SELF-INSTRUCT: Aligning Language Models with Self-Generated Instructions
SELF-INSTRUCT: 通过自生成指令对齐语言模型
Yizhong Wang♣ Yeganeh Kordi♢ Swaroop Mishra♡ Alisa Liu♣ Noah A. Smith♣+ Daniel Khashabi♠ Hannaneh Hajishirzi♣+ ♣University of Washington ♢Tehran Polytechnic ♡Arizona State University ♠Johns Hopkins University +Allen Institute for AI yizhongw@cs.washington.edu
Yizhong Wang♣ Yeganeh Kordi♢ Swaroop Mishra♡ Alisa Liu♣ Noah A. Smith♣+ Daniel Khashabi♠ Hannaneh Hajishirzi♣+ ♣华盛顿大学 ♢德黑兰理工大学 ♡亚利桑那州立大学 ♠约翰斯·霍普金斯大学 +艾伦人工智能研究所 yizhongw@cs.washington.edu
Abstract
摘要
Large “instruction-tuned” language models (i.e., finetuned to respond to instructions) have demonstrated a remarkable ability to generalize zero-shot to new tasks. Nevertheless, they depend heavily on human-written instruction data that is often limited in quantity, diversity, and creativity, therefore hindering the generality of the tuned model. We introduce SELF-INSTRUCT, a framework for improving the instruction-following capabilities of pretrained language models by boots trapping off their own generations. Our pipeline generates instructions, input, and output samples from a language model, then filters invalid or similar ones before using them to finetune the original model. Applying our method to the vanilla GPT3, we demonstrate a $33%$ absolute improvement over the original model on SUPER-NATURAL INSTRUCTIONS, on par with the performance of Instruc $\mathrm{\Delta GPT_ {001}}$ ,1 which was trained with private user data and human annotations. For further evaluation, we curate a set of expert-written instructions for novel tasks, and show through human evaluation that tuning GPT3 with SELF-INSTRUCT outperforms using existing public instruction datasets by a large margin, leaving only a $5%$ absolute gap behind Instruc $\mathrm{\Delta GPT_ {001}}$ . SELF-INSTRUCT provides an almost annotation-free method for aligning pretrained language models with instructions, and we release our large synthetic dataset to facilitate future studies on instruction tuning.2
大型"指令调优"语言模型(即经过微调以响应指令)展现出零样本泛化到新任务的卓越能力。然而,这些模型严重依赖人工编写的指令数据,这些数据通常在数量、多样性和创造性方面有限,从而限制了调优模型的泛化能力。我们提出SELF-INSTRUCT框架,通过自举生成的方式提升预训练语言模型的指令遵循能力。我们的流程首先生成指令、输入和输出样本,然后过滤无效或相似样本,最终用于微调原始模型。将该方法应用于原始GPT3后,在SUPER-NATURAL INSTRUCTIONS基准上实现了33%的绝对性能提升,与使用私有用户数据和人工标注训练的InstrucΔGPT001性能相当。为进一步评估,我们整理了一组专家编写的新任务指令,通过人工评估表明:使用SELF-INSTRUCT微调的GPT3显著优于现有公共指令数据集,与InstrucΔGPT001仅存在5%的绝对差距。SELF-INSTRUCT提供了一种近乎无需标注的预训练语言模型指令对齐方法,我们发布了大规模合成数据集以促进未来指令调优研究。
1 Introduction
1 引言
The recent NLP literature has witnessed a tremendous amount of activity in building models that
近期自然语言处理(NLP)领域的研究文献显示,模型构建活动呈现爆发式增长
Instruction: Given an address and city, come up with the zip code.
指令:给定地址和城市,找出对应的邮政编码。
Input:
输入:
Address: 123 Main Street, City: San Francisco Output: 94105
地址: 123 Main Street, 城市: San Francisco 输出: 94105
Instruction: I am looking for a job and I need to fill out an application form. Can you please help me complete it?
我正在找工作,需要填写一份申请表。你能帮我完成吗?
Input:
输入:
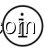
Figure 1: Selected tasks from the generated instruction data using vanilla GPT3. Some texts are reformatted for presentation. See Table 10 for more examples.
图 1: 使用原始GPT3生成的指令数据中选取的任务示例。部分文本为展示需要经过重新排版。更多示例参见表 10。
Instruction: How to write a code for converting degrees fahrenheit to celsius.
指令:如何编写将华氏度转换为摄氏度的代码。
Input: Null
输入:空
Output:
输出:
def convert fahrenheit to celsius(fahr): celsius $=$ (fahr - 32) * 5 / 9 return celsius
def convert fahrenheit to celsius(fahr): celsius $=$ (fahr - 32) * 5 / 9 return celsius
Instruction: Write a letter from the perspective of a cat.
指令:以猫的视角写一封信
Input: Nul
Nul
Output:
输出:
can follow natural language instructions (Mishra et al., 2022; Wei et al., 2022; Sanh et al., 2022; Wang et al., 2022; Ouyang et al., 2022; Chung et al., 2022, i.a.). These developments are powered by two key components: large pretrained language models (LM) and human-written instruction data (e.g., PROMPT SOURCE (Bach et al., 2022) and SUPERNATURAL INSTRUCTIONS (Wang et al., 2022, SUPERNI for short)). However, collecting such instruction data is costly and often suffers limited diversity given that most human generations tend to be popular NLP tasks, falling short of covering a true variety of tasks and different ways to describe them. Continuing to improve the quality and coverage of instruction-tuned models necessitates the development of alternative approaches for supervising the instruction tuning process.
能够遵循自然语言指令 (Mishra et al., 2022; Wei et al., 2022; Sanh et al., 2022; Wang et al., 2022; Ouyang et al., 2022; Chung et al., 2022等)。这些进展依赖于两个关键组件:大规模预训练语言模型 (LM) 和人工编写的指令数据 (例如 PROMPT SOURCE (Bach et al., 2022) 和 SUPERNATURAL INSTRUCTIONS (Wang et al., 2022, 简称 SUPERNI))。然而,收集此类指令数据成本高昂,且由于大多数人工生成内容倾向于热门 NLP 任务,往往存在多样性不足的问题,无法真正覆盖多样化的任务及其描述方式。要持续提升指令调优模型的质量和覆盖范围,需要开发替代方法来监督指令调优过程。

Figure 2: A high-level overview of SELF-INSTRUCT. The process starts with a small seed set of tasks as the task pool. Random tasks are sampled from the task pool, and used to prompt an off-the-shelf LM to generate both new instructions and corresponding instances, followed by filtering low-quality or similar generations, and then added back to the initial repository of tasks. The resulting data can be used for the instruction tuning of the language model itself later to follow instructions better. Tasks shown in the figure are generated by GPT3.
图 2: SELF-INSTRUCT 的概要流程。该流程从一个小型种子任务集作为任务池开始,从中随机采样任务,并利用现成的大语言模型生成新指令及对应实例,随后过滤低质量或相似生成内容,最终将优质结果添加回初始任务库。生成的数据后续可用于语言模型自身的指令微调 (instruction tuning) ,以提升其遵循指令的能力。图中所示任务由 GPT3 生成。
In this work, we introduce SELF-INSTRUCT, a semi-automated process for instruction-tuning a pretrained LM using instructional signals from the model itself. The overall process is an iterative bootstrapping algorithm (see Figure 2), which starts off with a limited (e.g., 175 in our study) seed set of manually-written tasks that are used to guide the overall generation. In the first phase, the model is prompted to generate instructions for new tasks. This step leverages the existing collection of instructions to create more broad-coverage instructions that define (often new) tasks. Given the newlygenerated set of instructions, the framework also creates input-output instances for them, which can be later used for supervising the instruction tuning. Finally, various heuristics are used to automatically filter low-quality or repeated instructions, before adding the remaining valid tasks to the task pool. This process can be repeated for many iterations until reaching a large number of tasks.
在本工作中,我们提出了SELF-INSTRUCT,这是一种利用模型自身指令信号对预训练大语言模型进行指令微调 (instruction-tuning) 的半自动化流程。整体流程采用迭代式自举算法 (参见图2),从少量人工编写的种子任务集(本研究中为175个)开始引导生成过程。第一阶段,模型被提示生成新任务的指令。该步骤利用现有指令集合来创建覆盖范围更广的(通常是新的)任务定义指令。针对新生成的指令集,该框架还会为其创建输入-输出实例,这些实例后续可用于监督指令微调。最后,在将剩余有效任务加入任务池之前,会采用多种启发式方法自动过滤低质量或重复指令。该流程可迭代多次直至生成大量任务。
To evaluate SELF-INSTRUCT empirically, we run this framework on GPT3 (Brown et al., 2020), which is a vanilla LM (§3). The iterative SELFINSTRUCT process on this model leads to about $52\mathrm{k\Omega}$ instructions, paired with about 82K instance inputs and target outputs. We observe that the resulting data provides a diverse range of creative tasks, as is demonstrated by examples in Figure 1. These generated tasks deviate from the distribution of typical NLP tasks, and also have fairly small overlap with the seed tasks (§3.2). On this resulting data, we build GPT3SELF-INST by finetuning GPT3 (i.e., the same model used for generating the instruction data). We evaluate GPT3SELF-INST in comparison to various other models on both typical NLP tasks included in SUPERNI (Wang et al., 2022), and a set of new instructions that are created for novel usage of instruction-following models (§4). The results indicate that GPT3SELF-INST outperforms GPT3 (the original model) by a large margin $(+33.1%)$ and nearly matches the performance of Instruc $\mathrm{\Delta GPT_ {001}}$ Moreover, our human evaluation on the newlycreated instruction set shows that GPT3SELF-INST demonstrates a broad range of instruction following ability, outperforming models trained on other publicly available instruction datasets and leaving only a $5%$ gap behind Instruc $\mathrm{\Delta GPT_ {001}}$ .
为实证评估SELF-INSTRUCT,我们在GPT3 (Brown et al., 2020) 这一基础语言模型上运行该框架(§3)。通过该模型的迭代式SELF-INSTRUCT过程,最终生成约52kΩ指令,并配套约82K实例输入与目标输出。如图1所示,生成数据展现出多样化的创造性任务分布。这些生成任务既偏离典型NLP任务分布,也与种子任务重叠度极低(§3.2)。基于该数据,我们通过微调GPT3(即用于生成指令数据的同款模型)构建出GPT3SELF-INST。我们在SUPERNI (Wang et al., 2022) 包含的典型NLP任务和专为指令跟随模型新颖用途创建的新指令集上,将GPT3SELF-INST与多个模型对比评估(§4)。结果表明:GPT3SELF-INST显著优于原始GPT3模型(+33.1%),且性能接近InstrucΔGPT001。此外,针对新指令集的人工评估显示,GPT3SELF-INST展现出广泛的指令跟随能力,优于基于其他公开指令数据集训练的模型,与InstrucΔGPT001仅有5%的性能差距。
In summary, our contributions are: (1) we introduce SELF-INSTRUCT, a method for inducing instruction following capabilities with minimal human-labeled data; (2) we demonstrate its effectiveness via extensive instruction-tuning experiments; and (3) we release a large synthetic dataset of 52K instructions and a set of manuallywritten novel tasks for building and evaluating future instruction-following models.
总结而言,我们的贡献包括:(1) 提出SELF-INSTRUCT方法,通过最少人工标注数据实现指令跟随能力的诱导;(2) 通过大量指令调优实验验证其有效性;(3) 发布包含5.2万条指令的大型合成数据集和一组人工编写的新任务集,用于构建和评估未来的指令跟随模型。
2 Method
2 方法
Annotating large-scale instruction data can be challenging for humans because it requires 1) creativity to come up with novel tasks and 2) expertise for writing the solutions to each task. Here, we detail our process for SELF-INSTRUCT, which refers to the pipeline of generating tasks with a vanilla pretrained language model itself, filtering the generated data, and then conducting instruction tuning with this generated data in order to align the LM to follow instructions better. This pipeline is depicted in Figure 2.
人工标注大规模指令数据面临双重挑战:1) 需要创造力构思新颖任务 2) 需专业知识撰写任务解决方案。我们详细阐述SELF-INSTRUCT流程:通过基础预训练语言模型自主生成任务,过滤生成数据,最终利用该数据执行指令微调 (instruction tuning) 以提升语言模型遵循指令的能力。该流程如图 2 所示。
2.1 Defining Instruction Data
2.1 定义指令数据
The instruction data we want to generate contains a set of instructions ${I_ {t}}$ , each of which defines a task $t$ in natural language. Task $t$ has $n_ {t}\geq1$ input-output instances ${(\boldsymbol{X}_ {t,i},Y_ {t,i})}_ {i=1}^{n_ {t}}$ . A model $M$ is expected to produce the output, given the task instruction and the corresponding input: $M(I_ {t},X_ {t,i}):=:Y_ {t,i}.$ for $i\in{1,\ldots,n_ {t}}$ . Note that the instruction and instance input does not have a strict boundary in many cases. For example, “write an essay about school safety” can be a valid instruction that we expect models to respond to directly, while it can also be formulated as “write an essay about the following topic” as the instruction, and “school safety” as an instance input. To encourage the diversity of the data format, we allow such instructions that do not require additional input (i.e., $X$ is empty).
我们想要生成的指令数据包含一组指令 ${I_ {t}}$,每个指令用自然语言定义一个任务 $t$。任务 $t$ 包含 $n_ {t}\geq1$ 个输入-输出实例 ${(\boldsymbol{X}_ {t,i},Y_ {t,i})}_ {i=1}^{n_ {t}}$。给定任务指令和对应输入时,模型 $M$ 应生成输出:$M(I_ {t},X_ {t,i}):=:Y_ {t,i}$,其中 $i\in{1,\ldots,n_ {t}}$。需要注意的是,指令和实例输入在许多情况下并无严格界限。例如,"写一篇关于校园安全的文章"既可以作为有效指令直接要求模型响应,也可以拆分为"根据以下主题写一篇文章"(指令)和"校园安全"(实例输入)的形式。为促进数据格式多样性,我们允许这类无需额外输入(即 $X$ 为空)的指令存在。
2.2 Automatic Instruction Data Generation
2.2 自动指令数据生成
Our pipeline for data generation consists of four steps: 1) generating task instructions, 2) determining if the instruction represents a classification task, 3) instance generation with either an input-first or output-first approach, and 4) filtering low-quality data.
我们的数据生成流程包含四个步骤:1) 生成任务指令,2) 判断指令是否代表分类任务,3) 采用输入优先或输出优先的方法生成实例,4) 过滤低质量数据。
Instruction Generation. At the first step, SELFINSTRUCT generates new instructions from a small set of seed human-written instructions in a bootstrapping fashion. We initiate the task pool with 175 tasks (1 instruction and 1 instance for each task).3 For every step, we sample 8 task instructions from this pool as in-context examples. Of the 8 instructions, 6 are from the human-written tasks, and 2 are from the model-generated tasks in previous steps to promote diversity. The prompting template is shown in Table 5.
指令生成。第一步,SELFINSTRUCT采用自举方式从少量人工编写的种子指令中生成新指令。我们用一个包含175项任务(每项任务含1条指令和1个实例)的初始任务池启动流程。在每一步迭代中,我们从该池中采样8条任务指令作为上下文示例。其中6条来自人工编写任务,2条来自先前步骤中模型生成的任务以提升多样性。提示模板如表5所示。
Classification Task Identification. Because we need two different approaches for classification and non-classification tasks, we next identify whether the generated instruction represents a classification task or not. We prompt the LM in a few-shot way to determine this, using 12 classification instructions and 19 non-classification instructions from the seed tasks. The prompting template is shown in Table 6.
分类任务识别。由于我们需要针对分类和非分类任务采用两种不同的方法,接下来需要判断生成的指令是否代表分类任务。我们采用少样本方式提示大语言模型进行判断,从种子任务中选取了12条分类指令和19条非分类指令。提示模板如表6所示。
Instance Generation. Given the instructions and their task type, we generate instances for each instruction independently. This is challenging because it requires the model to understand what the target task is, based on the instruction, figure out what additional input fields are needed and generate them, and finally complete the task by producing the output. We found that pretrained LMs can achieve this to a large extent when prompted with instruction-input-output in-context examples from other tasks. A natural way to do this is the Inputfirst Approach, where we can ask an LM to come up with the input fields first based on the instruction, and then produce the corresponding output. This generation order is similar to how models are used to respond to instruction and input, but here with in-context examples from other tasks. The prompting template is shown in Table 7.
实例生成。给定指令及其任务类型,我们为每条指令独立生成实例。这一过程具有挑战性,因为模型需要根据指令理解目标任务是什么,确定需要哪些额外的输入字段并生成它们,最后通过生成输出来完成任务。我们发现,当使用来自其他任务的指令-输入-输出上下文示例进行提示时,预训练的大语言模型在很大程度上能够实现这一目标。一种自然的方法是输入优先法 (Input-first Approach),即先让大语言模型根据指令生成输入字段,然后再生成相应的输出。这种生成顺序类似于模型用于响应指令和输入的方式,但此处使用的是来自其他任务的上下文示例。提示模板如表 7 所示。
However, we found that this approach can generate inputs biased toward one label, especially for classification tasks (e.g., for grammar error detection, it usually generates grammatical input). There- fore, we additionally propose an Output-first Approach for classification tasks, where we first generate the possible class labels, and then condition the input generation on each class label. The prompting template is shown in Table 8.5 We apply the outputfirst approach to the classification tasks identified in the former step, and the input-first approach to the remaining non-classification tasks.
