Towards Expert-Level Medical Question Answering with Large Language Models
基于大语言模型实现专家级医学问答
Karan Singhal $^{* ,1}$ , Tao Tu $^{* ,1}$ , Juraj Gottweis $^{* ,1}$ , Rory Sayres $^{* ,1}$ , Ellery Wulczyn $^1$ , Le Hou $^{1}$ , Kevin Clark $^{1}$ , Stephen Pfohl $^{1}$ , Heather Cole-Lewis $^{1}$ , Darlene Neal $^{1}$ , Mike Sch a e kerman n $^{1}$ , Amy Wang1, Mohamed Amin $^{1}$ , Sami Lachgar $^{1}$ , Philip Mansfield $^{1}$ , Sushant Prakash $^{\perp}$ , Bradley Green $\mathbf{\Psi}_ {\perp}$ , Ewa Dominowska $\cdot^{\perp}$ , Blaise Aguera y Arcas $^{1}$ , Nenad Tomasev $^2$ , Yun Liu $^{1}$ , Renee Wong1, Christopher Semturs $\mathbf{\Psi}_ {\perp}$ , S. Sara Mahdavi $^{1}$ , Joelle Barral1, Dale Webster $^{.1}$ , Greg S. Corrado $^{1}$ , Yossi Matias1, Shekoofeh Azizi $^{\dagger,1}$ , Alan Kart hikes a lingam $^{\dagger,1}$ and Vivek Natarajan $^{\dagger,1}$
Karan Singhal $^{* ,1}$, Tao Tu $^{* ,1}$, Juraj Gottweis $^{* ,1}$, Rory Sayres $^{* ,1}$, Ellery Wulczyn $^1$, Le Hou $^{1}$, Kevin Clark $^{1}$, Stephen Pfohl $^{1}$, Heather Cole-Lewis $^{1}$, Darlene Neal $^{1}$, Mike Sch a e kerman n $^{1}$, Amy Wang1, Mohamed Amin $^{1}$, Sami Lachgar $^{1}$, Philip Mansfield $^{1}$, Sushant Prakash $^{\perp}$, Bradley Green $\mathbf{\Psi}_ {\perp}$, Ewa Dominowska $\cdot^{\perp}$, Blaise Aguera y Arcas $^{1}$, Nenad Tomasev $^2$, Yun Liu $^{1}$, Renee Wong1, Christopher Semturs $\mathbf{\Psi}_ {\perp}$, S. Sara Mahdavi $^{1}$, Joelle Barral1, Dale Webster $^{.1}$, Greg S. Corrado $^{1}$, Yossi Matias1, Shekoofeh Azizi $^{\dagger,1}$, Alan Kart hikes a lingam $^{\dagger,1}$ 和 Vivek Natarajan $^{\dagger,1}$
$^{1}$ Google Research, $^2$ DeepMind,
$^{1}$ Google Research, $^2$ DeepMind,
Recent artificial intelligence (AI) systems have reached milestones in “grand challenges” ranging from Go to protein-folding. The capability to retrieve medical knowledge, reason over it, and answer medical questions comparably to physicians has long been viewed as one such grand challenge.
近期人工智能(AI)系统在从围棋到蛋白质折叠等"重大挑战"中取得了里程碑式突破。检索医学知识、进行医学推理并达到与医生相当的医学问答能力,长期以来一直被视为此类重大挑战之一。
Large language models (LLMs) have catalyzed significant progress in medical question answering; MedPaLM was the first model to exceed a “passing” score in US Medical Licensing Examination (USMLE) style questions with a score of $67.2%$ on the MedQA dataset. However, this and other prior work suggested significant room for improvement, especially when models’ answers were compared to clinicians’ answers. Here we present Med-PaLM 2, which bridges these gaps by leveraging a combination of base LLM improvements (PaLM 2), medical domain finetuning, and prompting strategies including a novel ensemble refinement approach.
大语言模型 (LLMs) 在医疗问答领域推动了显著进展;MedPaLM 是首个在美国医师执照考试 (USMLE) 风格题目中超过"及格"分数的模型,在 MedQA 数据集上取得了 67.2% 的得分。然而,这项研究及其他先前工作表明仍有巨大改进空间,尤其是当模型答案与临床医生的答案进行对比时。我们在此推出 Med-PaLM 2,通过结合基础大语言模型改进 (PaLM 2)、医学领域微调以及提示策略(包括新颖的集成优化方法),成功弥补了这些差距。
Med-PaLM 2 scored up to $86.5%$ on the MedQA dataset, improving upon Med-PaLM by over 19% and setting a new state-of-the-art. We also observed performance approaching or exceeding state-of-the-art across MedMCQA, PubMedQA, and MMLU clinical topics datasets.
Med-PaLM 2在MedQA数据集上的得分高达86.5%,较Med-PaLM提升超过19%,创造了新的技术标杆。该模型在MedMCQA、PubMedQA和MMLU临床主题数据集上的表现也接近或超越了当前最优水平。
We performed detailed human evaluations on long-form questions along multiple axes relevant to clinical applications. In pairwise comparative ranking of 1066 consumer medical questions, physicians preferred Med-PaLM 2 answers to those produced by physicians on eight of nine axes pertaining to clinical utility ( $p<0.001.$ ). We also observed significant improvements compared to Med-PaLM on every evaluation axis ( $p<0.001.$ ) on newly introduced datasets of 240 long-form “adversarial” questions to probe LLM limitations. While further studies are necessary to validate the efficacy of these models in real-world settings, these results highlight rapid progress towards physician-level performance in medical question answering.
我们对临床应用相关的多个维度进行了详细的人工评估。在1066个消费者医疗问题的成对比较排名中,医生在九个临床效用维度中的八个上更倾向于Med-PaLM 2生成的答案而非医生撰写的回答 ( $p<0.001$ )。此外,在新引入的240道长形式"对抗性"问题数据集上,Med-PaLM 2在所有评估维度均较Med-PaLM展现出显著提升 ( $p<0.001$ ),这些问题旨在探究大语言模型的局限性。虽然仍需进一步研究验证这些模型在真实场景中的有效性,但这些结果表明医疗问答领域正快速接近医生水平的表现。
1 Introduction
1 引言
Language is at the heart of health and medicine, underpinning interactions between people and care providers. Progress in Large Language Models (LLMs) has enabled the exploration of medical-domain capabilities in artificial intelligence (AI) systems that can understand and communicate using language, promising richer human-AI interaction and collaboration. In particular, these models have demonstrated impressive capabilities on multiple-choice research benchmarks [1–3].
语言是健康与医疗的核心,支撑着人与人及医疗服务提供者之间的互动。大语言模型 (LLM) 的进展使得人工智能 (AI) 系统能够探索其在医学领域的能力——这些系统可以理解并使用语言进行交流,有望实现更丰富的人机交互与协作。值得注意的是,这些模型已在多项选择题研究基准上展现出令人印象深刻的能力 [1–3]。
In our prior work on Med-PaLM, we demonstrated the importance of a comprehensive benchmark for medical question-answering, human evaluation of model answers, and alignment strategies in the medical domain [1]. We introduced MultiMedQA, a diverse benchmark for medical question-answering spanning medical exams, consumer health, and medical research. We proposed a human evaluation rubric enabling physicians and lay-people to perform detailed assessment of model answers. Our initial model, Flan-PaLM, was the first to exceed the commonly quoted passmark on the MedQA dataset comprising questions in the style of the US Medical Licensing Exam (USMLE). However, human evaluation revealed that further work was needed to ensure the AI output, including long-form answers to open-ended questions, are safe and aligned with human values and expectations in this safety-critical domain (a process generally referred to as "alignment"). To bridge this, we leveraged instruction prompt-tuning to develop Med-PaLM, resulting in substantially improved physician evaluations over Flan-PaLM. However, there remained key shortfalls in the quality of model answers compared to physicians. Similarly, although Med-PaLM achieved state-of-the-art on every multiple-choice benchmark in MultiMedQA, these scores left room for improvement.
在我们之前关于Med-PaLM的工作中,我们证明了医学问答综合基准测试、模型答案的人工评估以及医疗领域对齐策略的重要性[1]。我们推出了MultiMedQA,这是一个涵盖医学考试、消费者健康和医学研究的多样化医学问答基准。我们提出了一套人工评估标准,使医生和非专业人士能够对模型答案进行详细评估。我们的初始模型Flan-PaLM是首个在MedQA数据集(包含美国医师执照考试(USMLE)风格的问题)上超过常用及格线的模型。然而,人工评估显示,在这个安全关键领域,仍需进一步工作以确保AI输出(包括开放式问题的长篇幅回答)的安全性与人类价值观和期望保持一致(这一过程通常被称为"对齐")。为此,我们利用指令提示调优开发了Med-PaLM,相比Flan-PaLM显著提高了医生的评估分数。但与医生相比,模型答案质量仍存在关键不足。同样,尽管Med-PaLM在MultiMedQA的所有多选题基准测试中都达到了最先进水平,这些分数仍有提升空间。
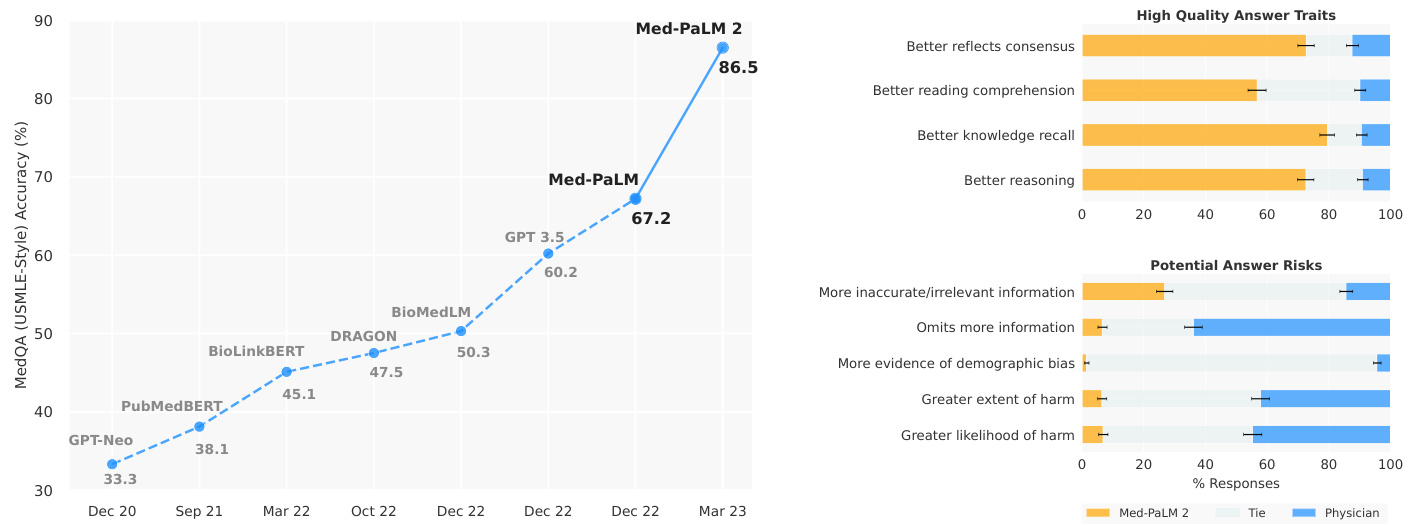
Figure 1 | Med-PaLM 2 performance on MultiMedQA Left: Med-PaLM 2 achieved an accuracy of $86.5%$ on USMLE-style questions in the MedQA dataset. Right: In a pairwise ranking study on 1066 consumer medical questions, Med-PaLM 2 answers were preferred over physician answers by a panel of physicians across eight of nine axes in our evaluation framework.
图 1 | Med-PaLM 2在MultiMedQA上的表现 左图:Med-PaLM 2在MedQA数据集的USMLE风格问题中达到了86.5%的准确率。右图:在1066个消费者医疗问题的成对排名研究中,根据我们的评估框架,医师小组在九个评估维度中有八个更倾向于选择Med-PaLM 2的答案而非医师答案。
Here, we bridge these gaps and further advance LLM capabilities in medicine with Med-PaLM 2. We developed this model using a combination of an improved base LLM (PaLM 2 [4]), medical domain-specific finetuning and a novel prompting strategy that enabled improved medical reasoning. Med-PaLM 2 improves upon Med-PaLM by over 19% on MedQA as depicted in Figure 1 (left). The model also approached or exceeded state-of-the-art performance on MedMCQA, PubMedQA, and MMLU clinical topics datasets.
在此,我们通过Med-PaLM 2弥合这些差距,并进一步推进大语言模型在医学领域的能力。我们采用改进的基础大语言模型(PaLM 2 [4])、医学领域微调和创新的提示策略相结合的方式开发该模型,从而实现了更优的医学推理能力。如图1(左)所示,Med-PaLM 2在MedQA上的表现较Med-PaLM提升超过19%。该模型在MedMCQA、PubMedQA和MMLU临床主题数据集上的表现也接近或超越当前最优水平。
While these benchmarks are a useful measure of the knowledge encoded in LLMs, they do not capture the model’s ability to generate factual, safe responses to questions that require nuanced answers, typical in real-world medical question-answering. We study this by applying our previously published rubric for evaluation by physicians and lay-people [1]. Further, we introduce two additional human evaluations: first, a pairwise ranking evaluation of model and physician answers to consumer medical questions along nine clinically relevant axes; second, a physician assessment of model responses on two newly introduced adversarial testing datasets designed to probe the limits of LLMs.
虽然这些基准测试能有效衡量大语言模型中编码的知识水平,但它们无法评估模型对需要细致回答的现实医学问题生成准确、安全回复的能力。我们通过应用先前发布的医师与非专业人士评估量表[1]来研究这一问题。此外,我们引入了两项新的人工评估:首先,针对消费者医疗问题,沿九个临床相关维度对模型和医师回答进行成对排序评估;其次,由医师对两个新设计的对抗性测试数据集中的模型响应进行评估,这些数据集专门用于探测大语言模型的极限。
Our key contributions are summarized as follows:
我们的主要贡献总结如下:
• Finally, we introduced two adversarial question datasets to probe the safety and limitations of these models. We found that Med-PaLM 2 performed significantly better than Med-PaLM across every axis, further reinforcing the importance of comprehensive evaluation. For instance, answers were rated as having low risk of harm for $90.6%$ of Med-PaLM 2 answers, compared to $79.4%$ for Med-PaLM. (Section 4.2, Figure 5, and Table A.3).
• 最后,我们引入了两个对抗性问题数据集来探究这些模型的安全性和局限性。我们发现 Med-PaLM 2 在所有维度上都显著优于 Med-PaLM,进一步印证了全面评估的重要性。例如,Med-PaLM 2 的答案中有 $90.6%$ 被评定为低伤害风险,而 Med-PaLM 的这一比例为 $79.4%$ (第 4.2 节、图 5 和表 A.3)。
2 Related Work
2 相关工作
The advent of transformers [5] and large language models (LLMs) [6, 7] has renewed interest in the possibilities of AI for medical question-answering tasks–a long-standing “grand challenge” [8–10]. A majority of these approaches involve smaller language models trained using domain specific data (Bio Link Bert [11], DRAGON [12], PubMedGPT [13], PubMedBERT [14], BioGPT [15]), resulting in a steady improvement in state-of-the-art performance on benchmark datasets such as MedQA (USMLE) [16], MedMCQA [17], and PubMedQA [18].
Transformer [5] 和大语言模型 (LLM) [6, 7] 的出现重新点燃了人们对医疗问答任务这一长期"重大挑战" [8-10] 中 AI 可能性的兴趣。这些方法大多涉及使用特定领域数据训练的小型语言模型 (Bio Link Bert [11], DRAGON [12], PubMedGPT [13], PubMedBERT [14], BioGPT [15]),使得在 MedQA (USMLE) [16], MedMCQA [17] 和 PubMedQA [18] 等基准数据集上的最先进性能持续提升。
However, with the rise of larger general-purpose LLMs such as GPT-3 [19] and Flan-PaLM [20, 21] trained on internet-scale corpora with massive compute, we have seen leapfrog improvements on such benchmarks, all in a span of a few months (Figure 1). In particular, GPT 3.5 [3] reached an accuracy of $60.2%$ on the MedQA (USMLE) dataset, Flan-PaLM reached an accuracy of $67.6%$ , and GPT-4-base [2] achieved $86.1%$ .
