Towards Unified Conversational Recommend er Systems via Knowledge-Enhanced Prompt Learning
基于知识增强提示学习的统一对话推荐系统研究
ABSTRACT
摘要
Conversational recommend er systems (CRS) aim to pro actively elicit user preference and recommend high-quality items through natural language conversations. Typically, a CRS consists of a recom mend ation module to predict preferred items for users and a conversation module to generate appropriate responses. To develop an effective CRS, it is essential to seamlessly integrate the two modules. Existing works either design semantic alignment strategies, or share knowledge resources and representations between the two modules. However, these approaches still rely on different architectures or techniques to develop the two modules, making it difficult for effective module integration.
对话推荐系统 (Conversational Recommender System, CRS) 旨在通过自然语言对话主动获取用户偏好并推荐高质量物品。通常,CRS由推荐模块和对话模块组成:推荐模块预测用户偏好的物品,对话模块生成合适的回复。为了构建高效的CRS,必须无缝整合这两个模块。现有研究要么设计语义对齐策略,要么在两个模块间共享知识资源和表征。然而,这些方法仍依赖不同架构或技术来开发两个模块,导致难以实现有效的模块集成。
To address this problem, we propose a unified CRS model named UniCRS based on knowledge-enhanced prompt learning. Our approach unifies the recommendation and conversation subtasks into the prompt learning paradigm, and utilizes knowledge-enhanced prompts based on a fixed pre-trained language model (PLM) to fulfill both subtasks in a unified approach. In the prompt design, we include fused knowledge representations, task-specific soft tokens, and the dialogue context, which can provide sufficient contextual information to adapt the PLM for the CRS task. Besides, for the recommendation subtask, we also incorporate the generated response template as an important part of the prompt, to enhance the information interaction between the two subtasks. Extensive experiments on two public CRS datasets have demonstrated the effectiveness of our approach. Our code is publicly available at the link: https://github.com/RUCAIBox/UniCRS.
为解决这一问题,我们提出了一种基于知识增强提示学习的统一CRS模型UniCRS。该方法将推荐和对话子任务统一到提示学习范式中,并利用基于固定预训练语言模型(PLM)的知识增强提示,以统一方式完成这两个子任务。在提示设计中,我们融合了知识表示、任务特定的软token以及对话上下文,这些都能为PLM适应CRS任务提供充分的上下文信息。此外,针对推荐子任务,我们还将生成的响应模板作为提示的重要组成部分,以增强两个子任务间的信息交互。在两个公开CRS数据集上的大量实验证明了我们方法的有效性。代码已开源:https://github.com/RUCAIBox/UniCRS。
CCS CONCEPTS
CCS概念
• Information systems $\rightarrow$ Recommend er systems.
• 信息系统 $\rightarrow$ 推荐系统
KEYWORDS
关键词
Conversational Recommend er System; Pre-trained Language Model; Prompt Learning
会话推荐系统;预训练语言模型;提示学习
ACM Reference Format:
ACM 参考文献格式:
Xiaolei Wang, Kun Zhou, Ji-Rong Wen, and Wayne Xin ZhaoB. 2022. Towards Unified Conversational Recommend er Systems via Knowledge-Enhanced Prompt Learning. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD ’22), August 14–18, 2022, Washington, DC, USA. ACM, New York, NY, USA, 9 pages. https://doi.org/10.1145/ 3534678.3539382
Xiaolei Wang、Kun Zhou、Ji-Rong Wen和Wayne Xin ZhaoB. 2022. 基于知识增强提示学习的统一对话推荐系统研究. 见: 第28届ACM SIGKDD知识发现与数据挖掘会议论文集 (KDD '22), 2022年8月14–18日, 美国华盛顿特区. ACM, 美国纽约, 9页. https://doi.org/10.1145/3534678.3539382
1 INTRODUCTION
1 引言
With the widespread of intelligent assistants, conversational recommender systems (CRSs) have become an emerging research topic, which provide the recommendation service to users through natural language conversations [5, 15]. From the perspective of functions, CRSs should be able to fulfill two major subtasks, a recommendation subtask that predicts items from a candidate set to users and a conversation subtask that generates appropriate questions or responses.
随着智能助手的普及,对话式推荐系统(CRS)已成为新兴研究课题,它通过自然语言对话为用户提供推荐服务[5, 15]。从功能角度看,CRS需要完成两个核心子任务:推荐子任务(从候选集中预测用户可能喜欢的物品)和对话子任务(生成恰当的问题或回复)。
To fulfill these two subtasks, existing methods [4, 16, 35] usually set up two separate modules for each subtask, namely the recommendation module and the conversation module. Since the two subtasks are highly coupled, it has been widely recognized that a capable CRS should be able to seamlessly integrate these two modules [4, 16, 30, 35], in order to share useful features or knowledge between them. One line of works incorporate shared knowledge resources (e.g., knowledge graphs [4] and reviews [22]) and their representations to enhance the semantic interaction. Another line of works design special representation alignment strategies, such as pre-training tasks and regular iz ation terms (e.g., mutual information maximization [35] and contrastive learning [38]), to guarantee the semantic consistency of the two modules.
为了实现这两个子任务,现有方法[4, 16, 35]通常为每个子任务设置两个独立模块,即推荐模块和对话模块。由于这两个子任务高度耦合,学界普遍认为一个合格的对话推荐系统(CRS)应当能够无缝整合这两个模块[4, 16, 30, 35],以实现特征或知识的共享。一类研究通过引入共享知识资源(如知识图谱[4]和用户评论[22])及其表征来增强语义交互;另一类研究则设计特殊的表征对齐策略(如预训练任务和正则化项),例如互信息最大化[35]和对比学习[38],来确保两个模块的语义一致性。
Table 1: An illustrative case of the semantic inconsistency between the recommendation and conversation modules in existing CRS methods. The mentioned movies and entities are marked in italic blue and red, respectively. Compared with the baseline, the generated response of our model is more consistent with the predicted recommendation.
| USER: HUMAN: | Hello!I amlookingforsomemovies. What kinds of movie do you like? I like animated movies such as Frozen (2013). |
| USER: | I donotlikeanimatedfilms.Iwouldlovetosee a movie like Pretty Woman (1990) starring Julia Roberts. Know any thataresimilar? |
| KGSF: | Recommendation:Frozen2(2019) Response:Pretty Woman (1990)is a great movie. |
| OURS: | Recommendation:MyBestFriend'sWedding(1997) Response: Have you seen My Best Friend's Wedding (1997)? Julia Roberts also stars in it. |
| HUMAN: | PrettyWoman(1990) )wasagoodone.Ifyouareinit forJuliaRobertsyoucantryR RunawayBride(1999) |
表 1: 现有对话推荐系统(CRS)方法中推荐模块与会话模块语义不一致的典型案例。提及的电影和实体分别用斜体蓝色和红色标注。相比基线模型,我们的模型生成回复与预测推荐结果具有更高一致性。
| USER: HUMAN: | 你好!我想找些电影看。你喜欢什么类型的电影?我喜欢《冰雪奇缘》(2013)这类动画电影。 |
| USER: | 我不喜欢动画电影。我想看朱莉娅·罗伯茨主演的《风月俏佳人》(1990)这类电影。有类似的推荐吗? |
| KGSF: | 推荐:《冰雪奇缘2》(2019) 回复:《风月俏佳人》(1990)是部好电影。 |
| OURS: | 推荐:《我最好朋友的婚礼》(1997) 回复:你看过《我最好朋友的婚礼》(1997)吗?也是朱莉娅·罗伯茨主演的。 |
| HUMAN: | 《风月俏佳人》(1990)确实不错。如果喜欢朱莉娅·罗伯茨,你可以试试《落跑新娘》(1999)。 |
Despite the progress of existing CRS methods, the fundamental issue of semantic inconsistency between the recommendation and conversation modules has not been well addressed. Figure 1 shows an inconsistent case of the prediction from a representative CRS model, KGSF [35], which utilizes mutual information maximization to align the semantic representations. Although the recommendation module predicts the movie “Frozen 2 (2019)”, the conversation module seems to be unaware of such a recommendation result and generates a mismatched response that contains another movie “Pretty Woman (1990)”. Even if we can utilize heuristic constraints to enforce the generation of the recommended movie, it cannot fundamentally resolve the semantic inconsistency of the two modules. In essence, such a problem is caused by two major issues in existing methods. First, most of these methods develop the two modules with different architectures or techniques. Even with some shared knowledge or components, it is still difficult to effectively associate the two modules seamlessly. Second, results from one module cannot be perceived and utilized by the other. For example, there is no way to leverage the generated response when predicting the recommendation results in KGSF [35]. To summarize, the root of semantic inconsistency is the different architecture designs and working mechanisms of the two modules.
尽管现有CRS方法取得了进展,但推荐模块与会话模块之间的语义不一致这一根本问题仍未得到很好解决。图1展示了代表性CRS模型KGSF[35]的预测不一致案例,该模型利用互信息最大化来对齐语义表征。虽然推荐模块预测了电影《冰雪奇缘2(2019)》,但会话模块似乎未感知该推荐结果,生成了包含另一部电影《风月俏佳人(1990)》的不匹配回复。即便采用启发式约束强制生成推荐电影,也无法从根本上解决两个模块的语义不一致问题。本质上,该问题源于现有方法的两个主要缺陷:首先,多数方法采用不同架构或技术开发两个模块,即使存在共享知识或组件,仍难以有效无缝关联;其次,模块间无法感知和利用彼此的输出结果,例如KGSF[35]在预测推荐结果时无法利用已生成的对话响应。究其根源,语义不一致源于两个模块架构设计和工作机制的差异性。
To address the above issues, we aim to develop a more effective CRS that implements both the recommendation and conversation modules in a unified manner. Our approach is inspired by the great success of pre-trained language models (PLMs) [2, 8, 12], which have been shown effective as a general solution to a variety of tasks even in very different settings. In particular, the recently proposed paradigm prompt learning [2, 8, 29] further unifies the use of PLMs on different tasks in a simple yet flexible manner. Generally speaking, prompt learning augments or extends the original input of
为解决上述问题,我们致力于开发一种更高效的CRS,以统一方式实现推荐与会话模块。该方法受预训练语言模型(PLMs) [2,8,12] 巨大成功的启发,这些模型已被证明可作为通用解决方案适用于多种任务,即使在差异显著的情境中。特别是最新提出的提示学习(prompt learning)范式 [2,8,29],以简洁灵活的方式进一步统一了PLMs在不同任务中的应用。简言之,提示学习通过扩充或延伸原始输入...
