ARTEMIS-DA: An Advanced Reasoning and Transformation Engine for Multi-Step Insight Synthesis in Data Analytics
ARTEMIS-DA:面向数据分析多步洞察合成的高级推理与转换引擎
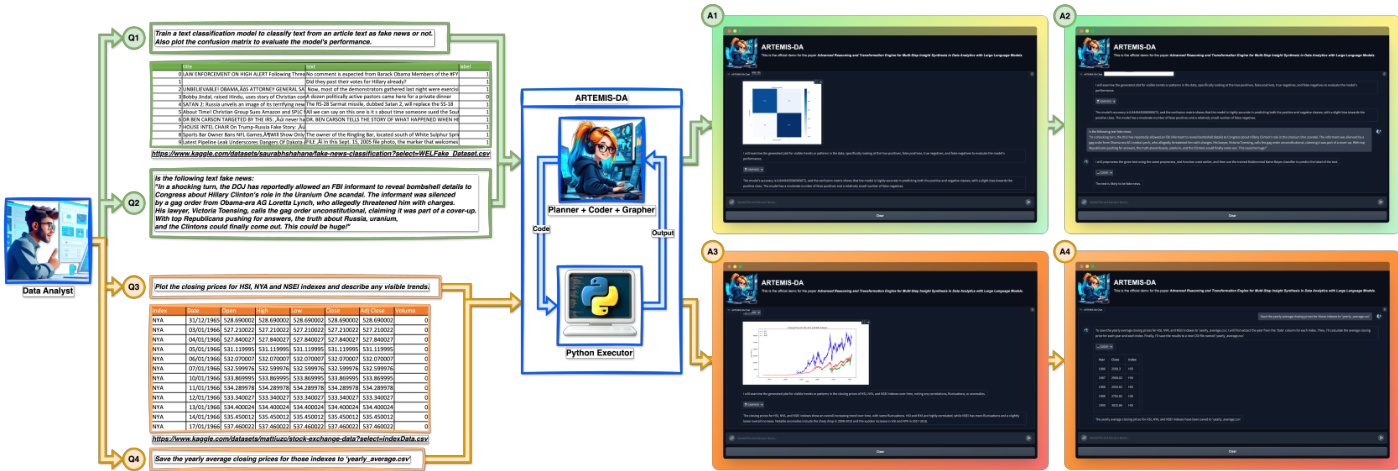
Figure 1: ARTEMIS-DA showcasing $\boldsymbol{\mathcal{Q}}\boldsymbol{I}$ . advanced reasoning for complex queries, $\boldsymbol{\mathcal{Q}}2$ . predictive modeling for text classification, $\boldsymbol{\mathcal{Q}3}$ . data visualization for insights, and $\pmb{Q4}$ . efficient data transformation for manipulating datasets.
图 1: ARTEMIS-DA 展示 $\boldsymbol{\mathcal{Q}}\boldsymbol{I}$ . 复杂查询的高级推理, $\boldsymbol{\mathcal{Q}}2$ . 文本分类的预测建模, $\boldsymbol{\mathcal{Q}3}$ . 洞察数据可视化, 以及 $\pmb{Q4}$ . 高效数据集操作的数据转换。
ABSTRACT
摘要
This paper presents the Advanced Reasoning and Transformation Engine for Multi-Step Insight Synthesis in Data Analytics (ARTEMIS-DA), a novel framework designed to augment Large Language Models (LLMs) for solving complex, multi-step data analytics tasks. ARTEMIS-DA integrates three core components: the Planner, which dissects complex user queries into structured, sequential instructions encompassing data preprocessing, transformation, predictive modeling, and visualization; the Coder, which dynamically generates and executes Python code to implement these instructions; and the Grapher, which interprets generated visualization s to derive actionable insights. By orchestrating the collaboration between these components, ARTEMIS-DA effectively manages sophisticated analytical workflows involving advanced reasoning, multi-step transformations, and synthesis across diverse data modalities. The framework achieves state-of-the-art (SOTA) performance on benchmarks such as WikiTable Questions and TabFact, demonstrating its ability to tackle intricate analytical tasks with precision and adaptability. By combining the reasoning capabilities of LLMs with automated code generation and execution and visual analysis, ARTEMIS-DA offers a robust, scalable solution for multi-step insight synthesis, addressing a wide range of challenges in data analytics.
本文提出了一种用于多步骤数据分析洞察合成的高级推理与转换引擎(ARTEMIS-DA),这是一种旨在增强大语言模型(LLM)解决复杂多步骤数据分析任务能力的新型框架。ARTEMIS-DA整合了三个核心组件:规划器(Planner)将复杂用户查询分解为包含数据预处理、转换、预测建模和可视化的结构化顺序指令;编码器(Coder)动态生成并执行Python语言代码来实现这些指令;图表解析器(Grapher)通过解读生成的可视化结果来获取可操作的见解。通过协调这些组件之间的协作,ARTEMIS-DA能有效管理涉及高级推理、多步骤转换以及跨多种数据模态合成的复杂分析工作流。该框架在WikiTable Questions和TabFact等基准测试中达到了最先进(SOTA)性能,展示了其精确且自适应地处理复杂分析任务的能力。通过将大语言模型的推理能力与自动化代码生成执行及视觉分析相结合,ARTEMIS-DA为多步骤洞察合成提供了一个强大、可扩展的解决方案,解决了数据分析领域的诸多挑战。
1 Introduction
1 引言
The advent of Large Language Models (LLMs), such as GPT-3 [1], GPT-4 [15], and Llama 3 [5], has revolutionized the fields of artificial intelligence (AI) and natural language processing (NLP). These models have demonstrated remarkable capabilities in complex interpretation, reasoning, and generating human-like language, achieving success in diverse applications such as language translation, sum mari z ation, content generation, and questionanswering. Their ability to process and generate coherent text has also made them powerful tools for tasks requiring nuanced understanding and reasoning. However, while LLMs have been extensively explored in these domains, their potential in transforming the field of data analytics remains under utilized. The inherent reasoning and code-generation capabilities of LLMs suggest immense promise for enabling non-technical users to interact with complex datasets using natural language, bridging the gap between advanced analytics and accessibility.
大语言模型(LLM)如GPT-3[1]、GPT-4[15]和Llama 3[5]的出现,彻底改变了人工智能(AI)和自然语言处理(NLP)领域。这些模型在复杂解释、推理和生成类人语言方面展现出卓越能力,在语言翻译、摘要生成、内容创作和问答系统等多样化应用中取得成功。其处理并生成连贯文本的能力,也使它们成为需要细致理解和推理任务的强大工具。然而,尽管大语言模型在这些领域已得到广泛探索,它们在变革数据分析领域的潜力仍未得到充分利用。大语言模型固有的推理和代码生成能力,预示着让非技术用户通过自然语言与复杂数据集交互的巨大前景,从而弥合高级分析与可访问性之间的鸿沟。
Recent efforts, including TableLLM [12], CABINET [18], and Chain-of-Table [22], have begun to explore this intersection. These studies focus on table-based question answering and reasoning tasks, leveraging LLMs to interpret and respond to queries grounded in structured datasets. While these works demonstrate the potential of
近期研究,包括TableLLM [12]、CABINET [18]和Chain-of-Table [22],已开始探索这一交叉领域。这些研究聚焦于基于表格的问答和推理任务,利用大语言模型(LLM)来解析和回应基于结构化数据集的查询。尽管这些工作展现了...
LLMs for data analytics, they primarily address singlestep tasks, leaving multi-step analytical processes—such as complex data transformation, predictive modeling, and visualization—relatively unexplored. These tasks often require sequential reasoning, complex task decomposition, and precise execution across diverse operations, presenting challenges that current frameworks are not yet equipped to manage effectively.
大语言模型在数据分析中的应用主要针对单步任务,而多步骤分析流程(如复杂数据转换、预测建模和可视化)仍相对未被探索。这些任务通常需要顺序推理、复杂任务分解以及跨多样化操作的精准执行,当前框架尚无法有效应对这些挑战。
To address this gap, we propose the Advanced Reasoning and Transformation Engine for Multi-Step Insight Synthesis in Data Analytics (ARTEMIS-DA), a comprehensive framework explicitly designed to unlock the potential of LLMs for advanced multi-step data analytics tasks. ARTEMIS-DA introduces a tri-component architecture consisting of a Planner, a Coder, and a Grapher, each playing a crucial, complementary role. The Planner acts as the framework’s coordinator, interpreting complex user queries and decomposing them into a sequence of structured instructions tailored to the dataset and analytical goals. These instructions encompass tasks such as data pre-processing, transformation, predictive analysis, and visualization. By leveraging the natural language understanding and reasoning capabilities of LLMs, the Planner ensures clarity and structure in task execution, addressing the intricacies of multi-step analytical workflows.
