Uncertainty-aware Action Decoupling Transformer for Action Anticipation
基于不确定性感知的动作解耦Transformer用于动作预测
Abstract
摘要
Human action anticipation aims at predicting what people will do in the future based on past observations. In this paper, we introduce Uncertainty-aware Action Decoupling Transformer (UADT) for action anticipation. Unlike existing methods that directly predict action in a verb-noun pair format, we decouple the action anticipation task into verb and noun anticipations separately. The objective is to make the two decoupled tasks assist each other and eventually improve the action anticipation task. Specifically, we propose a two-stream Transformer-based architecture which is composed of a verb-to-noun model and a noun-to-verb model. The verb-to-noun model leverages the verb information to improve the noun prediction and the other way around. We extend the model in a probabilistic manner and quantify the predictive uncertainty of each decoupled task to select features. In this way, the noun prediction leverages the most informative and redundancy-free verb features and verb prediction works similarly. Finally, the two streams are combined dynamically based on their uncertainties to make the joint action anticipation. We demonstrate the efficacy of our method by achieving state-of-the-art performance on action anticipation benchmarks including EPIC-KITCHENS, EGTEA Gaze+, and 50-Salads.
人类行为预测旨在基于过去的观察预测人们未来的行为。本文提出了一种用于行为预测的不确定性感知行为解耦Transformer (UADT)。与现有直接以动词-名词对格式预测行为的方法不同,我们将行为预测任务解耦为独立的动词预测和名词预测,目的是让这两个解耦任务相互辅助,最终提升行为预测性能。具体而言,我们提出了一个基于Transformer的双流架构,包含动词到名词模型和名词到动词模型。动词到名词模型利用动词信息改进名词预测,反之亦然。我们以概率方式扩展模型,量化每个解耦任务的预测不确定性以选择特征。这样,名词预测能利用最具信息量且无冗余的动词特征,动词预测同理运作。最终,基于各自不确定性动态融合双流信息,实现联合行为预测。通过在EPIC-KITCHENS、EGTEA Gaze+和50-Salads等行为预测基准测试中取得最先进性能,验证了方法的有效性。
1. Introduction
1. 引言
Human action anticipation aims at predicting the future action before it happens based on the current observation. It is an important research topic for intelligent systems since it is widely applied for autonomous driving [44], human-robot interaction [31], and smart homes [19].
人类行为预测旨在基于当前观察预测未来即将发生的动作。这是智能系统的重要研究课题,因其广泛应用于自动驾驶 [44] 、人机交互 [31] 和智能家居 [19] 等领域。
The task is very challenging as the future observation is unavailable and the anticipation needs to be made timely for real-time purposes [25]. Under most anticipation task settings [13, 28, 36, 38], the actions are represented as (verb, noun) pairs, which means both verbs and nouns needed to be predicted correctly. Most existing methods [20, 25, 26, 40, 48, 61] for action anticipation tackle the task as an one-class action classification problem without considering the underlying dynamics and dependencies between verbs and nouns. These models directly output the action prediction, which is later decomposed into verb and noun predictions in a post-processing. However, this mechanism has a critical drawback. If either the verb or noun of the action is difficult to predict due to the limited visual cues, the action can be very difficult to predict correctly since it requires both verb and noun to be correct [59, 60]. On the other hand, if either verb or noun is known, the remaining part is much easier to predict. For example, the verb of “drinking coffee” can be easier predicted when knowing the “coffee” and the noun of “stretch dough” is easier to predict when knowing “stretch”. In addition, the predictive uncertainty can be greatly reduced because the $p((v e r b,n o u n)|X)$ is converted to $p(v e r b|X,n o u n)$ or $p(n o u n|X,v e r b)$ , where $X$ is the input. The verb/noun in- formation serves as a prior for the complementary part so the anticipation is simplified.
该任务极具挑战性,因为未来观测数据不可获取,且需为实时目的及时进行预测 [25]。在多数预测任务设定下 [13, 28, 36, 38],动作被表示为(动词,名词)组合,这意味着需要同时正确预测动词和名词。现有大多数方法 [20, 25, 26, 40, 48, 61] 将动作预测视为单类别动作分类问题,未考虑动词与名词之间的潜在动态关系和依赖。这些模型直接输出动作预测结果,随后通过后处理分解为动词和名词预测。然而,该机制存在显著缺陷:若因视觉线索有限导致动作的动词或名词难以预测,则整个动作的正确预测将极为困难,因其要求动词和名词必须同时正确 [59, 60]。反之,若已知动词或名词中的任一要素,剩余部分的预测将大幅简化。例如,当已知"咖啡"时,"喝咖啡"的动词更易预测;当已知"拉伸"时,"拉伸面团"的名词更易推断。此外,预测不确定性可显著降低,因为 $p((动词,名词)|X)$ 被转化为 $p(动词|X,名词)$ 或 $p(名词|X,动词)$ ,其中 $X$ 为输入。动词/名词信息作为互补部分的先验知识,从而简化了预测过程。
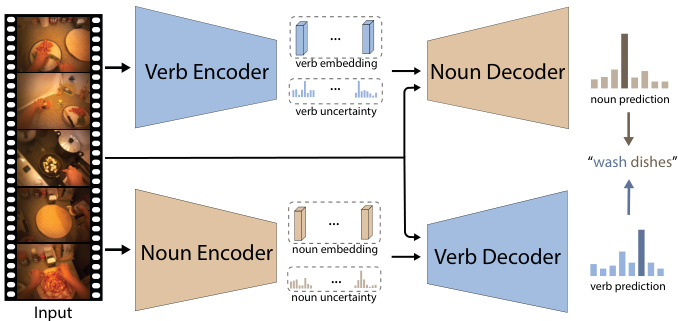
Figure 1. An illustration of uncertainty-aware action decoupling transformer (UADT). UADT is composed of a verb-tonoun model (VtN) and a noun-to-verb model (NtV), which aims at anticipating noun and verb respectively. VtN anticipates the noun with the assistance of verb information and NtV anticipates the verb with the assistance of noun information. VtN and NtV are dynamically combined based on the predictive uncertainty.
图 1: 不确定性感知动作解耦Transformer (UADT) 示意图。UADT由动词到名词模型 (VtN) 和名词到动词模型 (NtV) 组成,分别用于预测名词和动词。VtN在动词信息的辅助下预测名词,NtV在名词信息的辅助下预测动词。VtN和NtV根据预测不确定性进行动态组合。
To address the above issue of verb-noun modeling, we introduce Uncertainty-aware Action Decoupling Transformer (UADT), which decouples the action anticipation into verb and noun anticipations. Specifically, UADT is composed of a verb-to-noun model and a noun-to-verb model. Each model is composed of an encoder and a decoder. The encoder of the verb-to-noun model aims at generating verb embedding and its corresponding uncertainty. Then the embedding and its uncertainty are taken by the decoder to help the noun anticipation. We model the predictive uncertainty of the model because the encoder can generate bad embedding, which propagates the error to the following predictions. By quantifying the predictive uncertainty, we can leverage it to select reliable information and to filter the redundancy and irrelevance. In this way, the noun anticipation can be improved by benefiting from the verb information. Inversely, the noun-to-verb model first generates noun embeddings and the corresponding uncertainty. Then it performs the verb anticipation with assistance of noun information. In the end, we obtain the augmented noun and verb predictions. We dynamically combine them for the joint action anticipation based on their predictive uncertainties.
为了解决上述动词-名词建模的问题,我们引入了不确定性感知动作解耦Transformer (UADT),将动作预测解耦为动词预测和名词预测。具体而言,UADT由动词到名词模型和名词到动词模型组成。每个模型都包含编码器和解码器。动词到名词模型的编码器旨在生成动词嵌入及其对应不确定性,随后解码器利用该嵌入和不确定性辅助名词预测。我们建模预测不确定性的原因在于:编码器可能生成不良嵌入,从而将误差传播至后续预测。通过量化预测不确定性,我们可以据此筛选可靠信息并过滤冗余与无关内容。这种方式使得名词预测能够受益于动词信息。反之,名词到动词模型首先生成名词语嵌入及对应不确定性,随后在名词信息辅助下执行动词预测。最终我们获得增强的名词和动词预测结果,并基于它们的预测不确定性进行动态组合,实现联合动作预测。
To train UADT, we adopt a two-stage training strategy. The encoders and decoders are trained with different loss functions to guide them for their specific purposes. We firstly train the encoders to generate the high-quality embeddings. Then we fix the encoders and train decoders for joint action anticipation. We evaluated UADT on both egocentric and third-person action anticipation datasets including EPIC-KITCHENS-100 [15], EGTEA $\mathrm{Gaze+}$ [38], and 50-Salads [52]. Experiments results show the verb-to-noun model and noun-to-verb model effectively improve the anticipation of noun and verb respectively. We also demonstrate the effectiveness and benefits of proposed mechanisms and components by extensive ablation studies.