然而,我们发现这种方法生成的输入容易偏向某个标签,尤其针对分类任务(例如语法错误检测任务通常只生成语法正确的输入)。因此,我们额外提出了面向分类任务的输出优先法:首先生成可能的类别标签,再基于每个类别标签生成对应输入。提示模板如表8所示。我们将输出优先法应用于前一步筛选出的分类任务,其余非分类任务则采用输入优先法。
Filtering and Post processing. To encourage diversity, a new instruction is added to the task pool only when its ROUGE-L similarity with any existing instruction is less than 0.7. We also exclude instructions that contain some specific keywords (e.g., image, picture, graph) that usually can not be processed by LMs. When generating new instances for each instruction, we filter out instances that are exactly the same or those with the same input but different outputs. Invalid generations are identified and filtered out based on heuristics (e.g., instruction is too long or too short, instance output is a repetition of the input).
过滤与后处理。为提升多样性,只有当新指令与现有指令的ROUGE-L相似度低于0.7时才会被加入任务池。同时排除包含特定关键词(如image、picture、graph等)的指令,这些内容通常无法被语言模型处理。在为每条指令生成新实例时,会过滤掉完全相同的实例或输入相同但输出不同的实例。根据启发式规则(如指令过长/过短、实例输出是输入的重复等)识别并剔除无效生成结果。
2.3 Finetuning the LM to Follow Instructions
2.3 微调大语言模型以遵循指令
After creating large-scale instruction data, we use it to finetune the original LM (i.e., SELF-INSTRUCT). To do this, we concatenate the instruction and instance input as a prompt and train the model to generate the instance output in a standard supervised way. To make the model robust to different formats, we use multiple templates to encode the instruction and instance input together. For example, the instruction can be prefixed with “Task:” or not, the input can be prefixed with “Input:” or not, “Output:” can be appended at the end of the prompt or not, and different numbers of break lines can be put in the middle, etc.
在创建大规模指令数据后,我们用它来微调原始语言模型(即SELF-INSTRUCT)。具体操作中,我们将指令和实例输入拼接为提示词,并以标准监督式训练模型生成实例输出。为使模型适应不同格式,我们采用多种模板对指令和实例输入进行组合编码。例如:指令可添加"Task:"前缀或保持原样,输入可添加"Input:"前缀或省略,"Output:"可附加在提示词末尾或去除,中间还可插入不同数量的换行符等。
3 SELF-INSTRUCT Data from GPT3
3 来自GPT3的SELF-INSTRUCT数据
In this section, we apply our method for inducing instruction data to GPT3 as a case study. We use the largest GPT3 LM (“davinci” engine) accessed through the OpenAI API. The parameters for making queries are described in Appendix A.2. Here we present an overview of the generated data.
在本节中,我们以GPT3为例,应用我们的方法生成指令数据。我们通过OpenAI API访问最大的GPT3大语言模型("davinci"引擎)。查询参数详见附录A.2。以下展示生成数据的概览。
3.1 Statistics
3.1 统计
Table 1 describes the basic statistics of the generated data. We generate a total of over 52K instructions and more than 82K instances corresponding to these instructions after filtering.
表1描述了生成数据的基本统计信息。经过筛选后,我们总共生成了超过52K条指令和与之对应的82K多个实例。
Table 1: Statistics of the generated data by applying SELF-INSTRUCT to GPT3.
| statistic | |
| #ofinstructions | 52,445 |
| -#ofclassificationinstructions | 11,584 |
| -#ofnon-classificationinstructions | 40,861 |
| #ofinstances | 82,439 |
| -# of instances with empty input | 35,878 |
| ave.instructionlength(in words) | 15.9 |
| ave.non-emptyinputlength(inwords) | 12.7 |
| ave.outputlength(inwords) | 18.9 |
表 1: 通过将 SELF-INSTRUCT 应用于 GPT3 生成的数据统计
| statistic | |
|---|---|
| #ofinstructions | 52,445 |
| -#ofclassificationinstructions | 11,584 |
| -#ofnon-classificationinstructions | 40,861 |
| #ofinstances | 82,439 |
| -# of instances with empty input | 35,878 |
| ave.instructionlength(in words) | 15.9 |
| ave.non-emptyinputlength(inwords) | 12.7 |
| ave.outputlength(inwords) | 18.9 |
3.2 Diversity
3.2 多样性
To study what types of instructions are generated and how diverse they are, we identify the verb-noun structure in the generated instructions. We use the Berkeley Neural Parser7 (Kitaev and Klein, 2018; Kitaev et al., 2019) to parse the instructions and then extract the verb that is closest to the root as well as its first direct noun object. 26,559 out of the 52,445 instructions contain such structure; other instructions usually contain more complex clauses (e.g., “Classify whether this tweet contains political content or not.”) or are framed as questions (e.g., “Which of these statements are true?”). We plot the top 20 most common root verbs and their top 4 direct noun objects in Figure 3, which account for $14%$ of the entire set. Overall, we see quite diverse intents and textual formats in these instructions.
为了研究生成指令的类型及其多样性,我们识别了生成指令中的动词-名词结构。我们使用Berkeley Neural Parser7 (Kitaev and Klein, 2018; Kitaev et al., 2019) 对指令进行解析,然后提取最接近根节点的动词及其首个直接名词宾语。在52,445条指令中,有26,559条包含此类结构;其他指令通常包含更复杂的从句(例如"判断这条推文是否包含政治内容")或以问句形式呈现(例如"以下哪些陈述是正确的?")。我们在图3中展示了最常见的20个根动词及其前4个直接名词宾语,这些组合占整个数据集的14%。总体而言,这些指令在意图和文本格式上呈现出高度多样性。
We further study how the generated instructions differ from the seed instructions used to prompt the generation. For each generated instruction, we compute its highest ROUGE-L overlap with the 175 seed instructions. We plot the distribution of these ROUGE-L scores in Figure 4. The results indicate a decent number of new instructions were generated, which do not have much overlap with the seeds. We also demonstrate diversity in the length of the instructions, instance inputs, and instance outputs in Figure 5.
我们进一步研究了生成的指令与用于提示生成的种子指令之间的差异。对于每条生成的指令,我们计算其与175条种子指令的最高ROUGE-L重叠度,并在图4中绘制了这些ROUGE-L分数的分布。结果表明,生成了相当数量的新指令,这些指令与种子指令重叠度不高。图5还展示了指令长度、实例输入和实例输出方面的多样性。
3.3 Quality
3.3 质量
So far, we have shown the quantity and diversity of the generated data, but its quality remains uncertain. To investigate this, we randomly sample 200 instructions and randomly select 1 instance per instruction. We asked an expert annotator (author of this work) to label whether each instance is correct or not, in terms of the instruction, the instance input, and the instance output. Evaluation results in Table 2 show that most of the generated instructions are meaningful, while the generated instances may contain more noise (to a reasonable extent). However, we found that even though the generations may contain errors, most of them are still in the correct format or partially correct, which can provide useful guidance for training models to follow instructions. We listed a number of good examples and bad examples in Table 10 and 11, respectively.
目前我们已展示了生成数据的数量和多样性,但其质量仍待验证。为此,我们随机抽取200条指令,每条指令随机选择1个实例,并邀请专业标注员(本文作者)从指令、实例输入和实例输出三个维度评估每个实例的正确性。表2的评估结果显示:大多数生成指令具有实际意义,而生成的实例可能包含更多噪声(在合理范围内)。但研究发现,即使生成内容存在错误,其中大部分仍保持正确格式或部分正确,这能为训练模型遵循指令提供有效指导。我们在表10和表11中分别列举了若干优质案例和问题案例。
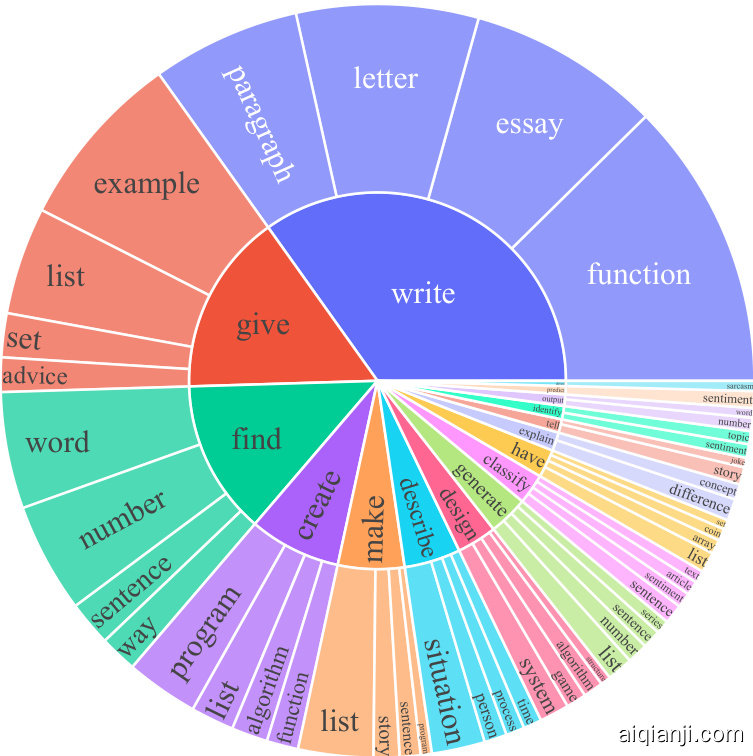
Figure 3: The top 20 most common root verbs (inner circle) and their top 4 direct noun objects (outer circle) in the generated instructions. Despite their diversity, the instructions shown here only account for $14%$ of all the generated instructions because many instructions (e.g., “Classify whether the user is satisfied with the service.”) do not contain such a verb-noun structure.
图 3: 生成指令中最常见的20个根动词(内圈)及其前4个直接名词宾语(外圈)。尽管这些指令具有多样性,但此处展示的指令仅占所有生成指令的14%,因为许多指令(例如"判断用户是否对服务满意")不包含此类动宾结构。

Figure 4: Distribution of the ROUGE-L scores between generated instructions and their most similar seed instructions.
图 4: 生成指令与其最相似种子指令之间的 ROUGE-L 分数分布。
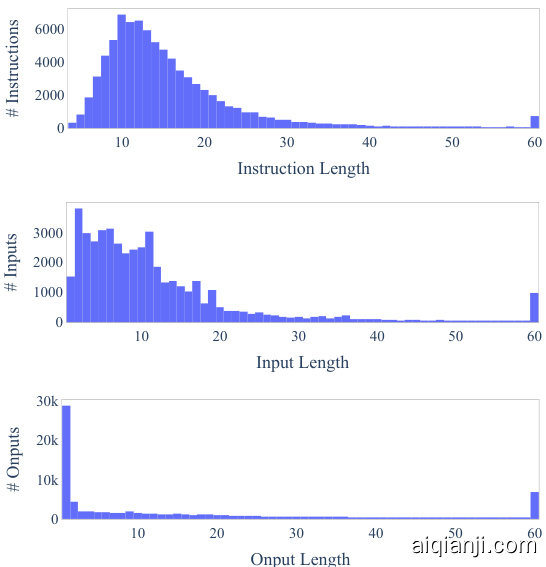
Figure 5: Length distribution of the generated instructions, non-empty inputs, and outputs.
图 5: 生成指令、非空输入及输出的长度分布。
Table 2: Data quality review for the instruction, input, and output of the generated data. See Table 10 and Table 11 for representative valid and invalid examples.
| QualityReviewQuestion | Yes % |
| Doestheinstruction describeavalidtask? | 92% |
| Is theinput appropriate for the instruction? | 79% |
| Is the output a correctand acceptable responseto theinstruction andinput? | 58% |
| Allfieldsarevalid | 54% |
表 2: 生成数据的指令、输入和输出的数据质量审查。代表性有效和无效示例见表 10 和表 11。
| 质量审查问题 | 是 % |
|---|---|
| 指令是否描述了一个有效任务? | 92% |
| 输入是否适合该指令? | 79% |
| 输出是否是对指令和输入的正确且可接受的响应? | 58% |
| 所有字段均有效 | 54% |
4 Experimental Results
4 实验结果
We conduct experiments to measure and compare the performance of models under various instruction tuning setups. We first describe our models and other baselines, followed by our experiments.
我们通过实验测量并比较了不同指令微调设置下模型的性能表现。首先介绍我们的模型及其他基线模型,随后阐述实验过程。
4.1 GPT3SELF-INST: finetuning GPT3 on its own instruction data
4.1 GPT3SELF-INST: 基于自身指令数据微调GPT3
Given the instruction-generated instruction data, we conduct instruction tuning with the GPT3 model itself (“davinci” engine). As described in $\S2.3$ , we use various templates to concatenate the instruction and input, and train the model to generate the output. This finetuning is done through the OpenAI finetuning API.8 We use the default hyper-parameters, except that we set the prompt loss weight to 0, and we train the model for 2 epochs. We refer the reader to Appendix A.3 for additional finetuning details. The resulting model is denoted by GPT3SELF-INST.
基于指令生成的指令数据,我们使用GPT3模型自身("davinci"引擎)进行指令微调。如$\S2.3$节所述,我们采用多种模板拼接指令与输入,并训练模型生成输出。此次微调通过OpenAI微调API完成,除将提示词损失权重设为0并训练2个周期外,其余均采用默认超参数。更多微调细节详见附录A.3。最终得到的模型记为GPT3SELF-INST。
4.2 Baselines
4.2 基线方法
Off-the-shelf LMs. We evaluate T5-LM (Lester et al., 2021; Raffel et al., 2020) and GPT3 (Brown et al., 2020) as the vanilla LM baselines (only pretraining, no additional finetuning). These baselines will indicate the extent to which off-the-shelf LMs are capable of following instructions naturally immediately after pre training.
现成的大语言模型。我们评估 T5-LM (Lester et al., 2021; Raffel et al., 2020) 和 GPT3 (Brown et al., 2020) 作为基础大语言模型基线 (仅预训练,无额外微调)。这些基线将表明现成大语言模型在预训练后自然遵循指令的能力程度。
Publicly available instruction-tuned models. T0 and T𝑘-INSTRUCT are two instruction-tuned models proposed in Sanh et al. (2022) and Wang et al. (2022), respectively, and are demonstrated to be able to follow instructions for many NLP tasks. Both of these models are finetuned from the T5 (Raffel et al., 2020) checkpoints and are publicly available.9 For both of these models, we use their largest version with 11B parameters.
公开可用的指令调优模型。T0和T𝑘-INSTRUCT分别是Sanh等人(2022)和Wang等人(2022)提出的两种指令调优模型,被证明能够遵循多种NLP任务的指令。这两个模型都基于T5(Raffel等人,2020)检查点进行微调,并已公开可用。对于这两个模型,我们使用其最大版本,包含110亿参数。
Instruction-tuned GPT3 models. We evaluate Instruct GP T (Ouyang et al., 2022), which is developed by OpenAI based on GPT3 to follow human instructions better and has been found by the community to have impressive zero-shot abilities. There are various generations of these models, where newer ones use more expansive data or algorithmic novelties. For our SUPERNI experiments in $\S4.3$ , we only compare with their text-davinci-001 engine, because their newer engines are trained with the latest user data and are likely to have already seen the SUPERNI test set. For our human evaluation on newly written instructions, we include their 001, 002 and 003 engines for completeness.
指令调优的GPT3模型。我们评估了由OpenAI基于GPT3开发的InstructGPT (Ouyang等人, 2022) ,该模型能更好地遵循人类指令,并被社区发现具有出色的零样本能力。这些模型有多代版本,较新的版本使用了更广泛的数据或算法创新。在$\S4.3$的SUPERNI实验中,我们仅与其text-davinci-001引擎进行比较,因为它们的新引擎使用了最新的用户数据训练,可能已经见过SUPERNI测试集。在对新编写指令进行人工评估时,为保持完整性,我们纳入了其001、002和003引擎。
Additionally, to compare SELF-INSTRUCT training with other publicly available instruction tuning data, we further finetune GPT3 model with data from PROMPT SOURCE and SUPERNI, which are used to train the T0 and $\mathrm{T}k$ -INSTRUCT models. We call them T0 training and SUPERNI training for short, respectively. To save the training budget, we sampled 50K instances (but covering all their instructions) for each dataset, which has a comparable size to the instruction data we generated. Based on the findings from Wang et al. (2022) and our early experiments, reducing the number of instances per training task does not degrade the model’s generalization performance to unseen tasks.
