Single Frame Semantic Segmentation Using Multi-Modal Spherical Images
基于多模态球面图像的单帧语义分割
Abstract
摘要
In recent years, the research community has shown a lot of interest to panoramic images that offer a $360^{\circ}$ directional perspective. Multiple data modalities can be fed, and complimentary characteristics can be utilized for more robust and rich scene interpretation based on semantic segmentation, to fully realize the potential. Existing research, however, mostly concentrated on pinhole RGB-X semantic segmentation. In this study, we propose a transformer-based cross-modal fusion architecture to bridge the gap between multi-modal fusion and omni directional scene perception. We employ distortion-aware modules to address extreme object deformations and panorama distortions that result from equirectangular representation. Additionally, we conduct cross-modal interactions for feature rectification and information exchange before merging the features in order to communicate long-range contexts for bi-modal and tri-modal feature streams. In thorough tests using combinations of four different modality types in three indoor panoramic-view datasets, our technique achieved state-ofthe-art mIoU performance: $60.60%$ on Stanford 2 D 3 DS [2] (RGB-HHA), $71.97%$ Structured 3 D [44] (RGB-D-N), and $35.92%$ Matter port 3 D [5] (RGB-D) 1.
近年来,研究界对提供360°全方位视角的全景图像表现出浓厚兴趣。为实现其潜力,可输入多种数据模态,并基于语义分割利用互补特征进行更鲁棒、更丰富的场景理解。然而现有研究主要集中于针孔RGB-X语义分割。本研究提出一种基于Transformer的跨模态融合架构,以弥合多模态融合与全向场景感知之间的差距。我们采用失真感知模块来解决等距柱状投影导致的极端物体形变和全景畸变。此外,在合并特征前进行跨模态交互以实现特征校正和信息交换,从而在双模态和三模态特征流中传递远程上下文关系。通过在三个室内全景数据集的四种模态组合上进行全面测试,我们的技术实现了最先进的mIoU性能:斯坦福2D3DS[2] (RGB-HHA)达60.60%,Structured3D[44] (RGB-D-N)达71.97%,Matterport3D[5] (RGB-D)达35.92%。
1. Introduction
1. 引言
With the increased availability of affordable commercial 3D sensing devices, in recent years, researchers are more interested in working with omni directional images, also often referred to as $360^{\circ}$ , panoramic, or spherical images. In contrast to pinhole cameras, the captured spherical images provide an ultra-wide $360^{\circ}\times180^{\circ}$ field-of-view (FoV) allowing for the capture of more detailed spatial information of the entire scene from a single frame [14, 43]. Practical applications of such immersive and complete view perception include holistic and dense visual scene understanding [1], augmented- and virtual reality (AR/VR) [26, 37], autonomous driving [11], and robot navigation [6].
随着经济型商用3D传感设备的普及,近年来研究者对全向图像(也称为$360^{\circ}$图像、全景图像或球面图像)的研究兴趣日益浓厚。与传统针孔相机相比,球面图像能提供超宽视场角 ($360^{\circ}\times180^{\circ}$ FoV),仅需单帧即可捕获整个场景更详尽的空间信息 [14, 43]。这类沉浸式全景感知技术的实际应用包括:整体稠密视觉场景理解 [1]、增强现实/虚拟现实 (AR/VR) [26, 37]、自动驾驶 [11] 以及机器人导航 [6]。
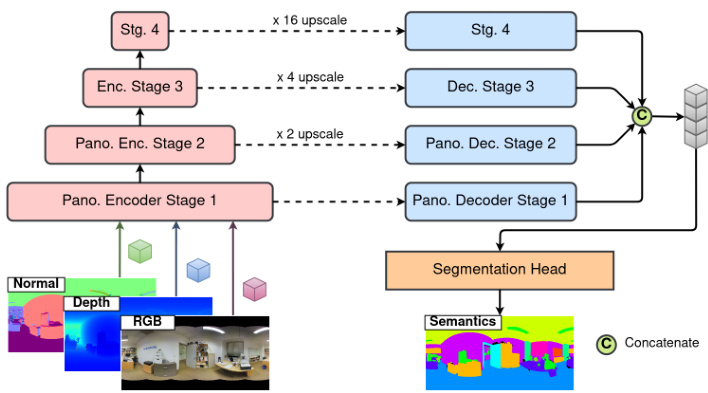
Figure 1. Overview of our multi-modal panoramic segmentation architecture. The inputs are an combination of RGB, Depth, and Normals.
图 1: 我们的多模态全景分割架构概览。输入为 RGB、Depth 和 Normals 的组合。
Generally, spherical images are represented using equirectangular projection (ERP) [38] or cubemap projection (CP) [31], which introduces additional challenges like scene discontinuities, large image distortions, object deformations, and lack of open-source datasets with diverse realworld scenarios. While extensive research has been conducted on pinhole based learning methods [4,22,24,34,35], approaches tailored for processing ultra-wide panoramic images and inherently accounting for spherical deformations remain ongoing research. Furthermore, the scarcity of labeled data, in indoor and outdoor scenarios, required for model training with panoramic images has slowed down the progress in this domain.
通常,球形图像使用等距柱状投影 (ERP) [38] 或立方体贴图投影 (CP) [31] 来表示,这带来了额外的挑战,如场景不连续性、大图像失真、物体变形以及缺乏多样真实场景的开源数据集。尽管基于针孔的学习方法已经进行了广泛研究 [4,22,24,34,35],但专门用于处理超宽全景图像并固有地考虑球形变形的方法仍是正在进行的研究。此外,在室内和室外场景中,全景图像模型训练所需的标记数据稀缺,也减缓了这一领域的进展。
While previous panorama segmentation techniques have attained state-of-the-art performance for RGB-only images, they do not take advantage of the complementary modalities to develop disc rim i native features in situations when it is difficult to discriminate only based on texture information. With comprehensive cross-modal interactions for RGB-X modality [22], our work expands the current Trans $4\mathrm{PASS+}$ [41] methodology for multimodal panoramic semantic segmentation. For the Stanford2D3DS [2] dataset, we evaluate on 4 distinct multimodal semantic segmentation tasks, including RGB, RGBDepth, RGB-Normal, and RGB-HHA, and we reach a state-of-the-art $60.60%$ with RGB-HHA semantic segmentation. We proposed a tri-modal fusion architecture and achieved top mIoU of $75.86%$ on Structure 3 D [44] (RGBD-N) and $39.26%$ on Matter port 3 D [5] (RGB-D-N) for situations when $\mathrm{HHA}^{2}$ is not accessible. The performance of our system on the aforementioned indoor panoramic-view datasets is shown in Fig. 2.
虽然先前的全景分割技术在仅使用RGB图像时已取得最先进的性能,但这些方法未能利用互补模态在纹理信息难以区分的场景下构建判别性特征。通过RGB-X模态的全面跨模态交互[22],我们的工作扩展了当前Trans $4\mathrm{PASS+}$[41]方法,用于多模态全景语义分割。在Stanford2D3DS[2]数据集中,我们评估了4种不同的多模态语义分割任务(包括RGB、RGB-Depth、RGB-Normal和RGB-HHA),其中RGB-HHA语义分割以$60.60%$的性能达到当前最优水平。我们提出了一种三模态融合架构,在无法获取$\mathrm{HHA}^{2}$数据时,于Structure3D[44](RGBD-N)和Matterport3D[5](RGB-D-N)数据集上分别取得$75.86%$和$39.26%$的最高mIoU。图2展示了我们的系统在上述室内全景数据集上的性能表现。
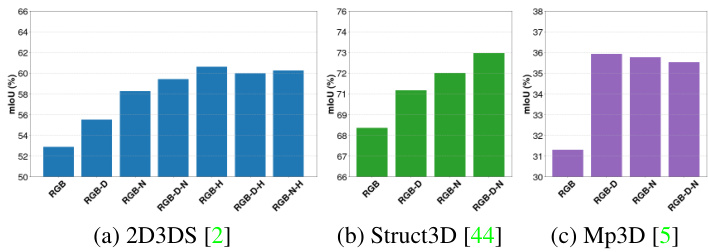
Figure 2. Our cross-modal panoramic segmentation results with RGB, Depth, Normals, and HHA combinations from Stanford2D3DS (left), Structure 3 D (middle) and Matter port 3 D (right) datasets.