为训练UADT,我们采用两阶段训练策略。编码器与解码器使用不同损失函数进行训练,以实现各自特定目标。首先训练编码器生成高质量嵌入向量,随后固定编码器参数并训练解码器进行联合动作预测。我们在第一视角和第三人称动作预测数据集上评估了UADT,包括EPIC-KITCHENS-100 [15]、EGTEA $\mathrm{Gaze+}$ [38] 和50-Salads [52]。实验结果表明动词-名词模型与名词-动词模型能分别有效提升名词和动词的预测准确率。通过大量消融实验,我们也验证了所提机制与组件的有效性和优势。
In summary, the main contributions of this paper are:
本文的主要贡献如下:
2. Related Work
2. 相关工作
2.1. Human Action Anticipation
2.1. 人类行为预测
Human action anticipation aims at predicting future actions before they occur. As for its practical applications, a number of benchmarks [15, 28, 36, 38, 52] have been built to boost related research. For anticipation, feature learning [22, 46, 55] and temporal modeling [3] are two main focuses. Recurrent neural network is widely adopted by many prior work [2–4, 20, 22, 35, 41, 51] to model the temporal relationship. For example, Furnari et al. [20] proposed rolling-unrolling LSTM (RULSTM) with a rolling LSTM to encode the historical information and an unrolling LSTM to decode the future actions.
人类行为预测旨在行为发生前预判未来动作。该领域已建立多个基准数据集 [15, 28, 36, 38, 52] 以推动相关研究。预测任务主要聚焦特征学习 [22, 46, 55] 与时序建模 [3] 两个方向。循环神经网络 (RNN) 被众多研究 [2–4, 20, 22, 35, 41, 51] 广泛采用以建模时序关系。例如 Furnari 等人 [20] 提出滚动-展开 LSTM (RULSTM),通过滚动 LSTM 编码历史信息,利用展开 LSTM 解码未来动作。
Recently, transformer-based methods [25–27, 47, 57, 61] become the mainstream because of its strong capability for capturing long-range spatial-temporal dependencies. Typically, Girdhar et al. [26] proposed antic ip at ive video transformer (AVT) with a pure self-attention design. Based on the transformer encoder, Girase et al. [25] introduced RAFTformer for real-time action forecasting with low inference latency. To leverage the overall goal of actions, multiple methods [43, 48, 49] are proposed to learn the hidden representations of goal to guide the anticipation. To utilize information from different sources such as audio and optical flow, various approaches [13, 20, 21, 32, 50, 65, 68] combined different modalities to improve the anticipation. Also, large language model (LLM) is also explored for action anticipation [66].
近年来,基于Transformer的方法[25–27, 47, 57, 61]因其强大的长程时空依赖捕捉能力成为主流。典型地,Girdhar等人[26]提出了采用纯自注意力设计的预期视频Transformer (AVT)。基于Transformer编码器,Girase等人[25]提出了具有低推理延迟的实时动作预测模型RAFTformer。为利用动作的全局目标,多项研究[43, 48, 49]提出学习目标的隐式表征来指导预测。为整合音频、光流等多源信息,多种方法[13, 20, 21, 32, 50, 65, 68]通过融合多模态数据提升预测性能。此外,大语言模型(LLM)在动作预测领域也得到探索[66]。
2.2. Uncertainty for Action Understanding
2.2. 动作理解的不确定性
Uncertainty is a measure of prediction confidence [24, 33]. It not only represents the reliability of prediction, but also provides specific information about the model [42]. Uncertainty quant if i cation techniques [33] have shown increasing importance in action understanding such as action recognition [30, 56, 64, 67] and temporal action detection [5, 7, 10– 12, 29, 37, 62, 63]. Wang et al. [56] leverages uncertainty sampling for active learning to select most informative instances for action recognition. Guo et al. [30] proposed uncertainty-guided probabilistic transformer (UGPT) for complex action recognition. Specifically, uncertainty is quantified to train two models for low-uncertainty and highuncertainty data respectively.
不确定性是衡量预测置信度的指标 [24, 33]。它不仅代表预测的可靠性,还提供了模型的具体信息 [42]。不确定性量化技术 [33] 在动作理解领域(如动作识别 [30, 56, 64, 67] 和时间动作检测 [5, 7, 10–12, 29, 37, 62, 63])中展现出日益重要的作用。Wang 等人 [56] 利用不确定性采样进行主动学习,为动作识别选择信息量最大的样本。Guo 等人 [30] 提出了不确定性引导的概率 Transformer (UGPT) 用于复杂动作识别。具体而言,通过量化不确定性来分别训练低不确定性和高不确定性数据的两个模型。
For anticipation task, a few work have explored the uncertainty of future actions. Furnari et al. [21] considered the uncertainty to design the loss function. Farha et al. [2] modeled the probability distribution of future action and generated multiple samples to account for the uncertainty. In some cases, the future action is almost impossible to infer, Suris et al. [53] proposed a hierarchical model to infer high-level activities when the simple action is difficult to anticipate. In this work, we model the uncertainty of verbs and nouns to identify reliable information and assist decision making.
在预测任务中,已有少量研究探索未来动作的不确定性。Furnari等人[21]通过考虑不确定性来设计损失函数。Farha等人[2]对未来动作的概率分布进行建模,并生成多个样本来解释不确定性。在某些情况下,未来动作几乎无法推断,Suris等人[53]提出分层模型,在简单动作难以预测时推断高层级活动。本工作中,我们通过对动词和名词的不确定性建模,识别可靠信息并辅助决策。
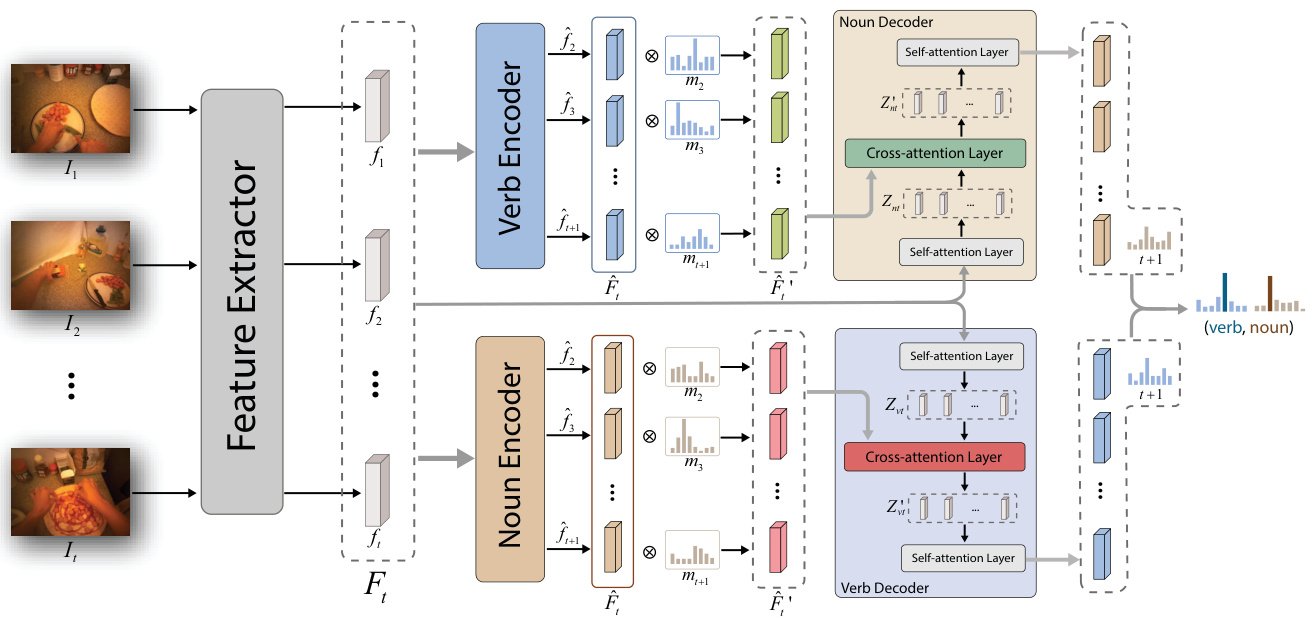
Figure 2. Overall framework of UADT. UADT is composed of a verb-to-noun (VtN) model on the top and a noun-to-verb (NtV) model on the bottom, which aims at anticipating the noun and the verb respectively. VtN is made up of a verb encoder and a noun decoder. NtV is made up of a noun encoder and a verb decoder. Given the input video, a pretrained backbone is firstly used to extract features. The extracted features are fed into two encoders to generate the verb/noun embeddings and their corresponding uncertainties, which are taken by the decoders to help the anticipation of the noun/verb. The decoders output the assisted verb and noun predictions. In the end, the VtN and NtV are dynamically combined based on their predictive uncertainties.
图 2: UADT整体框架。UADT由顶部的动词到名词(VtN)模型和底部的名词到动词(NtV)模型组成,分别用于预测名词和动词。VtN包含动词编码器和名词解码器,NtV包含名词编码器和动词解码器。给定输入视频后,首先使用预训练骨干网络提取特征。提取的特征被送入两个编码器以生成动词/名词嵌入及其对应不确定性,解码器利用这些信息辅助预测名词/动词。解码器输出辅助的动词和名词预测结果。最终根据预测不确定性动态融合VtN和NtV的输出。
3. Method
3. 方法
In this section, we first give an overview of Uncertaintyaware Action Decoupling Transformer (UADT) in Sec. 3.1 and formulate the action anticipation task in Sec. 3.2. Then we introduce UADT’s encoders and decoders in Sec. 3.3 and Sec. 3.4 respectively. The uncertainty-based fusion strategy is introduced in Sec. 3.5. Finally, we discuss the training procedures in Sec. 3.6.
