Relation3D: Enhancing Relation Modeling for Point Cloud Instance Segmentation
Relation3D:增强点云实例分割中的关系建模
Abstract
摘要
3D instance segmentation aims to predict a set of object instances in a scene, representing them as binary foreground masks with corresponding semantic labels. Currently, transformer-based methods are gaining increasing attention due to their elegant pipelines and superior predictions. However, these methods primarily focus on modeling the external relationships between scene features and query features through mask attention. They lack effective modeling of the internal relationships among scene features as well as between query features. In light of these disadvantages, we propose Relation3D: Enhancing Relation Modeling for Point Cloud Instance Segmentation. Specifically, we introduce an adaptive superpoint aggregation module and a contrastive learning-guided superpoint refinement module to better represent superpoint features (scene features) and leverage contrastive learning to guide the updates of these features. Furthermore, our relation-aware selfattention mechanism enhances the capabilities of modeling relationships between queries by incorporating positional and geometric relationships into the self-attention mechanism. Extensive experiments on the ScanNetV2, ScanNet++, ScanNet200 and S3DIS datasets demonstrate the superior performance of Relation3D. Code is available at this website.
3D实例分割旨在预测场景中的一组物体实例,将其表示为带有对应语义标签的二进制前景掩码。当前,基于Transformer的方法因其优雅的流程和卓越的预测性能受到越来越多的关注。然而,这些方法主要通过掩码注意力建模场景特征与查询特征之间的外部关系,缺乏对场景特征内部关系以及查询特征之间关系的有效建模。针对这些不足,我们提出Relation3D:增强点云实例分割的关系建模。具体而言,我们引入自适应超点聚合模块和对比学习引导的超点优化模块,以更好地表示超点特征(场景特征),并利用对比学习指导这些特征的更新。此外,我们的关系感知自注意力机制通过将位置和几何关系融入自注意力机制,增强了查询间关系的建模能力。在ScanNetV2、ScanNet++、ScanNet200和S3DIS数据集上的大量实验证明了Relation3D的优越性能。代码可通过此网站获取。
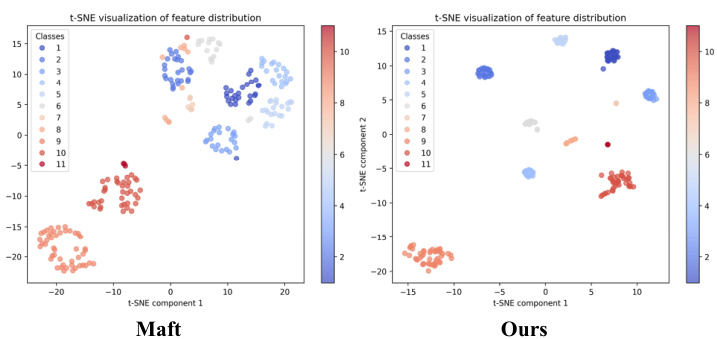
Figure 1. T-SNE visualization of the superpoint-level feature distributions on ScanNetV2 validation set. Different colors represent different instances. Our method highlights better inter-object diversity and intra-object similarity.
图 1: ScanNetV2验证集上超点级特征分布的T-SNE可视化。不同颜色代表不同实例。我们的方法展现出更优的物体间多样性和物体内相似性。
| 点特征变化 (Maft) | 1.8603 (过高) | |||
|---|---|---|---|---|
| 设置 | Maft | 我们的 (阶段 1) | 我们的 (阶段 2) | 我们的 (阶段 3) |
| Lcont | 1.057 | 0.7255 | 0.5841 | 0.5739 |
Table 1. Excessive feature variation among points within the same supepoint and comparison of $L_{c o n t}$ in different settings. The experiment is conducted on ScanNetV2 validation set. $L_{c o n t}$ measures the consistency of superpoint features within the same instance and the differences between features of different instances. Detailed information about $L_{c o n t}$ can be found in Equation 5. Stage 1 represents the features output by ASAM, while stages 2 and 3 represent the features after refinement by CLSR.
表 1: 同一超点内各点间的过度特征差异及不同设置下 $L_{cont}$ 的对比。实验在 ScanNetV2 验证集上进行。$L_{cont}$ 用于衡量同一实例内超点特征的一致性以及不同实例间特征的差异性。关于 $L_{cont}$ 的详细信息可参考公式 (5)。阶段 1 表示 ASAM 输出的特征,阶段 2 和 3 表示经过 CLSR 细化后的特征。
1. Introduction
1. 引言
Point cloud instance segmentation aims to identify and segment multiple instances of specific object categories in 3D space. With the rapid development of fields such as robotic grasping [1], augmented reality [2, 3], 3D/4D reconstruction [4–8], and autonomous driving [9, 10], as well as the widespread application of LiDAR and depth sensor technologies [11, 12], point cloud instance segmentation has become a core technology for achieving efficient and accurate scene understanding. However, the unordered, sparse, and irregular nature of point cloud data, combined with the complex distribution of objects and the numerous categories in realworld applications, presents unique challenges for effective point cloud analysis. To tackle these challenges, early approaches mainly concentrated on accurately generating 3D bounding boxes (top-down) [13–15] or effectively grouping the points into instances with clustering algorithms (bottomup) [16–18]. However, these methods have limitations: they either heavily rely on high-quality 3D bounding boxes, or require manual selection of geometric attributes.
点云实例分割旨在识别并分割3D空间中特定物体类别的多个实例。随着机器人抓取[1]、增强现实[2,3]、3D/4D重建[4–8]、自动驾驶[9,10]等领域的快速发展,以及LiDAR和深度传感技术[11,12]的广泛应用,该技术已成为实现高效精准场景理解的核心手段。然而,点云数据具有无序、稀疏、非规则化的特性,加之现实应用中物体分布复杂且类别繁多,为有效分析带来了独特挑战。早期方法主要通过精准生成3D边界框(自上而下)[13–15]或利用聚类算法将点分组为实例(自下而上)[16–18]来应对,但这些方案存在局限:要么高度依赖高质量的3D边界框,要么需人工选择几何属性。
Recently, researchers start to focus on the design of transformer-based methods [19–23]. These methods adopt an encoder-decoder framework (end-to-end), where each object instance is represented by an instance query. The encoder is responsible for learning the point cloud scene features, while the transformer decoder [24] iterative ly attends to the point cloud scene features to learn the instance queries. Ultimately, the instance queries can directly generate the masks for all instances in parallel. Current mainstream transformer-based methods commonly use maskattention [25] to effectively model the external relationships between scene features and query features. However, they lack effective modeling for the internal relationships among scene features and between query features. As shown in Table 1 and the left panel of Figure 1, we observe insufficient consistency in superpoint features within the same instances, inadequate differentiation between features of different instances, and excessive feature variation among points within the same superpoint. These erroneous relationships between scene features undoubtedly increase the difficulty of instance segmentation. Besides, the effectiveness of self-attention lies in its establishment of relationships between query features. However, simply computing similarity between query features is too implicit and lacks adequate spatial and geometric relationship modeling, whose importance has been demonstrated in [26–28]. Although position embeddings are used to guide self-attention in transformer-based methods, the spatial information position embeddings provide is typically imprecise. For instance, SPFormer’s [20] position embeddings are learnable and lack concrete spatial meaning, and in methods like Mask3D [19], Maft [22], and Query Former [21], discrepancies exist between the positions indicated by position embeddings and the actual spatial locations of each query’s corresponding mask. This limitation in conventional self-attention prevents effective integration of implicit relationship modeling with spatial and geometric relationship modeling.
