{D}_ {\mathrm{tgt}}$ here and leave the discussion of fine-tuning on $\mathcal{D}_ {\mathrm{tgt}}$ to the experiments. When predicting a target test example at test time, we directly apply our source-trained model to retrieve labeled tuples from $\mathcal{D}_{\mathrm{tgt}}$ and perform prediction. The key insight is that even if the source-trained model is not directly trained on target data, the retrieved tuples may contain the correct answer to the given target question, potentially improving model predictions in the target dataset.
概述:对于训练过程中的每个$(v,x,y)\in\mathcal{D}_ {\mathrm{src}}$,我们建议从训练数据集$\mathcal{D}_ {\mathrm{src}}$中检索相似元组,整合检索到的元组进行预测,并更新模型。我们还假设可以访问目标标注数据集$\mathcal{D}_ {\mathrm{tgt}}$以进行数据集适配。请注意,此处我们主要描述使用$\mathcal{D}_ {\mathrm{tgt}}$的上下文预测,而将对$\mathcal{D}_ {\mathrm{tgt}}$的微调讨论留到实验部分。在测试时预测目标测试样本时,我们直接应用源训练模型从$\mathcal{D}_{\mathrm{tgt}}$中检索标注元组并执行预测。关键洞见是,即使源训练模型未直接在目标数据上训练,检索到的元组可能包含给定目标问题的正确答案,从而可能提升模型在目标数据集中的预测效果。
3.1 Multimodal Prompt Encoding
3.1 多模态提示编码
For a VQA dataset, we can easily construct a mapping by using the image-question pair as the key and the answer as the value. Therefore we can use a multimodal encoder to encode the imagequestion pairs into multimodal features and perform K-Nearest Neighbors (KNN) search to find the most similar VQA tuples in the feature space.
对于一个VQA(Visual Question Answering)数据集,我们可以轻松构建一个映射关系:以图像-问题对作为键(key),答案作为值(value)。因此,我们可以使用多模态编码器将图像-问题对编码为多模态特征,并在特征空间中进行K近邻(K-Nearest Neighbors, KNN)搜索来寻找最相似的VQA元组。
Question-Image Encoding: Before model training, we use a pre-trained CLIP model (Radford et al., 2021) to encode image-question pairs in a retrieval dataset $\mathcal{R}$ , where $\mathcal{R}=\mathcal{D}_ {\mathrm{src}}$ during training and $\mathcal{R}=\mathcal{D}_ {\mathrm{tgt}}$ at testing. Specifically, we first preprocess each image by down sampling it to the $224\times224$ resolution and adopt CLIP’s vision transformer (Do sov it ski y et al., 2021) to obtain image features $\mathbf{v}_ {\mathrm{CLS}}$ of the image patch [CLS] token that summarizes the image content. Similarly, we process each question using CLIP’s corresponding text transformer to obtain question features $\mathbf{x}_ {\mathrm{EOT}}$ from the [EOT] token. These question and image features are concatenated to form a holistic vector represent ation $\mathbf{p}=\left[\mathbf{v}_ {\mathtt{C L S}};\mathbf{x}_ {\mathtt{E O T}}\right]$ of a question-image pair. These question-image vectors are paired along with the corresponding answers to construct the retrieval mapping set $\mathcal{M}={(\mathbf{p}_ {i},y_{i})}_{i=1}^{m}$ of $m$ items.
问题-图像编码:在模型训练前,我们使用预训练的CLIP模型 (Radford et al., 2021) 对检索数据集 $\mathcal{R}$ 中的图像-问题对进行编码,其中训练时 $\mathcal{R}=\mathcal{D}_ {\mathrm{src}}$,测试时 $\mathcal{R}=\mathcal{D}_ {\mathrm{tgt}}$。具体而言,我们首先通过将每张图像下采样至 $224\times224$ 分辨率进行预处理,并采用CLIP的视觉Transformer (Dosovitskiy et al., 2021) 获取图像块[CLS] token的特征向量 $\mathbf{v}_ {\mathrm{CLS}}$,该token用于概括图像内容。类似地,我们使用CLIP对应的文本Transformer处理每个问题,从[EOT] token获取问题特征 $\mathbf{x}_ {\mathrm{EOT}}$。这些问题和图像特征被拼接形成图像-问题对的整体向量表示 $\mathbf{p}=\left[\mathbf{v}_ {\mathtt{CLS}};\mathbf{x}_ {\mathtt{EOT}}\right]$。这些图像-问题向量与对应答案配对,构建包含 $m$ 个项目的检索映射集 $\mathcal{M}={(\mathbf{p}_ {i},y_{i})}_{i=1}^{m}$。
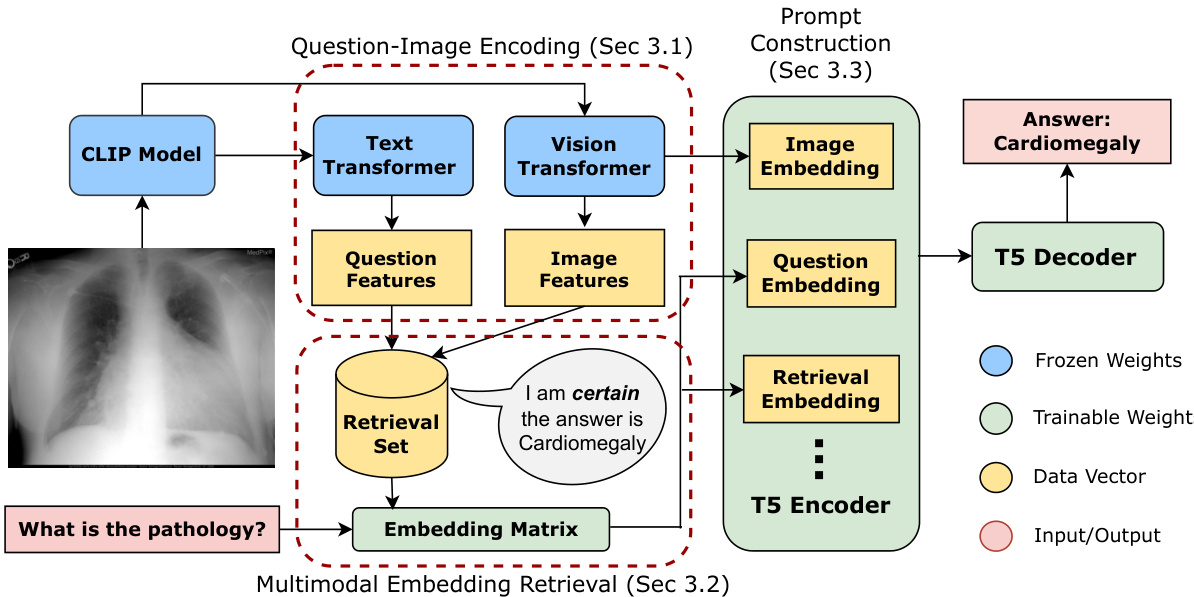
Figure 1: An overview of multimodal prompt retrieval (MPR). There are three primary components of the prompt we use for the encoder indicated by the three yellow boxes contained in the T5 encoder block. These components can be optionally omitted or further extended with additional data.
图 1: 多模态提示检索 (MPR) 概览。我们用于编码器的提示包含三个主要组成部分 (由 T5 编码器块中的三个黄色方框标示)。这些组件可选择性地省略或用额外数据进行扩展。
Retrieval Set Augmentation on Image-Caption
检索集增强在图像-标题对上的应用
Data: As many VQA datasets in a low-resourced target domain (e.g., medicine) often contain a limited amount of labeled examples, we propose a data augmentation method to create a synthetic VQA set $\mathcal{D}_ {\mathrm{syn}}$ from image-caption pairs and augment the retrieval set $\mathcal{R}$ . First, we determine a desired set of question types $\mathcal{Q}_ {\mathrm{type}}$ and answer types $\boldsymbol{\mathcal{A}_ {\mathrm{type}}}$ described in $\S2$ . For each combination of question and answer types $t\in\mathcal{Q}_ {\mathrm{type}}\times\mathcal{A}_ {\mathrm{type}}$ , we manually prepare a collection of question templates $\mathcal{T}_ {t}$ along with a corresponding collection of keywords $\mathcal{W}_ {t}$ . We then iterate through all the image-caption pairs and identify if the caption contains any keywords $w\in\mathcal{W}_ {t}$ . If any keywords match, we create a question by sampling a template from $\mathcal{T}_{t}$ uniformly at random and filling it with the matched keyword as the answer. Example templates from several question and answer types can be found in Appendix A.
数据:由于低资源目标领域(如医学)中的许多VQA数据集通常只包含有限数量的标注样本,我们提出了一种数据增强方法,通过图像-标题对创建合成VQA集$\mathcal{D}_ {\mathrm{syn}}$并扩充检索集$\mathcal{R}$。首先,我们确定$\S2$中描述的问题类型$\mathcal{Q}_ {\mathrm{type}}$和答案类型$\boldsymbol{\mathcal{A}_ {\mathrm{type}}}$的期望集合。对于每种问题类型和答案类型的组合$t\in\mathcal{Q}_ {\mathrm{type}}\times\mathcal{A}_ {\mathrm{type}}$,我们手动准备一组问题模板$\mathcal{T}_ {t}$以及对应的关键词集合$\mathcal{W}_ {t}$。然后,我们遍历所有图像-标题对,检查标题是否包含任何关键词$w\in\mathcal{W}_ {t}$。如果匹配到关键词,我们通过从$\mathcal{T}_{t}$中均匀随机采样一个模板,并用匹配的关键词作为答案填充模板来创建问题。附录A中提供了几种问题和答案类型的示例模板。
3.2 Multimodal Embedding Retrieval
3.2 多模态嵌入检索
To answer a question $x$ about an image $v$ , we propose to retrieve its top $k$ most similar examples from the retrieval mapping set $\mathcal{M}$ (as constructed in $\S3.1)$ . Specifically, we first encode the query question-image pair into an embedding $\mathbf{p}$ by the CLIP model and compute the cosine similarity between the query embedding $\mathbf{p}$ and each questionimage embedding in $\mathcal{M}$ . Therefore, we can obtain the $k$ nearest neighbors of image-question pairs in $\mathcal{M}$ , denoted as ${\cal K}={({\bf p}_ {i},y_{i})}_{i=1}^{k}$ . Note that if the size of $\mathcal{M}$ is large, KNN search can be implemented with efficient algorithms such as Maximum Inner Product Search (Shri vast ava and Li, 2014). The retrieved pairs are used to construct the retrieval prompt (detailed in $\S3.3)$ .
为了回答关于图像$v$的问题$x$,我们提出从检索映射集$\mathcal{M}$(如$\S3.1$所构建)中检索其最相似的$k$个示例。具体而言,我们首先通过CLIP模型将查询问题-图像对编码为嵌入向量$\mathbf{p}$,并计算查询嵌入$\mathbf{p}$与$\mathcal{M}$中每个问题-图像嵌入之间的余弦相似度。因此,我们可以得到$\mathcal{M}$中图像-问题对的$k$个最近邻,记为${\cal K}={({\bf p}_ {i},y_{i})}_{i=1}^{k}$。需要注意的是,若$\mathcal{M}$规模较大,可采用高效算法(如最大内积搜索[20])实现KNN检索。检索到的配对将用于构建检索提示(详见$\S3.3$)。
3.3 Prompt Construction
3.3 提示词构建
Inspired by the prompt tuning method (Lester et al., 2021) that appends several prompt embeddings to the original input before feeding to the transformer layers of the encoder, we propose to construct multimodal prompt embeddings to augment a question input, as shown in Figure 1. Specifically, given an image-question pair, the inputs to our model consist of three main components: image, question, and retrieval embeddings. Our model concatenates these embeddings as inputs to the subsequent stack of encoder layers in a T5 model (Raffel et al., 2020). We begin the prompt with the image embedding, followed by the question and retrieval embeddings, leaving experimentation with alternative concatenation orders to Appendix B.
受提示调优方法 (Lester et al., 2021) 的启发,该方法在输入编码器的Transformer层之前向原始输入附加若干提示嵌入,我们提出构建多模态提示嵌入来增强问题输入,如图 1 所示。具体而言,给定一个图像-问题对,模型的输入包含三个主要组成部分:图像、问题和检索嵌入。我们的模型将这些嵌入连接起来,作为后续T5模型 (Raffel et al., 2020) 编码器层的输入。提示以图像嵌入开始,随后是问题和检索嵌入,其他连接顺序的实验结果见附录 B。
Image Embedding: The image embedding is obtained using the same vision transformer of CLIP applied to construct the retrieval dataset. However, instead of using the [CLS] token which summarizes the image content, we use the intermediate output of the penultimate layer to obtain a col- lection of image token embeddings $\mathbf{v}_ {p}\in\mathbb{R}^{l_{v}\times d}$ , where $l_{v}$ denotes the number of image tokens.
