Aligning Large Language Models with Human: A Survey
大语言模型与人类对齐:综述
Yufei Wang, Wanjun Zhong, Liangyou Li, Fei Mi, Xingshan Zeng, Wenyong Huang Lifeng Shang, Xin Jiang, Qun Liu Huawei Noah’s Ark Lab {wang yu fei 44,zhong wan jun 1,liliangyou,mifei2,zeng.xingshan,wenyong.huang}@huawei.com {Shang.Lifeng,Jiang.Xin,qun.liu}@huawei.com
王宇飞, 钟万军, 李良友, 米飞, 曾行善, 黄文勇, 尚立峰, 姜欣, 刘群 华为诺亚方舟实验室 {wang yu fei 44,zhong wan jun 1,liliangyou,mifei2,zeng.xingshan,wenyong.huang}@huawei.com {Shang.Lifeng,Jiang.Xin,qun.liu}@huawei.com
Abstract
摘要
Large Language Models (LLMs) trained on extensive textual corpora have emerged as leading solutions for a broad array of Natural Lan- guage Processing (NLP) tasks. Despite their notable performance, these models are prone to certain limitations such as misunderstanding human instructions, generating potentially biased content, or factually incorrect (hallucinated) information. Hence, aligning LLMs with human expectations has become an active area of interest within the research community. This survey presents a comprehensive overview of these alignment technologies, including the following aspects. (1) Data collection: the methods for effectively collecting high-quality instructions for LLM alignment, including the use of NLP benchmarks, human annotations, and leveraging strong LLMs. (2) Training methodologies: a detailed review of the prevailing training methods employed for LLM alignment. Our exploration encompasses Supervised Fine-tuning, both Online and Offline human preference training, along with parameter-efficient training mechanisms. (3) Model Evaluation: the methods for evaluating the effectiveness of these human-aligned LLMs, presenting a multifaceted approach towards their assessment. In conclusion, we collate and distill our findings, shedding light on several promising future research avenues in the field. This survey, therefore, serves as a valuable resource for anyone invested in understanding and advancing the alignment of LLMs to better suit human-oriented tasks and expectations. An associated GitHub link collecting the latest papers is available at https://github. com/GaryYufei/Align LL M Human Survey.
大语言模型 (LLMs) 经过海量文本训练后,已成为解决各类自然语言处理 (NLP) 任务的主流方案。尽管表现卓越,这些模型仍存在误解人类指令、生成潜在偏见内容或事实错误 (幻觉) 信息等局限性。因此,如何让大语言模型符合人类期望已成为学界研究热点。本综述系统梳理了这些对齐技术,涵盖以下维度:(1) 数据收集:高效获取高质量指令的方法,包括利用 NLP 基准数据集、人工标注以及调用强大 LLMs;(2) 训练方法:详细分析主流对齐训练方案,涵盖监督微调、在线/离线人类偏好训练以及参数高效训练机制;(3) 模型评估:多维度评估对齐效果的方法体系。最后我们提炼核心发现,并指明该领域未来研究方向。本综述为致力于优化大语言模型人类对齐的研究者提供了系统参考。相关 GitHub 资源库持续更新最新论文:https://github.com/GaryYufei/AlignLLMHumanSurvey。
1 Introduction
1 引言
Foundational Large Language Models (LLMs) such as GPT-3 are pre-trained on a vast textual corpus with objectives to predict subsequent tokens. This process equips LLMs with world knowledge, facilitating the generation of coherent and fluent text in response to various inputs. Despite these strengths, foundational LLMs are not always adept at interpreting a wide range of instructions and can produce outputs that deviate from human expectations. Additionally, these models may produce biased content or invent (hallucinated) facts, which can limit their practical usefulness.
基础大语言模型 (LLM) 如 GPT-3 通过海量文本语料库进行预训练,其目标是预测后续 token。这一过程使大语言模型掌握了世界知识,能够针对各类输入生成连贯流畅的文本。尽管具备这些优势,基础大语言模型并不总能熟练解读多样化的指令,其输出结果也可能偏离人类预期。此外,这类模型可能生成带有偏见的内容或虚构 (hallucinated) 事实,这些局限会影响其实际应用价值。
Therefore, recent NLP research efforts focus on empowering LLMs to understand instructions and to align with human expectations. Early methods for training LLMs to follow instructions primarily use task instruction sets, which are compiled by combining manually crafted task instruction templates with instances from standard NLP tasks. However, such approaches often fall short of capturing the intricacies of practical user instructions, as these instructions tend to originate from artificial NLP tasks designed to test specific aspects of machine capabilities. Real-world user instructions, on the other hand, are significantly more diverse and complex. As a result, OpenAI explored Supervised Fine-Tuning (SFT) of LLMs using instructions annotated by a diverse group of human users. Models developed through this process, such as Instruct GP T (Ouyang et al., 2022) and ChatGPT 1, have demonstrated a marked improvement in understanding human instructions and solving complex tasks. To further enhance alignment, Ouyang et al. (2022) incorporate the Reinforcement Learning from Human Feedback (RLHF) approach, which involves learning from human preferences through a reward model trained with human-rated outputs.
因此,近期的自然语言处理研究致力于增强大语言模型对指令的理解能力,使其与人类期望保持一致。早期训练大语言模型遵循指令的方法主要采用任务指令集,这些指令集通过将人工设计的任务指令模板与标准自然语言处理任务实例相结合而构建。然而,这类方法往往难以捕捉实际用户指令的复杂性,因为这些指令通常源自为测试机器特定能力而设计的人工自然语言处理任务。相比之下,真实场景中的用户指令显著更为多样和复杂。为此,OpenAI探索了利用多样化人类用户标注的指令对大语言模型进行监督微调(Supervised Fine-Tuning,SFT)。通过这一过程开发的模型,如Instruct GPT(Ouyang等人,2022)和ChatGPT 1,在理解人类指令和解决复杂任务方面展现出显著提升。为进一步加强对齐效果,Ouyang等人(2022)引入了基于人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)方法,该方法通过经人类评分输出训练的奖励模型来学习人类偏好。
There are challenges in alignment processes and the subsequent evaluation: (a) Collecting highquality data for both SFT and RLHF stages can be costly and time-consuming. (b) The training strategies need to be optimized as SFT training is resource-consuming, and reinforcement learning in RLHF often lacks stability. (c) Evaluating LLMs comprehensively is challenging, as limited NLP benchmarks may not fully reveal the multifaceted capabilities of LLMs.
对齐过程及后续评估存在以下挑战:(a) 为SFT和RLHF阶段收集高质量数据可能成本高昂且耗时。(b) 训练策略需要优化,因为SFT训练消耗资源,而RLHF中的强化学习往往缺乏稳定性。(c) 全面评估大语言模型具有挑战性,因为有限的NLP基准测试可能无法充分揭示大语言模型的多方面能力。

Figure 1: Taxonomy of research in aligning Large Language Models (LLMs) with human that consists of alignment data, training strategy, and evaluation methods.
图 1: 大语言模型 (LLM) 与人类对齐研究的分类体系,包含对齐数据、训练策略和评估方法三部分。
To address these limitations, extensive research efforts have been devoted. In Figure 1, we provide a summary of these multi-aspect approaches. For aspect (a), the focus is on effectively collecting large-scale, high-quality data for LLM align- ment training. Researchers propose leveraging the power of existing NLP benchmarks, human annotators, and state-of-the-art LLMs (e.g., ChatGPT and GPT-4) to generate training instructions. To tackle aspect (b), solutions involve optimizing the training methods for better efficiency and stability in incorporating human preferences. Parameterefficient training methods have been proposed to reduce computation burden and improve efficiency in LLM alignment. Additionally, some researchers consider human preference as ranking-based training signals or replace scalar rewards with language- based feedback to enhance training stability and performance. Regarding aspect (c), various humancentric LLM evaluation benchmarks and automatic evaluation protocols (e.g., LLMs for evaluation) have been proposed to obtain a comprehensive eval
为解决这些局限性,学界已投入大量研究努力。图1: 我们总结了这些多维度解决方案。针对维度(a),研究重点在于高效收集用于大语言模型对齐训练的大规模高质量数据。研究者提出利用现有NLP基准测试、人工标注员和前沿大语言模型(如ChatGPT和GPT-4)来生成训练指令。对于维度(b),解决方案聚焦优化训练方法以提升人类偏好融入的效率和稳定性。参数高效训练方法被提出用于减轻计算负担并提升大语言模型对齐效率。部分研究者还将人类偏好视为基于排序的训练信号,或用基于语言的反馈替代标量奖励以增强训练稳定性和性能。关于维度(c),学界提出了多种以人为中心的大语言模型评估基准和自动评估方案(如采用大语言模型进行评估),以实现全面评估。
uation of aligned LLMs.
对齐大语言模型的评估
In this survey, we aim to provide a comprehensive overview of alignment technologies for large language models. In Section 2, we summarize various methods in effective high-quality data collection. Section 3 focuses on popular training methods to incorporate human preference data into LLMs. The evaluation benchmarks and automatic protocols for instruction-following LLMs are discussed in Section 4. By collating and distilling our findings, we shed light on several promising future research avenues in Section 5. Through this survey, we aim to provide an overview of the current state of LLM alignment, enabling researchers and practitioners to navigate the complexities of aligning LLMs with human values and expectations.
本次综述旨在全面梳理大语言模型对齐技术的研究进展。第2章系统总结了高效获取高质量数据的不同方法。第3章重点探讨将人类偏好数据融入大语言模型的流行训练方法。第4章讨论了指令跟随型大语言模型的评估基准与自动化方案。通过整合研究发现,第5章揭示了若干具有潜力的未来研究方向。本综述力图展现大语言模型对齐领域的研究现状,帮助研究者和从业者应对模型与人类价值观及期望对齐的复杂挑战。
2 Alignment Data Collection
2 对齐数据收集
Aligning LLMs with human expectations necessitates the collection of high-quality training data that authentically reflects human needs and expectations. For the purposes of this survey, we conceptualize an instruction as $I_ {k}=(x_ {k},y_ {k})$ , where $x_ {k}$ denotes the instruction input and $y_ {k}$ denotes the corresponding response. This data can be derived from an array of sources, encompassing both human-generated instructions and those generated by strong LLMs. In this section, we summarize these methods of instruction generation and effective strategies for constructing a composite of diverse training instructions.
要让大语言模型 (LLM) 符合人类预期,关键在于收集能真实反映人类需求和期望的高质量训练数据。在本综述中,我们将指令概念化为 $I_ {k}=(x_ {k},y_ {k})$ ,其中 $x_ {k}$ 表示指令输入, $y_ {k}$ 表示对应响应。这些数据可源自多种渠道,既包括人类生成的指令,也涵盖强大LLM生成的指令。本节将总结这些指令生成方法,以及构建多样化训练指令组合的有效策略。
2.1 Instructions from Human
2.1 人类指令
Human-provided instructions mainly originate from two main sources: pre-existing humanannotated NLP benchmarks and meticulously handcrafted instructions.
人类提供的指令主要来自两个来源:预先标注的自然语言处理(NLP)基准数据集和精心手工制作的指令。
2.1.1 NLP Benchmarks
2.1.1 NLP基准测试
An intuitive starting point for data collection involves adapting existing NLP benchmarks into natural language instructions. For instance, Figure 2 offers an example drawn from the Natural Language Inference task. Works such as PromptSource (Bach et al., 2022), FLAN (Wei et al., 2022a; Longpre et al., 2023), and SuperNatural Instruction (Wang et al., 2022b; Mishra et al., 2022) are at the forefront of this approach. These benchmarks represent a substantial array of diverse and heterogeneous NLP tasks, such as dialogue, reasoning tasks and coding tasks, unified under the framework of language instructions. In each NLP benchmark, they engage annotators to craft several natural language templates that smoothly integrate all input data into a sequential text. The objective is to enhance LLMs’ capability for multi-task learning across training tasks and foster generalization for unseen tasks. OIG (Nguyen et al., 2023) also combines instructions from FLAN-like NLP benchmarks with other types of open-ended instructions, such as how-to, maths and coding instructions. Concurrently, Honovich et al. (2022) put forth the concept of Unnatural Instructions, utilizing LLMs to generate new templates or instances bearing resemblance to the original instructions but with notable variances. Interestingly, the authors discovered that text-davinci-002 outperforms GPT-3 in responding to these generated instructions, given that GPT-3 often devolved into repetitive or tangential outputs after providing the correct answer. This model of instruction creation is highly scalable and can yield millions of instructions effectively. Further, Wang et al. (2023d) demonstrated that FLANstyle instructions considerably enhanced the reasoning capabilities of aligned LLMs.
数据收集的一个直观起点是将现有自然语言处理(NLP)基准任务转化为自然语言指令。例如,图2展示了来自自然语言推理任务的示例。PromptSource (Bach等,2022)、FLAN (Wei等,2022a;Longpre等,2023)和SuperNatural Instruction (Wang等,2022b;Mishra等,2022)等研究是该领域的先驱工作。这些基准涵盖了对话、推理任务和编程任务等大量多样化NLP任务,并通过语言指令框架实现了统一。在每个NLP基准中,研究者会邀请标注人员创建多个自然语言模板,将输入数据流畅地整合为连续文本。其目标是增强大语言模型在训练任务中的多任务学习能力,并提升对未见任务的泛化能力。OIG (Nguyen等,2023)还将类FLAN的NLP基准指令与其他开放式指令(如操作指南、数学和编程指令)相结合。与此同时,Honovich等(2022)提出了"非自然指令"的概念,利用大语言模型生成与原始指令相似但存在显著差异的新模板或实例。有趣的是,作者发现text-davinci-002在处理这些生成指令时表现优于GPT-3,因为GPT-3在给出正确答案后常会出现重复或偏离主题的输出。这种指令创建模式具有高度可扩展性,能有效生成数百万条指令。此外,Wang等(2023d)证明FLAN风格的指令显著提升了对齐后大语言模型的推理能力。

Figure 2: An Example of Instruction from a Natural Language Inference (NLI) benchmark.
图 2: 自然语言推理 (NLI) 基准中的指令示例。
2.1.2 Hand-crafted Instructions
2.1.2 手工制作指令
Constructing instructions from NLP benchmarks could be effective and painless. However, as many NLP datasets focus on a small and specific skill set, which means the resultant instructions are also relatively narrow in scope. Consequently, they may fall short in catering to the complex needs of realworld applications, such as engaging in dynamic human conversation.
从自然语言处理(NLP)基准构建指令可能高效且省力。然而,由于许多NLP数据集专注于小而特定的技能集,这意味着生成的指令范围也相对狭窄。因此,它们可能难以满足现实应用的复杂需求,例如进行动态的人类对话。
To combat the above issues, it is possible to construct instructions via intentional manual annotations. How to effectively design a humanin-the-loop annotation framework becomes the key issue. The Databricks company collects a 15k crowd-sourcing instruction dataset databricksdolly $I5k$ (Conover et al., 2023) from its employees. Those people are instructed to create prompt / response pairs in each of eight different instruction categories, including the seven outlined in Ouyang et al. (2022), as well as an open-ended free-form category. Importantly, they are explicitly instructed not to use external web information, as well as outputs from generative AI systems. Kopf et al. (2023) construct the Open Assistant corpus with over 10,000 dialogues using more than 13,000 inter national annotators. The annotation process includes a) writing initial prompts for dialogue; b) replying as an assistant or user; c) ranking dialogue quality to explicitly provide human preferences. As a result, this corpus can be used for SFT and human preference alignment training for LLMs. Zhang et al. (2023a) construct high-quality Chinese instructions from existing English instruction datasets. They first translate the English in- structions into Chinese, then verify whether these translations are usable. Finally, they hire annotators to correct and re-organize the instructions into the task description, input, output format in the selected corpus. ShareGPT 2, which is collected by Chiang et al. (2023), is an interesting exploration for crowd-sourcing human-written instructions. It is a website that encourages users to upload and share their interesting ChatGPT/GPT4 conversations. Such a mechanism can effectively collect a large number of diverse and human-written instructions that likely trigger high-quality ChatGPT/GPT4 responses. Popular online QA websites, such as Stack Overflow 3, Quora 4 and Zhihu 5, and large user-generated content databases, such as Wikipedia 6, are all reliable sources to provide high-quality human-written prompts for this purpose.Both Ding et al. (2023) and Xu et al. (2023c) propose to use these resources as the seed instructions to prompt GPT-3.5 to generate high-quality synthetic multi-turn dialogues.
为解决上述问题,可通过人工标注构建指令。如何设计有效的人机协同标注框架成为关键。Databricks公司从其员工中收集了15k众包指令数据集databricksdolly $I5k$ (Conover et al., 2023),要求参与者针对八类指令(包括Ouyang et al. (2022)提出的七类及开放式自由类别)创建提示/响应对,并明确规定不得使用外部网络信息及生成式AI系统输出。Kopf et al. (2023)通过13,000余名国际标注者构建了包含超10,000组对话的Open Assistant语料库,标注流程包括:a)编写对话初始提示;b)以助手或用户身份回复;c)对话质量排序以显式提供人类偏好。该语料库可用于大语言模型的监督微调(SFT)和人类偏好对齐训练。Zhang et al. (2023a)从现有英文指令数据集构建高质量中文指令:先英译中,再验证翻译可用性,最后聘请标注者修正并按任务描述、输入、输出格式重组指令。Chiang et al. (2023)收集的ShareGPT是众包人类撰写指令的创新探索——该网站鼓励用户分享有趣的ChatGPT/GPT4对话,能有效收集大量可能触发高质量响应的多样化人类指令。Stack Overflow、Quora、知乎等在线问答平台,以及维基百科等用户生成内容数据库,均为获取高质量人类撰写提示的可靠来源。Ding et al. (2023)与Xu et al. (2023c)均提出用这些资源作为种子指令,驱动GPT-3.5生成高质量合成多轮对话。
2.2 Instructions From Strong LLMs
2.2 来自强大语言模型的指令
With the emergence of strong closed-source LLMs (e.g., ChatGPT/GPT4), it is also feasible to automate the collection process to obtain various types of synthetic instructions (e.g., single-turn, multiturn, and multilingual instructions) by providing appropriate prompts to these LLMs. The main challenge is how to effectively prompt LLMs to generate diverse and high-quality instructions.
