TRIFORCE: Lossless Acceleration of Long Sequence Generation with Hierarchical Speculative Decoding
TRIFORCE: 采用分层推测解码实现长序列生成的无损加速
Abstract
摘要
With large language models (LLMs) widely deployed in long content generation recently, there has emerged an increasing demand for efficient long-sequence inference support. However, key-value (KV) cache, which is stored to avoid re-computation, has emerged as a critical bottleneck by growing linearly in size with the sequence length. Due to the autoregressive nature of LLMs, the entire KV cache will be loaded for every generated token, resulting in low utilization of computational cores and high latency. While various compression methods for KV cache have been proposed to alleviate this issue, they suffer from degradation in generation quality. We introduce TRIFORCE, a hierarchical speculative decoding system that is scalable for long sequence generation. This approach leverages the original model weights and dynamic sparse KV cache via retrieval as a draft model, which serves as an intermediate layer in the hierarchy and is further speculated by a smaller model to reduce its drafting latency. TRIFORCE not only facilitates impressive speedups for Llama2-7B-128K, achieving up to $2.31\dot{\times}$ on an A100 GPU but also showcases s cal ability in handling even longer contexts. For the offloading setting on two RTX 4090 GPUs, TRIFORCE achieves 0.108s/token—only half as slow as the auto-regressive baseline on an A100, which attains $\dot{7}.78\times$ on our optimized offloading system. Additionally, TRIFORCE performs $4.86\times$ than DeepSpeed-ZeroInference on a single RTX 4090 GPU. TRIFORCE’s robustness is highlighted by its consistently outstanding performance across various temperatures. The code is available at https://github.com/Infini-AI-Lab/TriForce.
随着大语言模型(LLM)在长文本生成领域的广泛应用,对高效长序列推理支持的需求日益增长。然而,为避免重复计算而存储的键值(KV)缓存已成为关键瓶颈,其大小随序列长度线性增长。由于LLM的自回归特性,每个生成的Token都需要加载整个KV缓存,导致计算核心利用率低下且延迟较高。虽然已有多种KV缓存压缩方法被提出以缓解此问题,但这些方法都会导致生成质量下降。我们提出了TRIFORCE——一个可扩展的长序列生成分层推测解码系统。该方法通过检索机制利用原始模型权重和动态稀疏KV缓存作为草稿模型,该草稿模型作为层次结构中的中间层,并由更小的模型进行进一步推测以降低起草延迟。TRIFORCE不仅为Llama2-7B-128K实现了显著的加速效果(在A100 GPU上最高可达$2.31\dot{\times}$),还展示了处理更长上下文的能力。在两块RTX 4090 GPU的卸载场景下,TRIFORCE达到0.108秒/Token的生成速度——仅为A100上自回归基线速度的一半,在我们的优化卸载系统上实现了$\dot{7}.78\times$的加速比。此外,在单块RTX 4090 GPU上,TRIFORCE比DeepSpeed-ZeroInference快$4.86\times$。TRIFORCE的鲁棒性体现在其在不同温度参数下持续保持的卓越性能。代码已开源:https://github.com/Infini-AI-Lab/TriForce。
1 Introduction
1 引言
Large language models (LLMs) with long-context capability, such as GPT-4 (Achiam et al., 2023), Gemini (Team et al., 2023), and LWM (Liu et al., 2024a) continue to emerge and gain proficient application in scenarios including chatbots, vision generation, and financial analysis (Touvron et al., 2023; Chowdhery et al., 2023; Zhao et al., 2023; Reddy et al., 2024). However, losslessly serving these LLMs efficiently is challenging. Because of the autoregressive nature of LLMs, the entire key-value (KV) cache, which stores intermediate key-value states from previous contexts to avoid re-computation, together with model parameters will be loaded into GPU SRAM for every token generated, resulting in low utilization of computational cores. In addition to the large volume of model parameters, the memory footprint of KV cache, which grows linearly with sequence length (Pope et al., 2023), is emerging as a new bottleneck for long sequence generation.
具备长上下文能力的大语言模型(LLM),如GPT-4 (Achiam et al., 2023)、Gemini (Team et al., 2023)和LWM (Liu et al., 2024a)不断涌现,并在聊天机器人、视觉生成和金融分析等场景中得到熟练应用 (Touvron et al., 2023; Chowdhery et al., 2023; Zhao et al., 2023; Reddy et al., 2024)。然而,高效无损地部署这些大语言模型仍面临挑战。由于大语言模型的自回归特性,为避免重复计算而存储中间键值状态(key-value cache, KV cache)的整个键值缓存,连同模型参数,都需要为每个生成的token加载到GPU SRAM中,导致计算核心利用率低下。除了庞大的模型参数外,随序列长度线性增长的KV缓存内存占用 (Pope et al., 2023),正在成为长序列生成的新瓶颈。
Recent methodologies have proposed KV cache eviction strategies (Xiao et al., 2023b; Zhang et al., 2024b; Liu et al., 2024c; Jiang et al., 2023; Ge et al., 2023) to mitigate the substantial memory footprint of KV cache, which selectively discard KV pairs from the cache based on a designed eviction policy, allowing models to generate texts with a limited KV cache budget. However, considering that discarded KV pairs cannot be restored and the difficulty in precisely foreseeing which KV pairs will be crucial for future text generation, they struggle with potential information loss, including hallucination and contextual in coherency (Yang et al., 2024), particularly in long contexts. Such challenges prevent these approaches from boosting speed without sacrificing the performance of models, as illustrated in Figure 1.
近期方法提出了KV缓存淘汰策略 (Xiao et al., 2023b; Zhang et al., 2024b; Liu et al., 2024c; Jiang et al., 2023; Ge et al., 2023) 来缓解KV缓存的内存占用问题。这些策略基于设计的淘汰原则选择性丢弃缓存中的KV键值对,使模型能在有限的KV缓存预算下生成文本。然而由于被丢弃的KV键值对无法恢复,且难以精准预判哪些KV键值对会对未来文本生成起关键作用,这类方法始终面临潜在信息丢失的困境,包括幻觉和上下文不连贯问题 (Yang et al., 2024),在长文本场景中尤为明显。如图1所示,这些挑战使得现有方法难以在不牺牲模型性能的前提下提升推理速度。

Figure 1: Left: TRIFORCE employs retrieval-based drafting and hierarchical speculation to effectively address the dual bottlenecks. It integrates two models and three caches, comprising a draft model, a target model, a Streaming LL M cache for the draft model, alongside a retrieval cache and a full cache for the target model. The process initiates by repeatedly drafting for $\gamma_{1}$ steps, assisting the target model with retrieved partial KV cache in generating over $\gamma_{2}$ tokens, which will be further verified by the target model using full KV cache. Right: Evaluating the Llama2-7B-128K on a needle retrieval task indicates that KV cache eviction-based methods, such as Streaming LL M, require a trade-off between latency and accuracy. In contrast, our TRIFORCE maintains low latency without sacrificing accuracy.
图 1: 左: TRIFORCE采用基于检索的草拟和分层推测机制,有效解决双重瓶颈问题。该系统整合了两个模型和三个缓存,包括草拟模型、目标模型、用于草拟模型的Streaming LLM缓存,以及用于目标模型的检索缓存和完整缓存。流程首先通过重复草拟$\gamma_{1}$步,借助检索到的部分KV缓存辅助目标模型生成超过$\gamma_{2}$个token,这些token随后将由目标模型使用完整KV缓存进行验证。右: 在Llama2-7B-128K上进行的针检索任务评估表明,基于KV缓存淘汰的方法(如Streaming LLM)需要在延迟和准确性之间权衡。相比之下,我们的TRIFORCE在保持低延迟的同时不牺牲准确性。
Concurrently, speculative decoding, which leverages a lightweight draft model to sequentially predict the next few tokens and let the target model verify the predicted tokens in parallel, is introduced to accelerate LLM inference while provably precisely preserving model output (Leviathan et al., 2023; Chen et al., 2023a; Xia et al., 2024). Nonetheless, de- ploying it for long sequence generation faces several challenges. First, training draft models to match the context length of target LLMs requires massive computation and it remains questionable whether these small models can achieve the same accuracy with a context length around 1M (Beltagy et al., 2020; Peng et al., 2023; Yan et al., 2024). Second, we found that draft models with existing training-free methods (e.g., KV cache eviction strategies) can result in poor speculating performance. A continuously increasing divergence (Leviathan et al., 2023) is witnessed as the sequence length increases, as shown in Figure 2a.
与此同时,推测解码 (speculative decoding) 技术通过轻量级草稿模型顺序预测后续若干token,并让目标模型并行验证预测结果,可在严格保证输出一致性的前提下加速大语言模型推理 (Leviathan et al., 2023; Chen et al., 2023a; Xia et al., 2024) 。但该技术应用于长序列生成时面临多重挑战:首先,训练草稿模型以匹配目标大语言模型的上下文长度需消耗大量算力,且当上下文长度达到百万量级时 (Beltagy et al., 2020; Peng et al., 2023; Yan et al., 2024) ,这些小模型能否保持相同精度仍存疑;其次,我们发现采用现有免训练方法(如KV缓存淘汰策略)的草稿模型会出现推测性能劣化问题,如图2a所示,随着序列长度增加会出现持续扩大的预测偏差 (Leviathan et al., 2023) 。
In pursuit of lossless acceleration, we utilize the lossless feature of speculative decoding as the foundation of our system. An ideal speculative decoding algorithm should (i) be training-free, (ii) maintain a high acceptance rate (Leviathan et al., 2023) with long contexts, and (iii) have low-cost drafting. However, two technical challenges need to be addressed to achieve the goal. First, it is not immediately apparent what we can use for low-latency drafting without training a smaller draft model to match the long context length. Second, the key factors for attaining a high acceptance rate with long contexts remain unclear.
为了实现无损加速,我们以推测解码(Speculative Decoding)的无损特性作为系统基础。理想的推测解码算法应当满足:(i) 无需训练,(ii) 在长上下文场景下保持高接受率(Leviathan et al., 2023),(iii) 具备低成本草稿生成能力。但实现该目标需解决两大技术挑战:首先,在不训练小型草稿模型的情况下,如何实现匹配长上下文长度的低延迟草稿生成尚不明确;其次,长上下文场景下获得高接受率的关键因素仍待探索。
Fortunately, based on our preliminary exploration, three key observations pave the way for designing an applicable system for serving LLMs with long contexts.
