Distributed Representations of Words and Phrases and their Compositional it y
词与短语的分布式表示及其组合性
Greg Corrado Google Inc. Mountain View gcorrado@google.com
Greg Corrado Google Inc. Mountain View gcorrado@google.com
Abstract
摘要
The recently introduced continuous Skip-gram model is an efficient method for learning high-quality distributed vector representations that capture a large number of precise syntactic and semantic word relationships. In this paper we present several extensions that improve both the quality of the vectors and the training speed. By sub sampling of the frequent words we obtain significant speedup and also learn more regular word representations. We also describe a simple alternative to the hierarchical softmax called negative sampling.
最近提出的连续Skip-gram模型是一种高效的方法,用于学习高质量的分布式向量表示,这些表示能捕捉大量精确的句法和语义词汇关系。本文提出了几种改进方法,既能提升向量质量又能加快训练速度。通过对高频词进行子采样,我们实现了显著加速,同时学到了更规则的词表示。我们还描述了一种称为负采样(negative sampling)的简单替代方案,用于取代分层softmax。
An inherent limitation of word representations is their indifference to word order and their inability to represent idiomatic phrases. For example, the meanings of “Canada” and “Air” cannot be easily combined to obtain “Air Canada”. Motivated by this example, we present a simple method for finding phrases in text, and show that learning good vector representations for millions of phrases is possible.
词表示的一个固有局限是它们对词序不敏感,且无法表示惯用短语。例如,"Canada"和"Air"的含义无法简单组合得到"Air Canada"。受此启发,我们提出了一种在文本中查找短语的简单方法,并证明为数百万短语学习优质向量表示是可行的。
1 Introduction
1 引言
Distributed representations of words in a vector space help learning algorithms to achieve better performance in natural language processing tasks by grouping similar words. One of the earliest use of word representations dates back to 1986 due to Rumelhart, Hinton, and Williams [13]. This idea has since been applied to statistical language modeling with considerable success [1]. The follow up work includes applications to automatic speech recognition and machine translation [14, 7], and a wide range of NLP tasks [2, 20, 15, 3, 18, 19, 9].
词语在向量空间中的分布式表示通过将相似词语分组,帮助学习算法在自然语言处理任务中获得更好性能。最早使用词语表示的研究可追溯到1986年Rumelhart、Hinton和Williams的工作 [13]。该思想随后被成功应用于统计语言建模 [1],后续研究还包括自动语音识别与机器翻译 [14, 7] 以及各类自然语言处理任务 [2, 20, 15, 3, 18, 19, 9]。
Recently, Mikolov et al. [8] introduced the Skip-gram model, an efficient method for learning highquality vector representations of words from large amounts of unstructured text data. Unlike most of the previously used neural network architectures for learning word vectors, training of the Skipgram model (see Figure 1) does not involve dense matrix multiplications. This makes the training extremely efficient: an optimized single-machine implementation can train on more than 100 billion words in one day.
最近,Mikolov等人[8]提出了Skip-gram模型,这是一种从大量非结构化文本数据中学习高质量词向量表示的高效方法。与之前大多数用于学习词向量的神经网络架构不同,Skip-gram模型的训练(见图1)不涉及密集矩阵乘法。这使得训练效率极高:经过优化的单机实现可以在一天内处理超过1000亿单词。
The word representations computed using neural networks are very interesting because the learned vectors explicitly encode many linguistic regularities and patterns. Somewhat surprisingly, many of these patterns can be represented as linear translations. For example, the result of a vector calculation vec(“Madrid”) - vec(“Spain”) $^+$ vec(“France”) is closer to vec(“Paris”) than to any other word vector [9, 8].
通过神经网络计算得到的词表征非常有趣,因为学习到的向量明确编码了许多语言规律和模式。有些令人惊讶的是,这些模式中有许多可以表示为线性转换。例如,向量计算 vec("Madrid") - vec("Spain") $^+$ vec("France") 的结果更接近 vec("Paris") 而非其他任何词向量 [9, 8]。
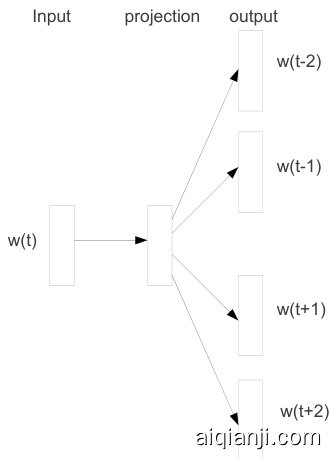
Figure 1: The Skip-gram model architecture. The training objective is to learn word vector representations that are good at predicting the nearby words.
图 1: Skip-gram模型架构。训练目标是学习擅长预测邻近单词的词向量表示。
In this paper we present several extensions of the original Skip-gram model. We show that subsampling of frequent words during training results in a significant speedup (around $2\mathrm{x}\textrm{-}10\mathrm{x}$ ), and improves accuracy of the representations of less frequent words. In addition, we present a simplified variant of Noise Contrastive Estimation (NCE) [4] for training the Skip-gram model that results in faster training and better vector representations for frequent words, compared to more complex hierarchical softmax that was used in the prior work [8].
本文提出了原始Skip-gram模型的若干扩展。我们发现,在训练过程中对高频词进行子采样能显著加速训练(约 $2\mathrm{x}\textrm{-}10\mathrm{x}$ ),同时提升低频词表征的准确性。此外,我们提出了一种简化的噪声对比估计(NCE) [4]变体用于训练Skip-gram模型,与先前工作中使用的复杂分层softmax方法[8]相比,该方法能加快训练速度并改善高频词的向量表征效果。
Word representations are limited by their inability to represent idiomatic phrases that are not compositions of the individual words. For example, “Boston Globe” is a newspaper, and so it is not a natural combination of the meanings of “Boston” and “Globe”. Therefore, using vectors to represent the whole phrases makes the Skip-gram model considerably more expressive. Other techniques that aim to represent meaning of sentences by composing the word vectors, such as the recursive auto encoders [15], would also benefit from using phrase vectors instead of the word vectors.
