A survey on large language model based autonomous agents
基于大语言模型的自主AI智能体综述
Lei WANG, Chen MA*, Xueyang FENG*, Zeyu ZHANG, Hao YANG, Jingsen ZHANG, Zhiyuan CHEN, Jiakai TANG, Xu CHEN $\left(\boxtimes\right)$ , Yankai LIN $\left(\boxtimes\right)$ , Wayne Xin ZHAO, Zhewei WEI, Jirong WEN
Lei WANG, Chen MA*, Xueyang FENG*, Zeyu ZHANG, Hao YANG, Jingsen ZHANG, Zhiyuan CHEN, Jiakai TANG, Xu CHEN (□), Yankai LIN (□), Wayne Xin ZHAO, Zhewei WEI, Jirong WEN
Gaoling School of Artificial Intelligence, Renmin University of China, Beijing 100872, China $\circleddash$ The Author(s) 2024. This article is published with open access at link.springer.com and journal.hep.com.cn
中国人民大学高瓴人工智能学院,中国北京 100872 $\circleddash$ 作者 2024。本文以开放获取形式发表于 link.springer.com 和 journal.hep.com.cn
Abstract Autonomous agents have long been a research focus in academic and industry communities. Previous research often focuses on training agents with limited knowledge within isolated environments, which diverges significantly from human learning processes, and makes the agents hard to achieve human-like decisions. Recently, through the acquisition of vast amounts of Web knowledge, large language models (LLMs) have shown potential in human-level intelligence, leading to a surge in research on LLM-based autonomous agents. In this paper, we present a comprehensive survey of these studies, delivering a systematic review of LLM-based autonomous agents from a holistic perspective. We first discuss the construction of LLM-based autonomous agents, proposing a unified framework that encompasses much of previous work. Then, we present a overview of the diverse applications of LLM-based autonomous agents in social science, natural science, and engineering. Finally, we delve into the evaluation strategies commonly used for LLM-based autonomous agents. Based on the previous studies, we also present several challenges and future directions in this field.
摘要
自主智能体 (Autonomous Agents) 长期以来一直是学术界和工业界的研究热点。先前研究通常局限于在孤立环境中训练知识有限的智能体,这与人类学习过程存在显著差异,导致智能体难以实现类人决策。近年来,通过获取海量网络知识,大语言模型 (LLM) 展现出人类水平智能的潜力,推动了基于大语言模型的自主智能体研究热潮。本文系统综述了该领域研究,从整体视角对基于大语言模型的自主智能体进行系统性梳理。我们首先探讨其构建方法,提出一个涵盖多数已有工作的统一框架;其次概述其在社会科学、自然科学和工程领域的多样化应用;最后深入分析常用的评估策略。基于现有研究,我们进一步提出该领域面临的挑战与未来发展方向。
Keywords autonomous agent, large language model, human-level intelligence
关键词 自主智能体 (autonomous agent), 大语言模型, 人类水平智能
1 Introduction
1 引言
“An autonomous agent is a system situated within and a part of an environment that senses that environment and acts on it, over time, in pursuit of its own agenda and so as to effect what it senses in the future.”
自主智能体 (autonomous agent) 是一种存在于环境中并作为环境组成部分的系统,它感知该环境并随时间推移对其采取行动,以追求自身目标,从而影响其未来的感知结果。
Franklin and Graesser (1997)
Franklin 和 Graesser (1997)
Autonomous agents have long been recognized as a promising approach to achieving artificial general intelligence (AGI), which is expected to accomplish tasks through selfdirected planning and actions. In previous studies, the agents are assumed to act based on simple and heuristic policy functions, and learned in isolated and restricted environments [1-6]. Such assumptions significantly differs from the human learning process, since the human mind is highly complex, and individuals can learn from a much wider variety of environments. Because of these gaps, the agents obtained from the previous studies are usually far from replicating humanlevel decision processes, especially in un constrained, opendomain settings.
自主智能体 (Autonomous Agents) 长期以来被视为实现通用人工智能 (AGI) 的有前景途径,其预期通过自主规划和行动完成任务。在以往研究中,智能体通常被假设基于简单启发式策略函数行动,并在孤立受限环境中学习 [1-6]。这些假设与人类学习过程存在显著差异——人类心智高度复杂,且能从更广泛的环境中学习。由于这些差距,既有研究获得的智能体往往难以复现人类水平的决策过程,尤其在非约束性开放领域场景中。
In recent years, large language models (LLMs) have achieved notable successes, demonstrating significant potential in attaining human-like intelligence [5–10]. This capability arises from leveraging comprehensive training datasets alongside a substantial number of model parameters. Building upon this capability, there has been a growing research area that employs LLMs as central controllers to construct autonomous agents to obtain human-like decisionmaking capabilities [11–17].
近年来,大语言模型(LLM)取得了显著成就,在实现类人智能方面展现出巨大潜力[5-10]。这种能力源于利用海量训练数据集和庞大的模型参数。基于此能力,一个新兴研究领域正逐渐形成:将大语言模型作为核心控制器来构建自主AI智能体,从而获得类人决策能力[11-17]。
Comparing with reinforcement learning, LLM-based agents have more comprehensive internal world knowledge, which facilitates more informed agent actions even without training on specific domain data. Additionally, LLM-based agents can provide natural language interfaces to interact with humans, which is more flexible and explain able.
与强化学习相比,基于大语言模型 (LLM) 的 AI智能体拥有更全面的内部世界知识,即使未经特定领域数据训练也能促成更明智的决策行为。此外,基于大语言模型的智能体可提供自然语言交互界面,其灵活性和可解释性更优。
Along this direction, researchers have developed numerous promising models (see Fig. 1 for an overview of this field), where the key idea is to equip LLMs with crucial human capabilities like memory and planning to make them behave like humans and complete various tasks effectively. Previously, these models were proposed independently, with limited efforts made to summarize and compare them holistic ally. However, we believe a systematic summary on this rapidly developing field is of great significance to comprehensively understand it and benefit to inspire future research.
沿着这一方向,研究人员已开发出众多前景广阔的模型(该领域概览见图1),其核心思路是为大语言模型配备记忆与规划等关键人类能力,使其能像人类一样行动并高效完成各类任务。此前这些模型被独立提出,缺乏系统性总结与整体对比。但我们认为,对这一快速发展领域进行系统梳理,将有助于全面理解其脉络并启发未来研究。
In this paper, we conduct a comprehensive survey of the field of LLM-based autonomous agents. Specifically, we organize our survey based on three aspects including the construction, application, and evaluation of LLM-based autonomous agents. For the agent construction, we focus on two problems, that is, (1) how to design the agent architecture to better leverage LLMs, and (2) how to inspire and enhance the agent capability to complete different tasks. Intuitively, the first problem aims to build the hardware fundamentals for the agent, while the second problem focus on providing the agent with software resources. For the first problem, we present a unified agent framework, which can encompass most of the previous studies. For the second problem, we provide a summary on the commonly-used strategies for agents’ capability acquisition. In addition to discussing agent construction, we also provide an systematic overview of the applications of LLM-based autonomous agents in social science, natural science, and engineering. Finally, we delve into the strategies for evaluating LLM-based autonomous agents, focusing on both subjective and objective strategies.
本文对大语言模型(LLM)驱动的自主AI智能体领域进行了全面综述。具体而言,我们从智能体构建、应用场景和评估方法三个维度组织本次调研。在智能体构建方面,我们聚焦两个核心问题:(1) 如何设计智能体架构以更好地利用大语言模型;(2) 如何激发和增强智能体完成多样化任务的能力。直观来看,第一个问题旨在为智能体构建硬件基础,而第二个问题则侧重于提供软件资源。针对第一个问题,我们提出了一个能涵盖多数现有研究的统一智能体框架;针对第二个问题,我们系统总结了智能体能力获取的常用策略。除构建方法外,我们还系统梳理了大语言模型智能体在社会科学、自然科学及工程领域的应用。最后,我们深入探讨了主客观相结合的大语言模型智能体评估策略。
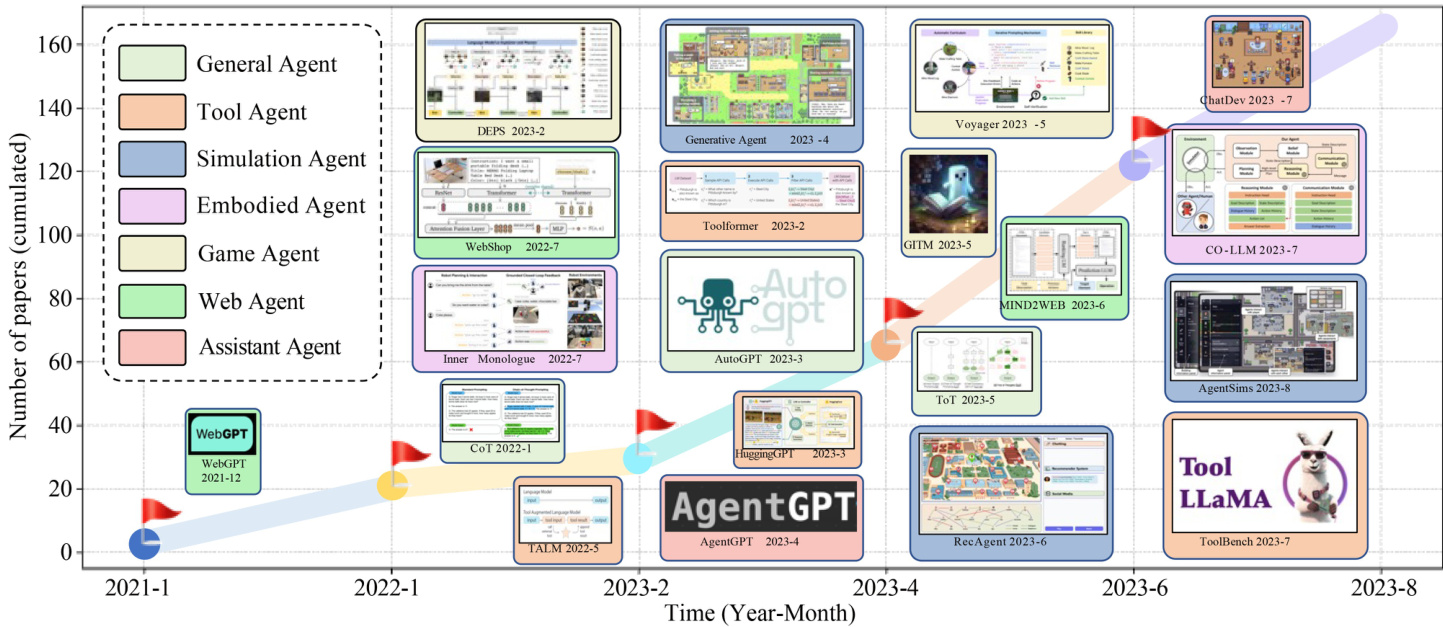
Fig. 1 Illustration of the growth trend in the field of LLM-based autonomous agents. We present the cumulative number of papers published from January 2021 to August 2023. We assign different colors to represent various agent categories. For example, a game agent aims to simulate a game-player, while a tool agent mainly focuses on tool using. For each time period, we provide a curated list of studies with diverse agent categories
图 1: 基于大语言模型的自主智能体领域增长趋势示意图。我们展示了2021年1月至2023年8月期间发表的论文累计数量,并使用不同颜色区分各类智能体。例如游戏智能体(Game Agent)旨在模拟游戏玩家,而工具智能体(Tool Agent)主要关注工具使用。每个时间段我们都精选了涵盖多种智能体类别的代表性研究。
In summary, this survey conducts a systematic review and establishes comprehensive taxonomies for existing studies in the burgeoning field of LLM-based autonomous agents. Our focus encompasses three primary areas: construction of agents, their applications, and methods of evaluation. Drawing from a wealth of previous studies, we identify various challenges in this field and discuss potential future directions. We expect that our survey can provide newcomers of LLMbased autonomous agents with a comprehensive background knowledge, and also encourage further groundbreaking studies.
总之,本综述对基于大语言模型(LLM)的自主AI智能体这一新兴领域的研究进行了系统性梳理,并建立了完整的分类体系。我们重点聚焦三个核心方向:智能体构建、应用场景及评估方法。通过整合大量前人研究,我们指出了该领域面临的诸多挑战,并探讨了未来潜在的发展路径。我们希望本次综述能为基于大语言模型的自主AI智能体领域的新研究者提供全面的背景知识,同时激励更多突破性研究的开展。
2 LLM-based autonomous agent construction
2 基于大语言模型的自主AI智能体构建
LLM-based autonomous agents are expected to effectively perform diverse tasks by leveraging the human-like capabilities of LLMs. In order to achieve this goal, there are two significant aspects, that is, (1) which architecture should be designed to better use LLMs and (2) give the designed architecture, how to enable the agent to acquire capabilities for accomplishing specific tasks. Within the context of architecture design, we contribute a systematic synthesis of existing research, culminating in a comprehensive unified framework. As for the second aspect, we summarize the strategies for agent capability acquisition based on whether they fine-tune the LLMs. When comparing LLM-based autonomous agents to traditional machine learning, designing the agent architecture is analogous to determining the network structure, while the agent capability acquisition is similar to learning the network parameters. In the following, we introduce these two aspects more in detail.
基于大语言模型(LLM)的自主AI智能体有望通过利用LLM类人能力高效执行多样化任务。为实现该目标,需关注两大核心:(1) 设计何种架构以优化LLM使用;(2) 既定架构下如何使智能体获得特定任务能力。在架构设计方面,我们对现有研究进行系统梳理,最终提出一个全面统一的框架。针对第二方面,我们根据是否微调LLM总结了智能体能力获取策略。相较于传统机器学习,设计智能体架构类似于确定网络结构,而能力获取则类似于学习网络参数。下文将详细阐述这两个方面。
2.1 Agent architecture design
2.1 AI智能体架构设计
Recent advancements in LLMs have demonstrated their great potential to accomplish a wide range of tasks in the form of question-answering (QA). However, building autonomous agents is far from QA, since they need to fulfill specific roles and autonomously perceive and learn from the environment to evolve themselves like humans. To bridge the gap between traditional LLMs and autonomous agents, a crucial aspect is to design rational agent architectures to assist LLMs in maximizing their capabilities. Along this direction, previous work has developed a number of modules to enhance LLMs. In this section, we propose a unified framework to summarize these modules. In specific, the overall structure of our framework is illustrated Fig. 2, which is composed of a profiling module, a memory module, a planning module, and an action module. The purpose of the profiling module is to identify the role of the agent. The memory and planning modules place the agent into a dynamic environment, enabling it to recall past behaviors and plan future actions. The action module is responsible for translating the agent’s decisions into specific outputs. Within these modules, the profiling module impacts the memory and planning modules, and collectively, these three modules influence the action module. In the following, we detail these modules.
近年来,大语言模型(LLM)的进步已展现出其通过问答(QA)形式完成广泛任务的巨大潜力。然而,构建自主AI智能体远非问答那么简单,因为它们需要履行特定角色,像人类一样自主感知环境并从中学习进化。为弥合传统大语言模型与自主智能体之间的鸿沟,设计合理的智能体架构以帮助LLM最大化其能力成为关键。沿此方向,先前研究已开发了多个增强模块。本节我们提出统一框架来归纳这些模块,具体结构如图2所示,由角色分析模块、记忆模块、规划模块和行动模块构成。角色分析模块用于确定智能体的职能定位,记忆与规划模块使智能体置身动态环境,能够回溯过往行为并规划未来行动。行动模块负责将智能体决策转化为具体输出。这些模块中,角色分析模块会影响记忆与规划模块,三者共同作用于行动模块。下文将详细阐述各模块。
2.1.1 Profiling module
2.1.1 性能分析模块
Autonomous agents typically perform tasks by assuming specific roles, such as coders, teachers and domain experts [18,19]. The profiling module aims to indicate the profiles of the agent roles, which are usually written into the prompt to influence the LLM behaviors. Agent profiles typically encompass basic information such as age, gender, and career [20], as well as psychology information, reflecting the personalities of the agent, and social information, detailing the relationships between agents [21]. The choice of information to profile the agent is largely determined by the specific application scenarios. For instance, if the application aims to study human cognitive process, then the psychology information becomes pivotal. After identifying the types of profile information, the next important problem is to create specific profiles for the agents. Existing literature commonly employs the following three strategies.
自主AI智能体通常通过承担特定角色来执行任务,例如程序员、教师和领域专家 [18,19]。画像模块旨在定义智能体角色的属性特征,这些特征通常被写入提示词以影响大语言模型的行为。智能体画像通常包含年龄、性别和职业等基本信息 [20],以及反映智能体个性的心理特征信息,还有描述智能体间社会关系的社交信息 [21]。选择哪些信息来构建智能体画像主要由具体应用场景决定。例如,若应用目标是研究人类认知过程,那么心理特征信息就至关重要。在确定画像信息类型后,接下来的关键问题是为智能体创建具体画像。现有文献通常采用以下三种策略。
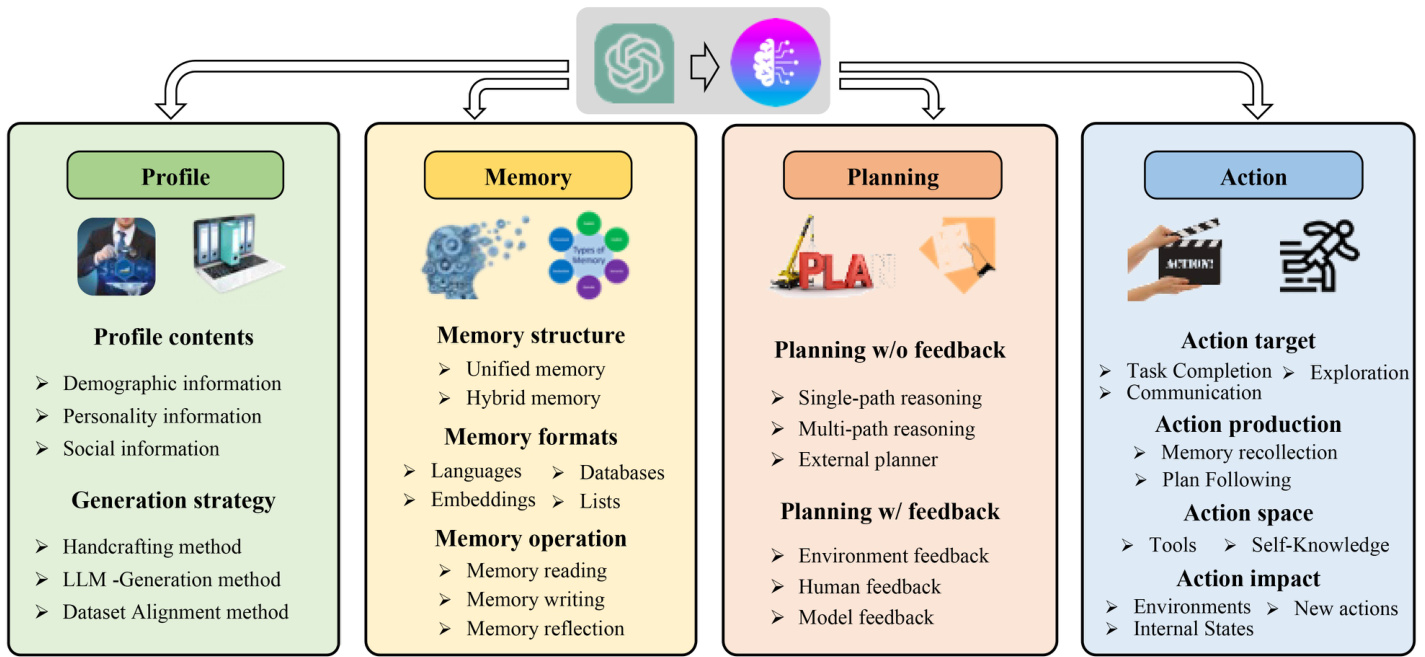
Fig. 2 A unified framework for the architecture design of LLM-based autonomous agent
图 2: 基于大语言模型的自主智能体架构设计统一框架
Handcrafting method: in this method, agent profiles are manually specified. For instance, if one would like to design agents with different personalities, he can use “you are an outgoing person” or “you are an introverted person” to profile the agent. The handcrafting method has been leveraged in a lot of previous work to indicate the agent profiles. For example, Generative Agent [22] describes the agent by the information like name, objectives, and relationships with other agents. MetaGPT [23], ChatDev [18], and Self-collaboration [24] predefine various roles and their corresponding responsibilities in software development, manually assigning distinct profiles to each agent to facilitate collaboration. PTLLM [25] aims to explore and quantify personality traits displayed in texts generated by LLMs. This method guides LLMs in generating diverse responses by manfully defining various agent characters through the use of personality assessment tools such as IPIP-NEO [26] and BFI [27]. [28] studies the toxicity of the LLM output by manually prompting LLMs with different roles, such as politicians, journalists and businessperson s. In general, the handcrafting method is very flexible, since one can assign any profile information to the agents. However, it can be also labor-intensive, particularly when dealing with a large number of agents.
手工制作方法:该方法通过人工指定AI智能体(agent)的配置文件。例如若要设计不同性格的智能体,可使用"你是个外向的人"或"你是个内向的人"来刻画其形象。该方法在先前诸多研究中被用于定义智能体特征:Generative Agent [22]通过姓名、目标、与其他智能体的关系等信息来描述智能体;MetaGPT [23]、ChatDev [18]和Self-collaboration [24]在软件开发中预定义不同角色及其对应职责,手动为每个智能体分配独特配置以促进协作;PTLLM [25]旨在探索和量化大语言模型生成文本中显现的人格特质,通过IPIP-NEO [26]和BFI [27]等人格评估工具手动定义各类角色,引导模型生成多样化响应;[28]则通过手动提示政治人物、记者、商人等不同角色,研究大语言模型输出的毒性。总体而言,手工制作方法具有高度灵活性,可为智能体分配任意配置信息,但在处理大量智能体时会显得耗时费力。
LLM-generation method: in this method, agent profiles are automatically generated based on LLMs. Typically, it begins by indicating the profile generation rules, elucidating the composition and attributes of the agent profiles within the target population. Then, one can optionally specify several seed agent profiles to serve as few-shot examples. At last, LLMs are leveraged to generate all the agent profiles. For example, RecAgent [21] first creates seed profiles for a few number of agents by manually crafting their backgrounds like age, gender, personal traits, and movie preferences. Then, it leverages ChatGPT to generate more agent profiles based on the seed information. The LLM-generation method can save significant time when the number of agents is large, but it may lack precise control over the generated profiles.