最近,研究者开始聚焦基于Transformer的方法设计[19-23]。这些方法采用编码器-解码器框架(端到端),其中每个对象实例由一个实例查询表示。编码器负责学习点云场景特征,而Transformer解码器[24]通过迭代关注点云场景特征来学习实例查询。最终,实例查询能并行生成所有实例的掩码。当前主流的基于Transformer的方法普遍使用掩码注意力[25]来有效建模场景特征与查询特征间的外部关系,但缺乏对场景特征内部及查询特征间内部关系的有效建模。如表1和图1左面板所示,我们观察到同一实例内的超点特征一致性不足、不同实例间特征区分不充分,以及同一超点内各点特征变异过大等问题。这些错误的场景特征关系无疑增加了实例分割的难度。此外,自注意力的有效性依赖于查询特征间关系的建立,但单纯计算查询特征相似性的方式过于隐式,缺乏足够的空间与几何关系建模——其重要性已在[26-28]中得到验证。尽管基于Transformer的方法使用位置嵌入来引导自注意力,但位置嵌入提供的空间信息通常不够精确。例如SPFormer[20]的位置嵌入是可学习的且缺乏具体空间意义,而Mask3D[19]、Maft[22]和Query Former[21]等方法中,位置嵌入指示的位置与每个查询对应掩码的实际空间位置存在偏差。传统自注意力的这一局限阻碍了隐式关系建模与空间几何关系建模的有效融合。
Based on the above discussion, we summarize two core issues that need to be considered and addressed in point cloud instance segmentation: 1) How to effectively model the relationships between scene features? Most previous methods use pooling operations to obtain superpoint features [20, 22], but this pooling operation introduces unsuitable features and blurs distinctive features when there are large feature differences between points within a superpoint. Therefore, we need a new way to model superpoint features to emphasizing the distinctive point features. Additionally, considering the significant feature differences between super points within the same instance, we need to introduce scene feature relation priors to guide the superpoint features and model better superpoint relationships. 2) How to better model the relationships between queries? Current self-attention designs rely on a simple computation of similarity between queries, but this implicit relationship modeling often requires extensive data and prolonged training to capture meaningful information. Therefore, integrating explicit spatial and geometric relationships is crucial, as it can refine attention focus areas and accelerate convergence. This motivates us to introduce instance-related biases to enhance the modeling of spatial and geometric relationships effectively.
基于上述讨论,我们总结了点云实例分割中需要考虑和解决的两个核心问题:1) 如何有效建模场景特征间的关系?现有方法多采用池化操作获取超点特征 [20, 22],但当超点内存在显著特征差异时,池化会引入不适宜特征并模糊关键特征。因此需要新的超点特征建模方式以突出关键点特征。此外,考虑到同一实例内超点间的显著特征差异,需引入场景特征关系先验来指导超点特征并建立更优的超点关系模型。2) 如何更好地建模查询(query)间的关系?当前自注意力设计仅依赖查询间的简单相似度计算,这种隐式关系建模往往需要大量数据和长时间训练才能捕获有效信息。因此,整合显式空间与几何关系至关重要,这能优化注意力聚焦区域并加速收敛。这促使我们引入实例相关偏置来有效增强空间与几何关系建模。
Inspired by the above discussion, we propose Relation3D: Enhancing Relation Modeling for Point Cloud In- stance Segmentation, which includes an adaptive superpoint aggregation module (ASAM), a contrastive learning-guided superpoint refinement module (CLSR), and relation-aware self-attention (RSA). To address the first issue, we propose an adaptive superpoint aggregation module and a contrastive learning-guided superpoint refinement module. In the adaptive superpoint aggregation module, we adaptively calculate weights for all points within each superpoint, emphasizing distinctive point features while diminishing the influence of unsuitable features. In the contrastive learning-guided superpoint refinement module, we first adopt a dual-path structure in the decoder, with bidirectional interaction and alternating updates between query features and superpoint features. This design enhances the representation ability of superpoint features. Furthermore, to optimize the update direction of superpoint features, we introduce contrastive learning [29–31] to provide contrastive supervision for superpoint features, reinforcing the consistency of superpoint features within instances and the differences between features of different instances, as is shown in Figure 1. To address the second issue, in relation-aware self-attention, we first model the explicit relationships between queries. By obtaining the mask and its bounding box corresponding to each query, we can model the positional and geometric relationships between queries. Next, we embed these relationships into self-attention as embeddings. Through this approach, we achieve an effective integration of implicit relationship modeling with spatial and geometric relationship modeling.
受上述讨论启发,我们提出Relation3D:点云实例分割的关系建模增强方法,包含自适应超点聚合模块(ASAM)、对比学习引导的超点优化模块(CLSR)以及关系感知自注意力(RSA)。针对第一个问题,我们提出自适应超点聚合模块和对比学习引导的超点优化模块。在自适应超点聚合模块中,我们为每个超点内的所有点动态计算权重,突出独特点特征的同时抑制不适宜特征的影响。在对比学习引导的超点优化模块中,解码器采用双路径结构,通过查询特征与超点特征的双向交互和交替更新来增强超点特征的表征能力。此外,为优化超点特征的更新方向,我们引入对比学习[29–31]对超点特征进行对比监督,强化实例内部超点特征的一致性以及不同实例特征间的差异性,如图1所示。针对第二个问题,在关系感知自注意力中,我们首先建模查询间的显式关系:通过获取每个查询对应的掩码及其边界框,可以建模查询间的空间位置与几何关系;随后将这些关系以嵌入形式整合到自注意力机制中,从而实现隐式关系建模与空间几何关系建模的有效融合。
The main contributions of this paper are as follows: (i) We propose Relation3D: Enhancing Relation Modeling for Point Cloud Instance Segmentation, which achieves accurate and efficient point cloud instance segmentation predictions. (ii) The adaptive superpoint aggregation module and the contrastive learning-guided superpoint refinement module effectively enhances the consistency of superpoint features within instances and the differences between features of different instances. The relation-aware self-attention improves the relationship modeling capability between queries by incorpora ting the positional and geometric relationships into self-attention. (iii) Extensive experimental results on four standard benchmarks, ScanNetV2 [32], ScanNet $^{++}$ [33], ScanNet200 [34], and S3DIS [35], show that our proposed model achieves superior performance compared to other transformer-based methods.
本文的主要贡献如下:(i) 我们提出了Relation3D: 增强点云实例分割的关系建模方法,实现了精准高效的点云实例分割预测。(ii) 自适应超点聚合模块和对比学习引导的超点优化模块有效增强了实例内超点特征的一致性以及不同实例间特征的差异性。关系感知自注意力机制通过将位置和几何关系融入自注意力计算,提升了查询(query)间的关系建模能力。(iii) 在ScanNetV2 [32]、ScanNet$^{++}$[33]、ScanNet200 [34]和S3DIS [35]四个标准基准上的大量实验表明,相比其他基于Transformer的方法,我们提出的模型取得了更优越的性能。
2. Related Work
2. 相关工作
Proposal-based Methods. Existing proposal-based methods are heavily influenced by the success of Mask R-CNN [36] for 2D instance segmentation. The core idea of these methods is to first extract 3D bounding boxes and then use a mask learning branch to predict the mask of each object within the boxes. GSPN [13] adopts an analysis-by-synthesis strategy to generate high-quality 3D proposals, refined by a region-based PointNet [37]. 3D-BoNet [15] employs PointNet $^{++}$ [38] for feature extraction from point clouds and applies Hungarian Matching[39] to generate 3D bounding boxes. These methods set high expectations for proposal quality.
基于提案的方法。现有基于提案的方法深受Mask R-CNN [36]在2D实例分割领域成功的启发。这类方法的核心思想是先提取3D边界框,再通过掩码学习分支预测框内每个物体的掩码。GSPN [13]采用合成分析策略生成高质量3D提案,并通过基于区域的PointNet [37]进行优化。3D-BoNet [15]使用PointNet$^{++}$[38]从点云中提取特征,并应用匈牙利匹配[39]生成3D边界框。这些方法对提案质量设定了较高要求。
Grouping-based Methods. Grouping-based methods follow a bottom-up processing flow, first generating predictions for each point (such as semantic mapping and geometric displacement), and then grouping the points into instances based on these predicted attributes. PointGroup [40] segments objects on original and offset-shifted point clouds and employs ScoreNet for instance score prediction. SoftGroup [18] groups on soft semantic scores and uses a topdown refinement stage to refine the positive samples and suppress false positives. ISBNet [41] introduces a cluster-free approach utilizing instance-wise kernels. Recently, Spherical Mask [42] has addressed the low-quality outcomes of coarse-to-fine strategies by introducing a new alternative instance representation based on spherical coordinates.
基于分组的方法。基于分组的方法遵循自底向上的处理流程,首先生成每个点的预测(如语义映射和几何位移),然后根据这些预测属性将点分组为实例。PointGroup [40] 在原始和偏移后的点云上分割对象,并采用 ScoreNet 进行实例分数预测。SoftGroup [18] 基于软语义分数进行分组,并使用自上而下的细化阶段来优化正样本并抑制误报。ISBNet [41] 提出了一种无需聚类的实例级核方法。最近,Spherical Mask [42] 通过引入基于球坐标的新型替代实例表示,解决了由粗到细策略导致的低质量结果问题。
Transformer-based Methods. Following 2D instance segmentation techniques [24, 43, 44], in the 3D field, each object instance is represented as an instance query, with query features learned through a vanilla transformer decoder. Transformer-based methods require the encoder to finely encode the point cloud structure in complex scenes and use the attention mechanism in the decoder to continuously update the features of the instance queries, aiming to learn the complete structure of the foreground objects as much as possible. Mask3D [19] and SPFormer [20] are pioneering works utilizing the transformer framework for 3D instance segmentation, employing FPS and learnable queries, respectively, for query initialization. Query Former [21] and Maft [22] build on Mask3D [19] and SPFormer [20] by improving query distribution. However, these works have not thoroughly explored the importance of internal relationships between scene features and between query features. Our method aims to enhance relation modeling for both scene features and query features to achieve better instance segmentation.