词表示法的局限性在于无法表达非单个词组合的惯用短语。例如,"Boston Globe"是一份报纸,并非"Boston"和"Globe"含义的自然组合。因此,使用向量表示整个短语能显著提升Skip-gram模型的表达能力。其他通过组合词向量来表征句子含义的技术(如递归自动编码器[15])同样会受益于使用短语向量而非词向量。
The extension from word based to phrase based models is relatively simple. First we identify a large number of phrases using a data-driven approach, and then we treat the phrases as individual tokens during the training. To evaluate the quality of the phrase vectors, we developed a test set of analogical reasoning tasks that contains both words and phrases. A typical analogy pair from our test set is “Montreal”:“Montreal Canadiens”::“Toronto”:“Toronto Maple Leafs”. It is considered to have been answered correctly if the nearest representation to vec(“Montreal Canadiens”) - vec(“Montreal”) $^+$ vec(“Toronto”) is vec(“Toronto Maple Leafs”).
从基于单词到基于短语的模型扩展相对简单。首先,我们采用数据驱动的方法识别大量短语,然后在训练过程中将这些短语视为独立token。为了评估短语向量的质量,我们开发了一个包含单词和短语的类比推理任务测试集。测试集中一个典型的类比对是"Montreal":"Montreal Canadiens"::"Toronto":"Toronto Maple Leafs"。当vec("Montreal Canadiens") - vec("Montreal") $^+$ vec("Toronto")的最近邻表示是vec("Toronto Maple Leafs")时,即认为回答正确。
Finally, we describe another interesting property of the Skip-gram model. We found that simple vector addition can often produce meaningful results. For example, vec(“Russia”) $^+$ vec(“river”) is close to vec(“Volga River”), and vec(“Germany”) $^+$ vec(“capital”) is close to vec(“Berlin”). This compositional it y suggests that a non-obvious degree of language understanding can be obtained by using basic mathematical operations on the word vector representations.
最后,我们描述Skip-gram模型的另一个有趣特性。我们发现简单的向量加法常能产生有意义的结果。例如,vec("Russia") $^+$ vec("river")接近vec("Volga River"),而vec("Germany") $^+$ vec("capital")接近vec("Berlin")。这种组合性表明,通过对词向量表征进行基础数学运算,可以获得非显式的语言理解能力。
2 The Skip-gram Model
2 Skip-gram模型
The training objective of the Skip-gram model is to find word representations that are useful for predicting the surrounding words in a sentence or a document. More formally, given a sequence of training words $w_ {1},w_ {2},w_ {3},\dots,w_ {T}$ , the objective of the Skip-gram model is to maximize the average log probability
Skip-gram模型的训练目标是找到对预测句子或文档中周围词汇有用的词向量表示。更正式地说,给定训练词序列$w_ {1},w_ {2},w_ {3},\dots,w_ {T}$,Skip-gram模型的目标是最大化平均对数概率
$$
\frac1T\sum_ {t=1}^{T}\sum_ {-c\leq j\leq c,j\neq0}\log p(w_ {t+j}|w_ {t})
$$
$$
\frac1T\sum_ {t=1}^{T}\sum_ {-c\leq j\leq c,j\neq0}\log p(w_ {t+j}|w_ {t})
$$
where $c$ is the size of the training context (which can be a function of the center word $w_ {t}$ ). Larger $c$ results in more training examples and thus can lead to a higher accuracy, at the expense of the
其中 $c$ 是训练上下文的大小(可以是中心词 $w_ {t}$ 的函数)。较大的 $c$ 会产生更多训练样本,从而提高准确率,但代价是
training time. The basic Skip-gram formulation defines $p(w_ {t+j}|w_ {t})$ using the softmax function:
训练时间。基础的 Skip-gram 模型使用 softmax 函数定义 $p(w_ {t+j}|w_ {t})$:
$$
p(w_ {O}|w_ {I})=\frac{\exp\left({v_ {w_ {O}}^{\prime}}^{\top}v_ {w_ {I}}\right)}{\sum_ {w=1}^{W}\exp\left({v_ {w}^{\prime}}^{\top}v_ {w_ {I}}\right)}
$$
$$
p(w_ {O}|w_ {I})=\frac{\exp\left({v_ {w_ {O}}^{\prime}}^{\top}v_ {w_ {I}}\right)}{\sum_ {w=1}^{W}\exp\left({v_ {w}^{\prime}}^{\top}v_ {w_ {I}}\right)}
$$
where $v_ {w}$ and $v_ {w}^{\prime}$ are the “input” and “output” vector representations of $w$ , and $W$ is the number of words in the vocabulary. This formulation is impractical because the cost of computing $\nabla\log p(w_ {O}|w_ {I})$ is proportional to $W$ , which is often large $\mathrm{10^{5}-10^{7}}$ terms).
其中 $v_ {w}$ 和 $v_ {w}^{\prime}$ 是 $w$ 的"输入"和"输出"向量表示,$W$ 是词汇表中的单词数量。这个公式在实际应用中不可行,因为计算 $\nabla\log p(w_ {O}|w_ {I})$ 的成本与 $W$ 成正比,而 $W$ 通常很大 (达到 $10^{5}-10^{7}$ 量级)。
2.1 Hierarchical Softmax
2.1 分层Softmax
A computationally efficient approximation of the full softmax is the hierarchical softmax. In the context of neural network language models, it was first introduced by Morin and Bengio [12]. The main advantage is that instead of evaluating $W$ output nodes in the neural network to obtain the probability distribution, it is needed to evaluate only about $\log_ {2}(W)$ nodes.
一种计算高效的完整softmax近似方法是分层softmax (hierarchical softmax)。在神经网络语言模型领域,该方法最早由Morin和Bengio [12]提出。其主要优势在于:无需评估神经网络中的$W$个输出节点来获取概率分布,仅需评估约$\log_ {2}(W)$个节点即可。
The hierarchical softmax uses a binary tree representation of the output layer with the $W$ words as its leaves and, for each node, explicitly represents the relative probabilities of its child nodes. These define a random walk that assigns probabilities to words.