大语言模型生成方法:该方法基于大语言模型自动生成智能体档案。通常,首先明确档案生成规则,阐明目标群体中智能体档案的构成与属性。随后可选择性地指定若干种子智能体档案作为少样本示例。最后利用大语言模型生成所有智能体档案。例如,RecAgent [21] 先通过手工创建少量智能体的背景信息(如年龄、性别、个人特质和电影偏好)来生成种子档案,再基于这些种子信息调用ChatGPT生成更多档案。当智能体数量庞大时,大语言模型生成方法能显著节省时间,但可能对生成档案缺乏精确控制。
Dataset alignment method: in this method, the agent profiles are obtained from real-world datasets. Typically, one can first organize the information about real humans in the datasets into natural language prompts, and then leverage it to profile the agents. For instance, in [29], the authors assign roles to GPT-3 based on the demographic backgrounds (such as race/ethnicity, gender, age, and state of residence) of participants in the American National Election Studies (ANES). They subsequently investigate whether GPT-3 can produce similar results to those of real humans. The dataset alignment method accurately captures the attributes of the real population, thereby making the agent behaviors more meaningful and reflective of real-world scenarios.
数据集对齐方法:该方法通过真实世界数据集获取智能体画像。通常可先将数据集中真实人类的自然语言提示信息进行结构化处理,再用于构建智能体特征。例如在[29]中,作者根据美国国家选举研究(ANES)参与者的种族/民族、性别、年龄和居住州等人口统计背景,为GPT-3分配角色,进而探究GPT-3能否产生与真实人类相似的结果。这种数据对齐方法能精确捕捉真实人群特征,使智能体行为更具现实意义并真实反映现实场景。
Remark. While most of the previous work leverage the above profile generation strategies independently, we argue that combining them may yield additional benefits. For example, in order to predict social developments via agent simulation, one can leverage real-world datasets to profile a subset of the agents, thereby accurately reflecting the current social status. Subsequently, roles that do not exist in the real world but may emerge in the future can be manually assigned to the other agents, enabling the prediction of future social development. Beyond this example, one can also flexibly combine the other strategies. The profile module serves as the foundation for agent design, exerting significant influence on the agent memorization, planning, and action procedures.
备注:虽然之前的工作大多独立运用上述角色生成策略,但我们认为组合使用可能带来额外收益。例如,在通过智能体模拟预测社会发展时,可以结合现实数据集为部分智能体构建角色档案,从而准确反映当前社会现状;同时为其他智能体人工分配现实中尚不存在但未来可能出现的角色,以此预测社会发展走向。除该案例外,其他策略也能灵活组合。角色模块作为智能体设计的基础,对其记忆、规划和行动流程具有重要影响。
2.1.2 Memory module
2.1.2 内存模块
The memory module plays a very important role in the agent architecture design. It stores information perceived from the environment and leverages the recorded memories to facilitate future actions. The memory module can help the agent to accumulate experiences, self-evolve, and behave in a more consistent, reasonable, and effective manner. This section provides a comprehensive overview of the memory module, focusing on its structures, formats, and operations.
记忆模块在智能体架构设计中扮演着至关重要的角色。它存储从环境中感知到的信息,并利用记录的记忆来促进未来的行动。记忆模块能帮助智能体积累经验、自我进化,并以更一致、合理且高效的方式行动。本节全面概述了记忆模块,重点介绍其结构、格式和操作。
Memory structures: LLM-based autonomous agents usually incorporate principles and mechanisms derived from cognitive science research on human memory processes. Human memory follows a general progression from sensory memory that registers perceptual inputs, to short-term memory that maintains information transient ly, to long-term memory that consolidates information over extended periods. When designing the agent memory structures, researchers take inspiration from these aspects of human memory. In specific, short-term memory is analogous to the input information within the context window constrained by the transformer architecture. Long-term memory resembles the external vector storage that agents can rapidly query and retrieve from as needed. In the following, we introduce two commonly used memory structures based on the short- and long-term memories.
记忆结构:基于大语言模型(LLM)的自主智能体通常借鉴了人类记忆过程的认知科学研究原理与机制。人类记忆遵循从感知输入的感觉记忆,到短暂维持信息的短期记忆,再到长期巩固信息的长时记忆这一递进过程。在设计智能体记忆结构时,研究者从人类记忆的这些特征中获得启发。具体而言,短期记忆类似于受Transformer架构限制的上下文窗口内的输入信息,长时记忆则类似于智能体可按需快速查询检索的外部向量存储。下文将介绍基于短时记忆和长时记忆的两种常用记忆结构。
● Unified memory. This structure only simulates the human shot-term memory, which is usually realized by in-context learning, and the memory information is directly written into the prompts. For example, RLP [30] is a conversation agent, which maintains internal states for the speaker and listener. During each round of conversation, these states serve as LLM prompts, functioning as the agent’s short-term memory. SayPlan [31] is an embodied agent specifically designed for task planning. In this agent, the scene graphs and environment feedback serve as the agent’s short-term memory, guiding its actions. CALYPSO [32] is an agent designed for the game Dungeons & Dragons, which can assist Dungeon Masters in the creation and narration of stories. Its short-term memory is built upon scene descriptions, monster information, and previous summaries. DEPS [33] is also a game agent, but it is developed for Minecraft. The agent initially generates task plans and then utilizes them to prompt LLMs, which in turn produce actions to complete the task. These plans can be deemed as the agent’s short-term memory. In practice, implementing short-term memory is straightforward and can enhance an agent’s ability to perceive recent or con textually sensitive behaviors and observations. However, due to the limitation of context window of LLMs, it’s hard to put all memories into prompt, which may degrade the performance of agents. This method has high requirements on the window length of LLMs and the ability to handle long contexts. Therefore, many researchers resort to hybrid memory to alleviate this question. However, the limited context window of LLMs restricts incorporating comprehensive memories into prompts, which can impair agent performance. This challenge necessitates LLMs with larger context windows and the ability to handle extended contexts. Consequently, numerous researchers turn to hybrid memory systems to mitigate this
● 统一内存。这种结构仅模拟人类的短期记忆,通常通过上下文学习实现,记忆信息直接写入提示词中。例如,RLP [30] 是一种对话智能体,会为说话者和听者维护内部状态。在每轮对话中,这些状态作为大语言模型的提示词,充当智能体的短期记忆。SayPlan [31] 是专为任务规划设计的具身智能体,其场景图和环境反馈作为短期记忆指导行动。CALYPSO [32] 是为游戏《龙与地下城》设计的智能体,可协助地下城主创作和叙述故事,其短期记忆基于场景描述、怪物信息和先前摘要构建。DEPS [33] 同样是游戏智能体,但针对《我的世界》开发,该智能体首先生成任务计划,随后利用这些计划提示大语言模型生成动作完成任务,这些计划可视为其短期记忆。实际应用中,实现短期记忆较为直接,能增强智能体感知近期或上下文敏感行为及观察的能力。但由于大语言模型上下文窗口的限制,难以将所有记忆纳入提示词,可能影响智能体表现。该方法对大语言模型的窗口长度和长上下文处理能力要求较高,因此许多研究者转向混合内存方案以缓解该问题。
issue.
问题
● Hybrid memory. This structure explicitly models the human short-term and long-term memories. The short-term memory temporarily buffers recent perceptions, while longterm memory consolidates important information over time. For instance, Generative Agent [20] employs a hybrid memory structure to facilitate agent behaviors. The short-term memory contains the context information about the agent current situations, while the long-term memory stores the agent past behaviors and thoughts, which can be retrieved according to the current events. AgentSims [34] also implements a hybrid memory architecture. The information provided in the prompt can be considered as short-term memory. In order to enhance the storage capacity of memory, the authors propose a long-term memory system that utilizes a vector database, facilitating efficient storage and retrieval. Specifically, the agent’s daily memories are encoded as embeddings and stored in the vector database. If the agent needs to recall its previous memories, the long-term memory system retrieves relevant information using embedding similarities. This process can improve the consistency of the agent’s behavior. In GITM [16], the short-term memory stores the current trajectory, and the long-term memory saves reference plans summarized from successful prior trajectories. Long-term memory provides stable knowledge, while shortterm memory allows flexible planning. Reflexion [12] utilizes a short-term sliding window to capture recent feedback and incorporates persistent long-term storage to retain condensed insights. This combination allows for the utilization of both detailed immediate experiences and high-level abstractions. SCM [35] selectively activates the most relevant long-term knowledge to combine with short-term memory, enabling reasoning over complex contextual dialogues. Simply Retrieve [36] utilizes user queries as short-term memory and stores long-term memory using external knowledge bases. This design enhances the model accuracy while guaranteeing user privacy. Memory Sandbox [37] implements long-term and short-term memory by utilizing a 2D canvas to store memory objects, which can then be accessed throughout various conversations. Users can create multiple conversations with different agents on the same canvas, facilitating the sharing of memory objects through a simple drag-and-drop interface. In practice, integrating both short-term and long-term memories can enhance an agent’s ability for long-range reasoning and accumulation of valuable experiences, which are crucial for accomplishing tasks in complex environments.
● 混合记忆 (Hybrid memory)。这种结构明确模拟了人类的短期记忆和长期记忆。短期记忆临时缓冲近期感知信息,而长期记忆会随时间推移巩固重要信息。例如,Generative Agent [20] 采用混合记忆结构来支持智能体行为。其短期记忆包含智能体当前情境的上下文信息,长期记忆则存储智能体过去的行为与思考,可根据当前事件进行检索。AgentSims [34] 同样实现了混合记忆架构,提示词中提供的信息可视为短期记忆。为增强记忆存储容量,作者提出使用向量数据库的长期记忆系统,实现高效存储检索。具体而言,智能体的日常记忆会被编码为嵌入向量存入数据库,当需要回忆时,长期记忆系统通过嵌入相似度检索相关信息,这一过程能提升智能体行为的一致性。在 GITM [16] 中,短期记忆存储当前轨迹,长期记忆保存从成功历史轨迹中总结的参考方案。长期记忆提供稳定知识,短期记忆支持灵活规划。Reflexion [12] 采用短期滑动窗口捕获近期反馈,同时通过持久化长期存储保留凝练的洞见,这种组合既能利用详细即时经验,也能调用高层抽象。SCM [35] 选择性激活最相关的长期知识并与短期记忆结合,从而支持复杂情境对话推理。Simply Retrieve [36] 将用户查询作为短期记忆,使用外部知识库存储长期记忆,这种设计在保障用户隐私的同时提升了模型准确性。Memory Sandbox [37] 通过二维画布存储记忆对象来实现长短期记忆,这些对象可在不同对话中调用。用户可在同一画布上与多个智能体创建对话,通过拖拽界面轻松实现记忆对象共享。实际应用中,整合短期与长期记忆能增强智能体的长程推理能力和价值经验积累,这对复杂环境中的任务执行至关重要。
Remark. Careful readers may find that there may also exist another type of memory structure, that is, only based on the long-term memory. However, we find that such type of memory is rarely documented in the literature. Our speculation is that the agents are always situated in continuous and dynamic environments, with consecutive actions displaying a high correlation. Therefore, the capture of short-term memory is very important and usually cannot be disregarded.
备注。细心的读者可能会发现,还可能存在另一种记忆结构,即仅基于长期记忆。然而,我们发现此类记忆在文献中鲜有记载。我们推测,AI智能体始终处于连续动态的环境中,其连续动作具有高度相关性,因此短期记忆的捕获非常重要且通常不可忽视。
Memory formats: In addition to the memory structure, another perspective to analyze the memory module is based on the formats of the memory storage medium, for example, natural language memory or embedding memory. Different memory formats possess distinct strengths and are suitable for various applications. In the following, we introduce several representative memory formats.
存储格式:除了内存结构外,分析内存模块的另一个角度是基于存储介质的格式,例如自然语言内存或嵌入内存。不同的存储格式具有不同的优势,适用于各种应用场景。下面我们介绍几种具有代表性的存储格式。
● Natural languages. In this format, memory information such as the agent behaviors and observations are directly described using raw natural language. This format possesses several strengths. Firstly, the memory information can be expressed in a flexible and understandable manner. Moreover, it retains rich semantic information that can provide comprehensive signals to guide agent behaviors. In the previous work, Reflexion [12] stores experiential feedback in natural language within a sliding window. Voyager [38] employs natural language descriptions to represent skills within the Minecraft game, which are directly stored in memory.
● 自然语言 (Natural languages)。在这种格式中,AI智能体 (AI Agent) 的行为和观察等记忆信息直接通过原始自然语言描述。该格式具有多重优势:首先,记忆信息能以灵活且易于理解的方式呈现;其次,它保留了丰富的语义信息,能为智能体行为提供全面的引导信号。在先前工作中,Reflexion [12] 将经验反馈以自然语言形式存储在滑动窗口内,而Voyager [38] 则采用自然语言描述来表征《我的世界》(Minecraft) 游戏中的技能,这些描述直接存储在记忆系统中。
● Embeddings. In this format, memory information is encoded into embedding vectors, which can enhance the memory retrieval and reading efficiency. For instance, MemoryBank [39] encodes each memory segment into an embedding vector, which creates an indexed corpus for retrieval. [16] represents reference plans as embeddings to facilitate matching and reuse. Furthermore, ChatDev [18] encodes dialogue history into vectors for retrieval.
● 嵌入 (Embeddings)。在这种格式中,记忆信息被编码为嵌入向量,可以提高记忆检索和读取效率。例如,MemoryBank [39] 将每个记忆片段编码为一个嵌入向量,从而创建了一个用于检索的索引语料库。[16] 将参考计划表示为嵌入向量以便于匹配和重用。此外,ChatDev [18] 将对话历史编码为向量用于检索。
● Databases. In this format, memory information is stored in databases, allowing the agent to manipulate memories efficiently and comprehensively. For example, ChatDB [40] uses a database as a symbolic memory module. The agent can utilize SQL statements to precisely add, delete, and revise the memory information. In DB-GPT [41], the memory module is constructed based on a database. To more intuitively operate the memory information, the agents are fine-tuned to understand and execute SQL queries, enabling them to interact with databases using natural language directly.
● 数据库。在这种形式中,记忆信息存储在数据库中,使得智能体能够高效且全面地操作记忆。例如,ChatDB [40] 使用数据库作为符号记忆模块,智能体可以利用 SQL 语句精确地添加、删除和修改记忆信息。在 DB-GPT [41] 中,记忆模块基于数据库构建。为了更直观地操作记忆信息,智能体经过微调以理解和执行 SQL 查询,使其能够直接用自然语言与数据库交互。
● Structured lists. In this format, memory information is organized into lists, and the semantic of memory can be conveyed in an efficient and concise manner. For instance, GITM [16] stores action lists for sub-goals in a hierarchical tree structure. The hierarchical structure explicitly captures the relationships between goals and corresponding plans. RETLLM [42] initially converts natural language sentences into triplet phrases, and subsequently stores them in memory.
● 结构化列表。该格式将记忆信息组织成列表形式,能以高效简洁的方式传递记忆语义。例如,GITM [16] 在分层树状结构中存储子目标对应的动作列表,这种层级结构明确捕获了目标与对应计划之间的关系。RETLLM [42] 先将自然语言句子转换为三元组短语,再将其存入记忆。
Remark. Here we only show several representative memory formats, but it is important to note that there are many uncovered ones, such as the programming code used by [38]. Moreover, it should be emphasized that these formats are not mutually exclusive; many models incorporate multiple formats to concurrently harness their respective benefits. A notable example is the memory module of GITM [16], which utilizes a key-value list structure. In this structure, the keys are represented by embedding vectors, while the values consist of raw natural languages. The use of embedding vectors allows for efficient retrieval of memory records. By utilizing natural languages, the memory contents become highly comprehensive, enabling more informed agent actions.
备注:这里我们仅展示了几种具有代表性的记忆格式,但需要注意的是,还存在许多未涵盖的格式,例如[38]所使用的编程代码。此外,必须强调的是这些格式并非互斥关系,许多模型会融合多种格式以同时发挥各自优势。一个典型例子是GITM[16]的记忆模块,它采用了键值对列表结构:其中键由嵌入向量(embedding vectors)表示,值则由原始自然语言构成。嵌入向量的运用实现了记忆记录的高效检索,而自然语言的采用使记忆内容具备高度可解释性,从而支撑智能体做出更明智的决策。
Above, we mainly discuss the internal designs of the memory module. In the following, we turn our focus to memory operations, which are used to interact with external
上文主要讨论了内存模块的内部设计。接下来,我们将重点转向用于与外部交互的内存操作。
environments.
环境。
Memory operations: The memory module plays a critical role in allowing the agent to acquire, accumulate, and utilize significant knowledge by interacting with the environment. The interaction between the agent and the environment is accomplished through three crucial memory operations: memory reading, memory writing, and memory reflection. In the following, we introduce these operations more in detail.
内存操作:内存模块在AI智能体通过与环境的交互获取、积累和利用重要知识方面发挥着关键作用。智能体与环境的交互通过三个核心内存操作实现:内存读取、内存写入和内存反思。下文将详细阐述这些操作。
● Memory reading. The objective of memory reading is to extract meaningful information from memory to enhance the agent’s actions. For example, using the previously successful actions to achieve similar goals [16]. The key of memory reading lies in how to extract valuable information from history actions. Usually, there three commonly used criteria for information extraction, that is, the recency, relevance, and importance [20]. Memories that are more recent, relevant, and important are more likely to be extracted. Formally, we conclude the following equation from existing literature for memory information extraction:
● 记忆读取。记忆读取的目标是从记忆中提取有意义的信息,以增强智能体的行为。例如,使用先前成功的动作来实现类似目标 [16]。记忆读取的关键在于如何从历史行为中提取有价值的信息。通常,信息提取有三个常用标准,即时效性、相关性和重要性 [20]。越新近、越相关且越重要的记忆越容易被提取。形式上,我们从现有文献中总结出以下记忆信息提取公式:
$$
m^{* }=\arg\operatorname*{min}_{m\in M}\alpha s^{r e c}(q,m)+\beta s^{r e l}(q,m)+\gamma s^{i m p}(m),
$$
$$
m^{* }=\arg\operatorname*{min}_{m\in M}\alpha s^{r e c}(q,m)+\beta s^{r e l}(q,m)+\gamma s^{i m p}(m),
$$
where $q$ is the query, for example, the task that the agent should address or the context in which the agent is situated. $M$ is the set of all memories. $s^{r e c}(\cdot),s^{r e l}(\cdot)$ , and $s^{i m p}(\cdot)$ are the scoring functions for measuring the recency, relevance, and importance of the memory $m$ . These scoring functions can be implemented using various methods, for example, $s^{r e l}(q,m)$ can be realized based on LSH, ANNOY, HNSW, FAISS, and so on. It should be noted that $s^{i m p}$ only reflects the characters of the memory itself, thus it is unrelated to the query $q,\alpha,\beta$ and $\gamma$ are balancing parameters. By assigning them with different values, one can obtain various memory reading strategies. For example, by setting $\alpha=\gamma=0$ , many studies [16,30,38,42] only consider the relevance score $s^{r e l}$ for memory reading. By assigning $\alpha=\beta=\gamma=1.0$ , [20] equally weights all the above three metrics to extract information from memory.
其中 $q$ 是查询,例如AI智能体需要处理的任务或所处情境。$M$ 表示所有记忆的集合。$s^{rec}(\cdot)$、$s^{rel}(\cdot)$ 和 $s^{imp}(\cdot)$ 分别是用于衡量记忆 $m$ 的新近性、相关性和重要性的评分函数。这些评分函数可通过多种方法实现,例如 $s^{rel}(q,m)$ 可基于LSH、ANNOY、HNSW、FAISS等技术实现。需注意 $s^{imp}$ 仅反映记忆本身的特征,因此与查询 $q$ 无关。$\alpha$、$\beta$ 和 $\gamma$ 是平衡参数,通过赋予不同值可获得多种记忆读取策略。例如,当设置 $\alpha=\gamma=0$ 时,许多研究[16,30,38,42]仅考虑相关性评分 $s^{rel}$ 进行记忆读取;而当 $\alpha=\beta=\gamma=1.0$ 时,文献[20]对上述三个指标进行等权重处理以从记忆中提取信息。
● Memory writing. The purpose of memory writing is to store information about the perceived environment in memory. Storing valuable information in memory provides a foundation for retrieving informative memories in the future, enabling the agent to act more efficiently and rationally. During the memory writing process, there are two potential problems that should be carefully addressed. On one hand, it is crucial to address how to store information that is similar to existing memories (i.e., memory duplicated). On the other hand, it is important to consider how to remove information when the memory reaches its storage limit (i.e., memory overflow). In the following, we discuss these problems more in detail. (1) Memory duplicated. To incorporate similar information, people have developed various methods for integrating new and previous records. For instance, in [7], the successful action sequences related to the same sub-goal are stored in a list. Once the size of the list reaches $\mathrm{N}(=5)$ , all the sequences in it are condensed into a unified plan solution using LLMs. The original sequences in the memory are replaced with the newly generated one. Augmented LLM [43] aggregates duplicate information via count accumulation, avoiding redundant storage. (2) Memory overflow. In order to write information into the memory when it is full, people design different methods to delete existing information to continue the memorizing process. For example, in ChatDB [40], memories can be explicitly deleted based on user commands. RET-LLM [42] uses a fixed-size buffer for memory, overwriting the oldest entries in a first-in-first-out (FIFO) manner.
● 记忆写入。记忆写入的目的是将感知到的环境信息存储到记忆中。将有价值的信息存入记忆,为未来检索有用记忆奠定了基础,使智能体能够更高效、更合理地行动。在记忆写入过程中,有两个潜在问题需要谨慎处理:一方面,如何存储与现有记忆相似的信息(即记忆重复)至关重要;另一方面,当记忆达到存储限制时如何移除信息(即记忆溢出)同样重要。下文将详细讨论这些问题。
(1) 记忆重复。为整合相似信息,研究者开发了多种新旧记录融合方法。例如文献[7]将与同一子目标相关的成功动作序列存储在列表中,当列表大小达到$\mathrm{N}(=5)$时,所有序列会通过大语言模型压缩为统一规划方案,并用新生成的方案替换原始记忆。Augmented LLM [43]通过计数累加来聚合重复信息,避免冗余存储。
(2) 记忆溢出。为解决记忆满载时的写入问题,研究者设计了不同方法来删除现有信息以继续记忆过程。例如ChatDB [40]支持根据用户指令显式删除记忆,RET-LLM [42]采用固定大小的记忆缓冲区,以先进先出(FIFO)方式覆盖最旧条目。
● Memory reflection. Memory reflection emulates humans’ ability to witness and evaluate their own cognitive, emotional, and behavioral processes. When adapted to agents, the objective is to provide agents with the capability to independently summarize and infer more abstract, complex and high-level information. More specifically, in Generative Agent [20], the agent has the capability to summarize its past experiences stored in memory into broader and more abstract insights. To begin with, the agent generates three key questions based on its recent memories. Then, these questions are used to query the memory to obtain relevant information. Building upon the acquired information, the agent generates five insights, which reflect the agent high-level ideas. For example, the low-level memories “Klaus Mueller is writing a research paper”, “Klaus Mueller is engaging with a librarian to further his research”, and “Klaus Mueller is conversing with Ayesha Khan about his research” can induce the high-level insight “Klaus Mueller is dedicated to his research”. In addition, the reflection process can occur hierarchically, meaning that the insights can be generated based on existing insights. In GITM [16], the actions that successfully accomplish the sub-goals are stored in a list. When the list contains more than five elements, the agent summarizes them into a common and abstract pattern and replaces all the elements. In ExpeL [44], two approaches are introduced for the agent to acquire reflection. Firstly, the agent compares successful or failed trajectories within the same task. Secondly, the agent learns from a collection of successful trajectories to gain experiences.