在本节中,我们首先在第3.1节概述不确定性感知动作解耦Transformer (UADT),并在第3.2节中制定动作预测任务。随后分别在第3.3节和第3.4节介绍UADT的编码器和解码器。第3.5节阐述了基于不确定性的融合策略,最后在第3.6节讨论训练流程。
3.1. Overview
3.1. 概述
An overall framework of UADT is shown in Figure 2. It is composed of a verb-to-noun (VtN) model and a noun-toverb (NtV) model. Given the input video up to time $t$ , features are firstly extracted by a pretrained backbone network. Then the extracted features are fed into a verb encoder and a noun encoder to generate the initial verb and noun embeddings. Meanwhile, the encoders also output the predictive uncertainty to identify informative and reliable embeddings. The initial verb embedding and its corresponding uncertainty are fed into noun decoder to assist the noun anticipation. And initial noun embedding and its corresponding uncertainty are fed into verb decoder to assist the verb anticipation. Besides noun and verb predictions, the decoders also output noun and verb uncertainties. Finally, the noun and verb predictions are dynamically combined based the uncertainty to make joint action anticipation.
UADT的整体框架如图2所示。它由动词到名词(VtN)模型和名词到动词(NtV)模型组成。给定时间$t$前的输入视频,首先通过预训练的主干网络提取特征。然后将提取的特征输入动词编码器和名词编码器,生成初始动词和名词嵌入。同时,编码器还会输出预测不确定性,以识别信息丰富且可靠的嵌入。初始动词嵌入及其对应不确定性被输入名词解码器以辅助名词预测,而初始名词嵌入及其对应不确定性则输入动词解码器以辅助动词预测。除名词和动词预测外,解码器还会输出名词和动词不确定性。最后,基于不确定性动态组合名词和动词预测,实现联合动作预测。
3.2. Anticipation Problem Formulation
3.2. 预期问题建模
Human action anticipation aims at predicting future actions before they occur. In this work, we follow the settings of short-term action anticipation in [13, 14]. Mathematically, denote the input at time $t$ as $X_{t}={I_{1},...,I_{t}}$ , where $I_{t^{\prime}}$ is the frame at time $t^{\prime}$ . The goal of anticipation is to predict the action in $(v e r b,n o u n)$ format at time $t+t_{f}$ , where $t_{f}$ is the time interval before the future action happens. So the problem can be formulated as a classification task as $y_{t+t_{f}}^{*}=\mathrm{argmax}_{\hat{y}}p(\hat{y}_{t+t_{f}}|X_{t})$ , where $y$ denotes the action label. An illustration is shown in Figure 3.
人类行为预测旨在行为发生前预判未来动作。本研究遵循[13, 14]中短期行为预测的设置。数学上,将时间$t$的输入表示为$X_{t}={I_{1},...,I_{t}}$,其中$I_{t^{\prime}}$是时刻$t^{\prime}$的帧图像。预测目标是以$(verb,noun)$格式预判$t+t_{f}$时刻的行为,$t_{f}$表示未来动作发生前的时间间隔。该问题可建模为分类任务$y_{t+t_{f}}^{*}=\mathrm{argmax}_{\hat{y}}p(\hat{y}_{t+t_{f}}|X_{t})$,其中$y$表示动作标签。示意图见图3:
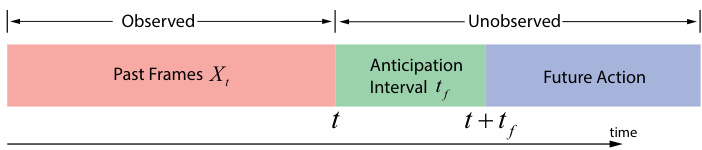
Figure 3. Action anticipation illustration. The task aims at predicting the future action after a time interval $t_{f}$ given the observation up to time $t$ .
图 3: 动作预测示意图。该任务旨在给定截止时间 $t$ 的观测数据后,预测经过时间间隔 $t_{f}$ 后的未来动作。
3.3. UADT Encoders
3.3. UADT 编码器
UADT has a verb encoder (VE) and a noun encoder (NE). The objective of these encoders is to generate verb/noun embeddings that can be used as a prior to assist the anticipation of the complementary part. To achieve this, we build two probabilistic encoders based on Transformer [54] encoder to encode verb/noun information and quantify the predictive uncertainty. We quantify the uncertainty because not all the generated embeddings are reliable and useful. Uncertainty is used to identify informative embeddings that can better serve the decoders.
UADT包含一个动词编码器(VE)和一个名词编码器(NE)。这些编码器的目标是生成动词/名词嵌入(embedding),作为预测互补部分的先验信息。为此,我们基于Transformer [54]编码器构建了两个概率编码器,用于编码动词/名词信息并量化预测不确定性。我们量化不确定性是因为并非所有生成的嵌入都可靠且有用。不确定性用于识别能更好服务于解码器的信息丰富嵌入。
For the architecture, we follow the standard transformer encoder design. To capture the predictive uncertainty, we extend the model in a probabilistic manner. Specifically, we replace the feed-forward networks in the last encoder layer with Gaussian probabilistic layers [33] to model the parameter distribution. To learn the model, re parameter iz a- tion trick [34] is used to perform forward pass and backpropagation. In this way, the model can generate multiple outputs based on the same input through sampling. Since only the forward process after the probabilistic layer needs to be repeated, the computational cost does not increase dramatically. Then the predictive uncertainty can be quantified based on these predictions.
在架构方面,我们遵循标准的Transformer编码器设计。为了捕捉预测不确定性,我们以概率方式扩展了模型。具体而言,我们将最后一层编码器中的前馈网络替换为高斯概率层 (Gaussian probabilistic layers) [33] 来建模参数分布。为了训练模型,我们使用重参数化技巧 (reparameterization trick) [34] 进行前向传播和反向传播。通过这种方式,模型可以通过采样基于同一输入生成多个输出。由于只需重复概率层之后的前向过程,计算成本不会显著增加。随后可以基于这些预测结果来量化预测不确定性。
To train the encoders to generate verb/noun-orientated embeddings, we design a verb/noun-guided training strategy. Given the input $X_{t}$ at time $t$ , a pretrained backbone first extracts the features as $\boldsymbol{F}{t}={f_{1},...,f_{t}}$ . Then encoders make verb/noun anticipation at each time step based on $\mathbf{\nabla}{F_{t}}$ :
为了训练编码器生成动词/名词导向的嵌入向量,我们设计了一种动词/名词引导的训练策略。给定时间 $t$ 的输入 $X_{t}$,预训练主干网络首先提取特征 $\boldsymbol{F}{t}={f_{1},...,f_{t}}$。随后编码器基于 $\mathbf{\nabla}{F_{t}}$ 在每个时间步进行动词/名词预测:
$$
{\hat{v}}{2},...,{\hat{v}}{t+1}=V E(F_{t}),{\hat{n}}{2},...,{\hat{n}}{t+1}=N E(F_{t})
$$
$$
{\hat{v}}{2},...,{\hat{v}}{t+1}=V E(F_{t}),{\hat{n}}{2},...,{\hat{n}}{t+1}=N E(F_{t})
$$
where $V_{t}={\hat{v}{2},...,\hat{v}{t+1}}$ and $\boldsymbol{N}{t}={\hat{n}{2},...,\hat{n}_{t+1}}$ are predicted verbs and nouns.
其中 $V_{t}={\hat{v}{2},...,\hat{v}{t+1}}$ 和 $\boldsymbol{N}{t}={\hat{n}{2},...,\hat{n}_{t+1}}$ 是预测的动词和名词。
To train the model for action anticipation, most approaches use cross-entropy-based loss functions to optimize the top-1 prediction. However, this may cause problems for our encoders since the top-1 prediction can be wrong and the error will propagate to the decoder part. To address this issue, we propose a top $K$ cross-entropy loss so that the encoder can tolerate certain erroneous predictions and encode more information. The loss function is defined as follows:
为了训练动作预测模型,大多数方法采用基于交叉熵的损失函数来优化Top-1预测。然而,这可能导致我们的编码器出现问题,因为Top-1预测可能存在错误,并且误差会传播到解码器部分。为了解决这个问题,我们提出了一种Top $K$ 交叉熵损失函数,使编码器能够容忍某些错误预测并编码更多信息。损失函数定义如下:
where $C$ is the total number of verb or noun classes, $K$ is a hyper-parameter, and $\hat{y}_{k}$ denotes the top $\mathbf{\nabla\cdot}\mathbf{k}$ predicted label. From Eq. 2, a classification result has less penalty if its top $K$ predictions include the ground-truth verb/noun. In this way, the encoding space is extended to $K$ verbs or nouns so it is more robust for wrong top-1 prediction. We empirically set $K=5$ based on the ablation study in Figure 5a.