基于Transformer的方法。遵循2D实例分割技术[24,43,44],在3D领域中,每个对象实例被表示为实例查询(instance query),其查询特征通过标准Transformer解码器学习。基于Transformer的方法要求编码器精细编码复杂场景中的点云结构,并利用解码器中的注意力机制持续更新实例查询的特征,旨在尽可能学习前景对象的完整结构。Mask3D[19]和SPFormer[20]是率先采用Transformer框架进行3D实例分割的开创性工作,分别使用FPS和可学习查询进行查询初始化。Query Former[21]和Maft[22]在Mask3D[19]和SPFormer[20]基础上改进了查询分布。然而这些工作尚未深入探索场景特征之间与查询特征之间内部关系的重要性。我们的方法旨在增强场景特征和查询特征的关系建模,以实现更好的实例分割。
Relation modeling. Many 2D methods have demonstrated the importance of relation modeling. CORE [26] first leverages a vanilla relation block to model the relations among all text proposals and further enhances relational reasoning through instance-level sub-text discrimination in a contrastive manner. RE-DETR [28] incorporates relation modeling into component detection by introducing a learnable relation matrix to model class correlations. RelationDETR [27] explores incorporating positional relation priors as attention biases to augment object detection. Our method is the first to explore the significance of relation priors in 3D instance segmentation. Through the adaptive superpoint aggregation module and the contrastive learning-guided superpoint refinement module, we progressively enhance the relationships among scene features. Additionally, relation-aware self-attention improves the relationships among queries.
关系建模。许多2D方法已经证明了关系建模的重要性。CORE [26] 率先利用基础关系块建模所有文本提议之间的关系,并通过对比学习方式增强实例级子文本区分的关联推理。RE-DETR [28] 通过引入可学习的关系矩阵建模类别相关性,将关系建模融入组件检测。RelationDETR [27] 探索将位置关系先验作为注意力偏置来增强目标检测。我们的方法首次探索了关系先验在3D实例分割中的重要性。通过自适应超点聚合模块和对比学习引导的超点优化模块,我们逐步增强场景特征间的关系。此外,关系感知自注意力机制改进了查询间的关系。
3. Method
3. 方法
3.1. Overview
3.1. 概述
The goal of 3D instance segmentation is to determine the categories and binary masks of all foreground objects in the scene. The architecture of our method is illustrated in Figure 2. Assuming that the input point cloud has $N$ points, each point contains position $(x,y,z)$ , color $(r,g,b)$ and normal $(n_{x},n_{y},n_{z})$ information. Initially, we utilize a Sparse UNet [45] to extract point-level feature $\boldsymbol{F}\in\mathbb{R}^{N\times C}$ Next, we perform adaptive superpoint aggregation module (Section 3.3) to acquire the superpoint-level features $F_{\mathrm{super}}\in\mathbb{R}^{M\times C}$ . Subsequently, we initialize several instance queries Q ∈ RK×C and input $Q$ and $F_{\mathrm{super}}$ into the transformer decoder. To improve the relationship modeling capability between queries, we propose the relation-aware self-attention (Section 3.5). To update the features of $F_{\mathrm{super}}$ , we design a superpoint refinement module (Section 3.4) in the decoder, which is also a cross attention operation. However, unlike conventional cross-attention, the scene features $F_{\mathrm{super}}$ act as the $\mathcal{Q}$ , while the instance queries $Q$ serve as the $\kappa$ and $\nu$ . To guide the update direction of the superpoint features $F_{\mathrm{super}}$ , we implement a contrastive learning approach, which enhances the consistency of superpoint features within instances and increases the differences between features of different instances.
3D实例分割的目标是确定场景中所有前景对象的类别和二进制掩码。我们的方法架构如图2所示。假设输入点云有$N$个点,每个点包含位置$(x,y,z)$、颜色$(r,g,b)$和法线$(n_{x},n_{y},n_{z})$信息。首先,我们使用Sparse UNet [45]提取点级特征$\boldsymbol{F}\in\mathbb{R}^{N\times C}$;接着通过自适应超点聚合模块(第3.3节)获取超点级特征$F_{\mathrm{super}}\in\mathbb{R}^{M\times C}$。随后初始化若干实例查询Q ∈ RK×C,并将$Q$与$F_{\mathrm{super}}$输入Transformer解码器。为增强查询间关系建模能力,我们提出关系感知自注意力机制(第3.5节)。为更新$F_{\mathrm{super}}$特征,在解码器中设计了超点优化模块(第3.4节),这也是一个交叉注意力操作——但与传统交叉注意力不同,场景特征$F_{\mathrm{super}}$作为$\mathcal{Q}$,而实例查询$Q$充当$\kappa$和$\nu$。为引导超点特征$F_{\mathrm{super}}$的更新方向,我们采用对比学习方法,增强实例内超点特征的一致性并扩大不同实例特征间的差异。
3.2. Backbone
3.2. 主干网络
We employ Sparse UNet [45] as the backbone for feature extraction, yielding features $F$ , which is consistent with SPFormer [20] and Maft [22]. Next, we aggregate the pointlevel features $F$ into superpoint-level features $F_{\mathrm{super}}$ via adaptive superpoint aggregation module, which will be introduced in the subsequent section.
我们采用 Sparse UNet [45] 作为特征提取的主干网络,生成特征 $F$ ,这与 SPFormer [20] 和 Maft [22] 保持一致。接着,通过自适应超点聚合模块将点级特征 $F$ 聚合成超点级特征 $F_{\mathrm{super}}$ ,该模块将在后续章节中介绍。
3.3. Adaptive Superpoint Aggregation Module
3.3. 自适应超点聚合模块
The purpose of this module is to aggregate point-level features into superpoint-level features. To emphasize distinctive and meaningful point features while diminishing the influence of unsuitable features, we design the adaptive superpoint aggregation module, as shown in Figure 2 (b). Specifically, we first perform max-pooling and mean-pooling on the point-level features $F$ according to the pre-obtained superpoints, resulting in $F_{\mathrm{max}}$ and $F_{\mathrm{mean}}$ respectively. Next, we calculate the difference between the superpoint-level features and the original point-level features $F$ . We then utilize two non-shared weight MLPs to predict the corresponding
该模块旨在将点级特征聚合为超点级特征。为突出独特且有意义的点特征,同时削弱不适宜特征的影响,我们设计了自适应超点聚合模块,如图 2 (b) 所示。具体而言,我们首先根据预获取的超点对点级特征 $F$ 执行最大池化和平均池化,分别得到 $F_{\mathrm{max}}$ 和 $F_{\mathrm{mean}}$。接着计算超点级特征与原始点级特征 $F$ 的差异,并利用两个非共享权重的 MLP 预测相应...
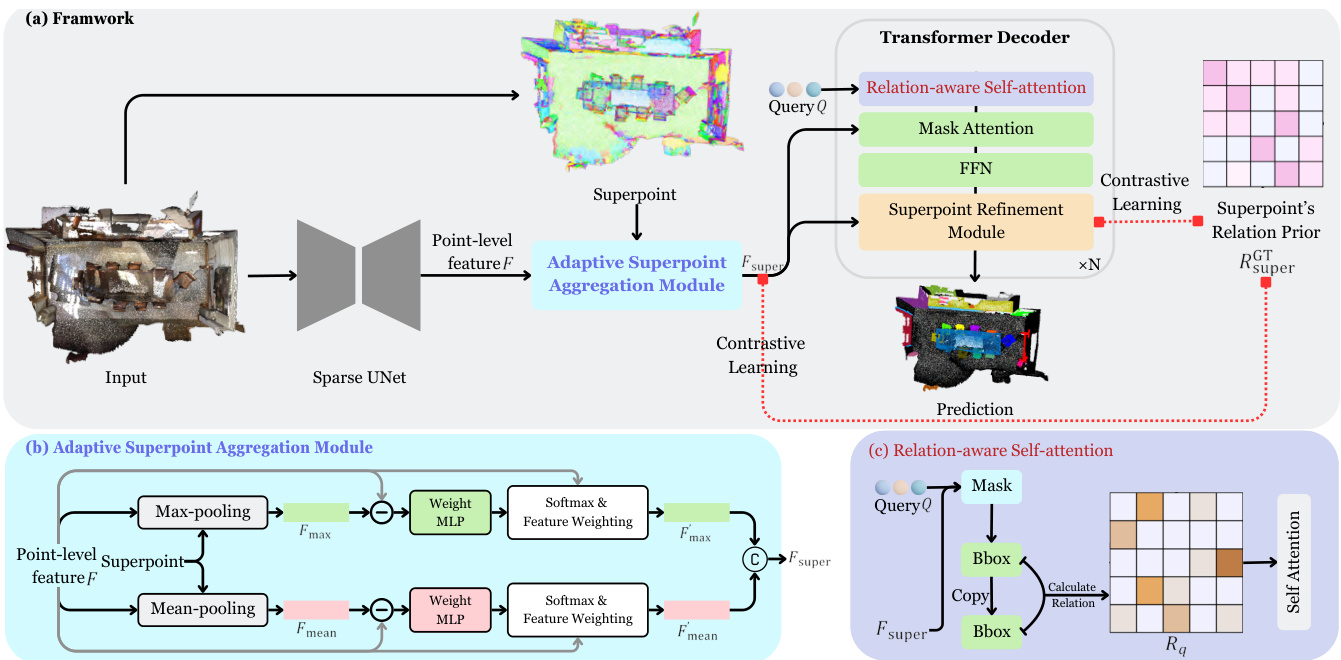
Figure 2. (a) The overall framework of our method Relation3D. (b) The details of our proposed adaptive superpoint aggregation module. (c) The details of our proposed relation-aware self-attention.