PLMs by prepending explicit or latent tokens, which might contain demonstrations, instructions, or learnable embeddings. Such a paradigm can unify different task formats or data forms to a large extent. For CRSs, since the two subtasks aim to fulfill specific goals based on the same conversational semantics, it is feasible to develop a unified CRS approach based on prompt learning.
通过在显式或潜在token前添加可能包含演示、指令或可学习嵌入的内容,PLMs能够很大程度上统一不同的任务格式或数据形式。对于CRS而言,由于两个子任务都基于相同的对话语义来实现特定目标,因此基于提示学习开发统一的CRS方法是可行的。
To this end, in this paper, we propose a novel unified CRS model based on knowledge-enhanced prompt learning, namely UniCRS. For the base PLM, we utilize DialoGPT [33] since it has been pretrained on a large-scale dialogue corpus. In our approach, the base PLM is fixed in solving the two subtasks, without fine-tuning or continual pre-training. To better inject the task knowledge into the base PLM, we first design a semantic fusion module that can capture the semantic association between words from dialogue texts and entities from knowledge graphs (KGs). The major technical contribution of our approach lies in that we formulate the two subtasks in the form of prompt learning, and design specific prompts for each subtask. In our prompt design, we include the dialogue context (specific tokens), task-specific soft tokens (latent vectors), and fused knowledge representations (latent vectors), which can provide sufficient semantic information about the dialogue context, task instructions, and background knowledge. Moreover, for recom mend ation, we incorporate the generated response templates from the conversation module into the prompt, which can further enhance the information interaction between the two subtasks.
为此,本文提出了一种基于知识增强提示学习的新型统一CRS模型UniCRS。我们选用DialoGPT [33] 作为基础PLM (预训练语言模型),因其已在大规模对话语料上进行预训练。该方法中,基础PLM在解决两个子任务时保持固定参数,不进行微调或持续预训练。为更好地将任务知识注入基础PLM,我们首先设计了语义融合模块,用于捕捉对话文本中的词语与知识图谱(KGs)实体间的语义关联。本方法的主要技术贡献在于:以提示学习形式构建两个子任务,并为每个子任务设计特定提示模板。在提示设计中,我们整合了对话上下文(特定token)、任务相关软token(潜在向量)和融合知识表征(潜在向量),这些要素能充分提供对话上下文、任务指令和背景知识的语义信息。此外,在推荐任务中,我们将对话模块生成的响应模板融入提示,进一步加强两个子任务间的信息交互。
To validate the effectiveness of our approach, we conduct experiments on two public CRS datasets. Experimental results show that our UniCRS outperforms several competitive methods on both the recommendation and conversation subtasks, especially when training data is limited. Our main contributions are summarized as: (1) To the best of our knowledge, it is the first time that a unified CRS has been developed in a general prompt learning way. (2) Our approach formulates the subtasks of CRS into a unified form of prompt learning, and designs task-specific prompts with corresponding optimization methods. (3) Extensive experiments on two public CRS datasets have demonstrated the effectiveness of our approach in both the recom mend ation and conversation tasks.
为验证我们方法的有效性,我们在两个公开的CRS数据集上进行了实验。实验结果表明,UniCRS在推荐和对话子任务上均优于多种竞争方法,尤其在训练数据有限时表现更优。我们的主要贡献可总结为:(1) 据我们所知,这是首次以通用提示学习 (prompt learning) 方式开发统一CRS的尝试。(2) 本方法将CRS子任务统一为提示学习形式,并设计了任务特定的提示及对应优化方法。(3) 在两个公开CRS数据集上的大量实验证明了该方法在推荐和对话任务中的有效性。
2 RELATED WORK
2 相关工作
Our work is related to the following two research directions, namely conversational recommendation and prompt learning.
我们的工作涉及以下两个研究方向,即对话式推荐和提示学习。
2.1 Conversational Recommendation
2.1 对话式推荐
With the rapid development of dialogue systems [3, 33], conversational recommend er systems (CRSs) have emerged as a research topic, which aim to provide accurate recommendations through conversational interactions with users [5, 7, 28]. A major category of CRS studies rely on pre-defined actions (e.g., intent slots or item attributes) to interact with users [5, 28, 36]. They focus on accomplishing the recommendation task within as few turns as possible. They adopt the multi-armed bandit model [5, 31] or reinforcement learning [28] to find the optimal interaction strategy. However, methods that belong to this category mostly rely on pre-defined actions and templates to generate responses, which largely limit their usage in various scenarios. Another category of CRS studies aim to generate both accurate recommendations and human-like responses [10, 15, 37]. To achieve this, these works usually devise a recommendation module and a conversation module to implement the two functions, respectively. However, such a design raises the issue of semantic inconsistency, and it is essential to seamlessly integrate the two modules as a system. Existing works mostly either share the knowledge resources and their representations [4, 22], or design semantic alignment pre-training tasks [35] and regularization terms [38]. However, it is still difficult for the effective integration of the two modules due to their different architectures or techniques. For example, it has been pointed out that the generated responses from the conversation module do not always match the predicted items from the recommendation module [18]. Our work follows the latter category and adopts prompt learning based on pre-trained language models (PLM) to unify the recommendation and conversation subtasks. In this way, the two subtasks can be formulated in a unified manner with elaborately designed prompts.
随着对话系统 [3, 33] 的快速发展,会话推荐系统 (Conversational Recommender Systems, CRSs) 已成为一个研究热点,其目标是通过与用户的对话交互提供精准推荐 [5, 7, 28]。一类主要的 CRS 研究依赖于预定义动作 (如意图槽或物品属性) 与用户交互 [5, 28, 36],重点关注以尽可能少的对话轮次完成推荐任务,采用多臂老虎机模型 [5, 31] 或强化学习 [28] 来寻找最优交互策略。但这类方法大多依赖预定义动作和模板生成回复,极大限制了其应用场景的多样性。另一类 CRS 研究则致力于同时生成精准推荐和拟人化回复 [10, 15, 37],通常设计推荐模块和对话模块分别实现这两个功能。然而这种设计会引发语义不一致问题,关键在于如何将两个模块无缝整合为统一系统。现有工作主要通过共享知识资源及其表征 [4, 22],或设计语义对齐预训练任务 [35] 与正则化项 [38] 来实现整合。但由于模块架构或技术差异,两者仍难以有效融合,例如对话模块生成的回复与推荐模块预测的物品常出现不匹配现象 [18]。本研究属于第二类方向,采用基于预训练语言模型 (Pre-trained Language Model, PLM) 的提示学习 (prompt learning) 来统一推荐和对话子任务,通过精心设计的提示 (prompt) 实现两个子任务的统一建模。
2.2 Prompt Learning
2.2 提示学习 (Prompt Learning)
Recent years have witnessed the remarkable performance of PLMs on a variety of tasks [6, 14]. Most of PLMs are pre-trained with the objective of language modeling but are fine-tuned on downstream tasks with quite different objectives. To overcome the gap between pre-training and fine-tuning, prompt learning (a.k.a., prompttuning) has been proposed [9, 19], which relies on carefully designed prompts to reformulate the downstream tasks as the pre-training task. Early works mostly incorporate manually crafted discrete prompts to guide the PLM [2, 24]. Recently, a surge of works focus on automatically optimizing discrete prompts for specific tasks [8, 12] and achieving comparable performance with manual prompts. However, these methods still rely on generative models or complex rules to control the quality of prompts. In contrast, some works propose to use learnable continuous prompts that can be directly optimized [13, 17]. On top of this, several works devise prompt pre-training tasks [9] or knowledgeable prompts [11] to improve the quality of the continuous prompts. In this work, we reformulate both the recommendation and conversation subtasks as the pre-training task of a PLM by prompt learning. In addition, to provide the PLM with task-related knowledge of CRS, we enhance the prompts with the information from an external KG and perform semantic fusion for prompt learning.
近年来,预训练语言模型(PLM)在各种任务中展现出卓越性能[6,14]。大多数PLM以语言建模为目标进行预训练,但在目标任务微调时却采用差异显著的优化目标。为弥合预训练与微调之间的鸿沟,研究者提出了提示学习(prompt learning,亦称prompt tuning)[9,19],该方法通过精心设计的提示(prompt)将下游任务重构为预训练任务形式。早期研究主要采用人工设计的离散提示来引导PLM[2,24]。近期大量工作聚焦于针对特定任务自动优化离散提示[8,12],其性能已可比拟人工提示。然而这些方法仍依赖生成式模型或复杂规则来控制提示质量。相比之下,部分研究提出直接优化可学习的连续提示[13,17]。在此基础上,一些工作设计了提示预训练任务[9]或知识增强提示[11]来提升连续提示质量。本文通过提示学习将推荐与会话子任务统一重构为PLM的预训练任务。此外,为向PLM注入对话推荐系统(CRS)相关领域知识,我们利用外部知识图谱(KG)信息增强提示表示,并通过语义融合优化提示学习。
3 PROBLEM STATEMENT
3 问题陈述
Conversational recommend er systems (CRSs) aim to conduct item recommendation through multi-turn natural language conversations. At each turn, the system either makes recommendations or asks clarification questions, based on the currently learned user preference. Such a process ends until the user accepts the recommended items or leaves. Typically, a CRS consists of two modules, i.e., the recommend er module and the conversation module, which are responsible for the recommendation and the response generation tasks, respectively. These two modules should be seamlessly integrated to generate consistent results, in order to fulfill the convers at ional recommendation task.
