iColoriT: Towards Propagating Local Hint to the Right Region in Interactive Color iz ation by Leveraging Vision Transformer
iColoriT: 利用Vision Transformer在交互式着色中将局部提示传播至正确区域
Abstract
摘要
Point-interactive image color iz ation aims to colorize grayscale images when a user provides the colors for specific locations. It is essential for point-interactive colorization methods to appropriately propagate user-provided col- ors (i.e., user hints) in the entire image to obtain a reasonably colorized image with minimal user effort. However, existing approaches often produce partially colorized results due to the inefficient design of stacking convolutional layers to propagate hints to distant relevant regions. To address this problem, we present iColoriT, a novel point-interactive color iz ation Vision Transformer capable of propagating user hints to relevant regions, leveraging the global receptive field of Transformers. The self-attention mechanism of Transformers enables iColoriT to selectively colorize relevant regions with only a few local hints. Our approach colorizes images in real-time by utilizing pixel shuffling, an efficient upsampling technique that replaces the decoder architecture. Also, in order to mitigate the artifacts caused by pixel shuffling with large upsampling ratios, we present the local stabilizing layer. Extensive quantitative and qualitative results demonstrate that our approach highly outperforms existing methods for point-interactive colorization, producing accurately colorized images with a user’s minimal effort. Official codes are available at https: //pmh9960.github.io/research/iColoriT/.
点交互式图像着色旨在当用户为特定位置提供颜色时对灰度图像进行着色。点交互式着色方法的关键在于将用户提供的颜色(即用户提示)适当传播至整张图像,从而以最少的用户操作获得合理的着色效果。然而,现有方法由于采用堆叠卷积层来传播提示至远处相关区域的低效设计,常产生局部着色结果。为解决该问题,我们提出iColoriT——一种利用Transformer全局感受野的新型点交互式着色视觉Transformer,能够将用户提示传播至相关区域。Transformer的自注意力机制使iColoriT仅需少量局部提示即可选择性着色相关区域。我们通过采用像素洗牌(一种替代解码器架构的高效上采样技术)实现实时图像着色。此外,为减轻大比例上采样导致的伪影,我们提出了局部稳定层。大量定量与定性结果表明,我们的方法显著优于现有点交互式着色技术,能以最少的用户操作生成精确着色的图像。官方代码详见https://pmh9960.github.io/research/iColoriT/。
1. Introduction
1. 引言
Unconditional image color iz ation [12, 13, 32, 35, 42, 44] has shown remarkable achievement in restoring the vibrance of grayscale photographs or films in a fullyautomatic manner. Interactive color iz ation methods [7, 16, 39, 40, 43, 46] further extend the task to allow users to generate colorized images with specific color conditions. These approaches can dramatically reduce the user effort for producing specific colorized images. It can also serve as an effective way of editing photos by re-coloring existing images to have a new color theme. Among different types of interactions provided by users (e.g., a reference image or a color palette), point- or scribble-based interactions [16,40,46] are designed to progressively colorize images when a user provides the colors at specific point locations.
无条件图像着色 [12, 13, 32, 35, 42, 44] 在完全自动恢复灰度照片或胶片色彩活力方面取得了显著成就。交互式着色方法 [7, 16, 39, 40, 43, 46] 进一步扩展了该任务,允许用户通过特定颜色条件生成着色图像。这些方法能大幅降低用户制作特定着色图像的工作量,也可作为重新着色现有图像以形成新色彩主题的有效照片编辑手段。在用户提供的各类交互方式中(如参考图像或调色板),基于点或涂鸦的交互 [16, 40, 46] 被设计用于当用户在特定位置提供颜色时逐步对图像进行着色。

Figure 1. Example results of various point-interactive color iz ation approaches. Previous approaches often produce partially colorized results even where the grayscale values are persistent (e.g., water, floor, and grass), which indicates that the user hints did not properly propagate to the relevant regions.
图 1: 多种点交互式着色方法的示例结果。先前方法即使在灰度值持续的区域(例如水面、地板和草地)也常产生局部着色效果,这表明用户提示未能有效传播至相关区域。
Practical point-interactive color iz ation methods assist the user to produce a colorized image with minimal user interaction. Thus, accurately estimating the regions relevant to the user hint can be beneficial for reducing the amount of user interactions. For example, using hand-crafted filters [16,40] to determine the region a user hint should fill in was an early approach for colorizing simple patterns within the image. Recently, Zhang et al. [46] proposed a learningbased model trained on a large-scale dataset [27] which produces colorized images with a simple U-Net architecture. However, existing methods tend to suffer from partially colorized results even in obvious regions where the grayscale values are persistent, as seen in Figure 1. This is due to the inefficient design of stacking convolutional layers in order to propagate hints to distant relevant regions. In other words, propagating hints to large semantic regions can only be done in the deep layers, which makes colorizing larger semantic regions more challenging than colorizing smaller regions. To overcome this hurdle, we leverage the global receptive field of self-attention layers [34] in Vision Transformers [4], enabling the model to selectively propagate user hints to relevant regions at each single layer.
实用点交互式着色方法通过最少的用户交互辅助生成彩色图像。因此,准确估计与用户提示相关的区域有助于减少交互次数。例如,早期采用手工设计的滤波器[16,40]来确定用户提示应填充的区域,用于处理图像中的简单图案。最近,Zhang等人[46]提出基于大规模数据集[27]训练的U-Net架构学习模型。但现有方法即使在灰度值一致的明显区域(如图1所示)仍存在局部着色问题,这源于堆叠卷积层传播提示至远端相关区域的低效设计。换言之,向大语义区域传播提示只能在深层网络实现,使得大语义区域着色比小区域更具挑战性。为此,我们利用Vision Transformers[4]中自注意力层[34]的全局感受野特性,使模型能在单层网络中智能地将用户提示传播至相关区域。
Learning how to propagate user hints to other regions aligns well with the self-attention mechanism. Specifically, directly computing the similarities of features from all spatial locations (i.e., the similarity matrix) can be viewed as deciding where the hint colors should propagate in the entire image. Thus, in this work, we present iColoriT, a novel point-interactive color iz ation framework utilizing a modified Vision Transformer for colorizing grayscale images. To the best of our knowledge, this is the first work to employ a Vision Transformer for point-interactive color iz ation.
学习如何将用户提示传播到其他区域与自注意力机制高度契合。具体而言,直接计算所有空间位置特征的相似度(即相似度矩阵)可视为决定提示颜色应在整幅图像中传播的位置。因此,本研究提出iColoriT——一个利用改进版Vision Transformer实现灰度图像点交互式着色的创新框架。据我们所知,这是首个采用Vision Transformer进行点交互式着色的研究。
Furthermore, promptly displaying the results for a newly provided user hint is essential for assisting users to progressively colorize images without delay. For this reason, we generate color images by leveraging the efficient pixel shuffling operation [29], an upsampling technique that reshapes the output channel dimension into a spatial resolution. Through the light-weight pixel shuffling operation, we are able to discard the conventional decoder architecture and offer a faster inference speed compared to existing baselines. Despite its efficiency, pixel shuffling with large upsampling ratios tends to generate unrealistic images with missing details and notable boundaries as seen in Figure 2. Therefore, we present the local stabilizing layer, which restricts the receptive field of the last layer, to mitigate the artifacts caused by pixel shuffling. Our contributions are as follows:
此外,即时显示新用户提示的着色结果对于帮助用户无延迟地逐步完成图像着色至关重要。为此,我们采用高效像素洗牌操作[29]生成彩色图像——这种上采样技术通过重塑输出通道维度来提升空间分辨率。轻量级像素洗牌操作使我们能够摒弃传统解码器架构,相比现有基线方法实现更快的推理速度。但如图2所示,大比例上采样的像素洗牌容易生成缺失细节、存在明显边界的失真图像。因此我们提出局部稳定层,通过限制最后一层的感受野来缓解像素洗牌导致的伪影。本文贡献如下:
• We are the first work to utilize a Vision Transformer for point-interactive color iz ation enabling users to selectively colorize relevant regions. • We achieve real-time color iz ation of images by effectively upsampling images with minimal cost, leveraging the pixel shuffling and the local stabilizing layer. • We provide quantitative and qualitative results demonstrating that iColoriT highly outperforms existing state-of-the-art baselines and generates reasonable results with fewer user interactions.