分层softmax使用输出层的二叉树表示,其中$W$个词作为叶子节点,并为每个节点显式表示其子节点的相对概率。这些定义了一个随机游走过程,为词分配概率。
More precisely, each word $w$ can be reached by an appropriate path from the root of the tree. Let $n(w,\bar{j})$ be the $j$ -th node on the path from the root to $w$ , and let $L(w)$ be the length of this path, so $n(w,1)=\mathrm{root}$ and $n(w,L(w))=w$ . In addition, for any inner node $n$ , let $\operatorname{ch}(n)$ be an arbitrary fixed child of $n$ and let $[[x]]$ be 1 if $x$ is true and $^{-1}$ otherwise. Then the hierarchical softmax defines $p(w_ {O}|w_ {I})$ as follows:
更准确地说,每个词 $w$ 都可以通过从树根出发的适当路径到达。设 $n(w,\bar{j})$ 为从根节点到 $w$ 的路径上的第 $j$ 个节点,$L(w)$ 表示该路径的长度,因此 $n(w,1)=\mathrm{root}$ 且 $n(w,L(w))=w$ 。此外,对于任意内部节点 $n$ ,设 $\operatorname{ch}(n)$ 为 $n$ 的任意固定子节点,并定义 $[[x]]$ 在 $x$ 为真时取值为1,否则为 $^{-1}$ 。那么分层softmax将 $p(w_ {O}|w_ {I})$ 定义如下:
$$
p(w|w_ {I})=\prod_ {j=1}^{L(w)-1}\sigma\left(\mathbb{I}\boldsymbol{n}(w,j+1)=\mathrm{ch}(\boldsymbol{n}(w,j))\mathbb{I}\cdot{v_ {n}^{\prime}}_ {(w,j)}\top\tau_ {w_ {I}}\right)
$$
$$
p(w|w_ {I})=\prod_ {j=1}^{L(w)-1}\sigma\left(\mathbb{I}\boldsymbol{n}(w,j+1)=\mathrm{ch}(\boldsymbol{n}(w,j))\mathbb{I}\cdot{v_ {n}^{\prime}}_ {(w,j)}\top\tau_ {w_ {I}}\right)
$$
where $\sigma(x)=1/(1+\exp(-x))$ . It can be verified that $\begin{array}{r}{\sum_ {w=1}^{W}p(w|w_ {I})=1}\end{array}$ . This implies that the cost of computing $\log p(w_ {O}|w_ {I})$ and $\nabla\log p(w_ {O}|w_ {I})$ is P proportional to $L(w_ {O})$ , which on average is no greater than $\log W$ . Also, unlike the standard softmax formulation of the Skip-gram which assigns two representations $v_ {w}$ and $v_ {w}^{\prime}$ to each word $w$ , the hierarchical softmax formulation has one representation $v_ {w}$ for each word $w$ and one representation $v_ {n}^{\prime}$ for every inner node $n$ of the binary tree.
其中 $\sigma(x)=1/(1+\exp(-x))$。可以验证 $\begin{array}{r}{\sum_ {w=1}^{W}p(w|w_ {I})=1}\end{array}$。这意味着计算 $\log p(w_ {O}|w_ {I})$ 和 $\nabla\log p(w_ {O}|w_ {I})$ 的代价与 $L(w_ {O})$ 成正比,平均不超过 $\log W$。此外,与Skip-gram的标准softmax公式(为每个词 $w$ 分配两个表示 $v_ {w}$ 和 $v_ {w}^{\prime}$)不同,分层softmax公式为每个词 $w$ 保留一个表示 $v_ {w}$,并为二叉树的每个内部节点 $n$ 分配一个表示 $v_ {n}^{\prime}$。
The structure of the tree used by the hierarchical softmax has a considerable effect on the performance. Mnih and Hinton explored a number of methods for constructing the tree structure and the effect on both the training time and the resulting model accuracy [10]. In our work we use a binary Huffman tree, as it assigns short codes to the frequent words which results in fast training. It has been observed before that grouping words together by their frequency works well as a very simple speedup technique for the neural network based language models [5, 8].
分层softmax所使用的树结构对性能有显著影响。Mnih和Hinton探索了多种构建树结构的方法及其对训练时间和模型准确率的影响 [10]。在我们的工作中,我们采用二进制哈夫曼树,因为它能为高频词分配短编码,从而加速训练。此前已有研究观察到,按词频对单词进行分组是一种非常简单的神经网络语言模型加速技术 [5, 8]。
2.2 Negative Sampling
2.2 负采样
An alternative to the hierarchical softmax is Noise Contrastive Estimation (NCE), which was introduced by Gutmann and Hyvarinen [4] and applied to language modeling by Mnih and Teh [11]. NCE posits that a good model should be able to differentiate data from noise by means of logistic regression. This is similar to hinge loss used by Collobert and Weston [2] who trained the models by ranking the data above noise.
分层softmax的替代方法是噪声对比估计(NCE),由Gutmann和Hyvarinen [4]提出,并被Mnih和Teh [11]应用于语言建模。NCE认为,好的模型应该能够通过逻辑回归区分数据和噪声。这与Collobert和Weston [2]使用的铰链损失类似,他们通过将数据排在噪声之上来训练模型。
While NCE can be shown to approximately maximize the log probability of the softmax, the Skipgram model is only concerned with learning high-quality vector representations, so we are free to simplify NCE as long as the vector representations retain their quality. We define Negative sampling (NEG) by the objective
虽然NCE可被证明能近似最大化softmax的对数概率,但Skipgram模型仅关注学习高质量的向量表示,因此只要向量表示保持质量,我们可以自由简化NCE。我们通过目标函数定义负采样(NEG)
$$
\log\sigma({v_ {w_ {O}}^{\prime}}^{\top}v_ {w_ {I}})+\sum_ {i=1}^{k}\mathbb{E}_ {w_ {i}\sim P_ {n}(w)}\left[\log\sigma(-{v_ {w_ {i}}^{\prime}}^{\top}v_ {w_ {I}})\right]
$$
$$
\log\sigma({v_ {w_ {O}}^{\prime}}^{\top}v_ {w_ {I}})+\sum_ {i=1}^{k}\mathbb{E}_ {w_ {i}\sim P_ {n}(w)}\left[\log\sigma(-{v_ {w_ {i}}^{\prime}}^{\top}v_ {w_ {I}})\right]
$$

Figure 2: Two-dimensional PCA projection of the 1000-dimensional Skip-gram vectors of countries and their capital cities. The figure illustrates ability of the model to automatically organize concepts and learn implicitly the relationships between them, as during the training we did not provide any supervised information about what a capital city means.
