A Survey on Evaluation of Large Language Models
大语言模型评估综述
Large language models (LLMs) are gaining increasing popularity in both academia and industry, owing to their unprecedented performance in various applications. As LLMs continue to play a vital role in both research and daily use, their evaluation becomes increasingly critical, not only at the task level, but also at the society level for better understanding of their potential risks. Over the past years, significant efforts have been made to examine LLMs from various perspectives. This paper presents a comprehensive review of these evaluation methods for LLMs, focusing on three key dimensions: what to evaluate, where to evaluate, and how to evaluate. Firstly, we provide an overview from the perspective of evaluation tasks, encompassing general natural language processing tasks, reasoning, medical usage, ethics, education, natural and social sciences, agent applications, and other areas. Secondly, we answer the ‘where’ and ‘how’ questions by diving into the evaluation methods and benchmarks, which serve as crucial components in assessing the performance of LLMs. Then, we summarize the success and failure cases of LLMs in different tasks. Finally, we shed light on several future challenges that lie ahead in LLMs evaluation. Our aim is to offer invaluable insights to researchers in the realm of LLMs evaluation, thereby aiding the development of more proficient LLMs. Our key point is that evaluation should be treated as an essential discipline to better assist the development of LLMs. We consistently maintain the related open-source materials at: https://github.com/MLGroupJLU/LLM-eval-survey.
大语言模型 (LLM) 凭借其在各类应用中的卓越表现,正日益受到学术界和工业界的广泛关注。随着大语言模型在研究和日常使用中扮演越来越重要的角色,对其评估也显得愈发关键——这不仅涉及任务层面的分析,更需从社会层面理解其潜在风险。过去几年中,研究者们从多角度对大语言模型进行了深入考察。本文系统梳理了这些评估方法,围绕三个核心维度展开:评估内容、评估场景与评估方法。
首先,我们从评估任务的角度进行概述,涵盖通用自然语言处理任务、推理、医疗应用、伦理、教育、自然科学与社会科学、智能体应用及其他领域。其次,通过剖析评估方法与基准测试(这些构成评估大语言模型性能的关键要素),我们解答了"何处评估"与"如何评估"的问题。随后,我们总结了大语言模型在不同任务中的成功与失败案例。最后,我们揭示了大语言模型评估领域未来面临的若干挑战。
本文旨在为大语言模型评估领域的研究者提供宝贵洞见,从而助力开发更高效的大语言模型。我们的核心观点是:应当将评估视为一门重要学科,以更好地促进大语言模型的发展。相关开源材料持续维护于:https://github.com/MLGroupJLU/LLM-eval-survey
CCS Concepts: • Computing methodologies $\rightarrow$ Natural language processing; Machine learning.
CCS概念:• 计算方法 $\rightarrow$ 自然语言处理;机器学习。
Additional Key Words and Phrases: large language models, evaluation, model assessment, benchmark
其他关键词和短语:大语言模型 (Large Language Models)、评估、模型评估、基准测试
ACM Reference Format:
ACM 参考文献格式:
Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, Wei Ye, Yue Zhang, Yi Chang, Philip S. Yu, Qiang Yang, and Xing Xie. 2018. A Survey on Evaluation of Large Language Models . J. ACM 37, 4, Article 111 (August 2018), 45 pages. https://doi.org/ XXXXXXX.XXXXXXX
常宇鹏、王旭、王金东、吴元、杨林一、朱凯杰、陈浩、易晓媛、王存祥、王一东、叶伟、张悦、常毅、Philip S. Yu、杨强、谢幸。2018。大语言模型评估综述。《ACM杂志》37卷4期,文章111(2018年8月),45页。https://doi.org/XXXXXXX.XXXXXXX
1 INTRODUCTION
1 引言
Understanding the essence of intelligence and establishing whether a machine embodies it poses a compelling question for scientists. It is generally agreed upon that authentic intelligence equips us with reasoning capabilities, enables us to test hypotheses, and prepares for future eventualities [92]. In particular, Artificial Intelligence (AI) researchers focus on the development of machine-based intelligence, as opposed to biologically based intellect [136]. Proper measurement helps to understand intelligence. For instance, measures for general intelligence in human individuals often encompass IQ tests [12].
理解智能的本质并判断机器是否具备智能,是科学家们面临的一个引人深思的问题。人们普遍认为,真正的智能使我们具备推理能力、能够验证假设并为未来可能发生的情况做好准备 [92]。人工智能 (AI) 研究者尤其关注基于机器的智能发展,而非基于生物学的智能 [136]。恰当的测量有助于理解智能。例如,针对人类个体通用智能的测量通常包括智商测试 [12]。
Within the scope of AI, the Turing Test [193], a widely recognized test for assessing intelligence by discerning if responses are of human or machine origin, has been a longstanding objective in AI evolution. It is generally believed among researchers that a computing machine that successfully passes the Turing Test can be considered as intelligent. Consequently, when viewed from a wider lens, the chronicle of AI can be depicted as the timeline of creation and evaluation of intelligent models and algorithms. With each emergence of a novel AI model or algorithm, researchers invariably scrutinize its capabilities in real-world scenarios through evaluation using specific and challenging tasks. For instance, the Perceptron algorithm [49], touted as an Artificial General Intelligence (AGI) approach in the 1950s, was later revealed as inadequate due to its inability to resolve the XOR problem. The subsequent rise and application of Support Vector Machines (SVMs) [28] and deep learning [104] have marked both progress and setbacks in the AI landscape. A significant takeaway from previous attempts is the paramount importance of AI evaluation, which serves as a critical tool to identify current system limitations and inform the design of more powerful models.
在AI领域内,图灵测试[193]作为一项通过辨别响应来源(人类或机器)来评估智能的广受认可测试,长期以来一直是AI发展的目标。研究者普遍认为,能成功通过图灵测试的计算机器可被视为具有智能。因此,从更宏观的视角看,AI的发展史可被描述为智能模型与算法创建及评估的时间线。每当新型AI模型或算法出现,研究者总会通过特定挑战性任务的评估来检验其实际场景中的能力。例如,20世纪50年代被誉为通用人工智能(AGI)方法的感知机算法[49],后因无法解决XOR问题而被证明存在局限。随后支持向量机(SVM)[28]与深度学习[104]的兴起与应用,既标志着AI领域的进步,也伴随着挫折。从过往尝试中获得的重要启示是:AI评估具有至关重要的意义,它既是发现当前系统缺陷的关键工具,也能为设计更强大模型提供依据。
Recently, large language models (LLMs) have incited substantial interest across both academic and industrial domains [11, 219, 257]. As demonstrated by existing work [15], the great performance of LLMs has raised promise that they could be AGI in this era. LLMs possess the capabilities to solve diverse tasks, contrasting with prior models confined to solving specific tasks. Due to its great performance in handling different applications such as general natural language tasks and domain-specific ones, LLMs are increasingly used by individuals with critical information needs, such as students or patients.
近年来,大语言模型(LLM)在学术界和工业界引发了广泛关注[11, 219, 257]。现有研究表明[15],大语言模型的卓越性能预示着它们可能成为这个时代的通用人工智能(AGI)。与以往局限于解决特定任务的模型不同,大语言模型具备处理多样化任务的能力。由于其在通用自然语言任务和领域特定任务等不同应用场景中的出色表现,越来越多具有关键信息需求的人群(如学生或患者)开始使用大语言模型。
Evaluation is of paramount prominence to the success of LLMs due to several reasons. First, evaluating LLMs helps us better understand the strengths and weakness of LLMs. For instance, the Prompt Bench [264] benchmark illustrates that current LLMs are sensitive to adversarial prompts, thus a careful prompt engineering is necessary for better performance. Second, better evaluations can provide better guidance for human-LLMs interaction, which could inspire future interaction design and implementation. Third, the broad applicability of LLMs underscores the paramount importance of ensuring their safety and reliability, particularly in safety-sensitive sectors such as financial institutions and healthcare facilities. Finally, as LLMs are becoming larger with more emergent abilities, existing evaluation protocols may not be enough to evaluate their capabilities and potential risks. Therefore, we aim to raise awareness in the community of the importance to LLMs evaluations by reviewing the current evaluation protocols and most importantly, shed light on future research about designing new LLMs evaluation protocols.
评估对于大语言模型(LLM)的成功至关重要,原因如下:首先,评估能帮助我们更好地理解大语言模型的优势与局限。例如,Prompt Bench [264]基准测试表明当前大语言模型对对抗性提示(prompt)敏感,因此需要精心设计提示以获得更好性能。其次,更好的评估能为人类与大语言模型的交互提供指导,启发未来的交互设计与实现。第三,大语言模型的广泛应用凸显了确保其安全可靠性的极端重要性,特别是在金融机构和医疗机构等安全敏感领域。最后,随着大语言模型规模扩大并涌现出更多新能力,现有评估方案可能不足以全面评估其能力与潜在风险。因此,我们旨在通过梳理当前评估方案来提高学界对评估重要性的认知,更重要的是为设计新型大语言模型评估方案的未来研究指明方向。
Fig. 1. Structure of this paper.
图 1: 本文结构。
With the introduction of ChatGPT [145] and GPT-4 [146], there have been a number of research efforts aiming at evaluating ChatGPT and other LLMs from different aspects (Figure 2), encompassing a range of factors such as natural language tasks, reasoning, robustness, trustworthiness, medical applications, and ethical considerations. Despite these efforts, a comprehensive overview capturing the entire gamut of evaluations is still lacking. Furthermore, the ongoing evolution of LLMs has also presented novel aspects for evaluation, thereby challenging existing evaluation protocols and reinforcing the need for thorough, multifaceted evaluation techniques. While existing research such as Bubeck et al. [15] claimed that GPT-4 can be seen as sparks of AGI, others contest this claim due to the human-crafted nature of its evaluation approach.
随着ChatGPT [145]和GPT-4 [146]的推出,已有大量研究从不同角度(图 2)评估ChatGPT及其他大语言模型,涵盖自然语言任务、推理、鲁棒性、可信度、医疗应用和伦理考量等多方面因素。尽管存在这些研究,目前仍缺乏全面涵盖所有评估维度的综述。此外,大语言模型的持续演进也催生了新的评估方向,这对现有评估方案提出了挑战,并凸显了多维度深度评估技术的必要性。虽然Bubeck等人[15]等研究声称GPT-4可视为通用人工智能的雏形,但由于其评估方法的人工设计特性,这一论断仍存在争议。
This paper serves as the first comprehensive survey on the evaluation of large language models. As depicted in Figure 1, we explore existing work in three dimensions: 1) What to evaluate, 2) Where to evaluate, and 3) How to evaluate. Specifically, “what to evaluate" encapsulates existing evaluation tasks for LLMs, “where to evaluate" involves selecting appropriate datasets and benchmarks for evaluation, while “how to evaluate" is concerned with the evaluation process given appropriate tasks and datasets. These three dimensions are integral to the evaluation of LLMs. We subsequently discuss potential future challenges in the realm of LLMs evaluation.
本文是关于大语言模型 (Large Language Model) 评估的首篇综合性综述。如图 1 所示,我们从三个维度探讨现有工作:1) 评估内容 (What to evaluate),2) 评估场景 (Where to evaluate),3) 评估方法 (How to evaluate)。具体而言,"评估内容"涵盖现有的大语言模型评估任务,"评估场景"涉及选择合适的评估数据集和基准测试,而"评估方法"则关注在给定任务和数据集情况下的评估流程。这三个维度构成了大语言模型评估的完整体系。最后我们讨论了大语言模型评估领域未来可能面临的挑战。
The contributions of this paper are as follows:
本文的贡献如下:
The paper is organized as follows. In Sec. 2, we provide the basic information of LLMs and AI model evaluation. Then, Sec. 3 reviews existing work from the aspects of “what to evaluate”. After that, Sec. 4 is the “where to evaluate” part, which summarizes existing datasets and benchmarks. Sec. 5 discusses how to perform the evaluation. In Sec. 6, we summarize the key findings of this paper. We discuss grand future challenges in Sec. 7 and Sec. 8 concludes the paper.
本文结构如下。第2节介绍大语言模型(LLM)和AI模型评估的基础知识。第3节从"评估内容"角度综述现有工作。第4节讨论"评估载体",总结现有数据集和基准测试。第5节阐述评估方法。第6节归纳本文核心发现。第7节探讨未来重大挑战,第8节总结全文。
2 BACKGROUND
2 背景
2.1 Large Language Models
2.1 大语言模型 (Large Language Models)
Language models (LMs) [36, 51, 96] are computational models that have the capability to understand and generate human language. LMs have the transformative ability to predict the likelihood of word sequences or generate new text based on a given input. N-gram models [13], the most common type of LM, estimate word probabilities based on the preceding context. However, LMs also face challenges, such as the issue of rare or unseen words, the problem of over fitting, and the difficulty in capturing complex linguistic phenomena. Researchers are continuously working on improving LM architectures and training methods to address these challenges.
语言模型 (Language Model, LM) [36, 51, 96] 是能够理解和生成人类语言的计算模型。它们具有预测词序列概率或根据给定输入生成新文本的变革性能力。N元语法模型 (N-gram) [13] 作为最常见的语言模型类型,通过上文语境来估算词汇概率。然而语言模型仍面临诸多挑战,包括罕见词或未登录词问题、过拟合现象以及复杂语言现象捕捉困难等。研究人员正持续改进模型架构与训练方法以应对这些挑战。
Large Language Models (LLMs) [19, 91, 257] are advanced language models with massive parameter sizes and exceptional learning capabilities. The core module behind many LLMs such as GPT-3 [43], Instruct GP T [149], and GPT-4 [146] is the self-attention module in Transformer [197] that serves as the fundamental building block for language modeling tasks. Transformers have revolutionized the field of NLP with their ability to handle sequential data efficiently, allowing for parallel iz ation and capturing long-range dependencies in text. One key feature of LLMs is in-context learning [14], where the model is trained to generate text based on a given context or prompt. This enables LLMs to generate more coherent and con textually relevant responses, making them suitable for interactive and conversational applications. Reinforcement Learning from Human Feedback (RLHF) [25, 268] is another crucial aspect of LLMs. This technique involves fine-tuning the model using human-generated responses as rewards, allowing the model to learn from its mistakes and improve its performance over time.
大语言模型 (LLM) [19, 91, 257] 是具有海量参数规模和卓越学习能力的先进语言模型。GPT-3 [43]、InstructGPT [149] 和 GPT-4 [146] 等众多大语言模型的核心模块均采用 Transformer [197] 的自注意力机制,该机制是语言建模任务的基础构建模块。Transformer 通过高效处理序列数据的能力彻底改变了自然语言处理领域,既能实现并行化计算,又能捕捉文本中的长距离依赖关系。
大语言模型的关键特性之一是上下文学习 (in-context learning) [14],该技术通过训练模型根据给定上下文或提示生成文本。这使得大语言模型能够生成更具连贯性和上下文相关性的响应,因此非常适用于交互式和对话式应用场景。
基于人类反馈的强化学习 (RLHF) [25, 268] 是大语言模型的另一项重要技术。该方法通过将人类生成的响应作为奖励信号来微调模型,使模型能够从错误中学习并持续提升性能。
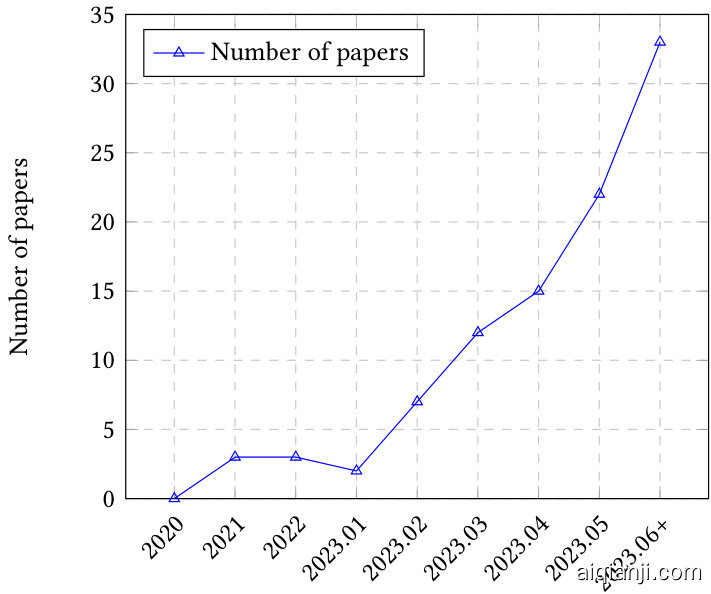
Fig. 2. Trend of LLMs evaluation papers over time (2020 - Jun. 2023, including Jul. 2023.).
图 2: 大语言模型 (LLM) 评估论文随时间变化趋势 (2020年-2023年6月,含2023年7月)。
In an auto regressive language model, such as GPT-3 and PaLM [24], given a context sequence $X$ , the LM tasks aim to predict the next token $y$ . The model is trained by maximizing the probability of the given token sequence conditioned on the context, i.e., $P(y|X)=P(y|x_ {1},x_ {2},...,x_ {t-1})$ , where $x_ {1},x_ {2},...,x_ {t-1}$ are the tokens in the context sequence, and $t$ is the current position. By using the chain rule, the conditional probability can be decomposed into a product of probabilities at each position:
在自回归语言模型(如GPT-3和PaLM [24])中,给定上下文序列$X$,语言模型的任务旨在预测下一个token $y$。模型通过最大化给定token序列在上下文条件下的概率进行训练,即$P(y|X)=P(y|x_ {1},x_ {2},...,x_ {t-1})$,其中$x_ {1},x_ {2},...,x_ {t-1}$是上下文序列中的token,$t$表示当前位置。通过链式法则,该条件概率可分解为各位置概率的乘积:
$$
P(y|X)=\prod_ {t=1}^{T}P(y_ {t}|x_ {1},x_ {2},...,x_ {t-1}),
$$
$$
P(y|X)=\prod_ {t=1}^{T}P(y_ {t}|x_ {1},x_ {2},...,x_ {t-1}),
$$
where $T$ is sequence length. In this way, the model predicts each token at each position in an auto regressive manner, generating a complete text sequence.
其中 $T$ 是序列长度。通过这种方式,模型以自回归的方式预测每个位置的token,生成完整的文本序列。
One common approach to interacting with LLMs is prompt engineering [26, 222, 263], where users design and provide specific prompt texts to guide LLMs in generating desired responses or completing specific tasks. This is widely adopted in existing evaluation efforts. People can also engage in question-and-answer interactions [83], where they pose questions to the model and receive answers, or engage in dialogue interactions, having natural language conversations with LLMs. In conclusion, LLMs, with their Transformer architecture, in-context learning, and RLHF capabilities, have revolutionized NLP and hold promise in various applications. Table 1 provides a brief comparison of traditional ML, deep learning, and LLMs.
与大语言模型交互的一种常见方法是提示工程 [26, 222, 263],用户通过设计和提供特定提示文本来引导大语言模型生成期望的响应或完成特定任务。这种方法在现有评估工作中被广泛采用。人们还可以进行问答交互 [83],即向模型提出问题并获取答案,或参与对话交互,与大语言模型进行自然语言对话。总之,凭借其 Transformer 架构、上下文学习能力和 RLHF 技术,大语言模型彻底改变了自然语言处理领域,并在多种应用中展现出潜力。表 1 简要对比了传统机器学习、深度学习与大语言模型的差异。
Chang et al.
Chang et al.
Table 1. Comparison of Traditional ML, Deep Learning, and LLMs
| Comparison | TraditionalML | DeepLearning | LLMs |
| TrainingDataSize | Large | Large | Verylarge |
| FeatureEngineering | Manual | Automatic | Automatic |
| ModelComplexity | Limited | Complex | VeryComplex |
| Interpretability | Good | Poor | Poorer |
| Performance | Moderate | High | Highest |
| HardwareRequirements | Low | High | VeryHigh |
表 1: 传统机器学习 (Traditional ML) 、深度学习 (Deep Learning) 与大语言模型 (LLMs) 对比
| 对比项 | 传统机器学习 | 深度学习 | 大语言模型 |
|---|---|---|---|
| 训练数据量 | 大 | 大 | 极大 |
| 特征工程 | 手动 | 自动 | 自动 |
| 模型复杂度 | 有限 | 复杂 | 极复杂 |
| 可解释性 | 良好 | 差 | 更差 |
| 性能表现 | 中等 | 高 | 最高 |
| 硬件需求 | 低 | 高 | 极高 |

Fig. 3. The evaluation process of AI models.
图 3: AI模型的评估流程。
2.2 AI Model Evaluation
2.2 AI模型评估
AI model evaluation is an essential step in assessing the performance of a model. There are some standard model evaluation protocols, including $k$ -fold cross-validation, holdout validation, leave one out cross-validation (LOOCV), bootstrap, and reduced set [8, 95]. For instance, $k$ -fold crossvalidation divides the dataset into $k$ parts, with one part used as a test set and the rest as training sets, which can reduce training data loss and obtain relatively more accurate model performance evaluation [48]; Holdout validation divides the dataset into training and test sets, with a smaller calculation amount but potentially more significant bias; LOOCV is a unique $k$ -fold cross-validation method where only one data point is used as the test set [223]; Reduced set trains the model with one dataset and tests it with the remaining data, which is computationally simple, but the applicability is limited. The appropriate evaluation method should be chosen according to the specific problem and data characteristics for more reliable performance indicators.
AI模型评估是衡量模型性能的关键步骤。常见的标准评估方法包括 $k$ 折交叉验证 (k-fold cross-validation)、留出法 (holdout validation)、留一交叉验证 (LOOCV)、自助法 (bootstrap) 和缩减集法 (reduced set) [8, 95]。例如:$k$ 折交叉验证将数据集划分为 $k$ 份,其中一份作为测试集,其余作为训练集,这种方法能减少训练数据损失并获得更准确的模型性能评估 [48];留出法将数据划分为训练集和测试集,计算量较小但可能产生较大偏差;留一交叉验证是 $k$ 折交叉验证的特例,每次仅用一个数据点作为测试集 [223];缩减集法使用一个数据集训练模型并用剩余数据测试,计算简单但适用性有限。应根据具体问题和数据特征选择合适的评估方法,以获取更可靠的性能指标。
Figure 3 illustrates the evaluation process of AI models, including LLMs. Some evaluation protocols may not be feasible to evaluate deep learning models due to the extensive training size. Thus, evaluation on a static validation set has long been the standard choice for deep learning models. For instance, computer vision models leverage static test sets such as ImageNet [33] and MS COCO [120] for evaluation. LLMs also use GLUE [200] or SuperGLUE [199] as the common test sets.
图 3: AI模型的评估流程,包括大语言模型。由于训练数据规模庞大,部分评估方案可能不适用于深度学习模型评估。因此,静态验证集评估长期以来都是深度学习模型的标准选择。例如,计算机视觉模型采用ImageNet [33]和MS COCO [120]等静态测试集进行评估,大语言模型则普遍使用GLUE [200]或SuperGLUE [199]作为测试集。
As LLMs are becoming more popular with even poorer interpret ability, existing evaluation protocols may not be enough to evaluate the true capabilities of LLMs thoroughly. We will introduce recent evaluations of LLMs in Sec. 5.