幸运的是,基于我们的初步探索,三个关键观察为设计适用于长上下文大语言模型的服务系统铺平了道路。
Hierarchical Speculation for Dual Memory Bottlenecks: As illustrated in Figures 2b and 2c, we recognize two memory bottlenecks: model weights and KV cache, and the latter gradually becomes the dominant bottleneck as context length increases. This inspires us to apply hierarchical speculation to tackle the two bottlenecks sequentially by different draft models.
分层推测应对双重内存瓶颈:如图 2b 和图 2c 所示,我们识别出两个内存瓶颈:模型权重和 KV 缓存 (key-value cache) ,随着上下文长度增加,后者逐渐成为主要瓶颈。这启发我们通过不同草稿模型依次解决这两个瓶颈,采用分层推测策略。
Leveraging Attention Sparsity for Speculative Decoding: We identify considerable redundancy within KV cache, finding that a relatively small portion of it is sufficient to achieve a high acceptance rate by using partial KV cache as a draft cache for self-speculation.
利用注意力稀疏性进行推测解码:我们发现KV缓存中存在大量冗余,通过将部分KV缓存用作自推测的草稿缓存,仅需相对较小部分即可实现高接受率。
Exploiting Contextual Locality for Drafting Efficiency: We discover that the information from long context tokens needed by adjacent tokens tends to be similar. This observation suggests that a specific segment of the cache can be effectively reused across multiple decoding steps, amortizing the overhead of constructing draft cache and enhancing drafting efficiency.
利用上下文局部性提升草拟效率:我们发现相邻token所需的长上下文token信息往往相似。这一观察表明,特定缓存段可在多个解码步骤中有效复用,从而分摊构建草拟缓存的开销并提升草拟效率。
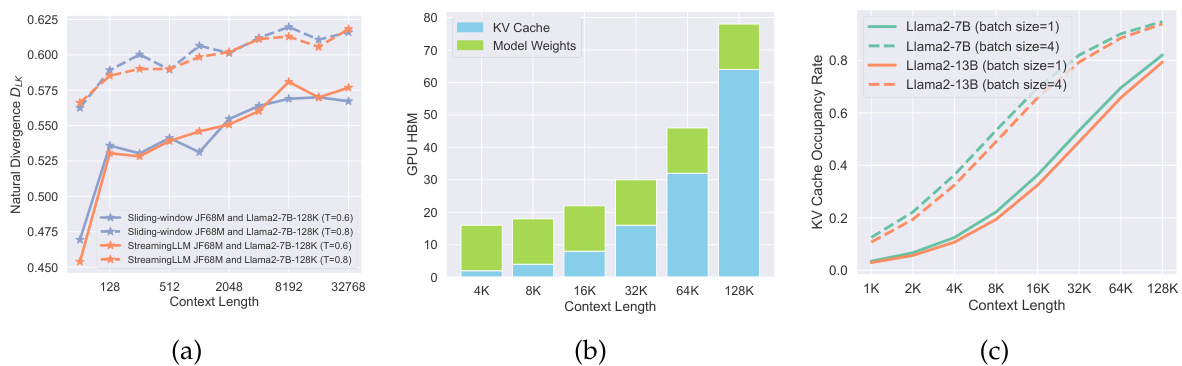
Figure 2: (a) A continuously increasing natural divergence (Leviathan et al., 2023) between the draft model with Streaming LL M or Sliding-window with Re-computation and Llama2- 7B-128K is witnessed as the sequence length increases, indicating a falling acceptance rate for speculative decoding with longer contexts. Additionally, temperature sensitivity signals a lack of robustness. (b) Compared with model weights, KV cache gradually becomes another bottleneck with long contexts. (c) KV cache occupies most of the memory as the context length increases.
图 2: (a) 随着序列长度增加,可观察到采用 Streaming LLM 或滑动窗口重计算的草稿模型与 Llama2-7B-128K 之间持续增大的自然分歧度 (Leviathan et al., 2023),表明长上下文场景下推测解码的接受率会下降。此外,温度敏感性也反映出其鲁棒性不足。(b) 与模型权重相比,KV缓存随上下文延长逐渐成为另一瓶颈。(c) 随着上下文长度增加,KV缓存占据了大部分内存空间。
Building on these insights, we introduce a hierarchical speculation approach. For a longcontext target model (e.g., Llama2-7B-128K (Peng et al., 2023)), we leverage the original model weights but only with a small proportion (e.g., $3%$ ) of KV cache as a draft to tackle the bottleneck of KV cache. Hierarchically, the draft model is further speculated by a lightweight model (e.g., Llama-68M) with Streaming LL M cache to address the bottleneck of model weights. We present TRIFORCE, depicted in Figure 1, a scalable and robust speculative decoding system that integrates retrieval-based drafting and hierarchical speculation, optimized for both on-chip and offloading scenarios. Specifically,
基于这些洞见,我们提出了一种分层推测方法。对于长上下文目标模型(如 Llama2-7B-128K (Peng et al., 2023)),我们利用原始模型权重但仅使用少量(如 $3%$) KV缓存作为草稿来解决KV缓存瓶颈。在分层结构中,草稿模型进一步由配备Streaming LLM缓存的轻量级模型(如Llama-68M)进行推测,以解决模型权重瓶颈。如图1所示,我们提出了TRIFORCE——一个可扩展且鲁棒的推测解码系统,它整合了基于检索的草拟和分层推测技术,并针对片上与卸载场景进行了优化。具体而言,
• In Section 4.1, by maintaining the full cache, we gain the flexibility to select KV pairs, allowing us to devise a superior selection method, termed retrieval-based drafting. This strategy retrieves required context information for future needs, which is characterized as lossless, particularly in comparison to eviction-based methods such as Streaming LL M and $_ {\mathrm{H}_{2}\mathrm{O}}$ . We further demonstrated its effectiveness and robustness on different datasets. • In Section 4.2, we propose a hierarchical system to address the dual memory bottlenecks. Using a lightweight model paired with a Streaming LL M cache for initial speculations, we can reduce the drafting latency for the subsequent speculation stage, thereby accelerating end-to-end inference.
• 在第4.1节中,通过维护完整缓存,我们获得了灵活选择键值对 (KV pairs) 的能力,从而设计出更优的选择方法,称为基于检索的草拟 (retrieval-based drafting)。该策略为未来需求检索所需的上下文信息,其特点是无损,特别是与基于淘汰的方法 (如 Streaming LLM 和 $_ {\mathrm{H}_{2}\mathrm{O}}$) 相比。我们进一步在不同数据集上验证了其有效性和鲁棒性。
• 在第4.2节中,我们提出分层系统来解决双重内存瓶颈。通过使用轻量级模型搭配 Streaming LLM 缓存进行初始推测,可以降低后续推测阶段的草拟延迟,从而加速端到端推理。
Empirically, in Section 5, we perform extensive experiments and ablation studies to demonstrate the effectiveness of TRIFORCE. We show that TRIFORCE achieves up to $2.31\times$ speedup for Llama2-7B-128K on a single A100 GPU on top of Hugging Face (Wolf et al., 2019) with CUDA graphs (NVIDIA & Fitzek, 2020). For the offloading setting, TRIFORCE attains an impressive $\mathrm{\dot{7}.78\times}$ on two RTX 4090 GPUs, reaching $0.108s.$ /token—only half as slow as the auto-regressive baseline on an A100. TRIFORCE can efficiently serve a Llama2-13B with 128K contexts with 0.226s/token, which is $7.94\times$ faster on our optimized offloading system. On a single RTX 4090 GPU, TRIFORCE is $4.86\times$ faster than DeepSpeed-Zero-Inference (Aminabadi et al., 2022) 1. Further, we show that: (i) TRIFORCE has a theoretical $13.1\times$ upper bound, demonstrating exceptional s cal ability when dealing with long contexts; (ii) TRIFORCE is robust across various temperature settings, maintaining an acceptance rate above 0.9 even for a temperature of 1.0; and (iii) TRIFORCE’s ability to efficiently process large batches, achieving a $1.9\times$ speedup for a batch size of six with 19K contexts per sample.
实验方面,在第5节中,我们进行了大量实验与消融研究以验证TRIFORCE的有效性。结果表明:在搭载CUDA图形加速 (NVIDIA & Fitzek, 2020) 的Hugging Face (Wolf et al., 2019) 框架上,TRIFORCE针对单块A100 GPU运行的Llama2-7B-128K实现了最高 $2.31\times$ 的加速;在双RTX 4090 GPU的卸载配置下,TRIFORCE取得惊人的 $\mathrm{\dot{7}.78\times}$ 加速,达到每token $0.108s$ ——仅为A100上自回归基线速度的一半。TRIFORCE还能以0.226秒/token的效率处理128K上下文的Llama2-13B,在我们的优化卸载系统上实现 $7.94\times$ 加速。单块RTX 4090 GPU上,TRIFORCE比DeepSpeed-Zero-Inference (Aminabadi et al., 2022) 快 $4.86\times$ 。此外我们发现:(i) TRIFORCE理论加速上限达 $13.1\times$ ,展现处理长上下文时的卓越扩展能力;(ii) 在不同温度参数下保持稳健,即使温度为1.0时接受率仍高于0.9;(iii) 能高效处理大批量数据,当批次大小为6且每个样本含19K上下文时实现 $1.9\times$ 加速。
2 Background
2 背景
2.1 Speculative Decoding
2.1 推测解码 (Speculative Decoding)
Speculative decoding (Stern et al., 2018; Leviathan et al., 2023; Chen et al., 2023a; Kim et al., 2024; Zhang et al., 2023; Santilli et al., 2023; Hooper et al., 2023) is featured by accelerating LLM decoding while precisely maintaining the model’s output distribution. As the speed of the auto-regressive decoding process is mainly bound by the time for loading model weights and KV cache to GPU SRAM, speculative decoding leverages the observation that generating one token takes the same time as processing tens of tokens in parallel. Tree-based speculation methods are proposed to fully utilize the speculation budget (Fu et al., 2024; Li et al., 2024). Instead of making one prediction for the next token, tree-based methods leverage multiple candidates to boost the acceptance rate so that more tokens can get accepted (Miao et al., 2023; Sun et al., 2024; Chen et al., 2024). Staged speculation techniques (Spector & Re, 2023; Chen et al., 2023b) have been suggested to further accelerate inference by using a cascade of draft models, and hierarchical speculation shares similarities with these approaches. However, our method focuses on long sequence generation tasks, which presents unique challenges. We use different drafting methods for each speculation phase to address two distinct bottlenecks in long-context scenarios, instead of focusing on model weights at every stage for acceleration. Meanwhile, self-speculation approaches such as Medusa (Cai et al., 2024; Ankner et al., 2024), which are orthogonal to our method, require training efforts and can be integrated into our intermediate draft model.