为解决这一空白,我们提出了高级推理与转换引擎(ARTEMIS-DA)——一个专为释放大语言模型在多步骤数据分析任务中的潜力而设计的综合框架。ARTEMIS-DA采用三组件架构:规划器(Planner)、编码器(Coder)和绘图器(Grapher),每个组件都承担着关键且互补的角色。规划器作为框架协调中枢,负责解析复杂用户查询并将其分解为适应数据集和分析目标的结构化指令序列,涵盖数据预处理、转换、预测分析和可视化等任务。通过利用大语言模型的自然语言理解与推理能力,规划器确保多步骤分析工作流执行时的清晰性与结构性。
The Coder, in turn, translates the Planner’s instructions into executable Python code, dynamically generating and executing the necessary operations within a Python environment. Whether performing data transformations, training predictive models, or creating visualization s, the Coder bridges the gap between high-level task specifications and low-level computational execution. This dynamic interplay between the Planner and Coder components enables ARTEMIS-DA to handle analytical tasks autonomously, requiring minimal user intervention.
程序员 (Coder) 将规划器 (Planner) 的指令转化为可执行的 Python语言 代码,在 Python 环境中动态生成并执行必要操作。无论是执行数据转换、训练预测模型还是创建可视化图表,程序员都能弥合高层级任务描述与低层级计算执行之间的鸿沟。规划器与程序员组件间的这种动态交互,使 ARTEMIS-DA 能够以最少用户干预自主处理分析任务。
The Grapher is another key component of ARTEMISDA, analyzing the generated graphs and visualization s to extract valuable insights. By interpreting visual representations of data, the Grapher enables a deeper understanding of the underlying patterns and trends. The Grapher works in close coordination with the Planner and Coder, facilitating the seamless integration of data analysis, visualization, and insight extraction into a unified framework. Together, these components empower ARTEMIS-DA to deliver actionable insights, facilitating natural language interactions with complex datasets and enhancing accessibility for users without programming expertise.
Grapher是ARTEMIS-DA的另一核心组件,通过分析生成的图表和可视化结果来提取有价值的洞见。该组件通过解读数据的视觉呈现,帮助用户更深入地理解底层模式和趋势。Grapher与Planner、Coder紧密协作,将数据分析、可视化和洞见提取无缝整合到统一框架中。这些组件共同使ARTEMIS-DA能够提供可操作的见解,支持用户以自然语言交互方式处理复杂数据集,并降低非编程专业人士的使用门槛。
ARTEMIS-DA’s effectiveness is underscored by its Stateof-the-Art (SOTA) performance on benchmarks such as WikiTable Questions [17] and TabFact [3]. These results highlight its ability to manage nuanced analytical tasks requiring advanced multi-step reasoning. Beyond answering structured dataset queries, ARTEMIS-DA demonstrates versatility in transforming datasets, visualizing results, and conducting predictive modeling, positioning it as a transformative tool in LLM-powered data analytics.
ARTEMIS-DA的有效性通过其在WikiTable Questions [17]和TabFact [3]等基准测试中的最先进(SOTA)性能得到凸显。这些结果彰显了其处理需要高级多步推理的细致分析任务的能力。除了回答结构化数据集查询外,ARTEMIS-DA还展现了在转换数据集、可视化结果以及进行预测建模方面的多功能性,使其成为大语言模型(LLM)驱动数据分析领域的变革性工具。
The remainder of this paper is structured as follows: Section 2 reviews related work on LLM applications in data analytics and automated task decomposition. Section 3 presents the architecture of ARTEMIS-DA, focusing on its components and their respective roles. Section 4 evaluates the framework’s performance on established benchmarks, while Section 5 demonstrates ARTEMIS-DA’s capabilities in generating visualization s and predictive modeling. Finally, Section 6 concludes with insights into future directions for advancing LLM-powered data analytics and further enhancing LLMs for other complex tasks that require multi-step reasoning.
本文其余部分的结构如下:第2节回顾了大语言模型(LLM)在数据分析和自动化任务分解方面的相关研究。第3节介绍ARTEMIS-DA的架构,重点阐述其组件及各自功能。第4节评估该框架在标准基准测试中的表现,第5节则展示ARTEMIS-DA在生成可视化视图和预测建模方面的能力。最后,第6节总结未来发展方向,包括推进基于大语言模型的数据分析技术,以及进一步优化大语言模型以应对其他需要多步推理的复杂任务。
Through the development of ARTEMIS-DA, we contribute a significant advancement to the emerging field of LLM-driven data analytics, offering a fully integrated end-to-end system capable of managing complex, multistep analytical queries with minimal user intervention. This framework aims to redefine the accessibility, efficiency, and scope of data analytics, establishing a new paradigm for LLM-assisted insight synthesis.
通过开发ARTEMIS-DA,我们为大语言模型(LLM)驱动数据分析这一新兴领域做出了重要贡献,提供了一个完全集成的端到端系统,能够以最少的用户干预管理复杂的多步骤分析查询。该框架旨在重新定义数据分析的可访问性、效率和范围,为大语言模型辅助的洞察合成建立新范式。
2 Related Works
2 相关工作
In recent years, Large Language Models (LLMs) have demonstrated promise in addressing complex tasks in natural language processing and reasoning. However, when applied to structured data, such as large tables, unique challenges arise, requiring specialized frameworks and adaptations. Recent studies have made significant strides in enhancing LLMs’ reasoning capabilities with tabular data, providing the foundation for the ARTEMIS-DA framework proposed in this paper.
近年来,大语言模型(LLM)在解决自然语言处理和推理领域的复杂任务方面展现出潜力。然而当应用于结构化数据(如大型表格)时,会面临独特挑战,需要专门的框架和适配方案。最新研究在提升大语言模型处理表格数据的推理能力方面取得重大进展,这为本文提出的ARTEMIS-DA框架奠定了基础。
Tabular Reasoning with Pre-trained Language Models. Traditional approaches with pre-trained language models such as TaBERT[27], TAPAS[7], TAPEX[11], ReasTAP[30], and PASTA[6] were developed to combine free-form questions with structured tabular data. These models achieved moderate success by integrating tablebased and textual training, enhancing tabular reasoning capabilities. However, their ability to generalize under table perturbations remains limited[2, 31]. Solutions such as LETA[31] and LATTICE[21] addressed these limitations using data augmentation and order-invariant attention. However, they require white-box access to models, making them incompatible with SOTA black-box LLMs.
基于预训练语言模型的表格推理。传统方法如TaBERT[27]、TAPAS[7]、TAPEX[11]、ReasTAP[30]和PASTA[6]旨在将自由形式问题与结构化表格数据相结合。这些模型通过整合基于表格和文本的训练,提升了表格推理能力,取得了中等程度的成功。然而,它们在表格扰动下的泛化能力仍然有限[2, 31]。LETA[31]和LATTICE[21]等解决方案通过数据增强和顺序不变注意力机制解决了这些限制,但需要白盒访问模型,因此无法兼容最先进的(SOTA)黑盒大语言模型。
Table-Specific Architectures for LLMs. Table-specific models further refined the use of structured tabular data, emphasizing row and column positioning such as Table Former[25] which introduced positional embeddings to capture table structure, mitigating the impact of structural perturbations. Despite these advances, frameworks like StructGPT[9] highlighted that generic LLMs still struggle with structured data unless enhanced with explicit symbolic reasoning. Recently proposed frameworks such as AutoGPT[20] and Data Copilot[29] began addressing table-specific challenges by incorporating advanced reasoning techniques. However, their performance remains constrained across diverse scenarios due to their reliance on generic programming for task execution.
