A Survey on Knowledge Distillation of Large Language Models
大语言模型知识蒸馏综述
Abstract—In the era of Large Language Models (LLMs), Knowledge Distillation (KD) emerges as a pivotal methodology for transferring advanced capabilities from leading proprietary LLMs, such as GPT-4, to their open-source counterparts like LLaMA and Mistral. Additionally, as open-source LLMs flourish, KD plays a crucial role in both compressing these models, and facilitating their selfimprovement by employing themselves as teachers. This paper presents a comprehensive survey of KD’s role within the realm of LLM, highlighting its critical function in imparting advanced knowledge to smaller models and its utility in model compression and selfimprovement. Our survey is meticulously structured around three foundational pillars: algorithm, skill, and vertical iz ation – providing a comprehensive examination of KD mechanisms, the enhancement of specific cognitive abilities, and their practical implications across diverse fields. Crucially, the survey navigates the interaction between data augmentation (DA) and KD, illustrating how DA emerges as a powerful paradigm within the KD framework to bolster LLMs’ performance. By leveraging DA to generate context-rich, skillspecific training data, KD transcends traditional boundaries, enabling open-source models to approximate the contextual adeptness, ethical alignment, and deep semantic insights characteristic of their proprietary counterparts. This work aims to provide an insightful guide for researchers and practitioners, offering a detailed overview of current methodologies in knowledge distillation and proposing future research directions. By bridging the gap between proprietary and open-source LLMs, this survey underscores the potential for more accessible, efficient, and powerful AI solutions. Most importantly, we firmly advocate for compliance with the legal terms that regulate the use of LLMs, ensuring ethical and lawful application of KD of LLMs. An associated Github repository is available at https://github.com/Tebmer/Awesome-Knowledge-Distillation-of-LLMs.
摘要—在大语言模型(LLM)时代,知识蒸馏(KD)成为将GPT-4等领先专有大语言模型的高级能力迁移至LLaMA、Mistral等开源模型的关键方法。此外,随着开源大语言模型的蓬勃发展,KD在模型压缩和通过自我教学实现模型自提升方面都发挥着至关重要的作用。本文系统综述了KD在大语言模型领域的作用,重点阐述了其在向小型模型传递高级知识方面的核心功能,以及在模型压缩与自提升中的应用价值。我们的综述围绕算法、技能和垂直化三大支柱展开——全面考察了KD机制、特定认知能力的增强及其在不同领域的实际应用。尤为关键的是,本文探讨了数据增强(DA)与KD的协同作用,阐明了DA如何作为KD框架内的强大范式来提升大语言模型性能。通过利用DA生成富含上下文、技能特定的训练数据,KD突破了传统限制,使开源模型能够接近专有模型所具备的上下文适应能力、伦理对齐和深层语义理解。本工作旨在为研究者和实践者提供深度指南,详细梳理当前知识蒸馏方法体系,并展望未来研究方向。通过弥合专有与开源大语言模型之间的鸿沟,本综述揭示了构建更易获取、更高效、更强大AI解决方案的潜力。最重要的是,我们坚决主张遵守大语言模型使用的法律条款,确保LLM知识蒸馏的伦理与合法应用。相关Github仓库详见https://github.com/Tebmer/Awesome-Knowledge-Distillation-of-LLMs。
Index Terms—Large language models, knowledge distillation, data augmentation, skill distillation, supervised fine-tuning
索引术语—大语言模型 (Large Language Model)、知识蒸馏 (knowledge distillation)、数据增强 (data augmentation)、技能蒸馏 (skill distillation)、监督微调 (supervised fine-tuning)
1 INTRODUCTION
1 引言
In the evolving landscape of artificial intelligence (AI), proprietary 1 Large Language Models (LLMs) such as GPT3.5 (Ouyang et al., 2022), GPT-4 (OpenAI et al., 2023), Gemini (Team et al., 2023) and Claude2 have emerged as groundbreaking technologies, reshaping our understanding of natural language processing (NLP). These models, characterized by their vast scale and complexity, have unlocked new realms of possibility, from generating human-like text to offering sophisticated problem-solving capabilities. The core significance of these LLMs lies in their emergent abilities (Wei et al., 2022a,b; Xu et al., 2024a), a phenomenon where the models display capabilities beyond their explicit training objectives, enabling them to tackle a diverse array of tasks with remarkable proficiency. These models excel in understanding and generation, driving applications from creative generation to complex problem-solving (OpenAI et al., 2023; Liang et al., 2022). The potential of these models extends far beyond current applications, promising to revolutionize industries, augment human creativity, and redefine our interaction with technology.
在人工智能 (AI) 快速发展的背景下,诸如 GPT3.5 (Ouyang et al., 2022)、GPT-4 (OpenAI et al., 2023)、Gemini (Team et al., 2023) 和 Claude2 等专有大语言模型 (LLM) 已成为突破性技术,重塑了我们对自然语言处理 (NLP) 的认知。这些模型以其庞大的规模和复杂性为特征,开启了从生成类人文本到提供复杂问题解决能力的新可能性领域。这些大语言模型的核心意义在于其涌现能力 (Wei et al., 2022a,b; Xu et al., 2024a),即模型展现出超越其明确训练目标的能力,使其能够以卓越的熟练度处理各种任务。这些模型在理解和生成方面表现出色,推动了从创意生成到复杂问题解决的应用 (OpenAI et al., 2023; Liang et al., 2022)。这些模型的潜力远超当前应用范围,有望彻底改变行业、增强人类创造力并重新定义我们与技术的交互方式。
Despite the remarkable capabilities of proprietary LLMs like GPT-4 and Gemini, they are not without their shortcomings, particularly when viewed in light of the advantages offered by open-source models. A significant drawback is their limited accessibility and higher cost (OpenAI et al., 2023). These proprietary models often come with substantial usage fees and restricted access, making them less attainable for individuals and smaller organizations. In terms of data privacy and security (Wu et al., 2023a), using these proprietary LLMs frequently entails sending sensitive data to external servers, which raises concerns about data privacy and security. This aspect is especially critical for users handling confidential information. Moreover, the generalpurpose design of proprietary LLMs, while powerful, may not always align with the specific needs of niche applications. The constraints of accessibility, cost, and adaptability thus present significant challenges in leveraging the full potential of proprietary LLMs.
尽管像GPT-4和Gemini这样的专有大语言模型具有卓越能力,但它们并非没有缺点,尤其是与开源模型提供的优势相比。一个显著缺陷是其有限的可用性和较高成本 (OpenAI et al., 2023)。这些专有模型通常伴随着高昂的使用费用和受限的访问权限,使得个人和小型组织难以获取。在数据隐私和安全性方面 (Wu et al., 2023a),使用这些专有大语言模型往往需要将敏感数据发送到外部服务器,这引发了关于数据隐私和安全的担忧。对于处理机密信息的用户而言,这一点尤为关键。此外,专有大语言模型的通用设计虽然强大,但可能并不总是符合特定领域应用的需求。因此,可用性、成本和适应性的限制对充分发挥专有大语言模型的潜力构成了重大挑战。
In contrast to proprietary LLMs, open-source models like LLaMA (Touvron et al., 2023) and Mistral (Jiang et al., 2023a) bring several notable advantages. One of the primary benefits of open-source models is their accessibility and adaptability. Without the constraints of licensing fees or restrictive usage policies, these models are more readily available to a broader range of users, from individual researchers to smaller organizations. This openness fosters a more collaborative and inclusive AI research environment, encouraging innovation and diverse applications. Additionally, the customizable nature of open-source LLMs allows for more tailored solutions, addressing specific needs that generic, large-scale models may not meet.
与专有大语言模型相比,LLaMA (Touvron et al., 2023) 和 Mistral (Jiang et al., 2023a) 等开源模型具有多项显著优势。开源模型的主要优点之一是其可访问性和适应性。由于不受许可费用或严格使用政策的限制,这些模型更容易被更广泛的用户群体获取,从个体研究者到小型组织皆可受益。这种开放性促进了更具协作性和包容性的人工智能研究环境,鼓励创新和多样化应用。此外,开源大语言模型的可定制特性使其能够提供更贴合需求的解决方案,解决通用大规模模型可能无法满足的特定需求。
However, the open-source LLMs also have their own set of drawbacks, primarily stemming from their relatively limited scale and resources compared to their proprietary counterparts. One of the most significant limitations is the smaller model scale, which often results in lower performance on real-world tasks with a bunch of instructions (Zheng et al., 2023a). These models, with fewer parameters, may struggle to capture the depth and breadth of knowledge embodied in larger models like GPT-4. Additionally, the pre-training investment in these open-source models is typically less substantial. This reduced investment can lead to a narrower range of pre-training data, potentially limiting the models’ understanding and handling of diverse or specialized topics (Liang et al., 2022; Sun et al., 2024a). Moreover, open-source models often undergo fewer fine-tuning steps due to resource constraints. Fine-tuning is crucial for optimizing a model’s performance for specific tasks or industries, and the lack thereof can hinder the model’s effectiveness in specialized applications. This limitation becomes particularly evident when these models are compared to the highly fine-tuned proprietary LLMs, which are often tailored to excel in a wide array of complex scenarios (OpenAI et al., 2023).
然而,开源大语言模型也存在固有缺陷,主要源于其规模与资源相较于闭源模型的局限性。最显著的制约在于模型规模较小,这往往导致其在处理复杂指令的现实任务时表现欠佳 (Zheng et al., 2023a) 。这类参数量较少的模型难以企及GPT-4等大型模型所涵盖的知识深度与广度。此外,开源模型通常获得的预训练投入相对有限,可能导致预训练数据覆盖面较窄,进而制约模型对多元化或专业化主题的理解与处理能力 (Liang et al., 2022; Sun et al., 2024a) 。由于资源限制,开源模型的微调步骤也往往较少,而微调对于优化模型在特定任务或行业的性能至关重要。这种缺陷在与经过深度优化的闭源大语言模型对比时尤为明显——后者通常被精心调校以适应各种复杂场景 (OpenAI et al., 2023) 。
Primarily, recognizing the disparities between proprietary and open-source LLMs, KD techniques have surged as a means to bridge the performance gap between these models (Gou et al., 2021; Gupta and Agrawal, 2022). Knowledge distillation, in this context, involves leveraging the more advanced capabilities of leading proprietary models like GPT-4 or Gemini as a guiding framework to enhance the competencies of open-source LLMs. This process is akin to transferring the ‘knowledge’ of a highly skilled teacher to a student, wherein the student (e.g., open-source LLM) learns to mimic the performance characteristics of the teacher (e.g., proprietary LLM). Compared to traditional knowledge distillation algorithms (Gou et al., 2021), data augmentation (DA) (Feng et al., 2021) has emerged as a prevalent paradigm to achieve knowledge distillation of LLMs, where a small seed of knowledge is used to prompt the LLM to generate more data with respect to a specific skill or domain (Taori et al., 2023). Secondly, KD still retains its fundamental role in compressing LLMs, making them more efficient without significant loss in performance. (Gu et al., 2024; Agarwal et al., 2024). More recently, the strategy of employing open-source LLMs as teachers for their own self-improvement has emerged as a promising approach, enhancing their capabilities significantly (Yuan et al., 2024a; Chen et al., 2024a). Figure 1 provides an illustration of these three key roles played by KD in the context of LLMs.
首先,认识到专有大语言模型与开源大语言模型之间的差异后,知识蒸馏(KD)技术作为弥合两者性能差距的手段迅速兴起(Gou等人,2021;Gupta和Agrawal,2022)。在此背景下,知识蒸馏利用GPT-4或Gemini等领先专有模型的先进能力作为指导框架,来提升开源大语言模型的性能。这一过程类似于将高技能教师的"知识"传授给学生,其中学生(如开源大语言模型)学习模仿教师(如专有大语言模型)的性能特征。与传统知识蒸馏算法(Gou等人,2021)相比,数据增强(DA)(Feng等人,2021)已成为实现大语言模型知识蒸馏的流行范式,即利用少量知识种子促使大语言模型生成特定技能或领域的更多数据(Taori等人,2023)。其次,知识蒸馏仍保留其在压缩大语言模型方面的基本作用,使其更高效且性能无明显损失(Gu等人,2024;Agarwal等人,2024)。最近,采用开源大语言模型作为教师进行自我提升的策略成为一种有前景的方法,显著增强了其能力(Yuan等人,2024a;Chen等人,2024a)。图1展示了知识蒸馏在大语言模型中的这三个关键作用。
A key aspect of the knowledge distillation is the enhancement of skills such as advanced context following (e.g., in-context learning (Huang et al., 2022a) and instruction following (Taori et al., 2023)), improved alignment with user intents (e.g., human values/principles (Cui et al., 2023a), and thinking patterns like chain-of-thought (CoT) (Mukherjee et al., 2023)), and NLP task specialization (e.g., semantic understanding (Ding et al., 2023a), and code generation (Chaudhary, 2023)). These skills are crucial for the wide array of applications that LLMs are expected to perform, ranging from casual conversations to complex problem-solving in specialized domains. For instance, in vertical domains like healthcare (Wang et al., 2023a), law (LAW, 2023), or science (Zhang et al., 2024), where accuracy and context-specific knowledge are paramount, knowledge distillation allows open-source models to significantly improve their performance by learning from the proprietary models that have been extensively trained and fine-tuned in these areas.
知识蒸馏的一个关键方面在于提升多项技能,包括高级上下文跟随(例如上下文学习 [Huang et al., 2022a] 和指令跟随 [Taori et al., 2023])、增强用户意图对齐(如人类价值观/原则 [Cui et al., 2023a] 和思维链 (CoT) 等思考模式 [Mukherjee et al., 2023]),以及 NLP 任务专项能力(例如语义理解 [Ding et al., 2023a] 和代码生成 [Chaudhary, 2023])。这些技能对大语言模型应对从日常对话到专业领域复杂问题解决等广泛场景至关重要。以医疗 [Wang et al., 2023a]、法律 [LAW, 2023] 或科学 [Zhang et al., 2024] 等垂直领域为例,当准确性和领域知识成为核心需求时,知识蒸馏能让开源模型通过向经过专业训练的商业模型学习,显著提升性能。

Fig. 1: KD plays three key roles in LLMs: 1) Primarily enhancing capabilities, 2) offering traditional compression for efficiency, and 3) an emerging trend of self-improvement via self-generated knowledge.
图 1: 知识蒸馏 (KD) 在大语言模型中发挥三大关键作用:1) 主要提升模型能力,2) 提供传统压缩方案以提高效率,3) 通过自生成知识实现自我提升的新兴趋势。
The benefits of knowledge distillation in the era of LLMs are multifaceted and transformative (Gu et al., 2024). Through a suite of distillation techniques, the gap between proprietary and open-source models is significantly narrowed (Chiang et al., 2023; Xu et al., 2023a) and even filled (Zhao et al., 2023a). This process not only streamlines computational requirements but also enhances the environmental sustainability of AI operations, as open-source models become more proficient with lesser computational over- head. Furthermore, knowledge distillation fosters a more accessible and equitable AI landscape, where smaller entities and individual researchers gain access to state-of-the-art capabilities, encouraging wider participation and diversity in AI advancements. This democratization of technology leads to more robust, versatile, and accessible AI solutions, catalyzing innovation and growth across various industries and research domains.
在大语言模型(LLM)时代,知识蒸馏(Knowledge Distillation)的优势具有多面性和变革性(Gu et al., 2024)。通过一系列蒸馏技术,专有模型与开源模型之间的差距被显著缩小(Chiang et al., 2023; Xu et al., 2023a)甚至消除(Zhao et al., 2023a)。这一过程不仅简化了计算需求,还提升了AI运行的环境可持续性——开源模型能以更低的计算开销实现更高性能。此外,知识蒸馏促进了更普惠、更公平的AI生态,使小型机构和独立研究者也能获得尖端能力,从而推动AI发展更广泛的参与度和多样性。这种技术民主化催生出更健壮、通用且易获取的AI解决方案,为各行业和研究领域注入创新动能与发展活力。
The escalating need for a comprehensive survey on the knowledge distillation of LLMs stems from the rapidly evolving landscape of AI (OpenAI et al., 2023; Team et al., 2023) and the increasing complexity of these models. As AI continues to penetrate various sectors, the ability to efficiently and effectively distill knowledge from proprietary LLMs to open-source ones becomes not just a technical aspiration but a practical necessity. This need is driven by the growing demand for more accessible, cost-effective, and adaptable AI solutions that can cater to a diverse range of applications and users. A survey in this field is vital for synthesizing the current methodologies, challenges, and breakthroughs in knowledge distillation. It may serve as a beacon for researchers and practitioners alike, guiding them to distill complex AI capabilities into more manageable and accessible forms. Moreover, such a survey can illuminate the path forward, identifying gaps in current techniques and proposing directions for future research.
对大语言模型知识蒸馏进行全面综述的需求日益增长,这源于AI领域的快速发展 (OpenAI等, 2023; Team等, 2023) 以及这些模型日益增加的复杂性。随着AI持续渗透各行各业,将知识从专有大语言模型高效蒸馏至开源模型的能力,已不仅是一项技术追求,更是实际需求。这一需求受到以下因素的推动:市场对更易获取、更具成本效益且适应性强的AI解决方案的需求不断增长,这些方案需要满足多样化应用场景和用户群体。
该领域的综述对于梳理当前知识蒸馏的方法论、挑战与突破至关重要。它能为研究者和从业者指明方向,帮助他们将复杂的AI能力蒸馏为更易管理和使用的形式。此外,这类综述能够揭示未来发展方向,指出现有技术的不足,并为后续研究提出建议路径。
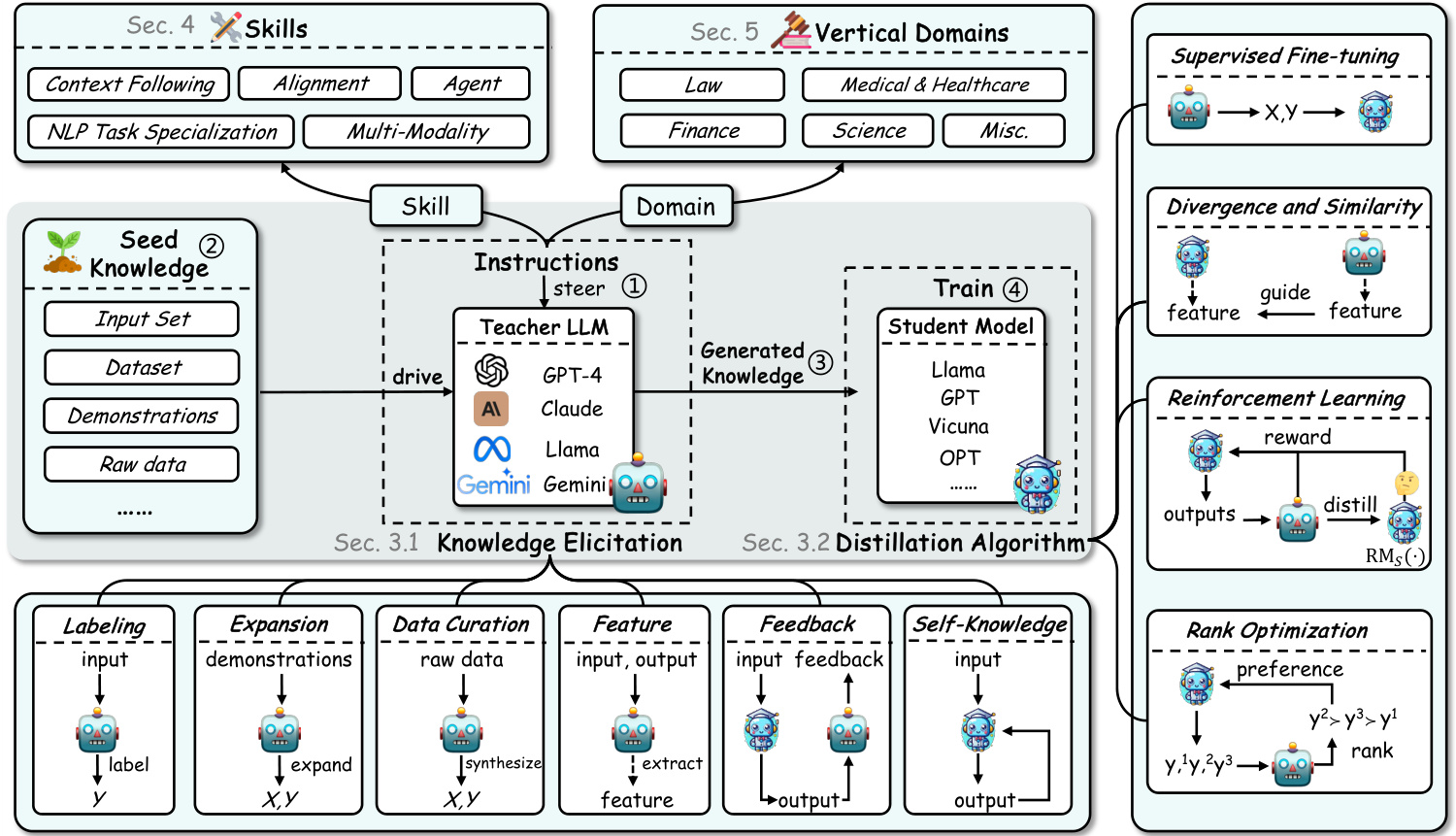
Fig. 2: An overview of this survey on knowledge distillation of large language models. Note that ‘Section’ is abbreviated as ‘Sec.’ in this figure. $\mathrm{RM}_{S}(\cdot)$ denotes the student reward model. denote the steps in KD of LLMs.
图 2: 大语言模型知识蒸馏综述概览。注意图中将"Section"缩写为"Sec."。$\mathrm{RM}_{S}(\cdot)$表示学生奖励模型。表示大语言模型知识蒸馏的步骤。
Survey Organization. The remainder of this survey is organized into several comprehensive sections, each designed to offer a deep dive into the multifaceted aspects of knowledge distillation within the realm ofLLMs. Following this introduction, §2 provides a foundational overview of knowledge distillation, comparing traditional techniques with those emerging in the era of LLMs and highlighting the role of data augmentation (DA) in this context. §3 delves into the approaches to elicit knowledge from teacher LLMs and core distillation algorithms, examining methods from supervised fine-tuning to more complex strategies involving divergence and similarity, reinforcement learning, and ranking optimization. Then, $\S4$ focuses on skill distillation, exploring how student models can be enhanced to improve context understanding, alignment with user intentions, and performance across a variety of NLP tasks. This includes discussions on natural language understanding (NLU), generation (NLG), information retrieval, recommendation systems, and the evaluation of text generation. In §5, we venture into domain-specific vertical distillation, showcasing how knowledge distillation techniques are applied within specialized fields such as law, healthcare, finance, and science, illustrating the practical implications and transformative impact of these approaches. The survey suggests open problems in §6, identifying current challenges and gaps in knowledge distillation research that offer opportunities for future work. Finally, the conclusion and discussion in $^{\S7}$ synthesize the insights gained, reflecting on the implications for the broader AI and NLP research community and proposing directions for future research. Figure 2 shows an overview of this survey.
调查结构。本综述的其余部分分为几个综合章节,每章旨在深入探讨大语言模型(LLM)领域中知识蒸馏的多方面内容。在引言之后,第2节提供了知识蒸馏的基础概述,比较了传统技术与大语言模型时代新兴技术,并重点阐述了数据增强(DA)在此背景下的作用。第3节深入探讨从教师大语言模型中提取知识的方法和核心蒸馏算法,研究范围从监督微调到涉及散度与相似性、强化学习和排序优化等更复杂的策略。接着第4节聚焦技能蒸馏,探索如何增强学生模型以提升上下文理解、用户意图对齐及各类NLP任务表现,涵盖自然语言理解(NLU)、生成(NLG)、信息检索、推荐系统以及文本生成评估等讨论。第5节深入特定领域垂直蒸馏,展示知识蒸馏技术在法律、医疗、金融和科学等专业领域的应用,阐明这些方法的实际意义和变革性影响。第6节提出开放性问题,指出当前知识蒸馏研究中的挑战与空白,为未来工作提供机遇。最后第7节的结论与讨论整合所得洞见,反思对更广泛AI和NLP研究界的影响,并提出未来研究方向。图2展示了本综述的概览结构。
2 OVERVIEW
2 概述
2.1 Comparing Traditional Recipe
2.1 传统食谱对比
The concept of knowledge distillation in the field of AI and deep learning (DL) refers to the process of transferring knowledge from a large, complex model (teacher) to a smaller, more efficient model (student) (Gou et al., 2021). This technique is pivotal in mitigating the challenges posed by the computational demands and resource constraints of deploying large-scale models in practical applications.
AI和深度学习(DL)领域中的知识蒸馏(Knowledge Distillation)概念,指的是将知识从庞大复杂的教师模型(teacher)迁移到更精简高效的学生模型(student)的过程 (Gou et al., 2021)。该技术对于缓解实际应用中部署大规模模型带来的计算需求和资源限制等挑战具有关键作用。
Historically, knowledge distillation techniques, prior to the era of LLMs, primarily concentrated on transferring knowledge from complex, often cumbersome neural networks to more compact and efficient architectures (Sanh et al., 2019; Kim and Rush, 2016). This process was largely driven by the need to deploy machine learning models in resource-constrained environments, such as mobile devices or edge computing platforms, where the computational power and memory are limited. The focus was predominantly on ad-hoc neural architecture selection and training objectives tailored for single tasks. These earlier methods involved training a smaller student network to mimic the output of a larger teacher network, often through techniques like soft target training, where the student learns from the softened softmax output of the teacher. Please refer to the survey (Gou et al., 2021) for more details on general knowledge distillation techniques in AI and DL.
历史上,在大语言模型(LLM)时代之前,知识蒸馏技术主要集中于将复杂且通常笨重的神经网络知识迁移到更紧凑高效的架构中(Sanh等人,2019;Kim和Rush,2016)。这一过程主要受限于在资源受限环境(如移动设备或边缘计算平台)中部署机器学习模型的需求,因为这些环境的计算能力和内存有限。研究重点主要集中在针对单一任务定制的临时神经网络架构选择和训练目标上。这些早期方法通过训练较小的学生网络来模仿较大教师网络的输出,通常采用软目标训练等技术,使学生从教师软化后的softmax输出中学习。更多关于人工智能和深度学习(DL)中通用知识蒸馏技术的细节,请参阅综述(Gou等人,2021)。
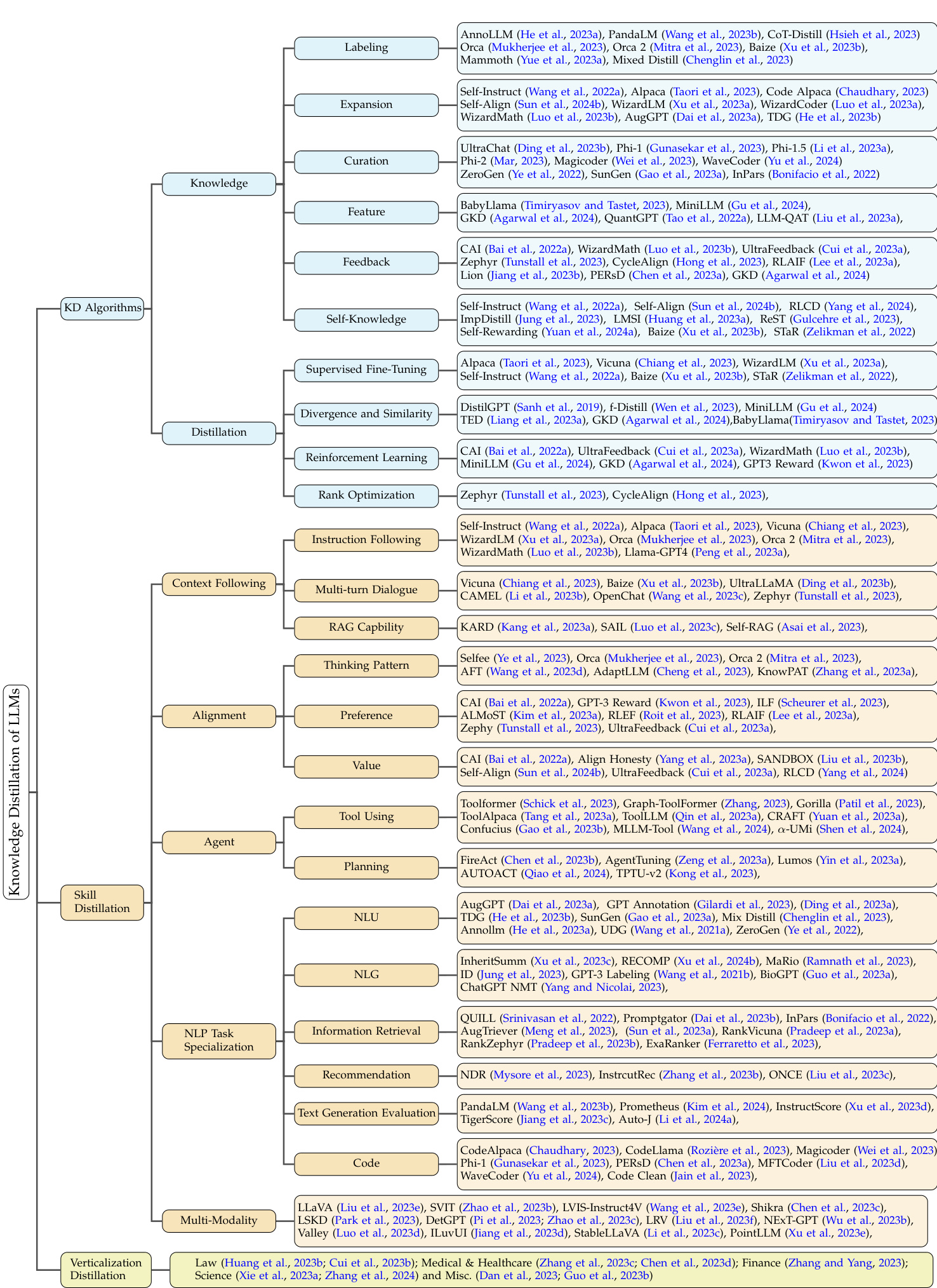
Fig. 3: Taxonomy of Knowledge Distillation of Large Language Models. The detailed taxonomy of Vertical iz ation Distillation is shown in Figure 7.
图 3: 大语言模型知识蒸馏分类体系。垂直化蒸馏的详细分类见图 7。
In contrast, the advent of LLMs has revolutionized the knowledge distillation landscape. The current era of knowledge distillation in LLMs shifts the focus from mere architecture compression to knowledge eli citation and transfer (Taori et al., 2023; Chaudhary, 2023; Tunstall et al., 2023). This paradigm change is largely due to the expansive and deep-seated knowledge that LLMs like GPT-4 and Gemini possess. And the inaccessible parameters of LLMs make it hard to compress them by using pruning (Han et al., 2016) or quantization (Liu et al., 2023a) techniques. Unlike the earlier era, where the goal was to replicate the output behavior of the teacher model or reduce the model size, the current focus in LLM-based knowledge distillation is to elicit the specific knowledge these models have.
相比之下,大语言模型(LLM)的出现彻底改变了知识蒸馏的格局。当前LLM知识蒸馏的时代,重点已从单纯的结构压缩转向知识提取与迁移 (Taori et al., 2023; Chaudhary, 2023; Tunstall et al., 2023)。这一范式转变主要归功于GPT-4和Gemini等大语言模型所具备的广博而深层的知识。由于LLM参数不可访问,使得通过剪枝(Han et al., 2016)或量化(Liu et al., 2023a)技术来压缩它们变得困难。与早期目标不同——当时旨在复现教师模型的输出行为或缩小模型规模,当前基于LLM的知识蒸馏更关注提取这些模型所拥有的特定知识。
The key to this modern approach lies in heuristic and carefully designed prompts, which are used to elicit specific knowledge (Ding et al., 2023b) or capabilities (Chaudhary, 2023) from the LLMs. These prompts are crafted to tap into the LLM’s understanding and capabilities in various domains, ranging from natural language understanding (He et al., 2023a) to more complex cognitive tasks like reasoning (Hsieh et al., 2023) and problem-solving (Qiao et al., 2024). The use of prompts as a means of knowledge elicitation offers a more flexible and dynamic approach to distillation. It allows for a more targeted extraction of knowledge, focusing on specific skills or domains of interest. This method is particularly effective in harnessing the emergent abilities of LLMs, where the models exhibit capabilities beyond their explicit training objectives.
这一现代方法的关键在于启发式精心设计的提示词(prompt),它们被用来从大语言模型中提取特定知识(Ding et al., 2023b)或能力(Chaudhary, 2023)。这些提示词经过精心设计,旨在挖掘大语言模型在多个领域的理解能力,涵盖从自然语言理解(He et al., 2023a)到推理(Hsieh et al., 2023)和问题解决(Qiao et al., 2024)等更复杂的认知任务。将提示词作为知识提取手段,为蒸馏过程提供了更灵活动态的途径,能够更有针对性地提取特定技能或目标领域的知识。这种方法在利用大语言模型涌现能力方面尤为有效,这些能力往往超出模型的显式训练目标。
Furthermore, this era of knowledge distillation also emphasizes the transfer of more abstract qualities such as reasoning patterns (Mitra et al., 2023), preference alignment (Cui et al., 2023a), and value alignment (Sun et al., 2024b). This is in stark contrast to the earlier focus on output replication (Taori et al., 2023), indicating a shift towards a more holistic and comprehensive transfer of cognitive capabilities. The current techniques involve not just the replication of outputs, but also the emulation of the thought processes (Mitra et al., 2023) and decision-making (Asai et al., 2023) patterns of the teacher model. This involves complex strategies like chain-of-thought prompting, where the student model is trained to learn the reasoning process of the teacher, thereby enhancing its problem-solving and decision-making capabilities.
此外,这一知识蒸馏时代还强调更抽象特质的迁移,例如推理模式 (Mitra et al., 2023)、偏好对齐 (Cui et al., 2023a) 和价值对齐 (Sun et al., 2024b)。这与早期专注于输出复现 (Taori et al., 2023) 形成鲜明对比,标志着向更全面认知能力迁移的转变。当前技术不仅涉及输出复现,还包括对教师模型思维过程 (Mitra et al., 2023) 和决策模式 (Asai et al., 2023) 的模拟。这涉及思维链提示等复杂策略,即训练学生模型学习教师的推理过程,从而增强其问题解决和决策能力。
2.2 Relation to Data Augmentation (DA)
2.2 与数据增强 (DA) 的关系
In the era of LLMs, Data Augmentation (DA) (Wang et al., 2022a; Ye et al., 2022) emerges as a critical paradigm integral to the process of knowledge distillation. Unlike traditional DA techniques such as paraphrasing (Gangal et al., 2022) or back-translation (Longpre et al., 2019), which primarily aim at expanding the training dataset in a somewhat mechanical manner, DA within the context of LLMs focuses on the generation of novel, context-rich training data tailored to specific domains and skills.
在大语言模型 (LLM) 时代,数据增强 (Data Augmentation, DA) [Wang et al., 2022a; Ye et al., 2022] 已成为知识蒸馏过程中不可或缺的关键范式。与传统 DA 技术 (如复述 [Gangal et al., 2022] 或回译 [Longpre et al., 2019]) 主要机械式扩展训练数据集不同,大语言模型语境下的 DA 专注于生成针对特定领域和技能、具有丰富上下文的新颖训练数据。
The relationship between DA and KD in LLMs is both symbiotic and foundational. By leveraging a set of seed knowledge, KD employs DA to prompt LLMs to produce explicit data that encapsulates specific skills or domain expertise (Chaudhary, 2023; West et al., 2022). This method stands out as a potent mechanism for bridging the knowledge and capability gap between proprietary and opensource models. Through DA, LLMs are prompted to create targeted, high-quality datasets that are not merely larger in volume but are also rich in diversity and specificity. This approach enables the distillation process to be more effective, ensuring that the distilled models not only replicate the teacher model’s output behavior but also embody its deep-seated understanding and cognitive strategies.