图 2: (a) 我们的方法 Relation3D 的整体框架。(b) 提出的自适应超点聚合模块细节。(c) 提出的关系感知自注意力机制细节。
weights,
权重
$$
\begin{array}{r}{\mathcal{W}{\mathrm{max}}=\mathrm{MLP}{1}(F_{\mathrm{max}}-F),}\ {\mathcal{W}{\mathrm{mean}}=\mathrm{MLP}{2}(F_{\mathrm{mean}}-F).}\end{array}
$$
$$
\begin{array}{r}{\mathcal{W}{\mathrm{max}}=\mathrm{MLP}{1}(F_{\mathrm{max}}-F),}\ {\mathcal{W}{\mathrm{mean}}=\mathrm{MLP}{2}(F_{\mathrm{mean}}-F).}\end{array}
$$
Getting the corresponding weights $\mathcal{W}{\mathrm{max}}$ and $\mathcal{W}{\mathrm{mean}}$ , we apply a softmax operation to them in each superpoint. In this way, we can obtain the contribution of each point to its corresponding superpoint. We then use these weights, which sum to 1 in each superpoint, to perform feature weighting on $F$ , resulting in $F_{\mathrm{max}}^{\prime}$ and $F_{\mathrm{mean}}^{\prime}$ . It’s worth noting that the computation for each superpoint can be parallel i zed with point-wise MLP and torch-scatter extension library [46], so this superpoint-level aggregation is actually efficient. Finally, we concatenate $F_{\mathrm{max}}^{\prime}$ and $F_{\mathrm{mean}}^{\prime}$ to $[F_{\mathrm{max}}^{\prime},F_{\mathrm{min}}^{\prime}]$ and input them into an MLP to reduce the $2C$ channels to $C$ , obtaining the final superpoint-level features $F_{\mathrm{super}}\in\mathbb{R}^{M\times C}$ .
得到对应的权重 $\mathcal{W}{\mathrm{max}}$ 和 $\mathcal{W}{\mathrm{mean}}$ 后,我们在每个超点中对它们应用softmax操作。通过这种方式,可以获取每个点对其对应超点的贡献度。随后使用这些在超点内求和为1的权重对 $F$ 进行特征加权,得到 $F_{\mathrm{max}}^{\prime}$ 和 $F_{\mathrm{mean}}^{\prime}$。值得注意的是,每个超点的计算可通过逐点MLP和torch-scatter扩展库[46]实现并行化,因此这种超点级聚合实际上非常高效。最后,我们将 $F_{\mathrm{max}}^{\prime}$ 和 $F_{\mathrm{mean}}^{\prime}$ 拼接为 $[F_{\mathrm{max}}^{\prime},F_{\mathrm{min}}^{\prime}]$ 并输入MLP,将 $2C$ 通道降维至 $C$,最终获得超点级特征 $F_{\mathrm{super}}\in\mathbb{R}^{M\times C}$。
3.4. Contrastive Learning-guided Superpoint Refinement Module
3.4. 对比学习引导的超点优化模块
In the previous section, we introduce the adaptive superpoint aggregation module to emphasize distinctive point features within super points. Next, to further enhance the expressiveness of super points, we will leverage query features to update superpoint features within the transformer decoder. This design, in conjunction with the original mask attention, forms a dual-path architecture, enabling direct communication between query and superpoint features. This approach accelerates the convergence speed of the iterative updates.
上一节中,我们介绍了自适应超点聚合模块以突出超点内的显著点特征。接下来,为了进一步增强超点的表达能力,我们将利用查询特征在Transformer解码器中更新超点特征。该设计与原始掩码注意力机制相结合,形成双路径架构,实现查询特征与超点特征间的直接交互,从而加速迭代更新的收敛速度。
Specifically, the superpoint refinement module employs a cross-attention mechanism for feature interaction. Here, we use the superpoint-level features $F_{\mathrm{super}}$ as the $\mathcal{Q}$ in the cross attention, while the instance queries $Q$ serve as the $\kappa$ and $\nu$ . The specific structure is illustrated in Figure 3. To reduce computational and memory costs, we do not perform self-attention for self-updating $F_{\mathrm{super}}$ . Furthermore, the superpoint refinement module is not applied at every decoder layer. Instead, we perform the refinement of $F_{\mathrm{super}}$ every $r$ layers to reduce computational resource consumption .
具体而言,超点(superpoint)优化模块采用交叉注意力机制进行特征交互。此处我们将超点级特征 $F_{\mathrm{super}}$ 作为交叉注意力中的 $\mathcal{Q}$,而实例查询 $Q$ 则作为 $\kappa$ 和 $\nu$。具体结构如图 3 所示。为降低计算和内存开销,我们不对 $F_{\mathrm{super}}$ 进行自注意力更新。此外,超点优化模块并非在每层解码器都执行,而是每隔 $r$ 层对 $F_{\mathrm{super}}$ 进行一次优化以节省计算资源。
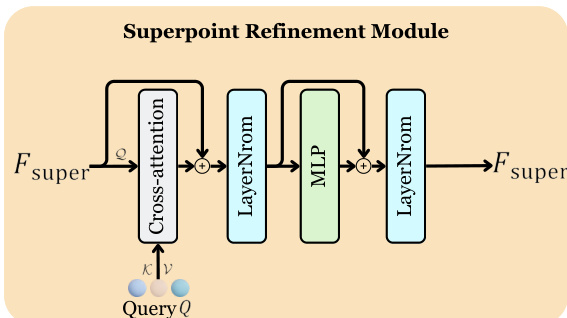
Figure 3. The superpoint refinement module. Superpoint-level features $F_{\mathrm{super}}$ serve as the $\mathcal{Q}$ in cross-attention, while the instance queries $Q$ serve as the $\kappa$ and $\nu$ .
图 3: 超点优化模块。超点级特征 $F_{\mathrm{super}}$ 作为交叉注意力机制中的 $\mathcal{Q}$,而实例查询 $Q$ 则充当 $\kappa$ 和 $\nu$。
where $i$ and $j$ represent two different super points. Next, we will compute the similarity between $F_{\mathrm{super}}$ features, defined
其中 $i$ 和 $j$ 代表两个不同的超点。接下来,我们将计算 $F_{\mathrm{super}}$ 特征之间的相似度,定义为
as follows,
如下,
$$
\begin{array}{r}{S=\mathbf{Norm}(F_{\mathrm{super}})@\mathbf{Norm}(F_{\mathrm{super}})^{\mathrm{T}}.}\end{array}
$$
$$
\begin{array}{r}{S=\mathbf{Norm}(F_{\mathrm{super}})@\mathbf{Norm}(F_{\mathrm{super}})^{\mathrm{T}}.}\end{array}
$$
Here, $s$ represents the similarity matrix where each element quantifies the relationship between pairs of superpoint features. Finally, we will apply contrastive learning by comparing $s$ and $R_{\mathrm{super}}^{\mathrm{GT}}$ as follows,
这里,$s$ 表示相似度矩阵,其中每个元素量化了超点特征对之间的关系。最后,我们将通过比较 $s$ 和 $R_{\mathrm{super}}^{\mathrm{GT}}$ 来应用对比学习,具体如下:
$$
L_{c o n t}=\mathrm{BCE}(\frac{S+1}{2},R_{\mathrm{super}}^{\mathrm{GT}}),
$$
$$
L_{c o n t}=\mathrm{BCE}(\frac{S+1}{2},R_{\mathrm{super}}^{\mathrm{GT}}),
$$
where $L_{c o n t}$ is the contrastive loss computed using binary cross-entropy (BCE). This loss will encourage the model to enhance the consistency of superpoint features within the same instance while reinforcing the differences between features of different instances. Notably, we also add this loss function after the adaptive superpoint aggregation module, which can guide ASAM to focus on meaningful features within the superpoint that help enhance the consistency of superpoint features within the same instance.