推测解码 (Stern et al., 2018; Leviathan et al., 2023; Chen et al., 2023a; Kim et al., 2024; Zhang et al., 2023; Santilli et al., 2023; Hooper et al., 2023) 的核心特点是在精确保持模型输出分布的同时加速大语言模型解码。由于自回归解码过程的速度主要受限于将模型权重和KV缓存加载到GPU SRAM的时间,推测解码利用了生成单个token与并行处理数十个token耗时相同的特性。基于树的推测方法被提出以充分利用推测预算 (Fu et al., 2024; Li et al., 2024) 。与仅预测下一个token不同,基于树的方法利用多个候选token来提高接受率,从而让更多token被采纳 (Miao et al., 2023; Sun et al., 2024; Chen et al., 2024) 。分阶段推测技术 (Spector & Re, 2023; Chen et al., 2023b) 通过使用级联草稿模型进一步加速推理,分层推测与这些方法具有相似性。然而,我们的方法专注于长序列生成任务,这带来了独特的挑战。我们针对长上下文场景中的两个不同瓶颈,在每个推测阶段采用不同的起草方法,而非仅关注各阶段模型权重的加速。与此同时,与我们方法正交的自推测方案如Medusa (Cai et al., 2024; Ankner et al., 2024) 需要训练投入,并可集成到我们的中间草稿模型中。
2.2 KV Cache Eviction Strategies
2.2 KV缓存淘汰策略
Streaming LL M (Xiao et al., 2023b) addresses the limitations of window attention and sliding window with re-computation by presenting a straightforward yet effective method that allows LLMs to handle infinitely long text sequences without fine-tuning. Streaming LL M stabilizes the performance by retaining critical attention sink tokens together with recent KV for attention computation. By prioritizing sink tokens, Streaming LL M ensures the attention score distribution remains stable, promoting consistent language modeling for long texts.
流式大语言模型 (Streaming LL M) (Xiao et al., 2023b) 通过提出一种简单而有效的方法,解决了窗口注意力 (window attention) 和带重计算的滑动窗口 (sliding window with re-computation) 的局限性,使大语言模型无需微调即可处理无限长的文本序列。该模型通过保留关键注意力汇聚token (attention sink tokens) 和最近的键值对 (KV) 进行注意力计算,从而稳定性能。通过优先处理汇聚token,流式大语言模型确保注意力分数分布保持稳定,从而实现对长文本的连贯语言建模。
$\mathbf{H}_ {2}\mathbf{O}$ (Zhang et al., 2024b) introduces a greedy but low-cost approach to processing infinitelength input streams, inspired by a simplified version of the heavy-hitters $(\mathrm{H}_ {2})$ eviction policy. This method dynamically updates the KV cache based on the cumulative attention scores, systematically removing the least critical KV to maintain a fixed cache size. By leveraging a greedy algorithm based on local statistics, $\mathrm{H}_{2}\mathrm{O}$ effectively selects which KV pairs to preserve in the cache, ensuring efficient inference without compromising quality.
$\mathbf{H}_ {2}\mathbf{O}$ (Zhang et al., 2024b) 提出了一种贪婪但低成本的方法来处理无限长度输入流,其灵感来源于简化版的高频驱逐策略 $(\mathrm{H}_ {2})$。该方法基于累积注意力分数动态更新KV缓存,通过系统性地移除最不重要的KV来维持固定缓存大小。通过利用基于局部统计的贪婪算法,$\mathrm{H}_{2}\mathrm{O}$ 能有效选择保留哪些KV对在缓存中,从而在不影响质量的前提下确保高效推理。
However, it is important to recognize that these techniques do not increase the context window size (Zhang et al., 2024a; Jin et al., 2024; Ge et al., 2023; Jiang et al., 2023). They focus on retaining only the most recent tokens along with either attention sinks or heavy-hitters, while discarding other tokens. These approaches limit the model to processing based on their designed eviction policies and recent tokens. Consequently, they might not be directly applicable to tasks that demand comprehensive, long-context understanding.
然而,需要明确的是,这些技术并未增加上下文窗口大小 (Zhang et al., 2024a; Jin et al., 2024; Ge et al., 2023; Jiang et al., 2023)。它们仅聚焦于保留最近的token及注意力汇聚点(attention sinks)或高频元素(heavy-hitters),同时丢弃其他token。这些方法将模型的处理能力限制在其设计的淘汰策略和近期token范围内,因此可能无法直接适用于需要全面、长上下文理解的任务。
2.3 KV Cache Quantization
2.3 KV Cache量化
Several approaches to KV cache quantization have been introduced to enhance the efficiency of inference for long sequence generation, aiming to maintain generation quality while reducing the memory consumption (Xiao et al., 2023a; Hooper et al., 2024; Sheng et al., 2023; Liu et al., $2023\mathsf{a}_{.}$ ; Zirui Liu et al., 2023; Yue et al., 2024). Quantization methods focus on compressing the bit width of KV cache activation s, which is orthogonal to our approach.
为提高长序列生成的推理效率,同时保持生成质量并降低内存消耗,研究者们提出了多种KV缓存量化方法 (Xiao et al., 2023a; Hooper et al., 2024; Sheng et al., 2023; Liu et al., $2023\mathsf{a}_{.}$; Zirui Liu et al., 2023; Yue et al., 2024)。量化方法主要关注压缩KV缓存激活值的位宽,这与我们的方法正交。
3 Observation
3 观察
Our design of TRIFORCE is inspired by two critical empirical observations regarding LLMs when dealing with long contexts, detailed as follows.
我们对TRIFORCE的设计灵感来源于处理长上下文时对大语言模型的两项关键实证观察,具体如下。
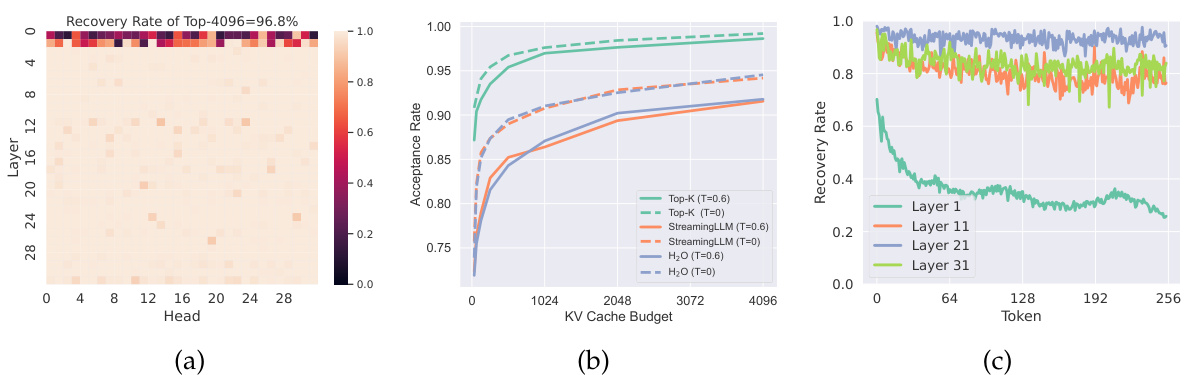
Figure 3: (a) The Llama2-7B-128K model demonstrates significant attention sparsity with a 120K context. Apart from the first two layers, the rest exhibit significant sparsity. (b) We can utilize partial KV cache and whole model weights to perform self-speculation. High acceptance rates are attainable using existing methods with a limited budget. (c) A notable degree of locality is observed in most layers, which gradually diminishes as context evolves.
图 3: (a) Llama2-7B-128K 模型在 120K 上下文长度下展现出显著的注意力稀疏性,除前两层外其余层均呈现高度稀疏性。(b) 可利用部分 KV 缓存和完整模型权重进行自推测推理,在有限计算预算下通过现有方法即可实现高接受率。(c) 大多数层中观察到明显的局部性特征,该特性随上下文演变逐渐减弱。
3.1 Leveraging Attention Sparsity for Speculative Decoding
3.1 利用注意力稀疏性进行推测解码
Observation The phenomenon of attention sparsity in pre-trained LLMs has been discovered by numerous studies (Zhang et al., 2024b; Xiao et al., 2023b; Liu et al., 2023b; 2024c). In our study, we conduct zero-shot inference on the PG-19 test set (Rae et al., 2019) with Llama2-7B-128K model. By visualizing the sparsity across different attention heads, demonstrated in Figure 3a, we observe that with a context length of ${120\mathrm{K}},$ it is possible to recover over $96%$ of the attention score with merely 4K tokens across almost all layers.
观察
预训练大语言模型中的注意力稀疏现象已被多项研究发现 (Zhang et al., 2024b; Xiao et al., 2023b; Liu et al., 2023b; 2024c)。我们在PG-19测试集 (Rae et al., 2019) 上使用Llama2-7B-128K模型进行零样本推理。如图3a所示,通过可视化不同注意力头的稀疏性,我们观察到当上下文长度达到 ${120\mathrm{K}}$ 时,几乎所有层仅需4K token即可恢复超过 $96%$ 的注意力分数。
Analysis The presence of sparsity within the attention blocks suggests that a fraction of KV cache could serve as a draft cache to attain a high acceptance rate during self-speculative decoding. Since KV cache is the bottleneck under this setting, we can load whole model weights with partial KV cache as a draft model. Figure 3b demonstrates that utilizing only 1K tokens could theoretically achieve a $97.6%$ acceptance rate with Top-K selection method. While this scenario represents an optimal theoretical upper bound, practical implementations like $\mathrm{H}_{2}\mathrm{O}$ and Streaming LL M exhibit promising results, achieving over $90.\dot{5}%$ acceptance rates with 1K KV cache budget. It should be noted that we maintain a full cache for the initial two layers for illustration purposes, while no layers are skipped in our practical system implementation for efficiency.