● 记忆反射。记忆反射模拟了人类观察和评估自身认知、情感及行为过程的能力。当应用于AI智能体时,其目标是让智能体具备独立总结并推断更抽象、复杂和高级信息的能力。具体而言,在Generative Agent [20]中,智能体能够将存储在记忆中的过往经历总结为更广泛、更抽象的见解。首先,智能体基于近期记忆生成三个关键问题;随后利用这些问题查询记忆以获取相关信息;基于所得信息,智能体会生成五项体现其高层思维的见解。例如,底层记忆"Klaus Mueller正在撰写研究论文"、"Klaus Mueller与图书馆员交流以推进研究"以及"Klaus Mueller与Ayesha Khan讨论研究"可推导出高层见解"Klaus Mueller专注于研究工作"。此外,反射过程可分层进行,即基于现有见解生成新见解。在GITM [16]中,成功完成子目标的行为会被存入列表,当列表元素超过五个时,智能体会将其归纳为通用抽象模式并替换所有元素。ExpeL [44]提出了两种获取反思的方法:一是比较同一任务中的成功或失败轨迹;二是通过分析成功轨迹集合来获取经验。
A significant distinction between traditional LLMs and the agents is that the latter must possess the capability to learn and complete tasks in dynamic environments. If we consider the memory module as responsible for managing the agents’ past behaviors, it becomes essential to have another significant module that can assist the agents in planning their future actions. In the following, we present an overview of how researchers design the planning module.
传统大语言模型与AI智能体的一个重要区别在于,后者必须具备在动态环境中学习和完成任务的能力。如果将记忆模块视为负责管理AI智能体过去行为的组件,那么另一个关键模块就显得至关重要——它需要帮助AI智能体规划未来行动。下文我们将概述研究人员如何设计这一规划模块。
2.1.3 Planning module
2.1.3 规划模块
When faced with a complex task, humans tend to deconstruct it into simpler subtasks and solve them individually. The planning module aims to empower the agents with such human capability, which is expected to make the agent behave more reasonably, powerfully, and reliably. In specific, we summarize existing studies based on whether the agent can receive feedback in the planing process, which are detailed as follows:
面对复杂任务时,人类倾向于将其拆解为更简单的子任务并逐个解决。规划模块旨在赋予AI智能体这种类人能力,使其行为更合理、强大且可靠。具体而言,我们根据智能体在规划过程中能否接收反馈,将现有研究分为以下两类:
Planning without feedback: In this method, the agents do not receive feedback that can influence its future behaviors after taking actions. In the following, we present several
无反馈规划:在此方法中,智能体在执行动作后不会收到可影响其未来行为的反馈。下文将介绍几种
representative strategies.
代表性策略。
● Single-path reasoning. In this strategy, the final task is decomposed into several intermediate steps. These steps are connected in a cascading manner, with each step leading to only one subsequent step. LLMs follow these steps to achieve the final goal. Specifically, Chain of Thought (CoT) [45] proposes inputting reasoning steps for solving complex problems into the prompt. These steps serve as examples to inspire LLMs to plan and act in a step-by-step manner. In this method, the plans are created based on the inspiration from the examples in the prompts. Zero-shot-CoT [46] enables LLMs to generate task reasoning processes by prompting them with trigger sentences like “think step by step”. Unlike CoT, this method does not incorporate reasoning steps as examples in the prompts. Re-Prompting [47] involves checking whether each step meets the necessary prerequisites before generating a plan. If a step fails to meet the prerequisites, it introduces a prerequisite error message and prompts the LLM to regenerate the plan. ReWOO [48] introduces a paradigm of separating plans from external observations, where the agents first generate plans and obtain observations independently, and then combine them together to derive the final results. HuggingGPT [13] first decomposes the task into many subgoals, and then solves each of them based on Hugging face. Different from CoT and Zero-shot-CoT, which outcome all the reasoning steps in a one-shot manner, ReWOO and HuggingGPT produce the results by accessing LLMs multiply times.
● 单路径推理 (Single-path reasoning)。该策略将最终任务分解为若干中间步骤,这些步骤以级联方式连接,每个步骤仅导向一个后续步骤。大语言模型通过遵循这些步骤实现最终目标。具体而言,思维链 (Chain of Thought, CoT) [45] 提出在提示词中输入解决复杂问题的推理步骤,这些步骤作为示例启发大语言模型进行分步规划与执行。该方法中的规划基于提示词中的示例启发生成。零样本思维链 (Zero-shot-CoT) [46] 通过"逐步思考"等触发句提示大语言模型生成任务推理过程,与CoT不同,该方法不会在提示词中包含推理步骤示例。重新提示 (Re-Prompting) [47] 在生成计划前会检查每个步骤是否满足必要前提条件,若未满足则引入前提错误信息并提示大语言模型重新生成计划。ReWOO [48] 提出将规划与外部观察分离的范式,智能体先独立生成规划并获取观察结果,再将二者结合得出最终结论。HuggingGPT [13] 首先将任务分解为多个子目标,再基于HuggingFace平台逐一解决。与CoT和零样本思维链一次性输出所有推理步骤不同,ReWOO和HuggingGPT通过多次访问大语言模型来生成结果。
● Multi-path reasoning. In this strategy, the reasoning steps for generating the final plans are organized into a tree-like structure. Each intermediate step may have multiple subsequent steps. This approach is analogous to human thinking, as individuals may have multiple choices at each reasoning step. In specific, Self-consistent CoT (CoT-SC) [49] believes that each complex problem has multiple ways of thinking to deduce the final answer. Thus, it starts by employing CoT to generate various reasoning paths and corresponding answers. Subsequently, the answer with the highest frequency is chosen as the final output. Tree of Thoughts (ToT) [50] is designed to generate plans using a tree-like reasoning structure. In this approach, each node in the tree represents a “thought,” which corresponds to an intermediate reasoning step. The selection of these intermediate steps is based on the evaluation of LLMs. The final plan is generated using either the breadth-first search (BFS) or depth-first search (DFS) strategy. Comparing with CoT-SC, which generates all the planed steps together, ToT needs to query LLMs for each reasoning step. In RecMind [51], the authors designed a self-inspiring mechanism, where the discarded historical information in the planning process is also leveraged to derive new reasoning steps. In GoT [52], the authors expand the tree-like reasoning structure in ToT to graph structures, resulting in more powerful prompting strategies. In AoT [53], the authors design a novel method to enhance the reasoning processes of LLMs by incorporating algorithmic examples into the prompts. Remarkably, this method only needs to query LLMs for only one or a few times. In [54], the LLMs are leveraged as zero-shot planners.
● 多路径推理。该策略将生成最终计划的推理步骤组织成树状结构,每个中间步骤可能包含多个后续步骤。这种方法模拟了人类思维方式,因为个体在每个推理步骤中可能存在多种选择。具体而言,自洽思维链 (CoT-SC) [49] 认为每个复杂问题都存在多种推导最终答案的思考路径,因此首先生成多条推理路径及对应答案,然后选择出现频率最高的答案作为最终输出。思维树 (ToT) [50] 采用树状推理结构生成计划,其中每个节点代表一个对应中间推理步骤的"思考",这些中间步骤的选择基于大语言模型的评估,最终计划通过广度优先搜索 (BFS) 或深度优先搜索 (DFS) 策略生成。与一次性生成所有计划步骤的CoT-SC相比,ToT需要为每个推理步骤查询大语言模型。RecMind [51] 设计了自我启发机制,利用规划过程中被丢弃的历史信息来推导新推理步骤。GoT [52] 将ToT的树状推理结构扩展为图结构,从而形成更强大的提示策略。AoT [53] 通过将算法示例融入提示词来增强大语言模型的推理过程,值得注意的是该方法仅需查询大语言模型一至数次。文献[54]则直接将大语言模型作为零样本规划器使用。
At each planning step, they first generate multiple possible next steps, and then determine the final one based on their distances to admissible actions. [55] further improves [54] by incorporating examples that are similar to the queries in the prompts. RAP [56] builds a world model to simulate the potential benefits of different plans based on Monte Carlo Tree Search (MCTS), and then, the final plan is generated by aggregating multiple MCTS iterations. To enhance comprehension, we provide an illustration comparing the strategies of single-path and multi-path reasoning in Fig. 3.
在每次规划步骤中,他们首先生成多个可能的下一步,然后根据这些步骤与可执行动作的距离确定最终选择。[55]通过在与查询相似的提示中加入示例,进一步改进了[54]的方法。RAP [56]构建了一个世界模型,基于蒙特卡洛树搜索(MCTS)模拟不同计划的潜在收益,最终通过聚合多次MCTS迭代生成最终计划。为了便于理解,我们在图3中提供了单路径与多路径推理策略的对比示意图。
● External planner. Despite the demonstrated power of LLMs in zero-shot planning, effectively generating plans for domain-specific problems remains highly challenging. To address this challenge, researchers turn to external planners. These tools are well-developed and employ efficient search algorithms to rapidly identify correct, or even optimal, plans. In specific, $\mathrm{LLM{+}P}$ [57] first transforms the task descriptions into formal Planning Domain Definition Languages (PDDL), and then it uses an external planner to deal with the PDDL. Finally, the generated results are transformed back into natural language by LLMs. Similarly, LLM-DP [58] utilizes LLMs to convert the observations, the current world state, and the target objectives into PDDL. Subsequently, this transformed data is passed to an external planner, which efficiently determines the final action sequence. CO-LLM [22] demonstrates that LLMs is good at generating high-level plans, but struggle with lowlevel control. To address this limitation, a heuristic ally designed external low-level planner is employed to effectively execute actions based on high-level plans.
● 外部规划器。尽管大语言模型在零样本规划中展现出强大能力,但针对特定领域问题有效生成计划仍极具挑战性。为解决这一难题,研究者转向外部规划器。这些工具发展成熟,采用高效搜索算法快速找到正确甚至最优方案。具体而言,$\mathrm{LLM{+}P}$ [57] 首先将任务描述转换为形式化的规划领域定义语言 (PDDL) ,随后调用外部规划器处理PDDL描述,最终由大语言模型将生成结果转回自然语言。类似地,LLM-DP [58] 利用大语言模型将观察数据、当前世界状态和目标对象转化为PDDL描述,再交由外部规划器高效确定最终动作序列。CO-LLM [22] 研究表明大语言模型擅长生成高层计划,但在底层控制方面表现欠佳。为此,该系统引入启发式设计的外部底层规划器,基于高层计划高效执行具体动作。
Planning with feedback: In many real-world scenarios, the agents need to make long-horizon planning to solve complex tasks. When facing these tasks, the above planning modules without feedback can be less effective due to the following reasons: firstly, generating a flawless plan directly from the beginning is extremely difficult as it needs to consider various complex preconditions. As a result, simply following the initial plan often leads to failure. Moreover, the execution of the plan may be hindered by unpredictable transition dynamics, rendering the initial plan non-executable. Simultaneously, when examining how humans tackle complex tasks, we find that individuals may iterative ly make and revise their plans based on external feedback. To simulate such human capability, researchers have designed many planning modules, where the agent can receive feedback after taking actions. The feedback can be obtained from environments, humans, and models, which are detailed in the following.
带反馈的规划:在许多现实场景中,智能体需要进行长周期规划来解决复杂任务。面对这些任务时,上述无反馈的规划模块可能因以下原因效率低下:首先,从一开始就生成完美计划极其困难,因为这需要考虑各种复杂的先决条件。因此,单纯遵循初始计划往往会导致失败。此外,计划的执行可能受到不可预测的状态转移动态阻碍,使初始计划无法实施。同时,观察人类处理复杂任务的方式时,我们发现个体会基于外部反馈迭代制定并修正计划。为模拟这种人类能力,研究者设计了多种规划模块,使智能体在执行动作后能接收反馈。反馈可来自环境、人类和模型,具体如下。
● Environmental feedback. This feedback is obtained from the objective world or virtual environment. For instance, it could be the game’s task completion signals or the observations made after the agent takes an action. In specific, ReAct [59] proposes constructing prompts using thought-actobservation triplets. The thought component aims to facilitate high-level reasoning and planning for guiding agent behaviors. The act represents a specific action taken by the agent. The observation corresponds to the outcome of the action, acquired through external feedback, such as search engine results. The next thought is influenced by the previous observations, which makes the generated plans more adaptive to the environment. Voyager [38] makes plans by incorporating three types of environment feedback including the intermediate progress of program execution, the execution error and self-verification results. These signals can help the agent to make better plans for the next action. Similar to Voyager, Ghost [16] also incorporates feedback into the reasoning and action taking processes. This feedback encompasses the environment states as well as the success and failure information for each executed action. SayPlan [31] leverages environmental feedback derived from a scene graph simulator to validate and refine its strategic formulations. This simulator is adept at discerning the outcomes and state transitions subsequent to agent actions, facilitating SayPlan’s iterative re calibration of its strategies until a viable plan is ascertained. In DEPS [33], the authors argue that solely providing information about the completion of a task is often inadequate for correcting planning errors. Therefore, they propose informing the agent about the detail reasons for task failure, allowing them to more effectively revise their plans. LLM-Planner [60] introduces a grounded re-planning algorithm that dynamically updates plans generated by LLMs when encountering object mismatches and unattainable plans during task completion. Inner Monologue [61] provides three types of feedback to the agent after it takes actions: (1) whether the task is successfully completed, (2) passive scene descriptions, and (3) active scene descriptions. The former two are generated from the environments, which makes the agent actions more reasonable.
● 环境反馈。这类反馈来自客观世界或虚拟环境。例如,游戏任务完成信号或智能体执行动作后的观察结果。具体而言,ReAct [59] 提出使用思考-行动-观察三元组构建提示。思考模块用于促进高层推理与规划以指导智能体行为,行动代表智能体执行的具体动作,观察则对应通过外部反馈(如搜索引擎结果)获取的动作结果。后续思考会受到先前观察的影响,从而使生成的计划更具环境适应性。Voyager [38] 通过整合三类环境反馈制定计划:程序执行的中间进度、执行错误及自我验证结果。这些信号能帮助智能体优化后续动作规划。与Voyager类似,Ghost [16] 也将反馈融入推理与行动过程,包括环境状态及每个已执行动作的成功/失败信息。SayPlan [31] 利用源自场景图模拟器的环境反馈来验证和完善策略方案,该模拟器能精准识别智能体动作后的结果与状态转换,支持策略的迭代优化直至确定可行方案。DEPS [33] 指出仅提供任务完成信息通常不足以修正规划错误,因此建议向智能体反馈任务失败的具体原因以提升计划修订效率。LLM-Planner [60] 提出基于场景的重新规划算法,当任务执行过程中出现对象不匹配或计划不可行时,动态更新大语言模型生成的计划。Inner Monologue [61] 在智能体行动后提供三类反馈:(1) 任务是否成功完成,(2) 被动场景描述,(3) 主动场景描述。前两类由环境生成,可使智能体行为更趋合理。

Fig. 3 Comparison between the strategies of single-path and multi-path reasoning. LMZSP is the model proposed in [54]
图 3: 单路径与多路径推理策略对比。LMZSP 是文献 [54] 提出的模型
● Human feedback. In addition to obtaining feedback from the environment, directly interacting with humans is also a very intuitive strategy to enhance the agent planning capability. The human feedback is a subjective signal. It can effectively make the agent align with the human values and preferences, and also help to alleviate the hallucination problem. In Inner Monologue [61], the agent aims to perform high-level natural language instructions in a 3D visual environment. It is given the capability to actively solicit feedback from humans regarding scene descriptions. Then, the agent incorporates the human feedback into its prompts, enabling more informed planning and reasoning. In the above cases, we can see, different types of feedback can be combined to enhance the agent planning capability. For example, Inner Monologue [61] collects both environment and human feedback to facilitate the agent plans.
● 人类反馈。除了从环境中获取反馈,直接与人类互动也是提升智能体规划能力的一种非常直观的策略。人类反馈是一种主观信号,它能有效使智能体与人类价值观和偏好对齐,并有助于缓解幻觉问题。在Inner Monologue [61]中,智能体旨在3D视觉环境中执行高级自然语言指令,被赋予了主动向人类征求场景描述反馈的能力。随后,智能体将人类反馈纳入其提示(prompt)中,从而实现更明智的规划和推理。从上述案例可以看出,不同类型的反馈可以结合使用以增强智能体规划能力。例如,Inner Monologue [61]同时收集环境和人类反馈来辅助智能体规划。
● Model feedback. Apart from the aforementioned environmental and human feedback, which are external signals, researchers have also investigated the utilization of internal feedback from the agents themselves. This type of feedback is usually generated based on pre-trained models. In specific, [62] proposes a self-refine mechanism. This mechanism consists of three crucial components: output, feedback, and refinement. Firstly, the agent generates an output. Then, it utilizes LLMs to provide feedback on the output and offer guidance on how to refine it. At last, the output is improved by the feedback and refinement. This output-feedback-refinement process iterates until reaching some desired conditions. SelfCheck [63] allows agents to examine and evaluate their reasoning steps generated at various stages. They can then correct any errors by comparing the outcomes. InterAct [64] uses different language models (such as ChatGPT and Instruct GP T) as auxiliary roles, such as checkers and sorters, to help the main language model avoid erroneous and inefficient actions. ChatCoT [65] utilizes model feedback to improve the quality of its reasoning process. The model feedback is generated by an evaluation module that monitors the agent reasoning steps. Reflexion [12] is developed to enhance the agent’s planning capability through detailed verbal feedback. In this model, the agent first produces an action based on its memory, and then, the evaluator generates feedback by taking the agent trajectory as input. In contrast to previous studies, where the feedback is given as a scalar value, this model leverages LLMs to provide more detailed verbal feedback, which can provide more comprehensive supports for the agent plans.
● 模型反馈。除了上述环境和人类反馈这类外部信号外,研究者还探索了利用AI智能体自身产生的内部反馈。这类反馈通常基于预训练模型生成。具体而言,[62]提出了一种自我优化机制,该机制包含三个关键组件:输出、反馈和优化。首先,智能体生成输出;接着利用大语言模型对输出提供反馈和改进建议;最终根据反馈进行优化。这种"输出-反馈-优化"流程会循环迭代直至满足预设条件。SelfCheck[63]允许智能体在不同阶段检视和评估自身生成的推理步骤,通过结果对比纠正错误。InterAct[64]采用不同语言模型(如ChatGPT和InstructGPT)作为校验器、排序器等辅助角色,帮助主语言模型规避错误和低效操作。ChatCoT[65]通过评估模块监控智能体推理步骤来生成模型反馈,从而提升推理质量。Reflexion[12]通过详细语言反馈增强智能体规划能力:智能体先基于记忆生成动作,评估器再以行为轨迹为输入生成反馈。与以往研究使用标量反馈不同,该模型利用大语言模型提供更详尽的语言反馈,为智能体规划提供更全面的支持。
Remark. In conclusion, the implementation of planning module without feedback is relatively straightforward. However, it is primarily suitable for simple tasks that only require a small number of reasoning steps. Conversely, the strategy of planning with feedback needs more careful designs to handle the feedback. Nevertheless, it is considerably more powerful and capable of effectively addressing complex tasks that involve long-range reasoning.
备注。总之,无反馈规划模块的实现相对简单直接。然而,它主要适用于仅需少量推理步骤的简单任务。相反,带反馈的规划策略需要更精细的设计来处理反馈信息,但其能力显著更强,能有效解决涉及长程推理的复杂任务。
2.1.4 Action module
2.1.4 行动模块
The action module is responsible for translating the agent’s decisions into specific outcomes. This module is located at the most downstream position and directly interacts with the environment. It is influenced by the profile, memory, and planning modules. This section introduces the action module from four perspectives: (1) Action goal: what are the intended outcomes of the actions? (2) Action production: how are the actions generated? (3) Action space: what are the available actions? (4) Action impact: what are the consequences of the actions? Among these perspectives, the first two focus on the aspects preceding the action (“before-action” aspects), the third focuses on the action itself (“in-action” aspect), and the fourth emphasizes the impact of the actions (“after-action” aspect).
动作模块负责将AI智能体的决策转化为具体结果。该模块位于最下游位置,直接与环境交互,并受档案、记忆和规划模块的影响。本节从四个角度介绍动作模块:(1) 动作目标:动作的预期结果是什么?(2) 动作生成:动作是如何产生的?(3) 动作空间:可用的动作有哪些?(4) 动作影响:动作会产生什么后果?其中前两个角度关注动作前的方面("动作前"阶段),第三个角度关注动作本身("动作中"阶段),第四个角度强调动作的影响("动作后"阶段)。
Action goal: The agent can perform actions with various objectives. Here, we present several representative examples: (1) Task Completion. In this scenario, the agent’s actions are aimed at accomplishing specific tasks, such as crafting an iron pickaxe in Minecraft [38] or completing a function in software development [18]. These actions usually have well-defined objectives, and each action contributes to the completion of the final task. Actions aimed at this type of goal are very common in existing literature. (2) Communication. In this case, the actions are taken to communicate with the other agents or real humans for sharing information or collaboration. For example, the agents in ChatDev [18] may communicate with each other to collectively accomplish software development tasks. In Inner Monologue [61], the agent actively engages in communication with humans and adjusts its action strategies based on human feedback. (3) Environment Exploration. In this example, the agent aims to explore unfamiliar environments to expand its perception and strike a balance between exploring and exploiting. For instance, the agent in Voyager [38] may explore unknown skills in their task completion process, and continually refine the skill execution code based on environment feedback through trial and error.