• 我们首次采用Vision Transformer实现点交互式上色,使用户能够选择性着色相关区域。
• 通过高效低成本上采样技术(结合像素重组与局部稳定层),我们实现了图像的实时上色。
• 定量与定性实验表明,iColoriT显著超越现有最优基线模型,且能以更少的用户交互生成合理结果。
2. Related Work
2. 相关工作
Interactive Color iz ation Learning-based methods for image colorization [12–14, 14, 32, 35, 42, 44, 47] have proposed fully-automated color iz ation methods, which generate reasonable color images without the need of any user intervention. Interactive color iz ation methods [7, 16–18, 22, 37, 39–41, 43, 46] are designed to colorize images given a user’s condition which conveys color-related information. A widely-studied condition type for interactive color iz ation methods are reference images [7, 17, 18, 22, 37, 39, 41, 43], which are already-colored exemplar images. Using reference images can be convenient since the user can provide the overall color tones with a single image. However, it is difficult for the user to further edit specific regions in the colorized image since a new reference image is likely to produce a different color iz ation result.
基于学习的图像着色方法 [12–14, 14, 32, 35, 42, 44, 47] 提出了全自动着色方案,无需用户干预即可生成合理的彩色图像。交互式着色方法 [7, 16–18, 22, 37, 39–41, 43, 46] 则通过用户提供的色彩相关条件进行着色。其中,参考图像 [7, 17, 18, 22, 37, 39, 41, 43] 作为交互式着色方法中广泛研究的条件类型,是指已着色的示例图像。使用参考图像非常便捷,用户只需提供单张图像即可确定整体色调。但由于更换参考图像会导致着色结果变化,用户难以对已着色图像的特定区域进行进一步编辑。

Figure 2. Images generated with large upsample ratios [5] tends to suffer from evident borders between image patches.
图 2: 采用大上采样比例 [5] 生成的图像往往会出现明显的图像块间边界。
Point-interactive Color iz ation Point-interactive colorization models [16, 40, 46] allow the user to progressively colorize images by specifying colors (i.e., user hints) at different point locations in the input grayscale image. Since commonly used point sizes for specifying the spatial locations range from $2\times2$ to $7\times7$ pixels, the user hints only cover a small portion of the entire image. Thus, a point-interactive color iz ation model is required to propagate user hints to the entire image in order to produce a reasonable result with minimal user interaction. Early approaches [16, 40] utilized hand-crafted image filters to determine the propagation region of each hint by detecting simple patterns. The colors of the user hints are then propagated within each region using optimization techniques. Recently, Zhang et al. [46] proposed a learning-based method by extending an existing unconditional color iz ation model [44] to produce color images given a grayscale image and user hints. Although these methods use user hints as a condition for generating color images, common failure cases presented in Figure 1 indicate that the models often propagate hints in completely. Stacking convolutional layers to propagate user hints indicates that propagating hints to distant relevant regions can only be done in the deeper layers, which makes colorizing larger semantic regions more challenging than nearby regions. Thus, we utilize the self-attention layer to enable user hints to propagate to any relevant regions at all layers.
点交互式着色
点交互式着色模型 [16, 40, 46] 允许用户通过在输入灰度图像的不同位置指定颜色(即用户提示)来逐步着色图像。由于常用的空间位置指定点尺寸范围为 $2\times2$ 至 $7\times7$ 像素,用户提示仅覆盖整个图像的极小部分。因此,点交互式着色模型需要将用户提示传播至整个图像,从而以最少的用户交互生成合理结果。早期方法 [16, 40] 使用手工设计的图像滤波器通过检测简单模式来确定每个提示的传播区域,随后利用优化技术在区域内传播用户提示的颜色。最近,Zhang 等人 [46] 提出了一种基于学习的方法,通过扩展现有无条件着色模型 [44],在给定灰度图像和用户提示时生成彩色图像。尽管这些方法将用户提示作为生成彩色图像的条件,但图 1 所示的常见失败案例表明,模型往往无法完全传播提示。通过堆叠卷积层传播用户提示意味着,仅能在深层将提示传播至远处相关区域,这使得为较大语义区域着色比邻近区域更具挑战性。因此,我们利用自注意力层(self-attention layer)使用户提示能在所有层传播至任意相关区域。
Image Color iz ation with Transformers Unlike the widely-used convolution-based approach for image synthesis, recent studies [5, 13, 15, 38] made efforts to synthesize images by only utilizing the Transformer architecture. Color iz ation Transformer (ColTran) [13] proposes an auto regressive model for unconditional color iz ation which uses the Transformer decoder architecture [34] in order to generate diverse color iz ation results. Despite its outstanding performance for unconditional color iz ation, the excessively slow inference speed of auto regressive models hinders its application to user-interactive scenarios. Specifically, it takes 3.5-5 minutes to colorize a batch of 20 images of size $64\times64$ images even with a P100 GPU. In this work, we leverage the Transformer encoder to generate the colors of a grayscale image. The multi-head attention of the Transformer encoder enables our approach to generate color images with a single forward pass which reduces the inference time of our model compared to auto regressive color iz ation.
基于Transformer的图像着色方法
与广泛使用的基于卷积的图像合成方法不同,近期研究[5,13,15,38]致力于仅通过Transformer架构实现图像合成。着色Transformer(ColTran)[13]提出了一种无条件着色的自回归模型,该模型采用Transformer解码器架构[34]来生成多样化的着色结果。尽管在无条件着色任务中表现优异,但自回归模型极慢的推理速度阻碍了其在用户交互场景中的应用。具体而言,即使使用P100 GPU,处理20张$64\times64$尺寸的图像批次仍需3.5-5分钟。本研究利用Transformer编码器生成灰度图像对应的色彩,其多头注意力机制使得我们的方法仅需单次前向传播即可生成彩色图像,相比自回归着色方法显著降低了推理耗时。
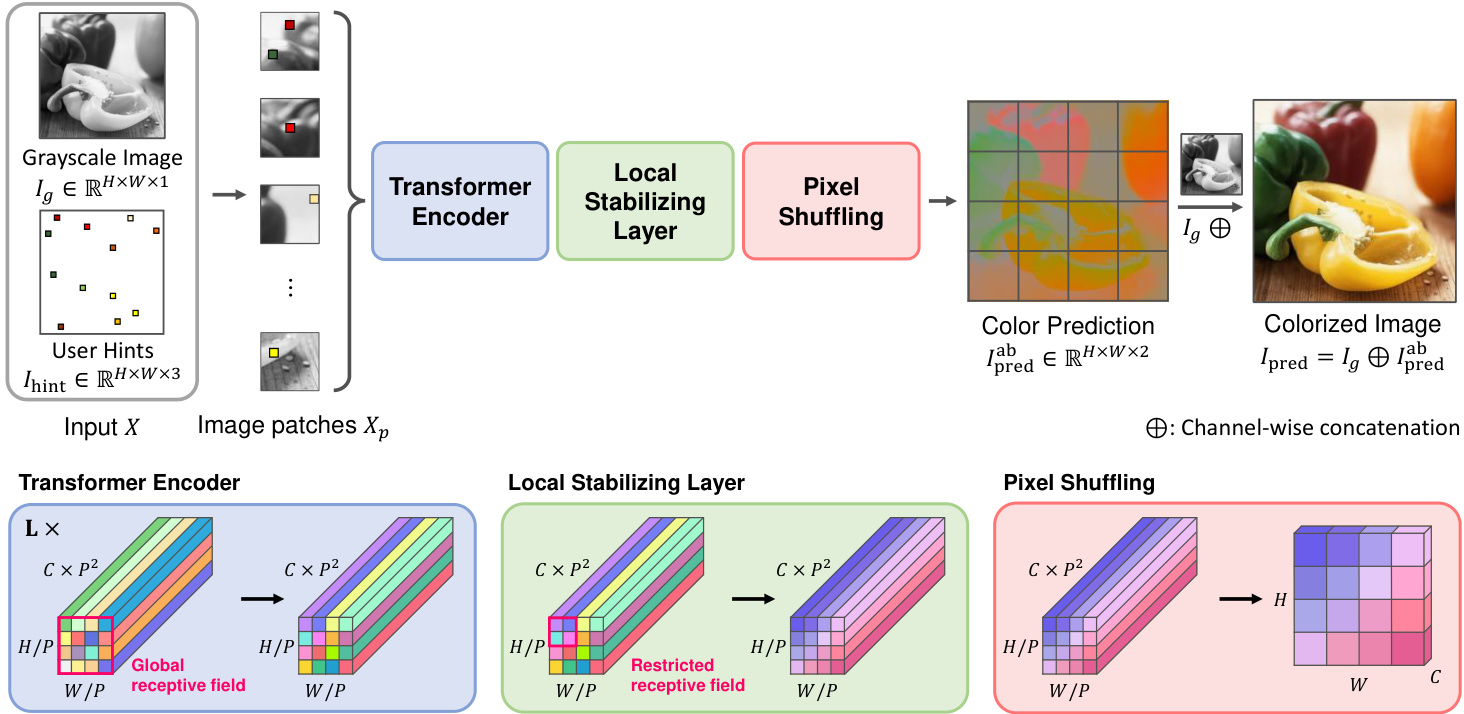