图 2: 我们在 Stanford2D3DS (左)、Structure 3D (中) 和 Matterport 3D (右) 数据集上采用 RGB、深度 (Depth)、法线 (Normals) 和 HHA 组合的跨模态全景分割结果。
In summary, we provide the following contributions:
我们主要贡献如下:
- We investigate multi-modal panoramic semantic segmentation in four types of sensory data combinations for the first time. 2. We explore the multi-modal fusion paradigm in this study and introduce the tri-modal paradigm with crossmodal interactions for exploring texture, depth, and geometry information in panoramas. 3. On three indoor panoramic datasets that include RGB, Depth, Normal, and HHA sensor data combinations, our technique provides state-of-the-art performance.
- 我们首次研究了四种感知数据组合的多模态全景语义分割。
- 本研究探索了多模态融合范式,并引入跨模态交互的三模态范式,用于挖掘全景中的纹理、深度和几何信息。
- 在包含RGB、深度(Depth)、法线(Normal)和HHA传感器数据组合的三个室内全景数据集上,我们的技术实现了最先进的性能。
2. Related Work
2. 相关工作
Semantic segmentation An encoder-decoder paradigm with two stages is typically used in existing semantic segmentation designs [3, 8]. A backbone encoder module [15, 17, 36] creates a series of feature maps in the earlier stage in order to capture high-level semantic data. Later, a decoder module gradually extracts the spatial data from the feature maps. Recent research has focused on replacing convolutional backbones with transformer-based ones in light of the success of vision transformer (ViT) in imagine classification [12]. Early studies mostly concentrated on the Transformer encoder design [9, 23, 33, 45], while later study avoided sophisticated decoders in favor of a lightweight All-MLP architecture [35], which produced results with improved efficiency, accuracy, and robustness.
语义分割
现有语义分割设计通常采用两阶段的编码器-解码器范式 [3, 8]。在前期阶段,主干编码器模块 [15, 17, 36] 会生成一系列特征图以捕获高层语义数据。随后,解码器模块逐步从特征图中提取空间数据。鉴于视觉 Transformer (ViT) 在图像分类中的成功 [12],近期研究重点转向用基于 Transformer 的架构替代卷积主干网络。早期研究主要聚焦 Transformer 编码器设计 [9, 23, 33, 45],而后续研究则采用轻量化的全 MLP 架构 [35] 替代复杂解码器,在效率、精度和鲁棒性方面均取得提升。
Panoramic segmentation Early methods for interpreting a picture holistic ally centered on using perspective image-based models in conjunction with distortedmitigated wide-field of view images. A distortion-mitigated locally-planar image grid tangents to a subdivided icosahedron is Eder et al. [13] novel proposal for a tangent image spherical representation. Lee et al. [21], on the other hand, uses a spherical polyhedron to symbolize comparable omnidirectional perspectives. Recent studies [25], however, use distortion-aware modules in the network architecture to directly operate on equirectangular representation. Sun et al. [30] suggests a discrete transformation for predicting dense features after an effective height compression module for latent feature representation. To improve the receptive field and learn the distortion distribution beforehand, Zheng et al. [46] combines the complimentary horizontal and vertical representation in the same line of research. In an encoder-decoder framework, Shen et al. [28] introduces a brand-new panoramic transformer block to take the place of the conventional block. Modern panoramic distortionaware and deformable modules [10] have been added to the state-of-the-art UNet [27] and SegFormer [35] segmentation architectures to improve their performance in the spherical domain [14, 25, 40, 41].
全景分割
早期解释图像整体性的方法主要集中在使用基于透视图像的模型结合畸变抑制的广视角图像。Eder等人[13]提出了一种新颖的切面图像球面表示法,即采用畸变抑制的局部平面图像网格切分二十面体。另一方面,Lee等人[21]使用球形多面体来象征类似的全向视角。然而,最近的研究[25]在网络架构中直接使用畸变感知模块处理等距柱状投影表示。Sun等人[30]提出了一种离散变换方法,在潜在特征表示的有效高度压缩模块后预测密集特征。Zheng等人[46]在同一研究方向中结合了互补的水平与垂直表示,以扩大感受野并预先学习畸变分布。Shen等人[28]在编码器-解码器框架中引入了一种全新的全景Transformer模块,取代了传统模块。现代全景畸变感知与可变形模块[10]已被集成到最先进的UNet[27]和SegFormer[35]分割架构中,以提升其在球面域的性能[14,25,40,41]。
Multimodal semantic segmentation Fusion strategies leverage the advantages of several data sources and show notable performance improvements for image-based semantic segmentation [7,18]. The key contributions for comprehending RGB-D scenes concentrated on: 1) creating new layers or operators based on the geometric properties of RGB-D data [4, 7, 32], and 2) creating specialized archi tec ture s for combining the complimentary data streams in various stages [18, 20, 28, 30]. When modalities other than depth maps are employed, these approaches perform less well because they were created exclusively for RGB-D modality [42]. Recent studies have concentrated on establishing unique fusion algorithms for RGB-X semantic segmentation that are adaptable across various sensing modality combinations [22, 34, 39]. In the omni directional realm, however, the integration of several modalities with crossmodal interactions is still an unresolved issue. The main issue in this scenario is to recognize the distorted and deformed geometric structures in the ultra-wide 360-degree images while taking advantage of a variety of comprehensive complementing information. To jointly use the many sources of information from RGB, Depth, and Normals equirectangular images, we propose our framework, which makes use of cross-modal interactions and panoramic perception abilities.
多模态语义分割融合策略利用多种数据源的优势,在基于图像的语义分割任务中展现出显著性能提升 [7,18]。理解RGB-D场景的核心贡献集中在:1) 基于RGB-D数据几何特性创建新层或算子 [4,7,32],2) 设计专门架构在不同阶段融合互补数据流 [18,20,28,30]。由于这些方法专为RGB-D模态设计 [42],当采用深度图以外的模态时性能会下降。近期研究专注于建立适用于RGB-X语义分割的通用融合算法,可适配不同传感模态组合 [22,34,39]。然而在全向感知领域,多模态与跨模态交互的融合仍是待解难题。该场景下的核心问题在于:利用多种互补信息的同时,识别超宽360度图像中扭曲变形的几何结构。为协同利用RGB、深度和法线等距柱状投影图像的多源信息,我们提出利用跨模态交互与全景感知能力的框架。
3. Methodology
3. 方法论
Section 3.1 provides a summary of the framework we propose for panoramic multi-modal semantic segmentation.
第3.1节概述了我们提出的全景多模态语义分割框架。
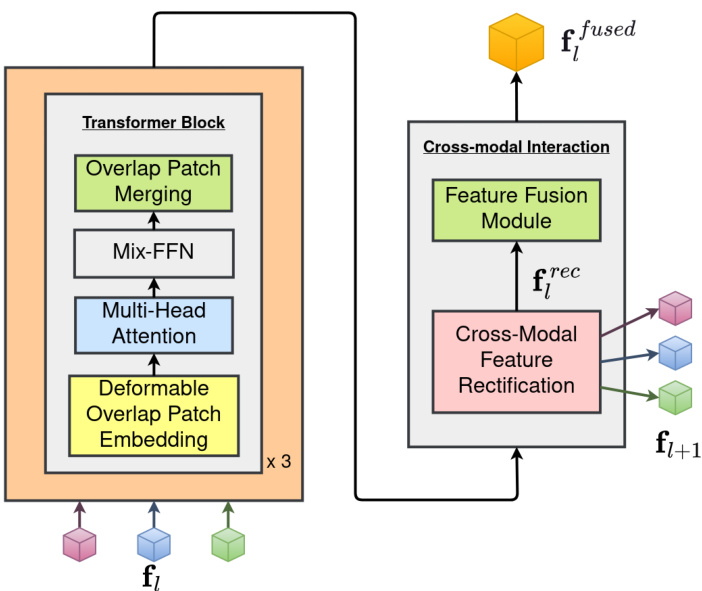
Figure 3. Panoramic encoder stage to extract RGB, Depth, and Normals features.