行动目标:AI智能体能够执行具有不同目的的动作。以下是几个典型示例:(1) 任务完成。这种情况下,智能体的动作旨在完成特定任务,例如在《我的世界》中制作铁镐[38]或在软件开发中实现某个功能[18]。这类动作通常具有明确目标,每个动作都对最终任务的完成有所贡献。现有文献中针对此类目标的动作十分常见。(2) 交流协作。此时动作的目的是与其他智能体或真实人类进行信息共享或协作。例如ChatDev[18]中的智能体会相互沟通以共同完成软件开发任务,而Inner Monologue[61]中的智能体则主动与人类交流,并根据人类反馈调整动作策略。(3) 环境探索。此类情况下,智能体旨在探索陌生环境以扩展认知,并在探索与利用之间取得平衡。例如Voyager[38]中的智能体在任务完成过程中可能发现未知技能,并通过试错不断优化技能执行代码。
Action production: Different from ordinary LLMs, where the model input and output are directly associated, the agent may take actions via different strategies and sources. In the following, we introduce two types of commonly used action production strategies. (1) Action via memory recollection. In this strategy, the action is generated by extracting information from the agent memory according to the current task. The task and the extracted memories are used as prompts to trigger the agent actions. For example, in Generative Agents [20], the agent maintains a memory stream, and before taking each action, it retrieves recent, relevant and important information from the memory steam to guide the agent actions. In GITM [16], in order to achieve a low-level sub-goal, the agent queries its memory to determine if there are any successful experiences related to the task. If similar tasks have been completed previously, the agent invokes the previously successful actions to handle the current task directly. In collaborative agents such as ChatDev [18] and MetaGPT [23], different agents may communicate with each other. In this process, the conversation history in a dialog is remembered in the agent memories. Each utterance generated by the agent is influenced by its memory. (2) Action via plan following. In this strategy, the agent takes actions following its pregenerated plans. For instance, in DEPS [33], for a given task, the agent first makes action plans. If there are no signals indicating plan failure, the agent will strictly adhere to these plans. In GITM [16], the agent makes high-level plans by decomposing the task into many sub-goals. Based on these plans, the agent takes actions to solve each sub-goal sequentially to complete the final task.
动作生成:与普通大语言模型直接关联输入输出不同,AI智能体可通过不同策略和来源采取行动。以下介绍两种常用动作生成策略。(1) 基于记忆回溯的动作生成。该策略通过从智能体记忆中提取与当前任务相关的信息来生成动作,任务内容和提取的记忆作为提示触发智能体行为。例如在Generative Agents [20]中,智能体维护记忆流,每次行动前会从记忆流中检索近期、相关且重要的信息来指导行为。GITM [16]为实现低级子目标,会查询记忆库中是否存在相关成功经验,若存在则直接调用历史成功动作处理当前任务。在ChatDev [18]和MetaGPT [23]等协作型智能体中,对话历史会被存入记忆,每个生成语句都受记忆影响。(2) 基于计划遵循的动作生成。该策略要求智能体按预设计划执行动作,如DEPS [33]中智能体先制定行动计划,若无失败信号则严格遵循计划。GITM [16]通过任务分解生成高层计划,智能体依次解决各子目标以完成最终任务。
Action space: Action space refers to the set of possible actions that can be performed by the agent. In general, we can roughly divide these actions into two classes: (1) external tools and (2) internal knowledge of the LLMs. In the following, we introduce these actions more in detail.
动作空间:动作空间指的是智能体可以执行的可能动作集合。总体而言,我们可以将这些动作大致分为两类:(1) 外部工具 和 (2) 大语言模型的内部知识。下文将更详细地介绍这些动作。
● External tools. While LLMs have been demonstrated to be effective in accomplishing a large amount of tasks, they may not work well for the domains which need comprehensive expert knowledge. In addition, LLMs may also encounter hallucination problems, which are hard to be resolved by themselves. To alleviate the above problems, the agents are empowered with the capability to call external tools for executing action. In the following, we present several representative tools which have been exploited in the literature.
● 外部工具。虽然大语言模型已被证明能有效完成大量任务,但在需要综合专业知识的领域可能表现欠佳。此外,大语言模型还存在幻觉问题,这类问题往往难以自主解决。为缓解上述问题,AI智能体被赋予调用外部工具执行操作的能力。下文列举了文献中已应用的几种代表性工具:
(1) APIs. Leveraging external APIs to complement and expand action space is a popular paradigm in recent years. For example, HuggingGPT [13] leverages the models on Hugging Face to accomplish complex user tasks. [66,67] propose to automatically generate queries to extract relevant content from external Web pages when responding to user request. TPTU [67] interfaces with both Python interpreters and LaTeX compilers to execute sophisticated computations such as square roots, factorials and matrix operations. Another type of APIs is the ones that can be directly invoked by LLMs based on natural language or code inputs. For instance, Gorilla [68] is a fine-tuned LLM designed to generate accurate input arguments for API calls and mitigate the issue of hallucination during external API invocations. ToolFormer [15] is an LLMbased tool transformation system that can automatically convert a given tool into another one with different functionalities or formats based on natural language instructions. API-Bank [69] is an LLM-based API recommendation agent that can automatically search and generate appropriate API calls for various programming languages and domains. API-Bank also provides an interactive interface for users to easily modify and execute the generated API calls. ToolBench [14] is an LLM-based tool generation system that can automatically design and implement various practical tools based on natural language requirements. The tools generated by ToolBench include calculators, unit converters, calendars, maps, charts, etc. RestGPT [70] connects LLMs with RESTful APIs, which follow widely accepted standards for Web services development, making the resulting program more compatible with real-world applications. TaskMatrix.AI [71] connects LLMs with millions of APIs to support task execution. At its core lies a multimodal conversational foundational model that interacts with users, understands their goals and context, and then produces executable code for particular tasks. All these agents utilize external APIs as their tools, and provide interactive interfaces for users to easily modify and execute the generated or transformed tools.
(1) API。近年来,利用外部API补充和扩展行动空间已成为流行范式。例如HuggingGPT [13]借助Hugging Face平台上的模型完成复杂用户任务。[66,67]提出在响应用户请求时自动生成查询以从外部网页提取相关内容。TPTU [67]通过对接Python语言解释器和LaTeX编译器来执行平方根、阶乘和矩阵运算等复杂计算。另一类API可直接通过自然语言或代码输入被大语言模型调用,如Gorilla [68]作为微调后的大语言模型,能生成精确的API调用参数并缓解外部API调用时的幻觉问题。ToolFormer [15]是基于大语言模型的工具转换系统,能根据自然语言指令将给定工具自动转化为具有不同功能或格式的新工具。API-Bank [69]是基于大语言模型的API推荐智能体,可自动搜索并生成适用于不同编程语言和领域的API调用,同时提供交互界面供用户修改和执行生成的API调用。ToolBench [14]是基于大语言模型的工具生成系统,能根据自然语言需求自动设计与实现各类实用工具,包括计算器、单位转换器、日历、地图、图表等。RestGPT [70]将大语言模型与遵循Web服务开发通用标准的RESTful API对接,使生成程序更兼容实际应用场景。TaskMatrix.AI [71]通过连接数百万API支持任务执行,其核心是多模态对话基础模型,可理解用户目标与上下文并生成特定任务的可执行代码。这些智能体均将外部API作为工具使用,并提供交互界面方便用户修改和执行生成或转换后的工具。
(2) Databases & Knowledge Bases. Integrating external database or knowledge base enables agents to obtain specific domain information for generating more realistic actions. For example, ChatDB [40] employs SQL statements to query databases, facilitating actions by the agents in a logical manner. MRKL [72] and OpenAGI [73] incorporate various expert systems such as knowledge bases and planners to access domain-specific information.
(2) 数据库与知识库。集成外部数据库或知识库使AI智能体能够获取特定领域信息,从而生成更符合实际的动作。例如,ChatDB [40] 使用SQL语句查询数据库,以逻辑方式辅助智能体执行动作。MRKL [72] 和 OpenAGI [73] 整合了多种专家系统(如知识库和规划器)来访问领域专有信息。
(3) External models. Previous studies often utilize external models to expand the range of possible actions. In comparison to APIs, external models typically handle more complex tasks. Each external model may correspond to multiple APIs. For example, to enhance the text retrieval capability, MemoryBank [39] incorporates two language models: one is designed to encode the input text, while the other is responsible for matching the query statements. ViperGPT [74] firstly uses Codex, which is implemented based on language model, to generate Python code from text descriptions, and then executes the code to complete the given tasks. TPTU [67] incorporates various LLMs to accomplish a wide range of language generation tasks such as generating code, producing lyrics, and more. ChemCrow [75] is an LLM-based chemical agent designed to perform tasks in organic synthesis, drug discovery, and material design. It utilizes seventeen expertdesigned models to assist its operations. MM-REACT [76] integrates various external models, such as VideoBERT for video sum mari z ation, X-decoder for image generation, and SpeechBERT for audio processing, enhancing its capability in diverse multimodal scenarios.
(3) 外部模型。先前研究常利用外部模型来扩展可能的行动范围。相比API,外部模型通常处理更复杂的任务。每个外部模型可能对应多个API。例如,为增强文本检索能力,MemoryBank [39] 整合了两个语言模型:一个负责编码输入文本,另一个负责匹配查询语句。ViperGPT [74] 首先使用基于语言模型实现的Codex从文本描述生成Python代码,再执行代码完成任务。TPTU [67] 整合了多种大语言模型来完成代码生成、歌词创作等广泛的语言生成任务。ChemCrow [75] 是一个基于大语言模型的化学智能体,用于执行有机合成、药物发现和材料设计任务,它借助17个专家设计的模型辅助运作。MM-REACT [76] 集成了多种外部模型,如用于视频摘要的VideoBERT、图像生成的X-decoder和音频处理的SpeechBERT,从而增强其在多模态场景下的能力。
● Internal knowledge. In addition to utilizing external tools, many agents rely solely on the internal knowledge of LLMs to guide their actions. We now present several crucial capabilities of LLMs that can support the agent to behave reasonably and effectively. (1) Planning capability. Previous work has demonstrated that LLMs can be used as decent planers to decompose complex task into simpler ones [45]. Such capability of LLMs can be even triggered without incorporating examples in the prompts [46]. Based on the planning capability of LLMs, DEPS [33] develops a Minecraft agent, which can solve complex task via sub-goal decomposition. Similar agents like GITM [16] and Voyager [38] also heavily rely on the planning capability of LLMs to successfully complete different tasks. (2) Conversation capability. LLMs can usually generate high-quality conversations. This capability enables the agent to behave more like humans. In the previous work, many agents take actions based on the strong conversation capability of LLMs. For example, in ChatDev [18], different agents can discuss the software developing process, and even can make reflections on their own behaviors. In RLP [30], the agent can communicate with the listeners based on their potential feedback on the agent’s utterance. (3) Common sense understanding capability. Another important capability of
● 内部知识。除了利用外部工具外,许多AI智能体仅依靠大语言模型的内部知识来指导其行为。我们接下来介绍大语言模型几项支撑智能体合理高效运行的关键能力:(1) 规划能力。已有研究表明大语言模型可作为优质规划器将复杂任务分解为简单子任务 [45],这种能力甚至能在提示词中不包含示例的情况下被触发 [46]。基于大语言模型的规划能力,DEPS [33] 开发了能通过子目标分解解决复杂任务的《我的世界》游戏智能体。类似GITM [16]和Voyager [38]等智能体也深度依赖大语言模型的规划能力来成功完成各类任务。(2) 对话能力。大语言模型通常能生成高质量对话,该能力使智能体表现更趋近人类。先前研究中,许多智能体都基于大语言模型的强大对话能力采取行动。例如ChatDev [18]中不同智能体可讨论软件开发流程,甚至能对自身行为进行反思;RLP [30]中的智能体能根据听众对其话语的潜在反馈与听众进行交流。(3) 常识理解能力。大语言模型的另一项重要能力是...
LLMs is that they can well comprehend human common sense. Based on this capability, many agents can simulate human daily life and make human-like decisions. For example, in Generative Agent, the agent can accurately understand its current state, the surrounding environment, and summarize high-level ideas based on basic observations. Without the common sense understanding capability of LLMs, these behaviors cannot be reliably simulated. Similar conclusions may also apply to RecAgent [21] and $\mathrm{S}^{3}$ [77], where the agents aim to simulate user recommendation and social behaviors.
大语言模型 (LLM) 的优势在于能够充分理解人类常识。基于这一能力,许多AI智能体可以模拟人类日常生活并做出类人决策。例如在Generative Agent中,该智能体能够准确理解自身当前状态、周边环境,并根据基础观察总结高层次想法。若缺乏大语言模型的常识理解能力,这些行为将无法被可靠地模拟。类似结论可能也适用于RecAgent [21] 和 $\mathrm{S}^{3}$ [77] ,这些智能体旨在模拟用户推荐和社交行为。
Action impact: Action impact refers to the consequences of the action. In fact, the action impact can encompass numerous instances, but for brevity, we only provide a few examples. (1) Changing environments. Agents can directly alter environment states by actions, such as moving their positions, collecting items, and constructing buildings. For instance, in GITM [16] and Voyager [38], the environments are changed by the actions of the agents in their task completion process. For example, if the agent mines three woods, then they may disappear in the environments. (2) Altering internal states. Actions taken by the agent can also change the agent itself, including updating memories, forming new plans, acquiring novel knowledge, and more. For example, in Generative Agents [20], memory streams are updated after performing actions within the system. SayCan [78] enables agents to take actions to update understandings of the environment. (3) Triggering new actions. In the task completion process, one agent action can be triggered by another one. For example, Voyager [38] constructs buildings once it has gathered all the necessary resources.
动作影响:动作影响指的是动作带来的后果。实际上,动作影响可能包含大量实例,但为了简洁,我们仅列举几个示例。(1) 改变环境。智能体可以通过动作直接改变环境状态,例如移动位置、收集物品和建造建筑。例如在GITM [16]和Voyager [38]中,环境会随着智能体执行任务过程中的动作而改变。如果智能体采集了三块木材,这些木材就会从环境中消失。(2) 改变内部状态。智能体采取的动作也可能改变其自身状态,包括更新记忆、形成新计划、获取新知识等。例如在Generative Agents [20]中,系统内执行动作后会更新记忆流。SayCan [78]使智能体能够通过动作更新对环境认知。(3) 触发新动作。在任务完成过程中,一个智能体动作可能触发另一个动作。例如Voyager [38]在收集完所有必要资源后就会开始建造建筑。
2.2 Agent capability acquisition
2.2 AI智能体能力获取
In the above sections, we mainly focus on how to design the agent architecture to better inspire the capability of LLMs to make it qualified for accomplishing tasks like humans. The architecture functions as the “hardware” of the agent. However, relying solely on the hardware is insufficient for achieving effective task performance. This is because the agent may lack the necessary task-specific capabilities, skills and experiences, which can be regarded as “software” resources. In order to equip the agent with these resources, various strategies have been devised. Generally, we categorize these strategies into two classes based on whether they require fine-tuning of the LLMs. In the following, we introduce each of them more in detail.
在前面的章节中,我们主要关注如何设计智能体架构以更好地激发大语言模型的能力,使其具备像人类一样完成任务的能力。该架构相当于智能体的"硬件"。然而,仅依靠硬件无法实现有效的任务执行,因为智能体可能缺乏必要的任务特定能力、技能和经验,这些可以被视为"软件"资源。为了让智能体具备这些资源,人们设计了多种策略。通常,我们根据这些策略是否需要微调大语言模型将其分为两类。下面我们将更详细地介绍每种策略。
Capability acquisition with fine-tuning: A straightforward method to enhance the agent capability for task completion is fine-tuning the agent based on task-dependent datasets. Generally, the datasets can be constructed based on human annotation, LLM generation or collected from real-world applications. In the following, we introduce these methods more in detail.
通过微调获取能力:提升AI智能体任务完成能力的一种直接方法是基于任务相关数据集对智能体进行微调。通常,这些数据集可通过人工标注、大语言模型生成或从实际应用中收集构建。下文将详细介绍这些方法。
● Fine-tuning with human annotated datasets. To fine-tune the agent, utilizing human annotated datasets is a versatile approach that can be employed in various application scenarios. In this approach, researchers first design annotation tasks and then recruit workers to complete them. For example, in CoH [79], the authors aim to align LLMs with human values and preferences. Different from the other models, where the human feedback is leveraged in a simple and symbolic manner, this method converts the human feedback into detailed comparison information in the form of natural languages. The LLMs are directly fine-tuned based on these natural language datasets. In RET-LLM [42], in order to better convert natural languages into structured memory information, the authors fine-tune LLMs based on a human constructed dataset, where each sample is a “triplet-natural language” pair. In WebShop [80], the authors collect 1.18 million real-world products form amazon.com, and put them onto a simulated ecommerce website, which contains several carefully designed human shopping scenarios. Based on this website, the authors recruit 13 workers to collect a real-human behavior dataset. At last, three methods based on heuristic rules, imitation learning and reinforcement learning are trained based on this dataset. Although the authors do not fine-tune LLM-based agents, we believe that the dataset proposed in this paper holds immense potential to enhance the capabilities of agents in the field of Web shopping. In EduChat [81], the authors aim to enhance the educational functions of LLMs, such as open-domain question answering, essay assessment, Socratic teaching, and emotional support. They fine-tune LLMs based on human annotated datasets that cover various educational scenarios and tasks. These datasets are manually evaluated and curated by psychology experts and frontline teachers. SWIFTSAGE [82] is an agent influenced by the dual-process theory of human cognition [83], which is effective for solving complex interactive reasoning tasks. In this agent, the SWIFT module constitutes a compact encoder-decoder language model, which is fine-tuned using human-annotated datasets.
● 基于人工标注数据集的微调。为微调AI智能体,利用人工标注数据集是一种通用方法,可适用于多种应用场景。该方法首先由研究者设计标注任务,再招募工作人员完成标注。例如在CoH[79]中,作者旨在使大语言模型与人类价值观及偏好对齐。与其他仅以简单符号化方式利用人类反馈的模型不同,该方法将人类反馈转化为自然语言形式的详细对比信息,并基于这些自然语言数据集直接微调大语言模型。RET-LLM[42]为更好地将自然语言转换为结构化记忆信息,基于人工构建的"三元组-自然语言"配对数据集进行微调。WebShop[80]从amazon.com收集118万件真实商品构建模拟电商网站,设计多个人类购物场景,招募13名工作人员采集真实人类行为数据集,最终基于该数据集训练启发式规则、模仿学习和强化学习三种方法。虽然作者未对大语言模型智能体进行微调,但我们认为该数据集对提升网络购物领域智能体能力具有巨大潜力。EduChat[81]为增强大语言模型的教育功能(如开放域问答、作文评分、苏格拉底式教学和情感支持),基于覆盖多教育场景任务的人工标注数据集进行微调,这些数据由心理学专家和一线教师人工评估筛选。SWIFTSAGE[82]是受人类认知双加工理论[83]启发的智能体,能有效解决复杂交互推理任务,其SWIFT模块采用紧凑型编码器-解码器语言模型,通过人工标注数据集进行微调。
● Fine-tuning with LLM generated datasets. Building human annotated dataset needs to recruit people, which can be costly, especially when one needs to annotate a large amount of samples. Considering that LLMs can achieve human-like capabilities in a wide range of tasks, a natural idea is using LLMs to accomplish the annotation task. While the datasets produced from this method can be not as perfect as the human annotated ones, it is much cheaper, and can be leveraged to generate more samples. For example, in ToolBench [14], to enhance the tool-using capability of open-source LLMs, the authors collect 16,464 real-world APIs spanning 49 categories from the RapidAPI Hub. They used these APIs to prompt ChatGPT to generate diverse instructions, covering both single-tool and multi-tool scenarios. Based on the obtained dataset, the authors fine-tune LLaMA [9], and obtain significant performance improvement in terms of tool using. In [84], to empower the agent with social capability, the authors design a sandbox, and deploy multiple agents to interact with each other. Given a social question, the central agent first generates initial responses. Then, it shares the responses to its nearby agents for collecting their feedback. Based on the feedback as well as its detailed explanations, the central agent revise its initial responses to make them more consistent with social norms. In this process, the authors collect a large amount of agent social interaction data, which is then leveraged to fine-tune the LLMs.
● 基于大语言模型生成数据集进行微调。构建人工标注数据集需要招募人员,成本可能很高,尤其是在需要标注大量样本时。考虑到大语言模型能在多种任务中展现类人能力,一个自然的思路是利用大语言模型完成标注任务。虽然这种方法产生的数据集可能不如人工标注完美,但成本更低廉,且能用于生成更多样本。例如在ToolBench [14]中,为增强开源大语言模型的工具使用能力,作者从RapidAPI Hub收集了覆盖49个类别的16,464个真实API,并利用这些API提示ChatGPT生成涵盖单工具和多工具场景的多样化指令。基于获得的数据集,作者对LLaMA [9]进行微调,在工具使用方面取得了显著性能提升。在[84]中,为赋予智能体社交能力,作者设计了一个沙盒环境,部署多个智能体进行交互:给定社交问题时,中心智能体首先生成初始响应,随后将响应分享给邻近智能体收集反馈,最终结合反馈和详细解释修订初始响应以使其更符合社会规范。在此过程中,作者收集了大量智能体社交交互数据用于微调大语言模型。
Fine-tuning with real-world datasets. In addition to building datasets based on human or LLM annotation, directly using real-world datasets to fine-tune the agent is also a common strategy. For example, in MIND2WEB [85], the authors collect a large amount of real-world datasets to enhance the agent capability in the Web domain. In contrast to prior studies, the dataset presented in this paper encompasses diverse tasks, real-world scenarios, and comprehensive user interaction patterns. Specifically, the authors collect over 2,000 open-ended tasks from 137 real-world websites spanning 31 domains. Using this dataset, the authors fine-tune LLMs to enhance their performance on Web-related tasks, including movie discovery and ticket booking, among others. In SQL-PALM [86], researchers fine-tune PaLM-2 based on a cross-domain large-scale text-to-SQL dataset called Spider. The obtained model can achieve significant performance improvement on text-to-SQL tasks.
基于真实数据集进行微调。除了通过人工或大语言模型标注构建数据集外,直接使用真实世界数据对智能体进行微调也是常见策略。例如在MIND2WEB [85]中,作者收集了大量真实数据集来增强智能体在网页领域的能力。与先前研究不同,该论文提出的数据集涵盖了多样化任务、真实场景和完整的用户交互模式。具体而言,作者从137个真实网站收集了跨越31个领域的2000多项开放式任务。利用该数据集,作者对大语言模型进行微调以提升其在网页相关任务(包括电影发现、票务预订等)上的表现。在SQL-PALM [86]中,研究人员基于名为Spider的跨领域大规模文本转SQL数据集对PaLM-2进行微调,所得模型在文本转SQL任务上实现了显著性能提升。
Capability acquisition without fine-tuning: In the era of tradition machine learning, the model capability is mainly acquired by learning from datasets, where the knowledge is encoded into the model parameters. In the era of LLMs, the model capability can be acquired either by training/fine-tuning the model parameters or designing delicate prompts (i.e., prompt engineer). In prompt engineer, one needs to write valuable information into the prompts to enhance the model capability or unleash existing LLM capabilities. In the era of agents, the model capability can be acquired based on three strategies: (1) model fine-tuning, (2) prompt engineer, and (3) designing proper agent evolution mechanisms (we called it as mechanism engineering). Mechanism engineering is a broad concept that involves developing specialized modules, introducing novel working rules, and other strategies to enhance agent capabilities. For clearly understanding such transitions on the strategy of model capability acquisition, we illustrate them in Fig. 4. In the following, we introduce prompting engineering and mechanism engineering for agent capability acquisition.