Figure 3. The overall workflow of iColoriT. We first obtain input $X$ by concatenating the grayscale image $I_{g}$ and the user hint $I_{\mathrm{hint}}$ containing color conditions. The input is reshaped into input patches for the Transformer encoder. The output features from the Transformer encoder are passed through the local stabilizing layer and the pixel shuffling layer to obtain the final colors $I_{\mathrm{pred}}^{\mathrm{ab}}.I_{\mathrm{pred}}^{\mathrm{ab}}$ is then concatenated with $I_{g}$ to produce the colorized image. 𝐻: Height 𝑊: Width 𝐶: Channel 𝐿: Number of layers $P$ : Patch size
图 3: iColoriT 的整体工作流程。我们首先通过将灰度图像 $I_{g}$ 和包含颜色条件的用户提示 $I_{\mathrm{hint}}$ 拼接起来获得输入 $X$。输入被重塑为 Transformer 编码器的输入块。Transformer 编码器的输出特征经过局部稳定层和像素洗牌层处理后,得到最终的色彩 $I_{\mathrm{pred}}^{\mathrm{ab}}$。$I_{\mathrm{pred}}^{\mathrm{ab}}$ 随后与 $I_{g}$ 拼接生成着色图像。𝐻: 高度 𝑊: 宽度 𝐶: 通道数 𝐿: 层数 $P$: 块大小
Upsampling via Pixel Shuffling Pixel shuffling [29] is an upsampling operation that rearranges a $(H,W,C\times P^{2})$ sized feature map into a shape of $(H\times P,W\times P,C)$ where each channel in the original feature map is reshaped into a $P\times P$ image patch. This can be viewed as upsampling via reshaping, and is often used in super-resolution approaches to effectively upsample an image with minimal computational overhead. ViTGAN [15] is a pioneering approach for using Transformer encoders for image generation and synthesizing image patches by pixel shuffling the output feature map. However, the usage of pixel shuffling was limited to a small upscale factor of 4 or 8, restricting the model to generate images in small resolutions (e.g., $32\times32$ and $64\times64)$ . A known issue [5] with pixel shuffling with larger upsampling ratios $\mathit{\check{P}}>8$ ) was that output images tend to contain evident borders between image patches as seen in Figure 2. This is due to upsampling different image patches from different locations in the feature map. To overcome this hurdle, we present a local stabilizing layer, which promotes neighboring image patches to have coherent colors, allowing iColoriT to effectively upsample images to higher resolutions $(i.e.,224\times224)$ without such artifacts.
通过像素重排进行上采样
像素重排 [29] 是一种上采样操作,它将尺寸为 $(H,W,C\times P^{2})$ 的特征图重新排列为 $(H\times P,W\times P,C)$ 的形状,其中原始特征图中的每个通道被重塑为一个 $P\times P$ 的图像块。这可以视为通过重塑实现的上采样,常用于超分辨率方法中,以最小的计算开销有效上采样图像。ViTGAN [15] 是首个使用 Transformer 编码器进行图像生成并通过像素重排输出特征图合成图像块的方法。然而,像素重排的使用仅限于较小的放大因子(如 4 或 8),限制了模型生成小分辨率图像(例如 $32\times32$ 和 $64\times64)$ 的能力。已知问题 [5] 是,当上采样比例较大($\mathit{\check{P}}>8$)时,输出图像往往会在图像块之间出现明显边界,如图 2 所示。这是由于从特征图的不同位置上采样不同的图像块所致。为克服这一障碍,我们提出了一种局部稳定层,促使相邻图像块具有连贯的颜色,从而使 iColoriT 能够有效上采样图像至更高分辨率 $(i.e.,224\times224)$ 且不产生此类伪影。
3. Proposed Method
3. 提出方法
3.1. Preliminaries
3.1. 预备知识
We first prepare the grayscale image $I_{g}\in\mathbb{R}^{H\times W\times1}$ and the simulated user hints $I_{\mathrm{hint}}\in\mathbb{R}^{H\times\tilde{W}\times3}$ to be used as our training sample. A grayscale image $I_{g}$ can be acquired from large-scale datasets by converting the color space from RGB to CIELab [30] and taking the $\mathrm{L}$ or lightness value. Similarly, the color condition $I_{\mathrm{hint}}$ provided by the user can be expressed with the remaining a, b channel values $\tilde{I}{\mathrm{hint}}\in\mathbb{R}^{H\times W\times2}$ by filling the a,b channel values of all non-hint regions with 0. The user hint $I_{\mathrm{hint}}\in\mathbb{R}^{H\times W\times3}$ is constructed by adding a third channel to $\tilde{I}_{\mathrm{hint}}$ that marks hint regions with 1 and non-hint regions with 0.
我们首先准备灰度图像 $I_{g}\in\mathbb{R}^{H\times W\times1}$ 和模拟用户提示 $I_{\mathrm{hint}}\in\mathbb{R}^{H\times\tilde{W}\times3}$ 作为训练样本。灰度图像 $I_{g}$ 可通过将RGB色彩空间转换为CIELab [30]并提取 $\mathrm{L}$ (亮度) 值,从大规模数据集中获取。类似地,用户提供的色彩条件 $I_{\mathrm{hint}}$ 可用剩余a、b通道值 $\tilde{I}{\mathrm{hint}}\in\mathbb{R}^{H\times W\times2}$ 表示,非提示区域的a、b通道值填充为0。用户提示 $I_{\mathrm{hint}}\in\mathbb{R}^{H\times W\times3}$ 通过向 $\tilde{I}_{\mathrm{hint}}$ 添加第三个通道构建,该通道用1标记提示区域,用0标记非提示区域。
During training, we simulate the user hints by determining the hint location and the color of the hint. We sample hint locations from a uniform distribution since a user may provide hints anywhere in the image. Once the hint location is decided, the color of the user hint is obtained by calculating the average color values for each channel within the hint region since a user is expected to provide a single color for a single hint location. Finally, given the grayscale image $I_{g}\in\overline{{\mathbb{R}^{H\times W\times1}}}$ and the simulated user hints $I_{\mathrm{hint}}\in\mathbb{R}^{H\times\check{W}\times3}$ , we obtain our input $X\in\mathbb{R}^{H\times W\times4}$ by
在训练过程中,我们通过确定提示位置和提示颜色来模拟用户提示。由于用户可能在图像任意位置提供提示,我们从均匀分布中采样提示位置。确定提示位置后,通过计算提示区域内各通道的平均颜色值来获取用户提示颜色,因为用户通常会在单个提示位置提供单一颜色。最终,给定灰度图像 $I_{g}\in\overline{{\mathbb{R}^{H\times W\times1}}}$ 和模拟用户提示 $I_{\mathrm{hint}}\in\mathbb{R}^{H\times\check{W}\times3}$ ,我们通过以下方式获得输入 $X\in\mathbb{R}^{H\times W\times4}$ :
$$
X=I_{g}\oplus I_{\mathrm{hint}},
$$
$$
X=I_{g}\oplus I_{\mathrm{hint}},
$$
where $\bigoplus$ is the channel-wise concatenation.