图 3: 全景编码器阶段用于提取 RGB (红绿蓝)、Depth (深度) 和 Normals (法线) 特征。
Although our framework may be used for bi-modal and tri-modal input scenarios,for simplicity, we explain only the encoder and decoder architectures design for crossmodal (RGB-Depth-Normals) panorama segmentation in Sec. 3.2 and Sec. 3.3, respectively. Our design is based on Trans4PASS+ [41] and uses an extension of CMX [22] for ternary modal streams feature extraction and fusion to learn object deformations and panoramic image distortions. We adopt a notation f to represent multi-modal feature maps, i.e. $\textbf{f}\in{{\bf f}{r g b},{\bf f}{d e p t h},{\bf f}_{n o r m a l}}$ , in order to keep the notation simple and avoid the $l$ notation for inputs and outputs to network modules in the $l$ -th encoder-decoder stage.
虽然我们的框架可用于双模态和三模态输入场景,但为简化说明,我们仅在3.2节和3.3节分别阐述跨模态(RGB-深度-法线)全景分割的编码器与解码器架构设计。该设计基于Trans4PASS+ [41],并扩展了CMX [22]的三模态流特征提取与融合方法,以学习物体形变和全景图像畸变。我们采用符号f表示多模态特征图,即$\textbf{f}\in{{\bf f}{r g b},{\bf f}{d e p t h},{\bf f}_{n o r m a l}}$,以简化符号体系,避免在第$l$个编码器-解码器阶段对网络模块输入输出使用$l$标注。
3.1. Framework Overview
3.1. 框架概述
In accordance with Xie et al. [35], we proposed the multi-modal panoramic segmentation architecture depicted in Fig. 1. The $H\times W\times3$ input image is first separated into patches. We provide panoramic hierarchical encoder stages to address the severe distortions in panoramas while allowing cross-modal interactions between RGB-Depth-Normals patch features, as described in Sec. 3.2. The encoder uses these patches as input to produce multi-level features at resolutions of ${1/4,1/8,1/16,1/32}$ of the original image. Finally, our panoramic decoder (refer Sec. 3.3) receives these multi-level features in order to predict the segmentation mask at a $H\times W\times N_{c l a s s}$ resolution, where $N_{c l a s s}$ is the number of object categories.
根据Xie等人[35]的研究,我们提出了图1所示的多模态全景分割架构。$H\times W\times3$的输入图像首先被分割为多个图像块。如第3.2节所述,我们设计了全景分层编码器阶段来处理全景图像中的严重畸变,同时实现RGB-深度-法线三种模态图像块特征的跨模态交互。编码器以这些图像块作为输入,生成原始图像${1/4,1/8,1/16,1/32}$分辨率下的多级特征。最终,我们的全景解码器(参见第3.3节)接收这些多级特征,以预测$H\times W\times N_{c l a s s}$分辨率的语义分割掩码,其中$N_{c l a s s}$表示目标类别数量。
3.2. Panoramic Hierarchical Encoding
3.2. 全景分层编码
Each stage of our encoding process for extracting hierarchical characteristics is specifically designed and optimized for semantic segmentation. Figure 3 illustrates how our architecture incorporates recently proposed Cross-modal Feature Rectification (CM-FRM) and Feature Fusion (FFM) modules [22] as well as Deformable Patch Embeddings (DPE) module [40] to deal with the severe distortions in RGB, Depth, and Normals panoramas caused by equirectangular representation.
我们为提取层次特征设计的编码流程每个阶段都专门针对语义分割任务进行了优化。图 3 展示了如何通过最新提出的跨模态特征校正 (CM-FRM) 、特征融合 (FFM) 模块 [22] 以及可变形块嵌入 (DPE) 模块 [40] 来处理等距柱状投影导致的 RGB、深度和法线全景图严重畸变问题。
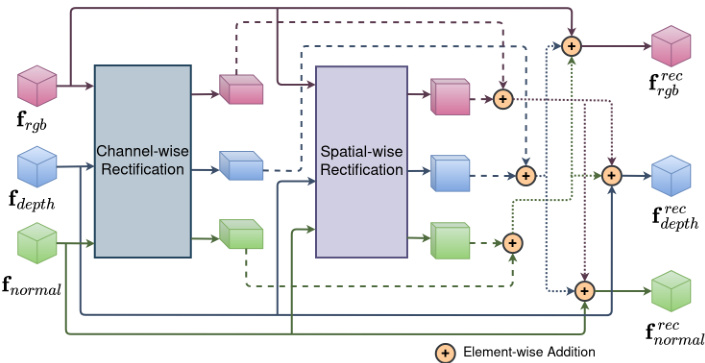
Figure 4. Cross-modal feature rectification module to calibrate RGB, Depth, and Normals features.
图 4: 用于校准RGB、Depth和Normals特征的跨模态特征校正模块。
Deformable patch embedding A typical Patch Embeddings (PE) module [12, 35] divides an input image or feature map of size $\mathbf{f}\in\mathbb{R}^{H\times W\times C_{i n}}$ into a flattened 2D patch sequence of shape $s\times s$ each. In this patch, the position offset with respect to a location $(i,j)$ is defined as $\Delta_{(i,j)}\in$ $\begin{array}{r}{\left[\frac{-s}{2},\frac{s}{2}\right]\times\left[\frac{-s}{2},\frac{s}{2}\right]}\end{array}$ , where $(i,j)\in[1,s]$ . However, these fixed sample points fail to learn deformation-aware features and do not respect object shape distortions. To learn a datadependent offset, we deploy a Deformable Patch Embeddings (DPE) module that was proposed by Zhang et al. [40]. We formulate Eq. (1), using the deformable convolution operation $g(.)$ [10] with a hyper parameter of $r=4$ .
可变形块嵌入
典型的块嵌入 (Patch Embeddings, PE) 模块 [12, 35] 将尺寸为 $\mathbf{f}\in\mathbb{R}^{H\times W\times C_{i n}}$ 的输入图像或特征图划分为形状为 $s\times s$ 的扁平化二维块序列。在该块中,相对于位置 $(i,j)$ 的偏移量定义为 $\Delta_{(i,j)}\in$ $\begin{array}{r}{\left[\frac{-s}{2},\frac{s}{2}\right]\times\left[\frac{-s}{2},\frac{s}{2}\right]}\end{array}$,其中 $(i,j)\in[1,s]$。然而,这些固定采样点无法学习变形感知特征,也无法适应物体形状畸变。为学习数据依赖型偏移,我们采用了 Zhang 等人 [40] 提出的可变形块嵌入 (Deformable Patch Embeddings, DPE) 模块。我们使用超参数 $r=4$ 的可变形卷积操作 $g(.)$ [10] 构建了公式 (1)。
$$
\pmb{\Delta}{(i,j)}^{D P E}=\left[\begin{array}{l}{m i n\big(m a x\big(-\frac{H}{r},g(\mathbf{f}){(i,j)}\big),\frac{H}{r}\big)}\ {m i n\big(m a x\big(-\frac{W}{r},g(\mathbf{f})_{(i,j)}\big),\frac{W}{r}\big)}\end{array}\right]
$$
$$
\pmb{\Delta}{(i,j)}^{D P E}=\left[\begin{array}{l}{m i n\big(m a x\big(-\frac{H}{r},g(\mathbf{f}){(i,j)}\big),\frac{H}{r}\big)}\ {m i n\big(m a x\big(-\frac{W}{r},g(\mathbf{f})_{(i,j)}\big),\frac{W}{r}\big)}\end{array}\right]
$$
Cross-modal feature rectification Measurements that are noisy are frequently present in the data from various complementing sensor modalities. By utilizing features from a different modality, the noisy information can be filtered and calibrated. Regarding this, Liu et al. [22] present a novel Cross-Modal Feature Rectification Module (CM-FRM) to execute feature rectification between parallel streams at each stage, throughout feature extraction process. In our work, we expand this calibration scheme using ternary features from RGB, Depth, and Normals panorama stream, as seen in Fig. 4. Our two-stage CMFRM processes the input features channel- and spatialwise to address noises and uncertainties in RGB-DepthNormals modalities, providing a comprehensive calibration for improved multi-modal feature extraction and inter- action. While the spatial-wise rectification stage focuses on local calibration, the channel-wise rectification stage is more concerned with global calibrations. Hyper para meters ${\lambda}{c},{\lambda}{s}~=~0.5$ are utilized to rectify the noisy input multi-modal features as shown in Eq. (2) by using the channel $\mathbf{f}_{c h a n n e l}^{r e c}$ and spatial f srpeactial weights that have been obtained.