无需微调的能力获取:在传统机器学习时代,模型能力主要通过从数据集中学习获得,知识被编码到模型参数中。在大语言模型时代,模型能力既可以通过训练/微调模型参数获得,也可以通过设计精巧的提示(即提示工程)来获取。在提示工程中,需要将有价值的信息写入提示以增强模型能力或释放现有大语言模型潜力。在智能体时代,模型能力可以通过三种策略获得:(1) 模型微调,(2) 提示工程,以及(3) 设计适当的智能体进化机制(我们称之为机制工程)。机制工程是一个广义概念,涉及开发专用模块、引入新颖工作规则等提升智能体能力的策略。为清晰理解模型能力获取策略的演变,我们在图4中进行了展示。下文将分别介绍用于智能体能力获取的提示工程与机制工程。
Prompting engineering. Due to the strong language comprehension capabilities, people can directly interact with LLMs using natural languages. This introduces a novel strategy for enhancing agent capabilities, that is, one can describe the desired capability using natural language and then use it as prompts to influence LLM actions. For example, in CoT [45], in order to empower the agent with the capability for complex task reasoning, the authors present the intermediate reasoning steps as few-shot examples in the prompt. Similar techniques are also used in CoT-SC [49] and ToT [50]. In SocialAGI [30], in order to enhance the agent self-awareness capability in conversation, the authors prompt LLMs with the agent beliefs about the mental states of the listeners and itself, which makes the generated utterance more engaging and adaptive. In addition, the authors also incorporate the target mental states of the listeners, which enables the agents to make more strategic plans. Retro former [87] presents a retrospective model that enables the agent to generate reflections on its past failures. The reflections are integrated into the prompt of LLMs to guide the agent’s future actions. Additionally, this model utilizes reinforcement learning to iterative ly improve the retrospective model, thereby refining the LLM prompt.
提示工程 (Prompting engineering)。由于大语言模型具备强大的语言理解能力,人们可以直接用自然语言与其交互。这为增强AI智能体能力引入了一种新策略:用自然语言描述期望能力,并将其作为提示词 (prompt) 来影响大语言模型行为。例如在CoT [45]中,为赋予智能体复杂任务推理能力,作者在提示词中提供了中间推理步骤作为少样本示例。类似技术也应用于CoT-SC [49]和ToT [50]。在SocialAGI [30]中,为增强对话中的自我认知能力,作者通过提示词向大语言模型输入智能体对听众及自身心理状态的信念,使生成的话语更具吸引力和适应性。此外,作者还融入了听众的目标心理状态,使智能体能够制定更具策略性的计划。Retroformer [87]提出了一种回顾模型,使智能体能够对过往失败生成反思。这些反思被整合到大语言模型的提示词中,以指导智能体未来行为。该模型还利用强化学习迭代优化回顾模型,从而持续改进大语言模型的提示词。
● Mechanism engineering. Unlike model fine-tuning and prompt engineering, mechanism engineering is a unique strategy to enhance agent capability. In the following, we present several representative methods of mechanism engineering.
● 机制工程 (Mechanism Engineering)。与模型微调 (fine-tuning) 和提示工程 (prompt engineering) 不同,机制工程是提升AI智能体 (AI Agent) 能力的独特策略。下文将介绍几种代表性的机制工程方法。
(1) Trial-and-error. In this method, the agent first performs an action, and subsequently, a pre-defined critic is invoked to judge the action. If the action is deemed unsatisfactory, then the agent reacts by incorporating the critic’s feedback. In RAH [88], the agent serves as a user assistant in recommend er systems. One of the agent’s crucial roles is to simulate human behavior and generate responses on behalf of the user. To fulfill this objective, the agent first generates a predicted response and then compares it with the real human feedback. If the predicted response and the real human feedback differ, the critic generates failure information, which is subsequently incorporated into the agent’s next action. In DEPS [33], the agent first designs a plan to accomplish a given task. In the plan execution process, if an action fails, the explainer generates specific details explaining the cause of the failure. This information is then incorporated by the agent to redesign the plan. In RoCo [89], the agent first proposes a sub-task plan and a path of 3D waypoints for each robot in a multi-robot collaboration task. The plan and waypoints are then validated by a set of environment checks, such as collision detection and inverse kinematics. If any of the checks fail, the feedback is appended to each agent’s prompt and another round of dialog begins. The agents use LLMs to discuss and improve their plan and waypoints until they pass all validations. In PREFER [90], the agent first evaluates its performance on a subset of data. If it fails to solve certain examples, LLMs are leveraged to generate feedback information reflecting on the reasons of the failure. Based on this feedback, the agent improves itself by iterative ly refining its actions.
(1) 试错法。该方法中,AI智能体首先执行一个动作,随后调用预定义的评判器对该动作进行评估。若动作被认为不理想,智能体会根据评判器的反馈调整行为。在RAH [88]中,智能体作为推荐系统的用户助手,其核心功能之一是模拟人类行为并代表用户生成响应。为此,智能体首先生成预测响应,再将其与真实用户反馈进行比对。当预测响应与真实反馈存在差异时,评判器会生成失败信息,这些信息将被整合到智能体的后续动作中。DEPS [33]中,智能体先制定任务执行计划,若计划执行过程中某个动作失败,解释器会生成详细的原因分析,智能体据此重新设计计划。RoCo [89]中,在多机器人协作任务中,智能体先为每个机器人提出子任务计划和3D路径点,这些方案需通过碰撞检测、逆运动学等环境验证。任一验证失败时,反馈信息会被附加到各智能体的提示中,开启新一轮对话。智能体们利用大语言模型讨论并优化方案,直至通过所有验证。PREFER [90]中,智能体先在数据子集上评估自身表现,若未能解决某些案例,则借助大语言模型生成失败原因分析反馈,基于该反馈通过动作迭代优化实现自我提升。
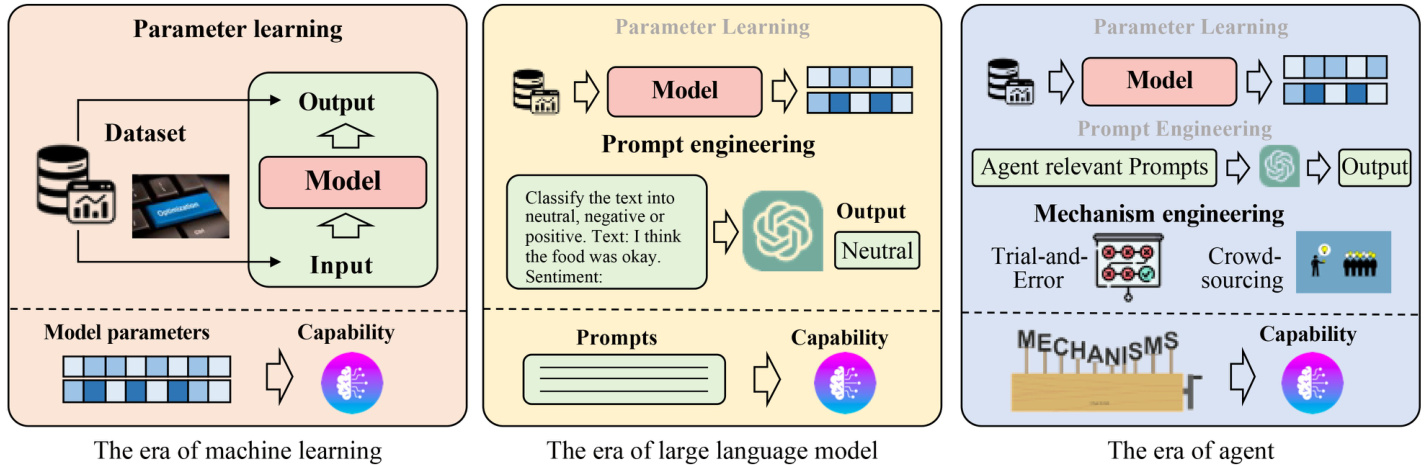
Fig. 4 Illustration of transitions in strategies for acquiring model capabilities
图 4: 模型能力获取策略转变示意图
(2) Crowd-sourcing. In [91], the authors design a debating mechanism that leverages the wisdom of crowds to enhance agent capabilities. To begin with, different agents provide separate responses to a given question. If their responses are not consistent, they will be prompted to incorporate the solutions from other agents and provide an updated response. This iterative process continues until reaching a final consensus answer. In this method, the capability of each agent is enhanced by understanding and incorporating the other agents’ opinions.
(2) 众包 (Crowd-sourcing)。在[91]中,作者设计了一种辩论机制,利用群体智慧增强AI智能体的能力。首先,不同智能体对给定问题提供独立回答。若回答不一致,系统会提示它们整合其他智能体的解决方案并更新响应。该迭代过程持续进行,直至达成最终共识答案。此方法通过理解和融合其他智能体的观点,提升了每个智能体的能力。
(3) Experience accumulation. In GITM [16], the agent does not know how to solve a task in the beginning. Then, it makes explorations, and once it has successfully accomplished a task, the actions used in this task are stored into the agent memory. In the future, if the agent encounters a similar task, then the relevant memories are extracted to complete the current task. In this process, the improved agent capability comes from the specially designed memory accumulation and utilization mechanisms. In Voyager [38], the authors equip the agent with a skill library, and each skill in the library is represented by executable codes. In the agent-environment interaction process, the codes for each skill will be iterative ly refined according to the environment feedback and the agent selfverification results. After a period of execution, the agent can successfully complete different tasks efficiently by accessing the skill library. In AppAgent [92], the agent is designed to interact with apps in a manner akin to human users, learning through both autonomous exploration and observation of human demonstrations. Throughout this process, it constructs a knowledge base, which serves as a reference for performing intricate tasks across various applications on a mobile phone. In MemPrompt [93], the users are requested to provide feedback in natural language regarding the problem-solving intentions of the agent, and this feedback is stored in memory. When the agent encounters similar tasks, it attempts to retrieve related memories to generate more suitable responses.
(3) 经验积累。在GITM [16]中,智能体最初并不知道如何解决任务。通过不断探索,当它成功完成某项任务时,该任务中使用的动作会被存储到智能体记忆中。未来遇到类似任务时,智能体会提取相关记忆来完成当前任务。这一能力提升源于专门设计的记忆积累与调用机制。Voyager [38]为智能体配备了技能库,其中每个技能都以可执行代码形式呈现。在智能体与环境交互过程中,每个技能的代码会根据环境反馈和智能体自验证结果进行迭代优化。经过一段时间运行后,智能体能通过调用技能库高效完成各类任务。AppAgent [92]的智能体被设计成以类人方式与应用程序交互,通过自主探索和观察人类示范进行学习,并在此过程中构建知识库,作为执行手机端各类复杂任务的参考依据。MemPrompt [93]则要求用户用自然语言提供关于智能体问题解决意图的反馈,这些反馈被存入记忆库。当智能体遇到相似任务时,会尝试检索相关记忆以生成更合适的响应。
(4) Self-driven evolution. In LMA3 [94], the agent can autonomously set goals for itself, and gradually improve its capability by exploring the environment and receiving feedback from a reward function. Following this mechanism, the agent can acquire knowledge and develop capabilities according to its own preferences. In SALLM-MS [95], by integrating advanced large language models like GPT-4 into a multi-agent system, agents can adapt and perform complex tasks, showcasing advanced communication capabilities, thereby realizing self-driven evolution in their interactions with the environment. In CLMTWA [96], by using a large language model as a teacher and a weaker language model as a student, the teacher can generate and communicate natural language explanations to improve the student’s reasoning skills via theory of mind. The teacher can also personalize its explanations for the student and intervene only when necessary, based on the expected utility of intervention. In NLSOM [97], different agents communicate and collaborate through natural language to solve tasks that a single agent cannot solve. This can be seen as a form of self-driven learning, utilizing the exchange of information and knowledge between multiple agents. However, unlike other models such as LMA3, SALLM-MS, and CLMTWA, NLSOM allows for dynamic adjustment of agent roles, tasks, and relationships based on the task requirements and feedback from other agents or the environment.
(4) 自主驱动进化。在LMA3 [94]中,AI智能体可自主设定目标,通过环境探索和奖励函数反馈逐步提升能力。该机制使智能体能根据自身偏好获取知识并发展能力。SALLM-MS [95]通过将GPT-4等先进大语言模型集成到多智能体系统,使智能体具备复杂任务适应能力和高级交互能力,实现与环境互动中的自主进化。CLMTWA [96]采用大语言模型作为教师模型,较弱模型作为学生模型,教师通过心智理论生成自然语言解释来提升学生的推理能力,并根据干预预期效用进行个性化解释和必要干预。NLSOM [97]通过自然语言实现多智能体协作,解决单体无法完成的任务,这种基于信息交换的协作可视为自主学习的表现形式。与LMA3、SALLM-MS和CLMTWA不同,NLSOM支持根据任务需求及其他智能体/环境反馈,动态调整智能体角色、任务和关系。
Remark. Upon comparing the aforementioned strategies for agent capability acquisition, we can find that the fine-tuning method improves the agent capability by adjusting model parameters, which can incorporate a large amount of taskspecific knowledge, but is only suitable for open-source LLMs. The method without fine-tuning usually enhances the agent capability based on delicate prompting strategies or mechanism engineering. They can be used for both open- and closed-source LLMs. However, due to the limitation of the input context window of LLMs, they cannot incorporate too much task information. In addition, the designing spaces of the prompts and mechanisms are extremely large, which makes it not easy to find optimal solutions.
备注。比较上述AI智能体能力获取策略时可以发现:微调方法通过调整模型参数来提升智能体能力,能融入大量任务特定知识,但仅适用于开源大语言模型;非微调方法通常基于精细提示策略或机制工程增强智能体能力,可同时用于开源和闭源大语言模型。但由于大语言模型输入上下文窗口的限制,这类方法无法融入过多任务信息。此外,提示设计和机制设计的探索空间极大,导致难以找到最优解。
In the above sections, we have detailed the construction of LLM-based agents, where we focus on two aspects including the architecture design and capability acquisition. We present the correspondence between existing work and the above taxonomy in Table 1. It should be noted that, for the sake of integrity, we have also incorporated several studies, which do not explicitly mention LLM-based agents but are highly related to this area.
在前文中,我们详细阐述了基于大语言模型(LLM)的AI智能体构建方法,重点聚焦架构设计与能力获取两大维度。表1展示了现有研究成果与上述分类体系的对应关系。需要说明的是,为保持体系完整性,我们纳入了部分虽未明确提及基于大语言模型的智能体、但与该领域高度相关的研究[20]。
3 LLM-based autonomous agent application
3 基于大语言模型 (LLM) 的自主AI智能体应用
Owing to the strong language comprehension, complex task reasoning, and common sense understanding capabilities, LLM-based autonomous agents have shown significant potential to influence multiple domains. This section provides a succinct summary of previous studies, categorizing them according to their applications in three distinct areas: social science, natural science, and engineering (see the left part of Fig. 5 for a global overview).
由于具备强大的语言理解能力、复杂任务推理能力和常识理解能力,基于大语言模型 (LLM) 的自主智能体展现出影响多个领域的巨大潜力。本节简要综述了先前研究,并根据其在三个不同领域的应用进行分类:社会科学、自然科学和工程学(全局概览见图5左半部分)。
3.1 Social science
3.1 社会科学
Social science is one of the branches of science, devoted to the study of societies and the relationships among individuals within those societies. LLM-based autonomous agents can promote this domain by leveraging their impressive humanlike understanding, thinking and task solving capabilities. In the following, we discuss several key areas that can be affected by LLM-based autonomous agents.
社会科学是科学的一个分支,致力于研究社会及其内部个体之间的关系。基于大语言模型 (LLM) 的AI智能体可通过其类人的理解、思考和任务解决能力推动该领域发展。下面我们将探讨基于大语言模型的AI智能体可能影响的几个关键领域。
Psychology: For the domain of psychology, LLM-based agents can be leveraged for conducting simulation experiments, providing mental health support and so on [102–105]. For example, in [102], the authors assign LLMs with different profiles, and let them complete psychology experiments. From the results, the authors find that LLMs are capable of generating results that align with those from studies involving human participants. Additionally, it was observed that larger models tend to deliver more accurate simulation results compared to their smaller counterparts. An interesting discovery is that, in many experiments, models like ChatGPT and GPT-4 can provide too perfect estimates (called “hyperaccuracy distortion”), which may influence the downstream applications. In [104], the authors systematically analyze the effectiveness of LLM-based conversation agents for mental well-being support. They collect 120 posts from Reddit, and find that such agents can help users cope with anxieties, social isolation and depression on demand. At the same time, they also find that the agents may produce harmful contents sometimes.
心理学:在心理学领域,基于大语言模型的AI智能体可用于开展模拟实验、提供心理健康支持等[102–105]。例如,文献[102]中研究者为不同配置的大语言模型分配角色,让其完成心理学实验。结果显示,这些模型能够生成与人类参与者研究相符的结果。此外研究发现,较大规模的模型通常能比较小模型提供更精确的模拟结果。一个有趣的发现是,在许多实验中,ChatGPT和GPT-4等模型会给出过于完美的评估(称为"超精确度偏差"),这可能影响下游应用。文献[104]系统分析了基于大语言模型的对话智能体在心理健康支持方面的有效性。研究者收集了Reddit上的120篇帖子,发现这类智能体能按需帮助用户应对焦虑、社交孤立和抑郁问题,同时也发现它们有时可能产生有害内容。
Table 1 For the profile module ①, ② , and ③ to represent the handcrafting method, LLM-generation method, and dataset alignment method, respectively. For the memory module, we focus on the implementation strategies for memory operation and memory structure. For memory operation, we use ① and ② to indicate that the model only has read/write operations and has read/write/reflection operations, respectively. For memory structure, we use ① and ② to represent unified and hybrid memories, respectively. For the planning module, we use ① and ② to represent planning w/o feedback and w/ feedback, respectively. For the action module, we use ① and ② to represent that the model does not use tools and use tools, respectively. For the agent capability acquisition (CA) strategy, we use ① and ② to represent the methods with and without fine-tuning, respectively. “−” indicates that the corresponding content is not explicitly discussed in the paper
| Model | Profile | Memory | Planning | Action | CA | Time | |
| Operation | Structure | ||||||
| WebGPT [66] | 一 | - | ① | 12/2021 | |||
| SayCan [78] | 一 | 一 | ① | ① | ② | 04/2022 | |
| MRKL [72] | 一 | ① | 一 | 05/2022 | |||
| Inner Monologue [61] | ② | ① | ② | 07/2022 | |||
| Social Simulacra [98] | ② | ① | 一 | 08/2022 | |||
| ReAct [59] | 一 | 一 | ② | ① | 10/2022 | ||
| MALLM [43] | ① | ② | ① | 一 | 01/2023 | ||
| DEPS [33] | ② | ① | ② | 02/2023 | |||
| Toolformer [15] | 一 | ① | ② | ① | 02/2023 | ||
| Reflexion [12] | 一 | ② | ② | ② | ① | ② | 03/2023 |
| CAMEL [99] | ①② | ② | ① | 一 | 03/2023 | ||
| API-Bank [69] | ② | ② | ② | 04/2023 | |||
| ViperGPT [74] | ② | 03/2023 | |||||
| HuggingGPT [13] | 一 | 一 | ① | ① | ② | 03/2023 | |
| Generative Agents [20] | ① | ② | ② | ② | ① | 04/2023 | |
| LLM+P [57] | 一 | ① | ① | 04/2023 | |||
| ChemCrow [75] | 一 | 一 | ② | ② | 一 | 04/2023 | |
| OpenAGI [73] | ② | ② | ① | 04/2023 | |||
| AutoGPT [100] | ① | ② | ② | ② | ② | 04/2023 | |
| SCM [35] | ② | ② | ① | 一 | 04/2023 | ||
| Socially Alignment [84] | ① | ② | ① | ① | 05/2023 | ||
| GITM [16] | ② | ② | ② | ① | ② | 05/2023 | |
| Voyager [38] | 一 | ② | ② | ② | ① | ② | 05/2023 |
| Introspective Tips [101] | 一 | ② | ① | ② | 05/2023 | ||
| RET-LLM [42] | ① | ② | ① | ① | 05/2023 | ||
| ChatDB [40] | 一 | ① | ② | ② | ② | 06/2023 | |
| S^3 [77] | ② | ② | ① | 07/2023 | |||
| ChatDev [18] | ① | ② | ② | ② | ① | ② | 07/2023 |
| ToolLLM [14] | 一 | ② | ② | ① | 07/2023 | ||
| MemoryBank [39] | 一 | ② | ② | ① | 07/2023 | ||
| MetaGPT [23] | ① | ② | ② | ② | ② | 二 | 08/2023 |
表 1: 对于档案模块,我们使用 ①、② 和 ③ 分别表示手工方法、大语言模型生成方法和数据集对齐方法。对于记忆模块,我们关注记忆操作和记忆结构的实现策略。对于记忆操作,① 和 ② 分别表示模型仅具有读/写操作和具有读/写/反思操作。对于记忆结构,① 和 ② 分别表示统一记忆和混合记忆。对于规划模块,① 和 ② 分别表示无反馈规划和有反馈规划。对于行动模块,① 和 ② 分别表示模型不使用工具和使用工具。对于智能体能力获取 (CA) 策略,① 和 ② 分别表示有微调和无微调的方法。“−”表示论文中未明确讨论相关内容。
| 模型 | 档案 | 记忆操作 | 记忆结构 | 规划 | 行动 | CA | 时间 |
|---|---|---|---|---|---|---|---|
| WebGPT [66] | - | - | - | - | - | ① | 12/2021 |
| SayCan [78] | - | - | - | ① | ① | ② | 04/2022 |
| MRKL [72] | - | - | - | ① | - | - | 05/2022 |
| Inner Monologue [61] | - | - | - | ② | ① | ② | 07/2022 |
| Social Simulacra [98] | ② | - | - | - | ① | - | 08/2022 |
| ReAct [59] | - | - | - | ② | - | ① | 10/2022 |
| MALLM [43] | - | ① | ② | - | ① | - | 01/2023 |
| DEPS [33] | - | - | - | ② | ① | ② | 02/2023 |
| Toolformer [15] | - | - | - | ① | ② | ① | 02/2023 |
| Reflexion [12] | - | ② | ② | ② | ① | ② | 03/2023 |
| CAMEL [99] | ①② | - | - | ② | ① | - | 03/2023 |
| API-Bank [69] | - | - | - | ② | ② | ② | 04/2023 |
| ViperGPT [74] | - | - | - | - | ② | - | 03/2023 |
| HuggingGPT [13] | - | - | ① | ① | ② | - | 03/2023 |
| Generative Agents [20] | ① | ② | ② | ② | ① | - | 04/2023 |
| LLM+P [57] | - | - | - | ① | ① | - | 04/2023 |
| ChemCrow [75] | - | - | - | ② | ② | - | 04/2023 |
| OpenAGI [73] | - | - | - | ② | ② | ① | 04/2023 |
| AutoGPT [100] | - | ① | ② | ② | ② | ② | 04/2023 |
| SCM [35] | - | ② | ② | - | ① | - | 04/2023 |
| Socially Alignment [84] | - | ① | ② | - | ① | ① | 05/2023 |
| GITM [16] | - | ② | ② | ② | ① | ② | 05/2023 |
| Voyager [38] | - | ② | ② | ② | ① | ② | 05/2023 |
| Introspective Tips [101] | - | - | - | ② | ① | ② | 05/2023 |
| RET-LLM [42] | - | ① | ② | - | ① | ① | 05/2023 |
| ChatDB [40] | - | ① | ② | ② | ② | - | 06/2023 |
| $3 [77] | - | ② | ② | - | ① | - | 07/2023 |
| ChatDev [18] | ① | ② | ② | ② | ① | ② | 07/2023 |
| ToolLLM [14] | - | - | - | ② | ② | ① | 07/2023 |
| MemoryBank [39] | - | ② | ② | - | ① | - | 07/2023 |
| MetaGPT [23] | ① | ② | ② | ② | ② | ② | 08/2023 |
Fig. 5 The applications (left) and evaluation strategies (right) of LLM-based agents
图 5: 基于大语言模型的智能体应用(左)与评估策略(右)
Political science and economy: LLM-based agents can also be utilized to study political science and economy [29,105,106]. In [29], LLM-based agents are utilized for ideology detection and predicting voting patterns. In [105], the authors focuses on understanding the discourse structure and persuasive elements of political speech through the assistance of LLM-based agents. In [106], LLM-based agents are provided with specific traits such as talents, preferences, and personalities to explore human economic behaviors in simulated scenarios.