其中 $\bigoplus$ 表示通道级拼接。
3.2. Propagating User Hints with Transformers
3.2. 基于Transformer的用户提示传播
We utilize the Vision Transformer [4] to achieve a global receptive field for propagating user hints across the image as shown in Figure 3. We first reshape our input $X\in$ $\mathbb{R}^{H\times W\times4}$ into a sequence of tokens $X_{p}\in\mathbb{R}^{N\times(P^{2}\times4)}$ where $H,W$ are the height and width of the original image, $P$ is the patch size, and $N=H W/P^{2}$ is the number of input tokens (i.e., sequence length). Thus, a $P\times P\times4$ size image patch from the original input $X$ is used as a single input token. These sequence of input tokens are passed through the Transformer encoder, which computes the input as,
我们利用Vision Transformer [4]实现了全局感受野,以在图像中传播用户提示,如图3所示。首先将输入$X\in$ $\mathbb{R}^{H\times W\times4}$重塑为token序列$X_{p}\in\mathbb{R}^{N\times(P^{2}\times4)}$,其中$H,W$为原始图像的高度和宽度,$P$为分块大小,$N=H W/P^{2}$为输入token数量(即序列长度)。因此,原始输入$X$中大小为$P\times P\times4$的图像分块被用作单个输入token。这些输入token序列通过Transformer编码器进行计算,其输入公式为
$$
\begin{array}{r}{z_{0}=X_{p}+E_{p o s},\quad E_{p o s}\in\mathbb{R}^{N\times d}}\end{array}
$$
$$
\begin{array}{r}{z_{0}=X_{p}+E_{p o s},\quad E_{p o s}\in\mathbb{R}^{N\times d}}\end{array}
$$
$$
z_{l}^{\prime}=\mathbf{M}\mathbf{S}\mathbf{A}(\mathbf{L}\mathbf{N}(z_{l-1}))+z_{l-1},
$$
$$
z_{l}^{\prime}=\mathbf{M}\mathbf{S}\mathbf{A}(\mathbf{L}\mathbf{N}(z_{l-1}))+z_{l-1},
$$
$$
z_{l}=\mathbf{M}\mathbf{L}\mathbf{P}(\mathbf{L}\mathbf{N}(z_{l}^{\prime}))+z_{l}^{\prime},
$$
$$
z_{l}=\mathbf{M}\mathbf{L}\mathbf{P}(\mathbf{L}\mathbf{N}(z_{l}^{\prime}))+z_{l}^{\prime},
$$
$$
y_{p}=\operatorname{LN}(z_{L}),
$$
$$
y_{p}=\operatorname{LN}(z_{L}),
$$
where $E_{p o s}$ denotes the sinusoidal positional encoding [4], ${\mathrm{MSA}}(\cdot)$ indicates the multi-head self-attention [34], $\operatorname{LN}(\cdot)$ indicates the layer normalization [2], $d$ denotes the hidden dimension, $l$ denotes the layer number, and $y_{p}\in\mathbb{R}^{N\times d}$ denotes the output of the Transformer encoder. Since selfattention does not utilize any position-related information, we add positional encoding $E_{p o s}$ to the input and relative positional bias [9,10,19,26] in the attention layer. Thus, the attention layer is computed as,
其中 $E_{pos}$ 表示正弦位置编码 [4],${\mathrm{MSA}}(\cdot)$ 表示多头自注意力 [34],$\operatorname{LN}(\cdot)$ 表示层归一化 [2],$d$ 表示隐藏维度,$l$ 表示层数,$y_{p}\in\mathbb{R}^{N\times d}$ 表示 Transformer 编码器的输出。由于自注意力未利用任何位置相关信息,我们在输入中添加位置编码 $E_{pos}$,并在注意力层中加入相对位置偏置 [9,10,19,26]。因此,注意力层的计算方式为:
$$
\mathrm{Attention}(Q,K,V)=\operatorname{softmax}(Q K^{T}/\sqrt{d}+B)V,
$$
$$
\mathrm{Attention}(Q,K,V)=\operatorname{softmax}(Q K^{T}/\sqrt{d}+B)V,
$$
where $Q,K,V\in\mathbb{R}^{N\times d}$ are the query, key and value matrices, $B\in\mathbb{R}^{N\times N}$ is the relative positional bias. The colors of the user hints are able to propagate to any spatial location at all layers due to the global receptive field of the selfattention mechanism.
其中 $Q,K,V\in\mathbb{R}^{N\times d}$ 是查询(query)、键(key)和值(value)矩阵, $B\in\mathbb{R}^{N\times N}$ 是相对位置偏置。由于自注意力(selfattention)机制具有全局感受野,用户提示的颜色能够在所有层传播到任意空间位置。
3.3. Pixel Shuffling and the Local Stabilizing Layer
3.3. 像素重排与局部稳定层
The output features of the Transformer encoder $y_{p}\in$ $\mathbb{R}^{N\times d}$ can be viewed as a feature map $y\in\mathbb{R}^{H/P\times W/P\times d}$ of the original image. The spatial resolution of the output feature map $y$ is smaller than the resolution of the input image by a factor of $P$ since image patches of size $P\times P$ consists of a single input token. Therefore, the output feature map $y$ needs to be upsampled in order to obtain a fullresolution color image. While previous approaches [32, 46] leverage a decoder for upsampling, we utilize pixel shuffling [29] which is an upsampling technique rearranging a $(H/P,W/P,C\times P^{2})$ feature map into a shape of $(H,W,C)$ to obtain a full-resolution image.
Transformer编码器的输出特征 $y_{p}\in$ $\mathbb{R}^{N\times d}$ 可视为原始图像的特征图 $y\in\mathbb{R}^{H/P\times W/P\times d}$。由于尺寸为 $P\times P$ 的图像块对应单个输入Token,输出特征图 $y$ 的空间分辨率比输入图像缩小了 $P$ 倍。因此需对 $y$ 进行上采样以获得全分辨率彩色图像。先前方法[32,46]采用解码器实现上采样,而本文使用像素重组[29]技术——该技术将 $(H/P,W/P,C\times P^{2})$ 特征图重排为 $(H,W,C)$ 形状来获得全分辨率图像。
However, as mentioned in Section 2, large upsampling ratios (e.g., $P>8,$ may lead to images with visible artifacts along the image patch boundaries as seen in Figure 4. Thus, in order to promote reasonable generation of colors, we propose a local stabilizing layer, which restricts the model to generate colors utilizing neighboring features, and place the layer before pixel shuffling. We provide experiments in Section 4.2 with various design choices for the local stabilizing layer (e.g., linear, convolutional layer, and local attention) and select a simple yet effective convolutional layer as our final model. To sum up, our upsampling process can be written as,
然而,如第2节所述,较大的上采样比例(例如$P>8$)可能导致图像块边界处出现可见伪影,如图4所示。因此,为促进合理的色彩生成,我们提出局部稳定层(local stabilizing layer),该层通过利用邻近特征来约束模型生成色彩,并将其置于像素洗牌操作之前。第4.2节中我们针对局部稳定层的不同设计方案(如线性层、卷积层和局部注意力)进行了实验,最终选择简单高效的卷积层作为最终模型。综上,我们的上采样过程可表述为:

Figure 4. Example images of inconsistent color iz ation results observed in images produced without the local stabilizing layer.