随着大语言模型 (LLM) 日益普及但其可解释性却更差,现有评估方法可能不足以全面衡量大语言模型的真实能力。我们将在第5节介绍近期的大语言模型评估进展。
3 WHAT TO EVALUATE
3 评估内容
What tasks should we evaluate LLMs to show their performance? On what tasks can we claim the strengths and weaknesses of LLMs? In this section, we divide existing tasks into the following categories: natural language processing, robustness, ethics, biases and trustworthiness, social sciences, natural science and engineering, medical applications, agent applications (using LLMs as agents), and other applications.
我们应该评估大语言模型在哪些任务上的表现?在哪些任务上我们可以宣称大语言模型的优势与不足?本节将现有任务划分为以下类别:自然语言处理、鲁棒性、伦理、偏见与可信度、社会科学、自然科学与工程、医疗应用、智能体应用(将大语言模型作为AI智能体使用)以及其他应用。
3.1 Natural Language Processing Tasks
3.1 自然语言处理任务
The initial objective behind the development of language models, particularly large language models, was to enhance performance on natural language processing tasks, encompassing both understanding and generation. Consequently, the majority of evaluation research has been primarily focused on natural language tasks. Table 2 summarizes the evaluation aspects of existing research, and we mainly highlight their conclusions in the following.2
语言模型(尤其是大语言模型)最初的发展目标是提升自然语言处理任务(包括理解和生成)的性能。因此,大多数评估研究主要聚焦于自然语言任务。表2总结了现有研究的评估维度,下文将重点阐述其结论。
3.1.1 Natural language understanding. Natural language understanding represents a wide spectrum of tasks that aims to obtain a better understanding of the input sequence. We summarize recent efforts in LLMs evaluation from several aspects.
3.1.1 自然语言理解。自然语言理解涵盖了一系列旨在更好地理解输入序列的任务。我们从多个方面总结了大语言模型 (LLM) 评估的最新进展。
Sentiment analysis is a task that analyzes and interprets the text to determine the emotional inclination. It is typically a binary (positive and negative) or triple (positive, neutral, and negative) class classification problem. Evaluating sentiment analysis tasks is a popular direction. Liang et al. [114] and Zeng et al. [243] showed that the performance of the models on this task is usually high. ChatGPT’s sentiment analysis prediction performance is superior to traditional sentiment analysis methods [129] and comes close to that of GPT-3.5 [159]. In fine-grained sentiment and emotion cause analysis, ChatGPT also exhibits exceptional performance [218]. In low-resource learning environments, LLMs exhibit significant advantages over small language models [251], but the ability of ChatGPT to understand low-resource languages is limited [6]. In conclusion, LLMs have demonstrated commendable performance in sentiment analysis tasks. Future work should focus on enhancing their capability to understand emotions in under-resourced languages.
情感分析是一项通过分析和解读文本来确定情感倾向的任务。它通常是二元(正面和负面)或三元(正面、中性和负面)分类问题。评估情感分析任务是当前热门研究方向。Liang等人[114]和Zeng等人[243]的研究表明,模型在该任务上的表现通常较高。ChatGPT的情感分析预测性能优于传统情感分析方法[129],并接近GPT-3.5的水平[159]。在细粒度情感及情感原因分析中,ChatGPT同样展现出卓越性能[218]。在低资源学习环境下,大语言模型相比小语言模型具有显著优势[251],但ChatGPT对低资源语言的理解能力有限[6]。综上所述,大语言模型在情感分析任务中展现了值得称赞的表现。未来工作应着重提升其对低资源语言情感理解的能力。
Text classification and sentiment analysis are related fields, text classification not only focuses on sentiment, but also includes the processing of all texts and tasks. The work of Liang et al. [114] showed that GLM-130B was the best-performed model, with an overall accuracy of $85.8%$ for miscellaneous text classification. Yang and Menczer [233] found that ChatGPT can produce credibility ratings for a wide range of news outlets, and these ratings have a moderate correlation with those from human experts. Furthermore, ChatGPT achieves acceptable accuracy in a binary classification scenario $\mathrm{AUC}{=}0.89$ ). Peña et al. [154] discussed the problem of topic classification for public affairs documents and showed that using an LLM backbone in combination with SVM class if i ers is a useful strategy to conduct the multi-label topic classification task in the domain of public affairs with accuracies over $85%$ . Overall, LLMs perform well on text classification and can even handle text classification tasks in unconventional problem settings as well.
文本分类与情感分析是相关领域,文本分类不仅关注情感,还包括对所有文本和任务的处理。Liang等人[114]的研究表明,GLM-130B是性能最佳的模型,在杂项文本分类任务中总体准确率达到$85.8%$。Yang和Menczer[233]发现,ChatGPT能够为各类新闻机构生成可信度评级,这些评级与人类专家的评估结果具有中等程度相关性。此外,ChatGPT在二元分类场景中达到了可接受的准确率$\mathrm{AUC}{=}0.89$)。Peña等人[154]探讨了公共事务文档的主题分类问题,证明将大语言模型骨干网络与SVM分类器结合使用,是在公共事务领域执行多标签主题分类任务的有效策略,准确率超过$85%$。总体而言,大语言模型在文本分类任务中表现优异,甚至能处理非常规问题设置下的文本分类任务。
Natural language inference (NLI) is the task of determining whether the given “hypothesis” logically follows from the “premise”. Qin et al. [159] showed that ChatGPT outperforms GPT-3.5 for NLI tasks. They also found that ChatGPT excels in handling factual input that could be attributed to its RLHF training process in favoring human feedback. However, Lee et al. [105] observed LLMs perform poorly in the scope of NLI and further fail in representing human disagreement, which indicates that LLMs still have a large room for improvement in this field.
自然语言推理 (NLI) 是判断给定"假设"是否从"前提"中逻辑推导出的任务。Qin等[159]发现ChatGPT在NLI任务上表现优于GPT-3.5。他们还指出ChatGPT擅长处理事实性输入,这可能归因于其RLHF训练过程对人类反馈的偏好。然而Lee等[105]观察到,大语言模型在NLI范围内表现不佳,且无法有效表征人类分歧,这表明大语言模型在该领域仍有很大改进空间。
Semantic understanding refers to the meaning or understanding of language and its associated concepts. It involves the interpretation and comprehension of words, phrases, sentences, and the relationships between them. Semantic processing goes beyond the surface level and focuses on understanding the underlying meaning and intent. Tao et al. [184] comprehensively evaluated the event semantic processing abilities of LLMs covering understanding, reasoning, and prediction about the event semantics. Results indicated that LLMs possess an understanding of individual events, but their capacity to perceive the semantic similarity among events is constrained. In reasoning tasks, LLMs exhibit robust reasoning abilities in causal and intentional relations, yet their performance in other relation types is comparatively weaker. In prediction tasks, LLMs exhibit enhanced predictive capabilities for future events with increased contextual information. Riccardi and Desai [166] explored the semantic proficiency of LLMs and showed that these models perform poorly in evaluating basic phrases. Furthermore, GPT-3.5 and Bard cannot distinguish between meaningful and nonsense phrases, consistently classifying highly nonsense phrases as meaningful. GPT-4 shows significant improvements, but its performance is still significantly lower than that of humans. In summary, the performance of LLMs in semantic understanding tasks is poor. In the future, we can start from this aspect and focus on improving its performance on this application.
语义理解 (Semantic understanding) 指对语言及其相关概念的含义或理解。它涉及对词语、短语、句子及其间关系的解释与理解。语义处理超越了表层结构,专注于理解深层含义和意图。Tao等人[184]全面评估了大语言模型在事件语义处理方面的能力,涵盖了对事件语义的理解、推理和预测。结果表明,大语言模型能够理解单个事件,但其感知事件间语义相似性的能力有限。在推理任务中,大语言模型在因果和意图关系上表现出强大的推理能力,但在其他关系类型上表现相对较弱。在预测任务中,随着上下文信息的增加,大语言模型对未来事件的预测能力有所提升。Riccardi和Desai[166]探究了大语言模型的语义能力,发现这些模型在评估基本短语时表现不佳。此外,GPT-3.5和Bard无法区分有意义和无意义的短语,始终将高度无意义的短语归类为有意义。GPT-4显示出显著改进,但其性能仍远低于人类水平。总之,大语言模型在语义理解任务中表现欠佳。未来,我们可以从这一方面入手,重点提升其在该应用中的性能。
Table 2. Summary of evaluation on natural language processing tasks: NLU (Natural Language Understanding, including SA (Sentiment Analysis), TC (Text Classification), NLI (Natural Language Inference) and other NLU tasks), Reasoning, NLG (Natural Language Generation, including Summ. (Sum mari z ation), Dlg. (Dialogue), Tran (Translation), QA (Question Answering) and other NLG tasks), and Multilingual tasks (ordered by the name of the first author).
| Reference | NLU | RNG. | Mul. | ||||||||
| SA TC | NLI | Others | Summ. | Dlg. | NLG Tran. | QA | Others | ||||
| Abdelali et al. [1] | |||||||||||
| Ahuja et al. [2] | |||||||||||
| Bian et al. [9] | √ | √ | |||||||||
| Bang et al. [6] | √ | √ | √ | √ | √ | √ | |||||
| Bai et al. [5] | √ | ||||||||||
| Chen et al. [20] | |||||||||||
| Choi et al. [23] | √ | ||||||||||
| Chia et al. [22] | √ | ||||||||||
| Frieder et al. [45] | √ | ||||||||||
| Fu et al. [47] | |||||||||||
| Gekhman et al. [55] | |||||||||||
| Gendron et al. [56] | |||||||||||
| Honovich et al. [74] | √ | √ | √ | √ | |||||||
| Jiang et al. [86] | |||||||||||
| Lai et al. [100] | √ | ||||||||||
| Laskar et al. [102] | √ | √ | √ | √ | √ | √ | |||||
| Lopez-Lira and Tang [129] | √ | ||||||||||
| Liang et al. [114] | √ | √ | |||||||||
| Lee et al. [105] | √ | ||||||||||
| Lin and Chen [121] | √ | ||||||||||
| Liévin et al. [117] | √ | ||||||||||
| Liu et al. [124] | |||||||||||
| Lyu et al. [130] | √ | ||||||||||
| Manakul et al. [133] | √ | ||||||||||
| Min et al. [138] | |||||||||||
| Orru et al. [147] | √ | ||||||||||
| Pan et al. [151] | √ | ||||||||||
| Pena et al. [154] | √ | ||||||||||
| Pu and Demberg [158] | √ | √ | |||||||||
| Pezeshkpour [156] | √ | ||||||||||
| Qin et al. [159] | √ | √ | √ | √ | √ | √ | |||||
| Riccardi and Desai [166] | √ | ||||||||||
| Saparov et al. [170] | √ | ||||||||||
| Tao et al. [184] Wang et al. [208] | |||||||||||
J. ACM, Vol. 37, No. 4, Article 111. Publication date: August 2018.
表 2: 自然语言处理任务评估总结: NLU (自然语言理解, 包括 SA (情感分析), TC (文本分类), NLI (自然语言推理) 和其他 NLU 任务), Reasoning (推理), NLG (自然语言生成, 包括 Summ. (摘要), Dlg. (对话), Tran (翻译), QA (问答) 和其他 NLG 任务), 以及 Multilingual (多语言) 任务 (按第一作者姓名排序)。
| Reference | NLU | RNG. | NLG | Mul. | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| SA TC | NLI | Others | Summ. | Dlg. | Tran. | QA | Others | ||||
| Abdelali et al. [1] | |||||||||||
| Ahuja et al. [2] | |||||||||||
| Bian et al. [9] | √ | √ | |||||||||
| Bang et al. [6] | √ | √ | √ | √ | √ | √ | |||||
| Bai et al. [5] | √ | ||||||||||
| Chen et al. [20] | |||||||||||
| Choi et al. [23] | √ | ||||||||||
| Chia et al. [22] | √ | ||||||||||
| Frieder et al. [45] | √ | ||||||||||
| Fu et al. [47] | |||||||||||
| Gekhman et al. [55] | |||||||||||
| Gendron et al. [56] | |||||||||||
| Honovich et al. [74] | √ | √ | √ | √ | |||||||
| Jiang et al. [86] | |||||||||||
| Lai et al. [100] | √ | ||||||||||
| Laskar et al. [102] | √ | √ | √ | √ | √ | √ | |||||
| Lopez-Lira and Tang [129] | √ | ||||||||||
| Liang et al. [114] | √ | √ | |||||||||
| Lee et al. [105] | √ | ||||||||||
| Lin and Chen [121] | √ | ||||||||||
| Liévin et al. [117] | √ | ||||||||||
| Liu et al. [124] | |||||||||||
| Lyu et al. [130] | √ | ||||||||||
| Manakul et al. [133] | √ | ||||||||||
| Min et al. [138] | |||||||||||
| Orru et al. [147] | √ | ||||||||||
| Pan et al. [151] | √ | ||||||||||
| Pena et al. [154] | √ | ||||||||||
| Pu and Demberg [158] | √ | √ | |||||||||
| Pezeshkpour [156] | √ | ||||||||||
| Qin et al. [159] | √ | √ | √ | √ | √ | √ | |||||
| Riccardi and Desai [166] | √ | ||||||||||
| Saparov et al. [170] | √ | ||||||||||
| Tao et al. [184] Wang et al. [208] |
J. ACM, 第 37 卷, 第 4 期, 文章 111. 出版日期: 2018 年 8 月。
In social knowledge understanding, Choi et al. [23] evaluated how well models perform at learning and recognizing concepts of social knowledge and the results revealed that despite being much smaller in the number of parameters, finetuning supervised models such as BERT lead to much better performance than zero-shot models using state-of-the-art LLMs, such as GPT [162], GPT-J-6B [202] and so on. This statement demonstrates that supervised models significantly outperform zero-shot models in terms of performance, highlighting that an increase in parameters does not necessarily guarantee a higher level of social knowledge in this particular scenario.
在社会知识理解方面,Choi等人[23]评估了模型在学习与识别社会知识概念方面的表现。结果显示,尽管参数量级小得多,但经过微调的监督式模型(如BERT)性能显著优于采用最先进大语言模型(如GPT[162]、GPT-J-6B[202]等)的零样本模型。这一结论表明,在该特定场景下,监督式模型在性能上明显超越零样本模型,同时揭示参数量的增加并不必然带来社会知识理解能力的提升。
3.1.2 Reasoning. The task of reasoning poses significant challenges for an intelligent AI model. To effectively tackle reasoning tasks, the models need to not only comprehend the provided information but also utilize reasoning and inference to deduce answers when explicit responses are absent. Table 2 reveals that there is a growing interest in evaluating the reasoning ability of LLMs, as evidenced by the increasing number of articles focusing on exploring this aspect. Currently, the evaluation of reasoning tasks can be broadly categorized into mathematical reasoning, commonsense reasoning, logical reasoning, and domain-specific reasoning.
3.1.2 推理。推理任务对智能AI模型提出了重大挑战。要有效解决推理任务,模型不仅需要理解所提供的信息,还需在缺乏明确答案时运用推理和推断能力得出结论。表2显示,随着探讨该领域的文章数量增加,评估大语言模型推理能力的研究兴趣正持续升温。目前推理任务的评估可大致分为数学推理、常识推理、逻辑推理和领域特定推理四大类。
ChatGPT exhibits a strong capability for arithmetic reasoning by outperforming GPT-3.5 in the majority of tasks [159]. However, its proficiency in mathematical reasoning still requires improvement [6, 45, 265]. On symbolic reasoning tasks, ChatGPT is mostly worse than GPT-3.5, which may be because ChatGPT is prone to uncertain responses, leading to poor performance [6]. Through the poor performance of LLMs on task variants of counter factual conditions, Wu et al. [227] showed that the current LLMs have certain limitations in abstract reasoning ability. On abstract reasoning, Gendron et al. [56] found that existing LLMs have very limited ability. In logical reasoning, Liu et al. [124] indicated that ChatGPT and GPT-4 outperform traditional fine-tuning methods on most benchmarks, demonstrating their superiority in logical reasoning. However, both models face challenges when handling new and out-of-distribution data. ChatGPT does not perform as well as other LLMs, including GPT-3.5 and BARD [159, 229]. This is because ChatGPT is designed explicitly for chatting, so it does an excellent job of maintaining rationality. FLAN-T5, LLaMA, GPT-3.5, and PaLM perform well in general deductive reasoning tasks [170]. GPT-3.5 is not good at keeping oriented for reasoning in the inductive setting [229]. For multi-step reasoning, Fu et al. [47] showed PaLM and Claude2 are the only two model families that achieve similar performance (but still worse than the GPT model family). Moreover, LLaMA-65B is the most robust open-source LLMs to date, which performs closely to code-davinci-002. Some papers separately evaluate the performance of ChatGPT on some reasoning tasks: ChatGPT generally performs poorly on commonsense reasoning tasks, but relatively better than non-text semantic reasoning [6]. Meanwhile, ChatGPT also lacks spatial reasoning ability, but exhibits better temporal reasoning. Finally, while the performance of ChatGPT is acceptable on causal and analogical reasoning, it performs poorly on multi-hop reasoning ability, which is similar to the weakness of other LLMs on complex reasoning [148]. In professional domain reasoning tasks, zero-shot Instruct GP T and Codex are capable of complex medical reasoning tasks, but still need to be further improved [117]. In terms of language insight issues, Orrù et al. [147] demonstrated the potential of ChatGPT for solving verbal insight problems, as ChatGPT’s performance was comparable to that of human participants. It should be noted that most of the above conclusions are obtained for specific data sets. In contrast, more complex tasks have become the mainstream benchmarks for assessing the capabilities of LLMs. These include tasks such as mathematical reasoning [226, 237, 244] and structured data inference [86, 151]. Overall, LLMs show great potential in reasoning and show a continuous improvement trend, but still face many challenges and limitations, requiring more in-depth research and optimization.
ChatGPT在算术推理方面展现出强大能力,在多数任务中表现优于GPT-3.5 [159]。但其数学推理能力仍需提升 [6, 45, 265]。在符号推理任务中,ChatGPT大多逊于GPT-3.5,这可能源于其易产生不确定响应而导致表现不佳 [6]。Wu等人 [227] 通过大语言模型在反事实条件任务变体上的糟糕表现,揭示了当前大语言模型在抽象推理能力上的局限。Gendron等 [56] 发现现有大语言模型的抽象推理能力非常有限。Liu等 [124] 指出在逻辑推理方面,ChatGPT和GPT-4在多数基准测试中超越传统微调方法,但两者处理新数据和分布外数据时仍面临挑战。ChatGPT在包括GPT-3.5和BARD在内的其他大语言模型中表现并不突出 [159, 229],因其专为对话设计而更擅长保持合理性。FLAN-T5、LLaMA、GPT-3.5和PaLM在一般演绎推理任务中表现良好 [170],但GPT-3.5不擅长归纳推理中的方向保持 [229]。Fu等 [47] 表明在多步推理中,PaLM和Claude2是仅有的两个性能接近(但仍逊于GPT系列)的模型系列,而LLaMA-65B是当前最稳健的开源大语言模型,其表现接近code-davinci-002。部分研究单独评估了ChatGPT在特定推理任务中的表现:其在常识推理任务中普遍较差,但优于非文本语义推理 [6];缺乏空间推理能力却展现出较好的时间推理能力;虽然在因果和类比推理中表现尚可,但在多跳推理能力上表现欠佳,这与其它大语言模型在复杂推理中的弱点相似 [148]。在专业领域推理任务中,零样本InstructGPT和Codex能处理复杂医疗推理任务,但仍需改进 [117]。Orrù等 [147] 证实ChatGPT在语言洞察问题解决上具有与人类参与者相当的表现潜力。需注意上述结论多基于特定数据集得出,而数学推理 [226, 237, 244] 和结构化数据推断 [86, 151] 等更复杂任务已成为评估大语言模型能力的主流基准。总体而言,大语言模型展现出持续进步的推理潜力,但仍面临诸多挑战与局限,需要更深入的研究和优化。
3.1.3 Natural language generation. NLG evaluates the capabilities of LLMs in generating specific texts, which consists of several tasks, including sum mari z ation, dialogue generation, machine translation, question answering, and other open-ended generation tasks.
3.1.3 自然语言生成
NLG评估大语言模型在生成特定文本方面的能力,包括摘要、对话生成、机器翻译、问答和其他开放式生成任务。
Sum mari z ation is a generation task that aims to learn a concise abstract for the given sentence. In this evaluation, Liang et al. [114] found that TNLG v2 (530B) [179] achieved the highest score in both scenarios, followed by OPT (175B) [247] in second place. The fine-tuned Bart [106] is still better than zero-shot ChatGPT. Specifically, ChatGPT demonstrates comparable zero-shot performance to the text-davinci-002 [6], but performs worse than GPT-3.5 [159]. These findings indicate that LLMs, particularly ChatGPT, have a general performance in sum mari z ation tasks.
摘要生成是一项旨在为给定句子学习简洁摘要的生成任务。在该评估中,Liang等人[114]发现TNLG v2(530B)[179]在两种场景下均获得最高分,OPT(175B)[247]位列第二。经过微调的Bart[106]仍优于零样本ChatGPT。具体而言,ChatGPT在零样本性能上与text-davinci-002[6]相当,但表现逊于GPT-3.5[159]。这些发现表明,大语言模型(特别是ChatGPT)在摘要生成任务中具有通用性能。
Evaluating the performance of LLMs on dialogue tasks is crucial to the development of dialogue systems and improving human-computer interaction. Through such evaluation, the natural language processing ability, context understanding ability and generation ability of the model can be improved, so as to realize a more intelligent and more natural dialogue system. Both Claude and ChatGPT generally achieve better performance across all dimensions when compared to GPT-3.5 [121, 159]. When comparing the Claude and ChatGPT models, both models demonstrate competitive performance across different evaluation dimensions, with Claude slightly outperforming ChatGPT in specific configurations. Research by Bang et al. [6] underscores that fully fine-tuned models tailored for specific tasks surpass ChatGPT in both task-oriented and knowledge-based dialogue contexts. Additionally, Zheng et al. [259] have curated a comprehensive LLMs conversation dataset, LMSYS-Chat-1M, encompassing up to one million samples. This dataset serves as a valuable resource for evaluating and advancing dialogue systems.
评估大语言模型(LLM)在对话任务中的表现对开发对话系统和改进人机交互至关重要。通过此类评估,可以提升模型的自然语言处理能力、上下文理解能力和生成能力,从而实现更智能、更自然的对话系统。与GPT-3.5相比[121, 159],Claude和ChatGPT在所有维度上通常都表现更优。在对比Claude和ChatGPT模型时,两者在不同评估维度上都展现出竞争力,其中Claude在特定配置下略优于ChatGPT。Bang等人的研究[6]表明,针对特定任务完全微调的模型在任务导向型和知识型对话场景中都优于ChatGPT。此外,Zheng等人[259]整理了一个包含多达百万样本的综合性大语言模型对话数据集LMSYS-Chat-1M,该数据集为评估和改进对话系统提供了宝贵资源。
While LLMs are not explicitly trained for translation tasks, they can still demonstrate strong performance. Wang et al. [208] demonstrated that ChatGPT and GPT-4 exhibit superior performance in comparison to commercial machine translation (MT) systems, as evaluated by humans. Additionally, they outperform most document-level NMT methods in terms of sacreBLEU scores. During contrastive testing, ChatGPT shows lower accuracy in comparison to traditional translation models. However, GPT-4 demonstrates a robust capability in explaining discourse knowledge, even though it may occasionally select incorrect translation candidates. The findings from Bang et al. [6] indicated that ChatGPT performs $\mathrm{X to Eng}$ translation well, but it still lacks the ability to perform $\mathrm{Eng to X}$ translation. Lyu et al. [130] investigated several research directions in MT utilizing LLMs. This study significantly contributes to the advancement of MT research and highlights the potential of LLMs in enhancing translation capabilities. In summary, while LLMs perform satisfactorily in several translation tasks, there is still room for improvement, e.g., enhancing the translation capability from English to non-English languages.