其中 $L_{c o n t}$ 是通过二元交叉熵 (BCE) 计算的对比损失。该损失函数会促使模型增强同一实例内超点特征的一致性,同时强化不同实例特征间的差异性。值得注意的是,我们在自适应超点聚合模块后也添加了这一损失函数,这能引导 ASAM 关注超点中有助于增强同实例内超点特征一致性的有意义特征。
3.5. Relation-aware Self-attention
3.5. 关系感知自注意力 (Relation-aware Self-attention)
Previous methods use traditional self-attention to model the relationships between queries, where each query contains a content embedding and a position embedding. They first add the position embedding to the content embedding before computing the attention map. However, in most methods [19– 22], the position embedding does not accurately match the actual position of the mask predicted by the corresponding query, leading to imprecise implicit modeling of positional relationships. More explanation can be found in the supplemental materials. Inspired by Relation-DETR [27], to enhance the self-attention’s ability to model positional relationships and to improve geometric relationship modeling, we propose a relation-aware self-attention (RSA).
先前的方法使用传统的自注意力机制来建模查询之间的关系,其中每个查询包含内容嵌入和位置嵌入。它们在计算注意力图之前,先将位置嵌入加到内容嵌入上。然而,在大多数方法[19–22]中,位置嵌入并未准确匹配对应查询预测的掩码实际位置,导致位置关系的隐式建模不够精确。更多解释可参考补充材料。受Relation-DETR[27]启发,为增强自注意力对位置关系的建模能力并改进几何关系建模,我们提出了一种关系感知自注意力机制(RSA)。
To be specific, we calculate the binary mask M for each instance query $Q$ . Next, we calculate the bounding box (bbox) corresponding to each mask, including its center point and scale: $x,y,z,l,w,h$ . With the bbox calculated, we compute the relative relationships between queries as follows,
具体来说,我们为每个实例查询 $Q$ 计算二值掩码 $M$。接着,计算每个掩码对应的边界框 (bbox),包括其中心点和尺度:$x,y,z,l,w,h$。在计算出边界框后,我们按如下方式计算查询之间的相对关系:
i. Positional Relative Relationship:
i. 位置相对关系:
$$
\left[\log\left(\frac{|x_{i}-x_{j}|}{l_{i}}+1\right),\log\left(\frac{|y_{i}-y_{j}|}{w_{i}}+1\right),\log\left(\frac{|z_{i}-z_{j}|}{h_{i}}+1\right)\right];
$$
$$
\left[\log\left(\frac{|x_{i}-x_{j}|}{l_{i}}+1\right),\log\left(\frac{|y_{i}-y_{j}|}{w_{i}}+1\right),\log\left(\frac{|z_{i}-z_{j}|}{h_{i}}+1\right)\right];
$$
ii. Geometric Relative Relationship:
ii. 几何相对关系:
$$
\left[\log\left(\frac{l_{i}}{l_{j}}\right),\log\left(\frac{w_{i}}{w_{j}}\right),\log\left(\frac{h_{i}}{h_{j}}\right)\right],
$$
$$
\left[\log\left(\frac{l_{i}}{l_{j}}\right),\log\left(\frac{w_{i}}{w_{j}}\right),\log\left(\frac{h_{i}}{h_{j}}\right)\right],
$$
where $i,j$ represents two different queries. Next, we concatenate these two sets of relationships to form an embedding, denoted as $\mathfrak{T}\in\mathbb{R}^{K\times K\times6}$ . Then, following past methods, we use conventional sine-cosine encoding to increase the dimensionality of T ∈ RK×K×6d,
其中 $i,j$ 表示两个不同的查询。接着,我们将这两组关系拼接形成一个嵌入,记为 $\mathfrak{T}\in\mathbb{R}^{K\times K\times6}$。然后,沿用以往方法,我们使用常规的正弦-余弦编码将 T ∈ RK×K×6d 的维度提升。
$$
\mathfrak{T}^{\prime}=\sin\cos(\mathfrak{T}).
$$
$$
\mathfrak{T}^{\prime}=\sin\cos(\mathfrak{T}).
$$
Finally, the embedding ${\mathfrak{T}}^{\prime}$ undergoes a linear transformation to obtain $R_{q}\in\mathbb{R}^{K\times\bar{K}\times\mathcal{H}}$ , where $\mathcal{H}$ denotes the number of attention heads.
最后,嵌入 ${\mathfrak{T}}^{\prime}$ 经过线性变换得到 $R_{q}\in\mathbb{R}^{K\times\bar{K}\times\mathcal{H}}$ ,其中 $\mathcal{H}$ 表示注意力头的数量。
After obtaining $R_{q}$ , we incorporate it into the traditional self-attention mechanism. The specific formula is as follows,
在获得 $R_{q}$ 后,我们将其融入传统的自注意力机制中。具体公式如下:
$$
\mathrm{RSA}(Q)=\mathrm{Softmax}(\frac{\mathcal{Q}\mathcal{K}^{T}}{\sqrt{\mathcal{C}}}+R_{q})\mathcal{V}.
$$
$$
\mathrm{RSA}(Q)=\mathrm{Softmax}(\frac{\mathcal{Q}\mathcal{K}^{T}}{\sqrt{\mathcal{C}}}+R_{q})\mathcal{V}.
$$
In this formulation, we have ${\mathcal{Q}}=Q W_{q}$ , $\begin{array}{r}{\boldsymbol{K}=Q W_{k}}\end{array}$ , and $\nu=Q W_{v}$ , where $W_{q},W_{k}$ , and $W_{v}$ denote the linear transformation matrices for query, key, and value respectively.
在此公式中,我们有 ${\mathcal{Q}}=Q W_{q}$ 、 $\begin{array}{r}{\boldsymbol{K}=Q W_{k}}\end{array}$ 以及 $\nu=Q W_{v}$ ,其中 $W_{q},W_{k}$ 和 $W_{v}$ 分别表示查询 (query) 、键 (key) 和值 (value) 的线性变换矩阵。
3.6. Model Training and Inference
3.6. 模型训练与推理
Apart from Maft’s losses [22], our method includes an additional contrastive loss $L_{c o n t}$ ,
除了Maft的损失[22],我们的方法还包括一个额外的对比损失$L_{cont}$,
$$
\begin{array}{r}{L_{a l l}=\lambda_{1}L_{c e}+\lambda_{2}L_{b c e}+\lambda_{3}L_{d i c e}}\ {+\lambda_{4}L_{c e n t e r}+\lambda_{5}L_{s c o r e}+\lambda_{6}L_{c o n t},}\end{array}
$$
$$
\begin{array}{r}{L_{a l l}=\lambda_{1}L_{c e}+\lambda_{2}L_{b c e}+\lambda_{3}L_{d i c e}}\ {+\lambda_{4}L_{c e n t e r}+\lambda_{5}L_{s c o r e}+\lambda_{6}L_{c o n t},}\end{array}
$$
where $\lambda_{1},\lambda_{2},\lambda_{3},\lambda_{4},\lambda_{5},\lambda_{6}$ are hyper parameters. During the model inference phase, we use the predictions from the final layer as the final output. In addition to the normal forward pass through the network, we also employ NMS [47] on the final output as a post-processing operation.
其中 $\lambda_{1},\lambda_{2},\lambda_{3},\lambda_{4},\lambda_{5},\lambda_{6}$ 是超参数。在模型推理阶段,我们使用最后一层的预测作为最终输出。除了常规的网络前向传播外,我们还在最终输出上采用非极大值抑制(NMS) [47] 作为后处理操作。
4. Experiments
4. 实验
4.1. Experimental Setup
4.1. 实验设置
Datasets and Metrics. We conduct our experiments on ScanNetV2 [32], ScanNet $^{++}$ [33], ScanNet200 [34], and S3DIS [35] datasets. ScanNetV2 comprises 1,613 scenes with 18 instance categories, of which 1,201 scenes are used for training, 312 for validation, and 100 for testing. Scan $\mathbf{Net}{+}+$ contains 460 high-resolution (sub-millimeter) indoor scenes with dense instance annotations across 84 unique instance categories. ScanNet200 uses the same point cloud data, but it enhances annotation diversity, covering 200 classes, 198 of which are instance classes. S3DIS is a largescale indoor dataset collected from six different areas, containing 272 scenes with 13 instance categories. Following previous works [22], we use the scenes in Area 5 for validation and the remaining areas for training. $\mathrm{AP@25}$ and $\mathrm{AP@50}$ represent the average precision scores with IoU thresholds of $25%$ and $50%$ , respectively. mAP is the mean of all AP scores, calculated with IoU thresholds ranging from $50%$ to $95%$ in $5%$ increments. On ScanNetV2, we report mAP, $\mathrm{AP@50}$ , and $\mathrm{AP@25}$ . Additionally, we report Box $\mathrm{AP@}50$ and $\mathrm{AP@25}$ results, as done in SoftGroup [18] and Maft [22]. For ScanNet200 and ScanNet++, we report mAP, $\mathrm{AP@}50$ , and AP $\ @25$ . On S3DIS, we report AP $\ @50$ and $\mathrm{AP@25}$ .