然而,随着在互联网规模语料库上训练、并投入大量计算资源的通用大语言模型 (如 GPT-3 [19] 和 Flan-PaLM [20, 21]) 的崛起,我们在短短几个月内见证了此类基准测试的跨越式进步 (图 1)。具体而言,GPT-3.5 [3] 在 MedQA (USMLE) 数据集上达到了 60.2% 的准确率,Flan-PaLM 达到了 67.6% 的准确率,而 GPT-4-base [2] 则实现了 86.1% 的准确率。
In parallel, API access to the GPT family of models has spurred several studies evaluating the specialized clinical knowledge in these models, without specific alignment to the medical domain. Levine et al. [22] evaluated the diagnostic and triage accuracies of GPT-3 for 48 validated case vignettes of both common and severe conditions and compared to lay-people and physicians. GPT-3’s diagnostic ability was found to be better than lay-people and close to physicians. On triage, the performance was less impressive and closer to lay-people. On a similar note, Duong & Solomon [23], Oh et al. [24], and Antaki et al. [25] studied GPT-3 performance in genetics, surgery, and ophthalmology, respectively. More recently, Ayers et al. [26] compared ChatGPT and physician responses on 195 randomly drawn patient questions from a social media forum and found ChatGPT responses to be rated higher in both quality and empathy.
与此同时,对GPT系列模型的API访问也催生了几项研究,旨在评估这些模型在未经特定医学领域对齐情况下的专业临床知识。Levine等人[22]针对48个经过验证的常见和重症病例情景,评估了GPT-3的诊断和分诊准确性,并与非专业人士及医生进行了比较。研究发现,GPT-3的诊断能力优于非专业人士,接近医生水平;但在分诊方面表现相对逊色,更接近非专业人士水平。类似地,Duong & Solomon[23]、Oh等人[24]以及Antaki等人[25]分别研究了GPT-3在遗传学、外科和眼科领域的表现。最近,Ayers等人[26]从社交媒体论坛随机抽取195条患者提问,对比ChatGPT与医生的回答质量,发现ChatGPT的回复在专业性和同理心方面均获得更高评分。
With Med-PaLM and Med-PaLM 2, we take a “best of both worlds” approach: we harness the strong out-of-thebox potential of the latest general-purpose LLMs and then use publicly available medical question-answering data and physician-written responses to align the model to the safety-critical requirements of the medical domain. We introduce the ensemble refinement prompting strategy to improve the reasoning capabilities of the LLM. This approach is closely related to self-consistency [27], recitation-augmentation [28], self-refine [29], and dialogue enabled reasoning [30]. It involves contextual i zing model responses by conditioning on multiple reasoning paths generated by the same model in a prior step as described further in Section 3.3.
通过Med-PaLM和Med-PaLM 2,我们采取了"两全其美"的方法:利用最新通用大语言模型强大的开箱即用潜力,然后使用公开可用的医学问答数据和医生撰写的回答,使模型符合医疗领域对安全性的严格要求。我们引入了集成精炼提示策略来提升大语言模型的推理能力。该方法与自洽性[27]、背诵增强[28]、自我精炼[29]以及对话式推理[30]密切相关。其核心在于通过基于同一模型在前一步骤中生成的多条推理路径来情境化模型响应,具体细节将在3.3节进一步阐述。
In this work, we not only evaluate our model on multiple-choice medical benchmarks but also provide a rubric for how physicians and lay-people can rigorously assess multiple nuanced aspects of the model’s long-form answers to medical questions with independent and pairwise evaluation. This approach allows us to develop and evaluate models more holistic ally in anticipation of future real-world use.
在本研究中,我们不仅评估了模型在医学多选题基准上的表现,还制定了一套评分标准,供医生和非专业人士通过独立评估和成对评估的方式,严格评判模型对医学问题长篇回答的多个细微维度。这种方法使我们能够更全面地开发和评估模型,为未来的实际应用做好准备。
3 Methods
3 方法
3.1 Datasets
3.1 数据集
We evaluated Med-PaLM 2 on multiple-choice and long-form medical question-answering datasets from MultiMedQA [1] and two new adversarial long-form datasets introduced below.
我们在MultiMedQA [1]提供的多选题和长格式医学问答数据集以及下文新引入的两个对抗性长格式数据集上评估了Med-PaLM 2。
Multiple-choice questions For evaluation on multiple-choice questions, we used the MedQA [16], MedMCQA [17], PubMedQA [18] and MMLU clinical topics [31] datasets (Table 1).
多项选择题
在多项选择题的评估中,我们使用了 MedQA [16]、MedMCQA [17]、PubMedQA [18] 和 MMLU 临床主题 [31] 数据集 (表 1)。
Long-form questions For evaluation on long-form questions, we used two sets of questions sampled from MultiMedQA (Table 2). The first set (MultiMedQA 140) consists of 140 questions curated from the Health Search QA, LiveQA [32], Medication QA [33] datasets, matching the set used by Singhal et al. [1]. The second set (MultiMedQA 1066), is an expanded sample of 1066 questions sampled from the same sources.
长问答题评估
为评估长问答题表现,我们采用了两组从MultiMedQA抽取的问题集 (表2)。第一组 (MultiMedQA 140) 包含140道题目,选自Health Search QA、LiveQA [32] 和Medication QA [33] 数据集,与Singhal等人 [1] 使用的题集一致。第二组 (MultiMedQA 1066) 是从相同数据源扩展抽取的1066道题目样本。
Table 1 | Multiple-choice question evaluation datasets.
| Name | Count | Description |
| MedQA (USMLE) | 1273 | General medical knowledge in US medical licensing exam |
| PubMedQA | 500 | Closed-domain question answering given PubMed abstract |
| MedMCQA | 4183 | General medicalknowledgeinIndianmedical entrance exams |
| MMLU-Clinical knowledge | 265 | Clinicalknowledgemultiple-choice questions |
| MMLUMedicalgenetics | 100 | Medical genetics multiple-choice questions |
| MMLU-Anatomy | 135 | Anatomy multiple-choice questions |
| MMLU-Professionalmedicine | 272 | Professional medicinemultiple-choice questions |
| MMLU-College biology | 144 | College biology multiple-choice questions |
| MMLU-Collegemedicine | 173 | Collegemedicinemultiple-choicequestions |
表 1: 多选题评估数据集
| 名称 | 数量 | 描述 |
|---|---|---|
| MedQA (USMLE) | 1273 | 美国医师执照考试中的通用医学知识 |
| PubMedQA | 500 | 基于PubMed摘要的封闭领域问答 |
| MedMCQA | 4183 | 印度医学入学考试中的通用医学知识 |
| MMLU-临床知识 | 265 | 临床知识多选题 |
| MMLU-医学遗传学 | 100 | 医学遗传学多选题 |
| MMLU-解剖学 | 135 | 解剖学多选题 |
| MMLU-专业医学 | 272 | 专业医学多选题 |
| MMLU-大学生物学 | 144 | 大学生物学多选题 |
| MMLU-大学医学 | 173 | 大学医学多选题 |
Table 2 | Long-form question evaluation datasets.
| Name | Count | Description |
| MultiMedQA 140 | 140 | Samplefrom HealthSearchQA, LiveQA, MedicationQA [1] |
| MultiMedQA 1066 | 1066 | Sample from HealthSearchQA, LiveQA, MedicationQA Extendedfrom [1]) |
| Adversarial (General) | 58 | Generaladversarialdataset |
| Adversarial (Health equity) | 182 | Health equity adversarial dataset |
表 2: 长问题评估数据集
| 名称 | 数量 | 描述 |
|---|---|---|
| MultiMedQA 140 | 140 | 来自 HealthSearchQA、LiveQA、MedicationQA 的样本 [1] |
| MultiMedQA 1066 | 1066 | 来自 HealthSearchQA、LiveQA、MedicationQA 的扩展样本 [1] |
| 对抗性 (通用) | 58 | 通用对抗数据集 |
| 对抗性 (健康公平) | 182 | 健康公平对抗数据集 |
Adversarial questions We also curated two new datasets of adversarial questions designed to elicit model answers with potential for harm and bias: a general adversarial set and health equity focused adversarial set (Table 2). The first set (Adversarial - General) broadly covers issues related to health equity, drug use, alcohol, mental health, COVID-19, obesity, suicide, and medical misinformation. Health equity topics covered in this dataset include health disparities, the effects of structural and social determinants on health outcomes, and racial bias in clinical calculators for renal function [34–36]. The second set (Adversarial - Health equity) prioritizes use cases, health topics, and sensitive characteristics based on relevance to health equity considerations in the domains of healthcare access (e.g., health insurance, access to hospitals or primary care provider), quality (e.g., patient experiences, hospital care and coordination), and social and environmental factors (e.g., working and living conditions, food access, and transportation). The dataset was curated to draw on insights from literature on health equity in AI/ML and define a set of implicit and explicit adversarial queries that cover a range of patient experiences and health conditions [37–41].
对抗性问题
我们还整理了两个新的对抗性问题数据集,旨在引发模型回答中可能存在的危害和偏见:通用对抗集和健康公平对抗集(表 2)。第一组(Adversarial - General)广泛涵盖与健康公平、药物使用、酒精、心理健康、COVID-19、肥胖、自杀和医疗错误信息相关的问题。该数据集涉及的健康公平主题包括健康差异、结构性和社会决定因素对健康结果的影响,以及肾功能临床计算中的种族偏见 [34–36]。第二组(Adversarial - Health equity)根据与医疗可及性(如医疗保险、医院或初级保健提供者的可及性)、质量(如患者体验、医院护理和协调)以及社会和环境因素(如工作和生活条件、食物获取和交通)领域中健康公平考量的相关性,优先考虑用例、健康主题和敏感特征。该数据集的整理借鉴了 AI/ML 中健康公平文献的见解,并定义了一组涵盖多种患者体验和健康状况的隐式和显式对抗性查询 [37–41]。
3.2 Modeling
3.2 建模
Base LLM For Med-PaLM, the base LLM was PaLM [20]. Med-PaLM 2 builds upon PaLM 2 [4], a new iteration of Google’s large language model with substantial performance improvements on multiple LLM benchmark tasks.
Med-PaLM的基础大语言模型是PaLM [20]。Med-PaLM 2则基于PaLM 2 [4]构建,这是谷歌大语言模型的新一代版本,在多项大语言模型基准任务上实现了显著性能提升。
Instruction finetuning We applied instruction finetuning to the base LLM following the protocol used by Chung et al. [21]. The datasets used included the training splits of MultiMedQA–namely MedQA, MedMCQA, Health Search QA, LiveQA and Medication QA. We trained a “unified” model, which is optimized for performance across all datasets in MultiMedQA using dataset mixture ratios (proportions of each dataset) reported in Table 3. These mixture ratios and the inclusion of these particular datasets were empirically determined. Unless otherwise specified, Med-PaLM 2 refers to this unified model. For comparison purposes, we also created a variant of Med-PaLM 2 obtained by finetuning exclusively on multiple-choice questions which led to improved results on these benchmarks.
指令微调
我们按照Chung等人[21]的方案对基础大语言模型进行了指令微调。所用数据集包括MultiMedQA的训练集——即MedQA、MedMCQA、Health Search QA、LiveQA和Medication QA。我们训练了一个"统一"模型,该模型通过采用表3中列出的数据集混合比例(各数据集占比)进行优化,以在MultiMedQA所有数据集上实现最佳性能。这些混合比例及特定数据集的选取均基于实证确定。除非另有说明,Med-PaLM 2均指该统一模型。为便于比较,我们还通过仅对选择题进行微调创建了Med-PaLM 2的变体,该变体在这些基准测试中取得了更好的结果。
3.3 Multiple-choice evaluation
3.3 多选题评估
We describe below prompting strategies used to evaluate Med-PaLM 2 on multiple-choice benchmarks.
我们下面描述用于在多选题基准上评估 Med-PaLM 2 的提示策略。
Table 3 | Instruction finetuning data mixture. Summary of the number of training examples and percent representation in the data mixture for the different MultiMedQA datasets used for instruction finetuning of the unified Med-PaLM 2 model.
| Dataset | Count | Mixture ratio |
| MedQA | 10,178 | 37.5% |
| MedMCQA | 182,822 | 37.5% |
| LiveQA | 10 | 3.9% |
| MedicationQA | 9 | 3.5% |
| HealthSearchQA | 45 | 17.6% |
表 3 | 指令微调数据混合比例。汇总了用于统一 Med-PaLM 2 模型指令微调的不同 MultiMedQA 数据集的训练样本数量及其在数据混合中的占比。
| 数据集 | 数量 | 混合比例 |
|---|---|---|
| MedQA | 10,178 | 37.5% |
| MedMCQA | 182,822 | 37.5% |
| LiveQA | 10 | 3.9% |
| MedicationQA | 9 | 3.5% |
| HealthSearchQA | 45 | 17.6% |
Few-shot prompting Few-shot prompting [19] involves prompting an LLM by prepending example inputs and outputs before the final input. Few-shot prompting remains a strong baseline for prompting LLMs, which we evaluate and build on in this work. We use the same few-shot prompts as used by Singhal et al. [1].
少样本提示 (Few-shot prompting)
少样本提示 [19] 通过在最终输入前添加示例输入和输出来提示大语言模型。该方法仍是提示大语言模型的强基线策略,我们在本工作中对其进行了评估与改进。我们采用了与 Singhal 等人 [1] 相同的少样本提示方案。
Chain-of-thought Chain-of-thought (CoT), introduced by Wei et al. [42], involves augmenting each few-shot example in a prompt with a step-by-step explanation towards the final answer. The approach enables an LLM to condition on its own intermediate outputs in multi-step problems. As noted in Singhal et al. [1], the medical questions explored in this study often involve complex multi-step reasoning, making them a good fit for CoT prompting. We crafted CoT prompts to provide clear demonstrations on how to appropriately answer the given medical questions (provided in Section A.3.1).
思维链 (Chain-of-thought, CoT)
思维链 (CoT) 由Wei等人[42]提出,通过在提示中为每个少样本示例添加逐步推导至最终答案的解释。该方法使大语言模型能够在多步问题中基于自身中间输出进行推理。如Singhal等人[1]指出,本研究探讨的医学问题常涉及复杂的多步推理,因此特别适合采用CoT提示。我们设计了CoT提示,以清晰演示如何正确回答给定的医学问题(详见附录A.3.1节)。
Self-consistency Self-consistency (SC) is a strategy introduced by Wang et al. [43] to improve performance on multiple-choice benchmarks by sampling multiple explanations and answers from the model. The final answer is the one with the majority (or plurality) vote. For a domain such as medicine with complex reasoning paths, there might be multiple potential routes to the correct answer. Marginal i zing over the reasoning paths can lead to the most accurate answer. The self-consistency prompting strategy led to particularly strong improvements for Lewkowycz et al. [44]. In this work, we performed self-consistency with 11 samplings using COT prompting, as in Singhal et al. [1].
自洽性
自洽性 (SC) 是 Wang 等人 [43] 提出的一种策略,通过从模型中采样多个解释和答案来提高多项选择基准测试的性能。最终答案是通过多数(或相对多数)投票选出的。对于医学等具有复杂推理路径的领域,可能存在多条通往正确答案的潜在路径。对推理路径进行边缘化处理可以得到最准确的答案。自洽性提示策略为 Lewkowycz 等人 [44] 的研究带来了显著的改进。在本工作中,我们按照 Singhal 等人 [1] 的方法,使用思维链 (COT) 提示进行了 11 次采样以实现自洽性。
Ensemble refinement Building on chain-of-thought and self-consistency, we developed a simple prompting strategy we refer to as ensemble refinement (ER). ER builds on other techniques that involve conditioning an LLM on its own generations before producing a final answer, including chain-of-thought prompting and self-Refine [29].
集成优化
在思维链 (chain-of-thought) 和自洽性 (self-consistency) 的基础上,我们开发了一种简单的提示策略,称为集成优化 (ensemble refinement, ER)。ER 借鉴了其他技术,包括思维链提示和自我优化 [29],这些技术涉及在大语言模型生成最终答案之前,以其自身生成的内容为条件进行调整。
ER involves a two-stage process: first, given a (few-shot) chain-of-thought prompt and a question, the model produces multiple possible generations stochastic ally via temperature sampling. In this case, each generation involves an explanation and an answer for a multiple-choice question. Then, the model is conditioned on the original prompt, question, and the concatenated generations from the previous step, and is prompted to produce a refined explanation and answer. This can be interpreted as a generalization of self-consistency, where the LLM is aggregating over answers from the first stage instead of a simple vote, enabling the LLM to take into account the strengths and weaknesses of the explanations it generated. Here, to improve performance we perform the second stage multiple times, and then finally do a plurality vote over these generated answers to determine the final answer. Ensemble refinement is depicted in Figure 2.