此外,为了比较SELF-INSTRUCT训练与其他公开可用的指令微调数据,我们进一步使用来自PROMPT SOURCE和SUPERNI的数据对GPT3模型进行微调,这些数据曾用于训练T0和$\mathrm{T}k$-INSTRUCT模型。我们分别简称为T0训练和SUPERNI训练。为节省训练预算,我们从每个数据集中采样了50K实例(但覆盖其所有指令),其规模与我们生成的指令数据相当。根据Wang等人(2022)的研究和我们早期实验发现,减少每个训练任务的实例数量不会降低模型对未见任务的泛化性能。
4.3 Experiment 1: Zero-Shot Generalization on SUPERNI benchmark
4.3 实验1: SUPERNI基准测试上的零样本泛化能力
We first evaluate the models’ ability to follow instructions on typical NLP tasks in a zero-shot fashion. We use the evaluation set of SUPERNI (Wang et al., 2022), which consists of 119 tasks with 100 instances in each task. In this work, we mainly focus on the zero-shot setup, i.e., the model is prompted with the definition of the tasks only, without incontext demonstration examples. For all our requests to the GPT3 variants, we use the deterministic generation mode (temperature as 0 and no nucleus sampling) without specific stop sequences.
我们首先评估模型在零样本方式下执行典型NLP任务指令的能力。使用SUPERNI (Wang et al., 2022) 的评估集,该集合包含119个任务,每个任务有100个实例。本工作主要关注零样本设置,即仅向模型提供任务定义提示,不包含上下文演示示例。对于所有向GPT3变体模型发起的请求,均采用确定性生成模式 (温度参数设为0且不使用核心采样),未设置特定停止序列。
Results. We make the following observations from the results in Table 3. SELF-INSTRUCT boosts the instruction-following ability of GPT3 by a large margin. The vanilla GPT3 model basically cannot follow human instructions at all. Upon manual analysis, we find that it usually generates irrelevant and repetitive text, and does not know when to stop generation. Compared with other models that are not specifically trained for SUPERNI, $\mathrm{GPT}3_ {\mathrm{SELF-INST}}$ achieves better performance than T0 or the GPT3 finetuned on the $\mathrm{T0}$ training set, which takes tremendous human labeling efforts. Notably, $\mathrm{GPT}3_ {\mathrm{SELF-INST}}$ also nearly matches the performance of Instruc $\mathbf{GPT}_ {001}$ , which is trained with private user data and human-annotated labels.
结果。我们从表3的结果中得出以下观察:SELF-INSTRUCT大幅提升了GPT3的指令遵循能力。原始GPT3模型基本无法遵循人类指令。通过人工分析发现,该模型通常生成无关且重复的文本,且不知道何时停止生成。与其他未针对SUPERNI专门训练的模型相比,$\mathrm{GPT}3_ {\mathrm{SELF-INST}}$的表现优于T0或在$\mathrm{T0}$训练集上微调的GPT3(后者需要耗费大量人工标注工作)。值得注意的是,$\mathrm{GPT}3_ {\mathrm{SELF-INST}}$的性能也几乎与Instruc $\mathbf{GPT}_ {001}$相当,后者使用了私有用户数据和人工标注标签进行训练。
Table 3: Evaluation results on unseen tasks from SUPERNI (§4.3). From the results, we see that ① SELFINSTRUCT can boost GPT3 performance by a large margin $(+33.1%)$ and ② nearly matches the performance of Instruc $\mathrm{\Delta GPT_ {001}}$ . Additionally, ③ it can further improve the performance even when a large amount of labeled instruction data is present.
| Model | #ParamsROUGE-L | |
| VanillaLMs | ||
| T5-LM | 11B | 25.7 |
| GPT3 | 175B | 6.8 |
| Instruction-tunedw/oSuPERNI TO | ||
| 11B | 33.1 | |
| GPT3+T0Training | 175B | 37.9 |
| GPT3 sELF-INsT (Ours) | 175B | 39.9 |
| 175B | 40.8 | |
| Instruction-tunedw/SuPERNI | ||
| TK-INSTRUCT | 11B | 46.0 |
| GPT3+SUPERNITraining | 175B | 49.5 |
| >GPT3seLF-INsT + SUPERNI Training (Ours) | 175B | 51.6 |
表 3: 在SUPERNI未见任务上的评估结果(§4.3)。从结果可以看出:①SELFINSTRUCT能大幅提升GPT3性能$(+33.1%)$;② 其表现几乎与Instruc$\mathrm{\Delta GPT_ {001}}$相当;③ 即使存在大量标注指令数据时仍能进一步提升性能。
| 模型 | #ParamsROUGE-L | |
|---|---|---|
| VanillaLMs | ||
| T5-LM | 11B | 25.7 |
| GPT3 | 175B | 6.8 |
| Instruction-tunedw/oSuPERNI TO | ||
| 11B | 33.1 | |
| GPT3+T0Training | 175B | 37.9 |
| GPT3 sELF-INsT (Ours) | 175B | 39.9 |
| 175B | 40.8 | |
| Instruction-tunedw/SuPERNI | ||
| TK-INSTRUCT | 11B | 46.0 |
| GPT3+SUPERNITraining | 175B | 49.5 |
| >GPT3seLF-INsT + SUPERNI Training (Ours) | 175B | 51.6 |
Models trained on the SUPERNI training set still achieve better performance on its evaluation set, which we attribute to the similar instruction style and formatting. However, we show that SELFINSTRUCT still brings in additional gains when combined with the SUPERNI training set, proving its value as complementary data.
在SUPERNI训练集上训练的模型在其评估集上仍表现更优,我们将其归因于相似的指令风格和格式。但研究表明,SELFINSTRUCT与SUPERNI训练集结合时仍能带来额外收益,证实了其作为补充数据的价值。
4.4 Experiment 2: Generalization to User-oriented Instructions on Novel Tasks
4.4 实验2:面向用户的新任务指令泛化能力测试
Despite the comprehensiveness of SUPERNI in collecting existing NLP tasks, most of these NLP tasks were proposed for research purposes and skewed toward classification. To better access the practical value of instruction-following models, a subset of the authors curate a new set of instructions motivated by user-oriented applications. We first brainstorm various domains where large LMs may be useful (e.g., email writing, social media, productivity tools, entertainment, programming), then craft instructions related to each domain along with an input-output instance (again, input is optional). We aim to diversify the styles and formats of these tasks (e.g., instructions may be long or short; input/output may take the form of bullet points, tables, codes, equations, etc.). In total, we create 252 instructions with 1 instance per instruction. We believe it can serve as a testbed for evaluating how instruction-based models handle diverse and unfamiliar instructions. Table 9 presents a small portion of them. The entire set is available in our GitHub repository. We analyze the overlap between this set set and the seed instructions in $\S\mathrm{A}.1$ .
尽管SUPERNI在收集现有NLP任务方面具有全面性,但这些任务大多出于研究目的而提出,且偏向分类任务。为更好评估指令跟随模型的实际价值,部分作者基于用户导向型应用场景策划了一套新指令集。我们首先头脑风暴了大语言模型可能适用的各个领域(如邮件撰写、社交媒体、生产力工具、娱乐、编程等),随后为每个领域设计相关指令及输入输出实例(输入仍为可选)。我们致力于多样化这些任务的风格与格式(例如指令可长可短;输入/输出可采用项目符号、表格、代码、公式等形式)。最终共创建252条指令,每条指令对应1个实例。我们相信这能作为评估基于指令的模型处理多样化陌生指令能力的测试平台。表9展示了其中一小部分,完整指令集可在GitHub仓库获取。我们分析了该指令集与$\S\mathrm{A}.1$中种子指令的重叠情况。

Figure 6: Performance of GPT3 model and its instruction-tuned variants, evaluated by human experts on our 252 user-oriented instructions (§4.4). Human evaluators are instructed to rate the models’ responses into four levels. The results indicate that $\mathrm{GPT}3_ {\mathrm{SELF-INST}}$ outperforms all the other GPT3 variants trained on publicly available instruction datasets. Additionally, $\mathrm{GPT}3_ {\mathrm{SELF-INST}}$ scores nearly as good as Instruc $\mathrm{\Delta{GPT_ {001}}}$ (cf. footnote 1).
图 6: GPT3模型及其指令调优变体在我们252条面向用户指令(§4.4)上由人类专家评估的性能表现。评估人员被要求将模型响应分为四个等级进行评估。结果表明,$\mathrm{GPT}3_ {\mathrm{SELF-INST}}$优于所有其他基于公开指令数据集训练的GPT3变体。此外,$\mathrm{GPT}3_ {\mathrm{SELF-INST}}$的评分几乎与Instruc $\mathrm{\Delta{GPT_ {001}}}$相当(参见脚注1)。
Human evaluation setup. Evaluating models’ performance on this evaluation set of diverse tasks is extremely challenging because different tasks require different expertise. Indeed, many of these tasks cannot be measured by automatic metrics or even be judged by normal crowd workers (e.g., writing a program, or converting first-order logic into natural language). To get a more faithful evaluation, we asked the authors of the instructions to judge model predictions. Details on how we set up this human evaluation are described in Appendix B. The evaluators were asked to rate the output based on whether it accurately and effectively completes the task. We implemented a four-level rating system for categorizing the quality of the models’ outputs:
人工评估设置。由于不同任务需要不同专业知识,评估模型在这个多样化任务评估集上的表现极具挑战性。事实上,许多任务无法通过自动指标衡量,甚至普通众包工作者也难以评判(例如编写程序或将一阶逻辑转换为自然语言)。为获得更可靠的评估结果,我们邀请任务指令的作者对模型预测进行评判。具体评估设置详见附录B。评估者需根据输出是否准确有效完成任务进行评级,我们采用四级评分系统对模型输出质量进行分类:
• RATING-A: The response is valid and satisfying. • RATING-B: The response is acceptable but has minor errors or imperfections. • RATING-C: The response is relevant and responds to the instruction, but it has significant errors in the content. For example, GPT3 might generate a valid output first, but continue to gen
- RATING-A: 回答有效且令人满意。
- RATING-B: 回答可接受但存在轻微错误或不完美之处。
- RATING-C: 回答与指令相关但内容存在重大错误。例如,GPT3可能首先生成有效输出,但后续继续生成...
erate other irrelevant things. • RATING-D: The response is irrelevant or completely invalid.
• RATING-D: 回答不相关或完全无效。
Results. Figure 6 shows the performance of GPT3 model and its instruction-tuned counterparts on this newly written instruction set (w. inter-rater agreement $\kappa=0.57$ on the 4-class categorical scale, see Appendix B for details). As anticipated, the vanilla GPT3 LM is largely unable to respond to instructions, and all instruction-tuned models demonstrate comparatively higher performance. Nonetheless, $\mathrm{GPT}3_ {\mathrm{SELF-INST}}$ (i.e., GPT3 model finetuned with SELF-INSTRUCT) outperforms those counterparts trained on T0 or SUPERNI data by a large margin, demonstrating the value of the generated data despite the noise. Compared with Instruc $\mathrm{\Delta GPT_ {001}}$ , $\mathrm{GPT}3_ {\mathrm{SELF-INST}}$ is quite close in performance—if we count acceptable response with minor imperfections (RATING-B) as valid, $\mathrm{GPT}3_ {\mathrm{SELF-INST}}$ is only $5%$ behind Instruc $\mathrm{\Delta GPT_ {001}}$ . Lastly, our evaluation confirms the impressive instruction-following ability of Instruc $\mathbf{GPT}_ {002}$ and Instruc $\mathrm{\Delta_ {tGPT_ {003}}}$ . Although there are many factors behind this success, we conjecture that future work can largely benefit from improving the quality of our generated data by using human annotators or training a reward model to select better generations, similar to the algorithm used by Ouyang et al. (2022).
结果。图 6 展示了 GPT3 模型及其经过指令微调的变体在新编写的指令集上的表现 (评分者间一致性 $\kappa=0.57$ ,采用 4 级分类量表,详见附录 B)。如预期所示,原始 GPT3 大语言模型基本无法响应指令,而所有经过指令微调的模型都表现出相对更高的性能。尽管如此, $\mathrm{GPT}3_ {\mathrm{SELF-INST}}$ (即通过 SELF-INSTRUCT 微调的 GPT3 模型) 显著优于基于 T0 或 SUPERNI 数据训练的模型,这表明生成数据尽管存在噪声仍具有重要价值。与 Instruc $\mathrm{\Delta GPT_ {001}}$ 相比, $\mathrm{GPT}3_ {\mathrm{SELF-INST}}$ 性能非常接近——若将存在轻微缺陷但可接受的响应 (RATING-B) 视为有效, $\mathrm{GPT}3_ {\mathrm{SELF-INST}}$ 仅落后 Instruc $\mathrm{\Delta GPT_ {001}}$ $5%$ 。最后,我们的评估证实了 Instruc $\mathbf{GPT}_ {002}$ 和 Instruc $\mathrm{\Delta_ {tGPT_ {003}}}$ 出色的指令遵循能力。虽然成功背后存在诸多因素,但我们推测未来工作可以通过以下方式显著提升生成数据质量:使用人工标注员训练,或训练奖励模型来筛选更优生成结果,类似 Ouyang 等人 (2022) 采用的算法。
4.5 Effect of Data Size and Quality
4.5 数据规模与质量的影响
Data size. SELF-INSTRUCT provides a way to grow instruction data at a low cost with almost no human labeling; could more of this generated data lead to better instruction-following ability? We conduct an analysis of the size of generated data by sub sampling different numbers of instructions from the generated dataset, finetuning GPT3 on the sampled subsets, and evaluating how the resulting models perform on the 252 user-oriented instruction set. We conduct the same human evaluation as in $\S4.4$ . Figure 7 presents the performance of $\mathrm{GPT}3_ {\mathrm{SELF-INST}}$ models finetuned with different sizes of generated data. Overall, we see consistent improvement as we grow the data size. However, this improvement almost plateaus after 16K. This is inline with the data scaling experiments in Wang et al. (2022, Fig. 5). Interestingly, when evaluating on SUPERNI we found the model’s performance gain plateaus earlier at around hundreds of instructions. This may be due to the fact that the new generated data is distinct from typical NLP tasks in SUPERNI, indicating that future research may benefit from using a combination of different instruction data for better performance on various types of tasks.
数据规模。SELF-INSTRUCT 提供了一种几乎无需人工标注、低成本扩展指令数据的方法;生成更多数据是否能提升指令遵循能力?我们通过从生成数据集中抽取不同数量的指令子集,在采样子集上微调 GPT3,并评估所得模型在 252 条用户导向指令集上的表现来分析生成数据规模的影响。采用与 $\S4.4$ 相同的人工评估方法。图 7 展示了使用不同规模生成数据微调的 $\mathrm{GPT}3_ {\mathrm{SELF-INST}}$ 模型性能。总体而言,随着数据规模增加,模型表现持续提升,但在超过 16K 条指令后改善趋于平缓,这与 Wang 等人 (2022, 图 5) 的数据规模实验结论一致。值得注意的是,在 SUPERNI 基准测试中,模型性能在数百条指令时即达到平台期,这可能是因为新生成数据与 SUPERNI 中典型 NLP 任务存在差异,表明未来研究可通过组合不同指令数据来提升各类任务的性能。
Data quality. Another direction to improve the model’s performance is to take our generated data and get better supervision (with less noise). We explore this idea by using Instruc $\mathbf{{GPT}}_ {003}$ (the best available general-purpose model) to regenerate the output field of all our instances given the instruction and input. We then use this improved version of our data to finetune GPT3. This can be regarded as a distillation of Instruc $\mathbf{{GPT}}_ {003}$ with our data. As is shown in Figure 7, the resulting model outperforms the counterpart trained with the original data by $10%$ , which suggests big room for future work on using our generation pipeline to get initial data and then improving the data quality with human experts or distillation from better models.
数据质量。提升模型性能的另一个方向是利用生成数据获得更优(噪声更少)的监督信号。我们通过使用Instruc $\mathbf{{GPT}}_ {003}$ (当前最优的通用模型)在给定指令和输入条件下重新生成所有实例的输出字段,验证了这一思路。随后用优化后的数据微调GPT3模型,这可视作基于我们数据的Instruc $\mathbf{{GPT}}_ {003}$蒸馏过程。如图7所示,新模型比原始数据训练的版本性能提升$10%$,这表明未来工作存在巨大空间:既可利用我们的生成管道获取初始数据,再通过人类专家或更优模型蒸馏来提升数据质量。
5 Related Work
5 相关工作
Instruction-following LMs. A series of works have found evidence that vanilla LMs can be effective at following general language instructions if tuned with annotated “instructional” data—datasets containing language instructional commands and their desired outcomes based on human annotation (Weller et al., 2020; Mishra et al., 2022; Wei et al., 2022; Sanh et al., 2022, i.a.). Additionally, they show a direct correlation between the size and diversity of the “instructional” data and the generalizability of resulting models to unseen tasks (Wang et al., 2022; Chung et al., 2022). However, since these developments largely focus on existing NLP tasks and depend on human-annotated instructions, this poses a bottleneck for progress toward more general iz able models (e.g., see Fig. 5a in Wang et al., 2022). Our work aims to move beyond classical NLP tasks and tackle the challenges of creating diverse instruction data by employing pretrained LMs. Instruct GP T (Ouyang et al., 2022) shares a similar goal as ours in building more generalpurpose LMs, and has demonstrated remarkable performance in following diverse user instructions. However, as a commercial system, their construction process still remains quite opaque. In particular, the role of data has remained understudied due to limited transparency and the private user data they used in their study. Addressing such challenges necessitates the creation of a large-scale, public dataset covering a broad range of tasks.