图 4: 未使用局部稳定层时生成的图像中观察到的色彩不一致结果示例。
$$
I_{\mathrm{pred}}^{\mathrm{ab}}=\mathcal{P}{\mathcal{S}}(\mathrm{LS}(y)),
$$
$$
I_{\mathrm{pred}}^{\mathrm{ab}}=\mathcal{P}{\mathcal{S}}(\mathrm{LS}(y)),
$$
where $\mathcal{P S}(\cdot)$ is the pixel shuffling operation, $\mathrm{LS}(\cdot)$ is the local stabilizing layer, and $I_{\mathrm{pred}}^{\mathrm{ab}}\in\mathbb{R}^{H\times W\times2}$ is the ab color channel outputs. The predicted color image $I_{\mathrm{pred}}\in{}$ $\mathbb{R}^{H\times W\times3}$ is obtained by
其中 $\mathcal{P S}(\cdot)$ 是像素混洗操作,$\mathrm{LS}(\cdot)$ 是局部稳定层,$I_{\mathrm{pred}}^{\mathrm{ab}}\in\mathbb{R}^{H\times W\times2}$ 是 ab 颜色通道输出。预测的彩色图像 $I_{\mathrm{pred}}\in{}$ $\mathbb{R}^{H\times W\times3}$ 通过以下方式获得:
$$
{\cal I}{\mathrm{pred}}={\cal I}{g}\oplus{\cal I}_{\mathrm{pred}}^{\mathrm{ab}},
$$
$$
{\cal I}{\mathrm{pred}}={\cal I}{g}\oplus{\cal I}_{\mathrm{pred}}^{\mathrm{ab}},
$$
which is the concatenation of the given grayscale input $I_{g}$ ( $\mathrm{L}$ channel) and $I_{\mathrm{pred}}^{\mathrm{ab}}$ (ab channel). Through pixel shuffling and the local stabilizing layer, we can effectively obtain a full-resolution color image without an additional decoder, allowing real-time color iz ation for the user (Section 4.1).
这是将给定的灰度输入 $I_{g}$ (L通道) 与 $I_{\mathrm{pred}}^{\mathrm{ab}}$ (ab通道) 进行拼接的结果。通过像素重组和局部稳定层,我们无需额外解码器即可高效获取全分辨率彩色图像,从而为用户实现实时着色 (详见第4.1节)。
3.4. Objective Function
3.4. 目标函数
We train our model with the Huber loss [11] between the predicted image and the original color image in the CIELab color space,
我们在CIELab色彩空间中使用预测图像与原始彩色图像之间的Huber损失[11]训练模型
$$
\begin{array}{l}{{\displaystyle{\cal L}{r e c o n}=}\displaystyle{\frac{1}{2}({\cal I}{\mathrm{pred}}-{\cal I}{G T})^{2}\mathbb{1}{|{\cal I}{\mathrm{pred}}-{\cal I}{G T}|<1}}}\ {~+\displaystyle{(|{\cal I}{\mathrm{pred}}-{\cal I}{G T}|-\frac{1}{2})\mathbb{1}{|{\cal I}{\mathrm{pred}}-{\cal I}_{G T}|\geq1}}.}\end{array}
$$
$$
\begin{array}{l}{{\displaystyle{\cal L}{r e c o n}=}\displaystyle{\frac{1}{2}({\cal I}{\mathrm{pred}}-{\cal I}{G T})^{2}\mathbb{1}{|{\cal I}{\mathrm{pred}}-{\cal I}{G T}|<1}}}\ {~+\displaystyle{(|{\cal I}{\mathrm{pred}}-{\cal I}{G T}|-\frac{1}{2})\mathbb{1}{|{\cal I}{\mathrm{pred}}-{\cal I}_{G T}|\geq1}}.}\end{array}
$$
4. Experiments
4. 实验
Implementation Details We follow the configurations of ViT-B [4] for the Transformer encoder blocks. For the local stabilizing layer, we use a single layer with a receptive field of 3. We experiment with two types of layers (Section 4.2), the local attention and the convolutional layer, and use the simple yet effective convolutional layer as the default local stabilizing layer. For training, we resize images to a $224\times224$ resolution and use a patch size of $P=16$ which also becomes the upsampling ratio. Thus, the sequence length $N$ is 196 and the last output dimension $d$ is 512. We sample hint locations uniformly across the image and sample the number of hints from a uniform distribution $\mathcal{U}(0,128)$ . We provide experiments on different model sizes, patch sizes, the local stabilizing layer, and the number of hints in Section 4.2 and the supplementary material.
实现细节
我们遵循 ViT-B [4] 的配置来构建 Transformer 编码器模块。对于局部稳定层,我们采用感受野为 3 的单层结构。实验中对比了两种层类型(第 4.2 节)——局部注意力层与卷积层,最终选择简单高效的卷积层作为默认局部稳定层。训练时,我们将图像调整为 $224\times224$ 分辨率,使用 $P=16$ 的块尺寸(同时作为上采样比例),因此序列长度 $N$ 为 196,最终输出维度 $d$ 为 512。提示点位置在图像上均匀采样,提示点数量从均匀分布 $\mathcal{U}(0,128)$ 中抽取。关于不同模型规模、块尺寸、局部稳定层类型及提示点数量的实验详见第 4.2 节与补充材料。
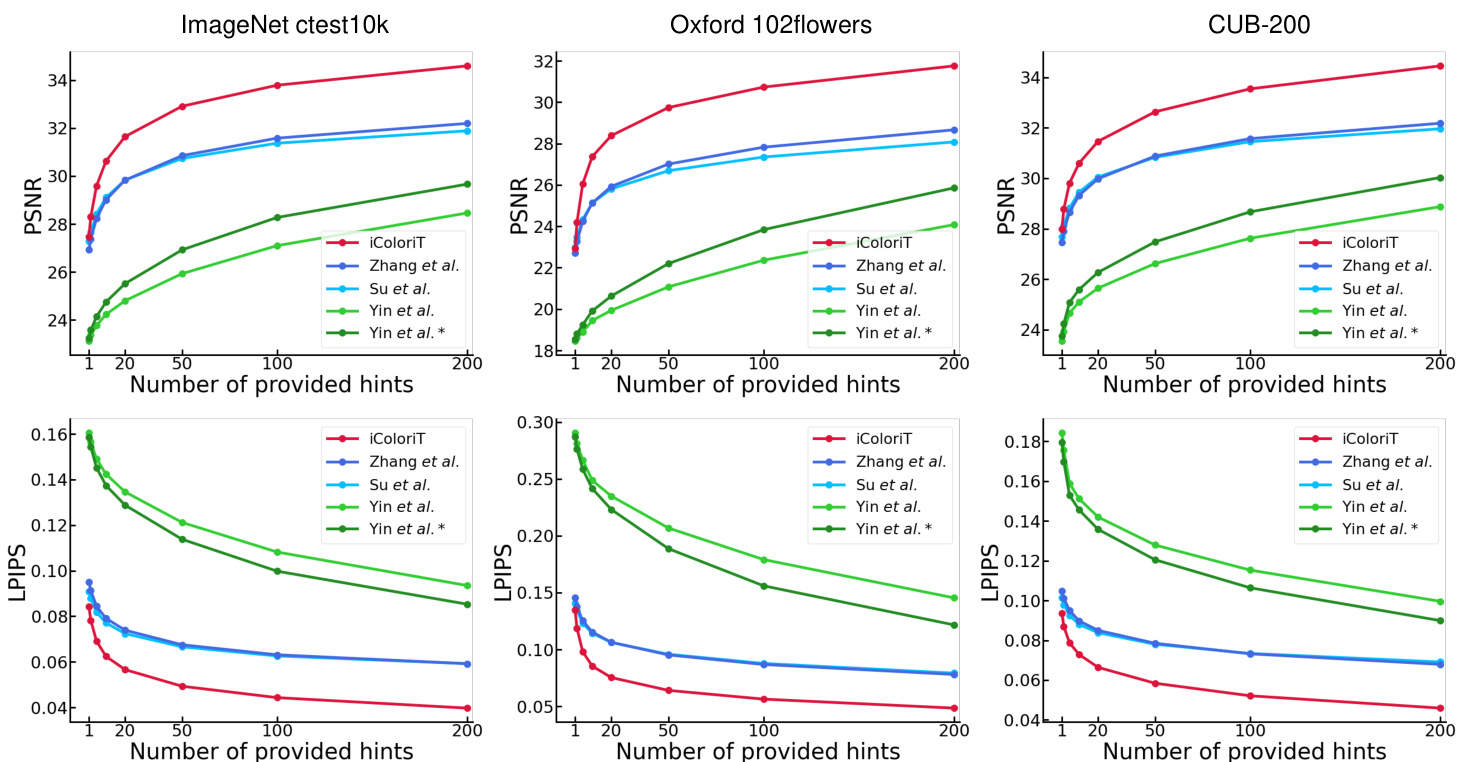
Figure 5. Average PSNR and LPIPS of the test images according to the number of provided hints. Hint locations are sampled from a uniform distribution and $2\times2$ hints are revealed to the model. Yin et al. ∗ [40] denotes the results evaluated with $2\times2$ hints and Yin et al. [40] denotes the results evaluated with $7\times7$ hints. iColoriT outperforms existing approaches by a large margin as the number of provided hints increases.