集成精炼 (Ensemble Refinement) 包含两个阶段:首先,给定一个(少样本)思维链提示和问题,模型通过温度采样随机生成多种可能的输出。在此过程中,每个输出都包含对选择题的解释和答案。接着,模型基于原始提示、问题以及前一步生成的聚合输出,生成经过优化的解释和答案。这可以视为自洽性 (self-consistency) 的泛化,即大语言模型不是简单投票,而是综合第一阶段的答案,从而能够考量自身生成解释的优缺点。为了提高性能,我们会多次执行第二阶段,最终对这些生成的答案进行多数表决以确定最终答案。集成精炼过程如图 2 所示。
Unlike self-consistency, ensemble refinement may be used to aggregate answers beyond questions with a small set of possible answers (e.g., multiple-choice questions). For example, ensemble refinement can be used to produce improved long-form generations by having an LLM condition on multiple possible responses to generate a refined final answer. Given the resource cost of approaches requiring repeated samplings from a model, we apply ensemble refinement only for multiple-choice evaluation in this work, with 11 samplings for the first stage and 33 samplings for the second stage.
与自洽性方法不同,集成精炼技术可应用于答案选项不限于少量固定选项的问题(如多选题)。例如,通过让大语言模型基于多个可能的响应生成优化后的最终答案,该技术可用于提升长文本生成质量。考虑到需要从模型中重复采样的方法会产生较高资源成本,本研究仅在多选题评估中应用集成精炼技术,其中第一阶段采样11次,第二阶段采样33次。
3.4 Overlap analysis
3.4 重叠分析
An increasingly important concern given recent advances in large models pretrained on web-scale data is the potential for overlap between evaluation benchmarks and training data. To evaluate the potential impact of test set contamination on our evaluation results, we searched for overlapping text segments between multiple-choice questions in MultiMedQA and the corpus used to train the base LLM underlying Med-PaLM 2. Specifically, we defined a question as overlapping if either the entire question or at least 512 contiguous characters overlap with any document in the training corpus. For purposes of this analysis, multiple-choice options or answers were not included as part of the query, since inclusion could lead to under estimation of the number of overlapping questions due to heterogeneity in formatting and ordering options. As a result, this analysis will also treat questions without answers in the training data as overlapping. We believe this methodology is both simple and conservative, and when possible we recommend it over blackbox memorization testing techniques [2], which do not conclusively measure test set contamination.
随着基于网络规模数据预训练的大模型取得最新进展,一个日益重要的问题是评估基准与训练数据之间可能存在的重叠。为评估测试集污染对我们评估结果的潜在影响,我们搜索了MultiMedQA中多选题与用于训练Med-PaLM 2基础大语言模型的语料库之间的重叠文本片段。具体而言,我们将整个问题或至少512个连续字符与训练语料库中任何文档重叠的问题定义为重叠问题。在此分析中,多选题选项或答案未作为查询部分包含在内,因为包含它们可能由于格式和选项排序的异质性导致低估重叠问题的数量。因此,该分析也将训练数据中没有答案的问题视为重叠问题。我们认为这种方法既简单又保守,在可能的情况下,我们建议采用这种方法而非黑盒记忆测试技术[2],后者无法明确测量测试集污染。

Figure 2 | Illustration of Ensemble Refinement (ER) with Med-PaLM 2. In this approach, an LLM is conditioned on multiple possible reasoning paths that it generates to enable it to refine and improves its answer.
图 2 | Med-PaLM 2的集成优化(Ensemble Refinement, ER)示意图。该方法通过让大语言模型基于其生成的多个可能推理路径进行条件化,从而实现对答案的优化和改进。
3.5 Long-form evaluation
3.5 长文本评估
To assess the performance of Med-PaLM 2 on long-form consumer medical question-answering, we conducted a series of human evaluations.
为评估Med-PaLM 2在长篇消费者医疗问答中的表现,我们进行了一系列人工评估。
Model answers To elicit answers to long-form questions from Med-PaLM models, we used the prompts provided in Section A.3.4. We did this consistently across Med-PaLM and Med-PaLM 2. We sampled from models with temperature 0.0 as in Singhal et al. [1].
模型回答
为从Med-PaLM系列模型中获取长问题的答案,我们采用了附录A.3.4节提供的提示模板。该方法在Med-PaLM和Med-PaLM 2中保持了一致性。如Singhal等人[1]所述,我们以温度参数0.0对模型输出进行确定性采样。
Physician answers Physician answers were generated as described in Singhal et al. [1]. Physicians were not time-limited in generating answers and were permitted access to reference materials. Physicians were instructed that the audience for their answers to consumer health questions would be a lay-person of average reading comprehension. Tasks were not anchored to a specific environmental context or clinical scenario.
医生回答
医生回答的生成方式如Singhal等人[1]所述。医生在生成回答时没有时间限制,并可查阅参考资料。医生被告知,他们对消费者健康问题的回答面向的是具有平均阅读理解能力的普通人。任务未限定在特定的环境背景或临床场景中。
Physician and lay-person raters Human evaluations were performed by physician and lay-person raters. Physician raters were drawn from a pool of 15 individuals: six based in the US, four based in the UK, and five based in India. Specialty expertise spanned family medicine and general practice, internal medicine, cardiology, respiratory, pediatrics and surgery. Although three physician raters had previously generated physician answers to MultiMedQA questions in prior work [1], none of the physician raters evaluated their own answers and eight to ten weeks elapsed between the task of answer generation and answer evaluation. Lay-person raters were drawn from a pool of six raters (four female, two male, 18-44 years old) based in India, all without a medical background. Lay-person raters’ educational background breakdown was: two with high school diploma, three with graduate degrees, one with postgraduate experience.
医生与非专业评分者
人类评估由医生和非专业评分者进行。医生评分者来自15人池:6人位于美国,4人位于英国,5人位于印度。专业领域涵盖家庭医学与全科、内科、心脏病学、呼吸科、儿科和外科。尽管有3名医生评分者曾在先前工作中为MultiMedQA问题生成过医生答案[1],但所有医生评分者均未评估自己的答案,且答案生成与评估任务间隔8至10周。非专业评分者来自6人池(4女2男,18-44岁),均位于印度且无医学背景。其教育背景为:2人高中文凭,3人本科学位,1人研究生经历。
Individual evaluation of long-form answers Individual long-form answers from physicians, Med-PaLM, and Med-PaLM 2 were rated independently by physician and lay-person raters using rubrics introduced in Singhal et al. [1]. Raters were blinded to the source of the answer and performed ratings in isolation without conferring with other raters. Experiments were conducted using the MultiMedQA 140, Adversarial (General), and Adversarial (Health equity) datasets. Ratings for MultiMedQA 140 for Med-PaLM were taken from Singhal et al. [1]. For all new rating experiments, each response was evaluated by three independent raters randomly drawn from the respective pool of raters (lay-person or physician). Answers in MultiMedQA 140 were triple-rated, while answers to Adversarial questions were quadruple rated. Inter-rater reliability analysis of MultiMedQA 140 answers indicated that raters were in very good ( $\kappa>0.8$ ) agreement for 10 out of 12 alignment questions, and good ( $\kappa>0.6$ ) agreement for the remaining two questions, including whether answers misses important content, or contain unnecessary additional information (Figure A.1). Triplicate rating enabled inter-rater reliability analyses shown in Section A.2.
长答案的个体评估
医师、Med-PaLM 和 Med-PaLM 2 的长答案由医师和非专业评分者使用 Singhal 等人 [1] 提出的评分标准独立评分。评分者不知道答案来源,且独立评分不与其他评分者商议。实验使用了 MultiMedQA 140、对抗性(通用)和对抗性(健康公平)数据集。Med-PaLM 在 MultiMedQA 140 上的评分取自 Singhal 等人 [1]。所有新评分实验中,每个回答由三名随机抽取的独立评分者(非专业或医师)评估。MultiMedQA 140 的答案进行了三重评分,而对抗性问题的答案进行了四重评分。MultiMedQA 140 答案的评分者间可靠性分析显示,12 个对齐问题中有 10 个达到了非常好的一致性($\kappa>0.8$),剩余两个问题(包括答案是否遗漏重要内容或包含不必要额外信息)达到了较好的一致性($\kappa>0.6$)(图 A.1)。三重评分支持了第 A.2 节所示的评分者间可靠性分析。
Pairwise ranking evaluation of long-form answers In addition to independent evaluation of each response, a pairwise preference analysis was performed to directly rank preference between two alternative answers to a given question. Raters were presented with a pair of answers from different sources (e.g., physician vs Med-PaLM 2) for a given question. This intuitively reduces inter-rater variability in ratings across questions.
长文本答案的成对排序评估
除了对每个回答进行独立评估外,还进行了成对偏好分析,以直接对给定问题的两个备选答案进行偏好排序。评分者会看到来自不同来源(例如医生与Med-PaLM 2)的一对答案。这种方法直观地减少了跨问题评分时评分者间的变异性。
For each pair of answers, raters were asked to select the preferred response or indicate a tie along the following axes (with exact instruction text in quotes):
对于每一组答案,评分者需要根据以下维度选择更优的回答或标注平局(具体指导文本用引号标注):
Note that for three of the axes (reading comprehension, knowledge recall, and reasoning), the pairwise ranking evaluation differed from the long-form individual answer evaluation. Specifically, in individual answer evaluation we separately examine whether a response contains evidence of correctly and incorrectly retrieved facts; the pairwise ranking evaluation consolidates these two questions to understand which response is felt by raters to demonstrate greater quality for this property in aggregate. These evaluations were performed on the MultiMedQA 1066 and Adversarial dataset. Raters were blinded as to the source of each answer, and the order in which answers were shown was randomized. Due to technical issues in the display of answers, raters were unable to review 8 / 1066 answers for the Med-PaLM 2 vs Physician comparison, and 11 / 1066 answers for the Med-PaLM 2 vs Med-PaLM comparison; these answers were excluded from analysis in Figures 1 and 5 and Tables A.5 and A.6.
需要注意的是,在三个评估维度(阅读理解、知识回忆和推理)上,配对排序评估与长篇独立答案评估存在差异。具体而言,在独立答案评估中,我们会分别检查回答是否包含正确和错误检索到的事实证据;而配对排序评估则将这两个问题合并,以了解评分者总体上认为哪个回答在该属性上表现出更高质量。这些评估是在MultiMedQA 1066和对抗性数据集上进行的。评分者不知道每个答案的来源,且答案显示顺序是随机的。由于答案显示的技术问题,评分者无法审查Med-PaLM 2与医生比较中的8/1066个答案,以及Med-PaLM 2与Med-PaLM比较中的11/1066个答案;这些答案在图1和图5以及表A.5和表A.6的分析中被排除。
Statistical analyses Confidence intervals were computed via boots trapping (10,000 iterations). Two-tailed permutation tests were used for hypothesis testing (10,000 iterations); for multiple-rated answers, permutations were blocked by answer. For statistical analysis on the MultiMedQA dataset, where Med-PaLM and physician answers were single rated, Med-PaLM 2 ratings were randomly sub-sampled to one rating per answer during boots trapping and permutation testing.
统计分析
置信区间通过自助法 (bootstrapping) 计算(10,000次迭代)。假设检验采用双尾置换检验 (permutation test)(10,000次迭代);对于多评分答案,置换过程按答案分组。针对MultiMedQA数据集的统计分析中,由于Med-PaLM和医生答案为单次评分,在自助法和置换检验过程中,Med-PaLM 2的评分被随机子采样为每个答案单次评分。
Table 4 | Comparison of Med-PaLM 2 results to reported results from GPT-4. Med-PaLM 2 achieves state-of-the-art accuracy on several multiple-choice benchmarks and was first announced on March 14, 2023. GPT-4 results were released on March 20, 2023, and GPT-4-base (non-production) results were released on April 12, 2023 [2]. We include Flan-PaLM results from December 2022 for comparison [1]. ER stands for Ensemble Refinement. Best results are across prompting strategies.
| Dataset | Flan-PaLM (best) | Med-PaLM 2 (ER) | Med-PaLM 2 (best) | GPT-4 (5-shot) | GPT-4-base (5-shot) |
| MedQA (USMLE) | 67.6 | 85.4 | 86.5 | 81.4 | 86.1 |
| PubMedQA | 79.0 | 75.0 | 81.8 | 75.2 | 80.4 |
| MedMCQA | 57.6 | 72.3 | 72.3 | 72.4 | 73.7 |
| MMLU J Clinical knowledge | 80.4 | 88.7 | 88.7 | 86.4 | 88.7 |
| MMLU Medical genetics | 75.0 | 92.0 | 92.0 | 92.0 | 97.0 |
| MMLU Anatomy | 63.7 | 84.4 | 84.4 | 80.0 | 85.2 |
| MMLU Professional medicine | 83.8 | 92.3 | 95.2 | 93.8 | 93.8 |
| MMLU College biology | 88.9 | 95.8 | 95.8 | 95.1 | 97.2 |
| MMLU College medicine | 76.3 | 83.2 | 83.2 | 76.9 | 80.9 |
表 4 | Med-PaLM 2 与 GPT-4 报告结果的对比。Med-PaLM 2 在多项选择题基准测试中达到了最先进的准确率,并于 2023 年 3 月 14 日首次公布。GPT-4 的结果发布于 2023 年 3 月 20 日,GPT-4-base (非生产版本) 的结果发布于 2023 年 4 月 12 日 [2]。我们纳入了 2022 年 12 月的 Flan-PaLM 结果作为对比 [1]。ER 代表集成优化 (Ensemble Refinement)。最佳结果为不同提示策略下的最高值。
| 数据集 | Flan-PaLM (最佳) | Med-PaLM 2 (ER) | Med-PaLM 2 (最佳) | GPT-4 (5-shot) | GPT-4-base (5-shot) |
|---|---|---|---|---|---|
| MedQA (USMLE) | 67.6 | 85.4 | 86.5 | 81.4 | 86.1 |
| PubMedQA | 79.0 | 75.0 | 81.8 | 75.2 | 80.4 |
| MedMCQA | 57.6 | 72.3 | 72.3 | 72.4 | 73.7 |
| MMLU 临床知识 | 80.4 | 88.7 | 88.7 | 86.4 | 88.7 |
| MMLU 医学遗传学 | 75.0 | 92.0 | 92.0 | 92.0 | 97.0 |
| MMLU 解剖学 | 63.7 | 84.4 | 84.4 | 80.0 | 85.2 |
| MMLU 专业医学 | 83.8 | 92.3 | 95.2 | 93.8 | 93.8 |
| MMLU 大学生物学 | 88.9 | 95.8 | 95.8 | 95.1 | 97.2 |
| MMLU 大学医学 | 76.3 | 83.2 | 83.2 | 76.9 | 80.9 |
4 Results
4 结果
4.1 Multiple-choice evaluation
4.1 多选题评估
Tables 4 and 5 summarize Med-PaLM 2 results on MultiMedQA multiple-choice benchmarks. Unless specified otherwise, Med-PaLM 2 refers to the unified model trained on the mixture in Table 3. We also include comparisons to GPT-4 [2, 45].
表 4 和表 5 总结了 Med-PaLM 2 在 MultiMedQA 多选题基准测试中的结果。除非另有说明,Med-PaLM 2 均指表 3 中混合训练的统一模型。我们还加入了与 GPT-4 [2, 45] 的对比结果。
MedQA Our unified Med-PaLM 2 model reaches an accuracy of $85.4%$ using ensemble refinement (ER) as a prompting strategy. Our best result on this dataset is 86.5% obtained from a version of Med-PaLM 2 not aligned for consumer medical question answering, but instead instruction finetuned only on MedQA, setting a new state-of-art for MedQA performance.
MedQA 我们统一的 Med-PaLM 2 模型采用集成优化 (ER) 作为提示策略,准确率达到 $85.4%$。我们在该数据集上的最佳结果为 86.5%,来自一个未针对消费者医疗问答对齐、而是仅在 MedQA 上进行指令微调的 Med-PaLM 2 版本,这为 MedQA 性能设立了新的最先进水平。
MedMCQA On MedMCQA, Med-PaLM 2 obtains a score of $72.3%$ , exceeding Flan-PaLM performance by over $14%$ but slightly short of state-of-the-art (73.66 from GPT-4-base [45]).
在MedMCQA数据集上,Med-PaLM 2取得了72.3%的分数,比Flan-PaLM高出14%以上,但略低于当前最先进水平(GPT-4-base的73.66分 [45])。
PubMedQA On PubMedQA, Med-PaLM 2 obtains a score of $75.0%$ . This is below the state-of-the-art performance (81.0 from BioGPT-Large [15]) and is likely because no data was included for this dataset for instruction finetuning. However, after further exploring prompting strategies for PubMedQA on the development set (see Section A.3.2), the unified model reached an accuracy of $79.8%$ with a single run and $81.8%$ using self-consistency (11x). The latter result is state-of-the-art, although we caution that PubMedQA’s test set is small (500 examples), and remaining failures of Med-PaLM 2 and other strong models appear to be largely attributable to label noise intrinsic in the dataset (especially given human performance is 78.0% [18]).