大语言模型中数据增强(DA)与知识蒸馏(KD)的关系既是共生的,也是基础性的。通过利用一组种子知识,KD采用DA来促使大语言模型生成包含特定技能或领域专业知识的显式数据(Chaudhary, 2023; West et al., 2022)。这种方法作为一种强大的机制脱颖而出,能够弥合专有模型与开源模型之间的知识和能力差距。通过DA,大语言模型被引导创建有针对性的高质量数据集,这些数据集不仅在数量上更大,而且在多样性和特异性方面也很丰富。这种方法使蒸馏过程更加有效,确保蒸馏后的模型不仅复制教师模型的输出行为,还体现其深层次的理解和认知策略。
DA acts as a force multiplier, enabling the distilled models to acquire and refine capabilities that would otherwise require exponentially larger datasets and computational resources. It facilitates a more effective transfer of knowledge, focusing on the qualitative aspects of learning rather than quantitative expansion. This strategic use of DA within KD processes underscores a pivotal shift towards a more efficient, sustainable, and accessible approach to harnessing the power of LLMs. It empowers open-source models with the ability to approximate the contextual adeptness, ethical alignment, and deep semantic insights characteristic of their proprietary counterparts, thereby democratizing access to advanced AI capabilities and fostering innovation across a broader spectrum of applications and users.
数据增强(Data Augmentation, DA)作为效能倍增器,使蒸馏模型能够获取并完善那些原本需要指数级更大数据集和计算资源才能获得的能力。它促进了更高效的知识迁移,聚焦于学习质量而非数量扩张。这种在知识蒸馏(Knowledge Distillation, KD)过程中对DA的策略性运用,标志着向更高效、可持续和普惠化利用大语言模型(LLM)能力的关键转变。它使开源模型能够逼近专有模型特有的语境适应力、伦理对齐和深层语义洞察力,从而推动先进AI技术的民主化应用,并在更广泛的应用场景和用户群体中激发创新。
2.3 Survey Scope
2.3 调查范围
Building on the discussions introduced earlier, this survey aims to comprehensively explore the landscape of knowledge distillation within the context of LLMs, following a meticulously structured taxonomy as in Figure 3. The survey’s scope is delineated through three primary facets: KD Algorithms, Skill Distillation, and Vertical iz ation Distillation. Each facet encapsulates a range of subtopics and methodologies. It’s important to note that KD algorithms provide the technical foundations for skill distillation and vertical iz ation distillation.
基于前文的讨论,本综述旨在全面探索大语言模型(LLM)背景下的知识蒸馏(Knowledge Distillation)领域,并遵循图3所示的精细分类体系。研究范围通过三个主要维度界定:KD算法(KD Algorithms)、技能蒸馏(Skill Distillation)和垂直领域蒸馏(Verticalization Distillation),每个维度涵盖若干子主题与方法论。需特别指出的是,KD算法为技能蒸馏和垂直领域蒸馏提供了技术基础。
KD Algorithms. This segment focuses on the technical foundations and methodologies of knowledge distillation. It includes an in-depth exploration of the processes involved in constructing knowledge from teacher models (e.g., proprietary LLMs) and integrating this knowledge into student models (e.g., open-source LLMs). Under the umbrella of ‘knowledge’, we delve into strategies such as labeling (Hsieh et al., 2023), expansion (Taori et al., 2023), curation (Gunasekar et al., 2023), feature understanding (Agarwal et al., 2024), feedback mechanisms (Tunstall et al., 2023), and selfknowledge generation (Wang et al., 2022a). This exploration seeks to uncover the various ways in which knowledge can be identified, expanded, and curated for effective distillation. The ‘distillation’ subsection examines learning approaches like supervised fine-tuning (SFT) (Wang et al., 2022a), divergence minimization (Agarwal et al., 2024), reinforcement learning techniques (Cui et al., 2023a), and rank optimization strategies (Tunstall et al., 2023). Together, these techniques demonstrate how KD enables open-source models to obtain knowledge from proprietary ones.
KD算法。本节重点探讨知识蒸馏的技术基础和方法论,包括深入分析从教师模型(如专有大语言模型)构建知识并将其整合到学生模型(如开源大语言模型)的过程。在"知识"框架下,我们研究了标注策略(Hsieh等人,2023)、扩展方法(Taori等人,2023)、知识筛选(Gunasekar等人,2023)、特征理解(Agarwal等人,2024)、反馈机制(Tunstall等人,2023)以及自知识生成(Wang等人,2022a),旨在揭示知识识别、扩展与筛选的有效蒸馏途径。"蒸馏"部分则探讨了监督微调(SFT)(Wang等人,2022a)、差异最小化(Agarwal等人,2024)、强化学习技术(Cui等人,2023a)和排序优化策略(Tunstall等人,2023)等学习方法。这些技术共同展示了知识蒸馏如何使开源模型从专有模型中获取知识。
Skill Distillation. This facet examines the specific competencies and capabilities enhanced through KD. It encompasses detailed discussions on context following (Taori et al., 2023; Luo et al., 2023c), with subtopics like instruction following and retrieval-augmented generation (RAG) Capability. In the realm of alignment (Mitra et al., 2023; Tunstall et al., 2023), the survey investigates thinking patterns, persona/preference modeling, and value alignment. The ‘agent’ category delves into skills such as Tool Using and Planning. NLP task specialization (Dai et al., 2023a; Jung et al., 2023; Chaudhary, 2023) is scrutinized through lenses like natural language understanding (NLU), natural language generation (NLG), information retrieval, recommendation systems, text generation evaluation, and code generation. Finally, the survey addresses multi-modality (Liu et al., 2023e; Zhao et al., 2023b), exploring how KD enhances LLMs’ ability to integrate multiple forms of input.
技能蒸馏 (Skill Distillation)。这一维度探讨通过知识蒸馏 (KD) 强化的具体能力范畴,包含对上下文跟随 (Taori et al., 2023; Luo et al., 2023c) 的详细讨论,其子主题涵盖指令跟随和检索增强生成 (RAG) 能力。在对齐领域 (Mitra et al., 2023; Tunstall et al., 2023),研究调查了思维模式、角色/偏好建模和价值对齐。"智能体"类别则深入探讨工具使用和规划等技能。通过自然语言理解 (NLU)、自然语言生成 (NLG)、信息检索、推荐系统、文本生成评估和代码生成等视角,审视NLP任务专项能力 (Dai et al., 2023a; Jung et al., 2023; Chaudhary, 2023)。最后,研究讨论了多模态能力 (Liu et al., 2023e; Zhao et al., 2023b),探索知识蒸馏如何增强大语言模型整合多形式输入的能力。
Vertical iz ation Distillation. This section assesses the application of KD across diverse vertical domains, offering insights into how distilled LLMs can be tailored for specialized fields such as Law (LAW, 2023), Medical & Healthcare (Wang et al., 2023a), Finance (Zhang and Yang, 2023), Science (Zhang et al., 2024), among others. This exploration not only showcases the practical implications of KD techniques but also highlights their transformative impact on domain-specific AI solutions.
垂直领域蒸馏。本节评估了知识蒸馏 (Knowledge Distillation, KD) 在不同垂直领域的应用,探讨了如何为大语言模型定制法律 (LAW, 2023)、医疗健康 (Wang et al., 2023a)、金融 (Zhang and Yang, 2023)、科学 (Zhang et al., 2024) 等专业领域蒸馏方案。该研究不仅展示了知识蒸馏技术的实际应用价值,更凸显了其对垂直领域AI解决方案的变革性影响。
Through these facets, this survey provides a comprehensive analysis of KD in LLMs, guiding researchers and practitioners through methodologies, challenges, and opport unities in this rapidly evolving domain.
通过这些方面,本综述对大语言模型(LLM)中的知识蒸馏(KD)进行了全面分析,为研究人员和实践者在这个快速发展的领域中提供了方法论、挑战和机遇的指导。
Declaration. This survey represents our earnest effort to provide a comprehensive and insightful overview of knowledge distillation techniques applied to LLMs, focusing on algorithms, skill enhancement, and domain-specific applications. Given the vast and rapidly evolving nature of this field, especially with the prevalent practice of eliciting knowledge from training data across academia, we acknowledge that this manuscript may not encompass every pertinent study or development. Nonetheless, it endeavors to introduce the foundational paradigms of knowledge distillation, highlighting key methodologies and their impacts across a range of applications.
声明:本综述旨在全面深入地概述大语言模型 (LLM) 知识蒸馏技术,聚焦算法、技能增强及领域应用。鉴于该领域发展迅猛且学术界普遍存在从训练数据中提取知识的实践,我们承认本文可能无法涵盖所有相关研究或进展。尽管如此,我们仍致力于阐释知识蒸馏的基础范式,重点分析核心方法及其在多类应用中的影响。
2.4 Distillation Pipeline in LLM Era
2.4 大语言模型 (Large Language Model) 时代的蒸馏流程
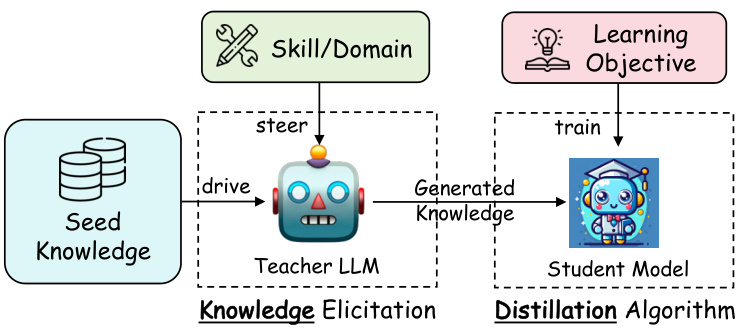
Fig. 4: An illustration of a general pipeline to distill knowledge from a large language model to a student model.
图 4: 大语言模型向学生模型蒸馏知识的通用流程示意图。
The general distillation pipeline of LLMs is a structured and methodical process aimed at transferring knowledge from a sophisticated teacher model to a less complex student model. This pipeline is integral for leveraging the advanced capabilities of models like GPT-4 or Gemini in more accessible and efficient open-source counterparts. The outline of this pipeline can be broadly categorized into four distinct stages, each playing a crucial role in the successful distillation of knowledge. An illustration is shown in Figure 4. The detailed pipeline could also be seen in Figure 2.
大语言模型 (LLM) 的通用蒸馏流程是一个结构化、系统化的过程,旨在将复杂教师模型的知识迁移至更精简的学生模型。该流程对于将 GPT-4 或 Gemini 等先进模型的能力移植到更易获取、高效的开源替代品中至关重要。该流程可大致划分为四个关键阶段,每个阶段都在知识蒸馏过程中发挥重要作用。如图 4 所示,具体流程亦可参见图 2。
I. Target Skill or Domain Steering Teacher LLM. The first stage involves directing the teacher LLM towards a specific target skill or domain. This is achieved through carefully crafted instructions or templates that guide the LLM’s focus. These instructions are designed to elicit responses that demonstrate the LLM’s proficiency in a particular area, be it a specialized domain like healthcare or law, or a skill such as reasoning or language understanding.
I. 目标技能或领域引导教师大语言模型
第一阶段涉及将教师大语言模型引导至特定目标技能或领域。这通过精心设计的指令或模板实现,以指导大语言模型的关注点。这些指令旨在激发大语言模型在特定领域(如医疗或法律等专业领域)或技能(如推理或语言理解)中展现其熟练度的响应。
II. Seed Knowledge as Input. Once the target area is defined, the next step is to feed the teacher LLM with seed knowledge. This seed knowledge typically comprises a small dataset or specific data clues relevant to the elicit skill or domain knowledge from the teacher LLM. It acts as a catalyst, prompting the teacher LLM to generate more elaborate and detailed outputs based on this initial information. The seed knowledge is crucial as it provides a foundation upon which the teacher model can build and expand, thereby creating more comprehensive and in-depth knowledge examples.
II. 种子知识作为输入。定义目标领域后,下一步是向教师大语言模型(LLM)输入种子知识。这些种子知识通常包含与目标技能或领域知识相关的小型数据集或特定数据线索,其作用是作为催化剂,促使教师大语言模型基于初始信息生成更详尽细致的输出。种子知识至关重要,它为教师模型提供了可扩展的基础,从而生成更全面深入的知识示例。
III. Generation of Distillation Knowledge. In response to the seed knowledge and steering instructions, the teacher LLM generates knowledge examples. These examples are predominantly in the form of question-and-answer (QA) dialogues or narrative explanations, aligning with the natural language processing/understanding capabilities of the LLM. In certain specialized cases, the outputs may also include logits or hidden features, although this is less common due to the complexity and specific requirements of such data forms. The generated knowledge examples constitute the core of the distillation knowledge, encapsulating the advanced understanding and skills of the teacher LLM.
III. 蒸馏知识的生成。针对种子知识和引导指令,教师大语言模型生成知识示例。这些示例主要以问答(QA)对话或叙述性解释的形式呈现,与大语言模型的自然语言处理/理解能力相匹配。在某些专业场景中,输出也可能包含logits或隐藏特征,但由于此类数据形式的复杂性和特殊要求,这种情况较为少见。生成的知识示例构成了蒸馏知识的核心,封装了教师大语言模型的高级理解能力和技能。
IV. Training the Student Model with a Specific Learning Objective. The final stage involves the utilization of the generated knowledge examples to train the student model. This training is guided by a loss function that aligns with the learning objectives. The loss function quantifies the student model’s performance in replicating or adapting the knowledge from the teacher model. By minimizing this loss, the student model learns to emulate the target skills or domain knowledge of the teacher, thereby acquiring similar capabilities. The process involves iterative ly adjusting the student model’s parameters to reduce the discrepancy between its outputs and those of the teacher model, ensuring the effective transfer of knowledge.
四、基于特定学习目标训练学生模型
最终阶段利用生成的知识样本训练学生模型,训练过程由符合学习目标的损失函数 (loss function) 指导。该损失函数量化学生模型在复制或适配教师模型知识时的表现,通过最小化损失值使学生模型学会模仿教师的目标技能或领域知识,从而获得相近能力。该过程通过迭代调整学生模型参数来缩小其输出与教师模型输出的差异,确保知识迁移的有效性。
In essential, the above four stages can be abstracted as two formulations. The first formulation represents the process of eliciting knowledge:
本质上,上述四个阶段可以抽象为两种表述。第一种表述代表知识获取的过程:
$$
{\mathcal{D}}{I}^{(\mathrm{kd})}={\mathrm{Parse}(o,s)|o\sim p_{T}(\mathsf{o}|I\oplus s),\forall s\sim{\mathcal{S}}},
$$
$$
{\mathcal{D}}{I}^{(\mathrm{kd})}={\mathrm{Parse}(o,s)|o\sim p_{T}(\mathsf{o}|I\oplus s),\forall s\sim{\mathcal{S}}},
$$
where $\bigoplus$ denotes fusing two pieces of text, $I$ denotes an instruction or a template for a task, skill, or domain to steer the LLM and elicit knowledge, $s\sim S$ denotes an example of the seed knowledge, upon which the LLM can explore to generate novel knowledge, Parse $(o,s)$ stands for to parse the distillation example ( e.g., $(x,y))$ from the teacher LLM’s output $o$ (plus the input $s$ in some cases), and $p_{T}$ represents the teacher LLM with parameters $\theta_{T}$ . Given the datasets $\mathcal{D}_{I}^{(\mathrm{kd})}$ built for distillation, we then define a learning objective as
其中 $\bigoplus$ 表示融合两段文本,$I$ 表示用于引导大语言模型并激发知识的任务、技能或领域的指令/模板,$s\sim S$ 表示种子知识的示例(大语言模型可基于此探索生成新知识),Parse $(o,s)$ 表示从教师大语言模型的输出 $o$(某些情况下还需结合输入 $s$)中解析蒸馏样本(例如 $(x,y)$),$p_{T}$ 表示参数为 $\theta_{T}$ 的教师大语言模型。基于构建的蒸馏数据集 $\mathcal{D}_{I}^{(\mathrm{kd})}$,我们定义如下学习目标:
$$
\begin{array}{r}{\mathcal{L}=\displaystyle\sum_{I}\mathcal{L}{I}(\mathcal{D}{I}^{(\mathrm{kd})};\theta_{S}),}\end{array}
$$
$$
\begin{array}{r}{\mathcal{L}=\displaystyle\sum_{I}\mathcal{L}{I}(\mathcal{D}{I}^{(\mathrm{kd})};\theta_{S}),}\end{array}
$$
where $\sum I$ denotes there could be multiple tasks or skills being distilled into one student model, $\bar{\mathcal{L}{I}}(\cdot;\cdot)$ stands for a specific learning objective, and $\theta_{S}$ parameter ize s the student model.
其中 $\sum I$ 表示可能有多个任务或技能被蒸馏到一个学生模型中,$\bar{\mathcal{L}{I}}(\cdot;\cdot)$ 代表特定的学习目标,而 $\theta_{S}$ 是学生模型的参数。
Following our exploration of the distillation pipeline and the foundational concepts underlying knowledge distillation in the LLM era, we now turn our focus to the specific algorithms that have gained prominence in this era.
在我们探讨了大语言模型(LLM)时代的知识蒸馏流程和基础概念后,现在将重点关注该时期涌现的重要算法。
3 KNOWLEDGE DISTILLATION ALGORITHMS
3 知识蒸馏算法
This section navigates through the process of knowledge distillation. According to Section 2.4, it is categorized into two principal steps: ‘Knowledge,’ focusing on eliciting knowledge from teacher LLMs (Eq.1), and ‘Distillation,’ centered on injecting this knowledge into student models (Eq.2). We will elaborate on these two processes in the subsequent sections.
本节将介绍知识蒸馏的过程。根据第2.4节的内容,该过程可分为两个主要步骤:"知识"(Knowledge)和"蒸馏"(Distillation)。"知识"步骤侧重于从教师大语言模型(LLM)中提取知识(式1),而"蒸馏"步骤则专注于将这些知识注入学生模型(式2)。我们将在后续章节中详细阐述这两个过程。
3.1 Knowledge
3.1 知识
This section focuses on the approaches to elicit knowledge from teacher LLMs. According to the manners to acquire knowledge, we divided them into Labeling, Expansion, Data Curation, Feature, Feedback, and Self-Knowledge. Figure 5 shows an illustration of these knowledge eli citation methods.
本节重点探讨从教师大语言模型中提取知识的方法。根据知识获取方式,我们将其分为标注 (Labeling)、扩展 (Expansion)、数据整理 (Data Curation)、特征 (Feature)、反馈 (Feedback) 和自我知识 (Self-Knowledge)。图5展示了这些知识提取方法的示意图。
3.1.1 Labeling
3.1.1 标注
Labeling knowledge refers to using a teacher LLM to label the output $y$ for a given input $x$ as the seed knowledge, according to the instruction $I$ or demonstrations $c,$ where $c=(x_{1},y_{1}),\ldots,(x_{n},y_{n})$ . This method of eliciting knowledge from teacher LLMs is straightforward yet effective and has been widely applied across various tasks and applications. It requires only the collection of an input dataset and feeding it into LLMs to obtain the desired generations. Moreover, the generation of $y$ is controllable through the predefined $I$ and $c$ . This process can be formulated as follows:
标注知识是指利用教师大语言模型根据指令$I$或演示$c$(其中$c=(x_{1},y_{1}),\ldots,(x_{n},y_{n})$)为给定输入$x$标注输出$y$作为种子知识。这种从教师大语言模型中提取知识的方法简单却有效,已被广泛应用于各种任务和应用场景。它仅需收集输入数据集并输入大语言模型即可获得所需生成结果。此外,通过预定义的$I$和$c$可实现对$y$生成过程的控制。该过程可表述如下:
$$
{\mathcal{D}}^{(\mathrm{lab})}={x,y|x\sim\chi,y\sim p_{T}(y|I\oplus c\oplus x)}.
$$
$$
{\mathcal{D}}^{(\mathrm{lab})}={x,y|x\sim\chi,y\sim p_{T}(y|I\oplus c\oplus x)}.
$$
Input $x$ could be sourced from existing NLP task datasets, which serve as typical reservoirs for distillation efforts. Numerous works have sought to harness the capabilities of powerful LLMs as teachers for annotating dataset samples across a range of tasks. For instance, efforts in natural language understanding involve using LLMs to categorize text (Gilardi et al., 2023; Ding et al., 2023a; He et al., 2023a), while in natural language generation, LLMs assist in generating sequences for outputs (Hsieh et al., 2023; Jung et al., 2023; Wang et al., 2021b). Text generation evaluation tasks leverage LLMs to label evaluated results (Li et al., 2024b; Wang et al., 2023b), and reasoning tasks utilize LLMs for labeling Chains of Thought (CoT) explanations (Hsieh et al., 2023; Li et al., 2022; Ho et al., 2023; Magister et al., 2023; Fu et al., 2023; Ramnath et al., 2023; Li et al., 2023d; Liu et al., $2023\mathrm{g},$ ), among others. Rather than concentrating on specific tasks, many current works focus on labeling outputs based on instructions, thereby teaching student models to solve tasks in a more flexible way by following instructions. Collections of various NLP tasks, complemented by instructional templates, serve as valuable input sources for $x$ . For instance, FLAN-v2 collections (Longpre et al., 2023) offers extensive publicly available sets of tasks with instructions, which are labeled with responses generated by teacher LLMs in Orca (Mukherjee et al., 2023; Mitra et al., 2023). The instructions from these NLP tasks are built from predefined templates, which lack diversity and may have gaps between human’s natural query. The real conversations between humans and chat models provide large-scale data with real queries and generations labeled by powerful LLMs, like ShareGPT. Additionally, Xu et al. (2023b) and Anand et al. (2023) label the real questions sampled from forums like Quora and Stack Overflow.
输入 $x$ 可以来源于现有的自然语言处理(NLP)任务数据集,这些数据集是蒸馏工作的典型资源库。许多研究致力于利用强大 大语言模型 作为教师,为各类任务的数据集样本进行标注。例如,在自然语言理解领域,研究利用 大语言模型 对文本进行分类 (Gilardi et al., 2023; Ding et al., 2023a; He et al., 2023a);在自然语言生成领域,大语言模型 协助生成输出序列 (Hsieh et al., 2023; Jung et al., 2023; Wang et al., 2021b)。文本生成评估任务借助 大语言模型 标注评估结果 (Li et al., 2024b; Wang et al., 2023b),而推理任务则利用 大语言模型 标注思维链(CoT)解释 (Hsieh et al., 2023; Li et al., 2022; Ho et al., 2023; Magister et al., 2023; Fu et al., 2023; Ramnath et al., 2023; Li et al., 2023d; Liu et al., $2023\mathrm{g},$ )等。与聚焦特定任务不同,当前许多研究专注于基于指令标注输出,从而指导学生模型以更灵活的方式遵循指令解决问题。各类NLP任务的集合配合指令模板,为 $x$ 提供了宝贵的输入来源。例如,FLAN-v2集合 (Longpre et al., 2023) 提供了大量带指令的公开任务集,这些任务在Orca (Mukherjee et al., 2023; Mitra et al., 2023) 中由教师 大语言模型 生成响应标注。这些NLP任务的指令基于预定义模板构建,缺乏多样性且可能与人类自然查询存在差距。人类与聊天模型间的真实对话(如ShareGPT)提供了大规模真实查询数据,并由强大 大语言模型 标注生成内容。此外,Xu et al. (2023b) 和 Anand et al. (2023) 对来自Quora和Stack Overflow等论坛的真实问题进行了标注。
Moreover, the process of labeling could be guided by instructions $I$ or demonstrations c. A commonly used instruction type for guiding labeling is chain-of-thought (CoT) prompt (Hsieh et al., 2023; Fu et al., 2023; Magister et al., 2023). Mukherjee et al. (2023) add multiple system messages (e.g. “You must generate a detailed and long answer.” or “explain like $\mathrm{{I^{\prime}m}}$ five, think step-by-step”) to elicit rich signals. Yue et al. (2023a) and Chenglin et al. (2023) label a hybrid of knowledge of chain-of-thought (CoT) and program-of-thought (PoT) rationales. Xu et al. (2023b) propose a self-chat technique that two teacher LLMs simulate the real conversational to generate multi-turn dialogues for a question from Quora and Stack Overflow.
此外,标注过程可以通过指令 $I$ 或演示 c 进行引导。一种常用的引导标注指令类型是思维链 (CoT) 提示 (Hsieh et al., 2023; Fu et al., 2023; Magister et al., 2023)。Mukherjee et al. (2023) 添加了多条系统消息 (例如 "你必须生成详细且冗长的答案" 或 "用五岁小孩能懂的方式解释,逐步思考") 以激发丰富信号。Yue et al. (2023a) 和 Chenglin et al. (2023) 标注了思维链 (CoT) 与程序思维 (PoT) 推理的混合知识。Xu et al. (2023b) 提出了一种自对话技术,让两个教师大语言模型模拟真实对话,为 Quora 和 Stack Overflow 的问题生成多轮对话。
3.1.2 Expansion
3.1.2 扩展
While the labeling approach is simple and effective, it faces certain limitations. Primarily, it is constrained by the scale and variety of the input data. In real-world applications, especially those involving user conversations, there are also concerns regarding the privacy of the data involved. To address these limitations, various expansion methods have been proposed (Wang et al., 2022a; Taori et al., 2023; Chaudhary, 2023; Si et al., 2023; Ji et al., 2023a; Luo et al., 2023b,a; Wu et al., 2023c; Sun et al., 2024b; Xu et al., 2023a; Guo et al., 2023c; Roziere et al., 2023; West et al., 2022). These methods take the demonstrations as seed knowledge and aim to expand a large scale and various data by in-context learning.
虽然标注方法简单有效,但它面临一些局限性。主要受限于输入数据的规模和多样性。在实际应用中,特别是涉及用户对话的场景,还存在数据隐私方面的顾虑。为解决这些限制,研究者提出了多种扩展方法 (Wang et al., 2022a; Taori et al., 2023; Chaudhary, 2023; Si et al., 2023; Ji et al., 2023a; Luo et al., 2023b,a; Wu et al., 2023c; Sun et al., 2024b; Xu et al., 2023a; Guo et al., 2023c; Roziere et al., 2023; West et al., 2022)。这些方法将演示样本作为种子知识,通过上下文学习来扩展大规模多样化数据。
A key characteristic of these expansion methods is the utilization of the in-context learning ability of LLMs to generate data similar to the provided demonstrations $c$ . Unlike in the labeling approach, where the input $x$ is sampled from the existing dataset, in the expansion approach, both $x$ and $y$ are generated by teacher LLMs. This process can be formulated as follows:
这些扩展方法的一个关键特性是利用大语言模型 (LLM) 的上下文学习能力来生成与给定演示样本 $c$ 相似的数据。与标注方法中从现有数据集采样输入 $x$ 不同,在扩展方法中,$x$ 和 $y$ 均由教师大语言模型生成。该过程可表述如下:
$$
{\mathcal D}^{(\mathrm{exp})}={(x,y)|x\sim p_{T}(x|I\oplus c),y\sim p_{T}(y|I\oplus x)}.
$$
$$
{\mathcal D}^{(\mathrm{exp})}={(x,y)|x\sim p_{T}(x|I\oplus c),y\sim p_{T}(y|I\oplus x)}.
$$
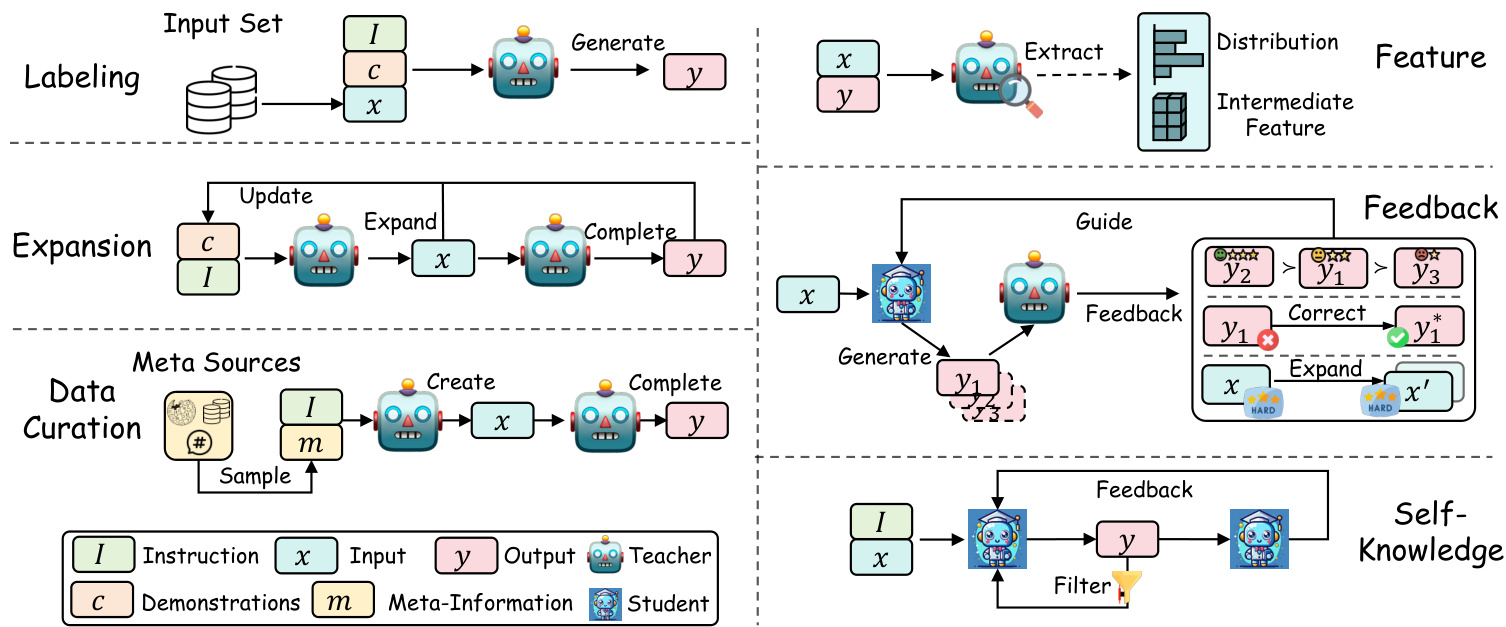
Fig. 5: An illustration of different knowledge eli citation methods from teacher LLMs. Labeling: The teacher generates the output from the input; Expansion: The teacher generates samples similar to the given demonstrations through incontext learning; Data Curation: The teacher synthesizes data according to meta-information, such as a topic or an entity; Feature: Feed the data into the teacher and extract its internal knowledge, such as logits and features; Feedback: The teacher provides feedback on the student’s generations, such as preferences, corrections, expansions of challenging samples, etc; Self-Knowledge: The student first generates outputs, which is then filtered for high quality or evaluated by the student itself.
图 5: 教师大语言模型中不同知识提取方法的示意图。标注 (Labeling): 教师根据输入生成输出;扩展 (Expansion): 教师通过上下文学习生成与给定示例相似的样本;数据整理 (Data Curation): 教师根据元信息(如主题或实体)合成数据;特征提取 (Feature): 将数据输入教师模型并提取其内部知识(如logits和特征);反馈 (Feedback): 教师对学生的生成结果提供反馈(如偏好、修正、挑战性样本的扩展等);自知识 (Self-Knowledge): 学生首先生成输出,随后自行筛选高质量结果或进行自我评估。
In this formulation, $x$ and $y$ represent the new inputoutput pairs generated by the teacher LLM. The input $x$ is generated based on a set of input-output demonstrations $c$ . The output $y$ is then generated in response to the new input $x$ under the guidance of an instruction $I$ . Note that the demonstrations could be predefined or dynamically updated by adding the newly generated samples.
在这个公式中,$x$ 和 $y$ 表示由教师大语言模型生成的新输入-输出对。输入 $x$ 是基于一组输入-输出演示 $c$ 生成的。随后,输出 $y$ 在指令 $I$ 的指导下响应新输入 $x$ 而生成。需要注意的是,演示可以是预定义的,也可以通过添加新生成的样本动态更新。
Expansion techniques have been widely utilized to extract extensive instruction-following knowledge from teacher LLMs. Wang et al. (2022a) first introduces an iterative boots trapping method, Self-Instruct, to utilize LLMs to generate a wide array of instructions based on several demonstrations sampled from 175 manually-written instructions. The newly generated instructions are then added back to the initial pool, benefiting subsequent expansion iterations. Subsequently, Taori et al. (2023) applies this expansion method to a more powerful teacher LLM, textdavinci-003, to distill 52K high-quality data. To improve the diversity and coverage during expansion, Wu et al. (2023c) and (Sun et al., 2024b) prompt the teacher LLM to generate instructions corresponding to some specific topics. Xu et al. (2023a) propose an Evol-Instruct method to expand the instructions from two dimensions: difficulty (e.g. rewriting the question to be more complex) and diversity (e.g. generating more long-tailed instructions). This EvolInstruct method is domain-agnostic and has been used to expand the distillation of coding (Luo et al., 2023a) and math (Luo et al., 2023b). Additionally, expansion methods can significantly augment NLP task datasets with similar samples, thereby enhancing task performance. For instance, AugGPT (Dai et al., 2023a) leverages a teacher LLM to rephrase each sentence in the training samples into multiple conceptually similar, but semantically varied, samples to improve classification performance. Similarly, TDG (He et al., 2023b) proposes the Targeted Data Generation (TDG) framework, which automatically identifies challenging subgroups within data and generates new samples for these subgroups using LLMs through in-context learning.
扩展技术已被广泛用于从教师大语言模型中提取大量指令遵循知识。Wang等人(2022a)首次提出了一种迭代自举方法Self-Instruct,利用大语言模型基于175条人工编写指令中的若干示例生成多样化指令。新生成的指令随后被添加回初始池,助力后续扩展迭代。Taori等人(2023)将此扩展方法应用于更强大的教师模型textdavinci-003,蒸馏出52K高质量数据。为提高扩展过程中的多样性和覆盖率,Wu等人(2023c)和Sun等人(2024b)引导教师模型生成特定主题对应的指令。Xu等人(2023a)提出Evol-Instruct方法,从难度(如改写问题使其更复杂)和多样性(如生成更多长尾指令)两个维度扩展指令。这种Evol-Instruct方法不依赖特定领域,已被用于扩展编码(Luo等人,2023a)和数学(Luo等人,2023b)的蒸馏。此外,扩展方法能通过生成相似样本显著增强NLP任务数据集,从而提升任务表现。例如AugGPT(Dai等人,2023a)利用教师模型将训练样本中的每个句子改写成多个概念相似但语义不同的样本,以提高分类性能。类似地,TDG(He等人,2023b)提出目标数据生成(TDG)框架,通过上下文学习自动识别数据中的困难子群,并利用大语言模型为这些子群生成新样本。
In summary, the expansion method leverages the incontext learning strengths of LLMs to produce more varied and extensive datasets with both inputs and outputs. However, the quality and diversity of the generated data are heavily reliant on the teacher LLMs and the initial seed demonstrations. This dependence can lead to a dataset with inherent bias from LLMs (Yu et al., $2023\mathsf{a}.$ ; Wei et al., 2023) and a homogeneity issue where the generations may be prone to similarity ultimately, limiting the diversity this method seeks to achieve (Ding et al., 2023b). Moreover, the expansion process may inadvertently amplify any biases present in the seed data.
总之,扩展方法利用大语言模型(LLM)的上下文学习优势,生成输入输出更多样、更广泛的数据集。然而,生成数据的质量和多样性高度依赖于教师大语言模型和初始种子示例。这种依赖性可能导致数据集存在大语言模型固有偏见(Yu et al., $2023\mathsf{a}$; Wei et al., 2023)以及同质化问题,即生成内容最终可能趋于相似,从而限制该方法试图实现的多样性(Ding et al., 2023b)。此外,扩展过程可能会无意中放大种子数据中存在的任何偏见。
3.1.3 Data Curation
3.1.3 数据治理
The pursuit of high-quality and scalable data generation in knowledge distillation from LLMs has led to the emergence of the Data Curation approach. This method arises in response to the limitations observed in both the Labeling and Expansion approaches. These methods often yield data of variable quality and face constraints in quantity. In Labeling, the seed knowledge is sourced from task datasets, leading to potential noise and dirty data. Meanwhile, in Expansion, the input $x$ is derived from seed demonstrations, which can result in homogeneous data when generated in large quantities. To overcome these challenges, the Data Curation method curates high-quality or large-scale data by extensive meta-information as seed knowledge (Ding et al., 2023b; Gunasekar et al., 2023; Li et al., 2023a; Mar, 2023; Liu et al., 2023d; Wei et al., 2023; Yu et al., 2024; Ye et al., 2022; Gao et al., 2023a; Yang and Nicolai, 2023).