图 2: 国家及其首都城市的1000维Skip-gram向量二维PCA投影图。该图展示了模型自动组织概念并隐式学习其间关系的能力,因为在训练过程中我们没有提供任何关于首都含义的监督信息。
which is used to replace every $\log P(w_ {O}|w_ {I})$ term in the Skip-gram objective. Thus the task is to distinguish the target word $w_ {O}$ from draws from the noise distribution $P_ {n}(w)$ using logistic regression, where there are $k$ negative samples for each data sample. Our experiments indicate that values of $k$ in the range 5–20 are useful for small training datasets, while for large datasets the $k$ can be as small as 2–5. The main difference between the Negative sampling and NCE is that NCE needs both samples and the numerical probabilities of the noise distribution, while Negative sampling uses only samples. And while NCE approximately maximizes the log probability of the softmax, this property is not important for our application.
用于替换Skip-gram目标函数中每个$\log P(w_ {O}|w_ {I})$项。该任务旨在通过逻辑回归从噪声分布$P_ {n}(w)$的采样中区分目标词$w_ {O}$,其中每个数据样本对应$k$个负样本。实验表明,对于小规模训练数据集,$k$值取5-20效果较好;而对于大规模数据集,$k$可小至2-5。负采样(negative sampling)与噪声对比估计(NCE)的主要区别在于:NCE需要同时使用噪声分布的样本及其数值概率,而负采样仅需样本。此外,虽然NCE能近似最大化softmax的对数概率,但这一特性对我们的应用并不重要。
Both NCE and NEG have the noise distribution $P_ {n}(w)$ as a free parameter. We investigated a number of choices for $P_ {n}(w)$ and found that the unigram distribution $U(w)$ raised to the $3/4\mathrm{rd}$ power (i.e., $U(w)^{3/4}/Z)$ outperformed significantly the unigram and the uniform distributions, for both NCE and NEG on every task we tried including language modeling (not reported here).
NCE和NEG都将噪声分布$P_ {n}(w)$作为自由参数。我们研究了$P_ {n}(w)$的多种选择,发现对于包括语言建模(此处未报告)在内的所有任务,无论是NCE还是NEG,将一元分布$U(w)$提升至$3/4$次方(即$U(w)^{3/4}/Z$)的表现均显著优于一元分布和均匀分布。
2.3 Sub sampling of Frequent Words
2.3 高频词子采样
In very large corpora, the most frequent words can easily occur hundreds of millions of times (e.g., “in”, “the”, and “a”). Such words usually provide less information value than the rare words. For example, while the Skip-gram model benefits from observing the co-occurrences of “France” and “Paris”, it benefits much less from observing the frequent co-occurrences of “France” and “the”, as nearly every word co-occurs frequently within a sentence with “the”. This idea can also be applied in the opposite direction; the vector representations of frequent words do not change significantly after training on several million examples.
在超大规模语料库中,最高频词(如"in"、"the"、"a")的出现次数可能高达数亿次。这类高频词的信息价值通常低于罕见词。例如,Skip-gram模型虽然能从"France"和"Paris"的共现中获益,但"France"与"the"这类高频共现(几乎所有词都会与"the"在句子中共现)带来的训练收益则小得多。这一现象也存在反向效应:高频词的向量表征在经过数百万样本训练后往往不会发生显著变化。
To counter the imbalance between the rare and frequent words, we used a simple sub sampling approach: each word $w_ {i}$ in the training set is discarded with probability computed by the formula
为了应对罕见词与高频词之间的不平衡问题,我们采用了一种简单的子采样方法:训练集中的每个词 $w_ {i}$ 会按照以下公式计算出的概率被丢弃
$$
P(w_ {i})=1-{\sqrt{\frac{t}{f(w_ {i})}}}
$$
Table 1: Accuracy of various Skip-gram 300-dimensional models on the analogical reasoning task as defined in [8]. NEG $k$ stands for Negative Sampling with $k$ negative samples for each positive sample; NCE stands for Noise Contrastive Estimation and HS-Huffman stands for the Hierarchical Softmax with the frequency-based Huffman codes.
| Method | Time[min] | Syntactic[%] | Semantic[%] | Total accuracy [%] |
| NEG-5 | 38 | 63 | 54 | 59 |
| NEG-15 | 97 | 63 | 58 | 61 |
| HS-Huffman | 41 | 53 | 40 | 47 |
| NCE-5 | 38 | 60 | 45 | 53 |
| The following results use 10-5 subsampling | ||||
| NEG-5 | 14 | 61 | 58 | 60 |
| NEG-15 | 36 | 61 | 61 | 61 |
| HS-Huffman | 21 | 52 | 59 | 55 |
表 1: 不同Skip-gram 300维模型在[8]定义的类比推理任务上的准确率。NEG $k$ 表示每个正样本使用 $k$ 个负样本的负采样;NCE表示噪声对比估计,HS-Huffman表示基于频率的霍夫曼编码的分层Softmax。
| 方法 | 时间[分钟] | 句法[%] | 语义[%] | 总准确率[%] |
|---|---|---|---|---|
| NEG-5 | 38 | 63 | 54 | 59 |
| NEG-15 | 97 | 63 | 58 | 61 |
| HS-Huffman | 41 | 53 | 40 | 47 |
| NCE-5 | 38 | 60 | 45 | 53 |
| 以下结果使用10-5子采样 | ||||
| NEG-5 | 14 | 61 | 58 | 60 |
| NEG-15 | 36 | 61 | 61 | 61 |
| HS-Huffman | 21 | 52 | 59 | 55 |
where $f(w_ {i})$ is the frequency of word $w_ {i}$ and $t$ is a chosen threshold, typically around $10^{-5}$ . We chose this sub sampling formula because it aggressively subsamples words whose frequency is greater than $t$ while preserving the ranking of the frequencies. Although this sub sampling formula was chosen heuristic ally, we found it to work well in practice. It accelerates learning and even significantly improves the accuracy of the learned vectors of the rare words, as will be shown in the following sections.