图像嵌入:图像嵌入是通过与构建检索数据集相同的CLIP视觉Transformer获得的。不过,我们并非使用汇总图像内容的[CLS] token,而是采用倒数第二层的中间输出,得到一组图像token嵌入$\mathbf{v}_ {p}\in\mathbb{R}^{l_{v}\times d}$,其中$l_{v}$表示图像token的数量。
Question Embedding: To encode a question corresponding to an image, we use the embedding matrix of a pre-trained T5 encoder. Following the practice of T5, we include a short text snippet (e.g., “Answer the abnormality question:”) at the beginning of the question to instruct the model to perform a QA task. The combined text is first tokenized according to T5’s subword token iz ation, followed by an embedding lookup to fetch the corresponding embedding vectors $\mathbf{\bar{x}}_ {q}\in\mathbb{R}^{l_{q}\times d}$ from T5’s input embedding matrix.
问题嵌入:为了编码与图像对应的问题,我们使用预训练T5编码器的嵌入矩阵。遵循T5的实践,我们在问题开头加入简短文本提示(例如"回答异常问题:")以指导模型执行问答任务。组合文本首先根据T5的子词token化方法进行分词,然后通过嵌入查找从T5的输入嵌入矩阵中获取对应的嵌入向量$\mathbf{\bar{x}}_ {q}\in\mathbb{R}^{l_{q}\times d}$。
Retrieval Embedding: Based on the top $k$ similar examples retrieved $\kappa$ , we define an ordered list of quantifier words $\mathcal{Q} = [q_{1},\dots,q_{M}]$ (e.g., [very unlikely, ..., very likely, certainly]) and a text template $T_{\mathrm{prompt}}$ . We define a confidence score that counts the frequency of the retrieved answers in $\kappa$ , and then select the most frequent answer $y_{r}^{* }$ from $\kappa$ in Eq. (3). We then apply a threshold function to select an appropriate quantifier $q_{r}^{* }$ from $\mathcal{Q}$ based on the confidence score of $y_{r}^{*}$ by Eq. (4).
检索嵌入 (Retrieval Embedding):基于检索到的前 $k$ 个相似示例 $\kappa$,我们定义一个有序的量词列表 $\mathcal{Q} = [q_{1},\dots,q_{M}]$(例如 [极不可能, ..., 极有可能, 必然])和一个文本模板 $T_{\mathrm{prompt}}$。我们定义一个置信度分数来统计 $\kappa$ 中检索答案的频率,然后通过式 (3) 从 $\kappa$ 中选择最频繁的答案 $y_{r}^{* }$。接着,我们应用一个阈值函数,根据 $y_{r}^{* }$ 的置信度分数,通过式 (4) 从 $\mathcal{Q}$ 中选择合适的量词 $q_{r}^{*}$。
$$
\begin{array}{l}{{\displaystyle{\bf p}_ {r}^{* },y_{r}^{* }=\arg\underset{({\bf p},y)\in{\cal K}}{\mathrm{max}}\mathrm{Freq}(y,{\cal K})}}\ {{\displaystyle q_{r}^{* }=q_{i},\mathrm{if}\frac{i-1}{M}\le\frac{\mathrm{Freq}(y_{r}^{*},{\cal K})}{k}<\frac{i}{M}}}\end{array}
$$
$$
\begin{array}{l}{{\displaystyle{\bf p}_ {r}^{* },y_{r}^{* }=\arg\underset{({\bf p},y)\in{\cal K}}{\mathrm{max}}\mathrm{Freq}(y,{\cal K})}}\ {{\displaystyle q_{r}^{* }=q_{i},\mathrm{if}\frac{i-1}{M}\le\frac{\mathrm{Freq}(y_{r}^{*},{\cal K})}{k}<\frac{i}{M}}}\end{array}
$$
We then construct the retrieval prompt by filling in the template $T_{\mathrm{prompt}}$ with the quantifier $\overset{\cdot}{q}_ {r}^{* }$ and the retrieved answer $y_{r}^{*}$ . We detail example templates and prompt variants we explored in Appendix A. The same pre-trained T5 model used for the question prompt is used to tokenize the retrieval prompt and obtain the retrieval embeddings $\mathbf{x}_ {r}\in\mathbb{R}^{l_{r}\times d}$ .
然后,我们通过将量化器 $\overset{\cdot}{q}_ {r}^{* }$ 和检索到的答案 $y_{r}^{*}$ 填入模板 $T_{\mathrm{prompt}}$ 来构建检索提示。附录 A 详细列出了我们探索的示例模板和提示变体。使用与问题提示相同的预训练 T5 模型对检索提示进行 Token 化处理,得到检索嵌入 $\mathbf{x}_ {r}\in\mathbb{R}^{l_{r}\times d}$。
3.4 Generative Visual Question Answering
3.4 生成式视觉问答
Encoder: Following prompt construction, we obtain a combination of embeddings $[\mathbf{v}_ {p};\mathbf{x}_ {q};\mathbf{x}_ {r}]$ which is further fed as inputs to the transformer encoder layers of a pre-trained T5 model, and obtain contextual i zed representations of the combined sequence from the top encoder layer, where we denote as $\mathbf{X}=\operatorname{Encoder}([\mathbf{v}_ {p};\mathbf{x}_ {q};\mathbf{x}_{r}])$ . In this work, we use a moderately sized model with around 60 million parameters, T5-small, and leave models with more parameters for future exploration.
编码器(Encoder): 在提示构建完成后,我们获得嵌入组合 $[\mathbf{v}_ {p};\mathbf{x}_ {q};\mathbf{x}_ {r}]$ ,将其作为输入馈送至预训练T5模型的Transformer编码器层,并从顶层编码器层获取组合序列的上下文表示,记为 $\mathbf{X}=\operatorname{Encoder}([\mathbf{v}_ {p};\mathbf{x}_ {q};\mathbf{x}_{r}])$ 。本工作采用中等规模的T5-small模型(约6000万参数),更大参数的模型留待未来探索。
Decoder: While most prior works use a discriminative architecture for medical VQA, we experiment with a decoder to predict free-form text. A transformer decoder from T5 is used to predict words in the vocabulary auto regressive ly. As each answer label $y$ has a corresponding text string $z$ of varying length, we formulate the likelihood of an answer string $z$ given an image $\mathbf{v}$ and a question $\mathbf{x}$ by the following conditional probability:
解码器:虽然先前大多数研究在医疗VQA任务中使用判别式架构,我们尝试采用解码器来预测自由格式文本。我们使用T5的Transformer解码器以自回归方式预测词汇表中的单词。鉴于每个答案标签$y$都对应着长度可变的文本字符串$z$,我们通过以下条件概率公式建立给定图像$\mathbf{v}$和问题$\mathbf{x}$时答案字符串$z$的似然函数:
$$
P_{\mathrm{gen}}(z|\mathbf{X})=\prod_{j=0}^{|z|}P_{\phi}(z_{j}|\mathbf{X},z_{<j}).
$$
$$
P_{\mathrm{gen}}(z|\mathbf{X})=\prod_{j=0}^{|z|}P_{\phi}(z_{j}|\mathbf{X},z_{<j}).
$$
We finally optimize the generative model using a cross-entropy loss between the conditional probability $P_{\mathrm{gen}}(z|\mathbf{X})$ and the ground-truth answer string $z$ on the training dataset. This formulation allows for more flexible answers, which can easily change depending on the task, but may produce answers that are essentially the same with minor differences (e.g., extra whitespace, synonyms, etc.). To resolve these minor discrepancies, we utilize a simple string-matching heuristic that matches the longest continuous sub sequence 2 between the generated answer and the closest possible label in the answer label set. Thus, our final generative model predicts answers as follows:
我们最终通过在训练数据集上计算条件概率 $P_{\mathrm{gen}}(z|\mathbf{X})$ 与真实答案字符串 $z$ 之间的交叉熵损失来优化生成模型。这种设计允许更灵活的答案形式,可根据任务轻松调整,但可能产生本质上相同但存在细微差异的答案(例如多余空格、同义词等)。为解决这些微小差异,我们采用简单的字符串匹配启发式方法,在生成答案与答案标签集中最接近的标签之间匹配最长连续子序列。因此,我们的最终生成模型按如下方式预测答案:
$$
\begin{array}{r l}&{z^{* }=\arg\operatorname*{max}_ {z}P_{g e n}(z|\mathbf{X})}\ &{y^{* }=\mathrm{LongestCommonString}(z^{*},y).}\end{array}
$$
$$
\begin{array}{r l}&{z^{* }=\arg\operatorname*{max}_ {z}P_{g e n}(z|\mathbf{X})}\ &{y^{* }=\mathrm{LongestCommonString}(z^{*},y).}\end{array}
$$
Compared to the exact match between the generated answer string $z^{*}$ and the ground-truth string $z$ , we observe a $3-4%$ improvement in accuracy when using this heuristic on the VQA-RAD dataset and a $1%$ gain on the SLAKE dataset.
与生成答案字符串 $z^{*}$ 和真实字符串 $z$ 的精确匹配相比,我们观察到在 VQA-RAD 数据集上使用此启发式方法时准确率提高了 $3-4%$,在 SLAKE 数据集上提高了 $1%$。
4 Experimental Setup
4 实验设置
We perform our analysis on the VQA-RAD and SLAKE datasets, which are anonymous and preprocessed following prior works (Eslami et al., 2021; Zhan et al., 2020). We use an AdamW optimizer with an initial learning rate $1e^{-4}$ for T5 finetuning. We use a $\mathrm{ViT-B}/32$ architecture for our CLIP models, and T5-small for answer generation. The plateau learning rate scheduler is used to decay the learning rate by a factor of 10 if the validation loss does not decrease for 10 consecutive epochs.
我们在VQA-RAD和SLAKE数据集上进行分析,这些数据集已匿名化并按照先前工作(Eslami et al., 2021; Zhan et al., 2020)进行了预处理。对于T5微调,我们使用初始学习率为$1e^{-4}$的AdamW优化器。我们的CLIP模型采用$\mathrm{ViT-B}/32$架构,答案生成使用T5-small模型。若验证损失连续10个epoch未下降,则采用平台学习率调度器将学习率降低10倍。
All model training used a batch size of 16 and took 2-3 hours on average on a RTX 3090 GPU. All results were seeded with the best run of Eslami et al. (2021); Zhan et al. (2020) for reproducibility.3
所有模型训练均使用16的批次大小,在RTX 3090 GPU上平均耗时2-3小时。为确保可复现性,所有结果均采用Eslami等人(2021)和Zhan等人(2020)的最佳运行作为种子。3
4.1 Datasets
4.1 数据集
SLAKE The SLAKE dataset comprises 642 images and over 14,000 VQA pairs in English and Chinese. We only use the English portion to match the language of the T5 pre training corpus. We use the provided train, validation and test splits, corresponding to 4918, 1053, and 1061 QA pairs. SLAKE consists of 10 different question types.4
SLAKE
SLAKE数据集包含642张图像和超过14,000个中英文视觉问答(VQA)对。为匹配T5预训练语料库的语言,我们仅使用英文部分。采用官方划分的训练集、验证集和测试集,分别对应4918、1053和1061组问答对。该数据集涵盖10种不同的问题类型[4]。
VQA-RAD VQA-RAD is a high-quality dataset consisting of 315 patient scans and 3515 questions. We use the train and eval splits provided with the original data, following prior works (Tanwani et al., 2022; Eslami et al., 2021; Nguyen et al., 2019). VQA-RAD consists of 11 different question types.
VQA-RAD
VQA-RAD 是一个高质量数据集,包含315份患者扫描影像和3515个问题。我们遵循先前研究 (Tanwani et al., 2022; Eslami et al., 2021; Nguyen et al., 2019) 的做法,使用原始数据提供的训练集和评估集划分。该数据集涵盖11种不同的问题类型。
Radiology Objects in Context (ROCO) The ROCO dataset (Pelka et al., 2018) has over 81,000 radiology image-caption pairs, making it a popular medical dataset for pre training vision-language models (Pelka et al., 2018). Each image-caption pair also contains keywords and semantic types used by existing works for masked language modeling on salient spans (Khare et al., 2021).
放射学上下文对象 (ROCO)
ROCO数据集 (Pelka et al., 2018) 包含超过81,000个放射学图像-标题对,使其成为预训练视觉-语言模型的流行医学数据集 (Pelka et al., 2018)。每个图像-标题对还包含关键词和语义类型,现有工作已将其用于显著跨度的掩码语言建模 (Khare et al., 2021)。
Synthetic VQA Data Using the image-caption data from the ROCO dataset, we construct a largescale synthetic VQA dataset consisting of over 50,000 question-answer pairs. Using our procedure (§3.1), we create question and keyword templates focusing on organ, modality, and plane questions.
利用ROCO数据集中的图像标题数据,我们构建了一个包含超过50,000个问答对的大规模合成VQA数据集。通过我们的流程(§3.1),我们创建了聚焦于器官、模态和平面问题的问答模板及关键词模板。
4.2 Training Settings
4.2 训练设置
Dataset Adaptation (DA): To evaluate the genera liz ation of VQA models across datasets, we examine a setting where we train a model on a source-labeled dataset and use it to answer questions from a different target dataset with access to a target dataset. We further compare models using the target labeled examples for (a) in-context prediction without updating source-trained models or (b) continued fine-tuning.