跨模态特征校正
不同互补传感器模态的数据中常存在噪声测量。通过利用另一模态的特征,可以过滤和校准噪声信息。对此,Liu等人[22]提出了一种新颖的跨模态特征校正模块(CM-FRM),在特征提取过程中对各阶段的并行流执行特征校正。如图4所示,我们的工作通过RGB、深度和法线全景流的三元特征扩展了这一校准方案。我们的两阶段CMFRM对输入特征进行通道和空间维度的处理,以解决RGB-深度-法线模态中的噪声和不确定性,为改进的多模态特征提取与交互提供全面校准。空间校正阶段侧重于局部校准,而通道校正阶段更关注全局校准。超参数${\lambda}{c},{\lambda}{s}~=~0.5$用于通过已获得的通道权重$\mathbf{f}{channel}^{rec}$和空间权重$f_{spatial}^{rec}$来校正噪声输入的多模态特征,如式(2)所示。
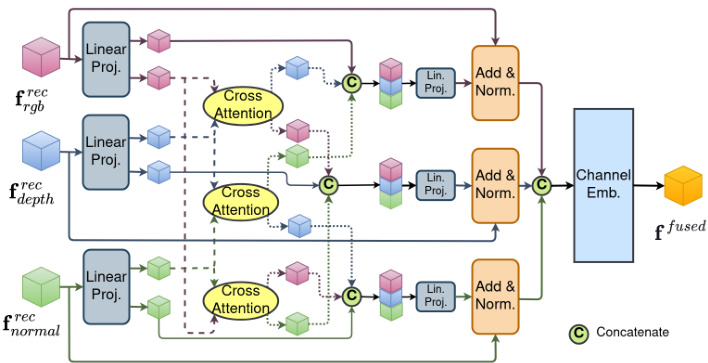
Figure 5. Cross-modal feature fusion module to fuse RGB, Depth, and Normals features.
图 5: 跨模态特征融合模块,用于融合 RGB、深度和法线特征。
$$
\textbf{f}^{r e c}=\textbf{f}+\lambda_{c}\textbf{f}{c h a n n e l}^{r e c}+\lambda_{s}\textbf{f}_{s p a t i a l}^{r e c}
$$
$$
\textbf{f}^{r e c}=\textbf{f}+\lambda_{c}\textbf{f}{c h a n n e l}^{r e c}+\lambda_{s}\textbf{f}_{s p a t i a l}^{r e c}
$$
Cross-modal feature fusion To improve information interaction and combine the features into a single feature map the rectified multi-modal feature maps f rec are passed through a two-stage Feature Fusion Module (FFM) at the end of each encoder stage. As seen in Fig. 5, we use a ternary multi-head cross-attention mechanism to expand Liu et al. [22] information sharing stage by allowing for global information flow between the RGB, Depth, and Normals modalities. In the fusion stage, a channel embedding [22] is utilized to combine ternary features to f fused and passed through the decoding step for semantics prediction.
跨模态特征融合
为提升信息交互并将特征整合为单一特征图,校正后的多模态特征图 f rec 在每个编码器阶段末尾通过两阶段特征融合模块 (FFM)。如图 5 所示,我们采用三元多头交叉注意力机制扩展了 Liu 等人 [22] 的信息共享阶段,实现 RGB、深度和法线模态间的全局信息流。在融合阶段,利用通道嵌入 [22] 将三元特征组合为 f fused,并传递至解码步骤进行语义预测。
3.3. Panoramic Token Mixer Decoder
3.3. 全景 Token 混合解码器
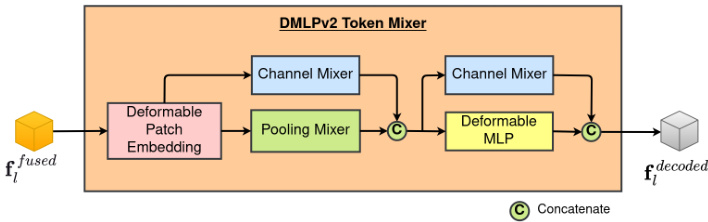
Figure 6. Panoramic decoder stage with fused features from RGB, Depth, and Normals modalities.
图 6: 融合了RGB、深度和法线模态特征的全景解码器阶段。
The Channel Mixer (CX) of the DMLPv2 considers space-consistent yet channel-wise feature re weighting, strengthening the feature by emphasizing informative channels. Focusing on spatial-wise sampling using fixed and adaptive offsets, respectively, the Pooling Mixer (PX) and Deformable MLP (DMLP) are used in DMLPv2. The nonparametric Pooling Mixer (PX) is implemented by an average pooling operator. The adaptive data-dependent spatial offset $\Delta_{(i,j,c)}^{D\widetilde{M}L\dot{P}}$ is predicted channel-wise.
DMLPv2中的通道混合器 (CX) 采用空间一致但通道自适应的特征重加权策略,通过增强信息丰富的通道来强化特征。DMLPv2分别使用固定偏移和自适应偏移进行空间采样的池化混合器 (PX) 和可变形MLP (DMLP) 。非参数化的池化混合器 (PX) 通过平均池化算子实现,而自适应数据依赖的空间偏移 $\Delta_{(i,j,c)}^{D\widetilde{M}L\dot{P}}$ 则以通道为单位进行预测。
Finally, to output the prediction for $N_{c l a s s}$ semantics masks, the decoded features from the four steps are concatenated and given to a segmentation header module, depicted in Fig. 1.
最后,为了输出 $N_{c l a s s}$ 个语义掩码的预测结果,将四个步骤解码得到的特征拼接起来,并输入到一个分割头模块中,如图 1 所示。
4. Experiments
4. 实验
4.1. Datasets
4.1. 数据集
For the purpose of evaluating our suggested cross-modal framework for interior settings, we use three multi-modal equirectangular semantic segmentation datasets. In each of our tests, we resize the input image to $512\times1024$ , and then we compute evaluation metrics, such as Mean Region Intersection Over Union (mIoU), Pixel Accuracy (aAcc), and Mean Accuracy (mAcc), using the MM Segmentation IoU script3.
为了评估我们提出的室内场景跨模态框架,我们使用了三个多模态等距柱状投影语义分割数据集。在每次测试中,我们将输入图像尺寸调整为$512\times1024$,并使用MM Segmentation IoU脚本计算评估指标,如平均区域交并比(mIoU)、像素准确率(aAcc)和平均准确率(mAcc)。
Stanford 2 D 3 DS dataset [2] contains 1713 multi-modal equirectangular images with 13 object categories. We split the data from area 1 to area 6 for training and validation in a manner similar to Armeni et al. [2], using a 3-fold crossvalidation scheme, and we give the mean values across the folds. Furthermore, the publicly accessible code4 is used to compute the panoramic HHA [16] modality using the appropriate depth and camera parameters.
斯坦福2D-3DS数据集[2]包含1713张多模态等距柱状投影图像,涵盖13个物体类别。我们参照Armeni等人[2]的方法,将区域1至区域6的数据划分为训练集和验证集,采用3折交叉验证方案,并给出各折的平均值。此外,使用公开代码4结合深度和相机参数计算全景HHA[16]模态。
Structured 3 D dataset [44] offers 40 NYU-Depthv2 [29] object categories, 196515 synthetic, multi-modal, equirectangular images with a variety of lighting setups. In line with Zheng et al. [44], we establish typical training, validation, and test splits as follows: scene 00000 to scene 02999 for training, scene 03000 to scene 03249 for validation, and scene 03250 to scene 03499 for testing. For all of the tests we conduct, we use rendered raw lighting images with full furniture arrangements.
结构化3D数据集[44]提供了40个NYU-Depthv2[29]物体类别,包含196,515张合成、多模态、等距柱状投影图像,涵盖多种光照配置。参照Zheng等人[44]的方法,我们划分了标准的训练集、验证集和测试集:场景00000至场景02999用于训练,场景03000至场景03249用于验证,场景03250至场景03499用于测试。所有测试均使用完整家具布局的渲染原始光照图像。
Matter port 3 D dataset [5] The 10800 panoramic views in the Matter port 3 D [5] collection are represented by 18 viewpoints per image frame, necessitating an explicit conversion to an equirectangular format. Second, the associated semantic annotations are spread among four files (xxx.house, xxx.ply, xxx.fsegs.json, and xxx.semseg.json). We employ the open-source matterport utils5 code for postprocessing, where the mpview script is used to produce annotation images and the prepare pano script is used to stitch the 18 images that were taken into a 360-degree panorama. For our trials using the 40 object categories, we created own training, validation, and test splits, refer to appendix.