其中 $f(w_ {i})$ 是单词 $w_ {i}$ 的频率,$t$ 是选定的阈值,通常约为 $10^{-5}$。我们选择这个子采样公式是因为它能积极对频率高于 $t$ 的单词进行子采样,同时保留频率的排序。尽管这个子采样公式是启发式选择的,但我们发现它在实践中效果良好。如下文所示,它加速了学习过程,甚至显著提高了罕见词向量的学习准确性。
3 Empirical Results
3 实证结果
In this section we evaluate the Hierarchical Softmax (HS), Noise Contrastive Estimation, Negative Sampling, and sub sampling of the training words. We used the analogical reasoning task introduced by Mikolov et al. [8]. The task consists of analogies such as “Germany” : “Berlin” :: “France” : ?, which are solved by finding a vector $\mathbf{x}$ such that $\operatorname{vec}(\mathbf{x})$ is closest to vec(“Berlin”) - vec(“Germany”) $^+$ vec(“France”) according to the cosine distance (we discard the input words from the search). This specific example is considered to have been answered correctly if $\mathbf{x}$ is “Paris”. The task has two broad categories: the syntactic analogies (such as “quick” : “quickly” :: “slow” : “slowly”) and the semantic analogies, such as the country to capital city relationship.
在本节中,我们评估了分层Softmax (HS)、噪声对比估计、负采样以及训练词的子采样方法。我们采用了Mikolov等人[8]提出的类比推理任务。该任务包含类似"德国" : "柏林" :: "法国" : ?的类比问题,解决方法是通过寻找向量$\mathbf{x}$,使得$\operatorname{vec}(\mathbf{x})$在余弦距离上最接近vec("柏林") - vec("德国") $^+$ vec("法国")(搜索时排除输入词)。如果$\mathbf{x}$为"巴黎",则认为该特例回答正确。该任务分为两大类:句法类比(如"快" : "快速地" :: "慢" : "慢慢地")和语义类比(如国家与首都的关系)。
For training the Skip-gram models, we have used a large dataset consisting of various news articles (an internal Google dataset with one billion words). We discarded from the vocabulary all words that occurred less than 5 times in the training data, which resulted in a vocabulary of size 692K. The performance of various Skip-gram models on the word analogy test set is reported in Table 1. The table shows that Negative Sampling outperforms the Hierarchical Softmax on the analogical reasoning task, and has even slightly better performance than the Noise Contrastive Estimation. The sub sampling of the frequent words improves the training speed several times and makes the word representations significantly more accurate.
为了训练Skip-gram模型,我们使用了一个包含各类新闻文章的大型数据集(谷歌内部数据集,包含10亿单词)。我们从词汇表中剔除了训练数据中出现次数少于5次的所有单词,最终得到一个包含69.2万单词的词汇表。表1展示了不同Skip-gram模型在词语类比测试集上的表现。结果表明,在类比推理任务中,负采样(Negative Sampling)的表现优于层次Softmax(Hierarchical Softmax),甚至略优于噪声对比估计(Noise Contrastive Estimation)。对高频词进行子采样不仅使训练速度提升数倍,还显著提高了词向量的准确性。
It can be argued that the linearity of the skip-gram model makes its vectors more suitable for such linear analogical reasoning, but the results of Mikolov et al. [8] also show that the vectors learned by the standard sigmoidal recurrent neural networks (which are highly non-linear) improve on this task significantly as the amount of the training data increases, suggesting that non-linear models also have a preference for a linear structure of the word representations.
可以认为,skip-gram模型的线性特性使其向量更适合此类线性类比推理,但Mikolov等人的研究结果[8]也表明,随着训练数据量的增加,标准sigmoid循环神经网络(具有高度非线性)学习到的向量在该任务上也有显著提升,这表明非线性模型同样偏好词表征的线性结构。
4 Learning Phrases
4 学习短语
As discussed earlier, many phrases have a meaning that is not a simple composition of the meanings of its individual words. To learn vector representation for phrases, we first find words that appear frequently together, and infrequently in other contexts. For example, “New York Times” and “Toronto Maple Leafs” are replaced by unique tokens in the training data, while a bigram “this is” will remain unchanged.
如前所述,许多短语的含义并非其单个词语意义的简单组合。为了学习短语的向量表示,我们首先找出频繁共现但在其他上下文中罕见的词语组合。例如,"New York Times"和"Toronto Maple Leafs"在训练数据中被替换为唯一token,而二元词组"this is"则保持不变。
Table 2: Examples of the analogical reasoning task for phrases (the full test set has 3218 examples). The goal is to compute the fourth phrase using the first three. Our best model achieved an accuracy of $72%$ on this dataset.