政治学与经济学:基于大语言模型的AI智能体也可用于研究政治学与经济学 [29,105,106]。在 [29] 中,研究者利用基于大语言模型的AI智能体进行意识形态检测和投票模式预测。[105] 聚焦于通过AI智能体辅助分析政治演讲的话语结构与说服要素。[106] 则为AI智能体赋予才能、偏好和性格等特定特质,以模拟场景中的人类经济行为。
Social simulation: Previously, conducting experiments with human societies is often expensive, unethical, or even infeasible. With the ever prospering of LLMs, many people explore to build virtual environment with LLM-based agents to simulate social phenomena, such as the propagation of harmful information, and so on [20,34,77,79,107–110]. For example, Social Simulacra [79] simulates an online social community and explores the potential of utilizing agent-based simulations to aid decision-makers to improve community regulations. [107,108] investigates the potential impacts of different behavioral characteristics of LLM-based agents in social networks. Generative Agents [20] and AgentSims [34] construct multiple agents in a virtual town to simulate the human daily life. SocialAI School [109] employs LLM-based agents to simulate and investigate the fundamental social cognitive skills during the course of child development. $\mathrm{S}^{3}$ [77] builds a social network simulator, focusing on the propagation of information, emotion and attitude. CGMI [111] is a framework for multi-agent simulation. CGMI maintains the personality of the agents through a tree structure and constructs a cognitive model. The authors simulated a classroom scenario using CGMI.
社会模拟:过去,在人类社会中进行实验往往成本高昂、有违伦理甚至难以实现。随着大语言模型 (LLM) 的蓬勃发展,许多研究者开始探索用基于大语言模型的AI智能体构建虚拟环境来模拟社会现象,例如有害信息传播等 [20,34,77,79,107–110]。例如,Social Simulacra [79] 模拟了一个在线社交社区,探索基于智能体的模拟如何帮助决策者改进社区规范。[107,108] 研究了基于大语言模型的AI智能体在社交网络中不同行为特征的潜在影响。Generative Agents [20] 和 AgentSims [34] 在虚拟小镇中构建多个智能体来模拟人类日常生活。SocialAI School [109] 使用基于大语言模型的AI智能体模拟研究儿童发展过程中的基础社会认知能力。$\mathrm{S}^{3}$ [77] 构建了一个专注于信息、情绪和态度传播的社交网络模拟器。CGMI [111] 是一个多智能体模拟框架,通过树状结构保持智能体个性并构建认知模型,作者使用CGMI模拟了课堂场景。
Jurisprudence: LLM-based agents can serve as aids in legal decision-making processes, facilitating more informed judgements [112,113]. Blind Judgement [113] employs several language models to simulate the decision-making processes of multiple judges. It gathers diverse opinions and consolidates the outcomes through a voting mechanism. ChatLaw [112] is a prominent Chinese legal model based on LLM. It adeptly supports both database and keyword search strategies, specifically designed to mitigate the hallucination issue prevalent in such models. In addition, this model also employs self-attention mechanism to enhance the LLM’s capability via mitigating the impact of reference inaccuracies.
法学应用:基于大语言模型的AI智能体可作为法律决策辅助工具,帮助形成更全面的司法判断[112,113]。Blind Judgement[113]采用多语言模型并行模拟法官决策流程,通过投票机制整合多元意见。ChatLaw[112]是当前中国法律领域具有代表性的大语言模型,该模型创新性地融合数据库检索与关键词搜索策略,专门针对法律场景下的幻觉(hallucination)问题进行优化。此外,该模型还引入自注意力(self-attention)机制,通过降低参考信息误差的影响来增强模型性能。
Research assistant: Beyond their application in specialized domains, LLM-based agents are increasingly adopted as versatile assistants in the broad field of social science research [105,114]. In [105], LLM-based agents offer multifaceted assistance, ranging from generating concise article abstracts and extracting pivotal keywords to crafting detailed scripts for studies, showcasing their ability to enrich and streamline the research process. Meanwhile, in [114], LLM-based agents serve as a writing assistant, demonstrating their capability to identify novel research inquiries for social scientists, thereby opening new avenues for exploration and innovation in the field. These examples highlight the potential of LLM-based agents in enhancing the efficiency, creativity, and breadth of social science research.
研究助理:除了在专业领域的应用外,基于大语言模型 (LLM) 的AI智能体正日益成为社会科学研究领域的通用助手 [105,114]。在 [105] 中,基于大语言模型的AI智能体提供多方位协助,从生成简洁的文章摘要、提取关键关键词到撰写详细的研究脚本,展现了其丰富和简化研究流程的能力。与此同时,在 [114] 中,基于大语言模型的AI智能体作为写作助手,展示了其为社会科学家识别新研究问题的能力,从而为该领域的探索和创新开辟了新途径。这些例子凸显了基于大语言模型的AI智能体在提升社会科学研究效率、创造力和广度方面的潜力。
3.2 Natural science
3.2 自然科学
Natural science is one of the branches of science concerned with the description, understanding and prediction of natural phenomena, based on empirical evidence from observation and experimentation. With the ever prospering of LLMs, the application of LLM-based agents in natural sciences becomes more and more popular. In the following, we present many representative areas, where LLM-based agents can play important roles.
自然科学是科学的一个分支,致力于基于观察和实验获得的经验证据来描述、理解和预测自然现象。随着大语言模型(LLM)的蓬勃发展,基于大语言模型的AI智能体在自然科学中的应用越来越广泛。下文我们将展示多个代表性领域,这些领域都能充分发挥基于大语言模型的AI智能体的重要作用。
Documentation and data management: Natural scientific research often involves the collection, organization, and synthesis of substantial amounts of literature, which requires a significant dedication of time and human resources. LLMbased agents have shown strong capabilities on language understanding and employing tools such as the internet and databases for text processing. These capabilities empower the agent to excel in tasks related to documentation and data management [75,115,116]. In [115], the agent can efficiently query and utilize internet information to complete tasks such as question answering and experiment planning. ChatMOF [116] utilizes LLMs to extract important information from text descriptions written by humans. It then formulates a plan to apply relevant tools for predicting the properties and structures of metal-organic frameworks. ChemCrow [75] utilizes chemistry-related databases to both validate the precision of compound representations and identify potentially dangerous substances. This functionality enhances the reliability and comprehensiveness of scientific inquiries by ensuring the accuracy of the data involved.
文档与数据管理:自然科学研究通常涉及大量文献的收集、整理和综合,这需要投入大量时间和人力资源。基于大语言模型 (LLM) 的智能体在语言理解及运用互联网、数据库等工具进行文本处理方面展现出强大能力 [75,115,116]。这些能力使其在文档与数据管理相关任务中表现卓越:文献 [115] 中的智能体可高效查询并利用网络信息完成问答和实验规划等任务;ChatMOF [116] 通过大语言模型从人类撰写的文本描述中提取关键信息,进而制定计划调用相关工具预测金属有机框架的性质与结构;ChemCrow [75] 则利用化学数据库既验证化合物表征的精确性,又识别潜在危险物质,该功能通过确保数据准确性提升了科学研究的可靠性与全面性。
Experiment assistant: LLM-based agents have the ability to independently conduct experiments, making them valuable tools for supporting scientists in their research projects [75,115]. For instance, [115] introduces an innovative agent system that utilizes LLMs for automating the design, planning, and execution of scientific experiments. This system, when provided with the experimental objectives as input, accesses the Internet and retrieves relevant documents to gather the necessary information. It subsequently utilizes Python code to conduct essential calculations and carry out the following experiments. ChemCrow [75] incorporates 17 carefully developed tools that are specifically designed to assist researchers in their chemical research. Once the input objectives are received, ChemCrow provides valuable recommendations for experimental procedures, while also emphasizing any potential safety risks associated with the proposed experiments.
实验助手:基于大语言模型的AI智能体具备独立开展实验的能力,使其成为辅助科学家开展研究项目的宝贵工具 [75,115]。例如,[115] 提出了一种创新性智能体系统,利用大语言模型实现科学实验设计、规划与执行的自动化。该系统在接收实验目标输入后,会访问互联网检索相关文献以获取必要信息,随后使用Python语言编写代码进行核心计算并开展后续实验。ChemCrow [75] 整合了17种精心开发的工具,专门用于辅助化学研究。当接收到输入目标后,ChemCrow不仅能提供有价值的实验流程建议,还会重点提示拟议实验中可能存在的安全风险。
Natural science education: LLM-based agents can communicate with humans fluently, often being utilized to develop agent-based educational tools [115,117–119]. For example, [115] develops agent-based education systems to facilitate students learning of experimental design, methodologies, and analysis. The objective of these systems is to enhance students’ critical thinking and problem-solving skills, while also fostering a deeper comprehension of scientific principles. Math Agents [117] can assist researchers in exploring, discovering, solving and proving mathematical problems. Additionally, it can communicate with humans and aids them in understanding and using mathematics. [118] utilize the capabilities of CodeX [119] to automatically solve and explain university-level mathematical problems, which can be used as education tools to teach students and researchers. CodeHelp [120] is an education agent for programming. It offers many useful features, such as setting course-specific keywords, monitoring student queries, and providing feedback to the system. EduChat [81] is an LLMbased agent designed specifically for the education domain. It provides personalized, equitable, and empathetic educational support to teachers, students, and parents through dialogue. FreeText [121] is an agent that utilizes LLMs to automatically assess students’ responses to open-ended questions and offer feedback.
自然科学教育:基于大语言模型的AI智能体能够流畅地与人类交流,常被用于开发基于智能体的教育工具[115,117–119]。例如,[115]开发了基于智能体的教育系统,帮助学生掌握实验设计、方法学和分析技能。这些系统旨在提升学生的批判性思维和问题解决能力,同时深化对科学原理的理解。数学智能体[117]能协助研究者探索、发现、解决和证明数学问题,还能与人类互动并辅助数学理解与应用。[118]利用CodeX[119]的能力自动求解和解释大学阶段的数学问题,可作为面向学生和研究者的教学工具。编程教育智能体CodeHelp[120]具备课程关键词设定、学生问题监控及系统反馈等功能。EduChat[81]是专为教育领域设计的大语言模型智能体,通过对话为教师、学生和家长提供个性化、公平且具同理心的教育支持。FreeText[121]则利用大语言模型自动评估学生对开放性问题的作答并给予反馈。
3.3 Engineering
3.3 工程
LLM-based autonomous agents have shown great potential in assisting and enhancing engineering research and applications. In this section, we review and summarize the applications of LLM-based agents in several major engineering domains.
基于大语言模型(LLM)的自主智能体在辅助和增强工程研究与应用方面展现出巨大潜力。本节将回顾并总结基于大语言模型的智能体在几大主要工程领域的应用。
Civil engineering: In civil engineering, LLM-based agents can be used to design and optimize complex structures such as buildings, bridges, dams, roads. [122] proposes an interactive framework where human architects and agents collaborate to construct structures in a 3D simulation environment. The interactive agent can understand natural language instructions, place blocks, detect confusion, seek clarification, and incorporate human feedback, showing the potential for human-AI collaboration in engineering design.
土木工程:在土木工程领域,基于大语言模型的AI智能体可用于设计和优化建筑、桥梁、大坝、道路等复杂结构。[122]提出了一种交互式框架,人类建筑师与智能体在3D仿真环境中协作构建结构。该交互式智能体能够理解自然语言指令、放置模块、检测混淆、寻求澄清并整合人类反馈,展现了工程设计中人机协作的潜力。
Computer science & software engineering: In the field of computer science and software engineering, LLMbased agents offer potential for automating coding, testing, debugging, and documentation generation [14,18,23,24,123–125]. ChatDev [18] proposes an end-to-end framework, where multiple agent roles communicate and collaborate through natural language conversations to complete the software development life cycle. This framework demonstrates efficient and cost-effective generation of executable software systems. ToolBench [14] can be used for tasks such as code auto-completion and code recommendation. MetaGPT [23] abstracts multiple roles, such as product managers, architects, project managers, and engineers, to supervise code generation process and enhance the quality of the final output code. This enables low-cost software development. [24] presents a self-collaboration framework for code generation using LLMs. In this framework, multiple LLMs are assumed to be distinct “experts” for specific subtasks. They collaborate and interact according to specified instructions, forming a virtual team that facilitates each other’s work. Ultimately, the virtual team collaborative ly addresses code generation tasks without requiring human intervention. LLIFT [126] employs LLMs to assist in conducting static analysis, specifically for identifying potential code vulnerabilities. This approach effectively manages the tradeoff between accuracy and s cal ability. ChatEDA [127] is an agent developed for electronic design automation (EDA) to streamline the design process by integrating task planning, script generation, and execution. CodeHelp [120] is an agent designed to assist students and developers in debugging and testing their code. Its features include providing detailed explanations of error messages, suggesting potential fixes, and ensuring the accuracy of the code. PENTESTGPT [128] is a penetration testing tool based on LLMs, which can effectively identify common vulnerabilities, and interpret source code to develop exploits. DB-GPT [41] utilizes the capabilities of LLMs to systematically assess potential root causes of anomalies in databases. Through the implementation of a tree of thought approach, DB-GPT enables LLMs to backtrack to previous steps in case the current step proves unsuccessful, thus enhancing the accuracy of the diagnosis process.
计算机科学与软件工程:在计算机科学和软件工程领域,基于大语言模型的智能体为编码、测试、调试和文档生成自动化提供了潜力[14,18,23,24,123–125]。ChatDev[18]提出了一种端到端框架,其中多个智能体角色通过自然语言对话进行沟通协作,完成软件开发生命周期。该框架展示了高效且经济实惠的可执行软件系统生成能力。ToolBench[14]可用于代码自动补全和代码推荐等任务。MetaGPT[23]抽象出产品经理、架构师、项目经理和工程师等多重角色,监督代码生成过程并提升最终输出代码质量,实现了低成本软件开发。[24]提出了一种基于大语言模型的代码生成自协作框架,将多个大语言模型视为特定子任务的独立"专家",它们按照指定指令进行协作交互,形成相互促进的虚拟团队,最终无需人工干预即可协同完成代码生成任务。LLIFT[126]利用大语言模型辅助进行静态分析,专门用于识别潜在代码漏洞,有效平衡了准确性与可扩展性。ChatEDA[127]是为电子设计自动化(EDA)开发的智能体,通过集成任务规划、脚本生成与执行来优化设计流程。CodeHelp[120]是专为帮助学生和开发者调试测试代码而设计的智能体,其功能包括提供错误信息详细解释、建议潜在修复方案以及确保代码准确性。PENTESTGPT[128]是基于大语言模型的渗透测试工具,能有效识别常见漏洞,并通过解读源代码开发漏洞利用方案。DB-GPT[41]利用大语言模型能力系统评估数据库异常的根本原因,通过实施思维树方法,使大语言模型在当前步骤失败时可回溯至先前步骤,从而提升诊断过程的准确性。
Industrial automation: In the field of industrial automation, LLM-based agents can be used to achieve intelligent planning and control of production processes. [129] proposes a novel framework that integrates large language models (LLMs) with digital twin systems to accommodate flexible production needs. The framework leverages prompt engineering techniques to create LLM agents that can adapt to specific tasks based on the information provided by digital twins. These agents can coordinate a series of atomic functionalities and skills to complete production tasks at different levels within the automation pyramid. This research demonstrates the potential of integrating LLMs into industrial automation systems, providing innovative solutions for more agile, flexible and adaptive production processes. IELLM [130] showcases a case study on LLMs’ role in the oil and gas industry, covering applications like rock physics, acoustic reflect ome try, and coiled tubing control.
工业自动化:在工业自动化领域,基于大语言模型的AI智能体可用于实现生产流程的智能规划与控制。[129]提出了一种将大语言模型(LLM)与数字孪生系统相结合的新型框架,以满足柔性生产需求。该框架利用提示工程(prompt engineering)技术创建能根据数字孪生提供信息适配特定任务的LLM智能体。这些智能体可协调自动化金字塔不同层级的一系列原子化功能与技能,完成生产任务。该研究展示了将大语言模型融入工业自动化系统的潜力,为更敏捷、灵活、自适应的生产流程提供了创新解决方案。IELLM [130]展示了关于大语言模型在石油天然气行业中应用的案例研究,涵盖岩石物理、声波反射测量和连续油管控制等应用场景。
Robotics & embodied artificial intelligence: Recent works have developed more efficient reinforcement learning agents for robotics and embodied artificial intelligence [16,38,78,131–138]. The focus is on enhancing autonomous agents’ abilities for planning, reasoning, and collaboration in embodied environments. In specific, [135] proposes a unified agent system for embodied reasoning and task planning. In this system, the authors design high-level commands to enable improved planning while propose low-level controllers to translate commands into actions. Additionally, one can leverage dialogues to gather information [136] to accelerate the optimization process. [137,138] employ autonomous agents for embodied decision-making and exploration. To overcome the physical constraints, the agents can generate executable plans and accomplish long-term tasks by leveraging multiple skills. In terms of control policies, SayCan [78] focuses on investigating a wide range of manipulation and navigation skills utilizing a mobile manipulator robot. Taking inspiration from typical tasks encountered in a kitchen environment, it presents a comprehensive set of 551 skills that cover seven skill families and 17 objects. These skills encompass various actions such as picking, placing, pouring, grasping, and manipulating objects, among others. TidyBot [139] is an embodied agent designed to personalize household cleanup tasks. It can learn users’ preferences on object placement and manipulation methods through textual examples.
机器人技术与具身人工智能:近期研究开发了更高效的强化学习智能体,用于机器人技术和具身人工智能领域[16,38,78,131–138]。研究重点在于提升自主智能体在具身环境中的规划、推理与协作能力。具体而言,[135]提出了一种用于具身推理与任务规划的通用智能体系统,通过设计高层命令增强规划能力,同时采用底层控制器将指令转化为动作。此外,研究者可利用对话收集信息[136]以加速优化过程。[137,138]采用自主智能体进行具身决策与探索,通过整合多种技能生成可执行计划以突破物理限制,完成长期任务。在控制策略方面,SayCan[78]重点研究利用移动机械臂实现多样化操作与导航技能,基于厨房环境典型任务构建了涵盖7大类技能族、17种对象的551项技能库,包含抓取、放置、倾倒、操控等动作。TidyBot[139]是专为个性化家居整理设计的具身智能体,能通过文本示例学习用户对物品摆放及操作方式的偏好。
To promote the application of LLM-based autonomous agents, researchers have also introduced many open-source libraries, based on which the developers can quickly implement and evaluate agents according to their customized requirements [19,108,124,140–153]. For example, LangChain [145] is an open-source framework that automates coding, testing, debugging, and documentation generation tasks. By integrating language models with data sources and facilitating interaction with the environment, LangChain enables efficient and cost-effective software development through natural language communication and collaboration among multiple agent roles. Based on LangChain, XLang [143] comes with a comprehensive set of tools, a complete user interface, and support three different agent scenarios, namely data processing, plugin usage, and Web agent. AutoGPT [100] is an agent that is fully automated. It sets one or more goals, breaks them down into corresponding tasks, and cycles through the tasks until the goal is achieved. WorkGPT [146] is an agent framework similar to AutoGPT and LangChain. By providing it with an instruction and a set of APIs, it engages in back-and-forth conversations with AI until the instruction is completed. GPT-Engineer [125], SmolModels [123] and DemoGPT [124] are open-source projects that focus on automating code generation through prompts to complete development tasks. AGiXT [142] is a dynamic AI automation platform designed to orchestrate efficient AI command management and task execution across many providers. AgentVerse [19] is a versatile framework that facilitates researchers in creating customized LLM-based agent simulations efficiently. GPT Researcher [148] is an experimental application that leverages large language models to efficiently develop research questions, trigger Web crawls to gather information, summarize sources, and aggregate summaries. BMTools [149] is an open-source repository that extends LLMs with tools and provides a platform for community-driven tool building and sharing. It supports various types of tools, enables simultaneous task execution using multiple tools, and offers a simple interface for loading plugins via URLs, fostering easy development and contribution to the BMTools ecosystem.