对话推荐系统 (CRS) 旨在通过多轮自然语言对话进行物品推荐。在每一轮交互中,系统会根据当前学习的用户偏好,要么进行推荐,要么提出澄清问题。该过程将持续到用户接受推荐物品或离开为止。典型的CRS包含两个模块:推荐模块和对话模块,分别负责推荐任务和回复生成任务。这两个模块需要无缝集成以生成一致的结果,从而完成对话式推荐任务。
Formally, let $u$ denote a user, 𝑖 denote an item from the item set $\boldsymbol{\underbar{\boldsymbol{\jmath}}}$ , and $\boldsymbol{w}$ denote a word from the vocabulary $\mathcal{V}$ . A conversation is denoted as $C={s_{t}}{t=1}^{n}$ , where $s_{t}$ denotes the utterance at the $t$ -th turn and each utterance $s_{t}={w_{j}}{j=1}^{m}$ consists of a sequence of words from the vocabulary $_\mathcal{V}$ .
形式上,设 $u$ 表示用户,$i$ 表示物品集 $\boldsymbol{\underbar{\boldsymbol{\jmath}}}$ 中的物品,$\boldsymbol{w}$ 表示词汇表 $\mathcal{V}$ 中的单词。对话表示为 $C={s_{t}}{t=1}^{n}$,其中 $s_{t}$ 表示第 $t$ 轮的语句,每个语句 $s_{t}={w_{j}}{j=1}^{m}$ 由词汇表 $_\mathcal{V}$ 中的单词序列构成。
With the above definitions, the task of conversational recommendation is defined as follows. At the $t$ -th turn, given the dialogue history $C={s_{j}}{j=1}^{t-1}$ and the item set $\boldsymbol{\mathit{I}}$ , the system should (1) select a set of candidate items $\mathcal{T}{t}$ from the entire item set to recommend, and (2) generate the response $R=s_{t}$ that includes the items in $\mathcal{T}{t}$ . Note that $\mathcal{T}_{t}$ might be empty, when there is no need for recommendation.
基于上述定义,对话式推荐任务定义如下:在第$t$轮对话时,给定对话历史$C={s_{j}}{j=1}^{t-1}$和物品集合$\boldsymbol{\mathit{I}}$,系统需要:(1) 从整个物品集合中筛选候选推荐项$\mathcal{T}{t}$;(2) 生成包含$\mathcal{T}{t}$中物品的响应$R=s_{t}$。需注意当无需推荐时,$\mathcal{T}_{t}$可能为空集。
4APPROACH
4 方法
In this section, we present a unified CRS approach with knowledgeenhanced prompt learning based on a PLM, namely UniCRS. We first give an overview of our approach, then discuss how to fuse semantics from words and entities as part of the prompts, and finally present the knowledge-enhanced prompting approach to the CRS task. The overall architecture of our proposed model is presented in Figure 1.
在本节中,我们提出了一种基于预训练语言模型(PLM)、融合知识增强提示学习的统一对话推荐系统(CRS)方法——UniCRS。首先概述方法框架,接着阐述如何融合词语与实体语义作为提示模板组成部分,最后介绍面向CRS任务的知识增强提示学习方法。我们提出的模型整体架构如图1所示。
4.1 Overview of the Approach
4.1 方法概述
Previous studies on CRS [4, 15, 35] usually develop specific modules for the recommendation and conversation subtasks respectively, and they need to connect the two modules in order to fulfill the task goal of CRS. Different from existing CRS methods, we aim to develop a unified approach with prompt learning based on PLM.
以往关于CRS的研究[4,15,35]通常分别为推荐和对话子任务开发特定模块,并需要连接这两个模块以实现CRS的任务目标。与现有CRS方法不同,我们旨在基于PLM开发一种采用提示学习(prompt learning)的统一方法。
The Base PLM. In our approach, we take DialoGPT [33] as our base PLM. DialoGPT adopts a Transformer-based auto regressive architecture and is pre-trained on a large-scale dialogue corpus extracted from Reddit. It has been shown that DialoGPT can generate coherent and informative responses, making it a suitable base model for the CRS task [18, 29]. Let $f(\cdot\mid\Theta_{p l m})$ denote the base PLM parameterized by $\Theta_{p l m}$ , taking a token sequence as input and producing contextual i zed representations for each token. Unless otherwise specified, we will use the representation of the last token from DialoGPT for subsequent prediction or generation tasks.
基础PLM。在我们的方法中,采用DialoGPT [33]作为基础PLM。DialoGPT采用基于Transformer的自回归架构,并在从Reddit提取的大规模对话语料库上进行预训练。研究表明,DialoGPT能够生成连贯且信息丰富的响应,使其成为CRS任务的合适基础模型 [18, 29]。设 $f(\cdot\mid\Theta_{p l m})$ 表示由 $\Theta_{p l m}$ 参数化的基础PLM,它以token序列作为输入,并为每个token生成上下文表示。除非另有说明,我们将使用DialoGPT最后一个token的表示进行后续预测或生成任务。
A Unified Prompt-Based Approach to CRS. Given the dialogue history ${s_{j}}{j=1}^{t-1}$ at the $t$ -th turn, we concatenate each utterance into a text sequence 𝐶 = {𝑤𝑘 }𝑘=𝑊1 . The basic idea is to encode the dialogue history $C$ , obtain its contextual i zed representations, and solve the recommendation and conversation subtasks via generation (i.e., generating either the recommended items or the response utterance), with the base PLM. In this way, the two subtasks can be fulfilled in a unified approach. However, since the base PLM is fixed, it is difficult to achieve satisfactory performance compared with fine-tuning due to lack of task adaptation. Therefore, we adopt the prompting apborately designed or learned prompt tokens, denoted by ${p_{k}}{k=1}^{n_{P}}$ $\overset{\cdot}{n}\overset{\cdot}{P}$ is the number of prompt tokens). In practice, prompt tokens can be either explicit tokens or latent vectors. It has been shown that prompting is an effective paradigm to leverage the knowledge of PLMs to solve various tasks without fine-tuning [2, 8].
基于提示的统一CRS方法。给定第$t$轮对话历史${s_{j}}{j=1}^{t-1}$,我们将每个话语连接成文本序列𝐶 = {𝑤𝑘 }𝑘=𝑊1。基本思路是编码对话历史$C$,获取其上下文表征,并通过生成(即生成推荐项或响应话语)利用基础PLM (预训练语言模型) 解决推荐和对话子任务。通过这种方式,两个子任务能以统一方法完成。但由于基础PLM固定,缺乏任务适配性,其性能往往难以达到微调效果。因此我们采用提示方法,通过精心设计或学习的提示token(记为${p_{k}}{k=1}^{n_{P}}$,其中$\overset{\cdot}{n}\overset{\cdot}{P}$为提示token数量)来增强模型。实际应用中,提示token既可以是显式token也可以是潜在向量。研究表明,提示是一种无需微调即可利用PLM知识解决各类任务的有效范式[2, 8]。
Prompt-augmented Dialogue Context. By incorporating the prompts, the original dialogue history $C$ can be extended to a longer sequence (called context sequence), denoted as 𝐶:
提示增强的对话上下文。通过整合提示词,原始对话历史 $C$ 可扩展为更长的序列(称为上下文序列),记作 𝐶:
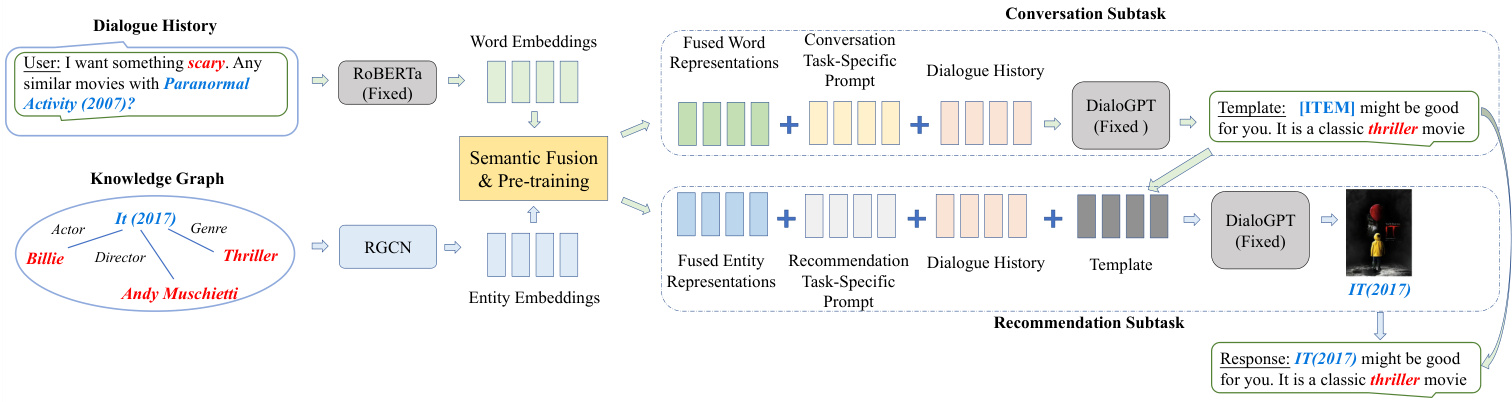
Figure 1: The overview of the proposed framework UniCRS. Blocks in grey indicate that their parameters are frozen, while other parameters are tunable. We first perform pre-training to fuse semantics from both words and entities, then prompt the PLM to generate the response template and use the template as part of the prompt for recommendation. Finally, the recommended items are filled into the template as a complete response.
图 1: 提出的UniCRS框架概述。灰色模块表示其参数被冻结,其余参数可调。我们首先进行预训练以融合单词和实体的语义,然后提示PLM生成响应模板,并将该模板作为推荐提示的一部分。最后,将推荐项填入模板形成完整响应。
$$
\widetilde{C}\to p_{1},\dots,p_{n_{P}},w_{1}\cdot\cdot\cdot w_{n_{W}}.
$$
$$
\widetilde{C}\to p_{1},\dots,p_{n_{P}},w_{1}\cdot\cdot\cdot w_{n_{W}}.
$$
As before, we utilize the base PLM to obtain contextual i zed representations of the context sequence for solving the recommendation and conversation subtasks. In order to better adapt to the task characteristics, we can construct and learn different prompts, and obtain corresponding context sequences denoted as $\widetilde{C}{r e c}$ for recommendation and $\widetilde{C}_{c o n}$ for conversation.