Matterport 3D数据集[5]
Matterport 3D[5]集合中的10800张全景图以每帧18个视角呈现,需显式转换为等距柱状投影格式。其次,相关语义标注分散在四个文件中(xxx.house、xxx.ply、xxx.fsegs.json和xxx.semseg.json)。我们采用开源matterport utils5代码进行后处理:使用mpview脚本生成标注图像,通过prepare pano脚本将18张拍摄图像拼接为360度全景图。针对40个物体类别的实验,我们自行划分了训练集、验证集和测试集,详见附录。
4.2. Implementation Details
4.2. 实现细节
With an initial learning rate of 6e-5 programmed by the poly strategy with power 0.9 over the training epochs, we train our models using a pre-trained SegFormer MiT $\mathbf{B}2^{6}$ RGB backbone on the RTXA6000 GPU. For Stanford2D3DS [2], Structured 3 D [44], and Matter port 3 D [5] experiments, there are 200 training epochs, 50, and 100 respectively. The optimizer AdamW [19] is employed with the following parameters: batch size 4, epsilon 1e-8, weight decay 1e-2, and betas (0.9, 0.999). Random horizontal flipping, random scaling to scales of ${0.5,0.75,1,1.25,1.5,1.75}$ , and random cropping to $512\times512$ are added for image argumentation s. Deformable Patch Embedding module (DPE), refer to Sec. 3.2, is used for the panoramic encoder stage-1 and a conventional Overlapping Patch Embedding (OPE) module [35], for the other stages of our framework. More specific settings are described in detail in the appendix.
我们采用初始学习率为6e-5的多项式策略(power=0.9)进行训练,在RTXA6000 GPU上使用预训练的SegFormer MiT $\mathbf{B}2^{6}$ RGB主干网络。对于Stanford2D3DS [2]、Structured3D [44]和Matterport3D [5]数据集,分别设置200、50和100个训练周期。优化器采用AdamW [19],参数配置为:批量大小4、epsilon 1e-8、权重衰减1e-2、betas (0.9, 0.999)。数据增强包括随机水平翻转、随机缩放比例 ${0.5,0.75,1,1.25,1.5,1.75}$ 以及随机裁剪至 $512\times512$ 尺寸。全景编码器第一阶段使用可变形块嵌入模块(DPE)(参见第3.2节),框架其他阶段采用传统重叠块嵌入模块(OPE)[35]。更多细节设置详见附录。
We conducted our tests for the following fusion config u rations: RGB-only, RGB-Depth, RGB-Normal, RGBHHA, and RGB-Depth-Normal, RGB-Depth-HHA, and RGB-Normal-HHA. In our tests, we only use pathways and modules in our encoding-decoding stages and skip any unnecessary parts of our framework based on these combinations. For example, in the CM-FRM and FFM modules discussed in Sec. 3.2, we employ bi-directional features for cross-modal interactions for the RGB-Depth scenario, whereas for the RGB-Depth-Normal situation, we use routes that lead to tri-directional interactions across the features.
我们测试了以下融合配置:仅RGB、RGB-深度、RGB-法线、RGBHHA、RGB-深度-法线、RGB-深度-HHA以及RGB-法线-HHA。测试中,我们仅在编码-解码阶段使用对应路径和模块,并根据这些组合跳过框架中不必要的部分。例如,在第3.2节讨论的CM-FRM和FFM模块中,针对RGB-深度场景采用双向特征进行跨模态交互,而在RGB-深度-法线场景中则使用引发三向特征交互的路径。
4.3. Experiment Results and Analysis
4.3. 实验结果与分析
We carry out comprehensive tests on multimodal segmentation datasets for indoor settings to demonstrate the effectiveness of our proposed architecture of cross-modal fusion using panoramas. We employ the aforementioned training epochs, random crop-size, and batch size variables to compare our method against the current stateof-the-art approaches Trans4PASS+ [41], HoHoNet [30], PanoFormer [28], CMNeXt [39], and Token Fusion [34]. For a detailed description of their implementation, see the corresponding works. While all other approaches have been reproduced using the conditions of our experiment, the CBFC [46] and Tangent [13] results described here are from the related original paper. In Figure 2, Figure 7 and Figure 8, as well as in Table 1 and Table 2, are visualization s of the quantitative results and comparisons to the state-ofthe-art.
我们在室内场景的多模态分割数据集上进行了全面测试,以验证所提出的全景跨模态融合架构的有效性。采用前述训练周期、随机裁剪尺寸和批量大小等变量,将本方法与当前最先进方法Trans4PASS+ [41]、HoHoNet [30]、PanoFormer [28]、CMNeXt [39]和Token Fusion [34]进行对比。具体实现细节请参阅对应文献。除CBFC [46]和Tangent [13]直接引用原始论文结果外,其他方法均在本实验条件下复现。定量结果的可视化对比详见 图2、图7、图8 以及 表1、表2。
Table 1. Results on Stanford 2 D 3 DS [2].
表 1: Stanford 2D-3DS [2] 上的结果
| 方法 | 模态 | 3折验证 mIoU (%) | mAcc (%) |
|---|---|---|---|
| Trans4PASS+ [41] HoHoNet [30] PanoFormer [28] CBFC [46] Tangent [13] OURS | RGB | 52.04 51.99 52.35 52.20 45.60 52.87 | 63.98 62.97 64.31 65.60 65.20 63.96 |
| HoHoNet [30] PanoFormer [28] CBFC [46] Tangent [13] OURS | RGB-D | 56.73 57.03 56.70 52.50 55.49 | 68.23 68.08 70.80 70.10 68.57 |
| OURS | RGB-N RGB-H RGB-D-N RGB-D-H RGB-N-H | 58.24 60.60 59.43 59.99 60.24 | 68.79 70.68 69.03 70.44 70.61 |
Results on Stanford 2 D 3 DS Table 1 presents the thorough comparisons between our method and other current panoramic methods. Overall, our method delivers cutting-edge performance in the merging of complementary modalities for semantic segmentation. Our method produces results that are comparable to those of existing methods [13,28,30,46] when used with RGB-Depth panoramas, and it further improved the results when RGB, Depth, Normals, and HHA combinations were combined. With RGB-HHA image-based fusion, the highest mIoU was reached at $60.60%$ . By utilizing the complementary geometric, disparity, and textural information, the mIoU metric increased from RGB-only to gradually fusing Depth and Normals, $52.87%\rightarrow55.49%\rightarrow59.43%$
斯坦福2D-3DS数据集上的结果
表1: 展示了我们的方法与当前其他全景方法的全面对比。总体而言,我们的方法在多模态融合的语义分割任务中实现了最先进的性能。在使用RGB-深度全景图时,我们的方法取得了与现有方法[13,28,30,46]相当的结果,而在结合RGB、深度、法线及HHA特征时进一步提升了性能。基于RGB-HHA图像的融合达到了最高mIoU指标 $60.60%$ 。通过利用互补的几何、视差和纹理信息,mIoU指标从仅使用RGB时的 $52.87%$ 逐步提升至融合深度和法线特征后的 $55.49%\rightarrow59.43%$ 。
Results on Structured 3 D We further test Structured 3 D using simply RGB, Depth, and Normals, as seen in Table 2. On the validation and test data splits, our RGB-only model performs at the cutting edge at $71.94%$ and $68.34%$ , respectively. Additionally, by combining depth and normals data, we were able to outperform benchmark results for (validation, test) by $\left(+1.84,+1.83\right)$ for RGB-Depth, $(+2.44,+2.66)$ for RGB-Normals, and $(+3.92,3.63)$ for RGB-Depth-Normals fusion.