虽然大语言模型并未针对翻译任务进行专门训练,但其仍能展现出强劲性能。Wang等人[208]通过人工评估证明,ChatGPT和GPT-4相较于商用机器翻译(MT)系统具有更优异的表现。此外,它们在sacreBLEU分数上也超越了大多数文档级神经机器翻译(NMT)方法。在对比测试中,ChatGPT相比传统翻译模型准确率较低,但GPT-4展现出强大的语篇知识解释能力,尽管偶尔会误选翻译候选词。Bang等人[6]的研究表明,ChatGPT在$\mathrm{X to Eng}$翻译任务中表现良好,但在$\mathrm{Eng to X}$翻译方面仍有不足。Lyu等人[130]探索了利用大语言模型进行机器翻译的多个研究方向,该研究显著推动了机器翻译领域的进展,并凸显了大语言模型提升翻译能力的潜力。总体而言,虽然大语言模型在多项翻译任务中表现令人满意,但仍有改进空间,例如提升英语到非英语语言的翻译能力。
Question answering is a crucial technology in the field of human-computer interaction, and it has found wide application in scenarios like search engines, intelligent customer service, and QA systems. The measurement of accuracy and efficiency in QA models will have significant implications for these applications. According to Liang et al. [114], among all the evaluated models, Instruct GP T davinci v2 (175B) exhibited the highest performance in terms of accuracy, robustness, and fairness across the 9 QA scenarios. Both GPT-3.5 and ChatGPT demonstrate significant advancements compared to GPT-3 in their ability to answer general knowledge questions. In most domains, ChatGPT surpasses GPT-3.5 by more than $2%$ in terms of performance [9, 159]. However, ChatGPT performs slightly weaker than GPT-3.5 on the Commonsense QA and Social IQA benchmarks. This can be attributed to ChatGPT’s cautious nature, as it tends to decline to provide an answer when there is insufficient information available. Fine-tuned models, such as Vícuna and ChatGPT, exhibit exceptional performance with near-perfect scores, surpassing models that lack supervised fine-tuning by a significant margin [5, 6]. Laskar et al. [102] evaluated the effectiveness of ChatGPT on a range of academic datasets, including various tasks such as answering questions, summarizing text, generating code, reasoning with commonsense, solving math problems, translating languages, detecting bias, and addressing ethical issues. Overall, LLMs showcase flawless performance on QA tasks and hold the potential for further enhancing their proficiency in social, event, and temporal commonsense knowledge in the future.
问答是人机交互领域的一项关键技术,已广泛应用于搜索引擎、智能客服和问答系统等场景。问答模型的准确性和效率衡量对这些应用具有重要意义。根据Liang等人[114]的研究,在所有评估模型中,Instruct GPT davinci v2 (175B)在9个问答场景的准确性、鲁棒性和公平性方面表现出最高性能。GPT-3.5和ChatGPT在回答常识性问题方面相比GPT-3都有显著提升。在大多数领域,ChatGPT的性能比GPT-3.5高出超过$2%$[9, 159]。但ChatGPT在Commonsense QA和Social IQA基准测试中表现略逊于GPT-3.5,这归因于ChatGPT的谨慎特性——当信息不足时往往会拒绝回答。经过微调的模型(如Vícuna和ChatGPT)表现出近乎完美的卓越性能,显著超越未经监督微调的模型[5, 6]。Laskar等人[102]评估了ChatGPT在学术数据集上的有效性,涵盖问答、文本摘要、代码生成、常识推理、数学解题、语言翻译、偏见检测和伦理问题处理等任务。总体而言,大语言模型在问答任务中展现出无懈可击的性能,并有望在未来进一步提升其对社会、事件和时间常识知识的掌握能力。
There are also other generation tasks to explore. In the field of sentence style transfer, Pu and Demberg [158] demonstrated that ChatGPT surpasses the previous SOTA supervised model through training on the same subset for few-shot learning, as evident from the higher BLEU score. However, when it comes to controlling the formality of sentence style, ChatGPT’s performance still differs significantly from human behavior. In writing tasks, Chia et al. [22] discovered that LLMs exhibit consistent performance across various categories such as informative, professional, argumentative, and creative writing. This finding implies that LLMs possess a general proficiency in writing capabilities. In text generation quality, Chen et al. [20] revealed that ChatGPT excels in assessing text quality from multiple angles, even in the absence of reference texts, surpassing the performance of most existing automated metrics. Employing ChatGPT to generate numerical scores for text quality emerged as the most reliable and effective approach among the various testing methods studied.
还有其他生成任务值得探索。在句子风格转换领域,Pu和Demberg[158]通过在同一子集上进行少样本学习训练,证明ChatGPT超越了之前的SOTA监督模型,这一点从更高的BLEU分数中可以看出。然而,在控制句子风格的正式程度方面,ChatGPT的表现仍与人类行为存在显著差异。在写作任务中,Chia等人[22]发现大语言模型在信息性、专业性、议论性和创意写作等各类别中表现一致,这表明大语言模型具备通用的写作能力。在文本生成质量方面,Chen等人[20]揭示ChatGPT即使在没有参考文本的情况下,也能从多角度出色评估文本质量,其表现超越大多数现有自动化指标。在研究的各种测试方法中,使用ChatGPT生成文本质量的数值评分被证明是最可靠有效的方案。
3.1.4 Multilingual tasks. While English is the predominant language, many LLMs are trained on mixed-language training data. The combination of multilingual data indeed helps LLMs gain the ability to process inputs and generate responses in different languages, making them widely adopted and accepted across the globe. However, due to the relatively recent emergence of this technology, LLMs are primarily evaluated on English data, leading to a potential oversight of evaluating their multilingual performance. To address this, several articles have provided comprehensive, open, and independent evaluations of LLMs’ performance on various NLP tasks in different non-English languages. These evaluations offer valuable insights for future research and applications.
3.1.4 多语言任务。虽然英语是主导语言,但许多大语言模型 (LLM) 都基于混合语言训练数据进行训练。多语言数据的结合确实帮助大语言模型获得了处理不同语言输入和生成响应的能力,使其在全球范围内得到广泛采用和认可。然而,由于该技术出现时间相对较短,大语言模型主要基于英语数据进行评估,可能导致对其多语言性能评估的忽视。为解决这一问题,多篇论文对不同非英语语言中各种 NLP 任务上的大语言模型性能进行了全面、开放且独立的评估。这些评估为未来研究和应用提供了宝贵见解。
Abdelali et al. [1] evaluated the performance of ChatGPT in standard Arabic NLP tasks and observed that ChatGPT exhibits lower performance compared to SOTA models in the zero-shot setting for most tasks. Ahuja et al. [2], Bang et al. [6], Lai et al. [100], Zhang et al. [250] utilized a greater number of languages across multiple datasets, encompassing a wider range of tasks, and conducted a more comprehensive evaluation of LLMs, including BLOOM, Vicuna, Claude, ChatGPT, and GPT-4. The results indicated that these LLMs perform poorly when it came to non-Latin languages and languages with limited resources. Despite translating the input to English and using it as the query, generative LLMs still displays subpar performance across tasks and languages compared to SOTA models [2]. Furthermore, Bang et al. [6] highlighted that ChatGPT still faces a limitation in translating sentences written in non-Latin script languages with rich linguistic resources. The aforementioned demonstrates that there are numerous challenges and ample opportunities for enhancement in multilingual tasks for LLMs. Future research should prioritize achieving multilingual balance and addressing the challenges faced by non-Latin languages and low-resource languages, with the aim of better supporting users worldwide. At the same time, attention should be paid to the impartiality and neutrality of the language in order to mitigate any potential biases, including English bias or other biases, that could impact multilingual applications.
Abdelali等人[1]评估了ChatGPT在标准阿拉伯语NLP任务中的表现,发现ChatGPT在多数任务的零样本设置下性能低于SOTA模型。Ahuja等人[2]、Bang等人[6]、Lai等人[100]、Zhang等人[250]使用了更多语言跨多数据集,涵盖更广泛的任务范围,并对BLOOM、Vicuna、Claude、ChatGPT和GPT-4等大语言模型进行了更全面的评估。结果表明,这些大语言模型在处理非拉丁语系和资源匮乏语言时表现欠佳。即使将输入翻译为英语作为查询,生成式大语言模型在跨任务和跨语言场景中仍表现逊于SOTA模型[2]。此外,Bang等人[6]指出ChatGPT在翻译具有丰富语言资源的非拉丁文字语言时仍存在局限。上述研究表明,大语言模型在多语言任务中仍面临诸多挑战和改进机遇。未来研究应优先实现多语言平衡,解决非拉丁语系和低资源语言面临的挑战,以更好地服务全球用户。同时需关注语言的公正性与中立性,以减轻可能影响多语言应用的潜在偏见(包括英语偏见或其他偏见)。
3.1.5 Factuality. Factuality in the context of LLMs refers to the extent to which the information or answers provided by the model align with real-world truths and verifiable facts. Factuality in LLMs significantly impacts a variety of tasks and downstream applications, such as QA systems, information extraction, text sum mari z ation, dialogue systems, and automated fact-checking, where incorrect or inconsistent information could lead to substantial misunderstandings and misinterpretations. Evaluating factuality is of great importance in order to trust and efficiently use these models. This includes the ability of these models to maintain consistency with known facts, avoid generating misleading or false information (known as “factual hallucination"), and effectively learn and recall factual knowledge. A range of methodologies have been proposed to measure and improve the factuality of LLMs.
3.1.5 事实性。大语言模型中的事实性指模型提供的信息或答案与现实世界真相及可验证事实的吻合程度。大语言模型的事实性显著影响各类任务与下游应用,例如问答系统、信息抽取、文本摘要、对话系统和自动事实核查,其中错误或不一致信息可能导致严重误解与误判。评估事实性对于信任并高效使用这些模型至关重要,包括模型保持与已知事实一致性的能力、避免生成误导或虚假信息(即"事实性幻觉")的能力,以及有效学习与回忆事实性知识的能力。目前已提出多种方法来衡量和改进大语言模型的事实性。
Wang et al. [204] assessed the internal knowledge capabilities of several large models, namely Instruct GP T, ChatGPT-3.5, GPT-4, and BingChat [137], by examining their ability to answer open questions based on the Natural Questions [98] and TriviaQA [88] datasets. The evaluation process involved human assessment. The results of the study indicated that while GPT-4 and BingChat can provide correct answers for more than $80%$ of the questions, there is still a remaining gap of over $15%$ to achieve complete accuracy. In the work of Honovich et al. [74], they conducted a review of current factual consistency evaluation methods and highlighted the absence of a unified comparison framework and the limited reference value of related scores compared to binary labels. To address this, they transformed existing fact consistency tasks into binary labels, specifically considering only whether there is a factual conflict with the input text, without factoring in external knowledge. The research discovered that fact evaluation methods founded on natural language inference and question generation answering exhibit superior performance and can complement each other. Pez es hk pour [156] proposed a novel metric, based on information theory, to assess the inclusion of specific knowledge in LLMs. The metric utilized the concept of uncertainty in knowledge to measure factual ness, calculated by LLMs filling in prompts and examining the probability distribution of the answer. The paper discussed two methods for injecting knowledge into LLMs: explicit inclusion of knowledge in the prompts and implicit fine-tuning of the LLMs using knowledge-related data. The study demonstrated that this approach surpasses traditional ranking methods by achieving an accuracy improvement of over $30%$ . Gekhman et al. [55] improved the method for evaluating fact consistency in sum mari z ation tasks. It proposed a novel approach that involved training student NLI models using summaries generated by multiple models and annotated by LLMs to ensure fact consistency. The trained student model was then used for sum mari z ation fact consistency evaluation. Manakul et al. [133] operated on two hypotheses regarding how LLMs generate factual or hallucinated responses. It proposed the use of three formulas (BERTScore [249], MQAG [134] and n-gram) to evaluate factuality and employed alternative LLMs to gather token probabilities for black-box language models. The study discovered that simply computing sentence likelihood or entropy helped validate the factuality of the responses. Min et al. [138] broke down text generated by LLMs into individual “atomic" facts, which were then evaluated for their correctness. The FActScore is used to measure the performance of estimators through the calculation of F1 scores. The paper tested various estimators and revealed that current estimators still have some way to go in effectively addressing the task. Lin et al. [119] introduced the TruthfulQA dataset, designed to cause models to make mistakes. Multiple language models were tested by providing factual answers. The findings from these experiments suggest that simply scaling up model sizes may not necessarily improve their truthfulness, and recommendations are provided for the training approach. This dataset has become widely used for evaluating the factuality of LLMs [89, 146, 192, 220].
Wang等[204]通过考察InstructGPT、ChatGPT-3.5、GPT-4和BingChat[137]在Natural Questions[98]与TriviaQA[88]数据集上回答开放问题的能力,评估了这些大模型的内部知识能力。该评估过程采用人工判定的方式,研究结果表明:虽然GPT-4和BingChat能对超过$80%$的问题给出正确答案,但距离完全准确仍存在超过$15%$的差距。Honovich等[74]对现有事实一致性评估方法进行综述,指出当前缺乏统一比较框架,且相关分数相比二元标签的参考价值有限。为此他们将现有事实一致性任务转化为二元标签,特别仅考虑是否与输入文本存在事实冲突,而不纳入外部知识。研究发现基于自然语言推理和问答生成的事实评估方法表现更优,且能形成互补。Pez es hk pour[156]提出基于信息论的新指标来评估大语言模型对特定知识的包含程度,该指标利用知识不确定性的概念来衡量事实性,通过大语言模型填充提示词并考察答案概率分布来计算。论文讨论了两种向大语言模型注入知识的方法:在提示词中显式包含知识,以及使用相关知识数据隐式微调大语言模型。研究表明该方法超越传统排序方法,准确率提升超过$30%$。Gekhman等[55]改进了摘要任务中的事实一致性评估方法,提出通过大语言模型标注多模型生成的摘要来训练学生NLI模型,进而用于摘要事实一致性评估的新方案。Manakul等[133]基于大语言模型生成事实性或幻觉性响应的两种假设,提出使用BERTScore[249]、MQAG[134]和n-gram三种公式评估事实性,并采用替代大语言模型为黑盒语言模型收集token概率。研究发现单纯计算句子似然或熵有助于验证响应的真实性。Min等[138]将大语言模型生成文本分解为独立"原子"事实进行正确性评估,通过计算F1分数使用FActScore衡量评估器性能。论文测试了多种评估器,揭示当前评估器在有效解决该任务方面仍有提升空间。Lin等[119]提出TruthfulQA数据集,该数据集旨在诱使模型犯错,通过提供事实性答案测试了多种语言模型。实验结果表明单纯扩大模型规模未必能提升真实性,并对训练方法提出建议。该数据集已成为评估大语言模型事实性的常用基准[89, 146, 192, 220]。
Table 3. Summary of LLMs evaluation on robustness, ethics, biases, and trustworthiness (ordered by the name of the first author).
| Reference | Robustness | Ethics and biases | Trustworthiness |
| Cao et al. [16] | |||
| Dhamala et al. [37] | |||
| Deshpande et al. [35] | |||
| Ferrara [42] | |||
| Gehman et al. [53] | |||
| Hartmann et al. [65] | |||
| Hendrycks et al. [69] | |||
| Hagendorff and Fabi [62] | √ | ||
| Li et al. [111] | √ | ||
| Liu et al.[123] | |||
| Liu et al. [123] | |||
| Li et al. [113] | |||
| Parrish et al. [153] | |||
| Rutinowski et al.[167] | √ | ||
| Rawte et al. [163] | √ | ||
| Sheng et al. [175] | |||
| Simmons [176] | |||
| Wang et al. [207] | √ | ||
| Wang et al. [206] | |||
| Wang et al. [201] | √ | √ | |
| Wang et al. [209] | |||
| Xie et al. [228] | |||
| Yang et al. [234] | |||
| Zhao et al. [258] | √ | ||
| Zhuo et al. [267] | √ | ||
| Zhu et al. [264] | |||
| Zhuo et al. [266] | |||
| Zhang et al. [253] | √ |
表 3: 大语言模型在鲁棒性、伦理、偏见和可信度方面的评估总结 (按第一作者姓名排序)
| 参考文献 | 鲁棒性 | 伦理与偏见 | 可信度 |
|---|---|---|---|
| Cao等 [16] | |||
| Dhamala等 [37] | |||
| Deshpande等 [35] | |||
| Ferrara [42] | |||
| Gehman等 [53] | |||
| Hartmann等 [65] | |||
| Hendrycks等 [69] | |||
| Hagendorff和Fabi [62] | √ | ||
| Li等 [111] | √ | ||
| Liu等 [123] | |||
| Liu等 [123] | |||
| Li等 [113] | |||
| Parrish等 [153] | |||
| Rutinowski等 [167] | √ | ||
| Rawte等 [163] | √ | ||
| Sheng等 [175] | |||
| Simmons [176] | |||
| Wang等 [207] | √ | ||
| Wang等 [206] | |||
| Wang等 [201] | √ | √ | |
| Wang等 [209] | |||
| Xie等 [228] | |||
| Yang等 [234] | |||
| Zhao等 [258] | √ | ||
| Zhuo等 [267] | √ | ||
| Zhu等 [264] | |||
| Zhuo等 [266] | |||
| Zhang等 [253] | √ |
3.2 Robustness, Ethic, Bias, and Trustworthiness
3.2 鲁棒性、伦理、偏见与可信度
The evaluation encompasses crucial aspects of robustness, ethics, biases, and trustworthiness. These factors have gained increasing importance in assessing the performance of LLMs comprehensively.
评估涵盖了鲁棒性、伦理、偏见和可信度等关键方面。这些因素在全面评估大语言模型性能时日益重要。
3.2.1 Robustness. Robustness studies the stability of a system when facing unexpected inputs. Specifically, out-of-distribution (OOD) [207] and adversarial robustness are two popular research topics for robustness. Wang et al. [206] is an early work that evaluated ChatGPT and other LLMs from both the adversarial and OOD perspectives using existing benchmarks such as AdvGLUE [203], ANLI [140], and DDXPlus [41] datasets. Zhuo et al. [267] evaluated the robustness of semantic parsing. Yang et al. [234] evaluated OOD robustness by extending the GLUE [200] dataset. The results of this study emphasize the potential risks to the overall system security when manipulating visual input. For vision-language models, Zhao et al. [258] evaluated LLMs on visual input and transferred them to other visual-linguistic models, revealing the vulnerability of visual input. Li et al. [111] provided an overview of OOD evaluation for language models: adversarial robustness, domain generalization, and dataset biases. Bridging these lines of research, the authors conducted a comparative analysis, unifying the three approaches. They succinctly outlined the data-generation processes and evaluation protocols for each line of study, all while emphasizing the prevailing challenges and future research prospects. Additionally, Liu et al. [123] introduced a large-scale robust visual instruction dataset to enhance the performance of large-scale multi-modal models in handling relevant images and human instructions.
3.2.1 鲁棒性
鲁棒性研究系统在面对意外输入时的稳定性。具体而言,分布外 (out-of-distribution, OOD) [207] 和对抗鲁棒性是鲁棒性研究的两个热门方向。Wang等人[206] 是早期通过AdvGLUE [203]、ANLI [140] 和DDXPlus [41] 等现有基准数据集,从对抗和OOD角度评估ChatGPT及其他大语言模型的工作。Zhuo等人[267] 评估了语义解析的鲁棒性。Yang等人[234] 通过扩展GLUE [200] 数据集评估了OOD鲁棒性。该研究结果强调了操纵视觉输入对整体系统安全的潜在风险。针对视觉语言模型,Zhao等人[258] 在视觉输入上评估大语言模型并将其迁移至其他视觉语言模型,揭示了视觉输入的脆弱性。Li等人[111] 综述了语言模型的OOD评估:对抗鲁棒性、领域泛化和数据集偏差。作者通过对比分析桥接这三类研究,统一了三种方法,简要概述了每类研究的数据生成流程和评估协议,同时强调了当前挑战与未来研究方向。此外,Liu等人[123] 提出了大规模鲁棒视觉指令数据集,以提升大规模多模态模型处理相关图像和人类指令的性能。
For adversarial robustness, Zhu et al. [264] evaluated the robustness of LLMs to prompts by proposing a unified benchmark called Prompt Bench. They comprehensively evaluated adversarial text attacks at multiple levels (character, word, sentence, and semantics). The results showed that contemporary LLMs are vulnerable to adversarial prompts, highlighting the importance of the models’ robustness when facing adversarial inputs. As for new adversarial datasets, Wang et al. [201] introduced AdvGLUE $^{++}$ benchmark data for assessing adversarial robustness and implemented a new evaluation protocol to scrutinize machine ethics via jail breaking system prompts.
在对抗鲁棒性方面,Zhu等人[264]通过提出名为Prompt Bench的统一基准,评估了大语言模型对提示的鲁棒性。他们从多个层面(字符、单词、句子和语义)全面评估了对抗性文本攻击。结果表明,当代大语言模型容易受到对抗性提示的影响,凸显了模型在面对对抗性输入时鲁棒性的重要性。至于新的对抗数据集,Wang等人[201]引入了AdvGLUE$^{++}$基准数据用于评估对抗鲁棒性,并通过越狱系统提示实施新的评估协议来审查机器伦理。
3.2.2 Ethic and bias. LLMs have been found to internalize, spread, and potentially magnify harmful information existing in the crawled training corpora, usually, toxic languages, like offensiveness, hate speech, and insults [53], as well as social biases like stereotypes towards people with a particular demographic identity (e.g., gender, race, religion, occupation, and ideology) [175]. More recently, Zhuo et al. [266] used conventional testing sets and metrics [37, 53, 153] to perform a systematic evaluation of ChatGPT’s toxicity and social bias, finding that it still exhibits noxious content to some extend. Taking a further step, Deshpande et al. [35] introduced role-playing into the model and observed an increase in generated toxicity up to 6x. Furthermore, such role-playing also caused biased toxicity towards specific entities. Different from simply measuring social biases, Ferrara [42] investigated the sources, underlying mechanisms, and corresponding ethical consequences of these biases potentially produced by ChatGPT. Beyond social biases, LLMs have also been assessed by political tendency and personality traits [65, 167] based questionnaires like the Political Compass Test and MBTI test, demonstrating a propensity for progressive views and an ENFJ personality type. In addition, LLMs like GPT-3 were found to have moral biases [176] in terms of the Moral Foundation theory [58]; The study conducted by [69] reveals that existing LMs have potential in ethical judgment, but still need improvement. [256] proposes a Chinese conversational bias evaluation dataset CHBias, discovers bias risks in pre-trained models, and explores debiasing methods. Moreover, in the assessment of GPT-4 alignment, [209] discovered a systematic bias. ChatGPT is also observed to exhibit somewhat bias on cultural values [16]. Wang et al. [201] also incorporated an evaluation dataset specifically aimed at gauging stereotype bias, using both targeted and untargeted system prompts. All these ethical issues might elicit serious risks, impeding the deployment of LLMs and having a profound negative impact on society.