为促进基于大语言模型的自主AI智能体应用,研究人员已推出诸多开源库,开发者可基于这些工具快速实现并评估符合定制化需求的智能体[19,108,124,140–153]。例如LangChain[145]是一个自动化编码、测试、调试及文档生成任务的开源框架,通过将语言模型与数据源集成并促进环境交互,使多角色AI智能体可通过自然语言沟通协作实现高效低成本的软件开发。基于LangChain的XLang[143]配备了全套工具链、完整用户界面,支持数据处理、插件调用和网络代理三种智能体场景。AutoGPT[100]是完全自动化智能体,通过目标分解与任务循环机制实现自主执行。WorkGPT[146]是类似AutoGPT和LangChain的框架,给定指令与API集合后即可与AI展开多轮对话直至任务完成。GPT-Engineer[125]、SmolModels[123]和DemoGPT[124]是通过提示词自动生成代码完成开发任务的开源项目。AGiXT[142]是支持多平台AI指令管理与任务调度的动态自动化平台。AgentVerse[19]为研究者提供高效创建定制化大语言模型智能体模拟的通用框架。GPT Researcher[148]作为实验性应用,能利用大语言模型生成研究问题、触发网络爬虫、汇总文献并整合结论。BMTools[149]作为开源工具库,通过工具扩展大语言模型能力,提供社区化工具构建与共享平台,支持多工具并行任务执行,并可通过URL便捷加载插件以促进生态贡献。
Remark. Utilization of LLM-based agents in supporting above applications may also entail risks and challenges. On one hand, LLMs themselves may be susceptible to illusions and other issues, occasionally providing erroneous answers, leading to incorrect conclusions, experimental failures, or even posing risks to human safety in hazardous experiments. Therefore, during experimentation, users must possess the necessary expertise and knowledge to exercise appropriate caution. On the other hand, LLM-based agents could potentially be exploited for malicious purposes, such as the development of chemical weapons, necessitating the implementation of security measures, such as human alignment, to ensure responsible and ethical use.
备注:利用基于大语言模型的AI智能体支持上述应用也可能伴随风险和挑战。一方面,大语言模型本身可能存在幻觉等问题,偶发提供错误答案,导致错误结论、实验失败,甚至在高危实验中危及人身安全。因此实验过程中,使用者需具备必要的专业知识以保持审慎。另一方面,基于大语言模型的AI智能体可能被恶意利用(例如开发化学武器),需通过人类对齐等安全措施确保其负责任和符合伦理的使用。
Table 2 Representative applications of LLM-based autonomous agents
| Domain | Work | |
| Social Science | Psychology Political Science and | TE[102],Akata et al.[103],Ziems et al.[105],Ma et al.[104] |
| Economy | Out of One [29], Horton [106], Ziems et al. [105] | |
| SocialSimulation | Social Simulacra[79],GenerativeAgents[20],SocialAI School[109],AgentSims[34], S3[77],Williams et al.[110],Liet al.[107],Chaoet al.[108] | |
| Jurisprudence | ChatLaw[112],Blind Judgement [113] | |
| ResearchAssistant | Ziems et al.[105], Bail et al.[114] | |
| Natural Science | Documentationand DataManagement | ChemCrow[75],Boiko et al.[115] |
| ExperimentAssistant Natural Science | ChemCrow [75], Boiko et al. [115], Grossmann et al. [154] | |
| Education | ChemCrow[75],CodeHelp[120],Boikoet al.[115],MathAgent[117],Drori et al.[118] | |
| Engineering | CS&SE | |
| Industrial Automation | GPT4IA[129], IELLM [130], TaskMatrix.AI[71] | |
| Robotics& Embodied AI | LMMWM [157], TidyBot [139], RoCo [89], SayPlan [31] | |
表 2: 基于大语言模型的自主智能体代表性应用
| 领域 | 子领域 | 研究项目 |
|---|---|---|
| 社会科学 | 心理学与政治学 | TE[102], Akata等[103], Ziems等[105], Ma等[104] |
| 经济学 | Out of One[29], Horton[106], Ziems等[105] | |
| 社会模拟 | Social Simulacra[79], Generative Agents[20], SocialAI School[109], AgentSims[34], S3[77], Williams等[110], Li等[107], Chao等[108] | |
| 法学 | ChatLaw[112], Blind Judgement[113] | |
| 研究助理 | Ziems等[105], Bail等[114] | |
| 自然科学 | 文档与数据管理 | ChemCrow[75], Boiko等[115] |
| 实验辅助 | ChemCrow[75], Boiko等[115], Grossmann等[154] | |
| 教育 | ChemCrow[75], CodeHelp[120], Boiko等[115], MathAgent[117], Drori等[118] | |
| 工程学 | 计算机科学与软件工程 | |
| 工业自动化 | GPT4IA[129], IELLM[130], TaskMatrix.AI[71] | |
| 机器人学与具身AI | LMMWM[157], TidyBot[139], RoCo[89], SayPlan[31] |
In summary, in the above sections, we introduce the typical applications of LLM-based autonomous agents in three important domains. To facilitate a clearer understanding, we have summarized the relationship between previous studies and their respective applications in Table 2.
总而言之,在上述章节中,我们介绍了基于大语言模型的AI智能体在三个重要领域的典型应用。为便于更清晰理解,我们在表2中总结了现有研究与其对应应用之间的关系。
4 LLM-based autonomous agent evaluation
4 基于大语言模型的AI智能体评估
Similar to LLMs themselves, evaluating the effectiveness of LLM-based autonomous agents is a challenging task. This section outlines two prevalent approaches to evaluation: subjective and objective methods. For a comprehensive overview, please refer to the right portion of Fig. 5.
与大语言模型(LLM)本身类似,评估基于大语言模型的自主AI智能体(AI Agent)效能是一项具有挑战性的任务。本节概述了两种主流评估方法:主观评估与客观评估。完整概览请参阅图5右侧部分。
4.1 Subjective evaluation
4.1 主观评估
Subjective evaluation measures the agent capabilities based on human judgements [20,22,29,79,158]. It is suitable for the scenarios where there are no evaluation datasets or it is very hard to design quantitative metrics, for example, evaluating the agent’s intelligence or user-friendliness. In the following, we present two commonly used strategies for subjective evaluation.
主观评估基于人类判断来衡量智能体能力 [20,22,29,79,158]。该方法适用于缺乏评估数据集或难以设计量化指标的场景,例如评估智能体的智能水平或用户友好性。下文介绍两种常用的主观评估策略。
Human annotation: This evaluation method involves human evaluators directly scoring or ranking the outputs generated by various agents [22,29,102]. For example, in [20], the authors employ many annotators, and ask them to provide feedback on five key questions that directly associated with the agent capability. Similarly, [159] assess model effectiveness by having human participants rate the models on harmlessness, honesty, helpfulness, engagement, and unbiased ness, subsequently comparing these scores across different models. In [79], annotators are asked to determine whether the specifically designed models can significantly enhance the development of rules within online communities.
人工标注:该评估方法通过人类评估员直接对各类智能体生成的输出进行评分或排序[22,29,102]。例如在[20]中,研究者雇佣大量标注员,要求其针对与智能体能力直接相关的五个核心问题提供反馈。[159]则通过让人类参与者从无害性、诚实性、有用性、参与度和无偏见性五个维度对模型评分,进而比较不同模型的得分差异。[79]要求标注员判断特定设计的模型是否能显著促进网络社区规则的发展。
Turing test: This evaluation strategy necessitates that human evaluators differentiate between outputs produced by agents and those created by humans. If, in a given task, the evaluators cannot separate the agent and human results, it demonstrates that the agent can achieve human-like performance on this task. For instance, researchers in [29] conduct experiments on free-form Partisan text, and the human evaluators are asked to guess whether the responses are from human or LLM-based agent. In [20], the human evaluators are required to identify whether the behaviors are generated from the agents or real-humans. In Emotion Bench [160], human annotations are collected to compare the emotional states expressed by LLM software and human participants across various scenarios. This comparison serves as a benchmark for evaluating the emotional intelligence of the LLM software, illustrating a nuanced approach to understanding agent capabilities in mimicking human-like performance and emotional expression.
图灵测试:该评估策略要求人类评估者区分智能体生成的输出与人类创作的内容。如果在特定任务中评估者无法分辨智能体与人类的结果差异,则表明智能体在该任务上能达到类人水平。例如,[29]的研究人员对自由派文本进行实验,要求人类评估者猜测回答来自人类还是基于大语言模型的智能体。[20]中则要求评估者判断行为是由智能体生成还是真实人类所为。Emotion Bench [160]通过收集人类标注数据,对比大语言模型软件与人类参与者在不同场景中表达的情感状态,这种比较成为评估大语言模型软件情商的基准,展现了理解智能体模仿人类表现与情感表达的精细化方法。
Remark. LLM-based agents are usually designed to serve humans. Thus, subjective agent evaluation plays a critical role, since it reflects human criterion. However, this strategy also faces issues such as high costs, inefficiency, and population bias. To address these issues, a growing number of researchers are investigating the use of LLMs themselves as intermediaries for carrying out these subjective assessments. For example, in ChemCrow [75], researchers assess the experimental results using GPT. They consider both the completion of tasks and the accuracy of the underlying processes. Similarly, ChatEval [161] introduces a novel approach by employing multiple agents to critique and assess the results generated by various candidate models in a structured debate format. This innovative use of LLMs for evaluation purposes holds promise for enhancing both the credibility and applicability of subjective assessments in the future. As LLM technology continues to evolve, it is anticipated that these methods will become increasingly reliable and find broader applications, thereby overcoming the current limitations of direct human evaluation.
备注:基于大语言模型(LLM)的智能体通常被设计为人类服务,因此反映人类标准的主观评估至关重要。然而这种策略也存在成本高、效率低和群体偏见等问题。为应对这些挑战,越来越多研究者开始探索利用大语言模型本身作为执行主观评估的中介工具。例如在ChemCrow [75]中,研究人员使用GPT评估实验结果,同时考量任务完成度和底层流程的准确性。类似地,ChatEval [161]创新性地采用多智能体结构化辩论形式,对候选模型生成结果进行批判性评估。这种利用大语言模型进行评价的创新方法,有望提升未来主观评估的可信度与适用性。随着大语言模型技术的持续发展,预计这些方法将日益可靠并获得更广泛应用,从而克服当前人工直接评估的局限性。
4.2 Objective evaluation
4.2 客观评估
Objective evaluation refers to assessing the capabilities of LLM-based autonomous agents using quantitative metrics that can be computed, compared and tracked over time. In contrast to subjective evaluation, objective metrics aim to provide concrete, measurable insights into the agent performance. For conducting objective evaluation, there are three important aspects, that is, the evaluation metrics, protocols and benchmarks. In the following, we introduce these aspects more in detail.
客观评估是指使用可计算、可比较和可随时间追踪的量化指标来评估基于大语言模型 (LLM) 的自主AI智能体的能力。与主观评估相比,客观指标旨在为AI智能体性能提供具体、可衡量的洞察。进行客观评估时,有三个重要方面,即评估指标、协议和基准测试。接下来,我们将更详细地介绍这些方面。
Metrics: In order to objectively evaluate the effectiveness of the agents, designing proper metrics is significant, which may influence the evaluation accuracy and comprehensiveness. Ideal evaluation metrics should precisely reflect the quality of the agents, and align with the human feelings when using them in real-world scenarios. In existing work, we can conclude the following representative evaluation metrics. (1) Task success metrics: These metrics measure how well an agent can complete tasks and achieve goals. Common metrics include success rate [12,22,57,59], reward/score [22,59,122], coverage [16], and accuracy [18,40,102]. Higher values indicate greater task completion ability. (2) Human similarity metrics: These metrics quantify the degree to which the agent behaviors closely resembles that of humans. Typical examples include trajectory/location accuracy [38,162], dialogue similarities [79,102], and mimicry of human responses [29,102]. Higher similarity suggests better human simulation performance. (3) Efficiency metrics: In contrast to the aforementioned metrics used to evaluate the agent effectiveness, these metrics aim to assess the efficiency of agent. Commonly considered metrics encompass the length of planning [57], the cost associated with development [18], the speed of inference [16,38], and number of clarification dialogues [122].
指标:为了客观评估AI智能体的有效性,设计合适的指标至关重要,这将影响评估的准确性和全面性。理想的评估指标应精确反映智能体质量,并与真实场景中的人类使用感受保持一致。现有工作中可归纳出以下代表性指标:(1) 任务成功率指标:衡量智能体完成任务和实现目标的能力,常用指标包括成功率[12,22,57,59]、奖励/得分[22,59,122]、覆盖率[16]和准确率[18,40,102]。数值越高表明任务完成能力越强。(2) 人类相似度指标:量化智能体行为与人类行为的接近程度,典型指标包括轨迹/位置准确度[38,162]、对话相似度[79,102]和人类响应模仿度[29,102]。相似度越高表明人类模拟性能越好。(3) 效率指标:与上述评估有效性的指标不同,这类指标旨在评估智能体效率,常用指标包含规划长度[57]、开发成本[18]、推理速度[16,38]和澄清对话次数[122]。
Protocols: In addition to the evaluation metrics, another important aspect for objective evaluation is how to leverage these metrics. In the previous work, we can identify the following commonly used evaluation protocols: (1) Realworld simulation: In this method, the agents are evaluated within immersive environments like games and interactive simulators. The agents are required to perform tasks autonomously, and then metrics like task success rate and human similarity are leveraged to evaluate the capability of the agents based on their trajectories and completed objectives [16,22,33,38,59,80,122,162,163,164]. This method is expected to evaluate the agents’ practical capabilities in real-world scenarios. (2) Social evaluation: This method utilizes metrics to assess social intelligence based on the agent interactions in simulated societies. Various approaches have been adopted, such as collaborative tasks to evaluate teamwork skills, debates to analyze argumentative reasoning, and human studies to measure social aptitude [34,98,102,165,166]. These approaches analyze qualities such as coherence, theory of mind, and social IQ to assess agents’ capabilities in areas including cooperation, communication, empathy, and mimicking human social behavior. By subjecting agents to complex interactive settings, social evaluation provides valuable insights into agents’ higher-level social cognition. (3) Multi-task evaluation: In this method, people use a set of diverse tasks from different domains to evaluate the agent, which can effectively measure the agent generalization capability in open-domain environments [29,80,153,163,165,166,167]. (4) Software testing: In this method, researchers evaluate the agents by letting them conduct tasks such as software testing tasks, such as generating test cases, reproducing bugs, debugging code, and interacting with developers and external tools [166,168,169,170]. Then, one can use metrics like test coverage and bug detection rate to measure the effectiveness of LLM-based agents.
协议:
除了评估指标外,客观评估的另一个重要方面是如何利用这些指标。在先前的工作中,我们可以识别以下常用的评估协议:
(1) 真实世界模拟:在这种方法中,AI智能体在游戏和交互式模拟器等沉浸式环境中进行评估。智能体需要自主执行任务,然后利用任务成功率和人类相似性等指标,根据其轨迹和完成的目标来评估其能力 [16,22,33,38,59,80,122,162,163,164]。这种方法旨在评估智能体在现实场景中的实际能力。
(2) 社交评估:这种方法利用指标来评估智能体在模拟社会中的互动所表现出的社交智能。采用了多种方法,例如协作任务评估团队合作能力、辩论分析论证推理,以及人类研究测量社交能力 [34,98,102,165,166]。这些方法分析一致性、心理理论和社交智商等特质,以评估智能体在合作、沟通、共情和模仿人类社交行为等方面的能力。通过将智能体置于复杂的交互环境中,社交评估为智能体的高级社交认知提供了有价值的见解。
(3) 多任务评估:在这种方法中,人们使用来自不同领域的一组多样化任务来评估智能体,可以有效衡量其在开放域环境中的泛化能力 [29,80,153,163,165,166,167]。
(4) 软件测试:在这种方法中,研究人员通过让智能体执行软件测试任务(如生成测试用例、复现错误、调试代码以及与开发者和外部工具交互)来评估其能力 [166,168,169,170]。然后,可以使用测试覆盖率和错误检测率等指标来衡量基于大语言模型的智能体的有效性。
Benchmarks: Given the metrics and protocols, a crucial remaining aspect is the selection of an appropriate benchmark for conducting the evaluation. In the past, people have used various benchmarks in their experiments. For example, many researchers use simulation environments like ALFWorld [59], IGLU [122], and Minecraft [16,33,38] as benchmarks to evaluate the agent capabilities. Tachikuma [164] is a benchmark that leverages TRPG game logs to evaluate LLMs’ ability to understand and infer complex interactions with multiple characters and novel objects. AgentBench [167] provides a comprehensive framework for evaluating LLMs as autonomous agents across diverse environments. It represents the first systematic assessment of LLMs as agents on realworld challenges across diverse domains. SocKET [165] is a comprehensive benchmark for evaluating the social capabilities of LLMs across 58 tasks covering five categories of social information such as humor and sarcasm, emotions and feelings, and credibility. AgentSims [34] is a versatile framework for evaluating LLM-based agents, where one can flexibly design the agent planning, memory and action strategies, and measure the effectiveness of different agent modules in interactive environments. ToolBench [149] is an open-source project that aims to support the development of powerful LLMs with general tool-use capability. It provides an open platform for training, serving, and evaluating LLMs based on tool learning. WebShop [80] develops a benchmark for evaluating LLM-based agents in terms of their capabilities for product search and retrieval. The benchmark is constructed using a collection of 1.18 million real-world items. MobileEnv [163] is an extendable interactive platform which can be used to evaluate the multi-step interaction capabilities of LLM-based agents. WebArena [171] offers a comprehensive website environment that spans multiple domains. Its purpose is to evaluate agents in an end-to-end fashion and determine the accuracy of their completed tasks. GentBench [172] is a benchmark designed to evaluate the agent capabilities, including their reasoning, safety, and efficiency, when utilizing tools to complete complex tasks. RocoBench [89] is a benchmark with six tasks evaluating multi-agent collaboration across diverse scenarios, emphasizing communication and coordination strategies to assess adaptability and generalization in cooperative robotics. Emotion Bench [160] evaluates the emotion appraisal ability of LLMs, i.e., how their feelings change when presented with specific situations. It collects over 400 situations that elicit eight negative emotions and measures the emotional states of LLMs and human subjects using self-report scales. PEB [128] is a benchmark tailored for assessing LLM-based agents in penetration testing scenarios, comprising 13 diverse targets from leading platforms. It offers a structured evaluation across varying difficulty levels, reflecting real-world challenges for agents. ClemBench [173] contains five Dialogue Games to assess LLMs’ ability as a player. E2E [174] is an end-to-end benchmark for testing the accuracy and usefulness of chatbots.
基准测试:在确定指标和协议后,关键环节是选择合适的评估基准。过去研究者采用了多种实验基准,例如ALFWorld [59]、IGLU [122]和Minecraft [16,33,38]等模拟环境常被用于评估智能体能力。Tachikuma [164]通过TRPG游戏日志评估大语言模型对多角色交互及新物体理解的推理能力。AgentBench [167]作为首个跨领域现实挑战的系统性评估框架,为自主智能体提供了多环境测试标准。SocKET [165]是涵盖58项任务的综合基准,针对幽默讽刺、情感体验、可信度等五类社交能力进行评估。AgentSims [34]支持灵活设计智能体的规划、记忆与行动策略,可测量交互环境中不同模块的效能。ToolBench [149]作为开源项目,致力于培养大语言模型的通用工具使用能力,提供工具学习的训练、部署与评估平台。WebShop [80]基于118万真实商品构建了产品搜索检索能力测试基准。MobileEnv [163]作为可扩展交互平台,专门评估智能体的多步骤交互能力。WebArena [171]构建跨领域网站环境,用于端到端任务完成准确率测试。GentBench [172]聚焦工具使用场景,评估智能体在复杂任务中的推理、安全与效率表现。RocoBench [89]通过六项任务测试多智能体协作,重点考察适应性及机器人协同的泛化能力。Emotion Bench [160]收集400余种诱发八类负面情绪的情境,采用自评量表对比大语言模型与人类的情感评估能力。PEB [128]专为渗透测试设计,包含13个主流平台目标,提供分级难度评估体系。ClemBench [173]通过五类对话游戏测试大语言模型的玩家角色表现。E2E [174]是面向聊天机器人准确性与实用性的端到端评估基准。
Remark. Objective evaluation facilitates the quantitative analysis of capabilities in LLM-based agents through a variety of metrics. While current techniques can not perfectly measure all types of agent capabilities, objective evaluation provides essential insights that complement subjective assessment. Continued advancements in benchmarks and methodologies for objective evaluation will enhance the development and understanding of LLM-based autonomous agents further.
备注:客观评估通过多种指标促进对大语言模型(LLM)智能体能力的量化分析。虽然现有技术尚无法完美衡量所有类型的智能体能力,但客观评估提供了补充主观判断的关键洞察。基准测试和方法论的持续进步,将进一步提升基于大语言模型的自主智能体的开发与认知水平。
In the above sections, we introduce both subjective and objective strategies for LLM-based autonomous agents evaluation. The evaluation of the agents play significant roles in this domain. However, both subjective and objective evaluation have their own strengths and weakness. Maybe, in practice, they should be combined to comprehensively evaluate the agents. We summarize the correspondence between the previous work and these evaluation strategies in Table 3.
在前面的章节中,我们介绍了基于大语言模型(LLM)的AI智能体评估的主观和客观策略。智能体评估在该领域扮演着重要角色。然而,主观评估和客观评估各有优缺点。或许在实践中,应该将两者结合以全面评估智能体。我们在表3中总结了先前工作与这些评估策略的对应关系。
5 Related surveys
5 相关综述
With the vigorous development of large language models, a variety of comprehensive surveys have emerged, providing detailed insights into various aspects. [176] extensively introduces the background, main findings, and mainstream technologies of LLMs, encompassing a vast array of existing works. On the other hand, [177] primarily focus on the applications of LLMs in various downstream tasks and the challenges associated with their deployment. Aligning LLMs with human intelligence is an active area of research to address concerns such as biases and illusions. [178] have compiled existing techniques for human alignment, including data collection and model training methodologies. Reasoning is a crucial aspect of intelligence, influencing decisionmaking, problem-solving, and other cognitive abilities. [179] presents the current state of research on LLMs’ reasoning abilities, exploring approaches to improve and evaluate their reasoning skills. [180] propose that language models can be enhanced with reasoning capabilities and the ability to utilize tools, termed Augmented Language Models (ALMs). They conduct a comprehensive review of the latest advancements in ALMs. As the utilization of large-scale models becomes more prevalent, evaluating their performance is increasingly critical. [181] shed light on evaluating LLMs, addressing what to evaluate, where to evaluate, and how to assess their performance in downstream tasks and societal impact. [182] also discusses the capabilities and limitations of LLMs in various downstream tasks. The aforementioned research encompasses various aspects of large models, including training, application, and evaluation. However, prior to this paper, no work has specifically focused on the rapidly emerging and highly promising field of LLM-based Agents. In this study, we have compiled 100 relevant works on LLMbased Agents, covering their construction, applications, and evaluation processes.