在大语言模型知识蒸馏中追求高质量、可扩展的数据生成,催生了数据精选(Data Curation)方法。该方法的出现是为了应对标注(Labeling)和扩展(Expansion)两种途径的局限性——这些方法往往产生质量参差不齐的数据且面临数量限制。标注法的种子知识来源于任务数据集,可能导致噪声和脏数据;而扩展法的输入$x$源自种子示例,大规模生成时易产生同质化数据。为突破这些限制,数据精选法通过海量元信息作为种子知识(Ding et al., 2023b; Gunasekar et al., 2023; Li et al., 2023a; Mar, 2023; Liu et al., 2023d; Wei et al., 2023; Yu et al., 2024; Ye et al., 2022; Gao et al., 2023a; Yang and Nicolai, 2023),实现了高质量或大规模数据的精选。
A distinct feature of Data Curation is its approach to synthesize data from scratch. Numerous diverse metainformation, such as topics or knowledge points, could be incorporated into this process to generate controllable $x$ and $y$ . Thus, this process can be meticulously controlled to yield datasets that are not only large in scale but also of high quality. The formulation for Data Curation can be represented as:
数据整理 (Data Curation) 的一个显著特点是其从零开始合成数据的方法。在此过程中可以融入多种多样的元信息 (metainformation) ,例如主题或知识点,从而生成可控的 $x$ 和 $y$ 。因此,这一过程可以被精细控制,最终产出不仅规模庞大而且质量优异的数据集。数据整理的公式化表示如下:
$$
{\mathcal{D}}^{\mathrm{(cur)}}={(x,y)|x\sim p_{T}(x|I\oplus m),y\sim p_{T}(y|I\oplus x)}.
$$
$$
{\mathcal{D}}^{\mathrm{(cur)}}={(x,y)|x\sim p_{T}(x|I\oplus m),y\sim p_{T}(y|I\oplus x)}.
$$
In this formulation, $m$ represents the diverse metainformation used to guide the synthesis of $x,$ and $I$ is the instruction guiding teacher LLMs to generate $x$ or $y$ .
在此公式中,$m$ 代表用于指导 $x$ 合成的多样化元信息,$I$ 是指导教师大语言模型生成 $x$ 或 $y$ 的指令。
Different studies primarily vary in their source and method of leveraging meta-information. UltraChat (Ding et al., 2023b) effectively demonstrates the process of curating both high-quality and diverse data by distilled knowledge. They collect extensive meta-information across three domains: Questions about the World, Creation and Generation, and Assistance on Existing Materials. For example, under Questions about the World, they explore 30 meta-topics like ”Technology” and ”Food and Drink.” the teacher LLMs then use this meta-information to distill a broad array of instructions and conversations, achieving a substantial scale of 1.5 million instances. UltraChat stands out with its lexical and topical diversity. The UltraLLaMA model, finetuned on this data, consistently surpasses other open-source models. Another notable series, phi (Gunasekar et al., 2023; Li et al., 2023a; Mar, 2023), focuses on distilling smaller, high-quality datasets akin to ”textbooks.” Phi-1(Gunasekar et al., 2023) experiments with synthesizing ”textbook quality” data in the coding domain. Their approach involves distilling clear, self-contained, instructive, and balanced content from LLMs, guided by random topics or function names to enhance diversity. The distilled data is a synthesis of 1 billion tokens of Python textbooks, complete with natural language explanations and code snippets, as well as 180 million tokens of Python exercises with solutions. Remarkably, the phi-1 model, despite its smaller size, outperforms nearly all open-source models on coding benchmarks like HumanEval and MBPP while being 10 times smaller in model size and 100 times smaller in dataset size. MFTCoder (Liu et al., 2023d) utilizes hundreds of Python knowledge points as meta-information to create a Code Exercise Dataset. In contrast, Magicoder (Wei et al., 2023) and WaveCoder (Yu et al., 2024) get raw code collections from open-source code datasets, using this as meta-information for generating instructional data. In the context of NLU tasks, certain studies (Ye et al., 2022; Gao et al., $2023\mathsf{a},$ ; Wang et al., 2021a) explore the use of labels as meta-information to synthesize corresponding samples for data augmentation. Similarly, in information retrieval tasks, there are efforts to utilize documents as meta-information for generating potential queries, thereby constructing large-scale retrieval pairs (Bonifacio et al., 2022; Meng et al., 2023).
不同研究主要在元信息的来源和利用方法上存在差异。UltraChat (Ding et al., 2023b) 通过知识蒸馏有效展示了同时获取高质量与多样化数据的过程。他们收集了三大领域的广泛元信息:"关于世界的问题"、"创作与生成"以及"现有材料辅助"。例如在"关于世界的问题"下,他们探索了"技术"、"食品饮料"等30个元主题,随后教师大语言模型利用这些元信息蒸馏出大量指令和对话,最终达到150万实例的规模。UltraChat以其词汇和主题多样性著称,基于该数据微调的UltraLLaMA模型持续超越其他开源模型。另一个著名系列phi (Gunasekar et al., 2023; Li et al., 2023a; Mar, 2023) 则专注于蒸馏类似"教科书"的小型高质量数据集。Phi-1(Gunasekar et al., 2023) 尝试在编码领域合成"教科书级"数据,其方法是通过随机主题或函数名引导,从大语言模型中蒸馏出清晰、自包含、具有指导性且平衡的内容。最终蒸馏数据包含10亿token的Python教科书(含自然语言解释和代码片段)以及1.8亿token的Python练习题(含解答)。值得注意的是,phi-1模型虽然在规模上小10倍、数据集小100倍,却在HumanEval和MBPP等编码基准测试中超越几乎所有开源模型。MFTCoder (Liu et al., 2023d) 使用数百个Python知识点作为元信息构建代码练习数据集,而Magicoder (Wei et al., 2023) 和WaveCoder (Yu et al., 2024) 则从开源代码数据集获取原始代码集合作为生成教学数据的元信息。在自然语言理解任务中,部分研究 (Ye et al., 2022; Gao et al., $2023\mathsf{a},$ ; Wang et al., 2021a) 探索将标签作为元信息来合成相应样本以实现数据增强。类似地,在信息检索任务中也有研究尝试以文档为元信息生成潜在查询,从而构建大规模检索对 (Bonifacio et al., 2022; Meng et al., 2023)。
In conclusion, Data Curation through teacher LLMs has emerged as a promising technique for synthesizing datasets that are not only high-quality and diverse but also large in scale. The success of models like phi-1 in specialized domains underscores the efficacy of this method. The ability to create synthetic datasets will become a crucial technical skill and a key area of focus in AI (Li et al., 2023a).
总之,通过教师大语言模型进行数据治理已成为一种前景广阔的技术,不仅能合成高质量、多样化的数据集,还能实现大规模生成。phi-1等模型在专业领域的成功验证了该方法的有效性。创建合成数据集的能力将成为一项关键技术技能,也是人工智能领域的重点研究方向 (Li et al., 2023a)。
3.1.4 Feature
3.1.4 特征
The previously discussed knowledge eli citation methods are typically applied to powerful black-box models, which are expensive and somewhat un reproducible due to calling API. In contrast, white-box distillation offers a more transparent and accessible approach for researchers. It involves leveraging the output distributions, intermediate features, or activation s from teacher LLMs, which we collectively refer to as Feature knowledge. White-box KD approaches have predominantly been studied for smaller encoder-based LMs, typically those with fewer than 1 billion parameters (cf. Gou et al. (2021) for detail). However, recent research has begun to explore white-box distillation in the context of generative LLMs (Timiryasov and Tastet, 2023; Liang et al., 2023a; Gu et al., 2024; Agarwal et al., 2024; Liu et al., 2023a; Wen et al., 2023; Wan et al., 2024a; Zhao and Zhu, 2023; Qin et al., 2023b; Boizard et al., 2024; Zhong et al., 2024).
先前讨论的知识提炼方法通常应用于强大的黑盒模型,这些模型由于需要调用API而成本高昂且难以复现。相比之下,白盒蒸馏为研究者提供了更透明、更易获取的途径。该方法利用教师大语言模型的输出分布、中间特征或激活值,我们统称为特征知识 (Feature knowledge)。白盒知识蒸馏 (KD) 方法主要针对较小的基于编码器的语言模型进行研究,通常参数少于10亿 (详见Gou等人 (2021) )。然而,最近的研究开始探索生成式大语言模型中的白盒蒸馏 (Timiryasov和Tastet, 2023; Liang等人, 2023a; Gu等人, 2024; Agarwal等人, 2024; Liu等人, 2023a; Wen等人, 2023; Wan等人, 2024a; Zhao和Zhu, 2023; Qin等人, 2023b; Boizard等人, 2024; Zhong等人, 2024)。
The typical method for acquiring this feature knowledge involves teacher LLMs annotating the output sequence $y$ with its internal representations. These annotations are then distilled into the student model using methods such as Kullback-Leibler Divergence (KLD). The process of eliciting feature knowledge can be formulated as follows:
获取这一特征知识的典型方法涉及教师大语言模型用其内部表征对输出序列 $y$ 进行标注。随后,这些标注通过诸如Kullback-Leibler散度(KLD)等方法蒸馏到学生模型中。特征知识的激发过程可表述如下:
$$
{\mathcal{D}}^{(\mathrm{feat})}={(x,y,\phi_{\mathrm{feat}}(x,y;\theta_{T}))|x\sim\chi,y\sim y}.
$$
$$
{\mathcal{D}}^{(\mathrm{feat})}={(x,y,\phi_{\mathrm{feat}}(x,y;\theta_{T}))|x\sim\chi,y\sim y}.
$$
In this formulation, $\mathcal{V}$ is the output set, which can be generated by teacher LLMs, the student model, or directly sourced from the dataset. $\phi_{\mathrm{feat}}(\cdot;\theta_{T})$ represents the operation of extracting feature knowledge (such as output distribution) from the teacher LLM.
在此公式中,$\mathcal{V}$ 是输出集,可由教师大语言模型、学生模型生成,或直接从数据集中获取。$\phi_{\mathrm{feat}}(\cdot;\theta_{T})$ 表示从教师大语言模型中提取特征知识(如输出分布)的操作。
The most straightforward method to elicit feature knowledge of teacher is to label a fixed dataset of sequences with token-level probability distributions (Sanh et al., 2019; Wen et al., 2023). To leverage the rich semantic and syntactic knowledge in intermediate layers of the teacher model, TED (Liang et al., 2023a) designs task-aware layer-wise distillation. They align the student’s hidden representations with those of the teacher at each layer, selectively extracting knowledge pertinent to the target task. Gu et al. (2024) and Agarwal et al. (2024) introduce a novel approach where the student model first generates sequences, termed ‘selfgenerated sequences.’ The student then learns by using feedback (i.e. output distribution) from teacher on these sequences. This method is particularly beneficial when the student model lacks the capacity to mimic teacher’s distribution. Moreover, various LLM-quantization methods with distilling feature knowledge from teacher LLMs have been proposed (Tao et al., 2022a; Liu et al., 2023a; Kim et al., 2023b). These methods aim to preserve the original output distribution when quantizing the LLMs, ensuring minimal loss of performance. Additionally, feature knowledge could serve as a potent source for multi-teacher knowledge distillation. Timiryasov and Tastet (2023) leverages an ensemble of GPT-2 and LLaMA as teacher models to extract output distributions. Similarly, FuseLLM (Wan et al., 2024a) innovatively combines the capabilities of various LLMs through a weighted fusion of their output distributions, integrating them into a singular LLM. This approach has the potential to significantly enhance the student model’s capabilities, surpassing those of any individual teacher LLM.
激发教师模型特征知识最直接的方法是为固定序列数据集标注token级别的概率分布 (Sanh et al., 2019; Wen et al., 2023)。为利用教师模型中间层丰富的语义和句法知识,TED (Liang et al., 2023a) 设计了任务感知的逐层蒸馏方法,通过将学生模型的隐藏表示与教师模型每一层对齐,选择性提取与目标任务相关的知识。Gu et al. (2024) 和 Agarwal et al. (2024) 提出了一种创新方法:学生模型首先生成"自生成序列",然后通过教师模型对这些序列的反馈(即输出分布)进行学习。当学生模型难以模仿教师分布时,这种方法尤为有效。此外,研究者们提出了多种结合教师大语言模型特征知识的量化方法 (Tao et al., 2022a; Liu et al., 2023a; Kim et al., 2023b),这些方法旨在量化大语言模型时保持原始输出分布,确保性能损失最小。特征知识还可作为多教师知识蒸馏的强大来源:Timiryasov and Tastet (2023) 采用GPT-2和LLaMA的集成作为教师模型来提取输出分布;类似地,FuseLLM (Wan et al., 2024a) 通过加权融合多个大语言模型的输出分布,创新性地将其整合为单一模型。这种方法有望显著提升学生模型能力,使其超越任何单个教师大语言模型。
In summary, feature knowledge offers a more transparent alternative to black-box methods, allowing for deeper insight into and control over the distillation process. By utilizing feature knowledge from teacher LLMs, such as output distributions and intermediate layer features, white-box approaches enable richer knowledge transfer. While showing promise, especially in smaller models, its application is not suitable for black-box LLMs where internal parameters are inaccessible. Furthermore, student models distilled from white-box LLMs may under perform compared to their black-box counterparts, as the black-box teacher LLMs (e.g. GPT-4) tend to be more powerful.
总之,特征知识为黑盒方法提供了更透明的替代方案,使人们能够更深入地洞察和控制蒸馏过程。通过利用教师大语言模型中的特征知识(如输出分布和中间层特征),白盒方法实现了更丰富的知识迁移。尽管这一方法在小型模型中展现出潜力,但由于无法获取内部参数,它并不适用于黑盒大语言模型。此外,从白盒大语言模型蒸馏出的学生模型性能可能逊色于黑盒模型,因为黑盒教师大语言模型(如GPT-4)通常更强大。
3.1.5 Feedback
3.1.5 反馈
Most previous works predominantly focus on one-way knowledge transfer from the teacher to the student for imitation, without considering feedback from the teacher on the student’s generation. The feedback from the teacher typically offers guidance on student-generated outputs by providing preferences, assessments, or corrective information. For example, a common form of feedback involves teacher ranking the student’s generations and distilling this preference into the student model through Reinforcement Learning from AI Feedback (RLAIF) (Bai et al., 2022a). Here is a generalized formulation for eliciting feedback knowledge:
以往的研究大多侧重于教师向学生单向传递知识以供模仿,而忽略了教师对学生生成结果的反馈。教师的反馈通常通过提供偏好、评估或修正信息来指导学生生成输出。例如,一种常见的反馈形式是教师对学生生成内容进行排序,并通过AI反馈强化学习 (Reinforcement Learning from AI Feedback, RLAIF) (Bai et al., 2022a) 将这些偏好提炼到学生模型中。以下是获取反馈知识的通用公式:
$$
\mathcal{D}^{(\mathrm{fb})}={(x,y,\phi_{\mathrm{fb}}(x,y;\theta_{T}))|x\sim\chi,y\sim p_{S}(y|x)},
$$
$$
\mathcal{D}^{(\mathrm{fb})}={(x,y,\phi_{\mathrm{fb}}(x,y;\theta_{T}))|x\sim\chi,y\sim p_{S}(y|x)},
$$
where $y$ denotes the output generated by the student model in response to $x,$ and $\phi_{\mathrm{fb}}(\cdot;\theta_{T})\rangle$ represents providing feedback from teacher LLMs. This operation evaluates the student’s output $y$ given the input $x.$ , by offering assessment, corrective information, or other forms of guidance. This feedback knowledge can not only be distilled into the student to also generate feedback (such as creating a student preference model) but, more importantly, enable the student to refine its responses based on the feedback. Various methods have been explored to elicit this advanced knowledge (Bai et al., 2022a; Luo et al., 2023b; Cui et al., 2023a; Kwon et al., 2023; Jiang et al., 2023b; Chen et al., 2023a; Gu et al., 2024; Agarwal et al., 2024; Chen et al., 2024b; Guo et al., 2024; Ye et al., 2023; Hong et al., 2023; Lee et al., 2023a).
其中 $y$ 表示学生模型根据输入 $x$ 生成的输出,$\phi_{\mathrm{fb}}(\cdot;\theta_{T})\rangle$ 代表教师大语言模型提供的反馈。该操作通过评估、纠正信息或其他形式的指导,对给定输入 $x$ 时学生输出 $y$ 进行评价。这种反馈知识不仅可以蒸馏到学生模型中使其也能生成反馈(例如创建学生偏好模型),更重要的是能让学生根据反馈优化其响应。已有多种方法被探索用于获取这种高级知识 (Bai et al., 2022a; Luo et al., 2023b; Cui et al., 2023a; Kwon et al., 2023; Jiang et al., 2023b; Chen et al., 2023a; Gu et al., 2024; Agarwal et al., 2024; Chen et al., 2024b; Guo et al., 2024; Ye et al., 2023; Hong et al., 2023; Lee et al., 2023a)。
Preference, as previously discussed, represents a notable form of feedback knowledge from teacher models. Various knowledge of preferences could be distilled from teachers by prompting it with specific criteria. Bai et al. (2022a) introduce RLAIF for distilling harmlessness preferences from LLMs. This involves using an SFT-trained LLM to generate response pairs for each prompt, then ranking them for harmlessness to create a preference dataset. This dataset is distilled into a Preference Model (PM), which then guides the RL training of a more harmless LLM policy. WizardMath (Luo et al., 2023b) places emphasis on mathematical reasoning. They employ ChatGPT as teacher to directly provide process supervision and evaluate the correctness of each step in the generated solutions. To scale up highquality distilled preference data, Cui et al. (2023a) develop a large-scale preference dataset for distilling better preference models, Ultra Feedback. It compiles various instructions and models to produce comparative data. Then, GPT-4 is used to score candidates from various aspects of preference, including instruction-following, truthfulness, honesty and helpfulness.
偏好 (Preference) 作为教师模型反馈知识的重要形式,可以通过特定标准提示从教师模型中提取多种偏好知识。Bai et al. (2022a) 提出 RLAIF 方法,用于从大语言模型中提取无害偏好:首先使用经过监督微调 (SFT) 的大语言模型为每个提示生成响应对,然后根据无害性进行排序以构建偏好数据集,最终将其蒸馏为偏好模型 (PM) 来指导强化学习训练,从而获得更具无害性的大语言模型策略。WizardMath (Luo et al., 2023b) 专注于数学推理领域,采用 ChatGPT 作为教师模型直接提供过程监督,评估生成解题过程中每个步骤的正确性。为扩大高质量蒸馏偏好数据规模,Cui et al. (2023a) 开发了大规模偏好数据集 Ultra Feedback,通过整合多样化指令和模型生成对比数据,并利用 GPT-4 从指令遵循、真实性、诚实性和帮助性等多维度对候选响应进行评分,以蒸馏更优的偏好模型。
Beyond merely assessing student generations, teachers can also furnish extensive feedback on instances where students under perform. In Lion (Jiang et al., 2023b), teacher model pinpoints instructions that pose challenges to the student model, generating new, more difficult instructions aimed at bolstering the student’s abilities. PERsD (Chen et al., 2023a) showcases a method where teacher offers tailored refinement feedback on incorrect code snippets generated by students, guided by the specific execution errors encountered. Similarly, SelFee (Ye et al., 2023) leverages ChatGPT to generate feedback and revise the student’s answer based on the feedback. In contrast, FIGA (Guo et al., 2024) revises the student’s response by comparing it to the ground-truth response. Furthermore, teacher model’s distribution over the student’s generations can itself act as a form of feedback. MiniLLM (Gu et al., 2024) and GKD (Agarwal et al., 2024) present an innovative strategy wherein the student model initially generates sequences, followed by teacher model producing an output distribution as feedback. This method leverages the teacher’s insight to directly inform and refine the student model’s learning process.
除了评估学生生成的内容外,教师还可以针对学生表现不佳的案例提供详细反馈。在Lion (Jiang et al., 2023b)中,教师模型会识别对学生模型构成挑战的指令,并生成新的、更复杂的指令以提升学生能力。PERsD (Chen et al., 2023a)展示了一种方法,教师根据具体执行错误,对学生生成的错误代码片段提供定制化的改进反馈。类似地,SelFee (Ye et al., 2023)利用ChatGPT生成反馈,并基于反馈修改学生答案。相比之下,FIGA (Guo et al., 2024)通过将学生回答与标准答案对比来进行修正。此外,教师模型对学生生成内容的分布本身也可作为一种反馈形式。MiniLLM (Gu et al., 2024)和GKD (Agarwal et al., 2024)提出了一种创新策略:学生模型首先生成序列,随后教师模型生成输出分布作为反馈。这种方法利用教师的洞察力直接指导并优化学生模型的学习过程。
3.1.6 Self-Knowledge
3.1.6 自我认知
The knowledge could also be elicited from the student itself, which we refer to as Self-Knowledge. In this setting, the same model acts both as the teacher and the student, iterative ly improving itself by distilling and refining its own previously generated outputs. This knowledge uniquely circumvents the need for an external, potentially proprietary, powerful teacher model, such as GPT-series LLMs. Furthermore, it allows the model to surpass the limitations or “ceiling” inherent in traditional teacher-student methods. Eliciting self-knowledge could be formulated as:
知识也可以从学生本身中提取,我们称之为自我知识 (Self-Knowledge)。在这种设定下,同一个模型同时扮演教师和学生的角色,通过蒸馏和优化自身先前生成的输出迭代地提升自己。这种知识独特地规避了对GPT系列大语言模型等外部、可能专有的强大教师模型的需求。此外,它使模型能够超越传统师生方法固有的限制或"天花板"。自我知识的提取可以表述为:
$$
\mathcal{D}^{(\mathrm{sk})}={(x,y,\phi_{\mathrm{sk}}(x,y))|x\sim\mathcal{S},y\sim p_{S}(y|I\oplus x)},
$$
$$
\mathcal{D}^{(\mathrm{sk})}={(x,y,\phi_{\mathrm{sk}}(x,y))|x\sim\mathcal{S},y\sim p_{S}(y|I\oplus x)},
$$
where $\phi_{\mathrm{sk}}(\cdot)$ is a generalized function that represents an additional process to the self-generated outputs $y,$ which could include but is not limited to filtering, rewarding, or any other mechanisms for enhancing or evaluating $y$ . It could be governed by external tools or the student itself $\theta_{S}$ . Recent research in this area has proposed various innovative methodologies to elicit self-knowledge, demonstrating its potential for creating more efficient and autonomous learning systems. (Allen-Zhu and Li, 2020; Wang et al., 2022a; Sun et al., 2024b; Yang et al., 2024; Jung et al., 2023; Huang et al., 2023a; Gulcehre et al., 2023; Yuan et al., 2024a; Xu et al., 2023b; Zelikman et al., 2022; Chen et al., 2024a; Zheng et al., 2024; Li et al., 2024c; Zhao et al., 2024; Singh et al., 2023; Chen et al., 2024c; Hosseini et al., 2024)
其中 $\phi_{\mathrm{sk}}(\cdot)$ 是一个广义函数,表示对自生成输出 $y$ 的附加处理过程,可能包括但不限于过滤、奖励或其他用于增强或评估 $y$ 的机制。该过程可由外部工具或学生模型本身 $\theta_{S}$ 控制。该领域最新研究提出了多种激发自我认知的创新方法,证明了其在构建更高效自主学习系统方面的潜力 (Allen-Zhu and Li, 2020; Wang et al., 2022a; Sun et al., 2024b; Yang et al., 2024; Jung et al., 2023; Huang et al., 2023a; Gulcehre et al., 2023; Yuan et al., 2024a; Xu et al., 2023b; Zelikman et al., 2022; Chen et al., 2024a; Zheng et al., 2024; Li et al., 2024c; Zhao et al., 2024; Singh et al., 2023; Chen et al., 2024c; Hosseini et al., 2024)。
A notable example of this methodology is SelfInstruct (Wang et al., 2022a), which utilizes GPT-3 for data augmentation through the Expansion approach, generating additional data samples to enhance the dataset. This enriched dataset subsequently fine-tunes the original model. Other methods aim to elicit targeted knowledge from student models by modifying prompts, and leveraging these data for further refinement. In Self-Align (Sun et al., 2024b), they find that models fine-tuned by Self-Instruct data tend to generate short or indirect responses. They prompt this model with verbose instruction to produce indepth and detailed responses. Then, they employ contextdistillation (Askell et al., 2021) to distill these responses paired with non-verbose instructions back to the model. Similarly, RLCD (Yang et al., 2024) introduces the use of contrasting prompts to generate preference pairs from an unaligned LLM, encompassing both superior and inferior examples. A preference model trained on these pairs then guides the enhancement of the unaligned model through reinforcement learning. Several other approaches employ filtering methods to refine self-generated data. For example, Impossible Distillation (Jung et al., 2023) targets sentence sum mari z ation tasks, implementing filters based on entailment, length, and diversity to screen self-generated summaries. LMSI (Huang et al., 2023a) generates multiple CoT reasoning paths and answers for each question, and then retains only those paths that lead to the most consistent answer.
该方法论的一个显著案例是SelfInstruct (Wang et al., 2022a),它通过扩展(Expansion)方法利用GPT-3进行数据增强,生成额外数据样本以扩充数据集。经过强化的数据集随后用于微调原始模型。其他方法则致力于通过修改提示词从学生模型中提取目标知识,并利用这些数据进行进一步优化。在Self-Align (Sun et al., 2024b)中,研究者发现经Self-Instruct数据微调的模型倾向于生成简短或间接的响应。他们通过详细指令提示该模型,使其产生深入细致的回答,继而运用上下文蒸馏(context distillation) (Askell et al., 2021)技术将这些回答与非详细指令配对后反哺给模型。类似地,RLCD (Yang et al., 2024)引入对比提示词方法,从未对齐的大语言模型中生成包含优劣示例的偏好对,基于这些配对训练的偏好模型通过强化学习指导未对齐模型的改进。另有若干方法采用过滤机制优化自生成数据。例如Impossible Distillation (Jung et al., 2023)针对文本摘要任务,基于蕴含关系、长度和多样性等维度实施过滤以筛选自生成摘要。LMSI (Huang et al., 2023a)为每个问题生成多条思维链(CoT)推理路径和答案,仅保留能得出最一致答案的路径。
Note that refined self-knowledge can be iterative ly acquired as the student model continuously improves, further enhancing the student’s capabilities. This is Gulcehre et al. (2023) introduces a Reinforced Self-Training (ReST) framework that cyclically alternates between Grow and Improve stages to progressively obtain better self-knowledge and refine the student model. During the Grow stage, the student model generates multiple output predictions. Then, in the Improve stage, these self-generated outputs are ranked and filtered using a scoring function. Subsequently, the language model undergoes fine-tuning on this curated dataset, employing an offline RL objective. Self-Play (Chen et al., 2024a) introduces a framework resembling iterative DPO, where the language model is fine-tuned to differentiate the self-generated responses from the human-annotated data. These self-generated responses could be seen as “negative knowledge” to promote the student to better align with the target distribution. Self-Rewarding (Yuan et al., 2024a) explores a novel and promising approach by utilizing the language model itself as a reward model. It employs LLMas-a-Judge prompting to autonomously assign rewards for the self-generated responses. The entire process can then be iterated, improving instruction following and reward modeling capabilities.
需要注意的是,精炼的自我认知可以随着学生模型的持续改进而迭代获取,从而进一步提升学生模型的能力。Gulcehre等人(2023)提出的强化自训练(ReST)框架通过"成长"和"改进"阶段的循环交替,逐步获得更好的自我认知并优化学生模型。在成长阶段,学生模型生成多个输出预测;在改进阶段,这些自生成输出会通过评分函数进行排序和筛选。随后,语言模型基于这个精选数据集采用离线强化学习目标进行微调。Self-Play(Chen等人,2024a)提出了一个类似迭代DPO的框架,通过微调语言模型来区分自生成响应与人工标注数据。这些自生成响应可视为"负知识",用于促进学生模型更好地对齐目标分布。Self-Rewarding(Yuan等人,2024a)探索了一种新颖且有前景的方法,将语言模型本身作为奖励模型,采用LLMas-a-Judge提示来自主评估自生成响应的奖励值。整个过程可迭代执行,从而同步提升指令跟随和奖励建模能力。
3.2 Distillation
3.2 蒸馏
This section focuses on the methodologies for effectively transferring the elicited knowledge from teacher LLMs into student models. We explore a range of distillation techniques, from the strategies that enhance imitation by $S u\cdot$ - pervised Fine-Tuning, Divergence and Similarity, to advanced methods like Reinforcement Learning and Rank Optimization, as shown in Figure 3.
本节重点探讨如何有效地将教师大语言模型(LLM)中提取的知识迁移到学生模型中。我们研究了一系列蒸馏技术,从通过监督微调(SFT)、散度与相似性增强模仿的策略,到强化学习和排序优化等先进方法,如图 3 所示。
3.2.1 Supervised Fine-Tuning
3.2.1 监督微调
Supervised Fine-Tuning (SFT), or called Sequence-Level KD (SeqKD) (Kim and Rush, 2016), is the simplest and one of the most effective methods for distilling powerful black-box
监督微调 (Supervised Fine-Tuning, SFT) ,或称序列级知识蒸馏 (Sequence-Level KD, SeqKD) (Kim and Rush, 2016) ,是蒸馏强大黑盒模型最简单且最有效的方法之一
TABLE 1: Functional forms of $D$ for various divergence types. $p\mathrm{.}$ : reference
| Divergence Type | D(p,q) Function |
| Forward KLD | ∑p(t) 1og |
| Reverse KLD | |
| JS Divergence | (∑p(t) log 2p(t) +∑q(t)log 2q(t) p(t)+q(t) p(t)+q(t) |
表 1: 不同散度类型中 $D$ 的函数形式。$p\mathrm{.}$ : 参考
| 散度类型 | D(p,q) 函数 |
|---|---|
| 前向KLD | ∑p(t) 1og |
| 反向KLD | |
| JS散度 | (∑p(t) log 2p(t) +∑q(t)log 2q(t) p(t)+q(t) p(t)+q(t) |
TABLE 2: Summary of similarity functions in knowledge distillation.
| SimilarityFunctionLF | Expression |
| L2-Norm Distance | Φr(fr(,y))-Φs(fs(,y))ll2 |
| L1-Norm Distance | ΦT(fT(c,y))-Φs(fs(c,y))1 |
| Cross-EntropyLoss | ∑ΦT(fr(c,y))log(Φs(fs(x,y))) |
| MaximumMeanDiscrepancy | MMD(ΦT(fT(c,y)),Φs(fs(x,y))) |
表 2: 知识蒸馏中的相似度函数总结。
| 相似度函数 | 表达式 |
|---|---|
| L2范数距离 | Φr(fr(,y))-Φs(fs(,y))ll2 |
| L1范数距离 | ΦT(fT(c,y))-Φs(fs(c,y))1 |
| 交叉熵损失 | ∑ΦT(fr(c,y))log(Φs(fs(x,y))) |
| 最大均值差异 | MMD(ΦT(fT(c,y)),Φs(fs(x,y))) |
LLMs. SFT finetunes student model by maximizing the likelihood of sequences generated by the teacher LLMs, aligning the student’s predictions with those of the teacher. This process can be mathematically formulated as minimizing the objective function:
大语言模型。监督式微调 (SFT) 通过最大化教师大语言模型生成序列的似然概率来微调学生模型,使学生的预测与教师保持一致。该过程可数学表述为最小化目标函数:
$$
\mathcal{L}{\mathrm{SFT}}=\mathbb{E}{x\sim\mathcal{X},y\sim p_{T}(y|x)}\left[-\log p_{S}(y|x)\right],
$$
$$
\mathcal{L}{\mathrm{SFT}}=\mathbb{E}{x\sim\mathcal{X},y\sim p_{T}(y|x)}\left[-\log p_{S}(y|x)\right],
$$
where $y$ is the output sequence produced by the teacher model. This simple yet highly effective technique forms the basis of numerous studies in the field. Numerous researchers have successfully employed SFT to train student models using sequences generated by teacher LLMs (Taori et al., 2023; Chiang et al., 2023; Wu et al., 2023c; Xu et al., $2023\mathsf{a},$ ; Luo et al., 2023b). Additionally, SFT has been explored in many self-distillation works (Wang et al., 2022a; Huang et al., 2023c; Xu et al., 2023b; Zelikman et al., 2022). Due to the large number of KD works applying SFT, we only list representative ones here. More detailed works can be found in §4.
其中 $y$ 是由教师模型生成的输出序列。这一简单却高效的技术构成了该领域众多研究的基础。许多研究者已成功运用监督式微调 (SFT) 技术,通过教师大语言模型生成的序列来训练学生模型 (Taori et al., 2023; Chiang et al., 2023; Wu et al., 2023c; Xu et al., $2023\mathsf{a},$ ; Luo et al., 2023b)。此外,监督式微调也在众多自蒸馏研究中得到探索 (Wang et al., 2022a; Huang et al., 2023c; Xu et al., 2023b; Zelikman et al., 2022)。由于采用监督式微调的知识蒸馏研究数量庞大,此处仅列举代表性成果,更多细节研究可参阅§4节。
3.2.2 Divergence and Similarity
3.2.2 发散性与相似性
This section mainly concentrates on algorithms designed for distilling feature knowledge from white-box teacher LLMs, including distributions and hidden state features. These algorithms can be broadly categorized into two groups: those minimizing divergence in probability distributions and those aimed at enhancing the similarity of hidden states.
本节主要关注从白盒教师大语言模型中提取特征知识的算法,包括概率分布和隐藏状态特征。这些算法大致可分为两类:最小化概率分布差异的算法和提升隐藏状态相似度的算法。
Divergence. Divergence-based methods minimize divergence between the probability distributions of the teacher and student models, represented by a general divergence function $D$ :
散度。基于散度的方法通过最小化教师模型和学生模型概率分布之间的散度来实现知识迁移,这一过程由通用散度函数 $D$ 表示:
$$
\begin{array}{r}{L_{\mathrm{Div}}=\underset{x\sim\mathcal{X},y\sim\mathcal{Y}}{\mathbb{E}}\left[D\left(p_{T}(y|x),p_{S}(y|x)\right)\right],}\end{array}
$$
$$
\begin{array}{r}{L_{\mathrm{Div}}=\underset{x\sim\mathcal{X},y\sim\mathcal{Y}}{\mathbb{E}}\left[D\left(p_{T}(y|x),p_{S}(y|x)\right)\right],}\end{array}
$$
The specific form of $D$ varies depending on the type of divergence employed. Table 1 outlines the functional forms of $D$ for different divergence measures. The commonly-used standard KD objectives essentially minimize the approximated forward Kullback-Leibler divergence (KLD) between the teacher and the student distribution (Sanh et al., 2019;
$D$ 的具体形式因所采用的散度类型而异。表 1 概述了不同散度度量下 $D$ 的函数形式。常用的标准知识蒸馏 (KD) 目标本质上是最小化教师分布与学生分布之间的近似前向 Kullback-Leibler 散度 (KLD) (Sanh et al., 2019;
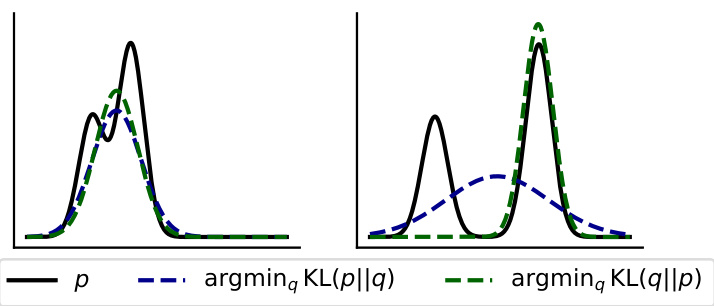
Fig. 6: Comparison of Forward and Reverse KL Divergences in Approximating a Target Distribution. Forward KL divergence approach tends to cover all modes of the target distribution but is less precise, i.e. “mode-covering” behavior. Reverse KL divergence method focuses predominantly on the most prominent mode, thereby exhibiting a “mode-seeking” behavior.