图 5: 根据提供的提示数量计算的测试图像平均 PSNR 和 LPIPS。提示位置从均匀分布中采样,并向模型展示 $2\times2$ 的提示。Yin et al. ∗ [40] 表示使用 $2\times2$ 提示评估的结果,Yin et al. [40] 表示使用 $7\times7$ 提示评估的结果。随着提示数量的增加,iColoriT 大幅优于现有方法。
We use the AdamW optimizer [21] with a learning rate of 0.0005 managed by the cosine annealing scheduler [20]. The model is trained for $2.5\mathbf{M}$ iterations with a batch size of 512.
我们使用 AdamW 优化器 [21],学习率为 0.0005,并通过余弦退火调度器 [20] 进行管理。模型训练了 $2.5\mathbf{M}$ 次迭代,批次大小为 512。
Datasets For training, we use the ImageNet 2012 train split [27] which consists of 1,281,167 images. We do not use the classification labels during training since our model is trained in a self-supervised manner. We evaluate our method on three datasets from different domains, all of which are colorful validation datasets suitable for evaluating color iz ation approaches. Note that we do not additionally finetune the model for each validation dataset. The ImageNet c test 10 k 10 k [14] is a subset of the ImageNet validation split used as a standard benchmark for evaluating color iz ation models. ImageNet ctest10k excludes any grayscale image from ImageNet and consists of 10,000 color images. We also evaluate on the Oxford 102flowers dataset [24] and the CUB-200 dataset [36] which provide 1,020 colorful flower images from 102 categories and 3,033 samples of bird images from 200 different species, respectively.
数据集
对于训练,我们使用包含1,281,167张图像的ImageNet 2012训练集[27]。由于我们的模型采用自监督训练方式,训练过程中不使用分类标签。我们在三个不同领域的验证数据集上评估方法,这些数据集均为适合评估着色技术的彩色验证集。请注意,我们没有针对每个验证集额外微调模型。
ImageNet ctest10k[14]是ImageNet验证集的子集,包含10,000张彩色图像(已排除灰度图像),被广泛用作着色模型的标准基准测试集。我们还评估了Oxford 102flowers数据集[24](包含102个类别的1,020张花卉彩色图像)和CUB-200数据集[36](涵盖200个物种的3,033张鸟类图像)。
Baselines We compare the performance of iColoriT with existing interactive color iz ation methods [40, 46]. We also extend a recent unconditional color iz ation model by Su et al. [32], which utilizes an off-the-shelf object detector [6] to individually color multiple instances, to a point-interactive color iz ation model. Since the model proposed by Su et al. [32] employs the same model architecture and objective function as the point-interactive color iz ation model by Zhang et al. [46], we are able to effortlessly extend the approach to a point-interactive color iz ation method by conditioning the model with user hints in the same manner. The extended model is trained under the configurations provided by Zhang et al. [46] and Su et al. [32] using ImageNet [27]. Note that although the model proposed by Su et al. [32] is trained with the ImageNet [27] dataset, this approach is assisted by an off-the-shelf object detector pre-trained on a large-scale object detection dataset [3]. All baselines are trained and evaluated with the publicly available official codes.
基线方法
我们将iColoriT与现有的交互式着色方法[40, 46]进行性能对比。同时将Su等人[32]提出的无条件着色模型(使用现成目标检测器[6]对多个实例单独着色)扩展为点交互式着色模型。由于Su等人[32]采用的模型架构和目标函数与Zhang等人[46]的点交互式着色模型完全一致,我们只需以相同方式用用户提示信息作为条件输入,即可将其扩展为点交互式着色方法。扩展模型在ImageNet[27]数据集上采用Zhang等人[46]和Su等人[32]提供的配置进行训练。需注意的是,虽然Su等人[32]模型使用ImageNet[27]训练,但其方法通过在大规模目标检测数据集[3]上预训练的现成目标检测器提供辅助。所有基线方法均使用公开的官方代码进行训练和评估。
4.1. Comparison with Existing Approaches
4.1. 与现有方法的对比
Quantitative Evaluation of iColoriT We plot the average peak signal-to-noise ratio (PSNR) and the learned perceptual image patch similarity (LPIPS) [45] of the test images according to the number of provided hints in Figure 5. For evaluating the point-interactive color iz ation models, we simulate user hints with the ground-truth colors from the image, considering a situation where the user intends to colorize the grayscale image into the original color image. User hints are simulated by randomly selecting hint locations from a uniform distribution. The hint sizes are set to $2\times2$ and the hint color is given as the average color within each hint region in the original color image following the protocol of Zhang et al. [46]. We empirically find that smaller hint sizes are usually beneficial for both the color iz ation model and the user in terms of receiving and giving accurate color conditions. However, the method proposed by Yin et al. [40] assumes that a user provides an abundant amount of user hints. Thus, we further evaluate this method by revealing larger hints of size $7\times7$ which is the result we report for all following evaluations.
iColoriT的定量评估
我们根据图5中提供的提示数量绘制了测试图像的平均峰值信噪比(PSNR)和学习感知图像块相似度(LPIPS)[45]。为评估点交互式着色模型,我们采用图像真实颜色模拟用户提示,模拟用户意图将灰度图像还原为原始彩色图像的情景。用户提示通过均匀分布随机选取提示位置进行模拟,提示区域尺寸设为$2\times2$,其颜色值取原始彩色图像对应区域的平均颜色,遵循Zhang等人[46]的协议。实验发现较小的提示尺寸通常更有利于着色模型接收精确颜色条件,也便于用户操作。但Yin等人[40]提出的方法假设用户会提供大量提示,因此我们额外评估了尺寸为$7\times7$的较大提示方案,该结果将用于后续所有评估。

Figure 6. Qualitative results of point-interactive color iz ation methods given 1, 5, 10, and 100 user hints. iColoriT is able to produc reasonable color images by appropriately propagating user hints.
图 6: 基于1、5、10和100个用户提示的点交互式着色方法定性结果。iColoriT能够通过合理传播用户提示生成逼真的彩色图像。
We empirically find that methods proposed by Zhang et al. [46] and Su et al. [32] tend to arbitrarily colorize images without reflecting user hints. While this may be helpful for achieving a relatively higher initial PSNR when the arbitrarily colorized color is the ground-truth color, it hinders further control for the user to achieve a high PSNR in subsequent stages of color iz ation. As seen in Figure 5, iColoriT quickly reflects the user hints and aids the user to efficiently colorize grayscale images with minimal interaction. The PSNR in the early stages of color iz ation notably increases with each additional hint. The results indicate that iColoriT highly outperforms existing baselines for generating colorized images a user specifically has in mind.