数据集适配 (DA): 为评估VQA模型在跨数据集上的泛化能力,我们研究了一种设定:在带标注的源数据集上训练模型,并将其用于回答来自不同目标数据集的问题(同时可访问目标数据集)。我们进一步比较了两种使用目标标注样本的方案:(a) 不更新源训练模型的情况下进行上下文预测,或 (b) 持续微调。
In-domain Evaluation (IDE): In this setting, we adopt a standard split of each dataset into train/validation/test sets. We then train models on the train set, select the best checkpoints by the validation set, and evaluate models on the test set.
域内评估 (IDE): 在此设置中,我们采用标准划分方式将每个数据集分为训练集/验证集/测试集。随后在训练集上训练模型,通过验证集选择最佳检查点,并在测试集上评估模型。
4.3 Baselines
4.3 基线方法
Mixture of Enhanced Visual Features (MEVF) Nguyen et al. (2019) utilize model agnostic metalearning (MAML) in conjunction with a convolutional denoising auto encoder (CDAE) to learn medical image latent feature representations.
增强视觉特征混合 (MEVF)
Nguyen et al. (2019) 结合模型无关元学习 (MAML) 与卷积去噪自编码器 (CDAE) 来学习医学图像的潜在特征表示。
Question Answering with Conditional Reasoning (QCR) Zhan et al. (2020) introduce novel task-conditioned, open, and closed reasoning modules to distinguish between answer types and improve open question accuracy.
带条件推理的问答系统(QCR)
Zhan等人(2020)提出新型任务条件化开放与封闭推理模块,用于区分答案类型并提升开放问题准确率。
PubMedCLIP Eslami et al. (2021) utilize the ROCO dataset to finetune a general CLIP model on medical image-caption pairs. They modify existing architectures with the finetuned vision encoder to achieve improved results.
PubMedCLIP Eslami等人(2021)利用ROCO数据集在医学图像-标题对上微调通用CLIP模型。他们通过微调后的视觉编码器改进现有架构,从而获得更好的结果。
MMBERT Khare et al. (2021) introduces a BERT-based method that utilizes pre training on the ROCO dataset with a masked language modeling objective. The model predicts answers by performing an average pooling on the last layer features followed by a linear classification layer.
MMBERT Khare等人 (2021) 提出了一种基于BERT的方法,该方法通过在ROCO数据集上进行掩码语言建模 (masked language modeling) 目标的预训练。该模型通过对最后一层特征进行平均池化 (average pooling) 并接一个线性分类层来预测答案。
$\mathbf{MPR_{disc}}$ (Ours): $\mathrm{MPR}_ {\mathrm{disc}}$ refers to our discriminative variant by replacing a generative decoder with a prediction head to predict a finite set of answers. M PR disc BAN uses a prediction head similar to $\mathrm{MPR}_{\mathrm{disc}}$ , but fuses the image and text features with a bilinear attention network (Kim et al., 2018).
$\mathbf{MPR_{disc}}$ (Ours): $\mathrm{MPR}_ {\mathrm{disc}}$ 指代我们的判别式变体,通过将生成式解码器替换为预测头来预测有限答案集。MPR disc BAN采用与$\mathrm{MPR}_{\mathrm{disc}}$相似的预测头,但通过双线性注意力网络 (Kim et al., 2018) 融合图像和文本特征。
$\mathbf{MPR_{gen}}$ (Ours): ${\mathrm{MPR}}_ {\mathrm{gen}}$ refers to our generative architecture which outputs flexible answers. ${\bf M P R_{g e n_P M}}$ has the same architecture as ${\mathrm{MPR}}_{\mathrm{gen}}$ , but is initialized with a pre-trained checkpoint from PubMedCLIP (Eslami et al., 2021).5
$\mathbf{MPR_{gen}}$ (我们的方法): ${\mathrm{MPR}}_ {\mathrm{gen}}$ 指代我们能够输出灵活答案的生成式架构。${\bf M P R_{g e n_P M}}$ 与 ${\mathrm{MPR}}_{\mathrm{gen}}$ 结构相同,但使用PubMedCLIP (Eslami等人,2021)的预训练检查点进行初始化。5
5 Results and Analysis
5 结果与分析
This section describes the results of our main experiments (§5.1) and fine-grained analysis thereafter.
本节介绍主要实验(§5.1)的结果及后续细粒度分析。
5.1 In-context Prediction for Adaptation
5.1 适应性的上下文预测
First, we evaluate our proposed method’s generalization capability of in-context predictions. We define a $k$ -shot setting where our model retrieves Top $k$ similar image-question pairs from the retrieval set. We compare the performance of the $k=1$ setting with zero-shot MPR (i.e., MPR w/o retrieval) on two medical domain adaptation tasks.
首先,我们评估所提出方法在上下文预测中的泛化能力。我们定义了一个 $k$ 样本设置,模型从检索集中获取Top $k$ 个相似的图像-问题对。在两个医疗领域适应任务上,将 $k=1$ 设置与零样本MPR (即无检索的MPR) 的性能进行对比。
| Context | Method | SLAKE→VQA-RAD | VQA-RAD → SLAKE | ||
| Open Closed | Overall | Open Closed | Overall | ||
| Image and Question | MPRgen_PM | 6.0 | 34.6 | 18.3 | 52.2 46.4 |
| MPRgen | 4.9 | 33.3 | 16.9 | 28.5 | |
| Image, Question, and Retrieval | MPRgen_PM | 42.9 | 76.2 63.0 | 45.1 | 67.3 |
| MPRgen | 41.8 | 61.4 | 38.4 | 46.0 | |
Table 1: Performances of our generative prompting method in a domain adaptation setting with different levels of context. When provided with retrieval context, the models query for $k=1$ relevant image-question pairs.
| 上下文 | 方法 | SLAKE→VQA-RAD | VQA-RAD → SLAKE |
|---|---|---|---|
| 开放/封闭 | 总体 | ||
| 图像和问题 | MPRgen_PM | 6.0 | 34.6 |
| MPRgen | 4.9 | 33.3 | |
| 图像、问题和检索 | MPRgen_PM | 42.9 | 76.2 63.0 |
| MPRgen | 41.8 | 61.4 |
表 1: 我们的生成式提示方法在不同上下文级别的领域适应设置中的性能。当提供检索上下文时,模型查询 $k=1$ 个相关图像-问题对。
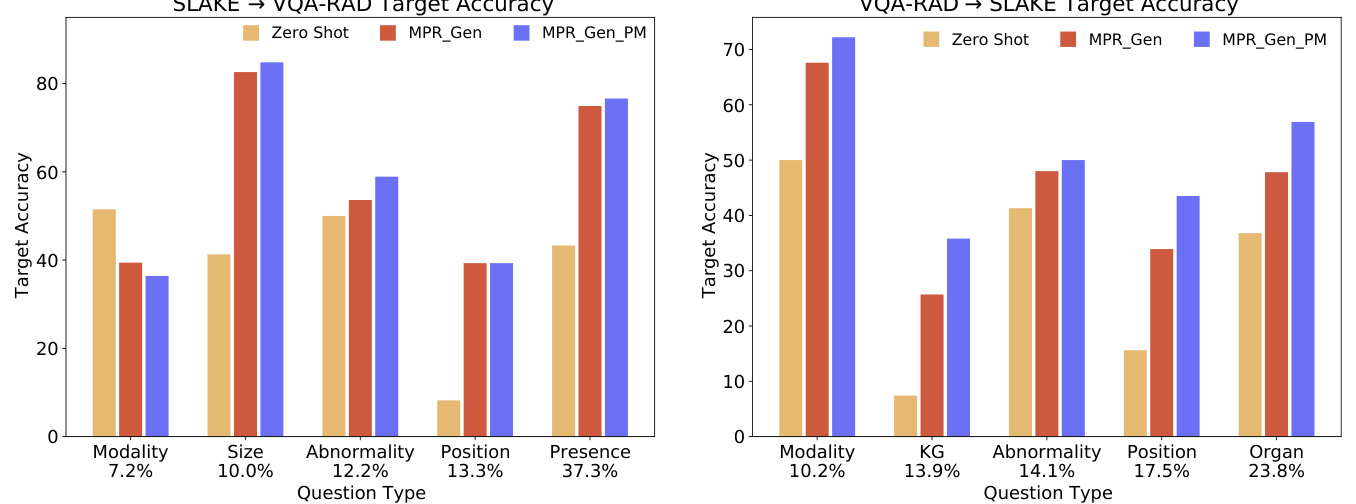
Figure 2: Domain adapation accuracy for the top 5 most common question types in the SLAKE and VQARAD datasets. Percentages on the $\mathbf{X}$ -axis indicate each question type’s proportion of the dataset. $\mathrm{MPR}_ {\mathrm{gen}}$ and ${\bf M P R_{g e n_P M}}$ use retrieval and query for $k=1$ relevant image-question pairs. Retrieval-based models outperform our zero-shot baseline, and initializing MPR with a PubMedCLIP checkpoint helps.
图 2: SLAKE和VQARAD数据集中前5种最常见问题类型的领域适应准确率。X轴上的百分比表示每种问题类型在数据集中的占比。$\mathrm{MPR}_ {\mathrm{gen}}$和${\bf M P R_{g e n_P M}}$使用检索和查询获取$k=1$个相关图像-问题对。基于检索的模型优于我们的零样本基线,且使用PubMedCLIP检查点初始化MPR有所助益。
Overall Accuracy: Table 1 compares the performances of our generative models under domain shift. Most notably, allowing the models to access a retrieval set universally improves performance, especially on questions with open answers. We also demonstrate that initializing our model with a PubMedCLIP pre-trained checkpoint results in higher accuracy than a general CLIP checkpoint. As the other disc rini mati ve baselines can only predict a fixed set of answers, they cannot perform adaptation over different answer sets. We only compare them for our in-domain analysis (§5.5).
总体准确率:表1比较了我们的生成式模型在领域迁移下的表现。最值得注意的是,允许模型访问检索集普遍提升了性能,尤其是开放答案问题。我们还证明,使用PubMedCLIP预训练检查点初始化模型比通用CLIP检查点获得更高准确率。由于其他判别式基线只能预测固定答案集,无法适应不同答案集,我们仅在领域内分析(§5.5)中与之比较。
Fine-grained Accuracy over QA Types: Figure 2 summarizes our model performances across individual QA types in a domain adaptation setting. We find that zero-shot MPR struggles with question types that require logical reasoning, such as Knowledge Graph (KG) or Position questions, while in-context retrieval increases model performance significantly in these question types. Using a PubMedCLIP vision encoder further increases accuracy for these challenging question types.
细粒度QA类型准确率:图2总结了我们的模型在领域适应设置下各QA类型的表现。我们发现零样本MPR在需要逻辑推理的问题类型(如知识图谱(KG)或位置问题)上表现不佳,而上下文检索显著提升了模型在这些问题类型上的性能。使用PubMedCLIP视觉编码器进一步提高了这些挑战性问题类型的准确率。
5.2 Retrieval Sets for In-context Prediction
| Source→→Target | RetrievalSet | Open | Closed | Overall |
| SLAKE→VQA-RAD | None (Zero-shot) | 6.0 | 53.4 | 34.6 |
| Synthetic | 11.5 | 49.8 | 34.6 | |
| VQA-RAD | 42.9 | 76.2 | 63.0 | |
| VQA-RAD+Synthetic | 44.5 | 76.5 | 63.8 | |
| VQA-RAD→SLAKE | None (Zero-shot) | 16.9 | 46.4 | 28.5 |
| Synthetic | 18.3 | 50.2 | 30.8 | |
| SLAKE | 45.1 | 67.3 | 53.8 | |
| SLAKE+Synthetic | 45.1 | 67.3 | 53.8 |
Table 2: Results of zero-/few-shot in-context prediction for domain adaptation with varying degrees of retrieval dataset access. We use ${\bf M P R}_{\mathrm{gen_PM}}$ with $k=1$ for all settings except $k=50$ for the noisy synthetic dataset.