指令跟随大语言模型。一系列研究发现,若用标注的"指令"数据(即包含语言指令命令及人工标注预期结果的数据集)进行调优,普通大语言模型能有效遵循通用语言指令 (Weller et al., 2020; Mishra et al., 2022; Wei et al., 2022; Sanh et al., 2022等)。研究还表明,"指令"数据的规模及多样性与模型对未知任务的泛化能力直接相关 (Wang et al., 2022; Chung et al., 2022)。但由于这些进展主要集中于现有NLP任务且依赖人工标注指令,这为开发更通用的模型设置了瓶颈(如参见Wang et al. (2022) 的图5a)。本研究旨在超越传统NLP任务,通过使用预训练大语言模型解决创建多样化指令数据的挑战。InstructGPT (Ouyang et al., 2022) 与我们构建通用大语言模型的目标相似,并在遵循多样化用户指令方面展现出卓越性能。但作为商业系统,其构建过程仍不透明,特别是由于透明度有限及使用私有用户数据,数据作用尚未得到充分研究。应对这些挑战需要创建覆盖广泛任务的大规模公开数据集。

Figure 7: Human evaluation performance of $\mathrm{GPT}3_ {\mathrm{SELF-INST}}$ models tuned with different sizes of instructions. $x$ -axis is in log scale. The smallest size is 175, where only the seed tasks are used for instruction tuning. We also evaluate whether improving the data quality will further improve the performance by distilling the outputs from Instruc $\mathrm{\mathbf{tGPT}}_ {003}$ . We see consistent improvement from using larger data with better quality.
图 7: 不同指令规模微调的 $\mathrm{GPT}3_ {\mathrm{SELF-INST}}$ 模型的人类评估性能。$x$ 轴采用对数刻度。最小规模为175条指令(仅使用种子任务进行指令微调)。我们还通过蒸馏 Instruc $\mathrm{\mathbf{tGPT}}_ {003}$ 的输出评估了提升数据质量是否能进一步改善性能。实验表明,使用更大规模且更高质量的数据能带来持续提升。
Language models for data generation and augmentation. A variety of works have proposed using LMs for data generation (Schick and Schütze, 2021; Wang et al., 2021; Liu et al., 2022; Meng et al., 2023) or augmentation (Feng et al., 2021; Yang et al., 2020; Mekala et al., 2022). Our work differs from this line in that it is not specific to a particular task (say, QA or NLI). In contrast, a distinct motivation for SELF-INSTRUCT is to bootstrap new task definitions that may not have been defined before by NLP practitioners (though potentially still important for real users). In parallel with our work, Honovich et al. (2022a) also propose to generate large-scale instruction data (so-called Unnatural Instructions) with GPT3 models. The major differences are that 1) they use tasks in SUPERNI (Wang et al., 2022) as their seed tasks, resulting in a different distribution of generated tasks; 2) they employ Instruc $\mathrm{tGPT}_ {002}$ for generating the data, in which sense they are distilling knowledge from an already instruction-tuned model, while we solely rely on the vanilla LM; 3) the detailed generation pipeline and templates are different. Nevertheless, we believe that both efforts in expanding instruction data are complementary, and the community will benefit from these diverse datasets.
用于数据生成与增强的语言模型。已有多种研究提出使用大语言模型进行数据生成 (Schick and Schütze, 2021; Wang et al., 2021; Liu et al., 2022; Meng et al., 2023) 或数据增强 (Feng et al., 2021; Yang et al., 2020; Mekala et al., 2022) 。本研究的区别在于不针对特定任务 (如问答或自然语言推理) ,而是通过SELF-INSTRUCT机制引导生成NLP实践者尚未定义过 (但可能对真实用户重要) 的新任务。与本研究同期,Honovich等人 (2022a) 也提出用GPT3模型生成大规模指令数据 (称为Unnatural Instructions) ,主要差异在于:1) 他们使用SUPERNI (Wang et al., 2022) 的任务作为种子任务,导致生成任务分布不同;2) 他们采用Instruc $\mathrm{tGPT}_ {002}$ 生成数据,本质是从已指令调优的模型中蒸馏知识,而我们仅依赖原始大语言模型;3) 具体生成流程与模板不同。我们认为这两种扩展指令数据的努力具有互补性,社区将从这些多样化数据集中受益。
Instruction generation. A series of recent works (Zhou et al., 2022b; Ye et al., 2022; Singh et al., 2022; Honovich et al., 2022b) generate in- structions of a task given a few examples. While SELF-INSTRUCT also involves instruction generation, a major difference in our case is it is taskagnostic; we generate new tasks (instructions along with instances) from scratch.
指令生成。近期一系列研究 (Zhou et al., 2022b; Ye et al., 2022; Singh et al., 2022; Honovich et al., 2022b) 通过少量示例生成任务的指令。虽然 SELF-INSTRUCT 同样涉及指令生成,但本研究的关键差异在于其任务无关性:我们直接从零开始生成新任务(包含指令与实例)。
Model self-training. A typical self-training framework (He et al., 2019; Xie et al., 2020; Du et al., 2021; Amini et al., 2022; Huang et al., 2022) uses trained models to assign labels to unlabeled data and then leverages the newly labeled data to improve the model. In a similar line, Zhou et al. (2022a) use multiple prompts to specify a single task and propose to regularize via prompt consistency, encouraging consistent predictions over the prompts. This allows either finetuning the model with extra unlabeled training data, or direct application at inference time. While SELF-INSTRUCT has similarities with the self-training literature, most self-training methods assume a specific target task as well as unlabeled examples under it; in contrast, SELF-INSTRUCT produces a variety of tasks from scratch.
模型自训练。典型的自训练框架 (He et al., 2019; Xie et al., 2020; Du et al., 2021; Amini et al., 2022; Huang et al., 2022) 使用训练好的模型为未标注数据分配标签,然后利用新标注的数据改进模型。类似地,Zhou et al. (2022a) 使用多个提示 (prompt) 来指定单个任务,并提出通过提示一致性进行正则化,鼓励不同提示下的预测保持一致。这种方法既可以用额外的未标注训练数据微调模型,也可以在推理时直接应用。虽然 SELF-INSTRUCT 与自训练文献有相似之处,但大多数自训练方法假设存在特定目标任务及其对应的未标注样本;相比之下,SELF-INSTRUCT 是从零开始生成多样化任务。
Knowledge distillation. Knowledge distillation (Hinton et al., 2015; Sanh et al., 2019; West et al., 2021; Magister et al., 2022) often involves the transfer of knowledge from larger models to smaller ones. SELF-INSTRUCT can also be viewed as a form of “knowledge distillation", however, it differs from this line in the following ways: (1) the source and target of distillation are the same, i.e., a model’s knowledge is distilled to itself; (2)
知识蒸馏 (Knowledge distillation)。知识蒸馏 (Hinton et al., 2015; Sanh et al., 2019; West et al., 2021; Magister et al., 2022) 通常涉及将知识从较大模型转移到较小模型。SELF-INSTRUCT 也可被视为一种"知识蒸馏"形式,但其在以下方面与此类方法不同:(1) 蒸馏的源和目标相同,即模型的知识被蒸馏到自身;(2)
the content of distillation is in the form of an instruction task (i.e., instructions that define a task, and a set of examples that instantiate it).
蒸馏的内容以指令任务的形式呈现(即定义任务的指令,以及实例化任务的一组示例)。
Boots trapping with limited resources. A series of recent works use language models to bootstrap some inferences using specialized methods. NPPrompt (Zhao et al., 2022) provides a method to generate predictions for semantic labels without any finetuning. It uses a model’s own embeddings to automatically find words relevant to the label of the data sample and hence reduces the dependency on manual mapping from model prediction to label (verbalize rs). STAR (Zelikman et al., 2022) iterative ly leverages a small number of rationale examples and a large dataset without rationales, to bootstrap a model’s ability to perform reasoning. Self-Correction (Welleck et al., 2023) decouples an imperfect base generator (model) from a separate corrector that learns to iterative ly correct imperfect generations and demonstrates improvement over the base generator. Our work instead focuses on bootstrapping new tasks in the instruction paradigm.
有限资源下的自举方法。近期一系列研究利用语言模型通过专门方法进行自举推理。NPPrompt (Zhao et al., 2022) 提出无需微调即可生成语义标签预测的方法,通过模型自身嵌入自动识别与数据样本标签相关的词汇,从而减少人工将模型预测映射到标签(verbalizers)的依赖。STAR (Zelikman et al., 2022) 迭代利用少量带逻辑依据的样本和大量无逻辑依据的数据集,自举模型推理能力。自我修正 (Welleck et al., 2023) 将不完美的基础生成器(模型)与独立修正器解耦,后者通过迭代修正不完美生成结果展现出优于基础生成器的性能。我们的研究则聚焦于指令范式下新任务的自举。
Multi-modal instruction-following. Instructionfollowing models have also been of interest in the multi-modal learning literature (Fried et al., 2018; Shridhar et al., 2020; Min et al., 2022; Weir et al., 2022). SELF-INSTRUCT, as a general approach to expanding data, can potentially also be helpful in those settings, which we leave to future work.
多模态指令跟随。指令跟随模型在多模态学习领域也引起了广泛关注 (Fried et al., 2018; Shridhar et al., 2020; Min et al., 2022; Weir et al., 2022)。作为一种通用的数据扩展方法,SELF-INSTRUCT在这些场景中也可能发挥作用,我们将此留待未来研究。
6 Conclusion
6 结论
We introduce SELF-INSTRUCT, a method to improve the instruction-following ability of LMs via their own generation of instruction data. On experi men ting with vanilla GPT3, we automatically construct a large-scale dataset of 52K instructions for diverse tasks, and finetuning GPT3 on this data leads to a $33%$ absolute improvement on SUPERNI over the original GPT3. Furthermore, we curate a set of expert-written instructions for novel tasks. Human evaluation on this set shows that tuning GPT3 with SELF-INSTRUCT outperforms using existing public instruction datasets by a large margin and performs closely to Instruct $\mathbf{{GPT}_ {001}}$ . We hope SELF-INSTRUCT can serve as the first step to align pretrained LMs to follow human instructions, and future work can build on top of this data to improve instruction-following models.
我们提出SELF-INSTRUCT方法,通过大语言模型自主生成指令数据来提升其遵循指令的能力。在原始GPT3上的实验表明,该方法自动构建了包含52K条多样化任务指令的大规模数据集,基于该数据微调后的GPT3在SUPERNI基准上比原始版本绝对提升了33%。此外,我们还整理了一组专家撰写的新任务指令集。人工评估显示,使用SELF-INSTRUCT调优的GPT3大幅优于现有公共指令数据集,其表现与Instruct $\mathbf{{GPT}_ {001}}$ 相当接近。我们希望SELF-INSTRUCT能作为对齐预训练模型与人类指令的第一步,未来研究可基于此数据进一步改进指令遵循模型。
7 Broader Impact
7 更广泛的影响
Beyond the immediate focus of this paper, we believe that SELF-INSTRUCT may help bring more transparency to what happens “behind the scenes” of widely-used instruction-tuned models like Instruct GP T or ChatGPT. Unfortunately, such industrial models remain behind API walls as their datasets are not released, and hence there is little understanding of their construction and why they demonstrate impressive capabilities. The burden now falls on academia to better understand the source of success in these models and strive for better—and more open—models. We believe our findings in this paper demonstrate the importance of diverse instruction data, and our large synthetic dataset can be the first step toward higher-quality data for building better instruction-following models. At this writing, the central idea of this paper has been adopted in several follow-up works for such endeavors (Taori et al., 2023; Xu et al., 2023; Sun et al., 2023, i.a.).
除本文的直接关注点外,我们相信SELF-INSTRUCT有助于提高对InstructGPT或ChatGPT等广泛使用的指令调优模型"幕后机制"的透明度。遗憾的是,由于数据集未公开,这类工业模型仍被API高墙阻隔,导致人们对其构建原理和卓越能力来源知之甚少。学术界现在肩负着理解这些模型成功根源、并开发更优(且更开放)模型的重任。本文研究证明了多样化指令数据的重要性,我们的大型合成数据集可视为构建更优质指令遵循模型的第一步。截至撰稿时,本文核心思想已被多项后续研究采纳(如Taori等人2023年工作;Xu等人2023年研究;Sun等人2023年成果等)。
8 Limitations
8 局限性
Here, we discuss some limitations of this work to inspire future research in this direction.
在此,我们讨论本工作的一些局限性,以启发未来在该方向的研究。
Tail phenomena. SELF-INSTRUCT depends on LMs, and it will inherit all the limitations that carry over with LMs. As recent studies have shown (Razeghi et al., 2022; Kandpal et al., 2022), tail phenomena pose a serious challenge to the success of LMs. In other words, LMs’ largest gains correspond to the frequent uses of languages (head of the language use distribution), and there might be minimal gains in the low-frequency contexts. Similarly, in the context of this work, it would not be surprising if the majority of the gains by SELFINSTRUCT are skewed toward tasks or instructions that present more frequently in the pre training corpus. As a consequence, the approach might show brittleness with respect to uncommon and creative instructions.
尾部现象。SELF-INSTRUCT依赖于大语言模型,因此会继承大语言模型的所有局限性。近期研究表明(Razeghi et al., 2022; Kandpal et al., 2022),尾部现象对大语言模型的成功构成了严峻挑战。换言之,大语言模型的最大收益对应于语言的高频使用(语言使用分布的头部),而在低频语境中可能收益甚微。同理,在本研究背景下,若SELF-INSTRUCT的大部分收益偏向于预训练语料库中更频繁出现的任务或指令,也不足为奇。因此,该方法在面对不常见和创造性指令时可能表现出脆弱性。
Dependence on large models. Because of SELFINSTRUCT’s dependence on the inductive biases extracted from LMs, it might work best for larger models. If true, this may create barriers to access for those who may not have large computing resources. We hope future studies will carefully study the gains as a function of model size or various other parameters. It is worthwhile to note that instruction-tuning with human annotation also suffers from a similar limitation: gains of instruction-tuning are higher for larger models (Wei et al., 2022).
依赖大模型。由于SELFINSTRUCT依赖于从大语言模型中提取的归纳偏差(inductive biases),它可能对更大的模型效果最佳。如果确实如此,这可能为那些没有强大计算资源的人设置门槛。我们希望未来的研究能仔细考察模型规模或其他各种参数带来的收益变化。值得注意的是,人工标注的指令调优也存在类似局限:模型越大,指令调优的收益越高(Wei et al., 2022)。
Reinforcing LM biases. A point of concern for the authors is the unintended consequences of this iterative algorithm, such as the amplification of problematic social biases (stereotypes or slurs about gender, race, etc.). Relatedly, one observed challenge in this process is the algorithm’s difficulty in producing balanced labels, which reflected models’ prior biases. We hope future work will lead to better understanding of the pros and cons of the approach.
强化大语言模型的偏见。作者们关注的一个问题是这种迭代算法可能带来的意外后果,例如放大存在问题的社会偏见(关于性别、种族等的刻板印象或侮辱性言论)。与此相关的是,在此过程中观察到一个挑战:算法难以生成平衡的标签,这反映了模型原有的偏见。我们希望未来的工作能更好地理解这种方法的优缺点。
Acknowledgements
致谢
The authors would like to thank the anonymous reviewers for their constructive feedback. We especially thank Sewon Min, Eric Wallace, Ofir Press, and other members of UWNLP and AllenNLP for their encouraging feedback and intellectual support. This work was supported in part by DARPA MCS program through NIWC Pacific (N66001-19- 2-4031), ONR N00014-18-1-2826, ONR MURI N00014-18-1-2670, and gifts from AI2 and an Allen Investigator award.
作者感谢匿名评审的建设性意见。特别感谢Sewon Min、Eric Wallace、Ofir Press以及UWNLP和AllenNLP团队其他成员给予的鼓励性反馈与智力支持。本研究部分获得了DARPA MCS项目(通过NIWC Pacific N66001-19-2-4031)、ONR N00014-18-1-2826、ONR MURI N00014-18-1-2670的资助,以及AI2的捐赠和Allen Investigator奖项的支持。
References
参考文献
In Conference on Empirical Methods in Natural Language Processing (EMNLP) - Findings.
在自然语言处理实证方法会议 (EMNLP) - Findings。
Lucie Charlotte Magister, Jonathan Mallinson, Jakub Adamek, Eric Malmi, and Aliaksei Severyn. 2022. Teaching small language models to reason. arXiv preprint arXiv:2212.08410.
Lucie Charlotte Magister、Jonathan Mallinson、Jakub Adamek、Eric Malmi 和 Aliaksei Severyn。2022。教小语言模型推理。arXiv预印本 arXiv:2212.08410。
Dheeraj Mekala, Tu Vu, Timo Schick, and Jingbo Shang. 2022. Leveraging qa datasets to improve generative data augmentation. arXiv preprint arXiv:2205.12604.
Dheeraj Mekala、Tu Vu、Timo Schick和Jingbo Shang。2022。利用问答数据集提升生成式数据增强。arXiv预印本arXiv:2205.12604。
Yu Meng, Martin Michalski, Jiaxin Huang, Yu Zhang, Tarek Abdelzaher, and Jiawei Han. 2023. Tuning language models as training data generators for augmentation-enhanced few-shot learning. In International Conference on Machine Learning (ICML).
