Will we run out of data? Limits of LLM scaling based on human-generated data
人类生成数据会耗尽吗?基于人类数据的大语言模型扩展极限
Pablo Villalobos 1 Anson Ho 1 Jaime Sevilla 1 2 Tamay Besiroglu 1 3 Lennart Heim 1 4 Marius Hobbhahn 1 5
Pablo Villalobos 1 Anson Ho 1 Jaime Sevilla 1 2 Tamay Besiroglu 1 3 Lennart Heim 1 4 Marius Hobbhahn 1 5
Abstract
摘要
We investigate the potential constraints on LLM scaling posed by the availability of public humangenerated text data. We forecast the growing demand for training data based on current trends and estimate the total stock of public human text data. Our findings indicate that if current LLM development trends continue, models will be trained on datasets roughly equal in size to the available stock of public human text data between 2026 and 2032, or slightly earlier if models are over trained. We explore how progress in language modeling can continue when human-generated text datasets cannot be scaled any further. We argue that synthetic data generation, transfer learning from datarich domains, and data efficiency improvements might support further progress.
我们研究了公开人类生成文本数据的可用性对大语言模型(LLM)扩展的潜在限制。根据当前趋势预测了训练数据需求的增长,并估算了公开人类文本数据的总存量。研究发现:若当前大语言模型的发展趋势持续,模型训练所用数据集规模将在2026至2032年间达到公开人类文本数据存量的水平(若存在过训练情况可能稍早)。探讨了当人类生成文本数据集无法继续扩展时语言建模的持续发展路径,认为合成数据生成、数据丰富领域的迁移学习以及数据效率提升可能支持后续进展。
1. Introduction
1. 引言
Recent progress in language modeling has relied heavily on unsupervised training on vast amounts of human-generated text, primarily sourced from the web or curated corpora (Zhao et al., 2023). The largest datasets of human-generated public text data, such as RefinedWeb, C4, and RedPajama, contain tens of trillions of words collected from billions of web pages (Penedo et al., 2023; Together.ai, 2023).
语言建模的最新进展很大程度上依赖于对海量人类生成文本的无监督训练,这些文本主要来自网络或精选语料库 (Zhao et al., 2023) 。最大规模的人类生成公开文本数据集(如 RefinedWeb、C4 和 RedPajama)包含从数十亿网页收集的数万亿单词 (Penedo et al., 2023; Together.ai, 2023) 。
The demand for public human text data is likely to continue growing. In order to scale the size of models and training runs efficiently, large language models (LLMs) are typically trained according to neural scaling laws (Kaplan et al., 2020; Hoffmann et al., 2022). These relationships imply that increasing the size of training datasets is crucial for efficiently improving the performance of LLMs.
对公共人类文本数据的需求可能会持续增长。为了高效扩展模型规模和训练轮次,大语言模型 (LLMs) 通常遵循神经缩放定律 (Kaplan et al., 2020; Hoffmann et al., 2022) 进行训练。这些关系表明,增加训练数据集的规模对于高效提升大语言模型的性能至关重要。
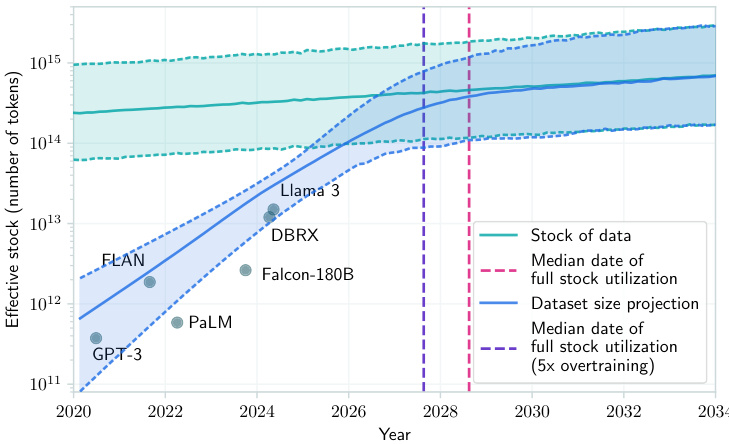
Figure 1. Projections of the effective stock of human-generated public text and dataset sizes used to train notable LLMs. The intersection of the stock and dataset size projection lines indicates the median year (2028) in which the stock is expected to be fully utilized if current LLM development trends continue. At this point, models will be trained on dataset sizes approaching the total effective stock of text in the indexed web: around 4e14 tokens, corresponding to training compute of ${\sim}5{\mathrm{e}}28$ FLOP for non-over trained models. Individual dots represent dataset sizes of specific notable models. The model is explained in Section 2
图 1: 人类生成公开文本有效存量与知名大语言模型训练数据集规模的预测。存量线与数据集规模预测线的交点表示中位年份(2028年),若当前大语言模型发展趋势持续,预计该年份将完全耗尽现有文本存量。此时模型训练将使用接近整个索引网络文本总有效存量的数据集规模:约4e14个token,对应未过拟合模型的训练计算量约${\sim}5{\mathrm{e}}28$FLOP。各圆点代表特定知名模型的数据集规模。该模型详见第2节说明
In this paper, we argue that human-generated public text data cannot sustain scaling beyond this decade. To support this conclusion, we develop a model of the growing demand for training data and the production of public human text data. We use this model to predict when the trajectory of LLM development will fully exhaust the available stock of public human text data. We then explore a range of potential strategies to circumvent this constraint, such as synthetic data generation, transfer learning from data-rich domains, and the use of non-public data.
本文认为,人类生成的公共文本数据无法支撑未来十年之后的规模扩展。为支持这一结论,我们建立了一个关于训练数据需求增长与公共人类文本数据生产的模型,并借此预测大语言模型发展轨迹何时会耗尽现有公共人类文本数据存量。随后探讨了突破这一限制的潜在策略,包括合成数据生成、从数据丰富领域进行迁移学习,以及使用非公开数据等方案。
1.1. Related work
1.1. 相关工作
Stock of internet data Several studies have sought to quantify the internet’s size and information content. Murray H. & Moore (2000) estimated the internet’s size at approximately 2.1 billion unique web pages containing 21 terabytes of data. Coffman & Odlyzko (1998) and Odlyzko (2016) found that public internet traffic experienced a rapid growth rate of approximately $100%$ per year in the early 1990s, which slowed down to double-digits in the late 2010s, particularly in developed countries.
互联网数据存量
多项研究尝试量化互联网的规模和信息容量。Murray H. & Moore (2000) 估算互联网包含约21亿个独立网页,数据量为21太字节。Coffman & Odlyzko (1998) 和 Odlyzko (2016) 发现,20世纪90年代初公共互联网流量年增长率约为 $100%$,到2010年代末已放缓至两位数,尤其在发达国家更为明显。
More recently, Reinsel et al. (2018) estimate the total amount of new data created, captured, or replicated worldwide in any given year to be 33 billion terabytes. Unfortunately, the analysis does not break this down into different data modalities (e.g. images, videos, or text data). Focusing just on Google’s index, van den Bosch et al. (2016) estimated the stock from 2006 to 2015, finding that it varied significantly over time but is on the order of tens of billions of web pages.
最近,Reinsel等人(2018) 估计全球每年新增、获取或复制的数据总量达到330亿太字节。遗憾的是,该分析并未将这些数据按不同模态(如图像、视频或文本数据)进行细分。仅针对谷歌索引,van den Bosch等人(2016) 估算了2006至2015年的存量数据,发现其随时间波动显著,但规模维持在数百亿网页量级。
Data bottlenecks in machine learning Mu en nigh off et al. (2023) studied several techniques to mitigate data scarcity for training LLMs. In particular, they considered repeating data, adding more code data, and relaxing the quality filters used during data preprocessing. They quantified the loss of performance when using these techniques to compensate for a smaller data budget, finding that both repeating data and including more code data can compensate for a decrease of up to $75%$ in the text data budget. Xue et al. (2023) also studied multi-epoch training as a solution for data scarcity. Nost algebra is t (2022) argued that high-quality training data would soon become a bottleneck for machine learning.
机器学习中的数据瓶颈
Mu en nigh off等人(2023)研究了几种缓解大语言模型(LLM)训练数据稀缺的技术。他们特别考察了数据重复、增加代码数据量以及放宽数据预处理阶段的质量过滤标准等方法。通过量化这些技术在补偿较小数据预算时的性能损失,他们发现数据重复和增加代码数据可补偿高达$75%$的文本数据预算缩减。Xue等人(2023)同样研究了多轮次训练作为数据稀缺的解决方案。Nost algebra is t(2022)指出,高质量训练数据将很快成为机器学习的瓶颈。
Leading AI researchers have expressed concerns about data availability limiting the progress of machine learning systems. Dario Amodei, the CEO of Anthropic, estimates a $10%$ chance that the scaling of AI systems could stagnate due to insufficient data (Roose & Newton, 2023). This underscores the importance of investigating the limitations posed by the finite supply of public human text data.
领先的AI研究人员对数据可用性限制机器学习系统发展表示担忧。Anthropic首席执行官Dario Amodei估计,由于数据不足,AI系统规模扩展停滞的可能性达10% (Roose & Newton, 2023)。这凸显了研究公共人类文本数据有限供应所造成限制的重要性。
Table 1. Estimates of the stock of data on the web in tokens. $^3\mathrm{In}$ the case of images and video we only have point estimates.
| Estimate | Median | 95% CI |
| CommonCrawl | 130T | [100T,260T] |
| Indexedweb | 510T | [130T,2100T] |
| Wholeweb | 3100T | [1900T, 5200T] |
| Images | 300T | N/A |
| Video | 1350T | N/A |
表 1: 网络数据存量估算(以Token计)。$^3\mathrm{In}$ 对于图像和视频,我们只有点估计值。
| 估算来源 | 中位数 | 95%置信区间 |
|---|---|---|
| CommonCrawl | 130T | [100T,260T] |
| Indexedweb | 510T | [130T,2100T] |
| Wholeweb | 3100T | [1900T,5200T] |
| Images | 300T | N/A |
| Video | 1350T | N/A |
2. A model of data scarcity
2. 数据稀缺模型
The core question we aim to answer is whether the limited availability of public human text data could constrain further LLM scaling. We consider two key variables: the total amount of public human text data available for use (“data stock”) and what quantity of this data is actually used in practice during LLM training (“dataset size”). In this section, we develop a model to project both the data stock and dataset sizes.
我们旨在回答的核心问题是:公开人类文本数据的有限可用性是否会制约大语言模型的进一步扩展。我们考虑两个关键变量:可供使用的公开人类文本数据总量("数据存量")以及大语言模型训练中实际使用的数据量("数据集规模")。本节将建立模型来预测数据存量和数据集规模。
2.1. Quantifying dataset sizes
2.1. 量化数据集规模
Specifying our model requires being explicit about how we quantify “data”. To this end, we define the dataset size as the number of tokens in the training dataset of interest.4 In large samples of English text, one token usually corresponds to around 0.8 words (see Appendix E).
明确我们的模型需要量化“数据”的具体方式。为此,我们将数据集规模定义为目标训练数据集中的token数量。在大量英文文本样本中,1个token通常对应约0.8个单词(见附录E)。
One limitation of this definition is that the size of a text corpus in tokens depends on how the text is tokenized. That said, in practice, the number of tokens in a corpus does not vary greatly between common tokenizers. Moreover, the two most prominent alternatives – the number of words and the storage size in bytes – can vary significantly between modalities or even be undefined.
该定义的一个局限在于,文本语料库的token数量取决于文本的分词(tokenization)方式。不过在实际应用中,常见分词器产生的token数量差异并不显著。此外,两种主流替代指标——单词数量和字节存储大小——在不同模态间可能存在显著差异,甚至无法定义。
2.2. Estimating data stocks
2.2. 估算数据存量
The first main variable of our model is the data stock $S$ . We estimate this by calculating the size of the indexed web and the amount of data that is contained in the average web page, using statistics from Common Crawl.
我们模型的第一个主要变量是数据存量 $S$。我们通过计算索引网页的规模及平均网页包含的数据量来估算该变量,所用统计数据来自Common Crawl。
Since web data contains many low-quality segments of text that do not contribute to model performance (Penedo et al., 2023), we adjust our estimate to account for differences in data quality. We also adjust for the possibility of multiepoch training. We explain these adjustments in greater detail in Section 2.3. As a further robustness check, we estimate the amount of internet text generated each year based on the world population. Table 1 shows the results of these estimates.
由于网络数据包含大量低质量文本片段,这些内容对模型性能提升无益 [Penedo et al., 2023],我们调整了估算方法以考虑数据质量差异,同时针对多轮次训练的可能性进行了修正。第2.3节将详细说明这些调整方法。作为额外的稳健性检验,我们还基于全球人口规模估算了每年产生的互联网文本量。表1展示了这些估算结果。
We model our uncertainty about all the observed variables of our models as log-normal distributions, and report our $95%$ confidence intervals (CIs) for each of them. The CIs for the latent variables are obtained by Monte Carlo simulations of the functional relationships that define those variables.
我们将模型所有观测变量的不确定性建模为对数正态分布,并报告各变量的95%置信区间(CI)。通过蒙特卡洛模拟定义潜变量的函数关系,获得其置信区间。
2.2.1. INDEXED WEB
2.2.1. 索引化网络
Common Crawl, a regularly updated open-source collection of scraped web data consisting of over 250 billion web pages (Common Crawl, 2024),8 serves as the basis for most open web datasets, such as RefinedWeb, C4, and RedPajama. As a subset of the indexed web, Common Crawl’s maximum size is inherently bounded by the size of the indexed web.9
Common Crawl是一个定期更新的开源网络爬取数据集,包含超过2500亿个网页 (Common Crawl, 2024),是大多数开放网络数据集(如RefinedWeb、C4和RedPajama)的基础。作为索引网络的子集,Common Crawl的最大规模本质上受限于索引网络的体量。
To estimate the size of the indexed web, we use the size of Google’s index as a proxy.10 Applying the methodology proposed by van den Bosch et al. (2016), we estimate that Google’s index contains approximately 250 billion web pages, with a $95%$ confidence interval ranging from 100 billion to 1200 billion web pages (see Appendix B).
为了估算被索引网络的大小,我们以Google索引规模作为代理指标。10 采用van den Bosch等人 (2016) 提出的方法,估算Google索引包含约2500亿个网页,其95%置信区间介于1000亿至1.2万亿个网页之间 (详见附录B)。
Assuming that Common Crawl is a representative sample of the indexed web,11 we can use it to estimate the average amount of plain text bytes per web page. This number has increased over time, from around 6100 bytes in 2013 to about 8200 bytes in 2021.12 We estimate the average plain text bytes per web page to be 7000 $95%$ : 6100, 8200].13
假设Common Crawl是索引网络的一个代表性样本[11],我们可以用它来估算每个网页的平均纯文本字节数。这个数字随时间增长,从2013年的约6100字节增至2021年的8200字节[12]。我们估算每个网页的平均纯文本字节数为7000(95%置信区间:[6100, 8200])[13]。
Each token corresponds to 4 bytes of plain text $[95%$ : 2, 5] (see Appendix E), so the raw stock of tokens on the indexed web in 2024, calculated according to Equation 1 is around 510 trillion $95%$ : 130T, 2100T].
每个token对应4字节纯文本 $[95%$ : 2, 5] (参见附录E),因此根据公式1计算,2024年索引网络中的原始token存量约为510万亿 $95%$ : 130T, 2100T]。
Since 2013, the plain-text size of the average Common Crawl web page has been growing by between $2%$ and $4%$ each year. However, estimating the growth rate of the total number of web pages is more challenging due to conflicting evidence. The methodology employed by van den Bosch et al. (2016) suggests that the size of Google’s index has remained relatively constant over the past decade, which is a counter intuitive result since new web pages are regularly created. Appendix B discusses alternative explanations for this apparent lack of growth in Google’s index size.
自2013年以来,Common Crawl网页的平均纯文本大小每年增长约$2%$至$4%$。然而,由于证据相互矛盾,估算网页总数的增长率更具挑战性。van den Bosch等人(2016)采用的方法表明,谷歌索引规模在过去十年中保持相对稳定,这一反直觉的结果与网页持续新增的现象相悖。附录B讨论了谷歌索引规模看似未增长的其他可能解释。
Indexed Web Projected Growth
索引网络预计增长
$$
S_ {I W}(y)=N_ {I W}\times B_ {P}\times T_ {B}\times(1+g)^{y-y_ {0}}
$$
$$
S_ {I W}(y)=N_ {I W}\times B_ {P}\times T_ {B}\times(1+g)^{y-y_ {0}}
$$
where $S_ {I W}(y)$ is the estimate of the current stock of tokens in the indexed web in a given year $y$ , $N_ {I W}$ is the number of unique web pages in the indexed web, $B_ {P}$ is the average number of bytes per web page, $T_ {B}$ is the average number of tokens per byte, and $g$ is the estimated rate of growth of the total number of tokens.