图 6: 目标分布近似中前向与反向KL散度的对比。前向KL散度方法倾向于覆盖目标分布的所有模态但精度较低,即呈现"模态覆盖"行为。反向KL散度方法主要聚焦于最显著的模态,从而表现出"模态追寻"行为。
Wen et al., 2023; Timiryasov and Tastet, 2023; Liang et al., $2023\mathsf{a}.$ ; Chen et al., 2024d) , which forces $p_{S}$ to cover all the modes of $p_{T}$ . However, when a student model is unable to learn all modes of a highly complex teacher, the resultant “mode-covering” behavior might cause the student to assign probability mass to tokens with low probability under the teacher’s distribution (cf. Figure 6 blue curve). This mode-covering phenomenon can potentially lead to hallucinations and low-quality generations. Alternatively, mode-seeking divergences like reverse KL prioritize tokens where the teacher assigns high probabilities (cf. Figure 6 green curve). This approach can mitigate the risk of lowquality outputs, fostering more accurate generations. However, it often does so at the cost of reduced diversity. Gu et al. (2024) adopt reverse KL divergence to prevent students from overestimating low-probability regions of the teacher’s distribution, employing Policy Gradient methods for optimization. Both Agarwal et al. (2024) and Sason and Verdu (2016) assess the effect of different divergence functions in LLM distillation, finding the optimal divergence to be task-dependent. For instance, forward KL divergence is more suitable for tasks like Machine Translation, where the output has fewer modes or variations, while reverse KL divergence is preferable for tasks like dialogue generation and instruction tuning, which involve multiple modes and a wider range of potential responses. Thus, the nature of the task significantly influences the selection of the divergence function for optimal performance.
Wen等, 2023; Timiryasov和Tastet, 2023; Liang等, $2023\mathsf{a}.$; Chen等, 2024d) 的研究强制 $p_{S}$ 覆盖 $p_{T}$ 的所有模态。然而当学生模型无法学习高度复杂教师的所有模态时,由此产生的"模态覆盖"行为可能导致学生为教师分布中低概率的token分配概率质量 (见图6蓝色曲线)。这种模态覆盖现象可能引发幻觉和低质量生成。相反,像反向KL这样的模态寻求散度会优先处理教师分配高概率的token (见图6绿色曲线)。这种方法可以降低低质量输出的风险,促进更准确的生成,但往往以牺牲多样性为代价。Gu等 (2024) 采用反向KL散度防止学生高估教师分布的低概率区域,并运用策略梯度方法进行优化。Agarwal等 (2024) 与Sason和Verdu (2016) 评估了不同散度函数在大语言模型蒸馏中的效果,发现最优散度取决于具体任务。例如前向KL散度更适用于机器翻译等输出模态较少的任务,而反向KL散度更适合对话生成和指令调优等多模态、响应范围更广的任务。因此,任务特性会显著影响散度函数的选择以实现最佳性能。
Similarity. Similarity-based methods in knowledge distillation aim to align the hidden states or features of the student model with those of the teacher. These methods use various similarity metrics to measure and optimize the congruence of internal representations between the two models. The objective is to ensure that the student model not only produces similar outputs to the teacher but also processes information in a comparable manner. The formulation for a similarity-based objective might look like this:
相似性。基于相似性的知识蒸馏方法旨在将学生模型的隐藏状态或特征与教师模型对齐。这些方法使用多种相似性指标来衡量和优化两个模型内部表征的一致性。其目标是确保学生模型不仅产生与教师相似的输出,还能以可比较的方式处理信息。基于相似性的目标函数可表述为:
$$
\mathcal{L}{\mathrm{Sim}}=\underset{x\sim\mathcal{X},y\sim\mathcal{Y}}{\mathbb{E}}\left[\mathcal{L}{F}\left(\Phi_{T}\left(f_{T}(x,y)\right),\Phi_{S}\left(f_{S}(x,y)\right)\right)\right],
$$
$$
\mathcal{L}{\mathrm{Sim}}=\underset{x\sim\mathcal{X},y\sim\mathcal{Y}}{\mathbb{E}}\left[\mathcal{L}{F}\left(\Phi_{T}\left(f_{T}(x,y)\right),\Phi_{S}\left(f_{S}(x,y)\right)\right)\right],
$$
where $f_{T}(x,y)$ and $f_{S}(x,y)$ are the feature maps of the teacher and student models, respectively. The transformation functions $\Phi_{T}$ and $\Phi_{S}$ are applied to these feature maps to ensure they are in the same shape, facilitating direct comparison. The similarity function $\mathcal{L}{F}$ is used to match these transformed feature maps. Table 2 shows common choices for $\mathcal{L}_{F}$ . Few works have employed similarity-based methods in the KD of LLMs. Among them, Liang et al. (2023a) propose Task-Aware Layer-Wise Distillation (TED), a method that utilizes task-aware filters. These filters are designed to selectively capture the most pertinent information for a specific task from the teacher model. The key objective is to minimize the discrepancy between the filtered representations in both teacher and student models. While similarity-based approaches are common in encoder-based LMs (Sun et al., 2019, 2020; Jiao et al., 2020; Hou et al., 2020; Zuo et al., 2022; Liang et al., 2021), their application in LLM knowledge distillation is not as widespread. However, considering their effectiveness, we anticipate an increase in research exploring these methods for LLM distillation in the near future.
其中 $f_{T}(x,y)$ 和 $f_{S}(x,y)$ 分别是教师模型和学生模型的特征图。变换函数 $\Phi_{T}$ 和 $\Phi_{S}$ 作用于这些特征图以确保它们具有相同形状,便于直接比较。相似度函数 $\mathcal{L}{F}$ 用于匹配这些变换后的特征图。表 2 展示了 $\mathcal{L}_{F}$ 的常见选择。
目前只有少数研究将基于相似度的方法应用于大语言模型的知识蒸馏 (KD)。其中,Liang 等人 (2023a) 提出了任务感知分层蒸馏 (TED) 方法,该方法利用任务感知过滤器。这些过滤器旨在从教师模型中选择性捕获特定任务最相关的信息,其核心目标是最小化教师模型和学生模型之间过滤表征的差异。
虽然基于相似度的方法在基于编码器的语言模型中很常见 (Sun 等人, 2019, 2020; Jiao 等人, 2020; Hou 等人, 2020; Zuo 等人, 2022; Liang 等人, 2021),但其在大语言模型知识蒸馏中的应用尚未普及。考虑到这些方法的有效性,我们预计未来将有更多研究探索这些方法在大语言模型蒸馏中的应用。
3.2.3 Reinforcement Learning
3.2.3 强化学习
This section explores advanced methods of distilling knowledge into student models using reinforcement learning (RL). This approach is especially relevant for leveraging the feedback from teacher to train student models (Bai et al., 2022a; Cui et al., $2023\mathsf{a},$ Luo et al., 2023b; Agarwal et al., 2024; Chen et al., ${2024\mathrm{b}},$ ; Ma et al., 2023a; Pang et al., 2023; Du et al., 2023a). The RL-based distillation process typically involves two main stages:
本节探讨利用强化学习(RL)将知识蒸馏到学生模型中的先进方法。该方法特别适用于利用教师模型的反馈来训练学生模型(Bai et al., 2022a; Cui et al., $2023\mathsf{a},$ Luo et al., 2023b; Agarwal et al., 2024; Chen et al., ${2024\mathrm{b}},$ ; Ma et al., 2023a; Pang et al., 2023; Du et al., 2023a)。基于强化学习的蒸馏过程通常包含两个主要阶段:
Distilled Reward Model Training. The first stage involves training a reward model rϕ using the feedback data D(fd) generated by teacher LLMs. Preference data, as one of the typical feedback, is employed to train the student reward model (Bai et al., 2022a; Cui et al., $2023\mathsf{a},$ ; Lee et al., $2023\mathsf{a},$ Kim et al., 2023a). They usually consist of input-output pairs $(x,y_{w},y_{l})$ . Here, $y_{w}$ and $y_{l}$ represent “winning” and “losing” outputs relative to the teacher’s preferences. The loss function for the reward model is defined as:
蒸馏奖励模型训练。第一阶段利用教师大语言模型生成的反馈数据D(fd)训练奖励模型rφ。偏好数据作为典型反馈之一,被用于训练学生奖励模型 (Bai et al., 2022a; Cui et al., $2023\mathsf{a},$ ; Lee et al., $2023\mathsf{a},$ Kim et al., 2023a)。这些数据通常由输入-输出对$(x,y_{w},y_{l})$组成,其中$y_{w}$和$y_{l}$分别表示相对于教师偏好的"优胜"和"劣汰"输出。奖励模型的损失函数定义为:
$$
\begin{array}{r}{\mathcal{L}{\mathrm{RM}}\left(r_{\phi},\mathcal{D}^{\mathrm{(fd)}}\right)=-\underset{\left(x,y_{w},y_{l}\right)\sim\mathcal{D}^{(\mathrm{fd)}}}{\mathbb{E}}\left[\log\sigma\left(r_{\phi}\left(x,y_{w}\right)-r_{\phi}\left(x,y_{l}\right)\right)\right]}\end{array}
$$
$$
\begin{array}{r}{\mathcal{L}{\mathrm{RM}}\left(r_{\phi},\mathcal{D}^{\mathrm{(fd)}}\right)=-\underset{\left(x,y_{w},y_{l}\right)\sim\mathcal{D}^{(\mathrm{fd)}}}{\mathbb{E}}\left[\log\sigma\left(r_{\phi}\left(x,y_{w}\right)-r_{\phi}\left(x,y_{l}\right)\right)\right]}\end{array}
$$
This formulation guides the reward model to correctly distinguish between more and less preferable outputs based on the teacher’s criteria. Instead of learning the instancelevel rewards, RLMEC (Chen et al., 2024b) adopts a different approach by training a generative reward model. It is trained on an erroneous solution rewriting data distilled from a teacher LLM. This distilled reward model can produce token-level rewards for RL training.
该公式指导奖励模型根据教师标准正确区分更优和次优输出。RLMEC (Chen et al., 2024b) 未采用实例级奖励学习策略,而是通过训练生成式奖励模型实现目标。该模型基于从教师大语言模型提炼的错误解法重写数据进行训练,最终可生成用于强化学习的 token 级奖励信号。
Reinforcement Learning Optimization. In the second stage, the student model, represented by a policy $\pi_{\theta}$ , is optimized to maximize the expected reward as per the trained reward model. Simultaneously, it minimizes the divergence from a reference policy $\pi_{\mathrm{ref}},$ typically the initial policy of the student model trained by SFT, controlled by a factor $\beta$ . The RL objective is given by:
强化学习优化。在第二阶段,学生模型(由策略$\pi_{\theta}$表示)通过优化以最大化根据训练好的奖励模型所得到的预期奖励。同时,它最小化与参考策略$\pi_{\mathrm{ref}}$的差异(通常是由SFT训练的学生模型初始策略),这一过程由系数$\beta$控制。强化学习目标函数如下:
$$
\operatorname*{max}{\pi_{\theta}}\operatorname*{\mathbb{E}}{x\sim X,y\sim\pi_{\theta}(y\mid x)}\left[r_{\phi}(x,y)\right]-\beta D_{\mathrm{KL}}\left[\pi_{\theta}(y\mid x)|\pi_{\mathrm{ref}}(y\mid x)\right]
$$
$$
\operatorname*{max}{\pi_{\theta}}\operatorname*{\mathbb{E}}{x\sim X,y\sim\pi_{\theta}(y\mid x)}\left[r_{\phi}(x,y)\right]-\beta D_{\mathrm{KL}}\left[\pi_{\theta}(y\mid x)|\pi_{\mathrm{ref}}(y\mid x)\right]
$$
This RL framework not only ensures that the student model learns the explicit content from the teacher but also effectively adopts the teacher’s preference patterns. The use of ${\mathrm{RL}},$ particularly with the PPO (Schulman et al., 2017) algorithm, offers a robust mechanism for aligning the student model’s outputs with the teacher. Alternatively, the teacher LLM can also serve as the reward model to directly assign rewards during RL, circumventing the need for training a reward model (Lee et al., 2023a; Kwon et al., 2023). While this approach may exhibit superior performance, it comes at a higher computational cost compared to employing a smaller distilled reward model.
这一强化学习 (RL) 框架不仅能确保学生模型从教师模型中学习显性内容,还能有效采纳教师的偏好模式。使用 ${\mathrm{RL}}$(尤其是 PPO 算法 [Schulman et al., 2017])为学生模型输出与教师模型的对齐提供了稳健机制。此外,教师大语言模型也可作为奖励模型,直接在强化学习过程中分配奖励,从而避免训练额外奖励模型 [Lee et al., 2023a; Kwon et al., 2023]。虽然这种方法可能展现出更优性能,但与使用小型蒸馏奖励模型相比,其计算成本更高。
3.2.4 Ranking Optimization
3.2.4 排序优化
Ranking optimization presents a stable and computationally efficient alternative to RL for injecting preference feedback into language models (Rafailov et al., 2023; Song et al., 2023a; Yuan et al., 2023b). This method, diverging from traditional RL approaches, directly incorporates ranking information into language models from a fixed preference dataset during fine-tuning. Intuitively, it directly updates policy to increase the relative likelihood of preferred over less favored responses. This direct optimization of preferences, without the need for sampling outputs, makes the process more stable and efficient. Recently, some works have been proposed to explore using ranking optimization to distill teacher’s preferences into student models (Tunstall et al., 2023; Hong et al., 2023; Yuan et al., 2024a).
排序优化为将偏好反馈注入语言模型提供了一种稳定且计算高效的替代强化学习方案 (Rafailov et al., 2023; Song et al., 2023a; Yuan et al., 2023b) 。该方法不同于传统强化学习路径,在微调阶段直接从固定偏好数据集中提取排序信息融入语言模型。其核心思想是通过直接更新策略,提升优质回复相对于劣质回复的相对概率。这种无需采样输出即可直接优化偏好的特性,使整个流程更加稳定高效。近期部分研究开始探索利用排序优化技术将教师模型的偏好知识蒸馏至学生模型 (Tunstall et al., 2023; Hong et al., 2023; Yuan et al., 2024a) 。
Zephyr (Tunstall et al., 2023) utilizes Direct Preference Optimization (DPO) (Rafailov et al., 2023) to distill the preference alignment in teacher LLMs. DPO streamlines the objective of reinforcement learning (as in Eq. 13), which involves reward maximization with a KL-divergence constraint, into a single-stage policy training.
Zephyr (Tunstall et al., 2023) 采用直接偏好优化 (DPO) (Rafailov et al., 2023) 来提炼教师大语言模型中的偏好对齐。DPO 将强化学习目标(如公式 13 所示)简化为单阶段策略训练,该目标涉及带 KL 散度约束的奖励最大化。
where $y_{w}$ is preferred over $y_{l}$ according to the teacher LLM. Hong et al. (2023) (Hong et al., 2023) adopt two ranking-based optimization objectives, Rank Responses to align Human Feedback (RRHF) (Yuan et al., 2023b) and Preference Ranking Optimization (PRO) (Song et al., 2023a), for preference distillation. RRHF (Yuan et al., 2023b) focuses on a ranking loss defined as:
其中 $y_{w}$ 是根据教师大语言模型 (teacher LLM) 优于 $y_{l}$ 的响应。Hong 等人 (2023) (Hong et al., 2023) 采用两种基于排序的优化目标——对齐人类反馈的响应排序 (Rank Responses to align Human Feedback, RRHF) (Yuan 等人, 2023b) 和偏好排序优化 (Preference Ranking Optimization, PRO) (Song 等人, 2023a)——进行偏好蒸馏。RRHF (Yuan 等人, 2023b) 的核心是定义为以下形式的排序损失:
$$
\mathcal{L}{\mathrm{RRHF}}=\sum_{r_{i}<r_{j}}\operatorname*{max}(0,p_{i}-p_{j}),
$$
$$
\mathcal{L}{\mathrm{RRHF}}=\sum_{r_{i}<r_{j}}\operatorname*{max}(0,p_{i}-p_{j}),
$$
where $r_{i}$ and $r_{j}$ are the reward scores assigned by the teacher LLM for responses $y_{i}$ and $y_{j}.$ , respectively, and $p_{i},p_{j}$ are their corresponding conditional log probabilities under the policy $\pi_{\theta}$ . This approach emphasizes direct comparison and ranking of responses based on the teacher’s preferences. PRO (Song et al., 2023a) expands the concept of pairwise comparison to handle preference rankings of any length. For a given instruction $x$ and a sequence of responses ordered by teacher preference as $y_{1}\succ y_{2}\succ\dots\succ y_{n},$ the RPO training objective is:
其中 $r_{i}$ 和 $r_{j}$ 分别表示教师大语言模型为响应 $y_{i}$ 和 $y_{j}$ 分配的奖励分数,$p_{i},p_{j}$ 是它们在策略 $\pi_{\theta}$ 下对应的条件对数概率。该方法强调基于教师偏好对响应进行直接比较和排序。PRO (Song et al., 2023a) 将成对比较的概念扩展到处理任意长度的偏好排序。对于给定指令 $x$ 和按教师偏好排序的响应序列 $y_{1}\succ y_{2}\succ\dots\succ y_{n}$,RPO训练目标为:
$$
\mathcal{L}{\mathrm{PRO}}=-\sum_{k=1}^{n-1}\log\frac{\exp{\left(p_{k}\right)}}{\sum_{i=k}^{n}\exp{\left(p_{i}\right)}},
$$
$$
\mathcal{L}{\mathrm{PRO}}=-\sum_{k=1}^{n-1}\log\frac{\exp{\left(p_{k}\right)}}{\sum_{i=k}^{n}\exp{\left(p_{i}\right)}},
$$
where $p_{k}$ represents the conditional log probabilities for $y_{k}$ under the student policy $\pi_{\theta}$ . By iterative ly contrasting the likelihood of generating responses, PRO optimizes the student LM to prioritize the most preferred response while progressively ranking the rest in the order of diminishing preference.
其中 $p_{k}$ 表示学生策略 $\pi_{\theta}$ 下 $y_{k}$ 的条件对数概率。通过迭代对比生成响应的可能性,PRO(偏好排序优化)使学生大语言模型优先生成最优响应,同时按偏好递减顺序对其余响应进行渐进排序。
4 SKILL DISTILLATION
4 技能蒸馏
Building upon the foundation laid out in Section 3 about eliciting knowledge and distillation algorithms, we shift our focus to how these techniques facilitate the distillation of specific skills in LLMs. Our exploration will encompass a diverse range of skills exhibited by LLMs, including Context Following, Alignment, Agent, NLP Task Specialization and Multi-Modality. Context Following focuses on the student’s ability to comprehend and respond effectively to input information. Alignment delves into the student’s capability to align its output with the teacher’s responses. Moving forward, Agent underscores the autonomous nature of language models. NLP Task Specialization highlights the LLM’s versatility in specializing across various Natural Language Processing tasks, demonstrating its adaptability. Finally, Multi-Modality encompasses the knowledge transfer from teacher LLMs to multi-modal models. Table 3 summarizes the representative works, encompassing details such as the skills involved, seed knowledge, teacher LLM, student model, knowledge eli citation method, and training objectives.
基于第3节所述的知识激发与蒸馏算法基础,我们将重点转向这些技术如何促进大语言模型(LLM)中特定技能的提炼。我们的探索将涵盖大语言模型展现的多样化技能,包括上下文跟随(Context Following)、对齐(Alignment)、智能体(Agent)、自然语言处理任务专精(NLP Task Specialization)以及多模态(Multi-Modality)。上下文跟随关注学生模型对输入信息的理解和有效响应能力;对齐探究学生模型输出与教师模型响应的匹配能力;智能体强调语言模型的自主特性;自然语言处理任务专精突显大语言模型在各类自然语言处理任务中的专业化多面性,展示其适应能力;最后,多模态涵盖从教师大语言模型到多模态模型的知识迁移。表3总结了代表性工作,包含所涉技能、种子知识、教师大语言模型、学生模型、知识激发方法及训练目标等细节。
4.1 Context Following
4.1 上下文跟随
This part concentrates on the distillation of context following skills from LLMs. This process involves transferring the ability of LLMs to handle a variety of complex contexts — such as few-shot demonstrations, intricate instructions, dialogue history, and retrieval-augmented information — into smaller models. Many research efforts in this domain aim to imbue smaller models with these sophisticated, contextfollowing capabilities. Our discussion here will dissect this facet of skill distillation, categorizing it based on different types of context and elaborating on how each is distilled and incorporated into smaller, efficient models.
这部分重点探讨如何从大语言模型(LLM)中提炼上下文跟随能力。该过程涉及将大语言模型处理各类复杂上下文(如少样本演示、复杂指令、对话历史和检索增强信息)的能力迁移至小型模型。该领域许多研究致力于让小型模型具备这些精密的上下文跟随能力。我们将通过剖析不同上下文类型,分别阐述其蒸馏方法及如何整合到高效的小型模型中。
4.1.1 Instruction Following
4.1.1 指令跟随
Instruction-following capacity enables LLMs to understand and follow user-given instructions. This ability significantly enhances human-AI interaction, allowing for seamless under standing and execution of tasks as directed by users. A primary method for acquiring this skill involves constructing instruction-like prompt-response pairs and employing Supervised Fine Tuning (SFT) for model training. Data for this purpose can be manually curated by human experts or transformed from existing NLP tasks into instructional formats with templates, such as prefacing machine translation data with ”Translate this sentence to Spanish:”. However, these approaches have limitations. Manual data creation is labor-intensive, while template-based transformation lacks diversity in instructions and may not align well with natural human input. LLMs like GPT-4 offer an efficient alternative for creating diverse and controlled SFT data by their capabilities of in-context learning and instruction following. Most relevant works use OpenAI’s GPT series models to generate prompt-response data pairs and then train the student LLMs by supervised fine-tuning (Wang et al., 2022a; Taori et al., 2023; Chiang et al., 2023; Wu et al., 2023c; Xu et al., 2023a; Mukherjee et al., 2023; Mitra et al., 2023; Luo et al., 2023b; Peng et al., 2023a).
指令跟随能力使大语言模型(LLM)能够理解并执行用户给出的指令。这一能力显著提升了人机交互体验,使其能够流畅地理解并执行用户指示的任务。获取该能力的主要方法是构建指令式提示-响应对,并采用监督微调(SFT)进行模型训练。相关数据可由人工专家手动编制,或通过模板将现有自然语言处理(NLP)任务转化为指令格式,例如在机器翻译数据前添加"将这句话翻译成西班牙语:"等前缀。但这些方法存在局限:人工创建数据费时费力,而基于模板的转换又缺乏指令多样性,且可能不符合自然的人类输入模式。像GPT-4这样的大语言模型凭借上下文学习和指令跟随能力,为生成多样化且可控的监督微调数据提供了高效替代方案。现有研究大多采用OpenAI的GPT系列模型生成提示-响应对,再通过监督微调训练学生模型(Wang et al., 2022a; Taori et al., 2023; Chiang et al., 2023; Wu et al., 2023c; Xu et al., 2023a; Mukherjee et al., 2023; Mitra et al., 2023; Luo et al., 2023b; Peng et al., 2023a)。
TABLE 3: A summary of skill distillation works. IF: Instruction Following, MD: Multi-turn Dialoue, TP: Think Pattern, RAG: Retrieval-Augmented Generation, NLU: Natural Language Understanding, NLG: Natural Language Generation, IR: Information Retrieval, SFT: Supervised Fine-Tuning, D&S: Divergence and Similarity, RL: Reinforcement Learning, RO: Ranking Optimization.
| 方法 | 技能 | 种子知识 | 教师模型 | 学生模型 | 知识提取 | 目标 |
|---|---|---|---|---|---|---|
| 上下文跟随 | ||||||
| Self-Instruct (Wang et al., 2022a) | 175个人工标注任务 | |||||
| Alpaca (Taori et al., 2023) | IF | 175个人工标注任务 | GPT3 | LLaMA | 扩展+自知识 | SFT |
| LaMini-LM (Wu et al., 2023c) | IF | 3.5K维基百科类别+混合数据集 | ChatGPT | 多种模型 | 扩展 | SFT |
| WizardLM (Xu et al., 2023a) | IF | Alpaca数据 | ChatGPT | LLaMA | 扩展 | SFT |
| Lion (Jiang et al., 2023b) BabyLlama (Timiryasov and Tastet, 2023) | IF | 1000万词BabyLM数据集 | GPT-2 + 小型LLaMA | 5800万参数LLaMA | 标注+扩展+反馈特征 | D&S |
| MiniLLM (Gu et al., 2024) | IF | Dolly数据集 | GPT2 + OPT + LLaMA | GPT2 + OPT + LLaMA | 特征 | D&S |
| Self-Align (Sun et al., 2024b) | IF | 人工编写原则 | LLaMA | LLaMA | 扩展+自知识 | SFT |
| Self-Rewarding (Yuan et al., 2024a) | IF | 人工编写样本算术+CommonsenseQA+GSM8K | LLaMA | LLaMA GPT-J | 自知识 | SFT + RL |
| STaR (Zelikman et al., 2022) | IF | Alpaca数据集 | GPT-J GPT4 | LLaMA | 自知识标注 | SFT |
| Llama-GPT4 (Peng et al., 2023a) Reflection-Tuning (Li et al., 2023e) | IF | Alpaca/WizardLM数据集 | ChatGPT | LLaMA | 标注 | SFT |
| Selective Reflection-Tuning (Li et al., 2024d) | IF | Alpaca/WizardLM数据集 | ChatGPT | LLaMA | 标注 | SFT |
| Vicuna (Chiang et al.,2023) | IF/MD | 人类对话 | ChatGPT + GPT4 | LLaMA | 标注 | SFT |
| Koala (Geng et al., 2023) | IF/MD | 人类对话 | ChatGPT | LLaMA | 标注 | SFT |
| Baize (Xu et al., 2023b) | IF/MD | Quora + Stack Overflow | ChatGPT | LLaMA | 扩展+自知识 | SFT |
| UltraChat (Ding et al., 2023b) | IF/MD | Wikidata + 文本材料 + C4 | ChatGPT | LLaMA | 整理 | SFT |
| Orca (Mukherjee et al., 2023) | IF/TP | FLAN-v2 + 少样本/数学/合成数据 | ChatGPT + GPT4 | LLaMA | 标注 | SFT |
| Orca2 (Mitra et al., 2023) | IF/TP | 人类对话, Flan/代码/数学集合 | GPT4 | LLaMA | 标注 | SFT |
| SelFee (Ye et al., 2023) CoT-Distill (Hsieh et al., 2023) | IF/TP | e-SNLI + ANLI + CQA + SVAMP | ChatGPT | LLaMA T5 | 标注 | SFT |
| KnowPAT (Zhang et al., 2023a) | IF/TP | CPKG + QA数据 | PaLM | LLaMA | 标注 | SFT |
| DEBATunE (Li et al., 2024e) | IF/TP | 争议性话题 | ChatGPT + ChatGLM + Vicuna-7B | LLaMA | 标注 | SFT |
| Phi-1 (Gunasekar et al., 2023) | IF/Code | phi-1 | 整理 | SFT | ||
| Phi-1.5 (Li et al., 2023a) SAIL (Luo et al., 2023c) | IF/Code IF/RAG | 20k网络主题 Alpaca数据+网络内容 | GPT3.5 GPT4 | LLaMA | 整理+标注 | SFT |
| 对齐 | IF/RAG | Open-Instruct | GPT4 | LLaMA | 标注 | SFT + D&S |
| OpenChat (Wang et al., 2023c) | IF/Preference | 人类对话 | ChatGPT + GPT4 | LLaMA | 标注 | SFT + RL |
| Zephyr (Tunstall et al., 2023) ALMoST (Kim et al., 2023a) | IF/Preference | 混合数据集 人工编写提示 | GPT4 | Mistral | 标注+反馈 | SFT + RO |
| RLCD (Yang et al., 2024) | IF/Preference | 人工编写提示 | LLaMA | LLaMA | 扩展+标注 | SFT + RL |
| RLAIF (Lee et al., 2023a) | IF/Preference | 人工编写提示 | PaLM 2 | PaLM 2 | 标注 | SFT + RL |
| GPT3 Reward (Kwon et al., 2023) | Preference | 人工编写提示 | GPT3 | GPT3 | 标注 | RL |
| ILF (Scheurer et al., 2023) | Preference | 任务特定数据集 | GPT3 + FeedME | GPT3 | 标注 | RL |
| ULTRAFEEDBACK (Cui et al., 2023a) Constitutional AI (Bai et al., 2022a) | Preference Preference/Value | 混合数据集 人工编写提示 | GPT4 自定义学生模型 | LLaMA 自定义模型 | 标注 标注+扩展+反馈 | RL |
| 工具 | ||||||
| Toolformer (Schick et al., 2023) | Tool | CCNet | GPT-J | GPT-J | 标注 | SFT |
| Graph-ToolFormer(Zhang.2023) Gorilla (Patil et al., 2023) | Tool Tool | 混合图数据集 在线API文档 | ChatGPT | GPT-J + LLaMA | 标注 | SFT |
| GPT4Tools (Yang et al, 2023b) | Tool | 图像内容 | GPT4 ChatGPT | LLaMA | 扩展 | SFT |
| ToolAlpaca (Tang et al., 2023a) | Tool | Public-apis仓库 | ChatGPT | LLaMA | 整理+扩展 | SFT |
| ToolLLM (Qin et al., 2023a) | Tool | 真实世界API | ChatGPT | LLaMA | 整理 | SFT |
| MLLM-Tool (Wang et al., 2024) | Tool | HuggingFace模型卡片 | GPT4 | LLaMA | 整理 | SFT |
| 规划 | ||||||
| FireAct (Chen et al., 2023b) | Planning | 混合QA数据集 | GPT4 | LLaMA | 标注 | SFT |
| AgentTuning (Zeng et al., 2023a) Lumos (Yin et al., 2023a) | Planning Planning | 6个智能体任务 混合交互任务 | GPT4 + ChatGPT GPT4 | LLaMA | 标注+扩展 标注 | SFT |
| AUTOACT (Qiao et al., 2024) | Planning | 混合QA任务 | LLaMA | LLaMA | 标注 | SFT |
| NLU | ||||||
| AugGPT (Dai et al., 2023a) | NLU | Amazon/症状/PubMed20k数据集 | ChatGPT | BERT | 标注 | |
| TDG (He et al., 2023b) | NLU | SST + QQP + MNLI | GPT3 | BERT | 扩展 | SFT |
| SunGen (Gao et al., 2023a) | NLU | 文本分类任务 | GPT2 | DistilBERT | 整理 | SFT |
| NLG | ||||||
| UDG (Wang et al., 2021a) | NLG | Pile + ArXiv + CNN/DM + WikiHow | GPT3.5 | ZCode++ | 扩展 | SFT |
| InheritSumm (Xu et al., 2023c) DIMSUM+ (Jung et al., 2023) | NLG | 无 | GPT2 + CTRL + BioGPT | T5 | 标注 整理+自知识 | SFT |
| Genie (Yehudai et al., 2024) | NLG | ELI5 + ASQA + NQ + CNN/DM | Falcon + LLaMA | FLAN + LLaMA | 标注 | SFT |
| IR | ||||||
| GKD(Agarwal et al, 2024) | NLG/NLU/IF IR | XSum+WMT14 en-de+GSM8K+FLAN2021 IR数据集 | T5-XL | T5 | 特征+反馈 | D&S + RL |
| QUILL (Srinivasan et al., 2022) | IR | IR数据集 | T5 ChatGPT ChatGPT + GPT4 | 4层Transformer LLaMA | 内部知识 标注 | D&S SFT |
| RankVicuna (Pradeep et al., 2023a) RankZephyr (Pradeep et al., 2023b) | IR 推荐 |
表 3: 技能蒸馏工作汇总。IF: 指令跟随, MD: 多轮对话, TP: 思维模式, RAG: 检索增强生成, NLU: 自然语言理解, NLG: 自然语言生成, IR: 信息检索, SFT: 监督微调, D&S: 差异与相似性, RL: 强化学习, RO: 排序优化。
Basic Instructions. Self-Instruct (Wang et al., 2022a) leverages the in-context learning capability of GPT-3 to expand a seed pool of 175 tasks to 52K task-agnostic instructions, ensuring a broad spectrum of general instructions. Additionally, a filtering and post-processing stage is introduced to eliminate redundant or similar instructions. Notably, through training with this enriched dataset, GPT-3 acquires the ability to follow instructions, enabling it to perform comparably to Instruct GP T in zero-shot instruction tasks and when provided with expert-written instructions for novel tasks. Based on the self-instruct method, Taori et al. (2023) train an Alpaca model using the Llama 7B model on 52K instruction-following demonstrations, generated in a similar style as self-instruct but utilizing the more robust text-davinci-003 model. To enhance the diversity of instructional data, Wu et al. (2023c) introduce a technique known as Topic-Guided Instruction Generation. This method involves gathering 3.5K common topics from Wikipedia to serve as guidance during the generation process.
基本指令。Self-Instruct (Wang et al., 2022a) 利用 GPT-3 的上下文学习能力,将 175 个任务的种子池扩展至 52K 个任务无关的指令,确保覆盖广泛的通用指令范围。此外,该方法引入了过滤和后处理阶段,以消除冗余或相似的指令。值得注意的是,通过使用这一增强数据集进行训练,GPT-3 获得了遵循指令的能力,使其在零样本指令任务中表现与 Instruct GPT 相当,并在面对专家编写的新任务指令时也能有效执行。基于 Self-Instruct 方法,Taori et al. (2023) 使用 Llama 7B 模型在 52K 条指令跟随演示上训练了 Alpaca 模型,这些演示以类似 Self-Instruct 的风格生成,但采用了更强大的 text-davinci-003 模型。为了提升指令数据的多样性,Wu et al. (2023c) 提出了一种称为主题引导指令生成 (Topic-Guided Instruction Generation) 的技术,该方法通过从维基百科收集 3.5K 个常见主题作为生成过程中的引导。
Complex Instructions. Some works promote students to solve more complex instructions (Xu et al., 2023a; Luo et al., 2023b,a; Guo et al., 2023c). According to Xu et al. (2023a), instruction datasets derived from human-written seeds often exhibit low to moderate complexity. To enhance the complex instruction-following capabilities of smaller models, WizardLM (Xu et al., 2023a) introduces Evol-Instruct. This method gradually transforms instructions into more complex forms through a multi-step evolution process, focusing on both increasing difficulty levels and expanding the diversity of topics. They conducted four rounds of evolution using the OpenAI ChatGPT API, resulting in a dataset of 250k complex instructions. Subsequently, they trained the LLaMA 7B model, referred to as WizardLM, on this dataset. In the high-difficulty section of test instructions, WizardLM even outperformed ChatGPT, achieving a win rate $7.9%$ higher than ChatGPT. Zhao et al. (2023e) further conduct preliminary studies revealing the effectiveness of increasing instruction complexity. Instruction Fusion (Guo et al., 2023c) further uses teacher LLMs to increase the complexity by fusing two distinct evolved instructions. Furthermore, this concept of “evolving” instructions has been extended to distill specific skills such as coding (Luo et al., 2023a) and mathematics (Luo et al., 2023b).
复杂指令。部分研究致力于提升学生解决复杂指令的能力 (Xu et al., 2023a; Luo et al., 2023b,a; Guo et al., 2023c)。Xu等人 (2023a) 指出,基于人工编写种子生成的指令数据集通常呈现中低复杂度。为增强小模型处理复杂指令的能力,WizardLM (Xu et al., 2023a) 提出Evol-Instruct方法,通过多步进化过程逐步将指令转化为更复杂的形式,重点提升难度层级并扩展主题多样性。他们使用OpenAI ChatGPT API进行了四轮进化,最终生成包含25万条复杂指令的数据集。基于该数据集训练的LLaMA 7B模型(命名为WizardLM)在高难度测试指令环节甚至超越ChatGPT,胜出率高出 $7.9%$。Zhao等人 (2023e) 的初步研究进一步验证了提升指令复杂度的有效性。指令融合技术 (Guo et al., 2023c) 则通过教师大语言模型融合两条进化指令来增强复杂度。此外,这种指令"进化"理念已延伸至代码生成 (Luo et al., 2023a) 和数学推理 (Luo et al., 2023b) 等特定技能的提炼领域。
Human Instructions. In contrast to works that rely on generating instructions from ChatGPT, which may lack diversity and have gaps with real human instructions, Vicuna (Chiang et al., 2023) and Koala (Geng et al., 2023) showcase impressive performance by using human conversations and natural instructions from community-contributed conversations. These conversations, found in platforms like ShareGPT, provide a forum for users to share their interactions with ChatGPT. It’s important to note, however, that models trained on such natural conversations might mimic the style but may not fully capture the reasoning process of the original teacher (Gudibande et al., 2023; Mukherjee et al., 2023).