随着强大闭源大语言模型(LLM)(如ChatGPT/GPT4)的出现,通过向这些大语言模型提供适当的提示(prompt),自动化收集过程以获取各类合成指令(如单轮、多轮和多语言指令)也变得可行。主要挑战在于如何有效提示大语言模型生成多样且高质量的指令。
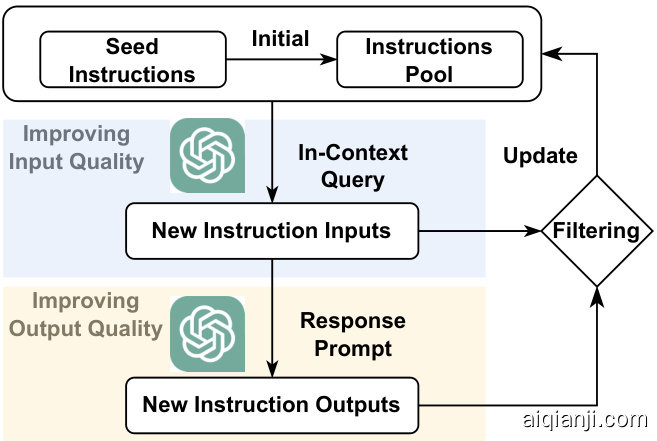
Figure 3: The overview of self-instruction. Starting from instructions in the pool, self-instruction leverages LLMs to produce new instructions via in-context learning. After filtering, LLMs are then prompted to respond to the remaining instructions. The full instructions are then added to the pool. Research efforts have been devoted to 1) Improving instruction input quality, and 2) Improving instruction output quality.
图 3: 自我指令 (self-instruction) 流程概览。该方法从指令池出发,通过上下文学习 (in-context learning) 驱动大语言模型生成新指令。经过筛选后,大语言模型继续为剩余指令生成响应。最终完整的指令会被添加回指令池。当前研究主要聚焦于:1) 提升指令输入质量;2) 提升指令输出质量。
2.2.1 Self-Instruction
2.2.1 自指令 (Self-Instruction)
Self-Instruct (Wang et al., 2022a) were among the pioneers to automate the instruction collection process. It employed the in-context learning capability of ChatGPT to generate large-scale instructions from a pre-defined set of human-annotated instructions covering diverse topics and task types, as illustrated in Figure 3. The automatically generated instructions are followed by a quality control filtering process, and this iterative process continues until the desired data volume has been achieved. Interestingly, the researchers discovered that GPT3 (Brown et al., 2020), fine-tuned with these instructions, performed better than models fine-tuned using instructions derived from NLP benchmarks SuperNI benchmark (Wang et al., 2022b) and UserOriented Instructions, as discussed in Section 2.1). Several follow-up attempts, such as Aplaca (Taori et al., 2023) and its variants (Cui et al., 2023a) follow this Self-Instruct framework. More subsequent research efforts w.r.t. enhancing instruction diversity, quality, and complexity will be elaborated as follows.
Self-Instruct (Wang等人,2022a) 是自动化指令收集流程的先驱之一。该方法利用ChatGPT的上下文学习能力,从一组预定义的人工标注指令(涵盖多样化主题和任务类型)中生成大规模指令,如图3所示。自动生成的指令会经过质量控制过滤流程,这一迭代过程持续进行直至达到目标数据量。值得注意的是,研究人员发现:用这些指令微调后的GPT3 (Brown等人,2020) 表现优于基于NLP基准SuperNI benchmark (Wang等人,2022b) 和用户导向指令(见第2.1节讨论)微调的模型。后续多项尝试(如Alpaca (Taori等人,2023) 及其变体 (Cui等人,2023a))都沿用了Self-Instruct框架。关于提升指令多样性、质量和复杂度的更多研究进展将在下文详述。
Improving Input Quality One limitation of the synthetic instructions from strong LLMs often suffer from diversity issues. For example, Jentzsch and Kersting (2023) find that when prompting to generate jokes, ChatGPT only produces 25 unique joke patterns in thousands of samples. To improve the instruction input diversity, Wang et al. (2022a) propose different input and output generation strategies for different types of instructions. They first prompt ChatGPT to classify gen- erated instruction into classification tasks or nonclassification tasks. Then, they deploy output-first and input-first strategies for classification tasks and non-classification tasks, respectively. Others propose to add various external information into the input prompts to enhance diversity and factuality, including Wikipedia Category Keywords (Wu et al., 2023), user-generated questions on the Internet (e.g., Quora, Stack Overflow) (Xu et al., 2023c; Anand et al., 2023) and instructions from the Super Natural Instruction benchmark (Honovich et al., 2022). Yu et al. (2023b) also shows that explicitly adding meta-information (e.g., length, topics, style) into the data generation prompts can effectively remove the bias in the generated synthetic data and improve the diversity of those synthetic data. Furthermore, Xu et al. (2023b) propose a novel Evol-Instruct framework to obtain complex and difficult instructions gradually. Instead of using existing instructions to prompt LLMs to produce new instructions via in-context learning, in EvolInstruct, there are five different manually-designed prompts to explicitly instruct LLMs to rewrite the existing simple instructions into complex ones using in-depth methods (i.e., including more information on particular topics) or in-Breadth methods (i.e, improving topics/information coverage). The resulting WizardLM model is ranked top in the MTBench (Zheng et al., 2023) and AlpacaEval (Dubois et al., 2023). Luo et al. (2023) further expand this idea to produce complex code and programming instructions from the simple ones and propose the Wizard Code r model, which outperforms several strong commercial LLMs, e.g., Anthropic’s Claude and Google’s Bard. Gunasekar et al. (2023) propose to generate textbook-like instructions prompted with sufficient background knowledge to promote reasoning and basic algorithmic skills of LLMs. They find that the resulting 1.3B LLMs phi-1 successfully outperform various much larger LLMs, showing the importance of data quality.
提升输入质量
大语言模型生成的合成指令常存在多样性不足的问题。例如,Jentzsch和Kersting (2023) 发现,在要求生成笑话时,ChatGPT在数千个样本中仅产生25种独特的笑话模式。为提升指令输入的多样性,Wang等人 (2022a) 针对不同类型指令提出了差异化的输入输出生成策略:先通过ChatGPT将指令分类为分类任务或非分类任务,再分别采用输出优先和输入优先策略处理。另有研究通过融入外部信息增强多样性与事实性,包括维基百科分类关键词 (Wu等人, 2023)、网络用户生成问题 (如Quora、Stack Overflow) (Xu等人, 2023c; Anand等人, 2023) 以及Super Natural Instruction基准指令 (Honovich等人, 2022)。Yu等人 (2023b) 证实,在数据生成提示中显式添加元信息 (如长度、主题、风格) 可有效消除合成数据偏差并提升多样性。
Xu等人 (2023b) 提出Evol-Instruct框架逐步生成复杂指令:通过5种人工设计的提示模板,指导大语言模型采用深度方法 (增加特定主题细节) 或广度方法 (扩展主题覆盖) 将简单指令重写为复杂指令。由此训练的WizardLM模型在MTBench (Zheng等人, 2023) 和AlpacaEval (Dubois等人, 2023) 评测中表现优异。Luo等人 (2023) 将该思路扩展到代码领域,开发的WizardCoder模型性能超越Claude、Bard等商业大模型。Gunasekar等人 (2023) 通过注入背景知识生成教科书式指令,其1.3B参数的phi-1模型超越多个更大规模模型,印证了数据质量的重要性。
Improving Output Quality Aside from the provision of high-quality instruction input, a critical requisite is to skillfully prompt LLMs to yield highquality responses. The conventional method of enhancing response quality entails appending LLM prompts with additional conditions, encompassing the following facets.
提升输出质量
除提供高质量指令输入外,关键要求是熟练地提示大语言模型以生成高质量响应。提升响应质量的常规方法包括为大语言模型提示添加额外条件,涵盖以下方面。
(1) Reasoning-Provoking Conditions: Wei et al. (2022b) proposed the Chain-of-Thought (CoT) reasoning approach, which includes preconditions in the LLM prompts and generation the intermediate reasoning processes for complex problems, thereby assisting LLMs in problem-solving. Inspired by CoT, Mukherjee et al. (2023) developed the Orca model, which learns not only the superficial response text from LLMs, but also captures complex reasoning process signals. Specifically, they guided LLMs to respond to reasoningintensive FLAN instructions with a series of predefined system prompts (e.g., “think step-by-step and justify your response”), spurring LLMs (e.g., GPT4) to disclose their reasoning process information. Thanks to these advancements, the Orca model significantly outperformed several powerful open-sourced LLMs.
(1) 激发推理的条件:Wei等人(2022b)提出了思维链(Chain-of-Thought,CoT)推理方法,该方法在大语言模型提示中设置前提条件,并为复杂问题生成中间推理过程,从而辅助大语言模型解决问题。受CoT启发,Mukherjee等人(2023)开发了Orca模型,该模型不仅学习大语言模型的表层响应文本,还能捕捉复杂的推理过程信号。具体而言,他们通过一系列预定义系统提示(如"逐步思考并证明你的回答")引导大语言模型响应需要密集推理的FLAN指令,促使大语言模型(如GPT4)披露其推理过程信息。得益于这些进步,Orca模型显著优于多个强大的开源大语言模型。
(2) Hand-crafted Guiding Principles: Sun et al. (2023b) introduced self-alignment framework that incorporates 16 manually devised principle rules into input prompts, thereby steering LLMs towards generating useful, ethical, and reliable responses. To augment the impact of these rules, they employed the Chain-of-Thoughts (CoT) technology (Wei et al., 2022b), elucidating five examples to coach LLMs in discerning which rules to implement prior to generating actual response contents.
(2) 手工制定的指导原则:Sun等人 (2023b) 提出了一种自对齐框架,将16条人工设计的准则规则融入输入提示中,从而引导大语言模型生成有用、道德且可靠的响应。为增强这些规则的效果,他们采用了思维链 (Chain-of-Thoughts, CoT) 技术 (Wei等人, 2022b),通过五个示例指导大语言模型在生成实际响应内容前判断应应用哪些规则。
(3) Role-playing Conditions: Chen et al. (2023e) devised a method to generate a set of role profiles using a blend of ChatGPT and manual efforts. They created seed instructions for each role profile and applied self-instruction to the combination of role profiles and instructions to obtain nuanced responses from LLMs. Xu et al. (2023a) proposed a two-stage instruction response framework in which an expert profile is initially generated based on the instructions to be answered, followed by using both the expert profile and actual instructions to prompt LLMs for high-quality responses.
(3) 角色扮演条件: Chen等 (2023e) 设计了一种结合ChatGPT和人工干预的角色档案生成方法。他们为每个角色档案创建种子指令,并对角色档案与指令的组合应用自指令技术,从而从大语言模型中获取细致入微的响应。Xu等 (2023a) 提出了一个两阶段指令响应框架:首先生成基于待解答指令的专家档案,随后结合专家档案和实际指令来提示大语言模型,以获得高质量响应。
(4) Difficulty-monitoring Conditions: Jiang et al. (2023) proposed monitoring the quality of instruction response based on external LLM-based evaluations. They first fine-tune foundational LLMs with instruction data to obtain “student LLMs”. Then, for each of training instruction, they gather responses from both teacher LLMs (e.g.,
(4) 难度监控条件: Jiang等人 (2023) 提出基于外部大语言模型评估来监控指令响应的质量。他们首先用指令数据微调基础大语言模型以获得"学生大语言模型"。然后,对于每条训练指令,他们同时收集教师大语言模型(如...
ChatGPT) and student LLMs and prompted LLMs to conduct pairwise evaluation on the quality of both responses. Instructions are retained only when the student LLMs’ response falls short of that from the teacher LLMs.
ChatGPT) 和学生大语言模型,并提示大语言模型对两种回答的质量进行成对评估。只有当学生大语言模型的回答不及教师大语言模型时,才会保留指令。
2.2.2 Multi-turn Instructions
2.2.2 多轮指令
In previous sections, we mainly focus on collecting synthetic single-turn instructions. However, LLMs well aligned with human should be capable to interact with users in a dialogue-based setting. To achieve this goal, some research efforts attempt to collect synthetic multi-turn instructions from strong LLMs. When aligning LLaMA with human, Vicuna (Chiang et al., 2023) leverage instructions from ShareGPT which is website hosting interesting human-LLMs joint conversations. However, ShareGPT requires large volumes of users to upload their conversations. Xu et al. (2023c) propose a novel Self-Chatting framework where questions from popular QA websites are used as the starting topics, then Chat-3.5 is prompted to chat with itself about this question in a four-turn dialogue. Li et al. (2023a) propose CAMEL, a “role-playing” framework where a human annotators first provide a topic, then LLMs are separately prompted to be “AI Users” and “AI Assistants” to discuss about this topic. Ji et al. (2023) take a step further and prompt LLMs to first determine the conversation topic and then ask LLMs to chat with themselves to produce dialogue corpus. Ye et al. (2023a) propose a novel revision-based multi-turn dialogue corpus. Specifically, after instructions and initial responses, they further prompt LLMs to generate feedback and the revised version of responses if necessary. They use this dataset to train the SelFee model and show that SelFee can effectively improve its own answers when prompted to do so without any external guidance. The UltraLLaMA model (Ding et al., 2023) leverages a wide range of real-world information, including (a) real-world knowledge from LLMs and Wikipedia; (b) various text creation tasks; (c) high-quality textual corpus, to produce initial questions and instructions that guide LLMs to generate diverse and high-quality multi-turn dialogues.
在前面的章节中,我们主要关注收集合成的单轮指令。然而,与人类良好对齐的大语言模型应该能够在基于对话的环境中与用户互动。为了实现这一目标,一些研究工作尝试从强大的大语言模型中收集合成的多轮指令。在将LLaMA与人类对齐时,Vicuna (Chiang et al., 2023) 利用了来自ShareGPT的指令,这是一个托管有趣的人机联合对话的网站。然而,ShareGPT需要大量用户上传他们的对话。Xu et al. (2023c) 提出了一个新颖的Self-Chatting框架,其中来自热门问答网站的问题被用作起始话题,然后提示Chat-3.5围绕这个问题进行四轮对话。Li et al. (2023a) 提出了CAMEL,一个“角色扮演”框架,其中人类标注者首先提供一个话题,然后分别提示大语言模型扮演“AI用户”和“AI助手”来讨论这个话题。Ji et al. (2023) 更进一步,提示大语言模型首先确定对话主题,然后让大语言模型与自己聊天以生成对话语料。Ye et al. (2023a) 提出了一种基于修订的多轮对话语料。具体来说,在指令和初始响应之后,他们进一步提示大语言模型生成反馈,并在必要时生成响应的修订版本。他们使用这个数据集训练了SelFee模型,并表明SelFee在被提示时能够有效地改进自己的答案,而无需任何外部指导。UltraLLaMA模型 (Ding et al., 2023) 利用了广泛的现实世界信息,包括 (a) 来自大语言模型和维基百科的现实世界知识; (b) 各种文本创作任务; (c) 高质量的文本语料,以生成初始问题和指令,指导大语言模型生成多样化和高质量的多轮对话。
2.2.3 Multilingual Instructions
2.2.3 多语言指令
The above-generated instructions or dialogues are mostly based on English. To align LLMs with human who speak other languages, it is urgent and essential to expand the existing English resources into Multilingual ones. One straightforward idea is to translate instruction inputs and outputs into the target languages. Chen et al. (2023e) propose two translation strategies: (a) Post-answering which first translates the instruction inputs into the target language and then prompts strong LLMs to answer it. This could potentially preserve the specific culture patterns embedded in the target languages, but the output quality may be low as existing strong LLMs are often English-dominated; (b) Post-translating which first prompts strong LLMs to respond the instructions in English, then translate both inputs and outputs. This approach could obtain high-quality output text, but lost the specific culture information. Li et al. (2023b) follow the Post-answering strategy to construct instruction data for 52 popular languages using Google- Translate, then use these data to fine-tune LLaMA using the LoRA technology. An alternative solution is to mix several langauges in a multi-turn dialogue. BayLing (Zhang et al., 2023c) introduces a set of multi-turn interactive translation instructions to simultaneously improve multilingual and instruction-following ability for LLMs. Specifically, each multi-turn instruction is essentially a translation task where users first ask LLMs to translate a sentence to another language, then the users gradually add additional requirements (e.g., could you only use 10 words?). This process naturally connects different languages as well as human preferences with LLMs. We also summarize how to effectively adapt English-oriented LLMs to other languages in Appendix A.1.
上述生成的指令或对话大多基于英语。为了让大语言模型与使用其他语言的人类对齐,将现有英语资源扩展为多语言资源显得尤为迫切和必要。一个直接的想法是将指令输入和输出翻译为目标语言。Chen等人(2023e)提出了两种翻译策略:(a) 后应答策略,即先将指令输入翻译为目标语言,再提示强大模型进行回答。这种方法可能保留目标语言中嵌入的特定文化模式,但由于现有强大模型多以英语为主,输出质量可能较低;(b) 后翻译策略,即先提示强大模型用英语回答指令,再翻译输入和输出。这种方法可获得高质量输出文本,但会丢失特定文化信息。Li等人(2023b)采用后应答策略,通过谷歌翻译为52种常用语言构建指令数据,随后使用LoRA技术对LLaMA进行微调。另一种解决方案是在多轮对话中混合多种语言。BayLing(Zhang等人,2023c)引入了一套多轮交互式翻译指令,同时提升大语言模型的多语言能力和指令跟随能力。具体而言,每个多轮指令本质上是一个翻译任务:用户先要求模型将句子翻译为另一种语言,随后逐步添加额外要求(如"能否只用10个单词?")。这一过程自然地将不同语言与人类偏好连接起来。我们在附录A.1中还总结了如何有效将英语导向的大语言模型适配至其他语言。
2.3 Instruction Data Management
2.3 指令数据管理
As discussed above, there are extensive approaches focusing on generating high-quality instructions from different sources. Naturally, it becomes critical to effectively manage all of these instruction data in the LLMs alignment.
如上所述,目前存在大量从不同来源生成高质量指令的方法。在大语言模型对齐过程中,如何有效管理这些指令数据变得至关重要。
Instruction Implications Several studies focus on the implications of instruction data. Ji et al. (2023) demonstrate that an increment in the total count of training instructions can be advantageous for standard NLP tasks (e.g., information extraction, classification, Closed QA, sum mari z ation). Yet, it bears negligible influence on complex reasoning tasks such as Math, Code, CoT, and Brainstorming. Intriguingly, Mu en nigh off et al. (2023) discover that adding approximately $50%$ of programming instructions not only leaves unaffected the general conversational performance but also enhances the reasoning prowess of LLMs. In parallel, Ghosal et al. (2023) observe that integrating FLAN-style instructions with synthetic instructions from ChatGPT/GPT-4 effectively enhances LLMs reasoning and problem-solving capacity.