其中 $S_ {I W}(y)$ 是给定年份 $y$ 中被索引网页当前token存量的估计值,$N_ {I W}$ 是被索引网页中唯一页面的数量,$B_ {P}$ 是每个网页的平均字节数,$T_ {B}$ 是每字节的平均token数,$g$ 是token总数的估计增长率。
To better estimate the growth rate of the indexed web, we consider several proxies: global IP traffic, link rot rates, and the growth in the number of internet users. Global IP traffic was increasing by $24%$ in 2016 (Cisco, 2017), which can be considered an upper bound on the growth rate of web pages, as the majority of traffic corresponds to consumption rather than creation of text data. Conversely, the number of internet users is growing by approximately $2\cdot4%$ per year (Section 2.2.2), and estimates of the link rot rate range from $2%$ to $16%$ (Appendix B). For Google’s index size to remain constant, the link rot rate must be offset by the creation of new web pages or links, suggesting possible growth rates of around $10%$ .
为了更好地估算被索引网页的增长率,我们参考了以下指标:全球IP流量、链接失效率以及互联网用户数量增长。2016年全球IP流量增长率为$24%$ (Cisco, 2017),这可以视为网页增长率的上限,因为大部分流量对应的是文本数据的消费而非生产。相反,互联网用户数量每年增长约$2\cdot4%$(第2.2.2节),而链接失效率估计在$2%$至$16%$之间(附录B)。要使谷歌索引规模保持稳定,新网页或链接的创建必须抵消链接失效率,这表明可能的增长率约为$10%$。
However, double-digit growth rates would imply that the average internet user is creating significantly more web pages over time, a trend that appears to be contradicted by some observations, such as the roughly constant rate of tweets per user on Twitter (GDELT, 2020) and similar observations for other platforms such as Wikipedia (Wikipedia). Given these considerations, we settle on a confidence interval between $0%$ and $10%$ a year.14
然而,两位数的增长率意味着普通互联网用户随时间推移会创建显著更多的网页,这一趋势似乎与某些观察结果相矛盾,例如 Twitter 上每位用户的推文发布率基本保持稳定 (GDELT, 2020) ,以及维基百科 (Wikipedia) 等其他平台的类似观察。基于这些考量,我们将年增长率置信区间设定在 $0%$ 到 $10%$ 之间。14
2.2.2. INTERNET POPULATION
2.2.2. 互联网人口
We consider an alternative model of data stocks that explicitly accounts for the process that generates data. This model relies on the observation that much of the internet’s text data is user-generated and stored on platforms such as social media, blogs, and forums. While AI-generated text is becoming more prevalent, we exclude it from this model and discuss it in Section 3. In principle, we can estimate the amount of public human-generated text data by considering the number of internet users and the average data produced per user, with growth in data generation primarily driven by the increasing number of internet users.
我们考虑一种替代的数据存量模型,该模型明确考虑了数据生成过程。该模型基于一个观察结果:互联网上的大部分文本数据由用户生成,并存储在社交媒体、博客和论坛等平台上。尽管AI生成的文本日益普遍,但我们在此模型中将其排除,并在第3节讨论。理论上,我们可以通过考虑互联网用户数量及人均生成数据量来估算公开的人类生成文本数据总量,数据生成的增长主要由互联网用户数量的增加驱动。
We model the increase in the number of internet users as coming from two contributors: (1) increases in the human population, and (2) increases in “internet penetration,” i.e. the percentage of the population that uses the internet. For the former, we turn to standard projections by the United Nations (United Nations, 2022). Since internet penetration has broadly followed an S-curve from ${\sim}0%$ in 1990 to $50%$ in 2016 to over $60%$ today (Ritchie & Roser, 2017), we model this using a sigmoid function, fitting it to the data in Ritchie & Roser (2017).
我们将互联网用户数量的增长归因于两个因素:(1) 人口增长,(2) "互联网普及率"(即使用互联网的人口百分比)提升。对于前者,我们采用联合国标准预测数据 (United Nations, 2022)。由于互联网普及率总体上遵循S型曲线增长(从1990年的${\sim}0%$到2016年的$50%$,再到如今超过$60%$ (Ritchie & Roser, 2017)),我们使用Sigmoid函数对此建模,并基于Ritchie & Roser (2017) 的数据进行拟合。
Finally, the amount of data generated per internet user varies across countries and over time due to differences in culture, demographics, socioeconomic factors, and online services. Quantifying these variations is complex and beyond the scope of this analysis, so we assume that the average data production rate per user remains constant to enable a tractable estimate.
最后,由于文化、人口统计、社会经济因素和在线服务的差异,每个互联网用户产生的数据量在不同国家和不同时期会有所不同。量化这些差异非常复杂,超出了本分析的范围,因此我们假设每位用户的平均数据生成率保持不变,以便进行可行的估算。
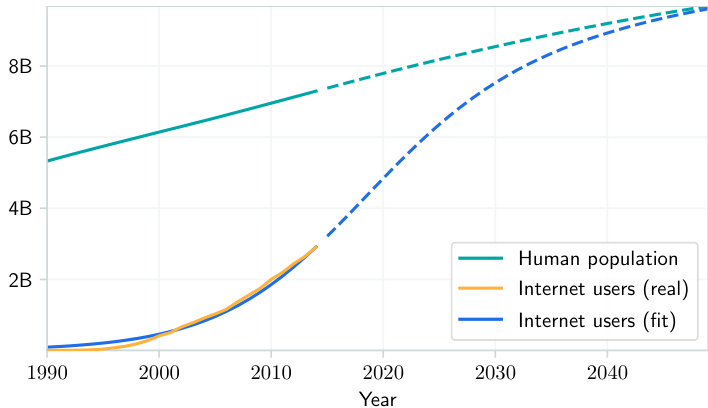
Figure 2. Historical and projected evolution of internet users. Historical data is from Ritchie & Roser (2020).
图 2: 互联网用户历史及预测演变趋势。历史数据来自 Ritchie & Roser (2020)。
This model of the number of internet users closely matches the historical data (Figure 2). A more detailed explanation of this model can be found in Appendix A.
该互联网用户数量模型与历史数据高度吻合(图 2)。关于该模型的更详细说明可参阅附录A。
Based on reported user statistics for major online platforms (see Appendix C), we estimate the total volume of text data uploaded to the internet in 2024 was between 180T and 500T tokens. To project future data accumulation, we scale this initial 2024 estimate by the projected number of internet users in each subsequent year. This provides the estimated annual data contribution from the global online population. We then cumulatively sum these yearly contributions over time to model the total stock of internet text data. The final estimate is 3100T $[95%$ : 1900T, 5200T] tokens. This estimate includes both data on the indexed web and the deep web, and therefore serves as an upper bound on the size of the indexed web.
根据主要在线平台的用户统计数据(见附录C),我们估算2024年上传至互联网的文本数据总量在180T至500T token之间。为预测未来数据累积量,我们将这一初始估算值按后续年份的互联网用户预计数量进行比例调整,得出全球网民每年的预估数据贡献量。随后对这些逐年贡献量进行累加,以模拟互联网文本数据的总存量。最终估算结果为3100T [95%置信区间: 1900T, 5200T] token。该估算涵盖索引网络和深网数据,因此可作为索引网络规模的上限值。
2.3. Data quality and multi-epoch training
2.3. 数据质量与多轮训练
The preceding subsections outline the core basis of the model that we use in our analysis. However, before performing forecasts, we first need to account for a few additional considerations.
前文小节概述了我们分析所用模型的核心基础。但在进行预测前,我们还需考虑几个额外因素。
In particular, since our focus is on data constraints in the scaling of language models, the literal number of tokens in the training dataset may not be what matters for improving LLM performance. For example, differences in data quality (Li et al., 2023) and the number of training epochs (Mu en nigh off et al., 2023) can potentially have a substantial effect on final model performance. In this subsection, we analyze the significance of these factors and modify our model accordingly. Our adjustments for data quality and multi-epoch training are illustrated in Figure 3.
特别是,由于我们关注的是语言模型扩展中的数据限制,训练数据集中的token数量可能并非提升大语言模型性能的关键。例如,数据质量差异 [20] 和训练轮次数量 [21] 都可能对最终模型性能产生重大影响。本节我们将分析这些因素的重要性并相应调整模型。图 3 展示了我们对数据质量和多轮训练所做的调整。
2.3.1. DATA QUALITY
2.3.1. 数据质量
One way in which only considering the measure of “number of tokens” is too simplistic is that not all public human text data is created equal. Intuitively, we would expect models that are trained primarily on books or Wikipedia to outperform models that are purely trained on YouTube comments. In this way, public human text data from books are “higher quality” than YouTube comments. Such intuitions are in fact supported by some empirical observations. For example, data processing techniques like de duplication (Lee et al., 2022) and data filtering (Gao, 2021) have been shown to improve model performance.
仅考虑"token数量"这一衡量标准过于简单化的一个原因是,并非所有公开的人类文本数据都具有同等价值。直观来看,我们预期主要基于书籍或维基百科训练的模型表现会优于纯粹基于YouTube评论训练的模型。从这个角度看,书籍中的公开人类文本数据"质量更高"于YouTube评论。这种直觉实际上得到了一些实证观察的支持。例如,去重处理(Lee等人,2022)和数据过滤(Gao,2021)等数据处理技术已被证明能提升模型性能。
However, building in these effects into our model is nontrivial. For one, there is no standard accepted measure of data quality (Mitchell et al., 2023). Instead, we are forced to rely on a fairly vague working definition: A dataset is of higher quality than another if training on it leads to higher performance, at similar dataset sizes.
然而,将这些效应纳入我们的模型并非易事。首先,目前尚无公认的数据质量衡量标准 (Mitchell et al., 2023) 。因此我们不得不采用一个较为模糊的工作定义:在数据集规模相近的情况下,使用某数据集训练能获得更高性能,则该数据集质量更高。
Recent findings show that with adequate filtering, data extracted from the web can outperform datasets constructed from human-curated sources (Penedo et al., 2023). In addition, Xie et al. (2023) found that in The Pile, which is a dataset consisting of web data and human-curated sources, increasing the proportion of web data up to $40{-}70%$ led to substantially higher performance. These empirical findings suggest that while much of internet public human text data is on average “lower quality” than human-curated sources, one can potentially make up for this through careful data processing.
近期研究表明,经过充分过滤后,从网络提取的数据可以超越人工精选来源构建的数据集 [20]。此外,Xie等人 [23] 发现,在由网络数据和人工精选来源组成的The Pile数据集中,将网络数据比例提升至$40{-}70%$会显著提高模型性能。这些实证结果表明,尽管互联网公开人类文本数据的平均"质量"通常低于人工精选来源,但通过精细的数据处理仍有可能弥补这一差距。
Given these considerations, we can attempt to determine how much we need to adjust our previous model to account for data quality. We operational ize this in terms of how much “low quality” data is filtered to achieve optimal performance in practice. Penedo et al. (2023) create a 5T-token dataset that outperforms curated corpora by carefully filtering and de duplicating raw data from Common Crawl. The filtering part of this process reduced the size of the web dataset by around $30%$ . Meanwhile, Marion et al. (2023) found that pruning around $50%$ of de duplicated data from a subset of Common Crawl using a perplexity measure led to optimal performance.15 Based on these empirical results, we believe with $95%$ certainty that between $10%$ and $40%$ of de duplicated web data can be used for training without significantly compromising performance.
考虑到这些因素,我们可以尝试确定需要如何调整之前的模型以应对数据质量问题。我们通过量化实际应用中需过滤多少"低质量"数据才能达到最佳性能来衡量这一点。Penedo等人 (2023) 通过精心过滤和去重Common Crawl原始数据,创建了一个5T-token数据集,其表现优于人工精选语料库。该过程中的过滤环节使网络数据集规模缩减了约$30%$。同时,Marion等人 (2023) 发现使用困惑度指标对Common Crawl子集去重后数据修剪约$50%$时能达到最佳性能[15]。基于这些实证结果,我们有$95%$的把握认为:在不显著影响性能的前提下,$10%$至$40%$的去重网络数据可用于训练。
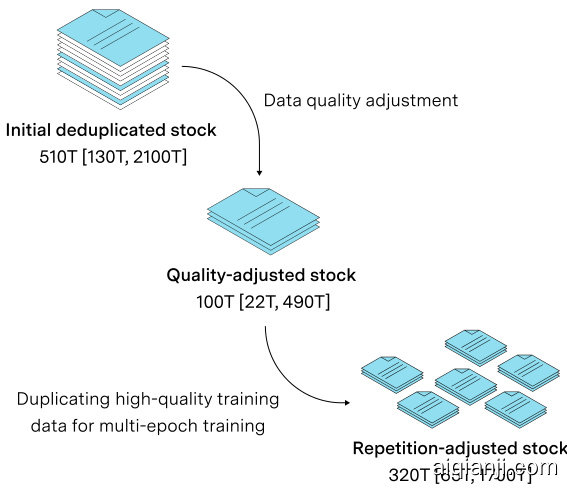
Figure 3. Illustration of the adjustments for quality and repetition and the adjusted stock sizes in number of tokens. First the lowerquality data is filtered out, and then the resulting dataset is duplicated for multi-epoch training.
图 3: 质量和重复性调整及调整后token数量级库存规模的示意图。首先过滤掉低质量数据,然后对结果数据集进行复制以实现多轮次训练。
2.3.2. MULTIPLE EPOCHS
2.3.2. 多轮训练周期
Besides data quality, using the “number of tokens” as a measure does not account for the possibility of multi-epoch training. The degree to which stocks should be adjusted for multiple epochs depends on the effectiveness of training on the same data over multiple epochs, compared to training on new “unique” data.
除了数据质量外,使用"token数量"作为衡量标准并未考虑多轮次训练的可能性。股票调整程度应根据多轮次训练相同数据与训练新"独特"数据的效果对比来决定。
Mu en nigh off et al. (2023) investigate this empirically, fitting a scaling law for the performance of a model trained for multiple epochs. Concretely, for a given model trained on multiple epochs, this law gives an estimate of the dataset size that would produce an equally capable model with just one epoch.. This is the “effective dataset size” of a multiepoch training run. The authors estimate the maximum increase in the effective dataset size that can be gained from multiple epochs at between $3\mathbf{x}$ and $15\mathrm{x}$ , and we anchor to this estimate in adjusting our model. Because additional epochs yield diminishing returns, the upper extreme of $15\mathrm{x}$ would require a very inefficient training procedure with a large number of epochs that does not correspond to common practices.16 For this reason we reduce it to $\operatorname{5x}$ .
Mu en nigh off等人 (2023) 通过实证研究拟合出多轮训练模型的性能扩展律。具体而言,对于经过多轮训练的给定模型,该定律可估算出仅需单轮训练就能达到同等能力所需的数据集规模,即多轮训练的"有效数据集规模"。作者估计多轮训练带来的有效数据集规模最大增幅介于 $3\mathbf{x}$ 至 $15\mathrm{x}$ 之间,我们在模型调整中以此估算为基准。由于额外训练轮次的收益递减,达到 $15\mathrm{x}$ 的极端值需要采用极低效的多轮训练方案,这与常规实践不符。因此我们将该值调整为 $\operatorname{5x}$。
Historical Dataset Size Growth Projection
历史数据集规模增长预测
$$
D_ {H}(y)=G_ {D}^{y-y_ {0}}D(y_ {0})
$$
$$
D_ {H}(y)=G_ {D}^{y-y_ {0}}D(y_ {0})
$$
where $D_ {H}$ is the training dataset size, $G_ {D}$ is the factor growth per year, $Y_ {0}$ is some base year, and $Y$ is the year. Both $G_ {D}$ and $D(y_ {0})$ are lognormal distributions.
其中 $D_ {H}$ 是训练数据集大小,$G_ {D}$ 是每年增长因子,$Y_ {0}$ 是基准年份,$Y$ 是当前年份。$G_ {D}$ 和 $D(y_ {0})$ 均服从对数正态分布。
2.4. Projecting growth in dataset sizes
2.4. 数据集规模增长预测
To project the future values of our second key variable, the training dataset size $D$ , we begin by examining historical growth rates and extrapolating them forward.