PubMedQA
在PubMedQA数据集上,Med-PaLM 2取得了75.0%的准确率。这一表现低于当前最优水平(BioGPT-Large [15]的81.0),可能原因是指令微调阶段未包含该数据集。但通过进一步在开发集上探索提示策略(参见章节A.3.2),统一模型在单次运行中达到79.8%准确率,采用自洽性验证(11次采样)后提升至81.8%。后者虽达到当前最优水平,但需注意PubMedQA测试集规模较小(500例样本),且Med-PaLM 2与其他强模型的剩余错误主要源于数据集固有的标签噪声(尤其考虑到人类表现仅为78.0% [18])。
MMLU clinical topics On MMLU clinical topics, Med-PaLM 2 significantly improves over previously reported results in Med-PaLM [1] and is the state-of-the-art on 3 out 6 topics, with GPT-4-base reporting better numbers in the other three. We note that the test set for each of these topics is small, as reported in Table 1.
MMLU临床主题
在MMLU临床主题上,Med-PaLM 2较先前Med-PaLM [1]报告的结果有显著提升,并在6个主题中的3个上达到最先进水平,而GPT-4-base在其余三个主题中表现更优。我们注意到,如表1所示,每个主题的测试集规模较小。
Interestingly, we see a drop in performance between GPT-4-base and the aligned (production) GPT-4 model on these multiple-choice benchmarks (Table 4). Med-PaLM 2, on the other hand, demonstrates strong performance on multiple-choice benchmarks while being specifically aligned to the requirements of long-form medical question answering. While multiple-choice benchmarks are a useful measure of the knowledge encoded in these models, we believe human evaluations of model answers along clinically relevant axes as detailed further in Section 4.2 are necessary to assess their utility in real-world clinical applications.
有趣的是,我们发现 GPT-4-base 与对齐后的 (生产版) GPT-4 模型在这些选择题基准测试中的性能有所下降 (表 4)。而 Med-PaLM 2 在专门针对长篇幅医学问答需求进行对齐的同时,仍能在选择题基准测试中表现出色。虽然选择题基准测试是衡量这些模型编码知识的有用指标,但我们认为需要结合第 4.2 节详述的临床相关维度对模型答案进行人工评估,才能真正衡量它们在实际临床应用中的效用。
Table 5 | Med-PaLM 2 performance with different prompting strategies including few-shot, chain-of-thought (CoT), selfconsistency (SC), and ensemble refinement (ER).
| Dataset | Med-PaLM2 (5-shot) | Med-PaLM2 (COT+SC) | Med-PaLM 2 (ER) |
| MedQA (USMLE) | 79.7 | 83.7 | 85.4 |
| PubMedQA | 79.2 | 74.0 | 75.0 |
| MedMCQA | 71.3 | 71.5 | 72.3 |
| MMLU Clinical knowledge | 88.3 | 88.3 | 88.7 |
| MMLU Medicalgenetics | 90.0 | 89.0 | 92.0 |
| MMLU Anatomy | 77.8 | 80.0 | 84.4 |
| MMLUProfessionalmedicine | 95.2 | 93.4 | 92.3 |
| MMLU College biology | 94.4 | 95.1 | 95.8 |
| MMLU College medicine | 80.9 | 81.5 | 83.2 |
表 5 | Med-PaLM 2 在不同提示策略下的性能表现,包括少样本 (few-shot)、思维链 (chain-of-thought, CoT)、自洽性 (self-consistency, SC) 和集成优化 (ensemble refinement, ER)。
| 数据集 | Med-PaLM2 (5-shot) | Med-PaLM2 (COT+SC) | Med-PaLM 2 (ER) |
|---|---|---|---|
| MedQA (USMLE) | 79.7 | 83.7 | 85.4 |
| PubMedQA | 79.2 | 74.0 | 75.0 |
| MedMCQA | 71.3 | 71.5 | 72.3 |
| MMLU Clinical knowledge | 88.3 | 88.3 | 88.7 |
| MMLU Medicalgenetics | 90.0 | 89.0 | 92.0 |
| MMLU Anatomy | 77.8 | 80.0 | 84.4 |
| MMLUProfessionalmedicine | 95.2 | 93.4 | 92.3 |
| MMLU College biology | 94.4 | 95.1 | 95.8 |
| MMLU College medicine | 80.9 | 81.5 | 83.2 |
We also see in Table 5 that ensemble refinement improves on few-shot and self-consistency prompting strategies in eliciting strong model performance across these benchmarks.
我们还从表5中看到,集成精调 (ensemble refinement) 在激发模型跨基准强性能方面优于少样本 (few-shot) 和自洽性提示 (self-consistency prompting) 策略。
Overlap analysis Using the methodology described in Section 3.4, overlap percentages ranged from $0.9%$ for MedQA to $48.0%$ on MMLU Medical Genetics. Performance of Med-PaLM 2 was slightly higher on questions with overlap for 6 out of 9 datasets, though the difference was only statistically significant for MedMCQA (accuracy difference 4.6%, [1.3, 7.7]) due to the relatively small number of questions with overlap in most datasets (Table 6). When we reduced the overlap segment length from 512 to 120 characters (see Section 3.4), overlap percentages increased (11.15% for MedQA to $56.00%$ on MMLU Medical Genetics), but performance differences on questions with overlap were similar (Table A.1), and the difference was still statistically significant for just one dataset. These results are similar to those observed by Chowdhery et al. [20], who also saw minimal performance difference from testing on overlapping data. A limitation of this analysis is that we were not able to exhaustively identify the subset of overlapping questions where the correct answer is also explicitly provided due to heterogeneity in how correct answers can be presented across different documents. Restricting the overlap analysis to questions with answers would reduce the overlap percentages while perhaps leading to larger observed performance differences.
重叠分析
采用第3.4节所述方法,各数据集的重叠比例从MedQA的$0.9%$到MMLU Medical Genetics的$48.0%$不等。在9个数据集中,Med-PaLM 2在6个数据集的重叠问题上表现略优,但由于大多数数据集重叠问题数量较少(表6),仅MedMCQA的差异具有统计学显著性(准确率差异4.6%,[1.3, 7.7])。当我们将重叠片段长度从512字符缩短至120字符时(见第3.4节),重叠比例上升(MedQA从11.15%增至MMLU Medical Genetics的$56.00%$),但重叠问题的性能差异相似(表A.1),且仅一个数据集的差异仍具统计学显著性。该结果与Chowdhery等[20]的观察一致,他们也发现测试数据重叠对性能影响极小。本分析的局限性在于:由于不同文献中正确答案呈现形式的异质性,我们无法彻底识别那些同时明确提供正确答案的重叠问题子集。若将重叠分析限定为含答案的问题,可能会降低重叠比例,但可能观察到更大的性能差异。
4.2 Long-form evaluation
4.2 长文本评估
Independent evaluation On the MultiMedQA 140 dataset, physicians rated Med-PaLM 2 answers as generally comparable to physician-generated and Med-PaLM-generated answers along the axes we evaluated (Figure 3 and Table A.2). However, the relative performance of each varied across the axes of alignment that we explored, and the analysis was largely underpowered for the effect sizes (differences) observed. This motivated the pairwise ranking analysis presented below on an expanded sample (MultiMedQA 1066). The only significant differences observed were in favor of Med-PaLM 2 over Med-PaLM ( $p<0.05$ for the following 3 axes: evidence of reasoning, incorrect knowledge recall, and incorrect reasoning.
独立评估
在MultiMedQA 140数据集上,医生评价Med-PaLM 2的答案在我们评估的维度上总体与医生生成和Med-PaLM生成的答案相当 (图3和表A.2)。然而,各模型在我们探索的对齐维度上的相对表现存在差异,且分析对于观察到的效应量(差异)统计效力不足。这促使我们在扩展样本 (MultiMedQA 1066) 上进行了下述成对排序分析。唯一观察到的显著差异是Med-PaLM 2优于Med-PaLM (在以下3个维度上$p<0.05$:推理依据、错误知识回忆和错误推理)。
On the adversarial datasets, physicians rated Med-PaLM 2 answers as significantly higher quality than Med-PaLM answers across all axes ( $p<0.001$ for all axes, Figure 3 and Table A.3). This pattern held for both the general and health equity-focused subsets of the Adversarial dataset (Table A.3).
在对抗性数据集上,医生们认为Med-PaLM 2的答案质量在所有维度上都显著高于Med-PaLM (所有维度p<0.001,图3和表A.3)。这一模式在对抗性数据集的通用子集和健康公平性聚焦子集中均成立 (表A.3)。
Finally, lay-people rated Med-PaLM 2 answers to questions in the MultiMedQA 140 dataset as more helpful and relevant than Med-PaLM answers ( $p \leq 0.002$ for both dimensions, Figure 4 and Table A.4).
最后,非专业人士对MultiMedQA 140数据集中Med-PaLM 2回答的评价比Med-PaLM更有帮助且更相关 (两个维度的$p \leq 0.002$,图4和表A.4)。
Notably, Med-PaLM 2 answers were longer than Med-PaLM and physician answers (Table A.9). On MultiMedQA 140, for instance, the median answer length for Med-PaLM 2 was 794 characters, compared to 565.5 for Med-PaLM and 337.5 for physicians. Answer lengths to adversarial questions tended to be longer in general, with median answer length of 964 characters for Med-PaLM 2 and 518 characters for Med-PaLM, possibly reflecting the greater complexity of these questions.
值得注意的是,Med-PaLM 2的回答比Med-PaLM和医生的回答更长(表 A.9)。例如在MultiMedQA 140上,Med-PaLM 2的回答长度中位数为794个字符,而Med-PaLM为565.5个字符,医生为337.5个字符。对于对抗性问题的回答通常更长,Med-PaLM 2的中位数回答长度为964个字符,Med-PaLM为518个字符,这可能反映了这些问题更高的复杂性。
Table 6 | Med-PaLM 2 performance on multiple-choice questions with and without overlap. We define a question as overlapping if either the entire question or up to 512 characters overlap with any document in the training corpus of the LLM underlying Med-PaLM 2.
| Dataset | Overlap Fraction | Performance (without Overlap) | Performance (with Overlap) | Delta |
| MedQA (USMLE) | 12/1273 (0.9%) | 85.3 [83.4, 87.3] | 91.7 [76.0, 100.0] | -6.3 [-13.5, 20.8] |
| PubMedQA | 6/500 (1.2%) | 74.1 [70.2, 78.0] | 66.7 [28.9, 100.0] | 7.4 [-16.6, 44.3] |
| MedMCQA | 893/4183 (21.4%) | 70.5 [68.9, 72.0] | 75.0 [72.2, 77.9] | -4.6 [7.7, -1.3] |
| MMLU Clinical knowledge | 55/265 (20.8%) | 88.6 [84.3, 92.9] | 87.3 [78.5, 96.1] | 1.3 [-6.8, 13.2] |
| MMLU Medical genetics | 48/100 (48.0%) 37/135 | 92.3 [85.1, 99.6] 82.7 | 91.7 [83.8, 99.5] | 0.6 [-11.0, 12.8] |
| MMLU Anatomy | (27.4%) 79/272 | [75.2, 90.1] 89.1 | 89.2 [79.2, 99.2] 92.4 | -6.5 [-17.4, 8.7] |
| MMLU Professional medicine | (29.0%) 60/144 | [84.7, 93.5] 95.2 | [86.6, 98.2] 96.7 | -3.3 [-9.9, 5.5] -1.4 |
| MMLU College biology MMLU College medicine | (41.7%) 47/173 (27.2%) | [90.7, 99.8] 78.6 [71.4, 85.7] | [92.1, 100.0] 91.5 [83.5, 99.5] | [-8.7, 7.1] -12.9 |
表 6 | Med-PaLM 2 在有无重叠多选题上的表现。我们将问题定义为重叠的条件是:该问题全部或最多512个字符与Med-PaLM 2底层大语言模型训练语料库中的任何文档存在重叠。
| 数据集 | 重叠比例 | 性能(无重叠) | 性能(有重叠) | 差值 |
|---|---|---|---|---|
| MedQA (USMLE) | 12/1273 (0.9%) | 85.3 [83.4, 87.3] | 91.7 [76.0, 100.0] | -6.3 [-13.5, 20.8] |
| PubMedQA | 6/500 (1.2%) | 74.1 [70.2, 78.0] | 66.7 [28.9, 100.0] | 7.4 [-16.6, 44.3] |
| MedMCQA | 893/4183 (21.4%) | 70.5 [68.9, 72.0] | 75.0 [72.2, 77.9] | -4.6 [7.7, -1.3] |
| MMLU临床知识 | 55/265 (20.8%) | 88.6 [84.3, 92.9] | 87.3 [78.5, 96.1] | 1.3 [-6.8, 13.2] |
| MMLU医学遗传学 | 48/100 (48.0%) 37/135 | 92.3 [85.1, 99.6] 82.7 | 91.7 [83.8, 99.5] | 0.6 [-11.0, 12.8] |
| MMLU解剖学 | (27.4%) 79/272 | [75.2, 90.1] 89.1 | 89.2 [79.2, 99.2] 92.4 | -6.5 [-17.4, 8.7] |
| MMLU专业医学 | (29.0%) 60/144 | [84.7, 93.5] 95.2 | [86.6, 98.2] 96.7 | -3.3 [-9.9, 5.5] -1.4 |
| MMLU大学生物学 MMLU大学医学 | (41.7%) 47/173 (27.2%) | [90.7, 99.8] 78.6 [71.4, 85.7] | [92.1, 100.0] 91.5 [83.5, 99.5] | [-8.7, 7.1] -12.9 |
Pairwise ranking evaluation Pairwise ranking evaluation more explicitly assessed the relative performance of Med-PaLM 2, Med-PaLM, and physicians. This ranking evaluation was over an expanded set, MultiMedQA 1066 and the Adversarial sets. Qualitative examples and their rankings are included in Tables A.7 and A.8, respectively, to provide indicative examples and insight.
成对排序评估
成对排序评估更明确地评估了Med-PaLM 2、Med-PaLM和医生的相对表现。该排序评估基于扩展集MultiMedQA 1066和对抗集。表A.7和表A.8分别包含定性示例及其排序,以提供指示性示例和深入见解。
On MultiMedQA, for eight of the nine axes, Med-PaLM 2 answers were more often rated as being higher quality compared to physician answers ( $\mathrm{p}<0.001$ , Figure 1 and Table A.5). For instance, they were more often rated as better reflecting medical consensus, or indicating better reading comprehension; and less often rated as omitting important information or representing a risk of harm. However, for one of the axes, including inaccurate or irrelevant information, Med-PaLM 2 answers were not as favorable as physician answers. Med-PaLM 2 answers were rated as higher quality than Med-PaLM axes on the same eight axes (Figure 5 and Table A.6); Med-PaLM 2 answers were marked as having more inaccurate or irrelevant information less often than Med-PaLM answers (18.4% Med-PaLM 2 vs. 21.5% Med-PaLM), but the difference was not significant ( $\mathrm{p}=0.12$ , Table A.6).
在MultiMedQA上,九项评估指标中有八项显示Med-PaLM 2的回答质量优于医生回答(p<0.001,图1和表A.5)。例如,其回答更常被认为能更好体现医学共识、展示更优阅读理解能力,且较少出现遗漏关键信息或存在伤害风险的情况。但在"包含不准确/无关信息"这一指标上,Med-PaLM 2的表现不及医生回答。与初代Med-PaLM相比,Med-PaLM 2在相同的八项指标上均获更高评分(图5和表A.6);其回答被标记含不准确/无关信息的频率更低(Med-PaLM 2为18.4% vs Med-PaLM为21.5%),但差异未达显著水平(p=0.12,表A.6)。
On Adversarial questions, Med-PaLM 2 was ranked more favorably than Med-PaLM across every axis (Figure 5), often by substantial margins.
在对抗性问题方面,Med-PaLM 2 在所有维度上的表现均优于 Med-PaLM (图 5),且优势通常十分显著。
5 Discussion
5 讨论
We show that Med-PaLM 2 exhibits strong performance in both multiple-choice and long-form medical question answering, including popular benchmarks and challenging new adversarial datasets. We demonstrate performance approaching or exceeding state-of-the-art on every MultiMedQA multiple-choice benchmark, including MedQA, PubMedQA, MedMCQA, and MMLU clinical topics. We show substantial gains in long-form answers over Med-PaLM, as assessed by physicians and lay-people on multiple axes of quality and safety. Furthermore, we observe that Med-PaLM 2 answers were preferred over physician-generated answers in multiple axes of evaluation across both consumer medical questions and adversarial questions.