指令数据的影响
多项研究聚焦于指令数据的影响。Ji等人 (2023) 表明,增加训练指令的总量有利于标准NLP任务(如信息抽取、分类、封闭式问答、摘要)。然而,它对数学、代码、思维链和头脑风暴等复杂推理任务的影响微乎其微。有趣的是,Muennighoff等人 (2023) 发现,添加约50%的编程指令不仅不会影响通用对话性能,还能提升大语言模型的推理能力。与此同时,Ghosal等人 (2023) 指出,将FLAN风格指令与ChatGPT/GPT-4生成的合成指令相结合,可有效增强大语言模型的推理和问题解决能力。
Wang et al. (2023d) conduct a comprehensive analysis of the impacts of various instructions derived from different sources on factual knowledge, reasoning, coding, multilingual, and open-ended scenarios. They also reveal that instructions pertaining to CoT and Coding are vital for augmenting the reasoning capability of LLMs. Additionally, they ascertain that different instructions can affect different LLM capabilities. Therefore, a composite of all instruction types empowers the corresponding LLMs to reach their better overall performance, hinting at the need for more advanced instruction collection techniques and technologies.
Wang等人 (2023d) 对不同来源指令在事实知识、推理、编码、多语言和开放场景中的影响进行了全面分析。他们发现,与思维链 (CoT) 和编码相关的指令对于提升大语言模型的推理能力至关重要。此外,他们还确认不同指令会影响大语言模型的不同能力。因此,综合所有指令类型能使对应的大语言模型达到更优的整体性能,这表明需要更先进的指令收集技术。
Instruction Quantity Another critical question in instruction data management is the optimal quantity of instruction data required for effective LLM alignment. AlShikh et al. (2023) address this question by introducing a novel early-stopping criterion known as IFS. The premise of IFS rests on the observation that, given an input textual prefix, foundational LLMs typically predict ensuing tokens and generate "continuation-like" outputs, while fully instruction-tuned LLMs interpret the input prefix as questions, thereby generating "answer-like" outputs. IFS is quantified as the proportion of "answerlike" outputs within all its outputs given the instructions. The researchers train an external classifier to discriminate between "continuation-like" and "answer-like" outputs, concluding that LLaMA necessitates approximately 8K instructions to achieve a high IFS score. More instructions could potentially induce a semantic shift in the foundational LLMs. Zhou et al. (2023) similarly discern that merely 6K high-quality instructions suffice to align with human preferences. Motivated by these findings, researchers are investigating high-quality instruction selection. Cao et al. (2023) aim to identify predictive features of high-quality instructions. Initially, they extract representative features from the instruction dataset, then utilize these instructions to fine-tune LLMs. The feature importance is based on the model’s performance. Their experiments demonstrate the better performance of LLMs trained on the resultant instructions. Differently, Chen et al. (2023b) propose using ChatGPT to directly assess the quality of instructions by assigning scores. They report that the LLM trained on the top 9K instructions notably outperforms those trained on the complete set of 52K Alpaca instructions.
指令数量
指令数据管理中的另一个关键问题在于实现有效大语言模型对齐所需的最优指令数据量。AlShikh等人(2023)通过提出名为IFS的新型早停准则解决了这一问题。IFS的前提基于以下观察:给定输入文本前缀时,基础大语言模型通常预测后续token并生成"类延续"输出,而完全指令调优的大语言模型则将输入前缀解读为问题,从而生成"类回答"输出。IFS通过指令输入下"类回答"输出占总输出的比例进行量化。研究人员训练了一个外部分类器来区分"类延续"和"类回答"输出,最终发现LLaMA需要约8K条指令才能获得较高的IFS分数。更多指令可能导致基础大语言模型发生语义偏移。Zhou等人(2023)同样发现仅需6K条高质量指令即可实现与人类偏好对齐。受这些发现启发,研究者们正在探索高质量指令的筛选方法。Cao等人(2023)致力于识别高质量指令的预测性特征:首先从指令数据集中提取代表性特征,再利用这些指令微调大语言模型,特征重要性基于模型表现判定。实验证明基于结果指令训练的模型性能更优。Chen等人(2023b)则提出直接使用ChatGPT通过评分评估指令质量,他们发现基于前9K条优质指令训练的模型表现显著优于使用全部52K条Alpaca指令训练的模型。
3 Alignment Training
3 对齐训练
After collecting instructions from various sources, we then consider using these data to fine-tune existing foundational LLMs to align with human. The native solution is Supervised Fine-Tuning (SFT). Specifically, given instruction input $x$ , SFT calculates the cross-entropy loss over the ground-truth response $y$ as follows:
从多种渠道收集指令后,我们考虑利用这些数据对现有基础大语言模型进行微调以实现与人类对齐。最直接的解决方案是监督式微调(SFT)。具体而言,给定指令输入$x$时,SFT会按如下公式计算真实响应$y$的交叉熵损失:
$$
L_ {f t}=-\sum_ {t}\log P_ {L L M}(y_ {i^{\prime},t}|x,y_ {i^{\prime},<t})
$$
$$
L_ {f t}=-\sum_ {t}\log P_ {L L M}(y_ {i^{\prime},t}|x,y_ {i^{\prime},<t})
$$
Essentially, SFT helps LLMs to understand the semantic meaning of prompts and make meaningful responses. The main limitation of SFT is that it only teaches LLMs about the best responses and cannot provide fine-grained comparisons to suboptimal ones. However, it is worth noting that SFT objective or SFT model parameters has also been integrated into many human preference training objective to regularize and stabilize the training process of LLMs. We summarize the research efforts built on top of SFT into: Online human preference training, Offline human preference training and Parameter-effective fine-tuning solutions.
本质上,SFT (Supervised Fine-Tuning) 帮助大语言模型理解提示的语义并做出有意义的回应。SFT 的主要局限在于它仅教会模型最佳回复,而无法提供对次优选项的细粒度比较。不过值得注意的是,SFT 目标函数或 SFT 模型参数已被整合到许多人机偏好训练目标中,用于规范并稳定大语言模型的训练过程。我们将基于 SFT 的研究工作归纳为:在线人机偏好训练、离线人机偏好训练以及参数高效微调方案。
3.1 Online Human Preference Training
3.1 在线人类偏好训练
Reinforcement learning from Human Feedback (RLHF) (Ouyang et al., 2022) is designed to learn the human preference signals from external reward models under the PPO framework. Specifically, RLHF consists of three main stages:
从人类反馈中强化学习 (RLHF) (Ouyang et al., 2022) 旨在通过PPO框架从外部奖励模型中学习人类偏好信号。具体而言,RLHF包含三个主要阶段:
• Step 1: Collecting a high-quality instruction set and conducting SFT of pre-trained LLMs. • Step 2: Collecting manually ranked comparison response pairs and train a reward model IR to justify the quality of generated responses. • Step 3: Optimizing the SFT model (policy) under the PPO reinforcement learning framework with reward calculated by IR.
- 第一步:收集高质量的指令集,并对预训练大语言模型进行监督微调 (SFT)。
- 第二步:收集人工排序的对比响应配对,训练奖励模型 (IR) 以评估生成响应的质量。
- 第三步:在PPO强化学习框架下优化SFT模型 (策略),使用IR计算的奖励值。
In Step 3, to mitigate over-optimization issues, Ouyang et al. (2022) add a KL-divergence regular iz ation between the current model weight and the SFT model weight obtained in Step 1. However, despite being effective in learning human preferences, PPO training is difficult in implementation and stable training. Therefore, Dong et al. (2023) try to remove the PPO training in the above process and propose a novel Reward rAnked FineTuning $(R A F T)$ method, which uses an existing reward model to select the best set of training samples based on the model outputs. Specifically, RAFT first samples a large batch of instructions, then uses the current LLMs to respond to these instructions. These data are then ranked by the reward model and only top $\frac{1}{k}$ instances are applied for SFT. RAFT can also be used in offline human preference learning where the global instruction set is continually updated with the top-ranked instructions in each batch. This contiguous ly updates the global instruction set to improve training data quality at each step.
在步骤3中,为缓解过优化问题,Ouyang等人 (2022) 在当前模型权重与步骤1获得的SFT模型权重之间添加了KL散度正则化。然而,尽管PPO训练能有效学习人类偏好,但其实现难度大且训练稳定性差。为此,Dong等人 (2023) 尝试移除上述流程中的PPO训练,提出了一种新颖的奖励排序微调 $(RAFT)$ 方法,该方法利用现有奖励模型根据模型输出选择最佳训练样本集。具体而言,RAFT首先采样大批量指令,随后使用当前大语言模型响应这些指令。这些数据经奖励模型排序后,仅保留前 $\frac{1}{k}$ 的实例用于SFT。RAFT也可应用于离线人类偏好学习场景,通过每批次中排名靠前的指令持续更新全局指令集。这种连续更新机制逐步提升训练数据质量。
3.2 Offline Human Preference Training
3.2 离线人类偏好训练
Although the above online algorithms have been shown effective in learning human preference, implementing these algorithms could be non-trivial because its training procedure requires interaction between policy, behavior policy, reward, and value model, which requires many hyper-parameters to be tuned to achieve better stability and performance. To avoid this issue, researchers also explore learning human preferences in an offline fashion.
虽然上述在线算法已被证明能有效学习人类偏好,但实现这些算法可能并不简单,因为其训练过程需要策略、行为策略、奖励和价值模型之间的交互,这需要调整大量超参数以实现更好的稳定性和性能。为避免这一问题,研究人员也探索了以离线方式学习人类偏好的方法。
3.2.1 Ranking-based Approach
3.2.1 基于排序的方法
As human preferences are often expressed as a ranking result over a set of responses, some research efforts directly incorporate the ranking information into the LLMs fine-tuning stage. Rafailov et al. (2023) propose Direct Preference Optimization (DPO), which implicitly optimizes the same objective as existing RLHF algorithms (i.e., reward function with a KL-divergence term) discussed above. Specifically, the DPO training objective can be written as:
由于人类偏好通常表现为对一组回复的排序结果,部分研究直接将排序信息融入大语言模型的微调阶段。Rafailov等人 (2023) 提出直接偏好优化 (Direct Preference Optimization, DPO),该方法隐式优化了与前述RLHF算法相同的目标(即包含KL散度项的奖励函数)。具体而言,DPO的训练目标可表述为:
$$
{\mathcal{L}}_ {\mathrm{DP0}}=\log\sigma\left[\beta\log({\frac{\pi_ {\theta}(y_ {w}\mid x)}{\pi_ {\mathrm{SFT}}(y_ {w}\mid x)}}\cdot{\frac{\pi_ {\mathrm{SFT}}(y_ {l}\mid x)}{\pi_ {\theta}(y_ {l}\mid x)}})\right]
$$
where $(x,y_ {w},y_ {l})$ is one instruction and two of the corresponding outputs with $y_ {w}$ ranked higher than $y_ {l}$ . Similarly, Song et al. (2023) propose Preference Ranking Optimization (PRO) method, an extended version of reward model training objective proposed in Ziegler et al. (2019), to further finetune LLMs to align with human preference. Given instruction $x$ and a set of responses with human preference order $y^{1}\succ y^{2}\succ\dots\succ y^{n}$ , the objective can be defined as follows:
其中 $(x,y_ {w},y_ {l})$ 表示一条指令及两个对应输出,且 $y_ {w}$ 的排序高于 $y_ {l}$。类似地,Song等人 (2023) 提出了偏好排序优化(PRO)方法,该方法扩展了Ziegler等人 (2019) 提出的奖励模型训练目标,用于进一步微调大语言模型以对齐人类偏好。给定指令 $x$ 和一组符合人类偏好排序的响应 $y^{1}\succ y^{2}\succ\dots\succ y^{n}$,其目标函数可定义为:
$$
{\mathcal{L}}_ {\mathrm{PRO}}=-\sum_ {k=1}^{n-1}\log{\frac{\exp{\left(\pi_ {\theta}(y^{k}\mid x)\right)}}{\sum_ {i=k}^{n}\exp{\left(\pi_ {\theta}(y^{i}\mid x)\right)}}}
$$
PRO also adds SFT training objective for the regularization purpose. Instead of adapting the reward training objective, Zhao et al. (2023) take the first step to calibrate the sequence likelihood using various ranking functions, including rank loss, margin loss, list rank loss (Liu et al., 2022c) and expected rank loss (Edunov et al., 2018). In addition, they also explore to use SFT training objective and KLdivergence as the regular iz ation term. The experiment results on various text generation tasks show that the rank loss with the KL-divergence term performs the best. However, this paper only uses the BERTScore (Zhang* et al., 2020) between each candidate output and the ground-truth reference to simulate human preferences and they only conduct experiment on small pre-trained language models (i.e., no larger than 2B). Yuan et al. (2023) propose RRHF, which further optimizes LLaMA-7B to align with human preferences using a similar framework described above. RRHF is based on the list rank loss, but removes the margin terms based on the empirical results. In addition, different from Liu et al. (2022c), RRHF finds that the SFT training objective is more effective and efficient than KL-divergence in preventing LLMs from over-fitting. These results show that different ranking strategies should be adapted for LLMs with different size.
PRO 还加入了监督微调 (SFT) 训练目标作为正则化手段。与调整奖励训练目标不同,Zhao 等人 (2023) 首次尝试使用多种排序函数来校准序列似然,包括排序损失 (rank loss)、边际损失 (margin loss)、列表排序损失 (list rank loss) (Liu 等人, 2022c) 和期望排序损失 (expected rank loss) (Edunov 等人, 2018)。此外,他们还探索了使用 SFT 训练目标和 KL 散度 (KL-divergence) 作为正则化项。在多种文本生成任务上的实验结果表明,结合 KL 散度的排序损失表现最佳。但该研究仅使用候选输出与真实参考文本之间的 BERTScore (Zhang* 等人, 2020) 来模拟人类偏好,且仅在小型预训练语言模型 (不超过 20 亿参数) 上进行了实验。Yuan 等人 (2023) 提出的 RRHF 采用类似框架进一步优化 LLaMA-7B 以对齐人类偏好。RRHF 基于列表排序损失,但根据实证结果移除了边际项。此外,与 Liu 等人 (2022c) 不同,RRHF 发现 SFT 训练目标在防止大语言模型过拟合方面比 KL 散度更有效高效。这些结果表明,不同规模的模型需要适配不同的排序策略。

Figure 4: The overview of the Chain of Hindsigt (CoH) method. Responses with different quality are associated with different prefix. The CoH training loss is only applied on model output tokens (highlighted by red).
图 4: Chain of Hindsight (CoH) 方法概览。不同质量的响应关联不同前缀。CoH训练损失仅作用于模型输出token (红色高亮部分)。
3.2.2 Language-based Approach
3.2.2 基于语言的方法
As reinforcement learning algorithms are hard to optimize and LLMs have strong text understanding ability, some works propose to directly use natural language to inject human preference via SFT. Wang et al. (2023a) introduce the concept of “conditional behavior cloning” from offline reinforcement learning literature (Nguyen et al., 2022) to train LLMs to distinguish high-quality and lowquality instruction responses. Specifically, they design different language-based prefixes for different quality responses (e.g., high-quality response with “Assistant GPT4:” and low-quality response with “Assistant GPT3:”). This approach can effectively leverage both low- and high-quality training data to align LLMs with humans. Chain of Hindsight (CoH) (Liu et al., 2023b), on the other hand, directly incorporates human preference as a pair of parallel responses discriminated as low-quality or high-quality using natural language prefixes. As shown in Figure 4, after assigning human feedback to each model output, CoH concatenates the input instructions, LLMs outputs, and the corresponding human feedback together as the input to LLMs. Note that CoH only applies the fine-tuning loss to the actual model outputs, rather than the human feedback sequence and the instructions. During inference, CoH directly puts position feedback (e.g., good) after the input instructions to encourage the LLMs to produce high-quality outputs. It is worthnoting that, similar to Liu et al. (2022a); Ouyang et al. (2022), CoH also incorporates SFT objectives and random words masking to prevent LLMs from over-fitting.
由于强化学习算法难以优化且大语言模型(LLM)具备强大的文本理解能力,部分研究提出直接通过监督微调(SFT)使用自然语言注入人类偏好。Wang等(2023a)从离线强化学习文献(Nguyen等, 2022)引入"条件行为克隆"概念,训练大语言模型区分高质量与低质量的指令响应。具体而言,他们为不同质量响应设计基于语言的前缀(例如高质量响应标注"Assistant GPT4:",低质量响应标注"Assistant GPT3:")。该方法能有效利用高低质量训练数据实现大语言模型与人类的对齐。
后见之链(Chain of Hindsight, CoH)(Liu等, 2023b)则直接将人类偏好转化为带有自然语言前缀的平行响应对(标注为低质量/高质量)。如图4所示,在为每个模型输出分配人类反馈后,CoH将输入指令、大语言模型输出及对应人类反馈拼接作为模型输入。需注意的是,CoH仅对实际模型输出(而非人类反馈序列和指令)应用微调损失。在推理阶段,CoH直接在输入指令后添加正向反馈(如"good")以激励大语言模型生成高质量输出。值得注意的是,与Liu等(2022a)、Ouyang等(2022)类似,CoH也结合了监督微调目标和随机词掩码技术以防止模型过拟合。
Alternative approach is to explicitly incorporate revision-based instructions into LLMs training. Some preliminary studies have shown that many existing state-of-the-art LLMs have the capability to improve the quality of their responses when explicitly prompting them to do so (Chen et al., 2023c). Motivated by these findings, Liu et al. (2022b) recommend training LMs to produce edit operations between source (i.e., low-quality responses) and target (i.e., high-quality responses) sequences, which are subsequently integrated into a dynamic programming framework. Liu et al. (2023d) propose a novel type of instruction called realignment, designed to revise responses based on previously generated low-quality feedback and instructions. This compiled data is employed to instruct LLMs to self-correct when they generate bad responses. Similarly, Ye et al. (2023a) accumulate a multi-turn dialogue corpus utilizing this selfcorrection mechanism built with the ChatGPT models. Each dialogue starts with standard instructions, such as those from the Stanford Alpaca dataset. After ChatGPT has responded to the initial instructions, further revisions are explicitly requested until ChatGPT elects to terminate. They found that LLMs trained using these dialogues demonstrated an effective capacity to elevate the quality of their own responses.
另一种方法是将基于修订的指令明确纳入大语言模型(LLM)的训练中。初步研究表明,当明确提示时,许多现有的先进大语言模型具备提升其回答质量的能力(Chen et al., 2023c)。受这些发现启发,Liu等人(2022b)建议训练语言模型生成源序列(即低质量回答)和目标序列(即高质量回答)之间的编辑操作,随后将这些操作整合到动态编程框架中。Liu等人(2023d)提出了一种称为"重新对齐(realignment)"的新型指令,旨在基于先前生成的低质量反馈和指令来修订回答。这些编译数据被用于指导大语言模型在生成不良回答时进行自我校正。类似地,Ye等人(2023a)利用ChatGPT模型构建的自我校正机制积累了一个多轮对话语料库。每个对话都始于标准指令,例如来自斯坦福Alpaca数据集的指令。在ChatGPT对初始指令作出回应后,会明确要求进一步修订,直到ChatGPT选择终止。他们发现,使用这些对话训练的大语言模型展现出有效提升自身回答质量的能力。
3.3 Parameter-Effective Training
3.3 参数高效训练
Directly fine-tuning all parameters in large language models (LLMs) would theoretically enable these models to adhere to provided instructions. However, this approach demands not only substantial computational resources, such as vast GPU memory but also extensive datasets for instruction training. In an effort to mitigate both com- putational and data requirements for constructing instruction-following LLMs, one potential route is the implementation of Parameter-Effective Finetuning strategies. Specifically, these methods froze the major part of LLM parameters and only train a limited set of additional parameters.