为了预测我们第二个关键变量——训练数据集大小 $D$ 的未来值,我们首先考察历史增长率并据此进行外推。
To estimate historical growth, we use the database of notable machine learning models in Epoch (2022), a comprehensive database that contains annotations of over 300 machine learning models. We filter this data to include only large language models (LLMs) from papers published between 2010 and 2024, resulting in a subset of around 80 data points. We then perform a linear regression on the logarithm of the dataset size against time, as shown in Equation 2. This yields a median estimate of 0.38 orders of magnitude per year (OOM/y), or around $2.4\mathbf{X}$ per year, with a boots trapped $95%$ confidence interval of 0.27 to $0.48\mathrm{OOM/y}$ .
为估算历史增长趋势,我们采用Epoch (2022) 的知名机器学习模型数据库,该库包含300多个机器学习模型的标注信息。我们筛选2010至2024年间论文发表的大语言模型 (LLM) ,得到约80个数据点。随后对数据集规模的对数与时间进行线性回归,如公式2所示。结果显示年增长中位数为0.38个数量级/年 (OOM/y) ,约合每年$2.4\mathbf{X}$,自助法计算的95%置信区间为0.27至$0.48\mathrm{OOM/y}$。
To project this trend forward, we first need to determine the size of the largest datasets used today, which are typically around 10T tokens.1718 Naively projecting the historical trend from this baseline suggests that systems could be trained on over one quadrillion tokens by the end of the decade (see Figure 4).
要预测这一趋势的未来发展,我们首先需要确定当前使用的最大数据集规模,通常在10T token左右。[17][18] 从这个基线简单推演历史趋势表明,到本年代末系统可能接受超过一千万亿token的训练 (见图4)。
The historical growth rate in dataset sizes cannot continue indefinitely, even if the data stock was unlimited. In the past, the increasing scale of computing power has driven the demand for larger training datasets, consistent with neural scaling laws for dense transformers which suggest that training data size should scale roughly with the square root of training compute (Hoffmann et al., 2022; Dey et al., 2023; Fetterman et al., 2023).
数据集规模的历史增长速度不可能无限持续,即便数据存量不受限制。过去,计算能力的持续提升推动了对更大训练数据集的需求,这与稠密Transformer的神经扩展定律一致——该定律指出训练数据量应与计算资源的平方根成正比 (Hoffmann et al., 2022; Dey et al., 2023; Fetterman et al., 2023)。
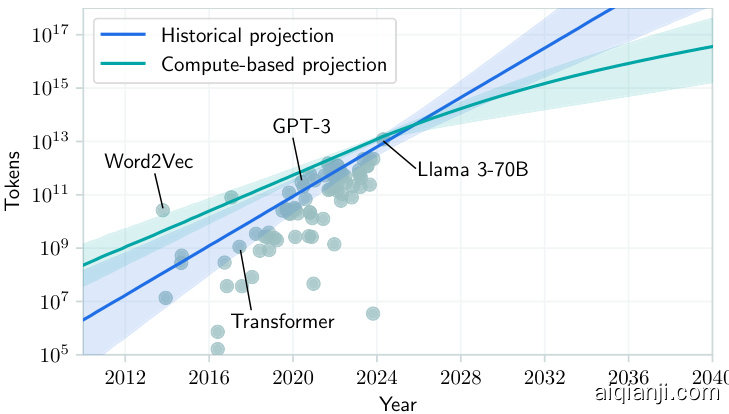
Figure 4. Projections of data usage. Two extrapolations of data usage, one from past trends and one from compute availability estimations plus scaling laws. The shaded areas denote a $90%$ CI for the extrapolated median. The dots are individual training runs.
图 4: 数据使用量预测。基于历史趋势的推算与基于计算资源可用性估算及扩展规律的推算。阴影区域表示推算中位数的90%置信区间,圆点代表独立训练实例。
However, the growth in compute is also subject to limits, and current fast rates may not be sustained indef intel y. Technical limitations, such as the energy efficiency of computing devices (Ho et al., 2023) and limits on the electricity supply to data centers,19 restrict the feasible amount of compute. Other factors like chip production capacity and economic constraints could slow down the rate at which computing power used in training can scale. Consequently, if the ability to scale computing power is constrained, it will likely lead to a deceleration in the historical trends of dataset size growth.
然而,计算能力的增长同样面临限制,当前的高速增长可能无法无限持续。技术限制(如计算设备的能效(Ho et al., 2023)和数据中心的电力供应限制)制约了可行的计算规模。芯片产能、经济约束等其他因素也可能减缓训练所用算力的扩展速度。因此,若算力扩展能力受限,很可能会导致数据集规模增长的历史趋势放缓。
To introduce this constraint into our model, we need estimates of the maximum compute budget for training that will be available in the future. For this purpose, we use the results from Besiroglu et al. (2022), which performs such a projection based on estimated training compute growth rates in frontier machine learning systems between 2010 and 2022.20 Following Hoffmann et al. (2022), we further assume that compute-optimality involves training on 20 tokens per parameter, per Equation 3.
为了将这一约束引入我们的模型,需要预估未来可用的最大训练计算预算。为此,我们采用了Besiroglu等人(2022)的研究成果,该研究基于2010至2022年间前沿机器学习系统的训练算力增长率进行了此类预测[20]。参照Hoffmann等人(2022)的方法,我们进一步假设计算最优性需要按照公式3,以每个参数对应20个token的比例进行训练。
Compute-based Dataset Size Growth Projection
基于计算的数据集规模增长预测
$$
D_ {C}(y)=\sqrt{\frac{20}{6}\cdot C(y)}
$$
$$
D_ {C}(y)=\sqrt{\frac{20}{6}\cdot C(y)}
$$
where $D_ {C}(y)$ is the projected amount of data used in notable training runs and $C(y)$ is the probabilistic projection of largest compute spent on a training run, modeled following Besiroglu et al. (2022). 6 is the number of FLOP per parameter per token and 20 is the approximate number of training tokens per parameter according to Hoffmann et al. (2022).
其中 $D_ {C}(y)$ 是显著训练运行中使用的数据量的投影值,$C(y)$ 是单次训练运行最大计算量的概率投影,模型遵循 Besiroglu et al. (2022) 的方法。6 表示每个参数每 Token 的 FLOP 数,20 是根据 Hoffmann et al. (2022) 得出的每个参数近似训练 Token 数。
As illustrated in Figure 4, the resulting model closely matches the historical trend and its projection until around 2030. It then slows down over time.
如图 4 所示,所得模型与历史趋势及其预测高度吻合,直至约 2030 年。此后增速逐渐放缓。
Our final projection of growth in dataset sizes is an equallyweighted mixture of both the historical and compute-based projections 21 (see Equation 4). It is illustrated in Figure 1.
我们对数据集规模增长的最终预测是历史预测和基于计算的预测21的等权重混合(见公式4)。如图1所示。
Mixture Projection of Dataset Size Growth
数据集规模增长的混合投影
$$
F_ {D(y)}=\frac{1}{2}\left(F_ {D_ {H}(y)}+F_ {D_ {C}(y)}\right)
$$
$$
F_ {D(y)}=\frac{1}{2}\left(F_ {D_ {H}(y)}+F_ {D_ {C}(y)}\right)
$$
where $D_ {H}(y)$ is the historical projection of dataset sizes, $D_ {C}(y)$ is the compute-based projection, and $F_ {X}$ is the cumulative distribution function of the random variable $X$ .
其中 $D_ {H}(y)$ 是数据集大小的历史投影,$D_ {C}(y)$ 是基于计算的投影,$F_ {X}$ 是随机变量 $X$ 的累积分布函数。
2.5. When will the stock of public human text data be fully utilized?
2.5 公共人类文本数据存量何时耗尽?
Combining our projections of dataset size increases, and our estimate of the stock of data, we can estimate when the full stock will be used in a training run if past trends continue. Figure 5 shows the projected availability and usage of effective data. The intersection between these projections corresponds to public text data being exhausted. The median exhaustion year is 2028, and by 2032 exhaustion becomes very likely. At the point the data stock is fully utilized, models will be using around 5e28 FLOP during training.
结合我们对数据集规模增长的预测以及对数据存量的估算,若历史趋势延续,可以推算出何时所有存量数据将被一次训练耗尽。图 5: 展示了有效数据的预计可用量与使用量。两条预测线的交点意味着公共文本数据将被耗尽,中位耗尽年份为2028年,到2032年耗尽几乎已成定局。当数据存量被完全利用时,模型训练将消耗约5e28 FLOP运算量。
An important assumption in our projections is that models are trained compute-optimal ly 22. However, many developers might instead decide to “overtrain” models to achieve better efficiency during inference (Sardana & Frankle, 2023), which would require more data. The degree of over training that will be chosen by developers depends on a multitude of factors, in particular how many tokens will be generated during inference (Sardana & Frankle, 2023), and is hard to predict in advance. That said, based on our analysis in Appendix F, we consider over training by $\operatorname{5x}$ to be a reasonable choice.23 This would result in a data bottleneck one year earlier than our projections indicate, at a training compute level of ${\sim}6\mathrm{e}27$ FLOP.24
我们预测中的一个重要假设是模型按照计算最优 (compute-optimal) 方式训练 [22]。然而,许多开发者可能会选择"过度训练 (overtrain)"模型以提高推理效率 (Sardana & Frankle, 2023),这将需要更多数据。开发者选择的过度训练程度取决于多种因素,特别是推理过程中将生成的 token 数量 (Sardana & Frankle, 2023),且难以提前预测。尽管如此,根据我们在附录 F 中的分析,我们认为 5 倍的过度训练是一个合理的选择 [23]。这将导致数据瓶颈比我们的预测提前一年出现,在训练计算量达到 6e27 FLOP 时发生 [24]。
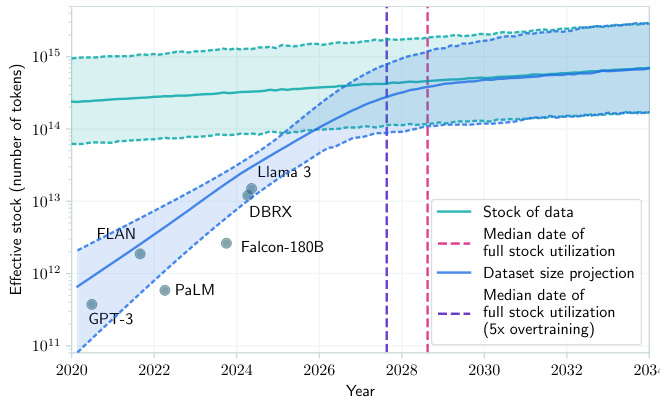
Figure 5. Projection of effective stock of human-generated public text and dataset sizes used to train notable LLMs. The intersection of the stock and dataset size projection lines indicates the median year (2028) in which the stock is expected to become fully utilized if current LLM development trends continue. At this point, models will be trained on dataset sizes approaching the total effective stock of text in the indexed web: around 4e14 tokens, corresponding to training compute of ${\sim}5{\mathrm{e}}28$ FLOP for non-over trained models.
图 5: 人类生成公开文本有效存量与知名大语言模型训练数据集规模的预测。存量线与数据集规模预测线的交点表示按当前大语言模型发展趋势,预计存量将被完全利用的中位年份(2028)。此时模型训练所用数据集规模将接近索引网络中文本总有效存量:约4e14个token,对应未经过拟合训练的模型需消耗${\sim}5{\mathrm{e}}28$FLOP计算量。

Figure 6. Compute-based data usage projection, assuming that frontier models will be over trained by $5\mathrm{x}$ starting from 2025. This policy results in the stock of data being fully used earlier than with a compute-optimal scaling policy.
图 6: 基于计算力的数据使用量预测 (假设前沿模型从2025年起将接受5倍过训练)。该策略导致数据储备比计算最优缩放策略更早耗尽。
According to our projections, data could become a significant bottleneck for training LLMs this decade, particularly if LLMs continue to be intensively over trained. This timeline allows for potentially substantial improvements in LLM performance, given the rapid progress in recent years (Ho et al., 2024; Sevilla et al., 2022). However, when considering the near 70-year history of AI, this timeframe is relatively short. While significant advancements can be made in the coming years, the impending data bottleneck presents an urgent challenge for the long-term progress of AI. For AI progress to continue into the 2030s, either new sources of data or less data-hungry techniques must be developed. The following sections of this paper will address some of these possibilities.
根据我们的预测,数据可能成为本十年训练大语言模型 (LLM) 的重大瓶颈,尤其是在大语言模型持续被过度训练的情况下。考虑到近年来的快速进展 (Ho et al., 2024; Sevilla et al., 2022),这一时间线为大语言模型性能的潜在显著提升提供了空间。然而,纵观人工智能近70年的发展史,这一时间段相对较短。尽管未来几年可能取得重大进展,但迫在眉睫的数据瓶颈对人工智能的长期发展构成了紧迫挑战。若要使人工智能的进步持续到2030年代,必须开发新的数据来源或减少数据依赖的技术。本文后续章节将探讨其中一些可能性。
3. Beyond public human text data
3. 超越公共人类文本数据
While the core focus of this paper is on public human text data in particular, understanding the broader implications of our model’s predictions requires considering ways in which the model might be wrong or incomplete. Crucially, although the model predicts that public human text data will be fully utilized at around the end of the decade, this does not necessarily imply that training data will bottleneck ML scaling at that time. In this section, we briefly survey possible ways of circumventing bottlenecks in public human text data.
尽管本文的核心关注点在于公共人类文本数据,但要理解我们模型预测的更广泛影响,就需要考虑模型可能存在错误或不完整的情况。关键在于,虽然模型预测公共人类文本数据将在本年代末期被充分利用,但这并不一定意味着训练数据会在那时成为机器学习扩展的瓶颈。本节我们简要探讨几种可能绕过公共人类文本数据瓶颈的途径。
For example, our model assumes no substantial change in the underlying process of increasing the public human text data stock. One naive way in which this assumption breaks is if significantly more humans are paid to generate more text. While this might be valuable at small scale for certain types of data, it is unlikely to be an economical way to generate an appreciable increase in text for general-purpose pre-training.25
例如,我们的模型假设公共人类文本数据存量增长的基本过程不会发生实质性变化。这一假设被打破的一种简单方式是雇佣更多人付费生成文本。虽然小规模操作对某些类型的数据可能具有价值,但作为通用预训练文本的增产方式,这种做法不太可能具有经济性。25
Out of the remaining strategies for circumventing public human text data bottlenecks, we identify three broad categories of techniques that appear particularly promising. These are: a) using models themselves to generate more data, b) multi modality and transfer learning, which involves training language models on other existing datasets (e.g. from different domains), and c) using non-public data.
在规避公开人类文本数据瓶颈的其他策略中,我们确定了三类特别有前景的技术:a) 利用模型自身生成更多数据,b) 多模态与迁移学习(即在不同领域现有数据集上训练语言模型),以及 c) 使用非公开数据。
3.1. AI-generated data
3.1. AI生成的数据
OpenAI alone reportedly generates 100B words per day (Griffin, 2024). Within a year, this corresponds to around $36.5\mathrm{T}$ words, not far from our estimates of the total number of high-quality words in Common Crawl. If outputs are accumulated across different models and across time, the growth in the stock of training data could expand dramatically in principle, assuming this approach works.
据报道,仅OpenAI每天就生成1000亿个单词 (Griffin, 2024)。一年内,这相当于约$36.5\mathrm{T}$个单词,与我们估算的Common Crawl中高质量单词总量相差不远。如果不同模型和不同时间段的输出被累积起来,理论上训练数据存量可能会大幅增长——前提是这种方法有效。
However, the evidence for the effectiveness of training on generated (synthetic) data is currently mixed. One challenge is that models might lose information about the original human data distribution, such that iterative ly training on model outputs results in increasingly homogeneous and unrealistic outputs (Shumailov et al., 2023). More generally, repeatedly training on synthetic data can yield diminishing or even negative returns (Singh et al., 2023), and worse scaling behavior (Fan et al., 2023; Dohmatob et al., 2024). These challenges can be mitigated to some extent by using training data with greater diversity (Fan et al., 2023; OpenAI et al., 2019), or by training on a mixture of human-generated and synthetic data (Gunasekar et al., 2023; Shumailov et al., 2023; Ger st grass er et al., 2024; Ale mohammad et al., 2023).