与之前一样,我们利用基础PLM获取上下文序列的语境化表征,以解决推荐和对话子任务。为了更好地适应任务特性,我们可以构建并学习不同的提示,得到对应的上下文序列,分别表示为$\widetilde{C}{rec}$(推荐)和$\widetilde{C}_{con}$(对话)。
To implement such a unified approach, we identify two major problems to solve: (1) how to fuse conversational semantics and related knowledge semantics in order to adapt the base PLM for CRS (Section 4.2), and (2) how to design and learn suitable prompts for the recommendation and conversation subtasks (Section 4.3). In what follows, we will introduce the two parts in detail.
为实现这一统一方法,我们明确了两个待解决的核心问题:(1) 如何融合对话语义与相关知识语义,使基础预训练语言模型(PLM)适配对话推荐系统(CRS)(第4.2节);(2) 如何为推荐和对话子任务设计并学习合适的提示(第4.3节)。下文将详细阐述这两个部分。
4.2 Semantic Fusion for Prompt Learning
4.2 提示学习的语义融合
Since DialoGPT is pre-trained on a general dialogue corpus, it lacks the specific capacity for the CRS task and cannot be directly used. Following previous studies [4, 35], we incorporate KGs as the taskspecific knowledge resources, since it involves useful knowledge about entities and items mentioned in the dialogue. However, it has been found that there is a large semantic gap between the semantic spaces of dialogues and KGs [35, 38]. We need to first fuse the two semantic spaces for effective knowledge alignment and enrichment. Specially, the purpose of this step is to fuse the token and entity embeddings from different encoders.
由于DialoGPT是在通用对话语料库上预训练的,它缺乏针对CRS任务的特有能力,无法直接使用。遵循先前研究[4, 35],我们将知识图谱(KG)作为任务特定的知识资源,因为它包含对话中提到的实体和项目的有用知识。然而,研究发现对话与知识图谱的语义空间之间存在较大语义鸿沟[35, 38]。我们需要先融合这两个语义空间以实现有效的知识对齐和丰富。具体而言,此步骤的目的是融合来自不同编码器的token和实体嵌入。
Encoding Word Tokens and KG Entities. Given a dialogue history $C$ , we first separately encode the dialogue words and KG entities that appear in $C$ into word embeddings and entity embeddings. To complement our base PLM DialoGPT (a unidirectional decoder), we employ another fixed PLM RoBERTa [20] (a bi-directional encoder) to derive the word embeddings. The contextual i zed token representations derived from the fixed encoder RoBERTa are concatenated into a word embedding matrix, i.e., $\mathbf T=[h_{1}^{T};\dots;h_{n_{W}}^{T}]$ For entity embeddings, following previous works [4, 35], we first perform entity linking based on an external KG DBpedia [1], and then obtain the corresponding entity embeddings via a relational graph neural networks (RGCN) [25], which can model the relational semantics through information propagation and aggregation over the KG. Similarly, the derived entity embedding matrix is denoted as $\mathbf{E}=[h_{1}^{E};\dots;{\dot{h}}{n_{E}}^{E}]$ , where $n_{E}$ is the number of mentioned entities in the dialogue history.
编码词Token与知识图谱实体。给定对话历史$C$,我们首先分别将$C$中出现的对话词汇和知识图谱实体编码为词嵌入和实体嵌入。为补充基础单向解码器PLM DialoGPT,我们采用另一个固定参数的双向编码器PLM RoBERTa [20]生成词嵌入。从固定编码器RoBERTa获取的上下文Token表征被拼接为词嵌入矩阵$\mathbf{T}=[h_{1}^{T};\dots;h_{n_{W}}^{T}]$。对于实体嵌入,遵循先前研究[4,35],我们首先基于外部知识图谱DBpedia [1]进行实体链接,随后通过关系图神经网络(RGCN) [25]获取对应实体嵌入,该网络能通过知识图谱上的信息传播与聚合建模关系语义。类似地,生成的实体嵌入矩阵表示为$\mathbf{E}=[h_{1}^{E};\dots;{\dot{h}}{n_{E}}^{E}]$,其中$n_{E}$为对话历史中提及的实体数量。
Word-Entity Semantic Fusion. In order to bridge the semantic gap between words and entities, we use a cross interaction mechanism to associate the two kinds of semantic representations via a bilinear transformation:
词-实体语义融合。为了弥合词语与实体之间的语义鸿沟,我们采用交叉交互机制,通过双线性变换将两种语义表征进行关联:
$$
\begin{array}{r l}&{\mathbf{A}=\mathbf{T}^{\top}\mathbf{W}\mathbf{E},}\ &{\widetilde{\mathbf{T}}=\mathbf{T}+\mathbf{E}\mathbf{A},}\ &{\widetilde{\mathbf{E}}=\mathbf{E}+\mathbf{T}\mathbf{A}^{\top},}\end{array}
$$
$$
\begin{array}{r l}&{\mathbf{A}=\mathbf{T}^{\top}\mathbf{W}\mathbf{E},}\ &{\widetilde{\mathbf{T}}=\mathbf{T}+\mathbf{E}\mathbf{A},}\ &{\widetilde{\mathbf{E}}=\mathbf{E}+\mathbf{T}\mathbf{A}^{\top},}\end{array}
$$
where A is the affinity matrix between the two representations, W is the transformation matrix, $\widetilde{\sf T}$ is the fused word representations, and $\widetilde{\mathbf E}$ is the fused entity repr e sent at ions. Here we use the bilinear transformation between $\boldsymbol{\mathrm{T~}}$ and E for simplicity, and leave the further exploration of complex interaction mechanisms for future work.
其中A表示两种表征间的亲和矩阵,W是变换矩阵,$\widetilde{\sf T}$为融合后的词表征,$\widetilde{\mathbf E}$为融合后的实体表征。此处为简化计算,我们采用$\boldsymbol{\mathrm{T~}}$与E之间的双线性变换,更复杂的交互机制留待未来研究。
Pre-training the Fusion Module. After semantic fusion, we can establish the semantic association between words and entities. However, such a module involves additional learnable parameters, denoted as $\Theta_{f u s e}$ . To better optimize the parameters of the fusion module, we propose a prompt-based pre-training approach that leverages the self-supervision signals from the dialogues. Specifically, we prepend the fused entity representations E (Eq. 4) and append the response to the dialogue context, namely $\widetilde{C}{p r e}=[\widetilde{\mathbf{E}};C;\bar{R]}$ , where we use the bold font to denote the latent vectors (E) and the plain font to denote the explicit tokens $(C,R)$ . For this pre-training task, we simply utilize the prompt-augmented context sequence $\widetilde{C}_{p r e}$ to predict the entities appearing in the response. The prediction probability of the entity $e$ is formulated as:
预训练融合模块。经过语义融合后,我们可以建立词语与实体间的语义关联。但该模块涉及额外可学习参数 $\Theta_{f u s e}$ 。为更好地优化融合模块参数,我们提出基于提示词(prompt)的预训练方法,利用对话中的自监督信号。具体而言,我们将融合后的实体表示E(式4)前置,并将响应追加至对话上下文,即 $\widetilde{C}{p r e}=[\widetilde{\mathbf{E}};C;\bar{R]}$ ,其中粗体表示潜在向量(E),普通字体表示显式token $(C,R)$ 。在此预训练任务中,我们直接使用提示词增强的上下文序列 $\widetilde{C}_{p r e}$ 来预测响应中出现的实体。实体 $e$ 的预测概率公式为:
$$
\operatorname*{Pr}(e\mid\widetilde{C}{p r e})=\operatorname{Softmax}(h_{u}\cdot h_{e}),
$$
$$
\operatorname*{Pr}(e\mid\widetilde{C}{p r e})=\operatorname{Softmax}(h_{u}\cdot h_{e}),
$$
where $h_{u}=\mathrm{Pooling}[f(\widetilde{C}{p r e}\mid\Theta_{p l m};\Theta_{f u s e})]$ is the learned representation of the context by pooling the contextual i zed representations of all the tokens in $\bar{C}{p r e}$ , and $\pmb{h}{e}$ is the fused entity represen- tation for the entity $e$ . N ote that only the parameters of the fusion module $\Theta_{f u s e}$ are required to optimize, while the parameters of the base PLM $\Theta_{p l m}$ are fixed. We adopt the cross-entropy loss for the pre-training task.
其中 $h_{u}=\mathrm{Pooling}[f(\widetilde{C}{p r e}\mid\Theta_{p l m};\Theta_{f u s e})]$ 是通过对 $\bar{C}{p r e}$ 中所有token的上下文表征进行池化学习到的上下文表示,$\pmb{h}{e}$ 是实体 $e$ 的融合实体表征。注意仅需优化融合模块参数 $\Theta_{f u s e}$,而基础PLM的参数 $\Theta_{p l m}$ 保持固定。我们采用交叉熵损失作为预训练任务目标。
After semantic fusion, we obtain the fused knowledge representations for words and entities from the dialogue history, namely T (Eq. 3) and $\widetilde{\mathbf E}$ (Eq. 4), respectively. These representations are subs equently us ed as part of prompts, as shown in Section 4.3.
经过语义融合后,我们分别从对话历史中获得了词语和实体的融合知识表示,即 T (式 3) 和 $\widetilde{\mathbf E}$ (式 4)。这些表示随后被用作提示(prompt)的一部分,如第4.3节所示。
4.3 Subtask-specific Prompt Design
4.3 子任务特定提示设计
Though the base PLM is fixed without fine-tuning, we can design specific prompts to adapt it to different subtasks of CRS. For each subtask (either recommendation or conversation), the major design of prompting consists of three parts, namely the dialogue history, subtask-specific soft tokens, and fused knowledge representations. For recommendation, we further incorporate the generated response templates as additional prompt tokens. Next, we describe the specific prompting designs for the two subtasks in detail.