理论上,直接微调大语言模型(LLM)中的所有参数可以使这些模型遵循提供的指令。然而,这种方法不仅需要大量计算资源(如庞大的GPU内存),还需要用于指令训练的广泛数据集。为了减少构建指令遵循型LLM的计算和数据需求,一种潜在途径是实施参数高效微调(Parameter-Effective Finetuning)策略。具体而言,这些方法冻结LLM的大部分参数,仅训练有限的附加参数集。
Supplementary Parameters Building upon this strategy, prefix tuning (Li and Liang, 2021) and prompt tuning (Lester et al., 2021) are inspired by the successful application of textual prompts in pre-trained language models (Brown et al., 2020). These methods either prepend trainable tokens to the input layer or each hidden layer, leaving the parameters of LLMs frozen during fine-tuning. Subsequently, He et al. (2022); Chen et al. (2023a) consolidated these strategies into unified frameworks, fostering more effective solutions for parameterefficient fine-tuning.
补充参数
基于这一策略,前缀调优 (Li and Liang, 2021) 和提示调优 (Lester et al., 2021) 受到文本提示在预训练语言模型 (Brown et al., 2020) 中成功应用的启发。这些方法要么在输入层前添加可训练的 token,要么在每个隐藏层前添加,同时在大语言模型微调期间保持其参数冻结。随后,He et al. (2022) 和 Chen et al. (2023a) 将这些策略整合为统一框架,为参数高效微调提供了更有效的解决方案。
Shadow Parameters While the above methodologies introduce supplementary parameters to LLMs, the following methods focus on training the weight representing model parameter variance without modifying the number of total model parameters during inference. For instance, Low-Rank Adaptation (LoRA) (Hu et al., 2022) suggests the addition of pairs of rank-decomposition trainable weight matrices (i.e., update matrices) to the existing weights, which are kept frozen. For example, given a neural layer $h=W_ {0}x$ , LoRA modifies the forward pass as follows:
影子参数
虽然上述方法为大语言模型引入了补充参数,但以下方法专注于训练代表模型参数方差的权重,而不在推理过程中修改模型参数的总数。例如,低秩自适应 (LoRA) (Hu et al., 2022) 建议在现有冻结权重的基础上添加成对的秩分解可训练权重矩阵(即更新矩阵)。例如,给定神经网络层 $h=W_ {0}x$,LoRA 将前向传播修改如下:
$$
h=W_ {0}x+B A x
$$
$$
h=W_ {0}x+B A x
$$
where $W_ {0}\in\mathbb{R}^{d\times k}$ , $\boldsymbol{B}\in\mathbb{R}^{d\times r}$ , $A\in\mathbb{R}^{r\times k}$ , with the rank $r\ll\operatorname* {min}(d,k)$ . LoRA only updates the parameters of $A$ and $B$ during training. Despite being effective, LoRA equally allocates parameter budgets over the whole LLMs, ignoring the varying importance of different weight parameters. Zhang et al. (2023b) propose AdaLoRA to combat this issue. Specifically, AdaLoRA first calculates the parameter importance using the training gradient and then determines the $r$ values for different parameters matrix. Dettmers et al. (2023) propose QLoRA that further improves over LoRA by reducing memory usage, enabling a 65B LLM to be fine-tuned using a single 48G GPU. Specifically, QLoRA quantizes the transformer backbone model to 4-bit precision and uses paged optimizers to handle memory spikes.
其中 $W_ {0}\in\mathbb{R}^{d\times k}$ , $\boldsymbol{B}\in\mathbb{R}^{d\times r}$ , $A\in\mathbb{R}^{r\times k}$ ,且秩 $r\ll\operatorname* {min}(d,k)$ 。LoRA 在训练期间仅更新参数 $A$ 和 $B$ 。尽管效果显著,LoRA 在整个大语言模型中均等分配参数预算,忽略了不同权重参数的重要性差异。Zhang 等人 (2023b) 提出 AdaLoRA 来解决这一问题。具体而言,AdaLoRA 首先利用训练梯度计算参数重要性,然后为不同参数矩阵确定 $r$ 值。Dettmers 等人 (2023) 提出的 QLoRA 通过降低内存使用进一步改进了 LoRA,使得单个 48G GPU 即可微调 650 亿参数的大语言模型。具体实现上,QLoRA 将 Transformer 主干模型量化为 4 位精度,并采用分页优化器处理内存峰值问题。
Trade-offs For Parameter-efficient Training There are some successful applications of parameter-efficient training technologies, including the Alpaca-LoRA project 7, which is based on the Hugging Face’s PEFT library (Mangrulkar et al., 2022) to train Alpaca using a single commercial GPU and Xu et al. (2023c), which apply LoRA to all linear layers in LLaMA to improve its adaption capabilities. However, such an effective training approach could also result in under-fitting issues. Sun et al. (2023a) find that given the same set of training instructions, LLMs with LoRA perform worse than the fully fine-tuned ones. Furthermore, they also show that when using LoRA, it is preferable to use larger LLMs than larger training instruction datasets because the former solution uses less training costs and achieves better performance than the later one.
参数高效训练的权衡取舍
参数高效训练技术已有一些成功应用案例,包括基于Hugging Face的PEFT库 (Mangrulkar et al., 2022) 的Alpaca-LoRA项目7(使用单块商用GPU训练Alpaca),以及Xu等人 (2023c) 将LoRA应用于LLaMA所有线性层以提升适应能力的研究。然而,这种高效训练方法也可能导致欠拟合问题。Sun等人 (2023a) 发现,在相同训练指令集下,采用LoRA的大语言模型表现逊色于全参数微调模型。此外,他们的研究还表明,使用LoRA时,选择更大规模的大语言模型比扩大训练指令集更可取,因为前者能以更低训练成本获得优于后者的性能表现。
4 Alignment Evaluation
4 对齐评估
After collecting instructions and training LLMs on these instructions, we finally consider the evaluation for alignment quality. In this section, we will discuss benchmarks used for evaluation in Section 4.1 and the evaluation protocols in Section 4.2.
在收集指令并基于这些指令训练大语言模型后,我们最终考虑对齐质量的评估。本节将讨论4.1节中用于评估的基准测试以及4.2节中的评估协议。
4.1 Evaluation Benchmarks
4.1 评估基准
There are various benchmarks to evaluate the aligned LLMs. In general, these benchmarks can be categorized into Closed-set Benchmarks and Open-set Benchmarks. The former type focuses on evaluating the skills and knowledge of aligned LLMs, while the latter type often concentrates on the open scenarios where there are no standardized answers.
评估对齐大语言模型有多种基准测试。总体而言,这些基准可分为封闭集基准 (Closed-set Benchmarks) 和开放集基准 (Open-set Benchmarks) 。前者侧重于评估对齐大语言模型的技能和知识,后者则通常关注没有标准答案的开放场景。
4.1.1 Closed-set Benchmarks
4.1.1 闭集基准测试
The closed-set benchmarks mostly include testing instances whose possible answers are prede- fined and limited to a finite set (e.g., multiple choices). We discuss some of the most commonly used benchmarks below. We refer readers to Chang et al. (2023) for more comprehensive introduction of LLMs’ evaluation benchmarks.
闭集基准测试主要包括那些答案已预先定义且限定在有限集合内的测试实例(例如选择题)。下面我们将讨论一些最常用的基准测试。关于大语言模型评估基准的更全面介绍,我们建议读者参考 Chang et al. (2023)。
General Knowledge MMLU (Hendrycks et al., 2021) is an English-based benchmark to evaluate LLMs knowledge in zero-shot and few-shot settings. It comprehensively includes questions from the elementary level to an advanced professional level from 57 subjects including STEM, the humanities, the social sciences, etc. The granularity and breadth of the subjects make MMLU ideal for identifying LLMs’ blind spots. There are also several benchmarks attempting in evaluating the general knowledge in Chinese LLMs. C-MMLU (Li et al., 2023c), C-Eval (Huang et al., 2023), M3KE (Liu et al., 2023a) and AGIEval (Zhong et al., 2023) are all Chinese counterparts of MMLU that include diverse sets of questions from multiple subjects with different difficulty levels from various Chinese standardized exams, including Chinese college entrance exams, advanced maths competitions and law exams. The KoLA benchmark (Yu et al., 2023a) is proposed to evaluate the general realworld knowledge of LLMs.
通用知识评测基准MMLU (Hendrycks et al., 2021) 是一个基于英语的基准测试,用于评估大语言模型在零样本和少样本设置下的知识水平。它全面涵盖了从基础到高级专业水平的57个学科问题,包括STEM、人文社科等领域。其学科粒度和广度使MMLU成为识别大语言模型知识盲点的理想工具。目前也有多个针对中文大语言模型的通用知识评测基准:C-MMLU (Li et al., 2023c)、C-Eval (Huang et al., 2023)、M3KE (Liu et al., 2023a) 和AGIEval (Zhong et al., 2023) 都是MMLU的中文对应版本,这些基准整合了中国各类标准化考试(如高考、高等数学竞赛、法律考试等)中不同难度等级的多学科试题。KoLA评测基准 (Yu et al., 2023a) 则专注于评估大语言模型对现实世界通用知识的掌握程度。
Reasoning Reasoning is a fundamental type of human intelligence that are crucial in solving complicated tasks. Interestingly, research find that LLMs have exhibit emergent behaviors, including the reasoning ability, when they are sufficiently large. Thus, there are several benchmarks in evaluating the ability of arithmetic, commonsense, and symbolic reasoning for LLMs. GSM8K (Cobbe et al., 2021) and Maths (Hendrycks et al., 2021) are designed to evaluate the arithmetic reasoning ability for LLMs. CSQA (Talmor et al., 2019) and StrategyQA (Geva et al., 2021) are proposed to evaluate the commonsense reasoning ability which requires the LLMs to use daily life commonsense to infer in novel situations. Wei et al. (2022b) propose two novel tasks, Last Letter Concatenation and Coin Flip and measure the Symbolic reasoning ability that involves the manipulation of symbols according to formal rules. BBH (Suzgun et al., 2022), a challenging subset of BIG-Bench (bench authors, 2023), focus on evaluating a wide range of reasoning skills, such as Date Understanding, Word Sorting, and Causal Judgement.
推理
推理是人类智能的基本类型,对解决复杂任务至关重要。有趣的是,研究发现,当大语言模型 (LLM) 规模足够大时,会展现出包括推理能力在内的涌现行为。因此,目前存在多个评估大语言模型算术、常识和符号推理能力的基准。GSM8K (Cobbe et al., 2021) 和 Maths (Hendrycks et al., 2021) 用于评估大语言模型的算术推理能力。CSQA (Talmor et al., 2019) 和 StrategyQA (Geva et al., 2021) 则旨在评估常识推理能力,要求大语言模型运用日常生活常识在新情境中进行推断。Wei et al. (2022b) 提出了两个新任务——Last Letter Concatenation 和 Coin Flip,用于测量涉及按形式规则操作符号的符号推理能力。BBH (Suzgun et al., 2022) 作为 BIG-Bench (bench authors, 2023) 的挑战性子集,专注于评估广泛的推理技能,例如日期理解、单词排序和因果判断。
Coding HumanEval (Chen et al., 2021), HumanEval+ (Liu et al., 2023c), and MBPP (Austin et al., 2021) are extensively used benchmarks to evaluate the coding skills of LLMs. They encompass a vast collection of Python programming problems and corresponding test cases to automatically verify the code generated by Code LLMs. The DS1000 benchmark (Lai et al., 2022) comprises 1,000 distinct data science workflows spanning seven libraries. It assesses the performance of code generations against test cases and supports two evaluation modes: completion and insertion.
Coding HumanEval (Chen et al., 2021) 、HumanEval+ (Liu et al., 2023c) 和 MBPP (Austin et al., 2021) 是广泛用于评估大语言模型编程能力的基准测试。它们包含大量 Python语言 编程问题及对应测试用例,可自动验证代码生成模型的输出。DS1000 基准测试 (Lai et al., 2022) 涵盖 7 个库的 1000 个不同数据科学工作流,通过测试用例评估代码生成性能,并支持补全和插入两种评估模式。
4.1.2 Open-ended Benchmarks
4.1.2 开放式基准测试
In contrast to the closed-set benchmarks, the responses to open-set benchmarks can be more flexible and diverse, where aligned LLMs are usually given chatting questions or topics that do not have any fixed reference answers. Early attempts of open-ended benchmarks, such as Vicuna-80 (Chiang et al., 2023), Open-Assistant-953 (Kopf et al., 2023), User-Instructions-252 (Wang et al., 2022a), often leverage a small number of syntactic instructions from LLMs as testing instances. All evaluation candidate LLMs are prompted with the same instructions to provide responses, which are then evaluated against human-based or LLMs-based evaluators. However, these types of benchmarks can only provide comparison several LLMs at a time, making it challenging to reveal a fair comparison among a board range of LLMs, as well as incremental updates when new LLMs become available. AlpacaEval (Dubois et al., 2023) tackles this issue by reporting the Win Rate of the LLMs candidate to the reference LLM text-davinci-003. Accordingly, LLMs with higher Win Rate are generally better than the ones with lower Win Rate. MT-Bench (Zheng et al., 2023) further increases the evaluation difficulty by proposing 80 multi-turn evaluation instances and wishes LLMs could effectively capture context information in previous turns. FLASK (Ye et al., 2023b) proposed to provide finegrained evaluation towards aligned LLMs. FLASK includes 1,700 instances from 120 datasets. Each testing instance is labelled with a set of 12 foundational and essential “alignment skills” (e.g., logical thinking, user alignment, etc.). Accordingly, it is straightforward to evaluate LLMs’ capabilities on these skills separately.
与闭集基准测试不同,开放集基准测试的响应可以更加灵活多样,通常会给对齐后的大语言模型提出没有固定参考答案的聊天问题或话题。早期的开放式基准测试尝试,如Vicuna-80 (Chiang et al., 2023)、Open-Assistant-953 (Kopf et al., 2023)、User-Instructions-252 (Wang et al., 2022a),往往利用少量来自大语言模型的语法指令作为测试实例。所有待评估的大语言模型都会收到相同的指令来生成响应,然后由人工或基于大语言模型的评估者对这些响应进行评分。然而,这类基准测试一次只能比较少数几个大语言模型,难以在广泛的大语言模型范围内进行公平比较,也无法适应新发布大语言模型的增量更新。AlpacaEval (Dubois et al., 2023) 通过计算候选大语言模型相对于参考模型text-davinci-003的胜率来解决这个问题。因此,胜率较高的大语言模型通常优于胜率较低的模型。MT-Bench (Zheng et al., 2023) 进一步提高了评估难度,提出了80个多轮对话评估实例,期望大语言模型能有效捕捉前文中的上下文信息。FLASK (Ye et al., 2023b) 提出了针对对齐后大语言模型的细粒度评估方案。FLASK包含来自120个数据集的1700个实例,每个测试实例都标注了12项基础且关键的"对齐技能"(如逻辑思维、用户对齐等),从而可以分别评估大语言模型在这些技能上的表现。
4.2 Evaluation Paradigm
4.2 评估范式
As open-ended benchmarks often do not have reference answers, it is essential to rely on external human or LLMs evaluators. In this section, we will introduce both human- and LLMs-based evaluation paradigm.
由于开放式基准测试通常没有参考答案,必须依赖外部人类或大语言模型评估者。本节将介绍基于人类和大语言模型的评估范式。
4.2.1 Human-based Evaluation
4.2.1 基于人工的评估
Automatic metrics, such as BLUE (Papineni et al., 2002) and ROUGE (Lin, 2004), require groundtruth references and have relatively low correlation with human judgments. Thus, they are not feasible for evaluating responses to open-ended questions. To bridge this gap, human annotators are used to evaluate the quality of open-ended model responses. Wang et al. (2022a); Wu et al. (2023) propose to evaluate the response quality in an ordinal classification setting where human annotators are instructed to categorize each response into one of the four levels (i.e., acceptable, minor errors, major errors and unacceptable), separately. However, some other research have found that such classification annotation strategy heavily depend on the subjectivity of annotators, which can result in poor inter-rater reliability (Kalpathy-Cramer et al., 2016). Accordingly Taori et al. (2023) propose to use a pairwise comparison framework for evaluating the output quality of two LLMs systems. Given the instruction inputs and two model outputs, the human annotators are asked to select a better one. Furthermore, to accurately evaluate multiple LLMs, Zheng et al. (2023); Dettmers et al. (2023) further introduce the Elo rating system which calculates the relative skill levels of players in zero-sum games such as chess games. Specifically, in Elo system, the player scores are updated based on the result of each pairwise comparison and the current player scores.
自动评估指标,如 BLUE (Papineni et al., 2002) 和 ROUGE (Lin, 2004),需要真实参考答案且与人类判断相关性较低,因此不适用于评估开放性问题回答。为解决这一问题,研究者采用人工标注评估开放式模型回答的质量。Wang et al. (2022a) 和 Wu et al. (2023) 提出在序数分类设置中评估回答质量,要求标注者将每个回答分别归类到四个等级(即可接受、小错误、大错误和不可接受)。然而其他研究发现这种分类标注策略高度依赖标注者的主观性,可能导致评分者间信度较低 (Kalpathy-Cramer et al., 2016)。为此,Taori et al. (2023) 提出使用成对比较框架评估两个大语言模型系统的输出质量:给定指令输入和两个模型输出,标注者需选择更优答案。为更准确评估多个大语言模型,Zheng et al. (2023) 和 Dettmers et al. (2023) 进一步引入 Elo 评分系统——该算法通过每轮成对比较结果和当前玩家分数来更新棋类等零和游戏中玩家的相对技能等级。
4.2.2 LLMs-based Evaluation
4.2.2 基于大语言模型的评估
While human evaluations are often of high quality, it could be inefficient and expensive. In addition, the increasing quality of generated text from LLMs makes it more challenging for human annotators to distinguish between human-written and LLMgenerated text in the open-ended NLP tasks (Clark et al., 2021). Given the strong text capability of LLMs, recent studies propose to incorporate LLMs into the output text evaluation in various NLP tasks without additional expensive references and human efforts. Tang et al. (2023) propose to improve the traditional automatic metrics by increasing the number of references via LLMs-based paraphrasing systems. However, such method still requires one reference for each evaluation instance. In contrast, Liu et al. (2023e); Fu et al. (2023); Chen et al. (2023d); Chiang and Lee (2023) propose to directly use LLMs to evaluate the generated text quality without a single reference in a wide range of Natural Language Generation (NLG) tasks. Specifically, they construct complicated input instructions with tasks background and evaluation rules and prompt LLMs to follow these evaluation instructions to provide scores for output text. There are also some research efforts that propose LLMs-based evaluation framework for specific NLG tasks, including text sum mari z ation Gao et al. (2023), code generation (Zhuo, 2023), open-ended QA (Bai et al., 2023) and conversations (Lin and Chen, 2023). Due to the flexibility of prompts, it is also possible to conduct multi-dimensional evaluation towards the generated text (Lin and Chen, 2023; Fu et al., 2023). Min et al. (2023); Zha et al. (2023) propose to evaluate factual correctness using both closedsourced and open-sourced LLMs. Similar to human evaluation, there are also research efforts in explicitly prompting LLMs to conduct pairwise comparisons. To compare the capabilities of two LLMs, instead of assigning scores separately, Dubois et al. (2023); Zheng et al. (2023) explicitly to prompt GPT-4 to select the better response for the same instruction inputs.