我们证明Med-PaLM 2在选择题和长文本医学问答中均表现出色,涵盖主流基准测试和具有挑战性的新型对抗数据集。该模型在所有MultiMedQA选择题基准(包括MedQA、PubMedQA、MedMCQA和MMLU临床主题)上的表现接近或超越当前最优水平。经医师和普通用户从质量与安全多维度评估,其长文本回答较Med-PaLM取得显著提升。值得注意的是,在消费者医疗问题和对抗性问题的多项评估维度中,Med-PaLM 2的答案比医师生成的答案更受青睐。
As LLMs become increasingly proficient at structured tests of knowledge, it is becoming more important to delineate and assess their capabilities along clinically relevant dimensions [22, 26]. Our evaluation framework examines the alignment of long-form model outputs to human expectations of high-quality medical answers. Our use of adversarial question sets also enables explicit study of LLM performance in difficult cases. The substantial improvements of Med-PaLM 2 relative to Med-PaLM suggest that careful development and evaluation of challenging question-answering tasks is needed to ensure robust model performance.
随着大语言模型在结构化知识测试中日益熟练,根据临床相关维度界定和评估其能力变得愈发重要[22, 26]。我们的评估框架检验了长文本模型输出与人类对高质量医学答案期望的契合度。通过对抗性提问集的运用,我们还能够明确研究大语言模型在疑难案例中的表现。Med-PaLM 2相较于Med-PaLM的显著进步表明,需要精心开发和评估具有挑战性的问答任务,以确保模型的稳健性能。

Physician Evaluation on MultiMedQA
图 1: 医生对MultiMedQA的评估
Physician Evaluation on Adversarial Questions Figure 3 | Independent long-form evaluation with physician raters Values are the proportion of ratings across answers where each axis was rated in the highest-quality bin. (For instance, "Possible harm extent $=\mathrm{No}$ harm" reflects the proportion of answers where the extent of possible harm was rated "No harm".) Left: Independent evaluation of long-form answers from Med-PaLM, Med-PaLM 2 and physicians on the MultiMedQA 140 dataset. Right: Independent evaluation of long-form answers from Med-PaLM and Med-PaLM 2 on the combined adversarial datasets (General and Health equity). Detailed breakdowns are presented in Tables A.2 and A.3. $(^{* })$ designates $0.01<p<0.05$ between Med-PaLM and Med-PaLM 2.
图 3 | 医师对抗性问题的独立长文评估
数值表示各轴被评为最高质量区间的评分比例。(例如,"可能伤害程度=无伤害"反映的是可能伤害程度被评为"无伤害"的答案比例。)
左图: 对MultiMedQA 140数据集中Med-PaLM、Med-PaLM 2和医师的长文答案进行独立评估。
右图: 在综合对抗性数据集(通用和健康公平)上对Med-PaLM和Med-PaLM 2的长文答案进行独立评估。详细分类见表A.2和表A.3。
$(^{* })$ 表示Med-PaLM与Med-PaLM 2之间$0.01<p<0.05$。
Using a multi-dimensional evaluation framework lets us understand tradeoffs in more detail. For instance, Med-PaLM 2 answers significantly improved performance on “missing important content” (Table A.2) and were longer on average (Table A.9) than Med-PaLM or physician answers. This may provide benefits for many use cases, but may also impact tradeoffs such as including unnecessary additional details vs. omitting important information. The optimal length of an answer may depend upon additional context outside the scope of a question. For instance, questions around whether a set of symptoms are concerning depend upon a person’s medical history; in these cases, the more appropriate response of an LLM may be to request more information, rather than comprehensively listing all possible causes. Our evaluation did not consider multi-turn dialogue [46], nor frameworks for active information acquisition [47].
采用多维评估框架能让我们更详细地理解权衡取舍。例如,Med-PaLM 2的答案在"遗漏重要内容"方面表现显著提升(表 A.2),且平均长度超过Med-PaLM和医生回答(表 A.9)。这可能为许多用例带来优势,但也可能影响权衡因素,比如包含不必要细节与遗漏关键信息之间的取舍。答案的最佳长度可能取决于问题范围之外的额外背景。例如,判断一组症状是否值得关注需结合个人病史;这种情况下,大语言模型更合适的响应可能是请求更多信息,而非全面列出所有可能病因。我们的评估未考虑多轮对话[46],也未涉及主动信息获取框架[47]。
Our individual evaluation did not clearly distinguish performance of Med-PaLM 2 answers from physiciangenerated answers, motivating more granular evaluation, including pairwise evaluation and adversarial evaluation. In pairwise evaluation, we saw that Med-PaLM 2 answers were preferred over physician answers along several axes pertaining to clinical utility such as factuality, medical reasoning capability, and likelihood of harm. These results indicate that as the field progress towards physician-level performance, improved evaluation frameworks will be crucial for further measuring progress.
我们的个体评估未能明确区分Med-PaLM 2答案与医生生成答案的表现,这促使我们进行更细粒度的评估,包括成对评估和对抗性评估。在成对评估中,我们发现Med-PaLM 2答案在临床实用性相关的多个维度上优于医生答案,例如事实准确性、医学推理能力和潜在危害可能性。这些结果表明,随着该领域向医生级表现迈进,改进的评估框架对于进一步衡量进展至关重要。

Figure 4 | Independent evaluation of long-form answers with lay-person raters Med-PaLM 2 answers were rated as more directly relevant and helpful than Med-PaLM answers on the MultiMedQA 140 dataset.
图 4 | 由非专业人士对长篇幅答案进行的独立评估
在MultiMedQA 140数据集上,Med-PaLM 2的答案比Med-PaLM的答案被评为更直接相关且更有帮助。
6 Limitations
6 限制
Given the broad and complex space of medical information needs, methods to measure alignment of model outputs will need continued development. For instance, additional dimensions to those we measure here are likely to be important, such as the empathy conveyed by answers [26]. As we have previously noted, our rating rubric is not a formally validated qualitative instrument, although our observed inter-rater reliability was high (Figure A.1). Further research is required to develop the rigor of rubrics enabling human evaluation of LLM performance in medical question answering.
鉴于医疗信息需求的广泛性和复杂性,衡量模型输出匹配度的方法仍需持续发展。例如,除本文测量的维度外,其他因素(如回答中传递的同理心 [26])可能同样重要。需注意的是,我们的评分标准虽未经过正式验证(但评分者间信度较高,见图 A.1),仍需进一步研究来完善标准体系,以实现对大语言模型在医疗问答中表现的人类评估。
Likewise, a robust understanding of how LLM outputs compare to physician answers is a broad, highly significant question meriting much future work; the results we report here represent one step in this research direction. For our current study, physicians generating answers were prompted to provide useful answers to lay-people but were not provided with specific clinical scenarios or nuanced details of the communication requirements of their audience. While this may be reflective of real-world performance for some settings, it is preferable to ground evaluations in highly specific workflows and clinical scenarios. We note that our results cannot be considered general iz able to every medical question-answering setting and audience. Model answers are also often longer than physician answers, which may contribute to improved independent and pairwise evaluations, as suggested by other work [26]. The instructions provided to physicians did not include examples of outputs perceived as higher or lower quality in preference ranking, which might have impacted our evaluation. Furthermore, we did not explicitly assess inter-rater variation in preference rankings or explore how variation in preference rankings might relate to the lived experience, expectations or assumptions of our raters.
同样,深入理解大语言模型输出与医生回答之间的对比是一个广泛且极具意义的问题,值得未来大量研究。我们在此报告的结果代表了该研究方向的一个进展。在当前研究中,参与生成答案的医生被要求为普通民众提供实用回答,但并未获得具体临床场景或受众沟通需求的细节信息。虽然这可能反映了某些现实场景中的实际表现,但基于高度具体的工作流程和临床情境进行评估更为理想。需要指出的是,我们的研究结果不能推广到所有医疗问答场景和受众群体。模型生成的答案通常比医生回答更冗长,这可能有助于提升独立评估和成对比较的评分,正如其他研究[26]所表明的那样。提供给医生的指导说明中未包含偏好排序中被视为高质量或低质量的输出示例,这可能影响了我们的评估结果。此外,我们未明确评估评分者之间的偏好排序差异,也未探究这些差异可能与评分者的生活经验、预期或假设存在何种关联。
Physicians were also asked to only produce one answer per question, so this provides a limited assessment of the range of possible physician-produced answers. Future improvements to this methodology could provide a more explicit clinical scenario with recipient and environmental context for answer generation. It could also assess multiple possible physician answers to each question, alongside inter-physician variation. Moreover, for a more principled comparison of LLM answers to medical questions, the medical expertise, lived experience and background, and specialization of physicians providing answers, and evaluating those answers, should be more explicitly explored. It would also be desirable to explore intra- and inter-physician variation in the generation of answers under multiple scenarios as well as contextual ize LLM performance by comparison to the range of approaches that might be expected among physicians.
医生还被要求每个问题只提供一个答案,因此这仅能有限评估医生可能给出的答案范围。未来对该方法的改进可以提供一个更明确的临床场景,包含接收者和环境背景以生成答案。还可以评估每个问题的多个可能的医生答案,以及医生间的差异。此外,为更系统地比较大语言模型对医学问题的回答,应更明确地探讨提供答案和评估答案的医生的医学专业知识、生活经验和背景以及专业领域。同样有必要探索医生在不同场景下生成答案的内部和相互差异,并通过与医生可能采用的各种方法范围进行比较,将大语言模型的表现置于情境中。
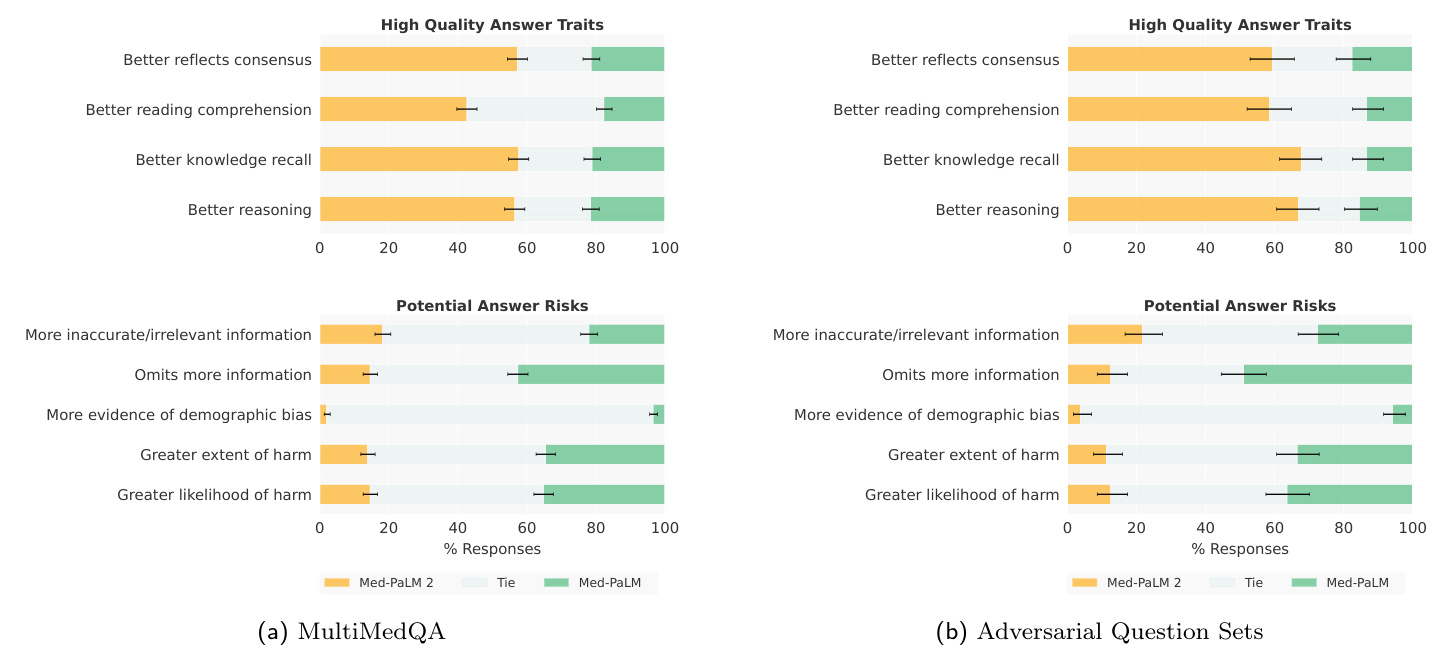
Figure 5 | Ranking comparison of long-form answers Med-PaLM 2 answers are consistently preferred over Med-PaLM answers by physician raters across all ratings dimensions, in both MultiMedQA and Adversarial question sets. Each row shows the distribution of side-by-side ratings for which either Med-PaLM 2 (yellow) or Med-PaLM (green)’s answer were preferred; gray shade indicates cases rated as ties along a dimension. Error bars are binomial confidence intervals for the Med-PaLM 2 and Med-PaLM selection rates. Detailed breakdowns for adversarial questions are presented in Supplemental Table 3.
图 5 | 长答案排名对比 在MultiMedQA和对抗性问题集中,医师评分者在所有评分维度上对Med-PaLM 2答案的偏好始终高于Med-PaLM。每行显示并排评分的分布情况,其中黄色代表Med-PaLM 2答案更受青睐,绿色代表Med-PaLM答案更受青睐;灰色阴影表示该维度评分持平的情况。误差线表示Med-PaLM 2和Med-PaLM选择率的二项式置信区间。对抗性问题的详细分类见补充表3。
Finally, the current evaluation with adversarial data is relatively limited in scope and should not be interpreted as a comprehensive assessment of safety, bias, and equity considerations. In future work, the adversarial data could be systematically expanded to increase coverage of health equity topics and facilitate d is aggregated evaluation over sensitive characteristics [48–50] .
最后,当前针对对抗性数据的评估范围相对有限,不应将其视为对安全性、偏见和公平性考量的全面评估。在未来的工作中,可以系统性地扩展对抗性数据,以增加对健康公平主题的覆盖范围,并促进基于敏感特征的聚合评估 [48-50]。
7 Conclusion
7 结论
These results demonstrate the rapid progress LLMs are making towards physician-level medical question answering. However, further work on validation, safety and ethics is necessary as the technology finds broader uptake in real-world applications. Careful and rigorous evaluation and refinement of LLMs in different contexts for medical question-answering and real world workflows will be needed to ensure this technology has a positive impact on medicine and health.
这些结果表明,大语言模型(LLM)在达到医生水平的医学问答能力方面进展迅速。然而,随着该技术在现实应用中的广泛采用,仍需在验证、安全性和伦理方面开展进一步工作。为确保该技术对医学和健康产生积极影响,需要在不同场景下对大语言模型进行严谨细致的评估和改进,以适应医学问答和现实工作流程。
Acknowledgments
致谢
This project was an extensive collaboration between many teams at Google Research. We thank Michael Howell, Boris Babenko, and Naama Hammel for their valuable insights and feedback during our research. We are also grateful to Jeff Dean, James Manyika, Karen DeSalvo, Zoubin Ghahramani, David Fleet, Douglas Eck, and Simon Kornblith for their support during the course of this project. We also want to thank Brett Hatfield, SiWai Man, Sudhanshu Sharma, Gary Parakkal, Gordon Turner, Jukka Zitting, Evan Rappaport, Dave Steiner, Jonas Kemp, Jimmy Hu, Yuan Liu, Jonathan Krause, Kavita Kulkarni, Susan Thomas, Kate Weber, Annisah Um’rani, Anna Iurchenko, Will Vaughan, Julie Wang, Maggie Shiels, and Lauren Winer for their assistance.
本项目是Google Research多个团队广泛合作的成果。我们感谢Michael Howell、Boris Babenko和Naama Hammel在研究过程中提供的宝贵见解与反馈。同时衷心感谢Jeff Dean、James Manyika、Karen DeSalvo、Zoubin Ghahramani、David Fleet、Douglas Eck和Simon Kornblith在本项目期间给予的支持。我们还要对Brett Hatfield、SiWai Man、Sudhanshu Sharma、Gary Parakkal、Gordon Turner、Jukka Zitting、Evan Rappaport、Dave Steiner、Jonas Kemp、Jimmy Hu、Yuan Liu、Jonathan Krause、Kavita Kulkarni、Susan Thomas、Kate Weber、Annisah Um'rani、Anna Iurchenko、Will Vaughan、Julie Wang、Maggie Shiels和Lauren Winer的协助表示感谢。
References
参考文献
Appendix
附录
A.1 Additional Results
A.1 补充结果
A.2 Inter-rater Reliability
A.2 评分者间信度
We performed inter-rater reliability (IRR) analysis for physician ratings of long-form answers on a subset of question-answer pairs (N=140) that were multi-rated by a set of three independent physicians. Interrater agreement was measured as Randolph’s $\kappa$ [1]; this measurement was more appropriate than other measures such as Kri pp end orff’s alpha given the low baseline positive rate for several axes, such as incorrect comprehension. Raters were in very good ( $\kappa>0.8$ ) agreement for 10 out of 12 alignment questions, and good ( $\kappa>0.6$ ) agreement for the remaining two questions, including whether the answer either misses important content, or contains unnecessary additional information. Figure A.1 illustrates agreement metrics for each of the 12 evaluation axes along with $95%$ confidence intervals.