结构化3D数据集上的结果
我们进一步测试了仅使用RGB、深度(Depth)和法线(Normals)数据的结构化3D模型,如表2所示。在验证集和测试集划分上,我们的纯RGB模型分别达到了最先进的71.94%和68.34%准确率。此外,通过融合深度和法线数据,我们在(RGB-深度)组合上以(+1.84,+1.83)的幅度超越基准结果,(RGB-法线)组合提升(+2.44,+2.66),而(RGB-深度-法线)融合方案则实现了(+3.92,3.63)的性能增益。
表2:
Table 2. Results on Structured 3 D [44] and Matter port 3 D [5] datasets.
| 方法 | 模态 | Structured3D 验证集 mIoU (%) | Structured3D 测试集 mIoU (%) | Matterport3D 验证集 mIoU (%) | Matterport3D 测试集 mIoU (%) |
|---|---|---|---|---|---|
| Trans4PASS+ [41] | RGB | 66.74 | 66.90 | 33.43 | 29.19 |
| HoHoNet [30] | RGB | 66.09 | 64.41 | 31.91 | 29.33 |
| RGB | 55.57 | 54.87 | 30.04 | 26.87 | |
| OURS | 71.94 | 68.34 | 35.15 | 31.30 | |
| HoHoNet [30] | 69.51 | 66.99 | 35.36 | 32.02 | |
| 60.98 | 59.27 | 33.99 | 31.23 | ||
| OURS | 73.78 | 70.17 | 39.19 | 35.92 | |
| OURS | RGB-N | 74.38 | 71.00 | 38.91 | 35.77 |
| RGB-D-N | 75.86 | 71.97 | 39.26 | 35.52 |
表 2: Structured3D [44] 和 Matterport3D [5] 数据集上的结果。
Results on Matter port 3 D Table 2 shows further trials using Matter port 3 D [5] with comparable RGB, Depth, and Normals combinations in addition to the Structured3D [44] dataset. Our method outperforms the current panoramic techniques in this case for both RGBonly and RGB-Depth based semantic segmentation. Our validation and test pair mIoU metrics values for RGBonly and RGB-Depth, respectively, are $(35.15%$ , $31.30%,$ ) and $(39.19%,35.92%)$ , respectively, when compared to the benchmark. However, we discovered that the combination of the multi-modal fusion with normals did not result in the expected improvement in performance, as demonstrated in other tests, $(38.91%,35.92%)$ for RGB-Normal and $(39.26%,35.52%)$ for RGB-Depth-Normal. Our hypothesis is that the depth and normals data result in a limited amount of modal differences, and thus modal addition may be unnecessary.
Matterport 3D数据集上的结果
表2展示了使用Matterport 3D [5]数据集进行的更多试验,除了Structured3D [44]数据集外,还比较了RGB、深度和法线组合。我们的方法在仅RGB和基于RGB-深度的全景语义分割任务中均优于当前技术。验证集和测试集的mIoU指标值分别为$(35.15%, 31.30%)$(仅RGB)和$(39.19%, 35.92%)$(RGB-深度)。然而我们发现,与其他测试中$(38.91%, 35.92%)$(RGB-法线)和$(39.26%, 35.52%)$(RGB-深度-法线)的结果相比,多模态融合结合法线并未带来预期的性能提升。我们推测这是由于深度和法线数据产生的模态差异有限,因此模态叠加可能没有必要。
4.4. Qualitative Analysis
4.4. 定性分析
The segmentation outcomes of panoramic techniques are shown in Fig. 7, which displays the findings from left to right and from top to bottom across several indoor datasets. Overall, our approach is able to take advantage of depth and geometry data as well as textures from RGB, Depth and Normal modalities and correctly identify object semantics with a better level of accuracy, as indicated. While our baseline Trans $4\mathrm{PASS+}$ [41] accurately classifies the book shelf, sofa, and chair in the first row, the architecture was unable to predict the exact geometrical shapes. Using depth information, PanoFormer [28] and HoHoNet [30] were able to estimate the exact geometry of the chair and bookshelf, however, former method incorrectly guessed the object class of the sofa. The third row findings of the RGB-only and RGBDepth based techniques show a similar trend. When compared to current state-of-the-art baselines, our method consistently predicted geometric shapes that were considerably clearer and had precise object semantics in these situations. The approach can even handle thin structures like the neck of a guitar and items on a dining table, as shown in the second row.
全景技术的分割结果如图7所示,从左到右、从上到下展示了多个室内数据集的发现。总体而言,我们的方法能够利用深度和几何数据以及RGB、深度和法线模态的纹理,并如所示以更高的准确度正确识别物体语义。虽然我们的基线Trans $4\mathrm{PASS+}$ [41]准确分类了第一行的书架、沙发和椅子,但该架构无法预测精确的几何形状。使用深度信息,PanoFormer [28]和HoHoNet [30]能够估计椅子和书架的确切几何形状,然而前者错误地猜测了沙发的物体类别。仅基于RGB和RGBDepth技术的第三行结果显示出类似的趋势。与当前最先进的基线相比,我们的方法在这些情况下始终预测出明显更清晰且具有精确物体语义的几何形状。如第二行所示,该方法甚至能处理像吉他颈部这样的薄结构以及餐桌上的物品。
The qualitative results of different Stanford 2 D 3 DS [2] multi-modal combinations, including RGB-only, RGBDepth, RGB-Normal, RGB-HHA, and RGB-DepthNormal, are shown in Fig. 8 using our paradigm. While in the scenarios shown in Fig. 8 (a) and Fig. 8 (b), using complementary data from other modalities is advantageous, this may not always be the case when the model cannot tell the difference between the distorted door and the wall (Fig. 8 (c)), or the distorted door and the bookshelf (Fig. 8 (d)). We hypothesize that these failed cases happened as a result of the scene objects’ ambiguity, which makes it difficult to distinguish using any of the accessible modalities.
不同Stanford 2D-3DS [2]多模态组合(包括仅RGB、RGB-Depth、RGB-Normal、RGB-HHA和RGB-DepthNormal)的定性结果如图8所示。在图8(a)和图8(b)所示场景中,使用其他模态的互补数据具有优势,但当模型无法区分扭曲的门与墙壁(图8(c))或扭曲的门与书架(图8(d))时,情况可能并非如此。我们假设这些失败案例是由于场景对象的模糊性导致的,这使得使用任何可访问模态都难以区分。
4.5. Ablation Studies
4.5. 消融研究
In the context of panoramic semantic segmentation, we investigated the state-of-the-art fusion architectures CMX [22], CMNeXt [39], and Token Fusion [34]. Our architecture, which was expanded to include a tri-modal panoramas scenario, is inspired on CMX [22]. In order to address panorama distortions, Deformable Patch Embeddings (DPE) modules, which are detailed in Sec. 3.2, are added to these encoder’s backbone. The stages of the panorama decoder, as defined in Sec. 3.3, have not changed. We employ two versions of CMNeXt [39], one with and one without a Self-Query Hub (SQ-Hub), with the former version demonstrating the ability to handle up to 81 modalities with minimal overhead and processing demands. Furthermore, it is expected that SQ-Hub will soft-select informative features while remaining robust to sensor failure.
在全景语义分割领域,我们研究了当前最先进的融合架构CMX [22]、CMNeXt [39]和Token Fusion [34]。我们的架构受CMX [22]启发,扩展至三模态全景场景。为解决全景畸变问题,我们在编码器主干网络中加入了可变形块嵌入 (Deformable Patch Embeddings,DPE) 模块(详见第3.2节)。全景解码器阶段(定义见第3.3节)保持不变。我们采用两个版本的CMNeXt [39]:一个配备自查询枢纽 (Self-Query Hub,SQ-Hub),另一个未配备。前者被证明能以最小开销和处理需求支持多达81种模态,同时SQ-Hub有望实现信息特征的软选择,并保持对传感器故障的鲁棒性。

Figure 7. Results of multi-modal panoramic semantic segmentation for the RGB-only, RGB-Depth, and RGB-Depth-Normals methods are visualized. For RGB segmentation, we use Trans4PASS+ [41] baseline, which employs the same SegFormer MiT-B2 backbone [35] with Deformable Patch Embeddings (DPE) and DMLPv2 decoder as ours, as detailed in Sec. 3.3. PanoFormer [28] uses a cutting-edge panoramic transformer-based architecture for RGB-Depth segmentation, while HoHoNet [30] is built on pre-trained ResNet-101 [17] in conjunction with a sophisticated horizon-to-dense module. Our strategy leverages RGB-Depth-Normal fusion to improve performance by utilizing all available features.