虽然人工评估通常质量较高,但效率低下且成本昂贵。此外,大语言模型生成文本质量的不断提升,使得在开放式自然语言处理任务中,人工标注者更难区分人类撰写和LLM生成的文本 (Clark et al., 2021)。鉴于大语言模型强大的文本能力,近期研究提出将LLM纳入各类自然语言处理任务的输出文本评估中,无需额外昂贵参考或人工参与。Tang等人 (2023) 提出通过基于LLM的复述系统增加参考文本数量来改进传统自动评估指标,但该方法仍要求每个评估实例具备一个参考文本。相比之下,Liu等人 (2023e)、Fu等人 (2023)、Chen等人 (2023d) 以及Chiang和Lee (2023) 提出直接在多种自然语言生成(NLG)任务中使用LLM评估生成文本质量,无需任何参考文本。具体而言,他们构建包含任务背景和评估规则的复杂输入指令,提示LLM遵循这些评估指令为输出文本提供评分。另有研究针对特定NLG任务提出基于LLM的评估框架,包括文本摘要 (Gao et al., 2023)、代码生成 (Zhuo, 2023)、开放式问答 (Bai et al., 2023) 和对话系统 (Lin and Chen, 2023)。得益于提示的灵活性,还能对生成文本进行多维度评估 (Lin and Chen, 2023; Fu et al., 2023)。Min等人 (2023) 和Zha等人 (2023) 提出使用闭源和开源LLM评估事实准确性。与人工评估类似,也有研究明确提示LLM进行成对比较:为比较两个LLM的能力,Dubois等人 (2023) 和Zheng等人 (2023) 不采用单独评分,而是直接提示GPT-4对相同指令输入选择更优响应。
LLMs Evaluation Bias Despite LLMs achieve impressive consistency with human judgment, Wang et al. (2023b) find that such LLM-based evaluation paradigm suffers from a positional bias and those strong LLMs (i.e., GPT-4) tend to assign higher scores to the first appeared candidates. To calibrate such bias, they propose to a) repeat the LLM evaluation process multiple times with different candidate ordering and b) explicitly prompt LLMs to provide chain-of-thoughts for the evaluation before assigning the actual score. (Wu and Aji, 2023) find that LLM-based evaluation prefer candidates with factual errors over shorter candidates and candidates with grammatical errors, despite the former one could impose greater danger than the latter ones. To address this bias, they propose a multi-dimensional Elo rating system which separately evaluates the candidates from the perspective of accuracy, helpfulness and language. Such approach allows a more comprehensive under standing towards the candidates quality than previous one-shot evaluation. Concretely, (Zheng et al., 2023) systematically show the bias LLMsbased evaluation systems. On top of positional and length bias, they also discover Self-enhancement bias which means LLMs favor their own responses than the ones from other sources. To tackle these biases, their solutions include swapping responses, adding few-shot examples and leveraging CoT and references information.
大语言模型评估偏差
尽管大语言模型(LLM)与人类判断具有令人印象深刻的一致性,Wang等人(2023b)发现这种基于LLM的评估范式存在位置偏差,且强LLM(如GPT-4)倾向于给首先出现的候选答案分配更高分数。为校准此类偏差,他们提出:a)以不同候选排序多次重复LLM评估过程;b)在评分前明确提示LLM提供评估的思维链。(Wu和Aji,2023)发现基于LLM的评估更偏爱包含事实错误的候选答案而非较短答案或含语法错误的答案,尽管前者可能比后者带来更大风险。针对此偏差,他们提出多维Elo评分系统,分别从准确性、帮助性和语言角度评估候选答案。该方法相比先前单次评估能更全面理解候选质量。(Zheng等人,2023)系统揭示了基于LLM评估体系的多种偏差:除位置和长度偏差外,他们还发现自我增强偏差(即LLM更青睐自身生成的回答)。解决方案包括交换回答位置、添加少样本示例,以及利用思维链和参考信息。
Evaluation-Specific LLM Despite achieving high-quality automatic evaluation results, the above approaches heavily rely on state-of-the-art closedsource LLMs (e.g., GPT-4) which could result in data privacy issues. (Zheng et al., 2023) propose to train evaluation-specific LLMs. PandaLM (Wang et al., 2023c) is such a specialized evaluation LLMs by fine-tuning LLaMA-7B using around 300K high-quality synthetic evaluation instructions generated from GPT-3.5. Specifically, they first collect large volumes of instructions as well as outputs from a diverse range of open-sourced LLMs, such as LLaMA-7B and Bloom-7B. They then prompt GPT-3.5 to analysis and evaluate the quality of a pair of outputs. Their results on human-annotated meta-evaluation shows that, despite bebing much smaller, PandaLM achieves on-par evaluation performance comparing to GPT-3.5 and GPT-4.
评估专用大语言模型
尽管上述方法能实现高质量的自动评估效果,但这些方法严重依赖最先进的闭源大语言模型(如GPT-4),可能导致数据隐私问题。(Zheng et al., 2023)提出训练评估专用大语言模型的方案。PandaLM (Wang et al., 2023c)就是通过使用GPT-3.5生成的约30万条高质量合成评估指令对LLaMA-7B进行微调,构建的专用评估大语言模型。具体而言,他们首先从LLaMA-7B、Bloom-7B等多种开源大语言模型中收集大量指令及输出结果,然后提示GPT-3.5对输出结果对进行质量分析与评估。在人工标注的元评估测试中,PandaLM虽然模型规模小得多,但评估性能与GPT-3.5和GPT-4相当。
5 Challenges and Future Directions
5 挑战与未来方向
The development of LLM alignment is still in a rudimentary stage and thus leaves much room for improvement. In this section, we summarize existing important research efforts of aligning LLMs with human in Table 1. Below, we will discuss some of the challenges as well as the corresponding future research directions.
大语言模型对齐的发展仍处于初级阶段,因此存在很大的改进空间。在本节中,我们将现有重要的对齐大语言模型与人类的研究成果总结在表1中。下面,我们将讨论一些挑战以及相应的未来研究方向。
Fine-grained Instruction Data Management While research on LLMs alignment have been unprecedent ed ly active, many of these research efforts propose to leverage training instructions from diverse sources, making it challenging to fairly compare among different methods. As discussed in Section 2.3, there are some interesting findings about the implication of particular instruction dataset. For example, FLAN and programming instructions can improve reasoning capability aligned LLMs (Ghosal et al., 2023) and ShareGPT general performs well across a wide range of benchmarks (Wang et al., 2023d). However, there are still many issues in other aspects of instruction data management remaining unclear, including the optimal quality control towards instruction data, optimal instruction training sequence, how to effectively mix-up different instructions. These research efforts could finally enable fine-grained instruction management, allowing researchers and practitioners to construct high-quality instruction data.
细粒度指令数据管理
尽管大语言模型对齐研究空前活跃,但许多研究都提议利用来自不同来源的训练指令,这使得公平比较不同方法变得具有挑战性。如第2.3节所述,关于特定指令数据集的影响已有一些有趣发现。例如,FLAN和编程指令可以提升推理能力对齐的大语言模型 (Ghosal et al., 2023) ,而ShareGPT通常在广泛基准测试中表现良好 (Wang et al., 2023d) 。然而,指令数据管理的其他方面仍存在许多未解决的问题,包括指令数据的最佳质量控制、最优指令训练序列,以及如何有效混合不同指令。这些研究最终可能实现细粒度的指令管理,使研究人员和实践者能够构建高质量的指令数据。
| Aligned LLM | Size | Lang. | Initial LLMs | Training | Self Instruction | NLP Benchmarks | Human Annotations | Human Eval | Auto. Benchmark Eval | LLM Eval |
| Alpaca (Taori et al., 2023) Vicuna (Chiang et al, 2023) | 7B 7B, 13B, 33B | EN EN | LLaMA LLaMA | SFT SFT | Text-Davinci-003 GPT-3.5 | 70K ShareGPT | Author Verification | Vicuna-80 | ||
| GPT4ALL (Anand et al., 2023) | 6B, 13B | EN | LLaMA | SFT | Bloomz-P3 | OIG, ShareGPT, Dolly | Common Sense Reasoning | |||
| GPT-J | Text-Davinci-003 | Stack Overflow | User-Instructions-252 | |||||||
| LLaMA-GPT4 (Peng et al., 2023) | 7B | EN, CN | LLaMA | SFT | LdD | Pairwise, AMT | Unnatural Instructions | Vicana-80 | ||
| Phoenix (Chen et al., 2023e) | 7B, 13B | LLaMA BLOOMZ | SFT | GPT-3.5 Multilingual and Dialogue Data | ShareGPT | Volunteers | GPT-3.5, GPT-4 | |||
| UltraLLaMA (Ding et al., 2023) | 13B | EN | LLaMA | SFT | GPT-3.5 Dialogue Data | GPT 3.5 Vicwna-80 sogsonb osanp 00 | ||||
| Baize (Xu et al., 2023c) | 7B, 13B, 30B | EN | LLaMA | Revision, LoRA | GPT-3.5 self-Chat Data | Quora Questions | X | x | LdD | |
| WizardLM (Xu et al., 2023b) | 7B, 13B, 30B | EN | LLaMA | SFT | GPT-3.5, Alpaca Complex Instructions | ShareGPT | 10 Annotators Pairwise Comparison | x | GPT-4, WizedLM-218 | |
| WizardCoder (Luo et al., 2023) | 15B | EN, Code | StarCoder | SFT | GPT-3.5, Code Alpaca Complex Instructions | HumanEval, MBPP HumanEval+, DS-1000 | ||||
| OpenChat (Wang et al., 2023a) | 13B | EN | LLaMA | Language | GPT 3.5 & GPT4 ShareGPT | MMLU | GPT-4 | |||
| Guanaco (Dettmers et al., 2023) | 13B, 33B, 65B | N3 | LLaMA | QLoRA | Alpaca, SELF-INSTRUCT Unnatural instructions | FLAN | Chip2 | Elo, Vicuna-80 | MMLU | Elo, Vicuna-80 Open-Assistant-953 |
| MPT-chat (Team, 2023) | 13B, 30B | N3 | MPT | SFT | GPTeacher, Guanaco Baize Instructions | Vicuna ShareGPT | X | MMLU | GPT4, MT-bench | |
| FLACUNA (Ghosal et al., 2023) | 13B | EN | Vicuna | LoRA | Alpaca, Code Alpaca | FLAN | ShareGPT | MMLU, BBH, DROP | GPT 3.5, IMPACT | |
| Bactrian-X (Li et al., 2023b) | 7B | LLaMA | LoRA | Alpaca | CRASS, HumanEval XCOPA, XStoryCloze | GPT 4 | ||||
| Ocra (Mukherjee et al., 2023) | 13B | EN | BLOOMZ LLaMA | SFT | oes o | FLAN | XWinograd, SentimentX AGIEval, BBH | Multilingual Vicuna-80 GPT-4, Vicuna-80 | ||
| Phi-1 (Gunasekar et al., 2023) | 350M, 1.3B | EN, Code | Phi-1-base | SFT | GPT-3.5 | X | Python, The Stack | HumanEval | WizedLM-218, Awesome-164 GPT-4 Grading | |
| Chinese Alpaca (Cui et al., 2023b) | 7B, 13B, 33B | EN, CN | Chinese LLaMA | LoRA | Synthetic Textbook STEM | PCLUE | Stack Overflow | |||
| Lion (Jiang et al., 2023) | 7B, 13B | EN | LLaMA | Org. and Trans. Alpaca Alpaca | HHH | C-Eval | ||||
| Stable Alignment (Liu et al., 2023d) | SFT | GPT 3.5 Adv. Instruction GPT-3.5 | User-Instructions-252 | GPT-4, Vicuna-80 LdD | ||||||
| Dromedary (Sun et al., 2023b) | 7B | EN | Alpaca | SFT | Social Aligned Instructions | x | HHH, HHH-A | |||
| Dolly-v2 (Conover et al., 2023) | 65B | N3 | LLaMA | SFT | LLaMA-65B, Sef-Align | 175 Munnal Examples 16 Principle Rules | TruthfulQA, BBH | GPT-4, Vicuna-80 | ||
| Selfee (Ye et al., 2023a) | 3B, 7B, 12B 7B, 13B | EN | Pythia LLaMA | SFT | GPT 3.5 Self-Improve | databricks-dolly-15k | LLM Harness | |||
| TOLU (Wang et al., 2023d) | 7B, 13B, 30B, 65B | Revision | Alpaca Alpaca, Code Alpaca | FLAN, Maths, Code | ShareGPT Dolly, ShareGPT | Acceptability | MMLU, GSM, BBH | GPT-4, Vicuna-80 GPT4 on Vicuna-80, Koala | ||
| EN | LLaMA | SFT | GPT4-Alpaca, Self-instruct | FLAN, CoT | Open Assistant | Pairwise Comparison 100 AMT Annotators | TydiQA, Codex-Eval | Open Assistant Benchmarks | ||
| Koala (Geng et al., 2023) | 13B | EN | LLaMA | Language | Alpaca | OIG, HC3, Anthropic HH OpenAI WebGPT Summary C | on Aipaca and Koala Test | |||
| Bayling (Zhang et al., 2023c) | 7B, 13B | Multilingual | LLaMA | SFT | Alpaca GPT 3.5 Interactive Translation | ShareGPT | Translation Quality | WMT22 Multilingual Translation Lexically Constrained Translation | ||
| Wombat ( Yuan et al., 2023) | 7B | EN | Alpaca | Rank | Alpaca ChatGPT Ratings | Helpful and Harmless | GPT-4, Vicuna-80 | |||
| Lamini-lm (Wu et al., 2023) | 840 | EN | T5-Flan | SFT | Alpaca Self-instruct | P3, FLAN | Human Rating | LLM harmess |
Table 1: An overview of popular aligned LLMs, including their Size, supported languages, initial LLMs, alignment training method, alignment data, and alignment evaluation.
| 对齐大语言模型 | 规模 | 语言 | 初始大语言模型 | 训练方式 | 自指令数据 | NLP基准测试 | 人工标注数据 | 人工评估 | 自动基准评估 | 大语言模型评估 |
|---|---|---|---|---|---|---|---|---|---|---|
| Alpaca (Taori等人, 2023) Vicuna (Chiang等人, 2023) | 7B 7B, 13B, 33B | 英文 英文 | LLaMA LLaMA | SFT SFT | Text-Davinci-003 GPT-3.5 | 70K ShareGPT | 作者验证 | Vicuna-80 | ||
| GPT4ALL (Anand等人, 2023) | 6B, 13B | 英文 | LLaMA | SFT | Bloomz-P3 | OIG, ShareGPT, Dolly | 常识推理 | |||
| GPT-J | Text-Davinci-003 | Stack Overflow | User-Instructions-252 | |||||||
| LLaMA-GPT4 (Peng等人, 2023) | 7B | 英文, 中文 | LLaMA | SFT | LdD | 成对比较, AMT | 非自然指令 | Vicana-80 | ||
| Phoenix (Chen等人, 2023e) | 7B, 13B | LLaMA BLOOMZ | SFT | GPT-3.5 多语言和对话数据 | ShareGPT | 志愿者 | GPT-3.5, GPT-4 | |||
| UltraLLaMA (Ding等人, 2023) | 13B | 英文 | LLaMA | SFT | GPT-3.5 对话数据 | GPT 3.5 Vicwna-80 sogsonb osanp 00 | ||||
| Baize (Xu等人, 2023c) | 7B, 13B, 30B | 英文 | LLaMA | 修订, LoRA | GPT-3.5 自对话数据 | Quora问题 | X | x | LdD | |
| WizardLM (Xu等人, 2023b) | 7B, 13B, 30B | 英文 | LLaMA | SFT | GPT-3.5, Alpaca复杂指令 | ShareGPT | 10名标注者成对比较 | x | GPT-4, WizedLM-218 | |
| WizardCoder (Luo等人, 2023) | 15B | 英文, 代码 | StarCoder | SFT | GPT-3.5, Code Alpaca复杂指令 | HumanEval, MBPP HumanEval+, DS-1000 | ||||
| OpenChat (Wang等人, 2023a) | 13B | 英文 | LLaMA | 语言 | GPT 3.5 & GPT4 ShareGPT | MMLU | GPT-4 | |||
| Guanaco (Dettmers等人, 2023) | 13B, 33B, 65B | N3 | LLaMA | QLoRA | Alpaca, SELF-INSTRUCT非自然指令 | FLAN | Chip2 | Elo, Vicuna-80 | MMLU | Elo, Vicuna-80 Open-Assistant-953 |
| MPT-chat (Team, 2023) | 13B, 30B | N3 | MPT | SFT | GPTeacher, Guanaco Baize指令 | Vicuna ShareGPT | X | MMLU | GPT4, MT-bench | |
| FLACUNA (Ghosal等人, 2023) | 13B | 英文 | Vicuna | LoRA | Alpaca, Code Alpaca | FLAN | ShareGPT | MMLU, BBH, DROP | GPT 3.5, IMPACT | |
| Bactrian-X (Li等人, 2023b) | 7B | LLaMA | LoRA | Alpaca | CRASS, HumanEval XCOPA, XStoryCloze | GPT 4 | ||||
| Ocra (Mukherjee等人, 2023) | 13B | 英文 | BLOOMZ LLaMA | SFT | oes o | FLAN | XWinograd, SentimentX AGIEval, BBH | 多语言Vicuna-80 GPT-4, Vicuna-80 | ||
| Phi-1 (Gunasekar等人, 2023) | 350M, 1.3B | 英文, 代码 | Phi-1-base | SFT | GPT-3.5 | X | Python语言, The Stack | HumanEval | WizedLM-218, Awesome-164 GPT-4评分 | |
| Chinese Alpaca (Cui等人, 2023b) | 7B, 13B, 33B | 英文, 中文 | Chinese LLaMA | LoRA | 合成教材STEM | PCLUE | Stack Overflow | |||
| Lion (Jiang等人, 2023) | 7B, 13B | 英文 | LLaMA | 组织和翻译Alpaca Alpaca | HHH | C-Eval | ||||
| Stable Alignment (Liu等人, 2023d) | SFT | GPT 3.5高级指令 GPT-3.5 | User-Instructions-252 | GPT-4, Vicuna-80 LdD | ||||||
| Dromedary (Sun等人, 2023b) | 7B | 英文 | Alpaca | SFT | 社会对齐指令 | x | HHH, HHH-A | |||
| Dolly-v2 (Conover等人, 2023) | 65B | N3 | LLaMA | SFT | LLaMA-65B, 自对齐 | 175个手动示例 16条原则规则 | TruthfulQA, BBH | GPT-4, Vicuna-80 | ||
| Selfee (Ye等人, 2023a) | 3B, 7B, 12B 7B, 13B | 英文 | Pythia LLaMA | SFT | GPT 3.5自我改进 | databricks-dolly-15k | LLM Harness | |||
| TOLU (Wang等人, 2023d) | 7B, 13B, 30B, 65B | 修订 | Alpaca Alpaca, Code Alpaca | FLAN, 数学, 代码 | ShareGPT Dolly, ShareGPT | 可接受性 | MMLU, GSM, BBH | GPT-4, Vicuna-80 GPT4在Vicuna-80, Koala | ||
| 英文 | LLaMA | SFT | GPT4-Alpaca, 自指令 | FLAN, CoT | Open Assistant | 成对比较 100名AMT标注者 | TydiQA, Codex-Eval | Open Assistant基准测试 | ||
| Koala (Geng等人, 2023) | 13B | 英文 | LLaMA | 语言 | Alpaca | OIG, HC3, Anthropic HH OpenAI WebGPT摘要C | 在Alpaca和Koala测试上 | |||
| Bayling (Zhang等人, 2023c) | 7B, 13B | 多语言 | LLaMA | SFT | Alpaca GPT 3.5交互式翻译 | ShareGPT | 翻译质量 | WMT22多语言翻译 词汇约束翻译 | ||
| Wombat (Yuan等人, 2023) | 7B | 英文 | Alpaca | 排名 | Alpaca ChatGPT评分 | 有帮助和无害 | GPT-4, Vicuna-80 | |||
| Lamini-lm (Wu等人, 2023) | 840 | 英文 | T5-Flan | SFT | Alpaca自指令 | P3, FLAN | 人工评分 | LLM harmess |
表 1: 流行对齐大语言模型概览,包括其规模、支持语言、初始大语言模型、对齐训练方法、对齐数据和对齐评估。
LLMs Alignment for non-English Languages Most of existing research in LLMs alignment are English-dominated. While many approaches, such as complex instruction generation (Xu et al., 2023b) and explanation tuning (Mukherjee et al., 2023), are language-agnostic, they only explore Englishbased prompts and it is unclear how well these prompts perform when adapting to other languages, severely hindering the application of LLMs to nonEnglish regions. It is interesting to see 1) how these alignment technologies perform in various languages, in particular low-resource languages, and 2) how to effectively transfer the effect of LLMs alignment across different languages.