然而,关于生成式(合成)数据训练有效性的证据目前尚无定论。一个挑战在于模型可能会丢失原始人类数据分布的信息,导致在模型输出上迭代训练会产生越来越同质化且不真实的输出 (Shumailov et al., 2023)。更普遍的情况是,重复使用合成数据训练可能导致收益递减甚至负收益 (Singh et al., 2023),以及更差的扩展表现 (Fan et al., 2023; Dohmatob et al., 2024)。这些挑战可以通过使用更具多样性的训练数据 (Fan et al., 2023; OpenAI et al., 2019),或混合人类生成数据与合成数据进行训练 (Gunasekar et al., 2023; Shumailov et al., 2023; Gerstgrass er et al., 2024; Ale mohammad et al., 2023) 来部分缓解。
On the other hand, training on synthetic data has shown much promise in domains where model outputs are relatively easy to verify, such as mathematics, programming, and games (Yang et al., 2023; Liu et al., 2023; Haluptzok et al., 2023).26 For example, AlphaZero (Silver et al., 2017) was famously trained using self-play, and more recently Alpha Geometry (Trinh et al., 2024) was trained purely using synthetic data from attempts to solve geometry problems. What is less clear is whether the usefulness of synthetic data will generalize to domains where output verification is more challenging, such as natural language.27
另一方面,在模型输出相对容易验证的领域(如数学、编程和游戏)(Yang et al., 2023; Liu et al., 2023; Haluptzok et al., 2023),使用合成数据进行训练已展现出巨大潜力。例如,AlphaZero (Silver et al., 2017) 通过自我对弈训练而闻名,而最近的Alpha Geometry (Trinh et al., 2024) 则完全使用解决几何问题尝试生成的合成数据进行训练。目前尚不明确的是,合成数据的有效性是否能推广到输出验证更具挑战性的领域(如自然语言)。
We consider synthetic data to be one of the most promising avenues for circumventing data bottlenecks because of its potential to produce training data at an massive scale, its demonstrated success in certain domains, and the existence of potential strategies to mitigate the challenges associated with its use.
我们认为合成数据是绕过数据瓶颈最有前景的途径之一,因为它具备大规模生成训练数据的潜力,在某些领域已取得实证成功,且存在缓解其使用相关挑战的潜在策略。
3.2. Multimodal and transfer learning
3.2. 多模态与迁移学习
Another option is to go beyond text data, and train models on data from other domains or non-text modalities, like images. Appendix D includes some rough estimates of the stock of data for some of the most prominent modalities, concluding that current video and image stocks are not large enough to prevent a data bottleneck.
另一种选择是超越文本数据,在其他领域或非文本模态(如图像)的数据上训练模型。附录D包含了一些主要模态数据存量的粗略估计,结论是当前的视频和图像存量不足以避免数据瓶颈。
But there are other sources that can provide orders of magnitude more data of various types (e.g. financial market data, scientific databases, etc.). For illustration, (Stephens et al., 2015) forecasts growth rates of between 2-40 million terabytes of genomics data every year by 2025.
但还有其他来源能提供数量级更丰富的多类型数据(如金融市场数据、科学数据库等)。例如 (Stephens et al., 2015) 预测到2025年,基因组学数据每年将增长200万至4000万TB。
While it is not clear that leveraging data-rich domains for language modeling is always possible, there is already evidence that this is feasible in some specific cases. For instance, current frontier models like GPT-4V are trained on both image and text data (OpenAI, 2023; Pichai & Hassabis, 2023). Aghajanyan et al. (2023) study this question for several modalities of data and show that these modalities have some synergy with text, when training on an even mix of both. In general, better understanding the feasibility of transfer learning would require further research, such as scaling laws for transfer learning (Hernandez et al., 2021).
虽然尚不清楚利用数据丰富的领域进行语言建模是否总是可行,但已有证据表明在某些特定情况下是可行的。例如,当前的前沿模型如 GPT-4V 就同时训练了图像和文本数据 (OpenAI, 2023; Pichai & Hassabis, 2023)。Aghajanyan 等人 (2023) 针对多种数据模态研究了这一问题,并表明当两种模态的数据均衡混合训练时,它们与文本之间存在一定的协同效应。总体而言,要更好地理解迁移学习的可行性,还需要进一步的研究,例如迁移学习的扩展规律 (Hernandez 等人, 2021)。
3.3. Using non-public data
3.3. 使用非公开数据
While the indexed web is vast, its size is small relative to the deep web: the part of the web that is not accessible by search engines. The largest components of the deep web are closed content platforms like Facebook, Instagram or Twitter. While part of these platforms are indexed, the vast majority is not. Another large reservoir of non-public text data can be found in instant-messaging applications like WhatsApp or Facebook Messenger.
虽然被索引的网络规模庞大,但其体量相较于深网(deep web)仍相形见绌——后者是指搜索引擎无法访问的网络部分。深网的最大组成部分是Facebook、Instagram或Twitter等封闭内容平台。尽管这些平台部分内容被索引,但绝大多数仍处于不可见状态。另一个非公开文本数据的巨大储库存在于WhatsApp或Facebook Messenger等即时通讯应用中。
In Appendix C, we estimate that content platforms and instant messaging apps both contain on the order of one quadrillion tokens. Combining this with the similarly-sized upper estimate of the raw stock of text in the indexed web, the total stock could reach 3 quadrillion tokens. This increase would delay a data bottleneck by about a year and a half relative to using only data from the indexed web.
在附录 C 中,我们估计内容平台和即时通讯应用各自包含约一千万亿 (quadrillion) token。结合索引网络中原始文本规模的上限估计值,总存量可能达到三千万亿 token。相较于仅使用索引网络数据,这一增量将使数据瓶颈延迟约一年半。
However, the non-public stock seems unlikely to be as useful as indicated by our estimate. First of all, training on this data would be a grave violation of the privacy of the users who submitted the data to platforms without expecting it to be used for training AI models and probably would face legal challenges. Second, the quality of social media content is probably substantially lower than that of web content. Finally, this data is fragmented across several closed platforms that are controlled by different actors, so it is unlikely that all of it can be used in a single training run.
然而,非公开股票数据可能并不像我们预估的那样有用。首先,使用这些数据进行训练会严重侵犯用户隐私——他们向平台提交数据时并未预期其会被用于AI模型训练,此举很可能面临法律挑战。其次,社交媒体内容的质量很可能显著低于网络内容。最后,这些数据分散在不同主体控制的多个封闭平台中,因此不太可能将所有数据用于单次训练。
3.4. Data efficiency techniques
3.4. 数据效率技术
According to Ho et al. (2024), training techniques and algorithms for LLMs have been improving at a rate of 0.4 OOM/y $[95%$ : 0.1, 0.8], meaning that roughly 0.4 fewer OOMs of compute are needed each year to achieve the same levels of performance. This is partially due to more efficient data use. Similarly large gains in sample efficiency has been found for reinforcement learning (Dorner, 2021). Although we do not know precisely what fraction of LLM efficiency gains result from “doing more with less data,” it is possible that improvements in data efficiency are occurring at a pace that could compensate for the exhaustion of data stocks.
根据 Ho 等人 (2024) 的研究,大语言模型 (LLM) 的训练技术和算法正以每年 0.4 个数量级 (OOM/y) 的速度提升 [95% 置信区间: 0.1, 0.8],这意味着每年只需减少 0.4 个数量级的计算量即可达到相同性能水平。这部分归功于更高效的数据利用方式。强化学习领域也发现了类似的样本效率大幅提升现象 (Dorner, 2021)。虽然我们无法精确量化大语言模型效率提升中有多少来自"用更少数据实现更多",但数据效率的提升速度很可能足以抵消数据存量耗尽的影响。
3.5. Other techniques
3.5. 其他技术
Another possibility is learning from interactions with the real world, which might include LLMs training on the messages received from users or, if ML models become sophisticated enough to act autonomously, learning from sensory observations or from the results of real-world experiments. This form of learning will probably become necessary at some point if AI models are to surpass human knowledge about the real world.
另一种可能性是从与现实世界的交互中学习,这可能包括大语言模型基于用户消息进行训练,或者如果机器学习模型足够先进以实现自主行动,则通过感官观察或现实实验的结果进行学习。若要使AI模型超越人类对现实世界的认知,这种学习形式在某个阶段很可能成为必要。
One additional broad category of techniques is data selection, in which we include techniques like pruning (Marion et al., 2023), domain composition tuning (Xie et al., 2023), and curriculum learning (Campos, 2021). However, we do not find this class of techniques very promising since the gains tend to be modest.28
另一大类技术是数据选择,其中包括剪枝 (Marion et al., 2023)、领域组合调优 (Xie et al., 2023) 和课程学习 (Campos, 2021) 等技术。然而,我们发现这类技术的前景并不十分乐观,因为其带来的提升往往有限。28
4. Discussion
4. 讨论
In this paper, we examine the challenges and opportunities that lie ahead for scaling machine learning systems, particularly in light of the finite nature of public human text data. Our analysis reveals a critical juncture approaching by the end of this decade, where the current reliance on public human text data for training ML models may become unsustainable. Despite this looming bottleneck, we identify transfer learning and self-generated data as viable and promising pathways that could enable the continued growth and evolution of ML systems beyond the constraints of public human text data.
本文探讨了扩展机器学习系统所面临的挑战与机遇,尤其关注公共人类文本数据的有限性。我们的分析表明,到本十年末将迎来一个关键转折点——当前依赖公共人类文本数据训练ML模型的做法可能难以为继。尽管存在这一迫近的瓶颈,我们发现迁移学习和自生成数据是两条可行且前景广阔的路径,有望推动机器学习系统突破公共人类文本数据的限制持续发展。
Our conclusions are thus twofold. On the one hand, we expect that the current paradigm based on public human text data will not be able to continue a decade from now. On the other hand, it is likely that alternative sources of data will likely be adopted before then, allowing ML systems to continue scaling.
我们的结论是双重的。一方面,我们预计基于公开人类文本数据的当前范式在未来十年内将无法持续。另一方面,替代数据源很可能在此之前被采用,使机器学习系统能够继续扩展。
While our arguments about alternative sources of data are mostly qualitative, a better understanding of data quality could make it possible to make quantitative estimates of the benefits of transfer learning and synthetic data. For example, scaling experiments for transfer learning could be used to quantify the proximity or synergy between different distributions (Hernandez et al., 2021; Aghajanyan et al., 2023) and identify new datasets which can effectively expand the stock of data.
虽然我们关于替代数据源的论证主要是定性的,但更好地理解数据质量可能有助于定量评估迁移学习(transfer learning)和合成数据(synthetic data)的收益。例如,迁移学习的扩展实验可用于量化不同分布之间的接近度或协同效应 [Hernandez et al., 2021; Aghajanyan et al., 2023],并识别能够有效扩充数据储备的新数据集。
This paper does not explore certain considerations that might be relevant for understanding the future role of data. Firstly, the choice of data should depend on the desired skills or capabilities of the model. Identifying economically or scient if ic ally valuable skills and the datasets needed to teach them could reveal critical data gaps. Secondly, future ML breakthroughs, such as systems capable of autonomous realworld exploration and experimentation, might change the dominant source of information for learning.
本文未探讨某些可能对未来数据角色理解至关重要的因素。首先,数据选择应取决于模型所需的技能或能力。识别具有经济或科学价值的技能及训练这些技能所需的数据集,可能揭示关键的数据缺口。其次,未来的机器学习突破(例如能够自主进行现实世界探索与实验的系统)可能改变学习信息的主要来源。
5. Conclusion
5. 结论
We have projected the growth trends in both the training dataset sizes used for state-of-the-art language models and the total stock of available human-generated public text data. Our analysis suggests that, if rapid growth in dataset sizes continues, models will utilize the full supply of public human text data at some point between 2026 and 2032, or one or two years earlier if frontier models are over trained. At this point, the availability of public human text data may become a limiting factor in further scaling of language models.
我们预测了用于最先进语言模型的训练数据集规模与人类生成公开文本数据总量的增长趋势。分析表明,若数据集规模持续快速增长,模型将在2026至2032年间耗尽全部公开人类文本数据供给(若前沿模型被过度训练,该时间点可能提前1-2年)。届时,公开人类文本数据的可获得性可能成为语言模型进一步扩展的限制因素。
However, after accounting for steady improvements in data efficiency and the promise of techniques like transfer learning and synthetic data generation, it is likely that we will be able to overcome this bottleneck in the availability of public human text data.
然而,考虑到数据效率的稳步提升以及迁移学习 (transfer learning) 和合成数据生成 (synthetic data generation) 等技术的潜力,我们很可能能够克服公开人类文本数据可用性的这一瓶颈。
It is important to acknowledge the inherent uncertainty in making long-term projections, especially considering the rapid pace of advancements in the field of AI. Our results highlight the need for further research to quantify data efficiency growth rates and the potential performance gains from emerging methods. Additionally, future work should explore the feasibility and effectiveness of transfer learning from diverse data domains and the impact of synthetic data generation on model performance, among other things.
必须承认,在人工智能领域快速发展的背景下,进行长期预测存在固有的不确定性。我们的研究结果凸显了进一步量化数据效率提升速率、评估新兴方法潜在性能增益的必要性。此外,未来工作还应探索跨数据域迁移学习的可行性及有效性、合成数据生成对模型性能的影响等方向。
Acknowledgments
致谢
We thank the ICML reviewers, Nuno Sempere, Eli Lifland, Ege Erdil, Matthew Barnett and Joshua You for their thoughtful comments and contributions to this paper.
我们感谢ICML审稿人、Nuno Sempere、Eli Lifland、Ege Erdil、Matthew Barnett和Joshua You对本论文提出的宝贵意见和贡献。
Impact Statement
影响声明
The practice of scraping data from the web and using it for large-scale training of AI systems raises important issues regarding fairness and justice. In particular, there are strong arguments in favor of compensating the creators of the data used to train these systems. While AI has the potential to greatly increase productivity and overall welfare, it is important to factor in these justice-related considerations to ensure that the benefits are distributed equitably.
从网络抓取数据并用于AI系统大规模训练的做法,引发了关于公平与正义的重要问题。特别值得关注的是,有充分理由主张应对用于训练这些系统的数据创作者进行补偿。尽管AI有望大幅提升生产力和整体福祉,但必须将这些与正义相关的考量纳入其中,以确保利益得到公平分配。
Our work suggests that data from social media platforms and messaging apps could serve as a significant and valuable resource for training AI systems. However, using this type of data for training raises serious privacy and security concerns. Without proper safeguards in place, sensitive personal information from these platforms could be exposed to users of the AI systems .The risks associated with using non-indexed platform data for training may be substantial enough to outweigh the potential benefits gained from using this data.
我们的研究表明,社交媒体平台和即时通讯应用的数据可能成为训练AI系统的重要且有价值的资源。然而,使用这类数据进行训练会引发严重的隐私和安全问题。若缺乏适当的保护措施,这些平台中的敏感个人信息可能会被AI系统的用户获取。使用非索引平台数据进行训练所带来的风险,可能足以抵消使用这些数据所获得的潜在收益。
References
参考文献
org/ojs/index.php/fm/article/downloa d/620/541?inline $=1$ .
org/ojs/index.php/fm/article/downloa d/620/541?inline $=1$ .
Common Crawl. Common crawl, 2024. URL https: //common crawl.org/.
Common Crawl. Common crawl, 2024. URL https: //common crawl.org/.
Cottier, B. Trends in the dollar training cost of machine learning systems, 2023. URL https://epochai. org/blog/trends-in-the-dollar-train ing-cost-of-machine-learning-systems. Accessed: 2024-02-01.
Cottier, B. 机器学习系统的美元训练成本趋势, 2023. URL https://epochai.org/blog/trends-in-the-dollar-training-cost-of-machine-learning-systems. 访问日期: 2024-02-01.
Delétang, G., Ruoss, A., Duquenne, P.-A., Catt, E., Genewein, T., Mattern, C., Grau-Moya, J., Wenliang, L. K., Aitchison, M., Orseau, L., Hutter, M., and Veness, J. Language modeling is compression, 2023. URL https: //arxiv.org/abs/2309.10668.
Delétang, G., Ruoss, A., Duquenne, P.-A., Catt, E., Genewein, T., Mattern, C., Grau-Moya, J., Wenliang, L. K., Aitchison, M., Orseau, L., Hutter, M., and Veness, J. 语言建模即压缩, 2023. URL https://arxiv.org/abs/2309.10668.
Dey, N., Gosal, G., Zhiming, Chen, Khachane, H., Marshall, W., Pathria, R., Tom, M., and Hestness, J. Cerebrasgpt: Open compute-optimal language models trained on the cerebras wafer-scale cluster, 2023. URL https: //arxiv.org/abs/2304.03208.
Dey, N., Gosal, G., Zhiming, Chen, Khachane, H., Marshall, W., Pathria, R., Tom, M., and Hestness, J. Cerebrasgpt: 基于Cerebras晶圆级集群训练的开源计算最优大语言模型, 2023. URL https://arxiv.org/abs/2304.03208.
Dohmatob, E., Feng, Y., Yang, P., Charton, F., and Kempe, J. A tale of tails: Model collapse as a change of scaling laws, 2024.
Dohmatob, E., Feng, Y., Yang, P., Charton, F., and Kempe, J. 尾部物语:模型崩塌作为缩放定律的转变, 2024.