虽然基础预训练语言模型(PLM)未经微调是固定的,但我们可以设计特定提示(prompt)使其适配对话推荐系统(CRS)的各个子任务。针对每个子任务(推荐或对话),提示设计主要包含三部分:对话历史、子任务专属软token(soft tokens)以及融合知识表征(fused knowledge representations)。对于推荐任务,我们还会将生成的响应模板作为额外提示token加入。接下来详细阐述两个子任务的提示设计方案。
4.3.1 Prompt for Response Generation. The subtask of response generation aims to generate informative utterances in order to clarify user preferences or reply to users’ utterances. The prompting design mainly enhances the textual semantics for better dialogue understanding and response generation.
4.3.1 回复生成的提示。回复生成子任务旨在生成信息性话语,以澄清用户偏好或回应用户话语。提示设计主要通过增强文本语义来优化对话理解和回复生成。
The Prompt Design. The prompt for response generation consists of the original dialogue history (in the form of word tokens $C$ ), generation-specific soft tokens (in the form of latent vectors $\mathbf{P}_{g e n}$ ) and fused textual context (in the form of latent vectors $\widetilde{\mathbf{T}},$ ), which is formally denoted as:
提示设计。用于生成回复的提示由原始对话历史(以词元 $C$ 形式表示)、生成专用软标记(以潜在向量 $\mathbf{P}_{g e n}$ 形式表示)和融合文本上下文(以潜在向量 $\widetilde{\mathbf{T}}$ 形式表示)组成,其正式表达式为:
$$
\widetilde{C}{g e n}\rightarrow[\widetilde{\textbf{T}};\mathbf{P}_{g e n};C],
$$
$$
\widetilde{C}{g e n}\rightarrow[\widetilde{\textbf{T}};\mathbf{P}_{g e n};C],
$$
where we use the bold and plain fonts to denote soft and hard token sequences, respectively. In this design, the subtask-specific prompts $\mathbf{P}_{g e n}$ instruct the PLM by the signal from the generation task, the KG-enhanced textual representations T (Eq. 3), and the original dialogue history $C$ .
我们使用粗体和普通字体分别表示软token序列和硬token序列。在该设计中,特定子任务提示 $\mathbf{P}_{g e n}$ 通过生成任务的信号、知识图谱增强的文本表示 T (式3) 以及原始对话历史 $C$ 来指导PLM。
Prompt Learning. In the above prompting design, the only tunable parameters are the fused textual representations T that have been pre-trained, and generation-specific soft token s $\mathbf{P}{g e n}$ . They are denoted as $\Theta_{g e n}$ . We use the prompt-augmented context $\widetilde{C}{g e n}$ to derive the prediction loss for learning $\Theta_{g e n}$ , which is formal lye given as:
提示学习 (Prompt Learning)。在上述提示设计中,唯一可调参数是经过预训练的融合文本表示 T 和生成专用软token $\mathbf{P}{g e n}$,它们被记为 $\Theta_{g e n}$。我们使用提示增强的上下文 $\widetilde{C}{g e n}$ 来推导预测损失以学习 $\Theta_{g e n}$,其形式化表达式为:
$$
\begin{array}{l}{{{\displaystyle{\cal L}{g e n}(\Theta_{g e n})=-\frac{1}{N}\sum_{j=1}^{N}\log\operatorname*{Pr}(R_{j}\mid\widetilde{C}{g e n}^{(j)};\Theta_{g e n})}}}\ {{~=-\displaystyle{\frac{1}{N}\sum_{i=1}^{N}\sum_{j=1}^{l_{i}}\log\operatorname*{Pr}(w_{i,j}\mid\widetilde{C}{g e n}^{(j)};\Theta_{g e n};w_{<j})},}}\end{array}
$$
$$
\begin{array}{l}{{{\displaystyle{\cal L}{g e n}(\Theta_{g e n})=-\frac{1}{N}\sum_{j=1}^{N}\log\operatorname*{Pr}(R_{j}\mid\widetilde{C}{g e n}^{(j)};\Theta_{g e n})}}}\ {{~=-\displaystyle{\frac{1}{N}\sum_{i=1}^{N}\sum_{j=1}^{l_{i}}\log\operatorname*{Pr}(w_{i,j}\mid\widetilde{C}{g e n}^{(j)};\Theta_{g e n};w_{<j})},}}\end{array}
$$
where $N$ is the number of training instances (a pair of the context and target utterances), and $l_{i}$ is the length of the $i$ -th target utterance, and $w_{<j}$ denotes the words proceeding the $j$ -th position.
其中 $N$ 是训练实例的数量(上下文和目标话语的对),$l_{i}$ 是第 $i$ 个目标话语的长度,$w_{<j}$ 表示第 $j$ 个位置之前的单词。
Response Template Generation. Besides sharing the base PLM, we find that it is also important to share intermediate results of different subtasks to achieve more consistent final results. For example, given the generated response of the conversation task, the PLM might be able to predict more relevant recommendations according to such extra contextual information. Based on this intuition, we propose to include response templates as part of the prompt for the recommendation subtask. Specifically, we add a special token [ITEM] into the vocabulary $_\mathcal{V}$ of the base PLM and replace all the items that appear in the response with the [ITEM] token. At each time step, the PLM generates either the special token [ITEM] or a general token from the original vocabulary. All the slots will be filled after the recommended items are generated.
响应模板生成。除了共享基础PLM外,我们发现共享不同子任务的中间结果对实现更一致的最终结果也很重要。例如,根据对话任务生成的响应,PLM可能能够利用这些额外的上下文信息预测更相关的推荐。基于这一直觉,我们建议将响应模板作为推荐子任务提示的一部分。具体来说,我们在基础PLM的词表$_\mathcal{V}$中添加一个特殊token [ITEM],并将响应中出现的所有物品替换为[ITEM] token。在每个时间步,PLM会生成特殊token [ITEM]或原始词表中的通用token。所有空缺将在推荐物品生成后被填充。
4.3.2 Prompt for Item Recommendation. The subtask of recommendation aims to predict items that a user might be interested in. The prompting design mainly enhances the user preference semantics, in order to predict more satisfactory recommendations.
4.3.2 物品推荐提示词设计
推荐子任务旨在预测用户可能感兴趣的物品。提示设计主要通过增强用户偏好语义,以预测更符合需求的推荐结果。
The Prompt Design. The item recommendation prompts consist of the original dialogue history $C$ (in the form of word tokens), recommendation-specific soft tokens $\mathbf{P}_{r e c}$ (in the form of latent vectors), fused entity context $\widetilde{\mathbf E}$ (in the form of latent vectors), and the response template $S$ (in the form of word tokens), formally described as:
提示设计。物品推荐提示由原始对话历史 $C$(以词token形式)、推荐专用软token $\mathbf{P}_{r e c}$(以潜在向量形式)、融合实体上下文 $\widetilde{\mathbf E}$(以潜在向量形式)以及响应模板 $S$(以词token形式)组成,其形式化描述为:
$$
\widetilde{C}{r e c}\rightarrow[\widetilde{\bf E};{\bf P}_{r e c};C;S],
$$
$$
\widetilde{C}{r e c}\rightarrow[\widetilde{\bf E};{\bf P}_{r e c};C;S],
$$
where the subtask-specific prompts $\mathbf{P}_{r e c}$ instruct the PLM by the signal from the recommendation task, the KG-enhanced entity representations $\widetilde{\mathbf E}$ (Eq. 4), the original dialogue history $C$ , and the response templa te $S$ .
其中特定子任务提示 $\mathbf{P}_{r e c}$ 通过推荐任务的信号指导PLM,知识图谱增强的实体表示 $\widetilde{\mathbf E}$ (式4)、原始对话历史 $C$ 以及响应模板 $S$。
A key difference between the prompts of the two subtasks is that we utilize entity representations for recommendation, and word representations for generation. This is because their prediction targets are items and sentences, respectively. Besides, we have a special design for recommendation, where we include the response template as part of the prompts. This can enhance the subtask connections and alleviate the risk of semantic inconsistency.
两个子任务提示语的关键区别在于:推荐任务使用实体表征 (entity representations),生成任务采用词语表征 (word representations)。这是因为它们的预测目标分别是物品和句子。此外,我们对推荐任务进行了特殊设计——将回复模板作为提示语的一部分,这能增强子任务关联性并降低语义不一致风险。
Prompt Learning. In the above prompting design, the only tunable parameters are the fused entity representations E that have been pre-trained, and recommendation-specific soft t okens $\mathbf{P}{g e n}$ . They are denoted as $\Theta_{r e c}$ . We utilize the prompt-augmented context $\widetilde{C}{r e c}$ to derive the prediction loss for learning $\Theta_{r e c}$ , which is form ally given as:
提示学习 (Prompt Learning)。在上述提示设计中,唯一可调参数是经过预训练的融合实体表征 E 和推荐专用软token $\mathbf{P}{g e n}$。它们被记为 $\Theta_{r e c}$。我们利用提示增强上下文 $\widetilde{C}{r e c}$ 来推导预测损失以学习 $\Theta_{r e c}$,其形式化表达式为:
$$
L_{r e c}(\Theta_{r e c})=-\sum_{j=1}^{N}\sum_{i=1}^{M}\big[y_{j,i}\cdot\log\operatorname*{Pr}{j}(i)+(1-y_{j,i})\cdot\log(1-\operatorname*{Pr}_{j}(i))\big],
$$
$$
L_{r e c}(\Theta_{r e c})=-\sum_{j=1}^{N}\sum_{i=1}^{M}\big[y_{j,i}\cdot\log\operatorname*{Pr}{j}(i)+(1-y_{j,i})\cdot\log(1-\operatorname*{Pr}_{j}(i))\big],
$$
where $N$ is the number of training instances (a pair of the context and a target item), $M$ is the total number of items, $y_{j,i}$ denotes a binary ground-truth label which is equal to 1 when item 𝑖 is the correct label for the $j$ -th training instance, and $\mathrm{Pr}{j}(i)$ is an abbreviation of $\mathrm{Pr}(i\mid\widetilde{C}{r e c}^{(j)};\Theta_{r e c})$ , which is computed following a similar way in Eq. 5 by efirst pooling contextual i zed representations and then computing the softmax score.