其中 $C$ 是动词或名词类别的总数,$K$ 是一个超参数,$\hat{y}_{k}$ 表示前 $\mathbf{\nabla\cdot}\mathbf{k}$ 个预测标签。根据公式2,如果分类结果的前 $K$ 个预测包含真实动词/名词,则惩罚较小。通过这种方式,编码空间扩展到 $K$ 个动词或名词,因此对错误的top-1预测更具鲁棒性。基于图5a的消融研究,我们经验性地设定 $K=5$。
On the other hand, we also make the encoders do feature anticipation at each time step: $\hat{\pmb{F}}{t}={\hat{\pmb{f}}{2},...,\hat{\pmb{f}}{t+1}}$ , where $\hat{\pmb f}{\tau}$ is the predicted future feature of $\boldsymbol{f}{\u{\tau}}$ . Specifically, the output embeddings of the last encoder layer are treated as the anticipated features. We train them by minimizing the mean squared error loss $\mathcal{L}_{f e a t}$ between predicted features and true features in a self-supervised manner:
另一方面,我们还让编码器在每个时间步进行特征预测:$\hat{\pmb{F}}{t}={\hat{\pmb{f}}{2},...,\hat{\pmb{f}}{t+1}}$,其中$\hat{\pmb f}{\tau}$是$\boldsymbol{f}{\u{\tau}}$的预测未来特征。具体而言,将最后一层编码器的输出嵌入作为预测特征,并通过最小化预测特征与真实特征之间的均方误差损失$\mathcal{L}_{f e a t}$以自监督方式进行训练:
$$
\mathcal{L}{f e a t}=|\pmb{F}{t+1}-\hat{\pmb{F}}{t}|_{2}^{2}
$$
$$
\mathcal{L}{f e a t}=|\pmb{F}{t+1}-\hat{\pmb{F}}{t}|_{2}^{2}
$$
where $\boldsymbol{F}{t+1}={\boldsymbol{f}{2},...,\boldsymbol{f}_{t+1}}$ .
其中 $\boldsymbol{F}{t+1}={\boldsymbol{f}{2},...,\boldsymbol{f}_{t+1}}$。
The VE and NE are trained separately by jointly minimizing the top $K$ verb/noun loss and the feature loss. The total encoder loss function can be written as:
VE和NE通过联合最小化前$K$个动词/名词损失和特征损失分别进行训练。总编码器损失函数可表示为:
$$
\mathcal{L}{e n}=\mathcal{L}{t o p.K}^{v e r b/n o u n}+\lambda\mathcal{L}_{f e a t}
$$
$$
\mathcal{L}{e n}=\mathcal{L}{t o p.K}^{v e r b/n o u n}+\lambda\mathcal{L}_{f e a t}
$$
where $\lambda$ is a hyper-parameter that measures the weight of the feature anticipation loss. After training the verb and noun encoders, their outputs encode the verb and noun information, which are utilized by the following decoders.
其中 $\lambda$ 是衡量特征预期损失权重的超参数。在训练动词和名词编码器后,它们的输出会编码动词和名词信息,供后续解码器使用。
Uncertainty quant if i cation. The generated embeddings above contain misleading information or redundancy. To address this issue, we measure the predictive uncertainty to identify the reliable embeddings. Modeling the uncertainty is effective for action anticipation because the observation of future action is unavailable and there is intra-class ambiguity. Even the same observed actions can lead to different future actions [53]. For example, “get cup” and “pour coffee” both exist in “make coffee” and “make tea”. And different people may perform the same action in different ways and in different orders. Therefore, it is important to model the predictive uncertainty for reliable future prediction.
不确定性量化。上述生成的嵌入(embedding)包含误导信息或冗余内容。为解决该问题,我们通过测量预测不确定性来识别可靠嵌入。由于未来动作的观察结果不可得且存在类内模糊性,对不确定性建模对动作预测尤为重要。即使是相同的已观察动作也可能导致不同的未来动作[53]。例如"拿杯子"和"倒咖啡"在"泡咖啡"和"泡茶"场景中同时存在。不同个体执行相同动作的方式和顺序也可能存在差异。因此,建立预测不确定性模型对实现可靠的未来预测至关重要。
Specifically, the predictive uncertainty is composed of epistemic uncertainty and aleatoric uncertainty [33]. Epistemic uncertainty, also known as model uncertainty, captures the lack of knowledge of model and is inversely proportional to the training data. In action anticipation task, epistemic uncertainty accounts for the unreliability of model for future actions. Aleatoric uncertainty, also known as data uncertainty, measures the noise in the data. This kind of uncertainty is related to the label and imperfect ness of action data. Please refer to [1] for more details. These two types of uncertainties add up to the total predictive uncertainty. As epistemic uncertainty account for the internal property of model for the unknowns, it is more effective for anticipation task. We demonstrate this claim in the ablation study $(\S~4.4)$ . In this work, we mainly leverage the epistemic uncertainty.
具体而言,预测不确定性由认知不确定性 (epistemic uncertainty) 和偶然不确定性 (aleatoric uncertainty) 组成 [33]。认知不确定性又称模型不确定性,反映了模型知识的不足,与训练数据量成反比。在动作预测任务中,认知不确定性体现了模型对未来动作预测的不可靠性。偶然不确定性又称数据不确定性,用于衡量数据中的噪声。这类不确定性与动作数据的标签缺陷及不完整性相关,详见文献 [1]。这两类不确定性共同构成了总体预测不确定性。由于认知不确定性反映了模型对未知内容的内部特性,因此对预测任务更具参考价值。我们通过消融实验 $(\S~4.4)$ 验证了这一观点。本文主要利用认知不确定性进行预测。
By extending the model in a probabilistic manner, we learned the distribution of parameters. So we can obtain $N$ sets of parameters ${\theta_{1},...,\theta_{N}}$ by sampling and then get $N$ predictions from the same input by repeating the forward process with different parameters. Generally, the total predictive uncertainty is quantified as the entropy of the predictions as $\begin{array}{r}{\mathcal{H}[\hat{y}|x]=-\dot{\sum}_{c=1}^{C}p(\hat{y}|x)\log p(\hat{y}|\dot{x})}\end{array}$ , where $y$ is the output label and $x$ is the input. The epistemic uncertainty can be quantified as follows [42]:
通过以概率方式扩展模型,我们学习了参数的分布。因此我们可以通过采样获得 $N$ 组参数 ${\theta_{1},...,\theta_{N}}$,然后通过使用不同参数重复前向过程,从同一输入获得 $N$ 个预测。通常,总预测不确定性量化为预测的熵 $\begin{array}{r}{\mathcal{H}[\hat{y}|x]=-\dot{\sum}_{c=1}^{C}p(\hat{y}|x)\log p(\hat{y}|\dot{x})}\end{array}$,其中 $y$ 是输出标签,$x$ 是输入。认知不确定性可以如下量化 [42]:
$$
\mathcal{U}{e}\approx\mathcal{H}[\frac{1}{N}\sum_{n}^{N}p(\hat{y}|x,\theta_{n})]-\frac{1}{N}\sum_{n}^{N}\mathcal{H}[p(\hat{y}|x,\theta_{n})]
$$
$$
\mathcal{U}{e}\approx\mathcal{H}[\frac{1}{N}\sum_{n}^{N}p(\hat{y}|x,\theta_{n})]-\frac{1}{N}\sum_{n}^{N}\mathcal{H}[p(\hat{y}|x,\theta_{n})]
$$
In Eq. 5, we use average of $N$ samples to approximate the true value since it is intractable to integrate over the parameter space. The second term on the right is an approximation
在式5中,我们使用$N$个样本的平均值来逼近真实值,因为对参数空间进行积分是不可行的。右边的第二项是一个近似值
of aleatoric uncertainty:
偶然不确定性:
$$
\mathcal{U}{a}\approx\frac{1}{N}\sum_{n}^{N}\mathcal{H}[p(\hat{y}|x,\theta_{n})]
$$
$$
\mathcal{U}{a}\approx\frac{1}{N}\sum_{n}^{N}\mathcal{H}[p(\hat{y}|x,\theta_{n})]
$$
We follow the same procedure for every time step so that every generated embedding has its corresponding uncertainty. The generated embeddings along with their uncertainties are fed into the decoder make the final anticipation.
我们对每个时间步遵循相同的流程,确保每个生成的嵌入(embedding)都有其对应的不确定性。生成的嵌入及其不确定性被输入解码器以做出最终预测。
3.4. UADT Decoders
3.4. UADT 解码器
The objective of decoders is to make the verb/noun anticipation by leveraging the noun/verb embeddings and uncertainties from the encoders. They take both the extracted features from backbone and the embeddings from the encoders.