Domo. Data Never Sleeps 10.0. https://www.do mo.com/data-never-sleeps, 2022. [Accessed 12-04-2024].
Domo. Data Never Sleeps 10.0. https://www.domo.com/data-never-sleeps, 2022. [访问日期 12-04-2024].
Dorner, F. E. Measuring progress in deep reinforcement learning sample efficiency, 2021. URL https://ar xiv.org/abs/2102.04881.
Dorner, F. E. 深度强化学习样本效率的进展测量, 2021. URL https://arxiv.org/abs/2102.04881.
Do sov it ski y, A., Beyer, L., Kolesnikov, A., Weiss en born, D., Zhai, X., Unter thin er, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., and Houlsby, N. An image is worth 16x16 words: Transformers for image recognition at scale, 2021. URL https://arxiv.or g/abs/2010.11929.
Do sov it ski y, A., Beyer, L., Kolesnikov, A., Weiss en born, D., Zhai, X., Unter thin er, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., and Houlsby, N. 一张图像值16x16个词:大规模图像识别的Transformer, 2021. URL https://arxiv.org/abs/2010.11929.
Du, N., Huang, Y., Dai, A. M., Tong, S., Lepikhin, D., Xu, Y., Krikun, M., Zhou, Y., Yu, A. W., Firat, O., Zoph, B., Fedus, L., Bosma, M., Zhou, Z., Wang, T., Wang, Y. E., Webster, K., Pellat, M., Robinson, K., Meier-Hellstern, K., Duke, T., Dixon, L., Zhang, K., Le, Q. V., Wu, Y., Chen, Z., and Cui, C. Glam: Efficient scaling of language models with mixture-of-experts, 2021. URL https: //arxiv.org/abs/2112.06905.
Du, N., Huang, Y., Dai, A. M., Tong, S., Lepikhin, D., Xu, Y., Krikun, M., Zhou, Y., Yu, A. W., Firat, O., Zoph, B., Fedus, L., Bosma, M., Zhou, Z., Wang, T., Wang, Y. E., Webster, K., Pellat, M., Robinson, K., Meier-Hellstern, K., Duke, T., Dixon, L., Zhang, K., Le, Q. V., Wu, Y., Chen, Z., and Cui, C. Glam: 基于专家混合的高效语言模型扩展, 2021. URL https://arxiv.org/abs/2112.06905.
Epoch. Parameter, compute and data trends in machine learning, 2022. URL https://epochai.org/da ta/epochdb/visualization. Accessed: 2024- 01-29.
Epoch。机器学习中的参数、算力和数据趋势,2022。网址 https://epochai.org/data/epochdb/visualization。访问日期:2024-01-29。
Epoch. Key trends and figures in machine learning, 2023. URL https://epochai.org/trends. Accessed: 2024-01-27.
Epoch。2023年机器学习关键趋势与数据。URL https://epochai.org/trends。访问日期:2024-01-27。
Erdil, E. and Besiroglu, T. Algorithmic progress in computer vision, 2023. URL https://arxiv.org/abs/22 12.05153.
Erdil, E. 和 Besiroglu, T. 计算机视觉中的算法进展, 2023. URL https://arxiv.org/abs/22 12.05153.
Fan, L., Chen, K., Krishnan, D., Katabi, D., Isola, P., and Tian, Y. Scaling laws of synthetic images for model training ... for now, 2023.
Fan, L., Chen, K., Krishnan, D., Katabi, D., Isola, P., and Tian, Y. 合成图像对模型训练的缩放规律... 2023.
Fetterman, A. J., Kitanidis, E., Albrecht, J., Polizzi, Z., Fo- gelman, B., Knutins, M., Wroblewski, B., Simon, J. B., and Qiu, K. Tune as you scale: Hyper parameter optimization for compute efficient training, 2023. URL https://arxiv.org/abs/2306.08055.
Fetterman, A. J., Kitanidis, E., Albrecht, J., Polizzi, Z., Fogelman, B., Knutins, M., Wroblewski, B., Simon, J. B., and Qiu, K. 随规模调参:面向计算高效训练的超参数优化, 2023. URL https://arxiv.org/abs/2306.08055.
Friel, N., McKeone, J. P., Oates, C. J., and Pettitt, A. N. Inve stig ation of the widely applicable bayesian information criterion, 2016. URL https://arxiv.org/abs/ 1501.05447.
Friel, N., McKeone, J. P., Oates, C. J., and Pettitt, A. N. 广泛适用贝叶斯信息准则的研究, 2016. URL https://arxiv.org/abs/1501.05447.
Gao, L. An empirical exploration in quality filtering of text data, 2021. URL https://arxiv.org/abs/2109 .00698.
Gao, L. 文本数据质量过滤的实证探索, 2021. URL https://arxiv.org/abs/2109.00698.
Gao, L., Biderman, S., Black, S., Golding, L., Hoppe, T., Foster, C., Phang, J., He, H., Thite, A., Nabeshima, N., Presser, S., and Leahy, C. The pile: An 800gb dataset of diverse text for language modeling, 2021. URL https: //arxiv.org/abs/2101.00027.
Gao, L., Biderman, S., Black, S., Golding, L., Hoppe, T., Foster, C., Phang, J., He, H., Thite, A., Nabeshima, N., Presser, S., and Leahy, C. The pile: 一个用于语言建模的800GB多样化文本数据集,2021. URL https://arxiv.org/abs/2101.00027.
GDELT. Visualizing Twitter’s Evolution 2012-2020 And How Tweeting Is Changing In The COVID-19 Era. ht tps://blog.g del t project.org/visualiz ing-twitters-evolution-2012-2020-and -how-tweeting-is-changing-in-the-cov id-19-era/, 2020. [Accessed 12-04-2024].
GDELT. 可视化Twitter在2012-2020年的演变及COVID-19时代推文变化趋势. https://blog.gdeltproject.org/visualizing-twitters-evolution-2012-2020-and-how-tweeting-is-changing-in-the-covid-19-era/, 2020. [访问于12-04-2024].
Ger st grass er, M., Schaeffer, R., Dey, A., Rafailov, R., Sleight, H., Hughes, J., Korbak, T., Agrawal, R., Pai, D., Gromov, A., Roberts, D. A., Yang, D., Donoho, D. L., and Koyejo, S. Is model collapse inevitable? breaking the curse of recursion by accumulating real and synthetic data, 2024.
Ger st grass er, M., Schaeffer, R., Dey, A., Rafailov, R., Sleight, H., Hughes, J., Korbak, T., Agrawal, R., Pai, D., Gromov, A., Roberts, D. A., Yang, D., Donoho, D. L., and Koyejo, S. 模型崩溃不可避免吗?通过积累真实与合成数据打破递归诅咒,2024。
Griffin, A. Chatgpt creators openai are generating 100 billion words per day, ceo says, 2024. URL www.independent.co.uk/tech/chatgpt-o penai-words-sam-altman-b2494900.html.
Griffin, A. ChatGPT 创造者 OpenAI 每日生成 1000 亿单词,首席执行官称,2024。URL https://www.independent.co.uk/tech/chatgpt-openai-words-sam-altman-b2494900.html。
Gunasekar, S., Zhang, Y., Aneja, J., Mendes, C. C. T., Giorno, A. D., Gopi, S., Javaheripi, M., Kauffmann, P., de Rosa, G., Saarikivi, O., Salim, A., Shah, S., Behl, H. S., Wang, X., Bubeck, S., Eldan, R., Kalai, A. T., Lee, Y. T., and Li, Y. Textbooks are all you need, 2023.
Gunasekar, S., Zhang, Y., Aneja, J., Mendes, C. C. T., Giorno, A. D., Gopi, S., Javaheripi, M., Kauffmann, P., de Rosa, G., Saarikivi, O., Salim, A., Shah, S., Behl, H. S., Wang, X., Bubeck, S., Eldan, R., Kalai, A. T., Lee, Y. T., and Li, Y. 《教科书即所需》,2023。
Haluptzok, P., Bowers, M., and Kalai, A. T. Language models can teach themselves to program better, 2023. URL https://arxiv.org/abs/2207.14502.
Haluptzok, P., Bowers, M., and Kalai, A. T. 语言模型能自我学习编程提升, 2023. URL https://arxiv.org/abs/2207.14502.
National Electrical Manufacturers Association (NEMA). Comments on innovative advanced transformers. RFI Response DE-FOA-0003021, U.S. Department of Energy, Washington, DC, May 2023. URL https://www.ne ma.org/docs/default-source/advocacy-d ocument-library/nema-comments-on-inn ovative-advanced-transformers-rfi-may -5-2023.pdf?sfvrsn $=\in{15}$ ffc3c_ 3. Response to the Department of Energy’s request for information on Innovative Advanced Transformers.
国家电气制造商协会 (NEMA)。关于创新先进变压器 (Innovative Advanced Transformers) 的评论。RFI Response DE-FOA-0003021,美国能源部,华盛顿特区,2023年5月。URL https://www.nema.org/docs/default-source/advocacy-document-library/nema-comments-on-innovative-advanced-transformers-rfi-may-5-2023.pdf?sfvrsn $=\in{15}$ ffc3c_ 3。对美国能源部创新先进变压器信息征询的回复。
on journal of travel research: A study. Library Progress (International), 42(2):412–420, 2022.
《旅游研究期刊:一项研究》。Library Progress (International),42(2):412–420,2022。
Saunders, W., Yeh, C., Wu, J., Bills, S., Ouyang, L., Ward, J., and Leike, J. Self-critiquing models for assisting human evaluators, 2022.
Saunders, W., Yeh, C., Wu, J., Bills, S., Ouyang, L., Ward, J., and Leike, J. 用于辅助人类评估者的自批判模型, 2022.
Hron, J., Kenealy, K., Swersky, K., Mahajan, K., Culp, L., Xiao, L., Bileschi, M. L., Constant, N., Novak, R., Liu, R., Warkentin, T., Qian, Y., Bansal, Y., Dyer, E., Neyshabur, B., Sohl-Dickstein, J., and Fiedel, N. Beyond human data: Scaling self-training for problem-solving with language models, 2023.
Hron, J., Kenealy, K., Swersky, K., Mahajan, K., Culp, L., Xiao, L., Bileschi, M. L., Constant, N., Novak, R., Liu, R., Warkentin, T., Qian, Y., Bansal, Y., Dyer, E., Neyshabur, B., Sohl-Dickstein, J., and Fiedel, N. 超越人类数据:基于大语言模型的问题解决自训练扩展, 2023.
Singh, M. WhatsApp is now delivering roughly 100 billion messages a day. https://techcrunch.com/2 020/10/29/whatsapp-is-now-deliverin g-roughly-100-billion-messages-a-day, 2020. [Accessed 15-04-2024].
Singh, M. WhatsApp 目前每天发送约 1000 亿条消息。https://techcrunch.com/2020/10/29/whatsapp-is-now-delivering-roughly-100-billion-messages-a-day, 2020. [访问日期 15-04-2024]。
Size, W. W. W. World wide web size, 2024. URL https: //www.worldwide web size.com/.
Size, W. W. W. World wide web size, 2024. URL https: //www.worldwide web size.com/.
Stephens, Z. D., Lee, S., Faghri, F., Campbell, R. H., Zhai, C., Efron, M., Iyer, R. K., Schatz, M. C., Sinha, S., and Robinson, G. E. Big data: Astronomical or genomical? PLoS Biology, 13, 2015. URL https://journals .plos.org/plo s biology/article?id $=10$ . 1371/journal.pbio.1002195.
Stephens, Z. D., Lee, S., Faghri, F., Campbell, R. H., Zhai, C., Efron, M., Iyer, R. K., Schatz, M. C., Sinha, S., and Robinson, G. E. 大数据:天文级还是基因组级?《公共科学图书馆·生物学》, 13, 2015. URL https://journals.plos.org/plosbiology/article?id=10.1371/journal.pbio.1002195.
Taniguchi, M., Ueda, Y., Taniguchi, T., and Ohkuma, T. A large-scale corpus of E-mail conversations with standard and two-level dialogue act annotations. In Scott, D., Bel, N., and Zong, C. (eds.), Proceedings of the $28t h$ International Conference on Computational Linguistics, pp. 4969–4980, Barcelona, Spain (Online), December 2020. International Committee on Computational Linguistics. doi: 10.18653/v1/2020.coling-main.436. URL https://a cl anthology.org/2020.coling -main.436.
Taniguchi, M., Ueda, Y., Taniguchi, T., and Ohkuma, T. 带有标准和两级对话行为标注的大规模电子邮件会话语料库。见 Scott, D., Bel, N., 和 Zong, C. (编), 《第28届国际计算语言学会议论文集》, 第4969–4980页, 西班牙巴塞罗那(线上), 2020年12月. 国际计算语言学委员会. doi: 10.18653/v1/2020.coling-main.436. URL https://aclanthology.org/2020.coling-main.436.
Taylor, R., Kardas, M., Cucurull, G., Scialom, T., Hartshorn, A., Saravia, E., Poulton, A., Kerkez, V., and Stojnic, R. Galactica: A large language model for science, 2022. URL https://arxiv.org/abs/2211.09085.
Taylor, R., Kardas, M., Cucurull, G., Scialom, T., Hartshorn, A., Saravia, E., Poulton, A., Kerkez, V., and Stojnic, R. Galactica: 面向科学的大语言模型, 2022. URL https://arxiv.org/abs/2211.09085.
Thorgren, E., Mohammadi no doo shan, A., and Carlsson, N. Temporal dynamics of user engagement on instagram: A comparative analysis of album, photo, and video interactions. URL https://api.semantic scholar. org/CorpusID:268241757.
Thorgren, E., Mohammadi no doo shan, A., 和 Carlsson, N. Instagram用户参与度的时间动态:相册、照片和视频互动的对比分析。URL https://api.semantic scholar. org/CorpusID:268241757。
Tirumala, K., Simig, D., Aghajanyan, A., and Morcos, A. S. D4: Improving llm pre training via document deduplication and diversification, 2023. URL https: //arxiv.org/abs/2308.12284.
Tirumala, K., Simig, D., Aghajanyan, A., 和 Morcos, A. S. D4: 通过文档去重和多样化改进大语言模型预训练, 2023. URL https://arxiv.org/abs/2308.12284.
Together.ai. Redpajama-data-v2: An open dataset with 30 trillion tokens for training large language models, 2023. URL https://www.together.ai/blog/red pajama-data-v2.
Together.ai. Redpajama-data-v2: 一个包含30万亿token的开源数据集,用于训练大语言模型,2023。URL https://www.together.ai/blog/red pajama-data-v2.
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., and Bhosale S. et al. Llama 2: Open Foundation and Fine-Tuned Chat Models, 2023. URL https://arxi v.org/abs/2307.09288.
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., and Bhosale S. et al. Llama 2: 开放基础与微调对话模型, 2023. URL https://arxiv.org/abs/2307.09288.
Trinh, T. H., Wu, Y., Le, Q. V., He, H., and Luong, T. Solving olympiad geometry without human demonstrations. Nature, 625(7995):476–482, January 2024. ISSN 1476-4687. doi: 10.1038/s41586-023-06747-5. URL http://dx.doi.org/10.1038/s41586-023 -06747-5.
Trinh, T. H., Wu, Y., Le, Q. V., He, H., and Luong, T. 无需人类演示的奥林匹克几何解题方法. Nature, 625(7995):476–482, January 2024. ISSN 1476-4687. doi: 10.1038/s41586-023-06747-5. URL http://dx.doi.org/10.1038/s41586-023 -06747-5.
United Nations. World population prospects 2022, online edition, 2022. URL https://population.un.or g/wpp/.
联合国. 2022年世界人口展望, 网络版, 2022. URL https://population.un.org/wpp/.
van den Bosch, A., Bogers, T., and de Kunder, M. Esti- mating search engine index size variability: A 9-year longitudinal study. Sci en to metrics, 107(2):839–856, Feb 2016. doi: 10.1007/s11192-016-1863-z.
van den Bosch, A., Bogers, T., and de Kunder, M. 搜索引擎索引规模变异性估算:一项为期9年的纵向研究。科学计量学, 107(2):839–856, 2016年2月. doi: 10.1007/s11192-016-1863-z.
Villalobos, P. and Ho, A. Trends in training dataset sizes. https://epochai.org/blog/trends-in-t raining-dataset-sizes, 2022. Accessed: 2022- 09-27.
Villalobos, P. 和 Ho, A. 训练数据集规模趋势。https://epochai.org/blog/trends-in-training-dataset-sizes, 2022. 访问日期: 2022-09-27.