分析
注意力模块中的稀疏性表明,部分KV缓存可作为草稿缓存,在自推测解码过程中实现高接受率。由于KV缓存是该场景下的瓶颈,我们可以加载完整模型权重并搭配部分KV缓存作为草稿模型。图3b显示:仅使用1K token时,Top-K选择方法理论上可实现97.6%的接受率。虽然这是理想化的理论上限,但实际系统如$\mathrm{H}_{2}\mathrm{O}$和Streaming LLM已取得显著成果——在1K KV缓存预算下实现了超过90.$\dot{5}$%的接受率。需说明的是,为便于演示我们保留了前两层的完整缓存,而在实际系统实现中为保障效率并未跳过任何层。
3.2 Exploiting Contextual Locality for Drafting Efficiency
3.2 利用上下文局部性提升草稿生成效率
Observation Our exploration reveals that the information from long context tokens needed by adjacent tokens tends to be similar. In our experiments, with the context length established at $120\mathrm{K},$ we instruct the model to generate 256 tokens. By choosing the top-4K indices according to the attention score of the last prefilled token, we use these indices to gather the attention scores for the subsequently generated tokens and assess the score’s recovery rate for the initially prefilled 120K tokens. As shown in Figure 3c, it leads to high recovery across almost all layers and a slowly decreasing trend as the number of tokens increases.
观察
我们的探索发现,相邻token所需的长上下文token信息往往相似。实验中设定上下文长度为$120\mathrm{K}$时,我们指导模型生成256个token。通过根据最后一个预填充token的注意力分数选取前4K个索引,用这些索引收集后续生成token的注意力分数,并评估其对初始预填充120K token的分数恢复率。如图3c所示,该策略在几乎所有层都实现了高恢复率,且随着token数量增加呈现缓慢下降趋势。
Insights This observation allows for a single construction of the cache to suffice for multiple decoding steps, thereby amortizing the latency of constructing draft cache and boosting efficiency. As new KV cache are introduced, guided by the understanding that recent words are more strongly correlated with the tokens currently being decoded, these entries will replace the less significant ones. Cache re-building operations can be scheduled at regular intervals or adaptively in response to a drop in the acceptance rate, which ensures that the cache remains dynamically aligned with the evolving context. Notably, both Streaming LL M and $\mathrm{H}_ {2}\mathrm{O}$ incorporate this principle implicitly. $\mathrm{\bar{H}}_{2}\mathrm{O}$ consistently retains tokens with high scores, and Streaming LL M reuses extensive local information and sink tokens, which both reduce the necessity for complete cache reconstruction.
洞察
这一观察使得缓存的单次构建即可满足多个解码步骤的需求,从而分摊构建草稿缓存的延迟并提升效率。随着新KV缓存的引入(基于"近期词汇与当前解码token相关性更强"的认知),这些新条目将替换重要性较低的缓存内容。缓存重建操作可按固定间隔调度,或根据接受率下降情况自适应触发,从而确保缓存始终与动态演变的上下文保持对齐。值得注意的是,Streaming LLM和$\mathrm{H}_ {2}\mathrm{O}$都隐式采用了这一原则——$\mathrm{\bar{H}}_{2}\mathrm{O}$持续保留高分token,而Streaming LLM则复用大量局部信息和sink token,两者都降低了完整缓存重建的必要性。
4 TRIFORCE
4 TRIFORCE
This section aims to introduce the TRIFORCE, which leverages a retrieval-based KV cache selection policy and a hierarchical speculation system. We first argue that our retrievalbased drafting approach is intuitive and lossless compared to existing strategies such as Streaming LL M and $_ {\mathrm{H}_{2}\mathrm{O}}$ . Subsequently, we introduce the hierarchical system designed to effectively address the dual bottlenecks in speculative decoding, facilitating a substantial improvement in overall speed-up. Finally, TRIFORCE is elaborated in Section 4.3.
本节旨在介绍TRIFORCE,它采用了基于检索的KV缓存选择策略和分层推测系统。我们首先论证,与Streaming LLM和$_ {\mathrm{H}_{2}\mathrm{O}}$等现有策略相比,基于检索的草拟方法直观且无损。随后,我们介绍了旨在有效解决推测解码中双重瓶颈的分层系统,从而实现整体加速的大幅提升。最后,第4.3节详细阐述了TRIFORCE。
4.1 Retrieval-based Drafting
4.1 基于检索的草拟 (Retrieval-based Drafting)
In scenarios requiring long-term contextual dependencies, methods like Streaming LL M and $_ {\mathrm{H}_ {2}\mathrm{O}}$ under perform due to their cache updating strategies, which are ineffective at accurately retrieving detailed contextual information because they inevitably and irrecoverably discard KV pairs. In our experiment, we challenge Streaming LL M and $\mathrm{\hat{H}}_{2}\mathrm{O}$ with a needle retrieval task (Liu et al., 2024b; Peng et al., 2023; Liu et al., 2024a). As detailed in
在需要长期上下文依赖的场景中,Streaming LLM和$_ {\mathrm{H}_ {2}\mathrm{O}}$等方法由于缓存更新策略的缺陷表现不佳,这些策略无法准确检索详细上下文信息,因为它们不可避免地会不可逆地丢弃KV键值对。我们的实验中,我们通过针检索任务(Liu et al., 2024b; Peng et al., 2023; Liu et al., 2024a)对Streaming LLM和$\mathrm{\hat{H}}_{2}\mathrm{O}$进行了挑战。具体而言
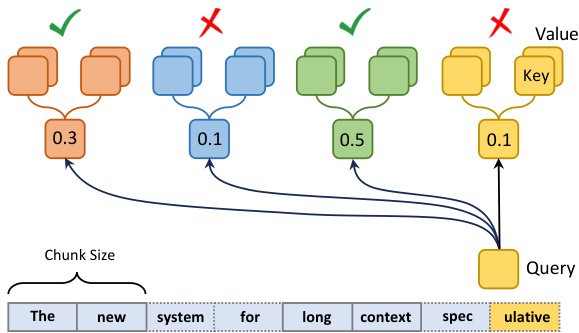
Figure 4: Retrieval-based drafting
图 4: 基于检索的草拟
Table 1, there is a notable drop in their acceptance rates compared to their performance on the PG-19 dataset, highlighting their limitations. Essentially, Streaming LL M and $_ {\mathrm{H}_{2}\mathrm{O}}$ operate on a lossy principle, as evicted tokens are permanently discarded, making them a poor fit for settings requiring the preservation of full KV cache for the target model.
表1: 与PG-19数据集上的表现相比,它们的接受率显著下降,突显了其局限性。本质上,Streaming LLM和$_ {\mathrm{H}_{2}\mathrm{O}}$采用有损原则运行,因为被驱逐的token会被永久丢弃,这使得它们不适合需要为目标模型保留完整KV缓存(Key-Value cache)的场景。
The necessity of keeping the entire KV cache in our settings allows us to select KV cache more freely (Singhal et al., 2001). This insight leads us to develop a more effective selection policy for lossless approximations. In our approach, demonstrated in Figure 4, KV cache is segmented into small chunks. During the retrieval phase, we calculate the attention between a given query and the average key cache within each chunk. This method effectively highlights the most relevant chunks, enabling us to gather KV cache with a fixed budget based on the scores. As illustrated in Table 1, retrieval-based method excels by actively identifying the most crucial information for the task rather than relying on passive and timebased cache management methods. By focusing on relevance over recency, retrieval-based policy demonstrates its potential to handle con textually dense datasets.
在我们的设置中保留整个KV缓存的必要性使我们能够更自由地选择KV缓存 (Singhal et al., 2001)。这一洞见促使我们为无损近似开发更有效的选择策略。如图4所示,我们的方法将KV缓存分割为小块。在检索阶段,我们计算给定查询与每个块内平均键缓存之间的注意力。这种方法能有效突出最相关的块,使我们能够基于分数以固定预算收集KV缓存。如表1所示,基于检索的方法通过主动识别任务最关键的信息而非依赖被动且基于时间的缓存管理方式表现出色。基于检索的策略通过关注相关性而非时效性,展现了处理上下文密集数据集的潜力。
Table 1: Acceptance rates are shown across various tasks, utilizing a 120K context and a 4K budget, while bypassing the initial two layers. There is a notable drop in Streaming LL M and $\mathrm{\bar{H}}_{2}\mathrm{O^{\prime}}$ s results on needle retrieval. For reference, Top-K is the theoretical upper bound.
| Method | Top-K (Ref.) | StreamingLLM | H2O | Retrieval |
| PG-19 | 0.9921 | 0.9156 | 0.9179 | 0.9649 |
| Needle Retrieval | 0.9989 | 0.0519 | 0.0739 | 0.9878 |
表 1: 各任务在120K上下文和4K预算条件下(绕过初始两层)的接受率。StreamingLLM和$\mathrm{\bar{H}}_{2}\mathrm{O^{\prime}}$在针检索任务上表现显著下降。作为参考,Top-K为理论上限。
| 方法 | Top-K (参考) | StreamingLLM | H2O | 检索 |
|---|---|---|---|---|
| PG-19 | 0.9921 | 0.9156 | 0.9179 | 0.9649 |
| 针检索 (Needle Retrieval) | 0.9989 | 0.0519 | 0.0739 | 0.9878 |
4.2 Hierarchical Speculation
4.2 层级化推测
While addressing the KV cache bottleneck enhances efficiency, the requirement to load whole model weights for drafting reintroduce s latency, shifting the bottleneck to model weights again. To tackle this challenge, we implement a hierarchical system, as illustrated in Figure 1. This system employs a secondary, lightweight model with Streaming LL M cache to perform initial speculations for the target model with retrieval-based cache (which serves as a draft model for the target model with full KV cache). By establishing this sequential speculation hierarchy, we effectively reduce drafting latency and accelerate overall inference.