3.2.2 伦理与偏见
研究发现,大语言模型(LLM)会内化、传播并可能放大训练语料中已有的有害信息,通常包括攻击性言论、仇恨言论和侮辱性语言等毒性内容[53],以及针对特定人群(如性别、种族、宗教、职业和意识形态)的社会偏见[175]。最近,Zhuo等人[266]采用传统测试集和指标[37,53,153]对ChatGPT的毒性和社会偏见进行了系统评估,发现其仍在一定程度上表现出有害内容。Deshpande等人[35]进一步将角色扮演引入模型,观察到生成内容的毒性最高增加了6倍,且这种角色扮演还会导致针对特定实体的偏见性毒性。Ferrara[42]不同于简单地测量社会偏见,而是研究了ChatGPT可能产生这些偏见的来源、内在机制及相应的伦理后果。除社会偏见外,研究者还通过政治倾向测试(Political Compass Test)和MBTI测试等问卷评估了大语言模型的政治倾向与人格特质[65,167],发现其表现出进步主义倾向和ENFJ人格类型。此外,基于道德基础理论(Moral Foundation theory)[58],研究发现GPT-3等模型存在道德偏见[176];[69]的研究表明现有语言模型虽具备伦理判断潜力,但仍需改进。[256]提出了中文对话偏见评估数据集CHBias,发现预训练模型的偏见风险并探索了去偏方法。在GPT-4对齐评估中,[209]还发现了系统性偏差。研究也观察到ChatGPT在文化价值观方面存在一定偏差[16]。Wang等人[201]还构建了专门评估刻板偏见的数据集,同时采用定向和非定向系统提示。这些伦理问题可能引发严重风险,阻碍大语言模型部署,并对社会产生深远的负面影响。
3.2.3 Trustworthiness. Some work focuses on other trustworthiness problems in addition to robustness and ethics.3 In their 2023 study, Decoding Trust, Wang et al. [201] offered a multifaceted exploration of trustworthiness vulnerabilities in the GPT models, especially GPT-3.5 and GPT-4. Their evaluation expanded beyond the typical trustworthiness concerns to include eight critical aspects: toxicity, stereotype bias, adversarial and out-of-distribution robustness, robustness to adversarial demonstrations, privacy, machine ethics, and fairness. Decoding Trust’s investigation employs an array of newly constructed scenarios, tasks, and metrics. They revealed that while GPT-4 often showcases improved trustworthiness over GPT-3.5 in standard evaluations, it is simultaneously more susceptible to attacks.
3.2.3 可信度。除鲁棒性和伦理问题外,部分研究还关注其他可信度问题。Wang等人在2023年的研究《Decoding Trust》[201]中对GPT模型(尤其是GPT-3.5和GPT-4)的可信度漏洞进行了多维度探究。该评估超越了典型可信度范畴,涵盖八大关键维度:毒性、刻板偏见、对抗性与分布外鲁棒性、对抗演示鲁棒性、隐私性、机器伦理以及公平性。研究通过构建全新场景、任务和度量体系发现:尽管GPT-4在标准评估中通常表现出优于GPT-3.5的可信度,但其对攻击的敏感性也更高。
In another study by Hagendorff and Fabi [62], LLMs with enhanced cognitive abilities were evaluated. They found that these models can avoid common human intuitions and cognitive errors, demonstrating super-rational performance. By utilizing cognitive reflection tests and semantic illusion experiments, the researchers gained insights into the psychological aspects of LLMs. This method offers new perspectives for evaluating model biases and ethical issues that may not have been previously identified. Furthermore, a study by [228] brings attention to a significant concern: the consistency of judgment in LLMs diminishes notably when faced with disruptions such as questioning, negation, or misleading cues, even if their initial judgments were accurate. The research delves into various prompting methods designed to mitigate this issue and successfully demonstrates their efficacy.
在Hagendorff和Fabi的另一项研究[62]中,评估了具备增强认知能力的大语言模型。他们发现这些模型能够避开常见的人类直觉和认知错误,展现出超理性的表现。通过采用认知反射测试和语义错觉实验,研究人员深入理解了大语言模型的心理层面。这种方法为评估模型偏差和以往可能未被发现的伦理问题提供了新视角。此外,[228]的一项研究指出了一个重要问题:大语言模型在面对质疑、否定或误导性线索等干扰时,其判断一致性会显著下降,即便初始判断是准确的。该研究深入探讨了旨在缓解这一问题的多种提示方法,并成功证明了其有效性。
LLMs are capable of generating coherent and seemingly factual text. However, the information generated can include factual inaccuracies or statements ungrounded in reality, a phenomenon known as hallucination [163, 253]. Evaluating these issues helps improve the training methods of LLMs to reduce the occurrence of hallucinations. For the evaluation of illusions in large-scale visual models, Liu et al. [123] introduced a comprehensive and robust large-scale visual instruction dataset: LRV-Instruction. Through the GAVIE method, they fine-tuned the evaluation visual instructions, and experimental results demonstrated that LRV-Instruction effectively alleviates illusions in LLMs. In addition, Li et al. [113] conducted an assessment of illusions in large-scale visual language models, revealing through experiments that the distribution of objects in visual instructions significantly impacts object illusions in LVLMs. To enhance the assessment of object illusions in LVLMs, they introduced a polling-based query method, known as POPE. This method provides an improved evaluation of object illusions in LVLMs.
大语言模型(LLM)能够生成连贯且看似真实的文本。然而,生成的信息可能包含事实错误或脱离现实的陈述,这种现象被称为幻觉(hallucination) [163, 253]。评估这些问题有助于改进大语言模型的训练方法以减少幻觉发生。针对大规模视觉模型中的幻觉评估,Liu等人[123]提出了一个全面且鲁棒的大规模视觉指令数据集:LRV-Instruction。通过GAVIE方法,他们对评估视觉指令进行了微调,实验结果表明LRV-Instruction有效缓解了大语言模型中的幻觉问题。此外,Li等人[113]对大规模视觉语言模型中的幻觉进行了评估,实验表明视觉指令中物体的分布会显著影响LVLM中的物体幻觉。为提升LVLM中物体幻觉的评估效果,他们提出了一种基于投票的查询方法POPE,该方法为LVLM中的物体幻觉提供了更优的评估方案。
3.3 Social Science
3.3 社会科学
Social science involves the study of human society and individual behavior, including economics, sociology, political science, law, and other disciplines. Evaluating the performance of LLMs in social science is important for academic research, policy formulation, and social problem-solving. Such evaluations can help improve the applicability and quality of models in the social sciences, increasing understanding of human societies and promoting social progress.
社会科学涉及对人类社会中个体行为的研究,包括经济学、社会学、政治学、法学等学科。评估大语言模型(LLM)在社会科学中的表现对于学术研究、政策制定和社会问题解决具有重要意义。此类评估有助于提升模型在社会科学领域的适用性和质量,增进对人类社会的理解并推动社会进步。
Wu et al. [224] evaluated the potential use of LLMs in addressing scaling and measurement issues in social science and found that LLMs can generate meaningful responses regarding political ideology and significantly improve text-as-data methods in social science.
Wu等[224]评估了大语言模型在解决社会科学领域扩展性和测量问题方面的潜在应用,发现大语言模型能够生成关于政治意识形态的有意义响应,并显著改进社会科学中的文本即数据方法。
In computational social science (CSS) tasks, Ziems et al. [269] presented a comprehensive evaluation of LLMs on several CSS tasks. During classification tasks, LLMs exhibit the lowest absolute performance on event argument extraction, character tropes, implicit hate, and empathy classification, achieving accuracy below $40%$ . These tasks either involve complex structures (event arguments) or subjective expert taxonomies with semantics that differ from those learned during LLM pre training. Conversely, LLMs achieve the best performance on misinformation, stance, and emotion classification. When it comes to generation tasks, LLMs often produce explanations that surpass the quality of gold references provided by crowd workers. In summary, while LLMs can greatly enhance the traditional CSS research pipeline, they cannot completely replace it.
在计算社会科学(CSS)任务中,Ziems等人[269]对大语言模型(LLM)在多项CSS任务上进行了全面评估。在分类任务中,大语言模型在事件论元提取、角色刻板印象、隐性仇恨和共情分类等任务上表现最差,准确率低于$40%$。这些任务要么涉及复杂结构(事件论元),要么包含与大语言模型预训练所学语义存在差异的主观专家分类体系。相比之下,大语言模型在虚假信息检测、立场分析和情感分类任务中表现最佳。在生成任务方面,大语言模型生成的解释往往优于众包工作者提供的黄金参考标准。总体而言,虽然大语言模型能显著提升传统CSS研究流程的效率,但仍无法完全取代该流程。
Some articles also evaluate LLMs on legal tasks. The zero-shot performance of LLMs is mediocre in legal case judgment sum mari z ation. LLMs have several problems, including incomplete sentences and words, meaningless sentences merge, and more serious errors such as inconsistent and hallucinated information [34]. The results showed that further improvement is necessary for LLMs to be useful for case judgment sum mari z ation by legal experts. Nay et al. [139] indicated that LLMs, particularly when combined with prompting enhancements and the correct legal texts, could perform better but not yet at expert tax lawyer levels.
一些文章还评估了大语言模型在法律任务上的表现。在法律案件判决摘要任务中,大语言模型的零样本表现平平。这些模型存在若干问题,包括句子和词语不完整、无意义句子合并,以及更严重的错误,如信息不一致和幻觉生成[34]。结果表明,要让大语言模型对法律专家的案件判决摘要工作有所帮助,还需要进一步改进。Nay等人[139]指出,大语言模型在结合提示增强和正确法律文本的情况下表现会更好,但尚未达到税务律师专家的水平。
Lastly, within the realm of psychology, Frank [44] adopted an interdisciplinary approach and drew insights from developmental psychology and comparative psychology to explore alternative methods for evaluating the capabilities of LLMs. By integrating different perspectives, researchers can deepen their understanding of the essence of cognition and effectively leverage the potential of advanced technologies such as large language models, while mitigating potential risks.
最后,在心理学领域,Frank [44] 采用跨学科方法,借鉴发展心理学和比较心理学的观点,探索评估大语言模型 (LLM) 能力的替代方法。通过整合不同视角,研究人员能够深化对认知本质的理解,有效利用大语言模型等先进技术的潜力,同时规避潜在风险。
In conclusion, the utilization of LLMs has significantly benefited individuals in addressing social science-related tasks, leading to improved work efficiency. The outputs produced by LLMs serve as valuable resources for enhancing productivity. However, it is crucial to acknowledge that existing LLMs cannot completely replace human professionals in this domain.
总之,大语言模型(LLM)的应用显著帮助人们处理社会科学相关任务,提升了工作效率。大语言模型生成的输出成为提高生产力的宝贵资源。但必须认识到,现有的大语言模型尚无法完全替代该领域的人类专业人士。
Table 4. Summary of evaluations on natural science and engineering tasks based on three aspects: Mathematics, General science and Engineering (ordered by the name of the first author).
| Reference | Mathematics | Generalscience | Engineering |
| Arora et al.[3] | |||
| Bubeck et al.[15] | |||
| CastroNascimento andPimentel[18] | |||
| Collins et al. [27] | |||
| Dao and Le [31] | |||
| Guo et al. [61] | |||
| Liu et al. [125] | |||
| Pallagani et al. [150] | |||
| Sridhara et al.[181] | |||
| Valmeekam et al.[194] | |||
| Valmeekam et al.[195] | |||
| Wei et al. [221] | |||
| Wu et al. [225] | √ | ||
| Yuan et al. [241] | |||
| Yu et al. [237] | |||
| Zhuang et al.[265] | √ |
表 4: 基于数学、通用科学和工程三个方面的自然科学与工程任务评估总结(按第一作者姓名排序)。
| 参考文献 | 数学 | 通用科学 | 工程 |
|---|---|---|---|
| Arora et al. [3] | |||
| Bubeck et al. [15] | |||
| CastroNascimento and Pimentel [18] | |||
| Collins et al. [27] | |||
| Dao and Le [31] | |||
| Guo et al. [61] | |||
| Liu et al. [125] | |||
| Pallagani et al. [150] | |||
| Sridhara et al. [181] | |||
| Valmeekam et al. [194] | |||
| Valmeekam et al. [195] | |||
| Wei et al. [221] | |||
| Wu et al. [225] | √ | ||
| Yuan et al. [241] | |||
| Yu et al. [237] | |||
| Zhuang et al. [265] | √ |
3.4 Natural Science and Engineering
3.4 自然科学与工程
Evaluating the performance of LLMs in natural science and engineering can help guide applications and development in scientific research, technology development, and engineering studies.
评估大语言模型 (LLM) 在自然科学与工程领域的性能表现,有助于指导科研、技术开发和工程研究中的应用与发展。
3.4.1 Mathematics. For fundamental mathematical problems, most large language models (LLMs) demonstrate proficiency in addition and subtraction, and possess some capability in multiplication. However, they face challenges when it comes to division, exponentiation, trigonometry functions, and logarithm functions. On the other hand, LLMs exhibit competence in handling decimal numbers, negative numbers, and irrational numbers [241]. In terms of performance, ChatGPT and GPT-4 outperform other models significantly, showcasing their superiority in solving mathematical tasks [221]. These two models have a distinct advantage in dealing with large numbers (greater than 1e12) and complex, lengthy mathematical queries. GPT-4 outperforms ChatGPT by achieving a significant increase in accuracy of 10 percentage points and a reduction in relative error by $50%$ , due to its superior division and trigonometry abilities, proper understanding of irrational numbers, and consistent step-by-step calculation of long expressions.
3.4.1 数学。针对基础数学问题,大多数大语言模型(LLM)能熟练完成加减运算,并具备一定的乘法能力,但在除法、幂运算、三角函数和对数函数方面存在困难。另一方面,LLM在处理小数、负数和无理数时表现尚可[241]。性能方面,ChatGPT和GPT-4显著优于其他模型,展现出解决数学任务的卓越能力[221]。这两个模型在处理大数(大于1e12)和复杂冗长的数学问题时具有明显优势。得益于更优的除法和三角函数能力、对无理数的正确理解以及长表达式分步计算的稳定性,GPT-4以10个百分点的准确率提升和$50%$的相对误差降低超越了ChatGPT。
When confronted with complex and challenging mathematical problems, LLMs exhibit subpar performance. Specifically, GPT-3 demonstrates nearly random performance, while GPT-3.5 shows improvement, and GPT-4 performs the best [3]. Despite the advancements made in the new models, it is important to note that the peak performance remains relatively low compared to that of experts and these models lack the capability to engage in mathematical research [15]. The specific tasks of algebraic manipulation and calculation continue to pose challenges for GPTs [15, 27]. The primary reasons behind GPT-4’s low performance in these tasks are errors in algebraic manipulation and difficulties in retrieving pertinent domain-specific concepts. Wu et al. [225] evaluated the use of GPT-4 on difficult high school competition problems and GPT-4 reached $60%$ accuracy on half of the categories. Intermediate algebra and pre calculus can only be solved with a low accuracy rate of around $20%$ . ChatGPT is not good at answering questions on topics including derivatives and applications, Oxyz spatial calculus, and spatial geometry [31]. Dao and Le [31], Wei et al. [221] showed that ChatGPT’s performance worsens as task difficulty increases: it correctly answered $83%$ of the questions at the recognition level, $62%$ at the comprehension level, $27%$ at the application level, and only $10%$ at the highest cognitive complexity level. Given those problems at higher knowledge levels tend to be more complex, requiring in-depth understanding and problem-solving skills, such results are to be expected.
面对复杂且具有挑战性的数学问题时,大语言模型表现欠佳。具体而言,GPT-3的表现近乎随机,GPT-3.5有所改进,而GPT-4表现最佳[3]。尽管新模型取得了进展,但需注意其峰值性能仍远低于专家水平,且这些模型不具备开展数学研究的能力[15]。代数运算和计算等特定任务仍对GPT系列模型构成挑战[15, 27]。GPT-4在这些任务中表现不佳的主要原因是代数运算错误和领域特定概念检索困难。Wu等人[225]评估了GPT-4在高中数学竞赛难题上的表现,其在半数题型中达到60%准确率,但中级代数与微积分预备知识相关问题的正确率仅约20%。ChatGPT在导数应用、Oxyz空间微积分和空间几何等主题的问题解答中表现较差[31]。Dao和Le[31]、Wei等人[221]的研究表明,ChatGPT的表现随任务难度提升而下降:在识别层级问题中正确率为83%,理解层级为62%,应用层级为27%,而在最高认知复杂度层级仅达10%。鉴于高知识层级的问题往往更复杂,需要深度理解与解题技巧,此类结果实属预期。
These results indicate that the effectiveness of LLMs is highly influenced by the complexity of problems they encounter. This finding holds significant implications for the design and development of optimized artificial intelligence systems capable of successfully handling these challenging tasks.
这些结果表明,大语言模型(LLM)的有效性深受其遇到问题复杂性的影响。这一发现对设计和开发能够成功处理这些挑战性任务的优化人工智能系统具有重要意义。
3.4.2 General science. Further improvements are needed in the application of LLMs in the field of chemistry. Castro Nascimento and Pimentel [18] presented five straightforward tasks from various subareas of chemistry to assess ChatGPT’s comprehension of the subject, with accuracy ranging from $25%$ to $100%$ . Guo et al. [61] created a comprehensive benchmark that encompasses 8 practical chemistry tasks, which is designed to assess the performance of LLMs (including GPT-4, GPT-3.5, and Davinci-003) for each chemistry task. Based on the experiment results, GPT-4 demonstrates superior performance compared to the other two models. [3] showed that LLMs perform worse on physics problems than chemistry problems, probably because chemistry problems have lower inference complexity than physics problems in this setting. There are limited evaluation studies on LLMs in the field of general science, and the current findings indicate that further improvement is needed in the performance of LLMs within this domain.
3.4.2 基础科学
大语言模型在化学领域的应用仍需进一步改进。Castro Nascimento 和 Pimentel [18] 通过化学各子领域的五项基础任务评估 ChatGPT 的化学理解能力,其准确率介于 $25%$ 至 $100%$ 之间。Guo 等学者 [61] 构建了涵盖 8 项实际化学任务的综合基准,用于评估 GPT-4、GPT-3.5 和 Davinci-003 等大语言模型在化学任务中的表现。实验结果表明,GPT-4 的性能优于另外两个模型。[3] 指出大语言模型在物理问题上的表现逊于化学问题,这可能是因为在当前设定中化学问题的推理复杂度低于物理问题。目前针对基础科学领域的大语言模型评估研究较为有限,现有结果表明该领域的大语言模型性能仍需提升。
3.4.3 Engineering. Within engineering, the tasks can be organized in ascending order of difficulty, including code generation, software engineering, and commonsense planning.
3.4.3 工程领域。在工程领域,任务可按难度升序组织,包括代码生成、软件工程和常识规划。
In code generation tasks, the smaller LLMs trained for the tasks are competitive in performance, and CodeGen-16B [141] is comparable in performance to ChatGPT using a larger parameter setting, reaching about a $78%$ match [125]. Despite facing challenges in mastering and comprehending certain fundamental concepts in programming languages, ChatGPT showcases a commendable level of coding level [265]. Specifically, ChatGPT has developed superior skills in dynamic programming, greedy algorithm, and search, surpassing highly capable college students, but it struggles in data structure, tree, and graph theory. GPT-4 demonstrates an advanced ability to generate code based on given instructions, comprehend existing code, reason about code execution, simulate the impact of instructions, articulate outcomes in natural language, and execute pseudocode effectively [15].
在代码生成任务中,专为该任务训练的小型大语言模型在性能上具有竞争力,CodeGen-16B [141] 的性能与采用更大参数规模的 ChatGPT 相当,匹配率约为 $78%$ [125]。尽管在掌握和理解编程语言的某些基础概念方面面临挑战,ChatGPT 仍展现出值得称赞的编码水平 [265]。具体而言,ChatGPT 在动态规划、贪心算法和搜索方面表现出色,超越了能力出众的大学生,但在数据结构、树和图论方面存在困难。GPT-4 则展现出更高级的能力:能根据给定指令生成代码、理解现有代码、推理代码执行过程、模拟指令影响、用自然语言阐述结果,并能有效执行伪代码 [15]。
In software engineering tasks, ChatGPT generally performs well and provides detailed responses, often surpassing both human expert output and SOTA output. However, for certain tasks such as code vulnerability detection and information retrieval-based test prior it iz ation, the current version of ChatGPT fails to provide accurate answers, rendering it unsuitable for these specific tasks [181].
在软件工程任务中,ChatGPT通常表现优异,能提供详细回复,其输出质量常超越人类专家和SOTA(State-of-the-art)成果。但对于代码漏洞检测和基于信息检索的测试优先级划分等特定任务,当前版本的ChatGPT无法给出准确答案,因此不适用于这些具体场景 [181]。
In commonsense planning tasks, LLMs may not perform well, even in simple planning tasks where humans excel [194, 195]. Pallagani et al. [150] demonstrated that the fine-tuned CodeT5 [214] performs the best across all considered domains, with the shortest inference time. Moreover, it explored the capability of LLMs for plan generalization and found that their generalization capabilities appear to be limited. It turns out that LLMs can handle simple engineering tasks, but they perform poorly on complex engineering tasks.
在常识性规划任务中,大语言模型可能表现不佳,即使在人类擅长的简单规划任务中也是如此 [194, 195]。Pallagani等人 [150] 证明,经过微调的CodeT5 [214] 在所有考虑的领域中表现最佳,且推理时间最短。此外,研究还探讨了大语言模型在规划泛化方面的能力,发现其泛化能力似乎有限。事实证明,大语言模型可以处理简单的工程任务,但在复杂的工程任务上表现较差。
3.5 Medical Applications
3.5 医疗应用
The application of LLMs in the medical field has recently received significant attention. As a result, this section aims to provide a comprehensive review of the ongoing efforts dedicated to implementing LLMs in medical applications. We have categorized these applications into three aspects as shown in Table 5: medical query, medical examination, and medical assistants. A detailed examination of these categories will enhance our understanding of the potential impact and advantages that LLMs can bring to the medical domain.