我们通过实验发现,Zhang等人[46]和Su等人[32]提出的方法倾向于对图像进行任意着色,而未能反映用户提示。虽然当任意着色的颜色恰好是真实颜色时,这种方法可能有助于获得相对较高的初始PSNR值,但它阻碍了用户在后续着色阶段通过进一步控制实现高PSNR值。如图5所示,iColoriT能快速响应用户提示,并通过最简交互帮助用户高效完成灰度图像着色。在着色初期阶段,每增加一个提示都会显著提升PSNR值。结果表明,在生成用户特定设想的着色图像方面,iColoriT显著优于现有基线方法。
Qualitative Results of iColoriT We provide qualitative results produced by the baselines and iColoriT in Figure 6 when given an original grayscale image and the simulated user hints. iColoriT is able to produce realistic images that closely resemble the ground-truth image indicating that a user can colorize images as they please. Also, as seen in the colorized results in Figure 1 and Figure 6, iColoriT is capable of appropriately colorizing large areas even with a small number of user hints while other approaches leave most regions uncolored or incorrectly colored. iColoriT can also colorize detailed regions when given a sufficient number of hints as shown in the last row of Figure 6.
iColoriT的定性结果
我们在图6中展示了基线方法和iColoriT在给定原始灰度图像及模拟用户提示时的生成效果。iColoriT能够生成逼真且接近真实色彩的图像,这表明用户可以随心所欲地为图像上色。此外,从图1和图6的着色结果可以看出,即使只提供少量用户提示,iColoriT也能正确着色大面积区域,而其他方法要么保留大部分区域未着色,要么着色错误。如第6图最后一行所示,当提供足够数量的提示时,iColoriT还能精细处理复杂细节区域的着色。
iColoriT is also suitable for producing diverse colorized images when given various user hints as seen in Figure 7. Instead of the simulated user hints from the ground-truth image, we provide multiple sets of hand-picked user hints to colorize a single grayscale image. We fix the hint locations for an image and alter the user-provided colors to observe the colorized results. iColoriT can produce various realistic color iz ation results that reflect the intention of the user. We provide uncurated qualitative results and a demo video in the supplementary material. Also, we will release the iColoriT demo including the graphical user interface, providing a powerful tool for image color iz ation.
iColoriT 也适用于根据多种用户提示生成多样化的着色图像,如图 7 所示。我们不再使用从真实图像模拟的用户提示,而是提供多组手动挑选的用户提示来为同一张灰度图像着色。固定图像中的提示位置并调整用户提供的颜色后,iColoriT 能生成反映用户意图的多种逼真着色效果。补充材料中提供了未经筛选的定性结果和演示视频。此外,我们将发布包含图形用户界面的 iColoriT 演示工具,为图像着色提供强大支持。

Figure 7. Images colorized with different colors provided by the user. The images from the ImageNet ctest10k [14] are colored by hand-picking hint locations and changing the hint colors.
Table 1. S cal ability of iColoriT to lightweight models. PSNR and LPIPS given 10 user hints $\mathrm{PSNR}@10$ and LPIPS $@10$ ) on the ImageNet ctest10k [14] are reported for each model.
图 7: 用户提供不同颜色着色的图像。ImageNet ctest10k [14] 中的图像通过手动选取提示位置并更改提示颜色进行着色。
| 方法 | PSNR@10 | LPIPS@10 |
|---|---|---|
| iColoriT-T | 28.86 | 0.084 |
| iColoriT-S | 29.67 | 0.073 |
| iColoriT | 30.63 | 0.062 |
表 1: iColoriT 在轻量级模型上的可扩展性。每个模型在 ImageNet ctest10k [14] 上给定 10 个用户提示时的 PSNR (PSNR@10) 和 LPIPS (LPIPS@10) 结果。
Scaling to Lightweight Models iColoriT can easily scale to smaller models and still achieve high performance. We train iColoriT in smaller scales using the configurations of the ViT-S and the ViT-Ti [31] for our Transformer encoder. We report the PSNR and the LPIPS given 10 hints $(\mathrm{PNSR}@10$ and $\mathrm{LPIPS}@10)$ for ImageNet ctest10k and compare them against other models in Table 1. We were able to train iColoriT-S and iColoriT-T with only a slight performance drop and still maintain a high performance. We believe that the Transformer architecture and the self-attention mechanism are central for propagating hints to larger semantic regions, achieving a high PSNR even in small-scale models.
扩展到轻量级模型
iColoriT 可轻松适配小型模型并保持高性能。我们使用 ViT-S 和 ViT-Ti [31] 的配置训练了缩小版的 Transformer 编码器。表 1 展示了 ImageNet ctest10k 数据集在 10 个提示点下的 PSNR 与 LPIPS 指标 (PNSR@10 和 LPIPS@10) 与其他模型的对比。iColoriT-S 和 iColoriT-T 仅出现轻微性能下降,仍保持优异表现。我们认为 Transformer 架构和自注意力机制能有效将提示点信息传递至更大语义区域,这是小规模模型也能实现高 PSNR 的关键。
Real-time Inference The inference speed (i.e., latency) of point-interactive models is important for providing a satisfying user experience. Thus, we measure the time required for a single forward pass and compare it with the latency of baseline models in Table 2. We report the speed on both CPU and GPU using a commercial AMD Ryzen 5 PRO 4650G and a single NVIDIA RTX 3090. We also provide the number of floating-point operations (FLOPs) and the number of parameters required for each model. We were not able to measure GPU latency, FLOPs, and the number of parameters for Yin et al. [40] since the method is not a learning-based model. The model proposed by Su et al. [32] operates in two stages, an initial object detection stage and an instance-wise color iz ation stage. We only report the latency for the second stage which still exhibits a slow inference speed since the color iz ation model needs to color multiple objects individually. Due to the efficient pixel shuffling for upsampling images, iColoriT enjoys a short latency of $540\mathrm{ms}$ and $14\mathrm{ms}$ on a CPU and GPU device respectively, providing real-time color iz ation results for the user. iColoriT-T and iColoriT-S show an exceptionally fast inference speed on a CPU-only device (i.e., 177ms and $253\mathrm{ms}$ , respectively), which makes the model an appealing option when considering applications to real-world scenarios where accelerators may not be available.
实时推理
点交互模型的推理速度(即延迟)对于提供良好的用户体验至关重要。因此,我们测量了单次前向传播所需的时间,并与基线模型的延迟进行了对比(表2)。我们在商用AMD Ryzen 5 PRO 4650G CPU和单块NVIDIA RTX 3090 GPU上分别测试了速度,同时提供了各模型所需的浮点运算量(FLOPs)和参数量。由于Yin等人[40]的方法并非基于学习的模型,我们无法测量其GPU延迟、FLOPs和参数量。Su等人[32]提出的模型分为两个阶段运行:初始目标检测阶段和实例级着色阶段。我们仅报告了第二阶段的延迟,但由于着色模型需逐个为多个对象上色,其推理速度仍然较慢。得益于高效的像素混洗上采样技术,iColoriT在CPU和GPU设备上分别实现了540ms和14ms的低延迟,为用户提供实时着色效果。iColoriT-T和iColoriT-S在纯CPU设备上表现出极快的推理速度(分别为177ms和253ms),这使得该模型在缺乏加速器的实际应用场景中极具吸引力。
Table 2. Inference speed of iColoriT and each baseline model. We provide the latency of each model in a CPU device and a GPU device along with the computational cost measured in FLOPs and number of parameters.
| 方法 | CPU 延迟 | GPU 延迟 | GFLOPs |
|---|---|---|---|
| Zhang 等人 [46] | 881ms | 24ms | 58.04 |
| Yin 等人 [40] | 15,248ms | - | - |
| Su 等人 [32] | 1,389ms | 45ms | 123.48 |
| iColoriT-T | 177ms | 13ms | 1.43 |
| iColoriT-S | 253ms | 14ms | 4.95 |
| iColoriT | 540ms | 14ms | 18.22 |
表 2: iColoriT 与各基线模型的推理速度对比。我们提供了各模型在 CPU 设备和 GPU 设备上的延迟时间,以及以 FLOPs 和参数量衡量的计算成本。
4.2. Ablation Study
4.2. 消融研究
Designing the Local Stabilizing Layer We provide an ablation study on the local stabilizing layer by replacing it with different operations such as the linear layer and the local self-attention layer [25]. Using a linear layer can be viewed as eliminating the local stabilizing layer since a linear layer does not utilize neighboring features for generating the final output. In order to quantify the inconsistent color generation among image patches seen in Figure 4, we measure the mean squared error (MSE) for each image patch and report the variance of the errors within an image. We denote this measure the patch error variance (PEV). A high PEV implies that the model has varying accuracy depending on the image patch. The local stabilizing layer resolves this issue in a simple yet effective manner by predicting the ab channel values of an image patch from neighboring output features as illustrated in Figure 3. We also measure the PSNR near the image patch boundaries (i.e., one pixel from the patch borders) to observe the accuracy in the regions containing inconsistent color generation. As seen in Table 3, adding an operation with a limited receptive field (i.e., convolution and local self-attention) lowers the PEV and increases the PSNR along the patch boundaries, indicating that the model generates colors with consistent accuracy across the image. The convolutional layer serves as a simple yet effective approach for reducing artifacts caused by pixel shuffling and generating realistic colorized images. Changing the Upsampling Ratio We experiment on various patch sizes $P$ (i.e., $P=8,16$ , and 32), which also becomes the upscaling ratio for pixel shuffling. While smaller patch sizes may allow fine-grained calculation of the similarity matrix, the computational cost escalates biquadratically, since the computational complexity for the selfattention follows $\mathcal{O}(N^{2})$ and $N~=~H W/P^{2}$ is the sequence length. Thus, we were not able to train our base model with a smaller patch size due to the prohibitive computational overhead. Instead, we compare the results on the smaller iColoriT-T model and report the average PSNR $@10$ and CPU latency on Table 4. While using a smaller patch size may be beneficial for achieving a higher PSNR, the increased computational cost hinders scaling to larger models for an additional performance gain and increases the CPU latency. We choose a patch size of $16\times16$ since it can obtain both a short latency and a high PSNR while also being scalable to larger models (i.e., iColoriT-S and iColoriT).