在解决KV缓存瓶颈提升效率的同时,加载完整模型权重进行草稿生成会重新引入延迟,使瓶颈再次转移到模型权重上。为解决这一挑战,我们采用了如图1所示的分层系统。该系统利用配备Streaming LLM缓存的轻量级二级模型(作为目标模型的草稿模型,采用基于检索的缓存机制)为目标模型(具备完整KV缓存)执行初始推测。通过建立这种顺序推测层级结构,我们有效降低了草稿生成延迟,从而加速整体推理过程。
Correctness: The original output distribution is preserved during the final speculation phase, which is identical to the standard speculative decoding algorithm (Leviathan et al., 2023; Chen et al., 2023a), and the proof is trivial.
正确性:在最终推测阶段保留了原始输出分布,这与标准推测解码算法 (Leviathan et al., 2023; Chen et al., 2023a) 相同,其证明过程是平凡的。
4.3 Algorithm
4.3 算法
TRIFORCE is devised to exploit the bottlenecks associated with both model weights and KV cache to enhance the inference speed of LLMs for long sequence generation. We present the pseudocode for the TRIFORCE in Algorithm 1. It starts by prefilling the target model $M_{p}$ with full cache $C_{p}$ and draft model $M_{q}$ with Streaming LL M cache $C_{q}$ using a given input prefix, and then constructs the retrieval cache $C_{r}$ . The initialization and update mechanism for the retrieval cache $C_{r}$ is guided by the insights of contextual locality discussed in Section 3.2. We first construct $C_{r}$ using the last token of the prefix, arranging tokens by the descending order of importance. In subsequent inferences, we overwrite tokens with the least importance, maintaining the relevance and utility of the cache. A reconstruction of $C_{r}$ is triggered either when the rolling average acceptance rate drops below a threshold or at a designed stride.
TRIFORCE旨在突破模型权重和KV缓存的瓶颈,以提升大语言模型在长序列生成中的推理速度。我们在算法1中给出了TRIFORCE的伪代码实现:首先使用给定输入前缀为目标模型$M_{p}$预填充完整缓存$C_{p}$,同时为草稿模型$M_{q}$预填充Streaming LLM缓存$C_{q}$,随后构建检索缓存$C_{r}$。检索缓存$C_{r}$的初始化与更新机制遵循3.2节讨论的上下文局部性原理——初始时采用前缀的最后一个token按重要性降序构建$C_{r}$,在后续推理中持续覆写重要性最低的token以保持缓存相关性。当滚动平均接受率低于阈值或达到预设步长时,将触发$C_{r}$的重建机制。
The inference progresses iterative ly until it reaches the target sequence length $T$ . After each iteration, cache $\breve{C_{r}}$ and $C_{q}$ are updated to prepare for the subsequent speculation phase. Each iteration encompasses two speculations: initially, $M_{q}$ utilizes $\hat{C}_ {q}$ to predict $M_{p}$ with $C_{r}$ for $\gamma_{1}$ steps until $n\geq\gamma_{2}$ . Subsequently, these $n$ tokens are self-verified (Zhang et al., 2023) by $M_{p}$ with $C_{p}$ . This process constructs a hierarchy: the first layer of hierarchy employs a smaller, faster model ${\bar{M}}_ {q}$ with local context $C_{q}$ to speculate the large model $M_{p}$ with partial but high-quality global context $C_{r},$ addressing the model weights bottleneck. The second layer utilizes model $M_{p}$ with retrieval cache for self-speculation, overcoming the bottleneck caused by KV cache. This hierarchical speculation algorithm boosts efficiency by effectively addressing both bottlenecks. System implementation is detailed in Appendix A.
推理过程会迭代进行,直到达到目标序列长度 $T$。每次迭代后,缓存 $\breve{C_{r}}$ 和 $C_{q}$ 会更新,为后续推测阶段做准备。每次迭代包含两次推测:首先,$M_{q}$ 利用 $\hat{C}_ {q}$ 预测 $M_{p}$ 使用 $C_{r}$ 进行 $\gamma_{1}$ 步,直到 $n\geq\gamma_{2}$。随后,这些 $n$ 个 token 由 $M_{p}$ 使用 $C_{p}$ 进行自验证 (Zhang et al., 2023)。这一过程构建了一个层次结构:第一层使用较小、较快的模型 ${\bar{M}}_ {q}$ 和局部上下文 $C_{q}$ 来推测大模型 $M_{p}$ 的部分但高质量的全局上下文 $C_{r}$,从而解决模型权重的瓶颈问题。第二层利用模型 $M_{p}$ 和检索缓存进行自推测,克服由 KV 缓存引起的瓶颈。这种分层推测算法通过有效解决这两个瓶颈问题提高了效率。系统实现细节详见附录 A。
Algorithm 1 TRIFORCE
算法 1 TRIFORCE
Table 2: On-chip results (A100): We indicate the average acceptance rate in parentheses alongside the speedup factor. T means sampling temperature. In the A100 on-chip experiments, with a prompt length of $122\mathrm{K},$ and a generation length of 256, we evaluate TRIFORCE against the JF68M model with Streaming LL M cache (Naive Policy). The results clearly demonstrate that TRIFORCE significantly surpasses its performance.
| Method | T | Speedup | Naive Policy |
| TRIFORCE | 0.0 | 2.31x (0.9234) | 1.56× (0.4649) |
| TRIFORCE | 0.2 | 2.25× (0.9203) | 1.54× (0.4452) |
| TRIFORCE | 0.4 | 2.20×( (0.9142) | 1.47× (0.4256) |
| TRIFORCE | 0.6 | 2.19 x (0.9137) | 1.42× (0.4036) |
| TRIFORCE | 0.8 | 2.08×( (0.8986) | 1.34× (0.3131) |
| TRIFORCE | 1.0 | 2.08× (0.9004) | 1.29× (0.2872) |
| TRIFORCE | 1.2 | 2.02× (0.8902) | 1.27× (0.2664) |
| Retrieval w/o Hierarchy | 0.6 | 1.80× (0.9126) | |
| StreamingLLM w/ Hierarchy | 0.6 | 1.90× (0.8745) |
表 2: 片上结果 (A100): 我们在括号中标明平均接受率及加速倍数。T表示采样温度。在A100片上实验中,设定提示长度为$122\mathrm{K}$、生成长度为256时,我们将TRIFORCE与采用Streaming LLM缓存 (Naive Policy) 的JF68M模型进行对比。结果明确显示TRIFORCE性能显著超越后者。
| 方法 | T | 加速倍数 | Naive Policy |
|---|---|---|---|
| TRIFORCE | 0.0 | 2.31x (0.9234) | 1.56× (0.4649) |
| TRIFORCE | 0.2 | 2.25× (0.9203) | 1.54× (0.4452) |
| TRIFORCE | 0.4 | 2.20× (0.9142) | 1.47× (0.4256) |
| TRIFORCE | 0.6 | 2.19 x (0.9137) | 1.42× (0.4036) |
| TRIFORCE | 0.8 | 2.08× (0.8986) | 1.34× (0.3131) |
| TRIFORCE | 1.0 | 2.08× (0.9004) | 1.29× (0.2872) |
| TRIFORCE | 1.2 | 2.02× (0.8902) | 1.27× (0.2664) |
| Retrieval w/o Hierarchy | 0.6 | 1.80× (0.9126) | |
| StreamingLLM w/ Hierarchy | 0.6 | 1.90× (0.8745) |
Table 3: Offloading results (RTX 4090): We present latency comparison between TRIFORCE and Auto-regressive (AR) baseline for various models on different GPU setups. The sampling temperature is set to 0.6. The results indicate that TRIFORCE achieves significant speedups across a range of models and hardware configurations. The entries marked with an asterisk represent the baseline using DeepSpeed-ZeRO-Inference (Aminabadi et al., 2022).
| GPUs | Target Model | TRIFORCE (ms) | AR (ms) | Speedup |
| 2×RTX 4090s | Llama2-7B-128K | 108 | 840 | 7.78x |
| 2×RTX4090s | LWM-Text-Chat-128K | 114 | 840 | 7.37x |
| 2×RTX4090s | Llama2-13B-128K | 226 | 1794 | 7.94x |
| 1× RTX 4090 | Llama2-7B-128K | 312 | 1516* | 4.86x |
| 1×RTX4090 | LWM-Text-Chat-128K | 314 | 1516* | 4.83x |
表 3: 卸载结果 (RTX 4090): 我们展示了 TRIFORCE 与自回归 (AR) 基线在不同 GPU 配置下针对多种模型的延迟对比。采样温度设为 0.6。结果表明 TRIFORCE 在一系列模型和硬件配置上均实现了显著加速。带星号的条目表示使用 DeepSpeed-ZeRO-Inference (Aminabadi et al., 2022) 的基线结果。
| GPU 配置 | 目标模型 | TRIFORCE (毫秒) | AR (毫秒) | 加速比 |
|---|---|---|---|---|
| 2×RTX 4090 | Llama2-7B-128K | 108 | 840 | 7.78x |
| 2×RTX 4090 | LWM-Text-Chat-128K | 114 | 840 | 7.37x |
| 2×RTX 4090 | Llama2-13B-128K | 226 | 1794 | 7.94x |
| 1×RTX 4090 | Llama2-7B-128K | 312 | 1516* | 4.86x |
| 1×RTX 4090 | LWM-Text-Chat-128K | 314 | 1516* | 4.83x |
5 Empirical Evaluation
5 实证评估
In this section, our goal is to showcase the capabilities of TRIFORCE, a scalable and robust speculative decoding algorithm designed to expedite the inference of LLMs for long sequence generation, which significantly reduces the wall-clock time. We first present our end-to-end system, highlighting the overall speedup achieved, including both on-chip and offloading settings, followed by a comparison with other methods and ablation experiments.
本节旨在展示TRIFORCE的能力,这是一种可扩展且鲁棒的推测解码算法,专为加速大语言模型(LLM)生成长序列的推理过程而设计,能显著缩短实际耗时。我们首先介绍端到端系统,重点展示包括片上计算和卸载计算场景下的整体加速效果,随后与其他方法进行对比并开展消融实验。
5.1 End-to-end Results
5.1 端到端结果
We demonstrate that TRIFORCE accelerates long sequence generation, up to $2.31\times$ on an A100 in the on-chip setting and $7.78\times$ on two RTX 4090s with offloading for Llama2-7B-128K.