Yu Meng、Martin Michalski、Jiaxin Huang、Yu Zhang、Tarek Abdelzaher 和 Jiawei Han。2023。将语言模型调校为训练数据生成器以实现增强型少样本学习。见国际机器学习会议 (ICML)。
So Yeon Min, Devendra Singh Chaplot, Pradeep Ravikumar, Yonatan Bisk, and Ruslan Salak hut dino v. 2022. FILM: Following Instructions in Language with Modular Methods. In International Conference on Learning Representations (ICLR).
So Yeon Min、Devendra Singh Chaplot、Pradeep Ravikumar、Yonatan Bisk 和 Ruslan Salakhutdinov. 2022. FILM: 基于模块化方法的语言指令跟随. 发表于国际学习表征会议 (ICLR).
Swaroop Mishra, Daniel Khashabi, Chitta Baral, and Hannaneh Hajishirzi. 2022. Cross-Task Generalization via Natural Language Crowd sourcing Instruc- tions. In Annual Meeting of the Association for Computational Linguistics (ACL).
Swaroop Mishra、Daniel Khashabi、Chitta Baral 和 Hannaneh Hajishirzi。2022。通过自然语言众包指令实现跨任务泛化。载于《计算语言学协会年会》(ACL)。
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training Language Models to Follow Instructions with Human Feedback. In Advances in Neural Information Processing Systems (NeurIPS).
Long Ouyang、Jeff Wu、Xu Jiang、Diogo Almeida、Carroll L Wainwright、Pamela Mishkin、Chong Zhang、Sandhini Agarwal、Katarina Slama、Alex Ray 等。2022。基于人类反馈的指令跟随大语言模型训练。载于《神经信息处理系统进展》(NeurIPS)。
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research (JMLR).
Colin Raffel、Noam Shazeer、Adam Roberts、Katherine Lee、Sharan Narang、Michael Matena、Yanqi Zhou、Wei Li 和 Peter J Liu. 2020. 探索统一文本到文本Transformer的迁移学习极限. Journal of Machine Learning Research (JMLR).
Yasaman Razeghi, Robert L Logan IV, Matt Gardner, and Sameer Singh. 2022. Impact of pre training term frequencies on few-shot reasoning. arXiv preprint arXiv:2202.07206.
Yasaman Razeghi、Robert L Logan IV、Matt Gardner和Sameer Singh。2022。预训练词频对少样本推理的影响。arXiv预印本arXiv:2202.07206。
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. 2019. Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter. In Advances in Neural Information Processing Systems (NeurIPS) Workshop on Energy Efficient Machine Learning and Cognitive Computing.
Victor Sanh、Lysandre Debut、Julien Chaumond和Thomas Wolf。2019。DistilBERT:BERT的蒸馏版本——更小、更快、更经济、更轻量。收录于《神经信息处理系统进展》(NeurIPS)研讨会"高效节能机器学习与认知计算"。
Victor Sanh, Albert Webson, Colin Raffel, Stephen Bach, Lintang Sutawika, Zaid Alyafeai, Antoine Chaffin, Arnaud Stiegler, Arun Raja, Manan Dey, M Saiful Bari, Canwen Xu, Urmish Thakker, Shanya Sharma Sharma, Eliza Szczechla, Taewoon Kim, Gunjan Chhablani, Nihal Nayak, Debajyoti Datta, Jonathan Chang, Mike Tian-Jian Jiang, Han Wang, Matteo Manica, Sheng Shen, Zheng Xin Yong, Harshit Pandey, Rachel Bawden, Thomas Wang, Trishala
Victor Sanh、Albert Webson、Colin Raffel、Stephen Bach、Lintang Sutawika、Zaid Alyafeai、Antoine Chaffin、Arnaud Stiegler、Arun Raja、Manan Dey、M Saiful Bari、Canwen Xu、Urmish Thakker、Shanya Sharma Sharma、Eliza Szczechla、Taewoon Kim、Gunjan Chhablani、Nihal Nayak、Debajyoti Datta、Jonathan Chang、Mike Tian-Jian Jiang、Han Wang、Matteo Manica、Sheng Shen、Zheng Xin Yong、Harshit Pandey、Rachel Bawden、Thomas Wang、Trishala
Neeraj, Jos Rozen, Abheesht Sharma, Andrea Santilli, Thibault Fevry, Jason Alan Fries, Ryan Teehan, Teven Le Scao, Stella Biderman, Leo Gao, Thomas Wolf, and Alexander M Rush. 2022. Multitask Prompted Training Enables Zero-Shot Task Genera liz ation. In International Conference on Learning Representations (ICLR).
Neeraj、Jos Rozen、Abheesht Sharma、Andrea Santilli、Thibault Fevry、Jason Alan Fries、Ryan Teehan、Teven Le Scao、Stella Biderman、Leo Gao、Thomas Wolf 和 Alexander M Rush。2022。多任务提示训练实现零样本任务泛化。发表于国际学习表征会议 (ICLR)。
Timo Schick and Hinrich Schütze. 2021. Generating datasets with pretrained language models. In Conference on Empirical Methods in Natural Language Processing (EMNLP).
Timo Schick 和 Hinrich Schütze. 2021. 使用预训练语言模型生成数据集. 见: 自然语言处理实证方法会议 (EMNLP).
Mohit Shridhar, Jesse Thomason, Daniel Gordon, Yonatan Bisk, Winson Han, Roozbeh Mottaghi, Luke Z ett le moyer, and Dieter Fox. 2020. ALFRED: A Benchmark for Interpreting Grounded Instructions for Everyday Tasks. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
Mohit Shridhar、Jesse Thomason、Daniel Gordon、Yonatan Bisk、Winson Han、Roozbeh Mottaghi、Luke Zettlemoyer和Dieter Fox。2020。ALFRED:一个用于理解日常任务中基于场景指令的基准测试。IEEE计算机视觉与模式识别会议(CVPR)。
Chandan Singh, John X Morris, Jyoti Aneja, Alexander M Rush, and Jianfeng Gao. 2022. Explaining patterns in data with language models via interpret able auto prompting. arXiv preprint arXiv:2210.01848.
Chandan Singh、John X Morris、Jyoti Aneja、Alexander M Rush 和 Jianfeng Gao。2022。利用可解释自动提示通过语言模型解释数据模式。arXiv预印本 arXiv:2210.01848。
Zhiqing Sun, Yikang Shen, Qinhong Zhou, Hongxin Zhang, Zhenfang Chen, David Cox, Yiming Yang, and Chuang Gan. 2023. Principle-driven selfalignment of language models from scratch with minimal human supervision. arXiv preprint arXiv:2305.03047.
Zhiqing Sun、Yikang Shen、Qinhong Zhou、Hongxin Zhang、Zhenfang Chen、David Cox、Yiming Yang和Chuang Gan。2023。基于原则驱动的语言模型自对齐方法:最小化人工监督的从零训练。arXiv预印本arXiv:2305.03047。
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023. Stanford alpaca: An instruction-following llama model. https: //github.com/tatsu-lab/stanford alpaca.
Rohan Taori、Ishaan Gulrajani、Tianyi Zhang、Yann Dubois、Xuechen Li、Carlos Guestrin、Percy Liang 和 Tatsunori B. Hashimoto。2023。斯坦福Alpaca:一个遵循指令的LLaMA模型。https://github.com/tatsu-lab/stanford_alpaca。
Yizhong Wang, Swaroop Mishra, Pegah Alipoormolabashi, Yeganeh Kordi, Amirreza Mirzaei, Anjana Arunkumar, Arjun Ashok, Arut Selvan Dhana sekar an, Atharva Naik, David Stap, Eshaan Pathak, Giannis Karam a no lak is, Haizhi Gary Lai, Ishan Purohit, Ishani Mondal, Jacob Anderson, Kirby Kuznia, Krima Doshi, Maitreya Patel, Kuntal Kumar Pal, Mehrad Moradshahi, Mihir Parmar, Mirali Purohit, Neeraj Varshney, Phani Rohitha Kaza, Pulkit Verma, Ravsehaj Singh Puri, Rushang Karia, Shailaja Keyur Sampat, Savan Doshi, Siddhartha Mishra, Sujan Reddy, Sumanta Patro, Tanay Dixit, Xudong Shen, Chitta Baral, Yejin Choi, Noah A. Smith, Hannaneh Hajishirzi, and Daniel Khashabi. 2022. Super-natural instructions: Generalization via declarative instructions on $1600+$ tasks. In Conference on Empirical Methods in Natural Language Processing (EMNLP).
Yizhong Wang、Swaroop Mishra、Pegah Alipoormolabashi、Yeganeh Kordi、Amirreza Mirzaei、Anjana Arunkumar、Arjun Ashok、Arut Selvan Dhanasekaran、Atharva Naik、David Stap、Eshaan Pathak、Giannis Karamanolakis、Haizhi Gary Lai、Ishan Purohit、Ishani Mondal、Jacob Anderson、Kirby Kuznia、Krima Doshi、Maitreya Patel、Kuntal Kumar Pal、Mehrad Moradshahi、Mihir Parmar、Mirali Purohit、Neeraj Varshney、Phani Rohitha Kaza、Pulkit Verma、Ravsehaj Singh Puri、Rushang Karia、Shailaja Keyur Sampat、Savan Doshi、Siddhartha Mishra、Sujan Reddy、Sumanta Patro、Tanay Dixit、Xudong Shen、Chitta Baral、Yejin Choi、Noah A. Smith、Hannaneh Hajishirzi和Daniel Khashabi。2022。超自然指令:通过1600+任务的声明式指令实现泛化。载于《自然语言处理实证方法会议》(EMNLP)。
Zirui Wang, Adams Wei Yu, Orhan Firat, and Yuan Cao. 2021. Towards zero-label language learning. arXiv preprint arXiv:2109.09193.
Zirui Wang, Adams Wei Yu, Orhan Firat, and Yuan Cao. 2021. 迈向零标签语言学习. arXiv preprint arXiv:2109.09193.
Jason Wei, Maarten Bosma, Vincent Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M. Dai, and Quoc V Le. 2022. Finetuned Language Models are Zero-Shot Learners. In International Conference on Learning Representations (ICLR).
Jason Wei、Maarten Bosma、Vincent Zhao、Kelvin Guu、Adams Wei Yu、Brian Lester、Nan Du、Andrew M. Dai 和 Quoc V Le。2022. 微调语言模型是零样本学习者。发表于国际学习表征会议 (ICLR)。
Nathaniel Weir, Xingdi Yuan, Marc-Alexandre Côté, Matthew Hausknecht, Romain Laroche, Ida Momen- nejad, Harm Van Seijen, and Benjamin Van Durme. 2022. One-Shot Learning from a Demonstration with Hierarchical Latent Language. arXiv preprint arXiv:2203.04806.
Nathaniel Weir、Xingdi Yuan、Marc-Alexandre Côté、Matthew Hausknecht、Romain Laroche、Ida Momen-nejad、Harm Van Seijen 和 Benjamin Van Durme。2022。基于分层潜在语言的单次演示学习。arXiv预印本 arXiv:2203.04806。
Sean Welleck, Ximing Lu, Peter West, Faeze Brahman, Tianxiao Shen, Daniel Khashabi, and Yejin Choi. 2023. Generating sequences by learning to self-correct. In International Conference on Learning Representations (ICLR).
Sean Welleck、Ximing Lu、Peter West、Faeze Brahman、Tianxiao Shen、Daniel Khashabi 和 Yejin Choi。2023。通过自我纠错学习生成序列。收录于国际学习表征会议 (ICLR)。
Orion Weller, Nicholas Lourie, Matt Gardner, and Matthew Peters. 2020. Learning from Task Descriptions. In Conference on Empirical Methods in Natural Language Processing (EMNLP).
Orion Weller、Nicholas Lourie、Matt Gardner 和 Matthew Peters。2020. 从任务描述中学习。载于《自然语言处理实证方法会议》(EMNLP)。
Peter West, Chandra Bhaga va tula, Jack Hessel, Jena D Hwang, Liwei Jiang, Ronan Le Bras, Ximing Lu, Sean Welleck, and Yejin Choi. 2021. Symbolic knowledge distillation: from general language models to commonsense models. In Conference of the North American Chapter of the Association for Computational Linguistics (NAACL).
Peter West、Chandra Bhagavatula、Jack Hessel、Jena D Hwang、Liwei Jiang、Ronan Le Bras、Ximing Lu、Sean Welleck 和 Yejin Choi。2021. 符号知识蒸馏:从通用语言模型到常识模型。载于北美计算语言学协会会议 (NAACL)。
Qizhe Xie, Minh-Thang Luong, Eduard Hovy, and Quoc V Le. 2020. Self-training with noisy student improves imagenet classification. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 10687–10698.
Qizhe Xie, Minh-Thang Luong, Eduard Hovy, and Quoc V Le. 2020. 带噪声学生的自训练提升ImageNet分类性能. 发表于IEEE计算机视觉与模式识别会议 (CVPR), 页码10687–10698.
Canwen Xu, Daya Guo, Nan Duan, and Julian McAuley. 2023. Baize: An open-source chat model with parameter-efficient tuning on self-chat data. arXiv preprint arXiv:2304.01196.
Canwen Xu、Daya Guo、Nan Duan和Julian McAuley。2023。Baize:基于自对话数据参数高效调优的开源聊天模型。arXiv预印本arXiv:2304.01196。
Yiben Yang, Chaitanya Malaviya, Jared Fernandez, Swabha S way am dip ta, Ronan Le Bras, Ji-Ping Wang, Chandra Bhaga va tula, Yejin Choi, and Doug Downey. 2020. Generative data augmentation for commonsense reasoning. In Conference on Empirical Methods in Natural Language Processing (EMNLP) - Findings.
Yiben Yang、Chaitanya Malaviya、Jared Fernandez、Swabha Swayamdipta、Ronan Le Bras、Ji-Ping Wang、Chandra Bhagavatula、Yejin Choi和Doug Downey。2020。常识推理的生成式数据增强 (Generative Data Augmentation for Commonsense Reasoning)。载于《自然语言处理实证方法会议 (EMNLP)-研究发现》。
Seonghyeon Ye, Doyoung Kim, Joel Jang, Joongbo Shin, and Minjoon Seo. 2022. Guess the instruction! making language models stronger zero-shot learners. arXiv preprint arXiv:2210.02969.
Seonghyeon Ye、Doyoung Kim、Joel Jang、Joongbo Shin 和 Minjoon Seo。2022。猜指令!让语言模型成为更强的零样本学习者。arXiv预印本 arXiv:2210.02969。
Eric Zelikman, Jesse Mu, Noah D Goodman, and Yuhuai Tony Wu. 2022. STar: Self-taught reasoner boots trapping reasoning with reasoning. In Advances in Neural Information Processing Systems (NeurIPS).
Eric Zelikman、Jesse Mu、Noah D Goodman 和 Yuhuai Tony Wu。2022。STar:自学习推理器通过推理提升推理能力。载于《神经信息处理系统进展》(NeurIPS)。
Xuandong Zhao, Siqi Ouyang, Zhiguo Yu, Ming Wu, and Lei Li. 2022. Pre-trained language models can be fully zero-shot learners. arXiv preprint arXiv:2212.06950.
Xuandong Zhao、Siqi Ouyang、Zhiguo Yu、Ming Wu 和 Lei Li。2022。预训练语言模型可实现完全零样本学习。arXiv预印本 arXiv:2212.06950。
Chunting Zhou, Junxian He, Xuezhe Ma, Taylor BergKirkpatrick, and Graham Neubig. 2022a. Prompt Consistency for Zero-Shot Task Generalization. In Conference on Empirical Methods in Natural Language Processing (EMNLP) - Findings.
周春霆、贺俊贤、马学哲、Taylor BergKirkpatrick和Graham Neubig。2022a。零样本任务泛化的提示一致性。载于《自然语言处理实证方法会议(EMNLP)-研究发现》。
Supplemental Material
补充材料
A Implementation Details
实现细节
A.1 Writing the Seed Tasks
A.1 编写种子任务
Our method relies on a set of seed tasks to bootstrap the generation. The seed tasks are important for both encouraging the task diversity and demonstrating correct ways for solving the diverse tasks. For example, with coding tasks to prompt the model, it has a larger chance to generate coding-related tasks; it’s also better to have coding output to guide the model in writing code for new tasks. So, the more diverse the seed tasks are, the more diverse and better quality the generated tasks will be.