5.2 上下文预测的检索集
| 源→→目标 | 检索集 | 开放 | 封闭 | 总体 |
|---|---|---|---|---|
| SLAKE→VQA-RAD | 无 (零样本) | 6.0 | 53.4 | 34.6 |
| SLAKE→VQA-RAD | 合成 | 11.5 | 49.8 | 34.6 |
| SLAKE→VQA-RAD | VQA-RAD | 42.9 | 76.2 | 63.0 |
| SLAKE→VQA-RAD | VQA-RAD+合成 | 44.5 | 76.5 | 63.8 |
| VQA-RAD→SLAKE | 无 (零样本) | 16.9 | 46.4 | 28.5 |
| VQA-RAD→SLAKE | 合成 | 18.3 | 50.2 | 30.8 |
| VQA-RAD→SLAKE | SLAKE | 45.1 | 67.3 | 53.8 |
| VQA-RAD→SLAKE | SLAKE+合成 | 45.1 | 67.3 | 53.8 |
表 2: 不同检索数据集访问程度下领域适应的零样本/少样本上下文预测结果。我们使用 ${\bf M P R}_{\mathrm{gen_PM}}$ ,除噪声合成数据集使用 $k=50$ 外,其余设置均采用 $k=1$ 。
We also examine the effect of using different datasets for retrieval. Table 2 illustrates the zeroshot/few-shot accuracies when applying a source model to a target dataset with different retrieval datasets. Increasing the retrieval dataset’s quality improves the model’s adaptation capability to new questions. Without any retrieval, open question accuracy is as low as $6%$ . Providing access to a noisy synthetic retrieval dataset improves open question performance. Using a higher quality in-domain retrieval set further enhances performance in all categories, achieving over $30%$ improvement in open question accuracy compared to the zero-shot baselines. Combining in-domain retrieval data with noisy synthetic data further boosts accuracy in all three accuracy categories on VQA-RAD. However, we observed no further improvement when combining the synthetic and SLAKE datasets. With a manual investigation, we find that questions in SLAKE have much simpler synthetic variants than those in VQA-RAD. Therefore, SLAKE already provides the most similar examples during retrieval, and additional synthetic data provides minimal gains.
我们还研究了使用不同检索数据集的影响。表2展示了将源模型应用于不同检索数据集的目标数据集时的零样本/少样本准确率。提高检索数据集的质量可以增强模型对新问题的适应能力。在不使用任何检索的情况下,开放问题的准确率低至$6%$。提供嘈杂的合成检索数据集可以提升开放问题的性能。使用更高质量的同领域检索集能进一步提升所有类别的性能,与零样本基线相比,开放问题准确率提高了超过$30%$。将同领域检索数据与嘈杂的合成数据结合,可以进一步提升VQA-RAD上所有三个准确率类别的表现。然而,当结合合成数据和SLAKE数据集时,我们没有观察到进一步的提升。通过人工调查,我们发现SLAKE中的问题比VQA-RAD中的问题有更简单的合成变体。因此,SLAKE在检索时已经提供了最相似的示例,额外的合成数据带来的增益微乎其微。
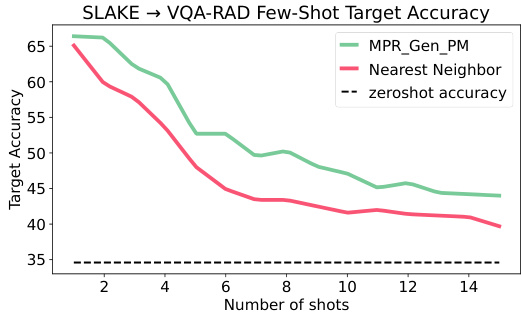
Figure 3: A generative model ${\bf M P R}_{\mathrm{gen_PM}}$ trained on the SLAKE dataset is evaluated on the VQA-RAD dataset over different numbers of few-shot retrievals.
图 3: 在SLAKE数据集上训练的生成模型 ${\bf M P R}_{\mathrm{gen_PM}}$ 在VQA-RAD数据集上针对不同数量少样本检索的评估结果。
5.3 How Many Shots are Needed?
5.3 需要多少样本?
For adaptation at test time, we investigate the effect of varying the number of retrieved image-question pairs from the target dataset for constructing the retrieval prompts in Figure 3. Regardless of the number of pairs retrieved, the overall target accuracy of ${\mathrm{MPR}}_ {\mathrm{gen}}$ is always above the none-retrieval baseline (i.e., zero-shot). We hypothesize that accuracy peaks when $k=1$ and stabilizes as $k$ increases due to the small dataset size. ${\mathrm{MPR}}_{\mathrm{gen}}$ outperforms a purely nearest neighbor-based approach when testing on the VQA-RAD dataset. However, on a syntactically simpler dataset (i.e., SLAKE), we also find that a nearest neighbor-based classifier can achieve higher accuracy than our model.
为了在测试时进行适配,我们研究了从目标数据集中检索不同数量的图像-问题对来构建检索提示的效果(如图3所示)。无论检索多少对数据,${\mathrm{MPR}}_ {\mathrm{gen}}$的总体目标准确率始终高于无检索基线(即零样本)。我们假设当$k=1$时准确率达到峰值,并随着$k$的增加而趋于稳定,这是由于数据集规模较小所致。在VQA-RAD数据集上测试时,${\mathrm{MPR}}_{\mathrm{gen}}$的表现优于纯基于最近邻的方法。然而在句法更简单的数据集(如SLAKE)上,我们也发现基于最近邻的分类器可以获得比我们模型更高的准确率。
5.4 In-context Prediction vs Finetuning
5.4 上下文预测与微调对比
While further finetuning neural models on the target dataset often successfully learns to adapt to the new distribution, this technique often results in catastrophic forgetting (Thompson et al., 2019). Figure 4 shows our experiments with further finetuning a source-trained model on a target dataset. First, we initialize three models with a $\mathbf{MPR_{gen_PM}}$ checkpoint trained on SLAKE and adapt them to VQA-RAD. The first model is frozen, only using in-context prediction with retrieved target data (green). Another model is further finetuned on the target data without in-context prediction (red). The last model uses fine-tuning first and then does in-context predictions with retrieval (blue).
虽然在目标数据集上进一步微调神经模型通常能成功适应新分布,但该技术往往会导致灾难性遗忘 (Thompson et al., 2019)。图 4 展示了我们在目标数据集上对源训练模型进行进一步微调的实验。首先,我们用基于 SLAKE 训练的 $\mathbf{MPR_{gen_PM}}$ 检查点初始化三个模型,并将其适配到 VQA-RAD 数据集。第一个模型被冻结,仅使用检索到的目标数据进行上下文预测 (绿色)。另一个模型在目标数据上进一步微调,但不使用上下文预测 (红色)。最后一个模型先进行微调,然后结合检索进行上下文预测 (蓝色)。
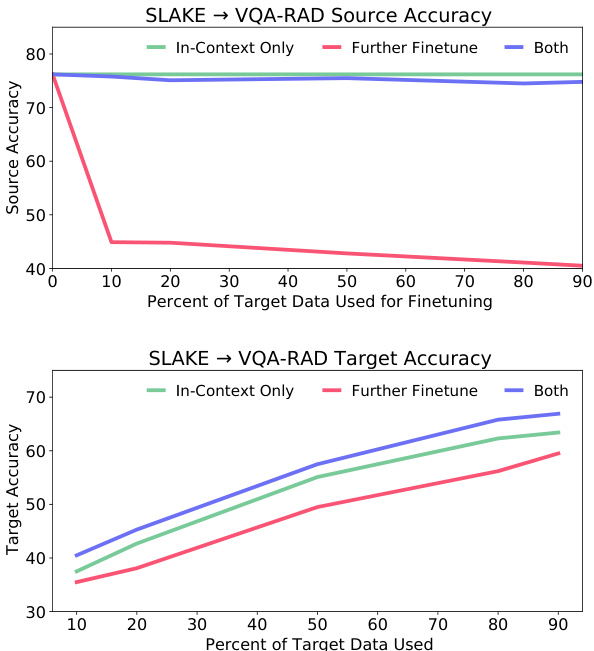
Figure 4: We vary the finetuning dataset size and observe the accuracy of finetuning compared to in-context prediction. All models start from a ${\bf M P R}_{\mathrm{gen_PM}}$ checkpoint and are either further finetuned (red $^+$ blue) or kept the same (green).
图 4: 我们改变微调数据集规模,并观察微调与上下文预测的准确率对比。所有模型均从 ${\bf M P R}_{\mathrm{gen_PM}}$ 检查点开始,分别进行进一步微调 (红色 $^+$ 蓝色) 或保持原状 (绿色)。
Several findings can be observed. First, we find that in-context prediction with $\mathrm{MPR}_{\mathrm{gen_PM}}$ can mitigate the forgetting issue and improve cross-dataset adaptation. Second, when target data is scarce, incontext prediction outperforms further finetuning. Although the finetuned model achieved higher test accuracy when using all the target data, it suffered significant performance loss in its original domain. Lastly, combining in-context prediction with further finetuning eliminates most of this forgetting with minimal target domain performance loss.
可以观察到以下几点发现。首先,我们发现使用 $\mathrm{MPR}_{\mathrm{gen_PM}}$ 进行上下文预测能够缓解遗忘问题并提升跨数据集适应能力。其次,当目标数据稀缺时,上下文预测的表现优于进一步微调。尽管在使用全部目标数据时微调模型获得了更高的测试准确率,但其在原始领域的性能损失显著。最后,将上下文预测与进一步微调相结合,能以最小的目标域性能损失消除大部分遗忘现象。
5.5 In-domain Evaluation
5.5 领域内评估
Overall Accuracy We also compare our proposed model with existing models for the indomain setting on SLAKE and VQA-RAD. We highlight the overall, open, and closed test accuracy for each dataset. We also evaluate our method with three contexts to analyze the effect of each component of our prompting method in Table 3.
整体准确率
我们还将提出的模型与SLAKE和VQA-RAD领域内现有模型进行对比,突出各数据集的整体、开放和封闭测试准确率。通过三种上下文设置评估方法效果,分析提示策略各组件的影响(表3)。
As expected, the model variants perform worse when we only provide questions as inputs. Under the same setting where both the question and image features are provided, our generative model is competitive with the state-of-the-art discriminative models. Besides, we also find that using an in-domain dataset for retrieval does not provide performance gains, indicating that models can easily fit a small in-domain dataset, and retrieving prompts from the same training set does not provide extra useful information.
正如预期,当我们仅提供问题作为输入时,模型变体的表现较差。在同时提供问题和图像特征的相同设置下,我们的生成式模型与最先进的判别式模型具有竞争力。此外,我们还发现使用领域内数据集进行检索并不能带来性能提升,这表明模型可以轻松拟合小型领域内数据集,且从同一训练集中检索提示词无法提供额外的有用信息。
| Context | Method | SLAKE | VQA-RAD | ||||
| Open | Closed | Overall | Open | Closed | Overall | ||
| QuestionOnly | MPRgen | 45.6 | 68.3 | 54.9 | 22.5 | 63.5 | 50.3 |
| MPRdisc | 48.5 | 66.6 | 55.6 | 38.5 | 72.6 | 59.0 | |
| ImageandQuestion | MPRgen | 71.5 | 76.7 | 73.5 | 57.7 | 77.6 | 69.7 |
| MPRgen_PM | 74.1 | 82.2 | 77.3 | 62.6 | 78.3 | 72.1 | |
| MPRdisc | 78.3 | 84.9 | 80.9 | 57.7 | 76.2 | 68.8 | |
| MPRdisc_BAN | 76.0 | 79.8 | 77.5 | 60.4 | 81.6 | 73.2 | |
| PubMedCLIP (Eslami et al.,2021) | 78.4 | 82.5 | 80.1 | 60.1 | 80.0 | 72.1 | |
| MMBert(Khare et al.,2021) | 63.1 | 77.9 | 72.0 | ||||
| QCR(Zhan et al.,2020) | 60.0 | 79.3 | 71.6 | ||||
| MEVF (Nguyen et al.,2019) | 43.9 | 75.1 | 62.7 | ||||
| Image, Question, and Retrieval | MPRgen | 73.0 | 79.8 | 75.7 | 57.7 | 77.3 | 69.5 |
| MPRgen_PM | 73.5 | 80.5 | 76.2 | 60.4 | 80.9 | 72.8 | |
| MPRdisc | 75.0 | 81.0 | 77.4 | 51.6 | 78.0 | 67.5 | |
| MPRdisc_BAN | 77.5 | 82.2 | 79.4 | 62.6 | 80.1 | 73.2 | |
Table 3: Performances of our prompting method with different levels of context provided to the model. In most cases, our model is competitive with state-of-the-art methods even in the generative based cases. Retrieval context is provided by querying for the 15 most relevant image-question pairs. Bold values indicate the maximum in each column.
| 上下文 | 方法 | SLAKE_开放 | SLAKE_封闭 | SLAKE_总体 | VQA-RAD_开放 | VQA-RAD_封闭 | VQA-RAD_总体 |
|---|---|---|---|---|---|---|---|
| 仅问题 | MPRgen | 45.6 | 68.3 | 54.9 | 22.5 | 63.5 | 50.3 |
| 仅问题 | MPRdisc | 48.5 | 66.6 | 55.6 | 38.5 | 72.6 | 59.0 |
| 图像和问题 | MPRgen | 71.5 | 76.7 | 73.5 | 57.7 | 77.6 | 69.7 |
| 图像和问题 | MPRgen_PM | 74.1 | 82.2 | 77.3 | 62.6 | 78.3 | 72.1 |
| 图像和问题 | MPRdisc | 78.3 | 84.9 | 80.9 | 57.7 | 76.2 | 68.8 |
| 图像和问题 | MPRdisc_BAN | 76.0 | 79.8 | 77.5 | 60.4 | 81.6 | 73.2 |
| 图像和问题 | PubMedCLIP (Eslami et al., 2021) | 78.4 | 82.5 | 80.1 | 60.1 | 80.0 | 72.1 |
| 图像和问题 | MMBert (Khare et al., 2021) | - | - | - | 63.1 | 77.9 | 72.0 |
| 图像和问题 | QCR (Zhan et al., 2020) | - | - | - | 60.0 | 79.3 | 71.6 |
| 图像和问题 | MEVF (Nguyen et al., 2019) | - | - | - | 43.9 | 75.1 | 62.7 |
| 图像、问题和检索 | MPRgen | 73.0 | 79.8 | 75.7 | 57.7 | 77.3 | 69.5 |
| 图像、问题和检索 | MPRgen_PM | 73.5 | 80.5 | 76.2 | 60.4 | 80.9 | 72.8 |
| 图像、问题和检索 | MPRdisc | 75.0 | 81.0 | 77.4 | 51.6 | 78.0 | 67.5 |
| 图像、问题和检索 | MPRdisc_BAN | 77.5 | 82.2 | 79.4 | 62.6 | 80.1 | 73.2 |
表 3: 在不同上下文级别下我们提示方法的性能表现。在大多数情况下,即使在基于生成的情况下,我们的模型也与最先进的方法具有竞争力。检索上下文通过查询15个最相关的图像-问题对来提供。加粗数值表示每列中的最大值。
Fine grained Accuracy Figure 5 in Appendix also shows the in-domain performance of our model variants across different question types for both datasets. The results indicate that all models generally struggle with questions requiring more complex reasoning, such as Position, Abnormality, and Knowledge Graph (KG) questions.