解码器的目标是通过利用名词/动词嵌入和编码器的不确定性来进行动词/名词预测。它们同时接收来自骨干网络的提取特征和编码器的嵌入。
As shown in Figure 2, the decoders are composed of self-attention layers and cross-attention layers. The selfattention layers are transformer encoders with causal masks to make sure each step can only access its past information. They first take the input features $\mathbf{\nabla}{F_{t}}$ to generate the intermediate noun embeddings $Z_{n t}={z_{n1},...,z_{n t}}$ and intermediate verb embeddings $Z_{v t}={z_{v1},...,z_{v t}}$ . $Z_{n t}$ and $Z_{v t}$ are orientated to anticipate the noun and verb respectively, which are used for cross-attention.
如图 2 所示,解码器由自注意力层和交叉注意力层组成。自注意力层是带有因果掩码的 Transformer 编码器,确保每一步只能访问其过去的信息。它们首先接收输入特征 $\mathbf{\nabla}{F_{t}}$,生成中间名词嵌入 $Z_{n t}={z_{n1},...,z_{n t}}$ 和中间动词嵌入 $Z_{v t}={z_{v1},...,z_{v t}}$。$Z_{n t}$ 和 $Z_{v t}$ 分别用于预测名词和动词,并参与交叉注意力计算。
Before the encoder embeddings enter the crossattention layer, we apply an uncertainty mask $\begin{array}{r l}{M_{t}}&{{}=}\end{array}$ ${m_{2},...,m_{t+1}}$ to select the most informative embedding. We assume the embeddings with large uncertainty tend to be less reliable and less relevant to the actions being anticipated. So the weights of masks are inversely proportional to the uncertainty. Specifically, the weights of the uncertainty mask at time $t$ can be computed as follows:
在编码器嵌入进入交叉注意力层之前,我们应用不确定性掩码 $\begin{array}{r l}{M_{t}}&{{}=}\end{array}$ ${m_{2},...,m_{t+1}}$ 来选择信息量最大的嵌入。我们假设具有较大不确定性的嵌入往往可靠性较低,且与预期动作的相关性较弱。因此,掩码权重与不确定性成反比。具体而言,时间 $t$ 处的不确定性掩码权重可按如下方式计算:
$$
m_{t^{\prime}}=1-(\mathcal{U}{t}-\mathcal{U}{m i n})/(\mathcal{U}{m a x}-\mathcal{U}_{m i n})
$$
$$
m_{t^{\prime}}=1-(\mathcal{U}{t}-\mathcal{U}{m i n})/(\mathcal{U}{m a x}-\mathcal{U}_{m i n})
$$
where $\boldsymbol{\mathcal{U}}{t^{\prime}}$ is the epistemic uncertainty of embedding at time $t^{\prime}$ , and $\mathcal{U}{m a x}$ , ${{\mathcal{U}}{m i n}}$ are the maximum and minimum epistemic uncertainty within each batch. The uncertainty mask is multiplied to the encoder embeddings at each time step to generate the weighted embeddings $\hat{F^{\prime}}{t}={m_{2}\hat{\pmb f}{2},...,m_{t+1}\hat{\pmb f}{t+1}}$ . Same procedures are used for both models. Then we perform the cross attention between ${Z_{v t}}/{Z_{n t}}$ and encoder embeddings $\hat{\pmb{F^{\prime}}}_{t}$ of noun/verb model. After cross-attention, the updated embeddings are fed into the last self-attention layer to generate the final embeddings.
其中 $\boldsymbol{\mathcal{U}}{t^{\prime}}$ 表示时间 $t^{\prime}$ 处嵌入的认知不确定性 (epistemic uncertainty),$\mathcal{U}{m a x}$ 和 ${{\mathcal{U}}{m i n}}$ 分别是每批次内的最大和最小认知不确定性。不确定性掩码在每个时间步与编码器嵌入相乘,生成加权嵌入 $\hat{F^{\prime}}{t}={m_{2}\hat{\pmb f}{2},...,m_{t+1}\hat{\pmb f}{t+1}}$。两个模型均采用相同处理流程。随后我们对 ${Z_{v t}}/{Z_{n t}}$ 与名词/动词模型的编码器嵌入 $\hat{\pmb{F^{\prime}}}_{t}$ 执行交叉注意力计算。经过交叉注意力层后,更新后的嵌入被送入最后一个自注意力层以生成最终嵌入。
To train the decoders, we first have a standard crossentropy loss to train the decoder at time $t$ for next verb/noun anticipation:
为了训练解码器,我们首先使用标准交叉熵损失来训练时刻 $t$ 的下一动词/名词预测解码器:
$$
\mathcal{L}{n e x t}=-\log\hat{y}{t}[c_{t+1}]
$$
$$
\mathcal{L}{n e x t}=-\log\hat{y}{t}[c_{t+1}]
$$
where $\hat{y}{t}$ is the predicted label at time $t$ and $c_{t+1}$ is the ground-truth label of frame $t+1$ .
其中 $\hat{y}{t}$ 是时间 $t$ 的预测标签,$c_{t+1}$ 是帧 $t+1$ 的真实标签。
In addition, we follow the same procedures as the encodes to make feature anticipation by minimizing $\mathcal{L}_{f e a t}$ in
此外,我们遵循与编码器相同的流程,通过最小化 $\mathcal{L}_{f e a t}$ 来实现特征预测。
Eq. 3. We also train the model to do verb/noun anticipation before time $t$ . Specifically, each output embedding goes through a linear layer to output the verb/action prediction. We train this sub-task with a cross-entropy loss as follows:
式3。我们还训练模型在时间$t$之前进行动词/名词预测。具体来说,每个输出嵌入都通过一个线性层输出动词/动作预测。我们使用交叉熵损失训练这个子任务如下:
$$
\mathcal{L}{v e r b/n o u n}=-\sum_{\tau=1}^{t-1}\log\hat{y}{\tau}[c_{\tau+1}]
$$
$$
\mathcal{L}{v e r b/n o u n}=-\sum_{\tau=1}^{t-1}\log\hat{y}{\tau}[c_{\tau+1}]
$$
where $\hat{y}_{\tau}$ is the predicted verb or noun label at time $\tau$
其中 $\hat{y}_{\tau}$ 表示时间 $\tau$ 的预测动词或名词标签
The total loss function for training the decoders can be written as:
训练解码器的总损失函数可表示为:
$$
\mathcal{L}{d e}=\mathcal{L}{n e x t}+\lambda_{1}\mathcal{L}{f e a t}+\lambda_{2}\mathcal{L}_{v e r b/n o u n}
$$
$$
\mathcal{L}{d e}=\mathcal{L}{n e x t}+\lambda_{1}\mathcal{L}{f e a t}+\lambda_{2}\mathcal{L}_{v e r b/n o u n}
$$
where $\lambda_{1}$ and $\lambda_{2}$ are hyper-parameters.
其中 $\lambda_{1}$ 和 $\lambda_{2}$ 是超参数。
Decoder uncertainty. The last self-attention layer in the decoder is also extended in a probabilistic manner. And decoders output the predictive uncertainty of the anticipated verb and noun. The noun and verb uncertainties represent the the reliability of the verb-to-noun model and noun-toverb model respectively. The noun and verb predictions along with their uncertainties are combined for the final action anticipation.
解码器不确定性。解码器的最后一层自注意力层也以概率方式扩展。解码器输出预测动词和名词的不确定性。名词和动词的不确定性分别表示动词-名词模型和名词-动词模型的可靠性。将名词和动词的预测结果及其不确定性相结合,用于最终的动作预测。
3.5. Uncertainty-based Fusion
3.5. 基于不确定性的融合
Joint action anticipation. To combine the predictions of verb-to-noun model and noun-to-verb model, we proposed an uncertainty-based fusion strategy. We assume the prediction with low uncertainty is more reliable so it should be assigned higher weights. The fusion of the two models can be written as:
联合动作预测。为了结合动词到名词模型和名词到动词模型的预测结果,我们提出了一种基于不确定性的融合策略。我们假设不确定性较低的预测更可靠,因此应赋予更高权重。两个模型的融合可表示为:
$$
\begin{array}{r}{p(v e r b)=\alpha p_{v\rightarrow n}^{e n}+(1-\alpha)p_{n\rightarrow v}^{d e}}\ {\alpha=\sigma((\mathcal{U}{n\rightarrow v}-\mathcal{U}{m i n}^{v}/\mathcal{U}{m a x}^{v}-\mathcal{U}_{m i n}^{v}))}\end{array}
$$
$$
\begin{array}{r}{p(v e r b)=\alpha p_{v\rightarrow n}^{e n}+(1-\alpha)p_{n\rightarrow v}^{d e}}\ {\alpha=\sigma((\mathcal{U}{n\rightarrow v}-\mathcal{U}{m i n}^{v}/\mathcal{U}{m a x}^{v}-\mathcal{U}_{m i n}^{v}))}\end{array}
$$
$$
p(n o u n)=\beta p_{n\to v}^{e n}+(1-\beta)p_{v\to n}^{d e}
$$
$$
p(n o u n)=\beta p_{n\to v}^{e n}+(1-\beta)p_{v\to n}^{d e}
$$
$$
\beta=\sigma((\mathcal{U}{v\rightarrow n}-\mathcal{U}{m i n}^{n}/\mathcal{U}{m a x}^{n}-\mathcal{U}_{m i n}^{n}))
$$
$$
\beta=\sigma((\mathcal{U}{v\rightarrow n}-\mathcal{U}{m i n}^{n}/\mathcal{U}{m a x}^{n}-\mathcal{U}_{m i n}^{n}))
$$
where $p$ denotes the prediction and $\sigma$ is the sigmoid function. $\alpha$ and $\beta$ are functions of the predictive epistemic uncertainty. In this way, the prediction that has high uncertainty is less considered in the final anticipation. The fusion is dynamic since it depends on the input uncertainty. By considering the uncertainty of future verb/noun in the decision process, the final anticipation is made by the most reliable verb and noun combination.