我们的方法依赖于一组种子任务来启动生成过程。种子任务对于鼓励任务多样性和展示解决多样化任务的正确方法都很重要。例如,通过编码任务来提示模型,它更有可能生成与编码相关的任务;同时,拥有编码输出也能更好地指导模型为新任务编写代码。因此,种子任务越多样化,生成的任务就会越多样化且质量越高。
Our seed tasks were written when we initiated this project, and targeted for the diverse and interesting usages of LLMs. The tasks were written by the authors and our labmates at UWNLP, without explicit reference to existing datasets or specific testing tasks. We further categorized the tasks into classification and non-classification tasks, based on whether the task has a limited output label space. In total, there are 25 classification tasks and 150 non-classification tasks. We release this data in our GitHub repository.11
我们的种子任务是在项目启动时编写的,旨在探索大语言模型(LLM)的多样化和有趣用途。这些任务由作者和UWNLP实验室成员编写,没有明确参考现有数据集或特定测试任务。我们根据任务是否具有有限的输出标签空间,进一步将任务分为分类任务和非分类任务。总共有25个分类任务和150个非分类任务。我们在GitHub仓库中发布了这些数据。11
To provide a sense of how much the model is generalizing beyond these seed tasks, we further quantify the overlap between the instructions of these seed tasks and the instructions of our test sets, including both SUPERNI task instructions (§4.3) and the user-oriented instructions in our human evaluation(§4.4). We compute ROUGE-L similarities between each seed instruction and its most similar instruction in the test set. The distribution of the ROUGE-L scores are plotted in Figure 8, with the average ROUGE-L similarity between the seed instructions and SUPERNI as 0.21, and the average ROUGE-L similarity between the seed instructions and user-oriented instructions as 0.34. We see a decent difference between the seed tasks and both test sets. There is exactly one identical seed instruction occurring in the user-oriented instruction test set, which is “answer the following question” and the following questions are actually very different.
为了评估模型在这些种子任务之外的泛化能力,我们进一步量化了种子任务指令与测试集指令的重叠程度,包括SUPERNI任务指令(第4.3节)和人工评估中面向用户的指令(第4.4节)。我们计算了每条种子指令与测试集中最相似指令之间的ROUGE-L相似度。图8展示了ROUGE-L分数的分布情况,其中种子指令与SUPERNI的平均ROUGE-L相似度为0.21,种子指令与面向用户指令的平均ROUGE-L相似度为0.34。可以看出,种子任务与两个测试集之间存在明显差异。在面向用户指令测试集中仅出现了一条完全相同的种子指令——“回答以下问题”,但后续问题的实际内容差异很大。

Figure 8: Distribution of the ROUGE-L scores between seed instructions and their most similar instructions in SUPERNI (left) and the 252 user-oriented instructions (right).
图 8: SUPERNI 中种子指令与其最相似指令的 ROUGE-L 分数分布 (左) 和 252 条面向用户的指令分布 (右)。
A.2 Querying the GPT3 API
A.2 查询 GPT3 API
We use different sets of hyper parameters when querying GPT3 API for different purposes. These hyperparameters are found to work well with the GPT3 model (“davinci” engine) and the other instruction-tuned GPT3 variants. We listed them in Table 4. OpenAI charges $\$0.02$ per 1000 tokens for making completion request to the “davinci” engine as of December, 2022. The generation of our entire dataset cost around $\$600$ .
我们在查询GPT3 API时针对不同用途采用了不同的超参数组合。这些参数被证实与GPT3模型("davinci"引擎)及其他经过指令调优的GPT3变体配合良好。具体参数如 表4 所示。截至2022年12月,OpenAI对"davinci"引擎的补全请求按每1000个token收费$0.02美元。我们整个数据集的生成成本约为$600美元。
A.3 Finetuning GPT3
A.3 微调 GPT3
GPT3SELF-INST and some of our baselines are finetuned from GPT3 model (“davinci” engine with 175B parameters). We conduct this finetuning via OpenAI’s finetuning API. While the details of how the model is finetuned with this API are not currently available (e.g., which parameters are updated, or what the optimizer is), we tune all our models with the default hyper parameters of this API so that the results are comparable. We only set the “prompt loss weight” to 0 since we find this works better in our case, and every finetuning experiment is trained for two epochs to avoid over fitting the training tasks. Finetuning is charged based on the number of tokens in the training file. In our case, finetuning $\mathrm{GPT}3_ {\mathrm{SELF-INST}}$ from the GPT3 model on the entire generated data cost $\$338$ .
GPT3SELF-INST 和部分基线模型是基于 GPT3 模型(参数规模为 1750 亿的 "davinci" 引擎)进行微调的。我们通过 OpenAI 的微调 API 完成这一过程。虽然该 API 的具体微调机制尚未公开(例如更新哪些参数或使用何种优化器),但所有模型均采用该 API 的默认超参数以确保结果可比性。我们将 "prompt loss weight" 设为 0(经测试该设置在本场景效果更优),且所有微调实验均训练两个周期以防止对训练任务过拟合。微调费用根据训练文件的 token 数量计费,本研究中基于全部生成数据对 $\mathrm{GPT}3_ {\mathrm{SELF-INST}}$ 进行微调的总成本为 $\$338$。
Table 4: Hyper-parameters for querying OpenAI API in different experiments.
| Experiments ↓ | Temp. Top_ P Freq. Penalty | PresencePenalty | Beam Size Max Length | StopSequences | |||
| Generatinginstructions | 0.7 | 0.5 | 0 | 2 | 1 | 1024 | "\n\n", "\n16","16.", "16." |
| Identifying clf. tasks | 0 | 0 | 0 | 0 | 1 | 3 | "\n","Task:" |
| Generatinginstances | 0 | 0 | 0 | 1.5 | 1 | 300 | "Task:" |
| Evaluating models | 0 | 0 | 0 | 0 | 0 | 1024 | None (default) |
表 4: 不同实验中查询 OpenAI API 的超参数。
| 实验 ↓ | Temp. Top_ P Freq. Penalty | PresencePenalty | Beam Size Max Length | StopSequences | |||
|---|---|---|---|---|---|---|---|
| 生成指令 | 0.7 | 0.5 | 0 | 2 | 1 | 1024 | "\n\n", "\n16","16.", "16." |
| 识别分类任务 | 0 | 0 | 0 | 0 | 1 | 3 | "\n","Task:" |
| 生成实例 | 0 | 0 | 0 | 1.5 | 1 | 300 | "Task:" |
| 评估模型 | 0 | 0 | 0 | 0 | 0 | 1024 | None (default) |
A.4 Prompting Templates for Data Generation
A.4 数据生成的提示模板
SELF-INSTRUCT relies on a number of prompting templates in order to elicit the generation from language models. Here we provide our four templates for generating the instruction (Table 5), classifying whether an instruction represents a classification task or not (Table 6), generating non-classification instances with the input-first approach (Table 7), and generating classification instances with the output-first approach (Table 8).
SELF-INSTRUCT 依赖于多种提示模板来引导语言模型生成内容。在此我们提供了四种模板:用于生成指令(表5)、判断指令是否代表分类任务(表6)、通过输入优先方法生成非分类实例(表7)以及通过输出优先方法生成分类实例(表8)。
| Come up with a series of tasks: | ||||||
| Task1: | {instruction for existing task 1} | |||||
| Task2: | {instruction for existing task 2} | |||||
| Task3: | {instruction for existing task 3} | |||||
| Task4: | {instruction for existing task 4} | |||||
| Task5: | {instruction for existing task 5} | |||||
| Task6: | {instruction for existing task 6} | |||||
| Task7: | {instruction for existing task 7} | |||||
| Task8: | Task9: | {instruction for existing task 8} |
| 提出一系列任务: | ||||||
|---|---|---|---|---|---|---|
| 任务1: | {现有任务1的指令} | |||||
| 任务2: | {现有任务2的指令} | |||||
| 任务3: | {现有任务3的指令} | |||||
| 任务4: | {现有任务4的指令} | |||||
| 任务5: | {现有任务5的指令} | |||||
| 任务6: | {现有任务6的指令} | |||||
| 任务7: | {现有任务7的指令} | |||||
| 任务8: | 任务9: | {现有任务8的指令} |
Table 5: Prompt used for generating new instructions. 8 existing instructions are randomly sampled from the task pool for in-context demonstration. The model is allowed to generate instructions for new tasks, until it stops its generation, reaches its length limit or generates “Task $16^{,}$ tokens.
表 5: 用于生成新指令的提示词。从任务池中随机抽取8条现有指令作为上下文示例。允许模型为新任务生成指令,直至其停止生成、达到长度限制或生成"Task $16^{,}$" tokens。
| Task: Given my personality and the job, tell me if I would be suitable. Is it classification? Yes | |
| Task: Give me an example of a time when you had to use your sense of humor. Is it classification?No | |
| Is it classification?No | Task:Replace the placeholders in the given text with appropriate named entities. |
| knowledge and common sense. Is itclassification?Yes | |
| Task:Return the SSN number for the person. Is it classification?No | |
| Task:Detect if the Reddit thread contains hate speech. Is it classification? Yes | |
| Task: Analyze the Sentences below to identify biases. Is it classification?No | |
| Task: Select the longest sentence in terms of the number of words in the paragraph,output | |
| Is it classification? Yes | the sentence index. |
| Is it classification?No | Task:Find out the toxic word or phrase in the sentence. |
| Task:Rank these countries by their population. Is it classification?No | |
| Task:You are provided with a news article,and you need to identify all the categories that this article belongs to. Possible categories include: Music,Sports,Politics, Tech,Finance, | |
| by one,seperated by comma. Is it classification? Yes | Basketball,Soccer,Tennis,Entertainment,Digital Game,World News.Output its categories one |
| Task:Given the name of an exercise,explain how to do it. | |
| Is it classification?No | |
| Task:Select the oldest person from the list. Is itclassification?Yes | |
| Task: Find the four smallest perfect numbers. Is it classification?No | |
| "Unsupport". Is it classification? Yes | |
| Task: Create a detailed budget for the given hypothetical trip. Is it classification?No | |
| explain the stereotype.Else,output no. | Task:Given a sentence,detect if there is any potential stereotype in it.If so,you should |
| Is it classification? No | |
| Task:To make the pairs have the same analogy,write the fourth word. | |
| Is it classification?No | |
| Is it classification?No | |
| 任务 | 是否分类任务 |
|---|---|
| 根据我的性格和工作,判断我是否适合。 | 是 |
| 举例说明你曾运用幽默感的经历。 | 否 |
| 用适当的命名实体替换文本中的占位符。 | 否 |
| 检测Reddit帖子是否包含仇恨言论。 | 是 |
| 分析以下句子以识别偏见。 | 否 |
| 选出段落中单词数量最长的句子,输出句子索引。 | 是 |
| 找出句子中的侮辱性词汇或短语。 | 否 |
| 按人口数量对这些国家进行排序。 | 否 |
| 识别新闻文章所属类别(可选类别包括:音乐、体育、政治、科技、金融、篮球、足球、网球、娱乐、电子游戏、国际新闻),输出时用逗号分隔各类别。 | 是 |
| 根据给定运动名称说明其操作方法。 | 否 |
| 从列表中选出最年长者。 | 是 |
| 找出四个最小的完全数。 | 否 |
| 为假设的旅行制定详细预算。 | 否 |
| 检测句子中是否存在潜在刻板印象,若存在则予以说明,否则输出"无"。 | 否 |
| 补全类比关系的第四个词汇。 | 否 |
Table 6: Prompt used for classifying whether a task instruction is a classification task or not.
表 6: 用于判断任务指令是否为分类任务的提示词模板
| Come up with examples for the following tasks. Try to generate multiple examples when possible. If the task doesn't require additional input,you can generate the output directly. | |
| Task:Which exercises are best for reducing belly fat at home? Output: | |
| Lying Leg Raises Leg In And Out Plank | |
| SidePlank Sit-ups | |
| Task: Extract all the country names in the paragraph, list them separated by commas. Example 1 | |
| Secret Service agent James Bond. Written at Fleming's Goldeneye estate in Jamaica, it was | |
| o o g No. Bond travels to No's Caribbean island and meets Honeychile Rider,who is there to collect | |
| shells.They are captured and taken to a luxurious facility carved into a mountain.The character of Doctor No,the son of a German missionary and a Chinese woman,was influenced by | |
| Sax Rohmer's Fu Manchu stories.Dr.No was the first of Fleming's novels to face widespread | |
| Output: English,British,Jamaica,the United Kingdom,German,Chinese,Britain,the United States. | |
| Task:Converting 85 F to Celsius. 0utput:85°F=29.44°C | |
| Task: Sort the given list ascendingly. Example 1 | |
| List:[10,92,2,5,-4,92,5,101] | |
| 0utput:[-4,2,5,5,10,92,92,101] Example 2 | |
| Input 2-List:[9.99,10,-5,-1000,5e6,999] | |
| 0utput:[-1000,-5,9.99,10,999,5e6] | |
| Task: Suggest a better and more professional rephrasing of the following sentence. Example 1 | |
| candidates. | |
| Output:This house does not seem to be constructed well,so you may need to spend more money to fix it after you purchase it. I would suggest that you look at other properties. | |
| Example2 | |
| language model can improve itself! | |
| Output: Our experiments last week demonstrated surprising results, proving that the language | |
| modelcan improve itself. | |
| Output:Hi [Recruiter], | |
| a a | |
| company for a number of years, and am a proud endorser of its products. However, after further | |
| consideration of where I currently am in my career, I've decided to accept an offer at another | |
| company. | |
| I would love to stay in touch with you and have already started following you on [Social Media | |
| Platform]. Again, thank you so much for your time and consideration. | |
| Thanks again, | |
| [Your Name] | |
| 任务 | 输出示例 |
|---|---|
| 哪些运动最适合在家减少腹部脂肪? | 仰卧举腿 腿内外摆动 平板支撑 侧平板支撑 仰卧起坐 |
| 从段落中提取所有国家名称,用逗号分隔列出。示例1 | 英国、牙买加、德国、中国、美国 |
| 将85华氏度转换为摄氏度 | 85°F=29.44°C |
| 将给定列表按升序排序。示例1 | |
| 列表:[10,92,2,5,-4,92,5,101] | |
| 输出:[-4,2,5,5,10,92,92,101] | |
| 示例2 | |
| 输入2-列表:[9.99,10,-5,-1000,5e6,999] | |
| 输出:[-1000,-5,9.99,10,999,5e6] | |
| 为以下句子建议更专业的重述方式。示例1 | |
| 输出:这栋房屋似乎建造质量不佳,购买后可能需要花费更多资金修缮。建议您考虑其他房产。 | |
| 示例2 | |
| 输出:我们上周的实验结果证明了语言模型具备自我提升能力。 | |
| 输出:嗨[招聘官], | |
| 多年来我一直很荣幸能为贵公司效力,并是其产品的忠实推荐者。但经过对职业发展的综合考虑,我决定接受另一家公司的录用。 | |
| 希望能与您保持联系,并已在[社交媒体平台]关注您。再次感谢您的时间与考虑。 | |
| 此致 | |
| [您的姓名] |
Table 7: Prompt used for the input-first approach of instance generation. The model is prompted to generate the instance first, and then generate the corresponding output. For instructions that don’t require additional input, the output is allowed to be generated directly.
表 7: 输入优先方法在实例生成中使用的提示词。该模型被要求首先生成实例,然后再生成相应的输出。对于不需要额外输入的指令,允许直接生成输出。
| Given the classification task definition and the class labels,generate an input that correct class label. |
| Task: Classify the sentiment of the sentence into positive,negative,or mixed. Class label: mixed |
| Class label:Positive |
| Sentence: I had a great day today. The weather was beautiful and I spent time with friends. Class label: Negative |
| Sentence: I was really disappointed by the latest superhero movie. I would not recommend it. |
| Task: Given a dialogue,classify whether the user is satisfied with the service.You should Class label:Satisfied |
| Dialogue: Agent: Thank you for your feedback. We will work to improve our service in the future. Customer: I am happy with the service you provided. Thank you for your help. |
| Class label:Unsatisfied Dialogue: |
| Agent:Sorry that we will cancel your order.You will get a refund within 7 business days. Customer:oh that takes too long.I want you to take quicker action on this. |
| Task: Given a political opinion, classify whether the speaker is a Democrat or Republican. Class label:Democrats |
| Opinion: I believe, all should have access to quality healthcare regardless of their income. Class label: Republicans |
| a a a od a a should notbetaxedat highrates. |
| Class label: Promotion |
| Email:Check out our amazing new sale! We've got discounts on all of your favorite products. Class label:Not Promotion |
| Email: We hope you are doing well. Let us know if you need any help. |
| Task:Detect if the Reddit thread contains hate speech. Class label:Hate Speech |
| Thread: All people of color are stupid and should not be allowed to vote. Class label: Not Hate Speech |
| Thread:The best way to cook a steak on the grill. |
| Class label:Unsupport |
| - d s a home prices soar to new highs, the U.S. housing market finally is slowing. While demand and |
| price gains are cooling, any correction is likely to be a modest one, housing economists and analysts say. No one expects price drops on the scale of the declines experienced during the |
| Great Recession. Claim:The US housing market is going to crash soon. |
| Class label:Support Document:The U.S.housing market is showing signs of strain,with home sales and prices |
| of homes for sale is increasing. This could be the beginning of a larger downturn, with some Claim: The US housing market is going to crash soon. |
| Task:Which of the following is not an input type?(a)number (b)date (c) phone number (d) email address (e) all of these are valid inputs. |
| Class label:(e) |
| 任务定义与类别标签 | 生成符合正确类别标签的输入 |
|---|---|
| 任务: 将句子情感分类为积极、消极或混合。类别标签: 混合 | |
| 类别标签: 积极 | |
| 句子: 我今天度过了美好的一天。天气很好,还和朋友共度了时光。类别标签: 消极 | |
| 句子: 我对最新的超级英雄电影非常失望,不会推荐它。 | |
| 任务: 给定对话,判断用户是否对服务满意。类别标签: 满意 | |
| 对话: 客服: 感谢您的反馈,我们将努力改进服务。顾客: 我对你们的服务很满意,谢谢帮助。 | |
| 类别标签: 不满意 | |
| 对话: 客服: 很抱歉我们将取消您的订单,7个工作日内退款。顾客: 这太慢了,请加快处理。 | |
| 任务: 根据政治观点判断发言者属于民主党还是共和党。类别标签: 民主党 | |
| 观点: 我认为所有人都应获得优质医疗,不论收入。类别标签: 共和党 | |
| 观点: 高收入者不应被课以重税。 | |
| 类别标签: 促销邮件 | |
| 邮件: 来看看我们的超值新品促销!您喜爱的商品全部打折。类别标签: 非促销邮件 | |
| 邮件: 祝您安好,如需帮助请告知。 | |
| 任务: 检测Reddit帖子是否包含仇恨言论。类别标签: 仇恨言论 | |
| 帖子: 所有有色人种都是蠢货,不该有投票权。类别标签: 非仇恨言论 | |
| 帖子: 烤牛排的最佳方法。 | |
| 类别标签: 不支持 | |
| 文档: 随着房价创新高,美国楼市终于放缓。经济学家称需求与价格涨幅正在降温,但任何调整都将是温和的,不会出现大萧条时期的暴跌。 | |
| 主张: 美国楼市即将崩盘。 | |
| 类别标签: 支持 | |
| 文档: 美国楼市显现压力迹象,待售房屋数量增加,可能是更大衰退的开端。 | |
| 主张: 美国楼市即将崩盘。 | |
| 任务: 以下哪项不是输入类型?(a) 数字 (b) 日期 (c) 电话号码 (d) 电子邮箱 (e) 以上都是有效输入。 | |
| 类别标签: (e) |
Table 8: Prompt used for the output-first approach of instance generation. The model is prompted to generate the class label first, and then generate the corresponding input. This prompt is used for generating the instances for classification tasks.