大语言模型 (LLM) 在医疗领域的应用近期受到广泛关注。因此,本节旨在全面综述当前将大语言模型应用于医疗场景的研究进展。如表 5 所示,我们将这些应用划分为三类:医疗问询、医学检验和医疗助手。深入分析这些类别将有助于我们理解大语言模型为医疗领域带来的潜在影响与优势。
Table 5. Summary of evaluations on medical applications based on the three aspects: Medical queries, Medical assistants, and Medical examination (ordered by the name of the first author).
| Reference | Medical queries | Medicalexamination | Medicalassistants |
| Cascella et al.[17] | |||
| Chervenaket al.[21] | |||
| Duong and Solomon [39] | √ | ||
| Gilson et al. [57] | |||
| Hamidi and Roberts[63] | |||
| Holmes et al. [73] | |||
| Jahan et al. [81] | √ | ||
| Johnson et al. [87] | √ | ||
| Khan et al. [93] | √ | ||
| Kung et al. [97] | √ | ||
| Lahat et al. [99] | |||
| Lyu et al. [131] | √ | ||
| Oh et al. [143] | √ | ||
| Samaan et al. [169] | |||
| Thirunavukarasu et al.[186] | |||
| Wang et al. [217] | √ |
表 5: 基于医学查询、医学助手和医学检查三方面的评估总结 (按第一作者姓名排序)
| 参考文献 | 医学查询 | 医学检查 | 医学助手 |
|---|---|---|---|
| Cascella 等人 [17] | |||
| Chervenak 等人 [21] | |||
| Duong 和 Solomon [39] | √ | ||
| Gilson 等人 [57] | |||
| Hamidi 和 Roberts [63] | |||
| Holmes 等人 [73] | |||
| Jahan 等人 [81] | √ | ||
| Johnson 等人 [87] | √ | ||
| Khan 等人 [93] | √ | ||
| Kung 等人 [97] | √ | ||
| Lahat 等人 [99] | |||
| Lyu 等人 [131] | √ | ||
| Oh 等人 [143] | √ | ||
| Samaan 等人 [169] | |||
| Thirunavukarasu 等人 [186] | |||
| Wang 等人 [217] | √ |
3.5.1 Medical queries. The significance of evaluating LLMs on medical queries lies in providing accurate and reliable medical answers to meet the needs of healthcare professionals and patients for high-quality medical information. As shown in Table 5, the majority of LLMs evaluations in the medical field concentrate on medical queries. ChatGPT generated relatively accurate information for various medical queries, including genetics [39], radiation oncology physics [73], bio medicine [81], and many other medical disciplines [63, 87, 169], demonstrating its effectiveness in the field of medical queries to a certain extent. As for the limitations, Thiru nav uk a rasu et al. [186] assessed ChatGPT’s performance in primary care and found that its average score in the student comprehensive assessment falls below the passing score, indicating room for improvement. Chervenak et al. [21] highlighted that while ChatGPT can generate responses similar to existing sources in fertility-related clinical prompts, its limitations in reliably citing sources and potential for fabricating information restrict its clinical utility.
3.5.1 医疗查询
评估大语言模型在医疗查询中的意义在于提供准确可靠的医学答案,以满足医疗从业者和患者对高质量医疗信息的需求。如表5所示,医疗领域大多数大语言模型评估都集中在医疗查询上。ChatGPT为遗传学[39]、放射肿瘤物理学[73]、生物医学[81]等各类医学学科[63, 87, 169]的查询生成了相对准确的信息,一定程度上证明了其在医疗查询领域的有效性。关于局限性,Thirunavukarasu等人[186]评估了ChatGPT在初级护理中的表现,发现其在学生综合评估中的平均分数低于及格线,表明存在改进空间。Chervenak等人[21]指出,虽然ChatGPT能针对生育相关临床提示生成与现有资料相似的回复,但其在可靠引用文献方面的局限性及可能捏造信息的风险限制了其临床应用价值。
3.5.2 Medical examination. The studies by Gilson et al. [57], Kung et al. [97] have evaluated the performance of LLMs in medical examination assessment through the United States Medical Licensing Examination (USMLE) . In the study of [57], ChatGPT’s performance in answering USMLE Step 1 and Step 2 exam questions was assessed using novel multiple-choice question sets. The results indicated that ChatGPT achieves varying accuracies across different datasets. However, the presence of out-of-context information was found to be lower compared to the correct answer in the NBME-Free-Step1 and NBME-Free-Step2 datasets. Kung et al. [97] showed that ChatGPT achieves or approaches the passing threshold in these exams with no tailored training. The model demonstrates high consistency and insight, indicating its potential to assist in medical education and clinical decision-making. ChatGPT can be used as a tool to answer medical questions, provide explanations, and support decision-making processes. This offers additional resources and support for medical students and clinicians in their educational and clinical practices. Moreover, Sharma et al. [173] found that answers generated by ChatGPT are more context-aware with better deductive reasoning abilities compared to Google search results.
3.5.2 医学考试评估
Gilson等[57]和Kung等[97]通过美国医师执照考试(USMLE)评估了大语言模型在医学考试中的表现。[57]研究采用新型多选题集测试ChatGPT在USMLE Step 1和Step 2中的答题表现,结果显示其准确率因数据集而异,但NBME-Free-Step1和NBME-Free-Step2数据集中脱离上下文的信息出现频率低于正确答案。Kung等[97]表明ChatGPT无需针对性训练即可达到或接近考试通过阈值,展现出高度一致性与洞察力,预示其在医学教育和临床决策中的辅助潜力。该模型可作为回答医学问题、提供解释及支持决策流程的工具,为医学生和临床医师的教育与实践提供额外资源。此外,Sharma等[173]发现相较于谷歌搜索结果,ChatGPT生成的答案具有更强的上下文感知与演绎推理能力。
3.5.3 Medical assistants. In the field of medical assistance, LLMs demonstrate potential applications, including research on identifying gastrointestinal diseases [99], dementia diagnosis [217], accelerating the evaluation of COVID-19 literature [93], and their overall potential in healthcare [17]. However, there are also limitations and challenges, such as lack of originality, high input requirements, resource constraints, uncertainty in answers, and potential risks related to misdiagnosis and patient privacy issues.
3.5.3 医疗助手。在医疗辅助领域,大语言模型展现出多项潜在应用,包括胃肠道疾病识别研究 [99] 、痴呆症诊断 [217] 、加速COVID-19文献评估 [93] ,以及其在医疗健康领域的整体潜力 [17] 。但也存在局限性与挑战,如缺乏原创性、输入要求高、资源受限、答案不确定性,以及误诊风险和患者隐私问题等潜在隐患。
Moreover, several studies have evaluated the performance and feasibility of ChatGPT in the medical education field. In the study by Oh et al. [143], ChatGPT, specifically GPT-3.5 and GPT-4 models, were evaluated in terms of their understanding of surgical clinical information and their potential impact on surgical education and training. The results indicate an overall accuracy of $46.8%$ for GPT-3.5 and $76.4%$ for GPT-4, demonstrating a significant performance difference between the two models. Notably, GPT-4 consistently performs well across different subspecialties, suggesting its capability to comprehend complex clinical information and enhance surgical education and training. Another study by Lyu et al. [131] explores the feasibility of utilizing ChatGPT in clinical education, particularly in translating radiology reports into easily understandable language. The findings demonstrate that ChatGPT effectively translates radiology reports into accessible language and provides general recommendations. Furthermore, the quality of ChatGPT has shown improvement compared to GPT-4. These findings suggest that employing LLMs in clinical education is feasible, although further efforts are needed to address limitations and unlock their full potential.
此外,多项研究评估了ChatGPT在医学教育领域的表现与可行性。Oh等人[143]的研究针对GPT-3.5和GPT-4模型,评估了其对手术临床信息的理解能力及其对外科教学培训的潜在影响。结果显示:GPT-3.5总体准确率为$46.8%$,而GPT-4达到$76.4%$,表明两代模型存在显著性能差异。值得注意的是,GPT-4在各个外科亚专科均表现稳定,证明其具备理解复杂临床信息并提升外科教学的能力。Lyu等人[131]的另一项研究探讨了ChatGPT在临床教育(特别是将放射学报告转化为通俗语言)中的应用可行性。研究发现ChatGPT不仅能有效转换放射报告为易懂表述,还能提供通用建议。相较于GPT-4,ChatGPT的质量已呈现提升趋势。这些发现表明大语言模型应用于临床教育具有可行性,但仍需进一步解决局限性以释放其全部潜力。
3.6 Agent Applications
3.6 AI智能体应用
Instead of focusing solely on general language tasks, LLMs can be utilized as powerful tools in various domains. Equipping LLMs with external tools can greatly expand the capabilities of the model [160]. ToolLLM [161] provides a comprehensive framework to equip open-source large language models with tool use capabilities. Huang et al. [77] introduced KOSMOS-1, which is capable of understanding general patterns, following instructions, and learning based on context. The study by MRKL Karpas et al. [90] emphasized the importance of understanding when and how to utilize external symbolic tools, as this knowledge is dependent on the capabilities of LLMs, particularly when these tools can reliably perform functions. Additionally, two other studies, Toolformer [172] and TALM [152], explored the utilization of tools to enhance language models. Toolformer employs a training approach to determine the optimal usage of specific APIs and integrates the obtained results into subsequent token predictions. On the other hand, TALM combines indistinguishable tools with text-based methods to augment language models and employs an iterative technique known as “self-play", guided by minimal tool demonstrations. Furthermore, Shen et al. [174] proposed the HuggingGPT framework, which leverages LLMs to connect various AI models within the machine learning community (such as Hugging Face), aiming to address AI tasks.
大语言模型不仅可以专注于通用语言任务,还能作为强大工具应用于各领域。为模型配备外部工具可极大扩展其能力 [160]。ToolLLM [161] 提供了为开源大语言模型赋予工具使用能力的完整框架。Huang等人 [77] 提出的KOSMOS-1能够理解通用模式、遵循指令并进行上下文学习。MRKL Karpas等人的研究 [90] 强调了理解何时及如何使用外部符号工具的重要性,因为这种知识取决于大语言模型的能力,特别是当这些工具能可靠执行功能时。此外,Toolformer [172] 和TALM [152] 两项研究探索了利用工具增强语言模型的方法:Toolformer采用训练方法确定特定API的最佳使用方式,并将获取结果整合到后续token预测中;TALM则将不可区分工具与基于文本的方法相结合来增强语言模型,并采用名为"自我博弈"的迭代技术,通过少量工具演示进行引导。Shen等人 [174] 提出的HuggingGPT框架利用大语言模型连接机器学习社区中的各类AI模型(如Hugging Face),旨在解决AI任务。
3.7 Other Applications
3.7 其他应用
In addition to above areas, there have been evaluations in various other domains, including education, search and recommendation, personality testing, and specific applications.
除上述领域外,还在教育、搜索与推荐、性格测试及特定应用等多个其他领域进行了评估。
3.7.1 Education. LLMs have shown promise in revolutionizing the field of education. They have the potential to make significant contributions in several areas, such as assisting students in improving their writing skills, facilitating better comprehension of complex concepts, expediting the delivery of information, and providing personalized feedback to enhance student engagement. These applications aim to create more efficient and interactive learning experiences, offering students a broader range of educational opportunities. However, to fully harness the potential of LLMs in education, extensive research, and ongoing refinement are necessary.
3.7.1 教育
大语言模型 (LLM) 在革新教育领域展现出巨大潜力。它们可在多个方面作出重要贡献,例如帮助学生提升写作能力、促进复杂概念的理解、加速信息传递,以及通过个性化反馈增强学生参与度。这些应用旨在创造更高效、更具互动性的学习体验,为学生提供更广泛的教育机会。但若要充分发挥大语言模型在教育中的潜力,仍需开展大量研究并持续优化。
Table 6. Summary of evaluations on other applications based on the four aspects: Education, Search and recommendation, Personality testing and Specific applications (ordered by the name of the first author).
| Reference | Education | 1Searchandrecommendation | Personality testingSpecific applications | |
| Bodroza et al.[10] | √ | |||
| Dai et al. [30] | ||||
| de Winter [32] | ||||
| Dai et al. [29] | √ | |||
| Fan et al. [40] | ||||
| Hellas et al. [67] | √ | |||
| JentzschandKersting[84] | √ | |||
| Lanzi and Loiacono [101] | √ | |||
| Le and Zhang [103] | ||||
| Li et al. [110] | √ | |||
| Liang et al. [115] | 人 | |||
| Sun et al. [183] | √ | |||
| Song et al. [180] | ||||
| Safdari et al.[168] | ||||
| Thakur et al.[185] | √ | |||
| WangandDemszky[210] Wang et al. [212] | ||||
| Wang et al. [216] | √ | |||
| Xu et al. [232] | ||||
| Yuan et al. [240] | ||||
| Zhang et al.[246] |
表 6. 基于教育、搜索与推荐、性格测试和特定应用四个维度的其他应用评估总结(按第一作者姓名排序)。
| 参考文献 | 教育 | 搜索与推荐 | 性格测试 | 特定应用 |
|---|---|---|---|---|
| Bodroza et al. [10] | √ | |||
| Dai et al. [30] | ||||
| de Winter [32] | ||||
| Dai et al. [29] | √ | |||
| Fan et al. [40] | ||||
| Hellas et al. [67] | √ | |||
| Jentzsch and Kersting [84] | √ | |||
| Lanzi and Loiacono [101] | √ | |||
| Le and Zhang [103] | ||||
| Li et al. [110] | √ | |||
| Liang et al. [115] | 人 | |||
| Sun et al. [183] | √ | |||
| Song et al. [180] | ||||
| Safdari et al. [168] | ||||
| Thakur et al. [185] | √ | |||
| Wang and Demszky [210] Wang et al. [212] | ||||
| Wang et al. [216] | √ | |||
| Xu et al. [232] | ||||
| Yuan et al. [240] | ||||
| Zhang et al. [246] |
The evaluation of LLMs for educational assistance aims to investigate and assess their potential contributions to the field of education. Such evaluations can be conducted from various perspectives. According to Dai et al. [30], ChatGPT demonstrates the ability to generate detailed, fluent, and coherent feedback that surpasses that of human teachers. It can accurately assess student assignments and provide feedback on task completion, thereby assisting in the development of student skills. However, ChatGPT’s responses may lack novelty or insightful perspectives regarding teaching improvement [210]. Additionally, the study conducted by Hellas et al. [67] revealed that LLMs can successfully identify at least one actual problem in student code, although instances of misjudgment are also observed. In conclusion, the utilization of LLMs shows promise in addressing program logic issues, although challenges remain in achieving proficiency in output formatting. It is important to note that while these models can provide valuable insights, they may still generate errors similar to those made by students.
对大语言模型(LLM)在教育辅助领域的评估旨在探究并衡量其对教育行业的潜在贡献。此类评估可从多维度展开。Dai等人[30]指出,ChatGPT能够生成比人类教师更详尽、流畅且连贯的反馈,可准确评估学生作业并提供任务完成度反馈,从而助力学生技能发展。但该模型在教学方法改进方面可能缺乏新颖性或深刻见解[210]。Hellas等人[67]的研究表明,大语言模型能成功识别学生代码中至少一个实际问题,但也存在误判情况。总体而言,大语言模型在解决程序逻辑问题方面展现潜力,但在输出格式处理上仍需提升。需注意的是,这些模型虽能提供有价值的见解,但仍可能产生与学生类似的错误。
In educational exams, researchers aim to evaluate the application effectiveness of LLMs, including automatic scoring, question generation, and learning guidance. de Winter [32] showed that ChatGPT achieves an average of $71.8%$ correctness, which is comparable to the average score of all participating students. Subsequently, the evaluation was conducted using GPT-4, and it achieved a score of 8.33. Furthermore, this evaluation showed the effectiveness of leveraging boots trapping that combines randomness via the “temperature” parameter in diagnosing incorrect answers. Zhang et al. [248] claimed that GPT-3.5 can solve MIT math and EECS exams with GPT-4 achieving better performance. However, it turned out to be not fair since they accidentally included the correct answers into the prompts.
在教育考试领域,研究人员致力于评估大语言模型(LLM)的应用效果,包括自动评分、试题生成和学习指导。de Winter [32] 研究表明,ChatGPT平均正确率达到71.8%,与所有参与学生的平均成绩相当。随后使用GPT-4进行评估,其得分为8.33分。此外,该评估证明了通过"temperature"参数结合随机性的自助法(bootstrapping)在诊断错误答案方面的有效性。Zhang等[248]声称GPT-3.5能够解决MIT数学和EECS考试题目,而GPT-4表现更优。但后来发现该评估存在不公平性,因为他们无意中将正确答案包含在了提示词中。
3.7.2 Search and recommendation. The assessment of LLMs in search and recommendation can be broadly categorized into two areas. Firstly, in the realm of information retrieval, Sun et al. [183] investigated the effectiveness of generative ranking algorithms, such as ChatGPT and GPT-4, for information retrieval tasks. Experimental results demonstrate that guided ChatGPT and GPT-4 exhibit competitive performance on popular benchmark tests, even outperforming supervised methods. Additionally, the extraction of ChatGPT’s ranking functionality into a specialized model shows superior performance when trained on 10K ChatGPT-generated data compared to training on 400K annotated MS MARCO data in the BEIR dataset [185]. Furthermore, Xu et al. [232] conducted a randomized online experiment to investigate the behavioral differences of users when performing information retrieval tasks using search engines and chatbot tools. Participants were divided into two groups: one using tools similar to ChatGPT and the other using tools similar to Google Search. The results show that the ChatGPT group spent less time on all tasks and the difference between these two groups is not significant.
3.7.2 搜索与推荐
大语言模型在搜索与推荐领域的评估可大致分为两个方向。首先在信息检索方面,Sun等人[183]研究了ChatGPT、GPT-4等生成式排序算法在信息检索任务中的有效性。实验结果表明,经过引导的ChatGPT和GPT-4在主流基准测试中展现出竞争优势,甚至超越有监督方法。此外,将ChatGPT的排序功能提取为专用模型时,使用1万条ChatGPT生成数据训练的表现优于基于BEIR数据集中40万条标注MS MARCO数据训练的结果[185]。Xu等人[232]通过随机在线实验研究了用户使用搜索引擎与聊天机器人工具执行信息检索任务时的行为差异:参与者被分为两组,一组使用类ChatGPT工具,另一组使用类Google搜索工具。结果显示ChatGPT组在所有任务上耗时更少,且两组差异不显著。
Secondly, moving to the domain of recommendation systems, LLMs have emerged as essential components that leverage their natural language processing capabilities to comprehend user preferences, item descriptions, and contextual information [40]. By incorporating LLMs into recommendation pipelines, these systems can offer more accurate and personalized recommendations, thereby improving user experience and overall recommendation quality. However, it is crucial to address the potential risks associated with using LLMs for recommendations. Recent research by Zhang et al. [246] has highlighted the issue of unfair recommendations generated by ChatGPT. This emphasizes the importance of evaluating fairness when employing LLMs in recommendation scenarios. Dai et al. [29] suggest that ChatGPT exhibits strong performance in recommend er systems. The use of listwise ranking is found to strike the best balance between cost and performance. Furthermore, ChatGPT shows promise in addressing the cold-start problem and providing interpret able recommendations. Moreover, the research by Yuan et al. [240] and Li et al. [110] demonstrated the promising potential of the modality-based recommendation model (MoRec) and text-based collaborative filtering (TCF) in recommendation systems.
其次,在推荐系统领域,大语言模型(LLM)凭借其自然语言处理能力,已成为理解用户偏好、商品描述和上下文信息的关键组件[40]。通过将大语言模型整合到推荐流程中,这些系统能提供更精准、个性化的推荐,从而提升用户体验和整体推荐质量。但必须警惕大语言模型在推荐场景中的潜在风险。Zhang等人[246]的最新研究指出ChatGPT存在生成不公平推荐的问题,这强调了在推荐系统中应用大语言模型时评估公平性的重要性。Dai等人[29]认为ChatGPT在推荐系统中表现优异,其中列表排序(listwise ranking)能在成本与性能间达到最佳平衡。此外,ChatGPT在解决冷启动问题和提供可解释推荐方面也展现潜力。Yuan等人[240]与Li等人[110]的研究则证实了基于模态的推荐模型(MoRec)和基于文本的协同过滤(TCF)在推荐系统中的广阔前景。
3.7.3 Personality testing. Personality testing aims to measure individuals’ personality traits and behavioral tendencies, and LLMs as powerful natural language processing models have been widely applied in such tasks.
3.7.3 人格测试。人格测试旨在衡量个体的性格特征和行为倾向,而大语言模型作为强大的自然语言处理模型,在此类任务中已得到广泛应用。
Research conducted by Bodroza et al. [10] investigated the personality features of using Davinci003 as a chatbot and found variations in the consistency of its answers, despite exhibiting prosocial characteristics. However, there remains uncertainty regarding whether the chatbot’s responses are driven by conscious self-reflection or algorithmic processes. Song et al. [180] examined the manifestation of personality in language models and discovered that many models perform unreliably in self-assessment tests and exhibit inherent biases. Therefore, it is necessary to develop specific machine personality measurement tools to enhance reliability. These studies offer vital insights to better understand LLMs in personality testing. Safdari et al. [168] proposed a comprehensive approach to conduct effective psycho metric testing for the personality traits in the text generated by LLMs. In order to evaluate the emotional intelligence of LLMs, Wang et al. [212] developed a new psycho metric assessment method. By referencing a framework constructed from over 500 adults, the authors tested various mainstream LLMs. The results showed that most LLMs achieve above-average scores in emotional quotient (EQ), with GPT-4 scoring 117, surpassing $89%$ of human participants. However, a multivariate pattern analysis indicated that certain LLMs achieve human-level performance without relying on mechanisms resembling those found in humans. This is evident from the distinct differences in the quality of their representational patterns, as compared to humans. Liang et al. [115] employed the word guessing game to evaluate LLMs’ language and theory of mind intelligence s, a more engaging and interactive assessment method. Jentzsch and Kersting [84] discussed the challenges of incorporating humor into LLMs, particularly ChatGPT. They found that while ChatGPT demonstrates impressive capabilities in NLP tasks, it falls short in generating humorous responses. This study emphasizes the importance of humor in human communication and the difficulties that LLMs face in capturing the subtleties and context-dependent nature of humor. It discusses the limitations of current approaches and highlights the need for further research on more sophisticated models that can effectively understand and generate humor.