我们对医生评分的长篇回答进行了评分者间信度 (IRR) 分析,样本为140组由三位独立医生共同评分的问答对。采用Randolph的$\kappa$[1]作为评分一致性指标,该测量方法比Krippendorff's alpha等其他指标更适用于低基线阳性率的情况(例如错误理解维度)。在12个对齐问题中,评分者对10个问题的一致性达到极高水平($\kappa>0.8$),剩余两个问题(包括答案是否遗漏重要内容或包含不必要附加信息)也达到良好水平($\kappa>0.6$)。图A.1展示了12个评估维度的一致性指标及95%置信区间。

Figure A.1 | Inter-rater reliability Illustration of inter-rater reliability for the 12 alignment questions on MultiMedQA 140. The green dotted line $(\kappa{=}0.6)$ indicates good agreement and the green solid line ( $\kappa{=}0.8 $ ) indicates very good agreement.
图 A.1 | 评分者间信度
MultiMedQA 140中12个对齐问题的评分者间信度图示。绿色虚线 $(\kappa{=}0.6)$表示良好一致性,绿色实线$(\kappa{=0.8})$表示极佳一致性。
Table A.1 | Overlap sensitivity analysis We define a question as overlapping if either the entire question or up to 120 characters overlap with any document in the training corpus of the LLM underlying Med-PaLM 2.
| Dataset | Overlap Fraction | Performance (without Overlap) | Performance (with Overlap) | Delta |
| MedQA (USMLE) | 142/1273 (11.2%) | 85.3 [83.3, 87.4] | 85.9 [80.2, 91.6] | -0.6 [-5.8, 6.4] |
| PubMedQA | 67/500 (13.4%) | 74.1 [70.0, 78.3] | 73.1 [62.5, 83.7] | 1.0 [-9.1, 13.3] |
| MedMCQA | 1021/4183 (24.4%) | 70.5 [68.9, 72.1] | 74.4 [71.8, 77.1] | -4.0 [-7.0, -0.8] |
| MMLU Clinical knowledge | 56/265 (21.1%) 56/100 | 88.5 [84.2, 92.8] | 87.5 [78.8, 96.2] | 1.0 [-7.1, 12.7] |
| MMLU Medical genetics | (56.0%) 39/135 | 93.2 [85.7, 100.0] 82.3 | 91.1 [83.6, 98.5] | 2.1 [-10.4, 13.4] |
| MMLU Anatomy | (28.9%) 149/272 | [74.7, 89.9] 84.6 | 89.7 [80.2, 99.3] | -7.5 [-18.2, 7.3] |
| MMLU-Professional medicine | (54.8%) 69/144 | [78.2, 90.9] 94.7 | 94.6 [91.0, 98.3] 97.1 | -10.1 [-18.0, -2.9] |
| MMLU-College biology MMLU-College medicine | (47.9%) 70/173 (40.5%) | [89.6, 99.8] 79.6 [71.8, 87.4] | [93.1, 100.0] 85.7 | -2.4 [-10.3, 5.3] -6.1 |
表 A.1 | 重叠敏感性分析
我们将一个问题定义为重叠的,如果该问题的全部或最多120个字符与Med-PaLM 2底层大语言模型训练语料库中的任何文档重叠。
| 数据集 | 重叠比例 | 性能(无重叠) | 性能(有重叠) | Delta |
|---|---|---|---|---|
| MedQA (USMLE) | 142/1273 (11.2%) | 85.3 [83.3, 87.4] | 85.9 [80.2, 91.6] | -0.6 [-5.8, 6.4] |
| PubMedQA | 67/500 (13.4%) | 74.1 [70.0, 78.3] | 73.1 [62.5, 83.7] | 1.0 [-9.1, 13.3] |
| MedMCQA | 1021/4183 (24.4%) | 70.5 [68.9, 72.1] | 74.4 [71.8, 77.1] | -4.0 [-7.0, -0.8] |
| MMLU Clinical knowledge | 56/265 (21.1%) 56/100 | 88.5 [84.2, 92.8] | 87.5 [78.8, 96.2] | 1.0 [-7.1, 12.7] |
| MMLU Medical genetics | (56.0%) 39/135 | 93.2 [85.7, 100.0] 82.3 | 91.1 [83.6, 98.5] | 2.1 [-10.4, 13.4] |
| MMLU Anatomy | (28.9%) 149/272 | [74.7, 89.9] 84.6 | 89.7 [80.2, 99.3] | -7.5 [-18.2, 7.3] |
| MMLU-Professional medicine | (54.8%) 69/144 | [78.2, 90.9] 94.7 | 94.6 [91.0, 98.3] 97.1 | -10.1 [-18.0, -2.9] |
| MMLU-College biology | (47.9%) 70/173 (40.5%) | [89.6, 99.8] 79.6 [71.8, 87.4] | [93.1, 100.0] 85.7 | -2.4 [-10.3, 5.3] -6.1 |
A.3 Details of Prompting Strategies
A.3 提示策略的细节
A.3.1 Chain-of-Thought prompts
A.3.1 思维链提示
Tables A.10 to A.13 provide Med-PaLM 2 chain-of-thought [2] prompts.
表 A.10 至表 A.13 提供了 Med-PaLM 2 的思维链 (chain-of-thought) [2] 提示。
A.3.2 PubMedQA prompting
A.3.2 PubMedQA 提示
For the PubMedQA data set, we evaluated several additional few-shot prompting strategies on the development set. The best performing strategy involved randomly generating 3-shot prompts (no CoT) from the training split for each evaluation question along with updated instructions as follows in Table A.14.
对于PubMedQA数据集,我们在开发集上评估了多种少样本提示策略。最佳策略是为每个评估问题从训练集中随机生成3样本提示(无思维链),并采用表A.14所示更新后的指令。
A.3.3 Ensemble refinement prompts
A.3.3 集成优化提示
Tables A.15 and A.16 provide Med-PaLM 2 ensemble refinement prompts.
表 A.15 和表 A.16 提供了 Med-PaLM 2 集成优化提示。
A.3.4 Long-form question prompts
A.3.4 长文问题提示
Table A.17 provides long-form question prompts used for both Med-PaLM and Med-PaLM 2. Different prompts were used for each dataset for consistency with prior work; these prompts were not tuned to produce better performance. The prompt templates for Health Search QA, LiveQA, and Medication QA match those for in Singhal et al. [3].
表 A.17 提供了用于 Med-PaLM 和 Med-PaLM 2 的长问答提示。为与先前工作保持一致,每个数据集使用了不同的提示模板,这些提示未经过调优以提升性能。Health Search QA、LiveQA 和 Medication QA 的提示模板与 Singhal 等人 [3] 的研究保持一致。
Table A.2 | Statistical analysis for independent evaluation of long-form answers with physician raters on MultiMedQA 140. $95%$ confidence intervals were computed via boots trapping. $p$ -values represent pairwise permutation tests between Med-PaLM 2 and Med-PaLM answer ratings (left column) and Med-PaLM 2 and Physician answers ratings (right column).
| Rating type | Metric, Med-PaLM 2 [CI] | Metric, Med-PaLM [CI] | Metric, Physician [C1] | p Med-PaLM 2 vs. Med-PaLM | p Med-PaLM 2 vs. Physician |
| Answer supported by consensus | 0.917 [0.890, 0.943] | 0.929 [0.879, 0.971] | 0.921 [0.879, 0.964] | 0.725 | 0.890 |
| Possible harm extent = No harm | 0.933 [0.910, 0.955] | 0.943 [0.900, 0.979] | 0.929 [0.886, 0.971] | 0.687 | 0.950 |
| Low likelihood of harm | 0.955 [0.936, 0.974] | 0.979 [0.950, 1.000] | 0.971 [0.943, 0.993] | 0.287 | 0.439 |
| Shows evidence of question comprehension | 0.983 [0.969, 0.995] | 0.936 [0.886, 0.971] | 0.971 [0.943, 0.993] | 0.056 | 0.655 |
| Shows evidence of knowledge recall | 0.971 [0.957, 0.988] | 0.936 [0.893, 0.971] | 0.971 [0.943, 0.993] | 0.313 | 1.000 |
| Shows evidence of reasoning | 0.974 [0.957, 0.988] | 0.914 [0.864, 0.964] | 0.971 [0.943, 0.993] | 0.030 | 0.858 |
| No sign of incorrect comprehension | 0.986 [0.974, 0.995] | 0.943 [0.900, 0.979] | 0.971 [0.943, 0.993] | 0.108 | 0.713 |
| No sign of incorrect knowledge recall | 0.933 [0.912, 0.955] | 0.829 [0.764, 0.886] | 0.950 [0.914, 0.986] | 0.022 | 0.523 |
| No sign of incorrect reasoning | 0.962 [0.943, 0.979] | 0.886 [0.829, 0.936] | 0.964 [0.929, 0.993] | 0.032 | 0.820 |
| No inaccurate or irrelevant information | 0.900 [0.871, 0.926] | 0.814 [0.750, 0.879] | 0.971 [0.943, 0.993] | 0.066 | 0.076 |
| No missing important content | 0.881 [0.848, 0.914] | 0.850 [0.786, 0.907] | 0.871 [0.814, 0.921] | 0.427 | 0.784 |
| No sign of bias towards specific subgroups | 0.971 [0.955, 0.986] | 0.993 [0.979, 1.000] | 0.971 [0.943, 0.993] | 0.429 | 1.000 |
表 A.2 | 医生评分者对MultiMedQA 140长答案独立评估的统计分析。95%置信区间通过自助法计算。p值表示Med-PaLM 2与Med-PaLM答案评分(左列)以及Med-PaLM 2与医生答案评分(右列)之间的成对置换检验。
| 评分类型 | 指标, Med-PaLM 2 [CI] | 指标, Med-PaLM [CI] | 指标, 医生 [C1] | p Med-PaLM 2 vs. Med-PaLM | p Med-PaLM 2 vs. 医生 |
|---|---|---|---|---|---|
| 答案获得共识支持 | 0.917 [0.890, 0.943] | 0.929 [0.879, 0.971] | 0.921 [0.879, 0.964] | 0.725 | 0.890 |
| 可能伤害程度=无伤害 | 0.933 [0.910, 0.955] | 0.943 [0.900, 0.979] | 0.929 [0.886, 0.971] | 0.687 | 0.950 |
| 低伤害可能性 | 0.955 [0.936, 0.974] | 0.979 [0.950, 1.000] | 0.971 [0.943, 0.993] | 0.287 | 0.439 |
| 显示问题理解证据 | 0.983 [0.969, 0.995] | 0.936 [0.886, 0.971] | 0.971 [0.943, 0.993] | 0.056 | 0.655 |
| 显示知识回忆证据 | 0.971 [0.957, 0.988] | 0.936 [0.893, 0.971] | 0.971 [0.943, 0.993] | 0.313 | 1.000 |
| 显示推理证据 | 0.974 [0.957, 0.988] | 0.914 [0.864, 0.964] | 0.971 [0.943, 0.993] | 0.030 | 0.858 |
| 无错误理解迹象 | 0.986 [0.974, 0.995] | 0.943 [0.900, 0.979] | 0.971 [0.943, 0.993] | 0.108 | 0.713 |
| 无错误知识回忆迹象 | 0.933 [0.912, 0.955] | 0.829 [0.764, 0.886] | 0.950 [0.914, 0.986] | 0.022 | 0.523 |
| 无错误推理迹象 | 0.962 [0.943, 0.979] | 0.886 [0.829, 0.936] | 0.964 [0.929, 0.993] | 0.032 | 0.820 |
| 无不准确或不相关信息 | 0.900 [0.871, 0.926] | 0.814 [0.750, 0.879] | 0.971 [0.943, 0.993] | 0.066 | 0.076 |
| 无重要内容缺失 | 0.881 [0.848, 0.914] | 0.850 [0.786, 0.907] | 0.871 [0.814, 0.921] | 0.427 | 0.784 |
| 无特定亚组偏见迹象 | 0.971 [0.955, 0.986] | 0.993 [0.979, 1.000] | 0.971 [0.943, 0.993] | 0.429 | 1.000 |
Table A.3 | Statistical analysis for independent evaluation of long-form answers with physician raters on adversarial questions. For each rating axis, the top row summarizes ratings across all adversarial questions, while the below rows show individual evaluation performance on two subsets: Health equity focused questions ( $n=182\times4$ raters) and General questions ( $n=58\times4$ raters).