表 8: 用于实例生成的输出优先方法的提示。该提示要求模型首先生成类别标签,再生成对应的输入内容。此提示用于分类任务中的实例生成。
B Human Evaluation Details for Following the User-oriented Instructions
B 面向用户指令遵循的人工评估细节
B.1 Human Evaluation Setup
B.1 人工评估设置
Here we provide more details for the human evaluation described in $\S4.4$ for rating the models’ responses to the 252 user-oriented instructions. To ensure faithful and reliable evaluation, we asked two authors of these instructions (and of this paper) to judge model predictions. These two evaluators coordinated the standards for the 4-level rating system before starting annotation and then each of them rated all the instances independently. They were presented with the instruction, instance input, target output (as a reference), and model responses. Model responses are listed in random order, with all the model information anonymized. Figure 9 provides a screenshot of the annotation interface. The reported performance in this paper is based on the results from one of the evaluators, and the trends from the other evaluator’s results are the same.
在此,我们针对$\S4.4$中描述的252条用户导向指令的模型响应评分提供更详细的人类评估说明。为确保评估的忠实性与可靠性,我们邀请了两名指令设计者(也是本文作者)对模型预测进行评判。两位评估者在开始标注前统一了4级评分体系的标准,随后各自独立完成所有实例的评分。评估界面会展示指令、实例输入、目标输出(作为参考)以及随机排序且匿名的模型响应。图9展示了标注界面的截图。本文报告的性能数据基于其中一位评估者的结果,另一评估者的结果趋势与之完全一致。
| A | B | C | D | E | F | ||
| task | instruction 一 | ndu! 一 | target | response | Rating | ||
| 1179 | 147You will be tested on your knowledge of classic witticisms and aphorisms by completing the given aphorism.Write the originalquote as the answer. | Ctwo things are infinite | The universe and human stupidity; and I'm not sure about the universe. (attributed to Albert Einstein) | theuniverse and human stupidity B | |||
| 1180 | 147You will be tested on your knowledge of classic witticisms and aphorismsby completing the given aphorism.Write the original quote as the answer. | two things are infinite | The universe and human stupidity; and I'm not sure about the universe. (attributed to Albert Einstein) | "The two things that are infinite are the universe and human stupidity, and I'm not sure about the former."-Albert Einstein | A | ||
| 1181 | 147You willbe tested onyour knowledge of classic witticisms and aphorismsby completing the given aphorism.Write the original quote as the answer. | two things areinfinite | The universe and human stupidity; andI'm not sure about the universe. (attributed toAlbert Einstein) | the universe and human stupidity Input:Ihave never let my schooling interfere with my education. Input:Ihave never let my schooling interfere with my education. Input:1 have neverlet my schooling | |||
| 1182 | 147You will be tested on your knowledge of classic witticisms and aphorisms by completing the given aphorism.Write the original quote as the answer. | two things areinfinite | The universe and human stupidity; and I'm not sure about the universe. (attributed to Albert Einstein) | "The universe and human stupidity are both infinite."-Albert Einstein | A | ||
| 1183 | 147You will be tested on your knowledge of classic witticisms and aphorismsby completing the given aphorism.Write the original quote as the answer. | two things are infinite | The universe and human stupidity; and I'm not sure about the universe. (attributed to Albert Einstein) | the universe and human stupidity | B | ||
| 1184 | 147You will be tested on your knowledge of classic witticismsand aphorismsby completing the given aphorism.Write the original quote as the answer. | two things are infinite | The universe and human stupidity; and I'm not sure about the universe. (attributed to Albert Einstein) | The universe and human stupidity. Albert Einstein | B | ||
| A | B | C | D | E | F | |
|---|---|---|---|---|---|---|
| 任务 | 指令一 | ndu! 一 | 目标 | 响应 | 评分 | |
| 1179 | 147你将通过完成给定的格言来测试你对经典妙语和格言的了解。写出原始引文作为答案。 | 两样东西是无限的 | 宇宙和人类的愚蠢;而对于宇宙,我还不太确定。(归功于阿尔伯特·爱因斯坦) | 宇宙和人类的愚蠢 B | ||
| 1180 | 147你将通过完成给定的格言来测试你对经典妙语和格言的了解。写出原始引文作为答案。 | 两样东西是无限的 | 宇宙和人类的愚蠢;而对于宇宙,我还不太确定。(归功于阿尔伯特·爱因斯坦) | "两样无限的东西是宇宙和人类的愚蠢,而对于前者,我还不太确定。"-阿尔伯特·爱因斯坦 | A | |
| 1181 | 147你将通过完成给定的格言来测试你对经典妙语和格言的了解。写出原始引文作为答案。 | 两样东西是无限的 | 宇宙和人类的愚蠢;而对于宇宙,我还不太确定。(归功于阿尔伯特·爱因斯坦) | 宇宙和人类的愚蠢 输入:我从未让学校教育干扰我的教育。 输入:我从未让学校教育干扰我的教育。 输入:1从未让学校教育 | ||
| 1182 | 147你将通过完成给定的格言来测试你对经典妙语和格言的了解。写出原始引文作为答案。 | 两样东西是无限的 | 宇宙和人类的愚蠢;而对于宇宙,我还不太确定。(归功于阿尔伯特·爱因斯坦) | "宇宙和人类的愚蠢都是无限的。"-阿尔伯特·爱因斯坦 | A | |
| 1183 | 147你将通过完成给定的格言来测试你对经典妙语和格言的了解。写出原始引文作为答案。 | 两样东西是无限的 | 宇宙和人类的愚蠢;而对于宇宙,我还不太确定。(归功于阿尔伯特·爱因斯坦) | 宇宙和人类的愚蠢 | B | |
| 1184 | 147你将通过完成给定的格言来测试你对经典妙语和格言的了解。写出原始引文作为答案。 | 两样东西是无限的 | 宇宙和人类的愚蠢;而对于宇宙,我还不太确定。(归功于阿尔伯特·爱因斯坦) | 宇宙和人类的愚蠢。阿尔伯特·爱因斯坦 | B |
Figure 9: Human evaluation in done using a Google sheet, with predictions from different models present in random order and the model information being anonymized. Our expert evaluators are required to read the instruction and input, refer to the target, and then select the rating for the model’s response from A/B/C/D, corresponding to the 4 levels described in $\S4.4$ .
图 9: 人工评估通过Google表格进行,其中不同模型的预测结果以随机顺序呈现且模型信息匿名化。我们的专家评估员需阅读指令和输入内容,参考目标输出,然后从A/B/C/D四个等级中选择对模型响应的评分,对应 (4.4) 节中描述的4个级别。
B.2 Human Evaluation Agreement
B.2 人工评估一致性
To measure how reliable our human evaluation is, we calculate the inner-rater agreement between our two evaluators.
为了衡量我们人工评估的可靠性,我们计算了两位评估者之间的内部评分一致性。
We first report Cohen’s $\kappa$ , which is commonly used to measure inter-rater agreement for categorical items. When calculating this, we treat the 4-level rating (A-D) as a categorical variable, leading to a $\kappa$ of 0.58, which is a moderate agreement according to common practice.13 Furthermore, we also calculate the agreement of our evaluators on classifying acceptable responses ((A or B) vs. (C or D)), with a final $\kappa$ of 0.75, indicating substantial agreement.
我们首先报告 Cohen 的 $\kappa$,该指标通常用于衡量分类项目的评估者间一致性。在计算时,我们将4级评分(A-D)视为分类变量,得出 $\kappa$ 值为0.58,根据惯例属于中等一致性[13]。此外,我们还计算了评估者在可接受回答分类((A或B) vs. (C或D))上的一致性,最终 $\kappa$ 值为0.75,表明具有高度一致性。
We also compute the Spearman correlation coefficient $\rho$ between the ratings of our two evaluators by treating the rating as an ordinal variable $\mathrm{A}{>}\mathrm{B}{>}\mathrm{C}{>}\mathrm{D}$ ). The final coefficient is $\rho=0.81$ , indicating a high
我们还计算了两位评估者评分之间的斯皮尔曼相关系数$\rho$,将评分视为有序变量$\mathrm{A}{>}\mathrm{B}{>}\mathrm{C}{>}\mathrm{D}$)。最终系数为$\rho=0.81$,表明高度相关。
correlation between the two evaluators.
两位评估者之间的相关性。
B.3 Example Predictions from GPT3SELF-INST
B.3 GPT3SELF-INST 的预测示例
We present a selection of user-oriented tasks, the corresponding $\mathrm{GPT}3_ {\mathrm{SELF-INST}}$ -produced responses and annotator ratings in Table 9. We see that even for responses rated as level C, the model demonstrates extensive steps in solving the task, even though its final output is incorrect.
我们在表9中展示了一系列面向用户的任务、相应的$\mathrm{GPT}3_ {\mathrm{SELF-INST}}$生成回复以及标注者评分。可以看到,即使是评级为C的回复,模型在解决任务时也展现了详尽的步骤,尽管最终输出结果不正确。
Table 9: Examples in the user-oriented instructions dataset $(\S4.4)$ and predictions from $\mathrm{GPT}3_ {\mathrm{SELF-INST}}$ . The right column indicates one of the four quality ratings assigned to the model’s response, with “A” indicating “valid and satisfying” responses (highest) and “D” indicating “irrelevant or invalid response” (lowest).
| Instruction:Give students tips on how to keep their nerves under control during class presentations. | Everyone gets a little nervous when speaking in front of a group.That's normal. But the morepreparationyou'vedone-meaningplentyof researching,organizing,and rehearsing-the more confident you'll be.Preparation is the key. And if you make a mistake or stumble over your words,just regroup and keep going.Nobody's perfect,and nobody expects you to be. | Practice your presentation in front of friends and family. -Don't drink too much caffeine before the presentation. Take deep breaths before you start speaking. If you feel nervous, smile. Remember that everyone in the audience is rooting for you. | |
| Instruction:Make a list of the pros and cons of the given decision. Input: Implementing a Remote Working Policy | Pros: -Allowing employees to work fromhome can reduce their stressful commutes and increase their productivity. -Remote working provides greater flexibility, particularly for working parents and caregivers who have other responsibilities. ...(more points) Cons: It may be more difficult for team members | Pros: -Employees can work from home and save on commuting costs. Employees can spend more time with their families. Cons: Employees may not be as productive as they would be in the office. Employees may not be as motivated to work. | |
| Instruction: A user story is an informal,general explanation of a software feature written from the perspective of the end-user or customer.Write a user story for a | ..(more points) As a user,I want to be able to recover the password to my account,so that I will be able to access my account in case I forgot | As a user,I want to be able to send emails tomyfriends and family. want to be able to attach files to my emails.I want tobe able to search | H |
| given software. Input:Gmail Instruction:A color description has been provided.Find the CSS code associated with that color. | #DB7093( | #ff66cc | B |
| Instruction: Someone gives you some information about where they want togoandwhattheyenjoyseeing and doing.Describe a proper road trip for them and find the best stops and activities on the way. Input:I'm looking for a west coast road trip.My goal is to start near | Begin near the city of San Diego and make the first stop in coastal La Jolla. This upscale a day of sunbathing at La Jolla Shores Beach, or a cocktail with a view.Just 20 minutes north,stop into beachy Encinitas to window shop the boutiques or sample fish tacos. Walk through the coastal meditation garden at the Self-Realization Fellowship or join surfers | You should start your trip in San Diego,California. You can visit the little village is a great place for an overnight,San Diego Zoo,which is one of the best zoos in the world. Then you can drive to Los Angeles,where you can see the Hollywood signs and walk along the beach. | |
| Instruction:Give some examples of what people usually say in the given social situation. Input:when someone arrives safely | beaches here ...(more ideas) -“"Glad you made it safe and sound."" -“"Good to see you got here unscathed."" -‘"So,bulletproof vests actually work!"" | Thank God,I made it. | |
| in first-order logic. Translate it into natural language. Input:xVy(soldier(x)→general(x,y) | Instruction:You are given a sentence There is someone (x)such that if he is a soldier,then he is general of everyone. | There exists a soldier such that for every general,he is a general. | |
| Instruction: Make a questionnaire to help hotel guests write hotel reviews. | Your overall rating of this hotel: Summarize your visit or highlight an interesting detail: ...(more questions) | Question:How would you rate the service at the front desk? Answer:Excellent,Good,Average,Poor | |
| Instruction: Design an outline for a blog post based on the given information and list the sections accordingly. Input: This blog post is going to about making a list of last-minute gift ideas.Also,the tone of the | Section: Movie tickets -Section: A fun game console Section: Personalized items with photos/artwork ...(more sections) Takeaway:Don't stress about out running out | Introduction List of Gift Ideas Conclusion | |
| Instruction:Write a Jira ticket for the given task. Input:New Employee onboarding | Title: Prepare a desk,chair,and computer for them to use. Create their company account,email,and temporary password. Grant access to company | Please help our new employee get settled. Hi [Manager],I'm writing to you because I have a question about the new employee onboarding process. I've been working here for a few months now,and I'm still not sure how it works.Could | |
| Instruction:Create alliterations by finding synonyms for words in the given sentence. | David dons a derby daily. | you please explain it to me? David wears a hat every day. |
表 9: 面向用户的指令数据集示例 $(\S4.4)$ 及 $\mathrm{GPT}3_ {\mathrm{SELF-INST}}$ 的预测结果。右侧列显示模型响应的四种质量评级之一,其中"A"表示"有效且令人满意"的响应(最高),"D"表示"无关或无效响应"(最低)。
| 指令:给学生一些关于如何在课堂演讲中控制紧张的技巧。 | 每个人在众人面前讲话时都会有点紧张。这很正常。但你准备得越充分——包括充分的研究、组织和排练——你就会越自信。准备是关键。如果你犯了错误或说话结巴,只需调整状态继续下去。没有人是完美的,也没有人期望你完美。 | 在朋友和家人面前练习演讲。- 演讲前不要喝太多咖啡因。- 开始讲话前深呼吸。- 如果感到紧张,就微笑。- 记住观众中的每个人都在支持你。 | |
| 指令:列出给定决策的利弊。输入:实施远程工作政策 | 优点:- 允许员工在家工作可以减少他们压力大的通勤时间并提高工作效率。- 远程工作提供了更大的灵活性,特别是对有其他责任的工作父母和照顾者...(更多要点)缺点:团队成员之间可能更难... | 优点:- 员工可以在家工作,节省通勤费用。- 员工可以有更多时间陪伴家人。缺点:- 员工可能不如在办公室时高效。- 员工可能缺乏工作动力。 | |
| 指令:用户故事是从最终用户或客户角度编写的软件功能的非正式通用说明。为给定软件编写用户故事。输入:Gmail | ...(更多要点)作为一个用户,我希望能够找回我的账户密码,这样在我忘记密码时仍能访问我的账户 | 作为一个用户,我希望能够给我的朋友和家人发送电子邮件。我希望能够给我的电子邮件添加附件。我希望能够搜索... | H |
| 指令:已提供颜色描述。找到与该颜色关联的CSS代码。 | #DB7093( | #ff66cc | B |
| 指令:有人向你提供了一些关于他们想去哪里以及喜欢看什么和做什么的信息。为他们描述一次合适的公路旅行,并找到沿途最佳停留点和活动。输入:我正在寻找一次西海岸公路旅行。我的目标是开始靠近... | 从圣地亚哥市附近开始,第一站选在沿海的拉霍亚。这个高档社区适合在拉霍亚海岸海滩享受日光浴,或边喝鸡尾酒边欣赏美景。向北仅20分钟,可以驻足海滩小镇恩西尼塔斯逛逛精品店或品尝鱼肉卷。漫步海岸冥想花园或加入冲浪者... | 你应该从加利福尼亚的圣地亚哥开始你的旅行。你可以参观小村庄,这是一个过夜的好地方,圣地亚哥动物园是世界上最好的动物园之一。然后你可以开车去洛杉矶,在那里你可以看到好莱坞标志并在海滩上散步。 | |