表 1: 大语言模型的表格专用架构
表格专用模型进一步优化了结构化表格数据的使用,强调行列定位。例如 Table Former[25] 引入了位置嵌入 (positional embeddings) 来捕捉表格结构,从而减轻结构扰动的影响。尽管取得了这些进展,但 StructGPT[9] 等框架指出,通用大语言模型仍难以处理结构化数据,除非通过显式符号推理进行增强。最近提出的框架如 AutoGPT[20] 和 Data Copilot[29] 开始通过整合高级推理技术来解决表格专用挑战,但由于依赖通用编程来执行任务,其性能在不同场景中仍受限。
Noise Reduction in Table-Based Question Answering. Handling noise in large, complex tables is another active research area. CABINET[18] introduced a Content Relevance-Based Noise Reduction strategy, significantly improving LLM performance by employing an Unsupervised Relevance Scorer (URS). By filtering irrelevant information and focusing on content relevant to user queries, CABINET achieved notable accuracy improvements on datasets like WikiTable Questions[17] and FeTaQA[13], underscoring the importance of noise reduction in reliable table-based reasoning.
基于表格问答的噪声消除。处理大型复杂表格中的噪声是另一个活跃的研究领域。CABINET[18]提出了一种基于内容相关性的噪声消除策略,通过采用无监督相关性评分器(URS)显著提升了大语言模型的性能。该方法通过过滤无关信息并聚焦与用户查询相关的内容,在WikiTable Questions[17]和FeTaQA[13]等数据集上实现了显著的准确率提升,印证了噪声消除对可靠表格推理的重要性。
Few-Shot and Zero-Shot Learning for Tabular Reasoning. Few-shot and zero-shot learning methods have shown considerable promise in tabular understanding tasks. Chain-of-Thought (CoT) prompting[23] improved LLMs’ sequential reasoning capabilities. Building on this, studies such as[4, 26] integrated symbolic reasoning into CoT frameworks, enhancing query decomposition and understanding. However, these techniques are not tailored to tabular structures, leading to performance gaps. Chain-of-Table[22] addressed these limitations by introducing an iterative approach to transforming table contexts, enabling more effective reasoning over structured data and achieving state-of-the-art results on benchmarks such as WikiTable Questions[17] and TabFact[3].
少样本和零样本学习在表格推理中的应用。少样本和零样本学习方法在表格理解任务中展现出显著潜力。思维链 (Chain-of-Thought, CoT) 提示技术[23]提升了大语言模型的序列推理能力。基于此,[4, 26]等研究将符号推理融入CoT框架,强化了查询分解与理解能力。然而这些技术未针对表格结构进行优化,导致性能差距。Chain-of-Table[22]通过引入迭代式表格上下文转换方法解决了这些局限,实现对结构化数据更高效的推理,并在WikiTable Questions[17]和TabFact[3]等基准测试中取得最优结果。
Programmatic Approaches to Tabular Question Answering. Leveraging programmatic techniques has significantly advanced the field of table-based question answering by enabling models to interpret and process structured data more effectively. Text-to-SQL models such as TAPEX[11] and OmniTab[10] trained large language models (LLMs) to translate natural language questions into SQL operations, demonstrating the potential for automated interaction with tabular datasets. Despite their promise, these models struggled with noisy and large tables due to limited query comprehension. Programmatically enhanced solutions, such as Binder[4] and LEVER[14], improved performance by generating and verifying SQL or Python code. However, their reliance on single-pass code generation restricted their adaptability to queries requiring dynamic reasoning.
基于编程方法的表格问答
利用编程技术显著推动了基于表格的问答领域发展,使模型能更高效地解析和处理结构化数据。TAPEX[11] 和 OmniTab[10] 等文本转SQL (Text-to-SQL) 模型通过训练大语言模型将自然语言问题转换为SQL操作,展现了与表格数据集自动化交互的潜力。尽管前景广阔,这些模型因查询理解能力有限,在处理噪声多或规模大的表格时表现欠佳。Binder[4] 和 LEVER[14] 等编程增强方案通过生成并验证SQL或Python代码提升了性能,但其依赖单次代码生成的特性限制了应对需要动态推理的查询时的适应性。
Building on these advancements and addressing the limitations of previous models, we introduce the Advanced Reasoning and Transformation Engine for MultiStep Insight Synthesis in Data Analytics (ARTEMISDA). Unlike prior models, ARTEMIS-DA features a tricomponent architecture consisting of a Planner, a Coder, and a Grapher, which collaborative ly address complex, multi-step analytical queries. The Planner generates dynamic task sequences tailored to specific datasets and queries, encompassing data transformation, predictive analysis, and visualization. The Coder translates these sequences into Python code and executes them in real time. Finally, the Grapher extracts actionable insights from the visualization s produced by the Coder, enhancing result inter pre t ability and ensuring the seamless integration of visual insights into user workflows.
基于这些进步并针对先前模型的局限性,我们推出了用于数据分析中多步洞察合成的先进推理与转换引擎(ARTEMISDA)。与之前模型不同,ARTEMIS-DA采用三组件架构,包含规划器(Planner)、编码器(Coder)和绘图器(Grapher),协同处理复杂的多步骤分析查询。规划器生成针对特定数据集和查询定制的动态任务序列,涵盖数据转换、预测分析和可视化。编码器将这些序列转换为Python语言代码并实时执行。最后,绘图器从编码器生成的可视化结果中提取可操作洞察,提升结果可解释性,并确保视觉洞察无缝融入用户工作流程。
This seamless integration of the Planner, Coder, and Grapher components enables ARTEMIS-DA to tackle intricate tasks requiring sequential reasoning, synthesis, and visualization, achieving state-of-the-art performance on benchmarks such as WikiTable Questions[17] and TabFact[3]. ARTEMIS-DA extends LLM functionality in data analytics, providing a robust, automated solution that empowers technical and non-technical users to interact with complex datasets through natural language.
Planner、Coder和Grapher组件的无缝集成使ARTEMIS-DA能够处理需要顺序推理、综合和可视化的复杂任务,在WikiTable Questions[17]和TabFact[3]等基准测试中实现了最先进的性能。ARTEMIS-DA扩展了大语言模型在数据分析中的功能,提供了一个强大的自动化解决方案,使技术用户和非技术用户都能通过自然语言与复杂数据集交互。
3 ARTEMIS-DA Framework
3 ARTEMIS-DA 框架
The Advanced Reasoning and Transformation Engine for Multi-Step Insight Synthesis in Data Analytics (ARTEMIS-DA) is designed to address the challenges of complex data analytics by combining advanced reasoning capabilities with dynamic, real-time code generation, execution and visual analysis. The framework, shown in Figure 2, consists of three core components: the Planner, the Coder and the Grapher. Working in unison, these components decompose complex queries into sequential tasks, automatically generate and execute the required code for each task, and synthesize insights based on generated graphs with minimal user intervention.
高级推理与多步洞察合成引擎(ARTEMIS-DA)通过将先进推理能力与动态实时代码生成、执行及可视化分析相结合,旨在解决复杂数据分析的挑战。如图 2 所示,该框架包含三个核心组件:规划器 (Planner)、编码器 (Coder) 和绘图器 (Grapher)。这些组件协同工作,将复杂查询分解为顺序任务,自动生成并执行每个任务所需的代码,并基于生成的图表以最少用户干预合成洞察。
For the experiments in this paper, all three components utilize the LLaMA 3 70B model[5], which demonstrated superior performance across benchmarks. The Grapher component also employs the LLaMA 3.2 Vision 90B model for understanding generated graphs. However, the framework is model-agnostic and can be adapted to work with other state-of-the-art large language models (LLMs), such as GPT-4[15] or Mixtral-8x7B[8].
本文实验中,所有三个组件均采用LLaMA 3 70B模型[5],该模型在各项基准测试中展现出卓越性能。Grapher组件还额外使用LLaMA 3.2 Vision 90B模型来理解生成的图表。但该框架具有模型无关性,可适配其他前沿大语言模型(如GPT-4[15]或Mixtral-8x7B[8])。
The following sections provide an in-depth exploration of the Planner, Coder and Grapher components, detailing their roles and interactions. Together, they exemplify ARTEMIS-DA’s ability to streamline end-to-end data analytics workflows effectively and efficiently.
以下章节将深入探讨Planner、Coder和Grapher组件,详细说明它们的作用及交互方式。这些组件共同体现了ARTEMIS-DA高效简化端到端数据分析工作流程的能力。
3.1 Planner Component
3.1 规划器组件
The Planner serves as the central reasoning and taskdecomposition unit within the ARTEMIS-DA framework, converting user queries into structured sequences of tasks. Its primary responsibilities include parsing user inputs, organizing them into a logical workflow, and interpreting the outputs of executed code and generated visual insights to guide subsequent steps in the analytical process. The Planner is adept at managing complex, multifaceted queries that require diverse operations, such as data transformation, predictive modeling, and visualization. By leveraging the advanced reasoning capabilities of large language models (LLMs), it decomposes intricate requirements into optimized task sequences aligned with the input data, prior outputs, and specific details of the user’s query, ensuring clarity for seamless execution by the Coder and Grapher as required.