图 7: 展示了仅使用RGB、RGB-Depth以及RGB-Depth-Normals方法的多模态全景语义分割结果可视化。对于RGB分割任务,我们采用Trans4PASS+ [41] 基线模型,其使用与我们相同的SegFormer MiT-B2主干网络 [35] ,并配备可变形块嵌入 (DPE) 和DMLPv2解码器,详见第3.3节。PanoFormer [28] 采用基于Transformer的前沿全景架构处理RGB-Depth分割,而HoHoNet [30] 则基于预训练的ResNet-101 [17] 结合精密的水平到密集模块构建。我们的策略通过RGB-Depth-Normal特征融合充分利用所有可用特征以提升性能。

Figure 8. Visualization of semantic segmentation results for our framework using Stanford 2 D 3 DS [2] for RGB-only, RGB-Depth, RGBNormals, RGB-HHA, and RGB-Depth-Normals (top-to-bottom) combinations. By utilizing complementary traits, our method was successful in identifying deformed and visually identical building structures like doors in columns (a) and (b). Under ambiguity, we were unable to differentiable between the distorted door and the wall or the deformed door and the bookcase in columns (c) and (d), respectively.
图 8: 使用Stanford 2D-3DS [2]数据集对我们的框架进行语义分割结果可视化,展示了仅RGB、RGB-深度、RGB-法线、RGB-HHA以及RGB-深度-法线(从上到下)多种数据组合的效果。通过利用互补特征,我们的方法成功识别了形变和视觉相似建筑结构(如a/b列中的门)。在存在歧义的情况下,我们未能区分c列中扭曲的门与墙面,以及d列中变形的门与书架。
Table 3. An analysis of the various cross-modal fusion techniques applied to the encoder stages of our multi-modal panoramic architecture.
表 3. 对我们多模态全景架构编码器阶段应用的各种跨模态融合技术的分析。
| 方法 | 模态 | Stanford2D3DS [2] | Structured3D [44] | Matterport3D [5] | |||
|---|---|---|---|---|---|---|---|
| mIoU(%) | mAcc(%) | mIoU(%) | mAcc(%) | mIoU(%) | mAcc(%) | ||
| OURS - TokenFusion[34] | RGB-D | 58.88 | 68.57 | 62.58 | 70.54 | 36.48 | 49.30 |
| OURS - CMNeXt (S)[39] | RGB-D | 56.49 | 66.27 | 68.35 | 76.54 | 35.38 | 49.71 |
| OURS - CMNeXt [39] | RGB-D | 54.27 | 64.13 | 69.31 | 78.12 | 34.99 | 49.42 |
| OURS | RGB-D | 55.49 | 66.02 | 70.17 | 77.88 | 35.92 | 49.24 |
| OURS - TokenFusion [34] | RGB-N | 57.86 | 67.39 | 62.76 | 70.91 | 35.71 | 48.92 |
| OURS - CMNeXt (S) [39] | RGB-N | 53.61 | 63.26 | 68.47 | 76.82 | 33.10 | 46.32 |
| OURS - CMNeXt [39] | RGB-N | 50.47 | 60.83 | 68.62 | 76.99 | 33.80 | 47.02 |
| OURS | RGB-N | 58.24 | 68.79 | 71.00 | 78.68 | 35.77 | 50.39 |
| OURS - TokenFusion[34] | RGB-H | 59.06 | 68.07 | - | - | - | - |
| OURS - CMNeXt (S) [39] | RGB-H | 55.70 | 65.79 | - | - | - | - |
| OURS - CMNeXt [39] | RGB-H | 52.48 | 62.78 | - | - | - | - |
| OURS | RGB-H | 60.60 | 70.68 | - | - | - | - |
| OURS - CMNeXt (S)[39] | RGB-D-H | 57.62 | 67.80 | - | - | - | - |
| OURS - CMNeXt [39] | RGB-D-H | 54.54 | 64.22 | - | - | - | - |
| OURS | RGB-D-N | 59.99 | 70.44 | - | - | - | - |
| OURS - CMNeXt (S) [39] | RGB-D-N | 55.72 | 65.86 | 69.55 | 77.50 | 35.18 | 49.79 |
| OURS - CMNeXt [39] | RGB-D-N | 54.65 | 64.53 | 69.11 | 77.54 | 35.55 | 50.09 |
| OURS | RGB-D-N | 59.43 | 69.03 | 71.97 | 79.67 | 35.52 | 50.01 |
| OURS - CMNeXt (S) [39] | RGB-N-H | 55.45 | 65.24 | - | - | - | - |
| OURS - CMNeXt [39] | RGB-N-H | 52.50 | 62.19 | - | - | - | - |
| OURS | RGB-D-N-H | 60.24 | 70.62 | - | - | - | - |
| OURS - CMNeXt (S) [39] | RGB-D-N-H | 55.55 | 65.33 | - | - | - | - |
| OURS - CMNeXt [39] | RGB-D-N-H | 54.48 | 64.21 | - | - | - | - |
Table 3 compares ${$ RGB-Depth, RGB-Normals, and RGB-HHA $}$ bi-modal fusion, ${$ RGB-Depth-Normal, RGB-Depth-HHA, and RGB-Normal-HHA $}$ tri-modal fusion, and ${$ RGB-Depth-Normal-HHA $}$ quad-modal fusion. Overall, the CMX [22] technique we adopted had greater performance. Our methodology, which uses TokenFusion [34] for feature extraction and fusion, performs well on the Matter port 3 D [5] dataset, although it lags behind Stanford 3 D 2 DS [2] and Structured 3 D [44] by a wider margin. Thanks to Self-Query Hub (SQ-Hub), our approach to using encoded features from CMNeXt [39] performs comparably across datasets with fewer computational overload. However, in the majority of cases, in our panoramic trials, we have observed similar outcomes without SQ-Hub.
表 3 比较了 ${$ RGB-Depth、RGB-Normals 和 RGB-HHA $}$ 双模态融合,${$ RGB-Depth-Normal、RGB-Depth-HHA 和 RGB-Normal-HHA $}$ 三模态融合,以及 ${$ RGB-Depth-Normal-HHA $}$ 四模态融合。总体而言,我们采用的 CMX [22] 技术表现更优。尽管在 Matterport3D [5] 数据集上,我们使用 TokenFusion [34] 进行特征提取和融合的方法表现良好,但仍以较大差距落后于 Stanford3D2DS [2] 和 Structured3D [44]。得益于自查询枢纽 (SQ-Hub),我们采用 CMNeXt [39] 编码特征的方法在计算负载更少的情况下,各数据集表现相当。然而,在大多数全景实验中,我们观察到不使用 SQ-Hub 也能获得类似结果。
5. Conclusion
5. 结论
In this work, we revisit multi-modal semantic segmentation at the pixel level for a holistic scene understating. Through a cutting-edge panoramic encoder design, we present the framework with distortion awareness and crossmodal interactions. Our encoder learns severe object deformations and panoramic image distortions with equirectangular representations, and leverages feature interaction and feature fusion for cross-modal global reasoning in RGBX panoramic segmentation. Our architecture produces superior performance on indoor panoramic benchmarks using RGB-Depth, RGB-Normal, and RGB-HHA combina- tions. Furthermore, we rebuild our cross-modal panoramic encoder to learn textual, disparity, and geometrical features using tri-modal (RGB-Depth-Normals) fusion, hence removing the requirement to compute HHA representations while maintaining the same performance. One major drawback of our method is that having two or more input streams active at once typically results in a large rise in complexity, refer to appendix. We’ll look for techniques to combine multi-modal panoramas and 3D LiDAR data in the future with the least amount of processing effort possible.
在本工作中,我们重新审视像素级的多模态语义分割技术,以实现对场景的整体理解。通过前沿的全景编码器设计,我们提出了具备畸变感知和跨模态交互能力的框架。该编码器通过等距柱状投影表征学习严重物体形变和全景图像畸变,并利用特征交互与融合机制实现RGBX全景分割中的跨模态全局推理。我们的架构在室内全景基准测试中采用RGB-深度、RGB-法线及RGB-HHA组合时展现出卓越性能。此外,我们重构了跨模态全景编码器,通过三模态(RGB-深度-法线)融合学习文本、视差和几何特征,从而在保持同等性能的同时免除了HHA表征的计算需求。该方法的主要局限在于:同时激活两个以上输入流通常会导致复杂度显著增加(详见附录)。未来我们将探索以最小计算量融合多模态全景与3D激光雷达数据的技术方案。
Acknowledgement. This work was partially funded by the EU Horizon Europe Framework Program under grant agreement 101058236 (HumanTech).