其中 $N$ 表示训练实例数量(上下文与目标物品对),$M$ 表示物品总数,$y_{j,i}$ 为二元真实标签,当物品 𝑖 是第 $j$ 个训练实例的正确标签时取值为 1,而 $\mathrm{Pr}{j}(i)$ 是 $\mathrm{Pr}(i\mid\widetilde{C}{r e c}^{(j)};\Theta_{r e c})$ 的缩写,其计算方式与公式 5 类似,先对上下文表征进行池化操作,再计算 softmax 分数。
Table 2: Statistics of the datasets after preprocessing.
表 2: 预处理后数据集的统计信息。
| Dataset | #Dialogs | #Utterances | #Items |
|---|---|---|---|
| INSPIRED | 1,001 | 35,811 | 1,783 |
| ReDial | 10,006 | 182,150 | 51,699 |
4.4 Parameter Learning
4.4 参数学习
The parameters of our model consist of four groups, namely the base PLM, the semantic fusion module, and the subtask-specific soft tokens for recommendation and conversation. They are denoted as $\Theta_{p l m},\Theta_{f u s e},\Theta_{r e c}$ and $\Theta_{g e n}$ , respectively.
我们模型的参数由四部分组成,分别是基础PLM、语义融合模块,以及推荐和对话两个子任务专用的软Token (soft tokens) ,分别记为 $\Theta_{p l m}$ 、 $\Theta_{f u s e}$ 、 $\Theta_{r e c}$ 和 $\Theta_{g e n}$ 。
During the overall training process, the parameters of the base PLM $\Theta_{p l m}$ are always fixed, and we only optimize the rest parameters. First, we pre-train the parameters of the semantic fusion module $\Theta_{f u s e}$ . Given the dialogue history and KG, we encode the dialogue tokens with a fixed text encoder RoBERTa and the KG entities with a learnable graph encoder RGCN. Then, we perform semantic fusion to obtain the fused word representations $\widetilde{\mathsf{T}}$ using Eq. 3 and entity representations $\widetilde{\mathbf E}$ using Eq. 4. After that , ewe optimize $\Theta_{f u s e}$ based on the self-s upervised entity prediction task. Next, we randomly initialize the parameters of the subtask-specific soft tokens $\Theta_{r e c}$ and $\Theta_{g e n}$ , and compose the response generation prompts using Eq. 6. We utilize the supervised signal from the conversation task to learn $\Theta_{g e n}$ using Eq. 7 and generate the response template. Finally, we compose the item recommendation prompts using Eq. 8 and leverage the supervised signal from the recommendation task to learn $\Theta_{r e c}$ using Eq. 9.
在整个训练过程中,基础PLM (Pre-trained Language Model) 的参数 $\Theta_{p l m}$ 始终保持固定,我们仅优化其余参数。首先,我们对语义融合模块的参数 $\Theta_{f u s e}$ 进行预训练。给定对话历史和知识图谱(KG),我们使用固定的文本编码器RoBERTa编码对话token,并通过可学习的图编码器RGCN编码KG实体。随后,通过公式3进行语义融合得到融合词表征 $\widetilde{\mathsf{T}}$,通过公式4获得实体表征 $\widetilde{\mathbf E}$。接着基于自监督实体预测任务优化 $\Theta_{f u s e}$。然后随机初始化子任务专用软token参数 $\Theta_{r e c}$ 和 $\Theta_{g e n}$,使用公式6构建响应生成提示。利用对话任务的监督信号,通过公式7学习 $\Theta_{g e n}$ 并生成响应模板。最后通过公式8构建项目推荐提示,借助推荐任务的监督信号,通过公式9学习 $\Theta_{r e c}$。
5 EXPERIMENT
5 实验
In this section, we first set up the experiments, and then report the results and give detailed analysis.
在本节中,我们首先设置实验,然后报告结果并进行详细分析。
5.1 Experimental Setup
5.1 实验设置
Datasets. To evaluate the performance of our model, we conduct experiments on the ReDial [15] and INSPIRED [10] datasets. The ReDial dataset is an English CRS dataset about movie recommendations, and is constructed through crowd-sourcing workers on Amazon Mechanical Turk (AMT). Similar to ReDial, the INSPIRED dataset is also an English CRS dataset about movie recommendations, but with a smaller size. These two datasets are widely used for evaluating CRS models. The statistics of both datasets are summarized in Table 2.
数据集。为了评估我们模型的性能,我们在ReDial [15] 和INSPIRED [10] 数据集上进行了实验。ReDial数据集是一个关于电影推荐的英文对话推荐系统 (CRS) 数据集,由Amazon Mechanical Turk (AMT) 上的众包工作者构建。与ReDial类似,INSPIRED数据集也是一个关于电影推荐的英文CRS数据集,但规模较小。这两个数据集被广泛用于评估CRS模型。两个数据集的统计信息总结在表 2 中。
Baselines. For CRS, we consider two major subtasks for evaluation, namely recommendation and conversation. For comparison, we select several representative methods (including both CRS models and adapted PLMs) tailored to each subtask.
基线方法。对于CRS,我们主要评估两个子任务:推荐和对话。为便于比较,我们为每个子任务选取了若干代表性方法(包括CRS模型和适配的PLMs)。
• ReDial [15]: It is proposed along with the ReDial dataset, which incorporates a conversation module based on HRED [27] and a recommendation module based on auto-encoder [26].
• ReDial [15]: 该模型与ReDial数据集一同提出,包含基于HRED [27]的对话模块和基于自动编码器 (auto-encoder) [26]的推荐模块。
• KBRD [4]: It utilizes an external KG to enhance the semantics of entities mentioned in the dialogue history, and adopts a selfattention based recommendation module and a Transformer-based conversation module.
• KBRD [4]: 该方法利用外部知识图谱(KG)增强对话历史中提及实体的语义,采用基于自注意力(self-attention)的推荐模块和基于Transformer的对话模块。
• KGSF [35]: It incorporates two KGs to enhance the semantic representations of words and entities, and utilizes the Mutual Information Maximization method to align the semantic spaces of the two KGs.
• KGSF [35]: 该方法整合了两个知识图谱 (KG) 来增强词语和实体的语义表示,并利用互信息最大化方法对齐两个知识图谱的语义空间。
• GPT-2 [23]: It is an auto-regressive PLM. We concatenate the historical utterances of a conversation as the input, and take the generated text as the response and the representation of the last token for recommendation.
• GPT-2 [23]: 它是一个自回归式预训练语言模型(PLM)。我们将对话历史语句拼接作为输入,生成文本作为回复,并取最后一个token的表征用于推荐。
• DialoGPT [33]: It is an auto-regressive model pre-trained on a large-scale dialogue corpus. Similar to GPT-2, we also adopt the generated text and the last token representation for the conversation and recommendation tasks, respectively.
• DialoGPT [33]: 这是一个基于大规模对话语料预训练的自回归模型。与GPT-2类似,我们同样采用生成文本和最后一个token表征分别处理对话任务和推荐任务。
• BERT [6]: It is pre-trained via the masked language model task on a large-scale general corpus. We utilize the representation of the 𝐶𝐿𝑆 token for recommendation.
• BERT [6]: 它通过在大规模通用语料库上进行掩码语言模型任务进行预训练。我们利用𝐶𝐿𝑆 token的表示进行推荐。
• BART [14]: It is a seq2seq model pre-trained with the denoising auto-encoding task on a large-scale general corpus. We also adopt the generated text and the last token representation for the conversation and recommendation tasks, respectively.
• BART [14]: 这是一个在大规模通用语料库上通过去噪自编码任务预训练的序列到序列模型。我们分别采用生成文本和最后一个token表示来完成对话和推荐任务。
Among these baselines, ReDial [15], KBRD [4] and KGSF [35] are conversational recommendation methods, where the latter two incorporate external knowledge graphs; BERT [6], GPT-2 [23], BART [14], and DialoGPT [33] are pre-trained language models, where BERT, GPT-2 and BART are pre-trained on a general corpus, and DialoGPT is pre-trained on a dialogue corpus.
在这些基线方法中,ReDial [15]、KBRD [4] 和 KGSF [35] 是对话式推荐方法,其中后两种方法融合了外部知识图谱;BERT [6]、GPT-2 [23]、BART [14] 和 DialoGPT [33] 是预训练语言模型,其中 BERT、GPT-2 和 BART 基于通用语料库预训练,而 DialoGPT 基于对话语料库预训练。
Evaluation Metrics. Following previous CRS works [15, 35], we adopt different metrics to evaluate the recommendation and conversation task separately. For the recommendation task, following [4, 35], we use Recall@𝑘 $(k{=}1,10,50)$ for evaluation. For the conversation task, following [4, 35], we adopt Distinct $n$ $(n{=}2,3,4)$ at the word level to evaluate the diversity of the generated responses. Besides, following KGSF [35], we invite three annotators to score the generated responses of our model and baselines from two aspects, namely Fluency and Informative ness. The range of scores is 0 to 2. For all the above metrics, we calculate and report the average scores on all test examples.
评估指标。遵循先前CRS研究[15,35]的做法,我们采用不同指标分别评估推荐任务和对话任务。对于推荐任务,参照[4,35]使用Recall@𝑘 $(k{=}1,10,50)$ 进行评估。对于对话任务,参照[4,35]采用词级别的Distinct $n$ $(n{=}2,3,4)$ 来衡量生成回复的多样性。此外,按照KGSF[35]的方法,我们邀请三位标注员从流畅性(Fluency)和信息量(Informative ness)两个维度对模型及基线生成的回复进行评分,分值范围为0到2分。所有指标均计算并报告测试集上的平均得分。
Implementation Details. We select the DialoGPT-small model as the base PLM, which is pre-trained on 147M dialogues collected from Reddit. It consists of 12 transformer layers, and the dimension of its embeddings is 768. We freeze all its parameters during the overall training process. To be consistent with DialoGPTsmall, the hidden size of our designed prompts is also set to 768. In the semantic fusion module, we utilize a fixed RoBERTa-base model for encoding the input tokens, and set the layer number of R-GCN to 1 following KGSF [35]. Besides, we set the length of soft prompt tokens to 10 for the recommendation task and 50 for the conversation task according to our parameter tuning results. We use AdamW [21] with the default parameter setting to optimize the tunable parameters in our approach. The batch size is set to 64 for the recommendation subtask and 8 for the conversation subtask, and the learning rate is 0.0005 for prompt pre-training and 0.0001 for the two subtasks. We implement all baseline models using the open-source toolkit CRSLab [34] , which contains comprehensive conversational recommendation models and benchmark datasets.