数据集与评估指标。我们在ScanNetV2 [32]、ScanNet++ [33]、ScanNet200 [34]和S3DIS [35]数据集上进行实验。ScanNetV2包含1,613个场景和18个实例类别,其中1,201个场景用于训练,312个用于验证,100个用于测试。ScanNet++包含460个高分辨率(亚毫米级)室内场景,涵盖84个独特实例类别的密集实例标注。ScanNet200使用相同点云数据,但扩展了标注多样性,覆盖200个类别(其中198个为实例类别)。S3DIS是从六个不同区域采集的大规模室内数据集,包含272个场景和13个实例类别。遵循先前工作[22],我们使用Area 5场景进行验证,其余区域用于训练。$\mathrm{AP@25}$和$\mathrm{AP@50}$分别表示IoU阈值为$25%$和$50%$时的平均精度分数。mAP是所有AP分数的平均值,计算时IoU阈值从$50%$到$95%$以$5%$为间隔递增。在ScanNetV2上,我们报告mAP、$\mathrm{AP@50}$和$\mathrm{AP@25}$。此外如SoftGroup [18]和Maft [22]所做,我们还报告Box $\mathrm{AP@}50$和$\mathrm{AP@25}$结果。对于ScanNet200和ScanNet++,我们报告mAP、$\mathrm{AP@}50$和AP $\ @25$。在S3DIS上,我们报告AP $\ @50$和$\mathrm{AP@25}$。
Implementation Details. We build our model on PyTorch framework [46] and train our model on a single
实现细节。我们在PyTorch框架[46]上构建模型,并在单个
Table 2. Comparison on ScanNetV2 validation and hidden test set. The second and third rows are the non-transformer-based and transformer-based methods, respectively. $\ddagger$ denotes using surface normal.
表 2. ScanNetV2验证集和隐藏测试集的对比。第二行和第三行分别为非Transformer架构和Transformer架构的方法。$\ddagger$表示使用了表面法向量。
| 方法 | ScanNetV2验证集 mAP | AP@50 | AP@25 | BoxAP@50 | BoxAP@25 | ScanNetV2测试集 5mAP | AP@50 | AP@25 |
|---|---|---|---|---|---|---|---|---|
| 3D-SIS [14] | / | 18.7 | 35.7 | 22.5 | 40.2 | 16.1 | 38.2 | 55.8 |
| 3D-MPA [16] | 35.3 | 51.9 | 72.4 | 49.2 | 64.2 | 35.5 | 61.1 | 73.7 |
| DyCo3D [49] | 40.6 | 61.0 | / | 45.3 | 58.9 | 39.5 | 64.1 | 76.1 |
| PointGroup [40] | 34.8 | 56.9 | 71.3 | 48.9 | 61.5 | 40.7 | 63.6 | 77.8 |
| MaskGroup [50] | 42.0 | 63.3 | 74.0 | / | / | 43.4 | 66.4 | 79.2 |
| OccuSeg [51] | 44.2 | 60.7 | / | / | / | 48.6 | 67.2 | 74.2 |
| HAIS [52] | 43.5 | 64.4 | 75.6 | 53.1 | 64.3 | 45.7 | 69.9 | 80.3 |
| SSTNet [17] | 49.4 | 64.3 | 74 | 52.7 | 62.5 | 50.6 | 69.8 | 78.9 |
| SoftGroup [18] | 45.8 | 67.6 | 78.9 | 59.4 | 71.6 | 50.4 | 76.1 | 86.5 |
| DKNet [53] | 50.8 | 66.9 | 76.9 | 59.0 | 67.4 | 53.2 | 71.8 | 81.5 |
| ISBNet [41] | 54.5 | 73.1 | 82.5 | 62.0 | 78.1 | 55.9 | 75.7 | 83.5 |
| Spherical Mask [42] | 62.3 | 79.9 | 88.2 | / | / | 61.6 | 81.2 | 87.5 |
| Mask3D [19] | 55.2 | 73.7 | 82.9 | 56.6 | 71.0 | 56.6 | 78.0 | 87.0 |
| QueryFormer [21] | 56.5 | 74.2 | 83.3 | 61.7 | 73.4 | 58.3 | 78.7 | 87.4 |
| SPFormer [20] | 56.3 | 73.9 | 82.9 | / | / | 54.9 | 77.0 | 85.1 |
| Maft [22] | 58.4 | 75.9 | 84.5 | 63.9 | 73.5 | 57.8 | 77.4 | / |
| Maft# [22] | 59.9 | 76.5 | / | / | / | 59.6 | 78.6 | 86.0 |
| Ours | 62.5 | 80.2 | 87.0 | 66.7 | 75.3 | 62.2 | 81.6 | 90.1 |
RTX4090 with a batch size of 6 for 512 epochs. We employ Maft [22] as the baseline. We employ AdamW [48] as the optimizer and PolyLR as the scheduler, with a maximum learning rate of 0.0002. Point clouds are voxelized with a size of $0.02\mathrm{m}$ . For hyper parameters, we tune $K,r$ as 400, 3 respectively. $\lambda_{1},\lambda_{2},\lambda_{3},\lambda_{4},\lambda_{5},\lambda_{6}$ in Equation 8 are set as 0.5, 1, 1, 0.5, 0.5, 1. Since $\mathrm{ScanNet++}$ and ScanNet200 have more categories and instances, we set $K$ as 500. All the other hyper parameters are the same for all datasets.
使用批大小为6的RTX4090进行512个epoch的训练。我们采用Maft [22]作为基线方法,选用AdamW [48]作为优化器,并采用PolyLR作为学习率调度器,最大学习率设为0.0002。点云体素化尺寸为$0.02\mathrm{m}$。在超参数设置上,我们将$K,r$分别调优为400和3。公式8中的$\lambda_{1},\lambda_{2},\lambda_{3},\lambda_{4},\lambda_{5},\lambda_{6}$分别设为0.5、1、1、0.5、0.5、1。由于$\mathrm{ScanNet++}$和ScanNet200具有更多类别和实例,我们将$K$设为500。所有其他超参数在各数据集中保持一致。
4.2. Comparison with existing methods.
4.2. 与现有方法的对比
Results on ScanNetV2. Table 2 reports the results on ScanNetV2 validation and hidden test set. Due to our focus on modeling the internal relationships between the scene features and between the queries, our approach outperforms other transformer-based methods, achieving an increase in mAP by 2.6, $\mathrm{AP@}50$ by 3.7, $\mathrm{AP@25}$ by 2.5, Box $\mathrm{AP@50}$ by 2.8 and Box $\mathrm{AP@25}$ by 1.8 in the validation set, and a rise in mAP by 2.6, $\mathrm{AP@}50$ by 3.0 and $\mathrm{AP@25}$ by 4.1 in the hidden test set. To vividly illustrate the differences between our method and others, we visualize the qualitative results in Figure 4. From the regions highlighted in red boxes, it is evident that our method can generate more accurate predictions.
ScanNetV2 上的结果。表 2 报告了 ScanNetV2 验证集和隐藏测试集的结果。由于我们专注于建模场景特征之间以及查询之间的内部关系,我们的方法优于其他基于 Transformer 的方法,在验证集上 mAP 提升了 2.6,$\mathrm{AP@}50$ 提升了 3.7,$\mathrm{AP@25}$ 提升了 2.5,Box $\mathrm{AP@50}$ 提升了 2.8,Box $\mathrm{AP@25}$ 提升了 1.8;在隐藏测试集上 mAP 提升了 2.6,$\mathrm{AP@}50$ 提升了 3.0,$\mathrm{AP@25}$ 提升了 4.1。为了生动展示我们的方法与其他方法的差异,我们在图 4 中可视化了定性结果。从红色框突出显示的区域可以看出,我们的方法能生成更准确的预测。
Results on $\mathbf{ScanNet{++}}$ . Table 3 presents the results on ScanNet $^{\mathsf{H}+}$ validation and hidden test set. The notable performance enhancement underscores the efficacy of our method in handling denser point cloud scenes.