其中 $p$ 表示预测值,$\sigma$ 为 sigmoid 函数。$\alpha$ 和 $\beta$ 是预测认知不确定性 (predictive epistemic uncertainty) 的函数。通过这种方式,不确定性较高的预测在最终预期中所占权重较低。由于融合过程依赖于输入不确定性,因此具有动态特性。通过在决策过程中考虑未来动词/名词的不确定性,最终预期由最可靠的动词和名词组合生成。
Post-processing. After the fusion of verb-to-noun model and noun-to-verb model, we obtain the joint action prediction. However, the verbs and nouns are predicted separately, which means some $(v e r b,n o u n)$ pairs can be implausible such as “drinking potatoes”. To correct implausible verb-noun pairs, we perform a post-processing by selecting the verb-noun pair that has the maximum joint probability among valid $(v e r b,n o u n)$ combinations.
后处理。在动词到名词模型和名词到动词模型融合后,我们得到联合动作预测。然而,动词和名词是分别预测的,这意味着某些$(v e r b,n o u n)$组合可能不合理,例如"喝土豆"。为了修正不合理的动词-名词对,我们通过从有效的$(v e r b,n o u n)$组合中选择具有最大联合概率的动词-名词对进行后处理。
$$
(v e r b,n o u n)^{}=\operatorname*{argmax}_{(v e r b,n o u n)\in\mathcal{V}}p(v e r b)p(n o u n)
$$
$$
(v e r b,n o u n)^{}=\operatorname*{argmax}_{(v e r b,n o u n)\in\mathcal{V}}p(v e r b)p(n o u n)
$$
Algorithm 1 UADT Training
算法 1 UADT训练
where $\mathcal{V}$ is the set that contains all plausible $(v e r b,n o u n)$ combinations.
其中 $\mathcal{V}$ 是包含所有合理 $(动词,名词)$ 组合的集合。
3.6. Training Procedures
3.6. 训练流程
To train the UADT, we adopt a two-stage (2S) training strategy. We first train the verb encoder and noun encoder separately by minimizing $\mathcal{L}{e n}$ in Eq. 4. Afterwards, we fix the encoders and train the noun decoder and verb decoder by minimizing $\mathcal{L}_{d e}$ in Eq. 10. The training procedures are summarized in Algorithm 1. In addition, we also trained the model in an end-to-end (E2E) manner. E2E training gives better performance than the 2S training. An ablation study of training strategies is available in Sec. 4.4.
为了训练UADT,我们采用了两阶段(2S)训练策略。首先通过最小化公式4中的$\mathcal{L}{e n}$分别训练动词编码器和名词编码器。随后固定编码器参数,通过最小化公式10中的$\mathcal{L}_{d e}$训练名词解码器和动词解码器。完整训练流程如算法1所示。此外,我们还尝试了端到端(E2E)训练方式,其性能优于两阶段训练。具体训练策略的消融实验详见第4.4节。
4. Experiments
4. 实验
We first introduce the benchmark and evaluation metrics (§ 4.1). Then we provide the implementation details $(\S4.2)$ . Next we compare UADT with state-of-the-art methods $(\S4.3)$ . Finally, we present ablation studies of the proposed mechanisms and components (§ 4.4).
我们首先介绍基准测试和评估指标(§4.1),随后提供实现细节(§4.2),接着将UADT与最先进方法进行对比(§4.3),最后展示所提出机制和组件的消融研究(§4.4)。
4.1. Datasets and Evaluation Metrics
4.1. 数据集与评估指标
EPIC-KITCHENS-100 (EK100) [15] is a large-scale egocentric video dataset. It contains 700 cooking activity videos. There are 3806 actions with 97 verbs and 300 nouns. In this work, we evaluate our proposed method on the validation dataset as previous work [20, 25] without additional training data. Following the settings in [21], we report the top-5 recalls of action, verb, and noun.
EPIC-KITCHENS-100 (EK100) [15] 是一个大规模的第一人称视角视频数据集,包含700段烹饪活动视频,涵盖3806个动作、97个动词和300个名词。本工作沿用先前研究[20, 25]的设置,在不使用额外训练数据的情况下,在验证集上评估所提方法。根据[21]的实验配置,我们报告动作、动词和名词的top-5召回率。
EGTEA $\mathbf{GAZE+}$ [38] is a large-scale dataset for firstperson-view (FPV) actions and gaze. It contains 28 hours cooking activity videos from 86 unique sessions of 32 subjects. There are totally 106 actions with 19 verbs and 51 nouns. Top-1 accuracy is used as the evaluation metric.
EGTEA $\mathbf{GAZE+}$ [38] 是一个用于第一人称视角 (FPV) 动作与视线追踪的大规模数据集。它包含32名受试者在86个独立烹饪环节中录制的28小时活动视频,共标注106个动作(含19个动词和51个名词),采用Top-1准确率作为评估指标。
Table 1. Experiment results on EK100 validation set. UADT achieves state-of-the-art performance under different settings.
表 1: EK100验证集上的实验结果。UADT在不同设置下均实现了最先进的性能。
| 方法 | 初始化 | 模态 | Top-5召回率 | ||
|---|---|---|---|---|---|
| 动词 | 名词 | 动作 | |||
| TempAgg [50] | IN1k | RGB | 24.2 | 29.8 | 13.0 |
| RULSTM [20] | IN1k | RGB | 13.3 | ||
| RULSTM [20] | IN1k | RGB+Flow+Obj | 30.8 | 27.8 | 14.0 |
| TempAgg [50] | IN1k | Flow+Obj+ROI | 21.2 | 31.4 | 14.7 |
| AVT [26] | IN21k | RGB | 30.2 | 31.7 | 14.9 |
| AVT+ [26] | IN21k | RGB+Obj | 28.2 | 32.0 | 15.9 |
| TSN-AVT+ [26] | IN21k | RGB+Obj | 31.8 | 25.5 | 14.8 |
| MeMViT [61] | K400 | RGB | 32.8 | 33.2 | 15.1 |
| RAFTformer [25] | K400+IN1k | RGB | 33.3 | 35.5 | 17.6 |
| UADT (ours) | K400 | RGB | 35.2 | 38.5 | 18.8 |
| MeMViT [61] | K700 | RGB | 32.2 | 37.0 | 17.7 |
| RAFTformer [25] | K700 | RGB | 33.7 | 37.1 | 18.0 |
| RAFTformer-2B [25] | K700+IN1k | RGB | 33.8 | 37.9 | 19.1 |
| UADT (ours) | K700 | RGB | 38.2 | 41.4 | 20.3 |
| UADT (ours) | K700 | RGB+Flow+Obj | 43.5 | 46.6 | 23.0 |
50-Salads [52] is a third-person video dataset for action under standing. It captures 25 people preparing 2 mixed salads in 966 activity instances. There are totally 17 different actions. Following [50], we report the top-1 action accuracy over the pre-defined splits for comparison.
50-Salads [52] 是一个用于动作理解的第三人称视频数据集。它记录了25个人准备2份混合沙拉的过程,共包含966个活动实例,总计17种不同的动作。按照[50]的方法,我们报告了预定义分割上的top-1动作准确率以便比较。
4.2. Implementation Details
Feature extraction. For EK100 dataset, we adopt MViTb [17, 39] as the backbone. We pre-trained the $16\times4$ MViTb on Kinetics-400 [8] for action classification. The $16~\times$ 4 model uses 16 frames sampled 4 frames apart at 30fps, which leads to 2 seconds for each clip at 8fps. On the other hand, the Kinetics-700 [9] pretrained features are obtained by a $32\times3$ MViT, which uses 32 frames sampled 3 frames apart at 30fps. For EGTEA $\mathrm{Gaze+}$ , a TSN [58] pretrained on ImageNet-1K is used to extract features following the procedure in RULSTM [20]. For 50-Salads dataset, we used the I3D [8] features provided in [18]. In this way, we use the same feature as the SOTA [48] for fair comparisons. More details can be found in the supplementary.