实现细节。我们选择DialoGPT-small模型作为基础预训练语言模型(PLM),该模型基于从Reddit收集的1.47亿条对话进行预训练。它包含12层Transformer结构,嵌入维度为768。在整个训练过程中我们冻结其所有参数。为保持与DialoGPT-small一致,我们设计的提示词(hidden size)也设为768。在语义融合模块中,我们采用固定的RoBERTa-base模型对输入token进行编码,并参照KGSF[35]将R-GCN的层数设为1。此外,根据参数调优结果,我们将推荐任务的软提示token长度设为10,对话任务设为50。使用AdamW优化器[21](默认参数设置)来优化我们方法中的可调参数。推荐子任务的批次大小设为64,对话子任务设为8;提示预训练的学习率为0.0005,两个子任务的学习率均为0.0001。所有基线模型均通过开源工具包CRSLab[34]实现,该工具包含全面的对话推荐模型和基准数据集。
Table 3: Results on the recommendation task. Numbers marked with * indicate that the improvement is statistically significant compared with the best baseline (t-test with pvalue $\mathbf{<0.05|}$ ).
表 3: 推荐任务结果。标有*的数字表示与最佳基线相比改进具有统计学显著性 (t检验 p值 $\mathbf{<0.05|}$ )。
| 模型 | R@1 | R@10 | R@50 | R@1 | R@10 | R@50 |
|---|---|---|---|---|---|---|
| ReDial | 0.023 | 0.129 | 0.287 | 0.003 | 0.117 | 0.285 |
| KBRD | 0.033 | 0.175 | 0.343 | 0.058 | 0.146 | 0.207 |
| KGSF | 0.035 | 0.177 | 0.362 | 0.058 | 0.165 | 0.256 |
| GPT-2 | 0.023 | 0.147 | 0.327 | 0.034 | 0.112 | 0.278 |
| DialoGPT | 0.030 | 0.173 | 0.361 | 0.024 | 0.125 | 0.247 |
| BERT | 0.030 | 0.156 | 0.357 | 0.044 | 0.179 | 0.328 |
| BART | 0.034 | 0.174 | 0.377 | 0.037 | 0.132 | 0.247 |
| UniCRS | 0.051* | 0.224* | 0.428* | 0.094* | 0.250* | 0.410* |

Figure 2: Ablation study on the ReDial dataset about the recommendation task. PT denotes the pre-training task of semantic fusion. Word and entity refer to two kinds of data signals in the fusion module. SP and template refer to taskspecific soft tokens and response templates, respectively.
图 2: 在ReDial数据集上关于推荐任务的消融研究。PT表示语义融合的预训练任务。Word和entity指融合模块中的两种数据信号。SP和template分别指任务特定的软token和响应模板。
5.2 Evaluation on Recommendation Task
5.2 推荐任务评估
In this part, we conduct experiments to evaluate the effectiveness of our model on the recommendation task.
在本部分,我们通过实验评估模型在推荐任务上的有效性。
Automatic Evaluation. Table 3 shows the performance of different methods on the recommendation task. For the three CRS methods, the performance order is consistent cross all datasets, i.e., $K G S F>K B R D>R e D i a l$ . KGSF and KBRD both incorporate external KGs into their recommendation modules, which can enrich the semantics of entities mentioned in the dialogue history to better capture user intents and preferences. Besides, KGSF also adopts the mutual information maximization method to further improve the entity representations. For the four pre-trained models, we can see that BERT and BART perform better than GPT-2 and DialoGPT. The reason might be that GPT-2 and DialoGPT are based on unidirectional Transformer architecture, which limits their capacity of dialogue understanding. Furthermore, we can see that BART achieves comparable performance and even outperforms BERT on the ReDial dataset. It indicates that BART can also understand the dialogue semantics well for the recommendation task.
自动评估。表3展示了不同方法在推荐任务上的性能表现。对于三种CRS方法,其性能排序在所有数据集中保持一致,即$K G S F>K B R D>R e D i a l$。KGSF和KBRD都在推荐模块中融入了外部知识图谱(KG),这能丰富对话历史中提及实体的语义信息,从而更好地捕捉用户意图和偏好。此外,KGSF还采用互信息最大化方法进一步优化实体表示。在四个预训练模型中,BERT和BART的表现优于GPT-2和DialoGPT,原因可能是GPT-2和DialoGPT基于单向Transformer架构,限制了其对话理解能力。值得注意的是,BART在ReDial数据集上取得了与BERT相当甚至更优的性能,这表明BART也能很好地理解对话语义以完成推荐任务。
Finally, we can see that our model outperforms all the baselines by a large margin. We utilize specially designed prompts to guide the base PLM, and incorporate KGs to improve the quality of prompts with a pre-training task. Such a way can effectively endow the PLM with the background knowledge for better performance on the recommendation task. Besides, we also use the response template generated by the conversation module as part of the prompt, which further improves the recommendation performance. Note that our approach only tunes a few parameters compared with full parameter fine-tuning, hence it is also much more efficient than those PLMbased methods.
最后,我们可以看到我们的模型大幅超越了所有基线方法。我们通过精心设计的提示(prompt)来引导基础预训练语言模型(PLM),并结合知识图谱(KG)通过预训练任务提升提示质量。这种方法能有效赋予PLM背景知识,从而在推荐任务中获得更优表现。此外,我们还将会话模块生成的响应模板作为提示组成部分,进一步提升了推荐性能。值得注意的是,与全参数微调相比,我们的方法仅需调整少量参数,因此比基于PLM的其他方法更为高效。
Table 4: Automatic evaluation results on the conversation task. We abbreviate Distinct-2,3,4 as Dist-2,3,4. Numbers marked with * indicate that the improvement is statistically significant compared with the best baseline (t-test with pvalue $\mathbf{<0.05}$ ).
表 4: 对话任务的自动评估结果。我们将 Distinct-2,3,4 缩写为 Dist-2,3,4。标有 * 的数字表示相比最佳基线具有统计显著性提升 (t检验 p值 $\mathbf{<0.05}$ )。
| 数据集 | ReDial | INSPIRED | ||||
|---|---|---|---|---|---|---|
| 模型 | Dist-2 | Dist-3 | Dist-4 | Dist-2 | Dist-3 | Dist-4 |
| ReDial | 0.225 | 0.236 | 0.228 | 0.406 | 1.226 | 2.205 |
| KBRD | 0.281 | 0.379 | 0.439 | 0.567 | 2.017 | 3.621 |
| KGSF | 0.302 | 0.433 | 0.521 | 0.608 | 2.519 | 4.929 |
| GPT-2 | 0.354 | 0.486 | 0.441 | 2.347 | 3.691 | 4.568 |
| DialoGPT | 0.476 | 0.559 | 0.486 | 2.408 | 3.720 | 4.560 |
| BART | 0.376 | 0.490 | 0.435 | 2.381 | 2.964 | 3.041 |
| UniCRS | 0.492* | 0.648* | 0.832* | 3.039* | 4.657* | 5.635* |
Ablation Study. Our approach designs a set of prompt components to improve the performance of CRS. To verify the effectiveness of each component, we conduct the ablation study on the ReDial dataset, and report the results of Recall $@10$ and Recall $@50$ . We consider removing the pre-training task of the semantic fusion module, token or entity information in the fused knowledge representations, task-specific soft tokens, and the response template, respectively.
消融实验。我们的方法设计了一组提示组件来提升CRS的性能。为验证每个组件的有效性,我们在ReDial数据集上进行消融实验,并报告Recall $@10$ 和Recall $@50$ 的结果。我们分别考虑移除语义融合模块的预训练任务、融合知识表征中的token或实体信息、任务特定软token以及响应模板。
The results are shown in Figure 2. We can see that removing any component would lead to performance degradation. It indicates that all the components in our model are useful to improve the performance of the recommendation task. Among them, the performance decreases the most after removing the pre-training task in the semantic fusion module. It indicates that such a pre-training process is important in our approach, since it can learn the semantic correlations between entities and tokens, which enforces the entity semantics to be aligned with the base PLM.
结果如图 2 所示。我们可以看到,移除任何组件都会导致性能下降。这表明我们模型中的所有组件都有助于提升推荐任务的性能。其中,移除语义融合模块中的预训练任务后性能下降最为明显。这表明这种预训练过程在我们的方法中非常重要,因为它能学习实体与 token 之间的语义关联,从而使实体语义与基础 PLM (Pre-trained Language Model) 保持对齐。
5.3 Evaluation on Conversation Task
5.3 对话任务评估
In this part, we conduct experiments to verify the effectiveness of our model on the conversation task.
在此部分,我们通过实验验证模型在对话任务上的有效性。
Automatic Evaluation. We show the evaluation results of automatic metrics about different methods in Table 4. As we can see, among the three CRS methods, the performance order is also consistent with $K G S F>K B R D>R e D i a l.$ It is because KBRD adopts KG-based token bias to promote the probabilities of low-frequency tokens, and KGSF devises KG-enhanced cross-attention layers to improve the feature interactions of entities and tokens in the generation process. Besides, we can see that PLMs achieve better performance than the three CRS methods. The possible reason is that they have been pre-trained with generative tasks on a large-scale general corpus, so they can quickly adapt to the CRS task and generate diverse responses after fine-tuning. Among these PLMs, DialoGPT achieves the best performance. Since DialoGPT has been continually pre-trained on a large-scale dialogue corpus, it is more capable of generating informative responses in the CRS scenario.