在 $\mathbf{ScanNet{++}}$ 上的结果。表 3 展示了 ScanNet $^{\mathsf{H}+}$ 验证集和隐藏测试集的结果。显著的性能提升凸显了我们的方法在处理更密集点云场景时的有效性。
Results on ScanNet200. Table 4 reports the results on ScanNet200 validation set. The significant performance improvement demonstrates the effectiveness of our method in handling complex and challenging scenes with a broader range of categories.
ScanNet200 上的结果。表 4 展示了 ScanNet200 验证集上的结果。显著的性能提升证明了我们的方法在处理更广泛类别、更复杂和更具挑战性场景时的有效性。
Results on S3DIS. We evaluate our method on S3DIS using Area 5 in Table 5. Our proposed method achieves better performance compared to previous methods, with gains in both $\mathrm{AP@50}$ and $\mathrm{AP@25}$ , demonstrating the effectiveness and generalization of our method.
S3DIS 上的结果。我们在表 5 中使用 Area 5 评估了我们的方法。与之前的方法相比,我们提出的方法在 $\mathrm{AP@50}$ 和 $\mathrm{AP@25}$ 上均取得了更好的性能,证明了我们方法的有效性和泛化能力。

Figure 4. Visualization of instance segmentation results on ScanNetV2 and ScanNet $^{\cdot+}$ validation set. The red boxes highlight the key regions.
图 4: ScanNetV2 和 ScanNet$^{\cdot+}$验证集上的实例分割结果可视化。红色方框标出了关键区域。
Table 3. Comparison on ScanNet $^{++}$ validation and hidden test set. ScanNet $^{++}$ contains denser point cloud scenes and wider instance classes than ScanNetV2, with 84 distinct instance classes.
表 3. ScanNet++ 验证集和隐藏测试集的对比。ScanNet++ 相比 ScanNetV2 包含更密集的点云场景和更广泛的实例类别,共有 84 个不同的实例类别。
| 方法 | ScanNet++验证集 mAP AP@50 AP@25 | ScanNet++测试集 mAP AP@50 AP@25 |
|---|---|---|
| PointGroup[40] | / / / | 8.9 14.6 21.0 |
| HAIS [52] | / / / | 12.1 16.7 19.9 29.7 29.5 38.9 |
| SoftGroup[18] | 23.1 32.6 39.7 | 20.9 31.3 40.4 |
| Maft [22] Ours | 28.2 39.3 46.1 | 24.2 35.5 44.0 |
Table 4. Comparison on ScanNet200 validation set. ScanNet200 employs the same point cloud data as ScanNetV2 but enhances more annotation diversity, with 198 instance classes.
表 4. ScanNet200验证集对比。ScanNet200采用与ScanNetV2相同的点云数据,但增强了标注多样性,包含198个实例类别。
| 方法 | ScanNet200验证集 mAP | AP@50 | AP@25 |
|---|---|---|---|
| SPFormer [20] | 25.2 | 33.8 | 39.6 |
| Mask3D [19] | 27.4 | 37.0 | 42.3 |
| QueryFormer [21] | 28.1 | 37.1 | 43.4 |
| Maft [22] | 29.2 | 38.2 | 43.3 |
| Ours | 31.6 | 41.2 | 45.6 |
Table 5. Comparison on S3DIS Area5. S3DIS contains 13 instance categories.
表 5: S3DIS Area5对比结果。S3DIS包含13个实例类别。
| 方法 | AP@50 | AP@25 |
|---|---|---|
| PointGroup [40] | 57.8 | / |
| MaskGroup [50] | 65.0 | / |
| SoftGroup [18] | 66.1 | / |
| SSTNet [17] | 59.3 | / |
| SPFormer [20] | 66.8 | / |
| Mask3D [19] | 68.4 | 75.2 |
| QueryFormer [21] | 69.9 | / |
| Maft [22] | 69.1 | 75.7 |
| Spherical Mask [42] | 72.3 | / |
| Ours | 72.5 | 78.5 |
Table 6. Evaluation of the model with different designs on ScanNetV2 validation set. ASAM refers to the adaptive superpoint aggregation module. CLSR refers to the contrastive learning-guided superpoint refinement module. RSA refers to the relation-aware self-attention.
表 6. 不同设计方案在 ScanNetV2 验证集上的模型评估。ASAM 指自适应超点聚合模块,CLSR 指对比学习引导的超点优化模块,RSA 指关系感知自注意力机制。
| ASAM | CLSR | RSA | mAP | AP@50 | AP@25 | |
|---|---|---|---|---|---|---|
| [A] | 59.8 | 77.4 | 85.4 | |||
| [B] | × | 60.1 | 77.9 | 85.6 | ||
| [C] | × | 60.9 | 78.7 | 86.2 | ||
| [D] | 61.5 | 78.8 | 86.3 | |||
| [E] | 61.0 | 78.5 | 86.0 | |||
| [F] | √ | 62.5 | 80.2 | 87.0 |
4.3. Ablation Studies
4.3. 消融实验
Evaluation of the model with different designs. To further study the effectiveness of our designs, we conduct ablation studies on ScanNetV2 validation set. As shown in Table 6, [A] represents the baseline of our method, which is Maft [22] using surface normals and NMS. [B] demonstrates that with the assistance of ASAM, which aims to better aggregate point-level features into superpoint-level features and emphasize distinctive and meaningful point features while diminishing the influence of unsuitable features, there is a performance improvement: mAP increases by 0.3, $\mathrm{AP@50}$ by 0.5, and $\mathrm{AP@25}$ by 0.2. However, due to the lack of guidance from contrastive loss (introduced in the CLSR), the aggregation direction of super points cannot be effectively controlled as expected, so the performance gain is limited. To validate this point, as shown in Table 7, adding contrastive loss to guide ASAM leads to further performance enhancement.
不同设计方案的模型评估。为进一步验证各设计的有效性,我们在ScanNetV2验证集上进行了消融实验。如表6所示,[A]代表基线方法(采用表面法向量和NMS的Maft [22])。[B]显示引入ASAM模块(通过聚合点级特征至超点级特征,强化显著特征并抑制无效特征)后性能有所提升:mAP提高0.3,$\mathrm{AP@50}$提升0.5,$\mathrm{AP@25}$增长0.2。但由于缺乏对比损失(CLSR模块引入)的引导,超点特征聚合方向未能实现有效控制,因此性能增益有限。为验证该结论,表7表明引入对比损失指导ASAM后性能得到进一步提升。
[C] shows that with the help of CLSR, we can interactively update superpoint features, and the use of contrastive learning guides the update direction by enforcing consistency of superpoint features within the same instance and increasing the difference between features of different instances. Compared to the baseline [A], the performance improves significantly, with mAP increasing by 1.1, $\mathrm{AP@}50$ by 1.3, and $\mathrm{AP@25}$ by 0.8. [D] combines ASAM and CLSR. In this design, not only the contrastive learning embedded within CLSR provides ASAM with a clear direction for feature aggregation but also ASAM can offer better-initialized superpoint features to CLSR. This synergistic design cooperates well and results in a $0.6\mathrm{mAP}$ improvement. [E] demonstrates the effectiveness of RSA, which enhances the self-attention mechanism’s ability to model positional rela tion ships and improves geometric relationship modeling. Compared to [A], RSA leads to an improvement of $1.2\mathrm{mAP}$ and 1.1 $\mathrm{AP@}50$ . Finally, in [F], we present the performance of the complete model, underscoring the essential roles played by each module in 3D instance segmentation.
[C] 表明,借助 CLSR (Contrastive Learning for Superpoint Representation),我们可以交互式地更新超点特征,而对比学习的应用通过强制同一实例内超点特征的一致性并增大不同实例间特征的差异来指导更新方向。与基线 [A] 相比,性能显著提升:mAP 提高 1.1,$\mathrm{AP@}50$ 提高 1.3,$\mathrm{AP@25}$ 提高 0.8。[D] 结合了 ASAM (Adaptive Superpoint Aggregation Module) 和 CLSR。在该设计中,不仅 CLSR 内嵌的对比学习为 ASAM 提供了清晰的特征聚合方向,ASAM 还能为 CLSR 提供更优初始化的超点特征。这种协同设计配合良好,实现了 $0.6\mathrm{mAP}$ 的提升。[E] 验证了 RSA (Relation-aware Self-Attention) 的有效性,该模块增强了自注意力机制对位置关系的建模能力,并改善了几何关系建模。相比 [A],RSA 带来 $1.2\mathrm{mAP}$ 和 1.1 $\mathrm{AP@}50$ 的提升。最终,[F] 展示了完整模型的性能,凸显了各模块在 3D 实例分割中的关键作用。
Importance of different designs. I: RSA incorporates explicit relationship modeling between queries, which helps the network learn and converge more easily by focusing on more relevant queries, compared to purely implicit modeling. II: ASAM and CLSR are essentially a unified entity (designed to solve the same problem: better modeling of scene relationships). We separated them only for clarity in description. Both I and II are equally important for instance segmentation, and their contributes comparably to the final performance.