Bodroza等人[10]的研究调查了使用Davinci003作为聊天机器人时的个性特征,发现尽管其表现出亲社会特性,但回答一致性存在波动。然而,该聊天机器人的回应究竟源于自觉的自我反思还是算法过程,目前仍无定论。Song等人[180]探究了语言模型中的人格表现,发现许多模型在自我评估测试中表现不可靠,并存在固有偏见。因此有必要开发专门的机器性格测量工具以提升可靠性。这些研究为理解大语言模型在人格测试中的表现提供了重要洞见。Safdari等人[168]提出了一套综合方法,用于对大语言模型生成文本中的人格特质进行有效心理测量评估。为评估大语言模型的情商,Wang等人[212]开发了新的心理测量评估方法。通过参照基于500多名成年人构建的框架,作者测试了多种主流大语言模型。结果显示大多数大语言模型在情商(EQ)上达到中上水平,其中GPT-4得分117分,超过89%的人类参与者。但多元模式分析表明,某些大语言模型虽达到人类水平,却未依赖类人机制——这从其表征模式质量与人类的显著差异中得以印证。Liang等人[115]采用猜词游戏评估大语言模型的语言和心理理论智能,提供了一种更具互动性的评估方式。Jentzsch与Kersting[84]探讨了将幽默融入大语言模型(特别是ChatGPT)的挑战。他们发现尽管ChatGPT在自然语言处理任务中表现优异,但在生成幽默回应方面仍有不足。该研究强调了幽默在人类交流中的重要性,以及大语言模型在捕捉幽默微妙性和语境依赖性方面面临的困难,同时指出当前方法的局限性,强调需要进一步研究能有效理解并生成幽默的更复杂模型。
Table 7. Summary of existing LLMs evaluation benchmarks (ordered by the name of the first author).
| Benchmark | Focus | Domain | Evaluation Criteria |
| SOCKET [23] | Social knowledge | Specific downstream task | Social language understanding |
| MME [46] | Multimodal LLMs | Multi-modal task | Ability of perception and cognition |
| Xiezhi [59] | Comprehensive domain knowledge | General language task | Overall performance across multiplebenchmarks |
| Choice-75[75] | Script learning | Specific downstream task | Overall performance of LLMs |
| CUAD [71] | Legal contract review | Specific downstream task | Legal contract understanding |
| TRUSTGPT[79] | Ethic | Specific downstream task | Toxicity,bias,and value-alignment |
| MMLU [70] | Text models | General language task | Multitask accuracy |
| MATH [72] | Mathematicalproblem | Specific downstream task | Mathematical ability |
| APPS [68] | Coding challenge competence | Specific downstream task | Code generation ability |
| CELLO [66] | Complex instructions | Specific downstream task | Four designated evaluation criteria |
| C-Eval [78] | Chinese evaluation | General language task | 52 Exams in a Chinese context |
| EmotionBench [76] | Empathy ability | Specific downstream task | Emotional changes |
| OpenLLM[80] | Chatbots | General language task | Leaderboardrankings |
| DynaBench [94] | Dynamic evaluation | General language task | NLI, QA,sentiment,and hate speech |
| Chatbot Arena[128] | Chat assistants | General language task | Crowdsourcing and Elorating system |
| AlpacaEval[112] | Automatedevaluation | General language task | Metrics, robustness,and diversity |
| CMMLU[108] | Chinese multi-tasking | Specific downstream task | Multi-tasklanguageunderstanding capabilities |
| HELM [114] | Holistic evaluation | General language task | Multi-metric |
| API-Bank [109] | Tool utilization | Specific downstream task | API call, retrieval, and planning |
| M3KE [122] | Multi-task | Specific downstream task | Multi-task accuracy |
| MMBench[126] | Large vision-language models(LVLMs) | Multi-modal task | Multifaceted capabilities ofVLMs |
| SEED-Bench [107] | Multimodal Large Language Models | Multi-modal task | GenerativeunderstandingofMLLMs |
| UHGEval [116] | Hallucination of ChineseLLMs | Specific downstream task | Form,metric and granularity |
| ARB [171] | Advanced reasoning ability | Specific downstream task | Multidomain advanced reasoning ability |
| BIG-bench [182] | Capabilities and limitations of LMs | General language task | Model performance and calibration |
| MultiMedQA[177] | Medical QA | Specific downstream task | Accuracy and human evaluation |
| CVALUES [230] | Safety and responsibility | Specific downstream task | Alignment ability of LLMs |
| LVLM-eHub [231] | LVLMs | Multi-modal task | MultimodalcapabilitiesofLVLMs |
| ToolBench [191] | Software tools | Specific downstream task | Execution success rate |
| FRESHQA [198] | Dynamic QA | Specific downstream task | Correctness and hallucination |
| CMB [211] | Chinese comprehensivemedicine | Specific downstream task | Expert evaluation and automatic evaluation |
| PandaLM [216] | Instruction tuning | General language task | Winrate judged by PandaLM |
| MINT [213] | Multi-turn interaction | Specific downstream task | Success rate with k-turn budget SRk |
| Dialogue CoT[205] | In-depth dialogue | Specific downstream task | Helpfulness and acceptness of LLMs |
| BOSS [239] | OOD robustness in NLP | General language task | OOD robustness |
| MM-Vet [238] | Complicated multi-modal tasks | Multi-modal task | Integratedvision-language capabilities |
| LAMM [235] | Multi-modal point clouds | Multi-modal task | Task-specificmetrics |
| GLUE-X[234] | OODrobustness for NLP tasks | General language task | OODrobustness |
| KoLA [236] | Knowledge-oriented evaluation | General language task | Self-contrast metrics |
| AGIEval [262] | Human-centeredfoundationalmodels | General language task | General |
| PromptBench [264] | Adversarial promptresilience | General language task | Adversarial robustness |
| MT-Bench [260] | Multi-turn conversation | General language task | Winrate judged by GPT-4 |
| M3Exam [250] | Multilingual, multimodal and multilevel | Specific downstream task | Task-specific metrics |
| GAOKAO-Bench[245] | Chinese Gaokao examination | Specific downstream task | Accuracy and scoring rate |
| SafetyBench [254] | Safety | Specific downstream task | Safety abilities of LLMs |
| LLMEval²[252] | LLM Evaluator | General language task | Acc,macro-f1 and kappa correlation coefficient |
表 7: 现有大语言模型评估基准总结(按第一作者姓名排序)
| 基准名称 | 关注点 | 领域 | 评估标准 |
|---|---|---|---|
| SOCKET [23] | 社会知识 | 特定下游任务 | 社会语言理解 |
| MME [46] | 多模态大语言模型 | 多模态任务 | 感知与认知能力 |
| Xiezhi [59] | 综合领域知识 | 通用语言任务 | 跨多个基准的整体表现 |
| Choice-75 [75] | 脚本学习 | 特定下游任务 | 大语言模型整体表现 |
| CUAD [71] | 法律合同审查 | 特定下游任务 | 法律合同理解 |
| TRUSTGPT [79] | 伦理 | 特定下游任务 | 毒性、偏见和价值对齐 |
| MMLU [70] | 文本模型 | 通用语言任务 | 多任务准确率 |
| MATH [72] | 数学问题 | 特定下游任务 | 数学能力 |
| APPS [68] | 编程挑战能力 | 特定下游任务 | 代码生成能力 |
| CELLO [66] | 复杂指令 | 特定下游任务 | 四项指定评估标准 |
| C-Eval [78] | 中文评估 | 通用语言任务 | 中文语境下的52项考试 |
| EmotionBench [76] | 共情能力 | 特定下游任务 | 情绪变化 |
| OpenLLM [80] | 聊天机器人 | 通用语言任务 | 排行榜排名 |
| DynaBench [94] | 动态评估 | 通用语言任务 | 自然语言推理、问答、情感和仇恨言论 |
| Chatbot Arena [128] | 聊天助手 | 通用语言任务 | 众包和Elo评分系统 |
| AlpacaEval [112] | 自动化评估 | 通用语言任务 | 指标、鲁棒性和多样性 |
| CMMLU [108] | 中文多任务 | 特定下游任务 | 多任务语言理解能力 |
| HELM [114] | 整体评估 | 通用语言任务 | 多指标 |
| API-Bank [109] | 工具使用 | 特定下游任务 | API调用、检索和规划 |
| M3KE [122] | 多任务 | 特定下游任务 | 多任务准确率 |
| MMBench [126] | 大型视觉语言模型(LVLM) | 多模态任务 | 视觉语言模型的多方面能力 |
| SEED-Bench [107] | 多模态大语言模型 | 多模态任务 | 多模态大语言模型的生成理解能力 |
| UHGEval [116] | 中文大语言模型幻觉 | 特定下游任务 | 形式、指标和粒度 |
| ARB [171] | 高级推理能力 | 特定下游任务 | 多领域高级推理能力 |
| BIG-bench [182] | 语言模型能力与局限 | 通用语言任务 | 模型表现和校准 |
| MultiMedQA [177] | 医学问答 | 特定下游任务 | 准确率和人工评估 |
| CVALUES [230] | 安全与责任 | 特定下游任务 | 大语言模型对齐能力 |
| LVLM-eHub [231] | 大型视觉语言模型 | 多模态任务 | 大型视觉语言模型的多模态能力 |
| ToolBench [191] | 软件工具 | 特定下游任务 | 执行成功率 |
| FRESHQA [198] | 动态问答 | 特定下游任务 | 正确性和幻觉 |
| CMB [211] | 中文综合医学 | 特定下游任务 | 专家评估和自动评估 |
| PandaLM [216] | 指令调优 | 通用语言任务 | PandaLM判定的胜率 |
| MINT [213] | 多轮交互 | 特定下游任务 | k轮预算下的成功率(SRk) |
| Dialogue CoT [205] | 深度对话 | 特定下游任务 | 大语言模型的帮助性和接受度 |
| BOSS [239] | NLP中的OOD鲁棒性 | 通用语言任务 | OOD鲁棒性 |
| MM-Vet [238] | 复杂多模态任务 | 多模态任务 | 综合视觉语言能力 |
| LAMM [235] | 多模态点云 | 多模态任务 | 任务特定指标 |
| GLUE-X [234] | NLP任务的OOD鲁棒性 | 通用语言任务 | OOD鲁棒性 |
| KoLA [236] | 知识导向评估 | 通用语言任务 | 自我对比指标 |
| AGIEval [262] | 以人为中心的基础模型 | 通用语言任务 | 通用 |
| PromptBench [264] | 对抗性提示韧性 | 通用语言任务 | 对抗鲁棒性 |
| MT-Bench [260] | 多轮对话 | 通用语言任务 | GPT-4判定的胜率 |
| M3Exam [250] | 多语言、多模态和多层次 | 特定下游任务 | 任务特定指标 |
| GAOKAO-Bench [245] | 中国高考 | 特定下游任务 | 准确率和得分率 |
| SafetyBench [254] | 安全性 | 特定下游任务 | 大语言模型安全能力 |
| LLMEval² [252] | 大语言模型评估器 | 通用语言任务 | 准确率、宏观F1和kappa相关系数 |
3.7.4 Specific applications. Moreover, various research endeavors have been conducted to explore the application and evaluation of LLMs across a wide spectrum of tasks, such as game design [101], model performance assessment [216], and log parsing [103]. Collectively, these findings enhance our comprehension of the practical implications associated with the utilization of LLMs across diverse tasks. They shed light on the potential and limitations of these models while providing valuable insights for performance improvement.
3.7.4 具体应用
此外,已有大量研究探索大语言模型 (LLM) 在各种任务中的应用与评估,例如游戏设计 [101] 、模型性能评估 [216] 和日志解析 [103] 。这些研究共同深化了我们对大语言模型跨任务实际应用的理解,揭示了其潜力与局限性,并为性能优化提供了宝贵洞见。
4 WHERE TO EVALUATE: DATASETS AND BENCHMARKS
4 评估场景:数据集与基准测试
LLMs evaluation datasets are used to test and compare the performance of different language models on various tasks, as depicted in Sec. 3. These datasets, such as GLUE [200] and SuperGLUE [199], aim to simulate real-world language processing scenarios and cover diverse tasks such as text classification, machine translation, reading comprehension, and dialogue generation. This section will not discuss any single dataset for language models but benchmarks for LLMs.
大语言模型评估数据集用于测试和比较不同语言模型在各种任务上的性能,如第3节所述。这些数据集(例如GLUE [200]和SuperGLUE [199])旨在模拟现实世界中的语言处理场景,涵盖文本分类、机器翻译、阅读理解及对话生成等多样化任务。本节将不讨论针对单一语言模型的数据集,而是聚焦大语言模型的基准测试。
A variety of benchmarks have emerged to evaluate their performance. In this study, we compile a selection of 46 popular benchmarks, as shown in Table 7. Each benchmark focuses on different aspects and evaluation criteria, providing valuable contributions to their respective domains. For a better sum mari z ation, we divide these benchmarks into three categories: benchmarks for general language tasks, benchmarks for specific downstream tasks, and benchmarks for multi-modal tasks.
为评估其性能,各类基准测试应运而生。本研究汇总了46个热门基准测试(如表7所示),每个测试聚焦不同维度和评估标准,为各自领域提供了重要参考。为便于归纳,我们将这些基准分为三类:通用语言任务基准、特定下游任务基准以及多模态任务基准。
4.1 Benchmarks for General Tasks
4.1 通用任务基准测试
LLMs are designed to solve a vast majority of tasks. To this end, existing benchmarks tend to evaluate the performance in different tasks.
大语言模型旨在解决绝大多数任务。为此,现有基准倾向于评估不同任务中的性能。
Chatbot Arena [128] and MT-Bench [260] are two significant benchmarks that contribute to the evaluation and advancement of chatbot models and LLMs in different contexts. Chatbot Arena provides a platform to assess and compare diverse chatbot models through user engagement and voting. Users can engage with anonymous models and express their preferences via voting. The platform gathers a significant volume of votes, facilitating the evaluation of models’ performance in realistic scenarios. Chatbot Arena provides valuable insights into the strengths and limitations of chatbot models, thereby contributing to the progress of chatbot research and advancement.
Chatbot Arena [128] 和 MT-Bench [260] 是两个重要的基准测试,它们在不同场景下推动了对聊天机器人模型和大语言模型的评估与进步。Chatbot Arena 通过用户参与和投票提供了一个评估和比较多样化聊天机器人模型的平台。用户可以与匿名模型互动,并通过投票表达他们的偏好。该平台收集了大量投票数据,有助于评估模型在真实场景中的表现。Chatbot Arena 为聊天机器人模型的优势和局限性提供了宝贵见解,从而推动了聊天机器人研究和发展。
Meanwhile, MT-Bench evaluates LLMs on multi-turn dialogues using comprehensive questions tailored to handling conversations. It provides a comprehensive set of questions specifically designed for assessing the capabilities of models in handling multi-turn dialogues. MT-Bench possesses several distinguishing features that differentiate it from conventional evaluation methodologies. Notably, it excels in simulating dialogue scenarios representative of real-world settings, thereby facilitating a more precise evaluation of a model’s practical performance. Moreover, MT-Bench effectively overcomes the limitations in traditional evaluation approaches, particularly in gauging a model’s competence in handling intricate multi-turn dialogue inquiries.
与此同时,MT-Bench通过专为处理对话设计的综合性问题来评估大语言模型在多轮对话中的表现。它提供了一套专门用于评估模型处理多轮对话能力的综合性问题集。MT-Bench具备多项区别于传统评估方法的显著特征:尤其擅长模拟现实场景中的对话情境,从而更精准地评估模型的实际性能;此外,它有效克服了传统评估方法的局限性,特别是在衡量模型处理复杂多轮对话查询能力方面。
Instead of focusing on specific tasks and evaluation metrics, HELM [114] provides a comprehensive assessment of LLMs. It evaluates language models across various aspects such as language understanding, generation, coherence, context sensitivity, common-sense reasoning, and domainspecific knowledge. HELM aims to holistic ally evaluate the performance of language models across different tasks and domains. For LLMs Evaluator, Zhang et al. [252] introduces LLMEval2, which encompasses a wide range of capability evaluations. In addition, Xiezhi [59] presents a comprehensive suite for assessing the knowledge level of large-scale language models in different subject areas. The evaluation conducted through Xiezhi enables researchers to comprehend the notable limitations inherent in these models and facilitates a deeper comprehension of their capabilities in diverse fields. For evaluating language models beyond their existing capacities, BIG-bench [182] introduces a diverse collection of 204 challenging tasks contributed by 450 authors from 132 institutions. These tasks cover various domains such as math, childhood development, linguistics, biology, common-sense reasoning, social bias, physics, software development, etc.
HELM [114] 没有局限于特定任务和评估指标,而是对大语言模型进行全面评估。它从语言理解、生成、连贯性、上下文敏感性、常识推理和领域知识等多个维度评估语言模型。HELM旨在对不同任务和领域的语言模型性能进行整体评估。针对大语言模型评估,Zhang等人 [252] 提出了LLMEval2,涵盖广泛的能力评估。此外,Xiezhi [59] 提供了一套综合测试套件,用于评估大规模语言模型在不同学科领域的知识水平。通过Xiezhi进行的评估使研究人员能够理解这些模型固有的显著局限性,并促进对其在不同领域能力的深入理解。为了评估语言模型超越现有能力范围的表现,BIG-bench [182] 汇集了来自132个机构450位作者贡献的204项挑战性任务。这些任务涵盖数学、儿童发展、语言学、生物学、常识推理、社会偏见、物理学、软件开发等多个领域。
Recent work has led to the development of benchmarks for evaluating language models’ knowledge and reasoning abilities. The Knowledge-Oriented Language Model Evaluation KoLA [236] focuses on assessing language models’ comprehension and utilization of semantic knowledge for inference. As such, KoLA serves as an important benchmark for evaluating the depth of language understanding and reasoning in language models, thereby driving progress in language comprehension. To enable crowd-sourced evaluations of language tasks, DynaBench [94] supports dynamic benchmark testing. DynaBench explores new research directions including the effects of closed-loop integration, distribution al shift characteristics, annotator efficiency, influence of expert annotators, and model robustness to adversarial attacks in interactive settings. Furthermore, to evaluate language models’ ability to learn and apply multidisciplinary knowledge across educational levels, the Multidisciplinary Knowledge Evaluation M3KE [122] was recently introduced. M3KE assesses knowledge application within the Chinese education system.
近期研究推动了评估语言模型知识与推理能力的基准测试发展。知识导向语言模型评估 KoLA [236] 专注于评估语言模型对语义知识的理解与推理运用能力,成为衡量语言模型深层理解与推理水平的重要基准,从而推动语言理解领域的进步。为支持语言任务的众包评估,DynaBench [94] 实现了动态基准测试,其研究涵盖闭环集成效应、分布偏移特性、标注者效率、专家标注者影响以及交互场景下模型对抗攻击鲁棒性等新方向。此外,多学科知识评估 M3KE [122] 最新提出用于评估语言模型跨学科、跨教育阶段的知识学习与应用能力,该基准基于中国教育体系设计知识应用测试。
The development of standardized benchmarks for evaluating LLMs on diverse tasks has been an important research focus. MMLU [70] provides a comprehensive suite of tests for assessing text models in multi-task contexts. AlpacaEval [112] stands as an automated evaluation benchmark, which places its focus on assessing the performance of LLMs across various natural language processing tasks. It provides a range of metrics, robustness measures, and diversity evaluations to gauge the capabilities of LLMs. AlpacaEval has significantly contributed to advancing LLMs in diverse domains and promoting a deeper understanding of their performance. Furthermore, AGIEval [262], serves as a dedicated evaluation framework for assessing the performance of foundation models in the domain of human-centric standardized exams. Moreover, OpenLLM [80] functions as an evaluation benchmark by offering a public competition platform for comparing and assessing different LLM models’ performance on various tasks. It encourages researchers to submit their models and compete on different tasks, driving progress and competition in LLM research.
构建标准化基准以评估大语言模型(LLM)在多样化任务中的表现已成为重要研究方向。MMLU [70] 提供了一套综合性测试套件,用于评估多任务场景下的文本模型。AlpacaEval [112] 作为自动化评估基准,专注于评估大语言模型在各种自然语言处理任务中的表现,提供包括指标度量、鲁棒性测试和多样性评估在内的多维能力测评体系,对推动大语言模型跨领域发展及深化性能认知具有显著贡献。AGIEval [262] 则是专门针对基础模型在人类标准化考试领域表现的评估框架。此外,OpenLLM [80] 通过提供公开竞赛平台来比较和评估不同大语言模型在各类任务中的表现,鼓励研究者提交模型参与多任务竞赛,从而推动大语言模型研究领域的进步与竞争。
As for tasks beyond standard performance, there are benchmarks designed for OOD, adversarial robustness, and fine-tuning. GLUE-X [234] is a novel attempt to create a unified benchmark aimed at evaluating the robustness of NLP models in OOD scenarios. This benchmark emphasizes the significance of robustness in NLP and provides insights into measuring and enhancing the robustness of models. In addition, Yuan et al. [239] presents BOSS, a benchmark collection for assessing out-of-distribution robustness in natural language processing tasks. Prompt Bench [264] centers on the importance of prompt engineering in fine-tuning LLMs. It provides a standardized evaluation framework to compare different prompt engineering techniques and assess their impact on model performance. Prompt Bench facilitates the enhancement and optimization of fine-tuning methods for LLMs. To ensure impartial and equitable evaluation, PandaLM [216] is introduced as a disc rim i native large-scale language model specifically designed to differentiate among multiple high-proficiency LLMs through training. In contrast to conventional evaluation datasets that predominantly emphasize objective correctness, PandaLM incorporates crucial subjective elements, including relative conciseness, clarity, adherence to instructions, comprehensiveness, and formality.
至于超出标准性能的任务,有针对OOD(分布外)、对抗鲁棒性和微调的基准测试。GLUE-X [234] 是一项创新尝试,旨在创建统一基准以评估NLP模型在OOD场景中的鲁棒性。该基准强调了鲁棒性在NLP中的重要性,并为衡量和提升模型鲁棒性提供了见解。此外,Yuan等人[239]提出了BOSS,一个用于评估自然语言处理任务中分布外鲁棒性的基准集合。Prompt Bench [264] 聚焦于提示工程在微调大语言模型中的重要性,提供了标准化评估框架以比较不同提示工程技术并评估其对模型性能的影响。Prompt Bench促进了针对大语言模型的微调方法改进与优化。为确保公正公平的评估,PandaLM [216] 被提出作为一个判别式大规模语言模型,专门通过训练来区分多个高性能大语言模型。与传统评估数据集主要强调客观正确性不同,PandaLM纳入了关键主观要素,包括相对简洁性、清晰度、指令遵循度、全面性和正式性。
4.2 Benchmarks for Specific Downstream Tasks
4.2 特定下游任务的基准测试
Other than benchmarks for general tasks, there exist benchmarks specifically designed for certain downstream tasks.
除通用任务基准外,还存在专为特定下游任务设计的基准测试。
Question-answering benchmarks have become a fundamental component in the assessment of LLMs and their overall performance. MultiMedQA [177] is a medical QA benchmark that focuses on medical examinations, medical research, and consumer healthcare questions. It consists of seven datasets related to medical QA, including six existing datasets and one new dataset. The goal of this benchmark is to evaluate the performance of LLMs in terms of clinical knowledge and QA abilities. To assess the ability of LLMs in dynamic QA about current world knowledge, Vu et al. [198] introduced FRESHQA. By incorporating relevant and current information retrieved from search engines into prompts, there is a significant enhancement in the performance of LLMs on
问答基准已成为评估大语言模型 (LLM) 及其整体性能的基本组成部分。MultiMedQA [177] 是一个专注于医学考试、医学研究和消费者健康问题的医疗问答基准。它包含七个与医疗问答相关的数据集,包括六个现有数据集和一个新数据集。该基准的目标是评估大语言模型在临床知识和问答能力方面的表现。
为了评估大语言模型在动态问答中关于当前世界知识的能力,Vu 等人 [198] 提出了 FRESHQA。通过将搜索引擎检索到的相关且最新的信息整合到提示中,大语言模型在动态问答任务中的性能得到了显著提升。
FRESHQA. To effectively assess in-depth dialogue, Wang et al. [205] introduced the Dialogue CoT, incorporating two efficient dialogue strategies: Explicit CoT and CoT.
FRESHQA。为了有效评估深度对话,Wang等人[205]提出了对话思维链(Dialogue CoT),融合了两种高效对话策略:显式思维链(Explicit CoT)和思维链(CoT)。
The assessment of LLMs in diverse and demanding tasks has garnered substantial attention in recent research. To this end, a range of specialized benchmarks have been introduced to evaluate LLMs’ capabilities in specific domains and applications. Among these, ARB, as presented by Sawada et al. [171], focuses on probing the performance of LLMs in advanced reasoning tasks spanning multiple domains. Additionally, ethical considerations in LLMs have become an area of paramount importance. TRUSTGPT, as tailored by Huang et al. [79], addresses critical ethical dimensions, including toxicity, bias, and value alignment, within the context of LLMs. Furthermore, the simulation of human emotional reactions by LLMs remains an area with significant potential for improvement, as highlighted by the Emotion Bench benchmark by Huang et al. [76]. In terms of security evaluation, Zhang et al. [254] have introduced Safety Bench, a benchmark specifically designed to test the security performance of a range of popular Chinese and English LLMs. The results of this evaluation reveal substantial security flaws in current LLMs. To evaluate the daily decision-making capabilities of intelligent systems, Hou et al. [75] introduced Choice-75. Additionally, to assess LLMs’ aptitude in understanding complex instructions, He et al. [66] have introduced CELLO. This benchmark encompasses the design of eight distinctive features, the development of a comprehensive evaluation dataset, and the establishment of four evaluation criteria alongside their respective measurement standards.