人类指令。与依赖从ChatGPT生成指令(可能缺乏多样性且与真实人类指令存在差距)的工作不同,Vicuna (Chiang et al., 2023) 和 Koala (Geng et al., 2023) 通过使用人类对话和社区贡献对话中的自然指令展示了令人印象深刻的表现。这些对话来自ShareGPT等平台,为用户提供了分享与ChatGPT互动记录的论坛。但需注意,基于此类自然对话训练的模型可能模仿了风格,却未能完全捕捉原始教师的推理过程 (Gudibande et al., 2023; Mukherjee et al., 2023)。
System Instructions. To encourage student models to learn the reasoning process, Orca and Orca 2 (Mukherjee et al., 2023; Mitra et al., 2023) enhance the prompt, response data pairs by introducing a system message (e.g., ”explain like $\mathrm{I^{\prime}m}$ five, think step-by-step”) to encourage student models to grasp the reasoning process. This system message prompts GPT-4 to provide explanation traces that elucidate the teacher’s reasoning process. Orca 2 (Mitra et al., 2023) further trains the student model to identify the most effective solution strategy for each task, guided by Orca’s performance. This approach significantly improves the ability of smaller models to follow instructions that involve reasoning.
系统指令。为了鼓励学生模型学习推理过程,Orca和Orca 2 (Mukherjee et al., 2023; Mitra et al., 2023) 通过引入系统消息(例如"像五岁孩子一样解释,逐步思考")来增强提示-响应对数据,以促进学生模型掌握推理过程。该系统消息会提示GPT-4提供解释轨迹,阐明教师的推理过程。Orca 2 (Mitra et al., 2023) 进一步训练学生模型,在Orca性能的指导下,为每个任务识别最有效的解决策略。这种方法显著提升了较小模型在涉及推理的指令跟随能力。
High-Quality Instructions. As demonstrated in Zhou et al. (2023a) and (Li et al., 2024f), the data quality is crucial for instruction following training. UltraChat (Ding et al., 2023b) distills large-scale data with high-quality and diverse instructions from teacher LLMs by various metainformation. The UltraLLaMA model, fine-tuned on this data, consistently surpasses other open-source models. The Phi series models (Gunasekar et al., 2023; Li et al., $2023\mathsf{a},$ Mar, 2023) prioritize data quality and employ synthetic methods to generate data of “textbook quality” to enhance the learning experience for smaller models. Notably, Phi exhibits the ability to follow instructions effectively even without specific instruction fine-tuning. What’s particularly remarkable is that Phi-2, with just 2.7 billion parameters, outperforms Mistral and Llama-2 models with 7B and 13B parameters across various benchmark evaluations.
高质量指令。如Zhou等人(2023a)和Li等人(2024f)所示,数据质量对指令跟随训练至关重要。UltraChat(Ding等人,2023b)通过多种元信息从教师大语言模型中提炼出大规模高质量多样化指令数据。基于该数据微调的UltraLLaMA模型持续超越其他开源模型。Phi系列模型(Gunasekar等人,2023;Li等人,$2023\mathsf{a},$ 2023年3月)注重数据质量,采用合成方法生成"教科书级质量"数据以提升小模型学习效果。值得注意的是,Phi模型即使未经过特定指令微调也展现出优秀的指令跟随能力。尤为突出的是,仅27亿参数的Phi-2模型在多项基准测试中超越了70亿和130亿参数的Mistral与Llama-2模型。
Improved Instructions. Another line of work focuses on improving the quality of existing instruction data, including both the improvement of instruction and corresponding response. SelFee (Ye et al., 2023) utilizes the ChatGPT to iteratively improve the quality of responses. Expert LLaMA (Xu et al., 2023f) improves the quality of responses by augmenting vanilla instructions with specialized Expert Identity descriptions. Reflection-Tuning (Li et al., 2023e) improves both the instruction and response sequentially by reflecting on specific criteria. DEITA (Liu et al., 2023h) proposes to enhance and score instructions in three directions including complexity, quality, and diversity to get high-quality distillation data. MUFFIN (Lou et al., 2023) proposes to scale the instruction according to the input by diversifying these tasks with various input facets. Selective ReflectionTuning (Li et al., 2024d) first involves the student model in the data improvement pipeline with a novel studentselection module, in which the student model is able to decide the data learn from.
改进指令。另一项工作聚焦于提升现有指令数据的质量,包括优化指令及其对应响应。SelFee (Ye et al., 2023) 利用ChatGPT迭代优化响应质量。Expert LLaMA (Xu et al., 2023f) 通过为原始指令添加专家身份描述来提升响应质量。Reflection-Tuning (Li et al., 2023e) 通过基于特定标准进行反思,依次改进指令和响应。DEITA (Liu et al., 2023h) 提出从复杂性、质量和多样性三个维度对指令进行增强与评分,以获取高质量蒸馏数据。MUFFIN (Lou et al., 2023) 建议根据输入动态扩展指令,通过多样化任务输入维度实现。Selective ReflectionTuning (Li et al., 2024d) 首次将学生模型纳入数据改进流程,采用新型学生选择模块使其自主决定学习数据。
In summary, distilling instruction data from teachers presents a promising avenue for training cheap and reproducible instruction-following language models. Current small models have made strides in enhancing various aspects of instruction-following ability, like diversity, complexity and explanation. However, student models trained on instruction data expanded by ChatGPT of- ten mimic ChatGPT’s style without replicating its factual accuracy (Gudibande et al., 2023). Achieving a more capable instruction-following capability requires a stronger teacher LLM (Gudibande et al., 2023) and access to diverse, high-quality instruction data, such as the one used in Orca (Mukherjee et al., 2023; Mitra et al., 2023), which incorporates extensive task instructions from the Flan 2022 Collection (Longpre et al., 2023).
总之,从教师模型中蒸馏指令数据为训练廉价且可复现的指令跟随语言模型提供了可行路径。当前的小模型在提升指令跟随能力的多样性、复杂性和解释性等方面已取得进展。然而,基于ChatGPT扩展指令数据训练的学生模型往往只模仿ChatGPT的风格,却无法复现其事实准确性 (Gudibande et al., 2023)。要获得更强大的指令跟随能力,需要更强的大语言模型教师 (Gudibande et al., 2023) 以及多样化高质量指令数据,例如Orca采用的包含Flan 2022集合 (Longpre et al., 2023) 海量任务指令的数据 (Mukherjee et al., 2023; Mitra et al., 2023)。
4.1.2 Multi-turn Dialogue
4.1.2 多轮对话
While instruction following focuses on single-instance command execution, multi-turn dialogue extends this to comprehend and maintain context through ongoing interactions. This skill is vital for models to engage meaningfully in human-like conversations and respond coherently over successive dialogue turns. Some works have been dedicated to train to small chat models by distilling multi-turn knowledge from teacher LLMs (Chiang et al., 2023; Xu et al., 2023b; Ding et al., 2023b; Li et al., 2023b; Wang et al., 2023c; Tunstall et al., 2023).
指令跟随专注于单实例命令执行,而多轮对话则将其扩展到通过持续交互来理解和维护上下文。这项技能对于模型在类人对话中进行有意义的互动并在连续对话轮次中保持连贯回应至关重要。部分研究致力于通过从教师大语言模型蒸馏多轮知识来训练小型聊天模型 (Chiang et al., 2023; Xu et al., 2023b; Ding et al., 2023b; Li et al., 2023b; Wang et al., 2023c; Tunstall et al., 2023)。
ShareGPT serves as a platform for users to share their conversations with ChatGPT, offering a vast repository of multi-turn conversations readily available. Some small chat models are trained using this data to acquire the capability for engaging in multi-turn dialogues (Chiang et al., 2023; Ye et al., 2023; Wang et al., 2023c). For example, Vicuna (Chiang et al., 2023) is a chat model exclusively trained on ShareGPT data. Despite its sole training source being ShareGPT, Vicuna achieves a high MT-Bench (Zheng et al., 2023a) score assigned by GPT $\cdot4^{3}$ . In the study conducted by Wang et al. (2023c), GPT-3.5 and GPT-4 are employed to generate mixed responses using ShareGPT data. They assign higher rewards to responses generated by GPT-4, aiming to in centi viz e student models to produce high-quality responses. Additionally, Ye et al. (2023) enhance the quality of multi-turn data from ShareGPT by generating self-feedback on model responses and iterative ly refining the responses based on the received feedback.
ShareGPT是一个供用户分享与ChatGPT对话内容的平台,提供了大量现成的多轮对话资源。部分小型对话模型利用该数据进行训练,以获得多轮对话能力 (Chiang et al., 2023; Ye et al., 2023; Wang et al., 2023c)。例如Vicuna (Chiang et al., 2023)就是仅基于ShareGPT数据训练的对话模型。尽管训练数据完全来自ShareGPT,Vicuna在GPT$\cdot4^{3}$评分的MT-Bench (Zheng et al., 2023a)中仍获得了高分。Wang等人 (2023c)的研究使用GPT-3.5和GPT-4基于ShareGPT数据生成混合响应,并为GPT-4生成的响应分配更高奖励,旨在激励学生模型产生高质量响应。此外,Ye等人 (2023)通过生成模型响应的自我反馈,并基于反馈迭代优化响应,从而提升了ShareGPT多轮对话数据的质量。
To enhance the multi-turn capabilities of student models, another line of research focuses on expanding conversational datasets through self-chat and using them to train smaller models (Xu et al., 2023b; Ding et al., 2023b; Tunstall et al., 2023). For instance, Xu et al. (2023b) initiate their work by using questions sourced from Quora and Stack Overflow as seeds, resulting in the collection of $111.5\mathrm{k}$ dialogues through self-chat. Subsequently, they employ parameterefficient tuning to train a chat model named Baize. Ding et al. (2023b) first construct a significantly larger dataset called UltraChat, comprising 1.5 million high-quality multiturn dialogues. They achieve this by distilling instructions and dialogues from ChatGPT. Notably, UltraChat encompasses a wide range of topics and instructions. Building upon the UltraChat dataset, they fine-tune a LLaMA model, resulting in the creation of a powerful chat model known as UltraLLaMA. UltraLLaMA consistently outperforms other open-source chat models, including Vicuna and Baize. Furthermore, UltraChat is employed in conjunction with an AI preference-aligned chat model named Zephyr (Tunstall et al., 2023). Zephyr enhances intent alignment through the application of distilled direct preference optimization (dDPO).
为增强学生模型的多轮对话能力,另一研究方向聚焦于通过自对话扩展会话数据集并用于训练小模型 (Xu et al., 2023b; Ding et al., 2023b; Tunstall et al., 2023)。例如,Xu等人 (2023b) 以Quora和Stack Overflow的问题作为种子启动研究,通过自对话收集了$111.5\mathrm{k}$组对话,随后采用参数高效调优方法训练出名为Baize的聊天模型。Ding等人 (2023b) 首先构建了规模更大的UltraChat数据集,包含150万组高质量多轮对话,其通过蒸馏ChatGPT的指令和对话实现。值得注意的是,UltraChat涵盖了广泛的主题和指令。基于该数据集,他们微调LLaMA模型得到高性能聊天模型UltraLLaMA,其表现持续优于Vicuna、Baize等开源聊天模型。此外,UltraChat还被用于训练偏好对齐的聊天模型Zephyr (Tunstall et al., 2023),该模型通过蒸馏直接偏好优化 (dDPO) 技术提升了意图对齐能力。
4.1.3 RAG Capbility
4.1.3 RAG能力
LLMs are known to lack the ability to utilize up-to-date knowledge, and often produce responses containing factual inaccuracies due to their sole reliance on the parametric knowledge. Retrieval-Augmented Generation (RAG) is a promising technique to decrease this issue. Handling the augmented context of retrieved information is also a nontrivial skill of LLMs. Several approaches to distill RAG capabilities have been proposed (Kang et al., $2023\mathsf{a},$ ; Luo et al., 2023c; Asai et al., 2023).
大语言模型 (LLM) 因仅依赖参数化知识而缺乏利用最新信息的能力,常生成包含事实错误的回答。检索增强生成 (Retrieval-Augmented Generation, RAG) 是缓解该问题的有效技术。处理检索信息的增强上下文也是大语言模型的重要能力。目前已有多种方法用于提炼RAG能力 (Kang等, $2023\mathsf{a}$, ; Luo等, 2023c; Asai等, 2023)。
SAIL (Luo et al., 2023c) starts by retrieving search results for each training case using search APIs, creating searchaugmented instructions that include both the instruction and grounding information. To encourage the language model to prioritize informative retrieval results, they input each retrieved passage along with the ground truth response into the entailment model to label each retrieval result for relevance. Subsequently, the search-augmented instructions and relevance labels are fed into teacher LLMs (like GPT4) for generating responses. Following fine-tuning on this training set, the student model becomes proficient at denoising search results and generating accurate responses. KARD (Kang et al., 2023b) distills rationales $r$ from the teacher LLM in response to questions $x$ . These rationales are then utilized to train two models: a student LM and a Reranker. For training the student LM, the rationales serve as a means to retrieve relevant knowledge $d,$ and the student LM is subsequently fine-tuned using the rationales alongside questions and knowledge. However, during inference, only questions are available. To address this, the Reranker is trained to mimic how the retriever scores passages with the rationale by minimizing the KL divergence between Retriever $(d|r)$ and Reranker $(d\vert x)$ . However, the integration of a fixed number of passages in language models, without considering their necessity or relevance, can reduce versatility and lead to the generation of unhelpful responses. To equip student LMs with adaptive RAG capabilities, SelfRag (Asai et al., 2023) distills this adaptive ability from teacher LLMs into a small critic model. This critic model determines whether retrieval is necessary and evaluates the quality of the retrieved results by generating ‘reflection tokens.’ For instance, Self-Rag initiates the retrieval operation when generating the reflection token $\boxed{R e t r i e v e}.$ To distill this critic data, GPT-4 is prompted to assess the need for retrieval using few-shot demonstrations $I_{\cdot}$ , the task input $x,$ and output $y$ to predict a reflection token $r$ as follows: $p(r|I,x,y)$ .
SAIL (Luo et al., 2023c) 首先通过搜索API为每个训练案例检索结果,创建包含指令和基础信息的搜索增强指令。为了让语言模型优先考虑信息性检索结果,他们将每个检索到的段落与真实答案输入蕴含模型,以标注检索结果的相关性。随后,搜索增强指令和相关性标签被输入教师大语言模型(如GPT4)生成响应。在该训练集上微调后,学生模型能够熟练去噪搜索结果并生成准确回答。KARD (Kang et al., 2023b) 从教师大语言模型中提取针对问题 $x$ 的推理依据 $r$,这些依据用于训练两个模型:学生语言模型和重排序器。训练学生语言模型时,推理依据作为检索相关知识 $d$ 的手段,随后结合问题与知识进行微调。但在推理阶段仅有问题可用,为此训练重排序器通过最小化检索器 $(d|r)$ 与重排序器 $(d\vert x)$ 之间的KL散度,来模拟带推理依据的段落评分机制。然而,不考虑必要性或相关性而固定集成段落数量的做法会降低语言模型灵活性,导致生成无用响应。为使学生语言模型具备自适应RAG能力,SelfRag (Asai et al., 2023) 将教师大语言模型的这种自适应能力提炼到小型评判模型中。该评判模型通过生成"反思token"来判断是否需要检索并评估结果质量,例如当生成反思token $\boxed{R e t r i e v e}$ 时触发检索操作。为提炼评判数据,使用少样本示例 $I_{\cdot}$、任务输入 $x$ 和输出 $y$ 来提示GPT-4预测反思token $r$,即 $p(r|I,x,y)$。
4.2 Alignment
4.2 对齐
4.2.1 Thinking Pattern
4.2.1 思维模式
Most existing methods mainly focus on directly aligning the direct responses of the student models to the responses of teacher models (Taori et al., 2023). Though effective, these models might suffer the problems that they tend to learn to imitate the response style of the teacher models, but not the reasoning process (Mukherjee et al., 2023). Thus in order to better distill from the teacher models, methods are proposed that not only imitate the pure responses but some novel thinking patterns (Ye et al., 2023; Mukherjee et al., 2023; Mitra et al., 2023; Wang et al., 2023d; Cheng et al., 2023; Zhang et al., 2023a).
现有方法主要关注将学生模型的直接响应与教师模型的响应对齐 (Taori et al., 2023) 。虽然有效,但这些模型可能存在仅模仿教师模型响应风格而未能学习推理过程的问题 (Mukherjee et al., 2023) 。为了更好地从教师模型中进行知识蒸馏,研究者提出了不仅能模仿纯响应还能学习新颖思维模式的方法 (Ye et al., 2023; Mukherjee et al., 2023; Mitra et al., 2023; Wang et al., 2023d; Cheng et al., 2023; Zhang et al., 2023a) 。
Motivated by the effectiveness of LLMs in generating their own feedback without relying on external models (Schick et al., 2022; Madaan et al., 2023; Saunders et al., 2022), SelFee (Ye et al., 2023) proposes to train a model that has been fine-tuned to continuously revise its own answer until it provides a high-quality response in a single inference. During training, it utilizes both the final response and feedback chain as the fitting target. This pattern, response with the revision process, shows a promising performance gain. Following SelFee, Reflection-Tuning (Li et al., 2023e, 2024d) also utilizes the reflection process as the learning pattern. Noticing the lack of reasoning imitation of the previous methods, Orca (Mukherjee et al., 2023) first proposes Explanation tuning, which aims to learn the reasoning steps, including explanation traces, step-by-step thought processes, and other complex instructions, from the teacher model, rather than just the vanilla styles. Extensive experiments verify the effectiveness of distilling with this thinking pattern. The following Orca2 (Mitra et al., 2023) further presents to equip the student models with the ability to utilize different solution strategies for different tasks, motivated by the capability discrepancies between the smaller and larger models. By employing this training pattern, the student models are able to gain a better reasoning ability. Besides learning with the corresponding revision or reflection process, another thinking pattern that recently appeared is generating both responses and preferences. Zhang et al. (2023a) propose to learn both the knowledge and corresponding preference for domain-specific QA with LLMs. Recently, DEBATunE (Li et al., 2024e) proposes to improve the control l ability of LLMs in generating statements on controversial topics. By engaging two agents in a structured multi-round debate on controversial topics, salient and indepth statements can be obtained and further distilled into the student models.
受大语言模型在不依赖外部模型的情况下生成自身反馈的有效性启发 (Schick et al., 2022; Madaan et al., 2023; Saunders et al., 2022),SelFee (Ye et al., 2023) 提出训练一个经过微调的模型,使其能够持续修订自身答案,直到在单次推理中生成高质量响应。训练过程中,它同时将最终响应和反馈链作为拟合目标。这种附带修订过程的响应模式显示出显著的性能提升。继SelFee之后,Reflection-Tuning (Li et al., 2023e, 2024d) 同样将反思过程作为学习模式。注意到先前方法缺乏推理模仿能力,Orca (Mukherjee et al., 2023) 首次提出解释微调 (Explanation tuning),旨在从教师模型中学习推理步骤(包括解释轨迹、逐步思考过程等复杂指令),而不仅仅是基础形式。大量实验验证了这种思维模式在知识蒸馏中的有效性。后续的Orca2 (Mitra et al., 2023) 进一步提出让学生模型具备针对不同任务采用不同解决策略的能力,其动机源于大模型与小模型之间的能力差异。通过采用这种训练模式,学生模型能够获得更好的推理能力。除了学习相应的修订或反思过程外,近期出现的另一种思维模式是同时生成响应和偏好。Zhang et al. (2023a) 提出让大语言模型同时学习领域特定问答的知识和相应偏好。最近,DEBATunE (Li et al., 2024e) 提出增强大语言模型在争议话题上生成陈述的可控性。通过让两个智能体就争议话题进行结构化多轮辩论,可以获得突出且深入的陈述,并将其蒸馏到学生模型中。
4.2.2 Preference
4.2.2 偏好
The previously mentioned methods primarily focus on the basic capability of student models to produce outcomes that are strictly accurate but may not align with human preferences, reaching alignment at this level enables these models to aid in various tasks without meeting higher-level demands. Early methods mainly utilize human feedback for the alignment of human preferences (Ziegler et al., 2019; Stiennon et al., 2020; Wu et al., 2021; Ouyang et al., 2022; Bai et al., 2022b; Kopf et al., 2023; Yuan et al., 2023b). However, obtaining human feedback is costly and labor-intensive, thus methods that learn from AI feedback are also proposed to align with human preferences (Bai et al., 2022a; Kwon et al., 2023; Scheurer et al., 2023; Kim et al., 2023a; Roit et al., 2023; Yang et al., 2024; Lee et al., 2023a; Tunstall et al., 2023; Cui et al., $2023\mathrm{a};$ ; Wang et al., 2023f).
前述方法主要关注学生模型产生严格准确结果的基本能力,但这些结果可能不符合人类偏好。达到这一层面的对齐后,这些模型虽能协助完成各类任务,却无法满足更高层次的需求。早期方法主要利用人类反馈实现人类偏好对齐 [Ziegler et al., 2019; Stiennon et al., 2020; Wu et al., 2021; Ouyang et al., 2022; Bai et al., 2022b; Kopf et al., 2023; Yuan et al., 2023b]。然而获取人类反馈成本高昂且耗费人力,因此也出现了基于AI反馈学习的方法来实现人类偏好对齐 [Bai et al., 2022a; Kwon et al., 2023; Scheurer et al., 2023; Kim et al., 2023a; Roit et al., 2023; Yang et al., 2024; Lee et al., 2023a; Tunstall et al., 2023; Cui et al., $2023\mathrm{a};$ ; Wang et al., 2023f]。
The concept of RLAIF, introduced by Bai et al. (2022a), involves the integration of preferences labeled by LLMs with those labeled by humans. This approach is designed to simultaneously optimize two key objectives: ensuring the helpfulness of the output and minimizing any potential harm, making the responses of LLMs more aligned with Human preferences. Kwon et al. (2023) develop a proxy reward function using LLMs like GPT-3, which is created by first providing the LLM with a description of the behaviors desired by the user, along with a small number of examples. The LLM then produces rewards by evaluating how closely the outputs of a model align with the provided descriptions, essentially measuring their relevance to the established ground truth. Scheurer et al. (2023) propose Imitation Learning from Language Feedback, in which a language model is utilized to improve various outputs generated by a model. This refinement is based on a reference provided by a human. Following this process, the most effectively refined output is chosen to be used in further supervised fine-tuning. As outlined by Kim et al. (2023a), ALMoST involves condensing human preferences into a set of heuristic guidelines. An example of such a rule is the idea that larger LLMs that utilize more comprehensive and higher-quality prompts are likely to yield superior responses. Based on these established guidelines, comparison data is generated using responses from LLMs of different sizes and with varying prompts. This data is then used to train a reward model. Yang et al. (2024) propose Reinforcement Learning from Contrast Distillation, which aims to align language models without relying on human feedback. This approach involves training a preference model using simulated pairs of preferences, including both high-quality and low-quality examples which are generated through contrasting prompts, positive and negative.
RLAIF(Reinforcement Learning from AI Feedback)的概念由Bai等人(2022a)提出,通过将大语言模型标注的偏好与人类标注的偏好相结合,旨在同步优化两个关键目标:确保输出内容的实用性并最小化潜在危害,从而使大语言模型的响应更符合人类偏好。Kwon等人(2023)利用GPT-3等大语言模型开发了代理奖励函数,其构建方式是先向大语言模型提供用户期望行为的描述及少量示例,随后大语言模型通过评估模型输出与给定描述的匹配程度来生成奖励值,本质上衡量其与既定事实的相关性。Scheurer等人(2023)提出基于语言反馈的模仿学习,利用语言模型改进模型生成的各种输出,这种改进以人类提供的参考为依据,最终选择优化效果最佳的输出来进行后续监督微调。Kim等人(2023a)提出的ALMoST方法将人类偏好浓缩为一组启发式准则,例如"使用更全面、更高质量提示的较大规模大语言模型往往能产生更优响应"。基于这些既定准则,通过不同规模大语言模型及多样化提示生成的响应来构建对比数据,进而训练奖励模型。Yang等人(2024)提出基于对比蒸馏的强化学习,该方法无需依赖人类反馈即可实现语言模型对齐,通过使用包含高质量与低质量示例的模拟偏好对(由正负对比提示生成)来训练偏好模型。
Lee et al. (2023a) further highlight the effectiveness of RLAIF. This work proposes that RLAIF not only matches but in some cases surpasses RLHF, and interestingly, RLAIF can also enhance the performance of Supervised Fine-Tuning. Another notable discovery is that directly prompting the LLM for reward scores during reinforcement learning can be more effective than the conventional approach of training a reward model based on LLM preferences. Wang et al. (2023f) propose Conditioned-RLFT, which treats different data sources as coarse-grained reward labels and develops a class-conditioned policy to effectively utilize the varying qualities of data, which is a Reinforcement Learning-free supervised learning approach. Cui et al. (2023a) propose a large-scale, high-quality, and diversified preference dataset labeled by GPT4 for comprehensive feedback. Tunstall et al. (2023), by proposing distilled Direct Preference Optimization (Rafailov et al., 2023) on Ultra Feedback, obtaining a small by powerful LLM.
Lee等人 (2023a) 进一步强调了RLAIF的有效性。该研究提出RLAIF不仅能够匹配RLHF,在某些情况下甚至超越RLHF,有趣的是RLAIF还能提升监督微调 (Supervised Fine-Tuning) 的性能。另一个重要发现是:在强化学习过程中直接提示大语言模型获取奖励分数,可能比基于大语言模型偏好训练奖励模型的传统方法更有效。Wang等人 (2023f) 提出了Conditioned-RLFT,该方法将不同数据源视为粗粒度奖励标签,并开发了类条件策略以有效利用数据的质量差异,这是一种无需强化学习的监督学习方法。Cui等人 (2023a) 提出了一个由GPT4标注的大规模、高质量、多样化偏好数据集用于全面反馈。Tunstall等人 (2023) 通过在Ultra Feedback上提出蒸馏式直接偏好优化 (Direct Preference Optimization) (Rafailov等人, 2023),获得了小而强的大语言模型。
4.2.3 Value
4.2.3 价值
Attaining alignment with human preferences allows large models to optimize human satisfaction by operating in a manner that aligns with human preferences. However, to establish trustworthy LLMs, the notion of ’aligning LLMs with human values’ is proposed and the key principles of alignment are often summarized as the ${}^{\prime\prime}\mathrm{HHH}^{\prime\prime}$ criteria: helpful, harmless, honest (Weidinger et al., 2021; Askell et al., 2021). Numerous methods have been undertaken for building trustworthy LLMs. However, due to the intrinsic difficulty of this aim, which is still an unsolved problem for proprietary models (Sun et al., 2024a), most existing methods rely on constructing high-quality human preference datasets (Ji et al., 2023b; Solaiman and Dennison, 2021; Bai et al., 2022b; Qiu et al., 2022; Kiesel et al., 2022; Liu et al., 2022a), utilizing human-written rules as constrains (Glaese et al., 2022; Sun et al., 2023b, 2024b), etc. For detailed progress on trustworthy LLMs, please further refer to Yao et al. (2023a); Liu et al. (2023i); Sun et al. (2024a).
使大模型与人类偏好对齐,可以让其以符合人类偏好的方式运作,从而优化人类满意度。然而,为建立可信赖的大语言模型,学界提出了"使大语言模型与人类价值观对齐"的概念,其核心对齐原则通常被概括为"HHH"标准:有帮助的(helpful)、无害的(harmless)、诚实的(honest)(Weidinger et al., 2021; Askell et al., 2021)。目前已有多种方法用于构建可信赖的大语言模型,但由于该目标本身存在固有难度(对专有模型而言仍是未解难题)(Sun et al., 2024a),现有方法主要依赖于构建高质量人类偏好数据集(Ji et al., 2023b; Solaiman and Dennison, 2021; Bai et al., 2022b; Qiu et al., 2022; Kiesel et al., 2022; Liu et al., 2022a),或采用人工编写的规则作为约束条件(Glaese et al., 2022; Sun et al., 2023b, 2024b)等。关于可信赖大语言模型的详细进展,可进一步参阅Yao et al. (2023a); Liu et al. (2023i); Sun et al. (2024a)。
Though slightly under-explored, aligning LLMs with human values by distilling is still possible (Bai et al., 2022a;
尽管探索尚不充分,但通过蒸馏方法使大语言模型(LLM)与人类价值观对齐仍是可行的 (Bai et al., 2022a;
Cui et al., 2023a; Yang et al., 2024; Sun et al., 2024b). For instance, Bai et al. (2022a) propose RLAIF, utilizing AIgenerated labels to interactively improve both helpfulness and harmlessness. Sun et al. (2024b) prompt the student model with 16 principles as guidelines for generating helpful, ethical, and reliable responses. Similarly, both harmless and harmful generations could be elicited by modifying the prompts, and then are used to train the preference model (Yang et al., 2024). Cui et al. (2023a) utilize GPT4 to rank generations regarding helpfulness, truthfulness, and honesty. Liu et al. (2023b) advance the alignment of LLMs with societal values by incorporating simulated social interactions into the training process. This approach encompasses a range of elements, including demonstrations that are both in alignment and in conflict with social norms, as well as collective ratings, in-depth feedback, and responses that are revised iterative ly.
Cui等人, 2023a; Yang等人, 2024; Sun等人, 2024b). 例如, Bai等人 (2022a) 提出了RLAIF, 利用AI生成的标签交互式提升助益性和无害性。Sun等人 (2024b) 通过16条原则提示学生模型, 作为生成有益、道德且可靠回复的指导方针。类似地, 通过修改提示既可能引发无害也可能引发有害的生成结果, 这些结果随后被用于训练偏好模型 (Yang等人, 2024). Cui等人 (2023a) 使用GPT4对生成结果在助益性、真实性和诚实度方面进行排序。Liu等人 (2023b) 通过将模拟社交互动融入训练过程, 推进了大语言模型与社会价值观的对齐。该方法包含多种要素, 既有符合也有违背社会规范的示例, 以及集体评分、深度反馈和迭代修订的响应。
4.3 Agent
4.3 AI智能体
4.3.1 Tool Using
4.3.1 工具使用
While recent LLMs have shown proficiency in solving various tasks, they still tend to make mistakes when handling large numerical values or executing intricate mathematical calculations (Qian et al., 2022; She et al., 2023; Manikandan et al., 2023; Liang et al., 2023b; Mialon et al., 2023). Thus equipping LLM agents with the capability to utilize tools has been increasingly focused on. Commonly used methods mainly relied on human-curated data for training (Parisi et al., 2022; Nakano et al., 2022; Qin et al., 2023c; Song et al., 2023b) or prompt designing(Cai et al., 2023; Shen et al., 2023a; Hao et al., 2024). Recently, distillation-based methods are also proposed (Schick et al., 2023; Zhang, 2023; Patil et al., 2023; Tang et al., 2023a; Qin et al., 2023a; Yuan et al., 2023a; Gao et al., 2023b; Wang et al., 2024; Shen et al., 2024; Yuan et al., 2024b).
尽管当前的大语言模型已展现出解决各类任务的能力,但在处理大数值或执行复杂数学运算时仍容易出错 (Qian et al., 2022; She et al., 2023; Manikandan et al., 2023; Liang et al., 2023b; Mialon et al., 2023) 。因此,赋予大语言模型智能体使用工具的能力正日益受到关注。常用方法主要依赖人工标注数据进行训练 (Parisi et al., 2022; Nakano et al., 2022; Qin et al., 2023c; Song et al., 2023b) 或提示设计 (Cai et al., 2023; Shen et al., 2023a; Hao et al., 2024) 。近期也涌现出基于蒸馏的方法 (Schick et al., 2023; Zhang, 2023; Patil et al., 2023; Tang et al., 2023a; Qin et al., 2023a; Yuan et al., 2023a; Gao et al., 2023b; Wang et al., 2024; Shen et al., 2024; Yuan et al., 2024b) 。
Toolformer (Schick et al., 2023) utilizes a self-supervised manner, avoiding large human annotations, to obtain the most required APIs to use and further distill this capability to the model itself. The performance of the GPT-J-based Toolformer surpasses OPT (66B) (Zhang et al., 2022) and GPT3 (175B) (Brown et al., 2020) greatly. Graph-ToolFormer (Zhang, 2023) aims to equip LLMs with the ability to process and reason over complex graph data, which is designed to enhance LLMs with graph reasoning skills using external graph reasoning API tools by adopting ChatGPT to annotate and augment a larger graph reasoning statement dataset for training. Gorilla (Patil et al., 2023) addresses the limitations of current LLMs in generating accurate input arguments and reduces the problem of ”hallucination” or generating incorrect API usage and it collects thousands of models from platforms like Hugging Face and Torch Hub as the API calls and utilizes GPT4 to generate synthetic instruction data for training. GPT4Tools (Yang et al., 2023b) introduces to enable open-source LLMs like LLaMA and OPT to use multimodal tools, a capability previously limited to advanced proprietary models like ChatGPT and GPT-4. The approach involves generating an instruction-following dataset by prompting an advanced teacher model with multimodal contexts, using the Low-Rank Adaptation optimization. ToolAlpaca (Tang et al., 2023a) proposes a framework aimed at enhancing the tool-use capabilities of compact language models for embodied intelligence. It creates a dataset with 3938 instances from over 400 real-world tool APIs across 50 categories and utilizes ChatGPT to generate documentation for each prompt for later training. ToolLLM (Qin et al., 2023a) proposes a comprehensive framework for enhancing LLMs with tool-use proficiency, focusing on data creation, model training, and evaluation by distilling from chatGPT. Their ToolLLaMA shows impressive performance in executing complex instructions and handling new APIs, rivaling ChatGPT. CRAFT (Yuan et al., 2023a) builds a general tool creation and retrieval framework, which utilizes GPT4 to generate code snippets as the created tools. During the inference, other small LLMs could select and retrieve from the generated code snippets to execute or generate other methods conditioned on the given snippets. Confucius (Gao et al., 2023b) introduces a tiered training strategy for LLMs to master tool usage through a graduated curriculum and an innovative method called Iterative Selfinstruction from Introspective Feedback (ISIF) for dynamic dataset enhancement to handle complex tools. MLLM-Tool (Wang et al., 2024) is a multi-modal tool agent capable of interpreting instructions embedded in visual or audio content through the integration of multi-modal encoders with open-source large language models. As a trainable method, the initial instruction-answer pairs are generated by utilizing GPT4. Shen et al. (2024) demonstrate that small LLMs are weak tool learners and proposes a multi-LLM framework that decomposes the tool-use ability of a single model into a planner, caller, and summarizer for the tool using, leading to a supreme performance. The two-stage training strategy introduced by this work is powered by ChatGPT and GPT4 for collecting execution trajectories for the training set. Yuan et al. (2024b) notice the potential issue of the current lengthy tool documentation, which hinders LLMs from understanding how to utilize a tool, thus proposing EASYTOOL to purify the important information from extensive documentation. The ground truth sum mari z ation of the training documents is obtained by using ChatGPT.