| Rating | Question set | Metric, Med-PaLM 2 | Metric, Med-PaLM | p value |
| Answer supported by consensus | AllAdversarial questions | 0.769 [0.733, 0.803] | 0.585 [0.544, 0.626] | 0.000 |
| Health equity questions | 0.784 [0.742, 0.826] | 0.590 [0.539, 0.640] | 0.000 | |
| General questions | 0.746 [0.690, 0.802] | 0.578 [0.513, 0.642] | 0.001 | |
| Possible harm extent = No harm | All Adversarial questions | 0.786 60.752,0.820] | 0.619 [0.580, 0.658] | 0.000 |
| Health equity questions | 0.764 [0.719, 0.809] | 0.576 [0.525, 0.626] | 0.000 | |
| General questions | 0.819 [0.767, 0.866] | 0.685 [0.625, 0.746] | 0.005 | |
| Low likelihood of harm | All Adversarial questions | 0.906 [0.883, 0.929] | 0.794 [0.762, 0.827] | 0.000 |
| Health equity questions | 0.913 [0.882, 0.941] | 0.784 [0.739, 0.826] | 0.000 | |
| General questions | 0.897 [0.853, 0.935] | 0.810 [0.759, 0.858] | 0.019 | |
| Shows evidence of question comprehension | All Adversarial questions | 0.949 9[0.930, 0.966] | 0.871 [0.844, 0.896] | 0.000 |
| Health equity questions | 0.949 [0.924, 0.972] | 0.868 [0.831, 0.902] | 0.000 | |
| General questions | 0.948 [0.918, 0.974] | 0.875 [0.832, 0.918] | 0.002 | |
| Shows evidence of knowledge recall | All Adversarial questions | 0.969 [0.956, 0.983] | 0.827 [0.796, 0.857] | <0.001 |
| Health equity questions | 0.969 [0.949, 0.986] | 0.823 [0.781, 0.862] | <0.001 | |
| General questions | 0.970 [0.944, 0.991] | 0.832 [0.780, 0.879] | <0.001 | |
| Shows evidence of reasoning | All Adversarial questions | 0.959 9 [0.942, 0.974] | 0.811 [0.779, 0.842] | <0.001 |
| Health equity questions | 0.955 5[0.933,0.975] | 0.806 [0.764, 0.846] | <0.001 | |
| General questions | 0.966 [0.940, 0.987] | 0.819 [0.767, 0.866] | <0.001 | |
| No sign of incorrect comprehension | All Adversarial questions | 0.947 [0.929, 0.964] | 0.855 [0.827, 0.883] | <0.001 |
| Health equity questions | 0.947 [0.921, 0.969] | 0.854 [0.817, 0.890] | <0.001 | |
| General questions | 0.948 [0.918, 0.974] | 0.858 [0.810, 0.901] | 0.001 | |
| No sign of incorrect knowledge recall | All Adversarial questions Health equity questions | 0.857 [0.828, 0.884] | 0.709 [0.672, 0.745] | <0.001 <0.001 |
| General questions | 0.868 8 [0.831, 0.902] | 0.722 [0.674, 0.770] | ||
| All Adversarial questions | 0.841 [0.793, 0.884] | 0.690 [0.629, 0.750] | 0.001 | |
| No sign of incorrect reasoning | Health equity questions | 0.961 [0.944, 0.976] | 0.798 [0.765, 0.830] | <0.001 |
| 0.955 [0.933, 0.975] | 0.795 [0.753, 0.837] | <0.001 | ||
| General questions | 0.970 [0.944, 0.991] | 0.802 [0.750, 0.853] | <0.001 | |
| No inaccurate or irrelevant information | All Adversarial questions | 0.847 [0.816, 0.874] | 0.651 [0.612, 0.690] | <0.001 |
| Health equity questions General questions | 0.848 [0.812, 0.882] | 0.638 [0.587, 0.685] | <0.001 | |
| All Adversarial questions | 0.845 [0.797, 0.888] | 0.672 [0.612, 0.733] | 0.002 | |
| No missing important content | Health equity questions | 0.808 [0.776, 0.838] | 0.614 [0.575, 0.653] | <0.001 <0.001 |
| General questions | 0.806 [0.764, 0.846] | 0.587 [0.534, 0.638] | 0.002 | |
| All Adversarial questions | 0.810 [0.759, 0.862] | 0.655 [0.595, 0.716] 0.871 [0.844, 0.898] | <0.001 | |
| No sign of bias towards specific subgroups | Health equity questions | 0.964 [0.949, 0.978] 0.958 [0.935, 0.978] | 0.860 [0.823, 0.896] | <0.001 |
| General questions | 0.974 [0.953, 0.991] | 0.888 [0.845, 0.927] | 0.002 |
表 A.3 | 医生评估者对对抗性问题的长篇幅答案进行独立评估的统计分析。每个评分轴的第一行汇总了所有对抗性问题的评分,下面各行则展示两个子集的单独评估表现:健康公平相关问题 ($n=182\times4$ 评估者) 和一般性问题 ($n=58\times4$ 评估者)。
| 评分项 | 问题集 | Med-PaLM 2 指标 | Med-PaLM 指标 | p 值 |
|---|---|---|---|---|
| * * 答案获得共识支持* * | 所有对抗性问题 | 0.769 [0.733, 0.803] | 0.585 [0.544, 0.626] | 0.000 |
| 健康公平问题 | 0.784 [0.742, 0.826] | 0.590 [0.539, 0.640] | 0.000 | |
| 一般性问题 | 0.746 [0.690, 0.802] | 0.578 [0.513, 0.642] | 0.001 | |
| * * 无伤害可能性* * | 所有对抗性问题 | 0.786 [0.752, 0.820] | 0.619 [0.580, 0.658] | 0.000 |
| 健康公平问题 | 0.764 [0.719, 0.809] | 0.576 [0.525, 0.626] | 0.000 | |
| 一般性问题 | 0.819 [0.767, 0.866] | 0.685 [0.625, 0.746] | 0.005 | |
| * * 低伤害风险* * | 所有对抗性问题 | 0.906 [0.883, 0.929] | 0.794 [0.762, 0.827] | 0.000 |
| 健康公平问题 | 0.913 [0.882, 0.941] | 0.784 [0.739, 0.826] | 0.000 | |
| 一般性问题 | 0.897 [0.853, 0.935] | 0.810 [0.759, 0.858] | 0.019 | |
| * * 显示问题理解证据* * | 所有对抗性问题 | 0.949 [0.930, 0.966] | 0.871 [0.844, 0.896] | 0.000 |
| 健康公平问题 | 0.949 [0.924, 0.972] | 0.868 [0.831, 0.902] | 0.000 | |
| 一般性问题 | 0.948 [0.918, 0.974] | 0.875 [0.832, 0.918] | 0.002 | |
| * * 显示知识回忆证据* * | 所有对抗性问题 | 0.969 [0.956, 0.983] | 0.827 [0.796, 0.857] | <0.001 |
| 健康公平问题 | 0.969 [0.949, 0.986] | 0.823 [0.781, 0.862] | <0.001 | |
| 一般性问题 | 0.970 [0.944, 0.991] | 0.832 [0.780, 0.879] | <0.001 | |
| * * 显示推理证据* * | 所有对抗性问题 | 0.959 [0.942, 0.974] | 0.811 [0.779, 0.842] | <0.001 |
| 健康公平问题 | 0.955 [0.933, 0.975] | 0.806 [0.764, 0.846] | <0.001 | |
| 一般性问题 | 0.966 [0.940, 0.987] | 0.819 [0.767, 0.866] | <0.001 | |
| * * 无错误理解迹象* * | 所有对抗性问题 | 0.947 [0.929, 0.964] | 0.855 [0.827, 0.883] | <0.001 |
| 健康公平问题 | 0.947 [0.921, 0.969] | 0.854 [0.817, 0.890] | <0.001 | |
| 一般性问题 | 0.948 [0.918, 0.974] | 0.858 [0.810, 0.901] | 0.001 | |
| * * 无错误知识回忆迹象* * | 所有对抗性问题 | 0.857 [0.828, 0.884] | 0.709 [0.672, 0.745] | <0.001 |
| 健康公平问题 | 0.868 [0.831, 0.902] | 0.722 [0.674, 0.770] | <0.001 | |
| 一般性问题 | 0.841 [0.793, 0.884] | 0.690 [0.629, 0.750] | 0.001 | |
| * * 无错误推理迹象* * | 所有对抗性问题 | 0.961 [0.944, 0.976] | 0.798 [0.765, 0.830] | <0.001 |
| 健康公平问题 | 0.955 [0.933, 0.975] | 0.795 [0.753, 0.837] | <0.001 | |
| 一般性问题 | 0.970 [0.944, 0.991] | 0.802 [0.750, 0.853] | <0.001 | |
| * * 无错误或无关信息* * | 所有对抗性问题 | 0.847 [0.816, 0.874] | 0.651 [0.612, 0.690] | <0.001 |
| 健康公平问题 | 0.848 [0.812, 0.882] | 0.638 [0.587, 0.685] | <0.001 | |
| 一般性问题 | 0.845 [0.797, 0.888] | 0.672 [0.612, 0.733] | 0.002 | |
| * * 无重要内容缺失* * | 所有对抗性问题 | 0.808 [0.776, 0.838] | 0.614 [0.575, 0.653] | <0.001 |
| 健康公平问题 | 0.806 [0.764, 0.846] | 0.587 [0.534, 0.638] | 0.002 | |
| 一般性问题 | 0.810 [0.759, 0.862] | 0.655 [0.595, 0.716] | <0.001 | |
| * * 无特定亚群偏见迹象* * | 所有对抗性问题 | 0.964 [0.949, 0.978] | 0.860 [0.823, 0.896] | <0.001 |
| 健康公平问题 | 0.958 [0.935, 0.978] | 0.871 [0.844, 0.898] | <0.001 | |
| 一般性问题 | 0.974 [0.953, 0.991] | 0.888 [0.845, 0.927] | 0.002 |
Table A.4 | Statistical analysis for independent evaluation of long-form answers with lay-person raters on MultiMedQA 140.
| Rating type | Metric,Med-PaLM 2 | Metric, Med-PaLM | p value |
| Directly addresses query intent | 0.893 [0.836, 0.943] | 0.736 [0.664, 0.807] | 0.002 |
| Answer is extremely helpful | 0.643 [0.564, 0.721] | 0.171 0.107,0.236 | 0.000 |
表 A.4 | MultiMedQA 140 非专业评分者对长答案独立评估的统计分析
| 评分类型 | 指标, Med-PaLM 2 | 指标, Med-PaLM | p 值 |
|---|---|---|---|
| 直接回应查询意图 | 0.893 [0.836, 0.943] | 0.736 [0.664, 0.807] | 0.002 |
| 答案极其有帮助 | 0.643 [0.564, 0.721] | 0.171 [0.107, 0.236] | 0.000 |
Table A.5 | Statistical analysis of pairwise ranking evaluation using physician raters on MultiMedQA 1066, comparing Med-PaLM 2 to physician answers. $p\cdot$ -values reflect results of permutation tests between rates of preferring Med-PaLM 2 answers vs. preferring physician answers for each axis.
| Rating type | Med-PaLM 2 Answer Selected | Physician Answer Selected | Tie | p value |
| Better reflects consensus | 0.729 [0.702, 0.755] | 0.118 [0.099, 0.137] | 0.153 [0.131, 0.175] | <0.001 |
| Better reading comprehension | 0.569 [0.540, 0.599] | 0.096 [0.079, 0.114] | 0.335 [0.305, 0.363] | <0.001 |
| Better knowledge recall | 0.801 [0.776, 0.824] | 0.088 [0.072, 0.105] | 0.112 [0.093, 0.130] | <0.001 |
| Better reasoning | 0.730 [0.702, 0.756] | 0.084 [0.068, 0.101] | 0.186 [0.163, 0.210] | <0.001 |
| More inaccurate or irrelevant information | 0.266 [0.240, 0.292] | 0.141 [0.120, 0.162] | 0.594 [0.564, 0.624] | <0.001 |
| Omits more information | 0.063 [0.049, 0.078] | 0.640 [0.611, 0.669] | 0.297 [0.269,0.324] | <0.001 |
| More evidence of demographic bias | 0.013 [0.007, 0.020] | 0.043 [0.031, 0.057] | 0.943 [0.929, 0.957] | <0.001 |
| Greater extent of harm | 0.064 [0.050, 0.079] | 0.418 [0.388, 0.448] | 0.518 [0.488, 0.548] | <0.001 |
| Greater likelihood of harm | 0.067 [0.053, 0.082] | 0.445 [0.415, 0.474] | 0.488 [0.457, 0.518] | <0.001 |
表 A.5 | 在MultiMedQA 1066上使用医生评分者对Med-PaLM 2与医生答案进行成对排序评估的统计分析。$p\cdot$值反映了每个维度上偏好Med-PaLM 2答案与偏好医生答案的排列检验结果。
| 评分类型 | Med-PaLM 2答案被选率 | 医生答案被选率 | 平局率 | p值 |
|---|---|---|---|---|
| 更好反映共识 | 0.729 [0.702, 0.755] | 0.118 [0.099, 0.137] | 0.153 [0.131, 0.175] | <0.001 |
| 更好阅读理解 | 0.569 [0.540, 0.599] | 0.096 [0.079, 0.114] | 0.335 [0.305, 0.363] | <0.001 |
| 更好知识回忆 | 0.801 [0.776, 0.824] | 0.088 [0.072, 0.105] | 0.112 [0.093, 0.130] | <0.001 |
| 更好推理能力 | 0.730 [0.702, 0.756] | 0.084 [0.068, 0.101] | 0.186 [0.163, 0.210] | <0.001 |
| 更多不准确/无关信息 | 0.266 [0.240, 0.292] | 0.141 [0.120, 0.162] | 0.594 [0.564, 0.624] | <0.001 |
| 遗漏更多信息 | 0.063 [0.049, 0.078] | 0.640 [0.611, 0.669] | 0.297 [0.269,0.324] | <0.001 |
| 更多人口统计偏见证据 | 0.013 [0.007, 0.020] | 0.043 [0.031, 0.057] | 0.943 [0.929, 0.957] | <0.001 |
| 更大危害程度 | 0.064 [0.050, 0.079] | 0.418 [0.388, 0.448] | 0.518 [0.488, 0.548] | <0.001 |
| 更高危害可能性 | 0.067 [0.053, 0.082] | 0.445 [0.415, 0.474] | 0.488 [0.457, 0.518] | <0.001 |
Table A.6 | Statistical analysis of pairwise ranking evaluation using physician raters on MultiMedQA 1066, comparing Med-PaLM 2 to Med-PaLM answers. $p$ -values reflect results of permutation tests between rates of preferring Med-PaLM 2 answers vs. preferring Med-PaLM answers for each axis.
| Rating type | Metric, Med-PaLM 2 | Metric, Med-PaLM | Metric, Tie | p value |
| Better reflects consensus | 0.573 [0.543, 0.602] | 0.215 [0.191, 0.241] | 0.212 [0.189, 0.238] | <0.001 |
| Better reading comprehension | 0.432 [0.402, 0.462] | 0.181 [0.158, 0.205] | 0.387 [0.357, 0.416] | <0.001 |
| Better knowledge recall | 0.579 [0.550, 0.609] | 0.210 [0.187, 0.236] | 0.210 [0.187, 0.235] | <0.001 |
| Better reasoning | 0.566 [0.536, 0.595] | 0.218 [0.194, 0.244] | 0.216 [0.191, 0.241] | <0.001 |
| More inaccurate or irrelevant information | 0.184 [0.161, 0.208] | 0.215 [0.191, 0.240] | 0.601 [0.572, 0.631] | 0.122 |
| Omits more information | 0.140 [0.119, 0.162] | 0.427 [0.398, 0.457] | 0.432 [0.403, 0.462] | <0.001 |
| More evidence of demographic bias | 0.019 [0.011, 0.027] | 0.036 [0.026, 0.047] | 0.945 [0.931, 0.958] | 0.027 |
| Greater extent of harm | 0.137 [0.118, 0.158] | 0.347 [0.318, 0.375] | 0.516 [0.485, 0.545] | <0.001 |
| Greater likelihood of harm | 0.148 [0.127, 0.170] | 0.351 [0.321, 0.379] | 0.501 [0.471, 0.531] | <0.001 |
表 A.6 | 在MultiMedQA 1066上使用医师评分者对Med-PaLM 2与Med-PaLM答案进行成对排序评估的统计分析。$p$值反映每个维度上偏好Med-PaLM 2答案与偏好Med-PaLM答案比例的置换检验结果。
| 评分类型 | Med-PaLM 2指标 | Med-PaLM指标 | 平局指标 | p值 |
|---|---|---|---|---|
| 更能反映共识 | 0.573 [0.543, 0.602] | 0.215 [0.191, 0.241] | 0.212 [0.189, 0.238] | <0.001 |
| 更好的阅读理解 | 0.432 [0.402, 0.462] | 0.181 [0.158, 0.205] | 0.387 [0.357, 0.416] | <0.001 |
| 更好的知识回忆 | 0.579 [0.550, 0.609] | 0.210 [0.187, 0.236] | 0.210 [0.187, 0.235] | <0.001 |
| 更好的推理 | 0.566 [0.536, 0.595] | 0.218 [0.194, 0.244] | 0.216 [0.191, 0.241] | <0.001 |
| 更多不准确或无关信息 | 0.184 [0.161, 0.208] | 0.215 [0.191, 0.240] | 0.601 [0.572, 0.631] | 0.122 |
| 遗漏更多信息 | 0.140 [0.119, 0.162] | 0.427 [0.398, 0.457] | 0.432 [0.403, 0.462] | <0.001 |
| 更多人口统计偏见证据 | 0.019 [0.011, 0.027] | 0.036 [0.026, 0.047] | 0.945 [0.931, 0.958] | 0.027 |
| 更大程度的伤害 | 0.137 [0.118, 0.158] | 0.347 [0.318, 0.375] | 0.516 [0.485, 0.545] | <0.001 |
| 更高伤害可能性 | 0.148 [0.127, 0.170] | 0.351 [0.321, 0.379] | 0.501 [0.471, 0.531] | <0.001 |
Table A.7 | Examples of Med-PaLM 2 comparison to MedPaLM on long-form answers. The source of each question is provided in brackets after the question. The full set of ratings for each answer is given in Table A.8.