Wei, T., Zhao, L., Zhang, L., Zhu, B., Wang, L., Yang, H., Li, B., Cheng, C., Lu, W., Hu, R., Li, C., Yang, L., Luo, X., Wu, X., Liu, L., Cheng, W., Cheng, P., Zhang, J., Zhang, X., Lin, L., Wang, X., Ma, Y., Dong, C., Sun, Y., Chen, Y., Peng, Y., Liang, X., Yan, S., Fang, H., and Zhou, Y. Skywork: A more open bilingual foundation model, 2023. URL https://arxiv.org/abs/2310.19341.
Wei, T., Zhao, L., Zhang, L., Zhu, B., Wang, L., Yang, H., Li, B., Cheng, C., Lu, W., Hu, R., Li, C., Yang, L., Luo, X., Wu, X., Liu, L., Cheng, W., Cheng, P., Zhang, J., Zhang, X., Lin, L., Wang, X., Ma, Y., Dong, C., Sun, Y., Chen, Y., Peng, Y., Liang, X., Yan, S., Fang, H., and Zhou, Y. Skywork: 更开放的双语基础模型, 2023. URL https://arxiv.org/abs/2310.19341.
White, K. Publications output: U.s. trends and international comparisons, 2019. URL https://ncses.nsf.go v/pubs/nsb20206/.
White, K. 出版物产出:美国趋势与国际比较,2019. URL https://ncses.nsf.go v/pubs/nsb20206/.
Wikipedia. Wikipedia:Size of Wikipedia. https://en .wikipedia.org/wiki/Wikipedia:Size_ o f Wikipedia. [Accessed 22-04-2024].
维基百科。维基百科:维基百科的规模。https://en.wikipedia.org/wiki/Wikipedia:Size_ of_ Wikipedia。[访问日期22-04-2024]。
Xie, S. M., Pham, H., Dong, X., Du, N., Liu, H., Lu, Y., Liang, P., Le, Q. V., Ma, T., and Yu, A. W. Doremi: Optimizing data mixtures speeds up language model pretraining, 2023. URL https://arxiv.org/abs/ 2305.10429.
Xie, S. M., Pham, H., Dong, X., Du, N., Liu, H., Lu, Y., Liang, P., Le, Q. V., Ma, T., and Yu, A. W. Doremi: 优化数据混合加速语言模型预训练, 2023. URL https://arxiv.org/abs/2305.10429.
Xue, F., Fu, Y., Zhou, W., Zheng, Z., and You, Y. To repeat or not to repeat: Insights from scaling llm under tokencrisis, 2023. URL https://arxiv.org/abs/23 05.13230.
Xue, F., Fu, Y., Zhou, W., Zheng, Z., and You, Y. 重复还是不重复:从token危机下扩展大语言模型获得的启示, 2023. URL https://arxiv.org/abs/23 05.13230.
XVERSE Technology Inc. Xverse-65b: A multilingual large language model, 2024. URL https://gith ub.com/xverse-ai/XVERSE-65B. Apache-2.0 License.
XVERSE Technology Inc. Xverse-65b: 多语言大语言模型,2024。URL https://github.com/xverse-ai/XVERSE-65B。Apache-2.0许可证。
Yang, G., Hu, E. J., Babuschkin, I., Sidor, S., Liu, X., Farhi, D., Ryder, N., Pachocki, J., Chen, W., and Gao, J. Tensor programs v: Tuning large neural networks via zero-shot hyper parameter transfer. arXiv preprint arXiv:2203.03466, 2022.
Yang, G., Hu, E. J., Babuschkin, I., Sidor, S., Liu, X., Farhi, D., Ryder, N., Pachocki, J., Chen, W., and Gao, J. Tensor programs v: 大神经网络的零样本超参数迁移调优. arXiv preprint arXiv:2203.03466, 2022.
Yang, K., Swope, A. M., Gu, A., Chalamala, R., Song, P., Yu, S., Godil, S., Prenger, R., and Anandkumar, A. Leandojo: Theorem proving with retrieval-augmented language models, 2023.
Yang, K., Swope, A. M., Gu, A., Chalamala, R., Song, P., Yu, S., Godil, S., Prenger, R., and Anandkumar, A. Leandojo: 基于检索增强语言模型的定理证明, 2023.
Ye, W., Liu, S., Kurutach, T., Abbeel, P., and Gao, Y. Mastering atari games with limited data, 2021. URL https://arxiv.org/abs/2111.00210.
Ye, W., Liu, S., Kurutach, T., Abbeel, P., and Gao, Y. 用有限数据掌握雅达利游戏, 2021. URL https://arxiv.org/abs/2111.00210.
Yole D veloppement. Status of the CMOS Image Sensor Industry 2021. https://medias.yolegroup.com /uploads/2021/08/YINTR21167-Status-o f-the-CMOS-Image-Sensor-Industry-202 1-Sample.pdf, 2021. [Accessed 17-04-2024].
Yole D veloppement. 《2021年CMOS图像传感器产业现状》。https://medias.yolegroup.com/uploads/2021/08/YINTR21167-Status-of-the-CMOS-Image-Sensor-Industry-2021-Sample.pdf, 2021. [访问日期: 2024-04-17].
YouTube. YouTube for Press. URL https://blog.y outube/press/. [Accessed 02-02-2024].
YouTube. YouTube 新闻中心. URL https://blog.youtube/press/. [访问日期 02-02-2024].
Zellner, A. Optimal information processing and bayes’s theorem. The American Statistician, 42(4):278–280, 1988. ISSN 00031305. URL http://www.jstor.org/ stable/2685143.
Zellner, A. 最优信息处理与贝叶斯定理。美国统计学家,42(4):278–280,1988。ISSN 00031305。URL http://www.jstor.org/stable/2685143。
Zhang, H. and Parkes, D. C. Chain-of-thought reasoning is a policy improvement operator, 2023. URL https: //arxiv.org/abs/2309.08589.
张 H. 和 Parkes D. C. 思维链推理是一种策略改进算子,2023。URL https://arxiv.org/abs/2309.08589。
Zhao, W. X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y., Min, Y., Zhang, B., Zhang, J., Dong, Z., Du, Y., Yang, C., Chen, Y., Chen, Z., Jiang, J., Ren, R., Li, Y., Tang, X., Liu, Z., Liu, P., Nie, J.-Y., and Wen, J.-R. A survey of large language models, 2023. URL https://arxiv. org/abs/2303.18223.
赵威翔, 周昆, 李佳, 唐涛, 王旭, 侯越, 闵勇, 张博, 张健, 董震, 杜宇, 杨超, 陈阳, 陈哲, 姜军, 任瑞, 李岩, 唐翔, 刘钊, 刘鹏, 聂建云, 和文继荣. 大语言模型综述, 2023. URL https://arxiv.org/abs/2303.18223.
Zimmerman, Z., Goggin, M., and Gramlich, R. Ready-togo transmission projects 2023. Technical report, Grid Strategies, September 2023. URL https://cleane nergygrid.org/wp-content/uploads/202 3/09/ACE G Transmission-Projects-Rea dy-To-Go September-2023.pdf. Support from Americans for a Clean Energy Grid.
Zimmerman, Z., Goggin, M., and Gramlich, R. 《2023年待建输电项目》。技术报告,Grid Strategies,2023年9月。网址 https://cleane nergygrid.org/wp-content/uploads/202 3/09/ACE G Transmission-Projects-Rea dy-To-Go September-2023.pdf。由Americans for a Clean Energy Grid提供支持。
Zittrain, J., Bowers, J., and Stanton, C. The paper of record meets an ephemeral web: An examination of linkrot and content drift within the new york times. SSRN Electronic Journal, 2021. URL https://api.semanticsc holar.org/CorpusID:236595511.
Zittrain, J., Bowers, J., 和 Stanton, C. 记录之报遭遇瞬息万变之网: 纽约时报内部链接失效与内容漂移研究. SSRN电子期刊, 2021. 网址 https://api.semanticscholar.org/CorpusID:236595511.
A. Theoretical growth model of the web
A. 网络的理论增长模型
We explain in more detail our theoretical model of data accumulation rates developed in Section 2.2.2 and check it on Reddit submission data. The model is explained in Equation 5.
我们将在2.2.2节中详细阐述数据积累速率的理论模型,并通过Reddit提交数据进行验证。该模型的具体表述见公式5。
A purely exponential model cannot reproduce the decrease in the growth rate of Reddit submissions over time, while a purely sigmoidal model plateaus at zero growth. The exponential times sigmoid model is able to better capture the deceleration in submission size growth (see Figure 7).
纯指数模型无法重现Reddit提交量增长率随时间下降的趋势,而纯S型模型则会停滞在零增长状态。指数乘S型模型能更好地捕捉提交量增长的减速现象 (见图7)。
In our actual model, the slowdown in population growth (which becomes sub exponential) leads to additional deceleration, but the time period covered by the Reddit submission dataset seems too short for slowing population growth to be noticeable in the data.
在我们实际模型中,人口增长放缓(呈现次指数级增长)会导致进一步减速,但Reddit提交数据集覆盖的时间段似乎过短,无法在数据中观察到人口增长放缓的迹象。
Projection Based on the Number of Internet Users
基于互联网用户数量的预测
$$
S_ {I U}(y)=D_ {y_ {0}}\int_ {1950}^{y}{\frac{H(x)\sigma\left((x-s_ {0})\times0.15\right)}{H(y_ {0})\sigma\left((y_ {0}-s_ {0})\times0.15\right)}}d x
$$
$$
S_ {I U}(y)=D_ {y_ {0}}\int_ {1950}^{y}{\frac{H(x)\sigma\left((x-s_ {0})\times0.15\right)}{H(y_ {0})\sigma\left((y_ {0}-s_ {0})\times0.15\right)}}d x
$$
where $D_ {Y_ {0}}$ is the amount of data produced in some reference year $Y_ {0}$ , $H(Y)$ is the projected human population in a certain year, and the sigmoid $\sigma$ models internet penetration, which is approximately $0%$ in 1950 (this why we choose it as the initial point for the integral) and $50%$ in $s_ {0}=2016.0.15$ is a fitted scale parameter. The integral represents the total number of person-years of internet use, normalized by the internet use in the reference year.
其中 $D_ {Y_ {0}}$ 是某参考年份 $Y_ {0}$ 产生的数据量,$H(Y)$ 是某年预计人口数量,S型函数 $\sigma$ 模拟互联网普及率 (1950年约为 $0%$ ,因此我们将其选为积分起点) ,2016年普及率为 $50%$ 。$s_ {0}=2016.0.15$ 是拟合的比例参数。该积分表示互联网使用总人年数,并以参考年份的互联网使用量为归一化基准。
B. Estimating the size of the indexed web
B. 估算索引网络的规模
The “indexed web” comprises those web pages that are included in the indices of search engines. In particular, since Google is the most popular search engine worldwide, we tried to estimate the number of web pages in Google’s index.
“索引网络”由包含在搜索引擎索引中的网页组成。具体而言,由于Google是全球最受欢迎的搜索引擎,我们尝试估算Google索引中的网页数量。
We replicate the methodology of van den Bosch et al. (2016). We calculate the frequency of words in a large corpus of clean web documents: the RefinedWeb dataset (Penedo et al., 2023). Then we select a set of words at logarithmic ally equidistant intervals of frequency, called “pivot words” in van den Bosch et al. (2016). Using the number of results that Google reports when searching each of the pivot words, we can extrapolate the total size of Google’s index, assuming that the frequencies of the words are similar in our corpus and in Google’s index.
我们复现了van den Bosch等人(2016)的研究方法。首先在一个经过清洗的大型网页文档语料库(RefinedWeb数据集)(Penedo等人,2023)中计算词频,然后按照对数等距频率间隔选取一组"枢轴词"(van den Bosch等人,2016年术语)。通过统计Google搜索每个枢轴词返回的结果数量,并假设这些词语在我们语料库和Google索引中的出现频率相似,即可推算出Google索引的总规模。
Each pivot word provides a noisy estimate of the total size, so we take the average to arrive at a more robust estimate.
每个枢纽词都提供了对总大小的噪声估计,因此我们取平均值以获得更稳健的估计。
Using 100 pivot words, the distribution of estimated sizes is approximately log-normal, with a mean of 330B web pages, a median of 250B web pages, and a $95%$ CI between 100B and 1200B (see 8). This is about 4 times more than Common Crawl, which only has 75B unique urls.
使用100个关键(pivot)词估算的网页规模分布近似对数正态分布,均值为3300亿个网页,中位数为2500亿个网页,95%置信区间(CI)介于1000亿至12000亿之间(参见8)。这一数字约为Common Crawl数据集(仅包含750亿个独立URL)的4倍。
Our results are substantially higher than those obtained by van den Bosch et al. (2016). This is mostly because we retrieved the number of Google results for each word using the Google Custom Search JSON API. However, van den Bosch et al. (2016) used the numbers shown in Google’s web interface, which are around half as big for the same search terms.
我们的结果显著高于van den Bosch等人 (2016) 的研究。这主要是因为我们通过Google Custom Search JSON API获取了每个词的谷歌搜索结果数量,而van den Bosch等人 (2016) 使用的是谷歌网页界面显示的数字——相同搜索词条件下,该数值约为前者的一半。

Figure 8. Histogram of the estimates of the size of Google’s index from each pivot word.
图 8: 各锚点词估算的Google索引规模直方图

Figure 7. Monthly user submissions to Reddit, in linear scale(down) and log scale(up). While the three functions appear to fit the data reasonably well in the log scale, the linear plot shows that the sigmoid times exponential function predicts much better the recent years.
图 7: Reddit 月提交量的线性比例(下)与对数比例(上)图示。虽然三种函数在对数比例下都能较好地拟合数据,但线性图显示sigmoid乘指数函数对近年数据的预测明显更准确。
We evaluated whether a change in the relative frequency of words in the web over time might lead to inaccuracies when the same frequencies are used to estimate the size of the index across several years. To do this, we computed word frequencies for webs sampled in different years between 2013 and 2021. The difference in the resulting estimates was smaller than $10%$ , so we conclude that this is unlikely to add significant noise to the estimate.
我们评估了网络词汇相对频率随时间变化是否会导致在多年间使用相同频率估算索引大小时出现偏差。为此,我们计算了2013至2021年间不同年份网络样本的词汇频率。最终估算结果的差异小于$10%$,因此我们认为这不太可能对估算产生显著干扰。
B.1. Distribution across languages
B.1. 语言分布
The exact distribution of languages in the web is hard to estimate. In Common Crawl, around $45%$ of webpages is in English. This is broadly consistent with the $58.8%$ reported by the “Digital 2023: Global Overview Report” (Kemp, 2023a). However, the Observatory of Linguistic and Cultural Diversity in the Internet reports that in 2023 around $20%$ of the content of the web was in English (OBDILCI, 2024).
网络上语言的准确分布难以估算。在Common Crawl数据中,约$45%$的网页使用英语。这与《Digital 2023: Global Overview Report》(Kemp, 2023a)报告的$58.8%$大体一致。但互联网语言文化多样性观察站(OBDILCI)指出,2023年网络中约$20%$的内容为英文(OBDILCI, 2024)。
If Common Crawl does not constitute a representative sample of the web, then our previous method for estimating the size of the web might be biased. However, a reduction in the English share from $45%$ to $20%$ would only increase the estimate of the total size by a factor of 2.25, which is not enough to significantly change our conclusions.
如果Common Crawl不能代表网络的典型样本,那么我们之前估算网络规模的方法可能存在偏差。然而,英语占比从$45%$降至$20%$仅会使总量估计值增加2.25倍,这不足以显著改变我们的结论。
B.2. Growth in the size of the indexed web
B.2. 索引网页规模的增长
As documented in van den Bosch et al. (2016), the size of Google’s index has varied significantly over the past decade. However, this variation does not seem to follow any monotonic temporal pattern, and instead consists of seemingly random movement around a stable mean. The fact that the temporal mean of the index size has not increased over time is surprising: the number of internet users grows by about $1.8%$ a year (Kemp, 2023a), the number of pages in Wikipedia grows by $2.6%$ per year (Wikipedia), and the global size of IP traffic grew by $24%$ per year in 2016 (Cisco, 2017). Given these facts, it seems unlikely that the overall number of web pages has not grown significantly.
正如van den Bosch等人(2016)所记载的,Google索引规模在过去十年间波动显著。然而这种波动并未呈现任何单调的时间模式,而是围绕稳定均值呈现看似随机的变动。索引规模的时间均值未随时间增长这一事实令人惊讶:互联网用户数量每年增长约$1.8%$(Kemp, 2023a),维基百科页面数量每年增长$2.6%$(Wikipedia),而2016年全球IP流量规模年增长达$24%$(Cisco, 2017)。基于这些事实,网页总量未显著增长的可能性似乎很低。
We propose several hypotheses. One is based on link rot, the phenomenon of web links becoming inaccessible over time due to deletion, failure, restructuring of web sites, or other reasons. There have been several estimates of the rate of link rot over time, but most claim that between $2%$ and $16%$ of links break during a year (Howell & Burtis, 2022; Loan & Shah, 2020; Loan et al., 2023; Ott, 2022; Satyanarayana & Damodar, 2022; Zittrain et al., 2021). Some of the broken links will be replaced by new links to the same content (think of a change in domain name, for example, in which the new domain will point to the same documents as the old one), but part of that content will be irreversibly lost. If the rate of growth of the web is similar to the rate of link rot, the two effects might partially cancel each other and lead to a more stable index size.