| 指令:给出人们在给定社交场合通常会说的一些例子。输入:当某人安全到达时 | 这里的海滩...(更多想法)- "很高兴你平安到达。"- "很高兴看到你毫发无损地到达这里。"- "看来防弹背心真的有用!" | 谢天谢地,我到了。 | |
| 指令:将一阶逻辑句子翻译成自然语言。输入:xVy(soldier(x)→general(x,y) | 指令:给定一个句子存在某人(x),如果他是士兵,那么他是所有人的将军。 | 存在一个士兵,对于每个将军来说,他都是将军。 | |
| 指令:制作一份问卷帮助酒店客人撰写酒店评论。 | 您对这家酒店的整体评分:总结您的入住体验或突出一个有趣的细节:...(更多问题) | 问题:您如何评价前台的服務?答案:优秀、良好、一般、差 | |
| 指令:根据给定信息设计博客文章大纲并列出相应章节。输入:这篇博客文章将介绍最后一刻的礼物创意清单。另外,文章的基调是... | 章节:电影票-章节:有趣的游戏机章节:带有照片/艺术品的个性化物品...(更多章节)要点:不要因为时间紧迫而压力过大 | 引言礼物创意清单结论 | |
| 指令:为给定任务编写Jira工单。输入:新员工入职 | 标题:为他们准备办公桌、椅子和电脑。创建他们的公司账户、邮箱和临时密码。授予公司... | 请帮助我们新员工安顿下来。嗨[经理],我写信给你是因为我对新员工入职流程有疑问。我在这里工作了几个月,仍然不清楚它是如何运作的。你能... | |
| 指令:通过为给定句子中的单词找到同义词来创作头韵句。 | David每天都戴一顶圆顶礼帽。 | 你能给我解释一下吗?David每天都戴帽子。 | |
C Task and Instance Examples from the Generated Instruction Data
C 生成指令数据中的任务和实例示例
| Instruction + Instance Input | Target Output | Validity |
| Instruction:Generatea random password with at least 6characters. | def generateRandomPassword(): password = "" while len(password)< 6: password += chr(random.randint(65,90)) return password | Instruction: √ Input:√ Output:√ |
| Instruction: Write a paragraph describing how to tie shoelaces for people who have never tied their shoes before.explain each step briefly. | Paragraph: To tie shoelaces, first you need to make a loop with one end of the lace. Then pass the other end through the loop and pull it tight. Next, you need to wrap the lace around the shoe several times. Finally,tuck in the loose end into the wrapped part of the lace. | Instruction: Input: √ Output:√ |
| Instruction:Given a word,find out its length and its number of vowels. Input: Word = "hello" | Length = 5, Number of vowels = 2 | Instruction: Input: √ Output: √ |
| Instruction: Write a story with three characters:a person,an animal and an object. Input: Person: John, a programmer. Animal: A dog. Object: A laptop. | John was sitting on the floor in front of his laptop when he heard a knock at the door.He opened it to find a dog standing there.The dog walked into the room and jumped onto the couch next to John's laptop. | Instruction:√ Input: √ Output:√ |
| Instruction:Compose an email and send it to your friend,asking for advice on what to do in this situation. Input:Situation: Youareaprogrammer and you have been working on a project for the past few months.The deadline is approaching,but you haven't finished yet. Your manager has asked you to staylate | Hi [Friend], I'm having a bit of trouble with my current job.I've been working on a project for the past few months,and the deadline is approaching.My manager has asked me to stay late every day this week to finish it.I don't think I can do that because I have other commitments.What should I do? | Instruction:√ Input:√ Output: √ |
| Instruction: What are some ways we can make our school more eco-friendly? | -Use reusable water bottles instead of disposable plastic ones. Turn off lights when you leave a room. - Recycle paper, cans and bottles. Plant trees to absorb carbon dioxide. | Instruction: √ Input:√ Output: √ |
| Instruction:I am looking for a new apartment. there are many options available but they are all quite expensive. i want to move as soon as possible.give meadviceon what todo. | You should look for a cheaper apartment.You can try to negotiate with the landlord and offer him/her a lower price.If you are lucky, they will accept your offer.Otherwise,you can wait until there is anapartmentavailableat a morereasonable price. | Instruction: Input: √ Output:√ |
| Instruction:Write a dialogue between two people who have been friends for a long time,and one of them is trying to convince the other to dosomething that he orshedoesn'twanttodo. | A: Hey, I have a great idea! Let's go to the beach today. B:No thanks,I'm not really in the mood for that. A:Come on,it'll be fun!We haven't been there together in ages. B: I know, but I just don't feel like going. swimming and lying in the sun. B:Yeah,I do.It's just that I've been feeling kind of tired lately. A:Oh,come on.You're never tired.You're always so energetic. | Instruction:√ Input: √ Output: √ |
| Instruction: How can i create an app that will be able to identify different kinds of plants by taking photos of them? | You can use the following steps to create an app that will be able to identify different kinds of plants by taking photos of them. you want to identify. Step 2: Create a user interface for your application. Step 3:Use image recognition techniques to identify the plant in the photo. | Instruction: Input: √ Output:√ |
| Instruction: Find the closest matching emoji to a given one. Input:Emoji: | Instruction:√ Input:√ Output: √ | |
| Instruction:Describe your favorite video game using only verbs. Input:Game:The Legend of Zelda | Explore,fight,solve,upgrade,repeat | Instruction: √ Input: √ Output:√ |
| 指令 + 实例输入 | 目标输出 | 有效性 |
|---|---|---|
| 指令:生成一个至少6个字符的随机密码。 | def generateRandomPassword(): password = "" while len(password)< 6: password += chr(random.randint(65,90)) return password |
指令:√ 输入:√ 输出:√ |
| 指令:为从未系过鞋带的人写一段描述如何系鞋带的文字,简要解释每个步骤。 | 段落:系鞋带时,首先需要用鞋带的一端打一个环。然后将另一端穿过这个环并拉紧。接着,你需要将鞋带在鞋上缠绕几圈。最后,将松散的末端塞入缠绕的部分。 | 指令:√ 输入:√ 输出:√ |
| 指令:给定一个单词,找出它的长度和元音数量。输入:单词 = "hello" | 长度 = 5, 元音数量 = 2 | 指令:√ 输入:√ 输出:√ |
| 指令:写一个故事,包含三个角色:一个人、一只动物和一个物品。输入:人物:John,一名程序员。动物:一只狗。物品:一台笔记本电脑。 | John正坐在地板上对着他的笔记本电脑,这时他听到了敲门声。他打开门,发现一只狗站在那儿。狗走进房间,跳到了John笔记本电脑旁边的沙发上。 | 指令:√ 输入:√ 输出:√ |
| 指令:写一封邮件发给你的朋友,询问在这种情况下该怎么做。输入:情况:你是一名程序员,过去几个月一直在做一个项目。截止日期快到了,但你还没完成。你的经理要求你每天加班。 | 嗨[朋友],我目前的工作遇到了一些麻烦。我过去几个月一直在做一个项目,截止日期快到了。经理要求我这周每天加班完成它。我觉得我做不到,因为我还有其他承诺。我该怎么办? | 指令:√ 输入:√ 输出:√ |
| 指令:我们有哪些方法可以让学校更环保? | - 使用可重复使用的水瓶代替一次性塑料瓶。离开房间时关灯。- 回收纸张、易拉罐和瓶子。种树吸收二氧化碳。 | 指令:√ 输入:√ 输出:√ |
| 指令:我正在找新公寓。有很多选择,但都很贵。我想尽快搬家。给我一些建议。 | 你应该找更便宜的公寓。可以尝试与房东协商,提出更低的价格。如果幸运,他们会接受你的报价。否则,你可以等到有价格更合理的公寓出现。 | 指令:√ 输入:√ 输出:√ |
| 指令:写一段两个长期朋友的对话,其中一人试图说服另一人做他或她不想做的事。 | A:嘿,我有个好主意!今天去海滩吧。B:不了,谢谢,我没那个心情。A:来吧,会很有趣的!我们好久没一起去了。B:我知道,但就是不想去游泳和晒太阳。B:是的,我只是最近感觉有点累。A:哦,得了吧。你从不累的。你总是那么精力充沛。 | 指令:√ 输入:√ 输出:√ |
| 指令:如何创建一个能通过拍照识别不同种类植物的应用? | 你可以按照以下步骤创建一个能通过拍照识别不同种类植物的应用。你想识别的植物。步骤2:为你的应用创建一个用户界面。步骤3:使用图像识别技术识别照片中的植物。 | 指令:√ 输入:√ 输出:√ |
| 指令:找到与给定表情符号最接近的匹配。输入:表情符号: | 指令:√ 输入:√ 输出:√ | |
| 指令:仅用动词描述你最喜欢的电子游戏。输入:游戏:塞尔达传说 | 探索、战斗、解决、升级、重复 | 指令:√ 输入:√ 输出:√ |
Table 10: Representative valid tasks generated by GPT3. As is discussed in $\S3$ , these generated tasks cover a broad range of formats, text types, and underlying expertise, while being correct on more than half of all the generated tasks.
表 10: GPT3生成的典型有效任务。如 $\S3$ 所述,这些生成任务覆盖了多种格式、文本类型和底层专业知识,同时在超过半数生成任务中保持正确性。
Table 11: Representative invalid tasks generated by GPT3. The problematic fields are indicated in the validity column. As discussed in $\S3.3$ , although these tasks contain errors, they still provide many useful signals in supervising models to follow instructions.
| Instruction + Instance Input Instruction:Given a set of words = {w1,w2,,wn} where each word w; has n letters,write a function that | Target Output def wordSubsetSum(w,1): S=[] for i in range(len(w)): | Validity Instruction: x Input: √ Output: x |
| takes a target length l and returns a new set of words s such that |sl =l and I{i : w; ∈ s}|≤l/|w|. Instruction:The house on fire!go! | if len(s)+ 1 < 1: s.append(w[i]) return s -Goto the kitchen and take a pan. | Instruction: x Input: √ |
| Instruction: Find out if you have any | - Take water from the tap. -Pour water into the pan. -Put out the fire with the pan. def hasFriendsWhoLikeToPlayFootball0rChess(self): friends = [] | Output: x Instruction: x |
| friends who like to play football or chess. Instruction:A number of people are lined up for an interview. they are asked | for friend in self.friends: friends.append(friend) return 1en(friends)>0 Highest salary | Input:√ Output:√ Instruction:√ |
| several questions and their answers are recorded as numbers.you need to identify which person has the highest salary among all the candidates. Input:Person 1:2,3,4,5,6 Person 2:7,8,9,10,11 Person 3:12,13,14,15,16 Person 4:17,18,19,20,21 Person 5:22,23,24,25,26 Person 6:27,28,29,30,31 Instruction: Given a list of words, generate a story about a group of people who live on a planet.the story should | Instruction:√ | Input: X Output: x |
| contain at least 10 sentences. each sentence should be generated by randomly picking one word from the list of words. | their daily lives. One day,they decided to create a machine that can make foodfor them.The machine was ableto produce foodbut it also produced something else.It produced a liquid that could be didn't need to go out and look for food or fuel anymore. They had everything they needed right there in their homes.However,one day,the machine stopped working.The people tried to fix it but couldn't figure out what went wrong.Theytried to find someone whocould helpthem but no one knew how tofix the machine.After a few days,the people realized that they would die if they didn't do anything about it.So,they decided to send some of their best scientists to space to find a new planet where they could live.The scientiststraveled for a longtimebeforetheyfoundaplanetthat looked like a good place to live.They sent a message back to the people telling them about the planet.The people were excited and started preparing for the journey.Theybuilt spaceships and flew to the new planet.When theyarrived,they saw that theplanet was beautiful.There were trees and rivers and mountains.The people were so happy that they finally found a new home.They started building houses and planting crops. They lived happily ever after. | Input:X Output:√ |
| Instruction:Find out what the author's attitudetowards working part-timeis. | Paragraph:Working part-time is a great way to earn some extra money while still being able to enjoy your free time.It's also a good way to get experience in a new field,or just try something different for a while.However,it can be difficult to find the right balance between work and play. Theauthor seems tobe positive about working part-time. | Instruction:√ Input: X Output:√ |
| Instruction: Is it ethical to use a new technology that could potentiallycause harm to others? | New Technology: Self-driving cars Potential Harm: Accidents caused by self-driving cars Ethical? Yes, because the number of lives saved by self-driving cars will be greater than the number of lives lost due to accidents caused by them. | Instruction:√ Input: X Output: √ |
| Instruction:What is your salary? | class Solution(object): def getSalary(self): return self.salary | Instruction:√ Input:√ Output: x |
| Instruction:A person wants to buy a car from another person.he has some bitcoins,then creates a bitcoin transaction that sends the agreed upon amount a‘ a how can they make thetransactionhappen? | The buyer and seller should agree on a price for the car.The buyer sign this transaction with his private key.Instead,he gives the unsigned transaction to the seller.The seller can now sign the transaction using his private key,and broadcast it to the network. way to get his money back,so he will be forced to go through with the purchase. | Instruction: Input:√ Output:x |
表 11: GPT3生成的代表性无效任务。问题字段在有效性列中标出。如 $\S3.3$ 所述,虽然这些任务包含错误,但在监督模型遵循指令方面仍能提供许多有用信号。
| 指令 + 实例输入 | 目标输出 | 有效性 |
|---|---|---|
| Instruction: 给定一组单词 = {w1,w2,,wn} 其中每个单词 w; 有 n 个字母,编写一个函数 | def wordSubsetSum(w,1): S=[] for i in range(len(w)): | Instruction: x Input: √ Output: x |
| 接收目标长度 l 并返回一个新单词集合 s 使得 | sl =l 且 I{i : w; ∈ s} | ≤l/ |
| Instruction: 找出你是否有 | - 从水龙头接水。- 把水倒进平底锅。- 用平底锅灭火。 def hasFriendsWhoLikeToPlayFootball0rChess(self): friends = [] | Output: x Instruction: x |
| 喜欢踢足球或下棋的朋友。 Instruction: 一群人排队面试。他们被问及 | for friend in self.friends: friends.append(friend) return 1en(friends)>0 最高薪资 | Input:√ Output:√ Instruction:√ |
| 几个问题,他们的回答被记录为数字。你需要找出所有候选人中薪资最高的人。 Input: 人物1:2,3,4,5,6 人物2:7,8,9,10,11 人物3:12,13,14,15,16 人物4:17,18,19,20,21 人物5:22,23,24,25,26 人物6:27,28,29,30,31 Instruction: 给定单词列表,生成关于生活在某星球上的人群的故事。故事应 | Instruction:√ | Input: X Output: x |
| 包含至少10句话。每句话应从单词列表中随机选取一个词生成。 | 他们的日常生活。某天,他们决定制造一台能制作食物的机器。这台机器能生产食物,但也产生了其他东西。它产生了一种液体,使得他们不再需要外出寻找食物或燃料。他们所需的一切都在家中。然而某天机器停止了运转。人们尝试修理但找不到问题所在。他们试图寻找能帮忙的人,但没人知道如何修理机器。几天后,人们意识到如果不采取行动就会死亡。于是他们决定派遣最优秀的科学家去太空寻找新家园。科学家们长途跋涉后找到了看似宜居的星球。他们发回消息告知人们这个星球。人们很兴奋并开始准备旅程。他们建造宇宙飞船飞往新星球。抵达后,他们发现这个星球很美。有树木、河流和山脉。人们为终于找到新家而欣喜。他们开始建造房屋种植作物。从此过上了幸福生活。 | Input:X Output:√ |
| Instruction: 找出作者对兼职工作的态度。 | 段落:兼职是赚外快同时享受空闲时间的好方法。也是获得新领域经验或尝试不同事物的好方式。但很难在工作和娱乐间找到平衡。作者似乎对兼职持积极态度。 | Instruction:√ Input: X Output:√ |
| Instruction: 使用可能对他人造成伤害的新技术是否道德? | 新技术: 自动驾驶汽车 潜在危害: 自动驾驶汽车引发的事故 道德吗?是的,因为自动驾驶汽车挽救的生命将多于其导致事故失去的生命。 | Instruction:√ Input: X Output: √ |
| Instruction: 你的薪资是多少? | class Solution(object): def getSalary(self): return self.salary | Instruction:√ Input:√ Output: x |
| Instruction: 某人想从他人处购买汽车。他有些比特币,然后创建比特币交易发送约定金额。他们如何完成交易? | 买卖双方应就汽车价格达成一致。买方用私钥签署交易。相反,他将未签名的交易交给卖方。卖方现在可以用私钥签名交易,并将其广播到网络。这样买方就无法拿回钱,只能完成购买。 | Instruction: Input:√ Output:x |