近年来,大语言模型(LLM)在多样化高难度任务中的评估受到广泛关注。为此,研究者们开发了一系列专业基准测试来评估大语言模型在特定领域和应用中的能力。其中,Sawada等人[171]提出的ARB专注于测评大语言模型在跨领域高级推理任务中的表现。此外,大语言模型的伦理问题已成为至关重要的研究领域。Huang等人[79]开发的TRUSTGPT针对大语言模型中的毒性、偏见和价值对齐等关键伦理维度进行评估。值得注意的是,Huang等人[76]通过Emotion Bench基准测试指出,大语言模型在模拟人类情感反应方面仍有巨大改进空间。在安全评估方面,Zhang等人[254]提出了Safety Bench基准,专门用于测试中英文主流大语言模型的安全性能,测试结果揭示了当前模型存在重大安全缺陷。为评估智能系统的日常决策能力,Hou等人[75]开发了Choice-75测试集。此外,He等人[66]提出的CELLO基准用于评估大语言模型理解复杂指令的能力,该基准包含八项独特功能设计、综合评估数据集构建,以及四项评估标准及其对应的测量指标体系。
Other specific benchmarks such as C-Eval [78], which is the first extensive benchmark to assess the advanced knowledge and reasoning capabilities of foundation models in Chinese. Additionally, Li et al. [108] introduces CMMLU as a comprehensive Chinese proficiency standard and evaluates the performance of 18 LLMs across various academic disciplines. The findings reveal that the majority of LLMs demonstrate suboptimal performance in Chinese language environments, highlighting areas for improvement. M3Exam [250] provides a unique and comprehensive evaluation framework that incorporates multiple languages, modalities, and levels to test the general capabilities of LLMs in diverse contexts. Additionally, GAOKAO-Bench [245] provides a comprehensive evaluation benchmark for gauging the proficiency of large language models in intricate and context-specific tasks, utilizing questions sourced from the Chinese Gaokao examination. On the other hand, SOCKET [23] serves as an NLP benchmark designed to evaluate the performance of LLMs in learning and recognizing social knowledge concepts. It consists of several tasks and case studies to assess the limitations of LLMs in social capabilities. MATH [72] concentrates on assessing reasoning and problem-solving prof ici enc ies of AI models within the domain of mathematics. APPS [68] is a more comprehensive and rigorous benchmark for evaluating code generation, measuring the ability of language models to generate python code according to natural language specifications. CUAD [71] is an expert-annotated, domain-specific legal contract review dataset that presents a challenging research benchmark and potential for enhancing deep learning models’ performance in contract understanding tasks. CVALUES [230] introduces a humanistic evaluation benchmark to assess the alignment of LLMs with safety and responsibility standards. In the realm of comprehensive Chinese medicine, Wang et al. [211] introduced CMB, a medical evaluation benchmark rooted in the Chinese language and culture. It addresses the potential inconsistency in the local context that may arise from relying solely on English-based medical assessments. In the realm of hallucination assessment, [116] has developed UHGEval, a benchmark specifically designed to evaluate the performance of Chinese LLMs in text generation without being constrained by hallucination-related limitations.
其他特定基准如C-Eval [78],这是首个全面评估基础模型在中文环境下高级知识与推理能力的大规模基准。此外,Li等人[108]提出的CMMLU作为综合性中文能力标准,评估了18个大语言模型在多个学科领域的表现。研究结果显示,大多数大语言模型在中文环境中表现欠佳,凸显了改进空间。M3Exam [250]提供了一种独特且全面的评估框架,融合多语言、多模态和多层级测试,以考察大语言模型在多样化场景中的通用能力。GAOKAO-Bench [245]则基于中国高考真题构建综合评估基准,用于衡量大语言模型在复杂情境任务中的熟练度。另一方面,SOCKET [23]作为自然语言处理基准,专门评估大语言模型对社会知识概念的学习与识别能力,通过多任务和案例研究揭示其社会认知局限。MATH [72]专注于评估AI模型在数学领域的推理与问题解决能力。APPS [68]是更全面严格的代码生成评估基准,测试语言模型根据自然语言描述生成Python语言代码的能力。CUAD [71]作为专家标注的领域特定法律合同审查数据集,为合同理解任务中的深度学习模型提供了挑战性研究基准。CVALUES [230]提出人文主义评估基准,用于检验大语言模型与安全责任标准的对齐程度。在中医药综合评估领域,Wang等人[211]开发的CMB植根于中文语言文化,解决了仅依赖英文医学评估可能导致的本土情境不一致问题。针对幻觉评估,[116]构建的UHGEval基准专门评测中文大语言模型在不受幻觉限制的文本生成性能。
In addition to existing evaluation benchmarks, there is a research gap in assessing the effectiveness of utilizing tools for LLMs. To address this gap, the API-Bank benchmark [109] is introduced as the first benchmark explicitly designed for tool-augmented LLMs. It comprises a comprehensive Tool-Augmented LLM workflow, encompassing 53 commonly used API tools and 264 annotated dialogues, encompassing a total of 568 API calls. Furthermore, the ToolBench project [191] aims to empower the development of large language models that effectively leverage the capabilities of general-purpose tools. By providing a platform for creating optimized instruction datasets, the ToolBench project seeks to drive progress in language models and enhance their practical applications. To evaluate LLMs in multi-turn interactions, Wang et al. [213] proposed MINT, which utilizes tools and natural language feedback.
除了现有的评估基准外,在评估大语言模型(LLM)使用工具的有效性方面还存在研究空白。为解决这一问题,API-Bank基准[109]作为首个专为工具增强型大语言模型设计的基准被提出。它包含一个完整的工具增强型大语言模型工作流程,涵盖53个常用API工具和264个标注对话,共计568次API调用。此外,ToolBench项目[191]旨在推动能有效利用通用工具能力的大语言模型开发。通过提供创建优化指令数据集的平台,ToolBench项目致力于推动语言模型的进步并增强其实际应用。为评估大语言模型在多轮交互中的表现,Wang等人[213]提出了MINT方法,该方法利用工具和自然语言反馈。
Table 8. Summary of new LLMs evaluation protocols.
| Method | References | ||
| Human-in-the-loop | AdaVision [50], AdaTest [164] | ||
| Crowd-sourcingtesting | DynaBench [94], DynaBoard | [132],DynamicTempLAMA | A [135],DynaTask [188] |
| More challenging tests | HELM [114],AdaFilter [157], CheckList | [165],Big-Bench | [182],DeepTest [190] |
表 8: 新大语言模型评估方法总结
| 方法 | 参考文献 |
|---|---|
| 人在回路 (Human-in-the-loop) | AdaVision [50], AdaTest [164] |
| 众包测试 (Crowd-sourcingtesting) | DynaBench [94], DynaBoard [132], DynamicTempLAMA [135], DynaTask [188] |
| 更具挑战性的测试 (More challenging tests) | HELM [114], AdaFilter [157], CheckList [165], Big-Bench [182], DeepTest [190] |
4.3 Benchmarks for Multi-modal task
4.3 多模态任务基准测试
For the evaluation of Multimodal Large Language Models (MLLMs), MME [46] serves as an extensive evaluative benchmark, aiming to assess their perceptual and cognitive aptitudes. It employs meticulously crafted instruction-answer pairs alongside succinct instruction design, thereby guaranteeing equitable evaluation conditions. To robustly evaluate large-scale vision-language models, Liu et al. [126] introduced MMBench, which comprises a comprehensive dataset and employs a Circular E val assessment method. Additionally, MMICL [255] enhances visual language models for multimodal inputs and excels in tasks such as MME and MMBench. Furthermore, LAMM [235] extends its research to encompass multimodal point clouds. LVLM-eHub [231] undertakes an exhaustive evaluation of LVLMs using an online competitive platform and quantitative capacity assessments. To comprehensively assess the generative and understanding capabilities of Multi-modal Large Language Models (MLLMs), Li et al. [107] introduced a novel benchmark named SEED-Bench. This benchmark consists of 19,000 multiple-choice questions that have been annotated by human assessors. Additionally, the evaluation covers 12 different aspects, including the models’ proficiency in understanding patterns within images and videos. In summary, recent works have developed robust benchmarks and improved models that advance the study of multimodal languages.
在多模态大语言模型(Multimodal Large Language Models, MLLMs)评估方面,MME [46]作为综合性评估基准,旨在检验模型的感知与认知能力。该基准采用精心设计的指令-答案对及简洁指令结构,确保评估条件公平性。为全面评估大规模视觉语言模型,Liu等人[126]提出了包含丰富数据集的MMBench,并采用环形评估(Circular Eval)方法。此外,MMICL [255]通过增强视觉语言模型的多模态输入处理能力,在MME和MMBench等任务中表现优异。LAMM [235]则将研究范围扩展至多模态点云领域。LVLM-eHub [231]通过在线竞技平台和量化能力评估对LVLMs进行系统性测评。为全面评估多模态大语言模型的生成与理解能力,Li等人[107]提出包含19,000道人工标注选择题的新基准SEED-Bench,评测涵盖图像/视频模式理解等12个维度。总体而言,近期研究通过建立强健的评估基准和改进模型,推动了多模态语言研究的发展。
5 HOW TO EVALUATE
5 如何评估
In this section, we introduce two common evaluation methods: automatic evaluation and human evaluation. Our categorization is based on whether or not the evaluation criterion can be automatically computed. If it can be automatically calculated, we categorize it into automatic evaluation; otherwise, it falls into human evaluation.
在本节中,我们介绍两种常见的评估方法:自动评估和人工评估。我们的分类依据是评估标准是否能够自动计算。如果可以自动计算,则归类为自动评估;否则,归入人工评估。
5.1 Automatic Evaluation
5.1 自动评估
Automated evaluation is a common, and perhaps the most popular, evaluation method that typically uses standard metrics and evaluation tools to evaluate model performance. Compared with human evaluation, automatic evaluation does not require intensive human participation, which not only saves time, but also reduces the impact of human subjective factors and makes the evaluation process more standardized. For example, both Qin et al. [159] and Bang et al. [6] use automated evaluation methods to evaluate a large number of tasks. Recently, with the development of LLMs, some advanced automatic evaluation techniques are also designed to help evaluate. Lin and Chen [121] proposed LLM-EVAL, a unified multidimensional automatic evaluation method for open-domain conversations with LLMs. PandaLM [216] can achieve reproducible and automated language model assessment by training an LLM that serves as the “judge” to evaluate different models. Proposing a self-supervised evaluation framework, Jain et al. [82] enabled a more efficient form of evaluating models in real-world deployment by eliminating the need for laborious labeling of new data. In addition, many benchmarks also apply automatic evaluation, such as MMLU [70], HELM[114], C-Eval [78], AGIEval [262], AlpacaFarm [38], Chatbot Arena [128], etc.
自动化评估是一种常见且可能是最流行的评估方法,通常使用标准指标和评估工具来衡量模型性能。与人工评估相比,自动评估无需密集的人力参与,不仅节省时间,还能减少人类主观因素的影响,使评估过程更加标准化。例如,Qin等[159]和Bang等[6]都采用自动化评估方法对大量任务进行评测。近年来,随着大语言模型的发展,一些先进的自动评估技术也被设计出来辅助评测。Lin和Chen[121]提出了LLM-EVAL,这是一种面向大语言模型开放域对话的统一多维自动评估方法。PandaLM[216]通过训练一个充当"裁判"的大语言模型来评估不同模型,实现了可复现的自动化语言模型评估。Jain等[82]提出了一种自监督评估框架,通过消除对新数据进行繁琐标注的需求,实现了现实部署中更高效的模型评估形式。此外,许多基准测试也应用了自动评估,如MMLU[70]、HELM[114]、C-Eval[78]、AGIEval[262]、AlpacaFarm[38]、Chatbot Arena[128]等。
Table 9. Key metrics of automatic evaluation.
| Generalmetrics | Metrics |
| Accuracy | Exactmatch,Quasi-exact match,F1score,ROUGEscore [118] |
| Calibrations | Expectedcalibrationerror [60],Areaunderthecurve [54] |
| Fairness | Demographic parity difference [242],Equalizedoddsdifference [64] |
| Robustness | Attack success rate[203],Performance drop rate[264] |
表 9: 自动评估的关键指标
| 通用指标 | 指标项 |
|---|---|
| 准确度 | 精确匹配、准精确匹配、F1分数、ROUGE分数 [118] |
| 校准度 | 预期校准误差 [60]、曲线下面积 [54] |
| 公平性 | 人口统计均等差异 [242]、均衡机会差异 [64] |
| 鲁棒性 | 攻击成功率 [203]、性能下降率 [264] |
Based on the literature that adopted automatic evaluation, we summarized the main metrics in automatic evaluation in Table 9. The key metrics include the following four aspects:
基于采用自动评估的文献,我们在表9中总结了自动评估的主要指标。关键指标包括以下四个方面:
(1) Accuracy is a measure of how correct a model is on a given task. The concept of accuracy may vary in different scenarios and is dependent on the specific task and problem definition. It can be measured using various metrics such as Exact Match, F1 score, and ROUGE score. • Exact Match (EM) is a metric used to evaluate whether the model’s output in text generation tasks precisely matches the reference answer. In question answering tasks, if the model’s generated answer is an exact match with the manually provided answer, the EM is 1; otherwise, it is 0. • The F1 score is a metric for evaluating the performance of binary classification models, combining the model’s precision and recall. The formula for calculation is as follows: $F1=$ $\frac{2\times P r e c i s i o n\times R e c a l l}{P r e c i s i o n+R e c a l l}$ . • ROUGE is primarily employed to assess the performance of tasks such as text sum mari z ation and machine translation, involving considerations of overlap and matching between texts.
(1) 准确率是衡量模型在给定任务上正确程度的指标。准确率的概念在不同场景下可能有所差异,取决于具体任务和问题定义。它可以通过多种指标来衡量,例如精确匹配 (Exact Match)、F1分数和ROUGE分数。
• 精确匹配 (EM) 是用于评估文本生成任务中模型输出是否与参考答案完全一致的指标。在问答任务中,若模型生成的答案与人工提供的答案完全一致,则EM为1;否则为0。
• F1分数是评估二分类模型性能的指标,综合了模型的精确率和召回率。计算公式如下:$F1=$ $\frac{2\times P r e c i s i o n\times R e c a l l}{P r e c i s i o n+R e c a l l}$。
• ROUGE主要用于评估文本摘要和机器翻译等任务的性能,涉及文本之间的重叠和匹配考量。
) Calibrations pertains to the degree of agreement between the confidence level of the model output and the actual prediction accuracy. • Expected Calibration Error (ECE) is one of the commonly used metrics to evaluate model calibration performance [60]. Tian et al. [189] utilized ECE to study the calibration of RLHFLMs, including ChatGPT, GPT-4, Claude 1, Claude 2 and Llama2. For the calculation of ECE, they categorize model predictions based on confidence and measure the average accuracy of the predictions within each confidence interval. • Area Under the Curve of selective accuracy and coverage (AUC) [54] is another commonly used metric.
• 校准 (Calibrations) 指模型输出置信度与实际预测准确度的一致性程度。
• 预期校准误差 (Expected Calibration Error, ECE) 是评估模型校准性能的常用指标之一 [60]。Tian 等人 [189] 使用 ECE 研究了包括 ChatGPT、GPT-4、Claude 1、Claude 2 和 Llama2 在内的 RLHFLMs 的校准情况。计算 ECE 时,他们根据置信度对模型预测进行分类,并测量每个置信区间内预测的平均准确率。
• 选择性准确率与覆盖率曲线下面积 (Area Under the Curve of selective accuracy and coverage, AUC) [54] 是另一个常用指标。
(3) Fairness refers to whether the model treats different groups consistently, that is, whether the model’s performance is equal across different groups. This can include attributes such as gender, race, age, and more. Decoding Trust [201] employs the following two metrics for measuring fairness:
公平性 (Fairness) 指模型是否对不同群体保持一致的对待,即模型在不同群体间的表现是否平等。这可以包括性别、种族、年龄等属性。Decoding Trust [201] 采用以下两个指标来衡量公平性:
• Demographic Parity Pifference (DPD) measures whether the model’s predictions are distributed equally across different population groups. If predictions differ significantly between groups, the DPD is high, indicating that the model may be unfairly biased against different groups. The calculation of DPD involves the prediction of the model and the true label, and the following formula can be used: $D P D=P(\hat{y}|Z=1)-P(\hat{y}|Z=0)$ , where $\hat{y}$ is the binary classification prediction of the model, $Z$ is the identifier of the population group (usually binary, indicating two different groups, such as men and women), $P(\hat{y}|Z=1)$ and $P(\hat{y}|Z=0)$ respectively represent the probabilities of predicting the positive class in population $Z=1$ and $Z=0$ .
• 人口统计均等差异 (Demographic Parity Difference, DPD) 用于衡量模型预测结果在不同人群组中的分布是否均衡。若预测结果在组间差异显著,则DPD值较高,表明模型可能对不同群体存在不公平偏见。DPD的计算涉及模型预测与真实标签,可采用以下公式:$D P D=P(\hat{y}|Z=1)-P(\hat{y}|Z=0)$,其中$\hat{y}$为模型的二分类预测结果,$Z$为人群组标识符(通常为二元变量,表示两个不同群体,例如男性和女性),$P(\hat{y}|Z=1)$与$P(\hat{y}|Z=0)$分别表示在$Z=1$和$Z=0$人群中预测为正类的概率。
• Equalized Odds Difference (EOD) aims to ensure that the model provides equal error rates across different populations, that is, the model’s prediction error probability distribution is similar for different populations. The calculation of EOD involves probabilities related to true positive (TP), true negative (TN), false positive (FP), and false negative (FN) predictions. The formula for EOD is as follows: $max{P(\hat{y}=1|Y=1,Z=1)-P(\hat{y}=1|Y=1,Z=0),P(\hat{y}=1|Y=1,Z=1)}$ ${1|Y=0,Z=1)-P(\hat{y}=1|Y=0,Z=0)}$ where $\hat{y}$ is the binary classification prediction of the model, $Y$ is the true label, $Z$ is the demographic group identifier (typically binary, representing two different groups), and $P(\hat{y}=1|Y=1,Z=1)$ denotes the probability of the model predicting a positive class when the true label is positive and belongs to group $Z=1$ .
• 均衡几率差异 (Equalized Odds Difference, EOD) 旨在确保模型在不同群体间提供相同的错误率,即模型的预测错误概率分布对不同群体相似。EOD的计算涉及真阳性 (True Positive, TP)、真阴性 (True Negative, TN)、假阳性 (False Positive, FP) 和假阴性 (False Negative, FN) 预测的相关概率。EOD的公式如下:
$m a x{P(\hat{y}=1|Y=1,Z=1)-P(\hat{y}=1|Y=1,Z=0),P(\hat{y}=1|Y=1,Z=1)}$
${1|Y=0,Z=1)-P(\hat{y}=1|Y=0,Z=0)}$
其中 $\hat{y}$ 是模型的二分类预测,$Y$ 是真实标签,$Z$ 是人口群体标识符(通常为二元,表示两个不同群体),$P(\hat{y}=1|Y=1,Z=1)$ 表示当真实标签为阳性且属于群体 $Z=1$ 时,模型预测为阳性类的概率。
(4) Robustness evaluates the performance of a model in the face of various challenging inputs, including adversarial attacks, changes in data distribution, noise, etc.
(4) 鲁棒性 (Robustness) 评估模型在面对各种挑战性输入时的性能表现,包括对抗攻击 (adversarial attacks)、数据分布变化、噪声干扰等。
• Attack Success Rate (ASR) serves as a metric for evaluating the adversarial robustness of LLMs [206]. Specifically, consider a dataset $\mathcal{D}={(x_ {i},y_ {i})}_ {i=1}^{N}$ containing $N$ pairs of samples $x_ {i}$ and ground truth $y_ {i}$ . For an adversarial attack method $\mathcal{A}$ , given an input $x$ , this method can produce adversarial examples $\mathcal{A}(x)$ to attack surrogate model $f$ , with the success rate is calculated as: 𝐴𝑆𝑅 = Í(𝑥,𝑦∈𝐷) I[𝑓 (𝑓A𝑥(𝑥 )=)𝑦 𝑦 , where $\boldsymbol{\mathcal{I}}$ is the indicator function [203]. • Performance Drop Rate (PDR), a new unified metric, effectively assesses the robustness of prompt in LLMs [264]. PDR quantifies the relative performance degradation after a prompt attack, and the formula is as follows: $\begin{array}{r}{P D R=1-\frac{\bar{\sum_ {(x,y)\in D}{\mathcal{M}[f([A(P),x\bar{]}),y]}}}{\sum_ {(x,y)\in D}{\mathcal{M}[f([P,x]),y]}}}\end{array}$ Í(Í𝑥,(𝑦𝑥), 𝑦∈) 𝐷∈𝐷MM[ [(𝑓[([(𝑃,𝑥) ]),]𝑦) ] ] , where 𝐴 represents the adversarial attack applied to prompt $P$ , and $M$ denotes the evaluation function, which varies across different tasks [264].
• 攻击成功率 (ASR) 是评估大语言模型对抗鲁棒性的指标 [206]。具体而言,给定数据集 $\mathcal{D}={(x_ {i},y_ {i})}_ {i=1}^{N}$ 包含 $N$ 个样本 $x_ {i}$ 和真实标签 $y_ {i}$ 的组合。对于对抗攻击方法 $\mathcal{A}$,给定输入 $x$,该方法能生成对抗样本 $\mathcal{A}(x)$ 来攻击代理模型 $f$,其成功率计算公式为:𝐴𝑆𝑅 = Í(𝑥,𝑦∈𝐷) I[𝑓 (𝑓A𝑥(𝑥 )=)𝑦 𝑦,其中 $\boldsymbol{\mathcal{I}}$ 是指示函数 [203]。
• 性能下降率 (PDR) 作为新型统一指标,能有效评估大语言模型中提示的鲁棒性 [264]。该指标量化提示攻击后的相对性能衰减,计算公式为:$\begin{array}{r}{P D R=1-\frac{\bar{\sum_ {(x,y)\in D}{\mathcal{M}[f([A(P),x\bar{]}),y]}}}{\sum_ {(x,y)\in D}{\mathcal{M}[f([P,x]),y]}}}\end{array}$ Í(Í𝑥,(𝑦𝑥), 𝑦∈) 𝐷∈𝐷MM[ [(𝑓[([(𝑃,𝑥) ]),]𝑦) ] ],其中 𝐴 表示应用于提示 $P$ 的对抗攻击,$M$ 为随任务变化的评估函数 [264]。
5.2 Human Evaluation
5.2 人工评估
The increasingly strengthened capabilities of LLMs have certainly gone beyond standard evaluation metrics on general natural language tasks. Therefore, human evaluation becomes a natural choice in some non-standard cases where automatic evaluation is not suitable. For instance, in open-generation tasks where embedded similarity metrics (such as BERTScore) are not enough, human evaluation is more reliable [142]. While some generation tasks can adopt certain automatic evaluation protocols, human evaluation in these tasks is more favorable as generation can always go better than standard answers.