附录中的图5还展示了我们不同模型变体在两个数据集上针对各类问题的领域内性能表现。结果表明,所有模型在处理需要更复杂推理的问题时普遍存在困难,例如位置 (Position) 、异常 (Abnormality) 和知识图谱 (KG) 类问题。
6 Related Work
6 相关工作
Retrieval-Based VQA Retrieval-based methods typically combine parametric models with nonparametric external memory for prediction. This idea first surfaces in KNN-LMs (Khandelwal et al., 2020), which utilizes a static retrieval data store to help language models adapt rapidly to new domains without further training. Guu et al. (2020) extends this idea by introducing a parametric retriever that learns to attend to relevant documents during training. Recently, Gao et al. (2022) summarizes visual information into natural language to use as a query for dense passage retrieval. The retrieved passages allow for the VQA model to outperform existing works, especially on questions which require outside knowledge. Lin and Byrne (2022) consider training the retriever in an end-toend manner similar to Lewis et al. (2020) and find that this results in higher answer quality and lower computational training cost.
基于检索的视觉问答
基于检索的方法通常将参数化模型与非参数化外部记忆相结合进行预测。这一思路最早出现在KNN-LMs (Khandelwal等人,2020)中,该方法利用静态检索数据存储帮助语言模型无需额外训练即可快速适应新领域。Guu等人 (2020)通过引入参数化检索器扩展了这一理念,该检索器在训练过程中学习关注相关文档。近期,Gao等人 (2022)将视觉信息归纳为自然语言作为密集段落检索的查询依据,检索到的段落使VQA模型性能超越现有工作,尤其在需要外部知识的问题上表现突出。Lin和Byrne (2022)采用类似Lewis等人 (2020)的端到端方式训练检索器,发现这种方式能提升答案质量并降低训练计算成本。
Different from these methods, we propose to construct multimodal prompts from retrieval to perform zeroshot dataset adaptation. While dataset adaptation of VQA models has been investigated in Agrawal et al. (2023), we focus on the effect of retrieval on generalization capability.
与这些方法不同,我们提出通过检索构建多模态提示(multimodal prompts)来实现零样本(zero-shot)数据集适配。虽然Agrawal等人(2023)已研究过VQA模型的数据集适配问题,但我们重点关注检索对泛化能力的影响。
Generative QA Generative QA models focus on predicting answers auto regressive ly based on the input question. In this setting, the model may either generate the response based solely on model parameters (closed book) (Khashabi et al., 2021; Roberts et al., 2020) or rely on additional retrieved contexts (open book) (Karpukhin et al., 2020; Lewis et al., 2020). Our prompt construction method is inspired by the retrieval augmented generator (RAG) model (Lewis et al., 2020), which retrieves relevant documents to answer questions. Instead of retrieving documents exclusively, we identify suitable imagequestion pairs to perform VQA.
生成式问答
生成式问答模型专注于根据输入问题以自回归方式预测答案。在此设定下,模型可能仅基于模型参数生成响应(闭卷模式)(Khashabi et al., 2021; Roberts et al., 2020),或依赖额外检索的上下文(开卷模式)(Karpukhin et al., 2020; Lewis et al., 2020)。我们的提示构建方法受检索增强生成器(RAG)模型 (Lewis et al., 2020) 启发,该模型通过检索相关文档来回答问题。与仅检索文档不同,我们通过识别合适的图像-问题对来执行视觉问答(VQA)。
VQA First introduced by Antol et al. (2015), most VQA systems learn a joint embedding space for images and text to answer questions (Malinowski et al., 2015; Gao et al., 2015). These ap- proaches combine image and text features through either bilinear pooling or attention-based mechanisms (Yang et al., 2016; Lu et al., 2016; Anderson et al., 2018; Guo et al., 2021). To help mod- els understand the relationships between objects in an image, graph convolutional neural networks were introduced for VQA (Norcliffe-Brown et al., 2018; Li et al., 2019). Current methods often combine supplemental knowledge with fusion-based approaches to achieve state-of-the-art performance (Shevchenko et al., 2021; Marino et al., 2021; Wu et al., 2022; Chen et al., 2022). We take a similar approach by using supplementary knowledge to construct context-aware prompts.
VQA 由 Antol 等人 (2015) 首次提出,大多数 VQA 系统通过学习图像和文本的联合嵌入空间来回答问题 (Malinowski 等人, 2015; Gao 等人, 2015)。这些方法通过双线性池化或基于注意力的机制结合图像和文本特征 (Yang 等人, 2016; Lu 等人, 2016; Anderson 等人, 2018; Guo 等人, 2021)。为了帮助模型理解图像中物体间的关系,图卷积神经网络被引入 VQA 领域 (Norcliffe-Brown 等人, 2018; Li 等人, 2019)。当前方法通常将补充知识与基于融合的方法相结合,以实现最先进的性能 (Shevchenko 等人, 2021; Marino 等人, 2021; Wu 等人, 2022; Chen 等人, 2022)。我们采用类似方法,利用补充知识构建上下文感知提示。
7 Conclusion
7 结论
In this work, we propose a flexible prompt-based method for VQA in the medical domain. While our approach is designed for low-resource domains, the generative architecture of our model, in combination with a retrieval component, enables genera liz ation to other fields. Our results are on par with state-of-the-art accuracies on the SLAKE and VQA-RAD datasets and show promising zero-shot and few-shot transfer results across different medical datasets. We hope these results can offer a baseline to compare with future work on knowledgeintensive and reasoning tasks.
在这项工作中,我们提出了一种灵活的基于提示(prompt-based)的医疗领域视觉问答(VQA)方法。虽然我们的方法专为低资源领域设计,但模型的生成式架构结合检索组件,能够泛化至其他领域。我们在SLAKE和VQA-RAD数据集上取得了与最先进精度相当的结果,并展示了跨不同医疗数据集的零样本和少样本迁移潜力。希望这些成果能为未来知识密集型和推理任务研究提供可比较的基线。
8 Limitations
8 局限性
When evaluating our model in a cross-dataset adaptation setting, our experiments indicate the importance of using a retrieval dataset. It is challenging to procure high-quality and volume retrieval datasets, especially in low-resource domains such as the medical field. Fortunately, the VQA-RAD and SLAKE datasets we evaluate on contain profess ion ally annotated medical images. We also overcome the lack of data by creating a synthetic dataset from the medical ROCO image-captioning dataset.
在跨数据集适应设置下评估我们的模型时,实验结果表明使用检索数据集的重要性。获取高质量且数量充足的检索数据集具有挑战性,尤其是在医疗领域等低资源领域。幸运的是,我们评估所用的VQA-RAD和SLAKE数据集包含专业标注的医学图像。我们还通过从医学ROCO图像描述数据集创建合成数据集来克服数据不足的问题。
Additionally, our model struggles with questions requiring multi-step reasoning, such as knowledge graph, abnormality, and position questions. Although performances in these question types are not far below the overall accuracy, future work may consider supplementary knowledge-based retrieval to assist in these challenging question types.
此外,我们的模型在处理需要多步推理的问题时存在困难,例如知识图谱 (knowledge graph)、异常检测 (abnormality) 和位置相关问题。尽管这些题型的表现与整体准确率相差不大,但未来工作可以考虑引入基于知识的检索 (knowledge-based retrieval) 来辅助解决这些具有挑战性的问题类型。
9 Ethics Statement
9 伦理声明
Although medical VQA provides exciting opportunities for future AI-assisted clinical diagnostic tools, there are several ethical challenges associated with these approaches.
尽管医疗VQA为未来AI辅助临床诊断工具提供了令人振奋的机遇,但这些方法也伴随着若干伦理挑战。
Patient Safety and Model Transparency Since the model decision process for deep learning models is difficult to understand, these models should only be used as an auxiliary tool. This obscure decision process is crucial to clarify in the medical domain, in which a poor diagnosis or choice of treatment can significantly affect patient lives. For example, medical experts found that cancer treatment recommendation software often gave unsafe or incorrect treatment advice in a recent study (Ross and Swetlitz, 2018).
患者安全与模型透明度
由于深度学习模型的决策过程难以理解,这些模型应仅作为辅助工具使用。在医疗领域,这种不透明的决策过程尤为关键,因为错误的诊断或治疗方案可能严重影响患者生命。例如,医学专家在近期研究中发现,癌症治疗推荐软件经常给出不安全或不正确的治疗建议 (Ross and Swetlitz, 2018)。
Dataset Biases The fairness of medical AI systems depends on the distribution of people in its training dataset. To ensure that AI algorithms display fairness to all races, genders, and ethnic groups, practitioners should verify that the training dataset contains an equal representation of all groups. Before deploying our architecture or other deep learning-based models to a clinical setting, practitioners should ensure that their patient’s background is adequately represented in the training data.
数据集偏差
医疗AI系统的公平性取决于其训练数据集中的人群分布。为确保AI算法对所有种族、性别和民族群体表现出公平性,从业者应验证训练数据集是否均衡包含所有群体。在将我们的架构或其他基于深度学习的模型部署到临床环境之前,从业者应确保训练数据充分体现患者背景特征。
References
参考文献
Aishwarya Agrawal, Ivana Kajic, Emanuele Bug liar ello, Elnaz Davoodi, Anita Gergely, Phil Blunsom, and Aida Nematzadeh. 2023. Rethinking evaluation practices in visual question answering: A case study on out-of-distribution generalization. In Proceedings of the 2023 European Chapter of the Association for Computational Linguistics (Findings).
Aishwarya Agrawal、Ivana Kajic、Emanuele Bugliarello、Elnaz Davoodi、Anita Gergely、Phil Blunsom 和 Aida Nematzadeh。2023。重新思考视觉问答中的评估实践:关于分布外泛化的案例研究。载于《2023年欧洲计算语言学协会会议论文集》(Findings)。
Peter Anderson, Xiaodong He, Chris Buehler, Damien Teney, Mark Johnson, Stephen Gould, and Lei Zhang. 2018. Bottom-up and top-down attention for image captioning and visual question answering. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 6077–6086.
Peter Anderson、Xiaodong He、Chris Buehler、Damien Teney、Mark Johnson、Stephen Gould 和 Lei Zhang。2018. 自底向上与自顶向下注意力机制在图像描述生成和视觉问答中的应用。见《IEEE计算机视觉与模式识别会议论文集》,第6077-6086页。
Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Mar- garet Mitchell, Dhruv Batra, C Lawrence Zitnick, and Devi Parikh. 2015. Vqa: Visual question answering. In Proceedings of the IEEE international conference on computer vision, pages 2425–2433.
Stanislaw Antol、Aishwarya Agrawal、Jiasen Lu、Margaret Mitchell、Dhruv Batra、C Lawrence Zitnick 和 Devi Parikh。2015. VQA: 视觉问答。见《IEEE国际计算机视觉会议论文集》,第2425–2433页。
Wenhu Chen, Hexiang Hu, Xi Chen, Pat Verga, and William W Cohen. 2022. Murag: Multimodal retrieval-augmented generator for open question answering over images and text. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing.
Wenhu Chen、Hexiang Hu、Xi Chen、Pat Verga 和 William W Cohen。2022。Murag:面向图文开放问答的多模态检索增强生成器。载于《2022年自然语言处理实证方法会议论文集》。
Alexey Do sov it ski y, Lucas Beyer, Alexander Kolesnikov, Dirk Weiss en born, Xiaohua Zhai, Thomas Unter thin er, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. 2021. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations.