自动评估。我们在表4中展示了不同方法的自动指标评估结果。可以看出,在三种对话推荐系统(CRS)方法中,性能排序同样符合 $K G S F>K B R D>R e D i a l.$ 这是因为KBRD采用基于知识图谱(KG)的token偏置机制来提升低频token的概率,而KGSF设计了KG增强的交叉注意力层来改善生成过程中实体与token的特征交互。此外,预训练语言模型(PLM)的表现优于三种CRS方法,可能原因是它们已在大规模通用语料上经过生成任务预训练,因此经过微调后能快速适应CRS任务并生成多样化回复。其中DialoGPT表现最佳,因其持续在大规模对话语料上进行预训练,更擅长在CRS场景中生成信息丰富的响应。
Table 5: Human evaluation results about the conversation task on the ReDial dataset. Numbers marked with * indicate that the improvement is statistically significant compared with the best baseline (t-test with $\mathbf{p}$ -value $\mathbf{<0.05},$ ).
表 5: ReDial数据集上对话任务的人工评估结果。标有*的数字表示与最佳基线相比改进具有统计学显著性 (t检验,$\mathbf{p}$值$\mathbf{<0.05}$)。
| 模型 | 流畅性 | 信息量 |
|---|---|---|
| ReDial | 1.31 | 0.98 |
| KBRD | 1.21 | 1.16 |
| KGSF | 1.49 | 1.39 |
| GPT-2 | 1.62 | 1.48 |
| DialoGPT | 1.68 | 1.56 |
| BART | 1.63 | 1.43 |
| UniCRS | 1.72* | 1.64 |

Figure 3: Ablation study on the ReDial dataset about the conversation task. PT denotes the pre-training task of sematic fusion. Word and entity refer to two kinds of data signals in the fusion module. SP refers to task-specific soft tokens.
图 3: 在ReDial数据集上关于对话任务的消融研究。PT表示语义融合的预训练任务。Word和entity指融合模块中的两种数据信号。SP指任务特定的软token。
Finally, compared with these baselines, our model also consistently performs better. In our approach, we perform semantic fusion and prompt pre-training. In this way, we can effectively inject taskspecific knowledge into the PLM, and help generate informative responses. Besides, since we only tune a few parameters compared with full parameter fine-tuning, we can alleviate the catastrophe forgetting problem of the PLM.
最后,与这些基线相比,我们的模型也始终表现更优。在我们的方法中,我们执行语义融合和提示预训练。通过这种方式,我们可以有效地将任务特定知识注入到PLM中,并帮助生成信息丰富的响应。此外,由于与全参数微调相比,我们仅调整少量参数,因此可以缓解PLM的灾难性遗忘问题。
Human Evaluation. To further verify the effectiveness of our method, we conduct the human evaluation following previous works [35]. Table 5 presents the results of human evaluation for the conversation task on the ReDial dataset.
人工评估。为了进一步验证我们方法的有效性,我们按照先前工作[35]进行了人工评估。表5展示了在ReDial数据集上对话任务的人工评估结果。
First, among the three CRS methods, KGSF performs the best in both metrics, since it utilizes a KG-enhanced Transformer decoder that performs cross attention between the entity and word representations. Besides, among the three PLM models, we can see that DialoGPT achieves the best performance. A possible reason is that DialoGPT has been continually pre-trained on a large-scale dialogue corpus, which endows it with a better capacity to generate high-quality responses. Finally, our approach also outperforms all the baseline models. In our approach, we perform semantic fusion to inject the task-specific knowledge into DialoGPT, and also design a pre-training strategy to further enhance the prompt. In this way, our model can effectively understand the dialogue history, and generate fluent and informative responses.
首先,在三种CRS方法中,KGSF在两项指标上表现最佳,因为它采用了基于知识图谱增强的Transformer解码器,能够对实体表征和词表征进行交叉注意力计算。此外,在三个预训练语言模型中,DialoGPT取得了最优性能,这可能得益于其在大规模对话语料上的持续预训练,使其具备生成高质量回复的更强能力。最终,我们的方法也超越了所有基线模型。我们通过语义融合将任务特定知识注入DialoGPT,并设计了预训练策略进一步强化提示效果,从而使模型能有效理解对话历史并生成流畅且信息丰富的回复。

Figure 4: Performance comparison w.r.t. different amount of training data on ReDial dataset.
图 4: 在ReDial数据集上不同训练数据量下的性能对比。
Ablation Study. In our approach, our proposed prompt design can also improve the performance of the conversation task. To verify the effectiveness of each component, we conduct the ablation study on the ReDial dataset to analyze the contribution of each part. We adopt Distinct-3 and Distinct-4 as the evaluation metrics, and consider removing the pre-training task of the semantic fusion module, token or entity information in the fused knowledge representations, and task-specific soft tokens, respectively.
消融实验。在我们的方法中,提出的提示设计也能提升对话任务性能。为验证各模块有效性,我们在ReDial数据集上进行消融实验以分析各部分的贡献。采用Distinct-3和Distinct-4作为评估指标,分别考察移除语义融合模块的预训练任务、融合知识表征中的token或实体信息,以及任务特定软token的影响。
The ablation results are shown in Figure 3. We can see that removing any component would lead to a decrease in the model performance. It shows the effectiveness of all these components in our approach. Besides, the entity information seems to be more important than others, which yields a larger performance drop after being removed. These entities contain domain-specific knowledge about items, which is helpful for our model to generate more informative responses.
消融实验结果如图 3 所示。我们可以看出,移除任何组件都会导致模型性能下降,这证明了所有组件在我们方法中的有效性。此外,实体信息似乎比其他组件更重要,移除后性能下降幅度更大。这些实体包含了物品相关的领域知识,有助于模型生成信息更丰富的响应。
5.4 Performance Comparison w.r.t. Different Amount of Training Data
5.4 不同训练数据量下的性能对比
Learning the parameters of CRSs requires a considerable amount of training data. However, in real-world applications, it is likely to suffer from the cold start issue caused by insufficient data, which may increase the risk of over fitting. Fortunately, since our approach only needs to optimize a few parameters in the prompt and incorporates a prompt pre-training strategy, the risk of over fitting can be reduced to some extent. To validate this, we simulate a data scarcity scenario by sampling different proportions of the training data, and report the results of Recall $@10$ and Recall $\ @50$ on the ReDial dataset.
学习CRS参数需要大量训练数据。然而在实际应用中,很可能因数据不足而遭遇冷启动问题,这会增加过拟合风险。幸运的是,由于我们的方法只需优化提示中的少量参数,并采用了提示预训练策略,能在一定程度上降低过拟合风险。为验证这一点,我们通过采样不同比例的训练数据模拟数据稀缺场景,并在ReDial数据集上报告Recall $@10$和Recall $\ @50$的结果。
Figure 4 shows the evaluation results in different data scarcity settings. As we can see, the performance of baseline models substantially drops with less available training data, while our method is consistently better than all the baseline models in all cases. It indicates that our model can efficiently utilize the limited data and alleviate the cold start problem. With extremely limited data (i.e., $20%$ ), we find that our model still achieves a comparable performance with the best baseline that is trained with full data. It further indicates the effectiveness of our model in the cold start scenario.
图4展示了不同数据稀缺设置下的评估结果。如图所示,基线模型在训练数据减少时性能显著下降,而我们的方法在所有情况下都 consistently优于所有基线模型。这表明我们的模型能高效利用有限数据并缓解冷启动问题。在数据极度匮乏的情况下(即20%),我们发现模型仍能达到与使用全量数据训练的最佳基线相当的性能,进一步验证了模型在冷启动场景中的有效性。
6 CONCLUSION
6 结论
In this paper, we proposed a novel conversational recommendation model named UniCRS to fulfill both the recommendation and conversation subtasks in a unified approach. First, taking a fixed PLM (i.e., DialoGPT) as the backbone, we utilized a knowledge-enhanced prompt learning paradigm to reformulate the two subtasks. Then, we designed multiple effective prompts to support both subtasks, which include fused knowledge representations generated by a pre-trained semantic fusion module, task-specific soft tokens, and the dialogue context. We also leveraged the generated response template from the conversation subtask as an important part of the prompt to enhance the recommendation subtask. The above prompt design can provide sufficient information about the dialogue context, task instructions, and background knowledge. By only optimizing these prompts, our model can effectively accomplish both the recommendation and conversation subtasks. Extensive experimental results have shown that our approach outperforms several competitive CRS and PLM methods, especially when only limited training data is available.
本文提出了一种名为UniCRS的新型对话推荐模型,通过统一方法同时完成推荐和对话两个子任务。首先,我们以固定的大语言模型(即DialoGPT)为骨干,采用知识增强的提示学习范式重构这两个子任务。其次,我们设计了多个有效提示来支持两个子任务,包括预训练语义融合模块生成的融合知识表征、任务特定的软token以及对话上下文。我们还利用对话子任务生成的回复模板作为提示的重要组成部分来增强推荐子任务。上述提示设计能够提供关于对话上下文、任务指令和背景知识的充分信息。仅通过优化这些提示,我们的模型就能有效完成推荐和对话两个子任务。大量实验结果表明,我们的方法优于多个具有竞争力的对话推荐系统和大语言模型方法,在训练数据有限时优势尤为显著。
In the future, we will apply our model to more complicated scenarios, such as topic-guided CRS [37] and multi-modal CRS [32]. We will also consider devising more effective prompt pre-training strategies for quick adaptation to various CRS scenarios.
未来,我们将把模型应用于更复杂的场景,例如主题引导的CRS [37] 和多模态CRS [32]。我们还将考虑设计更有效的提示预训练策略,以快速适应各种CRS场景。
ACKNOWLEDGEMENT
致谢
This work was partially supported by Beijing Natural Science Foundation under Grant No. 4222027, National Natural Science Foundation of China under Grant No. 61872369, and Beijing Outstanding Young Scientist Program under Grant No. BJ J W ZY J H 012019100020098. This work is also partially supported by Beijing Academy of Artificial Intelligence(BAAI). Xin Zhao is the corresponding author.
本研究部分受到北京市自然科学基金(No. 4222027)、国家自然科学基金(No. 61872369)和北京市科技新星计划(No. BJJWZYJH012019100020098)资助。同时感谢北京智源人工智能研究院(BAAI)对本研究的支持。通讯作者为Xin Zhao。