我们证明TRIFORCE能加速长序列生成,在A100芯片上最高达$2.31\times$,在两块RTX 4090卸载Llama2-7B-128K时最高达$7.78\times$。
Setup. Our experiments are based on Llama2 and LWM models with 128K context window size (Touvron et al., 2023; Liu et al., 2024a; Peng et al., 2023), which serve as our target models. In this setup, we utilize a 4K retrieval cache as an intermediate draft cache in our hierarchical system, while leveraging the JackFram/Llama68M (JF68M) (Miao et al., 2023) model as the initial draft model. For experiments involving offloading, we aim to maximize memory utilization by filling it up as much as possible and offloading the remaining KV cache to the CPU (AMD EPYC 9754 $@$ $\begin{array}{r}{\partial2.25\operatorname{GHz}}\end{array}$ ), while keeping the model weights on the GPU. Our evaluation is carried out on the PG-19 (Rae et al., 2019) and Narrative QA (Kocisky et al., 2018) dataset, each testing on 100 examples, configured to a prompt length of 122K for on-chip settings and 127K for offloading settings, and aiming for a generation of 256 tokens. The performance of TRIFORCE is analyzed across various hardware configurations, including on-chip experiments on an A100, and offloading experiments on RTX 4090 GPUs.
实验设置。我们的实验基于Llama2和LWM模型(上下文窗口大小为128K)(Touvron et al., 2023; Liu et al., 2024a; Peng et al., 2023),这些模型作为目标模型。在此设置中,我们使用4K检索缓存作为分层系统中的中间草稿缓存,同时采用JackFram/Llama68M(JF68M)(Miao et al., 2023)模型作为初始草稿模型。对于涉及卸载的实验,我们通过尽可能填满内存并将剩余KV缓存卸载到CPU(AMD EPYC 9754 $@$ $\begin{array}{r}{\partial2.25\operatorname{GHz}}\end{array}$)来最大化内存利用率,同时将模型权重保留在GPU上。我们的评估在PG-19 (Rae et al., 2019)和Narrative QA (Kocisky et al., 2018)数据集上进行,每个数据集测试100个示例,配置为片上设置的提示长度为122K,卸载设置为127K,目标生成256个token。TRIFORCE的性能分析涵盖多种硬件配置,包括在A100上进行的片上实验和在RTX 4090 GPU上进行的卸载实验。
Naive Policy. Since it is hard to train a draft model with long contexts, we consider JF68M with Streaming LL M cache as a naive policy approach, and its budget is set to 1K. Additionally, we experiment with various temperatures to test its robustness.
朴素策略 (Naive Policy)。由于训练具有长上下文的草稿模型较为困难,我们将采用JF68M搭配流式大语言模型缓存作为朴素策略方案,其预算设为1K。此外,我们还测试了不同温度参数以验证其鲁棒性。
Main Results. We evaluate TRIFORCE using different temperatures, as depicted in Table 2. We observe that TRIFORCE reaches up to $2.31\times$ speedup for the on-chip setting with a minimal 4K KV cache budget for Llama2-7B-128K. For offloading settings, we provide end-to-end results on consumer GPUs for more models, including Llama2-7B128K, Llama2-13B-128K, and LWM-Text-Chat-128K. Remarkably, in Table 3 we demonstrate that TRIFORCE can efficiently serve a Llama2-13B with 128K contexts on two RTX 4090s, reaching an average time between tokens as low as 0.226 seconds, which is $7.94\times$ faster than a highly optimized offloading system. Moreover, with TRIFORCE, Llama2-7B-128K can be served with 0.108s/token—only half as slow as the auto-regressive baseline on an A100. We also illustrate how TRIFORCE boosts the efficiency of batched inference, a more frequently employed setting in real-world model serving. TRIFORCE achieves $1.9\times$ for a batch size of six, with each sample in the batch having 19K contexts, which is demonstrated in Table 4.
主要结果。我们使用不同温度评估了TRIFORCE的性能,如表 2 所示。在Llama2-7B-128K仅配置4K KV缓存预算的片上场景中,TRIFORCE最高可实现$2.31\times$的加速比。针对卸载场景,我们在消费级GPU上对更多模型(包括Llama2-7B128K、Llama2-13B-128K和LWM-Text-Chat-128K)进行了端到端测试。值得注意的是,表 3 显示TRIFORCE能在两块RTX 4090上高效服务128K上下文的Llama2-13B模型,平均Token间隔时间低至0.226秒,相比高度优化的卸载系统实现$7.94\times$加速。此外,TRIFORCE可使Llama2-7B-128K的推理速度达到0.108秒/Token——仅比A100上的自回归基线慢一半。我们还展示了TRIFORCE如何提升批处理推理效率(实际模型服务中更常用的场景),如表 4 所示,在批大小为6且每个样本含19K上下文时,TRIFORCE实现了$1.9\times$加速比。

Figure 5: TRIFORCE’s excellent s cal ability with longer contexts
图 5: TRIFORCE 在长上下文场景下的卓越扩展能力
Table 4: Batching results (A100): TRIFORCE showcases its exceptional capability in efficiently handling large batch sizes, consistently exceeding the performance of the JF68M model with Streaming LL M cache across all configurations for Llama2-7B-128K.
| Batch | Budget | T | Speedup | Naive Policy |
| (2,56K) | (2,1024) | 0.0 | 1.89x | 1.46x |
| (2,56K) | (2,1024) | 0.6 | 1.75x | 1.35x |
| (6,19K) | (6,768) | 0.0 | 1.90x | 1.39x |
| (6,19K) | (6,768) | 0.6 | 1.76x | 1.28x |
| (10,12K) | (10,768) | 0.0 | 1.72X | 1.34x |
| (10,12K) | (10,768) | 0.6 | 1.61x | 1.21x |
表 4: 批处理结果 (A100): TRIFORCE 在处理大批量数据时展现出卓越能力, 在 Llama2-7B-128K 的所有配置中持续超越带有 Streaming LLM 缓存的 JF68M 模型性能。
| Batch | Budget | T | Speedup | Naive Policy |
|---|---|---|---|---|
| (2,56K) | (2,1024) | 0.0 | 1.89x | 1.46x |
| (2,56K) | (2,1024) | 0.6 | 1.75x | 1.35x |
| (6,19K) | (6,768) | 0.0 | 1.90x | 1.39x |
| (6,19K) | (6,768) | 0.6 | 1.76x | 1.28x |
| (10,12K) | (10,768) | 0.0 | 1.72x | 1.34x |
| (10,12K) | (10,768) | 0.6 | 1.61x | 1.21x |
Analysis. (1) Effectiveness: TRIFORCE’s integration of the hierarchical system significantly enhances speedup, with TRIFORCE showing marked improvements over both the Streaming LL M method with hierarchical speculation and retrieval method without the hierarchical system. (2) S cal ability: As depicted in Figure 5, TRIFORCE demonstrates excellent s cal ability with longer context lengths. This s cal ability is attributed to its high acceptance rate and the growing gap between the draft and the target model’s latencies. Theoretically, TRIFORCE could achieve a speedup of up to $13.1\times,7$ times higher than the naive policy, underscoring its significant scaling potential. (3) Robustness: Unlike vanilla speculative decoding methods, TRIFORCE maintains relatively consistent performance across various temperature settings. It exhibits less temperature sensitivity, maintaining an acceptance rate above 0.9 even when the temperature is set to 1.0, highlighting its stability and reliability.
分析。(1) 有效性:TRIFORCE通过集成层级系统显著提升了加速效果,相较于采用层级推测的Streaming LLM方法和未采用层级系统的检索方法均展现出明显优势。(2) 可扩展性:如图5所示,TRIFORCE在更长上下文长度下表现出卓越的可扩展性。这一特性源于其高接受率以及草稿模型与目标模型延迟差距的扩大。理论上,TRIFORCE可实现高达$13.1\times$的加速比,是基础策略的7倍,凸显其强大的扩展潜力。(3) 鲁棒性:与原始推测解码方法不同,TRIFORCE在不同温度设置下保持相对稳定的性能。其温度敏感性较低,即使温度设为1.0时仍能维持0.9以上的接受率,体现了优异的稳定性和可靠性。
5.2 Comparison with Other Methods
5.2 与其他方法的对比
We provide a comparison with REST (He et al., 2023) and Skipping Layers (Zhang et al., 2023). Table 5 compares TRIFORCE, REST, and Skipping Layers with Llama2-7B128K on an A100 using PG-19 dataset, showing TRIFORCE achieves the best speedup for long sequence generation.
我们与REST (He et al., 2023) 和Skipping Layers (Zhang et al., 2023) 进行了对比。表5展示了TRIFORCE、REST和Skipping Layers在A100上使用PG-19数据集运行Llama2-7B128K时的性能比较,结果表明TRIFORCE在生成长序列时实现了最佳的加速效果。
| Method | Speedup |
| TRIFORCE | 2.31x |
| REST | 1.47x |
| Skipping Layers | 1.36x |
| 方法 | 加速倍数 |
|---|---|
| TRIFORCE | 2.31x |
| REST | 1.47x |
| Skipping Layers | 1.36x |
Table 5: Speedup comparison
表 5: 加速比对比
TRIFORCE retrieves information from the KV cache, al- with REST and Skipping Layers lowing dynamic adaptation to contexts, while REST uses an external predefined datastore. In Table 5, Skipping Layers utilizes $68%$ of the KV cache, whereas TRIFORCE efficiently uses only $3%$ , addressing the bottleneck in long-context scenarios better.
TRIFORCE从KV缓存中检索信息,允许动态适应上下文,而REST使用外部预定义的数据存储。在表5中,Skipping Layers利用了68%的KV缓存,而TRIFORCE仅高效使用了3%,更好地解决了长上下文场景中的瓶颈问题。

Figure 6: (a) Analyzing speedup and acceptance rates across different KV cache budgets reveals that a 4K budget is optimal, balancing acceptance rates and the drafting overhead. (b) For a 4K KV cache budget, excessively small chunk sizes may overfit individual tokens, while overly large chunk sizes could limit selection diversity. (c) TRIFORCE is compatible with tree-based speculations, enhancing the theoretical average number of tokens generated per decoding step of the target model by employing larger speculation budgets.