Alexey Dosovitskiy、Lucas Beyer、Alexander Kolesnikov、Dirk Weissenborn、Xiaohua Zhai、Thomas Unterthiner、Mostafa Dehghani、Matthias Minderer、Georg Heigold、Sylvain Gelly等。2021。一幅图像值16x16个词:大规模图像识别的Transformer。收录于国际学习表征会议。
Sedigheh Eslami, Gerard de Melo, and Christoph Meinel. 2021. Does clip benefit visual question answering in the medical domain as much as it does in the general domain? arXiv preprint arXiv:2112.13906.
Sedigheh Eslami、Gerard de Melo 和 Christoph Meinel。2021。CLIP 在医疗领域的视觉问答中是否与通用领域表现相当?arXiv 预印本 arXiv:2112.13906。
Feng Gao, Qing Ping, Govind Thattai, Aishwarya Reganti, Ying Nian Wu, and Prem Natarajan. 2022. Transform-retrieve-generate: Natural languagecentric outside-knowledge visual question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5067–5077.
Feng Gao、Qing Ping、Govind Thattai、Aishwarya Reganti、Ying Nian Wu 和 Prem Natarajan。2022。Transform-retrieve-generate:以自然语言为中心的外部知识视觉问答。载于《IEEE/CVF计算机视觉与模式识别会议论文集》,第5067–5077页。
Haoyuan Gao, Junhua Mao, Jie Zhou, Zhiheng Huang, Lei Wang, and Wei Xu. 2015. Are you talking to a machine? dataset and methods for multilingual image question. Advances in neural information processing systems, 28.
高浩源、毛俊华、周杰、黄志恒、王磊和徐伟。2015。你在和机器对话吗?多语言图像问答数据集及方法。神经信息处理系统进展,28。
Dalu Guo, Chang Xu, and Dacheng Tao. 2021. Bilinear graph networks for visual question answering. IEEE Transactions on Neural Networks and Learning Systems.
Dalu Guo、Chang Xu 和 Dacheng Tao. 2021. 用于视觉问答的双线性图网络. IEEE Transactions on Neural Networks and Learning Systems.
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Mingwei Chang. 2020. Retrieval augmented language model pre-training. In International Conference on Machine Learning, pages 3929–3938. PMLR.
Kelvin Guu、Kenton Lee、Zora Tung、Panupong Pasupat和Mingwei Chang。2020。检索增强的语言模型预训练。见《国际机器学习会议》,第3929-3938页。PMLR。
Sadid A Hasan, Yuan Ling, Oladimeji Farri, Joey Liu, Henning Müller, and Matthew P Lungren. 2018. Overview of imageclef 2018 medical domain visual question answering task. In Conference and Labs of the Evaluation Forum (Working Notes).
Sadid A Hasan、Yuan Ling、Oladimeji Farri、Joey Liu、Henning Müller和Matthew P Lungren。2018。ImageCLEF 2018医疗领域视觉问答任务概述。见于《评测论坛会议与实验室(工作笔记)》。
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense passage retrieval for opendomain question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing.
Vladimir Karpukhin、Barlas Oguz、Sewon Min、Patrick Lewis、Ledell Wu、Sergey Edunov、Danqi Chen和Wen-tau Yih。2020。开放域问答的密集段落检索。载于《2020年自然语言处理实证方法会议论文集》。
Urvashi Khandelwal, Omer Levy, Dan Jurafsky, Luke Z ett le moyer, and Mike Lewis. 2020. Generalization through memorization: Nearest neighbor language models. In International Conference on Learning Representations.
Urvashi Khandelwal、Omer Levy、Dan Jurafsky、Luke Zettlemoyer 和 Mike Lewis。2020。通过记忆实现泛化:最近邻语言模型。In International Conference on Learning Representations。
Yash Khare, Viraj Bagal, Minesh Mathew, Adithi Devi, U Deva Priyakumar, and CV Jawahar. 2021. Mmbert: multimodal bert pre training for improved medical vqa. In 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI), pages 1033–1036. IEEE.
Yash Khare、Viraj Bagal、Minesh Mathew、Adithi Devi、U Deva Priyakumar和CV Jawahar。2021. Mmbert: 面向医学视觉问答改进的多模态BERT预训练。收录于《2021年IEEE第18届国际生物医学成像研讨会(ISBI)》,第1033–1036页。IEEE。
Daniel Khashabi, Sewon Min, Tushar Khot, Ashish Sabharwal, Oyvind Tafjord, Peter Clark, and Hannaneh Hajishirzi. 2021. Unifiedqa: Crossing format boundaries with a single qa system. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (Findings).
Daniel Khashabi、Sewon Min、Tushar Khot、Ashish Sabharwal、Oyvind Tafjord、Peter Clark 和 Hannaneh Hajishirzi。2021。UnifiedQA:跨格式边界的统一问答系统。载于《2021年自然语言处理实证方法会议论文集》(Findings)。
Jin-Hwa Kim, Jaehyun Jun, and Byoung-Tak Zhang. 2018. Bilinear attention networks. Advances in neural information processing systems, 31.
Jin-Hwa Kim、Jaehyun Jun 和 Byoung-Tak Zhang。2018. 双线性注意力网络 (Bilinear Attention Networks)。神经信息处理系统进展,31。
Olga Kovaleva, Chaitanya Shivade, Satyananda Kashyap, Karina Kanjaria, Joy Wu, Deddeh Ballah, Adam Coy, Alexandros Karargyris, Yufan Guo, David Beymer Beymer, Anna Rumshisky, and Vandana Mukherjee Mukherjee. 2020. Towards visual dialog for radiology. In Proceedings of the 19th SIGBioMed Workshop on Biomedical Language Processing, pages 60–69, Online. Association for Computational Linguistics.
Olga Kovaleva、Chaitanya Shivade、Satyananda Kashyap、Karina Kanjaria、Joy Wu、Deddeh Ballah、Adam Coy、Alexandros Karargyris、Yufan Guo、David Beymer Beymer、Anna Rumshisky和Vandana Mukherjee Mukherjee。2020。迈向放射学视觉对话。载于《第19届SIGBioMed生物医学语言处理研讨会论文集》,第60-69页,线上。计算语言学协会。
Jason J Lau, Soumya Gayen, Asma Ben Abacha, and Dina Demner-Fushman. 2018. A dataset of clinically generated visual questions and answers about radiology images. Scientific data, 5(1):1–10.
Jason J Lau、Soumya Gayen、Asma Ben Abacha 和 Dina Demner-Fushman。2018. 一个关于放射学图像的临床生成视觉问答数据集。《科学数据》,5(1):1-10。
Brian Lester, Rami Al-Rfou, and Noah Constant. 2021. The power of scale for parameter-efficient prompt tuning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 3045–3059, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
Brian Lester、Rami Al-Rfou和Noah Constant。2021。规模效应对参数高效提示调优的影响。载于《2021年自然语言处理实证方法会议论文集》,第3045–3059页,线上会议及多米尼加共和国蓬塔卡纳。计算语言学协会。
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rock- täschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33:9459–9474.
Patrick Lewis、Ethan Perez、Aleksandra Piktus、Fabio Petroni、Vladimir Karpukhin、Naman Goyal、Heinrich Küttler、Mike Lewis、Wen-tau Yih、Tim Rocktäschel 等。2020。面向知识密集型 NLP 任务的检索增强生成。神经信息处理系统进展,33:9459-9474。
Linjie Li, Zhe Gan, Yu Cheng, and Jingjing Liu. 2019. Relation-aware graph attention network for visual question answering. In Proceedings of the IEEE/CVF international conference on computer vision, pages 10313–10322.
Linjie Li、Zhe Gan、Yu Cheng 和 Jingjing Liu。2019。面向视觉问答的关系感知图注意力网络。载于《IEEE/CVF 国际计算机视觉会议论文集》,第 10313–10322 页。
Weizhe Lin and Bill Byrne. 2022. Retrieval augmented visual question answering with outside knowledge. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing.
Weizhe Lin和Bill Byrne。2022。基于外部知识的检索增强视觉问答。载于《2022年自然语言处理实证方法会议论文集》。
Zhihong Lin, Donghao Zhang, Qingyi Tao, Danli Shi, Gholamreza Haffari, Qi Wu, Mingguang He, and Zongyuan Ge. 2021. Medical visual question answering: A survey. ArXiv, abs/2111.10056.
林志宏、张东浩、陶清怡、石丹丽、Gholamreza Haffari、吴琦、何明光、葛宗元。2021。医学视觉问答综述。ArXiv, abs/2111.10056。
Bo Liu, Li-Ming Zhan, Li Xu, Lin Ma, Yan Yang, and Xiao-Ming Wu. 2021. Slake: a semantically-labeled knowledge-enhanced dataset for medical visual question answering. In 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI), pages 1650–1654. IEEE.
刘波、詹立明、徐立、马林、杨岩和吴晓明。2021. Slake: 一个用于医学视觉问答的语义标注知识增强数据集。收录于《2021年IEEE第18届国际生物医学成像研讨会(ISBI)》,第1650–1654页。IEEE。
Jiasen Lu, Jianwei Yang, Dhruv Batra, and Devi Parikh. 2016. Hierarchical question-image co-attention for visual question answering. Advances in neural information processing systems, 29.
Jiasen Lu、Jianwei Yang、Dhruv Batra 和 Devi Parikh。2016。视觉问答中的分层问题-图像协同注意力机制。神经信息处理系统进展,29。
Mateusz Malinowski, Marcus Rohrbach, and Mario Fritz. 2015. Ask your neurons: A neural-based approach to answering questions about images. In Proceedings of the IEEE international conference on computer vision, pages 1–9.
Mateusz Malinowski、Marcus Rohrbach和Mario Fritz。2015. 问你的神经元:基于神经网络的图像问答方法。见《IEEE国际计算机视觉会议论文集》,第1-9页。
Kenneth Marino, Xinlei Chen, Devi Parikh, Abhinav Gupta, and Marcus Rohrbach. 2021. Krisp: Integrating implicit and symbolic knowledge for opendomain knowledge-based vqa. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14111–14121.
Kenneth Marino、Xinlei Chen、Devi Parikh、Abhinav Gupta 和 Marcus Rohrbach。2021. Krisp:融合隐式与符号知识实现开放域知识库视觉问答。发表于《IEEE/CVF计算机视觉与模式识别会议论文集》,第14111–14121页。
Jong Hak Moon, Hyungyung Lee, Woncheol Shin, Young-Hak Kim, and Edward Choi. 2022. Multimodal understanding and generation for medical images and text via vision-language pre-training. IEEE Journal of Biomedical and Health Informatics.
Jong Hak Moon、Hyungyung Lee、Woncheol Shin、Young-Hak Kim 和 Edward Choi。2022。基于视觉-语言预训练的医学图像与文本多模态理解与生成。《IEEE生物医学与健康信息学杂志》。
Medhini Narasimhan and Alexander G Schwing. 2018. Straight to the facts: Learning knowledge base retrieval for factual visual question answering. In Proceedings of the European conference on computer vision (ECCV), pages 451–468.
Medhini Narasimhan 和 Alexander G Schwing。2018。直奔事实:学习知识库检索以实现事实性视觉问答。载于《欧洲计算机视觉会议论文集》(ECCV),第451-468页。
Binh D Nguyen, Thanh-Toan Do, Binh X Nguyen, Tuong Do, Erman Tjiputra, and Quang D Tran. 2019. Overcoming data limitation in medical visual question answering. In International Conference on Med- ical Image Computing and Computer-Assisted Intervention, pages 522–530. Springer.
Binh D Nguyen、Thanh-Toan Do、Binh X Nguyen、Tuong Do、Erman Tjiputra 和 Quang D Tran。2019. 克服医学视觉问答中的数据限制。载于《医学图像计算与计算机辅助干预国际会议》,第522–530页。Springer出版社。
Will Norcliffe-Brown, Stathis Vafeias, and Sarah Parisot. 2018. Learning conditioned graph structures for inter pre table visual question answering. Advances in neural information processing systems, 31.
Will Norcliffe-Brown、Stathis Vafeias和Sarah Parisot。2018。学习条件化图结构以实现可解释的视觉问答。神经信息处理系统进展,31。
Obioma Pelka, Sven Koitka, Johannes Rückert, Felix Nensa, and Christoph M Friedrich. 2018. Radiology objects in context (roco): a multimodal image dataset. In Intra vascular Imaging and Computer Assisted Stenting and Large-Scale Annotation of Biomedical Data and Expert Label Synthesis, pages 180–189. Springer.
Obioma Pelka、Sven Koitka、Johannes Rückert、Felix Nensa和Christoph M Friedrich。2018. 放射学对象上下文数据集(ROCO):一种多模态图像数据集。载于《血管内成像与计算机辅助支架术及生物医学数据大规模标注与专家标签合成》,第180-189页。Springer出版社。
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning transferable visual models from natural language supervision. In Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pages 8748–8763. PMLR.