随着大语言模型 (Large Language Model) 的蓬勃发展,各类综合性研究相继涌现,从多维度提供了深入洞察。[176] 全面介绍了大语言模型的背景知识、核心发现与主流技术,涵盖了大量现有成果。[177] 则主要聚焦大语言模型在下游任务中的应用及其部署面临的挑战。
为使大语言模型与人类智能对齐,学界正积极研究如何解决偏见与幻觉等问题。[178] 系统梳理了人类对齐的现有技术,包括数据收集与模型训练方法。推理能力作为智能的核心要素,直接影响决策制定、问题解决等认知活动。[179] 阐述了大语言模型推理能力的研究现状,探讨了提升与评估其推理技能的方法。[180] 提出可通过增强推理能力与工具使用能力来升级语言模型,并将其定义为增强型语言模型 (Augmented Language Models, ALMs),同时对ALMs的最新进展进行了全面综述。
随着大模型应用日益广泛,性能评估变得至关重要。[181] 揭示了大语言模型的评估要点,包括评估内容、评估场景以及如何衡量其在下游任务与社会影响中的表现。[182] 也探讨了大语言模型在各下游任务中的能力边界。上述研究涵盖了大模型的训练、应用与评估等维度,但在本文之前,尚未有工作专门聚焦于基于大语言模型的AI智能体 (AI Agent) 这一快速崛起且极具前景的领域。本研究系统整理了100项相关成果,涵盖基于大语言模型的智能体构建、应用及评估全流程。
Table 3 For subjective evaluation, we use ① and ② to represent human annotation and the Turing test, respectively. For objective evaluation, we use ① , ③ , and ④ to represent environment simulation, social evaluation, multi-task evaluation, and software testing, respectively. $\mathbf{\omega}^{\cdot\leftarrow}\not\subset\mathbf{\gamma}^{\cdot\rightarrow}$ indicates that the evaluations are based on benchmarks
| Model | Subjective | Objective | Benchmark | Time |
| WebShop [80] | 一 | ①③ | √ | 07/2022 |
| Social Simulacra [98] | ① | ② | 08/2022 | |
| TE [102] | ② | 08/2022 | ||
| LIBRO [168] | ④ | 一 | 09/2022 | |
| ReAct [59] | ① | √ | 10/2022 | |
| Out of One, Many [29] | ② | ②③ | 02/2023 | |
| DEPS [33] | ① | 02/2023 | ||
| Jalil et al. [169] | ④ | 02/2023 | ||
| Reflexion [12] | ①③ | 一 | 03/2023 | |
| IGLU [122] | 一 | ① | 04/2023 | |
| Generative Agents [20] | ①② | 一 | 一 | 04/2023 |
| ToolBench [149] | ? | 04/2023 | ||
| GITM [16] | 一 | ① | 05/2023 | |
| Two-Failures [162] | ? | 05/2023 | ||
| Voyager [38] | ① | 05/2023 | ||
| SocKET [165] | ②③ | 05/2023 | ||
| MobileEnv [163] | ①③ | 05/2023 | ||
| Clembench [173] | ①③ | 05/2023 | ||
| Dialop [175] | ② | 06/2023 | ||
| Feldt et al. [170] | 一 | ④ | 06/2023 | |
| CO-LLM [22] | ① | ① | 07/2023 | |
| Tachikuma [164] | ① | ① | 07/2023 | |
| WebArena [171] | ① | 07/2023 | ||
| RocoBench [89] | 一 | ①②③ | 07/2023 | |
| AgentSims [34] | ② | 一 | 08/2023 | |
| AgentBench [167] | ? | 08/2023 | ||
| BOLAA [166] | 一 | ①③④ | 08/2023 | |
| Gentopia [172] | ? | 08/2023 | ||
| EmotionBench [160] | ① | 08/2023 | ||
| PTB [128] | 一 | ④ | 二 | 08/2023 |
表 3: 主观评估使用①和②分别表示人工标注和图灵测试,客观评估使用①、②、③、④分别表示环境模拟、社会评估、多任务评估和软件测试。$\mathbf{\omega}^{\cdot\leftarrow}\not\subset\mathbf{\gamma}^{\cdot\rightarrow}$表示评估基于基准测试。
| 模型 | 主观 | 客观 | 基准 | 时间 |
|---|---|---|---|---|
| WebShop [80] | 一 | ①③ | √ | 07/2022 |
| Social Simulacra [98] | ① | ② | 08/2022 | |
| TE [102] | ② | 08/2022 | ||
| LIBRO [168] | ④ | 一 | 09/2022 | |
| ReAct [59] | ① | √ | 10/2022 | |
| Out of One, Many [29] | ② | ②③ | 02/2023 | |
| DEPS [33] | ① | 02/2023 | ||
| Jalil et al. [169] | ④ | 02/2023 | ||
| Reflexion [12] | ①③ | 一 | 03/2023 | |
| IGLU [122] | 一 | ① | 04/2023 | |
| Generative Agents [20] | ①② | 一 | 一 | 04/2023 |
| ToolBench [149] | ? | 04/2023 | ||
| GITM [16] | 一 | ① | 05/2023 | |
| Two-Failures [162] | ? | 05/2023 | ||
| Voyager [38] | ① | 05/2023 | ||
| SocKET [165] | ②③ | 05/2023 | ||
| MobileEnv [163] | ①③ | 05/2023 | ||
| Clembench [173] | ①③ | 05/2023 | ||
| Dialop [175] | ② | 06/2023 | ||
| Feldt et al. [170] | 一 | ④ | 06/2023 | |
| CO-LLM [22] | ① | ① | 07/2023 | |
| Tachikuma [164] | ① | ① | 07/2023 | |
| WebArena [171] | ① | 07/2023 | ||
| RocoBench [89] | 一 | ①②③ | 07/2023 | |
| AgentSims [34] | ② | 一 | 08/2023 | |
| AgentBench [167] | ? | 08/2023 | ||
| BOLAA [166] | 一 | ①③④ | 08/2023 | |
| Gentopia [172] | ? | 08/2023 | ||
| EmotionBench [160] | ① | 08/2023 | ||
| PTB [128] | 一 | ④ | 二 | 08/2023 |
6 Challenges
6 挑战
While previous work on LLM-based autonomous agent has obtained many remarkable successes, this field is still at its initial stage, and there are several significant challenges that need to be addressed in its development. In the following, we present many representative challenges.
虽然基于大语言模型的AI智能体研究已取得诸多显著成果,该领域仍处于起步阶段,其发展过程中仍需应对若干重大挑战。下文我们将列举多项具有代表性的挑战。
6.1 Role-playing capability
6.1 角色扮演能力
Different from traditional LLMs, autonomous agent usually has to play as specific roles (e.g., program coder, researcher, and chemist) for accomplishing different tasks. Thus, the capability of the agent for role-playing is very important. Although LLMs can effectively simulate many common roles such as movie reviewers, there are still various roles and aspects that they struggle to capture accurately. To begin with, LLMs are usually trained based on web-corpus, thus for the roles which are seldom discussed on the Web or the newly emerging roles, LLMs may not simulate them well. In addition, previous research [30] has shown that existing LLMs may not well model the human cognitive psychology characters, leading to the lack of self-awareness in conversation scenarios. Potential solution to these problems may include fine-tuning LLMs or carefully designing the agent prompts/architectures [183]. For example, one can firstly collect real-human data for uncommon roles or psychology characters, and then leverage it to fine-tune LLMs. However, how to ensure that fine-tuned model still perform well for the common roles may pose further challenges. Beyond fine-tuning, one can also design tailored agent prompts/architectures to enhance the capability of LLM on role-playing. However, finding the optimal prompts/ architectures is not easy, since their designing spaces are too large.
与传统大语言模型不同,自主AI智能体通常需要扮演特定角色(如程序员、研究员、化学家)来完成不同任务。因此,智能体的角色扮演能力至关重要。尽管大语言模型能有效模拟影评人等常见角色,但在许多角色和维度上仍难以准确刻画。首先,大语言模型通常基于网络语料训练,对于网络上鲜少讨论或新出现的角色,其模拟效果可能不佳。此外,已有研究[30]表明现有大语言模型可能无法很好建模人类认知心理特征,导致对话场景中缺乏自我意识。潜在解决方案包括微调大语言模型或精心设计智能体提示/架构[183]。例如,可以先收集罕见角色或心理特征的真实人类数据,然后利用这些数据微调模型。但如何确保微调后的模型在常见角色上仍保持良好表现,可能带来新的挑战。除微调外,也可通过定制化设计智能体提示/架构来增强大语言模型的角色扮演能力。然而,由于设计空间过大,寻找最优提示/架构并非易事。
6.2 Generalized human alignment
6.2 广义人类对齐
Human alignment has been discussed a lot for traditional LLMs. In the field of LLM-based autonomous agent, especially when the agents are leveraged for simulation, we believe this concept should be discussed more in depth. In order to better serve human-beings, traditional LLMs are usually fine-tuned to be aligned with correct human values, for example, the agent should not plan to make a bomb for avenging society. However, when the agents are leveraged for real-world simulation, an ideal simulator should be able to honestly depict diverse human traits, including the ones with incorrect values. Actually, simulating the human negative aspects can be even more important, since an important goal of simulation is to discover and solve problems, and without negative aspects means no problem to be solved. For example, to simulate the real-world society, we may have to allow the agent to plan for making a bomb, and observe how it will act to implement the plan as well as the influence of its behaviors. Based on these observations, people can make better actions to stop similar behaviors in real-world society. Inspired by the above case, maybe an important problem for agent-based simulation is how to conduct generalized human alignment, that is, for different purposes and applications, the agent should be able to align with diverse human values. However, existing powerful LLMs including ChatGPT and GPT-4 are mostly aligned with unified human values. Thus, an interesting direction is how to “realign” these models by designing proper prompting strategies.
人类对齐 (Human alignment) 在传统大语言模型中已被广泛讨论。在基于大语言模型的自主AI智能体领域,尤其是当智能体被用于模拟时,我们认为这一概念需要更深入的探讨。为了更好地服务人类,传统大语言模型通常会被微调以符合正确的人类价值观,例如智能体不应策划制造炸弹来报复社会。然而,当智能体被用于现实世界模拟时,理想的模拟器应当能够真实刻画多样化的人类特质,包括那些具有错误价值观的行为。实际上,模拟人类的负面特质可能更为重要,因为模拟的重要目标是发现问题并解决问题,而缺乏负面特质意味着没有问题需要解决。例如,在模拟现实社会时,我们可能需要允许智能体策划制造炸弹,并观察其如何实施计划以及其行为产生的影响。基于这些观察,人们可以采取更好的行动来阻止现实社会中类似行为的发生。受上述案例启发,基于智能体的模拟可能需要解决一个关键问题:如何实现广义的人类对齐——即针对不同目的和应用场景,智能体应当能够适配多样化的人类价值观。然而,包括ChatGPT和GPT-4在内的现有强大模型大多遵循统一的人类价值观。因此,一个有趣的研究方向是如何通过设计合适的提示策略来对这些模型进行"再对齐"。
6.3 Prompt robustness
6.3 提示词鲁棒性
To ensure rational behavior in agents, it’s a common practice for designers to embed supplementary modules, such as memory and planning modules, into LLMs. However, the inclusion of these modules necessitates the development of more complex prompts in order to facilitate consistent operation and effective communication. Previous research [184,185] has highlighted the lack of robustness in prompts for LLMs, as even minor alterations can yield substantially different outcomes. This issue becomes more pronounced when constructing autonomous agents, as they encompass not a single prompt but a prompt framework that considers all modules, wherein the prompt for one module has the potential to influence others. Moreover, the prompt frameworks can vary significantly across different LLMs. The development of a unified and resilient prompt framework applicable across diverse LLMs remains a critical and unresolved challenge. There are two potential solutions to the aforementioned problems: (1) manually crafting the essential prompt elements through trial and error, or (2) automatically generating prompts using GPT.
为确保AI智能体行为合理,设计者通常会在LLM中嵌入额外模块(如记忆和规划模块)。然而,这些模块的引入需要开发更复杂的提示词(prompt)以实现稳定运行和有效沟通。先前研究[184,185]指出,大语言模型的提示词缺乏鲁棒性,即使细微改动也可能导致结果显著差异。该问题在构建自主智能体时更为突出,因其涉及的不是单一提示词,而是需统筹所有模块的提示框架——其中某个模块的提示词可能影响其他模块。此外,不同LLM间的提示框架可能存在显著差异。开发适用于各类大语言模型的统一且稳健的提示框架,仍是亟待解决的关键挑战。现有两种潜在解决方案:(1) 通过试错手动构建核心提示要素;(2) 利用GPT自动生成提示词。
6.4 Hallucination
6.4 幻觉
Hallucination poses a fundamental challenge for LLMs, characterized by the models’ tendency to produce false information with a high level of confidence. This challenge is not limited to LLMs alone but is also a significant concern in the domain of autonomous agents. For instance, in [186], it was observed that when confronted with simplistic instructions during code generation tasks, the agent may exhibit hallucinatory behavior. Hallucination can lead to serious consequences such as incorrect or misleading code, security risks, and ethical issues [186]. To mitigate this issue, incorporating human correction feedback directly into the iterative process of human-agent interaction presents a viable approach [23]. More discussions on the hallucination problem can be seen in [176].
幻觉 (Hallucination) 是大语言模型面临的根本性挑战,表现为模型倾向于高度自信地生成虚假信息。这一挑战不仅限于大语言模型,在自主AI智能体领域也备受关注。例如,[186] 研究发现,在代码生成任务中遇到简单指令时,智能体可能出现幻觉行为。幻觉可能导致严重后果,包括错误或误导性代码、安全隐患及伦理问题 [186]。将人工修正反馈直接纳入人机交互的迭代过程是缓解该问题的可行方案 [23]。更多关于幻觉问题的讨论可参阅 [176]。
6.5 Knowledge boundary
6.5 知识边界
A pivotal application of LLM-based autonomous agents lies in simulating diverse real-world human behaviors [20]. The study of human simulation has a long history, and the recent surge in interest can be attributed to the remarkable advancements made by LLMs, which have demonstrated significant capabilities in simulating human behavior. However, it is important to recognize that the power of LLMs may not always be advantageous. Specifically, an ideal simulation should accurately replicate human knowledge. In this context, LLMs may display overwhelming capabilities, being trained on a vast corpus of Web knowledge that far exceeds what an average individual might know. The immense capabilities of LLMs can significantly impact the effectiveness of simulations. For instance, when attempting to simulate user selection behaviors for various movies, it is crucial to ensure that LLMs assume a position of having no prior knowledge of these movies. However, there is a possibility that LLMs have already acquired information about these movies. Without implementing appropriate strategies, LLMs may make decisions based on their extensive knowledge, even though real-world users would not have access to the contents of these movies beforehand. Based on the above example, we may conclude that for building believable agent simulation environment, an important problem is how to constrain the utilization of user-unknown knowledge of LLM.
基于大语言模型的自主智能体关键应用在于模拟多样化的现实人类行为 [20]。人类行为模拟研究由来已久,近期关注度激增可归因于大语言模型取得的显著进展,这些模型在模拟人类行为方面展现出卓越能力。但必须认识到,大语言模型的能力并非总是优势。具体而言,理想的模拟应当精确复现人类认知水平。在此背景下,大语言模型可能表现出压倒性能力——其训练数据涵盖的网络知识量远超普通个体的认知范围。大语言模型的强大能力会显著影响模拟效果。例如在模拟用户对不同电影的选择行为时,必须确保模型处于对这些电影毫无先验知识的状态。然而实际情况可能是模型已掌握相关电影信息。若未采取适当策略,大语言模型可能基于其庞杂知识库做出决策,而现实用户本不可能提前知晓这些电影内容。通过上述案例可知,构建可信的智能体模拟环境时,核心问题在于如何约束模型使用用户未知知识。
6.6 Efficiency
6.6 效率
Due to their auto regressive architecture, LLMs typically have slow inference speeds. However, the agent may need to query LLMs for each action multiple times, such as extracting information from memory, make plans before taking actions and so on. Consequently, the efficiency of agent actions is greatly affected by the speed of LLM inference.
由于其自回归架构,大语言模型(LLM)通常推理速度较慢。然而,AI智能体可能需要对每个动作多次查询大语言模型,例如从记忆中提取信息、在采取行动前制定计划等。因此,智能体动作的效率很大程度上受大语言模型推理速度的影响。
7 Conclusion
7 结论
In this survey, we systematically summarize existing research in the field of LLM-based autonomous agents. We present and review these studies from three aspects including the construction, application, and evaluation of the agents. For each of these aspects, we provide a detailed taxonomy to draw connections among the existing research, summarizing the major techniques and their development histories. In addition to reviewing the previous work, we also propose several challenges in this field, which are expected to guide potential future directions.
在本综述中,我们系统性地总结了基于大语言模型(LLM)的AI智能体领域现有研究。我们从智能体的构建、应用和评估三个维度对这些研究进行了梳理与评述。针对每个维度,我们提供了详细的分类框架以建立现有研究间的关联,总结了主要技术及其发展历程。除回顾前人工作外,我们还提出了该领域面临的若干挑战,这些发现有望为未来潜在研究方向提供指引。
Acknowledgements This work was supported in part by the National Natural Science Foundation of China (Grant No. 62102420), the Beijing Outstanding Young Scientist Program (No. BJ J W ZY J H 012019100020098), Intelligent Social Governance Platform, Major Innovation & Planning Interdisciplinary Platform for the “Double-First Class” Initiative, Renmin University of China, Public Computing Cloud, Renmin University of China, fund for building world-class universities (disciplines) of Renmin University of China, Intelligent Social Governance Platform.
致谢
本研究部分得到以下项目资助:国家自然科学基金 (Grant No. 62102420) 、北京市杰出青年科学家计划 (No. BJ J W ZY J H 012019100020098) 、中国人民大学"双一流"学科交叉重大创新规划平台智能社会治理平台、中国人民大学公共计算云、中国人民大学世界一流大学 (学科) 建设基金、智能社会治理平台。
Competing interests The authors declare that they have no competing interests or financial conflicts to disclose.
利益冲突 作者声明不存在需要披露的利益冲突或财务纠纷。
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.
开放获取 本文遵循知识共享署名4.0国际许可协议 (Creative Commons Attribution 4.0 International License) ,允许以任何媒介或格式使用、共享、改编、分发和复制,但须注明原作者及来源、提供知识共享许可协议链接并标明是否作出修改。
The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit creative commons.org/licenses/by/4.0/.
本文中的图片或其他第三方材料均包含在文章的创作共用许可中,除非在材料署名行中另有说明。如果材料未包含在文章的创作共用许可中,且您的预期用途未被法定法规允许或超出许可范围,您需要直接获取版权持有者的授权。要查看该许可的副本,请访问creativecommons.org/licenses/by/4.0/。
References
参考文献
Lei Wang is a PhD candidate at Renmin University of China, China. His research focuses on recommend er systems and agent-based large language models.
王磊是中国人民大学的博士研究生,主要研究方向为推荐系统和基于智能体的大语言模型。


Chen Ma is currently pursuing a Master’s degree at Renmin University of China, China. His research interests include recommend er system, agent based on large language model.
陈马目前在中国人民大学攻读硕士学位。他的研究方向包括推荐系统、基于大语言模型的AI智能体。

Jiakai Tang is currently pursuing a Master’s degree at Renmin University of China, China. His research interests include recommend er system.
Jiakai Tang目前在中国人民大学攻读硕士学位,他的研究方向包括推荐系统。

Xueyang Feng is currently studying for a PhD degree at Renmin University of China, China. His research interests include recommend er system, agent based on large language model.
薛勇峰目前在中国人民大学攻读博士学位,研究方向包括推荐系统、基于大语言模型的AI智能体。

Xu Chen obtained his PhD degree from Tsinghua University, China. Before joining Renmin University of China, he was a postdoc researcher at University College London, UK. In the period from March to September of 2017, he was studying at Georgia Institute of Technology, USA as a visiting scholar. His research mainly focuses
徐晨在中国清华大学获得博士学位。在加入中国人民大学之前,他是英国伦敦大学学院的博士后研究员。2017年3月至9月期间,他曾作为访问学者在美国佐治亚理工学院学习。他的研究主要聚焦于

Zeyu Zhang is currently pursuing a Master’s degree at Renmin University of China, China. His research interests include recommend er system, causal inference, agent based on large language model.
张泽宇目前在中国人民大学攻读硕士学位,研究方向包括推荐系统、因果推理以及基于大语言模型的AI智能体。
on the recommend er system, reinforcement learning, and causal inference.
推荐系统、强化学习和因果推断。
Hao Yang is currently studying for a PhD degree at Renmin University of China, China. His research interests include recommend er system, causal inference.
郝阳目前在中国人民大学攻读博士学位,主要研究方向包括推荐系统 (recommender system) 和因果推断 (causal inference)。

Yankai Lin received his BE and PhD degrees from Tsinghua University, China in 2014 and 2019, respectively. After that, he worked as a senior researcher in Tencent WeChat, and joined Renmin University of China, China in 2022 as a tenuretrack assistant professor. His main research interests are pretrained models and natural
林恺毅于2014年和2019年分别在中国清华大学获得学士和博士学位。此后,他曾在腾讯微信担任高级研究员,并于2022年加入中国人民大学担任终身轨助理教授。他的主要研究方向是预训练模型和自然

language processing.
语言处理。

Wayne Xin Zhao received his PhD degree in Computer Science from Peking University, China in 2014. His research interests include data mining, natural language processing and information retrieval in general. The main goal is to study how to organize, analyze and mine user generated data for improving the service of real
赵鑫(Wayne Xin Zhao)于2014年获得北京大学计算机科学博士学位,主要研究方向包括数据挖掘、自然语言处理及信息检索,核心目标是研究如何组织、分析和挖掘用户生成数据以提升实际服务效能。
Jingsen Zhang is currently studying for a PhD degree at Renmin University of China, China. His research interests include recommend er system.
张靖森目前在中国人民大学攻读博士学位,研究方向包括推荐系统。

world applications.
实际应用。

Zhiyuan Chen is pursuing his PhD in Gaoling school of Artificial Intelligence, Renmin University of China, China. His research mainly focuses on language model reasoning and agent based on large language model.
陈志远正在中国人民大学高瓴人工智能学院攻读博士学位,主要研究方向为大语言模型 (Large Language Model) 推理及基于大语言模型的AI智能体 (AI Agent)。

Zhewei Wei received his PhD degree in Computer Science and Engineering from The Hong Kong University of Science and Technology, China. He did postdoctoral research in Aarhus University, Denmark from 2012 to 2014, and joined Renmin University of China, China in 2014.
韦泽伟在香港科技大学获得计算机科学与工程博士学位,2012至2014年在丹麦奥胡斯大学从事博士后研究,2014年加入中国人民大学。

Jirong Wen is a full professor, the executive dean of Gaoling School of Artificial Intelligence, and the dean of School of Information at Renmin University of China, China. He has been working in the big data and AI areas for many years, and publishing extensively on prestigious international conferences and journals.
温日荣是中国中国人民大学高瓴人工智能学院执行院长、信息学院院长,全职教授。他长期从事大数据与人工智能领域研究,并在国际顶级会议和期刊上发表大量论文。