特征提取。对于EK100数据集,我们采用MViTb [17, 39]作为主干网络。我们在Kinetics-400 [8]上预训练了$16\times4$ MViTb用于动作分类。该$16~\times$4模型使用30fps下间隔4帧采样的16帧序列,相当于8fps下每段2秒的片段。另一方面,Kinetics-700 [9]预训练特征由$32\times3$ MViT生成,该模型采用30fps下间隔3帧采样的32帧序列。对于EGTEA $\mathrm{Gaze+}$数据集,我们按照RULSTM [20]的方法使用ImageNet-1K预训练的TSN [58]提取特征。针对50-Salads数据集,我们采用[18]提供的I3D [8]特征。通过这种方式,我们使用与SOTA [48]相同的特征以保证公平比较。更多细节可参阅补充材料。
Settings. The proposed framework is implemented in PyTorch [45]. The UADT is optimized using AdamW optimizer with momentum 0.8 and weight decay of $10^{-3}$ . We train the model for 50 epochs using a cosine scheduler with a 20 warmup epochs. The batch size is set to 512. The base learning rate is set to $10^{-4}$ and end learning rate is set to $10^{-6}$ . The batch size is set to 512. The dropout rate of transformer is set to 0.25. $\lambda$ is set to 6 in $\mathcal{L}{e n}$ . And we set $\lambda_{1}=5$ and $\lambda_{2}=0.1$ in $\mathcal{L}_{d e}$ . More details are available in the supplementary.
设置。所提出的框架在PyTorch [45]中实现。UADT使用AdamW优化器进行优化,动量为0.8,权重衰减为$10^{-3}$。我们使用余弦调度器训练模型50个周期,其中包含20个预热周期。批量大小设置为512。基础学习率设为$10^{-4}$,最终学习率设为$10^{-6}$。Transformer的dropout率设为0.25。在$\mathcal{L}{en}$中$\lambda$设为6。在$\mathcal{L}{de}$中我们设置$\lambda{1}=5$和$\lambda_{2}=0.1$。更多细节见补充材料。
4.3. Comparison to state-of-the-art
4.3. 与最先进技术的对比
EK100. The experiment results on EK100 are shown in Table 1. Only using the RGB modality, our proposed UADT outperforms the state-of-the-art RAFTformer [25] by a large margin with both K400 and K700 features. We also show that the performance can be further boosted by incorporating more modalities in the ablation study $(\S4.4)$ . EGTEA Gaze+. The comparison is shown in Table 2. Using the same TSN/1N1k features, our UADT significantly outperforms the RAFTformer by $4.9%$ .
EK100。EK100上的实验结果如表1所示。仅使用RGB模态时,我们提出的UADT在K400和K700特征上均大幅超越当前最先进的RAFTformer [25]。消融研究$(\S4.4)$表明,通过引入更多模态可以进一步提升性能。EGTEA Gaze+。对比结果如表2所示,在使用相同TSN/1N1k特征时,我们的UADT以$4.9%$的优势显著优于RAFTformer。
Table 2. Experiment results on EGTEA Gaze+. UADT achieves SOTA performance using the same TSN/IN1k features.
表 2: EGTEA Gaze+ 上的实验结果。UADT 使用相同的 TSN/IN1k 特征实现了 SOTA 性能。
| 方法 | 初始化 | 模态 | Top-5 召回率 |
|---|---|---|---|
| DMR [55] | RGB | 38.1 | |
| ASTN [13] | TSN/IN1k | RGB+Flow | 31.6 |
| MCE [21] | TSN/IN1k | RGB+Flow | 43.8 |
| TCN [6] | RGB | 47.1 | |
| FN [16] | VGG-16 | RGB | 42.7 |
| RED [23] | VGG-16/TS | RGB+Flow | 54.6 |
| RULSTM [20] | TSN/IN1k | RGB+Flow+Obj | 58.6 |
| RAFTformer[25] | TSN/IN1k | RGB | 63.5 |
| UADT (ours) | TSN/IN1k | RGB | 68.4 |
Table 3. Experiment results on 50-Salads. Using the same I3D features as prior work, UADT outperforms all state-of-theart methods. * indicates reproduced results.
表 3: 50-Salads数据集上的实验结果。使用与先前工作相同的I3D特征,UADT超越了所有最先进方法。*表示复现结果。
| 方法 | Top-1准确率 (%) |
|---|---|
| DMR [55] | 6.2 |
| RNN [3] | 30.1 |
| CNN [3] | 29.8 |
| ActionBanks[50] | 40.7 |
| AVT [26] | 48.0 |
| RAFTformer* [25] | 53.2 |
| Latent-goal [48] | 59.6 |
| UADT (ours) | 62.7 |
50-Salads. The results are shown in Table 3. Our UADT outperforms the Latent-goal [48] by $3.1%$ using the same I3D features. This demonstrates that UADT can generalize to third-person dataset for anticipation.
50-Salads。结果如表 3 所示。使用相同的 I3D 特征时,我们的 UADT 比 Latent-goal [48] 高出 $3.1%$。这表明 UADT 可以泛化到第三人称数据集进行预测。
4.4. Ablation Studies
4.4. 消融实验
Different input modalities. To further study UADT, we incorporate results using additional modalities including the optical flow and object features. Specifically, we concatenate the feature vectors of different modalities at each time step. The results are shown in Table 4. By comparison, the performance is significantly improved by adding extra modalities. The optical flow features significantly improve the verb anticipation since they contain motion patterns. The object features are relatively effective for noun anticipation as the detected objects are highly-related to the noun of the action.
不同输入模态。为了进一步研究UADT,我们结合了光流和物体特征等其他模态的结果。具体来说,我们在每个时间步将不同模态的特征向量进行拼接。结果如表4所示。通过对比发现,添加额外模态后性能显著提升。光流特征因包含运动模式而显著提升了动词预测效果,物体特征则对名词预测相对有效,因为检测到的物体与动作名词高度相关。
Encoder uncertainty modeling. To demonstrate the effectiveness of uncertainty from the decoder, we implemented a baseline verb-to-noun model (VtN-b) and noun-to-verb model (NtV-b) without uncertainty mask. The two models have exactly the same architectures as the probabilistic ones we proposed. A comparison of performance is shown in Table 5. From the results, the uncertainty-based singlestream VtN/NtV and UADT outperform their baseline version, which demonstrates the effectiveness of the encoder uncertainty modeling.
编码器不确定性建模。为验证解码器不确定性的有效性,我们实现了不带不确定性掩码的基线动词-名词模型(VtN-b)和名词-动词模型(NtV-b)。这两个模型与我们提出的概率模型架构完全相同。性能对比结果如表5所示:基于不确定性的单流VtN/NtV和UADT均优于基线版本,证明了编码器不确定性建模的有效性。
Table 4. Experiment results of different modalities on EK100 val with K700 features. By incorporating additional modalities, the performance is significantly improved.
表 4: 基于K700特征的EK100验证集多模态实验结果。通过引入额外模态,性能得到显著提升。
| RGB | Flow Obj | Top-5 Recall (%) |
|---|---|---|
| Verb | ||
| 38.2 | ||
| √ | 41.7 | |
| √ | 41.0 | |
| √ | √ | 43.5 |
Table 5. Ablation study of encoder uncertainty on EK100 val. “b” denotes the baseline version and “U” denotes the uncertaintybased version.
表 5. EK100验证集上编码器不确定性的消融研究。"b"表示基线版本,"U"表示基于不确定性的版本。
| 方法 | K400 (Top-5召回率) | K700 (Top-5召回率) | ||||
|---|---|---|---|---|---|---|
| 动词 | 名词 | 动作 | 动词 | 名词 | 动作 | |
| VtN-b | 35.5 | 1 | 38.7 | |||
| VtN-U | - | 37.7 | - | 40.8 | ||
| NtV-b | 31.7 | 1 | 35.1 | |||
| NtV-U | 34.3 | 37.5 | ||||
| UADT-b | 33.2 | 36.5 | 18.0 | 36.0 | 39.1 | 19.4 |
| UADT | 35.2 | 38.5 | 18.8 | 38.2 | 41.4 | 20.3 |
Table 6. Ablation study of different types of uncertainties on EK100 val. Epistemic uncertainty is the most effective.
表 6: EK100验证集上不同类型不确定性的消融研究。认知不确定性 (Epistemic uncertainty) 效果最佳。
| 方法 | K400 (Top-5召回率) | K700 (Top-5召回率) | ||||
|---|---|---|---|---|---|---|
| 动词 | 名词 | 动作 | 动词 | 名词 | 动作 | |
| Baseline | 33.2 | 36.5 | 18.0 | 36.0 | 39.1 | 19.4 |
| Total-U | 34.7 | 38.0 | 18.5 | 37.7 | 41.0 | 20.1 |
| Aleatoric-U | 33.6 | 37.1 | 18.2 | 36.8 | 40.2 | 19.6 |
| Epistemic-U | 35.2 | 38.5 | 18.8 | 38.2 | 41.4 | 20.3 |
Types of uncertainty. We quantify the epistemic uncertainty in Eq. 5, aleatoric uncertainty in Eq. 6, as well as the total uncertainty. Then we generate the uncertainty masks based on different types of uncertainties and test the model. The comparison is shown in Table 6. The baseline method is implemented in same architecture without uncertainty modeling. From the results, the epistemic uncertainty is more effective than the other two types of uncertainties, which demonstrates our claim in Sec. 3.3.