Planner(规划器)作为ARTEMIS-DA框架中的核心推理与任务分解单元,负责将用户查询转换为结构化任务序列。其主要职责包括解析用户输入、将其组织为逻辑工作流,并解释执行代码的输出与生成的可视化洞察以指导分析流程的后续步骤。该组件擅长处理需要多样化操作(如数据转换、预测建模和可视化)的复杂多维查询。通过利用大语言模型(LLM)的高级推理能力,它能将复杂需求分解为与输入数据、先前输出及用户查询细节相匹配的优化任务序列,确保Coder(编码器)和Grapher(图表生成器)按需无缝执行。
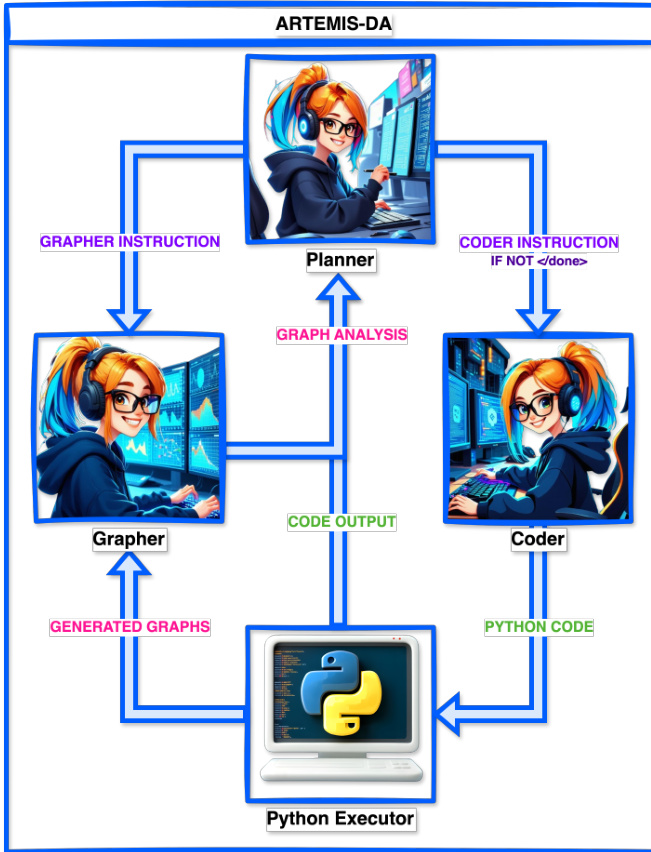
Figure 2: ARTEMIS-DA Framework
图 2: ARTEMIS-DA 框架
For instance, when tasked with analyzing sales patterns and forecasting future trends, the Planner systematically outlines essential steps, such as data pre-processing, feature engineering, model training, evaluation and forecasting, organizing them into a coherent workflow. This process is dynamically tailored to the dataset’s properties and the nuances of the query, enabling an adaptive approach to multi-step analytical tasks. Each task specification is then relayed to the Coder or Grapher in sequence, ensuring a smooth and collaborative workflow across the components of the ARTEMIS-DA framework.
例如,当需要分析销售模式并预测未来趋势时,Planner会系统性地列出关键步骤(如数据预处理、特征工程、模型训练、评估与预测),并将其组织成连贯的工作流。该流程会根据数据集特性和查询细节进行动态调整,从而实现对多步骤分析任务的适应性处理。随后,每个任务说明会依次传递给Coder或Grapher,确保ARTEMIS-DA框架各组件间形成流畅的协作工作流。
marization to advanced predictive modeling and visualization. For instance, when the user requests predictive analysis on time-series data, the Planner decomposes the query into multiple simple steps such as splitting the data, training a suitable model, and visualizing the results. The Coder generates and executes code for each step, with the Planner overseeing all steps in the process. This iterative exchange between the Planner and Coder ensures accurate execution of each analytical step, maintaining a continuous feedback loop until the analysis is fully completed.
从摘要到高级预测建模和可视化的全面数据分析任务。例如,当用户请求对时间序列数据进行预测分析时,规划器(Planner)会将查询分解为多个简单步骤,包括数据拆分、训练合适模型和结果可视化。编码器(Coder)为每个步骤生成并执行代码,规划器则监督整个流程中的所有步骤。规划器与编码器之间的这种迭代交互确保了每个分析步骤的准确执行,通过持续反馈循环直至分析完全完成。
3.3 Grapher Component
3.3 图表组件
The Grapher serves as a critical component for deriving actionable insights from visual data, responding to instructions generated by the Planner. Upon receiving a directive to analyze a generated graph from the Planner, the Grapher processes the visual output and provides insights in a structured question-and-answer format. Its analytical capabilities encompass a broad spectrum, ranging from basic data extraction from plots to advanced interpretation and trend analysis of complex plots.
绘图器 (Grapher) 是从视觉数据中提取可操作见解的关键组件,负责响应规划器 (Planner) 生成的指令。当收到分析生成图表的指令时,绘图器会处理视觉输出,并以结构化问答形式提供见解。其分析能力涵盖广泛领域,包括从图表中提取基础数据,到对复杂图表进行高级解读和趋势分析。
For instance, if the Planner requests an analysis of timeseries data, and the Coder generates a corresponding line plot, the Grapher can identify trends, detect anomalies, and highlight significant observations. This feedback enables the Planner to refine its understanding and produce more nuanced insights. Additionally, the Grapher supports a wide variety of graph types, including bar charts, pie charts, scatter plots, and heatmaps, among others, ensuring versatility across diverse data visualization needs. By seamlessly integrating graph interpretation into the workflow, the Grapher enhances the framework’s capacity to provide meaningful, data-driven conclusions.
例如,若规划器 (Planner) 请求分析时间序列数据,而编码器 (Coder) 生成了相应的折线图,绘图器 (Grapher) 便能识别趋势、检测异常并突出关键观察结果。这种反馈使规划器能优化其理解并产生更细致的洞察。此外,绘图器支持多种图表类型,包括柱状图、饼图、散点图和热力图等,确保满足多样化的数据可视化需求。通过将图表解读无缝集成到工作流中,绘图器增强了该框架提供有意义、数据驱动结论的能力。
3.4 Workflow and Interaction between Components
3.4 组件间的工作流程与交互
The ARTEMIS-DA framework employs a systematic workflow to process user queries with precision and efficiency. This process, illustrated in Figure 3, highlights the seamless interaction between the Planner, Coder, and Grapher components as outlined below:
ARTEMIS-DA框架采用系统化工作流程来精准高效地处理用户查询。如图3所示,该流程突出了Planner、Coder与Grapher组件之间的无缝协作,具体如下:
3.2 Coder Component
3.2 编码器组件
Following the Planner’s generation of a structured task sequence, the Coder translates these tasks into executable Python code. It processes instructions for each step—such as loading data, creating visualization s, or training predictive models—producing con textually relevant and functionally precise code tailored to the task’s requirements. Operating in real time within a Python environment, the Coder executes each code snippet, generating intermediate outputs that are fed back to the Planner for further analysis and informed decision-making.
在规划器生成结构化任务序列后,编码器将这些任务转换为可执行的Python语言代码。它处理每个步骤的指令——例如加载数据、创建可视化或训练预测模型——生成与任务需求相匹配、上下文相关且功能精确的代码。编码器在Python语言环境中实时运行,执行每个代码片段,生成中间输出并反馈给规划器进行进一步分析和决策制定。
The Coder’s capabilities encompass a broad range of analytical operations, from basic data cleaning and sum
程序员的能力涵盖广泛的分析操作,从基础的数据清洗和求和
- Input: The workflow begins when the user submits a dataset and a natural language query describing their analytical objectives. The Coder starts by generating the Python code to load the dataset and display the column types and the first five rows of the dataset.
- 输入:工作流始于用户提交数据集及描述分析目标的自然语言查询。Coder首先生成Python代码加载数据集,并显示列类型及数据集前五行。
- Decomposition: The Planner analyzes the query and decomposes it into a structured sequence of tasks, leveraging outputs from df.info() and df.head() to extract actionable context. For instance, a query to compare media categories might involve counting the number of TV shows and movies, creating a pie chart for visualization, and analyzing the generated chart for insights. Each task is methodically assigned to the Coder or Grapher as appropriate.