| Newspapers | |||
| NewYork SanJose | NewYorkTimes SanJoseMercuryNews | Baltimore Cincinnati | BaltimoreSun Cincinnati Enquirer |
| NHL Teams | |||
| Boston Phoenix | Boston Bruins Phoenix Coyotes | Montreal Nashville | MontrealCanadiens NashvillePredators |
| NBATeams | |||
| Detroit Oakland | DetroitPistons GoldenStateWarriors Airlines | Toronto Memphis | Toronto Raptors Memphis Grizzlies |
| AustrianAirlines | |||
| Austria Belgium | Brussels Airlines | Spain Greece | Spainair AegeanAirlines |
| Company executives | |||
| SteveBallmer Samuel J.Palmisano | Microsoft IBM | Larry Page WernerVogels | Google Amazon |
表 2: 短语类比推理任务示例(完整测试集包含3218个样本)。目标是根据前三个短语计算出第四个短语。我们最佳模型在该数据集上达到了72%的准确率。
| 报纸 | |||
|---|---|---|---|
| NewYork SanJose | NewYorkTimes SanJoseMercuryNews | Baltimore Cincinnati | BaltimoreSun Cincinnati Enquirer |
| NHL球队 | |||
| Boston Phoenix | Boston Bruins Phoenix Coyotes | Montreal Nashville | MontrealCanadiens NashvillePredators |
| NBA球队 | |||
| Detroit Oakland | DetroitPistons GoldenStateWarriors Airlines | Toronto Memphis | Toronto Raptors Memphis Grizzlies |
| 奥地利航空公司 | |||
| Austria Belgium | Brussels Airlines | Spain Greece | Spainair AegeanAirlines |
| 公司高管 | |||
| SteveBallmer Samuel J.Palmisano | Microsoft IBM | Larry Page WernerVogels | Google Amazon |
This way, we can form many reasonable phrases without greatly increasing the size of the vocabulary; in theory, we can train the Skip-gram model using all $\mathbf{n}$ -grams, but that would be too memory intensive. Many techniques have been previously developed to identify phrases in the text; however, it is out of scope of our work to compare them. We decided to use a simple data-driven approach, where phrases are formed based on the unigram and bigram counts, using
这样,我们无需大幅增加词表规模就能构成大量合理短语;理论上可以使用所有$\mathbf{n}$元语法训练Skip-gram模型,但这会导致内存占用过高。此前已有多种文本短语识别技术,但比较这些方法超出了我们的研究范围。我们采用了一种简单的数据驱动方法,基于单字词和双字词频统计来构建短语,具体公式为:
$$
\operatorname{score}(w_ {i},w_ {j})={\frac{\operatorname{count}(w_ {i}w_ {j})-\delta}{\operatorname{count}(w_ {i})\times\operatorname{count}(w_ {j})}}.
$$
$$
\operatorname{score}(w_ {i},w_ {j})={\frac{\operatorname{count}(w_ {i}w_ {j})-\delta}{\operatorname{count}(w_ {i})\times\operatorname{count}(w_ {j})}}.
$$
The $\delta$ is used as a discounting coefficient and prevents too many phrases consisting of very infrequent words to be formed. The bigrams with score above the chosen threshold are then used as phrases. Typically, we run 2-4 passes over the training data with decreasing threshold value, allowing longer phrases that consists of several words to be formed. We evaluate the quality of the phrase representations using a new analogical reasoning task that involves phrases. Table 2 shows examples of the five categories of analogies used in this task. This dataset is publicly available on the web2.
$\delta$ 用作折扣系数,防止形成过多由极低频词组成的短语。得分高于选定阈值的二元组将被用作短语。通常,我们会以递减的阈值对训练数据进行2-4轮处理,从而形成由多个单词组成的更长短语。我们通过一个新的涉及短语的类比推理任务来评估短语表示的质量。表2展示了该任务中使用的五种类比示例。该数据集已在web2上公开。
4.1 Phrase Skip-Gram Results
4.1 短语 Skip-Gram 结果
Starting with the same news data as in the previous experiments, we first constructed the phrase based training corpus and then we trained several Skip-gram models using different hyperparameters. As before, we used vector dimensionality 300 and context size 5. This setting already achieves good performance on the phrase dataset, and allowed us to quickly compare the Negative Sampling and the Hierarchical Softmax, both with and without sub sampling of the frequent tokens. The results are summarized in Table 3.
基于与先前实验相同的新闻数据,我们首先构建了基于短语的训练语料库,随后使用不同超参数训练了多个Skip-gram模型。与之前一样,我们采用300维向量和5个词的上下文窗口。该设置在短语数据集上已表现出良好性能,使我们能快速比较负采样( Negative Sampling )和分层Softmax( Hierarchical Softmax )两种方法,同时考察是否对高频token进行子采样。结果汇总于表3:
The results show that while Negative Sampling achieves a respectable accuracy even with $k=5$ , using $k=15$ achieves considerably better performance. Surprisingly, while we found the Hierarchical Softmax to achieve lower performance when trained without sub sampling, it became the best performing method when we down sampled the frequent words. This shows that the sub sampling can result in faster training and can also improve accuracy, at least in some cases.
结果显示,虽然负采样 (Negative Sampling) 在 $k=5$ 时就能达到不错的准确率,但使用 $k=15$ 能显著提升性能。有趣的是,我们发现层次Softmax (Hierarchical Softmax) 在不进行子采样时表现较差,但在对高频词降采样后却成为性能最佳的方法。这表明子采样不仅能加速训练,在某些情况下还能提高准确率。
2code.google.com/p/word2vec/source/browse/trunk/questions-phrases.txt
| Method | Dimensionality | No subsampling [%] | 10-5 subsampling [%] |
| NEG-5 | 300 | 24 | 27 |
| NEG-15 | 300 | 27 | 42 |
| HS-Huffman | 300 | 19 | 47 |
2code.google.com/p/word2vec/source/browse/trunk/questions-phrases.txt
| 方法 | 维度 | 无降采样 [%] | 10-5降采样 [%] |
|---|---|---|---|
| NEG-5 | 300 | 24 | 27 |
| NEG-15 | 300 | 27 | 42 |
| HS-Huffman | 300 | 19 | 47 |
Table 3: Accuracies of the Skip-gram models on the phrase analogy dataset. The models were trained on approximately one billion words from the news dataset.