Alec Radford、Jong Wook Kim、Chris Hallacy、Aditya Ramesh、Gabriel Goh、Sandhini Agarwal、Girish Sastry、Amanda Askell、Pamela Mishkin、Jack Clark、Gretchen Krueger 和 Ilya Sutskever。2021。通过自然语言监督学习可迁移的视觉模型。载于《第38届国际机器学习会议论文集》,《机器学习研究论文集》第139卷,第8748–8763页。PMLR。
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J Liu, et al. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21(140):1–67.
Colin Raffel、Noam Shazeer、Adam Roberts、Katherine Lee、Sharan Narang、Michael Matena、Yanqi Zhou、Wei Li、Peter J Liu 等. 2020. 探索迁移学习的极限:基于统一文本到文本Transformer的研究. Journal of Machine Learning Research, 21(140):1–67.
Adam Roberts, Colin Raffel, and Noam Shazeer. 2020. How much knowledge can you pack into the parameters of a language model? In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing.
Adam Roberts、Colin Raffel 和 Noam Shazeer。2020. 语言模型的参数能承载多少知识?载于《2020年自然语言处理实证方法会议论文集》。
Casey Ross and Ike Swetlitz. 2018. Ibm’s watson supercomputer recommended ‘unsafe and incorrect’cancer treatments, internal documents show. Stat, 25.
Casey Ross和Ike Swetlitz。2018。IBM的Watson超级计算机被曝推荐"不安全且错误"的癌症治疗方案,内部文件显示。《Stat》杂志,25。
Violetta Shevchenko, Damien Teney, Anthony Dick, and Anton van den Hengel. 2021. Reasoning over vision and language: Exploring the benefits of supplemental knowledge. arXiv preprint arXiv:2101.06013.
Violetta Shevchenko、Damien Teney、Anthony Dick 和 Anton van den Hengel。2021。视觉与语言推理:探索补充知识的优势。arXiv 预印本 arXiv:2101.06013。
Anshumali Shri vast ava and Ping Li. 2014. Asymmetric lsh (alsh) for sublinear time maximum inner product search (mips). In Advances in Neural Information Processing Systems, volume 27. Curran Associates, Inc.
Anshumali Shrivastava 和 Ping Li. 2014. 用于次线性时间最大内积搜索(MIPS)的非对称局部敏感哈希(ALSH). In Advances in Neural Information Processing Systems, volume 27. Curran Associates, Inc.
Ajay K Tanwani, Joelle Barral, and Daniel Freedman. 2022. Repsnet: Combining vision with language for automated medical reports. In International Conference on Medical Image Computing and ComputerAssisted Intervention, pages 714–724. Springer.
Ajay K Tanwani、Joelle Barral 和 Daniel Freedman。2022. Repsnet:结合视觉与语言生成自动化医疗报告。载于《国际医学图像计算与计算机辅助干预会议》,第714-724页。Springer出版社。
Brian Thompson, Jeremy Gwinnup, Huda Khayrallah, Kevin Duh, and Philipp Koehn. 2019. Overcoming catastrophic forgetting during domain adaptation of neural machine translation. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 2062–2068.
Brian Thompson、Jeremy Gwinnup、Huda Khayrallah、Kevin Duh 和 Philipp Koehn。2019。神经机器翻译领域适应中克服灾难性遗忘的研究。载于《2019年北美计算语言学协会人类语言技术会议论文集》第1卷(长文与短文),第2062–2068页。
Jialin Wu, Jiasen Lu, Ashish Sabharwal, and Roozbeh Mottaghi. 2022. Multi-modal answer validation for knowledge-based vqa. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 2712–2721.
Jialin Wu、Jiasen Lu、Ashish Sabharwal 和 Roozbeh Mottaghi。2022. 基于知识VQA的多模态答案验证。见《AAAI人工智能会议论文集》第36卷,第2712-2721页。
Zichao Yang, Xiaodong He, Jianfeng Gao, Li Deng, and Alex Smola. 2016. Stacked attention networks for image question answering. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 21–29.
Zichao Yang、Xiaodong He、Jianfeng Gao、Li Deng 和 Alex Smola。2016。基于堆叠注意力网络的图像问答。载于《IEEE计算机视觉与模式识别会议论文集》,第21-29页。
Li-Ming Zhan, Bo Liu, Lu Fan, Jiaxin Chen, and XiaoMing Wu. 2020. Medical visual question answering via conditional reasoning. In Proceedings of the 28th ACM International Conference on Multimedia, pages 2345–2354.
Li-Ming Zhan, Bo Liu, Lu Fan, Jiaxin Chen, and XiaoMing Wu. 2020. 基于条件推理的医学视觉问答. In Proceedings of the 28th ACM International Conference on Multimedia, pages 2345–2354.
Yangyang Zhou, Xin Kang, and Fuji Ren. 2019. Tua1 at imageclef 2019 vqa-med: a classification and generation model based on transfer learning. In Conference and Labs of the Evaluation Forum (Working Notes).
Yangyang Zhou、Xin Kang和Fuji Ren。2019。Tua1在imageclef 2019 vqa-med中的应用:基于迁移学习的分类与生成模型。见于Conference and Labs of the Evaluation Forum(工作笔记)。
Appendix
附录
Table 4: Example templates for different question categories and question types.
| Q Type | A TypeQuestionTemplates&AnswerTemplates(Tt) | AnswerTemplates | |
| Organ | Open | Q:What part of the body is being imaged?What is the organ shown in this image?...A:{Brain, Chest, ...} | |
| Organ | Closed | Q:Doesthepicturecontain{}?Isthisastudyofthe{}?.. | A:{Yes,No} |
| OrganSystem | Open | Q:Whatorgansystemispictured?What systemisthispathologyin?.. | A:{RespiratorySystem,CardiovascularSystem,...} |
| OrganSystem | Closed | Q:Is this an image of the {}?Is the {} shown?... | A:{Yes,No} |
| Modality | Open | Q:Whatkind of scanis this?Howwas this image taken?.. | A:{MRI, X-ray, ...} |
| Modality | Closed | Q: Is this a {}?Is the image a {}?.. | A:{Yes,No} |
| Plane | Open | Q:What image plane is this?How is the image oriented?... | A:{Axial,Coronal,...} |
| Plane | Closed | Q:Is this a{}plane?Is the image a{}section? | A:{Yes,No} |
表 4: 不同问题类别与问题类型的示例模板。
| Q类型 | A类型问题模板&回答模板(Tt) | 回答模板 | |
|---|---|---|---|
| 器官 | 开放式 | Q:正在成像的是身体的哪个部位?这张图像显示的器官是什么?...A:{大脑, 胸部, ...} | |
| 器官 | 封闭式 | Q:图片中是否包含{}?这是{}的研究吗?... | A:{是,否} |
| 器官系统 | 开放式 | Q:图中显示的是哪个器官系统?这种病理属于哪个系统?... | A:{呼吸系统,心血管系统,...} |
| 器官系统 | 封闭式 | Q:这是{}的图像吗?显示了{}吗?... | A:{是,否} |
| 成像方式 | 开放式 | Q:这是什么类型的扫描?这张图像是如何拍摄的?... | A:{MRI,X射线,...} |
| 成像方式 | 封闭式 | Q:这是{}吗?图像是{}吗?... | A:{是,否} |
| 成像平面 | 开放式 | Q:这是什么成像平面?图像是如何定向的?... | A:{轴向,冠状,...} |
| 成像平面 | 封闭式 | Q:这是{}平面吗?图像是{}截面吗? | A:{是,否} |
Table 5: Example keywords for different question types.
| Q&A Types (t E Qtype × Atype) | Keywords(Wt) |
| Organ&Open | Heart, Lungs, Lung, Liver, Breasts, Chest, Cardiovascular System, Respiratory System .. |
| Plane&Open | Axial,Coronal,Supratentorial,Posteroanterior ... |
| Modality&Open | MRI, T1, T2, CT, X-ray, Ultrasound, Flair .. |
表 5: 不同问题类型的关键词示例。
| 问答类型 (t ∈ Qtype × Atype) | 关键词(Wt) |
|---|---|
| Organ&Open | 心脏、肺、肝脏、乳房、胸部、心血管系统、呼吸系统等 |
| Plane&Open | 轴向、冠状、幕上、后前位等 |
| Modality&Open | MRI、T1、T2、CT、X射线、超声、Flair等 |
A Templates
模板
We use the question and keyword templates in Tables 4 and 5 to construct a synthetic retrieval set. For open questions, the question template is static. However, the answer to open questions may be any of the keywords $w\in\mathcal{W}_ {t}$ . Closed question templates have a slot that is filled in by one of the keywords $w\in\mathcal{W}_{t}$ , and the answer to these questions is either yes or no:
我们使用表4和表5中的问题和关键词模板构建了一个合成检索集。对于开放性问题,问题模板是静态的。然而,开放性问题的答案可能是关键词$w\in\mathcal{W}_ {t}$中的任何一个。封闭式问题模板有一个由关键词$w\in\mathcal{W}_{t}$填充的槽位,这些问题的答案只有是或否两种:
| PromptConstructionOrder | Prompt Template (Tprompt) | PossibleQuantifiers(Q) | Open Closed Overall | ||
| Question,Retrieval,Image | Ibelieve the answer is{quantifier}{answer} | veryunlikely,unlikely,maybe,likely,verylikely,certainly | 39.6 | 65.0 | 54.9 |
| Image,Retrieval,QuestionIbelieve the answeris{quantifier}{answer} | veryunlikely,unlikely,maybe,likely,verylikely,certainly | 39.0 | 65.3 | 54.9 | |
| Image,Question,Retrieval | {answer}is{quantifier}theanswer | veryunlikely,unlikely,maybe,likely,verylikely,certainly | 37.9 | 68.6 | 56.4 |
| 55.1 |
| PromptConstructionOrder | Prompt Template (Tprompt) | PossibleQuantifiers(Q) | Open Closed Overall | ||
|---|---|---|---|---|---|
| Question,Retrieval,Image | Ibelieve the answer is{quantifier}{answer} | veryunlikely,unlikely,maybe,likely,verylikely,certainly | 39.6 | 65.0 | 54.9 |
| Image,Retrieval,QuestionIbelieve the answeris{quantifier}{answer} | veryunlikely,unlikely,maybe,likely,verylikely,certainly | 39.0 | 65.3 | 54.9 | |
| Image,Question,Retrieval | {answer}is{quantifier}theanswer | veryunlikely,unlikely,maybe,likely,verylikely,certainly | 37.9 | 68.6 | 56.4 |
| 55.1 |
Table 6: Using different variants of our prompt results in similar performances. This table shows the open, closed, and overall accuracy of ${\bf M P R_{g e n_P M}}$ in a domain adaptation setting from SLAKE to VQA-RAD, retrieving $\mathrm{k}{=}1$ nearest question-image pairs.
表 6: 不同提示词变体对性能影响相近。本表展示了 ${\bf M P R_{g e n_P M}}$ 在从SLAKE到VQA-RAD的领域适应场景中,检索 $\mathrm{k}{=}1$ 个最近邻问答图像对时的开放型、封闭型及总体准确率。
B Prompt Variations
B 提示词变体
During the prompt construction process, we experiment with different prompt ordering and wording of retrieval prompts. We illustrate different template wording in the Prompt Template column of Table 6. Each prompt contains a quantifier that is filled in with an expression ranging from “very unlikely" to “certainly" based on the confidence score of $y^{*}$ , described in Section 3.2. We found that performance does not significantly change when changing these aspects of the prompt, and we ultimately decided to use settings in the last row of the table.
在提示构建过程中,我们尝试了不同的提示排序和检索提示的措辞方式。表6的"Prompt Template"列展示了不同模板措辞的示例。每个提示包含一个量化词,该词会根据$y^{*}$的置信度分数(如第3.2节所述)填入从"极不可能"到"肯定"不等的表达。我们发现改变提示的这些方面对性能影响不大,最终决定采用表格最后一行的设置。
C Dataset Information
C 数据集信息
Tables 7 and 8 report descriptive statistics about the datasets used in our experiments. Although the synthetic data contains more question-answer pairs than SLAKE and VQA-RAD, it has noisier labels and more limited question types. SLAKE and VQA-RAD have larger question-answer diversity and share several question types, such as Organ, Position, and Abnormality questions.
表7和表8展示了我们实验所用数据集的描述性统计信息。尽管合成数据比SLAKE和VQA-RAD包含更多问答对,但其标签噪声更大且问题类型更有限。SLAKE和VQA-RAD具有更大的问答多样性,并共享器官(Organ)、位置(Position)、异常(Abnormality)等若干问题类型。
Figure 5 displays our model’s in-domain accuracies on SLAKE and VQA-RAD. The models perform best on Color, Attribute, and Size questions in VQA-RAD. The disc rim i native variants have better accuracy overall, but can not be directly applied to other datasets. We observed lower accuracy on Modality and Organ questions in VQA-RAD, which we attribute to the diversity of question and answer phrasing in these VQA-RAD question types.