- 分解:Planner分析查询并将其分解为结构化的任务序列,利用df.info()和df.head()的输出提取可操作上下文。例如,比较媒体类别的查询可能涉及统计电视剧和电影的数量、创建饼图进行可视化,以及分析生成的图表以获取洞察。每个任务会被系统性地分配给Coder或Grapher。
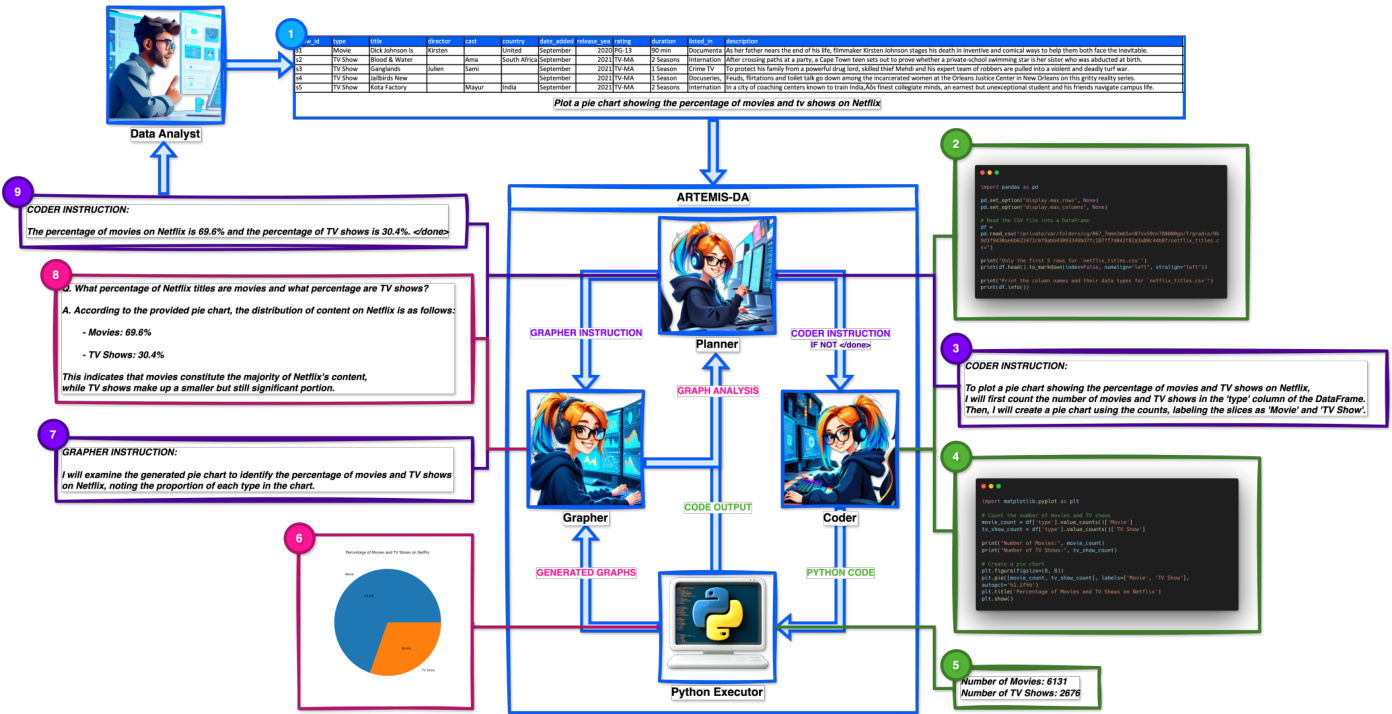
Figure 3: Workflow of the ARTEMIS-DA framework showcasing its multi-component collaboration.
图 3: ARTEMIS-DA框架的工作流程,展示其多组件协作。
- Execution: The Coder translates the Planner’s instructions into executable Python code. Tasks are executed sequentially, producing intermediate outputs. In the sample query, the Coder generates the code to count the specified categories, generate the pie chart, and prepare the visual output for analysis.
- 执行:Coder 将 Planner 的指令转换为可执行的 Python语言 代码。任务按顺序执行,生成中间输出。在示例查询中,Coder 生成用于统计指定类别、生成饼图以及准备可视化输出以进行分析的代码。
- Analysis: The Grapher processes the Planner’s instructions to derive insights from generated visuals. In the sample query, the Grapher analyzes the pie chart to calculate and report the proportions of TV shows and movies, presenting insights in a structured format.
- 分析:Grapher处理Planner的指令,从生成的视觉内容中提取洞察。在示例查询中,Grapher分析饼图以计算并报告电视节目和电影的比例,以结构化格式呈现洞察结果。
- Feedback Loop: Intermediate outputs, such as computed values, visualization s, and insights, are returned to the Planner. The Planner evaluates these results to determine if additional steps are necessary. If further actions are required, new instructions are dynamically generated for the Coder or Grapher, maintaining a responsive feedback loop to achieve the task.
- 反馈循环:计算值、可视化和洞察等中间输出结果会返回给规划模块 (Planner)。规划模块评估这些结果以判断是否需要额外步骤。如需进一步操作,则会动态生成新的指令给编码模块 (Coder) 或绘图模块 (Grapher),通过响应式反馈循环持续优化任务执行。
- Final iz ation: Once all tasks are completed, the Planner aggregates the results, refines the insights, and compiles the final output. The final result, enhanced with additional insights if necessary, is presented to the user along with a tag, indicating the successful conclusion of the workflow.
- 最终定稿:当所有任务完成后,规划器(Planner)会汇总结果、提炼洞察并汇编最终输出。必要时会加入额外洞察进行增强的最终成果将呈现给用户,并附上标签以表明工作流已成功完成。
3.5 Advantages of the ARTEMIS-DA Framework
3.5 ARTEMIS-DA框架的优势
The ARTEMIS-DA framework represents a significant advancement in data analytics by integrating sophisticated natural language understanding with precise computational execution and visual insight synthesis. Its tricomponent architecture—comprising the Planner, Coder, and Grapher—enables the framework to efficiently handle complex, multi-step analytical tasks, all while providing an intuitive interface suitable for users across various levels of technical expertise.
ARTEMIS-DA框架通过将复杂的自然语言理解、精确的计算执行与可视化洞察合成相结合,代表了数据分析领域的重大进步。其三组件架构——包括规划器(Planner)、编码器(Coder)和绘图器(Grapher)——使该框架能够高效处理复杂的多步骤分析任务,同时为不同技术水平的用户提供直观的界面。
ARTEMIS-DA achieves state-of-the-art performance on challenging datasets such as WikiTable Questions[17], TabFact[3], and FeTaQA[13], demonstrating its versatility in extracting comprehensive, data-driven insights. The framework’s ability to dynamically interpret user queries, generate and execute Python code in real-time, and analyze generated visuals further enhances its adaptability and practical value. These features collectively position ARTEMIS-DA as a cutting-edge solution for addressing the modern challenges of data analytics with precision, efficiency, and user-centered design.
ARTEMIS-DA 在 WikiTable Questions[17]、TabFact[3] 和 FeTaQA[13] 等具有挑战性的数据集上实现了最先进的性能,展现了其提取全面数据驱动洞察的通用性。该框架能动态解释用户查询、实时生成并执行 Python语言 代码、分析生成的可视化结果,进一步提升了适应性和实用价值。这些特性共同使 ARTEMIS-DA 成为以精准性、高效性和用户为中心的设计应对现代数据分析挑战的前沿解决方案。
4 Experiments and Evaluation
4 实验与评估
This section provides an overview of the benchmark datasets utilized for evaluation, the metrics employed to compare the performance of the models, the results achieved by the ARTEMIS-DA framework, and a comprehensive analysis of these results.