Toolformer (Schick et al., 2023) 采用自监督方式,避免大量人工标注,筛选最需要的API并进一步将该能力蒸馏至模型本身。基于GPT-J的Toolformer性能大幅超越OPT (66B) (Zhang et al., 2022) 和GPT3 (175B) (Brown et al., 2020)。Graph-ToolFormer (Zhang, 2023) 旨在赋予大语言模型处理复杂图数据的能力,通过调用外部图推理API工具,采用ChatGPT标注并扩增大规模图推理语句数据集以增强模型的图推理技能。Gorilla (Patil et al., 2023) 解决了当前大语言模型生成准确输入参数的局限性,减少"幻觉"或错误API调用问题,它从Hugging Face和Torch Hub等平台收集数千个模型作为API调用,并利用GPT4生成合成指令数据用于训练。GPT4Tools (Yang et al., 2023b) 使LLaMA和OPT等开源大语言模型具备使用多模态工具的能力,该能力此前仅限ChatGPT和GPT-4等专有模型。该方法通过多模态上下文提示高级教师模型生成指令跟随数据集,采用低秩自适应优化。ToolAlpaca (Tang et al., 2023a) 提出增强紧凑语言模型工具使用能力的框架,创建包含50个类别400余个真实API的3938个实例数据集,并利用ChatGPT为每个提示生成文档用于后续训练。ToolLLM (Qin et al., 2023a) 提出提升大语言模型工具使用能力的完整框架,通过ChatGPT蒸馏实现数据创建、模型训练和评估,其ToolLLaMA在执行复杂指令和处理新API方面表现优异,媲美ChatGPT。CRAFT (Yuan et al., 2023a) 构建通用工具创建与检索框架,利用GPT4生成代码片段作为工具。推理时其他小型大语言模型可从生成代码片段中选择执行或生成条件方法。Confucius (Gao et al., 2023b) 引入分层训练策略,通过渐进课程和自省反馈迭代自指令(ISIF)方法动态增强数据集以掌握复杂工具。MLLM-Tool (Wang et al., 2024) 是多模态工具智能体,通过整合多模态编码器与开源大语言模型解析视觉或音频内容中的指令,初始指令-答案对由GPT4生成。Shen et al. (2024) 证明小型大语言模型工具学习能力较弱,提出将单一模型的工具使用能力分解为规划器、调用器和总结器的多模型框架,其两阶段训练策略利用ChatGPT和GPT4收集训练集执行轨迹。Yuan et al. (2024b) 发现当前冗长工具文档阻碍模型理解工具使用,提出EASYTOOL从文档中提炼关键信息,训练文档摘要真值由ChatGPT生成。
4.3.2 Planning
4.3.2 规划
Another important aspect for LLM agents is the ability to decompose high-level tasks to a chosen set of actionable steps (Huang et al., 2022b), which is especially useful when acting in interactive environments. Huang et al. (2022b) first demonstrate that LLMs can generate plausible goal-driven action plans without training, introduces non-invasive tools to enhance model exe cut ability, and assesses these methods through human evaluation to balance exe cut ability and semantic accuracy. Most existing methods utilize prompting strategies for task planning (Singh et al., 2022; Zhou et al., 2023b; Song et al., 2023c; Wang et al., $2023\mathrm{g},$ ; Yao et al., 2023b; Liu et al., 2023j; Hao et al., 2023; Hu et al., 2023a), or building human-curated data for training (Lin et al., 2023a; Valmeekam et al., 2023). Recently, there have also been some distilling methods emerging (Chen et al., 2023b; Zeng et al., 2023a; Yin et al., 2023a; Qiao et al., 2024; Kong et al., 2023).
大语言模型智能体的另一个重要能力是将高级任务分解为一组可执行步骤 (Huang et al., 2022b),这种能力在交互环境中尤为实用。Huang等人 (2022b) 首次证明了大语言模型无需训练即可生成合理的目标驱动型行动计划,引入了非侵入式工具来增强模型执行能力,并通过人工评估来平衡执行效率与语义准确性。现有方法多采用提示策略进行任务规划 (Singh et al., 2022; Zhou et al., 2023b; Song et al., 2023c; Wang et al., $2023\mathrm{g},$ ; Yao et al., 2023b; Liu et al., 2023j; Hao et al., 2023; Hu et al., 2023a),或构建人工标注数据进行训练 (Lin et al., 2023a; Valmeekam et al., 2023)。近期还涌现出一些蒸馏方法 (Chen et al., 2023b; Zeng et al., 2023a; Yin et al., 2023a; Qiao et al., 2024; Kong et al., 2023)。
FireAct (Chen et al., 2023b) introduces an innovative approach for refining LLMs. This method involves fine-tuning smaller-scale LLMs using agent trajectories that are derived from a variety of tasks and prompting techniques. Applying this method with trajectories generated by GPT4 has been shown to consistently enhance performance. Agent Tuning (Zeng et al., 2023a) aims to enhance the performance of LLMs in executing agent tasks without sacrificing their wide-ranging capabilities. By utilizing a new dataset called Agent Instruct, which includes high-quality interaction trajectories, it applies a hybrid instruction-tuning approach that merges these trajectories with general domain instructions. Lumos (Yin et al., 2023a) pertains to a novel framework designed to train agents using a unified data format and modular architecture based on open-source LLMs. This system comprises three key modules: planning, grounding, and execution, enabling the decomposition of tasks into subgoals and actionable steps. TPTU-v2 (Kong et al., 2023) focuses on improving the task planning and tool usage abilities of LLMs in real-world scenarios, by utilizing data generated by human experts or LLMs. It introduces a framework comprising three components: an API Retriever, an LLM Finetuner, and a Demo Selector. AUTOACT (Qiao et al., 2024) proposes an agent learning framework that does not require large-scale annotated data or synthetic trajectories from high-resource models like GPT-4. Instead, it uses a selfinstruct method to generate its own planning trajectories with limited initial data. It then applies a division-of-labor strategy, creating sub-agents specialized in different aspects of the task completion process.
FireAct (Chen et al., 2023b) 提出了一种改进大语言模型的创新方法。该方法通过使用来自多种任务和提示技术的智能体轨迹对较小规模的大语言模型进行微调。实验证明,采用GPT4生成的轨迹应用此方法能持续提升性能。
Agent Tuning (Zeng et al., 2023a) 旨在不损害大语言模型广泛能力的前提下,提升其执行智能体任务的性能。通过使用名为Agent Instruct的新数据集(包含高质量交互轨迹),该方法采用混合指令微调策略,将这些轨迹与通用领域指令相结合。
Lumos (Yin et al., 2023a) 提出了一种基于开源大语言模型、采用统一数据格式和模块化架构训练智能体的新框架。该系统包含三个核心模块:规划、 grounding 和执行,可将任务分解为子目标和可操作步骤。
TPTU-v2 (Kong et al., 2023) 专注于提升大语言模型在真实场景中的任务规划与工具使用能力,其利用人类专家或大语言模型生成的数据。该框架包含三个组件:API检索器、大语言模型微调器和演示选择器。
AUTOACT (Qiao et al., 2024) 提出了一种无需大规模标注数据或依赖GPT-4等高资源模型合成轨迹的智能体学习框架。该框架采用自指导方法,仅需有限初始数据即可生成规划轨迹,并通过分工策略创建专注于任务完成不同环节的子智能体。
Distillation also works out for the training of embodied multi-modal agents (Sumers et al., 2023; Yang et al., 2023c; Ma et al., $2023\mathsf{a}.$ ; Du et al., 2023a; Sumers et al., 2023). For instance, Sumers et al. (2023) aim to enhance the ability of AI agents to follow instructions by using pretrained visionlanguage models to provide supervision for understanding and acting upon language within their operational environment, leveraging model distillation and hindsight experience replay to teach them con textually relevant interactions in a simulated 3D setting. Emma (Yang et al., 2023c) evaluates the challenges and inefficiency of training an embodied agent in a noisy visual world without expert guidance, and proposes to train them in a simulated environment using imitation learning, guided by an expert Language Model (like ChatGPT), which operates in a corresponding textbased simulation, focusing on the same tasks.
蒸馏方法同样适用于具身多模态智能体 (embodied multi-modal agents) 的训练 (Sumers et al., 2023; Yang et al., 2023c; Ma et al., $2023\mathsf{a}$; Du et al., 2023a; Sumers et al., 2023)。例如,Sumers等人 (2023) 通过使用预训练的视觉语言模型为智能体在其操作环境中理解和执行语言指令提供监督,结合模型蒸馏和事后经验回放技术,在模拟3D环境中教会它们执行上下文相关的交互行为。Emma (Yang et al., 2023c) 评估了在缺乏专家指导的嘈杂视觉世界中训练具身智能体所面临的挑战和低效问题,提出在模拟环境中采用模仿学习进行训练,并由专家语言模型 (如ChatGPT) 在对应的文本模拟环境中执行相同任务来提供指导。
4.4 NLP Task Specialization
4.4 NLP任务专业化
NLP tasks often grapple with challenges like data scarcity, interpret ability issues, privacy concerns, and noisy data. The “Knowledge” section of our survey illustrates various methods for distilling knowledge from LLMs, effectively setting the stage for student models to adapt to a range of NLP tasks. This knowledge provides supervision for the training of student models through information augmentation (e.g., CoT and explanation), data augmentation, and semantic representation. By transferring the distilled knowledge from LLMs, student models can better handle diverse NLP challenges, improving task performance and addressing data limitations more robustly.
自然语言处理(NLP)任务常面临数据稀缺、可解释性问题、隐私担忧和噪声数据等挑战。我们调研报告的"知识"章节阐述了从大语言模型(LLM)中提炼知识的多种方法,为学生模型适应各类NLP任务奠定了良好基础。这些知识通过信息增强(如思维链(CoT)和解释)、数据增强和语义表示等方式,为学生模型的训练提供监督指导。通过迁移从大语言模型提炼的知识,学生模型能更有效地应对多样化的NLP挑战,提升任务表现并更稳健地解决数据限制问题。
4.4.1 Natural Language Understanding
4.4.1 自然语言理解
Natural Language Understanding (NLU) is a fundamental NLP task that involves comprehending and interpreting human language. The knowledge distilled from LLMs, such as through data labeling or augmentation, is typically transferred into encoder-based language models like BERT (Vaswani et al., 2017) and RoBERTa (Liu et al., 2019).
自然语言理解 (Natural Language Understanding, NLU) 是自然语言处理的基础任务,涉及对人类语言的理解与解释。从大语言模型 (LLM) 中提炼的知识(例如通过数据标注或数据增强)通常会迁移到基于编码器的语言模型中,例如 BERT (Vaswani et al., 2017) 和 RoBERTa (Liu et al., 2019)。
Regarding the task of classification, certain studies have been noteworthy (Dai et al., 2023a; Gilardi et al., 2023; He et al., 2023b; Gao et al., 2023a; Chenglin et al., 2023; Li et al., $2023\mathrm{g},$ . AugGPT (Dai et al., 2023a) focuses on both general and clinical domain text classification. To address the limitations of small-scale clinical datasets, which often lack expert annotation and are subject to stringent privacy regulations, AugGPT utilizes knowledge from teacher LLMs to rephrase each sentence in the training samples. This process creates multiple conceptually similar but semantically distinct samples, enhancing the dataset’s richness and diversity. Another approach is demonstrated by Gilardi et al. (2023), who employ ChatGPT as an annotator to categorize inputs. This method has been shown to outperform crowd-workers in several tasks, including relevance, stance, topics, and frame detection. Furthermore, He et al. (2023b) propose Targeted Data Generation (TDG), a novel approach for identifying challenging subgroups within a dataset. TDG leverages LLMs, along with human-in-the-loop, to generate new data specifically tailored for these subgroups, thereby enriching the dataset and improving model performance in sentiment analysis and natural language inference tasks. To facilitate the clinical information extraction task, Tang et al. (2023b) elicit diverse samples from LLMs by providing examples and different seeds of clinical entities, i.e. the Curation manner.
关于分类任务,一些研究值得关注 (Dai et al., 2023a; Gilardi et al., 2023; He et al., 2023b; Gao et al., 2023a; Chenglin et al., 2023; Li et al., $2023\mathrm{g},$)。AugGPT (Dai et al., 2023a) 同时关注通用领域和临床领域的文本分类。为解决小规模临床数据集缺乏专家标注且受严格隐私法规限制的问题,AugGPT 利用教师大语言模型的知识对训练样本中的每个句子进行改写,生成多个概念相似但语义不同的样本,从而提升数据集的丰富性和多样性。Gilardi 等人 (2023) 则展示了另一种方法,他们使用 ChatGPT 作为标注器对输入进行分类。该方法在相关性、立场、主题和框架检测等多个任务中表现优于众包工作者。此外,He 等人 (2023b) 提出了目标数据生成 (Targeted Data Generation, TDG) 方法,通过大语言模型结合人在回路 (human-in-the-loop) 机制,针对数据集中具有挑战性的子组生成定制化新数据,从而增强情感分析和自然语言推理任务的模型性能。为促进临床信息抽取任务,Tang 等人 (2023b) 通过提供临床实体示例和不同种子 (即 Curation 方式) 从大语言模型中获取多样化样本。
Several studies have also focused on multiple NLU tasks (Ding et al., 2023a; He et al., 2023a; Wang et al., 2021a; He et al., 2022; Ye et al., 2022; Meng et al., 2022). For example, He et al. (2023a) utilize the knowledge in GPT-3.5 to annotate inputs with labels and explanations for various NLU tasks, including user input and keyword relevance assessment, BoolQ, and WiC. Wang et al. (2021a) employ few-shot prompts to expand high-quality training data using GPT-3, i.e. the Expansion manner. Beyond merely employing a single approach to elicit NLP task knowledge, Ding et al. (2023a) explore a combination of Labeling, Expansion, and Curation methods to extract knowledge from GPT-3 for distilling data for both sequence- and token-level NLP tasks.
多项研究也聚焦于多种自然语言理解(NLU)任务 (Ding et al., 2023a; He et al., 2023a; Wang et al., 2021a; He et al., 2022; Ye et al., 2022; Meng et al., 2022)。例如,He等人(2023a)利用GPT-3.5中的知识为各类NLU任务标注输入数据和解释说明,涵盖用户输入与关键词相关性评估、BoolQ和WiC等任务。Wang等人(2021a)采用少样本提示词,通过GPT-3扩展高质量训练数据,即扩展(Expansion)方式。Ding等人(2023a)则突破单一方法局限,综合运用标注(Labeling)、扩展(Expansion)和精修(Curation)三种方法,从GPT-3中提取知识以蒸馏出适用于序列级和token级NLP任务的数据。
4.4.2 Natural Language Generation
4.4.2 自然语言生成
Natural Language Generation (NLG) is a key aspect of evaluating the capabilities of LLMs, encompassing tasks such as sum mari z ation, machine translation, and other open-ended text generation tasks. Known for their potent generative abilities and creativity, LLMs excel in these areas, making them prime sources for distilling knowledge into student models tailored for NLG tasks (Xu et al., 2023c, 2024b; Ramnath et al., 2023; Agarwal et al., 2024). Additionally, the knowledge distilled from LLMs can be effectively used for NLG task-specific data augmentation (Jung et al., 2023; Wang et al., 2021b; Guo et al., 2023a; Yang and Nicolai, 2023; Wang et al., 2023h; Yang et al., 2023d). While the previous sections have focused on the works about openended generation and multi-turn dialogue, this part will specifically highlight the distillation techniques relevant to other NLG tasks.
自然语言生成(NLG)是评估大语言模型能力的关键方面,涵盖摘要生成、机器翻译和其他开放式文本生成任务。大语言模型以其强大的生成能力和创造力著称,在这些领域表现优异,使其成为针对NLG任务提炼知识到学生模型的主要来源 (Xu et al., 2023c, 2024b; Ramnath et al., 2023; Agarwal et al., 2024)。此外,从大语言模型中提炼的知识可有效用于NLG任务的特定数据增强 (Jung et al., 2023; Wang et al., 2021b; Guo et al., 2023a; Yang and Nicolai, 2023; Wang et al., 2023h; Yang et al., 2023d)。虽然前文主要关注开放式生成和多轮对话相关研究,本节将重点探讨与其他NLG任务相关的知识蒸馏技术。
Although automatic metrics often favor smaller, finetuned models in sum mari z ation tasks, human evaluators tend to prefer the summaries generated by LLMs. Addressing this discrepancy, Xu et al. (2023c) develop a student summarization model by distilling a GPTSUMM dataset, which comprises over 4 million paragraph-summary pairs generated by querying GPT-3.5. In a different approach, Jung et al. (2023) introduce ‘Impossible Distillation,’ a method that creates high-quality sum mari z ation-specific dataset from weak teacher LLMs. This method involves training a student model on the generated dataset and enhancing its capabilities through Self-Knowledge. Turning to the task of machine translation, where creating parallel corpora is traditionally expensive and time-consuming, Yang and Nicolai (2023) propose a three-step distillation process. This process involves generating seeds of verbs and nouns, forming sentences, and then translating these sentences. Their findings suggest that while the distilled dataset may lack diversity, it effectively improves the translation signal for training student translation models. To distill high-quality contentgrounded data automatically, Genie (Yehudai et al., 2024) proposes a general methodology containing three key steps: (a) preparation of the content, (b) distillation of responses from a teacher LLM corresponding to the content, and (c) filtering mechanism to ensure the quality and faithfulness of the generated data. Genie demonstrates that student models trained through this distilled data can match or even surpass models trained on human-generated data.
尽管自动评估指标在摘要任务中往往更青睐经过微调的小型模型,但人类评估者通常更偏好大语言模型生成的摘要。针对这一差异,Xu等人 (2023c) 通过蒸馏GPTSUMM数据集开发了一个学生摘要模型,该数据集包含通过查询GPT-3.5生成的400多万个段落-摘要对。Jung等人 (2023) 则提出了"不可能蒸馏"方法,通过弱教师大语言模型创建高质量的特定摘要数据集,该方法包括在生成的数据集上训练学生模型,并通过自知识增强其能力。在机器翻译任务中,传统并行语料库构建成本高昂且耗时,Yang和Nicolai (2023) 提出了三步蒸馏流程:生成动词和名词种子、构建句子、翻译句子。他们的研究表明,虽然蒸馏数据集可能缺乏多样性,但能有效提升学生翻译模型的训练信号质量。为自动蒸馏高质量内容数据,Genie (Yehudai等人, 2024) 提出包含三个关键步骤的通用方法:(a) 内容准备,(b) 从教师大语言模型蒸馏对应内容的响应,(c) 过滤机制确保生成数据的质量与保真度。实验证明,通过该蒸馏数据训练的学生模型可达到甚至超越基于人类生成数据训练的模型。
4.4.3 Information Retrieval
4.4.3 信息检索
Information Retrieval (IR) represents a crucial branch of computer science, focused on efficiently retrieving information relevant to user queries from extensive repositories (Cai et al., 2022; Liu et al., 2022b; Feng et al., 2023; Shen et al., 2023b). A typical IR system encompasses three main components: the query rewriter, the retriever, and the reranker. Recent studies have highlighted the effectiveness of employing LLMs in IR systems, e.g. in enhancing the reranking stage through both point-wise and list-wise ranking methods (Ma et al., 2023b; Sun et al., 2023a; Qin et al., 2023d). However, the practical application of LLMs in IR systems faces challenges, primarily due to their slower generation speed, which conflicts with the low-latency requirements of IR tasks (Sun et al., 2023a). As a result, the KD of LLMs emerges as a more promising approach for IR, offering a way to infuse the distilled knowledge from LLMs into various stages of the IR pipeline without compromising on speed. There has been a significant body of work demonstrating how knowledge distilled from LLMs can benefit each component of the IR system, including the Query Rewriter (Srinivasan et al., 2022; Ma et al., 2023c), the Retriever (Dai et al., 2023b; Sachan et al., 2022, 2023; Schick and Schiitze, 2021; Meng et al., 2023; Peng et al., 2023b), and the Reranker (Bonifacio et al., 2022; Sun et al., 2023a; Pradeep et al., 2023a,b; Saad-Falcon et al., 2023; Ferraretto et al., 2023; Jeronymo et al., 2023; Sun et al., 2023c).
信息检索 (Information Retrieval, IR) 是计算机科学的重要分支,致力于从海量存储库中高效获取与用户查询相关的信息 (Cai et al., 2022; Liu et al., 2022b; Feng et al., 2023; Shen et al., 2023b)。典型IR系统包含三个核心组件:查询重写器、检索器和重排序器。近期研究表明,大语言模型在IR系统中具有显著效果,例如通过点级排序和列表级排序方法提升重排序阶段性能 (Ma et al., 2023b; Sun et al., 2023a; Qin et al., 2023d)。然而,大语言模型在IR系统中的实际应用仍面临挑战,主要因其生成速度较慢,难以满足IR任务的低延迟需求 (Sun et al., 2023a)。因此,大语言模型的知识蒸馏 (Knowledge Distillation, KD) 成为更可行的IR解决方案,可在不损失速度的前提下,将蒸馏知识注入IR流程的各个环节。现有大量研究证明,大语言模型蒸馏知识可优化IR系统各组件性能,包括查询重写器 (Srinivasan et al., 2022; Ma et al., 2023c)、检索器 (Dai et al., 2023b; Sachan et al., 2022, 2023; Schick and Schiitze, 2021; Meng et al., 2023; Peng et al., 2023b) 和重排序器 (Bonifacio et al., 2022; Sun et al., 2023a; Pradeep et al., 2023a,b; Saad-Falcon et al., 2023; Ferraretto et al., 2023; Jeronymo et al., 2023; Sun et al., 2023c)。
Query Rewriter. The Query Rewriter (QR) is a pivotal component in IR systems, tasked with enhancing the precision and expressiveness of user queries by refining or modifying the initial query to more accurately align with the user’s information needs. One notable approach is QUILL (Srinivasan et al., 2022), which introduces a two-stage distillation method for query intent understanding. Initially, a retrievalaugmented LLM, serving as the ‘professor,’ is distilled into a non-retrieval augmented teacher LLM, aiming to bolster its understanding capabilities. Subsequently, this enhanced teacher LLM is distilled into a final student model using a large dataset, further refining the process. Incorporating the QR into IR systems, Ma et al. (2023c) develop a ’RewriteRetrieve-Read’ framework. This process begins with an LLM rewriting the queries via prompting, followed by a retrieval-augmented reading stage. To integrate the rewritten queries effectively into the IR system, the knowledge gleaned from the LLM is distilled into a compact student rewriter. This rewriter is then fine-tuned using feedback from the LLM reader through reinforcement learning.
查询重写器 (Query Rewriter)。查询重写器 (QR) 是信息检索 (IR) 系统中的关键组件,其任务是通过优化或修改初始查询来提升用户查询的精确性和表达能力,使其更准确地匹配用户的信息需求。QUILL (Srinivasan et al., 2022) 提出了一种两阶段蒸馏方法用于查询意图理解:首先将检索增强的大语言模型作为"教授"蒸馏到非检索增强的教师大语言模型中,以增强其理解能力;随后利用大规模数据集将优化后的教师大语言模型蒸馏到最终的学生模型中,进一步精炼该过程。Ma et al. (2023c) 提出了"重写-检索-阅读"框架将QR集成到IR系统中:先由大语言模型通过提示重写查询,再进行检索增强的阅读阶段。为了将重写查询有效整合到IR系统,从大语言模型获取的知识被蒸馏到紧凑的学生重写器中,随后通过强化学习利用大语言模型阅读器的反馈对该重写器进行微调。
Retriever and Reranker. In IR systems, the Retriever is designed to efficiently locate the top-k relevant texts from a large corpus. It encodes both queries and documents into vector representations and performs retrieval by computing the dot product between these vectors. The Reranker further refines the order of the retrieved documents to improve the overall quality of the output. This is achieved in two primary ways, including Pointwise Reranker and Listwise Reranker. Pointwise Reranker takes both the query and a single candidate document as input to directly generate a relevance score. Listwise Reranker directly reorders a list of input documents in terms of their relevance.
检索器与重排序器。在信息检索(IR)系统中,检索器(Retriever)的设计目标是从大规模语料库中高效定位前k个相关文本。它将查询和文档编码为向量表示,并通过计算这些向量间的点积来执行检索。重排序器(Reranker)则进一步优化检索结果排序以提升输出质量,主要通过两种方式实现:点式重排序器(Pointwise Reranker)和列式重排序器(Listwise Reranker)。点式重排序器同时接收查询和单个候选文档作为输入,直接生成相关性分数;列式重排序器则根据相关性直接对输入文档列表进行重新排序。
Retriever and Pointwise Reranker. For the retriever and pointwise reranker, a common application of KD from LLMs is the generation of pseudo-queries for given documents. This approach aims to expand the pairwise data, enhancing the training of dense retrievers or rerankers. For example, InPars (Bonifacio et al., 2022) utilizes GPT-3 to generate multiple pseudo-queries for an unlabeled document. To ensure the relevance of these queries, the system filters them based on the highest log probabilities of generating a query conditioned on the documents. Subsequently, InPars fine-tunes a reranker based on monoT5 (Raffel et al., 2020). Another similar approach, Prompt a gator (Dai et al., 2023b), introduces a few-shot dense retrieval method that leverages a small number of demonstrations from the target domain for pseudo-query generation. Diverging from the reliance on unlabeled documents, Sachan et al. (2022) distill knowledge from GPT-4 to curate diverse synthetic data for text embedding tasks across nearly 100 languages. They finetune powerful decoder-only LLMs, such as Mistral-7b (Jiang et al., 2023a), on this synthetic data using standard contrastive loss. Remarkably, this method demonstrates strong performance on text embedding and multilingual retrieval benchmarks without any labeled data. Beyond generating pseudo-queries, teacher LLMs can also be employed to generate relevance scores as soft labels. These scores are used to train the retriever by minimizing the KL-divergence loss between the teacher and student distributions, as explored by Sachan et al. (2023).
检索器与逐点重排序器。对于检索器和逐点重排序器,大语言模型(LLM)知识蒸馏(KD)的常见应用是为给定文档生成伪查询。该方法旨在扩展成对数据,增强稠密检索器或重排序器的训练。例如,InPars (Bonifacio等人,2022)利用GPT-3为未标注文档生成多个伪查询。为确保查询相关性,系统根据文档条件下生成查询的最高对数概率进行筛选。随后,InPars基于monoT5 (Raffel等人,2020)微调重排序器。另一类似方法Promptagator (Dai等人,2023b)提出少样本稠密检索技术,利用目标域少量示例进行伪查询生成。与依赖未标注文档不同,Sachan等人(2022)从GPT-4蒸馏知识,为近100种语言的文本嵌入任务构建多样化合成数据。他们使用标准对比损失在该合成数据上微调仅解码器的大语言模型(如Mistral-7b,Jiang等人,2023a)。值得注意的是,该方法在文本嵌入和多语言检索基准上展现出强劲性能,且无需任何标注数据。除生成伪查询外,教师大语言模型还可生成作为软标签的相关性分数。如Sachan等人(2023)所述,通过最小化师生分布的KL散度损失,这些分数可用于训练检索器。
Listwise Reranker. A distinct set of studies focuses on listwise reranking, where its advantage lies in comparing multiple documents simultaneously to determine the optimal reorder. RankGPT (Sun et al., 2023a) leverages GPT-4 to generate permutations for a group of candidate passages. To distill this listwise ranking knowledge into a pointwise student reranker, various training loss functions are employed, such as Listwise Cross-Entropy (Bruch et al., 2019), RankNet (Burges et al., 2005), and LambdaLoss (Wang et al., 2018). Building upon RankGPT’s framework, RankVicuna (Pradeep et al., 2023a) and RankZephyr (Pradeep et al., 2023b) further refine this approach by directly finetuning a listwise reranker using teacher-generated textual permutations. This enables the student reranker to produce sequences of ranked results directly, bypassing the intermediate step of calculating individual relevance scores.
列表重排序器。一系列独特的研究聚焦于列表重排序,其优势在于同时比较多个文档以确定最优重排顺序。RankGPT (Sun et al., 2023a) 利用 GPT-4 为一组候选段落生成排列。为了将这种列表排序知识提炼到点式学生重排序器中,研究者采用了多种训练损失函数,如列表交叉熵 (Listwise Cross-Entropy, Bruch et al., 2019)、RankNet (Burges et al., 2005) 和 LambdaLoss (Wang et al., 2018)。基于 RankGPT 框架,RankVicuna (Pradeep et al., 2023a) 和 RankZephyr (Pradeep et al., 2023b) 通过直接使用教师生成的文本排列微调列表重排序器,进一步优化了该方法。这使得学生重排序器能直接生成排序结果序列,省去了计算单个相关性分数的中间步骤。
4.4.4 Recommendation
4.4.4 推荐
Recommend er systems are integral to enhancing user experience in various online services, providing personalized content based on user preferences and behaviors. Many works have demonstrated that LLMs could be directly used as recommend ers without fine-tuning (Wang et al., 2023i; Dai et al., 2023c) or generate auxiliary textual features to benefit recommend er systems (Xi et al., 2023; Ren et al., 2023; Wei et al., 2024). (Wang et al., 2023j; Ren et al., 2023; Wei et al., 2024). However, the real-time nature of online recommender systems demands rapid response times, posing a challenge with the inherent inference latency associated with LLMs. To address this, several studies have explored ways to distill and integrate the knowledge from LLMs into recommend er systems, thereby leveraging their advanced capabilities while mitigating latency issues for efficient realtime recommendations (Mysore et al., 2023; Zhang et al., 2023b; Liu et al., 2023c).
推荐系统在提升各类在线服务的用户体验中扮演着关键角色,它能够根据用户偏好和行为提供个性化内容。多项研究表明,大语言模型(LLM)无需微调即可直接作为推荐系统使用 (Wang et al., 2023i; Dai et al., 2023c),或通过生成辅助文本特征来优化推荐系统性能 (Xi et al., 2023; Ren et al., 2023; Wei et al., 2024)。然而,在线推荐系统对实时性的要求与LLM固有的推理延迟形成矛盾。为此,近期研究探索了将LLM知识蒸馏整合到推荐系统的方法 (Mysore et al., 2023; Zhang et al., 2023b; Liu et al., 2023c),在保留其先进能力的同时解决延迟问题,实现高效实时推荐。
Mysore et al. (2023) tackle data scarcity in narrativedriven recommendation (NDR), where users provide detailed descriptions of their preferences. They utilize GPT-3 to create synthetic narrative queries from user-item interactions via few-shot prompting, then distill this data into retrieval models for NDR. Similarly, GENRE (Liu et al., 2023c) employs GPT-3.5 to augment datasets with new knowledge about news sum mari z ation, user profiles, and personalized content, aiding the training of content-based recommendation models. To bridge the gap between language models and recommend er systems, some research views behavior modeling as an extension of language modeling (Cui et al., 2022; Liu et al., 2023k). InstructRec (Zhang et al., 2023b), for instance, interprets recommendation as instruction following. They use ChatGPT to distill a wealth of userpersonalized instruction data reflecting diverse preferences and intentions based on real historical interactions. This data is then used to fine-tune a 3B student language model specifically for recommendation purposes.
Mysore等人(2023)解决了叙事驱动推荐(NDR)中的数据稀缺问题,其中用户需详细描述其偏好。他们通过少样本提示(prompting)利用GPT-3从用户-物品交互中生成合成叙事查询,并将这些数据蒸馏到NDR的检索模型中。类似地,GENRE(Liu等人,2023c)使用GPT-3.5增强数据集,补充新闻摘要、用户画像和个性化内容等新知识,辅助基于内容的推荐模型训练。为弥合语言模型与推荐系统间的鸿沟,部分研究将行为建模视为语言建模的延伸(Cui等人,2022;Liu等人,2023k)。例如InstructRec(Zhang等人,2023b)将推荐任务视为指令遵循过程,他们使用ChatGPT从真实历史交互中提炼出反映多样化偏好和意图的用户个性化指令数据,并利用这些数据专门针对推荐任务微调了一个30亿参数的学生语言模型。
4.4.5 Text Generation Evaluation
4.4.5 文本生成评估
Text generation evaluation, i.e. NLG evaluation, focuses on assessing the quality of generated content. Unlike traditional NLG evaluation metrics like BLEU (Papineni et al., 2002) or ROUGE (Lin, 2004), which primarily rely on surface-level text comparisons, LLMs, trained on extensive corpora and refined through techniques like RLHF, offer a more human-aligned assessment. This sophistication has led to the increasing use of LLMs in NLG evaluation (detailed further in (Li et al., 2024b)). Through KD of LLMs, student evaluators could enhance inference efficiency and achieve more flexible and highly customized evaluation (Wang et al., 2023b; Kim et al., 2024; Xu et al., 2023d; Jiang et al., 2023c; Li et al., 2024a).
文本生成评估(即自然语言生成评估)的核心在于衡量生成内容的质量。传统评估指标如BLEU (Papineni et al., 2002) 和ROUGE (Lin, 2004) 主要依赖表层文本对比,而基于海量语料训练并通过RLHF等技术优化的大语言模型 (LLM) 能提供更贴近人类判断的评估。这种优势促使LLM在自然语言生成评估中的应用日益广泛 (详见 (Li et al., 2024b)) 。通过大语言模型的知识蒸馏 (KD) ,学生评估器可提升推理效率,实现更灵活、高度定制化的评估 (Wang et al., 2023b; Kim et al., 2024; Xu et al., 2023d; Jiang et al., 2023c; Li et al., 2024a) 。
PandaLM (Wang et al., 2023b) concentrates on a pairwise evaluator designed to compare two pieces of generated content. It utilizes a teacher LLM (GPT-3.5) to judge which response is better for a given instruction and input, providing reasons for its decision. Addressing the need for customized and flexible criteria to meet realistic user demands, Prometheus (Kim et al., 2024) distills GPT-4 to construct a training dataset that includes reference answers and a variety of customized scoring rubrics. This dataset is then used to tune LLaMA for evaluating model-generated responses. Instructs core (Xu et al., 2023d) takes a more fine-grained approach by using GPT-4 to create detailed analysis data. This data is employed to tune LLaMA, enabling it to perform error analysis on generated texts compared to reference texts. The system further refines its evaluation capabilities through self-training with real model-generated responsereference pairs. For reference-free evaluation across diverse domains, TigerScore (Jiang et al., 2023c) samples data from a variety of text generation datasets, such as summarization, translation, and data-to-text. It distills error analysis knowledge from GPT-4 and uses this to fine-tune LLaMA. Lastly, to adapt evaluation to real-world scenarios beyond conventional NLP tasks, Auto-J (Li et al., 2024a) collects real-world user queries and their evaluations from a teacher LLM. This massive dataset of real-world scenarios is then used to distill evaluation knowledge into LLaMA through fine-tuning, enhancing its practical applicability.
PandaLM (Wang et al., 2023b) 专注于设计成对比较生成内容的评估器,利用教师大语言模型 (GPT-3.5) 判断给定指令和输入下哪个响应更优,并提供决策依据。为满足用户定制化需求,Prometheus (Kim et al., 2024) 通过蒸馏 GPT-4 构建包含参考答案和多样化评分准则的训练数据集,进而微调 LLaMA 实现模型生成响应的评估。InstructScore (Xu et al., 2023d) 采用更细粒度的方法:使用 GPT-4 生成详细分析数据微调 LLaMA,使其能对生成文本与参考文本进行错误分析,并通过真实模型生成-参考对的自训练持续优化评估能力。针对跨领域无参考评估,TigerScore (Jiang et al., 2023c) 从摘要、翻译、数据到文本等多类文本生成数据集中采样,蒸馏 GPT-4 的错误分析知识微调 LLaMA。最后,为适应传统 NLP 任务之外的真实场景评估,Auto-J (Li et al., 2024a) 收集真实用户查询及其教师大语言模型评价,通过海量现实场景数据集微调将评估知识蒸馏至 LLaMA,提升其实用性。
4.4.6 Code
4.4.6 代码
LLMs, trained on extensive corpora containing code, are highlighted for their proficiency in code-related tasks. Their capabilities extend beyond direct code generation to include the provision of external knowledge and data, which is crucial in distilling their expertise into smaller, more efficient models. Several works have successfully distilled code knowledge from LLMs into those compact and specialized code models (Chaudhary, 2023; Roziere et al., 2023; Gunasekar et al., 2023; Wei et al., 2023; Chen et al., 2023a; Liu et al., 2023d; Yu et al., 2024; Jain et al., 2023; Su and McMillan, 2023; Guo et al., 2023d).