图 6: (a) 分析不同KV缓存预算下的加速比和接受率表明,4K预算在平衡接受率和草拟开销方面达到最优。(b) 对于4K KV缓存预算,过小的分块大小可能导致对单个token的过拟合,而过大的分块大小则会限制选择多样性。(c) TRIFORCE与基于树的推测方法兼容,通过采用更大的推测预算,可提升目标模型每个解码步骤生成token的理论平均数。
5.3 Ablation Results
5.3 消融实验结果
We present extensive ablation studies of TRIFORCE, focusing on three key points: (1) the influence of different KV cache budgets, (2) the impact of chunk size selection, and (3) TRIFORCE’s compatibility with tree-based speculative decoding.
我们对TRIFORCE进行了广泛的消融研究,重点关注三个关键点:(1) 不同KV缓存预算的影响,(2) 分块大小选择的影响,以及(3) TRIFORCE与基于树的推测解码的兼容性。
5.3.1 KV Cache Budget
5.3.1 KV Cache预算
As illustrated in Figure 6a, for Llama2-7B-128K, the acceptance rate rises with the cache budget up to 4K, then plateaus towards 1.0. This suggests that increasing the cache size beyond 4K offers diminishing benefits due to drafting latency. Thus, a 4K KV cache budget is optimal for TRIFORCE, balancing high acceptance rates and minimal drafting overhead.
如图 6a 所示,对于 Llama2-7B-128K,接受率随着缓存预算增加而上升直至 4K,随后趋于稳定至 1.0。这表明由于草拟延迟的存在,将缓存大小增加到超过 4K 带来的收益会递减。因此,4K 的 KV (Key-Value) 缓存预算是 TRIFORCE 的最佳选择,能够在高接受率和最小草拟开销之间取得平衡。
5.3.2 KV Cache Chunk Size
5.3.2 KV Cache块大小
Since we utilize contextual locality to reuse the retrieval cache, we need to examine the impact of KV cache chunk size on performance. Figure 6b shows that smaller chunks may overfit to single tokens, limiting generalization, while larger chunks may dilute high-score tokens with low-score ones, resulting in reduced differentiation among chunks. Large chunks also reduce selection flexibility, constraining diversity within a fixed cache budget.
由于我们利用上下文局部性来重用检索缓存,因此需要研究KV缓存块大小对性能的影响。图6b显示,较小的块可能过度拟合单个token,限制泛化能力,而较大的块可能会用低分token稀释高分token,导致块间区分度降低。大块还会降低选择灵活性,在固定缓存预算内限制多样性。
5.3.3 Compatibility with Tree-based Speculative Decoding
5.3.3 基于树的推测解码兼容性
We explore the possibility of integrating TRIFORCE with tree-based speculative decoding. Specifically, for Llama2-7B-128K on an A100, we estimate the theoretical number of generated tokens when TRIFORCE is combined with tree structures, including Sequoia (Chen et al., 2024) and Independent Sequences. As depicted in Figure 6c, this integration can potentially improve the end-to-end speedup by utilizing additional speculation budgets.
我们探索了将TRIFORCE与基于树的推测解码技术相结合的可能性。具体而言,在A100上针对Llama2-7B-128K模型,我们估算了TRIFORCE与树结构(包括Sequoia (Chen et al., 2024)和Independent Sequences)结合时的理论生成token数量。如图6c所示,通过利用额外的推测预算,这种集成有望进一步提升端到端加速效果。
6 Conclusion
6 结论
In this work, we introduced TRIFORCE, a hierarchical speculative decoding system aimed at significantly enhancing the efficiency of serving LLMs with long contexts. Leveraging insights from attention sparsity and contextual locality, TRIFORCE mitigates the dual bottlenecks associated with KV cache and model weights. Our empirical experiments demonstrate TRIFORCE’s remarkable performance, including a notable speedup of up to $2.31\times$ on an A100 and $7.78\times$ on two RTX 4090s with offloading, achieving 0.108s/token—only half as slow as the auto-regressive baseline on an A100. These achievements illustrate TRIFORCE’s potential to revolutionize the serving of long-context models for long sequence generation.
在本工作中,我们提出了TRIFORCE——一种层级化推测解码系统,旨在显著提升长上下文大语言模型的推理效率。通过利用注意力稀疏性和上下文局部性的洞见,TRIFORCE有效缓解了KV缓存和模型权重带来的双重瓶颈。实验结果表明,TRIFORCE在A100上实现了高达$2.31\times$的加速,在启用卸载模式的双RTX 4090上达到$7.78\times$加速,每Token耗时仅0.108秒——比A100上的自回归基线仅慢一半。这些成果展现了TRIFORCE在长序列生成任务中革新长上下文模型推理服务的潜力。
References
参考文献
Coleman Hooper, Sehoon Kim, Hiva Mohammad za deh, Michael W Mahoney, Yakun Sophia Shao, Kurt Keutzer, and Amir Gholami. Kvquant: Towards 10 million context length llm inference with kv cache quantization. arXiv preprint arXiv:2401.18079, 2024.
Coleman Hooper、Sehoon Kim、Hiva Mohammadzadeh、Michael W Mahoney、Yakun Sophia Shao、Kurt Keutzer 和 Amir Gholami。Kvquant:通过KV缓存量化实现千万级上下文长度的大语言模型推理。arXiv预印本 arXiv:2401.18079,2024。
Albert Q Jiang, Alexandre S a blay roll es, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al. Mistral 7b. arXiv preprint arXiv:2310.06825, 2023.
Albert Q Jiang, Alexandre S a blay roll es, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier 等. Mistral 7b. arXiv预印本 arXiv:2310.06825, 2023.
Hongye Jin, Xiaotian Han, Jingfeng Yang, Zhimeng Jiang, Zirui Liu, Chia-Yuan Chang, Huiyuan Chen, and Xia Hu. Llm maybe longlm: Self-extend llm context window without tuning. arXiv preprint arXiv:2401.01325, 2024.
Hongye Jin、Xiaotian Han、Jingfeng Yang、Zhimeng Jiang、Zirui Liu、Chia-Yuan Chang、Huiyuan Chen和Xia Hu。Llm maybe longlm: Self-extend llm context window without tuning。arXiv预印本arXiv:2401.01325,2024。
Sehoon Kim, Karttikeya Mangalam, Suhong Moon, Jitendra Malik, Michael W Mahoney, Amir Gholami, and Kurt Keutzer. Speculative decoding with big little decoder. Advances in Neural Information Processing Systems, 36, 2024.
Sehoon Kim、Karttikeya Mangalam、Suhong Moon、Jitendra Malik、Michael W Mahoney、Amir Gholami 和 Kurt Keutzer。基于大小解码器的推测解码 (Speculative Decoding with Big Little Decoder)。Advances in Neural Information Processing Systems,36,2024。
Tomas Kocisky, Jonathan Schwarz, Phil Blunsom, Chris Dyer, Karl Moritz Hermann, Gabor Melis, and Edward Gre fens te tte. The Narrative QA reading comprehension challenge. Transactions of the Association for Computational Linguistics, 6:317–328, 2018. doi: 10.1162/ tacl a 00023. URL https://a cl anthology.org/Q18-1023.
Tomas Kocisky、Jonathan Schwarz、Phil Blunsom、Chris Dyer、Karl Moritz Hermann、Gabor Melis 和 Edward Grefenstette。《Narrative QA 阅读理解挑战》。计算语言学协会汇刊,6:317–328,2018。doi: 10.1162/tacl_a_00023。URL https://acl anthology.org/Q18-1023。
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with paged attention. In Proceedings of the 29th Symposium on Operating Systems Principles, pp. 611–626, 2023.
Woosuk Kwon、Zhuohan Li、Siyuan Zhuang、Ying Sheng、Lianmin Zheng、Cody Hao Yu、Joseph Gonzalez、Hao Zhang和Ion Stoica。基于分页注意力机制的大语言模型服务高效内存管理。载于《第29届操作系统原理研讨会论文集》,第611-626页,2023年。
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. In International Conference on Machine Learning, pp. 19274–19286. PMLR, 2023.
Yaniv Leviathan、Matan Kalman 和 Yossi Matias。基于推测解码的Transformer快速推理。见《国际机器学习会议》第19274–19286页。PMLR,2023。
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. Eagle: Speculative sampling requires rethinking feature uncertainty. arXiv preprint arXiv:2401.15077, 2024.
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. Eagle: 投机采样需要重新思考特征不确定性. arXiv预印本 arXiv:2401.15077, 2024.
Hao Liu, Wilson Yan, Matei Zaharia, and Pieter Abbeel. World model on million-length video and language with ring attention. arXiv preprint arXiv:2402.08268, 2024a.
Hao Liu、Wilson Yan、Matei Zaharia 和 Pieter Abbeel。基于环形注意力机制的百万长度视频与语言世界模型。arXiv预印本 arXiv:2402.08268,2024a。
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts. Transactions of the Association for Computational Linguistics, 12:157–173, 2024b.
Nelson F Liu、Kevin Lin、John Hewitt、Ashwin Paranjape、Michele Bevilacqua、Fabio Petroni 和 Percy Liang。迷失在中间:大语言模型如何利用长上下文。计算语言学协会汇刊,12:157–173,2024b。
Zechun Liu, Barlas Oguz, Changsheng Zhao, Ernie Chang, Pierre Stock, Yashar Mehdad, Yangyang Shi, Raghuraman Krishna moor thi, and Vikas Chandra. Llm-qat: Data-free quantization aware training for large language models. arXiv preprint arXiv:2305.17888, 2023a.