大语言模型在非英语语言中的对齐研究
现有的大语言模型对齐研究大多以英语为主导。尽管许多方法(如复杂指令生成(Xu et al., 2023b)和解释调优(Mukherjee et al., 2023))是语言无关的,但它们仅探索了基于英语的提示,这些提示在适应其他语言时的表现尚不明确,严重阻碍了大语言模型在非英语地区的应用。值得关注的是:1)这些对齐技术在不同语言(尤其是低资源语言)中的表现如何;2)如何有效实现大语言模型对齐效果在不同语言间的迁移。
LLMs Alignment Training Technologies As shown in Table 1, most of existing aligned LLMs are based on the simple SFT technology. However, SFT does not explicitly incorporate human preference into LLMs. As a result, aligning LLMs solely based on SFT could require a lot more instruction data and training resources. In general, there is a lacking of comprehensive investigation over the effect of various training technologies to incorporate human preference into LLMs. Thus, it is critical to come up with resource-constrained LLM alignment training framework where certain alignment resources are given at a certain level (e.g., maxi $\mathrm{mum10K}$ instructions, 5 hours training time, etc.), allowing researchers and practitioners to verify the effectiveness of various training methods. As increasing number of instruction data have become available, this exploration could further promote effective and environmental-friendly LLMs alignment solutions.
大语言模型对齐训练技术
如表 1 所示,现有的大多数对齐大语言模型都基于简单的监督微调 (SFT) 技术。然而,SFT 并未明确将人类偏好融入大语言模型中。因此,仅依靠 SFT 对齐大语言模型可能需要更多的指令数据和训练资源。总体而言,目前缺乏关于各种训练技术将人类偏好融入大语言模型效果的全面研究。因此,建立一个资源受限的大语言模型对齐训练框架至关重要,该框架在给定特定水平的对齐资源(例如最多 10K 条指令、5 小时训练时间等)的情况下,能让研究者和从业者验证各种训练方法的有效性。随着可用指令数据量的增加,这一探索有望进一步推动高效且环保的大语言模型对齐解决方案的发展。
Human-in-the-loop LLMs Alignment Data Gen- eration Table 1 has shown that ShareGPT data has been widely adapted for LLMs alignment. The preliminary analysis in Wang et al. (2023d) also reveal that ShareGPT performs consistly well across a wide range of NLP tasks. These results indicate that human is still a key factor in improving LLMs alignment quality. Different from traditional human annotation framework where human provides annotation based on the instructions, ShareGPT is a human-in-the-loop alignment solution where human can freely determine what LLMs should generate. This shows the great potential of humanin-the-loop data generation solution in LLMs alignment. It will be interesting to explore other types of human-in-the-loop solutions to further facilitate LLMs alignment.
人机协同的大语言模型对齐数据生成
表 1 显示 ShareGPT 数据已被广泛用于大语言模型对齐。Wang et al. (2023d) 的初步分析也表明,ShareGPT 在各类 NLP 任务中表现稳定。这些结果表明人类仍是提升大语言模型对齐质量的关键因素。与传统人工标注框架(人类根据指令提供标注)不同,ShareGPT 是一种人机协同对齐方案,人类可自由决定大语言模型的生成内容。这展现了人机协同数据生成方案在大语言模型对齐中的巨大潜力。探索其他类型的人机协同方案以进一步促进大语言模型对齐将是一个有趣的方向。
Human-LLM Joint Evaluation Framework Existing LLM evaluation frameworks either use LLMs for effective evaluation or leverage crowdsourcing for high-quality evaluation. As shown in (Wu and Aji, 2023; Liu et al., 2023e), state-ofthe-art LLMs have demonstrated similar or superior evaluation capability in various NLP tasks. It is feasible to use LLMs as special evaluation annotators and develop LLM-human joint evaluation framework where LLMs and human are assigned with different evaluation tasks based on their own strengths to maintain both efficiency and quality of the evaluation procedure for LLM alignment .
人机协同评估框架
现有的大语言模型评估框架要么利用大语言模型进行高效评估,要么通过众包实现高质量评估。(Wu and Aji, 2023; Liu et al., 2023e) 研究表明,当前最先进的大语言模型在各种自然语言处理任务中展现出与人类相当甚至更优的评估能力。将大语言模型作为特殊评估标注者,开发人机协同评估框架具有可行性——根据各自优势为大语言模型和人类分配不同评估任务,从而在大模型对齐过程中兼顾评估效率与质量。
6 Conclusion
6 结论
This survey provides an up-to-date review to recent advances of LLMs alignment technologies. We summarize these research efforts into Alignment Instruction Collection, Alignment Training and Alignment Evaluation. Finally, we pointed out several promising future directions for LLMs alignment. We hope this survey could provide insightful perspectives and inspire further research in improving LLMs alignment.
本综述对近期大语言模型(LLM)对齐技术的最新进展进行了全面回顾。我们将这些研究工作归纳为对齐指令收集、对齐训练和对齐评估三大方向。最后,我们指出了大语言模型对齐领域若干具有前景的未来研究方向。希望本综述能为改进大语言模型对齐提供深刻见解,并激发更多相关研究。
References
参考文献
for Computational Linguistics: System Demonstrations, pages 93–104, Dublin, Ireland. Association for Computational Linguistics.
计算语言学系统演示,第93-104页,爱尔兰都柏林。计算语言学协会。
Yushi Bai, Jiahao Ying, Yixin Cao, Xin Lv, Yuze He, Xiaozhi Wang, Jifan Yu, Kaisheng Zeng, Yijia Xiao, Haozhe Lyu, et al. 2023. Benchmarking foundation models with language-model-as-an-examiner. arXiv preprint arXiv:2306.04181.
Yushi Bai、Jiahao Ying、Yixin Cao、Xin Lv、Yuze He、Xiaozhi Wang、Jifan Yu、Kaisheng Zeng、Yijia Xiao、Haozhe Lyu等。2023。以语言模型为考官的基础模型评测。arXiv预印本arXiv:2306.04181。
BIG bench authors. 2023. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research.
BIG bench作者. 2023. 超越模仿游戏: 量化与推演语言模型的能力. Transactions on Machine Learning Research.
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neel a kant an, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. In Advances in Neural Information Processing Systems, volume 33, pages 1877–1901. Curran Associates, Inc.
Tom Brown、Benjamin Mann、Nick Ryder、Melanie Subbiah、Jared D Kaplan、Prafulla Dhariwal、Arvind Neelakantan、Pranav Shyam、Girish Sastry、Amanda Askell、Sandhini Agarwal、Ariel Herbert-Voss、Gretchen Krueger、Tom Henighan、Rewon Child、Aditya Ramesh、Daniel Ziegler、Jeffrey Wu、Clemens Winter、Chris Hesse、Mark Chen、Eric Sigler、Mateusz Litwin、Scott Gray、Benjamin Chess、Jack Clark、Christopher Berner、Sam McCandlish、Alec Radford、Ilya Sutskever 和 Dario Amodei。2020. 大语言模型是少样本学习者。载于《神经信息处理系统进展》第33卷,第1877-1901页。Curran Associates公司出版。
Yihan Cao, Yanbin Kang, and Lichao Sun. 2023. Instruction mining: High-quality instruction data selection for large language models. arXiv preprint arXiv:2307.06290.
Yihan Cao、Yanbin Kang和Lichao Sun。2023。指令挖掘:面向大语言模型的高质量指令数据选择。arXiv预印本arXiv:2307.06290。
Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Kaijie Zhu, Hao Chen, Linyi Yang, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, et al. 2023. A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109.
Yupeng Chang、Xu Wang、Jindong Wang、Yuan Wu、Kaijie Zhu、Hao Chen、Linyi Yang、Xiaoyuan Yi、Cunxiang Wang、Yidong Wang 等. 2023. 大语言模型评估综述. arXiv预印本 arXiv:2307.03109.
Jiaao Chen, Aston Zhang, Xingjian Shi, Mu Li, Alex Smola, and Diyi Yang. 2023a. Parameter-efficient fine-tuning design spaces. In The Eleventh International Conference on Learning Representations.
Jiaao Chen、Aston Zhang、Xingjian Shi、Mu Li、Alex Smola 和 Diyi Yang。2023a。参数高效微调设计空间。载于第十一届国际学习表征会议。
Lichang Chen, Shiyang Li, Jun Yan, Hai Wang, Kalpa Gunaratna, Vikas Yadav, Zheng Tang, Vijay Srinivasan, Tianyi Zhou, Heng Huang, et al. 2023b. Alpagasus: Training a better alpaca with fewer data. arXiv preprint arXiv:2307.08701.
Lichang Chen, Shiyang Li, Jun Yan, Hai Wang, Kalpa Gunaratna, Vikas Yadav, Zheng Tang, Vijay Srinivasan, Tianyi Zhou, Heng Huang, 等. 2023b. Alpagasus: 用更少数据训练更好的Alpaca. arXiv预印本 arXiv:2307.08701.
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374.
Mark Chen、Jerry Tworek、Heewoo Jun、Qiming Yuan、Henrique Ponde de Oliveira Pinto、Jared Kaplan、Harri Edwards、Yuri Burda、Nicholas Joseph、Greg Brockman 等. 2021. 评估基于代码训练的大语言模型. arXiv预印本 arXiv:2107.03374.
Xinyun Chen, Maxwell Lin, Nathanael Schärli, and Denny Zhou. 2023c. Teaching large language models to self-debug. arXiv preprint arXiv:2304.05128.
Xinyun Chen、Maxwell Lin、Nathanael Schärli 和 Denny Zhou。2023c。教大语言模型自我调试。arXiv预印本 arXiv:2304.05128。
Yann Dubois, Xuechen Li, Rohan Taori, Tianyi Zhang, Ishaan Gulrajani, Jimmy Ba, Carlos Guestrin, Percy Liang, and Tatsunori B Hashimoto. 2023. Alpacafarm: A simulation framework for methods that learn from human feedback. arXiv preprint arXiv:2305.14387.
Yann Dubois、Xuechen Li、Rohan Taori、Tianyi Zhang、Ishan Gulrajani、Jimmy Ba、Carlos Guestrin、Percy Liang 和 Tatsunori B Hashimoto。2023。Alpacafarm: 一种基于人类反馈学习方法模拟框架。arXiv预印本 arXiv:2305.14387。
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan AllenZhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations.
Edward J Hu、yelong shen、Phillip Wallis、Zeyuan AllenZhu、Yuanzhi Li、Shean Wang、Lu Wang 和 Weizhu Chen。2022。LoRA:大语言模型的低秩自适应 (Low-rank Adaptation of Large Language Models)。收录于国际学习表征会议 (International Conference on Learning Representations)。
Yuzhen Huang, Yuzhuo Bai, Zhihao Zhu, Junlei Zhang, Jinghan Zhang, Tangjun Su, Junteng Liu, Chuancheng Lv, Yikai Zhang, Jiayi Lei, Yao Fu, Maosong Sun, and Junxian He. 2023. Ceval: A multi-level multi-discipline chinese evaluation suite for foundation models. arXiv preprint arXiv:2305.08322.
Yuzhen Huang, Yuzhuo Bai, Zhihao Zhu, Junlei Zhang, Jinghan Zhang, Tangjun Su, Junteng Liu, Chuancheng Lv, Yikai Zhang, Jiayi Lei, Yao Fu, Maosong Sun, and Junxian He. 2023. CEval: 面向基础模型的多层级多学科中文评估套件. arXiv预印本 arXiv:2305.08322.
Sophie Jentzsch and Kristian Kersting. 2023. Chatgpt is fun, but it is not funny! humor is still challenging large language models. arXiv preprint arXiv:2306.04563.
Sophie Jentzsch 和 Kristian Kersting. 2023. ChatGPT 很有趣,但它并不好笑!幽默对大语言模型仍是挑战. arXiv 预印本 arXiv:2306.04563.
Yunjie Ji, Yan Gong, Yong Deng, Yiping Peng, Qiang Niu, Baochang Ma, and Xiangang Li. 2023. Towards better instruction following language models for chinese: Investigating the impact of training data and evaluation. CoRR, abs/2304.07854.
Yunjie Ji、Yan Gong、Yong Deng、Yiping Peng、Qiang Niu、Baochang Ma和Xiangang Li。2023。面向中文的指令跟随语言模型优化:训练数据与评估影响探究。CoRR,abs/2304.07854。
Yuxin Jiang, Chunkit Chan, Mingyang Chen, and Wei Wang. 2023. Lion: Adversarial distillation of closed-source large language model. ArXiv, abs/2305.12870.
Yuxin Jiang、Chunkit Chan、Mingyang Chen 和 Wei Wang。2023。Lion: 闭源大语言模型的对抗蒸馏。ArXiv, abs/2305.12870。
ayashree Kalpathy-Cramer, J. Peter Campbell, Deniz Erdogmus, Peng Tian, Dharanish Ke dar is etti, Chace Moleta, James D. Reynolds, Kelly Hutcheson, Michael J. Shapiro, Michael X. Repka, Philip Ferrone, Kimberly Drenser, Jason Horowitz, Kemal Sonmez, Ryan Swan, Susan Ostmo, Karyn E. Jonas, R.V. Paul Chan, Michael F. Chiang, Michael F. Chiang, Susan Ostmo, Kemal Sonmez, J. Peter Campbell, R.V. Paul Chan, Karyn Jonas, Jason Horowitz, Osode Coki, Cheryl-Ann Eccles, Leora Sarna, Audina Berrocal, Catherin Negron, Kimberly Denser, Kristi Cumming, Tammy Osentoski, Tammy Check, Mary Za je chow ski, Thomas Lee, Evan Kruger, Kathryn McGovern, Charles Simmons, Raghu Murthy, Sharon Galvis, Jerome Rotter, Ida Chen, Xiaohui Li, Kent Taylor, Kaye Roll, Jayashree Kalpathy-Cramer, Deniz Erdogmus, Maria Ana Martinez-Castellano s, Samantha Salinas-Longoria, Rafael Romero, Andrea Arriola, Francisco OlguinManriquez, Miroslava Meraz-Gutierrez, Carlos M. Dulanto-Reinoso, and Cristina Montero-Mendoza. 2016. Plus disease in ret in opa thy of prematurity: Improving diagnosis by ranking disease severity and using quantitative image analysis. Ophthalmology, 123(11):2345–2351.
Jayashree Kalpathy-Cramer、J. Peter Campbell、Deniz Erdogmus、Peng Tian、Dharanish Kedarisetti、Chace Moleta、James D. Reynolds、Kelly Hutcheson、Michael J. Shapiro、Michael X. Repka、Philip Ferrone、Kimberly Drenser、Jason Horowitz、Kemal Sonmez、Ryan Swan、Susan Ostmo、Karyn E. Jonas、R.V. Paul Chan、Michael F. Chiang、Michael F. Chiang、Susan Ostmo、Kemal Sonmez、J. Peter Campbell、R.V. Paul Chan、Karyn Jonas、Jason Horowitz、Osode Coki、Cheryl-Ann Eccles、Leora Sarna、Audina Berrocal、Catherin Negron、Kimberly Denser、Kristi Cumming、Tammy Osentoski、Tammy Check、Mary Zajechowski、Thomas Lee、Evan Kruger、Kathryn McGovern、Charles Simmons、Raghu Murthy、Sharon Galvis、Jerome Rotter、Ida Chen、Xiaohui Li、Kent Taylor、Kaye Roll、Jayashree Kalpathy-Cramer、Deniz Erdogmus、Maria Ana Martinez-Castellanos、Samantha Salinas-Longoria、Rafael Romero、Andrea Arriola、Francisco OlguinManriquez、Miroslava Meraz-Gutierrez、Carlos M. Dulanto-Reinoso 和 Cristina Montero-Mendoza。2016。早产儿视网膜病变中的 Plus 病变: 通过疾病严重程度分级和定量图像分析改进诊断。Ophthalmology, 123(11):2345–2351。
Andreas Kopf, Yannic Kilcher, Dimitri von Rutte, Sotiris An agno s tid is, Zhi Rui Tam, Keith Stevens, Abdullah Barhoum, Nguyen Minh Duc, Oliver Stanley, Rich’ard Nagyfi, ES Shahul, Sameer Suri, David Glushkov, Arnav Dantuluri, Andrew Maguire, Christoph Schuhmann, Huu Nguyen, and Alexander Mattick. 2023. Open assistant conversations - demo crat i zing large language model alignment. ArXiv, abs/2304.07327.