图 5 展示了我们的模型在SLAKE和VQA-RAD数据集上的领域内准确率。模型在VQA-RAD的Color(颜色)、Attribute(属性)和Size(尺寸)问题上表现最佳。判别式变体整体准确率更高,但无法直接应用于其他数据集。我们观察到模型在VQA-RAD的Modality(模态)和Organ(器官)问题上准确率较低,我们认为这是由于这些VQA-RAD问题类型中问题和答案表述的多样性所致。
Table 7: Statistics about the datasets in our experiments. The synthetic data contains three different question types because other types require domain-specific knowledge (e.g. abnormality, knowledge graph, etc).
| Dataset | TrainSplit | ValidationSplit | Test Split | Number of Question Types |
| SLAKE | 4918 | 1053 | 1061 | 10 |
| VQA-RAD | 3064 | 451 | 11 | |
| ROCO (image-caption only) | 65460 | 8183 | 8182 | |
| Synthetic | 56526 | 3 |
表 7: 实验中使用的数据集统计信息。合成数据包含三种不同的问题类型,因为其他类型需要领域特定知识 (例如异常检测、知识图谱等)。
| Dataset | TrainSplit | ValidationSplit | Test Split | Number of Question Types |
|---|---|---|---|---|
| SLAKE | 4918 | 1053 | 1061 | 10 |
| VQA-RAD | 3064 | 451 | 11 | |
| ROCO (image-caption only) | 65460 | 8183 | 8182 | |
| Synthetic | 56526 | 3 |
| SLAKE | VQA-RAD | Synthetic | |||
| QuestionType | PercentageofTestData | QuestionType | PercentageofTestData | QuestionType | PercentageofData |
| Shape | 0.66 | Color | 0.87 | Modality | 30.61 |
| Color | 3.20 | Quantity/Counting | 1.31 | Plane | 30.65 |
| Quantity | 4.90 | Organ | 2.18 | Organ | 38.74 |
| Plane | 5.47 | Attribute | 4.36 | ||
| Size | 6.13 | Other | 5.66 | ||
| Modality | 10.18 | Plane | 5.66 | ||
| Knowledge Graph | 13.95 | Modality | 7.19 | ||
| Abnormality | 14.14 | Size | 10.02 | ||
| Position | 17.53 | Abnormality | 12.20 | ||
| Organ | 23.85 | Position | 13.29 | ||
| Presence | 37.25 | ||||
Table 8: Composition of the datasets in our experiments. We use the English portion of the SLAKE dataset.
| SLAKE | VQA-RAD | Synthetic | |||
|---|---|---|---|---|---|
| 问题类型 | 测试数据百分比 | 问题类型 | 测试数据百分比 | 问题类型 | 数据百分比 |
| 形状 | 0.66 | 颜色 | 0.87 | 模态 | 30.61 |
| 颜色 | 3.20 | 数量/计数 | 1.31 | 平面 | 30.65 |
| 数量 | 4.90 | 器官 | 2.18 | 器官 | 38.74 |
| 平面 | 5.47 | 属性 | 4.36 | ||
| 大小 | 6.13 | 其他 | 5.66 | ||
| 模态 | 10.18 | 平面 | 5.66 | ||
| 知识图谱 | 13.95 | 模态 | 7.19 | ||
| 异常 | 14.14 | 异常 | 12.20 | ||
| 位置 | 17.53 | 位置 | 13.29 | ||
| 器官 | 23.85 | 存在 | 37.25 |
表 8: 实验中使用的数据集构成。我们使用了SLAKE数据集的英文部分。


Accuracies Across Question Types for VQA-RAD Data Figure 5: Accuracy for each question type for the SLAKE and VQA-RAD test datasets. Percentages on the $\mathbf{X}$ -axis indicate each question type’s proportion of the dataset.
图 5: SLAKE 和 VQA-RAD 测试数据集中各问题类型的准确率。X 轴上的百分比表示各问题类型在数据集中的占比。
D Attention Visualization
D Attention Visualization
Transformer-based models utilize attention to calculate dependencies between inputs which may be important for prediction. Since our MPR model uses a pretrained T5 encoder to combine features from several sources, a visualization of its attention scores may indicate which parts of the image contribute to its answers. Figure 6 illustrates the encoder self-attention in different attention heads and layers of our model when asked a challenging position question. The results suggest that some attention modules may attend to the entire input image (Layer 1, Head 4), whereas others may look for local dependencies by attending to adjacent tokens (Layer 2, Head 7).
基于Transformer的模型利用注意力机制计算输入之间的依赖关系,这些关系可能对预测很重要。由于我们的MPR模型使用预训练的T5编码器来组合多个来源的特征,其注意力分数的可视化可以表明图像的哪些部分对答案有贡献。图6展示了当模型被问到一个具有挑战性的位置问题时,在不同注意力头和层中的编码器自注意力情况。结果表明,一些注意力模块可能会关注整个输入图像(第1层,第4个头),而其他模块则可能通过关注相邻的Token来寻找局部依赖关系(第2层,第7个头)。
In addition to encoder self-attention, cross attention in encoder-decoder transformer architectures may also illustrate which tokens from the input prompt contribute the most when generating answer tokens. Since the prompt to our model consists of image tokens, we visualize which image regions have the highest attention scores in 8.
除了编码器自注意力机制外,编码器-解码器Transformer架构中的交叉注意力也能展示输入提示(prompt)中哪些token对生成答案token的贡献最大。由于我们模型的输入提示由图像token组成,我们在图8中可视化了哪些图像区域具有最高的注意力分数。
Existing work has shown the effectiveness of using retrieval from a data store to rapidly adapt language models to new domains (Khandelwal et al., 2020). KNN LMs uses a blending parameter $\lambda\in[0,1]$ to control the influence of retrieved information towards prediction:
现有研究表明,利用数据存储检索能有效实现语言模型对新领域的快速适配 (Khandelwal et al., 2020) 。KNN LMs通过混合参数$\lambda\in[0,1]$控制检索信息对预测的影响程度:
$$
\lambda\mathrm{pkNN}(y|x)+(1-\lambda)\mathrm{pLM}(y|x)
$$
$$
\lambda\mathrm{pkNN}(y|x)+(1-\lambda)\mathrm{pLM}(y|x)
$$
This method assumes the availability of a language model $\mathrm{pLM}(y|x)$ and a retrieval model $\mathrm{pkNN}(y|x)$ which can predict the next vocabulary token $y$ given context $x$ . However, given our retrieval set which consists of variable length answers and image data, it is difficult to estimate $\mathrm{pkNN}(y|x)$ directly from our data store. Consequently, we augment our model input with retrieval prompts to allow for the implicit learning of retrieval reliance in an end-to-end manner. Figure 7 shows the average cross attention scores to the retrieval portion of the prompt when evaluating on test data. The results demonstrate that when the model prediction matches the retrieved answer, the attention scores to the corresponding prompt section are significantly higher. Based on this observation, we believe the model has learned how to weigh the retrieved information through end-to-end training.
该方法假设存在一个语言模型 $\mathrm{pLM}(y|x)$ 和一个检索模型 $\mathrm{pkNN}(y|x)$ ,它们能够根据上下文 $x$ 预测下一个词汇token $y$ 。然而,由于我们的检索集包含可变长度的答案和图像数据,很难直接从数据存储中估计 $\mathrm{pkNN}(y|x)$ 。因此,我们通过检索提示来增强模型输入,从而以端到端的方式隐式学习对检索的依赖。图 7 展示了在测试数据上评估时,对提示中检索部分的平均交叉注意力分数。结果表明,当模型预测与检索到的答案匹配时,对相应提示部分的注意力分数显著更高。基于这一观察,我们认为模型通过端到端训练学会了如何权衡检索到的信息。

Figure 6: Selected encoder self-attention visualization s across different encoder layers and attention heads. ITK represents an image-token from the input image.
图 6: 不同编码器层和注意力头中选取的编码器自注意力可视化。ITK表示输入图像中的图像token。

Figure 7: Average attention score to the retrieval prompt for each attention module in our T5 encoder. When the model predicts the retrieved answer, attention scores to the retrieved information is significantly higher.
图 7: T5编码器中各注意力模块对检索提示的平均注意力分数。当模型预测检索答案时,对检索信息的注意力分数显著更高。

Figure 8: Top: The original image and question input to the model, followed by the average attention scores for each image patch, with darker patches corresponding to lower scores. Bottom: When predicting each word in the answer span, which input image regions are attended to.
图 8: 上: 输入模型的原始图像和问题,随后是每个图像块的平均注意力分数,颜色越深的块对应分数越低。下: 在预测答案范围内每个词时,模型关注了哪些输入图像区域。
A For every submission:
针对每份提交:
A1. Did you describe the limitations of your work? Section 8
A1. 是否描述了工作的局限性? 第8节
A2. Did you discuss any potential risks of your work? Section 9
A2. 是否讨论了工作的潜在风险?第9节
A3. Do the abstract and introduction summarize the paper’s main claims? Section 1
A3. 摘要和引言是否总结了论文的主要主张? 第1节
A4. Have you used AI writing assistants when working on this paper? Left blank.
A4. 在撰写本文时是否使用了AI写作助手?留空。
B Did you use or create scientific artifacts?
B 是否使用或创建了科学制品?
Section 3
第3节
B1. Did you cite the creators of artifacts you used? Section 3, Section 4.3
B1. 你是否引用了所使用产物的创作者?第3节、第4.3节
α B2. Did you discuss the license or terms for use and / or distribution of any artifacts? All datasets and artifact models used in this study are publicly available and we provide links/citations to them.
B2. 是否讨论了任何产物的使用和/或分发许可或条款?本研究中使用的所有数据集和模型均为公开可用,我们提供了相关链接/引用。
B3. Did you discussif your use of existing artifact(s) was consistent with their intended use, provided that it was specified? For the artifacts you create, do you specify intended use and whether that is compatible with the original access conditions (in particular, derivatives of data accessed for research purposes should not be used outside of research contexts)? Section 3
B3. 你是否讨论过对现有成果(artifact)的使用是否符合其指定用途(前提是用途已明确说明)? 对于你创建的成果,是否明确指定了预期用途及其是否与原始访问条件兼容(特别是基于研究目的获取的数据衍生物不应在研究情境之外使用)? 第3节
C Did you run computational experiments?
C 是否进行了计算实验?
Section 5
第5节
C1. Did you report the number of parameters in the models used,the total computational budget (e.g., GPU hours), and computing infrastructure used? Section 3.4, Section 4
C1. 是否报告了所用模型的参数量、总计算预算(如 GPU 小时数)以及使用的计算基础设施?第 3.4 节,第 4 节
C2. Did you discuss the experimental setup, including hyper parameter search and best-found hyper parameter values? Section 4
C2. 是否讨论了实验设置,包括超参数搜索和找到的最佳超参数值?第4节
C3. Did you report descriptive statistics about your results e.g., error bars around results, summary statistics from sets of experiments), and is it transparent whether you are reporting the max, mean, etc. or just a single run? Section 4, Section 5
C3. 是否报告了结果的描述性统计信息(例如误差条、多组实验的汇总统计),并明确说明报告的是最大值、均值等指标还是单次运行结果?第4节、第5节
C4. If yuu exsting ackages (, fr prep roe sing,fr rm aliz ation, or fr val at in, you report the implementation, model, and parameter settings used (e.g., NLTK, Spacy, ROUGE, etc.)? Section 4. Code and instructions to reproduce our results are provided in our GitHub repository.
C4. 如果使用了现有工具包(例如用于预处理、规范化或验证的工具包,如 NLTK、Spacy、ROUGE 等),是否报告了所用实现、模型和参数设置?第4节。我们的 GitHub 仓库中提供了复现结果的代码和说明。
D α Did you use human annotators (e.g., crowd workers) or research with human participants? Left blank.
D α 是否使用了人工标注员(例如众包工作者)或进行了人类参与者研究?留空。
□ D1. Did you report the full text of instructions given to participants, including e.g., screenshots, disclaimers of any risks to participants or annotators, etc.? No response.
□ D1. 是否报告了提供给参与者的完整指令文本,包括例如截图、对参与者或标注者任何风险的免责声明等?未回应。
□ D2. Did you report information about how you recruited (e.g., crowd sourcing platform, students) and paid participants, and discuss if such payment is adequate given the participants’ demographic (e.g., country of residence)? No response.
□ D2. 你是否报告了招募参与者(例如众包平台、学生)和支付报酬的方式,并讨论了根据参与者人口统计特征(例如居住国家)该报酬是否合理?无回应。
□ D3. Did you discuss whether and how consent was obtained from people whose data you’re using/curating? For example, if you collected data via crowd sourcing, did your instructions to crowd workers explain how the data would be used? No response.
□ D3. 你是否讨论了从数据提供者/管理者处获取同意的方式及过程?例如,若通过众包收集数据,是否向众包工作者说明数据用途?未答复。
□ D4. Was the data collection protocol approved (or determined exempt) by an ethics review board? No response.
□ D4. 数据收集方案是否获得伦理审查委员会批准(或判定为豁免)?无回应。
□ D5. Did you report the basic demographic and geographic characteristics of the annotator population that is the source of the data? No response.
□ D5. 是否报告了作为数据来源的标注人群的基本人口统计学和地理特征?未回应。