表 3: Skip-gram模型在短语类比数据集上的准确率。这些模型在新闻数据集约十亿单词上进行训练。
Table 4: Examples of the closest entities to the given short phrases, using two different models.
| NEG-15with10-5 subsampling | HSwith 10-5 subsampling | |
| VascodeGama | Lingsugur | Italianexplorer |
| LakeBaikal | GreatRiftValley | AralSea |
| AlanBean | RebbecaNaomi | moonwalker |
| IonianSea | Ruegen | IonianIslands |
| chessmaster | chess grandmaster | Garryk Kasparov |
表 4: 使用两种不同模型对给定短语最接近实体的示例
| NEG-15with10-5 subsampling | HSwith 10-5 subsampling | |
|---|---|---|
| VascodeGama | Lingsugur | Italianexplorer |
| LakeBaikal | GreatRiftValley | AralSea |
| AlanBean | RebbecaNaomi | moonwalker |
| IonianSea | Ruegen | IonianIslands |
| chessmaster | chess grandmaster | Garryk Kasparov |
| Czech+currency | Vietnam + capital | German+airlines | Russian+river | French+actress |
| koruna Checkcrown Polish zolty | Hanoi Ho Chi Minh City VietNam | airline Lufthansa carrier Lufthansa flag carrier Lufthansa | Moscow VolgaRiver upriver | JulietteBinoche VanessaParadis Charlotte Gainsbourg |
| 捷克+货币 | 越南+首都 | 德国+航空公司 | 俄罗斯+河流 | 法国+女演员 |
|---|---|---|---|---|
| 克朗 捷克克朗 波兰兹罗提 | 河内 胡志明市 越南 | 航空公司 汉莎航空 承运商 汉莎航空 旗舰航空 汉莎航空 | 莫斯科 伏尔加河 上游 | 朱丽叶·比诺什 凡妮莎·帕拉迪丝 夏洛特·甘斯布 |
Table 5: Vector compositional it y using element-wise addition. Four closest tokens to the sum of two vectors are shown, using the best Skip-gram model.
表 5: 基于逐元素相加的向量组合性。使用最佳 Skip-gram 模型展示两个向量之和最接近的四个 Token。
To maximize the accuracy on the phrase analogy task, we increased the amount of the training data by using a dataset with about 33 billion words. We used the hierarchical softmax, dimensionality of 1000, and the entire sentence for the context. This resulted in a model that reached an accuracy of $72%$ . We achieved lower accuracy $66%$ when we reduced the size of the training dataset to 6B words, which suggests that the large amount of the training data is crucial.
为了在短语类比任务上实现最高准确率,我们通过使用约330亿单词的数据集来增加训练数据量。模型采用分层softmax (hierarchical softmax) 、1000维词向量,并使用完整句子作为上下文。最终模型准确率达到 $72%$ 。当训练数据集规模缩减至60亿单词时,准确率下降至 $66%$ ,这表明海量训练数据具有关键作用。
To gain further insight into how different the representations learned by different models are, we did inspect manually the nearest neighbours of infrequent phrases using various models. In Table 4, we show a sample of such comparison. Consistently with the previous results, it seems that the best representations of phrases are learned by a model with the hierarchical softmax and sub sampling.
为了进一步了解不同模型学习到的表征差异,我们手动检查了各模型对低频短语的最近邻结果。表4展示了部分对比样本。与之前结果一致,采用分层softmax和子采样技术的模型似乎能学习到最佳的短语表征。
5 Additive Compositional it y
5 加性组合性
We demonstrated that the word and phrase representations learned by the Skip-gram model exhibit a linear structure that makes it possible to perform precise analogical reasoning using simple vector arithmetic s. Interestingly, we found that the Skip-gram representations exhibit another kind of linear structure that makes it possible to meaningfully combine words by an element-wise addition of their vector representations. This phenomenon is illustrated in Table 5.
我们证明了Skip-gram模型学习到的词和短语表征呈现一种线性结构,使得通过简单的向量算术运算就能进行精确的类比推理。有趣的是,我们发现Skip-gram表征还呈现另一种线性结构,使得通过向量表征的逐元素相加就能有意义地组合词语。表5展示了这一现象。
The additive property of the vectors can be explained by inspecting the training objective. The word vectors are in a linear relationship with the inputs to the softmax non linearity. As the word vectors are trained to predict the surrounding words in the sentence, the vectors can be seen as representing the distribution of the context in which a word appears. These values are related logarithmic ally to the probabilities computed by the output layer, so the sum of two word vectors is related to the product of the two context distributions. The product works here as the AND function: words that are assigned high probabilities by both word vectors will have high probability, and the other words will have low probability. Thus, if “Volga River” appears frequently in the same sentence together with the words “Russian” and “river”, the sum of these two word vectors will result in such a feature vector that is close to the vector of “Volga River”.
向量的可加性可以通过分析训练目标来解释。词向量与softmax非线性层的输入呈线性关系。由于词向量被训练用于预测句子中的上下文词语,这些向量可视为词语出现语境分布的表示。这些数值与输出层计算出的概率呈对数关联,因此两个词向量之和与两个语境分布的乘积相关。这里的乘积起到AND函数的作用:被两个词向量同时赋予高概率的词语将获得高概率值,其他词语则保持低概率。因此,若"Volga River"频繁与"Russian"和"river"出现在同一句子中,这两个词向量的和将生成接近"Volga River"向量的特征向量。
6 Comparison to Published Word Representations
6 与已发布的词表示对比
Many authors who previously worked on the neural network based representations of words have published their resulting models for further use and comparison: amongst the most well known authors are Collobert and Weston [2], Turian et al. [17], and Mnih and Hinton [10]. We downloaded their word vectors from the web3. Mikolov et al. [8] have already evaluated these word representations on the word analogy task, where the Skip-gram models achieved the best performance with a huge margin.