大语言模型 (LLM) 日益增强的能力显然已超越通用自然语言任务的标准评估指标。因此,在自动评估不适用的非标准场景中,人工评估成为自然选择。例如,在开放生成任务中,当嵌入相似性指标(如 BERTScore)不足时,人工评估更为可靠 [142]。虽然某些生成任务可采用特定自动评估方案,但由于生成结果可能始终优于标准答案,这些任务中的人工评估仍更受青睐。
Human evaluation is a way to evaluate the quality and accuracy of model-generated results through human participation. Compared with automatic evaluation, manual evaluation is closer to the actual application scenario and can provide more comprehensive and accurate feedback. In the manual evaluation of LLMs, evaluators (such as experts, researchers, or ordinary users) are usually invited to evaluate the results generated by the model. For example, Ziems et al. [269] used the annotations from experts for generation. By human evaluation, Liang et al. [114] assessed on sum mari z ation and disinformation scenarios on 6 models and Bang et al. [6] evaluated analogical reasoning tasks. Bubeck et al. [15] did a series of human-crafted tests using GPT-4 and they found that GPT-4 performs close to or even exceeds human performance on multiple tasks. This evaluation requires human evaluators to actually test and compare the performance of the models, not just evaluate the models through automated evaluation metrics. Note that even human evaluations can have high variance and instability, which could be due to cultural and individual differences [155]. In practical applications, these two evaluation methods are considered and weighed in combination with the actual situation.
人工评估是一种通过人类参与来评价模型生成结果质量和准确性的方法。相比自动评估,人工评估更贴近实际应用场景,能提供更全面准确的反馈。在大语言模型的人工评估中,通常会邀请评估者(如专家、研究者或普通用户)对模型生成结果进行评判。例如,Ziems等人[269]采用了专家标注进行生成评估。Liang等人[114]通过人工评估对6个模型的摘要生成和虚假信息场景进行了测评,Bang等人[6]则评估了类比推理任务。Bubeck等人[15]使用GPT-4进行了一系列人工设计的测试,发现其在多项任务上的表现接近甚至超越人类水平。这类评估要求人类评估者实际测试比较模型表现,而非仅通过自动化评估指标进行评判。需注意的是,人工评估同样存在较高方差和不稳定性,这可能源于文化及个体差异[155]。实际应用中需结合具体情况对两种评估方法进行权衡考量。
Exploring the human evaluation methods of LLMs requires thoughtful attention to various crucial factors to guarantee the dependability and precision of assessments [178]. Table 10 provides a concise overview of the essential aspects of human evaluation, including the number of evaluators, evaluation criteria, and evaluator’s expertise level. Primarily, the number of evaluators emerges as a crucial factor intricately intertwined with adequate representation and statistical significance. A judiciously chosen number of evaluators contributes to a more nuanced and comprehensive understanding of the LLMs under scrutiny, enabling a more reliable extrapolation of the results to a broader context.
探索大语言模型(LLM)的人类评估方法需要审慎考虑多个关键因素,以确保评估的可靠性和准确性[178]。表10简要概述了人类评估的核心要素,包括评估者数量、评估标准和评估者专业水平。其中,评估者数量作为关键因素,与充分代表性和统计显著性密切相关。合理选择评估者数量有助于更细致全面地理解被测大语言模型,从而将结果更可靠地推及更广泛场景。
Table 10. Summary of key factors in human evaluation
| EvaluationCriteria | KeyFactor | |
| Numberofevaluators | Adequaterepresentation | [7],Statistical significance |
| Evaluationrubrics | Accuracy [178],Relevance [261],Fluency alignment | [196], Transparency,Safety [85], Human |
| Evaluator's expertiselevel | Relevantdomainexpertise | e[144],Taskfamiliarity,Methodological training |
表 10: 人工评估关键因素总结
| 评估标准 | 关键因素 |
|---|---|
| 评估者数量 | 充分代表性 [7], 统计显著性 |
| 评估细则 | 准确性 [178], 相关性 [261], 流畅性对齐 [196], 透明度, 安全性 [85], 人工 |
| 评估者专业水平 | 相关领域专业知识 [144], 任务熟悉度, 方法论训练 |
Furthermore, evaluation criteria are fundamental components of the human assessment process. Expanding upon the principles of the 3H rule (Helpfulness, Honesty, and Harmlessness) [4], we have elaborated them into the following 6 human assessment criteria. These criteria include accuracy, relevance, fluency, transparency, safety, and human alignment. Through the application of these standards, a thorough analysis of LLMs’ performance in syntax, semantics, and context is achieved, allowing for a more comprehensive evaluation of the quality of generated text.
此外,评估标准是人类评估过程的基本组成部分。基于3H规则(Helpfulness、Honesty、Harmlessness) [4] 的原则,我们将其细化为以下6项人类评估标准,包括准确性、相关性、流畅性、透明度、安全性以及人类对齐性。通过应用这些标准,可以实现对大语言模型在句法、语义和上下文表现上的全面分析,从而更全面地评估生成文本的质量。
Lastly, the expertise level of evaluators is a critical consideration, encompassing relevant domain knowledge, task familiarity, and methodological training. Delineating the requisite expertise level for evaluators ensures that they possess the necessary background knowledge to accurately comprehend and assess the domain-specific text generated by LLMs. This strategy adds a layer of rigor to the evaluation process, reinforcing the credibility and validity of the findings.
最后,评估者的专业水平是一个关键考量因素,包括相关领域知识、任务熟悉度以及方法学训练。明确评估者所需的专业水平能确保他们具备必要的背景知识,以准确理解和评估大语言模型生成的领域特定文本。这一策略为评估过程增添了严谨性,增强了研究结果的可信度和有效性。
6 SUMMARY
6 总结
In this section, we summarize the key findings based on our review in sections 3, 4, and 5.
在本节中,我们基于第3、4、5章的综述总结关键发现。
First of all, we would like to highlight that despite all the efforts spent on summarizing existing works on evaluation, there is no evidence to explicitly show that one certain evaluation protocol or benchmark is the most useful and successful, but with different characteristics and focuses. This also demonstrates that not a single model can perform best in all kinds of tasks. The purpose of this survey is to go beyond simply determining the “best” benchmark or evaluation protocol. By summarizing and analyzing existing efforts on LLMs evaluation, we may identify the current success and failure cases of LLMs, derive new trends for evaluation protocols, and most importantly, propose new challenges and opportunities for future research.
首先,我们要强调的是,尽管在总结现有评估工作方面付出了诸多努力,但尚无明确证据表明某一种评估方案或基准最具实用性和成功性,它们只是具备不同的特性和侧重点。这也说明没有任何单一模型能在所有任务中都表现最优。本综述的目的并非简单地判定"最佳"基准或评估方案,而是希望通过总结分析现有的大语言模型评估工作,明确当前的成功与失败案例,推导评估方案的新趋势,最重要的是为未来研究提出新的挑战与机遇。
6.1 Task: Success and Failure Cases of LLMs
6.1 任务:大语言模型 (LLM) 的成功与失败案例
We now summarize the success and failure cases of LLMs in different tasks. Note that all the following conclusions are made based on existing evaluation efforts and the results are only dependent on specific datasets.
我们现在总结大语言模型 (LLM) 在不同任务中的成功与失败案例。请注意,以下所有结论均基于现有评估工作,且结果仅依赖于特定数据集。
6.1.1 What can LLMs do well?
6.1.1 大语言模型擅长什么?
6.1.2 When can LLMs fail?
6.1.2 大语言模型何时会失效?
6.2 Benchmark and Evaluation Protocol
6.2 基准测试与评估协议
With the rapid development and widespread use of LLMs, the importance of evaluating them in practical applications and research has become crucial. This evaluation process should include not only task-level evaluation but also a deep understanding of the potential risks they pose from a societal perspective. In this section, we summarize existing benchmarks and protocols in Table 8.
随着大语言模型(LLM)的快速发展和广泛应用,评估其在实践应用与研究中的重要性变得至关重要。这一评估过程不仅应包括任务级评估,还需从社会角度深入理解其潜在风险。本节我们将现有基准和方案总结在表8中。
First, a shift from objective calculation to human-in-the-loop testing, allowing for greater human feedback during the evaluation process. AdaVision [50], an interactive process for testing vision models, enables users to label a small amount of data for model correctness, which helps users identify and fix coherent failure modes. In AdaTest [164], the user filters test samples by only selecting high-quality tests and organizing them into semantically related topics.
首先,从客观计算转向人在回路 (human-in-the-loop) 测试,允许在评估过程中获得更多人类反馈。AdaVision [50] 是一种用于测试视觉模型的交互式流程,它允许用户标记少量数据以验证模型正确性,从而帮助用户识别并修复连贯的故障模式。在 AdaTest [164] 中,用户通过仅选择高质量测试样本并将其组织到语义相关的主题中来筛选测试样本。
Second, a move from static to crowd-sourcing test sets is becoming more common. Tools like DynaBench [94], DynaBoard [132], and DynaTask [188] rely on crowd workers to create and test hard samples. Additionally, Dynamic Temp LAMA [135] allows for dynamically constructed time-related tests.
其次,从静态测试集转向众包测试集的做法正变得越来越普遍。DynaBench [94]、DynaBoard [132] 和 DynaTask [188] 等工具依赖众包工作者创建和测试困难样本。此外,Dynamic Temp LAMA [135] 支持动态构建时间相关的测试。
Third, a shift from a unified to a challenging setting in evaluating machine learning models. While unified settings involve a test set with no preference for any specific task, challenging settings create test sets for specific tasks. Tools like DeepTest [190] use seeds to generate input transformations for testing, CheckList [165] builds test sets based on templates, and AdaFilter [157] adversarial ly constructs tests. However, it is worth noting that AdaFilter may not be entirely fair as it relies on adversarial examples. HELM [114] evaluates LLMs from different aspects, while the Big-Bench [182] platform is used to design hard tasks for machine learning models to tackle. Prompt Bench [264] aims to evaluate the adversarial robustness of LLMs by creating adversarial prompts, which is more challenging and the results demonstrated that current LLMs are not robust to adversarial prompts.
第三,从统一评估转向挑战性评估机器学习模型的转变。统一评估使用无特定任务偏好的测试集,而挑战性评估则为特定任务构建测试集。DeepTest [190] 等工具通过种子生成输入变换进行测试,CheckList [165] 基于模板构建测试集,AdaFilter [157] 则采用对抗方式构造测试。但需注意,AdaFilter 可能不完全公平,因其依赖对抗样本。HELM [114] 从多维度评估大语言模型,Big-Bench [182] 平台专为机器学习模型设计高难度任务。Prompt Bench [264] 通过生成对抗性提示词来评估大语言模型的抗干扰鲁棒性,其更具挑战性的测试结果表明当前大语言模型对对抗性提示缺乏稳健性。
7 GRAND CHALLENGES AND OPPORTUNITIES FOR FUTURE RESEARCH
7 未来研究的重大挑战与机遇
Evaluation as a new discipline: Our sum mari z ation inspires us to redesign a wide spectrum of aspects related to evaluation in the era of LLMs. In this section, we present several grand challenges. Our key point is that evaluation should be treated as an essential discipline to drive the success of LLMs and other AI models. Existing protocols are not enough to thoroughly evaluate the true capabilities of LLMs, which poses grand challenges and triggers new opportunities for future research on LLMs evaluation.
评估作为新兴学科:我们的总结启发我们重新设计与大语言模型(LLM)时代评估相关的广泛领域。本节将提出若干重大挑战,核心观点在于应将评估视为推动大语言模型及其他AI模型成功的关键学科。现有评估方案尚不足以全面检验大语言模型的真实能力,这既构成重大挑战,也为未来大语言模型评估研究创造了新机遇。
7.1 Designing AGI Benchmarks
7.1 设计通用人工智能(AGI)基准
As we discussed earlier, while all tasks can potentially serve as evaluation tools for LLMs, the question remains as to which can truly measure AGI capabilities. As we expect LLMs to demonstrate AGI abilities, a comprehensive understanding of the differences between human and AGI capacities becomes crucial in the creation of AGI benchmarks. The prevailing trend seems to conceptualize AGI as a superhuman entity, thereby utilizing cross-disciplinary knowledge from fields such as education, psychology, and social sciences to design innovative benchmarks. Nonetheless, there remains a plethora of unresolved issues. For instance, does it make sense to use human values as a starting point for test construction, or should alternative perspectives be considered? Developing suitable AGI benchmarks presents many open questions demanding further exploration.
正如我们之前所讨论的,虽然所有任务都可能作为大语言模型的评估工具,但问题在于哪些才能真正衡量通用人工智能能力。随着我们期望大语言模型展现通用人工智能能力,全面理解人类与通用人工智能能力之间的差异对于创建通用人工智能基准变得至关重要。当前趋势似乎将通用人工智能概念化为超人实体,从而利用教育、心理学和社会科学等领域的跨学科知识来设计创新基准。然而,仍存在大量未解决的问题。例如,以人类价值观作为测试构建的起点是否有意义,还是应考虑其他视角?开发合适的通用人工智能基准提出了许多有待进一步探索的开放性问题。
7.2 Complete Behavioral Evaluation
7.2 完整行为评估
An ideal AGI evaluation should contain not only standard benchmarks on common tasks, but also evaluations on open tasks such as complete behavioral tests. By behavioral test, we mean that AGI models should also be evaluated in an open environment. For instance, by treating LLMs as the central controller, we can construct evaluations on a robot manipulated by LLMs to test its behaviors in real situations. By treating LLMs as a completely intelligent machine, the evaluations of its multi-modal dimensions should also be considered. In fact, complete behavioral evaluations are complementary to standard AGI benchmarks and they should work together for better testing.
理想的通用人工智能(AGI)评估不仅应包含常见任务的标准基准测试,还应涵盖开放性任务的评估,例如完整的行为测试。所谓行为测试,是指AGI模型需要在开放环境中进行评估。例如,将大语言模型作为中央控制器,我们可以构建对由其操控的机器人进行评估,以测试其在真实场景中的行为表现。若将大语言模型视为完全智能的机器,其多模态维度的评估同样需要纳入考量。事实上,完整的行为评估与标准AGI基准测试互为补充,二者应协同作用以实现更全面的测试。
7.3 Robustness Evaluation
7.3 鲁棒性评估
Beyond general tasks, it is crucial for LLMs to maintain robustness against a wide variety of inputs in order to perform optimally for end-users, given their extensive integration into daily life. For instance, the same prompts but with different grammars and expressions could lead ChatGPT and other LLMs to generate diverse results, indicating that current LLMs are not robust to the inputs. While there are some prior work on robustness evaluation [206, 264], there are much room for advancement, such as including more diverse evaluation sets, examining more evaluation aspects, and developing more efficient evaluations to generate robustness tasks. Concurrently, the concept and definition of robustness are constantly evolving. It is thus vital to consider updating the evaluation system to better align with emerging requirements related to ethics and bias.
除了通用任务外,鉴于大语言模型(LLM)在日常生活中的广泛应用,确保其对各类输入的鲁棒性至关重要,从而为终端用户提供最佳性能。例如,相同提示但采用不同语法和表达方式时,ChatGPT等大语言模型可能生成截然不同的结果,这表明当前大语言模型对输入的鲁棒性不足。尽管已有一些关于鲁棒性评估的研究[206, 264],但在构建更多样化的评估集、考察更全面的评估维度、开发更高效的鲁棒性任务生成方法等方面仍有改进空间。与此同时,鲁棒性的概念和定义也在持续演进。因此,及时更新评估体系以更好地适应伦理和偏见等新兴需求显得尤为重要。
7.4 Dynamic and Evolving Evaluation
7.4 动态演进式评估
Existing evaluation protocols for most AI tasks rely on static and public benchmarks, i.e., the evaluation datasets and protocols are often publicly available. While this facilitates rapid and convenient evaluation within the community, it is unable to accurately assess the evolving abilities of LLMs, given their rapid rate of development. The capabilities of LLMs may enhance over time which cannot be consistently evaluated by existing static benchmarks. On the other hand, as LLMs grow increasingly powerful with larger model sizes and training set sizes, static and public benchmarks are likely to be memorized by LLMs, resulting in potential training data contamination. Therefore, developing dynamic and evolving evaluation systems is the key to providing a fair evaluation of LLMs.
现有针对大多数AI任务的评估协议依赖于静态公开基准,即评估数据集和协议通常对外公开。虽然这便于在社区内快速便捷地进行评估,但鉴于大语言模型(LLM)的快速发展速度,静态基准无法准确评估其持续演进的能力。随着时间推移,大语言模型的能力可能不断提升,而现有静态基准无法持续反映这种进步。另一方面,随着模型规模和训练集规模扩大,日益强大的大语言模型可能会记忆静态公开基准,导致潜在的训练数据污染问题。因此,开发动态演进的评估系统是实现大语言模型公平评估的关键。
7.5 Principled and Trustworthy Evaluation
7.5 原则性与可信度评估
When introducing an evaluation system, it is crucial to ascertain its integrity and trustworthiness. Therefore, the necessity for trustworthy computing extends to the requirement for reliable evaluation systems as well. This poses a challenging research question that intertwines with measurement theory, probability, and numerous other domains. For instance, how can we ensure that dynamic testing truly generates out-of-distribution examples? There is a scarcity of research in this domain, and it is hoped that future work will aim to scrutinize not only the algorithms but the evaluation system itself.
在引入评估系统时,确保其完整性和可信度至关重要。因此,可信计算的需求同样延伸至可靠评估系统的要求。这提出了一个与测量理论、概率及众多领域交织的挑战性研究问题。例如,如何确保动态测试真正生成分布外样本?该领域的研究尚显不足,期待未来工作不仅能审视算法,还能深入检验评估系统本身。
7.6 Unified Evaluation that Supports All LLMs Tasks
7.6 支持所有大语言模型任务的统一评估
There are many other research areas of LLMs and we need to develop evaluation systems that can support all kinds of tasks such as value alignment, safety, verification, interdisciplinary research, fine-tuning, and others. For instance, PandaLM [216] is an evaluation system that assists LLMs
大语言模型还有许多其他研究领域,我们需要开发能够支持各类任务的评估系统,包括价值对齐、安全性、验证、跨学科研究、微调等。例如,PandaLM [216] 就是一个辅助大语言模型的评估系统。
fine-tuning by providing an open-source evaluation model, which can automatically assess the performance of fine-tuning. We expect that more evaluation systems are becoming more general and can be used as assistance in certain LLMs tasks.
通过提供开源评估模型来优化微调过程,该模型可自动评估微调性能。我们期待更多评估系统趋向通用化,能够辅助特定大语言模型任务。
7.7 Beyond Evaluation: LLMs Enhancement
7.7 超越评估:大语言模型 (LLM) 增强
Ultimately, evaluation is not the end goal but rather the starting point. Following the evaluation, there are undoubtedly conclusions to be drawn regarding performance, robustness, stability, and other factors. A proficient evaluation system should not only offer benchmark results but should also deliver an insightful analysis, recommendations, and guidance for future research and development. For instance, Prompt Bench [264] provides not only robustness evaluation results on adversarial prompts but also a comprehensive analysis through attention visualization, elucidating how adversarial texts can result in erroneous responses. The system further offers a word frequency analysis to identify robust and non-robust words in the test sets, thus providing prompt engineering guidance for end users. Subsequent research can leverage these findings to enhance LLMs. Another example is that Wang et al. [215] first explored the performance of large vision-language models on imbalanced (long-tailed) tasks, which demonstrates the limitation of current large models. Then, they explored different methodologies to enhance the performance on these tasks. In summary, enhancement after evaluation helps to build better LLMs and much can be done in the future.
最终,评估并非终点,而是起点。在评估之后,必然会得出关于性能、鲁棒性、稳定性等方面的结论。一个优秀的评估系统不仅应提供基准测试结果,还应提供深入的分析、建议以及对未来研发的指导。例如,Prompt Bench [264] 不仅提供了对抗性提示 (adversarial prompts) 的鲁棒性评估结果,还通过注意力可视化进行了全面分析,阐明了对抗性文本如何导致错误响应。该系统还提供了词频分析,以识别测试集中的鲁棒和非鲁棒词汇,从而为终端用户提供提示工程 (prompt engineering) 指导。后续研究可以利用这些发现来改进大语言模型。另一个例子是 Wang 等人 [215] 的研究,他们首先探索了大视觉语言模型 (large vision-language models) 在不平衡(长尾)任务上的表现,揭示了当前大模型的局限性,随后探索了提升这些任务性能的不同方法。总之,评估后的改进有助于构建更好的大语言模型,未来还有许多工作可做。
8 CONCLUSION
8 结论
Evaluation carries profound significance, becoming imperative in the advancement of AI models, especially within the context of large language models. This paper presents the first survey to give a comprehensive overview of the evaluation on LLMs from three aspects: what to evaluate, how to evaluate, and where to evaluate. By encapsulating evaluation tasks, protocols, and benchmarks, our aim is to augment understanding of the current status of LLMs, elucidate their strengths and limitations, and furnish insights for future LLMs progression.
评估在AI模型尤其是大语言模型的发展中具有深远意义,已成为不可或缺的环节。本文首次从评估内容、评估方法和评估场景三个维度,系统综述了大语言模型的评估研究。通过梳理评估任务、评估协议和基准测试,我们旨在深化对大语言模型现状的认知,阐明其优势与局限,并为未来大语言模型的发展提供洞见。
Our survey reveals that current LLMs exhibit certain limitations in numerous tasks, notably reasoning and robustness tasks. Concurrently, the need for contemporary evaluation systems to adapt and evolve remains evident, ensuring the accurate assessment of LLMs’ inherent capabilities and limitations. We identify several grand challenges that future research should address, with the aspiration that LLMs can progressively enhance their service to humanity.
我们的调查显示,当前的大语言模型在众多任务中表现出一定局限性,尤其是推理和鲁棒性任务。与此同时,当代评估体系仍需适应和发展,以确保准确评估大语言模型的内在能力和局限。我们提出了未来研究应解决的若干重大挑战,并期望大语言模型能逐步提升其为人类服务的能力。
ACKNOWLEDGEMENTS
致谢
This work is supported in part by NSF under grant III-2106758.
本研究部分由美国国家科学基金会(NSF)资助(项目编号III-2106758)。
DISCLAIMER
免责声明
The goal of this paper is mainly to summarize and discuss existing evaluation efforts on large language models. Results and conclusions in each paper are original contributions of their corresponding authors, particularly for potential issues in ethics and biases. This paper may discuss some side effects of LLMs and the only intention is to foster a better understanding.
本文的主要目标是总结和讨论现有关于大语言模型 (Large Language Model) 的评估工作。各篇论文中的结果和结论均为对应作者原创贡献,特别是关于伦理和偏见方面的潜在问题。本文可能会讨论大语言模型的一些副作用,唯一目的是促进更深入的理解。
Due to the evolution of LLMs especially online services such as Claude and ChatGPT, it is very likely that they become stronger and some of the limitations described in this paper are mitigated (and new limitations may arise). We encourage interested readers to take this survey as a reference for future research and conduct real experiments in current systems when performing evaluations.
由于大语言模型 (LLM) 的演进,特别是 Claude 和 ChatGPT 等在线服务的出现,它们很可能变得更强大,本文所述的部分局限性将得到缓解 (同时可能出现新的局限性)。我们建议感兴趣的读者以本调研为未来研究参考,并在当前系统中进行实际实验以开展评估。
Finally, the evaluation of LLMs is continuously developing, thus we may miss some new papers or benchmarks. We welcome all constructive feedback and suggestions.
最后,大语言模型的评估仍在持续发展,因此我们可能遗漏了一些新论文或基准测试。欢迎提供所有建设性的反馈与建议。
REFERENCES
参考文献
Received 20 February 2007; revised 12 March 2009; accepted 5 June 2009
2007年2月20日收稿;2009年3月12日修订;2009年6月5日录用