Zechun Liu、Barlas Oguz、Changsheng Zhao、Ernie Chang、Pierre Stock、Yashar Mehdad、Yangyang Shi、Raghuraman Krishnamoorthi 和 Vikas Chandra。Llm-qat: 大语言模型的无数据量化感知训练。arXiv预印本 arXiv:2305.17888,2023a。
Zichang Liu, Jue Wang, Tri Dao, Tianyi Zhou, Binhang Yuan, Zhao Song, Anshumali Shri vast ava, Ce Zhang, Yuandong Tian, Christopher Re, et al. Deja vu: Contextual sparsity for efficient llms at inference time. In International Conference on Machine Learning, pp. 22137–22176. PMLR, 2023b.
Zichang Liu, Jue Wang, Tri Dao, Tianyi Zhou, Binhang Yuan, Zhao Song, Anshumali Shrivastava, Ce Zhang, Yuandong Tian, Christopher Re, et al. Deja vu: 大语言模型推理时的高效上下文稀疏化技术. In International Conference on Machine Learning, pp. 22137–22176. PMLR, 2023b.
Zichang Liu, Aditya Desai, Fangshuo Liao, Weitao Wang, Victor Xie, Zhaozhuo Xu, Anastasios Kyrillidis, and Anshumali Shri vast ava. Scissorhands: Exploiting the persistence of importance hypothesis for llm kv cache compression at test time. Advances in Neural Information Processing Systems, 36, 2024c.
Zichang Liu、Aditya Desai、Fangshuo Liao、Weitao Wang、Victor Xie、Zhaozhuo Xu、Anastasios Kyrillidis 和 Anshumali Shri vast ava。Scissorhands: 利用重要性持久性假设实现大语言模型 KV 缓存测试时压缩。Advances in Neural Information Processing Systems, 36, 2024c。
Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Xinhao Cheng, Zeyu Wang, Rae Ying Yee Wong, Zhuoming Chen, Daiyaan Arfeen, Reyna Abhyankar, and Zhihao Jia. Specinfer: Accelerating generative llm serving with speculative inference and token tree verification. arXiv preprint arXiv:2305.09781, 2023.
Xupeng Miao、Gabriele Oliaro、Zhihao Zhang、Xinhao Cheng、Zeyu Wang、Rae Ying Yee Wong、Zhuoming Chen、Daiyaan Arfeen、Reyna Abhyankar 和 Zhihao Jia。Specinfer: 通过推测推理和Token树验证加速生成式大语言模型服务。arXiv预印本 arXiv:2305.09781, 2023。
Péter Vingelmann NVIDIA and Frank HP Fitzek. Cuda, release: 10.2. 89. URL https://developer. nvidia. com/cuda-toolkit. Cited, pp. 148, 2020.
Péter Vingelmann NVIDIA 和 Frank HP Fitzek。 CUDA,版本:10.2.89。 URL https://developer.nvidia.com/cuda-toolkit。 引用,第148页,2020年。
Acknowledgments
致谢
We thank Yang Zhou, Ranajoy Sadhukhan, Harry Dong, and Jian Chen for their helpful discussions and feedback on early drafts of the paper.
我们感谢Yang Zhou、Ranajoy Sadhukhan、Harry Dong和Jian Chen对论文早期草稿的有益讨论和反馈。
A System Implementation
系统实现
We implement the draft and target models using Transformers (Wolf et al., 2019). Leveraging a predetermined cache budget enables the effective use of PyTorch CUDA graphs (Paszke et al., 2019; NVIDIA & Fitzek, 2020), significantly minimizing the kernel launching overhead during speculative decoding. Flash Attention is used to accelerate attention operations (Dao et al., 2022; Dao, 2023; Kwon et al., 2023; Hong et al., 2023). Notably, we maintain full layer sparsity without omitting the initial two layers for system efficiency, ensuring our approach stays within the fixed KV cache budget. Although this strategy might lead to a lower acceptance rate, the benefit of maintaining a constant drafting cost makes it a worthwhile compromise. Additionally, to facilitate a faster speculation phase, we also implement two extra speculation cache structures, including our retrieval cache and Streaming LL M cache.
我们使用Transformer (Wolf等人,2019) 实现草案模型和目标模型。利用预定的缓存预算可以有效使用PyTorch CUDA图 (Paszke等人,2019; NVIDIA & Fitzek,2020),显著减少推测解码过程中的内核启动开销。采用Flash Attention加速注意力运算 (Dao等人,2022; Dao,2023; Kwon等人,2023; Hong等人,2023)。值得注意的是,为保持系统效率,我们维持全层稀疏性而不跳过前两层,确保方法始终处于固定的KV缓存预算内。虽然该策略可能导致接受率降低,但保持恒定草案生成成本的优势使其成为值得的折衷方案。此外,为加速推测阶段,我们还实现了两种额外的推测缓存结构,包括检索缓存和Streaming LLM缓存。
B Additional Experiments
B 补充实验
B.1 TRIFORCE’s S cal ability for Longer Inputs
B.1 TRIFORCE 对更长输入的扩展性
For longer inputs, a solution is offloading the KV cache to the CPU memory. Below are experiments on a single L40 GPU with offloading for longer inputs on LWM-Text models (Liu et al., 2024a) using the PG-19 dataset, showing impressive speedup.
对于较长的输入,一种解决方案是将KV缓存卸载到CPU内存。以下是在单个L40 GPU上进行的实验,使用PG-19数据集对LWM-Text模型 (Liu et al., 2024a) 进行长输入卸载,结果显示显著加速。
Table 6: TRIFORCE’s S cal ability for longer inputs
| Model | Speedup |
| LWM-Text-256K | 11.81x |
| LWM-Text-512K | 12.10x |
表 6: TRIFORCE 对更长输入的扩展性
| 模型 | 加速倍数 |
|---|---|
| LWM-Text-256K | 11.81倍 |
| LWM-Text-512K | 12.10倍 |
B.2 TRIFORCE’s S cal ability for Longer Outputs
B.2 TRIFORCE 在生成长输出时的可扩展性
In the previous sections of the paper, we focused on a long input and a short output to illustrate the efficiency gains in a commonly encountered setting. Here we provide additional experiments with longer output sequences up to 2K with Llama2-7B-128K on an A100 GPU using the PG-19 dataset:
在本文的前几部分中,我们重点分析了长输入短输出的常见场景以展示效率提升。此处我们使用PG-19数据集,在A100 GPU上对Llama2-7B-128K模型进行了输出序列长达2K的补充实验:
Table 7: TRIFORCE’s S cal ability for longer outputs
| Output Sequence Length | Speedup |
| 256 | 2.31x |
| 512 | 2.28x |
| 768 | 2.34x |
| 1024 | 2.32x |
| 1536 | 2.28x |
| 2048 | 2.29 x |
表 7: TRIFORCE 生成长文本的可扩展性
| 输出序列长度 | 加速比 |
|---|---|
| 256 | 2.31倍 |
| 512 | 2.28倍 |
| 768 | 2.34倍 |
| 1024 | 2.32倍 |
| 1536 | 2.28倍 |
| 2048 | 2.29倍 |
As seen in Table 7, the performance of TRIFORCE remains relatively stable. This stability is due to the retrieval cache being reconstructed at fixed intervals, ensuring it stays aligned with the evolving context. Furthermore, our retrieved cache can be effectively reused across multiple decoding steps, amortizing the overhead of retrieval. These results demonstrate the s cal ability of TRIFORCE and its robustness in handling varying output lengths, thereby addressing the concern about its general iz ability.
如表 7 所示,TRIFORCE 的性能保持相对稳定。这种稳定性源于检索缓存会按固定间隔重建,确保其与不断变化的上下文保持一致。此外,我们的检索缓存可在多个解码步骤中有效复用,从而分摊检索开销。这些结果证明了 TRIFORCE 的可扩展性及其处理不同输出长度的鲁棒性,由此解决了对其泛化能力的担忧。
B.3 Ablation of $\gamma_1,\gamma_2$
B.3 $\gamma_1,\gamma_2$ 消融实验
Here we provide additional ablation results of $\gamma_{1},\gamma_{2}$ in Table 8 with Llama2-7B-128K on an A100 GPU using the PG-19 dataset. Due to the gap between JF68M with Streaming LL M
我们在A100 GPU上使用PG-19数据集,以Llama2-7B-128K模型为基础,在表8中提供了$\gamma_{1},\gamma_{2}$的额外消融实验结果。由于JF68M与Streaming LLM之间存在差异
and Llama-7B-128K with retrieval cache, the acceptance rate of the first speculation phase in our speculation hierarchy is low. As shown in the table, the optimal value for $\gamma_{1}$ is 2 and for $\gamma_{2}$ is 6.
采用检索缓存的Llama-7B-128K模型在推测层级的第一阶段接受率较低。如表所示,$\gamma_{1}$ 的最优值为2,$\gamma_{2}$ 的最优值为6。
| Y2 | Speedup |
| 1 | 1.62x |
| 2 | 1.90x |
| 3 | 2.13x |
| 4 | 2.22x |
| 5 | 2.26x |
| 6 | 2.31x |
| 7 | 2.24x |
| 8 | 2.20x |
| Y2 | 加速比 |
|---|---|
| 1 | 1.62倍 |
| 2 | 1.90倍 |
| 3 | 2.13倍 |
| 4 | 2.22倍 |
| 5 | 2.26倍 |
| 6 | 2.31倍 |
| 7 | 2.24倍 |
| 8 | 2.20倍 |
Table 8: Ablation of γ1, γ2
| Y1 | Speedup |
| 1 | 2.30x |
| 2 | 2.31x |
| 3 | 2.24x |
| 4 | 2.17x |
| 5 | 2.09x |
| 6 | 2.01x |
| 7 | 1.92x |
| 8 | 1.83 x |
表 8: γ1、γ2 消融实验
| Y1 | 加速倍数 |
|---|---|
| 1 | 2.30x |
| 2 | 2.31x |
| 3 | 2.24x |
| 4 | 2.17x |
| 5 | 2.09x |
| 6 | 2.01x |
| 7 | 1.92x |
| 8 | 1.83x |
(a) Speedup at different $\gamma_{1}$ values with $\gamma_{2}=6$ (b) Speedup at different $\gamma_{2}$ values with $\gamma_{2}=2$
(a) 不同 $\gamma_{1}$ 值下的加速比 ($\gamma_{2}=6$)
(b) 不同 $\gamma_{2}$ 值下的加速比 ($\gamma_{2}=2$)