许多曾致力于基于神经网络词表示研究的学者已公开发布了其训练好的模型以供后续使用和比较,其中最知名的包括Collobert和Weston [2]、Turian等人 [17],以及Mnih和Hinton [10]。我们从网页3下载了这些词向量。Mikolov等人 [8] 此前已在词语类比任务上评估过这些词表示方法,其中Skip-gram模型以显著优势取得了最佳性能。
Table 6: Examples of the closest tokens given various well known models and the Skip-gram model trained on phrases using over 30 billion training words. An empty cell means that the word was not in the vocabulary.
| Model (training time) | Redmond | Havel | ninjutsu | graffiti | capitulate |
| Collobert (50d) (2 months) | conyers lubbock keene | plauen dzerzhinsky osterreich | reiki kohona karate | cheesecake gossip dioramas | abdicate accede rearm |
| Turian (200d) (few weeks) | McCarthy Alston Cousins | Jewell Arzu Ovitz | gunfire emotion impunity | ||
| Mnih (100d) (7 days) | Podhurst Harlang Agarwal | Pontiff Pinochet Rodionov | anaesthetics monkeys Jews | Mavericks planning hesitated | |
| Skip-Phrase (1000d,1 day) | RedmondWash. RedmondWashington Microsoft | VaclavHavel president Vaclav Havel VelvetRevolution | ninja martial arts swordsmanship | spray paint grafitti taggers | capitulation capitulated capitulating |
表 6: 不同知名模型与基于超过300亿训练词训练的Skip-gram短语模型给出的最接近token示例。空白单元格表示词汇表中不存在该词。
| 模型 (训练时长) | Redmond | Havel | ninjutsu | graffiti | capitulate |
|---|---|---|---|---|---|
| Collobert (50d) (2个月) | conyers lubbock keene | plauen dzerzhinsky osterreich | reiki kohona karate | cheesecake gossip dioramas | abdicate accede rearm |
| Turian (200d) (数周) | McCarthy Alston Cousins | Jewell Arzu Ovitz | gunfire emotion impunity | ||
| Mnih (100d) (7天) | Podhurst Harlang Agarwal | Pontiff Pinochet Rodionov | anaesthetics monkeys Jews | Mavericks planning hesitated | |
| Skip-Phrase (1000d,1天) | RedmondWash. RedmondWashington Microsoft | VaclavHavel president Vaclav Havel VelvetRevolution | ninja martial arts swordsmanship | spray paint grafitti taggers | capitulation capitulated capitulating |
To give more insight into the difference of the quality of the learned vectors, we provide empirical comparison by showing the nearest neighbours of infrequent words in Table 6. These examples show that the big Skip-gram model trained on a large corpus visibly outperforms all the other models in the quality of the learned representations. This can be attributed in part to the fact that this model has been trained on about 30 billion words, which is about two to three orders of magnitude more data than the typical size used in the prior work. Interestingly, although the training set is much larger, the training time of the Skip-gram model is just a fraction of the time complexity required by the previous model architectures.
为了更深入地了解学习向量质量的差异,我们通过表6展示低频词最近邻的实证对比。这些实例表明,在大规模语料上训练的Skip-gram大模型在学习表征质量上明显优于其他所有模型。这在一定程度上归因于该模型训练数据量达到约300亿词,比先前工作中使用的典型数据规模高出两到三个数量级。值得注意的是,尽管训练集规模显著增大,Skip-gram模型的训练时间仅为先前模型架构所需时间复杂度的一小部分。
7 Conclusion
7 结论
This work has several key contributions. We show how to train distributed representations of words and phrases with the Skip-gram model and demonstrate that these representations exhibit linear structure that makes precise analogical reasoning possible. The techniques introduced in this paper can be used also for training the continuous bag-of-words model introduced in [8].
本研究有以下几项关键贡献:我们展示了如何用Skip-gram模型训练词与词组的分布式表示,并证明这些表征呈现线性结构,可实现精确的类比推理。本文提出的技术也可用于训练[8]中提出的连续词袋模型(continuous bag-of-words model)。
We successfully trained models on several orders of magnitude more data than the previously published models, thanks to the computationally efficient model architecture. This results in a great improvement in the quality of the learned word and phrase representations, especially for the rare entities. We also found that the sub sampling of the frequent words results in both faster training and significantly better representations of uncommon words. Another contribution of our paper is the Negative sampling algorithm, which is an extremely simple training method that learns accurate representations especially for frequent words.
我们成功训练了比先前发表模型数据量大几个数量级的模型,这得益于计算高效的模型架构。这显著提升了所学单词和短语表征的质量,尤其是对稀有实体的表征。我们还发现对高频词进行子采样不仅能加速训练,还能显著改善低频词的表征效果。本文的另一贡献是负采样(Negative sampling)算法,这种极其简单的训练方法能学习到精确的表征,尤其适用于高频词。
The choice of the training algorithm and the hyper-parameter selection is a task specific decision, as we found that different problems have different optimal hyper parameter configurations. In our experiments, the most crucial decisions that affect the performance are the choice of the model architecture, the size of the vectors, the sub sampling rate, and the size of the training window.
训练算法和超参数的选择需针对具体任务而定,因为我们发现不同问题存在不同的最优超参数配置。实验中,对性能影响最关键的因素包括模型架构的选择、向量维度、子采样率以及训练窗口大小。
A very interesting result of this work is that the word vectors can be somewhat meaningfully combined using just simple vector addition. Another approach for learning representations of phrases presented in this paper is to simply represent the phrases with a single token. Combination of these two approaches gives a powerful yet simple way how to represent longer pieces of text, while having minimal computational complexity. Our work can thus be seen as complementary to the existing approach that attempts to represent phrases using recursive matrix-vector operations [16].
这项工作的一个非常有趣的结果是,仅通过简单的向量加法就能在一定程度上实现词向量的有意义组合。本文提出的另一种学习短语表征的方法是直接用单个token表示短语。这两种方法的结合提供了一种强大而简单的方式来表征更长的文本片段,同时计算复杂度极低。因此,我们的工作可以被视为对现有方法[16]的补充,后者试图通过递归矩阵-向量运算来表征短语。
We made the code for training the word and phrase vectors based on the techniques described in this paper available as an open-source project .
我们基于本文所述技术,将训练词向量和短语向量的代码作为开源项目发布。
References
参考文献