不确定性类型。我们在公式5中量化认知不确定性 (epistemic uncertainty),在公式6中量化偶然不确定性 (aleatoric uncertainty),以及总不确定性。然后基于不同类型的不确定性生成不确定性掩码并测试模型。对比结果如表6所示。基线方法采用相同架构但不包含不确定性建模。结果表明,认知不确定性比其他两种类型的不确定性更有效,这验证了我们在第3.3节的结论。
Uncertainty sampling. In the uncertainty quant if i cation process, we repeat the forward process to obtain $N$ predictions. The number of samples affects the accuracy of uncertainty and further affects the anticipation performance. We varied the number of samples for different types of uncertainties. A comparison is shown in Figure 4. From the plots, it takes around 25 sampling times to obtain the relatively stable performance. Although the performance is still improving by increasing sampling times, we reported the performance of 25 sampling times in this paper due to the efficiency concern. The inference latency comparison with different sampling times can be found in the supplementary.
不确定性采样 (uncertainty sampling)。在不确定性量化过程中,我们重复前向过程以获得 $N$ 次预测。采样次数会影响不确定性的准确性,进而影响预测性能。我们对不同类型的不确定性采用了不同的采样次数。对比结果如图 4 所示。从图中可以看出,约需25次采样才能获得相对稳定的性能。虽然增加采样次数仍能提升性能,但出于效率考虑,本文采用25次采样的性能数据。不同采样次数下的推理延迟对比可参阅补充材料。

Figure 4. Ablation study of the uncertainty sampling and different types of uncertainty on EK100 val. By increasing the number of samples, the uncertainty quant if i cation is more accurate and it further improves the anticipation.
图 4: EK100验证集上不确定性采样及不同类型不确定性的消融研究。通过增加样本数量,不确定性量化更准确,从而进一步提升动作预测性能。
Table 7. Ablation study of training strategies on EK100 val. The proposed two-stage training can be improved by E2E training.
表 7: EK100验证集上训练策略的消融研究。提出的两阶段训练可通过端到端 (E2E) 训练进一步提升。
| 训练方式 | 特征 | 动词 | 名词 | 动作 |
|---|---|---|---|---|
| 两阶段 | K400 | 35.2 | 38.5 | 18.8 |
| 端到端单阶段 | K400 | 37.3 | 40.1 | 19.3 |
| 端到端两阶段 | K400 | 37.4 | 40.4 | 19.5 |
| 两阶段 | K700 | 38.2 | 41.4 | 20.3 |
| 端到端单阶段 | K700 | 41.2 | 42.8 | 21.1 |
| 端到端两阶段 | K700 | 41.5 | 43.0 | 21.2 |
Training strategies. For UADT, we adopt a two-stage (2S) training mechanism. The encoders are fixed after the firststage training and decoders are trained afterwards. To better optimize the model for anticipation, we also trained the model in an end-to-end (E2E) manner. We implemented two types of E2E training, namely the one-stage version and two-stage version. Specifically, the one-stage E2E trains the encoders and decoders together from scratch. For the two-stage E2E, we train the encoders first by minimizing $\mathcal{L}{e n}$ . Then we jointly train the encoders and decoders in the second stage by minimizing $\mathcal{L}_{d e}$ . The experiment results are shown in Table 7. The end-to-end methods obtain better results because the encoders are further optimized for anticipation after being trained for generating embeddings. The two-stage E2E converges faster than the one-stage E2E since the encoders are learned beforehand. In the comparison with state-of-the-art methods, we reported the results obtained by the 2S training instead of E2E training because the latter increases the training cost. A detailed comparison of training cost is available in supplementary.
训练策略。对于UADT,我们采用两阶段(2S)训练机制。编码器在第一阶段训练后固定,解码器随后进行训练。为了更好地优化模型的预测能力,我们还以端到端(E2E)方式训练模型。我们实现了两种E2E训练方式,即单阶段版本和两阶段版本。具体而言,单阶段E2E从头开始同时训练编码器和解码器。对于两阶段E2E,我们首先通过最小化$\mathcal{L}{e n}$来训练编码器,然后在第二阶段通过最小化$\mathcal{L}_{d e}$联合训练编码器和解码器。实验结果如表7所示。端到端方法获得更好结果,因为编码器在为生成嵌入训练后进一步针对预测进行了优化。两阶段E2E比单阶段E2E收敛更快,因为编码器已预先学习。在与最先进方法的比较中,我们报告了2S训练而非E2E训练的结果,因为后者会增加训练成本。训练成本的详细比较见补充材料。
Loss function. The encoder loss function $\mathcal{L}{e n}$ is composed of a top $K$ verb/noun loss and mean-squared error feature loss. To study the effect of $K$ and the balance between two terms. We varied $K$ and $\lambda$ during training. The results with different $K$ on EK100 val are shown in Figure 5a. Note the top $K$ loss becomes standard cross-entropy loss when $K=1$ . So the comparison also demonstrates the superiority of the top $K$ loss against the standard cross-entropy loss. The ablation study of $\lambda$ is plotted in Figure 5b. From the results, we empirically set $K=5$ and $\lambda:=:6$ since these settings output best performance under different settings. The ablation studies of $\lambda_{1}$ and $\lambda_{2}$ in the decoder loss function can be found in the supplementary.
损失函数。编码器损失函数 $\mathcal{L}{e n}$ 由前 $K$ 个动词/名词损失和均方误差特征损失组成。为了研究 $K$ 的影响以及两项之间的平衡,我们在训练过程中调整了 $K$ 和 $\lambda$。不同 $K$ 在 EK100 val 上的结果如图 5a 所示。注意当 $K=1$ 时,前 $K$ 损失变为标准交叉熵损失,因此该比较也证明了前 $K$ 损失相对于标准交叉熵损失的优越性。$\lambda$ 的消融研究结果如图 5b 所示。根据结果,我们经验性地设定 $K=5$ 和 $\lambda:=:6$,因为这些设置在不同配置下能输出最佳性能。解码器损失函数中 $\lambda_{1}$ 和 $\lambda_{2}$ 的消融研究详见补充材料。

Figure 5. Ablation study of encoder loss function on EK100 val. The top $K$ loss effectively improve the performance. We set $K=5$ and $\lambda=6$ since they output the best results under different settings.
图 5: EK100验证集上编码器损失函数的消融研究。Top $K$ 损失有效提升了性能。我们设定 $K=5$ 和 $\lambda=6$,因为它们在多种设置下能输出最佳结果。
Table 8. Ablation study of fusion strategies on EK100 val. All methods use by two-stage training with epistemic uncertainty.
表 8: EK100验证集上融合策略的消融研究。所有方法均采用带有认知不确定性 (epistemic uncertainty) 的两阶段训练。
| 方法 | K400 (Top-5召回率) | K700 (Top-5召回率) | ||||
|---|---|---|---|---|---|---|
| Verb | Noun | Action | Verb | Noun | Action | |
| VtN | 37.7 | 40.8 | ||||
| NtV | 34.3 | 37.5 | ||||
| Earlyfusion | 32.1 | 35.9 | 17.9 | 36.1 | 38.9 | 19.2 |
| Latefusion | 34.5 | 37.8 | 18.3 | 37.7 | 40.9 | 20.0 |
| Attention[20] | 34.8 | 38.0 | 18.5 | 37.8 | 41.1 | 20.1 |
| Uncertainty (s 3.5) | 35.2 | 38.5 | 18.8 | 38.2 | 41.4 | 20.3 |
Comparison of fusion strategies. In this work, we proposed an uncertainty-based fusion strategy of the verb-tonoun model and noun-to-verb model. To demonstrate its effec ti ve ness, we compare it with other types of fusion methods. First, we test the early fusion method by combing the predictions of verb and noun encoders. Second, we test late fusion by combing the predictions of both verb-to-noun model and noun-to-verb model. Additionally, we test the attention fusion method proposed in [20]. The results and comparison are shown in Table 8. The uncertainty-based fusion outperforms other methods using either K400 or K700 features, which demonstrates its effectiveness.
融合策略对比。在本研究中,我们提出了基于不确定性的动词-名词模型与名词-动词模型融合策略。为验证其有效性,我们将其与其他融合方法进行对比:首先测试通过合并动词和名词编码器预测结果的早期融合方法;其次测试合并动词-名词模型与名词-动词模型预测结果的晚期融合方法;此外还测试了文献[20]提出的注意力融合方法。如表8所示,基于不确定性的融合策略在使用K400或K700特征时均优于其他方法,验证了该策略的有效性。
5. Conclusion and Future Work
5. 结论与未来工作
In this paper, we introduced UADT for action anticipation. By combining a verb-to-noun model and a noun-to-verb model, the verb and noun predictions assist each other to improve joint action anticipation.
本文介绍了用于动作预测的UADT方法。通过结合动词到名词模型和名词到动词模型,动词与名词预测相互辅助以提升联合动作预测性能。
In the future, we plan to extend it for long-term action anticipation that aims at predicting a larger number of future actions. And we also plan to leverage large language models to capture the verb and noun dependencies.
未来,我们计划将其扩展用于长期动作预测,旨在预测更多未来动作。同时,我们计划利用大语言模型来捕捉动词和名词的依赖关系。