我们提出若干假设。其中一个基于链接失效 (link rot) 现象,即由于删除、故障、网站重构或其他原因导致网页链接随时间推移无法访问。关于链接失效率的现有研究显示,每年约有 $2%$ 至 $16%$ 的链接会失效 (Howell & Burtis, 2022; Loan & Shah, 2020; Loan et al., 2023; Ott, 2022; Satyanarayana & Damodar, 2022; Zittrain et al., 2021)。部分失效链接会被指向相同内容的新链接替代(例如域名变更后,新域名仍指向原文档),但部分内容将永久丢失。若网络增长速度与链接失效率相近,这两种效应可能相互抵消,从而使索引规模保持相对稳定。
Another possibility is that Google is keeping the size of their index within a fixed range due to economic or engineering considerations. In this case, perhaps the web pages deemed least valuable or useful are eliminated from the index as more valuable pages appear. It is known that Google does not index all the pages they crawl (Alpert & Hajaj, 2008) due to quality considerations.
另一种可能是,出于经济或工程考量,Google将其索引规模控制在固定范围内。这种情况下,当更有价值的网页出现时,那些被认为价值最低或最无用的网页可能会被从索引中剔除。众所周知,出于质量考虑,Google并未为所有抓取的网页建立索引 (Alpert & Hajaj, 2008)。
A final possibility is that all of our estimation methods are biased towards content in the Anglo sphere or the West more generally. It is possible that both Google and Common Crawl are not representative examples of the global web, but only a part of it. Since most of the recent growth in the number of internet users has been in non-Western countries (Kemp, 2023a), it is possible that our estimates are missing this growth.
最后一种可能性是我们的所有估算方法都偏向于英语圈或更广义的西方内容。Google和Common Crawl可能并不能代表全球网络的整体情况,而只是其中一部分。由于近期互联网用户数量的增长大多来自非西方国家 (Kemp, 2023a),我们的估算可能遗漏了这部分增长。
C. Non-public text data
C. 非公开文本数据
The term “deep web” refers to that portion of the web that is not accessible by search engines. While this includes many categories of data, in this section we focus on closed29 content platforms, since they attract a large share of all web traffic.30
术语“深网 (deep web)”指的是搜索引擎无法访问的那部分网络。虽然这包含许多类别的数据,但本节我们重点关注封闭内容平台,因为它们吸引了大量网络流量。[30]
Given the power-law nature of web pages usage, we can obtain a fairly reliable estimate of the total size of the deep web just by examining a few of the most-visited platforms. In particular, we estimate the amount of data in Facebook, Instagram and Twitter, three of the largest social media platforms, as well as Reddit, an indexed and open social media platform that we use as a sanity check. We then divide the estimate of the stock of each platform by its share of global traffic to arrive at a global estimate.
鉴于网页访问量的幂律分布特性,我们只需分析少数头部平台即可较可靠地估算深层网络(deep web)的总规模。具体而言,我们测算三大社交媒体平台Facebook、Instagram和Twitter的数据存量,并以开放索引的Reddit平台作为验证基准。随后将各平台数据存量除以其全球流量占比,最终得出全球总量估算值。
Facebook: Facebook has about 3B users, who on average make one post and five comments per month (Kemp, 2023c). From a sample of 70,000 posts and 200,000 comments (Krebs et al., 2017) we calculate the average post has 60 tokens, while the average comment has 26 tokens.31. This corresponds to 10T tokens being produced each year. Since Facebook has had a roughly similar number of users for the past 10 years or so, its total stock is around 100T tokens.
Facebook: Facebook拥有约30亿用户,平均每人每月发布1篇帖子和5条评论 (Kemp, 2023c)。根据对7万篇帖子和20万条评论的样本分析 (Krebs et al., 2017),我们测算出平均每篇帖子包含60个token,每条评论含26个token。这相当于每年产生10万亿token。由于Facebook过去十年用户规模基本稳定,其平台累计内容存量约为100万亿token。
Instagram: Instagram has 1.6B users (Kemp, 2023a), who in aggregate make about 66,000 posts per minute (Domo, 2022), or about 100 million per year. The average post has about 8-16 tokens (Thorgren et al.), for a total of around 800B tokens generated per year. Over the past 10 years or so, this corresponds to 8T tokens.
Instagram: Instagram拥有16亿用户 (Kemp, 2023a),每分钟约产生6.6万条帖子 (Domo, 2022),即每年约1亿条。平均每条帖子包含8-16个token (Thorgren等),每年共生成约8000亿token。过去十年间累计生成约8万亿token。
Twitter: Twitter has close to 300M monthly active users. Each user posts 1.3 times per day, and the average post has about 7 tokens (GDELT, 2020). This corresponds to about 1.5T tokens per year, and since Twitter has had a roughly constant number of users for the past 12 years, the total stock is around 17T tokens.
Twitter: Twitter拥有近3亿月活跃用户。每位用户日均发布1.3条推文,平均每条推文包含约7个token (GDELT, 2020) 。据此推算年生成量约为1.5万亿token,由于Twitter过去12年用户规模基本稳定,其历史总存量约为17万亿token。
Reddit: Reddit is public and indexed, so accurate statistics are available. The number of posts per day was about 60,000 in 2020, while the number of comments was about 500,000 (Baumgartner et al., 2020). These have grown close to linearly since 2011, so the total is equivalent to about 7 years of submissions at that rate. Each post has on average 48 tokens, and each comment has 21.32 This corresponds to a total of 75B tokens per year, or about 600B tokens in total.
Reddit: Reddit是公开且被索引的,因此可以获得准确的统计数据。2020年每天的发帖量约为6万条,评论量约为50万条 (Baumgartner et al., 2020)。自2011年以来这些数据呈接近线性增长,因此按该速率计算总量相当于约7年的提交内容。每篇帖子平均包含48个token,每条评论包含21.32个token。这相当于每年总计750亿token,或总量约6000亿token。
Finally, we divide each estimate by the share of traffic of the corresponding platform to arrive at an estimate of the total stock in the web. We take the average of the estimates of each platform. As shown in Table 2, the results indicate that the size of the deep web is roughly comparable to the size of the indexed web, so using this source of data would only delay a data bottleneck by a couple years.
最后,我们将每个估计值除以相应平台的流量份额,得出网络中的总存量估计。取各平台估计值的平均数。如表 2 所示,结果表明深网 (deep web) 的规模与索引网络 (indexed web) 大致相当,因此使用这一数据源仅能将数据瓶颈推迟几年。
| Platform | Tokens | Trafficshare | Totalstockestimate |
| 100T | 3.6% | 3000T | |
| 8T | 1.5% | 580T | |
| 17T | 1.3% | 1370T | |
| 600B | 0.44% | 140T | |
| Geom.mean | 760T |
| 平台 | Token数 | 流量份额 | 总存量估值 |
|---|---|---|---|
| 100T | 3.6% | 3000T | |
| 8T | 1.5% | 580T | |
| 17T | 1.3% | 1370T | |
| 600B | 0.44% | 140T | |
| 几何平均数 | 760T |
Table 2. Estimates of the stock of data in the deep web. Estimates of the total stock are produced by dividing the estimate of the number of tokens by the share of traffic. These estimates are rough, and expected to be accurate only up to an order of magnitude.
表 2: 深层网络数据存量估算。通过将token数量估算值除以流量份额得出总存量估算值。这些估算较为粗略,预计仅在一个数量级内准确。
C.1. Instant messaging and email
C.1. 即时通讯与电子邮件
Instant messaging applications are widely used: Facebook Messenger alone has over a billion users (Kemp, 2023b). They consequently contain a vast amount of nonindexed data. In 2020, the messaging apps owned by Meta (then Facebook) were processing 100B messages per day (Mosseri & Chudnovsky, 2020). In a sample of 6 million WhatsApp messages, Rosenfeld et al. (2018) found that the average message had 5.66 words, or about 4.5 tokens. This corresponds to $165\mathrm{T}$ tokens generated per year, for a total stock over a quadrillion tokens.
即时通讯应用被广泛使用:仅Facebook Messenger就有超过10亿用户 (Kemp, 2023b)。因此这些应用中包含了大量未被索引的数据。2020年,Meta(当时名为Facebook)旗下的即时通讯应用每天处理1000亿条消息 (Mosseri & Chudnovsky, 2020)。在600万条WhatsApp消息样本中,Rosenfeld等人 (2018) 发现平均每条消息包含5.66个单词,约合4.5个token。据此推算,每年产生的token量达到$165\mathrm{T}$,累计存量超过千万亿token。
Note that the quality of instant messaging data relative to web data is not well documented, so this source of data might be much less useful for training than our calculation of the number of tokens suggests. That said, even if we take the number of tokens at face value, it is comparable to the stock of text in the indexed and deep web, and therefore instant messaging data only increases the stock of text by $50%$ , which would delay a data bottleneck by less than one year.
需要注意的是,即时通讯数据相对于网络数据的质量并未得到充分记录,因此这一数据源对训练的实用性可能远低于我们基于token数量估算的结果。即便如此,若仅按token数量计算,其规模仍与表层及深层网络中的文本存量相当,这意味着即时通讯数据仅能使文本存量增加50%,至多将数据瓶颈的出现时间推迟不到一年。
Emails could also be a large source of data, comparable to the overall size of the deep web. There are reportedly over 300B emails received per day (Radicati), which amounts to around 100T emails per year. It is unclear how many tokens of unique content this contains. It is likely that most are ”mass emails” such as advertisements or newsletters such that most received emails are not unique or have substantial duplicate content. If we conservatively suppose that $10%$ of emails are unique and contain about 50 words on average (consistent with some existing estimates, see Taniguchi et al. (2020)), this would represent about 625T tokens, which is the same order of magnitude as our estimates of the stock of deep web text.
电子邮件同样可能成为庞大的数据来源,其规模可与深网总量相媲美。据统计,全球每日接收邮件量超过3000亿封(Radicati),相当于每年约100万亿封邮件。目前尚不清楚这些邮件中包含多少独特内容的token。其中大部分很可能是广告或新闻简报等"群发邮件",因此多数接收邮件并非独一无二,或存在大量重复内容。若保守估计其中10%为独特邮件,且平均每封包含50个单词(与Taniguchi等人(2020)的现有估算一致),则对应约625万亿token,这与我们估算的深网文本存量处于同一数量级。
D. Non-text data
D. 非文本数据
There are significant sources of public data in modalities different than text. Most notably, the web contains large quantities of images and videos which might be used to train multimodal systems. However, we believe that the amount of useful information contained in these additional sources of data is not enough to meaningfully change our conclusions. In this appendix we arrive at some rough estimates for the amount of data available for other common modalities to justify this conclusion.
存在大量非文本形式的公开数据来源。最显著的是,网络包含大量可能用于训练多模态系统的图像和视频。然而,我们认为这些额外数据源中包含的有用信息量不足以显著改变我们的结论。在本附录中,我们对其他常见模态的可用数据量进行粗略估算,以支持这一结论。
Images It is hard to know exactly how many pictures are taken globally per year, but a reasonable estimate is on the order of a couple trillion (Lee, 2021). 33 Henighan et al. (2020) estimates that one image has at least as much information as around three tokens of text. Meanwhile, image encoders often use hundreds of tokens per image (Do sov it ski y et al., 2021), but there is probably significant redundancy in this representation. We take the geometric average of these two extremes to arrive at a reasonable middle point of ${\sim}30$ tokens per image. Assuming that this rate of image capture has been maintained for 10 years, this corresponds to a few hundred trillion tokens, roughly the same scale as the raw size of Common Crawl. For this reason, including images in our model is not likely to produce large changes in our results.
图像
全球每年拍摄的照片数量难以精确统计,但合理估计约为数万亿张 (Lee, 2021)。Henighan等人 (2020) 估算单张图像包含的信息量至少相当于约3个文本token。而图像编码器通常每张图像会使用数百个token (Dosovitskiy等人, 2021),但这种表示方式可能存在显著冗余。我们取这两个极值的几何平均数,得出每张图像约${\sim}30$个token的合理中间值。假设这一拍摄速率已持续10年,对应的token量约为数百万亿,与Common Crawl原始数据规模大致相当。因此,在模型中加入图像数据不太可能对结果产生重大影响。
Video In the case of video, YouTube is the most-used video hosting platform worldwide. More than 500 hours of video are uploaded to YouTube every minute (YouTube), which corresponds to 1 trillion seconds of video uploaded per year. Using again the hypothesis that the information in an image corresponds to around 30 tokens of text,34 assuming each second of video is as valuable as an independent image, and maintaining the same rate of video upload for 10 years, we arrive at an estimate of 100 trillion text-tokenequivalents. YouTube represents $7%$ of the share of internet traffic (Similarweb, 2024), so if we assume that the share of content is similar to the share of traffic,35 the total stock of video might be on the order of one quadrillion tokens. Since this is similar to the stock of data in the web, including video data in our estimates of the stock would not significantly change our results.
视频
在视频领域,YouTube是全球使用最广泛的视频托管平台。每分钟有超过500小时的视频被上传至YouTube (YouTube),相当于每年上传1万亿秒的视频内容。沿用"图像信息约等同于30个文本token"的假设[34],假设视频每秒价值等同于独立图像,并保持十年相同的视频上传速率,我们得出约100万亿文本token当量的估值。YouTube占据互联网流量的7% (Similarweb, 2024),若假设内容占比与流量占比相近[35],视频数据总量可能达到千万亿token级别。由于该数值与网页数据总量相当,将视频数据纳入总量估算不会显著改变我们的研究结论。
One relevant consideration regarding video and images is that their production is much easier to scale than text. 7B CMOS image sensors were produced in 2020 (Yole D veloppement, 2021). If all of them were used for recording, in a single year they could produce 2e17 seconds of video, 1000 times more than the current stock in the web.
关于视频和图像的一个相关考虑是,它们的生产比文本更容易规模化。2020年生产了70亿个CMOS图像传感器 (Yole Développement, 2021) 。如果所有这些传感器都用于录制,仅一年就能产生2e17秒的视频,比当前网络上的存量多1000倍。
Exotic modalities Stephens et al. (2015) estimated that astronomy and genomics produce several million terabytes of compressed data per year. At face value, this corresponds to a stock of roughly 1e18 tokens, a thousand times larger than our estimates of the stock for text, images and video.
奇异模态
Stephens et al. (2015) 估算天文学和基因组学每年产生数百万TB的压缩数据。表面来看,这相当于约1e18个token的存量,比我们对文本、图像和视频存量的估算高出千倍。
However, these modalities of data have extremely high redundancy and significant noise. The amount of synergy that these modalities have with text is also an open question. For this reason, we currently cannot evaluate whether these alternative modalities can provide a lasting source of data.
然而,这些数据模态具有极高的冗余度和显著噪声。它们与文本之间的协同程度仍是一个悬而未决的问题。因此,我们目前无法评估这些替代模态是否能提供持久的数据来源。
E. Token iz ation Schemes Across Datasets
E. 跨数据集的Token切分方案
This appendix examines the performance of various tokenization schemes across different datasets by analyzing the average number of tokens produced and the average number of characters per token. The data presented in Tables 3, 4, and 5 collectively demonstrate that common tokenizers produce a similar number of tokens across a diverse range of texts.
本附录通过分析不同数据集下各分词方案产生的平均token数量及每个token的平均字符数,考察了多种分词方案的性能表现。表3、表4和表5的数据共同表明,常见分词器在多样化文本上产生的token数量相近。
E.1. Token iz ation in RefinedWeb Dataset
E.1. RefinedWeb数据集中的Token切分
Table 3 compares three tokenizers (BERT, GPT2, and XLMNet) on 1000 random web pages in the first segment of the RefinedWeb dataset, showing that the average number of tokens produced by each tokenizer is similar, ranging from 621 to 653, with a consistent number of characters per token (around 4.2 to 4.4). In this dataset the average length of a word in bytes including whitespace is 5.5, so on average there are $4.4/5.5=0.8$ words per token.