大语言模型(LLM)在包含代码的大规模语料库上训练,因其在代码相关任务中的熟练表现而备受关注。它们的能力不仅限于直接生成代码,还包括提供外部知识和数据,这对于将其专业知识提炼到更小、更高效的模型中至关重要。多项研究已成功将大语言模型中的代码知识蒸馏到这些紧凑且专业化的代码模型中 [Chaudhary, 2023; Roziere et al., 2023; Gunasekar et al., 2023; Wei et al., 2023; Chen et al., 2023a; Liu et al., 2023d; Yu et al., 2024; Jain et al., 2023; Su and McMillan, 2023; Guo et al., 2023d]。
A primary focus in these student code models is on code generation, a task of both common utility and practical significance. For instance, Code Alpaca (Chaudhary, 2023) fine-tunes Llama using self-instruct with ChatGPT-distilled instructions specifically for code generation tasks. Similarly, Code Llama-instruct (Roziere et al., 2023) is fine-tuned via self-instruct, prompting Llama-2 (Touvron et al., 2023) with coding problems, and further refined with unit tests. Phi1 (Gunasekar et al., 2023) aims to enhance the quality of distilled code data by extracting “textbook quality” data from a teacher LLM, incorporating Python textbook and exercise data. Magicoder (Wei et al., 2023) addresses potential biases in teacher LLMs by referencing a wealth of open-source code, yielding more diverse and grounded data for code generation. To consider the capability of the student model and leverage the feedback of the teacher, PERsD (Chen et al., 2023a) introduces a Personalized Distillation method where the teacher LLM refines the student’s generated code based on the execution feedback of the executor.
这些学生代码模型的主要关注点是代码生成,这是一项兼具通用性和实用意义的任务。例如,Code Alpaca (Chaudhary, 2023) 通过使用ChatGPT提炼的指令进行自指导微调Llama,专门用于代码生成任务。类似地,Code Llama-instruct (Roziere et al., 2023) 通过自指导微调,用编码问题提示Llama-2 (Touvron et al., 2023),并通过单元测试进一步优化。Phi1 (Gunasekar et al., 2023) 旨在通过从教师大语言模型中提取"教科书质量"的数据,结合Python语言教材和练习数据,提高蒸馏代码数据的质量。Magicoder (Wei et al., 2023) 通过参考大量开源代码解决教师大语言模型中潜在的偏见,为代码生成提供更多样化和接地气的数据。为了考虑学生模型的能力并利用教师的反馈,PERsD (Chen et al., 2023a) 引入了一种个性化蒸馏方法,教师大语言模型根据执行器的反馈优化学生生成的代码。
However, these models primarily target the code generation task, lacking general iz ability across a broader range of code-related tasks. To address this issue, MFTCoder (Liu et al., 2023d) utilizes self-instruct to distill diverse code data from teacher LLMs for various tasks, such as code completion and text-to-code generation, training a student model via multi-task learning. WaveCoder (Yu et al., 2024), in contrast, creates a comprehensive instruction tuning dataset covering four universal code-related tasks distilled from GPT-3.5-turbo. WaveCoder first selects a diverse coreset of raw data using the K Center Greedy (Sener and Savarese, 2018) clustering method, then employs the teacher LLM for generating task definitions and outputs. The teacher model also plays a role in evaluating and filtering this data. Notably, WaveCoder demonstrates superior generalization across different code-related tasks compared to other opensource models.
然而,这些模型主要针对代码生成任务,缺乏在更广泛代码相关任务中的通用能力。为解决这一问题,MFTCoder (Liu et al., 2023d) 利用自指令(self-instruct)从教师大语言模型中蒸馏出多样化的代码数据,涵盖代码补全、文本到代码生成等多种任务,并通过多任务学习训练学生模型。相比之下,WaveCoder (Yu et al., 2024) 创建了一个全面的指令调优数据集,包含从GPT-3.5-turbo蒸馏出的四项通用代码相关任务。WaveCoder首先使用K中心贪婪(K Center Greedy)聚类方法 (Sener and Savarese, 2018) 选择多样化的原始数据核心集,然后利用教师大语言模型生成任务定义和输出。该教师模型还负责评估和过滤这些数据。值得注意的是,与其他开源模型相比,WaveCoder在不同代码相关任务中展现出更优异的泛化能力。
4.5 Multi-Modality
4.5 多模态
Multimodal Large Language Models (MLLMs) surpass traditional language-only LLMs by understanding and processing information across multiple modalities, more closely mirroring human perception and enabling a broader range of real-world applications. There is a growing trend towards developing MLLMs that follow multimodal instructions, facilitating tasks with enhanced levels of interactivity. To address the scarcity of multimodal instruction-following data and to harness the commonsense and world knowledge embedded in teacher LLMs, numerous studies have focused on multimodal knowledge distillation from LLMs (Liu et al., 2023e; Zhao et al., 2023b; Wang et al., 2023e; Chen et al., 2023c; Park et al., 2023; Pi et al., 2023; Zhao et al., 2023c; Liu et al., 2023f; Wu et al., 2023b; Luo et al., 2023d; Jiang et al., 2023d; Li et al., 2023c; Xu et al., 2023e).
多模态大语言模型 (MLLM) 通过理解和处理跨模态信息,超越了传统纯文本大语言模型,更贴近人类感知方式并支持更广泛的现实应用。当前发展趋势聚焦于开发遵循多模态指令的 MLLM,以提升交互式任务能力。为解决多模态指令数据的稀缺性并利用教师大语言模型中嵌入的常识与世界知识,大量研究致力于从大语言模型进行多模态知识蒸馏 (Liu et al., 2023e; Zhao et al., 2023b; Wang et al., 2023e; Chen et al., 2023c; Park et al., 2023; Pi et al., 2023; Zhao et al., 2023c; Liu et al., 2023f; Wu et al., 2023b; Luo et al., 2023d; Jiang et al., 2023d; Li et al., 2023c; Xu et al., 2023e)。
Vision-Language. In the vision-language domain, LLaVA (Liu et al., 2023e) pioneers the extension of the Self-Instruct approach from the language to the multimodal field. It translates images into textual descriptions, including captions and bounding boxes, and distills GPT-4 for generating new data in the context of seed examples. This approach creates a LLaVA-Instruct-150k dataset, which serves as the foundation for further developments like LLaVA-1.5 (Liu et al., 2023l) and GPT4ROI (Zhang et al., 2023e), enhancing the instructionfollowing capabilities of MLLMs. To expand the dataset’s scale, SVIT (Zhao et al., 2023b) introduces a 4.2 million image dataset, distilled from GPT-4 by leveraging manual image annotations. It employs a novel data recipe to select an informative, diverse, and balanced subset of training data. LVIS-Instruct4V (Wang et al., 2023e) leverages GPT4V (OpenAI, 2023), a powerful large multimodal model, as a teacher to distill a more accurate and context-aware instruction-following dataset, focusing on fine-grained understanding. Further advancements include integrating specific region referencing in image-based instruction following. For instance, Shikra (Chen et al., 2023c) uses
视觉-语言。在视觉-语言领域,LLaVA (Liu et al., 2023e) 率先将自指导 (Self-Instruct) 方法从纯语言领域扩展到多模态领域。该方法将图像转化为文本描述(包括标题和边界框),并利用 GPT-4 在种子示例背景下生成新数据,从而创建了 LLaVA-Instruct-150k 数据集。该数据集成为后续 LLaVA-1.5 (Liu et al., 2023l) 和 GPT4ROI (Zhang et al., 2023e) 等发展的基础,增强了多模态大语言模型 (MLLM) 的指令跟随能力。为扩大数据集规模,SVIT (Zhao et al., 2023b) 通过人工图像标注从 GPT-4 提炼出一个包含 420 万张图像的数据集,并采用新颖的数据筛选方法选择信息丰富、多样且平衡的训练数据子集。LVIS-Instruct4V (Wang et al., 2023e) 则利用强大的多模态大模型 GPT4V (OpenAI, 2023) 作为教师模型,提炼出更精准、具有上下文感知能力的细粒度理解指令数据集。最新进展还包括在图像指令跟随中整合特定区域引用功能,例如 Shikra (Chen et al., 2023c) 使用
GPT-4 to distill referential question-answer pairs from the Flickr30K (Plummer et al., 2015) dataset, enhancing the understanding of referential regions within images. LSKD (Park et al., 2023) introduces localized references to specific image regions, prompting the teacher LLM to generate commonsense inferences about these areas. To enhance the visual instruction tuning pipeline with text-rich images, LLaVAR (Zhang et al., 2023d) employs the text-only GPT-4 as a teacher, using recognized texts and image captions to generate 16K conversation pairs for text-rich images. The resultant student MLLM demonstrates enhanced interaction skills in content that combines both text and imagery.
GPT-4从Flickr30K数据集(Plummer等人,2015)中蒸馏出指代性问答对,以增强对图像中指代区域的理解。LSKD(Park等人,2023)引入了对特定图像区域的局部指代,促使教师大语言模型生成关于这些区域的常识推理。为了在富含文本的图像上增强视觉指令调优流程,LLaVAR(Zhang等人,2023d)采用纯文本GPT-4作为教师模型,利用识别文本和图像描述为富含文本的图像生成16K对话对。最终训练得到的学生多模态大语言模型在图文结合内容上展现出更强的交互能力。
Multiple Modalities. To extend knowledge distillation of LLMs to encompass more modalities, such as audio and video, several innovative approaches have been introduced. These methods typically involve transforming these modalities into a textual format comprehensible to teacher LLMs, followed by the distillation of the teacher. Macaw-LLM (Lyu et al., 2023) leverages GPT-4 to generate instruction-response pairs corresponding to the content of images or videos. MIMIC-IT (Li et al., 2023f) aims to broaden the scope to language, image, and video understanding, creating a substantial dataset with 2.8 million multimodal instruction-response pairs distilled from ChatGPT. ChatBridge (Zhao et al., 2023d), on the other hand, represents a novel approach in multimodal language modeling. It translates various non-textual modalities into text, combining fine-grained and global descriptions. This information is then used to distill responses from ChatGPT or GPT-4 through an in-context learning process, effectively bridging the gap between different modalities.
多模态。为了将大语言模型(LLM)的知识蒸馏扩展到音频和视频等多模态领域,研究者提出了多种创新方法。这些方法通常涉及将多模态数据转换为教师大语言模型可理解的文本格式,再进行知识蒸馏。Macaw-LLM (Lyu et al., 2023) 利用 GPT-4 生成与图像或视频内容对应的指令-响应对。MIMIC-IT (Li et al., 2023f) 旨在拓展至语言、图像和视频理解领域,通过从ChatGPT蒸馏创建了包含280万条多模态指令-响应对的大规模数据集。ChatBridge (Zhao et al., 2023d) 则提出了一种多模态语言建模新方法,通过将各类非文本模态转化为文本形式,结合细粒度和全局描述,并基于上下文学习过程从ChatGPT或GPT-4蒸馏响应,有效弥合了不同模态间的鸿沟。
Others. Beyond distilling instruction-following data, several methods have emerged that concentrate on harnessing different aspects of knowledge from LLMs. For instance, EMMA (Yang et al., 2023c) trains an MLLM to act as an embodied reflex agent within a visual environment. It achieves this by distilling GPT-4’s skills in a parallel textual world, generating actions and providing reflective feedback. Silkie (Li et al., 2023h) takes a unique approach by distilling preferences from GPT-4V, focusing on criteria like helpfulness and visual faithfulness. Ha et al. (2023) represent another innovative direction, where it generates, labels, and distills diverse robot-centric exploration experiences by LLMs into a multi-task visuo-linguo-motor policy.
其他方法。除了提炼指令跟随数据外,还出现了几种专注于利用大语言模型不同知识层面的方法。例如,EMMA (Yang et al., 2023c) 训练了一个多模态大语言模型 (MLLM) 作为视觉环境中的具身反射智能体,通过提炼 GPT-4 在平行文本世界中的技能来生成动作并提供反思反馈。Silkie (Li et al., 2023h) 采用了一种独特方法,从 GPT-4V 中提炼偏好,重点关注有用性和视觉保真度等标准。Ha et al. (2023) 则代表了另一个创新方向,通过大语言模型生成、标记并提炼多样化的以机器人为中心的探索经验,最终形成多任务视觉-语言-运动策略。
5 DOMAIN-SPECIFIED VERTICAL DISTILLATION
5 领域专用垂直蒸馏
This section shifts from skill distillation to examine KD of LLMs in various vertical domains, including Law, Medical & Healthcare, Finance, and Science, etc. It delves into customizing distilled LLMs for these fields, showing its significant role in enhancing domain-specific AI applications. The taxonomy of these works is shown in Figure 7.
本节从技能蒸馏转向探讨大语言模型在不同垂直领域的知识蒸馏 (KD) 应用,包括法律、医疗健康、金融和科学等。重点研究如何为这些领域定制蒸馏后的大语言模型,展示其在增强特定领域AI应用方面的重要作用。相关工作分类如图7所示。
5.1 Law
5.1 法律
Law holds a crucial position in molding societies, overseeing human interactions, and ensuring justice prevails. Informed decision-making, legal interpretation, and the provision of legal advice by professionals hinge on precise and current information. Legal intelligent applications in different scenarios usually require combinations of multiple fundamental capabilities of legal text retrieval, understanding, reasoning and generating (Zhang et al., $2023\mathrm{g}.$ ; Sun, 2023; Lai et al., 2023). To address challenges like legal terminology, subtle interpretations, and the constant evolution of legislation presents distinctive challenges that demand customized resolutions. To handle the above challenges, several studies have investigated the customization of LLMs for intelligent legal services (Cui et al., 2023b; Yue et al., 2023b; Huang et al., 2023b; Wu et al., 2023d). This involves a continued pre-training process on extensive legal corpora, followed by fine-tuning with self-constructed instructions or augmented data using advanced LLMs.
法律在塑造社会、规范人际互动和维护正义方面具有关键地位。专业人士的决策制定、法律解释和咨询服务都依赖于准确且及时的信息。法律智能应用在不同场景中通常需要结合法律文本检索、理解、推理和生成等多项基础能力 (Zhang et al., $2023\mathrm{g}.$ ; Sun, 2023; Lai et al., 2023)。针对法律术语、微妙解释以及法规持续更新等挑战,需要定制化的解决方案。为应对这些挑战,多项研究探索了如何为大语言模型定制智能法律服务 (Cui et al., 2023b; Yue et al., 2023b; Huang et al., 2023b; Wu et al., 2023d),包括在大量法律语料上进行持续预训练,再通过自建指令或利用先进大语言模型增强数据进行微调。

Fig. 7: Taxonomy of Vertical iz ation Distillation.
图 7: 垂直蒸馏分类法。
Huang et al. (2023b) have unveiled a Chinese legal large model named Lawyer LLaMA. The model undergoes an initial pre-training phase on an extensive legal corpus, systematically assimilating knowledge of the Chinese legal system. Subsequently, fine-tuning occurs through the analysis of objective questions from the Chinese National Judicial Examination (Zhong et al., 2020) and the gathering of responses to legal consultations using ChatGPT. This process equips the model with the ability to apply legal knowledge to specific scenarios. Cui et al. (2023b) present LawGPT, built upon the foundation of OpenLLAMA. The model is trained using a construction process that incorporates realworld legal text, legal regulations, judicial interpretations, and actual legal consultation data. Additionally, the authors utilize the ChatGPT API for assisted construction, enabling the generation of supplementary data derived from the existing dataset. Wu et al. (2023d) have developed a largescale Chinese legal model (named Fuzi) with ChatGLM as its foundation. This model undergoes training on an extensive Chinese legal corpus, which incorporates unsupervised judicial language data, including diverse judgment documents and legal regulations. Additionally, it undergoes supervised judicial fine-tuning with data encompassing legal QA and case retrieval. Fuzi’s training also involves both general instruction fine-tuning datasets, such as Alpaca, and domain-specific instruction fine-tuning datasets from Lawyer LLaMA (Huang et al., 2023b) and LawGPT (Cui et al., 2023b).
Huang等人 (2023b) 发布了一个名为Lawyer LLaMA的中文法律大模型。该模型首先在大量法律语料上进行预训练,系统学习中国法律体系知识,随后通过分析中国国家司法考试客观题 (Zhong等人, 2020) 和收集ChatGPT生成的法律咨询回复进行微调,使其具备将法律知识应用于具体场景的能力。Cui等人 (2023b) 提出了基于OpenLLAMA构建的LawGPT,采用真实法律文本、法律法规、司法解释和实际法律咨询数据进行训练,并利用ChatGPT API辅助构建衍生数据。Wu等人 (2023d) 开发了以ChatGLM为基础的大规模中文法律模型Fuzi,其训练数据包含无监督司法语言数据 (各类判决书和法律条文) 和有监督司法微调数据 (法律问答和案例检索),同时结合Alpaca等通用指令微调数据集及Lawyer LLaMA (Huang等人, 2023b) 和LawGPT (Cui等人, 2023b) 的领域专用指令微调数据集。
5.2 Medical and Healthcare
5.2 医疗与健康
The integration of LLMs holds great potential for transforming medicine and healthcare. Extensive research has focused on adapting general-purpose LLMs to the medical domain (Singhal et al., 2023), such as electronic health records, and healthcare applications like patient care (Zhu et al., 2023). Recent work has focused on enhancing medical instruction-following data with advanced teacher LLMs to better align with complex user instructions. Given the abundance of medical data, most studies combine realworld data with distilled instruction data from teacher LLMs (Zhang et al., 2023c; Xiong et al., 2023; Zhang et al., 2023f; Wang et al., 2023a; Li et al., 2023i; Han et al., 2023; Wu et al., 2023f; Bao et al., 2023a; Chen et al., 2023d).
大语言模型(LLM)的整合为医疗健康领域带来巨大变革潜力。大量研究致力于将通用大语言模型适配到医疗领域(Singhal et al., 2023),如电子健康档案系统,以及患者护理等医疗应用场景(Zhu et al., 2023)。近期研究重点通过先进教师大语言模型增强医疗指令跟随数据,以更好对齐复杂用户指令。鉴于医疗数据资源丰富,多数研究将真实世界数据与教师大语言模型提炼的指令数据相结合(Zhang et al., 2023c; Xiong et al., 2023; Zhang et al., 2023f; Wang et al., 2023a; Li et al., 2023i; Han et al., 2023; Wu et al., 2023f; Bao et al., 2023a; Chen et al., 2023d)。
While existing studies predominantly concentrate on training using dedicated medical dialogue datasets comprising medical textbooks (Wu et al., 2023e), biomedical papers (Luo et al., 2023e) medical knowledge-graphs (Bao et al., 2023b), or authentic doctor-patient interactions (Bao et al., 2023b), an expanding body of research is delving into the augmentation of medical instruction-following data with advanced LLMs to enhance the alignment with practical user instructions. Zhang et al. (2023c) introduce HuatuoGPT specifically tailored for medical consultations. The model leverages both distilled data from ChatGPT and real-world data from doctors during the supervised finetuning stage. In a parallel effort, Xiong et al. (2023) construct a dataset of medical dialogues in Chinese, employing ChatGPT’s assistance. Their methodology encompassed various techniques to train DoctorGLM, an easily deployable LLM designed for tasks such as diagnoses, drug recommendations, and other medical advice. Zhang et al. (2023f) fine-tune LLaMA-series models using $52\mathrm{k\Omega}$ diverse, machine-generated, medical instruction-following data named Med Instruct-52k. This effort resulted in the development of AlpaCare, a model demonstrating robust medical proficiency and general iz ability across both general and medical-specific domain free-form instruction evaluations. In a different vein, Wang et al. (2023a) propose HuaTuo, a LLaMA-based model that undergoes supervised fine-tuning with generated QA instances. This refinement process enhances the model’s possession of more reliable medical knowledge. Li et al. (2023i) introduce ChatDoctor, which was first trained as a generic conversation model based on LLaMA. It utilized 52K instruction-following data from Stanford University’s Alpaca project (Taori et al., 2023). Subsequently, the conversation model underwent fine-tuning on a dataset of 100K patient-physician conversations collected from an online medical consultation website. This two-step training process underscores the model’s adaptability to diverse conversational contexts, particularly those specific to patient-physician interactions.
现有研究主要集中于使用专业医疗对话数据集进行训练,这些数据集包含医学教材 (Wu et al., 2023e)、生物医学论文 (Luo et al., 2023e)、医学知识图谱 (Bao et al., 2023b) 或真实医患互动记录 (Bao et al., 2023b)。与此同时,越来越多的研究开始探索利用先进的大语言模型增强医疗指令跟随数据,以提升与实际用户指令的契合度。Zhang et al. (2023c) 推出了专为医疗问诊设计的华佗GPT (HuatuoGPT),该模型在监督微调阶段同时采用了从ChatGPT提炼的数据和真实医生诊疗数据。类似地,Xiong et al. (2023) 借助ChatGPT构建了中文医疗对话数据集,通过多种技术训练出易于部署的DoctorGLM模型,可用于诊断、用药建议等医疗任务。Zhang et al. (2023f) 使用名为Med-Instruct-52k的52kΩ多样化机器生成医疗指令数据对LLaMA系列模型进行微调,最终开发出在通用和医疗领域自由指令评估中均展现出色医学专业性和泛化能力的AlpaCare模型。Wang et al. (2023a) 则提出了基于LLaMA的华佗模型 (HuaTuo),通过生成式QA实例进行监督微调,显著提升了模型的可靠医学知识储备。Li et al. (2023i) 开发的ChatDoctor首先基于LLaMA框架和斯坦福大学Alpaca项目 (Taori et al., 2023) 的52K指令数据训练通用对话模型,随后使用在线问诊平台采集的10万条医患对话进行微调,这种两阶段训练突显了模型对医患对话等特定场景的适应能力。
Built upon existing datasets, MedAlpaca (Han et al., 2023) proposes to reconstruct the data with GPT-3.5-Turbo, which is then used to fine-tune LLMs for effective medical applications. Furthermore, PMC-LLaMA (Wu et al., 2023f) proposes a training framework (i.e., continual pre-training and domain-specific multi-task supervised fine-tuning) to adapt a general LLM to the medicine domain, where GPT4 is leveraged to write synonymous sentences for data augmentation in the SFT. To adapt LLMs to real-world medical consultation, DISC-MedLLM (Bao et al., 2023a) leverages GPT-3.5 to 1) construct 50K QA pairs in a fewshot manner and 2) re-generate the $420\mathrm{k\Omega}$ dialogues based on real cases, which are then used to train LLMs in a supervised fine-tuning manner. More recently, HuatuoGPTII (Chen et al., 2023d) proposes a one-stage training with instruction-formatting unification of domain data collection for medical adaption upon LLMs, where GPT-4 is used to formulate medical questions to fine-tuning instructions.
在现有数据集的基础上,MedAlpaca (Han et al., 2023) 提出用 GPT-3.5-Turbo 重构数据,随后用于微调大语言模型以实现有效的医疗应用。此外,PMC-LLaMA (Wu et al., 2023f) 提出了一种训练框架(即持续预训练和领域特定多任务监督微调),将通用大语言模型适配到医学领域,其中利用 GPT4 生成同义句以增强监督微调阶段的数据。为了让大语言模型适应现实世界的医疗咨询场景,DISC-MedLLM (Bao et al., 2023a) 借助 GPT-3.5 实现:1) 以少样本方式构建 5 万组问答对,2) 基于真实病例重新生成 $420\mathrm{k\Omega}$ 条对话数据,随后以监督微调方式训练大语言模型。最近,HuatuoGPTII (Chen et al., 2023d) 提出单阶段训练方法,通过统一领域数据收集的指令格式实现大语言模型的医疗适配,其中使用 GPT-4 将医学问题转化为微调指令。
These diverse studies collectively contribute to the advancing field of the medical domain, facilitated by knowledge distillation from advanced LLMs. Through the exploration of various methodologies, these approaches provide valuable insights into the challenges and potential breakthroughs at the intersection of cutting-edge language models and medical applications.
这些多样化的研究共同推动了医学领域的进步,其发展得益于从先进大语言模型中进行的知识蒸馏。通过探索多种方法,这些研究为尖端语言模型与医疗应用交叉领域的挑战和潜在突破提供了宝贵见解。
5.3 Finance
5.3 金融
The application of LLMs to the finance domain (Xue et al., 2023) significantly transforms how financial data is analyzed, decisions are made, and customer interactions are managed. In finance, LLMs offer unprecedented capabilities in understanding complex financial documents, predicting market trends, and automating risk assessment, thus enabling more informed and faster decision-making processes. By processing and analyzing vast amounts of unstructured financial data, such as news articles, reports, and real-time market feeds, LLMs can identify patterns and insights that were previously inaccessible, leading to more accurate forecasts and strategic financial planning. Furthermore, LLMs enhance customer experiences through personalized financial advice, automated customer service, and sophisticated chatbots that can handle complex queries. This level of automation and insight has the potential to increase efficiency, reduce operational costs, and improve compliance and risk management practices in financial institutions, making LLMs a transformative force in the finance sector. Knowledge distillation from a proprietary LLM is still under-explored, and most existing works focus on adapting LLMs to finance applications by continual pretraining on finance-specific corpora (Wu et al., $2023\mathrm{g};$ Lu et al., 2023) or fine-tuning in a supervised manner on multitask finance-specific instructions (Yang et al., 2023e; Xie et al., 2023b; Wang et al., 2023k).
大语言模型在金融领域的应用 (Xue et al., 2023) 显著改变了金融数据分析、决策制定和客户互动的方式。在金融领域,大语言模型展现出理解复杂金融文档、预测市场趋势和自动化风险评估的前所未有能力,从而实现更明智、更快速的决策流程。通过处理和分析大量非结构化金融数据 (如新闻文章、报告和实时市场数据流),大语言模型能够识别以往难以发现的模式和洞察,进而生成更精准的预测和战略性财务规划。此外,大语言模型通过个性化财务建议、自动化客户服务和能处理复杂查询的智能聊天机器人,提升了客户体验。这种自动化水平和洞察力有望提高金融机构的效率、降低运营成本并改善合规与风险管理实践,使大语言模型成为金融行业的变革力量。目前针对专有大语言模型的知识蒸馏研究仍显不足,现有工作主要集中于两种途径:在金融领域特定语料库上进行持续预训练 (Wu et al., 2023g; Lu et al., 2023),或基于多任务金融领域指令进行监督式微调 (Yang et al., 2023e; Xie et al., 2023b; Wang et al., 2023k)。
Specifically, XuanYuan (Zhang and Yang, 2023) leverages self-instruct over seed data and self-QA over structured/unstructured data to generate instruction data in the finance domain, which is used to train a finance LLM.
具体而言,XuanYuan (Zhang and Yang, 2023) 通过种子数据的自指令(self-instruct)和结构化/非结构化数据的自问答(self-QA)生成金融领域的指令数据,用于训练金融大语言模型(LLM)。
5.4 Science
5.4 科学
The integration of LLMs into the science domain (Taylor et al., 2022; Yin et al., 2023b) represents a paradigm shift in research, knowledge discovery, and the dissemination of scientific information. In science, LLMs are leveraged to digest and synthesize vast amounts of literature, aiding in the identification of new research opportunities and the acceleration of scientific breakthroughs. They facilitate the under standing of complex scientific concepts by summarizing research papers, generating hypotheses, and even drafting research proposals and manuscripts, thus significantly reducing the time researchers spend on literature review and enabling them to focus more on experimental work. LLMs also democratize access to scientific knowledge by providing layperson summaries of complex research findings, making science more accessible to non-experts and fostering a broader public understanding of scientific advancements. By enhancing the efficiency of research workflows and fostering interdisciplinary collaborations, LLMs are poised to accelerate the pace of scientific discovery and innovation across various fields. To distill knowledge from an LLM, DARWIN Series (Xie et al., 2023a) utilizes a semi selfinstruct for instruction generation for science papers, which is then used to fine-tune an LLM. SciGLM (Zhang et al., 2024) proposes to train a scientific LLM, which prompts a teacher LLM to generate detailed answers for unlabelled scientific questions, as well as a self-reflective critic-andrevise to improve data quality. Besides the above knowledge distillation methods to adapt LLMs to science, we will also delve into how the distillation happens in sub-domains, e.g., mathematics, astronautics, chemistry, etc.
将大语言模型 (LLM) 整合到科学领域 (Taylor et al., 2022; Yin et al., 2023b) 代表了研究、知识发现和科学信息传播的范式转变。在科学领域,大语言模型被用于消化和综合大量文献,帮助识别新的研究机会并加速科学突破。它们通过总结研究论文、生成假设甚至起草研究提案和手稿,促进对复杂科学概念的理解,从而显著减少研究人员在文献综述上花费的时间,使他们能够更多地专注于实验工作。大语言模型还通过提供复杂研究发现的通俗摘要,使非专业人士更容易接触科学知识,促进公众对科学进步的更广泛理解。通过提高研究工作流程的效率和促进跨学科合作,大语言模型有望加速各个领域的科学发现和创新步伐。为了从大语言模型中提炼知识,DARWIN系列 (Xie et al., 2023a) 使用半自指导方法生成科学论文的指令,然后用于微调大语言模型。SciGLM (Zhang et al., 2024) 提出训练一个科学大语言模型,该模型会提示教师大语言模型为未标记的科学问题生成详细答案,并通过自我反思的批评与修订来提高数据质量。除了上述适应科学领域的大语言模型知识蒸馏方法外,我们还将深入探讨在数学、航天、化学等子领域中如何进行知识蒸馏。
Mathematics. The application of LLMs within the subdomain of mathematics heralds a transformative era in mathematical research, education, and problem-solving (Azerbayev et al., 2023; Yu et al., 2023b). LLMs in mathematics facilitate the exploration and understanding of complex mathematical theories and problems by providing intuitive explanations, proofs, and solutions that can bridge the gap between advanced mathematical concepts and learners at various levels. These models have shown potential in conjecturing new mathematical theorems and patterns, thus opening new avenues for research and discovery that might not have been readily accessible to humans alone. In education, they serve as personalized tutors, offering students step-by-step guidance through mathematical problems and adapting explanations to the learner’s level of under standing. This democratizes access to high-quality mathematical education and fosters a deeper appreciation and understanding of mathematics among a broader audience. By enhancing collaborative efforts through the generation of new ideas and the simplification of complex concepts, LLMs are poised to significantly advance the field of mathematics, making it more accessible, efficient, and innovative. WizardMath (Luo et al., 2023b) enhances the mathematical reasoning capabilities of Llama-2 by applying the novel Reinforcement Learning from Evol-Instruct Feedback (RLEIF) method, significantly outperforming other opensource LLMs on the GSM8k and MATH benchmarks, as well as surpassing several closed-source LLMs including ChatGPT-3.5 and Minerva. MAmmoTH (Yue et al., 2023a) is a series of open-source LLMS specifically developed for general math problem-solving, achieving superior performance on nine mathematical reasoning datasets. Utilizing a novel instruction tuning dataset called Math Instruct, which combines chain-of-thought and program-of-thought rationales, MAmmoTH models demonstrate substantial improvements over existing models. TORA (Gou et al., 2024), a series of Tool-integrated Reasoning Agents, significantly advances mathematical problem-solving by combining natural language reasoning with the use of external computational tools. It markedly outperforms existing open-source models on 10 mathematical reasoning datasets, showcasing notable improvements over both rationale-based and programbased approaches, and introduces innovative training techniques such as output space shaping to enhance model reasoning capabilities. G-LLaVA (Gao et al., 2023c) introduces a significant advancement in geometric problem-solving for LLMs by leveraging a multimodal approach that combines text and image data. This model, utilizing the Geo170K dataset comprising over 170,000 geometric image-caption and question-answer pairs, demonstrates remarkable improvements over GPT-4V on the MathVista benchmark.
数学。大语言模型(LLM)在数学子领域的应用预示着数学研究、教育和问题解决将迎来变革性时代[20][21]。数学领域的LLM通过提供直观的解释、证明和解决方案,帮助探索和理解复杂的数学理论与问题,从而弥合高阶数学概念与不同水平学习者之间的鸿沟。这些模型在猜想新数学定理和模式方面展现出潜力,为人类单独难以企及的研究发现开辟了新途径。在教育领域,它们充当个性化导师,为学生提供数学问题的分步指导,并根据理解水平调整讲解方式,从而普及优质数学教育,促进更广泛群体对数学的深层认知。通过激发新思路和简化复杂概念来增强协作效能,LLM必将显著推动数学领域发展,使其更具普适性、高效性和创新性。
WizardMath[22]采用创新的"进化指令反馈强化学习"(RLEIF)方法,显著提升了Llama-2的数学推理能力,在GSM8k和MATH基准测试中远超其他开源LLM,甚至超越ChatGPT-3.5和Minerva等闭源模型。MAmmoTH[23]是专为通用数学解题开发的开源LLM系列,在九个数学推理数据集上表现卓越。该模型通过融合思维链和程序思维原理的Math Instruct指令微调数据集,实现了对现有模型的显著改进。TORA[24]系列工具集成推理智能体,通过结合自然语言推理与外部计算工具,在10个数学推理数据集上大幅领先现有开源模型,其创新的输出空间整形等训练技术有效提升了模型推理能力。G-LLaVA[25]采用文本-图像多模态方法,基于包含17万组几何图文对的Geo170K数据集,在MathVista基准测试中实现了对GPT-4V的显著超越。
Astronautics. The application of LLMs in astronautics (Nguyen et al., 2023) propels the field forward. AstroLLaMA-Chat (Perkowski et al., 2024) is an advancement of the AstroLLaMA model, leveraging a 7Bparameter LLaMA-2 model and targeted continual pre- training on a curated astronomy corpus to enhance performance in astronomy-focused question-answering. This model demonstrates significant improvements in specialized topic comprehension and introduces a chat-enabled version for the astronomy community, highlighting the effectiveness of domain-specific knowledge distillation in achieving superior performance on specialized topics.
航天学。大语言模型在航天学中的应用 (Nguyen et al., 2023) 推动了该领域的发展。AstroLLaMA-Chat (Perkowski et al., 2024) 是AstroLLaMA模型的升级版,它利用了一个70亿参数的LLaMA-2模型,并针对精选的天文学语料库进行了定向持续预训练,以提升在天文学问答任务中的表现。该模型在专业主题理解方面展现出显著进步,并为天文学界推出了支持聊天的版本,凸显了领域特定知识蒸馏在专业主题上实现卓越性能的有效性。
Chemistry and Materials Science. The integration of LLMs into Chemistry and Materials Science has revolutionized the way researchers approach the discovery and development of new compounds and materials. By analyzing vast datasets and scientific literature, LLMs can predict the properties and behaviors of substances, significantly accelerating the innovation cycle.
化学与材料科学。大语言模型(LLM)在化学与材料科学领域的整合彻底改变了研究人员探索新化合物和新材料的方式。通过分析海量数据集和科学文献,大语言模型能够预测物质的性质和行为,显著加速创新周期。
GIMLET (Zhao et al., 2023f), Graph Instruction based MolecuLe zEro-shoT learning, is a novel approach to molecule property prediction that integrates graph and text data within a single language model framework, aiming to improve instruction-based zero-shot learning for molecular tasks. By leveraging a transformer mechanism with generalized position embedding and decoupled attention, GIMLET significantly outperforms traditional molecule-text baselines in zero-shot learning scenarios, demonstrating the model’s effectiveness in generalizing from instructions to a broad range of molecule-related tasks without prior explicit task-specific training. LLM-Prop (Rubungo et al., 2023), leveraging the T5 model, showcases how LLMs can outperform SoTA graph neural networks in predicting the physical and electronic properties of crystalline solids from text descriptions. This approach underscores the potential of text-based methods in materials science, offering significant improvements in prediction accuracy while also contributing a benchmark dataset, TextEdge, to foster further re- search in this emerging field. Instruct Mol (Cao et al., 2023a) integrates multi-modal data, aligning molecular structures with natural language instructions for drug discovery tasks. Through a novel two-stage instruction-tuning approach, it significantly enhances performance in molecule-related tasks, establishing a reliable molecular assistant that outperforms existing LLMs and reduces the performance gap with specialized models. This demonstrates the value of multimodal integration in developing versatile tools for complex domains like drug discovery.