设计局部稳定层
我们通过用线性层和局部自注意力层[25]等不同操作替换局部稳定层来进行消融研究。使用线性层可视为消除局部稳定层,因为线性层不会利用相邻特征生成最终输出。为量化图4中图像块间不一致的着色效果,我们测量每个图像块的均方误差(MSE)并计算图像内误差的方差,将该指标称为块误差方差(PEV)。高PEV值表明模型在不同图像块上的准确度存在波动。如图3所示,局部稳定层通过从相邻输出特征预测图像块的ab通道值,以简单有效的方式解决了这个问题。我们还测量了图像块边界附近(即距离边界1像素处)的PSNR值,以观察着色不一致区域的准确度。如表3所示,添加感受野受限的操作(即卷积和局部自注意力)能降低PEV并提升边界PSNR,表明模型能在整幅图像中保持稳定的着色精度。卷积层可有效减少像素重组导致的伪影,生成逼真的着色图像。
调整上采样比率
我们测试了不同图像块尺寸$P$(即$P=8,16$和32),该尺寸也决定了像素重组的上采样比率。较小块尺寸虽能实现更精细的相似度矩阵计算,但由于自注意力计算复杂度为$\mathcal{O}(N^{2})$且序列长度$N~=~H W/P^{2}$,计算成本会呈双二次方增长。因此基础模型无法承受更小块尺寸的训练开销。我们改在小型iColoriT-T模型上比较结果,表4展示了平均PSNR$@10$和CPU延迟。虽然较小块尺寸有助于提升PSNR,但激增的计算成本阻碍了向更大模型的扩展,同时增加了CPU延迟。我们最终选择$16\times16$块尺寸,因其能兼顾低延迟与高PSNR,同时具备向大型模型(iColoriT-S和iColoriT)扩展的能力。
Table 3. Ablation study on the local stabilizing layer. $\mathrm{PSNR}@10$ , PSNR along the boundary $(\mathbf{B}-\mathrm{PSNR}@10)$ , and PEV on the ImageNet ctest10k [14] are reported for each model. All models are trained with the iColoriT-T configuration.
表 3: 局部稳定层的消融研究。报告了各模型在ImageNet ctest10k [14]上的$\mathrm{PSNR}@10$、边界PSNR $(\mathbf{B}-\mathrm{PSNR}@10)$和PEV指标。所有模型均采用iColoriT-T配置训练。
| 方法 | PSNR@10 | B-PSNR@10 | PEV↓ |
|---|---|---|---|
| Linear | 28.78 | 28.71 | 39.39 |
| Local Attention | 28.85 | 28.77 | 38.82 |
| Convolution | 28.86 | 28.80 | 38.81 |
Table 4. iColoriT different upsampling ratios. $\mathrm{PSNR}@10$ , $\mathrm{LPIPS}@10$ , and CPU latency are reported for each model on the ImageNet ctest10k [14] test set. All models are trained with the iColoriT-T configuration.
| PatchSize | PSNR@10 | CPU Latency |
|---|---|---|
| 8x8 | 29.17(+0.31) | 373ms(+196ms) |
| 32×32 | 28.32(-0.54) | 147ms(-30ms) |
| 16 x 16 | 28.86 | 177ms |
表 4: iColoriT 不同上采样比例。在 ImageNet ctest10k [14] 测试集上报告了各模型的 $\mathrm{PSNR}@10$、$\mathrm{LPIPS}@10$ 和 CPU 延迟。所有模型均采用 iColoriT-T 配置训练。
4.3. Visualizing the Internal Representation
4.3. 可视化内部表征
We further provide analysis on the self-attention mechanism to examine how our model is propagating user hints to other regions. We use the attention rollout method [1] to interpret the attention weights from the Transformer encoder for specific spatial locations. We visualize the attention maps for the input tokens which contain a user hint in Figure 8. Attention maps for hint locations can be directly interpreted as how the hint is propagating to other locations since tokens with high similarities are likely to be colorized with similar color as the color of the user hint. The self-attention mechanism enables iColoriT to selectively colorize relevant locations, even for regions with spatially complicated structures. These visualization aligns well with our qualitative and quantitative results demonstrating that iColoriT can effectively aid users to colorize images with minimal interaction.
我们进一步分析了自注意力机制(self-attention mechanism),以研究模型如何将用户提示传播到其他区域。采用注意力展开方法(attention rollout) [1] 来解释Transformer编码器中特定空间位置的注意力权重。在图8中,我们可视化了包含用户提示的输入token的注意力图。提示位置的注意力图可以直接解释为提示如何传播到其他位置,因为具有高相似性的token很可能被着色为用户提示颜色的相似颜色。这种自注意力机制使iColoriT能够选择性地为相关区域着色,即使是空间结构复杂的区域。这些可视化结果与我们的定性和定量结果高度吻合,表明iColoriT能够通过最少的交互有效辅助用户完成图像着色。

Figure 8. Visualization of the self-attention mechanism employing the attention rollout [1] method. iColoriT appropriately attends the user hint to relevant locations even for complex structures.
图 8: 采用注意力 rollout [1] 方法的自注意力机制可视化。iColoriT 即使在复杂结构下也能准确将用户提示关联到相关区域。

Figure 9. A common failure case for point-interactive color iz ation models in detailed regions.
图 9: 点交互式着色模型在细节区域的常见失败案例。
5. Conclusion and Limitations
5. 结论与局限性
In this paper, we present iColoriT, a novel real-time point-interactive color iz ation framework capable of selectively propagating colors of the user hints to relevant regions. Through the Transformer encoder, pixel shuffling and the local stabilizing layer, iColoriT highly outperforms existing baselines, being able colorize images with minimal user interaction. Also, qualitative results indicate that iColoriT can generate diverse and realistic results when given various user hints. We justify our novel design through extensive experiments and ablation studies.
本文提出iColoriT——一种新颖的实时点交互式着色框架,能够选择性地将用户提示色彩传播至相关区域。通过Transformer编码器、像素洗牌操作与局部稳定层,iColoriT显著超越现有基线模型,仅需极少用户交互即可完成图像着色。定性实验表明,该系统在接收不同用户提示时可生成多样化且逼真的结果。我们通过大量实验与消融研究验证了该创新设计的有效性。
Although iColoriT shows its strength even in detailed regions as shown in both quantitative and qualitative results, iColoriT may not be able to colorize small objects or distinguish close objects with the same grayscale intensity, since it does not leverage any semantic labels. This is a common drawback of point-interactive color iz ation approaches as seen in Figure 9 since models are trained in a self-supervised manner. Directly utilizing segmentation labels for training a point-interactive color iz ation model can be a promising future work. Nonetheless, we believe that the iColoriT is a practical application for real-world scenarios, effectively assisting the user to colorize images.
尽管iColoriT在定量和定性结果中均显示出对细节区域的着色能力,但由于未利用任何语义标签,它可能无法对小物体进行着色或区分具有相同灰度强度的邻近物体。这是点交互式着色方法的普遍局限(如图9所示),因为模型是以自监督方式训练的。直接利用分割标签训练点交互式着色模型可能成为未来有价值的研究方向。尽管如此,我们认为iColoriT在实际场景中具有实用价值,能有效辅助用户完成图像着色。