不同设计的重要性。I: RSA (Relevance Score Aggregation) 通过显式建模查询间关系,使网络能聚焦更相关的查询,相比纯隐式建模更易学习收敛。II: ASAM (Adaptive Scene Affinity Module) 与 CLSR (Cross-Level Scene Relation) 本质上是统一体 (均用于解决场景关系建模问题),仅为表述清晰才作区分。I 和 II 对实例分割同等重要,二者对最终性能的贡献相当。
Table 7. Effectiveness of contrastive loss to ASAM.
表 7: 对比损失对 ASAM 的有效性
| 设置 | mAP | AP@50 | AP@25 |
|---|---|---|---|
| 无对比损失 | 60.1 | 77.9 | 85.6 |
| 有对比损失 | 60.5 | 78.4 | 85.9 |
Table 8. Ablation study on ASAM.
| Setting | mAP | AP@50 | AP@25 |
| W max-pooling | 62.2 | 79.9 | 86.7 |
| Wmean-pooling | 62.3 | 79.7 | 86.7 |
| W max-pooling & mean-pooling | 62.5 | 80.2 | 87.0 |
表 8: ASAM消融实验
| 设置 | mAP | AP@50 | AP@25 |
|---|---|---|---|
| W max-pooling | 62.2 | 79.9 | 86.7 |
| W mean-pooling | 62.3 | 79.7 | 86.7 |
| W max-pooling & mean-pooling | 62.5 | 80.2 | 87.0 |
Ablation study on the adaptive superpoint aggregation module. In this section, we conduct experiments on the adaptive superpoint aggregation module (ASAM). First, we perform an ablation study on max-pooling and mean-pooling, as shown in Table 8, where “W max-pooling” indicates that ASAM includes only the max-pooling branch. The results show that both mean-pooling and max-pooling contribute to performance gains. Furthermore, to illustrate the character istics of the learned weight distribution in ASAM, we present corresponding visualization in Figure 6. From the figure, it is evident that ASAM places greater emphasis on the edges and corner regions of objects—areas that are typically distinctive for each instance. Therefore, with the assistance of ASAM and contrastive learning, the model is able to aggregate more disc rim i native superpoint features.
自适应超点聚合模块的消融研究。本节我们对自适应超点聚合模块(ASAM)进行实验研究。首先针对最大池化和平均池化进行消融实验,如表8所示,其中"W max-pooling"表示ASAM仅包含最大池化分支。实验结果表明,平均池化和最大池化均能提升模型性能。此外,为展示ASAM学习到的权重分布特征,我们在图6中提供了相应的可视化结果。从图中可以明显看出,ASAM更加关注物体的边缘和角落区域——这些区域通常对每个实例具有区分性特征。因此,在ASAM和对比学习的共同作用下,模型能够聚合更具判别力的超点特征。
Effectiveness of the relation-aware self-attention. As shown in Figure 5, we compare the attention maps and attention weight distributions between traditional self-attention and relation-aware self-attention. From Figure 5(a), it can be observed that our proposed relation-aware self-attention has more high-weight focal points in its attention map, which is further supported by the data in Figure 5(b). Notably, we have excluded points with attention values ranging from 0 to 0.03 from our statistical analysis, as these account for the vast majority (approximately $99%$ ) of the attention map and would otherwise obscure the meaningful patterns in our study. Furthermore, we substantiate this from a visualization perspective. As demonstrated in Figure 5(c), with the aid of RSA, the representative query can forge connections with a broader set of relevant queries, in contrast to traditional attention mechanisms that concentrate on a limited number of specific queries. This enhancement facilitates the generation of superior instance masks. These observations indicate that relation-aware self-attention achieves a more focused attention when modeling position and geometric relationships. Unlike traditional self-attention, which has relatively dispersed attention without any specific focal query, relationaware self-attention selectively emphasizes relevant queries, resulting in a more precise and meaningful representation.
关系感知自注意力机制的有效性。如图 5 所示,我们比较了传统自注意力与关系感知自注意力的注意力图及权重分布。从图 5(a) 可见,我们提出的关系感知自注意力在注意力图中具有更多高权重聚焦点,这一结论进一步得到图 5(b) 数据的支持。值得注意的是,我们排除了注意力值在 0 至 0.03 范围内的点进行统计分析,因为这些点占据了注意力图的绝大多数 (约 $99%$ ),若不排除会掩盖研究中的有效模式。此外,我们从可视化角度验证了这一点。如图 5(c) 所示,借助 RSA (Relation-aware Self-Attention),代表性查询能与更广泛的相关查询建立连接,而传统注意力机制仅集中于少量特定查询。这种改进有助于生成更优质的实例掩码。这些观察表明,关系感知自注意力在建模位置和几何关系时实现了更集中的注意力。不同于注意力相对分散且无特定聚焦查询的传统自注意力,关系感知自注意力能选择性强调相关查询,从而获得更精确且有意义的表征。

Figure 5. (a) Comparison of attention maps for traditional self-attention vs. relation-aware self-attention. We display the progression of attention maps from layer 1, 3, 5. (b) Comparison of attention weight distributions for traditional self-attention vs. relation-aware self-attention. The attention weight distributions are also shown from layer 1, 3, 5. (c) Query (yellow bbox) with its highly related queries.
图 5: (a) 传统自注意力与关系感知自注意力的注意力图对比。我们展示了第1、3、5层的注意力图变化。(b) 传统自注意力与关系感知自注意力的注意力权重分布对比。同样展示了第1、3、5层的注意力权重分布。(c) 查询(黄色边界框)及其高度相关的查询。

Figure 6. Visualization of weights in the adaptive superpoint aggregation module. A deeper red color indicates a higher weight assigned to point feature during the “Softmax & Feature Weighting” stage (Figure 2 (b)).
图 6: 自适应超点聚合模块中的权重可视化。红色越深表示在"Softmax & 特征加权"阶段(图 2(b))分配给点特征的权重越高。
Contribution to the convergence speed. As shown in Figure 7, our method demonstrates a faster convergence speed compared to the baseline. This improvement can be attributed to the relation priors introduced by CLSR and RSA: contrastive learning provides relation priors for superpoints to guide feature aggregation, while RSA introduces position and geometric relation priors for query features, enhancing self-attention. Additionally, the superpoint refinement module in CLSR forms a dual-path architecture, enabling direct communication between query features and superpoint features, speeding up the convergence.
对收敛速度的贡献。如图 7 所示,我们的方法相比基线展现出更快的收敛速度。这一改进可归因于 CLSR 和 RSA 引入的关系先验:对比学习为超点提供特征聚合的关系先验,而 RSA 为查询特征引入位置与几何关系先验,增强了自注意力机制。此外,CLSR 中的超点优化模块构成双路径架构,实现了查询特征与超点特征的直接交互,从而加速了收敛过程。

Figure 7. The convergence curve on ScanNet-v2 validation set.
图 7: ScanNet-v2 验证集上的收敛曲线。
5. Conclusion
5. 结论
In this paper, we propose a novel 3D instance segmentation method called Relation3D. We focus on modeling the internal relationships among scene features as well as between query features, an aspect that past methods have not explored sufficiently. Specifically, we introduce an adaptive superpoint aggregation module to better represent superpoint features and a contrastive learning-guided superpoint refinement module that updates superpoint features in dual directions while guiding the direction of these updates with the help of contrastive learning. Additionally, our proposed relationaware self-attention mechanism enhances the modeling of relationships between queries by improving the representation of positional and geometric relationships. Extensive experiments conducted on the several datasets demonstrate the effectiveness of Relation3D.
本文提出了一种名为Relation3D的新型3D实例分割方法。我们重点建模场景特征之间以及查询特征之间的内部关系,这是以往方法未充分探索的方向。具体而言,我们引入了自适应超点聚合模块以更好地表示超点特征,以及对比学习引导的超点细化模块,该模块通过对比学习的辅助在双向更新超点特征的同时指导更新方向。此外,我们提出的关系感知自注意力机制通过改进位置和几何关系的表示,增强了查询间关系的建模能力。在多个数据集上的大量实验验证了Relation3D的有效性。