GIMLET (Zhao et al., 2023f) ,即基于图指令的分子零样本学习 (Graph Instruction based MolecuLe zEro-shoT learning) ,是一种整合图与文本数据到单一语言模型框架的新颖分子属性预测方法,旨在提升分子任务的指令驱动零样本学习性能。通过采用带有广义位置嵌入和解耦注意力机制的Transformer架构,GIMLET在零样本场景中显著超越传统分子-文本基线模型,证明了该模型仅通过指令就能泛化至广泛分子相关任务的能力,而无需事先进行显式的任务专项训练。LLM-Prop (Rubungo et al., 2023) 基于T5模型,展示了大语言模型在通过文本描述预测晶体固体物理与电子属性时如何超越图神经网络的最先进水平。该方法凸显了基于文本的方法在材料科学中的潜力,不仅显著提升了预测精度,还贡献了基准数据集TextEdge以推动这一新兴领域的深入研究。Instruct Mol (Cao et al., 2023a) 整合多模态数据,将分子结构与自然语言指令对齐以支持药物发现任务。通过创新的两阶段指令微调方法,该模型显著提升了分子相关任务的性能,建立了一个超越现有大语言模型、缩小与专业模型差距的可靠分子助手,证明了多模态整合在开发药物发现等复杂领域通用工具中的价值。
Biology. In the field of Biology, particularly in the study of proteins, DNA, and RNA, LLMs are revolutionizing our understanding of the fundamental molecules of life. By analyzing vast datasets of biological sequences and structures, LLMs can predict the three-dimensional shapes of proteins, potential functions, and interactions at a scale and speed beyond traditional computational methods. This capability is critical for unraveling the complexities of biological systems, advancing drug discovery by identifying targets and designing molecules with high precision, and understanding genetic diseases through the interpretation of genomic variations.
生物学。在生物学领域,特别是蛋白质、DNA和RNA的研究中,大语言模型(LLM)正在彻底改变我们对生命基本分子的理解。通过分析海量生物序列与结构数据集,大语言模型能以超越传统计算方法的规模和速度预测蛋白质三维构象、潜在功能及相互作用。这种能力对破解生物系统复杂性至关重要:既能通过精准识别靶点与设计分子来推动药物研发,又能通过解读基因组变异来理解遗传疾病。
Prot2Text (Abdine et al., 2023) introduces a novel multimodal framework for generating protein function descriptions in free text by combining GNNs and LLMs. This approach, which integrates structural and sequential protein information, highlights the transformative impact of knowledge distillation through the fusion of GNNs and LLMs for accurate protein function prediction, potentially revolutionizing research in bioinformatics and biological sciences. BioMedGPT (Luo et al., 2023e) introduces a multimodal generative pre-trained transformer specifically designed for the bio medicine domain, emphasizing the significance of aligning molecular, protein, and natural language modalities to enhance biomedical question-answering, molecule, and protein QA tasks. This framework showcases the critical role of knowledge distillation in bridging the gap between complex biological data and human language, thereby facilitating groundbreaking advancements in drug discovery and therapeutic target identification. xTrimoPGLM (Chen et al., 2024e), a unified 100B-scale pre-trained transformer model, addresses both protein understanding and generation tasks by integrating auto encoding and auto regressive pre-training objectives. Its significant advancements over existing models in 18 protein understanding benchmarks and its capability in de novo protein sequence generation highlight the model’s importance in advancing the field of protein science through knowledge distillation.
Prot2Text (Abdine等人,2023)提出了一种新颖的多模态框架,通过结合图神经网络(GNN)和大语言模型(LLM)生成自由文本形式的蛋白质功能描述。该方法整合了蛋白质的结构和序列信息,强调了通过GNN与LLM融合实现知识蒸馏对准确预测蛋白质功能的变革性影响,可能彻底改变生物信息学和生物科学领域的研究。BioMedGPT (Luo等人,2023e)推出了一种专为生物医学领域设计的多模态生成式预训练Transformer,着重强调了分子、蛋白质与自然语言模态对齐对提升生物医学问答、分子及蛋白质问答任务的重要性。该框架展示了知识蒸馏在弥合复杂生物数据与人类语言之间鸿沟的关键作用,从而推动药物发现和治疗靶点识别领域的突破性进展。xTrimoPGLM (Chen等人,2024e)作为统一的百亿规模预训练Transformer模型,通过集成自编码和自回归预训练目标,同时处理蛋白质理解与生成任务。该模型在18项蛋白质理解基准测试中对现有模型的显著超越,以及其在新蛋白质序列生成方面的能力,凸显了通过知识蒸馏推动蛋白质科学领域发展的重要价值。
Geography, Geology, and Environmental Science. The integration of LLMs into Geography, Geology, and Environmental Science is revolutionizing these fields by enhancing data analysis, predictive modeling, and interdisciplinary research (Roberts et al., 2023; Lin et al., 2023b; Wang et al., 2023l).
地理学、地质学与环境科学。大语言模型(LLM)与这些领域的结合正在通过增强数据分析、预测建模和跨学科研究引发革命性变革 (Roberts et al., 2023; Lin et al., 2023b; Wang et al., 2023l)。
K2 (Deng et al., 2023), the first-ever LLM specialized in the geoscience domain, demonstrates the significant impact of knowledge distillation in vertical domain specialization. By adapting the general-domain LLaMA-7B model with a 5.5B token geoscience corpus and introducing the GeoSignal instruction tuning dataset, K2 showcases enhanced performance in geoscience knowledge understanding and utilization. The model’s development highlights a novel approach to efficiently gather domain-specific data and align model responses to specialized user queries. OceanGPT (Bi et al., 2023), introduced as the first LLM for ocean science tasks, underscores the vital role of knowledge distillation in the vertical domain of oceanography. It leverages DOINSTRUCT, a novel framework for generating domainspecific instruction data through multi-agent collaboration, and establishes OCEANBENCH, a benchmark for evaluating LLMs in the ocean domain. MarineGPT (Zheng et al., 2023b) showcases the transformative potential of knowledge distillation in the marine domain by leveraging a novel vision-language model tailored for marine science. Utilizing the Marine-5M dataset, which includes over 5 million marine image-text pairs, MarineGPT excels in providing detailed, accurate, and domain-specific responses. Geo Galactica (Lin et al., 2024) represents a pioneering step in specializing LLMs for geoscience, leveraging a 30 billion parameter model pre-trained on a vast geoscience corpus. This model is notable for being the largest of its kind within the geoscience domain.
K2 (Deng et al., 2023) 作为首个专注于地球科学领域的大语言模型,展示了知识蒸馏在垂直领域专业化中的显著影响。该模型通过使用包含55亿token的地球科学语料库对通用领域LLaMA-7B模型进行适配,并引入GeoSignal指令调优数据集,展现了在地球科学知识理解与应用方面的增强性能。其开发过程凸显了一种高效收集领域特定数据并使模型响应与专业用户查询对齐的创新方法。
OceanGPT (Bi et al., 2023) 是首个面向海洋科学任务的大语言模型,强调了知识蒸馏在海洋学垂直领域的关键作用。它利用DOINSTRUCT这一通过多智能体协作生成领域特定指令数据的新框架,并建立了OCEANBENCH这一评估海洋领域大语言模型的基准。
MarineGPT (Zheng et al., 2023b) 通过采用专为海洋科学定制的新型视觉语言模型,展示了知识蒸馏在海洋领域的变革潜力。借助包含超过500万海洋图文对的Marine-5M数据集,该模型能够提供详尽、准确且领域特定的响应。
Geo Galactica (Lin et al., 2024) 代表了在地球科学领域专业化大语言模型的开创性尝试,其基于300亿参数模型并利用大规模地球科学语料库进行预训练。该模型因其在地球科学领域同类模型中规模最大而备受瞩目。
5.5 Miscellaneous
5.5 其他
Knowledge distillation of LLMs has vast potential across various verticals beyond the ones previously discussed, highlighting their versatility and transformative impact across different industries. For instance, in the education sector, EduChat (Dan et al., 2023) exemplifies a chatbot system that provides tailored support to teachers, students, and parents. KD is central to its design, leveraging pretraining on educational data followed by fine-tuning with custom instructions to deliver capabilities such as essay evaluation and emotional support. Similarly, Owl (Guo et al., 2023b), an LLM designed for IT operations, boosts operational efficiency using the Owl-Instruct dataset, which is distilled from ChatGPT. By applying a mixture-of-adapter strategy for domain-specific tuning, it enhances analysis and performance in IT-related tasks.
大语言模型的知识蒸馏 (Knowledge Distillation) 在先前讨论的领域之外还具有广泛的应用潜力,展现了其跨行业的通用性和变革性影响。例如在教育领域,EduChat (Dan et al., 2023) 是一个为教师、学生和家长提供定制化支持的聊天机器人系统,其核心设计采用知识蒸馏技术:先对教育数据进行预训练,再通过定制指令微调,最终实现作文批改和情感支持等功能。同样地,专为IT运维设计的Owl大模型 (Guo et al., 2023b) 利用从ChatGPT蒸馏得到的Owl-Instruct数据集提升运维效率,通过混合适配器 (adapter) 策略进行领域调优,显著增强了IT相关任务的分析与执行能力。
6 OPEN PROBLEMS
6 开放性问题
Further Data Selection How much data is required for LLM distillation and how to filter out the low-quality data remain open-domain questions. In the field of instruction tuning, one of the most commonly used methods for distillation, Zhou et al. (2023a) propose that only 1000 human-curated high-quality data is enough for the alignment of LLMs, hypothesizing that LLMs have learned the required knowledge from pre training and only a small amount of data is required for the alignment. Its finding further raises a new question, how to automatically select the data for better distillation? Chen et al. (2023e) directly apply ChatGPT to rate each data sample together with explanations, and then the data is selected based on the rating. Cao et al. (2023b) split the existing instruction-tuning datasets and trains a linear function to select the most effective data based on their statistical properties. Li et al. (2023j) propose a data selection pipeline similar to self-distillation, in which the LLM firstly learns from a small subset of the data to get the basic ability, and then further uses this learned model to rate for the original dataset. Du et al. (2023b) propose to consider three aspects including quality, coverage, and necessity for the filtering process. Li et al. (2023k) select instruction data by evaluating their one-shot improvement on a hold-out set. Li et al. (2024f) recently propose Super filtering, which is able to utilize small language models like GPT2 to filter out the high-quality subset from a given high-quality dataset. Despite the emergence of these works working on data filtering, How to efficiently select the optimal distillation data for LLMs, and How much data is required for distillation are still unsolved.
进一步的数据选择
大语言模型蒸馏需要多少数据以及如何过滤低质量数据仍是开放性问题。在指令微调领域(最常用的蒸馏方法之一),Zhou等人 (2023a) 提出仅需1000条人工标注的高质量数据即可实现大语言模型的对齐,其假设是大语言模型已通过预训练掌握了所需知识,对齐过程仅需少量数据。这一发现引出了新问题:如何自动选择数据以实现更好的蒸馏?Chen等人 (2023e) 直接使用ChatGPT对每个数据样本进行评分并生成解释,然后根据评分筛选数据。Cao等人 (2023b) 将现有指令微调数据集拆分,通过训练线性函数基于统计特征选择最有效的数据。Li等人 (2023j) 提出类似自蒸馏的数据选择流程:大语言模型先从小规模数据子集学习基础能力,再用习得模型对原始数据集进行评分。Du等人 (2023b) 提出从质量、覆盖度和必要性三个维度进行数据过滤。Li等人 (2023k) 通过评估指令数据在留出集上的少样本提升效果进行筛选。Li等人 (2024f) 近期提出的超级过滤(Super filtering)技术,可利用GPT2等小语言模型从高质量数据集中筛选优质子集。尽管这些数据过滤研究不断涌现,但如何高效选择最优蒸馏数据以及蒸馏所需数据量仍是未解难题。
Reduce the Distillation Cost (Lightweight Methods) Despite the remarkable abilities of the latest LLMs, their significant resource requirements underscore the urgent need to find efficient solutions to overcome these challenges. Common ways to further reduce the distillation cost include Model Compression and Efficient Fine-Tuning. In the realm of Model Compression, Quantization (Frantar et al., 2023; Dettmers et al., 2022; Kim et al., 2023c; Tao et al., 2022b; Yao et al., 2022; Xiao et al., 2023), Parameter Pruning (Ma et al., 2023d; Zhang et al., 2023h; Frantar and Alistarh, 2023), and Low-Rank Approximation (Xu et al., $2023\mathrm{g};$ ; Li et al., 2023l) are commonly utilized. In the realm of Efficient Fine-Tuning, Parameter Efficient Fine-Tuning (Hu et al., 2023b; Liu et al., 2022c; Wang et al., 2022b; Hu et al., 2021; Li and Liang, 2021; Liu et al., 2022d), and Memory Efficient Fine-Tuning (Dettmers et al., 2023; Kim et al., 2023d; Malladi et al., 2024) are utilized. A detailed survey on Efficient Large Language Models can be found here in Wan et al. (2024b). The problem that remains is how can we further compress the model and build effective distillation algorithms.
降低蒸馏成本(轻量级方法)
尽管最新的大语言模型(LLM)展现出卓越能力,但其巨大的资源需求凸显了寻找高效解决方案的迫切性。常见的进一步降低蒸馏成本方法包括模型压缩(Model Compression)和高效微调(Efficient Fine-Tuning)。在模型压缩领域,量化(Quantization) (Frantar et al., 2023; Dettmers et al., 2022; Kim et al., 2023c; Tao et al., 2022b; Yao et al., 2022; Xiao et al., 2023)、参数剪枝(Parameter Pruning) (Ma et al., 2023d; Zhang et al., 2023h; Frantar and Alistarh, 2023)和低秩近似(Low-Rank Approximation) (Xu et al., $2023\mathrm{g};$ ; Li et al., 2023l)被广泛采用。在高效微调领域,参数高效微调(Parameter Efficient Fine-Tuning) (Hu et al., 2023b; Liu et al., 2022c; Wang et al., 2022b; Hu et al., 2021; Li and Liang, 2021; Liu et al., 2022d)和内存高效微调(Memory Efficient Fine-Tuning) (Dettmers et al., 2023; Kim et al., 2023d; Malladi et al., 2024)是主要技术。关于高效大语言模型的详细综述可参阅Wan et al. (2024b)。当前核心问题在于如何进一步压缩模型并构建有效的蒸馏算法。
Multi-Teacher Distillation Most of the existing distilled models are distilled from a single teacher model, however, it is widely accepted that models trained with different sources of data have various capabilities. Thus a question arises: Is it possible to distill knowledge from different teacher models into one student model? BabyLlama (Timiryasov and Tastet, 2023) proposes to distill the knowledge from both the GPT2 and LLaMA into the smallsize student models. Ensemble-Instruct (Lee et al., 2023b) tries to generate both instructions and responses ensembled from several different LLMs with RougeL as the indicator. FUSELLM (Wan et al., 2024a) external ize s the collective knowledge and unique strengths by leveraging the generative distributions of different LLMs aiming to train a student model beyond those of any individual source LLM. Despite the recent progress in this topic, it still remains an underexplored topic.
多教师蒸馏
现有大多数蒸馏模型都是从单一教师模型蒸馏而来,但学界普遍认为使用不同数据源训练的模型具备多样化能力。这自然引出一个问题:能否将不同教师模型的知识蒸馏到单一学生模型中?BabyLlama (Timiryasov and Tastet, 2023) 提出同时从GPT2和LLaMA中蒸馏知识到小规模学生模型。Ensemble-Instruct (Lee et al., 2023b) 尝试通过RougeL指标集成多个不同大语言模型生成的指令和响应。FUSELLM (Wan et al., 2024a) 通过利用不同大语言模型的生成分布,外化集体知识和独特优势,旨在训练超越任何单一源大语言模型的学生模型。尽管该领域近期取得进展,但仍属研究不足的方向。
Explore Richer Knowledge from Teacher LLMs As indicated in Table 3, the majority of teacher LLMs are closed-source due to their advanced capabilities. Consequently, current methodologies primarily focus on using the generations from these models as hard labels, training student models through simple supervised fine-tuning. However, beyond the straightforward imitation of output behaviors via hard labels, there is a growing interest in harnessing richer knowledge from teacher LLMs, including feedback and feature knowledge, as well as exploring diverse combinations of knowledge eli citation methods. As highlighted in the Feedback section, teachers can provide various types of feedback based on the student’s outputs (Lee et al., 2023a; Jiang et al., 2023b; Chen et al., 2023a). Similarly, the Feature section discusses how knowledge based on features, such as logits serving as soft labels, can offer deeper, intrinsic insights into the teacher model (Gu et al., 2024; Agarwal et al., 2024). These explorations have demonstrated promising outcomes, suggesting that access to a broader spectrum of knowledge can significantly enhance student model performance beyond what is achievable through simple SFT distillation alone. This highlights the critical need for further research into varied knowledge extraction methods from teacher LLMs to augment the effectiveness of KD processes.
探索教师大语言模型中更丰富的知识
如表 3 所示,大多数教师大语言模型因其先进能力而闭源。因此,当前方法主要关注将这些模型的生成结果作为硬标签,通过简单的监督微调训练学生模型。然而,除了通过硬标签直接模仿输出行为外,学界越来越关注从教师大语言模型中获取更丰富的知识,包括反馈和特征知识,以及探索多种知识抽取方法的组合。如反馈部分所述,教师可以根据学生输出提供多种类型的反馈 (Lee et al., 2023a; Jiang et al., 2023b; Chen et al., 2023a)。类似地,特征部分讨论了基于特征的知识(如作为软标签的 logits)如何提供对教师模型更深层次的内在洞察 (Gu et al., 2024; Agarwal et al., 2024)。这些探索已展现出积极成果,表明获取更广泛的知识可以显著提升学生模型性能,超越单纯通过 SFT 蒸馏所能达到的效果。这凸显了进一步研究从教师大语言模型中提取多样化知识的方法对提升知识蒸馏 (KD) 过程有效性的关键需求。
Overcoming Catastrophic Forgetting During Distillation Previous research has delved into the fine-tuning of LLMs to acquire the ability to follow instructions or transfer knowledge for forthcoming tasks, skills, or domains, leveraging advancements in LLM technology. Nevertheless, inve stig at ions have revealed that the continual fine-tuning of LLMs on particular datasets (skills, domains) can lead to a phenomenon known as catastrophic forgetting, wherein previously acquired knowledge and problem-solving abilities for earlier tasks are compromised (Chen et al., 2023f; Kotha et al., 2023; Koloski et al., 2023; Wu et al., 2024; Luo et al., 2023f). Earlier studies in machine learning and deep learning have investigated various techniques to help mitigate forgetting during the fine-tuning or continue learning process, such as rehearsal, which entails periodically revisiting and training on past data (Kirkpatrick et al., 2017; Rostami et al., 2019; Rolnick et al., 2019), as well as regu lari z ation methods like elastic weight consolidation (Lee et al., 2017), or dynamic architecture methods (Mallya et al., 2018; Wang et al., 2022c; Hu et al., 2023c; Chen et al., 2023f). To address the challenges of catastrophic forgetting and to enhance the diversity of generated instructions in knowledge distillation for LLMs, Jiang et al. (2023b) randomly sample an instruction from the easy instructions and also prompt the generator to generate a new instruction that belongs to the same domain as the sampled one. In a similar vein, Li et al. (2023m) study the problem of instructiontuning in multi-modal LLMs knowledge distillation and introduce a competitive distillation framework. The model tries to produce new instructions that differ in content but are similar in difficulty to the original pictures in the multimodal augmentation phase, so as to alleviate catastrophic forgetting of the model and enhance the diversity of the instruction tuning pool. Chen et al. (2023f) propose the Lifelong-MoE (Mixture-of Experts) architecture based on general language models, which dynamically adds model capacity via adding experts with regularized pre training. Additionally, the model also introduces implicit regularization via distillation of the knowledge from old experts and gatings to effectively preserve old knowledge. Zeng et al. (2023b) propose a new generative-based rehearsal method as Dirichlet Continual Learning (DCL). This method combines task distribution modeling and knowledge distillation to mitigate catastrophic forgetting without requiring access to the old data. To evaluate the effectiveness of instruction tuning in the context of continuous learning tasks, Zhang et al. (2023i) introduce a more challenging yet practical problem called Continual Instruction Tuning (CIT) and also establish a benchmark suite consisting of learning and evaluation protocols. Although current research has explored some simple methods to alleviate knowledge forgetting during model fine-tuning or knowledge distillation processes, effectively avoiding catastrophic forgetting across domains and skills remains a challenging issue. How to retain the original model’s capabilities effectively during knowledge distillation or transfer processes is still a challenging problem.
蒸馏过程中克服灾难性遗忘
先前研究探索了通过微调大语言模型(LLM)来获得遵循指令或迁移知识的能力,以应对未来任务、技能或领域,这得益于LLM技术的进步。然而研究表明,在特定数据集(技能、领域)上持续微调LLM可能导致灾难性遗忘现象,即先前获得的知识和早期任务的问题解决能力会受到损害 (Chen et al., 2023f; Kotha et al., 2023; Koloski et al., 2023; Wu et al., 2024; Luo et al., 2023f)。早期机器学习和深度学习研究已探索多种技术来缓解微调或持续学习过程中的遗忘,例如通过周期性回顾和训练历史数据来实现的重演法 (Kirkpatrick et al., 2017; Rostami et al., 2019; Rolnick et al., 2019),以及弹性权重固化等正则化方法 (Lee et al., 2017),或动态架构方法 (Mallya et al., 2018; Wang et al., 2022c; Hu et al., 2023c; Chen et al., 2023f)。
为解决灾难性遗忘挑战并增强LLM知识蒸馏中生成指令的多样性,Jiang et al. (2023b) 从简单指令中随机采样,并提示生成器产生与采样指令同领域的新指令。类似地,Li et al. (2023m) 研究多模态LLM知识蒸馏中的指令调优问题,提出竞争性蒸馏框架。该模型在多模态增强阶段尝试生成内容不同但难度与原始图片相似的指令,以缓解模型灾难性遗忘并增强指令调优池的多样性。Chen et al. (2023f) 提出基于通用语言模型的Lifelong-MoE(专家混合)架构,通过添加经过正则化预训练的专家来动态扩展模型容量,同时通过旧专家知识和门控机制的蒸馏引入隐式正则化以有效保留旧知识。Zeng et al. (2023b) 提出基于生成的重演方法Dirichlet持续学习(DCL),该方法结合任务分布建模和知识蒸馏来缓解灾难性遗忘,且无需访问旧数据。
为评估持续学习任务中指令调优的有效性,Zhang et al. (2023i) 提出更具挑战性但更实际的持续指令调优(CIT)问题,并建立包含学习和评估协议的基准套件。虽然当前研究探索了一些简单方法来缓解模型微调或知识蒸馏过程中的知识遗忘,但如何有效避免跨领域和跨技能的灾难性遗忘仍是挑战性问题。在知识蒸馏或迁移过程中如何有效保留原始模型能力,这仍然是一个悬而未决的难题。
Trustworthy Knowledge Distillation Trustworthiness in LLMs is paramount, encompassing attributes such as truthfulness, safety, fairness, robustness, privacy, and adherence to machine ethics (Sun et al., 2024a). The rapid advancement of LLMs brings to the forefront concerns regarding their trustworthiness, stemming from their complex outputs, the biases present in vast training datasets, and the potential inclusion of private information. Current efforts in KD of LLMs primarily focus on distilling various skills from LLMs, with relatively little attention paid to trustworthiness aspects. Existing studies tend to concentrate on a subset of trustworthiness aspects, such as helpfulness, honesty, and harmlessness (Bai et al., 2022a; Yang et al., 2024; Cui et al., 2023a). Consequently, in the distillation process, student models may inherit issues related to trustworthiness from their teacher LLMs. As assessed in Sun et al. (2024a), smaller open-source LLMs generally fall short of their proprietary counterparts in trustworthiness metrics. Therefore, considering trustworthiness alongside the distillation of capabilities into student models is crucial. It is imperative that future research on KD not only enhances the capabilities of student models but also ensures that broader aspects of trustworthiness are meticulously addressed.
可信知识蒸馏
大语言模型(LLM)的可信性至关重要,涵盖真实性、安全性、公平性、鲁棒性、隐私性和机器伦理遵循等属性 (Sun et al., 2024a)。大语言模型的快速发展使其可信性问题凸显,这源于其复杂输出、海量训练数据中的偏见以及可能包含的隐私信息。当前大语言模型知识蒸馏(KD)的研究主要集中于从大语言模型中提取各类技能,对可信性方面的关注相对较少。现有研究往往聚焦于可信性的部分维度,例如有用性、诚实性和无害性 (Bai et al., 2022a; Yang et al., 2024; Cui et al., 2023a)。因此,在蒸馏过程中,学生模型可能会继承教师大语言模型存在的可信性问题。如Sun等人(2024a)评估所示,较小规模的开源大语言模型在可信性指标上通常不及专有模型。因此,在将能力蒸馏至学生模型时兼顾可信性考量至关重要。未来知识蒸馏研究不仅需要提升学生模型的能力,还必须确保更广泛的可信性维度得到细致考量。
Weak-to-strong Distillation. The concept of “weak-tostrong generalization” in LLMs (Burns et al., 2023) emphasizes the potential to leverage weak supervision to elicit the advanced capabilities of more powerful models. This approach challenges the traditional distillation paradigm by suggesting that even with limited or imperfect supervision, it is possible to enhance the performance of LLMs significantly. This necessitates exploring innovative strategies that enable weaker models to guide the learning process of stronger ones effectively, highlighting the importance of developing methods that can bridge the gap between these models. Such research could unlock new avenues for improving LLMs’ efficiency and effectiveness, making the pursuit of “weak-to-strong distillation” a crucial area for future investigations in this LLM era. Initially, Burns et al. (2023) investigates whether weak model supervision can unlock the full capabilities of much stronger models. Through experiments with pre-trained language models in the GPT-4 family across NLP, chess, and reward modeling tasks, it finds that finetuning strong models on weak labels leads to better performance than their weak supervisors, demonstrating weak-to-strong generalization. Then, Li et al.
弱监督到强监督的蒸馏。大语言模型中的"弱监督到强监督泛化"概念(Burns等人,2023)强调了利用弱监督激发更强大模型高级能力的潜力。这种方法通过表明即使使用有限或不完美的监督,也能显著提升大语言模型的性能,从而对传统蒸馏范式提出了挑战。这需要探索创新策略,使较弱模型能有效指导更强模型的学习过程,突显了开发能弥合模型间差距方法的重要性。此类研究可能为提升大语言模型效率和效果开辟新途径,使"弱监督到强监督蒸馏"成为大语言模型时代未来研究的关键领域。最初,Burns等人(2023)研究了弱模型监督是否能释放更强模型的全部能力。通过在NLP、国际象棋和奖励建模任务中对GPT-4系列预训练语言模型进行实验,发现强模型在弱标签上微调后的表现优于其弱监督者,证明了弱监督到强监督的泛化能力。随后,Li等人...
$(2024g)$ introduce Super filtering, a method that employs smaller, weaker models like GPT-2 to select high-quality data for fine-tuning larger, more capable models such as LLaMA2. This approach is rooted in discovering a strong consistency in evaluating instruction tuning data difficulty across models of varying sizes. More recently, Ji et al. (2024) introduce Aligner, a novel approach for aligning LLMs with human values and intentions by utilizing weak supervisory signals from smaller models to improve the performance of larger models. However, Burns et al. (2023) find that achieving the full capabilities of strong models requires more than naive finetuning, suggesting the need for further research in this area. Therefore, open questions still remain about 1) What are the theoretical and practical limits of weak-to-strong distillation? Can weak supervision reliably extract and enhance the full spectrum of capabilities in stronger models across all domains, or are there inherent limitations based on model architecture or task specificity? 2) How do we identify or design the optimal weak supervisors for distilling knowledge into stronger models? Is there a framework or criteria to predict which weak models would be most effective in guiding the learning process of more complex models for specific tasks? 3) To what extent are weak-to-strong distillation techniques transferable and scalable across different sizes and types of models? How can these methods be adapted to ensure efficacy and efficiency in distilling knowledge from very large models to significantly smaller ones, especially in resource-constrained environments?
$(2024g)$ 提出了超级过滤(Super filtering)方法,该方法采用GPT-2等较小、较弱的模型来选择高质量数据,用于微调LLaMA2等更大、更强大的模型。该方法基于一个发现:不同规模模型在评估指令调优数据难度时存在高度一致性。最近,Ji等人(2024)提出了Aligner方法,通过利用小模型的弱监督信号来改进大模型性能,从而将大语言模型与人类价值观和意图对齐。然而,Burns等人(2023)发现,要实现强大模型的全部能力,仅靠简单微调是不够的,这表明该领域仍需进一步研究。因此,以下问题仍然悬而未决:1) 弱到强蒸馏(weak-to-strong distillation)的理论和实践极限是什么?弱监督能否在所有领域可靠地提取并增强强模型的全部能力,还是存在基于模型架构或任务特性的固有局限?2) 如何识别或设计最佳弱监督器来向强模型蒸馏知识?是否存在框架或标准来预测哪些弱模型在指导更复杂模型针对特定任务的学习过程中最有效?3) 弱到强蒸馏技术在不同规模和类型模型间的可迁移性和可扩展性如何?特别是在资源受限环境中,如何调整这些方法以确保从超大模型向极小模型高效蒸馏知识?
Self-Alignment. Aligning LLMs traditionally relies heavily on human or teacher LLMs to supply extensive preference data. Consequently, the alignment of the student model is limited by the quantity of distilled preference data and the teacher’s capabilities. Self-alignment offers a promising alternative, aiming to enhance alignment beyond the constraints of teacher-provided preferences. In self-alignment, the student model endeavors to autonomously improve and align its responses with desired behaviors, including generating model-written feedback, critiques, and explanations. Several studies have explored utilizing the student model’s inherent capabilities to generate knowledge for alignment (Bai et al., 2022a; Sun et al., 2024b; Li et al., 2024c; Yuan et al., 2024a). Beyond merely producing improved responses (Bai et al., 2022a; Sun et al., 2024b), implementations of self-alignment include employing the student as its reward model to offer feedback (Yuan et al., 2024a), a strategy that merges Self-Knowledge with Feedback methods of eliciting knowledge. We advocate for increasingly leveraging the student model itself to provide feedback, thereby enhancing self-alignment capabilities. This approach not only facilitates moving beyond traditional human/teacher preference-based rewards but also opens avenues for continual self-improvement and alignment.
自对齐 (Self-Alignment)。传统的大语言模型对齐方法高度依赖人类或教师模型提供大量偏好数据,导致学生模型的对齐效果受限于蒸馏偏好数据的数量及教师模型的能力。自对齐提供了一种突破性替代方案,旨在超越教师提供偏好的限制来增强对齐效果。该方法使学生模型能够自主优化响应行为,包括生成模型自反馈、批判性分析和解释说明。多项研究探索了利用学生模型内在能力生成对齐知识 (Bai et al., 2022a; Sun et al., 2024b; Li et al., 2024c; Yuan et al., 2024a),其实现方式不仅涵盖生成优化响应 (Bai et al., 2022a; Sun et al., 2024b),还包括将学生模型作为自身奖励模型来提供反馈 (Yuan et al., 2024a)——这种策略融合了自我知识 (Self-Knowledge) 与反馈式知识激发方法。我们主张通过增强学生模型的自我反馈能力来提升自对齐效能,该方法不仅能突破传统人类/教师偏好奖励的局限,还为持续自我优化与对齐开辟了新路径。
7 CONCLUSION AND DISCUSSION
7 结论与讨论
This survey has explored the diverse landscape of knowledge distillation for LLMs, highlighting key techniques, applications, and challenges. KD plays a crucial role in democratizing access to advanced LLM capabilities, providing cutting-edge advancements without the high costs of training and deployment. Our review emphasizes various KD approaches, from algorithmic innovations to skill enhancement and vertical distillation. Notably, data augmentation and synthesis within KD emerge as vital tools for improving distillation, revealing the powerful synergy between enriched training data and effective model distillation. As the AI landscape evolves, rapid advancements in model architectures and training methods present both challenges and research opportunities for KD of LLMs. Future innovation will need to focus on achieving efficiency, transparency, and ethics while maintaining model trustworthiness. Furthermore, promising areas such as weakto-strong generalization, self-alignment, and multi-modal LLMs offer the potential to enhance the capabilities of distilled models. In conclusion, the KD of LLMs is set to play a pivotal role in the future of AI research. As highlighted in this survey, sustained research efforts will be critical in developing accessible, efficient, and responsible AI for all. Importantly, when conducting KD of LLMs like ChatGPT or Llama, it’s essential to comply with the model providers’ terms4, such as the restrictions on developing competitive products.
本综述探讨了大语言模型(LLM)知识蒸馏(Knowledge Distillation)的多样化格局,重点分析了关键技术、应用场景与挑战。知识蒸馏在降低先进大语言模型使用门槛方面发挥着关键作用,无需承担高昂训练与部署成本即可获得前沿技术突破。我们从算法创新、技能增强到垂直蒸馏等多维度梳理了各类蒸馏方法,特别指出数据增强与合成技术已成为提升蒸馏效果的重要工具,揭示了高质量训练数据与高效模型蒸馏间的强大协同效应。随着AI领域发展,模型架构与训练方法的快速进步既带来挑战,也为大语言模型蒸馏创造了研究机遇。未来创新需聚焦于效率、透明度与伦理的平衡,同时保持模型可信度。弱到强泛化、自对齐及多模态大语言模型等方向有望进一步提升蒸馏模型能力。综上所述,大语言模型蒸馏必将在AI研究未来中扮演关键角色。正如本综述强调的,持续的研究投入对开发普惠、高效且负责任的AI至关重要。需特别注意的是,对ChatGPT或Llama等大语言模型进行蒸馏时,必须遵守模型提供方的条款(如禁止开发竞品的限制)[4]。
REFERENCES
参考文献
. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray et al., “Training language models to follow instructions with human feedback,” Advances in Neural Information Processing Systems, vol. 35, pp. 27 730–27 744, 2022. penAI, :, J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Alten schmidt, S. Altman, S. Anadkat, R. Avila, I. Babuschkin, S. Balaji, V. Balcom, P. Baltescu, H. Bao, M. Bavarian, J. Belgum, I. Bello, J. Berdine, G. Bernadett-Shapiro, C. Berner, L. Bogdonoff, O. Boiko, M. Boyd, A.-L. Brakman, G. Brockman, T. Brooks, M. Brundage, K. Button, T. Cai, R. Campbell, A. Cann, B. Carey, C. Carlson, R. Carmichael, B. Chan, C. Chang, F. Chantzis, D. Chen, S. Chen, R. Chen, J. Chen, M. Chen, B. Chess, C. Cho, C. Chu, H. W. Chung, D. Cummings, J. Currier, Y. Dai, C. Decareaux, T. Degry, N. Deutsch, D. Deville, A. Dhar, D. Dohan, S. Dowling, S. Dunning, A. Ecoffet, A. Eleti, T. Eloundou, D. Farhi, L. Fedus, N. Felix, S. P. Fishman, J. Forte, I. Fulford, L. Gao, E. Georges, C. Gibson, V. Goel, T. Gogineni, G. Goh, R. Gontijo-Lopes, J. Gordon, M. Grafstein, S. Gray, R. Greene, J. Gross, S. S. Gu, Y. Guo, C. Hallacy, J. Han, J. Harris, Y. He, M. Heaton, J. Heidecke, C. Hesse, A. Hickey, W. Hickey, P. Hoeschele, B. Houghton, K. Hsu, S. Hu, X. Hu, J. Huizinga, S. Jain, S. Jain, J. Jang, A. Jiang, R. Jiang, H. Jin, D. Jin, S. Jomoto, B. Jonn, H. Jun, T. Kaf- tan, Łukasz Kaiser, A. Kamali, I. Kani tsch eider, N. S. Keskar, T. Khan, L. Kilpatrick, J. W. Kim, C. Kim, Y. Kim, H. Kirchner, J. Kiros, M. Knight, D. Kokotajlo, Łukasz Kondraciuk, A. Kondrich, A. Konstantin id is, K. Kosic, G. Krueger, V. Kuo, M. Lampe, I. Lan, T. Lee, J. Leike, J. Leung, D. Levy, C. M. Li, R. Lim, M. Lin, S. Lin, M. Litwin, T. Lopez, R. Lowe, P. Lue, A. Makanju, K. Malfacini, S. Manning, T. Markov, Y. Markovski, B. Mar
Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray等人在《训练语言模型通过人类反馈遵循指令》一文中提出,该研究发表于《神经信息处理系统进展》第35卷,第27730–27744页,2022年。OpenAI团队包括J. Achiam, S. Adler, S. Agarwal等众多研究人员,涉及领域涵盖模型训练、算法优化及人工智能伦理等方向。