致谢。本研究部分由欧盟地平线欧洲框架计划资助(项目编号101058236,HumanTech)。
Table 4. Dataset split for Matter port 3 D [5] segmentation.
表 4: Matterport3D [5] 分割数据集划分。
| 划分类型 | BuildingSceneIds |
|---|---|
| 评估集 | UwV83HsGsw3, X7HyMhZNosO, Z6MFQCViBuw, e9zR4mvMWw7, q9vSo1VnCiC, rqfALeAoiTq, uNb9QFRL6hY, rPc6DW4iMge, wC2JMjhGNzB |
| 测试集 | VFuaQ6m2Qom, jh4fc5c5qoQ, pa4otMbVnkk, D7G3Y4RVNrH, GdvgFV5R1Z5, gYvKGZ5eRqb, YmJkqBEsHnH, VLzqgDo317F, ZMojNkEp431, jtcxE69GiFV, pRbA3pwrgk9, dhjEzFoUFzH |
| 训练集 | /所有未包含在评估集和测试集中的其他场景/ |
A. Experimentation details
A. 实验细节
A.1. Matter port 3 D dataset
A.1. Matterport3D 数据集
To divide the 10800 panoramic equirectangular images in the Matter port 3 D [5] dataset, we create standard training, evaluation, and test splits. The 90 building-scale scenarios, which included a range of scene types like residences, offices, and churches, were divided into an 80-10-10 split. For all our segmentation experiments using the 40 object categories, we use these training, validation, and test splits.
为了划分Matterport3D数据集[5]中的10800张全景等距柱状投影图像,我们创建了标准的训练集、验证集和测试集划分。这90个建筑级场景涵盖住宅、办公室、教堂等多种场景类型,按80-10-10比例进行划分。在使用40个物体类别的所有分割实验中,我们均采用这套训练集、验证集和测试集划分方案。
B. Qualitative analysis
B. 定性分析
B.1. Multi-modal panoramic semantic segmentation
B.1. 多模态全景语义分割
Figure 10 and Figure 9, which come from the Stanford2D3DS [2] evaluation set and the Structured 3 D [44] test set, respectively, show further qualitative comparisons between various fusion combinations for our proposed framework. In Fig. 10 (a) and (b), our tri-model (RGB-D-N) is able to give better segmentation results in the categories denoted by the black dashed rectangles, such as the Door, Window, and Bookshelf, while the baseline (RGB-only) model struggles to recognize these significantly distorted objects. The RGB-only baseline models wrongly segment the Door in figure Fig. 9 (c) as a part of the Wall. Our tri-model (RGB-D-N) in this case achieves the correct segmentation results with greater accuracy than RGB-D techniques. The same conditions apply to the Cabinet in Fig. 9 (a) and the support between the Bed and Cabinet in Fig. 9 (b). Compared to other approaches, In Fig. 9 (d), along with the precise geometry shapes for objects placed inside the Cabinet structure, a better segmentation result from our multi-modal (RGB-D-N) is displayed. However, due to visual ambiguity, the category is incorrectly predicted by all models.
图 10 和图 9 分别来自 Stanford2D3DS [2] 评估集和 Structured 3D [44] 测试集,展示了我们提出的框架在不同融合组合间的进一步定性对比。在图 10 (a) 和 (b) 中,我们的三模态 (RGB-D-N) 模型在黑色虚线矩形标注的类别(如门、窗和书架)上能提供更好的分割结果,而基线 (仅 RGB) 模型难以识别这些严重畸变的物体。仅 RGB 的基线模型将图 9 (c) 中的门错误分割为墙的一部分,而我们的三模态 (RGB-D-N) 在此情况下以高于 RGB-D 技术的精度实现了正确分割。类似情况也适用于图 9 (a) 中的橱柜及图 9 (b) 中床与橱柜间的支撑结构。与其他方法相比,图 9 (d) 展示了我们多模态 (RGB-D-N) 对橱柜内部物体几何形状的精确分割结果。然而由于视觉歧义,所有模型均对该类别做出了错误预测。
Table 5. Comparison of computational complexity calculated $@$ $512\times1024\times3$ input dimensional.
表 5. 计算复杂度对比 (输入维度为 $512\times1024\times3$)
| #输入类型 | 方法 | 参数量 (G) | TFLOPs |
|---|---|---|---|
| Unary | Trans4PASS+[41] | 0.039 | 0.131 |
| HoHoNet [30] | 0.070 | 0.125 | |
| PanoFormer [28] | 0.020 | 0.081 | |
| OURS | 0.040 | 0.079 | |
| HoHoNet [30] | 0.070 | 0.126 | |
| Binary | PanoFormer [28] | 0.020 | 0.081 |
| OURS | 0.081 | 0.106 | |
| Ternary | OURS | 0.123 | 0.133 |
C. Quantitative analysis
C. 定量分析
C.1. Computational complexity
C.1. 计算复杂度
For tri-modal (RGB-Depth-Normals), bi-modal (RGBDepth), and uni-modal (RGB-Only) panoramic fusion on Stanford 2 D 3 DS [2], we compare the computational complexity of our framework with that of existing methods in Tab. 5. As the number of input streams rises, our study indicates that our method’s complexity also significantly rises.
在斯坦福2D-3DS数据集[2]上进行的全景融合实验中,我们对比了三模态(RGB-深度-法线)、双模态(RGB-深度)和单模态(仅RGB)场景下本框架与现有方法的计算复杂度,结果如 表5 所示。研究表明,随着输入数据流的增加,本方法的计算复杂度也显著上升。
C.2. Detailed results in indoor scenarios
C.2. 室内场景详细结果
More qualitative comparisons based on three-fold cross validation of Stanford 2 D 3 DS [2] indoor scenarios are shown in Tab. 6 to support our propose approach. When compared to the current panoramic approaches, our multimodel fusion models segment objects in regularly used categories including ceiling, wall, floor, window, and office furniture better. Our RGB-Depth-Normals fusion model receives top score mIoU in 8 out of 13 categories. However, this model struggled to segment the Beam, Column, and Wall categories.
基于斯坦福2D-3DS [2] 室内场景三折交叉验证的更多定性对比结果如表6所示,这些结果支持了我们提出的方法。与当前全景方法相比,我们的多模态融合模型在常规使用类别(包括天花板、墙壁、地板、窗户和办公家具)上实现了更好的物体分割效果。我们的RGB-深度-法线融合模型在13个类别中有8个获得了最高mIoU分数,但在横梁、立柱和墙壁等类别的分割上表现欠佳。
Figure 11 shows the advantage of combining multimodalities, such as RGB, Depth, and Normals, over the baseline of our technique that uses RGB alone to utilize complimentary textual, geometric, and disparity information. With our tri-fusion model (RGB-D-N), we generally observe a considerable improvement across all object categories. For the Pillow and Mirror categories on Structured3D [44], refer Fig. 11 (a), as well as the Bathtub and Gym Equipment categories on Matter port 3 D [5], refer Fig. 11 (b), we saw a considerable rise of mIoU of up to $10%$ and $15%$ , respectively. However, the box category on Structured 3 D [44] and the Cabinet, Plant, and Toilet categories on [5] also had drops of $1%$ to $4%$ .
图 11 展示了结合多模态(如RGB、深度和法线)相较于仅使用RGB的基线技术的优势,以利用互补的文本、几何和视差信息。通过我们的三模态融合模型(RGB-D-N),我们普遍观察到所有物体类别都有显著提升。在Structured3D [44]的Pillow和Mirror类别(见图11(a)),以及Matterport3D [5]的Bathtub和Gym Equipment类别(见图11(b))中,mIoU分别提升了高达$10%$和$15%$。然而,Structured3D [44]的box类别以及[5]中的Cabinet、Plant和Toilet类别也出现了$1%$至$4%$的下降。

Figure 9. Structured 3 D [44] segmentation visualization s. Zoom in for better view..
图 9: 结构化3D [44]分割可视化效果。放大查看更清晰。

Figure 10. Stanford 2 D 3 DS [2] segmentation visualization s. Zoom in for better view.
图 10: Stanford 2D-3DS [2] 分割可视化效果。放大可查看更佳效果。