本节概述了用于评估的基准数据集、比较模型性能的指标、ARTEMIS-DA框架取得的成果以及对这些成果的全面分析。
4.1 Datasets
4.1 数据集
The ARTEMIS-DA framework is evaluated on three table-based reasoning datasets: WikiTable Questions [17], TabFact [3], and FeTaQA [13]. We evaluate ARTEMISDA exclusively on the test sets of these datasets without any training or fine-tuning on the training sets. The details of each dataset are as follows:
ARTEMIS-DA框架在三个基于表格的推理数据集上进行了评估:WikiTable Questions [17]、TabFact [3] 和 FeTaQA [13]。我们仅在这些数据集的测试集上评估ARTEMIS-DA,未对训练集进行任何训练或微调。各数据集的详细信息如下:
Table 1: Performance comparison for models on WikiTable Questions, TabFact and FeTaQA datasets.
| 模型 | WikiTableQuestions | TabFact | FeTaQA | |
|---|---|---|---|---|
| 准确率 | 准确率 | S-BLEU | BLEU | |
| 经过微调/训练 | ||||
| ReasTAP-Large [30] | 58.7 | 86.2 | ||
| OmniTab-Large [10] | 63.3 | 34.9 | ||
| LEVER [14] CABINET [18] | 65.8 69.1 | 40.5 | ||
| 未经微调/训练 | ||||
| Binder [4] | 64.6 | 86.0 | ||
| DATER [26] | 65.9 | 87.4 | 30.9 | 29.5 |
| Tab-PoT [24] | 66.8 | 85.8 | ||
| Chain-of-Table [22] | 67.3 | 86.6 | 32.6 | |
| SynTQA (RF) [28] | 71.6 | |||
| Mix-SC [12] | 73.6 | 88.5 | ||
| SynTQA (GPT) [28] | 74.4 | |||
| ARTEMIS-DA (Ours) | 80.8 (+6.4) | 93.1 (+4.6) | 62.7 (+22.2) | 46.4 (+13.8) |
表 1: 各模型在WikiTable Questions、TabFact和FeTaQA数据集上的性能对比。
Table 2: Ablation study of ARTEMIS-DA on WikiTable Questions, TabFact and FeTaQA datasets.
| 模型 | WikiTableQuestions | TabFact | FeTaQA | |
|---|---|---|---|---|
| 准确率 | 准确率 | S-BLEU | BLEU | |
| BestSOTAModel | 74.4 [28] | 88.5 [12] | 40.5 [18] | 32.6 [22] |
| LLaMA370B | 72.1 | 85.1 | 11.0 | 20.4 |
| Single Step ARTEMIS-DA | 76.6 | 87.6 | 40.8 | 32.8 |
| ARTEMIS-DA (Ours) | 80.8 (+4.2) | 93.1 (+4.6) | 62.7 (+21.9) | 46.4 (+13.6) |
表 2: ARTEMIS-DA 在 WikiTable Questions、TabFact 和 FeTaQA 数据集上的消融研究。
• TabFact [3]: This dataset serves as a benchmark for table-based fact verification, comprising statements created by crowd workers based on Wikipedia tables. For example, a statement such as “the industrial and commercial panel has four more members than the cultural and educational panel” must be classified as “True” or “False” based on the corresponding table. We report the accuracy on the test-small set, which consists of 2,024 statements and 298 tables.
• TabFact [3]: 该数据集作为基于表格的事实验证基准,包含众包工作者根据维基百科表格创建的陈述。例如,对于"工商界别比文化教育界别多四名成员"这样的陈述,必须根据对应表格分类为"正确"或"错误"。我们报告了由2,024条陈述和298张表格组成的test-small测试集的准确率。
• WikiTable Questions [17]: This dataset includes complex questions generated by crowd workers that are based on Wikipedia tables. The questions require various complex operations such as comparison, aggregation, and arithmetic, necessitating compositional reasoning across multiple entries in the given table. We utilize the standard test set, containing 4,344 samples.
• WikiTable Questions [17]: 该数据集包含众包工作者基于维基百科表格生成的复杂问题。这些问题需要执行比较、聚合和算术等多种复杂操作,要求对给定表格中的多个条目进行组合推理。我们使用标准测试集,包含4,344个样本。
• FeTaQA [13]: This dataset consists of free-form tables questions that demand advanced reasoning. Most questions are based on information extracted from discontinuous sections of the table. We evaluate ARTEMIS-DA on the test set, which includes 2,003 samples.
• FeTaQA [13]: 该数据集包含需要高级推理的自由格式表格问题。大多数问题基于从表格不连续区域提取的信息。我们在包含2003个样本的测试集上评估ARTEMIS-DA。
4.2 Evaluation Metrics
4.2 评估指标
To assess the performance of ARTEMIS-DA across the datasets, we employ a range of metrics tailored to the specific tasks. For the TabFact [3] dataset, which focuses on table-based fact verification, we utilize binary classification accuracy to evaluate the correctness of statements in relation to the provided tables. In the case of WikiTableQuestions [17], we measure denotation accuracy to determine whether the predicted answers align with the ground truth, leveraging the LLaMA 3 70B[5] model for verification. Since FeTaQA [13] aims to generate comprehensive, long-form answers rather than short phrases, we adopt both BLEU [16] and SacreBLEU [19] as our evaluation metrics. BLEU, a widely used metric in machine translation, assesses the quality of generated text by comparing it to high-quality reference translations, producing scores that range from 0 to 1, with higher values indicating greater similarity. SacreBLEU addresses inconsistencies commonly found in BLEU score reporting by providing a standardized framework for computation, ensuring that results are shareable, comparable, and reproducible across studies. The use of two distinct metrics for the FeTaQA [13] dataset is warranted due to the variation in metrics employed in different studies. By leveraging these metrics, we can effectively evaluate ARTEMIS-DA’s capabilities in table-based reasoning tasks and benchmark its performance against existing models.
为了评估ARTEMIS-DA在各数据集上的性能,我们采用了针对特定任务定制的一系列指标。对于专注于基于表格的事实验证的TabFact [3]数据集,我们使用二元分类准确率来评估语句与所提供表格之间的正确性。在WikiTableQuestions [17]的案例中,我们通过LLaMA 3 70B [5]模型进行验证,测量指称准确率以判断预测答案是否与真实答案一致。由于FeTaQA [13]旨在生成全面的长文本答案而非短短语,我们同时采用BLEU [16]和SacreBLEU [19]作为评估指标。BLEU是机器翻译中广泛使用的指标,通过将生成文本与高质量参考译文进行对比来评估文本质量,得分范围从0到1,数值越高表示相似度越大。SacreBLEU通过提供标准化计算框架解决了BLEU分数报告中常见的不一致问题,确保结果在不同研究间可共享、可比较且可复现。由于不同研究采用的指标存在差异,因此在FeTaQA [13]数据集上使用两种不同指标是必要的。通过这些指标,我们能够有效评估ARTEMIS-DA在基于表格的推理任务中的能力,并将其性能与现有模型进行基准测试。
4.3 Results
4.3 结果
Table 1 highlights ARTEMIS-DA’s state-of-the-art performance across the WikiTable Questions[17], TabFact[3], and FeTaQA[13] datasets. These results highlight the framework’s adaptability and effectiveness in understanding, processing, and reasoning over structured tabular data across diverse domains and use cases.
表 1: 展示了 ARTEMIS-DA 在 WikiTable Questions [17]、TabFact [3] 和 FeTaQA [13] 数据集上的前沿性能。这些结果突显了该框架在跨领域和多样化应用场景中理解、处理及推理结构化表格数据时的适应性和高效性。
In the WikiTable Questions[17] dataset, ARTEMIS-DA achieves an accuracy of $80.8%$ , outperforming previous models such as SynTQA (GPT)[28], CABINET[18], and LEVER[14]. This significant improvement of $+6.4%$ over the prior best underscores ARTEMIS-DA’s superior compositional reasoning abilities, enabling it to effectively address complex table-based questions that require multi-step logical reasoning.
在WikiTable Questions[17]数据集中,ARTEMIS-DA实现了80.8%的准确率,超越了SynTQA (GPT)[28]、CABINET[18]和LEVER[14]等先前模型。这一结果较之前最佳水平提升了+6.4%,凸显了ARTEMIS-DA卓越的组合推理能力,使其能有效解决需要多步逻辑推理的复杂表格问题。
Similarly, for the TabFact[3] dataset, ARTEMIS-DA achieves an accuracy of $93.1%$ , surpassing Mix-SC[12] by $+4.6%$ . This result demonstrates ARTEMIS-DA’s efficiency in verifying factual statements against tabular data with high precision, showcasing its strength in factchecking tasks across diverse data representations.