表 3 比较了三种分词器 (BERT、GPT2 和 XLMNet) 在 RefinedWeb 数据集第一部分的 1000 个随机网页上的表现,结果显示各分词器生成的平均 token 数量相近,范围在 621 至 653 之间,且每个 token 对应的字符数保持稳定 (约 4.2 至 4.4)。该数据集中包含空格在内的单词平均字节长度为 5.5,因此平均每个 token 对应 $4.4/5.5=0.8$ 个单词。
Table 3. Token iz ation schemes in the first segment of RefinedWeb
| Tokenizer | Mean Tokens | Chars/Token |
| BERT | 621 | 4.4 |
| GPT2 | 645 | 4.2 |
| XLMNet | 653 | 4.2 |
表 3: RefinedWeb 第一部分的 Token 化方案
| Tokenizer | Mean Tokens | Chars/Token |
|---|---|---|
| BERT | 621 | 4.4 |
| GPT2 | 645 | 4.2 |
| XLMNet | 653 | 4.2 |
E.2. Token iz ation Using GPT2 Tokenizer Across Various Datasets
E.2. 使用GPT2分词器 (Tokenizer) 在不同数据集上的分词效果
Table 4 demonstrates the performance of the GPT2 tokenizer across various datasets, with the characters per token metric remaining relatively consistent, ranging from 2.22 to 4.15. This suggests that the GPT2 tokenizer produces a similar number of tokens per character across diverse text data, despite differences in the nature and average character length of the datasets.
表 4: 展示了 GPT2 Tokenizer 在不同数据集上的性能表现,其中每个 Token 对应的字符数指标保持相对稳定,范围在 2.22 到 4.15 之间。这表明尽管数据集的属性和平均字符长度存在差异,GPT2 Tokenizer 在不同文本数据上生成的每个字符对应的 Token 数量相似。
Table 4. GPT2 Tokenizer performance across multiple datasets
| Dataset | TextsAvg Char Length | Chars/Token |
| EnronEmails | 1010 1618 | 3.44 |
| FreeLaw | 5094 | 15707 3.53 |
| GitHub | 18337 | 5238 2.53 |
| EuroParl | 133 62975 | 2.5 |
| DM-Mathematics | 2007 | 8194 2.22 |
| ArXiv | 2434 47345 | 3.05 |
| Books3 | 301 587352 | 4.15 |
表 4: GPT2 Tokenizer 在多个数据集上的表现
| 数据集 | 文本平均字符长度 | 字符数/Token |
|---|---|---|
| EnronEmails | 1010 1618 | 3.44 |
| FreeLaw | 5094 | 15707 3.53 |
| GitHub | 18337 | 5238 2.53 |
| EuroParl | 133 62975 | 2.5 |
| DM-Mathematics | 2007 | 8194 2.22 |
| ArXiv | 2434 47345 | 3.05 |
| Books3 | 301 587352 | 4.15 |
E.3. Performance of Modern Tokenizers on Selected Datasets
E.3. 现代分词器在选定数据集上的性能
Table 5 compares the performance of multiple tokenizers used in modern models (Mixtral-7B, Command-plus-R, and cl100k base/GPT-4) on selected datasets. The characters per token metric remains fairly consistent for each tokenizer across the datasets and always between 2 and 5, indicating that the choice of tokenizer does not significantly affect the number of tokens produced per character.
表 5: 比较了现代模型 (Mixtral-7B、Command-plus-R 和 cl100k base/GPT-4) 中使用的多种分词器在选定数据集上的性能。每个分词器在各数据集上的字符/token (characters per token) 指标保持相对稳定,始终介于 2 到 5 之间,这表明分词器的选择不会显著影响每个字符生成的 token 数量。
Table 5. Performance of various tokenizers across selected datasets
| Tokenizer | Dataset | Chars/Token |
| Mixtral-7B | Books3 | 3.8 |
| GitHub | 2.88 | |
| Chinese Modern Po- | 2.17 | |
| Command-plus-R | etry Books3 | 4.17 |
| GitHub | 3.29 | |
| Chinese Modern Po- | 3.22 | |
| etry | ||
| cl100k_ base | Books3 | 4.31 |
| GitHub | 3.78 | |
| RefinedWeb | 4.41 | |
| DM-mathematics | 2.25 | |
| Chinese Modern Po- etry | 2.1 |
表 5: 不同分词器在选定数据集上的性能
| 分词器 | 数据集 | 字符数/Token |
|---|---|---|
| Mixtral-7B | Books3 | 3.8 |
| GitHub | 2.88 | |
| Chinese Modern Po- | 2.17 | |
| Command-plus-R | etry Books3 | 4.17 |
| GitHub | 3.29 | |
| Chinese Modern Po- | 3.22 | |
| etry | ||
| cl100k_ base | Books3 | 4.31 |
| GitHub | 3.78 | |
| RefinedWeb | 4.41 | |
| DM-mathematics | 2.25 | |
| Chinese Modern Po- etry | 2.1 |
The consistency in the characters per token metric across different tokenizers and datasets supports the conclusion that the conversion from the number of words to the number of tokens is roughly independent of the tokenizer used. This finding has implications for the comparability of tokenization results across studies using different tokenizers and datasets. Further statistical analysis, such as examining the variance or standard deviation of the characters per token metric, could provide additional insights into the consistency of token iz ation across datasets and tokenizers.
不同分词器和数据集之间每个token的字符数指标的一致性支持了从单词数到token数的转换大致独立于所用分词器的结论。这一发现对使用不同分词器和数据集的研究中token化结果的可比性具有重要意义。进一步的统计分析(例如检查每个token字符数的方差或标准差)可以为跨数据集和分词器的token化一致性提供更多洞见。
F. Over training in the context of data scarcity
F. 数据稀缺背景下的过度训练
In this appendix we sketch a model of optimal scaling decisions under data scarcity. In particular, we examine how the decision to overtrain models might be affected by data scarcity.
在本附录中,我们概述了一个数据稀缺情况下最优扩展决策的模型。具体而言,我们研究了数据稀缺如何影响过度训练模型的决定。
Our starting point is the parametric scaling law of Hoffmann et al. (2022), which predicts the reducible loss of a model $L$ given its number of parameters $N$ and the size of its training dataset $D$ (see Equation 9). Hoffmann et al. (2022) derive from this scaling law a relation between the sizes of the model and the dataset that minimize the reducible loss of their model given a fixed training compute budget. In particular, in compute-optimal models the ratio $D/N$ is around 20. We call this the Chinchilla scaling law, and we call models that follow it Chinchilla-optimal.
我们的起点是Hoffmann等人 (2022) 提出的参数化缩放定律,该定律根据模型的参数量 $N$ 和训练数据集大小 $D$ 预测模型的可减少损失 $L$ (见公式9)。Hoffmann等人 (2022) 从这个缩放定律推导出:在固定训练计算预算下,最小化模型可减少损失时模型规模与数据集大小之间的关系。具体而言,计算最优模型中 $D/N$ 的比值约为20。我们称之为Chinchilla缩放定律,并将遵循该定律的模型称为Chinchilla最优模型。
Models for which the ratio $D/N$ is above the Chinchillaoptimal ratio are commonly called over trained, while models that are below that ratio are called under trained. At a fixed training compute budget, over trained models require less compute during inference but more data during training. This is currently attractive for developers, as compute is relatively scarce compared to data. As a consequence, some well-known models, like Llama 3 (Meta, 2024), are over trained.36
$D/N$ 比值高于 Chinchilla 最优比值的模型通常被称为过训练 (over trained) 模型,而低于该比值的则被称为欠训练 (under trained) 模型。在固定的训练计算预算下,过训练模型在推理阶段需要更少的计算量,但在训练阶段需要更多数据。这对开发者目前颇具吸引力,因为计算资源相对数据更为稀缺。因此,一些知名模型(如 Llama 3 (Meta, 2024))采用了过训练策略。
Profit maximization problem
利润最大化问题
$$
\boxed{\begin{array}{r l}{\mathrm{maximize}}&{I(P-2N)-6N D}\ {\mathrm{s.t.}}&{6N D+2N I=C_ {0}}\ {\mathrm{where}}&{I=I_ {0}(A N^{-a}+B D^{-b})^{-r}P^{-h}}\end{array}}
$$
$$
\boxed{\begin{array}{r l}{\mathrm{maximize}}&{I(P-2N)-6N D}\ {\mathrm{s.t.}}&{6N D+2N I=C_ {0}}\ {\mathrm{where}}&{I=I_ {0}(A N^{-a}+B D^{-b})^{-r}P^{-h}}\end{array}}
$$
Here $N$ is the number of parameters of the model, $D$ is the size of the training dataset in tokens and $P$ is the price of each inference token in (some multiple of) dollars. $C_ {0}$ is the total computational budget for training and inference and $I$ is the number of tokens produced during inference. $A,a,B$ and $b$ are fitted parameters of the scaling law, and $I_ {0},r$ and $h$ are parameters of the inference demand function. All parameters are positive.
这里 $N$ 是模型的参数量,$D$ 是以token为单位的训练数据集大小,$P$ 是每个推理token的价格(以美元的某个倍数计)。$C_ {0}$ 是训练和推理的总计算预算,$I$ 是推理过程中产生的token数量。$A,a,B$ 和 $b$ 是缩放定律的拟合参数,$I_ {0},r$ 和 $h$ 是推理需求函数的参数。所有参数均为正数。
We now examine the relationship between over training and under training in the context of a data bottleneck. To simplify the analysis, here we ignore the cost of gathering data and focus on the computational cost of the model during training and inference. We assume that developers want to achieve the maximum possible profit within their computational budget, and that this computational budget includes both training and inference. In particular, given $N$ and $D$ , as well as a certain number of inference tokens, $I$ , the compute cost $C$ is given by Equation 7.
我们现在研究数据瓶颈背景下过度训练与训练不足之间的关系。为简化分析,此处忽略数据收集成本,重点关注训练和推理过程中的模型计算成本。假设开发者希望在计算预算内实现最大利润,且该预算同时涵盖训练和推理。具体而言,给定参数$N$和$D$,以及一定数量的推理token$I$时,计算成本$C$由公式7给出。
We assume that inference demand is a function that increases with model quality and decreases with the price of inference. We use the inverse reducible loss $L^{-1}$ as a proxy for quality.37 The functional form is given by Equation 8.
我们假设推理需求是一个随模型质量增加而增加、随推理价格增加而减少的函数。我们使用逆可约损失 $L^{-1}$ 作为质量的代理指标[37],其函数形式由公式8给出。
The optimal scaling policy depends on the values of $r$ and $h$ . If $h=0$ or $r=0$ , demand for inference is independent of price or capabilities, respectively. If $h=1$ , demand is constant in dollar terms. If $h>1$ , demand is decreasing in dollar terms. Since demand decreases with dollar price for most goods, we try values of $h$ greater than one. Since the loss of a compute-optimal model scales as $\sim C^{-0.15}$ , for the profit to increase as a function of training compute (which is what we would expect) $r$ must be higher than $0.15^{-1}\approx7$ .
最优扩展策略取决于 $r$ 和 $h$ 的取值。若 $h=0$ 或 $r=0$,则推理需求分别与价格或能力无关。当 $h=1$ 时,需求以美元计价保持恒定。若 $h>1$,需求会随美元计价下降。由于大多数商品的需求会随美元价格上涨而减少,我们尝试 $h$ 取值大于1的情况。鉴于计算最优模型的损失按 $\sim C^{-0.15}$ 比例缩放,要使利润随训练计算量增长(符合预期),$r$ 必须高于 $0.15^{-1}\approx7$。

Figure 9. Scaling policies obtained by solving the optimization problem given by Equations 6-8. The dashed lines represent data and compute budgets of 100T tokens and 1e27 FLOP, respectively. Achievable configurations given these budgets are indicated by solid lines, while un achievable ones are indicated by dotted lines. Some scaling policies exhaust the compute budget first, meaning they are compute-constrained, while others exhaust the data budget first, indicating they are data-constrained.
图 9: 通过求解公式6-8给出的优化问题获得的扩展策略。虚线分别表示100T token的数据预算和1e27 FLOP的计算预算。实线表示在这些预算下可实现的配置,而虚线表示不可实现的配置。部分扩展策略会先耗尽计算预算(即受计算约束),而另一些则先耗尽数据预算(即受数据约束)。
In general, higher values of $r$ and $h$ lead to greater returns to over training, due to additional demand and price sensitivity. Figure 9 shows some optimal scaling curves for different values of these parameters of the inference demand function. In particular, the values $r=7,h=1.1$ lead to a policy that is very close to Chinchilla-optimal, while the values $r=7,h=2$ lead to about ${5}\mathbf{{X}}$ over training, $r=10,h=2.4$ lead to a level of over training that increases with training compute, and is around $100\mathrm{x}$ at 5e25 FLOP.
一般来说,$r$ 和 $h$ 值越高,由于额外的需求和价格敏感性,过度训练带来的回报就越大。图 9 展示了推理需求函数中这些参数取不同值时的最优扩展曲线。具体而言,$r=7,h=1.1$ 时的策略非常接近 Chinchilla 最优值,而 $r=7,h=2$ 时会导致约 ${5}\mathbf{{X}}$ 的过度训练,$r=10,h=2.4$ 时的过度训练水平会随着训练计算量的增加而上升,在 5e25 FLOP 时约为 $100\mathrm{x}$。
While Chinchilla-optimal scaling is bottle necked by compute, under some assumptions the optimal scaling policy is instead bottle necked by data. In any case, more over training leads to the stock of data being completely used earlier, as shown in Figure 10.
虽然Chinchilla最优缩放受限于算力,但在某些假设下,最优缩放策略反而受限于数据。无论如何,如[图10]所示,过度训练会导致数据储备被提前耗尽。

Figure 10. Compute-based projections of data usage and stock utilization years for the three profit-maximizing scaling policies from Figure 9. Only medians are shown for the dataset size projections.
图 10: 基于计算的数据使用量和库存利用年限预测,展示了图9中三种利润最大化扩展策略的结果。数据集规模预测仅显示中位数。
Scaling law for reducible loss
可约损失的比例定律
$$
L=A N^{-a}+B D^{-b}
$$
$$
L=A N^{-a}+B D^{-b}
$$
Here $L$ is the reducible loss, $N$ is the number of parameters in the model, and $B$ is the size of the dataset in tokens. The values of the parameters $A,a,B$ and $b$ are taken from Besiroglu et al. (2024).
这里 $L$ 是可约损失,$N$ 是模型中的参数量,$B$ 是以token为单位的数据集大小。参数 $A,a,B$ 和 $b$ 的取值来自 Besiroglu et al. (2024)。
G. Limits of under training in a data bottleneck
G. 数据瓶颈下训练不足的局限性
If data becomes scarce relative to compute, researchers might opt to undertrain increasingly large models on the existing stock of data. Using again the parametric scaling law found by Hoffmann et al. (2022), we can predict how much additional performance could be obtained from this approach.
如果数据相对于计算资源变得稀缺,研究人员可能会选择在现有数据存量上对日益增大的模型进行欠训练。再次利用 Hoffmann 等人 (2022) 发现的参数化缩放定律,我们可以预测这种方法能获得多少额外性能。
In particular, we assume that the training data is fixed at $300\mathrm{T}$ tokens and calculate the reducible loss predicted by Equation 9 as we increase the training compute by adding more parameters to the model. Figure 11 shows the result from this model: under training can provide the equivalent of up to 2 additional orders of magnitude of compute-optimal scaling, but requires 2-3 orders of magnitude more compute. This is enough to sustain a decreasing rate of progress for 3-6 additional years before the final plateau.
特别地,我们假设训练数据固定为 $300\mathrm{T}$ token,并通过向模型添加更多参数来增加训练计算量,根据公式 9 计算可减少的损失。图 11 展示了该模型的结果:训练不足可提供相当于最多 2 个数量级的计算最优扩展,但需要多消耗 2-3 个数量级的计算资源。这足以在最终平台期到来前,维持 3-6 年的递减式进步速率。

Figure 11. A toy model of under training in a data bottleneck scenario in which the stock of data is fixed at $300\mathrm{T}$ tokens. The value of the loss is predicted using the parametric scaling law from Hoffmann et al. (2022), with the revised parameter estimates from Besiroglu et al. (2024). The compute-optimal training compute corresponding to a dataset size of 300T tokens is shown in the left-most black vertical line. We also plot compute-optimal scaling with unlimited data for comparison.
图 11: 数据瓶颈场景下的训练不足玩具模型,其中数据存量固定为 $300\mathrm{T}$ token。损失值预测采用 Hoffmann 等人 (2022) 提出的参数化缩放定律,并基于 Besiroglu 等人 (2024) 修正后的参数估计。左侧黑色垂直线表示 300T token 数据集规模对应的计算最优训练算力。作为对比,我们还绘制了数据无限时的计算最优缩放曲线。