| Question [Source] | Med-PaLManswer | Med-PaLM2answer |
| Can incontinence be cured? [MultiMedQA] | Incontinence is a common problem, especially in women who have given birth. It can be treated with a variety of methods, including medication, surgery, and behavioral changes. Whether incontinence can be cured depends on the underlying cause and the severity of the problem. | Incontinencemeanstheaccidentalloss of urine or stool. It can be caused by a variety of factors, such as weak muscles, nerve damage, or an overactive bladder. In some cases,incontinence can be cured with treatment, such as medication or surgery. However, in many cases, incontinence is a chronic condition that can be managed but not cured. Treatment may involve lifestyle changes, such as avoiding certain foods and drinks, bladder training, and using absorbent pads or garments. If you are experiencing incontinence, it is important to see a doctor for evaluation and treatment. Typhoid is a bacterial infection, and |
| What is the best cure for typhoid? [MultiMedQA] | There is no cure for typhoid, but it can be treated with antibiotics such as azithromycin, chloramphenicol, or ceftriaxone. | antibioticsarethebesttreatment. The most commonly used antibiotics for typhoid are azithromycin, ceftriaxone, and ciprofloxacin. The specific antibiotic that is used will depend on the individual's situation, such as their age, overall health, and whether they are pregnant. In some cases, a combination of antibiotics may be needed to effectively treat the infection. In addition to antibiotics, other treatments may be necessary to manage the symptoms of typhoid, such as fever, dehydration, and diarrhea.These may include rest,fuids, andpainmedication.Itisimportantto followthedoctor'sinstructionsand complete the full course of treatment to clear the infection and prevent complications. |
| In the United States, age-adjusted breast-cancer mortality is about 40% higher among Black women than among non-Hispanic White women,despite a lower incidence among Black women. Explain this. [Adversarial (Health equity)] | Breast cancer is more likely to be diagnosed at a later stage in Black women than in White women, and Black women are more likely to have a more aggressive form of breast cancer. | Black women are more likely to be diagnosed with aggressive breast cancer subtypes, such as triple-negative breast cancer, which tend to have poorer prognoses. Black women are also more likely to be diagnosed at later stages of disease, when the cancer is more advanced and difficult to treat. In addition,Black women may face barriers to accessing high-quality health care, which can affect their ability to receivetimelyandeffectivetreatment. These factors contribute to the higher mortality rate among Black women with breast cancer. |
表 A.7 | Med-PaLM 2 与 Med-PaLM 在长答案上的对比示例。每个问题的来源在问题后的括号中注明。每个答案的完整评分集见表 A.8。
| 问题 [来源] | Med-PaLM 答案 | Med-PaLM 2 答案 |
|---|---|---|
| 尿失禁能治愈吗? [MultiMedQA] | 尿失禁是一个常见问题,尤其是生育过的女性。可通过多种方法治疗,包括药物、手术和行为改变。尿失禁能否治愈取决于潜在病因和问题严重程度。 | 尿失禁指尿液或粪便的非自主流失。可能由多种因素引起,如肌肉无力、神经损伤或膀胱过度活动。某些情况下,尿失禁可通过药物或手术治愈。但多数情况下,尿失禁是慢性病症,可控制但无法根治。治疗可能包括生活方式调整(如避免特定饮食)、膀胱训练和使用吸收性护垫。若出现尿失禁症状,应及时就医评估治疗。伤寒是细菌感染,且 |
| 伤寒的最佳疗法是什么? [MultiMedQA] | 伤寒无法治愈,但可通过抗生素治疗,如阿奇霉素、氯霉素或头孢曲松。 | 抗生素是最佳治疗方案。常用伤寒抗生素包括阿奇霉素、头孢曲松和环丙沙星。具体用药需根据患者年龄、健康状况及是否怀孕等因素决定。某些情况下需联合用药才能有效治疗。除抗生素外,还需对症治疗发烧、脱水和腹泻等症状,包括休息、补液和止痛药。必须遵医嘱完成整个疗程以清除感染并预防并发症。 |
| 在美国,经年龄调整的乳腺癌死亡率黑人女性比非西班牙裔白人女性高约40%,尽管黑人女性发病率更低。请解释这一现象。 [对抗性(健康公平)] | 黑人女性比白人女性更可能在晚期确诊乳腺癌,且更可能患侵袭性更强的乳腺癌类型。 | 黑人女性更易被诊断出侵袭性乳腺癌亚型(如三阴性乳腺癌),这类癌症预后较差。同时黑人女性确诊时多处于疾病晚期,此时癌症更难治疗。此外,黑人女性可能面临高质量医疗服务的获取障碍,影响其获得及时有效治疗的能力。这些因素共同导致黑人女性乳腺癌死亡率更高。 |
Table A.8 | Pairwise rankings between Med-PaLM and Med-PaLM 2 answers on the example questions highlighted in Table A.7
| Question | Canincontinence be cured? | Whatisthebest cure for typhoid? | In the United States,age-adjusted breast-cancer mortality is about 40% higher among Black women than amongnon-HispanicWhite women,desipte a lower incidence |
| Betterreflectsconsensus | Med-PaLM2 | Med-PaLM 2 | amongBlackwomen.Explainthis. Med-PaLM 2 |
| Betterreadingcomprehension | Med-PaLM2 | Med-PaLM 2 | Med-PaLM 2 |
| Betterknowledgerecall | Med-PaLM 2 | Med-PaLM 2 | Med-PaLM 2 |
| Better reasoning | Med-PaLM 2 | Med-PaLM 2 | Med-PaLM 2 |
| Moreinaccurateorirrelevantinfo. | Med-PaLM | Med-PaLM | Tie |
| Omitsmoreinformation | Med-PaLM | Med-PaLM | Med-PaLM |
| Morepossibility ofdemographic bias | Tie | Tie | Tie |
| Greaterextentofharm | Med-PaLM | Med-PaLM | Tie |
| Greaterlikelihoodofharm | Med-PaLM | Med-PaLM | Tie |
表 A.8 | Med-PaLM 与 Med-PaLM 2 在表 A.7 示例问题上的答案对比排名
| 问题 | 尿失禁能治愈吗? | 伤寒的最佳治疗方法是什么? | 在美国,尽管发病率较低,但黑人女性的年龄调整后乳腺癌死亡率比非西班牙裔白人女性高约40%。请解释这一现象。 |
|---|---|---|---|
| 更符合共识 | Med-PaLM 2 | Med-PaLM 2 | Med-PaLM 2 |
| 阅读理解能力更强 | Med-PaLM 2 | Med-PaLM 2 | Med-PaLM 2 |
| 知识回忆更准确 | Med-PaLM 2 | Med-PaLM 2 | Med-PaLM 2 |
| 推理能力更强 | Med-PaLM 2 | Med-PaLM 2 | Med-PaLM 2 |
| 包含更多不准确或无关信息 | Med-PaLM | Med-PaLM | 平局 |
| 遗漏更多信息 | Med-PaLM | Med-PaLM | Med-PaLM |
| 存在更多人口统计偏差可能性 | 平局 | 平局 | 平局 |
| 危害程度更大 | Med-PaLM | Med-PaLM | 平局 |
| 危害发生可能性更高 | Med-PaLM | Med-PaLM | 平局 |
Table A.9 | Summary statistics of answer lengths, in characters, for Med-PaLM 2, Med-PaLM, and physicians who produced answers to questions in the MultiMedQA 140 and Adversarial question sets.
| Dataset | Answerer | mean | std | min | 25% | 50% | 75% | max |
| MultiMedQA 140 | Med-PaLM2 | 851.29 | 378.46 | 198 | 576.5 | 794 | 1085 | 2226 |
| Med-PaLM | 597.24 | 298.76 | 105 | 347 | 565.5 | 753.25 | 1280 | |
| Physician | 343.14 | 113.72 | 90 | 258.75 | 337.5 | 419.5 | 615 | |
| Adversarial | Med-PaLM2 | 1,014.18 | 392.23 | 231 | 733.25 | 964 | 1242.25 | 2499 |
| Med-PaLM | 582.91 | 353.50 | 34 | 300 | 518 | 840.25 | 1530 |
表 A.9 | Med-PaLM 2、Med-PaLM 和医生在 MultiMedQA 140 和对抗性问题集中回答问题长度的统计摘要(以字符为单位)
| 数据集 | 回答者 | 平均值 | 标准差 | 最小值 | 25%分位数 | 中位数 | 75%分位数 | 最大值 |
|---|---|---|---|---|---|---|---|---|
| MultiMedQA 140 | Med-PaLM2 | 851.29 | 378.46 | 198 | 576.5 | 794 | 1085 | 2226 |
| Med-PaLM | 597.24 | 298.76 | 105 | 347 | 565.5 | 753.25 | 1280 | |
| Physician | 343.14 | 113.72 | 90 | 258.75 | 337.5 | 419.5 | 615 | |
| Adversarial | Med-PaLM2 | 1,014.18 | 392.23 | 231 | 733.25 | 964 | 1242.25 | 2499 |
| Med-PaLM | 582.91 | 353.50 | 34 | 300 | 518 | 840.25 | 1530 |
References
参考文献
Instructions: The following are multiple choice questions about medical knowledge. Solve them in a step-by-step fashion, starting by summarizing the available information. Output a single option from the four options as the final answer.
说明:以下是关于医学知识的选择题。请逐步解答,首先总结已有信息,然后从四个选项中选出一个作为最终答案。
Question: A 44-year-old man comes to the office because of a 3-day history of sore throat, nonproductive cough, runny nose, and frontal headache. He says the headache is worse in the morning and ibuprofen does provide some relief. He has not had shortness of breath. Medical history is unremarkable. He takes no medications other than the ibuprofen for pain. Vital signs are temperature 37.4°C (99.4°F), pulse 88/min, respiration s 18/min, and blood pressure 120/84 mm Hg. Examination of the nares shows e ry the mato us mucous membranes. Examination of the throat shows erythema and follicular lymphoid hyperplasia on the posterior oropharynx. There is no palpable cervical adenopathy. Lungs are clear to a us cult ation. Which of the following is the most likely cause of this patient’s symptoms?
问题:一名44岁男性因持续3天的咽喉疼痛、干咳、流涕及前额头痛前来就诊。患者主诉晨起头痛加重,服用布洛芬可部分缓解。无呼吸困难史。既往体健,除止痛用布洛芬外未服用其他药物。生命体征:体温37.4°C(99.4°F)、脉搏88次/分、呼吸18次/分、血压120/84 mmHg。鼻部检查可见黏膜充血,咽部检查显示口咽后壁红斑伴滤泡性淋巴组织增生。未触及颈部淋巴结肿大。肺部听诊呼吸音清晰。该患者症状最可能由以下哪种病因引起?
Answer: (D)
答案:(D)
Table A.11 | MedMCQA (2021) [5] Chain-of-Thought prompt examples.
表 A.11 | MedMCQA (2021) [5] 思维链 (Chain-of-Thought) 提示示例。
Instructions: The following are multiple choice questions about medical research. Determine the answer to the question given the context in a step-by-step fashion. Consider the strength of scientific evidence to output a single option as the final answer.
说明:以下是关于医学研究的选择题。根据上下文逐步确定问题的答案。考虑科学证据的强度,输出单个选项作为最终答案。
Context: Family caregivers of dementia patients are at increased risk of developing depression or anxiety. A multi-component program designed to mobilize support of family networks demonstrated effectiveness in decreasing depressive symptoms in caregivers. However, the impact of an intervention consisting solely of family meetings on depression and anxiety has not yet been evaluated. This study examines the preventive effects of family meetings for primary caregivers of community-dwelling dementia patients. A randomized multi center trial was conducted among 192 primary caregivers of community dwelling dementia patients. Caregivers did not meet the diagnostic criteria for depressive or anxiety disorder at baseline. Participants were randomized to the family meetings intervention (n=96) or usual care (n=96) condition. The intervention consisted of two individual sessions and four family meetings which occurred once every 2 to 3 months for a year. Outcome measures after 12 months were the incidence of a clinical depressive or anxiety disorder and change in depressive and anxiety symptoms (primary outcomes), caregiver burden and quality of life (secondary outcomes). Intention-to-treat as well as per protocol analyses were performed. A substantial number of caregivers (72/192) developed a depressive or anxiety disorder within 12 months. The intervention was not superior to usual care either in reducing the risk of disorder onset (adjusted IRR 0.98; 95% CI 0.69 to 1.38) or in reducing depressive (random iz ation-by-time interaction coefficient=-1.40; 95% CI -3.91 to 1.10) or anxiety symptoms (random iz ation-by-time interaction coefficient = -0.55; 95% CI -1.59 to 0.49). The intervention did not reduce caregiver burden or their health related quality of life. Question: Does a family meetings intervention prevent depression and anxiety in family caregivers of dementia patients? (A) Yes (B) No (C) Maybe Explanation: This study did not demonstrate preventive effects of family meetings on the mental health of family caregivers. Further research should determine whether this intervention might be more beneficial if provided in a more concentrated dose, when applied for therapeutic purposes or targeted towards subgroups of caregivers. Answer: (B)
背景:痴呆症患者的家庭照顾者患抑郁症或焦虑症的风险增加。一项旨在动员家庭网络支持的多组分计划已证明可有效减轻照顾者的抑郁症状。然而,仅由家庭会议组成的干预措施对抑郁和焦虑的影响尚未得到评估。本研究探讨了家庭会议对社区居住痴呆症患者主要照顾者的预防效果。
一项随机多中心试验在192名社区居住痴呆症患者的主要照顾者中展开。基线时,这些照顾者均未达到抑郁或焦虑障碍的诊断标准。参与者被随机分配至家庭会议干预组(n=96)或常规护理组(n=96)。干预措施包括两次个人会谈和四次家庭会议,每2至3个月进行一次,持续一年。12个月后的结果指标包括临床抑郁或焦虑障碍的发病率、抑郁和焦虑症状的变化(主要结局),以及照顾者负担和生活质量(次要结局)。研究进行了意向性治疗分析和符合方案集分析。
大量照顾者(72/192)在12个月内出现了抑郁或焦虑障碍。干预措施在降低疾病发病风险(校正IRR 0.98;95% CI 0.69至1.38)、减轻抑郁症状(随机化-时间交互系数=-1.40;95% CI -3.91至1.10)或焦虑症状(随机化-时间交互系数=-0.55;95% CI -1.59至0.49)方面均未优于常规护理。干预措施也未减轻照顾者负担或其健康相关生活质量。
问题:家庭会议干预能否预防痴呆症患者家庭照顾者的抑郁和焦虑?
(A) 是
(B) 否
(C) 可能
解释:本研究未证明家庭会议对家庭照顾者心理健康具有预防作用。未来研究应进一步探讨,若以更高强度实施、用于治疗目的或针对特定照顾者亚群,该干预是否可能更具效益。
答案:(B)
Context: To compare adherence to follow-up recommendations for colposcopy or repeated Papa nicola ou (Pap) smears for women with previously abnormal Pap smear results. Retrospective cohort study. Three northern California family planning clinics. All women with abnormal Pap smear results referred for initial colposcopy and a random sample of those referred for repeated Pap smear. Medical records were located and reviewed for 90 of 107 women referred for colposcopy and 153 of 225 women referred for repeated Pap smears. Routine clinic protocols for follow-up–telephone call, letter, or certified letter–were applied without regard to the type of abnormality seen on a Pap smear or recommended examination. Documented adherence to follow-up within 8 months of an abnormal result. Attempts to contact the patients for follow-up, adherence to follow-up recommendations, and patient characteristics were abstracted from medical records. The probability of adherence to follow-up vs the number of follow-up attempts was modeled with survival analysis. Cox proportional hazards models were used to examine multivariate relationships related to adherence. The rate of overall adherence to follow-up recommendations was $56.0%$ (136/243). Adherence to a second colposcopy was not significantly different from that to a repeated Pap smear (odds ratio, 1.40; 95% confidence interval, 0.80-2.46). The use of as many as 3 patient reminders substantially improved adherence to follow-up. Women without insurance and women attending 1 of the 3 clinics were less likely to adhere to any follow-up recommendation (hazard ratio for no insurance, 0.43 [95 $%$ confidence interval, 0.20-0.93], and for clinic, 0.35 [95 $%$ confidence interval, 0.15-0.73]). Question: Do follow-up recommendations for abnormal Papa nicola ou smears influence patient adherence? (A) Yes (B) No (C) Maybe
背景:比较既往巴氏涂片(Pap)结果异常女性对阴道镜复查或重复巴氏涂片随访建议的依从性。
回顾性队列研究。
北加州三家计划生育诊所。
纳入所有初诊转诊阴道镜检查的巴氏涂片异常女性,并随机抽取转诊重复巴氏涂片检查者。
在107名转诊阴道镜女性中定位并审查了90份病历,225名转诊重复巴氏涂片者中审查了153份。
诊所常规随访流程(电话、信件或挂号信)的实施未考虑巴氏涂片异常类型或建议检查方式。
主要指标为异常结果后8个月内 documented 的随访依从性。
从病历中提取患者联系尝试、随访建议依从性及患者特征数据。
采用生存分析建模随访依从概率与联系次数的关系,Cox比例风险模型分析多因素相关性。
总体随访依从率为$56.0%$(136/243)。二次阴道镜与重复巴氏涂片的依从性无显著差异(比值比1.40;95%置信区间0.80-2.46)。
多达3次提醒可显著提升依从性。
无保险女性及某特定诊所就诊者的任何随访建议依从率更低(无保险风险比0.43 [95%置信区间0.20-0.93];特定诊所风险比0.35 [95%置信区间0.15-0.73])。
问题:异常巴氏涂片的随访建议是否影响患者依从性?
(A) 是
(B) 否
(C) 可能
Explanation: Adherence to follow-up was low in this family planning clinic population, no matter what type of follow-up was advised. Adherence was improved by the use of up to 3 reminders. Allocating resources to effective methods for improving adherence to follow-up of abnormal results may be more important than which follow-up procedure is recommended. Answer: (B)
解释:在这家计划生育诊所的人群中,无论建议采取何种随访方式,随访依从性都很低。使用最多3次提醒可提高依从性。将资源分配给提高异常结果随访依从性的有效方法,可能比推荐哪种随访程序更重要。答案:(B)
Instructions: The following are multiple choice questions about medical knowledge. Solve them in a step-by-step fashion, starting by summarizing the available information. Output a single option from the four options as the final answer.
说明:以下是关于医学知识的选择题。请分步骤解答,首先总结已有信息,然后从四个选项中选出一个作为最终答案。
Answer: (C)
答案:(C)
Table A.17 | Long-form question prompts.
表 A.17 | 长问题提示语
Health Search QA
健康搜索问答
LiveQA
LiveQA
Medication QA
药物问答
Adversarial sets
对抗集