Andreas Kopf、Yannic Kilcher、Dimitri von Rutte、Sotiris Anagnostidis、Zhi Rui Tam、Keith Stevens、Abdullah Barhoum、Nguyen Minh Duc、Oliver Stanley、Richard Nagyfi、ES Shahul、Sameer Suri、David Glushkov、Arnav Dantuluri、Andrew Maguire、Christoph Schuhmann、Huu Nguyen 和 Alexander Mattick。2023。Open Assistant Conversations——大语言模型对齐的民主化。ArXiv, abs/2304.07327。
Yuhang Lai, Chengxi Li, Yiming Wang, Tianyi Zhang, Ruiqi Zhong, Luke Z ett le moyer, Scott Wen tau Yih, Daniel Fried, Sida Wang, and Tao Yu. 2022. Ds-1000: A natural and reliable benchmark for data science code generation. ArXiv, abs/2211.11501.
Yuhang Lai、Chengxi Li、Yiming Wang、Tianyi Zhang、Ruiqi Zhong、Luke Zettlemoyer、Scott Wen-tau Yih、Daniel Fried、Sida Wang和Tao Yu。2022。DS-1000: 一个自然且可靠的数据科学代码生成基准。ArXiv, abs/2211.11501。
Brian Lester, Rami Al-Rfou, and Noah Constant. 2021. The power of scale for parameter-efficient prompt tuning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 3045–3059, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
Brian Lester、Rami Al-Rfou 和 Noah Constant。2021. 规模效应对参数高效提示调优的影响。载于《2021年自然语言处理实证方法会议论文集》,第3045–3059页,线上会议及多米尼加共和国蓬塔卡纳。计算语言学协会。
Guohao Li, Hasan Abed Al Kader Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. 2023a. CAMEL: communicative agents for "mind" exploration of large scale language model society. CoRR, abs/2303.17760.
Guohao Li、Hasan Abed Al Kader Hammoud、Hani Itani、Dmitrii Khizbullin 和 Bernard Ghanem。2023a. CAMEL: 大语言模型社会"思维"探索的交流智能体。CoRR, abs/2303.17760。
Haonan Li, Fajri Koto, Minghao Wu, Alham Fikri Aji, and Timothy Baldwin. 2023b. Bactrian-x: A multilingual replicable instruction-following model with lowrank adaptation. arXiv preprint arXiv:2305.15011.
Haonan Li, Fajri Koto, Minghao Wu, Alham Fikri Aji, and Timothy Baldwin. 2023b. Bactrian-x: 基于低秩自适应技术的多语言可复现指令跟随模型. arXiv preprint arXiv:2305.15011.
Haonan Li, Yixuan Zhang, Fajri Koto, Yifei Yang, Hai Zhao, Yeyun Gong, Nan Duan, and Timothy Baldwin. 2023c. Cmmlu: Measuring massive multitask language understanding in chinese. arXiv preprint arXiv:2306.09212.
Haonan Li, Yixuan Zhang, Fajri Koto, Yifei Yang, Hai Zhao, Yeyun Gong, Nan Duan, and Timothy Baldwin. 2023c. CMMLU: 中文海量多任务语言理解评估基准. arXiv预印本 arXiv:2306.09212.
Xiang Lisa Li and Percy Liang. 2021. Prefix-tuning: Optimizing continuous prompts for generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 4582– 4597, Online. Association for Computational Linguistics.
Xiang Lisa Li 和 Percy Liang. 2021. 前缀调优 (Prefix-tuning): 面向生成的连续提示优化. 见《第59届计算语言学协会年会暨第11届自然语言处理国际联合会议论文集(第一卷: 长论文)》, 第4582–4597页, 线上会议. 计算语言学协会.
Chin-Yew Lin. 2004. ROUGE: A package for automatic evaluation of summaries. In Text Summarization Branches Out, pages 74–81, Barcelona, Spain. Association for Computational Linguistics.
Chin-Yew Lin. 2004. ROUGE: 自动摘要评估工具包。In Text Summarization Branches Out, pages 74–81, Barcelona, Spain. Association for Computational Linguistics.
Yen-Ting Lin and Yun-Nung Chen. 2023. Llm-eval: Unified multi-dimensional automatic evaluation for open-domain conversations with large language models. arXiv preprint arXiv:2305.13711.
Yen-Ting Lin和Yun-Nung Chen。2023。Llm-eval:基于大语言模型的开放域对话统一多维自动评估。arXiv预印本arXiv:2305.13711。
Chuang Liu, Renren Jin, Yuqi Ren, Linhao Yu, Tianyu Dong, Xiaohan Peng, Shuting Zhang, Jianxiang Peng, Peiyi Zhang, Qingqing Lyu, et al. 2023a. M3ke: A massive multi-level multi-subject knowledge evaluation benchmark for chinese large language models. arXiv preprint arXiv:2305.10263.
Chuang Liu、Renren Jin、Yuqi Ren、Linhao Yu、Tianyu Dong、Xiaohan Peng、Shuting Zhang、Jianxiang Peng、Peiyi Zhang、Qingqing Lyu 等. 2023a. M3KE: 面向中文大语言模型的大规模多层次多学科知识评估基准. arXiv预印本 arXiv:2305.10263.
Hao Liu, Xinyang Geng, Lisa Lee, Igor Mordatch, Sergey Levine, Sharan Narang, and P. Abbeel. 2022a. Towards better few-shot and finetuning performance with forgetful causal language models.
Hao Liu、Xinyang Geng、Lisa Lee、Igor Mordatch、Sergey Levine、Sharan Narang 和 P. Abbeel。2022a。通过遗忘因果语言模型提升少样本与微调性能。
Hao Liu, Carmelo Sferrazza, and Pieter Abbeel. 2023b. Languages are rewards: Hindsight finetuning using human feedback. arXiv preprint arXiv:2302.02676.
Hao Liu、Carmelo Sferrazza 和 Pieter Abbeel。2023b。语言即奖励:基于人类反馈的事后微调。arXiv预印本 arXiv:2302.02676。
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. 2023c. Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation. arXiv preprint arXiv:2305.01210.
Jiawei Liu、Chunqiu Steven Xia、Yuyao Wang和Lingming Zhang。2023c。你的代码真的由ChatGPT生成正确吗?对大语言模型代码生成的严格评估。arXiv预印本arXiv:2305.01210。
Ruibo Liu, Chenyan Jia, Ge Zhang, Ziyu Zhuang, Tony X Liu, and Soroush Vosoughi. 2022b. Second thoughts are best: Learning to re-align with human values from text edits. In Advances in Neural Information Processing Systems.
Ruibo Liu、Chenyan Jia、Ge Zhang、Ziyu Zhuang、Tony X Liu 和 Soroush Vosoughi。2022b。三思而行:从文本编辑中学习重新对齐人类价值观。载于《神经信息处理系统进展》。
Ruibo Liu, Ruixin Yang, Chenyan Jia, Ge Zhang, Denny Zhou, Andrew M Dai, Diyi Yang, and Soroush Vosoughi. 2023d. Training socially aligned language models in simulated human society. arXiv preprint arXiv:2305.16960.
Ruibo Liu、Ruixin Yang、Chenyan Jia、Ge Zhang、Denny Zhou、Andrew M Dai、Diyi Yang 和 Soroush Vosoughi。2023d。在模拟人类社会中训练社交对齐的语言模型。arXiv预印本 arXiv:2305.16960。
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023e. Gpte- val: Nlg evaluation using gpt-4 with better human alignment. arXiv preprint arXiv:2303.16634.
Yang Liu、Dan Iter、Yichong Xu、Shuohang Wang、Ruochen Xu 和 Chenguang Zhu。2023e。GPTE-val: 使用 GPT-4 进行自然语言生成评估并实现更好的人类对齐。arXiv 预印本 arXiv:2303.16634。
Yixin Liu, Pengfei Liu, Dragomir Radev, and Graham Neubig. 2022c. BRIO: Bringing order to abstract ive sum mari z ation. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2890–2903, Dublin, Ireland. Association for Computational Linguistics.
Yixin Liu、Pengfei Liu、Dragomir Radev 和 Graham Neubig。2022c。BRIO: 为抽象摘要带来秩序。载于《第60届计算语言学协会年会论文集(第一卷:长论文)》,第2890–2903页,爱尔兰都柏林。计算语言学协会。
Shayne Longpre, Le Hou, Tu Vu, Albert Webson, Hyung Won Chung, Yi Tay, Denny Zhou, Quoc V Le, Barret Zoph, Jason Wei, et al. 2023. The flan collection: Designing data and methods for effective instruction tuning. arXiv preprint arXiv:2301.13688.
Shayne Longpre、Le Hou、Tu Vu、Albert Webson、Hyung Won Chung、Yi Tay、Denny Zhou、Quoc V Le、Barret Zoph、Jason Wei等。2023。FLAN集合:设计数据与方法以实现高效指令调优。arXiv预印本arXiv:2301.13688。
Ziyang Luo, Can Xu, Pu Zhao, Qingfeng Sun, Xiubo Geng, Wenxiang Hu, Chongyang Tao, Jing Ma, Qingwei Lin, and Daxin Jiang. 2023. Wizard code r: Empowering code large language models with evolinstruct. arXiv preprint arXiv:2306.08568.
罗子阳、徐灿、赵普、孙庆丰、耿希波、胡文翔、陶重阳、马静、林庆伟、蒋大新。2023. WizardCoder:基于Evol-Instruct的代码大语言模型赋能研究。arXiv预印本 arXiv:2306.08568。
Sourab Mangrulkar, Sylvain Gugger, Lysandre Debut, Younes Belkada, and Sayak Paul. 2022. Peft: Stateof-the-art parameter-efficient fine-tuning methods. https://github.com/hugging face/peft.
Sourab Mangrulkar、Sylvain Gugger、Lysandre Debut、Younes Belkada 和 Sayak Paul。2022。PEFT:最先进的参数高效微调方法。https://github.com/huggingface/peft。
Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Wei Koh, Mohit Iyyer, Luke Z ett le moyer, and Hannaneh Hajishirzi. 2023. Factscore: Fine-grained atomic evaluation of factual precision in long form text generation. arXiv preprint arXiv:2305.14251.
Sewon Min、Kalpesh Krishna、Xinxi Lyu、Mike Lewis、Wen-tau Yih、Pang Wei Koh、Mohit Iyyer、Luke Zettlemoyer 和 Hannaneh Hajishirzi。2023。FactScore: 长文本生成中事实精度的细粒度原子评估。arXiv预印本 arXiv:2305.14251。
Swaroop Mishra, Daniel Khashabi, Chitta Baral, and Hannaneh Hajishirzi. 2022. Cross-task generalization via natural language crowd sourcing instructions. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3470–3487, Dublin, Ireland. Association for Computational Linguistics.
Swaroop Mishra、Daniel Khashabi、Chitta Baral 和 Hannaneh Hajishirzi。2022. 通过自然语言众包指令实现跨任务泛化。载于《第60届计算语言学协会年会论文集(第一卷:长论文)》,第3470–3487页,爱尔兰都柏林。计算语言学协会。
Niklas Mu en nigh off, Alexander M Rush, Boaz Barak, Teven Le Scao, Aleksandra Piktus, Nouamane Tazi, Sampo Pyysalo, Thomas Wolf, and Colin Raffel.
Niklas Muennighoff, Alexander M Rush, Boaz Barak, Teven Le Scao, Aleksandra Piktus, Nouamane Tazi, Sampo Pyysalo, Thomas Wolf, Colin Raffel.
Subhabrata Mukherjee, Arindam Mitra, Ganesh Jawahar, Sahaj Agarwal, Hamid Palangi, and Ahmed Awadallah. 2023. Orca: Progressive learning from complex explanation traces of gpt-4. arXiv preprint arXiv:2306.02707.
Subhabrata Mukherjee、Arindam Mitra、Ganesh Jawahar、Sahaj Agarwal、Hamid Palangi 和 Ahmed Awadallah。2023。Orca: 从GPT-4的复杂解释轨迹中进行渐进式学习。arXiv预印本 arXiv:2306.02707。
Huu Nguyen, Sameer Suri, Ken Tsui, and Christoph Schuhmann. 2023. The oig dataset.
Huu Nguyen、Sameer Suri、Ken Tsui 和 Christoph Schuhmann。2023。OIG数据集。
Tung Nguyen, Qinqing Zheng, and Aditya Grover. 2022. Cons er weight ive behavioral cloning for reliable offline reinforcement learning. arXiv preprint arXiv:2210.05158.
Tung Nguyen、Qinqing Zheng 和 Aditya Grover。2022。面向可靠离线强化学习的保守行为克隆。arXiv预印本 arXiv:2210.05158。
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Gray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. 2022. Training language models to follow instructions with human feedback. In Advances in Neural Information Processing Systems.
Long Ouyang、Jeffrey Wu、Xu Jiang、Diogo Almeida、Carroll Wainwright、Pamela Mishkin、Chong Zhang、Sandhini Agarwal、Katarina Slama、Alex Gray、John Schulman、Jacob Hilton、Fraser Kelton、Luke Miller、Maddie Simens、Amanda Askell、Peter Welinder、Paul Christiano、Jan Leike 和 Ryan Lowe。2022。通过人类反馈训练语言模型遵循指令。载于《神经信息处理系统进展》。
Kishore Papineni, Salim Roukos, Todd Ward, and WeiJing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pages 311–318, Philadelphia, Pennsylvania, USA. Association for Computational Linguistics.
Kishore Papineni、Salim Roukos、Todd Ward和WeiJing Zhu。2002年。BLEU:一种机器翻译自动评估方法。载于《第40届计算语言学协会年会论文集》,第311-318页,美国宾夕法尼亚州费城。计算语言学协会。
Baolin Peng, Chunyuan Li, Pengcheng He, Michel Gal- ley, and Jianfeng Gao. 2023. Instruction tuning with gpt-4. arXiv preprint arXiv:2304.03277.
Baolin Peng、Chunyuan Li、Pengcheng He、Michel Galley 和 Jianfeng Gao。2023。使用 GPT-4 进行指令调优。arXiv 预印本 arXiv:2304.03277。
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D Manning, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model. arXiv preprint arXiv:2305.18290.
Rafael Rafailov、Archit Sharma、Eric Mitchell、Stefano Ermon、Christopher D Manning 和 Chelsea Finn。2023。直接偏好优化:你的语言模型其实是个奖励模型。arXiv预印本 arXiv:2305.18290。
Feifan Song, Bowen Yu, Minghao Li, Haiyang Yu, Fei Huang, Yongbin Li, and Houfeng Wang. 2023. Preference ranking optimization for human alignment. arXiv preprint arXiv:2306.17492.
Feifan Song, Bowen Yu, Minghao Li, Haiyang Yu, Fei Huang, Yongbin Li, and Houfeng Wang. 2023. 面向人类对齐的偏好排序优化. arXiv preprint arXiv:2306.17492.
Xianghui Sun, Yunjie Ji, Baochang Ma, and Xiangang Li. 2023a. A comparative study between fullparameter and lora-based fine-tuning on chinese instruction data for instruction following large language model. arXiv preprint arXiv:2304.08109.
孙祥晖、纪云杰、马宝昌和李先刚。2023a。基于全参数与LoRA微调的中文指令数据对大语言模型指令跟随能力的对比研究。arXiv预印本arXiv:2304.08109。
Zhiqing Sun, Yikang Shen, Qinhong Zhou, Hongxin Zhang, Zhenfang Chen, David D. Cox, Yiming Yang, and Chuang Gan. 2023b. Principle-driven self-alignment of language models from scratch with minimal human supervision.
孙志清、沈宜康、周启宏、张宏鑫、陈振方、David D. Cox、杨一鸣和甘创。2023b。基于原则驱动的语言模型自对齐方法:极少量人工监督下的从零训练。
Mirac Suzgun, Nathan Scales, Nathanael Schärli, Se- bastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc V Le, Ed H Chi, Denny Zhou, , and Jason Wei. 2022. Challenging big-bench
Mirac Suzgun、Nathan Scales、Nathanael Schärli、Sebastian Gehrmann、Yi Tay、Hyung Won Chung、Aakanksha Chowdhery、Quoc V Le、Ed H Chi、Denny Zhou 和 Jason Wei。2022。挑战 Big-Bench
Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. 2019. Commonsense QA: A question answering challenge targeting commonsense knowledge. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4149–4158, Minneapolis, Minnesota. Association for Computational Linguistics.
Alon Talmor、Jonathan Herzig、Nicholas Lourie 和 Jonathan Berant。2019. Commonsense QA: 一个针对常识知识的问答挑战。载于《2019年北美计算语言学协会人类语言技术会议论文集》第1卷(长论文与短论文),第4149–4158页,明尼苏达州明尼阿波利斯市。计算语言学协会。
Tianyi Tang, Hongyuan Lu, Yuchen Eleanor Jiang, Haoyang Huang, Dongdong Zhang, Wayne Xin Zhao, and Furu Wei. 2023. Not all metrics are guilty: Improving nlg evaluation with llm paraphrasing. arXiv preprint arXiv:2305.15067.
Tianyi Tang、Hongyuan Lu、Yuchen Eleanor Jiang、Haoyang Huang、Dongdong Zhang、Wayne Xin Zhao和Furu Wei。2023。并非所有指标都有罪:利用大语言模型改写改进自然语言生成评估。arXiv预印本arXiv:2305.15067。
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023. Stanford alpaca: An instruction-following llama model. github.com/tatsu-lab/stanford alpaca.
Rohan Taori、Isha Gulrajani、Tianyi Zhang、Yann Dubois、Xuechen Li、Carlos Guestrin、Percy Liang 和 Tatsunori B. Hashimoto。2023。斯坦福羊驼 (Stanford Alpaca):一个遵循指令的 LLaMA 模型。https://github.com/tatsu-lab/stanford_alpaca。
MosaicML NLP Team. 2023. Introducing mpt-30b: Raising the bar for open-source foundation models. Accessed: 2023-06-22.
MosaicML NLP 团队. 2023. 发布 MPT-30B: 提升开源基础模型标杆. 访问时间: 2023-06-22.