同样地,在TabFact[3]数据集上,ARTEMIS-DA达到了93.1%的准确率,比Mix-SC[12]高出4.6%。这一结果表明ARTEMIS-DA在基于表格数据验证事实性陈述时具备高效性和高精度,展现了其在不同数据表征的事实核查任务中的优势。
For the FeTaQA[13] dataset, ARTEMIS-DA delivers exceptional results in generating high-quality long-form answers. It achieves S-BLEU[19] and BLEU[16] scores of 62.7 and 46.4, respectively, representing a substantial improvement over previous models, including CABINET[18] and Chain-of-Table[22], with gains of $+22.2$ and $\mathbf{+13.8}$ , respectively. These results highlight ARTEMIS-DA’s ability to extract, synthesize, and integrate discontinuous information from tables, providing coherent and con textually rich answers.
在FeTaQA[13]数据集上,ARTEMIS-DA在生成长篇高质量答案方面表现卓越。其S-BLEU[19]和BLEU[16]分数分别达到62.7和46.4,较CABINET[18]和Chain-of-Table[22]等先前模型实现了显著提升,分别获得$+22.2$和$\mathbf{+13.8}$的增益。这些结果凸显了ARTEMIS-DA从表格中提取、合成并整合不连续信息的能力,能提供连贯且上下文丰富的答案。
Overall, ARTEMIS-DA establishes itself as a highly versatile and effective solution for table-based reasoning and computational tasks. Leveraging the LLaMA 3 70B[5] and LLaMA 3.2 Vision 90B models, ARTEMIS-DA consistently delivers state-of-the-art results across multiple datasets, further cementing its role as a transformative tool for compositional reasoning, fact verification, and longform answer generation in diverse domains.
总体而言,ARTEMIS-DA 成为基于表格的推理和计算任务中高度通用且高效的解决方案。依托 LLaMA 3 70B[5] 和 LLaMA 3.2 Vision 90B 模型,ARTEMIS-DA 在多个数据集上持续取得最先进成果,进一步巩固了其作为跨领域组合推理、事实核查和长文本生成的变革性工具的地位。
4.4 Ablation Study
4.4 消融研究
To thoroughly assess the necessity of the multi-step design in the ARTEMIS-DA framework for addressing complex data analytics tasks, we conduct a detailed ablation study. The Single-Step ARTEMIS-DA variant eliminates the multi-step reasoning capability and instead processes each query in a single step. By including this simplified variant, we aim to isolate and highlight the specific contributions of the multi-step reasoning approach employed by ARTEMIS-DA when applied to a diverse set of benchmark datasets.
为了全面评估ARTEMIS-DA框架中多步骤设计对于处理复杂数据分析任务的必要性,我们进行了详细的消融实验。单步版ARTEMIS-DA移除了多步骤推理能力,改为单步处理每个查询。通过引入这个简化版本,我们旨在分离并凸显ARTEMIS-DA采用的多步骤推理方法在多样化基准数据集上的具体贡献。
As shown in Table 2, Single-Step ARTEMIS-DA achieves $76.6%$ accuracy on WikiTable Questions, $87.6%$ on TabFact, and achieves 40.8 S-BLEU and 32.8 BLEU on FeTaQA, surpassing LLaMA 3 70B ( $72.1%$ , $85.1%$ , 11.0 S-BLEU, and 20.4 BLEU, respectively) but falling short of ARTEMIS-DA. The complete model outperforms both, achieving $80.8%$ accuracy on WikiTable Questions $4.2%$ gain) and $93.1%$ on TabFact $4.6%$ gain), exceeding the SOTA benchmarks of $74.4%$ and $88.5%$ respectively. On FeTaQA, ARTEMIS-DA achieves 62.7 S-BLEU and 46.4 BLEU, representing significant improvements of ${\bf+21.95}$ - BLEU and $\mathbf{+13.6}$ BLEU over Single-Step ARTEMIS-DA. These results confirm the value of ARTEMIS-DA’s multistep approach in handling complex queries, essential for accurate data analysis with LLMs.
如表 2 所示,单步 ARTEMIS-DA 在 WikiTable Questions 上达到 76.6% 准确率,在 TabFact 上达到 87.6%,在 FeTaQA 上获得 40.8 S-BLEU 和 32.8 BLEU,优于 LLaMA 3 70B (分别为 72.1%、85.1%、11.0 S-BLEU 和 20.4 BLEU) 但略逊于完整版 ARTEMIS-DA。完整模型以 80.8% 准确率 (+4.2%) 和 93.1% 准确率 (+4.6%) 分别超越 WikiTable Questions 和 TabFact 的 SOTA 基准 (原纪录为 74.4% 和 88.5%)。在 FeTaQA 任务中,ARTEMIS-DA 取得 62.7 S-BLEU 和 46.4 BLEU,相较单步版本实现 S-BLEU +21.9 和 BLEU +13.6 的显著提升。这些结果验证了 ARTEMIS-DA 多步推理方法在处理复杂查询时的价值,这对基于大语言模型的精准数据分析至关重要。
5 ARTEMIS Capability Demonstration
5 ARTEMIS 能力演示
This section presents ARTEMIS-DA’s capabilities in plot visualization and predictive modeling across a range of datasets, highlighting its versatility and robustness.
本节展示 ARTEMIS-DA 在多种数据集上的绘图可视化和预测建模能力,突出其多功能性与鲁棒性。
5.1 Plot Visualization
5.1 绘图可视化
Figure 4 presents a diverse collection of visualization s generated by ARTEMIS-DA, demonstrating its analytical capabilities using the Spotify Most Streamed Songs dataset from Kaggle. These visualization s address a range of analytical questions, showcasing ARTEMIS-DA’s ability to effectively generate, interpret, and extract insights from various plot types. For instance, the box plot compares streams for tracks released in the last 10 years, identifying streaming trends over time. The pie chart analyzes the proportion of tracks released by year over the past five years, highlighting production patterns and identifying peak and low-release years. A heatmap reveals correlations among attributes like dance ability $%$ , energy $%$ , and valence $%$ , uncovering relationships between musical features. Additionally, the bar plot highlights the top 10 tracks by total streams, offering a view of popular listener preferences, while the scatter plot explores potential correlations between energy $%$ and dance ability $%$ . The histogram details the distribution of dance ability $%$ across all tracks, providing insights into its variability. A line plot illustrates the trend of average energy $%$ of tracks over the years, shedding light on changes in the energy levels over time. The violin plot compares the distributions of danceability $%$ and energy $%$ , providing a nuanced understanding of their variability. Lastly, the radar chart contrasts attributes such as dance ability $%$ , valence $%$ , energy $%$ , and acoustic ness $%$ for the top 5 tracks by total streams, offering a comparison of these popular tracks. Together, these plots underscore ARTEMIS-DA’s versatility and effec ti ve ness in generating insightful, data-driven visualizations from complex datasets.
图 4: 展示了由ARTEMIS-DA生成的一系列多样化可视化作品,这些作品基于Kaggle的Spotify最高流量歌曲数据集,展现了其分析能力。这些可视化图表解答了多种分析问题,彰显了ARTEMIS-DA有效生成、解读并从各类图表中提取洞察的能力。例如,箱线图比较了过去10年发布歌曲的流量情况,揭示了随时间变化的流量趋势;饼图分析了近五年歌曲按年份发布的比例,突出了制作模式并识别出高产与低产年份;热力图展示了诸如舞蹈性(danceability $%$)、活力(energy $%$)和愉悦度(valence $%$)等属性间的相关性,揭示了音乐特征间的关联。此外,条形图按总流量列出了前10首歌曲,呈现了听众偏好的热门趋势;散点图探索了活力(energy $%$)与舞蹈性(danceability $%$)之间的潜在关联;直方图详细展示了所有歌曲舞蹈性(danceability $%$)的分布情况,提供了其变异性的洞察;折线图描绘了多年来歌曲平均活力(energy $%$)的变化趋势,揭示了能量水平的历时演变;小提琴图对比了舞蹈性(danceability $%$)与活力(energy $%$)的分布,提供了对两者变异性的细致理解;最后,雷达图对比了总流量前5歌曲的舞蹈性(danceability $%)、愉悦度(valence $%)、活力(energy $%)及原声度(acousticness $%)等属性,实现了对这些热门歌曲的多维度比较。这些图表共同印证了ARTEMIS-DA从复杂数据集中生成富有洞察力、数据驱动的可视化成果的多功能性和高效性。

Figure 4: ARTEMIS-DA’s visualization s using the Spotify Most Streamed Songs dataset.
图 4: ARTEMIS-DA使用Spotify Most Streamed Songs数据集的可视化效果。
5.2 Predictive Modeling
5.2 预测建模
Figure 5 illustrates ARTEMIS-DA’s predictive modeling capabilities, emphasizing its effectiveness across diverse datasets and analytical tasks. These examples demonstrate the framework’s ability to adapt seamlessly to various problem domains, showcasing ARTEMIS-DA as a robust solution for a wide range of predictive applications.