Guan Wang, Sijie Cheng, Qiying Yu, and Changling Liu. 2023a. OpenChat: Advancing Open-source Language Models with Imperfect Data.
王冠、程思捷、余启颖和刘长玲。2023a。OpenChat:利用不完美数据推进开源大语言模型。
Peiyi Wang, Lei Li, Liang Chen, Dawei Zhu, Binghuai Lin, Yunbo Cao, Qi Liu, Tianyu Liu, and Zhifang Sui. 2023b. Large language models are not fair evaluators. arXiv preprint arXiv:2305.17926.
Peiyi Wang, Lei Li, Liang Chen, Dawei Zhu, Binghuai Lin, Yunbo Cao, Qi Liu, Tianyu Liu, and Zhifang Sui. 2023b. 大语言模型并非公平评估者。arXiv预印本 arXiv:2305.17926。
Yidong Wang, Zhuohao Yu, Zhengran Zeng, Linyi Yang, Cunxiang Wang, Hao Chen, Chaoya Jiang, Rui Xie, Jindong Wang, Xing Xie, et al. 2023c. Pandalm: An automatic evaluation benchmark for llm instruction tuning optimization. arXiv preprint arXiv:2306.05087.
王艺东、余卓浩、曾正然、杨林毅、王存祥、陈浩、姜超亚、谢瑞、王金东、谢星等。2023c。Pandalm:大语言模型指令调优自动评估基准。arXiv预印本arXiv:2306.05087。
Yizhong Wang, Hamish Ivison, Pradeep Dasigi, Jack Hessel, Tushar Khot, Khyathi Raghavi Chandu, David Wadden, Kelsey MacMillan, Noah A Smith, Iz Beltagy, et al. 2023d. How far can camels go? exploring the state of instruction tuning on open resources. arXiv preprint arXiv:2306.04751.
Yizhong Wang、Hamish Ivison、Pradeep Dasigi、Jack Hessel、Tushar Khot、Khyathi Raghavi Chandu、David Wadden、Kelsey MacMillan、Noah A Smith、Iz Beltagy等。2023d。骆驼能走多远?探索开放资源上的指令微调现状。arXiv预印本arXiv:2306.04751。
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi. 2022a. Self-instruct: Aligning language model with self generated instructions. CoRR, abs/2212.10560.
Yizhong Wang、Yeganeh Kordi、Swaroop Mishra、Alisa Liu、Noah A. Smith、Daniel Khashabi 和 Hannaneh Hajishirzi。2022a。Self-instruct: 通过自生成指令对齐语言模型。CoRR, abs/2212.10560。
Yizhong Wang, Swaroop Mishra, Pegah Alipoormolabashi, Yeganeh Kordi, Amirreza Mirzaei, Atharva Naik, Arjun Ashok, Arut Selvan Dhana sekar an, Anjana Arunkumar, David Stap, Eshaan Pathak, Giannis Karam a no lak is, Haizhi Lai, Ishan Purohit, Ishani Mondal, Jacob Anderson, Kirby Kuznia, Krima Doshi, Kuntal Kumar Pal, Maitreya Patel, Mehrad Moradshahi, Mihir Parmar, Mirali Purohit,
Yizhong Wang, Swaroop Mishra, Pegah Alipoormolabashi, Yeganeh Kordi, Amirreza Mirzaei, Atharva Naik, Arjun Ashok, Arut Selvan Dhanasekaran, Anjana Arunkumar, David Stap, Eshaan Pathak, Giannis Karamanolakis, Haizhi Lai, Ishan Purohit, Ishani Mondal, Jacob Anderson, Kirby Kuznia, Krima Doshi, Kuntal Kumar Pal, Maitreya Patel, Mehrad Moradshahi, Mihir Parmar, Mirali Purohit,
Neeraj Varshney, Phani Rohitha Kaza, Pulkit Verma, Ravsehaj Singh Puri, Rushang Karia, Savan Doshi, Shailaja Keyur Sampat, Siddhartha Mishra, Sujan Reddy A, Sumanta Patro, Tanay Dixit, and Xudong Shen. 2022b. Super-Natural Instructions: Generalization via declarative instructions on $1600+$ NLP tasks. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 5085–5109, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
Neeraj Varshney、Phani Rohitha Kaza、Pulkit Verma、Ravsehaj Singh Puri、Rushang Karia、Savan Doshi、Shailaja Keyur Sampat、Siddhartha Mishra、Sujan Reddy A、Sumanta Patro、Tanay Dixit和Xudong Shen。2022b。超自然指令:通过1600+项NLP任务的声明式指令实现泛化。载于《2022年自然语言处理实证方法会议论文集》,第5085–5109页,阿拉伯联合酋长国阿布扎比。计算语言学协会。
Jason Wei, Maarten Bosma, Vincent Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M. Dai, and Quoc V Le. 2022a. Finetuned language models are zero-shot learners. In International Conference on Learning Representations.
Jason Wei、Maarten Bosma、Vincent Zhao、Kelvin Guu、Adams Wei Yu、Brian Lester、Nan Du、Andrew M. Dai 和 Quoc V Le。2022a. 微调语言模型是零样本学习者。收录于《国际学习表征会议》。
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed H. Chi, Quoc V Le, and Denny Zhou. 2022b. Chain of thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems.
Jason Wei、Xuezhi Wang、Dale Schuurmans、Maarten Bosma、Brian Ichter、Fei Xia、Ed H. Chi、Quoc V Le 和 Denny Zhou。2022b。思维链提示激发大语言模型中的推理能力。载于《神经信息处理系统进展》。
Minghao Wu and Alham Fikri Aji. 2023. Style over substance: Evaluation biases for large language models. ArXiv, abs/2307.03025.
吴明浩和Alham Fikri Aji。2023。形式大于实质:对大语言模型的评估偏见。ArXiv,abs/2307.03025。
Minghao Wu, Abdul Waheed, Chiyu Zhang, Muhammad Abdul-Mageed, and Alham Fikri Aji. 2023. Lamini-lm: A diverse herd of distilled models from large-scale instructions. CoRR, abs/2304.14402.
Minghao Wu、Abdul Waheed、Chiyu Zhang、Muhammad Abdul-Mageed 和 Alham Fikri Aji。2023。Lamini-lm: 基于大规模指令蒸馏的多样化模型群。CoRR, abs/2304.14402。
Benfeng Xu, An Yang, Junyang Lin, Quan Wang, Chang Zhou, Yongdong Zhang, and Zhendong Mao. 2023a. Expert prompting: Instructing large language models to be distinguished experts. arXiv preprint arXiv:2305.14688.
Benfeng Xu、An Yang、Junyang Lin、Quan Wang、Chang Zhou、Yongdong Zhang 和 Zhendong Mao。2023a。专家提示:指导大语言模型成为杰出专家。arXiv预印本 arXiv:2305.14688。
Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, and Daxin Jiang. 2023b. Wizardlm: Empowering large language models to follow complex instructions.
徐灿、孙庆峰、郑凯、耿修波、赵普、冯家展、陶重阳、姜大昕。2023b。WizardLM:赋能大语言模型遵循复杂指令。
Canwen Xu, Daya Guo, Nan Duan, and Julian J. McAuley. 2023c. Baize: An open-source chat model with parameter-efficient tuning on self-chat data. CoRR, abs/2304.01196.
Canwen Xu、Daya Guo、Nan Duan 和 Julian J. McAuley。2023c。Baize:基于自对话数据参数高效调优的开源聊天模型。CoRR,abs/2304.01196。
Seonghyeon Ye, Yongrae Jo, Doyoung Kim, Sungdong Kim, Hyeonbin Hwang, and Minjoon Seo. 2023a. Selfee: Iterative self-revising llm empowered by selffeedback generation. Blog post.
Seonghyeon Ye、Yongrae Jo、Doyoung Kim、Sungdong Kim、Hyeonbin Hwang 和 Minjoon Seo。2023a。Selfee: 通过自我反馈生成实现迭代自修订的大语言模型。博客文章。
Seonghyeon Ye, Doyoung Kim, Sungdong Kim, Hyeonbin Hwang, Seungone Kim, Yongrae Jo, James Thorne, Juho Kim, and Minjoon Seo. 2023b. Flask: Fine-grained language model evaluation based on alignment skill sets.
Seonghyeon Ye、Doyoung Kim、Sungdong Kim、Hyeonbin Hwang、Seungone Kim、Yongrae Jo、James Thorne、Juho Kim 和 Minjoon Seo. 2023b. Flask: 基于对齐技能集的细粒度语言模型评估
Jifan Yu, Xiaozhi Wang, Shangqing Tu, Shulin Cao, Daniel Zhang-Li, Xin Lv, Hao Peng, Zijun Yao, Xiaohan Zhang, Hanming Li, et al. 2023a. Kola: Carefully benchmarking world knowledge of large language models. arXiv preprint arXiv:2306.09296.
Jifan Yu, Xiaozhi Wang, Shangqing Tu, Shulin Cao, Daniel Zhang-Li, Xin Lv, Hao Peng, Zijun Yao, Xiaohan Zhang, Hanming Li, 等. 2023a. Kola: 大语言模型世界知识的严谨基准测试. arXiv预印本 arXiv:2306.09296.
Yue Yu, Yuchen Zhuang, Jieyu Zhang, Yu Meng, Alexander Ratner, Ranjay Krishna, Jiaming Shen, and Chao Zhang. 2023b. Large language model as attributed training data generator: A tale of diversity and bias. arXiv preprint arXiv:2306.15895.
Yue Yu、Yuchen Zhuang、Jieyu Zhang、Yu Meng、Alexander Ratner、Ranjay Krishna、Jiaming Shen 和 Chao Zhang。2023b。大语言模型 (Large Language Model) 作为属性训练数据生成器:多样性与偏差的故事。arXiv预印本 arXiv:2306.15895。
Zheng Yuan, Hongyi Yuan, Chuanqi Tan, Wei Wang, Songfang Huang, and Fei Huang. 2023. Rrhf: Rank responses to align language models with human feedback without tears.
郑元、袁弘毅、谭传奇、王伟、黄松芳和黄飞。2023。RRHF:无需费力通过排序响应实现语言模型与人类反馈的对齐。
Yuheng Zha, Yichi Yang, Ruichen Li, and Zhiting Hu. 2023. Alignscore: Evaluating factual consistency with a unified alignment function. arXiv preprint arXiv:2305.16739.
Yuheng Zha、Yichi Yang、Ruichen Li和Zhiting Hu。2023。Alignscore: 使用统一对齐函数评估事实一致性。arXiv预印本arXiv:2305.16739。
Ge Zhang, Yemin Shi, Ruibo Liu, Ruibin Yuan, Yizhi Li, Siwei Dong, Yu Shu, Zhaoqun Li, Zekun Wang, Chenghua Lin, Wen-Fen Huang, and Jie Fu. 2023a. Chinese open instruction generalist: A preliminary release. ArXiv, abs/2304.07987.
Ge Zhang、Yemin Shi、Ruibo Liu、Ruibin Yuan、Yizhi Li、Siwei Dong、Yu Shu、Zhaoqun Li、Zekun Wang、Chenghua Lin、Wen-Fen Huang和Jie Fu。2023a。Chinese open instruction generalist: 初步发布。ArXiv, abs/2304.07987。
Qingru Zhang, Minshuo Chen, Alexander Bukharin, Pengcheng He, Yu Cheng, Weizhu Chen, and Tuo Zhao. 2023b. Adaptive budget allocation for parameter-efficient fine-tuning. In The Eleventh Inter national Conference on Learning Representations.
张清如、陈敏硕、Alexander Bukharin、何鹏程、程宇、陈伟柱、赵拓。2023b。参数高效微调的自适应预算分配。见《第十一届国际学习表征会议》。
Shaolei Zhang, Qingkai Fang, Zhuocheng Zhang, Zhengrui Ma, Yan Zhou, Langlin Huang, Mengyu Bu, Shangtong Gui, Yunji Chen, Xilin Chen, and Yang Feng. 2023c. Bayling: Bridging cross-lingual alignment and instruction following through interactive translation for large language models. ArXiv, abs/2306.10968.
Shaolei Zhang、Qingkai Fang、Zhuocheng Zhang、Zhengrui Ma、Yan Zhou、Langlin Huang、Mengyu Bu、Shangtong Gui、Yunji Chen、Xilin Chen和Yang Feng。2023c。Bayling: 通过交互式翻译实现大语言模型的跨语言对齐与指令跟随。ArXiv, abs/2306.10968。
Tianyi Zhang* , Varsha Kishore* , Felix $\mathbf{W}\mathbf{u}^{* }$ , Kilian Q. Weinberger, and Yoav Artzi. 2020. Bertscore: Evaluating text generation with bert. In International Conference on Learning Representations.
Tianyi Zhang* , Varsha Kishore* , Felix $\mathbf{W}\mathbf{u}^{* }$, Kilian Q. Weinberger, Yoav Artzi. 2020. BERTScore: 基于BERT的文本生成评估方法. 发表于国际学习表征会议 (ICLR).
Yao Zhao, Mikhail Khalman, Rishabh Joshi, Shashi Narayan, Mohammad Saleh, and Peter J Liu. 2023. Calibrating sequence likelihood improves conditional language generation. In The Eleventh International Conference on Learning Representations.
Yao Zhao、Mikhail Khalman、Rishabh Joshi、Shashi Narayan、Mohammad Saleh 和 Peter J Liu。2023。校准序列似然改善条件语言生成。载于《第十一届国际学习表征会议》。
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena. arXiv preprint arXiv:2306.05685.
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, 等. 2023. 用MT-Bench和Chatbot Arena评估大语言模型作为裁判的能力. arXiv预印本 arXiv:2306.05685.
Wanjun Zhong, Ruixiang Cui, Yiduo Guo, Yaobo Liang, Shuai Lu, Yanlin Wang, Amin Saied, Weizhu Chen, and Nan Duan. 2023. Agieval: A human-centric benchmark for evaluating foundation models. arXiv preprint arXiv:2304.06364.
钟万君、崔瑞祥、郭一多、梁耀波、陆帅、王彦霖、Amin Saied、陈伟柱和段楠。2023。Agieval: 一个以人为中心的基准测试用于评估基础模型。arXiv预印本 arXiv:2304.06364。
Chunting Zhou, Pengfei Liu, Puxin Xu, Srini Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, Lili Yu, et al. 2023. Lima: Less is more for alignment. arXiv preprint arXiv:2305.11206.
Chunting Zhou、Pengfei Liu、Puxin Xu、Srini Iyer、Jiao Sun、Yuning Mao、Xuezhe Ma、Avia Efrat、Ping Yu、Lili Yu 等. 2023. Lima: 少即是多 (Less is More for Alignment). arXiv预印本 arXiv:2305.11206.
Terry Yue Zhuo. 2023. Large language models are state-of-the-art evaluators of code generation. arXiv preprint arXiv:2304.14317.
Terry Yue Zhuo. 2023. 大语言模型 (Large Language Model) 是代码生成的最先进评估器。arXiv预印本 arXiv:2304.14317。
Daniel M. Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B. Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. 2019. Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593.
Daniel M. Ziegler、Nisan Stiennon、Jeffrey Wu、Tom B. Brown、Alec Radford、Dario Amodei、Paul Christiano 和 Geoffrey Irving。2019. 基于人类偏好微调语言模型。arXiv 预印本 arXiv:1909.08593。
A Appendix
A 附录
Table 2: The outputs of original LLaMA and Chinese Tokenizer. This example is from Cui et al. (2023b).
| Inputs:人工智能是计算机科学、心理学、哲学等 学科融合的交叉学科。 |
| LLaMIA:_ ,人,工,智,能,是,计,算,机,科,学,、 理,学,、,0xE5,0x93,0xB2,学,等,学,科,0xE8, 0x9E,0x8D,合,的,交,0xE5,0x8F,0x89,学,科,, |
| Chinese:_ ,人工智能,是,计算机,科学,、,心理学,、 |
| ,哲学,等,学科,融合,的,交叉,学科,, |
表 2: 原始LLaMA与中文分词器的输出对比。本示例来自Cui et al. (2023b)。
| 输入文本 | 人工智能是计算机科学、心理学、哲学等学科融合的交叉学科。 |
|---|---|
| LLaMA | _ ,人,工,智,能,是,计,算,机,科,学,、,理,学,、,0xE5,0x93,0xB2,学,等,学,科,0xE8,0x9E,0x8D,合,的,交,0xE5,0x8F,0x89,学,科,, |
| 中文分词器 | _ ,人工智能,是,计算机,科学,、,心理学,、,哲学,等,学科,融合,的,交叉,学科,, |
A.1 Training Language-Specific LLMs
A.1 训练特定语言的大语言模型 (LLM)
Existing LLMs described above are mostly Englishoriented. Thus, it becomes necessary to adapt the superior linguistic ability to other languages. Ji et al. (2023); Cui et al. (2023b) demonstrate existing English-dominated LLaMA has less than 1,000 Chinese characters in its vocabulary and LLaMA has to represent Chinese characters using the byte-based fallback strategy, which significantly increases input length and decreases the inference efficiency. As shown in Table 2, compared to the default LLaMA tokenizer, the specialized Chinese tokenizer trained using large-scale Chinese corpus can produce more compact and semantically meaningful token representations (e.g., long and complex Chinese phrases). To leverage the linguistic knowledge in orginal LLaMA, Cui et al. (2023b) propose a two-stage Chinese pretraining solution to enable LLaMA to better understand Chinese inputs. Before training they first add 20K Chinese words and phrases into the existing LLaMA vocabulary. In the first stage, they only train the input word embeddings and keep the rest parameters in LLaMA frozen. In the second stage, to save training resources, they add LoRA parameters and jointly train the parameters in the input word embeddings, self-attentive heads and LoRA parameters. Ji et al. (2023) also report the benefits of such strategy under a GPT-4 evaluation framework.
上述现有的大语言模型主要面向英语。因此,有必要将其卓越的语言能力适配到其他语言。Ji等人(2023)和Cui等人(2023b)的研究表明,现有以英语为主的LLaMA词汇表中包含的中文字符不足1000个,且LLaMA必须使用基于字节的回退策略来表示中文字符,这显著增加了输入长度并降低了推理效率。如表2所示,与默认的LLaMA分词器相比,使用大规模中文语料训练的专业中文分词器能生成更紧凑且语义丰富的token表示(例如长而复杂的中文短语)。为利用原始LLaMA中的语言知识,Cui等人(2023b)提出了一种两阶段中文预训练方案,使LLaMA能更好地理解中文输入。在训练前,他们首先在现有LLaMA词汇表中添加了2万个中文单词和短语。第一阶段仅训练输入词嵌入,保持LLaMA其余参数冻结;第二阶段为节省训练资源,添加LoRA参数并联合训练输入词嵌入、自注意力头和LoRA参数。Ji等人(2023)也在GPT-4评估框架下验证了该策略的优势。