图 5: 展示了 ARTEMIS-DA 的预测建模能力,重点突出了其在不同数据集和分析任务中的有效性。这些示例证明了该框架能够无缝适应各种问题领域,展现了 ARTEMIS-DA 作为广泛预测应用场景的强大解决方案。
• Classification of Gender Data: The top-left subfigure highlights ARTEMIS-DA’s ability to handle binary classification tasks using the Gender Classification dataset. By building a model to predict gender based on input features, ARTEMIS-DA achieves an accuracy of $96.7%$ , demonstrating its proficiency in solving classification problems and its applicability to tasks such as customer profiling and demographics analysis.
• 性别数据分类:左上子图突显了ARTEMIS-DA在使用性别分类数据集处理二元分类任务的能力。通过构建一个基于输入特征预测性别的模型,ARTEMIS-DA实现了 $96.7%$ 的准确率,展示了其在解决分类问题上的熟练度,以及在客户画像和人口统计分析等任务中的适用性。
• Clustering of Superhero Powers: The top-right subfigures demonstrate ARTEMIS-DA’s clustering capabilities using the Superhero Power Analytics Dataset. ARTEMIS-DA groups superheroes based on their power attributes, leveraging dimensionality reduction and visualization techniques. This task highlights ARTEMIS-DA’s versatility in unsupervised learning, particularly in applications such as customer segmentation, anomaly detection, and clustering-based insights.
• 超级英雄能力聚类:右上角子图展示了 ARTEMIS-DA 使用超级英雄能力分析数据集 (Superhero Power Analytics Dataset) 的聚类能力。该工具通过降维和可视化技术,根据英雄的能力属性进行分组。该任务凸显了 ARTEMIS-DA 在无监督学习中的多功能性,尤其适用于客户分群、异常检测和基于聚类的洞察等应用场景。
• Time Series Forecasting on Stock Exchange Data: The middle-left sub-figure demonstrates ARTEMISDA’s strength in time-series forecasting. Utilizing an advanced Long Short-Term Memory (LSTM) model, ARTEMIS-DA predicts trends and fluctuations in stock prices using historical data from the Stock Exchange Data dataset. This capability highlights ARTEMIS-DA’s applicability to predictive financial analysis, such as stock market forecasting, economic modeling, and investment strategy development.
• 股票交易数据的时间序列预测:中左子图展示了 ARTEMISDA 在时间序列预测方面的优势。通过采用先进的长短期记忆网络 (LSTM) 模型,ARTEMIS-DA 利用股票交易数据数据集中的历史数据预测股价趋势与波动。这一能力凸显了 ARTEMIS-DA 在预测性金融分析(如股市预测、经济建模和投资策略制定)中的适用性。
• Text Classification of BBC Articles: The middle-right sub-figures showcase ARTEMIS-DA’s application to natural language processing (NLP), specifically in text classification. Using the BBC Document Classification dataset, ARTEMIS-DA successfully categorizes news articles by topic. This task underscores ARTEMISDA’s ability to process unstructured text data, making it an effective tool for applications like content categorization, sentiment analysis, and automated tagging.
• BBC文章文本分类:中间右侧的子图展示了ARTEMIS-DA在自然语言处理(NLP)领域的应用,特别是文本分类任务。通过BBC文档分类数据集,ARTEMIS-DA成功实现了按主题对新闻文章进行分类。该任务凸显了ARTEMIS-DA处理非结构化文本数据的能力,使其成为内容分类、情感分析和自动标记等应用场景的有效工具。
• Sentiment Analysis on Disneyland Reviews: The bottom-left sub-figure illustrates ARTEMIS-DA’s ability to perform sentiment analysis on text reviews using the Disneyland Reviews dataset. ARTEMIS-DA effectively identifies the Disneyland location with the highest percentage of positive reviews, showcasing its utility in analyzing customer or consumer sentiment.
• 迪士尼乐园评论情感分析:左下子图展示了 ARTEMIS-DA 使用迪士尼乐园评论数据集对文本评论进行情感分析的能力。ARTEMIS-DA 能有效识别出正面评价占比最高的迪士尼乐园地点,展现了其在分析客户或消费者情感方面的实用性。

Figure 5: ARTEMIS-DA’s predictive modeling capabilities demonstrated through classification for numerical features and text datasets, time series forecasting on stock exchange data and clustering of superhero stats.
图 5: ARTEMIS-DA通过数值特征与文本数据集分类、股票交易所数据时间序列预测以及超级英雄统计数据聚类展示的预测建模能力。
• Regression for Housing Prices: The bottom-right sub-figures demonstrate ARTEMIS-DA’s regression modeling capabilities using the Housing Price Dataset. ARTEMIS-DA applies feature selection via heatmaps and builds a regression model that achieves an $R^{2}$ score of 0.78, highlighting its ability to uncover relationships between variables and predict continuous outcomes.
• 房价回归分析:右下角的子图展示了 ARTEMIS-DA 在房价数据集上的回归建模能力。ARTEMIS-DA 通过热力图进行特征选择,并构建了一个 $R^{2}$ 得分为 0.78 的回归模型,突显了其发现变量间关系并预测连续结果的能力。
These examples illustrate ARTEMIS-DA’s adaptability in addressing a broad spectrum of predictive modeling tasks, from binary classification and NLP to time-series forecasting, clustering, sentiment analysis, and regression. ARTEMIS-DA’s robust performance across different domains makes it an ideal solution for data-driven applications in diverse industries, offering powerful tools for data exploration and predictive analytics, machine learning.
这些示例展示了ARTEMIS-DA在应对广泛预测建模任务时的适应性,包括二分类、自然语言处理 (NLP)、时间序列预测、聚类、情感分析和回归。ARTEMIS-DA在不同领域的稳健表现使其成为各行业数据驱动应用的理想解决方案,为数据探索、预测分析和机器学习提供了强大工具。
6 Conclusion
6 结论
This paper presents the Advanced Reasoning and Transformation Engine for Multi-Step Insight Synthesis in Data Analytics (ARTEMIS-DA), a ground breaking framework that extends the analytical capabilities of Large Language Models (LLMs) to handle complex, multi-step, data-driven queries with minimal user intervention. By integrating the Planner, Coder, and Grapher components, ARTEMIS-DA seamlessly combines high-level reasoning, real-time code generation, and visual analysis to orchestrate sophisticated analytics workflows encompassing data transformation, predictive modeling, and visualization.
本文介绍了一种突破性框架——数据分析多步洞察合成高级推理与转换引擎(ARTEMIS-DA),该框架通过扩展大语言模型(LLM)的分析能力,能够以最少用户干预处理复杂的多步骤数据驱动查询。通过整合规划器(Planner)、编码器(Coder)和绘图器(Grapher)三大组件,ARTEMIS-DA将高层级推理、实时代码生成与可视化分析无缝结合,可协调包含数据转换、预测建模和可视化在内的复杂分析工作流。
Our evaluations highlight ARTEMIS-DA’s state-of-theart performance on benchmarks such as TabFact[3], WikiTable Questions[17], and FeTaQA[13], demonstrating its effectiveness in managing nuanced, multi-step analytical tasks. By decomposing natural language queries into logical tasks, executing precise code for each step and performing visual analysis of generated graphs, the framework bridges the gap between intuitive user interactions and advanced computational execution.
我们的评估突显了ARTEMIS-DA在TabFact[3]、WikiTable Questions[17]和FeTaQA[13]等基准测试中的前沿性能,证明了其在处理复杂多步骤分析任务时的有效性。该框架通过将自然语言查询分解为逻辑任务、为每个步骤执行精确代码以及对生成图表进行可视化分析,弥合了直观用户交互与高级计算执行之间的鸿沟。
ARTEMIS-DA empowers both technical and nontechnical users by simplifying precise analysis of complex datasets. Future directions include enhancing the framework’s adaptability to broader tasks, improving its computational efficiency, and exploring its application in domains such as software engineering, where rapid and accurate multi-step analysis is essential.
ARTEMIS-DA通过简化复杂数据集的精准分析,赋能技术与非技术用户。未来方向包括增强框架对更广泛任务的适应性、提升计算效率,并探索其在软件工程等领域的应用,这些领域需要快速准确的多步骤分析。